
โลกของปัญญาประดิษฐ์กำลังย่างก้าวสู่บทต่อไปที่มากกว่าแค่การจดจำรูปแบบหรือการตอบสนองตามนโยบายที่เรียนรู้มาแล้ว — นั่นคือการสร้าง "โมเดลโลก" (world models) ภายในระบบ ซึ่งทำให้เครื่องจักรสามารถจำลอง พยากรณ์ และวางแผนภายใต้ความไม่แน่นอนได้เหมือนมนุษย์ แนวคิดนี้ไม่ใช่เพียงทฤษฎีใหม่ แต่เป็นกุญแจสำคัญที่ช่วยยกระดับความสามารถของ AI ทั้งด้านการประหยัดข้อมูล การปรับตัวต่อสถานการณ์ที่ไม่เคยเจอ และการตัดสินใจเชิงเหตุผลที่ซับซ้อนยิ่งขึ้น
บทนำนี้จะพาอ่านถึงภาพรวมและประเด็นสำคัญที่บทความเต็มจะลงลึก ได้แก่ ความแตกต่างระหว่างการเรียนรู้แบบ model-free และ model-based, หลักการทำงานของโมเดลโลกเชิงเทคนิค, ตัวอย่างงานวิจัยสำคัญเช่น World Models, MuZero และ Dreamer, รวมถึงกรณีศึกษาการใช้งานจริงในโรโบติกส์ การขับขี่อัตโนมัติ และระบบวางแผนเชิงพาณิชย์ งานวิจัยบางฉบับชี้ให้เห็นว่าแนวทางแบบมีโมเดลสามารถลดความต้องการข้อมูลฝึกสอนได้อย่างมีนัยสำคัญและเพิ่มประสิทธิภาพการวางแผนภายใต้ความไม่แน่นอน — ข้อค้นพบเหล่านี้มีนัยต่อทั้งนักวิจัยและผู้ประกอบการที่ต้องการนำ AI ไปใช้ในสภาพแวดล้อมจริง
หากคุณสนใจทั้งมุมมองเชิงปฏิบัติและเชิงเทคนิค บทความฉบับเต็มจะเสนอการวิเคราะห์เชิงลึก ข้อดีข้อจำกัด แนวทางการนำไปใช้จริง และคำแนะนำสำหรับองค์กรที่ต้องการเริ่มต้นหรือขยายการใช้งานโมเดลโลก เมื่อเข้าใจและนำโมเดลโลกมาใช้ได้อย่างถูกต้อง เราอาจกำลังก้าวเข้าสู่ยุคที่ AI ไม่เพียงแค่เรียนรู้จากข้อมูล แต่สามารถคิด พยากรณ์ และร่วมมือกับมนุษย์ได้อย่างมีเหตุผลมากขึ้น
บทนำ: ทำไมโมเดลโลกจึงเป็นประเด็นสำคัญในยุคต่อไปของ AI
ในบริบทของปัญญาประดิษฐ์สมัยใหม่ โมเดลโลก (world model) หมายถึงตัวแทนภายในที่ระบบสร้างขึ้นเพื่อทำนายพฤติกรรมของสิ่งแวดล้อม—เช่น การคาดการณ์สถานะถัดไป ภาพจากเซนเซอร์ หรือผลลัพธ์ของการกระทำ ตัวอย่างที่เข้าใจง่ายคือ หุ่นยนต์จับวัตถุที่เรียนรู้กฎฟิสิกส์พื้นฐานของการล้มและการกระเด็น เพื่อนำไปใช้คาดการณ์ตำแหน่งในอนาคตแทนที่จะทดลองจับซ้ำๆ จนได้ผล วิธีการนี้เปลี่ยนจากการเรียนรู้โดยตรงจากการกระทำ (trial-and-error) เป็นการเรียนรู้ผ่านการจำลองภายในที่ช่วยให้ทดสอบสถานการณ์ต่างๆ ได้เร็วและปลอดภัยกว่า
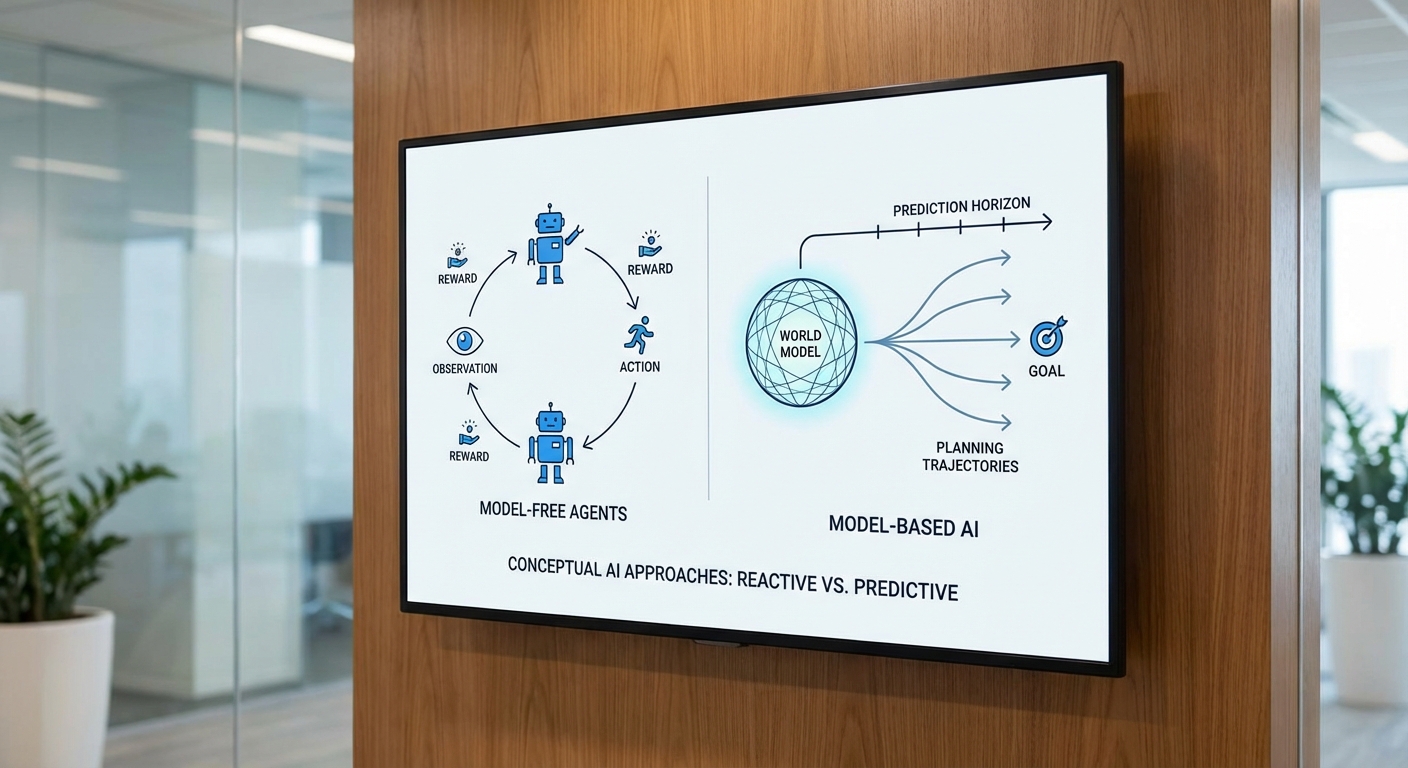
ความแตกต่างระหว่าง model-free กับ model-based
แนวทางการสร้างเอเจนต์ใน RL และระบบอัตโนมัติทั่วไป สามารถแยกเป็นสองกลุ่มใหญ่คือ model-free และ model-based:
- Model-free: เรียนรู้กลยุทธ์ (policy) หรือค่าของการกระทำ (value) โดยตรงจากข้อมูลการโต้ตอบกับสภาพแวดล้อม ข้อได้เปรียบคือสถาปัตยกรรมมักเรียบง่ายและไม่ต้องพึ่งพาการสร้างโมเดลความถูกต้องของสภาพแวดล้อม แต่ข้อจำกัดสำคัญคือ ต้องการตัวอย่างจำนวนมาก และมักขาดการทั่วไปเมื่อเจอสถานการณ์ใหม่ที่ต่างไปจากข้อมูลฝึก
- Model-based: สร้างหรือเรียนรู้โมเดลของสภาพแวดล้อม (เช่น ฟังก์ชันการเปลี่ยนสถานะหรือการจำลองแบบเชิงนัย) แล้วใช้โมเดลนั้นในการวางแผนหรือฝึกนโยบาย ข้อดีคือ ประหยัดตัวอย่าง (sample-efficient), สามารถทำการคิดเชิงคาดการณ์หรือทำการทดลองแบบนามธรรมภายในได้ และเอื้อให้เกิดการถ่ายโอนความรู้ไปยังงานใหม่ได้ง่ายกว่า ข้อเสียคือความเสี่ยงจาก model bias — หากโมเดลไม่แม่นยำ การตัดสินใจที่อิงโมเดลอาจนำไปสู่ผลลัพธ์ที่ผิดพลาด และการพัฒนาโมเดลที่ดีมักมีความซับซ้อนทั้งเชิงคำนวณและการออกแบบ
เมื่อใดจึงเหมาะใช้แต่ละแนวทาง
- Model-free เหมาะเมื่อมีข้อมูลปริมาณมากและความปลอดภัยต่อการทดลองไม่เป็นปัญหา เช่น เกมอิเล็กทรอนิกส์หรือสภาพแวดล้อมจำลองที่เข้าถึงได้ง่าย
- Model-based เหมาะอย่างยิ่งเมื่อการเก็บตัวอย่างมีค่าใช้จ่ายสูงหรือเสี่ยง (เช่น หุ่นยนต์ในโลกจริง ยานยนต์ไร้คนขับ หรือระบบทางการแพทย์) และเมื่อต้องการความยืดหยุ่นในการวางแผนหรือการประเมินผลในสภาวะใหม่ๆ
หลักฐานเชิงประจักษ์: สถิติและงานวิจัยที่สนับสนุน
สรุปเชิงสถิติจากงานต่างๆ ได้แก่การรายงานการลดจำนวนตัวอย่างที่ต้องใช้ได้ตั้งแต่ประมาณ 2–10 เท่า ในงานทดลองบางชุดเมื่อเทียบกับวิธี model-free แบบมาตรฐาน ในพื้นที่เฉพาะอย่างกระดานเกมที่ต้องวางแผน (เช่น Go/Chess/Shogi) MuZero ซึ่งเป็นวิธีที่เรียนรู้โมเดลภายในแล้วใช้การค้นหาเชิงวางแผน แสดงให้เห็นว่าการเรียนรู้โมเดลสามารถทดแทนพื้นฐานการจำลองแบบสมบูรณ์ได้และให้ผลลัพธ์ในระดับมนุษย์หรือเหนือมนุษย์
นอกจากตัวเลขด้านตัวอย่างแล้ว ผลประโยชน์เชิงปฏิบัติยังรวมถึงต้นทุนการฝึกที่ลดลง ความเสี่ยงต่อการทดลองในโลกจริงที่ต่ำลง และความสามารถในการอธิบายหรือวิเคราะห์การตัดสินใจผ่านตัวแทนภายใน—ปัจจัยที่มีความสำคัญต่อการนำ AI เข้าใช้ในภาคธุรกิจและอุตสาหกรรมที่มีข้อจำกัดด้านเวลา งบประมาณ และความปลอดภัย
สรุป โมเดลโลกไม่ได้เป็นเพียงเทคนิคทางวิจัยเชิงทฤษฎี แต่เป็นกลไกที่ช่วยให้ระบบ AI มีความคุ้มค่า ยืดหยุ่น และปลอดภัยมากขึ้นในการนำไปใช้งานจริง สำหรับองค์กรที่มองการณ์ไกล การลงทุนในแนวทาง model-based และการพัฒนา world models จึงเป็นหนึ่งในกุญแจสำคัญที่จะขับเคลื่อนนวัตกรรม AI ในยุคต่อไป
นิยาม ประเภท และองค์ประกอบหลักของโมเดลโลก
นิยามของโมเดลโลก
โมเดลโลก (world model) หมายถึงการนำเสนอเชิงคณิตศาสตร์หรือเชิงสถาปัตยกรรมของระบบและสิ่งแวดล้อมที่เอเย่นต์ต้องทำงานร่วมด้วย เพื่อทำนายการเปลี่ยนแปลงของสถานะและผลลัพธ์ของการกระทำ โมเดลโลกอาจเป็นแบบที่ออกแบบขึ้นโดยผู้เชี่ยวชาญ (analytic) หรือเรียนรู้จากข้อมูล (learned) และถูกใช้งานทั้งในการ วางแผน (planning) การควบคุม (control) และการเพิ่มประสิทธิภาพนโยบายในงานปัญญาประดิษฐ์ โดยแกนกลางคือการสร้างแบบจำลองของสถานะภายในและการเปลี่ยนผ่านของโลกเพื่อรองรับการตัดสินใจเชิงกลยุทธ์
ประเภทของโมเดลโลก
- Analytic / Explicit physics models — โมเดลประเภทนี้อาศัยกฎฟิสิกส์และสมการเชิงวิเคราะห์ที่ถูกออกแบบโดยผู้เชี่ยวชาญ เช่น แบบจำลอง Euler-Lagrange หรือซิมูเลเตอร์อย่าง MuJoCo เพื่อทำนายแรงและการเคลื่อนที่ เหมาะกับโดเมนที่มีกฎชัดเจน เช่น หุ่นยนต์อุตสาหกรรมหรือการจำลองกลศาสตร์ ตัวอย่างข้อดีคือความน่าเชื่อถือในการคาดการณ์และการตีความผลลัพธ์ได้ง่าย แต่ข้อจำกัดคือค่าใช้จ่ายในการสร้างและความยากเมื่อระบบมีความซับซ้อนสูง
- Learned latent world models — โมเดลชนิดเรียนรู้จากข้อมูล (เช่น PlaNet, Dreamer, MuZero ในรูปแบบต่าง ๆ) โดยมักใช้ตัวเข้ารหัส (encoder) เพื่อแมปการสังเกตเป็น latent state ที่มีมิติจำกัด แล้วเรียนรู้โมเดล dynamics ใน latent space ข้อดีคือความยืดหยุ่นในการจัดการกับภาพวัตถุจริง, เสียง และข้อมูลเชิงสังเกตอื่น ๆ แต่ความเสี่ยงคือความไม่แน่นอนในการทำนายและปัญหาในการตีความ
- Hybrid models — ผสมผสานทั้งแบบ analytic และ learned โดยใช้แบบจำลองเชิงฟิสิกส์เป็นโครงสร้างพื้นฐาน แล้วเติมส่วนที่ไม่แน่นอนหรือซับซ้อนด้วยโมดูลที่เรียนรู้จากข้อมูล (residual learning) วิธีนี้ช่วยให้ได้ทั้งความแม่นยำของกฎฟิสิกส์และความยืดหยุ่นของการเรียนรู้จากข้อมูลในโดเมนที่ซับซ้อน เช่น ยานยนต์ไร้คนขับที่ใช้แบบจำลองกลไกร่วมกับโมดูลที่เรียนรู้พฤติกรรมถนนจริง
องค์ประกอบหลักของโมเดลโลก
- Encoder — แปลงการสังเกต (observation) เช่น ภาพหรือเซนเซอร์ ให้อยู่ในรูปของตัวแทนเชิงตัวเลขเชิงสั้น (latent representation) ตัว encoder สามารถเป็น convolutional network, transformer หรือฟังก์ชันฟีเจอร์ที่กำหนดเอง การออกแบบ encoder มีผลโดยตรงต่อประสิทธิภาพของโมเดลโลก
- Latent state (state representation) — ตัวแทนภายในที่สรุปลักษณะสำคัญของสถานะโลก จุดประสงค์เพื่อลดมิติข้อมูลและจับเฉพาะปัจจัยที่จำเป็นต่อการพยากรณ์และการวางแผน ตัวแทนที่ดีช่วยให้โมเดล dynamics เรียนรู้ได้เร็วขึ้นและทำการวางแผนได้มีประสิทธิภาพมากขึ้น
- Dynamics / Transition model — ฟังก์ชันที่ทำนายสถานะถัดไปจากสถานะปัจจุบันและการกระทำ (s_{t+1} = f(s_t, a_t) หรือแบบสถิติ p(s_{t+1}|s_t,a_t)) Dynamics อาจเป็น deterministic หรือ stochastic และอาจเรียนรู้ใน latent space หรือกำหนดโดยกฎฟิสิกส์โดยตรง
- Decoder / Observation model (likelihood) — แปลง latent state กลับเป็นการสังเกตที่สามารถตีความได้ (เช่น ภาพ, การวัด) หรือคำนวณความน่าจะเป็นของการสังเกต p(o_t|s_t) ซึ่งจำเป็นเมื่อต้องเทียบการคาดการณ์กับข้อมูลจริงในการฝึกแบบ supervised หรือในกรอบ probabilistic
- Reward predictor — โมดูลที่ทำนายผลตอบแทน (reward) ที่สัมพันธ์กับสถานะหรือการกระทำ ซึ่งเป็นส่วนสำคัญในระบบเชิงเป้าหมาย โดยเฉพาะในงาน reinforcement learning โมดูลนี้ช่วยให้สามารถประเมินนโยบายแบบจำลองได้โดยไม่ต้องลงมือกระทำจริงเสมอไป
- Planner / Controller — อัลกอริทึมที่ใช้ world model เพื่อออกแบบลำดับการกระทำ (เช่น MPC, tree search, หรือ policy network ที่ใช้ imagination rollouts) Planner ใช้โมเดลเพื่อประเมินผลระยะสั้นและระยะยาวและส่งคืนการกระทำที่คาดว่าจะให้ผลลัพธ์ดีที่สุด
การเชื่อมต่อกับ Reinforcement Learning และ Supervised Learning
โมเดลโลกสร้างสะพานเชื่อมระหว่างกรอบงานการเรียนรู้หลายประเภท ในเชิงเทคนิค supervised learning มักถูกใช้ในการฝึก encoder, decoder และ dynamics โดยใช้วัตถุประสงค์การทำนาย (เช่น การลดความคลาดเคลื่อนของภาพถัดไปหรือลักษณะของสถานะ) ขณะที่ reinforcement learning (RL) ใช้ world model เพื่อเพิ่มประสิทธิภาพการเรียนรู้นโยบาย ผ่านการวางแผนในโมเดล (model-based planning) หรือการสร้างข้อมูลสังเคราะห์ด้วย imagination rollouts เพื่อลดความต้องการตัวอย่างจากโลกจริง
ในทางปฏิบัติ งานวิจัยหลายชิ้นรายงานว่าโมเดลโลกช่วยเพิ่ม sample efficiency เมื่อเทียบกับวิธี model-free โดยเฉพาะในสภาพแวดล้อมที่การเก็บข้อมูลมีราคาแพง เช่น หุ่นยนต์จริงหรือระบบสุขภาพ อย่างไรก็ตาม ผลลัพธ์ขึ้นอยู่กับความถูกต้องของโมเดล: โมเดลที่ผิดพลาดมากอาจนำไปสู่การวางแผนที่มีอคติ ดังนั้นแนวทาง hybrid และการฝึกแบบร่วม (joint training) ของโมเดลและนโยบายกำลังเป็นที่นิยมเพื่อลดผลกระทบจากความผิดพลาดของโมเดล
สรุปได้ว่าองค์ประกอบทั้งห้า (encoder, latent state, dynamics, decoder, planner) ร่วมมือกันในการสร้างระบบ world model ที่ใช้งานได้จริง และการเลือกประเภทโมเดล—analytic, learned หรือ hybrid—จะขึ้นกับข้อจำกัดของโดเมน ความพร้อมของข้อมูล และข้อกำหนดเรื่องความปลอดภัยและการตีความผลลัพธ์สำหรับการใช้งานในเชิงพาณิชย์
รากฐานทางเทคนิค: การแทนสถานะ, latent dynamics และการวางแผน
การสร้างและเรียนรู้ตัวแทนเชิงสถานะ (Latent Representations)
การสร้างตัวแทนเชิงสถานะ (latent representation) เป็นรากฐานของโมเดลโลกสมัยใหม่ เพราะการย่อข้อมูลเชิงสังเกต (observations) ไปยัง space ที่มีมิติที่ต่ำกว่าแต่มีความหมายทำให้การเรียนรู้ dynamics และการวางแผนมีประสิทธิภาพมากขึ้น เทคนิคหลัก ๆ ประกอบด้วย:
- Autoencoders — ใช้ encoder-decoder เพื่อบีบอัดข้อมูลและคืนค่า (reconstruction) เป็น loss หลัก การออกแบบอาจรวม convolutional encoder สำหรับภาพ และ decoder ที่เป็นแบบ deterministic ซึ่งเหมาะกับการได้ตัวแทนที่สามารถถอดรหัสกลับเป็นสัญญาณต้นฉบับได้
- Variational methods (VAE) — ขยายความคิดของ autoencoder โดยเพิ่มการประมาณความน่าจะเป็นบน latent space ผ่านการแมพไปยัง distribution (เช่น Gaussian) และใช้ KL divergence เป็น regularizer ผลคือ latent space มีโครงสร้าง probabilistic ที่รองรับการสุ่มและการวางแผนภายใต้ความไม่แน่นอน
- Contrastive learning — แทนที่จะฝึกจากการคืนค่าโดยตรง เทคนิคเชิงความแตกต่าง (เช่น InfoNCE) จะฝึกให้ตัวแทนของตัวอย่างที่เกี่ยวข้องกันใกล้กันใน latent space และตัวอย่างที่ไม่เกี่ยวข้องอยู่ห่างกัน ข้อดีสำคัญคือตัวแทนเหล่านี้มักนำไปสู่ประสิทธิภาพที่ดีใน downstream tasks โดยไม่ต้องพึ่งพา decoder
ตัวอย่างเชิงประสิทธิภาพ: งานวิจัยด้านการเรียนรู้เชิงสังเคราะห์และคอมพิวเตอร์วิชันพบว่า contrastive approaches มักให้คุณภาพตัวแทนที่ดีกว่า autoencoders แบบดั้งเดิมเมื่อวัดจากงานจำแนกและการทำ transfer learning ในขณะที่ VAE ให้ความสามารถในการประมาณความไม่แน่นอนที่มีประโยชน์สำหรับการวางแผนภายใต้ความไม่แน่นอน

การเรียนรู้ Dynamics ใน Latent Space: deterministic vs stochastic และ RSSM
เมื่อได้ latent representation เรียบร้อย ขั้นตอนถัดไปคือการเรียนรู้ dynamics ของระบบใน latent space เพื่อให้โมเดลสามารถพยากรณ์หลายก้าวข้างหน้า การออกแบบ dynamics มีสองแนวทางหลัก:
- Deterministic dynamics — ใช้ฟังก์ชันการเปลี่ยนสถานะแบบ deterministic (เช่น RNN หรือ MLP) ที่แมพ latent_t และ action_t ไปยัง latent_{t+1} ข้อดีคือคำนวณรวดเร็วและเหมาะกับระบบที่มีความไม่แน่นอนต่ำ แต่มีข้อจำกัดเมื่อระบบมีความไม่แน่นอนเชิงสถิติหรือการสังเกตที่ไม่สมบูรณ์
- Stochastic dynamics — โมเดลจะเรียนรู้ distribution ของการเปลี่ยนแปลง เช่น p(z_{t+1} | z_t, a_t) ซึ่งรองรับความไม่แน่นอนเชิงอาเลียโทริก (aleatoric) และ epistemic ความไม่แน่นอน เทคนิคเช่น VAE-based transitions หรือ probabilistic RNN จะเป็นตัวอย่าง
หนึ่งในสถาปัตยกรรมที่โดดเด่นคือ Recurrent State-Space Model (RSSM) ซึ่งผสานส่วนที่เป็น deterministic (hidden state h_t จาก RNN เพื่อเก็บประวัติ) และส่วนที่เป็น stochastic (latent z_t ที่จับความไม่แน่นอนของสถานะปัจจุบัน) โครงสร้างทั่วไปของ RSSM ประกอบด้วย:
- deterministic recurrence: h_t = f(h_{t-1}, z_{t-1}, a_{t-1})
- stochastic prior/transition: p(z_t | h_t)
- observation model: p(o_t | h_t, z_t)
โมเดลเช่น PlaNet และ Dreamer ใช้ RSSM เพื่อทำ multi-step prediction ใน latent space และแสดงให้เห็นถึงประสิทธิภาพด้าน sample efficiency ในงานควบคุมที่ซับซ้อน ความได้เปรียบสำคัญคือการรวมความทรงจำเชิงลำดับ (deterministic) กับการประมาณความไม่แน่นอน (stochastic) ส่งผลให้การพยากรณ์ระยะยาวมีความเสถียรและปรับตัวได้ในสภาพแวดล้อมที่ไม่แน่นอน
สำหรับการฝึก multi-step prediction มักใช้เทคนิคเช่น:
- Multi-step loss / latent overshooting — ขยาย loss ไปยังการพยากรณ์หลายขั้นเพื่อให้โมเดลเรียนรู้ความต่อเนื่องระยะยาว
- Teacher forcing และ scheduled sampling — ควบคุมการป้อนค่าจริง vs. การป้อนค่าที่พยากรณ์เพื่อป้องกันการล้มเหลวของ rollouts ระยะยาว
- Contrastive predictive coding (CPC) — ใช้ loss แบบ contrastive เพื่อฝึกให้ latent พยากรณ์คุณลักษณะอนาคตแทนการซ้ำคืนค่าเต็มรูปแบบ
การวางแผนบนโมเดล (Planning) และการควบคุม: MPC, Rollout-based Planning และ Value Gradients
เมื่อมี world model ที่สามารถพยากรณ์ใน latent space ได้ ขั้นตอนสำคัญถัดไปคือการใช้โมเดลนั้นเพื่อวางแผนและตัดสินใจโดยตรง เทคนิคการวางแผนที่นิยมมีดังนี้:
- Model Predictive Control (MPC) — เทคนิค receding-horizon ที่ค้นหาลำดับการกระทำ (action sequence) ในช่วงเวลาหนึ่งเพื่อเพิ่ม cumulative reward ตามโมเดล จากนั้นนำ action แรกไปใช้จริงและทำซ้ำในแต่ละสเต็ป MPC สามารถใช้ optimizer หลายแบบทั้ง gradient-based และ gradient-free (เช่น Cross-Entropy Method, CEM)
- Rollout-based planning — สร้างหลายเส้นทาง (rollouts) ใน latent space โดยอาศัย stochastic transitions แล้วประเมินผลตอบแทนรวมของแต่ละ rollout เพื่อเลือก action ดีที่สุด วิธีนี้เหมาะกับโมเดลที่สามารถรันช้อนได้และเมื่อต้องการสำรวจความไม่แน่นอน
- Value gradients / differentiable planning — ทำ backprop ผ่าน dynamics model และ value/policy network เพื่อหาการปรับปรุง action โดยตรง แนวทางนี้รวมถึงการใช้ gradients จาก value function เพื่อปรับ action sequence (เช่น Dyna-like schemes หรือ approaches ที่คล้ายกับ MuZero ในการเรียนรู้ value ที่สอดคล้องกับ model)
การประยุกต์ใช้งานเชิงปฏิบัติ: ระบบเชิงธุรกิจมักใช้การผสมผสานเทคนิคเหล่านี้ เช่น การใช้ MPC บน latent model เพื่อปฏิบัติการแบบ real-time แล้วใช้ policy distillation (สอน policy ให้เลียนแบบการวางแผน) เพื่อให้การทำงานใน production มี latency ต่ำ ในขณะที่ยังคงได้ประสิทธิภาพของการวางแผนระยะสั้น
ประเด็นทางธุรกิจและการปฏิบัติ: การรัน planning ใน latent space ลดความซับซ้อนของคำนวณและช่วยให้การวางแผนทั่วไปข้ามโดเมนได้เร็วขึ้น การเลือกระหว่าง deterministic/stochastic dynamics, ระยะ horizon ใน MPC, และวิธี optimize (CEM vs gradient) ต้องพิจารณา trade-off ระหว่างความเร็ว ความเสถียร และการรองรับความไม่แน่นอน ซึ่งมีผลโดยตรงต่อประสิทธิผลต้นทุนและความปลอดภัยในการนำระบบไปใช้งานจริง
สถาปัตยกรรมและงานวิจัยตัวอย่างที่สำคัญ
สถาปัตยกรรมและงานวิจัยตัวอย่างที่สำคัญ
ในยุคของ world models งานวิจัยเชิงบุกเบิกได้ชี้ให้เห็นว่า การเรียนรู้แบบมีแบบจำลองเชิงแฝง (latent dynamics) สามารถยกระดับ sample efficiency และความสามารถในการวางแผนได้อย่างชัดเจน งานตัวอย่างที่สำคัญตั้งแต่ PlaNet และ Dreamer ไปจนถึง MuZero และ Gato ได้วางรากฐานด้านสถาปัตยกรรมและกลยุทธ์การฝึกที่แตกต่างกัน — บางงานเน้นโมเดลของสภาพแวดล้อมใน latent space เพื่อการวางแผน (PlaNet, Dreamer) ขณะที่บางงานเน้นการเรียนรู้ dynamics พร้อมกับนโยบายและค่า (MuZero) และบางงานขยายแนวคิดสู่ระบบหลายภารกิจ/หลายสื่อ (Gato) ที่สามารถนำไปต่อยอดกับ LLM และเอเจนต์มัลติ-โมดัลได้ในงานวิจัยล่าสุด

ต่อไปนี้เป็นสรุปแนวทาง ผลลัพธ์เชิงตัวเลข และข้อดีข้อจำกัดของงานวิจัยสำคัญเหล่านี้:
-
PlaNet (Hafner et al., 2018)
แนวทาง: เรียนรู้ latent dynamics จากภาพพิกเซลโดยตรง แล้วใช้ถอยหลัง (planning) ใน latent space ด้วยการค้นหาเชิงคาดการณ์ (trajectory optimization / CEM)
ผลลัพธ์เชิงตัวเลข: ในชุดทดลองควบคุมต่อเนื่อง (เช่น MuJoCo-like tasks) PlaNet สามารถบรรลุผลใกล้เคียงหรือเหนือกว่า model-free baselines โดยใช้ จำนวน interaction ต่ำกว่าอย่างมาก — ในหลายกรณีเพียงประมาณ 10^5–10^6 environment steps เทียบกับ model-free ที่มักต้องการ >10^6–10^7 steps
ข้อดี/ข้อจำกัด: ข้อดี คือ sample efficiency ดีและสามารถวางแผนจากภาพได้โดยตรง; ข้อจำกัด คือความไวต่อการเบี่ยงเบนของโมเดล (model bias) และมีข้อจำกัดเมื่อต้องวางแผนในงานที่มีความไม่แน่นอนสูงหรือต้องการ long-horizon planning
-
Dreamer / DreamerV2 (Hafner et al., 2019/2020)
แนวทาง: ขยาย PlaNet ด้วยการฝึกนโยบายและค่าใน "imagined trajectories" ภายใน latent model (actor-critic บน latent rollouts) — ทำให้สามารถอัพเดตนโยบายได้โดยไม่ต้องเรียก environment จริงตลอดเวลา
ผลลัพธ์เชิงตัวเลข: Dreamer แสดงให้เห็นการเพิ่มขึ้นของประสิทธิภาพเทียบกับวิธี model-free ใน Atari และงานควบคุมต่อเนื่อง โดยทั่วไปต้องการ environment interactions ในระดับ 10^5–10^6 เพื่อให้ได้ผลลัพธ์ใกล้เคียงกับหรือดีกว่า baselines ที่ต้องใช้มากกว่า
ข้อดี/ข้อจำกัด: Dreamer ลดความจำเป็นในการโต้ตอบจริงกับสภาพแวดล้อมผ่าน imagination rollouts และมักได้ผลดีกว่า PlaNet ในงานที่ต้องเรียนรู้นโยบายเชิงต่อเนื่อง แต่การฝึกอาศัยการออกแบบ latent space ที่แข็งแรงและการเลือก horizon ในการจินตนาการ (imagined horizon) ที่เหมาะสม
-
MuZero (Schrittwieser et al., DeepMind)
แนวทาง: เรียนรู้ representation, dynamics, policy และ value โดยตรงจากผลลัพธ์ (rewards/observations) และผสานการค้นหาเชิงต้นไม้ (MCTS) บนโมเดลที่เรียนได้ — จุดเด่นคือไม่ต้องการแบบจำลองของกฎเกมโดยตรง
ผลลัพธ์เชิงตัวเลข: MuZero ทำผลงานระดับ SOTA ในเกมกระดาน (Go, Chess, Shogi) และชุดทดลอง Atari — สามารถเทียบหรือเกินประสิทธิภาพของ AlphaZero/other SOTA โดยเรียนรู้ dynamics เอง อย่างไรก็ดีการฝึกมักต้องการ การคำนวณและ interaction ในระดับสูง (มักเป็นหลายร้อยล้านถึงพันล้านขั้นตอน) ทำให้ค่าใช้จ่ายด้านตัวอย่างและคอมพิวติ้งสูง
ข้อดี/ข้อจำกัด: ข้อดี คือความยืดหยุ่นและประสิทธิภาพในโดเมนที่มีการจำลองค้นหาเชิงต้นไม้สำคัญ; ข้อจำกัด คือต้นทุนการคำนวณสูง และเมื่อย้ายไปยังโดเมนที่มีความซับซ้อนของสภาพแวดล้อมหรือการสังเกตแบบภาพระดับสูง อาจต้องปรับปรุงสถาปัตยกรรมให้เหมาะสม
-
Gato (Reed et al., DeepMind)
แนวทาง: ใช้ transformer-based sequence modeling ในการเรียนรู้พฤติกรรมจากข้อมูลที่หลากหลาย (ภาพ, คำสั่ง, ควบคุมหุ่นยนต์ ฯลฯ) — นับเป็นความพยายามสร้าง generalist agent หนึ่งโมเดลทำงานได้หลายพันแบบ
ผลลัพธ์เชิงตัวเลข: Gato ถูกฝึกบนชุดงานหลายร้อยงาน (รายงานต้นฉบับกล่าวถึง ~600 tasks) ด้วยพารามิเตอร์ระดับ ~1.2 พันล้าน ทำให้แสดงความสามารถหลายโมดัลพร้อมกันได้ แม้ประสิทธิภาพต่อภารกิจจะยังไม่เทียบกับโมเดลเชิงเฉพาะทางในหลายกรณี
ข้อดี/ข้อจำกัด: จุดแข็งคือความสามารถในการรวมข้อมูลหลายรูปแบบและทำหลายงานภายในโมเดลเดียว แต่ ข้อจำกัด คือคุณภาพต่อภารกิจมักต่ำกว่าโมเดลที่ฝึกเฉพาะทาง และต้องการข้อมูลการสอนปริมาณมากเพื่อครอบคลุมทุก task
-
งานล่าสุดที่ผสาน World Models กับ LLMs / Multi-modal Agents
แนวทาง: งานสมัยใหม่มักแบ่งบทบาทระหว่าง LLM (หรือโมเดลการวางแผนเชิงสัญลักษณ์/ภาษาธรรมชาติ) กับโมดูล world model ที่รับผิดชอบการพยากรณ์ผลลัพธ์เชิงกายภาพหรือสภาพแวดล้อม เช่นสถาปัตยกรรมที่ LLM ทำหน้าที่วางแผนเชิงนโยบายระดับสูง ขณะที่ world model (หรือ value/affordance estimator) ประเมินความเป็นไปได้ของการกระทำและผลลัพธ์
ตัวอย่างงานที่สำคัญได้แก่ SayCan (ใช้ LLM กับ affordance model ในหุ่นยนต์), PaLM-E / RT-1 / Voyager และงานวิจัยล่าสุดที่รวม latent dynamics เข้ากับ LLMs เพื่อให้เกิดการวางแผนและจำลองผลลัพธ์ข้ามโมดอล ผลการทดลองมักแสดงให้เห็นว่า การผสานนี้ช่วยเพิ่มอัตราความสำเร็จในภารกิจเชิงรันไทม์และปรับปรุงการถ่ายโอนความรู้ระหว่างงาน ตัวเลขที่รายงานในหลายบทความระบุว่าอัตราความสำเร็จหรือ sample efficiency อาจเพิ่มขึ้นอย่างมีนัยสำคัญ (ในบางกรณีเป็น สองเท่าหรือมากกว่า) เมื่อเทียบกับ pipeline ที่พึ่งพา LLM เพียงฝ่ายเดียวหรือ controller แบบแบบดั้งเดิม
ข้อจำกัดเชิงปฏิบัติ: การรวมกันต้องจัดการกับช่องว่างระหว่างการพยากรณ์เชิงสถิตของ world model กับการสัญญะเชิงภาษา/ความรู้ของ LLM เช่น การประกันความสอดคล้อง (consistency) ใน long-horizon planning, การจัดการความไม่แน่นอน, และต้นทุนการคำนวณ/การเก็บข้อมูลที่สูงขึ้น
สรุปเชิงเปรียบเทียบอย่างย่อ: model-based approaches (PlaNet, Dreamer) มักได้เปรียบด้าน sample efficiency — โดยลด interactions ลงได้เป็นทศนิยมเทียบกับ model-free — แต่ต้องแลกมาด้วยความเสี่ยงของ model bias และความซับซ้อนในการออกแบบ latent space; MuZero แสดงให้เห็นการผสาน learning + search ที่ทรงพลังในโดเมนเกม แต่มีต้นทุนสูง; ในขณะที่ Gato และงาน multi-modal แสดงทิศทางสู่เอเจนต์ทั่วไปที่รวม world model แบบฝังตัวกับความสามารถทางภาษา/ภาพ แม้ยังต้องการข้อมูลมากและไม่ได้เหนือกว่าผลงานเฉพาะทางในทุกกรณี
ภาพรวม: แนวทางที่มีแนวโน้มสูงคือสถาปัตยกรรมผสมที่ใช้ latent world models เพื่อความประหยัดตัวอย่าง ควบคู่กับ LLMs หรือ planner สำหรับการสื่อสารและการวางแผนเชิงนโยบายระดับสูง — ซึ่งผสานกันได้ทั้งในแง่ทฤษฎีและผลการทดลอง แต่การนำไปใช้เชิงอุตสาหกรรมยังต้องเอาชนะอุปสรรคด้านความเสถียรของโมเดล ความสามารถในการปรับตัวข้ามโดเมน และต้นทุนการฝึก/รันไทม์
การประยุกต์ใช้งานและกรณีศึกษาเชิงปฏิบัติ
การประยุกต์ใช้งานและกรณีศึกษาเชิงปฏิบัติ
โมเดลโลก (world models) ได้กลายเป็นเทคโนโลยีเชิงกลยุทธ์ที่ขับเคลื่อนการประยุกต์ใช้งานในหลายโดเมน โดยเฉพาะในงานที่ต้องการการตัดสินใจแบบหลายขั้นตอนและการจำลองผลลัพธ์ก่อนการลงมือทำจริง ตัวอย่างเด่น ๆ ได้แก่ หุ่นยนต์ควบคุม (robotic manipulation), ยานยนต์ไร้คนขับ, ระบบ agents ในเกมและการจำลอง รวมถึงการบูรณาการร่วมกับ Large Language Models (LLMs) เพื่อการวางแผน (planning) และการตัดสินใจ (decision-making) ที่มีความซับซ้อนสูง ในเชิงธุรกิจ โมเดลโลกช่วยลดต้นทุนการทดลองจริง เพิ่มความเร็วในการพัฒนาผลิตภัณฑ์ และลดความเสี่ยงจากการทดลองในสภาพแวดล้อมที่อันตรายหรือมีค่าใช้จ่ายสูง
หุ่นยนต์ควบคุม: หนึ่งในประโยชน์ที่ชัดเจนของ world models คือการลดจำนวน interactions ในโลกจริงโดยการฝึกในสภาพแวดล้อมจำลอง (sim-to-real transfer) งานวิจัยและการทดลองเชิงอุตสาหกรรมหลายชิ้นแสดงให้เห็นว่า การฝึกนโยบายใน latent space หรือในจำลองสามารถลดการทดลองจริงได้อย่างมีนัยสำคัญ — บางกรณีรายงานการลดลงหลายเท่า (เช่น หลายสิบเท่าถึงหลายร้อยเท่า ขึ้นกับงานและการออกแบบจำลอง) ตัวอย่างเชิงปฏิบัติที่เป็นที่รู้จัก ได้แก่ OpenAI Dactyl ที่ใช้การฝึกใน simulator สำหรับการจับและจัดการวัตถุอย่างประณีต และงานจากภาควิจัยอย่าง PlaNet/Dreamer ที่แสดงให้เห็นว่าโมเดลโลกเชิง latent สามารถเรียนรู้การควบคุมแบบต่อเนื่อง (continuous control) ด้วย sample-efficiency ที่ดีกว่า model-free baselines
เกมและการจำลอง (Game-playing agents): ในวงการเกม โมเดลโลกได้แสดงศักยภาพในการลดค่าใช้จ่ายเชิงคำนวณและการใช้งานจริงอย่างมีประสิทธิภาพ ตัวอย่างสำคัญคือ MuZero จาก DeepMind ซึ่งเรียนรู้ dynamics ของสภาพแวดล้อมร่วมกับการค้นหา (search) โดยไม่ต้องใช้โมเดลที่อาศัยความรู้ล่วงหน้าเกี่ยวกับกติกา MuZero ประสบความสำเร็จใน board games และ Atari โดยแสดงสมรรถนะสูงเทียบเท่าหรือเหนือกว่าเทคนิคก่อนหน้า โดยจุดเด่นคือความสามารถในการวางแผนจากการจำลองภายใน (internal rollouts) แทนที่จะพึ่งการทดลองจริงจำนวนมาก ซึ่งในเชิงปฏิบัติช่วยลด sample complexity และปรับใช้ได้กับเกมที่มีสภาพแวดล้อมซับซ้อน
การรวม world models กับ LLMs สำหรับ planning และ tool use: การเชื่อมต่อโมเดลโลกกับ LLMs เป็นแนวทางที่กำลังได้รับความสนใจอย่างมาก โดย LLMs มักจะทำหน้าที่ให้แผนเชิงสัญลักษณ์หรือคำแนะนำระดับสูง ขณะที่ world models จะทำหน้าที่จำลองผลลัพธ์เชิงสถานะ (state transitions) เพื่อตรวจสอบความเป็นไปได้และความเสี่ยงของแต่ละทางเลือก การผสานสองระบบนี้ช่วยแก้ปัญหา multi-step reasoning และการใช้เครื่องมือ (tool use) ได้ดีขึ้น ตัวอย่างเชิงงานวิจัยและเชิงปฏิบัติ ได้แก่ SayCan ของ Google ที่ผสม LLM กับ affordance model สำหรับหุ่นยนต์ เพื่อคัดกรองและจัดลำดับการกระทำที่เป็นไปได้ และ Toolformer ที่ฝึกให้ LLM เรียนรู้การเรียกใช้เครื่องมือต่าง ๆ เมื่อจำเป็น การร่วมกันนี้ทำให้ระบบสามารถสร้างแผนเชิงเหตุผลและทดสอบแผนเหล่านั้นในจำลองก่อนสั่งให้ฮาร์ดแวร์ปฏิบัติจริง
กรณีศึกษาความสำเร็จและอุปสรรคเชิงปฏิบัติ: มีกรณีศึกษาหลายชุดที่แสดงทั้งความสำเร็จและข้อจำกัดของการใช้โมเดลโลก:
- กรณีความสำเร็จ: ระบบจำลองแบบ latent เช่น Dreamer/PlaNet ช่วยให้ตัวแทนเรียนรู้การควบคุมในสภาพแวดล้อมแบบต่อเนื่องด้วยความต้องการตัวอย่างจากสภาพแวดล้อมจริงที่น้อยลง ในเชิงอุตสาหกรรม การใช้ sim-to-real ร่วมกับ domain randomization ทำให้หุ่นยนต์อุตสาหกรรมสามารถนำโมเดลจาก simulator ไปใช้งานจริงได้รวดเร็วขึ้น ลด downtime ในโรงงาน และลดต้นทุนการทดสอบ
- อุปสรรคเชิงปฏิบัติ: ปัญหา \"sim-to-real gap\" ยังคงเป็นอุปสรรคสำคัญ — ความเบี่ยงเบนระหว่างจำลองกับโลกจริงทำให้โมเดลที่เรียนมาใน simulator ทำงานผิดพลาดเมื่อย้ายสู่สภาพแวดล้อมจริง นอกจากนี้ การคาดคะเนผลระยะยาวจากโมเดลโลกอาจสะสมข้อผิดพลาด (compounding errors) ทำให้การวางแผนระยะยาวไม่แม่นยำ
- ข้อจำกัดเชิงคำนวณและเชิงวิศวกรรม: แม้การรัน rollout ภายในโมเดลจะถูกกว่าการทดลองจริง แต่การฝึก world models ขนาดใหญ่และการวางแผนอาจต้องใช้ทรัพยากรคอมพิวต์และข้อมูลจำนวนมาก รวมทั้งการออกแบบตัววัดความไม่แน่นอน (uncertainty estimation) องค์ประกอบทางวิศวกรรมสำหรับการผสานกับ LLM เช่น interface ของ tool calls และการปรับปรุง latency ในระบบจริงก็เป็นความท้าทายเชิงอุตสาหกรรม
เพื่อบรรเทาความเสี่ยงเหล่านี้ องค์กรมักใช้กลยุทธ์ผสมผสาน เช่น domain randomization, online fine-tuning ด้วยข้อมูลจริงจำนวนน้อย, การใช้ ensembles หรือโมเดลที่ประมาณความไม่แน่นอน และการออกแบบวงป้อนกลับ (feedback loop) ระหว่าง LLM กับโมเดลโลกเพื่อตรวจสอบและปรับแผนก่อนการดำเนินการจริง ในมุมมองเชิงธุรกิจ การลงทุนในโครงสร้างพื้นฐานจำลองที่มีคุณภาพ การรวบรวมข้อมูลที่เป็นระบบ และการตั้งค่าเกณฑ์การตรวจสอบความปลอดภัยก่อนวางระบบสู่การใช้งานจริงเป็นปัจจัยสำคัญที่ช่วยเพิ่มอัตราความสำเร็จและลดความเสี่ยง
สรุปได้ว่า world models เป็นกุญแจสำคัญที่เปิดทางสู่การเรียนรู้ที่มีประสิทธิภาพสูงและการตัดสินใจเชิงกลยุทธ์ในหลายอุตสาหกรรม แต่การนำไปใช้อย่างประสบความสำเร็จต้องแก้ไขปัญหาทางเทคนิคและการบริหารจัดการความเสี่ยงอย่างเป็นระบบ โดยเฉพาะอย่างยิ่งเมื่อผสานกับ LLMs เพื่อให้ได้ระบบที่ทั้งมีเหตุผล เชื่อถือได้ และพร้อมใช้งานเชิงพาณิชย์
ความท้าทาย ข้อจำกัด และประเด็นด้านความปลอดภัย
ความท้าทาย ข้อจำกัด และประเด็นด้านความปลอดภัย
โมเดลโลก (world models) เสนอโอกาสในการขยายขอบเขตความสามารถของระบบปัญญาประดิษฐ์จากการจำลองเหตุการณ์ไปสู่การตัดสินใจเชิงยุทธศาสตร์ แต่ในทางปฏิบัติยังเผชิญกับความท้าทายเชิงเทคนิคและเชิงจริยธรรมที่สำคัญ ก่อนอื่นคือปัญหา sim-to-real gap — ช่องว่างระหว่างพฤติกรรมที่โมเดลเรียนรู้จากสภาพแวดล้อมจำลองกับพฤติกรรมในโลกจริง การศึกษาด้านหุ่นยนต์และอัตโนมัติชี้ให้เห็นว่าผลการทดลองในซิมูเลชันมักให้ค่าประสิทธิภาพสูงกว่าที่สังเกตได้จริงและการลดลงของประสิทธิภาพเมื่อย้ายไปสู่โลกจริงอาจมีขนาดตั้งแต่หลักสิบเปอร์เซ็นต์ขึ้นไป ข้อจำกัดนี้สร้างความเสี่ยงเมื่อใช้โมเดลในการควบคุมระบบที่มีความเสี่ยงสูง เช่น ยานยนต์อัตโนมัติหรือหุ่นยนต์ผ่าตัด
เทคนิคในการลดช่องว่างดังกล่าวมีทั้งการปรับวิธีการฝึกและการออกแบบสถาปัตยกรรม ตัวอย่างเช่น domain randomization ที่เพิ่มความหลากหลายของสภาพแวดล้อมจำลอง (เช่น แสง เงา พื้นผิว สัมประสิทธิ์การเสียดทาน) เพื่อให้โมเดลเรียนรู้ฟีเจอร์ที่ทนทานต่อความแปรปรวน ในขณะที่ domain adaptation มุ่งปรับตัวแบบสอนหรือไม่สอนให้เข้ากับตัวอย่างจากโดเมนจริง เทคนิคอื่นๆ ได้แก่การใช้ sim-to-real fine-tuning, การเพิ่ม noise ในการรับรู้ และการรวมข้อมูลจริงจำนวนเล็กน้อยในกระบวนการฝึก อย่างไรก็ตามแต่ละวิธีต้องแลกมาด้วยต้นทุนการคำนวณหรือความซับซ้อนในการออกแบบที่สูงขึ้น
อีกประเด็นสำคัญคือ การโอเวอร์ฟิตใน latent space และการเกิด hallucination ขณะพยากรณ์ เมื่อโมเดลโลกสร้างตัวแทนแฝง (latent representations) ที่จับลักษณะเฉพาะของชุดฝึกได้มากเกินไป จะทำให้โมเดลทำนายพฤติกรรมที่ไม่สอดคล้องกับความเป็นจริงเมื่อนำไปใช้นอกชุดข้อมูลนั้น ผลลัพธ์คือการพยากรณ์ที่ดูสมเหตุสมผลแต่ไม่แม่นยำ (hallucination) ซึ่งอาจก่อให้เกิดการตัดสินใจผิดพลาดในระบบอัตโนมัติ การป้องกันรวมถึงการใช้การทำ regularization (เช่น dropout, weight decay), การเพิ่มความหลากหลายของข้อมูล, การบีบคอ (information bottlenecks) ในสถาปัตยกรรม และเทคนิคการเรียนรู้ที่ส่งเสริมการแยกปัจจัย (disentanglement) ใน latent space
เพื่อประเมินและลดความเสี่ยงจาก hallucination จำเป็นต้องมีมาตรการวัดความน่าเชื่อถือของการพยากรณ์ เช่น การวัดการปรับความเชื่อมั่น (calibration metrics เช่น Expected Calibration Error), การวัดความไม่แน่นอน (uncertainty quantification) ผ่าน ensembles, Bayesian neural networks หรือการใช้วิธี conformal prediction และการตรวจจับข้อมูลนอกจำแนก (out-of-distribution detection) ในเชิงปฏิบัติ การรวมสัญญาณเชื่อมั่นเหล่านี้เข้าเป็นองค์ประกอบของระบบตัดสินใจช่วยให้ผู้บริหารสามารถตั้งข้อจำกัดหรือยกเลิกรายการคำสั่งเมื่อความเชื่อมั่นต่ำ
นอกจากนี้ โมเดลโลกยังเปราะบางต่อ distribution shift ทั้งในรูปแบบ covariate shift และ concept shift เมื่อสภาพแวดล้อมหรือพฤติกรรมของผู้ใช้เปลี่ยนไป จะส่งผลให้ประสิทธิภาพลดลงอย่างรวดเร็ว การเฝ้าติดตามแบบเรียลไทม์ (online monitoring), การปรับแบบทดสอบเวลาจริง (test-time adaptation), และการออกแบบระบบที่สนับสนุนการเรียนรู้ต่อเนื่อง (continual learning) เป็นแนวทางปฏิบัติที่ช่วยบรรเทา แต่ไม่สามารถขจัดความเสี่ยงทั้งหมดได้โดยปราศจากการวางนโยบายสำรองและการทดสอบเชิงสภาพแวดล้อมจริงอย่างต่อเนื่อง
ประเด็นด้านทรัพยากรและผลกระทบทางสังคมก็ไม่ควรถูกมองข้าม: การฝึกโมเดลโลกขนาดใหญ่ต้องการทั้งข้อมูลที่มีคุณภาพและทรัพยากรคอมพิวต์ในระดับสูง นำไปสู่ต้นทุนทางการเงินและคาร์บอนฟุตพริ้นต์ที่เพิ่มขึ้น รวมทั้งความเสี่ยงในการผูกขาดความสามารถทางเทคโนโลยีโดยองค์กรที่มีทรัพยากรมากกว่า ผู้ประกอบการควรพิจารณาการจัดสรรทรัพยากร การใช้เทคนิคประหยัดพลังงาน เช่น model compression และการรีไซเคิลข้อมูล รวมถึงการร่วมมือเชิงนโยบายเพื่อให้เกิดการเข้าถึงเทคโนโลยีอย่างเป็นธรรม
- ข้อควรระวังด้านจริยธรรมและความปลอดภัย — การใช้โมเดลโลกเปิดช่องทางการใช้งานผิดวัตถุประสงค์ (misuse) เช่น การจำลองพฤติกรรมมนุษย์เพื่อการหลอกลวงหรือการโจมตีเชิงไซเบอร์
- ความเสี่ยงจากความเป็นอิสระ (autonomy risks) — เมื่อนำโมเดลโลกไปใช้กับระบบที่มีอำนาจการตัดสินใจสูง อาจเกิดสถานการณ์ที่ระบบดำเนินการโดยไม่สามารถถูกยับยั้งได้ทันเวลา หากไม่มีกลไกการแทรกแซงที่ชัดเจน
- ความโปร่งใสและการตรวจสอบ (transparency & accountability) — ผู้ใช้งานและผู้มีส่วนได้ส่วนเสียต้องการความเข้าใจว่าการตัดสินใจมาจากข้อมูลและสมมติฐานใด จึงจำเป็นต้องมีการอธิบายตัวแบบ การบันทึก provenance ของข้อมูล และการตรวจสอบโดยอิสระ
สรุปได้ว่า โมเดลโลกมีศักยภาพในการพลิกโฉมหลายอุตสาหกรรม แต่การนำไปใช้เชิงพาณิชย์ต้องคำนึงถึงช่องว่าง sim-to-real, การควบคุม overfitting ใน latent space, การจัดการ hallucination, การรับมือ distribution shift รวมถึงกรอบจริยธรรมและการบริหารความเสี่ยงที่ชัดเจน สำหรับองค์กรที่ต้องการลงทุน ควรวางนโยบายการทดสอบภาคสนาม การวัดความเชื่อมั่นเชิงปริมาณ และกลไกกำกับดูแลเพื่อให้การใช้โมเดลโลกเป็นไปอย่างปลอดภัยและยั่งยืน
แนวทางปฏิบัติและคำแนะนำสำหรับการนำไปใช้ในองค์กร
แนวทางปฏิบัติและภาพรวมเชิงกลยุทธ์
การนำโมเดลโลก (world model) ไปใช้จริงในองค์กรต้องมีการวางแผนเชิงวิศวกรรมและเชิงธุรกิจควบคู่กัน ตั้งแต่การกำหนดเป้าหมายเชิงธุรกิจที่ชัดเจน การเลือก metric ที่สอดคล้อง ไปจนถึงการเตรียมข้อมูลและการวางระบบการทดสอบแบบค่อยเป็นค่อยไป (progressive validation) ข้อแนะนำต่อไปนี้เป็นแนวทางปฏิบัติแบบขั้นตอนสำหรับทีมวิจัยและทีมปฏิบัติการ (R&D & Ops) ที่ต้องการย้ายงานวิจัยสู่การใช้งานจริงในสเกลองค์กร
1) กำหนดเป้าหมายเชิงธุรกิจและ metrics ที่สอดคล้อง
ก่อนเริ่มพัฒนาต้องนิยามผลลัพธ์เชิงธุรกิจที่ต้องการชี้วัด พร้อมระบุ metric เทียบเคียงเพื่อประเมินความคุ้มค่าและความเสี่ยง ตัวอย่างเช่น:
- Sample efficiency — จำนวนตัวอย่างที่ต้องใช้จนได้ถึงระดับ performance ที่ยอมรับได้ (เช่น ตัวอย่าง/episode หรือก้าวสู่ reward ≥ X ภายใน N ขั้น) ซึ่งสำคัญเมื่อข้อมูลจริงมีต้นทุนสูง
- Task reward / success rate — ค่า reward เฉลี่ย, อัตราความสำเร็จ (success rate) หรือเวลาที่ใช้จบงาน (time-to-completion) ในงานเชิงปฏิบัติการ
- Prediction calibration — ความเที่ยงตรงของการคาดการณ์ความไม่แน่นอน เช่น Expected Calibration Error (ECE), Negative Log Likelihood (NLL) หรือความต่างระหว่าง predictive distribution กับความเป็นจริง (e.g., RMSE, KL divergence)
- Transfer gap — การลดลงของ performance เมื่อย้ายจากซิมูเลเตอร์สู่โลกจริง (sim-to-real gap) วัดเป็นสัดส่วนหรือค่าต่าง (e.g., performance_real / performance_sim)
- Operational metrics — latency, throughput, resource cost (GPU-hours), และ SLA ที่เกี่ยวข้อง
2) เริ่มจากจำลองขนาดเล็กและแบ่งขั้นตอนการทดสอบก่อน transfer
ให้เริ่มพัฒนาในสภาพแวดล้อมจำลองขนาดเล็ก (minimal viable sim) เพื่อทดสอบหลักการและลดความเสี่ยง จากนั้นค่อยเพิ่มความซับซ้อนแบบมีขั้นตอน (staged testing) ดังนี้:
- หนีบชุดทดสอบแบบ unit-level สำหรับโมดูลการพยากรณ์ของโลก (dynamics model) และโมดูล policy
- ทำการ validation ด้วยชุดข้อมูล holdout และ scenario-based tests (corner cases) ก่อน transfer
- ประเมิน sim-to-sim generalization โดยเปลี่ยนพารามิเตอร์ในซิม (domain randomization) เพื่อวัดความทนทาน
- ทดลอง transfer แบบ shadow mode บนระบบจริง: ให้โมเดลทำงานขนานโดยไม่ควบคุมการตัดสินใจสุดท้าย เพื่อเก็บ metric และประเมิน transfer gap
- ใช้ canary / staged rollout: เริ่มจากสเกลเล็ก ๆ แล้วขยายเมื่อ metric อยู่ในเกณฑ์ที่ยอมรับได้
3) การเตรียมข้อมูลและกลยุทธ์การสร้างชุดข้อมูล
คุณภาพและความหลากหลายของข้อมูลเป็นปัจจัยสำคัญสำหรับ world model แนะนำแนวทางปฏิบัติดังนี้:
- ผสมข้อมูลจริงและซินเธติก — สร้างข้อมูลด้วย domain randomization ในซิมเพื่อเสริม diversity และลด overfitting
- ออกแบบการรวบรวมข้อมูล — กำหนด policy logging, sensor fidelity models และการเก็บ metadata (เช่น เงื่อนไขแวดล้อม, เวอร์ชันซอฟต์แวร์) เพื่อช่วยการ debug และการวิเคราะห์
- แยกชุดข้อมูล — train / validation / test และ holdout scenarios สำหรับ stress tests และ safety validation
- ใช้ augmentation และ balancing — เพิ่มตัวอย่าง rare events ด้วย oversampling หรือ synthetic augmentation เพื่อให้โมเดลเรียนรู้ edge cases
- มาตรฐานคุณภาพข้อมูล — กำหนด threshold สำหรับ missing data, sensor noise และขอบเขต label quality
4) ตั้ง baseline และการออกแบบการทดลอง (experimental design)
ตั้ง baseline ที่หลากหลายเพื่อประเมินประโยชน์ของ world model อย่างเป็นระบบ:
- Baseline แบบสุ่ม (random policy) และ heuristic rule-based เพื่อเป็น lower bound
- Model-free RL ที่เป็นมาตรฐาน (เช่น PPO, SAC) เป็น baseline ในการเปรียบเทียบ sample efficiency และ asymptotic performance
- World model benchmarks เช่น Dreamer / PlaNet / MuZero (หากเกี่ยวข้อง) เป็น baseline เชิงวิชาการ
- การทำ ablation study: ปิด/เปิดส่วนประกอบต่าง ๆ (latent dynamics, predictive decoder, uncertainty estimator) เพื่อตีความผลกระทบ
- กำหนด success criteria ชัดเจน เช่น “ต้องปรับปรุง sample efficiency อย่างน้อย 2x เมื่อเทียบกับ baseline model-free ภายในงบประมาณตัวอย่างที่กำหนด”
5) การผสานกับระบบปฏิบัติการและการทดสอบ sim-to-real
การย้ายโมเดลสู่ระบบปฏิบัติการจริงต้องคำนึงถึงสถาปัตยกรรม ซอฟต์แวร์ และความปลอดภัย:
- สถาปัตยกรรมแบบโมดูล — แยก world model, policy, safety monitor และ logging service ให้ชัดเจนเพื่อให้สามารถทดสอบแยกชิ้นได้
- Shadow deployments — รันโมเดลแบบอ่านค่า (observational) บนข้อมูลจริงโดยไม่แทรกแซงการตัดสินใจทันที เพื่อเปรียบเทียบผลลัพธ์ก่อนเปิดใช้จริง
- Canary / phased rollout — เปิดใช้งานเฉพาะกลุ่มเล็ก ๆ และติดตาม metric แบบเรียลไทม์ก่อนขยายสเกล
- Safety overrides และ human-in-the-loop — ต้องมี mechanism ให้มนุษย์หรือ rule-based controller สามารถยึดการควบคุมเมื่อระบบตรวจพบความเสี่ยง
- Sim-to-real validation — ใช้ domain randomization, system identification และ fine-tuning บนข้อมูลจริงแบบจำกัด เพื่อลด sim-to-real gap
6) Hybrid approach และมาตรการมอนิเตอร์เพื่อความปลอดภัย
การผสาน world model กับ model-free components มักให้ผลดีที่สุดในแง่ความยืดหยุ่นและความปลอดภัย:
- Hybrid design — ใช้ world model สำหรับ planning / imagination-based rollouts และใช้ model-free policy สำหรับการตัดสินใจเชิงนโยบายที่รวดเร็วและทนทาน
- Uncertainty-aware control — ผนวกตัวชี้วัดความไม่แน่นอน (ensembles, MC dropout, Bayesian NN) เพื่อปรับการตัดสินใจเมื่อความเชื่อมั่นต่ำ
- Monitoring & alarms — ติดตาม drift ของ observation distribution, reward prediction error, calibration metrics (e.g., ECE) และตั้ง threshold สำหรับการทำ safe-fallback
- Red teaming และ stress tests — ทดสอบระบบด้วยโจมตีเชิง adversarial และสถานการณ์ผิดปกติเพื่อหา failure modes
- Audit trails — บันทึกการตัดสินใจและเหตุผลที่สำคัญสำหรับการตรวจสอบหลังเกิดเหตุ (post-mortem)
7) แพ็กเกจเครื่องมือและทรัพยากรที่แนะนำเพื่อเริ่มต้น
เครื่องมือและทรัพยากรต่อไปนี้ช่วยลดเวลาในการตั้งค่าและเร่งกระบวนการนำไปใช้:
- Simulators: NVIDIA Isaac Sim, Isaac Gym, MuJoCo, PyBullet, CARLA, Habitat — สำหรับการสร้าง environment และ domain randomization
- RL Frameworks: Stable Baselines3, RLlib (Ray), Acme — สำหรับ baseline model-free และการฝึกแบบ distributed
- Deep Learning: PyTorch, TensorFlow — สำหรับพัฒนา world model และ uncertainty modules
- Experiment Tracking & MLOps: Weights & Biases, MLflow, Neptune — สำหรับ logging, metric tracking และ reproducibility
- Orchestration: Docker, Kubernetes, Ray — สำหรับ deployment แบบ scalable และ reproducible
- Monitoring & Observability: Prometheus, Grafana, ELK stack — สำหรับการมอนิเตอร์ performance และการแจ้งเตือน
- Benchmark Suites & Papers: OpenAI Gym, DeepMind Control Suite, Benchmark papers (Dreamer, PlaNet, MuZero) — ใช้เปรียบเทียบประสิทธิภาพและวิธีการ
สรุปเชิงปฏิบัติ
การนำ world model มาใช้ในองค์กรเป็นงานแบบหลายมิติที่ต้องผสานทั้งเป้าหมายเชิงธุรกิจ การออกแบบการทดลอง การเตรียมข้อมูล ระบบการ deploy และมาตรการความปลอดภัย เริ่มจากการกำหนด KPI ที่ชัดเจนและ baseline ที่เหมาะสม จากนั้นใช้การพัฒนาแบบขั้นบันได (from small sims → staged validation → shadow → canary → full rollout) พร้อมกับ hybrid architecture และ monitoring เพื่อควบคุมความเสี่ยง การเตรียมเครื่องมือและทรัพยากรที่แนะนำจะช่วยให้องค์กรข้ามช่องว่างระหว่างการวิจัยกับการใช้งานจริงได้อย่างเป็นระบบและมีความรับผิดชอบ
บทสรุป
โมเดลโลกเป็นเทคโนโลยีพื้นฐานที่ช่วยเพิ่มความยืดหยุ่นและประสิทธิภาพให้กับระบบปัญญาประดิษฐ์ โดยเฉพาะงานที่ต้องการการวางแผนเชิงอนาคตและการเรียนรู้ที่ประหยัดตัวอย่าง (sample-efficient) เช่น หุ่นยนต์เคลื่อนที่ ระบบยานยนต์ไร้คนขับ และระบบโต้ตอบเชิงซับซ้อน งานวิจัยบางชิ้นรายงานว่าการใช้โมเดลโลกร่วมกับกลยุทธ์การวางแผนอาจลดความต้องการตัวอย่างการฝึกได้หลายเท่า (ตัวอย่างเช่น 5–10x ในบางกรณี) ซึ่งนำไปสู่การลดต้นทุนการพัฒนาและการเร่งเวลาสู่การใช้งานจริง
การนำโมเดลโลกไปใช้จริงยังต้องเผชิญความท้าทายสำคัญ เช่น ช่องว่างระหว่างการจำลองกับโลกจริง (sim-to-real), การประเมินความมั่นคงและความทนทานของโมเดลภายใต้สภาวะแวดล้อมไม่แน่นอน, และข้อพิจารณาด้านจริยธรรมทั้งความเป็นส่วนตัว ความเป็นธรรม และความเสี่ยงจากการใช้งานในทางที่ไม่พึงประสงค์ อย่างไรก็ดี หากออกแบบและประเมินระบบอย่างรอบคอบ—โดยใช้เทคนิคเช่น domain randomization, การปรับจูนบนข้อมูลจริง, และกรอบการทดสอบความปลอดภัย—โมเดลโลกจะมอบประโยชน์ทั้งเชิงเทคนิค (การตัดสินใจที่แม่นยำขึ้น การใช้งานทรัพยากรน้อยลง) และเชิงธุรกิจ (ลดต้นทุน ต่อยอดบริการใหม่ ๆ เพิ่มความเร็วในการพัฒนาผลิตภัณฑ์)
มองไปข้างหน้า โครงสร้างผสมระหว่างโมเดลโลกกับวิธีการเรียนรู้แบบไม่ขึ้นรูปจะเข้ามามีบทบาทสำคัญ ขณะที่ซิมูเลเตอร์ที่สามารถดิฟเฟอเรนเชียเบิลได้ การประเมินมาตรฐานใหม่ และกรอบกฎหมายด้านความปลอดภัยและจริยธรรมจะช่วยขับเคลื่อนการนำไปใช้เชิงอุตสาหกรรมในวงกว้าง ในระยะยาว โมเดลโลกที่ได้รับการพัฒนาอย่างยั่งยืนอาจกลายเป็นแกนกลางของระบบดิจิทัลทวิน (digital twins) และเอเจนต์อเนกประสงค์ ช่วยให้ธุรกิจและสังคมได้ประโยชน์จากการตัดสินใจเชิงคาดการณ์และการทำงานอัตโนมัติที่ปลอดภัยมากขึ้น แต่อย่างไรก็ตามความสำเร็จนั้นต้องอาศัยการร่วมมือระหว่างนักวิจัย วิศวกร ผู้กำกับดูแล และภาคธุรกิจเพื่อออกแบบการใช้งานที่รับผิดชอบและมีประสิทธิผล
📰 แหล่งอ้างอิง: Scientific American



