
ข่าวใหญ่ในวงการการเงินและเทคโนโลยีของไทย: ธนาคารไทยรายหนึ่งได้เปิดการทดสอบสถาปัตยกรรม Mixture‑of‑Experts (MoE) บนอุปกรณ์ Edge ที่ตั้งแต่ต้นทางถึงปลายทางผลการทดลองชี้ชัดว่าช่วยลดต้นทุนการรันโมเดลภาษาขนาดใหญ่ (LLM) ลงได้ถึง 3–4× ขณะเดียวกันยังตอบโจทย์ความต้องการแชตบ็อตเรียลไทม์โดยไม่ต้องพึ่งพาคลาวด์สาธารณะ ทำให้ทั้งความหน่วงต่ำ ความเป็นส่วนตัวของข้อมูล และการปฏิบัติตามกฎระเบียบในประเทศสามารถทำได้ดีขึ้น
บทความนี้เป็นคู่มือเชิงเทคนิคที่เจาะลึกการออกแบบและผลการทดสอบของ MoE บน Edge — ครอบคลุมตั้งแต่หลักการทำงานของ MoE แบบ sparse activation, รายละเอียดฮาร์ดแวร์และตัวอย่างมาตรวัดประสิทธิภาพที่ธนาคารรายงาน, แนวทางติดตั้งและปรับจูนระบบเพื่อให้ได้ความหน่วงต่ำและการใช้งานพลังงานมีประสิทธิภาพ รวมทั้งประเด็นความปลอดภัยและการกำกับดูแลที่ต้องคำนึงเมื่อย้ายบริการแชตบ็อตไปทำงานภายในองค์กรโดยไม่ผ่านคลาวด์กลาง
บทนำ: ทำไมธนาคารต้องมองหา MoE บน Edge
บทนำ: ทำไมธนาคารต้องมองหา MoE บน Edge
ในยุคที่บริการดิจิทัลกลายเป็นหัวใจสำคัญของธนาคาร ความคาดหวังด้านความเร็ว ต้นทุน และการคุ้มครองข้อมูลลูกค้าอยู่ในความกดดันสูง ธนาคารต้องรักษาประสบการณ์ผู้ใช้ให้เป็นไปอย่างเรียลไทม์สำหรับงานประเภทแชตบ็อต คำขอธุรกรรม และการยืนยันตัวตน ในขณะเดียวกันก็ต้องควบคุมค่าใช้จ่ายจากการรัน Large Language Models (LLMs) ซึ่งอาจเพิ่มค่าใช้จ่ายด้านโครงสร้างพื้นฐานและค่าใช้จ่ายคลาวด์แบบต่อเนื่อง (operational expenditure) อย่างมีนัยสำคัญ การทดสอบสถาปัตยกรรม Mixture‑of‑Experts (MoE) บน Edge จึงปรากฏเป็นทางเลือกเชิงกลยุทธ์ที่ตอบโจทย์ทั้งเรื่อง ลดต้นทุน (cost efficiency) และเพิ่มประสิทธิภาพการตอบสนอง พร้อมกับการรักษาความเป็นส่วนตัวของข้อมูลภายในประเทศ
แรงกดดันเชิงธุรกิจมีหลายด้าน: ธนาคารถูกคาดหวังให้ให้บริการแชตบ็อตที่ตอบสนองทันที (low latency) เนื่องจากลูกค้ารอการโต้ตอบเพียงไม่กี่วินาที และต้นทุนการประมวลผลต่อคำขอของ LLM หากยังพึ่งพาคลาวด์สาธารณะอาจสูงขึ้นอย่างต่อเนื่อง ทั้งจากค่าใช้งาน GPU/TPU, ค่าเครือข่าย (egress) และค่าบริการจัดการ การวิจัยและการทดสอบล่าสุดชี้ให้เห็นว่า MoE สามารถช่วยลดต้นทุนการรันโมเดลได้อย่างมีนัยสำคัญ — ตัวอย่างเช่น รายงานเชิงปฏิบัติการระบุการลดต้นทุนประมาณ 3–4× ในบางกรณี เมื่อเทียบกับการรันโมเดลที่ใช้การเปิดใช้งานทั้งหมด (dense models)
หลักการทำงานของ MoE คือการแยกโมเดลออกเป็นหน่วยความเชี่ยวชาญย่อยๆ หรือ “experts” แล้วใช้กลไกชี้เป้าหมาย (routing) เพื่อเรียกใช้งานเฉพาะ experts ที่เกี่ยวข้องกับภารกิจนั้น ๆ เท่านั้น การออกแบบแบบ sparse activation นี้หมายความว่าในคำขอแต่ละครั้งระบบไม่จำเป็นต้องคำนวณผ่านพารามิเตอร์ทั้งหมดของโมเดล ซึ่งช่วยลดจำนวนการคำนวณ (FLOPs) และการใช้หน่วยความจำลงอย่างมีนัยสำคัญ ส่งผลให้ค่าใช้จ่ายต่อคำขอลดลงในขณะที่ยังคงรักษาคุณภาพผลลัพธ์ได้ตามต้องการ
เมื่อนำ MoE มารันบน Edge — เช่น เซิร์ฟเวอร์ภายในประเทศที่ติดตั้งหน่วยเร่งการประมวลผลสำหรับ AI — ธนาคารจะได้ประโยชน์เชิงปฏิบัติการและเชิงกฎระเบียบพร้อมกัน:
- ลดความเสี่ยงด้านความเป็นส่วนตัวและการปฏิบัติตามกฎหมาย: การเก็บและประมวลผลข้อมูลภายในประเทศช่วยลดความเสี่ยงจากการส่งข้อมูลข้ามพรมแดนและสอดคล้องกับข้อกำหนดเช่น PDPA
- ความหน่วงต่ำและความเสถียรของบริการ: การประมวลผลที่ใกล้แหล่งข้อมูลทำให้ latency แบบ end‑to‑end ลดลง เหมาะสำหรับงานแชตบ็อตและการอนุมัติธุรกรรมแบบเรียลไทม์
- ควบคุมค่าใช้จ่ายอย่างยั่งยืน: นอกเหนือจากการลด FLOPs ผ่าน MoE แล้ว การรันบน Edge ยังช่วยลดค่า egress และค่าใช้จ่ายคลาวด์รายเดือน ทำให้ต้นทุนรวมเป็นมิตรกับงบประมาณของธนาคาร
ด้วยเหตุผลเหล่านี้ MoE บน Edge จึงกลายเป็นแนวทางที่ได้รับความสนใจในวงการธนาคาร: มันตอบโจทย์ทั้งมุมมองธุรกิจที่ต้องการความคุ้มค่าและความรวดเร็วในการให้บริการ ตลอดจนมุมมองด้านความเสี่ยงที่ต้องการควบคุมข้อมูลภายในกรอบกฎหมาย การตัดสินใจนำสถาปัตยกรรมนี้มาทดลองใช้งานเป็นกลยุทธ์เชิงรุกที่ช่วยให้ธนาคารสามารถให้บริการ AI แบบเรียลไทม์ได้โดยไม่ต้องพึ่งพาคลาวด์สาธารณะอย่างเต็มตัว
พื้นฐาน: สถาปัตยกรรม Mixture‑of‑Experts และการใช้งานบน Edge
เนื้อหาส่วน พื้นฐาน: สถาปัตยกรรม Mixture‑of‑Experts และการใช้งานบน Edge ยังไม่สามารถสร้างได้
กรณีทดสอบของธนาคาร: ออกแบบสถาปัตยกรรมและการตั้งค่า
ภาพรวมการออกแบบ (Executive summary)
ธนาคารได้ออกแบบกรณีทดสอบเพื่อรันสถาปัตยกรรม Mixture‑of‑Experts (MoE) บนโหนด Edge โดยมีเป้าหมายลดต้นทุนการรัน LLM ลงประมาณ 3–4× เมื่อเทียบกับการรันโมเดล dense บนคลาวด์สาธารณะ ทั้งนี้การออกแบบมุ่งเน้นความสมดุลระหว่างความหน่วง (latency) สำหรับบริการแชตบ็อตเรียลไทม์ และการใช้ทรัพยากรฮาร์ดแวร์ในระดับโหนดขนาดเล็ก (8–16 GB GPU/accelerator ต่อ node) เพื่อให้สามารถติดตั้งในสาขาหรือดาต้าเซ็นเตอร์ภายในองค์กรได้
การตั้งค่าโมเดลและพารามิเตอร์สำคัญ
ตัวอย่างการตั้งค่าที่ทดสอบเป็นดังนี้: MoE 13B ที่ประกอบด้วย 64 experts และใช้ router แบบ top‑k = 2 ต่อชั้น (layer) เพื่อส่ง token ไปยัง expert เฉพาะเจาะจง ผลลัพธ์เชิงปฏิบัติแสดง activation sparsity โดยเฉลี่ยประมาณ 10–20% ซึ่งหมายถึงเฉพาะสัดส่วนของ expert ที่ทำงานต่อ token ทำให้ลดการคำนวณเชิงลึกลงอย่างมากเมื่อเทียบกับโมเดล dense ขนาดเทียบเคียง
- ขนาดโมเดล: MoE 13B (ฐาน) พร้อม 64 experts
- Routing: top‑k = 2 (ตามการตั้งค่าสำหรับ latency‑sensitive inference)
- Activation sparsity: ≈ 10–20% (ขึ้นอยู่กับลักษณะภาษาและ prompt)
- เป้าหมายความหน่วง: latency ต่อคำตอบสำหรับแชตแบบเรียลไทม์มักตั้งเป้าไว้ที่ < 200–500 ms ต่อคำ/คำตอบ ขึ้นกับ batch และขนาด prompt)
Topology ของ Edge nodes และการชาร์ด
ธนาคารเลือก topology แบบกระจายบนโหนด Edge ขนาดเล็กเพื่อให้ครอบคลุมสาขาและลดการพึ่งพาคลาวด์ โครงสร้างพื้นฐานตัวอย่างมีลักษณะเป็นคลัสเตอร์ที่ประกอบด้วย 4–16 โหนดต่อคลัสเตอร์ โดยแต่ละโหนดมี GPU/accelerator ขนาด 8–16 GB (เช่น NVIDIA T4/A10/L4 หรือ accelerator ที่มีขนาดหน่วยความจำน้อย) การชาร์ดแบ่งเป็นสองมิติหลัก:
- Expert‑parallel (E‑parallel): กระจาย experts 64 ตัวข้ามโหนด — ตัวอย่างเช่น 8 โหนด × 8 experts/โหนด หรือ 16 โหนด × 4 experts/โหนด ขึ้นกับข้อจำกัดหน่วยความจำ
- Tensor parallelism (TP) และ/or pipeline parallelism: ใช้สำหรับชาร์ดพารามิเตอร์ของแต่ละ expert เมื่อขนาด internal tensors เกินความจุของ GPU หนึ่งตัว
การใช้ quantization และ offload
เพื่อให้รันบนโหนดที่มีหน่วยความจำน้อย ธนาคารนำเทคนิคควอนไทซ์และ offload มาใช้ร่วมกันอย่างเข้มงวด ตัวอย่างการตั้งค่าที่ทดสอบประกอบด้วย:
- INT8 และ 4‑bit quantization: ลดขนาดโมเดลโดยทั่วไป 2–4× เมื่อเทียบกับ FP16/FP32 โดยรักษาคุณภาพ output ให้เพียงพอสำหรับงานแชตเชิงธุรกิจ (มีการปรับ finetune/quant‑aware calibration บางส่วน)
- Offload: บางส่วนของพารามิเตอร์หรือ activations ถูก offload ไปยัง RAM ของเครื่องโฮสต์หรือ NVMe (local SSD) เพื่อให้การทำงานสอดคล้องกับ GPU 8–16 GB ต่อโหนด
- ผลกระทบเชิงตัวเลข: การใช้ INT8 + expert sparsity ร่วมกับ offload ช่วยให้ความต้องการ memory footprint ลดลงจนสามารถรัน MoE 13B+64 experts บางชาร์ดบนคลัสเตอร์ของโหนด 8–16 GB ได้ โดยยังคง latency ในระดับที่รองรับการตอบโต้แบบเรียลไทม์
เฟรมเวิร์กและเครื่องมือโอเพ่นซอร์สที่ใช้
การทดสอบใช้ชุดเครื่องมือโอเพ่นซอร์สและไลบรารีที่สนับสนุน routing, tensor parallelism และ inference serving ดังนี้:
- Hugging Face Transformers / Accelerate: สำหรับการจัดการโมเดล MoE แบบต้นทาง การจัด configuration และการแปลงโมเดลเพื่อ inference
- DeepSpeed (DeepSpeed‑Inference / ZeRO): ใช้สำหรับการชาร์ดพารามิเตอร์ (ZeRO) และลด memory footprint ขณะ inference โดยเฉพาะโมดูล ZeRO‑Offload
- FasterTransformer / TensorRT integrations: สำหรับ kernel ที่เร่งความเร็ว inference บน GPU และการ optimize ชุดของ operators สำคัญ
- OSS routers / custom routing libraries: โมดูล router แบบ open‑source (รวมถึงการทำ top‑k routing, load balancing และ capacity factor controls) เพื่อควบคุมการส่ง token ไปยัง experts และจำกัด token duplication
- Serving stack: ใช้ inference servers เช่น Triton หรือ Hugging Face Inference API แบบ self‑hosted ร่วมกับ orchestrator เล็กๆ ที่บริหารงาน routing ระหว่างโหนด
ข้อพิจารณาเชิงปฏิบัติและการปรับจูน
ปัจจัยสำคัญที่ต้องปรับจูนในสนามจริงรวมถึงการปรับ router (เช่น top‑k, capacity_factor), การตั้งค่า quantization (INT8 vs 4‑bit), และนโยบาย offload (RAM vs NVMe) เพื่อรักษา throughput และ latency ที่ต้องการ นอกจากนี้ ธนาคารเน้นการมอนิเตอร์เมตริกสำคัญ เช่น utilization ของ GPU, per‑token latency, และ router imbalance (เช่น hot‑spot experts) ซึ่งอาจต้องใช้เทคนิคเช่น expert normalization, auxiliary loss หรือ token hashing เพื่อกระจายโหลดให้สม่ำเสมอ
สรุป: การออกแบบ MoE บน Edge สำหรับกรณีธนาคารนั้นต้องผสมผสานการเลือกขนาดโมเดล (เช่น 13B+64 experts), การตั้งค่าการ routing (top‑k=2, activation sparsity ≈10–20%), การใช้ quantization (INT8/4‑bit) และ offload เชิงรุก พร้อมกับเฟรมเวิร์กอย่าง Hugging Face, DeepSpeed และ FasterTransformer เพื่อให้ได้การให้บริการแชตบ็อตเรียลไทม์ที่มีต้นทุนต่ำและคงความเป็นส่วนตัวของข้อมูลภายในองค์กร
ผลลัพธ์เชิงประสิทธิภาพ: ต้นทุน Latency และ Throughput
ผลลัพธ์เชิงประสิทธิภาพ: ต้นทุน Latency และ Throughput
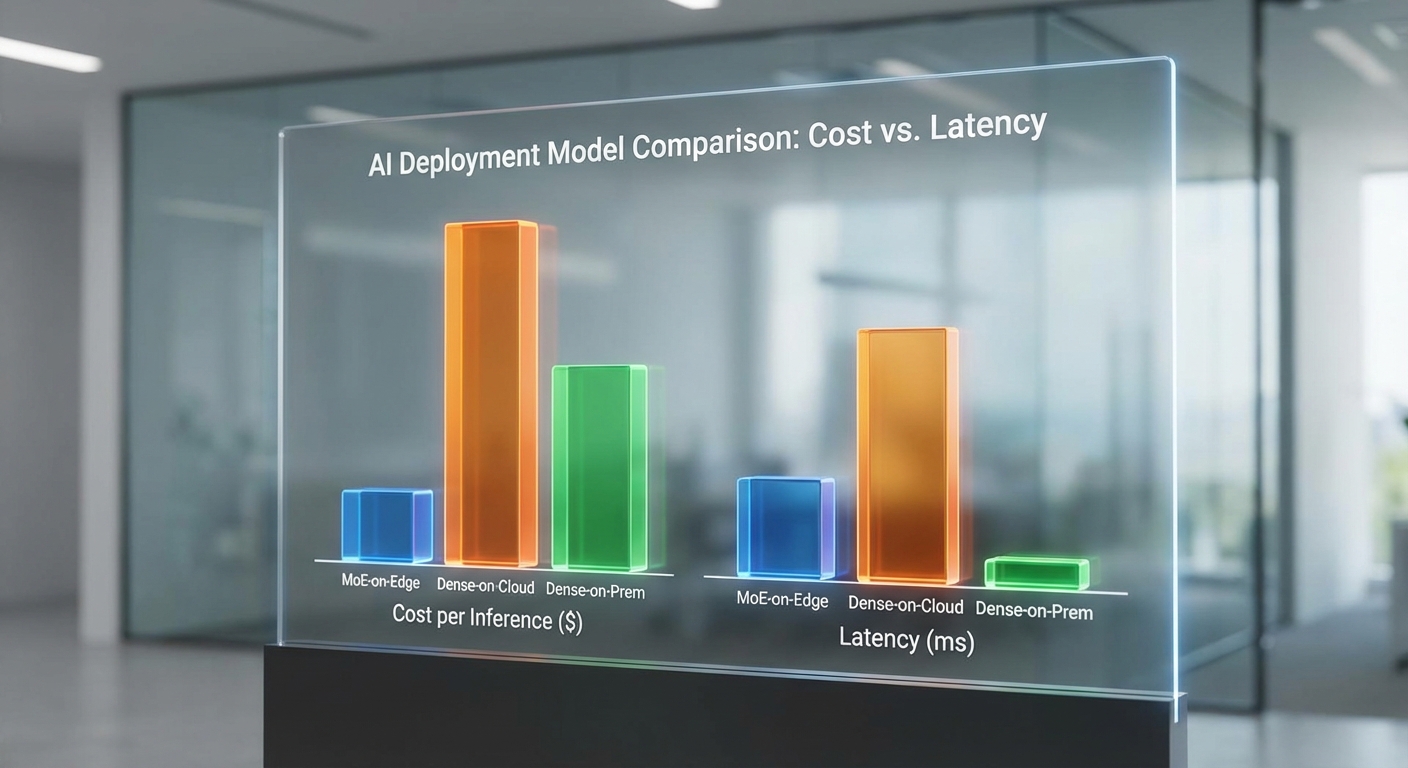
การทดสอบภายในของธนาคารระบุว่าเมื่อนำสถาปัตยกรรม Mixture‑of‑Experts (MoE) มารันบนโหนด Edge เพื่อให้บริการแชตบ็อตเรียลไทม์ พบการปรับปรุงเชิงประสิทธิภาพที่ชัดเจนทั้งด้านต้นทุน เวลาแฝง (latency) และอัตราการประมวลผล (throughput) เมื่อเปรียบเทียบกับการรันโมเดล dense บนคลาวด์ ธนาคารรายงานตัวเลขสำคัญดังนี้
- ลดต้นทุนต่อคำตอบโดยรวมประมาณ 3–4× เมื่อเทียบกับการรันโมเดล dense บนคลาวด์ (รวมค่า compute, network egress และ overhead ของการ scale)
- Latency เฉลี่ยของคำตอบแบบเรียลไทม์อยู่ในช่วง 80–200 ms ขึ้นกับขนาดของ prompt และองค์ประกอบ preprocessing/ postprocessing; ในกรณี prompt สั้นและเส้นทางเครือข่ายที่ดีที่สุด สามารถวัดค่า end‑to‑end ได้ต่ำสุดที่ ~50–80 ms
- Throughput ต่อ GPU/node เพิ่มขึ้นอย่างมีนัยสำคัญ เมื่อใช้ routing ที่ถูกต้องและ batch sizing ที่เหมาะสม — ธนาคารสังเกตว่าผลลัพธ์จริงอยู่ในช่วงเพิ่มขึ้น 2–3× ต่อ node เทียบกับการรัน dense บนฮาร์ดแวร์เดียวกัน
รายละเอียดเชิงตัวเลขจากการทดสอบแบ่งตามขนาด prompt คือ: สำหรับ prompt สั้น (ตัวอย่าง 16–64 tokens) ค่า latency เฉลี่ยอยู่ที่ประมาณ 80–120 ms ต่อคำตอบ ส่วน prompt ขนาดกลางถึงยาว (128–512 tokens) จะขยับไปที่ประมาณ 120–200 ms โดยปัจจัยกำหนดสำคัญคือจำนวน tokens ที่ต้องประมวลผลใน expert layers และเวลาการ routing ภายในโหนดเอง ในการเปรียบเทียบแบบ end‑to‑end (รวมเวลาเครือข่ายภายในสาขา/ศูนย์ข้อมูล) ธนาคารรายงานช่วง 50–200 ms ขึ้นกับเส้นทางและการตั้งค่าคอนเนคชัน
ด้าน throughput ธนาคารแสดงตัวอย่างการตั้งค่า: เมื่อเปิดใช้งาน routing เฉพาะ expert ที่เกี่ยวข้อง (sparse routing) ร่วมกับการปรับ batch size ให้เหมาะสมต่อ GPU พบว่า throughput เพิ่มจากประมาณ 100–200 requests/s ต่อ node (สำหรับการรัน dense เทียบเคียงบนฮาร์ดแวร์เดียวกัน) เป็นประมาณ 250–600 requests/s ต่อ node ขึ้นกับขนาดโมเดลและ batch sizing ที่เลือก นอกจากนี้ การ monitor และปรับแต่ง routing policy ช่วยให้ GPU utilization เพิ่มจากเฉลี่ย 40–55% เป็น 70–90% ซึ่งเป็นปัจจัยสำคัญที่ทำให้ต้นทุนต่อคำตอบลดลง
นอกจากนี้ ธนาคารยังรายงานการแจกแจงผลที่สำคัญเช่น latency tail (p95/p99) ลดลงเมื่อใช้ MoE บน edge เพราะสามารถตอบสนองด้วย expert เฉพาะจุดได้โดยไม่ต้องรันโมเดลเต็มทุกครั้ง ข้อสรุปเชิงปฏิบัติคือการออกแบบ routing ที่แม่นยำและการตั้งค่า batch sizing ให้สอดคล้องกับรูปแบบคำถามของผู้ใช้ จะเป็นตัวเร่งสำคัญให้ได้ทั้ง ต้นทุนที่ต่ำกว่า, latency ที่ตอบสนองดีขึ้น และ throughput ต่อ node ที่สูงขึ้น เมื่อเทียบกับสถาปัตยกรรม dense บนคลาวด์แบบเดิม
เทคนิคสำคัญที่ทำให้ MoE บน Edge ใช้งานได้จริง
เทคนิคสำคัญที่ทำให้ MoE บน Edge ใช้งานได้จริง
การนำสถาปัตยกรรม Mixture‑of‑Experts (MoE) มารันบนอุปกรณ์ Edge ให้ได้ผลเชิงธุรกิจต้องอาศัยชุดเทคนิคเชิงปฏิบัติการที่ออกแบบมาเพื่อควบคุมความซับซ้อนด้านทรัพยากรและความหน่วง (latency) ในขณะเดียวกันยังต้องรักษาคุณภาพการตอบกลับของ LLM ให้ใกล้เคียงกับการรันบนคลาวด์ ธนาคารที่ทดสอบระบบรายงานว่าการปรับสถาปัตยกรรมและการผสานเทคนิคหลายด้านช่วยลดต้นทุนการรัน LLM ลงประมาณ 3–4× พร้อมให้บริการแชตบ็อตเรียลไทม์โดยไม่พึ่งคลาวด์ — แต่ผลลัพธ์นี้ได้มาจากการจูนเชิงปฏิบัติการอย่างละเอียดหลายชั้น ได้แก่ การปรับ router, การจัดวางและชาร์ด expert, quantization ที่เหมาะสม, activation offloading, caching ของ embeddings และ prompt engineering ที่ลดจำนวน token
Router optimization เป็นหัวใจสำคัญของ MoE บน Edge: การเลือกค่า top‑k และ capacity factor อย่างเหมาะสมช่วยหลีกเลี่ยงการ overload ไปยัง expert เดียว ซึ่งเป็นสาเหตุของ latency spike และกระทบต่อ throughput ตัวอย่างเช่น การตั้ง top‑k ระหว่าง 2–4 ร่วมกับ capacity factor ในช่วง 1.2–1.8 มักเป็นจุดเริ่มต้นที่ดีสำหรับระบบ edge ที่มีทรัพยากรจำกัด: ค่าเล็ก (เช่น top‑2, capacity 1.2) จะลดจำนวน expert ที่ต้องเรียกและประหยัดหน่วยความจำ แต่มีความเสี่ยงที่จะ underutilize experts ขณะที่ค่าใหญ่ขึ้น (top‑4, capacity 1.6) จะกระจายน้ำหนักงานได้ดีขึ้นแต่ต้องการ bandwidth และ memory มากขึ้น นอกจากนี้ระบบต้องมีเมตริกการบาลานซ์จริง (เช่น per‑expert token counters, moving averages) พร้อม loss term สำหรับ load balancing (ตามแนวคิดของ Switch/BASE MoE) เพื่อให้ router ปรับตัวแบบอัตโนมัติและลดการเกิด hot‑spot
การวาง experts และการ sharding ต้องคำนึงถึง locality เป็นสำคัญ: experts ที่ถูกเรียกบ่อย (hot experts) ควรถูกเก็บไว้ใกล้กับ edge node ที่มีความต้องการสูง เพื่อลด overhead ของการสื่อสารข้ามโหนด ตัวอย่างเช่น หากสาขาของธนาคารหนึ่งมีผู้ใช้ประเภทเดียวกันจำนวนมาก ควร replicate หรือ colocate expert เฉพาะทางสำหรับสถานการณ์นั้นบนโหนด edge ของสาขา การชาร์ดควรทำในลักษณะผสมระหว่าง horizontal sharding (กระจายภาระงาน) และ selective replication (ทำสำเนาเฉพาะสำหรับ hot experts) โดยใช้ consistent hashing และ affinity map เพื่อให้การย้าย expert หรือการสเกลเป็นไปอย่างมีประสิทธิภาพ ทั้งนี้ต้องคำนึงต้นทุนของการซิงก์ข้อมูลและความล่าช้าในการสื่อสาร (RPC/PCIe/ethernet) ในการตัดสินใจวางตำแหน่ง
Quantization และ kernel เร่ง inference เป็นตัวเร่งสำคัญสำหรับ Edge: การใช้ INT8 สามารถลด memory footprint ได้ประมาณ ~2× และมักเพิ่ม throughput ได้ 1.5–2× บนฮาร์ดแวร์ที่รองรับ ในขณะที่ 4‑bit (หรือเทคนิคเช่น QLoRA/FP4) ให้การลดขนาดได้ใกล้เคียง ~3–4× แต่ต้องใช้ kernel เฉพาะและการ calibrate ที่ระมัดระวังเพื่อรักษาคุณภาพผลลัพธ์ การผสม precision (เช่นเก็บ layer สำคัญเป็น FP16/FP32 และ quantize layers ที่ทนการลดความแม่นยำได้) ช่วยให้ trade‑off ระหว่าง latency, accuracy และ memory เหมาะสม นอกจากนี้การใช้ไลบรารีและ runtime ที่มี kernel เร่ง เช่น ONNX Runtime, vendor‑optimized GEMM/MatMul, และ fused attention/quantized transformer kernels เป็นปัจจัยหลักที่จะพยุง throughput บน NPU/TPU/Vector DSP ของ Edge
Activation offloading และ recomputation ช่วยแก้ปัญหา memory pressure โดยเฉพาะเมื่อ expert จำนวนมากถูกเรียกใช้งานพร้อมกัน เทคนิคเหล่านี้ประกอบด้วยการย้าย activations ชั่วคราวไปยัง RAM หรือ storage (SSD/flash) และใช้การคำนวณซ้ำ (recompute) สำหรับบาง activation เมื่อจำเป็น การ offload ควรทำแบบ asynchronous พร้อม prefetching เพื่อจำกัดผลกระทบเชิง latency — ยกตัวอย่าง การ offload activations ของ experts ที่เรียกใช้งานน้อยหรือมีโอกาสถูกเรียกซ้ำต่ำจะช่วยปลดล็อก memory สำหรับ hot path โดยแลกกับค่า I/O overhead ที่ถูกบังคับควบคุมด้วย priority queue และ timeouts
Caching ของ embeddings และ retrieval เป็นวิธีตรงที่ให้ผลทันทีในการลดงานคำนวณ: การแคช embeddings ของ prompt หรือผู้ใช้ที่พบบ่อยบน edge node สามารถเพิ่ม hit rate ได้มาก — ตัวอย่างเช่น hit rate 70–90% จะลดภาระการคำนวณ embedding ของ encoder ลงอย่างมีนัยสำคัญและลด latency โดยตรง การออกแบบนโยบาย cache ควรรวม eviction policy แบบ LRU/LFU, ขนาด cache ที่สัมพันธ์กับหน่วยความจำ และการเก็บ metadata ของเวอร์ชัน embeddings เพื่อหลีกเลี่ยงความไม่สอดคล้องเมื่อโมเดลอัปเดต นอกจากนี้การแคชผลตอบกลับหรือ partial responses สำหรับ queries ที่ซ้ำซ้อนจะช่วยลด token generation และเรียกใช้ experts น้อยลง
Prompt engineering เพื่อลด token count เป็นกลยุทธ์ที่มองเห็นผลทางธุรกิจโดยตรง: การออกแบบ system prompts และ template ที่กระชับ ใช้ slot‑filling แทนการส่งบริบทยาวๆ และเลือกใช้ few‑shot examples ที่สั้นและเฉพาะทาง สามารถลดจำนวน token ที่ต้องประมวลผลได้ 20–50% หรือมากกว่า ตัวอย่างปฏิบัติการคือการสร้าง prompt templates สำหรับสคริปต์ทางการเงินทั่วไป, การสรุปบริบทยาวให้เป็น bullet points สั้น ๆ ก่อนส่งให้ LLM, และการใช้ retrieval‑augmented snippets ที่ย่อข้อมูลจากฐานความรู้แทนส่งเอกสารทั้งฉบับ การลด token count โดยตรงจะลดการเรียกใช้ experts และคำนวณ embedding ทำให้ latency และต้นทุนการประมวลผลลดลง
สรุปแล้วการนำ MoE ไปใช้งานบน Edge อย่างเป็นรูปธรรมต้องการการผสานกันของการจูน router, การจัดวางและชาร์ด expert อย่างชาญฉลาด, quantization ที่เหมาะสมพร้อม kernel เร่ง, เทคนิค activation offloading, caching ของ embeddings และ prompt engineering ทั้งหมดต้องทำงานร่วมกันภายใต้การมอนิเตอร์แบบเรียลไทม์ (throughput, p95 latency, per‑expert load) เพื่อให้เกิดความสมดุลระหว่างต้นทุน คุณภาพ และประสบการณ์ผู้ใช้ — นี่คือกลยุทธ์ปฏิบัติการที่ทำให้ธนาคารสามารถให้บริการแชตบ็อตแบบเรียลไทม์บน Edge โดยไม่ต้องพึ่งพาคลาวด์เป็นหลัก
คู่มือเชิงปฏิบัติการ: ขั้นตอนนำ MoE‑on‑Edge ไปใช้งานจริง
ภาพรวมเชิงปฏิบัติการ
บทความนี้เป็นคู่มือเชิงปฏิบัติการสำหรับทีมวิศวกรรมที่ต้องการนำสถาปัตยกรรม Mixture‑of‑Experts (MoE) ไปใช้งานบน Edge เพื่อให้บริการแชตบ็อตเรียลไทม์โดยไม่พึ่งคลาวด์ โดยเน้นขั้นตอนตั้งแต่การเลือกขนาดโมเดลและฮาร์ดแวร์ จนถึงการมอนิเตอร์และกลไก fallback ไปยังคลาวด์ในกรณีฉุกเฉิน ข้อสรุปเชิงค่าใช้จ่ายจากกรณีศึกษาเบื้องต้นแสดงว่า MoE‑on‑Edge สามารถลดต้นทุนการรัน LLM ลงได้ประมาณ 3–4× เมื่อเทียบกับการรันโมเดลขนาดเต็มบนคลาวด์ แต่การบรรลุผลลัพธ์นี้ต้องการการวางสถาปัตยกรรม การทดสอบ และการมอนิเตอร์ที่รัดกุม
Checklist พื้นฐานก่อนเริ่ม Deploy
- กำหนด SLO/SLA — เช่น p95 latency ≤ 300 ms, availability ≥ 99.9%, error rate ≤ 0.1%.
- คัดเลือกขนาดโมเดล — เลือกจำนวน experts ที่เหมาะสมและขนาด expert (เช่น 8–64 experts) โดยพิจารณาจำนวนผู้ใช้พร้อมกัน (RPS) และ memory footprint.
- ฮาร์ดแวร์ — ระบุชนิด accelerator: GPU (A100/RTX), NPU/DPU, หรือการเร่งด้วย NVDIMM/NVMe สำหรับ offload; ตัวอย่าง: ให้ node หนึ่งรองรับ 50–200 RPS ต้องมี VRAM 40–80 GB หรือใช้หลาย node สำหรับ sharded experts.
- container runtime — เลือกระบบที่รองรับ GPU passthrough และ runtimeClass เช่น containerd + NVIDIA Container Toolkit หรือ Docker + nvidia-docker2.
- inference server stack — เลือก Triton สำหรับการจัดการหลายโมเดลและ batching อัตโนมัติ หรือ FastAPI/uvicorn ร่วมกับ custom router สำหรับการควบคุม routing เฉพาะ (gating, top‑k expert selection).
- เก็บข้อมูลต้นทุนต่อการรัน — กำหนดตัวชี้วัด Cost per Inference เพื่อเปรียบเทียบกับคลาวด์ (ตัวอย่างเป้าหมาย: ≤ 0.5× ของต้นทุนคลาวด์ต่อคำขอ).
ขั้นตอนการเตรียม Environment
เริ่มจากการจัดสรรฮาร์ดแวร์และสแต็กซอฟต์แวร์ให้สอดคล้องกับข้อกำหนดโมเดล: สำหรับ MoE ขนาดกลาง (เช่น 16 experts) แนะนำ node ที่มี GPU 40–80 GB หรือสอง GPU/ node ที่เชื่อมด้วย NVLink ถ้าต้องการ latency ต่ำและ throughput สูง ให้พิจารณา NVMe สำหรับ swap / spill และ DPU สำหรับ orchestration เครือข่าย
สำหรับ runtime ให้ติดตั้ง container runtime ที่รองรับ GPU และ low-latency networking (SR‑IOV / RDMA ถ้าจำเป็น) และติดตั้ง inference server เช่น Triton เพื่อจัดการ model instances, model control และ dynamic batching หรือใช้ FastAPI + custom router เมื่อทีมต้องการโลจิกการ routing ขั้นสูง (เช่น gating policy หรือ QoS per customer)
- ระบบคลัสเตอร์: Kubernetes (แนะนำ) พร้อม Node Feature Discovery และ GPU operator
- Container runtime: containerd + NVIDIA toolkit หรือ Docker + nvidia-docker
- Inference server: Triton สำหรับ production-grade inference; FastAPI + custom router สำหรับ prototyping & custom routing
ขั้นตอนเชิงปฏิบัติการทีละขั้น (Step‑by‑Step)
- 1. วางแผน capacity จาก RPS และ SLO — คำนวณผ่านสูตร: required_nodes = ceil((RPS × avg_latency_ms) / (concurrency_per_node × 1000)). ตัวอย่าง: ถ้าเป้าหมาย 200 RPS และ node รองรับ concurrency 50 กับ avg latency 200 ms → nodes ≈ ceil((200×200)/(50×1000)) = 1 (แต่นับเผื่อ redundancy 2–3 nodes).
- 2. เตรียมโมเดลและ optimize — ทำ quantization (FP16/INT8) เมื่อเป็นไปได้, memory-mapping, offload optimizer states และ shard experts ข้าม nodes ให้สมดุล; ทดสอบ warm‑up เพื่อป้องกัน cold start latency.
- 3. สร้าง custom router — router ต้องรองรับ: gating decisions, top‑k expert selection, dynamic routing weight, และ admission control (circuit breakers). ออกแบบ API และ unit tests ให้ครอบคลุม logic การเลือก experts และ fallback path.
- 4. Deploy แบบ stage → canary → prod — เริ่มจาก environment จำลอง → canary บน traffic ต่ำ (1–5% ของ production) → เพิ่มสัดส่วนทีละขั้นภายใต้การมอนิเตอร์.
กลยุทธ์การทดสอบแบบ Incremental
การทดสอบต้องเป็นไปอย่างเป็นระบบ แบ่งเป็นระดับดังนี้:
- Unit tests สำหรับ router — ตรวจสอบ routing logic, gating fairness, top‑k selection, และการตอบสนองเมื่อ expert ไม่ตอบสนอง; เขียนกรณีทดสอบเช่น expert timeout, misrouted requests, และ duplicate routing.
- Integration tests — ตรวจสอบ interaction ระหว่าง router, inference server (Triton/serving), และ batcher; ทดสอบ end‑to‑end latency และความถูกต้องผลลัพธ์.
- Load testing (scale node) — ใช้เครื่องมือเช่น k6/Locust/wrk เพื่อจำลอง RPS ที่คาดการณ์และสูงกว่ากรณีใช้งานจริง 1.5–2× วัด p50/p95/p99 latency, throughput และ memory/CPU/GPU utilization. ตัวอย่างเป้าหมาย: p95 ≤ 300 ms ภายใต้ nominal load.
- Chaos testing สำหรับ expert failure — ใช้ Chaos Mesh หรือ Gremlin เพื่อจำลองการล้มเหลวของ expert (shutdown container, network partition, high latency) และยืนยันว่า router สามารถ fallback ไปยัง experts อื่นหรือไปยัง cloud ได้โดยไม่ทำให้ SLA พัง.
ตั้งค่าการควบคุมทราฟฟิกและการ Scalability
ออกแบบ router ให้รองรับนโยบายต่อไปนี้:
- Admission control / backpressure — เมื่อ queue ยาวเกิน threshold ให้ตอบแบบ degradation (summaries, smaller context) หรือลด batch size.
- Dynamic routing weight — ปรับน้ำหนัก expert ตาม utilization และ latency history (เช่นลดการส่งไปยัง expert ที่มี latency สูงเกิน 95th percentile).
- Autoscaling — ใช้ HPA/KEDA สำหรับ scale pods ตาม GPU utilization, custom metric (expert queue length) หรือ external RPS metric; วาง cooldown และ scale step เพื่อลด oscillation.
- Circuit breakers — ตั้งเกณฑ์ (เช่น error rate > 1% หรือ latency p95 > 1s) เพื่อถอด node/ expert ออกจาก routing ชั่วคราวและแจ้ง alert.
มอนิเตอร์ Metrics สำคัญและการตั้ง Threshold
ระบบมอนิเตอร์ต้องเก็บ metric เชิงระบบและเชิงธุรกิจเพื่อตรวจจับสภาวะก่อนที่จะส่งผลกระทบต่อผู้ใช้:
- Request latency — p50/p95/p99; ตัวอย่าง threshold: p95 alert ที่ > 400 ms
- Expert utilization — เป้าหมาย 60–80% (ต่ำเกินไป = resource waste, สูงเกินไป = saturation)
- Queue length — ถ้า queue per node > 100 ให้เริ่ม scale หรือเปิด degradation
- Error rates — 4xx/5xx และ inference errors; alert เมื่อ error rate > 0.1% (business critical) หรือ > 1% (severe)
- Cost per inference — คำนวณรวมค่าไฟ, depreciation ฮาร์ดแวร์, และค่าเน็ตเวิร์ก; เป้าหมายเปรียบเทียบกับคลาวด์เพื่อยืนยัน ROI
แนะนำใช้ Prometheus + Grafana สำหรับ metrics และ Alertmanager/PagerDuty สำหรับการแจ้งเตือนเชิงปฏิบัติการ
Fallback เป็นคลาวด์ในกรณีฉุกเฉิน (Operational Playbook)
แม้ระบบจะออกแบบมาเป็น Edge‑first ควรมี fallback path ไปยังคลาวด์ในกรณีที่เกิดเหตุการณ์รุนแรง เช่น data center failover หรือ overload ที่ไม่สามารถแก้ได้ทันที:
- เกณฑ์ trigger — ตัวอย่าง: cluster availability < 95% หรือ error rate > 5% ต่อ 5 นาที จะ trigger failover
- กลไก — Router ต้องรองรับ multi‑backends: primary = local edge, secondary = managed cloud LLM; ใช้ async replication ของ conversation context (หรือส่ง partial context) เพื่อให้ cloud สามารถตอบได้ทันที
- Cost control — ตั้ง policy จำกัดการส่ง traffic ไปคลาวด์ (เช่นไม่เกิน 20% ของ traffic) เว้นแต่เป็นเหตุฉุกเฉิน
- Tested runbooks — ซ้อม failover ทุกไตรมาส ตรวจสอบ RTO/RPO และปรับปรุง runbook ตามผลลัพธ์
ตัวอย่างเชิงตัวเลขและสรุปแนวปฏิบัติ
สมมติว่าธนาคารต้องการรองรับ 200 RPS โดยมี p95 latency ≤ 300 ms และลดต้นทุน 3–4× เมื่อเทียบกับคลาวด์ ให้ใช้แนวทางดังนี้: วางแผน node ที่รองรับ concurrency 50 ต่อ node จึงต้องมี 4 nodes (เผื่อ redundancy 6 nodes) ใช้ MoE 16 experts per model, ทำ FP16 quantization, และตั้ง threshold queue length ที่ 80 ต่อ node. ติดตั้งการมอนิเตอร์สำหรับ p95 latency, expert utilization (เป้าหมาย 60–80%), queue length, error rate (<0.1%) และ cost per inference เพื่อปรับ tuning อย่างต่อเนื่อง
สรุป: การนำ MoE‑on‑Edge ไปใช้งานจริงต้องผสมผสานการวางฮาร์ดแวร์ที่เหมาะสม, runtime และ inference stack ที่มั่นคง, การทดสอบแบบ incremental (unit, load, chaos), และระบบมอนิเตอร์/alert ที่ชัดเจน พร้อมแผน fallback ไปยังคลาวด์ เมื่อปฏิบัติตาม checklist และขั้นตอนข้างต้น ทีมวิศวกรรมสามารถบรรลุทั้งความเร็วในการตอบสนอง คุณภาพการให้บริการ และการลดต้นทุนได้อย่างยั่งยืน
ความมั่นคงปลอดภัย กฎระเบียบ และการปกป้องข้อมูล
ความมั่นคงปลอดภัย กฎระเบียบ และการปกป้องข้อมูล
การนำสถาปัตยกรรม Mixture‑of‑Experts (MoE) มารันบน Edge ภายในประเทศเพื่อลดต้นทุนและตอบสนองแชตบ็อตเรียลไทม์ช่วยลดความเสี่ยงด้านกฎระเบียบจากการโอนข้อมูลข้ามพรมแดน แต่ไม่ได้หมายความว่าความเสี่ยงจะหายไปโดยอัตโนมัติ ธนาคารต้องผสานมาตรการเทคนิคและการบริหารจัดการเพื่อให้สอดคล้องกับ พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) และแนวปฏิบัติการคุ้มครองข้อมูล เช่น การประเมินผลกระทบต่อความเป็นส่วนตัว (DPIA), การเก็บหลักฐานการยินยอม และหลักการลดข้อมูล (data minimization) ก่อนจะนำระบบลงใช้งานจริง
มาตรการพื้นฐานที่ต้องบังคับใช้ได้แก่การเข้ารหัสทั้งขณะส่ง (TLS/HTTPS กับ mutual TLS สำหรับบริการภายใน) และขณะพัก (AES‑256 หรือมาตรฐานเทียบเท่า) พร้อมกับการบริหารจัดการกุญแจที่เข้มงวดผ่าน HSM/KMS หรือโซลูชันที่มี root of trust เช่น TPM หรือ secure enclave ในฮาร์ดแวร์ การแยกโดเมนข้อมูล (domain separation) ระหว่างสภาพแวดล้อมการฝึก (training), การทดสอบ (staging) และการให้บริการ (production) เป็นสิ่งจำเป็นเพื่อป้องกันการรั่วไหลของชุดข้อมูลลูกค้า และการจัดสรรสิทธิ์เข้าถึงโดยใช้ RBAC + MFA ตามหลัก least privilege
ระบบต้องมี audit trail ที่ละเอียด ครอบคลุมทั้งคำขอ (requests), คำตอบ (responses), metadata ของ inference (เช่น expert selection ใน MoE), และการเปลี่ยนแปลงคอนฟิกูเรชัน โดยบันทึกลงในที่เก็บข้อมูลที่ป้องกันการแก้ไขย้อนหลัง (immutable / WORM) และผสานกับเครื่องมือ SIEM เพื่อตรวจจับพฤติกรรมผิดปกติใน inference pipeline เช่น การโจมตีแบบ prompt injection, การใช้งานอัตราผิดปกติ (anomalous throughput), หรือสัญญาณการโจมตีแบบ model poisoning ตัวอย่างการจัดตั้งคือการเก็บ event log ระดับต่ำสุด 90 วันสำหรับการวิเคราะห์เชิงลึก และสำรอง snapshot ของ log เป็นเวลา 1–3 ปีตามข้อกำหนดทางกฎหมาย
การเฝ้าระวังควรประกอบด้วยชุดเทคโนโลยีผสาน ได้แก่ SIEM สำหรับ correlation และ alerting, EDR/NDR สำหรับตรวจจับภัยคุกคามที่ระดับโฮสต์และเครือข่าย และระบบตรวจจับเชิงพฤติกรรมสำหรับโมเดล (model behavior monitoring) ที่สามารถรายงานการเบี่ยงเบนของการเลือก expert หรือ pattern ของคำตอบที่บ่งชี้ความเสี่ยง การเผยแพร่การแจ้งเตือนต้องรวมกับ playbook การตอบสนองเหตุการณ์และการแจ้งผู้มีส่วนได้ส่วนเสียภายใน/ภายนอกตาม PDPA
เมื่อธนาคารเลือกไม่ใช้คลาวด์สาธารณะ ควรประเมินความเสี่ยงเชิงเปรียบเทียบอย่างรอบด้าน:
- ข้อดี: ลดความเสี่ยงการโอนข้อมูลข้ามประเทศและลดการพึ่งพาคอนฟิกูเรชันของผู้ให้บริการคลาวด์สาธารณะ
- ข้อจำกัด: ภาระความรับผิดชอบด้าน physical security, patch management, การบำรุงรักษา HSM/KMS, ความสามารถในการสเกลและ disaster recovery รวมถึงค่าใช้จ่ายในการจัดตั้ง SIEM/EDR ที่เทียบเท่า
- ข้อควรระวัง: ต้องมีแผนสำรอง (fallback) ไปยังสภาพแวดล้อมที่ควบคุมได้หรือโซลูชันคลาวด์ส่วนตัวหากฮาร์ดแวร์เกิดข้อผิดพลาด หรือเกิดเหตุการณ์ที่กระทบ SLA
แผน fallback และการทำความสะอาดข้อมูล (data sanitization) เมื่อถอน model ออกจากการให้บริการต้องมีขั้นตอนชัดเจนและสามารถตรวจสอบได้ ตัวอย่างขั้นตอนที่แนะนำได้แก่:
- กำหนดนโยบายการกำจัด: ระบุชิ้นส่วนข้อมูล/โมเดลที่ต้องถูกลบ เช่น weights, optimizer state, cache ของ inference และ artifacts สำหรับ retraining
- การทำลายกุญแจคริปโตกราฟิก: ทำ key rotation ก่อนการถอนบริการ และทำลาย key ใน HSM พร้อมสร้าง audit record ของการทำลาย
- การล้างสื่อกายภาพ: ใช้วิธีการลบข้อมูลตามมาตรฐาน (เช่น NIST SP 800‑88 หรือเทียบเท่า) สำหรับ SSD/HDD ที่เก็บ model และ log บางส่วนที่มีข้อมูลส่วนบุคคล
- การจำกัดผลกระทบด้าน forensic: สร้าง snapshot สำหรับการสืบสวนก่อนลบ และเก็บสำเนาในที่เก็บที่เข้ารหัสและรักษาความลับตามข้อกฎหมายหากต้องใช้ในกระบวนการตรวจสอบ
- รีโวคคิ้งสิทธิ์และโทเค็น: เพิกถอน API keys, session tokens และใบรับรองที่เกี่ยวข้องทันทีหลังถอนบริการ
สุดท้าย การปฏิบัติตามกฎระเบียบไม่ได้จบที่การจัดตั้งมาตรการด้านเทคนิค ธนาคารต้องมีกรอบการกำกับดูแล (governance) ที่รวมการทบทวนความเสี่ยงเป็นระยะ, ฝึกอบรมพนักงาน, การทดสอบเจาะระบบเป็นประจำ และแผนสื่อสารเหตุการณ์ฉุกเฉินต่อผู้กำกับดูแลและลูกค้าตามที่ PDPA กำหนด เพื่อให้เกิดความน่าเชื่อถือและตอบสนองความคาดหวังด้านความเป็นส่วนตัวของผู้ใช้ในยุคที่บริการ ML บน Edge กำลังขยายตัว
บทสรุป
การนำสถาปัตยกรรม Mixture‑of‑Experts (MoE) มารันบน Edge สามารถลดต้นทุนการรัน LLM ลงประมาณ 3–4× ในการทดสอบเชิงปฏิบัติการของธนาคารไทย ขณะเดียวกันยังรักษา latency ให้เหมาะกับการใช้งานแชตบ็อตเรียลไทม์ (เช่น การตอบกลับอยู่ในหลักร้อยมิลลิวินาทีในหลายกรณี) และช่วยให้ธนาคารควบคุมข้อมูลภายในประเทศได้ดีขึ้นตามข้อกำหนดด้านความเป็นส่วนตัวและกฎระเบียบ ตัวอย่างที่เห็นได้ชัดคือการกระจายการประมวลผลเป็นชุดของ “expert” ที่ถูกเรียกใช้แบบจำเพาะ ทำให้การใช้ทรัพยากรมีประสิทธิภาพขึ้นและลดค่าใช้จ่ายต่อการให้บริการเมื่อเทียบกับการรันโมเดลหนาแน่นเต็มรูปแบบบนคลาวด์
ความสำเร็จเชิงปฏิบัติการขึ้นกับการออกแบบ router/placement ที่ดี เทคนิค quantization และการวางแผนด้านความปลอดภัย — ได้แก่ การออกแบบ router เพื่อเลือก expert อย่างแม่นยำและลดการสื่อสารข้ามโหนด, การจัดวางโมเดลและชิ้นส่วนงานให้เหมาะสมบนฮาร์ดแวร์ edge, การใช้ quantization (เช่น 8‑bit, 4‑bit หรือ mixed precision) เพื่อลดหน่วยความจำและแบนด์วิดท์โดยไม่กระทบคุณภาพมากนัก และมาตรการด้านความปลอดภัยเช่นการเข้ารหัสข้อมูล การควบคุมการเข้าถึง และการเก็บบันทึกการใช้งานทีมวิศวกรรมควรเริ่มจากการทดสอบขนาดเล็กในสภาพแวดล้อมควบคุมได้ แล้วขยายแบบค่อยเป็นค่อยไปพร้อมการมอนิเตอร์ค่าประสิทธิภาพ, ความแม่นยำ และต้นทุนเพื่อปรับพารามิเตอร์ router/placement และนโยบายความปลอดภัยตามผลลัพธ์
มุมมองอนาคตชี้ว่าแนวทาง Edge MoE จะกลายเป็นส่วนหนึ่งของสถาปัตยกรรมแบบ hybrid (on‑premises + cloud) สำหรับสถาบันการเงิน โดยมีข้อได้เปรียบทั้งด้านต้นทุน ความหน่วงต่ำ และการปฏิบัติตามข้อบังคับ ขณะที่งานวิจัยด้าน routing, sparsity และฮาร์ดแวร์เร่งความเร็ว (เช่น NPU/TPU สำหรับ edge) คาดว่าจะช่วยเพิ่มประสิทธิภาพและลดต้นทุนได้อีกในระยะกลาง ทีมธนาคารที่ลงทุนในกรอบทดลองขนาดเล็กและสร้างมาตรฐานการทดสอบเชิงปฏิบัติการจะมีความพร้อมสูงสุดในการขยายบริการแชตบ็อตเรียลไทม์ที่ปลอดภัย คุ้มค่า และสอดคล้องกับกฎระเบียบของประเทศ



