
เมื่อโมเดลภาษาขนาดใหญ่ (Large Language Models — LLMs) ถูกนำมาใช้ในงานบริการสาธารณะเพิ่มขึ้น ความเสี่ยงทั้งเรื่องความโปร่งใส อคติ และความปลอดภัยกลายเป็นข้อกังวลที่รัฐต้องตอบรับ หน่วยงานรัฐไทยจึงเริ่มทดลองระบบ “LLM Audit Mark” ซึ่งเป็นตราประเมินเพื่อใช้ตรวจก่อนนำโมเดลมาให้บริการต่อประชาชน เป้าหมายคือสร้างกรอบการประเมินที่ชัดเจนทั้งเชิงเทคนิคและเชิงนโยบาย เพื่อป้องกันผลกระทบด้านสิทธิขั้นพื้นฐานและเสริมสร้างความเชื่อมั่นของสาธารณชน
บทนำชิ้นนี้จะนำผู้อ่านสำรวจภาพรวมของโครงการทดลอง ตั้งแต่เกณฑ์ประเมินหลักที่ครอบคลุมความโปร่งใส ข้อมูลตั้งต้น (data provenance) ความเป็นกลางของผลลัพธ์ การอธิบายการตัดสินใจ (explainability) และความทนทานต่อการโจมตี เทคนิคการทดสอบที่ใช้ทั้งเชิงปริมาณ (เช่น benchmark metrics, ROC/precision/recall) และเชิงคุณภาพ (เช่น red‑team, human‑in‑the‑loop review) รวมถึงผลกระทบเชิงนโยบายต่อการจัดซื้อจัดจ้างมาตรฐานการกำกับดูแล และแนวทางปฏิบัติที่หน่วยงานภาครัฐและผู้พัฒนาควรปฏิบัติเพื่อให้การใช้งาน LLM ในภาครัฐเป็นไปอย่างปลอดภัยและรับผิดชอบ
บทนำ: ทำไมไทยต้องมี 'LLM Audit Mark'?
บทนำ: ทำไมไทยต้องมี 'LLM Audit Mark'?
ในช่วงไม่กี่ปีที่ผ่านมา การใช้งานโมเดลภาษาขนาดใหญ่ (Large Language Models: LLM) ในภาครัฐและบริการสาธารณะขยายตัวอย่างรวดเร็ว ด้วยศักยภาพในการตอบคำถามอัตโนมัติ ช่วยทำงานเอกสาร และปรับปรุงประสิทธิภาพการให้บริการพลเมือง หลายการสำรวจเชิงสากลชี้ว่า "หน่วยงานภาครัฐในหลายประเทศ" อยู่ระหว่างทดลองหรือนำระบบ AI เข้ามาใช้จริงในกระบวนการให้บริการ ทั้งในด้านข้อมูลสุขภาพ การพิจารณาสิทธิประโยชน์ และการให้คำปรึกษาด้านกฎหมาย ทำให้ประเทศไทยจำเป็นต้องพิจารณากรอบการประเมินความปลอดภัยและความโปร่งใสก่อนการนำ LLM มาให้บริการประชาชนอย่างเป็นทางการ
ความเสี่ยงจากการนำ LLM มาใช้กับบริการสาธารณะมีหลายด้านที่ไม่อาจมองข้ามได้ ได้แก่
- ข้อมูลผิดพลาด (disinformation / hallucination): โมเดลสามารถสร้างคำตอบที่อ่านสมเหตุสมผลแต่ไม่ถูกต้องจริงได้ ซึ่งในบริบทภาครัฐอาจนำไปสู่คำแนะนำที่ทำให้ผู้ได้รับบริการเสียสิทธิหรือเกิดความเสียหายได้
- อคติและการเลือกปฏิบัติ (bias): โมเดลที่ถูกฝึกด้วยข้อมูลที่มีความเอนเอียงอาจให้ผลลัพธ์ที่ไม่เป็นธรรมต่อกลุ่มคนบางกลุ่ม เช่น การประเมินความเสี่ยงหรือการคัดกรองสิทธิควรมีความเป็นกลางมากที่สุด
- ความเป็นส่วนตัวและการรั่วไหลของข้อมูล (privacy): มีงานวิจัยและรายงานหลายชิ้นที่แสดงให้เห็นว่าโมเดลสามารถจดจำหรือสกัดข้อมูลส่วนบุคคลจากชุดข้อมูลฝึกได้ หากไม่มีการจัดการข้อมูลที่เหมาะสม อาจเกิดการรั่วไหลของข้อมูลประชาชน
แนวโน้มระดับโลกชี้ให้เห็นว่าหลายประเทศและองค์กรระหว่างประเทศเริ่มออกเกณฑ์กำกับ จัดทำแนวปฏิบัติ และกำหนดมาตรฐานสำหรับ AI เช่น ข้อเสนอข้อบังคับของสหภาพยุโรป (EU AI Act) แนวทางการกำกับดูแลของสหราชอาณาจักร คำแนะนำเชิงนโยบายขององค์การเพื่อความร่วมมือทางเศรษฐกิจและการพัฒนา (OECD) รวมถึงกรอบแนวปฏิบัติของบางประเทศในเอเชีย การเคลื่อนไหวเหล่านี้ยืนยันว่าการตรวจสอบความโปร่งใส ความสามารถในการอธิบายผลลัพธ์ และการประเมินอคติกลายเป็นองค์ประกอบสำคัญก่อนการนำเทคโนโลยีไปใช้กับประชาชน ซึ่งหากประเทศไทยไม่มีกระบวนการประเมินที่เข้มแข็ง อาจเสี่ยงต่อปัญหาทางกฎหมาย ภาพลักษณ์ และความเชื่อมั่นของประชาชน
ด้วยเหตุนี้ แนวคิดเรื่อง 'LLM Audit Mark' จึงเกิดขึ้นเพื่อทำหน้าที่เป็นตราประเมินที่บ่งชี้ว่าระบบโมเดลภาษาได้รับการทดสอบ ตรวจสอบ และมีเอกสารกำกับในประเด็นสำคัญก่อนนำไปใช้กับบริการสาธารณะ วัตถุประสงค์หลักของ Audit Mark ได้แก่
- เพิ่มความเชื่อมั่นของประชาชนและผู้มีส่วนได้เสีย ว่าบริการที่ใช้ LLM มีการควบคุมและผ่านการทดสอบด้านความถูกต้องและความเป็นธรรม
- ลดความเสี่ยงทางกฎหมายและสังคม โดยการตรวจสอบอคติ การรั่วไหลของข้อมูล และการจัดการกับผลลัพธ์ที่ผิดพลาดก่อนส่งมอบบริการ
- สร้างมาตรฐานเชิงปฏิบัติ สำหรับหน่วยงานภาครัฐในการจัดทำเอกสารทางเทคนิค การประเมินความเสี่ยง และการติดตามผลลัพธ์หลังการใช้งาน
- ส่งเสริมความโปร่งใสและความรับผิดชอบ โดยให้ข้อมูลเกี่ยวกับแหล่งข้อมูลการฝึก การตั้งค่าการใช้งาน และกระบวนการแก้ไขข้อผิดพลาดแก่ผู้ใช้อย่างชัดเจน
สรุปแล้ว การมี LLM Audit Mark สำหรับการนำโมเดลภาษาไปใช้กับบริการสาธารณะไม่เพียงแต่เป็นกลไกเชิงเทคนิค แต่ยังเป็นเครื่องมือเชิงนโยบายเพื่อคุ้มครองสิทธิของประชาชน เสริมสร้างความเชื่อมั่น และรองรับการเติบโตของการใช้ AI ในภาครัฐอย่างยั่งยืนและรับผิดชอบ
LLM Audit Mark คืออะไร — นิยามและเกณฑ์หลัก
LLM Audit Mark คืออะไร — นิยามและเกณฑ์หลัก
LLM Audit Mark เป็นตราประเมินมาตรฐานที่ออกแบบมาเพื่อใช้ตรวจสอบและรับรองความเหมาะสมของโมเดลภาษาขนาดใหญ่ (Large Language Models — LLMs) ก่อนนำไปใช้ในงานให้บริการสาธารณะ โดยมีวัตถุประสงค์หลักคือการประกันความโปร่งใส ความเป็นธรรม ความทนทาน ความคุ้มครองข้อมูลส่วนบุคคล และความสามารถในการอธิบายผลลัพธ์ให้ผู้ใช้งานและหน่วยงานกำกับดูแลเข้าใจได้ การมี Audit Mark ช่วยให้หน่วยงานรัฐและประชาชนประเมินความเสี่ยงและประสิทธิผลของการนำ LLM มาใช้ในเชิงพาณิชย์และสาธารณะได้อย่างเป็นระบบ
ชุดเกณฑ์ประเมินของ LLM Audit Mark แบ่งเป็นเกณฑ์หลักหลายมิติที่ครอบคลุมปัญหาสำคัญทั้งเชิงเทคนิคและเชิงนโยบาย โดยแต่ละเกณฑ์มีคำอธิบายสั้น ๆ ดังนี้:
- Transparency (การเปิดเผยข้อมูล) — ระบุข้อมูลเกี่ยวกับสถาปัตยกรรม โมเดลที่ใช้ ชุดข้อมูลฝึกสอน และนโยบายการอัปเดต เช่น สัดส่วนข้อมูลสาธารณะ/ส่วนบุคคล, ช่วงเวลาการเทรน
- Fairness (ความเป็นธรรม / อคติ) — ตรวจวัดอคติทางเพศ เชื้อชาติ วัย หรือกลุ่มเปราะบาง และประเมินผลกระทบที่ไม่เป็นธรรมต่อกลุ่มต่าง ๆ
- Robustness (ความทนทานต่อการโจมตีและข้อผิดพลาด) — ทดสอบความเสถียรเมื่อเผชิญกับการโจมตีแบบ adversarial, ข้อมูลที่ผิดพลาด หรือ input ที่นอกขอบเขต
- Privacy & Data Governance (การจัดการข้อมูลและความเป็นส่วนตัว) — ตรวจสอบการปฏิบัติตามมาตรการความเป็นส่วนตัว เช่น การใช้ differential privacy, การลบข้อมูลส่วนบุคคล และการควบคุมการเข้าถึงข้อมูล
- Explainability (ความสามารถอธิบายผลลัพธ์) — ประเมินความสามารถของโมเดลในการให้คำอธิบายที่เข้าใจได้เกี่ยวกับเหตุผลของคำตอบและระดับความเชื่อมั่น
สำหรับแต่ละด้าน จะมีตัวชี้วัดเชิงปริมาณที่แนะนำเพื่อการประเมินที่เป็นรูปธรรม ตัวอย่างเมตริกที่ใช้ได้แก่:
- Accuracy / Utility: precision, recall, F1-score สำหรับงานเชิงข้อความเฉพาะ เช่น การสกัดข้อมูล, การตอบคำถาม (ตัวอย่าง: F1 ≥ 0.85 สำหรับงานสำคัญในการให้บริการประชาชน)
- Bias Score: ค่าความต่างระหว่างกลุ่ม (group disparity) เช่น demographic parity difference, equalized odds difference — เป้าหมายเชิงปริมาณอาจเป็น <0.1 หรือ <10% แตกต่างกันขึ้นกับบริบทการใช้งาน
- Adversarial Robustness: อัตราความสำเร็จของการโจมตี (attack success rate) และการลดทอนประสิทธิภาพภายใต้โจมตี เช่น ลดความแม่นยำไม่เกิน 10% ภายใต้การโจมตีชนิดมาตรฐาน
- Privacy Metrics: ค่า differential privacy (ε) ระบุขอบเขตความคุ้มครอง เช่น ε ≤ 1 หรือค่าที่ยอมรับได้ตามนโยบายที่ตกลงกัน, อัตราการตรวจจับข้อมูลส่วนบุคคลที่คงเหลือ (residual personal data rate)
- Explainability / Fidelity: fidelity ของการอธิบาย (เช่น SHAP/Integrated Gradients fidelity ≥ 0.8), ความเสถียรของคำอธิบาย (explanation stability) และระดับความเข้าใจของผู้ใช้ (user study score)
- Operational Metrics: เวลาตอบสนอง (latency), อัตราความล้มเหลวในการให้บริการ (uptime), และ coverage ของการทดสอบ (test coverage ของชุดกรณีใช้งาน)
การให้คะแนนสำหรับ LLM Audit Mark แนะนำรูปแบบเป็นระดับตรา 3 ระดับ เพื่อความชัดเจนและสามารถสื่อสารความเสี่ยงได้อย่างรวดเร็ว ดังนี้:
- Certified — โมเดลผ่านเกณฑ์ขั้นต่ำของทุกมิติและอยู่ในช่วงค่ามาตรฐานเชิงปริมาณที่กำหนด (ตัวอย่าง: F1 ≥ 0.85; bias difference < 0.05; adversarial accuracy drop < 5%; ε ≤ 1) โดยมีเอกสารประกอบครบถ้วนและแผนการตรวจสอบต่อเนื่อง
- Conditional — โมเดลผ่านบางมิติแต่ต้องแก้ไขหรือจำกัดการใช้งานในบางกรณี (ตัวอย่าง: utility สูงแต่ bias difference อยู่ระหว่าง 0.05–0.15 หรือ ε ระหว่าง 1–5) ต้องมีข้อผูกมัด เช่น การจำกัดโดเมนการใช้งาน การปรับปรุงชุดข้อมูล หรือการติดป้ายคำเตือนเมื่อให้บริการ
- Not Recommended — โมเดลไม่ผ่านเกณฑ์สำคัญหรือมีความเสี่ยงเชิงระบบ (ตัวอย่าง: bias difference > 0.15, adversarial success rate สูงหรือมีการรั่วไหลของข้อมูลส่วนบุคคลที่ไม่สามารถแก้ไขได้) และไม่แนะนำให้นำไปใช้ในสภาพแวดล้อมให้บริการสาธารณะ
เชิงปฏิบัติ LLM Audit Mark ควรถูกประเมินด้วยการทดสอบเชิงเทคนิคที่มาตรฐาน (benchmarks, adversarial suites, privacy audits) ประกอบกับการประเมินเชิงนโยบายและบทสรุปความเสี่ยง (risk assessment report) ที่เปิดเผยต่อสาธารณะ โดยระบบการให้คะแนนอาจใช้โมเดลถ่วงน้ำหนัก (weighted scoring) เพื่อสะท้อนความสำคัญของแต่ละมิติและบริบทการใช้งาน เช่น บริการด้านสาธารณสุขและความยุติธรรมมีน้ำหนักของ fairness และ privacy สูงกว่าบริการเชิงข้อมูลทั่วไป
กระบวนการทดสอบและวิธีการประเมิน (Technical Audit Workflow)
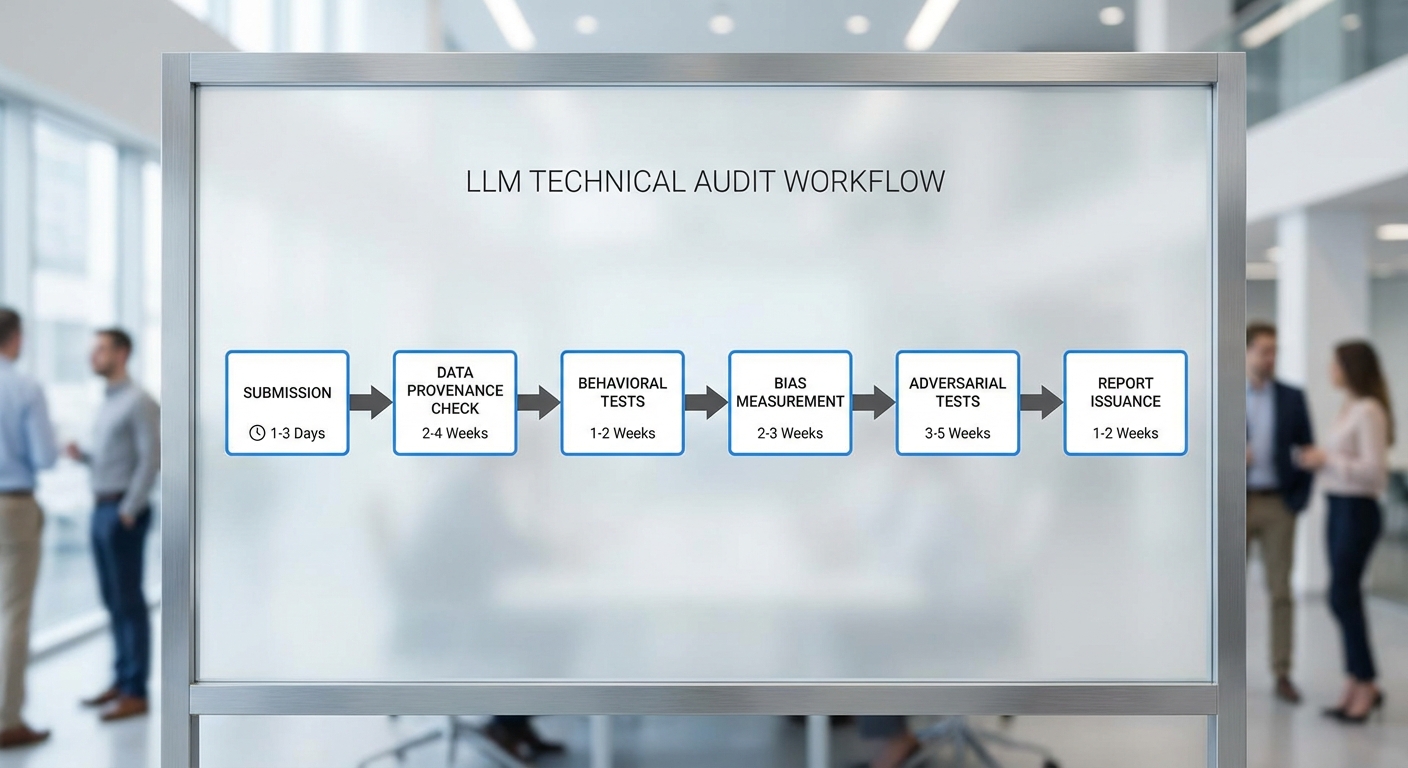
บทความนี้สรุปกระบวนการเชิงปฏิบัติสำหรับการประเมินโมเดลภาษาใหญ่ (LLM) เพื่อออก LLM Audit Mark สำหรับการนำไปใช้ให้บริการสาธารณะ โดยออกแบบให้ครอบคลุมตั้งแต่การยื่นเอกสารเบื้องต้นถึงการออกใบรับรองอย่างโปร่งใสและตรวจสอบได้ กระบวนการแบ่งเป็นขั้นตอนหลัก 6–8 ขั้นตอนที่เชื่อมต่อกัน มีผู้มีส่วนได้ส่วนเสียหลายฝ่าย และระบุช่วงเวลาประเมินเบื้องต้นเพื่อให้หน่วยงานรัฐและผู้พัฒนาวางแผนทรัพยากรได้อย่างเหมาะสม

ขั้นตอนที่ 1 — การเตรียมและยื่นเอกสาร (Model Card Submission)
เริ่มจากผู้พัฒนายื่นชุดเอกสารเบื้องต้น ประกอบด้วย model card, รายงานสถาปัตยกรรม, เงื่อนไขการใช้งาน, ข้อมูลเชิงเทคนิค เช่น ขนาดพารามิเตอร์ เวลาฝึก สถิติการประเมินภายใน และนโยบายความเป็นส่วนตัว ระยะเวลาที่คาด: 1–2 สัปดาห์ เพื่อยืนยันความสมบูรณ์ของเอกสารก่อนเข้าสู่การตรวจสอบเชิงลึก
ขั้นตอนที่ 2 — ตรวจสอบแหล่งข้อมูลฝึกสอน (Data Provenance & Documentation)
Auditor ตรวจสอบแหล่งข้อมูล (data provenance) โดยใช้แนวทางเช่น datasheets และเครื่องมือการติดตามแหล่งที่มา (metadata lineage) เพื่อยืนยันสิทธิ์การใช้งาน ตรวจสอบการกรองข้อมูลที่อาจนำไปสู่การลำเอียง (e.g., over-representation, copyright issues) และประเมินความหลากหลายของข้อมูล ระยะเวลาที่คาด: 2–4 สัปดาห์ ขึ้นอยู่กับความซับซ้อนของชุดข้อมูลและการเข้าถึงข้อมูลต้นทาง
ขั้นตอนที่ 3 — การทดสอบเชิงพฤติกรรม (Behavioral Testing)
ใช้ชุดทดสอบแบบมาตรฐานและเชิงปฏิบัติ ได้แก่ CheckList, RobustnessGym และชุดทดสอบพิเศษที่จำลองการใช้งานภาครัฐ เช่น คำถามเชิงนโยบาย บริการประชาชน และภาษาท้องถิ่น การทดสอบวัดความสอดคล้องของผลลัพธ์ ความเชื่อถือได้ (consistency) และการตอบสนองต่อคำถามที่ไม่ชัดเจน ระยะเวลาที่คาด: 2–6 สัปดาห์ (รวมการสังเกตกรณีมุมมองจริง)
ขั้นตอนที่ 4 — การวัดอคติและความเป็นธรรม (Bias Audits)
ดำเนินการประเมินอคติด้วยกรอบการวัดหลายมิติ ได้แก่ การใช้ชุดข้อมูลเช่น StereoSet, CrowS-Pairs, BBQ และชุดทดสอบประเด็นทางสังคมที่ปรับให้เหมาะกับบริบทไทย ใช้เมตริกเช่น demographic parity, equalized odds, calibration และการประเมินความเป็นธรรมเชิงบริบท ระยะเวลาที่คาด: 3–6 สัปดาห์ รวมการวิเคราะห์สาเหตุและการให้ข้อเสนอแนะเชิงแก้ไข
ขั้นตอนที่ 5 — การทดสอบโจมตีและความทนทาน (Adversarial & Robustness Testing)
ทดสอบความทนทานต่อการโจมตีเชิงภาษาด้วยเครื่องมือเช่น TextAttack, OpenAI Red Teaming Framework, IBM ART และการโจมตีเชิงตรรกะ/ข้อมูลผิดพลาด (data poisoning, prompt injection) ตลอดจนทดสอบการจัดการกับ input ที่มีเจตนาเป็นอันตราย ระยะเวลาที่คาด: 2–4 สัปดาห์ ขึ้นอยู่กับขอบเขตของการโจมตีที่ต้องจำลอง
ขั้นตอนที่ 6 — การบูรณาการผลและการแก้ไข (Remediation & Iterative Testing)
รวบรวมผลการทดสอบทั้งหมด ให้ผู้พัฒนาแก้ไขโมเดลหรือ pipeline ตามข้อเสนอแนะ จากนั้นดำเนินการทดสอบซ้ำเพื่อยืนยันการปรับปรุง (regression tests) เครื่องมือสนับสนุนได้แก่ continuous evaluation frameworks และชุดทดสอบ synthetic ที่ออกแบบมาเฉพาะงาน ระยะเวลาที่คาด: 4–8 สัปดาห์ ขึ้นกับความจำเป็นของการปรับสถาปัตยกรรมหรือการเก็บข้อมูลเพิ่ม
ขั้นตอนที่ 7 — การจัดทำรายงานเชิงเทคนิคและความโปร่งใส (Reporting & Transparency)
ผู้ตรวจสอบจัดทำรายงานฉบับสมบูรณ์ที่ระบุผลการทดสอบ เมตริกที่ใช้ ขอบเขตการทดสอบ ชุดข้อมูลตัวอย่าง โค้ดที่ใช้ทดสอบ (หรือวิธีการเข้าถึง) และข้อจำกัดของการประเมิน รายงานต้องมีความโปร่งใส เช่น ระบุตัวแปรสุ่ม (random seeds), เวอร์ชันของโมเดล และการเปิดเผยข้อจำกัดเชิงบริบท เพื่อให้หน่วยงานกำกับและสาธารณะสามารถวิเคราะห์ซ้ำได้ ระยะเวลาที่คาด: 2–3 สัปดาห์
ขั้นตอนที่ 8 — การออกตราประเมินและติดตามภายหลัง (Certification & Post-deployment Monitoring)
เมื่อผ่านเกณฑ์ที่กำหนด Auditor ภายนอก และ/หรือหน่วยงานกำกับออก LLM Audit Mark ระบุระดับความเสี่ยงและข้อจำกัด พร้อมข้อกำชับการใช้งาน (conditions of use) รวมถึงข้อกำหนดการติดตามหลังเปิดใช้งาน เช่น การตรวจสอบแบบเรียลไทม์สำหรับ toxicity, drift detection และ periodic re-audit (แนะนำทุก 6–12 เดือน) ระยะเวลาที่คาดสำหรับการออกตรา: 1–2 สัปดาห์ หลังรับรองการปฏิบัติตามข้อกำหนด
เครื่องมือ ชุดข้อมูลมาตรฐาน และเกณฑ์เปรียบเทียบ
- Benchmarks พื้นฐาน: GLUE/SuperGLUE, MMLU, HellaSwag — สำหรับสมรรถนะเชิงความเข้าใจและความรู้ทั่วไป
- Behavioral & robustness: CheckList, RobustnessGym, TextAttack, RobustBench
- Bias & fairness datasets: StereoSet, CrowS-Pairs, BBQ, HolisticBias (และชุดข้อมูลที่ออกแบบสำหรับบริบทท้องถิ่น)
- Toxicity & safety: Perspective API, Jigsaw datasets, SafetyBench
- Provenance & documentation: Datasheets for Datasets, Model Cards, Metadata lineage tools
- Synthetic tests: สคริปต์จำลองการโจมตีและชุดคำถามเชิงจริยธรรมที่ปรับแต่งตามบริการสาธารณะ
บทบาทผู้มีส่วนได้ส่วนเสียและความโปร่งใสของรายงาน
- ผู้พัฒนา (Developer): จัดเตรียม model card, ให้การเข้าถึงข้อมูลและ pipeline, ดำเนินการแก้ไขตามคำแนะนำ
- auditor ภายนอก (External Auditor): ดำเนินการทดสอบอิสระ จัดทำรายงานเชิงเทคนิค และเสนอข้อกำชับเพื่อการออกตรา — ต้องเปิดเผยเมตริกและวิธีการทดสอบในระดับที่เหมาะสม
- หน่วยงานกำกับ (Regulator): กำหนดขอบเขตการประเมิน เกณฑ์ความเสี่ยง และกำกับการออกตรา รวมถึงการกำหนดนโยบายการติดตามหลังการใช้งาน
- ผู้มีส่วนได้ส่วนเสียสาธารณะ: ควรมีขั้นตอนให้ผู้ใช้หรือคณะกรรมการจริยธรรมตรวจสอบรายงานสรุปและขอข้อมูลเพิ่มเติมได้เพื่อความโปร่งใส
สรุปโดยรวม กระบวนการทั้งหมดตั้งแต่การยื่นเอกสารจนถึงการออกตราประเมินสำหรับการใช้งานสาธารณะมักใช้เวลาประมาณ 3–6 เดือน ขึ้นกับขนาดและความซับซ้อนของโมเดล รวมทั้งความพร้อมของข้อมูลและความร่วมมือจากผู้พัฒนา เพื่อให้การประเมินมีความน่าเชื่อถือ ควรเน้นการเปิดเผยข้อมูลที่เพียงพอเพื่อให้รายงานสามารถตรวจสอบซ้ำได้ และกำหนดกลไกการติดตาม (monitoring) หลังนำระบบไปใช้งานจริง
การประเมินอคติ (Bias) และความโปร่งใส (Transparency): วิธีวัดและตัวอย่างผลลัพธ์

แนวทางเทคนิคในการตรวจจับอคติ
การประเมินอคติของโมเดลภาษาใหญ่ (LLM) สำหรับการให้บริการสาธารณะต้องอาศัยชุดเทคนิคที่หลากหลายเพื่อจับทั้งอคติชัด (explicit) และอคติแฝง (implicit) เทคนิคหลักๆ ได้แก่
- Subgroup evaluation — แยกการประเมินตามกลุ่มประชากร (เช่น เพศ อายุ จังหวัด เชื้อชาติ ภาษา) เพื่อวัดความแตกต่างของผลลัพธ์ เช่น อัตราคำตอบเชิงลบ, อัตราการปฏิเสธคำขอ หรืออัตราความผิดพลาดของการจัดประเภท ระบุค่าช่องว่าง (disparity) ระหว่างกลุ่ม
- Counterfactual evaluation — สร้างข้อความตัวอย่างโดยเปลี่ยนเพียงแค่คุณลักษณะด้านประชากร (เช่น เปลี่ยนคำว่า "เขา" เป็น "เธอ" หรือเปลี่ยนเมือง) แล้ววัดการเปลี่ยนแปลงในคำตอบหรือคะแนนความน่าเชื่อถือ (probability) เพื่อค้นหา sensitivity ที่ไม่พึงประสงค์
- Calibration across demographics — วัดการปรับความเชื่อมั่นของโมเดล (calibration) แยกตามกลุ่ม เช่น คำนวณ Expected Calibration Error (ECE) สำหรับแต่ละกลุ่ม เพื่อดูว่าความมั่นใจที่โมเดลแสดงสอดคล้องกับความถูกต้องจริงหรือไม่
- Outcome-based fairness metrics — วัดช่องว่างเชิงผลลัพธ์ เช่น False Positive Rate (FPR) gap, False Negative Rate (FNR) gap, Positive Predictive Value (PPV) gap ระหว่างกลุ่ม ซึ่งเป็นมาตรฐานที่สำนักงานกำกับดูแลมักต้องการ
- Bias score synthesis — รวมค่า metric หลายค่าเป็นคะแนนอคติรวม (bias score) เพื่อให้ง่ายต่อการรายงานและติดตาม เช่น สร้างดัชนีรวมโดยถ่วงน้ำหนัก FPR gap, FNR gap และ ECE
ตัวอย่างเชิงตัวเลขและกรณีสมมติ
พิจารณาโมเดล LLM ที่ใช้ช่วยคัดกรองสิทธิ์รับสวัสดิการสาธารณะในสมมติฐานหนึ่ง ทีมงานทำการประเมินเบื้องต้นพบผลดังนี้ (ตัวเลขสมมติเพื่ออธิบายแนวทาง):
- Bias score (ดัชนีรวม): 0.28 (ค่าสูงหมายถึงอคติเชิงระบบสูง)
- FPR gap ระหว่างชาย/หญิง: 0.15 (15 percentage points)
- ECE เฉลี่ย: 0.12 แต่สำหรับกลุ่มวัยชรา ECE = 0.22
- Counterfactual flip-rate: เมื่อลองเปลี่ยนคำบ่งชี้เพศในคำร้อง ผลลัพธ์เปลี่ยนจากอนุมัติเป็นปฏิเสธใน 22% ของกรณี
การดำเนินการแก้ไขรวมถึงการใช้เทคนิค reweighting ของตัวอย่างฝึก, data augmentation สำหรับกลุ่มที่ถูกละเลย และการปรับ loss ด้วย penalty term สำหรับ disparity ทีมงานทดสอบอีกครั้งหลังการแก้ไขและพบผลลัพธ์ดังนี้:
- Bias score ลดลงเป็น 0.12 (จาก 0.28)
- FPR gap ลดลงเป็น 0.03 (จาก 0.15)
- ECE เฉลี่ยลดลงเป็น 0.07 และ ECE ของกลุ่มวัยชราลดเป็น 0.09
- Counterfactual flip-rate ลดลงเป็น 5% (จาก 22%)
ตัวอย่างเชิงตัวเลขนี้แสดงให้เห็นว่าเทคนิค debiasing แบบผสม (pre-processing + in-training penalty + post-processing calibration) สามารถลดช่องว่างเชิงอคติได้อย่างมีนัยสำคัญ แต่อาจแลกมาด้วยต้นทุนการฝึกและอาจกระทบความแม่นยำรวมเล็กน้อยซึ่งต้องรายงานควบคู่กัน
กระบวนการรายงานผลและกรอบการเปิดเผย
เพื่อให้การประเมินอคติและความโปร่งใสมีมาตรฐานสอดคล้องกัน ควรกำหนดกรอบการรายงานผลที่ชัดเจน ประกอบด้วยองค์ประกอบหลักดังนี้
- Model card — รายงานสรุปคุณลักษณะของโมเดล เช่น จุดประสงค์การใช้งาน ข้อมูลฝึกที่ใช้ ชุดทดสอบ (benchmarks) เมตริกที่รายงาน (bias metrics, accuracy, calibration) และข้อจำกัด ควรระบุเวอร์ชันวันที่และวิธีการทดสอบอย่างละเอียด
- Audit report — รายงานฉบับเต็มสำหรับหน่วยงานกำกับ ประกอบด้วยผลการทดสอบโดยกลุ่มย่อย ตารางก่อน/หลังการแก้ไข ค่าพารามิเตอร์การ debiasing และการวิเคราะห์ความเสี่ยงที่ยังคงหลงเหลือ
- Explainability modules — เปิดเผยผลของเครื่องมืออธิบายเช่น SHAP, LIME, Integrated Gradients หรือ attention visualization พร้อมตัวอย่างกรณี (case studies) ที่แสดงสาเหตุที่โมเดลตัดสินใจอย่างใดอย่างหนึ่ง
- Public test suites — เผยแพร่ชุดตัวอย่างทดสอบที่เป็นตัวแทนของกลุ่มเปราะบาง เพื่อให้บุคคลภายนอกหรือนักวิจัยอิสระสามารถทำซ้ำการตรวจสอบได้
- Versioning และ Change log — รายงานการเปลี่ยนแปลงที่ทำเพื่อแก้ไขอคติและผลกระทบต่อเมตริกต่างๆ พร้อมวันที่และผู้รับผิดชอบ
แนวทางการเปิดเผยข้อมูลต่อสาธารณะอย่างรับผิดชอบ
การเปิดเผยข้อมูลเกี่ยวกับอคติและความโปร่งใสของโมเดลที่ใช้ในบริการสาธารณะควรเป็นไปอย่างสมดุล ระหว่างความโปร่งใสและการคุ้มครองข้อมูลส่วนบุคคล — แนวปฏิบัติแนะนำได้แก่
- เผยแพร่ Model card และสรุป Audit report ฉบับย่อสำหรับประชาชน พร้อมลิงก์ไปยังรายงานฉบับเต็มสำหรับหน่วยงานกำกับ
- ระบุเมตริกหลัก (bias score, FPR/FNR gap, ECE) และค่าเป้าหมายหรือเกณฑ์ที่ยอมรับได้ (thresholds) เพื่อให้ประชาชนประเมินความเสี่ยงได้
- เปิดชุดทดสอบสาธารณะในรูปแบบ anonymized และให้คำแนะนำวิธีการรันเทสต์ เพื่อสนับสนุนการตรวจสอบอิสระ
- อธิบายข้อจำกัดของการทดสอบ (เช่น ข้อมูลฝึกอาจไม่ครบถ้วน) และแผนการแก้ไขในระยะยาว (roadmap)
- จัดให้มีช่องทางรับข้อร้องเรียนและรายงานเหตุขัดข้องจากผู้ใช้จริง พร้อมมาตรการเยียวยาเมื่อพบผลกระทบต่อกลุ่มเปราะบาง
สรุปคือ การวัดอคติและประเมินความโปร่งใสสำหรับ LLM ที่จะใช้ในบริการสาธารณะต้องอาศัยทั้งชุดเทคนิคเชิงวิศวกรรม (subgroup evaluation, counterfactuals, calibration) และกรอบการรายงานที่ชัดเจน (model cards, audit reports, explainability outputs) โดยการนำเสนอผลลัพธ์เชิงตัวเลขก่อน-หลังการแก้ไข เช่น bias score จาก 0.28 ลดเป็น 0.12 และ FPR gap ลดจาก 0.15 เป็น 0.03 จะช่วยให้หน่วยงานตัดสินใจเชิงนโยบายได้เป็นรูปธรรม และสร้างความเชื่อมั่นต่อสาธารณะได้มากขึ้น
ปัจจัยทางกฎหมาย จริยธรรม และการกำกับดูแล
กรอบกฎหมายและการคุ้มครองข้อมูลส่วนบุคคล
การนำเครื่องหมาย LLM Audit Mark มาใช้กับโมเดลที่ให้บริการสาธารณะต้องสอดคล้องกับกฎหมายคุ้มครองข้อมูลส่วนบุคคล เช่น พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ในประเทศ และหลักการสากลอย่าง GDPR ซึ่งจะกำหนดข้อบังคับสำคัญ ได้แก่ การขอความยินยอมที่ชัดเจน, การจำกัดวัตถุประสงค์, การลดการเก็บข้อมูล (data minimization) และการจัดมาตรการด้านความปลอดภัย (technical and organizational measures)
ในเชิงปฏิบัติ หน่วยงานที่ประเมินควรเรียกร้องให้มี DPIA (Data Protection Impact Assessment) ก่อนการประเมิน LLM เพื่อประเมินความเสี่ยงต่อสิทธิและเสรีภาพของบุคคล เช่น ความเสี่ยงจากการรั่วไหลของข้อมูลอ่อนไหว การระบุตัวตนกลับได้ (re-identification) และผลกระทบต่อกลุ่มผู้เปราะบาง นอกจากนี้ ต้องคำนึงถึงการย้ายข้อมูลข้ามพรมแดน การเข้ารหัส การทำให้เป็นนิรนามหรือ pseudo-anonymization และนโยบายการเก็บรักษา/ทำลายข้อมูล
ความรับผิดชอบต่อคำตอบของ AI (Liability) และการแบ่งความรับผิด
ประเด็นความรับผิดชอบเมื่อระบบ LLM ให้คำตอบที่ก่อให้เกิดความเสียหายเป็นประเด็นสำคัญ โดยต้องพิจารณาแนวทางผสมระหว่างความรับผิดตามสัญญา (contractual liability) และความรับผิดทางแพ่งหรืออาญาในกรณีที่เกิดความเสียหาย สำคัญคือต้องระบุความรับผิดชัดเจนระหว่าง ผู้พัฒนาโมเดล (model developer), ผู้บริการ/หน่วยงานที่นำไปใช้ (service deployer) และ ผู้ให้ข้อมูล/ผู้ควบคุมข้อมูล (data controller)
มาตรการที่ควรบรรจุในกรอบ Audit Mark ได้แก่:
- ข้อกำหนดสัญญาเพื่อจัดสรรความรับผิดและการประกันภัย (e.g., mandatory liability insurance หรือ indemnity clauses)
- ระบบการติดตามและบันทึกเหตุการณ์ (logging & provenance) เพื่อให้สามารถสืบสวนและพิสูจน์ต้นเหตุเมื่อเกิดข้อผิดพลาด
- กลไกการเยียวยาและชดเชยสำหรับผู้ที่ได้รับผลกระทบ เช่น ช่องทางร้องเรียน การเยียวยาทางการเงิน หรือการแก้ไขข้อมูล
ประเด็นจริยธรรม: ความเท่าเทียม การแจ้งผู้ใช้ และสิทธิในการอุทธรณ์
นอกเหนือจากข้อกฎหมายแล้ว ต้องคำนึงถึงหลักจริยธรรมพื้นฐาน เช่น ความเท่าเทียม (equity), การไม่เลือกปฏิบัติ (non-discrimination), และ ความโปร่งใส (transparency) โดยเฉพาะเมื่อระบบถูกนำไปใช้ในบริการสาธารณะที่มีผลต่อสิทธิขั้นพื้นฐานของประชาชน
ข้อบังคับด้านจริยธรรมควรครอบคลุม:
- การแจ้งผู้ใช้ (user notice/consent): ผู้ใช้ต้องได้รับการแจ้งอย่างชัดเจนว่าได้รับบริการจาก LLM ที่ผ่านการประเมิน และระบบใดบ้างที่อาจมีผลกระทบต่อข้อมูลส่วนบุคคลหรือสิทธิของตน; ในบางกรณีต้องมีการขอความยินยอมแบบสมัครใจ
- สิทธิในการอุทธรณ์และโต้แย้ง (right to contest): ผู้ได้รับผลกระทบต้องสามารถยื่นคำร้องขอทบทวนคำตอบของ AI และขอการตรวจสอบจากหน่วยงานที่เป็นกลางได้ โดยต้องมีกรอบเวลาและกระบวนการตอบกลับที่ชัดเจน
- ความสามารถในการอธิบาย (explainability): แม้โมเดล LLM บางประเภทจะอธิบายได้ยาก แต่ต้องพัฒนามาตรการเพื่อให้คำอธิบายระดับเหตุผลหรือบริบทว่าเหตุใดระบบจึงให้คำตอบดังกล่าว
แนวทางการกำกับดูแล: ความโปร่งใส การประเมินซ้ำ และมาตรการลงโทษ
โครงสร้างการกำกับดูแลที่เหมาะสมสำหรับ LLM Audit Mark ควรรวมทั้งนโยบายเชิงเทคนิคและกลไกบังคับใช้ที่เข้มงวด โดยแนวทางหลักได้แก่ audit transparency, periodic reassessment และ sanctions
- Audit transparency: รายงานผลการประเมินต้องเปิดเผยระดับที่เหมาะสมต่อสาธารณะ เช่น คะแนนความโปร่งใส อคติ (bias) และค่าความเสี่ยง พร้อมข้อมูลเชิงเทคนิคบางส่วน (model cards, data sheets) เพื่อให้ผู้ใช้และผู้กำกับสามารถตรวจสอบได้
- Periodic reassessment: กำหนดให้มีการทบทวนและประเมินซ้ำเป็นระยะ (เช่น ทุก 6–12 เดือน หรือเมื่อมีการอัปเดตโมเดล/ข้อมูลครั้งใหญ่) เพื่อคุมความเปลี่ยนแปลงของพฤติกรรมโมเดลและความเสี่ยงที่เกิดขึ้นใหม่
- Sanctions and enforcement: กำหนดมาตรการลงโทษที่ชัดเจนเมื่อมีการฝ่าฝืน เช่น ปรับทางการเงิน การเพิกถอน LLM Audit Mark ชั่วคราว/ถาวร คำสั่งห้ามใช้งานในบริการสาธารณะ และการเปิดเผยการละเมิดต่อสาธารณะ
สรุปแล้ว การออกแบบกรอบกฎหมาย จริยธรรม และการกำกับดูแลสำหรับ LLM Audit Mark ควรเป็นระบบผสมผสานที่เชื่อมโยงข้อกำหนดด้านข้อมูลส่วนบุคคล ความชัดเจนในความรับผิดชอบ การคุ้มครองสิทธิผู้ใช้ และกลไกกำกับดูแลที่โปร่งใสและมีประสิทธิภาพ เพื่อสร้างสมดุลระหว่างนวัตกรรมและการคุ้มครองผลประโยชน์สาธารณะ
แผนทดลองในไทย: กรณีศึกษาและแผนการนำร่อง
แผนทดลองในไทย: แนวทางทั่วไปและกรอบการนำร่อง
เพื่อทดสอบการให้คะแนนตามแนวคิด LLM Audit Mark ในบริบทของหน่วยงานรัฐไทย แนะนำให้ดำเนินการเป็นชุดการทดลองนำร่อง (pilot) แบบมีเฟสชัดเจน โดยคำนึงถึงความหลากหลายของบริการสาธารณะ ความเสี่ยงต่อประชาชน และลักษณะข้อมูลที่ใช้ ในภาพรวม กระบวนการนำร่องควรแบ่งเป็น 5 เฟสหลัก ได้แก่ การเตรียมการ (planning), การเก็บและจัดการข้อมูล (data readiness), การตรวจสอบและปรับปรุงก่อนใช้งาน (pre-deployment audit), การใช้งานเชิงจำกัดและการตรวจสอบเชิงปฏิบัติ (live pilot & monitoring) และ การประเมินผลและขยายผล (evaluation & scale) ซึ่งแต่ละเฟสควรกำหนดกิจกรรม ผลลัพธ์ที่คาดหวัง และตัวชี้วัดความสำเร็จเป็นลายลักษณ์อักษร
ตัวอย่างการนำร่องกับบริการสาธารณะ (กรณีศึกษา)
ต่อไปนี้เป็นตัวอย่างแผนทดลองสามกรณีที่มีระดับความเสี่ยงและข้อกำหนดวิชาการต่างกัน เหมาะสำหรับการทดสอบมาตรฐาน LLM Audit Mark ในบริบทไทย
-
ระบบตอบคำถามสาธารณะด้านสาธารณสุข (Health Information Chatbot)
ขอบเขต: ให้ข้อมูลเชิงสาธารณะ เช่น ข้อมูลวัคซีน ตารางให้บริการ และคำแนะนำเบื้องต้น ไม่ได้ทดแทนคำปรึกษาแพทย์ การนำร่อง 6 เดือน โดยเริ่มที่จังหวัดนำร่อง 1–2 แห่ง
กิจกรรมสำคัญ: เก็บข้อมูลคำถาม-คำตอบจริง ปรับชุดข้อมูลฝึก ติดตั้งระบบ logging สำหรับ traceability ดำเนินการ red-team testing เพื่อตรวจหาคำตอบที่เป็นอันตรายหรือชี้นำผิด
-
ระบบช่วยประเมินสิทธิ์สวัสดิการแรงงาน (Eligibility Pre-Screener)
ขอบเขต: ประเมินเบื้องต้นว่าแรงงานมีแนวโน้มได้รับสิทธิใดบ้าง แต่ไม่แทนการตัดสินขั้นสุดท้ายของเจ้าหน้าที่ การนำร่อง 9 เดือน โดยร่วมกับสำนักงานแรงงานจังหวัด
กิจกรรมสำคัญ: ตรวจสอบความเป็นกลางของโมเดลต่อกลุ่มประชากรต่าง ๆ ทดสอบกรณีขอบ (edge cases) และวิเคราะห์ผลกระทบที่อาจเกิดขึ้นหากมีการตัดสินใจบนพื้นฐานคำตอบที่ผิดพลาด
-
ระบบให้คำแนะนำด้านการยื่นคำร้องทะเบียนราษฎร์ (Civil Registry Assistant)
ขอบเขต: ให้คำแนะนำเกี่ยวกับเอกสารและขั้นตอน ไม่อนุญาตให้แก้ไขข้อมูลสำคัญของทะเบียนโดยอัตโนมัติ การนำร่อง 6–8 เดือน ในสำนักงานเขตหรืออำเภอที่มีปริมาณคำถามสูง
กิจกรรมสำคัญ: ตรวจสอบความสอดคล้องกับกฎหมายคุ้มครองข้อมูลส่วนบุคคล (PDPA) และตั้งมาตรการป้องกัน leakage ของข้อมูลส่วนบุคคล
ขั้นตอนการนำร่องและระยะเวลาเชิงปฏิบัติ
- เดือนที่ 0–1 (Planning): แต่งตั้งทีมโครงการ ระบุขอบเขต เลือกบริการนำร่อง และเขียนแผนการวัดผล
- เดือนที่ 2–3 (Data readiness): Audit ข้อมูล สร้างชุดทดสอบ (benchmark datasets) และกำหนดเกณฑ์ LLM Audit Mark
- เดือนที่ 4–6 (Pre-deployment audit): ดำเนินการประเมินภายนอก (third-party auditors) ทดสอบ bias, safety, explainability และจัดทำรายงานเบื้องต้น
- เดือนที่ 7–9 (Live pilot): เปิดใช้งานในวงจำกัด เก็บ telemetry, feedback และ incident reports แบบเรียลไทม์
- เดือนที่ 10–12 (Evaluation & scale decision): วิเคราะห์ผล ปรับปรุงโมเดล สรุปบทเรียน และตัดสินใจว่าจะขยายการใช้หรือยุติ
ตัวชี้วัดความสำเร็จของการทดลอง
การประเมินผลควรใช้ทั้งตัวชี้วัดเชิงปริมาณและเชิงคุณภาพ ตัวอย่างตัวชี้วัดที่แนะนำมีดังนี้
- Reliability: ความแม่นยำของคำตอบ (accuracy) และความคงที่ของผลลัพธ์ (consistency) เช่น เป้าหมาย accuracy ≥ 92% สำหรับคำถามเชิงข้อเท็จจริงในระบบข้อมูลสาธารณสุข
- User satisfaction: คะแนนความพึงพอใจผู้ใช้ (CSAT) หรือ Net Promoter Score (NPS) เป้าหมาย CSAT เพิ่มขึ้นจาก baseline อย่างน้อย 15-20% ภายใน 3 เดือนของการใช้งาน
- Reduction in incidents: อัตราการร้องเรียนหรือเหตุการณ์ความผิดพลาด (incidents) ควรลดลงหรือไม่เกินเกณฑ์ที่ยอมรับได้ เช่น ลดข้อร้องเรียนที่เกี่ยวกับคำตอบผิดพลาดลง ≥ 60% ภายในรอบการทดลอง
- Fairness metrics: การวัดความเหลื่อมล้ำเช่น disparate impact ratio ระหว่างกลุ่มประชากรไม่ควรเกิน 1.2 และไม่มีการปฏิเสธสิทธิ์อย่างไม่เป็นธรรมที่สอดคล้องกับตัวแปรเช่นเพศ/อายุ/ตำแหน่งที่ตั้ง
- Traceability & Explainability: ร้อยละของคำตอบที่สามารถอธิบายที่มาของข้อมูลได้ (provenance) ควรสูงกว่า 90% สำหรับคำตอบที่มีผลกระทบต่อสิทธิประชาชน
ทรัพยากรและทักษะที่หน่วยงานรัฐต้องเตรียม
การนำร่องที่มีประสิทธิผลต้องการทรัพยากรทั้งด้านบุคลากร เทคโนโลยี และงบประมาณ ตัวอย่างความต้องการรวมถึง:
- ทีม Auditor (ภายนอก/ภายใน): อย่างน้อย 2–4 ผู้เชี่ยวชาญต่อโครงการ ได้แก่ ผู้เชี่ยวชาญด้าน AI audit, นโยบายความเป็นธรรม, และผู้เชี่ยวชาญด้านความปลอดภัยของข้อมูล
- Data Stewards: 1–2 คนต่อชุดข้อมูล รับผิดชอบการทำความสะอาดข้อมูล การติดป้าย (labeling) และการจัดการ metadata
- เจ้าหน้าที่ฝ่ายเทคนิค: วิศวกร ML/DevOps 2–3 คนสำหรับการติดตั้ง logging, monitoring และการอัปเดตโมเดล
- เจ้าหน้าที่ด้านกฎหมายและคุ้มครองข้อมูล: ตรวจสอบความสอดคล้องกับ PDPA และข้อกฎหมายที่เกี่ยวข้อง
- งบประมาณ: ประมาณการเบื้องต้นต่อโครงการนำร่องอยู่ในช่วง 3–10 ล้านบาท ขึ้นกับขนาดของผู้ใช้และความซับซ้อนของการทดสอบ (รวมค่าบริการ auditor ภายนอก ค่าพัฒนาโมเดล ค่าโฮสติ้ง และการอบรมเจ้าหน้าที่)
- เครื่องมือและโครงสร้างพื้นฐาน: ระบบ logging ที่มีความสามารถเก็บ provenance, แพลตฟอร์มการทดสอบ bias, และสภาพแวดล้อมสำหรับ red-teaming
ตัวอย่างผลลัพธ์สมมติและบทเรียนที่คาดว่าจะได้รับ
จากการทดลองนำร่อง 3 กรณีข้างต้น หน่วยงานอาจพบผลลัพธ์สมมติและบทเรียนเช่น:
- กรณีระบบสาธารณสุข: ความแม่นยำคำตอบเริ่มต้น 88% หลังการปรับ dataset และกฎควบคุมเพิ่มเป็น 94% ผู้ใช้งานให้ CSAT เพิ่มจาก 70% เป็น 86% บทเรียนสำคัญคือการมี dataset ที่เป็นตัวแทนของภาษาท้องถิ่นช่วยลดความผิดพลาดด้านความหมาย
- กรณีสวัสดิการแรงงาน: พบอคติที่กระทบกลุ่มแรงงานนอกระบบ (disparate impact = 1.35) ซึ่งหลังจากปรับ sampling และปรับ objective ของโมเดล ลดค่า disparate impact เหลือ 1.08 ผลลัพธ์ชี้ให้เห็นว่าการทดสอบเชิง demographic stratification เป็นสิ่งจำเป็นก่อนการใช้งานจริง
- กรณีทะเบียนราษฎร์: พบปัญหาความเสี่ยงด้าน PDPA เมื่อระบบเก็บตัวอย่างข้อความจากผู้ใช้ โดยต้องเปิดใช้งานการ anonymization และ retention policy ผลลัพธ์แสดงให้เห็นว่าการออกแบบ flow เพื่อไม่ให้ระบบร้องขอข้อมูลอ่อนไหวเป็นแนวปฏิบัติที่ต้องกำหนดเป็นมาตรฐาน
สรุปเชิงนโยบายและข้อเสนอแนะ
การทดลองนำร่องตามกรอบ LLM Audit Mark จะให้ข้อมูลเชิงปฏิบัติในการกำหนดมาตรฐานการจัดซื้อและการอนุมัติใช้โมเดล AI ของหน่วยงานรัฐ โดยแนะนำให้หน่วยงาน:
- เริ่มจากบริการที่มีความเสี่ยงปานกลางก่อน แล้วค่อยขยับไปสู่บริการที่มีผลกระทบสูง
- กำหนดเกณฑ์ความสำเร็จเชิงปริมาณ เช่น threshold ของ accuracy, disparate impact และ reduction in incidents
- ลงทุนในบุคลากร (auditors, data stewards) และเครื่องมือมอนิเตอร์ เพื่อให้กระบวนการ audit เป็นไปอย่างต่อเนื่องไม่ใช่กิจกรรมครั้งเดียว
การดำเนินการเชิงรอบคอบและมีหลักฐานเชิงประจักษ์จะช่วยให้การให้บริการสาธารณะด้วย LLM มีความปลอดภัย เป็นธรรม และได้รับความไว้วางใจจากประชาชนมากขึ้น
คำแนะนำเชิงนโยบายและข้อสรุปสำหรับหน่วยงานรัฐและผู้พัฒนา
คำแนะนำเชิงนโยบายและข้อสรุปสำหรับหน่วยงานรัฐและผู้พัฒนา
เพื่อให้การนำ Large Language Models (LLMs) มาใช้ในบริการสาธารณะเป็นไปอย่างปลอดภัย โปร่งใส และยึดผลประโยชน์ของประชาชนเป็นหลัก จำเป็นต้องมีชุดแนวปฏิบัติเชิงนโยบายและแนวทางปฏิบัติทางเทคนิคที่ชัดเจน บทสรุปต่อไปนี้จะเสนอทั้งข้อเสนอเชิงนโยบายสำหรับหน่วยงานรัฐ, เช็คลิสต์สำหรับผู้พัฒนาโมเดลก่อนยื่นขอ LLM Audit Mark, และการเตือนข้อจำกัดรวมถึงแนวทางการประเมินความต่อเนื่องในการใช้งานจริง
ข้อเสนอเชิงนโยบาย 5 ข้อสำหรับหน่วยงานรัฐ
- กำหนดมาตรฐาน Audit Mark ขั้นพื้นฐานและชัดเจน — กำหนดระดับการประเมิน (เช่น ระดับพื้นฐาน/กลาง/สูง) ที่ครอบคลุมมาตรฐานด้านความโปร่งใส (transparency), ความเป็นธรรม (fairness), ความปลอดภัย (safety) และการคุ้มครองข้อมูลส่วนบุคคล (privacy). ตัวอย่างเช่น ระดับพื้นฐานอาจต้องมี model card, รายงานการทดสอบอคติเบื้องต้น และรายการข้อมูลต้นทาง (provenance) ส่วนระดับสูงจะรวมถึงการทดสอบเชิงสถานการณ์และการตรวจสอบแบบ third‑party.
- บูรณาการการฝึกอบรมบุคลากรและศูนย์ประเมินภายในประเทศ — จัดตั้งโปรแกรมฝึกอบรมเพื่อให้เจ้าหน้าที่มีทักษะในการอ่านผลการทดสอบ โมเดลการประเมินอคติ และการใช้เครื่องมืออัตโนมัติ เช่น toolkits สำหรับการวัด fairness/robustness. ควรมีหน่วยงานกลางหรือศูนย์ทดสอบที่รับรองความสามารถของผู้ประเมินภายในประเทศเพื่อลดการพึ่งพาบริการจากต่างประเทศ.
- สร้างกลไกการยื่นอุทธรณ์และการเปิดเผยต่อสาธารณะ — ผู้ใช้บริการต้องมีช่องทางยื่นข้อร้องเรียนและขอทบทวนผลการตัดสินใจที่เกี่ยวข้องกับ LLM; หน่วยงานต้องประกาศผล Audit Mark, รายงานการทดสอบสรุป และตัวชี้วัดที่เกี่ยวข้องในทะเบียนสาธารณะ (public registry) เพื่อเพิ่มความรับผิดชอบและความเชื่อมั่น.
- กำหนดกรอบการคุ้มครองข้อมูลและข้อกำหนดด้าน provenance — กำหนดให้ผู้พัฒนาต้องส่งข้อมูล provenance ของชุดข้อมูลฝึกสอนที่เกี่ยวข้องระบุแหล่งที่มา การอนุญาตใช้ข้อมูล และมาตรการลดความเสี่ยงเรื่องข้อมูลส่วนบุคคล; หากโมเดลถูกปรับด้วยข้อมูลภายในรัฐ ต้องมีการประเมินความเสี่ยงเป็นพิเศษและมาตรการป้องกันการรั่วไหลของข้อมูล.
- ติดตามและประเมินผลเชิงต่อเนื่อง (continuous monitoring) — กำหนดให้มีการรีวิวและรีเซ็นต์ Audit Mark เป็นระยะ (เช่น ทุก 12 เดือน หรือเมื่อมีการเปลี่ยนแปลงสำคัญของโมเดล) พร้อมกับเกณฑ์การรีวิวฉุกเฉินเมื่อมีเหตุการณ์ความเสี่ยง เช่น รายงานการละเมิดหรือเหตุการณ์ bias ที่ส่งผลกระทบต่อประชาชนเป็นวงกว้าง.
เช็คลิสต์สำหรับผู้พัฒนาก่อนยื่นขอ Audit Mark
- จัดทำ Model Card และ Datasheet แบบสมบูรณ์ — ระบุวัตถุประสงค์การใช้งาน, ข้อจำกัด, ข้อมูลการฝึกสอน, เวอร์ชันของโมเดล, ค่าใช้จ่ายทรัพยากร และตัวชี้วัดการประเมินประสิทธิภาพ.
- จัดเตรียม Provenance Data และสิทธิ์การใช้ข้อมูล — ระบุแหล่งข้อมูลที่ใช้ฝึกโมเดลพร้อมหลักฐานการได้รับสิทธิ์หรือการลบข้อมูลที่มีความเสี่ยงต่อความเป็นส่วนตัว. หากมีการใช้ข้อมูลภายในหน่วยงานรัฐ ควรแนบสัญญาและข้อกำหนดการคุ้มครองข้อมูล.
- ทำการทดสอบ Bias, Fairness และ Robustness — แนบรายงานการทดสอบที่ใช้มาตรฐานชัดเจน (เช่น การทดสอบกลุ่มประชากรต่าง ๆ, stress tests ต่อ prompt injection, adversarial attacks) พร้อมผลลัพธ์เชิงปริมาณและมาตรการลดผลกระทบ.
- เตรียม Toolkits และสคริปต์สำหรับการทวนสอบ — จัดเตรียมชุดเครื่องมือ (เช่น evaluation scripts, anonymized test datasets, reproducible pipelines) เพื่อให้หน่วยงานประเมินหรือ third‑party auditor สามารถทำซ้ำการทดสอบได้.
- จัดทำแผนการจัดการเวอร์ชันและการเปลี่ยนแปลง — ระบุกระบวนการ CI/CD สำหรับการอัพเดตโมเดล, การทดสอบก่อนปล่อยใช้งานจริง, และนโยบายการแจ้งเตือนเมื่อเกิดการเปลี่ยนแปลงที่มีนัยสำคัญ.
- กำหนดช่องทางการติดต่อและกระบวนการอุทธรณ์ — ระบุทีมรับผิดชอบที่ชัดเจนสำหรับการแก้ไขข้อร้องเรียนจากผู้ใช้ รวมถึง SLA ในการตอบกลับและขั้นตอนการแก้ไขผลลัพธ์ที่ไม่เป็นธรรม.
ข้อจำกัดและแนวทางการประเมินความต่อเนื่อง
แม้จะมีมาตรการ Audit Mark และการประเมินเชิงเทคนิค แต่องค์ประกอบหลายประการยังคงเป็นข้อจำกัดที่ต้องตระหนัก:
- ความไม่แน่นอนของผลทดสอบในสภาพแวดล้อมจริง — การทดสอบในห้องทดลอง (benchmarks) มักไม่สะท้อนพฤติกรรมในบริบทการใช้งานจริง 100%; งานวิจัยบ่งชี้ว่าผล performance อาจเบี่ยงเบนได้ในสภาพแวดล้อมที่มี input ที่แตกต่างกัน ดังนั้นจึงจำเป็นต้องมีการติดตามผลหลังการนำไปใช้ (post-deployment monitoring).
- ความเสี่ยงจากการเปลี่ยนแปลงเวอร์ชันและการปรับแต่ง — การอัพเดตโมเดลหรือการ fine-tune ด้วยข้อมูลใหม่อาจเปลี่ยนระดับอคติและความเสี่ยง จึงต้องมีนโยบาย re‑audit และการทดสอบ regression ก่อนนำเวอร์ชันใหม่ขึ้นให้บริการ.
- ขีดจำกัดของมาตรวัดอคติและ fairness — ไม่มีเมตริกใดที่ครอบคลุมทุกประเภทของความอยุติธรรมได้ ผู้ประเมินควรใช้ชุดตัวชี้วัดหลายมิติ (เช่น demographic parity, equalized odds, calibration) พร้อมคำอธิบายความหมายเชิงบริบท.
- ต้นทุนและความสามารถทางเทคนิค — การดำเนินการตรวจสอบอย่างละเอียดต้องใช้ทรัพยากรทั้งบุคลากรและการประมวลผล จึงควรวางแผนงบประมาณระยะยาวและใช้แนวทางค่อยเป็นค่อยไป (phased approach) โดยให้บริการสำคัญก่อนตามระดับความเสี่ยง.
- ความเสี่ยงด้านกฎหมายและจริยธรรม — แม้ผ่าน Audit Mark แล้ว การใช้งานยังต้องสอดคล้องกับกฎหมายคุ้มครองข้อมูล การไม่เลือกปฏิบัติ และหลักจริยธรรมของหน่วยงาน; จึงควรมีคณะกรรมการเฉพาะกิจที่ผสานมุมมองทางกฎหมายและสาธารณะ.
สรุปคือ LLM Audit Mark ควรถูกใช้เป็นเครื่องมือหนึ่งในระบบกำกับดูแล ไม่ใช่การรับประกันความปลอดภัยแบบเด็ดขาด หน่วยงานรัฐต้องผสานมาตรการทางนโยบาย การฝึกอบรม และการตรวจสอบต่อเนื่องเข้าด้วยกัน ในขณะที่ผู้พัฒนาต้องเตรียมเอกสารเชิงเทคนิค โปร่งใส และระบบทวนสอบที่สามารถทำซ้ำได้ เพื่อสร้างความเชื่อมั่นและลดความเสี่ยงต่อประชาชนเมื่อมีการนำโมเดลมาให้บริการสาธารณะ
บทสรุป
การพัฒนาและนำไปใช้ของ "LLM Audit Mark" มีศักยภาพเป็นเครื่องมือสำคัญในการสร้างความเชื่อมั่นและลดความเสี่ยงก่อนการนำโมเดลภาษาขนาดใหญ่ (LLM) มาให้บริการสาธารณะ โดยต้องออกแบบเกณฑ์และกระบวนการประเมินให้มีความโปร่งใส เป็นอิสระ และสามารถติดตามผลได้อย่างเป็นรูปธรรม ตัวอย่างแนวทางในการประเมินรวมถึงการใช้เมตริกเชิงปริมาณเพื่อวัดอคติ (เช่นการเปรียบเทียบอัตราข้อผิดพลาดระหว่างกลุ่มประชากร, False Positive/False Negative Rate), การจัดทำเอกสารประกอบโมเดล (model cards) และการตรวจสอบแหล่งที่มาของชุดข้อมูล (data provenance) พร้อมการเผยแพร่รายงานผลการประเมินแบบสาธารณะและการใช้ผู้ตรวจสอบอิสระเพื่อลดความขัดแย้งทางผลประเมิน
การนำ LLM Audit Mark ไปใช้จริงจำเป็นต้องเริ่มจากการทดลองนำร่อง สร้างขีดความสามารถของหน่วยงานที่เกี่ยวข้อง ทั้งในด้านบุคลากร เครื่องมือ และกระบวนการตรวจสอบ ตลอดจนกำหนดกรอบกฎหมายและมาตรฐานที่ชัดเจนเพื่อรองรับความรับผิดชอบทางกฎหมายและการคุ้มครองผู้ใช้ความร่วมมือระหว่างภาครัฐ ภาคเอกชน และภาคประชาสังคมมีความสำคัญต่อการออกแบบวิธีปฏิบัติร่วมกันและการแลกเปลี่ยนข้อมูล ในอนาคต หากมีการทดลองเชิงนโยบายอย่างเป็นขั้นตอนและการอัปเดตเกณฑ์อย่างต่อเนื่อง LLM Audit Mark อาจกลายเป็นมาตรฐานที่ช่วยเพิ่มความโปร่งใส ลดความเสี่ยงทางสังคม และเร่งการนำเทคโนโลยีไปใช้ในบริการสาธารณะอย่างรับผิดชอบ แต่ก็ต้องเตรียมทรัพยากรและกลไกการกำกับดูแลให้เพียงพอ รวมทั้งประสานงานในระดับนานาชาติเพื่อความสอดคล้องของมาตรฐาน



