
ในช่วงไม่กี่เดือนที่ผ่านมา องค์กรไทยจำนวนมากเริ่มหันมาทดลองแนวคิด "Agent Mesh" — สถาปัตยกรรมที่เชื่อมต่อโมเดลภาษาใหญ่ (LLM) หลายตัวเข้ากับไมโคร‑เอเจนต์แบบ Event‑Driven เพื่อออโตเมตงานข้ามแผนกอย่างยืดหยุ่นและทนทาน แนวทางนี้ช่วยให้แต่ละเอเจนต์ทำหน้าที่เฉพาะด้าน (เช่น การตรวจสอบข้อมูล การสร้างเอกสาร การวิเคราะห์เชิงนโยบาย) ขณะที่การประสานงานระหว่างเอเจนต์ทำงานผ่านเหตุการณ์ (events) ทำให้ระบบสามารถสเกลและตอบสนองต่อกระบวนการทางธุรกิจที่ซับซ้อนได้ดีขึ้น
จุดเด่นที่องค์กรไทยให้ความสนใจคือความสามารถในการใช้ LLM หลายตัวร่วมกันตามความเชี่ยวชาญ ลดต้นทุนการเรียกใช้งานโมเดลขนาดใหญ่สำหรับงานเล็ก ๆ เพิ่มความทนทานเมื่อโมเดลใดล้มเหลว และที่สำคัญคือการมี Audit Trail ที่บันทึกเหตุผลและบริบทของการตัดสินใจทุกขั้นตอน ซึ่งตอบโจทย์ด้านธรรมาภิบาลข้อมูลและการตรวจสอบสำหรับหน่วยงานที่ต้องปฏิบัติตามกฎระเบียบ บทความนี้จะสรุปแนวคิดเชิงปฏิบัติ ให้ภาพสถาปัตยกรรมตัวอย่าง และเสนอแนวทางทำ Proof of Concept (PoC) ที่องค์กรไทยสามารถนำไปทดลองใช้งานได้จริง
บทนำ: ทำไม Agent Mesh ถึงเป็นเทรนด์สำคัญสำหรับองค์กรไทย
บทนำ: ทำไม Agent Mesh ถึงเป็นเทรนด์สำคัญสำหรับองค์กรไทย
ในยุคที่การแปลงสภาพสู่ดิจิทัล (digital transformation) เป็นเรื่องจำเป็นสำหรับความยืดหยุ่นทางธุรกิจ แนวคิดของ Agent Mesh ปรากฏขึ้นเป็นทางเลือกใหม่สำหรับการเชื่อมต่อความสามารถของ Large Language Models (LLMs) กับระบบงานภายในองค์กรอย่างเป็นระบบ โดย Agent Mesh หมายถึงสถาปัตยกรรมที่ประกอบด้วยเอเจนต์ย่อยหลายตัว (micro‑agents) ทำงานแบบกระจายและสื่อสารกันผ่านเหตุการณ์ (event‑driven) แทนการพึ่งพาเอเจนต์เดี่ยวหรือโมโนลิธิก การออกแบบเช่นนี้ทำให้สามารถผสาน LLM หลายรุ่น หลายผู้ให้บริการ และฟังก์ชันธุรกิจต่าง ๆ เข้าด้วยกันอย่างยืดหยุ่นและขยายตัวได้ง่าย
ความต่างจากระบบเอเจนต์แบบเดิม อยู่ที่แนวคิดของความกระจาย (decentralization) และการสื่อสารด้วยเหตุการณ์ (event‑driven orchestration) แทนการออกคำสั่งแบบเรียงลำดับ ภายใน Agent Mesh แต่ละไมโคร‑เอเจนต์ถูกออกแบบให้รับผิดชอบงานเฉพาะด้าน (เช่น ดึงข้อมูลจาก ERP, ตรวจสอบนโยบายความเสี่ยง, หรือจัดทำสรุปสำหรับฝ่ายการตลาด) และสามารถเรียกใช้ LLM หลายตัวตามบริบทของงาน ส่งผลให้ระบบรวมมีความทนทานต่อความล้มเหลว (resilience) และง่ายต่อการอัปเกรดหรือเปลี่ยนโมเดลเมื่อเทคโนโลยีพัฒนา ต่างจากเอเจนต์แบบเดิมที่มักเป็นไดรเวอร์เดียวหรือระบบที่ผูกติดกับผู้ให้บริการเดียว
แรงผลักดันให้องค์กรไทยเริ่มทดลอง Agent Mesh มาจากหลายปัจจัยสำคัญ ได้แก่ การเร่งรัดการแปลงสู่ดิจิทัล ที่ต้องการเชื่อมระบบเก่า (legacy systems) กับความสามารถของ LLM, ปัญหาขาดแคลนบุคลากรที่มีทักษะเฉพาะ ซึ่งทำให้ต้องหาแนวทางเพิ่มประสิทธิภาพงานซ้ำซ้อน และความต้องการออกแบบเวิร์กโฟลว์ข้ามแผนกที่มีความซับซ้อน (cross‑department workflows) โดยไม่สูญเสียการควบคุมการตัดสินใจ (governance) ทั้งนี้ ความสามารถในการบันทึกเหตุผลการตัดสินใจ (audit trail) ของแต่ละไมโคร‑เอเจนต์กลายเป็นข้อกำหนดสำคัญสำหรับภาคธุรกิจที่ต้องปฏิบัติตามกฎระเบียบและต้องการความโปร่งใส
สถิติสนับสนุนแนวโน้มนี้อย่างชัดเจน: รายงานของ McKinsey Global Survey on AI (2023) พบว่าองค์กรกว่า 50–60% ได้เริ่มนำ AI มาใช้ในระดับหนึ่งภายในธุรกิจ ขณะที่ IDC (2024) รายงานการเติบโตของงบประมาณด้าน AI และระบบอัจฉริยะอย่างต่อเนื่อง โดยคาดการณ์การใช้จ่ายด้าน AI จะเพิ่มขึ้นอย่างมีนัยสำคัญในอีก 2–3 ปีข้างหน้า เหล่านี้สะท้อนว่าองค์กรทั่วโลกและในภูมิภาคเอเชียตะวันออกเฉียงใต้รวมถึงไทย กำลังมองหาแนวทางผสาน LLM เข้ากับระบบเดิมเพื่อเพิ่มความเร็วในการตัดสินใจและลดงานซ้ำซ้อน
ในทางปฏิบัติ Agent Mesh ช่วยให้องค์กรไทยได้รับประโยชน์หลายประการ เช่น
- ความเร็วในการตัดสินใจ จากการเรียกข้อมูลและสังเคราะห์ผลลัพธ์แบบเรียลไทม์
- การลดงานซ้ำซ้อน โดยการกระจายหน้าที่ให้ไมโคร‑เอเจนต์แต่ละตัวจัดการงานเฉพาะทาง
- ความสามารถในการตรวจสอบย้อนหลัง (auditability) ผ่านการเก็บเหตุผลและลำดับการตัดสินใจของแต่ละเอเจนต์
- การผสานหลายแหล่ง LLM ทำให้องค์กรไม่ผูกติดกับผู้ให้บริการรายใดรายหนึ่งและเลือกโมเดลที่เหมาะสมกับบริบทงาน
ด้วยปัจจัยเหล่านี้ ไม่แปลกที่องค์กรไทยจำนวนมากเริ่มทดลองแนวทาง Agent Mesh เป็นโครงการนำร่อง เพื่อทดสอบทั้งด้านเทคนิค ผลลัพธ์เชิงธุรกิจ และข้อกำกับดูแล ก่อนขยายผลในระดับองค์กร ซึ่งสอดคล้องกับการเปลี่ยนผ่านด้านเทคโนโลยีและความต้องการรักษาความโปร่งใสในการตัดสินใจที่เพิ่มสูงขึ้น
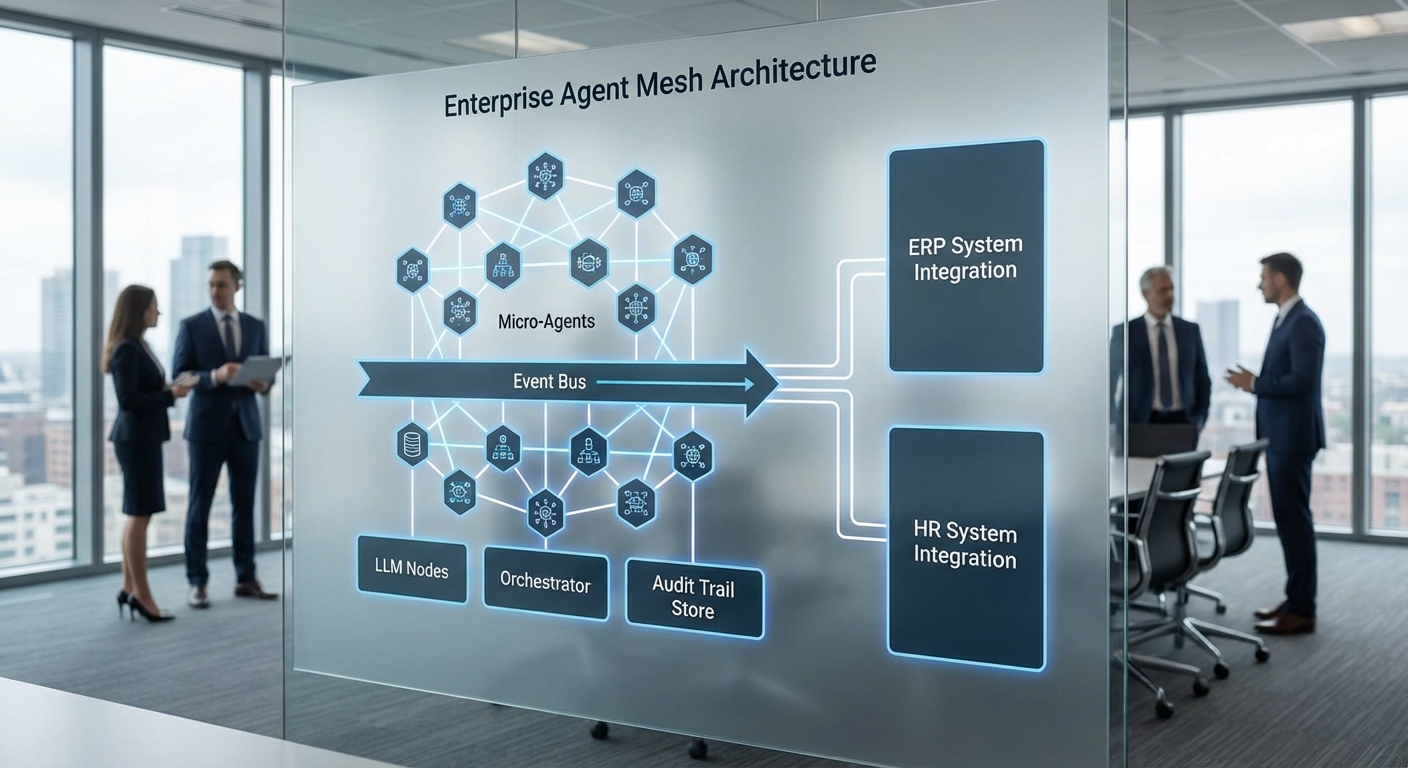
สถาปัตยกรรมภาพรวมของ Agent Mesh
สถาปัตยกรรมแบบ Agent Mesh สำหรับองค์กรไทยที่เริ่มนำ LLM หลายตัวมาเชื่อมกับไมโคร‑เอเจนต์แบบ Event‑Driven จะประกอบด้วยองค์ประกอบหลักหลายส่วนที่ทำงานร่วมกันเพื่อให้เกิดการออโตเมตงานข้ามแผนก มีการสเกลแบบยืดหยุ่น และเก็บบันทึกเหตุผลการตัดสินใจ (audit trail) อย่างเป็นระบบ ในภาพรวมจะเห็นว่าแต่ละชิ้นส่วนมีบทบาทชัดเจนทั้งในการรับส่งอีเวนต์ การเลือกใช้โมเดล การตรวจสอบความปลอดภัย และการบูรณาการกับระบบภายใน เช่น ERP, HR, Finance
องค์ประกอบหลักและบทบาทของแต่ละชิ้นส่วน
- Micro‑agents — หน่วยงานปฏิบัติการขนาดเล็ก (domain‑specific) ที่ออกแบบให้เป็น stateless หรือเก็บ state อย่างจำกัด โดยรับอีเวนต์จาก message bus ทำงานเฉพาะด้าน เช่น ตรวจสอบสิทธิ์ คำนวณภาษี หรือเตรียมข้อมูลสำหรับ LLM แต่ละตัว สามารถพัฒนา ทดสอบ และ deploy แยกจากกันเพื่อความเร็วในการพัฒนาและความทนทาน
- Event broker / Message bus — ระบบกลางสำหรับส่งผ่านอีเวนต์ระหว่างเอเจนต์ เช่น Kafka, RabbitMQ หรือ NATS ทำหน้าที่รับรองการจัดคิว การสตรีม และความทนทานของข้อความ ช่วยให้สถาปัตยกรรมเป็นแบบ decoupled ทำให้ scale แยกส่วนได้ง่าย
- LLM pool (หลายโมเดล) — สระของโมเดลภาษาจากผู้ให้บริการต่างๆ และรุ่นภายในองค์กร (on‑prem/finetuned) ใช้สำหรับการวิเคราะห์ภาษาธรรมชาติ สร้างคำตอบ หรือประมวลผลข้อความ ระบบจะมีนโยบายการเลือกโมเดล (model selection) เช่น latency, cost, ความแม่นยำ หรือความเสี่ยงด้านความเป็นส่วนตัว
- Orchestrator / Mediator — คอนโทรลระดับกลางที่กำหนดเส้นทางอีเวนต์และกลไกการประสานงาน เช่น การรัน workflow แบบ saga การเลือกใช้ micro‑agents และ LLM ตามบริบท รวมถึงการจัดการ retry และ error handling
- Observability & Audit Trail Store — เก็บข้อมูลการทำงาน การเรียกใช้โมเดล (model version, prompt, embeddings), คำตอบ, ค่า confidence และเหตุผลเชิงตรรกะที่นำไปสู่การตัดสินใจ เพื่อการตรวจสอบย้อนหลัง (forensics) และการปฏิบัติตามข้อกำหนดทางกฎหมาย
- Security Gateway — ชั้นควบคุมการเข้าถึงและนโยบายความปลอดภัย (authentication, authorization, encryption, data masking) พร้อมเชื่อมต่อกับ policy engine เพื่อบังคับใช้กฎความเป็นส่วนตัวและการใช้งานข้อมูล
- Integration Layer — ตัวกลางสำหรับเชื่อมต่อกับระบบภายในองค์กร (ERP, HR, Finance) ผ่าน API, adapters หรือ RPA connectors เพื่อดึง/เขียนข้อมูลธุรกรรมอย่างปลอดภัยและตรวจสอบได้
ภาพการไหลของอีเวนต์และจุดตัดของข้อมูล
ลำดับเหตุการณ์โดยย่อ: ผู้ใช้งานหรือระบบภายในส่งเหตุการณ์เข้า Event Broker → Orchestrator ตรวจสอบนโยบายและกำหนดเส้นทาง → Micro‑agents ที่เกี่ยวข้องถูกเรียกใช้งานแบบไม่ผูกพัน → หากต้องใช้ภาษาธรรมชาติ Orchestrator จะเรียก LLM จาก LLM pool พร้อมบริบทจาก Vector DB → คำตอบจาก LLM ถูกบันทึกพร้อม metadata ไปยัง Observability & Audit Trail Store → ผลลัพธ์ถูกส่งคืนผ่าน Integration Layer ไปยัง ERP/HR/Finance หรือแจ้งผู้ใช้
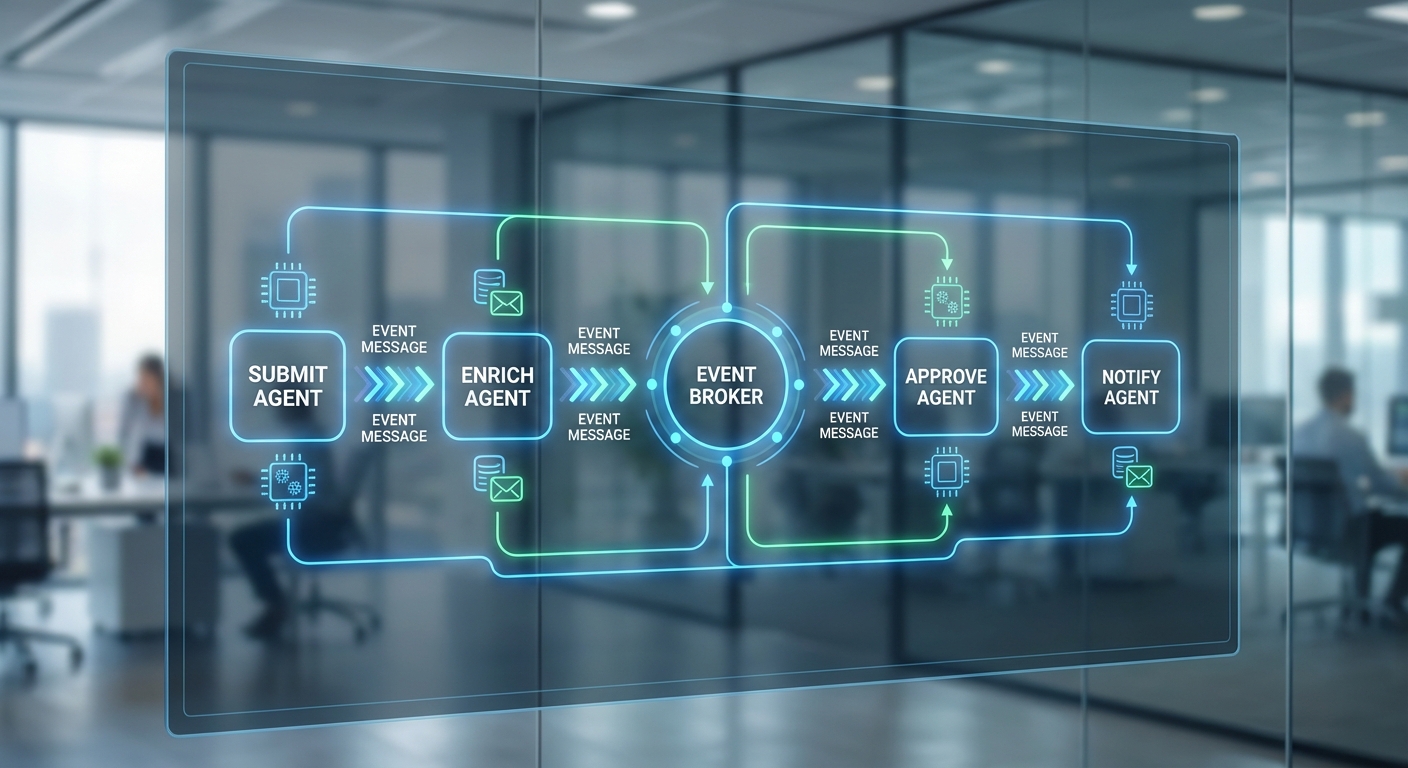
การออกแบบแบบแยกส่วน (decoupling) เพื่อรองรับการ scale และการทดสอบโมเดลหลายตัว
หลักการออกแบบที่สำคัญของ Agent Mesh คือการแยกส่วน (decoupling) ของหน้าที่ ทั้งในระดับ compute, data path และนโยบาย ซึ่งช่วยให้องค์กรสามารถ:
- สเกล micro‑agents ยกเว้นต้องอาศัย LLM ที่อาจมีข้อจำกัดด้าน latency — ทำให้สามารถเพิ่มหรือลด instances ของเอเจนต์โดยไม่กระทบระบบทั้งหมด
- ทดสอบและเปรียบเทียบโมเดลหลายรุ่น (A/B testing หรือ shadow mode) โดยไม่ต้องเปลี่ยนโค้ดของเอเจนต์ เพียงเปลี่ยน routing rule ใน Orchestrator
- นำเทคโนโลยีเฉพาะไปใช้ เช่น การแยก storage สำหรับ embeddings ใน Vector DB (เช่น Milvus, Pinecone) เพื่อเร่งการเรียกคืนข้อมูลบริบทสำหรับ RAG (retrieval‑augmented generation)
การออกแบบเช่นนี้สอดคล้องกับการใช้ Kubernetes ในการจัดการ container lifecycle, autoscaling และ deployment strategy (canary/blue‑green) ขณะที่ Event Broker เช่น Kafka ช่วยรับประกันการจัดส่งข้อความแบบทนทานและการสตรีมข้อมูลสำหรับการวิเคราะห์แบบเรียลไทม์
เทคโนโลยีที่มักใช้และแนวปฏิบัติ
- Message Brokers: Kafka สำหรับสตรีมมิงข้อมูลหนัก (high‑throughput), RabbitMQ สำหรับงานแบบ queue และ NATS สำหรับ low‑latency messaging
- Orchestration & Runtime: Kubernetes เป็นมาตรฐานสำหรับการจัดการ micro‑agents และ LLM inference services พร้อม service mesh เพื่อจัดการเครือข่ายภายใน
- API Gateway & Integration: API gateway สำหรับการควบคุมการเข้าถึงและ rate limiting, connector patterns สำหรับเชื่อม ERP/HR/Finance
- Data Stores: Vector DB สำหรับ embeddings, time‑series DB/PROMETHEUS สำหรับ metrics, และ immutable log store (เช่น append‑only object storage) สำหรับ audit trail
- Policy Engine: ใช้ policy engine (เช่น OPA) เพื่อบังคับใช้กฎการเข้าถึงข้อมูล การเลือกโมเดล และการมาสก์ข้อมูลที่เป็นความลับ
Observability, Audit Trail และข้อกำหนดด้านความปลอดภัย
Observability ไม่ใช่แค่การเก็บ metrics และ traces แต่รวมถึงการบันทึกเหตุผลการตัดสินใจของเอเจนต์และ LLM ด้วย เช่น prompt เวอร์ชัน, ชุดบริบทที่ดึงจาก Vector DB, โมเดลที่ถูกเรียกใช้ และคะแนนความเชื่อมั่น การออกแบบมักกำหนดให้ log เหล่านี้ถูกเขียนแบบเข้ารหัสและมีนโยบายการเก็บรักษาที่ชัดเจนเพื่อให้รองรับการตรวจสอบทางกฎหมาย และการสอดคล้องตามข้อกำหนด (compliance)
Security Gateway ทำหน้าที่เป็นจุดเดียวในการตรวจสอบตัวตน การอนุญาต และการกรองข้อมูล (data minimization/tokenization) ก่อนข้อมูลจะผ่านเข้าไปยัง LLM pool หรือระบบภายใน ตัวอย่างเช่น การทำ PII redaction ก่อนส่งไปยังโมเดลที่อยู่บนคลาวด์ พร้อมทั้งบังคับใช้ policy engine ในการตัดสินใจว่าจะอนุญาตให้ใช้โมเดลใดกับข้อมูลประเภทใด
สรุปเชิงปฏิบัติการสำหรับองค์กร
การออกแบบ Agent Mesh ที่แข็งแรงต้องคำนึงถึงการแยกส่วนเพื่อให้สามารถทดสอบโมเดลหลายตัวและสเกลในระดับต่างๆ ได้ โดยใช้ stack ที่ประกอบด้วย Kafka/RabbitMQ/NATS, Kubernetes, API Gateway, Vector DB และ Policy Engine รวมถึงการวางกลไก Observability & Audit Trail ที่บันทึกเหตุผลเชิงบริบทของการตัดสินใจ เพื่อให้สามารถตอบคำถามเชิงธุรกิจและความปลอดภัยได้เมื่อจำเป็น
ตัวอย่างเชิงตัวเลขจากโครงการนำร่องบางแห่งชี้ว่า การนำสถาปัตยกรรมแบบ Event‑Driven มาประยุกต์กับ Agent Mesh สามารถลดเวลาการตอบกลับเชิงธุรกรรมอัตโนมัติได้ราว 30–50% และเพิ่มความสามารถในการสเกลของระบบอัตโนมัติข้ามทีมเป็น 2–5 เท่า ขึ้นอยู่กับการออกแบบและภาระงาน
ไมโคร‑เอเจนต์แบบ Event‑Driven: การออกแบบและตัวอย่าง Workflow
ภาพรวมการออกแบบไมโคร‑เอเจนต์แบบ Event‑Driven
ไมโคร‑เอเจนต์ (micro‑agents) ที่ทำงานแบบ event‑driven เหมาะสำหรับองค์กรที่ต้องการเชื่อม LLM หลายตัวกับกระบวนการข้ามแผนก เพราะแต่ละเอเจนต์ทำงานเฉพาะหน้าที่ของตน รับอีเวนต์ เข้าใจคอนเท็กซ์ และส่งต่ออีเวนต์ใหม่เมื่อเสร็จงาน การออกแบบต้องคำนึงถึงรูปแบบอีเวนต์ (event types), โครงสร้างข้อความ (message schemas), การจัดการสถานะ (state), ความสามารถในการทำงานซ้ำได้ (idempotency), กลไก retry และการเก็บ Audit Trail ที่บันทึกเหตุผลการตัดสินใจของแต่ละเอเจนต์เพื่อรองรับการตรวจสอบภายหลัง
รูปแบบอีเวนต์และ metadata ที่จำเป็น
กำหนดชุด event types ให้ชัดเจนและมีระดับความละเอียดที่พอเหมาะ ตัวอย่าง event types สำหรับ workflow คำขอเบิกจ่าย ได้แก่:
- RequestSubmitted — ผู้ใช้ส่งคำขอเริ่มต้น
- RequestEnriched — ข้อมูลถูกเสริม (จาก HR/Directory/ERP)
- RequestValidated — ตรวจสอบข้อมูลทางธุรกิจและงบประมาณ
- RequestApproved / RequestRejected — ผลการอนุมัติ
- NotificationSent — แจ้งผู้ขอและผู้เกี่ยวข้อง
- RequestEscalated — กรณีต้องขึ้นบังคับหรือผิดปกติ
ทุกอีเวนต์ควรมี metadata อย่างน้อยเพื่อรองรับการติดตามและการจัดการข้อผิดพลาด ดังนี้:
- event_id (UUID) — รหัสเฉพาะของอีเวนต์
- correlation_id — เชื่อมอีเวนต์ทั้งหมดของคำขอเป็นชุดเดียว
- causation_id — ชี้ว่าอีเวนต์นี้เกิดจากอีเวนต์ใด
- timestamp — เวลาที่สร้างอีเวนต์
- source — ชื่อไมโคร‑เอเจนต์หรือบริการต้นทาง
- version — เวอร์ชันสคีมาอีเวนต์เพื่อรองรับการเปลี่ยนแปลง (event versioning)
- idempotency_key — คีย์สำหรับป้องกันการประมวลผลซ้ำ
- actor — ผู้ทำคำขอหรือระบบอัตโนมัติที่เกี่ยวข้อง
ตัวอย่าง message schema (เชิงแนวทาง)
เพื่อความเข้าใจ ตัวอย่างคำอธิบายฟิลด์สำคัญของ payload อาจประกอบด้วย:
- payload.request_id: รหัสคำขอ
- payload.amount: จำนวนเงิน
- payload.employee_id: ผู้ขอ (เชื่อมกับ HR)
- payload.purpose: เหตุผลการเบิก
- payload.attachments: ลิงก์เอกสารประกอบ
- payload.audit: โครงสร้างย่อยเก็บเหตุผลการตัดสินใจ เช่น { actor, decision, reason, model_version, confidence }
Sequence ตัวอย่าง: submit → enrich → validate → approve → notify
ตัวอย่าง workflow ข้ามแผนก (HR → Finance → IT) สำหรับคำขอเบิกจ่าย:
- 1. Submit (RequestSubmitted): ผู้ใช้ส่งคำขอผ่านพอร์ทัล โดยมี idempotency_key เพื่อป้องกันการกดส่งซ้ำ
- 2. Enrich (RequestEnriched): ไมโคร‑เอเจนต์ HR ดึงข้อมูลพนักงาน (ระดับ, สังกัด, สิทธิ์) เพิ่มเติม และแนบข้อมูลเข้า payload พร้อมบันทึก metadata ของการ enrichment
- 3. Validate (RequestValidated): ไมโคร‑เอเจนต์ Finance ตรวจสอบงบประมาณ เงื่อนไขภาษี และความสอดคล้องทางบัญชี ถ้าตรวจพบข้อขัดแย้งจะสร้าง RequestEscalated หรือส่งกลับพร้อมเหตุผล
- 4. Approve (RequestApproved): หากผ่านเงื่อนไข ผู้อนุมัติ (managers/auto‑approval rule) ตัดสินใจ โดยเอเจนต์บันทึกเหตุผลการอนุมัติรวมถึงเวอร์ชันของโมเดล LLM ที่ใช้เป็นส่วนหนึ่งของ audit trail
- 5. Notify (NotificationSent): ไมโคร‑เอเจนต์ Notification ส่งผลการอนุมัติ/ปฏิเสธไปยังผู้ขอและฝ่ายที่เกี่ยวข้อง
ในแต่ละขั้นตอนจะต้องแนบข้อมูลในส่วน audit เช่น prompt ที่ส่งให้ LLM, ผลลัพธ์, confidence score และรหัสเวอร์ชันของโมเดล เพื่อให้สามารถย้อนเหตุผลได้
Idempotency, Retry Logic และการจัดการ State เบื้องต้น
เพื่อความทนทานและความสม่ำเสมอของระบบ ควรปฏิบัติตามแนวทางต่อไปนี้:
- Idempotency: ใช้ idempotency_key พร้อมตารางดึงพัก (dedupe store) เมื่อได้รับอีเวนต์ซ้ำ ให้ตรวจสอบคีย์ก่อนประมวลผลและตอบกลับสถานะก่อนหน้า
- Retry logic: ใช้กลยุทธ์แบบ exponential backoff พร้อม jitter และจำกัดจำนวน retry ก่อนโยนไปยัง Dead‑Letter Queue (DLQ) เพื่อให้ทีมสามารถวิเคราะห์สาเหตุ
- State management: แยก state per agent — ใช้แบบ transactional state (เช่น DB) หรือ event sourcing เมื่อซับซ้อน ภายใต้หลักการ “single writer” เพื่อลดปัญหา race condition
- Compensation: สำหรับการกระทำที่ไม่สามารถย้อนกลับได้ ให้มีขั้นตอนการชดเชย (compensating actions) และบันทึกเหตุผลเพื่อ audit
Best Practices: Transactional Outbox, Event Versioning, Observability
เพื่อให้ระบบเชื่อถือได้และสามารถพัฒนาได้ต่อ การนำแนวปฏิบัติเหล่านี้ไปใช้สำคัญมาก:
- Transactional Outbox: เขียนการเปลี่ยนแปลง state และบันทึกอีเวนต์ลง outbox ภายใน transaction เดียวกัน จากนั้นมี Publisher อ่าน outbox และผลักอีเวนต์ไปยัง message broker ช่วยให้ไม่สูญหายและป้องกันการเกิด inconsistency
- Event Versioning: กำหนดนโยบายการเพิ่ม/เปลี่ยน field ในสคีมา ใช้ semantic versioning สำหรับอีเวนต์ และสนับสนุน backward/forward compatibility ผ่าน contract tests และ feature flags
- Observability: ตรวจสอบทุกระดับด้วย tracing, metrics และ structured logs — ใช้ correlation_id และ trace_id ข้ามบริการ เพื่อให้สามารถติดตามภาพรวมของคำขอจากต้นทางถึงปลายทาง
Audit Trail และการบันทึกเหตุผลการตัดสินใจ
Audit Trail ต้องบันทึกทั้งเหตุการณ์เชิงเทคนิคและเชิงธุรกิจ ได้แก่ timestamp, actor, decision, rationale, model_version, prompt และ confidence score การเก็บข้อมูลเหล่านี้ในรูปแบบที่ค้นหาได้ง่าย (เช่น log store + indexed events) ช่วยให้ฝ่ายตรวจสอบสามารถสืบสวนกรณีผิดพลาดหรือความไม่สอดคล้องได้อย่างโปร่งใสและรวดเร็ว
สรุปแล้ว การออกแบบไมโคร‑เอเจนต์แบบ event‑driven สำหรับ workflow ข้ามแผนกต้องเน้นสคีมาอีเวนต์ที่ชัดเจน, metadata เพื่อการติดตาม, กลไก idempotency และ retry ที่มีการจัดการดี รวมถึงสถาปัตยกรรมเช่น transactional outbox และ event versioning ที่ช่วยให้ระบบมีความทนทานและสามารถขยายตัวได้ พร้อมกันนี้ Audit Trail ที่ละเอียดจะเป็นกุญแจสำคัญในการสร้างความเชื่อมั่นเมื่อใช้ LLM และการตัดสินใจอัตโนมัติในองค์กร
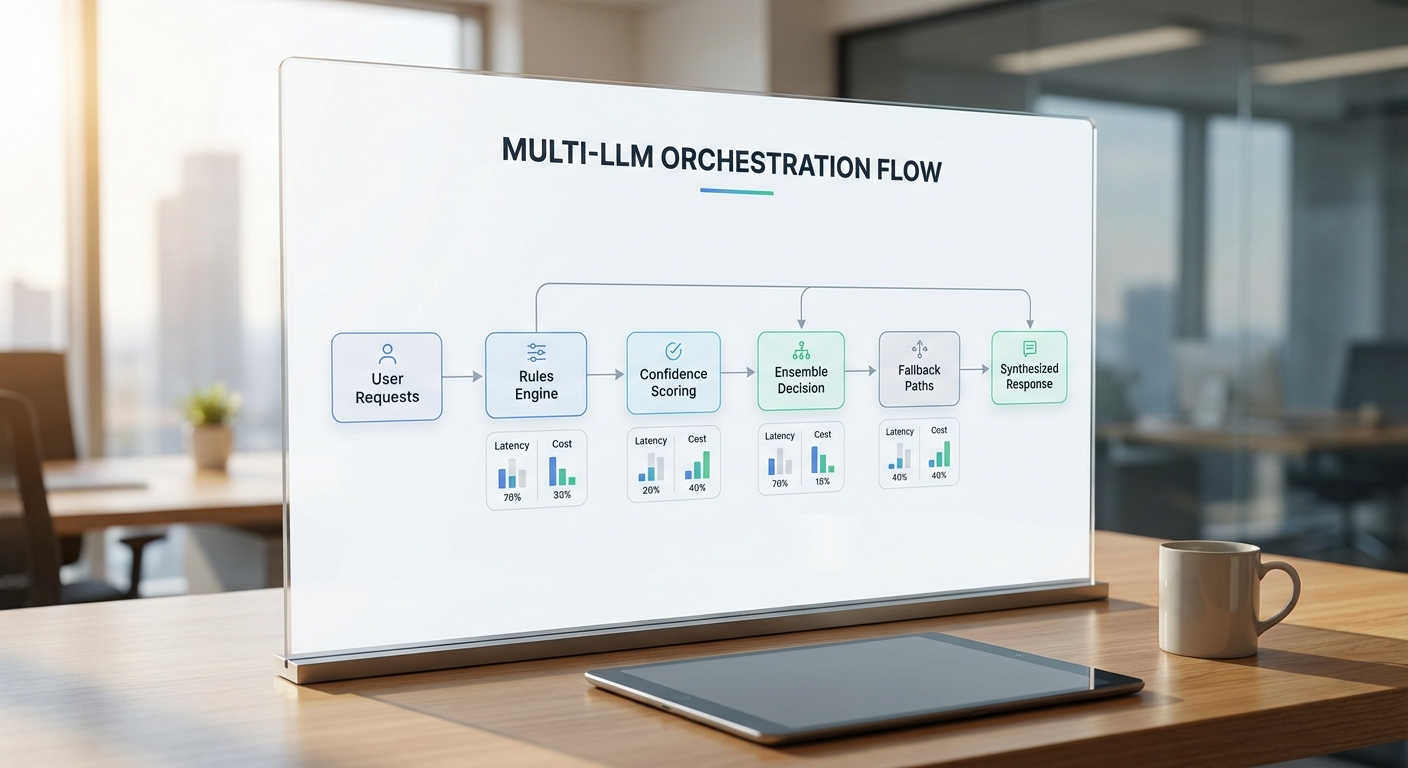
การเชื่อม LLM หลายตัว: Orchestration, Routing และ Fallback
แนวทางการกำหนดเส้นทาง (Routing Strategies)
การใช้ LLM หลายตัวในระบบแบบ Agent Mesh จำเป็นต้องออกแบบกฎการกำหนดเส้นทางอย่างชัดเจนเพื่อให้แต่ละคำขอไปยังโมเดลที่เหมาะสมที่สุดในแง่ความสามารถ ต้นทุน และความหน่วงเวลา ตัวอย่างของกลยุทธ์ที่ใช้บ่อยได้แก่
- Capability‑based routing — ส่งงานที่ต้องการความเชี่ยวชาญเฉพาะไปยังโมเดลที่ถูกฝึกหรือปรับจูนมาสำหรับงานนั้น เช่น ส่งงานกฎหมายไปยัง LLM ที่มี fine‑tuning ด้านกฎหมาย
- Cost‑based routing — กำหนดโมเดลตามงบประมาณหรือขีดจำกัดค่าใช้จ่าย เช่น ใช้โมเดลราคาประหยัดสำหรับคำถามทั่วไป และสลับไปใช้โมเดลพรีเมียมก็ต่อเมื่อคาดว่าจะได้ผลลัพธ์ที่มีมูลค่าเพิ่มสูง
- Latency‑based routing — เลือกโมเดลตามข้อจำกัดเวลาตอบสนอง เช่น งาน UI/UX ที่ต้องการตอบกลับ sub‑second อาจไปที่โมเดลขนาดเล็กที่ตอบเร็วกว่า แม้ความแม่นยำจะลดลงเล็กน้อย
- Contextual routing — ใช้เมตาดาต้า (เช่นประเภทคำขอ นโยบายความปลอดภัย ปริมาณข้อมูลอินพุต) เพื่อกำหนดเส้นทาง ตัวอย่างเช่น ถ้าข้อความมีข้อมูลส่วนบุคคลจะถูกส่งผ่านโมเดลที่รองรับการปฏิบัติตามกฎหมายความเป็นส่วนตัว
ในการปฏิบัติจริง องค์กรสามารถใช้ระบบ rule engine หรือ ML‑based router ที่ประเมินเมตริกหลายมิติ (เช่นค่าใช้จ่าย ความมั่นใจ เวลา) เพื่อเลือกโมเดลที่เหมาะสมแบบไดนามิก — เช่น ในการทดลองภายใน พบว่า การใช้ routing ผสม (capability + latency) ช่วยลดค่าใช้จ่ายเฉลี่ยลงประมาณ 25% ขณะรักษา P95 latency ภายในข้อกำหนด

การทำ Ensemble และการรวมคะแนนความมั่นใจ (Confidence Aggregation)
Ensemble เป็นกลยุทธ์สำคัญเมื่อผลลัพธ์เดียวจาก LLM อาจไม่เพียงพอ โดยมีเทคนิคที่นิยมใช้ เช่น
- Majority voting — เหมาะกับคำถามเชิงเลือกตอบหรือ classification
- Weighted averaging — นำผลจากแต่ละโมเดลมาถ่วงน้ำหนักตามประวัติความแม่นยำหรือความมั่นใจที่ calibrate แล้ว
- Rank aggregation / Borda count — ใช้เมื่อต้องการรวมลำดับคำตอบจากหลายโมเดล
การรวมคะแนนความมั่นใจต้องคำนึงถึงการ calibrate confidence เนื่องจากโมเดลแต่ละตัวมักให้คะแนนความมั่นใจไม่เชิงเส้น หากไม่ calibrate การนำคะแนนดิบมารวมอาจทำให้ผลลัพธ์ไม่ถูกต้องได้ วิธีการมาตรฐาน ได้แก่ Platt scaling หรือ isotonic regression สำหรับ calibrate ค่าความมั่นใจก่อนนำมารวม
ตัวอย่างเชิงปฏิบัติ: หากมี 3 โมเดล (A, B, C) และคะแนน confidence หลังการ calibrate เป็น 0.92, 0.78, 0.65 ระบบอาจใช้ weighted average เพื่อคำนวณความเชื่อมั่นรวมและตั้งเกณฑ์ (เช่น threshold = 0.80) เพื่อยอมรับคำตอบทันที หากไม่ถึงเกณฑ์จะส่งไปตรวจสอบบน human‑in‑the‑loop หรือเรียก ensemble เพิ่มเติม
กลไก Fallback และ Circuit Breaker เพื่อความมั่นคงของระบบ
แม้จะมี routing และ ensemble ที่ดีก็ตาม โมเดลอาจล้มเหลว (errors, hallucinations, slow responses) จึงจำเป็นต้องมีกลไก fallback และ circuit breaker เพื่อป้องกันผลกระทบต่อผู้ใช้และทรัพยากรของระบบ
- Fallback strategies — ตัวอย่างเช่น: ส่งคำขอไปยังโมเดลสำรองที่มีความทนทานกว่า (robust model), ลดความซับซ้อนของ prompt แล้วลองใหม่, หรือส่งไป human review เมื่อ confidence ต่ำกว่าเกณฑ์ (เช่น confidence < 0.6)
- Circuit breaker — ตรวจจับความล้มเหลวซ้ำ ๆ (เช่น error rate > 10% หรือ latency P95 > 1,000 ms ในช่วง 1 นาที) และตัดการส่งคำขอไปยังโมเดลปัญหาเป็นระยะเวลาหนึ่ง (cooldown) เช่น trip เมื่อเกิดความล้มเหลว 5 ครั้งภายใน 60 วินาที แล้ว cooldown 30–120 วินาที
- Graceful degradation — ในกรณีที่โมเดลพรีเมียมไม่พร้อม ให้เปลี่ยนไปใช้โหมดตอบแบบเรียบง่าย (short answers, template-based) เพื่อลดผลกระทบด้านประสบการณ์ผู้ใช้
ระบบควรบันทึกเหตุผลการตัดสินใจทุกครั้งลงใน Audit Trail — ระบุ model id, routing rule, confidence ก่อน/หลังการรวม, เหตุผลที่ fallback ถูกเรียกใช้ และผู้ที่ตรวจสอบ (ถ้ามี) เพื่อความโปร่งใสและการตรวจสอบย้อนหลัง
การบริหาร Trade‑offs: Latency, Cost และตัวชี้วัดคุณภาพ
การออกแบบ Orchestration ต้องบาลานซ์ระหว่างต้นทุนและคุณภาพ โดยแนะนำให้ติดตามตัวชี้วัดหลัก ได้แก่:
- Latency — P50, P95, P99 ของเวลาตอบกลับ
- Cost — ต้นทุนต่อ 1K tokens หรือ per‑request, ค่าใช้จ่ายรวมต่อเดือน
- Accuracy / Task success rate — วัดด้วยกรณีทดสอบที่มี label (เช่น accuracy, F1)
- Hallucination rate — สัดส่วนผลลัพธ์ที่มีข้อเท็จจริงผิดหรือสร้างข้อมูลเท็จ โดยควรกำหนดเกณฑ์ยอมรับได้ เช่น < 2% สำหรับงานที่ต้องการความน่าเชื่อถือสูง
- Confidence calibration — Brier score หรือ calibration error เพื่อดูว่าค่า confidence สอดคล้องกับความเป็นจริงหรือไม่
ตัวอย่างเชิงตัวเลข: หาก Model A มีค่าใช้จ่าย 0.02 USD/1K tokens, P95 latency = 120 ms, accuracy = 92% ขณะที่ Model B มีค่าใช้จ่าย 0.004 USD/1K tokens, P95 latency = 420 ms, accuracy = 85% ระบบอาจตั้งกฎว่า คำขอเชิงธุรกิจสำคัญ (high‑priority, high‑value) ให้ไปยัง Model A เสมอ แต่คำขอทั่วไปให้ใช้ Model B และเมื่อ confidence ของ Model B < 0.7 ให้ข้ามไปตรวจสอบด้วย Model A หรือเรียก ensemble
สรุป: การเชื่อม LLM หลายตัวด้วย orchestration ที่ออกแบบดีต้องประกอบด้วย routing rules ที่หลากหลาย, เทคนิค ensemble ที่ calibrate ความมั่นใจ, กลไก fallback/circuit breaker ที่ชัดเจน และระบบมอนิเตอริงตัวชี้วัดด้าน latency, cost, accuracy และ hallucination เพื่อรักษาความมั่นคงและคุณภาพของบริการในระดับองค์กร
Audit Trail และการบันทึกเหตุผลการตัดสินใจ (Decision Provenance)
Audit Trail และการบันทึกเหตุผลการตัดสินใจ (Decision Provenance)
ในสถาปัตยกรรม Agent Mesh ที่เชื่อม LLM หลายตัวกับไมโคร‑เอเจนต์แบบ event‑driven การออกแบบ Audit Trail เป็นหัวใจสำคัญทั้งด้านความน่าเชื่อถือ การตรวจสอบย้อนหลัง และการปฏิบัติตามกฎระเบียบ (compliance). Audit Trail ต้องสามารถจับทั้งเหตุการณ์ (events) ที่เกิดขึ้น อินพุตและเอาต์พุตของโมเดล รวมถึง metadata ทางการตัดสินใจ เช่น model id/version, prompt, confidence score, timestamps และตัวตนของผู้ใช้หรือระบบที่เกี่ยวข้อง เพื่อให้สามารถสร้างภาพเหตุการณ์ที่ครบถ้วนเมื่อต้องตรวจสอบหรือทำ forensic หลังเกิดเหตุ
ข้อมูลที่ควรบันทึกมีรายละเอียดหลากหลายระดับ ซึ่งอย่างน้อยควรรวมถึง:
- Event metadata: event id, correlation id (เชื่อมข้ามแผนก/transaction), timestamp (UTC), event type, source agent id
- อินพุตของ LLM: prompt (text), conversation context, attached structured data (เช่น JSON payload), client request headers ที่เกี่ยวข้อง
- เอาต์พุตของ LLM: raw response, tokens หรือ confidence/score ที่ระบบให้มา
- Model metadata: model id/version, model checksum/hash (เพื่อลิงก์กับเวอร์ชันที่แน่นอน), prompt template id หรือ prompt version
- การตัดสินใจและเหตุผล: decision rationale (ข้อความสรุปเหตุผลหรือ rationale tree), rules หรือ business logic ที่ถูกเรียกใช้, agent ที่อนุมัติการกระทำ
- การยืนยันผู้ใช้: user id, role, session id, IP address (ถ้าจำเป็นตามนโยบายความเป็นส่วนตัว)
- สภาพแวดล้อมการประมวลผล: container id/host, latency, resource metrics, deterministic seed หากต้องการ reproduction
ตัวอย่าง JSON schema ของ log entry ที่แสดงข้อมูลสำคัญ (เป็นตัวอย่างเพื่อใช้เป็นแนวทางการออกแบบ):
{ "event_id": "uuid-1234-5678", "correlation_id": "txn-9876-5432", "timestamp_utc": "2026-01-19T08:45:12Z", "event_type": "llm_inference", "agent_id": "agent-billing-01", "user": { "user_id": "user-1001", "role": "approver" }, "request": { "prompt_id": "prompt-v2-issue-refund", "prompt_text": "กรุณาตรวจสอบยอดและเสนอคำตัดสิน...", "context": {"invoice_id": "INV-2025-0001", "amount": 12500} }, "model": { "model_id": "llm-finance-bert", "model_version": "2025-12-07", "model_hash": "sha256:ab12cd..." }, "response": { "raw_output": "แนะนำให้คืนเงินเต็มจำนวนเนื่องจาก...", "confidence": 0.87, "tokens_used": 342 }, "decision": { "action": "approve_refund", "rationale": "พบเงื่อนไขคืนเงินครบถ้วนตาม policy#3", "approved_by_agent": "agent-billing-01" }, "integrity": { "entry_hash": "sha256:ff33aa...", "signature": "base64-signature...", "signed_by": "log-service-key-01" } }
เพื่อให้ log เป็น tamper‑evident และรองรับการตรวจสอบย้อนหลัง ควรผสานเทคนิคดังต่อไปนี้เข้าด้วยกัน:
- Append‑only storage: ใช้ระบบเก็บข้อมูลที่เขียนเพิ่มอย่างเดียว (append‑only) เช่น Kafka immutable topics, write‑once tables หรือฐานข้อมูล ledger (AWS QLDB, Azure Confidential Ledger)
- Hash chaining / Merkle tree: แต่ละ entry ควรมี hash ของตัวเองและ hash ของ entry ก่อนหน้า (blockchain‑style) หรือจัดเก็บ hash ของชุด entry ใน Merkle tree เพื่อให้การเปลี่ยนแปลงใด ๆ ตรวจจับได้ทันที
- Digital signatures: เซ็นแต่ละ log entry ด้วยคีย์ที่จัดการโดย HSM/KMS เพื่อให้สามารถยืนยันความถูกต้องและผู้ลงนาม (non‑repudiation)
- WORM (Write Once Read Many): ใช้สตอเรจแบบ WORM หรือนโยบาย S3 Object Lock เพื่อล็อกข้อมูลไม่ให้แก้ไขหรือลบในช่วงเวลาที่กำหนด
- Timestamping จากแหล่งน่าเชื่อถือ: ผนวก trusted timestamp (เช่น RFC 3161 timestamping) เพื่อยืนยันเวลาเกิดเหตุอย่างแม่นยำ
- เก็บ hash บางส่วนบน ledger ภายนอก: เพื่อความโปร่งใสและป้องกันการเปลี่ยนแปลงภายในระบบ เก็บเฉพาะ hash summary บน public/private blockchain หรือ ledger ภายนอก เพื่อใช้ยืนยันความสมบูรณ์ของชุด log
การนำ Audit Trail ไปใช้ประโยชน์เชิงปฏิบัติ ประกอบด้วยอย่างน้อยสามมิติสำคัญ:
- Debugging และ Root Cause Analysis: สามารถ replay sequence ของ events และ reconstruct state ณ เวลานั้นเพื่อค้นหาจุดบกพร่องของ agent, prompt หรือ model version ที่ก่อให้เกิดผลลัพธ์ผิดพลาด ตัวอย่างเช่น การค้นหาว่า prompt template ใดถูกส่งไปยัง model เวอร์ชันเก่าและทำให้เกิดการตัดสินใจที่ไม่ถูกต้อง
- Compliance Audit: ผู้ตรวจสอบจะสามารถตรวจสอบ chain‑of‑decisions ได้ว่าใครอนุมัติ การตัดสินใจสอดคล้องกับนโยบายหรือกฎระเบียบหรือไม่ โดยยืนยันความสมบูรณ์ของ log ด้วย signature และ hash chain ซึ่งช่วยสนับสนุนข้อกำหนดด้านการเก็บหลักฐานและการรายงาน
- ML Explainability และ Model Governance: ข้อมูล prompt, context, model id/version และ confidence score ช่วยให้ทีม ML อธิบายเหตุผลและวัดความน่าเชื่อถือของการตัดสินใจ ทำให้สามารถตรวจจับ model drift, bias หรือปัญหาความแม่นยำ ขณะเดียวกันช่วยแยกแยะว่าปัญหาเกิดจาก data, prompt หรือ logic ของ agent
คำแนะนำเชิงปฏิบัติ: ให้กำหนด schema ที่เป็นมาตรฐานทั่วทั้งองค์กร และใช้ correlation id เพื่อเชื่อมเหตุการณ์ข้ามบริการ ควรกำหนดนโยบายการจัดเก็บ (retention) และนโยบายการเข้าถึง (RBAC) อย่างชัดเจนเพื่อคุ้มครองข้อมูลส่วนบุคคล และพิจารณาการเก็บเฉพาะ snapshot ของ context ที่จำเป็นหรือการ redaction/pseudonymization สำหรับ PII เพื่อรักษาสมดุลระหว่างความโปร่งใสและความเป็นส่วนตัว นอกจากนี้ ควรเตรียมกระบวนการตรวจสอบอัตโนมัติ (integrity checks) เช่น การตรวจสอบ hash เป็นระยะ และการเรียกคืน log ที่ถูกต้องตามคำขอตรวจสอบจากหน่วยงานภายนอก
ขั้นตอนนำไปใช้จริง (POC) และตัวอย่างโค้ด/Checklist สำหรับทีมไอที
ภาพรวมสั้นก่อนเริ่ม POC
ก่อนเริ่มสาธิตการใช้งาน (POC) ของแนวทาง Agent Mesh ที่เชื่อม LLM หลายตัวกับไมโคร‑เอเจนต์แบบ event‑driven ต้องมีการกำหนดขอบเขต ความคาดหวัง และเกณฑ์ความสำเร็จอย่างชัดเจน POC ควรออกแบบให้เล็กพอที่จะพัฒนาภายใน 4–8 สัปดาห์ แต่ต้องเป็นเคสใช้งานจริง (realistic) ที่สะท้อนปัญหาข้ามแผนก เช่น การอนุมัติคำขอซื้อ การตอบข้อซักถามลูกค้าแบบซับซ้อน หรือการสรุปรายงานเหตุการณ์แบบอัตโนมัติ
ขั้นตอนนำไปใช้จริง (POC) แบบทีละขั้น
- 1) กำหนดขอบเขตและเป้าหมาย: เลือก use case เดียวที่เป็นตัวแทนของปัญหาข้ามแผนก ระบุ input/output ที่ชัดเจน เช่น ฟอร์มคำขอ, เหตุการณ์ระบบ, หรืออีเมลที่ต้องประมวลผล ระบุ SLA ที่ต้องการและ stakeholder ที่เกี่ยวข้อง
- 2) เลือก Event Broker: พิจารณา Kafka, RabbitMQ, NATS, หรือ service cloud events ตามความต้องการ throughput และ persistence หากต้องการ ordering สูงและ retention ระยะยาว ให้เลือก Kafka; หากต้องการความง่ายและ latency ต่ำ ให้พิจารณา NATS
- 3) เลือก LLMs และการผสมโมเดล: ระบุโมเดลสำหรับงานต่างกัน (e.g., GPT‑style สำหรับภาษา, smaller model สำหรับตรวจสอบกฎ) กำหนด fallback/ensemble strategy ระหว่างโมเดลภายในและ public APIs และวางแผนการจัดการเวอร์ชันโมเดล
- 4) สร้าง micro‑agents ขั้นต่ำ: พัฒนา agent แต่ละตัวให้มี responsibility เดียว (single responsibility) เช่น parser agent, policy agent, summarizer agent, executor agent แต่ละ agent รับ/ส่ง event ผ่าน broker และเรียก LLM ตาม trigger
- 5) Audit Trail & Decision Logging: ออกแบบ schema สำหรับบันทึกเหตุผลการตัดสินใจ (prompt, model_id, response, confidence, timestamp, agent_id, decision_rationale, human_override) เก็บใน append‑only store หรือ database ที่รองรับ immutable logs
- 6) Observability & Monitoring: ติดตั้ง tracing (OpenTelemetry), metrics (Prometheus), และ centralized logging (ELK/Opensearch) เพื่อมอนิเตอร์ latency, error rate, queue lag, และโมเดล usage
- 7) Compliance & Security Sign‑off: ตรวจสอบข้อมูลที่ส่งให้ LLM (PII redaction), การเข้ารหัสขณะส่งและพัก, กำหนด retention policy สำหรับ audit logs และขออนุมัติจากทีมกฎหมาย/ความปลอดภัยก่อนเปิดใช้งาน
- 8) แผน Rollout & Human‑in‑the‑loop: เริ่มจากโหมด supervised (human review) ก่อนค่อยขยับเป็น auto approve เมื่อ KPI ผ่านเกณฑ์
แผนทดสอบ (Test Plan) และเกณฑ์ความสำเร็จ
- Scenario tests: กำหนดชุดตัวอย่างจริง (10–100 events) ที่ครอบคลุมปกติ, edge cases, และ malicious inputs
- Integration tests: ทดสอบการไหลของ event ผ่าน broker → agent → LLM → audit log ตรวจสอบ ordering และ at‑least‑once/at‑most‑once semantics
- Load & resilience tests: ทดสอบค่า throughput ที่ต้องการ โดยจำลอง spikes และตรวจสอบ queue lag กับ retry/backoff behavior
- Human override tests: ทดลอง workflow ที่มนุษย์แก้ไขผลลัพธ์แล้วบันทึกการตัดสินใจทับ (audit trail ต้องสะท้อนการแก้ไข)
- Security & privacy tests: ตรวจสอบว่าไม่มี PII หลุดออกนอก boundary และ logs ถูกเข้ารหัสตาม policy
KPIs ที่ควรวัดสำหรับ POC
- Cycle time: เวลาเฉลี่ยจากการรับ event จนถึงผลลัพธ์สุดท้าย (ms/seconds) — ตั้งเป้าลดลงเมื่อเทียบกับกระบวนการเดิม
- Accuracy / Quality: อัตราการตอบถูกต้องหรือความตรงตามกฎธุรกิจ (%) วัดจาก golden dataset หรือ human labels
- Failure rate: เปอร์เซ็นต์ของเหตุการณ์ที่ล้มเหลวหรือต้อง escalation ไปยังมนุษย์
- Audit completeness: เปอร์เซ็นต์ของเหตุการณ์ที่มีข้อมูลเหตุผลการตัดสินใจครบถ้วนตาม schema (prompt, model_id, response, rationale, timestamp)
- Cost per transaction: ค่าใช้จ่ายเฉลี่ยต่อเหตุการณ์ รวมค่าโมเดล API, infrastructure, storage — เปรียบเทียบกับต้นทุนการดำเนินงานเดิม
- Throughput & Scalability: จำนวนเหตุการณ์ต่อวินาทีที่ระบบรองรับได้โดยยังรักษา SLA
ตัวอย่างโค้ดสั้น (pseudo‑code) — event handler -> call LLM -> record audit log
อธิบายสั้น: โค้ดด้านล่างเป็น pseudo‑code ที่สรุป flow หลัก: รับ event จาก broker, ส่ง prompt ไปยัง LLM, บันทึก audit trail พร้อมผลลัพธ์ และส่งต่อ event ถัดไป
// Event handler skeleton
on_event(event):
// parse and enrich
context = build_context(event)
prompt = render_prompt(template, context)
// call primary LLM
response = call_llm(model="llm‑primary‑v1", prompt=prompt)
// simple quality check / fallback
if not acceptable(response):
response = call_llm(model="llm‑fallback‑small", prompt=prompt)
// build audit record
audit = {
"event_id": event.id,
"timestamp": now(),
"agent_id": "policy_agent_01",
"model_id": response.model_id,
"prompt": prompt,
"response": response.text,
"confidence": response.confidence,
"rationale": extract_rationale(response)
}
// persist audit (append-only)
append_to_audit_store(audit)
// emit outcome
emit_event("decision.outcome", { "event_id": event.id, "action": decide_action(response) })
Checklist สรุปสำหรับทีมนำไปใช้วางแผน POC ได้ทันที
- Define scope: ระบุ use case, stakeholders, success criteria (KPIs) และ duration ของ POC
- Choose event broker: เลือก Kafka/NATS/RabbitMQ ตาม throughput/ordering/retention
- Select LLMs: ระบุกลยุทธ์หลายโมเดล (primary/fallback/specialist) และนโยบายเวอร์ชัน
- Implement minimal agents: สร้าง 3–5 micro‑agents ที่รับผิดชอบชัดเจน (parser, policy, executor, logger)
- Audit Trail design: กำหนด schema, storage (append‑only), retention และ encryption
- Observability: เปิด tracing, metrics, alerting (response latency, error rate, queue lag)
- Compliance sign‑off: ตรวจสอบ PII handling, legal approval, data residency และ retention policy
- Test plan ready: เตรียม test cases, load tests, human‑in‑loop scenarios และ rollback plan
- Success gates: กำหนดค่า KPI thresholds ที่ต้องผ่านก่อนขยายสเกล (e.g., accuracy ≥ 90%, audit completeness ≥ 99%, cost per tx ≤ budget)
เมื่อปฏิบัติตามขั้นตอนและ checklist นี้ ทีมนำไปออกแบบ POC ได้อย่างเป็นระบบและวัดผลได้จริง ทั้งยังรองรับการตรวจสอบย้อนหลังด้วย audit trail ที่ครบถ้วน ช่วยให้ผู้บริหารมั่นใจในการตัดสินใจขยายสู่การใช้งานจริงในระดับองค์กรต่อไป
ความเสี่ยง การกำกับดูแล และแนวปฏิบัติที่แนะนำ
ความเสี่ยงสำคัญที่องค์กรต้องตระหนัก
การนำ Agent Mesh เชื่อมโยง LLM หลายตัวกับไมโคร‑เอเจนต์แบบ Event‑Driven เพื่อออโตเมตงานข้ามแผนกเพิ่มความซับซ้อนด้านความเสี่ยงหลายประการ โดยเฉพาะ data exfiltration (การรั่วไหลของข้อมูล), model drift (การเปลี่ยนแปลงพฤติกรรมของโมเดลเมื่อเวลาผ่านไป) และ incorrect automation decisions (การตัดสินใจอัตโนมัติที่ผิดพลาด) ซึ่งอาจนำไปสู่ความเสียหายทางการเงิน ภาพลักษณ์ และความเป็นส่วนตัวของลูกค้าได้ ตัวอย่างความเสี่ยงเชิงโมเดลได้แก่ hallucination (การสร้างข้อมูลเท็จ), bias ที่ฝังอยู่ในโมเดล และการตอบสนองที่ไม่สอดคล้องกับนโยบายองค์กร เมื่อผนวกกับสถาปัตยกรรมที่เชื่อมต่อหลายระบบ ความเสี่ยงของการเข้าถึงข้อมูลโดยไม่ได้รับอนุญาตหรือการส่งข้อมูลออกนอกขอบเขตที่คาดหมายจะเพิ่มขึ้นอย่างมีนัยสำคัญ
มาตรการกำกับดูแล (Governance) ที่แนะนำ
องค์กรควรออกแบบกรอบกำกับดูแลแบบรวมศูนย์ที่ประกอบด้วย policy engine สำหรับบังคับใช้กฎเชิงเทคนิคและเชิงนโยบาย, ระบบควบคุมการเข้าถึงชั้นสูง และจุดตรวจสอบที่มีมนุษย์เป็นส่วนหนึ่งของการตัดสินใจ (human‑in‑the‑loop). นโยบายควรเป็นแบบ policy‑as‑code เพื่อให้สามารถตรวจสอบและทดสอบได้อัตโนมัติ และกำหนดเกณฑ์ความเสี่ยงที่ชัดเจนสำหรับการส่งงานไปยังระบบอัตโนมัติเต็มรูปแบบ
- Access control: ใช้ RBAC/ABAC, หลักการ least privilege, การยืนยันตัวตนแบบหลายปัจจัย และ credential แบบชั่วคราวสำหรับไมโคร‑เอเจนต์และเชื่อมต่อกับ LLM ภายนอก
- Policy enforcement: policy engine ที่ตรวจสอบคำขอ (prompts/inputs) และผลลัพธ์ (outputs) ก่อน/หลังการรัน รวมถึงกฎ DLP (Data Loss Prevention) และการกรองคำสั่งที่มีความเสี่ยง
- Human review gates: เกณฑ์ confidence-thresholds, เงื่อนไขความเสี่ยงสูง และจุดยืนยันโดยมนุษย์สำหรับการตัดสินใจที่กระทบลูกค้า เงิน หรือข้อมูลความลับ
แนวปฏิบัติด้านการดำเนินงานและความพร้อมในการตรวจสอบ (Audit Readiness)
เพื่อให้ระบบ Agent Mesh มีความน่าเชื่อถือและสามารถตรวจสอบได้ ควรบันทึก Audit Trail ที่ครอบคลุมทั้งเหตุผลการตัดสินใจ (decision rationale), เวอร์ชันของโมเดล, สถานะ policy checks และการกระทำของไมโคร‑เอเจนต์แบบ immutable log (เช่น WORM storage หรือการลง hash) การออกแบบแทร็กข้อมูลควรรองรับการสืบย้อนที่ชัดเจนเพื่อใช้ในกระบวนการตรวจสอบภายในหรือชี้แจงต่อหน่วยงานกำกับดูแล
- Audit logs: บันทึก input/output, confidence score, prompt templates, model version, และผู้อนุมัติ/ผู้ทบทวน
- Periodic model validation: กำหนดการทดสอบเชิงปฏิบัติการ เช่น regression tests, factuality checks, adversarial tests และ drift detection — สำหรับกระบวนการที่มีความเสี่ยงสูงแนะนำให้ตรวจสอบอย่างน้อยทุกเดือน ส่วนการใช้งานทั่วไปควรเป็นไตรมาส
- Release controls: ใช้ canary/blue‑green deployments, rollback plan และขีดจำกัดการใช้งานอัตโนมัติ (kill switch) เพื่อจำกัดผลกระทบเมื่อเกิดพฤติกรรมผิดปกติ
การปฏิบัติตาม PDPA และการคุ้มครองข้อมูลส่วนบุคคล
การนำ LLM และ Agent Mesh มาใช้งานต้องสอดคล้องกับ PDPA โดยมีแนวทางปฏิบัติพื้นฐาน ได้แก่ การทำ Data Protection Impact Assessment (DPIA) ก่อนเปิดใช้งาน, การบันทึกและจัดการความยินยอมของเจ้าของข้อมูล, การลดข้อมูลเหลือต่ำสุด (data minimization), และการใช้เทคนิค pseudonymization หรือ encryption ทั้งขณะส่งและเมื่อเก็บข้อมูล นอกจากนี้ ควรกำหนดนโยบายการเก็บรักษา log และข้อมูลเหตุผลการตัดสินใจให้สอดคล้องกับระยะเวลาและวัตถุประสงค์ทางกฎหมาย
- แต่งตั้ง Data Protection Officer (DPO) หรือผู้รับผิดชอบ PDPA และกำหนดกระบวนการรับคำขอจากเจ้าของข้อมูล
- ระบุและควบคุมผู้ให้บริการภายนอก (third‑party LLMs) โดยสัญญา SLA/ยืนยันมาตรการคุ้มครองข้อมูล และการตรวจสอบความปลอดภัยเป็นระยะ
การประเมินผลกระทบทางธุรกิจ, ROI และการสื่อสารกับผู้มีส่วนได้เสีย
ก่อนและหลังการนำ Agent Mesh ไปใช้ ควรวัดผลทั้งเชิงปริมาณและเชิงคุณภาพ เช่น อัตราความผิดพลาดของการตัดสินใจอัตโนมัติ (error rate), อัตราการยกเลิก/override โดยมนุษย์, เวลาเฉลี่ยในการแก้ไขเหตุผิดปกติ (MTTR), ต้นทุนต่อกระบวนการ และผลตอบแทนจากการลงทุน (ROI) ที่คำนวณจากการลดเวลาทำงานและความผิดพลาด
- กำหนด KPI ชัดเจนก่อน rollout (เช่น ลดเวลาในการประมวลผล 30%, ลดข้อผิดพลาดมนุษย์ 50%) และติดตามรายงานเป็นระยะ
- จัดตั้งคณะกรรมการกำกับดูแลข้ามหน่วยงาน (governance board) เพื่อรายงานผลการตรวจสอบ ความเสี่ยงที่พบ และแผนการผ่อนปรนความเสี่ยง
- การสื่อสารเชิงรุกกับผู้มีส่วนได้เสีย (ผู้บริหาร ฝ่ายกฎหมาย ฝ่ายความปลอดภัย ลูกค้า) รวมถึงการฝึกอบรมผู้ใช้งานและการจัดเอกสารนโยบายการใช้งานอย่างชัดเจน
โดยสรุป การนำ Agent Mesh มาใช้อย่างปลอดภัยต้องอาศัยกรอบการกำกับดูแลที่รวมทั้งเทคนิคและนโยบาย: ควบคุมการเข้าถึงและการไหลของข้อมูล, บังคับใช้ policies อัตโนมัติพร้อมจุดตรวจสอบโดยมนุษย์, การบันทึกเหตุผลการตัดสินใจอย่างโปร่งใส และการตรวจสอบ/ทดสอบโมเดลเป็นระยะ เพื่อให้เกิดสมดุลระหว่างนวัตกรรมด้านอัตโนมัติและการคุ้มครองความเสี่ยงต่อองค์กรและข้อมูลส่วนบุคคล
บทสรุป
Agent Mesh เป็นกรอบการออกแบบที่ให้ความยืดหยุ่นในการผสาน LLM หลายตัว เข้ากับไมโคร‑เอเจนต์ที่ทำงานแบบ Event‑Driven เพื่อผลักดันการออโตเมตงานข้ามแผนกอย่างมีประสิทธิภาพ โดยแต่ละไมโคร‑เอเจนต์จะตอบสนองต่อเหตุการณ์เฉพาะและเรียกใช้ LLM ที่เหมาะสม ทำให้ระบบสามารถแบ่งงานเป็นหน่วยเล็กๆ ที่ปรับปรุงหรือสลับโมดูลได้ง่าย อีกจุดสำคัญคือการฝัง Audit Trail เพื่อบันทึกเหตุผลของการตัดสินใจและเส้นทางการทำงาน ซึ่งเอื้อให้การตรวจสอบย้อนหลัง การอธิบายผลการทำงาน (explainability) และการตอบสนองต่อข้อกำหนดด้านกฎระเบียบเป็นไปได้จริงในระดับองค์กร
การนำ Agent Mesh ไปใช้จริงควรเริ่มจาก POC ขนาดเล็ก ที่มีขอบเขตชัดเจน (เช่น แผนกหนึ่งหรือกระบวนงานสำคัญหนึ่งกระบวน) เพื่อวัดผลด้านความถูกต้อง เวลาแฝง อัตราการถูกยกเลิกโดยมนุษย์ และความสมบูรณ์ของ Audit Trail ภายในระยะสั้น (ตัวอย่าง: 4–8 สัปดาห์) พร้อมการออกแบบ Audit Trail ที่แข็งแรงซึ่งบันทึกทั้งอินพุต โมเดลที่ถูกเรียกใช้ พารามิเตอร์สำคัญ และเหตุผลเชิงตรรกะของคำตอบ รวมทั้งการตั้งมาตรการ governance เพื่อควบคุมความเสี่ยงด้านความเป็นส่วนตัว ความปลอดภัย และการปฏิบัติตามกฎระเบียบ ในอนาคต คาดว่าองค์กรไทยจะขยายการใช้งาน Agent Mesh สู่การทำงานร่วมกับระบบ ERP/CRM ระดับองค์กร เกิดมาตรฐานการบันทึก Audit Trail ที่เข้มงวดขึ้น และมีเครื่องมือกลางสำหรับการตรวจสอบและอธิบายผลลัพธ์ของหลายโมเดล ซึ่งจะช่วยให้การออโตเมตข้ามแผนกมีความยืดหยุ่นมากขึ้นแต่ยังคงควบคุมความเสี่ยงได้อย่างเป็นระบบ



