
ในยุคที่ความไม่แน่นอนของซัพพลายเชนและความต้องการผู้บริโภคเปลี่ยนแปลงอย่างรวดเร็ว โรงงานยุคใหม่จำเป็นต้องมี “ดวงตาและสมอง” ที่ฉลาดขึ้นกว่าเดิม: Digital Twin แบบมัลติโมดัลซึ่งผสานความสามารถของ Large Language Models (LLM) กับ Graph Neural Networks (GNN) สามารถนำข้อมูลจากเซ็นเซอร์ภาพ เสียง ข้อมูลเครื่องจักร บันทึกการบำรุงรักษ และฐานข้อมูลสต็อก มาจำลองพฤติกรรมของซัพพลายเชนแบบเรียลไทม์ เพื่อคาดการณ์จุดคอขวดและแจ้งเตือนการหยุดสายการผลิตก่อนเกิดเหตุจริง ตัวอย่างการใช้งานในภาคอุตสาหกรรมชี้ว่าแนวทางนี้ช่วยลดปริมาณสต็อกล้นและลดเวลา Downtime ได้อย่างมีนัยสำคัญ ทำให้การตัดสินใจเชิงปฏิบัติการเป็นไปอย่างรวดเร็วและมีข้อมูลสนับสนุน
บทความฉบับนี้จัดทำในรูปแบบ Tutorial ที่ชี้ชัดทั้งแนวคิดและแนวทางปฏิบัติ: เราจะอธิบายสถาปัตยกรรมระบบ การออกแบบพายไลน์ข้อมูลมัลติโมดัล วิธีผนวกรวม LLM สำหรับการตีความภาษาธรรมชาติและนโยบายเชิงธุรกิจเข้ากับ GNN สำหรับการจำลองโครงสร้างเครือข่ายซัพพลายเชน การเทรนและการดีพลอยแบบเรียลไทม์ รวมถึง Roadmap การนำไปใช้ในโรงงานจริง พร้อมตัวชี้วัดความสำเร็จเชิงปฏิบัติการ เช่น อัตราการหมุนเวียนสต็อก (inventory turns), อัตราการหยุดสาย (downtime), ความแม่นยำในการคาดการณ์ความต้องการ และเวลาตอบสนองเมื่อเกิดเหตุผิดปกติ — เพื่อให้ผู้อ่านทั้งผู้บริหาร วิศวกรข้อมูล และผู้ปฏิบัติการโรงงานสามารถวางแผนและเริ่มต้นนำไปใช้ได้ทันที
บทนำ: ปัญหาในโรงงานสมัยใหม่และความจำเป็นของ Digital Twin แบบมัลติโมดัล
บทนำ: ปัญหาในโรงงานสมัยใหม่และความจำเป็นของ Digital Twin แบบมัลติโมดัล
โรงงานยุคใหม่เผชิญความท้าทายเชิงปฏิบัติการที่ซับซ้อนมากขึ้น ทั้งจากความผันผวนของอุปสงค์ การเปลี่ยนแปลงซัพพลายเชนทั่วโลก และความซับซ้อนของระบบเครื่องจักร ผลลัพธ์ที่ปรากฏเป็นรูปธรรมคือ สต็อกล้น (inventory overflow) ซึ่งผูกมัดทุนหมุนเวียนและเพิ่มต้นทุนเก็บรักษา การขาดแคลนวัตถุดิบบางรายการที่เกิดขึ้นแบบเฉียบพลัน และ การหยุดสายการผลิตแบบไม่คาดคิด (unplanned downtime) ที่สร้างผลกระทบรุนแรงต่อการส่งมอบสินค้าและรายได้ นอกจากนี้หลายโรงงานยังประสบปัญหา การขาด visibility ในซัพพลายเชนแบบเรียลไทม์ ทำให้การตัดสินใจต้องขึ้นกับข้อมูลที่ล้าสมัยหรือเป็นแบบแยกส่วน ส่งผลให้การตอบสนองต่อเหตุการณ์ฉุกเฉินและการวางแผนเชิงป้องกันทำได้ไม่เต็มประสิทธิภาพ
ตัวอย่างเชิงตัวเลขที่สะท้อนปัญหา ได้แก่ ต้นทุนการเก็บรักษาสต็อกที่มักอยู่ในสัดส่วนของมูลค่าสินค้าคงคลังราว 20–30% ต่อปี และความเสี่ยงของการหยุดสายการผลิตซึ่งสามารถสร้างความเสียหายทั้งทางตรงและทางอ้อม ในหลายอุตสาหกรรม การสูญเสียจากการหยุดทำงานที่ไม่คาดคิดอาจเท่ากับการขาดรายได้ที่มีนัยสำคัญต่อกำไรของโรงงาน การไม่มีข้อมูลแบบเรียลไทม์ที่ครอบคลุมทั้งสถานะเครื่องจักร สถานะวัตถุดิบ และสถานะการขนส่ง จึงทำให้การบริหารความเสี่ยงเชิงปฏิบัติการเป็นไปอย่างยากลำบาก
เพื่อตอบโจทย์ความซับซ้อนเหล่านี้ แนวคิด Digital Twin แบบมัลติโมดัล จึงปรากฏขึ้น โดยแตกต่างจาก Digital Twin แบบดั้งเดิมที่มักอ้างอิงเฉพาะข้อมูลเชิงเวลา (time series) หรือแบบจำลองทางกายภาพเท่านั้น รุ่นมัลติโมดัลผสานข้อมูลหลายรูปแบบเข้าด้วยกัน ได้แก่ time series จากเซนเซอร์และ PLC, ภาพถ่าย/วิดีโอ จากการตรวจสอบคุณภาพ, ข้อความ เช่น บันทึกการบำรุงรักษาและอีเมลซัพพลายเออร์, และ events เช่น การส่งมอบหรือการแจ้งเตือนเหตุการณ์ ระบบนี้ไม่ได้เป็นเพียงภาพสะท้อนของสถานะปัจจุบัน แต่เป็นแพลตฟอร์มเชิงเหตุผลที่สามารถสังเคราะห์ข้อมูลหลายมิติ เพื่อให้ได้มุมมองแบบองค์รวมของโรงงานและซัพพลายเชนแบบเรียลไทม์
ทางเทคนิค การผสาน Large Language Models (LLMs) กับ Graph Neural Networks (GNNs) เป็นแนวทางที่เหมาะสมและมีประสิทธิภาพสำหรับ Digital Twin แบบมัลติโมดัลด้วยเหตุผลสำคัญหลายประการ:
- LLM มีความสามารถในการประมวลผลและทำความเข้าใจข้อมูลเชิงข้อความและบริบทเชิงภาษา เช่น บันทึกการซ่อมบำรุง รายงานปัญหา หรือการสื่อสารกับซัพพลายเออร์ จึงช่วยแปลงข้อมูลที่ไม่เป็นโครงสร้างให้เป็นสัญญะเชิงความหมายและสร้างภาษากลางสำหรับการตัดสินใจ
- GNN เหมาะกับการจับโครงสร้างความสัมพันธ์แบบกราฟ เช่น โหนดที่เป็นเครื่องจักร ชิ้นส่วน ซัพพลายเออร์ และเส้นเชื่อมสัมพันธ์ของการส่งมอบหรือการพึ่งพิง การใช้ GNN ทำให้สามารถจำลองการแพร่กระจายของผลกระทบในระบบ เช่น ผลกระทบจากเครื่องจักรขัดข้องที่ลุกลามไปยังสายการผลิตและคำสั่งซื้อ
- การรวมกันของ LLM + GNN ช่วยให้เกิดทั้ง ความเข้าใจเชิงบริบท จากข้อมูลเชิงภาษาและ การจำลองความสัมพันธ์เชิงโครงสร้าง ทำให้ระบบสามารถวิเคราะห์เหตุและผล ตีความบันทึกเหตุการณ์ คาดการณ์ผลกระทบข้ามโหนด และเสนอการแทรกแซงเชิงปฏิบัติการ (prescriptive actions)
- ในบริบทของ multimodal data สถาปัตยกรรมแบบไฮบริดสามารถใช้ encoder เฉพาะทางสำหรับแต่ละ modality (เช่น CNN/vision encoder สำหรับภาพ, time-series encoder สำหรับเซนเซอร์) แล้วรวมโค้ดแสดงผลเข้ากับ GNN เป็น state และให้ LLM ทำหน้าที่ตีความ สรุปเหตุการณ์ และสร้างคำอธิบายที่มนุษย์เข้าใจได้
ด้วยแนวทางดังกล่าว โรงงานสามารถย้ายจากการตอบสนองเชิงปฏิกิริยาไปสู่การจัดการเชิงรุก: ลดความเสี่ยงของ inventory overflow ผ่านการคาดการณ์ความต้องการและการปรับแผนสั่งซื้ออัตโนมัติ ลด unplanned downtime โดยการตรวจจับสัญญาณผิดปกติก่อนเกิดความเสียหาย และเพิ่ม visibility ในซัพพลายเชนแบบเรียลไทม์ ทำให้ผู้บริหารสามารถตัดสินใจเชิงกลยุทธ์และเชิงปฏิบัติการที่รวดเร็วและมีข้อมูลรองรับ
สถาปัตยกรรมระบบ: ผสาน LLM กับ GNN เพื่อจำลองซัพพลายเชนเรียลไทม์
ภาพรวม Data Flow และชั้นสถาปัตยกรรม
สถาปัตยกรรมแบบมัลติโมดัลที่ผสาน Large Language Model (LLM) กับ Graph Neural Network (GNN) ต้องออกแบบเป็นชั้นชัดเจนเพื่อรองรับข้อมูลจำนวนมากจากเซ็นเซอร์ ข้อความไม่เป็นระเบียบ และภาพถ่าย โดยภาพรวมของ data flow คือ:
- Sensors → Edge: เซ็นเซอร์ไทม์ซีรีส์, PLC, กล้อง, ไมโครโฟน, และระบบ MES เกิดข้อมูลที่ขอบเครือข่าย
- Edge → Ingestion: การกรองเบื้องต้น, การบีบอัด, การตรวจจับเหตุการณ์ (event detection) และส่งผ่าน message broker (เช่น Kafka)
- Ingestion → Feature Store: ดาต้ารูปแบบเวลาจริง/เก็บแบบ batch จะถูกจัดเก็บใน feature store (เช่น Feast) และเวกเตอร์สโตร์สำหรับ embeddings
- Feature Store → Model Layer: โมดูล GNN และ LLM ดึงฟีเจอร์ทั้งเชิงตัวเลข รูปภาพ และ embeddings เพื่อทำการ inference และ simulation
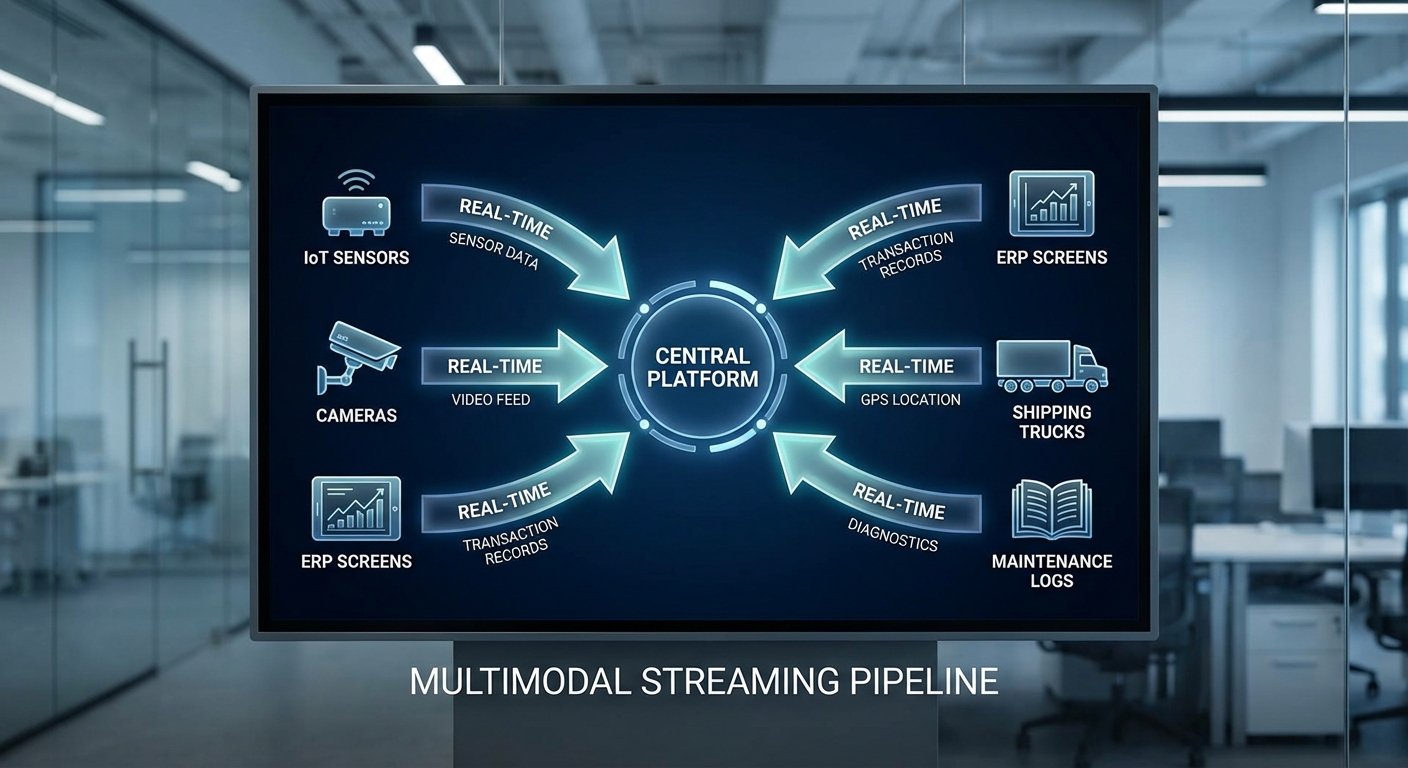
ตัวอย่างเชิงตัวเลข: โรงงานขนาดกลางอาจมีเซ็นเซอร์ 3,000–10,000 ตัว, 100–500 SKUs และสตรีมเหตุการณ์ 100k–1M events/วัน ระบบต้องรองรับ throughput หลายร้อยถึงหลายพัน events/วินาที
การ preprocess ข้อมูลแบบ Multimodal
การเตรียมข้อมูลเป็นหัวใจสำคัญสำหรับการรวม LLM และ GNN โดยขั้นตอนสำคัญมีดังนี้:
- Time alignment & resampling: ซิงโครไนซ์สัญญาณจากแหล่งต่าง ๆ ด้วย timestamp alignment และ resampling เป็น window ที่สอดคล้อง (เช่น 1s/5s/1min) เพื่อสร้าง snapshot สำหรับกราฟ
- Sensor preprocessing: กรองสัญญาณ, การเติมค่า (imputation), normalization, การแปลงทางความถี่ (FFT) และการสกัดฟีเจอร์เชิงสถิติ (mean, variance, trend)
- Image & audio embeddings: ใช้ CNN/ViT สำหรับภาพและโมเดล audio encoder สำหรับเสียง เพื่อดึง embeddings ความยาวคงที่ที่จัดเก็บในเวกเตอร์สโตร์
- Text processing: OCR บันทึกบำรุงรักษา, tokenization, entity extraction, และการใช้ LLM/embedding model เพื่อแปลงข้อความไม่เป็นระเบียบเป็นฟีเจอร์เชิงโครงสร้าง (เช่นเหตุการณ์, ความร้ายแรง, เวลา)
- Graph construction: แปลงข้อมูลเป็นโครงสร้างกราฟที่ประกอบด้วย node types (site, plant, supplier, SKU, equipment) และ edge types (supply, transport, dependency, co-location) พร้อมฟีเจอร์บน node/edge
บทบาทของ LLM ในสถาปัตยกรรม
LLM ทำหน้าที่หลายมิติที่ไม่สามารถแทนด้วยโมเดลเชิงตัวเลขเพียงอย่างเดียว:
- Parsing maintenance logs: LLM ถูกใช้ในการอ่านและแยกแยะบันทึกการซ่อมบำรุงที่ไม่เป็นระเบียบ เช่น ระบุชิ้นส่วนที่เปลี่ยน, อาการ, เวลาที่เกิดเหตุ และความสัมพันธ์เชิงสาเหตุ
- Translating unstructured text → structured events: แปลงข้อความธรรมชาติเป็นเหตุการณ์เชิงโครงสร้าง (event, severity, probable root cause) เพื่อป้อนให้ GNN เป็นฟีเจอร์
- Human-in-the-loop & reasoning: ในกรณีเหตุการณ์ซับซ้อน LLM ทำหน้าที่สรุปเหตุการณ์เป็นภาษาเข้าใจง่าย อธิบายผลลัพธ์จาก GNN และเสนอทางเลือกการตัดสินใจให้เจ้าหน้าที่ เพื่อให้สามารถอนุมัติหรือปรับแต่งการตอบสนองได้
- Natural-language explanations: สร้างรายงานเหตุการณ์และคำอธิบายเชิงสาเหตุ (root-cause explanations) ที่ใช้ภายในองค์กรหรือลูกค้า
ตัวอย่างการใช้งาน: เมื่อ sensor alarm + maintenance note พบความเสี่ยง LLM สามารถสกัดว่า "ปั๊ม A มีอัตราสั่นสะเทือนสูง และได้รับการเปลี่ยนแบริ่งเมื่อ 3 วันก่อน" จากนั้นส่ง event ไปยังโมดูล GNN พร้อมคำอธิบายสำหรับผู้ดูแล
บทบาทของ GNN ในการจำลองและแพร่กระจายผลกระทบ
GNN ถูกออกแบบมาเพื่อเรียนรู้ความสัมพันธ์และแพร่ propagation ของผลกระทบในโครงสร้างซัพพลายเชน:
- Model relations: โหนดแทน site, supplier, SKU, equipment; ขอบแทนความสัมพันธ์เช่น lead-time, transport capacity, dependency บนสายการผลิต
- Propagation of delays and risks: เมสเสจแพสซิง (message passing) ถูกใช้เพื่อคำนวณการแพร่กระจายของความล่าช้า—เช่น การล่าช้าใน supplier A จะเพิ่มความเสี่ยงให้กับ node ผลิตภัณฑ์ที่ขึ้นกับชิ้นส่วนนั้น และกระทบต่อ service level ใน downstream
- Temporal/dynamic graphs: ใช้ dynamic GNN หรือ TGNN เพื่อจับการเปลี่ยนแปลงตามเวลา, สามารถรัน simulation แบบ what-if (เช่น ปิดเส้นทางขนส่งหนึ่งชั่วโมง) เพื่อประมาณผลกระทบแบบเรียลไทม์
การคำนวณผลลัพธ์จาก GNN ให้ score เช่น node risk score, propagated delay estimate และ expected stockout probability ที่เป็นตัวเลขเพื่อให้ระบบตัดสินใจอัตโนมัติหรือส่งต่อให้มนุษย์ตรวจสอบ
การสื่อสารระหว่างโมดูลและ latency ที่ยอมรับได้
การเชื่อมต่อและ latency ถูกออกแบบตามความต้องการเชิงธุรกิจ:
- Transport & messaging: ใช้ Kafka/Redis Streams เป็น message bus สำหรับเหตุการณ์เรียลไทม์, และ gRPC/REST สำหรับเรียก inference service
- Feature store & vector DB: Feature store (เช่น Feast) ให้ค่าฟีเจอร์ล่าสุดพร้อม histories; vector DB (เช่น Milvus) เก็บ embeddings จาก LLM/vision encoders
- Latency targets:
- Edge preprocessing: <50 ms (สำหรับการกรองและ local detection)
- Ingestion → feature availability: 1–5 s (near-real-time สำหรับ snapshot ของกราฟ)
- GNN inference per snapshot: 100–500 ms (ขึ้นกับ graph size; สามารถขยายด้วย batching และ GPU)
- LLM parsing (log extraction & short reasoning): 200 ms – 2 s สำหรับโมเดลขนาดเล็ก/ฝังในองค์กร; หากเรียกใช้ LLM ขนาดใหญ่ผ่านคลาวด์ อาจขึ้นไปเป็นหลายวินาทีถึงนาทีสำหรับงานซับซ้อน
- การตัดสินใจอัตโนมัติ (alert generation): <5 s เพื่อให้ระบบสามารถสั่งการป้องกันก่อนเกิดการหยุดสาย
- Human-in-the-loop response window: 30 s – 5 min ขึ้นอยู่กับความร้ายแรงและกระบวนการอนุมัติ
ตัวอย่าง Flow การทำงานจริง (end-to-end)
สมมติมีความสั่นสะเทือนสูงที่มอเตอร์ใน Plant A:
- Edge node ตรวจจับสัญญาณ anomaly → ส่งเหตุการณ์ไปยัง ingestion (latency 20 ms)
- Ingestion ทำ OCR กับ maintenance note ล่าสุด แล้วส่งข้อความไปยัง LLM เพื่อ extract event (LLM ตอบภายใน ~300 ms)
- ระบบสร้าง/อัปเดตกราฟ: node equipment ในกราฟถูกปรับค่า feature และส่งเข้า GNN เพื่อประเมินผลกระทบต่อ SKUs และ lead-times (GNN inference ~200 ms)
- ผลลัพธ์ (risk score, probable delay) ถูกเก็บใน feature store และส่ง alert อัตโนมัติ หากเกิน threshold ระบบอาจสั่งเพิ่ม safety stock หรือ redirect order; ขณะเดียวกัน LLM สร้างรายงานสรุปเป็นภาษาธุรกิจสำหรับทีมปฏิบัติการ
สรุป: การผสาน LLM กับ GNN ในสถาปัตยกรรมมัลติโมดัลต้องอาศัย pipeline ที่ชัดเจนตั้งแต่ edge จนถึง model layer, preprocessing ที่เฉพาะเจาะจงสำหรับแต่ละ modality, และการออกแบบ latency ที่ตอบโจทย์การตัดสินใจแบบเรียลไทม์ การใช้ LLM ในการแปลงและให้คำอธิบายร่วมกับ GNN ที่จำลองความสัมพันธ์เชิงโครงสร้างของซัพพลายเชน จะช่วยให้โรงงานลดสต็อกล้นและป้องกันการหยุดสายก่อนเกิดเหตุได้อย่างมีประสิทธิภาพ
ข้อมูลและการเชื่อมต่อ: แหล่งข้อมูลมัลติโมดัลและการเตรียมข้อมูล
ข้อมูลและการเชื่อมต่อ: แหล่งข้อมูลมัลติโมดัลและการเตรียมข้อมูล
ระบบ Digital Twin สำหรับโรงงานยุคใหม่ต้องอาศัยแหล่งข้อมูลหลายรูปแบบ (multimodal) ที่ครอบคลุมทั้งข้อมูลเชิงเวลา (time-series), ภาพและวิดีโอ (camera/vision), ข้อมูลเชิงโครงสร้างจากระบบธุรกรรม (MES/ERP logs, supplier EDI, shipment events) และข้อความที่ไม่เป็นโครงสร้าง (maintenance text logs, operator notes) เพื่อให้การจำลองสถานะการผลิตและซัพพลายเชนเป็นไปแบบเรียลไทม์ ตัวอย่างแหล่งข้อมูลสำคัญได้แก่:
- PLC/IoT sensors — ค่าจากเซนเซอร์ความเร็ว, อุณหภูมิ, แรงดัน, กระแสไฟ ฯลฯ มักเป็น time-series ที่ส่งด้วยความถี่ตั้งแต่ 1 Hz ถึงหลาย kHz ผ่านโปรโตคอลเช่น OPC-UA, MQTT หรือ Modbus
- Camera / Vision — ภาพจากกล้องตรวจสอบสายการผลิต (30–60 fps) และภาพความละเอียดสูงสำหรับการตรวจสอบคุณภาพ (defect detection) ต้องประมวลผลด้วย pipeline ของ CV เพื่อแปลงเป็นฟีเจอร์หรือ embeddings
- MES/ERP logs — เหตุการณ์การสั่งงาน การเปลี่ยนไลน์ การบันทึกงาน (work orders) และสถานะสต็อกเป็นข้อมูลเชิงโครงสร้างที่เชื่อมโยงกับ SKU และคำสั่งผลิต
- Supplier EDI และ shipment events — ข้อมูลการสั่งซื้อ การยืนยันการส่ง และสถานะการขนส่ง (GPS, carrier events) ช่วยในการจำลอง lead time และความไม่แน่นอนของซัพพลายเชน
- Maintenance text logs — บันทึกการซ่อมบำรุง การแจ้งเตือนและรายงานอาการที่เป็นข้อความยาว ต้องผ่าน NLP pipeline เพื่อสกัดเหตุผลและสถานะความเสี่ยง
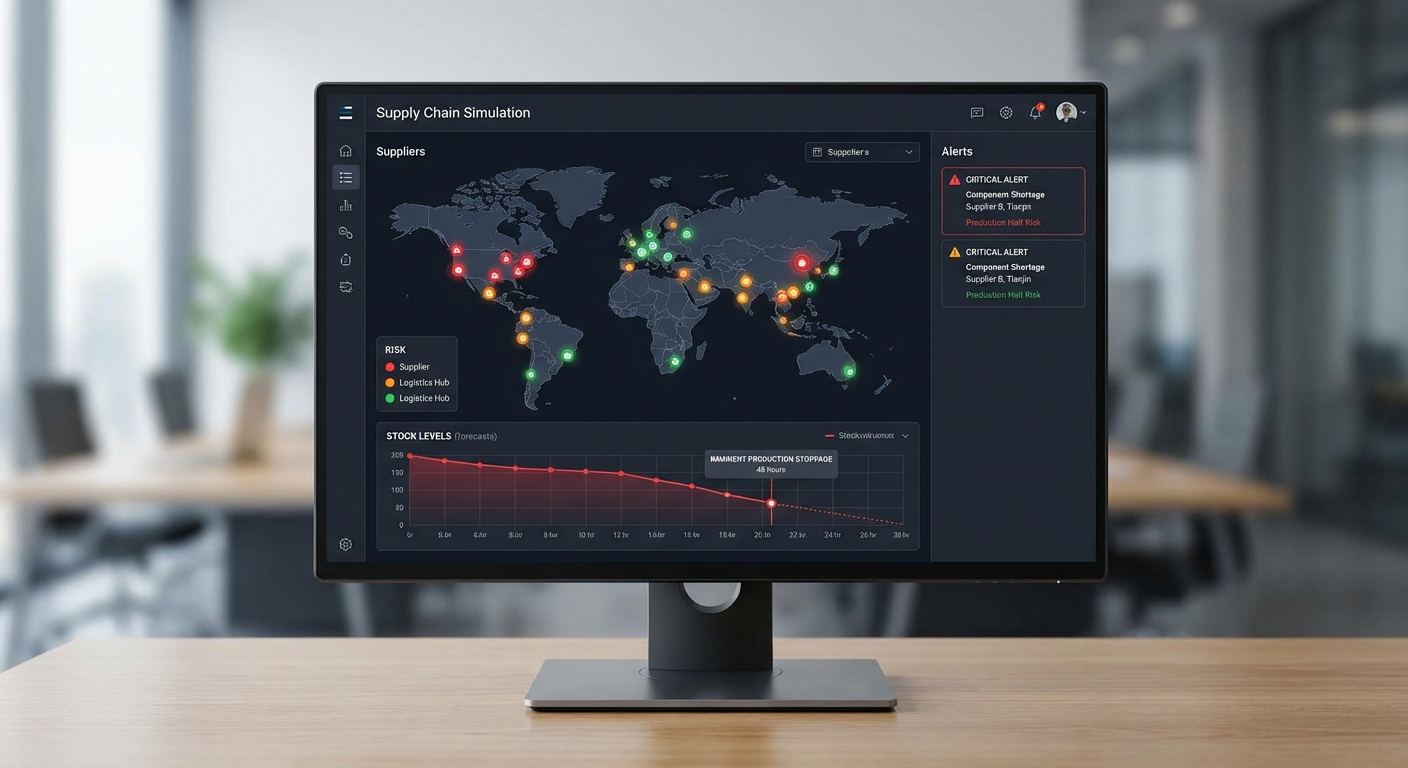
การออกแบบ data schema เชิงกลาง (canonical schema) เป็นหัวใจสำคัญของการรวมข้อมูลข้ามระบบ โดยควรกำหนดฟิลด์พื้นฐานร่วมกัน เช่น device_id, node_id, sku_id, timestamp (ISO 8601) และ quality_flag รวมถึงเมตาดาต้า (source, ingestion_time, schema_version) ตัวอย่าง pattern: สำหรับ time-series กำหนดช่องข้อมูล value/units/sample_rate; สำหรับภาพกำหนด image_id, resolution, codec, derived_embeddings; สำหรับข้อความกำหนด raw_text, language, extracted_tags
การจัดการเวลา (time alignment) ระหว่างโมดอลต่าง ๆ ต้องแยกแยะ event time กับ ingestion time และใช้นโยบาย watermarking ในระบบสตรีมมิ่งเพื่อลดปัญหาค่าล่าช้า (latency) เทคนิคที่ใช้บ่อยได้แก่ resampling ไปยังกรอบเวลาร่วม (e.g., 1s, 1min buckets), windowed aggregation (sliding/tumbling windows) และการทำ interpolation/aggregation เมื่อความถี่ข้อมูลต่างกัน ตัวอย่างเช่น การรวมสัญญาณสั่นสะเทือนที่จับได้ที่ 1 kHz กับเหตุการณ์การเปลี่ยนชิ้นงานทุก 5 วินาที อาจทำการ downsample หรือสรุปเป็นคุณลักษณะ (RMS, peak, spectral features) ต่อหน้าต่างเวลาเดียวกัน
การแก้ปัญหา missing data แบบเรียลไทม์ต้องใช้กลยุทธ์ผสมระหว่างกฎเชิงธุรกิจและวิธีทางสถิติ/โมเดล: forward-fill หรือ last-known สำหรับสัญญาณที่เปลี่ยนช้า, interpolation และ Kalman filter สำหรับสัญญาณเชิงฟิสิกส์, และการใช้โมเดลคาดการณ์ (e.g., LSTM/Temporal Conv) เพื่อเติมค่าเมื่อช่องว่างยาวหรือเมื่อตัวเซนเซอร์ขัดข้อง นอกจากนี้ควรบันทึกค่า uncertainty/confidence ของการเติมข้อมูลเพื่อให้ downstream models (LLM/GNN) สามารถถ่วงน้ำหนักข้อมูลเหล่านี้ได้
เพื่อรองรับการรวมข้อมูลแบบเรียลไทม์ ควรใช้สถาปัตยกรรม data integration ดังนี้:
- Streaming platforms — เช่น Apache Kafka, AWS Kinesis สำหรับส่ง event แบบเรียลไทม์ พร้อมรองรับ partitioning และ retention
- Change Data Capture (CDC) — ใช้ Debezium หรือบริการ CDC สำหรับซิงโครไนซ์การเปลี่ยนแปลงจากฐานข้อมูล MES/ERP ไปยัง data lake/stream เพื่อให้ข้อมูลธุรกรรมอัพเดตแบบ near-real-time
- Edge preprocessing — ทำ preprocessing ที่ edge (e.g., gateway หรือ edge compute) เพื่อลดแบนด์วิดท์ โดยคำนวณฟีเจอร์เบื้องต้นหรือส่งเฉพาะ events ที่สำคัญ (anomaly, threshold breach)
- Schema registry & governance — บริหาร schema versions และการแปลงรูปแบบด้วย Avro/Protobuf เพื่อให้ consumer หลายระบบเข้าใจข้อมูลเดียวกัน
การตรวจสอบคุณภาพข้อมูล (data quality checks) ควรทำทั้งแบบ batch และ real-time โดยรวมถึง:
- Schema validation และ type checking
- Range checks และ plausibility tests (e.g., อุณหภูมิไม่ควรเกิน/ต่ำกว่าค่าทางกายภาพ)
- Monotonicity/timestamp ordering และ heartbeat monitoring ของอุปกรณ์
- Deduplication, reconciliation กับ ERP (เช่นยอดสต็อก) และการตรวจสอบความสมบูรณ์ของ EDI messages
- Outlier detection และ automated alerts เมื่อคุณภาพตกลง (เช่น missing rate > 5%/ชั่วโมง)
สำหรับการทำ feature engineering แยกตามโมดอลเพื่อใช้กับ Graph Neural Network (GNN) และ Large Language Model (LLM):
- Time-series → GNN features: สร้าง aggregated features ต่อ node/edge เช่น mean, std, max/min, trend, FFT/PSD components, time-to-failure estimates และ anomaly scores ซึ่งสามารถเป็น node attributes สำหรับเครื่องจักร (machine nodes) หรือ edge attributes สำหรับความสัมพันธ์การขนส่ง
- Images → embeddings: ใช้ CNN/ViT เพื่อสกัด embeddings (เช่น 256–1024 dim) และ metadata (defect type, bbox) แล้วผนวกเป็น node features ของสายการผลิตหรือ SKU
- Structured records → relational features: จาก MES/ERP และ EDI สร้างตัวชี้วัดเชิงธุรกิจ (lead time, fill rate, order cycle) และใช้เป็น attributes ของ node เช่น supplier reliability score
- Text logs → LLM embeddings: ทำ NLP pipeline (tokenization, named entity extraction) และสร้าง contextual embeddings ด้วย LLM เพื่อสกัดเหตุผลการซ่อมบำรุง หรือสรุปเหตุการณ์สำคัญ จากนั้นเก็บเป็น node/edge features หรือ prompt context สำหรับ agent ที่เชื่อมกับ LLM
การออกแบบ graph schema ที่ชัดเจนมีผลต่อความสามารถในการจำลองและวิเคราะห์เชิงสัมพันธ์ ตัวอย่างโหนด (nodes) และความสัมพันธ์ (edges) ที่แนะนำ:
- Nodes:
- Plant (โรงงาน)
- Line (สายการผลิต)
- Machine (เครื่องจักรแต่ละตัว)
- Supplier
- SKU (สินค้าตามรหัส)
- Shipment / Batch
- Operator / Maintenance Crew
- Edges (ความสัมพันธ์):
- Plant → Line: มี/ขึ้นกับ
- Line → Machine: ประกอบด้วย
- Machine → SKU: ผลิต
- Supplier → SKU: จัดส่ง/จัดหา
- Shipment → SKU: ขนส่ง
- Machine → Machine: proximity / upstream-downstream
- Operator → Machine: assigned_to / reported_issue
สำหรับการใช้งานจริง ควรแนบเวลาและน้ำหนักให้กับ edges เพื่อรองรับ temporal graph และ dynamic relationships (เช่น lead_time, delay_probability) ซึ่งช่วยให้ GNN สามารถเรียนรู้ผลกระทบของเหตุการณ์เชิงเวลาต่อเครือข่ายการผลิตและซัพพลายเชนได้อย่างแม่นยำ ในหลายกรณีการผสานระหว่าง LLM สำหรับการตีความข้อความและสร้างคำอธิบายเหตุการณ์ กับ GNN สำหรับการวิเคราะห์เชิงโครงสร้าง สามารถช่วยคาดการณ์เหตุการณ์ล้มเหลวล่วงหน้าและเสนอการแก้ไขเชิงปฏิบัติ โดยการเก็บคุณลักษณะและความไม่แน่นอนจากแต่ละโมดอลเป็น first-class citizens ใน graph ทำให้ระบบ Digital Twin ตอบสนองแบบเรียลไทม์และลดสต็อกล้นหรือการหยุดสายการผลิตได้อย่างมีประสิทธิภาพ
อัลกอริทึมและการเทรน: GNN สำหรับโครงสร้างซัพพลายเชน และ LLM สำหรับเหตุผลเชิงภาษา
ภาพรวมอัลกอริทึม: ทำไมต้องผสาน GNN กับ LLM ใน Digital Twin ของซัพพลายเชน
ในโรงงานยุคใหม่ที่ใช้ Digital Twin แบบมัลติโมดัล การจับภาพความสัมพันธ์เชิงโครงสร้าง (supply relationships, transport links, production lines) จำเป็นต้องใช้ Graph Neural Network (GNN) สำหรับการแพร่กระจายของความล่าช้า ความเสี่ยง และผลกระทบข้ามโหนด ขณะที่ข้อมูลเชิงภาษา (maintenance logs, shift notes, SOP) ต้องการความสามารถเชิงเหตุผลของ Large Language Models (LLM) เพื่อสรุปสาเหตุ แนะนำนโยบาย และสร้างแผนปฏิบัติการร่วมกัน การออกแบบสถาปัตยกรรมและกลยุทธ์การเทรนที่เหมาะสมจึงเป็นหัวใจสำคัญของระบบที่สามารถทำนายการหยุดชะงักและลดสต็อกล้นได้อย่างเป็นรูปธรรม
การเลือกสถาปัตยกรรม GNN สำหรับ dynamic graphs และ temporal edges
สำหรับซัพพลายเชนที่เป็นกราฟไดนามิกพร้อมเหตุการณ์ตามเวลา ควรพิจารณาโมเดลต่อไปนี้ตามกรณีการใช้งาน:
- GraphSAGE: เหมาะกับการเรียนรู้แบบ inductive เมื่อโหนดใหม่/เส้นทางใหม่เกิดขึ้นบ่อย การใช้ neighbor sampling ช่วยสเกลกับกราฟขนาดใหญ่และรองรับข้อมูลเวลาที่แปะเป็นฟีเจอร์
- GAT (Graph Attention Network): เหมาะเมื่อความสำคัญของขอบ (เช่น lead time, reliability) แตกต่างกันมาก Attention ช่วยให้ระบบเรียนรู้การถ่วงน้ำหนักการแพร่ของดีเลย์หรือความเสี่ยงจากแต่ละ supplier/route
- Temporal GNNs (TGAT, TGN, EvolveGCN): สำหรับเหตุการณ์ตามเวลา (shipment delay events, machine failure events) ควรเลือกโมเดลที่รองรับ continuous-time temporal edges เช่น TGAT/TGN ที่ฝังตัวแสดงเวลา (time encoding / memory modules) เพื่อจับ causal sequences และการสะสมผลกระทบตลอดเวลา
ตัวอย่างเชิงปฏิบัติ: การใช้งาน TGAT/TGN สามารถจับ pattern ของ “delay cascade” ได้ดีกว่า GCN แบบสแตติกเมื่อต้องทำนายการหยุดชะงักภายในระยะเวลา 24-72 ชั่วโมงล่วงหน้า
เทคนิคการเทรน GNN: supervised, contrastive, temporal training
การเทรนควรรวมหลายเทคนิคเพื่อให้ได้ embedding ที่สามารถทำนายเหตุขัดข้องและสมดุลสต็อกได้ดีขึ้น:
- Supervised learning — กำหนดเป้าหมายเช่น next-disruption (binary/multi-class) และ inventory imbalance (regression) ใช้ loss แบบ cross-entropy สำหรับการจำแนก และ MSE/MAE สำหรับการทำนายปริมาณ
- Temporal training — สำหรับ event sequences ใช้ negative log-likelihood ของ temporal point process หรือตัวชี้วัดความน่าจะเป็นตามเวลา เพื่อปรับความจำ (memory) ของโหนดใน TGN หรือปรับ attention weights ใน TGAT
- Contrastive learning — ใช้ InfoNCE หรือ graph-level contrastive loss เพื่อเสริมให้ embedding มีความแยกชัดระหว่างสภาวะปกติและความเสี่ยง (augmentations เช่น edge masking, time perturbation, subgraph sampling)
- Sampling และ minibatch — สำหรับกราฟขนาดใหญ่ ใช้ neighbor sampling (GraphSAGE-style) หรือ temporal neighbor sampling เพื่อฝึกแบบมินิบัตช์โดยไม่ต้องโหลดกราฟทั้งหมด
ตัวอย่าง objective functions และการออกแบบ loss
การกำหนด objective ต้องสะท้อน KPI ของธุรกิจ และสามารถผสมผสานเป็น multi-task learning ได้ เช่น:
- Next-disruption prediction (classification): loss = cross-entropy ถ่วงน้ำหนักด้วย focal loss หากคลาสไม่สมดุล (unplanned downtime บ่อยแต่เป็นสัญญาณหายาก) ใช้ AUC-ROC, F1, precision @ k เป็น metrics
- Inventory imbalance score (regression): ตัวชี้วัดเป็น AbsError normalized เช่น imbalance = |stock_actual - stock_target| / stock_target; loss = weighted MAE โดยกำหนดน้ำหนักสูงกว่าเมื่อ shortage (กระทบการผลิต) มากกว่า overstock
- Propagation loss: เพิ่ม regularization ที่ลงโทษการคาดการณ์ที่ละเลยการแพร่ของดีเลย์ เช่น penalize predicted downstream impact ถ้า upstream disruption ถูกทำนายว่าแรง
- Contrastive loss: InfoNCE ระหว่าง positive pairs (same event trajectory) และ negative samples (แตกต่างกันตามเวลา/เส้นทาง) เพื่อแยก embedding space
สำหรับการประเมินเชิงธุรกิจ ควรทดสอบแบบ offline simulation กับ Digital Twin เพื่อวัดผลต่อ uptime และ inventory holding cost—ตัวอย่างเป้าหมายเช่น ลด unplanned downtime 20% และลดค่า holding cost 10% ภายใน 6 เดือนหลังใช้งาน
การ fine-tune LLM สำหรับ maintenance logs และ policy generation
LLM จำเป็นต้องถูกปรับให้เข้าใจภาษาภายในองค์กร (domain-adaptive) และสามารถให้คำแนะนำปฏิบัติการที่สอดคล้องกับข้อมูลเชิงโครงสร้างจาก GNN วิธีปฏิบัติที่แนะนำได้แก่:
- Domain-adaptive pretraining: ใช้ corpus ภายในองค์กร (maintenance logs, SOP, incident reports) เพื่อฝึกต่อก่อนการ fine-tune ลดปัญหาภาษาเฉพาะทางและคำย่อ
- Supervised fine-tuning: สอน LLM ให้ทำงานเฉพาะ เช่น classification ของ root cause, extraction ของ time-to-failure, หรือ generation ของ playbook โดยใช้คู่ (log, label/action) ที่มี annotation
- Parameter-efficient tuning: ใช้ LoRA / adapters เมื่อข้อมูลมีจำกัดและต้องการความเป็นส่วนตัวของโมเดล
- Retrieval-Augmented Generation (RAG): ผสาน retrieval (vector DB + sparse retrieval) เพื่อดึงข้อมูลอ้างอิงจากฐานข้อมูลเซนเซอร์, BOM, และประวัติการซ่อม ก่อนให้ LLM สังเคราะห์คำตอบ — ลด hallucination และเพิ่ม traceability ของคำแนะนำ
- Reward modeling / RLHF: หากต้องการให้โมเดลสร้างนโยบายที่คำนึง KPI ทางธุรกิจ สามารถออกแบบ reward function ที่สัมพันธ์กับ downtime reduction, cost savings แล้วทำ RL-based fine-tune
การเชื่อมต่อ GNN กับ LLM และการประเมินความแม่นยำ
สถาปัตยกรรมเชื่อมต่อกันโดยส่ง embedding จาก GNN (node/edge embeddings, predicted risk scores) เป็น context ให้ LLM พร้อมผลการดึงข้อมูลจาก RAG ซึ่งทำให้ LLM สามารถสร้างนโยบายหรือขั้นตอนการซ่อมที่ grounded ในข้อมูลเชิงโครงสร้างได้ เทคนิคการรวมข้อมูลระหว่างสองโมดูลอาจใช้การ concatenation ของ embeddings หรือ cross-attention layer สำหรับการเรียนรู้ร่วม
มาตรวัดความแม่นยำและความเชื่อถือได้ที่แนะนำ:
- Classification: AUC-ROC, PR-AUC, Precision@K, Recall, F1
- Regression: MAE, RMSE, MAPE (โดยเฉพาะสำหรับการทำนายปริมาณสต็อก)
- Calibration และ reliability: Brier score, calibration plot, Platt scaling/isotonic regression เพื่อให้ความน่าจะเป็นที่โมเดลให้สอดคล้องกับความเป็นจริง
- Business-level metrics: reduction in unplanned downtime (%), reduction in average inventory holding (cost), mean time to resolution (MTTR)
- LLM-specific: hallucination rate (เชิงเปอร์เซ็นต์), grounding rate (สัดส่วนคำตอบที่อ้างอิงเอกสารใน RAG), human-in-loop acceptability score
สรุปเชิงนโยบายสำหรับการนำไปใช้ในโรงงาน
การออกแบบระบบ Digital Twin ที่ผสาน GNN กับ LLM ควรเลือกสถาปัตยกรรม GNN ที่รองรับไดนามิกของซัพพลายเชน (เช่น TGAT/TGN สำหรับ temporal edges, GraphSAGE สำหรับการสเกลแบบ inductive และ GAT เมื่อความสำคัญของขอบแตกต่างกัน) และใช้ multi-task training พร้อม contrastive regularization เพื่อได้ embedding ที่มีประสิทธิภาพ ในทางกลับกัน LLM ควรถูก fine-tune และผนวกรวมกับ RAG เพื่อให้คำแนะนำที่มีหลักฐานรองรับและสอดคล้องกับ KPI ทางธุรกิจ การออกแบบ loss functions ควรสะท้อนน้ำหนักทางธุรกิจ (เช่น penalize shortage มากกว่า overstock) และการประเมินต้องรวมทั้ง metrics เชิงเทคนิคและผลลัพธ์เชิงธุรกิจก่อนนำไปใช้งานจริง
Use Cases: จำลองซัพพลายเชนเรียลไทม์และแจ้งเตือนก่อนหยุดการผลิต
Use Cases: จำลองซัพพลายเชนเรียลไทม์และแจ้งเตือนก่อนหยุดการผลิต
การผสาน Digital Twin แบบมัลติโมดัล ที่รวมความสามารถของ Large Language Models (LLMs) กับ Graph Neural Networks (GNNs) เปิดทางให้โรงงานสามารถรันการจำลองแบบ what‑if ในเวลาจริง เพื่อประเมินผลกระทบจากเหตุการณ์ต่างๆ และออกคำสั่งแก้ไขก่อนที่จะเกิดการหยุดสายการผลิตจริง ตัวอย่างเช่น เมื่อระบบตรวจพบอีเมลหรือข้อความจากซัพพลายเออร์ที่บ่งชี้ถึงความล่าช้า LLM จะสกัดเจตนาและความเสี่ยงเชิงบริบท ขณะเดียวกัน GNN จะประเมินการแพร่กระจายของความล่าช้านั้นผ่านโหนดซัพพลายเชน — คำนวณว่าชิ้นส่วนใดจะขาดภายในกี่ชั่วโมง และความน่าจะเป็นของการหยุดการผลิตคือเท่าใด
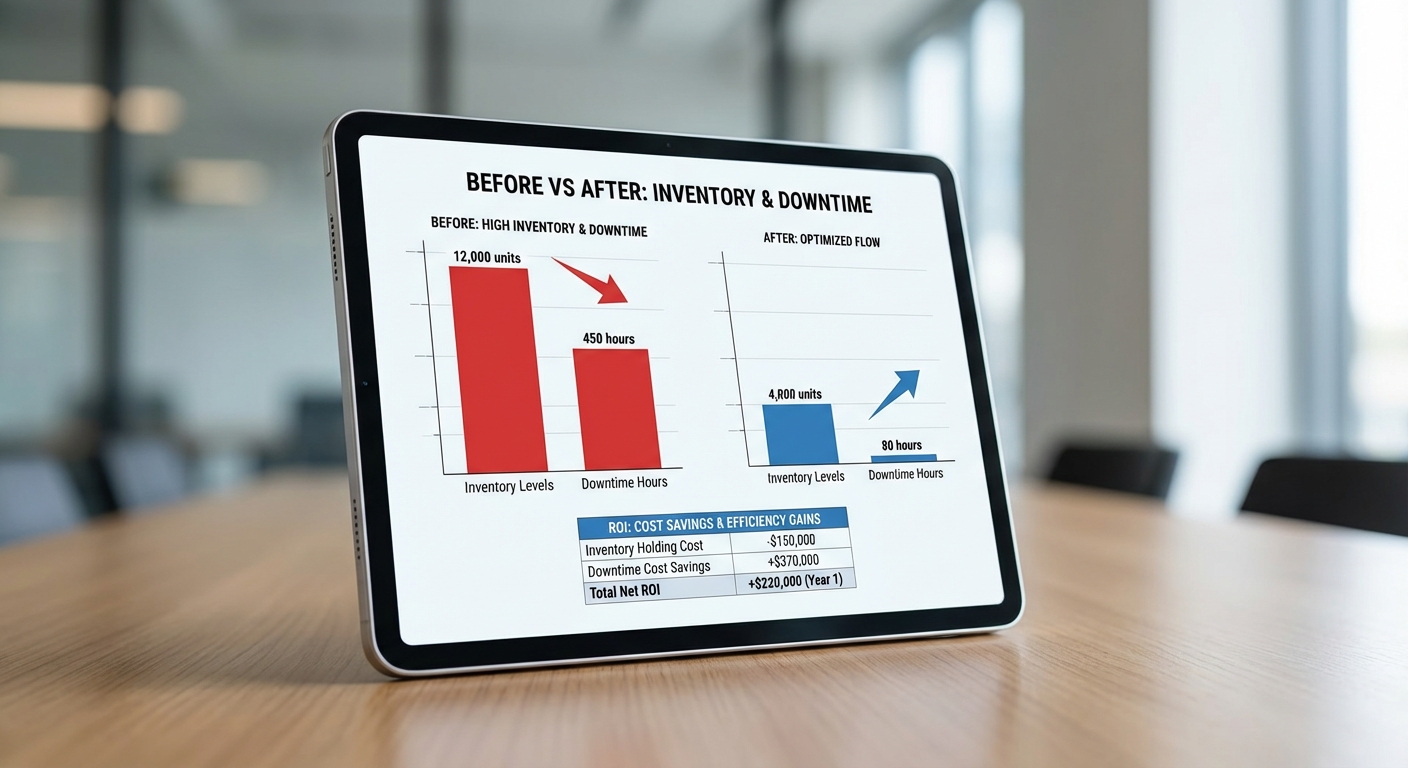
เคสตัวอย่างจริง: สมมติโรงงานผลิตชิ้นส่วนยานยนต์มีความต้องการเฉลี่ยวันละ 500 ชิ้น และใช้เวลาส่ง (lead time) เฉลี่ย 7 วัน เมื่อซัพพลายเออร์ A แจ้งความล่าช้าประมาณ 4 วัน ระบบจะรัน real‑time what‑if simulation เพื่อประเมินทางเลือก เช่น การเร่งจัดส่งจากซัพพลายเออร์สำรอง การปรับตารางการผลิต หรือการสับเปลี่ยนใช้ชิ้นส่วนทดแทน ผลการจำลองอาจแสดงว่าโดยไม่จัดการ ความน่าจะเป็นที่จะเกิดการหยุดสายการผลิตภายใน 72 ชั่วโมงคือ 65% แต่หากใช้มาตรการเร่งด่วนที่ระบบแนะนำ (เช่นสั่งด่วน 20% ของความต้องการจากซัพพลายเออร์ B และปรับสายการผลิตเฉพาะจุด) ความน่าจะเป็นจะลดลงเหลือ 12% — ทำให้ลดความเสี่ยงของการหยุดผลิตและต้นทุนฉุกเฉินลงอย่างมีนัยสำคัญ
ในด้าน predictive maintenance ระบบมัลติโมดัลจะรวมข้อมูลจากเซนเซอร์ (vibration, temperature, acoustic) ภาพจากกล้องและบันทึกการซ่อมแซมเดิมเข้าเป็นตัวแทนสภาพของอุปกรณ์ เมื่อ GNN โมเดลเชื่อมต่อความสัมพันธ์ระหว่างชิ้นส่วนและเส้นทางการส่งวัสดุร่วมกับ LLM ที่วิเคราะห์ log หรือบันทึกเชิงข้อความ ระบบสามารถส่ง alert แบบเชิงสาเหตุ (root‑cause alert) ได้ว่า "ความผิดปกติของแรงสั่นสะเทือนในมอเตอร์ X แสดงแนวโน้มการล้มเหลวของตลับลูกปืนภายใน 72 ชั่วโมง" การแจ้งเตือนเช่นนี้ช่วยให้ทีมบำรุงรักษาเตรียมอะไหล่และกำหนดเวลาปิดสายแบบวางแผน ผลลัพธ์จากเคสตัวอย่าง: MTTF เพิ่มจาก 1,200 ชั่วโมงเป็น 1,800 ชั่วโมง (+50%) และ MTTR ลดจากเฉลี่ย 8 ชั่วโมงเหลือ 2 ชั่วโมง (-75%) ส่งผลให้เวลาหยุดทำงานรวม (downtime) ลดลงราว 60–70% และต้นทุนจากการหยุดการผลิตลดลงอย่างมาก
สำหรับการ optimize safety stock ระบบใช้การคาดการณ์ความต้องการ (demand forecast) พร้อมการจำลองความแปรปรวนของ lead time ที่ได้จาก GNN — ซึ่งพิจารณาทั้งเครือข่ายซัพพลายเออร์และความสัมพันธ์ข้ามโรงงาน — เพื่อคำนวณระดับสต็อกสำรองแบบไดนามิก ไม่ใช่แบบคงที่ตามกฎเดิม ตัวอย่างเชิงตัวเลข: โรงงานที่มีสต็อกสำรองแบบดั้งเดิม 8,000 หน่วย สามารถลดลงเหลือ 5,600 หน่วย (ลด 30%) เมื่อใช้ simulation‑driven safety stock ที่ปรับตามความเสี่ยงจริงเวลา‑จริง หากต้นทุนถือครองสต็อกต่อหน่วยเท่ากับ 20 ดอลลาร์ การลดสต็อกนี้จะปลดปล่อยเงินทุนประมาณ 48,000 ดอลลาร์ให้ใช้งานหรือคืนสภาพคล่องให้ธุรกิจ
- Real‑time what‑if simulation: ช่วยตัดสินใจในหน้าต่างเวลาสั้น ๆ เพื่อลดความน่าจะเป็นของการหยุดการผลิต (ตัวอย่าง: ลดความเสี่ยงจาก 65% → 12%)
- Predictive maintenance: แจ้งเตือนเชิงสาเหตุ ทำให้เพิ่ม MTTF และลด MTTR (ตัวอย่าง: MTTF +50%, MTTR -75%) ลด downtime 60–70%
- Safety stock optimization: ใช้ GNN‑based simulation ร่วมกับ demand forecast เพื่อลดสต็อกสำรอง 20–35% ในเคสทั่วไป และลดต้นทุนถือครองสต็อกอย่างมีนัยสำคัญ
สรุปแล้ว การรวม LLM กับ GNN ใน Digital Twin ของโรงงานไม่เพียงแต่ให้ภาพสถานะปัจจุบันแบบมัลติโมดัล แต่ยังให้ความสามารถเชิงคาดการณ์และจำลองเชิงสาเหตุแบบเรียลไทม์ ทำให้ผู้บริหารและทีมปฏิบัติการสามารถเลือกมาตรการป้องกันหรือบรรเทาได้อย่างรวดเร็วและมีข้อมูลรองรับ ผลลัพธ์คือสต็อกที่มีประสิทธิภาพมากขึ้น เวลาหยุดทำงานที่ลดลง และความสามารถในการตอบสนองต่อความเปลี่ยนแปลงของซัพพลายเชนได้อย่างทันท่วงที
Roadmap การนำไปใช้และ best practices
Roadmap การนำไปใช้: ขั้นตอนจาก PoC สู่การสเกลแบบเป็นระบบ
การนำ Digital Twin แบบมัลติโมดัล (ผสาน LLM กับ Graph Neural Network) ไปใช้จริง ควรดำเนินตามขั้นตอนเชิงรุกที่ชัดเจน ได้แก่ PoC → Pilot → Production → Scale โดยเริ่มจากขอบเขตแคบที่สุด เช่น หนึ่งสายการผลิต (1 line) หรือหนึ่ง SKU เพื่อลดความเสี่ยงและวัดผลได้รวดเร็ว ในเชิงปฏิบัติ ขอแนะนำไทม์ไลน์มาตรฐานดังนี้:
- PoC (6–12 สัปดาห์) — เก็บข้อมูลพื้นฐานจากเซนเซอร์, MES และ ERP สำหรับ 1 line/1 SKU, ฝังโมเดล GNN เพื่อจำลองโหนดซัพพลายเชน และใช้ LLM สำหรับการแปลผลเชิงภาษาธุรกิจ (เหตุการณ์, คำอธิบาย) เป้าหมายคือยืนยันความถูกต้องของสัญญาณและความเป็นไปได้ทางธุรกิจ (เช่น ลด overstock, คาดการณ์ stop-line ได้ล่วงหน้า 4–24 ชั่วโมง)
- Pilot (3–6 เดือน) — ขยายไปยังหลายสายการผลิตหรือหลาย SKU แบบควบคุม เปิดใช้งานระบบในสถานะ shadow/monitor-only ก่อนให้มีการแนะนำเชิงปฏิบัติการ (recommendations) ให้ operator ตัดสินใจ เป้าหมายย่อยเช่นลด Days of Inventory (DOI) ลง 10–20% และลดเหตุการณ์หยุดสายลง 15–25%
- Production (6–12 เดือน) — เปิดใช้แบบ read-write กับระบบควบคุมที่ปลอดภัย เชื่อมต่อกับ MES/ERP เพื่อให้ระบบ Digital Twin สามารถส่งคำสั่งหรือแจ้งเตือนเชิงปฏิบัติการได้แบบวันต่อวัน รวมทั้งตั้งค่าการวัดผลแบบต่อเนื่อง (SLA, MTTR, Fill Rate)
- Scale (12–24 เดือน) — ขยายสู่โรงงานทั้งไซต์หรือหลายไซต์ ปรับโครงสร้าง data platform ให้รองรับงานข้ามโรงงาน และตั้งทีมกลางสำหรับ governance, model lifecycle และการปฏิบัติการแบบกระจาย
Best practices ด้าน Governance, Explainability และ Incident Playbooks
ระบบที่รวม LLM กับ GNN จำเป็นต้องมีกรอบการกำกับดูแลที่เคร่งครัดเพื่อให้ตอบได้ทั้งเรื่องความน่าเชื่อถือและการปฏิบัติเมื่อเกิดเหตุ ข้อแนะนำเชิงปฏิบัติ:
- Versioning — ใช้ model registry และ dataset versioning (เช่น MLflow, DVC) ระบุหมายเลขเวอร์ชันของโมเดล GNN/LLM, pipeline และ schema ของ graph เพื่อให้สามารถย้อนกลับได้เมื่อเกิดปัญหา
- Explainability — ติดตั้งเครื่องมืออธิบายผลทั้งเชิงโครงสร้าง (graph importance, edge/node contribution) และเชิงภาษาของ LLM (saliency, attention visualization, counterfactuals) เพื่อให้ plant SMEs และผู้บริหารเข้าใจที่มาของคำแนะนำ
- Incident playbooks — เตรียมชุดมาตรการมาตรฐาน: ตรวจจับ → ไตร่สวน → แยกขอบเขต → rollback/mitigation → สื่อสาร และ postmortem ตัวอย่างขั้นตอน: (1) alert พบบทคาดการณ์ผิดพลาด > threshold (2) สับระบบไปที่ read-only และแจ้งทีม on-call (3) เปิดการวิเคราะห์ root cause พร้อมเก็บ log & snapshot ของ model/data
- Data privacy & security — ใช้มาตรการเข้ารหัสข้อมูล, RBAC, pseudonymization เมื่อแชร์ข้อมูลซัพพลายเชนกับระบบกลาง และปฏิบัติตามกฎหมายเช่น PDPA/ GDPR ของประเทศที่เกี่ยวข้อง
- Audit trail และ compliance — บันทึกการตัดสินใจของระบบที่เชื่อมกับมนุษย์ (who accepted/overrode) เพื่อการตรวจสอบและการปรับปรุงในอนาคต
Human-in-the-loop, Continuous Measurement และการจัดการความเสี่ยง
การรักษามาตรฐานการปฏิบัติที่ดีจำเป็นต้องผสานองค์ประกอบของมนุษย์ในวงจรการตัดสินใจ โดยเฉพาะช่วงแรกของการนำไปใช้ human-in-the-loop ควรมีขั้นตอนชัดเจน เช่น operator รับ/ปฏิเสธ recommendation, ลงเหตุผล และ feedback ถูกส่งกลับเป็น labeled data เพื่อใช้ในการ retraining นอกจากนี้ควรตั้ง KPI และกลไกวัดผลต่อเนื่องดังนี้:
- Operational KPIs: downtime per line, MTTR, on-time delivery, Days of Inventory (DOI)
- Model KPIs: prediction accuracy, calibration, false-positive/negative rates สำหรับการเตือนก่อนหยุดสาย
- System KPIs: latency, availability, cost per inference
- Monitoring & Drift Detection: เซ็ต alert สำหรับ data drift ใน graph structure หรือ distribution shift ในข้อความที่ LLM ได้รับ เพื่อนัด retrain เมื่อ performance ลดลง เช่น threshold 5–10% ของ accuracy
ทีมและทรัพยากรที่ต้องเตรียม (ตัวอย่างทรัพยากรสำหรับโรงงานขนาดกลาง)
การนำระบบนี้สู่การผลิตต้องการทีมผสมและทรัพยากรด้านฮาร์ดแวร์/ซอฟต์แวร์ ดังตัวอย่างต่อไปนี้:
- Core team
- 1 Product / Program Manager (เชื่อมธุรกิจกับเทคนิค)
- 2–4 Data Engineers (data pipelines, integration MES/ERP, graph construction)
- 1–3 ML Engineers / MLOps (model training, deployment, CI/CD)
- 1–2 ML Research / GNN Specialists (ออกแบบ architecture และ tuning)
- 1–2 LLM Engineers (prompt engineering, safety, explainability)
- 2–4 Plant SMEs / Process Engineers (ให้ domain knowledge, การตรวจสอบผล)
- 1–2 Change Management / Training Leads (ฝึกอบรม operator และจัดการ adoption)
- Ops on-call rotation (1–2 คน) สำหรับ 24/7 monitoring ในขั้น Production
- Infra & Tools
- Data lake / warehouse, message broker (Kafka) และ stream processing
- GPU inference servers (หรือ cloud instances) สำหรับ GNN/LLM
- Model registry, CI/CD pipelines, monitoring stack (Prometheus/Grafana), logging (ELK)
- Integration adapters กับ MES/ERP/SCADA และ secure API gateway
- Annotation tools และ environment สำหรับ human feedback
ตัวอย่าง Timeline เชิงปฏิบัติการและการคาดการณ์ผลลัพธ์
ตัวอย่าง timeline สำหรับโรงงานขนาดกลางที่เริ่มจาก PoC 1 line/1 SKU:
- สัปดาห์ 0–6: เก็บข้อมูล, สร้าง graph prototype, พัฒนา LLM prompts สำหรับรายงานเหตุการณ์, เริ่ม PoC
- สัปดาห์ 7–18: Pilot ขยาย 3–5 lines, เปิด shadow mode, เริ่มรับ feedback จาก operator; คาดว่ามีการลด DOI 10–15% และลด events ที่ทำให้หยุดสาย 10–20%
- เดือน 5–12: เปิด Production สำหรับสายสำคัญ, ติดตั้ง governance, incident playbooks, on-call; คาดผลลด downtime 20–35% เมื่อระบบมี maturity
- เดือน 12–24: สเกลสู่ไซต์ทั้งโรงงาน/หลายไซต์, ปรับ platform ให้ multi-tenant, วาง roadmap retraining และ continuous improvement
ทรัพยากรต้นทุนที่ต้องคาดการณ์รวมถึงค่าเซนเซอร์/IoT integration (ขึ้นกับสภาพเดิมของโรงงาน), ค่า compute สำหรับ inference (GPU/cloud), และค่าแรงทีม (โดยเฉพาะ ML specialists) โดยทั่วไปการคืนทุน (ROI) สำหรับ use-case ลดสต็อกล้นและป้องกันหยุดสายสามารถเห็นได้ภายใน 12–24 เดือน ขึ้นกับมูลค่าการผลิตและอัตรา downtime ต่อหน่วยเวลา
สรุปเชิงปฏิบัติการ
การนำ Digital Twin แบบมัลติโมดัลสู่การปฏิบัติจำเป็นต้องเริ่มจากขอบเขตเล็ก แล้วค่อยขยายตามผลลัพธ์ พร้อมกรอบ governance ที่ครอบคลุม versioning, explainability และ incident playbooks รวมทั้งการออกแบบ human-in-the-loop เพื่อรักษาความน่าเชื่อถือ การวางแผนทรัพยากรและ timeline อย่างเป็นขั้นตอนจะช่วยให้การสเกลปลอดภัยและคุ้มค่า ทั้งนี้ควรตั้ง KPI ที่ชัดเจนและกระบวนการ retraining/monitoring เพื่อให้ระบบสามารถรักษาประสิทธิภาพและตอบโจทย์เชิงธุรกิจได้อย่างต่อเนื่อง
ตัวชี้วัดความสำเร็จ, ความเสี่ยง และแผนรับมือ
ตัวชี้วัดความสำเร็จ (Key Performance Indicators)
เพื่อประเมินผลลัพธ์ของการนำ Digital Twin แบบมัลติโมดัลที่ผสาน LLM และ Graph Neural Network มาใช้ในโรงงาน ควรตั้ง KPI เชิงปริมาณและเชิงคุณภาพที่ชัดเจน ดังต่อไปนี้ โดยกำหนดเป้าหมายเริ่มต้น (benchmarks) และกรอบเวลาวัดผล (เช่น 6–12 เดือน)
- % ลดสต็อก (Inventory reduction) — วัดเป็นร้อยละของมูลค่าสินค้าคงคลังหรือจำนวนวันของสต็อก (days of inventory). ตัวอย่างเป้าหมาย: ลดสต็อก 20–35% ภายใน 12 เดือน โดยควบคุมไม่ให้เพิ่มความเสี่ยงต่อการขาดแคลน
- Inventory turns — เพิ่มความถี่ในการหมุนเวียนสต็อก (turns per year). ตัวอย่างเป้าหมาย: เพิ่มจาก 4 เป็น 5–7 turns/ปี ส่งผลให้ลดทุนจมและปรับปรุงกระแสเงินสด
- % ลด downtime (Downtime reduction) — วัดชั่วโมงการหยุดสายการผลิต (downtime hours) หรือสัดส่วนเวลาที่สายผลิตทำงานได้ (uptime). ตัวอย่างเป้าหมาย: ลด downtime 15–40% โดยเฉพาะการป้องกัน incident ที่คาดเดาได้
- Time-to-detect (TTD) — เวลาเฉลี่ยจากเหตุการณ์เริ่มต้นถึงการแจ้งเตือนหรือการตรวจจับ. ตัวอย่างเป้าหมาย: ลดจากหลายชั่วโมงเป็น <1 ชั่วโมง (หรือ <30 นาที ในกรณี critical)
- Precision / Recall ของการแจ้งเตือน — วัดประสิทธิภาพของระบบในการส่ง alert ที่ถูกต้อง (precision) และการตรวจจับเหตุการณ์จริงทั้งหมด (recall). ตัวอย่างเป้าหมาย: precision ≥ 80% และ recall ≥ 85% สำหรับเหตุการณ์สำคัญ; ยอมรับ trade‑off ตามต้นทุนของ false positive/negative
- False positive alert rate — สัดส่วนการแจ้งเตือนผิดพลาดต่อทั้งหมด; ตัวอย่างเป้าหมาย: ลดเหลือต่ำกว่า 5–10% สำหรับ alerts ที่กระทบการดำเนินงาน
- Time-to-acknowledge / Time-to-resolve — เวลาตั้งแต่แจ้งเตือนจนผู้ปฏิบัติงานตอบรับหรือปิดเคส; ใช้เป็นตัวชี้วัดร่วมกับ TTD เพื่อวัดผลรวมของระบบและกระบวนการ
ความเสี่ยงสำคัญที่ต้องคำนึง
การผสาน LLM กับ GNN และข้อมูลซัพพลายเชนเรียลไทม์สร้างประโยชน์มหาศาล แต่ย่อมมาพร้อมความเสี่ยงหลายด้านที่ต้องระบุและประเมินอย่างเป็นระบบ:
- Data bias และ representativeness — ข้อมูลประวัติหรือข้อมูลเซนเซอร์ที่ไม่ครอบคลุมสถานการณ์จริง (seasonality, new product, rare failures) อาจทำให้โมเดลคาดการณ์ผิดหรือไม่สามารถตอบสนองกับเหตุการณ์ใหม่ได้ ส่งผลให้การตัดสินใจเชิงอัตโนมัติมี bias ต่อ supplier/line/shift บางกลุ่ม
- Overfitting ของโมเดล — การฝึกโมเดลด้วยชุดข้อมูลภายในโรงงานเพียงชุดเดียวอาจให้ผลดีในอดีตแต่ล้มเหลวเมื่อสภาพแวดล้อมเปลี่ยน (concept drift). GNN อาจจับรูปแบบชั่วคราวที่ไม่ทั่วไป และ LLM อาจสร้างคำอธิบายที่โน้มน้าวแต่ไม่ถูกต้อง
- Supplier data latency และ incompleteness — ข้อมูลจากผู้จัดหาหรือขนส่งที่ล่าช้าหรือขาดหาย ทำให้ Digital Twin ไม่สะท้อนสถานะซัพพลายเชนเรียลไทม์จริง ส่งผลให้การคาดการณ์สต็อกและชิ้นส่วนไม่แม่นยำ
- False alarms และ alert fatigue — อัตราการแจ้งเตือนเท็จสูงทำให้ผู้ปฏิบัติงานละเลยการแจ้งเตือนที่สำคัญ (alert fatigue) และลดความไว้วางใจในระบบ
- ความเป็นส่วนตัวและความมั่นคงของข้อมูล — การรวมข้อมูลหลายแหล่ง (IoT, ERP, third-party) เพิ่มความเสี่ยงเรื่องการรั่วไหลของข้อมูลเชิงพาณิชย์หรือข้อมูลส่วนบุคคล และข้อกำหนดทางกฎหมาย (เช่น ข้อตกลง NDA หรือกฎระเบียบคุ้มครองข้อมูล)
แผนรับมือและมาตรการลดผลกระทบ (Mitigation & Governance)
เพื่อให้ระบบ Digital Twin ทำงานได้อย่างปลอดภัยและมีประสิทธิภาพ จำเป็นต้องออกแบบมาตรการทั้งเชิงเทคนิคและเชิงนโยบาย ดังนี้
- Data governance และ lineage — กำหนดนโยบายการเข้าถึงข้อมูล, แหล่งอ้างอิงของข้อมูลแต่ละฟิลด์, เวอร์ชันข้อมูล และ SLA กับซัพพลายเออร์ที่ระบุความถี่และความหน่วงสูงสุดของการส่งข้อมูล (เช่น max latency ≤ 5 นาที สำหรับข้อมูล critical)
- Human-in-the-loop & operator feedback loops — ให้มนุษย์เป็นผู้อนุมัติการตัดสินใจเชิงสำคัญ เช่น การสั่งเพิ่ม/ลดสต็อกหรือหยุดสายการผลิตแบบอัตโนมัติ โดยเก็บ feedback ของผู้ปฏิบัติงานเป็นข้อมูลย้อนกลับ (label) เพื่อปรับโมเดลและปรับ threshold อย่างต่อเนื่อง
- Threshold tuning และ alert calibration — ปรับค่า threshold ของโมเดลแยกระดับความรุนแรง (low/medium/high) พร้อมนโยบายการตอบสนองต่างกัน เพื่อลด false positives; ใช้ precision–recall curve และ cost matrix ในการตัดสินสมดุล
- A/B testing ของ policy และการแจ้งเตือน — ทดสอบกลยุทธ์หลายแบบ (เช่น aggressive vs conservative alerts, auto-commit vs require-approval) ในกรอบทดลองแบบ A/B เพื่อตรวจวัดผลต่อ KPI เช่น downtime, false positive rate, และ throughput ก่อนขยายสู่การใช้งานจริง
- Simulation-based validation — ใช้การจำลอง (digital twin simulation) เพื่อรันเหตุการณ์หายาก (rare events), การเปลี่ยนซัพพลายเชน, หรือ failure modes ใหม่ๆ เพื่อตรวจสอบความทนทานของโมเดลและกระบวนการตอบสนอง โดยประเมินผลกระทบต่อ KPI (เช่น คาดการณ์ % ลดสต็อกและ % ลด downtime ภายใต้ stress test)
- Model lifecycle management — กำหนดรอบการ retrain, monitoring ของ model drift, และชุดเมตริกทั่วไป เช่น concept drift rate, feature importance shifts; ตั้งค่า alert เมื่อ performance ต่ำกว่าค่าที่ตกลง (เช่น precision ลดลง >5%)
- Privacy-preserving techniques — ใช้การทำ pseudonymization, encryption in transit/at rest, และพิจารณาเทคนิคเช่น differential privacy หรือ federated learning เมื่อทำงานร่วมกับข้อมูลผู้จัดหา/คู่ค้า เพื่อลดความเสี่ยงด้านข้อมูล
- Incident response และ root-cause analysis — สร้าง playbook กรณี false negative/positive สำคัญ กำหนดบทบาทความรับผิดชอบ (RACI), เวลาตอบสนองเป้าหมาย (SLA) เช่น time-to-acknowledge ≤ 15 นาที สำหรับ alerts ระดับสูง และติดตาม RCA เพื่อเป็น input ในการปรับปรุงโมเดลและกระบวนการ
- การวัดผลทางเศรษฐศาสตร์ (business impact) — ผสาน KPI ด้านต้นทุน เช่น reduction in carrying cost, reduction in unplanned maintenance cost และ ROI ของระบบ เพื่อให้การตัดสินใจด้านนโยบายมีข้อมูลเชิงตัวเลขรองรับ
โดยสรุป การติดตาม KPI ที่ชัดเจน เช่น % ลดสต็อก, % ลด downtime, และ precision/recall ของการแจ้งเตือน ควบคู่กับการจัดการความเสี่ยงผ่าน governance, simulation-based validation, และ feedback loop ของผู้ปฏิบัติงาน จะช่วยให้ Digital Twin แบบมัลติโมดัลสร้างมูลค่าได้จริงและยั่งยืน โดยลดโอกาสเกิดผลกระทบด้าน bias, latency และ false alarms ที่อาจทำลายความเชื่อมั่นและประสิทธิภาพการดำเนินงานได้
เคสตัวอย่าง (Hypothetical Case Study) พร้อมตัวเลขสมมติและการคำนวณ ROI
เคสตัวอย่าง (Hypothetical Case Study): โรงงานอิเล็กทรอนิกส์ขนาดกลาง — การนำ Digital Twin แบบมัลติโมดัลมาใช้
บทศึกษานี้เป็นตัวอย่างสมมติของโรงงานอิเล็กทรอนิกส์ขนาดกลางที่มีเป้าหมายลดสต็อกล้นและลดการหยุดสายการผลิตโดยใช้ Digital Twin แบบมัลติโมดัลซึ่งผสาน Large Language Model (LLM) กับ Graph Neural Network (GNN) เพื่อจำลองซัพพลายเชนและสถานะเครื่องจักรแบบเรียลไทม์ ก่อนการใช้งานมีการเก็บข้อมูล baseline เป็นเวลา 12 เดือนเพื่อทำการวัดตัวชี้วัดหลัก (KPIs) และตั้งสมมติฐานสำหรับการคำนวณผลลัพธ์หลังติดตั้ง
Baseline ที่วัดก่อนใช้งาน (12 เดือน)
- รายได้ประจำปี (สมมติ): 600,000,000 บาท
- มูลค่าสต็อกเฉลี่ย: 80,000,000 บาท
- อัตราค่าเก็บรักษาสต็อก (carrying cost): 20% ต่อปี => ค่าใช้จ่ายเก็บสต็อกต่อปี = 16,000,000 บาท
- ชั่วโมง downtime ต่อปี: 1,200 ชั่วโมง (ประมาณ 3.3 ชม./วัน)
- ต้นทุนการหยุดผลิตต่อชั่วโมง (lost contribution margin): 40,000 บาท/ชั่วโมง => ต้นทุน downtime ต่อปี = 48,000,000 บาท
- รวมต้นทุนที่เกี่ยวข้องกับสต็อกและ downtime ต่อปี (baseline) = 64,000,000 บาท
สมมติฐานหลังนำระบบ Digital Twin แบบมัลติโมดัลไปใช้ (12 เดือนหลังติดตั้ง)
- Inventory reduction: สมมติลดได้ 25% (ช่วงเปรียบเทียบที่เป็นไปได้ 20–30%)
- Downtime reduction: สมมติลดได้ 35% (ช่วงเปรียบเทียบที่เป็นไปได้ 20–40%)
- ต้นทุนการติดตั้ง (CapEx เบื้องต้น): 25,000,000 บาท (เซ็นเซอร์, ฮาร์ดแวร์, ซอฟต์แวร์ LLM/GNN, integration, การอบรม)
- ค่าใช้จ่ายการดำเนินงานประจำปี (Opex): 4,000,000 บาท/ปี (cloud, license, data operations, ทีมดูแล)
ผลลัพธ์เชิงตัวเลข (การคำนวณ)
- สต็อกลด 25%: มูลค่าสต็อกจาก 80,000,000 → 60,000,000 บาท => ประหยัดมูลค่าสต็อก 20,000,000 บาท
แต่ค่าใช้จ่ายเก็บสต็อกที่แท้จริงลดจาก 16,000,000 → 12,000,000 บาท => ประหยัดค่าพกพาสต็อก 4,000,000 บาท/ปี - downtime ลด 35%: ต้นทุน downtime จาก 48,000,000 → 31,200,000 บาท => ประหยัด 16,800,000 บาท/ปี
- รวมประหยัดต่อปี (Gross savings) = 4,000,000 + 16,800,000 = 20,800,000 บาท/ปี
- หักค่าใช้จ่ายการดำเนินงานประจำปี (Opex 4,000,000) => Net annual savings = 16,800,000 บาท/ปี
- ค่าใช้จ่ายติดตั้ง (Initial TCO / CapEx) = 25,000,000 บาท
- เวลาคืนทุน (Payback / Break-even) = Initial CapEx ÷ Net annual savings = 25,000,000 ÷ 16,800,000 ≈ 1.49 ปี (ประมาณ 18 เดือน)
- ROI แบบง่าย (ปีแรก, ค่า ROI ต่อปี) = (Net annual savings ÷ Initial CapEx) × 100 = (16,800,000 ÷ 25,000,000) × 100 ≈ 67.2% ต่อปี
- ผลลัพธ์ระยะ 3 ปี (สรุปเชิงการเงิน):
- รวม Gross savings 3 ปี = 20,800,000 × 3 = 62,400,000 บาท
- รวม Opex 3 ปี = 4,000,000 × 3 = 12,000,000 บาท => Net savings 3 ปี = 62,400,000 − 12,000,000 = 50,400,000 บาท
- หัก Initial CapEx 25,000,000 => กำไรสุทธิสะสมหลัง 3 ปี = 50,400,000 − 25,000,000 = 25,400,000 บาท
- 3-year ROI (ตามนิยาม net profit ÷ initial) ≈ (25,400,000 ÷ 25,000,000) × 100 ≈ 101.6%
การวิเคราะห์ความไว (Sensitivity)
- กรณีอนุรักษ์นิยม (Inventory reduction 20%, Downtime reduction 20%):
- สต็อกประหยัด = 3,200,000 บาท/ปี; downtime ประหยัด = 9,600,000 บาท/ปี; Gross = 12,800,000 บาท
- Net annual savings = 12,800,000 − 4,000,000 = 8,800,000 บาท => Payback ≈ 2.84 ปี (34 เดือน)
- กรณีห้วงบวก (Inventory reduction 30%, Downtime reduction 40%):
- สต็อกประหยัด = 4,800,000 บาท/ปี; downtime ประหยัด = 19,200,000 บาท/ปี; Gross = 24,000,000 บาท
- Net annual savings = 24,000,000 − 4,000,000 = 20,000,000 บาท => Payback = 25,000,000 ÷ 20,000,000 = 1.25 ปี (15 เดือน)
สรุปเชิงปฏิบัติการ
จากตัวอย่างสมมติข้างต้น ระบบ Digital Twin แบบมัลติโมดัลที่รวม LLM กับ GNN สามารถสร้างมูลค่าสัมผัสได้ชัดเจนทั้งในเชิงการลดสต็อกและลดการหยุดชะงักของการผลิต โดยในกรณีปานกลาง (25% inventory reduction และ 35% downtime reduction) โรงงานจะเห็น เวลาคืนทุนประมาณ 1.5 ปี และอัตราผลตอบแทนต่อปีสูงกว่า 60% ในแง่การเงิน นอกจากนี้การทำ baseline ที่รัดกุม การกำหนด KPI ชัดเจน และการติดตามผลเป็นประจำเป็นหัวใจสำคัญที่ทำให้การประเมิน ROI น่าเชื่อถือและสามารถปรับแต่งโมเดลให้เหมาะสมกับสภาพธุรกิจจริงได้
บทสรุป
Digital Twin แบบมัลติโมดัลที่ผสาน LLM และ Graph Neural Network (GNN) ช่วยเพิ่มความโปร่งใส (visibility) และความสามารถในการคาดการณ์ปัญหาในซัพพลายเชนแบบเรียลไทม์ โดยการรวมข้อมูลหลายมิติทั้งสัญญาณจากเซนเซอร์, ข้อมูลโลจิสติกส์, รายงานข้อความจากปฏิสัมพันธ์กับซัพพลายเออร์ และโครงสร้างเครือข่ายการไหลของชิ้นส่วน ทำให้ระบบสามารถตรวจจับความผิดปกติเชิงเครือข่ายได้เร็วขึ้นและประเมินผลกระทบต่อสายการผลิตอย่างเป็นเชิงสาเหตุ ตัวอย่างจาก PoC ในอุตสาหกรรมการผลิตชิ้นส่วนและอิเล็กทรอนิกส์ชี้ว่าแนวทางนี้สามารถลดสต็อกล้นได้ในระดับสิบเปอร์เซ็นต์ถึงสี่สิบเปอร์เซ็นต์ และลดความเสี่ยงการหยุดสายการผลิต (downtime) ได้อย่างมีนัยสำคัญเมื่อเทียบกับการมอนิเตอร์แบบเดิม โดยใช้ KPI เช่น Inventory Turnover, On-Time-In-Full (OTIF) และ Mean Time To Detect/Repair (MTTD/MTTR) ในการวัดผล
การนำไปใช้ที่ได้ผลต้องเริ่มจากการทำ Proof-of-Concept (PoC) ขนาดเล็กที่ตั้ง governance และ KPI ให้ชัดเจน พร้อมทีมข้ามสายงานที่ประกอบด้วยวิศวกรระบบปฏิบัติการ (OT), นักวิทยาศาสตร์ข้อมูล, ผู้จัดการซัพพลายเชน และฝ่ายความปลอดภัยไซเบอร์ เพื่อทดสอบสมมติฐานด้านข้อมูล คุณภาพข้อมูล และความเป็นไปได้ทางธุรกิจ ควรกำหนดมาตรการรับมือความเสี่ยง เช่น การจัดการ model drift, การสำรองข้อมูล, นโยบายความเป็นส่วนตัว และการอธิบายผล (explainability) ของโมเดล ก่อนขยายสู่การใช้งานระดับโรงงานหรือเครือข่ายซัพพลายเชนทั้งหมด
มุมมองอนาคต: เมื่อเทคโนโลยี edge IoT, federated learning และการประมวลผลข้ามระบบพัฒนาไปพร้อมกัน Digital Twin แบบมัลติโมดัลจะเชื่อมโยงเป็น ‘ดิจิทัลทรีด’ ข้ามองค์กร ช่วยให้การตัดสินใจแบบอัตโนมัติและการปรับปรุงแบบเรียลไทม์เป็นไปได้มากขึ้น โดย LLM จะทำหน้าที่แปลข้อมูลเชิงซ้อนเป็นคำแนะนำเชิงปฏิบัติ (actionable insights) ในรูปแบบภาษาธรรมชาติ ขณะที่ GNN จะประเมินผลกระทบเชิงโครงสร้างของเครือข่ายซัพพลายเชน เจ้าของธุรกิจที่เริ่มวางรากฐานตั้งแต่วันนี้ด้วย PoC ที่มี governance แข็งแรงจะได้เปรียบทั้งในเชิงต้นทุน การตอบสนองต่อเหตุผิดปกติ และความยืดหยุ่นของซัพพลายเชนในระยะยาว



