
คุณเคยสงสัยไหมว่าเบื้องหลังแอปที่แนะนำเพลงให้คุณ ทำนายความต้องการของลูกค้า หรือช่วยแพทย์วินิจฉัยโรค คือเทคโนโลยีอะไรที่ทำให้เครื่องจักรสามารถ "เรียนรู้" จากข้อมูลได้ด้วยตัวเอง คำตอบส่วนใหญ่คือ Machine Learning — หนึ่งในเสาหลักของปัญญาประดิษฐ์ที่เปลี่ยนโฉมหน้าธุรกิจและการใช้ชีวิตในยุคดิจิทัล บทความนี้จะพาไปทำความรู้จักกับคำศัพท์เทคโนโลยีสำคัญนี้อย่างกระชับแต่ครบถ้วน เพื่อให้ผู้อ่านเห็นภาพทั้งเชิงทฤษฎีและเชิงปฏิบัติ
ในบทนำนี้ เราจะชี้ให้เห็นประเด็นหลักที่จะถูกขยายความในบทความ ได้แก่ คำจำกัดความและแนวคิดพื้นฐานของ Machine Learning, ประเภทหลักเช่น Supervised/Unsupervised/Reinforcement Learning, กระบวนการทำงานตั้งแต่การเตรียมข้อมูลจนถึงการประเมินโมเดล รวมถึงตัวอย่างแอปพลิเคชันจริงที่ใกล้ตัว การเติบโตของการใช้งานในองค์กร ปัญหาด้านจริยธรรมและความเป็นส่วนตัว และแนวทางที่องค์กรควรปฏิบัติเมื่อต้องนำ Machine Learning มาใช้จริง เพื่อให้ผู้อ่านสามารถประเมินโอกาสและความเสี่ยงได้อย่างรอบด้านก่อนตัดสินใจลงทุนหรือพัฒนาเทคโนโลยีนี้ต่อไป
ภาพรวมและคำนิยามของ Machine Learning
ภาพรวมและคำนิยามของ Machine Learning
Machine Learning (การเรียนรู้ของเครื่อง) เป็นสาขาย่อยของปัญญาประดิษฐ์ (Artificial Intelligence — AI) ที่มุ่งเน้นการพัฒนาอัลกอริทึมและโมเดลเพื่อให้คอมพิวเตอร์สามารถเรียนรู้จากข้อมูลได้ด้วยตัวเอง แทนที่จะต้องเขียนกฎเกณฑ์แบบตายตัวโดยมนุษย์ หลักการพื้นฐานคือการใช้ข้อมูลตัวอย่าง (data) ในการฝึกโมเดลให้จับความสัมพันธ์ รูปแบบ และแนวโน้ม เมื่อผ่านการฝึกแล้ว โมเดลจะสามารถนำไปใช้ในการพยากรณ์ การจำแนก หรือการตัดสินใจในสถานการณ์ใหม่ได้
ในเชิงปฏิบัติ Machine Learning จะถูกนำไปใช้เพื่อแก้ปัญหาที่ต้องการการพยากรณ์หรือการตัดสินใจโดยอิงจากข้อมูล เช่น การทำนายยอดขาย การจำแนกข้อความ หรือการตรวจจับความผิดปกติ กระบวนการทั่วไปรวมถึงการเตรียมข้อมูล เลือกคุณลักษณะ (feature selection) การฝึกโมเดล และการประเมินประสิทธิภาพ ก่อนนำโมเดลไปใช้งานจริง จากมุมมองธุรกิจ ML จึงเป็นเครื่องมือสำคัญในการเปลี่ยนข้อมูลดิบให้กลายเป็นคุณค่า (data-to-value)
เพื่อให้เห็นภาพชัดเจน ขอยกตัวอย่างที่คุ้นเคยในชีวิตประจำวัน:
- ระบบกรองอีเมลขยะ (spam filter) — โมเดลเรียนรู้จากตัวอย่างอีเมลที่ถูกทำเครื่องหมายว่าเป็นสแปมหรือไม่สแปม เพื่อกรองข้อความที่ไม่พึงประสงค์ออกจากกล่องจดหมาย
- ระบบแนะนำ (recommendation) — เช่น การแนะนำภาพยนตร์หรือสินค้า โดยโมเดลวิเคราะห์พฤติกรรมผู้ใช้และความคล้ายคลึงระหว่างสินค้าเพื่อเสนอรายการที่น่าจะสนใจ
- การรู้จำภาพ (image recognition) — โมเดลเรียนรู้ที่จะจำแนกวัตถุหรือใบหน้าในภาพ เช่น ใช้ในระบบตรวจสอบคุณภาพของสินค้าในสายการผลิต
ความแตกต่างระหว่างคำศัพท์ที่มักสับสนกันมีดังนี้:
- AI (Artificial Intelligence) — แนวคิดกว้างที่ครอบคลุมเทคโนโลยีและวิธีการทำให้เครื่องจักรทำงานที่ต้องใช้ปัญญา เช่น การแก้ปัญหา การวางแผน และการทำความเข้าใจภาษา
- Machine Learning — เป็นสาขาหนึ่งภายใต้ AI ที่เน้นการสร้างโมเดลจากข้อมูลเพื่อให้ระบบ "เรียนรู้" และปรับปรุงการทำงานได้เอง
- Deep Learning — เป็นเทคนิคย่อยของ ML ที่ใช้โครงข่ายประสาทเทียมหลายชั้น (deep neural networks) เหมาะสำหรับงานที่มีข้อมูลขนาดใหญ่และมีความซับซ้อน เช่น การรู้จำภาพและการประมวลผลภาษาธรรมชาติ
ในเชิงสถิติและการนำไปใช้จริง การสำรวจหลายแห่งชี้ว่าองค์กรธุรกิจมากกว่าร้อยละ 50 ได้เริ่มนำเทคโนโลยี AI/ML มาใช้ในกระบวนการอย่างใดอย่างหนึ่งแล้ว ทั้งนี้การนำไปใช้มีตั้งแต่การเพิ่มประสิทธิภาพการดำเนินงาน การปรับปรุงประสบการณ์ลูกค้า จนถึงการสร้างโมเดลธุรกิจใหม่ ๆ ดังนั้นการเข้าใจพื้นฐานของ Machine Learning จึงเป็นสิ่งจำเป็นสำหรับผู้บริหารและนักธุรกิจที่ต้องการใช้ประโยชน์จากข้อมูลอย่างมีประสิทธิภาพ
ประวัติความเป็นมาและวิวัฒนาการสั้น ๆ
ประวัติความเป็นมาและวิวัฒนาการสั้น ๆ
แนวคิดพื้นฐานของปัญญาประดิษฐ์ (AI) และการเรียนรู้ของเครื่อง (Machine Learning) มีรากฐานมาตั้งแต่ศตวรรษที่ 20 โดยงานสำคัญเริ่มจากงานทฤษฎีด้านตรรกะและสมองเทียม เช่น แบบจำลองนิวรอนเชิงคณิตศาสตร์ของ McCulloch และ Pitts (1943) และการอภิปรายทางทฤษฎีของ Alan Turing ในปี 1950 ที่ตั้งคำถามเกี่ยวกับความสามารถของเครื่องจักรในการ “คิด” ต่อมาในปี 1958 Frank Rosenblatt พัฒนา Perceptron ซึ่งเป็นอัลกอริทึมการจำแนกแบบง่าย ๆ ที่เป็นจุดเริ่มต้นของการศึกษาการเชื่อมต่อระหว่างนิวรอนเทียม แม้ช่วงแรกจะมีความคาดหวังสูง แต่ข้อจำกัดของฮาร์ดแวร์และทฤษฎีทำให้เกิดช่วงเวลาที่เรียกว่า “AI winter” ในทศวรรษต่อมา
ในช่วงปลายศตวรรษที่ 20 ถึงต้นศตวรรษที่ 21 การพัฒนาอัลกอริทึมพื้นฐานของ Machine Learning ได้รับการขยายความอย่างรวดเร็ว อัลกอริทึมที่โดดเด่นได้แก่ k‑Nearest Neighbors, Decision Trees, Support Vector Machines (SVM), และเทคนิคทางสถิติอย่าง Bayesian methods ซึ่งช่วยให้แก้ปัญหาจริงในงานธุรกิจและวิทยาศาสตร์ข้อมูลได้มากขึ้น นอกจากนี้ การพัฒนาเทคนิคการฝึกแบบย้อนกลับ (backpropagation) ในปี 1986 เป็นตัวจุดชนวนให้โมเดลหลายชั้นสามารถเรียนรู้ได้ดีขึ้นและเป็นพื้นฐานสำคัญสำหรับการเกิดขึ้นของเครือข่ายนิวรอนลึกในอนาคต
จุดเปลี่ยนสำคัญของยุคสมัยเกิดขึ้นหลังปี 2012 เมื่อผลการแข่งขัน ImageNet Large Scale Visual Recognition Challenge (ILSVRC) ถูกพลิกโฉมโดยโมเดล AlexNet ที่ใช้โครงข่ายนิวรอนเชิงลึก (Deep Neural Networks) ร่วมกับการประมวลผลด้วย GPU ผลลัพธ์นี้ทำให้ความแม่นยำในการรู้จำภาพดีขึ้นอย่างมีนัยสำคัญและเปลี่ยนแปลงทิศทางของการวิจัยไปสู่ Deep Learning อย่างรวดเร็ว หลังจากนั้นโครงสร้างอื่นๆ เช่น Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs) และต่อมา Transformers (ตั้งแต่ 2017) ได้กลายเป็นแกนหลักของแอปพลิเคชันด้านภาพ เสียง และภาษาธรรมชาติ ช่วงไม่กี่ปีมานี้การเกิดขึ้นของ foundation models และการปรับขนาด (scaling) ทั้งด้านข้อมูลและพารามิเตอร์ ได้เร่งความสามารถของระบบ AI ให้สามารถนำไปใช้ในงานเชิงธุรกิจขนาดใหญ่ได้จริง
ปัจจัยสำคัญที่ทำให้ Machine Learning กลายเป็นเทคโนโลยีแกนหลักได้แก่
- การเพิ่มขึ้นของปริมาณข้อมูล (Big Data) — ข้อมูลจากธุรกรรม แพลตฟอร์มออนไลน์ อุปกรณ์ IoT และเซ็นเซอร์ต่าง ๆ ช่วยให้การฝึกโมเดลมีข้อมูลเพียงพอ
- การเติบโตของพลังประมวลผล — GPU, TPU และฮาร์ดแวร์เฉพาะทางทำให้การฝึกโมเดลขนาดใหญ่เป็นไปได้ในเวลาที่เหมาะสม
- ความก้าวหน้าทางอัลกอริทึมและโครงสร้าง — จาก perceptron สู่ deep networks และ Transformers ที่ขยายขอบเขตการใช้งาน
ในเชิงเศรษฐกิจ รายงานภาคอุตสาหกรรมล่าสุดชี้ว่า ตลาด AI/ML มีอัตราการเติบโตเฉลี่ย (CAGR) อยู่ในช่วงประมาณ 35–40% ต่อปี ซึ่งสะท้อนถึงการลงทุนที่เพิ่มขึ้นทั้งจากภาครัฐและเอกชน โดยองค์กรจำนวนมากเร่งนำ ML ไปใช้ในงานด้านการวิเคราะห์เชิงคาดการณ์ อัตโนมัติการบริการลูกค้า และการเพิ่มประสิทธิภาพการดำเนินงาน ดังนั้นสำหรับผู้บริหาร การเข้าใจวิวัฒนาการของ Machine Learning ตั้งแต่ perceptron ไปจนถึง deep learning และปัจจัยสนับสนุนด้านข้อมูลและฮาร์ดแวร์ จะช่วยให้สามารถวางกลยุทธ์การลงทุนด้านดิจิทัลได้อย่างรอบคอบและทันสมัย
แนวคิดพื้นฐานและประเภทของ Machine Learning
แนวคิดพื้นฐานและประเภทของ Machine Learning
Machine Learning (ML) เป็นสาขาหนึ่งของปัญญาประดิษฐ์ที่มุ่งเน้นให้คอมพิวเตอร์สามารถเรียนรู้จากข้อมูลและปรับพฤติกรรมโดยไม่ต้องถูกโปรแกรมคำสั่งโดยตรง สำหรับองค์กรเชิงธุรกิจ ML ช่วยให้สามารถแปลงข้อมูลให้เป็นโมเดลที่ใช้ทำนาย ตัดสินใจ หรือค้นหารูปแบบที่ซ่อนอยู่ ในทางปฏิบัติ ML แบ่งออกเป็นหลายประเภทหลักซึ่งแต่ละประเภทมีลักษณะการเรียนรู้ ข้อมูลที่ต้องการ และกรอบการประเมินผลที่แตกต่างกัน
ตามการสำรวจเชิงอุตสาหกรรมพบว่าองค์กรธุรกิจในหลายภาคส่วนนำ ML มาใช้เพื่อเพิ่มประสิทธิภาพการดำเนินงานและสร้างผลิตภัณฑ์ใหม่ ๆ โดยทั่วไปแล้ว การเลือกประเภทของ ML ขึ้นกับลักษณะข้อมูล (มีป้ายกำกับ/ไม่มีป้ายกำกับ), ความพร้อมของป้ายกำกับ (label) และลักษณะปัญหา (การจำแนก, การทำนาย, การค้นหารูปแบบ, หรืองานควบคุม/ตัดสินใจแบบต่อเนื่อง)
1. Supervised Learning
Supervised Learning เป็นการเรียนรู้โดยใช้ข้อมูลที่มีป้ายกำกับ (label) ซึ่งโมเดลจะเรียนรู้ความสัมพันธ์ระหว่างคุณลักษณะ (features) และป้ายกำกับ ผลลัพธ์ที่ได้ใช้สำหรับงานประเภท การจำแนก (classification) เช่น แยกอีเมลขยะกับอีเมลปกติ และ การถดถอย (regression) เช่น การทำนายยอดขายหรือราคาบ้าน
- ตัวอย่างอัลกอริทึมที่นิยม: linear regression, logistic regression, decision trees, random forest, support vector machines (SVM), gradient boosting, neural networks
- การใช้งานที่เหมาะสม: การให้คะแนนเครดิต (credit scoring), การทำนายยอดขาย, การตรวจจับการฉ้อโกง (เมื่อมีตัวอย่างที่ติดป้าย), การจำแนกรูปภาพเชิงธุรกิจ เช่น การแยกประเภทผลิตภัณฑ์ในอีคอมเมิร์ซ
- เกณฑ์ประเมิน: ความแม่นยำ (accuracy), ค่าเฉลี่ยความคลาดเคลื่อนกำลังสอง (MSE) สำหรับงานถดถอย, precision/recall/F1 ในกรณีข้อมูลไม่สมดุล
2. Unsupervised Learning
Unsupervised Learning ทำงานกับข้อมูลที่ไม่มีป้ายกำกับ โดยจุดประสงค์หลักคือการสำรวจและค้นหารูปแบบหรือโครงสร้างภายในข้อมูล เช่น กลุ่มของลูกค้าที่มีพฤติกรรมใกล้เคียงกัน หรือโครงสร้างมิติข้อมูลที่ลดความซับซ้อนลง งานประเภทนี้เหมาะกับการวิเคราะห์เชิงสำรวจและการสร้างอินไซต์เชิงธุรกิจ
- ตัวอย่างอัลกอริทึมที่นิยม: k-means clustering, hierarchical clustering, DBSCAN, principal component analysis (PCA), t-SNE
- การใช้งานที่เหมาะสม: segmentation ลูกค้าเพื่อการตลาดเชิงเป้าหมาย, การตรวจจับความผิดปกติ (anomaly detection) ในระบบเครือข่ายหรือธุรกรรม, การลดมิติข้อมูลเพื่อนำไปใช้ต่อในโมเดลทำนาย
- เกณฑ์ประเมิน: silhouette score, Davies–Bouldin index, การประเมินทางธุรกิจโดยการวัดผลกระทบของการแบ่งกลุ่ม
3. Semi-supervised Learning
Semi-supervised Learning เป็นแนวทางผสมผสานระหว่าง supervised และ unsupervised โดยใช้ข้อมูลที่มีป้ายกำกับบางส่วนและข้อมูลที่ไม่มีป้ายกำกับอีกจำนวนมาก วิธีนี้เหมาะเมื่อการติดป้ายกำกับข้อมูลมีค่าใช้จ่ายสูงหรือใช้เวลานาน เช่น การติดป้ายภาพทางการแพทย์
- ตัวอย่างอัลกอริทึม/เทคนิค: self-training, co-training, label propagation, semi-supervised SVM, consistency regularization (เช่นในงาน deep learning)
- การใช้งานที่เหมาะสม: งานที่ต้องการความแม่นยำสูงแต่มีป้ายกำกับจำกัด เช่น การวินิจฉัยจากภาพทางการแพทย์, การจำแนกเอกสารทางกฎหมาย, ระบบรู้จำเสียงที่มีตัวอย่างติดป้ายไม่เพียงพอ
- ข้อดี: ลดต้นทุนการติดป้ายข้อมูลและมักให้ประสิทธิภาพดีกว่าใช้ข้อมูลติดป้ายเพียงเล็กน้อย
4. Reinforcement Learning
Reinforcement Learning (RL) เป็นแนวทางที่โมเดลเรียนรู้ผ่านการลองทำ (trial-and-error) โดยได้รับสัญญาณรางวัล (reward) หรือโทษ (penalty) ตามผลลัพธ์ของการกระทำ RL เหมาะกับปัญหาที่มีลำดับการตัดสินใจและต้องการนโยบาย (policy) เพื่อเพิ่มผลตอบแทนระยะยาว เช่น งานควบคุมระบบหรือพฤติกรรมตัวแทนในสภาพแวดล้อมที่เปลี่ยนแปลงได้
- ตัวอย่างอัลกอริทึมที่นิยม: Q-learning, SARSA, Deep Q-Networks (DQN), policy gradient methods, Actor-Critic
- การใช้งานที่เหมาะสม: ระบบควบคุมหุ่นยนต์, ยานยนต์ไร้คนขับ, การปรับจูนพารามิเตอร์ในระบบเครือข่าย, การพัฒนาเอเยนต์เล่นเกม (เช่น AlphaGo ใช้ RL ผสานกับเทคนิคอื่น ๆ)
- เกณฑ์ประเมิน: cumulative reward, ความเสถียรของนโยบาย, ความสามารถในการปรับตัวต่อสภาพแวดล้อมใหม่
สรุปแล้ว การเลือกประเภทของ Machine Learning ขึ้นกับลักษณะข้อมูลและเป้าหมายเชิงธุรกิจ: ถ้ามีข้อมูลติดป้ายและต้องการทำนายหรือจำแนกให้ใช้ Supervised, ถ้าต้องการค้นหาโครงสร้างจากข้อมูลที่ไม่มีป้ายให้ใช้ Unsupervised, ถ้าต้องการผสมข้อมูลทั้งสองแบบให้ใช้ Semi-supervised, และ ถ้างานเป็นลำดับการตัดสินใจที่ต้องเรียนรู้จากการปฏิสัมพันธ์ให้ใช้ Reinforcement Learning การเข้าใจข้อจำกัดและเมตริกการประเมินจะช่วยองค์กรเลือกแนวทางที่คุ้มค่าและเหมาะสมกับผลลัพธ์ทางธุรกิจมากที่สุด
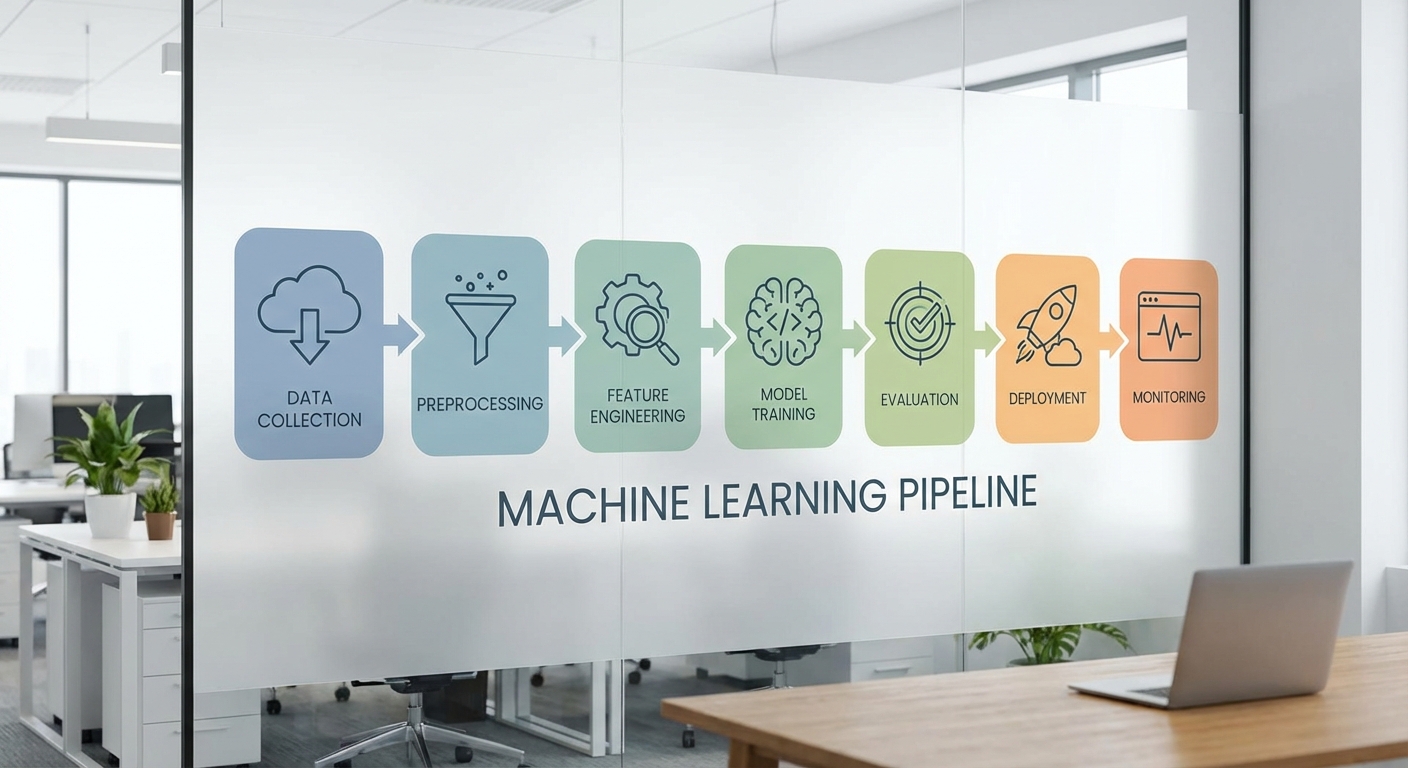
การทำงานของ Machine Learning: From Data to Deployment
กระบวนการทำงานของ Machine Learning (ML) เป็นเส้นทางที่เชื่อมจากข้อมูลดิบจนถึงระบบที่ใช้งานจริงในธุรกิจ โดยแต่ละขั้นตอนมีบทบาทสำคัญต่อคุณภาพและความน่าเชื่อถือของผลลัพธ์ ในภาพรวม pipeline ของ ML ครอบคลุมตั้งแต่การเก็บข้อมูล การเตรียมข้อมูล การสกัดคุณลักษณะ การฝึกและเลือกโมเดล การประเมินผล ไปจนถึงการนำโมเดลขึ้นใช้งานและการติดตามผลหลังการใช้งาน การเข้าใจแต่ละขั้นตอนช่วยให้องค์กรบริหารความเสี่ยง ลดต้นทุน และเพิ่มประสิทธิภาพในการตัดสินใจที่ใช้โมเดลเป็นพื้นฐาน

1. การเก็บและทำความสะอาดข้อมูล (Data Collection & Preprocessing)
ขั้นตอนแรกสุดคือการรวบรวมข้อมูลจากแหล่งต่าง ๆ เช่น ฐานข้อมูลภายใน ระบบบันทึกเหตุการณ์ (logs) เซนเซอร์ หรือข้อมูลจากพันธมิตร ภายหลังต้องดำเนินการทำความสะอาดข้อมูล เช่น การจัดการค่าที่หายไป (missing values), การตรวจหาค่าผิดปกติ (outliers), การแปลงค่าเวลา (timestamp normalization) และการรวมแหล่งข้อมูล (data integration) เพื่อให้ข้อมูลพร้อมสำหรับการวิเคราะห์
- เหตุผลสำคัญ: คุณภาพของข้อมูลมีผลโดยตรงต่อประสิทธิภาพของโมเดล — ข้อมูลสกปรกหรือมีความเบี้ยวจะทำให้โมเดลเกิด bias หรือให้ผลลัพธ์ไม่น่าเชื่อถือ
- ตัวอย่างการปฏิบัติ: การใช้ imputation แทนค่าที่ขาดด้วยค่าเฉลี่ย/median หรือใช้โมเดลพยากรณ์เพื่อเติมค่า, การลบหรือปรับค่าผิดปกติตามกฎธุรกิจ
- สถิติอ้างอิง: องค์กรที่ลงทุนในงานเตรียมข้อมูลมักลดเวลาในการพัฒนาโมเดลลงได้อย่างมีนัยสำคัญ — งานด้าน Data Ops/MLOps ถูกคาดว่าเป็นหนึ่งในปัจจัยหลักของความสำเร็จในการนำ ML ไปใช้เชิงพาณิชย์
2. การสกัดคุณลักษณะ (Feature Engineering)
Feature engineering คือการแปลงข้อมูลดิบให้เป็นตัวแทนที่โมเดลเข้าใจได้ดีขึ้น เช่น การสร้างตัวแปรเชิงสถิติ (summary statistics), การเข้ารหัสค่าที่เป็นประเภท (one-hot encoding, ordinal encoding), การสเกลค่า (normalization/standardization) และการสร้างฟีเจอร์เชิงโดเมนที่สะท้อนความรู้ธุรกิจ
- เหตุผลสำคัญ: ฟีเจอร์ที่ดีทำให้โมเดลเรียนรู้ได้เร็วขึ้นและมีความสามารถพยากรณ์ที่ดีขึ้น — บ่อยครั้งฟีเจอร์ดีกว่าจะส่งผลมากกว่าเลือกอัลกอริธึมที่ซับซ้อน
- ตัวอย่าง: ในระบบให้คำแนะนำ (recommendation) ฟีเจอร์เช่น "อายุใบสั่งเฉลี่ย" หรือ "ความถี่การซื้อในช่วง 30 วัน" มักมีค่ามากกว่าคุณลักษณะดิบเพียงอย่างเดียว
3. การเลือกและฝึกโมเดล (Model Selection & Training)
หลังได้ฟีเจอร์ที่เหมาะสม ขั้นตอนต่อไปคือการเลือกอัลกอริธึมที่สอดคล้องกับโจทย์ เช่น การจำแนกประเภท (classification) การถดถอย (regression) หรือการจัดกลุ่ม (clustering) แล้วทำการฝึก (training) โดยใช้ชุดข้อมูลฝึก (training set) เพื่อหาพารามิเตอร์ที่ดีที่สุด
- เทคนิคสำคัญ: การแบ่งข้อมูล (train/test split) แบบมาตรฐานเช่น 70/30 หรือ 80/20 และการใช้ cross-validation (เช่น k-fold โดย k=5 หรือ 10) เพื่อประเมินความเสถียรของโมเดล
- การจัดการ overfitting: ใช้วิธีการเช่น regularization (L1/L2), pruning ในต้นไม้ตัดสินใจ, dropout ในเครือข่ายประสาท, หรือ early stopping เพื่อป้องกันโมเดลจำข้อมูลฝึกจนอ่อนแอเมื่อต้องทำงานกับข้อมูลจริง
- การปรับไฮเปอร์พารามิเตอร์: ใช้ grid search, random search หรือ Bayesian optimization ร่วมกับ cross-validation เพื่อหาการตั้งค่าที่เหมาะสม
4. การประเมินผล (Validation & Testing)
การประเมินต้องคำนึงถึงเมตริกที่เหมาะสมตามลักษณะปัญหา ไม่เพียงแต่ดู accuracy เสมอไป โดยเฉพาะในปัญหาที่ข้อมูลไม่สมดุล (class imbalance)
- เมตริกพื้นฐาน:
- Accuracy — อัตราความถูกต้องโดยรวม (เหมาะเมื่อคลาสสมดุล)
- Precision — สัดส่วนผลทำนายบวกที่ถูกต้อง (เหมาะเมื่อต้นทุน false positive สูง)
- Recall — สัดส่วนตัวอย่างบวกที่จับได้จริง (เหมาะเมื่อหลีกเลี่ยง false negative สำคัญ เช่น การตรวจมะเร็ง)
- F1-score — ค่าเฉลี่ยฮาร์โมนิกระหว่าง precision และ recall (เหมาะเมื่อต้องการสมดุล)
- AUC (Area Under ROC Curve) — วัดความสามารถแยกแยะของโมเดลในระดับ threshold ต่าง ๆ (ทนต่อ class imbalance ได้ดีขึ้น)
- แนวปฏิบัติ: ควรมีชุดข้อมูลทดสอบ (hold-out test set) ที่แยกไว้ตั้งแต่ต้นเพื่อประเมินผลขั้นสุดท้าย และใช้ cross-validation เพื่อตรวจความเสถียรของผล
- ตัวอย่างเชิงตัวเลข: ในปัญหาการตรวจฉ้อโกงที่มีความไม่สมดุลสูง อาจมุ่งเป้า recall > 90% และ precision ที่ยอมรับได้ (เช่น 70%) ขึ้นอยู่กับนโยบายความเสี่ยง
5. การนำไปใช้งานจริง (Deployment) และการติดตามผลหลังใช้งาน (Monitoring)
การนำโมเดลขึ้นสู่ระบบการผลิตเป็นอีกความท้าทายหนึ่ง ต้องคำนึงถึงสเกล ความหน่วงเวลา ความปลอดภัย และการผสานกับระบบธุรกิจ เช่น API, batch jobs หรือ edge deployment ในอุปกรณ์ IoT
- กลยุทธ์การปล่อยใช้งาน: ใช้การทดสอบแบบ A/B, canary deployment หรือนำขึ้นใน sandbox ก่อน เพื่อจำกัดความเสี่ยงและตรวจสอบผลกระทบทางธุรกิจ
- การติดตามหลังใช้งาน: ตรวจสอบ performance metrics (เช่น precision/recall ในข้อมูลจริง), latency, อัตราการตอบสนองของระบบ และตัวชี้วัดธุรกิจ (KPIs) อย่างต่อเนื่อง
- การตรวจจับการเปลี่ยนแปลงของข้อมูล: ตั้งค่าการแจ้งเตือนสำหรับ data drift และ concept drift — เมื่อการกระจายข้อมูลเปลี่ยนไปหรือความสัมพันธ์ระหว่างฟีเจอร์และเป้าหมายเปลี่ยน โมเดลอาจต้อง retraining
- การปกป้องและการควบคุมคุณภาพ: เก็บบันทึกการตัดสินใจของโมเดล (logging), ใช้โมเดลเวอร์ชันคอนโทรล, และมีแผน rollback เมื่อประสิทธิภาพลดลง
แนวปฏิบัติที่ดีสรุป
สรุปแนวทางปฏิบัติที่ควรนำไปใช้ในทุกขั้นตอน ได้แก่ การแยกข้อมูลอย่างชัดเจน (train/validation/test), การใช้ cross-validation เพื่อประเมินความเสถียร, การเลือกเมตริกให้สอดคล้องกับเป้าหมายธุรกิจ, การป้องกัน overfitting ด้วยเทคนิคต่าง ๆ, และการวางระบบ Monitoring พร้อมกระบวนการ retraining อัตโนมัติเมื่อจำเป็น
หมายเหตุ: การนำ ML ไปใช้เชิงพาณิชย์ไม่ใช่เรื่องของโมเดลอย่างเดียว แต่เป็นระบบที่ผสานข้อมูล เทคโนโลยี และกระบวนการธุรกิจเข้าด้วยกัน — ความสำเร็จจึงมาจากการออกแบบ pipeline ทั้งหมดอย่างรอบคอบ
ตัวอย่างการใช้งานจริงในอุตสาหกรรมและสถิติ
ตัวอย่างการใช้งานจริงในอุตสาหกรรมและสถิติ
Machine Learning (ML) ถูกนำไปประยุกต์ใช้งานอย่างกว้างขวางในหลายอุตสาหกรรม โดยให้ผลเชิงปริมาณที่ชัดเจนทั้งด้านความแม่นยำของการวินิจฉัย การลดการฉ้อโกง และการเพิ่มรายได้จากการขายตรง ตัวอย่างและสถิติต่อไปนี้แสดงให้เห็นผลกระทบเชิงธุรกิจที่วัดผลได้ของ ML ในภาคอุตสาหกรรมต่าง ๆ
-
การแพทย์ (Diagnosis, Imaging)
ภาพรวม: งานวิจัยและโครงการเชิงพาณิชย์แสดงให้เห็นว่าโมเดล ML สามารถเพิ่มอัตราการตรวจพบโรคและลดข้อผิดพลาดของการอ่านภาพทางการแพทย์ได้อย่างมีนัยสำคัญ
ตัวอย่างเชิงวิชาการที่โดดเด่นได้แก่ผลงานของ Gulshan et al. (JAMA, 2016) สำหรับการตรวจคัดกรองโรคจอประสาทตาเบาหวาน (diabetic retinopathy) โดยอัลกอริธึมมีความไว (sensitivity) และความจำเพาะ (specificity) อยู่ในระดับสูงเมื่อเทียบกับการประเมินของผู้เชี่ยวชาญ ซึ่งรายงานความไวสูงกว่า 95% ในชุดข้อมูลทดสอบบางชุด นอกจากนี้งานของ McKinney et al. (Nature, 2020) ในการตรวจคัดกรองมะเร็งเต้านมด้วยแมมโมแกรมระบุว่าโมเดล AI สามารถลดอัตรา false positives ได้ประมาณ 5.7% และลด false negatives ได้ประมาณ 9.4% เมื่อเทียบกับการอ่านของมนุษย์ในชุดข้อมูลระหว่างประเทศ
ในสภาพการนำไปใช้จริง โรงพยาบาลหลายแห่งรายงานการเพิ่มอัตราการตรวจพบโรคตั้งแต่ 10–30% ในบางกรณีของการใช้ ML ร่วมกับการอ่านของแพทย์ ทั้งนี้ผลลัพธ์ขึ้นกับคุณภาพข้อมูลและการวางกระบวนการทำงานร่วมกันระหว่างคนและเครื่อง
-
การเงิน (Fraud Detection, Credit Scoring)
ภาพรวม: ระบบตรวจจับการฉ้อโกงที่ใช้ ML สามารถประมวลผลข้อมูลแบบเรียลไทม์ ระบุรูปแบบฉ้อโกงที่ซับซ้อน และลดการสูญเสียทางการเงินได้ในระดับสำคัญ
รายงานเชิงอุตสาหกรรมจากบริษัทวิจัยและที่ปรึกษาเช่น McKinsey ระบุว่าเทคโนโลยี AI/ML สามารถช่วยลดความสูญเสียจากการฉ้อโกงได้ในกรอบกว้างประมาณ 50–70% ในกรณีที่นำระบบไปปรับใช้ร่วมกับมาตรการความปลอดภัยอื่น ๆ พร้อมกัน ทั้งยังช่วยลดอัตราการปฏิเสธรายการที่ถูกต้อง (false positives) ราว 10–40% ซึ่งช่วยลดต้นทุนการตรวจสอบด้วยคนและเพิ่มประสบการณ์ของลูกค้า
กรณีศึกษาเชิงองค์กร เช่น การนำ ML มาช่วยในงานตรวจสอบเอกสารหรือสัญญา (เช่น โครงการ COiN ของ JPMorgan) ช่วยประหยัดชั่วโมงคนทำงานได้เป็นจำนวนมาก — รายงานหนึ่งระบุการประหยัดได้ถึงหลายแสนชั่วโมงต่อปี เมื่อคำนวณเป็นต้นทุนแล้วมีมูลค่าทางธุรกิจชัดเจน
-
การค้าปลีก (Recommendation, Demand Forecasting)
ภาพรวม: ในภาคค้าปลีก ML ถูกใช้เพื่อทำ personalization, ระบบแนะนำสินค้า (recommendation engines) และการพยากรณ์ความต้องการสินค้า (demand forecasting) ซึ่งส่งผลโดยตรงต่อยอดขายและต้นทุนสินค้าคงคลัง
สถิติที่มักถูกอ้างอิงคือ Amazon ซึ่งระบุว่าประมาณ 35% ของรายได้มาจากระบบแนะนำสินค้า ขณะที่ Netflix ประเมินว่าระบบแนะนำช่วยประหยัดมูลค่าทางธุรกิจได้เป็นพันล้านดอลลาร์ต่อปี (ประมาณการเชิงองค์กรที่มักอ้างอิง) นอกจากนี้งานวิจัยและรายงานจาก McKinsey ชี้ว่า การปรับส่วนบุคคล (personalization) สามารถเพิ่มรายได้ได้ราว 10–15% และเพิ่มอัตราการแปลง (conversion) ได้อย่างมีนัยสำคัญ ขึ้นกับความเป็นผู้ใช้และการออกแบบประสบการณ์
ด้านการพยากรณ์ความต้องการ สถิติโดยรวมแสดงว่าองค์กรที่ใช้ ML ใน forecasting สามารถลดความคลาดเคลื่อนของการพยากรณ์และลดสต็อกเกิน/ของขาดได้ ทำให้ต้นทุนโลจิสติกและการจัดเก็บลดลง เช่น การปรับปรุงความแม่นยำของการพยากรณ์ประมาณ 10–30% ในหลายกรณี ส่งผลให้ลด out-of-stock และเพิ่มอัตราการขายขึ้น
-
ยานยนต์ (Autonomous Driving)
ภาพรวม: ML เป็นหัวใจของระบบ perception, localization และ decision-making ของรถขับเคลื่อนอัตโนมัติ ช่วยให้รถสามารถรับรู้สภาพแวดล้อมและตอบสนองต่อสถานการณ์ที่ซับซ้อนได้แบบเรียลไทม์
บริษัทชั้นนำด้านรถยนต์ไร้คนขับ เช่น Waymo, Tesla และ Cruise ใช้การเรียนรู้เชิงลึกในระบบตรวจจับวัตถุและการตัดสินใจ ซึ่งนำไปสู่การปรับปรุงด้านความปลอดภัยและการลดการพึ่งพาการควบคุมของมนุษย์ รายงานการทดลองขับจริงและการจำลองแสดงให้เห็นการลดจำนวนเหตุการณ์ disengagements และการปรับปรุงอัตราการตอบสนองต่อเหตุการณ์ฉุกเฉิน แต่ตัวเลขเฉพาะจะแตกต่างกันตามสภาพถนน กฎระเบียบ และระดับการทดสอบ
ในภาพรวม เทคโนโลยี ML ช่วยให้การทดสอบและการพัฒนาปรับเร็วขึ้นผ่านการจำลองสถานการณ์จำนวนมาก (simulation) ซึ่งลดเวลาและต้นทุนในการพัฒนาเมื่อเทียบกับการพึ่งพาการทดสอบสนามจริงเพียงอย่างเดียว
สรุปคือ ML ให้ผลประโยชน์เชิงธุรกิจที่จับต้องได้: จากการเพิ่มอัตราการตรวจพบในแพทย์ การลดการสูญเสียจากการฉ้อโกง และการเพิ่มรายได้จากระบบแนะนำสินค้า ตัวเลขและกรณีศึกษาที่อ้างถึงข้างต้นแสดงให้เห็นว่า การลงทุนใน ML ที่ประกอบด้วยข้อมูลคุณภาพ กระบวนการทางธุรกิจที่ชัดเจน และการวัดผลที่เหมาะสม สามารถเปลี่ยนแปลงผลลัพธ์เชิงธุรกิจได้อย่างมีนัยสำคัญ
ความท้าทาย จริยธรรม และประเด็นด้านความเป็นส่วนตัว
ความท้าทาย จริยธรรม และประเด็นด้านความเป็นส่วนตัว
การนำ Machine Learning (ML) มาใช้ในงานเชิงธุรกิจและการตัดสินใจอัตโนมัติสร้างประโยชน์อย่างมาก แต่ก็ย่อมมาพร้อมกับความเสี่ยงเชิงจริยธรรมและความเป็นส่วนตัวที่ต้องจัดการอย่างเป็นระบบ ปัญหาอคติ (bias) และความไม่เป็นธรรม ในข้อมูลหรือโมเดลสามารถทำให้ผลลัพธ์ไม่เป็นธรรมต่อกลุ่มบุคคลบางกลุ่ม ตัวอย่างที่มีเอกสารประกอบชัดเจน ได้แก่ กรณีระบบประเมินความเสี่ยงผู้กระทำผิด (COMPAS) ซึ่งรายงานโดย ProPublica (2016) พบว่าโมเดลมีอัตรา false positive สูงกว่าต่อผู้ต้องหาผิวสี เมื่อเทียบกับผู้ต้องหาผิวขาว และรายงานของ NIST (2019) ระบุว่าระบบจดจำใบหน้ามีอัตราความผิดพลาดสูงขึ้นกับเพศและสีผิวบางกลุ่ม เหล่านี้เป็นตัวอย่างที่แสดงให้เห็นว่า ML ที่ขาดการตรวจสอบจะขยายความไม่เป็นธรรมแทนที่จะลดลง
ประเด็น ความเป็นส่วนตัว เป็นอีกด้านที่มีความสำคัญ โดยเฉพาะการใช้ข้อมูลส่วนบุคคลในปริมาณมาก เช่น ข้อมูลสุขภาพ พฤติกรรมออนไลน์ หรือข้อมูลทางการเงิน ประเทศไทยมีพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) และในระดับสากล GDPR กำหนดหลักการสำคัญ ได้แก่ การมีฐานทางกฎหมายของการประมวลผลข้อมูล (consent, legitimate interest ฯลฯ), หลักการจำกัดวัตถุประสงค์, การลดข้อมูลที่เก็บ (data minimization) และสิทธิของเจ้าของข้อมูล เช่น สิทธิขอเข้าถึง แก้ไข และลบ ในกรณีที่มีความเสี่ยงสูงต่อสิทธิขั้นพื้นฐาน องค์กรจำเป็นต้องทำ การประเมินผลกระทบต่อความเป็นส่วนตัว (DPIA) และจัดให้มีมาตรการป้องกันที่เหมาะสม
เพื่อลดผลกระทบด้านจริยธรรมและความเสี่ยงเชิงสังคม องค์กรควรนำแนวทางปฏิบัติหลายระดับมาใช้ร่วมกัน ได้แก่
- การทดสอบและวัดอคติ (Bias Testing & Fairness Metrics) — ใช้มาตรวัดที่หลากหลาย เช่น statistical parity, equalized odds, predictive parity และตรวจสอบผลลัพธ์ทั้งในมิติกลุ่มและมิติบุคคล เพื่อหลีกเลี่ยงการพึ่งพามาตรวัดเพียงค่าเดียว
- Explainable AI (XAI) — ประยุกต์เทคนิคเช่น LIME, SHAP หรือการอธิบายแบบ counterfactual เพื่อให้ผู้เกี่ยวข้องเข้าใจการตัดสินใจของโมเดล และใช้ Model Cards / Datasheets for Datasets เป็นเอกสารประกอบความโปร่งใส
- มาตรการคุ้มครองข้อมูล — ใช้เทคนิคเช่น differential privacy, federated learning, การทำ pseudonymization/ anonymization และจำกัดการเข้าถึงข้อมูลตามหลัก least privilege
- Data Governance และการตรวจสอบภายใน (Governance & Audit) — จัดตั้งนโยบายการจัดการข้อมูล ชุดมาตรฐานการทดสอบก่อนนำขึ้นใช้งาน จัดทำบันทึกการประมวลผลข้อมูล แต่งตั้ง Data Protection Officer (DPO) และกำหนดกระบวนการ audit ทั้งทางเทคนิคและนโยบาย
- มนุษย์ต้องอยู่ในวงจร (Human-in-the-loop) — สำหรับการตัดสินใจที่มีความเสี่ยงสูง ควรมีการตรวจสอบจากผู้เชี่ยวชาญหรือการยืนยันจากมนุษย์ และจัดให้มีช่องทางเยียวยาหรืออุทธรณ์สำหรับผู้ได้รับผลกระทบ
นอกจากนี้ ควรบูรณาการการปฏิบัติตามข้อกฎหมายเข้ากับวงจรชีวิตของโมเดลตั้งแต่ขั้นตอนออกแบบ (privacy-by-design, fairness-by-design) จนถึงการใช้งานจริงและการบำรุงรักษา การจัดทำ Algorithmic Impact Assessment รอบด้านก่อนเปิดใช้งานจริงเป็นแนวทางปฏิบัติที่ได้รับการยอมรับ เช่นเดียวกับการทำ monitoring เพื่อตรวจจับ model drift และอคติที่เกิดขึ้นใหม่หลังการใช้งานจริง
ท้ายที่สุด ความรับผิดชอบทางจริยธรรมขององค์กรที่ใช้ ML ไม่ใช่เพียงเรื่องเทคนิคแต่เป็นนโยบายระดับองค์กรและวัฒนธรรมการตัดสินใจ การลงทุนในกระบวนการทดสอบ ความโปร่งใส และการกำกับดูแล (governance) จะช่วยลดความเสี่ยงด้านกฎหมาย ภาพลักษณ์ และผลกระทบทางสังคม พร้อมทั้งเสริมสร้างความเชื่อมั่นให้กับผู้ใช้และผู้มีส่วนได้ส่วนเสีย
เครื่องมือ แพลตฟอร์ม และแนวทางการนำ Machine Learning ไปใช้ในองค์กร
เครื่องมือและไลบรารีพื้นฐานที่ควรรู้
การเริ่มต้นกับ Machine Learning ในองค์กรจำเป็นต้องมีชุดเครื่องมือพื้นฐานที่ทีมสามารถใช้งานร่วมกันได้อย่างเป็นระบบ สำหรับการพัฒนาโมเดลเชิงลึก (deep learning) สองไลบรารีที่ได้รับความนิยมสูงสุดคือ TensorFlow (และ Keras ในชั้น abstraction) และ PyTorch โดยทั่วไป TensorFlow เหมาะกับงานที่ต้องการ production-ready deployment ขณะที่ PyTorch เป็นที่นิยมในงานวิจัยและโปรโตไทป์ที่ต้องการความยืดหยุ่น สำหรับงานเรียนรู้ด้วยเครื่องแบบดั้งเดิม (classical ML) เช่น การจำแนกประเภทหรือการถดถอย scikit-learn ยังคงเป็นเครื่องมือมาตรฐานที่เข้าใจง่ายและเชื่อมต่อกับไลบรารีอื่นๆ ได้สะดวก
นอกจากไลบรารีหลักแล้ว ทีมควรรู้จักเครื่องมือสนับสนุนเช่น pandas, NumPy สำหรับการเตรียมข้อมูล, XGBoost และ LightGBM สำหรับโมเดล gradient boosting ซึ่งให้ประสิทธิภาพดีในปัญหาที่เป็นตารางข้อมูล กลุ่มเครื่องมือด้าน MLOps อย่าง MLflow, Kubeflow, Docker และ Kubernetes เป็นองค์ประกอบสำคัญสำหรับการจัดการ lifecycle ของโมเดล (experiment tracking, model registry, deployment) รวมถึงเครื่องมือจัดการเวอร์ชันข้อมูลอย่าง DVC และ feature store เช่น Feast จะช่วยให้การทำงานข้ามทีมมีความสอดคล้องและทวนซ้ำได้
บริการคลาวด์และแพลตฟอร์มจัดการ ML
องค์กรส่วนใหญ่มักเลือกใช้บริการคลาวด์สำหรับลดภาระการดูแล infrastructure และเร่งเวลาเข้าสู่ธุรกิจ บริการที่เป็นที่รู้จักได้แก่ AWS SageMaker (training, tuning, hosting, MLOps), Google Cloud Vertex AI (เดิมคือ AI Platform — มี AutoML, feature store และ integration กับ BigQuery) และ Azure Machine Learning (model registry, pipelines, integration กับ Azure Synapse) แต่ละผู้ให้บริการมีจุดเด่นต่างกัน เช่น การรองรับการฝึกโมเดลแบบกระจาย ขนาดงานที่ปรับได้ และราคาการเรียกใช้งานแบบ pay-as-you-go
ในการเลือกแพลตฟอร์ม ควรคำนึงถึงองค์ประกอบสำคัญ ได้แก่ ความสามารถในการรองรับงานแบบ real-time inference, เครื่องมือ MLOps ที่มีอยู่แล้ว, ความปลอดภัยและการปฏิบัติตามกฎระเบียบ (compliance), รวมถึงการเชื่อมต่อกับ data warehouse หรือ lake ขององค์กร เช่น BigQuery, Snowflake หรือ Amazon Redshift เพื่อให้การดึงและเตรียมข้อมูลเป็นไปอย่างราบรื่น
การจัดทีมและบทบาทที่ชัดเจน
- Data Engineer: รับผิดชอบการออกแบบและดูแล pipeline ของข้อมูล (ETL/ELT), data quality, การจัดเก็บและเชื่อมต่อกับ data lake/warehouse รวมถึงการทำงานร่วมกับทีม DevOps เพื่อจัดการ infrastructure ของข้อมูล
- Data Scientist: ออกแบบการทดลอง (experiments), สร้างและประเมินโมเดล, เลือก metric ทางสถิติและ business metric ที่เหมาะสม พร้อมการสื่อสารผลลัพธ์ให้ผู้มีส่วนได้ส่วนเสีย
- ML Engineer / MLOps: ดูแลการนำโมเดลขึ้นสู่ production, ออกแบบระบบ inference, CI/CD สำหรับโมเดล, การ monitor performance และการตั้งกลไก retraining
- Product Owner / Business Stakeholder: กำหนดเป้าหมายเชิงธุรกิจ, ให้ความสำคัญกับ KPI/OKR, ตัดสินใจด้านงบประมาณและ roadmap รวมถึงประสานงานระหว่างทีมเทคนิคและฝ่ายธุรกิจ
แนวทางการเริ่มต้นโครงการ ML: Proof of Concept → Pilot → Production
แนวทางปฏิบัติที่แนะนำคือการเดินโครงการแบบเป็นขั้นตอน เริ่มจาก Proof of Concept (PoC) เพื่อตรวจสอบว่าไอเดียแก้ปัญหาทางธุรกิจได้จริง ในขั้นนี้เน้นความเร็วและต้นทุนต่ำ โดยกำหนดเกณฑ์ความสำเร็จที่ชัดเจน เช่น ความแม่นยำขั้นต่ำ หรือ uplift ทางธุรกิจที่คาดหวัง หลังจาก PoC ผ่านจะขยับไปสู่ Pilot เพื่อทดสอบในสภาพแวดล้อมจริงกับกลุ่มผู้ใช้จำนวนน้อย และเมื่อผลทดสอบสอดคล้องกับ KPI จึงทำ Production พร้อมระบบ MLOps สำหรับการอัปเดตโมเดลและการมอนิเตอร์อย่างต่อเนื่อง
ตัวอย่าง Roadmap 3–6 เดือน (แนวทางเชิงปฏิบัติ):
- เดือนที่ 0–1 (Discovery & Data Readiness): ระบุปัญหาทางธุรกิจ เลือก metric (เช่น revenue uplift, churn reduction), เตรียมและสำรวจข้อมูล, ตั้งทีมข้ามสายงาน
- เดือนที่ 1–2 (PoC): สร้างโมเดลพื้นฐาน/benchmark ใช้ชุดข้อมูลตัวอย่าง กำหนดเกณฑ์ความสำเร็จเชิงธุรกิจและเทคนิค (precision, recall, latency)
- เดือนที่ 2–4 (Pilot): ขยายขอบเขตเป็นกลุ่มผู้ใช้จริง ตั้งระบบ monitoring เบื้องต้น วัดผลทางธุรกิจแบบ A/B test และประเมินความคุ้มค่า
- เดือนที่ 4–6 (Production & MLOps): เตรียม production-ready pipeline, ทำ CI/CD สำหรับโมเดล, ตั้งระบบ retraining/validation และ governance พร้อมวัด ROI ระยะสั้น
การวัดผลและ ROI: กำหนดตัวชี้วัดทั้งเชิงเทคนิค (เช่น accuracy, latency, false positive rate) และเชิงธุรกิจ (เช่นเพิ่มรายได้ต่อเดือน, ลดต้นทุนการดำเนินงาน, ลด churn) ใช้สูตรพื้นฐานสำหรับ ROI เช่น (ประโยชน์ทางธุรกิจที่เกิดขึ้น − ต้นทุนโครงการ) ÷ ต้นทุนโครงการ และติดตาม payback period เพื่อประเมินความคุ้มค่า นอกจากนี้ควรตั้ง KPI การมอนิเตอร์หลังขึ้น production เช่น model drift rate, data quality metrics, และ uptime ของ endpoint
สรุปคือ การนำ ML ไปสู่การสร้างคุณค่าในองค์กรต้องอาศัยการเลือกเครื่องมือที่เหมาะสม การจัดทีมบทบาทชัดเจน การออกแบบ data architecture ที่มั่นคง และกระบวนการที่เป็นขั้นเป็นตอน (PoC → Pilot → Production) พร้อมการวัดผลทางธุรกิจอย่างต่อเนื่องเพื่อให้การลงทุนคุ้มค่าและยั่งยืน
บทสรุป
Machine Learning (ML) เป็นเทคโนโลยีพื้นฐานที่ขับเคลื่อนการเปลี่ยนแปลงในหลายอุตสาหกรรม ตั้งแต่การเงิน การดูแลสุขภาพ ไปจนถึงการผลิตและการค้าปลีก อย่างไรก็ตาม การนำ ML ไปใช้ให้เกิดประโยชน์จริงจะไม่สำเร็จเพียงเพราะมีโมเดลเท่านั้น แต่ต้องคำนึงถึงคุณภาพของข้อมูล การออกแบบโมเดลที่โปร่งใสและเป็นธรรม ความรับผิดชอบเชิงจริยธรรม และการวัดผลเชิงธุรกิจที่ชัดเจน—เช่น ตัวชี้วัดผลตอบแทนการลงทุน (ROI), การลดต้นทุน หรือการเพิ่มประสิทธิภาพการให้บริการ—เพื่อให้แน่ใจว่าโซลูชันทำงานสอดคล้องกับเป้าหมายเชิงกลยุทธ์ขององค์กร
อนาคตของ ML จะเน้นไปที่การบูรณาการอย่างยั่งยืน โดยองค์กรที่เตรียมคน เทคโนโลยี และ governance ได้ดี—รวมถึงการลงทุนในโครงสร้างข้อมูล การนำแนวปฏิบัติ MLOps มาใช้ ทีมข้ามสายงานที่เข้าใจธุรกิจและเทคนิค และกรอบจริยธรรม/การกำกับดูแล—จะสามารถเปลี่ยน ML ให้เป็นเครื่องมือสร้างมูลค่าอย่างต่อเนื่องได้ การเตรียมความพร้อมเช่นนี้ช่วยให้รับมือกับความท้าทายในอนาคต เช่น กฎระเบียบที่เข้มงวดขึ้น ความต้องการความโปร่งใส และการใช้งาน ML ในสภาพแวดล้อมแบบ real-time หรือ edge ได้อย่างมั่นคงและยั่งยืน
📰 แหล่งอ้างอิง: The Economic Times



