
การเรียนรู้ของเครื่อง (Machine Learning) กำลังพลิกโฉมการพัฒนาแอปพลิเคชันจากภายในสู่ภายนอก — ไม่เพียงแต่ทำให้ประสบการณ์ผู้ใช้เป็นส่วนตัวมากขึ้น แต่ยังช่วยปรับปรุงประสิทธิภาพ ระบบแนะนำคอนเทนต์ ออโตเมชันการทดสอบ และการดำเนินงานด้านโครงสร้างพื้นฐานของซอฟต์แวร์ด้วย ผลสำรวจจากองค์กรวิจัยหลายแห่งชี้ว่า มากกว่า 70% ของธุรกิจที่นำ ML ไปใช้พบว่าการประยุกต์ใช้ดังกล่าวช่วยเพิ่มอัตราการมีส่วนร่วมและประสิทธิภาพของแอปฯ อย่างมีนัยสำคัญ ตัวอย่างเช่น ระบบแนะนำที่ขับเคลื่อนด้วย ML อาจยกระดับอัตราการคลิก (CTR) และการเก็บรักษาผู้ใช้ได้ตั้งแต่หลักสิบถึงหลายสิบเปอร์เซ็นต์ ขณะที่การนำ MLOps มาใช้ช่วยลดเวลาในการนำโมเดลขึ้นสู่การใช้งานจริงและเพิ่มความน่าเชื่อถือของเวิร์กโฟลว์การพัฒนา
บทความนี้จะพาผู้อ่านสำรวจภาพรวมของนวัตกรรมที่เกิดจากการรวม ML เข้ากับวงจรการพัฒนาแอปฯ ตั้งแต่กรณีใช้งานสำคัญ เช่น personalization, ระบบแนะนำคอนเทนต์, การตรวจจับการทุจริต และการปรับประสิทธิภาพการทำงานของแอปพลิเคชัน ไปจนถึงประเด็นเชิงปฏิบัติอย่าง MLOps, ความเสี่ยงด้านข้อมูลและความเป็นส่วนตัว รวมถึงแนวโน้มเทคโนโลยีในอนาคต เช่น on-device ML, federated learning และการใช้โมเดลภาษาใหญ่ (LLMs) เพื่อช่วยพัฒนาโค้ดและออกแบบ UX เราจะสรุปตัวอย่างเชิงสถิติ กรณีศึกษา และแนวทางปฏิบัติที่เป็นประโยชน์ต่อทั้งนักพัฒนาและองค์กรที่ต้องการนำ ML มาใช้ให้เกิดผลจริงในผลิตภัณฑ์
บทนำ: ทำไมการเรียนรู้ของเครื่องถึงสำคัญสำหรับการพัฒนาแอป
บทนำ: ทำไมการเรียนรู้ของเครื่องถึงสำคัญสำหรับการพัฒนาแอป
ในยุคดิจิทัลที่การแข่งขันด้านผลิตภัณฑ์และประสบการณ์ผู้ใช้ทวีความรุนแรงขึ้นอย่างรวดเร็ว การเรียนรู้ของเครื่อง (Machine Learning — ML) กลายเป็นองค์ประกอบสำคัญที่เปลี่ยนวิธีคิดและวิธีทำงานของการพัฒนาแอปพลิเคชันจากเดิมอย่างมีนัยสำคัญ แทนที่จะเป็นซอฟต์แวร์ที่ทำงานตามกฎที่เขียนขึ้นอย่างตายตัว แอปที่ฝัง ML จะสามารถเรียนรู้จากข้อมูล ปรับตัวตามพฤติกรรมผู้ใช้ และตัดสินใจหรือคาดการณ์ได้ด้วยตนเอง ซึ่งนำไปสู่ประสบการณ์ผู้ใช้ที่เป็นส่วนบุคคล (personalized), มีความฉลาดขึ้นเรื่อย ๆ และมีความยืดหยุ่นในการรองรับสถานการณ์ใหม่ ๆ
ความแตกต่างระหว่าง ML และซอฟต์แวร์แบบเดิม อยู่ที่หลักการทำงาน — ซอฟต์แวร์แบบดั้งเดิมอาศัยกฎและลอจิกที่ผู้พัฒนาเขียนขึ้นอย่างชัดเจน ในขณะที่ ML สร้างโมเดลโดยอาศัยข้อมูลเป็นหลัก ผลลัพธ์ของระบบจึงขึ้นกับการฝึกสอนและข้อมูลที่ได้รับ ทำให้ ML เหมาะกับงานที่มีความซับซ้อนหรือเปลี่ยนแปลงบ่อย เช่น การจดจำภาพ เสียง ระบบแนะนำสินค้า และการตรวจจับพฤติกรรมฉ้อโกง นอกจากนี้ ML ยังเปิดโอกาสให้เกิดการปรับปรุงแบบอัตโนมัติ (continuous learning) ซึ่งซอฟต์แวร์แบบเดิมทำได้ยากหรือใช้ทรัพยากรมนุษย์มากขึ้น
แนวโน้มการนำ ML ไปใช้ในแอปพลิเคชันมีการเติบโตอย่างรวดเร็วในระดับโลก: รายงานจากหน่วยงานวิจัยหลายแห่งสรุปตรงกันว่า การลงทุนและการใช้งาน AI/ML มีอัตราการเติบโตเป็นหลักหลายสิบเปอร์เซ็นต์ต่อปี (CAGR ประมาณ 30–40% ขึ้นอยู่กับแหล่งข้อมูลและช่วงเวลา) และมีการคาดการณ์ว่าตลาด AI/ML จะขยายไปสู่มูลค่าหลายแสนล้านดอลลาร์ภายในทศวรรษนี้ ในแง่การใช้งานเชิงปฏิบัติ ผลสำรวจขององค์กรไอทีจำนวนมากแสดงว่าแอปที่เปิดใช้ความสามารถ ML (ML-enabled apps) เพิ่มขึ้นอย่างมีนัยสำคัญในช่วง 2–4 ปีที่ผ่านมา โดยธุรกิจที่ผนวก ML เข้ากับผลิตภัณฑ์มักรายงานการเพิ่มขึ้นของการมีส่วนร่วม (engagement) และการรักษาผู้ใช้ (retention)
ในมุมมองเชิงธุรกิจและเชิงเทคนิค ประโยชน์จากการรวม ML ในแอปพลิเคชันมีหลายด้าน ซึ่งรวมถึงการเพิ่มอัตราการรักษาผู้ใช้และสร้างรายได้จากการปรับแต่งประสบการณ์ให้เป็นรายบุคคล ตัวอย่างเช่น การปรับเนื้อหาและข้อเสนอให้สอดคล้องกับพฤติกรรมผู้ใช้ (personalization) มักนำไปสู่การเพิ่ม conversion และรายได้ — งานศึกษาเชิงตลาดชี้ว่า personalization สามารถช่วยเพิ่มรายได้ได้ในช่วงประมาณ 10–30% ขึ้นอยู่กับอุตสาหกรรมและการนำไปใช้ นอกจากนี้ยังมีประโยชน์ทางเทคนิคและเชิงปฏิบัติอื่น ๆ เช่นความสามารถในการคาดการณ์ (predictive analytics), การลดภาระงานด้วยการทำงานอัตโนมัติ, การตรวจจับความผิดปกติแบบเรียลไทม์ และการปรับปรุงวงจรวิศวกรรมผ่านแนวทาง MLOps ที่ช่วยให้การอัปเดตโมเดลเป็นไปอย่างรวดเร็วและปลอดภัย
สรุปแล้ว การเรียนรู้ของเครื่องไม่ได้เป็นเพียงฟีเจอร์เสริม แต่เป็นกลไกสำคัญที่เปลี่ยนทั้งประสบการณ์ผู้ใช้และกระบวนการพัฒนาแอป ทำให้ธุรกิจสามารถแข่งขันได้ด้วยผลิตภัณฑ์ที่ฉลาดขึ้น ตอบโจทย์ผู้ใช้ได้ตรงกว่า และมีประสิทธิภาพในการดำเนินงานมากขึ้น
ตัวอย่างประเด็นที่แอปที่ใช้ ML มักได้รับประโยชน์อย่างชัดเจน ได้แก่:
- การปรับแต่งประสบการณ์ผู้ใช้แบบเรียลไทม์ (personalization) เพิ่มอัตราการมีส่วนร่วมและรายได้
- การคาดการณ์พฤติกรรมและการลดการทิ้งผู้ใช้ (improved retention)
- การทำงานอัตโนมัติและลดต้นทุนปฏิบัติการ
- การวิเคราะห์เชิงคาดการณ์และการตัดสินใจที่ขับเคลื่อนด้วยข้อมูล
- การปรับปรุงกระบวนการพัฒนาและการปรับใช้ผ่าน MLOps
เทคโนโลยีและเครื่องมือหลักที่พัฒนาแอปด้วย ML
เทคโนโลยีและเครื่องมือหลักที่พัฒนาแอปด้วย Machine Learning
การพัฒนาแอปพลิเคชันด้วย Machine Learning (ML) ต้องอาศัยสแต็กเทคโนโลยีที่หลากหลาย ตั้งแต่ประเภทโมเดลพื้นฐานจนถึงเครื่องมือสำหรับการฝึกสอน ทดสอบ และปรับใช้งานจริง ในภาพรวม มีการแบ่งเทคโนโลยีออกเป็นกลุ่มสำคัญ ได้แก่ ประเภทโมเดล (Supervised, Unsupervised, Reinforcement, Transformer), เฟรมเวิร์กและไลบรารียอดนิยม, และ เทคโนโลยีสำหรับ Edge & Mobile ซึ่งแต่ละกลุ่มมีบทบาทและขอบเขตการใช้งานที่ชัดเจนสำหรับการสร้างแอปที่มีประสิทธิภาพและเชื่อถือได้
ตัวอย่างแนวโน้มเชิงปฏิบัติ: รายงานสำรวจหลายฉบับชี้ว่าองค์กรมากกว่า 50% ได้เริ่มนำ AI/ML เข้ามาใช้ในกระบวนการธุรกิจอย่างน้อยหนึ่งฟังก์ชัน ซึ่งสะท้อนความต้องการทั้งแพลตฟอร์มการพัฒนาและการปรับใช้งานที่พร้อมใช้งานในระดับองค์กร
1) โมเดลพื้นฐานและการประยุกต์ใช้งาน
โมเดล ML แบ่งตามแนวทางการเรียนรู้หลักๆ ดังนี้
- Supervised learning — ใช้ข้อมูลมีป้ายกำกับ (label) เหมาะสำหรับงานจำแนกประเภท (classification) และการพยากรณ์ค่า (regression) เช่น ระบบแยกประเภทอีเมลสแปม, การทำนายยอดขาย
- Unsupervised learning — ใช้ข้อมูลไม่มีป้ายกำกับ เหมาะกับการค้นหารูปแบบหรือการจัดกลุ่ม เช่น การทำ clustering เพื่อแบ่งกลุ่มลูกค้า, การลดมิติข้อมูล (PCA) สำหรับการวิเคราะห์เชิงสำรวจ
- Reinforcement learning (RL) — เรียนรู้จากการลองผิดลองถูกและรับรางวัล เหมาะกับระบบตัดสินใจที่มีลำดับการกระทำ เช่น หุ่นยนต์ควบคุม, ระบบแนะนำเชิงโต้ตอบ
- Transformer models (NLP / Vision) — สถาปัตยกรรมแบบ attention เช่น BERT, GPT, ViT ที่เปลี่ยนวงการทั้งด้านการประมวลผลภาษาธรรมชาติและการประมวลผลภาพ ตัวอย่างการใช้งาน ได้แก่ การสรุปข้อความอัตโนมัติ, แชทบอทบริการลูกค้า, การตรวจจับความผิดปกติจากภาพทางการแพทย์
2) เฟรมเวิร์ก และไลบรารีที่ได้รับความนิยม
การเลือกเฟรมเวิร์กมีผลต่อความเร็วในการพัฒนา ความสามารถในการปรับขนาด และการสนับสนุนชุมชน โดยตัวเลือกยอดนิยมได้แก่:
- TensorFlow — เฟรมเวิร์กจาก Google ที่ครอบคลุมทั้งการฝึกสอนและการผลิต มีเครื่องมือเสริมเช่น TensorBoard (visualization) และ TensorFlow Extended (TFX) สำหรับงาน MLOps ตัวอย่างการใช้งาน: การฝึกโมเดลภาพเชิงการแพทย์และการให้บริการอินเฟอร์เรนซ์บนคลาวด์
- PyTorch — เป็นที่นิยมในงานวิจัยและการพัฒนาเชิงโปรโตไทป์ ด้วยความยืดหยุ่นและ API ที่เข้าใจง่าย ปัจจุบันถูกใช้ในระบบ production มากขึ้น รวมทั้งมี ecosystem เช่น TorchServe สำหรับ deployment ตัวอย่าง: โมเดล NLP ขั้นสูงและระบบ Computer Vision ในธุรกิจสื่อ
- ONNX (Open Neural Network Exchange) — รูปแบบกลางสำหรับแลกเปลี่ยนโมเดลระหว่างเฟรมเวิร์ก ช่วยให้สามารถแปลงโมเดลจาก PyTorch ไปยัง TensorFlow หรือรันด้วย ONNX Runtime เพื่อเพิ่มประสิทธิภาพในการ inference ข้ามแพลตฟอร์ม
- AutoML — เครื่องมือสำหรับอัตโนมัติการเลือกสถาปัตยกรรม การตั้งค่าไฮเปอร์พารามิเตอร์ และการเตรียมข้อมูล ตัวอย่างเช่น Google AutoML, H2O Driverless AI, AutoGluon (จาก AWS) เหมาะสำหรับองค์กรที่ต้องการลดค่าใช้จ่ายด้านงานวิจัยหรือเร่งความเร็วในการพัฒนาโมเดล
- บริการคลาวด์ (AWS SageMaker, GCP Vertex AI, Azure ML) — แพลตฟอร์มที่รวมเครื่องมือครบวงจรตั้งแต่การจัดการข้อมูล การฝึกสอนแบบกระจาย การสร้าง pipeline จนถึงการ deploy และ monitoring
- AWS SageMaker: มีฟีเจอร์ training, tuning, model registry และ inference endpoints
- GCP Vertex AI: รวม AutoML, notebook, hyperparameter tuning และ feature store ในแพลตฟอร์มเดียว
- Azure Machine Learning: เน้นการทำงานร่วมกับ ecosystem ของ Microsoft และ MLOps สำหรับองค์กร
3) เทคโนโลยีสำหรับ Edge & Mobile
สำหรับแอปที่ต้องการตอบสนองรวดเร็วหรือต้องการทำงานแบบออฟไลน์ การย้าย inference ไปยังอุปกรณ์ปลายทาง (on-device) เป็นกุญแจสำคัญเทคโนโลยีหลักได้แก่:
- TensorFlow Lite — แปลงและปรับแต่งโมเดล TensorFlow ให้เหมาะกับอุปกรณ์มือถือและ IoT รองรับการ quantization และ delegate สำหรับใช้ประสิทธิภาพเฉพาะฮาร์ดแวร์ เช่น GPU/NNAPI
- Core ML — เฟรมเวิร์กของ Apple สำหรับรันโมเดลบน iOS devices รองรับการแปลงจาก TensorFlow/PyTorch/ONNX และรองรับการเร่งด้วย Apple Neural Engine (ANE)
- Quantization — เทคนิคแปลงตัวเลขทศนิยม (float32) เป็นตัวเลขชนิดน้อยบิต (int8, int16) ช่วยลดขนาดโมเดลและเพิ่มความเร็ว inference โดยทั่วไปสามารถลดขนาดลงได้ ~4x เมื่อใช้ int8 และลด latency อย่างมีนัยสำคัญ
- Model pruning และ knowledge distillation — การตัดพารามิเตอร์ที่ไม่สำคัญ (pruning) หรือการฝึกโมเดลขนาดเล็กให้เลียนแบบโมเดลขนาดใหญ่ (distillation) ช่วยลดขนาดและการคำนวณโดยยังรักษาความแม่นยำใกล้เคียงกับโมเดลดั้งเดิม
ตัวอย่างการใช้งานจริง เช่น แอปตรวจสอบคุณภาพสินค้าบนสายการผลิตที่รันโมเดลตรวจจับข้อบกพร่องแบบ on-device เพื่อลด latency และยังคงทำงานแม้ออฟไลน์, แอปสุขภาพที่ใช้ Core ML ในการประมวลผลภาพจากกล้องเพื่อตรวจวินิจฉัยเบื้องต้นโดยไม่ส่งข้อมูลไปคลาวด์
สรุปเชิงกลยุทธ์
การเลือกสแต็กเทคโนโลยีควรพิจารณาจากเป้าหมายการใช้งาน เช่น หากต้องการนวัตกรรมและการทดลองเร็ว อาจเริ่มด้วย PyTorch และ transformer จากชุมชนวิจัย แต่หากมุ่งสู่การผลิตระดับองค์กรและต้องการเครื่องมือ MLOps ที่ครบวงจร การใช้ TensorFlow + TFX หรือบริการคลาวด์เช่น AWS SageMaker / GCP Vertex AI / Azure ML จะช่วยเร่งเวลาไปสู่ production ได้รวดเร็วขึ้น สำหรับงานที่ต้องการความเร็วและความเป็นส่วนตัวของผู้ใช้ ให้พิจารณาการปรับแต่งโมเดลด้วย quantization, pruning และนำมาใช้งานผ่าน TensorFlow Lite หรือ Core ML เพื่อบรรลุเป้าหมายด้าน latency และการใช้งานแบบออฟไลน์
กรณีใช้งานจริงในแอปพลิเคชัน: Personalization, Recommendation และการประมวลผลเชิงทำนาย
กรณีใช้งานจริงในแอปพลิเคชัน: Personalization, Recommendation และการประมวลผลเชิงทำนาย
การประยุกต์ใช้การเรียนรู้ของเครื่องในชั้นของ Personalization และระบบ Recommendation กลายเป็นหัวใจสำคัญของผลิตภัณฑ์ดิจิทัลสมัยใหม่ ทั้งในด้านการเพิ่ม engagement, ยืดอายุผู้ใช้ และเพิ่ม conversion rate ในเชิงธุรกิจ ตัวอย่างเทคนิคที่นิยมใช้ได้แก่ collaborative filtering สำหรับการจับคู่ผู้ใช้กับไอเท็มโดยอาศัยพฤติกรรมของกลุ่มผู้ใช้, ระบบค้นคืนแบบ embedding-based ที่แปลงคอนเทนต์และคิวรีเป็นเวกเตอร์เพื่อการค้นหาและแนะนำที่มีความหมายเชิงความคล้ายคลึงสูง, และ real-time ranking ที่ผสานสัญญาณจากการกระทำล่าสุดของผู้ใช้มาให้คะแนนผลลัพธ์แบบทันที (online personalization) ผลลัพธ์เชิงธุรกิจที่ถูกรายงานจากบริษัทชั้นนำ ได้แก่ Amazon ที่ระบบแนะนำสินค้าถูกประเมินว่าสร้างสัดส่วนรายได้ประมาณ ~35% ของยอดขายทั้งหมด และ Netflix ที่ความสามารถในการปรับคอนเทนต์เฉพาะบุคคลมีส่วนช่วยลดการยกเลิกบริการจนบริษัทประเมินว่าช่วยประหยัดได้เป็นมูลค่าหลายร้อยล้านถึงพันล้านดอลลาร์ต่อปี
ในเชิงเทคนิค การผสานกันของวิธีการเหล่านี้มักประกอบด้วย:
- Collaborative filtering — ใช้งานได้ดีกับข้อมูลพฤติกรรมเมื่อมีการป้อน-เล่นข้อมูลเพียงพอ (sparse vs dense tradeoffs)
- Embedding-based retrieval — ใช้โมเดลเช่น Word2Vec, BERT, หรือแนวทาง Siamese network เพื่อแม็ปคอนเทนต์และยูสเซอร์ไปยังเวกเตอร์สเปซเดียวกัน เพิ่มความเร็วและความแม่นยำของการค้นหา
- Real-time ranking — ใช้ feature store และ inference แบบ low-latency (เช่น online feature computation + streaming updates) เพื่อให้คะแนนรายการตามสัญญาณปัจจุบันของผู้ใช้
ด้านความปลอดภัยและการตรวจจับความผิดปกติ (Anomaly Detection) การเรียนรู้ของเครื่องช่วยลดความเสี่ยงและความสูญเสียจากพฤติกรรมทุจริตได้อย่างมีประสิทธิภาพ ระบบเหล่านี้ถูกนำไปใช้เพื่อตรวจจับธุรกรรมที่ผิดปกติ, การล็อกอินที่มีความเสี่ยงสูง, รวมถึงพฤติกรรมของบัญชีที่บ่งชี้การถูกแฮ็ก โดยเทคนิคที่นิยมได้แก่ unsupervised models (เช่น Isolation Forest, One-Class SVM), deep autoencoders สำหรับการจับความผิดปกติเชิงลึก, และ hybrid approaches ที่ผสม rule-based กับ ML scoring ในสเกลเวลารันไทม์
ตัวอย่างเชิงธุรกิจ: ผู้ให้บริการการชำระเงินและแพลตฟอร์มฟินเทครายใหญ่ระบุว่าการใช้ ML ในการตรวจจับการฉ้อโกงช่วยลดความสูญเสียและ false positive ได้อย่างมีนัยสำคัญ — ลดอัตราการฉ้อโกงลงเป็นสัดส่วนที่เห็นได้ชัด (หลายบริษัทรายงานการลดลงเป็นตัวเลขหลักหลายสิบเปอร์เซ็นต์ในความสูญเสียจากการฉ้อโกงหรืออัตรา chargeback) ขณะเดียวกันการลด false positives ยังช่วยรักษาประสบการณ์ผู้ใช้และลดต้นทุนการตรวจสอบด้วยมือ
ในมิติของ Predictive features ฟีเจอร์ที่คาดการณ์ได้ เช่น churn prediction และ predictive search เป็นเครื่องมือสำคัญสำหรับการตัดสินใจเชิงธุรกิจแบบเชิงรุก (proactive decision-making) — ตัวอย่างการใช้งานคือระบบจัดลำดับกลุ่มผู้ใช้ที่มีความเสี่ยงต่อการยกเลิกเพื่อนำเสนอแคมเปญรักษาผู้ใช้เฉพาะบุคคล หรือ predictive search ที่ปรับผลลัพธ์การค้นหาให้เดาทางความต้องการของผู้ใช้ก่อนพิมพ์จบ ช่วยลดเวลาในการค้นหาและเพิ่มอัตรา conversion
ผลเชิงตัวเลขจากการนำ predictive features มาใช้แสดงให้เห็นคุณค่าเชิงธุรกิจอย่างชัดเจน: การทำนาย churn และการรุกเข้าไปจัดการล่วงหน้าสามารถลด churn ได้ตั้งแต่ 5–15% ในหลายกรณี ซึ่งส่งผลตรงต่อรายได้รวมของบริษัท ในด้าน search/UX ระบบ predictive search และ autocomplete ที่เรียนรู้จากคอนเท็กซ์ของผู้ใช้สามารถลดเวลาในการหาสิ่งที่ต้องการและเพิ่มอัตราการสำเร็จของการค้นหาได้หลายเปอร์เซ็นต์ ซึ่งเมื่อรวมกับระบบ recommendation แล้วจะเป็นเส้นทางสู่การเพิ่มมูลค่าต่อผู้ใช้ (LTV) และประสิทธิภาพของช่องทางขาย
สรุปได้ว่าการผสมผสานระหว่าง personalization, anomaly detection, และ predictive features ไม่เพียงแต่ยกระดับประสบการณ์ผู้ใช้ แต่ยังเป็นเครื่องมือสำคัญในการเพิ่มประสิทธิภาพเชิงธุรกิจ — ลดต้นทุนความเสี่ยง เพิ่มรายได้จากการขาย และช่วยให้การตัดสินใจเชิงกลยุทธ์ทำได้อย่างรวดเร็วและมีข้อมูลรองรับ
กระบวนการพัฒนา ML ในแอป: Data Pipeline, Training และ MLOps

1. Data pipeline: การเก็บ บริหาร และจัดการการเปลี่ยนแปลงของข้อมูล
การสร้างระบบ ML ที่เชื่อถือได้เริ่มจาก คุณภาพของข้อมูล ขั้นตอน Data pipeline ต้องครอบคลุมการเก็บ (ingestion), การทำความสะอาด (cleaning), การจัดเก็บเชิงโครงสร้าง และการเตรียมข้อมูลสำหรับการสร้างฟีเจอร์ (feature engineering) อย่างเป็นระบบ ในปัจจุบันทีมวิจัยและอุตสาหกรรมมักรายงานว่า ประมาณ 60–80% ของเวลาที่ใช้ในโครงการ ML ถูกใช้ไปกับการเตรียมและตรวจสอบข้อมูล ดังนั้นการลงทุนใน pipeline ที่อัตโนมัติและตรวจสอบได้จึงให้ผลตอบแทนสูง
- การเก็บข้อมูล: ใช้ Kafka, Kinesis, หรือ Pub/Sub สำหรับสตรีมแบบเรียลไทม์ และใช้ batch ingestion ผ่าน Airflow, Prefect หรือ dbt
- การทำความสะอาดและตรวจสอบคุณภาพ: ใช้ Great Expectations, Deequ หรือ custom rules เพื่อคัดกรอง missing values, outliers และ schema drift
- Feature engineering: แยกเป็น offline (feature store เช่น Feast, Tecton) และ online store เพื่อให้ latency ต่ำสำหรับ request แบบเรียลไทม์
- การจัดการ Data Drift: ติดตั้งการตรวจจับ drift (เช่น Evidently AI, WhyLabs) เพื่อตรวจจับความแตกต่างของ distribution ระหว่าง training และ production แล้วตั้งเกณฑ์แจ้งเตือนอัตโนมัติ
2. Training & validation: การตั้งค่าระบบเทรน การปรับพารามิเตอร์ และการวัดผลที่เหมาะสม
หลังจากข้อมูลผ่านการเตรียมแล้ว ขั้นตอนสำคัญคือการตั้งค่าการเทรนและกระบวนการวัดผลที่ชัดเจน เพื่อหลีกเลี่ยง overfitting และยืนยันว่าตัวชี้วัดสอดคล้องกับเป้าหมายธุรกิจ การแบ่งชุดข้อมูลเป็น training/validation/test, การทำ cross-validation และการตรึง seed สำหรับ reproducibility เป็นแนวปฏิบัติพื้นฐาน
- ระบบการเทรน: เลือกสถาปัตยกรรมการเทรน (single-node GPU, distributed GPU/TPU ด้วย Horovod, Ray, Spark) ตามขนาดข้อมูลและความซับซ้อนของโมเดล
- Hyperparameter tuning: ใช้เครื่องมือเช่น Optuna, Ray Tune, Hyperopt หรือบริการที่ผู้ให้คลาวด์มีให้ (เช่น Vertex AI Tuner) เพื่อทำ Bayesian/Random/Population-based search และจัดเก็บผลการทดลอง (experiment tracking) ด้วย MLflow หรือ Weights & Biases
- เมตริกการประเมินผล: นิยาม KPI ตามกรณีใช้งาน เช่น AUC/F1 สำหรับ classification, RMSE/MAE สำหรับ regression, precision@k สำหรับ recommendation หรือ latency/throughput สำหรับระบบเรียลไทม์ โดยกำหนดเกณฑ์ยอมรับก่อน deploy
- ตัวอย่างเชิงตัวเลข: สำหรับแอปพลิเคชันลูกค้าที่ต้องตอบสนองแบบเรียลไทม์ ควรตั้งเป้าตัวชี้วัด latency ที่ p99 < 200 ms และเทียบประสิทธิภาพโมเดลใหม่กับ baseline ว่าต้องมี uplift อย่างน้อย 1–3% ใน metric ธุรกิจเพื่อส่งเข้า production
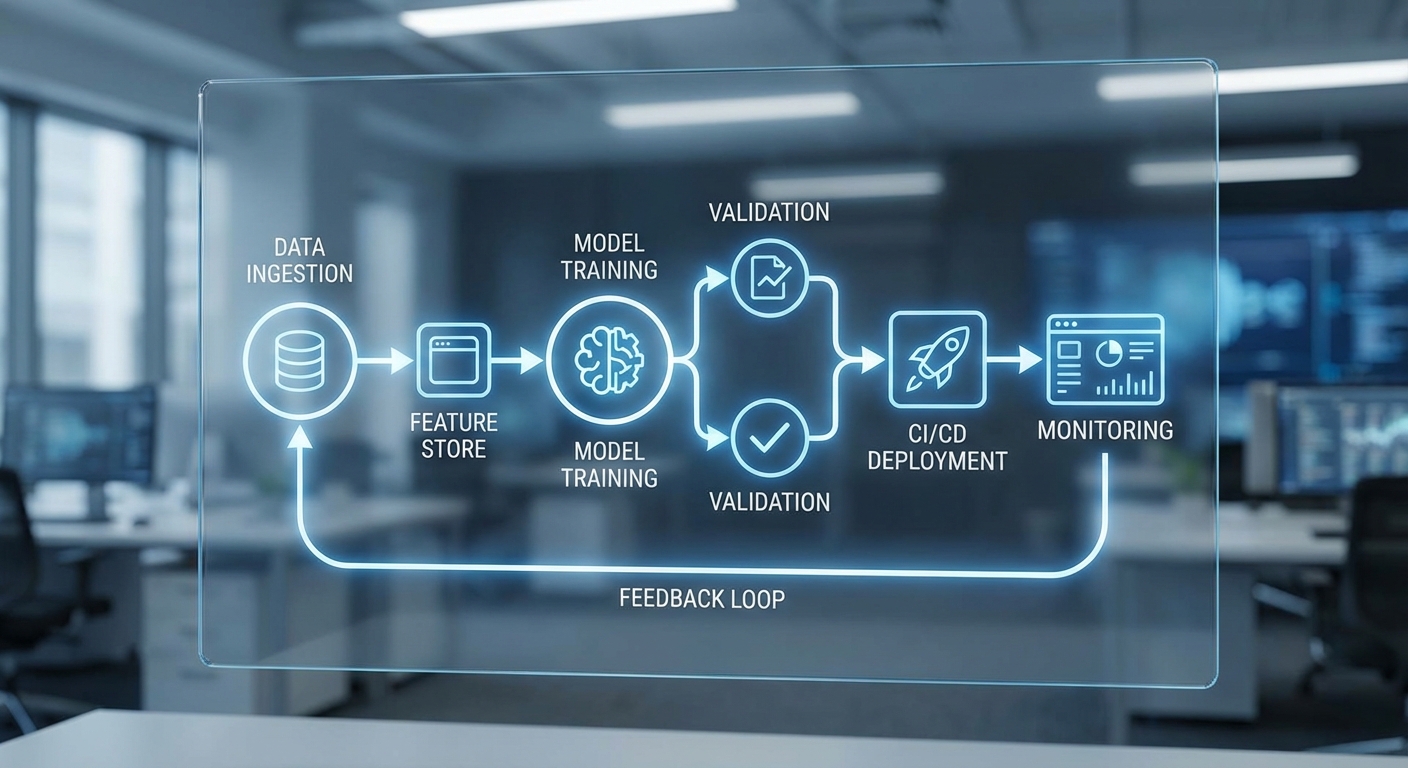
3. MLOps & deployment: CI/CD สำหรับโมเดล การติดตาม และการจัดการใน production
การนำโมเดลขึ้นสู่ production ต้องใช้แนวทาง MLOps ที่ผสานวิศวกรรมซอฟต์แวร์กับงานวิทยาศาสตร์ข้อมูลอย่างเป็นระบบ เวิร์กโฟลว์ CI/CD สำหรับโมเดล จะประกอบด้วยการทดสอบหน่วย (unit tests), การทดสอบเชิงประสิทธิภาพ, การทดสอบความถูกต้องของข้อมูล, การบรรจุเป็นคอนเทนเนอร์ และกระบวนการรีวิวก่อน deploy
- CI/CD สำหรับโมเดล: ใช้ Git + CI tools (GitHub Actions, GitLab CI, Jenkins) ร่วมกับการบิลด์ Docker image ของโมเดล และ deploy ผ่าน Kubernetes + Helm หรือบริการ serverless ของผู้ให้คลาวด์
- Model registry & versioning: เก็บ metadata และ artefact ของโมเดลใน MLflow, Seldon Core, หรือ Amazon SageMaker Model Registry พร้อมแท็กเวอร์ชันและ lineage เพื่อการ audit และ rollback
- Data versioning: ใช้ DVC, Delta Lake, LakeFS หรือ Pachyderm เพื่อบันทึก snapshot ของ dataset และเชื่อมโยงกับเวอร์ชันโมเดล (data provenance)
- Deployment patterns: Canary release, blue/green deployment, shadow testing และ feature flags เป็นวิธีการลดความเสี่ยงเมื่อนำโมเดลใหม่ขึ้น production
- Monitoring & observability: ติดตั้ง metric logging (Prometheus, Grafana), trace และ logs (ELK, Loki) ร่วมกับการมอนิเตอร์เชิงคุณภาพของโมเดล (model drift, data drift, prediction distribution) ด้วย Evidently, WhyLabs หรือเครื่องมือเชิงพาณิชย์
- Retraining strategy: เลือกระหว่าง scheduled retraining (เช่น ทุกสัปดาห์/เดือน), event-driven retraining (เมื่อ drift เกิน threshold) หรือ continuous learning โดยมี guardrails เพื่อหลีกเลี่ยงการ degrade ของระบบ
แนวปฏิบัติที่แนะนำ: ให้จับคู่การมอนิเตอร์เชิงเทคนิค (latency, error rate) กับการมอนิเตอร์เชิงธุรกิจ (conversion, revenue impact) ตั้งค่าเกณฑ์แจ้งเตือนที่ชัดเจน และเก็บทั้งรุ่นโมเดลและ snapshot ของข้อมูลเพื่อให้สามารถย้อนกลับและสืบค้นได้เมื่อเกิดปัญหา
โดยสรุป กระบวนการพัฒนา ML ที่เข้มแข็งต้องผสาน pipeline ที่เชื่อถือได้ การเทรนที่สามารถทำซ้ำและปรับแต่งได้อย่างเป็นระบบ รวมทั้ง MLOps ที่รองรับการ deploy และการมอนิเตอร์อย่างต่อเนื่อง องค์กรที่ลงทุนนโยบายการเวอร์ชันข้อมูลและโมเดล รวมถึงระบบ CI/CD ที่ออกแบบมาเฉพาะสำหรับ ML จะมีความได้เปรียบเชิงการแข่งขันในการนำโมเดลไปใช้งานจริงและรักษาคุณภาพของบริการในระยะยาว
ข้อจำกัด ความเสี่ยง และจริยธรรมในการนำ ML ไปใช้
ข้อจำกัดและความเสี่ยงโดยรวมในการนำ Machine Learning ไปใช้
การนำ Machine Learning (ML) ไปใช้ในแอปพลิเคชันเชิงธุรกิจให้ประโยชน์ที่ชัดเจน เช่น การปรับปรุงประสบการณ์ผู้ใช้และการตัดสินใจอัตโนมัติ แต่ก็มีข้อจำกัดและความเสี่ยงหลายด้านที่องค์กรต้องเผชิญ ทั้งด้านคุณภาพข้อมูล โครงสร้างต้นทุน ความปลอดภัย และภาระผูกพันทางกฎหมาย หากไม่จัดการอย่างเป็นระบบ อุปสรรคเหล่านี้อาจนำไปสู่ผลลัพธ์ที่ไม่เป็นธรรม สูญเสียความเชื่อมั่นของลูกค้า หรือความเสี่ยงทางการเงินและกฎหมาย
Data bias และความเสมอภาค (Fairness)
ปัญหาอคติของข้อมูล (data bias) เป็นหนึ่งในความเสี่ยงที่พบบ่อยที่สุดของระบบ ML ตัวอย่างจากงานวิจัยและเหตุการณ์จริง ได้แก่ ระบบคัดกรองผู้สมัครงานที่มีคะแนนต่ำต่อผู้หญิงเนื่องจากข้อมูลประวัติเป็นผู้ชายเป็นส่วนใหญ่ หรือระบบจองสินเชื่อที่ปฏิเสธกลุ่มชาติพันธุ์บางกลุ่ม ในกรณีของเครื่องมือประเมินความเสี่ยงด้านอาญา เช่น รายงาน ProPublica (2016) พบความลำเอียงในการประเมินความเสี่ยงซ้ำของผู้ต้องหา ซึ่งส่งผลกระทบต่อการตัดสินทางคดี
แนวทางตรวจสอบและลดอคติที่ควรนำไปปฏิบัติได้แก่
- การวิเคราะห์เชิงสำรวจของข้อมูล (Data Profiling) เพื่อหาช่องว่างเชิงประชากรและบ่งชี้ตัวแปรที่อาจนำไปสู่อคติ เช่น การกระจายเพศ/เชื้อชาติ/อายุ
- การเลือกตัวชี้วัดความเสมอภาค (Fairness Metrics) เช่น demographic parity, equalized odds, disparate impact เพื่อตั้งเกณฑ์วัดผลและเฝ้าระวัง
- การปรับสมดุลข้อมูล เช่น oversampling/undersampling, synthetic data generation (เช่น SMOTE) และการใช้ data augmentation เพื่อลดการขาดแคลนตัวอย่างของกลุ่มย่อย
- การออกแบบโมเดลที่คำนึงถึงความยุติธรรม เช่น การฝึกด้วย regularization เพื่อจำกัดช่องว่างของประสิทธิภาพระหว่างกลุ่ม หรือใช้ post-processing แก้ไขผลลัพธ์ก่อนเผยแพร่
- การทดสอบแบบ A/B และ human-in-the-loop เพื่อให้มนุษย์ตรวจสอบกรณีเปราะบางก่อนนำผลไปใช้ในระบบอัตโนมัติ
ความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบ
ความเป็นส่วนตัวของข้อมูลผู้ใช้เป็นทั้งข้อกังวลทางจริยธรรมและความเสี่ยงด้านกฎหมาย องค์กรที่ใช้ ML ต้องพิจารณากรอบข้อบังคับ เช่น GDPR ในสหภาพยุโรป ซึ่งกำหนดสิทธิของเจ้าของข้อมูลและบทลงโทษทางการเงินสูงสุด (เช่น สูงสุด 4% ของรายได้รวมทั่วโลกหรือ 20 ล้านยูโร) และ PDPA ของไทยที่มีข้อกำหนดการคุ้มครองข้อมูลบุคคล การไม่ปฏิบัติตามอาจมีผลทางการเงินและภาพลักษณ์
เทคนิคเชิงเทคนิคที่ช่วยลดความเสี่ยงด้านความเป็นส่วนตัวได้แก่
- Differential Privacy — เพิ่มสัญญาณความเป็นส่วนตัวให้กับการเรียนรู้หรือการเผยแพร่สถิติ เพื่อป้องกันการย้อนกลับไปหาบุคคลจากผลลัพธ์เชิงสถิติ
- Federated Learning — ฝึกโมเดลโดยเก็บข้อมูลไว้ที่ตัวอุปกรณ์ของผู้ใช้และส่งพารามิเตอร์หรือการอัปเดตแบบรวม เป็นการลดการย้ายข้อมูลส่วนบุคคลไปยังศูนย์กลาง
- การเข้ารหัสและเทคโนโลยีความปลอดภัยข้อมูล เช่น encryption-at-rest, encryption-in-transit, secure multi-party computation (SMPC) และ hardware enclaves (เช่น Intel SGX) สำหรับสถานการณ์ที่ต้องการความลับสูง
- การจัดทำ Data Governance และ Privacy Impact Assessment (PIA) เพื่อระบุความเสี่ยงด้านข้อมูล วัตถุประสงค์การใช้งาน และมาตรการคุ้มครองที่สอดคล้องกับ PDPA/GDPR
ต้นทุนคำนวณและความปลอดภัยของโมเดล
การพัฒนาและปรับใช้ ML โดยเฉพาะโมเดลขนาดใหญ่ มีต้นทุนทั้งด้านทรัพยากรคำนวณและพลังงาน ตัวอย่างเช่น การฝึกโมเดลภาษาใหญ่หรือโมเดลวิสัยทัศน์ในระดับองค์กรอาจมีค่าใช้จ่ายตั้งแต่หลักแสนถึงหลักล้านดอลลาร์ ทั้งในด้านฮาร์ดแวร์ (GPU/TPU), การจัดเก็บข้อมูล และต้นทุนบุคลากร องค์กรต้องทำการประเมิน Total Cost of Ownership (TCO) รวมทั้งค่าใช้จ่ายในการบำรุงรักษาและการอัพเดตโมเดลอย่างต่อเนื่อง (model retraining)
ด้านความปลอดภัย โมเดล ML เผชิญภัยคุกคามหลายรูปแบบ เช่น
- Adversarial Attacks — การปรับเปลี่ยนอินพุตอย่างละเอียดเพื่อหลอกให้โมเดลตัดสินใจผิด (ตัวอย่างเช่น การทำให้ระบบจดจำภาพผิดพลาดโดยการใส่สัญลักษณ์เล็กๆ ลงบนป้ายจราจร)
- Model Theft / Model Extraction — ผู้โจมตีสามารถค้นหาวิธีดึงโมเดลหรือพารามิเตอร์โดยการสอบถามแบบหลายครั้ง ซึ่งอาจนำไปสู่การละเมิดทรัพย์สินทางปัญญาหรือการสร้างสำเนาใช้งานในทางที่ไม่ต้องการ
- Data Poisoning — การป้อนข้อมูลที่เป็นพิษเข้าสู่กระบวนการฝึกเพื่อทำให้โมเดลทำงานผิดพลาดในสถานการณ์เฉพาะ
แนวทางลดความเสี่ยงด้านต้นทุนและความปลอดภัยประกอบด้วย
- การออกแบบสถาปัตยกรรมที่คุ้มค่า เช่น การใช้โมเดลขนาดเล็ก (model distillation), การใช้งานบน-edge เมื่อเหมาะสม, และการเลือกใช้บริการคลาวด์แบบ pay-as-you-go เพื่อควบคุมค่าใช้จ่าย
- การทดสอบความปลอดภัยเฉพาะทาง เช่น adversarial testing, red-team exercises, และการจำลองการโจมตีแบบ model extraction เพื่อค้นหาจุดอ่อนก่อนปล่อยใช้งาน
- มาตรการป้องกันการเข้าถึงและการใช้งานโมเดล เช่น rate limiting, API authentication, response perturbation เพื่อลดความเสี่ยงจากการสอบถามเพื่อขโมยโมเดล
- การติดตามประสิทธิภาพและการเปลี่ยนแปลงของข้อมูล (Monitoring & Drift Detection) เพื่อจับสัญญาณปัญหาได้รวดเร็วและดำเนินการ retraining หรือ rollback เมื่อจำเป็น
- การทำงานข้ามฟังก์ชันและการกำกับดูแล โดยมีทีมรักษาความปลอดภัย ข้อมูล และกฎหมายร่วมกันตั้งแต่การออกแบบจนถึงการผลิต (privacy by design, security by design)
สรุปและแนวทางปฏิบัติที่แนะนำ
การใช้งาน ML ในแอปพลิเคชันทางธุรกิจจำเป็นต้องมีการประเมินความเสี่ยงเชิงรุกและการออกแบบมาตรการรองรับ ทั้งด้านอคติ ความเป็นส่วนตัว ต้นทุน และความปลอดภัย เพื่อสร้างความเชื่อมั่นและลดผลกระทบเชิงลบ คำแนะนำสำคัญได้แก่การตั้งมาตรฐานการตรวจสอบข้อมูล การนำเทคนิคเช่น differential privacy และ federated learning มาใช้เมื่อจำเป็น การทดสอบและป้องกันการโจมตีเชิงรุก และการกำกับดูแลโดยนโยบายภายในที่สอดคล้องกับ PDPA/GDPR การผสมผสานมาตรการเชิงเทคนิคและการกำกับดูแลเชิงองค์กรจะช่วยให้องค์กรประโยชน์จาก ML ได้อย่างยั่งยืนและรับผิดชอบ
แนวโน้มอนาคตและนวัตกรรมที่น่าสนใจ
แนวโน้มอนาคตและนวัตกรรมที่น่าสนใจ
ในช่วง 3–5 ปีข้างหน้า การพัฒนาแอปพลิเคชันด้วยการเรียนรู้ของเครื่อง (Machine Learning: ML) จะได้รับแรงขับเคลื่อนจากชุดเทคโนโลยีที่ทำงานร่วมกันอย่างใกล้ชิด ตั้งแต่การย้ายการประมวลผลไปยังขอบเครือข่าย (Edge AI) การฝึกและปรับใช้โมเดลแบบกระจายด้วย federated learning ไปจนถึงการนำ foundation models/LLMs มาใช้ร่วมกับแพลตฟอร์มแบบ low-code/no-code และการผสานรวม AI เข้ากับ AR/VR ผลที่ตามมาจะไม่เพียงแค่เพิ่มสมรรถภาพของผลิตภัณฑ์ แต่ยังเปลี่ยนรูปแบบการให้บริการของธุรกิจหลายประเภท โดยเฉพาะในภาคการแพทย์ การผลิต ค้าปลีก และการบริการลูกค้า
Edge AI และการประมวลผลแบบกระจาย จะเป็นแกนกลางสำคัญในการลด latency และเสริมความเป็นส่วนตัวของข้อมูล โดยการย้าย inference หรือแม้กระทั่ง training บางส่วนไปยังอุปกรณ์ปลายทางหรือโหนดขอบเครือข่าย องค์กรที่ต้องการตอบสนองแบบเรียลไทม์ เช่น ยานยนต์ไร้คนขับ ระบบควบคุมการผลิต และแอป AR/VR สำหรับการฝึกงาน จะได้รับประโยชน์จากความหน่วงที่ต่ำลงและความเสี่ยงด้านความเป็นส่วนตัวที่ลดลง นอกจากนี้ การประมวลผลแบบกระจายยังช่วยลดการส่งข้อมูลกลับคลาวด์ ทำให้ประหยัดแบนด์วิดท์และค่าใช้จ่ายด้านการจัดเก็บข้อมูล ซึ่งเป็นปัจจัยสำคัญสำหรับอุปกรณ์ IoT จำนวนมากในภาคอุตสาหกรรม
Federated learning และเทคนิคการรักษาความเป็นส่วนตัว จะทำให้การแชร์ความสามารถของโมเดลเป็นไปได้โดยไม่จำเป็นต้องรวบรวมข้อมูลผู้ใช้เข้าศูนย์กลาง การใช้งานร่วมกับเทคนิคอย่าง differential privacy, secure aggregation, homomorphic encryption และ Trusted Execution Environments (TEEs) ช่วยให้สถาบันการเงินและหน่วยงานสาธารณสุขสามารถร่วมพัฒนาโมเดลที่มีประสิทธิภาพสูงโดยไม่เปิดเผยข้อมูลดิบ ตัวอย่างเช่น เครือโรงพยาบาลสามารถฝึกโมเดลตรวจวินิจฉัยภาพทางการแพทย์ร่วมกันได้โดยไม่ต้องแลกเปลี่ยนภาพผู้ป่วยจริง ซึ่งช่วยเพิ่มความแม่นยำของโมเดลและตอบสนองข้อกำหนดด้านกฎหมายความเป็นส่วนตัวได้ดียิ่งขึ้น
Foundation models, LLMs และแพลตฟอร์มแบบ low-code/no-code จะลดอุปสรรคในการนำ ML เข้าใช้จริงสำหรับทีมที่ไม่ใช่ data science โดยเฉพาะในองค์กรขนาดกลางและเล็ก Foundation models ที่ผ่านการ pre-train ขนาดใหญ่ (เช่น โมเดลภาษาหรือโมเดลภาพ) สามารถนำมาปรับจูน (fine-tune) เพื่อใช้ในงานเฉพาะทางได้เร็วขึ้น ในขณะเดียวกัน แพลตฟอร์มแบบ low-code/no-code และเครื่องมือ AutoML จะช่วยให้ผู้จัดการผลิตภัณฑ์ นักการตลาด และนักพัฒนาแบบ full-stack สามารถสร้างฟีเจอร์ที่ขับเคลื่อนด้วย ML ได้โดยไม่ต้องเขียนโค้ดจำนวนมาก ผลลัพธ์ที่คาดได้คือการออกแบบผลิตภัณฑ์เร็วขึ้น ต้นทุนพัฒนาเฉลี่ยต่อฟีเจอร์ลดลง และอัตราการทดลองเชิงนวัตกรรม (experimentation) เพิ่มขึ้นอย่างมีนัยสำคัญ
การรวม AI กับ AR/VR จะสร้างประสบการณ์แบบใหม่ที่มีความเป็นส่วนตัวและตอบสนองได้ทันทีเมื่อใช้ร่วมกับ Edge AI และ LLMs ตัวอย่างเช่น ร้านค้าปลีกสามารถใช้ AR เพื่อให้ลูกค้าลองเสื้อผ้าเสมือนจริงโดยมีระบบแนะนำไซส์และสไตล์แบบส่วนบุคคลที่ทำงานแบบเรียลไทม์, ฝ่ายบริการภาคสนามสามารถใช้แว่น AR ที่เชื่อมกับโมเดลตรวจจับปัญหาและคำแนะนำการซ่อม เพื่อเพิ่มประสิทธิภาพการแก้ปัญหาและลดเวลาหยุดทำงาน นวัตกรรมนี้จะเปลี่ยนกระบวนการขาย การฝึกอบรม และการให้บริการลูกค้าไปอย่างสิ้นเชิง
ตัวอย่างธุรกิจที่จะได้รับผลกระทบหรือเปลี่ยนแปลงอย่างมีนัยสำคัญ ได้แก่:
- ค้าปลีก: การนำ AR/AI มาใช้ในการทดลองสินค้าและ personalization แบบเรียลไทม์ ช่วยเพิ่มอัตราการซื้อและลดการคืนสินค้า
- การแพทย์: เครือข่ายโรงพยาบาลที่ใช้ federated learning จะสามารถพัฒนาโมเดลวินิจฉัยได้รวดเร็วขึ้นโดยไม่ละเมิดข้อมูลผู้ป่วย
- การผลิต: Edge AI สำหรับ predictive maintenance ร่วมกับ AR เพื่อแนะนำการซ่อมบำรุง ช่วยลด downtime และค่าใช้จ่ายการบำรุงรักษา
- การเงิน: การประยุกต์ใช้ privacy-preserving ML ในการตรวจจับการฉ้อโกงและการประเมินความเสี่ยง โดยคงความเป็นส่วนตัวของลูกค้า
- การศึกษาและการฝึกอบรม: การรวม LLMs กับสภาพแวดล้อม AR/VR จะสร้างบทเรียนแบบปรับตัว (adaptive learning) ที่สมจริงและมีปฏิสัมพันธ์สูง
สรุปแล้ว การบูรณาการระหว่าง Edge AI, federated learning, foundation models/LLMs และแพลตฟอร์มแบบ low-code/no-code รวมถึงการผสมผสานกับ AR/VR จะเป็นตัวเปลี่ยนเกมสำหรับการพัฒนาแอปใน 3–5 ปีข้างหน้า ธุรกิจที่เตรียมสถาปัตยกรรมแบบไฮบริด (edge–cloud), ลงทุนในมาตรฐานความเป็นส่วนตัว และพัฒนาทักษะระดับองค์กรมาก่อน จะมีความได้เปรียบเชิงแข่งขันอย่างชัดเจน
แนะนำแนวทางเริ่มต้นสำหรับนักพัฒนาและองค์กร
แนะนำแนวทางเริ่มต้นสำหรับนักพัฒนาและองค์กร
การนำการเรียนรู้ของเครื่อง (Machine Learning: ML) เข้าสู่ผลิตภัณฑ์ต้องเริ่มจากกรอบคิดเชิงธุรกิจและการปฏิบัติที่เป็นระบบ แนะนำให้เริ่มจากการกำหนดปัญหาที่ชัดเจน สามารถวัดผลได้ และมีความคุ้มค่าทางธุรกิจ (start with an MVP/POC) ก่อนขยายสเกล ตัวอย่างการใช้เคสที่คุ้มค่าได้แก่ การคาดการณ์ churn เพื่อรักษาลูกค้า การกรองสแปม การปรับแต่งคำแนะนำสินค้า ซึ่งมักให้ผลตอบแทนในการลงทุน (ROI) ที่จับต้องได้ในช่วง 3–6 เดือนแรกเมื่อออกแบบ KPI และกระบวนการทดลองอย่างรัดกุม
แผนปฏิบัติการทีละขั้นตอนสำหรับการเริ่มนำ ML มาใช้กับผลิตภัณฑ์ แบ่งออกเป็นขั้นตอนย่อยที่ชัดเจนดังนี้:
-
1) นิยามปัญหาและเลือก Use Case ที่คุ้มค่า
- กำหนด KPI ทางธุรกิจที่ชัดเจน เช่น เพิ่มอัตราการเก็บลูกค้า (retention +3%), ลดต้นทุนการบริการลูกค้า 10% หรือเพิ่มอัตราแปลง (conversion) 2–5%
- ประเมินความเสี่ยงและความซับซ้อนของการปฏิบัติการ (operational complexity) เพื่อเลือกเป็น POC ก่อน
-
2) ประเมินความพร้อมของข้อมูลและสถาปัตยกรรมพื้นฐาน
- ตรวจสอบปริมาณ (volume), ความต่อเนื่อง (velocity), ความหลากหลาย (variety), และคุณภาพ (quality) ของข้อมูล
- ทำ Data Profiling, Missing Value Analysis และ Data Lineage เพื่อระบุแหล่งข้อมูลหลักและจุดคอขวด
- ประเมินสถาปัตยกรรมพื้นฐาน (DB, Data Warehouse, Data Lake, streaming) และความสามารถด้านการจัดเก็บ/เข้าถึงข้อมูล เช่น latency ของการอ่านข้อมูลสำหรับ inference
- ถ้าพบปัญหาข้อมูล แนะนำให้ลงแผนงานแก้ไขก่อนลงทุนโมเดลซับซ้อน เช่น การเพิ่มการติดแท็กข้อมูล (labeling) และการจัดเก็บคุณสมบัติ (feature store)
-
3) ทดลองแบบ POC โดยเริ่มจาก Baseline Model
- ออกแบบ POC ที่มีขอบเขตจำกัด วัดผลด้วย KPI ที่กำหนด และตั้งเกณฑ์ความสำเร็จ (success criteria)
- เริ่มด้วยโมเดลง่าย ๆ (logistic regression, decision tree, simple neural network) เพื่อสร้าง baseline ก่อนจึงค่อยทดสอบโมเดลที่ซับซ้อนขึ้น
- ใช้วิธีการทดลองที่ดี เช่น cross-validation, A/B testing หรือ holdout set เพื่อประเมินความแน่นอนของผลลัพธ์
-
4) เลือกเทคโนโลยีและสแต็กที่เหมาะสม
- พิจารณาเครื่องมือและเฟรมเวิร์กที่สอดคล้องกับทักษะทีมและเป้าหมาย เช่น scikit-learn สำหรับโมเดลง่าย, TensorFlow/PyTorch สำหรับ deep learning, และเครื่องมือ MLOps เช่น MLflow, Kubeflow, TFX, Seldon
- ตัดสินใจระหว่าง cloud (AWS/GCP/Azure) หรือ on-premises โดยพิจารณาด้านความปลอดภัย ค่าใช้จ่าย และ latency ในการให้บริการ
- วางแผนโครงสร้างพื้นฐานสำหรับการเทรน การบริหารโมเดล และการให้บริการ (inference) รวมทั้ง feature store, model registry, และระบบคิว/streaming ถ้าจำเป็น
-
5) ตั้งทีมข้ามสายและกำหนดบทบาทชัดเจน
- จัดทีมข้ามสายที่ประกอบด้วย Product Manager, Data Engineer, ML Engineer/Scientist, DevOps/Infra และตัวแทนจากธุรกิจ/QA
- กำหนดหน้าที่รับผิดชอบ เช่น ผู้นำ product กำหนด KPI และ roadmap, data engineer ดูแล pipeline และคุณภาพข้อมูล, ML engineer ดูแลการเทรน/serving และ MLOps
- ส่งเสริมการสื่อสารด้วยระบบ backlog, sprint และการประชุมรีวิวผล POC เป็นประจำ
-
6) วางกระบวนการ MLOps ตั้งแต่ต้น
- ออกแบบ CI/CD สำหรับโมเดล: automated testing, model validation, deployment pipelines, และ rollback mechanisms
- กำหนดนโยบาย governance และ compliance: เวอร์ชันข้อมูล, audit trail, การจัดการคำขอการอธิบายโมเดล (explainability) และการปกป้องข้อมูลส่วนบุคคล
-
7) ขยายผลและการจัดการในระยะยาว
- เมื่อ POC สำเร็จ ให้วางแผน rollout แบบค่อยเป็นค่อยไป เช่น canary release หรือ gradual ramp-up พร้อมการติดตาม KPI แบบเรียลไทม์
- จัดกระบวนการรีเทรน (scheduled/triggered retraining), การตรวจจับ drift, และแผนการรักษา/ปรับปรุงโมเดล
เพื่อให้การนำ ML ประสบความสำเร็จ ควรกำหนดตัวชี้วัดความสำเร็จ (KPIs) ทั้งเชิงเทคนิคและเชิงธุรกิจ ตัวอย่างที่ควรติดตาม ได้แก่:
- Technical KPIs: Accuracy/Precision/Recall/F1 (ตามความเหมาะสมของปัญหา), AUC-ROC, inference latency (เช่น target <100–300 ms สำหรับ real-time services), throughput (requests/sec), model size และ resource utilization
- Operational KPIs: Time-to-deploy, % automated tests passed, mean time to recovery (MTTR) เมื่อเกิดปัญหา, จำนวนงาน retraining ต่อเดือน
- Business KPIs: Business uplift เช่น % เพิ่มยอดขายหรือ % ลด churn จาก A/B testing, ROI ของโครงการ (payback period), ค่าใช้จ่ายต่อการได้มาซึ่งลูกค้า (CAC) ที่ปรับปรุง
ท้ายที่สุด ให้ยึดหลักการทดลองอย่างรวดเร็วและเป็นระบบ: เริ่มจากโมเดลง่าย วัดผลเชิงธุรกิจอย่างเข้มงวด แล้วค่อยเพิ่มความซับซ้อนทางเทคนิคเมื่อข้อมูลและโครงสร้างพื้นฐานพร้อม การมีทีมข้ามสายที่ชัดเจนและกระบวนการ MLOps ที่ดีจะช่วยเปลี่ยน POC ให้กลายเป็นบริการที่เสถียรและสร้างคุณค่าอย่างต่อเนื่อง
บทสรุป
การเรียนรู้ของเครื่อง (Machine Learning) เป็นเครื่องมือทรงพลังที่สามารถยกระดับประสบการณ์ผู้ใช้และผลลัพธ์ทางธุรกิจได้อย่างมีนัยสำคัญเมื่อถูกนำมาออกแบบและใช้งานอย่างรอบคอบ: ตัวอย่างเช่น การปรับแต่งเนื้อหาและคำแนะนำ (personalization) ช่วยเพิ่มอัตราการมีส่วนร่วมและ conversion, การทำนายความต้องการหรือการบำรุงรักษาเชิงคาดการณ์ลดค่าใช้จ่ายการหยุดทำงาน, และการตรวจจับความผิดปกติช่วยเสริมความมั่นคงของระบบ งานวิจัยและการสำรวจหลายแห่งชี้ว่าการนำ ML มาใช้อย่างมีกรอบงานที่ชัดเจนสามารถเพิ่มประสิทธิภาพหรือรายได้ได้ในระดับที่น่าสนใจ ขณะเดียวกันความสำเร็จของโครงการ ML ไม่ได้ขึ้นกับเทคโนโลยีเพียงอย่างเดียว แต่ต้องผสานทั้งโครงสร้างพื้นฐานข้อมูล กระบวนการทางวิศวกรรม และแนวปฏิบัติด้านจริยธรรม เช่น การจัดการอคติ ความเป็นส่วนตัว และความสามารถในการอธิบายผล (explainability)
แนวทางปฏิบัติที่แนะนำสำหรับองค์กรคือเริ่มจากกรณีการใช้งานที่ชัดเจนและมีเป้าหมายทางธุรกิจที่วัดผลได้ ลงทุนในการสร้างข้อมูลคุณภาพสูงและระบบ MLOps ที่รองรับการพัฒนา การทดสอบ การนำขึ้นผลิตจริง และการตรวจสอบอย่างต่อเนื่อง รวมถึงการตั้ง KPI และกลไกการติดตามผลเพื่อปรับแต่งโมเดลตามผลลัพธ์จริง ตัวอย่างการดำเนินการที่ได้ผลรวมถึงการตั้งทีมข้ามสายงาน (data scientists, engineers, product owners และฝ่ายกฎหมาย/จริยธรรม) การสร้าง pipeline สำหรับข้อมูลและโมเดล และการใช้งานระบบมอนิเตอริ่งเพื่อตรวจจับการเสื่อมสภาพของโมเดล การลงทุนด้าน MLOps และการกำกับดูแลที่ดีมักช่วยลดความเสี่ยงและเวลาในการ deploy ขึ้นสู่การใช้งานจริงอย่างมีนัยสำคัญ
ในมุมมองอนาคต การเรียนรู้ของเครื่องจะผสานเข้ากับกระบวนการทางธุรกิจอย่างลึกซึ้งขึ้น ด้วยแนวโน้มเช่น MLOps อัตโนมัติ, การประมวลผลที่ปลายทาง (edge ML), และการกำกับดูแลด้าน AI ที่เข้มงวดมากขึ้น องค์กรที่วางพื้นฐานด้านข้อมูล กระบวนการ และจริยธรรมได้ดีกว่าจะได้เปรียบเชิงแข่งขัน ไม่เพียงแต่จากผลลัพธ์เชิงตัวเลขเท่านั้น แต่ยังจากความน่าเชื่อถือและความยั่งยืนของบริการ AI ที่ตอบโจทย์ผู้ใช้และกฎหมายควบคุมในระยะยาว
📰 แหล่งอ้างอิง: BetaNews



