
DevOps + LLM กำลังพลิกโฉมวิธีการพัฒนาและส่งมอบซอฟต์แวร์อย่างรวดเร็ว: เมื่อโมเดลภาษาขนาดใหญ่ (LLM) ถูกผสานเข้าเป็นส่วนหนึ่งของท่อ CI/CD ระบบสามารถตรวจจับช่องโหว่และบั๊กอัตโนมัติ สร้างแพตช์ที่เป็นไปได้ และรันชุดเทสต์ก่อนการดีพลอยจริง ทำให้การตอบสนองต่อปัญหาเร็วขึ้น และลดงานซ้ำซ้อนที่ทีมวิศวกรต้องทำซ้ำ ๆ ตัวอย่างเช่น องค์กรที่เริ่มนำการอัตโนมัติการแก้ไขระดับเบื้องต้นเข้ามาในกระบวนการพัฒนา รายงานการลดค่า MTTR (Mean Time To Repair) ได้ตั้งแต่ราว 30–50% และเปลี่ยนเวลาจากการแก้บั๊กหลายวันให้เหลือเป็นชั่วโมงในหลายกรณี
บทนำนี้จะชี้ให้เห็นประเด็นสำคัญ: วิธีการเชื่อม LLM เข้ากับท่อ CI/CD (ทั้งใน pre-merge และ post-commit), ขั้นตอนการตรวจจับช่องโหว่ (static analysis, dynamic analysis, SCA) ที่ LLM สามารถช่วยแปลผลได้, กระบวนการสร้างแพตช์อัตโนมัติ และการรันเทสต์อัตโนมัติก่อนดีพลอยเพื่อยืนยันความถูกต้องของการแก้ไข การออกแบบเช่นนี้ไม่เพียงลด MTTR และภาระงานซ้ำซ้อนของทีมพัฒนา แต่ยังช่วยเพิ่มความสอดคล้องของมาตรฐานความปลอดภัยโดยการบังคับให้แพตช์ผ่านเกทของ CI/CD ก่อนขึ้นโปรดักชัน
ในขณะเดียวกัน บทความจะเตือนถึงข้อควรระวังที่สำคัญ: LLM อาจสร้างแพตช์ที่ดูสมเหตุสมผลแต่ผิดพลาด (hallucination), ข้อจำกัดของชุดเทสต์ที่อาจไม่ครอบคลุมกรณีขอบ (edge cases), และความจำเป็นของการกำกับดูแล—เช่นการมี human-in-the-loop, การบันทึก audit trail, และมาตรฐานมาตรการความปลอดภัย ก่อนที่องค์กรจะนำระบบนี้มาใช้อย่างแพร่หลาย บทความฉบับเต็มจะลงลึกทั้งแนวทางปฏิบัติ ตัวอย่างการใช้งานจริง และแนวทางบริหารความเสี่ยงเพื่อให้ผู้อ่านเห็นภาพทั้งโอกาสและข้อจำกัดอย่างชัดเจน
บทนำ: ทำไมต้องผสาน LLM กับ DevOps
บทนำ: ทำไมต้องผสาน LLM กับ DevOps
ในสภาพแวดล้อมการพัฒนาซอฟต์แวร์สมัยใหม่ ปัญหาการตรวจพบข้อผิดพลาดและการแก้บั๊กยังคงเป็นคอขวดสำคัญที่ทำให้เวลาออกผลิตภัณฑ์ล่าช้าและต้นทุนเพิ่มขึ้น กระบวนการแก้บั๊กแบบดั้งเดิมมักมีข้อจำกัดหลายประการ เช่น ระยะเวลาการตรวจพบที่ช้า (time to detect), MTTR (Mean Time to Repair) ที่สูง และปริมาณงานค้าง (backlog) ที่ทับซ้อน ซึ่งทำให้ทีมวิศวกรรมต้องสลับบริบทบ่อยครั้ง (context switching) ส่งผลให้ประสิทธิภาพการทำงานลดลงและความล่าช้าในการส่งมอบคุณสมบัติใหม่ ตัวอย่างเช่น รายงานด้านประสิทธิภาพการพัฒนาซอฟต์แวร์ชี้ว่าองค์กรชั้นนำ (Elite) มี MTTR ต่ำกว่าองค์กรทั่วไปอย่างมีนัยสำคัญ และสามารถปล่อยซอฟต์แวร์ได้บ่อยครั้งขึ้น ทั้งนี้ปัญหาที่พบบ่อยคือการค้นหา root cause ช้า การสร้างแพตช์ต้องใช้เวลา และการทดสอบที่ไม่ครอบคลุมทำให้ข้อผิดพลาดกลับมาเกิดซ้ำอีก
ในบริบทนี้ Large Language Models (LLMs) กลายเป็นเครื่องมือที่น่าสนใจ เพราะมีความสามารถในการวิเคราะห์โค้ด การตีความคอนเท็กซ์ของบรรทัดโปรแกรม และการเสนอแนะแพตช์อัตโนมัติได้อย่างรวดเร็ว LLM ที่ผ่านการฝึกด้วยข้อมูลโค้ดและเอกสารทางเทคนิคสามารถสกัด pattern ของบั๊กที่พบบ่อย และสร้างโค้ดตัวอย่างหรือแพตช์ที่ตรงจุดได้ภายในเวลาไม่กี่วินาทีถึงนาที นอกจากนี้ LLM ยังสามารถสร้างชุดเทสต์อัตโนมัติ (unit/integration tests) หรือข้อเสนอแนะในการปรับปรุง static analysis rules ซึ่งเมื่อรวมเข้ากับ pipeline ของ CI/CD จะช่วยให้การตรวจจับและยืนยันการแก้ไขเกิดขึ้นก่อนการดีพลอยจริง
ความท้าทายในกระบวนการแก้บั๊กที่องค์กรมักเผชิญ สรุปได้เป็นหัวข้อสำคัญดังนี้
- MTTR สูง — เวลาที่ใช้ในการค้นหาและแก้ไขบั๊กส่งผลต่อความต่อเนื่องของธุรกิจและความพึงพอใจของลูกค้า
- Backlog สะสม — ปริมาณปัญหาที่ยังไม่ได้แก้ทำให้ทีมต้องจัดลำดับความสำคัญจนละเลยข้อบกพร่องที่สำคัญ
- Context switching — วิศวกรต้องหยุดงานที่กำลังทำเพื่อไปแก้บั๊ก ส่งผลให้ productivity ลดลงและเกิดความผิดพลาดเพิ่มเติม
เมื่อผสาน LLM เข้ากับกระบวนการ DevOps แล้ว จะเกิดประโยชน์เชิงธุรกิจและเชิงเทคนิคที่ชัดเจน: การลดเวลาในการแก้ไขบั๊ก ทำให้ MTTR ลดลง การสร้างแพตช์และการทดสอบอัตโนมัติใน CI/CD ช่วยลด backlog และลดการสลับบริบทของวิศวกร ทำให้องค์กรสามารถปล่อยซอฟต์แวร์ได้ถี่ขึ้นและรวดเร็วขึ้น—จากการสังเกตในตลาด การนำ automation และ AI เข้าร่วมกับ CI/CD มักทำให้อัตราการปล่อย (deployment frequency) เพิ่มขึ้นอย่างมีนัยสำคัญ และลดความเสี่ยงจากการดีพลอยที่มีปัญหา
ท้ายที่สุด การนำ LLM มาช่วยในวงจร DevOps ไม่ได้หมายความว่าแทนที่มนุษย์ แต่อยู่ในบทบาทของการเสริมความสามารถ (augmentation) โดยทำหน้าที่เป็นผู้ช่วยในการค้นหา สร้างแพตช์ และรันเทสต์เบื้องต้น ก่อนส่งให้วิศวกรตรวจสอบและอนุมัติ ซึ่งเป็นแนวทางที่ช่วยรักษาคุณภาพซอฟต์แวร์ ลดต้นทุนเวลาทำงาน และเพิ่มความเร็วในการนำคุณค่าใหม่สู่ตลาด หากออกแบบการบูรณาการอย่างรัดกุมพร้อมกับมาตรการตรวจสอบและการมอนิเตอร์ จะสามารถเก็บเกี่ยวผลประโยชน์ทั้งเชิงธุรกิจและเชิงเทคนิคได้อย่างยั่งยืน
สถาปัตยกรรม: การผนวก LLM เข้ากับ CI/CD
สถาปัตยกรรมโดยรวม: LLM เป็นบริการกลางใน CI/CD
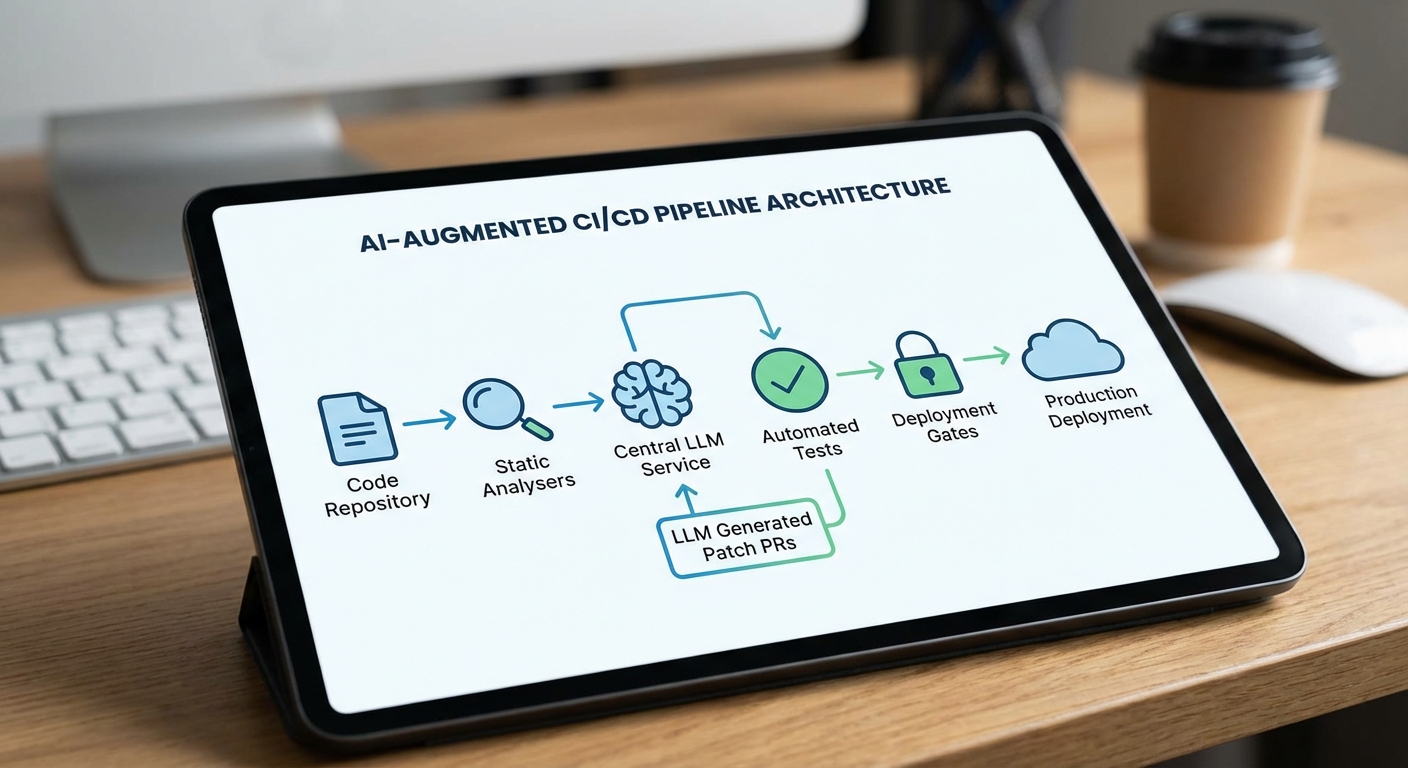
สถาปัตยกรรมที่นิยมสำหรับการผนวก Large Language Model (LLM) เข้ากับระบบ CI/CD มักออกแบบให้ LLM ทำหน้าที่เป็น บริการกลาง (centralized service) ที่รับข้อมูลจากหลายแหล่ง เช่น static analysis, SAST/DAST, SCA และ trigger ต่าง ๆ ใน pipeline (push, PR, nightly scan) ก่อนประมวลผลและผลลัพธ์จะถูกส่งกลับไปยังระบบ pipeline เพื่อสร้างแพตช์ โค้ด หรือสร้าง PR อัตโนมัติ การวาง LLM ในลักษณะนี้ช่วยให้มีจุดควบคุมเดียวสำหรับนโยบายความปลอดภัย การเก็บบันทึก (audit), การจัดการเวอร์ชันของ prompt และการผสานกับ tooling อื่น ๆ อย่างเป็นระบบ

ไหลการทำงานตั้งแต่การตรวจจับไปสู่การสร้างแพตช์อัตโนมัติ
Flow พื้นฐานประกอบด้วยขั้นตอนสำคัญดังนี้:
- Trigger — เหตุการณ์จาก pre-commit hooks, push/PR events หรือ nightly vulnerability scans กระตุ้นให้ pipeline ทำงาน
- Detection — SAST/DAST, SCA และ static analysis รายงานข้อบกพร่องหรือช่องโหว่ พร้อม metadata (ไฟล์, บรรทัด, vulnerability ID, CVE และคะแนนความร้ายแรง)
- Context aggregation — บริการจะรวมข้อมูลทั้งหมด: code snippet, stack trace, reproducer tests, dependency tree, CI logs และ test results เพื่อเตรียมข้อมูลเข้าสู่ LLM
- Patch generation — LLM สร้างโค้ดแก้ไขหรือแนะนำการแก้ พร้อมคำอธิบายเหตุผลและ list ของ unit/integration tests ที่เกี่ยวข้อง
- Validation — แพตช์ถูกรันผ่าน sandboxed CI runner เพื่อรัน unit/integration/e2e tests และ SAST/DAST ซ้ำอัตโนมัติ
- PR/Approval — หากผ่าน validation ระบบสามารถสร้าง PR อัตโนมัติและตั้งค่า reviewer/approval gates ก่อน merge
จุดเชื่อมต่อสำคัญ: pre-commit, PR analysis และ nightly scans
ระบบต้องรองรับการเชื่อมต่อกับจุดต่าง ๆ ในวงจรพัฒนาเพื่อให้ครอบคลุมทั้งการป้องกันล่วงหน้าและการแก้ไขภายหลัง:
- Pre-commit hooks — รัน lightweight checks และเรียก LLM ในโหมดแนะนำเร็วสำหรับโค้ดที่เพิ่งเขียน เพื่อจับปัญหาเบื้องต้นก่อน push
- PR analysis — เมื่อสร้าง PR ให้ทำการวิเคราะห์เชิงลึกกับ LLM โดยส่ง diff, intention (จาก PR description), failing tests และไฟล์ที่เกี่ยวข้อง เพื่อให้ LLM สร้าง patch เฉพาะส่วนที่เปลี่ยน
- Nightly vulnerability scan — สแกนแบบครบถ้วนด้วย SCA/SAST/DAST เป็นรอบเพื่อจับ issue ที่ไม่ปรากฏในการ commit ตามปกติ และให้ LLM สร้าง PR แก้ไขอัตโนมัติเป็นชุด (batch remediation)
การเก็บและส่งมอบ Context เพื่อความแม่นยำของ LLM
ความแม่นยำของการแก้ไขขึ้นกับ context ที่ให้กับ LLM จำเป็นต้องรวบรวมข้อมูลเชิงลึกเพื่อให้แก้ไขได้ตรงจุดและปลอดภัย:
- Reproducer — ตัวอย่างการรันที่ทำให้เกิดบั๊ก (minimal repro) จะช่วยให้ LLM เข้าใจเงื่อนไขที่ทำให้เกิดปัญหา
- Stack trace และ runtime logs — บ่งชี้ตำแหน่งปัญหาและ data flow ที่เกี่ยวข้อง
- Test cases — unit/integration tests ที่ล้มเหลวหรือที่เกี่ยวข้อง ควรถูกแนบเพื่อให้ LLM ปรับโค้ดโดยยังคงผ่านเทสต์
- Dependency & SCA metadata — เวอร์ชันไลบรารี, CVE ID, remediation path (upgrade/patch/mitigation)
- Code diffs และ PR intent — ช่วยให้ LLM ทำการแก้เฉพาะบริบทของการเปลี่ยนแปลง ไม่เปลี่ยนตามอำเภอใจ
เทคนิคเพิ่มเติมเช่นการจัดเก็บ context ใน Vector DB เพื่อ retrieval-aware prompting, การใช้ prompt templates ที่รวม test outputs และการจำกัดขนาด prompt จะช่วยให้ผลลัพธ์มีคุณภาพสูงและสามารถทำซ้ำได้
กลไกการอนุมัติ: automated PR + human-in-the-loop
แม้ระบบจะสามารถสร้างแพตช์และ PR อัตโนมัติได้ แต่การผสาน human-in-the-loop ยังเป็นสิ่งจำเป็นเพื่อความปลอดภัยและความรับผิดชอบ:
- Automated PR creation — เมื่อแพตช์ผ่านชุดทดสอบและ static checks ระบบสร้าง PR พร้อมรายละเอียดการเปลี่ยนแปลง, testผลลัพธ์, และ risk assessment
- Reviewer & approval gates — ตั้งค่า branch protection rules ให้ PR ต้องได้รับการอนุมัติจาก reviewer อย่างน้อยหนึ่งคนหรือจาก security approver ก่อน merge
- Policy engine — ใช้ policy ที่กำหนด เช่น ห้ามแก้ dependency ให้ข้าม major upgrade โดยไม่ผ่าน manual review หรือห้ามแก้โค้ดในส่วนที่มี sensitive domain โดยอัตโนมัติ
- Audit trail และ explainability — บันทึก prompt, LLM response, test logs และเหตุผลที่ใช้ในการแก้ เพื่อการตรวจสอบย้อนหลังและ compliance
การกำหนด SLA และ KPI เช่น time-to-fix ลดลง 30–50% ในการทดลองภายในหรือสภาพแวดล้อมบางกรณี จะช่วยชี้วัดผลประโยชน์ทางธุรกิจและความเสี่ยงที่เหลือ
ข้อพิจารณาด้านความปลอดภัยและการปฏิบัติ
เมื่อผนวก LLM ในวงจร CI/CD ต้องพิจารณาเรื่องความปลอดภัยและความน่าเชื่อถืออย่างเข้มงวด เช่น การรันแพตช์ใน sandboxed runners, การจำกัดสิทธิ์ของ service account ที่ LLM ใช้, การทำ code signing หลัง merge และการตรวจสอบย้อนกลับ (post-merge monitoring) เพื่อจับ regression หรือ false positive ที่อาจเกิดขึ้น การตั้ง guardrails และ human approval points ช่วยลดความเสี่ยงจากการแก้ไขอัตโนมัติที่อาจก่อผลกระทบต่อระบบผลิตจริง
การตรวจจับและจัดลำดับความสำคัญของบั๊กด้วย LLM
การรวบรวมสัญญาณ (Signal Aggregation)
การตรวจจับช่องโหว่ที่มีความแม่นยำสูงต้องเริ่มจากการรวบรวมสัญญาณหลายมิติ โดยทั่วไประบบ CI/CD ที่ผสาน LLM จะดึงข้อมูลจากแหล่งหลัก 3 ประการ ได้แก่ static analysis (เช่นผลจากเครื่องมือ SAST/linters), runtime traces (เช่น stack traces, logs, telemetry จากการรันทดสอบ) และ dependency vulnerabilities (เช่นรายการ CVE จากฐานข้อมูลแพ็กเกจ) การรวบรวมข้อมูลเหล่านี้เป็นชุดสัญญาณร่วม (multimodal signals) ช่วยให้โมเดลสามารถเปรียบเทียบความสอดคล้องของเหตุการณ์ เช่น ถ้าการสแกนโค้ดระบุการใช้ฟังก์ชันอันตรายแต่ log ระบุว่าเส้นทางโค้ดนั้นไม่เคยถูกรันจริง ก็อาจเป็นกรณี false positive
ตัวอย่างการรวบรวมสัญญาณเชิงปฏิบัติ: ระบบจะผสานผลจาก SAST (เช่น 120 รายการแจ้งเตือน), DAST (35 รายการที่พบจากการทดสอบรันไทม์) และฐานข้อมูล dependency (5 รายการ CVE ในไลบรารีที่ใช้) แล้วให้ LLM วิเคราะห์ภาพรวมเพื่อคัดกรองแจ้งเตือนที่มีความเป็นไปได้สูงสุด
การใช้ LLM เพื่อลด False Positives และให้คำอธิบายเชิงบริบท
LLM ถูกออกแบบมาเพื่อเข้าใจบริบทภาษาธรรมชาติและโค้ด จึงสามารถนำมาวิเคราะห์ผลสแกนเพื่อแยกแยะ false positives ได้ดีกว่ากฎตายตัว ตัวอย่างวิธีปฏิบัติที่นิยมใช้คือการป้อนสัญญาณร่วมเป็น prompt เพื่อให้ LLM ประเมินความน่าเชื่อถือของแจ้งเตือน เช่นการส่ง snippet โค้ด, ข้อความแจ้งเตือนจาก SAST, ตัวอย่าง stack trace และ metadata (file path, branch, commit id) ให้โมเดล และขอให้โมเดลให้คะแนนความน่าเชื่อ (confidence) พร้อมคำอธิบายสั้น ๆ ว่าเหตุใดจึงเป็นจริงหรือเป็นเท็จ
การลด false positives ทำได้ในรูปแบบดังนี้:
- Cross-check ระหว่าง static findings กับ runtime evidence — ถ้ามี log หรือ unit test ที่แสดงว่าเส้นทางนั้นไม่เคยถูกรัน โมเดลจะลดน้ำหนักแจ้งเตือน
- Dependency context — ถ้า CVE ที่พบไม่เกี่ยวกับเวอร์ชันที่ใช้งานจริง (เช่น patched ใน lockfile) โมเดลจะระบุว่าเป็น false positive
- Exploitability hints — โมเดลประเมินว่าโค้ดที่ค้นพบเปิดเผยพารามิเตอร์จากภายนอกหรือไม่ (input-controlled) เพื่อแยกแยะระดับความเสี่ยง
การจัดลำดับความเสี่ยง (Risk Prioritization) และ Actionable Summary
เมื่อ LLM ประเมินความถูกต้องของแจ้งเตือนได้แล้ว ขั้นตอนต่อไปคือการจัดลำดับตามความเสี่ยงโดยพิจารณา exploitability (เช่น entry points, authentication bypass, input control) และ impact (เช่น data exposure, RCE, service disruption) โมเดลสามารถให้คะแนนความเสี่ยงแบบเชิงตัวเลขและแปลงเป็นระดับ (Critical / High / Medium / Low)
ผลลัพธ์ที่ได้ควรถูกจัดเตรียมเป็น actionable summary สำหรับทีมพัฒนา ซึ่งประกอบด้วยรายการสรุปสั้น ๆ ที่อ่านเข้าใจได้ทันที เช่น:
- ความรุนแรง: High
- เหตุผล: Input validation ขาดใน endpoint /api/upload ทำให้เกิด file path traversal
- exploitability: เชิงปฏิบัติ (มีตัวอย่าง payload ที่ใช้งานได้ใน log)
- Recommendation เบื้องต้น: ตรวจสอบและเพิ่ม validation, ใช้ safe API สำหรับไฟล์, เพิ่ม unit test สำหรับกรณีนี้
- Suggested fix snippet: (ลิงก์ไปยัง PR หรือ patch ที่สร้างโดยระบบอัตโนมัติ)
ตัวอย่าง Prompt และ Few-shot Learning เพื่อเพิ่มประสิทธิภาพ
การออกแบบ prompt ที่มีความชัดเจนและ few-shot examples ช่วยให้ LLM ตอบได้แม่นยำขึ้น ตัวอย่าง prompt แบบสังเคราะห์ (ภาษาไทย) ที่ใช้ใน pipeline:
- Prompt Template: "ให้ประเมินความน่าเชื่อถือของแจ้งเตือนความปลอดภัยต่อไปนี้ โดยพิจารณาจาก snippet โค้ด, ข้อความของ SAST, log ที่เกี่ยวข้อง และรายการเวอร์ชันของ dependency. ให้คะแนนความน่าเชื่อถือ (0-100), อธิบายสั้น ๆ ว่าเหตุใด และแนะนำ 1-2 ขั้นตอนการแก้ไขอย่างสั้น."
- Few-shot Examples (สองตัวอย่าง):
- Example 1: SAST แจ้งเตือนว่าใช้ eval() ในไฟล์ utils.js. Snippet: ... Log: ไม่มีการเรียกใช้ในรันทดสอบ. Dependency: ไม่มี. Output ที่คาดหวัง: confidence=25, explanation="ฟังก์ชัน eval ถูกพบแต่ไม่มี evidence ว่าถูกเรียกจาก input ภายนอก", recommendation="เพิ่ม unit test และหากไม่จำเป็นให้ลบฟังก์ชัน"
- Example 2: SAST แจ้ง SQL injection จุดหนึ่ง, Snippet แสดงว่า query ประกอบจาก request.params.userId, Log แสดง stack trace จากการ request ที่มี payload แปลก. Output: confidence=90, explanation="parameter ถูกต่อเข้ากับ query โดยตรงและมี evidence จาก log", recommendation="ใช้ parameterized query และเพิ่มตรวจสอบ input"
การใช้ few-shot learning ช่วยให้โมเดลเรียนรู้รูปแบบการตัดสินใจและภาษาที่ต้องการสำหรับ actionable summary นอกจากนี้สามารถบังคับให้โมเดลส่งผลลัพธ์ในรูปแบบโครงสร้าง (เช่น JSON หรือ YAML) เพื่อให้ระบบอัตโนมัติสามารถอ่านและสร้าง issue/PR ต่อได้อย่างราบรื่น
สรุปการนำไปใช้งานในองค์กร
การผสาน LLM เข้ากับ pipeline ตรวจสอบความปลอดภัยช่วยสร้างมูลค่าชัดเจน โดยเฉพาะในด้านการลด false positives, เพิ่มความชัดเจนของคำอธิบาย และจัดลำดับตามความเสี่ยงอย่างเป็นระบบ การปฏิบัติที่แนะนำสำหรับองค์กรได้แก่:
- รวบรวมสัญญาณแบบ multimodal (static, runtime, dependency)
- ผลลัพธ์ต้องเป็น actionable summary ที่เชื่อมโยงกับ PR/issue automation
- ติดตามเมตริก เช่น อัตรา false positives, MTTR และเวลาที่ทีมใช้ตรวจสอบ เพื่อประเมินผล
การสร้างแพตช์โดยอัตโนมัติ: Workflow และตัวอย่าง
ภาพรวม Workflow การสร้างแพตช์โดยอัตโนมัติ
การสร้างแพตช์โค้ดโดยใช้ LLM ใน CI/CD ควรถูกออกแบบเป็น workflow แบบหลายขั้นตอนที่ผสานเครื่องมืออัตโนมัติและการควบคุมจากมนุษย์เพื่อรักษาคุณภาพและความปลอดภัยของซอฟต์แวร์ โดยทั่วไป workflow จะประกอบด้วยขั้นตอนสำคัญดังนี้: (1) ตรวจจับปัญหาโดยเครื่องมือ Static Analysis/Runtime Monitoring (เช่น Semgrep, Snyk, Error Reporting), (2) สั่งให้ LLM วิเคราะห์บริบทและเสนอแพตช์ตาม prompt/template ที่เตรียมไว้, (3) สร้างผลลัพธ์เป็นรูปแบบ diff หรือ PR พร้อม unit/integration tests ที่จำเป็น, (4) รัน pipeline บน CI เพื่อรันชุดทดสอบและตรวจความปลอดภัย, (5) เปิดให้ทีมรีวิวหรือทำการดีพลอยตาม policy อัตโนมัติ
รูปแบบการเรียก LLM: Direct edit vs. Generate diff vs. Suggested change in PR comment
มี 3 รูปแบบการเรียก LLM ที่นิยมในระบบ CI/CD:
- Direct edit — ให้ LLM แก้ไฟล์โดยตรงและคอมมิทการเปลี่ยนแปลง (เหมาะกับการแก้บั๊กเล็กหรือโค้ดที่ไม่เสี่ยงสูง แต่ต้องมี guardrails เช่น branch protection และ automated tests)
- Generate diff — ให้ LLM ส่งผลลัพธ์เป็น git diff หรือ patch file ซึ่ง CI จะนำไปทดสอบและถ้าโอเคจะสร้าง PR ให้ (สมดุลระหว่างอัตโนมัติและการควบคุม)
- Suggested change in PR comment — LLM วิเคราะห์ไฟล์และโพสต์ข้อเสนอแนะเป็นคอมเมนต์ใน PR (เหมาะกับกรณีที่ต้องการให้มนุษย์ตัดสินใจขั้นสุดท้าย)
ข้อดี/ข้อเสีย: direct edit เร็วสุดแต่เสี่ยง, generate diff ให้ auditing และ deterministic มากขึ้น, PR comment เหมาะกับ workflow ที่ให้ผู้พัฒนารับผิดชอบการตัดสินใจ
Prompt engineering, templates และตัวอย่าง prompt
การออกแบบ prompt และ template เป็นหัวใจสำคัญเพื่อให้ LLM สร้างแพตช์ที่ถูกต้องและตรวจสอบได้ ควรมีส่วนประกอบหลักดังนี้: context ของไฟล์ (ส่วนสำคัญของฟังก์ชัน), ข้อความอธิบายบั๊กหรือช่องโหว่, test case ที่ล้มเหลว (reproduction), ข้อจำกัดด้านความปลอดภัย (เช่น ห้ามใช้ reflection หรือ exec), และรูปแบบผลลัพธ์ที่ต้องการ (git diff/PR body/patch file)
ตัวอย่าง template แบบย่อ:
- Context: ใส่โค้ดฟังก์ชันที่เกี่ยวข้อง (ไม่เกินขนาดที่ LLM รับได้)
- Issue: อธิบายพฤติกรรมที่ผิดพลาดและเหตุการณ์ reproduction
- Tests: แนบ unit test ที่ล้มเหลวหรือ testcase reproduction
- Output format: "Return a git diff only. Include a new/modified test that reproduces the issue."
แนวทางแนบ Unit/Integration Tests และ Testcase Reproduction
การแนบชุดทดสอบเป็นส่วนที่จำเป็นเพื่อยืนยันว่าแพตช์ของ LLM แก้ปัญหาได้จริงและไม่สร้างการถดถอยใหม่ ควรปฏิบัติดังนี้:
- สร้างไฟล์ทดสอบแบบ minimal reproduction ที่แสดงอาการผิดพลาด (เช่น pytest หรือ JUnit) และส่งเป็น input ให้ LLM
- ให้ LLM ผลิตทั้งโค้ดที่แก้ไขและ/หรือทดสอบใหม่ที่ป้องกัน regression (เช่น เพิ่ม assertion ของกรณีพิเศษ)
- ใน CI ระบุขั้นตอนให้รันทั้ง unit และ integration tests พร้อม static analysis ก่อน merge
ตัวอย่าง pseudo-test (reproduction) ที่ส่งให้ LLM:
# Reproduction test (pseudo)
assert process_input("DROP TABLE users;") == "Invalid input" # เกิด SQL injection ก่อนแก้ไข
ตัวอย่างโค้ดก่อน-หลัง (pseudo-code)
ตัวอย่างก่อนแก้ไข (vulnerable):
def execute_query(q):
conn.execute("SELECT * FROM items WHERE name = '" + q + "'")
return conn.fetchall()
ตัวอย่างหลังแก้ไขโดย LLM (patch ที่คาดหวัง):
def execute_query(q):
safe_q = sanitize(q)
conn.execute("SELECT * FROM items WHERE name = %s", (safe_q,))
return conn.fetchall()
พร้อมเพิ่ม unit test :
def test_execute_query_prevents_injection():
assert execute_query("'; DROP TABLE users; --") == [] # ต้องไม่ทำลาย DB
รูปแบบผลลัพธ์ที่ระบบควรรองรับ (diff/PR/patch) และ metadata
ผลลัพธ์จาก LLM ควรรองรับอย่างน้อยรูปแบบต่อไปนี้:
- git diff/patch file — สามารถนำไปทดสอบแบบอัตโนมัติและบันทึกเป็น artifact
- Pull Request (PR) — รวมคำอธิบายปัญหา, รายการทดสอบที่เพิ่ม, ความเสี่ยง และ metadata เช่น confidence score, rule_id จาก static analysis
- PR comment suggestion — สำหรับ workflow ที่ต้องการ human-in-the-loop
ควรแนบ metadata เช่น source detector (ชื่อสแกนเนอร์), timestamp, LLM model และ prompt hash เพื่อให้ง่ายต่อการ audit
แนวทางจัดการกรณี LLM ให้คำตอบไม่สมบูรณ์หรือเสี่ยง
เมื่อ LLM ให้แพตช์ที่ไม่สมบูรณ์หรือมีความเสี่ยง ระบบ CI/CD ควรมี fallback policy ชัดเจน:
- ปฏิเสธอัตโนมัติ — ถ้าชุดทดสอบยังล้มเหลว หรือ static analysis รายงานความเสี่ยง ให้บล็อกการ merge อัตโนมัติ
- Human review gate — แท็กผู้เชี่ยวชาญที่เกี่ยวข้องให้รีวิว PR พร้อม checklist (security, performance, compatibility)
- Confidence thresholds — ใช้คะแนนความมั่นใจจาก LLM และผลลัพธ์จาก linters/taint-analysis เป็นเงื่อนไขการอนุญาต
- Auto-revert and canary — ดีพลอยแบบค่อยเป็นค่อยไป (canary) และมีสคริปต์ revert อัตโนมัติหากตรวจพบปัญหาใน runtime
- Retry with enhanced prompt — ถ้าแพตช์ไม่สมบูรณ์ ให้รัน flow อีกครั้งโดยส่ง context เพิ่มเติม เช่น stack trace, logs, หรือให้ LLM อธิบายเหตุผลก่อนเสนอแพตช์ใหม่
สรุปเชิงปฏิบัติ
การสร้างแพตช์โดยอัตโนมัติด้วย LLM สามารถลดเวลาแก้ไขบั๊กและช่องโหว่ได้อย่างมีนัยสำคัญ หากออกแบบ workflow ที่รวมการแนบ reproduction tests, ผลลัพธ์ในรูป diff/PR ที่ตรวจสอบได้, และ fallback strategy สำหรับกรณีที่ LLM แนะนำการเปลี่ยนแปลงไม่สมบูรณ์ ตัวอย่างภายในองค์กรขนาดกลางชี้ว่าเมื่อผสาน LLM กับ CI ที่มีการทดสอบและ gating ที่ดี สามารถลดเวลาการแก้บั๊กเฉลี่ยลงได้ (ตัวอย่างการทดลองภายในลดเวลา ~30–40%) แต่การรักษาสมดุลระหว่างความเร็วกับความปลอดภัยยังคงเป็นหัวใจสำคัญ — ดังนั้นควรมีกระบวนการ audit, human-in-the-loop และ automation guardrails ร่วมกัน
การทดสอบและยืนยันความถูกต้องใน CI: Sandbox, Replay และ CI Jobs
ภาพรวมการทดสอบและความต่อเนื่องของ Pipeline
การทดสอบและยืนยันความถูกต้องเป็นหัวใจสำคัญของระบบ CI ที่ใช้ LLM สร้างแพตช์โค้ดอัตโนมัติ โดยแนวทางปฏิบัติที่แนะนำคือ รันการทดสอบก่อนเปิด Pull Request (pre-PR) และรันชุดการทดสอบครบถ้วน (full test suite) ในสาขาของแพตช์ (patch branch) ทุกครั้ง เพื่อหลีกเลี่ยงการนำโค้ดที่ยังมีปัญหาเข้าสู่สาขาหลัก การทำเช่นนี้ช่วยลดความเสี่ยงของการเกิด regression และเพิ่มความเชื่อมั่นก่อนการรีวิวโดยมนุษย์ ตัวอย่าง workflow ทั่วไปคือ: เมื่อ LLM แนะนำแพตช์ ให้ CI ทำการรัน unit tests แบบรวดเร็วทันที ถ้าผ่านจึงดำเนินการรัน integration, e2e, fuzzing และ regression tests ในลำดับถัดไป
ประเภทการทดสอบที่ควรรันหลังแพตช์
ระบบควรครอบคลุมการทดสอบหลายชั้นเพื่อยืนยันความถูกต้องของแพตช์:
- Unit tests — ทดสอบฟังก์ชันหรือโมดูลเดี่ยว ใช้เวลาไม่นาน เหมาะสำหรับรันก่อนเปิด PR (fast feedback)
- Integration tests — ทดสอบการทำงานร่วมกันระหว่างโมดูลและบริการ เพื่อจับปัญหาที่ไม่ได้เกิดในระดับ unit
- End-to-end (E2E) tests — ทดสอบเส้นทางการใช้งานจริงของผู้ใช้หรือ API flow ทั้งระบบ
- Fuzzing — ให้ข้อมูลอิสระหรือข้อมูลที่ผิดรูปแบบกับอินพุตเพื่อตรวจจับช่องโหว่ความทนทาน (robustness)
- Regression tests — รันชุดกรณีทดสอบที่เคยล้มเหลวหรือสำคัญ เพื่อยืนยันว่าแพตช์ไม่ย้อนกลับไปทำให้บั๊กเดิมกลับมา
ค่าเป้าหมายเช่น unit tests ≥ 80% ผ่านภายใน 5 นาที, integration/e2e ผ่านภายใน 30–60 นาที ขึ้นอยู่กับขนาดและสถาปัตยกรรมของระบบ นอกจากนี้ ควรบันทึกเวลารันและอัตราการผ่านของแต่ละชั้นเพื่อติดตามประสิทธิภาพ CI ต่อเนื่อง
Sandbox, Canary และการ Replay Request เพื่อลดความเสี่ยง
การนำแพตช์เข้าสู่ production ควรเป็นไปอย่างค่อยเป็นค่อยไปโดยใช้ sandbox/canary environments ร่วมกับ feature flags ตัวอย่างเช่น ติดตั้งการ deploy แบบ canary โดยส่งทราฟฟิกเพียง 1–5% ไปยังเวอร์ชันที่มีแพตช์เป็นเวลา 24–72 ชั่วโมงเพื่อตรวจวัด error rate และ latency ก่อนจะทยอยเพิ่มสัดส่วน
การทำ replay ของ request เก็บตัวอย่างการเรียกใช้งานจริงจาก production (sanitized/anonymized) มาเล่นซ้ำใน sandbox ช่วยยืนยันว่าแพตช์ไม่ทำให้เส้นทางการทำงานเสียหาย ขั้นตอนสำคัญได้แก่:
- จับและเก็บ request/response ที่เกี่ยวข้อง (strip ข้อมูล PII และข้อมูลลับ)
- ทำ deterministic replay โดยควบคุมเวลาหรือค่า random seed เพื่อให้เทสต์ซ้ำได้ผลสม่ำเสมอ
- รันทดสอบภายใต้โหลดจำลองเพื่อดูผลด้าน performance และ resource consumption
- ผสมการ replay กับ fuzzing บางส่วนเพื่อตรวจหาเคสขอบเขต (edge cases)

ตัวอย่างการตั้งค่า CI Job และการเก็บผลเป็น Audit Trail
ตัวอย่างโครงแบบ CI job (ย่อรูปแบบ) ที่ทำงานร่วมกับ LLM patch flow:
job: llm-patch-test
stage: test
steps:
- checkout code
- run: npm ci && npm run test:unit --fast-fail
- if success: run integration and e2e in parallel
- run fuzzing and regression scheduler (nightly or long-running)
- on complete: upload artifacts & test-metadata to artifact store
สำคัญคือการบันทึกผลการทดสอบและ metadata อย่างละเอียดเพื่อการตรวจสอบย้อนหลัง (audit). ข้อมูลที่ควรเก็บประกอบด้วย:
- ผลการทดสอบ — รายงาน pass/fail, log, stack traces, coverage reports
- Artifact — build binary, container image digest (SHA) เพื่ออ้างอิงเวอร์ชัน
- Metadata เกี่ยวกับ LLM — prompt ที่ส่งให้ LLM, เวอร์ชันโมเดล, temperature/parameters, timestamp และการประเมินความมั่นใจ
- CI run metadata — job id, runner id, commit hash, branch name, environment (sandbox/canary), replay session id
ตัวอย่าง JSON metadata ที่อาจบันทึกเป็น artifact:
{ "commit":"abc1234", "branch":"fix/llm-patch-123", "ci_job":"llm-patch-test-2026-01-01-001", "llm": {"model":"gpt-xyz-v2","prompt_id":"prompt-987","params":{"temp":0.2}}, "tests": {"unit":{"passed":120,"failed":0},"e2e":{"passed":45,"failed":1}}, "artifacts":{"image_sha":"sha256:..."}, "replay_id":"replay-20260101-01", "timestamp":"2026-01-01T12:34:56Z" }
แนวทางปฏิบัติที่เป็นมาตรฐาน
เพื่อให้ระบบมีความน่าเชื่อถือ ควรปฏิบัติตามแนวทางดังนี้:
- รันชุดการทดสอบที่เหมาะสมตามขั้นตอน (pre-PR → branch full suite → canary → full rollout)
- ใช้ sandbox และ replay ในการยืนยันฟังก์ชันที่ซับซ้อน พร้อมป้องกันข้อมูลส่วนบุคคลก่อน replay
- เก็บผลลัพธ์และ metadata ของการทดสอบรวมถึงข้อมูล LLM เป็น audit trail ที่ค้นหาได้ (searchable) และไม่เปลี่ยนแปลง (immutable)
- ตั้งค่าเกณฑ์การยอมรับ (acceptance criteria) อัตโนมัติ เช่น error budget, latency thresholds, และ regression zero-tolerance สำหรับกรณีสำคัญ
การดำเนินการตามกรอบนี้จะช่วยให้องค์กรสามารถใช้ LLM ในการสร้างแพตช์โค้ดอย่างปลอดภัย ลดเวลาในการแก้ไขบั๊ก และยังคงรักษามาตรฐานการควบคุมความเสี่ยงสำหรับการดีพลอยจริง
ดีพลอย การมอนิเตอร์ และการกำกับดูแล (Governance)
ดีพลอย การมอนิเตอร์ และการกำกับดูแล (Governance) สำหรับระบบ LLM ใน CI/CD
การนำ LLM มาช่วยสร้างแพตช์โค้ดอัตโนมัติในกระบวนการ CI/CD จำเป็นต้องมีกรอบการกำกับดูแลที่เข้มงวดเพื่อป้องกันความเสี่ยงทั้งด้านความถูกต้องของโค้ด ความปลอดภัย และการปฏิบัติตามกฎหมาย แนวปฏิบัติพื้นฐานประกอบด้วยการกำหนด authorization ก่อนการ merge ผ่าน pull request gating, policy-as-code, และกลไก human-in-the-loop ที่ชัดเจน ตัวอย่างเช่น องค์กรสามารถกำหนดว่า PR ที่เกิดจาก LLM ต้องได้รับอนุมัติจากวิศวกรคนที่สองอย่างน้อยหนึ่งคน และต้องผ่านชุดการทดสอบ smoke / integration ก่อนถึงจะ merge ได้ รายงานภายในจากบริษัทเทคโนโลยีชั้นนำชี้ว่าองค์กรที่ใช้ human-in-the-loop ลดการปล่อยบั๊กสู่ production ได้ราว 30–50% เมื่อเทียบกับการอัตโนมัติแบบไร้การควบคุม
Policy-as-code ควรถูกนำมาใช้เพื่อกำหนดกฎเชิงเทคนิคที่บังคับใช้โดยอัตโนมัติ เช่น ข้อจำกัดเกี่ยวกับไฟล์ที่ LLM สามารถแก้ไขได้ (allowed file types), ขนาดการเปลี่ยนแปลงสูงสุด (diff size threshold), และพาธที่อนุญาต (เช่น ห้ามแก้ไขโฟลเดอร์ /infra, /security หรือไฟล์ CI/CD สำคัญเช่น pipelines.yml โดยตรง) ตัวอย่างนโยบายที่เป็นรูปธรรมได้แก่:
- Allowed file types: .py, .js, .md เฉพาะในโฟลเดอร์ src/ และ docs/ เท่านั้น
- Size limits: ไม่อนุญาตให้ PR ที่สร้างโดย LLM มีมากกว่า 500 บรรทัดของการเปลี่ยนแปลงหรือไฟล์เดี่ยวใหญ่กว่า 1MB
- Critical paths: การเปลี่ยนแปลงไฟล์ใน /security, Dockerfile, และ scripts/deploy ต้องมีการอนุมัติจากผู้ดูแลระบบความปลอดภัย
การจัดการ model versioning เป็นหัวใจสำคัญของการกำกับดูแล — ทุกการเรียกใช้ LLM ต้องผนึกข้อมูลเวอร์ชันของโมเดล (model name, version, hash), ชุดพารามิเตอร์ (temperature, max tokens), และ environment metadata ไว้ในเมทาดาต้าของ PR และบันทึกการรัน ตัวอย่างแนวปฏิบัติที่ควรนำมาใช้คือการติดแท็กโมเดลใน CI/CD pipeline, เก็บบันทึกการทดสอบกับโมเดลแต่ละเวอร์ชัน และมีกระบวนการอนุมัติเปลี่ยนโมเดลใน production (model rollout policy) เช่น A/B หรือ Canary rollouts ก่อนสลับไปใช้เวอร์ชันใหม่เต็มรูปแบบ
Logging ของ prompt/response ต้องทำด้วยความระมัดระวัง: เก็บทั้ง prompt และ response พร้อมเมทาดาต้า เช่น model version, timestamp, request id และ commit id เพื่อให้สามารถ audit และ reproduce ได้เมื่อเกิดปัญหา แต่ต้องมีการทำ redaction ของข้อมูลที่เป็นความลับหรือ PII ตามนโยบายความเป็นส่วนตัว (เช่น masking ของ token/secret) และจัดการสิทธิ์เข้าถึงบันทึกเหล่านี้ด้วย RBAC และการเข้ารหัสที่เหมาะสม โดยปกติควรกำหนด retention policy เช่น เก็บ logs ระดับละเอียด 90 วัน และ aggregated audit trails 1–3 ปีตามข้อกำหนดการปฏิบัติตามกฎหมาย
ข้อกำหนดด้านความปลอดภัยและกฎหมายที่ต้องคำนึงถึงรวมถึงการสร้างและรวม SBOM (Software Bill of Materials) สำหรับแพตช์ที่สร้างโดย LLM, รายงาน Compliance ที่รองรับมาตรฐานเช่น ISO 27001, PCI-DSS, หรือ GDPR ขึ้นอยู่กับอุตสาหกรรม และการเตรียมเอกสารสำหรับการตรวจสอบภายใน/ภายนอก (audit-ready reports) โดยทุกไฟล์ที่ถูกแก้ไขควรถูกผนึกกับ SBOM และรุ่นของเครื่องมือ/โมเดลที่ใช้ในการสร้างเพื่อให้ตรวจสอบย้อนกลับได้
การมอนิเตอร์หลังดีพลอย (observability) ต้องครอบคลุมทั้ง metrics, logs และ traces ของบริการ รวมถึงการติดตามคุณภาพของโค้ดที่ deploy โดยเฉพาะเมตริกเช่น error rate, latency, test pass rate, และการเปลี่ยนแปลงของการครอบคลุม unit/integration test นอกจากนี้ควรตั้ง SLO/SLA และการแจ้งเตือนเมื่อมีการเบี่ยงเบน ตัวอย่างกลไกการมอนิเตอร์ที่เป็นมาตรฐานได้แก่:
- Canary deployments พร้อมการตรวจวัด KPI สำคัญภายใน 5–15 นาทีหลังดีพลอย
- Automated smoke and regression tests ที่รันบนกลุ่มผู้ใช้จำกัด
- Drift detection สำหรับพฤติกรรมระบบที่เปลี่ยนแปลงเมื่อเทียบกับ baseline
แผนการ rollback/mitigation ต้องเตรียมพร้อมและเป็นระบบ เช่น การใช้ Blue-Green หรือ Canary พร้อม rollback trigger อัตโนมัติเมื่อเกิดเกณฑ์ล้มเหลว (เช่น error rate เพิ่มขึ้น > 2x, latency สูงกว่า threshold หรือการทดสอบสำคัญล้มเหลว) และมีขั้นตอน manual emergency rollback ที่ต้องบันทึกเหตุผลและ approver ตัวอย่างขั้นตอนปฏิบัติที่แนะนำ:
- ตั้งเงื่อนไข rollback อัตโนมัติใน pipeline และระบบมอนิเตอร์
- มีช่องทางสื่อสารฉุกเฉิน (on-call) และ playbook สำหรับ mitigation (เช่น ปิด feature flag, revert PR, หรือ scale up/patch hotfix)
- หลัง rollback ให้รัน forensic audit เพื่อหาต้นตอและอัปเดต policy-as-code/โมเดลเพื่อป้องกันซ้ำ
สุดท้าย การกำกับดูแลต้องมีการตรวจสอบและปรับปรุงเป็นรอบ (governance cadence) โดยรวมการประเมินความเสี่ยงของ LLM อย่างน้อยไตรมาสละครั้ง การทดสอบการตอบโต้เมื่อเกิดเหตุ (tabletop exercises) และการปรับแต่งกฎ policy-as-code ตามผลลัพธ์จริง เพื่อให้การใช้งาน LLM ใน CI/CD เป็นไปอย่างปลอดภัย เชื่อถือได้ และสามารถตรวจสอบย้อนกลับได้เมื่อเกิดเหตุไม่พึงประสงค์
ผลลัพธ์เชิงตัวเลข กรณีศึกษา และคำแนะนำการนำไปใช้จริง
ผลลัพธ์เชิงตัวเลขและกรณีศึกษา (ตัวอย่างและสมมติฐาน)
จากหลายโครงการนำร่องที่ผสมผสาน LLM กับกระบวนการ CI/CD เพื่อสร้างแพตช์โค้ดอัตโนมัติ พบแนวโน้มเชิงตัวเลขที่สอดคล้องกัน ได้แก่ การลด Mean Time To Repair (MTTR) อยู่ในช่วง 30–70% (ตัวอย่างเช่น โครงการนำร่องขนาดกลางรายหนึ่งรายงาน MTTR ลดจากเฉลี่ย 8 ชั่วโมงเหลือประมาณ 4–6 ชั่วโมง) และ จำนวน Pull Request ที่ต้อง revert/rollback ลดลงอย่างมีนัยสำคัญ (บางโครงการรายงานการลด reverts ถึง 50–80%)
ตัวอย่างกรณีศึกษาเชิงสมมติ/เป็นไปได้เพื่อประกอบการตัดสินใจ:
- บริษัทอีคอมเมิร์ซขนาดกลาง: หลังนำ LLM-assisted patching เข้าสู่ CI (ในโมดูลที่มี test coverage สูง) พบว่า MTTR ลดประมาณ 45% (จาก 8 ชั่วโมง → 4.4 ชั่วโมง), ความถี่การปล่อย release เพิ่มจาก 1 ครั้ง/สัปดาห์ เป็น 3 ครั้ง/สัปดาห์ และจำนวน PR revert ลดลง ~70% ผลลัพธ์ช่วยประหยัดเวลาทีมวิศวกรรมประมาณ 1,000–1,500 ชั่วโมงต่อปี (คิดเป็นมูลค่าโดยประมาณ 1.5–4.5 ล้านบาท/ปี ขึ้นกับอัตราค่าแรง)
- องค์กรการเงิน/ฟินเทค (พร้อมข้อกำกับความเสี่ยงสูง): ใน pilot ที่จำกัดเฉพาะ service non-critical พบอัตรา hotfix ลดลง 60% และอัตราข้อผิดพลาดหลังปล่อยสู่ production ลด 35% เนื่องจาก LLM ช่วยแก้บั๊กที่มีรูปแบบซ้ำได้รวดเร็ว ขณะที่การตรวจสอบโดยมนุษย์ยังคงเป็น gating
- ซอฟต์แวร์ระดับองค์กร (monolithic → microservices gradual rollout): ทีมรายงาน lead time ลด 20–40% และ mean time to merge ลด 25% เนื่องจาก LLM ช่วยสร้าง patch พร้อม unit test เบื้องต้น ทำให้ reviewers ใช้เวลาโฟกัสเชิงตรรกะมากขึ้น
คำแนะนำสำหรับการนำไปใช้จริง (Rollout Checklist)
การนำระบบ LLM เพื่อช่วยสร้างแพตช์อัตโนมัติเข้าสู่กระบวนการ CI/CD ต้องมีการวางแผนเป็นขั้นตอนและมีการควบคุมความเสี่ยง แนะนำ checklist ดังนี้:
- เริ่มจากโมดูลที่มี test coverage ดี: เลือก service/โมดูลที่มี unit/integration tests ครอบคลุมสูงเพื่อให้การตรวจสอบ patch เป็นไปได้ด้วยอัตโนมัติ
- ทดลองในวงปิด (sandbox) และใช้ feature flags/canary: ปล่อยแพตช์ในกลุ่มผู้ใช้จำกัดก่อนขยายสู่ production
- กำหนด human review เป็นบังคับ: ทุกแพตช์ที่ LLM สร้างให้ผ่าน gated code review โดยวิศวกรอย่างน้อยหนึ่งคนก่อน merge
- เก็บ telemetry และเมตริกพื้นฐาน: บันทึก MTTR, lead time, time-to-merge, จำนวน reverts, pass rate ของ automated tests, อัตร false positive/negative ของการตรวจจับบั๊ก
- ตั้งค่า CI policy และ automated tests เป็นกฎผ่าน: ห้าม merge หาก unit/integration/e2e tests ล้มเหลว หรือหาก static analysis พบปัญหาที่กำหนด
- เปิดใช้งาน license & security scanning: สแกนโค้ดที่ LLM เสนอหาไลเซนส์และช่องโหว่ด้วยเครื่องมืออัตโนมัติ (เช่น SPDX, SCA tools)
- กำหนดขั้นตอน rollback และ audit trail: ให้แต่ละแพตช์มีข้อมูล provenance, model version, prompt snapshot และปุ่ม rollback อัตโนมัติ
- เริ่มเป็น pilot ระยะสั้น (4–12 สัปดาห์) : วัดผลตาม KPI ที่กำหนด เช่น MTTR, release frequency, developer time saved ก่อนขยาย
ข้อควรระวังและการเตรียมความพร้อม
แม้ LLM จะเพิ่มประสิทธิภาพได้อย่างชัดเจน แต่ต้องเตรียมรับความเสี่ยงหลายประการ ดังนี้:
- Hallucination ของโมเดล: LLM อาจสร้างโค้ดที่ดูสมเหตุสมผลแต่ทำงานผิดพลาดหรือขาดบริบท จำเป็นต้องมีการทดสอบอัตโนมัติและการตรวจสอบโดยมนุษย์ก่อน deploy
- ปัญหาไลเซนส์จาก code suggestions: โมเดลอาจเสนอโค้ดที่มีเงื่อนไขไลเซนส์ไม่พึงประสงค์ (เช่น GPL) — จึงต้องมี SCA/OSS license scanning และนโยบายการอนุญาตก่อนใช้งาน
- การจัดการข้อมูลความลับและข้อมูลส่วนบุคคล: ห้ามส่ง secrets หรือข้อมูล PII ไปยังบริการ LLM ที่ไม่ควบคุมได้ ใช้การมาสก์/redaction, โมเดลภายในองค์กร หรือ VPC-hosted LLM เพื่อป้องกันการรั่วไหล
- การยืนยัน provenance และ traceability: ต้องบันทึก model version, prompt, input context, และผลลัพธ์เพื่อการตรวจสอบย้อนหลังและการรับผิดชอบทางกฎหมาย/การตรวจสอบ
- การฝึกอบรมทีมและการเปลี่ยนแปลงกระบวนการ: ให้การฝึกอบรม reviewer และ developer เกี่ยวกับการอ่านโค้ดที่ LLM สร้าง, การใช้ telemetry และวิธีปฏิบัติที่ปลอดภัย
- การตรวจสอบ performance และ model drift: ติดตามอัตราการสำเร็จของแพตช์, อัตร false positive/negative และปรับปรุง prompt/การตั้งค่าโมเดลอย่างต่อเนื่อง
สรุป การนำ LLM มาใช้ร่วมกับ CI/CD สำหรับสร้างแพตช์โค้ดอัตโนมัติสามารถลดเวลาแก้ไขบั๊กและเพิ่มความถี่การปล่อยซอฟต์แวร์ได้อย่างมีนัยสำคัญ แต่ต้องเริ่มแบบมีการควบคุม ตั้งเกณฑ์ human-in-the-loop และมีระบบ telemetry กับนโยบายความปลอดภัยที่เข้มงวดเพื่อจัดการความเสี่ยงด้าน hallucination, license และการรั่วไหลของข้อมูล
บทสรุป
การผสาน Large Language Models (LLM) เข้ากับกระบวนการ CI/CD มีศักยภาพชัดเจนในการลดเวลาแก้บั๊กและเพิ่มความคล่องตัวของการพัฒนาซอฟต์แวร์ โดย LLM สามารถตรวจจับช่องโหว่ แสดงข้อเสนอการแก้ไข สร้างแพตช์โค้ดอัตโนมัติ และรันชุดทดสอบก่อนการดีพลอย ทำให้กระบวนการแก้ปัญหาเร็วขึ้นและลดภาระงานเชิงมือที่ซ้ำซ้อน ผู้ประกอบการเทคโนโลยีบางองค์กรรายงานการลด MTTR ราว 20–50% และลด PR cycle time ได้ประมาณ 25–40% พร้อมกับการเพิ่มขึ้นของอัตราความสำเร็จของแพตช์ (patch success rate) ในช่วงประมาณ 10–30% อย่างไรก็ตาม ความแม่นยำของโมเดลและผลกระทบด้านความปลอดภัยยังจำเป็นต้องมีกระบวนการกำกับดูแล (governance) และการมี human-in-the-loop เพื่อรีวิว ตัดสินใจ และควบคุมการเปลี่ยนแปลงก่อนดีพลอยจริง
แนวปฏิบัติที่แนะนำคือเริ่มด้วยโครงการนำร่องที่ชัดเจน กำหนดขอบเขตของระบบอัตโนมัติ กำหนดนโยบายการอนุมัติและ auditing และวัดผลด้วยตัวชี้วัดเช่น MTTR, PR cycle time และ อัตราความสำเร็จของแพตช์ ก่อนการขยายสเกล หากออกแบบ governance ดีและผนวกการทดสอบอัตโนมัติกับการตรวจสอบโดยมนุษย์ องค์กรจะสามารถก้าวไปสู่การพัฒนาแบบ self-healing pipeline ได้ในอนาคต พร้อมทั้งต้องคำนึงถึงการอัปเดตโมเดล การจัดการความเสี่ยงเชิงความปลอดภัย และการเปลี่ยนแปลงทางวัฒนธรรมของทีมเพื่อให้ผลลัพธ์เป็นไปอย่างยั่งยืน



