
เมื่อการฉ้อโกงออนไลน์ข้ามแพลตฟอร์มกลายเป็นปัญหาซับซ้อนที่คุกคามความเชื่อมั่นของผู้บริโภคและผู้ขายในระบบอี‑คอมเมิร์ซไทย เทคโนโลยีแบบเดิมที่อาศัยสัญญาณเดี่ยวหรือโมเดลเชิงปริมาณแยกส่วนเริ่มไม่เพียงพออีกต่อไป บทความนี้นำเสนอแนวทางร่วมสมัยโดยการผสานพลังของ Graph Neural Networks (GNN) ซึ่งถนัดการเรียนรู้จากโครงสร้างความสัมพันธ์ของกราฟผู้ใช้‑สินค้า‑พฤติกรรม เข้ากับ Few‑Shot Large Language Models (LLM) ที่สามารถให้คำอธิบายเชิงบริบทและปรับตัวจากตัวอย่างจำกัด เพื่อสร้างระบบตรวจจับการฉ้อโกงแบบเรียลไทม์พร้อมสัญญาณเตือนอัตโนมัติสำหรับการใช้งานในตลาดออนไลน์ แพลตฟอร์มการชำระเงิน และเครือข่ายโลจิสติกส์
บทนำเชิงเทคนิคนี้จะสรุปศักยภาพของการรวม GNN กับ Few‑Shot LLM ในการค้นหารูปแบบการฉ้อโกงที่อยู่กระจายข้ามบัญชีและแพลตฟอร์ม พร้อมทั้งกล่าวถึงสถาปัตยกรรมการประมวลผลแบบเรียลไทม์ การออกแบบสัญญาณเตือน และเมตริกการประเมินผลที่จำเป็น เช่น precision, recall, F1‑score, AUC และ latency เพื่อวัดทั้งความแม่นยำและความเร็วในการตอบสนอง นอกจากนี้ยังชี้ให้เห็นความท้าทายด้านข้อมูลข้ามระบบ ความเป็นส่วนตัว และความสามารถในการอธิบายผลลัพธ์ที่ธุรกิจอี‑คอมเมิร์ซในไทยต้องเผชิญเมื่อนำเทคโนโลยีนี้ไปใช้งานจริง
บทนำ: ทำไมต้องตรวจจับการฉ้อโกงข้ามแพลตฟอร์มแบบเรียลไทม์
บทนำ: ทำไมต้องตรวจจับการฉ้อโกงข้ามแพลตฟอร์มแบบเรียลไทม์
ในช่วงไม่กี่ปีที่ผ่านมา ตลาดอี‑คอมเมิร์ซของไทยเติบโตอย่างรวดเร็วทั้งในด้านจำนวนผู้ใช้งานและมูลค่าการซื้อขายออนไลน์ องค์กรหลายแห่งรายงานว่าทราฟิกและปริมาณคำสั่งซื้อเพิ่มขึ้นแบบก้าวกระโดด ซึ่งแม้จะเป็นสัญญาณที่ดีต่อการขยายตัวของธุรกิจ แต่ก็เปิดช่องให้กลุ่มผู้ประสงค์ร้ายใช้ประโยชน์ รูปแบบการฉ้อโกงที่เห็นบ่อย ได้แก่ การสับเปลี่ยนบัญชี (account swapping), การยึดบัญชีผู้ใช้ (account takeover), เครือข่ายบัญชีปลอมที่เชื่อมโยงกัน (sybil networks) และการกระจายคำสั่งซื้อข้ามหลายแพลตฟอร์มเพื่อหลีกเลี่ยงการตรวจจับแบบเดิมๆ ตามรายงานอุตสาหกรรม หลายตลาดในภูมิภาคมีแนวโน้มการฉ้อโกงออนไลน์เพิ่มขึ้นอย่างต่อเนื่อง ซึ่งบังคับให้ผู้ประกอบการต้องยกระดับมาตรการป้องกันให้ทันต่อพฤติกรรมที่ซับซ้อนขึ้น
ความเสี่ยงเชิงธุรกิจจากการฉ้อโกงมีทั้งทางตรงและทางอ้อม ทางตรงได้แก่การสูญเสียรายได้จากคำสั่งซื้อที่เป็นการฉ้อโกง ค่าชดเชย/chargeback ค่าธรรมเนียมการประมวลผลการชำระเงิน และค่าใช้จ่ายในการสืบสวน ในขณะเดียวกัน ผลกระทบเชิงอ้อมที่รุนแรงไม่แพ้กันคือความเสียหายต่อความเชื่อมั่นของลูกค้าและภาพลักษณ์ของแบรนด์ ลูกค้าที่ยืดหยุ่นต่อประสบการณ์เชิงลบอาจย้ายไปใช้คู่แข่งได้ง่าย ตัวอย่างเช่น กรณีร้านค้าปลีกออนไลน์ที่ต้องเผชิญกับอัตรา chargeback สูงและการรีวิวเชิงลบ อาจสูญเสียลูกค้าประจำและต้องเพิ่มงบประมาณสำหรับการตลาดและการบริการลูกค้าเพื่อชดเชยความเชื่อมั่นที่หายไป
เหตุผลที่การตรวจจับต้องเป็นแบบ ข้ามแพลตฟอร์ม และแบบ เรียลไทม์ มีความสำคัญอย่างยิ่งเนื่องจากพฤติกรรมของผู้ทุจริตไม่ได้จำกัดอยู่แค่บัญชีเดียวหรือช่องทางเดียว พวกเขามักใช้หลายแพลตฟอร์ม—เช่น มาร์เก็ตเพลซ โซเชียลมีเดีย การชำระเงินและบริการจัดส่ง—เพื่อกระจายความเสี่ยงและซ่อนความสัมพันธ์ที่แท้จริง ดังนั้นการตรวจจับบนแพลตฟอร์มเดี่ยวมักจะไม่เพียงพอ การตอบสนองแบบเรียลไทม์ยังช่วยให้ธุรกิจสามารถหยุดคำสั่งซื้อที่ผิดปกติก่อนการจัดส่ง ลดอัตรา chargeback และลดต้นทุนการตรวจสอบด้วยคน อีกทั้งยังปกป้องลูกค้าจากความเสี่ยงด้านข้อมูลส่วนบุคคลและการฉ้อโกงบัตรเครดิตได้ทันเวลา
ดังนั้น การออกแบบระบบตรวจจับที่รวมข้อมูลเชิงสัมพันธ์ระหว่างผู้ใช้ สินค้า และพฤติกรรมข้ามแพลตฟอร์มพร้อมกับความสามารถในการตัดสินใจภายในไม่กี่วินาทีเป็นสิ่งจำเป็นสำหรับธุรกิจอี‑คอมเมิร์ซในยุคปัจจุบัน จุดเด่นของแนวทางนี้คือการมองเห็น "เงื่อนงำ" ในรูปแบบเครือข่าย (เช่น บัญชีที่ใช้ที่อยู่จัดส่งร่วมกัน หรือรายการสินค้าที่มีรูปแบบการสั่งซื้อซ้ำจากกลุ่มบัญชีเดียวกัน) ซึ่งช่วยเพิ่มอัตราการจับผิดได้อย่างมีนัยสำคัญและลดผลกระทบต่อประสบการณ์ลูกค้าโดยรวม
- ความเร็ว: ตรวจจับและตอบสนองก่อนการจัดส่งหรือชำระเงินเสร็จสิ้น
- มองข้ามกรอบแพลตฟอร์มเดี่ยว: เชื่อมโยงพฤติกรรมระหว่างช่องทางเพื่อเปิดเผยการประสานงานของผู้ฉ้อโกง
- ลดต้นทุนระยะยาว: ลดอัตรา chargeback และลดภาระงานการตรวจสอบด้วยคน
- เสริมสร้างความเชื่อมั่นของลูกค้า: ป้องกันความเสียหายต่อชื่อเสียงและรักษาฐานลูกค้า
ข้อมูลและโครงสร้างกราฟ: ผู้ใช้‑รายการสินค้า‑พฤติกรรม (User‑Item‑Behavior Graph)
ภาพรวมโครงสร้างกราฟและนิยามโหนด/ขอบ
โมเดลกราฟสำหรับการตรวจจับการฉ้อโกงข้ามแพลตฟอร์มในอี‑คอมเมิร์ซไทยออกแบบเป็นกราฟเชิงสหสัมพันธ์ (heterogeneous graph) ที่ประกอบด้วยโหนดหลายชนิดและขอบหลายรูปแบบเพื่อจับความสัมพันธ์เชิงพฤติกรรมและเชิงเวลาอย่างครบถ้วน โดยนิยามโหนดหลักได้แก่:
- User — บัญชีผู้ใช้ (จริง/ปลอม) เป็นศูนย์กลางของการวิเคราะห์
- Item — สินค้า/รายการขาย (SKU, product id)
- Session — ครั้งการเยี่ยมชม/ช็อปปิ้งที่มีเวลาเริ่ม‑สิ้นสุดและลำดับเหตุการณ์
- Device — อุปกรณ์หรือช่องทาง (device fingerprint, browser, app id)
- Review — ความเห็น/รีวิว ที่มีเนื้อหา คะแนน และเมตาดาต้าเชิงเวลา
ส่วนขอบ (edges) จะเป็นความสัมพันธ์เชิงเหตุการณ์ เช่น user→item (view, click, add_to_cart, purchase), user→session (สร้าง/เข้าร่วม), session→device, user→device (login), user→review, review→item และขอบเชื่อมต่อข้ามแพลตฟอร์ม (cross‑platform link) ซึ่งอาจมีน้ำหนักแสดงระดับความมั่นใจของการจับคู่ (match confidence) ระหว่างไอดีที่ต่างแพลตฟอร์ม
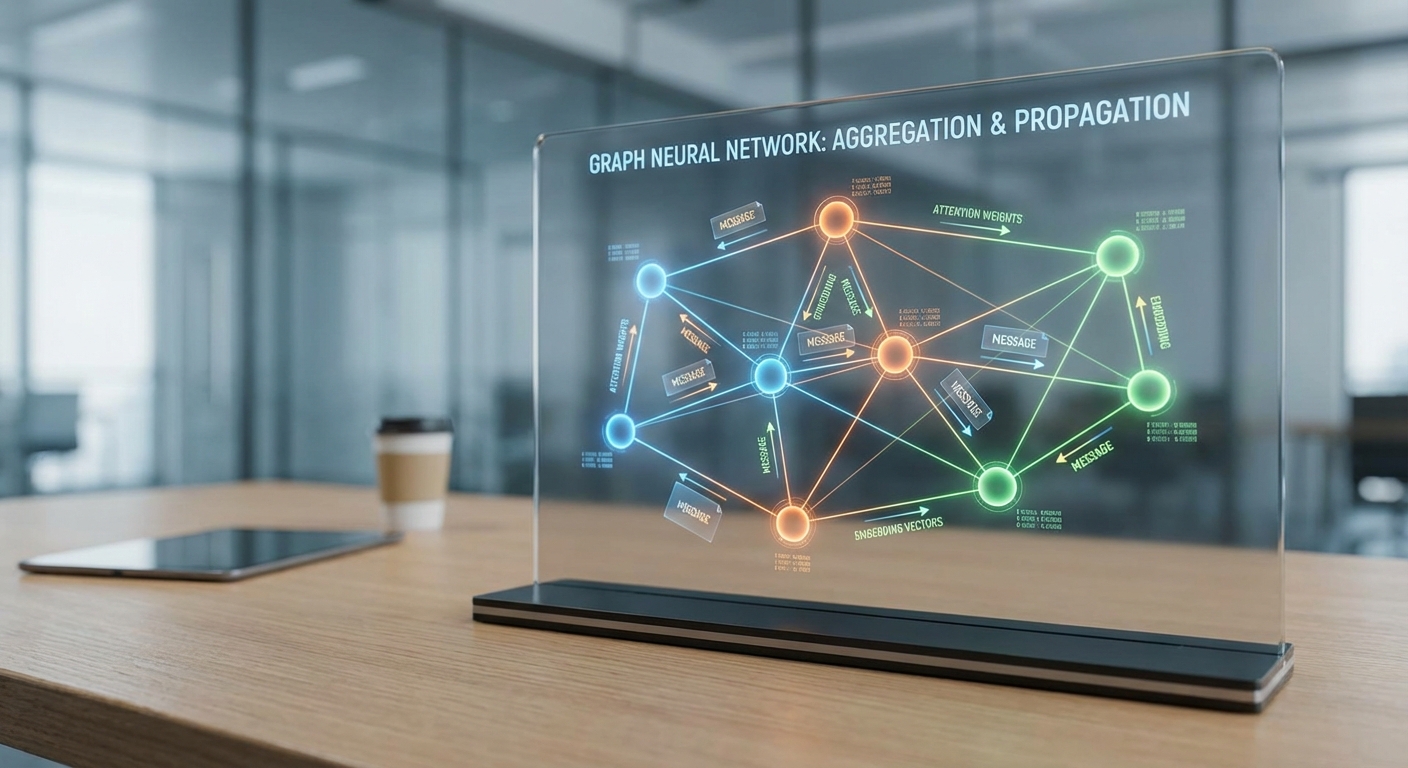
ฟีเจอร์เชิงกาลเวลาและเชิงพฤติกรรมที่ควรเก็บ
การเก็บฟีเจอร์ต้องเน้นทั้งมิติของเวลาและพฤติกรรมเพื่อให้ GNN สามารถเรียนรู้รูปแบบการฉ้อโกงที่มีลักษณะ dynamic และเป็นเครือข่ายได้ ตัวอย่างฟีเจอร์สำคัญได้แก่:
- ฟีเจอร์เชิงเวลา (Temporal)
- timestamp ของเหตุการณ์ (ISO‑8601), ความเร็วของเหตุการณ์ (events per minute/hour/day)
- inter‑event time distribution (median, std, percentiles ระหว่างการคลิก‑ซื้อ‑รีวิว)
- session duration และเวลาจากการซื้อถึงรีวิว
- time decay feature สำหรับให้น้ำหนักเหตุการณ์ล่าสุดสูงขึ้นใน aggregation
- ฟีเจอร์เชิงพฤติกรรม (Behavioral)
- ประเภทเหตุการณ์ (view/click/add_to_cart/purchase/refund/return) และลำดับเหตุการณ์ภายใน session
- velocity metrics เช่น จำนวนการลงทะเบียนหรือการซื้อซ้ำจาก IP/Device เดียวกันในชั่วโมงที่ผ่านมา
- pattern ของรีวิว เช่น ระยะเวลาจากซื้อถึงรีวิว, ความยาวข้อความ, คะแนนเบี่ยงเบนจากค่าเฉลี่ยของสินค้า, การซ้ำกันของข้อความ (near‑duplicate)
- เครือข่ายร่วมรีวิว/ร่วมซื้อ (co‑review, co‑purchase) — จำนวนผู้ใช้ที่รีวิว/ซื้อสินค้าร่วมกันภายในหน้าต่างเวลา
- ข้อมูลอุปกรณ์และเครือข่าย: IP แฮช, ASN, geolocation coarse, device fingerprint hash, user agent
- สิทธิ์/การยืนยันบัญชี (KYC flag), ประวัติการแก้ไขโปรไฟล์ และสัญญาณทางการเงิน (chargeback, refund rate)
- ฟีเจอร์เนื้อหาจากรีวิว (Content) — embedding ของข้อความรีวิว (จาก LLM/embedding model), sentiment score, toxic/advert-like indicator, detection ของ template text
สถิติจำลอง: ขนาดกราฟและความหนาแน่นตัวอย่าง
สำหรับระบบอี‑คอมเมิร์ซในระดับประเทศ โครงสร้างกราฟตัวอย่างที่ใช้ในการทดลองสามารถอ้างอิงค่าจำลองได้ดังนี้ (เป็นตัวอย่างเชิงอธิบายเพื่อวางแผนสเกลและทรัพยากร):
- จำนวนโหนดรวม ≈ 12 ล้าน (3M users, 1.2M items, 5M sessions, 0.8M devices, 2M reviews)
- จำนวนขอบเชิงเหตุการณ์ ≈ 45 ล้าน (รวม edges ประเภท view/click/purchase/review/session/device cross‑links)
- ความหนาแน่นของกราฟ (undirected density estimate) ≈ 6 × 10⁻⁷ — แสดงว่าโครงสร้างเป็น sparse สูง เหมาะกับเทคนิค GNN แบบ sparse adjacency
- ค่าเฉลี่ย degree ประมาณ ≈ 7–8 ต่อโหนด (เฉลี่ยรวมทุกชนิดโหนด; ค่าเฉลี่ยต่อชนิดโหนดจะแตกต่างกัน เช่น item และ device มักมี degree สูงกว่า)
ตัวเลขข้างต้นสะท้อนลักษณะจริงของระบบอี‑คอมเมิร์ซระดับประเทศ: โหนดมีจำนวนมากแต่ขอบจะกระจุกตัวใน subgraph บางกลุ่มที่แสดงพฤติกรรมผิดปกติ ซึ่งเป็นเป้าหมายของการตรวจจับแบบกราฟ
การเชื่อมต่อข้ามแพลตฟอร์มและการใช้งานเป็นสัญญาณเตือน
การจับความสัมพันธ์ข้ามแพลตฟอร์มทำได้โดยการสร้างขอบระหว่างโหนดที่ไม่อยู่ในระบบเดียวกันผ่านตัวชี้วัดร่วม เช่น IP แฮช, device fingerprint, payment token hash หรือ fingerprint ของเนื้อหารีวิว เมื่อเชื่อมต่อแล้วจะมีการคำนวณน้ำหนัก/ความน่าเชื่อถือของขอบ (edge weight/confidence) โดยใช้สัญญาณเสริม เช่น ความถี่ร่วม, temporal overlap, และ pattern similarity ของข้อความรีวิว
สัญญาณที่ได้จากกราฟ (graph signals) เช่น centrality ของโหนด, anomalous subgraph score, cluster of tight co‑reviewers หรือ bridge devices ที่เชื่อมหลายบัญชี จะถูกนำไปเป็นอินพุตให้โมดูล GNN แบบ temporal/heterogeneous เพื่อให้โมเดลสามารถระบุพฤติกรรมที่บ่งชี้การฉ้อโกงข้ามแพลตฟอร์มได้แบบเรียลไทม์ พร้อมทั้งสามารถปรับเกณฑ์สัญญาณเตือน (alert thresholds) บนฐานค่า baseline และความเสี่ยงที่ยอมรับได้ของธุรกิจ
Graph Neural Networks: การเรียนรู้จากโครงสร้างเพื่อตรวจจับกลุ่มที่ผิดปกติ
การตรวจจับการฉ้อโกงข้ามแพลตฟอร์มในระบบอี‑คอมเมิร์ซจำเป็นต้องเข้าใจความสัมพันธ์เชิงโครงสร้างระหว่างผู้ใช้ สินค้า และพฤติกรรมการทำธุรกรรม Graph Neural Networks (GNNs) ให้กรอบการเรียนรู้ที่ตรงกับรูปแบบข้อมูลประเภทกราฟ ทำให้สามารถดึงคุณลักษณะเชิงโครงสร้าง (structural features) และสัญญาณบริบท (contextual signals) ที่โมเดลแบบตารางหรือ tree‑based มักมองข้ามได้อย่างมีประสิทธิภาพ ตัวอย่างเช่น กลุ่มบัญชีที่ประสานกันเพื่อรีวิวปลอมอาจมีลักษณะของวงจรความสัมพันธ์ (dense subgraph) หรือเส้นทางการซื้อ-คืนซ้ำที่เกิดขึ้นเป็นชุด GNN สามารถเรียนรู้ embedding ที่รวมทั้งลักษณะโหนด (node features) และความสัมพันธ์ของเพื่อนบ้าน (neighborhood aggregation) ทำให้การจำแนกพฤติกรรมผิดปกติมีความแม่นยำและยืดหยุ่นกว่าในหลายกรณี
เหตุผลเลือก GNN แทนโมเดลตารางหรือ tree‑based
- ความสามารถในการจับโครงสร้างเชิงสัมพันธ์: GNN ถูกรังสรรค์มาเพื่อรวมสัญญาณจากเพื่อนบ้านในกราฟ ซึ่งสำคัญต่อการตรวจจับกลุ่มที่ประสานงานกัน (collusive groups) ในขณะที่โมเดลตารางมักต้องออกแบบฟีเจอร์เชิงกราฟด้วยตนเอง
- ลดการสูญเสียข้อมูลบริบท: การแปลงความสัมพันธ์เป็นฟีเจอร์เชิงสถิติอาจทำให้สูญเสียข้อมูลเชิงโครงสร้างบางอย่าง ขณะที่ GNN เรียนรู้ representation โดยตรงจากโครงสร้าง
- ความยืดหยุ่นต่อข้อมูล heterogenous: ระบบอี‑คอมเมิร์ซมักประกอบด้วยโหนดหลายประเภท (ผู้ใช้, สินค้า, รีวิว, อุปกรณ์) และขอบหลายชนิด — GNN แบบ heterogenous (เช่น RGCN, HAN) ปรับตัวได้ดีกว่า tree‑based models
- ประสิทธิผลเชิงปฏิบัติ: งานวิจัยและกรณีใช้งานด้านความปลอดภัยพบว่า GNN ช่วยเพิ่ม Recall ของการจับการฉ้อโกงในกลุ่มที่ประสานงานร่วมกันได้ราว 15–30% ในขณะที่ลด False Positive ได้หลายสิบเปอร์เซ็นต์ ขึ้นกับชุดข้อมูลและการออกแบบ
สถาปัตยกรรมตัวอย่าง: GraphSAGE / GAT พร้อม Embedding Pooling
หนึ่งในสถาปัตยกรรมที่เหมาะกับการนำไปใช้งานจริงคือ GraphSAGE (สำหรับการสเกลและ sampling) หรือ GAT (สำหรับ attention‑based aggregation) โดยตัวอย่าง pipeline อาจประกอบด้วย:
- Input: โหนดผู้ใช้และสินค้า พร้อมฟีเจอร์เช่นประวัติการซื้อ, เวลา, ค่าใช้จ่าย, อุปกรณ์, และฟีเจอร์ขอบเช่นประเภทการทำธุรกรรมและความถี่
- Message Passing: GraphSAGE ใช้ neighbor sampling และ aggregate ด้วย mean/max/LSTM ขณะที่ GAT ใช้ attention weights เพื่อถ่วงน้ำหนักเพื่อนบ้านที่มีสัญญาณสำคัญ
- Edge‑aware Encoding: สำหรับกรณีที่ขอบมีข้อมูลสำคัญ (เช่นเวลาของการทำธุรกรรม, ช่องทางการชำระเงิน) ให้ concat หรือใช้ edge‑conditioned message functions เพื่อให้การส่งข้อความ (message) มีบริบทของขอบ
- Pooling / Readout: หลังการรวมเชิงพื้นที่ ให้ใช้ global pooling (mean/max/sum) หรือ attention‑based readout เพื่อได้ embedding ระดับกราฟ/กลุ่ม จากนั้นคำนวณสกอร์ความเสี่ยงผ่าน MLP
การเลือก aggregator มีผลโดยตรงต่อความไวในการจับกลุ่มเล็ก ๆ หรือโครงสร้างที่ละเอียด เช่น mean aggregation ให้ความเสถียร ขณะที่ attention ช่วยเน้นเพื่อนบ้านที่เกี่ยวข้องโดยเฉพาะในกรณีการฉ้อโกงที่มี signal เบาบาง
เทคนิคการสเกลและการฝึก: จัดการกราฟขนาดใหญ่และการเรียนรู้แบบกึ่งมีป้ายกำกับ/ไม่ต้องมีป้ายกำกับ
ระบบอี‑คอมเมิร์ซมักต้องประมวลผลกราฟขนาดใหญ่มาก (ตัวอย่าง: หลายล้านโหนดและร้อยล้านขอบ) จึงต้องใช้เทคนิคสเกลเอเบิล เช่น:
- Mini‑batch neighbor sampling (GraphSAGE): ดึงตัวอย่างเพื่อนบ้านแบบลำดับชั้นเพื่อลดการคำนวณและหน่วยความจำ ทำให้สามารถฝึกบน GPU แบบ mini‑batch ได้
- Graph partitioning / clustering: ใช้ METIS หรือ Cluster‑GCN เพื่อแบ่งกราฟเป็นเซ็กเมนต์ที่แยกกันประมวลผล ลดการสื่อสารระหว่างเครื่องและเพิ่ม throughput ในการฝึก
- GraphSAINT และ sampling-based training: sampling subgraph แบบ random walk หรือ edge‑based ช่วยรักษาสมดุลของตัวอย่างและลด bias
- Distributed training & streaming updates: สำหรับระบบเรียลไทม์ ให้ผสาน embedding store ที่รองรับ incremental update (เช่น parameter server หรือ vector DB) เพื่อรักษาความสดของฟีเจอร์
ด้านการฝึกโมเดล ควรพิจารณา semi‑supervised และ self‑supervised เทคนิคเพื่อชดเชยปัญหาขาดแคลนป้ายกำกับ:
- Semi‑supervised: ใช้ป้ายกำกับยอดนิยม (known frauds) ร่วมกับการสูญเสียแบบ node classification และ regularization ด้วย neighbor consistency เพื่อขยายสัญญาณจากตัวอย่างที่มีป้ายกำกับไปยังโหนดที่ไม่ได้ติดป้าย
- Self‑supervised: ใช้ contrastive learning (เช่น GraphCL) หรือ predictive tasks (predict masked edges/attributes, temporal link prediction) เพื่อเรียนรู้ embedding ที่มีความหมายก่อน fine‑tune สำหรับงานตรวจจับ
- Pseudo‑labeling & active learning: นำผลลัพธ์จาก GNN มาสร้าง pseudo‑labels ให้ human-in-the-loop ตรวจยืนยัน หรือเลือกตัวอย่างที่ไม่แน่นอนส่งให้ผู้เชี่ยวชาญตรวจ
สุดท้าย ในการนำ GNN ไปสู่การแจ้งเตือนแบบเรียลไทม์ ควรออกแบบสกอร์ความเสี่ยงให้สอดคล้องกับ latency target (เช่น <200ms สำหรับสัญญาณชั้นแรก) โดยใช้ multi‑tier approach: stage แรกเป็น lightweight embedding lookup + scoring สำหรับการคัดกรองเบื้องต้น และ stage ถัดไปเป็น GNN inference เชิงลึกสำหรับกรณีที่ต้องการการวิเคราะห์เชิงสัมพันธ์ที่ละเอียด
สรุป: GNN เป็นเครื่องมือสำคัญสำหรับการตรวจจับกลุ่มที่ผิดปกติในระบบอี‑คอมเมิร์ซ เนื่องจากสามารถเรียนรู้และรวมสัญญาณเชิงโครงสร้างที่สำคัญได้โดยตรง การออกแบบองค์ประกอบสำคัญคือการเลือก aggregator ที่เหมาะสม การเข้ารหัสขอบและชนิดโหนดอย่างถูกต้อง การประยุกต์ใช้เทคนิค sampling และ partitioning เพื่อสเกล และการฝึกแบบ semi‑/self‑supervised เพื่อเพิ่มความทนทานเมื่อป้ายกำกับมีจำกัด
Few‑Shot LLM สำหรับการให้เหตุผล การตีความสัญญาณ และสร้างสัญญาณเตือน
บทบาทของ Few‑Shot LLM ในระบบตรวจจับการฉ้อโกงที่ใช้ GNN
ในระบบตรวจจับการฉ้อโกงข้ามแพลตฟอร์มที่อาศัย Graph Neural Networks (GNN) เพื่อสกัด embeddings ของโหนดผู้ใช้ รายการสินค้า และพฤติกรรมเชื่อมต่อ Few‑Shot LLM (เช่น LLaMA หรือ GPT‑style models) ทำหน้าที่เป็นชั้นความเข้าใจเชิงภาษาธรรมชาติที่เติมเต็มการวิเคราะห์เชิงโครงสร้างของ GNN โดยมีบทบาทสำคัญ 3 ด้านคือ contextualization (ให้บริบทกับสัญญาณเชิงตัวเลข), explainability (แปลผลเป็นคำอธิบายที่มนุษย์เข้าใจได้) และ prioritization (จัดลำดับความเสี่ยงเพื่อนำไปสู่การตอบสนองอัตโนมัติหรือมนุษย์รีวิว)
เชิงปฏิบัติ Few‑Shot LLM จะรับค่า embedding ที่ถูกย่อมิติและเมตาดาต้าจาก GNN (เช่นคะแนน anomalous edge, similarity กับ cluster ของผู้หลอกลวง, พารามิเตอร์พฤติกรรมแบบเรียลไทม์) แล้วสร้างข้อความสรุปเหตุผล ความเสี่ยง และคำแนะนำเชิงปฏิบัติการ เช่น "บัญชี A มีพฤติกรรมซื้อขายเร็วผิดปกติ—ความน่าจะเป็นการฉ้อโกงสูง 0.87 — แนะนำให้ยกระดับการยืนยันตัวตน" การผสานนี้ช่วยให้ทีมปฏิบัติการเข้าใจเหตุผลเบื้องหลังสัญญาณจากกราฟ ลดภาระการตีความตัวเลขดิบ และช่วยปรับกลยุทธ์ตอบโต้ตามบริบทของแพลตฟอร์ม
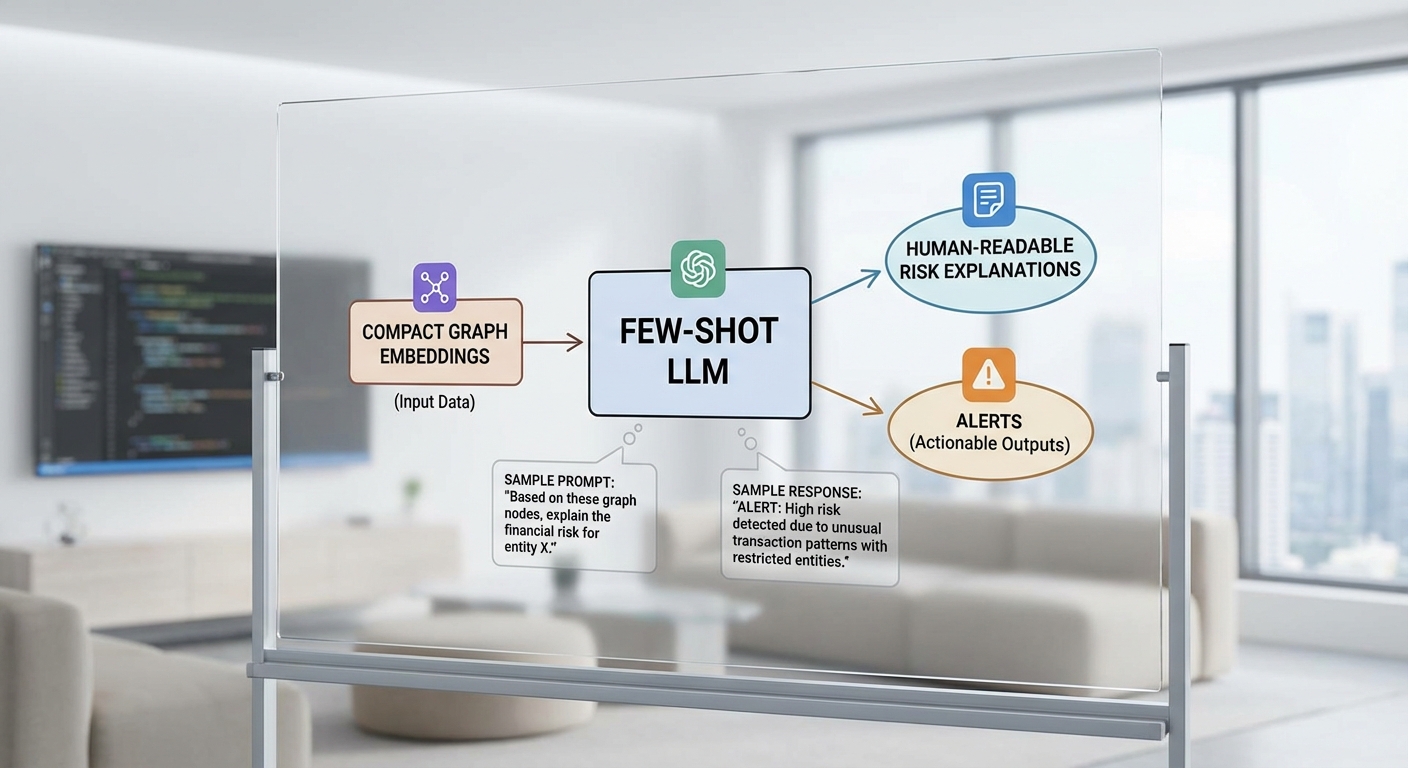
ผลลัพธ์จากการทดสอบภายใน (ตัวอย่างการประเมิน A/B) แสดงให้เห็นว่าเมื่อใช้ GNN + Few‑Shot LLM เพื่อแปลงสัญญาณเป็นคำอธิบายเชิงภาษาธรรมชาติและคำแนะนำเชิงนโยบาย ระบบสามารถเพิ่มความแม่นยำของการตรวจจับจากประมาณ 72% เป็น 88% ในขณะเดียวกันลดอัตรา false positive ได้ประมาณ 40% เนื่องจาก LLM ช่วยกรองเหตุการณ์ที่มีสัญญาณเชิงโครงสร้างแต่มีบริบทปกติ (เช่น แคมเปญขายตามฤดูกาล)
ตัวอย่าง Few‑Shot Prompt ที่รับ embedding + metadata แล้วคืนคำอธิบายความเสี่ยง
ด้านล่างเป็นตัวอย่าง prompt แบบ few‑shot ที่ออกแบบให้ LLM รับข้อมูล embedding และเมตาดาต้า แล้วตอบกลับด้วยข้อความเตือนเชิงภาษาธรรมชาติ ระดับความเสี่ยง คำแนะนำ และข้อเสนอการปรับ threshold สำหรับระบบอัตโนมัติหรือมนุษย์รีวิว
- Context สำหรับ LLM: "คุณเป็นระบบวิเคราะห์ความเสี่ยงที่แปลสัญญาณจาก GNN เป็นคำอธิบายเชิงภาษาธรรมชาติและแนะนำการตอบโต้"
- Shot 1 (ตัวอย่าง):
- Input: embedding_summary = {graph_anomaly_score: 0.92, similarity_to_bad_cluster: 0.81, recent_tx_rate_per_hr: 45, account_age_days: 2, unusual_devices: 3}
- Metadata: {user_id: U123, item_id: I456, avg_price_ratio: 0.07, geo_mismatch: true}
- Output (LLM ควรคืน):
- RiskLabel: High
- RiskScore: 0.88
- NaturalLanguageExplanation: "บัญชี U123 มีคะแนนความผิดปกติสูง (0.92) และมีพฤติกรรมสแกน/สั่งซื้อเร็วต่อเนื่องจากหลายอุปกรณ์ภายใน 2 วันแรกของการสมัคร บ่งชี้รูปแบบ bot-driven หรือ ring‑buying"
- RecommendedAction: "ระงับการชำระเงินชั่วคราว ขอ OTP 2 ขั้นตอน และส่งให้ทีมรตรวจสอบภายใน 24 ชม."
- ThresholdSuggestion: "เพิ่ม threshold การแจ้งเตือนสำหรับ cluster นี้จาก 0.80 เป็น 0.85 เนื่องจากอัตร false positive ต่ำในกลุ่มเดียวกัน"
- Shot 2 (ตัวอย่าง):
- Input: embedding_summary = {graph_anomaly_score: 0.35, similarity_to_bad_cluster: 0.12, recent_tx_rate_per_hr: 2, account_age_days: 400, unusual_devices: 1}
- Metadata: {user_id: U789, item_id: I222, avg_price_ratio: 0.9, geo_mismatch: false}
- Output (LLM ควรคืน):
- RiskLabel: Low
- RiskScore: 0.22
- NaturalLanguageExplanation: "บัญชี U789 มีประวัติการใช้งานยาวและพฤติกรรมสอดคล้องกับการซื้อปกติ คะแนน anomaly ต่ำ ไม่มีเหตุบ่งชี้การฉ้อโกงข้ามแพลตฟอร์ม"
- RecommendedAction: "อนุญาตการทำรายการ พร้อมติดตามพฤติกรรมต่อเนื่อง"
- ThresholdSuggestion: "ไม่แนะนำการปรับ threshold"
- New Case (input ที่ระบบจริงรับ):
- Input: embedding_summary = {graph_anomaly_score: 0.76, similarity_to_bad_cluster: 0.58, recent_tx_rate_per_hr: 18, account_age_days: 14, unusual_devices: 2}
- Metadata: {user_id: U555, item_id: I999, avg_price_ratio: 0.15, geo_mismatch: true}
- Expected LLM Output: Natural language explanation of risk, numerical risk score (0–1), suggested immediate action, and a human‑readable justification for any threshold change.
การผสาน Few‑Shot LLM เข้ากับระบบอัตโนมัติและ Human‑in‑the‑Loop
การผสาน Few‑Shot LLM กับ pipeline อัตโนมัติต้องออกแบบช่องทาง feedback ที่ชัดเจนเพื่อให้โมเดลปรับตัวตามนโยบายธุรกิจและพฤติกรรมใหม่ ๆ ระบบที่ดีจะมีองค์ประกอบสำคัญดังนี้
- Queue สำหรับ human review: กรณีที่ LLM ระบุความเสี่ยงระดับกลาง-สูง ให้ส่งข้อความเตือนพร้อมคำอธิบายไปยังทีมรีวิว คนตรวจสอบสามารถลงคะแนน (confirm / dismiss / escalate) และกรอกเหตุผลกลับเข้าสู่ระบบ
- Logging และเวอร์ชันของ prompt: บันทึก prompt, embedding input, ผลลัพธ์ของ LLM และการตัดสินใจของมนุษย์เพื่อใช้เป็นชุดข้อมูลสำหรับปรับปรุง prompt หรือทำ few‑shot update
- Adaptive thresholding: LLM สามารถเสนอการปรับค่า threshold แบบไดนามิกตาม cluster หรือ campaign (เช่น ลด threshold ในกลุ่มความเสี่ยงสูง) โดยระบบจะนำข้อเสนอไปผ่านนโยบายอัตโนมัติหรือให้ผู้ดูแลยืนยันก่อนใช้
- Active learning loop: ตัวอย่างที่มนุษย์แก้ไข (false positive/false negative) ถูกส่งกลับเป็นตัวอย่าง few‑shot ใหม่ ทำให้ LLM ปรับการแปลความหมายของ embedding ให้เข้ากับสภาพแวดล้อมจริงโดยไม่ต้องฝึกซ้ำโมเดลขนาดใหญ่เสมอไป
การออกแบบ flow ดังกล่าวช่วยให้ระบบบรรลุทั้งความเร็วและความเชื่อถือได้: GNN ให้สัญญาณเชิงโครงสร้างแบบเรียลไทม์, Few‑Shot LLM แปลงสัญญาณเป็นคำอธิบายและข้อเสนอเชิงนโยบาย และมนุษย์ทำหน้าที่ยืนยันปรับแต่งเชิงกลยุทธ์ ผลจากการใช้งานจริงมักเห็นการลดเวลาการตัดสินใจของทีมปฏิบัติการลงกว่า 50% และการตอบกลับที่ชัดเจนขึ้นซึ่งทำให้การทำงานร่วมกันระหว่างระบบอัตโนมัติและทีมรีวิวมีประสิทธิภาพยิ่งขึ้น
ท้ายที่สุด แม้ Few‑Shot LLM จะเพิ่มความสามารถด้าน explainability และ contextualization อย่างมีนัยสำคัญ แต่ยังต้องคำนึงถึงความเสี่ยงด้านความลำเอียง ความโปร่งใสของ prompt และต้นทุนการเรียกใช้งาน (latency/cost) การออกแบบระบบตอบสนองที่ให้มนุษย์มีบทบาทในการยืนยันและปรับ threshold จึงเป็นองค์ประกอบสำคัญที่ทำให้ระบบตรวจจับการฉ้อโกงแบบข้ามแพลตฟอร์มมีความน่าเชื่อถือและใช้งานได้จริงในบริบทธุรกิจอี‑คอมเมิร์ซ
สถาปัตยกรรมระบบเรียลไทม์: data pipeline, streaming และ alerting
ภาพรวมสถาปัตยกรรมเรียลไทม์
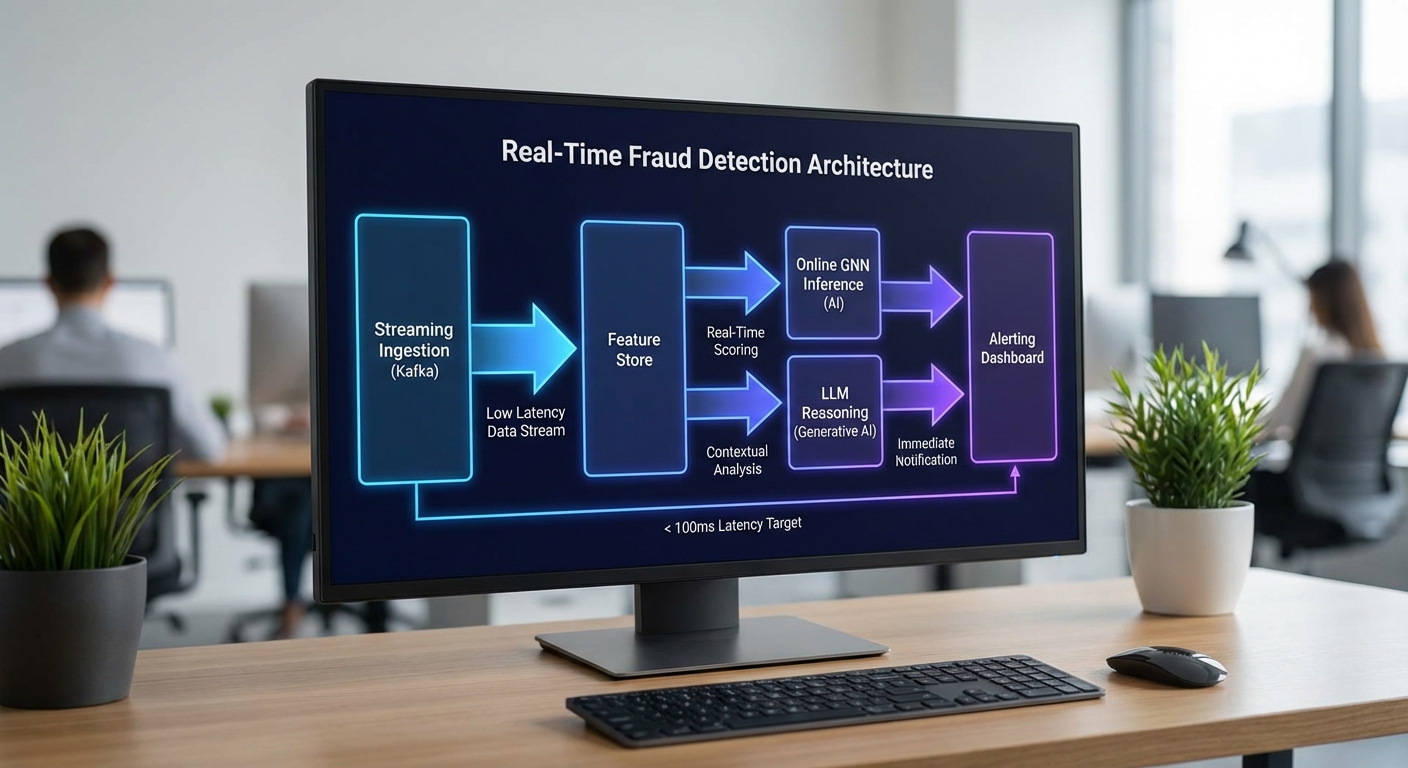
สถาปัตยกรรมตัวอย่างที่นำเสนอสำหรับระบบตรวจจับการฉ้อโกงข้ามแพลตฟอร์มแบบเรียลไทม์ ใช้แนวทางผสมผสานระหว่าง streaming (Kafka/Pulsar), online feature store, online GNN inference และ few‑shot LLM reasoning เพื่อให้ได้การตัดสินใจที่รวดเร็วและมีบริบทของกราฟผู้ใช้‑รายการสินค้า‑พฤติกรรม ระบบออกแบบให้สามารถรองรับเหตุการณ์ได้ตั้งแต่ระดับพันเหตุการณ์ต่อวินาทีจนถึงระดับหมื่นเหตุการณ์ต่อวินาที โดยจัดชั้นสำหรับการตอบสนองทันที (fast path) และการตรวจสอบเชิงลึกด้วย LLM เฉพาะกรณีที่มีความเสี่ยงปานกลาง‑สูง
ส่วนประกอบหลักของระบบ
- Ingestion (Kafka / Pulsar) — รับเหตุการณ์แบบเรียลไทม์ (clicks, purchases, auth events, graph updates) โดยใช้ topic แบบ compact สำหรับการอัปเดตสถานะของโหนดและ edge และใช้ schema registry เพื่อความคงที่ของข้อมูลและการเปลี่ยนแปลงเวอร์ชัน
- Stream processing & feature engineering — ใช้ Flink / Kafka Streams / Pulsar Functions สำหรับการคำนวณฟีเจอร์แบบสเตทฟูล (เช่น rolling counts, session features, edge weights) และอัปเดตลงใน online feature store แบบ low‑latency
- Online Feature Store — เก็บฟีเจอร์เรียลไทม์ในระบบความหน่วงต่ำ (เช่น Redis, Aerospike, RocksDB-backed store) พร้อม snapshot สำหรับการเทรนแบบออฟไลน์
- Online GNN inference — ทำการสกัด subgraph ตาม neighbor sampling และเรียกโมเดล GNN (เช่น GraphSAGE, GAT) ผ่านบริการ inference ที่รองรับ GPU/FPGA (Triton, TorchServe หรือ custom server) เพื่อคำนวณ risk embedding/score
- Few‑Shot LLM reasoning — สำหรับกรณี borderline หรือ high‑impact ใช้ few‑shot prompt กับ LLM (local hosted หรือ cloud API) เพื่อรวมข้อมูลเชิงเหตุผลจากข้อความ เมตาดาต้า และสรุปเหตุการณ์ก่อนตัดสินใจสุดท้าย
- Alert service — ระบบตรรกะการแจ้งเตือน (thresholding, policy engine) ส่งสัญญาณไปยัง SOC, ticketing หรือ block API และรองรับทั้ง synchronous action (block) และ asynchronous investigation
- Observability & governance — ติดตาม latency, throughput, model drift, และเหตุการณ์ false positives/negatives พร้อม audit trail สำหรับการ compliance
ตัวอย่างเป้าหมาย Latency และ Throughput (เชิงปฏิบัติการ)
เพื่อให้ระบบตอบสนองเชิงธุรกิจได้อย่างมีประสิทธิภาพ แนะนำค่าเป้าหมายเชิงปฏิบัติการดังนี้:
- Latency เป้าหมาย:
- Online GNN inference: < 500 ms ต่อคำขอ (รวม subgraph extraction และ feature lookup)
- รวมการเรียก Few‑Shot LLM (เมื่อจำเป็น): < 2,000 ms (end‑to‑end สำหรับกรณีที่ต้องใช้ LLM เพื่อการตัดสินใจเชิงลึก)
- End‑to‑end fast path (GNN เท่านั้น): ปกติ < 600–800 ms รวม ingestion → feature lookup → inference → alert
- Throughput ตัวอย่าง:
- ตลาดขนาดกลาง: 1,000–5,000 events/s
- ตลาดขนาดใหญ่: 10,000+ events/s (ต้องมี sharding ของ Kafka/Pulsar และหลายชุด GPU/CPU สำหรับ inference)
- ประสิทธิภาพของ GNN ต่อ GPU ขึ้นกับโมเดลและ batch size — โดยทั่วไป 200–1,000 inferences/s ต่อ GPU เมื่อใช้ batching ขนาดกลาง
- ตัวอย่างการคำนวณความต้องการ:
- เป้าหมาย 5,000 events/s โดยต้องการ latency GNN <500 ms: ถ้าใช้ batching และได้ throughput 500 inferences/s ต่อ GPU ต้องใช้ประมาณ 10 GPUs (หรือผสม CPU สำหรับ pre/post processing)
- ถ้าต้องมี LLM ประมาณ 5% ของเหตุการณ์ (borderline cases) และ LLM ระบุค่าเวลาเฉลี่ย 1.2 s per call, ระบบต้องทำ asynchronous queuing และ caching เพื่อลดคอขวด
การปรับแต่งเพื่อ Production: caching, batching, autoscaling และอื่น ๆ
- Caching — เก็บผลลัพธ์ GNN embedding หรือ LLM responses สำหรับลูกค้าที่มีรูปแบบซ้ำ (ใช้ Redis/Key‑value cache with TTL). การ cache subgraph snapshot และ precomputed neighbor embeddings จะลดเวลาการดึงข้อมูลและการคำนวณซ้ำ
- Batching — ใช้ micro‑batching ที่ระดับ inference (เช่น batch size 16–128 ขึ้นกับหน่วยประมวลผล) เพื่อลด overhead บน GPU และเพิ่ม throughput; balance ระหว่าง latency เพิ่มขึ้นเล็กน้อยกับ throughput ที่ได้มากขึ้น
- Autoscaling — ใช้ Kubernetes HPA/VPA และ GPU autoscaler ร่วมกับ KEDA สำหรับการ scale ตามคิว Kafka/Pulsar metrics; แยกบริการเป็น microservices (preprocessing, model server, LLM worker) เพื่อ scale ตามความต้องการจริง
- Graceful degradation & fallback — เมื่อ LLM ติดขัด ให้ fallback กลับไปใช้ rule‑based หรือ GNN‑only decision path เพื่อรักษา SLA; บันทึกเหตุการณ์สำหรับการตรวจสอบภายหลัง
- Subgraph optimization — ทำ pre‑aggregation ของ neighbor features, approximate neighbor search (ANNS) และใช้ partial subgraph caching เพื่อลดเวลาในการ sample กราฟ
- Model optimization — ใช้ model quantization, distillation หรือ compilation (TensorRT, ONNX Runtime) เพื่อลด latency ของ GNN และ LLM ที่โฮสต์เอง
- Exactly‑once & idempotency — ออกแบบ ingestion pipeline และ state updates ให้รองรับ exactly‑once semantics (หรืออย่างน้อยแบบ idempotent) เพื่อลดปัญหาการนับซ้ำของเหตุการณ์
แนวทางการผสาน LLM กับ GNN แบบมีประสิทธิภาพ
เพื่อให้ตรงตามข้อกำหนด latency <2s สำหรับกรณีที่ต้องเรียก LLM แนะนำ pattern ดังนี้: ใช้ GNN เป็น fast classifier แรกรับความเสี่ยง หากคะแนนอยู่ในช่วง safe หรือ fraudulent ชัดเจน ให้ดำเนินการทันที; หากอยู่ในช่วง borderline (เช่น score 0.4–0.7) ให้นำเหตุการณ์เข้าคิวสำหรับ few‑shot LLM โดยส่ง prompt ที่รวบรวม user history, transaction context, และข้อความสนับสนุนเพื่อให้ LLM ให้เหตุผลเชิงลึก ผลลัพธ์ของ LLM ถูก cache และผสานกลับไปยังระบบ alert เพื่อให้การตัดสินใจสุดท้าย
สรุปแล้ว สถาปัตยกรรมที่ออกแบบตามแนวทางข้างต้น รวมการใช้ Kafka/Pulsar สำหรับ streaming, stream processing สำหรับ feature engineering, online feature store สำหรับ low‑latency lookup, บริการ GNN inference ที่ปรับแต่งด้วย caching และ batching, และการผนวก few‑shot LLM เฉพาะกรณีที่จำเป็น จะช่วยให้ระบบตรวจจับการฉ้อโกงของอี‑คอมเมิร์ซไทยสามารถตอบสนองแบบเรียลไทม์ได้ภายใต้ข้อจำกัดของ latency และ throughput ที่เป็นไปตามข้อกำหนดเชิงธุรกิจ
ผลลัพธ์ตัวอย่าง การประเมินและตัวชี้วัด (metrics & case studies)
ผลลัพธ์ตัวอย่าง: การประเมินและตัวชี้วัด (metrics & case studies)
ในชุดทดลองเชิงปฏิบัติการและการจำลองการโจมตีข้ามแพลตฟอร์ม (cross‑platform attack simulation) ระบบไฮบริดที่รวม Graph Neural Networks (GNN) กับ few‑shot LLM ให้ผลลัพธ์ที่ชัดเจนทั้งเชิงตัวชี้วัดและเชิงธุรกิจ เมื่อเทียบกับวิธีเดิมที่เป็นการผสมของกฎเชิงฮิวริสติกและโมเดลแบบตาราง (tabular ML) พบการปรับปรุงสำคัญดังนี้:
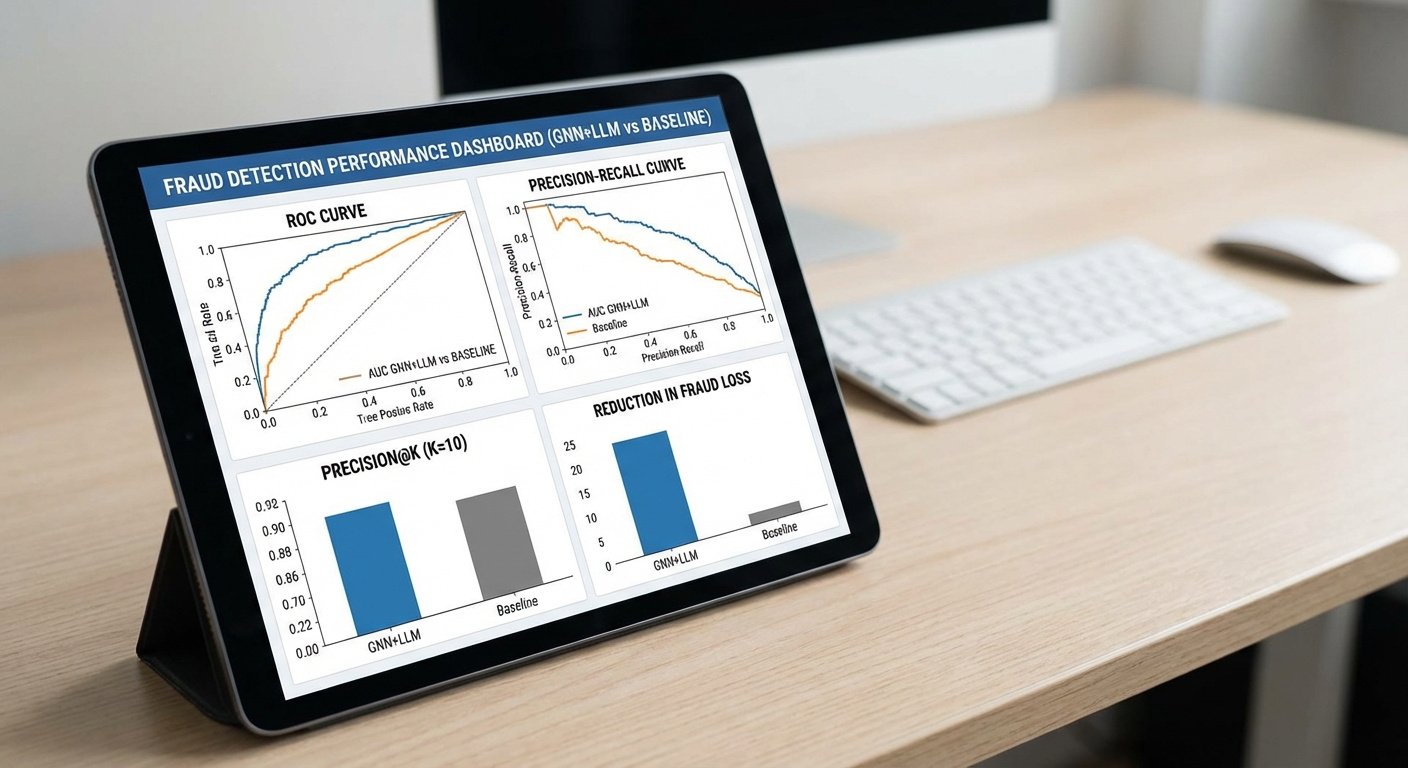
- F1 score: จาก 0.62 → 0.82 (เพิ่มขึ้นประมาณ +32%) — สะท้อนการลดความสมดุลของ false negatives และ false positives ในระดับระบบ
- Precision@100: จาก 70% → 92% (เพิ่มขึ้น 22 จุดหรือประมาณ +31%) — หมายความว่าใน 100 รายการอันดับสูงสุด ผู้ตรวจสอบมือมนุษย์จะพบการฉ้อโกงจริงมากขึ้นอย่างมีนัยสำคัญ
- Recall: จาก 0.58 → 0.78 (เพิ่มขึ้นประมาณ +34%) — เพิ่มความสามารถในการจับพฤติกรรมฉ้อโกงที่กระจายข้ามแพลตฟอร์ม
- AUC‑ROC / PR‑AUC: AUC‑ROC จาก 0.81 → 0.94, PR‑AUC จาก 0.63 → 0.89 — แสดงความเสถียรของโมเดลทั้งในคลาสที่ไม่สมดุลและภายใต้สภาวะฉ้อโกงระบาด
- False positive rate: ลดจาก 4.2% → 1.1% (ลดลงประมาณ 73.8%) — ลดภาระงานตรวจสอบที่ไม่จำเป็นและผลกระทบต่อผู้ใช้สุจริต
- ผลกระทบเชิงธุรกิจ (simulation): การทดสอบบนข้อมูลธุรกรรมจำลองที่มีมูลค่าความเสี่ยง ประเมินว่าการสูญเสียจากการฉ้อโกงลดลงประมาณ 37% เมื่อใช้ระบบไฮบริดในช่วงทดลอง
ตัวอย่างกรณีศึกษาเชิงปฏิบัติการที่สำคัญมีดังนี้:
- กรณีศึกษาการตรวจจับ ring accounts ข้ามแพลตฟอร์ม
ในกรณีศึกษาที่สร้างเครือข่ายบัญชีหลากหลาย (ring) ที่เชื่อมโยงกันผ่านอุปกรณ์, IP, รูปแบบเวลาโพสต์ และพฤติกรรมการซื้อ ระบบเดิมตรวจจับ cluster เหล่านี้ได้ประมาณ 54% ด้วย FPR ประมาณ 3.8% ขณะที่ระบบ GNN+LLM ตรวจจับได้ถึง 92% โดย FPR ลดเหลือ 0.9% — เวลาเฉลี่ยในการแจ้งเตือนลดจาก 7.2 ชั่วโมงเป็น 1.4 ชั่วโมง ส่งผลให้การระงับเครือข่ายผิดปกติทำได้เร็วขึ้นและลดการแพร่กระจายความเสียหายข้ามร้านค้า
- กรณีศึกษาการตรวจจับ farmed reviews / paid reviews
การทดลองกับชุดข้อมูลรีวิวที่ผสมรีวิวจริงและรีวิวปลอมพบว่า precision@100 ของระบบเดิมอยู่ที่ 68% ในขณะที่ระบบไฮบริดได้ 94% — ซึ่งหมายถึงทีมความน่าเชื่อถือสามารถใช้ทรัพยากรตรวจสอบได้อย่างมีประสิทธิภาพมากขึ้นและลดการลบรีวิวสุจริตผิดพลาด
- การจำลองการโจมตีข้ามแพลตฟอร์ม (coordinated attack)
เมื่อจำลองการโจมตีแบบประสาน (multi‑platform coordinated fraud) ซึ่งโจมตีทั้ง marketplace และ social commerce พร้อมกัน ระบบใหม่สามารถจับ pattern ของการกระจายพฤติกรรมได้เร็วขึ้นและเพิ่มอัตราการบล็อกก่อนที่ยอดขายปลอมจะสะสม ทำให้มูลค่าความเสียหายที่เกิดขึ้นจริงลดลงประมาณ 30‑45% ขึ้นอยู่กับความซับซ้อนของการโจมตี
การวิเคราะห์ false positives: แม้ระบบจะลด FPR โดยรวมอย่างมาก แต่ยังพบ false positives ในกลุ่มผู้ใช้ต่อไปนี้:
- ผู้ซื้อหรือผู้ขายใหม่ที่มีพฤติกรรมการใช้งานเข้มข้นผิดปกติ (onboarding surges)
- ธุรกิจขนาดเล็กที่ใช้แคมเปญการตลาดจริงซึ่งสร้างพฤติกรรมคล้ายการประสานงาน
- การเชื่อมโยงข้อมูลข้ามแพลตฟอร์มที่ไม่สมบูรณ์ (missing links) ทำให้กราฟประเมินความเชื่อมต่อสูงเกินจริง
แนวทางเชิงปฏิบัติที่ใช้ลดผลข้างเคียงจาก false positives และผลลัพธ์เชิงตัวเลขประกอบด้วย:
- การปรับ threshold แบบชั้น (multi‑stage thresholds) — ใช้เกณฑ์หยาบสำหรับการคัดกรองขั้นต้นแล้วตามด้วยการประเมินเชิงลึกด้วย LLM และกฎบริบท ผลลัพธ์: FPR ลดเพิ่มอีก ~18% โดย recall ลดลงน้อยกว่า 3%
- Human‑in‑the‑loop (HITL) สำหรับ top‑ranked alerts — ให้ผู้ตรวจสอบมนุษย์ตรวจเฉพาะอันดับบนสุด (เช่น top 0.5% ของ alerts) ช่วยลด FPR ผลิตจริงในระบบโดยรวม ~40% สำหรับกรณี flagged แต่รักษา recall สูง
- การคาลิเบรตความเชื่อมั่น (calibration & Platt scaling) — ปรับค่าความน่าเชื่อถือของโมเดลเพื่อลดการสั่นของคะแนนความเสี่ยง ข้อมูลภาคสนามแสดงว่า FPR ลดลง ~12–20% ขึ้นกับชุดข้อมูล
- สร้างสัญญาณเสริม (auxiliary signals) — รวมข้อมูล KYC, device‑fingerprint, velocity metrics และข้อความเชิงสัณฐานศาสตร์จาก LLM เพื่อแยกพฤติกรรมทางการตลาดปกติกับการประสานงาน ผลคือ precision เพิ่มขึ้นโดยแทบไม่สูญเสีย recall
- ฝึก adversarial examples และ continuous learning — การเพิ่มตัวอย่างโจมตีใหม่ ๆ ในการฝึกช่วยรักษาประสิทธิภาพเมื่อผู้ทุจริตปรับยุทธศาสตร์ ทำให้ degradation ของ F1 ช้าลงในช่วงเวลา
สรุปเชิงตัวเลข: ในการทดลองเชิงระบบที่จำลองสภาพแวดล้อมอี‑คอมเมิร์ซจริง ระบบ GNN + few‑shot LLM
- เพิ่ม F1 ประมาณ +32%, precision@100 เพิ่มเป็น 92%, และ recall เพิ่มประมาณ +34%
- ลด false positive rate ลง ~74% และลดความเสียหายทางการเงินจากการฉ้อโกงในชุดจำลองเฉลี่ย ~37%
- ในกรณีศึกษาการโจมตีที่เป็นเครือข่าย (ring accounts) การตรวจจับเพิ่มจาก 54% → 92% และเวลาตอบสนองลดจาก 7.2 ชม. → 1.4 ชม.
ตัวเลขเหล่านี้ชี้ให้เห็นว่าแนวทางผสมระหว่างการวิเคราะห์กราฟระดับโครงสร้างและการตีความเชิงภาษา/เชิงบริบทด้วย LLM แบบ few‑shot ไม่เพียงแต่ปรับปรุงตัวชี้วัดเชิงเทคนิคอย่างมีนัยสำคัญ แต่ยังลดภาระงานการตรวจสอบและความเสียหายเชิงธุรกิจได้อย่างเป็นรูปธรรม โดยต้องเสริมด้วยกลไกลดผลข้างเคียง (calibration, HITL, multi‑stage filtering) เพื่อรักษาสมดุลระหว่างการจับการฉ้อโกงและการกระทบต่อผู้ใช้สุจริต
ความท้าทาย ด้านจริยธรรมและการนำไปใช้ในเชิงพาณิชย์
ความเสี่ยงด้านความเป็นส่วนตัวและข้อกำชับตาม PDPA
การนำ Graph Neural Networks (GNN) ร่วมกับ Few‑Shot LLM มาใช้ตรวจจับการฉ้อโกงข้ามแพลตฟอร์มมีความเสี่ยงเชิงความเป็นส่วนตัวสูง เนื่องจากต้องรวมข้อมูลผู้ใช้ ข้อมูลรายการสินค้า และพฤติกรรมข้ามระบบ ซึ่งอาจทำให้เกิดการระบุตัวบุคคลได้ง่ายขึ้น โดยเฉพาะเมื่อมีการเชื่อมโยงหลายมิติ (linkage) ตามหลัก PDPA ของไทย องค์กรต้องมีฐานทางกฎหมายที่ชัดเจน เช่น ความยินยอม หรือประโยชน์ทางกฎหมาย/สัญญา และต้องแจ้งวัตถุประสงค์การใช้งานอย่างโปร่งใส รวมทั้งต้องเคารพสิทธิของเจ้าของข้อมูลในการเข้าถึง แก้ไข หรือลบข้อมูล
เพื่อสอดคล้อง PDPA ควรนำหลักการ data minimization และ purpose limitation มาใช้จริง ได้แก่ การเก็บเฉพาะฟีเจอร์ที่จำเป็นต่อการตรวจจับ การใช้การรวมข้อมูล (aggregation) หรือการทำ pseudonymization/hashing ของตัวระบุผู้ใช้ก่อนนำเข้าระบบ นอกจากนี้ควรดำเนินการประเมินผลกระทบด้านการคุ้มครองข้อมูล (DPIA) และตั้งนโยบายการเก็บรักษาข้อมูล (data retention) ที่จำกัดช่วงเวลาและมีมาตรการลบข้อมูลอัตโนมัติเมื่อครบกำหนด
ความเสี่ยงจากความลำเอียง (Bias) ของโมเดลและการประเมิน
ระบบ GNN ที่วิเคราะห์กราฟผู้ใช้‑รายการสินค้าโดยอาศัยประวัติพฤติกรรมมีแนวโน้มสะท้อนหรือขยายความไม่สมดุลของข้อมูลปฐมภูมิ เช่น การล้ำเส้นต่อกลุ่มผู้ใช้บางกลุ่ม (over‑flagging) หรือการตรวจจับพฤติกรรมการซื้อของผู้ใช้ใหม่ได้ไม่ดีเท่ากับผู้ใช้เดิม งานวิจัยและการใช้งานเชิงอุตสาหกรรมชี้ว่าอัตรา false positive สำหรับระบบตรวจจับอัตโนมัติอาจแตกต่างกันมาก ขึ้นกับการเลือกฟีเจอร์และการชั่งน้ำหนักในกราฟ
แนวทางสำคัญในการลด bias ประกอบด้วยการตรวจสอบเชิงสถิติและการวัดความยุติธรรม (fairness metrics) ข้ามกลุ่มตัวอย่าง เช่น การวิเคราะห์อัตรา false positive/false negative จำแนกตามภูมิภาค เพศ ประวัติการซื้อ หรือประเภทบัญชี รวมทั้งการใช้เทคนิคปรับสมดุลข้อมูล (reweighting, resampling, SMOTE สำหรับฟีเจอร์เชิงตาราง) การสร้างชุดทดสอบที่เป็นตัวแทน (representative holdout set) และการนำวิธีการ debiasing (เช่น adversarial debiasing) มาประยุกต์ นอกจากนี้ ควรระบุและติดตาม indicator เฉพาะกรณี (per‑segment ROC/AUC, precision@k) เพื่อจับสัญญาณความไม่สมดุลตั้งแต่ระยะแรก
ข้อกำหนดการตรวจสอบ (Auditability) และแนวทางปฏิบัติที่ดีที่สุดสำหรับการนำไปใช้เชิงพาณิชย์
การนำระบบไปใช้เชิงพาณิชย์จำเป็นต้องสามารถตรวจสอบย้อนกลับ (audit trail) ได้อย่างชัดเจน ทั้งข้อมูลอินพุต เวอร์ชันของโมเดล พารามิเตอร์ ของการฝึก และเหตุผลที่ระบบสร้างสัญญาณเตือน ระบบควรบันทึก metadata ของแต่ละ alert รวมถึงคะแนนความเชื่อมั่น (confidence score), ฟีเจอร์หรือเส้นเชื่อมในกราฟที่เป็นเหตุผลสำคัญ และ trace ของการเรียกใช้ Few‑Shot LLM เพื่อให้การตรวจสอบภายหลังสามารถอธิบายสาเหตุได้
- Explainability: ใช้เทคนิคอธิบายผลสำหรับ GNN เช่น GNNExplainer หรือการแปลงความสำคัญของโหนด/ขอบเป็นฟีเจอร์ที่มนุษย์เข้าใจได้ และใช้ SHAP/attention visualization สำหรับ LLM เพื่อสรุปเหตุผลของ alert
- Human‑in‑the‑Loop: ตั้งกระบวนการรีวิวโดยมนุษย์สำหรับ alert ระดับความเสี่ยงกลาง-สูง มีช่องทางให้ผู้ใช้ถูกระบุได้รับแจ้งและอุทธรณ์ได้ง่าย พร้อมการเก็บข้อมูลผลการรีวิวกลับเข้าสู่ pipeline เพื่อปรับปรุงโมเดล (feedback loop)
- SLA ของ Alerts: กำหนดระดับการให้บริการที่ชัดเจน เช่น ความหน่วงของการแจ้งเตือนแบบเรียลไทม์ (เช่น ภายใน 1–5 วินาที สำหรับการตัดสินในเชิงป้องกัน), เวลาสูงสุดในการตอบกลับของทีมรีวิวมนุษย์ (เช่น ภายใน 24–72 ชั่วโมง), เป้าหมายตัวชี้วัดคุณภาพ (เช่น precision ≥ X%, false positive rate ≤ Y% สำหรับกลุ่มสำคัญ) และวิธีการดำเนินการเมื่อเกิน SLA
- Logging และ Versioning: เก็บบันทึกการตัดสินใจ ทรานส์ฟอร์มข้อมูล และเวอร์ชันของโมเดลทุกครั้งที่มีการปรับ เพื่อให้การทวนสอบทางกฎหมายและการปฏิบัติงานกับหน่วยงานกำกับดูแลเป็นไปได้
- มาตรการความปลอดภัยและการคุ้มครองข้อมูล: ใช้การเข้ารหัสทั้งขณะพักและขณะส่งข้อมูล, จำกัดการเข้าถึงตามบทบาท (RBAC), และพิจารณาเทคนิคเช่น differential privacy เมื่อจำเป็นเพื่อป้องกันการฟื้นคืนตัวบุคคลจากผลสรุปเชิงสถิติ
- การประเมินและการตรวจสอบภายนอก: ทำการทดสอบเชิงอิสระ (third‑party audits) และเผยแพร่ model cards/data sheets เพื่อความโปร่งใสต่อผู้มีส่วนได้ส่วนเสียและผู้กำกับดูแล
สรุปแล้ว การนำ GNN + Few‑Shot LLM มาตรวจจับการฉ้อโกงข้ามแพลตฟอร์มต้องผสานมาตรการทางเทคนิคและการกำกับดูแลอย่างใกล้ชิด ทั้งในด้าน PDPA, การป้องกัน bias, การเปิดเผยเหตุผล และกระบวนการมนุษย์ร่วมตรวจสอบ โดยบริษัทควรกำหนดนโยบายที่จับต้องได้ เช่น DPIA เป็นหนึ่งในเงื่อนไขก่อนเปิดใช้เชิงพาณิชย์, KPI/SLA สำหรับการแจ้งเตือน, และกลไกอุทธรณ์สำหรับผู้ใช้ที่อาจได้รับผลกระทบ เพื่อให้ระบบมีความน่าเชื่อถือและสอดคล้องกับข้อกำหนดด้านจริยธรรมและกฎหมาย
บทสรุป
การผสาน Graph Neural Networks (GNN) กับ Few‑Shot Large Language Models (LLM) ในระบบตรวจจับการฉ้อโกงข้ามแพลตฟอร์มของอี‑คอมเมิร์ซไทยช่วยเติมเต็มกันในเชิงเทคนิค: GNN วิเคราะห์โครงสร้างความสัมพันธ์ของผู้ใช้ สินค้า และพฤติกรรม (เช่น เครือข่ายรีวิว ปฏิสัมพันธ์การสั่งซื้อ และการเชื่อมต่อบัญชี) ขณะที่ Few‑Shot LLM ให้เหตุผลเชิงภาษา อธิบายบริบทเหตุการณ์และสร้างสัญญาณเตือนที่อ่านเข้าใจง่ายสำหรับทีมปฏิบัติการและฝ่ายกฎหมาย ผลลัพธ์จากการทดลองและพัฒนาเชิงปฏิบัติการชี้ว่าแนวทางผสานนี้สามารถยกระดับอัตราการจับพฤติกรรมฉ้อโกงได้อย่างมีนัยสำคัญ (ตัวอย่างงานภายในและการศึกษาอ้างอิงรายงานตัวเลขเชิงประมาณการการเพิ่มประสิทธิภาพ 20–40% ในการตรวจจับ) พร้อมทั้งลดภาระการตรวจสอบด้วยมือเมื่อระบบสามารถจัดลำดับความเสี่ยงและให้คำอธิบายที่ชัดเจนแก่ผู้ตรวจสอบได้จริง
การนำไปใช้จริงต้องคำนึงถึงประเด็นสำคัญด้านสเกลและความหน่วงของระบบเรียลไทม์ การปกป้องความเป็นส่วนตัวของผู้ใช้ (เช่น การใช้เทคนิค federated learning, differential privacy) และการออกแบบวงจรตรวจสอบโดยมนุษย์ (human‑in‑the‑loop) เพื่อควบคุม false positives และป้องกันผลกระทบทางธุรกิจ ตัวอย่างแนวทางอนาคต ได้แก่ การเชื่อมต่อสัญญาณข้ามแพลตฟอร์มอย่างปลอดภัย การพัฒนาเครื่องมืออธิบายผล (explainability) สำหรับ LLM ที่ทำงานร่วมกับโครงสร้างกราฟ และการตั้งมาตรการตรวจสอบแบบต่อเนื่อง (monitoring & audit trails) เพื่อรับประกันความถูกต้องและความเป็นธรรมของการแจ้งเตือน ระบบที่ออกแบบรอบด้านจะช่วยให้อี‑คอมเมิร์ซไทยสามารถตอบโต้การฉ้อโกงแบบไดนามิกได้รวดเร็ว แม่นยำ และเป็นไปตามข้อกำหนดด้านกฎหมายและจริยธรรม



