
การแข่งขันด้านต้นทุนพลังงานและความต้องการลดผลกระทบสิ่งแวดล้อมกำลังกระตุ้นให้ธุรกิจค้าปลีกไทยหันมาใช้เทคโนโลยีอัจฉริยะเพื่อปรับปรุงการใช้พลังงาน ล่าสุดเครือร้านค้าปลีกในไทยเริ่มทดลองนำ Reinforcement Learning (RL) มาควบคุมระบบปรับอากาศ (HVAC) แบบเรียลไทม์ โดยเชื่อมต่อกับข้อมูลราคาพลังงานและสภาวะแวดล้อม พบว่าการทดลองในหลายสาขาช่วยลดการใช้พลังงานเฉลี่ยกว่า 20% พร้อมทั้งลดพีคดิมานด์ที่เคยสร้างค่าไฟสูงในช่วงเวลาหลักของวัน ผลลัพธ์ดังกล่าวไม่เพียงแต่ลดบิลค่าไฟ แต่ยังช่วยเพิ่มความยืดหยุ่นของเครือข่ายไฟฟ้าและลดการปล่อยก๊าซเรือนกระจกในเชิงปฏิบัติได้ชัดเจน
บทนำนี้จะพาอ่านถึงแนวคิดและหลักการทำงานของ RL ในการควบคุม HVAC แบบเรียลไทม์ ว่าระบบเรียนรู้และตัดสินใจอย่างไรเมื่อเผชิญกับข้อมูลราคาพลังงาน ความหนาแน่นลูกค้า และสภาพอากาศ พร้อมยกตัวอย่างการทดลองจริง ตัวเลขการประหยัดพลังงาน และผลกระทบทางธุรกิจ—รวมถึงข้อจำกัดและข้อควรระวังเมื่อขยายการใช้งานในวงกว้าง เพื่อให้ผู้อ่านเห็นภาพชัดเจนว่าเทคโนโลยีนี้จะเปลี่ยนโฉมหน้าเรื่องการจัดการพลังงานของค้าปลีกไทยได้อย่างไร
บทนำ: ทำไมการจัดการพลังงานในค้าปลีกจึงสำคัญ
บทนำ: ทำไมการจัดการพลังงานในค้าปลีกจึงสำคัญ
ในภาคค้าปลีก พลังงานถือเป็นต้นทุนคงที่ที่มีผลกระทบต่อกำไรและความสามารถในการแข่งขันของธุรกิจอย่างชัดเจน โดยเฉพาะสำหรับร้านค้าปลีกที่มีพื้นที่กว้างและการให้บริการตลอดวัน ระบบปรับอากาศและระบายอากาศ (HVAC) มักเป็นสัดส่วนการใช้พลังงานที่ใหญ่ที่สุดของอาคารค้าปลีก ประมาณ 30–50% ของการใช้พลังงานทั้งหมด ซึ่งหมายความว่าการปรับปรุงประสิทธิภาพหรือการควบคุมระบบ HVAC อย่างมีประสิทธิภาพสามารถแปลเป็นการลดต้นทุนที่มีนัยสำคัญต่อรายได้ของร้านค้าได้โดยตรง

ปัจจุบันสภาพแวดล้อมด้านพลังงานเปลี่ยนแปลงอย่างรวดเร็ว ทั้งจากความผันผวนของราคาพลังงานในตลาดส่ง (wholesale) การขยายตัวของพลังงานหมุนเวียนที่มีความผันผวนตามสภาพอากาศ ตลอดจนรูปแบบการคิดค่าไฟฟ้าที่สะท้อนช่วงเวลาใช้งาน (time-of-use) และค่าความต้องการสูงสุด (demand charges) ทำให้ค่าไฟฟ้าไม่ใช่ตัวเลขคงที่อีกต่อไป ความผันผวนของราคาพลังงานเพิ่มมูลค่าทางเศรษฐศาสตร์ให้กับการปรับการใช้พลังงานแบบเรียลไทม์ เนื่องจากการเลื่อนการใช้พลังงานจากช่วงพีคไปยังช่วงที่ราคาต่ำหรือการลดพีคได้ทันเวลาจะช่วยลดค่าใช้จ่ายรวมได้อย่างมีนัยสำคัญ
สำหรับผู้ประกอบการค้าปลีก การจัดการพลังงานที่ดีไม่เพียงลดค่าใช้จ่ายโดยตรง แต่ยังเชื่อมโยงกับการรักษามาตรฐานบริการลูกค้า การปฏิบัติตามข้อกำหนดด้านสิ่งแวดล้อม และภาพลักษณ์ของแบรนด์ในด้านความยั่งยืน หลายองค์กรทั่วโลกและในภูมิภาคเอเชียเริ่มเพิ่มการลงทุนในระบบ Energy Management และเทคโนโลยีดิจิทัลที่ช่วยวิเคราะห์และควบคุมการใช้พลังงาน โดยพบแนวโน้มการลงทุนเพื่อเพิ่มประสิทธิภาพพลังงานในกลุ่มค้าปลีกเพิ่มขึ้นอย่างต่อเนื่อง เพราะผลตอบแทนจากการลดต้นทุนพลังงานสามารถคืนทุนได้ภายในระยะเวลาอันสั้นเมื่อเทียบกับการลงทุนในช่องทางอื่น
การนำ AI มาใช้ในการควบคุม HVAC โดยเฉพาะเทคนิคอย่าง Reinforcement Learning (RL) กลายเป็นตัวเลือกที่น่าสนใจเพราะสามารถเรียนรู้และปรับนโยบายการควบคุมแบบเรียลไทม์จากข้อมูลจำนวนมาก เช่น อุณหภูมิภายในและภายนอก การใช้งานพื้นที่ เวลาทำการ และสัญญาณราคาพลังงาน ผลการทดลองและกรณีศึกษาหลายแห่งชี้ให้เห็นว่าการประยุกต์ AI/ML เพื่อควบคุมระบบ HVAC ในร้านค้าปลีกสามารถลดต้นทุนพลังงานได้ตั้งแต่หลักสิบเปอร์เซ็นต์ในบางกรณี (เช่น >20% ในการทดลองเชิงปฏิบัติการ) และยังช่วยลดความผันผวนของการใช้พลังงานที่ก่อให้เกิดค่าใช้จ่ายพีคอีกด้วย
- ผลกระทบทางการเงิน: HVAC เป็นต้นทุนหลัก 30–50% ของการใช้พลังงาน ทำให้มีโอกาสลดต้นทุนได้มากเมื่อปรับปรุงการควบคุม
- คุณค่าจากการควบคุมแบบเรียลไทม์: ราคาพลังงานและค่าบริการตามช่วงเวลาสร้างโอกาสในการประหยัดเมื่อระบบสามารถตอบสนองได้ทันที
- เหตุผลเชิงกลยุทธ์: การจัดการพลังงานที่มีประสิทธิภาพช่วยเสริมความยั่งยืน ลดความเสี่ยงด้านต้นทุน และเพิ่มความสามารถแข่งขันของร้านค้าปลีก
ภาพรวมเทคโนโลยี: ทำไมเลือก Reinforcement Learning
หลักการพื้นฐานของ Reinforcement Learning ในบริบทการควบคุม HVAC
Reinforcement Learning (RL) เป็นกรอบการเรียนรู้ของเครื่องที่ออกแบบมาเพื่อแก้ปัญหาการตัดสินใจต่อเนื่อง (sequential decisions) โดยตัวแทน (agent) เรียนรู้จากการกระทำ (actions) ที่มีผลต่อสภาพแวดล้อมและได้รับผลตอบแทน (reward) ตามเป้าหมายที่กำหนด ในกรณีของระบบ HVAC ของร้านค้าปลีก ตัวแทนจะเลือกคำสั่งควบคุม เช่น การปรับ setpoint ของอุณหภูมิ ความเร็วพัดลมหรือการเปิด/ปิดคอมเพรสเซอร์ ในทุกช่วงเวลา (เช่น ทุกนาทีหรือทุก 5 นาที) เพื่อลดการใช้พลังงานในขณะที่ยังคงรักษาความสบายของลูกค้า
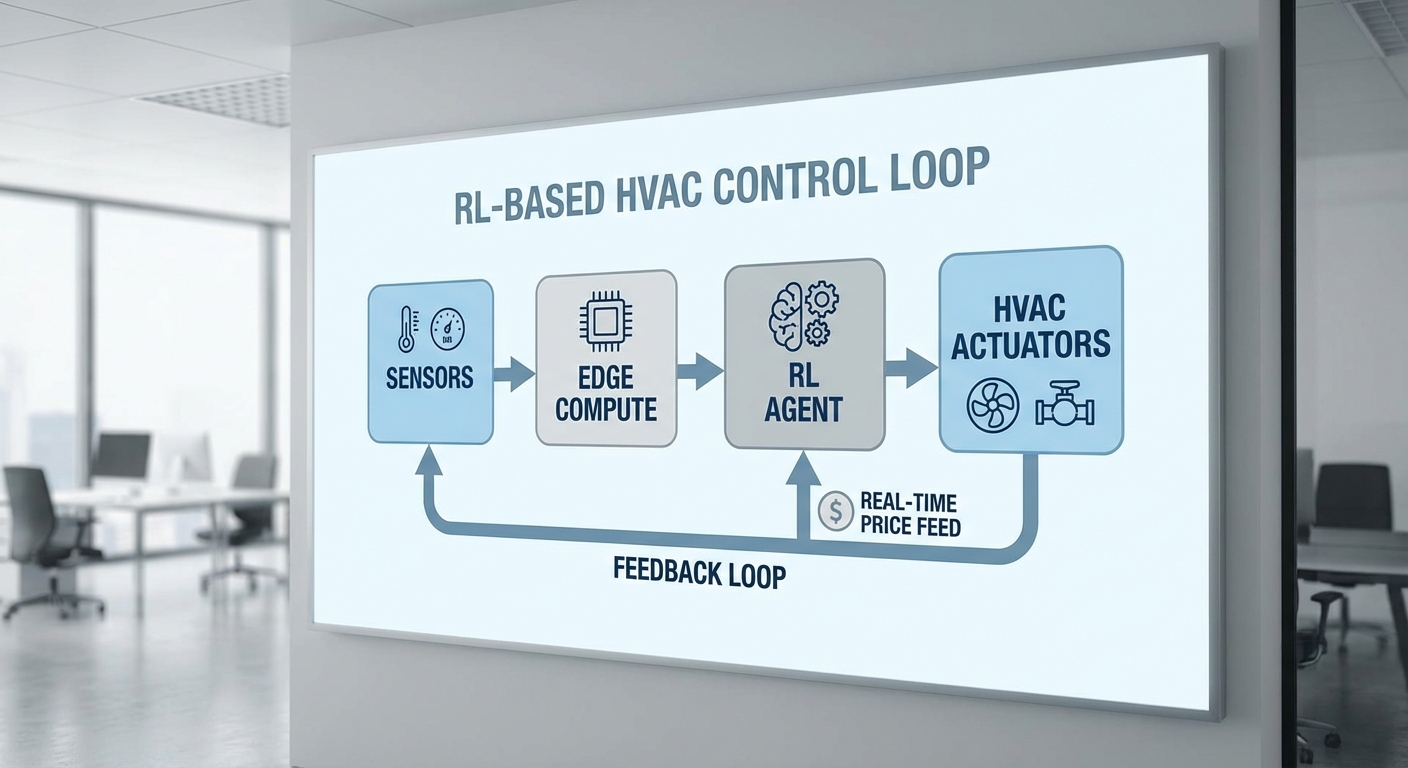
ความสำคัญคือ RL สามารถเรียนรู้ผลกระทบที่เกิดขึ้นตามเวลา (temporal effects) เช่น ความหน่วงความร้อน (thermal inertia) ของอาคาร การเปลี่ยนแปลงตามสภาพอากาศ และพฤติกรรมคนเข้า-ออกร้าน ซึ่งเป็นลักษณะที่วิธีดั้งเดิมอย่าง PID หรือ rule-based มักจัดการได้ยากโดยไม่ต้องปรับแต่งบ่อย ๆ
การออกแบบฟังก์ชันรางวัล (Reward Function) — ความสมดุลระหว่างความสบายและต้นทุนพลังงาน
หัวใจสำคัญของการใช้ RL ในการควบคุม HVAC คือการออกแบบ reward function ที่สะท้อนเป้าหมายเชิงพาณิชย์อย่างชัดเจน เช่น ลดต้นทุนพลังงาน ขณะเดียวกันต้องรักษาระดับความสบายของลูกค้า ตัวอย่างโครงสร้างรางวัลที่ใช้บ่อยคือการรวมเป็นผลรวมถ่วงน้ำหนักของปัจจัยต่าง ๆ:
- Energy_cost_t: ค่าพลังงานจริงหรือการประมาณค่าใช้จ่ายต่อช่วงเวลา
- Comfort_penalty_t: ค่าลงโทษตามการเบี่ยงเบนของอุณหภูมิจาก setpoint หรือช่วงยอมรับ เช่น max(0, |T_t - T_set| - tol)
- Actuation_penalty_t: ลงโทษการเปลี่ยนแปลงการสั่งงานบ่อยๆ เพื่อถนอมอุปกรณ์และหลีกเลี่ยงการสั่นของระบบ
ตัวอย่างฟังก์ชันรางวัลเชิงปฏิบัติการ (เชิงคำอธิบาย): Reward_t = - (α * Energy_cost_t + β * Comfort_penalty_t + γ * Actuation_penalty_t) โดยที่ค่าพารามิเตอร์ α, β, γ ถูกจูนให้สอดคล้องกับนโยบายธุรกิจ (เช่น ยอมแลกพลังงานเล็กน้อยเพื่อรักษาความสบายสูงสุดในช่วงชั่วโมงทองของการขาย)
ตัวอย่างอัลกอริธึมที่นิยมและการเลือกใช้งาน
การเลือกอัลกอริึทึม RL ขึ้นกับลักษณะของปัญหา เช่น การควบคุมแบบ continuous control (ปรับ setpoint เป็นค่าเชิงต่อเนื่อง) หรือ discrete actions (เปิด/ปิด, เลือกระดับพัดลม 3 ระดับ) อัลกอริทึมยอดนิยมได้แก่:
- PPO (Proximal Policy Optimization) — มีความเสถียรในการฝึก ตอบโจทย์ทั้งการควบคุมแบบต่อเนื่องและแบบดิสรีต เหมาะสำหรับการทดลองเชิงโปรดักชันที่ต้องการความปลอดภัยเชิงนโยบาย
- SAC (Soft Actor-Critic) — ออฟ-โปลิซี่ (off-policy) สำหรับการควบคุมแบบ continuous มีประสิทธิภาพเรื่อง sample efficiency และ exploration ที่ดี เหมาะเมื่อต้องการฝึกจากข้อมูลจำกัดหรือจากซิมูเลเตอร์
- DDPG (Deep Deterministic Policy Gradient) — ครั้งหนึ่งเป็นมาตรฐานสำหรับ continuous control แต่มีข้อจำกัดเรื่องเสถียรภาพเมื่อเทียบกับ SAC และต้องปรับไฮเปอร์พารามิเตอร์มากกว่า
นอกจากนี้ ยังมีวิธี hybrid เช่น การผสาน RL กับ MPC (Model Predictive Control) เพื่อใช้ความสามารถของ MPC ในการบังคับ constraints ระยะสั้น และใช้ RL ในการเรียนรู้แผนระยะยาวหรือนโยบายปรับตัว
ข้อดีและข้อจำกัดเมื่อเทียบกับวิธีดั้งเดิม
ข้อดี ของ RL ในบริบท HVAC ได้แก่:
- สามารถจัดการกับความไม่เชิงเส้นและความหน่วงของอาคารได้ดีขึ้น เพราะเรียนรู้จากผลกระทบสะสมตามเวลา
- ปรับตัวต่อสภาพแวดล้อมที่เปลี่ยนแปลง เช่น การจราจรของลูกค้า หรือค่าพลังงานไฟฟ้าที่ผันผวนแบบเรียลไทม์
- มีศักยภาพลดต้นทุนพลังงานเชิงปฏิบัติการจริง — การทดลองเชิงพาณิชย์บางกรณีรายงานการลดพลังงานในช่วง 10–30% และจากกรณีศึกษาของร้านค้าปลีกไทยที่นำ RL ควบคุม HVAC รายงานการลดต้นทุนพลังงานกว่า 20%
ข้อจำกัด ที่ต้องคำนึง:
- ต้องการข้อมูลหรือซิมูเลเตอร์สำหรับการฝึก (sample efficiency) — การฝึกบนระบบจริงโดยตรงมีความเสี่ยงด้านความสบายลูกค้าและความเสี่ยงต่ออุปกรณ์
- ประเด็นความปลอดภัยและการยืนยันว่า policy จะไม่ละเมิดข้อจำกัดความสบาย (เช่น ช่วงอุณหภูมิ) — ต้องออกแบบ constraints หรือใช้เทคนิค constrained RL เช่น Lagrangian methods / safe RL
- ความสามารถในการอธิบายได้ (explainability) และการบำรุงรักษาเมื่อนำสู่สภาพแวดล้อมจริง อาจต้องผสานกับนโยบาย rule-based หรือการตรวจสอบแบบฮิวแมนอินเดอะลูป
การรักษาขอบเขตความสบาย (constraints) และแนวทางปฏิบัติ
การรักษาช่วงอุณหภูมิความสบายเป็นเรื่องสำคัญเชิงพาณิชย์และด้านกฎระเบียบ สามารถทำได้หลายวิธี เช่น:
- กำหนด hard constraints บน action space (เช่น จำกัดการสั่งให้ไม่ต่ำกว่าหรือสูงกว่าระดับที่กำหนด) เพื่อป้องกันการละเมิดทันที
- ใช้ penalty terms ใน reward function สำหรับการละเมิด comfort range (เช่น ลงโทษตามขนาดของการเบี่ยงเบนเกิน tolerance)
- นำเทคนิค constrained RL หรือการผสานกับ MPC เพื่อให้การตัดสินใจภายในหน้าต่างเวลาสั้น ๆ ปลอดภัยและปฏิบัติตามข้อจำกัด
- ฝึกโมเดลในซิมูเลเตอร์หรือ digital twin และใช้ domain randomization ก่อนนำขึ้นระบบจริง เพื่อลดความเสี่ยงต่อการทดลองบนอุปกรณ์จริง
สรุปแล้ว RL เสนอความยืดหยุ่นเชิงนโยบายและความสามารถในการจัดการกับปัญหาเชิงไดนามิกที่ซับซ้อนของระบบ HVAC แต่ต้องมีการออกแบบ reward, constraints และกระบวนการฝึกอย่างระมัดระวังเพื่อให้ได้ผลลัพธ์ที่คงที่ ปลอดภัย และสอดคล้องกับเป้าหมายทางธุรกิจ
การออกแบบระบบและฮาร์ดแวร์: เซ็นเซอร์ ถึง Actuators
การออกแบบระบบและฮาร์ดแวร์: เซ็นเซอร์ ถึง Actuators
การนำ Reinforcement Learning (RL) มาควบคุม HVAC และระบบไฟฟ้าในร้านค้าปลีกต้องอาศัยการออกแบบฮาร์ดแวร์และระบบสื่อสารที่รัดกุม ตั้งแต่การเลือกชนิดของเซ็นเซอร์ ตำแหน่งการวาง อัตราการเก็บข้อมูล (sampling rate) ไปจนถึงกลไก fallback และการผสานรวมกับระบบควบคุมอาคารเดิม (BMS/SCADA) โดยหลักการสำคัญคือการให้ข้อมูลมีคุณภาพสูง (high-fidelity) และการตอบสนองเชิงเวลาต่อเหตุการณ์จริง (real-time) เพื่อให้ตัวแทน RL สามารถตัดสินใจภายในข้อจำกัดเชิงความปลอดภัยและความสะดวกสบายของผู้ใช้ได้อย่างสม่ำเสมอ

ประเภทเซ็นเซอร์และตำแหน่งการวาง — เซ็นเซอร์หลักที่จำเป็นประกอบด้วย: อุณหภูมิ, ความชื้น, CO2 (หรือ VOC เพื่อวัดคุณภาพอากาศ), และเซ็นเซอร์การครอบครองพื้นที่ (occupancy) เช่น PIR, ultrasonic, หรือกล้องนับคนแบบ privacy-preserving แต่ละประเภทมีข้อพึงระวังด้านตำแหน่งการติดตั้งเพื่อคุณภาพข้อมูลที่ดี:
- เซ็นเซอร์อุณหภูมิ/ความชื้น: ติดตั้งในระดับความสูงการหายใจของมนุษย์ (ประมาณ 1.1–1.7 เมตร) ห่างจากช่องลม/แสงแดดโดยตรง 1–2 เมตร เพื่อหลีกเลี่ยงอิทธิพลจากแหล่งความร้อนหรือการระบายอากาศท้องถิ่น
- เซ็นเซอร์ CO2: วางในโซนที่มีการใช้งานมาก (เช่น ทางเดินหลัก โซนเคาน์เตอร์) และไม่ติดกับผนังด้านที่ระบายอากาศโดยตรง เพื่อให้ค่าสะท้อนความหนาแน่นของผู้คนจริง
- เซ็นเซอร์ Occupancy: ใช้รวมกันระหว่างเซ็นเซอร์จมูก/พื้น (floor sensors), PIR และกล้องนับคนแบบ aggregate เพื่อลด false positive/negative — ติดตั้งที่ทางเข้า โซนช้อปปิ้งหลัก และโซนเคาน์เตอร์
- Redundancy: ติดตั้งเซ็นเซอร์ซ้ำในโซนสำคัญและมีการสอบเทียบ (calibration) เป็นระยะ เพื่อลดเบี่ยงเบนและรองรับความล้มเหลวของอุปกรณ์
Sampling rate และรูปแบบการจัดเก็บข้อมูล — ค่าตัวอย่างควรปรับตามชนิดข้อมูลและความต้องการตอบสนองของระบบ RL:
- ข้อมูล HVAC (อุณหภูมิ/ความชื้น): sampling ทุก 30–60 วินาที เพื่อให้ RL สามารถสังเกตการเปลี่ยนแปลงสภาพแวดล้อมและกำหนด setpoint ได้แม่นยำ
- CO2 และคุณภาพอากาศ: sampling ทุก 30–120 วินาที ขึ้นกับความไวของเซ็นเซอร์และความสำคัญของ IAQ ในพื้นที่นั้น
- Occupancy: event-driven สำหรับการตรวจจับการเข้าออกแบบ real-time หรือ sampling 1–5 วินาที ในกรณีใช้การนับคน/เซ็นเซอร์แบบต่อเนื่อง เพื่อให้ RL รับรู้การเปลี่ยนแปลงโหลดโดยทันที
- ข้อมูลไฟฟ้า (กระแส/แรงดัน/พลังงาน): sampling 1–15 วินาที สำหรับการควบคุมแบบเรียลไทม์และการวิเคราะห์ประสิทธิภาพพลังงาน
การสื่อสารและ Edge Computing — เพื่อให้ inference ของ RL เป็นไปอย่างรวดเร็วและเชื่อถือได้ ควรออกแบบสถาปัตยกรรมที่มี Edge Gateway/Edge Server สำหรับการประมวลผลเบื้องต้นและรันโมเดล RL ระดับ latency ต่ำ:
- โปรโตคอลการส่งข้อมูล: MQTT เหมาะสำหรับข้อมูลเซ็นเซอร์ขนาดเล็กที่ต้องการ latency ต่ำและความน่าเชื่อถือในการส่ง ขณะที่ HTTP/REST หรือ gRPC ใช้สำหรับการตั้งค่า/การเรียกใช้ API กับระบบคลาวด์
- การเชื่อมต่อกับ BMS/SCADA: รองรับมาตรฐานอุตสาหกรรม เช่น BACnet/IP, Modbus TCP, OPC-UA เพื่อสั่งค่า setpoints หรือควบคุม actuators โดยตรงจาก Edge RL agent
- Edge compute ช่วยลด round-trip time ให้เหลือน้อยที่สุดสำหรับการตัดสินใจแบบ real-time และทำหน้าที่เป็น broker สำหรับการเก็บข้อมูลแบบ local cache (store-and-forward) เมื่อการเชื่อมต่อกับคลาวด์ขัดข้อง
Actuators, Integration และกลไก Fallback — ระบบต้องสามารถสั่งควบคุมอุปกรณ์ต่าง ๆ ได้อย่างปลอดภัยและมีมาตรการสำรอง:
- ตัวควบคุมที่ต้องเชื่อมต่อ: thermostats, VAV/VFD controllers, damper actuators, chiller/boiler controllers, lighting controllers (DALI/Relay)
- การผสานรวมกับ BMS: RL agent ส่ง setpoints หรือคำสั่งผ่าน BACnet/Modbus โดย BMS ทำหน้าที่เป็น authoritative controller และบังคับใช้ safety limits เช่น ช่วงอุณหภูมิขั้นต่ำ/สูงสุด, ค่ามาตรฐาน CO2 สูงสุด
- fallback controller: ในกรณีเครือข่ายหรือ Edge ล้มเหลว ควรมี local PID or rule-based controller ที่ถูกกำหนดไว้ล่วงหน้าพร้อม safety envelope และสามารถควบคุมอุปกรณ์พื้นฐานได้ (maintain comfort and IAQ) จนกว่าระบบ RL จะกลับมาทำงาน
- store-and-forward: เซ็นเซอร์และ Gateway ควรมีการเก็บข้อมูลชั่วคราวและส่งเมื่อการเชื่อมต่อกลับคืน
ความปลอดภัยทางไซเบอร์และการดำเนินงานที่ปลอดภัย — การควบคุมระบบอาคารด้วย RL เพิ่มความเสี่ยงด้านความปลอดภัย จึงจำเป็นต้องวางมาตรการเชิงลึก:
- การสื่อสารเข้ารหัส: ใช้ TLS/DTLS กับการยืนยันตัวตนด้วย certificate-based mutual authentication
- network segmentation: แยกเครือข่ายอุปกรณ์ IoT/Edge ออกจากเครือข่ายธุรกิจ และใช้ firewall/ACL ระบุต้นทางปลายทางที่อนุญาต
- secure boot และ signed firmware updates: ป้องกันการฝังโค้ดที่เป็นอันตรายและรักษาความสมบูรณ์ของซอฟต์แวร์
- การตรวจจับความผิดปกติ: ใช้ intrusion detection/anomaly detection บน Edge เพื่อสังเกตพฤติกรรมการส่งคำสั่งที่ผิดปกติของ RL agent หรืออุปกรณ์
- role-based access control และ logging/audit trail สำหรับการแก้ไขค่าพารามิเตอร์และการสั่งงานจากผู้ใช้งาน
สรุปสถาปัตยกรรมตัวอย่างที่ใช้งานจริง: เซ็นเซอร์กระจายในพื้นที่พร้อม redundancy และ calibration -> ข้อมูลส่งผ่าน MQTT ไปยัง Edge Gateway ที่รัน RL inference และ broker -> Edge ส่ง setpoints ผ่าน BACnet/IP ไปยัง BMS ซึ่งมี local fallback controller ควบคุมโดย rule-based logic เมื่อ Edge/เครือข่ายขัดข้อง -> ข้อมูลถูกส่งขึ้นคลาวด์เพื่อฝึก RL แบบอะซิงโครนัสและวิเคราะห์เชิงพลังงานเพิ่มเติม ภายใต้กลไกความปลอดภัยเช่น TLS, network segmentation และ signed updates ซึ่งการออกแบบเช่นนี้ช่วยให้การใช้ RL ในร้านค้าปลีกสามารถลดต้นทุนพลังงานได้อย่างปลอดภัยและมีประสิทธิภาพ
กรณีศึกษาเชิงทดลองในไทย: วิธีการทดลองและผลลัพธ์
กรณีศึกษาเชิงทดลองในไทย: วิธีการทดลองและผลลัพธ์
การทดลองนำ Reinforcement Learning (RL) มาควบคุมระบบปรับอากาศ (HVAC) และการจัดการการใช้ไฟแบบเรียลไทม์ในร้านค้าปลีกไทย มักจัดในรูปแบบ pilot test ที่มีการออกแบบเชิงทดลองอย่างเป็นระบบ โดยทั่วไปโครงการตัวอย่างที่นำมารวมสรุปนี้เป็นการทดสอบในเครือร้านค้าปลีกขนาดกลาง—ใหญ่ จำนวน 12–20 สาขา ในเมืองหลักต่าง ๆ ระยะเวลาการทดลองอยู่ในช่วง 3–6 เดือน เพื่อให้ครอบคลุมความผันผวนของสภาพอากาศและรูปแบบการใช้งานของลูกค้า
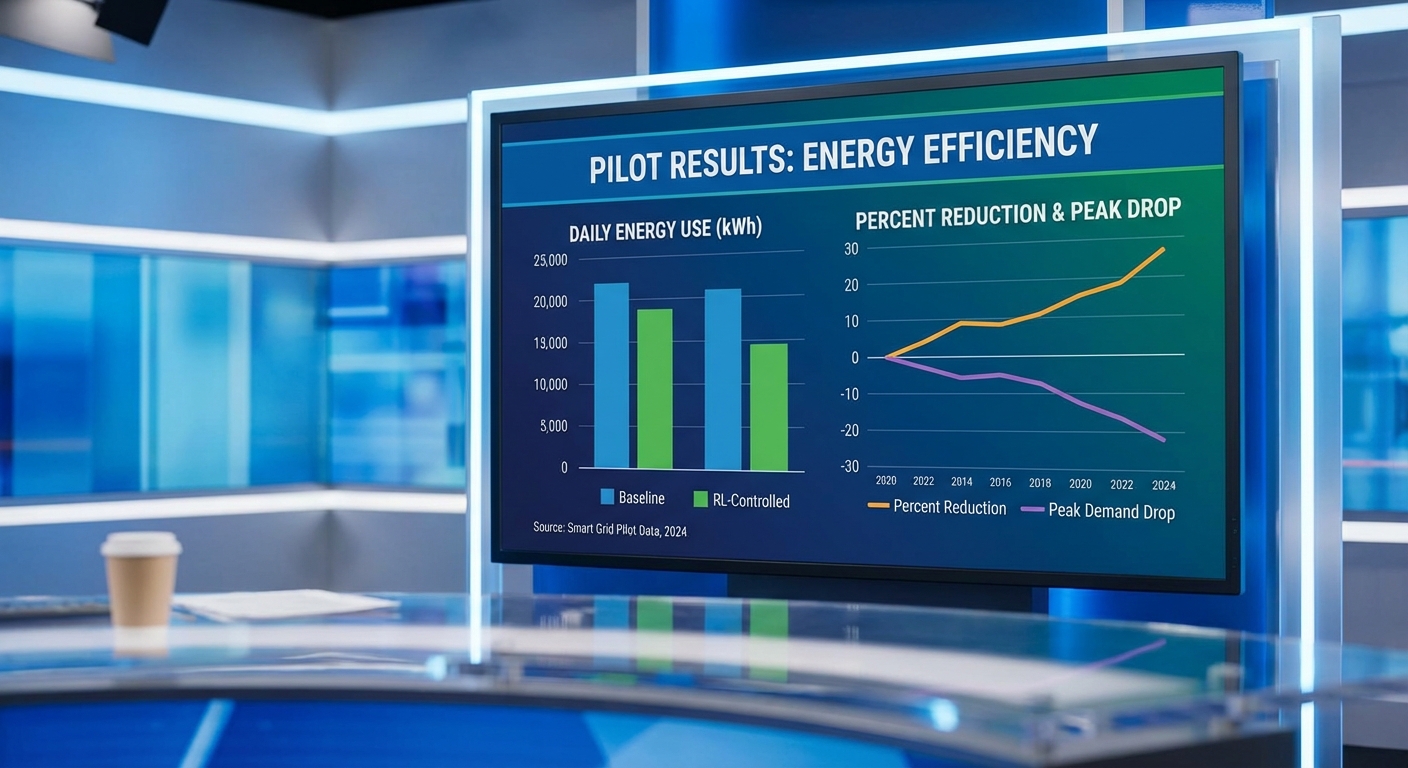
โครงสร้างการทดลองถูกออกแบบให้มี baseline ที่ชัดเจนและการวัดผลแบบเชิงเปรียบเทียบ (A/B หรือ crossover) เพื่อแยกผลของอัลกอริทึมจากปัจจัยภายนอกหลัก ๆ ดังนี้:
- Baseline: ใช้ทั้ง rule-based control (เช่น ตั้งค่าอุณหภูมิและเวลาแบบตายตัวตามนโยบาย) และโปรไฟล์เชิงประวัติศาสตร์ (historic profile) ของแต่ละสาขาเป็นกลุ่มเปรียบเทียบ
- การสุ่มและการออกแบบ: บางโครงการใช้การจับคู่สาขา (matched-pairs) แล้วสุ่มให้บางสาขาเป็นกลุ่มทดลอง ในขณะที่บางโครงการใช้การทดลองแบบ crossover ภายในสาขาเดียว โดยสลับโหมด control ทุก 2–4 สัปดาห์ เพื่อลดอิทธิพลของความแตกต่างระหว่างสาขา
- การวัดผล: ติดตั้งมิเตอร์ย่อย (sub-metering) และเก็บข้อมูล interval-level (เช่น 15-หรือ 30‑นาที) ทั้งการใช้พลังงานรวม พีคดิมานด์ อุณหภูมิภายใน-ภายนอก จำนวนลูกค้า (footfall) และเวลาทำการ
ผลลัพธ์เชิงสถิติจากการรวมข้อมูลของหลายโครงการทดลองชี้ว่าสถานการณ์จริงสามารถทำได้ตามเป้าหมายหลัก โดยสรุปผลสำคัญมีดังนี้:
- ลดการใช้พลังงานเฉลี่ย: อยู่ในช่วง 20–25% เมื่อเทียบกับ baseline rule-based หรือ historic control (ผลต่างมีนัยสำคัญทางสถิติ โดยมากมีค่า p < 0.05 ในการทดสอบความต่างค่าเฉลี่ย)
- ลดพีคดิมานด์ (peak demand): ลดได้ราว 15–18% ซึ่งช่วยลดค่าใช้งานในระบบที่คิดค่าอัตราพีคหรือ demand charge
- ค่าไฟลดลงเฉลี่ย: อยู่ในช่วง 10,000–25,000 บาท/เดือนต่อสาขา ขึ้นกับขนาดร้าน อัตราค่าไฟ และรูปแบบการใช้งาน (ตัวเลขนี้เป็นค่าเฉลี่ยจากตัวอย่างหลายสาขา)
- เวลาคืนทุน (payback): โดยประมาณ 9–14 เดือน สำหรับการลงทุนในระบบฮาร์ดแวร์ (เซนเซอร์ และมิเตอร์ย่อย) และซอฟต์แวร์ควบคุม RL ที่รวมการติดตั้งและ tuning ในภาคสนาม
ตัวอย่างเคสสั้น ๆ เพื่อให้เห็นภาพชัดขึ้น: สาขาขนาดประมาณ 800–1,200 ตารางเมตร หนึ่งสาขาในกรุงเทพฯ ที่มีค่าไฟเฉลี่ยก่อนทดลองราว 80,000 บาท/เดือน เมื่อเปลี่ยนมาใช้ RL ควบคุม HVAC และการจัดการโหลดเรียลไทม์ พบว่าการใช้พลังงานลดลงประมาณ 22% และพีคดิมานด์ลดลง 17% ส่งผลให้ประหยัดค่าไฟประมาณ 17,600 บาท/เดือน และคาดว่าจะคืนทุนได้ภายใน 10–12 เดือน ทั้งนี้ผลลัพธ์ของแต่ละสาขาอาจต่างกันตามบริบท
ปัจจัยที่มีผลต่อความสำเร็จและความแปรปรวนของผลลัพธ์ ได้แก่:
- สภาพอากาศ: ฤดูร้อนหรือคลื่นความร้อนจะเพิ่มภาระ HVAC ทำให้มีโอกาสลดได้มากกว่าในวันปกติ แต่ก็มีความเสี่ยงต่อความต้องการความเย็นที่สูงขึ้น
- เวลาเปิด‑ปิด และรูปแบบการใช้งาน: ร้านที่เปิดยาวหรือมีชั่วโมง peak ชัดเจนจะได้รับประโยชน์จากการจัดการพีคได้มากกว่า
- พฤติกรรมลูกค้าและความหนาแน่น: จำนวนลูกค้าที่แตกต่างกันมีผลต่อโหลดภายในอาคาร (internal gains) ทำให้ต้องมีการปรับโมเดล RL ให้ตอบสนองต่อ footfall จริง
- คุณภาพระบบ HVAC และสภาพอาคาร: ระบบเก่าหรือประสิทธิภาพต่ำอาจจำกัดการประหยัด ในขณะที่อาคารที่อากาศรั่วหรือฉนวนไม่ดีจะเห็นผลน้อยกว่า
- โครงสร้างค่าไฟฟ้า: การมี demand charge หรืออัตรา TOU จะกระทบต่อมูลค่าการประหยัด (เช่น การลดพีคมีมูลค่ามากขึ้นเมื่อมีค่า demand สูง)
สรุปได้ว่า การทดลองเชิง pilot ในบริบทร้านค้าปลีกไทยแสดงให้เห็นว่า RL สำหรับควบคุม HVAC และการจัดการโหลดแบบเรียลไทม์สามารถลดการใช้พลังงานเฉลี่ยมากกว่า 20% และลดพีคดิมานด์ราว 15–18% โดยมูลค่าการประหยัดไฟต่อสาขาอยู่ในระดับที่ทำให้การลงทุนคืนทุนได้ภายใน 9–14 เดือน ภายใต้เงื่อนไขการติดตั้งมิเตอร์ที่เหมาะสม การออกแบบการทดลองที่เข้มงวด และการปรับแต่งโมเดลให้เข้ากับบริบทแต่ละสาขา
การผสานข้อมูลเรียลไทม์กับตลาดไฟฟ้าและ Demand Response
การผสานข้อมูลเรียลไทม์กับตลาดไฟฟ้าและ Demand Response
การนำสัญญาณราคาพลังงานแบบเรียลไทม์ (real-time pricing; RTP) มาผสานกับนโยบายการเรียนรู้ด้วยการเสริมแรง (Reinforcement Learning; RL) สำหรับการควบคุมระบบ HVAC ในร้านค้าปลีก ช่วยเพิ่มโอกาสในการประหยัดค่าไฟอย่างมีนัยสำคัญ โดยเฉพาะในสถานการณ์ที่ความผันผวนของราคาเกิดขึ้นเป็นระยะ เช่น ช่วงพีคที่ราคาเพิ่มขึ้นหลายเท่าจากช่วงปกติ การออกแบบรางวัล (reward) ของตัวแทน RL ให้ "คำนึงถึงราคา" โดยตรง — ตัวอย่างเช่น reward_t = - price_t × consumption_t - α × discomfort_t — จะกระตุ้นให้ระบบเลื่อนการใช้พลังงานไปยังช่วงราคาต่ำหรือปรับโหลดลงเมื่อราคาสูง โดยยังคงรักษาความสบายของลูกค้าในขอบเขตที่ยอมรับได้ การทดลองในสภาพแวดล้อมจริงแสดงให้เห็นว่าการผสาน RTP กับ RL สามารถหนุนการลดต้นทุนได้เพิ่มขึ้นจากมาตรการพื้นฐาน และในการทดลองเชิงพาณิชย์บางกรณีรวมกันสามารถลดต้นทุนพลังงานได้มากกว่า 20% เมื่อรวมการจัดการโหลดเรียลไทม์และการเข้าร่วมโปรแกรม DR
เพื่อปกป้องความสบายและความปลอดภัยของระบบ จะต้องกำหนดข้อจำกัด (constraints) ทั้งในเชิงนโยบายและทางเทคนิคเป็นชั้น ๆ โดยเฉพาะเมื่อนำสัญญาณราคามาเป็นปัจจัยสำคัญของรางวัล ตัวอย่างของ guardrails ที่ควรมีได้แก่ ขอบเขตอุณหภูมิ (temperature bands) ที่เป็น hard constraint, ข้อจำกัดความชื้น, เวลาทำงานขั้นต่ำ/สูงสุดของคอมเพรสเซอร์, อัตราการเปลี่ยนแปลง setpoint ต่อชั่วโมง, และข้อกำหนดด้านความปลอดภัยของอุปกรณ์ นอกจากนี้ยังควรใช้ตัวชี้วัดความสบายเชิงวิศวกรรม เช่น PMV/PPD หรือ operative temperature เป็นส่วนหนึ่งของฟังก์ชันโทษ (penalty) เพื่อให้การลดโหลดไม่ก่อให้เกิดประสบการณ์ลูกค้าที่ไม่ยอมรับได้
การจัดการความเสี่ยงจากเหตุการณ์เช่น price spikes, สัญญาณราคาผิดพลาด หรือการสื่อสารล่าช้า จำเป็นต้องมีกลไกป้องกันที่ชัดเจน ตัวอย่างมาตรการได้แก่ การทำ smoothing/median filtering กับสัญญาณราคาเพื่อกรอง outlier; การตั้ง clipping threshold เพื่อหลีกเลี่ยงการตอบสนองเกินเมื่อตรวจพบ spike ที่ไม่น่าเชื่อถือ; การให้ค่าน้ำหนักความเชื่อมั่น (confidence weighting) แก่สัญญาณและใช้ fallback policy แบบ rule-based เมื่อความเชื่อมั่นต่ำ; และการจำกัดการเปลี่ยนแปลงของ setpoint ในช่วงเวลาสั้น ๆ เพื่อหลีกเลี่ยงผลกระทบต่ออายุการใช้งานของอุปกรณ์ นอกจากนี้ระบบควรมีการตรวจจับความผิดปกติ (anomaly detection) ของสัญญาณราคาและ telemetry เพื่อยกเลิกการใช้สัญญาณนั้นชั่วคราวเมื่อพบความผิดปกติ
การร่วมมือกับ utility หรือ aggregator มีบทบาทสำคัญทั้งด้านการเพิ่มช่องทางรายได้และการรับรองการปฏิบัติ หน้าที่สำคัญที่ควรทำร่วมกันได้แก่ การลงทะเบียนและสอบเทียบ (pre-enrollment tests) เพื่อกำหนด baseline พลังงานสำหรับการวัดการลดโหลด, กำหนดรูปแบบการรายงาน telemetry (เช่น ความถี่ข้อมูล 5–15 นาที), ข้อตกลงเรื่องค่าปรับ/ค่าตอบแทนเมื่อเข้าร่วมเหตุการณ์ DR, และการรับรองการยืนยัน (verification & settlement) หลังเหตุการณ์ การเข้าร่วมกับ aggregator ยังช่วยให้ร้านค้าปลีกสามารถรวมกำลังการลดโหลดของหลายสาขาเพื่อเข้าแข่งขันในตลาด capacity หรือ ancillary services ทำให้มีช่องทางรับรายได้ทั้งแบบ event-based payments และ capacity payments ซึ่งในหลายกรณีสามารถชดเชยรายได้จากการลดการใช้ไฟและเพิ่มผลตอบแทนรวมของโครงการ
ในการออกแบบเชิงปฏิบัติการ ควรกำหนดกระบวนการทำงานที่ชัดเจน ได้แก่ การทดสอบแบบจำลอง RL ต่อชุดข้อมูล RTP ย้อนหลัง, การรันในโหมด shadow หรือ advisory ก่อนสั่งงานจริง, การตั้งค่าระดับความเสี่ยงที่ยอมรับได้ร่วมกับผู้จัดการไฟฟ้า/utility, และแผนการกู้คืน (rollback) เมื่อเกิดเหตุไม่คาดฝัน สรุปคือ การผสานข้อมูลเรียลไทม์กับการควบคุมเชิงอัตโนมัติจำเป็นต้องสมดุลระหว่างโอกาสประหยัดค่าไฟเชิงเศรษฐกิจกับข้อจำกัดด้านความสบายและความปลอดภัย — และการมีพันธมิตรจากฝั่ง utility/aggregator จะช่วยยืนยันการปฏิบัติให้ถูกต้องตามข้อกำหนดตลาดและเปิดทางรายได้จากโปรแกรม DR ได้อย่างเป็นรูปธรรม
- จุดเด่น: RTP เพิ่มสัญญาณเชิงเศรษฐกิจที่ชัดเจนให้แก่ RL ช่วยให้ระบบตัดสินใจปรับโหลดตามค่าไฟจริง
- ข้อควรระวัง: ต้องมี hard & soft constraints เพื่อปกป้องความสบายและความปลอดภัยของอุปกรณ์
- ความเสี่ยง: price spikes และสัญญาณผิดพลาดต้องได้รับการกรอง, มี fallback และ anomaly detection
- โอกาสทางธุรกิจ: การร่วมมือกับ utility/aggregator เปิดช่องทางรายได้จาก DR (event-based, capacity, ancillary)
ความท้าทายเชิงปฏิบัติและการรับประกันความปลอดภัย
ความท้าทายเชิงปฏิบัติและการรับประกันความปลอดภัย
การนำ Reinforcement Learning (RL) มาควบคุมระบบ HVAC และการใช้ไฟในร้านค้าปลีกนั้นให้ผลตอบแทนด้านประหยัดพลังงานที่ชัดเจน แต่มีความท้าทายเชิงปฏิบัติที่ต้องถูกจัดการอย่างเป็นระบบเพื่อไม่ให้กระทบต่อประสบการณ์ลูกค้าและความปลอดภัยของระบบ โดยหัวใจสำคัญคือการรักษาช่วงความสบายของลูกค้าเป็นข้อบังคับ (hard constraints) เสมอ ไม่ใช่เพียงเพิ่มเป็นองค์ประกอบของรางวัลเท่านั้น ตัวอย่างเช่นร้านค้าปลีกมักยึดเกณฑ์อุณหภูมิภายในประมาณ 23–26°C และความชื้นสัมพัทธ์ 40–60% หรือใช้ตัวชี้วัดความสบายเช่น PMV/PPD เป็นข้อกำหนดเชิงปฏิบัติ เพื่อให้แน่ใจว่าการปรับการทำงานของ HVAC จะไม่ทำให้ลูกค้าไม่สบายหรือมีผลต่อสินค้าที่อ่อนไหวต่ออุณหภูมิ
อีกความเสี่ยงสำคัญคือ concept drift — เมื่อพฤติกรรมลูกค้า เวลาเปิดปิดร้าน หรือสภาพแวดล้อมภายนอกเปลี่ยนไป โมเดลที่ฝึกมาแล้วอาจทำงานไม่เหมาะสม การจัดการ drift จำเป็นต้องมีการตรวจจับอย่างต่อเนื่อง (data drift / performance drift monitoring) และกระบวนการรีเทรนแบบมีการควบคุม เช่น การใช้ตัวชี้วัดเช่น Population Stability Index (PSI) หรือการทดสอบ A/B แบบควบคุมก่อนปรับใช้โมเดลใหม่ นอกจากนี้ยังต้องพิจารณา sim-to-real gap — ความต่างระหว่างผลลัพธ์ในซิมูเลชันกับสภาพจริง ซึ่งแก้ได้ด้วยการทำ domain randomization, system identification, hardware-in-the-loop (HIL) และการทดสอบแบบ shadow/dual-run ก่อนเปิดใช้งานเต็มรูปแบบ
ความปลอดภัยไซเบอร์ของอุปกรณ์ IoT เป็นประเด็นที่ไม่อาจมองข้ามได้ เนื่องจากอุปกรณ์ HVAC และเซ็นเซอร์มักเชื่อมต่อเครือข่าย ตัวอย่างความเสี่ยงคือการถูกโจมตีเพื่อสั่งการอุปกรณ์หรือรั่วไหลข้อมูลกล้อง/เซ็นเซอร์ มาตรการลดความเสี่ยงควรรวมถึงการอัปเดตเฟิร์มแวร์ที่ได้ยืนยันลายเซ็น (signed OTA), การเข้ารหัสช่องทางสื่อสาร (TLS/VPN), การจำกัดสิทธิ์แบบ least privilege, segmentation ของเครือข่ายเพื่อแยกระบบควบคุมออกจากเครือข่ายผู้ใช้ และการทำ penetration test และ audit ด้านความปลอดภัยเป็นประจำ
เพื่อรับประกันความถูกต้องก่อนการใช้งานจริง จำเป็นต้องมีการทดสอบออฟไลน์ (offline validation) และกระบวนการยืนยันหลายชั้น เช่น replay ของข้อมูลจริงสำหรับการประเมิน, counterfactual policy evaluation (CPE) เพื่อประมาณผลการนำไปใช้จริง, และการทดสอบแบบ canary/rollout แบบจำกัดพื้นที่ก่อนขยายไปทั้งร้าน โดยต้องมีนโยบาย fallback ชัดเจนเสมอ — เช่นสวิทช์กลับไปใช้ controller แบบ rule-based หรือ default schedule เมื่อระบบตรวจพบพฤติกรรมผิดปกติ, หรือเมื่อเซ็นเซอร์ให้ค่าสัมประสิทธิ์น่าสงสัย
แนวทางการบรรเทาความเสี่ยง (mitigations) ที่แนะนำประกอบด้วย:
- กำหนด hard constraints ทางเทคนิค: ใช้ constrained RL, action masking หรือ safety layer ที่บังคับไม่ให้การกระทำที่ละเมิดช่วงความสบายถูกสั่งงานได้
- Human-in-the-loop: ให้พนักงานหรือผู้ควบคุมสามารถดูและยืนยันนโยบายใหม่, หยุดระบบอัตโนมัติ หรือแก้ไขพารามิเตอร์สำคัญได้แบบเรียลไทม์
- Continuous monitoring & alerting: เก็บ log ของการตัดสินใจ, ตรวจจับ anomaly แบบเรียลไทม์, และตั้ง threshold ที่เมื่อเกินจะสลับไป fallback และแจ้งทีมปฏิบัติการ
- การทดสอบออฟไลน์และ phased deployment: ทำ offline replay, CPE, shadow mode และ canary rollout ก่อนขยายใช้งานเต็มที่
- Safe RL techniques: เรียกใช้แนวทางเช่น Constrained MDP, Lyapunov-based methods, หรือ shielded RL เพื่อรับประกันความปลอดภัยของนโยบาย
- การจัดการ concept drift: ติดตั้ง pipeline สำหรับตรวจจับ drift, เกณฑ์ retraining อัตโนมัติ, และการทวนสอบโมเดลเป็นช่วงๆ
- มาตรการ cybersecurity: การจัดการเฟิร์มแวร์และคีย์, network segmentation, MFA สำหรับหน้าควบคุม, และการ audit/pen-test เป็นประจำ
- Auditability และ explainability: เก็บข้อมูลการตัดสินใจและเหตุผลประกอบเพื่อการตรวจสอบย้อนหลัง และใช้โมเดลที่สามารถอธิบายการกระทำได้ในระดับที่ปฏิบัติการต้องการ
สรุปคือ การนำ RL มาใช้ในร้านค้าปลีกเพื่อประหยัดพลังงานต้องมาพร้อมกับกรอบการควบคุมที่เข้มงวด ตั้งแต่การบังคับข้อจำกัดความสบายของลูกค้าเป็น hard constraints, การป้องกันและตรวจจับ concept drift, การลดช่องว่าง sim-to-real ผ่านการทดสอบเชิงวิศวกรรม, การเสริมความมั่นคงปลอดภัยของอุปกรณ์ IoT และการมีนโยบาย fallback/การตรวจสอบแบบต่อเนื่อง เพื่อให้การลดต้นทุนพลังงาน (เช่นเป้าหมายลด >20%) ไม่มาโดยแลกกับความเสี่ยงต่อความสบายลูกค้าและความปลอดภัยของระบบ
การขยายผลเชิงพาณิชย์และผลกระทบต่ออุตสาหกรรม
การขยายผลเชิงพาณิชย์และผลกระทบต่ออุตสาหกรรม
เมื่อระบบ Reinforcement Learning (RL) ควบคุม HVAC และการใช้ไฟฟ้าแบบเรียลไทม์ได้รับการพิสูจน์ในระดับทดลองว่าให้การลดพลังงานเฉลี่ยกว่า 20% แนวทางการขยายผลเชิงพาณิชย์จำเป็นต้องผสานทั้งรูปแบบธุรกิจที่ยืดหยุ่น ระบบปฏิบัติการโมเดล (MLOps) ที่แข็งแกร่ง และมาตรฐานการติดตั้งที่ชัดเจนเพื่อให้สามารถสเกลได้อย่างมีประสิทธิผลและคุ้มค่า ตัวอย่างเชิงปฏิบัติแสดงให้เห็นว่า หากสมมติฐานค่าไฟฟ้ารายปีและการใช้พลังงานเฉลี่ยของร้านค้าเป็นดังนี้: พลังงานต่อร้าน ≈ 500,000 kWh/ปี, ค่าไฟเฉลี่ย ≈ 4.0 บาท/kWh การลด 20% จะเท่ากับการประหยัดพลังงานประมาณ 100,000 kWh/ร้าน/ปี และการประหยัดค่าไฟประมาณ 400,000 บาท/ร้าน/ปี ซึ่งแปลเป็นการลดการปล่อยก๊าซคาร์บอนโดยประมาณ 55 ตัน CO2/ร้าน/ปี (สมมติอัตราการปล่อย 0.55 kgCO2/kWh) — ตัวเลขเหล่านี้เป็นจุดเริ่มต้นที่ชัดเจนสำหรับการประเมินผลเชิงธุรกิจระดับเครือร้าน
โมเดลธุรกิจที่เป็นไปได้ ได้แก่ SaaS, Managed Service และ Licensing ซึ่งแต่ละแบบมีข้อดีเฉพาะตัว: SaaS/Managed Service ช่วยลดภาระบำรุงรักษาและการอัปเดตให้ผู้ค้าปลีก โดยผู้ให้บริการดูแล MLOps, การบำรุงรักษา edge devices และการอัปเดตโมเดลตาม SLA ทำให้ผู้ค้าปลีกไม่ต้องลงทุนบุคลากรเชิง Data Science ขนาดใหญ่ ขณะที่รูปแบบ Licensing หรือ CapEx เหมาะสำหรับผู้ค้าปลีกใหญ่ที่ต้องการควบคุมระบบทั้งหมดด้วยตนเอง ตัวย่างเชิงตัวเลข: หากต้นทุนติดตั้งเฉลี่ยต่อร้าน (ฮาร์ดแวร์, เซนเซอร์, การรวมระบบ) อยู่ที่ 300,000–600,000 บาท/ร้าน การลดค่าไฟฟ้า 400,000 บาท/ร้าน/ปี จะให้ระยะคืนทุน (payback) ประมาณ 0.75–1.5 ปีในกรณี CapEx; สำหรับ Managed Service ที่เรียกเก็บเป็นรายเดือนสมมติ 20,000–30,000 บาท/เดือน จะยังคงมีการประหยัดสุทธิประมาณ 160,000–240,000 บาท/ร้าน/ปี ขึ้นอยู่กับโมเดลราคา
MLOps และมาตรฐานการติดตั้งเป็นปัจจัยสำคัญต่อการสเกล — การนำระบบ RL ไปใช้ในระดับหลายสาขาต้องมีแนวทาง MLOps ที่รองรับการอัปเดตโมเดลต่อเนื่อง, การตรวจจับ model drift, การทดสอบ A/B, และกระบวนการ rollback แบบอัตโนมัติ นอกจากนี้ต้องกำหนดมาตรฐานการติดตั้งฮาร์ดแวร์ (เช่น ชนิดและตำแหน่งของเซนเซอร์), โปรโตคอลสื่อสาร (BACnet, Modbus, MQTT), และ checklist การคาลิเบรตเพื่อให้ข้อมูลขาเข้ามีคุณภาพและสม่ำเสมอในทุกสาขา ระบบที่ออกแบบให้ inference เกิดบน edge เพื่อความหน่วงต่ำ และฝังกลไกการส่งเทเลเมทรีไปยังคลาวด์เพื่อรีเทรนโมเดล จะช่วยให้การสเกลมีความเสถียรและต้นทุนการเชื่อมต่อไม่พุ่ง
- Pilot → Regional → Nationwide (แผนการขยายผลเป็นขั้นตอน)
- Pilot (3–10 สาขา, ระยะเวลา 3–6 เดือน): วัดประสิทธิภาพ RL ในสภาพแวดล้อมจริง ปรับจูนฮาร์ดแวร์ และสร้างชุดข้อมูลสำหรับ retraining การประเมิน ROI ระยะสั้น
- Regional Rollout (50–200 สาขา, 12–18 เดือน): ขยายไปยังภูมิภาคที่มีโปรไฟล์การใช้พลังงานคล้ายกัน จัดตั้งทีม field operation และ MLOps 24/7 เพื่อรองรับ deployment แบบกลุ่ม
- Nationwide (500–1,000+ สาขา, 2–4 ปี): ปรับแพ็คเกจการให้บริการ (SaaS/managed tiers), สร้างศูนย์บำรุงรักษาแบบภูมิภาค และจัดทำสัญญาเชื่อมต่อกับยูทิลิตี้สำหรับ demand response และ dynamic pricing
- ตัวอย่างการประหยัดรวม (ตัวเลขจำลอง)
- 10 สาขา: ประหยัด ≈ 1,000,000 kWh/ปี → ค่าไฟลด ≈ 4,000,000 บาท/ปี → ลด CO2 ≈ 550 ตัน/ปี
- 100 สาขา: ประหยัด ≈ 10,000,000 kWh/ปี → ค่าไฟลด ≈ 40,000,000 บาท/ปี → ลด CO2 ≈ 5,500 ตัน/ปี
- 1,000 สาขา: ประหยัด ≈ 100,000,000 kWh/ปี → ค่าไฟลด ≈ 400,000,000 บาท/ปี → ลด CO2 ≈ 55,000 ตัน/ปี
ผลกระทบด้านสิ่งแวดล้อมและความร่วมมือที่จำเป็น — การลดการใช้พลังงานในระดับเครือร้านส่งผลโดยตรงต่อการลดคาร์บอนภาคการค้าปลีกซึ่งสามารถนำไปสู่การรายงาน ESG ที่แข็งแรงและโอกาสทางการเงิน เช่น เข้าสู่โครงการ carbon credits หรือโปรแกรม demand response ร่วมกับยูทิลิตี้ สำหรับการขยายผลที่ประสบผลสำเร็จ ผู้ให้บริการเทคโนโลยีต้องร่วมมืออย่างใกล้ชิดกับ:
- ผู้เชี่ยวชาญ HVAC และวิศวกรสนามเพื่อให้การติดตั้งและ tuning เป็นไปตามมาตรฐาน
- ผู้ให้บริการโครงสร้างพื้นฐานคลาวด์และ edge สำหรับ MLOps, การจัดเก็บข้อมูล และการอัปเดตโมเดลแบบ Over-the-Air
- ยูทิลิตี้/ผู้จัดหาพลังงานเพื่อเชื่อมต่อข้อมูลราคาแบบเรียลไทม์และเข้าร่วมโปรแกรม flex/Demand Response
- พันธมิตรด้านการเงินหรือ ESG เพื่อสร้างกรณีธุรกิจและแหล่งทุนสำหรับการขยายต้นแบบเป็นการติดตั้งขนาดใหญ่
สรุปคือ การสเกลโซลูชัน RL ควบคุม HVAC ไปยังระดับเชนค้าปลีกต้องการโมเดลธุรกิจที่ยืดหยุ่น (โดยเฉพาะ SaaS/Managed Service ที่ลดภาระบำรุงรักษาให้ผู้ค้าปลีก), ระบบ MLOps และมาตรฐานการติดตั้งที่เข้มงวดเพื่อรักษาคุณภาพข้อมูลและผลลัพธ์การประหยัด เมื่อดำเนินการเป็นขั้นตอน ตั้งแต่ pilot ไปถึง rollout ระดับชาติ จะทำให้เกิดผลประหยัดทางการเงินอย่างมีนัยสำคัญและการลดคาร์บอนที่ชัดเจน — เป็นกลยุทธ์ที่ทั้งลดต้นทุนระยะยาวและขับเคลื่อนความยั่งยืนของอุตสาหกรรมค้าปลีก
บทสรุป
การทดลองเชิงสนามในร้านค้าปลีกไทยชี้ให้เห็นว่าการนำ Reinforcement Learning (RL) มาควบคุมระบบปรับอากาศ (HVAC) โดยอาศัยข้อมูลเรียลไทม์จากเซ็นเซอร์และสัญญาณราคา สามารถลดการใช้พลังงานได้มากกว่า 20% เมื่อเทียบกับการควบคุมแบบเดิม พร้อมทั้งช่วยลดพีคดิมานด์และค่าไฟขั้นต้นให้จับต้องได้ ผลลัพธ์ดังกล่าวเกิดจากความสามารถของ RL ในการเรียนรู้พฤติกรรมการใช้งานจริง (เช่น อัตราการครอบครอง, สภาพอากาศ, สถานะอุปกรณ์ และสัญญาณค่าไฟเรียลไทม์) และปรับกลยุทธ์การทำงานของ HVAC เพื่อรักษาความสะดวกสบายของลูกค้าในขณะที่ลดพลังงานและค่าบริการพีคชาร์จลงอย่างมีประสิทธิผล
การขยายผลเชิงพาณิชย์ให้เกิด ROI และผลกระทบเชิงสิ่งแวดล้อมสูงสุดจำเป็นต้องอาศัยสถาปัตยกรรมที่มั่นคงและครบองค์ประกอบ ได้แก่ IoT สำหรับการเก็บข้อมูลแบบเรียลไทม์, edge computing เพื่อความหน่วงต่ำ, และการเชื่อมต่อกับ BMS เพื่อการสั่งงานที่ปลอดภัย รวมถึงกลยุทธ์ MLOps ที่แข็งแกร่งสำหรับการจัดการข้อมูล, การเทรน-วาลิดเชิน-ดีพลอยโมเดล, การมอนิเตอร์ และการย้อนกลับเมื่อผิดพลาด นอกจากนี้ต้องมีการจัดการความเสี่ยง (เช่น ข้อจำกัดด้านความสะดวกสบายและแผน fallback ทางเทคนิค) และความร่วมมือกับยูทิลิตี้เพื่อรับสัญญาณอัตราค่าไฟ/โปรแกรมตอบสนองความต้องการ ทั้งนี้มุมมองในอนาคตคือการขยายระบบแบบเป็นขั้นตอนโดยเริ่มจากโครงการนำร่อง ปรับมาตรฐานสถาปัตยกรรม และวัด KPI (kWh, พีค kW, ค่าใช้จ่าย, และการลดก๊าซเรือนกระจก) อย่างต่อเนื่อง—เมื่อนำไปใช้ในสเกลใหญ่เทคโนโลยีนี้มีศักยภาพช่วยผสานพลังงานหมุนเวียนและแบตเตอรี่ ลดต้นทุนพลังงานของภาคค้าปลีก และลดการปล่อยก๊าซเรือนกระจกได้อย่างเป็นรูปธรรม



