
ในยุคที่สมาร์ทโฟนกลายเป็นเครื่องมือพื้นฐานของเกษตรกรไทย เทคโนโลยีใหม่อย่าง Multimodal Foundation Models ที่ผสานการวิเคราะห์ภาพถ่าย สเปกโตรมิเตอร์แบบคลิป-ออน และเมตาดาต้าจากสภาพแวดล้อม กำลังพลิกโฉมการจัดการโรคพืชจากหน้าที่ของผู้เชี่ยวชาญมาอยู่ในมือของชาวสวนทันทีแบบเรียลไทม์ เทคโนโลยีนี้ไม่เพียงแค่บอกว่าใบพืชมีอาการอย่างไร แต่ยังประมวลผลสเปกตรัมของสารเคมีและสภาวะแวดล้อมเพื่อระบุสาเหตุ ให้คำแนะนำการรักษา และประเมินความรุนแรงอย่างแม่นยำในพื้นที่ปลูกจริง
บทความนี้จะพาไปสำรวจหลักการทำงานของระบบ Multimodal บนสมาร์ทโฟน ตัวอย่างการใช้งานจริงในฟาร์มไทย ผลประโยชน์ที่ช่วยลดการสูญเสียผลผลิตและการใช้สารเคมี รวมถึงข้อจำกัดด้านฮาร์ดแวร์ ความเป็นส่วนตัวของข้อมูล และแนวทางการนำไปปรับใช้ให้สอดคล้องกับบริบทการเกษตรของประเทศไทย เพื่อให้ผู้อ่านเห็นภาพชัดเจนว่าเทคโนโลยีดังกล่าวสามารถช่วยเสริมความเข้มแข็งให้กับภาคการเกษตรได้อย่างไร
ภาพรวมและความสำคัญ: ทำไม Multimodal บนสมาร์ทโฟนถึงเปลี่ยนวงการเกษตร
ภาพรวมและความสำคัญ: ทำไม Multimodal บนสมาร์ทโฟนถึงเปลี่ยนวงการเกษตร
ภาคการเกษตรของไทยเผชิญความท้าทายสำคัญด้านการวินิจฉัยโรคพืชและการจัดการศัตรูพืชที่ทันท่วงที การวินิจฉัยที่ล่าช้าหรือการอาศัยเพียงภาพถ่ายจากเกษตรกรมักนำไปสู่การใช้สารเคมีที่ไม่เหมาะสม เพิ่มต้นทุนการผลิต และทำให้เกิดความสูญเสียผลผลิตต่อฤดูกาลได้อย่างมีนัยสำคัญ ในหลายพื้นที่ ความล่าช้าในการเข้าถึงผู้เชี่ยวชาญหรือห้องปฏิบัติการทำให้การตอบสนองใช้เวลาหลายวันถึงสัปดาห์ ซึ่งผลการศึกษาระดับภูมิภาคชี้ว่าการตอบสนองที่ช้าสามารถเพิ่มอัตราการสูญเสียผลผลิตได้ ประมาณ 15–30% ในบางกรณี
ขณะเดียวกัน เทคโนโลยีอุปกรณ์พกพาและเซ็นเซอร์กำลังเปลี่ยนสมการด้านนี้อย่างรวดเร็ว ปัจจุบันชุมชนเกษตรในไทยมีอัตราการเข้าถึงสมาร์ทโฟนอยู่ในระดับสูง — ประมาณ 70–85% ของครัวเรือนเกษตร สามารถใช้สมาร์ทโฟนเพื่อสื่อสารและเก็บข้อมูลพื้นฐานได้ การลดลงของราคาสมาร์ทโฟนและอุปกรณ์เสริม เช่น เซ็นเซอร์สเปกโตรมิเตอร์แบบพกพา ทำให้การตรวจเชิงสนามที่เคยต้องพึ่งห้องแล็บเป็นไปได้ในพื้นที่ชนบท โดยอุปกรณ์สเปกโตรมิเตอร์คุณภาพพื้นฐานในปัจจุบันมีราคาเหลือเพียงหลักพันถึงหลักหมื่นบาท ซึ่งเหมาะสมต่อการลงทุนในระดับชุมชนหรือกลุ่มวิสาหกิจชุมชน
การประยุกต์ใช้ Multimodal Foundation Models บนสมาร์ทโฟน — ที่ผสานข้อมูลภาพถ่าย, สเปกตรัมจากเซ็นเซอร์ และเมตาดาต้าทางการเกษตร (เช่น พันธุ์พืช, อายุแปลง, สภาพอากาศ) — มีศักยภาพในการปรับปรุงความแม่นยำและความรวดเร็วของการวินิจฉัยอย่างชัดเจน งานวิจัยและตัวอย่างเชิงปฏิบัติแสดงให้เห็นว่า การรวมข้อมูลหลายมิติสามารถเพิ่มความแม่นยำในการจำแนกโรคเมื่อเทียบกับการวิเคราะห์ภาพเพียงอย่างเดียวได้ โดยทั่วไป 10–30% ส่งผลให้สามารถดำเนินมาตรการควบคุมได้เร็วขึ้นและตรงจุดมากขึ้น
ผลตอบแทนเชิงเศรษฐกิจจากการนำระบบเหล่านี้มาใช้มีความชัดเจน เมื่อการวินิจฉัยและคำแนะนำเชิงปฏิบัติการทำได้เรียลไทม์ เกษตรกรจะลดการสูญเสียผลผลิตและลดการใช้สารเคมีที่ไม่จำเป็น ตัวอย่างการประเมินผลประโยชน์เบื้องต้น ได้แก่:
- ลดการสูญเสียผลผลิต — คาดว่าจะลดการสูญเสียได้ 20–40% ในกรณีที่มีการตรวจพบและจัดการตั้งแต่ระยะเริ่มต้น
- ลดต้นทุนการผลิต — การใช้สารเคมีและปัจจัยการผลิตอย่างมีเป้าหมายสามารถลดต้นทุนได้ประมาณ 15–25%
- ผลตอบแทนการลงทุน (ROI) — โครงการติดตั้งเซ็นเซอร์และแอปบนสมาร์ทโฟนสำหรับกลุ่มเกษตรกรอาจคืนทุนภายใน 1–2 ปี ขึ้นกับขนาดการปลูกและความถี่ของปัญหาโรค
ด้วยเหตุนี้ Multimodal บนสมาร์ทโฟนจึงไม่ได้เป็นเพียงนวัตกรรมทางเทคนิคเท่านั้น แต่เป็นเครื่องมือทางเศรษฐกิจที่สามารถยกระดับความยั่งยืนของภาคเกษตรไทยได้ โดยลดความเสี่ยงจากโรคพืช ลดการใช้สารเคมีเกินความจำเป็น และเพิ่มประสิทธิภาพการผลิต ซึ่งเป็นประเด็นที่ผู้ประกอบการ นักลงทุน และภาครัฐควรให้ความสำคัญในการผลักดันสู่การนำไปใช้ในวงกว้าง
เทคโนโลยีพื้นฐาน: Multimodal Foundation Models คืออะไรและทำงานอย่างไร
เทคโนโลยีพื้นฐาน: Multimodal Foundation Models คืออะไรและทำงานอย่างไร
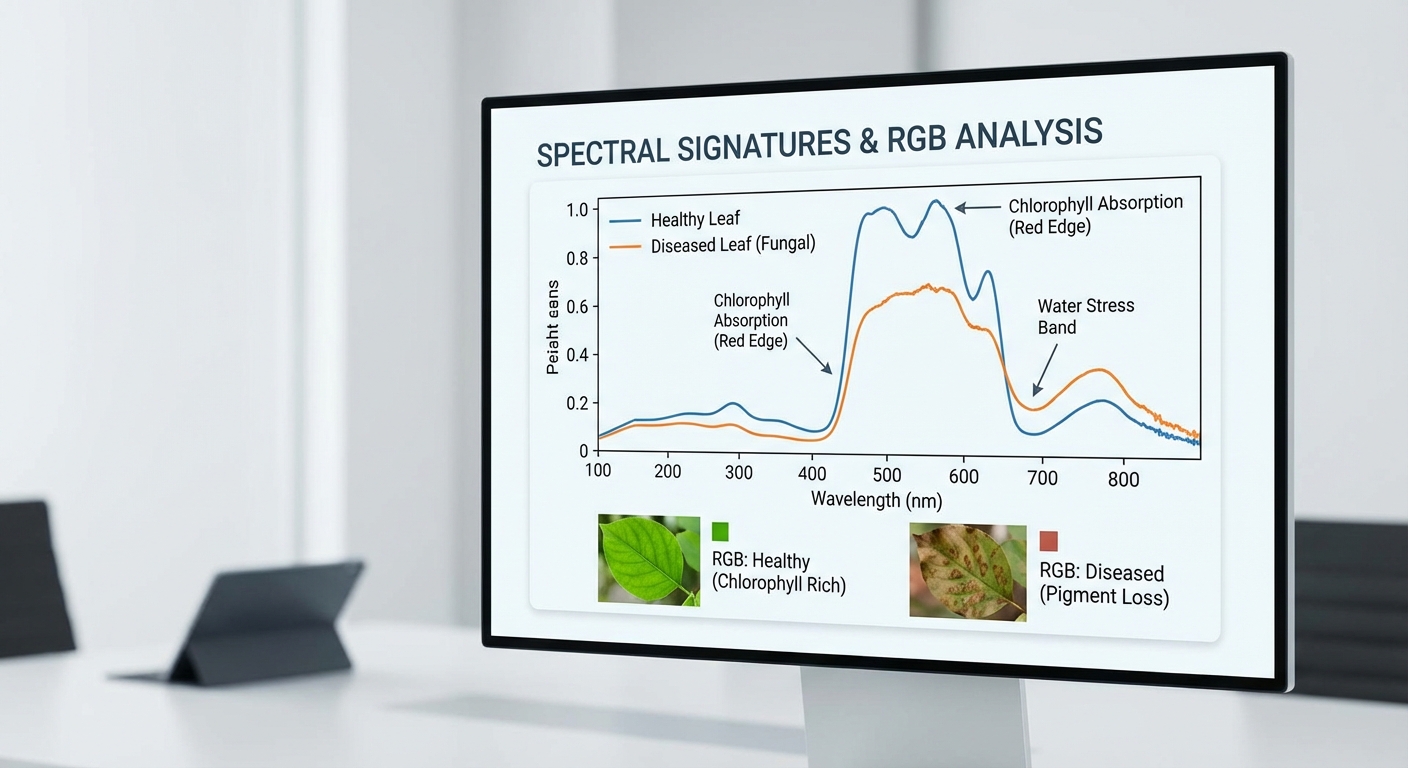
Multimodal Foundation Models เป็นแนวคิดเชิงสถาปัตยกรรมปัญญาประดิษฐ์ที่ออกแบบมาเพื่อประมวลผลข้อมูลหลายรูปแบบ (modalities) พร้อมกัน เพื่อสร้าง ตัวแทนร่วม (joint representation) ที่รวบรวมข้อมูลจากภาพถ่าย RGB, ข้อมูลสเปกตรัม (เช่น VNIR/NIR) และเมตาดาต้า (เช่น GPS, ชนิดพืช, อายุพืช, ข้อมูลสภาพอากาศ) ทำให้ระบบสามารถตัดสินใจได้แม่นยำและมีบริบทมากขึ้น การรวมหลายแหล่งข้อมูลดังกล่าวช่วยชดเชยข้อจำกัดของโมดัลใดโมดัลหนึ่ง เช่น ภาพ RGB อาจบอกลักษณะทางกายภาพของใบ แต่สเปกตรัมจะให้สัญญาณทางเคมีของความเครียดหรือการติดเชื้อ ในขณะที่เมตาดาต้าช่วยให้โมเดลตีความสภาวะเชิงพื้นที่และเวลาได้ถูกต้องมากขึ้น

ในเชิงปฏิบัติ สถาปัตยกรรมทั่วไปของระบบเหล่านี้มักประกอบด้วยส่วนย่อยหลักสามส่วน ได้แก่ vision encoder สำหรับจัดการภาพ RGB, spectral encoder สำหรับแปลงสัญญาณ VNIR/NIR ให้เป็นเวกเตอร์คุณลักษณะ และ fusion module ที่ผสานเอาต์พุตจากทั้งสองด้านเข้ากับ embedding ของเมตาดาต้า กระบวนการผสานอาจทำได้หลายวิธี เช่น การต่อเวกเตอร์ (concatenation) การถ่ายทอดความสนใจข้ามโมดัล (cross-attention) หรือการใช้ bottleneck latent space ที่โมเดลหลายโมดัลแชร์ร่วมกัน ตัวอย่างสถาปัตยกรรมที่นำไอเดียไปปรับใช้ได้แก่ Vision Transformers (ViT) สำหรับภาพ ร่วมกับ 1D-CNN หรือ transformer ขนาดเล็กสำหรับสเปกตรัม และ embedding layer แบบ dense สำหรับเมตาดาต้า
เทคนิคการฝึกสอนมีบทบาทสำคัญในการทำให้ multimodal models ใช้งานได้จริงสำหรับเกษตรกรรมบนสมาร์ทโฟน ตัวอย่างเทคนิคที่ใช้บ่อยได้แก่:
- Transfer learning: ใช้โมเดลที่ได้รับการฝึกบนข้อมูลภาพขนาดใหญ่ (เช่น ImageNet หรือโมเดล ViT ที่ผ่านการ pretrain) แล้ว fine-tune บนชุดข้อมูลผสมของภาพ–สเปกตรัม–เมตาดาต้า เพื่อลดความต้องการข้อมูลเฉพาะด้าน
- Contrastive learning: แนวทางแบบ CLIP ที่จับคู่ออบเจ็กต์จากโมดัลต่างๆ (เช่น ภาพกับสเปกตรัม หรือภาพกับเมตาดาต้า) เพื่อเรียนรู้ตัวแทนที่สอดคล้องกัน ช่วยให้โมเดลเรียนรู้ความสัมพันธ์ข้ามโมดัลแม้ไม่มีป้ายกำกับ (label) มาก
- Multimodal pretraining: ฝึกโมเดลร่วมบนงานหลายภารกิจ เช่น การกู้คืนสเปกตรัมจากภาพ การพยากรณ์โรคแบบ self-supervised หรือภารกิจการจับคู่องค์ประกอบ ช่วยให้โมเดลมีความยืดหยุ่นเมื่อนำไปใช้จริง
มีงานวิจัยและแนวคิดจากโมเดลระดับ foundation เช่น CLIP (คู่ภาพ-ข้อความ), Flamingo (few-shot multimodal reasoning) และ Perceiver (สถาปัตยกรรมที่ยืดหยุ่นต่อโมดัลหลายรูปแบบ) ที่ถูกนำมาปรับใช้เพื่อรองรับสเปกตรัม ตัวอย่างเช่น การขยายแนวคิด contrastive ของ CLIP ให้จับคู่ภาพ RGB กับสเปกตรัม VNIR หรือการใช้ cross-attention แบบ Flamingo เพื่อให้โมเดลสามารถให้คำตอบเชิงบริบทโดยอาศัยทั้งภาพ สเปกตรัม และเมตาดาต้า งานวิจัยในสาขาเกษตรแม่นยำรายงานว่า การผสานข้อมูลสเปกตรัมเข้ากับภาพและข้อมูลเชิงบริบทสามารถเพิ่มความแม่นยำในการจำแนกโรคและความเครียดของพืชได้อย่างมีนัยสำคัญ — โดยมีรายงานการเพิ่มขึ้นของความแม่นยำในระดับกว้างประมาณ 5–15% ขึ้นอยู่กับสภาพข้อมูลและภารกิจ
สำหรับการใช้งานบนสมาร์ทโฟน มีการออกแบบโมเดลให้มีความเบาและประหยัดพลังงาน เช่น การใช้ knowledge distillation เพื่อลดขนาดของโมเดล foundation ลงให้พอรันแบบ on-device ขณะเดียวกันยังใช้กลยุทธ์ hybrid คือรัน inference เบื้องต้นบนอุปกรณ์และส่งเวกเตอร์ตัวแทนบางส่วนไปประมวลผลต่อบนคลาวด์เมื่อต้องการการวิเคราะห์เชิงลึก ข้อได้เปรียบเชิงธุรกิจคือเกษตรกรสามารถรับผลการตรวจวินิจฉัยและคำแนะนำการรักษาแบบเรียลไทม์ คุณภาพการตัดสินใจดีขึ้นและลดการพึ่งพานักวิชาการในพื้นที่
ฮาร์ดแวร์และการผสานกับสมาร์ทโฟน: กล้อง, คลิป-ออนสเปกโตรมิเตอร์ และการเชื่อมต่อ
ฮาร์ดแวร์พื้นฐาน: กล้องสมาร์ทโฟนและคลิป-ออนสเปกโตรมิเตอร์
การนำ Multimodal Foundation Models มาใช้ในพื้นที่เกษตรกรรมบนสมาร์ทโฟนจำเป็นต้องมีฮาร์ดแวร์พื้นฐานสองประเภทที่ทำงานร่วมกันได้อย่างลงตัว ได้แก่ กล้อง RGB ของสมาร์ทโฟน สำหรับภาพถ่ายฝั่งมุมมอง/ภูมิประเทศและการวิเคราะห์รูปแบบ และ คลิป-ออนสเปกโตรมิเตอร์แบบ VNIR/NIR สำหรับการวัดสเปกตรัมสะท้อนในช่วง ~400–1000 nm ซึ่งครอบคลุมช่วงแสงที่สำคัญต่อการตรวจจับสภาวะทางชีวเคมีของพืช (เช่น ความชื้น โครมอพฟอร์สติก และการขาดสารอาหาร) โดยสเปกโตรมิเตอร์แบบคลิป-ออนที่ตลาดสำหรับเกษตรกรมักให้ความละเอียดสเปกตรัมตั้งแต่ ~1–10 nm ขึ้นกับรุ่น: รุ่นราคาประหยัดมักอยู่ที่ 5–10 nm ขณะที่อุปกรณ์ระดับวิจัยอาจให้ความละเอียด ≤1–2 nm
ประเภทเซ็นเซอร์และการเชื่อมต่อกับสมาร์ทโฟน
- กล้อง RGB สมาร์ทโฟน: เป็นเซ็นเซอร์หลักสำหรับภาพมุมกว้าง การตรวจวัดลักษณะใบ ตำแหน่งโรค รวมถึงการบันทึกเมตาดาต้า (GPS, เวลา, โมเดลพืช) ข้อจำกัดคือข้อมูลสเปกตรัมเชิงลึกถูกจำกัดไว้ที่ช่องสี RGB สามช่อง จึงต้องผสานกับสเปกโตรมิเตอร์เพื่อการวิเคราะห์ทางชีวเคมีที่แม่นยำ
- คลิป-ออน VNIR/NIR: ติดเข้ากับเลนส์สมาร์ทโฟนหรือพอร์ตเครื่อง มักครอบคลุมช่วง 400–1000 nm ซึ่งรวมทั้งแถบที่มองเห็นและใกล้อินฟราเรดตอนสั้น ความละเอียดสเปกตรัมทั่วไป 1–10 nm ขึ้นกับเซนเซอร์และค่าใช้จ่าย
- การเชื่อมต่อ: อุปกรณ์เชื่อมต่อได้ทั้งผ่าน USB-C/Lightning (OTG) สำหรับการส่งข้อมูลแบบเรียลไทม์ และ Bluetooth Low Energy (BLE) สำหรับการใช้พลังงานต่ำหรือการสตรีมข้อมูลที่มีแบนด์วิดท์ต่ำ การออกแบบต้องคำนึงถึงความเข้ากันได้ของพอร์ตสมาร์ทโฟนและพลังงานสำรอง
อุปกรณ์เสริมที่จำเป็น
การใช้งานในภาคสนามต้องพึ่งพาอุปกรณ์เสริมเพื่อสร้างความเสถียรและความเที่ยงตรงของการวัด ได้แก่:
- แหล่งแสงอ้างอิง (reference light): เช่น แผ่นขาวมาตรฐานหรือหลอด LED ที่มีสเปกตรัมทราบค่า ใช้สำหรับการสอบเทียบ (white reference) เพื่อลดผลของการเปลี่ยนแปลงแสงภายนอก
- การอ้างอิงค่า dark: การวัดค่าเบื้องต้นเมื่อเครื่องปิดแสงเพื่อหาค่าพื้นฐานของเซ็นเซอร์
- แท่นจับ/คลิปจับตัวอย่าง: แท่นยึดใบหรือผลไม้ ช่วยควบคุมมุมและระยะห่างระหว่างเซ็นเซอร์กับตัวอย่าง ลดความคลาดเคลื่อนจากการวัดแบบมือถือ
- ซองกันฝุ่น/กันน้ำและกรอบป้องกันแสงแวดล้อม: สำหรับใช้ในสภาพฟิลด์ ลดผลกระทบจากฝุ่น ละออง และการสะท้อนแสงภายนอก
ต้นทุน: ทางเลือกสำหรับเกษตรกร vs ระดับวิจัย
ด้านต้นทุนมีสเปกตรัมกว้างที่ควรพิจารณาเพื่อความคุ้มค่าและการเข้าถึงในชุมชนเกษตรกรรม:
- คลิป-ออนราคาประหยัดสำหรับเกษตรกร: อยู่ในช่วงประมาณ $20–200 ต่อหน่วย โดยรุ่นที่ใกล้เคียง $20–50 มักมีความละเอียดต่ำกว่า (5–10 nm) และเหมาะสำหรับการจำแนกอาการทั่วไปหรือการแจ้งเตือนเบื้องต้น ขณะที่รุ่นใกล้ $100–200 มักให้ความแม่นยำและความทนทานดีขึ้น
- อุปกรณ์ระดับวิจัย: ราคาเริ่มต้นที่หลายร้อยถึงหลายพันดอลลาร์ (เช่น $1,000–10,000) ให้ความละเอียดสูง (<1–2 nm), ความเสถียรทางเทอร์มอล และการสอบเทียบเชิงมาตรฐาน ซึ่งจำเป็นสำหรับงานวิจัยเชิงลึกและการพัฒนาโมเดลเชิงวิทยาศาสตร์
- กล้องสมาร์ทโฟน: แม้รุ่นทันสมัยจะมีค่าใช้จ่ายตั้งแต่ $100–1,500 แต่โดยทั่วไปกล้องสมาร์ทโฟนเชิงพาณิชย์ก็เพียงพอสำหรับการจับภาพ RGB ร่วมกับคลิป-ออนสเปกโตรมิเตอร์
ข้อจำกัดและความท้าทายเชิงปฏิบัติ
การนำฮาร์ดแวร์เหล่านี้ไปใช้ในภาคสนามต้องเผชิญกับความท้าทายสำคัญหลายประการ:
- การสอบเทียบนิ่ง (calibration): เพื่อให้ค่าสเปกตรัมข้ามเวลาและอุปกรณ์ต่างรุ่นเทียบกันได้ จำเป็นต้องมีกระบวนการสอบเทียบทั้งแบบ white/dark reference และการสอบเทียบภายใต้สภาวะแวดล้อมที่ควบคุมได้ การละเลยการสอบเทียบจะทำให้โมเดล ML/AI ให้ผลลัพธ์ผิดพลาดได้ง่าย
- ผลกระทบของสภาวะแสง: แสงธรรมชาติที่เปลี่ยนแปลงตามเวลาวันและมุมอาทิตย์ ส่งผลต่อความเข้มของสเปกตรัม การสะท้อนจากพื้นผิวที่เปียกหรือมีฝุ่น และการเงาของใบ สามารถสร้างความเบี่ยงเบนได้ถึงหลายเปอร์เซ็นต์ หากไม่ควบคุมด้วยแหล่งแสงอ้างอิงหรือกรอบป้องกัน
- ความเสถียรของการวัด: การจับด้วยมือถืออาจทำให้ระยะและมุมต่างกัน ส่งผลต่อสัญญาณ สถานการณ์นี้ต้องใช้แท่นจับหรือการแนะนำผู้ใช้ผ่าน UX เพื่อให้การจับซ้ำได้ (repeatability)
- ข้อจำกัดจากเซ็นเซอร์ RGB: กล้อง RGB ไม่สามารถแทนที่ข้อมูลสเปกตรัมเชิงลึกได้แม้จะประมวลผลภาพหลายมุมร่วมกันก็ตาม จึงต้องพึ่งพาคลิป-ออนสำหรับข้อมูลทางเคมีของพืช
การออกแบบ UX สำหรับเกษตรกรและการปฏิบัติการภาคสนาม
เพื่อให้เทคโนโลยีนี้ยอมรับได้ในภาคสนาม การออกแบบ UX ต้องให้ความสำคัญกับความเรียบง่ายและกระบวนการที่เป็นมาตรฐาน:
- ขั้นตอนการจับภาพที่ชัดเจน: อินเทอร์เฟซควรแนะนำผู้ใช้ทีละขั้นตอน (เช่น วางตัวอย่างในแท่น -> กดวัดค่า white reference -> วัด dark -> ถ่ายสเปกตรัม/ภาพ) พร้อมตัวชี้นำภาพ (overlay) และตัวจับเวลา
- การสอบเทียบอัตโนมัติและฟีดแบ็กแบบเรียลไทม์: แอปควรตรวจสอบคุณภาพสัญญาณทันที แจ้งเมื่อค่าผิดปกติ เช่น มีเงาบังหรือสัญญาณอ่อน และเสนอให้ทำการวัดซ้ำ
- การบริหารพลังงานและการเชื่อมต่อ: โหมดออฟไลน์สำหรับพื้นที่ไร้เครือข่ายเพื่อให้โมเดลรุ่นขนาดเล็กรันในเครื่อง (on-device) และมีการซิงค์ข้อมูลเมื่อเชื่อมต่อเครือข่าย การออกแบบต้องคำนึงถึงการใช้พลังงานของคลิป-ออนและการชาร์จ
- เมตาดาต้าและการบันทึกเชิงบริบท: เก็บข้อมูลเวลา, GPS, สภาพอากาศพื้นฐาน, สายพันธุ์พืช และผู้ใช้งานเพื่อช่วยให้โมเดลประมวลผลได้แม่นยำขึ้นและรองรับการวิเคราะห์เชิงธุรกิจ
สรุปเชิงธุรกิจ
การผสานกล้องสมาร์ทโฟนกับคลิป-ออนสเปกโตรมิเตอร์ (VNIR/NIR) เปิดช่องทางให้เกษตรกรเข้าถึงการตรวจวินิจฉัยพืชที่ให้ข้อมูลเชิงชีวเคมีได้ใกล้เคียงห้องแล็บในราคาที่จับต้องได้ โดยอุปสรรคเชิงเทคนิค เช่น การสอบเทียบและการควบคุมสภาวะแสง ต้องแก้ไขผ่านการออกแบบฮาร์ดแวร์เสริมและ UX ที่ชัดเจน ทางเลือกฮาร์ดแวร์มีตั้งแต่รุ่นราคาประหยัด (ประมาณ $20–200) สำหรับการแจ้งเตือนและการติดตามเชิงปริมาณเบื้องต้น ไปจนถึงอุปกรณ์ระดับวิจัยที่มีต้นทุนสูงขึ้นแต่ให้ความแม่นยำและความเสถียรที่จำเป็นสำหรับการพัฒนาโมเดลเชิงวิทยาศาสตร์และเชิงพาณิชย์
การจัดการข้อมูลและเมตาดาต้า: การเก็บ บริหาร และติดป้ายข้อมูล (labeling)
การจัดการข้อมูลและเมตาดาต้า: การเก็บ บริหาร และติดป้ายข้อมูล (labeling)
การออกแบบ pipeline การเก็บข้อมูลสำหรับระบบ Multimodal Foundation Models บนสมาร์ทโฟนเพื่อการตรวจโรคพืช จำเป็นต้องรวมการถ่ายภาพคุณภาพสูง การเก็บสเปกตรัมสังเกตการณ์ และเมตาดาต้าที่ครบถ้วนเป็นมาตรฐานตั้งแต่ต้นทาง ทั้งนี้เพื่อให้โมเดลสามารถเรียนรู้ความสัมพันธ์ข้ามมอดาลิตีได้อย่างมีประสิทธิภาพ ในทางปฏิบัติ pipeline ควรประกอบด้วยขั้นตอนหลัก ดังนี้: การเก็บภาพ (เชิงมาโครและมาโครใกล้), การเก็บสเปกตรัม (VNIR, SWIR หรือ NIR ตามเซนเซอร์), การบันทึกเมตาดาต้าเชิงบริบท, การติดป้าย (labeling) ระดับฟิลด์และระดับห้องปฏิบัติการ และการส่งข้อมูลเข้าสู่ระบบจัดการข้อมูล (ingest → validate → store → annotate).
เมตาดาต้าที่สำคัญต้องถูกบันทึกเป็นฟิลด์บังคับและมีฟอร์แมตมาตรฐานเพื่อการประมวลผลและการวิเคราะห์ภายหลัง ตัวอย่างรายการเมตาดาต้าที่ควรมีได้แก่:
- GPS: พิกัดความแม่นยำสูง (เช่น ±5 เมตร) และข้อมูลระบบพิกัด (WGS84)
- วันที่/เวลา: เวลาท้องถิ่นพร้อม timezone และ timestamp แบบ ISO 8601 เพื่อเชื่อมกับข้อมูลสภาพอากาศ
- อายุพืช/ระยะการเจริญเติบโต: วันหลังเพาะปลูก, ระยะ BBCH หรือสเตจการเจริญเติบโต
- สภาพอากาศ: อุณหภูมิ ความชื้นสัมพัทธ์ ปริมาณฝน และแสง (ถ้ามี) ณ เวลาบันทึก
- สารตกค้าง/ประวัติการใช้สาร: สารเคมีที่ใช้ล่าสุด ปริมาณ และเวลาที่ใช้
- สายพันธุ์/พันธุกรรม: ชื่อสายพันธุ์หรือรหัสพันธุ์
- ระดับอาการ: เกณฑ์การให้คะแนนความรุนแรง (เช่น 0–5 หรือ 0–100%) พร้อมนิยามตัวชี้วัด
- อุปกรณ์และการตั้งค่าเซนเซอร์: รุ่นสมาร์ทโฟน/เซนเซอร์สเปกตรัม, การตั้งค่า exposure, white reference และการคาลิเบรต
การติดป้าย (labeling) เป็นหนึ่งในความท้าทายสำคัญ เนื่องจากแหล่งที่มาของ label มีความแตกต่างกันทั้งในด้านความถูกต้องและความครอบคลุม โดยทั่วไปแบ่งเป็น lab-confirmed labels และ farmer-reported / expert visual labels ซึ่งมีข้อพิจารณาดังนี้:
- Lab-confirmed labels: การยืนยันด้วย PCR, การเพาะเชื้อ หรือการทดสอบทางโมเลกุลให้ความน่าเชื่อถือสูงสุด แต่มีต้นทุนต่อเคสสูงและใช้เวลานาน ตัวอย่างเช่น ชุดตัวอย่างยืนยัน 2,000 เคสจากห้องปฏิบัติการอาจใช้ค่าใช้จ่ายและเวลาเป็นเดือน แต่จะเป็น Gold Standard ในการฝึกและตรวจสอบโมเดล
- Farmer-reported / visual expert: สามารถเก็บข้อมูลจำนวนมากและเร็ว (เช่น หลายหมื่นตัวอย่าง) แต่มีความคลาดเคลื่อนของ label สูง ข้อผิดพลาดประเภทนี้อาจเป็นสาเหตุให้ประสิทธิภาพโมเดลลดลงหากไม่ได้มีการตรวจสอบเพิ่มเติม
- ความท้าทายการเก็บโรคเฉพาะ: ตัวอย่างโรคที่หายากหรือเกิดเป็นช่วงอาจทำให้เกิดความไม่สมดุลของชั้นข้อมูล (class imbalance) — ตัวอย่างจริงในภาคสนามสำหรับโรคหายากอาจน้อยกว่า 1% ของข้อมูลทั้งหมด
เพื่อจัดการกับความไม่แน่นอนของ label และเพิ่มคุณภาพของ dataset ควรนำแนวทางปฏิบัติดังต่อไปนี้มาใช้:
- การยืนยันแบบไฮบริด: ผสมผสานการเก็บข้อมูลจากฟิลด์และการยืนยันบางส่วนด้วยห้องปฏิบัติการ (stratified lab-confirmation) — ตัวอย่างเช่น จากแต่ละคลัสเตอร์ของ farmer-reported cases ให้สุ่มตัวอย่าง 5–10% เพื่อยืนยันด้วย PCR
- crowdsourcing ที่มีการตรวจสอบ: ใช้กลไก consensus (หลาย annotator) และเพิ่มชุดตัวอย่างทองคำ (gold-standard set) เพื่อตรวจสอบคุณภาพ annotator — การใช้เกณฑ์ความเชื่อมั่น (confidence score) และ inter-annotator agreement (เช่น Cohen's kappa) จะช่วยคัดกรอง label ที่น่าเชื่อถือ
- active learning & targeted sampling: เรียนรู้แบบแอคทีฟเพื่อเลือกตัวอย่างที่ไม่แน่นอนสูงไปยังการทดสอบห้องปฏิบัติการ ลดต้นทุนและเพิ่มประสิทธิภาพการยืนยัน
การจัดการคุณภาพข้อมูลเป็นสิ่งจำเป็นเพื่อให้สเปกตรัมและภาพสามารถนำไปใช้กับโมเดลได้อย่างมีประสิทธิภาพ ขั้นตอนสำคัญได้แก่:
- การทำความสะอาดข้อมูล (data cleaning): ลบทิ้งรูปภาพที่เบลอ/overexposed/underexposed, ตรวจจับและลบสเปกตรัมที่ผิดปกติหรือมีสัญญาณรบกวนสูง
- การคาลิเบรตและ normalization ของสเปกตรัม: ใช้วิธีมาตรฐานเช่น Standard Normal Variate (SNV), Multiplicative Scatter Correction (MSC), การลบ baseline, และการทำ smoothing หรือ Savitzky–Golay derivative เพื่อลดผลกระทบจากแสงและมุมถ่ายภาพ
- การจัดการ drift ของเซนเซอร์: บันทึก reference panels (เช่น white/black reference) เป็นประจำและเก็บ metadata ของการคาลิเบรตเพื่อตรวจสอบความคงที่ของอุปกรณ์เมื่อเวลาผ่านไป
- การลดมิติและตรวจหา outlier: ใช้ PCA หรือ t-SNE เพื่อตรวจหากลุ่มผิดปกติ และลงมาตรฐานสเกลของสเปกตรัมก่อนการป้อนเข้าโมเดล
เมื่อต้องการสร้าง dataset ขนาดใหญ่ที่ผสมข้อมูลภาคสนามกับข้อมูลห้องปฏิบัติการ ควรออกแบบโครงสร้างข้อมูลและการจัดการเวอร์ชันอย่างรัดกุม:
- สถาปัตยกรรมข้อมูลแบบ Tiered: แบ่งข้อมูลเป็นระดับ (Tier 1: lab-confirmed, Tier 2: expert-verified, Tier 3: farmer-reported) เพื่อให้สามารถเลือกใช้ข้อมูลตามการประยุกต์และระดับความเสี่ยง
- การเชื่อมโยงตัวอย่าง: ให้ทุกตัวอย่างมี unique ID ที่เชื่อมภาพ สเปกตรัม และเมตาดาต้ารวมถึงผลการทดสอบห้องปฏิบัติการ เพื่อความสืบค้นและการอ้างอิงข้ามชุดข้อมูล
- การทำ data augmentation และ sampling: ใช้เทคนิค augmentation ทางภาพ (rotation, color jitter) และเทคนิคสำหรับสเปกตรัม (noise injection, spectral shifting) พร้อมกลยุทธ์ oversampling สำหรับชั้นข้อมูลที่ขาดแคลน
- การผสานข้อมูลข้ามโดเมน: ก่อนผสานข้อมูลภาคสนามกับห้องปฏิบัติการให้ทำ harmonization ของเมตาดาต้าและการคาลิเบรตเซนเซอร์เพื่อลด domain shift และใช้เทคนิค domain adaptation เมื่อฝึกโมเดล
สุดท้าย ควรกำหนดนโยบายการปกป้องข้อมูลและมาตรฐานการเก็บยินยอม (consent) โดยเฉพาะเมื่อเก็บพิกัดฟาร์มและข้อมูลส่วนบุคคล และต้องมีการบันทึกเวอร์ชันของ dataset, schema metadata (เช่น JSON schema) และตัวชี้วัดคุณภาพ (เช่น อัตรา label-confirmation, inter-annotator agreement, อัตราส่วนตัวอย่างต่อชั้น) เพื่อให้การพัฒนาโมเดลเป็นไปอย่างโปร่งใสและสามารถตรวจสอบย้อนหลังได้ ตัวอย่างเป้าหมายเชิงปฏิบัติ เช่น การเก็บอย่างน้อย 50,000 ภาพและ 20,000 สเปกตรัมที่มีการยืนยันแบบ mixed-validation จะช่วยให้โมเดล multimodal ทนทานต่อความแปรปรวนภาคสนามและมีความแม่นยำเชิงการวินิจฉัยที่ใช้งานได้จริงในสภาพแวดล้อมของเกษตรกรไทย
ฝึกโมเดลและการวัดผล: ชุดข้อมูล ตัวชี้วัด และการนำไปทำงานบนอุปกรณ์จริง
ฝึกโมเดล: Pretraining + Fine-tuning ด้วยข้อมูลภาคสนาม
การพัฒนาโมเดล multimodal foundation สำหรับการตรวจโรคพืชบนสมาร์ทโฟนเริ่มต้นด้วยกระบวนการฝึกสองขั้นตอนหลัก ได้แก่ pretraining บนชุดข้อมูลขนาดใหญ่และ fine-tuning ด้วยข้อมูลภาคสนามที่มีป้ายกำกับ (labelled). ในขั้นตอน pretraining นิยมใช้ข้อมูลหลากหลายแหล่งทั้งภาพถ่ายระยะใกล้ (RGB/NIR), สเปกตรัมจากสเปกโตรมิเตอร์ และเมตาดาต้า (เช่น พันธุ์พืช สภาพดิน สภาพอากาศ) เพื่อให้โมเดลเรียนรู้คุณลักษณะพื้นฐานของรูปแบบร่วมกัน (joint representations) โดยวิธี self-supervised learning เช่น contrastive learning, masked multimodal modeling หรือ multimodal contrastive pretext tasks ที่ช่วยลดความจำเป็นของข้อมูลที่มีป้ายกำกับจำนวนมาก
หลังจาก pretraining แล้ว จะนำโมเดลไป fine-tuning ด้วยชุดข้อมูลภาคสนามที่เก็บจากเกษตรกรหรือการทดลองภาคสนามจริง ซึ่งต้องมีการจัดการข้อมูลอย่างรัดกุมเพื่อให้ครอบคลุมความแปรปรวนของสภาพการถ่ายภาพ (มุม กล้อง แสง) และความแตกต่างของสเปกตรัมตามสายพันธุ์หรือสภาพแวดล้อม การแบ่งข้อมูลควรทำเป็นแบบมีชั้น (stratified) และใช้เทคนิค cross-validation เช่น k-fold (k=5 หรือ 10) เพื่อประเมินความเสถียรของโมเดลและลดความลำเอียงจากการแบ่งข้อมูลแยกชุดทดสอบ/ชุดฝึก
การเพิ่มข้อมูล (Data Augmentation) สำหรับภาพและสเปกตรัม
- ภาพ (RGB/NIR/Multispectral): การหมุน (rotation), พลิก (flip), การปรับแสง/contrast, color jitter, Gaussian blur, random crop, scale, mixup และ CutMix เพื่อเพิ่มความหลากหลายและความทนทานต่อสภาพการถ่ายจริง
- สเปกตรัม: การเติม noise แบบ Gaussian, การเลื่อนไปในแกนความยาวคลื่น (wavelength shift) เล็กน้อย, การสุ่มลด/เพิ่มความละเอียดของสเปกตรัม, spectral mixing (ผสมสเปกตรัมจากตัวอย่างต่างชนิด) และการทำ baseline correction หรือ continuum removal เพื่อจำลองการเปลี่ยนแปลงเชิงฟื้นฐานของสเปกตรัม
- เทคนิคข้ามโดเมน: ใช้ GAN หรือวิธีการสังเคราะห์ข้อมูลแบบ physics-based model เพื่อสร้างตัวอย่างภาพและสเปกตรัมจำลองในกรณีที่ข้อมูลภาคสนามหายาก โดยผสมเมตาดาต้า (เช่น สภาพภูมิอากาศ) เพื่อให้สังเคราะห์ตัวอย่างที่สมจริง
การวัดผลและตัวชี้วัดสำคัญ
การประเมินประสิทธิภาพต้องวัดทั้งด้านคุณภาพการจำแนกและความพร้อมใช้งานเชิงปฏิบัติการ โดยตัวชี้วัดหลักประกอบด้วย:
- Accuracy: สัดส่วนของตัวอย่างที่ทำนายถูกต้อง — เหมาะสำหรับภาพรวม แต่ต้องระวังเมื่อมีความไม่สมดุลของคลาส
- Precision / Recall / F1-score: ใช้วัดความแม่นยำของการทำนายในแต่ละคลาส โดย recall สำคัญเมื่อเป้าหมายคือการตรวจจับโรคให้ได้มากที่สุด ขณะที่ precision สำคัญเพื่อลดการแจ้งเตือนผิดพลาด
- AUC (ROC AUC): สำหรับการประเมินความสามารถของโมเดลในการแยกคลาสแบบทวิภาค (binary) และข้ามเกณฑ์ความไว/ความจำเพาะ
- Latency / Response time: เวลาตอบสนองแบบ end-to-end (รวมการจับภาพ, preprocessing, inference และการแสดงผล) ซึ่งมีผลต่อประสบการณ์ผู้ใช้แบบเรียลไทม์ — สำหรับแอปพลิเคชันสนามที่ต้องการคำแนะนำทันที ค่าที่ดีมักอยู่ในช่วง ต่ำกว่า 200–1000 ms ขึ้นกับกรณีใช้งาน
- Memory footprint / Energy consumption: สำคัญเมื่อนำไปรันบนสมาร์ทโฟน โดยต้องตรวจสอบทั้งขนาดโมเดลและการใช้พลังงานต่อการสืบค้นหนึ่งครั้ง
จากงานวิจัยและการทดสอบภาคสนาม หลายการศึกษาแสดงให้เห็นว่าโมเดล multimodal ที่รวมภาพกับสเปกตรัมและเมตาดาต้า สามารถเพิ่มความแม่นยำได้อย่างมีนัยสำคัญเมื่อเทียบกับโมเดลภาพเดี่ยว — ในบางกรณีพบการเพิ่มขึ้นของความแม่นยำประมาณ 10–30% ในการจำแนกโรคพืชบางชนิด โดยเฉพาะเมื่อต้องแยกความแตกต่างระหว่างอาการที่มีลักษณะภาพใกล้เคียงกันแต่สเปกตรัมต่างกัน
การปรับแต่งเพื่อรันบนสมาร์ทโฟนและเทคนิคลด latency
การนำโมเดลขนาดใหญ่ไปใช้งานบนสมาร์ทโฟนจำเป็นต้องปรับให้มีขนาดเล็กและตอบสนองเร็ว โดยเทคนิคหลักได้แก่:
- Quantization: แปลงพารามิเตอร์จาก FP32 เป็น INT8 หรือ INT4 เพื่อลดขนาดโมเดลประมาณ 2–4 เท่าและเพิ่มความเร็ว inference บนฮาร์ดแวร์ที่รองรับ โดยมักมีการลดทอนความแม่นยำเล็กน้อย
- Pruning: ตัดพารามิเตอร์ที่ไม่สำคัญ (unstructured/structured pruning) เพื่อลด FLOPs และหน่วยความจำ การ prune แบบมีโครงสร้างช่วยให้เร่งความเร็วได้จริงบนฮาร์ดแวร์มือถือ
- Knowledge Distillation: ฝึกโมเดลขนาดเล็ก (student) ให้เลียนแบบโมเดลขนาดใหญ่ (teacher) เพื่อรักษาความแม่นยำในขนาดที่เล็กลง — วิธีนี้มักให้ trade-off ความแม่นยำต่ำสุดเมื่อเทียบกับการลดขนาดมาก
- การเลือกสถาปัตยกรรมที่เป็นมิตรต่อ edge: ใช้โมดูลที่มีค่า latency ต่ำ เช่น MobileNetV3, EfficientNet-Lite, หรือ Transformer ที่ถูกปรับแบบ lightweight และออกแบบโมดูล multimodal แบบแยกส่วน (separable encoders + lightweight fusion)
- การเร่งฮาร์ดแวร์และการคอมไพล์: ใช้เครื่องมือเช่น TFLite, ONNX Runtime Mobile, NNAPI หรือไลบรารีของผู้ผลิต (เช่น Qualcomm, MediaTek) ในการใช้ NPU/DSP ช่วยลด latency อย่างมาก
- Edge‑Cloud Hybrid: นำแนวทางผสมโดยให้การประเมินเบื้องต้น (triage) ทำบนอุปกรณ์เพื่อการตอบสนองทันที และส่งเฉพาะกรณีที่ต้องการวิเคราะห์เชิงลึกหรือการอัปเดตโมเดลไปยังคลาวด์ วิธีนี้ลด latency perceived และช่วยจำกัดการใช้แบนด์วิดท์ อีกทั้งรองรับ fallback เมื่อไม่มีการเชื่อมต่อ
- เทคนิคลด latency อื่นๆ: operator fusion, quantized kernels, early-exit networks (ตัดสินใจเร็วเมื่อมั่นใจ), caching ผล preprocessing และการประมวลผลแบบ asynchronous ระหว่างการจับภาพและ inference
ในการออกแบบ pipeline จริง ควรวัดผลแบบ end‑to‑end ได้แก่เวลาจับภาพและ preprocessing (ตัวอย่าง 50–200 ms), inference (เป้าหมาย 50–500 ms ขึ้นกับความซับซ้อน) และเวลาแสดงผล ทีมควรกำหนด Service‑level Objective (SLO) ที่สอดคล้องกับบริบทการใช้งาน เช่น SLO ≤ 500 ms สำหรับคำแนะนำแบบเรียลไทม์ หรือ ≤ 2 s สำหรับการประเมินเชิงวิเคราะห์ที่ลึกขึ้น
สรุปแนวปฏิบัติที่แนะนำ: ใช้ pretraining บนชุดข้อมูลขนาดใหญ่ร่วมกับการ fine‑tuning ด้วยข้อมูลภาคสนาม, ใช้ augmented และ domain adaptation เพื่อเพิ่มความทนทาน, วัดทั้งคุณภาพ (precision/recall/F1/AUC) และประสิทธิภาพเชิงปฏิบัติการ (latency, memory, energy), และปรับแต่งด้วย quantization/pruning/distillation พร้อมกลยุทธ์ edge-cloud hybrid เพื่อให้โมเดล multimodal ทำงานได้อย่างมีประสิทธิภาพบนสมาร์ทโฟนของเกษตรกรไทย
การปรับใช้จริง, UX และโมเดลธุรกิจ: จากแอปในมือถือสู่การสนับสนุนเกษตรกร
สถาปัตยกรรมการให้บริการ: On-device inference + Cloud sync
รูปแบบการปรับใช้ที่เหมาะกับบริบทชนบทของไทยคือแนวทาง Offline-first โดยให้โมเดลฐาน (multimodal foundation models ที่ผ่านการควอนไทซ์และปรับแต่ง) ทำงานประมวลผลเบื้องต้นบนเครื่อง (on-device inference) เพื่อระบุโรค ตีความสเปกตรัม และให้คำแนะนำทันทีโดยไม่ต้องพึ่งพาการเชื่อมต่ออินเทอร์เน็ตตลอดเวลา เมื่อมีการเชื่อมต่อ ระบบจะทำการ cloud sync เพื่อส่งรูปภาพ สเปกตรา และเมตาดาต้าที่ได้รับการคัดกรองขึ้นไปยังคลาวด์ เพื่อสำรองข้อมูล อัพเดตโมเดล และให้หน่วยงานส่งเสริมการเกษตรวิเคราะห์เชิงลึกต่อไป
การออกแบบชั้นสถาปัตยกรรมประกอบด้วย 3 ระดับหลัก: (1) Edge device — โมดูลสเปกโตรมิเตอร์และโมเดล inference ขนาดเล็กที่ทำงานบนสมาร์ทโฟน, (2) Sync gateway — ส่วนที่จัดการคิวงานการส่งข้อมูลแบบยืดหยุ่นเมื่อมีเครือข่าย (เช่น อัปโหลดเมื่อเชื่อม Wi‑Fi หรือเมื่อมีสัญญาณ 3G/4G), และ (3) Cloud backend — สำหรับการฝึกเพิ่ม (continuous learning), การรวมข้อมูลระดับภูมิภาค และการเชื่อมต่อกับระบบพยากรณ์หรือฐานความรู้ของหน่วยงานรัฐ/เอกชน
UX: หน้าแอปที่เข้าใจง่าย ให้ภาพและคำแนะนำเป็นภาษาท้องถิ่น
ประสบการณ์ผู้ใช้ต้องออกแบบสำหรับเกษตรกรรายย่อยที่อาจมีทักษะด้านดิจิทัลต่างกัน ดังนั้นอินเตอร์เฟซต้องเรียบง่าย ใช้ไอคอนชัดเจน และเน้นภาพประกอบ ภาพถ่ายตัวอย่างโรค และกราฟสเปกตรัมที่อ่านง่าย พร้อมคำอธิบายเป็นภาษาไทยถิ่นที่เหมาะสม (ตัวอย่างเช่น ภาษาไทยภาคเหนือ/อีสาน) และข้อความเสียงเป็นตัวเลือก
ฟีเจอร์ UX สำคัญ ได้แก่:
- หน้ากดถ่ายแบบชัดเจนพร้อมแถบเช็คลิสต์ (lighting, distance, leaf orientation) เพื่อลดความผิดพลาดของข้อมูล
- ผลการตรวจแบบเรียลไทม์ที่แสดงสถานะความรุนแรงในระดับ 1–5 พร้อมปุ่ม คำแนะนำแบบ step-by-step ที่อธิบายงานปฏิบัติ (เช่น วิธีพ่น/คลุกเมล็ด) และคำนวณปริมาณสารหรือปุ๋ยตามขนาดพื้นที่โดยอัตโนมัติ
- ทางเลือกการรักษาแบบยั่งยืน เช่น บอกปริมาณสารเคมีที่แนะนำต่อไร่, พร้อมทางเลือกชีวภาพ (biocontrol) และวิธีการจัดการเชิงวัฒนธรรม
- ระบบแจ้งเตือนแบบเรียลไทม์ (push notifications/SMS) สำหรับการระบาดที่เพิ่มขึ้นหรือคำเตือนสภาพอากาศที่เกี่ยวข้อง
- โหมดอธิบายผลแบบภาพนิ่งและวิดีโอสั้นเพื่อฝึกปฏิบัติการ และปุ่มเชื่อมต่อกับเจ้าหน้าที่ส่งเสริมการเกษตรในพื้นที่
การให้คำแนะนำเชิงปฏิบัติ: step-by-step และการคำนวณปริมาณสาร
เมื่อแอปตรวจพบโรค ระบบจะนำเสนอขั้นตอนการรักษาแบบละเอียด เช่น:
- วินิจฉัยโรคพร้อมความเชื่อมั่น (เช่น 85%) และระดับความรุนแรง
- คำแนะนำเป็นขั้นตอน (step 1–4) ตั้งแต่การตัดแต่งใบที่เป็นโรค การกำจัดเศษซาก ไปจนถึงการใช้สารกำจัดศัตรูพืช
- การคำนวณปริมาณสารหรือสารชีวภาพที่แนะนำตาม ขนาดพื้นที่ (เช่น มิลลิลิตร/ลิตร/ไร่) โดยให้ตัวเลือกหลายทางและผลกระทบด้านความปลอดภัย
- คำแนะนำด้านความปลอดภัย (PPE) และเวลาที่ควรเว้นก่อนเก็บเกี่ยว
ตัวอย่าง: หากตรวจพบเชื้อราที่ข้าวในแปลงขนาด 2 ไร่ แอปอาจแนะนำสารชีวภาพ A: ฉีด 50 มล. ต่อน้ำ 20 ลิตร ครอบคลุมแปลง 2 ไร่ โดยระบุช่วงเวลาการฉีดซ้ำ 7–10 วัน และทางเลือกใช้สารเคมีที่มีอัตราปริมาณแนะนำพร้อมคำเตือนเรื่องสารตกค้าง
การเชื่อมต่อกับเกษตรกรและหน่วยงานส่งเสริม
ระบบต้องรองรับช่องทางการสื่อสารสองทาง: เกษตรกรส่งข้อมูลและขอคำปรึกษา ในขณะเดียวกันหน่วยงานส่งเสริมสามารถเข้าดูแดชบอร์ดรวมเพื่อเฝ้าระวังการระบาดและออกคำแนะนำเป็นรายพื้นที่ได้แบบเรียลไทม์ การออกแบบ API สำหรับการเชื่อมต่อกับระบบฐานข้อมูลของกรมส่งเสริมการเกษตรหรือมหาวิทยาลัยเกษตรเป็นประเด็นสำคัญเพื่อการบูรณาการข้อมูลเชิงนโยบาย
โมเดลธุรกิจ: ทางเลือกสำหรับการนำไปใช้เชิงพาณิชย์และสังคม
มีโมเดลธุรกิจหลายทางที่เหมาะสมกับบริบทไทย โดยพิจารณาทั้งด้านการเข้าถึงของเกษตรกรและความยั่งยืนทางการเงินของผู้พัฒนา
- ขายฮาร์ดแวร์พร้อมบริการ (Hardware + Service) — จำหน่ายชุดสมาร์ทโฟนที่มาพร้อมโมดูลสเปกโตรมิเตอร์และการติดตั้ง สำหรับเกษตรกรที่ต้องการโซลูชันครบวงจร ราคาต่อชุดอาจอยู่ในช่วง 5,000–15,000 บาท ขึ้นกับคุณภาพเซนเซอร์และบริการหลังการขาย
- Subscription / SaaS สำหรับหน่วยงานส่งเสริม — เสนอแพลตฟอร์มระดับองค์กรให้กับหน่วยงานราชการหรือองค์กรเอกชนเกษตร โดยคิดค่าบริการแบบรายปีตามจำนวนฟาร์มหรือผู้ใช้ (เช่น 100–500 บาท/ปีต่อฟาร์ม) ซึ่งเอื้อให้หน่วยงานสามารถแจกจ่ายการบริการให้เกษตรกรโดยมีการอุดหนุน
- โมเดลชุมชน (Co-op / Sharing) — กลุ่มสหกรณ์หรือศูนย์เรียนรู้ชุมชนซื้ออุปกรณ์ร่วมกันและให้เช่าหรือให้บริการตรวจวินิจฉัยต่อสมาชิก วิธีนี้ช่วยลดต้นทุนต่อราย โดยต้นทุนต่อเกษตรกรอาจต่ำลงเหลือไม่กี่ร้อยบาทต่อปี ขึ้นกับอัตราการใช้
- สาธารณะแบบผสม (Public-Private Partnerships) — ความร่วมมือกับหน่วยงานรัฐในการอุดหนุนต้นทุนฮาร์ดแวร์หรือค่าบริการ เพื่อเร่งการขยายตัวและการเก็บข้อมูลเชิงสาธารณสุขพืช
การคาดการณ์ค่าใช้จ่ายและ ROI สำหรับเกษตรกรรายย่อย
เพื่อให้ภาพชัดเจน ขอยกตัวอย่างสมมติฐานสำหรับเกษตรกรรายย่อยมีแปลงขนาด 3 ไร่ (ประมาณ 0.48 เฮกตาร์):
- ต้นทุนฮาร์ดแวร์แบบคลิป‑on สเปกโตรมิเตอร์ + ติดตั้งแอป: ประมาณ 4,000–10,000 บาท
- ค่าสมัครบริการรายปี (อัพเดตโมเดล, การเชื่อมต่อเจ้าหน้าที่): 300–1,200 บาท/ปี
- ผลลัพธ์ที่คาดหวัง: การลดการใช้สารเคมีเกินความจำเป็น 10–30% และการเพิ่มผลผลิตจากการจัดการที่แม่นยำ 5–20% ขึ้นกับชนิดพืชและสภาพแวดล้อม
ตัวอย่างคำนวณ ROI แบบหยาบ: หากเกษตรกรจ่ายค่าอุปกรณ์เฉลี่ย 6,000 บาท และการใช้งานนำไปสู่การเพิ่มรายรับสุทธิ 4,000–12,000 บาทต่อปี (จากการเพิ่มผลผลิตและลดค่าใช้จ่ายสารเคมี) จะคืนทุนได้ภายใน 0.5–1.5 ปี ซึ่งทำให้โครงการมีความคุ้มค่าสำหรับเกษตรกรรายย่อย โดยเฉพาะเมื่อมีทางเลือกแบบชุมชนที่ลดต้นทุนเริ่มต้นลง
สรุปแล้ว การนำ multimodal foundation models ไปใช้ในสมาร์ทโฟนของเกษตรกรไทยจำเป็นต้องออกแบบทั้งสถาปัตยกรรมแบบ on-device inference + cloud sync ระบบ UX ที่เข้ากับผู้ใช้จริง และโมเดลธุรกิจที่ยืดหยุ่น (ฮาร์ดแวร์+บริการ, subscription, หรือโมเดลชุมชน) เพื่อให้การปรับใช้เกิดผลจริงและยั่งยืนในเชิงเศรษฐกิจและสังคม
กรณีศึกษา, ผลกระทบเชิงเศรษฐกิจ และข้อพิจารณาด้านกฎระเบียบ
กรณีศึกษาเชิงปฏิบัติ: โครงการนำร่องในนาข้าวและสวนผลไม้
ในการทดลองนำร่องสมมติที่ดำเนินการร่วมกับหน่วยงานภาครัฐและสตาร์ทอัพด้านเกษตรดิจิทัล จำนวนเกษตรกร 500 รายในจังหวัดภาคเหนือ (นาข้าว) และภาคใต้ (สวนผลไม้) พบผลลัพธ์เชิงปฏิบัติที่เด่นชัด โดยใช้โมเดลพื้นฐานแบบ Multimodal บนสมาร์ทโฟนที่ผสานภาพถ่าย ความถี่สเปกโตรมิเตอร์จากอุปกรณ์ต่อพ่วง และเมตาดาต้าพื้นที่/พันธุ์พืช เพื่อวินิจฉัยโรคและให้คำแนะนำการรักษาแบบเรียลไทม์
ผลการทดสอบแสดงว่าเวลาเฉลี่ยในการวินิจฉัยลดจาก 48–72 ชั่วโมง (ระบบเดิมที่อาศัยการส่งตัวอย่างไปห้องปฏิบัติการ) เหลือเพียง 2–5 นาที โดยที่ความแม่นยำการวินิจฉัยเบื้องต้นอยู่ในช่วง 85–92% ขึ้นอยู่กับความหลากหลายของโรค ในแง่การใช้สารเคมีกำจัดศัตรูพืชและสารกำจัดโรค พบการลดปริมาณการใช้สารเคมีเฉลี่ย 30–50% เนื่องจากการให้คำแนะนำที่แม่นยำและเป็นจุด (targeted treatment) ผลผลิตเฉลี่ยเพิ่มขึ้น 6–12% เมื่อเทียบกับกลุ่มควบคุม ทั้งนี้คาดการณ์ว่าการลดการใช้สารเคมีและการเพิ่มผลผลิตส่งผลให้เกษตรกรมีรายได้สุทธิเพิ่มขึ้นเฉลี่ย 2,000–5,000 บาท/ไร่/ฤดูกาล (ค่าตัวอย่างขึ้นอยู่กับพืชและราคาตลาด)
ตัวอย่างเชิงปฏิบัติ: กลุ่มนาข้าวรายหนึ่งรายงานว่าสามารถลดรอบการพ่นสารกำจัดโรคจาก 4 ครั้งต่อฤดูกาลเหลือ 2 ครั้ง และลดต้นทุนสารเคมีลงประมาณ 40% ขณะที่กลุ่มสวนมะม่วงในภาคใต้สามารถตรวจพบอาการรากเน่าได้ตั้งแต่ระยะเริ่มต้น ทำให้ลดการสูญเสียผลผลิตถึง 15% ในแปลงที่ใช้ระบบช่วยตัดสินใจ
ผลกระทบเชิงเศรษฐกิจ
การนำเทคโนโลยี Multimodal Foundation Models มาใช้ในภาคการเกษตรมีผลกระทบเชิงเศรษฐกิจทั้งในระดับไมโคร (เกษตรกรรายย่อย) และมาโคร (ห่วงโซ่อุปทานและเศรษฐกิจประเทศ) ดังนี้
- ลดต้นทุนการผลิต: การพ่นยาที่เป็นจุดและลดการใช้สารเคมีช่วยลดต้นทุนตรงของเกษตรกร ประมาณการลดต้นทุนสารเคมี 30–50% ต่อไร่ต่อฤดูกาล
- เพิ่มผลผลิตและคุณภาพสินค้า: การวินิจฉัยเร็วขึ้นช่วยลดการสูญเสียและปรับปรุงคุณภาพผลผลิต ส่งผลให้ราคาขายต่อหน่วยดีขึ้นโดยประมาณ 5–10% ในตัวอย่างโครงการ
- ประสิทธิภาพแรงงานและเวลา: เวลาในการตัดสินใจที่เร็วขึ้นทำให้การจัดการเวลาและแรงงานมีประสิทธิภาพกว่าเดิม ช่วยให้เกษตรกรมีเวลาเพิ่มขึ้นสำหรับกิจกรรมเชิงพาณิชย์อื่น ๆ
- ผลกระทบต่ออุตสาหกรรมต่อเนื่อง: ผู้ประกอบการปุ๋ย สารเคมี และบริการวิเคราะห์ตัวอย่างอาจต้องปรับธุรกิจเป็นบริการให้คำแนะนำแบบเชิงลึกหรือขายผลิตภัณฑ์ที่เฉพาะเจาะจงมากขึ้น ซึ่งอาจเปลี่ยนโครงสร้างตลาด
- ผลรวมระดับประเทศ: หากขยายการใช้อย่างมีประสิทธิภาพ คาดว่าจะช่วยลดการนำเข้าสารเคมีบางประเภทและเพิ่มมูลค่าการส่งออกผลผลิตคุณภาพสูง ซึ่งอาจมีผลต่อ GDP เกษตรในภาพรวม แต่ตัวเลขต้องประเมินจากการสเกลแบบเป็นทางการ
ข้อพิจารณาด้านความเป็นส่วนตัวและกฎระเบียบ
การใช้งานโมเดลที่อาศัยภาพและเมตาดาต้าเช่นพิกัดฟาร์ม พันธุ์ และผลการวินิจฉัยก่อให้เกิดความเสี่ยงด้านความเป็นส่วนตัวและความรับผิดชอบหลายประการที่ต้องบริหารจัดการอย่างเข้มงวด:
- ความเป็นส่วนตัวของข้อมูลพิกัดและฟาร์ม: ข้อมูลตำแหน่งแปลงและเมตาดาต้าพื้นที่เป็นข้อมูลเชิงพิกัดที่อาจบ่งชี้เจ้าของหรือความมั่งคั่งของฟาร์ม การเก็บรวบรวมและแบ่งปันต้องสอดคล้องกับพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) โดยต้องได้รับความยินยอมชัดแจ้งและระบุวัตถุประสงค์การใช้งานอย่างโปร่งใส
- ข้อมูลสุขภาพพืชและข้อมูลเชิงพาณิชย์: ข้อมูลการระบาดของโรคและการตอบสนองการรักษาเป็นสินทรัพย์ของเกษตรกรและอาจมีมูลค่าทางการตลาด จึงควรมีนโยบายการเข้าถึง การแบ่งปัน และการอนามัยข้อมูลที่ชัดเจน เช่น การทำให้ข้อมูลเป็นแบบไม่ระบุตัวตนก่อนใช้เพื่อพัฒนาระบบ
- ความรับผิดชอบต่อคำแนะนำ: คำแนะนำการรักษาที่ให้โดยโมเดลอาจส่งผลกระทบต่อผลผลิตและสิ่งแวดล้อม หากคำแนะนำผิดพลาดจำเป็นต้องกำหนดกรอบความรับผิดชอบอย่างชัดเจน — ควรกำหนดให้มี human-in-the-loop หรือการยืนยันจากผู้เชี่ยวชาญท้องถิ่นในกรณีที่การตัดสินใจมีความเสี่ยงสูง
- ความโปร่งใสและการตรวจสอบย้อนกลับ: ระบบควรเก็บบันทึกการตัดสินใจ (decision logs) ระบุเวอร์ชันของโมเดล ข้อมูลนำเข้า และเหตุผลที่ให้คำแนะนำ เพื่อให้สามารถตรวจสอบเมื่อเกิดข้อพิพาทหรือเหตุการณ์ไม่พึงประสงค์
ในเชิงกฎระเบียบ ควรมีแนวทางปฏิบัติต่อไปนี้เพื่อสร้างความมั่นคงและความเชื่อมั่นของผู้ใช้งาน:
- การทดสอบภาคสนามและการรับรอง: กำหนดมาตรฐานการทดสอบภาคสนามที่เป็นอิสระ (เช่น การทดสอบแบบ double-blind กับชุดข้อมูลจริงหลายภูมิภาค) และเกณฑ์ความแม่นยำขั้นต่ำเพื่อการรับรองก่อนการใช้งานเชิงพาณิชย์
- มาตรฐานการคุ้มครองข้อมูล: บังคับใช้มาตรฐานด้านความมั่นคงของข้อมูล เช่น การเข้ารหัสข้อมูลขณะส่งและจัดเก็บ การจำกัดสิทธิ์การเข้าถึง และนโยบายการเก็บรักษาข้อมูลที่ชัดเจน สอดคล้องกับ PDPA และมาตรฐานสากล (เช่น ISO/IEC 27001)
- การรับรองคำแนะนำทางการเกษตร: คำแนะนำที่มีผลต่อการใช้สารเคมีควรได้รับการตรวจสอบจากหน่วยงานด้านการเกษตร (เช่น กรมวิชาการเกษตร) และอาจต้องติดฉลากระบุระดับความแน่นอนของคำแนะนำ (confidence level) เพื่อให้เกษตรกรตัดสินใจได้อย่างรอบคอบ
- บทบาทรัฐและนโยบายสนับสนุน: รัฐควรส่งเสริม sandbox สำหรับนวัตกรรม การให้ทุนสนับสนุนโครงการนำร่อง และจัดตั้งกรอบกำกับดูแลที่ยืดหยุ่นแต่ชัดเจน ทั้งนี้รวมถึงการฝึกอบรมเจ้าหน้าที่ส่งเสริมการเกษตรให้สามารถใช้งานและตรวจสอบผลการประยุกต์ใช้เทคโนโลยีได้
- การประกันและความรับผิด: สร้างแนวทางประกันภัยสำหรับความผิดพลาดของระบบหรือคำแนะนำ และระบุกลไกการชดเชยกรณีเกิดความเสียหายจากการปฏิบัติตามคำแนะนำอัตโนมัติ
สรุปคือ การนำ Multimodal Foundation Models มาใช้ในภาคเกษตรสามารถสร้างประโยชน์เชิงเศรษฐกิจและสิ่งแวดล้อมได้ชัดเจน แต่ต้องควบคู่กับกรอบการทดสอบภาคสนาม มาตรฐานการรับรอง ความโปร่งใสด้านข้อมูล และการกำกับดูแลที่เข้มแข็งเพื่อจัดการความเสี่ยงด้านความเป็นส่วนตัวและความรับผิดชอบต่อคำแนะนำ โดยบทบาทของรัฐและหน่วยงานกำกับเป็นสิ่งสำคัญในการสร้างความเชื่อมั่นและส่งเสริมการขยายผลอย่างยั่งยืน
บทสรุป
Multimodal Foundation Models บนสมาร์ทโฟน — ที่ผสานทั้งภาพถ่าย สเปกโตรมิเตอร์ และเมตาดาต้า (เช่น ตำแหน่งพิกัด เวลา สภาพอากาศ) — มีศักยภาพสูงที่จะช่วยให้เกษตรกรไทยสามารถวินิจฉัยโรคพืชและรับคำแนะนำการรักษาได้อย่าง รวดเร็ว และ แม่นยำ ในพื้นที่จริง โดยลดความจำเป็นในการทิ้งตัวอย่างไปยังห้องแล็บและลดต้นทุนการวิเคราะห์ ตัวอย่างการใช้งานชี้ให้เห็นว่าการรวมสเปกตรัมกับภาพและเมตาดาต้าสามารถเพิ่มความแม่นยำในการจำแนกอาการโรคที่มีลักษณะคล้ายกัน และให้คำแนะนำการจัดการที่เจาะจงต่อสภาพแวดล้อมของแปลงมากขึ้น อย่างไรก็ดี ความสำเร็จบนสนามจริงต้องอาศัยการออกแบบร่วมกันทั้งฮาร์ดแวร์ (เช่น เซ็นเซอร์สเปกโตรมิเตอร์ที่เหมาะกับมือถือ) ซอฟต์แวร์ (โมเดลที่ถูกปรับให้ทำงานบนเครื่อง/edge) และนโยบายที่รองรับเพื่อให้เทคโนโลยีใช้งานได้อย่างยั่งยืนและยอมรับในวงกว้าง
การนำไปใช้จริงจำเป็นต้องคำนึงถึงประเด็นสำคัญหลายด้าน ได้แก่ คุณภาพและความหลากหลายของข้อมูล เพื่อให้โมเดลเรียนรู้กรณีต่าง ๆ ของโรคและเงื่อนไขทางภูมิภาค, การปรับโมเดลให้ทำงานบนเครื่อง (เช่น การบีบอัด โมเดล pruning และการประมวลผลแบบ on-device) เพื่อให้ตอบสนองแบบเรียลไทม์โดยไม่พึ่งการเชื่อมต่อเครือข่ายตลอดเวลา, การออกแบบ UX ที่เป็นมิตรกับเกษตรกร (ภาษา ทัศนคติ ขั้นตอนการใช้งานที่ชัดเจน) และกรอบกำกับดูแลที่ปกป้องข้อมูลส่วนบุคคล เกษตรกร และความรับผิดชอบของคำแนะนำทางการแพทย์พืช (accountability) เช่น มาตรฐานคุณภาพข้อมูล นโยบายการแบ่งปันข้อมูล และการกำกับความรับผิดชอบของผลคำแนะนำ โดยในอนาคตหากมีการทำงานร่วมกันระหว่างภาครัฐ ภาคเอกชน และชุมชนเกษตรกรอย่างเป็นระบบ เทคโนโลยีนี้มีแนวโน้มลดการใช้สารเคมีที่ไม่จำเป็น เพิ่มผลผลิต และยกระดับการจัดการพืชผลเชิงคาดการณ์ได้อย่างมีนัยสำคัญ



