
สตาร์ทอัพไทยเปิดตัวเครื่องมือใหม่ที่อาจเปลี่ยนวิธีการดีบั๊กโมเดลภาษาอย่างสิ้นเชิง — "LLM Visual Debugger" ที่แปลงกระบวนการคิดแบบ Chain‑of‑Thought ของโมเดล (การไหลของตรรกะภายใน) ให้กลายเป็นภาพกราฟิกที่เข้าใจง่าย ช่วยให้ทีม Machine Learning (ML) สามารถมองเห็น ลำดับเหตุผล และจุดผิดพลาดภายในโมเดลที่เคยเป็นเรื่องทึบและตรวจสอบยาก งานนำร่องภายในรายงานว่าเครื่องมือนี้ลดเวลาแก้บั๊กจากระดับหลายชั่วโมงหรือหลายวัน เหลือเพียงไม่กี่ชั่วโมงในหลายกรณี ทำให้การพัฒนาและปรับปรุงโมเดลเกิดขึ้นได้เร็วขึ้นและมีหลักฐานเชิงตรรกะประกอบการตัดสินใจมากขึ้น
บทความนี้จะพาอ่านถึงประเด็นสำคัญของการเปิดตัว — จากฟีเจอร์หลักที่สามารถแปลง Chain‑of‑Thought เป็นแผนภาพเชิงตรรกะ การใช้งานจริงในทีมวิจัยและหน่วยงานองค์กร ตัวอย่างเคสที่ทีมพบบั๊กที่มองไม่เห็นด้วยวิธีเดิม รวมถึงผลกระทบด้านความโปร่งใส (explainability) และการปฏิบัติตามข้อกำหนดด้านความรับผิดชอบของ AI ที่เครื่องมือนี้อาจช่วยเสริม ทีมงานผู้พัฒนายังชี้ว่า LLM Visual Debugger ถูกออกแบบให้ผสานเข้ากับ pipeline ที่มีอยู่ได้ง่าย เหมาะทั้งงานวิจัยและการนำไปใช้เชิงผลิต
ข่าวสั้น: อะไรเกิดขึ้น ทำไมถึงสำคัญ
ข่าวสั้น: อะไรเกิดขึ้น ทำไมถึงสำคัญ
สตาร์ทอัพไทย เปิดตัวผลิตภัณฑ์ใหม่ชื่อ LLM Visual Debugger ในช่วงมกราคม 2026 โดยสตาร์ทอัพระบุว่าเป็นเครื่องมือสำหรับทีมงานวิจัยและพัฒนาโมเดลภาษาขนาดใหญ่ (LLM) ที่สามารถไล่ตรรกะแบบ chain‑of‑thought เป็นภาพ ช่วยให้วิศวกรเห็นเส้นทางการคิดของโมเดลตั้งแต่ token แรกจนถึงคำตอบสุดท้าย ทำให้การหาจุดบกพร่องเชิงตรรกะและข้อผิดพลาดของการตอบสนองชัดเจนขึ้น

จุดขายสำคัญของผลิตภัณฑ์คือคำสัญญาว่า "ช่วยหาและแก้บั๊กโมเดลภายในชั่วโมง" โดยระบบทำงานผ่านการแสดงผลแบบชั้นต่อชั้นของการคิด การเน้นจุดเบี่ยงเบน (divergence) ระหว่างสถานะที่คาดหวังกับสถานะจริง และการให้คำแนะนำเชิงสาเหตุเบื้องต้นเพื่อชี้จุดที่ควรปรับพารามิเตอร์หรือข้อมูลฝึกฝน
ผลการทดลองเชิงเบื้องต้นที่ผู้พัฒนาระบุจากการทดสอบภายในกับทีม ML ขนาดกลางและการทดลองพาร์ทเนอร์บางรายระบุว่า:
- ลดเวลาเฉลี่ยในการระบุและแก้บั๊ก จากเดิมที่ใช้ประมาณ 3–5 วัน เหลือภายใน ไม่กี่ชั่วโมง ในเคสที่มีตรรกะชัดเจน (ผู้พัฒนาระบุการลดเวลาโดยประมาณ 70–90%)
- อัตราการค้นพบปัญหาเชิงตรรกะ เพิ่มขึ้นประมาณ 30–50% เมื่อเทียบกับการดีบั๊กแบบล็อกและรีเพลย์ข้อความอย่างเดียว
- ความแม่นยำในการชี้จุดสาเหตุเบื้องต้น อยู่ในช่วงที่ผู้พัฒนาระบุไว้คือประมาณ 60–80% ในชุดทดสอบภายใน ทั้งนี้ขึ้นกับความซับซ้อนของ prompt และรูปแบบข้อมูล
ความสำคัญของข่าวนี้อยู่ที่การลดต้นทุนเวลาและทรัพยากรของทีม ML โดยเฉพาะองค์กรที่ส่งผลิตภัณฑ์ AI เข้าสู่การใช้งานจริง (production) — หากผลลัพธ์ที่อ้างสามารถยืนยันได้จากการทดลองอิสระ เครื่องมือประเภทนี้อาจกลายเป็นเครื่องมือมาตรฐานสำหรับการตรวจสอบความถูกต้องเชิงตรรกะของ LLM ก่อนใช้งานเชิงพาณิชย์ อย่างไรก็ตาม ผู้พัฒนายังเน้นว่ายังต้องมีการทดสอบเพิ่มเติมในกรณีใช้งานจริง (real‑world) และสภาพแวดล้อมที่หลากหลายก่อนสรุประดับอุตสาหกรรม
เบื้องหลังเทคโนโลยี: วิธีแปลง Chain‑of‑Thought เป็นภาพ
เบื้องหลังเทคโนโลยี: แนวทางการดักจับ Chain‑of‑Thought (CoT)
ระบบ LLM Visual Debugger เริ่มจากการ ดักจับข้อมูล Chain‑of‑Thought (CoT) ที่เกิดขึ้นระหว่างการเรียกใช้งานโมเดล โดยมีสองแนวทางหลักที่นิยมนำมาใช้ในงานจริง: instrumentation/agent และ modified prompting. แนวทางแรกเป็นการฝังตัวดักจับ (instrumentation) ที่ชั้นแอปพลิเคชันหรือไลบรารีของโมเดล เพื่อเก็บทั้งข้อความกลาง (intermediate text), โทเค็น, และเมตริกภายใน (เช่น logits หรือ hidden states) ช่วยให้ได้ข้อมูลเชิงลึกละเอียด แต่เพิ่มความซับซ้อนด้านสถาปัตยกรรมและข้อกำหนดด้านความเป็นส่วนตัว ในทางกลับกัน แนวทาง modified prompting จะเตือนหรือชักนำให้โมเดลแสดง CoT ในรูปแบบข้อความที่อ่านได้ (explicit CoT) ผ่าน prompt แบบพิเศษ เช่น “โปรดแสดงขั้นตอนความคิดเป็นข้อๆ” ซึ่งติดตั้งง่ายและปลอดภัยกว่า แต่มีข้อจำกัดเรื่องความครบถ้วนของข้อมูลและความสามารถในการเข้าถึงสัญญาณภายในโมเดล
การแปลง CoT เป็นโหนดกราฟและการเชื่อมสัมพันธ์เหตุผล
เมื่อได้ข้อความ CoT แล้ว ระบบจะผ่านกระบวนการแยกวิเคราะห์ (parsing) เพื่อแปลงแต่ละย่อยของตรรกะเป็น โหนด และความสัมพันธ์เป็น ขอบ (edges) ในกราฟเหตุผล (reasoning graph). ขั้นตอนสำคัญได้แก่:
- การแบ่งข้อคิดเห็นเป็นหน่วยย่อย (segmenting) โดยใช้กฎไวยากรณ์และ ML-based classifiers เพื่อแยก premise, inference, และ assertion.
- การสกัดเอ็นทิตีและความสัมพันธ์ (entity/relation extraction) เพื่อทำให้โหนดมีแอตทริบิวต์เชิงความหมาย เช่น ประเภทข้อมูล น้ำหนักความเชื่อมั่น และช่วงเวลา
- การจัดลำดับเชิงตรรกะ (temporal/causal ordering) โดยใช้สัญญาณเช่นคีย์เวิร์ด (“ดังนั้น”, “เพราะว่า”) และการพึ่งพิงโทเค็น (token references) เพื่อระบุทิศทางของขอบ
- การรวมข้อมูลจากหลายแหล่ง (fusion) เมื่อระบบเชื่อมต่อกับ traces ภายในโมเดล (เช่น attention span) เพื่อยืนยันหรือแย้งความสัมพันธ์ที่แยกได้จากข้อความอย่างเดียว
ผลลัพธ์คือกราฟที่แสดงเส้นทางเหตุผลเป็นชุดของโหนด/โมดูล ทำให้นักพัฒนาสามารถมองเห็น "จุดเปลี่ยน" ของการตัดสินใจและไล่ตรรกะย้อนกลับได้อย่างเป็นระบบ
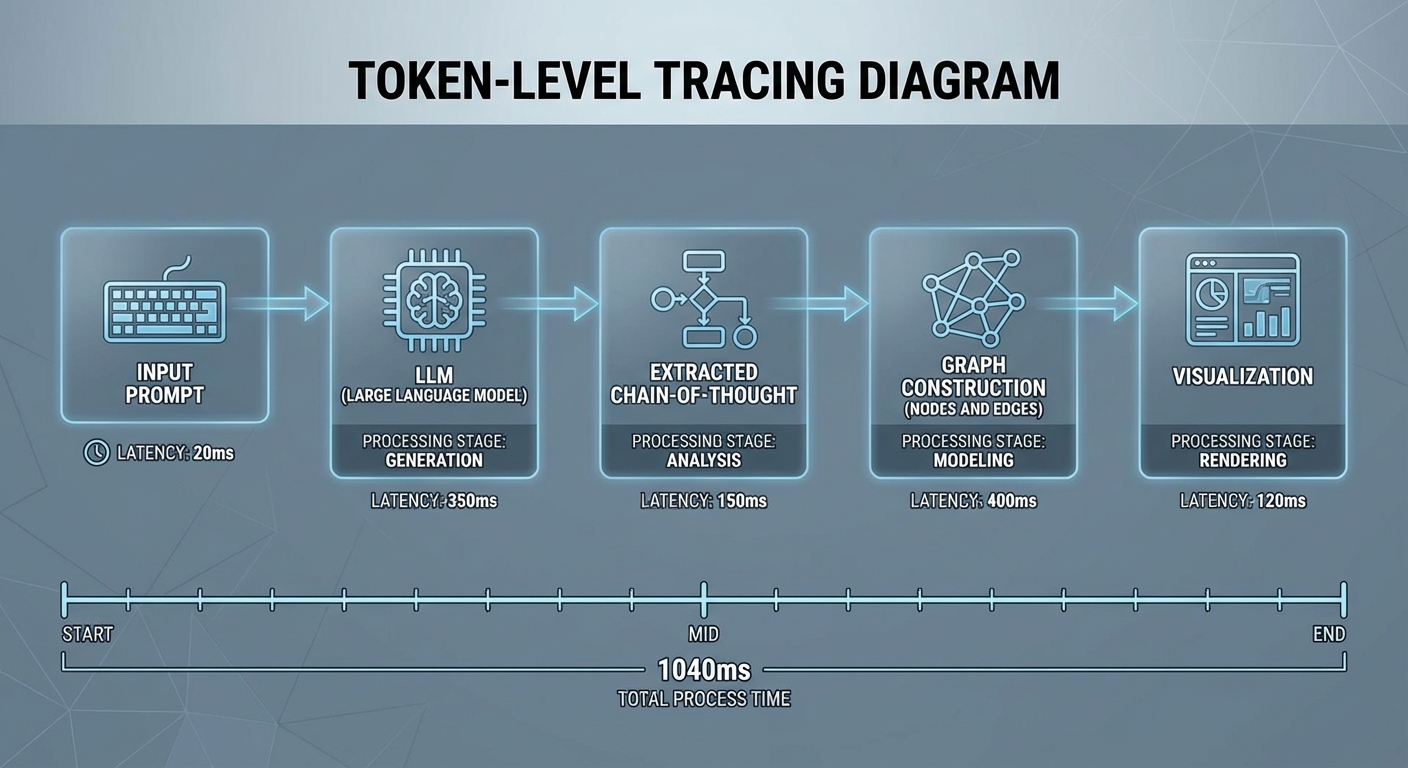
มาตรการลด ruido (noise) และการย่อยสรุปข้อมูล
การแปลง CoT เป็นภาพต้องรับมือกับเสียงรบกวน (noise) และความซ้ำซ้อนของข้อมูล เพื่อให้กราฟสะท้อนตรรกะที่มีความหมาย ระบบหลักๆ ที่ถูกนำมาใช้มีดังนี้:
- Filtering: ใช้กฎเชิงสัทศาสตร์ ร่วมกับโมเดลจัดอันดับ (ranking) เพากรองข้อความที่มีความสำคัญต่ำ เช่น คำอธิบายซ้ำหรือคำพูดเชิงความไม่แน่นอน (e.g., “อาจจะ”, “น่าจะ”). ตัวอย่างตัวเลข: การกรองเช่นนี้ลดจำนวนโหนดที่ไม่สำคัญได้เฉลี่ย 40–65% ขึ้นกับโดเมน
- Summarization: ย่อ CoT ยาวๆ ให้เหลือสาระสำคัญผ่านโมดูลสรุปที่ถูกฝึกเพื่อรักษาเหตุผลเชิงโครงสร้าง — โดยทั่วไปจะลดจำนวนโทเค็นได้ 35–60% ช่วยลดภาระการประมวลผลต่อชุดข้อมูลภาพ
- Clustering & Collapse: รวมโหนดที่มีความหมายใกล้เคียงกัน (semantic clustering) เพื่อหลีกเลี่ยงการแสดงเครือข่ายที่ซับซ้อนเกินจำเป็น
- Confidence Thresholding: ปฏิเสธการนำเสนอขอบที่มีค่าความเชื่อมั่นต่ำกว่าเกณฑ์ เพื่อเน้นเฉพาะเหตุผลที่มีน้ำหนัก
การใช้เทคนิคผสมผสานเหล่านี้ช่วยลด “visual noise” และทำให้การไล่บั๊กมีประสิทธิภาพขึ้น ทั้งในแง่ของความเร็วในการวิเคราะห์ของมนุษย์และการตัดสินใจเชิงระบบ
ผลกระทบต่อ Latency และ Throughput — ตัวเลขเชิงประจักษ์และวิธีบรรเทา
การเพิ่มชั้นการดักจับและการประมวลผล CoT ย่อมมีผลต่อประสิทธิภาพระบบ โดยทั่วไปผลกระทบขึ้นกับวิธีการที่เลือก:
- Instrumentation/agent: เก็บข้อมูลภายใน (เช่น logits, hidden states) มักเพิ่ม latency แบบ synchronous ประมาณ 20–40% หรือเพิ่มเวลาเฉลี่ย 30–120 ms ต่อคำขอในสถาปัตยกรรมที่มี latency พื้นฐาน 200–400 ms (ตัวเลขสมมติ/ตัวอย่างจากการใช้งานจริงของผู้พัฒนา)
- Modified prompting: ค่าใช้จ่ายโดยตรงต่ำกว่า โดยเพิ่ม latency ประมาณ 5–15% (เช่น 10–60 ms) แต่มีข้อจำกัดเรื่องความครบถ้วนของ CoT
- Post‑processing (parsing + graphing): การแปลงข้อความเป็นกราฟและวิชวลไลเซชันบนเซิร์ฟเวอร์อาจเพิ่ม overhead อีก 50–200 ms ต่อคำขอ ขึ้นกับขนาดของ CoT และความซับซ้อนของกราฟ
รวมทั้งหมด ถ้าเปิดใช้ฟีเจอร์ Visual Debugger แบบละเอียด (instrumentation + full parsing + visualization) ระบบอาจเห็น throughput ลดลงประมาณ 10–30% และ latency เพิ่มขึ้นโดยรวม 30–200 ms ต่อคำขอ อย่างไรก็ตามมีแนวทางบรรเทาเพื่อลดผลกระทบ:
- การประมวลผลแบบ asynchronous: ดักจับ CoT แบบ non‑blocking แล้วประมวลผลกราฟเป็นแบตช์ ทำให้ไม่เพิ่ม latency ต่อคำขอของผู้ใช้ปลายทาง
- Adaptive sampling: เก็บ CoT แบบละเอียดเฉพาะกับคำขอที่ผิดปกติหรือเมตริกความเชื่อมั่นต่ำ ส่วนคำขอปกติใช้แบบย่อ ลด overhead ลงได้ 50%+
- Edge/offload: ส่งงานการสรุปและแปลงกราฟไปยังงานแบคกราวด์หรืออินสแตนซ์เฉพาะ ช่วยรักษา throughput ของบริการหลัก
- Cache และ incremental updates: เก็บผลลัพธ์การสรุป/การแปลงก่อนหน้าและอัปเดตเฉพาะส่วนที่เปลี่ยน ช่วยลดงานซ้ำ
สรุปแล้ว การเปลี่ยน CoT ให้เป็นภาพที่ใช้งานได้จริงเป็นการผสมผสานระหว่างการดักจับที่เหมาะสม การแยกโครงสร้างและเชื่อมความสัมพันธ์เชิงตรรกะ และการลด noise อย่างมีนัยสำคัญ แม้จะมีผลกระทบต่อ latency/throughput แต่ด้วยแนวทางเช่น asynchronous processing, adaptive sampling และการบีบอัดข้อมูลเชิงเหตุผล ระบบสามารถให้ประโยชน์ด้านการไล่บั๊กและลดเวลาแก้ปัญหาในทีม ML ได้ภายในชั่วโมงโดยยังรักษาประสิทธิภาพการให้บริการในระดับยอมรับได้
กรณีศึกษา: ไล่ตรรกะและแก้บั๊กจริงภายในชั่วโมง
กรณีศึกษา: ไล่ตรรกะและแก้บั๊กจริงภายในชั่วโมง
ทีมวิศวกรรม ML ของสตาร์ทอัพด้านสาธารณสุขในกรุงเทพฯ เผชิญปัญหาที่พบบ่อยในการนำ LLM ไปใช้งานจริง — คำตอบที่ให้ข้อมูลผิดพลาดในกรณีขอบเขต (edge case) และการเกิด hallucination เมื่อระบบพยายามตอบคำถามเกี่ยวกับข้อมูลส่วนบุคคลของผู้ป่วย ทีมเคยใช้วิธีการดีบักแบบเดิม (log + manual prompt replay) ซึ่งต้องใช้เวลาเฉลี่ย 2 วัน (ประมาณ 48 ชั่วโมง) ตั้งแต่การพบปัญหา จนถึงการระบุสาเหตุและแก้ไขได้สำเร็จ หลังจากนำ LLM Visual Debugger เข้ามาใช้ ทีมสามารถลดเวลานั้นลงเหลือเฉลี่ย 1.5 ชั่วโมง และเพิ่มอัตราการค้นพบสาเหตุที่แท้จริงของบั๊กได้อย่างมีนัยสำคัญ

ขั้นตอนการทำงานแบบละเอียด (step-by-step) ที่ทีมใช้กับ Visual Debugger เป็นดังนี้:
- Reproduce — ทำซ้ำเคสที่ผิดพลาด : ส่ง prompt เดิมและ context เดิมที่ผู้ใช้งานรายงานมา ผ่านระบบ staging เพื่อให้ได้ผลลัพธ์ที่แสดงปัญหา
- Trace Capture — เก็บ visual traces : เปิด Visual Debugger เพื่อบันทึก chain‑of‑thought trace ของโมเดลในเชิง token/step-level พร้อมเมตริก confidence และ source attribution (เช่นผลการเรียกฐานข้อมูลภายนอก)
- Inspect — ไล่ตรรกะเป็นภาพ : ใช้ฟีเจอร์การกรอง (filter) เพื่อเน้น subchain ที่เกี่ยวข้องกับคำตอบผิด เช่น สถานะที่โมเดลยืนยันข้อมูลไม่ถูกต้อง หรือจุดที่มีการเรียกซ้อนกันของ prompt templates
- Compare — เปรียบเทียบกับ expected chain : นำ trace ของคำตอบที่ถูกต้อง (จาก golden prompt/ground truth) มาเทียบกับ trace ของคำตอบที่ผิด เพื่อดู token flow ที่แตกต่างกันและระบุจุดที่เริ่มเบนออก
- Isolate & Patch — แยกสาเหตุและแก้ไข : เมื่อพบว่าเป็นปัญหา prompt interference หรือการเรียก API ผิดพารามิเตอร์ ทีมจะแก้ prompt template หรือปรับ middleware ของ API แล้ว re-run บน Visual Debugger เพื่อยืนยันผล
ตัวอย่างชนิดของบั๊กที่ทีมพบจริงผ่านการใช้ Visual Debugger ได้แก่:
- Hallucination จาก prompt interference — trace แสดงว่าโมเดลนำข้อความแนะนำโครงสร้าง (system prompt) มาเป็นข้อเท็จจริงในคำตอบ ทำให้เกิดข้อมูลที่ไม่สอดคล้องกับฐานข้อมูลจริง ตัวอย่างเช่น โมเดลอ้างว่าผู้ป่วยมีอาการเฉพาะที่ไม่มีใน record
- Logic error ใน chain‑of‑thought — ในกรณีการสรุปผลการทดสอบหลายตัว โมเดลมี subchain ที่ตัดการเปรียบเทียบค่าผิดพลาดก่อนถึงขั้นตอนสรุป ทำให้ผลสรุปคลาดเคลื่อน สามารถเห็น token‑level decision ที่ข้ามเงื่อนไขสำคัญได้ชัดเจน
- Data leak / API connector bug — trace รวมการเรียก retrieval backend ซึ่งพบว่า query parameter ถูกตั้งค่าเป็นค่าเริ่มต้น (default) ส่งผลให้ผลการค้นคืนไม่ครอบคลุมและบางครั้งคืนข้อมูลจาก index ของระบบอื่น (data leak) Visual Debugger ช่วยระบุ call stack และ payload ที่ส่งผิดได้ทันที
ผลเชิงปริมาณก่อนและหลังการใช้เครื่องมือ (จากการทดลองภายในทีม 5 สปรินต์):
- เวลาที่ใช้ค้นหาและแก้ไข (MTTR) : ก่อนใช้ Visual Debugger เฉลี่ย 48 ชั่วโมง → หลังใช้เฉลี่ย 1.5 ชั่วโมง (ลดลง ~97%)
- อัตราการค้นพบสาเหตุที่แท้จริง : ก่อน ~28% (หลายกรณีถูกแก้แบบพลาง) → หลัง ~88% (ค้นพบ root cause ได้ชัดเจนจาก trace)
- อัตราผลลัพธ์ที่ถูกต้องในกรณีขอบเขต : ก่อน 78% → หลัง 95% (ปรับ prompt และแก้ connector แล้วทดสอบซ้ำ)
- อัตรา hallucination : ก่อน 12% → หลัง 2% (จากการแก้ prompt interference และเพิ่ม source attribution)
นอกจากตัวเลขข้างต้น Visual Debugger ยังเปลี่ยนวิธีคิดของทีมจากการเดา ("guess-and-patch") มาเป็นการไล่ตรรกะเชิงสาเหตุ (causal reasoning) โดยตรง — การเห็น flow ของความคิดและการเรียกทรัพยากรช่วยให้ทีมตัดสินใจได้เร็วขึ้นและมีหลักฐานรองรับการแก้ไข ซึ่งสำคัญต่อการใช้งาน LLM ในสภาพแวดล้อมที่ต้องการความถูกต้องและความปลอดภัยทางข้อมูล
ประโยชน์เชิงธุรกิจและต่อทีม ML
ประโยชน์เชิงธุรกิจและต่อทีม ML
ระบบ LLM Visual Debugger ที่แปลงตรรกะ Chain‑of‑Thought เป็นภาพ ช่วยให้องค์กรเห็นภาพการตัดสินใจภายในโมเดลอย่างเป็นรูปธรรม ส่งผลเชิงธุรกิจหลายด้าน ตั้งแต่การลดเวลาพัฒนาและแก้บั๊กที่ชัดเจน ไปจนถึงการเพิ่มความโปร่งใสและความเชื่อมั่นของผู้มีส่วนได้ส่วนเสียที่ไม่ใช่ทีม ML (non‑ML stakeholders) เช่น ฝ่ายผลิตภัณฑ์ กฎหมาย และ compliance โดยเปลี่ยนกระบวนการตรวจสอบจากข้อความเชิงเทคนิคเป็นภาพสรุปที่เข้าใจง่าย ซึ่งช่วยลดขั้นตอนการอธิบายและการประชุมข้ามฝ่ายลงอย่างมีนัยสำคัญ
ด้านการลดต้นทุนและเร่ง Time‑to‑Market (TTM) ระบบนี้ช่วยลดเวลาในการดีบักและวิเคราะห์สาเหตุของข้อผิดพลาดได้มาก—จากข้อมูลเชิงประจักษ์และการทดลองเบื้องต้นมักเห็นการลดเวลาดีบั๊กได้ระหว่าง 40%–70% ขึ้นอยู่กับความซับซ้อนของโมเดล ผลลัพธ์คือทีมสามารถปล่อยรุ่นใหม่ได้เร็วขึ้น (faster iteration) ลดรอบการทดลอง/ปรับจูนจากหลายสัปดาห์เหลือเป็นวันหรือสัปดาห์ เช่น หากโมเดลหนึ่งรอบการปล่อยเดิมใช้เวลา 8 สัปดาห์ การลดเวลา 25% จะช่วยให้ TTM ลดลง 2 สัปดาห์ ส่งผลต่อรายได้ที่เกิดขึ้นก่อนเวลาและความสามารถแข่งขันของผลิตภัณฑ์
นอกจากนี้ Visual debugger ยังเพิ่ม auditability และช่วยการปฏิบัติตามกฎ (compliance) ได้ง่ายขึ้น เพราะภาพเหตุผลภายในโมเดลทำให้การตรวจสอบย้อนหลัง (post‑hoc audit) มีหลักฐานที่จับต้องได้ ลดเวลาในการเตรียมรายงานเพื่อตอบข้อซักถามจากหน่วยงานภายใน/ภายนอก และช่วยป้องกันความเสี่ยงที่อาจนำไปสู่ค่าปรับหรือการหยุดให้บริการ ตัวอย่างเช่น ในการตรวจสอบสำคัญ ๆ ที่เคยใช้เวลาตรวจสอบ 10 วัน อาจลดลงเหลือ 1–2 วัน เมื่อมีภาพแสดง chain‑of‑thought ที่สรุปสาเหตุของคำตอบได้ชัดเจน
ด้านความคุ้มค่าทางธุรกิจ เราสามารถสมมุติตัวเลข ROI เพื่อแสดงภาพผลประโยชน์เชิงการเงินได้ดังนี้ (สมมุติค่าใช้จ่ายแรงงานเฉลี่ย = 1,200,000 บาท/ปี ต่อวิศวกร ML หรือประมาณ 600 บาท/ชั่วโมง เมื่อคิดที่ 2,000 ชั่วโมง/ปี):
- สตาร์ทอัพขนาดเล็ก (ทีม ML 3 คน): หาก Visual Debugger ลดเวลาดีบักรวม 8 ชั่วโมง/คน/สัปดาห์ = 24 ชม./สัปดาห์ หรือ ~96 ชม./เดือน คิดเป็นค่าประหยัดแรงงาน ~57,600 บาท/เดือน หรือ ~691,200 บาท/ปี หากค่าใช้จ่ายเทคโนโลยีและการติดตั้งรวม 300,000 บาท ก็จะคืนทุนภายใน ~5–6 เดือน นอกจากนี้การลด TTM 2 สัปดาห์ต่อการปล่อยรุ่นสามารถช่วยให้นำเสนอคุณสมบัติที่ทำรายได้เร็วขึ้น เพิ่มโอกาสทางการตลาด
- องค์กรขนาดกลาง (ทีม ML 10 คน): สมมุติการลดเวลาดีบัก 5 ชั่วโมง/คน/สัปดาห์ = 50 ชม./สัปดาห์ หรือ ~200 ชม./เดือน ประหยัด ~120,000 บาท/เดือน (~1.44 ล้านบาท/ปี) หากการใช้งาน Visual Debugger ช่วยเพิ่มอัตราแปลง (conversion) ของฟีเจนหนึ่งเพียง 0.5% บนรายได้เดือนละ 10 ล้านบาท จะเพิ่มรายได้ ~50,000 บาท/เดือน รวมเป็น ~170,000 บาท/เดือน ผลตอบแทนต่อการลงทุนต่อปีจะชัดเจนและเกินค่าใช้จ่ายระบบ
- องค์กรขนาดใหญ่/Enterprise (ทีม ML 50 คน): หากลดเวลา 3 ชั่วโมง/คน/สัปดาห์ = 150 ชม./สัปดาห์ หรือ ~600 ชม./เดือน ประหยัด ~360,000 บาท/เดือน (~4.32 ล้านบาท/ปี) ยิ่งไปกว่านั้น การลดเวลาตรวจสอบและเตรียมเอกสารสำหรับการ audit จากสัปดาห์เหลือวัน ช่วยลดความเสี่ยงเชิงกฎหมายและค่าใช้จ่ายภายนอก (consultant, auditor) ซึ่งอาจเท่ากับหลายล้านบาทต่อเหตุการณ์ อีกทั้งการเพิ่มความเชื่อมั่นให้กับ business stakeholders ช่วยให้การอนุมัติ deployment ใหม่เร็วขึ้น ส่งผลโดยตรงต่อการรักษาผู้ใช้และรายได้
สรุปได้ว่า LLM Visual Debugger ไม่ใช่เพียงเครื่องมือช่วยดีบั๊ก แต่เป็นตัวเร่งการตัดสินใจเชิงธุรกิจที่เพิ่มความโปร่งใส ลดความเสี่ยง และเพิ่มความเร็วในการนำผลิตภัณฑ์สู่ตลาด ผลประโยชน์ที่จับต้องได้ เช่น การลดต้นทุนแรงงาน, การลด TTM, การเพิ่มความน่าเชื่อถือต่อผู้มีส่วนได้ส่วนเสีย และการเสริมความพร้อมด้าน compliance ทำให้การลงทุนในระบบประเภทนี้มักคืนทุนได้ในช่วงระยะสั้นถึงปานกลาง ขึ้นอยู่กับขนาดทีมและลักษณะงานขององค์กร ดังนั้นคำแนะนำเชิงปฏิบัติคือเริ่มจาก pilot กับ use‑case ที่มีผลกระทบสูง (high‑impact, low‑risk) เพื่อวัดตัวเลขการประหยัดจริงและคำนวณ ROI ก่อนขยายสเกล
การผสานเข้ากับ MLOps และข้อกำหนดเชิงเทคนิค
การผสานเข้ากับ pipeline ของ MLOps (CI/CD, Model Registry และ Workflow)
การนำ LLM Visual Debugger ไปใช้งานจริงต้องวางจุดเชื่อมต่อกับ pipeline ของทีม ML ตั้งแต่ขั้นตอนพัฒนาไปจนถึง production: เชื่อมกับระบบ CI/CD (เช่น GitHub Actions, Argo CD) เพื่ออาศัยกระบวนการทดสอบอัตโนมัติ (unit tests, integration tests) และรันการวิเคราะห์ Chain‑of‑Thought เป็นส่วนหนึ่งของ pipeline ก่อน promotion ของ model ไปยัง stage ถัดไป รวมถึงเชื่อมกับ Model Registry (เช่น MLflow, Weights & Biases, Seldon) เพื่อบันทึกเวอร์ชันโมเดล พร้อมเมตริกและภาพ trace ของตรรกะเมื่อเกิดการเรียกใช้งานในแต่ละเวอร์ชัน
แนวปฏิบัติทั่วไปที่แนะนำคือให้ Visual Debugger ถูกเรียกในสองรูปแบบ: 1) Offline evaluation — รันบนชุดข้อมูล validation/edge-case ก่อน deploy เพื่อหา failure modes และ 2) Shadow/Canary mode — รันคู่ขนานกับ production traffic แต่ไม่ตอบผู้ใช้จริง เพียงเก็บ trace เพื่อวิเคราะห์ เมื่อผสานเข้ากับ CI/CD ควรมีเกณฑ์ (gate) เช่น ถ้าพบ pattern ของ hallucination มากกว่า X% ให้ deploy ล้มเหลวอัตโนมัติ

Integration Points: API hooks, Logging และ Observability
การเชื่อมต่อเชิงเทคนิคควรออกแบบเป็น modular API hooks ที่รองรับทั้งแบบ synchronous (REST/gRPC) และ asynchronous (webhooks, message queue เช่น Kafka หรือ Pub/Sub) เพื่อให้ฝัง Visual Debugger ใน flow ของ prompt pre-processing, post-processing และ token-level streaming ได้อย่างยืดหยุ่น โดยจุดสำคัญได้แก่:
- Pre/post prompt hooks — ดักจับ prompt inputs และ responses เพื่อเก็บตรรกะ chain-of-thought ก่อน/หลังการเรียกโมเดล
- Stream hooks — หากใช้การ stream คำตอบ ควรจับ token-level traces เพื่อแมปการตัดสินใจของโมเดลแบบเรียลไทม์
- Webhooks / Message sinks — ส่งเหตุการณ์ (events) ไปยังระบบบันทึกหรือ pipeline อื่น ๆ (เช่น data lake) สำหรับการวิเคราะห์ต่อ
ด้าน logging และ observability ควรใช้รูปแบบ log แบบมีโครงสร้าง (JSON) พร้อม metadata เช่น request_id, model_version, prompt_hash, latency_ms และ confidence_score เพื่อให้สามารถทำการค้นหาและเชื่อมโยงเหตุการณ์ได้ง่าย เครื่องมือที่แนะนำ ได้แก่ OpenTelemetry สำหรับ tracing, Prometheus + Grafana สำหรับเมตริก และ Sentry/Elastic สำหรับ error tracing นอกจากนี้ควรมีการ sample traces (เช่น 1–5% ของ traffic) และมี policy ในการ redaction ของ PII ก่อนบันทึก
Supported LLM Ecosystems และความเข้ากันได้
Visual Debugger ที่ออกแบบมาให้ใช้งานในองค์กรขนาดต่าง ๆ ควรรองรับทั้ง major cloud providers และ local LLM ecosystems ดังนี้:
- OpenAI / Azure OpenAI — รองรับ API-based prompts, streaming และสามารถดึง usage/latency metrics จาก provider
- Anthropic (Claude) — รองรับการเรียกใช้งานแบบข้อความ/การ stream และต้องปรับการ parse chain-of-thought ให้เข้ากับ output format ของ Claude
- Hugging Face / Inference endpoints — ใช้ได้ทั้ง hosted models และ self‑hosted endpoints ผ่าน API
- Local Llama variants / Llama 2 & 3, Mistral, other open models — ต้องรองรับ runtime เฉพาะ (e.g., GPU inference servers, Triton, orgguardians like GGML) และอาจต้องใช้การแปลง output หรือ wrapper เพื่อให้ tracing ทำงานได้เหมือนกับ cloud APIs
ความเข้ากันได้จะขึ้นกับสองปัจจัยหลัก: 1) รูปแบบการตอบของโมเดล (streaming vs non‑streaming) และ 2) สิทธิ์เข้าถึง metadata/usage metrics จาก provider สำหรับโมเดลบนคลาวด์บางแห่งอาจไม่มีการ expose token timestamps หรือ internal logits ทำให้ต้องอาศัย prompt‑level traces แทน token‑level
Deployment Options และ Trade‑offs ระหว่างความเร็วกับความเป็นส่วนตัว
เมื่อพิจารณา deployment มี 3 แนวทางหลัก: Cloud SaaS, On‑premises, และ Hybrid/Private‑VPC. แต่ละตัวเลือกมี trade‑offs ดังนี้:
- Cloud SaaS — ติดตั้งเร็ว รองรับ autoscaling และมี latency ต่ำเมื่อใช้ provider ใกล้ region แต่ข้อมูลสำคัญอาจต้องส่งออกนอกองค์กร (data residency) และมีข้อจำกัดด้านการควบคุมข้อมูลภายใน
- On‑premises / Private Data Center — ติดต่อกับข้อมูลภายในได้โดยตรง เหมาะสำหรับองค์กรที่มีข้อกำหนดทางกฎหมายหรือความลับสูง แต่ต้องลงทุนด้านฮาร์ดแวร์ (GPU), การดูแล และ scaling — latency ภายในจะต่ำสำหรับภายในเครือข่าย แต่ throughput อาจจำกัดหากทรัพยากรไม่พอ
- Hybrid / VPC Peering — รัน inference บน private VPC หรือใช้ private endpoints กับ cloud provider เพื่อรักษา privacy แต่ยังคงได้รับประโยชน์จาก cloud services บางส่วน
ในมุมของ performance: สำหรับงาน interactive ควรกำหนด SLO เช่น p95 latency ต่ำกว่า 300–500 ms ต่อคำตอบ (ขึ้นอยู่กับขนาดและชนิดของโมเดล) หากต้องการ token-level visualization latency อาจเพิ่มขึ้นอย่างมีนัยสำคัญ ดังนั้นแนะนำให้ใช้ sampling หรือเฉพาะช่วงโหมด debugging เท่านั้น ในงานที่ต้องการ throughput สูง (เช่น hundreds to thousands req/s) ควรออกแบบด้วย batching, GPU pooling และ autoscaling พร้อม backpressure/queue เพื่อป้องกัน latency spike
ข้อควรระวังเชิงปฏิบัติการและความปลอดภัย
ข้อควรระวังสำคัญได้แก่การจัดการข้อมูลที่เก็บโดย Visual Debugger — ต้องมีนโยบายการเก็บข้อมูล ข้อกำหนดการเข้าถึง (RBAC), การเข้ารหัสทั้งขณะส่งและพัก (TLS, at‑rest encryption), และการ redaction ของ PII ก่อนบันทึก traces นอกจากนี้ควรกำหนด sampling rate ที่สมดุลระหว่างต้นทุนการเก็บข้อมูลกับความสามารถในการหา root cause (ตัวอย่างเช่น sample 1–5% ใน production แต่ 100% ใน staging)
สรุปข้อแนะนำการนำไปใช้: เริ่มด้วยการผสาน Visual Debugger เป็นส่วนหนึ่งของ staging CI/CD และ model registry, จัดการ logging แบบ structured และ tracing ด้วย OpenTelemetry, ตั้ง sampling policy เพื่อควบคุมค่าใช้จ่ายและ latency, และเลือก deployment model ที่ตอบโจทย์ข้อกำหนดความเป็นส่วนตัวและการลงทุนขององค์กร — ทั้งนี้การออกแบบที่ยืดหยุ่นเพื่อรองรับทั้ง OpenAI/Anthropic และ local LLMs จะทำให้ทีมสามารถตรวจหาจุดบกพร่องและแก้ไขโมเดลได้ภายในชั่วโมงตามเป้าหมายเชิงปฏิบัติการ
ตลาด โมเดลธุรกิจ และการแข่งขัน
ขนาดตลาด (TAM) สำหรับเครื่องมือช่วยดีบัก LLM ในไทยและภูมิภาค SEA
พื้นที่ของเครื่องมือดีบักและ observability สำหรับโมเดลภาษาใหญ่ (LLM) เป็นส่วนย่อยของตลาด ML Ops และ AI observability ที่เติบโตอย่างรวดเร็ว ในระดับภูมิภาค เอเชียตะวันออกเฉียงใต้ (SEA) การลงทุนด้าน AI/ML ในหน่วยงานภาครัฐและเอกชนเพิ่มขึ้นอย่างต่อเนื่อง โดยเฉพาะในภาคการเงิน โทรคมนาคม และอีคอมเมิร์ซ ซึ่งเป็นกลุ่มผู้ใช้ LLM ระยะแรก ๆ
หากพิจารณาเป็นตัวเลขเชิงประมาณการแบบ conservative: สมมติว่าตลาด AI/ML tooling ใน SEA มีมูลค่าเป็นร้อยล้านดอลลาร์ภายใน 3–5 ปีข้างหน้า (ตัวอย่างสมมติ: 200–500 ล้านดอลลาร์) เครื่องมือที่เจาะเฉพาะด้านดีบัก LLM อาจมีสัดส่วน addressable อยู่ที่ 5–15% ของตลาด tooling ทั้งหมด ขึ้นอยู่กับอัตราการยอมรับขององค์กร การจัดการข้อมูล และการปรับใช้ LLM แบบ scale-up สำหรับประเทศไทย หากคำนึงขนาดเศรษฐกิจและจำนวนองค์กรที่พร้อมลงทุนจริง TAM สำหรับเครื่องมือดีบัก LLM ในไทยอาจอยู่ในระดับหลายล้านถึงหลักสิบล้านดอลลาร์ต่อปี (serviceable market) โดยมีอัตราการเติบโตสูงเมื่อองค์กรย้ายจาก PoC ไปสู่ production-scale
รูปแบบรายได้ที่เป็นไปได้และกลยุทธ์การตั้งราคา
โมเดลรายได้สำหรับเครื่องมือ LLM Visual Debugger สามารถผสมผสานรูปแบบต่าง ๆ เพื่อให้เหมาะกับความต้องการของลูกค้าที่หลากหลาย โดยรูปแบบหลักได้แก่:
- SaaS subscription: แผนรายเดือน/รายปี แบบ tiered (Starter / Pro / Enterprise) โดยกำหนดคุณสมบัติและขีดจำกัด เช่น จำนวนโมเดลที่ตรวจสอบ จำนวนทีม และความถี่ของการตรวจสอบ
- Seat-based pricing: เก็บตามจำนวนผู้ใช้งาน (seat) เหมาะกับทีม ML/AI ขนาดเล็กถึงกลาง เช่น $20–$200 ต่อ seat ต่อเดือน ขึ้นกับฟีเจอร์และ SLA
- Usage-based (token/inspect): เก็บตามปริมาณงานที่ถูกตรวจสอบ เช่น จำนวนคำถาม/ตัวอย่างที่ถูก trace หรือจำนวน token ที่ถูกวิเคราะห์ เหมาะกับลูกค้าที่ต้องการความยืดหยุ่น
- Enterprise license / On‑prem: สัญญาแบบรายปีสำหรับลูกค้าองค์กรที่ต้องการติดตั้งภายในเครือข่าย (on‑prem) รวมถึงการรับรองด้านความปลอดภัยและการปฏิบัติตามข้อกฎหมาย
- Professional services: บริการติดตั้ง ปรับแต่ง pipeline สร้าง integration กับระบบ enterprise เช่น SIEM, data warehouse, หรือ embedding stores, และบริการ training/consulting แบบ project-based
กลยุทธ์การตั้งราคาที่แนะนำควรเป็นแบบ hybrid: เสนอ free trial หรือ freemium เพื่อดึงทีม ML ให้ทดลองฟีเจอร์ visualization และ chain‑of‑thought tracing จากนั้นใช้ราคา tiered เพื่อขยายการใช้งาน พร้อมตัวเลือกการประเมินผลแบบ PoV (proof-of-value) ระยะสั้น (1–3 เดือน) สำหรับลูกค้าองค์กร และราคาพิเศษรวมบริการ professional onboarding เพื่อเร่งปิดดีล
คู่แข่งที่มีแนวโน้มและความได้เปรียบในการแข่งขัน
ตลาดมีทั้งผู้เล่นระดับโลกที่ขยายฟีเจอร์ observability ไปยัง LLM และสตาร์ทอัพเฉพาะทาง ตัวอย่างของคู่แข่งเชิงเทคนิคได้แก่ LangSmith (LangChain ecosystem), Arize AI, Weights & Biases, Fiddler, WhyLabs และโซลูชัน observability แบบกว้างเช่น Datadog หรือ Sentry ที่อาจเพิ่มฟีเจอร์ LLM inspection ในอนาคต นอกจากนี้ยังมีผู้ให้บริการระบบ AI/ML ในภูมิภาคและ SI (system integrators) ที่สามารถนำเสนอบริการปรับแต่งเป็นคู่แข่งทางธุรกิจ
จุดแข็งเชิงต่างที่สตาร์ทอัพไทยควรเน้นเพื่อแข่งขันได้ ได้แก่:
- การรองรับภาษาและบริบทท้องถิ่น (Thai‑first): การแสดง Chain‑of‑Thought เป็นภาพสำหรับภาษาไทยและโดเมนเฉพาะของไทย เช่น การเงิน การแพทย์ และการกำกับดูแล จะให้ความแม่นยำและความเข้าใจที่เหนือกว่าโซลูชันสากล
- การปฏิบัติตามกฎระเบียบและข้อมูลส่วนบุคคล: เสนอทางเลือก on‑prem หรือ VPC deployment รวมถึงการรับรองความปลอดภัยเชิงองค์กรที่ตอบโจทย์สถาบันการเงินและหน่วยงานรัฐในภูมิภาค
- เวลาแก้บั๊กและการวัดผลที่จับต้องได้: แสดงผลเป็นภาพ ช่วยให้ทีม ML ลดเวลา debugging จากหลายวัน/สัปดาห์ เหลือเป็นชั่วโมง ซึ่งเป็นตัววัดคุณค่าที่ลูกค้าองค์กรยอมจ่าย
- Integration กับ LLM APIs และ ML ecosystem: connector สำเร็จรูปกับ OpenAI, Anthropic, local LLM providers, embedding stores, MLOps pipelines และ issue trackers เพื่อความสะดวกในการ adopt
- บริการมืออาชีพและการสนับสนุนเชิงธุรกิจ: เสนอบริการ PoC และ consulting ในการออกแบบ evaluation, testcases, และ governance frameworks ที่ทำให้ลูกค้าเห็น ROI ชัดเจน
สรุปได้ว่า หากสตาร์ทอัพไทยสามารถแสดงผลประโยชน์เชิงธุรกิจที่จับต้องได้ เช่น ลด MTTR (mean time to resolution) ของบั๊ก LLM ลงอย่างมีนัยสำคัญ ประกอบกับการรองรับภาษาไทย การให้บริการที่สอดคล้องกับกฎระเบียบ และโมเดลสินค้าที่ยืดหยุ่น (SaaS + enterprise + professional services) ก็มีโอกาสสูงที่จะชิงส่วนแบ่งตลาดในไทยและขยายสู่ภูมิภาค SEA ได้สำเร็จ
ความเสี่ยง จริยธรรม และแนวทางควบคุมคุณภาพ
ความเสี่ยง จริยธรรม และแนวทางควบคุมคุณภาพ
การเก็บและแสดงผล Chain‑of‑Thought (CoT) ในรูปภาพเพื่อใช้ไล่ตรรกะของโมเดลอาจนำไปสู่ความเสี่ยงด้านความเป็นส่วนตัวและการรั่วไหลของข้อมูลสำคัญ หากร่องรอยการคำนวณ (trace) มีข้อความที่เป็นข้อมูลส่วนบุคคล (PII), ข้อมูลลูกค้าเชิงพาณิชย์ หรือ prompt ที่เปิดเผยกลยุทธ์ภายใน การจัดเก็บดังกล่าวจึงต้องปฏิบัติตามข้อกำหนดทางกฎหมาย เช่น PDPA/GDPR พร้อมมาตรการทางเทคนิค ได้แก่ การเข้ารหัสระหว่างทางและที่พักข้อมูล (TLS, AES‑256), การควบคุมการเข้าถึงแบบบทบาท (RBAC), การบันทึกเหตุการณ์ (audit trail) และนโยบายการเก็บรักษาข้อมูลที่ชัดเจน (เช่น การเก็บ trace แบบละเอียดเฉพาะช่วงเวลา debugging เท่านั้น แล้วทำการลบ/สรุปผลภายใน 30–90 วัน) เพื่อบรรเทาความเสี่ยงการรั่วไหลของข้อมูล
นอกจากความเสี่ยงด้านความเป็นส่วนตัวแล้ว การนำเสนอ CoT ในรูปแบบ visualization ยังมีข้อจำกัดเชิงการอธิบาย (explainability limits) ตัวอย่างเช่น ภาพที่แสดงอาจให้ความรู้สึกว่าเป็น “คำอธิบายเชิงสาเหตุ” ทั้งที่อาจเป็นเพียงการแสดงสัญญะหรือความสัมพันธ์เชิงสถิติเท่านั้น ซึ่งอาจก่อให้เกิด over‑trust — ทีมงานอาจยอมรับผลลัพธ์ของโมเดลโดยไม่ตรวจสอบอย่างละเอียดเพื่อผลลัพธ์ที่ดูชัดเจน การป้องกันต้องอาศัยการแสดงระดับความไม่แน่นอน (uncertainty), การระบุแหล่งที่มาของข้อมูล (provenance), การเชื่อมโยงกลับไปยัง raw trace ดั้งเดิม และการให้ทางเลือกของคำอธิบาย (เช่น counterfactuals หรือ alternative attributions) แทนที่จะพึ่งพาภาพเดียวเพียงอย่างเดียว
แนวทางควบคุมคุณภาพ (quality control) และการบูรณาการมนุษย์ในวงจร (human‑in‑the‑loop) มีบทบาทสำคัญในการลดความเสี่ยง เช่น การทดสอบ visualizer ด้วยชุดข้อมูลที่มี ground truth, การใช้การทดสอบแบบ mutation เพื่อประเมินความไว (sensitivity) ของภาพต่อการเปลี่ยนแปลงใน trace และการทำ red‑teaming เพื่อค้นหากรณีมุมอับที่ภาพอธิบายให้ผลบิดเบือน นอกจากนี้ ควรผสาน visual debug เข้ากับ MLOps pipeline—ตั้งค่าเกตก่อนปล่อย (pre‑deployment gates), การตรวจสอบแบบ sampling audit ใน production, และเมตริกเช่นอัตรา false positive/false negative ของการแจ้งเตือนบั๊ก ตัวอย่างเป้าหมายเชิงปฏิบัติอาจระบุไว้ว่า ลดอัตรา false positive ของ visualization ต่ำกว่า 5% และ จำกัดการเข้าถึง trace ที่ละเอียดให้ไม่เกินระดับบุคคลที่ได้รับสิทธิ์ (เช่น less than 10 authorized engineers)
เพื่อให้การใช้งานมีความรับผิดชอบและเชื่อถือได้ แนะนำแนวทางปฏิบัติสำคัญดังต่อไปนี้:
- นโยบายข้อมูลที่ชัดเจน: ระบุประเภทข้อมูลที่อนุญาตให้บันทึก, เวลาการเก็บรักษา, และกระบวนการลบหรือสรุปผล
- การปกป้องข้อมูลเชิงเทคนิค: ใช้การเข้ารหัสทั้งใน transit และ at‑rest, RBAC, และ secure enclaves สำหรับ trace ที่ละเอียด
- การลบและปิดบังข้อมูล (redaction & pseudonymization): กรองหรือแทนที่ PII และข้อมูลธุรกิจที่สำคัญก่อนจัดเก็บหรือแสดงเป็นภาพ
- แสดงความไม่แน่นอนและ provenance ใน visualization: ใส่ confidence bars, แหล่งที่มาของขั้นตอน, และลิงก์ไปยัง raw trace เพื่อให้ผู้ตรวจสอบสามารถไตร่ตรองได้มากขึ้น
- human‑in‑the‑loop และการควบคุมคุณภาพ: กำหนดกระบวนการตรวจทานด้วยมนุษย์ (review sign‑off), red‑team testing, และการทำ A/B testing ของวิธีการอธิบาย
- การวัดและประเมินผลอย่างต่อเนื่อง: ตั้ง KPI เช่น precision/recall ของการตรวจจับบั๊ก, อัตรา over‑trust จาก user study, และการรายงานการละเมิดเพื่อเป็น input ปรับปรุง
การนำ LLM Visual Debugger มาใช้ในองค์กรจึงต้องเดินควบคู่กับมาตรการเชิงเทคนิค นโยบาย และกระบวนการตรวจสอบอย่างเป็นระบบ เพื่อให้ได้ประโยชน์เชิงการปฏิบัติการโดยไม่แลกมากับความเสี่ยงด้านจริยธรรมและกฎหมาย ทีมบริหารความเสี่ยงควรรวมช่องทางรายงานปัญหา การฝึกอบรมการตีความ visualization สำหรับผู้ใช้งาน และการทบทวนเชิงสถิติเพื่อยืนยันความเที่ยงตรงของภาพก่อนขยายการใช้งานในระดับองค์กร
บทสรุป
LLM Visual Debugger เปลี่ยนกระบวนการดีบักโมเดลจากสิ่งที่ทึบและยากจะตรวจสอบ ให้กลายเป็นภาพการไล่ตรรกะของ Chain‑of‑Thought (CoT) ที่ทีมงานสามารถติดตามและวิเคราะห์ได้ทันที ผลลัพธ์คือการค้นหาและแก้ไขบั๊กเชิงตรรกะเป็นไปได้เร็วขึ้นอย่างมีนัยสำคัญ—จากกระบวนการที่เคยกินเวลาเป็นวันหรือสัปดาห์ มักลดลงเหลือภายในชั่วโมงสำหรับกรณีทั่วไป ตัวอย่างจากการใช้งานนำร่องแสดงให้เห็นว่าเครื่องมือนี้ช่วยให้ทีม ML สามารถระบุจุดผิดพลาดของการให้เหตุผลของโมเดล ตรวจสอบบริบทของข้อมูลนำเข้า และลดการเกิดปัญหาเมื่อขึ้นสู่สภาพแวดล้อมผลิตจริง ส่งผลให้ความน่าเชื่อถือของโมเดลเพิ่มขึ้นและลดความเสี่ยงต่อการนำโมเดลไปใช้จริง
การนำ LLM Visual Debugger ไปใช้จริงต้องพิจารณาเรื่องการบูรณาการเข้ากับ MLOps อย่างรัดกุม ความเป็นส่วนตัวของข้อมูล และมาตรการคุ้มครองความเสี่ยง เช่น การควบคุมการเข้าถึง การบันทึก (logging) เชิงตรวจสอบได้ การทำข้อมูลให้เป็นนามธรรม (data minimization) หรือใช้เทคนิคเช่น differential privacy และการจัดทำ model cards เพื่อความโปร่งใส หากมีการออกแบบกระบวนการและนโยบายที่เหมาะสม เครื่องมือนี้ไม่เพียงลดเวลาการพัฒนาและต้นทุนอย่างชัดเจน แต่ยังทำหน้าที่เป็นตัวเร่งการเปลี่ยนแปลงดิจิทัลสำหรับองค์กร ช่วยให้การนำ AI เข้าสู่การใช้งานจริงเป็นไปได้เร็วขึ้น มีกระบวนการตรวจสอบได้ และสอดคล้องกับข้อกำหนดด้านกฎระเบียบในอุตสาหกรรมต่างๆ



