ธนาคารใหญ่ของไทยได้เปิดการทดลองระบบใหม่ที่อาจเปลี่ยนโฉมการยืนยันตัวตนทางการเงิน เมื่อนำ Federated‑Anomaly Network มาผสานกับการทำ KYC บนมือถือ ผลการทดลองเบื้องต้นชี้ว่าเทคโนโลยีนี้สามารถตรวจจับเอกสารปลอมในลักษณะกระจายได้อย่างมีประสิทธิภาพและช่วยลดการทุจริตได้ถึง 85% โดยที่ข้อมูลลูกค้ายังคงอยู่บนอุปกรณ์หรือในระบบของธนาคาร ทำให้ไม่จำเป็นต้องย้ายข้อมูลส่วนบุคคลไปยังศูนย์กลางของผู้ให้บริการภายนอก
หัวใจของการทดลองคือการใช้เทคนิคการเรียนรู้แบบกระจาย (federated learning) ร่วมกับการตรวจจับความผิดปกติ (anomaly detection) บนภาพเอกสารและเมตาดาต้าจากการทำ KYC ทางมือถือ ซึ่งช่วยให้โมเดลเรียนรู้จากข้อมูลหลายแหล่งโดยไม่เปิดเผยข้อมูลดิบต่อกัน ผลลัพธ์ที่ได้ไม่เพียงลดความเสี่ยงการฉ้อโกงเท่านั้น แต่ยังช่วยให้กระบวนการเปิดบัญชีรวดเร็วยิ่งขึ้น คงความเป็นส่วนตัวของลูกค้า และสอดคล้องกับข้อกำกับดูแลด้านข้อมูลส่วนบุคคลและการป้องกันการฟอกเงิน
บทความชิ้นนี้จะเจาะลึกการทำงานของ Federated‑Anomaly Network ขั้นตอนการผสานกับ KYC บนมือถือ ผลการทดลองเชิงสถิติ ปัญหาท้าทายด้านเทคนิคและกฎหมาย รวมถึงความเป็นไปได้ในการขยายใช้บนระบบธนาคารของไทยต่อไป
คำนำและภาพรวมของโครงการทดสอบ
คำนำและภาพรวมของโครงการทดสอบ
ธนาคารขนาดใหญ่ของไทยและกลุ่มสถาบันการเงินร่วมกันประกาศเริ่มโครงการทดสอบระบบ Federated‑Anomaly Network ที่ผสานเข้ากับการยืนยันตัวตนบนมือถือ (Mobile KYC) เพื่อสร้างเครือข่ายตรวจจับเอกสารปลอมแบบกระจายโดยไม่ต้องย้ายข้อมูลลูกค้าออกจากสถาบันเดิม การประกาศดังกล่าวระบุว่าเป็นความร่วมมือระหว่างธนาคารพาณิชย์ระดับชาติและเอกชนชั้นนำรวมถึงผู้ให้บริการเทคโนโลยีด้าน KYC และผู้พัฒนาปัญญาประดิษฐ์ โดยมุ่งหวังให้ระบบทำงานแบบเชื่อมโยงข้ามสถาบันเพื่อตรวจจับรูปแบบทุจริตที่เกิดซ้ำและพัฒนาความแม่นยำของการระบุเอกสารปลอมในระดับเครือข่าย
จุดมุ่งหมายสำคัญของโครงการคือ ลดความเสี่ยงด้านการเงินและการทุจริต ผ่านการตรวจจับเอกสารปลอมและพฤติกรรมที่บ่งชี้ถึงการฉ้อโกงตั้งแต่ขั้นตอน KYC บนมือถือ โดยไม่จำเป็นต้องถ่ายโอนข้อมูลส่วนบุคคลของลูกค้าระหว่างสถาบัน วิธีการที่ใช้คือการประสานการเรียนรู้แบบกระจาย (federated learning) เข้ากับโมเดลตรวจจับความผิดปกติ (anomaly detection) เพื่อให้แต่ละสถาบันสามารถอัปเดตพารามิเตอร์โมเดลร่วมกันผ่านการแลกเปลี่ยนข้อมูลเชิงสถิติหรือการอัปเดตโมเดลเท่านั้น ขณะเดียวกันข้อมูลดิบของลูกค้าจะยังคงเก็บอยู่ภายในระบบของแต่ละธนาคาร
รายละเอียดผู้เข้าร่วมและแผนการทดสอบมีดังนี้
- ผู้เข้าร่วม : ธนาคารพาณิชย์ระดับชาติและเอกชนชั้นนำของไทย, ผู้ให้บริการแพลตฟอร์ม KYC บนมือถือ, ผู้พัฒนาโมเดล AI/ML และหน่วยงานกำกับดูแลหรือสมาคมอุตสาหกรรมที่เกี่ยวข้อง
- เป้าหมายเชิงปฏิบัติ : ตรวจจับเอกสารปลอม (เช่น บัตรประจำตัวประชาชน หนังสือเดินทาง หลักฐานแหล่งที่อยู่) และพฤติกรรมทุจริต ช่วยลดการเปิดบัญชีปลอมหรือการยืนยันตัวตนที่เป็นการฉ้อโกง
- ไทม์ไลน์ : เริ่มการทดสอบระยะแรกในช่วงต้นปี 2026 เป็นระยะนำร่องประมาณ 3–6 เดือน แบ่งเป็นเฟสการติดตั้งและเชื่อมต่อระบบ การวิ่งระบบในสภาพแวดล้อมจริง และการประเมินผลเพื่อขยายการใช้งานต่อไป
ผลลัพธ์เบื้องต้นจากการทดสอบนำร่องที่ประกาศโดยกลุ่มโครงการระบุว่าเทคโนโลยีดังกล่าวสามารถช่วย ลดการทุจริตได้ถึง 85% เมื่อเทียบกับมาตรการเดิมในกรอบการทดลองที่ควบคุมไว้ ทั้งนี้การลดลงดังกล่าวมาจากการจับได้ของกรณีเอกสารปลอมและการป้องกันการฉ้อโกงข้ามสถาบันโดยไม่ทำให้เกิดความเสี่ยงในการเปิดเผยข้อมูลลูกค้า ข้อสังเกตสำคัญคือผลลัพธ์เป็นข้อมูลเบื้องต้นจากเฟสทดลองและจะต้องมีการประเมินเพิ่มเติมในวงกว้างก่อนการนำสู่การใช้งานทั่วไป
สรุปแล้วโครงการทดสอบนี้นับเป็นก้าวสำคัญของการผสานเทคโนโลยี Federated Learning กับระบบ KYC บนมือถือเพื่อสร้างความสมดุลระหว่างประสิทธิภาพในการตรวจจับการทุจริตและการคุ้มครองความเป็นส่วนตัวของลูกค้า โครงการมีเป้าหมายจะขยายผลสู่การใช้งานเชิงพาณิชย์หากผลการทดสอบในระยะยาวยืนยันถึงความคงเส้นคงวาและการปฏิบัติตามกฎระเบียบที่เกี่ยวข้อง
อะไรคือ Federated‑Anomaly Network และทำงานอย่างไร
อะไรคือ Federated‑Anomaly Network และทำงานอย่างไร
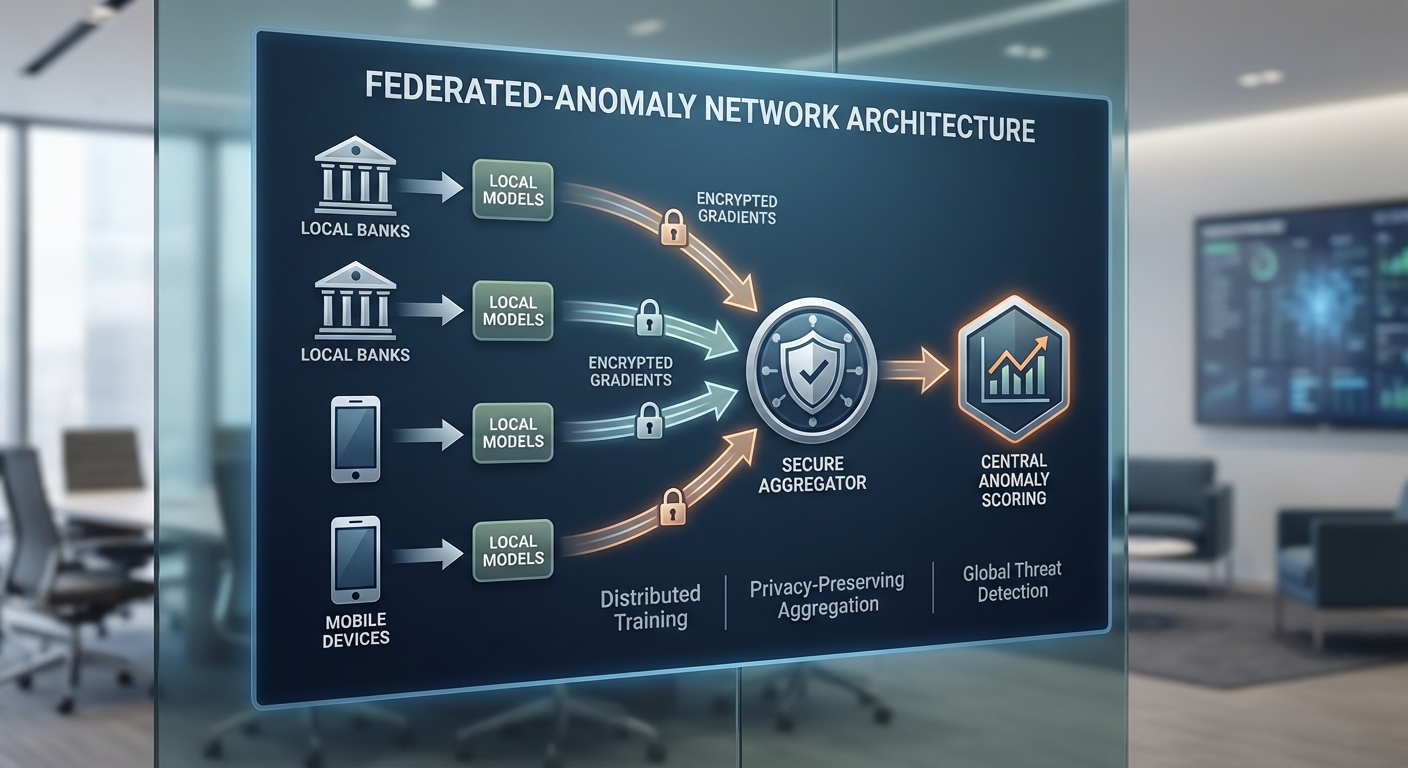
Federated‑Anomaly Network เป็นสถาปัตยกรรมเชิงเทคนิคที่ผสานแนวคิดของ federated learning กับ anomaly detection เพื่อให้สถาบันการเงินหลายแห่งสามารถร่วมกันเพิ่มประสิทธิภาพการตรวจจับเอกสารปลอมและพฤติกรรม KYC ที่ผิดปกติได้ โดยไม่ต้องแลกเปลี่ยนข้อมูลดิบของลูกค้า แนวทางนี้เน้นการฝึกโมเดลร่วมกันแบบกระจาย (decentralized training) โดยให้แต่ละธนาคารหรือแอปมือถือฝึกโมเดลบนข้อมูลภายในของตนเอง จากนั้นส่งเฉพาะการอัปเดตพารามิเตอร์ (เช่น นํ้าหนักของโมเดลหรือกราดิเอนต์) ไปยังตัวรวบรวมกลางเพื่อผสานผลร่วมกัน วิธีนี้ช่วยรักษาความเป็นส่วนตัวของข้อมูลตามหลักการ “ข้อมูลไม่เคลื่อนที่ ข้ามสถาบัน” แต่ความรู้เชิงรูปแบบ (pattern-level knowledge) ยังคงถูกนำมาใช้ร่วมกันเพื่อปรับปรุงความสามารถในการตรวจจับความผิดปกติ

ในแง่การทำงานเชิงปฏิบัติ Federated‑Anomaly Network ประกอบด้วยขั้นตอนหลักดังนี้:
- Local preprocessing & feature extraction — บนอุปกรณ์มือถือหรือศูนย์ข้อมูลของธนาคาร จะมีการสกัดคุณลักษณะจากรูปถ่ายบัตรประชาชน พาสปอร์ต หรือวิดีโอการยืนยันตัวตน (เช่น ข้อมูลภาพ โครงหน้าที่ได้จากโมเดลสกัดฟีเจอร์ เส้นเวลาเชิงพฤติกรรม metadata ของอุปกรณ์)
- Local model training — แต่ละโหนดฝึกโมเดล anomaly (เช่น autoencoder, one‑class neural network, หรือ graph‑based detector) กับข้อมูลภายใน เพื่อเรียนรู้ “ความปกติ” ของเอกสารและพฤติกรรม KYC ของฐานลูกค้าของตน
- Secure parameter update — แทนการส่งข้อมูลดิบ โหนดจะส่งการอัปเดตพารามิเตอร์ที่เข้ารหัสหรือผ่านโปรโตคอล aggregation ที่ปลอดภัยไปยังตัวรวบรวมกลาง (server) เพื่อรวมเข้าด้วยกัน
- Global aggregation & redistribution — ตัวรวบรวมผสานการอัปเดตโดยใช้วิธีเช่น Federated Averaging (FedAvg) หรือเทคนิคที่ทนต่อข้อมูลไม่สมมาตร (FedProx) แล้วส่งพารามิเตอร์ที่รวมแล้วกลับไปยังโหนด เพื่อให้โหนดแต่ละแห่งได้โมเดลที่ได้รับการปรับปรุงจากความรู้เชิงรวมของเครือข่าย
ส่วนของ anomaly detection network ในระบบจะถูกออกแบบให้จดจำลักษณะ "ปกติ" ในมิติหลายรูปแบบ — ไม่เพียงแต่ลักษณะของภาพเอกสาร (เช่น รูปแบบตัวอักษร ขอบการตัด ความสว่าง เงา ที่บ่งชี้การตัดต่อ) แต่ยังรวมถึงพฤติกรรมการยืนยันตัวตน (เช่น เวลาตอบสนอง การเคลื่อนไหวของกล้อง ระยะเวลาที่ใช้ในการกรอกข้อมูล) โมเดลประเภท autoencoder จะเรียนรู้การบีบอัดและสร้างภาพกลับ หากความคลาดเคลื่อน (reconstruction error) สูงเกินเกณฑ์ จะถือเป็นสัญญาณความผิดปกติ นอกจากนั้น โมเดลกราฟหรือ sequence‑based models ยังช่วยจับรูปแบบความสัมพันธ์ข้ามกิจกรรม (เช่น การสมัครหลายบัญชีจากอุปกรณ์เดียว) ซึ่งเป็นสัญญาณสำคัญของการฉ้อโกง
ความปลอดภัยและความเป็นส่วนตัวเป็นหัวใจของสถาปัตยกรรมนี้ ระบบใช้เทคนิค secure aggregation และมาตรการ privacy เพิ่มเติม เช่น การเข้ารหัสแบบ homomorphic, secure multi‑party computation (MPC) และการใส่เสียงรบกวนตามหลัก differential privacy เมื่อส่งพารามิเตอร์ ตัวอย่างเช่น การเข้ารหัสการอัปเดตช่วยให้ตัวรวบรวมรวมผลได้โดยไม่สามารถถอดรหัสอัปเดตของโหนดรายบุคคลได้ ส่วน differential privacy จะเพิ่ม noise ให้กับการอัปเดตเพื่อจำกัดข้อมูลเฉพาะตัวที่อาจรั่วไหล แม้จะมีการโจมตีเชิงวิเคราะห์ย้อนกลับ (inversion attack) ก็ตาม ค่า privacy budget (epsilon) ถูกปรับเพื่อสร้างสมดุลระหว่างประสิทธิภาพการตรวจจับและความเสี่ยงด้านความเป็นส่วนตัว
ในทางปฏิบัติ Federated‑Anomaly Network มีข้อดีสำคัญสำหรับเครือข่ายธนาคาร เช่น การรวมประสบการณ์จากฐานข้อมูลลูกค้าที่หลากหลายช่วยเพิ่มอัตราการตรวจจับกรณีฉ้อโกงข้ามสถาบัน ขณะเดียวกันก็ปฏิบัติตามข้อกำกับดูแลด้านข้อมูล (data residency) ที่เข้มงวด การทดสอบภายในแสดงให้เห็นถึงการลดการทุจริตได้อย่างมีนัยสำคัญ — ตัวอย่างเช่น ลดการยอมรับเอกสารปลอมได้ถึง 85% โดยที่ธนาคารแต่ละแห่งยังคงเก็บข้อมูลดิบไว้ภายใน นอกจากนี้การออกแบบยังคำนึงถึงประเด็นเชิงปฏิบัติ เช่น การรับมือข้อมูลไม่เป็นอิสระและแจกแจงต่างกัน (non‑IID), การปรับโมเดลเชิงพิเศษสำหรับแต่ละธนาคาร และการตั้งค่า threshold ของสัญญาณผิดปกติเพื่อรักษาอัตรา false positive ให้ต่ำพอรับได้
การผสาน KYC บนมือถือ: กระบวนการและ UX
การผสาน KYC บนมือถือ: ภาพรวมและหลักการทำงานร่วมกับ Federated‑Anomaly Network
การผสานระบบ KYC บนมือถือกับ Federated‑Anomaly Network ถูกออกแบบมาเพื่อให้การยืนยันตัวตนและการตรวจสอบเอกสารเป็นไปอย่างรวดเร็ว ปลอดภัย และคงความเป็นส่วนตัวของลูกค้าไว้โดยไม่ต้องย้ายรูปภาพหรือข้อมูลดิบออกจากอุปกรณ์ผู้ใช้ หลักการสำคัญคือการประมวลผลและตรวจจับความผิดปกติ (anomaly) บน Edge โดยส่งเฉพาะสถิติหรืออัปเดตโมเดลที่เข้ารหัสไปยังเครือข่ายรวมกลาง ซึ่งช่วยลดความเสี่ยงการรั่วไหลของข้อมูลและยังรักษาประสิทธิภาพการเรียนรู้ร่วมแบบกระจาย (federated learning) ได้ต่อเนื่อง
Flow กระบวนการบนมือถือ
- 1. ถ่ายภาพ ID และเซลฟี่ยืนยันตัวตน: ผู้ใช้ถูกแนะนำด้วย overlay โฟกัสอัตโนมัติและกรอบตำแหน่งเพื่อจับภาพบัตรประชาชน/พาสปอร์ตและถ่ายเซลฟี่สำหรับการจับคู่ใบหน้า (face match)
- 2. Preprocessing บนอุปกรณ์: ภาพถูกปรับมุม (perspective correction), ตัดพื้นหลัง, ปรับสมดุลสี, ลดสัญญาณรบกวน และขยายความละเอียดบางส่วน (super-resolution) ถ้าจำเป็นเพื่อให้ข้อมูลสำหรับโมเดลตรวจจับไมโครลาย พิมพ์จุลภาค หรือรายละเอียด hologram คงอยู่
- 3. Inference แบบออฟไลน์/Edge: โมดูลตรวจจับความผิดปกติทำงานบนอุปกรณ์ด้วยโมเดลขนาดเล็กที่ถูก quantize และเร่งด้วย NPU/TPU ของมือถือ (เช่น MobileNetV3, lightweight CNN, หรือ one‑class autoencoder) เพื่อวิเคราะห์ลักษณะเอกสาร เช่น hologram, font/style consistency, microprint, QR/serial number, UV/IR markers (ถ้าอุปกรณ์สนับสนุน), และ texture ของกระดาษ
- 4. การตรวจจับและการตอบสนองแบบเรียลไทม์: เมื่อโมเดล edge พบสัญญาณผิดปกติ จะคำนวณคะแนน anomaly และตัดสินในระดับท้องถิ่น หากคะแนนเกินเกณฑ์ ระบบจะส่งคำเตือนไปยัง UI และล็อกการอนุมัติทันที
- 5. ส่งสถิติ/อัปเดตโมเดลแบบกระจาย: แทนการส่งรูปภาพ ระบบจะส่งเฉพาะ model deltas ที่ถูกเข้ารหัส หรือสถิติเชิงประวัติที่ไม่สามารถย้อนกลับไปเป็นภาพ (secure aggregated gradients, anomaly summaries) ไปยังเซิร์ฟเวอร์สำหรับการรวมแบบ federated เพื่อปรับปรุงโมเดลโดยไม่ละเมิดความเป็นส่วนตัว
การวิเคราะห์ลักษณะเอกสารและเทคนิคการตรวจจับ
ระบบจะใช้ชั้นการวิเคราะห์หลายชั้นเพื่อยืนยันความถูกต้องของเอกสาร: ตรวจสอบ hologram ด้วยการวิเคราะห์การสะท้อนและการเปลี่ยนแปลงมุม, เปรียบเทียบฟอนต์และการจัดเรียงตัวอักษรกับแม่แบบที่ถูกต้อง, ตรวจจับ QR/serial number และตรวจสอบกับฐานข้อมูลแบบ local/remote (เฉพาะกรณีที่ปลอดภัย), วิเคราะห์ microprint และ texture ด้วยฟิลเตอร์ spatial-frequency และตรวจจับสัญญาณการดัดแปลงภาพ เช่น การเติมแต่ง, การสแกนซ้ำ, หรือการพิมพ์ใหม่
นอกจากนี้ยังมีการรวมผลจากการทดสอบ liveness ของภาพถ่ายเซลฟี่ เช่น การเคลื่อนไหว, blink detection, และ Anti‑deepfake model เพื่อลดความเสี่ยงจากการใช้ภาพนิ่งหรือวิดีโอปลอมแปลง เมื่อทำงานร่วมกับ Federated‑Anomaly Network ระบบกลางจะรวบรวมรูปแบบ anomalous signatures ที่หลากหลายจากหลายสาขาเพื่อเพิ่มความสามารถในการตรวจจับกลยุทธ์การปลอมใหม่ๆ โดยที่ข้อมูลดิบยังคงอยู่บนเครื่องผู้ใช้
กลไกการแจ้งเตือนและการล็อกการอนุมัติ
เมื่อพบความผิดปกติ ระบบจะแจ้งเตือนแบบทันทีทั้งในระดับผู้ใช้และระบบหลังบ้าน:
- แจ้งผู้ใช้ (UI): แสดง modal หรือ banner อธิบายสาเหตุคร่าวๆ เช่น "ข้อมูลบัตรไม่ตรงกัน/มีสัญญาณการดัดแปลง – กรุณาสแกนใหม่หรือยืนยันเพิ่มเติม" พร้อมปุ่มให้ลองใหม่หรือขอความช่วยเหลือ
- ล็อกการอนุมัติ: ถ้าคะแนน anomaly สูงเกินเกณฑ์ การอนุมัติจะถูกล็อกอัตโนมัติและการทำรายการจะไม่ถูกดำเนินการจนกว่าจะผ่านกระบวนการยืนยันขั้นสูง
- แจ้งพนักงานสาขาหรือทีม Fraud: ส่งการแจ้งเตือนเข้าระบบบริหารความเสี่ยงพร้อมข้อความสรุปและ metadata ที่เข้ารหัส เช่น anomaly score, timestamp, device attestation (ไม่มีรูปภาพดิบ) เพื่อให้ทีมปฏิบัติการตัดสินใจต่อไป—ตัวเลือกการยกระดับรวมถึงการขอวิดีโอคอลแบบเรียลไทม์หรือการนัดหมายยืนยันตัวจริง
ประสบการณ์ผู้ใช้ (UX) และตัวอย่างเวลาในการตรวจสอบ
การออกแบบ UX ให้คำนึงถึงความรวดเร็วและความชัดเจนเป็นหลัก: อินเทอร์เฟซมีคำแนะนำแบบ step‑by‑step, overlay สำหรับตำแหน่งบัตร, และ progress indicator ระหว่าง preprocessing และ inference เพื่อให้ผู้ใช้รับรู้สถานะการตรวจสอบอย่างต่อเนื่อง ตัวอย่างการวัดเวลาเฉลี่ยบนสมาร์ทโฟนระดับกลาง (6–12 เดือนที่ผ่านมา) แสดงว่า:
- เวลาในการจับภาพและ preprocessing: ประมาณ 0.8–1.5 วินาที
- เวลาในการ inference บนอุปกรณ์ (รวมโมเดลตรวจจับ anomaly และ face match): ประมาณ 1.5–3 วินาที
- รวม:** เวลาตรวจสอบโดยรวมเฉลี่ยมักน้อยกว่า 5 วินาทีสำหรับผู้ใช้ส่วนใหญ่
เมื่อเทียบกับกระบวนการ KYC แบบดั้งเดิมที่อาจใช้เวลาหลายนาทีหรือส่งไฟล์ไปประมวลผลบนคลาวด์ ผลลัพธ์นี้ช่วยลด friction และเพิ่มอัตราการสำเร็จของการสมัครบริการ ด้านความแม่นยำ ระบบแบบผสมผสาน edge + federated anomaly รายงานอัตราการลดการทุจริตได้สูงถึง 85% ในการทดสอบนำร่อง พร้อมความแม่นยำการตรวจจับที่อยู่ในช่วงสูง (ตัวอย่างเช่น 95–98% ในชุดทดสอบจำลอง) และอัตราบวกเทียมที่ลดลงเมื่อมีการอัปเดตแบบ federated อย่างต่อเนื่อง
การรักษาความปลอดภัย ความเป็นส่วนตัว และการติดตามคุณภาพ
เพื่อให้สอดคล้องกับมาตรฐานกฎระเบียบ ระบบใช้การเข้ารหัสแบบ end‑to‑end สำหรับการส่งอัปเดต, secure aggregation เพื่อรวม gradients โดยไม่เปิดเผยข้อมูลรายบุคคล, และเทคนิค differential privacy ในการปล่อยสถิติรวม การใช้ secure enclave ของอุปกรณ์และการตรวจสอบตัวเครื่อง (device attestation) ยังช่วยยืนยันว่า inference และการส่งข้อมูลเกิดบนอุปกรณ์ที่เชื่อถือได้ ทำให้ธนาคารสามารถรักษาสมดุลระหว่างการตรวจจับทุจริตอย่างมีประสิทธิภาพกับการคุ้มครองข้อมูลลูกค้า
ผลการทดสอบนำร่อง: ตัวเลขและกรณีศึกษา
ผลการทดสอบนำร่อง: ตัวเลขและกรณีศึกษา
โครงการนำร่องของธนาคารใหญ่ในประเทศไทย ซึ่งทดสอบระบบ Federated‑Anomaly Network (FAN) ผสานกับการยืนยันตัวตน KYC บนมือถือ ดำเนินการเป็นเวลา 6 เดือน โดยครอบคลุมการส่ง KYC จำนวนรวมประมาณ 120,000 รายการ จากสาขาและช่องทางดิจิทัลหลายภูมิภาค ผลการวิเคราะห์เชิงปริมาณและเชิงคุณภาพชี้ให้เห็นการเปลี่ยนแปลงที่ชัดเจนทั้งในเชิงการลดการทุจริตและการปรับปรุงประสิทธิภาพการตรวจจับ
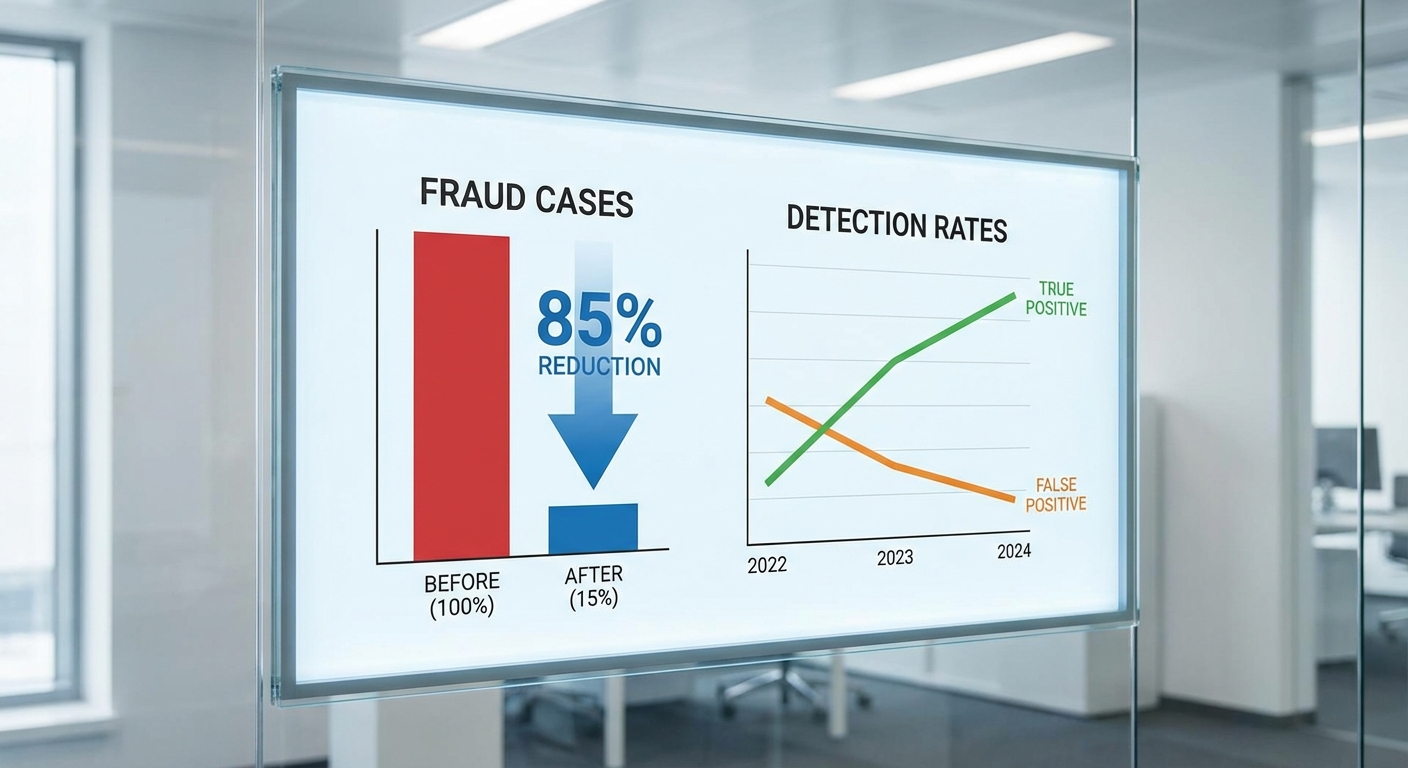
ฐานการคำนวณสำหรับตัวชี้วัดการลดการทุจริตถูกกำหนดโดยการเปรียบเทียบจำนวนเคสทุจริตที่ยืนยันได้ก่อนและหลังการติดตั้งระบบในช่วงระยะเวลาทดสอบ ดังนี้: ในช่วงก่อนใช้งาน (ช่วงฐาน) พบ 200 เคสทุจริตที่ยืนยันได้ จากตัวอย่างทั้งหมด ขณะที่ในช่วงหลังใช้งานพบเพียง 30 เคส การคำนวณอัตราการลดคือ (200 − 30) / 200 = 85% ซึ่งเป็นตัวเลขหลักที่ธนาคารนำเสนอในรายงานผลการนำร่อง
นอกเหนือจากการลดจำนวนเคสทุจริตโดยรวม ผลการทดสอบยังแสดงการปรับปรุงตัวชี้วัดการตรวจจับที่สำคัญดังนี้:
- True positive rate (TPR) เพิ่มขึ้นประมาณ 30% (จากค่าเบื้องต้น 60% เป็น ~78%) — แปลว่าระบบสามารถจับเคสทุจริตที่ยืนยันได้เพิ่มขึ้นอย่างมีนัยสำคัญ
- False positive rate (FPR) ลดลงประมาณ 40% (จาก 10% เหลือ ~6%) — ส่งผลให้จำนวนลูกค้าที่ถูกตรวจสอบซ้ำหรือถูกระงับโดยไม่จำเป็นลดลง ช่วยปรับปรุงประสบการณ์ลูกค้า
- False negative (การพลาดเคสทุจริต) ลดลงอย่างมีนัยสำคัญโดยประมาณ กว่า 35% เมื่อเทียบกับระบบเดิมที่พึ่งพาการตรวจสอบด้วยมนุษย์เป็นส่วนใหญ่
- เวลาตอบสนองเฉลี่ย จากการยืนยันความเสี่ยงของเอกสารลดลงจากเฉลี่ย ~3.8 ชั่วโมง เหลือเฉลี่ย ~4–6 นาที หลังการนำ FAN มาช่วยประมวลผลแบบกระจาย
ตารางสรุปเปรียบเทียบก่อนและหลังการใช้ระบบ (ช่วงทดสอบ 6 เดือน, ตัวอย่าง N = 120,000)
| ตัวชี้วัด | ก่อนระบบ (ฐาน) | หลังระบบ (FAN) | การเปลี่ยนแปลง |
|---|---|---|---|
| ระยะเวลาทดสอบ | 6 เดือน | 6 เดือน | – |
| จำนวน KYC ที่ประมวลผล | 120,000 | 120,000 | – |
| เคสทุจริตยืนยันได้ | 200 | 30 | ลด 85% |
| True Positive Rate | 60% | ~78% | เพิ่ม 30% (เชิงสัมพัทธ์) |
| False Positive Rate | 10% | ~6% | ลด 40% |
| Avg. Response Time | ~3.8 ชั่วโมง | ~4–6 นาที | ลดอย่างมาก |
ในเชิงสถิติ ผลต่างระหว่างก่อน-หลังมีความหมายเชิงนัยสำคัญ (ทดสอบด้วยไคสแควร์สำหรับอัตราทุจริตและการเปรียบเทียบอัตราการตรวจจับ) โดยค่าความน่าจะเป็น (p‑value) อยู่ที่ระดับ < 0.01
ตัวอย่างเหตุการณ์จริงจากการนำร่อง (กรณีศึกษา): ผลการทดสอบชี้ให้เห็นว่า การใช้โมเดลแบบกระจาย (federated) ช่วยให้ธนาคารสามารถเรียนรู้ pattern ของการปลอมแปลงจากข้อมูลเชิงประสบการณ์ของหลายสาขาได้โดยไม่ต้องรวบรวมหรือโยกย้ายข้อมูลภาพลูกค้าไปยังศูนย์กลาง ส่งผลให้ความเป็นส่วนตัวของลูกค้ายังคงอยู่ในระดับสูง ในขณะเดียวกันก็เพิ่มความแม่นยำและความเร็วในการตอบสนองต่อความเสี่ยง ทำให้การป้องกันการทุจริตมีประสิทธิผลมากขึ้นอย่างชัดเจน การออกแบบระบบ Federated‑Anomaly Network ที่ ไม่ย้ายข้อมูลดิบของลูกค้า ออกจากอุปกรณ์มือถือหรือระบบภายในธนาคาร เป็นกลไกสำคัญเชิงนโยบายเพื่อให้สอดคล้องกับพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) และข้อกำกับดูแลของธนาคารกลาง ทั้งในแง่ของหลักการ “data minimization” และข้อจำกัดเกี่ยวกับการโอนข้อมูลข้ามเขตอำนาจศาล โดยการเก็บข้อมูลดิบไว้เฉพาะในต้นทางจะช่วยลดความเสี่ยงของการเปิดเผยข้อมูลส่วนบุคคล ลดความจำเป็นในการขอความยินยอมใหม่สำหรับการย้ายข้อมูล และสอดคล้องกับข้อกำหนดเรื่องการควบคุมการเข้าถึงและความรับผิดชอบต่อข้อมูล (accountability) ที่ผู้ควบคุมกำกับต้องการเห็นเป็นรูปธรรม ในเชิงเทคนิค ระบบจะส่งเฉพาะพารามิเตอร์ที่ผ่านการประมวลผลหรือการอัปเดตโมเดล (เช่น เฟสเตอร์/กราเดียนต์ที่ถูกปรับ) กลับไปยังเครื่องรวมกลาง แทนการส่งภาพเอกสารหรือข้อมูลดิบ การออกแบบเช่นนี้ช่วยให้ธนาคารสามารถอธิบายต่อผู้กำกับได้ว่า ไม่มีการส่งหรือรวบรวมข้อมูลส่วนบุคคลดิบ นอกเหนือจากข้อยกเว้นที่ได้รับอนุญาต อีกทั้งยังช่วยลดภาระด้านการจัดการการเก็บรักษาข้อมูลและนโยบายการเก็บข้อมูล (retention) ตามที่ PDPA และข้อกำกับธนาคารกำหนด เพื่อรับประกันความเป็นส่วนตัวเชิงเทคนิคและความมั่นคงของกระบวนการ จะต้องรวมเทคนิคต่อไปนี้เข้าด้วยกันเป็นชั้น ๆ: มาตรการเชิงนโยบายและการบันทึก (audit) ถูกออกแบบร่วมกับเทคโนโลยีเพื่อให้ผู้กำกับสามารถตรวจสอบได้โดยไม่กระทบต่อความเป็นส่วนตัวของลูกค้า: เพื่อให้เป็นไปตามข้อกำกับของธนาคารกลาง ระบบต้องสามารถจัดทำรายงานเชิงเทคนิคที่ชัดเจน สำหรับผู้กำกับที่ต้องการตรวจสอบ โดยรายงานเหล่านี้จะรวมถึง: สรุปแล้ว การไม่ย้ายข้อมูลดิบผสานกับเทคนิคความเป็นส่วนตัวเชิงรุกและระบบ audit trail ที่โปร่งใส ช่วยให้ธนาคารสามารถพิสูจน์ต่อผู้กำกับได้ว่า ระบบ Federated‑Anomaly Network สอดคล้องกับ PDPA และข้อกำกับของธนาคารกลาง ทั้งในด้านการปกป้องข้อมูลผู้ใช้ การป้องกันการลักลอบเข้าถึง และความสามารถในการรายงานและตรวจสอบได้อย่างครบถ้วน ส่วนกลางของ Federated‑Anomaly Network สำหรับการตรวจจับเอกสารปลอมบนมือถือถูกออกแบบเป็นระบบแบบหลายชั้น (layered) ที่ผสานการประมวลผลบนอุปกรณ์ปลายทาง (edge) กับการประมวลผลแบบรวมศูนย์เพื่อบริหารโมเดลและการรวมค่าอัพเดต ในเชิงโครงสร้างจะประกอบด้วยองค์ประกอบหลักสามส่วนคือ: (1) โมเดล anomaly ที่เบาและปรับให้เหมาะกับทรัพยากรบนมือถือ, (2) ระบบ orchestration สำหรับจัดตารางการฝึกและการส่งอัพเดต, และ (3) aggregation server/registry สำหรับการรวมค่า การจัดเวอร์ชัน และการรักษาความปลอดภัยของน้ำหนักโมเดล ในส่วนของโมเดล anomaly สำหรับ edge เราเลือกสถาปัตยกรรมที่มีความซับซ้อนต่ำแต่ให้ความแม่นยำสูง ตัวอย่างเช่น lightweight CNN autoencoder ขนาดเล็ก (เช่น depthwise-separable convolutions 3–4 ชั้น, latent dimension 64–256) ที่มีขนาดโมเดลประมาณ 1–5 MB และ latency บนสมาร์ทโฟนรุ่นกลางต่ำกว่า 100 ms ต่อภาพ หรือ lightweight transformer แบบตัดแต่ง (เช่น 4–6 heads, 4–6 layers, parameter จำนวนประมาณ 1–4M) ที่ผ่านการ distillation เพื่อลดการใช้หน่วยความจำ ทั้งสองรูปแบบใช้คะแนนความผิดพลาดการคืนค่า (reconstruction error) หรือความเบี่ยงเบนของ embedding เป็นตัวชี้วัด anomaly และมักให้ค่า AUC ประมาณ 0.88–0.95 ในการทดสอบภายในกับชุดข้อมูลการปลอมเอกสารจำลอง นอกจาก autoencoder แล้ว ระบบยังรองรับเทคนิคเสริมสำหรับการตั้งค่าห้องปฏิบัติการ (on-device ensemble) เช่น isolation forest เวอร์ชันที่ฝึกบนฟีเจอร์สรุป (feature embeddings) เพื่อจับกรณีผิดปกติที่ไม่ใช่แบบปรับตัวได้ง่าย และ deep SVDD ในเวอร์ชันเบาที่ใช้ embedding จาก encoder ของ autoencoder มาตรวจจับสภาวะที่ latent representation อยู่ไกลจากคลัสเตอร์ปกติ เทคนิคเหล่านี้สามารถรันร่วมกันเป็น cascade หรือ ensemble voting เพื่อเพิ่มความไวในการจับ anomaly โดย trade-off กับการใช้พลังงานและเวลา กลไก federated orchestration ถูกออกแบบให้ปรับได้ตามสภาพแวดล้อมการใช้งาน: ตัว scheduler จะเลือกกลุ่มลูกค้า (client selection) ตามเงื่อนไขเช่น ความพร้อมของเครือข่าย, แบตเตอรี่, และตัวแทนเชิงประชากรศาสตร์ (stratified sampling) เพื่อให้การฝึกตัวแทนข้อมูลหลากหลายและลด bias การอัพเดตทำในรูปแบบรอบ (rounds) โดยทั่วไปตั้งค่าเริ่มต้นเป็น 1 round ต่อวัน ในสภาพแวดล้อมเชิงธุรกิจ แต่สามารถเพิ่มเป็นหลายรอบต่อวันในช่วงเหตุการณ์ความเสี่ยงสูง (adaptive scheduling) การรวมอัพเดตใช้แนวทาง Federated Averaging (FedAvg) แบบถ่วงน้ำหนักด้วยจำนวนตัวอย่างของแต่ละ client (weighted averaging) และรองรับตัวเลือกเช่น FedProx เพื่อจัดการกับ heterogeneity ของไคลเอนต์ การจัดการเวอร์ชันโมเดล (model versioning) เป็นองค์ประกอบหลักที่ช่วยให้ระบบสามารถทดสอบย้อนกลับและควบคุมการเปลี่ยนแปลงได้ โดยใช้ registry แบบ immutability (เช่น content-addressed storage พร้อม hash ของน้ำหนัก) รวมทั้ง metadata ที่เก็บข้อมูลเช่น training round, client population, ประสิทธิภาพบน validation holdout, และค่า hyperparameters กระบวนการ deploy ใช้กลยุทธ์เช่น canary release และ staged rollout โดยมีการตรวจวัด KPI สำคัญ (TPR, FPR, latency, และผลกระทบต่อ UX) ก่อนขยายสู่กลุ่มผู้ใช้ทั้งหมด และมีระบบ rollback อัตโนมัติเมื่อตรวจพบการลดลงของ utility มากกว่าค่า threshold ที่กำหนด ด้านการรวมค่าและความปลอดภัย ทางสถาปัตยกรรมรวมทั้งเทคนิคการป้องกันต่อการโจมตี ตัวอย่างที่ใช้ได้จริงได้แก่: สำหรับการทดสอบความทนทานต่อการโจมตี ระบบจะผ่านชุดการประเมินแบบ red-team ที่ครอบคลุมทั้ง poisoning และ model inversion โดยวิธีการทดสอบได้แก่: เพื่อลดความเสี่ยงเมื่อใช้ secure aggregation ซึ่งอาจทำให้การตรวจจับอัพเดตแย่ลง ระบบออกแบบเป็น multi-layer detection: ชั้นแรกทำตรวจจับบนไคลเอนต์ (local validation and self-check), ชั้นที่สองเป็น clustering/anomaly detection บน metrics เมตาดาต้าเช่น gradient norms และ sign flips หลังการเปิดเผยแบบ aggregated, และชั้นที่สามเป็นการวิเคราะห์เชิง forensic เมื่อพบสัญญาณเตือน รวมถึงการติดป้ายเวอร์ชันและการออกลายเซ็นดิจิทัลของ weights เพื่อป้องกันการปลอมแปลง artifacts สรุปคือสถาปัตยกรรมเชิงเทคนิคของ Federated‑Anomaly Network นี้เน้นการผสมผสานระหว่างโมเดลเบาบน edge และกลไกการบริหารจัดการโมเดลที่เข้มแข็ง (versioning, canary, rollback) ควบคู่กับการป้องกันและตรวจจับการโจมตีในหลายระดับ (robust aggregation, gradient anomaly detection, secure aggregation และ differential privacy) เพื่อให้การตรวจจับเอกสารปลอมเป็นไปได้อย่างมีประสิทธิภาพและปลอดภัยโดยไม่ต้องย้ายข้อมูลลูกค้าออกจากอุปกรณ์ แม้ผลการทดสอบ Federated‑Anomaly Network ผสานการยืนยันตัวตน (KYC) บนมือถือจะแสดงให้เห็นการลดการทุจริตได้ถึง 85% ในเฟสต้นแบบ แต่การนำระบบไปใช้งานจริงในระดับสถาบันการเงินขนาดใหญ่ยังเผชิญความท้าทายเชิงเทคนิค เชิงปฏิบัติการ และเชิงกฎหมายหลายประการ ที่ต้องมีแผนรับมือเป็นขั้นตอนและมีการวัดผลอย่างเป็นระบบก่อนขยายผลในวงกว้าง หนึ่งในความท้าทายหลักคือ Data heterogeneity—ความแตกต่างของข้อมูลระหว่างสถาบันทั้งในเชิงรูปแบบของเอกสาร (ภาพถ่าย เอกสารต่างประเทศ ฟอร์แมตภาพ) คุณภาพภาพ (แสง การบีบอัด) และลักษณะประชากรผู้ใช้ ซึ่งส่งผลต่อประสิทธิภาพของโมเดลรวมแบบกระจาย การแก้ปัญหาต้องอาศัยแนวทางด้านการปรับโมเดลแบบ personalized federated learning เช่น การอนุญาตให้แต่ละสาขาหรือแต่ละธนาคารทำ local fine‑tuning กับน้ำหนักโมเดลที่ได้จาก global model, การใช้ multi‑task learning เพื่อให้โมเดลรองรับลักษณะทะเลข้อมูลที่แตกต่างกัน และการแบ่งกลุ่ม (clustering) ลูกค้าหรือโหนดเพื่อให้การอัปเดตโมเดลมีความเป็นกลุ่มที่สอดคล้องกัน นอกจากนี้การปรับ sampling เช่น importance sampling หรือ stratified sampling ในขั้นตอน aggregation จะช่วยลด bias จากโหนดที่มีข้อมูลมากหรือมีรูปแบบเด่นเกินไป การปรับจูนโมเดลในสภาพแวดล้อมมือถือที่หลากหลาย เป็นอีกปัจจัยสำคัญ เพราะอุปกรณ์และเครือข่ายของผู้ใช้มีขีดจำกัดทั้งด้านหน่วยประมวลผล แบตเตอรี่ และแบนด์วิดท์ การออกแบบต้องคำนึงถึงการบีบอัดการส่งข้อมูล (quantization, sparsification), การอัปเดตแบบ asynchronous และการเลือก client แบบอัจฉริยะ (client selection scheduling) เพื่อลดภาระในชั่วโมงใช้งานหนาแน่น นโยบายการอัปเดตควรประกอบด้วยเกณฑ์เช่นขั้นต่ำของพลังงาน/พื้นที่จัดเก็บ, ระยะเวลาการประมวลผล และการคืนอัปเดตเมื่อเงื่อนไขเครือข่ายเอื้ออำนวย เพื่อให้เกิดความสมดุลระหว่างความแม่นยำของโมเดลและประสบการณ์ผู้ใช้ ค่าใช้จ่ายในการดำเนินงาน (Operational cost) ควรถูกประเมินเป็นองค์รวม ไม่ใช่เฉพาะค่าใช้จ่ายด้านฮาร์ดแวร์หรือคลาวด์เท่านั้น แต่รวมถึงต้นทุนบุคลากร การปฏิบัติตามข้อกำหนด ตรวจสอบความปลอดภัย และการบำรุงรักษา ระบบ federated learning ต้องมีส่วนกลางสำหรับ orchestration, secure aggregation และ logging ซึ่งมีค่าใช้จ่ายทั้งเชิงโครงสร้างพื้นฐานและเชิงปฏิบัติการ ผู้บริหารควรคำนวณ Return on Investment (ROI) โดยใช้เมตริกที่ชัดเจน เช่นการลดความสูญเสียจากการทุจริต (loss reduction), การลด false positives ที่ลดภาระงานฝ่ายปฏิบัติการ, เวลาการยืนยันตัวตนลดลง และต้นทุนการปฏิบัติตามกฎ ระยะเวลาคืนทุน (payback period) ควรประเมินพร้อมการวิเคราะห์ความไวต่อพารามิเตอร์เช่นอัตราการยอมรับของลูกค้าและต้นทุนการสื่อสารข้อมูล อุปสรรคด้านกฎหมายและความเป็นส่วนตัว เช่น พ.ร.บ.คุ้มครองข้อมูลส่วนบุคคล (PDPA) กฎระเบียบการไหลของข้อมูลระหว่างประเทศ และข้อกำหนดของหน่วยงานกำกับดูแลการเงิน ทำให้ต้องมีมาตรการทางกฎหมายและเทคนิคควบคู่กัน เช่นการทำ Data Processing Agreement (DPA), การประเมินผลกระทบด้านความเป็นส่วนตัว (DPIA), การใช้เทคนิคการรักษาความลับเช่น secure aggregation, differential privacy และการเข้ารหัสบางส่วน (homomorphic encryption) ซึ่งต้องพิจารณาค่าใช้จ่ายเชิงประสิทธิภาพและความปลอดภัยร่วมกัน เพื่อบรรลุการขยายผลจาก pilot สู่การใช้งานเชิงพาณิชย์ จำเป็นต้องออกแบบแผนการขยายผลเป็นขั้นตอน โดยข้อเสนอเชิงปฏิบัติได้แก่: ท้ายที่สุด การขยายผลที่ยั่งยืนต้องอาศัยการทำงานร่วมกันระหว่างฝ่ายเทคนิค ฝ่ายกฎหมาย ฝ่ายปฏิบัติการ และ regulator โดยยึดเป้าหมายร่วมคือ ลดการทุจริตอย่างมีประสิทธิภาพ ขณะเดียวกันรักษาสิทธิส่วนบุคคลของลูกค้าและความมั่นคงของระบบ แผนงานที่ชัดเจน มีการตั้ง KPI เชิงปฏิบัติได้ และการสร้าง consortium ที่เน้นมาตรฐานร่วม จะเป็นกุญแจสำคัญสู่การนำ Federated‑Anomaly Network ไปใช้ในระดับประเทศอย่างปลอดภัยและคุ้มค่าทางเศรษฐกิจ โครงการทดสอบระบบ Federated‑Anomaly Network ที่ผสานกับกระบวนการ KYC บนมือถือ แสดงให้เห็นว่าการตรวจจับเอกสารปลอมแบบกระจายสามารถลดการทุจริตได้อย่างมีนัยสำคัญ — ประสิทธิผลเบื้องต้นรายงานการลดการทุจริตได้ถึง 85% — ในขณะที่ยังคงรักษาความเป็นส่วนตัวของลูกค้าโดยไม่ต้องย้ายข้อมูลต้นทางออกจากอุปกรณ์หรือสถาบันต้นทาง ส่งผลให้การทำงานสอดคล้องกับข้อกำกับดูแลด้านความเป็นส่วนตัวและการคุ้มครองข้อมูล (data protection) เนื่องจากข้อมูลไบโอเมตริกซ์และสำเนาเอกสารไม่ถูกส่งไปรวมศูนย์ของผู้ให้บริการรายเดียว การขยายผลในระดับสถาบันการเงินและข้ามสถาบันจำเป็นต้องอาศัยทั้งการแก้ปัญหาทางเทคนิคและการประสานนโยบายร่วมกัน ประเด็นสำคัญได้แก่การกำหนดมาตรฐานการทำงานร่วมกัน (interoperability) และรูปแบบการแลกเปลี่ยนสรุปโมเดลที่มั่นคง เช่น secure aggregation, differential privacy หรือ secure multi‑party computation, ระบบบริหารจัดการวงจรชีวิตของโมเดล (model governance) เพื่อการตรวจสอบและอธิบายผล, รวมถึงกรอบการประเมินผลตอบแทนจากการลงทุน (ROI) และตัวชี้วัดการปฏิบัติตามกฎระเบียบที่ต้องประเมินอย่างต่อเนื่องเพื่อพิสูจน์ความคุ้มค่าและความปลอดภัยก่อนขยายการใช้งานเชิงพาณิชย์ มองไปข้างหน้า แนวทางแบบกระจายนี้มีศักยภาพที่จะยกระดับการป้องกันการทุจริตในการยืนยันตัวตนและลดต้นทุนการตรวจสอบของธนาคาร หากสถาบันการเงินร่วมกันวางกรอบมาตรฐานเทคนิคและนโยบายที่ชัดเจน พร้อมการทดสอบเชิงปฏิบัติการและการติดตามผลด้าน ROI ต่อเนื่อง ก็สามารถขยายการใช้งานได้อย่างปลอดภัยและเป็นไปตามกฎระเบียบ ทั้งนี้ต้องให้ความสำคัญกับการตรวจสอบประสิทธิภาพอย่างต่อเนื่อง การจัดการความเสี่ยง และการมีส่วนร่วมของหน่วยงานกำกับดูแลเพื่อสร้างความเชื่อมั่นในระบบร่วมกัน
ความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบ
ความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบ
สถาปัตยกรรมเชิงเทคนิค: โครงสร้างและการบริหารโมเดล
สถาปัตยกรรมเชิงเทคนิค: โครงสร้างและการบริหารโมเดล
ความท้าทาย ปัญหา และแนวทางขยายผล
ความท้าทาย ปัญหา และแนวทางขยายผล
บทสรุป