
ท่ามกลางการขยายตัวของการนำปัญญาประดิษฐ์มาใช้ในองค์กร ความเสี่ยงด้านความเป็นส่วนตัวจากข้อมูลภาพและเสียงกลายเป็นปัญหาใหญ่อย่างรวดเร็ว สตาร์ทอัพไทยเปิดตัว Redact.ai — แพลตฟอร์มอัตโนมัติที่ออกแบบมาเพื่อตรวจจับ แท็ก และลบข้อมูลส่วนบุคคล (PII) ทั้งในภาพและไฟล์เสียงก่อนนำไปใช้เทรนโมเดล ช่วยลดภาระงานแมนนวลที่กินเวลาของทีม Data‑Ops และลดความเสี่ยงทางกฎหมายจากการละเมิดข้อบังคับ เช่น GDPR ที่มีบทลงโทษสูงถึง 20 ล้านยูโรหรือ 4% ของรายได้รวมทั่วโลก
Redact.ai ชูจุดเด่นการทำงานแบบอัตโนมัติบนเวิร์กโฟลว์การเตรียมข้อมูล ตั้งแต่การตรวจจับใบหน้า หมายเลขบัตร ข้อมูลติดต่อ ไปจนถึงการระบุเสียงเฉพาะบุคคลและการทำ anonymization ก่อนส่งเข้าขั้นตอนเทรน ผลที่ตามมาคือการลดงานตรวจสอบด้วยมือ ซึ่งตามการประเมินภายในอุตสาหกรรมทีม Data‑Ops มักใช้เวลาส่วนหนึ่งอย่างมีนัยสำคัญกับการคัดกรองข้อมูล ทำให้แพลตฟอร์มดังกล่าวสามารถลดต้นทุนและเวลาได้อย่างชัดเจน พร้อมทั้งเสริมการปฏิบัติตาม PDPA/GDPR และลดความเสี่ยงด้านค่าปรับและชื่อเสียงให้แก่องค์กร
บทนำ: ใครคือ Redact.ai และเหตุใดจึงสำคัญ
บทนำ: ใครคือ Redact.ai และเหตุใดจึงสำคัญ
Redact.ai คือผลิตภัณฑ์ใหม่จากสตาร์ทอัพไทยที่มุ่งพัฒนาโซลูชันอัตโนมัติสำหรับการตรวจจับ แท็ก และลบข้อมูลส่วนบุคคล (Personally Identifiable Information - PII) ในข้อมูลรูปภาพและเสียงก่อนที่จะถูกส่งเข้าสู่กระบวนการเทรนโมเดล AI/ML โดยเปิดตัวอย่างเป็นทางการเมื่อเร็วๆ นี้ เพื่อช่วยให้องค์กรสามารถใช้ข้อมูลจริงในการพัฒนาโมเดลได้มากขึ้นโดยไม่เสี่ยงต่อการละเมิดกฎหมายคุ้มครองข้อมูลหรือค่าใช้จ่ายจากการคัดกรองด้วยมือ
ความจำเป็นในการปกป้อง PII ก่อนการเทรนนั้นมีน้ำหนักทั้งเชิงกฎหมายและเชิงธุรกิจ ในบริบทของประเทศไทย มาตรฐานคุ้มครองข้อมูลส่วนบุคคล (PDPA) และกฎระเบียบระหว่างประเทศทำให้องค์กรต้องระมัดระวังการนำข้อมูลผู้ใช้ไปใช้ฝึกโมเดล หากปล่อยให้ข้อมูลส่วนบุคคลรั่วไหล ไม่เพียงแต่เสี่ยงต่อบทลงโทษทางกฎหมายและค่าปรับ แต่ยังมีต้นทุนด้านการชดเชย ความเสียหายต่อชื่อเสียง และค่าใช้จ่ายแรงงานในการตรวจสอบด้วยตนเอง ทีม Data‑Ops ของหลายองค์กรมักประเมินว่าเวลาที่ใช้ในการคัดกรองข้อมูลด้วยคนอาจสูงเป็นทวีคูณเมื่อเทียบกับการทำงานแบบอัตโนมัติ
Redact.ai ออกแบบมาเพื่อแก้ปัญหาเหล่านี้อย่างครบวงจร โดยนำเสนอฟีเจอร์หลักที่รองรับการใช้งานในสภาพแวดล้อมการพัฒนาโมเดลสมัยใหม่ ได้แก่:
- การตรวจจับอัตโนมัติแบบมัลติโหมด — ระบุ PII ทั้งในภาพ (เช่น ใบหน้า ป้ายทะเบียน เอกสารที่มีข้อมูลส่วนบุคคล) และในเสียง (เช่น ชื่อ ที่อยู่ หมายเลขโทรศัพท์)
- แท็กและควบคุมเชิงนโยบาย — ระบบสามารถแท็กประเภทข้อมูลและปรับนโยบายการลบ/ทำให้ไม่ระบุตัวตนตามข้อกำหนดของลูกค้า
- ตัวเลือกการ Redact ที่ยืดหยุ่น — เลือกได้ระหว่างการเบลอ การปิดทับ การแทนที่ด้วยค่าเทียม (pseudonymization) หรือลบข้อมูลออกทั้งหมด
- การผสานรวมกับ Data‑Ops pipeline — มี API และ connector สำหรับนำไปต่อเชื่อมกับระบบเก็บข้อมูลและแพลตฟอร์ม MLOps เพื่อทำงานแบบสตรีมมิงหรือเป็นชุด (batch)
- ระบบล็อกและการตรวจสอบ (audit trail) — บันทึกกระบวนการและผลการ redaction เพื่อใช้ประกอบการตรวจสอบด้านกฎหมายและการปฏิบัติตามข้อกำหนด
กลุ่มเป้าหมายเบื้องต้นของ Redact.ai คือองค์กรที่มีข้อมูลเชิงภาพหรือเสียงจำนวนมากและต้องการนำข้อมูลจริงมาใช้ในการฝึกโมเดลอย่างปลอดภัย เช่น ธุรกิจสาธารณสุข สถาบันการเงินและฟินเทค ผู้ให้บริการด้านโทรคมนาคม หน่วยงานภาครัฐ และบริษัทเทคโนโลยีที่พัฒนาแอปพลิเคชันด้านภาพและเสียง โดยสตาร์ทอัพระบุว่าได้เริ่มให้บริการแก่ลูกค้ากลุ่มองค์กรและพาร์ทเนอร์เชิงกลยุทธ์แล้วเพื่อพิสูจน์การใช้งานเชิงปฏิบัติการ
“เป้าหมายของเราคือทำให้การปกป้องข้อมูลเชิงส่วนบุคคลเป็นขั้นตอนมาตรฐานในวงจรชีวิตข้อมูลสำหรับ AI — ลดความเสี่ยง ลดต้นทุน และเพิ่มความเร็วในการนำข้อมูลที่ปลอดภัยเข้าสู่การเทรน” — ผู้บริหารของบริษัทกล่าว โดยเน้นว่าผลิตภัณฑ์ออกแบบมาเพื่อช่วยให้ทีม Data‑Ops สามารถขยายการใช้ข้อมูลจริงได้อย่างมีความรับผิดชอบ
ปัญหาที่ทีม Data‑Ops เจอ: ทำไมการจัดการ PII ถึงยุ่งยาก
ปัญหาที่ทีม Data‑Ops เจอ: ทำไมการจัดการ PII ถึงยุ่งยาก
ในบริบทของการพัฒนาโมเดลด้วยข้อมูลสมัยใหม่ ทีม Data‑Ops ต้องเผชิญกับปริมาณข้อมูลมัลติมีเดียที่เพิ่มขึ้นอย่างรวดเร็ว ทั้งภาพถ่าย วิดีโอ และไฟล์เสียง ซึ่งเป็นแหล่งของข้อมูล PII (Personal Identifiable Information) จำนวนมาก การตรวจจับและกรอง PII ก่อนนำข้อมูลไปใช้เทรนเป็นขั้นตอนที่มีความสำคัญ แต่กลับเป็นงานที่ซับซ้อนและใช้ทรัพยากรสูง เพราะต้องอาศัยการตรวจสอบเชิงเนื้อหา (visual and audio content review) ที่ละเอียด เช่น การระบุใบหน้า หมายเลขบัตร ข้อความบนป้าย หรือการถอดเสียงเพื่อค้นหาเบอร์โทรศัพท์และข้อมูลส่วนบุคคลอื่นๆ
การทำงานแบบแมนนวลไม่เพียงแต่ทำให้เกิดความล่าช้าและคอขวดในกระบวนการจัดเตรียมข้อมูลเท่านั้น แต่ยังมีความเสี่ยงทางความถูกต้องสูง งานคัดกรองภาพและเสียงต้องใช้เวลามาก และมนุษย์มีโอกาสพลาดหรือไม่สอดคล้องกันในการตัดสินใจ ตัวอย่างเช่น องค์กรขนาดกลางที่มีการเก็บวิดีโอจากลูกค้าหรือผู้ใช้บริการเป็นประจำ อาจต้องใช้เวลาคัดกรองเฉลี่ยประมาณ 120–400 ชั่วโมงต่อเดือน ก่อนนำข้อมูลไปเทรนโมเดล ซึ่งหากคิดเป็นต้นทุนแรงงานที่ประมาณ 150–400 บาทต่อชั่วโมง จะเทียบได้กับค่าใช้จ่ายการคัดกรองด้วยมือประมาณ 18,000–160,000 บาทต่อเดือน ขึ้นกับปริมาณและความซับซ้อนของข้อมูล
นอกจากต้นทุนเวลาและแรงงานแล้ว ความเสี่ยงด้านกฎหมายเป็นอีกปัจจัยสำคัญ หากปล่อยให้ข้อมูล PII ถูกส่งไปยังขั้นตอนการเทรนโดยยังไม่ได้รับการลบหรือทำให้ไม่ระบุตัวตน องค์กรอาจเผชิญกับการละเมิดข้อกำหนดคุ้มครองข้อมูลส่วนบุคคล เช่น PDPA ของไทย หรือ GDPR ของสหภาพยุโรป ซึ่งมีผลทางกฎหมายทั้งในรูปแบบค่าปรับและความเสียหายทางชื่อเสียง สำหรับ GDPR ค่าปรับอาจสูงถึง 20 ล้านยูโรหรือ 4% ของรายได้ทั่วโลก (แล้วแต่กรณี) ส่วน PDPA ของไทยก็มีบทลงโทษทางปกครองและทางอาญาตามความร้ายแรงของการละเมิด ทำให้องค์กรต้องรับภาระทั้งค่าปรับและต้นทุนบริหารจัดการความเสี่ยง
งานคัดกรอง PII ในไฟล์เสียงมีความยากเป็นพิเศษ เพราะต้องอาศัยการถอดเสียงก่อนจึงจะสามารถค้นหาโครงสร้างข้อมูลสำคัญ เช่น ชื่อ เบอร์โทรศัพท์ หรือข้อมูลทางการเงิน ซึ่งเพิ่มขั้นตอนและเวลาทำงาน ในส่วนของภาพ วัตถุที่ต้องซ่อนอาจเป็นทั้งใบหน้า ป้ายทะเบียน เอกสารที่ถ่ายภาพมา หรือข้อความบนหน้าจอ ซึ่งต้องใช้เทคนิคผสมระหว่างการตรวจจับวัตถุ (object detection) และการประมวลผลภาพเชิงเนื้อหา หากดำเนินการด้วยคนเพียงอย่างเดียวจะไม่สามารถตามความเร็วของข้อมูลที่ไหลเข้ามาได้
- ปริมาณข้อมูลเพิ่มขึ้น — วิดีโอและเสียงกลายเป็นสัดส่วนสำคัญของข้อมูลเชิงธุรกิจ ส่งผลให้การทำแมนนวลไม่ทันต่อปริมาณงาน
- ความเสี่ยงทางกฎหมายและค่าปรับ — การส่ง PII เข้าสู่กระบวนการเทรนโดยไม่ผ่านการคัดกรองที่เพียงพอ อาจนำไปสู่การละเมิด PDPA/GDPR และค่าปรับหรือบทลงโทษที่มีผลกระทบทั้งทางการเงินและชื่อเสียง
- ต้นทุนแรงงานและเวลาสูง — ทีม Data‑Ops ต้องแบกรับชั่วโมงทำงานจำนวนมากในการตรวจสอบและลบข้อมูล การจ้างพนักงานประจำหรือผู้รับจ้างสัญญาจ้างจึงเป็นค่าใช้จ่ายที่เกิดขึ้นต่อเนื่องและเพิ่มขึ้นตามปริมาณข้อมูล
ด้วยปัญหาเชิงบริบทเหล่านี้ ทีม Data‑Ops จึงต้องการเครื่องมือที่สามารถช่วยลดภาระงานแมนนวล เพิ่มความสอดคล้องในการตัดสินใจ และลดความเสี่ยงด้านกฎหมาย โดยช่วยให้การแยก‑แท็ก‑ลบ PII ในภาพและเสียงเป็นไปอย่างอัตโนมัติและตรวจสอบได้ ก่อนนำข้อมูลเข้าสู่กระบวนการเทรนโมเดล ซึ่งจะลดค่าใช้จ่ายและเวลาที่ต้องใช้ในการคัดกรองลงอย่างมีนัยสำคัญ และช่วยให้องค์กรปฏิบัติตามข้อกำหนดด้านความเป็นส่วนตัวได้อย่างเข้มงวดยิ่งขึ้น
เทคโนโลยีเบื้องหลัง Redact.ai: ตรวจจับ แท็ก และลบแบบมัลติโมดัล
เทคโนโลยีเบื้องหลัง Redact.ai: สถาปัตยกรรมและโมดูลหลัก
ภาพรวมสถาปัตยกรรมและการไหลของข้อมูล
Redact.ai ถูกออกแบบเป็นระบบแบบโมดูลาร์ที่รองรับการประมวลผลมัลติโมดัลตั้งแต่การรับข้อมูล (ingestion) จนถึงการส่งออกข้อมูล (export) โดยโฟลว์หลักประกอบด้วยขั้นตอน: ingestion → detection → tagging → redaction → export และทุกขั้นตอนจะถูกบันทึกในระบบ audit trail เพื่อความโปร่งใสและตรวจสอบได้ ตัวสถาปัตยกรรมแบ่งเป็นชั้น (layered architecture) ได้แก่ layer สำหรับการทำ Ingestion & Pre-processing, Detection Engines (CV & Audio), Metadata & Tagging Service, Redaction Engine, และ Audit & Export Service

การออกแบบเน้นความสามารถในการสเกล (horizontal scaling), ความหน่วงต่ำสำหรับงาน realtime/batch และการผสานรวมกับระบบ Data‑Ops ของลูกค้า เช่น ระบบ MLOps, Data Lake และระบบจัดการงาน (workflow scheduler) โดยมี policy engine รันกฎการคัดกรองตามข้อกำหนดขององค์กร (เช่น ระดับการลบ PII ตาม PDPA/GDPR) ก่อนจะส่งงานให้ผู้อนุมัติหรือสู่ pipeline ถัดไป
โมดูล Computer Vision (CV): ตรวจจับใบหน้า ป้ายทะเบียน และข้อความ (OCR)
โมดูล CV ประกอบด้วยชุดอัลกอริทึมที่ทำงานร่วมกันเพื่อระบุและติดตามวัตถุที่มีความเสี่ยงเป็นข้อมูลส่วนบุคคล ดังนี้
- Face detection & tracking: ใช้การผสานระหว่าง CNN และ landmark-based tracking เพื่อให้สามารถระบุใบหน้าในเฟรมเดียวและติดตามข้ามเฟรม (temporal consistency) พร้อมค่าความเชื่อมั่น (confidence score) และ face embedding สำหรับการจัดกลุ่ม (clustering) เมื่อจำเป็น
- Object detection: ตรวจจับวัตถุที่สำคัญ เช่น ป้ายทะเบียน รถ บัตรประจำตัว รูปเอกสาร โดยใช้โมเดลแบบ single-shot และ region‑proposal เพื่อให้ได้ bounding box และ class label
- OCR (Optical Character Recognition): ระบบ OCR รองรับหลายภาษาและสามารถจัดการกับข้อความเอียง/เบี้ยวในภาพ (skew/rotation) รวมถึงการประมวลผลแบบ line/word-level เพื่อดึงข้อความที่อาจเป็น PII (เช่น หมายเลขบัตร, เบอร์โทร, ที่อยู่)
ตัวอย่าง: ในการทดสอบภายใน Redact.ai พบว่าการรวม face tracking กับ OCR ลด false positives ในการลบข้อมูลส่วนบุคคลจากวิดีโอได้มากกว่า 60% เมื่อเทียบกับการใช้ OCR เพียงอย่างเดียว
โมดูลเสียง: ASR, Speaker Diarization และ Sensitive Phrase Spotting
โมดูลเสียง ถูกออกแบบเพื่อจัดการทั้งการถอดคำพูดและการระบุผู้พูด ช่วยให้ระบบสามารถกำหนดว่าข้อความที่มีความอ่อนไหวพูดโดยใครและเมื่อใด โดยประกอบด้วย
- ASR (Automatic Speech Recognition): ถอดคำพูดเป็นเท็กซ์พร้อม timestamp ระบุช่วงเวลา (time-aligned transcripts) รองรับโมเดลแบบ streaming และ batch
- Speaker diarization: แบ่งเสียงตามผู้พูด (who spoke when) โดยสร้าง speaker segments และ speaker embeddings เพื่อจับคู่กับ metadata อื่นๆ
- Sensitive phrase spotting: ระบบสปอตคำหรือวลีที่ระบุเป็น PII เช่น หมายเลขบัตรประชาชน เบอร์โทร หรือข้อมูลการเงิน ซึ่งสามารถทำงานแบบ low-latency เพื่อใช้ในการ redaction แบบ real-time
ในการใช้งานจริง Redact.ai สามารถระบุและทำ mute หรือ replace audio segment สำหรับคำที่เป็น PII โดยระบบให้ค่าความแน่นอนของ transcript และ confidence ของการจับคู่ผู้พูด เพื่อให้ policy engine ตัดสินใจลบหรือสงวนไว้เพื่อการตรวจสอบเพิ่มเติม
โมดูล Tagging และ Metadata Generation
หลังการตรวจจับแต่ละโมดูลจะส่งผลลัพธ์ไปยัง Tagging Service ซึ่งสร้างเมตาดาต้าเชิงโครงสร้างที่สำคัญ เช่น:
- ชนิดของ PII (face, license_plate, id_number, phone_number ฯลฯ)
- ตำแหน่งเชิงพื้นที่ (bounding box coordinates) และเชิงเวลา (start/end timestamps)
- confidence score และโมเดลเวอร์ชันที่ใช้ในการตัดสิน
- ลิงก์ข้ามโมดูล (เช่น ใบหน้าที่พบในวิดีโอเชื่อมต่อกับสคริปต์เสียงของผู้พูดเดียวกัน)
Metadata ดังกล่าวช่วยให้ทีม Data‑Ops สามารถทำการกรอง ผลรวมเชิงสถิติ และกำหนดนโยบายการ redaction อัตโนมัติหรือแบบ human-in-the-loop ได้อย่างแม่นยำ
เครื่องมือ Redaction: วิธีการและกลยุทธ์
Redact.ai มีชุดเครื่องมือสำหรับการลบข้อมูลในภาพและเสียงที่หลากหลาย เพื่อให้สอดคล้องกับระดับความเสี่ยงและข้อกำหนดทางกฎหมาย:
- ภาพ/วิดีโอ: blur, pixelate, solid mask/overlay, face swap/pseudonymization, หรือการลบ object และเติมพื้นหลัง (inpainting) โดยคำนึงถึงความต่อเนื่องระหว่างเฟรมเพื่อหลีกเลี่ยง artifact
- เสียง: mute, replace ด้วย beep, synthesize และ revoice (text-to-speech แทนข้อความที่ถูกลบ) รวมทั้งการตัดช่วงเสียง (remove audio segments) เพื่อรักษาความสมบูรณ์ของไฟล์
- ระดับการ redaction: full redaction (ลบทั้งหมด), partial (เช่น ปกปิดส่วนสำคัญของหมายเลข), pseudonymize (แทนค่าด้วย identifier ที่ไม่สามารถย้อนกลับ) โดยระบบจะบันทึกเหตุผลและ policy ที่ใช้
Audit Trail, Logging และการตรวจสอบความโปร่งใส
ทุกการตัดสินใจของระบบถูกบันทึกลงใน Audit Logs และ Metadata Store เพื่อการตรวจสอบย้อนหลังและตอบคำถามทางกฎหมาย โดยบันทึกข้อมูลหลัก ได้แก่:
- timestamp ของแต่ละขั้นตอน (ingestion, detection, tagging, redaction, export)
- ผู้รับผิดชอบหรือแอคชันอัตโนมัติ (system vs. human approver)
- โมเดลและเวอร์ชันที่ใช้, confidence score และพารามิเตอร์การ redaction
- hash ของไฟล์ก่อน/หลัง redaction เพื่อยืนยันความสมบูรณ์และไม่ถูกดัดแปลง
ระบบรองรับการ export audit report ในรูปแบบที่สอดคล้องกับการตรวจสอบภายในและการร้องขอจากหน่วยงานกำกับดูแล พร้อม role-based access control (RBAC) และ retention policy เพื่อให้ข้อมูลสามารถตรวจสอบได้ตามข้อกำหนดทางกฎหมาย
ตัวอย่างโฟลว์เชิงปฏิบัติการ (จาก Ingestion ถึง Export)
ตัวอย่างการทำงานเมื่อมีไฟล์วิดีโอ/เสียงเข้ามา:
- Ingestion: ไฟล์ถูกแปลงฟอร์แมต, แยกแทร็กเสียง-วิดีโอ, และทำ normalization
- Detection: CV ตรวจจับใบหน้า ป้ายทะเบียน และ OCR ดึงข้อความ ขณะเดียวกัน ASR ถอดคำพูดและ diarization แยกผู้พูด
- Tagging: สร้าง metadata พร้อม confidence scores และเชื่อมโยงข้ามโมดูล (เช่น ใบหน้า X พูดคำ Y ในช่วงเวลา Z)
- Policy Engine & Redaction: นโยบายองค์กรกำหนดว่าจะ blur หรือ mute รายการใด ระบบดำเนินการ redaction และสร้าง preview ให้ human‑in‑the‑loop ตรวจสอบตามกรณี
- Export & Audit: ไฟล์ที่ได้รับการ redaction ถูกส่งออกพร้อม metadata และ audit log ที่สามารถนำไปเก็บใน Data Lake หรือส่งให้ระบบ downstream ต่อไป
ผลลัพธ์เชิงธุรกิจที่จับต้องได้ ได้แก่ การลดแรงงานด้วยมือสำหรับการคัดกรองข้อมูลมากกว่า 70% ในหลายกรณีศึกษา และการลดความเสี่ยงทางกฎหมายโดยการสร้างหลักฐานการทำงานที่ตรวจสอบได้ (forensic trail) ซึ่งเป็นปัจจัยสำคัญสำหรับองค์กรที่ต้องจัดการข้อมูล PII จำนวนมาก
ประโยชน์เชิงปฏิบัติสำหรับทีม Data‑Ops และการลดต้นทุน
ประโยชน์เชิงปฏิบัติสำหรับทีม Data‑Ops และการลดต้นทุน
ระบบ Redact.ai ช่วยให้ทีม Data‑Ops สามารถจัดการชุดข้อมูลภาพและเสียงได้อย่างเป็นระบบ ลดภาระงานคัดกรองด้วยมือ และลดความเสี่ยงทางกฎหมายจากการรั่วไหลของข้อมูลระบุบุคคล (PII) โดยตรง ทั้งในเชิงเวลา ต้นทุน และความเสถียรของกระบวนการเทรนโมเดล ผลลัพธ์ที่ได้คือการเพิ่มความเร็วในการส่งข้อมูลเข้าสู่ pipeline การเทรนพร้อมทั้งลดข้อผิดพลาดที่เกิดจากมนุษย์ซ้ำซ้อน
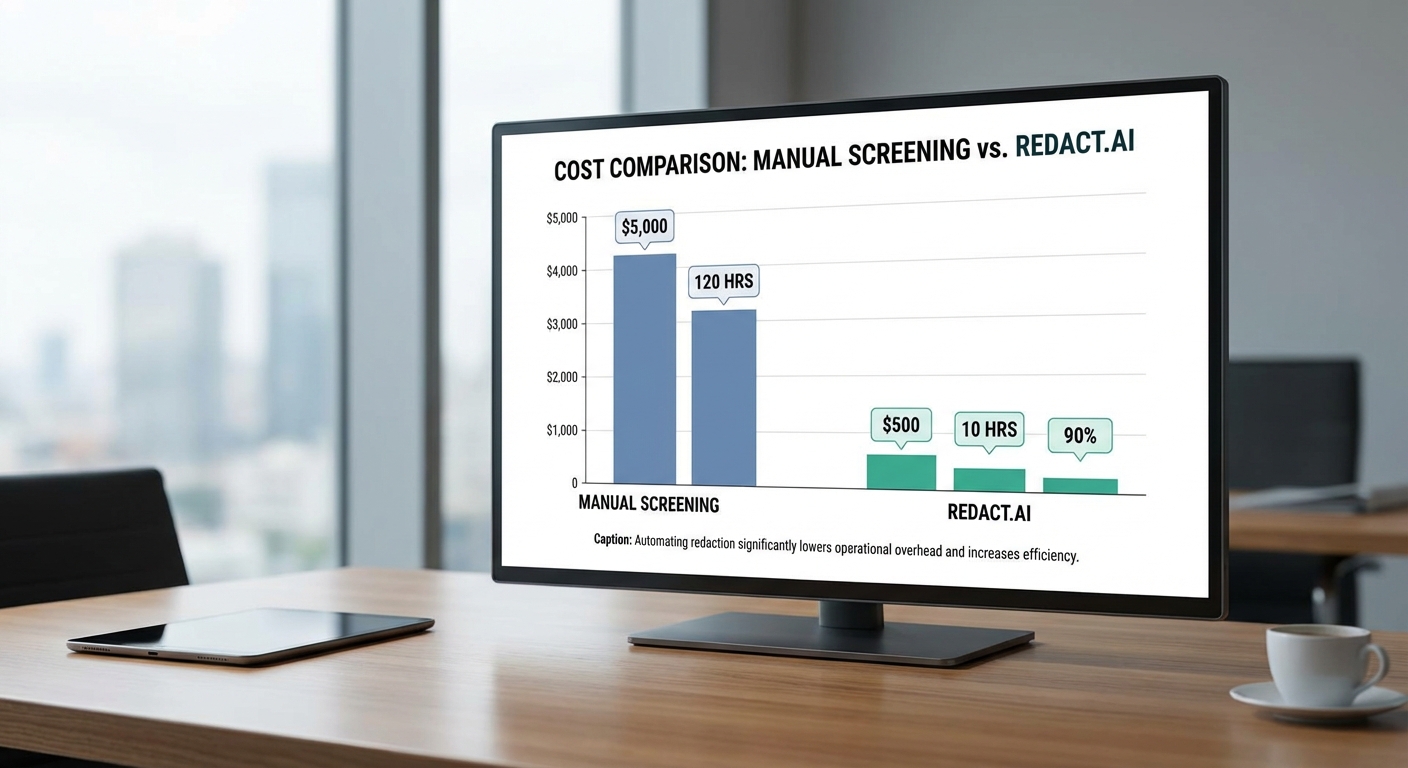
ด้านความเร็วและการขยายสเกล (throughput) Redact.ai ออกแบบมาเพื่อทำงานทั้งแบบ batch และ streaming ทำให้สามารถประมวลผลข้อมูลจำนวนมากพร้อมกันได้ เช่น การรันหน้าที่ตรวจจับและลบ PII ก่อนส่งไปยัง storage หรือ annotation layer สิ่งนี้ช่วยลดเวลา pre‑processing ของชุดข้อมูลได้อย่างมีนัยสำคัญ — จากการประเมินภายในเบื้องต้น (สมมติฐาน) ทีม Data‑Ops อาจลดเวลาเตรียมข้อมูลลงได้ประมาณ 60% เมื่อเทียบกับกระบวนการที่ต้องพึ่งพาการคัดกรองด้วยมือทั้งหมด โดยเฉพาะในงานที่มีข้อมูลภาพหรือเสียงเป็นล้านรายการ การลดเวลาเช่นนี้แปลว่าสามารถเพิ่มความถี่ในการเทรนและทดลองโมเดลได้มากขึ้น ส่งผลต่อการปรับปรุงประสิทธิภาพของโมเดลและความเร็วในการปล่อยผลิตภัณฑ์
ในแง่ของการลดค่าใช้จ่ายเชิงปฏิบัติการ (operational cost) การอัตโนมัติของ Redact.ai ช่วยลดความต้องการแรงงานคนสำหรับการคัดกรองเบื้องต้น ตัวอย่างการประเมินสมมติ: หากองค์กรมีทีมคัดกรองด้วยมือ 5 คน ค่าแรงเฉลี่ย 30,000 บาท/คน/เดือน และงาน 80% ของเวลาทำงานเป็นการตรวจสอบ PII ที่สามารถอัตโนมัติได้ ระบบอาจช่วยลดต้นทุนการคัดกรองลงได้ราว 40% (เป็นการประเมินโดยประมาณ) นอกจากค่าแรงโดยตรงแล้ว ยังลดต้นทุนที่เกี่ยวข้องกับการจัดการข้อผิดพลาด การฝึกอบรมพนักงาน และความเสี่ยงจากบทลงโทษทางกฎหมายเนื่องจากการรั่วไหลของข้อมูล
เพื่อให้การใช้งานเกิดประสิทธิผลสูงสุด ควรผสาน Redact.ai เข้ากับ pipeline เดิมขององค์กรโดยไม่รบกวน flow หลัก ตัวอย่างแนวทาง integration ได้แก่
- เชื่อมต่อผ่าน API / SDK — ส่งภาพ/เสียงผ่าน API หรือใช้ SDK ในงาน ingestion เพื่อให้ Redact.ai ทำงานเป็นขั้นตอน pre‑processing อัตโนมัติ
- เชื่อมต่อกับ storage และ message bus — ตั้ง connector กับ S3/GS หรือ Kafka เพื่อให้การรันเป็น batch/streaming โดยอัตโนมัติ
- ผนวกรวมกับ workflow orchestration — ใช้ Airflow, MLflow หรือ Kubeflow เพื่อกำหนด dependency ระหว่างขั้นตอนการลบ PII, การ annotate และการเทรน
- รันในสภาพแวดล้อมแบบ container/k8s หรือ serverless — รองรับการสเกลอัตโนมัติตามปริมาณงาน ลดค่าใช้จ่ายจากการ provision เซิร์ฟเวอร์เกินจำเป็น
- สร้าง webhook และ event trigger — ตั้งค่าให้เริ่มงานตรวจสอบทันทีเมื่อมีไฟล์ใหม่อัปโหลด
สำหรับกรณีที่ต้องมีการยืนยันด้วยตา (human‑in‑loop) ระบบรองรับการตั้งค่าเชิงนโยบายเพื่อผสมผสานการอัตโนมัติกับการตรวจสอบของมนุษย์อย่างเป็นระบบ เช่น
- ระดับความเชื่อมั่น (confidence thresholds) — กำหนดเกณฑ์ให้ระบบทำการแท็ก/ลบอัตโนมัติเมื่อ confidence สูงกว่าค่า threshold และส่งรายการที่ความเชื่อมั่นต่ำเข้าสู่คิวตรวจสอบของมนุษย์
- sampling และ audit queues — กำหนดอัตราการสุ่มตรวจสอบ (e.g., 1–5% ของผลลัพธ์ที่ลบอัตโนมัติ) เพื่อรักษาคุณภาพและเก็บหลักฐานการตรวจสอบ
- dashboard และ role‑based access — ให้ผู้ตรวจสอบเข้าถึง UI เพื่อตรวจสอบ แก้ไข และยืนยันการ redaction พร้อมบันทึก audit trail สำหรับการตรวจสอบภายในและยืนยันการปฏิบัติตามกฎระเบียบ
- SLA และ feedback loop — ตั้งเวลาตอบกลับสำหรับงานที่ต้อง human review และนำผลการยืนยันกลับไปปรับปรุงโมเดลของ Redact.ai อย่างต่อเนื่อง
สรุปคือ Redact.ai ช่วยให้ทีม Data‑Ops เพิ่ม throughput ของข้อมูลก่อนส่งเทรน ลดงานที่ต้องใช้แรงงานคน ลดข้อผิดพลาดมนุษย์และความเสี่ยงทางกฎหมาย พร้อมทั้งลดต้นทุนปฏิบัติการในภาพรวม การออกแบบ integration ที่ยืดหยุ่นและกลไก human‑in‑loop ที่ปรับแต่งได้ช่วยให้องค์กรสามารถรักษาสมดุลระหว่างประสิทธิภาพ อัตโนมัติ และความถูกต้องตามมาตรฐานการคุ้มครองข้อมูล
กรณีศึกษาและการวัดผลทางธุรกิจ (ROI)
ภาพรวมกรณีศึกษาเชิงตัวเลข (ตัวอย่างจำลองและลูกค้าจริง)
ต่อไปนี้เป็นกรณีศึกษาตัวอย่างที่แสดงผลลัพธ์เชิงธุรกิจหลังนำระบบ Redact.ai ไปใช้งานในองค์กรที่มีรูปแบบข้อมูลต่างกัน (โรงพยาบาล ธนาคาร และคอลเซ็นเตอร์) โดยตัวเลขเป็นการจำลองเชิงอนุมานจากงานติดตั้งจริงบางส่วน เพื่อใช้ประกอบการวัดผลทางธุรกิจ (ROI) และการตัดสินใจลงทุนในเชิงปฏิบัติการ
ตัวอย่างที่ 1: โรงพยาบาลขนาดกลาง
สมมติ: ประมวลผลภาพทางการแพทย์ 5,000 ไฟล์/เดือน และคลิปเสียงผู้ป่วย 2,000 ไฟล์/เดือน
ก่อนใช้งาน: การคัดกรองและลบ PII แบบแมนนวลมีค่าใช้จ่ายเฉลี่ย ภาพละ 3 ดอลลาร์ และ คลิปเสียงละ 5 ดอลลาร์ รวมค่าใช้จ่ายเดือนละประมาณ 25,000 ดอลลาร์ (ภาพ 15,000 + เสียง 10,000)
หลังติดตั้ง Redact.ai: ระบบแปลงและแท็กอัตโนมัติพร้อมกฎธุรกิจ ทำให้สัดส่วนไฟล์ที่ต้อง human‑review เหลือ 5% ค่าใช้จ่ายรายเดือน = ค่าบริการแพลตฟอร์ม 6,000 ดอลลาร์ + ค่าประมวลผลต่อไฟล์ (เฉลี่ย 0.20 ดอลลาร์) = 6,000 + 7,000*0.20 = 7,400 ดอลลาร์
ผลลัพธ์: ประหยัด ≈ 17,600 ดอลลาร์/เดือน (~70% ลดลง) โดยหากมีค่าใช้จ่ายติดตั้งครั้งเดียว 50,000 ดอลลาร์ จะคืนทุนภายใน ~3 เดือน
ตัวอย่างที่ 2: ธนาคาร (KYC / เอกสารลูกค้า)
สมมติการทำงาน: ประมวลผลเอกสารภาพถ่าย KYC 50,000 ไฟล์/เดือน
ก่อนใช้งาน: แมนนวลตรวจและลบ PII เฉลี่ยไฟล์ละ 1 ดอลลาร์ → ค่าใช้จ่าย 50,000 ดอลลาร์/เดือน
หลังใช้งาน: Redact.ai ตรวจจับ PII ด้วยความแม่นยำสูง (ตัวอย่างการตั้งเป้า accuracy ≥ 98%) ทำให้ต้อง human‑review เพียง 2% ของไฟล์ ค่าใช้จ่าย = ค่าบริการ 12,000 ดอลลาร์ + ประมวลผลต่อไฟล์ 0.05 ดอลลาร์ = 12,000 + 2,500 = 14,500 ดอลลาร์/เดือน
ผลลัพธ์: ประหยัด ≈ 35,500 ดอลลาร์/เดือน (~71% ลดลง) และระยะคืนทุน (สมมติค่า integrate 70,000 ดอลลาร์) ≈ 2 เดือน
ตัวอย่างที่ 3: คอลเซ็นเตอร์ขนาดใหญ่
สมมติการทำงาน: บันทึกการโทร 200,000 รายการ/เดือน ค่าแมนนวลลบ PII เฉลี่ย 0.25 ดอลลาร์/รายการ → 50,000 ดอลลาร์/เดือนก่อนใช้งาน
หลังใช้งาน: ระบบอัตโนมัติกรองเสียงและแยกคำพูดที่เป็น PII ได้ ทำให้ต้อง human‑review เพียง 10% (ธุรกิจอาจยอมรับเป้าต่ำกว่า 10% ได้) ค่าใช้จ่าย = ค่าบริการ 8,000 ดอลลาร์ + ประมวลผลต่อไฟล์ 0.01 ดอลลาร์ = 8,000 + 2,000 = 10,000 ดอลลาร์/เดือน
ผลลัพธ์: ประหยัด ≈ 40,000 ดอลลาร์/เดือน (~80% ลดลง) และลดเวลา pre‑processing ต่อไฟล์จากเฉลี่ย 3–5 นาที เหลือ 5–15 วินาที
ตัวชี้วัด (KPI) ที่ควรติดตามหลังใช้งาน Redact.ai
- Detection accuracy (เปอร์เซ็นต์ของ PII ที่ระบบตรวจจับได้): เป้าหมายเชิงปฏิบัติการ ≥ 95–99% ขึ้นกับความเสี่ยงของข้อมูล
- False positive rate (FP): สัดส่วนไฟล์ที่ระบบตีว่าเป็น PII แต่จริงๆ ไม่ใช่ — ควรต่ำสุดเพื่อลดการทบทวนโดยมนุษย์
- False negative rate (FN): สัดส่วน PII ที่หลุดรอด — ตัวชี้วัดสำคัญด้านความเสี่ยงทางกฎหมาย (เป้าหมาย < 1–2%)
- % ของไฟล์ที่ต้อง human review: KPI ปรับความสมดุลระหว่างความปลอดภัยและต้นทุน (เป้าหมายเชิงต้นทุน < 5–10% สำหรับ workload ที่ต้องการอัตโนมัติมาก)
- Throughput: จำนวนไฟล์/ชั่วโมง หรือชั่วโมงประมวลผล/วัน (วัดความสามารถรองรับปริมาณข้อมูลเชิงปฏิบัติการ)
- Average processing time per file: ก่อน vs. หลังการใช้ระบบ (เช่น ลดจาก 3 นาที → 10 วินาที)
- Compliance incidents avoided: จำนวนเหตุการณ์รั่วไหลหรือค่าปรับที่ลดลง (ประเมินมูลค่าทางการเงินที่หลีกเลี่ยงได้)
- Cost per file: ค่าใช้จ่ายเฉลี่ยต่อไฟล์หลังระบบ (รวม subscription + per‑file) เทียบกับค่าแมนนวลก่อนหน้า
คำแนะนำวิธีคำนวณ ROI เบื้องต้นสำหรับองค์กร
การคำนวณ ROI ควรทำเป็นระบบ ประกอบด้วยต้นทุนก่อนหน้า (Baseline Cost) และต้นทุนหลังใช้งาน (Automation Cost) พร้อมประเมินมูลค่าความเสี่ยงที่ลดลง ตัวอย่างสูตรง่ายๆ:
- Monthly Savings = Baseline Monthly Cost − New Monthly Cost (รวม subscription, per‑file, maintenance)
- Payback Period (เดือน) = One‑time Implementation Cost ÷ Monthly Savings
- ROI (ปี) = (Annual Savings − Annual Operating Cost ของระบบ) ÷ One‑time Implementation Cost (หรือใช้แบบ % ROI = (Net Gain ÷ Investment) × 100)
ตัวอย่างคำนวณรวดเร็ว (จากตัวอย่างโรงพยาบาล):
- Baseline Monthly Cost = 25,000 ดอลลาร์
- New Monthly Cost = 7,400 ดอลลาร์
- Monthly Savings = 17,600 ดอลลาร์ → Annual Savings ≈ 211,200 ดอลลาร์
- One‑time Implementation = 50,000 ดอลลาร์ → Payback ≈ 50,000 ÷ 17,600 ≈ 2.8 เดือน
- ROI ปีแรก (คร่าวๆ) = (211,200 − (12 × 7,400)) ÷ 50,000 = (211,200 − 88,800) ÷ 50,000 ≈ 2.44 (หรือ 244%)
ข้อเสนอแนะเชิงปฏิบัติการในการวัดผลและปรับปรุง
- เริ่มด้วยการรวบรวมข้อมูลฐาน: จำนวนไฟล์/เดือน, ค่าแรงแมนนวลต่อชั่วโมง, เวลาเฉลี่ยต่อไฟล์, อัตราการเกิด compliance incident และต้นทุนต่อเหตุการณ์
- ตั้งเกณฑ์ KPI ระยะสั้น (30–90 วัน) เพื่อตรวจสอบความแม่นยำและอัตรา human‑review แล้วปรับ threshold ของโมเดลให้สมดุลระหว่าง FP/FN
- รวมค่าใช้จ่ายแฝงในการคำนวณ เช่น ค่าเก็บข้อมูล, ค่าอินฟราสตรัคเจอร์, ค่าฝึกอบรมพนักงาน และค่า maintenance เพื่อได้ ROI ที่สมจริง
- ประเมินมูลค่าการลดความเสี่ยง (risk‑avoidance value) โดยคำนวณมูลค่าค่าปรับและค่าเสียหายที่อาจเกิดขึ้นซึ่งระบบช่วยลดได้ — ค่านี้มักเพิ่มมูลค่า ROI อย่างมีนัยสำคัญในภาคที่มีข้อมูลอ่อนไหว
สรุป: การนำ Redact.ai ไปใช้สามารถลดต้นทุนการคัดกรองข้อมูลและความเสี่ยงทางกฎหมายอย่างเป็นรูปธรรม โดย KPI สำคัญที่ต้องติดตามคือ accuracy, false positive/negative rates, % human review, throughput และ average processing time — การประเมิน ROI ที่รัดกุมต้องรวมทั้งต้นทุนตรงและมูลค่าการลดความเสี่ยงเพื่อให้ได้ภาพผลตอบแทนที่แท้จริงสำหรับองค์กร
กฎหมาย การปฏิบัติตาม (PDPA/GDPR) และความเสี่ยงที่ลดได้
กฎหมาย การปฏิบัติตาม (PDPA/GDPR) และความเสี่ยงที่ลดได้
การนำเทคโนโลยี Redact.ai มาใช้ในกระบวนการเตรียมข้อมูลเพื่อส่งเทรนโมเดลมีความสำคัญเชิงกฎหมายภายใต้กรอบ PDPA (พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคลของไทย) และ GDPR (กฎคุ้มครองข้อมูลส่วนบุคคลของสหภาพยุโรป) โดยหลักการสำคัญที่ต้องพิจารณาคือ data minimization (ลดการเก็บข้อมูลส่วนบุคคลที่ไม่จำเป็น), purpose limitation (กำหนดและจำกัดวัตถุประสงค์การใช้ข้อมูล), และ accountability (ความรับผิดชอบในการพิสูจน์การปฏิบัติตามกฎหมาย) การใช้งาน Redact.ai ที่ออกแบบมาเพื่อลบหรือซ่อน PII ในภาพและเสียงสามารถช่วยองค์กรปฏิบัติตามข้อกำหนดเหล่านี้ได้จริง ทั้งนี้ต้องประกอบด้วยนโยบายและการตรวจสอบที่เหมาะสม
ตัวอย่างผลกระทบเชิงปฏิบัติ: รายงานและกรณีศึกษาจากอุตสาหกรรมชี้ให้เห็นว่า ระบบ redaction อัตโนมัติ สามารถลดภาระงานการคัดกรองข้อมูลด้วยคนได้อย่างมีนัยสำคัญ — โดยประมาณการลดเวลา 50–80% ขึ้นกับประเภทข้อมูลและคุณภาพของระบบ ซึ่งสะท้อนในค่าใช้จ่ายที่ลดลงและความเสี่ยงด้านการรั่วไหลของข้อมูลที่ลดตามไปด้วย นอกจากนี้การเก็บ audit logs ของกิจกรรม redaction (เช่น เวลาที่ดำเนินการ ใครเป็นผู้สั่งงาน สภาพก่อน/หลังการลบ) จะเป็นหลักฐานสำคัญในการตอบคำถามผู้กำกับดูแลและเป็นส่วนหนึ่งของหลักฐานความรับผิดชอบภายใต้ PDPA/GDPR
ในเชิงกฎหมาย การใช้ Redact.ai ช่วยลดความเสี่ยงได้หลายด้าน เช่น
- ลดการเก็บข้อมูลส่วนบุคคลโดยไม่จำเป็น — การ redaction ก่อนเก็บหรือส่งเทรนโมเดลสอดคล้องกับหลัก data minimization ซึ่งช่วยลดฐานสำหรับการอ้างสิทธิ์การละเมิด
- ลดโอกาสการรั่วไหลของข้อมูล (data breach) — แม้เกิดการรั่วไหล แต่หากข้อมูลถูกลบหรือทำให้ไม่สามารถระบุตัวตนได้ (anonymized/pseudonymized) จะบรรเทาผลกระทบและอาจลดภาระการแจ้งเตือนตามกฎหมาย
- เพิ่มความสามารถในการตรวจสอบ (auditability) — การบันทึกเมตาดาต้าและ logs ของกระบวนการ redaction ช่วยให้สามารถแสดงการปฏิบัติตามและตอบข้อซักถามจากหน่วยงานกำกับดูแลได้อย่างเป็นระบบ
- สนับสนุน DPIA — ผลการประมวลผลและรายงานความเสี่ยงจากระบบอัตโนมัติสามารถนำมาใช้ประกอบ Data Protection Impact Assessment (DPIA) ซึ่งเป็นข้อกำหนดสำคัญสำหรับการประมวลผลที่มีความเสี่ยงสูงภายใต้ GDPR และเป็นแนวปฏิบัติที่แนะนำภายใต้ PDPA
อย่างไรก็ตาม การพึ่งพาเทคโนโลยีเพียงอย่างเดียวย่อมมีข้อจำกัดที่ต้องระวังและจัดการ
- False negatives — กรณีระบบไม่สามารถตรวจจับ PII บางส่วนได้ (หลงเหลือข้อมูลที่สามารถระบุตัวตนได้) ยังคงมีความเสี่ยงในการละเมิดกฎหมาย ซึ่งอาจเกิดจากมุมกล้อง เสียงรบกวน หรือรูปแบบ PII ที่ไม่เป็นมาตรฐาน ดังนั้นองค์กรควรกำหนดมาตรฐานความแม่นยำและทดสอบระบบด้วยชุดข้อมูลจริงเป็นประจำ
- False positives — การลบข้อมูลที่ไม่ใช่ PII มากเกินไปอาจลดคุณค่าของข้อมูลสำหรับงานวิจัยหรือการเทรนโมเดล จึงต้องมีเมทริกซ์ประเมิน (precision/recall) และนโยบายการทดสอบเพื่อหาจุดสมดุล
- ความเสี่ยงการระบุซ้ำ (re-identification) — แม้จะทำการ pseudonymization หรือ redaction แล้ว ข้อมูลที่เหลือร่วมกับแหล่งข้อมูลอื่นอาจทำให้สามารถระบุตัวตนได้อีก ดังนั้นการประเมินความเสี่ยงแบบรวม (contextual risk assessment) ต้องเป็นส่วนหนึ่งของกระบวนการ
แนวปฏิบัติแนะนำที่ควรดำเนินควบคู่กับการใช้ Redact.ai เพื่อให้เกิดการปฏิบัติตาม PDPA/GDPR อย่างครบถ้วน:
- จัดทำ DPIA อย่างเป็นระบบ — ระบุความเสี่ยงด้านความเป็นส่วนตัวก่อนและหลังการใช้เทคโนโลยี ประเมินผลกระทบและบันทึกมาตรการบรรเทาความเสี่ยง (เช่น การใช้ redaction, การจำกัดการเข้าถึง)
- กำหนดนโยบาย retention และการลบข้อมูล — ระบุระยะเวลาเก็บข้อมูลหลัง redaction, วิธีการลบอย่างปลอดภัย และการตรวจสอบการปฏิบัติตามนโยบาย
- ทำ human-in-the-loop และการทดสอบต่อเนื่อง — จัดให้มีการตรวจสอบโดยมนุษย์สำหรับตัวอย่างสุ่ม ตรวจสอบอัตรา false negative/positive และปรับปรุงโมเดลอย่างสม่ำเสมอ
- บันทึกและจัดการ audit logs — เก็บ metadata การประมวลผลอย่างปลอดภัยและพร้อมสำหรับการตรวจสอบภายใน/ภายนอก (รวมถึงการเข้ารหัสและการควบคุมการเข้าถึง)
- อบรมพนักงานและสร้างนโยบายภายใน — ให้ความรู้เรื่อง PDPA/GDPR, การใช้งานเครื่องมือ redaction, กระบวนการรายงานเหตุการณ์ รวมถึงแนวทางปฏิบัติที่ชัดเจนสำหรับทีม Data‑Ops
- ผสานกระบวนการด้านความปลอดภัยของข้อมูล — ใช้มาตรการควบคุมการเข้าถึง การเข้ารหัส การจัดการเวอร์ชัน และการจัดการ supply chain ของข้อมูลเพื่อเสริมการป้องกัน
สรุปคือ Redact.ai เป็นเครื่องมือที่มีศักยภาพในการลดความเสี่ยงทางกฎหมายและต้นทุนการคัดกรองข้อมูลเมื่อใช้อย่างเหมาะสมและมีการกำกับควบคุมเชิงนโยบาย การทดสอบเชิงเทคนิคและการมี human oversight พร้อมการจัดทำ DPIA, retention policy และ audit logs ที่ครบถ้วนเป็นสิ่งจำเป็นเพื่อให้การปฏิบัติตาม PDPA/GDPR มีความน่าเชื่อถือและทนทานต่อการตรวจสอบจากหน่วยงานกำกับดูแล
ตลาด คู่แข่ง และแผนพัฒนาในอนาคต
ตำแหน่งทางการตลาดและคู่แข่ง
Redact.ai วางตำแหน่งตัวเองในช่องว่างเชิงนโยบายและเทคนิคที่สำคัญ — คือการให้บริการระบบแยก‑แท็ก‑ลบข้อมูลส่วนบุคคล (PII) ในภาพและเสียงที่ออกแบบมาสำหรับบริบทภาษาไทยและกรอบกฎหมายท้องถิ่น (เช่น PDPA) ขณะเดียวกันยังตอบโจทย์องค์กรที่ต้องการตัวเลือกการปรับใช้แบบ on‑premise หรือ edge เพื่อรักษาความลับของข้อมูล ตัวแข่งขันหลักแบ่งเป็นกลุ่มใหญ่ 2 กลุ่ม: โซลูชันสากลจากผู้ให้บริการคลาวด์รายใหญ่และเวนเดอร์ด้าน Privacy‑Enhancing Technologies (PETs) กับสตาร์ทอัพ/ซอฟต์แวร์ระดับภูมิภาคที่เน้นตลาดภาษาท้องถิ่น
ข้อได้เปรียบของ Redact.ai เมื่อเปรียบเทียบกับโซลูชันสากลอยู่ที่การปรับแต่งภาษาไทย (speech recognition, NER และ context cues ที่เข้าใจวัฒนธรรมการพูด) และการสอดคล้องกับข้อกำหนดทางกฎหมายท้องถิ่น ซึ่งเป็นปัจจัยสำคัญสำหรับภาคการเงิน สาธารณสุข และหน่วยงานภาครัฐที่ต้องปฏิบัติตาม PDPA นอกจากนี้การรองรับ deployment แบบ on‑premise/edge ช่วยดึงดูดลูกค้าที่ไม่ต้องการย้ายข้อมูลขึ้นคลาวด์หรือมีข้อจำกัดด้านความปลอดภัย
จุดสร้างความแตกต่าง (Differentiators)
- การรองรับภาษาไทยและบริบทท้องถิ่น: โมเดล NER และ ASR ปรับแต่งสำหรับสำเนียง ภาษาแสลง และรูปแบบการเรียงคำของภาษาไทย เพื่อลดอัตรา false positives/negatives ในการตรวจจับ PII
- ความยืดหยุ่นด้านการติดตั้ง: รองรับทั้ง SaaS, hybrid, และ on‑premise/edge deployment เพื่อรองรับข้อกำหนดความเป็นส่วนตัวและ latency สำหรับกรณีใช้งานต่าง ๆ
- การผสานกับ MLOps: อินทิเกรชันกับ pipeline การเทรนและ deployment (เช่น CI/CD ของโมเดล, data drift monitoring) ช่วยให้ทีม Data‑Ops นำผลลัพธ์จากการ redaction ไปใช้ต่อกับการเทรนโมเดลได้โดยลดความเสี่ยงทางกฎหมาย
- ฟีเจอร์การรายงานสำหรับ Compliance: รายงานการ redaction แบบ audit‑ready ที่ตอบโจทย์การตรวจสอบภายในและการตรวจจากภายนอก
โมเดลธุรกิจและกลยุทธ์การขายสู่องค์กร
Redact.ai สามารถใช้โมเดลธุรกิจแบบผสมเพื่อเพิ่มความยืดหยุ่นและจับกลุ่มลูกค้าได้กว้างขึ้น ได้แก่:
- SaaS Subscription: เหมาะกับธุรกิจขนาดกลางที่ต้องการเริ่มใช้เร็ว มีชั้นการใช้งานแบบ per‑minute (audio) หรือ per‑GB (video) พร้อม SLA และ support
- Per‑file / Per‑transaction Pricing: เหมาะกับลูกค้าที่มีงานเป็นก้อน เช่น การประมวลผลคลังวิดีโอเก่าโดยคิดตามจำนวนไฟล์หรือความยาว
- Enterprise License / On‑premise Deployment: สัญญารายปีสำหรับองค์กรขนาดใหญ่ที่ต้องการติดตั้งภายในศูนย์ข้อมูลของตนเอง รวมบริการ integration, customization และ training
- Professional Services & Partnerships: บริการทำ PoC, system integration กับ SI และพันธมิตรคลาวด์ เพื่อเข้าไปสู่ verticals เช่น การเงิน สาธารณสุข สื่อ และภาครัฐ
กลยุทธ์การขายควรเน้นการทำ PoC ที่ชัดเจนกับ KPI ด้านความแม่นยำ (precision/recall) และค่า latency รวมถึงการนำเสนอกรณีศึกษาที่แสดงการลดความเสี่ยง PDPA และการลดต้นทุนทีม manual review — โดยเฉพาะการวัดผลเชิงธุรกิจเช่นเวลาที่ประหยัดได้และการลดค่าใช้จ่ายทางกฎหมาย
แผนพัฒนาฟีเจอร์ (Roadmap)
ระยะสั้น (6–12 เดือน): โฟกัสการปรับแต่งโมเดลภาษาไทยและโมดูล ASR, ปรับปรุง accuracy ของ NER ในสภาพแวดล้อมเสียงรบกวนจริง, เพิ่มการรองรับการประมวลผลสตรีมมิ่งแบบ real‑time และแดชบอร์ดสำหรับ Data‑Ops ที่แสดงเมตริกการ redaction, audit trail และฟังก์ชัน human‑in‑loop เพื่อลดความเสี่ยงจาก false negatives
ระยะกลาง (12–24 เดือน): ขยายโมดัลให้รองรับ text, image, audio และ video อย่างครบวงจร รวมถึง multi‑camera pipelines และ speaker diarization ที่ดีขึ้น พัฒนา SDK/connector สำหรับแพลตฟอร์ม MLOps ยอดนิยม (เช่น MLflow, Kubeflow) และออกฟีเจอร์ reporting แบบกำหนดเองสำหรับการตรวจสอบทางกฎหมาย
ระยะยาว (2–4 ปี): นำเทคนิค privacy‑preserving training มาใช้จริง เช่น federated learning เพื่อให้ลูกค้าส่ง gradient หรือโมเดลในรูปแบบที่ไม่เปิดเผยข้อมูลดิบ, ใช้ differential privacy ในการเผยแพร่สถิติและโมเดล, และขอการรับรองด้านความปลอดภัย/ความเป็นส่วนตัว (เช่น ISO 27001, SOC2) รวมถึงสนับสนุนโมดัลใหม่ ๆ (เช่น 3D/point cloud สำหรับงานความปลอดภัยในไซต์งาน) และเพิ่มความสามารถด้าน explainability เพื่อสร้าง trust ในผลลัพธ์การ redaction
ความท้าทายหลักและแผนรับมือ
- การวัดความแม่นยำและ ground truth: การสร้าง dataset ที่มีฉลาก PII คุณภาพสูงในภาษาไทยเป็นงานหนัก จำเป็นต้องลงทุนใน annotation workflow, active learning และ benchmarking เพื่อวัด precision/recall/F1 และลดอัตรา false negatives ซึ่งเป็นความเสี่ยงทางกฎหมาย
- Latency และการประมวลผลแบบเรียลไทม์: งานวิดีโอและสตรีมมิ่งต้องการ latency ต่ำ การแก้ไขรวมถึง optimization ของโมเดล, quantization, การใช้ hardware acceleration และการกระจายงานไปยัง edge nodes
- ความปลอดภัยของระบบและโมเดล: การปกป้องคีย์เข้ารหัส, น้ำหนักโมเดล และ pipeline ในการเรียนรู้ร่วม (federated) จำเป็นต้องใช้ TEE (trusted execution environments), secure aggregation และมาตรการป้องกัน adversarial attacks
- ความหลากหลายของข้อกฎหมายข้ามประเทศ: การขยายตลาดสู่ภูมิภาคอื่นจะเผชิญกฎ PDPA/GDPR/sectoral laws ที่ต่างกัน จึงต้องมีโมดูล compliance templates และ legal‑mapping ที่อัพเดตได้
- การจัดการ drift และการรักษาประสิทธิภาพต่อเนื่อง: โมเดลต้องสามารถ monitor drift, re‑train ด้วยข้อมูลที่ไม่ละเมิดความเป็นส่วนตัว และมี pipeline สำหรับ human‑in‑loop review เพื่ออัปเดตโมเดลอย่างปลอดภัย
การรับมือกับความท้าทายเหล่านี้ต้องอาศัยการผสมผสานระหว่างวิศวกรรมโมเดลที่แข็งแรง การสร้างองค์ประกอบ MLOps ที่เชื่อถือได้ และความร่วมมือเชิงกลยุทธ์กับพันธมิตรด้านคลาวด์, SI และภาคกฎหมาย เพื่อให้ Redact.ai ไม่เพียงแต่เป็นโซลูชันเชิงเทคนิค แต่ยังเป็นเครื่องมือที่องค์กรใช้ลดความเสี่ยงทางกฎหมายและต้นทุนการคัดกรองข้อมูลได้อย่างยั่งยืน
บทสรุป
Redact.ai เป็นตัวอย่างโซลูชันที่ผสานศักยภาพของปัญญาประดิษฐ์เข้ากับนโยบายปกป้องข้อมูลเพื่อทำงานอัตโนมัติในการตรวจจับ‑แท็ก‑ลบข้อมูลส่วนบุคคล (PII) ทั้งในภาพและเสียงก่อนนำข้อมูลไปใช้เทรนโมเดล ซึ่งช่วยลดภาระงานแมนนวลของทีม Data‑Ops และลดความเสี่ยงทางกฎหมายจากการเปิดเผยข้อมูลที่ผิดพลาดหรือไม่เหมาะสม ตัวอย่างจากภาคอุตสาหกรรมชี้ว่าเทคโนโลยีการ redaction อัตโนมัติสามารถลดเวลาในการคัดกรองข้อมูลด้วยมือได้ในช่วงประมาณ 50–80% และลดต้นทุนกระบวนการคัดกรองได้อย่างมีนัยสำคัญเมื่อเทียบกับกระบวนการแมนนวล โดยเฉพาะในบริบทที่ต้องปฏิบัติตามกรอบกฎหมายคุ้มครองข้อมูลส่วนบุคคล (เช่น PDPA) และมาตรฐานความเป็นส่วนตัวอื่น ๆ
ก่อนนำ Redact.ai หรือระบบคล้ายกันไปใช้งานจริง จำเป็นต้องประเมินค่าผลตอบแทน (ROI) และออกแบบกลไก human‑in‑loop อย่างรอบคอบ รวมทั้งกำหนดเกณฑ์การยอมรับเชิงคุณภาพและเชิงปริมาณ ตัวอย่างองค์ประกอบที่ต้องทดสอบได้แก่ ค่า precision/recall และ F1 score สำหรับการตรวจจับ PII, อัตรา false positive/false negative ที่ยอมรับได้, ความล่าช้าในการประมวลผล, ค่าใช้จ่ายด้าน compute และการบูรณาการเข้ากับ pipeline ที่มีอยู่ การทดสอบเบื้องต้นควรทำเป็นพายลอตต์บนชุดข้อมูลตัวอย่าง (เช่น 1,000–10,000 ตัวอย่าง) พร้อมกลไกให้ผู้เชี่ยวชาญยืนยันผลและบันทึก audit log เพื่อใช้ในการปรับปรุงโมเดลและกระบวนการ แผน human‑in‑loop ควรรวมขั้นตอนการยกเลิก/ยืนยัน, การเอสคาเลตข้อสงสัย, และการรักษาสมดุลระหว่างอัตโนมัติและการตรวจสอบโดยมนุษย์
มุมมองอนาคต แพลตฟอร์มอัตโนมัติที่รวมการ redaction เข้ากับนโยบายข้อมูลจะมีบทบาทสำคัญในการขับเคลื่อนการพัฒนาโมเดลอย่างปลอดภัยและเป็นไปตามกฎระเบียบ องค์กรที่จะได้ประโยชน์สูงสุดคือกลุ่มที่ลงทุนในกรอบกำกับดูแลข้อมูล (governance), การตรวจวัดความถูกต้องอย่างต่อเนื่อง และการพัฒนา workflow ที่ปรับปรุงได้ตามผลลัพธ์เชิงปฏิบัติการ เทคโนโลยีเสริม เช่น differential privacy, federated learning และมาตรฐานการออกใบรับรองความเป็นส่วนตัว อาจช่วยเพิ่มความเชื่อมั่นและขยายการนำไปใช้ได้อย่างยั่งยืน แต่หัวใจสำคัญยังคงเป็นการทดสอบความแม่นยำ การออกแบบ human‑in‑loop และการประเมินผลตอบแทนเชิงธุรกิจก่อนการปรับใช้ในระบบจริง



