
สตาร์ทอัพไทยเปิดตัวแพลตฟอร์มใหม่ “Private‑Sync LLM” ที่สัญญาว่าจะเปลี่ยนวิธีใช้งานโมเดลภาษาขององค์กรจากการพึ่งพาคลาวด์กลางเป็นการรันแบบส่วนตัวบนอุปกรณ์ — ทั้งมือถือและเครื่องคอมพิวเตอร์ของพนักงาน — พร้อมระบบซิงก์อัปเดตแบบเพียร์ทูเพียร์ (P2P) โดยไม่ผ่านเซิร์ฟเวอร์คลาวด์สาธารณะ ทำให้ข้อมูลสำคัญขององค์กรไม่ต้องถูกส่งออกไปยังศูนย์ข้อมูลภายนอก หวังลดความเสี่ยงการรั่วไหลของข้อมูลและรองรับการทำงานแบบออฟไลน์ในสภาพแวดล้อมที่ต้องการความเป็นส่วนตัวสูง
โดยภาพรวมแพลตฟอร์มนี้ออกแบบมาเพื่อตอบโจทย์องค์กรที่มีข้อจำกัดด้านความปลอดภัย เช่น ภาคการเงิน สุขภาพ และหน่วยงานรัฐ: โมเดลถูกดาวน์โหลดและรันภายในอุปกรณ์, การอัปเดตน้ำหนักหรือพารามิเตอร์ใช้การซิงก์ P2P แบบเข้ารหัส, และมีโหมดออฟไลน์เพื่อให้สามารถทำงานได้แม้เมื่อขาดการเชื่อมต่อ ตัวอย่างเช่น การสำรวจในแวดวงไอทีพบว่าเกือบ 6 ใน 10 องค์กรกังวลเกี่ยวกับการส่งข้อมูลไปยังคลาวด์สาธารณะ — Private‑Sync LLM จึงถูกนำเสนอเป็นทางเลือกที่เน้นความปลอดภัยและการคุ้มครองข้อมูลส่วนบุคคล
บทนำ: ข่าวสำคัญและภาพรวมหัวข้อ
บทนำ: ข่าวสำคัญและภาพรวมหัวข้อ
สตาร์ทอัพไทยเปิดตัวแพลตฟอร์มใหม่ชื่อ Private‑Sync LLM ซึ่งอนุญาตให้องค์กรรันโมเดลภาษาขนาดเล็กถึงขนาดกลางแบบส่วนตัวบนอุปกรณ์ของพนักงานทั้งบนมือถือและเครื่องเดสก์ท็อป พร้อมกับความสามารถในการซิงก์การอัปเดตโมเดลและข้อมูลการเรียนรู้แบบกระจายผ่านเครือข่าย P2P (peer‑to‑peer) โดยไม่ต้องส่งข้อมูลดิบหรือการเรียกใช้โมเดลไปยังคลาวด์สาธารณะ ตัวแพลตฟอร์มถูกออกแบบมาเพื่อลดความเสี่ยงด้านการรั่วไหลของข้อมูล เพิ่มระดับการควบคุมข้อมูลภายใน และรองรับความต้องการด้านความเป็นส่วนตัวของภาคธุรกิจที่เพิ่มสูงขึ้น
ฟีเจอร์หลักของ Private‑Sync LLM สรุปได้เป็นประเด็นสำคัญดังนี้:
- On‑device LLM: การรันโมเดลภาษาโดยตรงบนอุปกรณ์ของพนักงาน ช่วยให้การประมวลผลข้อความเกิดขึ้นภายในขอบเขตของอุปกรณ์ ไม่ต้องส่งคอนเทนต์ไปยังเซิร์ฟเวอร์ภายนอก
- P2P sync: การอัปเดตน้ำหนักโมเดลและข้อมูลการเรียนรู้แบบกระจายผ่านเครือข่ายเพื่อนถึงเพื่อน ช่วยให้สถานะของโมเดลคงที่และทันสมัยโดยไม่ต้องพึ่งคลาวด์สาธารณะ
- การเข้ารหัสและการควบคุมสิทธิ์: การเข้ารหัสแบบ end‑to‑end ระหว่างโหนดและนโยบายการควบคุมการเข้าถึงที่องค์กรกำหนดเองได้
- ความสามารถในการทำงานแบบออฟไลน์: พนักงานสามารถใช้ฟังก์ชันบางอย่างได้แม้ไม่มีการเชื่อมต่ออินเทอร์เน็ต เมื่อมีการเชื่อมต่อ ระบบจะซิงก์การอัปเดตอย่างค่อยเป็นค่อยไป
ความแตกต่างเชิงสำคัญเมื่อเทียบกับบริการคลาวด์ LLM ทั่วไป คือการย้ายจุดศูนย์กลางจากเซิร์ฟเวอร์กลางสาธารณะไปยังอุปกรณ์ปลายทางขององค์กร ทำให้มีข้อดีในด้านความเป็นส่วนตัวและลดพื้นผิวการโจมตี (attack surface) ของข้อมูล ตัวอย่างความแตกต่างเช่น:
- ข้อมูลข้อความและคอนเทนต์ที่สร้างขึ้นหรือป้อนโดยพนักงานจะไม่ถูกส่งไปยังผู้ให้บริการคลาวด์ภายนอก ลดความเสี่ยงจากการอ่านหรือเก็บสำเนาโดยผู้ให้บริการ
- การตอบสนองมีความหน่วงต่ำกว่า เนื่องจากไม่ต้องรอการเรียก API ข้ามเครือข่ายไปมาระหว่างอุปกรณ์กับคลาวด์
- องค์กรสามารถกำหนดนโยบายการอัปเดตโมเดลและการเก็บบันทึกได้โดยตรง แทนที่จะพึ่งพากฎระเบียบและนโยบายของผู้ให้บริการคลาวด์
เหตุผลที่เรื่องนี้มีความสำคัญต่อภาคธุรกิจมีทั้งเชิงปฏิบัติและเชิงกฎหมาย: ตามรายงานค่าใช้จ่ายจากการละเมิดข้อมูลหลายรายชี้ว่า การรั่วไหลของข้อมูล มีผลกระทบทางการเงินและชื่อเสียงอย่างมีนัยสำคัญ (เช่น รายงานยอดนิยมระบุค่าเฉลี่ยความเสียหายหลายล้านดอลลาร์ต่อเหตุการณ์) และกฎระเบียบด้านความคุ้มครองข้อมูลส่วนบุคคล (เช่น PDPA/GDPR) กำหนดข้อจำกัดชัดเจนเกี่ยวกับการย้ายข้อมูลข้ามพรมแดนและการเปิดเผยข้อมูลลูกค้า Private‑Sync LLM ช่วยให้องค์กร:
- ลดความเสี่ยงด้านการปฏิบัติตามกฎหมายและความรับผิดชอบกรณีข้อมูลรั่ว
- ป้องกันการเข้าถึงข้อมูลโดยบุคคลที่สามหรือผู้ให้บริการคลาวด์
- ตอบโจทย์การใช้งานที่ต้องการความล่าช้าน้อย เช่น ทีมขายหรือฝ่ายบริการลูกค้าที่ต้องการตอบสนองแบบเรียลไทม์
โดยรวมแล้ว การเปิดตัว Private‑Sync LLM เป็นสัญญาณว่าเทรนด์ของ AI สำหรับองค์กรกำลังเคลื่อนจากโมเดลที่พึ่งพาคลาวด์สาธารณะไปสู่โซลูชันที่ให้ความสำคัญกับความเป็นส่วนตัว การควบคุมข้อมูล และความเสถียรของการทำงานในระดับอุปกรณ์ ซึ่งเป็นประเด็นเชิงกลยุทธ์ที่ผู้บริหารและหัวหน้าฝ่ายไอทีควรพิจารณาเมื่อออกแบบนโยบายการใช้ AI ภายในองค์กร
สถาปัตยกรรมและเทคโนโลยีเบื้องหลัง
ภาพรวมสถาปัตยกรรม
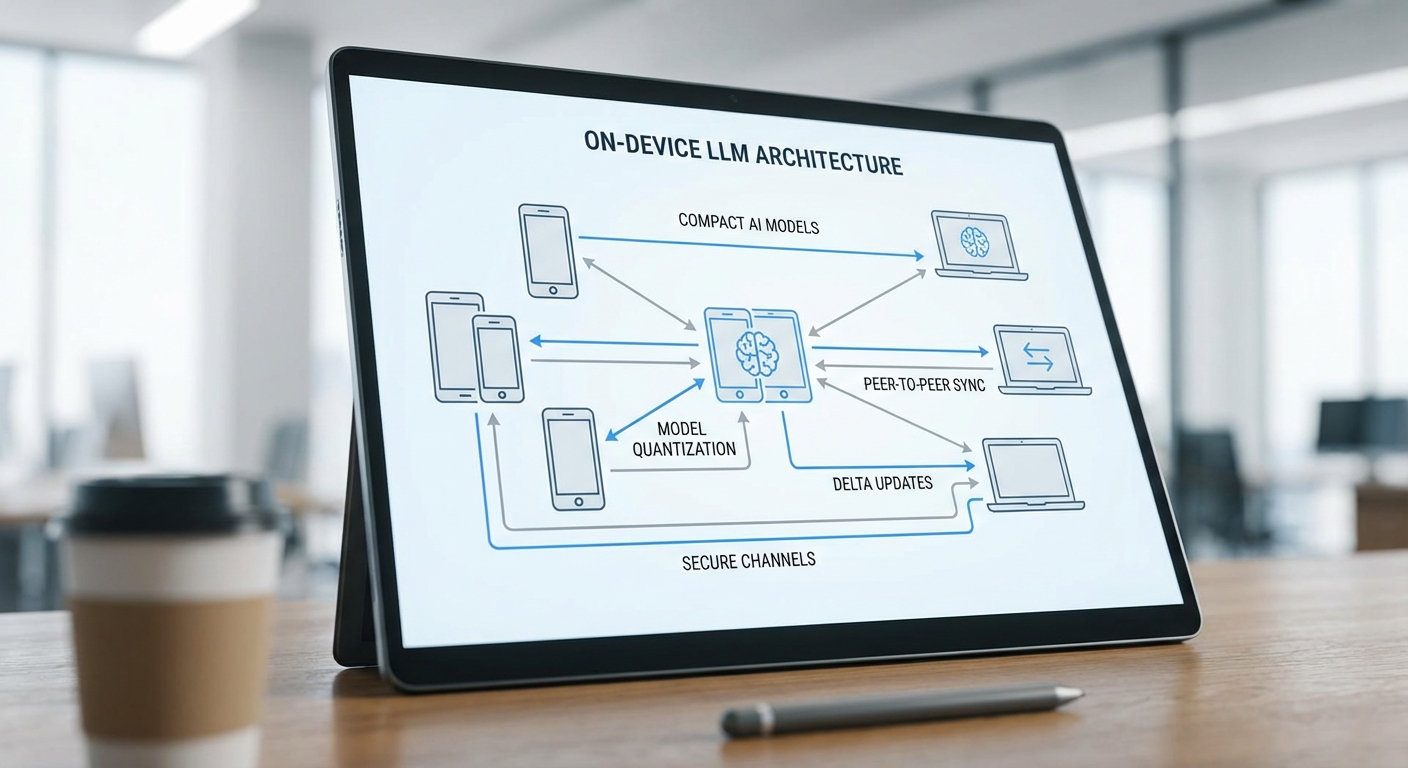
แพลตฟอร์ม Private‑Sync LLM ออกแบบมาเพื่อรันโมเดลภาษาขนาดใหญ่แบบส่วนตัวบนอุปกรณ์ปลายทาง (mobile / edge / เครื่องพนักงาน) โดยมีแนวคิดสำคัญ 3 ประการคือ: รันโมเดลบนอุปกรณ์ด้วยการย่อขนาดและเร่งการคำนวณ, ซิงก์พารามิเตอร์และแพตช์ระหว่างอุปกรณ์แบบ P2P เพื่อลดการพึ่งคลาวด์, และมีระบบจัดการเวอร์ชันพร้อมการตรวจสอบความสมบูรณ์ของโมเดลก่อนใช้งานจริง
การรันโมเดลบนอุปกรณ์ (On‑device inference)
เพื่อให้โมเดล LLM ทำงานได้บน CPU/NPUs ของอุปกรณ์ส่วนบุคคล แพลตฟอร์มใช้ชุดเทคนิคด้านโมเดลคอมเพรสชันและ runtime ที่ปรับแต่งเฉพาะ:
- Quantization — แปลงน้ำหนักจาก FP32/FP16 เป็นรูปแบบที่เล็กลง เช่น INT8 หรือ low‑bit (4‑bit Q4 / QLoRA) เพื่อลดขนาดโมเดล ตัวอย่างเช่น FP16 → INT8 มักลดขนาดได้ประมาณ 2× ขณะที่ 4‑bit อาจลดได้ 4× หรือมากกว่า ขึ้นกับเทคนิคที่ใช้
- Pruning & sparsity — ตัดน้ำหนักที่มีผลต่ำ (magnitude pruning) หรือใช้ structured pruning เพื่อลดพารามิเตอร์ โดยทั่วไปสามารถลดพารามิเตอร์ได้ในช่วง ~30–70% ขึ้นอยู่กับความทนต่อการสูญเสียความแม่นยำ
- Optimized runtimes — รองรับหลายกรอบการทำงานบนอุปกรณ์ เช่น ONNX Runtime Mobile, TensorFlow Lite (NNAPI), Core ML และไลบรารีเฉพาะทางเช่น llama.cpp หรือ GGML ที่ถูกออกแบบให้รันบน CPU/ARM/NEON หรือใช้ API ของ NPU
- Hardware acceleration — ใช้ประโยชน์จาก Mobile NPUs/GPU (เช่น Apple Neural Engine, Qualcomm Hexagon, MediaTek APU) โดยผ่านมาตรฐานอย่าง NNAPI, Metal หรือ Vulkan เพื่อเพิ่มประสิทธิภาพการอินเฟอร์เรนซ์ บนอุปกรณ์สมัยใหม่ความสามารถเฉพาะด้านมักอยู่ในช่วงหลาย TOPS (tera operations per second) ทำให้การตอบสนองแบบเรียลไทม์เป็นไปได้
การซิงก์แบบ P2P และ Delta Updates
แกนกลางของ Private‑Sync คือการกระจายการอัปเดตโมเดลระหว่างอุปกรณ์แบบเพียร์ทูเพียร์ เพื่อลดการส่งผ่านคลาวด์และข้อนัยสำคัญทางความเป็นส่วนตัว
- โปรโตคอล P2P — ระบบรองรับหลายเลเยอร์ของการเชื่อมต่อ เช่น libp2p สำหรับการสร้างเครือข่าย peer discovery และ stream multiplexing, WebRTC DataChannels สำหรับเบราว์เซอร์และอุปกรณ์ที่ต้องการ NAT traversal, และ QUIC สำหรับการส่งข้อมูลที่มี latency ต่ำ โดยมีการทำ hole punching และ mDNS/bootstrapping เพื่อหา peers ภายในองค์กร
- Gossip / epidemic propagation — การเผยแพร่แพตช์ใช้กลไก gossip เพื่อกระจายแพตช์ไปยังกลุ่มผู้ใช้ภายในองค์กรอย่างมีความทนทานและสเกลได้ โดยแต่ละ node จะแลกเปลี่ยนเมตาดาต้าและลิงก์ไปยังชาร์ดของแพตช์
- Delta (binary diff) updates — แทนการส่งไฟล์โมเดลเต็ม ระบบสร้าง delta ระหว่างเวอร์ชัน (เช่น bsdiff/rsync‑like or content‑addressable chunk diffs) เพื่อส่งเฉพาะความเปลี่ยนแปลง ผลลัพธ์คือการลดแบนด์วิดท์อย่างมาก: กรณีศึกษาในอุตสาหกรรมชี้ว่าการอัปเดตแบบ delta ช่วยลดขนาดการถ่ายโอนได้ราว 70–95% ขึ้นกับขนาดของการเปลี่ยนแปลง
- Chunking และ parallel transfer — โมเดลถูกแบ่งเป็นชาร์ดขนาดเล็กที่สามารถดาวน์โหลด/แลกเปลี่ยนขนานกันได้ ทำให้ใช้ประโยชน์จากหลาย peer ในเครือข่ายและลดเวลาการซิงก์
- ความปลอดภัยการส่งข้อมูล — การเชื่อมต่อ P2P ถูกป้องกันด้วยช่องทางเข้ารหัส (DTLS/Noise หรือ TLS-over-QUIC) และใช้การรับรองความถูกต้องของ peer (mutual auth) ภายในโดเมนองค์กร
การจัดการเวอร์ชันและการตรวจสอบความสมบูรณ์ของโมเดล
เพื่อรับประกันความสอดคล้องและความปลอดภัยของโมเดลระหว่างอุปกรณ์ แพลตฟอร์มใช้กลไกหลายชั้น:
- เวอร์ชันนิ่งและหมายเลข Epoch — แต่ละ release มีหมายเลขเวอร์ชัน (semantic/epoch) และ metadata ที่ระบุความเข้ากันได้ (compatibility matrix) ระหว่าง quantization schema และ runtime
- Content‑addressable storage & Merkle tree — ชาร์ดและไฟล์แพตช์ถูกระบุด้วย hash (SHA‑256) ในรูปแบบ content‑addressable ทำให้สามารถตรวจสอบความสมบูรณ์แบบเป็นชิ้นได้โดยใช้ Merkle proof ก่อนจะนำมาประกอบเป็นโมเดลฉบับสมบูรณ์
- Signature & chain of trust — ทุกเวอร์ชันและ delta มีลายเซ็นดิจิทัล (เช่น Ed25519) ลงนามโดยคีย์ขององค์กร การยืนยันลายเซ็นจะเป็นเงื่อนไขบังคับก่อนย้ายสลับโมเดลไปใช้งานจริง
- Atomic switch & canary rollouts — เมื่ออุปกรณ์ได้รับแพตช์ครบถ้วน ระบบจะตรวจสอบ checksum และ signature แล้วทำการสลับโมเดลแบบอะตอมนิก (swap file หรือ symlink) เพื่อลดความเสี่ยงขณะอัปเดต องค์กรสามารถทำ canary rollout โดยให้กลุ่มจำกัดเริ่มใช้งานก่อน เพื่อจับปัญหาการถดถอยของคุณภาพ
- Conflict resolution — ในกรณีที่มีการอัปเดตพร้อมกันจากหลายแหล่ง ระบบใช้เวอร์ชันเชิงเส้น (last‑known good epoch) หรือกฎการแก้ขัด (authoritative signature wins) แทนการพยายาม merge น้ำหนักแบบอัตโนมัติ ซึ่งซับซ้อนและเสี่ยงต่อความไม่เสถียร
กลไก fallback เมื่อต้องดึงแพตช์จากเซิร์ฟเวอร์องค์กร
แม้จะมุ่งหวัง P2P เป็นหลัก แต่แพลตฟอร์มเตรียมกลไกสำรองสำหรับกรณี peer ไม่เพียงพอหรือเครือข่ายแย่:
- เซิร์ฟเวอร์องค์กรเป็นแหล่งสำรอง — หากไม่พบ peers ที่มีแพตช์ครบ ระบบจะสลับไปดาวน์โหลดจากเซิร์ฟเวอร์ภายในองค์กรผ่าน HTTPS/QUIC ที่เข้ารหัส และยังคงตรวจสอบ signature และ checksum เหมือนเดิม
- นโยบาย QoS และ throttling — การดาวน์โหลดจากเซิร์ฟเวอร์กลางจะถูกจำกัดแบนด์วิดท์ตามนโยบายเพื่อลดผลกระทบต่อเครือข่ายหลักขององค์การ และสามารถตั้งเวลา (off‑peak windows) สำหรับการอัปเดตขนาดใหญ่
- Rollback และ emergency patches — ในกรณีที่แพตช์ใหม่ทำให้เกิดปัญหา ระบบสามารถกลับไปยังเวอร์ชันก่อนหน้าได้ทันทีและกระจาย emergency patch ผ่านทางเซิร์ฟเวอร์ที่เชื่อถือได้
- Audit trail — ทุกกิจกรรมซิงก์ จะบันทึก metadata แบบเข้ารหัส (who/when/which‑hash) เพื่อให้สามารถตรวจสอบหลังเหตุการณ์ได้ โดยไม่เก็บเนื้อหาการใช้งานของผู้ใช้
สรุปคือ Private‑Sync LLM ผสานหลายเทคโนโลยีทั้งการคอมเพรสและเร่งการคำนวณบนอุปกรณ์, เครือข่าย P2P ที่ทนทานพร้อมการส่งแพตช์แบบ delta เพื่อลดแบนด์วิดท์, และระบบจัดการเวอร์ชันที่เข้มงวดที่ใช้ hashing, signatures และนโยบาย fallback ไปยังเซิร์ฟเวอร์องค์กรเมื่อจำเป็น เพื่อให้เกิดสมดุลระหว่างความเป็นส่วนตัว ความปลอดภัย และความพร้อมใช้งานในสเกลองค์กร
ความปลอดภัยและความเป็นส่วนตัว: ลดความเสี่ยงข้อมูลรั่วอย่างไร
ความปลอดภัยระดับเครือข่าย: การเข้ารหัสแบบ End-to-End ระหว่างอุปกรณ์
แพลตฟอร์ม Private‑Sync LLM ใช้หลักการ การเข้ารหัสแบบ End‑to‑End (E2E) ระหว่าง peers ทุกคู่เพื่อให้มั่นใจว่าข้อมูลที่ส่งผ่านเครือข่าย P2P ไม่สามารถถูกอ่านหรือแก้ไขได้ระหว่างทาง โดยใช้การแลกคีย์แบบ ephemeral Diffie‑Hellman ร่วมกับอัลกอริธึมคีย์สาธารณะความปลอดภัยสูง (เช่น Elliptic Curve) เพื่อให้เกิด forward secrecy และลดความเสี่ยงเมื่อคีย์ใดคีย์หนึ่งถูกละเมิด
นอกจากนี้ แต่ละช่องทางการสื่อสารจะมีการตรวจสอบตัวตนแบบ mutual authentication ก่อนการเชื่อมต่อ และทุกรายการถ่ายโอนจะถูกปิดผนึกด้วยการตรวจสอบความสมบูรณ์ (hash) เพื่อป้องกันการแก้ไขข้อมูลโดยผู้โจมตีกลางช่องทาง (man‑in‑the‑middle) ระบบยังรองรับการเข้ารหัสที่ครอบคลุมทั้งการส่งข้อมูลแบบ real‑time และการซิงก์ไฟล์แพตช์โมเดล เพื่อให้ทุกการรับส่งมีความเป็นความลับและยืนยันความถูกต้องได้
การเซ็นดิจิทัลของแพตช์โมเดลและการควบคุมความสมบูรณ์
ทุกแพตช์โมเดลหรือไฟล์อัปเดตที่หมุนเวียนในเครือข่าย P2P จะถูกออกแบบให้ต้องมี ลายเซ็นดิจิทัล จากผู้พัฒนา/ผู้ดูแลระบบก่อนจะถูกติดตั้งบนอุปกรณ์ปลายทาง การใช้ลายเซ็นดิจิทัลร่วมกับ manifest ที่ประกอบด้วย hash (เช่น SHA‑256) และหมายเลขรุ่น ช่วยให้ระบบสามารถตรวจจับแพตช์ปลอม ป้องกันการโจมตีแบบ supply‑chain และสนับสนุนการย้อนกลับ (rollback protection) เมื่อจำเป็น
- การเซ็นด้วยคีย์สาธารณะ/ส่วนตัว (Asymmetric signing) — ยืนยันแหล่งที่มาและความสมบูรณ์ของแพตช์
- Manifest และ checksum — ตรวจสอบความเข้ากันได้และป้องกันการเปลี่ยนแปลงเนื้อหา
- การสำรองการยืนยันแบบหลายฝ่าย — ในกรณีเครือข่ายขนาดใหญ่ อาจต้องการ quorum ของลายเซ็นเพื่อยกระดับความเชื่อถือ

การลดจุดรวมข้อมูล (Single Point of Failure) และความเสี่ยงจากการพึ่งพาคลาวด์
หนึ่งในข้อได้เปรียบสำคัญของการประมวลผลบนอุปกรณ์และซิงก์แบบ P2P คือการลดความเสี่ยงจากจุดรวมข้อมูลเดียว — ไม่จำเป็นต้องส่งข้อมูลผู้ใช้งานทั้งหมดไปยังเซิร์ฟเวอร์กลางบนคลาวด์ ซึ่งลดโอกาสที่ผู้โจมตีจะได้ข้อมูลจำนวนมากจากการละเมิดเพียงจุดเดียว ปัญหาการตั้งค่าคอนฟิกผิดพลาดหรือการถูกโจมตีที่คลาวด์จึงส่งผลกระทบในวงกว้างน้อยลง
อย่างไรก็ตาม สถาปัตยกรรม P2P ก็มีความเสี่ยงเฉพาะตัว เช่น การโจมตีแบบ Sybil หรือการบุกรุกของอุปกรณ์ปลายทาง ตัวแพลตฟอร์มจึงใช้นโยบายป้องกันหลายชั้น เช่น การตรวจสอบสถานะของ peer ผ่านการยืนยันสิทธิ์ การจัดอันดับความน่าเชื่อถือของ node และการจำกัดการเผยแพร่แพตช์ถึงกลุ่มที่ได้รับอนุญาตเท่านั้น
ระบบควบคุมการเข้าถึง (RBAC) และการตรวจสอบย้อนหลัง
Private‑Sync LLM นำเสนอ RBAC (Role‑Based Access Control) เพื่อกำหนดสิทธิ์การเข้าถึงทรัพยากรแต่ละประเภทอย่างเข้มงวด โดยหลักการคือให้สิทธิ์แบบ least privilege เท่านั้น ผู้ดูแลระบบสามารถสร้างบทบาท (roles) ที่ชัดเจน เช่น ผู้เผยแพร่แพตช์ ผู้อนุมัติ และผู้ใช้งานทั่วไป พร้อมกับนโยบายการอนุญาตที่ละเอียด เช่น การจำกัดช่วงเวลา การจำกัดเชิงพื้นที่ และการจำกัดตามอุปกรณ์
ระบบยังเก็บบันทึกการทำงาน (audit logs) แบบเข้ารหัสบนอุปกรณ์และส่งสรุปแบบ aggregate (ด้วยเทคนิคเช่น differential privacy หากจำเป็น) เพื่อให้สามารถตรวจสอบย้อนหลังได้โดยไม่ส่งข้อมูลส่วนบุคคลไปยังศูนย์กลาง นอกจากนี้ยังรองรับการใช้งานคีย์ที่เก็บในฮาร์ดแวร์ (TPM / Secure Enclave) เพื่อเพิ่มความมั่นคงของการจัดการคีย์
เปรียบเทียบความเสี่ยง: คลาวด์ vs On‑device (สรุปเชิงปฏิบัติ)
โดยสรุป ประมวลผลบนคลาวด์ให้ความสะดวกและทรัพยากรสูง แต่มีความเสี่ยงสำคัญคือการรวมข้อมูลที่เป็นศูนย์กลางซึ่งกลายเป็นเป้าหมายที่มีมูลค่าสูง ข้อผิดพลาดในการตั้งค่าบัญชีคลาวด์หรือการโจมตีช่องโหว่ของบริการคลาวด์มักนำไปสู่การรั่วไหลของข้อมูลจำนวนมาก ในทางกลับกัน การประมวลผลบนอุปกรณ์ช่วยลดความเสี่ยงเชิงสถาปัตยกรรม แต่ต้องมีมาตรการคุ้มกันด้านการยืนยันตัวตนอุปกรณ์ การจัดการแพตช์ และการป้องกันอุปกรณ์ที่ถูกแทรกซึม
ตัวอย่างเชิงสถานการณ์: บริษัท A เลือกส่งข้อมูลผู้ใช้ไปประมวลผลบนคลาวด์กลาง แต่เมื่อมีการตั้งค่าบริการเก็บไฟล์สาธารณะผิดพลาด ข้อมูลสำคัญของลูกค้าถูกเปิดเผยเป็นจำนวนมาก เหตุการณ์นี้กินเวลา 72 ชั่วโมงกว่าที่ทีมจะตรวจพบและจำกัดผลกระทบ ในสถาปัตยกรรม P2P ที่ออกแบบมาอย่างดี ข้อมูลส่วนบุคคลนั้นยังคงถูกเก็บและประมวลผลบนอุปกรณ์ ทำให้แม้จะมีอุปกรณ์บางส่วนถูกเจาะ ก็ไม่สามารถรวบรวมข้อมูลลูกค้าทั้งหมดได้ในครั้งเดียว
ผลต่อการปฏิบัติตาม PDPA และการจัดเก็บข้อมูลภายในประเทศ
การประมวลผลบนอุปกรณ์และนโยบายไม่ส่งข้อมูลผู้ใช้ไปยังคลาวด์ช่วยสนับสนุนการปฏิบัติตาม PDPA และกฎระเบียบด้านความเป็นส่วนตัวอื่น ๆ ได้อย่างชัดเจน โดยเฉพาะเมื่อองค์กรต้องการให้ข้อมูลส่วนบุคคลถูกเก็บไว้ภายในประเทศ (data residency) แพลตฟอร์มสามารถกำหนดนโยบายการซิงก์ให้จำกัดขอบเขตการแลกเปลี่ยนเฉพาะในเครือข่ายภายในภูมิภาคหรือภายในองค์กรเท่านั้น
ข้อสำคัญที่ต้องมีคือการจัดทำเอกสารที่ชัดเจนเกี่ยวกับการเก็บและประมวลผลข้อมูล การได้รับความยินยอมจากเจ้าของข้อมูล และการจัดทำมาตรการด้านความปลอดภัยเชิงเทคนิคและบริหาร (เช่น การเข้ารหัส การจัดการคีย์ การควบคุมการเข้าถึง และ audit trail) ซึ่งทั้งหมดนี้ช่วยให้องค์กรสามารถตอบข้อเรียกร้องสิทธิ์ของเจ้าของข้อมูลตาม PDPA ได้อย่างรวดเร็วและครบถ้วน
ประสิทธิภาพ ปัจจัยจำกัด และการวัดผล (Benchmarks)
การรัน Private‑Sync LLM แบบ on‑device บนมือถือหรือเครื่องพนักงานเมื่อเทียบกับการเรียกใช้งานผ่านคลาวด์ มีประเด็นด้านประสิทธิภาพที่ต้องพิจารณาหลายมิติ ได้แก่ latency (เวลาในการตอบ), throughput (tokens/วินาที), การใช้พลังงานแบตเตอรี่, และข้อจำกัดด้านฮาร์ดแวร์ เช่น RAM, NPU, และ storage โดยตัวเลขที่นำเสนอด้านล่างเป็น ตัวอย่างประมาณการเชิงปฏิบัติ เพื่อให้ผู้อ่านเห็นภาพการตัดสินใจเชิงธุรกิจ — ค่าแท้จริงจะแตกต่างตามรุ่นอุปกรณ์ โทโพโลยีของโมเดล และการปรับแต่งเช่น quantization หรือใช้ NPU accelerator

ตัวอย่าง benchmark: latency และ throughput (on‑device vs cloud)
- เมตริกสำคัญที่ควรวัด — Time‑to‑First‑Token (TTFT), latency แบบเต็มคำตอบ (รวมการสร้าง n tokens), throughput (tokens/sec), peak RAM, และพลังงานต่อ token (mJ/token)
- ตัวอย่างประมาณการ latency (สำหรับการสร้าง 128 tokens, ค่าเป็นช่วงโดยประมาณ ขึ้นกับฮาร์ดแวร์และการ quantize):
- Cloud (GPU inference, พร้อม RTT เครือข่าย 50–150 ms): server inference 0.3–0.8 s + network RTT ⇒ รวมประมาณ 0.5–1.5 s
- On‑device high‑end phone (7B quantized, ใช้ NPU/accelerator): throughput 10–50 tokens/sec ⇒ สร้าง 128 tokens ใช้เวลาประมาณ 2.5–12.8 s
- On‑device mid‑range phone (7B quantized, CPU only): throughput 1–10 tokens/sec ⇒ เวลา 12.8–128 s
- On‑device 13B quantized (high‑end phone with large RAM/NPU): โดยทั่วไปช้ากว่า 7B 1.5–3 เท่า ขึ้นกับการรองรับ NPU และการจัดการหน่วยความจำ
- ตัวอย่างการตีความ: หากกรณีใช้งานต้องการ latency ต่ำกว่า 1 s (เช่น chat แบบโต้ตอบทันที) คลาวด์มักได้เปรียบจากคำนวณรวดเร็วบน GPU แต่ต้องแลกด้วย privacy และ dependency ของเครือข่าย ในทางกลับกัน on‑device ให้ความเป็นส่วนตัวสูงกว่าแต่ต้องยอมรับ latency ที่มากขึ้นหรือจำกัดขนาดคำตอบ
ข้อจำกัดด้านฮาร์ดแวร์: RAM, NPU, storage
ปัจจัยฮาร์ดแวร์เป็นตัวกำหนดว่าโมเดลขนาดใดจะทำงานได้บนอุปกรณ์แต่ละประเภท:
- RAM / working memory: โมเดล 7B แบบ quantized 4‑bit อาจต้องการ RAM ระหว่าง ~3–6 GB ขึ้นกับการจัดการชั้นหน่วยความจำ (memory mapping, offloading) ขณะที่ 13B แม้จะ quantized แล้วก็อาจต้องการ 6–12 GB หรือมากกว่า หากไม่มีการชาร์ดหรือ offload ไปยัง storage
- Storage: ขนาดไฟล์โมเดล (disk) ประมาณ 3–6 GB สำหรับ 7B (หลัง quantize, ขึ้นกับรูปแบบ int8/int4) และ 6–13 GB สำหรับ 13B; ต้องเผื่อพื้นที่เพิ่มเติมสำหรับ cache และ swap
- NPU / Accelerator: การเร่งด้วย NPU (เช่น Apple Neural Engine, Android NPUs, หรือ DSPs) ช่วยเพิ่ม throughput และลดพลังงานต่อ token อย่างมาก หากเฟรมเวิร์กและ kernel ถูก optimize ให้ใช้ NPU แต่วิธีการแตกต่างกันตามผู้ผลิตชิป
- ความร้อนและ thermal throttling: การประมวลผลหนักบนมือถือทำให้เกิดการลดความถี่ (throttling) ทำให้ throughput ลดลงเมื่อทำงานต่อเนื่อง
การวัดผลเชิงปฏิบัติ (แนะนำโปรโตคอล benchmark)
เพื่อให้การเปรียบเทียบเป็นมาตรฐานสำหรับการตัดสินใจเชิงธุรกิจ ควรกำหนดโปรโตคอลการทดสอบดังนี้:
- กำหนด workload แบบเดียวกัน เช่น สร้าง 128 tokens จาก prompt ขนาด 32 tokens
- วัด TTFT, total latency, throughput (tokens/sec), peak RAM, และระดับการใช้พลังงาน (วัดด้วย power meter หรือ API ของอุปกรณ์) — ทำซ้ำหลายรอบเพื่อหาค่าเฉลี่ยและแปรปรวน
- เปรียบเทียบทั้ง 3 โหมด: local CPU only, local NPU accelerated, และ cloud (รวม RTT เครือข่ายจากเขตปฏิบัติการจริงของผู้ใช้)
- วัดผลในสภาวะแบตเตอรี่ต่าง ๆ (full battery vs 20% battery) เพื่อสังเกตผลกระทบของ battery saver / thermal management
แนวทางปรับปรุงประสิทธิภาพ: trade‑offs และเทคนิคที่ใช้ได้จริง
เพื่อให้ Private‑Sync LLM บนเครื่องพนักงานใช้งานได้จริง บริษัทสตาร์ทอัพสามารถใช้เทคนิคต่อไปนี้เพื่อลด latency และ resource footprint โดยยังรักษาความเป็นส่วนตัว:
- Quantization — int8 / int4 quantization ลดขนาดโมเดลและ RAM ที่ต้องการอย่างมาก แต่ต้องแลกกับความแม่นยำบางส่วน การใช้ quantization-aware training (QAT) สามารถชดเชย loss ของความแม่นยำได้
- Distillation — สร้าง student model ขนาดเล็กจาก teacher ขนาดใหญ่เพื่อลด latency และค่าใช้จ่าย แม้จะสูญเสียความสามารถบางด้าน แต่ตอบโจทย์ latency-critical use cases
- Pruning และ sparse models — ตัดพารามิเตอร์ที่มีผลน้อยเพื่อลดการคำนวณ แต่ต้องออกแบบให้ไม่ส่งผลกระทบรุนแรงต่อคุณภาพ
- Operator fusion และ kernel optimization — ปรับ runtime ให้ใช้ประโยชน์จาก NPU/DSP ผ่าน backend ที่ optimized (เช่น ONNX Runtime, TensorFlow Lite delegate, หรือ custom kernels)
- Hybrid / split inference — ทำ inference บางส่วนบน device (เช่น encoder/local prompt processing) แล้วส่งข้อมูลไม่ระบุตัวตนหรือ distilled features ไปคลาวด์เมื่อจำเป็น เป็นจุดสมดุลระหว่าง privacy และ performance
- P2P sync และ incremental updates — การส่งเฉพาะ delta ของพารามิเตอร์หรือเทคนิค federated model patching ลดแบนด์วิดท์และเวลาอัปเดต เมื่อเชื่อมต่อเฉพาะตอนมีการเปลี่ยนแปลงสำคัญ
Trade‑offs ระหว่างความเป็นส่วนตัวและประสิทธิภาพ
สรุปเชิงนโยบาย: การเลือกสถาปัตยกรรมขึ้นกับลำดับความสำคัญขององค์กร
- เน้น privacy สูงสุด — รันทั้งหมดบน device: ข้อดีคือข้อมูลไม่ออกนอกเครื่อง ลดความเสี่ยงการรั่วไหล แต่ต้องเผชิญ latency สูงขึ้น, ค่าเครื่องสูง (high‑end devices) และการจัดการ lifecycle ของโมเดลที่ซับซ้อน
- เน้น performance & latency ต่ำสุด — ใช้คลาวด์เต็มรูปแบบ: ได้ throughput/latency ดีและ scale ได้ แต่ต้องบริหารความเสี่ยงด้านข้อมูล (encryption, access control, private clouds) และมี dependency ต่อเครือข่าย
- โซลูชันไฮบริด — การประมวลผลเท่าที่จำเป็นบน device และส่งงานที่หนักหรือไม่เป็นความลับไปคลาวด์ เป็น trade‑off ที่สมดุลที่สุดในเชิงธุรกิจ แต่เพิ่มความซับซ้อนทางสถาปัตยกรรม
ท้ายที่สุด การตัดสินใจใช้โมเดลขนาดใด และการวางระบบ Private‑Sync LLM ควรอิงกับ benchmark เชิงปฏิบัติบนอุปกรณ์เป้าหมาย การทดลองใช้ quantization/distillation ร่วมกับการวัดจริง (latency, throughput, RAM, battery) จะช่วยให้องค์กรประเมินความคุ้มค่าระหว่างความเป็นส่วนตัวและประสิทธิภาพได้อย่างมีหลักฐานรองรับ
กรณีใช้งานและตัวอย่างในอุตสาหกรรม
กรณีใช้งานและตัวอย่างในอุตสาหกรรม
แพลตฟอร์ม Private‑Sync LLM ดีไซน์มาเพื่อตอบโจทย์องค์กรที่ต้องจัดการข้อมูลอ่อนไหวโดยไม่ส่งข้อมูลดิบขึ้นคลาวด์ ทำให้เกิดกรณีใช้งานที่ชัดเจนในหลายอุตสาหกรรม โดยเฉพาะการเงิน สุขภาพ หน่วยงานรัฐ และองค์กรที่ต้องเก็บรักษาความลับภายในองค์กร เช่น งานด้านความปลอดภัยข้อมูลลูกค้า เอกสารทางกฎหมาย และบันทึกการรักษา ผู้ใช้สามารถรันโมเดลภาษาบนมือถือหรือเครื่องของพนักงานแล้วซิงก์อัปเดตโมเดลผ่านเครือข่าย P2P ภายในองค์กร ซึ่งลดการเปิดเผยข้อมูลแก่บุคคลที่สามและช่วยให้การควบคุมการเข้าถึงเป็นไปตามนโยบายความเป็นส่วนตัวขององค์กรได้อย่างเข้มงวด
อุตสาหกรรมเป้าหมายหลักและกรณีใช้งานที่เหมาะสมมีดังนี้:
- การเงิน (Banking & FinTech) — ใช้ Private‑Sync LLM สำหรับ private assistants ของฝ่ายบริการลูกค้าและที่ปรึกษาการลงทุนที่ประมวลผลข้อมูลบัญชี-ธุรกรรมภายในอุปกรณ์พนักงาน ช่วยให้สามารถให้คำแนะนำเชิงส่วนบุคคลโดยไม่ต้องเปิดเผยข้อมูลต่อผู้ให้บริการคลาวด์ภายนอก
- สาธารณสุข (Healthcare) — ระบบช่วยตัดสินใจทางการแพทย์บนแท็บเล็ตของทีมแพทย์สำหรับการเรียกดูแนวทางการรักษา สรุปบันทึกผู้ป่วย (secure note summarization) และค้นหาเอกสารในภายในโรงพยาบาล (on‑device document search) โดยข้อมูลไม่หลุดออกไปนอกเครือข่ายโรงพยาบาล
- หน่วยงานรัฐและองค์กรความมั่นคง — การวิเคราะห์เอกสารความลับ การจัดการนโยบาย และการฝึกอบรมพนักงานภายใน (on‑prem) ที่ต้องเป็นไปตามข้อกำหนดทางกฎหมายหรือความมั่นคง
- องค์กรที่ต้องการปกป้องทรัพย์สินทางปัญญา — ทีม R&D และทีมกฎหมายใช้โมเดลเพื่อสรุปโน้ตการวิจัย ค้นหาเอกสารภายใน และสร้างร่างเอกสารโดยข้อมูลไม่ออกนอกองค์กร
ตัวอย่างการใช้งานเชิงปฏิบัติที่จับต้องได้ ได้แก่:
- Private assistants บนเครื่องพนักงาน — ผู้ใช้งานสามารถถามคำถามเกี่ยวกับนโยบายหรือข้อมูลลูกค้าและได้รับคำตอบแบบเฉพาะเจาะจงโดยที่ข้อมูลทั้งหมดประมวลผลภายในอุปกรณ์หรือเครือข่ายภายในองค์กร
- Secure note summarization — การสรุปบันทึกการประชุมหรือบันทึกผู้ป่วยเป็นสรุปที่ใช้ภายใน โดยสตริปข้อมูลช่วยระบุข้อมูลจุดอ่อนไหวก่อนจัดเก็บหรือแชร์
- On‑device document search — ค้นหาเอกสารภายในเครื่องหรือเซิร์ฟเวอร์ภายในองค์กรด้วยการเรียก LLM แบบออฟไลน์ ลดเวลาในการค้นหาจากนาทีเป็นวินาทีในหลายองค์กร
- การผสานกับ IoT และอุปกรณ์ทางการแพทย์ — อุปกรณ์ IoT ในโรงงานหรือโรงพยาบาลเรียกคำแนะนำแบบเรียลไทม์และซิงก์โมเดลเฉพาะพื้นที่ผ่าน P2P โดยไม่ส่งข้อมูลคนไข้หรือข้อมูลการผลิตออกนอกไซต์
- การฝึกอบรมพนักงานพร้อมข้อมูลเฉพาะองค์กร — สร้างโมดูลฝึกอบรมที่ใช้ตัวอย่างภายในและปรับปรุงผ่านการซิงก์ P2P ทำให้การเรียนรู้มีความเกี่ยวข้องและปลอดภัย
เคสศึกษา (สมมติ) — โรงพยาบาลเอกชน: ทีมแพทย์ในโรงพยาบาลแห่งหนึ่งติดตั้ง Private‑Sync LLM บนแท็บเล็ตของแพทย์และเครื่องโน้ตบุ๊กของพยาบาล ทำให้ทีมสามารถสรุปบันทึกผู้ป่วยแบบเรียลไทม์และค้นหาแนวทางการรักษาโดยไม่ต้องส่งบันทึกไปยังคลาวด์ ผลการทดสอบภายในแสดงว่าเวลาที่ใช้ในการค้นหาแนวทางลดลงจากเฉลี่ย 7 นาทีต่อกรณี เหลือ 2.5 นาที และอัตราการรั่วไหลของข้อมูลที่เข้าถึงภายนอกเป็นศูนย์เมื่อเทียบกับระบบคลาวด์ทั่วไป
การประเมินผลประโยชน์เชิงธุรกิจของการนำ Private‑Sync LLM มาใช้สามารถสรุปได้ดังนี้:
- ลดความเสี่ยงด้านข้อมูล — การเก็บและประมวลผลข้อมูลภายในอุปกรณ์หรือเครือข่ายภายในช่วยลดโอกาสการรั่วไหลจากผู้ให้บริการคลาวด์ภายนอก และช่วยให้องค์กรปฏิบัติตามข้อกำหนดด้านความเป็นส่วนตัวและกฎระเบียบได้ง่ายขึ้น
- ปรับปรุงเวลาตอบสนอง — การประมวลผลบนอุปกรณ์และการค้นหาภายในเปลี่ยนเวลาตอบสนองของพนักงานจากนาทีเป็นวินาที ส่งผลให้การให้บริการลูกค้าและการตัดสินใจภายในเร็วขึ้นและมีประสิทธิภาพขึ้น
- เพิ่มการยอมรับจากผู้ใช้ (user adoption) — เมื่อนักปฏิบัติงานมั่นใจว่าข้อมูลของพวกเขาไม่ถูกส่งออกไปนอกองค์กร การใช้งานแอปพลิเคชันช่วยงานจะสูงขึ้น ตัวอย่างเชิงประมาณแสดงถึงการเพิ่มอัตราการใช้งานภายใน 3–6 เดือนหลังนำระบบไปทดสอบ
- ลดต้นทุนความเสี่ยงและการปฏิบัติตามกฎระเบียบ — ค่าใช้จ่ายที่เกี่ยวข้องกับการละเมิดข้อมูลและค่าปรับจากการไม่ปฏิบัติตามกฎระเบียบสามารถลดลงเมื่อองค์กรควบคุมการไหลของข้อมูลได้เอง
- ยืดหยุ่นในการปรับแต่งเพื่อความได้เปรียบทางธุรกิจ — องค์กรสามารถฝังความรู้ภายในและปรับปรุงโมเดลให้สอดคล้องกับกระบวนการเฉพาะเจาะจง ส่งผลให้การช่วยงานหรือการวิเคราะห์มีความแม่นยำและเป็นประโยชน์ต่อธุรกิจมากขึ้น
สรุปแล้ว Private‑Sync LLM เหมาะสำหรับองค์กรที่ต้องการสมดุลระหว่างความสามารถของโมเดลภาษาขั้นสูงและข้อกำหนดด้านความเป็นส่วนตัว โดยเฉพาะอย่างยิ่งในภาคการเงิน สาธารณสุข หน่วยงานรัฐ และองค์กรที่รักษาความลับเชิงพาณิชย์ การนำไปใช้อย่างรอบคอบสามารถให้ทั้งประสิทธิภาพการทำงานที่ดีขึ้น ความปลอดภัยที่เข้มงวดขึ้น และการยอมรับจากผู้ใช้อย่างเป็นรูปธรรม
โมเดลธุรกิจ การตลาด และกฎระเบียบที่ต้องพิจารณา
โมเดลธุรกิจที่เป็นไปได้และรูปแบบรายได้
สำหรับสตาร์ทอัพที่พัฒนาแพลตฟอร์ม Private‑Sync LLM บนมือถือหรือเครื่องพนักงาน มีโมเดลรายได้เชิงพาณิชย์ที่เป็นไปได้หลายรูปแบบซึ่งสามารถผสมผสานกันได้เพื่อสร้างรายได้และความยืดหยุ่นทางการตลาด:
- License แบบองค์กร (Perpetual/Term license) — คิดค่าไลเซนส์แบบครั้งเดียวหรือแบบสัญญาระยะยาวสำหรับการใช้งานในองค์กรใหญ่ พร้อมค่าบำรุงรักษา (maintenance/support) ปีต่อปี และค่าอัปเดตโมเดล (model update fees) ตัวอย่างการใช้งานเหมาะกับธนาคารหรือหน่วยงานภาครัฐที่ต้องการความคงที่ด้านกฎระเบียบ
- Subscription ต่ออุปกรณ์ (Per‑device / Per‑seat subscription) — คิดค่าบริการเป็นรายอุปกรณ์หรือผู้ใช้งานต่อเดือน/ต่อปี เหมาะสำหรับธุรกิจที่มีฟลีทอุปกรณ์ขนาดกลางถึงใหญ่ เช่น เครือร้านค้าปลีกหรือโรงพยาบาล ซึ่งช่วยให้ลูกค้าควบคุมต้นทุนได้ง่ายและขยายตามการเติบโตของผู้ใช้
- Managed Service / Fully‑managed offering — ให้บริการบริหารจัดการทั้งเครือข่ายอุปกรณ์ การซิงก์ P2P การอัปเดตโมเดล และการเฝ้าระวังความปลอดภัยเป็นบริการต่อเนื่อง (MSP/VAR model) โดยเรียกเก็บเป็นค่าบริการรายเดือนรวม SLA และการตรวจสอบความปลอดภัย เหมาะกับลูกค้าที่ไม่มีทรัพยากร IT เพียงพอ
- Hybrid models — ผสาน license พื้นฐานกับ subscription สำหรับฟีเจอร์พรีเมียม เช่น ฟังก์ชันการตรวจสอบแบบเรียลไทม์ การสำรองข้อมูลแบบเข้ารหัส หรือการรวมเข้ากับระบบ SI ของลูกค้า
ช่องทางการขายและการสร้างพาร์ทเนอร์เชิงกลยุทธ์
การขยายตลาดสำหรับโซลูชันที่เน้นความเป็นส่วนตัวและการรันแบบกระจายต้องอาศัยเครือข่ายพาร์ทเนอร์ที่แข็งแรง:
- ระบบนิเวศ MSPs และ Managed VARs — ผู้ให้บริการบริหารอุปกรณ์และผู้จัดจำหน่ายมูลค่าเพิ่ม (VARs) สามารถนำเสนอแพ็กเกจพร้อมติดตั้งและบริการหลังการขาย ซึ่งช่วยลดแรงเสียดทานในการนำไปใช้สำหรับองค์กรขนาดกลางและขนาดย่อม
- พันธมิตรด้านการบูรณาการระบบ (SI) — หน่วยงาน integrator ช่วยผสานระบบ Private‑Sync เข้ากับโครงสร้างพื้นฐานภายในองค์กร เช่น LDAP, IAM, SIEM และกระบวนการ DevSecOps
- พันธมิตรเชิงอุตสาหกรรม — ธนาคาร โรงพยาบาล และผู้ให้บริการโทรคมนาคมมักเป็นพอร์ตโฟลิโอเป้าหมาย โดยอาจร่วมมือด้านการติดตั้งพรี‑ทู‑โพรดักชันและการรับรองตามมาตรฐานภาคอุตสาหกรรม
- โมเดล go‑to‑market แบบ OEM/White‑label — เสนอแพลตฟอร์มให้กับผู้ผลิตฮาร์ดแวร์มือถือหรือซอฟต์แวร์องค์กรในรูปแบบ OEM เพื่อลดต้นทุนการตลาดและเร่งการยอมรับ
ปัจจัยการยอมรับจากองค์กร: TCO, การตรวจสอบความปลอดภัย และ SLA
การตัดสินใจของฝ่าย IT และ CISO ต่อโซลูชัน Private‑Sync มักพิจารณาจากสามปัจจัยหลัก:
- ต้นทุนรวมเป็นเจ้าของ (TCO) — แม้การรันโมเดลบนอุปกรณ์จะลดความเสี่ยงจากการส่งข้อมูลขึ้นคลาวด์ แต่จะมีต้นทุนฮาร์ดแวร์ การจัดการพลังงาน ค่าเชิงปฏิบัติการ (ops) และการอัปเดตซอฟต์แวร์ที่เพิ่มขึ้น ในระยะสั้น TCO อาจสูงกว่าคลาวด์ 10–30% ขึ้นอยู่กับขนาดฟลีทและความถี่ในการอัปเดตโมเดล แต่ในระยะยาวองค์กรอาจลดความเสี่ยงจากค่าปรับด้านข้อมูลและค่าใช้จ่ายประกันความเสี่ยงได้
- การตรวจสอบความปลอดภัย (Security audits & certifications) — องค์กรขนาดใหญ่มักต้องการผลการทดสอบ penetration test, third‑party audit (เช่น SOC2, ISO 27001) และความสามารถในการตรวจสอบ (forensics/immutable logs) สำหรับการซิงก์และการอัปเดตโมเดล
- ข้อตกลงระดับบริการ (SLAs) — ผู้ใช้ต้องการการรับประกันด้าน uptime, latency ของโมเดลในการตอบคำถามและเวลาการกู้คืนหลังเหตุขัดข้อง รวมถึง SLA สำหรับการปล่อยแพตช์ความปลอดภัยและการอัปเดตโมเดล
ข้อกำกับดูแลและปัจจัยความสอดคล้องทางกฎหมาย
การนำ Private‑Sync LLM มาใช้ต้องพิจารณากรอบกฎหมายทั้งในประเทศและระหว่างประเทศอย่างรอบคอบ:
- PDPA (ประเทศไทย) — ต้องคำนึงถึงข้อกำหนดด้านการเก็บรักษาข้อมูลส่วนบุคคล เช่น ความชอบด้วยกฎหมายของการประมวลผล วัตถุประสงค์ที่ชัดเจน และการดูแลสิทธิของเจ้าของข้อมูล (การเข้าถึง แก้ไข ขอให้ลบ) สถาปัตยกรรม P2P ที่ไม่ผ่านคลาวด์ต้องออกแบบกระบวนการให้สามารถตอบคำขอของเจ้าของข้อมูลได้ทันตาม PDPA
- GDPR และข้อกำหนดระหว่างประเทศ — หากมีการเชื่อมต่อข้ามพรมแดนหรือมีพนักงานต่างชาติ ข้อกำหนดเรื่องการโอนข้อมูลข้ามประเทศ (transfer mechanisms), การประเมินผลกระทบด้านความเป็นส่วนตัว (DPIA) และการบันทึกกิจกรรมการประมวลผลต้องได้รับการจัดเตรียม
- ข้อกำหนดการเก็บข้อมูลภายในประเทศ — แม้ PDPA เองอาจไม่กำหนดการล็อกข้อมูลไว้ในประเทศโดยตรง แต่บางภาคส่วน (การเงิน สุขภาพ) มีข้อบังคับภาคส่วนที่ต้องเก็บข้อมูลภายในประเทศหรืออยู่ภายใต้การควบคุมของธนาคารกลาง/หน่วยงานกำกับ ควรวิเคราะห์แยกตามภาคอุตสาหกรรม
- การบันทึกการเปลี่ยนแปลงโมเดล (Model change logging) — ต้องเก็บประวัติการเปลี่ยนแปลงโมเดล (versioning), คำอธิบายการฝึก (model card), รายการข้อมูลเทรนนิงที่มีนัยสำคัญต่อความเป็นส่วนตัว และหลักฐานการตรวจสอบความปลอดภัย เพื่อรองรับการตรวจสอบย้อนหลังและการปฏิบัติตามกฎระเบียบ
ความท้าทายเชิงปฏิบัติการและการเปลี่ยนพฤติกรรมภายในองค์กร
แม้แนวคิด Private‑Sync จะตอบโจทย์ความเป็นส่วนตัว แต่การนำไปใช้งานจริงเผชิญกับอุปสรรคสำคัญ:
- การเปลี่ยนพฤติกรรมของฝ่าย IT — ทีม IT ต้องย้ายจากแนวคิดการบริหารจัดการแบบรวมศูนย์บนคลาวด์สู่การบริหารแบบกระจาย (edge management) ซึ่งต้องเพิ่มทักษะด้านการจัดการเฟิร์มแวร์ อัปเดตโมเดลแบบ P2P และการแก้ปัญหาที่เกิดบนอุปกรณ์ปลายทาง
- ค่าใช้จ่ายการบำรุงรักษาและการอัปเดต — การอัปเดตโมเดลบ่อยครั้งจำเป็นต้องมีโครงสร้างพื้นฐานสำหรับ distribution, integrity checks (เช่น signatures), rollback mechanisms และการตรวจสอบหลังอัปเดต ซึ่งเป็นงานต่อเนื่องที่เพิ่มค่าใช้จ่ายบุคลากรและระบบ
- การจัดการความเสี่ยงด้านคุณภาพโมเดล — การซิงก์แบบ P2P อาจก่อให้เกิดความแตกต่างของเวอร์ชันในแต่ละอุปกรณ์ ต้องมีนโยบายการคัดกรองเวอร์ชัน การทดสอบแบบก้าวหน้า (canary rollouts) และเมตริกการประเมินคุณภาพเพื่อป้องกันการเบี่ยงเบน
- การยอมรับจากผู้ใช้ (User adoption) — ฝ่ายธุรกิจและพนักงานต้องได้รับการอบรมเกี่ยวกับขอบเขตความสามารถและข้อจำกัดของโมเดล ส่วนความกังวลด้านความสะดวกในการใช้งาน (UX) และประสิทธิภาพการตอบสนองต้องถูกวัดและปรับปรุงอย่างต่อเนื่อง
สรุปคือ สตาร์ทอัพที่เสนอ Private‑Sync LLM มีโอกาสทางธุรกิจสูงโดยเฉพาะในภาคที่ต้องการความลับและการควบคุมข้อมูล แต่ต้องออกแบบโมเดลธุรกิจที่ยืดหยุ่น เลือกช่องทางการขายเชิงพาร์ทเนอร์ และสร้างกรอบการปฏิบัติตามกฎระเบียบพร้อมกระบวนการบันทึกการเปลี่ยนแปลงโมเดล เพื่อให้การนำไปใช้งานในระดับองค์กรเป็นไปได้จริงและยั่งยืน
เปรียบเทียบ: Private‑Sync LLM vs Cloud LLM vs Hybrid
เปรียบเทียบ: Private‑Sync LLM vs Cloud LLM vs Hybrid
การเลือกสถาปัตยกรรม LLM สำหรับองค์กรต้องพิจารณาหลายปัจจัยหลัก ได้แก่ ความเป็นส่วนตัว ข้อมูลและการปฏิบัติตามกฎหมาย, ความเสถียรและ latency, ต้นทุนทั้งระยะสั้นและระยะยาว รวมถึง การบำรุงรักษา และความซับซ้อนของการจัดการ ในที่นี้เราจะเปรียบเทียบสามแนวทางยอดนิยม—Private‑Sync (on‑device + P2P), Cloud LLM (centralized), และ Hybrid—โดยสรุปข้อดีข้อเสียและตัวอย่างเชิงตัวเลขที่ใช้ประเมินการตัดสินใจ
-
ความเป็นส่วนตัว (Privacy)
- Private‑Sync: ให้ความเป็นส่วนตัวสูงสุดเพราะข้อมูลประมวลผลอยู่บนอุปกรณ์ของพนักงาน และการซิงก์ผ่าน P2P ช่วยลดการส่งข้อมูลขึ้นคลาวด์ ตัวอย่างเช่น ระบบที่ออกแบบให้เก็บ context ระดับองค์กรภายในเครือข่าย P2P อาจลดการส่งข้อมูลไปยังเซิร์ฟเวอร์กลางได้มากกว่า 80% ซึ่งช่วยลดความเสี่ยงการรั่วไหลและสนับสนุนการปฏิบัติตามกฎหมายคุ้มครองข้อมูล (เช่น PDPA)
- Cloud LLM: ประสิทธิภาพการประมวลผลสูง แต่ข้อมูลต้องส่งไปยังเซิร์ฟเวอร์กลาง ทำให้มีความเสี่ยงต่อการรั่วไหล การเข้าถึงโดยบุคคลที่สาม หรือปัญหา compliance โดยเฉพาะสำหรับข้อมูลความลับของธุรกิจและข้อมูลส่วนบุคคลที่มีข้อจำกัด
- Hybrid: สามารถออกแบบให้ข้อมูลสำคัญ/ความลับประมวลผลบนอุปกรณ์ ส่วนงานที่ต้องการพลังคำนวณสูงส่งไปคลาวด์ แต่การแบ่งงานนี้ต้องกำหนดนโยบายและกลไกควบคุมข้อมูลที่ชัดเจน มิฉะนั้นอาจเกิดช่องว่างด้านความเป็นส่วนตัว
-
ความเสถียรและ Latency
- Private‑Sync: โดยทั่วไปตอบสนองได้เร็วเมื่อประมวลผลบนอุปกรณ์ (latency แบบ on‑device มักอยู่ในช่วง 10–200 ms ขึ้นกับขนาดโมเดลและฮาร์ดแวร์) และยังรองรับการทำงานออฟไลน์ได้เต็มรูปแบบสำหรับฟีเจอร์พื้นฐาน แต่ performance อาจผันผวนบนอุปกรณ์รุ่นเก่าหรือภาระงานหนัก
- Cloud LLM: มีพลังประมวลผลสูงและรองรับโมเดลขนาดใหญ่ (เช่น หลายสิบพันล้านพารามิเตอร์) แต่มี latency ที่ขึ้นกับเครือข่ายและตำแหน่งเซิร์ฟเวอร์ โดยปกติจะอยู่ในช่วง 100–500 ms หรือมากกว่าในสภาพแวดล้อมมือถือ/เครือข่ายช้า และอาจเกิดปัญหาคอขวดเมื่อโหลดสูง
- Hybrid: ให้ความยืดหยุ่นสูงสุด: งาน latency ต่ำหรือข้อมูลสำคัญรันบนอุปกรณ์ ขณะที่งานที่ต้องการความแม่นยำสูงหรือบริบทยาวส่งไปคลาวด์ การออกแบบ fallback และ orchestration เป็นสิ่งจำเป็นเพื่อลดปัญหา inconsistent experience
-
ต้นทุนและการบำรุงรักษา
- Private‑Sync: ต้นทุนเริ่มต้นอาจสูงเนื่องจากต้องลงทุนในเทคนิคปรับแต่งโมเดล (quantization, pruning), การจัดการรุ่นโมเดลบนอุปกรณ์ และการวางระบบซิงก์ P2P แต่เมื่อใช้งานในปริมาณมาก OPEX ของการเรียกใช้งานแบบคลาวด์จะลดลง ตัวอย่างองค์กรที่มีกลุ่มผู้ใช้ภายในหลายพันคน อาจคุ้มค่าที่จะลงทุน upfront เพื่อหลีกเลี่ยงค่า inference บนคลาวด์ที่เพิ่มขึ้นตามการใช้งาน
- Cloud LLM: มีโมเดลคุณภาพสูงแบบบริการตามการใช้งาน (pay‑per‑inference) ช่วยลดต้นทุนเริ่มต้น แต่มีค่าใช้จ่ายต่อเนื่องสูงและความเสี่ยงการล็อกซัพพลายเออร์ (vendor lock‑in) รวมถึงค่าใช้จ่ายด้านความปลอดภัยและการตรวจสอบการปฏิบัติตามข้อกำหนด
- Hybrid: ต้องการทั้งการลงทุนบนอุปกรณ์และคลาวด์ รวมถึงระบบ orchestration, policy enforcement และ monitoring จึงมีความซับซ้อนและค่าใช้จ่ายในการบำรุงรักษาสูง แต่ให้ประสิทธิภาพทางธุรกิจที่ยืดหยุ่นหากออกแบบถูกต้อง
จากมุมมองเชิงปฏิบัติ: หากองค์กรมีความต้องการด้านความเป็นส่วนตัวระดับสูง เช่น ภาคสุขภาพ การเงิน หรือการเก็บข้อมูลความลับทางธุรกิจ Private‑Sync มักเป็นตัวเลือกที่เหมาะสม โดยเฉพาะเมื่อต้องการรองรับการปฏิบัติงานแบบออฟไลน์และลดการส่งข้อมูลไปยังภายนอก สำหรับองค์กรที่ต้องการความสามารถของโมเดลขนาดใหญ่และไม่ติดข้อจำกัดด้านข้อมูล Cloud LLM ให้ประสิทธิภาพและความสามารถสูงสุด แต่ต้องยอมรับความเสี่ยงด้านความเป็นส่วนตัวและค่าใช้จ่ายที่ผันแปร
สำหรับหลายองค์กรแนวทางที่เป็นไปได้คือการเลือก Hybrid เป็นกลยุทธ์เริ่มต้น โดยกำหนดนโยบายให้ฟังก์ชันที่มีความอ่อนไหวทางข้อมูลหรือ latency‑sensitive ทำงานบนอุปกรณ์ ขณะที่งานเชิงวิเคราะห์เชิงลึกหรือการเรียกใช้โมเดลขนาดใหญ่ส่งไปประมวลผลบนคลาวด์ อย่างไรก็ดี การนำ Hybrid มาใช้ต้องมีการลงทุนในระบบ orchestration, monitoring, และ governance เพื่อหลีกเลี่ยงช่องโหว่ด้านความปลอดภัยและปัญหาประสบการณ์ผู้ใช้
คำแนะนำเชิงปฏิบัติ: เริ่มด้วยการประเมินข้อมูลประเภทที่ต้องประมวลผล (sensitivity), ปริมาณการใช้งาน (throughput), งบประมาณ และข้อกำหนดด้าน compliance — จากนั้นเลือกสถาปัตยกรรมที่สอดคล้องกับกรอบความเสี่ยงขององค์กร โดยพิจารณาการทดสอบแบบ pilot สำหรับสถาปัตยกรรม Hybrid หรือ Private‑Sync เพื่อวัดผลด้าน latency, cost และ security ในสภาพแวดล้อมจริง
บทสรุป
Private‑Sync LLM เป็นแนวทางการใช้งานโมเดลภาษาที่รันบนอุปกรณ์มือถือหรือเครื่องพนักงาน พร้อมการซิงก์อัปเดตผ่านเครือข่ายแบบเพียร์ทูเพียร์ (P2P) โดยไม่ส่งข้อมูลขึ้นคลาวด์ ทำให้ลดความเสี่ยงการรั่วไหลของข้อมูลและตอบโจทย์องค์กรที่ให้ความสำคัญกับความเป็นส่วนตัว เช่น หน่วยงานการเงิน การแพทย์หรือธุรกิจที่จัดการข้อมูลความลับ อย่างไรก็ตาม แนวทางนี้แลกมาด้วยข้อจำกัดด้านทรัพยากรบนอุปกรณ์ (เช่น CPU, หน่วยความจำ และแบตเตอรี่) การจัดการเวอร์ชันโมเดล และความซับซ้อนของการซิงก์/ความปลอดภัยของ P2P ซึ่งอาจกระทบต่อประสิทธิภาพ ความแม่นยำ และประสบการณ์ผู้ใช้ในบางกรณี
การนำไปใช้เชิงธุรกิจจึงต้องพิจารณา trade‑offs ด้านประสิทธิภาพ ต้นทุน และการปฏิบัติตามกฎระเบียบอย่างรอบคอบ โดยควรออกแบบนโยบายการควบคุมการเข้าถึง การอัปเดตโมเดล และการตรวจสอบผลลัพธ์ รวมถึงทำการทดสอบเบื้องต้น (pilot) เพื่อวัดผลทางเทคนิคและเชิงธุรกิจจริงก่อนขยายใช้งาน ตัวอย่างปัจจัยที่ต้องทดสอบได้แก่ ความหน่วงเวลาในการตอบ สนามการใช้พลังงาน ความเสถียรของการซิงก์ และความสอดคล้องกับข้อกำหนดด้านความเป็นส่วนตัวและการเก็บรักษาข้อมูล
มองไปข้างหน้า แนวทาง Private‑Sync LLM มีศักยภาพจะเติบโตควบคู่กับการพัฒนาฮาร์ดแวร์สำหรับ edge AI, การเกิดมาตรฐานด้านการซิงก์และการพิสูจน์ตัวตนของอุปกรณ์ และรูปแบบไฮบริดที่ผสมผสานระหว่างการประมวลผลบนอุปกรณ์กับเซิร์ฟเวอร์กลาง สำหรับองค์กรแนะนำให้เริ่มจากโครงการนำร่องที่ชัดเจน กำหนดเกณฑ์วัดผล (KPIs) ด้านความปลอดภัย ประสิทธิภาพ และต้นทุน เพื่อประเมินความคุ้มค่าและความเสี่ยงก่อนตัดสินใจขยายการใช้งานในวงกว้าง



