
ในโลกที่ความเปลี่ยนแปลงเกิดขึ้นรวดเร็วและข้อมูลไหลทะลักไม่หยุด การคาดการณ์อนาคตกลายเป็นความจำเป็นเชิงกลยุทธ์สำหรับองค์กรทุกขนาด แมชชีนเลิร์นนิงไม่ได้เป็นเพียงเครื่องมือทางเทคนิคอีกต่อไป แต่กลายเป็นกล้องส่องอนาคตที่ช่วยให้เราเห็นแบบแผนที่สายตามนุษย์อาจมองไม่เห็น ตั้งแต่การพยากรณ์อุปสงค์ในธุรกิจค้าปลีก การบริหารความเสี่ยงทางการเงิน ไปจนถึงการวางแผนทรัพยากรบุคคล—ความสามารถในการแปลงข้อมูลให้เป็นการคาดการณ์ที่เชื่อถือได้คือสิ่งที่จะพลิกโฉมการตัดสินใจเชิงกลยุทธ์
บทความนี้จะพาคุณไล่ตั้งแต่พื้นฐานจนถึงการปฏิบัติจริง: วิธีการเตรียมข้อมูลให้พร้อมสำหรับโมเดลพยากรณ์ เทคนิคโมเดลเชิงสถิติและเชิงลึกที่ใช้บ่อย การวัดและการสื่อสารความไม่แน่นอน (uncertainty) ของการคาดการณ์ รวมถึงกรณีศึกษาจริงจากอุตสาหกรรมต่างๆ และแนวปฏิบัติสำหรับการนำไปใช้งานในองค์กรอย่างปลอดภัยและเกิดผลสัมฤทธิ์ อ่านต่อไปเพื่อรับทั้งความรู้เชิงเทคนิค ตัวอย่างเชิงปฏิบัติ และแนวทางที่องค์กรสามารถนำไปใช้ได้ทันที
บทนำ: ทำไมการคาดการณ์ด้วยแมชชีนเลิร์นนิงสำคัญ
บทนำ: ทำไมการคาดการณ์ด้วยแมชชีนเลิร์นนิงสำคัญ

การพยากรณ์ถือเป็นหัวใจสำคัญของการตัดสินใจเชิงกลยุทธ์ในภาคธุรกิจและสังคม ตั้งแต่การบริหารสต็อกสินค้า การวางแผนกำลังการผลิต การจัดการความเสี่ยงทางการเงิน ไปจนถึงการคาดการณ์ความต้องการพลังงานหรือการระบาดของโรค การทำนายล่วงหน้าช่วยให้องค์กรสามารถลดต้นทุน ปรับปรุงประสิทธิภาพ และเพิ่มความคล่องตัวในการตอบสนองต่อการเปลี่ยนแปลงของสภาพแวดล้อม เหตุผลหนึ่งที่ทำให้การคาดการณ์มีความสำคัญมากขึ้นคือข้อมูลที่มีปริมาณและความซับซ้อนเพิ่มขึ้นอย่างรวดเร็ว ซึ่งต้องการเทคนิคที่สามารถเรียนรู้รูปแบบจากข้อมูลขนาดใหญ่และหลายมิติได้อย่างมีประสิทธิภาพ
ความแตกต่างระหว่างการพยากรณ์แบบดั้งเดิมกับแมชชีนเลิร์นนิง อยู่ที่ความสามารถในการจัดการความไม่เชิงเส้น ความสัมพันธ์หลายมิติ และการเรียนรู้จากข้อมูลที่หลากหลาย วิธีสถิติแบบดั้งเดิม เช่น ARIMA หรือการถดถอยเชิงเส้น มีข้อดีในแง่ความเรียบง่ายและการตีความผล แต่มีข้อจำกัดเมื่อต้องเผชิญกับข้อมูลที่มีคุณลักษณะซับซ้อน เช่น seasonality ที่ซ้อนกัน ปัจจัยทางเศรษฐกิจแบบไม่เชิงเส้น หรือการกระจายตัวของความผิดปกติ ในทางกลับกัน แมชชีนเลิร์นนิง เช่น โมเดลแบบ tree-based, gradient boosting, หรือ deep learning สามารถจับรูปแบบที่ซับซ้อนได้ดีกว่า ปรับตัวแบบเรียลไทม์ และทำงานได้ดีกับข้อมูลหลากหลายแหล่ง เช่น ข้อมูลภาพ ข้อความ และชุดสัญญาณเวลา
ในมุมธุรกิจ ผลลัพธ์ที่วัดได้จากการนำ ML มาใช้ในการพยากรณ์ชี้ชัดถึงมูลค่าที่เพิ่มขึ้น ตัวอย่างจากกรณีศึกษาในอุตสาหกรรมค้าปลีกและห่วงโซ่อุปทานแสดงให้เห็นว่าโมเดล ML ขั้นสูงสามารถลดค่า MAPE (Mean Absolute Percentage Error) ได้ตั้งแต่ 20%–50% เมื่อเทียบกับวิธีแบบดั้งเดิม ในบางกรณีองค์กรรายงานการลดต้นทุนสต็อกได้ถึง 15%–30% และเพิ่มอัตราการตอบสนองต่อความต้องการลูกค้า (fill rate) ได้อย่างมีนัยสำคัญ นอกจากนี้รายงานด้านการเงินและประกันภัยพบว่าเมื่อใช้โมเดลพยากรณ์ที่มีความแม่นยำสูง ROI จากโครงการ AI/ML ด้านการพยากรณ์อาจอยู่ในช่วง 3–5 เท่า ขึ้นอยู่กับขนาดองค์กรและลักษณะธุรกิจ
บทบาทสำคัญของการพยากรณ์ในธุรกิจสามารถสรุปเป็นประเด็นได้ดังนี้
- ลดต้นทุน — การคาดการณ์ที่แม่นยำช่วยลดการสั่งซื้อเกินและลดต้นทุนการเก็บรักษาสต็อก
- บริหารสต็อกสินค้า — ปรับระดับสินค้าคงคลังให้เหมาะสม ลดสินค้าหมดและสินค้าล้น
- การบริหารความเสี่ยง — คาดการณ์ความผันผวนของตลาด ลดการขาดทุนจากเหตุการณ์ไม่คาดคิด
- การเพิ่มประสิทธิภาพการดำเนินงาน — วางแผนกำลังการผลิตและโลจิสติกส์ได้แม่นยำขึ้น ลดเวลาหน่วงและทรัพยากรที่สูญเสีย
ในภาพรวม การเปลี่ยนผ่านจากวิธีสถิติแบบดั้งเดิมสู่การใช้แมชชีนเลิร์นนิงในการพยากรณ์ไม่เพียงแต่เพิ่มความแม่นยำ แต่ยังเปิดโอกาสใหม่ ๆ สำหรับการนำข้อมูลมาสร้างมูลค่าเชิงธุรกิจ ตั้งแต่การลดต้นทุนโดยตรงจนถึงการเพิ่มรายได้และความได้เปรียบเชิงแข่งขัน ซึ่งเป็นเหตุผลว่าทำไมองค์กรสมัยใหม่จึงให้ความสำคัญกับการลงทุนในเทคโนโลยีพยากรณ์ด้วย ML อย่างต่อเนื่อง
การเตรียมข้อมูล: พื้นฐานก่อนสร้างโมเดลพยากรณ์
บทนำสู่การเตรียมข้อมูลสำหรับการพยากรณ์
การเตรียมข้อมูล (data preparation) เป็นพื้นฐานที่สำคัญที่สุดก่อนการสร้างโมเดลพยากรณ์เชิงเวลา โดยงานเตรียมข้อมูลมักใช้เวลาส่วนใหญ่ของโครงการแมชชีนเลิร์นนิง—งานวิจัยภาคสนามและผู้ปฏิบัติงานรายงานว่าการเตรียมข้อมูลอาจกินเวลา 60–80% ของทั้งโปรเจกต์ การเตรียมข้อมูลที่ดีไม่เพียงลดความเสี่ยงจากการรั่วไหลของข้อมูล (data leakage) แต่ยังเพิ่มความแม่นยำและความเสถียรของโมเดลเมื่อประยุกต์กับสถานการณ์จริง เช่น การคาดการณ์ความต้องการสินค้า การพยากรณ์การผลิตจากเซนเซอร์ หรือการคาดการณ์ปริมาณการใช้งานของบริการ

การรวบรวมและผสานข้อมูลจากหลายแหล่ง
ขั้นตอนแรกคือการระบุแหล่งข้อมูลที่เกี่ยวข้องและสร้างโครงแบบข้อมูล (data schema) ที่ชัดเจนสำหรับการผสานข้อมูล ตัวอย่างแหล่งข้อมูลได้แก่:
- ข้อมูลธุรกรรม (transactions): ยอดขาย รายการคำสั่งซื้อ โปรโมชั่น และสถานะการคืนสินค้า
- ข้อมูลจากเซนเซอร์ (sensor/IoT): การอ่านค่าแบบ time-stamped ที่อาจมีความถี่ไม่สม่ำเสมอ เช่น ทุกวินาทีหรือทุกนาที
- ข้อมูลภายนอก (external): สภาพอากาศ ปฏิทินวันหยุด ดัชนีเศรษฐกิจ และข้อมูลโซเชียลมีเดีย
การผสานข้อมูล (data merging) ต้องคำนึงถึงประเด็นสำคัญ เช่น เวลามาตรฐาน (time zones), การจัดรูปแบบ timestamp, และนโยบายการ join (left/inner/outer) เพื่อหลีกเลี่ยงการสูญเสียข้อมูลสำคัญ ตัวอย่างปฏิบัติการที่แนะนำคือการสร้างตารางหลักตามช่วงเวลา (time index) แล้วรวมค่าแต่ละแหล่งโดยใช้ aggregation (เช่น sum, mean, count) เมื่อ resampling ให้เป็นระดับความถี่เดียวกัน
การทำความสะอาด: ขาดค่า, ค่าเบี่ยงเบน และ seasonality
การจัดการกับค่าขาดหาย (missing values) และค่าผิดปกติ (outliers) มีผลโดยตรงต่อประสิทธิภาพของโมเดล เทคนิคที่นิยมใช้ได้แก่:
- การกำหนดนโยบาย missing: หากคอลัมน์มี missing เกินเกณฑ์ (เช่น >50%) พิจารณาลบคอลัมน์ออก แต่ถ้าเป็นคีย์ธุรกิจสำคัญ ให้เลือกวิธีเติมข้อมูล (imputation) เช่น forward-fill/backward-fill สำหรับข้อมูลเชิงเวลา หรือ linear interpolation สำหรับสัญญาณต่อเนื่อง
- การเติมแบบมีบริบท: การเติมตาม seasonality เช่น เติมค่าภายในสัปดาห์หรือเดือนเดียวกัน (seasonal interpolation) หรือใช้โมเดลคาดค่า (KNN, MICE, หรือ model-based imputation)
- การจัดการ outliers: ใช้สถิติ IQR (การตัดที่ Q1 − 1.5*IQR / Q3 + 1.5*IQR), z-score หรือเทคนิค robust เช่น winsorization และ isolation forest เมื่อต้องการตรวจจับ outlier เชิงพฤติกรรม
- การแยก seasonality และ trend: ใช้การสลายองค์ประกอบเชิงเวลา (เช่น STL decomposition) เพื่อตรวจจับและแยก trend, seasonal และ residual ซึ่งช่วยให้การเติมค่าขาดและการออกแบบฟีเจอร์มีความแม่นยำมากขึ้น
คำแนะนำเชิงปฏิบัติ: หากข้อมูลมี seasonality เด่นชัด (เช่น ยอดขายเพิ่มช่วงสิ้นเดือนหรือวันหยุด) ควรใช้วิธีเติมที่รักษารูปแบบ seasonal มิฉะนั้นอาจทำให้โมเดลเรียนรู้รูปแบบผิดพลาด
การหั่นช่วงเวลา (resampling) และการจัดการความถี่ของข้อมูล
การ resampling คือการแปลงข้อมูลจากความถี่หนึ่งไปยังอีกความถี่หนึ่ง เช่น จากรายนาทีเป็นรายวัน หรือจากการอ่านแบบไม่สม่ำเสมอเป็นช่วงเวลาเท่ากัน การเลือกวิธี aggregation มีผลต่อสัญญาณที่โมเดลเห็น ตัวอย่างการตัดสินใจ:
- สำหรับยอดขายรายวัน: ใช้ sum เพื่อรวมจำนวนรายการ
- สำหรับค่าเซนเซอร์: ใช้ mean หรือ median เพื่อกรอง noise และ max/min เมื่อสนใจพีค
- การ resample จากความถี่สูงไปต่ำ: พิจารณา downsampling พร้อมการกรอง low-pass เพื่อลด aliasing
นอกจากนี้ต้องจัดการกับ timestamp ที่ขาดหายหรือเกิด double timestamps โดยการ reindex ตามช่วงเวลาที่ต้องการและทำการเติมตามนโยบายที่กำหนด
การสร้างฟีเจอร์เชิงเวลา (time features)
ฟีเจอร์เวลาเป็นหัวใจของการพยากรณ์เชิงเวลา โดยฟีเจอร์ที่นิยมและมีประโยชน์ได้แก่:
- lags: ค่าล่าช้า เช่น lag-1, lag-7, lag-30 (ตัวอย่าง: ค่าสัปดาห์ก่อนหน้า lag=7 สำหรับข้อมูลรายวัน) โดยปกติเลือก lags จากการวิเคราะห์ ACF/PACF หรือตามปัจจัยธุรกิจ
- rolling statistics: rolling mean, rolling std, rolling median บนหน้าต่างต่าง ๆ เช่น 7, 14, 30 วัน เพื่อจับแนวโน้มระยะสั้นและความผันผวน (ตัวอย่าง: rolling_mean_7, rolling_std_30)
- calendar features: วันในสัปดาห์ (weekday), วันในเดือน, เดือน, ไตรมาส, และ flag สำหรับวันหยุด/โปรโมชั่น โดยใช้ฐานข้อมูลวันหยุดหรือ API ปฏิทินของประเทศเพื่อสร้าง holiday flags
- encoding แบบวงกลม (cyclic encoding): สำหรับฟีเจอร์เช่น hour, day-of-week ให้แปลงเป็น sin/cos เพื่อรักษาความต่อเนื่อง เช่น hour_sin = sin(2π·hour/24)
- diffs และ pct_change: ความเปลี่ยนแปลงระหว่างช่วงเวลา เช่น daily_diff, weekly_pct_change ช่วยโมเดลจับอัตราเปลี่ยนแปลง
ตัวอย่างเชิงปฏิบัติ: สำหรับการพยากรณ์ยอดขายรายวัน อาจสร้าง lags = [1,7,14,28] และ rolling windows = [7,30,90] ซึ่งจากประสบการณ์ภาคสนาม การเพิ่มฟีเจอร์เชิงเวลาที่สอดคล้องกับพฤติกรรมธุรกิจมักช่วยปรับปรุงความแม่นยำของโมเดลได้อย่างมีนัยสำคัญ
แนวปฏิบัติที่ควรยึดถือ
เพื่อให้การเตรียมข้อมูลมีคุณภาพและทวนซ้ำได้ ควรปฏิบัติดังนี้:
- จัดเก็บ pipeline การเตรียมข้อมูล (ETL/ELT) ในรูปแบบโค้ดและเวอร์ชันคอนโทรล
- ใช้ time-series cross-validation เพื่อหลีกเลี่ยงการใช้ข้อมูลอนาคตในการฝึก
- บันทึกสมมติฐาน (assumptions) และนโยบายการเติมค่า/จัดการ outliers ไว้เป็นเอกสารสำหรับทีมธุรกิจและวิศวกร
- ทดสอบผลของการสร้างฟีเจอร์ใหม่โดยการวัด performance ก่อน–หลัง เพื่อหลีกเลี่ยงฟีเจอร์ที่เพิ่มความซับซ้อนแต่ไม่เพิ่มประสิทธิภาพ
การเตรียมข้อมูลเชิงเวลาเป็นกระบวนการที่ต้องผสานความเข้าใจเชิงธุรกิจกับเทคนิคด้านข้อมูลอย่างใกล้ชิด เมื่อขั้นตอนเหล่านี้ถูกออกแบบและดำเนินการอย่างรอบคอบ จะเปิดทางให้โมเดลพยากรณ์สื่อสารผลลัพธ์ที่เชื่อถือได้และนำไปใช้ตัดสินใจเชิงธุรกิจได้อย่างมีประสิทธิภาพ
เทคนิคและโมเดลยอดนิยมสำหรับการคาดการณ์
เทคนิคและโมเดลยอดนิยมสำหรับการคาดการณ์
การเลือกเทคนิคและโมเดลสำหรับการคาดการณ์ (forecasting) ขึ้นกับลักษณะข้อมูล ขนาดชุดข้อมูล ระยะเวลาคาดการณ์ และข้อจำกัดด้านทรัพยากร ในภาพรวมสามารถแบ่งกลุ่มโมเดลได้เป็น 1) สถิติดั้งเดิม เช่น ARIMA และ ETS 2) โมเดลแบบ tree-based และ boosting เช่น Random Forest และ XGBoost 3) โมเดลเชิงลึก (deep learning) สำหรับลำดับ เช่น RNN / LSTM และ Transformer แต่ละกลุ่มมีข้อดีข้อจำกัดชัดเจนและเหมาะกับสถานการณ์ต่างกัน การเข้าใจข้อจำกัดเหล่านี้ช่วยให้ผู้บริหารและทีม data science ตัดสินใจเลือกวิธีที่คุ้มค่าและตรงกับเป้าหมายธุรกิจ

ARIMA / ETS — โมเดลสถิติพื้นฐานที่มีประสิทธิภาพเมื่อชุดข้อมูลมีขนาดเล็กถึงปานกลางและสมมติฐานถูกต้อง: ARIMA (AutoRegressive Integrated Moving Average) เหมาะกับข้อมูลซีรีส์เวลาเมื่อต้องการจับอัตาโนมัติของความสัมพันธ์เชิงชั่วคราว (autoregression) และความแตกต่าง (differencing) เพื่อให้เกิดสถานีภาพ ส่วน ETS (Error-Trend-Seasonality) เป็นโมเดลที่เหมาะกับการตีความแนวโน้มและฤดูกาลโดยตรง ข้อดีสำคัญคือความโปร่งใสและความสามารถในการอธิบายผล (interpretability) ทำให้ผู้บริหารเข้าใจ drivers ของการคาดการณ์ได้ง่าย ตัวอย่างการใช้งานที่เหมาะสม ได้แก่ การคาดการณ์ยอดขายสินค้าที่มีข้อมูลรายสัปดาห์/รายเดือน > 36–100 จุดข้อมูล หรือการพยากรณ์โหลดพลังงานระยะสั้น
- ข้อดี: ต้องการข้อมูลน้อย, อธิบายได้, ฝึกสอนได้รวดเร็ว
- ข้อจำกัด: สมมติฐาน stationarity และ linearity, จับความสัมพันธ์เชิงซ้อน (nonlinear) ได้ไม่ดี
- ตัวอย่างเมื่อเลือกใช้: ข้อมูลย้อนหลังน้อย (<500 จุด), ต้องการผลที่ตีความได้ง่าย, forecast horizon สั้น-กลาง
Tree-based และ Boosting (Random Forest, XGBoost, LightGBM) — เหมาะสำหรับปัญหาที่มีฟีเจอร์จำนวนมากและความสัมพันธ์แบบ nonlinear ระหว่างตัวแปร ตัวอย่างเช่น การคาดการณ์ความต้องการสินค้าจากตัวแปรหลายมิติ (ราคา โปรโมชั่น วันในสัปดาห์ สภาพอากาศ ฯลฯ) เทคนิคเหล่านี้สามารถจัดการข้อมูลที่มี missing values ได้ดีและมักให้ผลแม่นยำเมื่อมี features ที่มีสัญญาณสำคัญ การเตรียมข้อมูลมักจะรวมการสร้างคุณลักษณะเชิงเวลาที่สำคัญ เช่น lag features, rolling statistics และปฏิสัมพันธ์ระหว่างตัวแปร
- ข้อดี: จับ nonlinear relationships ได้ดี, แปรผันน้อยต่อการ scaling ของข้อมูล, ปรับแต่งได้สูง (hyperparameter tuning)
- ข้อจำกัด: ต้องการการสร้างฟีเจอร์เชิงเวลาอย่างรอบคอบ, เวลาเทรนนิ่งและการปรับจูนอาจสูง, ความสามารถในการอธิบายผลมีจำกัดแต่สามารถใช้เทคนิคเช่น SHAP เพื่อเพิ่มความโปร่งใส
- ตัวอย่างเมื่อเลือกใช้: มีชุดฟีเจอร์หลายสิบถึงหลายร้อยตัว, ต้องการจับ nonlinear effect ระหว่างตัวแปร, dataset มีขนาดตั้งแต่หลายพันถึงหลายแสนตัวอย่าง
LSTM / RNN และ Transformer — โมเดลเชิงลึกสำหรับลำดับที่เหมาะกับการจับบริบทระยะยาว (long-range dependencies) และรูปแบบที่ซับซ้อนในซีรีส์เวลา RNN แบบพื้นฐานมีปัญหา vanishing gradient ซึ่งถูกแก้โดย LSTM หรือ GRU ที่ออกแบบมาสำหรับการเก็บหน่วยความจำระยะยาว ในช่วงหลัง Transformer กลายเป็นมาตรฐานใหม่สำหรับการจับความสัมพันธ์ข้ามตำแหน่งอย่างมีประสิทธิภาพโดยใช้ attention mechanism — เหมาะกับลำดับข้อมูลยาวและหลายมิติ (multivariate time series) เช่น การคาดการณ์การใช้งานโครงข่ายโทรคมนาคมหรือการวิเคราะห์เวลาที่มีบริบทภายนอกจำนวนมาก
- ข้อดี: จับความสัมพันธ์ระยะยาวและความซับซ้อนได้ดี, สามารถเรียนรู้ representation จากดิบได้โดยตรง
- ข้อจำกัด: ต้องการข้อมูลจำนวนมาก (มักเป็นพันถึงหลายหมื่นตัวอย่างขึ้นไป) และทรัพยากรการคำนวณสูง (GPU), เสี่ยง overfitting หากข้อมูลน้อย, การอธิบายผลทำได้ยากกว่า
- ตัวอย่างเมื่อเลือกใช้: ลำดับยาว (>100–1,000 time steps), ต้องจับบริบทระยะยาว เช่น forecast horizon ยาว, มีข้อมูลเซนเซอร์หรือ log ที่ละเอียดเป็นรายวินาที
ในทางปฏิบัติ ทีมงานมักใช้แนวทางผสมผสาน (hybrid / ensemble) เพื่อให้ได้ผลที่สมดุล ตัวอย่างเช่น สร้าง baseline ด้วย ARIMA/ETS เพื่อจับเทรนด์พื้นฐาน แล้วใช้ XGBoost เพื่อผนวกฟีเจอร์ภายนอก หรือใช้ Transformer เป็นโมเดลหลักเมื่อมีข้อมูลปริมาณมากและต้องการประสิทธิภาพสูงสุด นอกจากนี้การประเมินประสิทธิภาพควรใช้เมตริกที่เหมาะสมกับธุรกิจ เช่น MAPE (Mean Absolute Percentage Error) สำหรับการคาดการณ์ยอดขาย หรือ RMSE สำหรับข้อผิดพลาดที่มีค่าผิดพลาดใหญ่ที่ไม่ต้องการให้เกิดบ่อย พร้อมทั้งใช้ time-series cross-validation (rolling / expanding window) เพื่อหลีกเลี่ยงความลำเอียงจากการสุ่ม
สรุปคือ ไม่มีโมเดลเดียวที่ดีที่สุดเสมอไป การเลือกต้องพิจารณา trade-offs ระหว่างความแม่นยำ ความโปร่งใส ทรัพยากร และปริมาณข้อมูล: หากข้อมูลน้อยและต้องการคำอธิบายชัดเจนให้เลือก ARIMA / ETS; หากมีฟีเจอร์จำนวนมากและความสัมพันธ์เชิงซ้อนให้ใช้ Random Forest / XGBoost; หากต้องการจับบริบทระยะยาวและมีข้อมูลปริมาณมาก ให้ลงทุนกับ LSTM / Transformer และเตรียมทรัพยากรการฝึกอบรมที่เหมาะสม
การประเมินผลและการจัดการความไม่แน่นอน
การประเมินผลและการจัดการความไม่แน่นอน
การประเมินประสิทธิภาพของโมเดลพยากรณ์เป็นหัวใจสำคัญของการนำแมชชีนเลิร์นนิงไปใช้ในบริบทเชิงธุรกิจ เพราะไม่เพียงแต่ต้องรู้ว่าโมเดล “แม่น” แค่ไหน แต่ต้องรู้ด้วยว่าโมเดลมีความแน่นอนหรือไม่ และความผิดพลาดนั้นมีผลกระทบอย่างไรต่อการตัดสินใจเชิงธุรกิจ ในเชิงปฏิบัติ เรามักใช้เมตริกชุดหนึ่งเพื่อประเมินความคลาดเคลื่อนและเมตริกอีกชุดเพื่อประเมินความไม่แน่นอนของการพยากรณ์
เมตริกที่ใช้บ่อยมีดังนี้:
- MAE (Mean Absolute Error) — ค่าเฉลี่ยของค่าความคลาดเคลื่อนแบบสัมบูรณ์: MAE = (1/N) Σ |y_i - ŷ_i|. เหมาะสำหรับการตีความเป็นหน่วยจริงของตัวแปร (เช่น หน่วยสินค้า, บาท)
- RMSE (Root Mean Squared Error) — ให้ค่าน้ำหนักมากขึ้นกับความคลาดเคลื่อนขนาดใหญ่: RMSE = sqrt((1/N) Σ (y_i - ŷ_i)^2). เหมาะเมื่อความผิดพลาดขนาดใหญ่มีความสำคัญเชิงความเสี่ยง
- MAPE (Mean Absolute Percentage Error) — ค่าความคลาดเคลื่อนเป็นร้อยละ: MAPE = (100/N) Σ |(y_i - ŷ_i) / y_i|. เหมาะสำหรับการเปรียบเทียบข้ามช่วงหรือสินค้าที่ต้องการเข้าใจเป็นเปอร์เซ็นต์ แต่มีข้อควรระวังเมื่อค่าจริง = 0 หรือมีค่าน้อยมาก
- CRPS (Continuous Ranked Probability Score) — เมตริกสำหรับการพยากรณ์แบบมีความไม่แน่นอน (probabilistic): ให้คะแนนการแจกแจงคาดการณ์ทั้งฉบับ ไม่ใช่เพียงจุดพยากรณ์เดียว ฟังก์ชัน: CRPS(F,x) = ∫ (F(y)-1_{y≥x})^2 dy. สำหรับ ensemble มีสูตรประมาณเชิงตัวอย่างที่ใช้งานได้จริง
แนวทางการเลือกเมตริกเชิงธุรกิจ:
- ถ้าผู้บริหารสนใจ ผลกระทบเชิงหน่วย (เช่น ต้นทุนการสต็อก): ให้ใช้ MAE หรือ RMSE แล้วเลือก RMSE หากต้องการให้ความผิดพลาดใหญ่มีน้ำหนักมากขึ้น
- หากต้องการเปรียบเทียบประสิทธิภาพข้ามผลิตภัณฑ์หรือช่วงเวลา เป็นเปอร์เซ็นต์ ให้ใช้ MAPE แต่ถ้ามีค่าจริงใกล้ศูนย์ ควรพิจารณา sMAPE หรือ MASE แทน
- เมื่อระบบต้องการ การตัดสินใจโดยคำนึงถึงความเสี่ยง (เช่น การตั้ง buffer, hedging หรือการจัดสรรสินทรัพย์) ควรประเมินด้วยเมตริกเชิงความไม่แน่นอน เช่น CRPS หรือ quantile loss
การวัดและจัดการความไม่แน่นอน (Uncertainty Quantification)
- Prediction intervals — ช่วงค่าที่คาดว่าค่าจริงจะตกอยู่ภายใน (เช่น 95% PI). สร้างได้จากการสมมติรูปแบบการกระจาย (เช่น Gaussian: mean ± 1.96*std) หรือจาก empirical quantiles ของ ensemble/bootstrapped forecasts (เช่น 2.5th และ 97.5th percentiles สำหรับ 95% PI).
- Quantile regression — ฝึกโมเดลให้พยากรณ์ค่ามุมมองต่างๆ ของการแจกแจง (เช่น τ=0.1,0.5,0.9) แทนการพยากรณ์ค่าเฉลี่ยอย่างเดียว วิธีนี้ให้ probabilistic forecast โดยตรง และประเมินด้วย quantile loss หรือ PICP/PI width
- Probabilistic forecasting — ผลลัพธ์เป็นการแจกแจง (CDF หรือ ensemble) แทนค่าจุดเดียว วิธีประเมินรวมถึง CRPS, log score และการตรวจสอบ coverage/ sharpness
ตัวอย่างแนวคิด pseudocode สำหรับการคำนวณเมตริกพื้นฐานและ CRPS (ensemble) รวมถึงการสร้าง prediction interval และ backtesting แบบ sliding window:
คำนวณ MAE, RMSE, MAPE
MAE = sum(abs(y - yhat)) / N
RMSE = sqrt(sum((y - yhat)^2) / N)
MAPE = 100 * sum(abs((y - yhat) / y)) / N # ระวัง y=0
CRPS สำหรับ ensemble forecasts (M สมาชิกของ ensemble)
ให้ ensemble = {f_1,...,f_M} และ observation x:
CRPS ≈ (1/M) * sum(|x - f_i|) - (1 / (2*M^2)) * sum_{i,j} |f_i - f_j|
สร้าง prediction interval จาก ensemble หรือ quantiles
- จาก ensemble: lower = quantile(ensemble, α/2), upper = quantile(ensemble, 1-α/2)
- จาก Gaussian approx: mean = μ, std = σ → lower = μ - z_{1-α/2} * σ, upper = μ + z_{1-α/2} * σ
Backtesting (sliding window) — แนวทางทั่วไป (pseudocode)
initialize results = []
for t in range(start, end):
train_data = data[t-window_size : t]
model = train_model(train_data)
forecast = model.predict(horizon) # จุดพยากรณ์หรือ ensemble/quantiles
obs = actuals[t : t+horizon]
metrics = compute_metrics(obs, forecast) # MAE, RMSE, MAPE, CRPS, coverage
results.append(metrics)
# สรุป: ค่าเฉลี่ย/ความแปรปรวนของ metrics เพื่อดูความเสถียร
การ backtesting ควรรวมการประเมิน coverage ของ prediction intervals (เช่น เปอร์เซ็นต์ของ observations ที่ตกอยู่ใน 95% PI ควรใกล้ 95%) และการประเมิน sharpness (width ของ intervals) เพื่อไม่ให้โมเดลได้ coverage สูงเพียงเพราะให้ช่วงกว้างเกินไป นอกจากนี้ควรตรวจสอบความไวของผลลัพธ์ต่อการเปลี่ยนแปลงข้อมูลด้วยการใช้ทั้ง sliding และ expanding windows รวมถึง stress tests กับเหตุการณ์สุดขั้ว
สรุป: การประเมินผลการพยากรณ์จำเป็นต้องเลือกเมตริกให้สอดคล้องกับเป้าหมายทางธุรกิจ รวมทั้งต้องวัดความไม่แน่นอนอย่างเป็นระบบผ่าน prediction intervals, quantile regression และ probabilistic scores เช่น CRPS การ backtesting ที่ออกแบบมาอย่างรอบด้านจะช่วยยืนยันความเสถียรและความเชื่อถือได้ของโมเดลเมื่อถูกนำไปใช้จริง
กรณีศึกษา: การใช้งานจริงในธุรกิจและสังคม
กรณีศึกษา: การใช้งานจริงในธุรกิจและสังคม
การพยากรณ์ด้วยแมชชีนเลิร์นนิงไม่ใช่เพียงทฤษฎีเชิงวิจัย แต่ถูกนำไปใช้จริงในธุรกิจและภาคสาธารณสุขด้วยผลลัพธ์ที่จับต้องได้ ตัวอย่างการใช้งานในโดเมนต่าง ๆ แสดงให้เห็นถึงความสามารถในการลดต้นทุน ปรับปรุงการให้บริการ และเพิ่มความยืดหยุ่นของระบบอย่างเป็นรูปธรรม โดยมักอาศัยเทคนิคเช่น time-series models (ARIMA, Prophet), recurrent neural networks (LSTM/GRU), และ hybrid models ที่ผสานข้อมูลจากหลายแหล่ง เช่น ข้อมูลการขาย ข้อมูลพยากรณ์อากาศ และข้อมูลประชากร
-
ค้าปลีก: การพยากรณ์ความต้องการ (Demand Forecasting)
ร้านค้ารายใหญ่และแพลตฟอร์มอีคอมเมิร์ซนำโมเดลแมชชีนเลิร์นนิงมาพยากรณ์ความต้องการสินค้าแบบรายวันและรายชั่วโมง ผลลัพธ์ที่รายงานรวมถึงการลด stockout ประมาณ 20% และการลดสต็อกส่วนเกิน (overstock) ราว 15–30% ผ่านการปรับแผนการสั่งซื้อและการจัดวางสินค้าตามคำทำนาย นอกจากนี้ การผสานข้อมูลโปรโมชัน ปฏิทินเทศกาล และการค้นหาจากอินเทอร์เน็ตยังช่วยเพิ่มความแม่นยำของการพยากรณ์ได้มากกว่า 25% ในหลายกรณี
-
โลจิสติกส์และห่วงโซ่อุปทาน: ลด spoilage และเพิ่มประสิทธิภาพ
ในอุตสาหกรรมอาหารและเภสัชภัณฑ์ การพยากรณ์ความต้องการร่วมกับการติดตามอุณหภูมิและสภาพการขนส่ง (IoT) ช่วยลดการสูญเสียจาก spoilage ได้อย่างมีนัยสำคัญ ตัวอย่างโครงการเชิงปฏิบัติรายงานการลดของเสียได้ราว 20–40% โดยการปรับเส้นทางการขนส่งและระยะเวลาเก็บรักษาตามการพยากรณ์ความเสี่ยงความเสียหาย ผลลัพธ์รวมถึงต้นทุนการจัดเก็บลดลงและอัตราการคืนสินค้าลดลง ซึ่งส่งผลต่อ margin ของผู้ค้าอย่างเป็นรูปธรรม
-
สาธารณสุข: การคาดการณ์การระบาดเพื่อวางแผนทรัพยากร
ระบบพยากรณ์การระบาดโดยใช้ข้อมูลจากเวชระเบียน อัตราการใช้บริการฉุกเฉิน และแนวโน้มการค้นหาข้อมูลทางอินเทอร์เน็ต สามารถเตือนล่วงหน้าได้ตั้งแต่สัปดาห์จนถึงหลายสัปดาห์ ทำให้หน่วยงานสาธารณสุขจัดสรรเตียง พยาบาล และวัสดุสิ้นเปลืองได้ดีขึ้น งานเชิงปฏิบัติหลายแห่งรายงานว่าเมื่อใช้โมเดลล่วงหน้า 2–4 สัปดาห์ สามารถลดอัตราการขาดแคลนอุปกรณ์และเตียงได้รวมประมาณ 10–20% และช่วยลดระยะเวลาในการตอบสนองต่อคลัสเตอร์การระบาด ส่งผลให้ลดการเข้ารักษาตัวแบบฉุกเฉินในบางบริบทได้อย่างมีความหมาย
-
พลังงานและสภาพอากาศ: พยากรณ์โหลดไฟฟ้าและเหตุการณ์รุนแรง
การพยากรณ์โหลดไฟฟ้าแบบเรียลไทม์และการคาดการณ์เหตุการณ์สภาพอากาศรุนแรงใช้โมเดลที่ผสานข้อมูลจากกริด พยากรณ์อากาศ และข้อมูลอุปสงค์ของผู้ใช้ ตัวอย่างการนำไปใช้ได้แก่ การลดค่าใช้จ่ายสำรองพลังงานโดยการปรับแผนผลิตไฟฟ้าล่วงหน้าซึ่งช่วยให้ผู้ประกอบการลดค่าใช้จ่ายเชื้อเพลิงได้หลายเปอร์เซ็นต์ และการเพิ่มสัดส่วนพลังงานหมุนเวียนในระบบไฟฟ้าได้ราว 10–15% ด้วยการพยากรณ์ความผันผวนของลมและแสงอาทิตย์ นอกจากนี้ การพยากรณ์เหตุการณ์รุนแรงเช่น พายุหรือคลื่นความร้อนที่ขยาย lead time ได้ 12–48 ชั่วโมง ทำให้หน่วยงานต่าง ๆ วางมาตรการป้องกันและลดความเสียหายต่อโครงสร้างพื้นฐานและชุมชนได้ดีขึ้น
จากกรณีศึกษาข้างต้น จะเห็นได้ว่า ผลประโยชน์เชิงธุรกิจ ไม่ได้จำกัดอยู่เพียงการเพิ่มรายได้เท่านั้น แต่ยังครอบคลุมการลดต้นทุน ปรับปรุงความพร้อมของทรัพยากร และการเพิ่มความยืดหยุ่นต่อเหตุการณ์ที่ไม่คาดคิด อย่างไรก็ตาม การนำแมชชีนเลิร์นนิงไปใช้ให้เกิดผลจริงต้องควบคู่กับการจัดการข้อมูลที่ดี การประเมินความเสี่ยงด้านจริยธรรมและความเป็นส่วนตัว และการออกแบบระบบที่สามารถอธิบายได้ (explainability) เพื่อให้ผู้มีหน้าที่ตัดสินใจยอมรับผลลัพธ์และใช้งานอย่างมั่นใจ
คู่มือปฏิบัติ: เครื่องมือ ไลบรารี และการนำไปใช้งาน (MLOps)
การเลือกไลบรารีตามกรณีใช้งาน
การเลือกไลบรารีที่เหมาะสมเป็นก้าวแรกที่สำคัญสำหรับโครงการพยากรณ์อนาคตด้วยแมชชีนเลิร์นนิง โดยควรพิจารณาจากประเภทข้อมูล ขนาดข้อมูล และข้อกำหนดด้าน latency ตัวอย่างคำแนะนำเบื้องต้น ได้แก่:
- scikit-learn — เหมาะสำหรับโมเดลแบบดั้งเดิม (linear models, tree-based, clustering) ใช้งานเร็ว ให้ API เรียบง่าย เหมาะสำหรับต้นแบบและงานที่ข้อมูลมีขนาดไม่ใหญ่มาก
- statsmodels — เหมาะกับการวิเคราะห์เชิงสถิติและโมเดลเชิงอนุกรม (ARIMA, SARIMAX) เมื่อต้องการคำอธิบายเชิงสถิติที่ชัดเจน
- Prophet — พัฒนาเพื่อพยากรณ์ชุดข้อมูลเวลา (seasonality, holidays) ใช้งานง่ายและให้ผลลัพธ์ที่ตีความได้สำหรับธุรกิจ
- TensorFlow และ PyTorch — เหมาะกับงาน deep learning, sequence models (RNN, Transformer) หรือเมื่อใช้ embeddings และ NLP/visual features; PyTorch มีความนิยมสูงในงานวิจัย ส่วน TensorFlow มี ecosystem สำหรับ production (TF Serving, TFX)
- เครื่องมือเสริม — สำหรับ data validation ใช้ Great Expectations, สำหรับ feature store ใช้ Feast, สำหรับ experiment tracking และ model registry ใช้ MLflow หรือ Weights & Biases
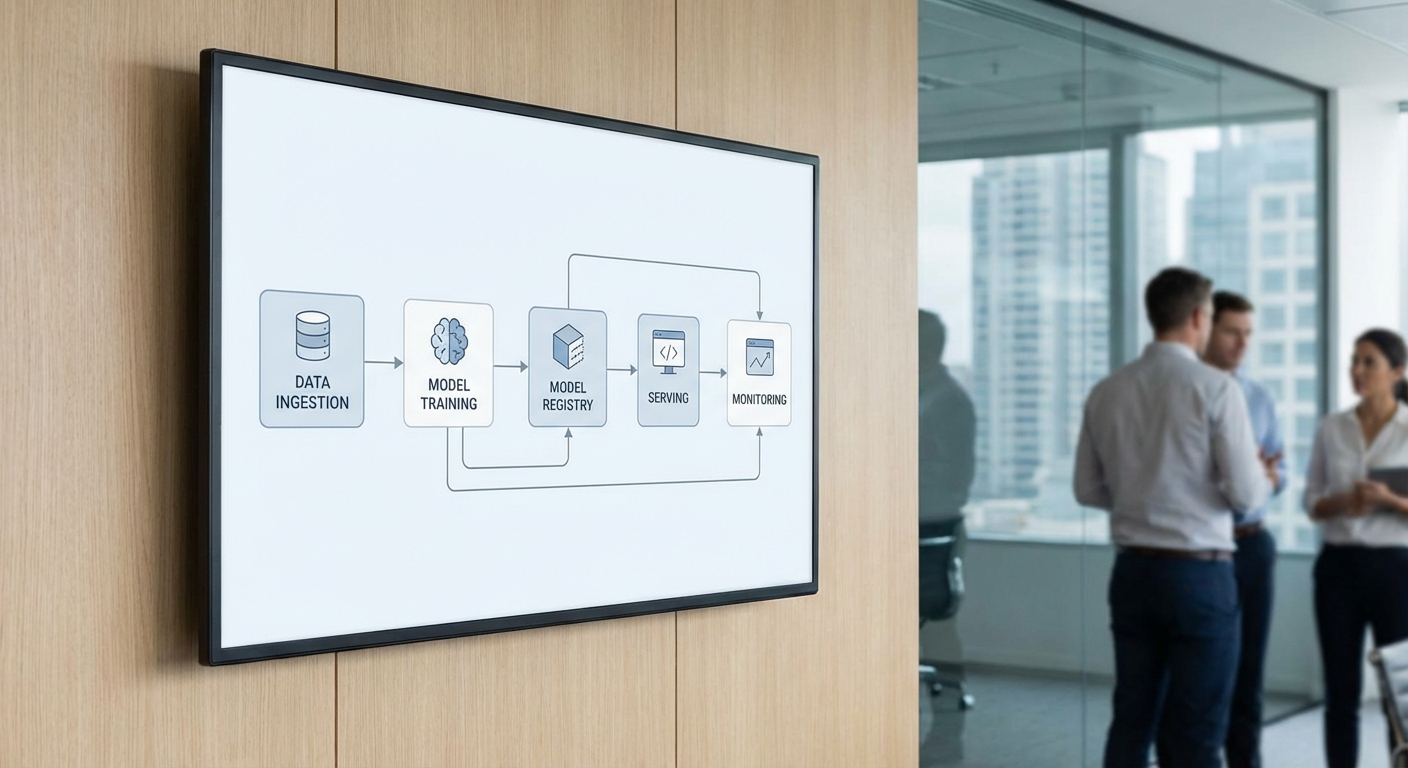
ขั้นตอนสร้าง Pipeline: จากการรับข้อมูลถึง Deployment
Pipeline มาตรฐานที่ปฏิบัติได้จริงประกอบด้วยขั้นตอนหลัก 4 ขั้นตอน: data ingestion → training → validation → deployment ซึ่งควรถูกออกแบบให้ทำงานแบบอัตโนมัติและสามารถทำซ้ำได้ ตัวอย่าง workflow ขั้นพื้นฐานมีดังนี้:
- Data ingestion: ดึงข้อมูลจากแหล่งต่าง ๆ (DB, event streams, S3) พร้อมการทำ cleansing และ validation (ใช้ Great Expectations) และบันทึก metadata/เวอร์ชันด้วย DVC หรือ Delta Lake
- Feature engineering & feature store: คำนวณและเก็บฟีเจอร์ลง feature store (Feast) เพื่อให้การฝึกและการให้บริการใช้ฟีเจอร์เดียวกัน ลดความไม่สอดคล้อง
- Training: ใช้ notebook/CI pipeline เรียกใช้ training script (scikit-learn / PyTorch / TensorFlow) บันทึก artifacts และ metrics ไปยัง experiment tracker (MLflow, W&B)
- Validation & testing: ทำ validation แบบ holdout / cross-validation, performance tests (precision/recall, MAPE สำหรับ time series) และ regression tests เพื่อป้องกัน performance regression
- Deployment: เลือกวิธี deploy เป็น batch หรือ real-time ขึ้นกับ use case (ดูรายละเอียดด้านล่าง) และลงทะเบียนโมเดลใน model registry ก่อนส่งไป production
แนวปฏิบัติ MLOps: Versioning, Monitoring และ Automated Retraining
เพื่อให้โมเดลมีความน่าเชื่อถือและสามารถใช้งานในระยะยาว ควรติดตั้งแนวปฏิบัติ MLOps ต่อไปนี้เป็นมาตรฐานที่องค์กรธุรกิจนิยมปฏิบัติ:
- Model & Data versioning: ใช้ DVC หรือ Delta Lake สำหรับเวอร์ชันของ dataset และใช้ Git ร่วมกับ MLflow/ModelDB ในการจัดการเวอร์ชันโมเดล การมี registry ช่วยให้ย้อนกลับ (rollback) ได้เมื่อเกิดปัญหา
- CI/CD สำหรับโมเดล: ตั้ง pipeline ทดสอบอัตโนมัติ (unit test, data schema test, model performance test) โดยใช้ GitHub Actions, Jenkins หรือ Tekton เมื่อผ่านแล้วให้ pipeline ทำการ build artifact และ deploy อัตโนมัติแบบ Canary/Blue–Green
- Monitoring: ตรวจวัดทั้ง system metrics (latency, throughput) และ model metrics (accuracy, MAPE, AUC) รวมถึงการตรวจจับ data drift/feature drift โดยใช้ Prometheus + Grafana ร่วมกับเครื่องมือเฉพาะเช่น Evidently หรือ WhyLabs
- Alerting & Governance: ตั้ง threshold สำหรับ performance degradation และ data drift หากค่าเกินค่า threshold ให้ trigger alert/automated rollback และบันทึกเหตุการณ์เพื่อการตรวจสอบ
- Automated retraining: กำหนดนโยบายในการ retrain เช่น ตามเวลา (daily/weekly), ตามจำนวนตัวอย่างใหม่ หรือเมื่อตรวจพบ drift/ลดลงของ performance โดยใช้ scheduler เช่น Airflow หรือ Kubeflow Pipelines เพื่อรัน retraining → validation → deploy อัตโนมัติ
การทดสอบ (Testing) และกลยุทธ์การ Deploy: Batch vs Real-time
การทดสอบและกลยุทธ์การ deploy ควรสอดคล้องกับความต้องการด้าน latency และปริมาณงาน:
- Batch prediction: เหมาะกับการประมวลผลจำนวนมากเป็นรอบ (รายวัน/รายชั่วโมง) เช่นการคาดการณ์ยอดขายประจำวัน ใช้ architecture แบบ ETL → model job → store ผลลัพธ์ลง DB หรือ data warehouse
- Real-time (online) prediction: เหมาะกับ use case ที่ต้องการ latency ต่ำ เช่น personalized recommendation หรือ fraud detection ใช้ทางเลือกเช่น REST/gRPC model servers (Seldon, Triton, TF Serving) หรือ serverless functions ผสานกับ streaming platform (Kafka, Kinesis)
- Testing: ทำ unit test ของ feature transformations, integration test กับ data sources, performance/load testing ของ serving layer และ shadow testing (รันโมเดลใหม่ขนานกับโมเดลเก่าโดยไม่ส่งผลต่อผู้ใช้)
ตัวอย่างสถาปัตยกรรมระบบแบบง่าย
สถาปัตยกรรมตัวอย่างที่สามารถเริ่มใช้งานได้รวดเร็วและขยายต่อได้ประกอบด้วยส่วนดังนี้:
- แหล่งข้อมูล (DB / Event Stream) → Data Ingestion (Airflow / Kafka Connect)
- Data Validation & Storage (Great Expectations, S3/Delta Lake) → Feature Store (Feast)
- Training Pipeline (Kubeflow / MLflow + Kubernetes) → Model Registry (MLflow)
- Model Serving: Batch (Spark job เข้าถึง model artifact) หรือ Real-time (Seldon/Triton ให้บริการผ่าน REST/gRPC)
- Monitoring & Observability: Prometheus + Grafana, Evidently สำหรับ model/data drift, Alerting ระบบแจ้งเตือน
สรุปคือ การตั้งค่า MLOps ที่ดีต้องอาศัยการเลือกเครื่องมือให้สอดคล้องกับกรณีใช้งาน การออกแบบ pipeline ที่สามารถอัตโนมัติและทวนซ้ำได้ รวมถึงแนวปฏิบัติในการ versioning, testing, monitoring และ retraining — ซึ่งทั้งหมดนี้ช่วยลดความเสี่ยง เพิ่มความเร็วในการนำโมเดลขึ้นสู่ production และทำให้ผลลัพธ์การพยากรณ์มีความเสถียรสำหรับการตัดสินใจเชิงธุรกิจ
ข้อควรระวังเชิงจริยธรรม ความเสี่ยง และแนวโน้มในอนาคต
ข้อควรระวังเชิงจริยธรรม ความเสี่ยง และแนวโน้มในอนาคต
การนำแมชชีนเลิร์นนิงมาใช้เพื่อการคาดการณ์เปิดโอกาสทางธุรกิจและสังคมอย่างมหาศาล แต่ก็มาพร้อมกับความเสี่ยงเชิงจริยธรรมที่ต้องพิจารณาอย่างเป็นระบบ โดยเฉพาะประเด็น อคติ (bias) และ ความยุติธรรม (fairness) ซึ่งหากละเลยอาจสร้างผลกระทบต่อผู้มีส่วนได้ส่วนเสียจำนวนมาก ตัวอย่างเช่น ระบบคัดกรองพนักงานอัตโนมัติที่เรียนรู้จากข้อมูลการจ้างงานในอดีตอาจสืบทอดความลำเอียงเชิงเพศหรือเชื้อชาติได้ ระบบทำนายความเสี่ยงทางการเงินอาจกีดกันกลุ่มประชากรบางกลุ่มจากการเข้าถึงสินเชื่อ การศึกษาพบว่าโมเดลที่ขาดการตรวจสอบอคติสามารถสร้างความเสียหายเชิงสังคมได้ทั้งในมิติการจ้างงาน การดูแลสุขภาพ และการบังคับใช้กฎหมาย
ความเสี่ยงด้านความเป็นส่วนตัวและความปลอดภัยของข้อมูลเป็นอีกประเด็นสำคัญ ระบบคาดการณ์มักต้องพึ่งพาชุดข้อมูลขนาดใหญ่ที่มีข้อมูลเชิงบุคคล ซึ่งอาจเสี่ยงต่อการรั่วไหลผ่านช่องโหว่ต่างๆ เช่น การโจมตีแบบ model inversion หรือ membership inference ที่สามารถสกัดข้อมูลการฝึกออกมาได้ นอกจากนี้ การรวมข้อมูลข้ามแหล่งเพื่อเพิ่มความแม่นยำยังเพิ่มความเสี่ยงด้านการปฏิบัติตามกฎระเบียบ เช่น GDPR และกฎหมายคุ้มครองข้อมูลท้องถิ่น ดังนั้นองค์กรจำเป็นต้องนำมาตรการเช่น differential privacy, การเข้ารหัสขณะใช้งาน (encryption-in-use), และการทดสอบเจาะระบบมาใช้ควบคู่กับนโยบายการจัดการข้อมูลที่ชัดเจน
ด้านความโปร่งใสและความสามารถในการตีความผล (explainability) มีความสำคัญเชิงกลยุทธ์สำหรับการตัดสินใจระดับสูง ผู้บริหารและผู้กำกับดูแลต้องเข้าใจว่าโมเดลให้คำตอบอย่างไรและด้วยเหตุผลอะไร การขาดความโปร่งใสทำให้ยากต่อการตรวจจับข้อผิดพลาดหรือการลำเอียง ดังนั้นแนวทางปฏิบัติที่ควรส่งเสริมได้แก่การใช้ model cards และ datasheets สำหรับโมเดลและชุดข้อมูล การดำเนินการประเมินผลกระทบเชิงจริยธรรม (algorithmic impact assessment) และการมีมนุษย์เป็นจุดตรวจสอบสุดท้าย (human-in-the-loop) เพื่อรับประกันว่าการคาดการณ์จะนำไปสู่การตัดสินใจที่ยุติธรรมและรับผิดชอบ
เพื่อรับมือกับความเสี่ยงและขยายขอบเขตการใช้งานที่ปลอดภัย แนวโน้มทางเทคโนโลยีในอนาคตจะเน้นไปที่การผสมผสานระหว่างความสามารถในการคาดการณ์ที่มีความไม่แน่นอน (uncertainty-aware) และการรักษาความเป็นส่วนตัว ตัวอย่างทิศทางสำคัญ ได้แก่:
- Probabilistic Machine Learning และการประมาณความไม่แน่นอน — การใช้วิธีแบบเบย์esian, Bayesian neural networks, ensembles หรือเทคนิคอย่าง conformal prediction ช่วยให้โมเดลไม่เพียงแต่ทำนายค่าแต่ยังประเมินความเชื่อมั่นในคำทำนายนั้นได้ ซึ่งสำคัญต่อการตัดสินใจที่มีความเสี่ยงสูง เช่น การแพทย์หรือการเงิน
- Federated Learning และการเรียนรู้แบบกระจาย — การฝึกโมเดลแบบไม่ดึงข้อมูลดิบจากแหล่งต้นทางช่วยลดความเสี่ยงด้านความเป็นส่วนตัว และเมื่อนำมารวมกับ differential privacy และ secure aggregation จะช่วยให้การใช้งานข้อมูลเชิงบุคคลเป็นไปได้ในกรอบที่ปลอดภัยยิ่งขึ้น
- การผสานกับ Causal Inference — การรวมโครงสร้างเชิงสาเหตุ (causal models, SCMs) กับ ML ช่วยให้การคาดการณ์สามารถตอบคำถามเชิงเหตุผล เช่น ผลของการแทรกแซง (what-if / counterfactuals) แทนที่จะอาศัยความสัมพันธ์เชิงสถิติเท่านั้น ซึ่งช่วยลดความเสี่ยงจากการสรุปผลแบบผิดพลาดที่เกิดจากความสัมพันธ์เทียม
- การออกแบบที่คำนึงถึงความยุติธรรมและการตรวจจับอคติอัตโนมัติ — เครื่องมือและมาตรฐานสำหรับการวัด fairness (เช่น disparate impact, counterfactual fairness) จะถูกรวมเข้ากับกระบวนการ CI/CD ของโมเดล เพื่อให้การตรวจสอบอคติเป็นกระบวนการต่อเนื่องไม่ใช่การตรวจสอบเพียงครั้งเดียว
สรุปแล้ว องค์กรที่ต้องการใช้แมชชีนเลิร์นนิงเพื่อการคาดการณ์อย่างยั่งยืนควรผสมผสานการพัฒนาเชิงเทคนิคกับกรอบธรรมาภิบาล (governance) ที่เข้มแข็ง การลงทุนในเทคโนโลยี probabilistic และ privacy-preserving วิธีการผสาน causal inference และมาตรการตรวจสอบอคติอย่างต่อเนื่องจะเป็นกุญแจสำคัญในการสร้างระบบคาดการณ์ที่ทั้งแม่นยำ โปร่งใส และยุติธรรม พร้อมทั้งปฏิบัติตามข้อกำหนดทางกฎหมายและคาดหวังของผู้มีส่วนได้ส่วนเสีย
บทสรุป
การคาดการณ์ด้วยแมชชีนเลิร์นนิงเป็นเครื่องมือทรงพลังที่สามารถพลิกโฉมการตัดสินใจเชิงธุรกิจได้—from การทำนายอุปสงค์และการจัดการสต็อกไปจนถึงการบำรุงรักษาเชิงคาดการณ์และการประเมินความเสี่ยง—แต่ต้องใช้อย่างรอบคอบและมีการเตรียมการที่ถูกต้อง ตั้งแต่การเก็บและทำความสะอาดข้อมูล การเลือกตัวชี้วัดที่เหมาะสม ไปจนถึงการประเมินความไม่แน่นอนของผลลัพธ์และการออกแบบการใช้งานที่รับผิดชอบ การเริ่มต้นโครงการควรเริ่มจากการนิยามปัญหาทางธุรกิจอย่างชัดเจน เลือกเทคนิคและสถาปัตยกรรมที่สอดคล้องกับขอบเขตงาน และวางระบบการติดตามผลอย่างต่อเนื่องเพื่อปรับปรุงโมเดล ลดความเสี่ยง และตอบสนองต่อการเปลี่ยนแปลงของข้อมูลและบริบททางธุรกิจ
มุมมองในอนาคตชี้ให้เห็นว่าองค์กรมากขึ้นจะผสานการคาดการณ์ด้วยแมชชีนเลิร์นนิงเข้ากับกระบวนการตัดสินใจแบบวันต่อวัน แต่ความสำเร็จจะขึ้นกับการนำแนวทางด้าน Governance, Explainability, และการคำนวณความไม่แน่นอนมาใช้ควบคู่ไปกับการออกแบบที่มีมนุษย์เป็นศูนย์กลาง (human-in-the-loop) แผนงานที่แนะนำได้แก่การกำหนดเป้าหมายเชิงธุรกิจและตัวชี้วัดอย่างชัดเจน สร้างท่อข้อมูลที่เชื่อถือได้ ทดลองด้วยโมเดลพื้นฐานก่อนยกระดับ สร้างระบบมอนิเตอร์และรีเทรนนิ่ง และติดตั้งมาตรการด้านจริยธรรมและความปลอดภัย เมื่อปฏิบัติตามกลยุทธ์เหล่านี้ องค์กรจะสามารถเก็บเกี่ยวประโยชน์จากการคาดการณ์ได้อย่างยั่งยืน ในขณะเดียวกันก็ลดความเสี่ยงที่อาจเกิดขึ้นจากผลลัพธ์ที่ไม่แน่นอนหรือการใช้งานที่ไม่เหมาะสม
📰 แหล่งอ้างอิง: ASU News



