
LawTech กำลังก้าวเข้าสู่ยุคใหม่ของการปฏิบัติด้านกฎหมายในกรุงเทพฯ — เมื่อสำนักงานกฎหมายเริ่มนำ Large Language Models (LLMs) ที่ออกแบบให้เชิงอธิบายและมีการอ้างอิงข้อมูลเข้ามาช่วยร่างคำให้การ สรุปคำพิพากษพร้อมแหล่งอ้างอิง และแปลเนื้อหากฎหมายเป็นภาษาที่เข้าใจได้สำหรับลูกค้า ผลลัพธ์ที่เกิดขึ้นไม่เพียงแค่ประหยัดเวลา แต่ยังยกระดับความโปร่งใสในการให้คำปรึกษาและการสื่อสารกับคู่ความ โดยมีรายงานเบื้องต้นว่าการนำเทคโนโลยีนี้มาใช้สามารถลดเวลาเตรียมคดีได้ถึงราว 70% ในหลายกรณี (ตัวอย่างเช่น จากการเตรียมงานคดีเฉลี่ย 40 ชั่วโมง ลดเหลือประมาณ 12 ชั่วโมง) ทำให้ทนายความสามารถโฟกัสกับงานเชิงกลยุทธ์และการวิเคราะห์ที่ซับซ้อนมากขึ้น
บทความนี้นำเสนอแนวทางเชิงปฏิบัติสำหรับสำนักงานกฎหมายที่ต้องการยกระดับกระบวนการทำงานด้วย LLM แบบอธิบาย-มีแหล่งอ้างอิง: วิธีร่างคำให้การที่เชื่อถือได้ วิธีสรุปคำพิพากษพร้อมอ้างแหล่งที่มาอย่างเป็นระบบ วิธีแปลกฎหมายเป็นภาษาชาวบ้านเพื่อเพิ่มความเข้าใจของลูกค้า และแผนการติดตั้งจริงรวมถึงข้อพึงระวังด้านจริยธรรมและการปฏิบัติตามกฎหมายข้อมูลส่วนบุคคล บทนำนี้จะเป็นประตูสู่คู่มือเชิงเทคนิคและเชิงกลยุทธ์ที่ช่วยให้สำนักงานกฎหมายในกรุงเทพฯ ปรับตัวอย่างมั่นคงและโปร่งใสในยุคดิจิทัล
ภาพรวม: LawTech และ LLM เชิงอธิบาย-อ้างอิงคืออะไร
ภาพรวม: LawTech และ LLM เชิงอธิบาย-อ้างอิงคืออะไร
LawTech หมายถึงการประยุกต์ใช้เทคโนโลยีดิจิทัลโดยตรงกับงานทางกฎหมายและกระบวนการให้บริการทางกฎหมาย ตั้งแต่ระบบจัดการคดี (case management) การทำ e-discovery การร่างเอกสารอัตโนมัติ ไปจนถึงการวิเคราะห์ความเสี่ยงเชิงกฎหมายด้วยข้อมูลขนาดใหญ่ ในบริบทของสำนักงานกฎหมาย โรลของ AI มีตั้งแต่การเพิ่มประสิทธิภาพงานที่ใช้เวลานาน เช่น การค้นพยานเอกสารและการร่างคำฟ้อง ตลอดจนการช่วยตัดสินใจเชิงยุทธศาสตร์โดยให้ข้อมูลเชิงวิเคราะห์ที่รองรับการต่อสู้คดีหรือการเจรจา ตัวอย่างเช่น การใช้ระบบอัตโนมัติช่วยร่างคำให้การหรือสรุปคำพิพากษาสามารถลดเวลาการเตรียมคดีอย่างมีนัยสำคัญ (เช่นกรณีที่อ้างว่า ลดเวลาเตรียมคดีได้ถึง 70%) และช่วยให้ทนายสามารถทุ่มทรัพยากรไปที่งานเชิงยุทธศาสตร์มากขึ้น
LLM เชิงอธิบาย-อ้างอิง (explainable & citation-enabled LLM) คือรุ่นของโมเดลภาษาขนาดใหญ่ที่ออกแบบมาไม่เพียงแต่ให้คำตอบภาษาเท่านั้น แต่ยังให้ข้อมูลอ้างอิง (provenance) และคำอธิบายเชิงเหตุผลประกอบคำตอบด้วย คุณสมบัติเหล่านี้มักถูกสร้างขึ้นจากการผสานเทคนิคเช่น Retrieval-Augmented Generation (RAG) ซึ่งดึงเอกสารกฎหมาย ข้อบังคับ หรือคำพิพากษามาเป็นฐานความรู้ก่อนให้คำตอบ ทำให้ผลลัพธ์มี “แหล่งที่มา” ระบุชัดเจน (เช่น อ้างถึงมาตรา คำพิพากษาฉบับที่/ปี/เลขคดี หรือย่อหน้าในเอกสารต้นฉบับ) และมักรวมถึงเมตาดาต้าเช่นคะแนนความเชื่อมั่นหรือข้อความระบุข้อจำกัดของข้อมูล วิธีนี้ช่วยให้ผู้ใช้สามารถตรวจสอบย้อนกลับแหล่งข้อมูลจริงได้ แทนที่จะยอมรับข้อความจากโมเดลแบบไร้หลักฐาน
ความแตกต่างสำคัญจาก LLM แบบ “black-box” อยู่ที่ ความสามารถในการตรวจสอบแหล่งที่มาและเหตุผลประกอบ โดย LLM แบบ black-box อาจให้คำตอบที่ดูน่าเชื่อถือแต่ไม่มีการอ้างอิงชัดเจนและมีความเสี่ยงของการเกิด hallucination (การสร้างข้อมูลเท็จ) ซึ่งในงานกฎหมายสามารถส่งผลร้ายแรง เช่น อ้างคำพิพากษาที่ไม่มีอยู่จริงหรือบิดเบือนมาตรา หากใช้คำแนะนำเหล่านั้นเป็นฐานของคำปรึกษาทางกฎหมาย ความรับผิดชอบต่อหน้ากฎหมายและจรรยาบรรณอาจถูกกระทบ ในทางตรงกันข้าม LLM เชิงอธิบาย-อ้างอิงช่วยเพิ่มความน่าเชื่อถือของคำปรึกษา เพราะผู้ใช้ (ทนายฝั่งลูกความหรือศาล) สามารถตรวจสอบแหล่งที่มาพร้อมกับคำอธิบายเหตุผล ทำให้คำแนะนำมีความโปร่งใสมากขึ้นและง่ายต่อการตรวจสอบทางวิชาชีพ
นอกจากนี้ LLM เชิงอธิบาย-อ้างอิงยังตอบโจทย์ข้อกังวลเชิงกฎระเบียบและความรับผิดชอบ (compliance & professional accountability) ได้ดีกว่า เช่น การจัดเก็บหลักฐานการให้คำปรึกษา การระบุข้อจำกัดของข้อมูล และการสร้าง audit trail ที่ชัดเจน ซึ่งสำคัญต่อสำนักงานกฎหมายที่ต้องปฏิบัติตามกฎระเบียบข้อมูลและมาตรฐานจรรยาบรรณ ในภาพรวม การเปลี่ยนจากระบบ black-box ไปสู่วิธีการที่ให้หลักฐานและเหตุผลประกอบจึงเป็นก้าวสำคัญของ LawTech ที่ต้องการทั้งประสิทธิภาพและความน่าเชื่อถือในงานด้านกฎหมาย
- จุดเด่นเชิงปฏิบัติ: ให้แหล่งอ้างอิงชัดเจน (มาตรา/คดี/ย่อหน้า), ให้เหตุผลประกอบ, ลดการเกิด hallucination
- ข้อได้เปรียบต่อสำนักงานกฎหมาย: เพิ่มความโปร่งใส, ลดเวลาเตรียมคดี, สร้าง audit trail และสนับสนุนการปฏิบัติตามมาตรฐานวิชาชีพ
- ความเสี่ยงที่ต้องจัดการ: คุณภาพฐานข้อมูลอ้างอิง, ความเป็นส่วนตัวของข้อมูลลูกความ, และการตรวจสอบโดยมนุษย์ก่อนใช้เป็นคำปรึกษาสุดท้าย
- แหล่งอ้างอิงเชิงแนวคิดและงานวิจัยที่เกี่ยวข้อง:
- McKinsey Global Institute, “A Future that Works” (เกี่ยวกับศักยภาพการอัตโนมัติของงาน)
- Thomson Reuters Institute, งานวิจัยด้านการยอมรับ AI ในวิชาชีพกฎหมาย (รายงานสรุปแนวโน้ม)
- เอกสารเชิงนโยบายของสหภาพยุโรปเกี่ยวกับ “Trustworthy AI” และแนวทางการอธิบายได้ของโมเดล
- งานวิจัยด้าน Retrieval-Augmented Generation และการพิสูจน์แหล่งที่มาของโมเดลภาษาจากสถาบันวิจัยหลายแห่ง (เช่น Stanford HAI และงานวิจัยในแวดวง NLP)
กรณีศึกษา: สำนักงานกฎหมายในกรุงเทพนำ LLM มาใช้จริง
กรณีศึกษา: สำนักงานกฎหมายในกรุเทพนำ LLM เชิงอธิบาย-อ้างอิงมาใช้จริง
ภาพรวมการนำระบบมาใช้
สำนักงานกฎหมายขนาดกลาง-ใหญ่ในกรุงเทพ (ต่อไปนี้เรียกสั้น ๆ ว่า สำนักงาน X) ดำเนินโครงการนำ Large Language Model (LLM) ที่มีความสามารถเชิงอธิบายและให้แหล่งอ้างอิงมาใช้ในงานประจำของสำนักงาน โดยตั้งเป้าลดภาระงานเอกสารและเพิ่มคุณภาพการให้คำปรึกษาในเชิงโปร่งใส โครงการเริ่มเป็นรูปธรรมในไตรมาสแรกของปี ทดสอบกับทีมคดีแพ่งและคดีแรงงานเป็นหลัก ผลลัพธ์เชิงปริมาณและเชิงคุณภาพถูกบันทึกและวิเคราะห์ภายใน 6 เดือนแรกของการใช้งาน
ลักษณะการใช้งานจริงในงานประจำ
การใช้งาน LLM ของสำนักงาน X ถูกออกแบบให้เป็นเครื่องมือที่ทำงานร่วมกับทนายความ เป็นไปตามกระบวนการดังนี้: ทนายความป้อนคำสั่ง (prompt) พร้อมบริบท เช่น ข้อเท็จจริงของคดี หัวข้อกฎหมายที่เกี่ยวข้อง และเอกสารอ้างอิงที่ต้องการให้วิเคราะห์ ระบบ LLM จะผลิตผลลัพธ์ในรูปแบบที่แยกชัดเจน ได้แก่
- ร่างคำฟ้อง/คำให้การ: LLM สร้างร่างข้อเท็จจริง โครงสร้างข้อกฎหมาย และข้อเรียกร้อง ซึ่งทนายความยังคงตรวจทานและปรับแก้ก่อนใช้งานจริง
- สรุปคำพิพากษาพร้อมอ้างแหล่ง: ระบบสรุปสาระสำคัญของคำพิพากษา ระบุมาตรา พยานหลักฐาน และอ้างอิงคำพิพากษาที่เกี่ยวข้องเป็นลิงก์หรือหมายเลขคำพิพากษา ทำให้การอ้างอิงชัดเจนและตรวจสอบกลับได้
- แปลกฎหมายเป็นภาษาชาวบ้าน: ระบบแปลงข้อความกฎหมายและผลกระทบทางกฎหมายเป็นภาษาที่เข้าใจง่ายสำหรับลูกความ เช่น อธิบายภาระผูกพันและความเสี่ยงใน 3-5 ข้อสั้น ๆ
ผลลัพธ์เชิงปริมาณและตัวอย่างสถิติ
จากการติดตามผลภายในสำนักงาน X พบตัวชี้วัดสำคัญดังนี้:
- ลดเวลาเตรียมคดีด้านเอกสาร 70% — ก่อนนำระบบมาใช้ เวลาเฉลี่ยที่ใช้จัดเตรียมเอกสารและร่างคำให้การ/คำฟ้องอยู่ที่ประมาณ 10 ชั่วโมงต่อคดี เมื่อใช้ LLM เวลาลดลงเหลือเฉลี่ย 3 ชั่วโมงต่อคดี (ข้อมูลตัวอย่างจากงานคดีแพ่งและแรงงาน 120 คดีในช่วง 6 เดือน)
- อัตราการจัดส่งสรุปคำพิพากษต่อทีมขึ้นจาก 40% เป็น 92% ภายในวันทำการถัดไป เพิ่มความรวดเร็วในการตัดสินใจเชิงยุทธศาสตร์
- จำนวนคดีที่สามารถรับเพิ่มได้ต่อทนายความเพิ่มขึ้นประมาณ 1.8 เท่า โดยไม่ลดคุณภาพของเอกสารที่ส่งให้ลูกความ
ผลด้านความโปร่งใสและความไว้วางใจของลูกความ
หนึ่งในประเด็นที่สำนักงาน X ให้ความสำคัญคือความโปร่งใสของการให้คำปรึกษา ด้วยการส่งเอกสารสรุปคำพิพากษาและร่างคำให้การที่มาพร้อม แหล่งอ้างอิงชัดเจน ลูกความสามารถตรวจสอบที่มาของข้อมูลได้ทันที ทำให้ความไว้วางใจเพิ่มขึ้นอย่างมีนัยสำคัญ ดังนี้
- ลูกความรายงานความพึงพอใจต่อความโปร่งใสของเอกสารเพิ่มขึ้นราว 30% (จากแบบสอบถามภายใน)
- การลดข้อพิพาทเรื่องข้อเท็จจริงหรือการตีความกฎหมายในขั้นเตรียมคดีลดลง เนื่องจากเอกสารอ้างอิงชัดเจนและสามารถตรวจสอบย้อนหลังได้
- ทนายความสามารถให้คำอธิบายเชิงนโยบายหรือคำแนะนำเชิงความเสี่ยงในภาษาที่ลูกความเข้าใจได้ ซึ่งช่วยให้การตัดสินใจของลูกความมีข้อมูลรองรับและโปร่งใสมากขึ้น
บทเรียนที่ได้และข้อพิจารณา
สำนักงาน X ชี้ว่า LLM เป็นเครื่องมือเสริม ไม่ใช่ตัวแทนทนายความ ขั้นตอนตรวจทานโดยผู้เชี่ยวชาญยังจำเป็นเพื่อรับประกันความถูกต้องทางกฎหมายและจริยธรรม นอกจากนี้การจัดการข้อมูลลับของลูกความและการบันทึกแหล่งอ้างอิงอย่างปลอดภัยเป็นข้อกำชับที่สำนักงานต้องพัฒนาควบคู่ไปด้วย การประยุกต์ใช้เชิงอธิบาย-อ้างอิงช่วยให้สำนักงานลดเวลาเตรียมคดีอย่างมีนัยสำคัญ เพิ่มความโปร่งใส และยกระดับการบริการให้สอดคล้องกับความคาดหวังของลูกความยุคดิจิทัล
ตัวอย่างงานที่ LLM ทำได้: ร่างคำให้การและสรุปคำพิพากษพร้อมอ้างแหล่ง
ตัวอย่างงานที่ LLM ทำได้: ร่างคำให้การและสรุปคำพิพากษพร้อมอ้างแหล่ง
ในบทบาทของ LawTech สำนักงานกฎหมายในกรุงเทพนำ LLM เชิงอธิบาย-อ้างอิงมาใช้เพื่อผลิตเอกสารสำคัญ เช่น ร่างคำให้การเบื้องต้น ร่างคำให้การฉบับปรับสำหรับยื่นศาล และสรุปคำพิพากษาพร้อมการอ้างแหล่งอ้างอิงย่อหน้าและเลขคดี การใช้งานจริงพบว่าเวิร์กโฟลว์ที่ผสาน LLM สามารถลดเวลาเตรียมคดีได้ประมาณ 70% โดย LLM ช่วยดึงประเด็นข้อเท็จจริง กฎหมายที่เกี่ยวข้อง และคำพิพากษาอ้างอิงเป็นแบบร่างให้ทนายตรวจแก้ไขก่อนยื่น (ตัวอย่าง: เวลาจาก 20 ชั่วโมงเหลือ 6 ชั่วโมงต่อคดีในงานเอกสารเชิงเทคนิค)
ตัวอย่างต่อไปนี้แสดงรูปแบบผลลัพธ์ที่ LLM สามารถสร้างได้ เพื่อให้ผู้อ่านเห็นภาพจริงของเนื้อหา รูปแบบการอ้างอิง และภาษาที่เหมาะสมทั้งในระดับภายในสำนักงานและสำหรับการยื่นศาล
1) ตัวอย่างร่างคำให้การ
-
ร่างคำให้การ (เบื้องต้น — สำหรับการวิเคราะห์ภายใน)
หมายเหตุ: แบบร่างนี้เน้นการรวบรวมข้อเท็จจริงหลัก ประเด็นข้อกฎหมายที่อาจนำมาใช้ และรายการเอกสารอ้างอิงที่ LLM ดึงมาให้เพื่อให้ทนายพิจารณา
คดีหมายเลข: (ระบุภายหลัง) — คู่ความ: นางสาว A (โจทก์) กับ บริษัท B (จำเลย)
ข้อเท็จจริงโดยสรุป: เมื่อวันที่ 15 มกราคม 2565 โจทก์ได้ทำสัญญาซื้อขายสินค้าเลขที่ X กับจำเลย ตามสัญญาจำเลยค้างส่งสินค้าและชำระค่าปรับไม่เป็นไปตามเงื่อนไข ส่งผลให้โจทก์ได้รับความเสียหายโดยประมาณ 200,000 บาท (เอกสารแนบ: สัญญา, ใบเสร็จ, อีเมลการทวงถาม)
ประเด็นข้อกฎหมายที่อาจนำสืบ: สัญญาผิดสัญญา (ตัวอย่าง: ประมวลกฎหมายแพ่งและพาณิชย์ มาตรา X) ว่าด้วยการบอกเลิกและค่าทดแทน; หลักการละเมิด (หากมีการกระทำที่เป็นการละเมิดเชิงแย้ง)
แหล่งอ้างอิงเบื้องต้นที่ LLM ดึงมา: คำพิพากษาฎีกาที่ 4567/2561 ข้อ 8–12 (ตัวอย่าง), มาตรา X วรรค 1 (ประมวลกฎหมายแพ่งฯ) (ตัวอย่าง)
ข้อเสนอแนะจากระบบ: รวบรวมหลักฐานการส่งมอบ, ถ่ายสำเนาอีเมลที่ยืนยันการทวงถาม, ขอคำชี้แจงรายละเอียดค่าเสียหายเป็นลายลักษณ์อักษรก่อนยื่นฟ้อง
-
ร่างคำให้การ (ฉบับปรับสำหรับยื่นศาล — รูปแบบทางการ)
หมายเหตุ: แบบฉบับนี้จัดรูปแบบตามที่ศาลคาดหวัง มีการอ้างมาตราและคำพิพากษาเป็นข้อๆ พร้อมคำขอและคำให้การที่ชัดเจน
ศาลแขวง XXXXX
คดีหมายเลข: กค.123/2566
คำให้การของจำเลย บริษัท Bข้อเท็จจริง: จำเลยขอให้ศาลรับทราบว่า จำเลยได้ลงนามในสัญญาซื้อขายสินค้าเลขที่ X เมื่อวันที่ 10 ธันวาคม 2564 และได้ทำการส่งมอบบางส่วนแก่โจทก์เมื่อวันที่ 20 ธันวาคม 2564 (ดูเอกสารหมายเลข 1–3) จำเลยปฏิเสธข้อกล่าวหาว่ามิได้พยายามชำระค่าปรับตามสัญญา โดยจำเลยได้ส่งอีเมลชี้แจงเมื่อวันที่ 5 มกราคม 2565 (เอกสารหมายเลข 4)
คำให้การตามข้อกล่าวหา: (1) ข้อกล่าวหาเรื่องการผิดสัญญา — จำเลยขอชี้แจงว่าได้ปฏิบัติตามภาระผูกพันบางส่วนและกรณีที่โจทก์เรียกร้องค่าชดเชยจำเลยขอให้ศาลพิจารณาตามหลักฐานตาม (ข้อ 2)
ฐานกฎหมายและคำอ้างอิง: ประมวลกฎหมายแพ่งและพาณิชย์ มาตรา X (การผิดสัญญา) (ตัวอย่าง); อ้างคำพิพากษาฎีกาที่ 4567/2561, ข้อ 10–12 (ตัวอย่าง) ซึ่งกำหนดหลักเกณฑ์การพิจารณาค่าเสียหายในกรณีการผิดสัญญาว่า “ต้องพิสูจน์ความเสียหายและความเกี่ยวเนื่อง” (ข้อความย่อ)
คำขอที่ยื่นต่อศาล: (1) ขอให้ยกคำขอของโจทก์ทั้งหมด (2) หากศาลเห็นว่าจำเลยมีความรับผิด ขอให้ศาลกำหนดวงเงินค่าเสียหายตามหลักฐานที่พิสูจน์ได้ (3) ขอให้ศาลพิพากษาให้โจทก์รับผิดชอบค่าใช้จ่ายศาล (ตามมาตรา Y)
ลายเซ็น: ตัวแทนจำเลย / วันที่
หมายเหตุการตรวจสอบ: LLM ระบุแหล่งอ้างอิงที่ต้องแนบ (สัญญา, ใบเสร็จ, รายการอีเมล) พร้อมรายการพยานที่ควรสอบสวนเพิ่มเติม
2) ตัวอย่างสรุปคำพิพากษา — รูปแบบที่ LLM จัดทำและอ้างแหล่ง
เมื่อ LLM สรุปคำพิพากษา ระบบจะจัดแบ่งเป็นหัวข้อชัดเจน ได้แก่ ประเด็นข้อกฎหมาย (Issues), เหตุผลของศาล (Reasoning), บทสรุปคำพิพากษา (Holding) และแหล่งอ้างอิงที่ชัดเจนครบถ้วน เช่น หมายเลขคดีและหมายเลขย่อหน้าที่ใช้อ้างอิง
-
ตัวอย่างสรุปคำพิพากษา (ตัวอย่าง): คำพิพากษาศาลฎีกาที่ 8910/2562
ประเด็นข้อกฎหมาย: ศาลพิจารณาว่าเหตุแห่งการบอกเลิกสัญญาจะต้องมีการแจ้งเป็นลายลักษณ์อักษรก่อนหรือไม่ (อ้างอิง: ข้อ 3–4)
เหตุผลของศาล: ศาลเห็นว่าตามสาระของสัญญาและพฤติการณ์ คู่สัญญาทั้งสองฝ่ายมีความชัดเจนในเจตนาในการปฏิบัติ หากฝ่ายหนึ่งฝ่ายใดไม่ปฏิบัติตามเงื่อนไขที่สำคัญ ฝ่ายอีกฝ่ายสามารถบอกเลิกสัญญาโดยไม่ต้องรอการแจ้งเป็นลายลักษณ์ (อ้างอิง: ข้อ 7–11) — ศาลยกหลักการจากคำพิพากษาฎีกาที่ 4567/2561, ข้อ 12 (ตัวอย่าง)
บทสรุป: ศาลยกฟ้องโจทก์เกี่ยวกับคำขอค่าทดแทนบางส่วน แต่พิพากษาให้ฝ่ายจำเลยชดใช้ความเสียหายบางประการตามที่พิสูจน์ได้ (อ้างอิง: ข้อ 15–18)
การอ้างแหล่งที่มาที่ LLM ให้: คำพิพากษาศาลฎีกาที่ 8910/2562 (ข้อ 3–18) — เอกสารฉบับเต็ม (URL หรือฐานข้อมูลคำพิพากษา: ตัวอย่างเช่น "ฐานข้อมูลคำพิพากษาศาลยุติธรรม/เลขที่คดี")
3) การแปลภาษากฎหมายเป็นภาษาชาวบ้าน — ตัวอย่างสั้นๆ
หนึ่งในงานที่สำคัญสำหรับความโปร่งใสของการให้คำปรึกษาคือการแปลข้อความกฎหมายและคำพิพากษาเป็นภาษาที่ลูกความทั่วไปเข้าใจได้ LLM สามารถสรุปเป็นประโยคสั้น ๆ ที่ชัดเจน โดยยังคงความถูกต้องของสาระกฎหมายไว้
-
ต้นฉบับกฎหมาย (ตัวอย่าง):
"การผิดสัญญาอันเป็นเหตุให้คู่สัญญาอีกฝ่ายได้รับความเสียหาย ผู้กระทำต้องรับผิดชดใช้ค่าเสียหายตามหลักฐานที่พิสูจน์ได้"
-
แปลเป็นภาษาชาวบ้าน (ตัวอย่างโดย LLM):
"ถ้าคนหนึ่งในสัญญาทำผิดจนอีกคนเสียหาย ฝ่ายที่ถูกทำให้เสียหายมีสิทธิเรียกเอาเงินชดเชยเท่าที่พิสูจน์ได้จริง" — เพิ่มคำอธิบาย: "เช่น ถ้าส่งของไม่ครบและทำให้เสียธุรกิจ ก็ควรมีหลักฐานค่าเสียหาย เช่น ใบเสร็จ ค่าเสียหายที่แนบได้"
ตัวอย่างเพิ่มเติมของการแปลการวางข้อเรียกร้องจากคำพิพากษา: จาก "ศาลพิจารณาตามดุลพินิจ" → แปลว่า "ศาลตัดสินโดยพิจารณาข้อเท็จจริงและกฎหมายทั้งหมด แล้วเลือกคำตัดสินที่เห็นว่าถูกต้อง"
บทสรุปเชิงการปฏิบัติ: ในการใช้งานจริง LLM สามารถสร้างร่างที่มีทั้งข้อเท็จจริง สรุปประเด็นกฎหมายและคำพิพากษาที่อ้างอิงเลขคดีและย่อหน้าได้อย่างเป็นระบบ ส่งผลให้ทนายสามารถตรวจแก้และยื่นเอกสารต่อศาลได้เร็วขึ้น นอกจากนี้การแปลกฎหมายเป็นภาษาชาวบ้านช่วยเพิ่มความโปร่งใสและความเข้าใจของลูกความ แต่ต้องคงไว้ซึ่งการทบทวนมนุษย์ (human review) เพื่อยืนยันความถูกต้องทางกฎหมายและการอ้างแหล่งอย่างเป็นทางการ
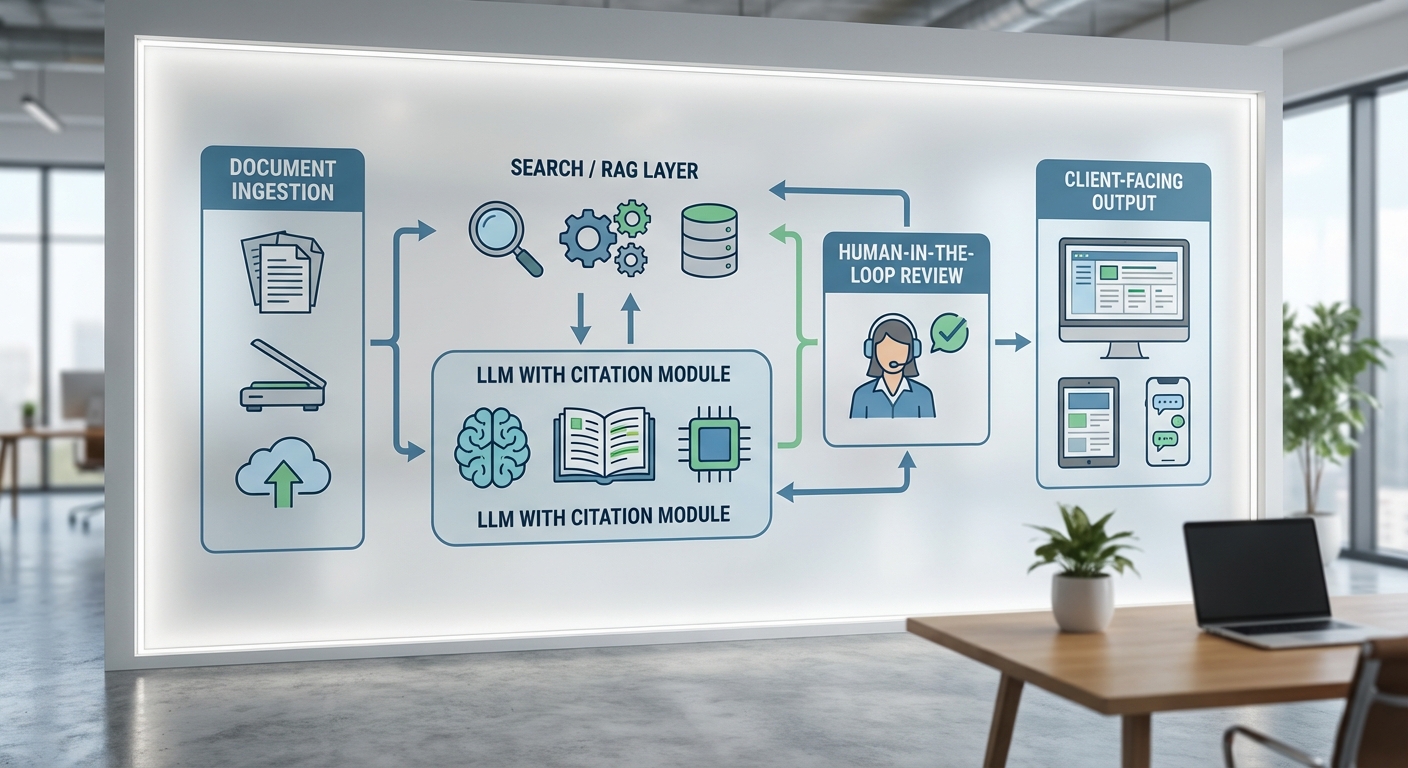
สถาปัตยกรรมทางเทคนิคและ workflow ของระบบในสำนักงานกฎหมาย
บทความนี้อธิบายสถาปัตยกรรมเชิงเทคนิคและขั้นตอนการทำงาน (workflow) ของโซลูชัน LawTech ที่สำนักงานกฎหมายในกรุงเทพฯ ใช้ LLM เชิงอธิบาย-อ้างอิง เพื่อร่างคำให้การ สรุปคำพิพากษ และแปลงกฎหมายเป็นภาษาชาวบ้าน โดยคำนึงถึงการตรวจสอบแหล่งที่มา (citation verification) และการมีส่วนร่วมของทนายความในแบบ human-in-the-loop ผลลัพธ์เชิงประสิทธิภาพที่สังเกตได้คือการลดเวลาเตรียมคดีเฉลี่ยราว 70% เมื่อเทียบกับกระบวนการแบบแมนนวล ซึ่งต้องอาศัยสถาปัตยกรรมที่รองรับการนำข้อมูลเข้า (ingestion), retrieval-augmented generation (RAG), ชั้นตรวจสอบแหล่งที่มา และระบบบันทึก/ตรวจสอบ (auditing/logging) ที่เข้มแข็ง
ส่วนประกอบหลักของสถาปัตยกรรม
- Ingestion Layer: กระบวนการนำข้อมูลเข้าแบบอัตโนมัติและแบบแมนนวล ครอบคลุมไฟล์คำพิพากษา (PDF/HTML), ฐานข้อมูลคำพิพากษา, ประมวลกฎหมาย, แนวปฏิบัติภายใน, และเอกสารคดีของลูกความ ข้อมูลจะถูกผ่านขั้นตอน OCR (สำหรับสแกน PDF), text normalization, chunking (ขนาด 500–1,000 คำพร้อม overlap), และการเพิ่ม metadata (ปี, ศาล, ประเภทคดี, หมายเลขคดี, ผู้แต่ง เอกสารต้นทาง)
- Vector Store / Retrieval Engine (RAG): เก็บ embeddings ของชิ้นข้อมูลใน vector DB (เช่น FAISS, Milvus, หรือ OpenSearch Vector) เพื่อรองรับการค้นคืนตามความคล้ายคลึง ใช้ embedding model ที่ปรับจูนภาษาไทยและคำศัพท์กฎหมาย การเรียกคืนจะคืนทั้งชิ้นข้อมูลต้นทางและตำแหน่งย่อหน้าเพื่อให้ LLM สามารถอ้างอิงอย่างแม่นยำ
- LLM และ Generation Module: LLM ที่ถูก fine-tune สำหรับงานสรุปและร่างคำให้การ ทำงานร่วมกับ prompt templates เฉพาะทาง (เช่น “สรุปข้อเท็จจริง”, “ร่างคำให้การโดยย่อและระบุข้อกฎหมายที่เกี่ยวข้อง”) โดยระบบจะรวมข้อมูลจาก RAG เพื่อสร้างคำตอบที่มีบริบทและแนบแหล่งอ้างอิง
- Citation Verification Layer: โมดูลแยกสำหรับตรวจสอบความถูกต้องของการอ้างอิง ทำงานสองขั้นตอน: (1) cross-check retrieval — ยืนยันว่า snippet ที่อ้างมาจากเอกสารจริง (matching text, page/paragraph id) และ (2) authority validation — ตรวจสอบความเป็นทางการของแหล่งที่มา (ศาลสูงสุด, ศาลอุทธรณ์, ประมวลกฎหมาย) พร้อมคำนวณคะแนนความเชื่อมั่นของการอ้างอิง (provenance confidence)
- Auditing / Logging: เก็บบันทึกที่ immutable ของทุกคำขอ (prompts), ชุดข้อมูลที่ถูกดึง (doc IDs, offsets), เวอร์ชันของโมเดล, คำตอบที่สร้าง, การแก้ไขของผู้ใช้ และกิจกรรมการอนุมัติ เหมาะสำหรับการตรวจสอบย้อนหลังตามข้อกำหนดกฎหมายและการปฏิบัติตามมาตรฐานการบริหารความเสี่ยง
Workflow ขั้นตอนการทำงาน (ภาพรวมสำหรับทีมไอทีและทนายความ)
ภาพรวม workflow แบ่งเป็นขั้นตอนหลักดังนี้:
- 1. นำเข้าข้อมูล (Ingestion) — ไอทีตั้ง connector กับแหล่งข้อมูลภายนอก (ฐานคำพิพากษา, ระบบราชการ, ฐานข้อมูลภายใน) และจัดตารางงาน ETL เพื่อเครื่องหมาย metadata และสร้าง embeddings ใหม่เมื่อมีเอกสารใหม่
- 2. Retrieval — ทนายความหรือระบบอัตโนมัติส่ง query เช่น “สรุปคำพิพากษาเกี่ยวกับข้อหาพ.ร.บ. X ปี 2560” ระบบ RAG จะดึงเอกสารที่เกี่ยวข้อง 10–20 ชิ้นพร้อมตำแหน่งย่อหน้า
- 3. Generation + Citation Attachment — LLM สร้างร่างคำให้การ/สรุป โดยฝัง citation token ที่ชี้ไปยัง doc ID และ offset ของแหล่งที่มา พร้อมแนบระดับความเชื่อมั่นของการอ้างอิง
- 4. Citation Verification — โมดูลตรวจสอบจับคู่ข้อความอ้างอิงกับต้นฉบับ หาก mismatch เกินเกณฑ์ที่กำหนด (เช่น >5% dissimilarity) จะทำเครื่องหมายว่า “ต้องตรวจสอบ”
- 5. Human-in-the-Loop Review — ทนายความตรวจสอบร่างและแหล่งที่มา แก้ไขเนื้อหา ปรับภาษา และยืนยัน/ปฏิเสธการอ้างอิง ก่อนกดอนุมัติให้เอกสารใช้งานจริง
- 6. Finalization & Audit — เมื่ออนุมัติ ระบบบันทึกรายการตรวจสอบทั้งหมด (who, when, what changed) และเผยแพร่เอกสารไปยังระบบจัดการคดีหรือส่งให้ลูกความ โดย log ถูกเก็บรักษาตามนโยบาย (ตัวอย่าง: เก็บขั้นต่ำ 7 ปีสำหรับคดีที่มีความเสี่ยงสูง)
บทบาทของ Human-in-the-Loop และแนวทางปฏิบัติ
Human-in-the-loop เป็นหัวใจสำคัญของการควบคุมความเสี่ยงในแวดวงกฎหมาย บทบาทหลักของทนายความรวมถึง:
- การตรวจสอบความถูกต้องของข้อเท็จจริงและการตีความกฎหมาย
- การยืนยัน/แก้ไขแหล่งอ้างอิงที่ระบบระบุไว้ (approve/override citations)
- การให้คำตัดสินเชิงกฎหมาย (legal judgement) เมื่อมีข้อขัดแย้งในข้อกฎหมายหรือแนวคำพิพากษา
- การตั้งค่า policy เช่น threshold ของ provenance confidence ที่ยอมรับได้ก่อนส่งเข้ากระบวนการอนุมัติอัตโนมัติ
ปฏิบัติการแนะนำ: ให้มีอย่างน้อยหนึ่งทนายความอาวุโสเซ็นชื่อรับรองเอกสารที่ส่งต่อไปยังลูกความสำหรับกรณีที่ผลลัพธ์มีความเสี่ยงสูง หรือเมื่อ provenance confidence ต่ำกว่า 95%
การเชื่อมต่อกับฐานข้อมูลกฎหมายและข้อกำหนดด้านไอที
ระบบต้องเชื่อมต่อกับแหล่งข้อมูลสำคัญอย่างปลอดภัย ได้แก่ ฐานข้อมูลคำพิพากษา (court repositories), ประมวลกฎหมาย (statutes), และแนวปฏิบัติภายในของสำนักงาน (internal precedents) โดยคำแนะนำเชิงเทคนิคมีดังนี้:
- การเชื่อมต่อแบบปลอดภัย: ใช้ VPN/IP allowlist, mutual TLS, และ OAuth2 สำหรับการเรียก API ระหว่างบริการ
- Data Residency & Encryption: กำหนดนโยบายการเก็บข้อมูล (on-premises หรือเฉพาะ region ใน cloud) และเข้ารหัสทั้งขณะพัก (AES-256) และขณะส่ง (TLS 1.2+)
- Metadata & Provenance: เมื่อดึงคำพิพากษา ต้องเก็บ metadata เช่น หมายเลขคดี, วันที่, ศาล, หน้า/พารากราฟที่อ้าง และ fingerprint ของเอกสาร เพื่อให้การตรวจสอบย้อนกลับเป็นไปได้
- Integration APIs: ให้ทีมไอทีมอบ API layer สำหรับการค้น (search endpoints), การเรียกใช้งาน RAG, และ webhook สำหรับแจ้งเตือนเมื่อเอกสารต้องรีวิว
- Monitoring & Alerting: ติดตั้ง metric สำหรับ latency ของ retrieval, quality metrics (เช่น % mismatch citations), และ model drift detection พร้อมระบบแจ้งเตือนเมื่อเกณฑ์สำคัญถูกกระทบ
สรุปคือ สถาปัตยกรรมต้องออกแบบให้ modular, auditable และปลอดภัย โดยผสาน RAG กับชั้นตรวจสอบแหล่งที่มาและ human-in-the-loop อย่างชัดเจน เพื่อให้สำนักงานกฎหมายสามารถลดเวลาเตรียมคดีได้อย่างมีนัยสำคัญ พร้อมเพิ่มความโปร่งใสและความรับผิดชอบในการให้คำปรึกษา
การวัดผล ประสิทธิภาพ และความเสี่ยงด้านความถูกต้อง
การนำ LLM เชิงอธิบาย-อ้างอิง มาใช้ในสำนักงานกฎหมายต้องมาพร้อมกับกรอบการวัดผลที่ชัดเจนและการบริหารความเสี่ยงเชิงระบบ เพื่อให้บรรลุเป้าหมายด้านประสิทธิภาพและความปลอดภัยของข้อมูลลูกความ การกำหนดตัวชี้วัด (KPIs) ที่เหมาะสม การออกแบบกระบวนการตรวจสอบแบบมนุษย์ร่วมกับระบบ (human-in-the-loop) และการติดตามข้อมูลย้อนกลับอย่างเป็นระบบ จะช่วยลดความเสี่ยงจากการอ้างแหล่งผิด (hallucination) และปัญหาด้านการคุ้มครองข้อมูล ความรับผิดชอบทางกฎหมาย และข้อกำกับดูแล
ตัวชี้วัดสำคัญ (KPIs) ที่แนะนำ
- เวลาเตรียมคดี (Case preparation time) — เป้าหมายตัวอย่าง: ลดเวลาเตรียมคดี 70% เช่น จากเฉลี่ย 10 ชั่วโมงต่อคดี เหลือ 3 ชั่วโมงต่อคดี โดยวัดจากเวลาเฉลี่ยต่อรายการงาน (time per task) ก่อน-หลังการใช้งาน
- ความถูกต้องของการอ้างอิง (Citation accuracy) — เป้าหมาย: >= 90% วัดด้วยการสุ่มตรวจ citation match กับแหล่งต้นฉบับ (source verifiability) และรายงานอัตรา False Positive/False Negative
- อัตราการแก้ไขของทนายความ (Human edit rate) — เป้าหมาย: ≤ 25–30% (นับเป็นสัดส่วนของเอกสารที่ต้องมีการแก้ไขเชิงเนื้อหาอย่างมีนัยสำคัญก่อนส่งให้ลูกค้า)
- อัตราการยอมรับของลูกความ (Client acceptance rate) — เป้าหมายเช่น ≥ 85% โดยวัดจากข้อเสนอแนะ/แบบประเมินความพึงพอใจหลังการรับบริการที่ใช้ระบบ
- อัตราการแก้คำร้องหรือต้องแจ้งแก้ไขหลังคำฟ้อง (Amendment/resubmission rate) — เป้าหมาย: ลดลงอย่างมีนัยสำคัญ ตัวอย่างเป้าหมาย ≤ 5%
- เวลาเฉลี่ยในการตรวจสอบแหล่งข้อมูล (Source verification time) — วัดเวลาที่ใช้ในการยืนยันเอกสารอ้างอิงต่อหนึ่ง citation เพื่อตั้งเกณฑ์ประสิทธิผลของการตรวจสอบอัตโนมัติ
การวัดเชิงปฏิบัติและแนวทางการทดสอบ
เพื่อให้ตัวชี้วัดมีความน่าเชื่อถือ ควรตั้งกระบวนการทดสอบเชิงสถิติและการตรวจสอบแบบสุ่ม (random sampling) เช่น
- กำหนดชุดข้อมูลตัวอย่าง (benchmark cases) ขนาดอย่างน้อย 200–500 รายการ เพื่อวัดการเปลี่ยนแปลงเวลาเตรียมคดีและความถูกต้องของ citation ด้วยระดับความเชื่อมั่นทางสถิติ
- ใช้การทดสอบ A/B หรือ phased rollout: เปรียบเทียบทีมที่ใช้ LLM กับทีมควบคุม เพื่อหาผลลัพธ์เชิงสาเหตุและวัดผลกระทบต่อ productivity และคุณภาพงาน
- ติดตามเมตริกเชิงคุณภาพ เช่น precision/recall ของการจับคู่ citation, F1-score สำหรับการดึงข้อกฎหมายที่เกี่ยวข้อง และการประเมินโดยผู้เชี่ยวชาญ (senior attorney blind review)
ความเสี่ยงด้านความถูกต้อง (Hallucination) และการป้องกัน
หนึ่งในความเสี่ยงสำคัญคือ LLM สร้างการอ้างแหล่งหรือข้อเท็จจริงที่ไม่ถูกต้อง (hallucination) ซึ่งอาจนำไปสู่ความผิดพลาดทางกฎหมายหรือความเสี่ยงทางจริยธรรมได้ กลยุทธ์ป้องกันที่แนะนำประกอบด้วย:
- Retrieval-augmented generation (RAG) — ผนวกรวมการดึงเอกสารจากฐานข้อมูลที่เชื่อถือได้ก่อนการผลิตข้อความ เพื่อให้ระบบอ้างอิงแหล่งที่มาที่สามารถตรวจสอบได้
- Source linking และ direct quoting — ให้ระบบแนบลิงก์/ID ของเอกสารต้นทาง พร้อมย่อหน้าหรือหน้าที่อ้างถึง (page/paragraph) เพื่อเพิ่ม traceability
- Confidence scoring และ flagging — ระบุระดับความมั่นใจของแต่ละ citation และทำเครื่องหมายให้ทนายความทบทวน (low-confidence citations ต้องผ่านการตรวจสอบมือ)
- Human-in-the-loop verification — ตั้งมาตรฐานการตรวจสอบโดยทนายความ เช่น ทุกเอกสารที่มี citation ใหม่ต้องผ่านการยืนยันโดยผู้เชี่ยวชาญก่อนส่งให้ลูกค้า
- Red-team testing และ adversarial prompts — ทำการโจมตีจำลองเพื่อตรวจหาจุดอ่อนของโมเดลในการสร้างข้อมูลเท็จ และปรับ prompt / retrieval rules ตามผล
Versioning, Audit Trail และการตรวจสอบย้อนหลัง
ระบบที่ใช้กับงานกฎหมายต้องเก็บบันทึกอย่างละเอียดเพื่อให้สามารถตรวจสอบย้อนหลังได้เมื่อเกิดข้อพิพาทหรือความผิดพลาด:
- บันทึกเวอร์ชันของโมเดล (model version), ชุดข้อมูลที่ใช้ในการดึงแหล่งข้อมูล, prompt templates และค่าพารามิเตอร์การ inference
- เก็บ immutable audit trail ของทั้ง prompt input, output, citation list, ผู้ตรวจสอบ และเวลา (timestamp) โดยอาจใช้เทคนิค cryptographic hashing หรือระบบบันทึกแบบไม่เปลี่ยนแปลง (append-only log)
- เก็บ snapshot ของเอกสารต้นทางที่ถูกอ้าง (source snapshot) เพื่อยืนยันว่าข้อความที่อ้างสามารถตรวจสอบได้ ณ เวลาที่สร้างเอกสาร
- จัดเก็บ metadata เช่น user ID, role, decision outcome, และเหตุผลการแก้ไข เพื่อสนับสนุนการตรวจสอบด้านคุณภาพและความรับผิดชอบ
ข้อกำกับดูแลและการคุ้มครองข้อมูลลูกความ
การปฏิบัติตามกฎระเบียบและการรักษาความลับวิชาชีพเป็นสิ่งจำเป็น:
- ความลับวิชาชีพ (Attorney-client privilege) — ต้องกำหนดนโยบายที่ชัดเจนว่าใครเข้าถึงข้อมูลลูกความได้ ระบบ LLM ควรทำงานภายใต้สภาพแวดล้อมที่ควบคุมได้ (on-premise หรือ private cloud ที่สัญญาว่าไม่มีการนำข้อมูลไปใช้ฝึกโมเดลภายนอก)
- การเข้ารหัสและการควบคุมการเข้าถึง — ข้อมูลต้องถูกเข้ารหัสทั้งขณะส่งและเก็บ (TLS, at-rest encryption) และมีการจัดการสิทธิ์ (RBAC, least privilege) พร้อมการตรวจสอบการเข้าถึง (access logs)
- การย่อข้อมูล (Data minimization) และ retention policy — เก็บเฉพาะข้อมูลที่จำเป็น และกำหนดระยะเวลาการเก็บข้อมูล พร้อมกระบวนการลบข้อมูลเมื่อครบกำหนด
- การประเมินผลกระทบด้านข้อมูลส่วนบุคคล (DPIA) — ดำเนินการประเมินผลกระทบต่อความเป็นส่วนตัวเมื่อมีการใช้ข้อมูลส่วนบุคคลของลูกความ และปฏิบัติตามกฎหมายที่เกี่ยวข้อง (เช่น PDPA ของไทย หรือ GDPR หากเกี่ยวข้อง)
- การรับรองและการกำกับดูแล — พิจารณาให้ระบบผ่านการตรวจรับรองความปลอดภัย (ISO 27001, SOC2) และปฏิบัติตามแนวทางจริยธรรมของสมาคมทนายความหรือหน่วยงานกำกับดูแล
โดยสรุป การวัดผลและการจัดการความเสี่ยงต้องเป็นกระบวนการต่อเนื่อง มีการกำหนด KPI ที่ชัดเจน เช่น ลดเวลาเตรียมคดี 70%, citation accuracy >= 90%, และอัตราการแก้ไขของมนุษย์ที่ยอมรับได้ พร้อมทั้งระบบการตรวจสอบย้อนกลับ (versioning & audit trail) และมาตรการคุ้มครองข้อมูลลูกความ เพื่อให้การใช้ LLM ในสำนักงานกฎหมายเป็นไปอย่างมีประสิทธิภาพ ปลอดภัย และรับผิดชอบทางกฎหมาย
แนวทางปฏิบัติและแผนการนำไปใช้สำหรับสำนักงานกฎหมาย
แนวทางปฏิบัติและแผนการนำไปใช้สำหรับสำนักงานกฎหมาย
การนำ Large Language Models (LLM) เชิงอธิบาย-อ้างอิง มาใช้จริงในสำนักงานกฎหมายควรดำเนินการตามกรอบที่เป็นระบบ เพื่อควบคุมความเสี่ยงและเพิ่มคุณภาพงานอย่างเป็นรูปธรรม ระยะการดำเนินงานหลักแบ่งเป็น Pilot → Validate → Scale โดยเริ่มจากขอบเขตจำกัด ทดลองจริง ตรวจวัดผล และขยายการใช้งานเมื่อผ่านเกณฑ์การประเมิน ในช่วงเริ่มต้นควรกำหนดวัตถุประสงค์เชิงธุรกิจที่ชัดเจน เช่น ลดเวลาเตรียมคดี 50–70% ในงานร่างคำให้การหรือสรุปคำพิพากษา เพิ่มอัตราการอ้างแหล่งข้อมูลที่สามารถตรวจสอบได้ (verifiable citation) ให้เป็นเกณฑ์วัดผลสำคัญ
ขั้นตอนแบบ Step-by-step (ภาพรวม):
- Pilot (3–6 เดือน): เลือก 1–2 practice areas (เช่น แพ่งและแรงงาน) และทีมขนาดเล็ก 3–5 คน ทดลองใช้ LLM ในงานร่างเอกสารเฉพาะ เช่น คำให้การร่างต้นฉบับ และสรุปคำพิพากษาที่มีการอ้างอิงแหล่งข้อมูล สร้างชุดข้อมูลฐานความรู้ (knowledge base) ที่ผ่านการคัดกรอง ประเมินความแม่นยำเชิงข้อเท็จจริง (factual accuracy) และวัดตัวชี้วัด เช่น เวลาเตรียมเอกสาร, อัตราการแก้ไขโดยผู้เชี่ยวชาญ
- Validate (3 เดือนถัดไป): รันชุดทดสอบแบบ double-blind โดยให้ผู้เชี่ยวชาญประเมินคุณภาพผลลัพธ์เปรียบเทียบกับงานที่ทำด้วยมือ วัด KPI ด้านความถูกต้องของการอ้างแหล่ง (citation verifiability), ความเป็นไปได้ทางกฎหมาย (legal soundness) และ feedback จากลูกค้า พัฒนา workflow ที่ผสานขั้นตอนการตรวจสอบของมนุษย์ (human-in-the-loop)
- Scale (ระยะขยาย): นำผลจากการทดสอบมาปรับปรุง governance และมาตรการด้านความปลอดภัย ผสาน LLM กับระบบจัดการคดี (CMS/ECM) ตั้งค่า role-based access และขยายสู่ practice areas อื่น พร้อมการติดตามประสิทธิภาพแบบเรียลไทม์และการปรับปรุงโมเดลอย่างต่อเนื่อง
นโยบายสำคัญที่ต้องกำหนดก่อนดำเนินการควรรวมถึง:
- Governance: กำหนดคณะกรรมการรับผิดชอบ (AI Steering Committee) ระบุผู้มีอำนาจอนุมัติ เกณฑ์ความเสี่ยง และเขตข้อมูลที่อนุญาตให้ LLM เข้าถึง
- Audit logs: บันทึกกิจกรรมทั้งหมดอย่างไม่เปลี่ยนแปลง (immutable logs) รวมทั้ง prompt, response, user edits, และผู้อนุมัติ พร้อมมาตรการการเข้ารหัสและการสำรองข้อมูลเพื่อการตรวจสอบย้อนหลัง
- Approval gates: กำหนดเงื่อนไขการอนุมัติ เช่น เอกสารที่มีผลกระทบทางกฎหมายสูง (pleadings, settlement agreements) ต้องผ่านการอนุมัติของทนายความอาวุโส หรือทุกกรณีที่ LLM ให้แหล่งอ้างอิงที่ไม่สามารถยืนยันได้ต้องถูกปิดกั้นจนกว่าจะมีการยืนยัน
- Data retention & privacy: นโยบายการเก็บรักษาข้อมูลและการลบข้อมูล (retention schedule) สอดคล้องกับ PDPA และมาตรฐานความปลอดภัย ควรกำหนดระยะเวลาจัดเก็บ prompt/response, วิธีการทำ anonymization และข้อจำกัดในการนำข้อมูลลูกค้าไปใช้ฝึกโมเดล
การฝึกอบรมและการเปลี่ยนแปลง workflow ของบุคลากรเป็นหัวใจสำคัญ:
- อบรมเชิงปฏิบัติการ (hands-on workshops): สอนวิธีใช้อินเทอร์เฟซ การสร้าง prompt ที่มีประสิทธิภาพ และแนวปฏิบัติในการป้อนข้อมูลที่ถูกต้อง เช่น การทำ redaction ก่อนนำเอกสารลูกค้าเข้าสู่ระบบ
- การอ่านและตรวจสอบการอ้างอิง: ฝึกทนายให้ตรวจสอบ citation โดยใช้ checklist ว่าลิงก์หรือบรรณานุกรมสอดคล้องกับข้อความหรือไม่, วันที่คำพิพากษาตรงกันหรือไม่, และถ้าจำเป็นต้องเข้าถึงแหล่งข้อมูลที่ behind-paywall ให้มีขั้นตอนขออนุญาตและสำเนา
- การจำลองสถานการณ์และ role-play: ให้ทีมฝึกตรวจแก้เอกสารที่ LLM สร้างขึ้นภายใต้สภาวะต่าง ๆ (เช่น ข้อมูลขาดหาย หรือกรณีที่มีความขัดแย้งของข้อเท็จจริง)
ตัวอย่าง Checklist สำหรับการนำไปใช้ภายใน (Pilot Phase):
- กำหนดวัตถุประสงค์เชิงธุรกิจและ KPI (เช่น ลดเวลาเตรียมคดี xx%)
- ระบุ practice areas และทีมผู้รับผิดชอบ
- ประเมินความเสี่ยงข้อมูลตาม PDPA และทำการ redaction ก่อนนำเข้าข้อมูล
- สร้างฐานความรู้ (curated KB) และนโยบายการอัปเดตข้อมูล
- กำหนด approval gates สำหรับเอกสารสำคัญ
- จัดการอบรมและทดสอบการอ่านการอ้างอิง
- รันการทดสอบคุณภาพและรวบรวม feedback จากผู้ใช้
ตัวอย่าง Template ภายใน (Prompt-to-Draft & Approval):
- Prompt Template สำหรับร่างคำให้การ:
“กรุณาร่างคำให้การในคดีหมายเลข [หมายเลขคดี] ระบุข้อเท็จจริงตามเอกสารแนบ [รายการเอกสาร] อ้างอิงคำพิพากษา/บทบัญญัติที่เกี่ยวข้องพร้อมการอ้างแหล่ง (URL/หนังสือ/เลขคำพิพากษา) และให้สรุปความเสี่ยงทางกฎหมาย 3 ประเด็นที่ควรแจ้งลูกค้า”
- Verification Template สำหรับการตรวจ citation:
1) ตรวจสอบ URL/เลขคำพิพากษาและวันที่ตีพิมพ์ — ตรง/ไม่ตรง
2) ยืนยันเนื้อหาที่ถูกอ้างว่ามีอยู่จริงในแหล่งที่มา — ยืนยัน/ไม่ยืนยัน
3) บันทึกการแก้ไขและผู้ตรวจสอบ — ชื่อ/เวลา - Approval Gate Template:
ประเภทเอกสาร: [Pleading/Contract/Memo] → หาก ผลกระทบทางกฎหมายสูง ให้ส่งต่อผู้อนุมัติ: [ชื่อทนายอาวุโส] ภายใน 48 ชั่วโมง พร้อม checklist การอ้างอิงครบถ้วน
ท้ายที่สุด ให้ตั้งระบบการติดตามผลหลังใช้งาน (post-deployment monitoring) โดยวัดตัวชี้วัด เช่น อัตราการยอมรับของผู้ใช้, จำนวนการแก้ไขต่อเอกสาร, อัตราความถูกต้องของการอ้างอิง และผลตอบรับจากลูกค้า พร้อมกำหนดวงรอบทบทวนนโยบายทุก 6–12 เดือน เพื่อให้เทคโนโลยีและกระบวนการสอดคล้องกับข้อกฎหมายและความต้องการของสำนักงานในระยะยาว
บทสรุป
LLM เชิงอธิบาย-อ้างอิงที่สำนักงานกฎหมายในกรุงเทพนำมาใช้มีศักยภาพเปลี่ยนวิธีเตรียมคดีและให้คำปรึกษาทางกฎหมายอย่างชัดเจน โดยสามารถร่างคำให้การ สรุปคำพิพากษาพร้อมอ้างแหล่งที่มา และแปลข้อกฎหมายเป็นภาษาชาวบ้านได้ ส่งผลให้ระยะเวลาเตรียมคดีลดลงได้ถึง ประมาณ 70% และเพิ่มความโปร่งใสในการให้คำปรึกษาแก่ลูกความ อย่างไรก็ตาม เทคโนโลยีดังกล่าวต้องผสานกับกระบวนการควบคุมคุณภาพและ governance ที่เข้มแข็งเพื่อป้องกันปัญหา เช่น ข้อผิดพลาดของข้อมูลหรือการอ้างแหล่งที่มาไม่ถูกต้อง การนำเทคนิคเช่น RAG (Retrieval-Augmented Generation) และ citation verification มาใช้ควบคู่กับแนวปฏิบัติทางกฎหมาย เช่น human-in-the-loop การตรวจสอบโดยผู้เชี่ยวชาญ ข้อกำกับดูแล และนโยบายความปลอดภัยของข้อมูล จะเป็นปัจจัยสำคัญที่ทำให้ผลลัพธ์เชื่อถือได้และเป็นไปตามมาตรฐานทางกฎหมาย
ในมุมมองอนาคต การนำ LLM เชิงอธิบาย-อ้างอิงไปใช้สำเร็จต้องเป็นการบูรณาการทั้งด้านเทคนิคและนโยบาย: พัฒนากระบวนการตรวจสอบแหล่งข้อมูลและการอ้างอิงอย่างต่อเนื่อง สร้าง audit trail และมาตรฐานการทดสอบเพื่อวัดความแม่นยำ รวมถึงการออกกรอบกฎระเบียบที่ชัดเจนเพื่อคุ้มครองข้อมูลลูกความและความรับผิดชอบในการให้คำแนะนำทางกฎหมาย เมื่อระบบถูกออกแบบโดยคำนึงถึงการควบคุมคุณภาพและการมีมนุษย์เข้าไปมีส่วนร่วมอย่างเหมาะสม ผลลัพธ์ที่คาดว่าจะเกิดขึ้นคือการเพิ่มประสิทธิภาพงานกฎหมาย การเข้าถึงความยุติธรรมที่ดีขึ้น และการสร้างความเชื่อมั่นต่อบริการด้านกฎหมายที่ขับเคลื่อนด้วย AI
ดังนั้น สำนักงานกฎหมายที่ต้องการเพิ่มประสิทธิภาพควรเริ่มจากโครงการนำร่องที่มีการประเมินความเสี่ยงและการกำกับดูแลอย่างเป็นระบบ ฝึกอบรมบุคลากรเพื่อทำงานร่วมกับ AI และลงทุนในโซลูชันที่รองรับการตรวจสอบแหล่งอ้างอิงแบบเรียลไทม์ เพื่อให้ประโยชน์จากการลดเวลาเตรียมคดีและความโปร่งใสเกิดขึ้นอย่างยั่งยืนภายใต้กรอบความปลอดภัยและความรับผิดชอบทางกฎหมาย



