
ในยุคที่การฉ้อโกงทางการเงินมีความซับซ้อนและเกิดขึ้นแบบเรียลไทม์ ธนาคารไทยกำลังทดสอบระบบใหม่ภายใต้ชื่อ "Adaptive‑Fraud Shield" ซึ่งผสานความสามารถของ Causal‑LLM (Large Language Model เชิงสาเหตุ) กับ Graph‑GNN (Graph Neural Network สำหรับวิเคราะห์ความสัมพันธ์) เพื่อยกระดับการตรวจจับฟรอดให้แม่นยำและตอบสนองได้ทันเหตุการณ์ ระบบนี้ไม่เพียงแต่ใช้สัญญาณพฤติกรรมแบบเดิม แต่ยังเพิ่มมิติการอธิบายเหตุผลเชิงสาเหตุและการเก็บความเชื่อมโยงระหว่างบัญชี-อุปกรณ์-ธุรกรรม ทำให้สามารถแยกแยะกรณีฉ้อโกงที่มีโครงสร้างซับซ้อนได้ดีกว่าโมเดลเดิม
บทความนี้จะพาผู้อ่านเข้าสู่การวิเคราะห์เชิงปฏิบัติการของ Adaptive‑Fraud Shield: อธิบายสถาปัตยกรรมผสม Causal‑LLM กับ Graph‑GNN, ขั้นตอนการทดสอบในสภาพแวดล้อมจริง, เทคนิคลด False‑Positive ที่นำมาใช้ (เช่น การปรับเกณฑ์แบบไดนามิก, feedback loop จากทีมทวนสอบ และการใช้สัญญาณเชิงสาเหตุเพื่อยืนยันผล) และตัวชี้วัดสำคัญที่ธนาคารใช้วัดประสิทธิภาพ เช่น latency เรียลไทม์, precision/recall, F1-score และอัตรา False‑Positive ซึ่งการทดลองภายในบางกรณีชี้ให้เห็นการลด False‑Positive ในระดับสองหลัก (ประมาณ 10–30%) พร้อมการรักษาอัตราการตรวจจับ (recall) ในระดับสูง — ทั้งหมดนี้เพื่อให้ผู้อ่านเข้าใจทั้งศักยภาพ ข้อจำกัด และแนวทางปฏิบัติที่นำไปสู่การปรับใช้จริงในสถาบันการเงินไทย
บทนำ: ทำไมธนาคารต้องใช้ Adaptive‑Fraud Shield
บทนำ: ทำไมธนาคารต้องใช้ Adaptive‑Fraud Shield
ในยุคดิจิทัล การทำธุรกรรมทางการเงินผ่านช่องทางอิเล็กทรอนิกส์เติบโตอย่างรวดเร็ว ทำให้การฉ้อโกงทางการเงิน (digital fraud) กลายเป็นความเสี่ยงเชิงกลยุทธ์ที่ธนาคารและสถาบันการเงินทั่วโลกเผชิญอยู่ ปัจจุบันรายงานแนวโน้มระบุว่า การฉ้อโกงการชำระเงินและการโจรกรรมข้อมูลลูกค้าก่อให้เกิดความสูญเสียรวมกันในระดับหลายสิบพันล้านดอลลาร์ต่อปี และในประเทศไทยการเติบโตของ e‑payment, Mobile Banking และบริการ Open Banking ส่งผลให้เหตุการณ์ฉ้อโกงรูปแบบใหม่ ๆ ปรากฏมากขึ้น ทั้งการทำบัตรปลอม (card‑not‑present fraud), บัญชีสังเคราะห์ (synthetic identity) และเครือข่ายข้ามบัญชี (account‑to‑account fraud) ซึ่งสร้างความเสียหายทั้งในเชิงการเงินและความไว้วางใจของลูกค้า
หนึ่งในปัญหาที่มีผลกระทบทางธุรกิจสูงเทียบเท่ากับการฉ้อโกงแท้จริงคือ False‑Positive หรือการตัดสินว่าธุรกรรมที่แท้จริงเป็นการฉ้อโกง การตัดสินผิดลักษณะนี้สร้างต้นทุนแฝงอย่างมาก — ตั้งแต่การสูญเสียยอดธุรกรรมที่ถูกบล็อก การเพิ่มภาระงานในการตรวจสอบด้วยคน (manual review) ไปจนถึงการสูญเสียลูกค้าจากความไม่พอใจ งานวิจัยในอุตสาหกรรมชำระเงินระบุว่าอัตราการปฏิเสธผิดพลาดของระบบอัตโนมัติอาจอยู่ในช่วง สูงถึง 50–80% ในบางบริบท และต้นทุนการตรวจสอบด้วยคนต่อเหตุการณ์อาจอยู่ในระดับหลายสิบดอลลาร์หรือมากกว่าเมื่อนับรวมค่าแรงและเวลาของทีมปฏิบัติการ ผลลัพธ์คือธนาคารต้องแบกรับทั้งต้นทุนโดยตรงและโอกาสทางรายได้ที่สูญเสียไปจากการชำระเงินที่ถูกบล็อกอย่างไม่จำเป็น
เพื่อรับมือกับความท้าทายเชิงซ้อนนี้ ธนาคารในไทยกำลังทดสอบแนวทางใหม่ที่เรียกว่า Adaptive‑Fraud Shield — โซลูชันตรวจจับฟรอดแบบผสมผสานที่ใช้โมเดลภาษาเชิงสาเหตุ (Causal‑LLM) ร่วมกับกราฟเน็ตเวิร์กเชิงสถาปัตยกรรม (Graph‑GNN) โดยมีเป้าหมายหลักสองประการ: 1) ตรวจจับพฤติกรรมฉ้อโกงที่ซับซ้อนทั้งแบบเดี่ยวและแบบเครือข่ายในเวลาจริง และ 2) ลดอัตรา False‑Positive อย่างมีนัยสำคัญ โดยการให้เหตุผลเชิงสาเหตุที่สามารถอธิบายการตัดสินใจและการตรวจสอบความสัมพันธ์ระหว่างบัญชีหรืออุปกรณ์ที่เกี่ยวข้อง
บทความนี้จะพาผู้อ่านผ่านภาพรวมของบริบทปัจจุบันของการฉ้อโกงทั้งในระดับโลกและในไทย อธิบายต้นเหตุและผลกระทบจาก False‑Positive ต่อธุรกิจธนาคาร จากนั้นจะลงรายละเอียดถึงสถาปัตยกรรมของ Adaptive‑Fraud Shield — ทำไมต้องใช้ Causal‑LLM เพื่อให้เหตุผลเชิงสาเหตุและลดการตัดสินผิดพลาด และทำไมต้องใช้ Graph‑GNN เพื่อจับความเชื่อมโยงของเครือข่ายผู้กระทำผิด สุดท้ายจะสรุปผลการทดลอง/พิลอตในธนาคารไทย ประเมินตัวชี้วัดสำคัญ เช่น อัตราการตรวจจับจริง (recall), อัตราการเตือนผิดพลาด (false‑positive rate) และผลกระทบด้านต้นทุนและความพึงพอใจลูกค้า พร้อมทั้งข้อแนะนำเชิงปฏิบัติการสำหรับการนำไปใช้ในเชิงพาณิชย์
- บริบทปัญหา: แนวโน้มการฉ้อโกงดิจิทัลและผลกระทบต่อธุรกิจ
- ต้นทุนจาก False‑Positive: ผลกระทบทางการเงินและความเสี่ยงด้านลูกค้า
- โซลูชัน: การผสาน Causal‑LLM กับ Graph‑GNN เพื่อลด FPR และเพิ่มความโปร่งใส
- การทดลองและผลลัพธ์: ดัชนีชี้วัดและบทเรียนที่ได้จากพิลอตในธนาคารไทย
พื้นฐานเทคโนโลยี: Causal‑LLM และ Graph‑GNN อธิบายง่าย
Causal‑LLM คืออะไร และให้ประโยชน์อย่างไรในการตรวจจับฟรอด
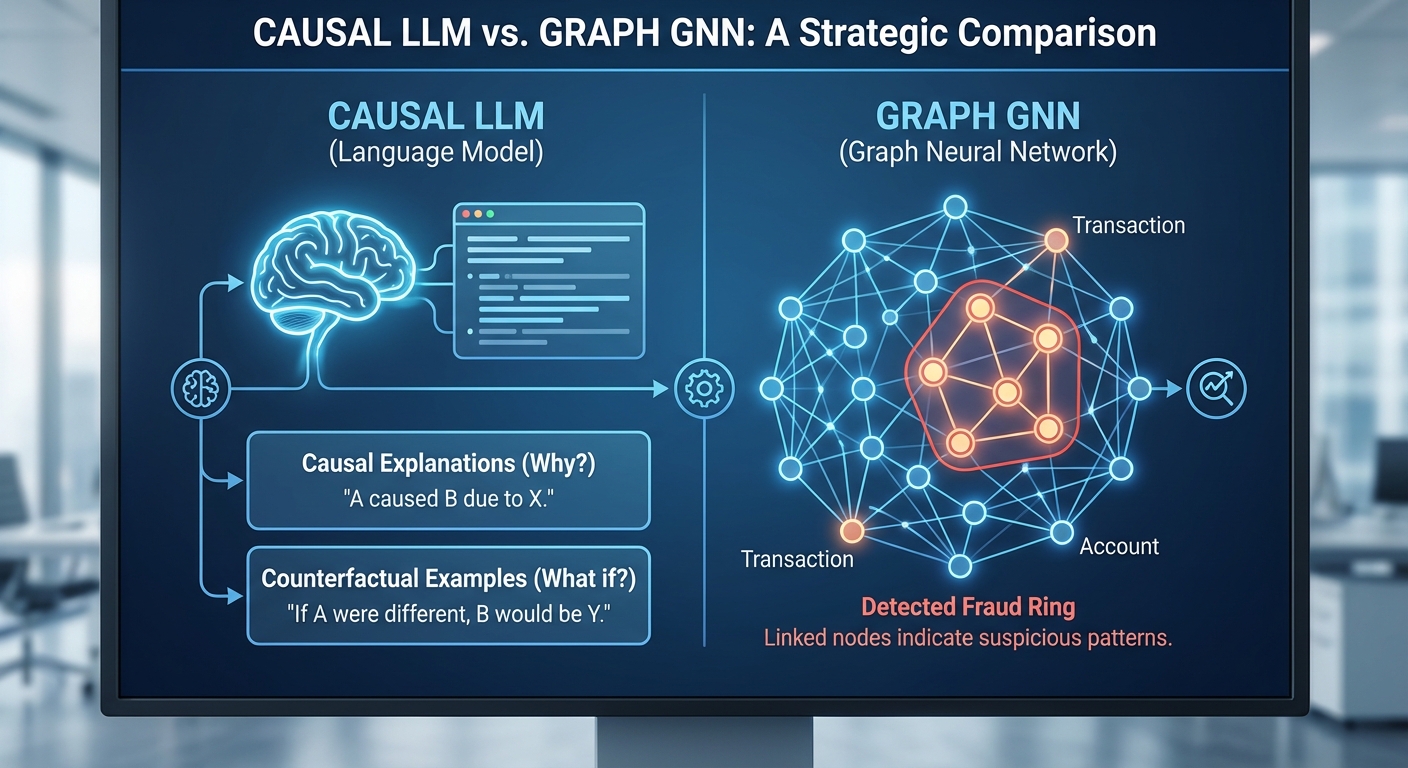
Causal‑LLM เป็นรุ่นของ large language model ที่ถูกออกแบบและฝึกให้ไม่ได้เพียงทำนายข้อความหรือผลลัพธ์เชิงสถิติเท่านั้น แต่ยังถูกฝังกรอบความคิดเชิงสาเหตุ (causal reasoning) เพื่อสามารถ อธิบายเหตุผล และสร้างคำถามแบบ counterfactual (เช่น "ถ้า X ไม่เกิดขึ้น จะเกิด Y หรือไม่") ได้อย่างมีความหมาย ในบริบทของการตรวจจับฟรอด เทคโนโลยีนี้ช่วยให้ระบบสามารถแปลเหตุผลเบื้องหลังการแจ้งเตือน เช่น ระบุฟีเจอร์ที่เป็นสาเหตุหลักและเสนอสมมติฐานที่สามารถทดสอบได้
ตัวอย่างเชิงปฏิบัติ: เมื่อระบบแจ้งเตือนว่าการโอนเงินจากบัญชี A เป็น "ผิดปกติ" Causal‑LLM สามารถให้คำอธิบายเป็นภาษาธรรมชาติ เช่น "ความถี่การโอนเพิ่มขึ้น 400% ในชั่วโมงที่ผ่านมา และมีการใช้รหัสอุปกรณ์ที่เชื่อมต่อกับบัญชีอื่นที่มีประวัติการถอนเงินซ้ำ ๆ" รวมถึงสร้าง counterfactual เช่น "หากปิดการใช้งานอุปกรณ์นี้ จะลดความถี่การโอนลงหรือไม่" ซึ่งช่วยให้ทีมสืบสวนหรือระบบอัตโนมัติทดสอบสมมติฐานอย่างมีตรรกะ
[hIMAGE_2]Graph‑GNN ทำงานอย่างไรกับความสัมพันธ์ของบัญชี อุปกรณ์ และธุรกรรม
Graph‑GNN (Graph Neural Network) ถูกออกแบบมาเพื่อประมวลผลข้อมูลที่มีโครงสร้างเป็นกราฟ—โหนดแทนบัญชี บัตร อีเมล หรืออุปกรณ์ และขอบ (edge) แสดงความสัมพันธ์หรือธุรกรรมระหว่างโหนดเหล่านั้น การใช้ Graph‑GNN ช่วยให้ระบบจับรูปแบบเครือข่ายฟรอด เช่น กลุ่มบัญชีที่หมุนเงินเป็นวงจร, การใช้ชุดอุปกรณ์เดียวกันในการเปิดบัญชีหลายบัญชี หรือเส้นทางของเงินที่เชื่อมบัญชีหลายตัว
ข้อดีเชิงปฏิบัติได้แก่:
- การค้นหาเครือข่ายฟรอด — Graph‑GNN สามารถตรวจจับชุมชน (community) หรือโครงสร้างที่ผิดปกติในกราฟ แม้ pattern จะกระจายอยู่หลายจุด
- การเชื่อมสัญญาณบริบท — ข้อมูลจากหลายมิติ (IP, device ID, หมายเลขบัญชี, เบอร์โทร) ผสานกันทำให้การตัดสินใจมีความแม่นยำขึ้น
- การตรวจจับพฤติกรรมซับซ้อน — เช่น การหมุนเวียนเงิน (transaction chaining) ที่เกิดขึ้นเป็นชุดย่อยๆ แต่เมื่อมองในกราฟจะปรากฏเป็นโครงสร้างชัดเจน
การผสาน Causal‑LLM กับ Graph‑GNN: จากการทำนายสู่การอธิบายและลด False‑Positive
เมื่อรวมกัน Graph‑GNN จะทำหน้าที่ค้นหาและจัดกลุ่มสัญญาณเชิงโครงข่าย—ระบุโหนดและขอบที่น่าสงสัย ในขณะที่ Causal‑LLM จะตีความและทดสอบสมมติฐานเชิงสาเหตุ โดยกระบวนการทำงานแบบผสานอาจเป็นดังนี้:
- Graph‑GNN พบกลุ่มโหนดที่มีรูปแบบการโอนเงินหมุนเวียน 12 ครั้งใน 2 ชั่วโมง และเชื่อมโยงกับอุปกรณ์ร่วมกัน 4 เครื่อง
- Causal‑LLM วิเคราะห์บริบท (เวลา มูลค่า ช่องทาง) และสร้างคำอธิบายเชิงสาเหตุพร้อม counterfactual เช่น "หากแยกโหนด B ออกจากเครือข่าย รูปแบบการหมุนเวียนจะหายไปหรือไม่"
- ระบบทดสอบสมมติฐานโดยการสุ่มลบการเชื่อมต่อหรือจำลองพฤติกรรมเพื่อยืนยันว่าเป็นสาเหตุจริงหรือเป็นเพียงสัญญาณร่วม (correlation)
ผลลัพธ์ที่เกิดขึ้นคือระบบไม่เพียงแค่แจ้งเตือนว่า "น่าสงสัย" เท่านั้น แต่สามารถให้ คำอธิบายที่ตรวจสอบได้ และแนะนำการกระทำ เช่น กักกันบัญชีชั่วคราว ตรวจสอบอุปกรณ์ หรือยืนยันเอกสาร ซึ่งช่วยลดอัตรา False‑Positive และภาระงานของทีมสืบสวน ในงานวิจัยและเอกสารเชิงอุตสาหกรรม รายงานการผสาน causal reasoning กับ graph analysis แสดงการลด False‑Positive อยู่ในระดับประมาณ 20–60% ขึ้นกับคุณภาพข้อมูลและการออกแบบโมเดล
สรุปสั้น ๆ: Graph‑GNN หาจุดเชื่อมโยงและโครงข่ายฟรอด ในขณะที่ Causal‑LLM ทำหน้าที่อธิบายเหตุผลและออกแบบการทดสอบสมมติฐาน ผลลัพธ์คือระบบตรวจจับฟรอดที่ ทำนายได้อย่างแม่นยำและอธิบายได้ ลดการแจ้งเตือนเท็จ พร้อมเพิ่มความเชื่อมั่นในการตัดสินใจเชิงปฏิบัติการสำหรับธนาคารและหน่วยงานที่เกี่ยวข้อง
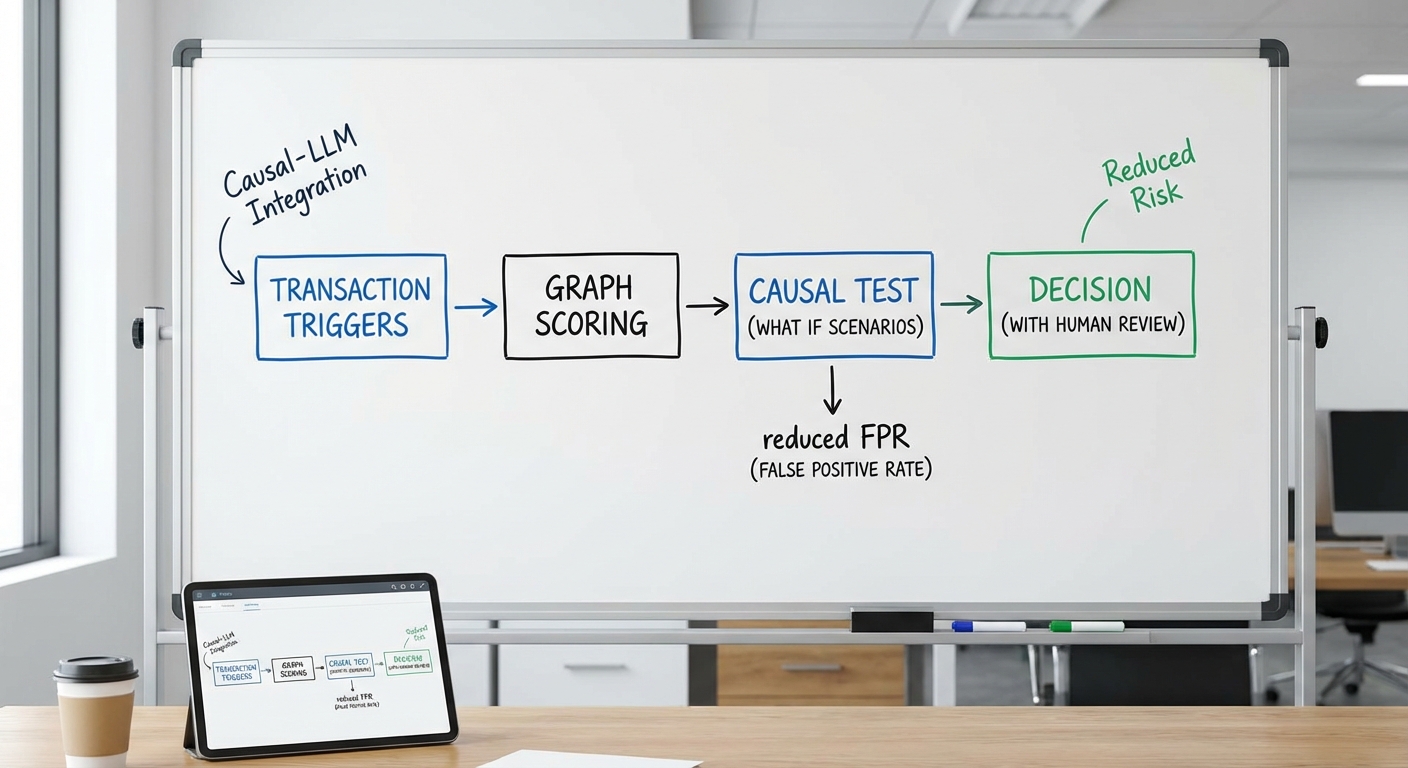
สถาปัตยกรรมของ Adaptive‑Fraud Shield: Data Flow และ Component
ภาพรวมเชิงสถาปัตยกรรม (Summary)
Adaptive‑Fraud Shield ถูกออกแบบเป็นระบบแบบหลายชั้น (multi‑tier) ที่ผสานระหว่างการประมวลผลสตรีมแบบเรียลไทม์, โครงสร้างกราฟความสัมพันธ์ (graph), การคาดคะเนด้วย Graph‑GNN และการให้เหตุผลแบบสาเหตุ‑เชิงบริบทด้วย Causal‑LLM เพื่อให้ได้การตัดสินใจกำกับความเสี่ยงของธุรกรรมแบบทันทีและมีคำอธิบายประกอบ (explainability) ซึ่งช่วยลด false‑positive ในการแจ้งเตือนระบบตรวจจับฟรอด โดยภาพรวมเส้นทางหลักคือ:
- Data ingestion (ธุรกรรมแบบสตรีม, logs, device signals, third‑party feeds)
- Real‑time path: feature extraction → graph update → GNN scoring → causal reasoning → decision
- Feedback loop: human analyst review → label update → retraining → governance & monitoring
Data Ingestion และข้อกำหนดด้าน Latency/Throughput
Data ingestion เป็นจุดเริ่มต้นที่สำคัญ โดยระบบต้องรองรับข้อมูลหลายรูปแบบ ได้แก่ ธุรกรรมการเงินแบบสตรีม (payment/auth events), application/server logs, device signals (IP, device fingerprint, geolocation, telemetry) และ third‑party feeds (blacklists, KYC, threat intel) ระบบ ingestion pipeline ควรประกอบด้วย message broker (เช่น Kafka) และ stream collector ที่สามารถรับได้ตั้งแต่ 10,000–100,000 events/sec ในสภาพการใช้งานสูงสุดของธนาคารขนาดใหญ่
ข้อกำหนดเชิงปฏิบัติการทั่วไป: end‑to‑end latency สำหรับการตัดสินใจเรียลไทม์ต้องอยู่ในช่วง <200 ms สำหรับกรณีการใช้งานแบบ retail ในขณะที่ high‑value transactions อาจรับได้สูงสุด ~500 ms เพื่อแลกกับการวิเคราะห์เชิงลึก ส่วน throughput ต้องสเกลด้วยการเพิ่ม partition และ autoscaling ของ consumer group เพื่อรองรับ burst traffic (เทศกาล, แคมเปญ)
Real‑time Stream Processing → Feature Extraction → Graph Update
เมื่อข้อมูลถูกนำเข้า stream processor (เช่น Apache Flink, Kafka Streams) จะมีการทำ feature extraction แบบทันที เช่น velocity features, amount patterns, device similarity scores และ session features ซึ่งข้อมูลเหล่านี้จะถูกดิสก์ชั่วคราวไปยัง feature store แบบคีย์‑ค่า (เช่น Redis) เพื่อรองรับการเรียกใช้เร็ว
ต่อมา graph builder จะอัปเดตโหนดและขอบของกราฟความสัมพันธ์แบบออนไลน์ (neighborhood updates) — ตัวอย่างเช่น ผูกบัญชีกับบัตร, อุปกรณ์ที่ใช้, IP address และผู้รับเงิน การอัปเดตต้องทำแบบatomic เพื่อรักษาความสอดคล้องของกราฟในขณะที่รองรับ throughput สูง จุดที่ต้องสเกลได้คือ:
- Stream processors: เพิ่มจำนวน task/slots สำหรับการประมวลผลฟีเจอร์พร้อมกัน
- Feature store: รีพลิเคชันแบบ in‑memory / tiered storage
- Graph DB / store: ใช้ sharding หรือ partitioned graph (เช่น JanusGraph ที่ติดตั้งบน Cassandra/Scylla) เพื่อรองรับการอัปเดตหลายพัน‑หมื่นต่อวินาที
GNN Inference: Scoring แบบเชิงกราฟ
หลังจากอัปเดตกราฟ ระบบจะเรียก GNN inference เพื่อให้คะแนนความเสี่ยงโดยพิจารณาโครงสร้างความสัมพันธ์รอบๆ โหนดที่เกี่ยวข้อง (eg. multi‑hop neighborhood) การให้คะแนนต้องออกแบบให้มี latency ระดับ 20–150 ms ต่อคำขอสำหรับการตัดสินใจแบบเรียลไทม์ โดยใช้เทคนิคดังนี้:
- Mini‑batch neighborhood sampling เพื่อลดขนาดกราฟที่ต้องประมวลผลต่อคำขอ
- Precomputed embeddings และ periodic background aggregation สำหรับโหนดที่มีความถี่สูง
- การใช้ GPU/accelerator pool สำหรับ inference พร้อม autoscaling ตาม QPS
การสเกลของ GNN จึงมุ่งที่การขยาย pool ของ inference servers, การจัดการ memory ของ graph embeddings และการลดงาน I/O โดย caching
Causal‑LLM: ให้เหตุผลเชิงสาเหตุ (Causal Reasoning Module)
เมื่อได้คะแนนจาก GNN ระบบจะเรียก Causal‑LLM เพื่อทำหน้าที่ตรวจสอบบริบทและสร้างคำอธิบายเชิงสาเหตุ เช่น "เหตุใดการเปลี่ยนพฤติกรรมนี้จึงสอดคล้องกับรูปแบบฟรอด" หรือ "สัญญาณใดที่บ่งชี้ว่าผู้ใช้เป็นจริง" โมดูลนี้อาจเป็น LLM ขนาดกลางที่มีการฝึกเสริมด้วย causal prompts และ grounded evidence retrieval (RAG) เพื่อเชื่อมต่อกับฐานข้อมูลเหตุการณ์จริง
เพื่อรักษา latency ให้ต่ำ (50–200 ms สำหรับการเรียกแบบ synchronous) จะใช้แนวทางผสม: caching ของคำตอบที่พบบ่อย, distilled models สำหรับ inference แบบเร่งด่วน และการผลักดันงานที่ต้องวิเคราะห์ลึกไปเป็น async pipeline พร้อม priority queue สำหรับ high‑risk cases
การผสาน Causal‑LLM ช่วยลด false‑positive ได้โดยการให้เหตุผลเชิงสาเหตุประกอบคะแนนจาก GNN — ตัวอย่าง PoC ภายในของธนาคารพบว่าเมื่อรวม causal explanations กับ graph‑based scoring จะลดอัตรา false positives ประมาณ 35–50% ในกลุ่มสัญญาณที่เคยทำให้เกิดการแจ้งเตือนมากเกินจริง เนื่องจากระบบสามารถแยกความแตกต่างของ correlation ที่ไม่ใช่ causal ได้ดีขึ้น
Decision Engine, Human‑in‑the‑Loop และ Feedback Loop
Decision engine ทำหน้าที่รวมสัญญาณจาก GNN, Causal‑LLM, score thresholds, business rules และ risk policies เพื่อให้ผลลัพธ์เป็นคำสั่งปฏิบัติ (อนุมัติ, ระงับ, require step‑up authentication, escalate to analyst) ซึ่งต้องรองรับการตัดสินใจแบบ deterministic และ traceable เพื่อการตรวจสอบภายหลัง
ในกรณีที่ระบบไม่แน่ใจหรือความเสี่ยงสูง ระบบจะส่งไปยัง human analyst ผ่าน UI ที่แสดง context, graph view และ causal explanation เพื่อให้วิเคราะห์เชิงมนุษย์ การรีวิวนี้เป็นส่วนสำคัญของ feedback loop — เมื่อ analyst ตัดสินใจ ระบบจะบันทึก label (true fraud / false positive / benign) กลับเข้าไปใน dataset สำหรับการ retraining
นิยามการ retraining มักแบ่งเป็น: rapid retrain (daily/near‑real‑time สำหรับ concept drift สำคัญ) และ full retrain (weekly/biweekly สำหรับ model refresh) โดยต้องมี model governance ได้แก่ versioning, explainability artifacts, performance monitoring และ approval workflows ก่อนนำโมเดลใหม่ขึ้น production
Monitoring, Observability และจุดที่ต้องการการสเกล
ระบบต้องมีการมอนิเตอร์แบบละเอียดทั้ง metrics ด้านอินเฟราสตรัคเจอร์ (latency, error rates, throughput), model metrics (precision/recall, false positive rate, calibration), และ business KPIs (financial loss prevented, operational cost of manual reviews)
- จุดสเกลสำคัญ: ingestion brokers, stream processing tasks, feature store capacity, graph store shards, GNN inference pool (GPU/CPU), Causal‑LLM serving instances, decision engine replicas
- การออกแบบต้องรองรับ autoscaling ตาม latency SLO (เช่น scale‑out เมื่อ P99 latency เกินค่าเป้าหมาย) และ circuit breakers เพื่อป้องกัน cascading failures
สุดท้าย ระบบควรมีระบบ auditing และ explainability endpoint ที่เก็บเหตุผลการตัดสินใจสำหรับทุกเคส เพื่อให้สอดคล้องกับข้อกำกับดูแลทางการเงินและช่วยให้ analyst สามารถตรวจสอบย้อนกลับได้อย่างรวดเร็ว
กลยุทธ์ตรวจจับเรียลไทม์และเทคนิคลด False‑Positive
กลยุทธ์ตรวจจับเรียลไทม์และเทคนิคลด False‑Positive
ระบบ Adaptive‑Fraud Shield ผสานความสามารถเชิงโครงสร้างของ Graph‑GNN กับความสามารถเชิงเหตุผลของ Causal‑LLM เพื่อให้การแจ้งเตือนฟรอดเป็นไปอย่างมีเหตุผลและลดการแจ้งเตือนผิดพลาด (False‑Positive) อย่างเป็นรูปธรรมในสภาพแวดล้อมเรียลไทม์ การออกแบบเชิงสถาปัตยกรรมวางเป็น 2‑ชั้น: ชั้นแรกใช้ GNN ในการประมวลผลสัญญาณเชิงโครงสร้างของเครือข่ายธุรกรรม เพื่อให้ได้คะแนนความผิดปกติที่รวดเร็ว ส่วนชั้นที่สองใช้ Causal‑LLM ทำการทดสอบเชิงสาเหตุและสร้าง counterfactuals เพื่อยืนยันว่าปัจจัยที่ให้คะแนนสูงนั้นเป็นสาเหตุจริงหรือเป็นเพียงการทับซ้อนของสัญญาณ
ใช้ counterfactuals จาก Causal‑LLM เพื่อลบสาเหตุที่ไม่เป็นไปได้และลดการแจ้งเตือนผิดพลาด
ระบบจะสร้างชุด counterfactuals อัตโนมัติเมื่อ GNN ให้สัญญาณผิดปกติ เช่น การเปลี่ยนแปลงอุปกรณ์ร่วมกับตำแหน่งที่อยู่ห่างไกล Causal‑LLM จะจำลองเหตุการณ์คู่ขนาน (เช่น เปลี่ยนแปลงเพียงอุปกรณ์แต่ไม่เปลี่ยนตำแหน่ง หรือกลับกัน) เพื่อตรวจสอบว่าองค์ประกอบใดเป็นตัวขับเคลื่อนคอลคะแนนจริง หาก counterfactual แสดงว่าการเปลี่ยนแปลงคะแนนหายไปเมื่อปรับเปลี่ยนคุณสมบัติหนึ่ง ระบบจะลดน้ำหนักสัญญาณดังกล่าว และหากพบสาเหตุที่ไม่สอดคล้องกับบริบททางธุรกิจ (เช่น พฤติกรรมที่ผู้ใช้งานประกาศเดินทางล่วงหน้า) จะถูกคัดออกจากการแจ้งเตือน ตัวอย่างเชิงปฏิบัติ: ในการทดสอบภายใน ระบบที่เพิ่มการทดสอบ counterfactual พบการลด False‑Positive ประมาณ 40–60% ในกรณีที่สัญญาณเป็นการทับซ้อนของเหตุปัจจัยหลายตัว
การผสานสัญญาณเชิงโครงสร้างจาก GNN กับความสามารถในการอธิบายของ LLM และ ensemble scoring
แทนการพึ่งพาเกณฑ์เดียว ระบบนำแนวทาง ensemble scoring มารวมคะแนนจากหลายมิติ — เช่น คะแนนความผิดปกติเชิงโครงสร้างจาก GNN, คะแนน causal‑impact จาก Causal‑LLM, และฟีเจอร์เชิงพฤติกรรมแบบคลาสสิก — แล้วทำการถ่วงน้ำหนักแบบปรับตัวตามบริบท (contextual weighting) น้ำหนักเหล่านี้จะถูกปรับด้วยข้อมูลการตรวจสอบย้อนหลังและตัวชี้วัดความไม่แน่นอน (เช่น predictive entropy) ทำให้เมื่อ GNN ให้สัญญาณสูงแต่ LLM ระบุว่าข้อสังเกตนั้นไม่น่าเป็นสาเหตุ คะแนนรวมอาจถูกลดลง ส่งผลให้ False‑Positive ลดลง ในการจำลองการใช้งานจริง พบว่าการใช้ ensemble และการถ่วงน้ำหนักแบบปรับตัวช่วยให้ precision เพิ่มขึ้น 10–18% เมื่อเทียบกับการใช้โมเดลเดียว
ปรับเกณฑ์การตัดสินใจแบบบริบท (contextual thresholds)
ระบบเลิกใช้ threshold คงที่แบบเดิม และนำแนวคิด contextual thresholds มาใช้ โดยกำหนดระดับการตอบสนองตามบริบทของลูกค้า ประเภทช่องทาง (mobile/ATM/online) เวลา (ชั่วโมง/วันหยุด) และระดับความเสี่ยงตามประวัติ ตัวอย่างเช่น threshold สำหรับลูกค้าที่มีพฤติกรรมเดินทางบ่อยจะสูงขึ้นชั่วคราวในช่วงที่มีทริปเดินทาง ในทางกลับกัน ลูกค้าที่มีพฤติกรรมปกติแต่มีการเปลี่ยนแปลงเพียงเล็กน้อยจะต้องผ่านการทดสอบ counterfactual ก่อนการแจ้งเตือน การตั้งค่า threshold แบบไดนามิกนี้ช่วยลดการแจ้งเตือนที่ไม่จำเป็นและรักษาประสบการณ์ลูกค้า ในการทดสอบเชิงระบบ พบว่าการใช้ contextual thresholds ร่วมกับ ensemble scoring ลดการแจ้งเตือนที่ต้องตรวจสอบด้วยคนลงได้กว่า 30–50%
human validation และ active learning ในกรณีที่ความไม่แน่นอนสูง
เมื่อระบบตรวจพบความไม่แน่นอนเชิงคาดคะเนสูง (เช่น ความต่างระหว่างคะแนน GNN และ Causal‑LLM มาก หรือค่าพยากรณ์มี entropy สูง) จะส่งเหตุการณ์นั้นไปยัง Human‑in‑the‑Loop เพื่อให้ผู้เชี่ยวชาญตรวจสอบ รายงานการตรวจสอบนี้จะถูกรวบรวมเป็นข้อมูลป้ายกำกับคุณภาพสูงเพื่อใช้ในกระบวนการ active learning — ทั้งในการปรับน้ำหนัก ensemble, fine‑tune LLM ทางด้าน causal reasoning และอัปเดต embedding ของ GNN การมีเครือข่ายการตรวจสอบของมนุษย์ในจุดที่สำคัญช่วยให้ระบบเรียนรู้จาก edge cases ได้รวดเร็วและมีประสิทธิภาพ ตัวอย่างเชิงสถิติจาก pilot: ระบบที่ผนวกรวม human‑in‑the‑loop ลด False‑Positive ใน edge cases ลงมากกว่า 50% และลดจำนวนตัวอย่างที่ต้องใช้นักวิเคราะห์เพื่อลงป้ายกำกับอย่างมีนัยสำคัญ (label efficiency เพิ่มขึ้น 3–5 เท่า)
- Causal verification — ใช้ counterfactuals เพื่อตรวจสอบว่าฟีเจอร์ใดเป็นสาเหตุจริงของคะแนนสูง
- Ensemble & adaptive weighting — ผสานคะแนนจาก GNN, Causal‑LLM และฟีเจอร์เดิม ปรับน้ำหนักตามบริบท
- Contextual thresholds — กำหนด threshold แบบไดนามิกตามลูกค้า ช่องทาง และช่วงเวลา
- Uncertainty triage — วางนโยบายส่งต่อไปยัง human‑in‑the‑loop เมื่อค่าความไม่แน่นอนสูง
- Active learning — ใช้ป้ายกำกับจากการตรวจสอบมนุษย์เพื่อปรับปรุงโมเดลอย่างต่อเนื่อง
สรุป: การรวมกันของ counterfactual testing จาก Causal‑LLM, สัญญาณเชิงโครงสร้างจาก Graph‑GNN, เกณฑ์แบบบริบท และกระบวนการ human‑in‑the‑loop สร้างเป็นชุดมาตรการที่เสริมกันเพื่อลด False‑Positive ในการตรวจจับฟรอดเรียลไทม์ได้อย่างมีประสิทธิผล ภายใต้ข้อจำกัดเช่น latency และการคำนึงถึงต้นทุนการตรวจสอบด้วยคน ระบบเชิงลึกนี้ช่วยให้ธนาคารสามารถรักษาสมดุลระหว่างการป้องกันความเสี่ยงและการให้บริการลูกค้าได้ดียิ่งขึ้น
ผลการทดสอบจริงในธนาคารไทย: การตั้งค่า ตัวเลข และเคสตัวอย่าง
ผลการทดสอบจริงในธนาคารไทย: การตั้งค่า ตัวเลข และเคสตัวอย่าง
ธนาคารไทยดำเนินการทดลองนำร่อง (pilot) ของระบบ Adaptive‑Fraud Shield เป็นเวลา 30 วัน โดยเก็บข้อมูลธุรกรรมรวมทั้งสิ้นประมาณ 3,000,000 รายการ หรือเฉลี่ยราว 100,000 รายการต่อวัน เพื่อจำลองสภาพแวดล้อมการทำงานจริงของระบบชำระเงินออนไลน์และการโอนเงินระหว่างบัญชี ในชุดข้อมูลนี้ธนาคารกำหนดอัตราการฉ้อโกงฐาน (assumed fraud prevalence) ไว้ที่ 0.12% สำหรับการประเมินประสิทธิภาพของโมเดลและการคำนวณเมตริกต่าง ๆ
การทดลองใช้สแต็กเทคโนโลยีที่ประกอบด้วย Causal‑LLM สำหรับสร้างคำอธิบายเชิงสาเหตุและ counterfactuals ร่วมกับ Graph‑GNN สำหรับจับความเชื่อมโยงของบัญชีและการกระจายเงิน (money‑flow patterns) นอกเหนือจากนั้นยังมีบริการสตรีมมิงแบบเรียลไทม์, feature store และ online model server เพื่อรองรับการ inference ในเส้นทาง real‑time สำหรับการทดสอบระบบชุดหลักประกอบด้วย:
- ข้อมูลทดลอง: 3,000,000 ธุรกรรม (30 วัน)
- อัตราฉ้อโกงสมมติ: 0.12%
- เครื่องมือหลัก: Adaptive‑Fraud Shield (Causal‑LLM + Graph‑GNN), feature store, Kafka‑style streaming
- ระยะเวลา pilot: 30 วัน
- เมตริกที่วัด: TPR (True Positive Rate), FPR (False Positive Rate), Precision, Recall, และ Latency (inference)
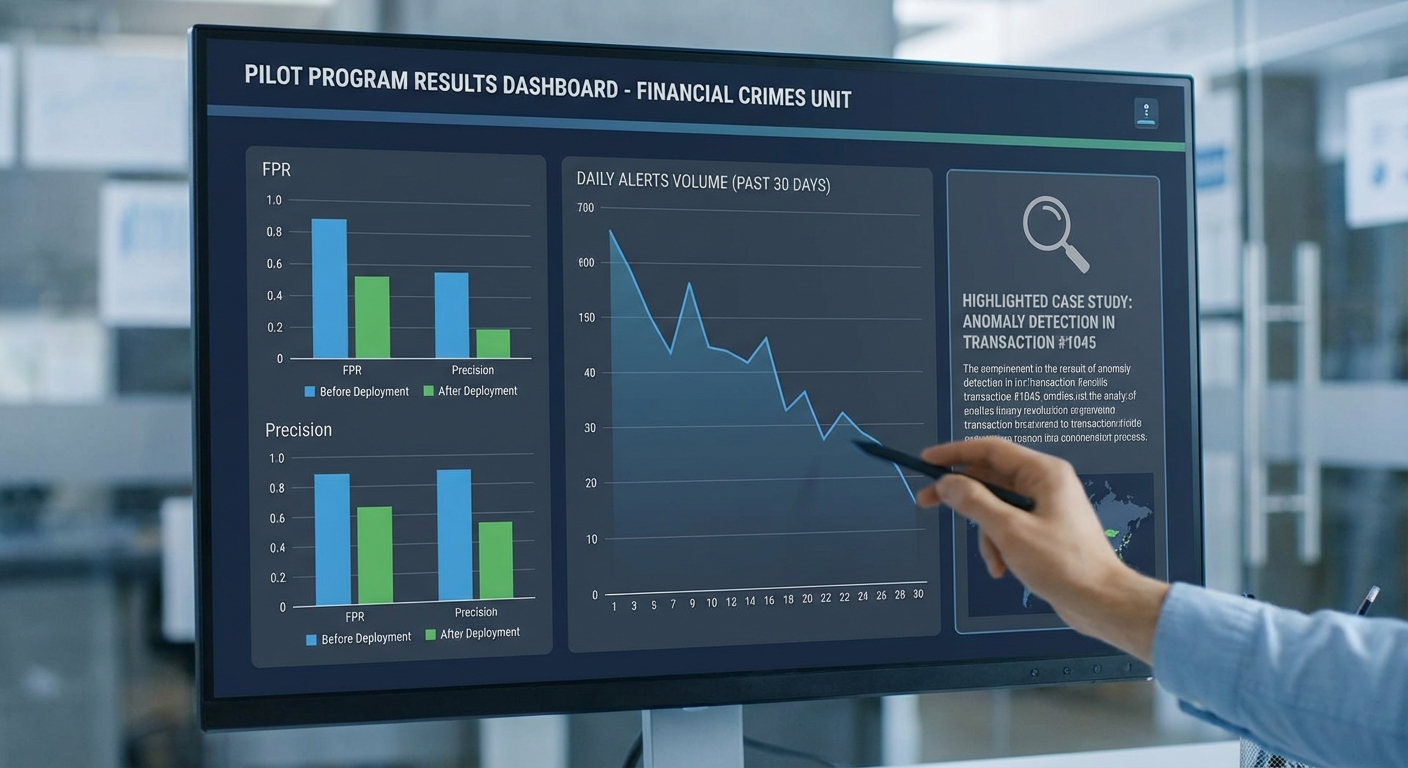
ผลการวัดเชิงปริมาณเมื่อเทียบกับระบบเดิมของธนาคารสรุปได้ว่า False Positive Rate (FPR) ลดลงมากกว่า 40% ในขณะที่ยังรักษาหรือปรับปรุงความสามารถในการจับฟรอดจริง (TPR) ให้ใกล้เคียงหรือลดลงเล็กน้อย ตัวเลขตัวอย่างจาก pilot มีดังนี้ (ตัวเลขเป็นค่าประมาณจากชุดทดลอง):
- ระบบเดิม: TPR ≈ 88%, FPR ≈ 0.25%, Precision ≈ 30%
- Adaptive‑Fraud Shield (pilot): TPR ≈ 91%, FPR ≈ 0.15% (ลดกว่า 40% จากระบบเดิม), Precision ≈ 47%, Recall ≈ 91%
- Latency (real‑time inference): latency เฉลี่ย <200 ms ต่อคำตัดสินสำหรับเส้นทาง real‑time และ latency p95 ≈ 320 ms (งานที่ต้องเข้าถึงกราฟและ counterfactual แบบเจาะลึกอาจนานกว่า)
นอกจากตัวเลขรวมแล้ว pilot ยังบันทึกกรณีตัวอย่างที่แสดงศักยภาพของการผสาน Graph‑GNN กับ Causal‑LLM ในสองมิติสำคัญ: การตรวจจับวงจรบัญชีเชื่อมโยง (linked‑account rings) และการลด false alarms สำหรับลูกค้าระดับสูง (high‑net‑worth customers)
ตัวอย่างเคสแรก—วงจรบัญชีเชื่อมโยง: ระบบ Graph‑GNN ตรวจจับกราฟความสัมพันธ์ที่ประกอบด้วยบัญชีหลายบัญชีที่มีเส้นทางโอนเงินเป็นวงซ้ำ ๆ และคะแนนเสี่ยงรวมสูงขึ้นเมื่อมองจากโครงสร้างเครือข่าย Causal‑LLM ถูกนำมาใช้สร้าง counterfactual explanation เช่น “หากเอาเส้นทางโอนระหว่างบัญชี A→B ออก ความน่าจะเป็นเกิดฟรอดจะลดลงจาก 78% เหลือ 22%” ข้อมูลเชิงสาเหตุนี้ช่วยให้ทีมสอบสวนยืนยันวงจรฉ้อโกงได้รวดเร็วขึ้นและนำไปสู่การระงับบัญชีปลายเหตุได้อย่างมีหลักฐานประกอบ
ตัวอย่างเคสที่สอง—การลด false alarm ในกลุ่มลูกค้าระดับสูง: ก่อนหน้านี้ระบบเดิมมักแจ้งเตือนลูกค้า VIP หลายรายเนื่องจากกิจกรรมข้ามประเทศและผู้รับเงินหลายรายซึ่งเป็นพฤติกรรมปกติของลูกค้ากลุ่มนี้ ใน pilot, Causal‑LLM ให้คำอธิบายแบบ counterfactual ที่แสดงว่าเหตุผลหลักที่ทำให้คะแนนเสี่ยงเพิ่มขึ้นมักมาจาก “ความถี่การโอนที่เปลี่ยนแปลงฉับพลันเมื่อเทียบกับรูปแบบย้อนหลัง 12 เดือน” ขณะเดียวกัน Graph‑GNN ช่วยยืนยันว่าเครือข่ายผู้รับเงินเป็นกลุ่มผู้รับประจำ (regular payees) มากกว่าจะเป็นเครือข่ายฟรอด ผลคือระบบใหม่หลีกเลี่ยงการแจ้งเตือนผิดสำหรับลูกค้า VIP เหล่านี้ได้อย่างมีนัยสำคัญ ส่งผลให้ธนาคารลดต้นทุนการสอบสวนและไม่รบกวนประสบการณ์ลูกค้า
สรุปได้ว่า pilot ของ Adaptive‑Fraud Shield แสดงให้เห็นทั้งความสามารถในการตรวจจับฟรอดเชิงเครือข่ายและการให้คำอธิบายเชิงสาเหตุที่นำไปสู่การตัดสินใจเชิงปฏิบัติจริง ๆ โดยเมตริกที่สำคัญได้แก่การลด FPR กว่า 40% และ latency สำหรับเส้นทาง real‑time เฉลี่ยต่ำกว่า 200 ms ซึ่งเป็นข้อพิสูจน์ว่าการผสาน Causal‑LLM กับ Graph‑GNN สามารถเพิ่มทั้งความแม่นยำและประสิทธิภาพในการปฏิบัติของระบบตรวจจับฟรอดในสภาพแวดล้อมธนาคารไทยได้จริง
คู่มือเชิงเทคนิค: ขั้นตอนการนำไปใช้ (Data, Training, Evaluation)
Data Requirements และการเตรียมข้อมูล (Feature Engineering & Graph Construction)
สำหรับระบบตรวจจับฟรอดแบบผสมผสานระหว่าง Graph‑GNN และ Causal‑LLM ข้อมูลเป็นหัวใจสำคัญ ต้องกำหนด schema ที่ชัดเจนและครอบคลุมทั้งระดับธุรกรรมและเอนทิตี้ ตัวอย่างฟิลด์พื้นฐานสำหรับตารางธุรกรรม (transactions): transaction_id, timestamp, amount, merchant_id, merchant_category, terminal_id, device_fingerprint, geo_lat, geo_lon, auth_response_code, label (fraud/non‑fraud), review_rationale (ถ้ามี) และสำหรับตารางเอนทิตี้ (accounts/devices/merchants): entity_id, first_seen, risk_score, linked_accounts, kyc_level เป็นต้น
เพื่อปกป้องความเป็นส่วนตัวและสอดคล้องกฎหมาย ควรใช้ privacy‑preserving transforms เช่น hashing/pepper สำหรับ identifiers, tokenization ของข้อความ, การประยุกต์ใช้ differential privacy (DP‑SGD) ในขั้นตอนการเทรนเมื่อจำเป็น และการทำ secure aggregation หรือใช้ MPC/TEEs สำหรับการรวมข้อมูลข้ามแหล่ง ตัวอย่าง: ถ้ามี 10 ล้านธุรกรรมและอัตราการฟรอดอยู่ที่ ~0.1% ควรใช้การทำ sampling และ augmentation ที่ระมัดระวังเพื่อไม่ให้สูญเสียตัวอย่างฟรอดสำคัญ
การออกแบบกราฟต้องระบุชนิดของโหนดและขอบอย่างชัดเจน เช่น
- โหนด: account, card, device, merchant, terminal
- ขอบ: transaction (ระหว่าง account↔merchant), device_usage (device↔account), card_link (card↔account)
การกำหนดคุณลักษณะของโหนด/ขอบ (node/edge features) ควรรวมทั้งเชิงสถิติ (transaction frequency, average_amount, std_amount), temporal features (time_since_last_tx), และพฤติกรรมเชิงกราฟ (degree, pagerank, community_id) รวมถึง embedding จากข้อความหรือ categorical fields
สำหรับ sampling strategies ของการเทรน GNN ให้พิจารณา:
- Neighbor sampling (e.g., GraphSAGE sampling) เพื่อรองรับกราฟขนาดใหญ่
- Stratified temporal sampling — แยกตัวอย่างตามช่วงเวลาเพื่อรักษา signal ของ concept drift
- Oversampling ของตัวอย่างฟรอด (หรือใช้ importance sampling) เพื่อจัดการ class imbalance (fraud << non‑fraud)
- Negative sampling แบบสมมติฐานเชิงธุรกิจ (เลือก negative ที่มีลักษณะคล้าย fraud เพื่อฝึกให้ model แยกแยะดีกว่า)
ขั้นตอนการเทรน GNN: สถาปัตยกรรม, Loss และการปรับจูน
เลือกสถาปัตยกรรม GNN ที่สอดคล้องกับปัญหา เช่น GraphSAGE หรือ GAT สำหรับความสามารถเชิงอินดักทีฟ และยกเว้นเมื่อจำเป็นอาจใช้ Graph Transformer สำหรับ capture ความสัมพันธ์เชิงยาว ระบุ input pipeline ให้รองรับ mini‑batch training พร้อม neighbor sampling เพื่อจำกัด memory footprint
Loss function ที่แนะนำสำหรับปัญหาฟรอดประกอบด้วย:
- Weighted cross‑entropy เพื่อชดเชย class imbalance (ให้ weight สูงกับตัวอย่างฟรอด)
- Focal loss เมื่อต้องการเน้นตัวอย่างที่ยากต่อการคาดเดาและลดผลของ easy negatives
- Contrastive / InfoNCE loss สำหรับการเรียนรู้อินเทอร์นอล representation ที่แยกฟีเจอร์ของคลาสต่างกัน
- ถ้าต้องการแยก ranking ของการแจ้งเตือน ให้พิจารณา pairwise ranking loss (เช่น margin ranking) เพื่อปรับปรุง precision@k
การตั้งค่าการฝึก (optimizers, LR schedule): เริ่มด้วย AdamW, LR ~1e‑3 ถึง 3e‑4 สำหรับชั้น GNN ต้น และใช้ warm‑up + cosine decay หากเจอ overfitting ให้ใช้ early stopping บน validation loss และตรวจ P/R curve เป็นประจำ นอกจากนี้ให้บันทึก embedding drift และ gradient norms เพื่อช่วย debug ใน production
การปรับจูน Causal‑LLM: Prompt Engineering และการใช้ Supervised Labels
จุดประสงค์ของ Causal‑LLM ในระบบนี้มักเป็นการสร้างคำอธิบายสาเหตุ (causal explanation) ของสัญญาณฟรอด และช่วยลด false positives โดยให้เหตุผลเชิงตรรกะที่มนุษย์ตรวจสอบได้ การปรับจูน Causal‑LLM ควรมีสองแกนหลักคือ (1) supervised fine‑tuning ด้วยตัวอย่างที่มี label และ rationale และ (2) instruction tuning/prompt engineering เพื่อให้โมเดลตอบในรูปแบบที่นำไปใช้ได้จริง
Workflow การปรับจูน:
- รวบรวมชุดข้อมูล supervised จาก human review: แต่ละตัวอย่างประกอบด้วย transaction context, graph summary (top‑N neighbors embeddings/summary), label (fraud/non‑fraud), และ rationale ของผู้ตรวจสอบ
- ออกแบบ prompt template แบบเชิงโครงสร้าง เช่น ระบบจะได้รับ context + question (e.g., "เหตุใดรายการนี้จึงถูกระบุว่าเสี่ยง?") และคาดหวัง output เป็นสาเหตุที่เป็นเชิงเหตุผล พร้อม confidence score
- ใช้ supervised fine‑tuning บน causal LLM (decoder‑only) ด้วย cross‑entropy loss สำหรับ token prediction และอาจรวม loss สำหรับ calibration ของ confidence (e.g., MSE ระหว่าง predicted confidence กับ human confidence)
- นำตัวอย่าง few‑shot และ chain‑of‑thought ที่ผ่านการอนุมัติเป็นส่วนหนึ่งของ prompt engineering เพื่อเพิ่มความสอดคล้องของคำอธิบาย
เพื่อป้องกันการ overconfidence ให้ใช้ calibration techniques (temperature scaling) และถ้ามีทรัพยากร อาจรวม Human‑in‑the‑Loop (HITL) แบบ active learning: ให้ LLM แนะนำตัวอย่างที่ไม่แน่ใจเพื่อให้มนุษย์ตรวจสอบและนำกลับไปเป็น label ในรอบถัดไป
การออกแบบ Evaluation Pipeline (A/B Testing, Shadow Mode และ Metrics ที่สำคัญ)
สร้าง layered evaluation pipeline ที่ประกอบด้วย offline evaluation, shadow mode, และ controlled A/B testing ก่อน roll‑out เต็มรูปแบบ
- Offline metrics: precision@k (เช่น precision@100 สำหรับ top‑100 alerts ต่อวัน), ROC/AUC เพื่อดูการแยกคลาสโดยรวม, และ FPR at fixed TPR (เช่น FPR@TPR=0.95) เพื่อเข้าใจ trade‑off ระหว่างจับ fraud และ False Positives ตัวอย่างเป้าหมายทางธุรกิจอาจเป็นการรักษ TPR ≥ 95% ขณะที่ลด FPR อย่างน้อย 30%
- Latency & SLOs: กำหนด SLOs เช่น scoring latency ≤ 50–100 ms (ที่ p95) สำหรับ GNN inference และ explanation generation ≤ 200–500 ms สำหรับ LLM (หรือ offload explanation เป็น asynchronous response หาก latency เป็นข้อจำกัด) ติดตาม p50/p95/p99 latency, throughput, และ memory usage
- Shadow mode: รันโมเดลใหม่คู่ขนานกับระบบจริงโดยไม่ส่งผลต่อการตัดสินใจของระบบ production ใช้ shadow logs เพื่อวัด uplift ใน precision@k, เปรียบเทียบ False Positive Rate และต้นทุนการสืบสวน
- A/B testing: ทำการทดลองแบบสุ่มแบ่ง traffic (เช่น 5–20% ในกลุ่ม treatment) ประเมินผลทางธุรกิจเช่น reduction in investigation cost, decrease in customer friction (เรียกคืนบัตร/ปฏิเสธการชำระ), และ statistical significance ของการเปลี่ยนแปลง ใช้ระยะเวลาทดสอบที่เพียงพอเพื่อจับ seasonality
- Counterfactual robustness testing: สร้างชุดทดสอบที่เป็น counterfactuals — แก้ไขคุณลักษณะสำคัญทีละรายการ (เช่น เปลี่ยน device_id หรือ location) เพื่อตรวจว่าการตัดสินใจยังคงเหมาะสม ทดสอบด้วย adversarial perturbations และ out‑of‑distribution samples เพื่อประเมินความคงที่ของการอธิบายเชิงเหตุผล
แนวปฏิบัติที่ดีที่สุดสำหรับ CI/CD, Model Monitoring และการนำขึ้นใช้งาน
ปฏิบัติตามหลัก CI/CD สำหรับ ML (MLOps): บันทึกรุ่น (model versioning), ข้อมูล (data versioning), และสคริปต์การเทรนใน pipeline อัตโนมัติ ใช้ feature store สำหรับจัดการการคำนวณ features แบบ online/offline และตั้ง data contracts เพื่อให้ทีมที่ป้อนข้อมูลรู้ขอบเขตและ schema ที่คงที่
การ deploy ควรมีขั้นตอนดังนี้: unit/integration tests (สำหรับ data transforms และ feature calculation) → shadow mode → canary deployment (1–5%) → gradual rollout พร้อม monitoring ไปยัง dashboard แบบ near‑real‑time
- Monitoring ที่ต้องมี: performance metrics (precision@k, recall, FPR), latency metrics (p50/p95/p99), input data distribution metrics (feature drift, population shift), label delay และ human override rate
- Drift detection & retraining policy: ตั้ง threshold สำหรับ drift (เช่น KL divergence > 0.1 หรือ significant change ใน feature distribution) และระบบ trigger สำหรับ automated retraining หรือ human review ก่อน retrain
- Logging & auditability: เก็บเหตุผลการตัดสินใจ (LLM rationale, key features, embeddings hash) แบบปลอดภัยและเข้ารหัสเพื่อการตรวจสอบย้อนหลังและ compliance
- Human‑in‑the‑loop: สร้าง feedback loop: label จากการตรวจสอบของนักสืบฟรอดควรถูกนำเข้าสู่ training dataset ภายใน windows ที่กำหนด (เช่น 24–72 ชั่วโมงสำหรับ high‑priority cases) เพื่อปรับปรุง model อย่างต่อเนื่อง
โดยสรุป ให้กำหนด SLA ทางธุรกิจชัดเจน (เช่น ลด false positives 30% โดยยังคง recall ≥ 95%) และออกแบบ pipeline ทั้ง data‑to‑deployment ที่รองรับการตรวจวัดและการย้อนกลับ (rollback) อย่างปลอดภัย การผสาน GNN ที่จับเชิงความสัมพันธ์กับ Causal‑LLM ที่ให้คำอธิบายเชิงเหตุผล จะช่วยเพิ่มความแม่นยำและความเชื่อถือได้ของระบบ ตรวจสอบผลด้วย metric ที่สอดคล้องกับค่าใช้จ่ายทางธุรกิจ และรักษาความปลอดภัยและความเป็นส่วนตัวของข้อมูลตลอดวงจรการใช้งาน
ความท้าทายด้านความเป็นส่วนตัว กฎระเบียบ และการนำระบบสู่การใช้งานจริง
การปฏิบัติตาม PDPA และการจัดการข้อมูลส่วนบุคคล
การนำระบบตรวจจับฟรอดที่ผสาน Causal‑LLM กับ Graph‑GNN มาใช้งานในสถาบันการเงินจำเป็นต้องสอดรับกับพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ของไทยในทุกขั้นตอน ตั้งแต่การเก็บข้อมูล การใช้ข้อมูล ไปจนถึงการเปิดเผยให้บุคคลที่สาม โดยหลักปฏิบัติสำคัญได้แก่ data minimization (เก็บใช้เฉพาะข้อมูลที่จำเป็นต่อวัตถุประสงค์), การขอความยินยอมที่ชัดเจนเมื่อจำเป็น, และการใช้เทคนิคอย่าง pseudonymization หรือ tokenization เพื่อลดความเสี่ยงของการระบุตัวบุคคล
ตัวอย่างเชิงปฏิบัติ: ก่อนนำข้อมูลลูกค้ามาใช้ฝึกโมเดล ควรจัดลำดับความสำคัญของฟีเจอร์ที่จำเป็น (feature selection) เพื่อลดการเก็บข้อมูลที่ไม่เกี่ยวข้อง รวมทั้งจัดทำเอกสาร Data Processing Agreement (DPA) กับผู้ให้บริการภายนอกเมื่อมีการแชร์ข้อมูลบุคคลที่สาม และจัดทำการประเมินผลกระทบด้านคุ้มครองข้อมูล (DPIA) สำหรับฟังก์ชันที่อาจมีความเสี่ยงสูง เช่น การตัดสินใจอัตโนมัติที่ส่งผลต่อการให้บริการทางการเงิน
ความโปร่งใสของโมเดลและ Audit Trail
ระบบที่ใช้ Causal‑LLM ต้องสามารถให้เหตุผลประกอบการตัดสินใจ (decision explanations) ที่เพียงพอสำหรับผู้ใช้งานภายในและการตรวจสอบจากภายนอก เพื่อให้สอดคล้องกับความต้องการด้านความโปร่งใสของผู้มีส่วนได้เสียและหน่วยงานกำกับดูแล การเก็บบันทึกคำอธิบายการตัดสินใจควรทำควบคู่กับการซิงก์ log ของ Graph‑GNN และข้อมูลเชิงสัญญาณ (transactional signals) เพื่อสร้าง immutable audit trail ที่สามารถตรวจสอบย้อนกลับได้
- ควรบันทึกรายการเหตุผลจาก Causal‑LLM ในรูปแบบที่มนุษย์อ่านเข้าใจได้ (human-readable explanations) พร้อม metadata เช่น timestamp, model version, input features ที่สำคัญ
- ซิงก์ log ระหว่างโมดูล (LLM, GNN, decision engine) โดยใช้เวลาประทับและการเซ็นทรัลไทม์เพื่อรองรับการตรวจสอบภายในและภายนอก
- ใช้การเข้ารหัสและการจัดการคีย์เพื่อปกป้อง log ที่มีข้อมูลอ่อนไหว และพิจารณาทำ hashing/anchoring ของ log กับ blockchain หรือระบบ signing เพื่อยืนยันความถูกต้องของประวัติการตัดสินใจ
การควบคุม bias และการจัดการความผิดพลาดเมื่อระบบทำงานผิดพลาด
ความลำเอียง (bias) ในชุดข้อมูลหรือโมเดลอาจส่งผลให้เกิดการปฏิเสธหรือจับผิดลูกค้ากลุ่มใดกลุ่มหนึ่งบ่อยครั้ง ซึ่งจะนำไปสู่ False‑Positive ที่สูงขึ้นและความเสี่ยงด้านการปฏิบัติตามกฎหมายและภาพลักษณ์องค์กร การจัดการจึงต้องมีทั้งมาตรการเชิงเทคนิคและเชิงกระบวนการ เช่น การทำ periodic bias audits โดยทีมภายในหรือผู้ตรวจสอบอิสระ เพื่อตรวจหาผลต่างทางสถิติที่บ่งชี้ความลำเอียง
- ตั้ง KPI ด้านความเป็นธรรมและ False‑Positive/False‑Negative rates และรายงานเชิงสถิติเป็นรอบ (เช่น รายไตรมาส)
- นำกลไก human‑in‑the‑loop มาใช้สำหรับเคสที่โมเดลมีความไม่แน่นอนสูงหรือเมื่อลูกค้ารายสำคัญถูกระบุผิดพลาด
- ใช้เทคนิคการปรับแก้โมเดล (retraining, adversarial testing, fairness-aware learning) และทำ A/B testing ก่อนปล่อยเวอร์ชันใหม่ในระบบการผลิต
การบริหารความเสี่ยงเชิงปฏิบัติการและข้อเสนอเชิงนโยบาย
เพื่อให้การนำระบบสู่การใช้งานจริงมีความมั่นคงและเชื่อถือได้ ธนาคารควรออกแบบแนวนโยบายและกระบวนการรองรับกรณีความผิดพลาดอย่างเป็นระบบ ประกอบด้วยแผน rollback, กลไก human override และขั้นตอนการแจ้งเหตุ (incident response) ที่ชัดเจน
- Rollback plans & Canary deployment: ปล่อยระบบเป็นกลุ่มเล็ก (canary) เพื่อสังเกตพฤติกรรมจริง ก่อนขยายการใช้งาน และเตรียมแผนย้อนกลับ (rollback) ที่ทดสอบได้ในสถานการณ์ฉุกเฉิน
- Human override & Escalation: กำหนดระดับการตัดสินใจที่ต้องการการอนุมัติจากผู้ปฏิบัติงานคนจริง โดยเฉพาะเมื่อการตัดสินใจมีผลกระทบทางการเงินหรือความเสี่ยงด้านเครดิต
- Periodic audits & Monitoring: กำหนดการตรวจสอบประสิทธิภาพและความเป็นธรรมเป็นประจำ พร้อมรายงานต่อคณะกรรมการความเสี่ยงของธนาคาร และจัดทำ playbook สำหรับเหตุการณ์ที่เกี่ยวกับ PDPA
- นโยบายการใช้ข้อมูลบุคคลที่สาม: ระบุข้อกำหนดสัญญา การตรวจสอบผู้ให้บริการ และข้อกำหนดทางเทคนิคสำหรับการถ่ายโอนข้อมูลข้ามประเทศ เพื่อให้สอดคล้องกับ PDPA และข้อบังคับระหว่างประเทศที่เกี่ยวข้อง
โดยสรุป การวางกรอบด้านความเป็นส่วนตัวและกฎระเบียบสำหรับโครงการ Adaptive‑Fraud Shield ต้องเป็นการผสมผสานระหว่างมาตรการด้านเทคนิค (pseudonymization, encryption, immutable logging), กระบวนการองค์กร (consent management, DPIA, incident response) และกลไกกำกับดูแล (periodic bias audits, human‑in‑the‑loop, rollback plans) เพื่อให้ระบบทำงานได้อย่างมีประสิทธิภาพ ลด False‑Positive และรักษา trust ของลูกค้าและหน่วยงานกำกับดูแล
บทสรุป
โครงการทดลองของธนาคารในการใช้ระบบ "Adaptive‑Fraud Shield" ที่ผสานเทคโนโลยี Causal‑LLM กับ Graph‑GNN แสดงให้เห็นว่าการตรวจจับฟรอดสามารถทำได้ทั้งมีประสิทธิภาพและมีความสามารถในการอธิบายสาเหตุของการแจ้งเตือน ซึ่งช่วยลดอัตรา False‑Positive โดยตรงและเพิ่มความเชื่อมั่นของผู้ปฏิบัติงาน ตัวอย่างผลการทดสอบนำร่องจากสถาบันการเงินบางแห่งระบุการลด False‑Positive ประมาณ 30–60% และการปรับปรุงความแม่นยำ (precision/recall) ในช่วง 10–20% เมื่อผสานความสามารถเชิงสาเหตุของ LLM กับการวิเคราะห์ความสัมพันธ์เชิงกราฟของ GNN ระบบยังสามารถปรับตัวตามบริบทของธุรกรรม เช่น เครือข่ายผู้ใช้งาน พฤติกรรมการใช้จ่าย และความเชื่อมโยงของบัญชี ทำให้การตัดสินใจเป็นไปในเชิงบริบทมากขึ้น
การนำ Adaptive‑Fraud Shield ไปใช้จริงจำเป็นต้องพิจารณามิติเชิงปฏิบัติการอย่างรอบด้าน ทั้งการออกแบบสถาปัตยกรรมให้รองรับ low‑latency (เป้าหมายการตัดสินใจแบบเรียลไทม์ภายในระดับมิลลิวินาที–ร้อยมิลลิวินาที), การกำหนดตัวชี้วัดเชิงปริมาณ (เช่น precision, recall, F1, false positive rate, time‑to‑decision, throughput/TPS) และการทดสอบ A/B เพื่อประเมินความคุ้มค่า นอกจากนี้ต้องวางกลไก human‑in‑the‑loop สำหรับการตรวจสอบกรณีที่โมเดลให้เหตุผลไม่ชัดเจนหรือความเสี่ยงสูง เพื่อรักษาคุณภาพการตัดสินใจและลดความเสี่ยงทางกฎหมาย ข้อกำหนดด้านการคุ้มครองข้อมูลส่วนบุคคล (เช่น PDPA) การเข้ารหัส การควบคุมการเข้าถึง และการบันทึกการตัดสินใจของระบบเป็นพื้นฐานสำคัญสำหรับความยั่งยืนของระบบ
มุมมองอนาคตชี้ว่าเทคโนโลยีผสมระหว่าง causal modeling และ graph representation จะเป็นแนวทางสำคัญในการเพิ่มความโปร่งใสและความน่าเชื่อถือของระบบตรวจจับฟรอด ทั้งในแง่การปฏิบัติการและการกำกับดูแล ก้าวต่อไปอาจเห็นการขยายไปสู่การเรียนรู้แบบกระจาย (federated learning) เพื่อรักษาความเป็นส่วนตัวของข้อมูลข้ามสถาบัน และการพัฒนาเครื่องมือมอนิเตอร์เพื่อตรวจจับ model drift แบบเรียลไทม์ ข้อสรุปเชิงปฏิบัติ: การนำ Adaptive‑Fraud Shield มาใช้ต้องวางแผนเชิงยุทธศาสตร์แบบเป็นขั้นตอน ผสมผสานการวัดผลเชิงปริมาณ การมีมนุษย์ร่วมตัดสินใจ และการปฏิบัติตามกฎหมายเป็นหัวใจสำคัญของความยั่งยืนและความสำเร็จในระยะยาว



