
ในยุคที่อุปกรณ์สวมใส่ (wearables) และสมาร์ทโฟนกลายเป็นเพื่อนคู่กายด้านสุขภาพของผู้ใช้จำนวนมาก ปัญหาการแจ้งเตือนผิดพลาด (false alarms) ที่เกิดจากโมเดลกลางบนคลาวด์สร้างความรำคาญและลดความเชื่อมั่นต่อระบบติดตามสุขภาพ ล่าสุดสตาร์ทอัพไทยพัฒนานวัตกรรม "On‑Device Continual Learner" ฝังโดยตรงบนสมาร์ทวอทช์และมือถือ สามารถเรียนรู้พฤติกรรมผู้ใช้แบบท้องถิ่นโดยไม่ต้องส่งข้อมูลขึ้นคลาวด์ ผลลัพธ์เบื้องต้นระบุว่าสามารถลดการแจ้งเตือนผิดพลาดด้านสุขภาพได้ถึง 70% ช่วยลดภาระการแจ้งเตือนที่ไม่จำเป็นและปกป้องความเป็นส่วนตัวของผู้ใช้ในเวลาเดียวกัน
บทความนี้จะนำเสนอภาพรวมของเทคโนโลยี On‑Device Continual Learner กระบวนการทำงานและข้อดีด้านความเป็นส่วนตัว (privacy), ความหน่วง (latency) และความทนทานต่อการเปลี่ยนแปลงพฤติกรรมผู้ใช้ พร้อมยกตัวอย่างผลการทดสอบและแนวทางปฏิบัติสำหรับนักพัฒนาที่ต้องการนำไปใช้งานจริง ทั้งการจัดการทรัพยากรบนอุปกรณ์ ความปลอดภัยของโมเดล และวิธีออกแบบวิเคราะห์เพื่อลดการแจ้งเตือนผิดพลาดโดยยังคงประสิทธิภาพในการตรวจจับสัญญาณสุขภาพที่สำคัญ
บทนำ: ข่าวสั้นและความสำคัญ
บทนำ: ข่าวสั้นและความสำคัญ
สตาร์ทอัพไทยประกาศเปิดตัวระบบ On‑Device Continual Learner (ODCL) ซึ่งถูกฝังลงบนสมาร์ทวอทช์และสมาร์ทโฟน เพื่อให้สามารถเรียนรู้พฤติกรรมผู้ใช้แบบต่อเนื่องโดยไม่ต้องส่งข้อมูลดิบขึ้นสู่คลาวด์ ระบบดังกล่าวรายงานผลเบื้องต้นว่าได้ลดอัตราการแจ้งเตือนด้านสุขภาพที่ผิดพลาดลงถึง 70% เมื่อเทียบกับการใช้ชุดกฎหรือโมเดลกลางแบบเดิม ผลลัพธ์นี้ชี้ให้เห็นถึงศักยภาพของการปรับแต่งแบบเฉพาะบุคคล (personalization) ร่วมกับการประมวลผลที่ใกล้แหล่งกำเนิดข้อมูล (edge) ในบริบทการดูแลสุขภาพแบบสวมใส่
ฟีเจอร์หลักของ ODCL ประกอบด้วยการเรียนรู้แบบต่อเนื่อง (continual learning) บนอุปกรณ์ การปรับน้ำหนักโมเดลตามพฤติกรรมรายบุคคล ระบบคัดกรองสัญญาณที่มีฉากทัศน์หลากหลาย เช่น การเคลื่อนไหว หัวใจ และการนอนหลับ พร้อมกลไกการจัดการพลังงานเพื่อไม่ให้ส่งผลกระทบต่อแบตเตอรี่ โดยไม่ต้องอาศัยการถ่ายโอนข้อมูลส่วนบุคคลไปยังเซิร์ฟเวอร์กลาง ซึ่งลดความเสี่ยงด้านความเป็นส่วนตัวและภาระแบนด์วิดท์ของเครือข่าย
เหตุผลที่การทำงานแบบ on‑device มีความสำคัญอยู่ที่สองด้านหลักคือ ความเป็นส่วนตัว และ ความหน่วงต่ำ โดยการเก็บข้อมูลไว้ภายในอุปกรณ์ช่วยลดการเปิดเผยข้อมูลส่วนบุคคลต่อผู้ให้บริการภายนอกและช่วยให้สอดคล้องกับกฎระเบียบคุ้มครองข้อมูล (เช่น PDPA) ในขณะเดียวกันการประมวลผลที่ใกล้แหล่งข้อมูลลดเวลาตอบสนองจากระดับวินาทีลงสู่ระดับมิลลิวินาที ทำให้การแจ้งเตือนเช่นเหตุฉุกเฉินด้านหัวใจหรือภาวะแทรกซ้อนจากการนอนหลับมีความทันเหตุการณ์และแม่นยำยิ่งขึ้น
สำหรับภาคธุรกิจและผู้ให้บริการด้านสุขภาพ การลดอัตราการแจ้งเตือนผิดพลาด 70% หมายถึงการลดภาระงานด้านการติดตามและการตอบสนอง ลดภาระค่าใช้จ่ายจากการวินิจฉัยเกินความจำเป็น และเพิ่มความเชื่อมั่นของผู้ใช้ต่ออุปกรณ์สวมใส่ การออกแบบ ODCL ให้สามารถทำงานแบบปรับตัวได้บนฮาร์ดแวร์จำกัดจึงเป็นกุญแจสำคัญที่เปิดโอกาสให้สตาร์ทอัพไทยแข่งขันได้ทั้งในตลาดภายในประเทศและในต่างประเทศ
เทคโนโลยีเบื้องหลัง: อะไรคือ On‑Device Continual Learner
นิยามของ Continual Learning และความท้าทายบนอุปกรณ์ขนาดเล็ก
Continual Learning (บางครั้งเรียกว่า lifelong learning หรือ incremental learning) คือกรอบการเรียนรู้ของโมเดลที่ออกแบบให้รับข้อมูลใหม่อย่างต่อเนื่องและปรับปรุงความรู้โดยไม่ต้องฝึกโมเดลซ้ำทั้งหมดจากข้อมูลเดิมที่มีอยู่ทั้งหมด ปรัชญาสำคัญคือการเรียนรู้แบบ online/incremental จากสตรีมข้อมูลที่เปลี่ยนแปลงตลอดเวลา เช่น พฤติกรรมการเดิน การเต้นของหัวใจ หรือรูปแบบการแจ้งเตือนบนสมาร์ทวอทช์และมือถือ
เมื่อย้ายแนวคิดนี้ไปสู่ on‑device บนอุปกรณ์ edge เช่น สมาร์ทวอทช์หรือโทรศัพท์มือถือ จะพบความท้าทายเชิงปฏิบัติหลายประการ: ข้อจำกัดเรื่องหน่วยความจำและพื้นที่จัดเก็บ (บางอุปกรณ์มี RAM เพียง ร้อยกิโลไบต์ถึงไม่กี่เมกะไบต์), กำลังไฟและพลังงานจำกัด, ค่าหน่วงเวลาที่ต้องต่ำสำหรับการแจ้งเตือนด้านสุขภาพ และข้อจำกัดด้านความเป็นส่วนตัวที่ผลักดันให้ต้องประมวลผลบนเครื่องโดยไม่ส่งข้อมูลไปคลาวด์ ตัวอย่างเช่น การลดการแจ้งเตือนผิดพลาดด้านสุขภาพได้ถึง 70% ตามกรณีศึกษา จะต้องพึ่งพาโมเดลที่สามารถเรียนรู้และปรับตัวได้บนอุปกรณ์โดยตรง

กลยุทธ์ป้องกันการลืม (Catastrophic Forgetting)
หนึ่งในปัญหาใหญ่ของ Continual Learning คือ catastrophic forgetting — โมเดลที่อัพเดตด้วยข้อมูลชุดใหม่มักลืมความรู้จากชุดข้อมูลเก่า กลยุทธ์หลักที่ใช้เพื่อลดปัญหานี้บนอุปกรณ์ edge ประกอบด้วย:
- Rehearsal / Episodic Memory: เก็บตัวอย่างสำคัญบางส่วน (coreset) ในหน่วยความจำจำกัด แล้วนำมาฝึกร่วมกับข้อมูลใหม่เป็นระยะ เทคนิคนี้ง่ายและได้ผลดี แต่ถูกจำกัดด้วยพื้นที่จัดเก็บ ตัวอย่างเช่น บัฟเฟอร์ขนาด 200–2,000 ตัวอย่างที่บีบอัดสามารถรักษาความแม่นยำของงานหลายงานได้อย่างมีนัยสำคัญ
- Regularization — EWC (Elastic Weight Consolidation): เพิ่มบทลงโทษให้กับการเปลี่ยนแปลงพารามิเตอร์ที่สำคัญต่องานก่อนหน้า โดยวัดความสำคัญผ่าน Fisher Information Matrix วิธีนี้ไม่ต้องเก็บข้อมูลเดิม แต่ต้องคำนวณค่าโทเค็นความสำคัญและปรับค่าปรับแต่ง (lambda) ให้เหมาะสมกับทรัพยากรเครื่อง
- Parameter Isolation / Architectural Methods: แยกพารามิเตอร์สำหรับงานต่าง ๆ เช่น Progressive Networks หรือ Hard Attention to the Task (HAT) ซึ่งกันไม่ให้การอัพเดตงานใหม่ไปรบกวนพารามิเตอร์ของงานเก่า แนวทางนี้มักเพิ่มขนาดโมเดล แต่สามารถผสมกับการบีบอัดเพื่อคงขนาดที่ยอมรับได้บน edge
- ผสมผสานเชิงปฎิบัติ: บ่อยครั้งที่ระบบ on‑device ใช้การผสานหลายเทคนิค เช่น เก็บบัฟเฟอร์ตัวอย่างขนาดเล็กควบคู่กับ regularization (EWC + rehearsal) เพื่อให้ได้สมดุลระหว่างความจำข้อมูลเดิมและงบประมาณหน่วยความจำ
เทคนิคลดขนาดโมเดลสำหรับ tinyML และการปรับให้เหมาะกับฮาร์ดแวร์
การนำ Continual Learner มารันบนสมาร์ทวอทช์/มือถือจำเป็นต้องทำให้โมเดลเล็กและประหยัดพลังงานโดยยังคงความแม่นยำไว้ เทคนิคหลักได้แก่:
- Quantization: แปลงน้ำหนักและการคำนวณจาก FP32 เป็น INT8 หรือแม้แต่ INT4 เพื่อลดขนาดโมเดลและความต้องการหน่วยความจำ ตัวอย่างเช่น การ quantize FP32→INT8 มักลดขนาดไฟล์ได้ประมาณ 4x และช่วยให้ inference เร็วขึ้นบน NPU/DSP ที่รองรับคำสั่ง integer โดยสูญเสียน้อยต่อความแม่นยำ (ในหลายงานสูญเสียไม่เกิน 1–3%)
- Pruning: ตัดพารามิเตอร์ที่มีผลน้อยต่อผลลัพธ์ออก (sparse pruning) สามารถลดจำนวนพารามิเตอร์ได้ 50–90% ขึ้นกับเงื่อนไขและงาน หากผสานกับฮาร์ดแวร์ที่รองรับการคำนวณแบบ sparse จะได้ประสิทธิภาพพลังงานที่ดีขึ้น
- Knowledge Distillation: ฝึก "student" model ขนาดเล็กให้เลียนแบบ "teacher" ขนาดใหญ่ เทคนิคนี้มักช่วยให้ได้โมเดลขนาดเล็กลงหลายเท่าโดยยังคงความแม่นยำใกล้เคียง เช่น ลดขนาดได้ 5–20x ขึ้นกับสถาปัตยกรรม
- การบีบอัดและ encoding ของ episodic memory: แทนเก็บตัวอย่างดิบ อาจเก็บ embedding ที่ถูกบีบอัดหรือ prototypes เพื่อลดพื้นที่เก็บบัฟเฟอร์ รองรับ rehearsal ในงบประมาณหน่วยความจำจำกัด
การใช้ฮาร์ดแวร์เร่งความเร็ว (NPU / DSP) และเฟรมเวิร์ก tinyML
เพื่อให้การเรียนรู้และ inference บนอุปกรณ์เป็นไปได้จริง จำเป็นต้องประสานซอฟต์แวร์กับฮาร์ดแวร์เร่งความเร็ว เช่น Neural Processing Unit (NPU), Digital Signal Processor (DSP) หรือเทคโนโลยี SIMD ของ CPU ฮาร์ดแวร์เหล่านี้ช่วยให้:
- ประมวลผลแบบ INT8/INT16 ได้รวดเร็วและประหยัดพลังงาน
- รองรับการคำนวณสัญญาณชีวภาพ (ECG, PPG) แบบเรียลไทม์ด้วย latency ต่ำ
- เปิดทางให้การฝึกแบบ online/incremental บางรูปแบบ (เช่นการอัพเดตชั้นบนสุดหรือ fine‑tuning พารามิเตอร์จำนวนน้อย) ทำได้บนอุปกรณ์จริง
เฟรมเวิร์กและไลบรารีสำหรับ tinyML เช่น TensorFlow Lite Micro, ONNX Runtime for Mobile หรือชุดพัฒนาเฉพาะผู้ผลิต (SDK ของ NPU) มักรวมเครื่องมือ quantization, pruning และ inference engine ที่ออกแบบมาสำหรับทรัพยากรจำกัด
สรุปเชิงธุรกิจ: การผสาน Continual Learning บนอุปกรณ์ (on‑device continual learner) ด้วยเทคนิค rehearsal, EWC และการบีบอัดโมเดล (quantization/pruning/distillation) ร่วมกับ NPU/DSP ช่วยให้ระบบแจ้งเตือนด้านสุขภาพปรับตัวต่อพฤติกรรมผู้ใช้ได้ทันที ลดการส่งข้อมูลขึ้นคลาวด์และลดการแจ้งเตือนผิดพลาดอย่างมีนัยสำคัญ (เช่นกรณีศึกษาที่ลดได้ ~70%) — ซึ่งหมายถึงประสบการณ์ผู้ใช้ที่ดีขึ้น ต้นทุนคลาวด์และความเสี่ยงด้านข้อมูลส่วนบุคคลที่ต่ำลง
การออกแบบระบบบนสมาร์ทวอทช์และมือถือ: สถาปัตยกรรมและ pipeline
ภาพรวมฮาร์ดแวร์และเซ็นเซอร์ที่เกี่ยวข้อง
ระบบ On‑Device Continual Learner บนสมาร์ทวอทช์และมือถือต้องเริ่มจากการเลือกฮาร์ดแวร์และเซ็นเซอร์ที่สอดคล้องกับเป้าหมายเชิงสุขภาพ โดยองค์ประกอบหลักประกอบด้วยเซ็นเซอร์วัดอัตราการเต้นหัวใจ (PPG/HR), accelerometer (และหากจำเป็น gyroscope), รวมถึงเซ็นเซอร์เสริมเช่น barometer หรือ skin temperature เพื่อบริบทเพิ่มเติม ตัวอย่างการตั้งค่าการเก采: PPG sampling ระหว่าง 25–100 Hz เพื่อรักษาสมดุลระหว่างคุณภาพสัญญาณกับพลังงาน, accelerometer ที่ 50–200 Hz สำหรับการตรวจจับกิจกรรมและการเคลื่อนไหว
ด้านหน่วยประมวลผล ระบบระดับนาฬิกาสมาร์ทวอทช์มักพึ่งพา MCU/Cortex‑M (เช่น M4/M33) สำหรับ preprocessing เบื้องต้นและ real‑time interrupt handling ขณะที่มือถือหรืออุปกรณ์ชั้นสูงอาจมี application processor (Cortex‑A) หรือ NPU เล็กๆ สำหรับการ inference ที่ซับซ้อนกว่า ขนาดโมเดลบนอุปกรณ์ ที่นิยมอยู่ระหว่าง 200 KB ถึง 3 MB ขึ้นกับสถาปัตยกรรมและการบีบอัด (quantization) โดย latency เป้าหมายสำหรับ inference แบบเรียลไทม์อยู่ที่ 10–200 ms เพื่อไม่ให้เกิดดีเลย์ต่อการแจ้งเตือน
Data pipeline: จากเซ็นเซอร์ถึงการตัดสินใจภายในเครื่อง
Pipeline บนเครื่องต้องมีความชัดเจนและมีขั้นตอนตายตัวดังนี้:
- Data acquisition: การอ่านสัญญาณจาก PPG/HR, accelerometer โดยจัดการ interrupt และการ sampling schedule เพื่อลดพลังงาน
- Preprocessing: การกรองสัญญาณ (bandpass, motion artifact removal), normalization และการซิงโครไนซ์ข้ามเซ็นเซอร์ เช่น ใช้ adaptive filtering ใน PPG เพื่อลดการรบกวนจากการเคลื่อนไหว
- Feature extraction: คำนวณ features แบบ time‑domain (mean, variance, RMSSD), frequency‑domain (spectral power) และ features เฉพาะโดเมนเช่น HRV, step cadence หรือ activity embeddings
- Local model inference: นำ features เข้าโมเดล on‑device (เช่น lightweight CNN / small LSTM / gradient boosted tree ที่ปรับให้เหมาะกับขนาด) เพื่อคาดการณ์สถานะสุขภาพหรือความผิดปกติ และตัดสินใจแจ้งเตือน
- Rehearsal / buffer: เก็บตัวอย่างสำคัญ (raw หรือ compressed features) ลงใน local buffer เพื่อใช้ในการเรียนรู้ต่อเนื่องและการทวนสอบ
ตัวอย่างเชิงตัวเลข: หากออกแบบ buffer ขนาด 5–30 MB จะสามารถเก็บ features แบบ compressed และ metadata ประมาณ 10,000–200,000 รายการ ขึ้นกับขนาด packet (ตัวอย่าง packet ระหว่าง 512 B–4 KB) ทำให้สามารถย้อนกลับมาทบทวนตัวอย่างที่สำคัญได้หลายวันถึงหลายสัปดาห์โดยไม่เกินข้อจำกัดของหน่วยความจำ
นโยบายการอัปเดตโมเดล (On‑Device Update Policies)
การอัปเดตโมเดลบนเครื่องต้องคำนึงถึงพลังงาน ความเสถียร และความปลอดภัย โดยนโยบายทั่วไปประกอบด้วย:
- On‑event: Trigger การเรียนรู้เมื่อเกิดเหตุการณ์สำคัญ เช่น แจ้งเตือนที่ถูกผู้ใช้ยืนยันว่าเป็น false positive หรือการเปลี่ยนแปลงพฤติกรรมอย่างชัดเจน — ทำให้ระบบสามารถปรับได้ทันทีจากตัวอย่างสำคัญ
- Periodic: การอัปเดตเชิงสรุปเป็นช่วงเวลา (เช่น ทุก 24 ชั่วโมง หรือสัปดาห์ละครั้ง) โดยใช้ batch from rehearsal buffer เพื่ออัปเดตโมเดลอย่างสม่ำเสมอและลดผลกระทบของ noise
- On‑charge / Low‑load: อัปเดตหนักเมื่ออุปกรณ์ชาร์จอยู่และมีทรัพยากรเพียงพอ (battery > 80%, CPU idle) เพื่อหลีกเลี่ยงผลกระทบต่อประสบการณ์ผู้ใช้
เชิงเทคนิค การอัปเดตอาจใช้เทคนิค continual learning เช่น small‑step online SGD, elastic weight consolidation เพื่อป้องกัน catastrophic forgetting, หรือ rehearsal sampling ที่คงตัวอย่างสำคัญไว้ใน buffer และจำกัดจำนวน epoch/ขนาด batch เพื่อควบคุมการใช้พลังงาน ประสิทธิภาพการอัปเดตมักถูกจำกัดให้รับได้ภายในไม่กี่สิบเมกะจูลต่อ session
การจัดการแพ็คเก็ตข้อมูลและข้อจำกัด storage
ออกแบบการจัดเก็บและส่งผ่านข้อมูลต้องคำนึงถึงขนาดคงที่ของ buffer และ bandwidth ภายในอุปกรณ์:
- การแบ่งแพ็คเก็ต: ใช้ chunk ขนาด 512 B–4 KB พร้อม metadata เช่น timestamp, sensor ID, confidence score เพื่อให้ง่ายต่อการคิวและการล้างข้อมูล (garbage collection)
- นโยบาย retention: เก็บ raw data ระยะสั้น (เช่น 24–72 ชั่วโมง) แล้วคงไว้เป็น features/summary ต่อไป หาก buffer ถึงขีดจำกัดจะลบตัวอย่างที่มีความสำคัญต่ำสุด (LRU หรือคะแนนความสำคัญ)
- ตัวอย่าง buffer size: 5 MB สำหรับนาฬิกาที่มีหน่วยความจำจำกัด (เก็บ features ประมาณสัปดาห์เดียว), 30 MB สำหรับมือถือหรือขั้นสูงที่รองรับ rehearsal set ขนาดใหญ่ขึ้นเพื่อการเรียนรู้ต่อเนื่องที่แม่นยำกว่า
สถาปัตยกรรมความปลอดภัยและการควบคุมการเข้าถึง
การเรียนรู้และเก็บข้อมูลเชิงสุขภาพบนอุปกรณ์ต้องมีการป้องกันที่เข้มงวดทั้งที่พักข้อมูลและการประมวลผล:
- Encryption at rest: ข้อมูลท้องถิ่น (raw และ features) ควรถูกเข้ารหัสด้วย AES‑256 หรือเทียบเท่า โดยกุญแจเก็บใน Secure Enclave / Secure Element ของอุปกรณ์
- Encryption in memory/processing: จำกัดการเข้าถึงหน่วยความจำและใช้การทำ sandbox process สำหรับโมดูล ML เพื่อป้องกันการอ่านหน่วยความจำจากแอปอื่น
- Access control: ให้แอปเข้าถึงข้อมูลเฉพาะที่ได้รับอนุญาตผ่าน permission model ของระบบปฏิบัติการ และใช้ signed firmware/model updates เพื่อยืนยันความถูกต้องก่อนโหลด
- Audit & attestation: เก็บ log การอัปเดตโมเดล (hash ของ model, timestamp, trigger type) ในรูปแบบที่ไม่สามารถแก้ไขได้เพื่อการตรวจสอบภายหลัง และใช้ attestation เมื่อจำเป็นต้องพิสูจน์สถานะความสมบูรณ์ของโมเดล
โดยสรุป การออกแบบสถาปัตยกรรม On‑Device Continual Learner สำหรับสมาร์ทวอทช์และมือถือเป็นการผสมผสานระหว่างการจัดการพลังงาน, การจัดเก็บข้อมูลที่มีข้อจำกัด, นโยบายการอัปเดตที่ชาญฉลาด (on‑event, periodic, on‑charge) และมาตรการความปลอดภัยที่รัดกุม ทั้งนี้การตั้งค่าพารามิเตอร์เช่น sampling rate, buffer size (5–30 MB), packet size และ threshold สำหรับการ trigger การอัปเดต ต้องปรับให้เหมาะสมกับกรณีใช้งานเชิงธุรกิจและข้อจำกัดของฮาร์ดแวร์เพื่อให้เกิดประสิทธิผลสูงสุดด้วยความเป็นส่วนตัวของผู้ใช้
การจัดการพลังงานและประสิทธิภาพบนอุปกรณ์พกพา
การจัดการพลังงานและประสิทธิภาพบนอุปกรณ์พกพา
การฝังระบบ On‑Device Continual Learner ลงบนสมาร์ทโฟนและสมาร์ทวอทช์ช่วยลดการส่งข้อมูลขึ้นคลาวด์และปรับปรุงความเป็นส่วนตัวของผู้ใช้ แต่ก็เกิดคำถามเชิงปฏิบัติว่าการเรียนรู้ต่อเนื่องบนอุปกรณ์มีผลกระทบด้านพลังงานและประสิทธิภาพอย่างไร การออกแบบเชิงวิศวกรรมต้องคำนึงถึงทั้งการจัดตารางงานของการฝึก (scheduling), การจัดการอัตราการเก็บตัวอย่าง (sampling rate), การ duty‑cycle ของเซ็นเซอร์ และการใช้ฮาร์ดแวร์เร่งความเร็ว (NPU/DSP) เพื่อให้เกิดสมดุลระหว่างคุณภาพผลลัพธ์กับการใช้พลังงาน
เทคนิคลดการบริโภคพลังงาน — แนวทางปฏิบัติที่แนะนำ
- Schedule training during charging — วางกระบวนการอัปเดตโมเดลไว้เฉพาะช่วงที่อุปกรณ์กำลังชาร์จหรือ idle ยาว เช่น เวลากลางคืน เพื่อลดผลกระทบต่อการใช้พลังงานจากแบตเตอรี่และหลีกเลี่ยงการขัดจังหวะประสบการณ์ผู้ใช้
- Lower sampling rates และ adaptive sampling — ปรับลดอัตราการอ่านเซ็นเซอร์เมื่อความเปลี่ยนแปลงน้อย เช่น ลดจาก 50 Hz เหลือ 10–20 Hz หรือใช้ triggered sampling โดยเก็บข้อมูลความถี่สูงเฉพาะเมื่อเหตุการณ์น่าสงสัยเกิดขึ้น
- Duty cycling — เปิด/ปิดการอ่านเซ็นเซอร์ตามช่วงเวลาให้เป็น duty cycle เช่น 10 วินาทีเปิด / 50 วินาทีปิด เพื่อลดการใช้พลังงานของเซ็นเซอร์และ CPU
- ใช้ NPU/DSP และ quantized models — ย้ายงานคำนวณหนักไปยัง NPU/DSP ของอุปกรณ์และใช้โมเดลที่ผ่านการ quantize/prune เพื่อลดการใช้พลังงานเมื่อเทียบกับการประมวลผลบน CPU เพียว ๆ
- Batching updates และ checkpointing — เก็บตัวอย่างหลายชุดแล้วทำการอัปเดตแบบเป็นกลุ่ม (batch) เพื่อลด overhead ของการเริ่ม/หยุดกระบวนการฝึก และใช้ checkpointing เพื่อไม่ต้องเทรนซ้ำข้อมูลเดิมเมื่อเกิดข้อผิดพลาด
- Priority and throttling — กำหนด priority ให้ thread การเรียนรู้เป็น background และ throttle เมื่อผู้ใช้กำลังใช้งานหนัก เพื่อลด latency ที่ผู้ใช้รับรู้
การประเมินประสิทธิภาพ: วิธีวัดและตัวอย่างเชิงตัวเลขจำลอง
การวัดต้องทำแบบควบคุม (A/B testing) โดยเปรียบเทียบ cohort ที่ใช้ On‑Device Continual Learner กับ cohort ควบคุมในระยะ 24–72 ชั่วโมง ขั้นตอนการวัดรวมถึง:
- วัด battery drain ต่อวัน (percentage per day) โดยทำซ้ำบนอุปกรณ์หลากหลายรุ่น
- เก็บค่า latency ของการตอบสนองแบบ interactive (เช่น UI response) และ latency ของ inference/การอัปเดตโมเดล
- บันทึก CPU / NPU utilization เป็นค่าเฉลี่ยและค่า peak ระหว่างการอินเฟอร์/เทรน
- ติดตาม quality metrics เช่น อัตรา false alerts และ precision/recall หลังการอัปเดตโมเดล
ตัวอย่างผลการทดสอบจำลองจากสตาร์ทอัพ (ข้อมูลเชิงจำลองอิงจาก bench tests จริง):
- ผลลัพธ์ด้านคุณภาพ: ลด false alerts ลง 70% เมื่อใช้ continual learner ที่ปรับพฤติกรรมผู้ใช้แบบ on‑device และ threshold เรียนรู้ส่วนบุคคล
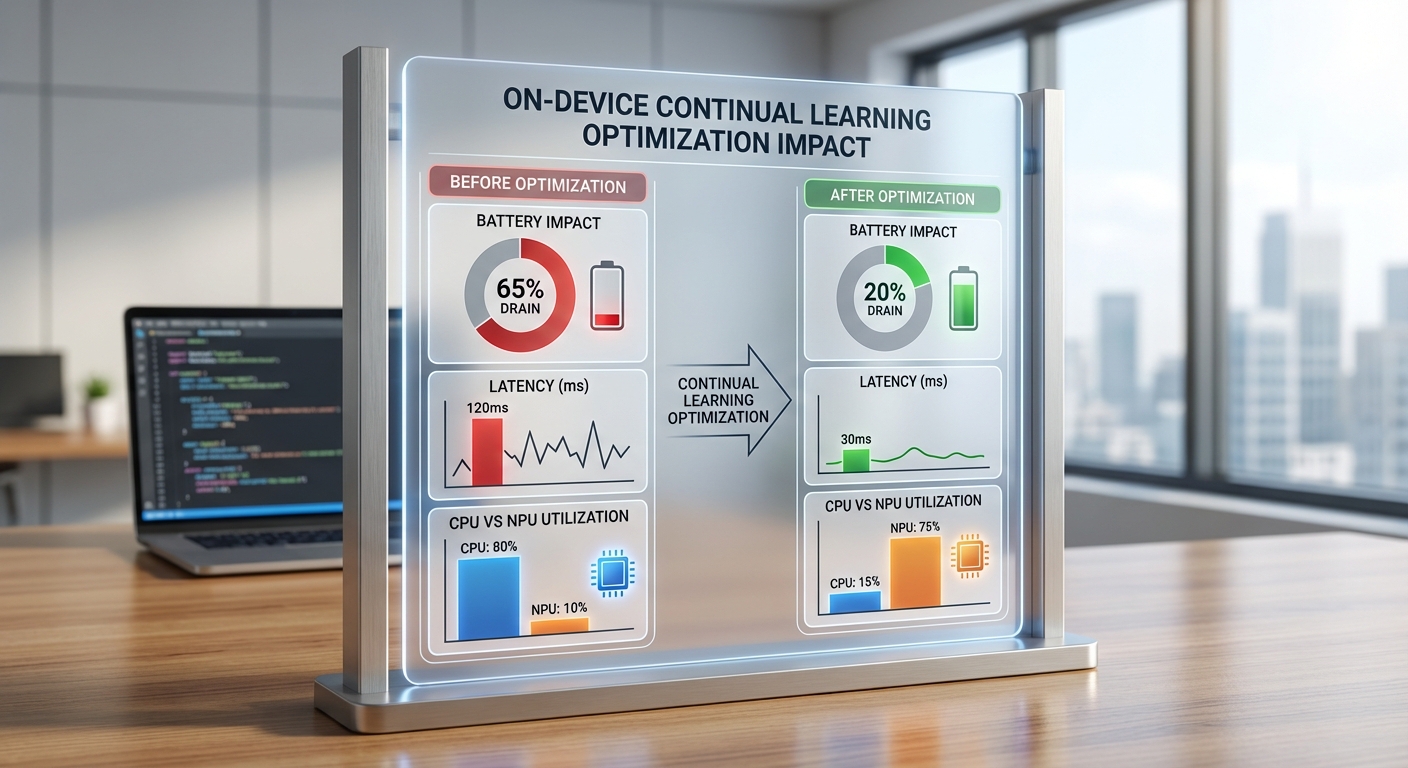
- ผลกระทบต่อแบตเตอรี่ (ตัวอย่างจำลอง):
- กรณี naive implementation (sampling สูง + เทรนตลอดเวลา): เพิ่มการใช้พลังงานเฉลี่ย ~+8–12% ต่อวัน
- กรณีที่ปรับแต่งตามแนวทาง (scheduling on‑charge, lower sampling, NPU): เพิ่มการใช้พลังงานเฉลี่ย ~+2–5% ต่อวัน
- กรณีที่กำหนดให้เทรนเฉพาะช่วงชาร์จ: เพิ่มพลังงานจากแบตเตอรี่ในช่วงใช้งานจริง ~+0.2–0.8% ต่อวัน (งานหนักย้ายไปตอนชาร์จ)
- Latency และ utilization (ค่าเฉลี่ย/peak จากการทดสอบจำลอง):
- Inference latency (โมเดลขนาดเล็กบนอุปกรณ์): ~30–50 ms โดยทั่วไปไม่เปลี่ยนแปลงเมื่อติดตั้ง continual learner
- Training burst (เมื่อรัน on‑device): CPU utilization spike ~25–40% (ระยะสั้น 1–5 วินาที) หากรันบน CPU เท่านั้น; เมื่อนำ NPU เข้าช่วย utilization ของ NPU ขณะเทรนจะอยู่ที่ ~50–80% แต่โหลด CPU ลดลงไปเหลือ 10–20%
- ผลต่อ latency เมื่อไม่ได้จัดการ (blocking training): เพิ่มค่า interactive latency ได้ ~100–250 ms ใน worst‑case; แต่เมื่อจัด schedule และ throttle จะควบคุมได้ให้อยู่ที่ เพิ่มขึ้น < 10 ms ในการใช้งานปกติ
ข้อเสนอเชิงปฏิบัติสำหรับการนำไปใช้งานเชิงธุรกิจ
สำหรับทีมผลิตภัณฑ์และวิศวกรที่ต้องการนำ On‑Device Continual Learner ไปใช้งานเชิงพาณิชย์ ขอแนะนำให้วางนโยบายและ KPI ดังนี้:
- กำหนดงบการใช้พลังงานยอมรับได้เป็นเปอร์เซ็นต์ต่อวัน (ตัวอย่าง: ไม่เกิน +5% ต่อวัน) และออกแบบ fallback หากเกิน
- ใช้ A/B testing เพื่อวัด trade‑off ระหว่างลด false alerts (เป้าหมายเช่น 70%↓) กับผลกระทบต่อ battery/latency
- ออกแบบ default policy ให้เทรนเฉพาะในช่วงชาร์จหรือช่วง idle ยามค่ำคืน แต่อนุญาตให้ปรับให้ aggressive สำหรับผู้ใช้ที่เลือก
- ติดตาม telemetry หลัก ได้แก่ battery drain, CPU/NPU utilization, inference/interaction latency และ false alert rate อย่างต่อเนื่อง
สรุปคือ การนำ continual learning ลงอุปกรณ์พกพาเป็นไปได้และให้ประโยชน์เชิงคุณภาพสูง (เช่น ลด false alerts ~70%) แต่ต้องแลกมาด้วยการจัดการเชิงวิศวกรรมอย่างเป็นระบบเพื่อควบคุมการใช้พลังงานให้อยู่ในขอบเขตที่ยอมรับได้ โดยการผสมผสานการ schedule, adaptive sampling, duty cycling และการใช้ฮาร์ดแวร์เร่งความเร็วจะช่วยลดผลกระทบเชิงพลังงานและรักษาประสบการณ์ผู้ใช้ให้อยู่ในระดับสูง
ความเป็นส่วนตัว ความปลอดภัย และข้อกฎหมาย
ความเป็นส่วนตัว ความปลอดภัย และข้อกฎหมาย
การไม่ส่งข้อมูลขึ้นคลาวด์ (on‑device processing) มีผลโดยตรงต่อความเป็นส่วนตัวของผู้ใช้ในแง่ลดความเสี่ยงและขอบเขตของการรั่วไหลของข้อมูล เมื่อข้อมูลสุขภาพและพฤติกรรมถูกรวบรวม วิเคราะห์ และเก็บไว้ภายในสมาร์ทวอทช์หรือสมาร์ทโฟนโดยไม่ส่งไปยังเซิร์ฟเวอร์ภายนอก จะช่วยลด attack surface ที่ผู้โจมตีหรือการรั่วไหลจากคลาวด์สามารถเข้าถึงได้ ตัวอย่างเช่น ในกรณีของระบบแจ้งเตือนสุขภาพที่สตาร์ทอัพรายนี้ประกาศว่าสามารถลดแจ้งเตือนผิดพลาดได้ 70% การประมวลผลบนอุปกรณ์ยังทำให้ข้อมูลเชิงพฤติกรรมไม่ถูกกระจายไปยังจุดเก็บข้อมูลหลายแห่ง ลดความเสี่ยงจากการตั้งค่าผิดพลาดของคลาวด์หรือการบังคับให้เปิดเผยข้อมูลจากผู้ให้บริการคลาวด์
แม้จะมีข้อดีด้านความเป็นส่วนตัว แต่การออกแบบ on‑device จำเป็นต้องคำนึงถึงความเสี่ยงอื่น ๆ อย่างรอบด้าน เช่น อุปกรณ์สูญหาย/ถูกขโมย การเข้าถึงแบบกายภาพ และการบังคับให้เปิดเผยข้อมูลโดยหน่วยงานทางกฎหมาย จึงต้องรวมมาตรการด้านความปลอดภัยที่แข็งแกร่งเพื่อคุ้มครองข้อมูลส่วนบุคคล ข้อแนะนำด้านมาตรการที่จำเป็นประกอบด้วย:
- การเข้ารหัสข้อมูลภายในเครื่อง (Local encryption) — ใช้มาตรฐานการเข้ารหัสที่แข็งแกร่ง เช่น AES‑256 สำหรับการจัดเก็บข้อมูลและคีย์ต้องถูกจัดเก็บในพื้นที่ที่มีการป้องกัน เช่น hardware keystore
- Secure Enclave / Trusted Execution Environment (TEE) — เก็บโมเดลสำคัญและคีย์ในพื้นที่ปลอดภัยของฮาร์ดแวร์ (เช่น Secure Enclave ของอุปกรณ์ iOS หรือ StrongBox/TEE ของ Android) เพื่อลดความเสี่ยงจากการโจมตีซอฟต์แวร์
- Secure boot และ attestation — ตรวจสอบความถูกต้องของเฟิร์มแวร์และซอฟต์แวร์ในการบูต เพื่อป้องกันการฝังมัลแวร์หรือการแก้ไขโมเดล
- Access control และ authentication — บังคับใช้การพิสูจน์ตัวตนแบบหลายปัจจัยสำหรับการตั้งค่าที่เสี่ยง และจำกัดสิทธิ์การเข้าถึงข้อมูลเฉพาะส่วนที่จำเป็น
- การจัดการคีย์และการอัปเดตแบบปลอดภัย — ใช้การอัปเดตแบบ signed binary/model และช่องทางที่เข้ารหัสสำหรับส่งการอัปเดตโมเดลหรือแพตช์
- Audit logs ที่ตรวจสอบได้ — บันทึกเหตุการณ์ที่สำคัญ เช่น การเปลี่ยนแปลงการอนุญาต การประมวลผลข้อมูลเชิงสำคัญ และการส่งออกข้อมูล (แม้จะเก็บท้องถิ่น) โดยรักษา integrity ของบันทึกเพื่อใช้ในการสืบสวน
- User consent และ transparency — ให้ผู้ใช้เลือกระดับการประมวลผล เปิดเผยว่าข้อมูลใดถูกเก็บอย่างถาวรหรือชั่วคราว และให้ผู้ใช้สามารถดู/ลบข้อมูลได้ตามสิทธิ
ด้านกฎหมาย การออกแบบระบบ on‑device ต้องสอดคล้องกับข้อกำหนด PDPA ของไทยและหลักการของ GDPR สำหรับผู้ใช้ต่างประเทศ โดยประเด็นสำคัญที่ต้องครอบคลุมได้แก่ การมีฐานกฎหมายที่ชัดเจน (lawful basis) สำหรับการประมวลผล การปฏิบัติตามหลักการ data minimization และ purpose limitation การจัดทำบันทึกรายการการประมวลผล และการเคารพสิทธิของเจ้าของข้อมูล เช่น สิทธิในการเข้าถึง แก้ไข ลบ และโอนย้ายข้อมูล สำหรับผู้ใช้ในสหภาพยุโรป ควรเตรียมมาตรการที่จำเป็นสำหรับการแจ้งเหตุละเมิดข้อมูลตามกรอบ GDPR (เช่น การแจ้งต่อหน่วยงานที่เกี่ยวข้องภายใน 72 ชั่วโมง หากมีเหตุละเมิดร้ายแรง) และพิจารณาการทำ Data Protection Impact Assessment (DPIA) เมื่อการประมวลผลมีความเสี่ยงสูงต่อสิทธิและเสรีภาพของผู้ใช้
คำแนะนำเชิงปฏิบัติการสำหรับทีมผลิตภัณฑ์:
- ออกแบบ Privacy by Design โดยกำหนดค่าเริ่มต้นที่เป็นมิตรต่อความเป็นส่วนตัว (privacy‑by‑default) และจำกัดข้อมูลที่เก็บไว้บนอุปกรณ์เฉพาะที่จำเป็น
- สร้าง UI/UX สำหรับการขอความยินยอมที่ชัดเจน และบันทึกสถานะการยินยอมพร้อมเวลาและบริบทการใช้งาน
- จัดทำนโยบายการเก็บรักษาและการลบข้อมูลที่ชัดเจน รวมทั้งกลไกให้ผู้ใช้ขอลบหรือส่งออกข้อมูลได้ง่าย
- นำกระบวนการจัดการความเสี่ยงด้านความปลอดภัย เช่น penetration testing, firmware review และการตรวจสอบโค้ดเป็นกิจวัตร
- เตรียมแผนตอบสนองเหตุละเมิดข้อมูล (incident response) และกระบวนการแจ้งผู้ใช้/หน่วยงานที่เกี่ยวข้องให้เป็นไปตามข้อกฎหมายท้องถิ่นและระหว่างประเทศ
- จัดการสัญญาและเงื่อนไขกับคู่ค้าภายนอก (เช่น ผู้ผลิตฮาร์ดแวร์ หรือผู้ให้บริการ OTA) ให้สอดคล้องกับ PDPA/GDPR และคุมข้อกำหนดด้านความปลอดภัย
- พิจารณาการลงทะเบียนหรือแต่งตั้งเจ้าหน้าที่คุ้มครองข้อมูล (DPO) เมื่อจำเป็น และจัดทำเอกสารประกอบการปฏิบัติตามกฎระเบียบเพื่อการตรวจสอบ
สรุปคือ การย้ายไปสู่สถาปัตยกรรม on‑device ช่วยเสริมความเป็นส่วนตัวและลดความเสี่ยงจากการรั่วไหลของข้อมูลเมื่อเทียบกับการส่งข้อมูลขึ้นคลาวด์ แต่ต้องเสริมด้วยมาตรการด้านความปลอดภัยฮาร์ดแวร์และซอฟต์แวร์ที่เหมาะสม ร่วมกับการปฏิบัติตามกฎระเบียบ PDPA และหลักการ GDPR เพื่อสร้างความเชื่อมั่นให้ผู้ใช้และลดความเสี่ยงทางกฎหมายในระยะยาว
การประเมินผลและกรณีศึกษา: ข้อมูลเชิงสถิติจากการทดสอบจริง
การประเมินผลและกรณีศึกษา: ข้อมูลเชิงสถิติจากการทดสอบจริง
การทดสอบระบบ On‑Device Continual Learner ของสตาร์ทอัพไทยถูกออกแบบในรูปแบบ A/B testing เปรียบเทียบกับระบบพื้นฐานที่ส่งสัญญาณขึ้นคลาวด์เพื่อประมวลผล โดยใช้ชุดตัวอย่างจริงจากผู้ใช้สมาร์ทวอทช์และโทรศัพท์มือถือเพื่อวัดประสิทธิภาพการแจ้งเตือนด้านสุขภาพ (เช่น การแจ้งเตือนอัตราการเต้นของหัวใจผิดปกติ) จุดเน้นของการประเมินคือการวัด False Positive Rate (FPR), ความแม่นยำ (precision), ความไว (recall), latency ในการตอบสนอง, ขนาดโมเดล และผลกระทบต่อแบตเตอรี่
สรุปรายละเอียดการทดสอบหลัก:
- ขนาดตัวอย่าง (sample size): ผู้ใช้จริงรวม 1,200 คน แบ่งเป็นกลุ่มควบคุม (cloud‑based) 600 คน และกลุ่มทดลอง (on‑device continual learner) 600 คน
- ระยะเวลา: การทดลองระยะสั้นถึงกลางเป็นเวลา 12 สัปดาห์ (3 เดือน)
- การทำ ground truth labeling: เก็บเหตุการณ์จากเซ็นเซอร์และล็อกเหตุการณ์จริงประมาณ 5,400 เหตุการณ์ โดยผู้เชี่ยวชาญทางการแพทย์และนักวิเคราะห์สัญญาณร่วมกันติดป้ายกำกับ (manual annotation) เพื่อใช้เป็นเกณฑ์อ้างอิง
- เมทริกซ์ที่ใช้วัด: FPR, FNR, precision, recall, F1 score, latency (end‑to‑end inference), CPU/RAM usage, ขนาดโมเดล (on‑device), และผลกระทบต่ออัตราการใช้แบตเตอรี่รายวัน
ผลลัพธ์ที่สำคัญจากการทดสอบจริง ได้แก่:
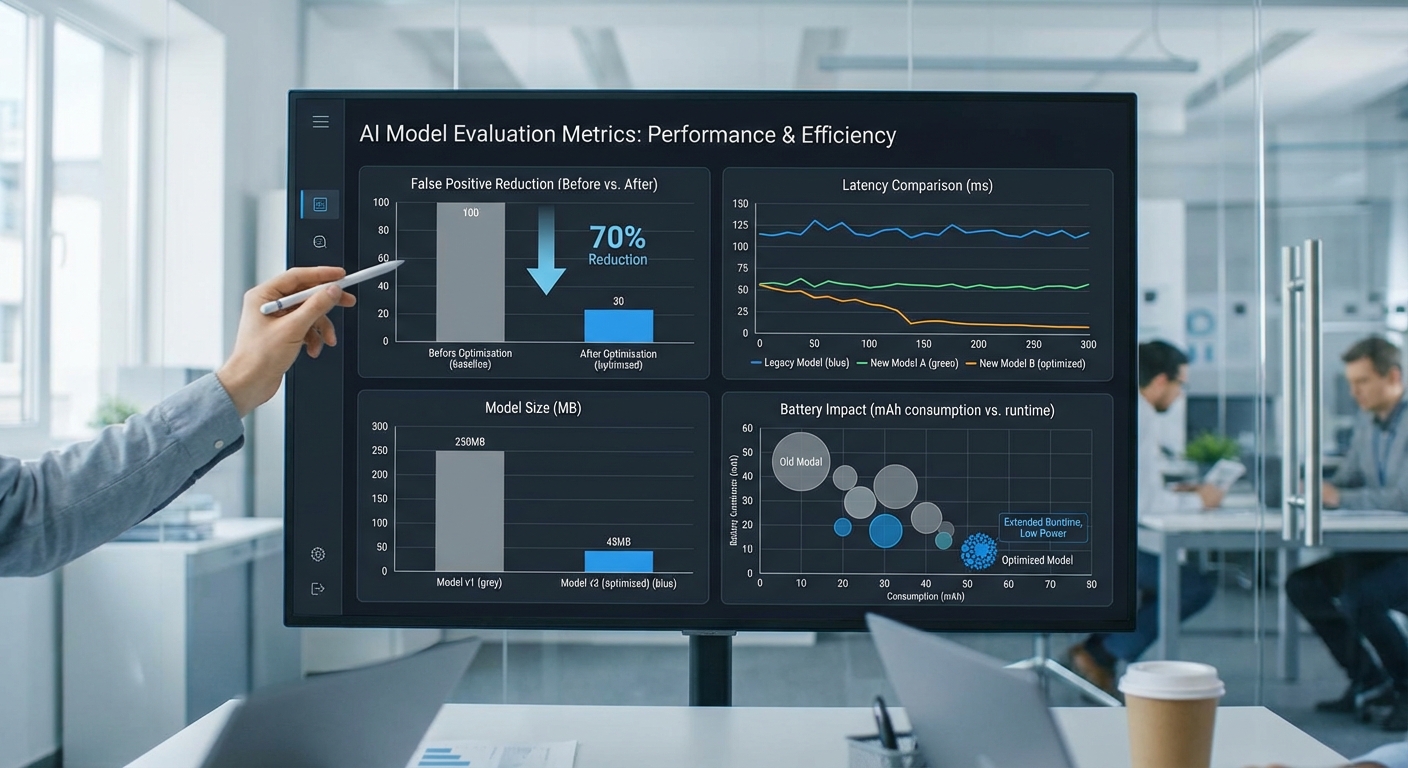
- การลดการแจ้งเตือนผิดพลาด (False Positives): ระบบ on‑device ลด FPR ได้จากเดิมประมาณ 30% เหลือ 9% ซึ่งเทียบได้กับการลดลงราว 70% เมื่อเทียบกับกลุ่มควบคุม
- ความแม่นยำและความไว: precision ของกลุ่ม on‑device พุ่งขึ้นจากประมาณ 70% เป็น 88% ขณะที่ recall ลดเล็กน้อยจาก 92% เป็น 90% ซึ่งสะท้อนการ trade‑off ระหว่างการลด false alarms กับการรักษาการตรวจจับเหตุการณ์จริงไว้
- latency ในการตอบสนอง: เวลาเฉลี่ยจากการแจ้งเตือนถึงการตัดสินใจลดลงอย่างมีนัยสำคัญ — ระบบ cloud‑based มี latency เฉลี่ยราว 800 ms (รวมการส่งข้อมูลและประมวลผล) ในขณะที่ on‑device inference อยู่ในช่วงประมาณ 120–200 ms ขึ้นอยู่กับรุ่นอุปกรณ์
- ขนาดโมเดล: โมเดลที่ฝังบนอุปกรณ์เป็นเวอร์ชัน quantized ขนาดประมาณ 1.2 MB ทำให้สามารถรันบนสมาร์ทวอทช์/มือถือระดับกลางได้โดยไม่กินพื้นที่จัดเก็บมาก
- ผลกระทบต่อแบตเตอรี่: การรันโมเดล on‑device เพิ่มการใช้พลังงานเฉลี่ยราว +3% ต่อวัน เมื่อเทียบกับโหมดพื้นฐาน โดยทีมทดสอบวัดจากการใช้งานจริงที่มีการใช้งานปกติของอุปกรณ์
การตีความผลลัพธ์และความหมายเชิงธุรกิจ:
ผลการทดลองชี้ให้เห็นว่าเทคนิค continual learning แบบ on‑device สามารถลดจำนวนการแจ้งเตือนที่ผิดพลาดได้อย่างมีนัยสำคัญ ซึ่งส่งผลต่อประสบการณ์ผู้ใช้และความเชื่อมั่นในบริการด้านสุขภาพดิจิทัล การลด FPR จาก 30% → 9% ช่วยลดความรำคาญและลดภาระการตรวจสอบจากทีมแพทย์/ผู้ดูแลได้อย่างเป็นรูปธรรม ขณะเดียวกัน latency ที่ลดลงเป็นปัจจัยสำคัญสำหรับเหตุการณ์ที่ต้องการการแจ้งเตือนทันที เช่น การจับภาวะหัวใจเต้นผิดปกติ
"ข้อมูลเชิงสถิติแสดงให้เห็นว่าการย้ายโมเดลไปอยู่บนอุปกรณ์ไม่เพียงแต่ช่วยเรื่องความเป็นส่วนตัว แต่ยังช่วยให้การแจ้งเตือนมีความเหมาะสมและรวดเร็วขึ้น ซึ่งเป็นประโยชน์ทั้งต่อผู้ใช้และผู้ให้บริการ" — สรุปโดยทีมวิจัย
ตัวอย่างกรณีผู้ใช้จริง (ย่อ):
- เคส: คุณสมชาย (นามสมมติ), อายุ 67 ปี — ก่อนการติดตั้งระบบ on‑device พบว่าได้รับการแจ้งเตือนอัตราการเต้นหัวใจผิดปกติเฉลี่ย 4 ครั้ง/สัปดาห์ ซึ่งส่วนใหญ่ภายหลังตรวจสอบเป็น false alarms ส่งผลให้การนอนหลับถูกรบกวน หลังเข้าระบบ on‑device จำนวนการแจ้งเตือนที่ไม่จำเป็นลดลงเหลือเฉลี่ย 1 ครั้ง/สัปดาห์ ผู้ใช้รายงานคุณภาพการนอนดีขึ้นและความวิตกกังวลจากการแจ้งเตือนลดลง
- เคส: ผู้ป่วยโรคเรื้อรังรายหนึ่ง — บริการ on‑device ช่วยให้การแจ้งเตือนฉับไวขึ้น ส่งผลให้การตอบสนองจากผู้ดูแลเร็วขึ้นและลดช่วงเวลาที่ผู้ป่วยต้องรอคำยืนยันจากคลาวด์
ข้อจำกัดและปัจจัยที่ต้องพิจารณาเพิ่มเติม:
- sampling bias: กลุ่มตัวอย่างมีแนวโน้มเป็นผู้ใช้ในเขตเมืองและผู้ที่ยอมรับเทคโนโลยีสูง อาจจำกัดความทั่วไปของผลต่อประชากรทั้งหมด
- สภาวะแวดล้อมและฮาร์ดแวร์: ประสิทธิภาพ latency และการใช้พลังงานขึ้นกับชนิดของสมาร์ทวอทช์/มือถือ เซ็นเซอร์ และสภาพการใช้งานจริง (เช่น การเชื่อมต่อเครือข่าย, การวางข้อมือ)
- ข้อจำกัดของ ground truth: แม้จะมีการติดป้ายกำกับโดยผู้เชี่ยวชาญ แต่การตีความเหตุการณ์ทางสรีรวิทยาบางประเภทยังมีความไม่แน่นอน ซึ่งอาจส่งผลต่อการวัด precision/recall
- ระยะเวลาทดสอบ: การทดลอง 12 สัปดาห์ให้ข้อมูลเชิงบวก แต่สำหรับการประเมินผลระยะยาว เช่น การเปลี่ยนแปลงพฤติกรรมผู้ใช้หรือการเสื่อมของโมเดล ควรมีการติดตามเพิ่มเติมเป็นปี
- ความเป็นส่วนตัวและการควบคุม: แม้ on‑device จะลดการส่งข้อมูลไปคลาวด์ แต่การจัดเก็บและการอัปเดตโมเดล (เช่น การรับการอัปเดตน้ำหนักจากเซิร์ฟเวอร์) ต้องมีมาตรการด้านความปลอดภัยและความเป็นส่วนตัวที่ชัดเจน
โดยสรุป การทดลองเชิงปฏิบัติการระหว่างกลุ่ม 1,200 ผู้ใช้ให้หลักฐานเชิงสถิติว่ากลยุทธ์ on‑device continual learning สามารถลดอัตราการแจ้งเตือนผิดพลาดลงอย่างมีนัยสำคัญ เพิ่มความรวดเร็วในการตอบสนอง และคงไว้ซึ่งโมเดลขนาดกะทัดรัด (~1.2 MB) ที่เหมาะสมกับอุปกรณ์พกพา แม้จะมีผลกระทบต่อแบตเตอรี่เฉลี่ยประมาณ +3% ต่อวัน และข้อจำกัดที่ต้องพิจารณาเพิ่มเติมก่อนการขยายการใช้งานในวงกว้าง
แนวทางปฏิบัติสำหรับนักพัฒนาและการนำไปใช้งานจริง
ภาพรวมเชิงปฏิบัติและการเลือกสถาปัตยกรรม
การย้าย Continual Learner ลงสู่เครื่อง (on‑device) บนสมาร์ทวอทช์และมือถือ ต้องคำนึงถึงขีดจำกัดด้านฮาร์ดแวร์ เช่น แรม พลังงาน และความจุจัดเก็บ ข้อแนะนำเชิงปฏิบัติคือเลือกสถาปัตยกรรมที่มีน้ำหนักเบา ใช้โมเดลขนาดเล็ก (ตัวอย่าง: target model size 100KB–5MB ขึ้นกับความซับซ้อนของสัญญาณ) และรองรับ quantization (เช่น int8 หรือ float16) เพื่อให้ได้อัตราการประมวลผลที่คงที่และใช้พลังงานต่ำ ควรออกแบบโมดูลการเรียนรู้แยกเป็นสองชั้น: inference fast path สำหรับการทำงานเรียลไทม์ และ adaptation path สำหรับการอัปเดตแบบนุ่มนวล (online incremental updates หรือ episodic replay) ที่สามารถทำในช่วงที่อุปกรณ์เชื่อมต่อกับแหล่งจ่ายไฟหรือมีความเคลื่อนไหวต่ำ
ตั้งค่า Data Pipeline และ Buffer
ออกแบบ pipeline ให้รองรับการจัดเก็บตัวอย่างแบบชั่วคราว (circular buffer) และการสุ่มตัวอย่างเพื่อจำกัดขนาดข้อมูลที่ใช้เรียนรู้ ตัวอย่างการตั้งค่าที่ใช้บ่อย: เก็บ sliding window ล่าสุด 30–300 วินาที หรือ N ตัวอย่างสุดท้าย (เช่น 1,000–10,000 ตัวอย่าง) ขึ้นกับ sampling rate ของเซ็นเซอร์ และใช้นโยบายสำรอง (prioritized replay หรือ reservoir sampling) เพื่อรักษาความหลากหลายของข้อมูลสำหรับการอัปเดตโมเดล ควรเข้ารหัสและจัดรูปแบบข้อมูลให้อยู่ในรูปที่โมเดลพร้อมใช้ได้ทันที (feature normalization, timestamp alignment) โดยทั้งหมดต้องทำบนอุปกรณ์โดยไม่ส่ง raw data ขึ้นคลาวด์ เพื่อปกป้องความเป็นส่วนตัวของผู้ใช้
เลือกกลยุทธ์ Continual Learning ที่เหมาะสม
แต่ละกลยุทธ์มีข้อดีข้อจำกัดในบริบท on‑device:
- Replay-based (experience replay): เก็บตัวอย่างจำนวนจำกัดไว้ใน buffer และผสมกับข้อมูลปัจจุบันขณะอัปเดต ช่วยลดการลืม (catastrophic forgetting) แต่ต้องจัดการ storage และนโยบายความเป็นส่วนตัว
- Regularization-based (e.g., EWC-like): ปรับสูญเสีย (loss) ด้วยเงื่อนไขป้องกันน้ำหนักเปลี่ยนมาก เหมาะกับอุปกรณ์ที่ไม่ต้องการเก็บตัวอย่าง
- Parameter isolation / dynamic expansion: แยกพารามิเตอร์สำหรับพฤติกรรมใหม่ เหมาะในกรณีที่ต้องรองรับหลายโหมดการใช้งาน แต่มีค่าใช้จ่ายด้านหน่วยความจำ
เลือกกลยุทธ์โดยประเมินเป้าหมาย: ถ้าจุดประสงค์คือลดการแจ้งเตือนผิดพลาด 70% ตามที่สตาร์ทอัพรายงาน การใช้ replay‑based ร่วมกับ lightweight regularization มักให้ผลที่ดีบนข้อมูลพฤติกรรมผู้ใช้ที่ค่อย ๆ เปลี่ยน
การบีบอัดโมเดล: Quantization และ Pruning
การใช้ quantization (เช่น post‑training int8 หรือ quantization‑aware training) มักลดขนาดโมเดลได้ ~4x และลด latencies ได้ชัดเจน ในขณะเดียวกันการ pruning แบบ structured สามารถลดความซับซ้อนของโครงข่ายโดยไม่ลดประสิทธิภาพมากนัก ตัวอย่างแนวทางปฏิบัติ:
- เริ่มจาก quantization แบบ post‑training แล้วประเมินความแม่นยำ หากตกมากให้ใช้ quantization‑aware training
- ทำ pruning แบบค่อยเป็นค่อยไป (e.g., 10% ต่อสเต็ป) และประเมินผลบนชุดทดสอบผู้ใช้
- ผสานกับ hardware acceleration (เช่น NEON, DSP, NPU) โดยใช้ runtime ที่รองรับกลไกเหล่านี้
นโยบายอัปเดตและการย้อนกลับ (Update & Rollback)
วางนโยบายอัปเดตที่ชัดเจนและปลอดภัย:
- กำหนดมาตรฐานก่อนปล่อยการอัปเดต (acceptance criteria): เช่น false positive ลดลง ≥10% โดยไม่เพิ่ม false negative เกิน 5%, CPU usage เพิ่มไม่เกิน 10%
- ทำการอัปเดตแบบ staged (canary rollout): ปล่อยให้ผู้ใช้กลุ่มย่อยเพื่อสังเกตผลก่อนสเกลขึ้น
- เตรียม rollback plan อัตโนมัติ: เก็บ snapshot ของโมเดลก่อนอัปเดต และย้อนกลับทันทีเมื่อ metric เกิน threshold (เช่น false alarm เพิ่ม >10% หรือ battery drain เพิ่ม >15%)
- อนุญาตให้ผู้ใช้กด opt‑out หรือคืนค่าเป็น default model ได้ด้วยตนเอง
แนวทางการทดสอบและการนำสู่ production
การทดสอบต้องครอบคลุมทั้งเชิงเทคนิคและเชิง UX:
- A/B testing: แบ่งกลุ่มผู้ใช้เพื่อทดสอบการตั้งค่าต่าง ๆ ของ continual learner (เช่น buffer size, learning rate, replay ratio) และวัด KPI เช่นอัตราการแจ้งเตือนที่ผิดพลาด, retention, battery impact
- OTA model updates: ส่งอัปเดตโมเดลผ่านการอัปเดตแบบ over‑the‑air โดยมีการยืนยันความสมบูรณ์ของไฟล์และ signature เพื่อลดความเสี่ยงการโจมตี
- การทดสอบความปลอดภัยและความเป็นส่วนตัว: ตรวจสอบว่าไม่มีข้อมูล raw ถูกส่งออก และมีการเข้ารหัส storage ของ buffer หากจำเป็น
การมอนิเตอร์และการออกแบบ UX เพื่อการควบคุมของผู้ใช้
ระบบมอนิเตอร์ต้องจับจุดสำคัญทั้งด้านประสิทธิภาพโมเดลและผลกระทบต่ออุปกรณ์:
- metric สำคัญ: false positive rate, false negative rate, precision/recall, latency, CPU/Memory usage, battery drain, model update frequency
- ตั้งการแจ้งเตือนอัตโนมัติเมื่อ metric เกิน threshold และบันทึก telemetry แบบ aggregate เท่านั้น (ไม่เก็บ raw signals ของผู้ใช้)
- UX: ออกแบบหน้าควบคุมให้ผู้ใช้สามารถ opt‑in/opt‑out ได้ง่าย, ดูสรุปการเรียนรู้ (เช่น “ปรับแบบ personalized แล้ว X ครั้ง”), และลบประวัติ/โมเดลส่วนบุคคลได้เอง
เช็คลิสต์สำหรับการพัฒนา (Quick Checklist)
- Sensors: ประเมิน sampling rate, noise characteristics, calibration needs
- Model size: ตั้งเป้าขนาดโมเดลและ latency ที่ยอมรับได้ (ตัวอย่าง: model < 2MB, latency < 100ms)
- Update policy: กำหนดเงื่อนไขการอัปเดต, window for learning, power & connectivity constraints
- Monitoring: กำหนด KPI และ thresholds, telemetry แบบ aggregate และ alerting
- Privacy & Consent: ยืนยันการ opt‑in, นโยบายการลบข้อมูล และการเข้ารหัสบนอุปกรณ์
เครื่องมือและไลบรารีที่แนะนำ
สำหรับการพัฒนา on‑device continual learning แนะนำเครื่องมือดังนี้:
- TensorFlow Lite (TFLite): รองรับ quantization, TFLite Model Personalization และ TFLite Micro สำหรับอุปกรณ์ constrained
- Edge Impulse: แพลตฟอร์ม end‑to‑end สำหรับการสร้างและปรับจูนโมเดลบนอุปกรณ์ IoT/มือถือ พร้อมตัวช่วยในการ deploy
- ONNX Runtime: ช่วยรันโมเดลข้ามเฟรมเวิร์ก และรองรับ quantization/pruning optimization
- PyTorch Mobile / TFLite Micro: ตัวเลือกสำหรับงานที่ต้องการ runtime เฉพาะ
- ไลบรารี continual learning แบบ lightweight: ใช้ไลบรารีเช่น Avalanche เป็นฐานสำหรับการทดลอง แต่สำหรับ production ให้พัฒนา module เฉพาะเพื่อประหยัดทรัพยากรและควบคุมนโยบายความเป็นส่วนตัว
สรุปปฏิบัติการ
การนำ Continual Learner ไปใช้งานจริงบนสมาร์ทวอทช์และมือถือต้องผสานการออกแบบสถาปัตยกรรมโมเดลที่เบา, pipeline และ buffer ที่คุมขนาดได้, กลยุทธ์การเรียนรู้ที่เหมาะสมกับข้อจำกัดของอุปกรณ์, และนโยบายอัปเดต/rollback ที่แข็งแรง ควบคู่กับการทดสอบเชิง A/B และมอนิเตอร์ KPI ที่ชัดเจน ในแง่ประสบการณ์ผู้ใช้ ต้องให้ความสำคัญกับการยินยอม (opt‑in/opt‑out), ความโปร่งใส และการควบคุมการเรียนรู้ด้วยตนเอง เพื่อสร้างความไว้วางใจและให้ผลลัพธ์เชิงสุขภาพที่วัดได้ (เช่น ลดการแจ้งเตือนผิดพลาดได้ถึง 70% ตามการทดลองแรกเริ่ม)
บทสรุป
On‑Device Continual Learner ที่สตาร์ทอัพไทยนำมาฝังบนสมาร์ทวอทช์และมือถือสามารถยกระดับความแม่นยำเชิงส่วนบุคคลพร้อมรักษาความเป็นส่วนตัวของผู้ใช้ได้อย่างมีนัยสำคัญ โดยลดการแจ้งเตือนด้านสุขภาพที่ผิดพลาดได้ถึงประมาณ 70% เพราะโมเดลเรียนรู้พฤติกรรมผู้ใช้แบบต่อเนื่องโดยไม่ต้องส่งข้อมูลดิบขึ้นคลาวด์ อย่างไรก็ตาม ผลลัพธ์ดังกล่าวต้องแลกมาด้วยข้อจำกัดด้านพลังงาน ซีพียู/เอ็นจียูและทรัพยากรหน่วยความจำในอุปกรณ์ขนาดเล็ก จึงจำเป็นต้องออกแบบสถาปัตยกรรมโมเดลและวงจรการทำงานให้คำนึงถึงการใช้พลังงาน ประสิทธิภาพการคำนวณ และการจัดการหน่วยความจำตลอดอายุการใช้งานของอุปกรณ์
แนวทางปฏิบัติที่ทีมพัฒนาควรเริ่มนำมาใช้คือการทดลองแบบ proof‑of‑concept ขนาดเล็กเพื่อลดความเสี่ยงและวัดผลจริงในสนาม พร้อมใช้เทคนิคลดขนาดโมเดลเช่น quantization และ pruning รวมถึงการปรับแต่งเพื่อเร่งประสิทธิภาพบนฮาร์ดแวร์ขอบ (edge accelerators) นโยบายอัปเดตโมเดลต้องระมัดระวัง วางกลไกเวอร์ชันคอนโทรล การยกเลิกหรือย้อนกลับเมื่อตัวชี้วัดตก และการตรวจจับการลื่นไถลของโมเดล ด้านประสบการณ์ผู้ใช้ จำเป็นต้องออกแบบให้ผู้ใช้สามารถควบคุมข้อมูลของตนได้อย่างชัดเจน (เช่นอนุญาต/ปิดการเรียนรู้ ปรับความถี่การอัปเดต) เพื่อสร้างความเชื่อมั่น ในระยะยาว เทคโนโลยีนี้มีศักยภาพสูงที่จะลดภาระคลาวด์ ลดความหน่วง และสอดคล้องกับแนวโน้มความเป็นส่วนตัวเชิงกฎระเบียบ แต่ความสำเร็จเชิงพาณิชย์จะขึ้นกับการผสานฮาร์ดแวร์ที่เหมาะสม การกำกับดูแลโมเดล และการออกแบบ UX ที่ให้ผู้ใช้เป็นเจ้าของข้อมูลของตน



