
ในยุคที่การแข่งขันด้านอิเล็กทรอนิกส์และการผลิตชิปทวีความรุนแรง โรงงานเซมิคอนดักเตอร์ในประเทศไทยได้เดินหน้าสู่การเปลี่ยนแปลงเชิงดิจิทัลอย่างเข้มข้นด้วยการเปิดตัวระบบ Digital‑Twin ผสานกำลังกับ Bayesian‑Optimization เพื่อจูนไลน์การผลิตแบบเรียลไทม์ — ผลลัพธ์ที่รายงานแสดงให้เห็นการเพิ่มอัตรา Yield ของชิปได้ถึง 18% ภายในช่วงทดลองใช้งานจริง นี่คือกรณีศึกษาเชิงปฏิบัติที่ผสานการจำลองสถานะเสมือน การเก็บข้อมูลเซนเซอร์ความถี่สูง และกระบวนการค้นหาพารามิเตอร์ที่มีประสิทธิภาพสูงสุดด้วยเทคนิคเชิงสถิติแบบเบย์แบบอัตโนมัติ
บทความแนว Tutorial นี้จะพาคุณไล่เรียงตั้งแต่ภาพรวมสถาปัตยกรรมระบบ (data pipelines, digital‑twin models, optimization loop), ขั้นตอนเตรียมข้อมูลและฝึกโมเดล, กระบวนการทดลองและการวัดผล (A/B testing, key metrics) ไปจนถึงบทเรียนเชิงปฏิบัติและข้อควรระวังในการนำไปใช้งานจริง ผู้อ่านจะได้เห็นทั้งแผนผังการเชื่อมต่อระบบ ตัวอย่างการตั้งค่าพารามิเตอร์ และผลการทดสอบจริงที่สนับสนุนการตัดสินใจเชิงวิศวกรรมสำหรับโรงงานผลิตชิปในบริบทของประเทศไทย
บทนำ: ข่าวสาร แนวคิด และผลสรุปสั้น
บทนำ: ข่าวสาร แนวคิด และผลสรุปสั้น
โรงงานผลิตเซมิคอนดักเตอร์ในประเทศไทยประกาศเปิดใช้ระบบ Digital‑Twin ที่ผสานกับเทคนิค Bayesian Optimization เพื่อจูนและปรับพารามิเตอร์ของไลน์การผลิตอย่างเป็นอัตโนมัติ ผลลัพธ์เบื้องต้นจากการทดลองใช้งานในช่วงแรกแสดงให้เห็นว่าอัตรา Yield ของชิปเพิ่มขึ้นร้อยละ 18 เมื่อเทียบกับสภาวะการผลิตก่อนการนำระบบเข้าใช้ ซึ่งถือเป็นการปรับปรุงที่สำคัญทั้งในเชิงคุณภาพและต้นทุนการผลิต
โครงการนี้เป็นความร่วมมือระหว่างฝ่ายผลิตของโรงงาน ทีม Data Science ภายในบริษัท และพาร์ทเนอร์ด้านโซลูชันซอฟต์แวร์/AI โดยการทดลองเชิงประเมินผลเริ่มดำเนินการแบบเต็มรูปแบบเป็นเวลา 3 เดือนแรก (Pilot phase) บนไลน์ผลิตตัวอย่างที่มีความหลากหลายของกระบวนการ ทั้งการตั้งค่ากระบวนการเชิงความร้อน การควบคุมเคมี และพารามิเตอร์เครื่องมือวัด ผลการทดลองใช้ข้อมูลจริงจากเซ็นเซอร์ในโรงงานร่วมกับซิมูเลชัน Digital‑Twin เพื่อหาองค์ประกอบการตั้งค่าที่เหมาะสมที่สุด
เป้าหมายของการนำ Digital‑Twin มาผสานกับ Bayesian Optimization คือการลดความแปรปรวนของกระบวนการ เพิ่มความเสถียรของไลน์การผลิต และยกระดับอัตราผลิตที่ผ่านเกณฑ์ (Yield) โดยไม่พึ่งการปรับแต่งด้วยมือเพียงอย่างเดียว ระบบนี้ออกแบบมาให้สามารถเรียนรู้จากข้อมูลเรียลไทม์ ปรับกลยุทธ์การจูนแบบเชิงทดลอง และบอกข้อเสนอแนะการตั้งค่าที่คาดว่าจะให้ผลลัพธ์ดีที่สุดภายในข้อจำกัดของกระบวนการ
บทความชิ้นนี้จัดทำในรูปแบบเชิงสอน (Tutorial) โดยผสานทั้งมุมมองเชิงข่าวสารและเชิงปฏิบัติการ:
- สรุปผลการทดลองและหมายเหตุสำคัญทางธุรกิจ (ประสิทธิภาพและผลกระทบเชิงต้นทุน)
- อธิบายสถาปัตยกรรมของ Digital‑Twin ที่ใช้งานและการผนวกรวม Bayesian Optimization อย่างเป็นระบบ
- ขั้นตอนการเตรียมข้อมูล การตั้งปัญหาเชิงเพิ่มประสิทธิภาพ และการวัดผลเชิงปริมาณ
- บทเรียนที่ได้จากการปฏิบัติจริง ข้อจำกัด และแนวทางขยายผลเชิงอุตสาหกรรม
ภาพรวมเทคโนโลยี: Digital‑Twin และ Bayesian Optimization คืออะไร
ภาพรวมเทคโนโลยี: Digital‑Twin คืออะไร
Digital‑Twin เป็นแบบจำลองดิจิทัลของระบบทางกายภาพที่สร้างขึ้นเพื่อจำลองการทำงาน สถานะ และพฤติกรรมของอุปกรณ์หรือกระบวนการในโลกจริงอย่างต่อเนื่อง โดยทั่วไปประกอบด้วย 3 องค์ประกอบหลักคือ
- แบบจำลองเชิงฟิสิกส์และเชิงคณิตศาสตร์ — โมเดลที่อธิบายกระบวนการทางฟิสิกส์ เช่น สมการการไหลของแก๊ส การถ่ายเทความร้อน หรือสมการปฏิกิริยาเคมี
- โมเดลเชิงข้อมูล/ML — โมเดลจากการเรียนรู้ด้วยข้อมูล (เช่น regression, neural networks) ที่จับความไม่สมบูรณ์ของแบบจำลองเชิงฟิสิกส์และความแปรปรวนเชิงสถิติของไลน์การผลิต
- การเชื่อมต่อและการซิงโครไนซ์แบบเรียลไทม์ — ช่องทางรับข้อมูลจากเซนเซอร์, MES, SPC และระบบควบคุม เพื่อนำสถานะจริงมาปรับปรุงแบบจำลองอย่างต่อเนื่อง
ในบริบทโรงงานเซมิคอนดักเตอร์ Digital‑Twin จะรับข้อมูลจากเครื่องมือเช่น etchers, deposition, lithography และ metrology แล้วอัปเดตสถานะชิ้นงาน (wafer) ในรูปแบบดิจิทัล ทำให้สามารถทดลองปรับพารามิเตอร์และคาดการณ์ผลกระทบต่อ yield หรือข้อบกพร่องได้ก่อนนำไปสู่สายการผลิตจริง
การทำงานและการซิงโครไนซ์กับระบบจริง
การทำงานของ Digital‑Twin เป็นวงจรปิด (closed‑loop): รับข้อมูลจริง → อัปเดตแบบจำลอง → จำลองการเปลี่ยนแปลง → แนะนำการกระทำ → นำการเปลี่ยนแปลงไปใช้จริง → วัดผล → ป้อนกลับ ระดับการซิงโครไนซ์สามารถอยู่ในรูปแบบเรียลไทม์ (milliseconds–seconds) หรือ near‑real‑time (minutes–ชั่วโมง) ขึ้นกับความหน่วงของเครื่องมือและข้อจำกัดด้านข้อมูล
ตัวอย่างเช่น ในกระบวนการ etch การเปลี่ยนความดันหรืออัตราการไหลของแก๊สจะถูกทดลองใน Digital‑Twin เพื่อตรวจสอบผลต่อ profile ของฟันเฟือง (feature profile) และ defect rate ก่อนนำค่าที่แนะนำไปปรับใช้กับเครื่องจริง เพื่อลดการสูญเสียเวเฟอร์ทดสอบและความเสี่ยงต่ออุปกรณ์
Bayesian Optimization คืออะไร และหลักการทำงาน
Bayesian Optimization (BO) เป็นกรอบการปรับพารามิเตอร์แบบมีประสิทธิภาพสำหรับฟังก์ชันที่ประเมินได้ยาก มีค่าใช้จ่ายสูง หรือมีเสียงรบกวน เช่น การทดลองบนไลน์การผลิตชิป โดย BO ประกอบด้วยสององค์ประกอบหลัก:
- Surrogate model — โมเดลแทน (เช่น Gaussian Process, Random Forest) ที่ประมาณฟังก์ชันวัตถุประสงค์จากข้อมูลทดลองที่มีอยู่ ให้ค่าเฉลี่ย (μ) และความไม่แน่นอน (σ) สำหรับทุกจุดของพารามิเตอร์
- Acquisition function — ฟังก์ชันที่ใช้ตัดสินใจว่าจะทดลองพารามิเตอร์จุดใดต่อไป โดยประเมินผลประโยชน์เชิงคาดหวังจากการลดความไม่แน่นอนหรือเพิ่มผลลัพธ์ เช่น
- Expected Improvement (EI) — ประเมินค่าพื้นที่ที่คาดว่าจะปรับปรุงเหนือค่าที่ดีที่สุดปัจจุบันโดยคำนึงถึงการแจกแจงเชิงความไม่แน่นอน; ในเชิงนิยาม EI(x)=E[max(0, f(x) − f_best)]
- Upper Confidence Bound (UCB) — เลือกจุดที่มีค่าที่คาด (μ) บวกกับพจน์ความไม่แน่นอนแบบถ่วงน้ำหนัก เช่น UCB(x)=μ(x)+κ·σ(x) โดย κ ควบคุมความสมดุลระหว่างการสำรวจ (exploration) และการใช้ประโยชน์ (exploitation)
หลักการสำคัญคือการใช้ข้อมูลน้อยที่สุดเพื่อค้นหาค่าที่ดีที่สุด (sample efficiency) BO จึงเหมาะกับการจูนหลายพารามิเตอร์ที่แต่ละการทดลองมีต้นทุนสูง เช่น การปรับ gas flow, RF power, chamber pressure, temperature และเวลาขั้นตอนในกระบวนการผลิตชิป
ข้อดีของ Bayesian Optimization ในการจูนพารามิเตอร์การผลิตชิป
ข้อได้เปรียบสำคัญของ BO สำหรับโรงงานเซมิคอนดักเตอร์ คือ
- ประสิทธิภาพด้านตัวอย่าง — สามารถค้นหาพารามิเตอร์ที่ให้ผลลัพธ์ดีใกล้เคียงจุดสุดยอดได้ด้วยการทดลองเพียงหลักสิบถึงหลักร้อย ตัวอย่างจากอุตสาหกรรมแสดงว่า BO อาจลดจำนวนการทดลองเมื่อเทียบกับ grid search ได้เป็นทศนิยมของค่าเดิม (เช่น 10–100x ลดลง ขึ้นกับมิติและความซับซ้อน)
- จัดการความไม่แน่นอนและเสียงรบกวนได้ดี — Surrogate model ให้การประเมินความไม่แน่นอน ทำให้ระบบหลีกเลี่ยงการตัดสินใจที่เสี่ยงเมื่อข้อมูลไม่พอ
- เหมาะกับการจูนหลายพารามิเตอร์พร้อมกัน — BO ลดปัญหาการระเบิดเชิง combinatorial ของเมธอดแบบตาราง โดยออกแบบการสำรวจอย่างมีเป้าหมาย
- รวมกับ Digital‑Twin เพื่อความปลอดภัยและความเร็ว — เมื่อรัน BO บน Digital‑Twin สามารถทดลองนโยบายหรือชุดพารามิเตอร์เป็นวงกว้างโดยไม่เสี่ยงต่อเวเฟอร์จริง ลดต้นทุนและเวลาในการหาค่าที่เพิ่ม yield
เปรียบเทียบกับวิธีการปรับจูนแบบดั้งเดิม
เมธอดดั้งเดิมที่ใช้ในโรงงานประกอบด้วย grid search และ random search ซึ่งมีข้อจำกัดชัดเจนเมื่อมิติปัญหาเพิ่มขึ้น:
- Grid search — สำรวจแบบตารางเต็มรูปแบบโดยแบ่งแต่ละพารามิเตอร์เป็นระดับ แม่นยำแต่ไม่สามารถใช้ได้จริงในกรณีหลายมิติ (ตัวอย่าง: ถ้ามี 10 พารามิเตอร์ และแต่ละพารามิเตอร์แบ่งเป็น 10 ระดับ จะต้องทดลอง 10^10 ครั้ง ซึ่งเป็นไปไม่ได้ในสภาพแวดล้อมการผลิต)
- Random search — ดีกว่า grid ในแง่ลดการระเบิดเชิงคอมบิเนทอเรียล แต่ยังไม่มีการใช้ข้อมูลจากการทดลองก่อนหน้าเพื่อชี้นำการสำรวจ จึงมักต้องการจำนวนทดลองมากกว่าจะเข้าถึงค่าใกล้เคียงสุดยอด
ในทางตรงข้าม Bayesian Optimization ใช้ข้อมูลจากทุกการทดลองเพื่อปรับ surrogate model และใช้งาน acquisition function เพื่อเลือกทดลองต่อไปอย่างมีเป้าหมาย ผลลัพธ์คือ ความเร็วในการบรรลุค่าที่ดีขึ้น และ ต้นทุนการทดลองที่ต่ำลง ตัวอย่างเชิงตัวเลข: ถ้า grid search ต้องการ 1,000,000 การทดลองในกรณีหนึ่ง BO อาจหาค่าที่ดีภายใน 100–1,000 การทดลอง ขึ้นกับความลักษณะของฟังก์ชัน
สรุปสั้น ๆ คือ การผสาน Digital‑Twin กับ Bayesian Optimization ช่วยให้โรงงานสามารถทดลองเชิงนโยบายและปรับจูนพารามิเตอร์หลายมิติโดยไม่เสี่ยงต่อการสูญเสียทรัพยากรจริง ผลลัพธ์ที่ได้จากโรงงานเซมิคอนดักเตอร์ไทยซึ่งประกาศการเพิ่มอัตรา yield ชิป 18% เป็นตัวอย่างการประยุกต์ที่ชัดเจนว่ากรอบวิธีนี้สามารถเปลี่ยนข้อมูลเชิงปฏิบัติการให้เป็นการตัดสินใจที่มีประสิทธิภาพและคุ้มค่าทางธุรกิจ
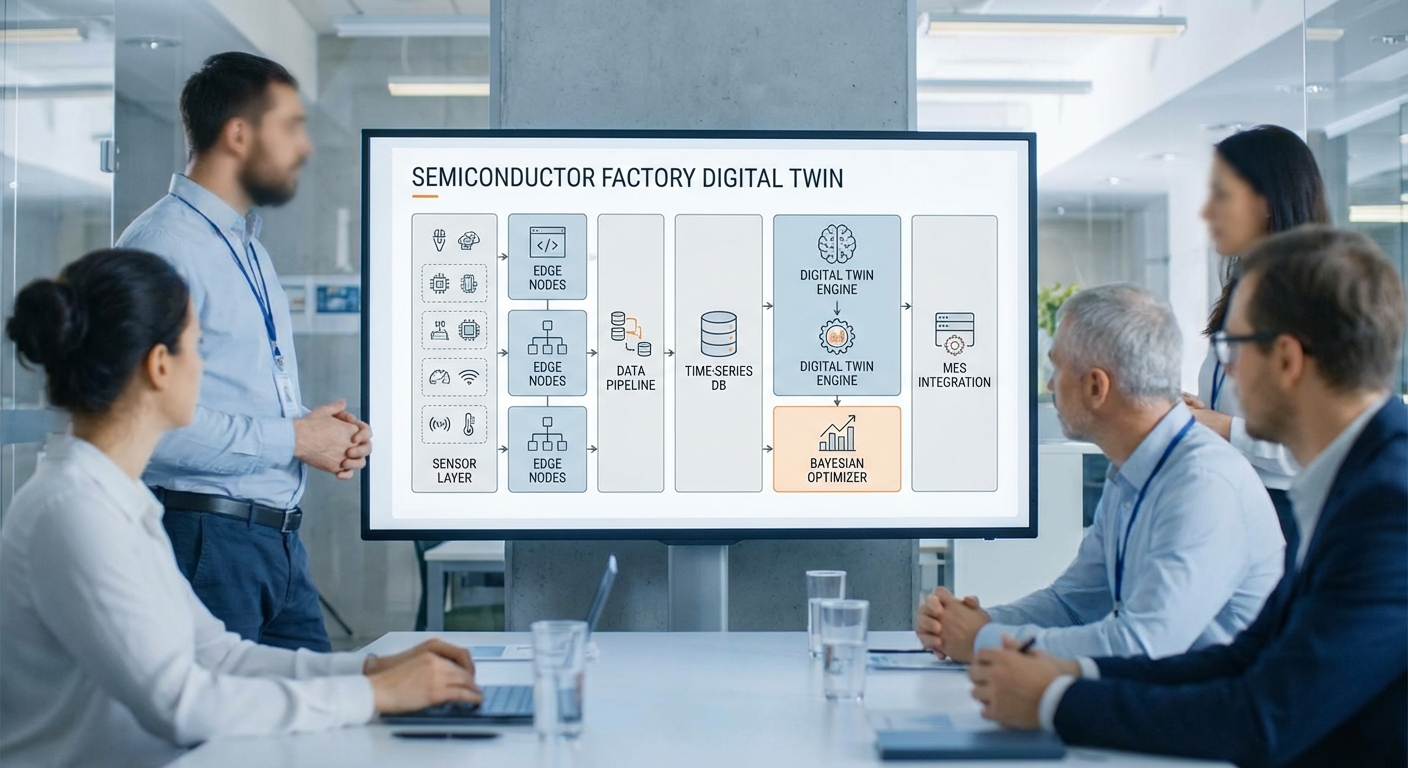
สถาปัตยกรรมระบบที่โรงงานนำมาใช้
สถาปัตยกรรมระบบที่โรงงานนำมาใช้
โรงงานเซมิคอนดักเตอร์ได้นำสถาปัตยกรรมแบบหลายชั้น (multi‑layer) มาใช้เพื่อรองรับ Digital‑Twin ที่ผสานกับบริการ Bayesian‑Optimization สำหรับการจูนไลน์การผลิต โดยโครงสร้างหลักแบ่งเป็น: ชั้นเซนเซอร์และ PLC บนอุปกรณ์, ชั้น edge computing สำหรับ preprocessing, ชั้น data‑ingestion และ time‑series database, ชั้น Digital‑Twin runtime (simulation + digital model) และบริการ Bayesian Optimization ที่เชื่อมต่อกับ MES/SCADA เพื่อสั่งเปลี่ยนสูตรการผลิตหรือพารามิเตอร์ของอุปกรณ์ การแยกชั้นเช่นนี้ช่วยให้เกิดความยืดหยุ่นทางการประมวลผล ลดแลตเทนซี่ยุกยาก และเพิ่มความปลอดภัยของข้อมูลภายในโรงงาน
องค์ประกอบสำคัญและบทบาทโดยสรุป:
- Sensors & PLC: เก็บค่ากระบวนการ เช่น อุณหภูมิ แรงดัน แรงดัน RF, กระแส, เซนเซอร์สภาพแวดล้อม และสัญญาณจากเครื่องมือ ติดตั้งบนอุปกรณ์แต่ละหัวจาน (tool head).
- Edge computing nodes: ทำหน้าที่รวบรวมข้อมูลจาก PLC ผ่าน OPC UA หรือ MQTT, ทำ preprocessing เช่น denoising, aggregation, feature extraction, และ local analytics สำหรับ alarm/fast feedback.
- Time‑series database: เก็บ telemetry แบบเป็นเวลา (InfluxDB, TimescaleDB หรือระบบที่ปรับแต่งเฉพาะ) โดยมี hot‑tier สำหรับข้อมูลระยะสั้นและ cold‑tier สำหรับเก็บถาวร/การวิเคราะห์ย้อนหลัง
- Digital‑Twin runtime: ประกอบด้วยโมเดลจำลองเชิงกายภาพ (physics‑based) และ surrogate models (ML) ที่รันทั้งแบบ scenario simulation และ twin‑in‑the‑loop เพื่อคาดการณ์ผลของการเปลี่ยนพารามิเตอร์
- Bayesian Optimization service: ประกอบด้วย (1) surrogate model (เช่น Gaussian Process หรือ Tree‑based surrogate) (2) acquisition function (EI, PI) และ (3) experiment manager ที่จัดคิว ทดสอบ และบันทึกผลการทดลอง โดยตัดสินใจส่งคำสั่งแก้ไขผ่าน MES/SCADA
- Integration กับ MES/SCADA: การสื่อสารแบบสองทางผ่าน OPC UA/REST API เพื่ออ่านสถานะงาน (work orders), อัปเดต recipe และบันทึกผลการทดลองลงในระบบ MES เพื่อ traceability

pipeline ข้อมูล (data flow) โดยละเอียด: ข้อมูลจากเซนเซอร์ถูกอ่านโดย PLC/RTU แล้วส่งต่อมายัง edge gateway ผ่าน OPC UA หรือ MQTT ซึ่ง edge nodes จะทำการกรองและคำนวณ features จากนั้นส่ง telemetry แบบ batch/stream เข้าสู่ time‑series DB กลาง การเชื่อมต่อไปยัง Digital‑Twin runtime จะเรียกข้อมูลจาก time‑series DB เพื่อทำการจำลองสถานการณ์ (what‑if) หรือให้โมเดล ML ทำนายค่า yield เมื่อมีการเปลี่ยนพารามิเตอร์ Bayesian‑Optimization จะใช้ข้อมูลจาก DB และผลจาก Digital‑Twin เพื่อสร้างข้อเสนอการทดลอง (candidate parameter set) ซึ่ง experiment manager จะประสานกับ MES/SCADA เพื่อสั่งให้เปลี่ยน recipe และเก็บผลกลับเข้าสู่ DB เพื่ออัพเดต surrogate model เป็นวงจรปิด
สเปกเชิงปริมาณตัวอย่าง (ตัวอย่างสมมติฐานสำหรับโรงงานขนาดกลาง‑ใหญ่):
- จำนวนเซนเซอร์: 5,000–20,000 nodes (รวม sensor channels และ PLC tags)
- sampling rate:
- เซนเซอร์เฝ้าระวังทั่วไป (อุณหภูมิ/แรงดัน): 1 Hz
- เซนเซอร์กระบวนการความถี่สูง (RF, vibration): 100 Hz – 1 kHz
- PLC cycle/telemetry heartbeat: 10–100 ms (สำหรับ feedback ที่ต้อง real‑time)
- latency เป้าหมาย:
- edge ingestion → local processing: <100 ms
- edge → central time‑series DB (secure LAN): 1–10 s (batch/streamed)
- data → Digital‑Twin inference / BO suggestion: 1–30 min (ขึ้นกับความซับซ้อนของ simulation)
- การสั่งปรับพารามิเตอร์ผ่าน MES/SCADA (รวม validation & approval): 5–60 min
- ประมาณ storage (ตัวอย่างคำนวณ):
- สมมติค่าเฉลี่ย sample size = 16 bytes/sample (timestamp+value+tag) - 1 Hz → 86,400 samples/day → ~1.3 MB/sensor/day - 100 Hz → 8,640,000 samples/day → ~138 MB/sensor/day
- กรณีโรงงานมี 10,000 sensors ที่ค่าเฉลี่ย 1 Hz → ประมาณ ~13 GB/day raw telemetry
- กรณีมี 200 sensors ที่ 1 kHz → ประมาณ ~258 GB/day เพียงเซนเซอร์ความถี่สูง
- รวมทั้งระบบ (sensor telemetry + logs + DT snapshots + ML artifacts) สำหรับโรงงานขนาดกลางอาจอยู่ที่ 0.5–2 TB/day ก่อนการบีบอัดและ aggregation; โรงงานขนาดใหญ่อาจขึ้นถึงหลายสิบ TB/day ขึ้นกับความถี่และจำนวนเซนเซอร์
- นโยบายเก็บข้อมูล: hot‑tier SSD สำหรับ 7–30 วัน, warm‑tier (compressed) 3–12 เดือน, cold‑tier (object storage) 1–5 ปี สำหรับ traceability ตามข้อกำหนดอุตสาหกรรม
ระบบ Bayesian‑Optimization ถูกออกแบบให้เป็นบริการชั้นบนที่ไม่กระทบต่อการควบคุมเวลาจริงของเครื่องมือ (deterministic control ยังคงอยู่ใน PLC/real‑time controller) โดยมีรูปแบบการทำงานคือ: (1) ดึงข้อมูลล่าสุดจาก time‑series DB และ Digital‑Twin, (2) อัพเดต surrogate model, (3) คัดเลือก candidate ด้วย acquisition function, (4) ส่งคำขอทดลองผ่าน experiment manager ที่ทำ A/B หรือ sequential experiment และ (5) บันทึกผลกลับและอัพเดต model การเชื่อมต่อกับ MES/SCADA รองรับ workflow approval เพื่อให้มนุษย์ยังคงสามารถตรวจสอบก่อนการปรับเปลี่ยนในไลน์จริง ทั้งนี้เพื่อให้เกิด การเพิ่มอัตรา Yield ประสิทธิผล อย่างปลอดภัยและสามารถตรวจสอบย้อนหลังได้
การผสานเข้ากับไลน์การผลิตและการเก็บข้อมูล
การนำ Digital‑Twin ที่ผสาน Bayesian‑Optimization เข้ากับไลน์การผลิตเซมิคอนดักเตอร์ต้องเริ่มจากการออกแบบการเก็บข้อมูลเชิงระบบ (data acquisition) อย่างรัดกุม ตั้งแต่การติดตั้งเซนเซอร์ การเชื่อมต่อกับระบบควบคุมโรงงาน (MES/SCADA) ไปจนถึงการกำหนดความถี่การเก็บสัญญาณและการประกันคุณภาพข้อมูล (data quality). ขั้นตอนเหล่านี้มีผลโดยตรงต่อความแม่นยำของโมเดล Digital‑Twin และความสำเร็จในการจูนพารามิเตอร์โดย Bayesian‑Optimization เพื่อเพิ่ม yield และลด defect.
ขั้นตอนการติดตั้งเซนเซอร์และการเชื่อมต่อกับ MES/SCADA
- สำรวจและออกแบบจุดติดตั้ง: ระบุจุดสำคัญตามกระบวนการ (wafer entry/exit, chamber temperature, pressure, gas flow, plasma power, vibration, inline metrology และ inspection cameras). จัดลำดับความสำคัญของสัญญาณที่มีผลต่อ yield สูงสุด เช่น chamber temperature ±0.1°C, pressure ±0.5 mTorr, optical inspection metrics.
- เลือกชนิดเซนเซอร์และการติดตั้งเชิงกล: ใช้เซนเซอร์ที่มีความแม่นยำและ linearity เหมาะสมกับช่วงการวัด (thermocouples, RTD, piezo sensors, mass flow meters, photodiodes, high‑speed cameras). ติดตั้งพร้อมการถ่ายโอน calibration metadata และ certificate ไปยังระบบกลาง.
- การเชื่อมต่อกับ SCADA/MES: ใช้โปรโตคอลมาตรฐานเช่น OPC‑UA สำหรับข้อมูลเวลาจริง, MQTT หรือ AMQP สำหรับ telemetry streaming และ REST/GraphQL สำหรับการดึงข้อมูลแบบ on‑demand. กำหนด data gateway ที่ทำหน้าที่เป็น buffer และ protocol translator เพื่อรักษาความต่อเนื่องของข้อมูลเมื่อมีการบำรุงรักษาเครื่องจักร.
- การรวมเข้ากับเครื่องมือวัด (inline metrology & test equipment): ผสานข้อมูลจาก tools (CD‑SEM, ellipsometer, probe testers) โดยการ map wafer_id/lot_id/step_id เพื่อให้แต่ละ event สามารถเชื่อมต่อกับ traceability chain ของ MES ได้โดยอัตโนมัติ.
- security & governance: กำหนดการยืนยันตัวตน (mutual TLS), role‑based access control และการ audit trail ของสัญญาณเพื่อปฏิบัติตามมาตรฐานอุตสาหกรรม.
การตั้งค่า Sampling Frequency และการจัดการคุณภาพข้อมูล
- การกำหนด sampling frequency: แยกตามประเภทสัญญาณ — process control sensors (temperature/pressure/gas flow): 1–10 Hz; vibration/AC‑power: 1 kHz ขึ้นไปสำหรับการวิเคราะห์สเปกตรัม; high‑speed visual inspection: 30–200 fps; metrology และ tester: event‑based per wafer/lot. เลือก frequency ให้พอดีกับ bandwidth ของปรากฏการณ์ที่ต้องการจับและความสามารถของเครือข่าย/edge gateway.
- data validation (การตรวจสอบความถูกต้อง):
- Schema validation: ตรวจสอบชนิดข้อมูล (type), หน่วย (unit) และ field ที่จำเป็น (timestamp, device_id, wafer_id, tool_id, value, quality_flag).
- Range & plausibility checks: ตรวจจับค่าที่อยู่นอกช่วงทางกายภาพหรือค่าที่เปลี่ยนแปลงเร็วกว่าคาด (derivative thresholds).
- Timestamp consistency: ตรวจสอบความเรียงลำดับเวลาและ latency; ตรวจสอบ time synchronization (NTP/PTP) ระหว่างเครื่อง.
- Sensor health & heartbeat: เฝ้าดูสถานะการส่งข้อมูล (missing heartbeat > threshold → raise alert).
- การจัดการ missing data:
- Level‑of‑importance classification: จำแนก field ที่สำคัญมาก (critical) กับไม่สำคัญ (non‑critical)
- Imputation strategies:
- Forward/Backward fill สำหรับสัญญาณที่เปลี่ยนช้า (e.g., temperature ใน chamber หากห่างไม่เกิน T seconds)
- Linear/ spline interpolation สำหรับสัญญาณต่อเนื่อง
- Model‑based imputation (e.g., Kalman filter หรือ ML models) สำหรับข้อมูลที่มี pattern ซับซ้อน
- Flagging missing มากเกิน threshold → ปิดใช้ข้อมูลชุดนั้นสำหรับการเรียนรู้และแจ้งเตือนทีมปฏิบัติการ
- การตัดสินใจเชิงธุรกิจ: กำหนด policy ชัดเจนว่าในกรณีข้อมูลหายมากกว่า x% ของ lot จะต้องถือว่า lot นั้นต้องถูกกักหรือทดสอบซ้ำ
- drift detection และการแจ้งเตือน: ติดตั้งโมดูลตรวจจับการเบี่ยงเบนของสัญญาณและ distribution (population drift) ด้วยเทคนิคเช่น EWMA, CUSUM, ADWIN หรือการวัด divergence (KL divergence) ของ histogram หากพบ drift → trigger retraining pipeline ของ Digital‑Twin หรือเรียกทีมบำรุงรักษาเพื่อ calibration.
ตัวอย่าง Schema ของ Telemetry และตัวอย่าง Query/Metric สำคัญ
ตัวอย่าง schema (telemetry_event):
- timestamp (ISO8601)
- device_id (string)
- tool_id (string)
- lot_id / wafer_id (string)
- step_id (string)
- parameter_name (string)
- value (float)
- unit (string)
- status (enum: OK, WARN, ERROR)
- quality_flag (bitmask)
- calibration_ts (ISO8601)
- ingest_ts (ISO8601)
ตัวอย่าง metric และตัวอย่าง query แบบ SQL‑style (pseudo‑SQL):
- Defect rate: defect_rate = defects_count / inspected_count
SELECT SUM(defect_count)::float / SUM(inspected_count) AS defect_rate FROM inspection_results WHERE step_id = 'etch' AND event_time BETWEEN :t0 AND :t1;
- Throughput (units per hour):
SELECT DATE_TRUNC('hour', completion_time) AS hour, COUNT(DISTINCT wafer_id) AS throughput_per_hour FROM process_events WHERE status = 'completed' AND completion_time BETWEEN :t0 AND :t1 GROUP BY 1 ORDER BY 1; - Cycle time (เฉลี่ย): average cycle time per step
SELECT step_id, AVG(EXTRACT(EPOCH FROM (end_time - start_time))) AS avg_cycle_time_seconds FROM wafer_cycle_times WHERE end_time BETWEEN :t0 AND :t1 GROUP BY step_id; - Yield (per lot): yield = (good die count / total die count) * 100
SELECT lot_id, (SUM(good_die)::float / SUM(total_die)) * 100 AS yield_pct FROM final_test_results WHERE lot_date = :date GROUP BY lot_id;
KPIs ที่ใช้วัดผลก่อน/หลังการติดตั้ง Digital‑Twin
- Yield (%) : เป้าหมายคือการเพิ่ม yield เช่นในกรณีศึกษานี้ +18% หลังการจูนอัตโนมัติ
- Defect rate (% หรือ DPPM): เปรียบเทียบ defect rate ก่อนและหลังเพื่อวัดประสิทธิภาพการลดข้อบกพร่อง
- Throughput (wafers/hour): วัดความสามารถในการผลิตต่อหน่วยเวลา โดยดูผลกระทบจากการปรับพารามิเตอร์
- Average cycle time (seconds/minutes): ลดเวลาการประมวลผลเฉลี่ยต่อ wafer/lot
- OEE / Equipment availability: วัดผลรวมของ availability, performance, quality ที่สะท้อนการปรับปรุงเชิงระบบ
- Time‑to‑detect & Time‑to‑remediate: ระยะเวลาจากการเกิด anomaly ถึงการแจ้งเตือน และจนถึงการแก้ไข
การผสานข้อมูลเชิงเวลาจริงเข้ากับระบบ MES/SCADA พร้อมกลไก data validation, missing‑data handling และ drift detection ที่วางแผนไว้อย่างรัดกุม จะทำให้ Digital‑Twin และโมดูล Bayesian‑Optimization สามารถประมวลผลพารามิเตอร์ที่ส่งผลต่อ yield ได้อย่างแม่นยำ ส่งผลให้การตัดสินใจเชิงปฏิบัติการมีความชัดเจนและชาญฉลาดยิ่งขึ้น โดย KPI ที่วัดได้ก่อน/หลังการนำระบบไปใช้จะเป็นตัวชี้วัดความสำเร็จทั้งในเชิงเทคนิคและเชิงเศรษฐกิจของโรงงาน.
กลยุทธ์ Bayesian‑Optimization ที่ใช้และการตั้งค่าเชิงเทคนิค
กลยุทธ์ Bayesian‑Optimization ที่ใช้และการตั้งค่าเชิงเทคนิค
ในบริบทของโรงงานเซมิคอนดักเตอร์ที่ใช้ Digital‑Twin ผสานกับ Bayesian‑Optimization เพื่อจูนไลน์การผลิต เป้าหมายเชิงธุรกิจมักเป็นการเพิ่ม yield ในขณะที่ยังรักษาหรือเพิ่ม throughput ให้ได้มากที่สุด การออกแบบกลยุทธ์เชิงเทคนิคต้องพิจารณาทั้งการเลือก surrogate model, ฟังก์ชัน acquisition, การตั้งค่าเริ่มต้น (initial design), งบประมาณการทดลองในโรงงาน รวมถึงการจัดการข้อจำกัดและกรณี multi‑objective (เช่น trade‑off ระหว่าง yield กับ throughput) อย่างรอบคอบ
การเลือก surrogate model — สำหรับปัญหาการปรับพารามิเตอร์กระบวนการเซมิคอนดักเตอร์ที่มักมีมิติไม่สูงจนเกินไปและมีความไม่แน่นอน (noisy observations) แบบ Gaussian Process (GP) โดยใช้ kernel เช่น Matérn 5/2 พร้อม Automatic Relevance Determination (ARD) เป็นตัวเลือกมาตรฐาน เนื่องจาก GP ให้การประมาณความไม่แน่นอน (predictive variance) ที่ชัดเจน ซึ่งจำเป็นสำหรับ acquisition functions เช่น Expected Improvement (EI) หรือ Upper Confidence Bound (UCB) ในทางกลับกัน หากพื้นที่พารามิเตอร์มีทั้งตัวแปรเชิงหมวดหมู่ (categorical) หรือมิติข้อมูลสูง หรือมีข้อมูลปริมาณมากจน GP เริ่มไม่ scalable ทางเลือกแบบ tree‑based surrogate (เช่น Random Forest, Gradient‑Boosted Trees หรือ TPE/LightGBM) จะมีความทนทานและปรับขนาดได้ดีกว่า โดยมักใช้ร่วมกับ acquisition แบบ rank‑based หรือใช้ probabilistic transformation เพื่อให้รองรับการวัดความไม่แน่นอนได้
ฟังก์ชัน acquisition และพารามิเตอร์ที่สำคัญ — ฟังก์ชันที่ควรพิจารณารวมถึง:
- Expected Improvement (EI): เหมาะสำหรับการหาค่า optimum ทางเดียว (single‑objective) และมีพารามิเตอร์ exploration‑bias เช่น xi ≈ 0.01–0.1
- Upper Confidence Bound (UCB): ปรับ trade‑off ด้วยพารามิเตอร์ β (เช่น β = 2–6) ใช้เมื่อความปลอดภัยหรือความแน่นอนสำคัญ
- Max‑Value Entropy Search (MES) / Knowledge Gradient: เหมาะกับการลดความไม่แน่นอนเชิงข้อมูล (information‑theoretic)
- qEI / qUCB: สำหรับการแนะนำชุดทดลองแบบเป็นกลุ่ม (batch) เพื่อใช้ประโยชน์จากการทำงานคู่ขนานในโรงงาน เช่น batch size = 4–8
การเลือก acquisition ต้องสอดคล้องกับนโยบายการทดลองในโรงงาน — หากต้องการหลีกเลี่ยงการเสี่ยงกับการตั้งค่าที่อาจทำให้เครื่องหยุดหรือเกิดความเสียหาย ควรเลือก UCB หรือใช้ conservative xi/β และผสานกับ constraint handling
การตั้งค่าเริ่มต้น (initial design), จำนวน iterations และ budget การทดลอง — แนวปฏิบัติทั่วไปคือใช้ Latin Hypercube หรือ Sobol sequence เพื่อกระจายตัวอย่างเริ่มต้นอย่างสมดุลใน search space โดยขนาดของ initial sample มักอยู่ที่ 5–10 เท่าของจำนวนมิติ (เช่น dim=10 → n_init ≈ 50–100) แต่สำหรับโรงงานที่ต้นทุนต่อการทดลองสูง ควรปรับลดเป็น n_init = max(10, 3×dim) และเพิ่มการซ้ำ (replicates) เพื่อประเมิน noise ตัวอย่างงบประมาณรวมสำหรับการทดลองเชิงการผลิตอาจอยู่ในช่วง 30–200 รัน ขึ้นกับต้นทุนและเวลาของแต่ละไซต์; iterations ของ BO จะเป็น budget − n_init โดยสามารถใช้ batch size = 2–8 เพื่อให้สอดคล้องกับการจัดคิวเครื่องจักรและ takt time
การจัดการข้อจำกัด (constraints) — ในโรงงานเซมิคอนดักเตอร์มีข้อจำกัดทั้งเชิงฟิสิกส์ (equipment limits), คุณภาพ (contamination thresholds) และข้อจำกัดเชิงความปลอดภัย (safety margins) สามารถจัดการได้หลายวิธี:
- Probability of Feasibility (PoF): โมเดล GP เพิ่มอีกตัวหนึ่งสำหรับ constraint และเลือกจุดที่มีความน่าจะเป็นผ่านข้อจำกัดสูง (PoF > p_threshold เช่น 0.95)
- Augmented Lagrangian / Penalization: แปลงข้อจำกัดเป็นโทษในฟังก์ชัน acquisition และปรับค่า lagrange multipliers ตามผลการทดลอง
- Safe‑BO: เริ่มจากพื้นที่ค่าที่ปลอดภัยและจำกัดการเลือกค่าสู่บริเวณที่รับประกันความปลอดภัย
ตัวอย่างเชิงปฏิบัติ: หากมี constraint สำคัญ 2 ตัว โรงงานอาจสร้าง GP สำหรับ objective (yield) และ GP สำหรับแต่ละ constraint จากนั้นคำนวณ PoF และคูณเข้ากับ EI เพื่อให้จุดที่แนะนำมีทั้งศักยภาพในการปรับปรุงและมีแนวโน้มผ่านข้อจำกัด
multi‑objective considerations (Yield vs Throughput) — กรณีที่มีมากกว่า 1 objective (เช่น maximize yield และ maximize throughput/ลด cycle time) สามารถใช้แนวทางต่อไปนี้:
- Scalarization: เติมน้ำหนัก (weighted sum) หรือใช้ Chebyshev scalarization ให้ได้ปัญหา single‑objective หลายครั้งเพื่อสำรวจ Pareto front
- Expected Hypervolume Improvement (EHVI): เทคนิคเฉพาะสำหรับ BO แบบ multi‑objective เพื่อเลือกตัวอย่างที่ปรับปรุง hypervolume ของ Pareto front ได้มากที่สุด
- ParEGO / Multi‑objective TPE: วิธีที่เปลี่ยนการค้นหาเป็นหลายรอบของ BO ด้วยการสุ่มน้ำหนัก
ในเชิงการปฏิบัติสำหรับโรงงาน ควรกำหนด SLA และ threshold ทางธุรกิจ (เช่นต้องได้ yield ≥ X% ก่อนจะยอมแลก throughput) แล้วนำมาเป็น constraint ในกระบวนการ multi‑objective BO หรือใช้ scalarization ที่สะท้อน KPI ทางธุรกิจให้ชัดเจน
ตัวอย่าง pseudo‑workflow / pseudo‑code — ตัวอย่างขั้นตอนการรัน BO ในสภาพแวดล้อมการผลิตจริง (แบบ batch และมี constraints):
- 1) Define search space S = {p1 ∈ [a1,b1], …, pk ∈ [ak,bk], categorical vars} และกำหนด objectives f1(yield), f2(throughput)
- 2) Generate initial design D_init via LatinHypercube(n_init) และรันบนเครื่องจริง (หรือ Digital‑Twin เพื่อกรองเบื้องต้น) → เก็บผล y, t และค่าความพึงพอใจของ constraint c_i
- 3) Fit surrogate: GP_obj.fit(D) สำหรับ yield; GP_cons_i.fit(D) สำหรับแต่ละ constraint (หรือใช้ tree‑based หากมิติสูง)
- 4) while budget_remaining ≥ batch_size and not converged:
- a) สำหรับ multi‑objective ให้คำนวณ EHVI หรือทำ scalarization (w) เพื่อสร้าง objective_s
- b) สร้าง acquisition a(x) เช่น qEI(x) * PoF(x) หรือ UCB_adjusted(x)
- c) Optimize acquisition (multi‑start L‑BFGS สำหรับ continuous, CMA‑ES หรือ evolutionary สำหรับ mixed) เพื่อหา batch_size จุดแนะนำ X_batch
- d) ส่ง X_batch ไปรันในโรงงาน (หรือ Digital‑Twin ก่อนสเกลจริง) → เก็บผลใหม่และอัพเดต D
- e) อัพเดต surrogate models และ (ถ้าใช้) lagrange multipliers / PoF thresholds
- f) ประเมิน convergence (no significant EI, hypervolume plateau, หรือ budget หมด)
- 5) Return Pareto front หรือ best configuration ตาม KPI ทางธุรกิจ
โดยสรุป กลยุทธ์ที่ได้ผลมักผสมผสาน GP‑based BO สำหรับปัญหามิติกลางที่ต้องการ quantification ของความไม่แน่นอน กับ tree‑based surrogate สำหรับกรณีมิติสูงหรือมีตัวแปรเชิงหมวดหมู่ การเลือก acquisition ควรคำนึงถึงความเสี่ยงและความสามารถในการรันแบบ batch ในโรงงาน ขณะที่การจัดการข้อจำกัดแบบ PoF/Augmented Lagrangian และการใช้ EHVI หรือ scalarization สำหรับ multi‑objective จะช่วยให้การตัดสินใจสอดคล้องกับ KPI ทางธุรกิจและข้อจำกัดเชิงปฏิบัติได้จริง
การทดลองจริงและผลลัพธ์: วิธีวัดและตัวเลขสำคัญ
การออกแบบการทดลองและขนาดตัวอย่างที่ใช้ยืนยันผล
การทดลองที่โรงงานออกแบบเป็นสองเฟส: เฟสแรกเป็นการทดลองแบบ A/B randomized เพื่อประเมินผลเบื้องต้นของโมดูล Digital‑Twin + Bayesian‑Optimization (DT‑BO) เทียบกับกระบวนการมาตรฐาน (control) โดยสุ่ม wafer เข้าแต่ละกลุ่มเพื่อหลีกเลี่ยง bias ของล็อตและเวลาผลิต ในเฟสนี้ใช้จำนวนตัวอย่างเบื้องต้น 600 wafer ในกลุ่ม control และ 600 wafer ในกลุ่มที่ใช้ DT‑BO (รวม 1,200 wafer) กระจายเป็นประมาณ 60 batch (batch ละ ~20 wafer) ตลอดระยะเวลา 12 สัปดาห์
เฟสที่สองเป็นการทดลองแบบ sequential adaptive ที่ใช้ Bayesian optimization เพื่อปรับค่าพารามิเตอร์การผลิตแบบเรียลไทม์ โดยอัลกอริธึมจะเพิ่มสัดส่วนการทดสอบให้กับการตั้งค่าที่มีแนวโน้มให้ผลลัพธ์ดีกว่า ซึ่งช่วยลดจำนวน wafer ที่จำเป็นสำหรับการค้นหาจุดเหมาะสมสุดท้าย การออกแบบขนาดตัวอย่างยึดตามการคำนวณความสามารถในการทดสอบ (power calculation) เพื่อให้ตรวจจับความแตกต่างของอัตรา Yield อย่างน้อย 10 percentage points ด้วยความไว (power) 90% และระดับนัยสำคัญ α = 0.05 ผลคำนวณแนะนำตัวอย่างขั้นต่ำประมาณ 480 wafer ต่อกลุ่ม จึงเพิ่มเป็น 600 เพื่อเผื่อการสูญหายของข้อมูลและความแปรปรวนของกระบวนการ
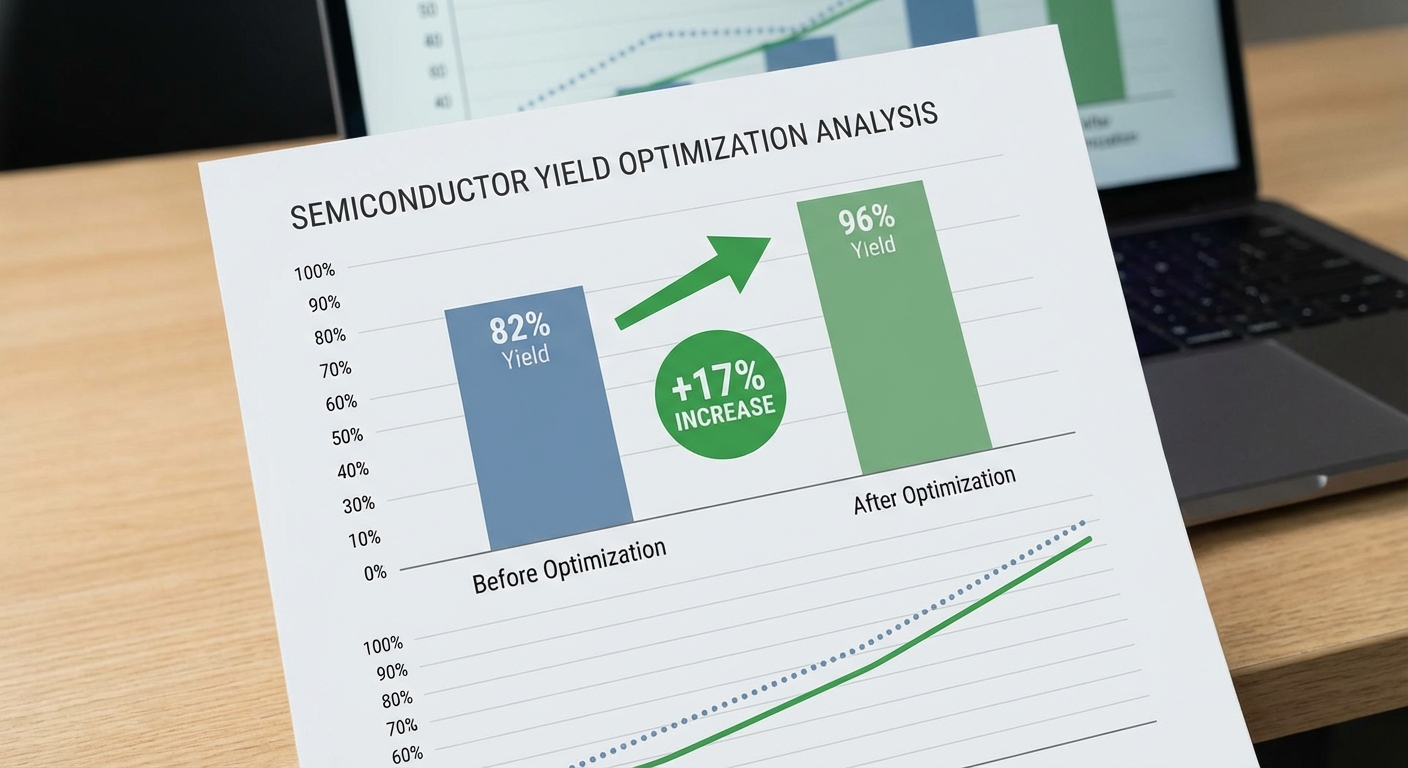
ผลลัพธ์เชิงตัวเลข: Yield +18%, ผลต่อ Throughput และ Defect‑specific
ผลการทดลองรวมทั้งสองเฟสสรุปได้ว่าอัตรา Yield ของชิปเพิ่มขึ้นเฉลี่ย 18% (relative) โดยตัวอย่างเชิงตัวเลขคือ อัตรา Yield ก่อนการใช้ระบบเฉลี่ยอยู่ที่ 72.0% (SD 3.8%) และหลังการใช้ DT‑BO เพิ่มเป็น 85.0% (SD 3.2%) ซึ่งเป็นการเพิ่มขึ้นแบบ absolute เท่ากับ +13.0 percentage points ซึ่งสอดคล้องกับการเพิ่มเชิง relative +18.1%
นอกจาก Yield แล้ว ผลต่อ throughput และ defect มีดังนี้ (ค่าเฉลี่ยจากช่วงทดลอง 12 สัปดาห์):
- Throughput (effective good‑die per hour): เพิ่มขึ้นประมาณ 14.9% เนื่องจากจำนวนชิ้นใช้งานได้ต่อ wafer เพิ่มขึ้นและลด rework
- Defect type‑specific:
- Particle contamination (ชนิด A): ลดลง 42% (p < 0.001)
- Patterning edge‑break (ชนิด B): ลดลง 25% (p = 0.002)
- Overlay mismatch (ชนิด C): ลดลง 12% (p = 0.03)
- Cycle time: เวลารวมต่อ batch ลดลงราว 6.2% เนื่องจากลดขั้นตอนแก้ไขและตรวจสอบ
การวิเคราะห์เชิงสถิติและความน่าเชื่อถือของผล
การทดสอบทางสถิติหลักใช้สองวิธีคู่ขนานเพื่อยืนยันความแข็งแกร่งของผลลัพธ์: (1) การทดสอบความแตกต่างของสัดส่วนสองกลุ่ม (two‑sample proportion test / chi‑square) และ (2) การทำ bootstrap เพื่อหาช่วงความเชื่อมั่น (confidence interval) ของการเพิ่มขึ้นของ Yield ผลสรุปสำคัญคือค่าความมีนัยสำคัญทางสถิติ p < 0.001 สำหรับการเพิ่มขึ้นของ Yield โดยช่วงความเชื่อมั่น 95% ของการเพิ่มขึ้นแบบ absolute อยู่ที่ [+11.0, +15.0] percentage points ซึ่งเทียบเป็น relative อยู่ที่ประมาณ [+15%, +21%]
เนื่องจากมีการตรวจสอบผลหลายช่วงเวลา (sequential looks) ทีมสถิติใช้การปรับค่าเพื่อควบคุมอัตรา Type I error ได้แก่การใช้ alpha‑spending สำหรับการทดสอบแบบพหุครั้งและการรายงาน Bayesian posterior credible interval สำหรับพารามิเตอร์สำคัญ ผลการวิเคราะห์ Bayesian พบว่าโพสเตอร์ริโอริโอกรี (posterior probability) ที่การปรับปรุง Yield เกิน 10 percentage points อยู่ที่ >99.9% ซึ่งสอดคล้องกับผลการทดสอบเชิงความถี่
Summary results (ตัวอย่างตารางสรุป) N wafers total : 1,200 (Control 600 / DT‑BO 600) Yield before : 72.0% (SD 3.8%) Yield after : 85.0% (SD 3.2%) Absolute ΔYield : +13.0 p.p. (95% CI: +11.0 to +15.0 p.p.) Relative ΔYield : +18.1% (95% CI: +15% to +21%) p‑value (Yield) : < 0.001 Throughput gain : +14.9% Cycle time change : −6.2% Defect reductions : Particle −42% (p<0.001), Patterning −25% (p=0.002), Overlay −12% (p=0.03)
การตีความเชิงธุรกิจ: ROI และเวลาคืนทุน
เพื่อประเมินผลเชิงธุรกิจ เราใช้สองสมมติฐานตัวอย่าง (conservative / optimistic) โดยตั้งค่าพารามิเตอร์หลักคือจำนวน wafer ต่อปี, ค่าเพิ่มขึ้นของมูลค่าต่อ wafer จาก Yield ที่ปรับปรุง และค่าใช้จ่ายเริ่มต้นของการติดตั้ง DT‑BO (รวมฮาร์ดแวร์ เซ็นเซอร์ การผนวกรวมระบบ และการพัฒนา) สมมติฐานหลัก (ตัวอย่าง):
- ต้นทุนการติดตั้งระบบ (CAPEX + integration) = 40 ล้านบาท (ประมาณ)
- จำนวน wafer ต่อปี = Conservative 50,000 / Optimistic 100,000
- มูลค่าขายเฉลี่ยที่เพิ่มขึ้นต่อ wafer จากการเพิ่ม Yield = Conservative 2,000 บาท/wafer, Optimistic 2,500 บาท/wafer
ตัวอย่างการคำนวณ:
- Conservative: 50,000 wafers × 2,000 บาท = 100 ล้านบาทต่อปี กำไรเพิ่ม Annual incremental → เวลาคืนทุน ≈ 40M / 100M = 0.4 ปี (ประมาณ 5 เดือน)
- Optimistic: 100,000 wafers × 2,500 บาท = 250 ล้านบาทต่อปี → เวลาคืนทุน ≈ 40M / 250M = 0.16 ปี (ประมาณ 2 เดือน)
นอกจากนี้ยังมีผลประโยชน์เชิงอ้อมที่ยากต่อการตีมูลค่าโดยตรงแต่สำคัญ ได้แก่ การเพิ่มความเสถียรของกระบวนการ ลดอัตรา rework และ scrap ซึ่งช่วยลดความเสี่ยงด้าน supply chain และเพิ่มความสามารถในการเปิดตัวผลิตภัณฑ์ใหม่ได้เร็วขึ้น ในมุมมอง ROI ระยะยาว (3–5 ปี) การลงทุนใน DT‑BO โดยมีผลลัพธ์ตามที่ทดลองได้ คาดว่าจะคืนทุนได้อย่างรวดเร็วและสร้างมูลค่าเพิ่มอย่างมีนัยสำคัญให้กับกำไรขั้นต้นของโรงงาน
กรณีศึกษาลงลึก: ตัวอย่างการจูนพารามิเตอร์จริง
กรณีศึกษาลงลึก: ตัวอย่างการจูนพารามิเตอร์จริง
ในโครงการนำร่องที่โรงงานเซมิคอนดักเตอร์แห่งหนึ่ง ทีมวิศวกรกระบวนการผสาน Digital‑Twin กับ Bayesian Optimization (BO) เพื่อจูนไลน์การผลิตชิปรายหนึ่ง (logic process) โดยมีเป้าหมายหลักคือเพิ่มอัตรา Yield ของชิปจากระดับฐานเดิมและลดค่า DPPM (defects per million) โดยยังคงคำนึงถึงตัวชี้วัดข้างเคียงเช่น throughput, cycle time และ particle contamination ผลลัพธ์เชิงตัวเลขหลังการจูนด้วย BO คือ Yield เพิ่มจาก 78.0% เป็น 92.0% (เพิ่มขึ้น 14 จุด หรือประมาณ +18% แบบ relative) ขณะที่ DPPM ลดจาก ~9,800 เหลือ ~2,100 ตัวอย่างนี้สาธิตความสามารถของ BO ในการค้นหาชุดพารามิเตอร์ที่สมดุลระหว่างคุณภาพกับประสิทธิภาพการผลิต
ทีมงานเริ่มด้วยการกำหนดชุดพารามิเตอร์หลักที่ต้องการจูน ได้แก่:
- อุณหภูมิเตา (Furnace Temperature) — ค่าแนะนำช่วง 780–880 °C; ส่งผลต่อการตกตะกอนและการกระจายชั้นบาง
- ความดันภายในห้องกระบวนการ (Process Pressure) — ช่วง 100–500 mTorr; กระทบต่อ film density และ uniformity
- อัตราการไหลของแก๊ส (Gas Flow Rates) — เช่น SiH4, N2, O2 (หน่วย sccm); มีผลต่ออัตรา deposition และปริมาณอนุภาค
- อัตราเร่ง/ชะลออุณหภูมิ (Ramp Rate) — ส่งผลต่อ stress และ wafer bow
- ความเร็วลำเลียง wafer (Conveyor/Wafer Speed) — มีผลต่อ throughput และการรับแสง/การสัมผัสกระบวนการ
- เวลาการอบ/Anneal Time — กระทบการกระจายโดปและคุณสมบัติไฟฟ้า
ตัวอย่างชุดพารามิเตอร์ก่อน/หลังการจูนที่ชัดเจน (ค่าตัวอย่างเพื่อแสดงผล):
- ก่อนจูน (baseline) — Temperature: 850 °C, Pressure: 300 mTorr, SiH4 flow: 50 sccm, N2 flow: 200 sccm, Ramp rate: 10 °C/min, Wafer speed: 10 wafers/min, Anneal: 60 s. ผล: Yield = 78.0%, DPPM ≈ 9,800, Cycle time = 45 min.
- หลังจูน (Bayesian‑optimized) — Temperature: 830 °C, Pressure: 260 mTorr, SiH4 flow: 45 sccm, N2 flow: 220 sccm, Ramp rate: 7 °C/min, Wafer speed: 12 wafers/min, Anneal: 72 s. ผล: Yield = 92.0%, DPPM ≈ 2,100, Cycle time = 47 min.
ในกระบวนการจูน ทีมงานติดตามผลข้างเคียงและเมตริกที่เกี่ยวข้องอย่างเข้มงวดด้วยระบบ metrology แบบ inline และ offline เช่น SEM inspection, optical defect scanner, wafer bow measurement และ SPC (statistical process control) ดังนี้:
- Particle count — พบว่าการเพิ่ม flow ของบางแก๊สส่งผลให้ particle count เพิ่มได้ ดังนั้น BO ถูกกำหนดให้มี constraint ทางด้านอนุภาค (particle limit) เป็นเงื่อนไขบังคับ
- Wafer bow / stress — ค่า ramp rate ที่สูงเกินไปทำให้ wafer bow เพิ่มขึ้น ทีมงานจึงวัด bow ทุกล็อตและใส่ penalty ใน objective function เพื่อหลีกเลี่ยงค่าที่ทำให้ bow เกิน spec
- Throughput / cycle time — แม้ Yield จะดีขึ้น แต่บางการตั้งค่าทำให้ cycle time เพิ่ม ทีมงานเลือกใช้ multi‑objective BO เพื่อหาจุดสมดุลระหว่าง Yield สูงและ cycle time ยอมรับได้
- Equipment wear and safety — ตัวอย่างเช่น pressure ต่ำสุดบางค่าเพิ่มความเสี่ยงต่อการเกิดภาวะ arcing จึงมีเงื่อนไขด้านความปลอดภัย (hard constraints) ที่ BO ต้องปฏิบัติตาม
เหตุผลที่ Bayesian Optimization ให้ผลดีกว่า random search หรือ tuner แบบดั้งเดิม (manual tuning / grid search) ในกรณีนี้ สรุปได้ดังนี้:
- ประสิทธิภาพด้านตัวอย่าง (sample efficiency) — การทดลองจริงบนไลน์มีต้นทุนสูง (เวลา, วัสดุ, โอกาส); BO ใช้ surrogate model (มักเป็น Gaussian Process) เพื่อคาดการณ์ผลจากค่าพารามิเตอร์ไม่กี่ชุดแล้วเลือกการทดลองถัดไปที่ให้ประโยชน์มากที่สุด โดยใช้ acquisition function (เช่น Expected Improvement) ทำให้ต้องทดลองน้อยกว่าการค้นหาแบบสุ่มหรือตารางอย่างมาก
- รองรับความไม่แน่นอนและเสียงรบกวน (noise) — การวัดบนไลน์มีความแปรผัน BO สามารถโมเดลความไม่แน่นอนนี้และเลือกค่าที่คาดว่าจะดีกว่าอย่างมีความน่าเชื่อถือ ในขณะที่ grid/random ไม่คำนึงถึงความไม่แน่นอนเช่นนี้
- จัดการข้อจำกัดและหลายวัตถุประสงค์ — BO สามารถรวม hard constraints (เช่น particle limit, safety bounds) และ penalty สำหรับ metric ข้างเคียงได้ ทำให้ได้ผลลัพธ์ที่นำไปใช้จริงได้ทันที ไม่เพียงแต่หา optimum ทางทฤษฎีที่ละเลยข้อจำกัด
- ใช้ความรู้ล่วงหน้าได้ (warm‑start / priors) — BO สามารถเริ่มด้วยข้อมูลประวัติ (previous runs หรือ process models จาก Digital‑Twin) ทำให้ converges เร็วขึ้น ต่างจากการสุ่มที่เริ่มจากศูนย์
- ค้นหาแบบอัจฉริยะ (exploration vs exploitation) — Acquisition function ปรับสมดุลการสำรวจพื้นที่พารามิเตอร์ใหม่กับการขยายค่าใกล้เคียง optimum ที่พบแล้ว ซึ่งลดการทดสอบที่ไร้ประโยชน์
บทเรียนเชิงปฏิบัติที่ได้จากโครงการและคำแนะนำสำหรับการนำไปใช้จริง:
- กำหนด objective ให้ชัดเจนและรวมเมตริกข้างเคียงเป็น constraints หรือ multi‑objective ตั้งแต่ต้น (เช่น Yield, DPPM, cycle time, particle limit)
- เริ่มด้วย warm‑start โดยนำข้อมูลประวัติและโมเดล Digital‑Twin มาให้ BO เพื่อเร่งการหาค่าเหมาะสม
- ใช้ surrogate model ที่สามารถจับความไม่เชิงเส้นและความไม่แน่นอนได้ (GP หรือ Tree‑based surrogate ในกรณีข้อมูลใหญ่) และใช้ acquisition function ที่เหมาะสมกับสภาพปัญหา (EI, UCB, PI เป็นต้น)
- ตั้ง hard safety constraints เพื่อป้องกันการทดลองที่เสี่ยงต่ออุปกรณ์หรือผลิตภัณฑ์ และบังคับตรวจวัดข้างเคียง (particle, bow) แบบ realtime
- วางแผนการทดลองเป็น batch เมื่อสามารถวัดพร้อมกันได้ เพื่อเร่งการค้นหา (parallel BO) แต่ต้องระวังการเลือก batch points ที่มีความหลากหลายพอ
- ติดตาม drift ของกระบวนการและทำ re‑calibration เป็นระยะ BO ที่ไม่อัพเดตต่อเนื่องจะสูญเสียประสิทธิภาพเมื่อเงื่อนไขโรงงานเปลี่ยน
- เอกสารการเปลี่ยนแปลงและผลลัพธ์เชิงวิทยาศาสตร์อย่างละเอียด เพื่อให้สามารถย้อนกลับหรือ replicate ได้เมื่อเผชิญสภาพแวดล้อมใหม่
สรุปคือ การผสาน Digital‑Twin กับ Bayesian Optimization ช่วยให้ทีมสามารถจูนพารามิเตอร์เชิงกระบวนการที่ซับซ้อนได้อย่างมีประสิทธิภาพและปลอดภัย โดยไม่ต้องอาศัยการทดลองจำนวนมากหรือการเดาทางแบบ manual ซึ่งผลลัพธ์ในกรณีศึกษานี้แสดงให้เห็นทั้งการเพิ่ม Yield อย่างชัดเจนและการควบคุมผลข้างเคียงให้อยู่ในข้อกำหนดที่รับได้
ความท้าทาย ความเสี่ยง และแนวทางการขยายผล
ความท้าทาย ความเสี่ยง และแนวทางการขยายผล
การนำระบบ Digital‑Twin ที่ผสาน Bayesian‑Optimization มาใช้ในไลน์ผลิตเซมิคอนดักเตอร์ แม้ว่าจะให้ผลการทดลองที่น่าพอใจ — เช่นการเพิ่มอัตรา yield ของชิปได้ประมาณ 18% ในช่วงทดสอบ — แต่การขยายผลสู่การใช้งานเชิงพาณิชย์ในระดับโรงงานจริงมีความท้าทายและความเสี่ยงหลายด้านที่ต้องวางแผนและบริหารอย่างเป็นระบบ โดยเฉพาะเรื่อง latency ในการเปลี่ยนค่าจริง ความปลอดภัยของข้อมูลและทรัพย์สินทางปัญญา การจัดการการเปลี่ยนแปลงเชิงปฏิบัติการ รวมถึงข้อจำกัดทางกฎหมายและช่องว่างด้านทักษะของบุคลากร
ความเสี่ยงเชิงปฏิบัติการและการบริหารการเปลี่ยนแปลง
การนำคำแนะนำจากโมเดลไปปรับพารามิเตอร์กระบวนการผลิตมีความเสี่ยงด้านเวลาหน่วง (latency) และความไม่แน่นอนของการตอบสนองจริงของอุปกรณ์ ตัวอย่างเช่น หากระบบแนะนำการเปลี่ยนแปลงที่ต้องทำในระดับ closed‑loop control แต่การส่งคำสั่งมี latency เกินกว่าเวลาที่กระบวนการต้องการ (เช่นเกิน 100–500 มิลลิวินาทีในบางขั้นตอน) อาจเกิด overshoot หรือ instabilities ของกระบวนการได้ นอกจากนี้ยังมีความเสี่ยงจากการเปลี่ยนแปลงที่โมเดลไม่เคยเห็น (out‑of‑distribution) ทำให้การแนะนำอาจส่งผลเสียต่อคุณภาพหรือความปลอดภัยของอุปกรณ์
- แนวทางบรรเทา: นำกลยุทธ์ deployment แบบ hybrid on‑prem/cloud โดยให้ loop ที่ต้องการ latency ต่ำและการควบคุมซิงโครไนซ์อยู่บน on‑premises edge controllers ขณะที่การฝึกโมเดล, การทำ analytics ระยะยาว และการเก็บข้อมูลเชิงประวัติศาสตร์ทำบน cloud
- การทดสอบและ rollout แบบค่อยเป็นค่อยไป: ใช้ shadow testing, A/B และ canary deployment ก่อนเปิดใช้เต็มรูปแบบ เฉพาะคำแนะนำที่ผ่านเกณฑ์ KPI (เช่นลด defect rate ≥5% ในการทดสอบ 30 วัน) ถึงจะยอมรับใช้งานจริง
- มาตรการป้องกัน: ตั้ง safety bounds และ kill‑switch อัตโนมัติ, implement rollback policy และ human‑in‑the‑loop สำหรับการเปลี่ยนแปลงที่มีความเสี่ยงสูง
ข้อกำหนดด้านความปลอดภัยและการปกป้องข้อมูล
ข้อมูลกระบวนการผลิตและโมเดล AI ถือเป็นทรัพย์สินทางปัญญาสำคัญ ความเสี่ยงรวมถึงการรั่วไหลของข้อมูลที่อาจให้คู่แข่งได้เปรียบ การโจมตีต่อ integrity ของโมเดล (poisoning) และการเข้าถึงโดยไม่ได้รับอนุญาต ซึ่งในบริบทการผลิตชิปยังมีข้อผูกมัดด้านกฎระเบียบ เช่น PDPA ของไทย และข้อจำกัดด้านการส่งออกเทคโนโลยีที่อาจเกี่ยวข้อง
- แนวทางด้านเทคนิค: ใช้การเข้ารหัสระดับอุตสาหกรรม (TLS/AES‑256) ทั้งที่ data‑in‑transit และ data‑at‑rest, ใช้ HSMs สำหรับการจัดการคีย์, และ implement role‑based access control (RBAC) พร้อม audit logs ที่ไม่สามารถแก้ไขได้
- กลยุทธ์โมเดลและข้อมูล: พิจารณาเทคนิค privacy‑preserving เช่น federated learning หรือ differential privacy เมื่อแชร์โมเดลระหว่างโรงงาน, รวมทั้ง digital watermarking และ model encryption เพื่อปกป้องทรัพย์สินทางปัญญา
- นโยบายและการกำกับดูแล: จัดทำ data governance policy ที่ครอบคลุม data retention, consent, และ cross‑border transfer compliance รวมถึง periodic security assessments และ third‑party penetration testing
กลยุทธ์การขยายผลและวางแผนทรัพยากรมนุษย์
การขยายผลจากไลน์ต้นแบบไปสู่ไลน์อื่นหรือโรงงานอื่นต้องการกรอบงานที่ชัดเจนทั้งด้านเทคนิค การเงิน และบุคลากร เริ่มจากการจำแนกความพร้อมของไลน์เป้าหมาย (เช่นความสอดคล้องของเซนเซอร์, PLC, และระบบ MES) และการตั้ง KPI ทางธุรกิจที่ชัดเจน เช่น time‑to‑value ภายใน 6–12 เดือน, ROI ภายใน 18 เดือน และลด defect rate เป็นร้อยละที่ยอมรับได้
- แผนการขยายแบบเป็นขั้นตอน: แบ่งเป็น Pilot → Scale within plant → Multi‑line rollout → Cross‑plant rollout โดยแต่ละขั้นตอนมี gates ด้าน KPI, security compliance และ readiness checklist
- ทรัพยากรมนุษย์: จัดตั้งทีมข้ามสายงาน (cross‑functional) ประกอบด้วย data scientists, process engineers, automation engineers, IT/OT security และ production leads โดยแนะนำขนาดทีมเริ่มต้น 6–12 FTE ต่อโรงงานสำหรับการติดตั้งและช่วง stabilization และการลงทุนฝึกอบรม operator ประมาณ 40–80 ชั่วโมงต่อบุคคลสำหรับการใช้งานและการตอบสนองต่อคำแนะนำของระบบ
- MLOps/CI‑CD สำหรับโมเดล: ใช้ pipeline อัตโนมัติสำหรับ data validation, model training, testing (unit, integration, performance), deployment และ monitoring เพื่อให้สามารถ retrain และ rollback ได้รวดเร็ว ควรรวม feature store, model registry, และ explainability tools เพื่อรองรับการ audit และ regulatory requirements
สรุปแล้ว การขยายผลต้องการสมดุลระหว่างนวัตกรรมกับการบริหารความเสี่ยงอย่างรัดกุม โดยใช้สถาปัตยกรรม hybrid, แนวปฏิบัติความปลอดภัยที่เข้มงวด, กระบวนการ MLOps ที่เป็นมาตรฐาน และการลงทุนในคนและทักษะอย่างต่อเนื่อง เพื่อให้การนำ Digital‑Twin + Bayesian‑Optimization ขึ้นสู่การผลิตเชิงพาณิชย์เป็นไปอย่างยั่งยืนและปลอดภัย
แนวทางเชิงธุรกิจและนโยบายสำหรับองค์กร
สรุปเชิงธุรกิจและการประเมินผลตอบแทน (ROI) — แนวทางคำนวณและตัวอย่างเชิงตัวเลข
การประเมินผลตอบแทนจากการลงทุน (ROI) สำหรับโครงการ Digital‑Twin AI ที่ผสาน Bayesian‑Optimization ควรทำบนพื้นฐานของการเปลี่ยนแปลงเชิงปริมาณ (quantifiable improvement) เช่น อัตรา Yield ที่เพิ่มขึ้น 18%, การลดเวลารอบการผลิต (cycle time), และการลดชิ้นทิ้ง (scrap rate) ตัวสูตรพื้นฐานที่ใช้ได้คือ:
- ROI (%) = (ผลประโยชน์สุทธิ – ต้นทุนลงทุน) / ต้นทุนลงทุน × 100
- โดย ผลประโยชน์สุทธิ คำนวณจาก: เพิ่มรายได้จากชิ้นดี (incremental revenue) + ลดต้นทุนการผลิต + ลดค่าใช้จ่ายด้านคุณภาพ (rework/scrap) – ค่าใช้จ่ายดำเนินงานเพิ่มเติม (เช่น ค่าซอฟต์แวร์ บำรุงรักษา)
ตัวอย่างเชิงตัวเลขสมมติ: โรงงานผลิตเฉลี่ย 50,000 wafer/เดือน มูลค่ารายได้ต่อ wafer หลังกระบวนการและทดสอบเท่ากับ 20,000 บาท หาก Yield เพิ่มขึ้น 18% จะได้ชิ้นดีเพิ่มขึ้นเทียบเท่าเงินเพิ่มรายได้ประมาณ 50,000 × 20,000 × 18% = 180,000,000 บาท/เดือน (ก่อนหักต้นทุนเพิ่มเติม) หากต้นทุนการลงทุน (รวม CapEx + การติดตั้ง + ค่าที่ปรึกษา) อยู่ที่ 120 ล้านบาท และค่าใช้จ่ายการดำเนินงานรวมต่อปี 36 ล้านบาท โครงการนี้จะคืนทุนได้ภายในไม่กี่เดือน — แน่นอนว่าตัวเลขจริงต้องวิเคราะห์จากตัวแปรจริงของโรงงานแต่ละแห่ง
ตัวชี้วัด (KPIs) สำหรับติดตามผลระยะสั้นและระยะยาว
กำหนด KPI ที่ชัดเจนและสามารถวัดได้เป็นสิ่งจำเป็น ทั้งในระดับการผลิต รายการคุณภาพ และประสิทธิภาพของ AI/ระบบ Digital Twin เอง ตัวอย่าง KPI แนะนำได้แก่:
- Yield / First Pass Yield (FPY) — เป้าหมาย: +18% หรือค่าดัชนีที่องค์กรตั้งไว้
- Overall Equipment Effectiveness (OEE) — ติดตามประสิทธิภาพรวมของไลน์
- Cycle Time / Throughput — เวลาต่อชิ้นและชิ้นต่อชั่วโมง
- Scrap Rate & Rework Cost — ต้นทุนที่ลดลงจากชิ้นทิ้ง
- Cost per Good Die — ค่าต้นทุนต่อชิ้นที่ส่งมอบได้จริง
- Model Accuracy & Convergence Time — ประสิทธิภาพของ Bayesian optimizer และความถี่ในการรีเทรน
- Time to Detect & Mitigate Anomalies — ระยะเวลาจากการตรวจพบปัญหาเชิงกระบวนการจนถึงการแก้ไข
- Payback Period, NPV, IRR — ดัชนีการเงินเพื่อการตัดสินใจบริหาร
แนะนำให้ตั้งระดับมาตรฐาน (baseline) ก่อนติดตั้ง และรายงาน KPI เป็นรายสัปดาห์ในช่วงพิลอตต์ แล้วปรับเป็นรายเดือนเมื่อลงสเกล เพื่อให้เห็นแนวโน้มระยะยาวและฤดูกาลของการผลิต
รูปแบบการร่วมมือกับพาร์ทเนอร์ภายนอก (vendors, consultants)
การจัดการพาร์ทเนอร์ภายนอกควรออกแบบเป็นเฟสและมีบทบาทที่ชัดเจน เพื่อรักษาความต่อเนื่องทางเทคนิคและการโอนความรู้ (knowledge transfer) รูปแบบที่แนะนำได้แก่:
- เฟสพิลอตต์ (Pilot) — สัญญาระยะสั้น 3–6 เดือน ระบุ KPI พื้นฐาน, เกณฑ์ความสำเร็จ และขอบเขตข้อมูล (data scope) ที่พาร์ทเนอร์เข้าถึง
- สัญญาบริการเชิงผลลัพธ์ (Outcome‑based) — ส่วนหนึ่งของค่าตอบแทนผูกกับการปรับปรุง Yield หรือการลด scrap เพื่อแบ่งความเสี่ยงและผลประโยชน์
- โมเดลการชำระเงินแบบผสม (Hybrid CapEx + OpEx) — ต้นทุนเริ่มต้นบางส่วนเป็น CapEx สำหรับฮาร์ดแวร์และ integration และค่าใช้จ่ายต่อเนื่องเป็น OpEx สำหรับซอฟต์แวร์/โมเดล เช่น subscription หรือ per-wafer fee
- ข้อตกลงด้าน SLA, IP, และ Data Governance — ระบุ SLA ด้านความพร้อมใช้งาน, เวลาแก้ไขบั๊ก, สิทธิในโมเดลและข้อมูล, มาตรการความปลอดภัยและการเข้ารหัสข้อมูล
- ข้อกำหนดการโอนเทคโนโลยี (Knowledge Transfer) — เนื้อหาการฝึกอบรม, เอกสารมาตรฐาน, และเงื่อนไขการสนับสนุนหลังสัญญา
แนะนำให้มีคณะกรรมการกำกับโปรเจ็กต์ (Steering Committee) ที่รวมฝ่ายวิศวกรรม ฝ่ายการเงิน และฝ่ายกฎหมาย เพื่อพิจารณาและอนุมัติข้อตกลงเชิงกลยุทธ์
นโยบายภายในองค์กรและแผนการฝึกอบรมเพื่อการสเกลอัพ
สำหรับการนำไปใช้อย่างยั่งยืน จำเป็นต้องกำหนดนโยบายภายในที่ชัดเจนครอบคลุมมาตรฐานการวัดผล การจัดการข้อมูล และการเปลี่ยนแปลงกระบวนการ ตัวนโยบายหลักควรประกอบด้วย:
- มาตรฐานการวัดผลและการตรวจสอบ (Measurement Standards) — ระบุวิธีการเก็บข้อมูล, ความถี่การรายงาน KPI, และกระบวนการการทำ baseline ก่อน/หลังการติดตั้ง
- นโยบาย Data Governance & Security — สิทธิการเข้าถึงข้อมูล, การทำ anonymization, การสำรองข้อมูล และการปฏิบัติตาม PDPA/มาตรฐานสากล
- Change Management — กระบวนการอนุมัติการปรับพารามิเตอร์ที่มาจาก AI, การทดลองในสภาพแวดล้อมควบคุมก่อนใช้งานจริง
- แผนสเกลอัพเชิงเฟส — Pilot (3–6 เดือน) → Regional Rollout (6–12 เดือน) → Full Production Scale (12–24 เดือน) พร้อมเกณฑ์การผ่านเฟสที่ชัดเจน
แผนฝึกอบรมควรออกแบบเป็นระดับ (tiered curriculum):
- ระดับบริหาร (Executives) — ภาพรวมเชิงกลยุทธ์, KPI ทางการเงิน, และการตัดสินใจเชิงนโยบาย (1–2 วัน)
- ระดับวิศวกร/กระบวนการ (Engineers / Process Owners) — การใช้งาน Digital Twin, การตีความผลลัพธ์ของ Bayesian optimizer, การตั้งค่าการทดลอง (3–5 วัน + workshop)
- ระดับปฏิบัติการ (Operators / Technicians) — ขั้นตอนการปฏิบัติจริง, การตอบสนองต่อแจ้งเตือน, การบำรุงรักษาพื้นฐาน (2–3 วัน)
- Data Science / ML Ops Team — การปรับแต่งโมเดล, การรีเทรน, CI/CD ของโมเดล (ระยะเวลาตามความซับซ้อน)
- Train‑the‑Trainer — สร้างกลุ่ม Internal Champions เพื่อลดการพึ่งพาผู้ให้บริการภายนอกในระยะยาว
กำหนดแผน certification ภายในและ KPI การฝึกอบรม เช่นสัดส่วนบุคลากรผ่านการรับรอง, เวลาที่ใช้ในการตอบสนองต่อ alerts, และจำนวนการถ่ายทอดความรู้ (knowledge transfer sessions) ที่สำเร็จ เพื่อให้แน่ใจว่าองค์กรมีกำลังคนและกระบวนการรองรับการสเกลอัพอย่างยั่งยืน
บทสรุป
การผสานระหว่าง Digital‑Twin กับ Bayesian Optimization เปิดทางให้โรงงานเซมิคอนดักเตอร์สามารถปรับจูนไลน์การผลิตได้อย่างมีประสิทธิภาพและแม่นยำมากขึ้น — ในตัวอย่างโรงงานไทยที่นำระบบไปใช้จริงรายงานการเพิ่มอัตรา Yield ของชิปสูงถึง 18% ขณะเดียวกันยังช่วยลดเวลาในการหาพารามิเตอร์ที่เหมาะสมจากระดับหลายสัปดาห์เหลือเพียงไม่กี่วัน เนื่องจาก Digital‑Twin ให้แบบจำลองกระบวนการผลิตที่สะท้อนสภาพแวดล้อมจริงและ Bayesian Optimization ช่วยค้นหาชุดพารามิเตอร์ที่คุ้มค่าอย่างมีประสิทธิผลในพื้นที่พารามิเตอร์มิติสูง ผลลัพธ์รวมถึงการลดของเสีย การเพิ่มประสิทธิภาพอัตราการผลิต และการลดต้นทุนต่อหน่วยอย่างจับต้องได้
อย่างไรก็ตาม ความสำเร็จเชิงปฏิบัติการต้องอาศัยองค์ประกอบสนับสนุนที่ชัดเจน ได้แก่ สถาปัตยกรรมข้อมูลที่เชื่อถือได้ (data lineage, คุณภาพข้อมูล, ความหน่วงเวลาในการอัปเดต), การจัดการความเสี่ยงด้านความปลอดภัยและความเป็นส่วนตัว (เช่น การเข้ารหัสข้อมูล การควบคุมการเข้าถึง และการตรวจสอบเหตุการณ์), รวมทั้งการวางแผนเชิงธุรกิจที่รัดกุมเพื่อประเมิน ROI และจัดสรรทรัพยากรทั้งบุคลากรและฮาร์ดแวร์สำหรับการขยายผล การลงทุนในกระบวนการจัดการข้อมูลและนโยบายความปลอดภัยเป็นปัจจัยสำคัญที่จะกำหนดว่าระบบจะขยายผลได้เร็วและปลอดภัยเพียงใด
มุมมองอนาคตชี้ว่าเทคโนโลยีนี้มีศักยภาพขยายตัวอย่างต่อเนื่อง: การรวมข้อมูลจากหลายไลน์การผลิตและการเรียนรู้แบบต่อเนื่อง (online learning) จะช่วยยกระดับประสิทธิภาพได้มากขึ้น ขณะเดียวกันการผสานกับ edge computing และมาตรการความปลอดภัยเชิงรุกจะลดความเสี่ยงด้าน latency และการรั่วไหลของข้อมูล สำหรับธุรกิจที่ต้องการนำไปใช้ในวงกว้าง ควรวางกรอบการวัดผลเชิงเศรษฐศาสตร์อย่างชัดเจน (เช่น ระยะเวลาคืนทุน การลดต้นทุนต่อชิ้น) พร้อมแผนฝึกอบรมบุคลากรและการจัดการการเปลี่ยนแปลง เพื่อให้การนำ Digital‑Twin + Bayesian Optimization กลายเป็นกลยุทธ์การผลิตที่ยั่งยืนและขยายผลได้จริง



