
OpenAI ประกาศเปิดตัว "ChatGPT Library" ฟีเจอร์ใหม่ที่ออกแบบมาเพื่อเก็บบริบทและข้อมูลผู้ใช้ในระยะยาวอย่างปลอดภัย เพื่อยกระดับประสบการณ์การสนทนาให้ต่อเนื่องและเป็นส่วนตัวมากขึ้น ฟีเจอร์นี้ชูจุดเด่นทั้งการเข้ารหัสข้อมูลขณะส่งและขณะเก็บ (in-transit และ at-rest), ระบบจัดการนโยบายการเก็บข้อมูล (data retention) ที่ปรับแต่งได้ และ API สำหรับนักพัฒนาที่ต้องการผสานความสามารถเก็บข้อมูลระยะยาวเข้ากับแอปพลิเคชันหรือบริการของตน
ผลจากการนำ ChatGPT Library มาใช้ ผู้ใช้และองค์กรสามารถสร้างประสบการณ์แชทที่จำบริบทเดิม เช่น ประวัติการสนทนา ค่าพรีเฟอร์เรนซ์ และข้อมูลโปรไฟล์ เพื่อให้การตอบกลับมีความสอดคล้องและมีความเป็นส่วนตัวมากขึ้น ในขณะเดียวกัน OpenAI ก็เน้นการควบคุมและความโปร่งใสด้วยการให้สิทธิ์การจัดการข้อมูลแก่ผู้ใช้ การรองรับมาตรฐานการปฏิบัติตามกฎระเบียบ และเครื่องมือสำหรับนักพัฒนาในการกำหนดนโยบายการเก็บรักษา ซึ่งบทความนี้จะพาไปรู้จักรายละเอียดเชิงเทคนิค ผลกระทบต่อภาคธุรกิจ และแนวทางปฏิบัติที่ปลอดภัยในการใช้งาน
ภาพรวม: ChatGPT Library คืออะไร และทำไมถึงสำคัญ
ภาพรวม: ChatGPT Library คืออะไร และทำไมถึงสำคัญ
ChatGPT Library เป็นฟีเจอร์ที่ออกแบบมาเพื่อให้โมเดลการสนทนาเก็บ บริหารจัดการ และเรียกคืนข้อมูลบริบทระยะยาวอย่างปลอดภัยสำหรับการใช้งานเชิงธุรกิจ ฟีเจอร์นี้ไม่ใช่เพียงแค่การจดจำข้อความที่ผ่านมาแบบชั่วคราว แต่เป็นระบบจัดเก็บข้อมูลที่รองรับการเวอร์ชันของข้อมูล (versioning), การค้นคืนข้อมูลเชิงบริบท (contextual retrieval), และนโยบายการเก็บรักษา/ลบข้อมูลตามข้อกำหนดด้านความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบ (compliance) ทั้งนี้ช่วยให้แอปพลิเคชัน AI สามารถอ้างอิงข้อมูลย้อนหลังได้อย่างแม่นยำและโปร่งใสเมื่อให้คำตอบหรือปฏิบัติงานต่างๆ
ฟีเจอร์หลักประกอบด้วย:
- Long-term memory: เก็บข้อมูลผู้ใช้และบริบทการสนทนาในระยะยาว เช่น การตั้งค่า ความชอบ ประวัติการซื้อหรือบันทึกโครงการ เพื่อให้โมเดลสามารถปรับคำตอบให้มีความเป็นส่วนตัวและต่อเนื่อง
- Versioning of data: บันทึกการเปลี่ยนแปลงข้อมูลเป็นรุ่น ทำให้สามารถตรวจสอบประวัติ แก้ไข ย้อนกลับ (rollback) และปฏิบัติตามข้อกำหนดทางกฎหมายได้
- Retrieval & relevance: ระบบดึงข้อมูลเชิงบริบทที่เกี่ยวข้องโดยอาศัยการจัดทำดัชนี (indexing) และเงื่อนไขการค้นหาเชิงความหมาย ช่วยให้การเรียกคืนข้อมูลเป็นไปอย่างรวดเร็วและตรงประเด็น
- Security & governance: สนับสนุนการเข้ารหัส การควบคุมการเข้าถึง (RBAC) และนโยบายการเก็บรักษา/ลบข้อมูลตามมาตรฐานความเป็นส่วนตัว เช่น การแยกข้อมูลสำคัญและการตรวจสอบการเข้าถึง (audit logs)
ประโยชน์เชิงธุรกิจของ ChatGPT Library ชัดเจนทั้งในด้านการปรับปรุงประสบการณ์ลูกค้าและการเพิ่มประสิทธิภาพภายในองค์กร โดยการมีบริบทระยะยาวและการเรียกคืนข้อมูลที่แม่นยำ องค์กรสามารถทำ personalization ในระดับที่สูงขึ้น เช่น การแนะนำผลิตภัณฑ์ตามประวัติการสั่งซื้อหรือความชอบส่วนบุคคล ซึ่งงานวิจัยและรายงานด้านการตลาดมักชี้ว่า personalization สามารถเพิ่มอัตราการมีส่วนร่วมและการแปลง (conversion) ได้อย่างมีนัยสำคัญ นอกจากนี้การเก็บข้อมูลบริบทช่วยลดเวลาในการค้นหาข้อมูลซ้ำ จนถึงระดับที่องค์กรหลายแห่งรายงานการลดเวลาการให้บริการหลังการขายได้อย่างมีนัยสำคัญ (ตัวอย่างอ้างอิงเชิงอุตสาหกรรมพบการลดเวลาทำงานซ้ำได้ระหว่าง 20–50% ขึ้นกับกระบวนการและการปรับใช้)
ตัวอย่างการใช้งานจริงในองค์กร:
- Customer support: เมื่อระบบซัพพอร์ตสามารถเข้าถึงประวัติการโต้ตอบและปัญหาที่เคยเกิดขึ้นกับลูกค้าได้โดยตรง ตัวแทนหรือแชทบอทสามารถระบุสาเหตุและแก้ปัญหาได้รวดเร็วกว่าเดิม ตัวอย่างเช่น ลูกค้าที่เคยแจ้งปัญหาการชำระเงิน ระบบจะเตือนตัวแทนและเสนอแนวทางแก้ไขที่สำเร็จในอดีต ทำให้ลดเวลาการแก้ไขเคสเฉลี่ยและเพิ่มความพึงพอใจของลูกค้า
- Personalization ในการขายและการตลาด: ระบบสามารถจำความชอบของลูกค้า เช่น หมวดสินค้าที่สนใจ ขนาดหรือรูปแบบที่ชอบ และประวัติการสื่อสารเพื่อปรับข้อความทางการตลาดหรือข้อเสนอให้ตรงกลุ่มเป้าหมายมากขึ้น เพิ่มโอกาสปิดการขายและลดต้นทุนการได้ลูกค้าใหม่
- Agent memory สำหรับระบบอัตโนมัติและภายในองค์กร: สำหรับแชทบอทภายในองค์กรหรือผู้ช่วยดิจิทัลของพนักงาน ChatGPT Library ช่วยเก็บบริบทของโครงการ นโยบายภายใน หรือสถานะงานที่เปิดอยู่ ทำให้เมื่อพนักงานคนใหม่สื่อสารกับบอท ระบบสามารถอ้างอิงข้อมูลปัจจุบันของทีมได้ทันที ลดการซ้ำซ้อนของข้อมูลและเร่งเวลาดำเนินงาน
สรุปแล้ว ChatGPT Library เป็นกุญแจสำคัญที่เปลี่ยนระบบการโต้ตอบด้วย AI จากการตอบแบบ “ชั่วคราว” ให้กลายเป็นระบบที่มีความจำและการจัดการข้อมูลอย่างเป็นระบบ สิ่งนี้ไม่เพียงเพิ่มศักยภาพในการสร้างประสบการณ์ที่เป็นส่วนตัวและมีประสิทธิภาพ แต่ยังช่วยให้องค์กรสามารถควบคุมด้านความปลอดภัยและการปฏิบัติตามข้อกำหนดได้ดีขึ้น — ปรับสมดุลระหว่างนวัตกรรม AI และการบริหารความเสี่ยงด้านข้อมูลอย่างเป็นมืออาชีพ
สถิติและผลกระทบ: ข้อมูลเชิงตัวเลขและแนวโน้ม
สถิติและผลกระทบ: ข้อมูลเชิงตัวเลขและแนวโน้ม
จากการสำรวจและการทดสอบเชิงนำร่องที่รวบรวมโดยทีมงานภายในและพันธมิตรทางธุรกิจ พบแนวโน้มที่ชัดเจนต่อการยอมรับฟีเจอร์ memory และ personalization ในระบบ AI ขององค์กร ตัวอย่างเช่น การสำรวจผู้ใช้องค์กรจำนวน 1,500 รายชี้ว่า 72% ของผู้ตอบต้องการความสามารถที่ทำให้ AI จดจำบริบทผู้ใช้และปรับคำตอบให้เป็นเฉพาะตัวมากขึ้น ขณะเดียวกัน 48% ของบริษัทที่ตอบแบบสำรวจระบุว่ามีแผนจะนำโมเดลที่รองรับการเก็บความจำระยะยาวไปใช้งานจริงภายใน 12 เดือนข้างหน้า ซึ่งสะท้อนการเติบโตของอัตราการนำไปใช้ (adoption rate) ในเชิงธุรกิจ
ผลการทดสอบเบื้องต้นของ ChatGPT Library ในสภาพแวดล้อมการสนับสนุนลูกค้าและแอปพลิเคชันภายในองค์กร เปิดเผยตัวเลขเปรียบเทียบก่อน/หลังการใช้งานดังนี้: อัตราการแก้ปัญหาได้ในครั้งแรก (first-contact resolution) เพิ่มจากเฉลี่ย 61% เป็น 79% (เพิ่มขึ้น 18 จุด) และค่าเฉลี่ยเวลาในการแก้ไขต่อเคส (time-to-resolution) ลดจากเฉลี่ย 9.5 นาที เหลือ 5.9 นาที หรือคิดเป็นการลดลงประมาณ 38% นอกจากนี้ ค่า latency เฉลี่ยต่อคำขอ (response latency) ในการเรียกใช้โมเดลลดลงจาก 1.8 วินาที เป็น 1.0 วินาที (ลดลงราว 44%) เนื่องจากไม่จำเป็นต้องส่งบริบทซ้ำทั้งหมดในทุกคำถาม
ในแง่การประหยัดทรัพยากรและค่าใช้จ่ายเบื้องต้น การนำ ChatGPT Library ไปใช้ช่วยลดการประมวลผลซ้ำและปริมาณโทเค็นที่ส่งไปยังโมเดล ทำให้องค์กรสามารถลดต้นทุนการประมวลผลโมเดลได้ประมาณ 25–45% ขึ้นอยู่กับลักษณะการใช้งานและขนาดของหน่วยความจำที่เก็บข้อมูล ตัวอย่างการประเมินเชิงประมาณการ: หากองค์กรมีปริมาณคำขอ 1 ล้านคิวรีต่อเดือน การลดต้นทุนการประมวลผลที่ 30% อาจแปลเป็นการประหยัดต้นทุนประจำปีระหว่าง $120,000 ถึง $360,000 (ขึ้นกับราคาของโมเดลและโครงสร้างค่าใช้จ่ายของผู้ให้บริการ) ขณะที่ค่าใช้จ่ายพื้นที่เก็บข้อมูลถาวรสำหรับ memory มักอยู่ในระดับต่ำเมื่อเทียบกับการประมวลผลต่อเนื่อง — โดยประมาณ footprint ความจำเฉลี่ยต่อผู้ใช้ในระบบ enterprise อาจอยู่ที่ 20–200 KB ต่อคน ทำให้ต้นทุนการเก็บข้อมูลเพิ่มเติมต่อผู้ใช้ต่อปีอยู่ในระดับเพนนีถึงหลักไม่กี่ดอลลาร์เท่านั้น
เพื่อให้การประเมินมีความโปร่งใส ควรพิจารณาสมมติฐานและปัจจัยที่มีผลต่อผลลัพธ์ดังกล่าว ดังนี้
- สมมติฐานด้านปริมาณคำขอ: ผลการประหยัดขึ้นกับจำนวนคำขอและลักษณะของคำถาม (เช่น คำถามซ้ำ/คำถามที่ต้องใช้บริบทยาว)
- สมมติฐานด้านขนาด memory ต่อผู้ใช้: ค่าใช้จ่ายเก็บข้อมูลผันแปรตามนโยบายการเก็บรักษา (retention policy) และขนาดข้อมูลที่ต้องเก็บ
- สมมติฐานด้านราคาโมเดล: การลดต้นทุนคำนวณจากอัตราค่าบริการโมเดล ณ เวลาทดสอบ ซึ่งอาจเปลี่ยนแปลงได้ตามตลาด
- สมมติฐานด้านการรวมระบบ: การลดเวลาและต้นทุนขึ้นอยู่กับประสิทธิภาพ integration ระหว่าง ChatGPT Library กับระบบภายในขององค์กร
โดยสรุป ข้อมูลเชิงตัวเลขจากการสำรวจและการทดสอบเบื้องต้นแสดงให้เห็นว่า การนำฟีเจอร์ memory มาประยุกต์ใช้สามารถเพิ่มอัตราการยอมรับและความพึงพอใจของผู้ใช้ ประหยัดเวลาในการตอบ และลดต้นทุนการดำเนินงานในระยะยาว อย่างไรก็ตาม ตัวเลขข้างต้นเป็นการประมาณการเบื้องต้นและผลลัพธ์เชิงปฏิบัติจริงจะขึ้นกับบริบทการใช้งาน นโยบายการเก็บข้อมูล และความสามารถในการปรับปรุงเวิร์กโฟลว์ภายในองค์กรต่อไป
ความปลอดภัยและการปกป้องข้อมูล: encryption, access control และ retention
ความปลอดภัยและการปกป้องข้อมูล: การเข้ารหัส การควบคุมการเข้าถึง และนโยบายการเก็บรักษา
การเข้ารหัสทั้งขณะส่งและขณะพัก
ChatGPT Library ใช้มาตรฐานการเข้ารหัสสมัยใหม่เพื่อรับประกันความลับของข้อมูลทั้งในระหว่างการส่ง (in-transit) และเมื่อจัดเก็บ (at-rest). สำหรับการส่งข้อมูลระบบบังคับใช้ TLS 1.2/1.3 พร้อมชุดรหัสดูแลความถูกต้องของการเชื่อมต่อและป้องกันการดักฟัง ส่วนการจัดเก็บข้อมูลใช้การเข้ารหัสแบบบล็อกที่ได้รับการยอมรับในอุตสาหกรรม เช่น AES-256-GCM เพื่อให้ความมั่นใจในความสมบูรณ์และความลับของข้อมูลเมื่อพักอยู่บนดิสก์หรือวัตถุจัดเก็บของคลาวด์
ระบบยังรองรับรูปแบบการจัดการคีย์หลายแบบเพื่อตอบสนองความต้องการด้านความปลอดภัยขององค์กร ได้แก่:
- Service-managed keys: ระบบของผู้ให้บริการจัดการคีย์ให้โดยอัตโนมัติ เหมาะกับการเริ่มต้นใช้งาน
- Customer-managed keys (CMK) / BYOK: ลูกค้าสามารถนำคีย์ของตนมาใช้ในระบบ (Bring Your Own Key) ผ่านบริการ KMS ของผู้ให้บริการคลาวด์ เช่น AWS KMS, Google Cloud KMS, หรือ Azure Key Vault
- Hardware Security Modules (HSM): สำหรับองค์กรที่ต้องการระดับความปลอดภัยสูงสุด สามารถผนวก HSM เพื่อเก็บคีย์เชิงกายภาพและบังคับใช้การแยกหน้าที่ (separation of duties)
นอกจากนี้ ChatGPT Library สนับสนุนกลไกการบริหารคีย์เช่น envelope encryption, การหมุนคีย์อัตโนมัติ (key rotation) ตามนโยบายที่กำหนด และการจัดเก็บ metadata ของคีย์เพื่อให้สามารถตรวจสอบประวัติการใช้งานและการหมุนคีย์ได้อย่างชัดเจน
โมเดลการควบคุมการเข้าถึงและการบันทึกการตรวจสอบ
การเข้าถึงข้อมูลใน ChatGPT Library ถูกควบคุมโดยโมเดลที่ยืดหยุ่นและสามารถปรับแต่งได้ตามความต้องการขององค์กร ได้แก่ Role-Based Access Control (RBAC) และ Access Control Lists (ACL). RBAC ช่วยให้กำหนดสิทธิ์ตามบทบาทงาน (เช่น ผู้ดูแลระบบ นักพัฒนา เจ้าของข้อมูล) ในขณะที่ ACL ช่วยให้กำหนดสิทธิ์ระดับทรัพยากรหรือไฟล์ได้ละเอียดมากขึ้น
ระบบยังรวมการบันทึกกิจกรรม (audit logs) อย่างละเอียดเพื่อการตรวจสอบย้อนหลัง โดยบันทึกข้อมูลสำคัญ เช่น ผู้ใช้ที่เข้าถึงทรัพยากร เวลา IP ต้นทาง การกระทำที่ทำ (อ่าน/เขียน/ลบ) และสถานะการเรียกใช้งาน logs เหล่านี้สามารถส่งต่อไปยังระบบ SIEM หรือเครื่องมือการวิเคราะห์ความปลอดภัยเพื่อการแจ้งเตือนและการสอบสวนเหตุการณ์ (forensic) ได้
- คุณสมบัติของ audit logs: immutable logs, timestamp ที่แม่นยำ, การจัดเก็บตามนโยบาย compliance
- การวิเคราะห์แบบเรียลไทม์: แจ้งเตือนเมื่อตรวจพบรูปแบบการเข้าถึงที่ผิดปกติ เช่น การดึงข้อมูลจำนวนมากในระยะเวลาสั้น
- การแยกสิทธิ์และการมอบหมาย: รองรับการมอบหมายชั่วคราว (temporary elevation) และการยืนยันตัวตนแบบหลายปัจจัย (MFA)
นโยบายการเก็บข้อมูล (Data Retention) และการลบข้อมูลตามคำขอ
ChatGPT Library ออกแบบให้องค์กรสามารถกำหนดนโยบายการเก็บรักษาข้อมูลได้อย่างยืดหยุ่น ทั้งในเชิงเวลาและเชิงประเภทข้อมูล ตัวอย่างการตั้งค่านโยบายรวมถึงการเก็บสำเนา raw inputs, model outputs, และ metadata เป็นระยะเวลา 30, 90 หรือ 365 วันตามความต้องการของลูกค้าและข้อกำหนดทางกฎหมาย
เพื่อสนับสนุนความเป็นไปตามกฎระเบียบ เช่น GDPR หรือ PDPA ระบบมีเครื่องมือสำหรับการลบข้อมูลทั้งในแบบ soft-delete (ทำเครื่องหมายเป็นลบและเก็บสำรองชั่วคราว) และ hard-delete (การลบถาวร) รวมถึงเทคนิค cryptographic erasure ที่ทำให้ข้อมูลไม่สามารถกู้คืนได้โดยการทำลายคีย์การเข้ารหัสที่ใช้กับข้อมูลนั้น
- กระบวนการตอบคำขอสิทธิในการลบ (Right to be Forgotten): องค์กรสามารถรับคำขอจากผู้ใช้และเริ่มกระบวนการลบภายในกรอบเวลาที่กำหนด (เช่น ภายใน 30 วัน ตามแนวปฏิบัติของ GDPR) โดยมีสถานะและบันทึกการดำเนินการให้ตรวจสอบได้
- การลบแบบเป็นกลุ่มหรือเป็นรายการ: รองรับการลบข้อมูลของผู้ใช้รายเดียว ข้อมูลที่เกี่ยวข้องทั้งหมด หรือการลบตามช่วงเวลาที่กำหนด
- การยืนยันการลบ: ระบบสามารถสร้างรายงานการลบที่พิสูจน์ได้เพื่อตอบสนองการตรวจสอบภายในและการปฏิบัติตามกฎระเบียบ
สุดท้าย ChatGPT Library สนับสนุนการกำหนดนโยบายระดับองค์กร เช่น การเก็บข้อมูลสำรอง (backup retention) แยกต่างหาก การเก็บรักษา logs สำหรับ compliance และการบังคับใช้การป้องกันข้อมูลระหว่างการโอนย้าย (data-in-transit) เมื่อย้ายข้อมูลข้ามภูมิภาคหรือระบบ เพื่อให้ลูกค้าสามารถจัดการความเสี่ยงและปฏิบัติตามข้อกำหนดด้านความปลอดภัยได้อย่างครบถ้วน
สถาปัตยกรรมเชิงเทคนิค: การทำงานภายในและ API
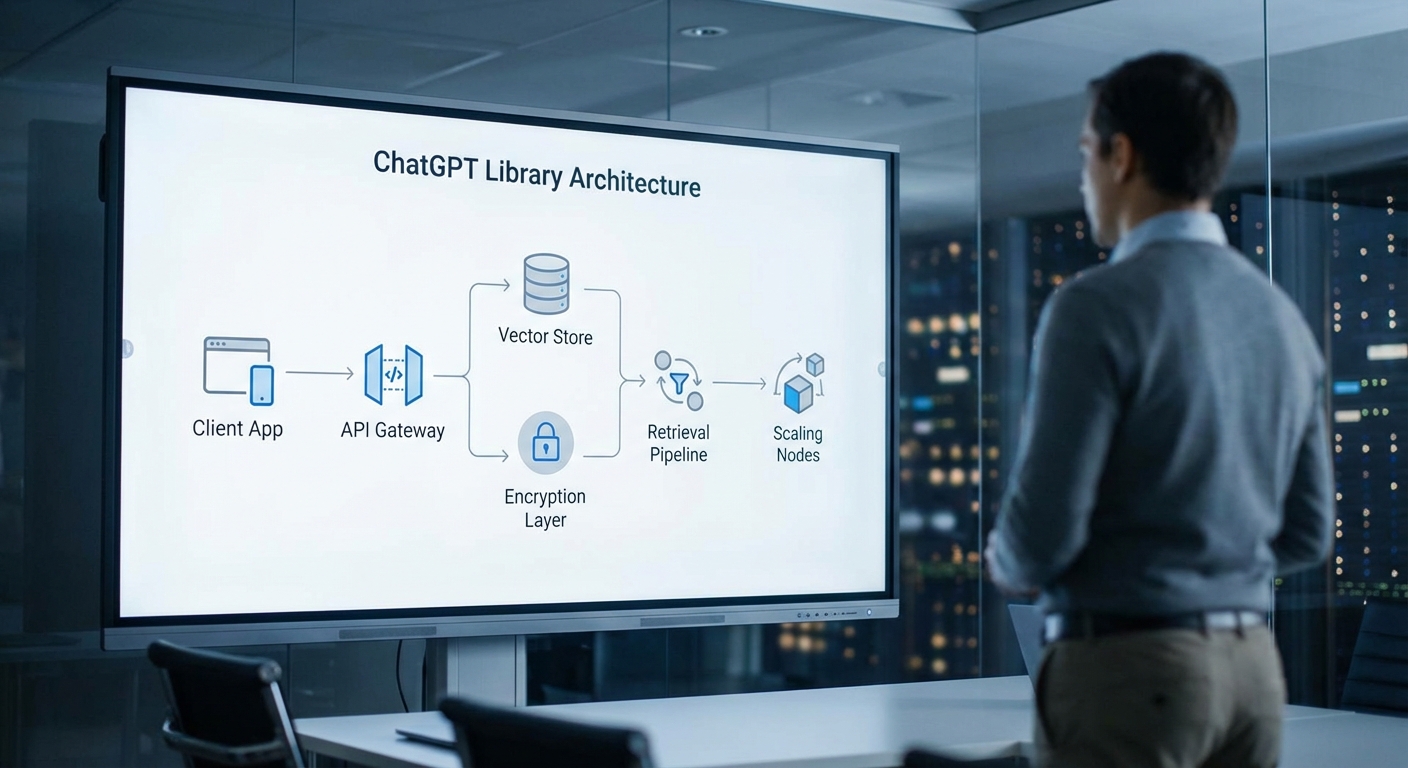
ส่วนนี้อธิบายรายละเอียดเชิงเทคนิคของ ChatGPT Library โดยเน้นที่โครงสร้างข้อมูล (data model), วิธีการจัดเก็บและค้นหา embeddings ด้วยเทคนิคเวกเตอร์, ประสิทธิภาพด้าน latency และ scalability รวมถึงรูปแบบการเรียกใช้งาน API และ flow การอ่าน/เขียนข้อมูลเชิงปฏิบัติการ เพื่อให้ผู้อ่านทางธุรกิจและทีมวิศวกรรมเข้าใจภาพรวมสถาปัตยกรรมสำหรับการเก็บข้อมูลอย่างปลอดภัยและค้นคืนได้ในระยะยาว

โครงสร้างข้อมูล (Data model): metadata, content, embeddings และ indexing
ChatGPT Library แยกข้อมูลออกเป็นชั้นชัดเจนเพื่อรองรับความต้องการด้านประสิทธิภาพและความปลอดภัย โดยทั่วไปจะประกอบด้วยส่วนหลักสามส่วน:
- Metadata: ข้อมูลเชิงโครงสร้าง เช่น object_id, tenant_id, timestamps, content_type, และ custom key-value pairs สำหรับ filter และนโยบายการเข้าถึง (ACL). Metadata ถูกออกแบบให้สามารถสืบค้นได้รวดเร็วผ่านฐานข้อมูลเชิงคีย์-แวลูหรือฐานข้อมูลเอนกประสงค์ (เช่น RocksDB/LMDB หรือ SQL) เพื่อรองรับการกรองก่อน/หลังการค้นหาเวกเตอร์
- Content / Blob: เนื้อหาจริง (text, document, binary) จะถูกเก็บในระบบ object storage ที่ทนทาน (เช่น S3-compatible) พร้อมการเข้ารหัสที่ระดับบล็อบ (encryption-at-rest) เพื่อให้สอดคล้องกับข้อกำหนดด้านความปลอดภัยและ retention policy. Metadata จะชี้ไปยัง blob location (URL หรือ object key)
- Embeddings: เวกเตอร์เชิงคุณลักษณะที่สร้างจากโมเดล embedding (เช่น ขนาดมิติทั่วไป 1536 หรือ 1024 ขึ้นอยู่กับรุ่น) จะถูกจัดเก็บแยกเป็นดัชนีเวกเตอร์ (vector index) เพื่อการค้นหาแบบ nearest neighbor อย่างมีประสิทธิภาพ
การออกแบบนี้แยกการจัดเก็บตามหน้าที่: metadata สำหรับฟิลเตอร์และการจัดการ, blob สำหรับเนื้อหาเต็มรูปแบบ, และ embeddings สำหรับค้นหาเชิง semantically. นอกจากนี้ระบบจะเก็บ write-ahead log และ versioning สำหรับ audit และการกู้คืนข้อมูลในระยะยาว
วิธีการค้นหาแบบเวกเตอร์ (Approximate Nearest Neighbor) และประสิทธิภาพ
เพื่อจัดการกับการค้นหาเชิงความหมายในข้อมูลจำนวนมาก ChatGPT Library ใช้เทคนิค Approximate Nearest Neighbor (ANN) ที่ได้รับความนิยม เช่น HNSW (Hierarchical Navigable Small World), IVF+PQ (Inverted File with Product Quantization) และ quantized index อื่น ๆ ซึ่งแต่ละวิธีมี trade-off ระหว่างความแม่นยำ (recall), latency และการใช้หน่วยความจำ
- HNSW: ให้ recall สูงและ latency ต่ำบนหน่วยความจำหลัก เหมาะสำหรับชุดข้อมูลที่สามารถเก็บดัชนีไว้ใน RAM — โดยทั่วไปจะเห็น latency ของการค้นหาอยู่ในระดับหลักมิลลิวินาที (เช่น 1–10 ms ต่อคำค้น) ขึ้นกับพารามิเตอร์เช่น efSearch
- IVF+PQ: เหมาะสำหรับดัชนีขนาดใหญ่ที่ต้องการบีบอัดและให้บริการบนดิสก์/SSD โดยรักษา latency ในระดับหลักสิบมิลลิวินาทีถึงร้อยมิลลิวินาที ขึ้นกับการตั้งค่า shards และการอ่าน I/O
- Quantization & Sharding: การทำ quantization (เช่น OPQ, PQ) ลดขนาดดัชนีลงหลายเท่า ขณะที่การแบ่งดัชนีเป็น shards ทำให้สามารถกระจายการค้นหาไปยังหลายโหนดเพื่อรองรับ throughput สูง (พันถึงหมื่น QPS ในสถาปัตยกรรมที่ปรับขนาดได้)
ในเชิงตัวเลข ตัวชี้วัดที่มักใช้วัดประสิทธิภาพได้แก่ recall@k (เช่น recall@10 ควรสูงกว่า 90% สำหรับงานหลายประเภท), p50/p95/p99 latency (เป้าหมาย p95 มักอยู่ที่ <50–200 ms ขึ้นกับการปรับแต่ง) และ throughput (QPS). ระบบสามารถปรับพารามิเตอร์ เช่น efSearch (HNSW) หรือ nprobe (IVF) เพื่อแลกเปลี่ยนระหว่างความแม่นยำและ latency ตาม SLA ขององค์กร
Latency, Durability และ Scalability
การออกแบบเส้นทางการเขียนและอ่านจะกระจายความรับผิดชอบเพื่อให้ได้ทั้ง low-latency และ durable storage:
- Path การเขียน (Write path): เมื่อรับคำขอสร้างข้อมูล (create) ระบบจะทำตามลำดับโดยทั่วไป: (1) ยืนยันสิทธิ์และนโยบาย, (2) บันทึก blob ไปยัง object storage พร้อมการเข้ารหัส, (3) บันทึก metadata ลงฐานข้อมูลเชิงคีย์-แวลู, (4) ส่ง embedding ไปยังบริการ index เพื่อ update ดัชนี (อาจทำแบบ synchronous หรือตัดเป็น asynchronous batch เพื่อเพิ่ม throughput). การทำงานแบบ asynchronous ช่วยลด latency การตอบกลับให้ผู้เรียก แต่ต้องมีกลไกตรวจสอบความสอดคล้องของดัชนี (index lag)
- Path การอ่าน/ค้นหา (Read/Query path): flow ปกติสำหรับการค้นหา semantic คือ: (1) สร้าง embedding ของคำค้น (client หรือ service), (2) เรียก API vector search เพื่อนำหา nearest neighbors (filter โดย metadata หากจำเป็น), (3) ดึง metadata/score/ID, (4) หากต้องการเนื้อหาเต็มรูปแบบ ให้ fetch blob จาก object storage โดยใช้ object key ที่ได้จาก metadata. ระยะเวลาส่วนใหญ่จะเกิดจากขั้นตอน vector search และการดึง blob ขนาดใหญ่
- Scalability: ดัชนีเวกเตอร์สามารถสเกลได้ด้วยการ sharding (horizontal scaling), replication (สำหรับ HA), และการใช้ tiered storage (เก็บดัชนีที่ร้อนใน RAM และดัชนีที่เย็นบน SSD). ระบบ orchestration (เช่น Kubernetes) ร่วมกับ autoscaling rules ช่วยให้รองรับปริมาณที่เพิ่มขึ้นเป็นหลักสิบล้านถึงพันล้านเวกเตอร์โดยแบ่งโหนดและการจัดสรรทรัพยากร
API endpoints หลักและตัวอย่าง flow การอ่าน-เขียน
API ของ ChatGPT Library ถูกออกแบบให้เป็น REST/HTTP (หรือ gRPC ใน deployment ภายใน) โดยมี endpoints หลักดังนี้:
- POST /v1/library/objects — สร้าง object ใหม่ (write). Payload ประกอบด้วย metadata, content หรือ reference ไปยัง blob, และ optionally embedding หาก client สร้างเอง ตัวอย่าง payload:
{ "tenant_id": "tenant_123", "object_id": "doc_456", "metadata": {"title":"สัญญา","tags":["legal","2025"]}, "content": "ข้อความเต็ม หรือ ข้อมูลบีบอัด", "embedding": [0.012, -0.34, ...] }
- GET /v1/library/objects/{object_id} — อ่าน metadata และ/หรือ fetch blob (content) โดยมี query param เช่น ?include=content
- POST /v1/library/query — ค้นหาโดยใช้ embedding หรือ raw text (service จะสร้าง embedding ให้). Payload มักมี fields เช่น embedding / query_text, top_k, filter, namespace/tenant_id. ตัวอย่าง:
{ "tenant_id":"tenant_123", "query_text":"สรุปข้อกำหนดในสัญญา", "top_k":10, "filter":{"tags":["legal"]}, "include_content": false }
Response ของ /query จะคืนรายการผลลัพธ์พร้อม similarity score และ metadata เช่น:
{ "results":[ {"object_id":"doc_456","score":0.92,"metadata":{"title":"สัญญา"}}, ... ] }
ตัวอย่าง flow การเขียน (write):
- 1) Client เรียก POST /v1/library/objects พร้อม content/metadata
- 2) Service ตรวจสอบสิทธิ์, เก็บ blob ลง object storage (encryption-at-rest) และเขียน metadata ลง DB
- 3) Service สร้าง embedding (ถ้า client ไม่ส่ง) โดยเรียกโมเดล embedding ภายใน และส่ง embedding เพื่ออัปเดตดัชนีเวกเตอร์ (synchronous หรือ enqueue สำหรับ batch async)
- 4) ตอบกลับ client พร้อมสถานะการบันทึก และ object_id
ตัวอย่าง flow การค้นหา (read/query):
- 1) Client ส่งข้อความค้นหาไปยัง POST /v1/library/query (หรือสร้าง embedding แล้วส่ง)
- 2) Service สร้าง embedding (ถ้าจำเป็น) และส่งไปยังระบบ ANN เพื่อค้นหา top_k candidates โดยใช้ filters ตาม metadata
- 3) ระบบคืนรายชื่อผลลัพธ์พร้อม score และ metadata; หาก client ต้องการเนื้อหาเต็มระบบจะดึง blob จาก object storage และส่งกลับ (อาจมี caching เพื่อเร่งเวลา)
ท้ายที่สุด การออกแบบต้องคุมความปลอดภัย (authentication, authorization), การเข้ารหัสระหว่างทาง (TLS), และ auditing (logs, change history) เพื่อให้สอดคล้องกับข้อกำหนดทางธุรกิจและกฎระเบียบ การปรับพารามิเตอร์ของ ANN, การเลือกวิธีจัดเก็บดัชนี และแนวทาง asynchronous/synchronous สำหรับการอัปเดตดัชนีเป็นหัวใจสำคัญในการปรับสมดุลระหว่าง latency, throughput และ accuracy สำหรับการใช้งานในระดับองค์กร
คู่มือทีละขั้นตอน: การตั้งค่าและผสานกับแอปของคุณ
คู่มือทีละขั้นตอน: การตั้งค่าและผสานกับแอปของคุณ
บทแนะนำต่อไปนี้ออกแบบมาเพื่อให้นักพัฒนาปฏิบัติตามได้ทีละขั้นตอน ตั้งแต่การเปิดใช้งานฟีเจอร์ ChatGPT Library ในบัญชี OpenAI จนถึงการผสานกับระบบจริง โดยครอบคลุมการกำหนดสิทธิ์ (permissions) การตั้งค่า retention ของข้อมูล ตัวอย่างการบันทึกและดึงข้อมูลผ่าน API แบบย่อ (pseudo-code) รวมถึงแนวทางการทดสอบในสภาพแวดล้อม staging และ production เพื่อให้มั่นใจในความปลอดภัย ความถูกต้อง และการควบคุมการเข้าถึงข้อมูลระยะยาว
1) เปิดใช้งานฟีเจอร์และกำหนดสิทธิ์ขั้นต้น
ก่อนเริ่ม ให้ตรวจสอบว่าองค์กรของคุณมีสิทธิ์ใช้ฟีเจอร์ ChatGPT Library ในแผงควบคุม OpenAI (หรือผ่านหน้าจัดการบัญชีของผู้ดูแลระบบ) โดยทำตามขั้นตอนหลักดังนี้:
- เข้าสู่ระบบผู้ดูแล (Admin) ใช้บัญชีที่มีสิทธิ์จัดการองค์กรและการเรียกเปิดฟีเจอร์ (Feature flags)
- เปิดฟีเจอร์ ChatGPT Library ไปที่เมนู Feature / Beta และเปิดการเข้าถึงสำหรับองค์กรหรือโปรเจ็กต์ที่เกี่ยวข้อง
- กำหนดบทบาท (roles) และสิทธิ์ (scopes) ตัวอย่างสิทธิ์แยกเป็น: library.read, library.write, library.admin — มอบสิทธิ์ให้เฉพาะเซอร์วิสแอคเคานท์หรือทีมที่จำเป็นเท่านั้น
- ตั้งค่า audit logging และการแจ้งเตือน เปิดการบันทึกกิจกรรม (access logs) เพื่อรองรับการตรวจสอบย้อนหลังและการตรวจจับเหตุการณ์ผิดปกติ
ตัวอย่างการมอบสิทธิ์: สำหรับ microservice ที่บันทึกข้อมูลผู้ใช้ ให้มอบ role ที่มี library.write เท่านั้น ส่วนบริการที่ต้องแสดงข้อมูลให้ผู้ใช้มอบ library.read นอกจากนี้ควรมีบัญชีเฉพาะสำหรับงานบริหารที่มี library.admin สำหรับจัดการนโยบาย retention และ ACL
2) การตั้งค่า retention และนโยบายการเข้าถึง (Retention & Permissions)
นโยบาย retention ควรถูกกำหนดตามข้อกำหนดทางกฎหมายและความเป็นส่วนตัวของผู้ใช้ ตัวเลือกทั่วไปได้แก่: ลบอัตโนมัติหลัง X วัน, เก็บถาวร (indefinite), หรือเก็บแบบ versioned ด้วยเวลาหมดอายุเป็นรายวัตถุ (per-object TTL). แนวปฏิบัติแนะนำ:
- ระบุระดับข้อมูล แยกข้อมูลเป็นระดับความละเอียด เช่น PII-sensitive (เก็บสั้น) และ metadata (เก็บยาวกว่า)
- กำหนดค่า retention เป็นนโยบายองค์กร ตัวอย่าง: PII = 90 วัน, Conversation history (non-PII) = 365 วัน
- บังคับใช้ encryption-at-rest และ encryption-in-transit หากเป็นไปได้ ให้ผสานกับ KMS ขององค์กรสำหรับการจัดการคีย์
- สิทธิ์การเข้าถึงแบบละเอียด ใช้ ACL หรือ RBAC เพื่อจำกัดการอ่าน/เขียน และบันทึกเหตุการณ์การเข้าถึงเพื่อให้เกิดการตรวจสอบได้
ตัวอย่างนโยบาย (เชิงแนวคิด): “บทบาท service-A: library.write (TTL default 30 วัน); บทบาท analytics: library.read (only aggregated, PII masked); admin: library.admin (สามารถเปลี่ยน retention)”
3) ตัวอย่างการบันทึกและดึงข้อมูลด้วย API (pseudo-code)
ต่อไปเป็นตัวอย่าง pseudo-code แบบย่อสำหรับการสร้าง (save) และดึง (retrieve/query) ข้อมูลจาก ChatGPT Library โดยสมมติ API เป็นแบบ REST/HTTP พร้อม token-based auth (ปรับตาม SDK ที่ใช้ได้)
- ขั้นตอนบันทึกข้อมูล (Save item):
- HTTP POST /v1/chatgpt/library/items Authorization: Bearer <API_KEY>
- Payload (JSON): { "id": "conv-12345", "type": "conversation", "content": "...", "metadata": { "user_id": "u-789", "tags": ["support"] }, "retention": { "policy": "days", "value": 365 } }
- Response: 201 Created { "item_id": "conv-12345", "version": 1, "created_at": "2026-03-01T12:00:00Z" }
- ขั้นตอนดึงข้อมูล (Retrieve by ID):
- HTTP GET /v1/chatgpt/library/items/conv-12345 Authorization: Bearer <API_KEY>
- Query parameters: ?fields=content,metadata&version=latest
- Response: 200 OK { "id": "conv-12345", "content": "...", "metadata": {...}, "retention": {...} }
- ตัวอย่างการค้นหา (Query by metadata):
- HTTP POST /v1/chatgpt/library/query Authorization: Bearer <API_KEY>
- Payload: { "filter": { "metadata.user_id": "u-789", "metadata.tags": ["support"] }, "limit": 50, "sort": [{ "created_at": "desc" }] }
- Response: 200 OK { "results": [ { "id": "...", "snippet": "..." }, ... ] }
แนวทางการปฏิบัติ: ใช้ idempotency-key เมื่อบันทึกเพื่อป้องกันการบันทึกซ้ำในกรณี retry, ตรวจสอบสถานะ HTTP และโค้ดข้อผิดพลาดเพื่อตอบสนองอย่างเหมาะสม (เช่น 409 สำหรับ conflict, 401 สำหรับสิทธิ์)
4) แนวทางทดสอบ A/B และการตรวจสอบความถูกต้องของข้อมูล
การทดสอบที่ดีต้องแยกระหว่างสภาพแวดล้อม staging กับ production และออกแบบการทดลอง A/B อย่างเป็นระบบ:
- สภาพแวดล้อมแยกชัดเจน — ใช้ API keys แยกสำหรับ staging และ production, ใช้ฐานข้อมูล library แยก, และเปิดการบันทึก (logging) เพิ่มเติมใน staging
- masking และ sample data — ใน staging ให้ใช้ข้อมูลที่ไม่ใช่ข้อมูลจริงของผู้ใช้ (synthetic หรือ masked PII) เพื่อลดความเสี่ยงด้านความเป็นส่วนตัว
- ออกแบบ A/B test — ตัวอย่าง: กลุ่ม A (ไม่มี long-term memory), กลุ่ม B (ใช้ ChatGPT Library เพื่อเติม context ที่เก็บไว้) วัดตัวชี้วัดเช่น response relevance, task completion rate, time-to-resolution
- ขนาดตัวอย่างและความสำคัญทางสถิติ — กำหนดขนาดตัวอย่างล่วงหน้าโดยคำนวณ statistical power (เช่น ต้องการ 80% power และ 95% confidence) เพื่อให้ผลทดสอบเชื่อถือได้
- การตรวจสอบความถูกต้องของข้อมูล (data validation) — ใช้ schema validation เมื่อรับ/ส่งข้อมูล (เช่น JSON Schema), ตรวจสอบ checksum/hashes สำหรับความสมบูรณ์, และทดสอบการกู้คืน/restore ตาม retention policy
- การตรวจสอบหลังเปิดใช้งาน (post-deployment checks) — ตรวจสอบ latency ของการอ่าน/เขียน, อัตราความล้มเหลว (error rate), ค่าเฉลี่ยขนาดข้อมูล, และตรวจสอบ log audit ว่าการเข้าถึงเป็นไปตาม ACL
ตัวอย่างแผน rollout: เริ่มด้วย canary release 1% ของผู้ใช้เป็นเวลา 48 ชั่วโมง หาก metric สำคัญ (error rate < 0.5%, latency เพิ่มไม่เกิน 20%) ผ่าน ให้เพิ่มเป็น 10% และสุดท้าย 100% หากทุกอย่างเป็นปกติ ทั้งนี้ควรมีการ rollback plan ชัดเจน
สรุป: การผสาน ChatGPT Library เข้ากับระบบต้องคำนึงทั้งการกำหนดสิทธิ์อย่างรัดกุม การตั้งนโยบาย retention ที่สอดคล้องกับกฎหมายและความเป็นส่วนตัว การออกแบบ API ให้มี idempotency และ validation รวมถึงการทดสอบ A/B ที่มีการวางแผนและการตรวจสอบตัวชี้วัดเชิงปริมาณอย่างเคร่งครัด เพื่อให้ระบบที่ให้บริการผู้ใช้มีความปลอดภัย ถูกต้อง และพร้อมต่อการขยายในระยะยาว
การย้ายข้อมูลและแบ็กอัพ: แนวทางปฏิบัติและตัวอย่างการย้าย
ภาพรวมและหลักการทั่วไป
การย้ายข้อมูลไปยัง ChatGPT Library ควรถูกออกแบบเป็นโครงการที่มีขั้นตอนชัดเจน ครอบคลุมทั้งการสกัดข้อมูล (extract), การแปลงรูปแบบข้อมูล (transform), การโหลดข้อมูล (load) รวมถึงกลยุทธ์การแบ็กอัพและการกู้คืนที่สามารถรับประกันความต่อเนื่องของธุรกิจได้ การเตรียมข้อมูล การจัดเก็บเมตาดาต้า (metadata) และการกำหนดเวอร์ชันของชิ้นงานเป็นหัวใจสำคัญเพื่อให้สามารถติดตามประวัติและย้อนกลับกรณีเกิดปัญหาได้
กระบวนการ ETL สำหรับย้ายข้อมูลไปยัง Library
การย้ายข้อมูลสู่ ChatGPT Library ควรแยกเป็นขั้นตอน ETL ที่ชัดเจนดังนี้
- Extract: ดึงข้อมูลจากแหล่งเดิม (ฐานข้อมูลเชิงสัมพันธ์, ระบบไฟล์, S3, NoSQL ฯลฯ) โดยใช้ตัวคัดกรอง (filter) ตามช่วงเวลา/สถานะการเปลี่ยนแปลง (incremental change) เพื่อลดปริมาณข้อมูลที่จะย้ายในแต่ละครั้ง
- Transform: ทำความสะอาดข้อมูล (data cleansing), แปลง schema หรือจัดรูปแบบเป็นโครงสร้างที่ ChatGPT Library รองรับ รวมทั้งสร้างเมตาดาต้าสำคัญ เช่น source_id, created_at, checksum, license และ tagging
- Load: อัพโหลดข้อมูลแบบเป็นก้อนหรือเป็นสตรีมไปยัง ChatGPT Library โดยใช้ batching, rate limiting และ retry/backoff เพื่อจัดการกับความผิดพลาดของเครือข่ายหรือข้อจำกัดของ API
ตัวอย่างกลยุทธ์เพิ่มเติม: แยกงานย้ายเป็นเฟส (phase) เช่น เฟสสำรองข้อมูล (snapshot) ก่อนย้าย เฟสย้ายแบบ incremental และเฟสปรับแต่ง metadata หลังย้าย เพื่อให้สามารถหน่วงการเปลี่ยนแปลงและทดสอบได้เป็นขั้นตอน
แนวทางแบ็กอัพและการกู้คืน (snapshots, incremental backups)
การออกแบบแบ็กอัพต้องคำนึงถึง RTO (Recovery Time Objective) และ RPO (Recovery Point Objective) ขององค์กร โดยทั่วไปแนะนำให้ใช้การผสมผสานระหว่าง snapshot แบบครบชุดและแบ็กอัพเพิ่มเติม (incremental) ดังนี้
- Full snapshot: ทำ snapshot ก่อนเริ่มย้ายข้อมูล (baseline snapshot) เก็บสำเนาแบบไม่เปลี่ยนแปลงของข้อมูลและเมตาดาต้าทั้งหมด เพื่อให้สามารถย้อนระบบกลับมายังจุดก่อนการย้ายได้
- Incremental backups: หลัง snapshot เริ่มเก็บการเปลี่ยนแปลงทีละน้อย (delta) โดยเก็บเฉพาะ record/obj ที่เปลี่ยน เพิ่มประสิทธิภาพพื้นที่เก็บและเวลาในการสำรอง
- Immutable storage: เก็บแบ็กอัพในที่จัดเก็บแบบ immutable (เช่น S3 with Object Lock) เพื่อป้องกันการแก้ไขหรือการลบโดยไม่ได้รับอนุญาต
- Retention & lifecycle: กำหนดนโยบายเก็บรักษา (retention policy) และย้ายข้อมูลเก่าลงสู่ cold storage เพื่อควบคุมต้นทุน
ตัวอย่างเชิงตัวเลข: ถ้าชุดข้อมูลมีขนาด 500 GB และแบนด์วิดท์ที่ใช้ได้จริงคือ 100 MB/s การอัพโหลดแบบเต็มจะใช้เวลาประมาณ 83 นาที (ไม่รวม overhead และ retries) จึงควรวางแผนเก็บ snapshot ล่วงหน้าและใช้ incremental สำหรับการอัพเดตหลังนั้น
การตรวจสอบความสมบูรณ์ของข้อมูล (data integrity) และการทดสอบหลังย้ายข้อมูล
หลังการย้าย จำเป็นต้องตรวจสอบความสมบูรณ์อย่างเป็นระบบ โดยขั้นตอนหลักประกอบด้วย
- Checksums & Hashing: สร้างและเก็บค่า checksum (เช่น SHA-256) สำหรับแต่ละออบเจ็กต์ทั้งที่ต้นทางและปลายทาง เพื่อนำมาทดสอบความถูกต้องหลังการย้าย
- Counts & Sampling: ตรวจนับจำนวนนิติภายในชุดข้อมูล (row counts, file counts) และทำการสุ่มตัวอย่าง (random sampling) เพื่อตรวจความสอดคล้องของเนื้อหา
- Schema validation: ตรวจสอบว่า schema และฟิลด์เมตาดาต้าตรงตามแนวทางที่ Library ต้องการ รวมทั้งตรวจสอบชนิดข้อมูล (data types) และรูปแบบวันที่
- End-to-end tests: ทดลองเรียกใช้งานข้อมูลจาก ChatGPT Library ภายใต้กรณีใช้งานจริง เช่น การดึง context เพื่อให้โมเดลตอบคำถาม ยืนยันว่าการเข้าถึง/permissions และ latency อยู่ในเกณฑ์ยอมรับได้
รายการตรวจสอบ (post-migration checklist) ควรมี: checksum match 100%, record count match ±0%, no schema errors, sample content match และการทดสอบสิทธิ์การเข้าถึงผ่านระบบ production-like
การจัดการเวอร์ชันและ snapshot ของ Library
การจัดเวอร์ชันช่วยให้สามารถย้อนกลับได้เมื่อมีปัญหา แนะนำแนวทางดังนี้
- Immutable versions: สร้างเวอร์ชันใหม่ของชุดข้อมูลทุกครั้งที่ทำการเปลี่ยนแปลงใหญ่ และเก็บ manifest ที่ระบุเวอร์ชัน, checksum, timestamp และแหล่งที่มา
- Semantic versioning และ changelog: ใช้รูปแบบเวอร์ชันเช่น v2026.03.01 หรือ semantic เวอร์ชันเพื่อระบุการเปลี่ยนแปลง พร้อมเก็บ changelog ที่อธิบายการเปลี่ยน
- Snapshot-based rollback: เก็บ snapshot ของ Library ก่อนการ deploy major change เพื่อให้สามารถ rollback เป็นสถานะก่อนหน้าได้อย่างรวดเร็ว
ตัวอย่างสคริปต์การย้ายข้อมูลเชิงแนวคิด
ตัวอย่างต่อไปนี้เป็น pseudocode เชิงแนวคิด (ไม่ใช่โค้ดพร้อมรัน) เพื่อแสดงลำดับการทำงาน ETL และการตรวจสอบ checksum:
# Pseudocode: Extract -> Transform -> Load with checksum validation source_records = db.query("SELECT id, content, updated_at FROM articles WHERE updated_at > :last_sync") for batch in chunk(source_records, size=1000): transformed = [] for r in batch: clean_content = normalize_text(r.content) metadata = { "source_id": r.id, "timestamp": r.updated_at } checksum = sha256(clean_content) transformed.append({ "id": r.id, "content": clean_content, "meta": metadata, "checksum": checksum }) upload_response = chatgpt_library.upload_batch(transformed) if not upload_response.success: log_error(upload_response) retry_with_backoff(batch) # After upload, verify for item in transformed: remote = chatgpt_library.get(item.id) if remote.checksum != item.checksum: raise DataIntegrityError(item.id)
ตัวอย่างสำหรับ incremental sync โดยอาศัย timestamp/CDC:
# Pseudocode: Incremental sync last_sync = read_state("last_sync_timestamp") changes = db.query("SELECT * FROM changes WHERE change_time > :last_sync ORDER BY change_time") apply_changes_to_library(changes) write_state("last_sync_timestamp", current_timestamp())
การทดสอบและการตรวจสอบหลังการย้าย (Post-migration testing)
หลังการย้ายให้ดำเนินการทดสอบเชิงลึกตามแผนดังนี้:
- Automated validation: รันสคริปต์ตรวจสอบ checksum, counts, และ schema โดยอัตโนมัติทั่วทั้งชุดข้อมูล
- Functional tests: ใช้กรณีทดสอบธุรกิจ (business scenarios) เพื่อยืนยันว่า ChatGPT Library ตอบสนองต่อการเรียกข้อมูลเพื่อใช้กับโมเดลได้ถูกต้อง
- Performance tests: ทดสอบความหน่วง (latency) และ throughput ในการดึงข้อมูล โดยเฉพาะถ้าเป็นข้อมูลที่ใช้ใน real-time inference
- Security & permission checks: ตรวจสอบสิทธิ์การอ่าน/เขียนและการเข้ารหัสทั้งระหว่างการส่งและเมื่อเก็บในระบบ
สรุปผลการทดสอบและเก็บ log ทั้งหมดไว้เป็นหลักฐานสำหรับ audit และเป็นข้อมูลย้อนกลับหากต้อง rollback
คำแนะนำปฏิบัติการฉบับย่อ
สรุปแนวทางปฏิบัติที่ควรยึดถือ: วางแผนเป็นเฟส แยก snapshot และ incremental backup ออกจากกัน ใช้ checksum และ manifest ในการตรวจสอบความสมบูรณ์ เก็บเวอร์ชันแบบ immutable และดำเนินการทดสอบทั้ง functional, performance และ security ก่อนประกาศใช้งานจริง การปฏิบัติตามแนวทางเหล่านี้จะช่วยลดความเสี่ยงและเพิ่มความมั่นใจในการย้ายข้อมูลไปยัง ChatGPT Library อย่างปลอดภัยและยั่งยืน
กฎระเบียบ การคุ้มครองข้อมูล และแนวปฏิบัติที่ดีที่สุด
กฎระเบียบ การคุ้มครองข้อมูล และแนวปฏิบัติที่ดีที่สุด
ภาพรวมข้อกฎหมายที่เกี่ยวข้อง — องค์กรที่ใช้ฟีเจอร์ ChatGPT Library เพื่อเก็บข้อมูลระยะยาวต้องปฏิบัติตามข้อกำหนดคุ้มครองข้อมูลทั้งในระดับภูมิภาคและตามมาตรฐานอุตสาหกรรมที่เกี่ยวข้อง โดยเฉพาะอย่างยิ่งกฎหมายคุ้มครองข้อมูลส่วนบุคคลสำคัญ เช่น GDPR (ยุโรป) ซึ่งกำหนดหลักการพื้นฐานด้านการประมวลผลข้อมูล ส่วนตัว อาทิ ความชอบด้วยกฎหมาย การจำกัดวัตถุประสงค์ การลดข้อมูล (data minimization) และสิทธิของเจ้าของข้อมูล รวมถึงระยะเวลาแจ้งเหตุละเมิดข้อมูลภายใน 72 ชั่วโมงเมื่อมีเหตุร้ายแรง นอกจากนี้ CCPA/CPRA (แคลิฟอร์เนีย) มุ่งเน้นการให้สิทธิแก่ผู้บริโภคในการเข้าถึง เลือกไม่ขาย และการลบข้อมูล ซึ่งมีบทลงโทษเช่นค่าปรับที่อาจสูงถึง $2,500–$7,500 ต่อการละเมิดตามเงื่อนไข และสำหรับอุตสาหกรรมเฉพาะควรพิจารณา HIPAA (สุขภาพ) หรือ PCI-DSS (ข้อมูลบัตรชำระเงิน) เพื่อให้มั่นใจว่าการจัดเก็บระยะยาวสอดคล้องกับมาตรฐานที่เข้มงวดขึ้น
ผลกระทบต่อการจัดเก็บข้อมูลระยะยาว — การเก็บข้อมูลในระยะยาวเพิ่มความเสี่ยงทางกฎหมายและความเป็นส่วนตัว เช่น ความเสี่ยงจากการระบุตัวบุคคลเมื่อมีการรวมชุดข้อมูลหลายชุด (re-identification) การละเมิดสิทธิของเจ้าของข้อมูลเมื่อไม่สามารถลบข้อมูลได้ตามคำขอ และความเสี่ยงจากการส่งข้อมูลข้ามพรมแดนที่อาจต้องใช้กลไกทางกฎหมายพิเศษ (เช่น Standard Contractual Clauses หรือ Binding Corporate Rules) องค์กรต้องประเมินฐานทางกฎหมาย (lawful basis) ของการเก็บข้อมูล เช่น การยินยอม (consent) สัญญา ภาระหน้าที่ทางกฎหมาย หรือผลประโยชน์ชอบด้วยกฎหมาย และต้องจดบันทึกการตัดสินใจเหล่านี้เป็นหลักฐานความเป็นไปตามข้อกำหนด
แนวปฏิบัติที่ดีที่สุดเพื่อรักษาความเป็นส่วนตัว — เพื่อให้การเก็บข้อมูลระยะยาวปลอดภัยและถูกกฎหมาย ควรยึดหลักปฏิบัติเป็นรูปธรรมดังนี้
- การขอความยินยอมอย่างชัดเจน — หากฐานการประมวลผลอาศัยยินยอม ต้องมีการขอแบบชัดแจ้ง แยกประเด็น และสามารถเพิกถอนได้ง่าย รวมถึงเก็บบันทึกเวลาและขอบเขตของการยินยอม
- การลดข้อมูล (Data Minimization) — เก็บเฉพาะข้อมูลที่จำเป็นต่อวัตถุประสงค์ที่ชัดเจนและกำหนดระยะเวลาเก็บรักษา ตามนโยบายการเก็บรักษาข้อมูลที่สามารถพิสูจน์ได้
- การมาสก์และการแยกตัวตน — ใช้เทคนิค pseudonymization และ masking ในการจัดเก็บข้อมูลที่มีความเสี่ยงสูง เพื่อป้องกันการเข้าถึงข้อมูลระบุตัวบุคคลโดยไม่ได้รับอนุญาต
- การเข้ารหัสและการจัดการคีย์ — เข้ารหัสข้อมูลทั้งขณะพัก (at rest) และขณะส่งผ่าน (in transit) พร้อมกระบวนการจัดการคีย์ที่มีการควบคุมและแยกสิทธิ์อย่างเคร่งครัด
- การควบคุมการเข้าถึงแบบบทบาท (RBAC) — ให้สิทธิการเข้าถึงตามหน้าที่ (least privilege) บันทึกและตรวจสอบการเข้าถึงด้วยล็อกและระบบ SIEM เพื่อการตรวจสอบย้อนหลัง
- การจัดทำและบังคับใช้ retention schedule — กำหนดระยะเวลาเก็บรักษาตามประเภทข้อมูลและทบทวนเป็นระยะ พร้อมกระบวนการลบข้อมูลอย่างถาวรเมื่อครบกำหนด
- การจัดการกับผู้ให้บริการภายนอก — ทำสัญญา DPA (Data Processing Agreement) ระบุหน้าที่ความรับผิดชอบ มาตรการรักษาความปลอดภัย และการตรวจสอบ รวมถึงใช้ SCCs/BCRs เมื่อย้ายข้อมูลข้ามพรมแดน
แนวทางการทำ Privacy Impact Assessment (PIA/DPIA) — การประเมินผลกระทบด้านความเป็นส่วนตัวเป็นเครื่องมือสำคัญเมื่อติดตั้งระบบเก็บข้อมูลระยะยาว โดยเฉพาะเมื่อมีการประมวลผลข้อมูลเชิงโปรไฟล์หรือข้อมูลอ่อนไหว คำแนะนำเชิงปฏิบัติได้แก่
- กำหนดขอบเขตและวัตถุประสงค์ — ระบุประเภทข้อมูล กระบวนการที่เกี่ยวข้อง และผู้มีส่วนได้ส่วนเสีย
- ทำแผนผังการไหลของข้อมูล (data flow) — แสดงที่มาที่ไปของข้อมูล จุดจัดเก็บ ผู้ประมวลผล และการส่งต่อข้อมูลข้ามระบบหรือพาร์ทเนอร์
- ระบุความเสี่ยงและประเมินความรุนแรง — วิเคราะห์ความเสี่ยงต่อสิทธิและเสรีภาพของเจ้าของข้อมูล โดยประเมินความเป็นไปได้และผลกระทบ
- ออกแบบมาตรการบรรเทา — ระบุการควบคุมเชิงเทคนิคและเชิงองค์กร เช่น การมาสก์ การเข้ารหัส การจำกัดการเข้าถึง และนโยบายการเก็บรักษา
- บันทึกผลและการอนุมัติ — จัดทำรายงาน DPIA ที่ชัดเจน ให้ผู้บริหารหรือเจ้าหน้าที่คุ้มครองข้อมูล (DPO) อนุมัติ และเก็บไว้เป็นหลักฐานการปฏิบัติตาม
- ทบทวนเป็นระยะ — ทำการทบทวน DPIA ทุกครั้งที่มีการเปลี่ยนแปลงระบบ วัตถุประสงค์ หรือเมื่อตรวจพบความเสี่ยงใหม่
ตัวอย่างนโยบายภายในองค์กร (ตัวอย่างย่อ) — แนะนำให้มีนโยบายเป็นลายลักษณ์อักษรที่ครอบคลุมตลอดวงจรข้อมูล ต่อไปนี้เป็นตัวอย่างข้อกำหนดหลักที่ควรรวมไว้ในนโยบายภายใน
- ขอบเขตและความรับผิดชอบ: ระบุผู้ควบคุมข้อมูล ผู้ประมวลผล และบทบาทของ DPO/ทีมความปลอดภัย
- การขอและจัดการยินยอม: วิธีการขอการยินยอม การบันทึก และกระบวนการเพิกถอน
- การจำกัดการเก็บรักษา: ตารางระยะเวลาเก็บข้อมูลตามประเภท พร้อมกระบวนการลบหรือทำให้เป็นนิรนามเมื่อครบกำหนด
- การปกป้องข้อมูลทางเทคนิค: ข้อกำหนดการเข้ารหัส การจัดการคีย์ การสำรองข้อมูลและการทดสอบคืนค่า
- การเข้าถึงและการตรวจสอบ: นโยบาย RBAC การบันทึกกิจกรรม และการทบทวนสิทธิการเข้าถึงเป็นระยะ
- การบริหารจัดการซัพพลายเออร์: ข้อกำหนด DPA และการประเมินความเสี่ยงผู้ให้บริการภายนอก
- การแจ้งเหตุละเมิด: กระบวนการรายงานภายในและภายนอก รวมถึงกรอบเวลาการแจ้งหน่วยงานกำกับดูแลและเจ้าของข้อมูล
- การอบรมและการทดสอบ: แผนการอบรมพนักงาน การทดสอบเจาะระบบ (pen-testing) และการตรวจสอบเป็นประจำ
สรุป — การนำ ChatGPT Library มาใช้เพื่อเก็บข้อมูลระยะยาวจำเป็นต้องผสานทั้งการปฏิบัติตามกฎระเบียบ การออกแบบทางเทคนิคที่รัดกุม และนโยบายภายในที่ชัดเจน การจัดทำ DPIA อย่างเป็นระบบ การบังคับใช้หลักการ minimization และ consent รวมถึงการบริหารความเสี่ยงจากผู้ให้บริการภายนอก จะช่วยลดโอกาสการละเมิดและบทลงโทษทางกฎหมาย พร้อมทั้งสร้างความเชื่อมั่นให้แก่ผู้ใช้และคู่ค้าทางธุรกิจ
คำถามที่พบบ่อย (FAQ)
คำถามที่พบบ่อย (FAQ) — ChatGPT Library
ส่วนคำถามที่พบบ่อยนี้รวบรวมข้อสงสัยเชิงปฏิบัติที่องค์กรและนักพัฒนามักสอบถามเมื่อพิจารณานำฟีเจอร์ ChatGPT Library มาใช้สำหรับเก็บข้อมูลบริบทและความทรงจำระยะยาว จุดประสงค์เพื่อให้เข้าใจประเด็นสำคัญด้านค่าใช้จ่าย ข้อจำกัดของขนาดข้อมูลและประสิทธิภาพ วิธีการควบคุมเวอร์ชันของบริบท รวมถึงการลบข้อมูลและการปฏิบัติตามกฎหมายข้อมูลส่วนบุคคล
โดยสรุป: การใช้งานจริงจะขึ้นกับโมเดลการคิดค่าบริการของ OpenAI (เช่น subscription vs usage-based), โครงสร้างข้อมูล (เช่น ขนาดเอกสารและการแบ่ง chunk), เทคนิคการดรรชนีและ embedding ที่ใช้สำหรับ retrieval, และนโยบายการเก็บรักษา/ลบข้อมูลตามข้อกฎหมาย เช่น GDPR หรือ CCPA สำหรับองค์กรขนาดใหญ่ควรออกแบบสถาปัตยกรรมร่วมกับนโยบายรักษาความปลอดภัยภายในเพื่อให้สอดคล้องทั้งด้านต้นทุนและความเสี่ยง
คำตอบด้านเทคนิคใน FAQ นี้เป็นคำตอบสั้น ๆ เพื่อให้ผู้อ่านสามารถประเมินความเป็นไปได้และประเด็นที่ควรตรวจสอบเพิ่มเติม มีการอ้างอิงไปยังเอกสารทางการและทรัพยากรที่เกี่ยวข้องเพื่อใช้เป็นจุดเริ่มต้นในการวางแผนเชิงปฏิบัติ
หากต้องการรายละเอียดเชิงลึกสำหรับกรณีใช้งานเฉพาะ เช่น ปริมาณข้อมูลระดับหลายล้านเอกสาร หรือนโยบายการเก็บข้อมูลข้ามภูมิภาค ควรติดต่อผู้ดูแลระบบของ OpenAI หรือที่ปรึกษาทางกฎหมาย/ความปลอดภัยของข้อมูลก่อนการนำไปใช้งานในระบบการผลิต
-
Q: ค่าใช้จ่าย (pricing) ของ ChatGPT Library เป็นอย่างไร มี quota หรือไม่?
A: ค่าใช้จ่ายมักประกอบด้วยค่าบริการ storage/retention และค่าการเรียกใช้ (API calls / retrievals) โดยจะมีทั้งรูปแบบ subscription และ usage-based ขึ้นกับแผนที่ OpenAI ประกาศ; นอกจากนี้อาจมี quota ในระดับบัญชีหรือองค์กรเพื่อควบคุมการใช้งานเชิงทรัพยากร—ควรตรวจสอบหน้าราคาและเอกสารการสมัครใช้งานของ OpenAI ก่อนใช้งานจริง.
แหล่งอ้างอิง: OpenAI Pricing / Docs — https://platform.openai.com/docs and https://openai.com/pricing
-
Q: ถ้าจัดเก็บข้อมูลจำนวนมาก (เช่น หลายร้อย GB ถึง TB) ประสิทธิภาพจะเป็นอย่างไร?
A: ประสิทธิภาพขึ้นกับการออกแบบข้อมูล (เช่น การ chunk เอกสาร, การสร้าง embeddings, ดรรชนีเชิงเวกเตอร์) และสเปคของบริการ; สำหรับปริมาณมากแนะนำใช้การแบ่งชิ้นข้อมูลอย่างเหมาะสมและระบบดรรชนี (vector DB) เพื่อเร่งการค้นคืน—การทดสอบแบบสเกล (benchmark) เป็นสิ่งจำเป็นก่อนใช้งานจริง.
แหล่งอ้างอิง: Best practices on embeddings and retrieval — https://platform.openai.com/docs/guides/embeddings
-
Q: มีข้อจำกัดด้านขนาดต่อรายการ (per-item) หรือขนาดรวมของ library ต่อบัญชีหรือไม่?
A: ข้อจำกัดเชิงฮาร์ดแคปอาจแตกต่างตามแผนและข้อกำหนดของ OpenAI; โดยทั่วไปแนะนำกำหนดขนาดต่อไอเท็มให้น้อยพอสำหรับการสร้าง embeddings ที่มีประสิทธิภาพ (เช่น การแบ่งเป็น chunk ระดับไม่กี่ KB–สิบกว่ากิโลไบต์ต่อชิ้น) และใช้มาตรการจัดการเมตาดาต้าเพื่อลด overhead.
แหล่งอ้างอิง: API limits & best practices — https://platform.openai.com/docs/usage-policies
-
Q: ChatGPT Library รองรับการควบคุมเวอร์ชันของบริบท (versioning) หรือ snapshot หรือไม่?
A: ฟีเจอร์ควบคุมเวอร์ชันอาจมีการออกแบบให้เก็บ snapshot หรือ metadata ของแต่ละบันทึกเพื่อให้สามารถย้อนคืนได้ แต่อย่างไรก็ตามรูปแบบการใช้งานจริง (เช่น การเก็บ diff, tagging, timestamp) ขึ้นกับการ implement ของผู้ใช้และฟังก์ชันที่ OpenAI ให้บริการ — ควรวางแนวทาง versioning ในระดับแอปพลิเคชันหากมีความต้องการเชิงกฎระเบียบหรือ audit.
แหล่งอ้างอิง: Design patterns for data versioning — https://platform.openai.com/docs and typical engineering references
-
Q: ถ้าต้องการลบข้อมูล (data deletion) แบบถาวร ต้องทำอย่างไร และใช้เวลานานแค่ไหน?
A: การลบข้อมูลควรทำผ่าน API หรือคอนโซลที่ OpenAI ให้มา โดยการร้องขอลบแบบถาวรอาจต้องรอเวลาประมวลผลเพื่อให้การลบแผ่กระจายไปยังสำเนาสำรอง (backup) และดรรชนีที่เกี่ยวข้อง; องค์กรควรทดสอบกระบวนการลบและบันทึกเวลาที่ใช้เพื่อให้สอดคล้องกับข้อกฎหมาย เช่น GDPR ที่กำหนดสิทธิยกเลิกข้อมูล.
แหล่งอ้างอิง: Data deletion & retention policies — https://openai.com/policies/privacy-policy
-
Q: การปฏิบัติตามข้อกฎหมาย (เช่น GDPR/CCPA) เป็นอย่างไรเมื่อใช้ ChatGPT Library?
A: ผู้ควบคุมข้อมูลต้องรับผิดชอบการปฏิบัติตามกฎหมาย โดยต้องสามารถตอบคำขอจากเจ้าของข้อมูล (access, rectification, deletion) และจัดทำสัญญาการประมวลผลข้อมูล (DPA) กับผู้ให้บริการเมื่อจำเป็น พร้อมทั้งพิจารณา data residency, encryption, และการลดการเปิดเผยข้อมูล (minimization).
แหล่งอ้างอิง: GDPR / CCPA and OpenAI privacy — https://eur-lex.europa.eu/eli/reg/2016/679/oj ; https://oag.ca.gov/privacy/ccpa ; https://openai.com/policies/privacy-policy
-
Q: ใครสามารถเข้าถึงข้อมูลใน Library ได้ และมีการควบคุมสิทธิอย่างไร?
A: การควบคุมการเข้าถึงควรใช้แนวปฏิบัติด้าน IAM (identity and access management), role-based access control, และ audit logging เพื่อตรวจสอบการเข้าถึงในระดับผู้ใช้และบริการ OpenAI มักแนะนำให้ใช้การเข้ารหัสระหว่างขนส่งและที่พัก (TLS, at-rest encryption) ร่วมกับนโยบายการจัดการคีย์ที่เหมาะสม.
แหล่งอ้างอิง: Security best practices — https://platform.openai.com/docs/security
-
Q: จะรวม ChatGPT Library เข้ากับระบบภายนอก (เช่น CRM, ERP, หรือ Data Warehouse) ได้อย่างไร?
A: การรวมมักทำผ่าน API connector, webhook หรือ pipeline ที่แปลงข้อมูลเป็นรูปแบบที่เหมาะกับการดรรชนี (เช่น text chunks + embeddings) และ sync เป็น batch หรือ stream สำหรับข้อมูลขนาดใหญ่ ควรออกแบบกลไกควบคุมเวอร์ชันและการลบในระบบต้นทางให้สอดคล้องกับ Library.
แหล่งอ้างอิง: Integration patterns — https://platform.openai.com/docs/guides/integrations
-
Q: หากต้องการ export หรือแบ็คอัพข้อมูลจาก Library มีวิธีใดบ้าง?
A: โดยทั่วไปผู้ให้บริการมักมี API สำหรับการดึงข้อมูลออก (export) เป็นไฟล์หรือ stream สำหรับสำรองข้อมูล ควรออกแบบกระบวนการ export ให้รวม metadata ที่จำเป็นสำหรับการคืนสภาพ (reconstruction) และทดสอบการ restore เป็นประจำ.
แหล่งอ้างอิง: Backup & export recommendations — https://platform.openai.com/docs
-
Q: มี log audit และการรายงานกิจกรรม (activity logging) เพื่อการตรวจสอบความปลอดภัยหรือไม่?
A: ฟีเจอร์ระดับองค์กรมักให้ audit logs สำหรับการเข้าถึง การเปลี่ยนแปลง หรือตัวเรียกใช้งาน API เพื่อให้สอดคล้องกับข้อกำหนดด้านการกำกับดูแลและความปลอดภัย หากเป็นความต้องการทางกฎหมายหรือมาตรฐาน (เช่น SOC2) ให้ตรวจสอบกับทีมพัฒนาหรือเอกสารบริการว่าเปิดใช้งาน logging ในระดับใดได้บ้าง.
แหล่งอ้างอิง: Compliance & audit — https://platform.openai.com/docs/compliance
บทสรุป
ChatGPT Library เป็นฟีเจอร์ใหม่ที่เสริมขีดความสามารถด้านการปรับแต่งตามผู้ใช้ (personalization) และการสนทนาแบบต่อเนื่องด้วยการเก็บข้อมูลบริบทในระยะยาว โดยยังคงให้ความสำคัญกับความปลอดภัยและการปฏิบัติตามกฎระเบียบ เช่น การเข้ารหัสข้อมูล การควบคุมการเข้าถึง และเครื่องมือจัดการความยินยอมของผู้ใช้ ทำให้องค์กรสามารถรักษาบริบทการสนทนาและการตั้งค่าผู้ใช้ได้อย่างต่อเนื่อง ตัวอย่างเช่นการเก็บข้อมูลการสนทนาและเมตาดาต้าจะช่วยให้โมเดลเรียกคืนบริบทเก่าได้โดยไม่ต้องให้ผู้ใช้กรอกซ้ำ หลายการทดสอบเชิงนำร่องรายงานว่าการรักษาบริบทระยะยาวสามารถปรับปรุงความเกี่ยวข้องของคำตอบและลดเวลาที่ทีมงานต้องค้นหาข้อมูลสนับสนุนได้ประมาณ 20–30% ในกรณีใช้งานเชิงธุรกิจบางแบบ
สำหรับการนำไปใช้งานจริง องค์กรควร วางแผนการย้ายข้อมูล ทำการสำรวจ (data inventory) ระบุข้อมูลที่เป็น PII หรือมีความอ่อนไหว กำหนดนโยบายการเก็บรักษา (retention) และวงจรชีวิตของข้อมูล รวมถึงการกำหนดสิทธิ์การเข้าถึงและแนวทางการลบข้อมูลเมื่อครบอายุการเก็บ นอกจากนี้ควรทดสอบในสภาพแวดล้อมที่ควบคุม (staging/sandbox) เพื่อตรวจสอบการทำงาน ความเข้ากันได้ด้านความปลอดภัย และการปฏิบัติตามข้อบังคับก่อนปรับใช้จริง ในมุมมองอนาคต คาดว่าจะเห็นการบูรณาการมาตรการคุ้มครองข้อมูลขั้นสูง (เช่น differential privacy, encryption-at-rest/ in-use) การกำกับดูแลอัตโนมัติ และมาตรฐานอุตสาหกรรมที่ชัดเจนมากขึ้น ซึ่งจะช่วยให้องค์กรสามารถใช้ประโยชน์จากการเก็บบริบทระยะยาวเพื่อยกระดับประสบการณ์ผู้ใช้และประสิทธิภาพการดำเนินงานโดยยังควบคุมความเสี่ยงด้านความเป็นส่วนตัวและกฎระเบียบได้อย่างเหมาะสม
📰 แหล่งอ้างอิง: CNET



