
ในยุคที่ปัญญาประดิษฐ์ (AI) ถูกนำมาใช้ในทุกหน่วยงานตั้งแต่การวิเคราะห์ข้อมูลเชิงลึกจนถึงการตัดสินใจเชิงธุรกิจ ความเสี่ยงด้านความมั่นคงปลอดภัยและความเป็นส่วนตัวก็ทวีความรุนแรงขึ้นตามไปด้วย Microsoft จึงเปิดตัวแนวทาง Zero Trust สำหรับ AI ซึ่งออกแบบมาเพื่อยกระดับการป้องกันด้านความปลอดภัย ลดความเสี่ยงจากการรั่วไหลของข้อมูล การโจมตีผ่านโมเดล และประเด็นด้านความรับผิดชอบทางกฎหมาย โดยมุ่งเน้นให้ผู้ดูแลระบบและนักพัฒนาสามารถนำแนวปฏิบัติไปใช้งานจริงได้อย่างเป็นระบบและมีมาตรฐานเดียวกัน
บทความนี้เป็นคู่มือเชิงปฏิบัติที่จะพาผู้อ่านสำรวจหลักการพื้นฐานของ Zero Trust สำหรับ AI สถาปัตยกรรมที่แนะนํา การดำเนินการเชิงเทคนิคตั้งแต่การจัดการข้อมูล การควบคุมการเข้าถึง การตรวจสอบพฤติกรรมของโมเดล ไปจนถึงข้อพิจารณาทางกฎหมายและการปฏิบัติตามข้อกำหนด โดยมีตัวอย่างและแนวทางการนำไปใช้งานจริงสำหรับ CTO, CISO, ผู้พัฒนาระบบ และทีมปฏิบัติการความปลอดภัย เพื่อให้การใช้ AI ขององค์กรทั้งมีประสิทธิภาพและปลอดภัยยิ่งขึ้น
สรุปการประกาศของ Microsoft
สรุปการประกาศของ Microsoft
Microsoft ประกาศแนวทาง Zero Trust สำหรับ AI อย่างเป็นทางการเมื่อวันที่ 20 มิถุนายน 2024 ผ่านแถลงการณ์ทางการและเอกสารแนะแนวปฏิบัติในหน้า Microsoft Security โดยการเปิดตัวครั้งนี้เกิดขึ้นในบริบทที่การนำเทคโนโลยีปัญญาประดิษฐ์ขยายตัวอย่างรวดเร็วในองค์กรทั่วโลก และมีความกังวลเพิ่มขึ้นทั้งในด้านความมั่นคงปลอดภัย ข้อมูลส่วนบุคคล และความรับผิดชอบต่อผลลัพธ์ของโมเดล AI
เป้าหมายหลักของแนวทางนี้คือการผสานหลักการ Zero Trust—เช่น การยืนยันและจำกัดสิทธิ์แบบละเอียด (least privilege), การตรวจสอบและการบังคับใช้แบบต่อเนื่อง (continuous monitoring and enforcement), และการแบ่งแยกทรัพยากร—เข้ากับวงจรชีวิตของระบบ AI โดยมีวัตถุประสงค์สำคัญ 2 ประการคือ เพิ่มความมั่นคงปลอดภัย (ป้องกันการรั่วไหลของข้อมูลและการโจมตีต่อโมเดล) และ เสริมความรับผิดชอบในการใช้งาน AI (governance, transparency, และการจัดการความเสี่ยงของโมเดล)
แนวทางที่ประกาศรวมถึงชุดมาตรการปฏิบัติการ เช่น การกำหนดนโยบายการเข้าถึงข้อมูลระดับเมตาดาต้าและข้อมูลฝึกสอน, การจัดทำ model cards และบันทึกการไหลของข้อมูล (data lineage) เพื่อการตรวจสอบย้อนหลัง, การทดสอบความปลอดภัยของโมเดลและการตรวจจับพฤติกรรมผิดปกติแบบเรียลไทม์ รวมถึงแนวปฏิบัติสำหรับการจัดซื้อและการประเมินความเสี่ยงของผู้ให้บริการ AI ภายนอก ตัวอย่างเช่น Microsoft แนะนำให้ใช้การตรวจสอบสิทธิ์หลายปัจจัยสำหรับ API ที่เกี่ยวข้องกับโมเดล และการเข้ารหัสข้อมูลทั้งขณะพักและขณะส่ง
ผลกระทบเบื้องต้นต่อองค์กรมีความหลากหลายและครอบคลุมหลายหน่วยงาน: ฝ่ายพัฒนา AI จะต้องยกระดับกระบวนการพัฒนาให้สอดคล้องกับหลัก Zero Trust เช่น การจัดการสิทธิ์และการทดสอบความปลอดภัยของโมเดล ฝ่ายความมั่นคงต้องขยายขอบเขตการตรวจสอบไปสู่โมเดลและ pipeline ของข้อมูล ฝ่ายกำกับดูแลต้องปรับนโยบายการปฏิบัติตามข้อกำหนดและการรายงานความเสี่ยง ส่วนผู้บริหารองค์กรจะต้องพิจารณาการจัดสรรงบประมาณและกรอบการกำกับดูแลเชิงกลยุทธ์เพื่อรองรับความเสี่ยงใหม่ๆ ที่มาจากการใช้งาน AI โดยตรง
โดยสรุป แนวทาง Zero Trust สำหรับ AI ของ Microsoft มุ่งสร้างมาตรฐานที่ปฏิบัติได้จริงสำหรับองค์กรที่ต้องการเร่งนำ AI มาใช้โดยไม่แลกมาด้วยความเสี่ยงด้านความมั่นคงและความรับผิดชอบ การนำแนวทางนี้ไปใช้คาดว่าจะช่วยลดช่องโหว่สำคัญ เพิ่มความโปร่งใสในการทำงานของโมเดล และช่วยให้องค์กรสามารถตอบสนองต่อข้อกำหนดด้านกฎระเบียบและความคาดหวังของผู้มีส่วนได้ส่วนเสียได้ดียิ่งขึ้น
- วันที่ประกาศ: 20 มิถุนายน 2024 (ประกาศอย่างเป็นทางการโดย Microsoft)
- เป้าหมายหลัก: เพิ่มความมั่นคงปลอดภัยและความรับผิดชอบในการใช้งาน AI
- กลุ่มผู้ได้รับผลกระทบ: ผู้พัฒนา AI, ฝ่ายความมั่นคง, ฝ่ายกำกับดูแล/Compliance, และผู้บริหารองค์กร
Zero Trust สำหรับ AI คืออะไร: หลักการและเหตุผล
แนวคิดพื้นฐานและความแตกต่างจาก Zero Trust แบบดั้งเดิม
Zero Trust สำหรับ AI ยืมหลักการพื้นฐานของแนวคิด never trust, always verify แต่ปรับให้สอดรับกับสถาปัตยกรรมและไลฟ์ไซเคิลของโมเดลปัญญาประดิษฐ์ (AI) แทนที่จะเน้นเพียงการป้องกันขอบเขตเครือข่าย (perimeter-based security) แบบดั้งเดิม Zero Trust สำหรับ AI มุ่งเน้นไปที่การพิสูจน์ตัวตน การควบคุมสิทธิ์ และการตรวจสอบในระดับองค์ประกอบภายในระบบ เช่น ข้อมูล (data), โมเดล (model), API และ pipeline ของการฝึกหรือให้บริการโมเดล
ความแตกต่างที่สำคัญคือในระบบ IT แบบเดิม Zero Trust มักเน้นการยืนยันตัวตนของผู้ใช้และอุปกรณ์ก่อนให้การเข้าถึงทรัพยากร ในขณะที่ Zero Trust สำหรับ AI ขยายขอบเขตการควบคุมไปยังองค์ประกอบภายในระบบ AI เอง เช่น การกำหนดสิทธิ์สำหรับชุดข้อมูลเฉพาะ, การอนุญาตให้เรียกใช้งานโมเดลแต่ละเวอร์ชัน, และการจำกัดการเข้าถึงพารามิเตอร์หรือฟีเจอร์ของโมเดลอย่างละเอียด ตัวอย่างเช่น แทนที่จะให้สิทธิ์เข้าถึงฐานข้อมูลทั้งหมด ระบบจะให้สิทธิ์อ่าน/เขียนเฉพาะฟีเจอร์ที่จำเป็นสำหรับโมเดลหนึ่ง ๆ เท่านั้น
หลักการสำคัญของ Zero Trust สำหรับ AI
Zero Trust สำหรับ AI ประกอบด้วยหลักการสำคัญที่ต้องนำไปปฏิบัติจริงในระดับองค์ประกอบของระบบ ดังนี้
- พิสูจน์ตัวตนและควบคุมสิทธิ์ระดับองค์ประกอบ — ใช้มาตรการยืนยันตัวตนแบบเข้มงวด (authentication) และการกำหนดสิทธิ์แบบละเอียด (fine‑grained authorization) สำหรับ data, model, pipeline, และ API แต่ละชิ้น เพื่อป้องกันการเข้าถึงโดยไม่ได้รับอนุญาตหรือการใช้งานที่เกินวัตถุประสงค์
- ไม่เชื่อโดยอัตโนมัติ ตรวจสอบเสมอ — ทุกการเรียกใช้งานโมเดลหรือการเข้าถึงข้อมูลต้องมีการตรวจสอบ (authorization, input validation, content filtering) และมีการยืนยันความถูกต้องของเวอร์ชันโมเดลก่อนใช้งาน
- การมองเห็นและการตรวจสอบแบบต่อเนื่อง — เก็บ telemetry ของการอินพุต เอาท์พุต เวอร์ชันโมเดล การเปลี่ยนแปลงพารามิเตอร์ และการเรียก API เพื่อตรวจจับพฤติกรรมผิดปกติ เช่น model drift, data poisoning, หรือการละเมิดนโยบาย
- การประเมินและลดความเสี่ยงของ supply chain — ตรวจสอบแหล่งที่มาของข้อมูล (data provenance), ความน่าเชื่อถือของ third‑party models, และความสอดคล้องของ pipeline ตั้งแต่การเก็บข้อมูลจนถึงการปรับใช้ (deployment)
การมองเห็น (telemetry) และการตรวจจับการเปลี่ยนแปลงของโมเดล
เพื่อให้ Zero Trust สำหรับ AI มีประสิทธิภาพ ต้องเพิ่มการมองเห็นในระดับที่สูงขึ้นกว่าเดิม โดยระบบต้องบันทึกและวิเคราะห์ข้อมูล telemetry หลายมิติ เช่น อินพุตที่เข้ามา คำตอบที่โมเดลให้ ค่า confidence หรือ uncertainty ของคำตอบ การเปลี่ยนแปลงของพารามิเตอร์ระหว่างเวอร์ชัน และเมตริกการใช้งานของ API การมีข้อมูลเชิงเหตุการณ์เหล่านี้ช่วยให้สามารถตรวจจับเหตุการณ์ผิดปกติได้เร็ว เช่น การโจมตีแบบ data poisoning ที่ทำให้โมเดลให้ผลลัพธ์บิดเบือน หรือการไหลของข้อมูลที่ไม่ได้รับอนุญาต
ตัวอย่างการนำไปใช้เชิงปฏิบัติ ได้แก่ การตั้ง alert เมื่อ distribution ของอินพุตเปลี่ยนแปลงเกินเกณฑ์ การล็อกเวอร์ชันโมเดล (model versioning) และการบังคับใช้ policy ให้เรียกใช้งานเฉพาะเวอร์ชันที่ผ่านการตรวจสอบแล้ว นอกจากนี้ การเก็บ audit trail ที่สามารถตรวจสอบย้อนกลับได้ (forensic-ready logging) เป็นหัวใจของการตอบสนองต่อเหตุการณ์และการปฏิบัติตามข้อกำหนดทางกฎหมาย
การประเมินความเสี่ยงของ supply chain โมเดล
Supply chain ของโมเดล AI ครอบคลุมตั้งแต่การเก็บและแหล่งที่มาของข้อมูล การเตรียมข้อมูล กระบวนการฝึก การเลือกใช้ third‑party model หรือไลบรารี ไปจนถึงการให้บริการโมเดลในสภาพแวดล้อมการผลิต Zero Trust สำหรับ AI ต้องมีแนวทางประเมินความเสี่ยงที่ชัดเจน เช่น:
- ตรวจสอบ data provenance และ lineage ว่าข้อมูลมาจากแหล่งที่เชื่อถือได้ มีสิทธิ์ใช้งาน และไม่มีการปรับแต่งที่น่าสงสัย
- ประเมินความน่าเชื่อถือของ third‑party models โดยพิจารณาแหล่งที่มา การเปิดเผยข้อมูลเกี่ยวกับวิธีฝึก (training recipe), การทดสอบความปลอดภัย และการจัดเตรียมเอกสารเช่น model cards หรือ datasheets
- ใช้แนวทาง SBOM (Software Bill of Materials) ในรูปแบบที่ประยุกต์สำหรับโมเดล (เช่น model BOM) เพื่อระบุ dependency ทั้งซอฟต์แวร์และข้อมูลที่เกี่ยวข้อง
- ดำเนินการทดสอบทางความปลอดภัย เช่น adversarial testing และ data integrity checks ก่อนนำโมเดลเข้าระบบผลิต
การประเมินเหล่านี้สำคัญเพราะการใช้โมเดลจากภายนอกหรือข้อมูลที่ไม่ชัดเจนอาจนำมาซึ่งความเสี่ยงทั้งทางด้านการละเมิดข้อมูล ความลำเอียงของโมเดล และช่องโหว่ที่ไม่คาดคิด การวางมาตรการ Zero Trust ตั้งแต่ต้นทางช่วยลดความเสี่ยงและสนับสนุนการบริหารจัดการความเสี่ยงเชิงรุก
เหตุผลเชิงธุรกิจที่ควรนำ Zero Trust สำหรับ AI มาใช้
การย้ายจากกลยุทธ์ป้องกันแบบ perimeter ไปสู่ Zero Trust สำหรับ AI ให้ประโยชน์เชิงธุรกิจที่ชัดเจน ได้แก่ การลดความเสี่ยงของการรั่วไหลของข้อมูล ความเสี่ยงด้านกฎหมายและการปฏิบัติตามข้อกำหนด (compliance), การเพิ่มความน่าเชื่อถือของระบบ AI และการลดผลกระทบจากเหตุการณ์ด้านความปลอดภัย เมื่อองค์กรมีการมองเห็นและการควบคุมในระดับองค์ประกอบ จะสามารถตอบสนองต่อเหตุการณ์ได้รวดเร็ว ลดเวลาการหยุดชะงัก และเพิ่มความมั่นใจแก่ผู้ใช้งานหรือคู่ค้าทางธุรกิจ
สรุปคือ Zero Trust สำหรับ AI ไม่ใช่การยืดแนวคิดเดิมไปใช้โดยตรง แต่เป็นการปรับสถาปัตยกรรมการพิสูจน์ตัวตน การควบคุมสิทธิ์ การมอนิเตอร์ และการประเมินความเสี่ยงให้สอดคล้องกับธรรมชาติของระบบ AI — โดยเน้นการป้องกันที่ละเอียดและการตรวจสอบอย่างต่อเนื่องสำหรับ data, models, APIs และ supply chain เพื่อสร้างความมั่นใจในการใช้เทคโนโลยีปัญญาประดิษฐ์ในระดับองค์กรมากขึ้น
องค์ประกอบสำคัญในแนวทางของ Microsoft
ภาพรวมองค์ประกอบสำคัญตามแนวทางของ Microsoft
ในเอกสารแนวทาง Zero Trust สำหรับ AI ของ Microsoft ได้สรุปองค์ประกอบสำคัญหลายด้านที่ต้องร่วมกันสร้างเป็นกรอบการปฏิบัติ เพื่อให้การนำปัญญาประดิษฐ์ไปใช้ในองค์กรมีความมั่นคง ยืดหยุ่น และตรวจสอบได้ โดยองค์ประกอบเหล่านี้ครอบคลุมตั้งแต่การจัดการตัวตนและการเข้าถึงข้อมูล จนถึงการตรวจจับปัญหาและตอบสนองเหตุการณ์อย่างเป็นระบบ แนวทางของ Microsoft เน้นการผสมผสานเทคโนโลยี นโยบาย และกระบวนการ เพื่อให้เกิดความรับผิดชอบในการใช้งาน AI ในระดับองค์กร
Identity & Access Management (IAM)
การพิสูจน์ตัวตนและการจัดการสิทธิ์เป็นหัวใจของแนวคิด Zero Trust สำหรับ AI เพราะโมเดลและข้อมูลเชิงประยุกต์มักถูกเรียกใช้งานโดยบริการแบบอัตโนมัติ (workloads) หรือผู้ใช้งานจำนวนมาก Microsoft แนะนำให้ใช้แนวทางแบบหลายชั้น เช่น การยืนยันตัวตนหลายปัจจัย (MFA), การควบคุมเงื่อนไขการเข้าถึง (Conditional Access) และการแยกแยะ workload identities เพื่อจำกัดสิทธิ์เฉพาะที่จำเป็นเท่านั้น
- ตัวอย่างเครื่องมือ: Azure Active Directory (Azure AD), Microsoft Entra (สำหรับการจัดการตัวตนและสิทธิ์สมัยใหม่), Conditional Access เพื่อบังคับนโยบายตามบริบท เช่น ตำแหน่งที่ตั้ง อุปกรณ์ หรือความเสี่ยงของการล็อกอิน
- กรณีใช้งาน: ตั้ง workload identity ให้กับบริการ inference ของโมเดลบน Azure Machine Learning และบังคับใช้ Conditional Access/managed identities เพื่อให้บริการนั้นเข้าถึงแหล่งข้อมูลเท่าที่จำเป็น
Data Protection
การปกป้องข้อมูลทั้งในสถานะเก็บ (at rest) และขณะส่ง (in transit) เป็นข้อกำหนดพื้นฐาน Microsoft เน้นการเข้ารหัสข้อมูลแบบครอบคลุม การลดปริมาณข้อมูล (data minimization) โดยให้เก็บและประมวลผลเฉพาะข้อมูลที่จำเป็น รวมทั้งการจัดหมวดหมู่และการควบคุมการเข้าถึงข้อมูลเชิงบริบทเพื่อป้องกันการรั่วไหล
- มาตรการสำคัญ: encryption at rest (เช่น Azure Storage encryption, Azure Disk Encryption) และ encryption in transit (TLS/HTTPS, Private Link) พร้อมการใช้ private endpoints และ VNet Integration เพื่อจำกัดการเชื่อมต่อ
- ตัวอย่างเครื่องมือ: Microsoft Purview สำหรับการจัดการข้อมูล, การค้นหา และการกำหนดนโยบายการรักษาความเป็นส่วนตัวและการจัดการข้อมูลเชิงบันทึก (data classification & catalog)
- แนวปฏิบัติ: ใช้นโยบาย data minimization และการทำ anonymization/pseudonymization ก่อนนำข้อมูลเข้าสู่กระบวนการฝึกโมเดล เพื่อลดความเสี่ยงด้านความเป็นส่วนตัว
Model Governance
Microsoft ให้ความสำคัญกับการกำกับดูแลโมเดลอย่างเป็นระบบ ซึ่งครอบคลุมการจัดการเวอร์ชั่น (versioning), บันทึกแหล่งที่มาและความสัมพันธ์ของข้อมูล (lineage), ความสามารถในการอธิบายผลลัพธ์ (explainability), การทดสอบเชิงคุณภาพและเชิงความปลอดภัย (testing) รวมถึงกระบวนการรับรองโมเดลก่อนใช้งานจริง (model certification)
- องค์ประกอบสำคัญ: เวอร์ชันของโมเดลและข้อมูล (model & data versioning), lineage เพื่อให้สามารถย้อนกลับไปยังข้อมูลและสคริปต์ที่ใช้สร้างโมเดลได้, explainability เพื่อเปิดเผยเหตุผลของการตัดสินใจที่สำคัญ
- ตัวอย่างเครื่องมือและฟีเจอร์: Azure Machine Learning (model registry, experiment tracking, deployment pipelines), เครื่องมือ Responsible AI เช่น InterpretML, Fairlearn และ Responsible AI dashboard สำหรับการอธิบายและประเมินพฤติกรรมโมเดล
- การรับรองและการทดสอบ: Microsoft แนะนำให้มีชุดการทดสอบอัตโนมัติ (unit tests, adversarial tests, performance tests) และกระบวนการรีวิว/รับรองภายใน (model cards, approval workflows) ก่อนปล่อยโมเดลสู่การใช้งานเชิงพาณิชย์
Secure MLOps
การผนวกรวมความมั่นคงปลอดภัยเข้าไปในวงจรชีวิตของโมเดล (Secure MLOps) ช่วยให้ทุกขั้นตอนตั้งแต่การพัฒนา ฝึก ทดสอบ จนถึงการปรับใช้ มีการควบคุมและตรวจสอบได้ Microsoft สนับสนุนการใช้ pipeline ที่มีการจัดการสิทธิ์ การสแกนความปลอดภัยของโค้ด และการทดสอบเชิงบูรณาการ
- เครื่องมือ: Azure DevOps, GitHub Actions สำหรับ CI/CD, Azure Machine Learning pipelines สำหรับการจัดการ workflow ของ ML, และ Azure Key Vault สำหรับจัดการความลับและคีย์เข้ารหัส
- แนวทางปฏิบัติ: แยกสภาพแวดล้อมระหว่างการทดสอบกับการใช้งานจริง, ใช้ infrastructure-as-code และ scan dependencies ก่อน build/ deploy
Supply Chain Security
ความมั่นคงของห่วงโซ่อุปทานซอฟต์แวร์ (software supply chain) เป็นอีกมุมที่ Microsoft เน้น โดยแนะนำให้ใช้ซัพพลายเชนที่ตรวจสอบได้ (verifiable), ตรวจสอบไลบรารีและแพ็กเกจที่นำมาใช้ และบังคับใช้นโยบายเกี่ยวกับซอร์สโค้ดและ dependency
- เครื่องมือ: GitHub Advanced Security, Dependabot สำหรับการอัปเดต dependency, การใช้ signed artifacts และการตรวจสอบ provenance ผ่านการบูรณาการกับเครื่องมืออย่าง Sigstore
- ตัวอย่าง: สร้าง image และ artifact ที่ได้รับการ sign ก่อนนำขึ้น registry และควบคุมการอนุญาตให้เฉพาะ pipeline ที่ผ่านการตรวจสอบเท่านั้นที่สามารถ deploy ได้
Continuous Monitoring และ Incident Response
หลังการปรับใช้ โมเดลต้องอยู่ภายใต้การเฝ้าระวังอย่างต่อเนื่องเพื่อตรวจจับการลื่นไถลของประสิทธิภาพ (model drift), พฤติกรรมที่ผิดปกติ หรือการโจมตีเชิงข้อมูล Microsoft แนะนำแผนการตอบสนองต่อเหตุการณ์ที่รวมทั้งการตรวจจับ การวิเคราะห์ผลกระทบ และการกู้คืน
- เครื่องมือ: Azure Monitor, Azure Application Insights, Microsoft Sentinel (SIEM) และ Microsoft Defender for Cloud สำหรับการตรวจจับเหตุการณ์และสร้าง playbooks อัตโนมัติ
- กระบวนการตอบสนอง: สร้าง runbooks/ playbooks สำหรับการ isolate endpoint, rollback ไปยังเวอร์ชันก่อนหน้า, แจ้งผู้เกี่ยวข้อง และทำ post-incident review เพื่อปรับปรุงนโยบาย
สรุปได้ว่าแนวทางของ Microsoft ครอบคลุมทั้งเทคโนโลยี นโยบาย และกระบวนการปฏิบัติในทุกชั้น ตั้งแต่การกำหนดตัวตน การปกป้องข้อมูล การกำกับดูแลโมเดล ไปจนถึงการเฝ้าระวังและตอบสนอง ซึ่งเมื่อประยุกต์ใช้ร่วมกันจะช่วยให้องค์กรสามารถนำ AI มาขับเคลื่อนธุรกิจได้อย่างมีความรับผิดชอบและมั่นคง
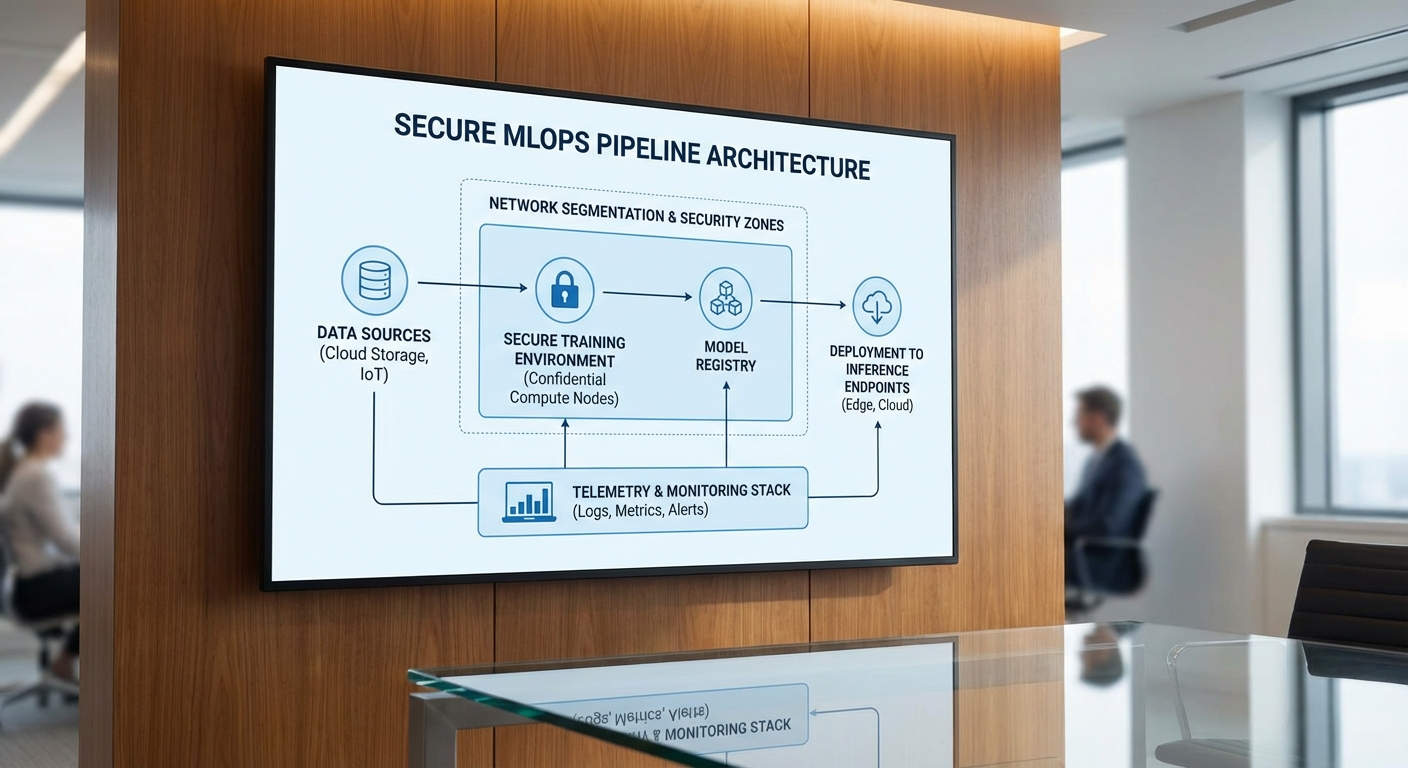
สถาปัตยกรรมและการควบคุมเชิงเทคนิค (Technical Controls)
ภาพรวมสถาปัตยกรรม Zero Trust สำหรับ AI
สถาปัตยกรรมตัวอย่างที่ผสานหลักการ Zero Trust กับกระบวนการ MLOps ประกอบด้วยการแยกโซนเครือข่าย (network zoning) เพื่อแยกความรับผิดชอบและขอบเขตความเสี่ยง ตั้งแต่ชั้น Data Ingestion ไปจนถึง Training และ Deployment โดยแต่ละโซนจะถูกกำหนดนโยบายการเข้าถึงแบบ least privilege, บังคับใช้การยืนยันตัวตนระดับเครื่องและบริการ (mutual TLS, workload identities) และมีชั้นควบคุมเพิ่มเติมเช่น API gateways และ secure enclaves เพื่อป้องกันการเข้าถึงที่ไม่พึงประสงค์
หลักการสำคัญ: “ไม่ไว้วางใจโดยอัตโนมัติ ยืนยันทุกคำขอ” — ทุกการเข้าถึงข้อมูล โมเดล หรือทรัพยากรต้องมีการพิสูจน์สิทธิ์และตรวจสอบบริบทก่อนอนุญาต
ออกแบบ pipeline: Data Ingestion → Training → Deployment ภายใต้หลัก least privilege
การออกแบบ pipeline ควรแยกขั้นตอนและกำหนดสิทธิ์เฉพาะตามบทบาท เพื่อให้แต่ละองค์ประกอบทำงานได้ด้วยสิทธิ์ระดับต่ำสุดที่จำเป็น ตัวอย่างการแบ่งชั้นงานและการควบคุม ได้แก่
- Data Ingestion Zone: พอร์ตและ endpoint เฉพาะสำหรับการรับข้อมูล มีการตรวจสอบ data provenance และ policy-driven filtering ก่อนนำเข้าสู่ staging area; สิทธิ์อ่าน/เขียนกำหนดผ่าน service accounts แบบเฉพาะเจาะจง
- Feature Store & Preprocessing: ฟีเจอร์ที่ใช้ซ้ำถูกจัดเก็บแยก มีการเข้ารหัสข้อมูลจรเข้าจรภายนอก (in transit) และรหัสผ่าน/คีย์ถูกจัดการผ่าน secret manager และ ephemeral credentials
- Training Cluster: โหนด training ทำงานภายในโซนที่แยกออกจากระบบการให้บริการจริง (production), ใช้งานแบบ ephemeral instances และ role-bound identities เพื่อป้องกัน lateral movement
- Model Registry & Signing: โมเดลที่ผ่านการเทรนจะถูกลงทะเบียนใน model registry และ digitally signed พร้อม metadata (provenance, lineage, validation results) ก่อนอนุญาตให้ deploy
- Deployment & Serving: การแจกจ่ายโมเดลผ่าน API gateway ที่บังคับใช้นโยบายความปลอดภัย (rate limiting, request authentication, request/response validation) และจำกัดสิทธิ์เรียกใช้งานตามตัวตนของผู้ร้องขอ
ตลอด pipeline ให้ใช้แนวปฏิบัติอย่าง CI/CD for models โดยผสานการทดสอบความปลอดภัยแบบอัตโนมัติ (security unit tests, adversarial tests, data leakage checks) ก่อนอนุญาตให้ข้ามขั้นไปยังโซนถัดไป
การใช้งาน Confidential Computing และ Hardware Attestation เพื่อปกป้องโมเดลและข้อมูลสำคัญ
เพื่อป้องกันความเสี่ยงจากการถูกขโมยหรือเปิดเผยข้อมูลขณะประมวลผล (data-in-use) ควรนำ Confidential Computing มาใช้ ร่วมกับ Trusted Execution Environments (TEEs) เช่น Intel SGX, AMD SEV หรือเทคโนโลยีคลาวด์เช่น Azure Confidential Computing และ Open Enclave โดยหลักการสำคัญมีดังนี้:
- รันขั้นตอนสำคัญของการเทรนหรือ inference ภายใน secure enclaves ที่เข้ารหัสหน่วยความจำ ทำให้ข้อมูลและโมเดลไม่ถูกเปิดเผยแม้ผู้ดูแลระบบโฮสต์จะมีสิทธิ์
- ใช้ remote attestation เพื่อยืนยันสถานะของฮาร์ดแวร์และซอฟต์แวร์ก่อนอนุญาตให้ส่งข้อมูลหรือโมเดลเข้า enclave — กระบวนการนี้สามารถผนวกรวมกับ policy engine เพื่อบังคับเงื่อนไขการ deploy
- จัดเก็บโมเดลที่ละเอียดอ่อนทั้งที่พักและขณะใช้งานด้วยการเข้ารหัส และให้โมเดลถูกถอดรหัสเฉพาะภายใน enclave เท่านั้น พร้อมการลงนามดิจิทัล (model signing) เพื่อยืนยันความถูกต้อง
การใช้ attestation ยังช่วยให้สามารถตรวจสอบความสมบูรณ์ของสภาพแวดล้อม (integrity) เพื่อป้องกันการโจมตีห่วงโซ่อุปทาน เช่น การแทรกโค้ดที่เป็นอันตรายหรือการเปลี่ยนแปลงไบนารีของ runtime ก่อนการรันโมเดล
การเก็บ Log และ Telemetry เพื่อการตรวจสอบและ Anomaly Detection แบบเรียลไทม์
ระบบต้องออกแบบ telemetry pipeline ที่เก็บข้อมูลจากทุกชั้นของ MLOps ได้แก่ audit logs, access logs, model inputs/outputs metadata, resource metrics และ security events เพื่อสนับสนุนการตรวจจับความผิดปกติ (anomaly detection) และการตอบสนองอัตโนมัติ (SOAR)
- ส่ง logs ไปยังระบบศูนย์กลาง (SIEM) พร้อมการทำ enrichment ด้วย context เช่น identity, model version, data lineage เพื่อให้ทีมวิเคราะห์สามารถเชื่อมโยงเหตุการณ์ได้ง่าย
- ใช้ telemetry streaming (เช่น Kafka/ADF/Event Hubs) เพื่อประมวลผลเหตุการณ์แบบ near-real-time และป้อนข้อมูลให้โมเดลตรวจจับความผิดปกติ เช่น drift detection, data distribution changes, latency spikes
- กำหนด retention และ privacy policy สำหรับ logs — สำรองข้อมูลที่จำเป็นสำหรับ audit แต่ปัดผลลัพธ์ที่เป็น sensitive ตามนโยบาย PDPA/GDPR
- ตั้งค่าการแจ้งเตือนและ playbooks: เมื่อระบบตรวจพบ anomaly เช่น การเรียกใช้โมเดลจากแหล่งที่ไม่คุ้นเคย หรือ pattern ของคำขอที่บ่งชี้การโจมตี ระบบจะต้องสามารถแยก traffic, ปิด endpoint ชั่วคราว, หรือย้อนกลับไปยังเวอร์ชันก่อนหน้าได้อัตโนมัติ
ตัวอย่างเชิงปฏิบัติ: องค์กรอาจกำหนดให้ telemetry ที่ละเอียด (trace-level) ถูก sampling ที่ 1–5% แต่เก็บ metrics และ alert-relevant logs แบบเต็มรูปแบบ เพื่อรักษาความสมดุลระหว่างความละเอียดของการตรวจสอบและต้นทุนการจัดเก็บ
โดยสรุป สถาปัตยกรรมที่ผสาน Zero Trust กับ MLOps ต้องประกอบด้วยการแบ่งโซนเครือข่ายที่ชัดเจน การบังคับใช้ least privilege ตลอด pipeline การนำ Confidential Computing และ hardware attestation มาใช้สำหรับปกป้องข้อมูลขณะใช้งาน และการออกแบบ telemetry pipeline เพื่อการตรวจสอบและตอบสนองแบบเรียลไทม์ — ทั้งหมดนี้จะช่วยเพิ่มความมั่นใจในการนำ AI ไปใช้เชิงธุรกิจอย่างปลอดภัยและเป็นไปตามข้อกำกับดูแล
คู่มือปฏิบัติ: ขั้นตอนการนำแนวทางไปใช้งาน (Tutorial)
คู่มือปฏิบัติ: ขั้นตอนการนำแนวทาง Zero Trust for AI ของ Microsoft ไปใช้งาน (Tutorial)
บทนำสั้น ๆ: คู่มือนี้ออกแบบมาเพื่อทีมเทคนิคและฝ่าย IT ที่ต้องการนำแนวทาง Zero Trust สำหรับ AI ของ Microsoft ไปปฏิบัติจริง โดยแบ่งขั้นตอนสำคัญตั้งแต่การประเมินช่องว่าง (gap analysis) การตั้งนโยบาย Identity และการจัดการโมเดลใน registry ไปจนถึงการเฝ้าระวังและทดสอบความปลอดภัย ทั้งนี้แต่ละขั้นตอนมาพร้อมตัวอย่างสคริปต์/นโยบายที่สามารถนำไปปรับใช้ได้ทันที
1. ขั้นตอนที่ 1 — Gap analysis และการจัดลำดับความสำคัญความเสี่ยง
เริ่มต้นด้วยการทำ Gap Analysis เพื่อระบุช่องว่างระหว่างสภาพปัจจุบันกับข้อกำหนด Zero Trust for AI ขององค์กร ขั้นตอนสำคัญประกอบด้วยการเก็บข้อมูลเกี่ยวกับแอปพลิเคชัน AI, แหล่งข้อมูล (data sources), การเข้าถึง (access patterns), โมเดลและ pipeline และกระบวนการบริหารจัดการโมเดล
แนวทางปฏิบัติ:
- สำรวจแอセット: ระบุโมเดล, dataset, endpoint, และ service accounts ทั้งหมด
- ประเมินความเสี่ยง: จัดลำดับความเสี่ยงโดยใช้เกณฑ์ผลกระทบต่อความเป็นส่วนตัว ความต่อเนื่องของธุรกิจ และความเสี่ยงด้านความลับสินค้า (IP)
- กำหนด PRIORITIZATION: ให้คะแนนตามความร้ายแรง และเริ่มจากไอเท็มที่มีความเสี่ยงสูงสุด
ตัวอย่าง checklist เบื้องต้น:
- มี inventory ของโมเดลและ dataset หรือไม่?
- ใครเข้าถึงโมเดลและข้อมูลได้บ้าง (มนุษย์/บริการ)?
- มีการเข้ารหัสข้อมูลขณะพักและขณะส่งข้อมูลหรือไม่?
- มีระบบ logging และการติดตามการใช้งานโมเดลหรือไม่?
2. ขั้นตอนที่ 2 — การตั้งนโยบาย Identity: Azure AD Conditional Access และการจัดการ Workload Identities
นโยบาย Identity เป็นหัวใจของ Zero Trust สำหรับ AI โดยเน้นการพิสูจน์ตัวตนและการมอบสิทธิ์แบบน้อยที่สุด (least privilege) สำหรับทั้งผู้ใช้งานและ workload
ข้อแนะนำปฏิบัติ:
- ใช้ Azure AD Conditional Access เพื่อบังคับใช้ MFA, บังคับใช้ compliance ของอุปกรณ์, และจำกัดการเข้าถึงตามสถานะเครือข่ายหรือบทบาท
- ย้ายบริการไปใช้ Managed Identities สำหรับ Azure resources แทนการเก็บ secret ในโค้ด
- สร้าง Service Principals ด้วยการจำกัด role assignment (Least privilege) และตั้งค่า secret/certificate rotation อัตโนมัติ
- ใช้ PIM (Privileged Identity Management) สำหรับผู้ดูแลระบบที่ต้องการสิทธิพิเศษแบบชั่วคราว
ตัวอย่าง Conditional Access policy (ตัวอย่างเชิงแนวคิด):
Policy: บังคับใช้ MFA และอุปกรณ์ที่เป็น compliant สำหรับการเข้าถึง endpoint ของโมเดล
Conditions: แอปเป้าหมาย = "AI Model Endpoints", ผู้ใช้ = "ทุกคน", สถานที่ = "นอกเครือข่ายองค์กร"
Grant controls: Require multi-factor authentication, Require device to be marked as compliant
ตัวอย่าง PowerShell (แนวทางการสร้างนโยบายอย่างง่าย):
# ตัวอย่างเชิงแนวคิด (ต้องปรับแต่งให้เข้ากับ tenant ขององค์กร)
Connect-AzureAD;
$policy = @{displayName="RequireMFAForAIEndpoints"; conditions=@{applications=@{includeApplications=@("model-endpoint-app-id")}; users=@{includeUsers=@("All")}}; grantControls=@{builtInControls=@("mfa")}};
New-AzureADMSConditionalAccessPolicy -InputObject $policy
3. ขั้นตอนที่ 3 — การเข้ารหัสข้อมูลและการจัดการคีย์
การปกป้องข้อมูลทั้งขณะพัก (data at rest) และขณะส่ง (data in transit) เป็นข้อกำหนดพื้นฐาน:
- ใช้ Azure Key Vault สำหรับจัดเก็บคีย์และความลับ พร้อมเปิดใช้งาน HSM-backed keys สำหรับข้อมูลสำคัญ
- บังคับ TLS 1.2+ สำหรับการสื่อสารระหว่างบริการ และใช้การเข้ารหัสแอปพลิเคชันสำหรับข้อมูลเฉพาะผู้ใช้งาน
4. ขั้นตอนที่ 4 — สร้าง Model Registry พร้อมนโยบายสำหรับ Versioning และ Automated Tests
การมี Model Registry ที่บริหารจัดการอย่างเป็นระบบช่วยให้การนำโมเดลขึ้นใช้งาน มีการตรวจสอบย้อนกลับ และควบคุมเวอร์ชันได้
แนวปฏิบัติ:
- ใช้ Azure Machine Learning Model Registry หรือระบบคล้ายกันเพื่อจัดเก็บ metadata, provenance และ artifacts
- กำหนดนโยบาย compulsory metadata (เช่น author, data sources, training dataset hash, evaluation metrics, lineage)
- ตั้ง policy สำหรับ versioning, approval workflow (staging → canary → production) และ automated pre-deployment tests
ตัวอย่างนโยบาย Model Registry (YAML นามธรรม):
name: model_policy_v1
rules:
- require: [version, author, training_data_hash, evaluation_metrics]
- versioning: semantic (major.minor.patch)
- automated_tests:
- unit_tests: pass
- performance: latency <= 200ms
- accuracy_threshold: accuracy >= 0.85
- adversarial_checks: pass basic membership-inference test
- signing: require_artifact_signature: true
ตัวอย่าง CI/CD pipeline สำหรับ automated tests (แนวคิด):
# Pseudocode
on: push to model_registry
jobs:
- name: run_unit_tests -> run evaluation -> if metrics pass -> promote to staging
- name: run_adversarial_checks -> run membership_inference_test -> if fail -> reject
5. ขั้นตอนที่ 5 — การตั้งค่า Monitoring, Logging และ Anomaly Detection
การติดตามการทำงานของโมเดลแบบเรียลไทม์และการตรวจจับพฤติกรรมผิดปกติเป็นสิ่งจำเป็น:
- เก็บ logs ของการเรียกใช้งานโมเดล (features input, predictions, latency) และบันทึกแบบ immutable
- ใช้ Azure Monitor / Azure Sentinel สำหรับการรวบรวม logs และสร้าง alerts สำหรับเหตุการณ์ที่ต้องสอบสวน
- ตั้งค่าโมดูล Model Drift Detection: ตรวจสอบ distribution ของ input และ output เมื่อมีการเปลี่ยนแปลงเกิน threshold ให้แจ้งเตือนและกักโมเดล
ตัวอย่าง query สำหรับ alert (แนวคิด KQL):
AIRequestLogs
| where Timestamp > ago(1h)
| summarize avgLatency=avg(DurationMs), p95Latency=percentile(DurationMs,95) by ModelId
| where p95Latency > 500
6. ขั้นตอนที่ 6 — การทดสอบความปลอดภัยและการตรวจสอบเชิงรุก
ก่อนนำโมเดลขึ้น production ควรดำเนินการทดสอบความปลอดภัยครอบคลุมหลายมิติ:
- Functional testing และ performance testing
- Adversarial testing: การโจมตีแบบ adversarial examples, model extraction, membership inference, data poisoning
- Penetration testing และ Red Team exercises เพื่อตรวจสอบ attack surface ของระบบที่ให้บริการโมเดล
- ตรวจสอบ supply chain ของโมเดล เช่น ไลบรารีที่ใช้, third-party models, และ dependencies
ตัวอย่าง checklist สำหรับการทดสอบก่อนปล่อย:
- Unit tests และ integration tests ผ่านทั้งหมด
- Evaluation metrics เกิน threshold ที่กำหนด
- ไม่มีช่องโหว่ที่ตรวจพบจาก static code analysis
- ผล adversarial tests อยู่ในเกณฑ์ที่ยอมรับได้
- มีแผน rollback และการกัก (quarantine) โมเดลหากเกิด anomaly
7. ตัวอย่าง Checklist สรุปสำหรับการนำไปปฏิบัติ
- Inventory: รวบรวมรายการโมเดล, dataset และ endpoints
- Gap Analysis: ระบุช่องว่างและจัดลำดับความสำคัญตามความเสี่ยง
- Identity: ตั้งค่า Azure AD Conditional Access + Managed Identities + PIM
- Encryption: ปรับใช้ Key Vault และ TLS
- Model Registry: ตั้ง policy สำหรับ metadata, versioning, automated tests และ signing
- Monitoring: เปิด logging, ตั้ง alerts และ drift detection
- Testing: ดำเนิน adversarial testing, pentest และมีแผน rollback
- Review: ทบทวนสิทธิ์และนโยบายเป็นระยะ เช่น ทุก 90 วัน
8. บทสรุปและคำแนะนำเชิงปฏิบัติ
การนำแนวทาง Zero Trust for AI ไปใช้งานเป็นกระบวนการต่อเนื่อง ต้องผสานทั้งเทคโนโลยี นโยบาย และกระบวนการตรวจสอบ โดยเริ่มจากการทำ gap analysis เพื่อกำหนดลำดับความสำคัญ จากนั้นตั้งค่าระบบ identity ที่เข้มงวด ใช้ model registry พร้อมนโยบาย versioning และ automated tests สุดท้ายคือการติดตั้งระบบ monitoring และการทดสอบเชิงรุกอย่างสม่ำเสมอ เพื่อลดความเสี่ยงในการนำ AI ไปใช้งานเชิงธุรกิจ
การกำกับดูแล กฎระเบียบ และการประเมินความเสี่ยง
การเชื่อมโยงมาตรการ Zero Trust กับข้อบังคับด้านข้อมูลส่วนบุคคล
Zero Trust เป็นกรอบการรักษาความมั่นคงที่สอดคล้องกับหลักการคุ้มครองข้อมูลส่วนบุคคล ได้แก่ data minimization, purpose limitation และการควบคุมการเข้าถึงอย่างเข้มงวด ซึ่งช่วยให้องค์กรปฏิบัติตามข้อกำหนดเช่น GDPR ได้จริงจัง ตัวอย่างมาตรการที่สอดคล้องกันได้แก่ การพิสูจน์ตัวตนแบบหลายปัจจัย (MFA), การแยกส่วนเครือข่ายและทรัพยากร (segmentation), การเข้ารหัสข้อมูลทั้งขณะพักและขณะส่ง (encryption in transit & at rest) และการบังคับสิทธิ์แบบน้อยที่สุด (least privilege).
ในเชิงกฎหมาย สิ่งสำคัญคือการรวม Zero Trust เข้ากับกระบวนการด้านการปฏิบัติตามกฎ ผู้ควบคุมข้อมูลต้องสามารถแสดงได้ว่าได้ประเมินผลกระทบต่อสิทธิส่วนบุคคล (Data Protection Impact Assessment — DPIA) สำหรับการใช้ AI โดยเฉพาะเมื่อมีการประมวลผลข้อมูลเชิงอ่อนไหวหรือการตัดสินใจอัตโนมัติ ภายใต้ GDPR ผู้ควบคุมต้องแจ้งเหตุละเมิดข้อมูลส่วนบุคคลต่อหน่วยงานกำกับภายใน 72 ชั่วโมงเมื่อเป็นไปได้ ดังนั้นการมีกลไก Zero Trust เพื่อจำกัดการเข้าถึงและตรวจจับเหตุผิดปกติแบบเรียลไทม์จะช่วยลดความเสี่ยงและเวลาในการตอบโต้
นอกจากนี้ การผนวกมาตรฐานสากล เช่น ISO/IEC 27001 สำหรับระบบบริหารความมั่นคงปลอดภัยสารสนเทศ และแนวทาง/มาตรฐานที่เกี่ยวข้องกับการจัดการ AI (ตัวอย่างเช่นชุดคำแนะนำ ISO/IEC ที่ครอบคลุมการจัดการความเสี่ยง AI) จะช่วยให้การออกแบบ Zero Trust มีโครงสร้างรองรับการตรวจสอบจากภายในและภายนอก ซึ่งเป็นหลักฐานสำคัญเมื่อถูกตรวจสอบโดยหน่วยงานกำกับหรือคู่ค้าทางธุรกิจ
การจัดทำ audit trail สำหรับการตัดสินใจของโมเดลและการเปลี่ยนแปลงใน pipeline
การสร้าง audit trail ที่ครอบคลุมเป็นหัวใจของการกำกับดูแล AI ภายใต้มาตรการ Zero Trust — บันทึกต้องชัดเจน สามารถสืบย้อน และถูกเก็บรักษาอย่างปลอดภัย ตัวอย่างของข้อมูลที่ควรถูกบันทึก ได้แก่:
- รายการข้อมูลนำเข้า (input) ที่เกี่ยวข้องกับการตัดสินใจ — โดยใช้การทำ pseudonymization หรือ redaction เพื่อปกป้องข้อมูลส่วนบุคคล
- รุ่นของโมเดล (model version), ชุดข้อมูลฝึก (dataset version), เกณฑ์การฝึก (hyperparameters) และวันที่/เวลาในการฝึกหรือนำขึ้นใช้งาน
- ผลลัพธ์ที่ส่งคืน (output), ค่าความเชื่อมั่น (confidence scores), และเมตริกที่ใช้ในการตัดสิน
- บันทึกการเข้าถึงและการอนุญาต (who accessed what and when) ตามหลัก Least Privilege
- การเปลี่ยนแปลงใน pipeline เช่นการอัปเดตโค้ด, แพตช์, หรือการปรับแต่งที่อาจกระทบต่อการทำงานของโมเดล
เพื่อให้ audit trail ใช้ได้จริงเมื่อมีการสอบสวน ควรจัดเก็บในรูปแบบที่ไม่สามารถแก้ไขได้ (tamper-evident) เช่น การใช้ล็อกแบบ append-only, การเซ็นดิจิทัล หรือการผนวกรวมกับระบบ SIEM และการรายงานอัตโนมัติ นโยบายการเก็บรักษา (retention) และการลบข้อมูลต้องสอดคล้องกับข้อกำหนดทางกฎหมายและหลักการความเป็นส่วนตัว การจัดทำรายงานสำหรับหน่วยงานกำกับ (regulatory reporting) ควรสามารถดึงข้อมูลเชิงสรุปและเชิงลึกได้ในรูปแบบที่ตรวจสอบได้
แนวทางการประเมินความเสี่ยงเชิงจริยธรรมและการทดสอบความลำเอียง (bias testing)
การประเมินความเสี่ยงของโมเดล AI ควรเป็นกระบวนการต่อเนื่องและมีหลายมิติ ประกอบด้วยการประเมินผลกระทบต่อสิทธิพื้นฐาน การระบุกลุ่มที่อาจได้รับผลกระทบไม่เป็นธรรม และการประเมินความน่าเชื่อถือของผลลัพธ์ ขั้นตอนสำคัญได้แก่การจัดทำ Risk Register สำหรับโมเดลแต่ละตัว การกำหนดระดับความเสี่ยง (เช่น สูง กลาง ต่ำ) และการกำหนดมาตรการบรรเทาที่ชัดเจน
สำหรับการทดสอบความลำเอียง ควรใช้ชุดวิธีการแบบผสมผสาน เช่น:
- การวัดเมตริกความเป็นธรรม (fairness metrics) เช่น demographic parity, equalized odds, disparate impact เพื่อตรวจหาความแตกต่างระหว่างกลุ่มประชากร
- การทดสอบแบบ counterfactual และ sensitivity analysis เพื่อตรวจสอบว่าการเปลี่ยนแปลงลักษณะเฉพาะของผู้ใช้ส่งผลต่อการตัดสินใจอย่างไร
- การใช้ชุดข้อมูลสังเคราะห์และชุดทดสอบข้ามกลุ่ม (cross-group testing) เพื่อค้นหาช่องว่างของประสิทธิภาพในกลุ่มย่อย
- red-team และ adversarial testing เพื่อตรวจหาจุดอ่อนทางจริยธรรมและช่องโหว่ที่อาจถูกล่วงละเมิด
เมื่อพบความลำเอียงหรือความเสี่ยงเชิงจริยธรรม ควรมีตัวเลือกการบรรเทาหลายทาง เช่น การปรับน้ำหนักข้อมูล (reweighting), การปรับชุดข้อมูล (data augmentation), การออกแบบข้อจำกัดในอัลกอริธึม (algorithmic constraints), หรือการนำเทคนิคความเป็นส่วนตัวเข้ามาช่วย เช่น differential privacy หรือ federated learning สำหรับกรณีที่ข้อมูลไม่สามารถย้ายออกจากต้นทางได้
การรวมแนวปฏิบัติสู่การกำกับดูแลและความรับผิดชอบ
สุดท้าย การกำกับดูแล AI ที่เชื่อถือได้ต้องประกอบด้วยโครงสร้างการกำกับดูแลที่ชัดเจน เช่น คณะทำงานด้านจริยธรรม AI, เจ้าของโมเดลที่มีความรับผิดชอบชัดเจน, และกระบวนการอนุมัติการใช้งาน (model approval lifecycle) นอกจากนี้ ควรจัดทำเอกสารประกอบเช่น model cards และ datasheets ที่อธิบายการออกแบบ, ข้อจำกัด, ผลการทดสอบ bias, และข้อพึงระวัง เมื่อต้องชี้แจงต่อหน่วยงานกำกับหรือผู้มีส่วนได้ส่วนเสีย เอกสารเหล่านี้รวมกับ audit trail จะเป็นหลักฐานเชิงปฏิบัติที่แสดงถึงความโปร่งใสและความรับผิดชอบ
การผสาน Zero Trust, กระบวนการ audit trail ที่แข็งแรง, และการประเมินความเสี่ยงเชิงจริยธรรมอย่างต่อเนื่อง จะช่วยให้องค์กรสามารถนำ AI ไปใช้ได้อย่างปลอดภัย สอดคล้องกับกฎหมาย และพร้อมสำหรับการตรวจสอบจากภายในและภายนอก โดยเฉพาะในภูมิทัศน์ทางกฎระเบียบที่เปลี่ยนแปลงอย่างรวดเร็วในปัจจุบัน
กรณีศึกษา ตัวอย่าง และสถิติที่เกี่ยวข้อง
กรณีศึกษา ตัวอย่าง และสถิติที่เกี่ยวข้อง
ตัวอย่างกรณีศึกษา (เชิงปฏิบัติ) — ธนาคารระดับภูมิภาคในสหรัฐฯ หนึ่งแห่งได้ทดลองนำแนวคิด Zero Trust มาปรับใช้กับสถาปัตยกรรม AI ที่ใช้ในการประมวลผลการขอสินเชื่อ โดยแยกสภาพแวดล้อมการฝึกและการให้บริการโมเดลออกเป็นชั้น (segmented environments) ใช้การตรวจสอบสิทธิ์แบบหลายปัจจัย (MFA) สำหรับการเข้าถึง API ของโมเดล และกำหนดสิทธิ์แบบ least privilege สำหรับทีม data science ผลลัพธ์ภายใน 12 เดือนรายงานว่าการเข้าถึงที่ไม่ได้รับอนุญาตต่อ endpoint ของโมเดลและการร้องขอข้อมูลที่ผิดปกติจากแอคเคาท์ภายในลดลงอย่างมีนัย โดยธนาคารสามารถติดตามแหล่งที่มาของคำขอได้ละเอียดขึ้นและจำกัดการรั่วไหลของข้อมูล PII ได้ดีขึ้น
ตัวอย่างจากภาคสาธารณสุข — หน่วยงานสาธารณสุขในยุโรปนำแนวทาง Zero Trust มาจัดการโมเดลวินิจฉัยภาพทางการแพทย์ โดยบังคับให้ข้อมูลผู้ป่วยทั้งหมดผ่านชั้นการอนุมัติและการทำ data anonymization ก่อนเข้าระบบฝึก และใช้การเข้ารหัสทั้งที่เหลือในที่พักข้อมูลและระหว่างการส่ง ผลลัพธ์คือความเสี่ยงจากการนำข้อมูลฝึกกลับมาเปิดเผยลดลง และสามารถตอบคำถามทางกฎหมายด้านการคุ้มครองข้อมูลได้รวดเร็วขึ้นเมื่อเทียบกับการจัดการแบบเดิม
สถิติและรายงานที่เกี่ยวข้อง — หลายรายงานความมั่นคงไซเบอร์ระดับสากลสนับสนุนการใช้แนวทาง Zero Trust เป็นมาตรการสำคัญ เช่น NIST SP 800-207 ที่เป็นเอกสารแนวทางมาตรฐานด้านสถาปัตยกรรม Zero Trust และรายงานจากผู้ให้บริการความปลอดภัยรายใหญ่ได้สรุปแนวโน้มที่สอดคล้องกัน ตัวอย่างที่น่าสังเกตคือการยืนยันจาก Microsoft ว่า
การใช้การพิสูจน์ตัวตนเชิงรุกอย่าง MFA สามารถป้องกันการโจมตีโดยอัตโนมัติได้เกินกว่า 99.9% (Microsoft security guidance) ซึ่งเป็นมาตรการหนึ่งที่มักถูกรวมในสถาปัตยกรรม Zero Trust นอกจากนี้ รายงานเช่น IBM "Cost of a Data Breach Report" แสดงให้เห็นความแตกต่างด้านต้นทุนและผลกระทบเมื่อองค์กรมีมาตรการความมั่นคงที่เข้มแข็ง (รวมถึงแนวคิด Zero Trust) โดยสรุปว่าการเตรียมการด้านความมั่นคงเชิงรุกสามารถลดต้นทุนและระยะเวลาในการฟื้นตัวจากเหตุการณ์ละเมิดข้อมูลได้ชัดเจน (IBM, รายงานประจำปี)
บทเรียนจากเหตุการณ์ breach และการ misuse ของโมเดล — เหตุการณ์ที่เกิดจากการละเลยการควบคุมมักมีรูปแบบซ้ำ ๆ ได้แก่ การรั่วไหลของ API key/credential ที่ให้สิทธิ์เข้าถึงโมเดล, การโจมตีแบบ prompt injection ที่ทำให้โมเดลเผยข้อมูลภายใน, การโจมตีแบบ model inversion/attribute inference ที่พยายามสกัดข้อมูลฝึก และการป้อนข้อมูลพิษ (data poisoning) ขณะฝึกอบรม ตัวอย่างเชิงปฏิบัติแสดงว่าการไม่แยกสภาพแวดล้อมการพัฒนาและการให้บริการ (dev/test/production) ทำให้ความเสี่ยงขยายวงได้เร็วขึ้น เมื่อเทียบกับองค์กรที่ออกแบบ Zero Trust เพื่อจำกัดขอบเขตการเข้าถึงและมีการตรวจจับที่ครอบคลุม
- ข้อค้นพบเชิงปฏิบัติ — การแยกขอบเขต (segmentation) และการควบคุมสิทธิ์ละเอียด (fine-grained RBAC) สำหรับโมเดล AI เป็นปัจจัยที่ช่วยลดความเสี่ยงจากการเข้าถึงและการโจมตีได้อย่างมีประสิทธิภาพ
- การตรวจสอบและล็อก — การเก็บ log ของคำขอไปยังโมเดล การตรวจจับพฤติกรรมผิดปกติ และการทำ audit trail เป็นกุญแจในการตอบสนองเหตุการณ์และการวิเคราะห์สาเหตุ
- การลดข้อมูล — การทำ data minimization และการลบ/anonimyze ข้อมูลที่ไม่จำเป็นก่อนนำเข้าสู่โมเดล ช่วยลดผลกระทบหากเกิดการละเมิด
- การทดสอบเชิงรุก — Red-team สำหรับโมเดล (prompt-injection testing, adversarial testing) และการรีวิว supply chain ของโมเดล ช่วยค้นหาจุดอ่อนก่อนจะถูกใช้โจมตีจริง
ข้อเสนอแนะเชิงปฏิบัติ — องค์กรที่ต้องการนำแนวทาง Zero Trust มาใช้กับ AI ควรเริ่มจากการวิเคราะห์ความเสี่ยงเชิงธุรกิจ (identify crown-jewel models) กำหนดนโยบายการเข้าถึงแบบ least privilege ใช้มาตรการรับรองตัวตนที่แข็งแกร่ง รวมทั้งผนวกการตรวจจับและการตอบสนอง (monitoring & incident response) สำหรับทราฟฟิกของโมเดลโดยเฉพาะ นอกจากนี้ ควรนำแนวทางการควบคุมข้อมูล (data governance) และการประเมินความเป็นธรรมของโมเดล (model governance) มาบูรณาการกับนโยบาย Zero Trust เพื่อให้ได้ทั้งความมั่นคงและความน่าเชื่อถือของระบบ AI
บทสรุป
แนวทาง Zero Trust สำหรับ AI ของ Microsoft เป็นกรอบการทำงานที่ออกแบบมาเพื่อผสานความมั่นคงปลอดภัยเข้ากับวงจรชีวิตของโมเดลปัญญาประดิษฐ์ ตั้งแต่การพัฒนา ฝึกสอน ติดตั้งใช้งาน จนถึงการบำรุงรักษา โดยเน้นหลักสำคัญสี่ด้านคือ identity (การพิสูจน์ตัวตนและการควบคุมสิทธิ์แบบละเอียด), data protection (การปกป้องข้อมูลทั้งขณะเคลื่อนที่และพักอยู่), model governance (การกำกับ ควบคุมเวอร์ชัน และความโปร่งใสของโมเดล) และ telemetry (การตรวจจับและบันทึกพฤติกรรมเพื่อการตรวจสอบอย่างต่อเนื่อง) การนำแนวทางนี้มาใช้จริงต้องเริ่มจากการประเมินความเสี่ยงขององค์กร ปรับสถาปัตยกรรม MLOps ให้สอดคล้องกับหลัก least privilege และใช้มาตรการเช่นการจัดการสิทธิ์ตามบทบาท การเข้ารหัสข้อมูล การตรวจสอบแหล่งที่มาของข้อมูลและโมเดล รวมถึงการติดตั้งการโทรเลข/การมอนิเตอร์แบบเรียลไทม์เพื่อจับพฤติกรรมที่ผิดปกติ
มุมมองอนาคตชี้ว่า แนวทาง Zero Trust สำหรับ AI จะเป็นพื้นฐานสำคัญในการยกระดับความเสถียรและความน่าเชื่อถือของระบบ AI ที่แพร่หลายมากขึ้น องค์กรที่ลงทุนประเมินความเสี่ยง ปรับ MLOps และติดตั้งการกำกับดูแลควบคู่กับการทดสอบอย่างต่อเนื่องจะมีความพร้อมทั้งด้านความปลอดภัยและการปฏิบัติตามกฎระเบียบ การดำเนินการลักษณะนี้ไม่เพียงลดความเสี่ยงจากการละเมิดข้อมูลและการใช้งานโมเดลที่ไม่พึงประสงค์ แต่ยังช่วยสร้างความเชื่อมั่นให้แก่ผู้ใช้และผู้มีส่วนได้ส่วนเสีย โดยเฉพาะในสภาพแวดล้อมที่มีการผสมผสานคลาวด์ สถาปัตยกรรมแบบไฮบริด และซัพพลายเชนของโมเดลที่ซับซ้อน การเริ่มต้นตั้งแต่การประเมินและปรับกระบวนการวันนี้จะช่วยให้องค์กรพร้อมรับความท้าทายในอนาคตและเพิ่มความยืดหยุ่นเชิงความปลอดภัยของระบบ AI ได้อย่างยั่งยืน
📰 แหล่งอ้างอิง: Microsoft



