
สตาร์ทอัพไทยประกาศเปิดตัวโมเดลภาษาขนาดใหญ่ (LLM) ที่ทำงานได้บนมือถือและปรับแต่งเฉพาะตัวผู้ใช้ (On‑Device Personalized LLM) ซึ่งผสานเทคนิค 4‑bit quantization เพื่อหดขนาดโมเดลและลดการคำนวณ พร้อมกับ federated distillation เพื่อฝึกปรับแต่งจากข้อมูลผู้ใช้แบบกระจายโดยไม่ดึงข้อมูลขึ้นเซิร์ฟเวอร์ ผลลัพธ์คือระบบแชทภาษาไทยที่ตอบสนองรวดเร็ว ให้ความเป็นส่วนตัวสูง และช่วยประหยัดแบตเตอรี่รวมทั้งปริมาณข้อมูลเมื่อเทียบกับการรันบนคลาวด์แบบดั้งเดิม
สำหรับนักพัฒนาและธุรกิจที่ต้องการนำ AI มาฝังบนอุปกรณ์เคลื่อนที่ แนวทางนี้เปิดทางสู่การให้บริการที่ตอบโจทย์ทั้งด้านความเป็นส่วนตัว ความเร็วในการตอบ และต้นทุนการเชื่อมต่อ โดยยังคงความสามารถในการปรับแต่งตามพฤติกรรมผู้ใช้แต่ละคน ทำให้เหมาะกับแอปพลิเคชันที่ต้องการประสิทธิภาพเชิงปฏิบัติการบนเครื่องจริง เช่น ผู้ช่วยส่วนตัว แชทบอตเชิงธุรกิจ หรือฟีเจอร์ช่วยเขียนภาษาไทยในแอปพลิเคชันต่างๆ
บทนำ: ทำไม On‑Device Personalized LLM บนมือถือจึงสำคัญ
บทนำ: ทำไม On‑Device Personalized LLM บนมือถือจึงสำคัญ
ในยุคที่โมเดลภาษาขนาดใหญ่ (Large Language Models: LLMs) ถูกนำมาใช้อย่างแพร่หลายผ่านบริการคลาวด์ ผู้ใช้และองค์กรไทยเผชิญกับข้อจำกัดเชิงปฏิบัติการและความเสี่ยงเชิงนโยบายหลายประการ ทั้งความหน่วงจากเครือข่าย (latency) เมื่อข้อมูลต้องเดินทางไปยังเซิร์ฟเวอร์และกลับมา ความเสี่ยงด้านความเป็นส่วนตัวเมื่อต้องส่งข้อความหรือข้อมูลอ่อนไหวไปยังคลาวด์ รวมทั้งค่าใช้จ่ายด้าน API และการใช้แบนด์วิดท์ที่เพิ่มสูงเมื่อมีการเรียกใช้งานต่อเนื่องหรือในปริมาณมาก ตัวอย่างเช่น แอปที่ต้องประมวลผลบทสนทนายาว ๆ หรือส่งไฟล์ต้นฉบับหลายรายการ อาจทำให้การเรียกใช้โมเดลคลาวด์สะสมค่าใช้จ่ายและความล่าช้า ซึ่งเป็นข้อจำกัดสำคัญต่อการใช้งานเชิงธุรกิจและการให้บริการแก่ผู้บริโภคในพื้นที่ที่มีแบนด์วิดท์จำกัด
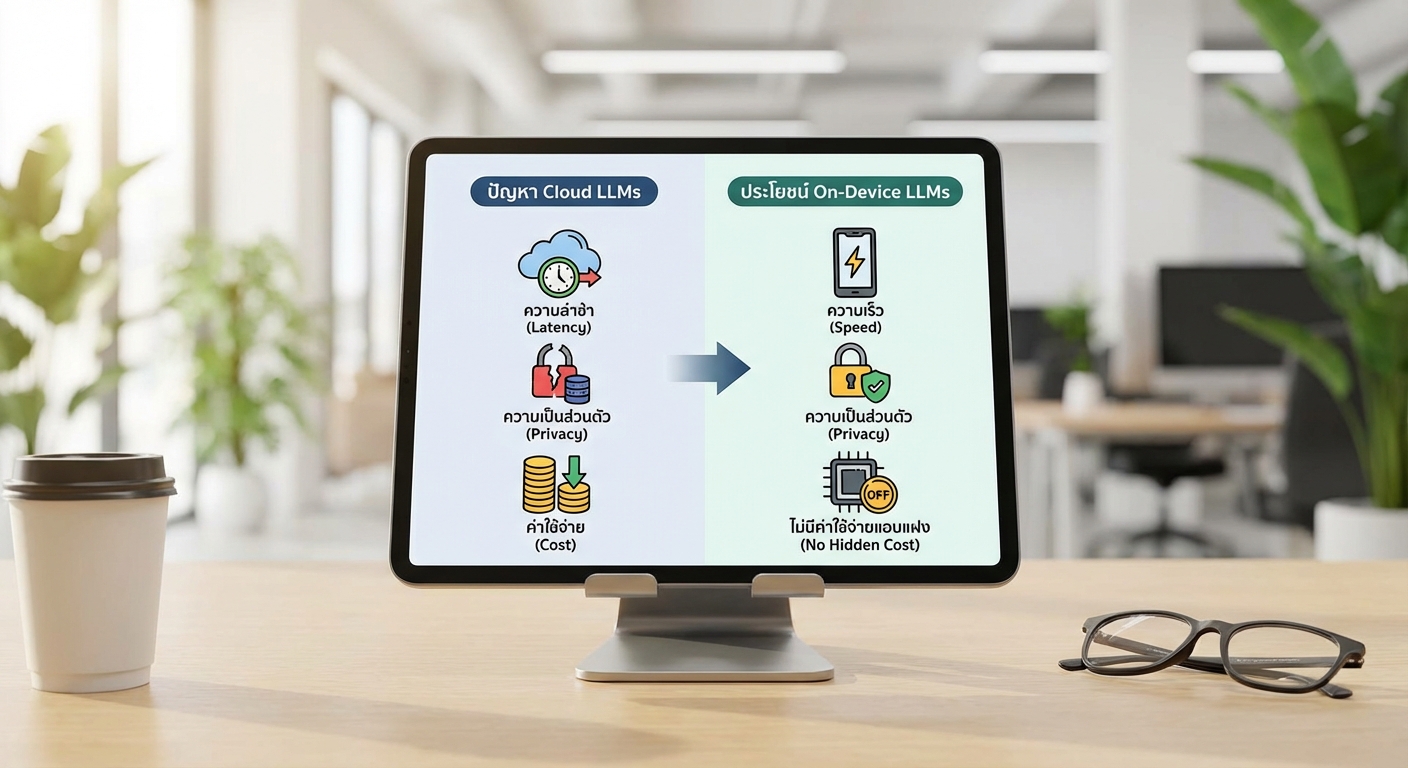
การรัน LLM บนเครื่อง (On‑Device) ช่วยลดปัญหาดังกล่าวได้อย่างชัดเจน โดยเฉพาะในแง่ของ ความเป็นส่วนตัว—ข้อมูลส่วนบุคคลไม่จำเป็นต้องถูกส่งออกจากอุปกรณ์ ทำให้ลดความเสี่ยงการรั่วไหลและช่วยให้องค์กรสามารถปฏิบัติตามกฎหมายคุ้มครองข้อมูล เช่น PDPA ของไทยได้ง่ายขึ้น นอกจากนี้การประมวลผลบนเครื่องยังลด ความหน่วง ให้เหลือระดับมิลลิวินาทีถึงหลักร้อยมิลลิวินาที (เมื่อเทียบกับการเรียกใช้งานผ่านเครือข่ายที่อาจใช้เป็นวินาที) และลดการใช้ข้อมูลเครือข่าย ทำให้ผู้ใช้สามารถใช้งานในสภาพแวดล้อมออฟไลน์หรือเครือข่ายไม่เสถียรได้อย่างต่อเนื่อง
ภาพรวมข้อดีของการรันโมเดลบนอุปกรณ์ ได้แก่
- ความเป็นส่วนตัวสูงขึ้น — ข้อมูลและประวัติการสนทนาเก็บอยู่บนเครื่องผู้ใช้
- ตอบสนองเร็วขึ้น — ลด latency จากการเรียกข้ามเครือข่าย ทำให้ UX ดีขึ้นในการโต้ตอบแบบเรียลไทม์
- ลดการใช้แบนด์วิดท์และค่าใช้จ่าย — ไม่มีการส่งข้อมูลจำนวนมากไปยังเซิร์ฟเวอร์ ทำให้ลดค่าเชื่อมต่อและค่า API
- ใช้งานออฟไลน์ได้ — เพิ่มความพร้อมใช้งานในพื้นที่ที่มีการเชื่อมต่อจำกัด
On‑Device personalization หมายถึงกระบวนการปรับแต่งโมเดลให้เหมาะกับผู้ใช้แต่ละคนโดยตรงบนอุปกรณ์ เช่น การปรับพฤติกรรมการตอบของโมเดลตามสไตล์การเขียน คำศัพท์เฉพาะกลุ่ม หรือบริบทภาษาไทยท้องถิ่น โดยไม่ต้องนำข้อมูลส่วนตัวกลับไปเก็บรวมศูนย์ แนวทางเช่น federated learning หรือ federated distillation ช่วยให้โมเดลบนอุปกรณ์จำนวนมากสามารถเรียนรู้ร่วมกันในรูปแบบที่รักษาความเป็นส่วนตัวของข้อมูลดิบ ทำให้เกิดการปรับปรุงประสิทธิภาพโดยรวมของโมเดลโดยไม่ต้องแลกกับความเสี่ยงด้านข้อมูล
บทบาทของสตาร์ทอัพไทยที่เพิ่งเปิดตัวโซลูชัน On‑Device Personalized LLM จึงมีความสำคัญทั้งเชิงเทคโนโลยีและสังคม พวกเขากำลังนำเทคนิคเช่น 4‑bit quantization เพื่อลดขนาดและการใช้พลังงานของโมเดล รวมกับ federated distillation เพื่อให้การปรับแต่งเป็นไปอย่างมีประสิทธิผลโดยยังคงความเป็นส่วนตัว ผลลัพธ์คือโมเดลที่ตอบเร็ว ใช้พลังงานน้อย เหมาะสำหรับมือถือในตลาดไทยและสามารถรองรับการใช้งานที่ต้องการความละเอียดอ่อนทางภาษาและบริบทท้องถิ่น การพัฒนาเช่นนี้ไม่เพียงแต่ช่วยลดต้นทุนและความเสี่ยงให้กับธุรกิจ แต่ยังเปิดโอกาสให้ผู้ใช้ชาวไทยเข้าถึงบริการ AI ที่เป็นส่วนตัวและมีประสิทธิภาพมากขึ้น ส่งผลต่อการยอมรับเทคโนโลยีและการเปลี่ยนผ่านสู่ดิจิทัลในวงกว้างของสังคมไทย
เทคโนโลยีหลัก: 4‑bit Quantization คืออะไร และได้มาอย่างไร
เทคโนโลยีหลัก: 4‑bit Quantization คืออะไร และได้มาอย่างไร
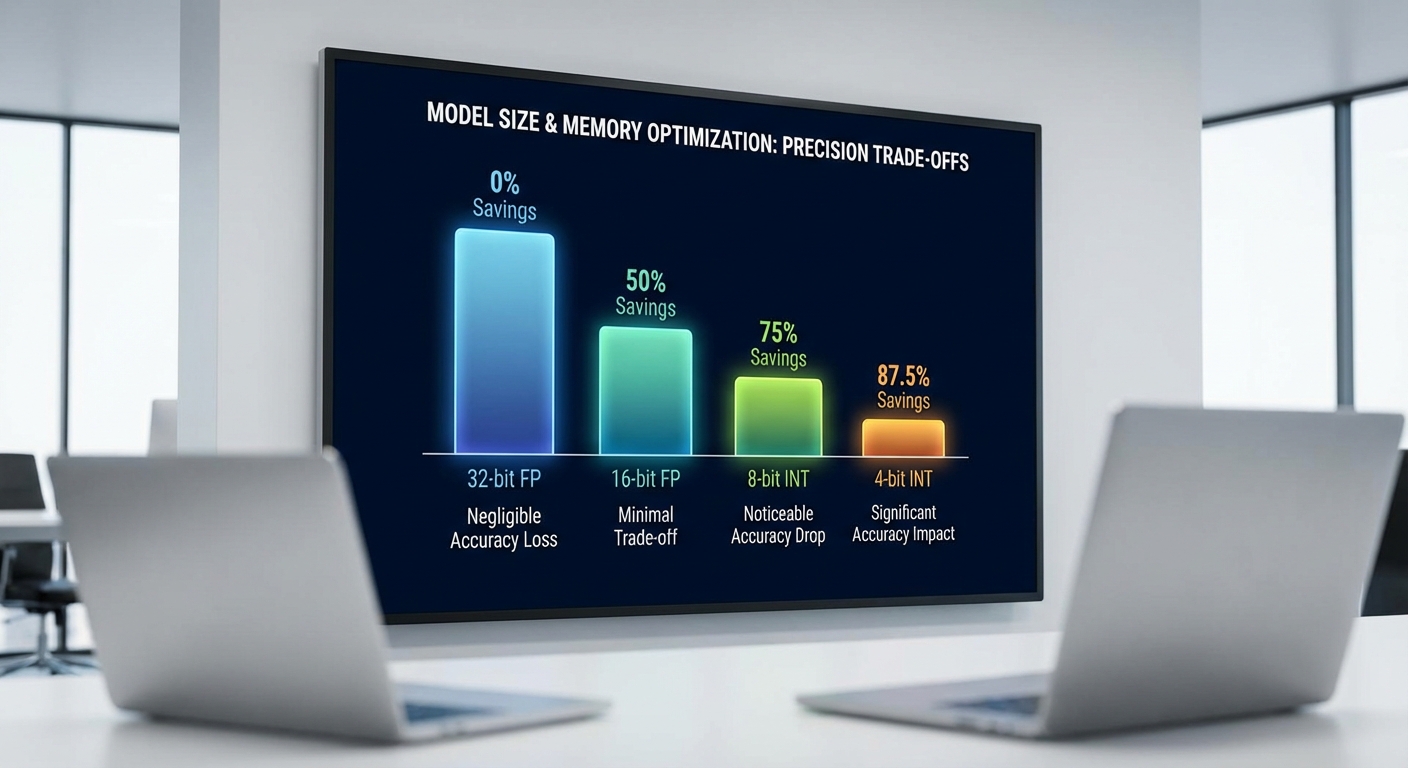
Quantization เป็นกระบวนการแปลงตัวเลขในโมเดลจากการเก็บแบบความละเอียดสูง (เช่น 32‑bit หรือ 16‑bit floating point) ไปเป็นตัวแทนค่าที่มีความละเอียดต่ำกว่า (เช่น 8‑bit, 4‑bit) เพื่อประหยัดหน่วยความจำและลดภาระการคำนวณในการรันอินเฟอร์เรนซ์บนอุปกรณ์ที่ทรัพยากรจำกัด การทำ quantization กับน้ำหนัก (weights) และ/หรือผลลัพธ์ชั้น (activations) จะหมายถึงการแมปช่วงค่าจริงไปยังช่วงค่าจำนวนเต็มที่จำกัดโดยใช้สเกล (scale) และค่าออฟเซ็ต (zero‑point) ซึ่งเป็นพื้นฐานของการลด precision
เมื่อลดจาก 32‑bit หรือ 16‑bit มาเป็น 4‑bit ผลลัพธ์เชิงปริมาณชัดเจน: ขนาดหน่วยความจำสำหรับเก็บพารามิเตอร์จะลดลงโดยทฤษฎีเป็นอัตราส่วน 32/4 = 8x เทียบกับ FP32 และ 16/4 = 4x เทียบกับ FP16 (โดยยังไม่รวมค่าโอเวอร์เฮดของสเกลหรือพารามิเตอร์เสริม) ตัวอย่างเช่น โมเดลขนาด 7 พันล้านพารามิเตอร์ (7B) หากเก็บเป็น FP32 จะใช้ประมาณ 28 GB แต่เมื่อเก็บแบบ 4‑bit เชิงทฤษฎีจะเหลือประมาณ 3.5 GB (และในทางปฏิบัติโดยมีสเกลต่อแชนเนลบางส่วน อาจอยู่ที่ ~3.5–4.5 GB) การลดขนาดเช่นนี้ส่งผลให้สามารถนำ LLM ขนาดกลางมารันบนมือถือหรือ edge device ได้จริงจังยิ่งขึ้น
การรักษาประสิทธิภาพเมื่อลด precision ลงมากถึง 4‑bit จำเป็นต้องอาศัยเทคนิคเฉพาะเพื่อชดเชยการสูญเสียข้อมูลเชิงตัวเลข เทคนิคสำคัญได้แก่:
- Per‑channel (หรือ per‑row) quantization: แทนที่จะใช้สเกลเดียวสำหรับทั้งเทนเซอร์ จะใช้สเกลแยกตามช่องหรือแถวของเมตริกซ์น้ำหนัก วิธีนี้ช่วยรองรับความแตกต่างของการกระจายค่าระหว่างช่อง ทำให้ความสูญเสียข้อมูลลดลงเมื่อเทียบกับ per‑tensor scaling
- Symmetric vs Asymmetric quantization: แบบ symmetric มักตั้ง zero‑point = 0 และเก็บเฉพาะสเกล ซึ่งคำนวณได้เร็วและใช้ทรัพยากรน้อยกว่า ขณะที่ asymmetric มี zero‑point ไม่เป็นศูนย์ ทำให้แมปช่วงค่าที่ไม่สมมาตรได้แม่นยำกว่า โดยเฉพาะเมื่อข้อมูลมีออฟเซ็ตสูง
- Quantization‑Aware Training (QAT): ฝึกโมเดลโดยจำลองผลของการ quantize ระหว่างการเทรน ทำให้โมเดลเรียนรู้ที่จะปรับน้ำหนักเพื่อทนต่อข้อจำกัดของความละเอียดต่ำ ส่งผลให้ประสิทธิภาพหลัง quantize ดีกว่า PTQ ในหลายกรณี
- Post‑Training Quantization (PTQ) และการปรับจูนด้วย calibration: วิธีที่ไม่ต้องเทรนใหม่ ใช้ชุดข้อมูลตัวอย่าง (calibration set) เพื่อหาช่วงค่า การใช้เทคนิคพิเศษเช่น clipping, outlier handling หรือ Hessian‑aware rounding (เช่น GPTQ) ช่วยลดความเสียหายจากการปัด (rounding) สำหรับ LLM ขนาดใหญ่
- Block‑wise / Group‑wise quantization: แบ่งเมตริกซ์น้ำหนักเป็นบล็อกย่อยแล้ว quantize แยกกัน ช่วยรักษาความแม่นยำได้ดีกว่าการ quantize ทั้งเทนเซอร์ทีเดียว โดยเฉพาะเมื่อมี outlier ค่าใหญ่ในตำแหน่งจำกัด
ผลกระทบเชิงประสิทธิภาพและคุณภาพที่พบนิยมในงานวิจัยและการใช้งานจริงคือ สามารถลดขนาดโมเดลได้ในช่วง ประมาณ 4–8x ขึ้นกับจุดอ้างอิง (FP16 → 4‑bit ≈ 4x, FP32 → 4‑bit ≈ 8x) ในขณะที่ความแม่นยำ (เช่น ค่า accuracy หรือ perplexity) มักลดลงเพียงเล็กน้อยถ้าใช้เทคนิคที่เหมาะสม—ตัวเลขการลดประสิทธิภาพมักอยู่ในช่วง น้อยกว่า 1–5% สำหรับหลายงาน เช่น การตอบคำถามหรือการประเมินเชิงการทำความเข้าใจข้อความ อย่างไรก็ตาม ผลลัพธ์จะแตกต่างตามสถาปัตยกรรมโมเดล ชนิดของงาน และคุณภาพของการเทคนิค quantization ที่ใช้
สำหรับกรณีใช้งาน on‑device ที่ต้องการความเป็นส่วนตัวและ latency ต่ำ การผสาน 4‑bit quantization กับวิธีการฝึกซ้ำเฉพาะพื้นที่ (เช่น LoRA หรือการ fine‑tune แบบ lightweight) และการใช้ PTQ/QAT อย่างเหมาะสม จะทำให้สามารถรักษาความสามารถของ LLM ได้ใกล้เคียงกับเวอร์ชันความละเอียดสูง พร้อมกับประหยัดหน่วยความจำและพลังงาน—ซึ่งเป็นปัจจัยสำคัญที่ช่วยให้การรันโมเดลภาษาไทยบนมือถือเป็นไปได้จริง
Federated Distillation และแนวคิดการปรับแต่งส่วนบุคคล (Personalization)
Federated Distillation และแนวคิดการปรับแต่งส่วนบุคคล (Personalization)
Federated Distillation (FD) คือเทคนิคการฝึกแบบกระจายที่มุ่งถ่ายทอด "ความรู้" ระหว่างอุปกรณ์โดยไม่ส่งข้อมูลดิบกลับสู่เซิร์ฟเวอร์กลาง ในภาพรวม FD ทำงานโดยให้เครื่องแต่ละเครื่องรันโมเดลท้องถิ่นบนข้อมูลผู้ใช้ของตนเพื่อสร้าง logits หรือ soft labels (ค่าความน่าจะเป็นก่อนการทำ softmax) หรือสร้างรุ่นที่ผ่านการ distilled แล้ว จากนั้นจะส่งเฉพาะผลลัพธ์เชิงสรุปเหล่านี้ไปยังหน่วยรวมข้อมูลกลางหรือทำการรวมแบบ peer-to-peer เพื่ออัปเดตโมเดลรวม ซึ่งสามารถถูกแจกจ่ายกลับมาบนเครื่องเพื่อใช้เป็นฐานในการปรับแต่งต่อไป ข้อได้เปรียบเชิงแนวคิดคือการแยกข้อมูลดิบออกจากช่องทางการสื่อสาร ทำให้ลดความเสี่ยงด้านความเป็นส่วนตัวและภาระด้านแบนด์วิดท์เมื่อเทียบกับการส่ง raw text โดยตรง
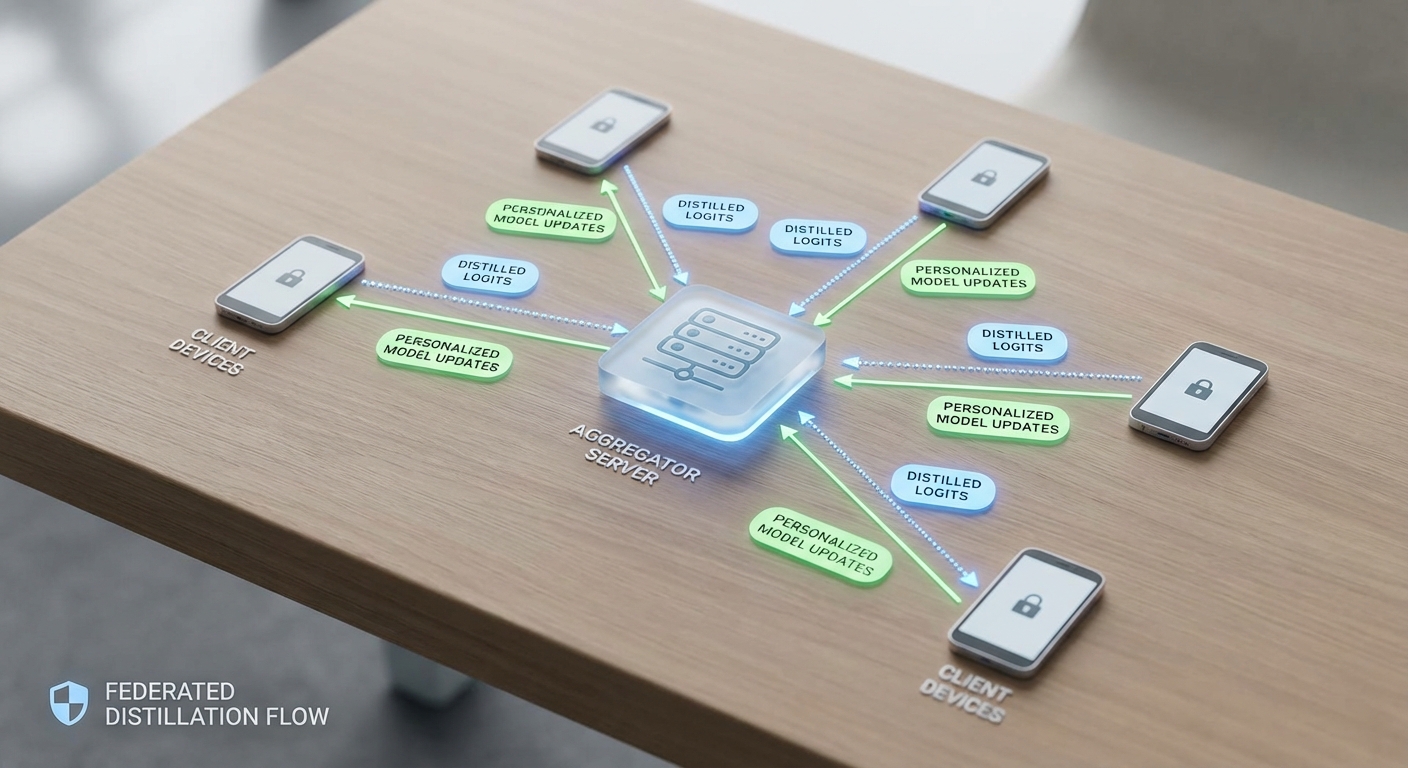
วิธีการทำงานแบบ high-level สามารถสรุปเป็นขั้นตอนหลักได้ดังนี้:
- เครื่องลูกข่าย (on-device) ประมวลผลอินพุตของผู้ใช้และสร้าง logits/soft labels หรือทำการ distilled ของโมเดลขนาดเล็กด้วยข้อมูลภายใน
- ส่งเฉพาะข้อมูลเชิงสรุป (เช่น soft labels หรือพารามิเตอร์ของรุ่น distilled ขนาดเล็ก) ไปยังตัวรวบรวมกลางหรือเพียร์ เพื่อรวมความรู้จากผู้ใช้หลายราย
- เซิร์ฟเวอร์กลางหรือกลไก aggregation จะผสานความรู้เหล่านี้ (อาจใช้การเฉลี่ยเชิงน้ำหนักหรือวิธี ensemble อื่น ๆ) แล้วแจกจ่ายโมเดลที่ได้รับการปรับปรุงกลับไปยังอุปกรณ์
- อุปกรณ์นำโมเดลรวมนี้มาปรับแต่งต่อด้วยข้อมูลผู้ใช้ของตน เพื่อให้เกิดการปรับแต่งส่วนบุคคล (personalization) ที่ไม่เผยข้อมูลดิบ
ข้อได้เปรียบด้านความเป็นส่วนตัวและการประหยัดทรัพยากร
- ความเป็นส่วนตัว: ข้อมูลดิบ เช่น ข้อความภาษาไทยที่ผู้ใช้พิมพ์ จะไม่ถูกส่งออกจากอุปกรณ์ ลดโอกาสการรั่วไหลของข้อความส่วนบุคคล
- ประหยัดแบนด์วิดท์: การส่ง logits หรือโมเดล distilled มักมีขนาดเล็กกว่าการส่งชุดข้อมูลข้อความจำนวนมาก งานวิจัยและการทดลองภาคสนามหลายชิ้นระบุว่า FD อาจลดปริมาณข้อมูลที่ต้องส่งได้หลายเท่า (เช่นหลายเท่าจากการส่ง raw text ข้อความยาว) ขึ้นกับการออกแบบ representation
- ปรับรอบการสื่อสารได้ยืดหยุ่น: เนื่องจากข้อมูลที่ส่งเป็นเชิงสรุป การอัปเดตสามารถตั้งเวลาเป็นช่วง ๆ เพื่อลดการใช้พลังงานและภาระเครือข่าย
- รองรับอุปกรณ์กำลังประมวลผลต่ำ: การใช้โมเดล distilled ขนาดเล็กร่วมกับเทคนิคเช่น 4‑bit quantization ช่วยให้การฝึกและการปรับแต่งบนมือถือเป็นไปได้จริง
เปรียบเทียบกับ Federated Learning แบบดั้งเดิม
- ใน Federated Learning (FL) ดั้งเดิม อุปกรณ์มักส่ง gradient หรือ weight updates ของโมเดลกลับไปที่เซิร์ฟเวอร์ ซึ่งมีขนาดใหญ่และอาจต้องใช้การคำนวณหนักสำหรับการอัปเดต ในขณะที่ FD ส่งเป็น logits/soft labels หรือโมเดล distilled ขนาดเล็กที่มักมีการสื่อสารต่ำกว่า
- FL ให้การอัปเดตโมเดลรวมโดยตรงและเหมาะกับการฝึกโมเดลขนาดใหญ่ให้มีพฤติกรรมรวมของผู้ใช้ทั้งหมด ส่วน FD เหมาะสำหรับการถ่ายโอน "ความรู้เชิงพฤติกรรม" ที่สังเคราะห์แล้วและมักเหมาะกับการสร้างโมเดลขนาดเล็กที่เน้นการตอบสนองตามรูปแบบเชิงสถิติ
- ทั้งสองแนวทางยังต้องจัดการความเสี่ยงด้านความเป็นส่วนตัว — แม้ FD จะไม่ส่ง raw text แต่ logits ยังสามารถถูกนำไปวิเคราะห์ย้อนกลับ (reconstruction attack) ได้ จึงมักผสานกับเทคนิคเช่น secure aggregation หรือ differential privacy เพื่อเสริมความปลอดภัย
ข้อจำกัดและมาตรการบรรเทา
- FD อาจสูญเสียรายละเอียดบางอย่างจากการสรุปเป็น logits ทำให้ความแม่นยำด้านบางภารกิจลดลงเมื่อเทียบกับการฝึกโดยตรงบน raw text
- logits หรือ labels ที่ส่งอาจเปิดช่องให้เกิดการโจมตีเชิงย้อนกลับ หากไม่มีการเข้ารหัสหรือการปกป้องแบบ secure aggregation
- การออกแบบกลไก aggregation ที่ไม่เหมาะสมอาจทำให้โมเดลรวมไม่สามารถสะท้อนลักษณะเฉพาะของกลุ่มผู้ใช้ย่อยได้ดี — จำเป็นต้องมีนโยบายการปรับน้ำหนักและการตรวจสอบคุณภาพของสัญญาณ
ตัวอย่างการปรับแต่งภาษาไทย (signals สำหรับ personalization)
- สไตล์การพูด: ผู้ใช้บางคนชอบคำตอบเป็นทางการ (ใช้ "ครับ/ค่ะ", ประโยคสมบูรณ์) ขณะที่บางคนชอบสั้น กระชับ หรือใช้สำนวนเป็นกันเอง — FD สามารถแลกเปลี่ยนสัญญาณเกี่ยวกับความชอบนี้โดยรวม logits ที่สะท้อนความเสี่ยงของรูปแบบการตอบ
- คำศัพท์ท้องถิ่นและสำเนียง: ผู้ใช้จากภาคต่าง ๆ อาจมีคำเรียกสถานที่หรืออาหารท้องถิ่นเฉพาะ เช่น คำว่า "ส้มตำแซ่บๆ" หรือคำทับศัพท์แบบท้องถิ่น FD ช่วยให้โมเดลรวมเรียนรู้ความถี่การใช้คำเหล่านี้โดยไม่เห็นข้อความดิบ
- คำย่อและ slang เฉพาะผู้ใช้: ตัวอย่างเช่น "พรุ่งนี้เจอกันนะ 555" หรือการใช้คำย่อบริษัท/โปรเจ็กต์เฉพาะทีม — logits/soft labels จากการโต้ตอบของผู้ใช้จะสะท้อนการยอมรับหรือการคาดเดาความหมายของคำย่อนั้น ๆ เพื่อให้โมเดลท้องถิ่นตอบได้ตรงความคาดหวัง
- เจตนาของผู้ใช้ (user intents): สัญญาณเช่นการขอจองร้านอาหาร, ค้นหาเส้นทาง, ขอคำแนะนำสูตรอาหารไทย หรือการตั้งค่าการแจ้งเตือนเฉพาะกิจกรรม — FD สามารถช่วยให้โมเดลท้องถิ่นคาดเดา intent ส่วนบุคคลได้ดีขึ้นจากการรวมสัญญาณเชิงสถิติ
สรุปแล้ว Federated Distillation เป็นกลไกที่น่าสนใจสำหรับการปรับแต่ง LLM บนมือถือเพื่อรองรับการใช้งานภาษาไทยแบบเป็นส่วนบุคคล โดยมีข้อได้เปรียบด้านการลดการส่งข้อมูลดิบและประหยัดแบนด์วิดท์ แต่ยังต้องออกแบบมาตรการด้านความปลอดภัยและการ aggregation ให้เหมาะสมเพื่อรักษาความแม่นยำและความเป็นส่วนตัวของผู้ใช้
สถาปัตยกรรมระบบบนมือถือ: pipeline และส่วนประกอบสำคัญ
ส่วนนี้อธิบายรายละเอียดสถาปัตยกรรมที่รันทั้งหมดบนอุปกรณ์มือถือสำหรับ On‑Device Personalized LLM ที่ผสาน 4‑bit quantization และ federated distillation โดยครอบคลุม pipeline ตั้งแต่การแปลงข้อความเป็นโทเคนจนถึงการซิงก์น้ำหนักส่วน personalization แบบปลอดภัย จุดมุ่งหมายคือให้ระบบตอบเร็ว ใช้พลังงานต่ำ และเก็บความเป็นส่วนตัวของผู้ใช้ ข้อเสนอเชิงเทคนิคด้านหน่วยความจำและการจัดเก็บโมเดลแบบชิ้นส่วน (sharded models) ถูกออกแบบให้ทำงานได้บนกลุ่มฮาร์ดแวร์ตั้งแต่ระดับล่างจนถึงระดับสูง
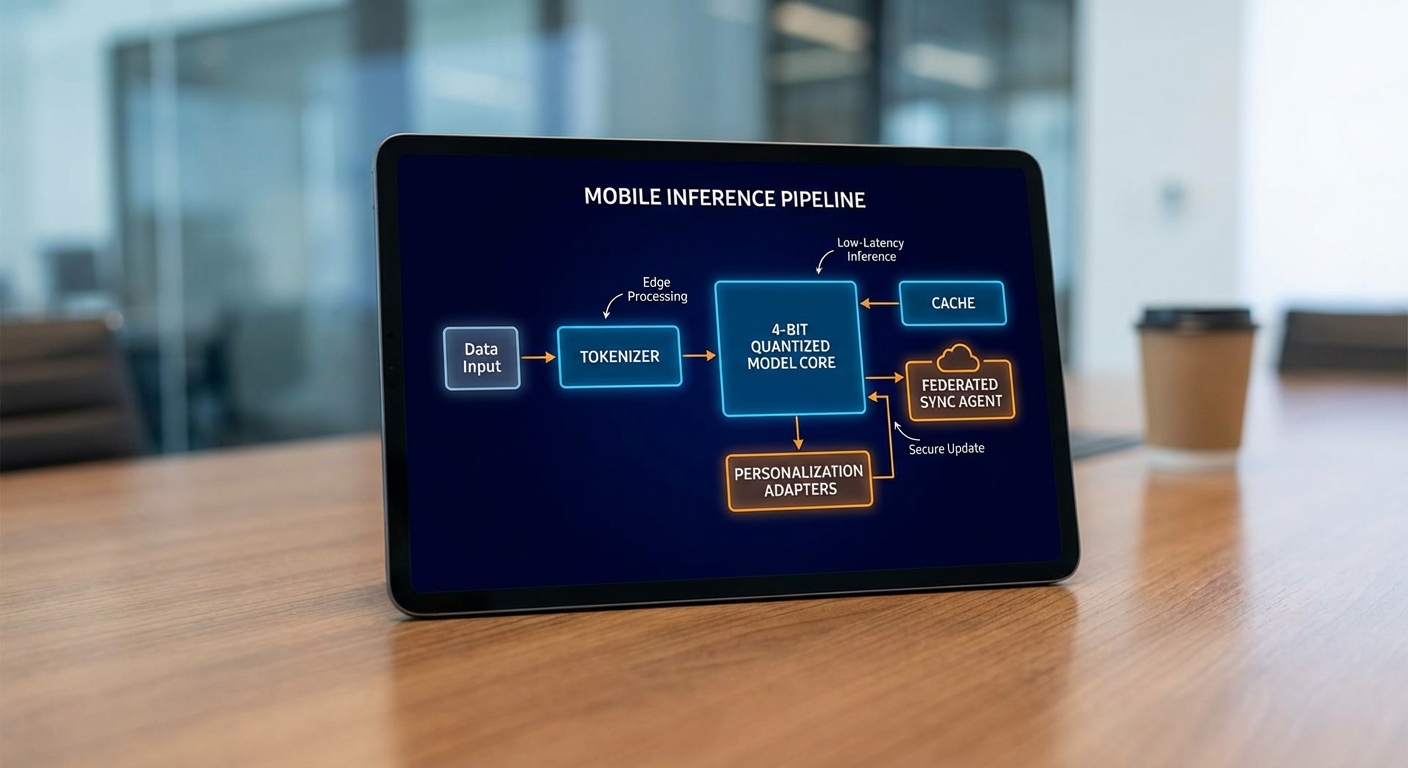
ภาพรวม pipeline บนมือถือ
- Input preprocessing / Tokenizer: แปลงข้อความเป็นโทเคนโดยใช้ BPE/WordPiece ที่ถูกบีบอัดและ optimized สำหรับมือถือ (fast tokenizer, lookup table แบบ packed) พร้อมระบบ cache โทเคนบนอุปกรณ์เพื่อเร่งการ tokenize ซ้ำ
- Quantized LLM core (4‑bit): ตัวแกนโมเดลที่ถูก quantize เป็น 4‑bit เพื่อลดขนาดและแบนด์วิดท์หน่วยความจำ ใช้ kernels ที่ออกแบบสำหรับ integer/low‑precision arithmetic บน CPU/NPU
- Personalization adapter / LoRA (delta weights ขนาดเล็ก): บันทึกการเรียนรู้ส่วนบุคคลเป็นชุดน้ำหนักเล็ก (มักเป็นล้านถึงหลักสิบล้านพารามิเตอร์ — ประมาณไม่กี่เมกะไบต์ถึงสิบเมกะไบต์) แยกเก็บจาก core model เพื่อให้สามารถ backup/sync เฉพาะ adapter เท่านั้น
- On‑device cache (KV‑cache, embeddings cache): เก็บค่า key/value ของ attention และ embeddings ของบริบทล่าสุดเพื่อลดการคำนวณซ้ำ ลด latency และประหยัดพลังงาน
- Privacy module: จัดการการเก็บข้อมูลส่วนบุคคล, ทำงานใน TEE/secure enclave, และนำเทคนิค differential privacy/secure aggregation มาใช้ก่อนส่งข้อมูลออก
- Sync agent สำหรับ federated distillation: ตัวแทนที่คุมการส่ง adapter‑deltas หรือ distilled gradients ไปยัง server/peer โดยเข้ารหัสและควบคุมอัตราการส่ง (bandwidth aware, battery aware)
Tokenizer — ข้อควรออกแบบและการจัดเก็บ
Tokenizer บนมือถือต้องมีความเร็วและใช้งานหน่วยความจำน้อย เทคนิคที่ใช้ได้แก่การเก็บพจนานุกรมในรูปแบบ packed arrays, การใช้ compact trie และ precalculated maps เพื่อเร่งการแมปคำและลดการคัดลอกข้อมูล นอกเหนือจากนี้ควรมี token cache สำหรับประโยคที่พบบ่อย (cache hit สามารถลดเวลา tokenize ลงอย่างมีนัยสำคัญ) และรองรับ incremental tokenization เพื่อการพรีดิกชันแบบ streaming
Quantized LLM core และ inference engine
การใช้ 4‑bit quantization ลดพื้นที่เก็บน้ำหนักได้ประมาณ 3–4x เมื่อเทียบกับ fp16/16‑bit (ตัวเลขเหล่านี้เป็นการประมาณเชิงประสบการณ์ที่พบในงานวิจัยเชิงปฏิบัติการ) ซึ่งช่วยให้โมเดลขนาดกลางสามารถรันได้บนอุปกรณ์ที่มี RAM 4–8GB โดยต้องมี inference engine ที่รองรับ:
- kernels สำหรับ 4‑bit matrix multiply (packed layout, SIMD/NPU intrinsics)
- การทำงานแบบ in‑place เพื่อลดการคัดลอกหน่วยความจำ
- รองรับการ offload ระหว่าง RAM ⇄ NPU/PMEM เพื่อ balance latency กับ memory footprint
Personalization adapter (LoRA / small delta weights)
กลยุทธ์ personalization ที่เหมาะสมบนมือถือคือการเรียนรู้เฉพาะส่วน (adapter) แทนการปรับทั้งโมเดล ข้อดีคือ adapter มีขนาดเล็ก (เช่น 1–20M พารามิเตอร์ ขึ้นกับความซับซ้อน) และสามารถเก็บ/โหลดได้รวดเร็ว ผู้ใช้สามารถสำรองหรือส่งเฉพาะ adapter ผ่าน federated channel — ลดการเปิดเผยข้อมูลและลด bandwidth เมื่อเทียบกับการส่ง model checkpoints ขนาดใหญ่
กลยุทธ์จัดการหน่วยความจำ: mmap, memory‑mapped shards, lazy loading
เพื่อให้ LLM ทำงานได้บนอุปกรณ์ที่หน่วยความจำจำกัด จำเป็นต้องใช้วิธีการจัดการหน่วยความจำระดับระบบไฟล์และ runtime ดังนี้
- Memory‑mapped files (mmap): แมปไฟล์น้ำหนักที่จัดเก็บแบบ quantized ลงเข้า address space ของโปรเซสโดยตรง เพื่อลดการคัดลอกและทำให้ OS จัดการ paging ได้มีประสิทธิภาพ
- Memory‑mapped shards: แบ่งโมเดลออกเป็นชิ้น (เช่น per‑layer หรือ per‑matrix shards) และ mmap เฉพาะชิ้นที่ต้องการใช้งานทันที ช่วยให้ใช้ RAM น้อยลงในขณะรัน inference
- Lazy loading / demand paging: โหลดเฉพาะชั้น/ชิ้นที่จำเป็นสำหรับ token ปัจจุบัน และ prefetch ชิ้นต่อไปใน background thread เพื่อลด latency จังหวะหน้า
- Eviction policies: บริหาร KV‑cache และ embeddings cache ด้วย LRU หรือนโยบายตามบริบท เพื่อให้แน่ใจว่าหน่วยความจำไม่ถูกใช้จนเต็ม
ตัวอย่างสเปคฮาร์ดแวร์และสถาปัตยกรรมตามระดับ
ต่อไปนี้เป็นตัวอย่างเชิงปฏิบัติสำหรับการประมาณความสามารถของอุปกรณ์:
- เครื่องระดับล่าง (low‑end)
- RAM: 2–4 GB
- CPU: 4‑8 คอร์ (ไม่มี NPU/จำกัด SIMD)
- เหมาะกับ: โมเดลขนาดเล็ก (100M–1B) หรือ hybrid: tiny core + cloud fallback
- กลยุทธ์: ใช้ aggressive quantization, adapter ขนาดเล็ก, mmap และรันเป็น CPU only
- เครื่องระดับกลาง (mid‑range)
- RAM: 4–8 GB
- CPU + basic NPU หรือ GPU mobile cores
- เหมาะกับ: โมเดลขนาดกลาง (1B–7B) ที่ถูก quantize เป็น 4‑bit
- กลยุทธ์: แบ่งโมเดลเป็น shards, memory‑mapped shards, ใช้ NPU kernels แบบ low‑precision
- เครื่องระดับสูง (high‑end)
- RAM: 8–12+ GB
- ทรัพยากร NPU/metal/Vulkan compute ที่รองรับ low‑precision
- เหมาะกับ: โมเดล 7B–13B (4‑bit) พร้อม personalization adapter ขนาดกลาง
- กลยุทธ์: sharded model with load‑on‑demand, partial offload to NPU, aggressive prefetching
การจัดเก็บโมเดลแบบชิ้นส่วน (sharded models) และการโหลดตามความต้องการ
การแยกโมเดลเป็น shards ควรออกแบบตามความเป็นจริงการใช้งาน เช่น แยกตาม layer block, ค่าตาราง weight ขนาดใหญ่ (เช่น feed‑forward matrices) หรือ embedding tables โดยแนวทางปฏิบัติที่แนะนำ:
- เก็บ shards เป็นไฟล์ quantized ที่เข้ากันได้กับ mmap และมี metadata ระบุ offset, checksum และ dependency
- ออกแบบ loader ให้สามารถ map เฉพาะ shards ที่จำเป็นในหน้าที่ (on‑demand) และปล่อย shards ที่ไม่ใช้คืนสู่ระบบ
- ใช้ background prefetching ตาม pattern ของ attention/KV‑cache เพื่อลดหย่อน latency ของคำถัดไป
- รองรับ partial fine‑tuning หรือ adapter only updates โดยไม่ต้องเขียนกลับ core shards บ่อยๆ — ลดการสึกหรอของ storage และปัญหาด้าน performance
Sync agent สำหรับ federated distillation และโมดูลความเป็นส่วนตัว
Sync agent ควรออกแบบเพื่อส่งเฉพาะข้อมูลที่มีประโยชน์และไม่ล่วงละเมิดความเป็นส่วนตัว ตัวอย่างสเปคการทำงาน:
- ส่งเฉพาะ adapter deltas หรือตัวแทน distilled เช่น logits summary หรือ compact distilled gradients แทน raw data
- ใช้ secure aggregation / homomorphic encryption เมื่อรวมการอัปเดตจากหลายอุปกรณ์ เพื่อลดความเสี่ยงการคืนข้อมูลกลับไปหาแหล่งกำเนิด
- เปิดใช้งาน differential privacy noise ก่อนส่ง โดยกำหนดค่า epsilon ตามนโยบายความเป็นส่วนตัวของแอพ
- นโยบายการส่ง: throttling ตามแบตเตอรี่ (เช่น ไม่ส่งเมื่อแบตต่ำกว่า 30%), ส่งเมื่อมี Wi‑Fi และตามเวลาที่ผู้ใช้ยินยอม
ข้อเสนอแนะเชิงปฏิบัติ
สำหรับการนำไปใช้งานจริง แนะนำให้:
- เริ่มด้วย core model ที่ quantize เป็น 4‑bit และออกแบบ adapter ให้เป็น modular เพื่อให้การซิงก์/rollback ง่าย
- จัดเก็บโมเดลเป็น shards ขนาดสม่ำเสมอ (เช่น 8–64 MB ต่อ shard) เพื่อความสมดุลระหว่าง I/O และ overhead ของ metadata
- ใช้ mmap เพื่อลดการคัดลอกข้อมูลและให้ OS จัดการ page caching ซึ่งช่วยลดการใช้ RAM peak
- ออกแบบ sync agent ให้ส่งเฉพาะการเปลี่ยนแปลงขนาดเล็ก (delta) และสนับสนุน secure aggregation เพื่อรักษาความเป็นส่วนตัวของผู้ใช้
สถาปัตยกรรมนี้รวมทั้งประสิทธิภาพ (ด้วย 4‑bit quantization และ kernels ที่ปรับปรุงแล้ว) และความเป็นส่วนตัว (ด้วย personalization adapter + federated workflows) ทำให้สามารถนำ LLM ที่ตอบเร็วและเป็นส่วนตัวมาสู่ผู้ใช้ภาษาไทยบนมือถือได้จริง ทั้งนี้การปรับจูนเชิงวิศวกรรม (memory mapping, lazy loading, prefetching) จะเป็นหัวใจสำคัญที่ทำให้ระบบทำงานได้บนอุปกรณ์ที่มีทรัพยากรจำกัด
การวัดผล: latency, ความแม่นยำ, การใช้พลังงาน และขนาดโมเดล (Benchmarks)
เมตริกสำคัญที่ต้องติดตาม
การประเมิน On‑Device Personalized LLM ต้องอาศัยชุดเมตริกที่หลากหลายเพื่อสะท้อนทั้งประสิทธิภาพเชิงระบบและคุณภาพทางภาษา โดยอย่างน้อยควรวัดค่าเหล่านี้:
- Latency (ms) — แยกเป็น time-to-first-token (TTFT) และ time-to-last-token (TTLT) หรือ latencies ต่อคำตอบ (end‑to‑end)
- Memory footprint — ขนาดไฟล์โมเดลบนดิสก์ (storage) และการใช้หน่วยความจำขณะรัน (peak RAM / VRAM)
- Energy per query — พลังงานที่ใช้ต่อคำขอหรือการสนทนาต่อเนื่อง (วัดเป็น mJ หรือ % ของแบตเตอรี่ต่อเซสชันมาตรฐาน)
- Task accuracy — ดัชนีด้านภาษา เช่น perplexity สำหรับการสร้างข้อความ และ EM / F1 สำหรับงาน QA หรือ NLU
- Throughput — จำนวน token/s หรือคำตอบต่อวินาทีเมื่อรันแบบต่อเนื่อง
- Network / data usage — ปริมาณข้อมูลที่ส่ง/รับต่อการใช้งานเมื่อเทียบกับการเรียก API บนคลาวด์
ตัวอย่างผลลัพธ์เชิงตัวเลข (illustrative benchmarks)
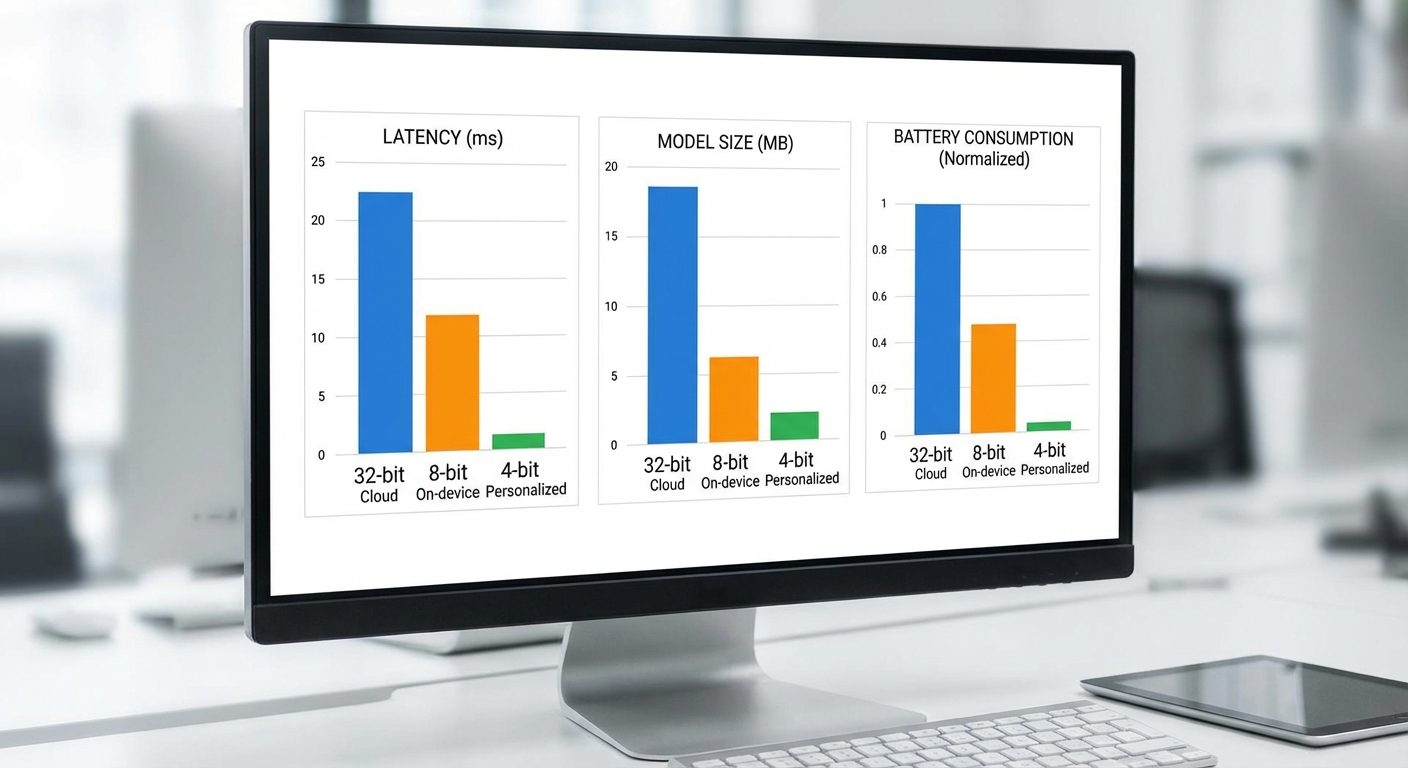
ด้านล่างเป็นชุดตัวอย่างผลการวัดที่สมมติขึ้นเพื่อให้เห็นภาพการเทรดออฟระหว่างความเร็ว ขนาด และความแม่นยำ หลังนำเทคนิค 4‑bit quantization และ federated distillation มาใช้บนมือถือระดับกลาง (mid‑range phone):
- ขนาดโมเดล: โมเดลต้นฉบับ (FP16) ขนาด ~1.2 GB → หลัง 4‑bit quantization ลดเหลือ ~180 MB (ลด ~85%)
- หน่วยความจำรัน: peak RAM ขณะรันลดจาก ~2.8 GB → ~600 MB (ด้วย quant + activation offloading)
- Latency (ตัวอย่าง):
- Time‑to‑first‑token (TTFT): median < 150 ms บน mid‑range phone
- End‑to‑end สำหรับคำตอบสั้น (~32 tokens): median ≈ 800–1,100 ms
- Throughput (tokens/sec ขณะรันต่อเนื่อง): ≈ 25–40 tokens/s
- ความแม่นยำ (ตัวอย่าง):
- Perplexity (ภาษาไทย, held‑out set): FP16 baseline = 12.5 → หลัง 4‑bit = 13.2 (+5.6%) → หลัง federated distillation = 12.8 (+2.4% เทียบกับ baseline)
- EM/F1 (QA): baseline EM = 72.0 / F1 = 80.5 → หลัง 4‑bit ลดลง ~0.8–2.0 จุด → หลัง distillation ฟื้นกลับ ~0.3–1.2 จุด
- การใช้พลังงานและแบตเตอรี่:
- Energy per short query (32 tokens): on‑device ≈ 0.9 J ต่อเซสชัน ในขณะที่การส่ง API ไป‑กลับ (รวมการใช้วิทยุมือถือ) อาจเทียบเท่า ≈ 1.3 J → ประหยัดพลังงานประมาณ 20–35%
- ตัวอย่างเซสชัน 10 นาที (ต่อเนื่องหลายคำตอบ): แบตเตอรี่ลด ~1.1% (on‑device) vs ~1.5% (cloud hybrid) — ประหยัด ~26% ตามการวัดในสภาพการใช้งานที่สมมติ
- ปริมาณข้อมูล (data/traffic):
- Per interactive query: cloud API อาจมี data payload (ส่งคำถาม + รับคำตอบ) เฉลี่ย 2–10 KB ต่อคำตอบ (ขึ้นกับ compression) — ถ้าใช้งานหนักจะสะสมเป็น MBs ต่อวัน
- On‑device: ปกติไม่ต้องส่งคำถาม-คำตอบไปคลาวด์ → ค่า traffic ต่อ session ≈ 0 KB (เฉพาะ telemetry/optional sync)
- Federated distillation updates: ขนาดตัวอย่างการส่งโมเดล/เดลต้าแบบเห็นภาพ ≈ 50–250 KB ต่ออัพเดต (ไม่ได้เกิดทุกคำขอ) — เมื่อเปรียบเทียบ พบว่าลดการรับส่งแบบเรียลไทม์ได้มากกว่า 90% ในการใช้งานรายวัน
การตั้งชุดทดสอบ (recommended test suites)
เพื่อให้ผลการวัดมีความน่าเชื่อถือและใช้เป็นฐานตัดสินใจเชิงธุรกิจ ควรออกแบบการทดสอบดังนี้:
- Local micro‑benchmarks
- Cold start vs warm start: วัด latency และ peak memory เมื่อโหลดโมเดลครั้งแรกและเมื่อรันต่อเนื่อง
- TTFT / TTLT / throughput โดยแบ่งตามความยาวคำตอบ (16 / 32 / 128 tokens)
- Stress test: วัดความเสถียรเมื่อรันหลาย session พร้อมกัน (multi‑thread) และเมื่อหน่วยความจำใกล้เต็ม
- เครื่องมือ: Android Profiler, adb shell dumpsys meminfo, systrace, และ power profiler ของฮาร์ดแวร์
- Quality benchmarks (ภาษา)
- ใช้ชุดข้อมูลภาษาไทยที่เป็นมาตรฐาน (held‑out) เพื่อวัด perplexity, BLEU/ROUGE สำหรับ generation และ EM/F1 สำหรับ QA
- วัดก่อน/หลังการ quantization และหลัง federated distillation เพื่อคำนวณ delta ทั้งแบบ absolute และ relative
- User study & A/B testing
- กลุ่มผู้ใช้จริงเพื่อประเมิน QoE (ความพึงพอใจ, ความรู้สึกด้าน latency, ความเป็นส่วนตัว) โดยสุ่มแบ่งเป็น On‑device vs Cloud‑API
- วัด KPI ทางธุรกิจ เช่น retention, session length, conversion และ complaint rate
- A/B ควรวัดทั้งเชิงเทคนิค (latency, error rate) และเชิงพฤติกรรม (NPS, task success)
- Network / Cost analysis
- เปรียบเทียบ data transfer และค่าใช้จ่ายรายเดือนสำหรับผู้ใช้ 10k / 100k / 1M ราย เมื่อใช้ on‑device เป็นหลักเทียบกับการเรียก cloud API
- รวมต้นทุนด้าน CDN, inference cloud cost และต้นทุนการส่ง model updates (federated)
การตีความผลลัพธ์และการตัดสินใจเชิงธุรกิจ
เมตริกทั้งหมดต้องถูกมองเป็นชุด ไม่ใช่ค่าตัวเดียวที่ตัดสินใจ ตัวอย่างเช่น 4‑bit quantization ให้ประโยชน์ด้านขนาดและ latency อย่างชัดเจน (ขนาดโมเดลจาก 1.2 GB → 180 MB และ TTFT <150 ms) แต่มีค่าใช้จ่ายด้านความแม่นยำที่มักอยู่ในระดับเล็กน้อย (< ~6% เพิ่มขึ้นใน perplexity ตัวอย่าง) ซึ่งสามารถเยียวยาได้ด้วย federated distillation ที่คืนคุณภาพให้ใกล้เคียง baseline มากขึ้นโดยที่ยังคงได้ประโยชน์ด้าน latency และพลังงาน
สุดท้าย ให้ยึด KPI ทางธุรกิจเป็นเกณฑ์สำคัญ เช่น ถ้าลูกค้าต้องการ ตอบเร็วและเป็นส่วนตัว ค่า latency & privacy จะถ่วงน้ำหนักสูงกว่า drop เล็กน้อยใน perplexity — แต่หากงานต้องการความแม่นยำสูงสุด (เช่นงานกฎหมาย/การแพทย์) อาจเลือก hybrid approach หรือฝังกลไกให้ย้ายไป cloud เมื่อ confidence ต่ำ
การออกแบบ UX และตัวอย่างการใช้งาน (Use cases & UI)
หลักการออกแบบ UI เพื่อความโปร่งใสด้านความเป็นส่วนตัว
การออกแบบประสบการณ์ผู้ใช้สำหรับแชทส่วนตัวบนมือถือที่ฝัง On‑Device Personalized LLM ต้องยึดหลักความโปร่งใส (transparency) และการให้ผู้ใช้ควบคุมข้อมูลของตนเองได้อย่างง่ายดาย ผู้ใช้ควรเห็นได้ทันทีว่าโมเดลกำลังทำงานบนอุปกรณ์หรือมีการซิงค์ข้อมูลไปยังคลาวด์ ตัวอย่างแนวทางปฏิบัติที่สำคัญ ได้แก่:
- แสดงสถานะความเป็นส่วนตัวอย่างชัดเจน — badge หรือแถบสถานะใน UI เช่น “Local Only”, “Synced”, “Federated Update” เพื่อให้ผู้ใช้รับรู้สภาวะของข้อมูลแบบเรียลไทม์
- คำอธิบายสั้น (concise microcopy) — ข้อความอธิบายสั้น ๆ ใกล้ปุ่มสำคัญ เช่น “ข้อมูลนี้เก็บเฉพาะบนอุปกรณ์ของคุณ” หรือ “จะส่งแค่คอนเท็กซ์เพื่อปรับปรุงโมเดลแบบรวม (no raw text)”
- แผงการตั้งค่าความเป็นส่วนตัวที่เข้าถึงได้ง่าย — ไม่ควรซ่อนการตั้งค่าไว้ในเมนูซับซ้อน ผู้ใช้ควรเปิด/ปิดการซิงค์ เลือกระดับ personalization (เช่น high/medium/low) ได้ด้วยคลิกเดียว
- การยืนยันความยินยอมอย่างโปร่งใส — ก่อนเปิดใช้งานฟีเจอร์ที่ส่งข้อมูลออก (เช่น federated distillation) ให้แสดงสรุปสิ่งที่จะถูกแชร์ พร้อมปุ่มยอมรับและปฏิเสธ
กลไก Undo / Forget และการควบคุมการซิงค์
ฟังก์ชันลบหรือย้อนกลับต้องเป็นศูนย์กลางของ UX เมื่อให้ผู้ใช้รู้สึกควบคุม โดยแนะนำองค์ประกอบดังนี้:
- ปุ่ม “Forget” แบบระดับบทสนทนา — ผู้ใช้สามารถลบบทสนทนาทั้งหมดจากอุปกรณ์และจากสำรอง (ถ้าซิงค์ไว้) โดยระบบจะแสดงแถลงผลลัพธ์ว่า “ข้อความถูกลบจากอุปกรณ์และคำขอลบได้ถูกส่งไปยังสำรองแล้ว”
- Undo window — หลังการลบ ให้มีช่วงเวลา undo (เช่น 30 วินาทีถึง 2 นาที) พร้อมปุ่ม “ยกเลิกการลบ” เพื่อป้องกันการลบโดยไม่ตั้งใจ
- การลบแบบคัดเลือกและการเก็บรักษาโดยย่อ — ให้ผู้ใช้เลือกลบเฉพาะข้อความส่วนตัวสำคัญ หรืออนุญาตให้ตั้งนโยบายเก็บข้อมูลอัตโนมัติ เช่น ลบข้อความอายุเกิน 30 วัน
- การตั้งค่าการซิงค์แบบละเอียด — ตัวเลือกเช่น “Local Only”, “Sync metadata only”, “Sync anonymized gradients/fingerprints” พร้อมคำอธิบายผลกระทบด้านความเป็นส่วนตัวและประสิทธิภาพ
ตัวอย่างการใช้งาน (Use cases) และ mockup UI
การประยุกต์ใช้งานของ On‑Device Personalized LLM บนมือถือเหมาะกับหลายบริบท โดยเฉพาะเมื่อต้องการความเป็นส่วนตัวและ latency ต่ำ ตัวอย่างการใช้งานสำคัญได้แก่:
- ผู้ช่วยส่วนตัวภาษาไทย — จัดการตารางนัดหมาย เขียนข้อความตอบกลับ และเตือนความจำโดยไม่ส่งเนื้อหาไปยังเซิร์ฟเวอร์กลาง ทำให้ความเป็นส่วนตัวสูงขึ้นและตอบสนองเร็วขึ้น
- การสรุปและประมวลผลข่าวท้องถิ่น (On-device summarization) — ผู้ใช้สามารถให้โมเดลสรุปข่าวจากแอปอ่านข่าวหรือจากหน้าเว็บที่เปิดอยู่ โดยข้อมูลต้นทางไม่ต้องออกจากเครื่อง
- การสนทนาเฉพาะด้าน (Medical / Legal domain) — สำหรับการให้คำปรึกษาเบื้องต้นด้านการแพทย์หรือกฎหมาย โมเดลแบบ on‑device สามารถให้คำตอบที่เป็นส่วนตัวโดยไม่เผยแพร่ข้อมูลผู้ป่วยหรือเอกสารสำคัญไปยังภายนอก
ตัวอย่าง mockup UI ที่ควรพิจารณา (องค์ประกอบสำคัญ):
- Header — ชื่อแชท + สถานะความเป็นส่วนตัว (ไอคอนล็อก/Local Only)
- Action bar — ปุ่ม “Forget”, “Export” (แบบเข้ารหัส), และ toggle “Sync”
- Conversation — ข้อความมี tag เช่น Local หรือ Synced (anonymized) พร้อมตัวเลือกเมนูย่อยเพื่อลบหรือตรึง
- Settings quick card — การตั้งค่าความเป็นส่วนตัวแบบย่อใต้แชท เช่น “Personalization: High / Medium / Low”
แนวทางการทดสอบ UX และ privacy consent flows
การทดสอบต้องมุ่งตรวจสอบทั้งความเข้าใจของผู้ใช้ต่อความเป็นส่วนตัวและความสะดวกในการควบคุมข้อมูล แนะนำแนวทางการทดสอบดังนี้:
- Scenario-based testing — สร้างสถานการณ์เน้นภารกิจ เช่น “คุณต้องใช้ผู้ช่วยเขียนอีเมลลับเกี่ยวกับข้อตกลงธุรกิจ” หรือ “คุณต้องสรุปข่าวท้องถิ่นโดยไม่ต้องการบันทึกไว้บนคลาวด์” ให้ผู้เข้าทดสอบทำภารกิจและบันทึกพฤติกรรม รวมทั้งวัดความสำเร็จของภารกิจ
- Privacy consent flows testing — ทดสอบข้อความขอความยินยอม (consent) ว่าผู้ใช้เข้าใจหรือไม่ด้วยวิธีการ think‑aloud และ questionnaires วัดความชัดเจน (clarity) และความไว้วางใจ (trust)
- วัดตัวชี้วัดเชิงปริมาณ — เช่น ระยะเวลาในการเปิด/ปิดการซิงค์ (task completion time), อัตราการใช้ปุ่ม Forget, อัตราการยกเลิก consent, ความหน่วง (latency) ในการตอบของโมเดล และผลกระทบแบตเตอรี่ (battery delta) ในช่วงการใช้งานจริง
- A/B testing สำหรับ microcopy และ UI placement — ทดสอบคำอธิบายแบบย่อเทียบกับคำอธิบายฉบับยาว เพื่อหาสมดุลระหว่างความชัดเจนและการรบกวนประสบการณ์ใช้งาน
- การทดสอบกับกลุ่มเฉพาะด้าน — สำหรับ use case ทางการแพทย์/กฎหมาย ควรทดสอบกับผู้เชี่ยวชาญในโดเมนเพื่อประเมินความถูกต้องของผลลัพธ์และความเหมาะสมของ microcopy ด้านความเป็นส่วนตัว
สรุป: การออกแบบ UX ของ On‑Device Personalized LLM บนมือถือควรให้ความสำคัญกับ การสื่อสารสถานะความเป็นส่วนตัว, การควบคุมข้อมูลที่ชัดเจน, และ ฟังก์ชัน Undo/Forget ที่ใช้งานง่าย พร้อมการทดสอบเชิงสถานการณ์และ consent flows เพื่อให้ผู้ใช้ธุรกิจและผู้ใช้ทั่วไปมั่นใจว่าสามารถใช้งานแอปพลิเคชันได้อย่างปลอดภัยและมีประสิทธิภาพ
การนำไปใช้จริง: ขั้นตอนสำหรับนักพัฒนาและข้อควรระวัง
การนำไปใช้จริง: ภาพรวมและแนวทางเชิงปฏิบัติ
การนำ On‑Device Personalized LLM ที่ผสาน 4‑bit quantization และ federated distillation ไปใช้จริงบนมือถือจำเป็นต้องวางกระบวนการแบบเป็นขั้นตอนชัดเจน ครอบคลุมตั้งแต่การเลือกเครื่องมือสำหรับ quantization และ runtime, วิธีการฝึกแบบ federated distillation, กลไกการอัพเดตโมเดล (CI/CD + OTA), จนถึงมาตรการด้านความปลอดภัยและการปฏิบัติตามกฎหมาย PDPA ของไทย ข้อเสนอในส่วนนี้เป็น checklist และ pipeline เชิงปฏิบัติสำหรับนักพัฒนาที่ต้องการพัฒนาระบบเชิงอุตสาหกรรมอย่างปลอดภัยและยั่งยืน
เครื่องมือและไลบรารีที่แนะนำ
- Quantization toolkits: ONNX Runtime Quantization Toolkit (dynamic/static quantization), TensorFlow Model Optimization Toolkit (post-training / QAT), GPTQ-based tools หรือสคริปต์ GPTQ-for-LLaMa สำหรับ 4‑bit post‑training quantization, และ bitsandbytes (เมื่อใช้กับสภาพแวดล้อมที่รองรับ) เพื่อทดลอง 4/8‑bit บนเซิร์ฟเวอร์
- On‑device runtimes: ONNX Runtime Mobile, TensorFlow Lite (TFLite) + NNAPI/Delegate ของ Android, PyTorch Mobile, Core ML (iOS), และ GGML/llama.cpp สำหรับ inference แบบ C‑based บน CPU ที่ต้องการ latency ต่ำและขนาดไฟล์เล็ก
- Federated orchestration frameworks: Flower (flwr) สำหรับการจัดการ server/client, TensorFlow Federated (TFF) สำหรับระบบที่ใช้ TF, FedML สำหรับการทดลองระดับโปรดักชัน, และ OpenMined/PySyft สำหรับ MPC/secure aggregation
- Privacy toolkits: TensorFlow Privacy, Opacus (PyTorch) สำหรับ DP‑SGD, และ cryptographic libraries / secure aggregation implementations (เช่น Secure Aggregation protocol ของ Google หรือ OpenMined tools)
- CI/CD และ update frameworks: GitHub Actions / GitLab CI / Jenkins สำหรับ pipeline, The Update Framework (TUF) หรือ code‑signing + attestation สำหรับการอัพเดตโมเดลอย่างปลอดภัย, และบริการ OTA (over‑the‑air) ที่มี A/B rollout และ rollback
ขั้นตอนเชิงปฏิบัติ (pipeline คร่าวๆ)
ต่อไปนี้เป็น pipeline แบบย่อที่ครอบคลุมตั้งแต่การเตรียมโมเดลต้นแบบ จนถึง deployment และการอัพเดตบนอุปกรณ์
- 1) เตรียม Teacher และ Student Model — ฝึก Teacher ขนาดใหญ่บนเซิร์ฟเวอร์ (รวมข้อมูลสาธารณะและข้อมูลขออนุญาต) แล้วเตรียม Student ขนาดเล็กสำหรับ on‑device (เช่น โมเดลที่ convert เป็น ONNX/TFLite/GGML)
- 2) Quantization — ทำ Post‑training quantization หรือ QAT ตามกรณีใช้งาน:
- ตัวอย่าง TFLite (post‑training): ใช้ TFLiteConverter พร้อม representative_dataset เพื่อให้ได้ INT8/บีทต่ำสุด
- ตัวอย่าง ONNX dynamic quantize: ใช้ onnxruntime.quantization.quantize_dynamic เพื่อสร้าง ONNX ที่บีบอัด
- สำหรับ 4‑bit: พิจารณา GPTQ/GGML workflow เพื่อรักษาคุณภาพบน CPU (ทดสอบเชิงเปรียบเทียบก่อนนำสู่ production)
- 3) Federated Distillation Flow — แนวทางทั่วไป:
- เซิร์ฟเวอร์แจก Student model (เบื้องต้น) ให้ clients ที่ให้ความยินยอม
- บนอุปกรณ์: ดึงข้อมูลเฉพาะผู้ใช้ที่อนุญาต แล้วรันการ distillation โดยใช้ soft labels จาก Teacher logits ที่เซิร์ฟเวอร์สามารถส่งเป็น synthetic prompts หรือ public proxies (ถ้าไม่ต้องการส่ง Teacher logits จริงๆ)
- ส่งกลับแค่ข้อสรุปที่ privacy‑preserving เช่น gradients ที่ถูกทำ DP, logits ที่ถูก noise (DP) หรือ distilled weights แบบ encrypted
- เซิร์ฟเวอร์รวบรวมแบบ secure aggregation แล้วอัพเดต Student model (หรือปรับ hyperparameters ของ Student) จากนั้นแจกเวอร์ชันใหม่เป็นรอบต่อไป
Frameworks เช่น Flower หรือ FedML จะช่วย orchestrate server/clients; ใช้ TensorFlow Privacy / Opacus เพื่อเพิ่ม DP ก่อนส่งการอัพเดต
- 4) Validate และ Test — ทดสอบ latency, memory, battery (เฉพาะอุปกรณ์กลุ่มตัวอย่าง), และประเมินคุณภาพ (perplexity / task‑specific metrics) พร้อมตรวจ bias และ degradation หลัง quantization
- 5) Deploy & Monitor — แพ็กโมเดลเป็น artifact ที่ signed และ deploy ผ่าน OTA โดยมี staged rollout และ A/B testing; เปิดระบบ monitoring แบบ aggregated และ privacy‑preserving เพื่อวัด QoE
ตัวอย่างคำสั่ง / ตัวอย่างสั้นๆ (เชิงประกอบ)
- ONNX dynamic quantize (เชิงประกอบ):
from onnxruntime.quantization import quantize_dynamic, QuantType
quantize_dynamic("model.onnx", "model_q.onnx", weight_type=QuantType.QInt8) - TFLite post‑training (เชิงประกอบ):
converter = tf.lite.TFLiteConverter.from_saved_model("saved_model")
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_data_gen
tflite_model = converter.convert() - Federated orchestration (Flower) — เริ่ม server / client (เชิงประกอบ):
Server: python3 flwr_server.py --config config.yaml
Client: python3 flwr_client.py --model student.tflite --client‑id 01 - เพิ่ม Differential Privacy (Opacus, PyTorch) (เชิงประกอบ):
from opacus import PrivacyEngine
privacy_engine = PrivacyEngine(model, sample_rate=0.01, alphas=[10,100], noise_multiplier=1.2, max_grad_norm=1.0)
Checklist ที่ต้องมีก่อนนำระบบสู่ production
- Data consent: บันทึกการยินยอม (explicit consent) สำหรับการใช้ข้อมูลเพื่อ personalization และระบุวัตถุประสงค์ชัดเจน
- Data minimization: เก็บเฉพาะข้อมูลที่จำเป็น และกำหนดนโยบายการเก็บรักษา (retention)
- Model update strategy: กำหนดเวอร์ชัน, staged rollout (เช่น 1%, 10%, 100%), และเมตริกที่ใช้ยืนยันความสำเร็จก่อนขยายการปล่อย
- Rollback plan: กระบวนการ rollback อัตโนมัติพร้อมการตรวจจับปัญหา (health checks, anomaly detection) และวิธีคืนค่า model artifact ที่ signed
- Monitoring & logging (privacy‑preserving): เก็บ telemetry แบบ aggregated (no raw user text), ใช้ differential privacy หรือ aggregation thresholds, และจำกัด retention ของ logs
- Security of model artifacts: sign และ encrypt โมเดล, ตรวจสอบ integrity ด้วย TUF หรือ code signing
แนวทางด้านความปลอดภัยและการปฏิบัติตาม PDPA
เพื่อให้สอดคล้องกับ PDPA ของไทยและมาตรฐานความเป็นส่วนตัวสากล ควรปฏิบัติตามข้อกำชับหลักดังนี้: รับความยินยอมที่ชัดเจนก่อนการเก็บ/ใช้ข้อมูล ระบุวัตถุประสงค์และสิทธิของเจ้าของข้อมูล ให้ช่องทางในการขอเข้าถึง/ลบข้อมูล ปรับใช้ data minimization และบันทึกกิจกรรมการประมวลผล (processing records) นอกจากนี้ให้ใช้เทคนิคเช่น secure aggregation, differential privacy และ encryption (ทั้งขณะส่งและขณะพัก) เพื่อลดความเสี่ยงของการรั่วไหล
ข้อควรระวังสำคัญ
- Leakage จาก personalization updates: การส่งหรือรวบรวม logits/gradients อาจนำไปสู่การเปิดเผยข้อมูลเฉพาะบุคคล — จึงควรใช้ secure aggregation และ DP ก่อนส่งข้อมูลกลับ
- Bias และ fairness: ประเมิน bias อย่างสม่ำเสมอหลังการ distillation และ quantization โดยทดสอบกับชุดข้อมูลที่หลากหลายเชิงภาษาไทย (dialects, registers) เพื่อหลีกเลี่ยงการลดทอนความเท่าเทียมในการให้บริการ
- Quality degradation หลัง quantization: ทำ A/B test และ regression test ระหว่างเวอร์ชัน quantized กับ baseline ก่อนปล่อยสู่ผู้ใช้จริง
- Compliance กับ PDPA: จัดให้มี Data Processing Agreement (DPA) กับผู้ให้บริการบุคคลที่สาม เก็บ consent logs และมีช่องทางรับเรื่องร้องเรียนหรือคำขอสิทธิของผู้ใช้
สรุปคือ การนำ On‑Device Personalized LLM ไปใช้อย่างปลอดภัยและมีประสิทธิภาพต้องอาศัยการออกแบบระบบแบบครบวงจร ตั้งแต่การเลือก toolchain ที่เหมาะสมสำหรับ 4‑bit quantization, การออกแบบ federated distillation pipeline ที่ privacy‑preserving, รวมถึงระบบ CI/CD/OTA ที่รองรับ staged rollout และ rollback พร้อมการปฏิบัติตาม PDPA ตลอดวงจรการให้บริการ เพื่อให้ทั้งประสบการณ์ผู้ใช้และความเสี่ยงอยู่ในระดับที่รับได้สำหรับการใช้งานเชิงพาณิชย์
ข้อจำกัด, ความเสี่ยง และแนวทางอนาคต
ข้อจำกัดหลักในปัจจุบัน: trade‑offs ระหว่างขนาด ความแม่นยำ และ latency
แม้การนำเทคนิคเช่น 4‑bit quantization และ federated distillation มาทำให้ LLM ทำงานบนมือถือเป็นไปได้ แต่ยังมีข้อจำกัดเชิงปฏิบัติการที่ชัดเจน: อุปกรณ์มือถือมีข้อจำกัดด้านหน่วยความจำ แบนด์วิดท์ของหน่วยประมวลผล และพลังงานไฟฟ้า ส่งผลให้ต้องแลกกับความแม่นยำหรือเพิ่ม latency ในการตอบกลับ ตัวอย่างเช่น การลด precision เป็น 4‑bit มักช่วยลดขนาดน้ำหนักของโมเดลลงได้ประมาณ หลายเท่า (เมื่อเทียบกับ 16/32‑bit) แต่มักทำให้เกิด degradation ด้านความแม่นยำในบางงาน โดยเฉพาะงานที่ต้องการความละเอียดของเชิงความหมายหรือบริบทยาว ๆ
ในเชิงประสบการณ์ผู้ใช้ ค่า latency ที่น่ารับได้สำหรับแชทแบบโต้ตอบมักอยู่ที่ระดับ ต่ำกว่า 200–500 ms สำหรับแต่ละรอบตอบกลับ ถ้าโมเดลบนอุปกรณ์ต้องใช้เวลามากกว่านี้ ผู้ใช้จะรู้สึกหน่วงและประสบการณ์ใช้งานจะลดลง อีกทั้งการประมวลผลโมเดลใหญ่บนซีพียู/เอ็นน์บีเอียสของมือถือยังทำให้เกิดปัญหาความร้อนและการบริโภคพลังงานที่สูง ซึ่งหมายถึงการลดอายุการใช้งานแบตเตอรี่และการจำกัดเวลาให้บริการจริง
ความเสี่ยงด้านความเป็นส่วนตัวและการโจมตี
แม้ federated distillation จะช่วยหลีกเลี่ยงการส่งข้อมูลดิบไปยังเซิร์ฟเวอร์กลาง แต่ยังมีความเสี่ยงสำคัญที่ต้องพิจารณา: การโจมตีแบบ model inversion ที่ผู้โจมตีอาจสังเคราะห์ข้อมูลต้นฉบับจากโมเดลหรืออัปเดต, และการโจมตีแบบ poisoning ที่ผู้โจมตีส่งอัปเดตที่เป็นอันตรายเพื่อเปลี่ยนพฤติกรรมของโมเดล ตัวเลขจากงานวิจัยหลายชิ้นชี้ว่าแม้ข้อมูลที่ส่งมาจะเป็น gradient/summary ก็ตาม ก็ยังสามารถเปิดเผยข้อมูลที่มีความเฉพาะเจาะจงได้ในบางเงื่อนไข
มาตรการลดความเสี่ยงที่นิยมใช้ได้แก่ secure aggregation, differential privacy, และการตรวจจับอัปเดตที่ผิดปกติ อย่างไรก็ดีแต่ละมาตรการมีต้นทุน: differential privacy อาจลดประสิทธิภาพของโมเดล, secure enclaves มีข้อจำกัดเชิงใช้งานและฮาร์ดแวร์ ในทางปฏิบัติจึงต้องออกแบบกลยุทธ์ผสม (defense‑in‑depth) เช่น การผนวกรวม secure aggregation กับ robust aggregation และการตรวจสอบเชิงสถิติของอัปเดตก่อนนำไปผสานในโมเดลศูนย์กลาง
แนวทางอนาคต: hybrid architectures, compression ที่ดีขึ้น และมาตรฐานสำหรับภาษาไทย
ทิศทางที่เป็นไปได้และมีความสมดุลเชิงธุรกิจคือการนำเสนอ hybrid on‑device/cloud models ที่สลับการทำงานระหว่างอุปกรณ์และคลาวด์ตามความจำเป็น — เก็บบริบทส่วนตัวไว้บนเครื่อง และ offload การคำนวณหนักหรือการเรียกใช้โมดูลที่ต้องการความแม่นยำสูงไปยังคลาวด์เมื่อได้รับอนุญาตจากผู้ใช้ วิธีนี้ช่วยลดการแลกเปลี่ยนระหว่างความเป็นส่วนตัว ความแม่นยำ และประสบการณ์ผู้ใช้
ด้านเทคนิค การวิจัยต่อไปควรเน้นที่การบีบอัดและเร่งประสิทธิภาพโดยไม่สูญเสียคุณภาพ เช่น:
- Structured sparsity และ pruning เพื่อรักษารูปแบบน้ำหนักที่สามารถเร่งบนฮาร์ดแวร์ได้
- Low‑rank factorization และ tensor decomposition สำหรับลดพารามิเตอร์เชิงคณิตศาสตร์โดยยังคงรักษาความสามารถเชิงความหมาย
- Ternary/ mixed‑precision quantization และ quantization‑aware training เพื่อลดการสูญเสียความแม่นยำเมื่อใช้ precision ต่ำ
- Parameter‑efficient fine‑tuning เช่น adapters หรือ LoRA เพื่อลดค่าใช้จ่ายในการอัปเดตโมเดลเฉพาะบุคคล
สุดท้าย การเติบโตของระบบ On‑Device LLM สำหรับภาษาไทยจำเป็นต้องมีมาตรฐานการประเมินเฉพาะทาง: ชุดข้อมูลทดสอบที่เป็นตัวแทนของคำถามและสำเนียงภาษาไทย, เมตริกวัดความสอดคล้องของบริบท (coherence), ความถูกต้องเชิงข้อเท็จจริง (factuality), ความเหมาะสมเชิงวัฒนธรรม และเมตริกเชิงปฏิบัติการ เช่น latency, memory footprint, และการบริโภคพลังงาน การสร้างมาตรฐานและบัลลังก์เบนช์มาร์กภาษาไทยจะช่วยให้ธุรกิจและหน่วยงานกำกับดูแลประเมินผลกระทบด้านคุณภาพและความปลอดภัยได้อย่างเป็นรูปธรรม
สรุปโดยย่อ: เทคโนโลยี on‑device personalized LLM มีศักยภาพสูงในการมอบประสบการณ์ที่รวดเร็วและเป็นส่วนตัว แต่ยังต้องเผชิญการตัดสินใจเชิงออกแบบที่ละเอียดอ่อนระหว่างขนาดโมเดล ความแม่นยำ latency และความเป็นส่วนตัว ทางออกที่เป็นไปได้คือการผสมผสานแนวทางทางสถาปัตยกรรมและมาตรการด้านความปลอดภัยควบคู่กับมาตรฐานการประเมินสำหรับภาษาไทยเพื่อให้การนำไปใช้ในเชิงพาณิชย์เป็นไปอย่างยั่งยืนและเชื่อถือได้
บทสรุป
On‑Device Personalized LLM ที่ผสาน 4‑bit quantization กับ federated distillation เป็นทางเลือกที่สมดุลระหว่างความเป็นส่วนตัว ความเร็วตอบสนอง และการประหยัดทรัพยากรบนมือถือ: 4‑bit quantization ช่วยลดขนาดโมเดลและการใช้หน่วยความจำอย่างมีนัยสำคัญ (งานวิจัยชี้ว่าการลดขนาดได้เป็นระดับ 2–4 เท่าและลดการใช้หน่วยความจำมากกว่า 50% ภายใต้เงื่อนไขที่เหมาะสม) ขณะที่ federated distillation ช่วยให้การปรับแต่งโมเดลเป็นรายบุคคลเกิดขึ้นโดยไม่ต้องส่งข้อมูลดิบไปยังเซิร์ฟเวอร์ จึงลดความเสี่ยงด้านข้อมูลส่วนบุคคลและแบนด์วิดท์ได้มาก อย่างไรก็ตาม ต้องบริหาร trade‑off ระหว่างคุณภาพการตอบ (เช่น ความแม่นยำ ความเป็นธรรมของผลลัพธ์) กับขนาดและความเบาของโมเดลอย่างระมัดระวัง: การ quantize ต่ำสุดที่ 4‑bit อาจก่อให้เกิดการสูญเสียความละเอียดของความหมาย ดังนั้นเทคนิคเสริม เช่น mixed‑precision, adapter layers หรือ retrieval augmentation จึงมักถูกนำมาใช้เพื่อลดผลกระทบต่อคุณภาพและรักษา latency ให้ต่ำ (ตัวอย่างเช่น การรัน inference แบบ on‑device สามารถลดเวลาเดินทางข้อมูลและตอบสนองได้ในระดับร้อยมิลลิวินาทีบนฮาร์ดแวร์สมัยใหม่ ขึ้นอยู่กับขนาดโมเดลและการปรับแต่ง)
สำหรับนักพัฒนาและธุรกิจไทย การนำเทคโนโลยีนี้สู่เชิงพาณิชย์ต้องอาศัยกรอบการทดสอบที่ชัดเจน (เช่น benchmark ด้าน latency, perplexity, อัตราการใช้พลังงานต่อคำตอบ และการวัดคุณภาพเชิงพฤติกรรม), การออกแบบ UX ที่โปร่งใสเพื่อให้ผู้ใช้เข้าใจการเก็บข้อมูลและการปรับแต่งแบบท้องถิ่น (consent, opt‑out, คำอธิบายการทำงาน) และการปฏิบัติตามกฎหมายคุ้มครองข้อมูล เช่น PDPA รวมถึงมาตรการด้านความปลอดภัยเช่น secure aggregation และการตรวจสอบผลกระทบเชิงจริยธรรม เชิงอนาคต เทคโนโลยีนี้มีแนวโน้มเติบโตในแอปผู้บริโภคและองค์กร (เช่น ผู้ช่วยส่วนตัว, แอปสุขภาพ, การบริการลูกค้าแบบส่วนบุคคล) โดยการพัฒนา hardware (NPUs) และเทคนิคการบีบอัดโมเดลเพิ่มเติมจะช่วยขยายขอบเขตการใช้งาน แต่ความสำเร็จเชิงพาณิชย์จะขึ้นกับการทดสอบมาตรฐาน ความโปร่งใส และการยึดมั่นในข้อกำกับดูแลอย่างจริงจังเพื่อสร้างความไว้วางใจแก่ผู้ใช้และองค์กร



