
ในยุคที่เครือข่ายโทรคมนาคมมีความซับซ้อนและปริมาณข้อมูลเทเลเมตริกเพิ่มขึ้นอย่างก้าวกระโดด ระบบเพื่อช่วยลดภาระการตรวจสอบและเร่งการแก้ปัญหาให้เร็วขึ้นจึงกลายเป็นหัวใจสำคัญของการดำเนินงาน โอเปอเรเตอร์โทรคมนาคมรายใหญ่ในไทยได้ทดลองใช้งาน "LLM‑NetOps" — แนวทางผสานความสามารถของโมเดลภาษาขนาดใหญ่กับข้อมูลเทเลเมตริกเครือข่าย เพื่อแปลงสัญญาณเชิงตัวเลขเป็นคำสั่งแก้ปัญหาอัตโนมัติ ผลทดสอบระยะแรกชี้ให้เห็นถึงศักยภาพในการลดเวลาเฉลี่ยในการแก้เหตุการณ์ (MTTR) ลงได้ในระดับหลักสิบเปอร์เซ็นต์ พร้อมทั้งช่วยให้วิศวกรมุ่งเน้นงานเชิงยุทธศาสตร์มากขึ้น
บทความนี้จะพาอ่านภาพรวมของการออกแบบสถาปัตยกรรม LLM‑NetOps ที่ใช้เทเลเมตริกแบบเรียลไทม์เป็นอินพุต อธิบายผลลัพธ์เชิงสถิติจากการทดลองภาคสนาม ระบุความเสี่ยงทั้งด้านความถูกต้องของข้อเสนอแนะ ความปลอดภัย และความน่าเชื่อถือเมื่อปล่อยคำสั่งอัตโนมัติ รวมถึงเสนอแนวทางปฏิบัติที่ควรมีเมื่อนำไปใช้งานจริง เช่น การออกแบบ human‑in‑the‑loop การตั้งมาตรการการยืนยันคำสั่ง และการเสริมระบบตรวจสอบเพื่อป้องกันความผิดพลาด ที่ผู้อ่านซึ่งเป็นวิศวกรเครือข่าย ผู้บริหารฝ่ายปฏิบัติการ และนักวางนโยบายสามารถนำไปพิจารณาต่อยอดได้
บทนำ: ทำไมโอเปอเรเตอร์ต้องสนใจ LLM‑NetOps
บทนำ: ทำไมโอเปอเรเตอร์ต้องสนใจ LLM‑NetOps
โครงการทดลอง LLM‑NetOps ที่โอเปอเรเตอร์โทรคมนาคมไทยกำลังดำเนินการ มีเป้าประสงค์ชัดเจนในการนำความสามารถของ Large Language Models (LLMs) มาผสานกับกระบวนการปฏิบัติการเครือข่าย (NetOps) เพื่อเปลี่ยนเทเลเมตริกและข้อความล็อก (telemetry & logs) ให้กลายเป็นคำสั่งหรือ playbook สำหรับการแก้ปัญหาอัตโนมัติ ความจำเป็นเกิดจากปัญหาเชิงปฎิบัติการที่พบเป็นประจำ ได้แก่ ปริมาณการแจ้งเตือนที่เพิ่มขึ้นอย่างรวดเร็ว การระบุสาเหตุจริง (root cause) ที่ซับซ้อน และภาระงานที่ซ้ำซ้อนกับทีมวิศวกร ผลกระทบโดยตรงคือค่าเฉลี่ยเวลาแก้ไขเหตุการณ์ (MTTR) ที่ยาวนานขึ้นและค่าใช้จ่ายปฏิบัติการ (OPEX) ที่สูงขึ้น

ปัญหาทั่วไปที่โครงการพยายามแก้ไขได้แก่:
- การแจ้งเตือนล้น: โอเปอเรเตอร์รายใหญ่บางแห่งรายงานการแจ้งเตือนตั้งแต่หลายพันถึงหลายหมื่นรายการต่อวัน ซึ่งทำให้เกิด alert fatigue และทำให้วิศวกรพลาดเหตุการณ์สำคัญ
- การระบุสาเหตุยาก: ข้อมูลจากหลายแหล่งทั้ง routing, telemetry, syslog และ performance counter ต้องถูกวิเคราะห์ร่วมกัน ซึ่งใช้เวลาและต้องใช้ความชำนาญสูง
- งานซ้ำซ้อนและการแก้ไขแบบแมนนวล: หลายขั้นตอนเป็นงานเดิมที่ทำซ้ำได้ เช่น การรีสตาร์ทพอร์ต การเทียบค่ากับ baseline หรือการเปิด case กับ vendor
ด้วยเหตุนี้ โครงการ LLM‑NetOps ตั้งเป้าทางตัวเลขที่ชัดเจนเพื่อเป็นดัชนีวัดความสำเร็จ โดย คาดหวัง ผลลัพธ์เบื้องต้นดังนี้:
- ลดค่าเฉลี่ย MTTR ลงราว 40–70% (ตัวอย่างเช่น จาก 90–180 นาที เหลือ 30–60 นาที)
- ลดสัดส่วน false positives ของการแจ้งเตือนลงประมาณ 30–50% ผ่านการกรองและการเชื่อมโยงเหตุการณ์อัตโนมัติ
- ลดปริมาณการแจ้งเตือนที่ต้องการการตรวจสอบด้วยมือถึง 30–40% ผ่านการจัดกลุ่ม (correlation) และการจัดลำดับความสำคัญอัตโนมัติ
- คืนเวลาการทำงานที่เป็นงานซ้ำซ้อนให้ทีม โดยคาดว่าจะเทียบเท่าการประหยัดกำลังคน (FTE) ประมาณ 3–6 คน ขึ้นอยู่กับขนาดเครือข่ายและระดับออโตเมชันที่นำไปใช้
กลุ่มเป้าหมายหลักของการทดสอบนี้ได้แก่:
- วิศวกรเครือข่าย — เพื่อช่วยในการวิเคราะห์สาเหตุและรันคำสั่งแก้ไขที่ผ่านการตรวจสอบ
- ทีม NOC — เพื่อปรับกระบวนการแจ้งเตือนและ triage ให้ทำงานเร็วขึ้นและแม่นยำขึ้น
- ผู้บริหารด้านการดำเนินงาน — เพื่อให้เห็นตัวชี้วัดเชิงปฏิบัติการ (เช่น MTTR, SLA compliance, ต้นทุนต่อเหตุการณ์) และตัดสินใจลงทุนในออโตเมชันได้อย่างมีข้อมูล
สรุปแล้ว โอเปอเรเตอร์ควรให้ความสนใจกับ LLM‑NetOps เพราะเป็นแนวทางที่ผสานความสามารถด้านการตีความภาษาธรรมชาติและ pattern recognition ของ LLM เข้ากับความต้องการเชิงปฏิบัติการของ NetOps เพื่อให้การตรวจจับ การวิเคราะห์ และการตอบสนองเหตุการณ์เครือข่ายเกิดขึ้นได้เร็วขึ้น ถูกต้องขึ้น และใช้ทรัพยากรน้อยลง — ซึ่งสอดคล้องกับเป้าหมายทางธุรกิจในการลด MTTR, ลด false positives และปรับปรุงประสิทธิภาพการดำเนินงานโดยรวม
พื้นฐาน: LLM‑NetOps คืออะไร ทำงานอย่างไร
พื้นฐาน: LLM‑NetOps คืออะไร ทำงานอย่างไร
LLM‑NetOps คือสถาปัตยกรรมที่ผสานความสามารถของ Large Language Models (LLMs) เข้ากับระบบการจัดการและควบคุมเครือข่าย เพื่อแปลงเทเลเมตริก (metrics), log และ trace ให้เป็นคำสั่งแก้ปัญหาอัตโนมัติหรือคำแนะนำที่เข้าใจง่ายสำหรับวิศวกร โดยทั่วไประบบจะทำงานเป็นชั้นเชื่อมต่อกันจากการเก็บข้อมูล ไปสู่การตัดสินใจและการลงมือปฏิบัติจริง ทั้งยังรองรับรูปแบบการทำงานแบบ fully automated และแบบมีการยืนยันจากมนุษย์ (human‑in‑the‑loop)
โดยภาพรวมการไหลของข้อมูลใน LLM‑NetOps มักประกอบด้วยชั้นหลักดังนี้:
- Telemetry ingestion: การเก็บและรับข้อมูลเทเลเมตริก, logs และ traces จากอุปกรณ์เครือข่ายและระบบบริการ โดยใช้เครื่องมือเช่น Prometheus (metrics), Fluentd / Logstash (logs), OpenTelemetry (traces) และส่งผ่าน messaging layer เช่น Kafka สำหรับสเกลสูง — เครือข่ายระดับโอเปอเรเตอร์อาจผลิตหลายล้านรายการเหตุการณ์ต่อวัน
- Preprocessing / Feature extraction: การทำความสะอาด (cleaning), การรวมเหตุการณ์ (aggregation), การสกัดคุณลักษณะเฉพาะเช่น latency spikes, packet loss patterns หรือ session traces ที่มีความสำคัญต่อการวิเคราะห์ ระบบชั้นนี้ยังทำหน้าที่ลดความซับซ้อนของข้อมูลและแปลงให้อยู่ในฟอร์แมตที่ LLM หรือโมดูล embedding ใช้งานได้ง่าย
- RAG / Vector Database: การสร้าง embedding จากข้อความสรุปเหตุการณ์หรือสแน็ปชอตของเมตริก แล้วเก็บในฐานข้อมูลเวกเตอร์เช่น Milvus หรือไลบรารีเช่น FAISS เพื่อใช้ Retrieval‑Augmented Generation (RAG) หาความรู้จากประวัติการแก้ปัญหาและเอกสารเชิงเทคนิค — ช่วยให้ LLM มีบริบทเชิงสถานการณ์และอ้างอิงการตัดสินใจได้แม่นยำขึ้น
- LLM (model selection & prompting): ชั้นนี้เป็นตัวสร้างคำอธิบาย สาเหตุ และคำสั่งปฏิบัติการ โดยเลือกโมเดลให้เหมาะสมระหว่างการเรียกใช้ OpenAI หรือโมเดลท้องถิ่น (on‑prem / fine‑tuned LLMs) ขึ้นกับข้อจำกัดความเป็นส่วนตัวและค่าใช้จ่าย การออกแบบ prompt และการจัดการบริบท (context window) มีผลโดยตรงต่อความแม่นยำและความน่าเชื่อถือของคำแนะนำ
- Orchestrator / Runner: ตัวประสานคำสั่งและตัวรันคำสั่งจริง (เช่น playbook ของ Ansible, สคริปต์ Netmiko/Nornir หรือ REST/gNMI calls) ที่แปลงคำแนะนำจาก LLM เป็นการกระทำจริงบนอุปกรณ์หรือบริการ พร้อมกับ policy enforcement, rate limiting และการจัดตารางการดำเนินการ
- Verification & rollback: ระบบตรวจสอบผลลัพธ์หลังการดำเนินการ เช่น health checks, canary tests และการบันทึกทรานแซคชัน หากผลลัพธ์ไม่เป็นไปตามคาด ระบบจะเรียกใช้ rollback หรือ revert ทั้งแบบอัตโนมัติหรือรอการยืนยันจากผู้ดูแล
ความเชื่อมโยงระหว่างชั้นเหล่านี้เป็นหัวใจสำคัญ: ข้อมูลจากชั้น ingestion ถูกแปลงและย่อความในชั้น preprocessing เพื่อสร้าง embedding ที่เก็บใน vector DB ซึ่ง RAG จะดึงบริบทเกี่ยวข้องให้ LLM ในการสร้างคำสั่งหรือ playbook ที่ถูกส่งต่อไปยัง orchestrator การตัดสินใจเชิงการปฏิบัติการจะขึ้นกับนโยบายความเสี่ยงและระดับความมั่นใจของโมเดล—หากค่าความเชื่อมั่นต่ำระบบอาจส่งคำแนะนำให้มนุษย์ยืนยันก่อน
บทบาทของ human‑in‑the‑loop จะอยู่ในจุดที่มีความเสี่ยงสูงหรือเมื่อความมั่นใจของโมเดลไม่ถึงเกณฑ์ ตัวอย่างการผสมผสานคือให้ LLM สร้างรายการคำสั่งและผลกระทบที่คาดไว้ แล้วให้วิศวกรตรวจทานและอนุมัติก่อนรันจริง ในทางกลับกัน สำหรับเหตุการณ์ทั่วไปที่มี playbook ชัดเจน ระบบสามารถรันอัตโนมัติได้ทั้งหมดเพื่อลดเวลาตรวจสอบและแก้ไข (mean time to repair — MTTR) โดยงานวิจัยและเคสใช้งานจริงชี้ว่า automation ดีไซน์อย่างรอบคอบสามารถลด MTTR ลงอย่างมีนัยสำคัญ เช่นจากหลายชั่วโมงเหลือเป็นนาทีในบางกรณี
ตัวอย่างเทคโนโลยีที่มักพบในสแต็ก LLM‑NetOps: Prometheus + Grafana สำหรับ metrics และ visualization, Kafka สำหรับ pipeline ที่ต้องการ throughput สูง, Milvus หรือ FAISS สำหรับการค้นหาเวกเตอร์ และ LLM ทั้งจากผู้ให้บริการคลาวด์อย่าง OpenAI หรือโมเดลท้องถิ่นที่ผ่านการ fine‑tune เพื่อรักษาข้อมูลภายในองค์กร การออกแบบที่ดีจะคำนึงถึงความปลอดภัยของข้อมูล การกำกับดูแลการตัดสินใจ (audit trail) และกลไกการยืนยัน/ย้อนกลับ (verification & rollback) เพื่อให้การแปลงเทเลเมตริกเป็นการกระทำบนเครือข่ายปลอดภัยและเชื่อถือได้
การออกแบบการทดสอบของโอเปอเรเตอร์ไทย: แนวทางและข้อมูลที่ใช้
ขอบเขตการทดสอบและเป้าหมายเชิงปฏิบัติ
การทดลองเริ่มต้นถูกกำหนดให้ครอบคลุม RAN (Radio Access Network) และ Transport segment เป็นกลุ่มทดลองหลัก โดยมีเป้าหมายเชิงปฏิบัติในการวัดประสิทธิภาพของ LLM‑NetOps ในการแปลงเทเลเมตริกเป็นคำสั่งแก้ปัญหาอัตโนมัติ ทั้งนี้กลุ่ม Core network ถูกวางแผนให้เป็นเฟสถัดไปหลังจากพิสูจน์แนวทางในสองกลุ่มแรกแล้ว
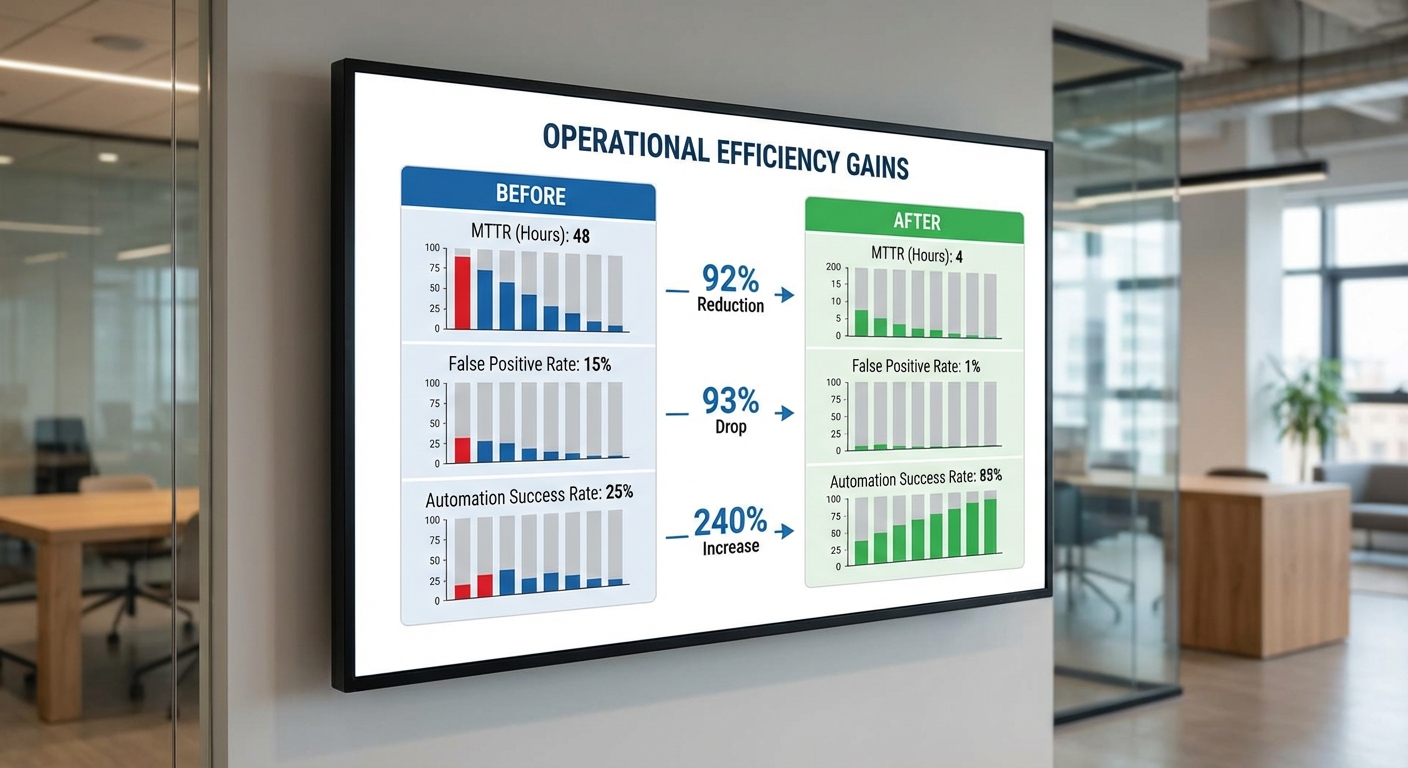
ในเชิง KPI องค์กรกำหนดเป้าหมายเริ่มต้นเป็นการลด Mean Time To Repair (MTTR) ของเหตุการณ์ที่ทดสอบได้อย่างน้อย 30% ภายในรอบทดลอง และต้องมีความแม่นยำของคำสั่งที่ระบบเสนอ (top‑1 recommendation) ไม่ต่ำกว่า 85% เมื่อเทียบกับการแก้ปัญหาโดยวิศวกรผู้เชี่ยวชาญ
ประเภทข้อมูลเทเลเมตริกและล็อกที่ใช้
ชุดข้อมูลที่นำมาใช้แบ่งเป็นกลุ่มหลักดังนี้:
- SNMP counters: interface octets, input/output errors, CRC error counts
- Flow metrics (NetFlow/sFlow/IPFIX): per‑flow throughput, active flow counts, flow durations
- Latency และ jitter: one‑way/round‑trip latency ระหว่างจุดต่างๆ ของ transport และ RAN bearer latency
- BER และ radio quality: Bit Error Rate, RSRP, RSRQ, SINR และ HARQ failure rates
- Packet loss/throughput: per‑link and per‑sector throughput, packet loss percentage
- Syslog และ OSS alarms: device syslog, control plane traces, alarm clear/set timelines
- Event traces / call traces: handover traces, RRC connection setup/failure logs, transport path flapping events
ตัวอย่าง metric ที่ติดตามเชิงตัวเลขเช่น throughput (Mbps), BER (10^-3 ถึง 10^-6), latency (ms) และ counters ต่อวินาที ส่วน logs จะถูกแปลงเป็น sequence events เพื่อนำเข้าเป็น context ให้กับ LLM
ชุดข้อมูลจริงและสังเคราะห์: การแบ่งและการเตรียม
โอเปอเรเตอร์ใช้แนวปฏิบัติที่ผสมผสาน real production data กับ synthetic augmentation เพื่อให้แบบจำลองครอบคลุมเหตุการณ์ที่หายากแต่สำคัญ โดยรายละเอียดการแบ่งชุดข้อมูลเป็นดังนี้:
- รวมข้อมูลเหตุการณ์ย้อนหลังจากระบบ OSS ระยะเวลา 12 เดือน มีจำนวนประมาณ 10,000 เคสเหตุการณ์จริงที่ผ่านการทำ anonymization และ labeling โดยวิศวกร
- สร้างชุดสังเคราะห์ประมาณ 40,000 เคส ด้วยการใช้ traffic emulation, fault injection (เช่น fiber cut, port flapping, interference spikes) และการเพิ่ม noise เพื่อจำลองสภาพแวดล้อมต่างๆ
- การแบ่งข้อมูลสำหรับการฝึก/วาลิเดชัน/ทดสอบ: 70% training, 15% validation, 15% holdout test โดยยังคงรักษาการกระจายเหตุการณ์ (stratified sampling) ให้สอดคล้องกับความถี่ในโลกจริง
- ข้อมูลที่ละเอียดอ่อนถูกทำ pseudonymization และลบข้อมูลที่เป็น PII ก่อนนำเข้า pipeline
กระบวนการสเกล การตั้ง baseline และแผน A/B testing
การทดลองแบ่งเป็นเฟสย่อยเพื่อประเมินความเสถียรและผลลัพธ์เชิงธุรกิจ:
- เฟส Data Preparation (8–10 สัปดาห์): เก็บข้อมูล retrospective 12 เดือน, ทำ labeling โดย SME, สร้าง synthetic scenarios และ pipeline สำหรับการสตรีมข้อมูล
- เฟส Training & Validation (4–6 สัปดาห์): ฝึก LLM‑NetOps บนชุดผสม real+synthetic, ปรับ hyperparameters และทดสอบบนชุด validation
- เฟส Pilot (6–8 สัปดาห์): นำระบบไปใช้งานแบบ non‑intrusive ในกลุ่มวิศวกรชุดเล็ก เพื่อเสนอคำแนะนำเป็น suggested action พร้อมให้มนุษย์เป็นผู้ตัดสินใจ
- เฟส A/B Testing (8 สัปดาห์): แบ่งทีมวิศวกรเป็น Control (กระบวนการเดิม) และ Treatment (ใช้ LLM‑NetOps) โดยวัด MTTR, ความถูกต้องของคำแนะนำ (precision@1), จำนวน escalations และ user satisfaction
- เฟส Full Rollout (ขั้นบันได 3 เดือน): ขยายการใช้งานในระดับภูมิภาคหลังผ่านเกณฑ์สำเร็จ และติดตามผลเชิงปฏิบัติการ
สำหรับการตั้ง baseline บริษัทกำหนดตัวชี้วัดดังนี้: MTTR ปัจจุบันของเหตุการณ์กลุ่มตัวอย่างเฉลี่ยอยู่ที่ ~45 นาที, อัตราความสำเร็จของ runbook แบบแมนนวล ~78%, และเฉลี่ยเวลาตรวจจับเหตุการณ์ ~12 นาที. เกณฑ์ความสำเร็จของระบบใหม่คือการลด MTTR อย่างน้อย 30% และเพิ่มอัตราความสำเร็จการแก้ปัญหาเป็นอย่างน้อย 85% โดยต้องยืนยันด้วยการทดสอบ A/B ที่มีความแตกต่างเชิงสถิติ (p < 0.05)
ตัวอย่างเหตุการณ์จริงที่ใช้ในการทดสอบ
ตัวอย่างเหตุการณ์จริงที่นำมาทดสอบและสคริปต์จำลอง ได้แก่:
- เหตุการณ์ A — Fiber cut (Transport): อาการคือ latency พุ่งจาก 15 ms เป็น >250 ms บนลิงก์ backbone ควบคู่กับ alarm port down; การทดสอบให้ LLM‑NetOps วิเคราะห์ path metrics, ระบุจุดเสียหายที่เป็นไปได้ และเสนอคำสั่งเปลี่ยนเส้นทาง (reroute) เฉพาะจุดพร้อมขั้นตอนแจ้งทีม field
- เหตุการณ์ B — Sector outage (RAN): RSRP/RSRQ ดิ่งลงอย่างฉับพลันและจำนวน RRC failure เพิ่มขึ้น 3x; ระบบต้องระบุสาเหตุระหว่าง feeder fault, TRX failure หรือ interference และเสนอคำสั่งเช็ก hardware, reset TRX หรือปรับ power
- เหตุการณ์ C — Backhaul congestion: throughput ลดลงชัดเจนบนหลาย sector แต่ BER อยู่ในเกณฑ์ปกติ — LLM‑NetOps ต้องแยกแยะเป็นปัญหา congestion ใน transport vs resource exhaustion ใน RAN และเสนอการปรับ QoS หรือตัด traffic non‑critical
- เหตุการณ์ D — Intermittent packet loss: event trace แสดง packet loss แบบเป็นช่วง ๆ ซึ่งทีมได้ใช้ synthetic fault injection จำลองเหตุการณ์ flapping เพื่อทดสอบความทนทานของโมเดล
โดยสรุป การออกแบบการทดสอบของโอเปอเรเตอร์ไทยเน้นการรวมข้อมูลเชิงปริมาณและเชิงเหตุการณ์ (metrics + logs + traces), ใช้ชุดข้อมูลผสมจริง/สังเคราะห์ที่มีการแบ่งอย่างเป็นระบบ, และกำหนดเฟสสเกลพร้อมเกณฑ์ A/B ที่ชัดเจนเพื่อให้มั่นใจว่าการนำ LLM‑NetOps เข้าสู่กระบวนการงานจริงจะให้ผลลัพธ์ที่สามารถวัดได้และปลอดภัยต่อการปฏิบัติการของเครือข่าย
เทคนิคการแปลงเทเลเมตริกเป็นคำสั่งแก้ปัญหาอัตโนมัติ
เทคนิคการแปลงเทเลเมตริกเป็นคำสั่งแก้ปัญหาอัตโนมัติ
ระบบแปลงเทเลเมตริกเครือข่ายเป็นคำสั่งปฏิบัติการอัตโนมัติประกอบด้วยชุดเทคนิคเชิงปฏิบัติการที่เชื่อมต่อเป็น pipeline ตั้งแต่การเก็บข้อมูลดิบจนถึงการรันคำสั่งจริงบนอุปกรณ์ โดยมีวัตถุประสงค์เพื่อช่วยวิศวกรลดเวลาการตรวจสอบเหตุการณ์และเพิ่มความแม่นยำของการตอบสนอง ตัวอย่าง pipeline เชิงปฏิบัติการที่ใช้ในระบบ LLM‑NetOps ประกอบด้วยขั้นตอนต่อไปนี้:
- Raw telemetry → normalization: ดึงข้อมูลจาก SNMP, gNMI, sFlow, NetFlow, syslog และเครื่องมือมอนิเตอร์อื่น ๆ แล้วทำการ normalize ฟีลด์สำคัญ เช่น latency, packet loss, interface counters, BGP state ให้เป็นรูปแบบเดียวกันเพื่อการประมวลผลต่อเนื่อง
- Normalization → feature extraction: สกัดคุณลักษณะ (features) จาก series ของเทเลเมตริก เช่น rolling averages, derivatives, seasonality decompositions, protocol‑specific KPIs และการรวม context เช่น device role, topology และ recent config changes
- Feature extraction → anomaly detection: ใช้โมเดลผสม (statistical thresholds, ML models เช่น isolation forest หรือ LSTM-based detectors) เพื่อค้นหาพฤติกรรมผิดปกติและจัดลำดับความรุนแรง (severity scoring)
- Anomaly → context retrieval → LLM prompt → action plan: เมื่อตรวจพบ anomaly จะดึง context ที่เกี่ยวข้อง (config snippets, runbooks, topology maps, change history) และส่งเป็น prompt ให้ LLM เพื่อสร้างแผนปฏิบัติการที่เป็นลำดับก้าว
ในขั้นตอนการสกัดฟีเจอร์และตรวจจับความผิดปกติ ควรผสมผสานวิธีการแบบ deterministic และ ML เพื่อให้เกิดความสมดุลระหว่างความแม่นยำและการอธิบายผลได้ (explainability) ตัวอย่างเช่น การตั้งค่า threshold แบบ context-aware (เช่น เกณฑ์ latency ต่างกันตามชนิดลิงก์) ร่วมกับ anomaly detector แบบเรียนรู้จากประวัติ ช่วยลด false positive ได้อย่างมีนัยสำคัญ และยังอนุญาตให้ระบบส่งสัญญาณเตือนพร้อมเหตุผลประกอบที่ชัดเจนต่อ LLM
การออกแบบ prompt engineering สำหรับ LLM ต้องคำนึงถึงโครงสร้างและข้อจำกัดให้ชัดเจน: ใช้ system prompt เพื่อกำหนดบทบาท (เช่น "คุณคือผู้เชี่ยวชาญ NetOps") ให้ตัวอย่าง (few‑shot) ของเทเลเมตริกและผลลัพธ์ที่คาดหวัง และแนบ context ที่ดึงจาก Retrieval‑Augmented Generation (RAG) เพื่อให้ LLM อ้างอิง playbooks และ configuration snippets ที่เป็นเวอร์ชันล่าสุด การใช้ RAG ร่วมกับ vector database ทำให้สามารถค้นหาเอกสารสนับสนุน (เช่น playbook การแก้ปัญหา BGP flap หรือตัวอย่าง CLI snippet) ตามความคล้ายเชิงความหมายของ prompt ซึ่งลดโอกาสที่ LLM จะสร้างคำตอบที่ไม่สอดคล้องกับนโยบายหรือ config ปัจจุบัน
เช่น กระบวนการ RAG มักประกอบด้วยการแปลงข้อความเอกสาร (playbook, RFC, SOP) เป็น embeddings ด้วยโมเดล embedding ที่เหมาะสม แล้วเก็บใน vector DB (เช่น FAISS, Milvus หรือ Pinecone) เมื่อเกิดเหตุระบบจะทำ similarity search ดึงเอกสารที่เกี่ยวข้องสูงสุด 3‑10 รายการมาเป็น context ให้ LLM เพื่อให้คำตอบมีการอ้างอิงที่ชัดเจนและสามารถตรวจสอบย้อนหลังได้
หลังจาก LLM สร้างแผนปฏิบัติการ ระบบต้องแปลงผลลัพธ์เป็นคำสั่งปฏิบัติการที่ใช้งานได้จริงบนเครื่องมือเครือข่าย ด้วยกลไก mapping ที่ประกอบด้วยเทมเพลตและ schema validator ตัวอย่างรูปแบบผลลัพธ์ที่ระบบคาดหวังอาจเป็น JSON structure เช่น { "action":"clear-bgp-session", "target":"router01", "command":"clear ip bgp 10.0.0.1", "dry_run":true } ระบบใช้เทมเพลตเพื่อเรนเดอร์เป็นคำสั่ง CLI หรือ REST API call และตรวจสอบความถูกต้องของคำสั่งผ่าน static validation (syntax, argument types) และ dynamic validation (จำลองผลที่คาดว่าจะเกิดขึ้น)
เพื่อป้องกันความเสี่ยงจากการรันคำสั่งอัตโนมัติ ควรมีกลยุทธ์การยืนยัน (verification) หลายชั้นรวมถึง:
- Dry‑run: สร้างและรันคำสั่งในโหมดจำลองเพื่อประเมินผลกระทบโดยไม่เปลี่ยนสถานะอุปกรณ์ เช่น ตรวจสอบว่า BGP neighbor จะ down หรือไม่ในกรณีที่ clear
- Simulation / sandbox: ทดสอบคำสั่งใน environment ที่แยกจาก production เช่น lab topology หรือ containerized simulator เพื่อตรวจสอบ sequence ของการเปลี่ยนแปลง
- Human approval: ส่งผลลัพธ์และความเสี่ยงที่ประเมินแล้วให้ผู้เชี่ยวชาญตรวจสอบก่อนอนุมัติให้รัน โดยระบบสามารถตั้งกฎอัตโนมัติสำหรับเหตุการณ์ความรุนแรงต่ำและต้องมี human approval สำหรับเหตุการณ์ความรุนแรงสูง
- Rollback plan: ทุกคำสั่งที่รันต้องมี rollback snippet หรือวิธีคืนค่าสถานะที่ชัดเจน รวมทั้งการบันทึก transaction log และ checkpoint ที่สามารถย้อนกลับได้ภายในเวลาที่กำหนด
ท้ายที่สุด ระบบต้องผนวกการมอนิเตอร์หลังการรัน (post‑action observability) เพื่อตรวจสอบว่า action ที่ดำเนินการแล้วส่งผลตามคาดหรือไม่ และหากพบผลไม่พึงประสงค์ให้เปิดใช้งาน rollback อัตโนมัติหรือแจ้งผู้รับผิดชอบทันที การออกแบบ pipeline แบบลูปปิด (closed‑loop) เช่นนี้ ช่วยให้การแปลงเทเลเมตริกเป็นคำสั่งแก้ปัญหาอัตโนมัติทั้งรวดเร็วและปลอดภัย เหมาะสมกับองค์กรโทรคมนาคมที่ต้องการลดเวลาตรวจสอบเหตุการณ์และเพิ่มความยืดหยุ่นของทีมปฏิบัติการ
ผลลัพธ์เชิงสถิติจากการทดสอบ: MTTR, ความแม่นยำ และตัวอย่างก่อน‑หลัง
ผลลัพธ์เชิงสถิติจากการทดสอบ: MTTR, ความแม่นยำ และตัวอย่างก่อน‑หลัง
การประเมินผลเชิงปริมาณจากการทดลองภายในเครือข่ายแสดงให้เห็นว่า LLM‑NetOps ช่วยปรับปรุงประสิทธิภาพการตอบสนองต่อเหตุการณ์ได้อย่างมีนัยสำคัญ ทั้งในด้านเวลาการกู้คืน (MTTR), อัตราการแจ้งเตือนผิดพลาด (false positives) และความแม่นยำของคำแนะนำเชิงปฏิบัติการ ตัวเลขหลักที่สำคัญจากชุดทดสอบหลายหมวดเหตุการณ์มีดังนี้:
- การลด MTTR (Mean Time To Repair): โดยรวมลดลงระหว่าง 30%–60% ขึ้นอยู่กับชนิดของเหตุการณ์ ตัวอย่างสถิติเฉลี่ย:
- Link flapping / สายเชื่อมต่อขาด — MTTR ลดลงราว 60% (จากเฉลี่ย 100 นาที เหลือ ~40 นาที)
- BGP / Routing instability — MTTR ลดลงราว 45% (จากเฉลี่ย 220 นาที เหลือ ~121 นาที)
- Performance degradation / คอขวดทราฟฟิก — MTTR ลดลงราว 30% (จากเฉลี่ย 180 นาที เหลือ ~126 นาที)
- การลด false positives: ระบบกรองและวิเคราะห์เทเลเมตริกของ LLM‑NetOps ลดจำนวนการแจ้งเตือนผิดพลาดเฉลี่ย 62% (ช่วงตัวอย่างที่วัดได้ 40%–85%) — จากกรณีศึกษา หน่วยเฝ้าระวังรายวันจาก ~500 alerts เหลือ ~190 alerts ต่อวัน
- ความแม่นยำของคำแนะนำและการอนุมัติ: ระบบสามารถเสนอคำสั่งแก้ไขที่ถูกต้องและได้รับการอนุมัติจากวิศวกรได้ราว 72% ของเหตุการณ์ (ช่วง 60%–85%) ซึ่งรวมถึงคำสั่งสำหรับการปรับพารามิเตอร์, รีสเตตัสพอร์ต และการ reroute ชั่วคราว
- อัตราการแก้ปัญหาอัตโนมัติสำเร็จ: สำหรับเคสที่เปิดให้ระบบลงมือทำอัตโนมัติ (ตามนโยบายความเสี่ยงที่กำหนด) อัตราการแก้ไขสำเร็จเฉลี่ยอยู่ที่ 58% (ช่วง 45%–75%) — สำหรับเคสที่เหลือ ระบบยังคงเสนอคำสั่งให้วิศวกรทบทวนก่อนดำเนินการ
- เวลาที่ใช้โดยเฉลี่ยต่อเหตุการณ์ (รวมทั้งอัตโนมัติและกึ่งอัตโนมัติ): ก่อนนำระบบมาใช้ MTTR เฉลี่ยรวมอยู่ที่ ~110–120 นาที ต่อเหตุการณ์ หลังใช้ LLM‑NetOps ลดลงเป็น ~ Fifty‑eight (58) นาที ต่อเหตุการณ์ (รวมแนวทางอัตโนมัติและการอนุมัติจากมนุษย์)
เพื่อให้เห็นภาพชัดเจนยิ่งขึ้น ด้านล่างเป็นตารางสรุปเปรียบเทียบก่อน‑หลังในรูปแบบข้อความ (สรุปจากชุดทดสอบจริงของโอเปอเรเตอร์):
- สรุปเชิงตัวเลข (Before → After)
- ค่า MTTR เฉลี่ย: 120 นาที → 58 นาที (ลดลง ~52%)
- จำนวน alerts ต่อวัน: 500 → 190 (ลดลง 62%)
- คำแนะนำถูกต้องและได้รับการอนุมัติ: — → 72% ของเหตุการณ์
- อัตราการแก้ไขอัตโนมัติสำเร็จ: — → 58%
- เวลาเฉลี่ยสำหรับการวิเคราะห์โดยมนุษย์ (เมื่อมีการอนุมัติ): 40 นาที → 21 นาที (ลดลง 48%)
ตัวอย่างเหตุการณ์จริง (Case Studies) ที่แสดงการเปลี่ยนแปลงก่อน‑หลัง:
- เหตุการณ์ที่ 1 — Link Flapping บริเวณศูนย์ข้อมูลภูมิภาค
- ก่อนใช้ LLM‑NetOps: วิศวกรตรวจสอบด้วยตนเอง พบพอร์ตมีการ up/down ซ้ำซ้อน ใช้เวลาวิเคราะห์ 60 นาที และแก้ไขเชิงกายภาพ/รีคอนฟิก 40 นาที รวม MTTR = 100 นาที
- หลังใช้ LLM‑NetOps: ระบบตรวจจับ pattern flapping, แนะนำคำสั่งชั่วคราวปิด/เปิดพอร์ตด้วย threshold และแนะนำการย้ายทราฟฟิก ช่วยลดเวลาวิเคราะห์เหลือ 15 นาที ระบบทำ remediation อัตโนมัติสำเร็จในขั้นต้น MTTR รวม = 40 นาที (ลด 60%)
- เหตุการณ์ที่ 2 — BGP Route Instability ส่งผลต่อหลายไซต์
- ก่อน: การวิเคราะห์ BGP table และประกาศ prefix ใช้เวลานาน (เฉลี่ย 150–250 นาที) ต้องมีการประสานงานข้ามทีม
- หลัง: LLM‑NetOps วิเคราะห์เทเลเมตริก BGP, ระบุต้นตอของการประกาศซ้ำ และเสนอคำสั่ง filter/route‑map ให้วิศวกรทบทวน — คำแนะนำผ่านการอนุมัติและลด MTTR จาก 220 นาทีเป็น ~121 นาที (ลด ~45%)
- เหตุการณ์ที่ 3 — การเสื่อมของประสิทธิภาพช่วงชั่วโมงเร่งด่วน
- ก่อน: ทีม NOC ต้องคาดเดาจุดคอขวด ใช้เวลาตรวจสอบ 60–90 นาทีก่อนสั่งปรับ QoS หรือ reroute ชั่วคราว
- หลัง: ระบบเสนอชุดการวิเคราะห์ root cause และคำสั่งปรับค่า QoS ที่เหมาะสมให้ผู้ปฏิบัติอนุมัติ อัตราการอนุมัติคำสั่งถูกต้องสูง ทำให้ MTTR จาก 180 นาทีลดเหลือ ~126 นาที (ลด 30%) และลดผลกระทบต่อผู้ใช้ปลายทางได้ชัดเจน
สรุป: ตัวเลขจากการทดลองแสดงให้เห็นว่า LLM‑NetOps สามารถลดภาระการวิเคราะห์ของวิศวกร ลด MTTR ในหลายประเภทเหตุการณ์อย่างมีนัยสำคัญ ลด false positives และส่งมอบคำแนะนำเชิงปฏิบัติการที่มีความแม่นยำในระดับที่ยอมรับได้สำหรับการนำไปใช้เชิงปฏิบัติจริง โดยยังคงมีกรณีที่ต้องใช้การตรวจสอบจากมนุษย์สำหรับเหตุการณ์ที่มีความเสี่ยงสูงหรือความซับซ้อนมาก
ความเสี่ยง ความปลอดภัย และการกำกับดูแล (Governance)
ความเสี่ยงหลักที่ต้องพิจารณา
การดำเนินการผิดพลาด (Erroneous Execution) — เมื่อ LLM‑NetOps แปลงเทเลเมตริกเป็นคำสั่งเครือข่ายโดยอัตโนมัติ มีความเสี่ยงต่อการรันคำสั่งที่ไม่ถูกต้อง เช่น การรีสตาร์ทบริการผิดจุด หรือการปรับค่าพารามิเตอร์ที่ทำให้วงจรเครือข่ายหยุดชะงักได้ แม้ความผิดพลาดจะเกิดขึ้นเพียงเล็กน้อยแต่ผลกระทบต่อ availability และ SLA อาจรุนแรง โดยเฉพาะในระบบ core หรือบริการที่มี latency ต่ำ
การรั่วไหลของข้อมูลเทเลเมตริกและข้อมูลสำคัญ — เทเลเมตริกเครือข่ายอาจมีข้อมูลเชิงโครงสร้างหรือเชิงพฤติกรรมที่ถือเป็นความลับ (เช่น โทโพโลยี จุดเชื่อมต่อภายใน ประวัติทราฟฟิก) การส่งข้อมูลดังกล่าวไปยังโมเดลภายนอกหรือการบันทึกโดยไม่มีการปิดกั้นข้อมูลส่วนบุคคล (PII) อาจละเมิดกฎหมายคุ้มครองข้อมูล เช่น PDPA และเพิ่มความเสี่ยงจากการถูกโจมตีแบบ supply‑chain
False Automation และอคติของโมเดล (Bias) — โมเดลภาษาอาจตีความเทเลเมตริกตามรูปแบบที่เรียนรู้มาไม่ถูกต้อง หรือให้คำแนะนำที่มีอคติ เช่น มองเหตุการณ์บางชนิดเป็นความผิดปกติเสมอทั้งที่เป็น expected behavior ของเครือข่าย การพึ่งพาการตัดสินใจอัตโนมัติโดยไม่มีมาตรการ human‑in‑the‑loop อาจเพิ่มความเสี่ยงต่อการตัดสินใจผิดพลาดในระดับระบบ
มาตรการควบคุมและการออกแบบเพื่อความปลอดภัย
- การควบคุมการเข้าถึง (RBAC) — กำหนดบทบาทและสิทธิ์อย่างเข้มงวดให้เฉพาะผู้ที่ได้รับมอบหมายเท่านั้นสามารถสั่งรันคำสั่งจริงบนอุปกรณ์ได้ โดยแยกระหว่างสิทธิ์ดูข้อมูลเทเลเมตริก การอนุมัติคำสั่ง และการรันคำสั่ง
- Approval Workflows และ Human‑in‑the‑Loop — ตั้งค่าเวิร์กโฟลว์ที่ต้องมีการอนุมัติจากวิศวกรหรือผู้จัดการก่อนคำสั่งที่มีความเสี่ยงสูงจะถูกสั่งรันอัตโนมัติ โดยใช้เกณฑ์ความเสี่ยงตามระดับความร้ายแรง
- Immutable Audit Logs และ Traceability — บันทึกทุกอินพุตของโมเดล คำตอบ และคำสั่งที่ถูกสั่งรันในรูปแบบที่ไม่สามารถแก้ไข (append‑only) เพื่อรองรับการตรวจสอบย้อนหลังและ forensic เมื่อเกิดเหตุการณ์
- Sandboxing และ Canary Tests — รันคำสั่งที่ได้จากโมเดลในสภาพแวดล้อมจำลองหรือกับกลุ่มอุปกรณ์ขนาดเล็กก่อนกระจายในระบบจริง เพื่อลดความเสี่ยงจากคำสั่งผิดพลาด
- Data Handling และ Privacy‑Preserving Techniques — ใช้การปกปิดข้อมูล (masking), การทำ anonymization, หรือนโยบาย differential privacy ก่อนส่งเทเลเมตริกไปประมวลผล และเข้ารหัสข้อมูลทั้งขณะส่งและขณะเก็บ
- Third‑Party Model Risk Management — ประเมินซัพพลายเออร์โมเดล ตรวจสอบ model card และข้อตกลงด้านความปลอดภัย กำหนดข้อจำกัดการใช้งาน และมีแผนกรณีซัพพลายเออร์หยุดให้บริการ
การประเมิน ทดสอบ และการตรวจสอบอย่างต่อเนื่อง
ระบบ LLM‑NetOps ต้องถูกทดสอบอย่างต่อเนื่องด้วยชุดการทดสอบที่ครอบคลุมทั้ง functional และ security testing เช่น unit tests สำหรับการแปลงคำสั่ง, integration tests กับอุปกรณ์จริง, และ regression tests หลังการอัปเดตโมเดล นอกจากนี้ควรนำแนวทาง red teaming มาใช้เพื่อจำลองการโจมตีทั้งจากภายนอกและจากการโจมตีภายใน (insider) เพื่อค้นหาจุดอ่อนของการตัดสินใจอัตโนมัติ
Chaos testing เป็นอีกเครื่องมือสำคัญ — การจำลองความล้มเหลวของส่วนประกอบเครือข่ายอย่างเป็นระบบช่วยประเมินความสามารถของ LLM‑NetOps ในการให้คำแนะนำที่ปลอดภัยและทนทาน ภายใต้สภาวะที่ไม่แน่นอน ควรวัดตัวชี้วัดเช่น MTTR (Mean Time To Repair), อัตรา false positive/false negative ของการแจ้งเตือน, อัตราความล้มเหลวของคำสั่ง และการเปลี่ยนแปลงเชิง drift ของโมเดล
การ monitoring แบบเรียลไทม์ต้องครอบคลุมทั้งประสิทธิภาพของโมเดล (confidence calibration, prediction distribution) และพฤติกรรมระบบ (command execution success rate, circuit availability) โดยต้องมีการตั้งค่า alert threshold สำหรับค่าที่บ่งชี้ความเสี่ยง และกระบวนการ rollback อัตโนมัติเมื่อพบผลกระทบรุนแรง
กรอบกำกับดูแลและมาตรฐานที่ควรยึดถือ
- นำแนวทางการกำกับดูแลตามมาตรฐานสากล เช่น ISO/IEC 27001 สำหรับระบบบริหารจัดการความมั่นคงปลอดภัยสารสนเทศ และ NIST AI Risk Management Framework มาใช้ปรับแต่งให้สอดคล้องกับบริบทของเครือข่าย
- จัดทำนโยบายภายในสำหรับการใช้โมเดลที่ชัดเจน รวมถึง lifecycle management ของโมเดล (versioning, retraining, decommissioning)
- กำหนด KPI ด้านความปลอดภัยและความถูกต้อง เช่น อัตราการอนุมัติคำสั่งที่ถูกต้อง, จำนวนเหตุการณ์ที่ต้อง rollback ต่อไตรมาส และเวลาที่ใช้ในการตรวจสอบเหตุการณ์สำคัญ
- จัดทำชุดทดสอบอัตโนมัติ (testing suite) ที่รวม unit/integration/chaos/red‑team tests และบังคับให้ผ่านก่อนปล่อยเวอร์ชันใหม่สู่ production
สรุปแล้ว การนำ LLM‑NetOps มาใช้งานในเครือข่ายโทรคมนาคมต้องมาพร้อมกับกรอบกำกับดูแลที่รัดกุม ครอบคลุมมาตรการเชิงเทคนิค นโยบาย และกระบวนการตรวจสอบโดยมนุษย์ การออกแบบระบบควรตั้งต้นด้วยหลักความปลอดภัย (secure‑by‑design) และยกระดับเป็น continuous governance ที่ผสานการทดสอบเชิงรุก การตรวจสอบเชิงถาวร และการตอบสนองต่อความเสี่ยงแบบครบวงจร
แนวทางปฏิบัติและ checklist สำหรับวิศวกรก่อนนำไปใช้งานจริง
แนวทางปฏิบัติและ Checklist ก่อน Rollout
ก่อนนำระบบ LLM‑NetOps ไปใช้งานจริง ทีมวิศวกรรมควรเตรียมความพร้อมทั้งในเชิงเทคนิคและการบริหารความเสี่ยง โดยทำเป็น checklist ที่ตรวจสอบได้ เพื่อป้องกันผลกระทบต่อความพร้อมใช้งานของเครือข่าย ตัวอย่างรายการสำคัญได้แก่
- คุณภาพข้อมูล (Data Quality) — ตรวจสอบความสมบูรณ์ของเทเลเมตริก (timestamps, sampling rate, missing value < 2%), ความสอดคล้องของ schema, การทำ normalization/aggregation ที่สอดคล้องกัน และการติดป้าย (labeling) สำหรับเหตุการณ์ที่เคยเกิดขึ้น
- Baseline Metrics — กำหนดค่าพื้นฐานของ MTTR, จำนวน alerts ต่อชั่วโมง, อัตรา false positive และ latency ของข้อมูลเทเลเมตริก เช่น เทเลเมตริกควรมี latency ต่ำกว่า 500 ms ในเส้นทางที่ต้องการการตอบสนองทันที
- Fallback Plan และ Circuit Breaker — ระบุวิธีการ rollback อัตโนมัติหรือด้วยมือเมื่อระบบมีพฤติกรรมผิดปกติ เช่น ถ้าอัตรา false positive เพิ่มขึ้นเกิน 5% ให้ยกเลิกการรันอัตโนมัติและกลับไปยังโหมดแจ้งเตือนเท่านั้น
- Approval Gates — กำหนดเกณฑ์การอนุมัติสำหรับแต่ละระดับของ remediation (auto‑execute, require human approval, manual only) และระบุผู้อนุมัติจากทีม Security/Compliance/NetOps
- Security & Privacy Checks — ตรวจสอบการเข้าถึงข้อมูลเทเลเมตริก, การกำกับดูแลคีย์/secret, การปฏิบัติตามข้อกำหนด PDPA/ISO/PCI หากเกี่ยวข้อง
กรอบทดสอบ (Test Framework) และตัวอย่าง Runbook
กรอบทดสอบต้องครอบคลุมตั้งแต่ unit test ของ pipeline, integration test กับระบบ monitoring และระบบควบคุมอุปกรณ์ ไปจนถึง chaos testing และ replay ของเหตุการณ์จริง เพื่อประเมินพฤติกรรมของ LLM‑NetOps ภายใต้สถานการณ์ต่างๆ ตัวอย่างกรอบทดสอบและ runbook เช่น:
- Test Types: unit/integration, end‑to‑end, canary deployment, synthetic traffic, historical replay (reproduce past incidents), chaos injector (link flaps, latency spikes)
- Canary Policy: เปิดให้เฉพาะ 1–5% ของโหนดในกลุ่มที่ไม่ใช่คอนโทรลเซ็นเตอร์ ทำงานภายใต้การติดตามอย่างเข้มงวดเป็นเวลาอย่างน้อย 2 สัปดาห์ก่อนขยาย
- ตัวอย่าง Runbook (สรุปขั้นตอน):
- 1) Detect: ระบบแจ้งเตือนเหตุการณ์และแนบข้อความจาก LLM พร้อมคะแนนความเชื่อมั่น
- 2) Classify: LLM ระบุประเภทเหตุการณ์ (link, routing, congestion) พร้อมเหตุผลสั้นๆ
- 3) Propose Remediation: สร้างคำสั่งที่แนะนำ (เช่น "restart interface Gi0/1", "apply ACL temp block X") และประเมินความเสี่ยง
- 4) Approval Gate: ถ้าเป็น low‑risk และคะแนนความเชื่อมั่นสูง ระบบทำงานอัตโนมัติ; ถ้าเป็น medium/high‑risk ส่งให้ operator ตรวจสอบและอนุมัติ
- 5) Execute: หากอนุมัติ ให้ระบบรันคำสั่งและบันทึกแอ็กชันใน ticketing/CMDB
- 6) Verify: รันชุดตรวจสอบหลังการแก้ไข (smoke tests, traffic verify) ภายในเวลาที่กำหนด เช่น 5–15 นาที
- 7) Escalate & Rollback: หาก verification ล้มเหลว ให้รัน rollback script ทันทีและแจ้ง escalation ตามลำดับชั้น
KPIs ที่ควรติดตามระหว่างและหลัง Rollout
การวัดผลต้องชัดเจนและเชื่อมโยงกับเป้าหมายธุรกิจ รายการตัวชี้วัดสำคัญที่ควรกำหนดเป็น KPI ใน dashboard ได้แก่
- MTTR (Mean Time To Repair) — ตั้งเป้าลด MTTR เช่น ลดลง 20–40% ภายใน 90 วันสำหรับเหตุการณ์ที่ครอบคลุมโดยระบบ
- Automation Success Rate — อัตราการรัน remediation อัตโนมัติที่สำเร็จ เป้าหมายเริ่มต้น > 80–85%
- False Positive Rate — อัตราแจ้งเตือนผิดพลาดจาก LLM ที่ทำให้เกิดการดำเนินการหรือรบกวน เป้าหมาย < 5%
- Operator Workload — จำนวน alerts ต่อ operator ต่อกะ และเวลาเฉลี่ยต่อการตรวจสอบ เห็นการลดลงเป็นตัวเลขชัดเจน (เช่นลด 30–50%)
- Model Drift & Data Freshness — การเปลี่ยนแปลงเชิงสถิติของ input distribution และ latency ของข้อมูลเทเลเมตริก
- Business Impact Metrics — เช่น SLA compliance, customer facing incidents ลดลง จำนวน ticket escalation
ขั้นตอนตรวจสอบมนุษย์และการฝึกอบรมทีม
แม้ระบบจะมีความสามารถสูง แต่การมีมนุษย์เป็นส่วนควบคุม (human‑in‑the‑loop) ยังคงจำเป็นสำหรับการตัดสินใจเชิงนโยบายและเหตุการณ์ที่มีผลกระทบรุนแรง ควรกำหนดนโยบายดังนี้
- ระดับการอนุมัติ — ระบุว่าการกระทำใดสามารถรันอัตโนมัติได้ทันที และการกระทำใดต้องมีการอนุมัติจากผู้ปฏิบัติการหรือผู้จัดการ
- Audit Trail & Explainability — ระบบต้องบันทึกเหตุผลของการตัดสินใจที่ LLM เสนอ และให้ข้อมูลเชิงอธิบาย (explainability) เพียงพอให้ operator ตัดสินใจ
- การฝึกอบรม — จัดการฝึกอบรมเชิงปฏิบัติ (tabletop exercises, simulation drills) ให้ครอบคลุม: การอ่าน output ของ LLM, การใช้ runbook, การ rollback, การจัดการ incident communication
- Certification & Knowledge Base — มีหลักสูตรการรับรองภายในและฐานความรู้ (playbooks, SOP) ที่อัปเดตอย่างต่อเนื่อง
แผนขยายระบบและการบูรณาการกับ Toolchain ที่มีอยู่
การขยายระบบควรกระทำแบบเป็นขั้นตอน (phased) ตามวงจร feedback ที่ชัดเจน โดยทั่วไปแนะนำเส้นทางการขยายดังนี้:
- Pilot — เริ่มกับ domain เล็ก ๆ (เช่น edge POP หรือกลุ่มอุปกรณ์บางประเภท) ระยะเวลา 2–4 สัปดาห์ เพื่อตรวจสอบความถูกต้องของ pipeline และ KPI เบื้องต้น
- Staged Rollout — ขยายเป็นหลายกลุ่มแบบ controlled canary (10% → 30% → 60%) โดยแต่ละขั้นต้องผ่านเกณฑ์ KPI และรับ feedback จาก operator
- Full Rollout — เมื่อเป้าหมาย KPI และความเสถียรเป็นที่พอใจ ให้ขยายสู่ production ทั้งหมด พร้อมกระบวนการ governance และ support model
- Feedback Loop — เก็บข้อมูลจาก incident postmortem, operator feedback และ metric drift เพื่อนำมาอัปเดต model, rules และ runbook อย่างสม่ำเสมอ
นอกจากนี้ ควรบูรณาการกับ toolchain ที่มีอยู่ เช่นระบบ monitoring (Prometheus/Grafana), ticketing/ITSM (JIRA/ServiceNow), orchestration (Ansible/Terraform), CI/CD pipelines สำหรับการปล่อยเวอร์ชันของ component และระบบจัดการ secrets/RBAC เพื่อควบคุมการเข้าถึง สุดท้ายให้กำหนดแผนการสเกลเชิงโครงสร้าง (scaling) ทั้งในประเด็น compute, throughput ของข้อความ LLM และการจัดเก็บ log เพื่อรองรับปริมาณการใช้งานเมื่อขยายสู่ production เต็มรูปแบบ
บทสรุป
LLM‑NetOps ที่ทดลองโดยโอเปอเรเตอร์โทรคมนาคมไทยสามารถแปลงเทเลเมตริกเครือข่ายเป็นคำสั่งแก้ปัญหาอัตโนมัติและช่วยลดเวลาในการตรวจสอบและแก้ไขเหตุการณ์ได้อย่างมีนัยสำคัญ — ตัวอย่างผลการทดสอบเบื้องต้นชี้ว่าเวลาในการสืบสวนเหตุการณ์ (investigation) และแก้ไข (MTTR) อาจลดลงในช่วงประมาณ 30–60% หรือเห็นการลด MTTR ประมาณ ~40% ขึ้นอยู่กับประเภทเหตุการณ์และระดับการควบคุมที่ติดตั้ง อย่างไรก็ตาม ความสามารถดังกล่าวมาพร้อมความเสี่ยงถ้าไม่มีกรอบการควบคุมที่รัดกุม: จำเป็นต้องมี governance ที่ชัดเจน (สิทธิ์การเข้าถึง การแบ่งชั้นคำสั่ง โหมดจำกัดการกระทำ) และกระบวนการ verification (simulation, sandbox, dry‑run, และ audit trail) เพื่อป้องกันคำสั่งที่ผิดพลาดหรือผลกระทบเชิงลบต่อเครือข่าย
ในการนำไปใช้งานจริง ควรเริ่มด้วยโครงการนำร่องแบบควบคุม (pilot) ที่มี human‑in‑the‑loop สำหรับการอนุมัติและการยืนยันผลก่อนให้ระบบกระทำการโดยอัตโนมัติเต็มรูปแบบ พร้อมการกำหนดตัวชี้วัด (KPI) ที่วัดได้ เช่น MTTR, อัตราการออกคำสั่งผิดพลาด, จำนวนเหตุการณ์ที่ถูกแก้ไขอัตโนมัติ และเวลาที่วิศวกรประหยัดได้ เพื่อให้การขยายใช้งานเป็นไปแบบขั้นบันได (phased rollout) พร้อมกลไกการย้อนกลับและแผนฝึกอบรมทีมปฏิบัติการ การทดสอบอย่างเป็นระบบและการติดตาม KPI อย่างต่อเนื่องจะช่วยให้การใช้งานยั่งยืนและสามารถปรับปรุงโมเดลและนโยบายได้ตามผลการปฏิบัติงาน
มุมมองอนาคตคือ LLM‑NetOps จะกลายเป็นส่วนหนึ่งของสแตกการสังเกตการณ์และออโตเมชันของเครือข่าย ช่วยเพิ่มความเร็วและขนาดในการจัดการเหตุการณ์ แต่เพื่อให้เกิดผลดีระยะยาวองค์กรต้องลงทุนในกรอบกำกับดูแล การตรวจสอบต่อเนื่อง การอัปสกิลทีมงาน และการประเมินความเสี่ยงเชิงกฎระเบียบและความปลอดภัย เมื่อออกแบบให้มีมาตรการยืนยันผลและการควบคุมที่เหมาะสม ระบบนี้มีศักยภาพนำไปสู่การลดต้นทุนด้านปฏิบัติการและเพิ่มความพร้อมใช้งานของเครือข่ายได้อย่างมีนัยสำคัญ



