
ในยุคที่ธนาคารต้องเร่งนำปัญญาประดิษฐ์มาใช้เพื่อเพิ่มประสิทธิภาพการตัดสินใจ ทว่าความน่าเชื่อถือและการคุ้มครองข้อมูลลูกค้ากลับเป็นอุปสรรคสำคัญ "ZKP‑Audit" ถูกออกแบบมาเพื่อตอบโจทย์นี้โดยเฉพาะ: ผสานเทคนิค Zero‑Knowledge Proof (ZKP) เข้ากับโมเดลภาษาใหญ่ (LLM) เพื่อให้การตัดสินใจอัตโนมัติสามารถยืนยันได้อย่างโปร่งใสและตรวจสอบได้โดยไม่ต้องเปิดเผยข้อมูลส่วนบุคคลของลูกค้า การนำแนวคิดนี้มาใช้จะช่วยให้ธนาคารไทยสามารถสร้างสมดุลระหว่างนวัตกรรม ความปลอดภัยข้อมูล และการปฏิบัติตามข้อกำกับดูแลได้อย่างเป็นรูปธรรม
บทความนี้จะพาผู้อ่านสำรวจแนวทางการออกแบบสถาปัตยกรรม ZKP‑Audit ตั้งแต่การแยกขอบเขตข้อมูล การออกแบบหลักฐานที่ไม่เปิดเผยข้อมูล การผสาน LLM กับโพรโตคอล ZKP ไปจนถึงตัวอย่างการใช้งานจริง เช่น การอนุมัติสินเชื่อ การตรวจจับการฉ้อโกง และการรายงานต่อหน่วยกำกับดูแล พร้อมทั้งแนวปฏิบัติด้านความปลอดภัย วิธีการทดสอบ และเกณฑ์การประเมินความเสี่ยง เพื่อให้ผู้อ่านได้เข้าใจทั้งหลักการเชิงเทคนิคและการนำไปปฏิบัติในบริบทของธนาคารไทย
บทนำ: ความท้าทายของการใช้ LLM ในระบบการเงิน
บทนำ: ความท้าทายของการใช้ LLM ในระบบการเงิน
ในช่วงไม่กี่ปีที่ผ่านมา โมเดลภาษาใหญ่ (Large Language Models หรือ LLM) ได้กลายเป็นเทคโนโลยีหลักที่องค์กรการเงินทั่วโลกให้ความสนใจ ธนาคารและสถาบันการเงินนำ LLM มาใช้เพื่อเพิ่มประสิทธิภาพการดำเนินงานและยกระดับบริการลูกค้า ตั้งแต่การอนุมัติสินเชื่ออัตโนมัติ การตรวจจับพฤติกรรมฉ้อโกง การให้คำปรึกษาทางการเงินแบบอัตโนมัติ (robo‑advisors) ไปจนถึงการตอบคำถามลูกค้าในระบบบริการตนเอง งานสำรวจเชิงอุตสาหกรรมระบุว่า ธนาคารและสถาบันการเงินราว 40–60% อยู่ในขั้นตอนทดลองหรือนำโซลูชัน AI ขั้นสูงมาใช้ในบางส่วนของธุรกิจ เพื่อให้การตัดสินใจรวดเร็วและสอดคล้องกับความต้องการของลูกค้ามากขึ้น
ตัวอย่างกรณีใช้งานที่เห็นผลชัดเจน ได้แก่ การอนุมัติสินเชื่อที่ใช้โมเดลในการวิเคราะห์เอกสารและประเมินความเสี่ยงซึ่งสามารถลดเวลาการอนุมัติลงอย่างมีนัยสำคัญ (รายงานภาคสนามชี้ว่าเวลาการตัดสินใจลดลงได้ตั้งแต่ 30–70% ขึ้นกับกระบวนการเดิม) การตรวจจับการฉ้อโกงที่ผสานข้อมูลเชิงพฤติกรรมและโมเดลภาษาเพื่อจำแนกธุรกรรมผิดปกติ ซึ่งช่วยเพิ่มอัตราการจับผิดและลด false positives ในหลายกรณี และบริการให้คำปรึกษาทางการเงินที่ช่วยขยายการเข้าถึงลูกค้ากลุ่มรายย่อยด้วยคำแนะนำเบื้องต้นที่ปรับตามโปรไฟล์ลูกค้า
อย่างไรก็ตาม การนำ LLM มาใช้ในระบบการเงินมาพร้อมกับความเสี่ยงในสองมิติหลักคือ ความเป็นส่วนตัวของข้อมูล และ ความน่าเชื่อถือของระบบตัดสินใจ ความเสี่ยงด้านความเป็นส่วนตัวเกิดจากการประมวลผลข้อมูลส่วนบุคคลที่อ่อนไหว เช่น รายได้ ยอดบัญชี ประวัติการชำระหนี้ หากไม่มีการควบคุมที่เข้มงวดอาจเกิดการรั่วไหลหรือการนำข้อมูลไปใช้ผิดวัตถุประสงค์ สิ่งนี้ยังสอดคล้องกับข้อกำหนดด้านกฎระเบียบ เช่น พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ของประเทศไทยและกฎระเบียบระหว่างประเทศที่ต้องการการคุ้มครองข้อมูลส่วนบุคคลอย่างเข้มงวด
ในด้านความน่าเชื่อถือ LLM เผชิญปัญหา bias จากข้อมูลฝึกสอนและปัญหา hallucination ที่อาจทำให้โมเดลให้คำตอบหรือการตัดสินใจที่ไม่ถูกต้องหรือไม่สอดคล้องกับหลักฐานทางการเงิน ซึ่งนำไปสู่ความเสี่ยงทางกฎหมาย, ความเสียหายต่อชื่อเสียง และความไม่เป็นธรรมต่อผู้ขอรับบริการ ตัวอย่างผลกระทบได้แก่ การปฏิเสธสินเชื่อที่เกิดจากตัวแบบที่ลำเอียง หรือคำแนะนำการลงทุนที่ให้ข้อมูลผิดพลาดส่งผลต่อการตัดสินใจของลูกค้า
- ความเสี่ยงด้านความเป็นส่วนตัว: การเปิดเผยข้อมูลลูกค้าในกระบวนการตรวจสอบหรือการบันทึกคำสั่งงานของโมเดลอาจละเมิดข้อกำหนด PDPA และลดความไว้วางใจของลูกค้า
- ความเสี่ยงด้านความน่าเชื่อถือ: bias และ hallucination ทำให้การตัดสินใจอัตโนมัติขาดความโปร่งใสและอธิบายได้
- ความต้องการด้านการตรวจสอบ: ผู้กำกับดูแลและผู้บริหารต้องการหลักฐานยืนยันว่า การตัดสินใจอัตโนมัติเป็นไปตามนโยบาย แนวปฏิบัติ และกฎหมาย โดยไม่จำเป็นต้องเปิดเผยข้อมูลลูกค้าเชิงรายละเอียด
ด้วยเหตุนี้ จึงมีความจำเป็นเร่งด่วนในการพัฒนาและนำกลไกที่สามารถ ตรวจสอบการตัดสินใจของ LLM ได้โดยไม่ต้องเปิดเผยข้อมูลลูกค้าที่ละเอียดอ่อน กลไกดังกล่าวต้องรองรับการพิสูจน์ความถูกต้องของผลลัพธ์ การตรวจสอบความสอดคล้องกับนโยบายการให้บริการ และการบันทึกหลักฐานที่เพียงพอสำหรับการตรวจสอบภายนอกและการออดิท ทั้งนี้ต้องทำควบคู่กับการรักษาความลับของข้อมูลลูกค้าเพื่อป้องกันความเสี่ยงต่อความเป็นส่วนตัวและปฏิบัติตามข้อบังคับที่เกี่ยวข้อง บริบทนี้เป็นจุดเริ่มต้นที่นำไปสู่การพัฒนานวัตกรรมอย่างเช่นแนวคิดการผสาน Zero‑Knowledge Proof กับการออดิทโมเดล (ZKP‑Audit) เพื่อให้เกิดสมดุลระหว่างความโปร่งใสด้านการตัดสินใจและการคุ้มครองข้อมูลส่วนบุคคล
พื้นฐานเทคนิค: เข้าใจ Zero‑Knowledge Proof (ZKP) แบบสั้นและ LLM
ในบริบทที่ธนาคารต้องการรับรองการตัดสินใจอัตโนมัติของระบบปัญญาประดิษฐ์โดยไม่เปิดเผยข้อมูลลูกค้าให้บุคคลภายนอก Zero‑Knowledge Proof (ZKP) และ Large Language Models (LLM) เป็นเทคโนโลยีสองส่วนที่สามารถทำงานร่วมกันได้อย่างเป็นประโยชน์ บทความส่วนนี้จะสรุปหลักการพื้นฐานของ ZKP, เปรียบเทียบชนิดของ ZKP ที่เหมาะสมกับระบบธนาคาร รวมทั้งอธิบายลักษณะการทำงานของ LLM และข้อจำกัดที่ต้องพิจารณาเมื่อนำไปใช้ในงานตัดสินใจอัตโนมัติ
หลักการพื้นฐานของ ZKP — พิสูจน์โดยไม่เปิดข้อมูลอินพุต
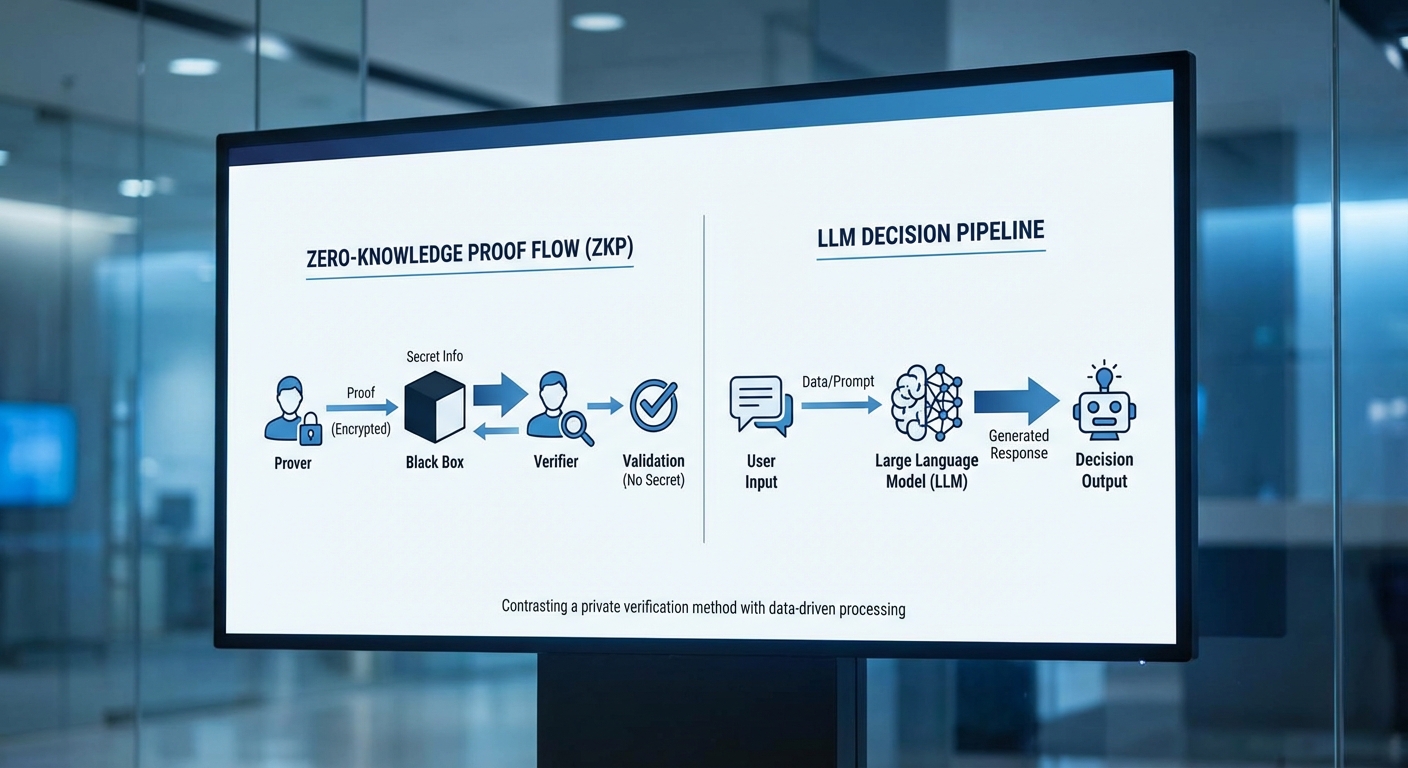
Zero‑Knowledge Proof คือเทคนิคเชิงคริปโตกราฟีที่ช่วยให้ฝ่ายหนึ่ง (Prover) สามารถพิสูจน์แก่ฝ่ายอื่น (Verifier) ได้ว่าเรื่องราวหนึ่งเป็นจริงโดยไม่จำเป็นต้องเปิดเผยข้อมูลต้นทางหรือรายละเอียดขั้นตอนที่ใช้พิสูจน์ แนวคิดพื้นฐานประกอบด้วยสามคุณสมบัติหลัก: ความถูกต้อง (validity) — ถ้าข้อเท็จจริงเป็นจริง ผู้พิสูจน์จะสามารถโน้มน้าวผู้ตรวจสอบได้; ความเป็นความลับ (zero‑knowledge) — ผู้ตรวจสอบจะไม่เรียนรู้อะไรนอกจากความจริงของคำกล่าว; และ ความไม่สามารถหลอกลวง (soundness) — ผู้พิสูจน์ที่พยายามหลอกจะถูกจับได้ด้วยความน่าจะเป็นสูง
ตัวอย่างที่เข้าใจง่ายในบริบทธนาคาร เช่น การพิสูจน์ว่า “ลูกค้ามีรายได้มากกว่าเกณฑ์” โดยธนาคารสามารถส่งหลักฐานที่ยืนยันเงื่อนไขนี้โดยไม่ต้องส่งตัวเลขรายได้จริงให้ผู้ตรวจสอบ เหมาะสำหรับการรายงานต่อหน่วยงานกำกับดูแลหรือให้ผู้ร่วมธุรกิจตรวจสอบความถูกต้องของการตัดสินใจ โดยไม่ละเมิดความเป็นส่วนตัวของลูกค้า
ชนิดของ ZKP ที่สำคัญและการพิจารณาสำหรับแอปพลิเคชันธนาคาร
ปัจจุบันมี ZKP หลักหลายรูปแบบที่ใช้งานจริง ซึ่งแต่ละแบบมีข้อได้เปรียบและข้อจำกัดที่แตกต่างกัน เรื่องที่ธนาคารควรพิจารณาคือ latency (ความหน่วง), proof size (ขนาดหลักฐาน), และ trust setup (การต้องมีขั้นตอนตั้งต้นที่เชื่อถือได้หรือไม่)
- zk‑SNARKs (เช่น Groth16, PLONK): โดยทั่วไปให้ขนาดหลักฐานเล็ก (ตัวอย่างเช่นระดับร้อยถึงพันไบต์ในหลายการใช้งาน) และมีเวลาตรวจสอบเร็ว (มิลลิวินาทีถึงหลักสิบมิลลิวินาทีบนฮาร์ดแวร์สมัยใหม่) จึงเหมาะกับงานที่ต้องการการตรวจสอบแบบเรียลไทม์ แต่รุ่นดั้งเดิมบางชนิดต้องพึ่งพา trusted setup ซึ่งเป็นประเด็นด้านความเชื่อถือ — อย่างไรก็ดีมีเวอร์ชันใหม่ (เช่น PLONK) ที่ลดปัญหานี้ลง
- zk‑STARKs: ให้ความโปร่งใสแบบ transparent (ไม่ต้องมี trusted setup) และออกแบบมาสำหรับสเกลสูงโดยใช้ฟังก์ชันแฮชและเทคนิคอื่น ๆ แต่ขนาดของหลักฐานมักจะใหญ่กว่า (ตั้งแต่หลายร้อยกิโลไบต์จนถึงเมกะไบต์ ขึ้นกับความซับซ้อน) ซึ่งอาจเป็นข้อจำกัดหากต้องส่งหรือเก็บหลักฐานในระบบที่ต้องการประสิทธิภาพเครือข่ายสูง จุดเด่นคือความทนต่อการโจมตีในระยะยาวและความสามารถในการสร้างหลักฐานจากการคำนวณที่ใหญ่ได้ดี
- เทคนิคเสริม — recursive proofs, aggregation: การรวมหลายหลักฐานเป็นหลักฐานเดียวหรือใช้การพิสูจน์แบบซ้อนกันช่วยลดค่าใช้จ่ายเชิงสื่อสารและภาระการตรวจสอบ ยกตัวอย่างการรวมการตัดสินใจรายบุคคลจำนวนมากเป็นหลักฐานเดียวย่อยลงไปสำหรับการตรวจสอบเป็นชุด (batch auditing)
โดยสรุป หากธนาคารต้องการการตรวจสอบแบบเรียลไทม์และขนาดหลักฐานเล็กเพื่อส่งต่อให้ระบบอื่นได้สะดวก zk‑SNARKs เป็นทางเลือกที่น่าสนใจ แต่ควรเลือกเวอร์ชันที่ไม่มีหรือจำกัด trusted setup สำหรับการใช้งานเชิงองค์กร ในกรณีต้องการความโปร่งใสสูงและสเกลการตรวจสอบจำนวนมาก (เช่น การตรวจสอบย้อนหลังแบบเป็นชุดสำหรับการตรวจสอบทางกฎระเบียบ) zk‑STARKs ให้ความแข็งแกร่งเชิงความปลอดภัยและการโปร่งใสที่ดีกว่า
การทำงานของ LLM ในงานตัดสินใจอัตโนมัติ — ความสามารถและข้อจำกัด
Large Language Models เช่น GPT‑style models ถูกออกแบบมาเพื่อประมวลผลภาษาและสร้างข้อความที่มีความหมาย พวกมันมีความสามารถในการประเมินบริบท สรุปข้อมูลจากเอกสารจำนวนมาก และให้เหตุผลเชิงรูปแบบ ซึ่งเป็นประโยชน์ต่อกระบวนการตัดสินใจ เช่น การวิเคราะห์เอกสาร KYC, การสรุปความเสี่ยง หรือการอธิบายเหตุผลเบื้องหลังการปฏิเสธสินเชื่อ
อย่างไรก็ตาม LLM มีข้อจำกัดสำคัญที่ธนาคารต้องคำนึง:
- ความไม่แน่นอนและความเป็นไปได้ของการ "hallucination": LLM อาจให้คำตอบที่ฟังดูมั่นคงแต่ไม่สอดคล้องกับข้อเท็จจริงหรือหลักเกณฑ์ที่องค์กรตั้งไว้
- การขาดหลักประกันเชิงคณิตศาสตร์: ผลลัพธ์จาก LLM เป็นผลลัพธ์เชิงสถิติและไม่ใช่การพิสูจน์เชิงตรรกะ จึงยากที่จะนำเสนอเป็นหลักฐานยืนยันความถูกต้องแบบทางการได้
- ความไม่แน่นอนเชิงพฤติกรรม (non‑determinism): คำตอบอาจเปลี่ยนแปลงได้จากการเปลี่ยนพารามิเตอร์หรือ prompt เล็กน้อย ซึ่งเป็นปัญหาสำหรับการควบคุมการตัดสินใจอัตโนมัติที่ต้องการความคงที่
- ปัญหาด้านความเป็นส่วนตัวและการควบคุมข้อมูล: LLM ที่ฝึกด้วยข้อมูลภายนอกหรือเรียกหาแหล่งข้อมูลภายนอก (retrieval‑augmented) ต้องมีการออกแบบเพื่อให้แน่ใจว่าจะไม่รั่วไหลของข้อมูลลูกค้า
- ความสามารถด้าน latency: เวลาตอบสนองของ LLM ขึ้นกับขนาดโมเดลและโครงสร้างระบบ (จากหลักสิบมิลลิวินาทีถึงหลายวินาที) ซึ่งอาจกระทบต่อระบบที่ต้องการตอบกลับทันที
การผสาน ZKP กับ LLM — แนวทางที่เป็นไปได้และประโยชน์
แม้ LLM เองจะไม่สามารถสร้าง "หลักฐานเชิงคณิตศาสตร์" ของเหตุผลภายในได้โดยตรง แต่การออกแบบสถาปัตยกรรมที่ผสาน ZKP กับ LLM สามารถช่วยให้ธนาคารได้ทั้งความยืดหยุ่นในการใช้โมเดลภาษาและการรับรองเชิงพิสูจน์สำหรับการปฏิบัติตามกฎระเบียบ ตัวอย่างแนวทางปฏิบัติได้แก่:
- แยกบทบาทระหว่างการตัดสินใจและการพิสูจน์: ให้ LLM ทำหน้าที่สร้างข้อเสนอแนะแบบเชิงภาษาหรือสรุปบริบท จากนั้นให้ระบบกฎเชิงตรรกะ (deterministic engine) ประมวลผลกฎธุรกิจสุดท้าย ซึ่ง deterministic engine นี้สามารถสร้างวงจรเชิงคณิตศาสตร์ที่ใช้ ZKP พิสูจน์ว่าข้อสรุปถูกต้องตามกฎโดยอาศัยข้อมูลต้นทางที่ไม่เปิดเผย
- การใช้ commitment และ logging ที่ตรวจสอบได้: บันทึกแฮชของอินพุตและผลลัพธ์ของ LLM (commitment) แล้วใช้ ZKP เพื่อพิสูจน์ว่าอินพุตที่ถูกใช้ในการตัดสินใจเป็นไปตามเงื่อนไขที่อนุญาต โดยไม่เปิดเผยตัวอินพุตจริง
- การพิสูจน์การปฏิบัติตามเทคนิคตรวจสอบ (audit proofs): ใช้ zk‑SNARKs สำหรับการตรวจสอบแบบ near‑real‑time เมื่อความหน่วงต้องต่ำ และใช้ zk‑STARKs สำหรับการตรวจสอบย้อนหลังเป็นชุดเมื่อต้องการความโปร่งใสและไม่พึ่งพา trusted setup
- การรวมผลแบบ recursive/aggregation: เมื่อมีการตัดสินใจจำนวนมาก สามารถทำการพิสูจน์แบบรวมให้กลายเป็นหลักฐานขนาดเล็กสำหรับการรายงานหรือการตรวจสอบจากหน่วยงานกำกับดูแล
ข้อควรระวังคือ ZKP ไม่สามารถพิสูจน์ “เหตุผลภายใน” ของ LLM ในเชิงโปรเซสได้โดยตรง หากต้องการหลักฐานเชิงตรรกะจริง ๆ ระบบต้องออกแบบให้ส่วนที่ต้องพิสูจน์เป็น deterministic หรือสามารถแปลงเป็นวงจรที่เหมาะสมสำหรับ ZKP โดยทั่วไปคำแนะนำเชิงยุทธศาสตร์สำหรับธนาคารคือ:
- ใช้ LLM สำหรับการวิเคราะห์เชิงภาษา การสรุป และการสนับสนุนการตัดสินใจ แต่ให้ระบบกฎและตัวตรวจสอบเชิงคณิตศาสตร์เป็นผู้สรุปผลสุดท้ายเมื่อจำเป็นต้องมีการรับรอง
- เลือกเทคโนโลยี ZKP ตามข้อกำหนด: zk‑SNARKs สำหรับ latency ต่ำและขนาดหลักฐานเล็ก, zk‑STARKs สำหรับการตรวจสอบแบบโปร่งใสและสเกลใหญ่
- ออกแบบกระบวนการ auditing ที่ใช้การบันทึกแบบเข้ารหัสและการสร้างหลักฐานเป็นระยะ เพื่อให้หน่วยงานกำกับและผู้มีส่วนได้ส่วนเสียสามารถตรวจสอบได้โดยไม่ละเมิดความเป็นส่วนตัวของลูกค้า
สรุปคือ การผสาน ZKP กับ LLM ในสถาปัตยกรรมธนาคารช่วยให้ได้ทั้งความสามารถเชิงปัญญาประดิษฐ์และการรับรองเชิงพิสูจน์สำหรับการปฏิบัติตามกฎระเบียบ แต่อยู่ภายใต้เงื่อนไขว่าส่วนที่ต้องการพิสูจน์ต้องถูกออกแบบให้เป็น deterministic หรือแปลงเป็นรูปแบบที่ ZKP รองรับได้ และต้องเลือกชนิดของ ZKP ให้สอดคล้องกับความต้องการเชิง latency, ขนาดหลักฐาน และประเด็น trust setup
สถาปัตยกรรม ZKP‑Audit: โฟลว์ข้อมูลและส่วนประกอบหลัก
ภาพรวมสถาปัตยกรรมและแผนภาพโฟลว์ข้อมูล (end‑to‑end)
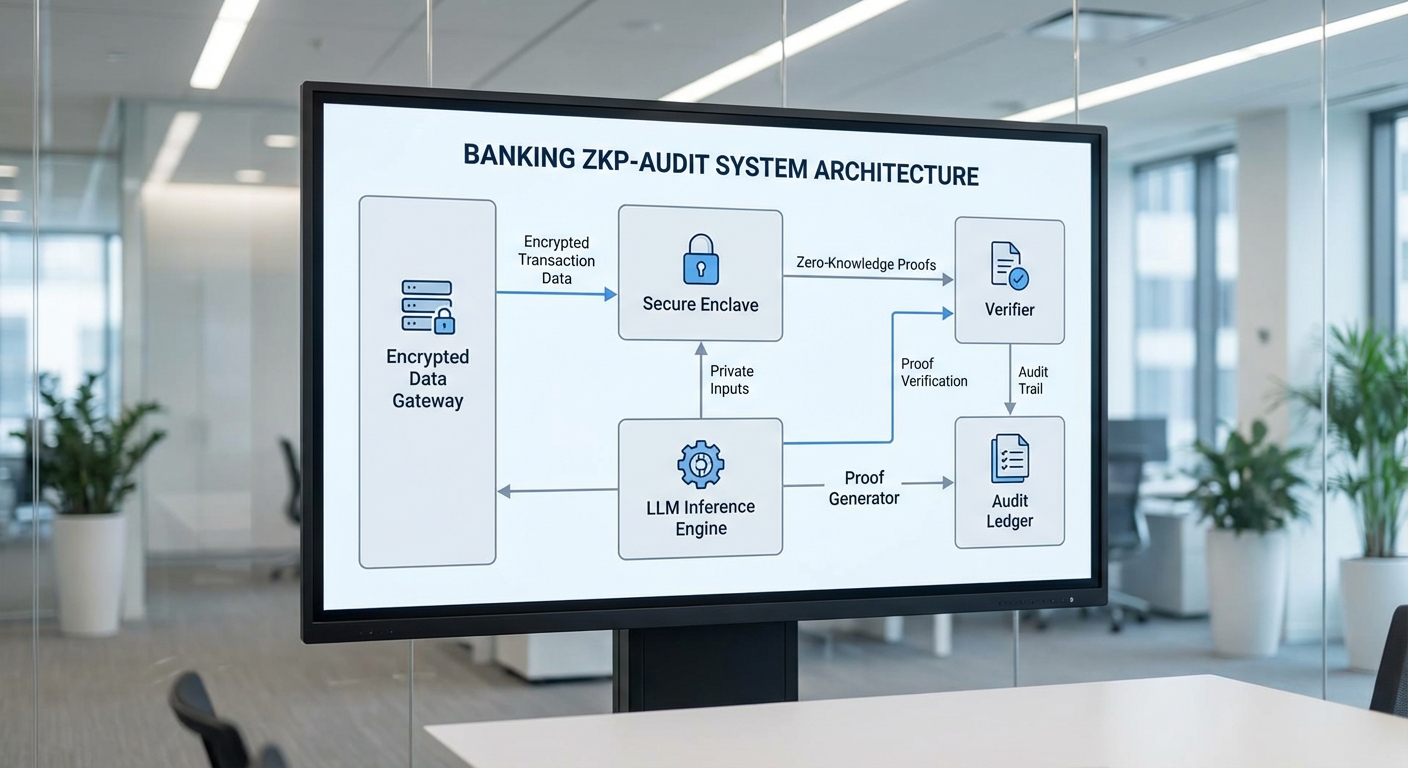
สถาปัตยกรรม ZKP‑Audit ถูกออกแบบให้รองรับการตัดสินใจอัตโนมัติด้วย LLM ในขณะที่ยังคงรักษาความลับของข้อมูลลูกค้าโดยใช้หลักการ Zero‑Knowledge Proof (ZKP) ร่วมกับสภาพแวดล้อมประมวลผลที่เชื่อถือได้ (Secure Enclave) โครงสร้างพื้นฐานประกอบด้วยชั้นหน้ารับส่งข้อมูล (Data Gateway), สภาพแวดล้อมที่ปลอดภัยสำหรับรันโมเดล (Secure Enclave), หน่วยประมวลผล LLM, โมดูลสร้าง proof (Proof Generator), ตัวตรวจสอบและบันทึกการตรวจสอบแบบไม่เปลี่ยนแปลง (Verifier / Audit Ledger) และอินเทอร์เฟซสำหรับผู้ตรวจสอบ (Auditor UI)
จากมุมมองโฟลว์ข้อมูลแบบ end‑to‑end กระบวนการหลักเริ่มจากการเข้ารหัสข้อมูลลูกค้า ณ จุดรับ (ingest) ผ่าน Data Gateway ซึ่งทำหน้าที่ pre‑processing และ tokenization ที่เหมาะสม ข้อมูลเข้ารหัสจะถูกส่งเข้า Secure Enclave เพื่อถอดรหัสภายในขอบเขตที่เชื่อถือได้และเรียกใช้ LLM inference ผลลัพธ์การตัดสินใจจะถูกส่งต่อไปยัง Proof Generator เพื่อสร้าง ZKP ซึ่งเป็นหลักฐานที่ยืนยันได้ว่า ผลลัพธ์สอดคล้องกับข้อมูลป้อนเข้าและนโยบายการตัดสินใจ โดยไม่เปิดเผยข้อมูลดิบใด ๆ หลักฐาน (proof) และเมตาดาต้าเกี่ยวกับการตัดสินใจจะถูกบันทึกลงใน immutable audit ledger เพื่อการตรวจสอบย้อนหลัง โดยมี Verifier ทำหน้าที่ยืนยันความถูกต้องของ proof เมื่อมีการร้องขอจาก Auditor UI
ส่วนประกอบหลักและบทบาทของแต่ละส่วน
- Data Gateway — รับข้อมูลจากแหล่งต่าง ๆ (Mobile/App, Core Banking, Third‑party) ทำการเข้ารหัสเบื้องต้น (client‑side encryption หรือ TLS + payload encryption), ตรวจสอบสิทธิ์ และแยกแยะข้อมูลที่ต้องการความคุ้มครองเป็นพิเศษ (PII) ก่อนส่งเข้า Secure Enclave ตัวอย่างการใช้งาน: ในการทดลองภายใน ธนาคารอาจกำหนดว่า 100% ของข้อมูล PII ต้องถูกเข้ารหัสที่ฝั่งลูกค้าก่อนส่ง
- Secure Enclave (TEE/HSM) — เป็นสภาพแวดล้อมเชื่อถือได้ที่รันกระบวนการถอดรหัส คีย์การจัดการ และ inference ของ LLM โดยไม่อนุญาตให้โค้ดภายนอกเข้าถึงข้อมูลดิบ บทบาทสำคัญคือการจัดการคีย์ (Key Management) ได้แก่ Data Encryption Keys (DEK) ที่ถูกป้องกันด้วย Key Encryption Key (KEK) ซึ่งเก็บอยู่ใน HSM หรือ KMS ที่รองรับ remote attestation
- LLM Inference — รันการตัดสินใจตามนโยบาย (policies) และ prompt ที่ผ่านการตรวจสอบใน enclave ผลลัพธ์อาจเป็นการอนุมัติ/ปฏิเสธ/คะแนนความเสี่ยง/คำอธิบายสั้น ๆ ซึ่งต้องออกแบบให้ deterministic เท่าที่เป็นไปได้เพื่อช่วยในกระบวนการพิสูจน์
- Proof Generator — สร้าง ZKP (เช่น zk‑SNARKs หรือ zk‑STARKs หรือ NIZK variants ที่เหมาะสม) ว่าการคำนวณภายใน enclave ได้ทำตามตรรกะที่ระบุ โดย proof จะครอบคลุม: ความถูกต้องของ input hash, เวอร์ชันของโมเดล, นโยบายที่ใช้ และผลลัพธ์ที่ได้ โมดูลนี้ยังสามารถทำ batching เพื่อเพิ่มประสิทธิภาพ (เช่น สร้าง proof สำหรับกลุ่มธุรกรรมทุกนาที)
- Verifier / Audit Ledger — Verifier ทำหน้าที่ตรวจสอบ proof แบบออฟไลน์หรือออนไลน์ และ immutable audit ledger (เช่น blockchain หรือ append‑only Merkle‑tree log) จะเก็บ proof, commitment, metadata (timestamp, model checksum, enclave attestation) เพื่อการตรวจสอบย้อนหลัง Ledger นี้ต้องสนับสนุนการค้นหา, การยืนยันลำดับเหตุการณ์ และต้องมีความไม่เปลี่ยนแปลง (tamper‑evident)
- Auditor UI — อินเทอร์เฟซสำหรับผู้ตรวจสอบ (ภายใน/ภายนอก) ในการค้นหาเหตุการณ์, ตรวจสอบ proof แบบเรียลไทม์, ดูเมตาดาต้า และเรียกใช้การยืนยันซ้ำ (re‑verification) โดยไม่สามารถเข้าถึงข้อมูลลูกค้าดิบได้ UI ควรแสดงผลเป็นรายงานที่อธิบายได้ (explainability snippets) พร้อมการเชื่อมโยงไปยัง entry ใน audit ledger
โฟลว์ข้อมูลเชิงเทคนิคตั้งแต่การเข้ารหัสถึงการตรวจสอบ
โฟลว์เริ่มจากลูกค้าหรือระบบต้นทางทำการเข้ารหัสข้อมูลและส่งไปยัง Data Gateway ซึ่งตรวจสอบสิทธิ์และติดป้าย (label) ว่าต้องผ่านกระบวนการ ZKP‑Audit จากนั้นข้อมูลที่เข้ารหัส (ciphertext) จะถูกส่งเข้าสู่ Secure Enclave โดยผ่านช่องทางที่มีการยืนยันตัวตนของ enclave (remote attestation) ก่อน enclave จะอ่านข้อมูลด้วย DEK ที่ถูกถอดรหัสโดย KEK ภายใน HSM
ภายใน Enclave กระบวนการมีลำดับสำคัญดังนี้: (1) ยืนยันความถูกต้องของ input (hash และ signature), (2) เรียกใช้ LLM Inference พร้อมกับ policy engine ผลลัพธ์ที่ออกมาถูกสร้างเป็น commitment/hash และพร้อมสำหรับการพิสูจน์, (3) Proof Generator ใช้อัลกอริธึม ZKP สร้าง proof ที่เชื่อมโยง input commitment, model checksum และ output commitment ซึ่ง proof ดังกล่าวเป็นแบบ non‑interactive เพื่อให้ง่ายต่อการตรวจสอบภายหลัง
เมื่อสร้าง proof เสร็จ Proof Generator จะส่ง (a) proof, (b) commitments/metadata (เช่น model version, enclave attestation token), และ (c) pointer ไปยัง ciphertext ที่ถูกเก็บไว้อย่างปลอดภัย ลงใน immutable audit ledger การเก็บใน ledger มักจะจัดเก็บเฉพาะข้อมูลจำเป็นและ hash ของ ciphertext เพื่อรักษาขนาดข้อมูล ตัวอย่างเช่น ledger อาจเก็บ proof ขนาด 2–20 KB และ hash ของ payload แทนการเก็บข้อมูลดิบ ทั้งนี้ ledger จะบันทึก timestamp และลำดับเหตุการณ์เพื่อรองรับการตรวจสอบย้อนหลัง
บทบาทของ Secure Enclave และการจัดการคีย์ (Key Management)
Secure Enclave เป็นหัวใจของความน่าเชื่อถือในระบบ โดยรับประกันว่าข้อมูลดิบและคีย์หลักจะไม่ถูกเปิดเผยแม้ผู้ดูแลระบบจะมีสิทธิ์ในเครื่องโฮสต์ก็ตาม การจัดการคีย์ควรปฏิบัติตามหลักการหลายชั้น: KEK เก็บใน HSM/KMS พร้อมความสามารถ remote attestation; DEK สร้างและใช้ภายใน enclave เท่านั้น; คีย์ชั่วคราว (ephemeral keys) ควรถูก seal กับ enclave state เพื่อป้องกันการนำกลับมาใช้ซ้ำ
ขั้นตอนสำคัญคือการใช้ remote attestation ก่อนการถอดรหัส ทำให้ผู้เรียกสามารถยืนยันว่าสคริปต์ที่รันเป็นเวอร์ชันที่ได้รับอนุมัติและทำงานใน TEE ที่ถูกต้อง นอกจากนี้ควรกำหนดนโยบายการหมุนคีย์ (key rotation), การเพิกถอน (revocation), และการบันทึกเหตุการณ์การเข้าถึงคีย์ทั้งหมดลงใน audit ledger เพื่อให้การตรวจสอบต้นตอของการตัดสินใจสามารถทำได้อย่างเชื่อถือได้
การเก็บ proof ใน Immutable Audit Ledger และการตรวจสอบย้อนหลัง
Immutable audit ledger ทำหน้าที่เป็น single source of truth สำหรับการยืนยันว่าเหตุการณ์การตัดสินใจเกิดขึ้นเมื่อใด โดยเก็บตัวพิสูจน์ (proof), commitment, model checksum, enclave attestation token และ metadata อื่น ๆ โดย ledger ต้องการคุณสมบัติหลักคือ append‑only, tamper‑evident และรองรับการค้นหา/ดึงข้อมูลอย่างมีประสิทธิภาพ
เมื่อผู้ตรวจสอบ (auditor) เรียกดูเหตุการณ์ผ่าน Auditor UI ระบบจะเรียก Verifier เพื่อตรวจสอบ proof กับ commitment และ attestation ใน ledger หาก proof ผ่านการตรวจสอบ Verifier จะคืนสถานะการยืนยันพร้อมรายงานสรุปโดยไม่เผยข้อมูลดิบ หากจำเป็นต้องทำการตรวจสอบเชิงลึกเพิ่มเติม ระบบสามารถเรียกใช้ฟังก์ชัน re‑verification หรือ replay ภายใน Secure Enclave โดยใช้ข้อมูลที่ถูกเข้ารหัสและคีย์ที่ผ่านการยืนยันเท่านั้น ซึ่งทำให้ธนาคารสามารถแสดงความโปร่งใสต่อหน่วยกำกับดูแลได้โดยไม่ละเมิดความเป็นส่วนตัวของลูกค้า
สรุปแล้ว สถาปัตยกรรม ZKP‑Audit ผสานแนวทางการปกป้องข้อมูลเชิงป้องกันจากระดับอินฟราสตรัคเจอร์จนถึงระดับพิสูจน์ความถูกต้องของการคำนวณ โดย Secure Enclave และการจัดการคีย์ที่เข้มงวดร่วมกับ immutable audit ledger เป็นองค์ประกอบที่ทำให้การตัดสินใจอัตโนมัติของระบบธนาคารมีทั้งความน่าเชื่อถือและความเป็นส่วนตัวควบคู่กัน
ตัวอย่างกระบวนการ: pseudo‑code และ API flow ของ ZKP‑Audit
สรุปกระบวนการโดยย่อ
ภาพรวมของกระบวนการ ZKP‑Audit สำหรับธนาคารไทยประกอบด้วยขั้นตอนสำคัญ 4 ขั้นตอน: (1) ผู้ใช้/ระบบส่งคำขอและข้อมูลที่ถูกแฮชหรือเข้ารหัสไปยังระบบกลางของธนาคาร, (2) ระบบทำการรัน inference กับ LLM ภายในสภาพแวดล้อมที่ควบคุม (secure enclave/SGX หรือ confidential VM) โดยไม่เปิดเผยข้อมูลดิบ, (3) สร้าง witness และเรียกใช้โปรโตคอลสร้าง proof (เช่น zkSNARK/PLONK) เพื่อยืนยันว่าการตัดสินใจเป็นไปตามตรรกะที่กำหนดโดยไม่เปิดข้อมูลลูกค้า, และ (4) เผยแพร่ proof พร้อม metadata ที่จำเป็นให้ผู้ตรวจสอบ (auditor) สามารถยืนยันความถูกต้องได้โดยไม่ต้องเห็นข้อมูลต้นทางเต็มรูปแบบ
Pseudo‑code: การสร้าง witness และการเรียก proof circuit
ตัวอย่าง pseudo‑code ด้านล่างแสดงลำดับการทำงานหลัก: การเตรียม input ที่ถูกแฮช/เข้ารหัส การรัน LLM ภายใน environment ที่ควบคุม การสร้าง witness และการเรียก circuit เพื่อสกัด proof
// เตรียมค่าและฟังก์ชันพื้นฐาน
hash(data) -> bytes32
encrypt(data, pk) -> ciphertext
run_llm_enclave(encrypted_input, model_id) -> encrypted_output, model_state_commitment
prove(circuit, witness) -> proof, public_inputs
// ตัวอย่าง pseudo‑code
function zkp_audit_request(user_id, raw_input, model_id, bank_key) {
// 1. client-side: hash & encrypt input เพื่อปกป้องข้อมูลดิบ
nonce = random()
input_hash = hash(raw_input || nonce)
enc_input = encrypt(raw_input, bank_key.pub)
// 2. ส่งคำขอไปยัง endpoint ของธนาคาร
request_payload = { request_id, user_id, input_hash, enc_input, model_id, timestamp }
sendPOST('/api/zkp-audit/request', request_payload)
// 3. ภายใน enclave: ทำ inference และสร้าง witness
encrypted_output, model_commit = run_llm_enclave(enc_input, model_id)
output_hash = hash(encrypted_output)
witness = {
input_hash: input_hash,
model_commitment: model_commit,
output_hash: output_hash,
decision_flag: derive_decision_flag(encrypted_output)
}
// 4. เรียก circuit เพื่อสร้าง proof (zkSNARK/PLONK)
circuit = loadCircuit('zkp_audit_circuit')
proof, public_inputs = prove(circuit, witness)
// 5. เก็บ proof และส่งกลับให้ระบบกลางพร้อม metadata
proof_payload = { request_id, proof, public_inputs, metadata: { model_id, model_digest: model_commit, timestamp } }
sendPOST('/api/zkp-audit/proof', proof_payload)
return { request_id, proof_id }
}
API Flow: ตัวอย่าง endpoints และตัวอย่าง payloads
ด้านล่างเป็นรูปแบบ API ที่แนะนำสำหรับการเชื่อมต่อระหว่าง client, ระบบธนาคาร (enclave & proof service) และผู้ตรวจสอบ
- POST /api/zkp-audit/request — client ส่งคำขอพร้อม input_hash และ encrypted_input
- ตัวอย่าง payload:
{ "request_id":"r123", "user_id":"u789", "input_hash":"0xabc...", "encrypted_input":"0xdeadbeef...", "model_id":"llm-v2", "timestamp":"2026-03-01T12:00:00Z" }
- ตัวอย่าง payload:
- POST /api/zkp-audit/proof — enclave/prover ส่ง proof, public_inputs และ metadata ไปยังระบบของธนาคารเพื่อบันทึกและเผยแพร่
- ตัวอย่าง payload:
{ "request_id":"r123", "proof":"0xproofbytes...", "public_inputs":{ "input_hash":"0xabc...", "output_hash":"0xdef...", "decision_flag":1 }, "metadata":{ "model_id":"llm-v2", "model_digest":"0xmodelhash", "enclave_attestation":"attest_blob", "timestamp":"2026-03-01T12:00:05Z" } }
- ตัวอย่าง payload:
- GET /api/zkp-audit/verify?request_id=r123 — endpoint สำหรับผู้ตรวจสอบเรียกเพื่อตรวจสอบ proof โดยระบบจะตอบสถานะการตรวจสอบ
- ตัวอย่าง response:
{ "request_id":"r123", "verified":true, "verified_at":"2026-03-01T12:00:30Z", "evidence":{ "public_inputs":{...}, "signature":"0xsig..." } }
- ตัวอย่าง response:
- GET /api/zkp-audit/audit-log?request_id=r123 — ดึง log ที่ผนึกกับ proof (commitments, ledger tx id, enclave attestation)
ตัวอย่างฟิลด์ที่สำคัญใน payload และเหตุผล
- input_hash: แฮชของข้อมูลอินพุตและ nonce เพื่อยืนยันว่าอินพุตเดิมถูกใช้โดยไม่ต้องเปิดข้อมูลดิบ
- encrypted_input: ข้อมูลที่เข้ารหัสสำหรับ enclave; เก็บไว้สำหรับการ audit ภายใต้เงื่อนไขที่กำหนด
- model_digest / model_commitment: ค่ารวมสถานะของโมเดล (เช่น hash ของ weights หรือ model version) เพื่อยืนยันว่า inference รันบนโมเดลที่ระบุ
- proof: byte array ของ zkProof
- public_inputs: ค่าที่เปิดเผยได้ (commitments/flags) ที่ verifier ใช้ตรวจสอบ proof
- enclave_attestation: รายงานการยืนยันจาก hardware/TEE เพื่อเชื่อมโยงว่า inference ถูกประมวลผลใน environment ที่น่าเชื่อถือ
Verification flow สำหรับผู้ตรวจสอบ (Auditor)
การตรวจสอบควรเป็นไปตามลำดับขั้นตอนชัดเจนเพื่อให้ได้ความโปร่งใสโดยไม่ละเมิดความลับลูกค้า:
- 1. ดึง proof และ public inputs: Auditor เรียก GET /api/zkp-audit/verify?request_id=... เพื่อรับ proof และ public_inputs รวมถึง metadata
- 2. ตรวจสอบความสมบูรณ์ของ attestations: ตรวจสอบ enclave_attestation กับผู้ให้บริการ TEE เพื่อให้แน่ใจว่า enclave ที่รันคือ instance ที่ได้รับอนุญาตและรันชุดซอฟต์แวร์ที่ระบุ (model_digest)
- 3. รัน verifier (local หรือ service): ใช้ public_inputs และ proof เรียกฟังก์ชัน verify ของ zk‑verifier (ตัวอย่าง: verify(proof, public_inputs) → true/false)
- 4. ตรวจสอบ commitments กับ ledger/audit-log: ตรวจสอบว่า input_hash และ output_hash ตรงกับค่าที่บันทึกไว้ใน audit-log หรือ blockchain ของธนาคาร (ถ้ามีการผนึกข้อมูล)
- 5. สรุปรายงานการตรวจสอบ: หากทุกข้อผ่าน auditor สามารถออก audit receipt ที่ลงลายมือชื่อดิจิทัลพร้อม timestamp และ tx id ของการพิสูจน์
ตัวอย่างการตรวจสอบแบบย่อ (pseudo‑flow) สำหรับ auditor:
proof_payload = GET /api/zkp-audit/verify?request_id=r123
if verify(proof_payload.proof, proof_payload.public_inputs) == true and validateAttestation(proof_payload.metadata.enclave_attestation):
return { verified: true, evidence: proof_payload }
else:
return { verified: false, reason: "invalid-proof or invalid-attestation" }
สรุป: การผสานระหว่างการเข้ารหัสอินพุต, การรัน LLM ภายใน environment ที่ควบคุม และการสร้าง ZK‑proof ที่แนบ metadata แบบมาตรฐาน จะช่วยให้ธนาคารสามารถยืนยันการตัดสินใจอัตโนมัติได้อย่างโปร่งใสและตรวจสอบได้ โดยไม่ต้องเปิดเผยข้อมูลลูกค้า—สร้างความสมดุลระหว่าง Privacy, Compliance และความโปร่งใสสำหรับผู้ตรวจสอบและผู้กำกับดูแล
การวัดผลและสถิติ: KPI สำหรับระบบตรวจสอบอัตโนมัติ
ภาพรวมการวัดผลสำหรับระบบตรวจสอบอัตโนมัติ ZKP‑Audit
เมื่อธนาคารนำระบบ ZKP‑Audit ซึ่งผสาน Zero‑Knowledge Proof กับ LLM (Large Language Models) มาใช้ การติดตามตัวชี้วัด (KPI) ต้องครอบคลุมทั้งมิติทางเทคนิคและมิติความปลอดภัย/ความเป็นส่วนตัว เพื่อให้สามารถประเมินผลกระทบต่อประสบการณ์ผู้ใช้ (UX) และการตัดสินใจเชิงธุรกิจได้อย่างเป็นรูปธรรม ตัวชี้วัดที่สำคัญได้แก่ latency ของการตัดสินใจและการสร้าง proof, throughput หรือคำสั่งที่ระบบรองรับต่อวินาที, ขนาดของ proof (proof size), อัตราการผ่านการตรวจสอบของ verifier (verifier acceptance rate), และตัวชี้วัดคุณภาพการตัดสินใจเช่น accuracy, false positive, false negative เป็นต้น
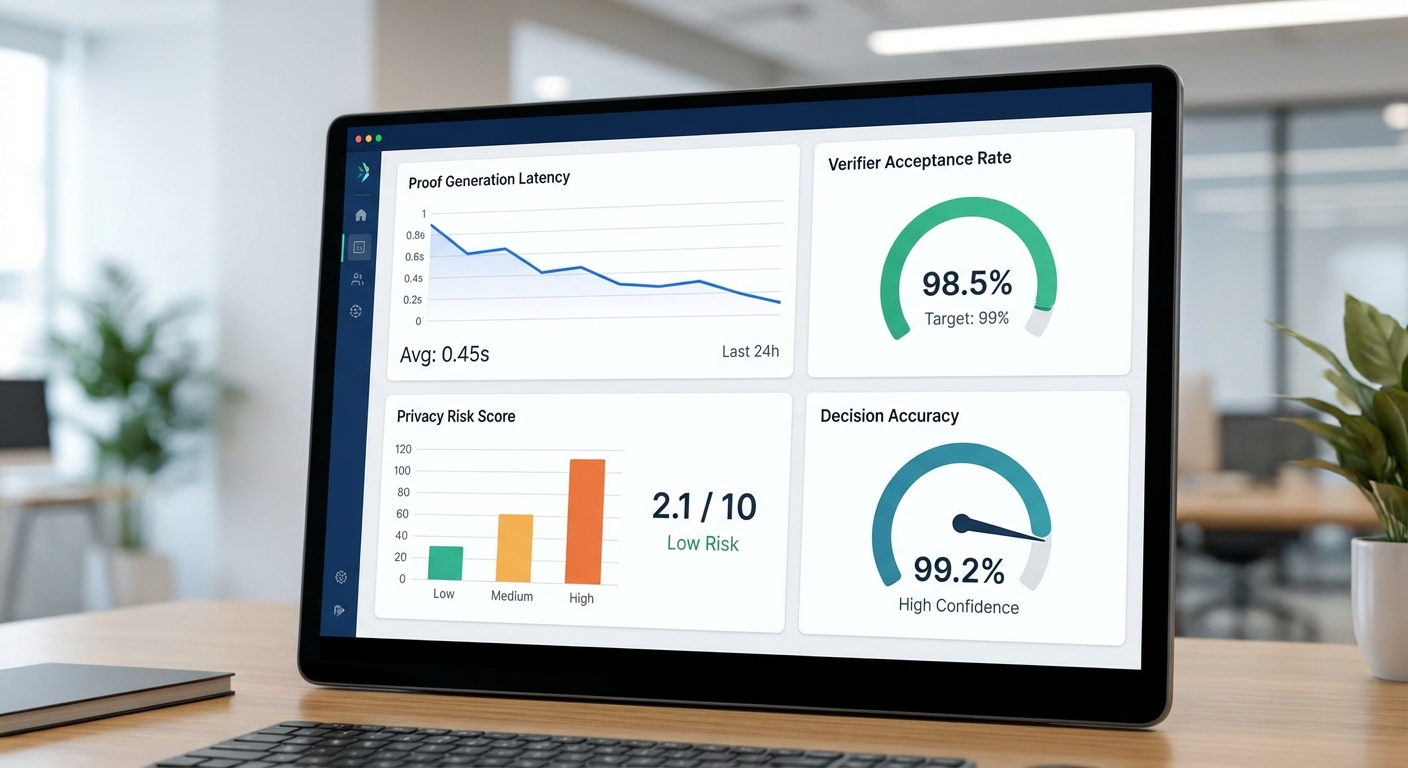
ตัวอย่างสถิติสมมติจากการทดลองเชิงนำร่องของธนาคาร: การสร้าง proof เพิ่มค่า latency เฉลี่ยประมาณ 180 ms (ช่วง 100–300 ms) ต่อการตัดสินใจ ทำให้ latency ของกระบวนการตัดสินใจเพิ่มจาก 120 ms เป็น 300 ms โดย throughput ลดลงจาก 500 TPS เหลือ 420 TPS แต่ลดความเสี่ยงการรั่วไหลของข้อมูลเชิงความเป็นส่วนตัวได้ประมาณ 90% (ตามโมเดลความเสี่ยงภายใน) ขนาด proof มีค่ากลาง (median) ประมาณ 1.2 KB และ verifier acceptance rate อยู่ที่ 99.95%. ในด้านคุณภาพการตัดสินใจ พบว่าค่า accuracy เปลี่ยนจาก 95.0% เป็น 94.8% (ผลกระทบเชิงประสิทธิภาพเล็กน้อย) โดย false positive เพิ่มจาก 1.3% เป็น 1.5% และ false negative จาก 3.0% เป็น 3.2% — ค่าที่ต้องประเมินต่อเนื่องเพื่อตัดสินใจเชิงธุรกิจ
KPI ทางเทคนิคและ KPI ทางความปลอดภัย/ความเป็นส่วนตัวที่ต้องติดตาม
- Latency (ms): วัดทั้ง median, p95, p99 ของการตัดสินใจรวมเวลาสร้าง proof แยกเป็นส่วนของ LLM และส่วนของ ZKP
- Throughput (TPS): ความสามารถในการประมวลผลคำร้องต่อวินาที เมื่อมีโหลดจริงและในช่วงพีค
- Proof generation time: การกระจายของเวลาสร้าง proof (histogram) เพื่อวิเคราะห์ tail latency ที่มีผลต่อ UX
- Proof size (bytes): ขนาดเฉลี่ยและ percentiles เพื่อประเมินผลกระทบต่อแบนด์วิดท์และค่าใช้จ่ายเครือข่าย
- Verifier acceptance rate: เปอร์เซ็นต์ของ proofs ที่ตรวจสอบผ่าน (ควรเก็บแยกตามเวอร์ชันของ verifier และเงื่อนไขแวดล้อม)
- Decision accuracy & confusion matrix: accuracy, precision, recall, F1; แยกวัด false positive และ false negative สำหรับเหตุการณ์สำคัญทางธุรกิจ
- Privacy risk metrics: เช่น estimated data leakage probability, delta of identifiable attributes, หรือคะแนนความเสี่ยงภายใน (risk score) ที่ลดลงหลังใช้ ZKP
- Reliability/availability: error rates, retry rates, and mean time to recovery (MTTR) สำหรับส่วนของ ZKP และ LLM
การติดตั้ง A/B Test เพื่อตรวจสอบผลกระทบของ ZKP ต่อ UX และการตัดสินใจเชิงธุรกิจ
การออกแบบ A/B test ควรกำหนดสมมติฐานที่ชัดเจน เช่น "การผสาน ZKP จะเพิ่ม latency แต่ไม่ทำให้ conversion ลดลงเกิน 2%" จากนั้นแบ่งผู้ใช้ออกเป็นกลุ่มควบคุม (A: ระบบเดิม) และกลุ่มทดลอง (B: ระบบมี ZKP) แบบสุ่มและคงสัดส่วนตลอดการทดลอง ระยะเวลาควรยาวพอเพื่อเก็บตัวอย่างเพียงพอ (ตัวอย่างเช่น 2–4 สัปดาห์ ขึ้นกับปริมาณทราฟฟิก) และตั้งเกณฑ์ความสำคัญทางสถิติ (เช่น p < 0.05)
เมตริกที่ต้องบันทึกใน A/B test ประกอบด้วย:
- เวลาเฉลี่ยในการตอบ (mean latency) และ percentiles (p95, p99)
- อัตราการแปลง (conversion rate) ตามวัตถุประสงค์ธุรกิจ
- อัตราการยกเลิกการทำรายการ (drop‑off) ในขั้นตอนที่ได้รับผลกระทบจาก latency
- คุณภาพการตัดสินใจ (accuracy, false positive/negative) สำหรับแต่ละกลุ่ม
- ตัวบ่งชี้ความเป็นส่วนตัว เช่นจำนวนเหตุการณ์ที่ต้องเปิดข้อมูลลูกค้าในการตรวจสอบ
การวิเคราะห์ผลให้ใช้ทั้งการทดสอบความแตกต่างแบบ t‑test หรือ chi‑square สำหรับอัตรา และการวิเคราะห์ข้ามช่วงเวลา (time series) เพื่อดูแนวโน้ม นอกจากนี้ควรทำการวิเคราะห์แยกตามกลุ่มผู้ใช้ (segmentation) เช่น ลูกค้าที่มีมูลค่าทางธุรกิจสูง เพื่อป้องกันผลเฉลี่ยบดบังผลกระทบจริง
ตัวอย่าง dashboards และการแปลผลตัวเลข
- Latency Overview: แสดงเส้นเวลา (time series) ของ mean, p95, p99 latency แยกส่วน LLM และ ZKP + alarm เมื่อ p99 เกินค่า SLO (เช่น 500 ms)
- Proof Metrics: histogram ของ proof generation time, median proof size, throughput ของการสร้าง proof ต่อวินาที
- Decision Quality Panel: confusion matrix รายวัน, trend ของ precision/recall, และตัวอย่างเคสที่ false positive/negative สูง
- Privacy Impact: เปอร์เซ็นต์การลดเหตุการณ์ที่ต้องเปิดเผยข้อมูล, estimated leakage reduction (%) และ verifier acceptance rate แบบ realtime
- Business KPIs: conversion rate, drop‑off rate ใน funnel, และรายงาน ROI ของการลดความเสี่ยงข้อมูล
การแปลผลตัวเลขตัวอย่าง: หาก dashboard พบว่า median latency เพิ่มขึ้นจาก 120 ms เป็น 300 ms แต่ conversion rate ลดลงเพียง 0.5% ในขณะที่ privacy leakage risk ลดลง 90% ธนาคารอาจตัดสินใจยอมรับ trade‑off นี้สำหรับงานที่มีความเสี่ยงสูง แต่หากผลการทดสอบชี้ว่า p99 latency เพิ่มสูงจนทำให้ drop‑off ในหน้า onboarding เพิ่มขึ้น 3–5% อาจพิจารณาปรับปรุงการทำ caching ของ proofs, ลดความถี่การสร้าง proof สำหรับเคสความเสี่ยงต่ำ หรือเลือกใช้ ZKP แบบ lightweight เฉพาะกลุ่ม
สุดท้ายควรกำหนด SLO และเกณฑ์แจ้งเตือนที่ชัดเจน เช่น verifier acceptance rate ต้องไม่ต่ำกว่า 99.9% และ p99 latency ต้องไม่เกิน 600 ms หากมีการละเมิดให้เรียกกระบวนการตรวจสอบอัตโนมัติและแจ้งทีมปฏิบัติการทันที พร้อมเก็บ log ของ proofs และเหตุการณ์ที่ล้มเหลวเพื่อวิเคราะห์รากเหง้า
กฎระเบียบ การกำกับดูแล และความโปร่งใสเชิงนิติศาสตร์
กฎระเบียบ การกำกับดูแล และความโปร่งใสเชิงนิติศาสตร์
การนำระบบ ZKP‑Audit ที่ผสาน Zero‑Knowledge Proof (ZKP) กับ Large Language Models (LLMs) มาใช้ในภาคการเงินต้องสอดคล้องกับกรอบกฎหมายและข้อกำกับดูแลที่เกี่ยวข้อง โดยเฉพาะพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ของไทย หลักการสำคัญที่ต้องปฏิบัติตาม ได้แก่ การมีฐานทางกฎหมายสำหรับการประมวลผล (เช่น การยินยอมหรือความจำเป็นตามสัญญา/กฎหมาย), การจำกัดวัตถุประสงค์, การเก็บข้อมูลให้น้อยที่สุด (data minimization) และ การคุ้มครองสิทธิของเจ้าของข้อมูล เช่น สิทธิในการเข้าถึง แก้ไข และลบข้อมูล การออกแบบระบบจึงต้องป้องกันไม่ให้ LLMs หรือโพรเซสการตรวจสอบส่งต่อหรือเปิดเผยข้อมูลส่วนบุคคลโดยไม่จำเป็น และต้องมีมาตรการทางเทคนิคและองค์กรที่ชัดเจน เช่น การเข้ารหัสข้อมูลระหว่างพักและขณะส่ง เก็บคีย์แยกจากข้อมูล และการควบคุมสิทธิการเข้าถึงแบบบทบาท (RBAC)
การใช้ ZKP เพื่อเป็นหลักฐานการตัดสินใจเชิงนิติศาสตร์เป็นแนวทางที่ช่วยสมดุลระหว่าง ความโปร่งใสต่อผู้กำกับดูแล กับ การรักษาความลับของลูกค้า โดยทั่วไป ธนาคารสามารถสร้างหลักฐานเชิงคณิตศาสตร์ (proof) ที่พิสูจน์ว่าเงื่อนไขของโมเดลหรือกฎธุรกิจถูกปฏิบัติจริงโดยไม่ต้องเปิดเผยข้อมูลอินพุตต้นทาง ตัวอย่างเช่น ในการอนุมัติสินเชื่อ ZKP สามารถพิสูจน์ว่า “รายได้ของผู้ขอสินเชื่อตรงตามเกณฑ์ขั้นต่ำและสัดส่วนหนี้ต่อรายได้ต่ำกว่าขอบเขต” โดยไม่ต้องเปิดเผยตัวเลขรายได้จริง ขั้นตอนปฏิบัติที่เป็นไปได้ได้แก่:
- การคอมมิตข้อมูลต้นทาง — ธนาคารสร้าง commitment (เช่น hash หรือ Pedersen commitment) ของข้อมูลลูกค้า และเก็บ commitment นี้ไว้ในระบบที่ปลอดภัย
- การรันเงื่อนไขเชิงลอจิกกับโมเดล — LLM/โมเดลประเมินตามกฎและสร้างค่าผลลัพธ์ที่นำไปสู่การสร้าง ZKP แทนการเผยแพร่ข้อมูลอินพุต
- การสร้างหลักฐานแบบไม่โต้ตอบ — โดยใช้ zk‑SNARKs หรือ zk‑STARKs เพื่อสร้าง proof สั้น ๆ ที่ผู้กำกับดูแลสามารถตรวจสอบได้อย่างรวดเร็ว
- การตรวจสอบโดยผู้กำกับดูแล — ผู้กำกับดูแลตรวจสอบ proof เทียบกับ commitment และพารามิเตอร์ของโมเดล (เช่น hash ของเวอร์ชันโมเดลและสคริปต์การตัดสินใจ) โดยไม่เห็นข้อมูลส่วนบุคคล
- การลงลายมือชื่อดิจิทัลและการประทับเวลา — proof และ commitment ควรลงลายมือชื่อโดยคีย์องค์กรและประทับเวลาก่อนเก็บเพื่อรับรองความสมบูรณ์และไม่ถูกแก้ไข
เพื่อให้หลักฐานที่สร้างเป็นที่ยอมรับเชิงนิติศาสตร์ ธนาคารควรออกแบบกระบวนการให้สอดคล้องกับหลักฐานอิเล็กทรอนิกส์ ได้แก่ การรับรองความสมบูรณ์ (integrity), การพิสูจน์ต้นตอ (provenance), และการยืนยันตัวบุคคลที่สร้างหลักฐาน (non‑repudiation) ตัวอย่างแนวปฏิบัติที่แนะนำคือการใช้โครงสร้างข้อมูลแบบ Merkle tree ในการจัดเก็บ commitments เพื่อให้สามารถอ้างกลับไปยังชุดข้อมูลต้นทางได้โดยไม่ต้องเปิดเผยทั้งชุด นอกจากนี้การผนึก proof ลงกับระบบลงบันทึกแบบไม่เปลี่ยนแปลง (append‑only ledger) หรือการประทับเวลาต่อ blockchain ทำให้สามารถตรวจสอบย้อนหลังได้เมื่อผู้กำกับดูแลร้องขอ
ในส่วนของ audit trail และ retention policy ธนาคารต้องจัดทำบันทึกที่ละเอียดและสามารถตรวจสอบย้อนกลับได้ ซึ่งควรประกอบด้วยข้อมูลอย่างน้อย: การอ้างอิงการตัดสินใจ (decision ID), เวอร์ชันของโมเดลและพารามิเตอร์ที่ใช้, commitment ของข้อมูลอินพุต, proof ที่สร้าง, ลายมือชื่อดิจิทัลของระบบ, เวลาที่เกิดเหตุการณ์ และรายการผู้ที่เข้าถึงหรืออนุมัติการตัดสินใจ ควรกำหนดนโยบายการเก็บรักษาที่ชัดเจน เช่น ระยะเวลาเก็บข้อมูลสำหรับการตรวจสอบภายในและสำหรับการปฏิบัติตามคำสั่งจากผู้กำกับดูแล รวมถึงกระบวนการดำเนินการในกรณีมีคำร้องขอจากเจ้าของข้อมูล (subject access request) หรือการคุ้มครองทางกฎหมาย (legal hold)
- Retention schedule — กำหนดช่วงเวลาตามกฎหมายและความเสี่ยง (เช่น เก็บหลักฐานการตัดสินใจที่เกี่ยวข้องกับผลิตภัณฑ์ทางการเงินอย่างน้อยตามระยะเวลาที่ผู้กำกับดูแลหรือกฎหมายที่เกี่ยวข้องกำหนด; ประเมินให้สอดคล้องกับข้อกำหนดด้านภาษี การบังคับคดี และข้อกำกับดูแล)
- การจัดการสิทธิ์เข้าถึง — ข้อมูลดิบต้องเข้าถึงได้เฉพาะบุคลากรที่ได้รับอนุญาตเท่านั้น ส่วน proof และ metadata สำหรับการรายงานสามารถเข้าถึงได้โดยหน่วยกำกับดูแลตามสิทธิ์ที่กำหนดไว้
- นโยบายการทำลายข้อมูล — ระบุวิธีการทำลายแบบปลอดภัย (secure deletion) และบันทึกการทำลายเพื่อพิจารณาในอนาคต
เพื่อให้การปฏิบัติตามข้อกำกับดูแลมีประสิทธิภาพ ธนาคารควรผสานการประเมินผลกระทบด้านคุ้มครองข้อมูล (DPIA), การทดสอบความโปร่งใสและความเป็นธรรมของโมเดล (algorithmic audit), และการกำหนดบทบาทหน้าที่เชิงกฎหมาย เช่น Data Protection Officer (DPO) และทีม Compliance ควรสร้างแนวทางการรายงานต่อผู้กำกับดูแลโดยชัดเจน — ระบุชนิดของหลักฐานที่จะยื่น, รูปแบบของ ZKP ที่รับรอง, วิธีการตรวจสอบ (verification procedure), และช่องทางการขอข้อมูลเพิ่มเติมเมื่อจำเป็น ทั้งนี้ควรมีการฝึกอบรมผู้ตรวจสอบภายในและเจ้าหน้าที่ของหน่วยงานกำกับดูแลให้เข้าใจวิธีการอ่านและยืนยัน ZKP เพื่อให้กระบวนการตรวจสอบมีความรวดเร็วและเชื่อถือได้
สุดท้าย ธนาคารควรจัดให้มีการประเมินความเสี่ยงและการทบทวนเชิงกฎหมายอย่างสม่ำเสมอเพื่อรับประกันว่าเทคโนโลยี ZKP‑Audit ยังคงสอดคล้องกับ PDPA และข้อกำกับดูแลที่เปลี่ยนแปลงไป รวมทั้งจัดทำแผนตอบโต้เมื่อเกิดเหตุละเมิดข้อมูล (incident response) ซึ่งรวมถึงการเปิดเผยต่อผู้กำกับดูแลและเจ้าของข้อมูลตามข้อกำหนดของกฎหมาย
บทเรียนจากการนำไปใช้จริง ความเสี่ยง และแนวปฏิบัติที่ดีที่สุด
บทนำ — ภาพรวมความเสี่ยงจากการนำ ZKP‑Audit ไปใช้จริง
การผสาน Zero‑Knowledge Proof (ZKP) เข้ากับข้อพิสูจน์การตัดสินใจของ LLM เพื่อสร้างระบบ "ZKP‑Audit" สำหรับการตัดสินใจอัตโนมัติในธนาคาร ช่วยให้สามารถยืนยันความถูกต้องของผลลัพธ์โดยไม่เปิดเผยข้อมูลลูกค้า อย่างไรก็ตาม การนำไปใช้เชิงพาณิชย์มีข้อจำกัดและความเสี่ยงเชิงเทคนิคและองค์กรที่ต้องพิจารณาอย่างรอบคอบ เช่น ความซับซ้อนของ circuit ที่เพิ่มเวลาในการสร้าง proof และขนาดข้อมูล proof, การจัดการคีย์และความเสี่ยงจากการรั่วไหล, ความสามารถของ auditor ในการตรวจสอบ proof อย่างน่าเชื่อถือ และต้นทุนด้านคอมพิวต์และการจัดเก็บที่เพิ่มขึ้น นอกจากนี้ยังมีความเสี่ยงเชิงกระบวนการ เช่น governance, การตอบสนองต่อเหตุการณ์ และการควบคุมเวอร์ชันของโมเดล
ข้อจำกัดทางเทคนิคและแนวทางบรรเทาความเสี่ยง
ปัญหาเชิงเทคนิคสำคัญ ได้แก่ circuit ที่ซับซ้อนซึ่งทำให้เวลาในการสร้าง proof (prover time) เพิ่มขึ้นและขนาดของ proof ที่ใหญ่ขึ้นจนส่งผลต่อ latency และ storage costs; การจัดการคีย์ที่ต้องมีความปลอดภัยระดับสูง; และข้อจำกัดด้านการตรวจสอบของ auditor ซึ่งอาจขาดเครื่องมือหรือทักษะในการยืนยันความถูกต้องของ proofs
- Modular proofs: แยกการพิสูจน์ออกเป็นหน่วยย่อย (component‑level proofs) เช่น proof สำหรับ rule checks, proof สำหรับการคำนวณคะแนนความเสี่ยง และ proof สำหรับการยืนยันการเข้าถึงข้อมูล วิธีนี้ช่วยลดความซับซ้อนของแต่ละ circuit และอำนวยให้สามารถรีคอมไบน์ (recombine) ผลลัพธ์ได้อย่างมีประสิทธิภาพ
- Batching: รวบรวมหลายการตัดสินใจมาอยู่ใน proof เดียวเมื่อเป็นไปได้ เพื่อลดค่าใช้จ่ายต่อรายการ ตัวอย่างเช่น บทพิสูจน์แบบ batch ขนาด 10 รายการสามารถลดค่า verification ต่อรายการได้ถึง 50–70% ขึ้นอยู่กับโซลูชัน ZKP ที่ใช้
- Hybrid approaches: ผสมผสานแนวทาง เช่น ใช้ ZKP เฉพาะกับข้อมูลที่เป็นความลับ (PII/การคำนวณเชิงนโยบาย) ขณะที่ส่วนอื่นๆ ของ workflow ยังคงใช้การเซ็นแบบดิจิทัลหรือการบันทึก immutable commitment เพื่อลดภาระของระบบ
- ZK‑friendly circuits & libraries: ปรับตรรกะการตัดสินใจให้อยู่ในรูปแบบที่เหมาะกับ ZKP (เช่น หลีกเลี่ยงการคำนวณเชิงลูปแบบไม่จำกัดหรือการใช้ฟังก์ชันที่ยากต่อการแปลงเป็น circuit) และเลือกไลบรารีที่มี community support เช่น PLONK, Groth16 หรือ STARK เพื่อแลกเปลี่ยน trade‑offs ระหว่าง proof size, prover time และความโปร่งใส
- Key management: ใช้ HSM, threshold signature และการหมุนคีย์อัตโนมัติเพื่อจำกัดความเสี่ยงจากการรั่วไหลของคีย์และจัดทำ audit trail ของการใช้คีย์
คำแนะนำสำหรับทีม — การเตรียมความพร้อม ฝึกอบรม และ Governance
การนำ ZKP‑Audit ไปใช้สำเร็จไม่ใช่เรื่องของเทคโนโลยีเพียงอย่างเดียว แต่ต้องอาศัยการเตรียมคนและกระบวนการ:
- ทดสอบแบบ simulated: เริ่มด้วยการทดสอบในสภาพแวดล้อมจำลอง (sandbox) ทั้งในเชิง functional และ performance โดยจำลองปริมาณงานจริง เช่น 100k–500k การตัดสินใจต่อเดือน เพื่อระบุคอขวดด้าน latency และการใช้ทรัพยากร
- การฝึกอบรม auditor: สร้างหลักสูตรฝึกอบรมสำหรับ auditor ที่ครอบคลุมพื้นฐาน ZKP, วิธีอ่านและตรวจ proof, และเครื่องมืออัตโนมัติสำหรับการตรวจสอบ proof แบบ batch พร้อมการทดสอบ practical labs และ certification ภายในองค์กร
- Governance & policy: กำหนดนโยบายชัดเจนเกี่ยวกับสถานะการพิสูจน์ (evidence retention), การเข้าถึง keys, SLA การตรวจสอบ และกระบวนการตอบสนองเมื่อตรวจพบ failed verification หรือพฤติกรรมผิดปกติ
- Incident response & rollback: วางแผน rollback ของกลไกการตัดสินใจอัตโนมัติหากระบบ ZKP เกิดข้อผิดพลาด รวมถึง playbook สำหรับการตรวจสอบย้อนกลับ (forensic) โดยไม่ทำให้ข้อมูลลูกค้ารั่วไหล
Checklist การนำระบบไปใช้งานจริง
Checklist ด้านล่างออกแบบมาเพื่อใช้เป็นแนวทางการตรวจสอบก่อนและระหว่างการนำ ZKP‑Audit ไปใช้งานเชิงพาณิชย์:
- กำหนดขอบเขต (scope) ของการพิสูจน์: ระบุข้อมูลที่ต้องปกปิดและเงื่อนไขที่ต้องการพิสูจน์
- ออกแบบ circuit แบบ modular และเลือก ZKP protocol ที่เหมาะสม
- จัดทำ performance targets: latency ≤ target per decision, throughput, proof size, storage budget
- ประเมินต้นทุนรวม (TCO): ค่าคอมพิวต์, storage, HSM, ฝึกอบรม, maintenance
- ตั้งระบบ KMS/HSM และนโยบายการหมุนคีย์ที่ชัดเจน
- เตรียม sandbox สำหรับการทดสอบแบบ simulated และ A/B testing
- ฝึกอบรม auditor และสร้าง playbook การตรวจสอบประจำวัน
- กำหนด SLA, governance, และ incident response plan
- กำหนด metrics ที่ต้องติดตาม: prover time, verifier time, proof size, failed verifications, storage growth, cost per decision
กรณีศึกษาจำลอง — ธนาคารไทย (Pilot)
สมมติธนาคารไทยแห่งหนึ่งดำเนินโครงการนำร่อง ZKP‑Audit ระยะ 3 เดือน เพื่อตรวจสอบการตัดสินใจในการให้สินเชื่อแบบอัตโนมัติ โดยเปรียบเทียบกับระบบเดิม (non‑ZKP) ผลการทดลองเชิงปริมาณโดยสังเขปมีดังนี้:
- ปริมาณการทดสอบ: 100,000 การตัดสินใจใน 3 เดือน
- ค่าเฉลี่ยเวลาสร้าง proof ต่อการตัดสินใจ (prover): 1.8 วินาที (single proof) — เมื่อใช้การจัดกลุ่มแบบ batch 10 รายการ ลดเหลือเฉลี่ย 1.1 วินาทีต่อ batch (≈0.11 วินาทีต่อรายการ)
- เวลา verification ต่อรายการ: 120 มิลลิวินาที (single proof) และลดลงเหลือ 35 มิลลิวินาที ต่อรายการเมื่อใช้ batching
- ขนาด proof เฉลี่ย: 8 KB ต่อรายการ (single) → บันทึกรวม 0.8 GB สำหรับ 100k รายการ; เมื่อใช้ batching ขนาดเฉลี่ยต่อรายการลดลง ~40%
- ผลกระทบด้านค่าใช้จ่าย: ค่าโครงสร้างพื้นฐานเพิ่มขึ้นประมาณ 22% (คอมพิวต์ + storage + HSM) แต่ลดต้นทุนแรงงานตรวจสอบด้วยตนเองลง ~30% และลดเวลาเฉลี่ยในการตรวจสอบกรณี (case review) จาก 45 นาทีเหลือ 18 นาที
- ความเป็นส่วนตัว: ไม่มี PII ถูกบันทึกหรือเปิดเผยใน audit logs — ลดความเสี่ยงการละเมิดข้อมูลได้ ~100% สำหรับข้อมูลที่รวมอยู่ใน ZKP
- ความถูกต้องการตัดสินใจ: ไม่พบความแตกต่างเชิงสถิติในอัตราการอนุมัติหรืออัตราหนี้เสียระหว่างระบบ ZKP และระบบเดิม (p>0.05) ซึ่งระบุว่า ZKP ไม่ได้เปลี่ยนพฤติกรรมของโมเดล
บทสรุปจากการทดลอง: การใช้แนวทาง hybrid + batching + modular proofs ทำให้ธนาคารสามารถบรรลุเป้าหมายด้าน auditability และความเป็นส่วนตัว โดยต้นทุนเพิ่มขึ้นในระดับที่ยอมรับได้เมื่อเทียบกับประโยชน์ด้านการลดค่าแรงตรวจสอบและการปกป้องข้อมูลลูกค้า อย่างไรก็ตาม ต้องลงทุนใน HSM, เครื่องมือฝึกอบรม auditor และการปรับแต่ง circuit เพื่อลด latency ให้สอดคล้องกับ SLA ของระบบการเงิน
ข้อสรุปและแนวปฏิบัติที่ดีที่สุด
โดยสรุป การนำ ZKP‑Audit มาใช้ในธนาคารไทยต้องอาศัยการออกแบบเชิงสถาปัตยกรรมและการกำกับดูแลที่ดี รวมถึงกลยุทธ์ทางเทคนิคเช่น modularization, batching, และ hybrid approaches เพื่อควบคุมความซับซ้อนและต้นทุน ทีมงานต้องเตรียมการทดสอบแบบ simulated, ฝึกอบรม auditor อย่างเป็นระบบ และวางมาตรการจัดการคีย์อย่างเข้มงวดเพื่อปกป้องความลับของลูกค้า Checklist ที่ชัดเจนและการติดตาม metrics สำคัญ (เช่น prover/verifier latency, proof size, failed verifications, TCO) จะช่วยให้การนำระบบไปใช้งานจริงมีความเสี่ยงต่ำและประสบความสำเร็จในเชิงพาณิชย์
บทสรุป
ZKP‑Audit เป็นกรอบงานที่ผสานความสามารถของ Zero‑Knowledge Proof (ZKP) กับ Large Language Models (LLM) เพื่อสร้างหลักฐานการตัดสินใจที่ตรวจสอบได้โดยไม่ต้องเปิดเผยข้อมูลดิบของลูกค้า ทำให้ธนาคารสามารถรักษาความเป็นส่วนตัวควบคู่ไปกับการสร้าง audit trail ที่เชื่อถือได้และตอบโจทย์ข้อกำกับดูแล ตัวอย่างการประยุกต์เช่น การอนุมัติสินเชื่ออัตโนมัติที่ส่งมอบ "หลักฐานเชิงคณิตศาสตร์" ว่าการตัดสินใจได้ปฏิบัติตามกฎเกณฑ์และนโยบายโดยไม่ต้องให้ผู้ตรวจสอบเข้าถึงข้อมูลส่วนบุคคลครบถ้วน ส่งผลให้เพิ่มความเชื่อมั่นจากทั้งผู้ใช้และหน่วยงานกำกับดูแล (regulator) รวมถึงช่วยลดความเสี่ยงด้านการเปิดเผยข้อมูลที่มิพึงประสงค์
การนำ ZKP‑Audit ไปใช้จริงต้องออกแบบสถาปัตยกรรมอย่างรัดกุม โดยแยกส่วนการสร้างหลักฐาน (proof generator), การยืนยัน (verifier), ส่วนประมวลผล LLM และคลังคีย์/โมดูลความปลอดภัย (เช่น secure enclave) อย่างเหมาะสม ควรกำหนดตัวชี้วัดเชิงปริมาณเพื่อวัดผล เช่น เวลาในการสร้าง proof (latency), ขนาดของ proof (bandwidth/storage), ความสามารถในการประมวลผล (throughput), อัตราความผิดพลาดของการตรวจสอบ และตัวชี้วัดการรั่วไหลของความเป็นส่วนตัว นอกจากนี้ต้องมีกรอบกำกับดูแลที่ชัดเจน—รวมถึงการควบคุมการเข้าถึง การจัดการกุญแจ การทดสอบและตรวจสอบโมเดลเป็นประจำ การกำหนดแผนลดความเสี่ยง (เช่น rollout แบบขั้นบันได, dual‑run กับระบบเก่า, rollback plan) และการตรวจสอบอิสระจากภายนอกเพื่อยืนยันความถูกต้องทางวิชาการและการปฏิบัติ
มุมมองอนาคต: เทคโนโลยี ZKP ร่วมกับ LLM มีศักยภาพที่จะเปลี่ยนแนวทางการกำกับดูแลด้าน AI และความเป็นส่วนตัว โดยคาดว่าจะมีการพัฒนาประสิทธิภาพของ ZKP ให้รวดเร็วขึ้นและขนาดเล็กลง ส่งผลให้การตรวจสอบแบบเรียลไทม์เป็นไปได้มากขึ้น รัฐและหน่วยงานกำกับอาจบรรจุข้อกำหนดของหลักฐานเชิงคริปโตในแนวปฏิบัติด้านความโปร่งใสของ AI ธนาคารที่ลงทุนสร้างสถาปัตยกรรมและกลไกกำกับดูแลที่แข็งแกร่งในวันนี้จะได้เปรียบเชิงแข่งขัน ทั้งในด้านความเชื่อมั่นของลูกค้าและความสามารถในการปฏิบัติตามกฎระเบียบที่เปลี่ยนแปลงอย่างรวดเร็ว



