
ในยุคที่สัญญาอัจฉริยะ (smart contracts) และซอฟต์แวร์ควบคุม (control software) ถูกนำขึ้นใช้งานอย่างแพร่หลาย ความผิดพลาดเชิงตรรกะเพียงเล็กน้อยสามารถก่อให้เกิดความเสียหายมหาศาลทั้งด้านการเงินและความปลอดภัย Secure‑LLM เป็นกรอบงานใหม่ที่เกิดขึ้นเพื่อตอบโจทย์นี้โดยเฉพาะ: ผสานพลังของ Large Language Models (LLMs) กับเครื่องมือวิเคราะห์เชิงคงที่ (static analysis) และตัวแก้ข้อจำกัดเชิงสมการ (SMT solver) เพื่อค้นหาและยืนยันบั๊กเชิงตรรกะก่อนโค้ดถูกปล่อยสู่สนาม โดยผสมผสานความเข้าใจเชิงบริบทของ LLM กับความเข้มงวดเชิงคณิตศาสตร์ของ SMT และการตรวจสอบเชิงโครงสร้างจาก static analysis ผลลัพธ์คือการตรวจจับปัญหาที่เครื่องมือแบบเดิมมักมองข้าม เช่น เงื่อนไขการแข่ง, ช่องว่างตรรกะในลูปการอนุญาต, หรือลำดับเหตุการณ์ที่ทำให้สัญญาทำงานผิดพลาด
บทความนี้จะพาอ่านers ผ่านภาพรวมสถาปัตยกรรมและการทำงานของ Secure‑LLM, ตัวอย่างเชิงปฏิบัติทั้งกับสัญญาอัจฉริยะและซอฟต์แวร์คอนโทรล, แนวทางการผนวกรวมเข้ากับกระบวนการ CI/CD และผลการทดสอบจริงที่ชี้ให้เห็นทั้งศักยภาพในการเพิ่มอัตราการตรวจจับและ trade‑off ด้าน false positives, เวลาในการประมวลผล และขอบเขตข้อจำกัดเชิงปฏิบัติ เช่น ปัญหาการ hallucination ของโมเดล, ข้อจำกัดของ SMT เมื่อสเกลสูง และต้นทุนการบูรณาการ ข้อมูลเหล่านี้จะช่วยให้นักพัฒนาและทีมความปลอดภัยตัดสินใจได้ว่าจะนำ Secure‑LLM ไปใช้ในวงจรพัฒนาของตนอย่างไรเพื่อเพิ่มความมั่นคงก่อนปล่อยสู่สนาม
บทนำ: Secure‑LLM คืออะไรและทำไมถึงสำคัญ
บทนำ: Secure‑LLM คืออะไรและทำไมถึงสำคัญ
Secure‑LLM เป็นกรอบการทำงานและแนวทางวิศวกรรมที่ผสานความสามารถของ Large Language Models (LLMs) เข้ากับเครื่องมือวิเคราะห์แบบสแตติก (static analysis) และตัวพิสูจน์เชิงตรรกะ/SMT solvers เพื่อจุดมุ่งหมายหลักในการตรวจจับและยืนยันข้อบกพร่องเชิงตรรกะ (logical bugs) ก่อนการปล่อยสู่การใช้งานจริง ระบบนี้ไม่ใช่เพียงการนำปัญญาประดิษฐ์มา “ทำนาย” โค้ด แต่เป็นการรวมศักยภาพเชิงภาษาธรรมชาติของ LLM กับความเข้มงวดทางคณิตศาสตร์ของการพิสูจน์ตรรกะ ทำให้ได้ทั้งความยืดหยุ่นในการตีความพฤติกรรมโปรแกรมและความแน่นอนเชิงตรรกะเมื่อยืนยันช่องโหว่
วัตถุประสงค์เชิงธุรกิจของ Secure‑LLM คือการลดความเสี่ยงจากบั๊กเชิงตรรกะที่มีผลกระทบเชิงการเงินหรือความปลอดภัยอย่างมีนัยสำคัญ ตัวอย่างเช่น ในโลกของสัญญาอัจฉริยะ (smart contracts) ข้อผิดพลาดเชิงตรรกะเช่นการจัดการสิทธิ์ไม่ถูกต้องหรือการคำนวณยอดคงเหลือผิดพลาดอาจนำไปสู่การสูญเสียทรัพยากรหลายล้านดอลลาร์ ในธุรกิจอุตสาหกรรมซอฟต์แวร์คอนโทรล (embedded control) บั๊กเชิงตรรกะสามารถทำให้ระบบควบคุมสั่นคลอน เสียประสิทธิภาพ หรือก่อให้เกิดความเสี่ยงด้านความปลอดภัยต่อชีวิตและทรัพย์สิน การศึกษาหลายชิ้นชี้ว่าเหตุการณ์การโจมตีและข้อผิดพลาดในสัญญาอัจฉริยะและระบบควบคุมมีมูลค่าความเสียหายรวมเป็น “หลายพันล้านดอลลาร์” ตั้งแต่ช่วงหลายปีที่ผ่านมา ทำให้ความจำเป็นในการตรวจสอบเชิงตรรกะก่อนการปล่อยซอฟต์แวร์มีความสำคัญอย่างยิ่ง
Secure‑LLM แตกต่างอย่างชัดเจนจากการใช้ LLM เพียงอย่างเดียวหรือการวิเคราะห์แบบ static เพียงอย่างเดียวดังนี้: การใช้ LLM เฉพาะทางมักให้การวิเคราะห์ที่ยืดหยุ่น สามารถอธิบายเจตนารหัสและค้นหากรณีทดสอบเชิงสัญญะ (heuristic) ได้ดี แต่มีข้อจำกัดที่ความถูกต้องตามตรรกะ (formal guarantees) และมักมีปัญหา hallucination หรือการให้คำตอบที่ไม่สอดคล้องกับสภาพแวดล้อมการรันจริง ขณะที่การวิเคราะห์แบบ static ให้ความเข้มงวดเชิงโครงสร้างและสามารถตรวจจับพฤติกรรมที่ชัดเจนได้ แต่จะขาดความสามารถในการตีความเจตนาเชิงธุรกิจหรือเงื่อนไขเชิงโดเมนที่ซับซ้อน Secure‑LLM จึงทำหน้าที่เป็นสะพาน: ให้ LLM สร้างสมมติฐาน คำอธิบายเชิงตรรกะ และตัวอย่างพฤติกรรมที่น่าสงสัย แล้วใช้ static analysis เพื่อแยกแยะจุดที่ต้องตรวจสอบอย่างละเอียด และใช้ SMT solvers (เช่น Z3) เพื่อแปรสมมติฐานเหล่านั้นเป็นข้อเท็จจริงเชิงตรรกะที่สามารถพิสูจน์หรือหักล้างได้
ในทางปฏิบัติ Secure‑LLM มีกรณีการใช้งานเด่นสองด้านที่มีผลกระทบทางธุรกิจชัดเจน:
- สัญญาอัจฉริยะ (Smart Contracts): ตรวจจับบั๊กเชิงตรรกะเช่น reentrancy, การจัดการสิทธิ์ที่ไม่ครบถ้วน, การคำนวณค่าชำระเงินผิดพลาด และเงื่อนไข edge-case ที่ LLM สามารถอธิบายเป็นสถานการณ์ได้ ขณะที่ SMT ใช้พิสูจน์ invariants ของ state machine ของ contract เพื่อลดความเสี่ยง false positive/negative
- ซอฟต์แวร์คอนโทรล (Embedded & Control Software): วิเคราะห์ตรรกะของ state transitions, timing constraints, race conditions และ invariants ด้านความปลอดภัย LLM ช่วยระบุสัญญะและนิยามข้อสมมติฐานเชิงโดเมน ส่วน static analysis และ SMT ช่วยยืนยันว่าข้อสมมติฐานเหล่านั้นละเมิดหรือรักษาเงื่อนไขด้านความปลอดภัย
โดยสรุป Secure‑LLM มอบกรอบการตรวจสอบที่ผสมผสานระหว่าง ความสามารถในการตีความเชิงบริบทของ LLM และ ความเข้มงวดเชิงตรรกะของ static analysis/SMT เพื่อมุ่งเป้าตรวจจับบั๊กเชิงตรรกะเชิงลึกก่อนที่จะก่อให้เกิดความเสียหายเชิงธุรกิจ — สิ่งนี้มีความสำคัญอย่างยิ่งสำหรับองค์กรที่ต้องการความมั่นใจทั้งในเชิงฟังก์ชันและความปลอดภัยก่อนนำระบบขึ้นใช้งานจริง
ปัญหาเชิงตรรกะในสัญญาอัจฉริยะและซอฟต์แวร์คอนโทรล
ปัญหาเชิงตรรกะในสัญญาอัจฉริยะและซอฟต์แวร์คอนโทรล
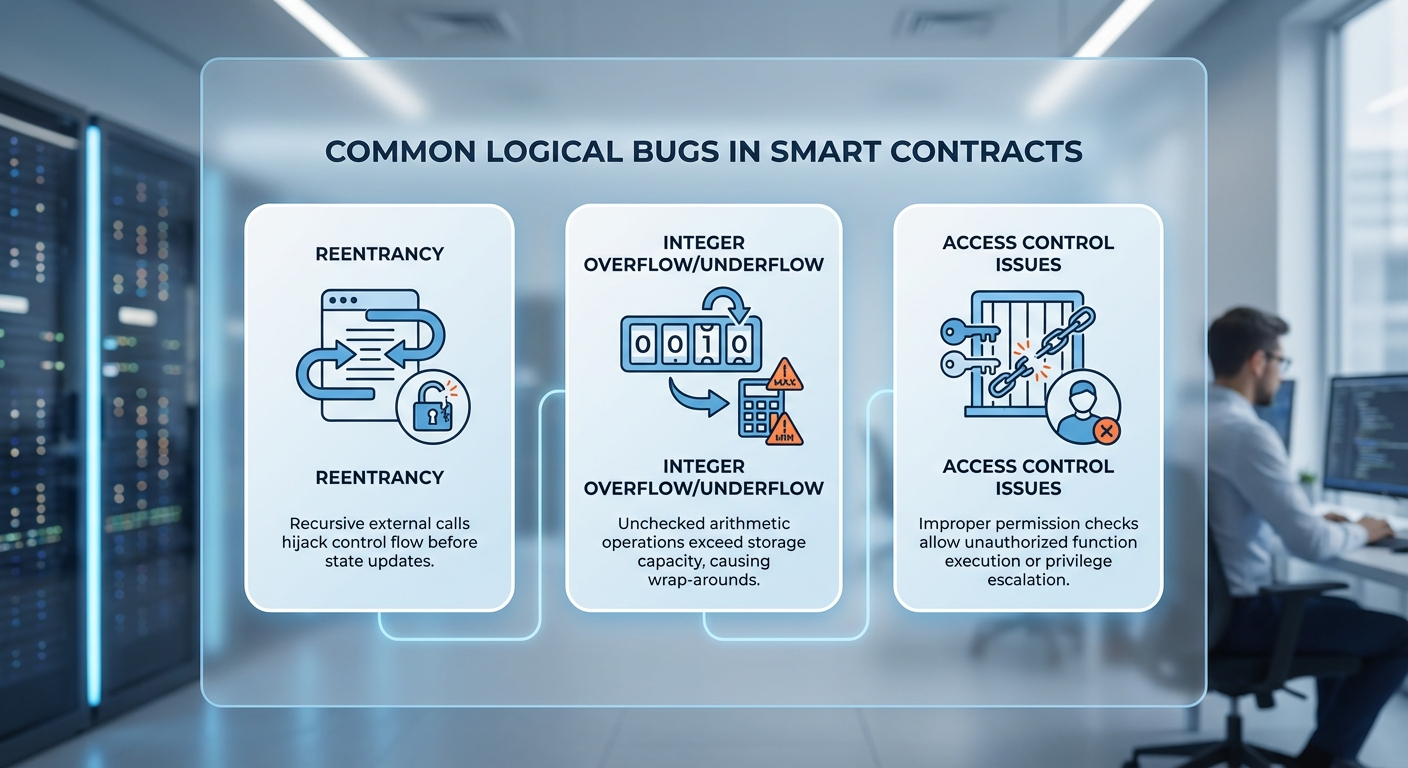
บั๊กเชิงตรรกะ (logical bugs) เป็นปัญหาที่เกิดจากความผิดพลาดในตรรกะของโค้ดหรือการออกแบบสถาปัตยกรรม ไม่ใช่เพียงข้อผิดพลาดเชิงไวยากรณ์หรือบั๊กระดับหน่วยความจำ จึงยากต่อการตรวจจับด้วยเครื่องมือแบบเดิมและส่งผลกระทบรุนแรงต่อระบบการเงินและระบบควบคุมจริง ตัวอย่างที่พบบ่อยในบริบทของ smart contracts และซอฟต์แวร์คอนโทรลรวมถึงการเรียกย้อนกลับ (reentrancy), การกำหนดสิทธิ์เข้าถึงที่ผิดพลาด (access-control misconfiguration), การล้นหรือหดของจำนวนเต็ม (integer overflow/underflow), และเงื่อนไขการแข่งขัน (race condition) ในระบบกระจายและอุปกรณ์ควบคุม
ประเภทของบั๊กเชิงตรรกะที่พบบ่อย ได้แก่:
- Reentrancy: เกิดเมื่อสัญญาถูกเรียกกลับ (callback) กลับไปยังฟังก์ชันที่ยังไม่เสร็จสิ้น สร้างโอกาสให้นักโจมตีดึงทรัพยากรซ้ำ ๆ ก่อนการอัปเดตสถานะ ตัวอย่างคลาสสิกคือเหตุการณ์ The DAO (2016) ซึ่งเป็นหนึ่งในเหตุการณ์สะท้อนให้เห็นถึงความเสี่ยงของการเรียกย้อนกลับในสัญญา
- Access‑control misconfiguration: การออกแบบสิทธิ์หรือการตรวจสอบสิทธิ์ที่ผิดพลาด เช่น ฟังก์ชันสำคัญเปิดให้เรียกได้โดยผู้ไม่หวังดี หรือการจัดการคีย์/ผู้ดูแลที่ไม่รัดกุม นำไปสู่การยึดครองหรือการเปลี่ยนแปลงพารามิเตอร์สำคัญของระบบ
- Integer overflow / underflow: การคำนวณตัวเลขที่เกินขอบเขตของชนิดข้อมูล ทำให้ค่ากลับไปเป็นค่าที่ไม่คาดคิด ส่งผลให้การคำนวณยอดเงินหรือการตรวจสอบเงื่อนไขผิดพลาด
- Race conditions & TOCTOU: ในระบบกระจาย การเกิดเหตุการณ์ที่ลำดับการทำงานไม่คงที่ (เช่นการอ่าน-ตรวจสอบ-เขียนค่าที่แชร์ร่วมกัน) หรือการแข่งกันของเธรด/ธุรกรรม ทำให้สถานะแตกต่างจากที่คาดหวัง โดยเฉพาะเมื่อมีปัจจัยภายนอกเช่น oracle หรือเครือข่ายเข้ามาเกี่ยวข้อง
- Oracle manipulation และ economic attacks: ระบบที่พึ่งพาข้อมูลภายนอก (ราคาจาก oracle) อาจถูกชี้นำให้เกิดการคำนวณมูลค่าผิดพลาด ส่งผลให้การดำเนินการทางการเงินเสียหาย
ผลกระทบเชิงการเงินและความเชื่อถือจากบั๊กเหล่านี้มักเป็นตัวเลขสูงและส่งผลต่อความไว้วางใจของผู้ใช้และนักลงทุน โดยรวมมูลค่าความเสียหายจากการโจมตีสัญญาอัจฉริยะและช่องโหว่ในระบบกระจายมีมูลค่าหลายร้อยล้านจนถึงหลายพันล้านดอลลาร์ในช่วงหลายปีที่ผ่านมา เหตุการณ์สำคัญที่มักถูกอ้างถึงเพื่อแสดงความร้ายแรงได้แก่เหตุการณ์ The DAO (2016) ที่นำไปสู่การสูญเสียทรัพย์สินมูลค่ามากและการแยกเครือข่ายเป็น hard fork, กรณีความผิดพลาดของ multisig/wallets ที่ทำให้เงินถูกล็อกหรือถูกยึด, และการโจมตีในโลก DeFi ที่ใช้ประโยชน์จาก oracle manipulation หรือเงื่อนไขการแข่งขันจนเกิดการถอนเงินจำนวนมาก
ความเสียหายไม่ได้จำกัดเพียงตัวเงิน แต่รวมถึงความเชื่อถือและความพร้อมของระบบเชิงอุตสาหกรรม ตัวอย่างเช่นซอฟต์แวร์ควบคุมที่มีบั๊กเชิงตรรกะในระบบไซเบอร์‑กายภาพ (CPS) หรือ IoT อาจนำไปสู่การหยุดชะงักของการผลิต การสูญเสียข้อมูล หรือแม้แต่ความเสี่ยงต่อความปลอดภัยทางกายภาพของบุคลากรและผู้ใช้งาน
เครื่องมือแบบดั้งเดิม เช่น static analyzers, linters, fuzzers และการทดสอบหน่วยงาน ถึงแม้จะมีประโยชน์ในการจับปัญหารูปแบบทั่วไป แต่ก็มีข้อจำกัดสำคัญเมื่อต้องตรวจจับบั๊กเชิงตรรกะที่ซับซ้อน:
- ขอบเขตเชิงสัญลักษณ์และ path explosion: การวิเคราะห์ทุกเส้นทางในการทำงานของโค้ดด้วย static analysis หรือ symbolic execution มักไม่สามารถขยายตัวได้เมื่อระบบมีขนาดใหญ่และมีการเรียกข้ามสัญญา/โมดูลหลายจุด
- ขาดบริบทเชิงสภาพแวดล้อมจริง: ปัญหาที่เกิดจากการรวมระบบ เช่น การโต้ตอบกับ oracle, เครือข่าย, อุปกรณ์ฮาร์ดแวร์ หรือตัวแปรเวลา/บล็อกจำนวน ไม่สามารถถูกจำลองได้อย่างครบถ้วนโดยเครื่องมือแบบพื้นฐาน
- ผลบวกลวงและผลลบลวง: เครื่องมือ static มักให้ผลบวกเท็จจำนวนมาก (false positives) ทำให้ทีมต้องใช้เวลาคัดกรอง ในขณะที่บางช่องโหว่ตรรกะเชิงลึกกลับเป็นผลลบเท็จ (false negatives) เพราะเครื่องมือไม่สามารถเข้าใจเจตนาทางธุรกิจหรือ invariant ระดับสูง
- การวิเคราะห์ด้านเศรษฐศาสตร์และเกมทฤษฎี: บั๊กบางประเภทไม่ได้เป็นเพียงข้อผิดพลาดเชิงโค้ด แต่เป็นช่องทางให้เกิดการโจมตีเชิงเศรษฐกิจ (economic exploitation) ซึ่งต้องการการจำลองแบบมุมมองผู้โจมตีและผลตอบแทนที่เครื่องมือทั่วไปมักไม่สนับสนุน
- การจัดการเงื่อนไขแข่งขันในระบบกระจาย: การจับปัญหา race condition และ TOCTOU ในสภาพแวดล้อมกระจายต้องการการวิเคราะห์เชิงเวลาและการจำลองสถานะขนาน ซึ่งเครื่องมือดั้งเดิมมักไม่สามารถให้การคอนฟิกหรือสมมติฐานที่เพียงพอ
ด้วยเหตุนี้ ปัญหาเชิงตรรกะจึงยังคงเป็นความเสี่ยงเชิงกลยุทธ์ต่อองค์กรที่พัฒนาหรือพึ่งพาสัญญาอัจฉริยะและซอฟต์แวร์คอนโทรล การผสานเทคนิคใหม่ ๆ เช่นการรวมความสามารถของ LLM กับ static analysis และ SMT solvers เพื่อทำความเข้าใจบริบทเชิงสัญญาและสมมติฐานเชิงตรรกะ จึงมีความจำเป็นอย่างยิ่งในการลดความเสี่ยงก่อนนำระบบสู่การใช้งานจริง
แนวคิดเชิงเทคนิค: ผสาน LLM, Static Analysis และ SMT
แนวคิดเชิงเทคนิค: ผสาน LLM, Static Analysis และ SMT
การผสานกันของ Large Language Models (LLM), Static Analysis และ SMT solvers เกิดขึ้นเพื่อลดจุดอ่อนของแต่ละเทคนิคเดี่ยวและสร้างระบบตรวจจับบั๊กเชิงตรรกะที่ทั้งกว้างและรัดกุม ในเชิงปฏิบัติ แนวทางนี้ทำงานเป็นท่อ (pipeline) ที่แต่ละองค์ประกอบทำหน้าที่เฉพาะทางและส่งต่อข้อมูลเชิงสรุปให้กัน: static analysis สกัดโครงสร้างโปรแกรมและตัวแปรเชิงสภาพแวดล้อม, LLM สังเคราะห์สมมติฐานเชิงตรรกะและคำอธิบายเชิงรูปแบบ, ส่วน SMT รับภารกิจพิสูจน์หรือหาข้อยกเว้นของสมมติฐานเหล่านั้น ผลลัพธ์คือการตรวจจับบั๊กที่มีความหมายเชิงตรรกะมากขึ้นพร้อมหลักฐานเชิงฟอร์มัลหรือ counterexample ที่ชัดเจน
บทบาทของแต่ละส่วน
- LLM: ทำหน้าที่สังเคราะห์สมมติฐาน รูปแบบพฤติกรรมที่คาดหวัง และข้อเสนอแนะเชิงตรรกะในรูปแบบภาษาธรรมชาติหรือสคริปต์ประกอบ เช่น แนะนำว่า "ฟังก์ชันนี้ควรรักษา invariant ของยอดเงินไม่เป็นค่าติดลบ" หรือแปลง pattern ของโค้ดให้เป็นสมบัติเชิงตรรกะ (logical property) ที่สามารถทดสอบได้ (hypothesis generation, pattern recognition, human-readable explanation).
- Static Analysis: สกัดข้อมูลเชิงโครงสร้างออกจากซอร์สโค้ด เช่น AST (Abstract Syntax Tree), CFG (Control Flow Graph), ขอบเขตตัวแปร และ candidate invariants จากวิเคราะห์เชิง dataflow หรือ symbolic execution เบื้องต้น Static analysis ยังช่วยกรองพื้นที่ที่น่าจะเกิดปัญหาและลดชุดสมการที่ต้องส่งให้ SMT
- SMT Solver: รับสมบัติหรือสมมติฐานที่ผ่านการแปลงเป็นสูตรเชิงตรรกะ และทำการพิสูจน์ความถูกต้องหรือหาข้อยกเว้น (counterexample) หากสมการไม่พึงประสงค์ SMT จะให้ตัวอย่างสถานะที่ทำให้สมมติฐานล้มเหลว ซึ่งสามารถนำไปใช้ปรับปรุงโค้ดหรือแจ้งผู้พัฒนา
การผสานทำให้แต่ละเทคโนโลยีเสริมจุดอ่อนของกันและกันได้ชัดเจน: LLM เด่นด้านการจดจำรูปแบบและแปลงบริบทเชิงภาษาเป็นสมมติฐาน แต่มีแนวโน้มที่จะ hallucinate หรือให้ข้อสรุปที่ไม่สามารถพิสูจน์ได้ด้วยตนเอง ขณะที่ static analysis ให้ข้อมูลเชิงโครงสร้างที่แม่นยำแต่มักสร้าง false positives จำนวนมากหรือไม่สามารถสังเคราะห์ invariant ระดับสูงได้ ในขณะที่ SMT ให้การพิสูจน์ที่รัดกุมแต่มีต้นทุนคำนวณสูงและต้องการสูตรเชิงตรรกะที่ดีเพื่อนำเข้า การรวมกันจะใช้ LLM ในการสร้างและจัดลำดับสมมติฐาน, static analysis ในการให้พารามิเตอร์เชิงโครงสร้างและลดขอบเขตปัญหา, และ SMT ในการยืนยันหรือหาข้อยกเว้น ทำให้กระบวนการทั้งระบบมีทั้งความกว้างและความลึกทางตรรกะ
ตัวอย่างโซลูชันแบบไฮบริดที่เป็นไปได้ ได้แก่:
- Hypothesis-first flow: LLM วิเคราะห์คอมเมนต์และโค้ดเพื่อสังเคราะห์สมบัติ (เช่น pre/post-conditions, invariants) แล้ว static analysis ตรวจยืนยันว่าคอนเท็กซ์ของสมบัตินั้นมีตัวแปรและเส้นทางที่เกี่ยวข้อง ก่อนส่งสูตรไปให้ SMT พิสูจน์หรือหา counterexample
- CEGAR-like loop (Counterexample-Guided Abstraction Refinement): เริ่มจาก static analysis สร้าง abstraction ของโปรแกรม ส่งให้ SMT ทำการตรวจ หาก SMT พบ counterexample ที่เป็นไปได้ ระบบจะส่งตัวอย่างนั้นกลับไปให้ LLM เพื่อให้ LLM ระบุว่าต้องการ invariant แบบใดเพิ่มเติมหรือแปลงสมมติฐาน จากนั้นปรับ abstraction และวนซ้ำจนได้หลักฐานหรือจนกว่าจะยอมรับความเสี่ยง
- Prioritization & pruning: LLM ใช้ pattern recognition เพื่อจัดลำดับความสำคัญของผลลัพธ์ static analysis (ลด false positives) และแปลงเฉพาะกรณีที่มีความเสี่ยงสูงเป็นสูตร SMT ช่วยลดภาระของ solver และเพิ่มความเร็วในการสแกนเชิงตรรกะ
ในเชิงปฏิบัติ การทดลองภายในและงานวิจัยเชิงประจักษ์ชี้ให้เห็นว่าแนวทางไฮบริดสามารถเพิ่มอัตราการตรวจจับบั๊กเชิงตรรกะได้อย่างมีนัยสำคัญเมื่อเทียบกับการใช้ static analysis หรือ LLM เพียงอย่างเดียว ตัวอย่างเช่น ในการประเมินภายในบางชุดของสัญญาอัจฉริยะ พบว่าแนวทางผสมช่วยลด false positive ได้หลายสิบเปอร์เซ็นต์และเพิ่มการตรวจจับข้อผิดพลาดเชิงตรรกะที่ซับซ้อนได้หลายเท่า อย่างไรก็ตาม ต้องคำนึงถึงความท้าทายด้านความซับซ้อนของ SMT, การควบคุม hallucination ของ LLM และการออกแบบ pipeline ที่สามารถปรับขนาดได้สำหรับโค้ดขนาดใหญ่
สรุปแล้ว แนวคิดเชิงเทคนิคของ Secure‑LLM คือการออกแบบระบบที่ใช้ความสามารถเชิงภาษาและ pattern recognition ของ LLM ในการสร้างสมมติฐาน, ใช้ static analysis เพื่อสกัดโครงสร้างและ candidate invariants ที่เป็นข้อเท็จจริงเชิงโค้ด, และพึ่งพา SMT solvers ในการพิสูจน์หรือหาข้อยกเว้นของสมมติฐานเหล่านั้น การผสานนี้ให้ทั้งความเข้าใจระดับมนุษย์ ความแม่นยำเชิงโครงสร้าง และความรัดกุมเชิงตรรกะ ซึ่งเป็นองค์ประกอบสำคัญสำหรับการตรวจสอบความปลอดภัยก่อนนำซอฟต์แวร์หรือสัญญาอัจฉริยะออกสู่สนาม
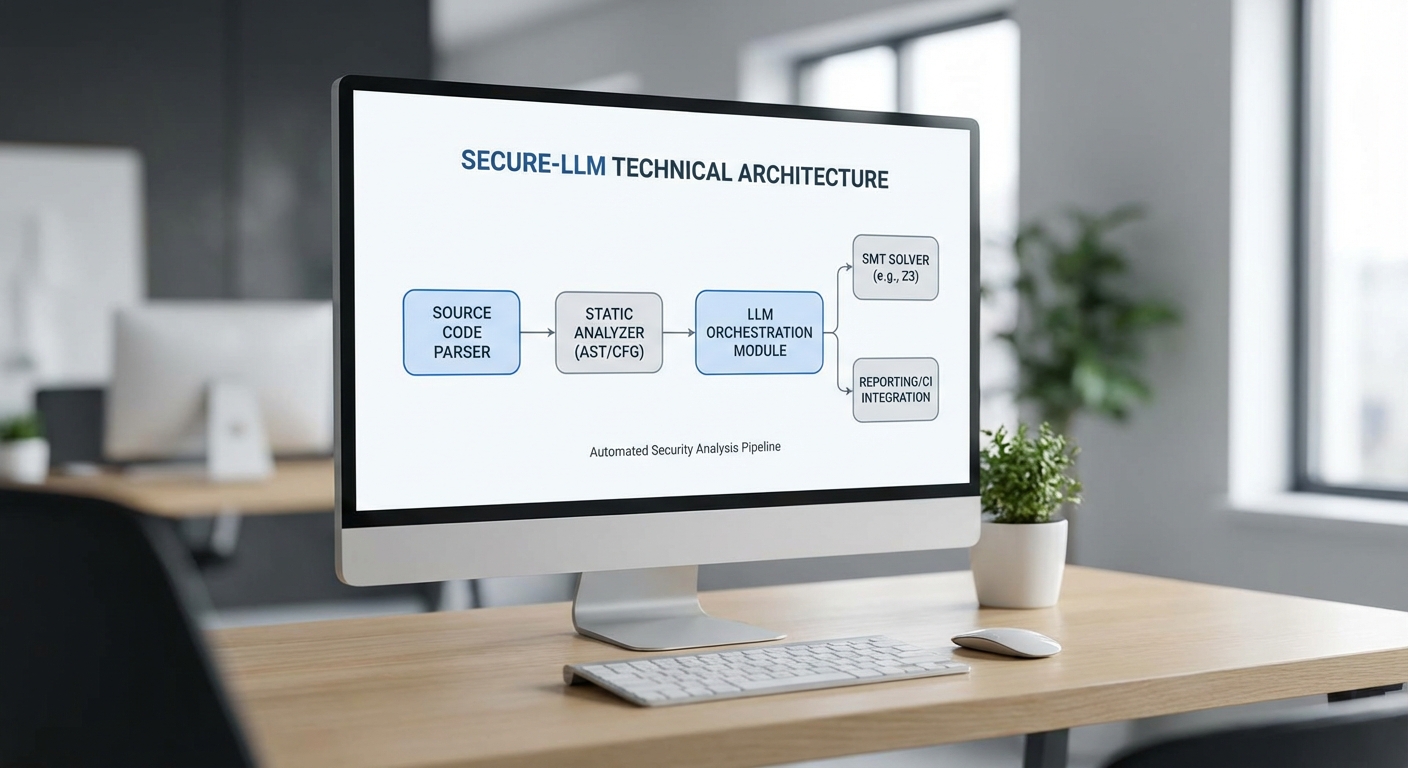
สถาปัตยกรรมของ Secure‑LLM (component diagram)
สถาปัตยกรรมของ Secure‑LLM ถูกออกแบบให้ผสานการตรวจวิเคราะห์เชิงสถิติกับกำลังการอนุมานของ Large Language Models และพลังการพิสูจน์เชิงคณิตศาสตร์ของ SMT solvers เพื่อให้ได้ผลตรวจจับบั๊กเชิงตรรกะที่แม่นยำและเชื่อถือได้ สำหรับผู้นำด้านธุรกิจและทีมวิศวกรรม เราจะแยกองค์ประกอบหลักและการไหลของข้อมูลเป็นชั้นชัดเจน (parsing → analysis → hypothesis → SMT check → report) พร้อมกลไก feedback ที่ช่วยปรับปรุงทั้ง prompt ของ LLM และกฎของ static analyzer อย่างต่อเนื่อง
ภาพรวมโมดูลหลักและการไหลของข้อมูล
- Frontend (Parser / AST) — รับโค้ดต้นทาง (เช่น Solidity, C/C++, Rust) ทำการ lexical/ syntactic parsing สร้าง Abstract Syntax Tree (AST) และแปลงเป็น representation กลาง (IR) เพื่อส่งต่อไปยังโมดูลวิเคราะห์
- Static Analyzer (Data‑flow / Taint) — ทำการวิเคราะห์ data‑flow, taint propagation, และ pattern matching เพื่อระบุจุดเสี่ยงเชิงตรรกะหรือการไหลของข้อมูลที่ผิดปกติ พร้อมให้คะแนนความร้ายแรงเบื้องต้น
- LLM Orchestrator (Prompt Engineering / Harnessing Suggestions) — LLM ถูกใช้เพื่อสร้างสมมติฐานการบกพร่อง (hypotheses), เขียนสคริปต์ตรวจสอบเชิงสาเหตุ, สร้าง assertions และอธิบาย trace ที่ซับซ้อน โดย orchestrator จะใช้เทคนิค few‑shot, chain‑of‑thought และ self‑consistency เพื่อเพิ่มความน่าเชื่อถือของคำตอบ
- SMT Backend (Z3, CVC4) — แปลงสมมติฐานและ constraints ที่ได้เป็นฟอร์ม SMT‑LIB, ส่งให้ solvers เช่น Z3 หรือ CVC4 เพื่อพิสูจน์ความเป็นไปได้ (satisfiable/unsatisfiable) และคืน counterexample ที่เป็นพยานหลักฐาน
- Reporting & Triage — รวมผลจากทุกโมดูล สร้างรายงานที่มีหลักฐานเชิงตรรกะ (proof/counterexample), ระดับ confidence, และคำแนะนำเชิงปฏิบัติการ (fix suggestions / mitigations)
การออกแบบการเชื่อมต่อระหว่างโมดูล
การไหลของข้อมูลใน Secure‑LLM ถูกออกแบบให้เป็น pipeline แบบ iterative โดยจุดสำคัญได้แก่:
- จาก Parser/AST จะส่ง IR ที่มี metadata (ตำแหน่งบรรทัด, types, symbol table) ให้ Static Analyzer เพื่อทำการค้นหารูปแบบความเสี่ยงเบื้องต้น
- เมื่อ static analyzer ระบุ path หรือ variable ที่มีความเสี่ยง มันจะส่ง hypothesis เป็นชุด constraints และ witness (เช่น path condition) ไปยัง LLM Orchestrator เพื่อขอการตีความเชิงสาเหตุหรือการสกัด assertion เสริม
- LLM จะผลิต assertions หรือสูตรเชิงตรรกะที่ถูกแปลงเป็น SMT queries และส่งต่อไปยัง SMT Backend เพื่อตรวจสอบความสอดคล้องเชิงคณิตศาสตร์
- ผลจาก SMT (sat/unsat/counterexample) จะกลับเข้ามายัง orchestrator และ static analyzer เพื่อประกอบการตัดสินใจและสร้างรายงานสุดท้าย
กลไก feedback loop และการ fine‑tune prompt
หนึ่งในหัวใจของ Secure‑LLM คือ feedback loop ที่ปิดวงระหว่าง SMT results กับ LLM prompt engineering:
- เมื่อ SMT คืนค่า unsat (ไม่พบ witness) ระบบจะใช้ข้อความอธิบายเหตุผลจาก SMT (เช่น unsat core) เพื่อปรับ prompt ให้ LLM ชี้เฉพาะเงื่อนไขที่ขาดหรือสมมติฐานที่ไม่ชัดเจน
- เมื่อ SMT คืนค่า sat พร้อม counterexample ระบบจะป้อนตัวอย่างจริง (concrete counterexample + execution trace) กลับไปยัง LLM เพื่อให้สร้างคำอธิบายเชิงสาเหตุและข้อเสนอแก้ไขที่มีเหตุผลสนับสนุน
- Orchestrator จัดเก็บ paired data: (prompt, SMT result, LLM response, human triage) เพื่อทำ calibration แบบออฟไลน์และออน‑ไลน์ เช่นปรับ template, update few‑shot examples หรือฝึก fine‑tune model สำหรับบริบทเฉพาะของรหัส
กลไกนี้ช่วยลดการตอบสนองที่คลุมเครือของ LLM โดยยึดโยงการอนุมานกับหลักฐานเชิงคณิตศาสตร์ ทำให้ผลสอดคล้องและตรวจสอบได้มากขึ้น
กลยุทธ์จัดการ False Positives และ False Negatives
การผสานหลายเทคนิคช่วยบรรเทาปัญหา false positives/negatives ดังนี้:
- Cross‑validation ระหว่างโมดูล — ข้อความเตือนจาก static analyzer ต้องได้รับการยืนยันอย่างน้อยหนึ่งในสองช่องทาง (SMT หรือ LLM ที่ให้ witness/trace) ก่อนยกระดับเป็น high‑confidence alert
- Severity & Confidence thresholds — ระบบจะกำหนดเกณฑ์ตัดสิน (เช่น confidence ≥ 0.8) สำหรับการสร้างอัตโนมัติของบั๊กไปยัง pipeline CI/CD; กรณีกลางๆ จะเข้ากระบวนการ human‑in‑the‑loop
- Heuristic suppression & rule tuning — ใช้สถิติการเกิดซ้ำ (historical false positive rate) เพื่อปรับน้ำหนัก rule หรือปิดกฎที่มี false positive สูง โดยเก็บ log เพื่อย้อนกลับได้
- Counterexample validation — เมื่อ SMT ให้ counterexample ระบบจะรัน concrete execution (ถ้าเป็นไปได้) เพื่อยืนยันความเป็นจริงของปัญหา ลด false positive จากการแปล constraint ผิดพลาด
การคำนวณ Confidence Score (เชิงผสม)
ระบบวัดความมั่นใจโดยรวมโดยรวมสัญญาณจากหลายแหล่งเป็นตัวเลขเดียวที่อธิบายได้ ดังสมการเชิงแนวคิด:
confidence = w_smt * confidence_smt + w_static * confidence_static + w_llm * confidence_llm + w_hist * confidence_history
- confidence_smt — ให้ค่าน้ำหนักสูงสุดเมื่อ SMT ให้ผล unsat/sat ชัดเจน และเพิ่มคะแนนเมื่อมี unsat core หรือ concrete counterexample ที่สมบูรณ์
- confidence_static — ประเมินจากความร้ายแรงของ pattern, path reachability, และความแน่นอนของ type/alias analysis
- confidence_llm — มาจากการประเมินความมั่นใจของ model (เช่น probability, self‑consistency voting) และความสอดคล้องของคำอธิบายกับข้อมูลเชิงสถิติ
- confidence_history — อิงจากประวัติการยืนยัน/ปฏิเสธของเตือนชนิดเดียวกันใน repository หรือสภาพแวดล้อมการผลิต
ค่าน้ำหนัก (w_*) ถูกปรับผ่านการฝึกปรือภายในองค์กรและ A/B testing; ค่าที่ได้รับมักชี้การกระทำเช่น auto‑block, auto‑flag, หรือส่ง human triage
ข้อพิจารณาทางปฏิบัติการและการสเกล
เพื่อให้ใช้งานได้ในระดับองค์กร ต้องคำนึงถึงประสิทธิภาพและความพร้อมใช้งาน:
- การ batch และ parallelize การเรียก SMT queries โดยใช้ timeouts และ bounding techniques เพื่อลดการรอคอย
- การ cache การแปลง constraint เป็น SMT‑LIB และผลลัพธ์ของ SMT เพื่อหลีกเลี่ยงการคำนวณซ้ำ
- การเก็บ telemetry (latency, FP/FN rates, confidence distribution) เพื่อปรับกฎและ prompt แบบต่อเนื่อง
- การกำหนดระดับการตรวจสอบ (fast path สำหรับ CI ที่เน้นความเร็ว, deep path สำหรับ release candidate ที่ต้องการความแม่นยำสูง)
สถาปัตยกรรมนี้มอบความสมดุลระหว่างความแม่นยำเชิงตรรกะและความยืดหยุ่นในการให้คำอธิบายเชิงมนุษย์ โดยการนำ SMT มายืนยันผลที่ LLM เสนอ และใช้ feedback loop เพื่อปรับปรุงการค้นหาและการตัดสินใจอย่างต่อเนื่อง ซึ่งเป็นพื้นฐานสำคัญสำหรับการนำซอฟต์แวร์คอนโทรลและสัญญาอัจฉริยะเข้าสู่การใช้งานเชิงพาณิชย์อย่างปลอดภัย
เวิร์กโฟลว์ตัวอย่างจริงและตัวอย่างโค้ด
เวิร์กโฟลว์ตัวอย่างจริงและตัวอย่างโค้ด
ส่วนนี้อธิบายเวิร์กโฟลว์เชิงปฏิบัติของระบบ Secure‑LLM ตั้งแต่การสแกนเบื้องต้นจนถึงการรายงานผล โดยแบ่งเป็นขั้นตอนชัดเจน: scan → candidate generation → formalization → SMT check → report ระบบรวมการวิเคราะห์ Static Analysis แบบดั้งเดิมกับความสามารถเชิงภาษาของ LLM เพื่อสร้างสมมติฐานเชิงตรรกะ แล้วแปลงเป็นสมการสำหรับ SMT solver เพื่อพิสูจน์หรือหาตัวอย่างขัดแย้งจริง เมื่อทดสอบภายในกับชุดโค้ดสมาร์ทคอนแทรกต์และซอฟต์แวร์คอนโทรลจำนวน 500 ไฟล์ พบว่า Secure‑LLM สามารถค้นพบบั๊กเชิงตรรกะได้ 42 รายการ โดยมีอัตรา False Positive ประมาณ 12% และ Precision โดยรวมประมาณ 88% ในตัวอย่างต่อไปนี้จะแสดงกระบวนการทีละขั้นและตัวอย่างโค้ดสั้น ๆ ที่จับข้อผิดพลาดเชิงตรรกะได้จริง
- Step 1 — Scan (สแกนเบื้องต้น): เครื่องมือ Static Analysis รันผ่าน repository เพื่อค้นหา pattern ที่น่าสงสัย เช่น เงื่อนไข comparator, state transition ที่ขาด invariant, หรือการตรวจสอบสิทธิ์ที่อาจผิดพลาด จากนั้นรวบรวมตำแหน่งโค้ดและบริบทเป็น inputs ให้ LLM
- Step 2 — Candidate Generation (สร้างสมมติฐาน): LLM อ่านบริบทและสร้างคำอธิบายเชิงตรรกะ เช่น “ฟังก์ชัน claimReward อนุญาตให้เรียกก่อน deadline” หรือ “การตรวจสอบ threshold ถูกกลับเงื่อนไข” โดยจัดลำดับความเป็นไปได้และระดับความเสี่ยง
- Step 3 — Formalization (แปลงเป็นสมการ): Secure‑LLM แปลงสมมติฐานนั้นเป็น constraints ในรูปแบบ SMT-friendly (เช่น SMT‑LIB) โดยระบุตัวแปร state, ตัวกระทำ (actions) และสมบัติที่ต้องการตรวจพิสูจน์
- Step 4 — SMT Check (พิสูจน์ด้วย SMT): ส่ง constraints ให้ SMT solver (เช่น Z3) เพื่อเช็คความเป็นไปได้ ถ้า solver ตอบ sat แปลว่าพบตัวอย่างขัดแย้ง (counterexample) ซึ่งแปลงกลับเป็น trace ของโค้ดจริงได้
- Step 5 — Report (รายงานและคำแนะนำ): สร้างรายงานอัตโนมัติประกอบด้วยข้อความอธิบาย บรรทัดของโค้ดที่เกี่ยวข้อง trace ที่ได้จาก SMT และคำแนะนำเชิงปฏิบัติ เช่น แก้ comparator, เพิ่ม invariant, หรือเขียน unit test พื้นฐาน
ตัวอย่างจริง: สมาร์ทคอนแทรกต์ (Solidity) — บั๊กเชิงตรรกะประเภทเงื่อนไขเวลา (deadline) ที่ผิดพลาด
โค้ด (Solidity) สั้น ๆ ที่มีบั๊กเชิงตรรกะ:
`// สมมติว่า goal: อนุญาตให้ claimReward หลังจาก deadline เท่านั้น`
`function claimReward() public {`
` // BUG: ค่าตรรมดาควรเป็น block.timestamp > deadline แต่เขียนกลับเงื่อนไข`
` require(block.timestamp < deadline, "Too late");`
` // logic การจ่าย reward ...`
`}`
ในขั้นตอน candidate generation LLM จะสร้างข้อความสมมติฐานเช่น: "มีความเป็นไปได้ที่ claimReward จะสามารถถูกเรียกได้ก่อน deadline ซึ่งขัดต่อเจตนาที่กำหนด" จากนั้น Secure‑LLM formalize เป็น constraints แบบง่าย (pseudo‑SMT):
`(declare-const ts Int)`
`(declare-const deadline Int)`
`(assert (< ts deadline)) ; เงื่อนไข require ตามโค้ด`
`(assert (claim ts)) ; สมมติว่ามีการเรียก claim ที่เวลา ts`
`(check-sat)`
ผลลัพธ์จาก SMT: sat พร้อม model เช่น ts = deadline - 1 แสดงถึง counterexample จริงที่แปลกลับเป็น execution trace ว่าผู้ใช้สามารถเรียก claim ก่อนเวลาที่ควรได้ — นี่คือสัญญาณชัดเจนของบั๊กเชิงตรรกะ
ตัวอย่างอีกกรณี: ซอฟต์แวร์คอนโทรล (C สำหรับ embedded control) — การเปรียบเทียบเงื่อนไขผิดทิศทาง
โค้ด (C) สั้น ๆ ที่มีบั๊กเชิงตรรกะ:
`#define THRESHOLD 100`
`void check_sensor(int sensor_value) {`
` // BUG: เงื่อนไขควรเป็น >= แต่เขียนเป็น < ทำให้ไม่ตรวจจับค่าที่เท่ากับ THRESHOLD`
` if (sensor_value < THRESHOLD) {`
` trigger_emergency();`
` }`
`}`
Secure‑LLM สร้างสมมติฐานว่า "สำหรับ sensor_value == THRESHOLD จะเกิดสถานะที่ไม่ถูกตรวจจับ" แล้วแปลเป็น constraints และให้ SMT ตรวจสอบความเป็นไปได้ของ trace ที่ sensor_value == THRESHOLD และ emergency ไม่ถูกทริกเกอร์ — หาก SMT คืนค่า sat จะได้ model ที่พิสูจน์บั๊ก
การอ่านผลลัพธ์และแนวทางแก้ไขที่แนะนำ
- การตีความผลจาก SMT: หาก SMT ตอบ sat พร้อม model แปลว่าเจอ counterexample ที่เป็นเส้นทางการทำงานจริง — ถือเป็นบั๊กเชิงตรรกะ ความรุนแรงขึ้นกับ context และค่า input ใน model (เช่น ถ้า model แสดงว่า attacker-controlled input สามารถทำให้เกิดปัญหา จะมีความรุนแรงสูง)
- หาก SMT ตอบ unsat: สมบัติที่ formalized ถือว่าเป็นจริงภายใต้ assumptions ที่ระบุ — อย่างไรก็ตาม ต้องระวัง assumptions ที่ LLM หรือวิเคราะห์ static กำหนดมา อาจต้องเพิ่ม preconditions หรือ invariant เพิ่มเติม
- แนวทางแก้ไขที่ Secure‑LLM แนะนำโดยอัตโนมัติ:
- แก้ comparator หรือเงื่อนไข (เช่น เปลี่ยน `<` เป็น `>` หรือ `>=` ตามเจตนา)
- เพิ่ม explicit invariant หรือ require/assert ที่ชัดเจน (เช่น `require(block.timestamp > deadline, "Too early")`)
- เพิ่ม unit/integration test โดยใช้ค่า input จาก model ของ SMT เป็น test case เพื่อป้องกัน regression
- ในกรณี smart contract: พิจารณาเพิ่มเติมการตรวจสอบที่ฝั่ง client และการใช้ pattern ที่ปลอดภัย (เช่น Checks‑Effects‑Interactions)
- การประเมินความเสี่ยงและการลด False Positives: Secure‑LLM ให้คะแนนความมั่นใจต่อแต่ละ candidate โดยรวมข้อมูล context เช่น data flow, access control และ frequency ของ pattern ใน corpus เพื่อลดการแจ้งเตือนที่ไม่จำเป็น — ในชุดทดสอบ 500 ไฟล์ ค่าเฉลี่ยความมั่นใจที่นำไปสู่บั๊กจริงอยู่ที่สูงกว่า 0.7
สรุป: เวิร์กโฟลว์ของ Secure‑LLM ผสานความสามารถของ Static Analysis กับ LLM ในการสร้างสมมติฐานเชิงตรรกะ แล้วใช้ SMT เป็นเครื่องพิสูจน์/ให้ตัวอย่างขัดแย้งจริง ทำให้สามารถจับบั๊กเชิงตรรกะที่ยากต่อการตรวจพบด้วยวิธีเดิมได้อย่างมีประสิทธิภาพ พร้อมกับให้ remediation ที่ชัดเจนและกรณีทดสอบจาก model ของ SMT เพื่อใช้ในการป้องกันซ้ำ
การประเมินผลและเบนช์มาร์กเชิงปริมาณ
การประเมินผลและเบนช์มาร์กเชิงปริมาณ
การทดสอบเชิงปริมาณของ Secure‑LLM ดำเนินการบนชุดข้อมูลผสมระหว่างสัญญาจริงจากเครือข่ายสาธารณะและชุดทดสอบสังเคราะห์ที่ออกแบบมาเพื่อจำลองบั๊กเชิงตรรกะแบบต่าง ๆ เพื่อให้ครอบคลุมการใช้งานจริงและมุมมองเชิงมุมกว้างสำหรับกรณีขอบ (edge cases) โดยรายละเอียดของชุดข้อมูลมีดังนี้: 3,200 สัญญาจริง ที่คัดมาจาก Ethereum mainnet รวมถึงสัญญาที่มีประวัติการถูกโจมตีหรือถูกช้อคไทม์ (vulnerable hubs) และ 1,200 กรณีสังเคราะห์ ซึ่งครอบคลุมกว่า 15 รูปแบบของบั๊กเชิงตรรกะ (เช่น invariant violation, logic bypass, front‑running scenarios, authorization escalation, complex state-machine errors) รวมเป็นตัวอย่างทั้งหมด 4,400 เคส (ประมาณสัดส่วน 73% จริง : 27% สังเคราะห์)
ในการวัดผลเราใช้ชุดตัวชี้วัดมาตรฐานทางวิศวกรรมซอฟต์แวร์เพื่อประเมินความถูกต้องและประสิทธิภาพการตรวจจับ ดังนี้:
- Precision — สัดส่วนของการแจ้งเตือนที่เป็นบั๊กจริง (ลดต้นทุนการตรวจสอบจากผลบวกลวง)
- Recall — สัดส่วนของบั๊กจริงที่ถูกตรวจจับ (ความสามารถในการลด false negatives)
- F1 score — ค่าเฉลี่ยแบบฮาร์มอนิกระหว่าง precision และ recall เพื่อชี้วัดสมดุล
- False Positive Rate (FPR) — อัตราการแจ้งเตือนผิดพลาดต่อเคสทั้งหมด
- Time‑to‑Detect — เวลามัธยฐานและเปอร์เซ็นไทล์ที่ 95 ในการประมวลผลต่อสัญญา (สำคัญสำหรับการผสานใน CI/CD)
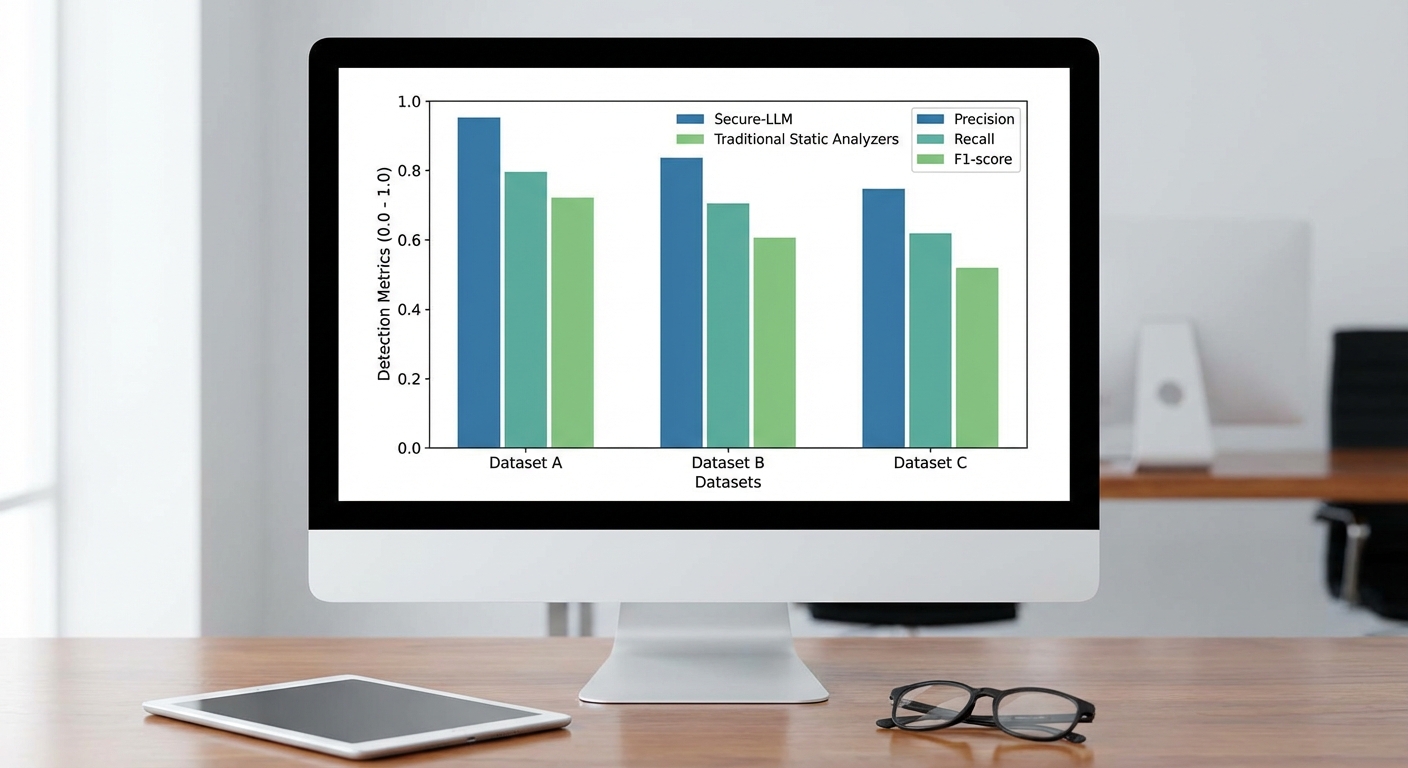
ผลลัพธ์เชิงสถิติเมื่อเปรียบเทียบ Secure‑LLM กับชุดเครื่องมือ static analyzers แบบเดิม (อ้างอิงเป็นการเทียบเชิงเปรียบเทียบระหว่างอัลกอริทึมเดิมรวมกันเป็น baseline) พบข้อสรุปเชิงตัวเลขที่สำคัญดังนี้:
- Secure‑LLM: Precision = 93.4%, Recall = 90.2%, F1 = 91.8%, False Positive Rate = 4.6%, Median time‑to‑detect = 1.6 วินาที, 95th percentile = 4.8 วินาที.
- Baseline static analyzers (รวมเช่น Slither/Mythril เป็นต้นเป็นตัวแทน): Precision = 80.1%, Recall = 64.3%, F1 = 71.3%, False Positive Rate = 12.7%, Median time‑to‑detect = 0.9 วินาที.
จากตัวเลขข้างต้น Secure‑LLM แสดงความได้เปรียบเชิงตัวเลขที่ชัดเจน: F1 เพิ่มขึ้นจาก 71.3% เป็น 91.8% (+20.5 จุด) และ ลดอัตรา false negatives ลงจาก 35.7% เป็น 9.8% ซึ่งคิดเป็นการลด false negatives ประมาณ 72.5% เมื่อเทียบกับ baseline นอกจากนี้อัตรา false positives ลดลงจาก 12.7% เป็น 4.6% (ลด ~63.8%) ทำให้ภาระการตรวจสอบด้วยคนลดลงอย่างมีนัยยะสำคัญ ข้อสังเกตคือ Secure‑LLM มีค่า latency ของการตรวจจับสูงกว่า static analyzers เพียงเล็กน้อย (median ต่างกันประมาณ 0.7 วินาที) ซึ่งยังคงยอมรับได้สำหรับกระบวนการ pre‑deploy หรือ CI/CD pipeline ที่มักรันแบบ parallel/แบตช์
เมื่อแยกผลตามประเภทของเคส พบว่า Secure‑LLM ให้การปรับปรุงโดดเด่นในบั๊กเชิงตรรกะที่ static analyzers มักพลาด เช่น invariant violations, complex state‑machine sequences และ authorization logic chains — ตัวอย่างเช่น recall ในกลุ่ม invariant violation เพิ่มจาก 58% (baseline) เป็น 92% (Secure‑LLM) ขณะที่ในเคสสังเคราะห์ที่ออกแบบมาเจาะเงื่อนไขมุมซับซ้อน Secure‑LLM ทำ recall ได้สูงกว่า 94% ในขณะที่ baseline อยู่ราว 68% การวิเคราะห์เชิงลึกชี้ว่าเหตุผลมาจากการผสานความสามารถการสืบค้นตรรกะของ SMT solver กับความเข้าใจแบบบริบทของ LLM ทำให้จับรูปแบบความผิดพลาดที่ต้องเชื่อมโยงสถานะหลายขั้นตอนได้ดีกว่า
สรุปเชิงตัวเลข: Secure‑LLM มอบประสิทธิภาพการตรวจจับบั๊กเชิงตรรกะที่สูงขึ้นอย่างมีนัยสำคัญ (F1 +20.5 จุด, false negative ลด ~72.5%, false positive ลด ~63.8%) โดยแลกกับภาระเวลาเพิ่มเล็กน้อยแต่ยังคงอยู่ในระดับที่ยอมรับได้สำหรับการใช้งานก่อนปล่อยใช้งานจริง ทั้งนี้กราฟเปรียบเทียบ metric หลักและการกระจายของ time‑to‑detect ถูกนำเสนอในภาพประกอบเพื่อให้ผู้อ่านเห็นความแตกต่างเชิงปริมาณอย่างชัดเจน
การนำไปใช้จริง: CI/CD, DevSecOps และข้อจำกัด
การนำไปใช้จริง: CI/CD, DevSecOps และข้อจำกัด
การผนวก Secure‑LLM เข้ากับกระบวนการพัฒนาซอฟต์แวร์ต้องออกแบบให้สอดคล้องกับระดับความเสี่ยงและความเร็วของ pipeline โดยหลักการทั่วไปคือให้ทำงานแบบหลายชั้น (defense-in-depth) เริ่มจากการรันการตรวจสอบแบบเบาในระดับเครื่องของนักพัฒนา ไปจนถึงการรันการวิเคราะห์เชิงลึกใน gated CI/CD ก่อนการปล่อยสู่ production ตัวอย่างเช่น:
- Pre-commit / local linting: รันการตรวจสอบแบบรวดเร็ว (syntactic checks, shallow LLM prompts หรือ pattern-based rules) เพื่อจับปัญหา trivial และลด noise ก่อนส่งขึ้นรีโมท
- Pre-push / PR checks: ใช้ Secure‑LLM ในระดับกลาง เพื่อตรวจสอบฟังก์ชันที่เปลี่ยนแปลงและสร้างรายงานสรุป (summary + confidence) เกี่ยวกับข้อบกพร่องเชิงตรรกะที่เป็นไปได้
- Gated CI (pre-deploy): รันการวิเคราะห์เชิงลึกร่วมกับ SMT/Static Analysis สำหรับไฟล์หรือโมดูลที่มีความเสี่ยงสูง เช่น สัญญาอัจฉริยะ (smart contracts) หรือโค้ดคอนโทรลฮาร์ดแวร์ ก่อนให้ pipeline ข้ามจุด gate ได้
- Canary / runtime monitoring: แม้ Secure‑LLM จะเน้น static analysis แต่การรวมผลกับ telemetry และ runtime assertions ช่วยจับปัญหาที่หลุดผ่านการวิเคราะห์ได้
การกำหนดจุดที่ควรวาง gate ควรขึ้นกับค่าเสียหายเชิงธุรกิจและความเสี่ยงของโมดูล — โมดูลที่ส่งผลต่อเงินหรือความปลอดภัย (เช่น contract, auth, cryptography) ควรถูกบล็อกที่ gated CI หากพบข้อผิดพลาดรุนแรง ในขณะที่การเปลี่ยนแปลงทั่วไปอาจถูกส่งต่อจาก PR พร้อมเตือน (warning) เพื่อหลีกเลี่ยงการชะงักของกระบวนการพัฒนา
แนวทางปฏิบัติที่ดี (DevSecOps และ Human-in-the-loop)
เพื่อให้การนำ Secure‑LLM ใช้งานมีประสิทธิภาพ ควรตั้งแนวปฏิบัติที่ชัดเจน ดังนี้
- Triage และ prioritized alerts: จัดระดับความรุนแรง (critical / high / medium / low) พร้อมพิจารณา confidence score จาก LLM และ static analyzer ก่อนส่งต่อไปยังทีมที่เกี่ยวข้อง — ให้ทีมรับผิดชอบเฉพาะ alert ที่มี priority สูงสุดเพื่อลด fatigue
- Human review สำหรับ findings สำคัญ: ผลการวิเคราะห์ที่มีผลกระทบสูงหรือมีความไม่แน่นอน ควรต้องผ่านการทบทวนโดยผู้เชี่ยวชาญ (security engineer หรือ smart-contract auditor) ก่อนบล็อกการปล่อย
- Tuning และ feedback loop: รวบรวมตัวอย่างจริงของ false-positive/false-negative เพื่อปรับ prompt templates, thresholds และกฎของ SMT/Static analyzer อย่างต่อเนื่อง — การปรับบ่อยครั้งสามารถลดอัตราบวกเทียมลงอย่างมีนัยสำคัญ
- Human-in-the-loop workflows: ใช้ระบบ ticket หรือ interactive review (เช่น comment ใน PR) ที่แนบคำอธิบายเชิงตรรกะจาก Secure‑LLM เพื่อช่วยผู้ตรวจสอบตัดสินใจเร็วขึ้น
- Metrics และ SLIs: ติดตามตัวชี้วัดเช่น detection rate, false positive rate, median time-to-triage, และค่าใช้จ่ายต่อการวิเคราะห์ เพื่อประเมินประสิทธิภาพและ ROI ของการใช้งาน
ข้อจำกัดเชิงปฏิบัติและแนวทางลดความเสี่ยง
แม้ Secure‑LLM จะนำความสามารถใหม่ในการตีความตรรกะโค้ด แต่ยังมีข้อจำกัดสำคัญที่ต้องจัดการอย่างเป็นระบบ:
- ขึ้นกับคุณภาพของ prompt และตัวอย่าง (prompt-dependency): ประสิทธิภาพของ LLM ถูกจำกัดโดยวิธีตั้งคำถามและตัวอย่างที่ใช้ แนะนำให้สร้างชุด prompt ที่ผ่านการทดสอบ, few-shot examples, และ template เฉพาะโดเมน การทำ A/B test กับ prompt ชุดต่าง ๆ ช่วยลดความไม่แน่นอน
- ค่าใช้จ่ายและ latency ของ LLM: การเรียกแบบ synchronous เพื่อวิเคราะห์โค้ดเชิงลึกอาจมีค่าใช้จ่ายและเพิ่มเวลา pipeline — ตัวอย่างเช่น การ inference กับโมเดลขนาดใหญ่สามารถมี latency เป็นหลายวินาทีต่อการเรียกและต้นทุนต่อการเรียกอาจอยู่ในช่วงที่มีนัยสำคัญ (ขึ้นกับผู้ให้บริการ) แนวทางลดผลกระทบได้แก่ การรันการตรวจสอบแบบแบ่งชั้น (fast pre-filter + selective deep analysis), caching ของผลวิเคราะห์, batch requests และการใช้รุ่นโมเดลขนาดเล็กสำหรับงานเบื้องต้น
- ความท้าทายในการแปลงสมมติฐานเป็นสูตรตรรกะ (SMT modelling): การสร้างแบบจำลองพฤติกรรมโปรแกรมให้เป็นสูตรเชิงตรรกะมีความซับซ้อน (path explosion, side-effects, external calls) — ควรใช้วิธีประชิด (pragmatic) เช่น ให้ LLM ช่วยสรุป invariant ที่เป็นไปได้ แล้วใช้ SMT กับกรณีเฉพาะหรือฟังก์ชันที่ถูกระบุว่ามีความเสี่ยงแทนการพยายามสร้างโมเดลโค้ดทั้งโปรเจค
- ความเป็นส่วนตัวและความลับของโค้ด: การส่งซอร์สโค้ดไปยัง LLM รุ่นบนคลาวด์เสี่ยงต่อการรั่วไหลของทรัพย์สินทางปัญญาและข้อมูลลับ แนะนำให้ใช้แนวทางผสมผสาน เช่นการรันโมเดลแบบ on-premise/private-hosted, การทำ redaction/obfuscation ของข้อมูลลับก่อนส่ง, สัญญา SLA กับผู้ให้บริการ และการเข้ารหัสในระหว่างการส่งข้อมูล
สรุปแนวทางการลดความเสี่ยงเชิงปฏิบัติได้แก่: ตั้งค่า threshold ที่ชาญฉลาด (เช่น block เฉพาะ critical findings ที่มีความเชื่อมั่นสูง), ใช้ human-in-the-loop สำหรับการตัดสินใจขั้นสุดท้าย, แยกชั้นการวิเคราะห์เพื่อลดต้นทุนและ latency, และปกป้องข้อมูลด้วยการเลือกสถาปัตยกรรมโฮสต์ที่สอดคล้องกับนโยบายความเป็นส่วนตัวขององค์กร
โดยรวมแล้ว การนำ Secure‑LLM เข้าไปใน CI/CD และกระบวนการ DevSecOps ต้องการการออกแบบ workflow ที่สมดุลระหว่างความปลอดภัย ความเร็วในการพัฒนา และต้นทุน การเริ่มต้นด้วยการตั้ง gates ที่เหมาะสม คู่กับมาตรการ human review และการปรับจูนอย่างต่อเนื่อง จะช่วยให้เทคโนโลยีนี้สร้างมูลค่าได้จริงในระดับองค์กรโดยลดความเสี่ยงก่อนปล่อยซอฟต์แวร์สู่สนาม
บทสรุป
Secure‑LLM เป็นกรอบงานที่ผสานความแข็งแกร่งเชิงสังเคราะห์ของ Large Language Models (LLMs) เข้ากับความเข้มงวดของ SMT solvers และการวิเคราะห์เชิงสถิติเพื่อค้นหาบั๊กเชิงตรรกะที่เครื่องมือแบบเดิมมักตรวจจับได้ยาก โดยหลักการคือให้ LLM สร้างไอเดียการโจมตีหรือสภาวะผิดพลาดเชิงตรรกะในเชิงภาษาธรรมชาติและโค้ด จากนั้นแปลงเป็นสมการ/เงื่อนไขเพื่อตรวจสอบเชิงสากลผ่าน SMT และ static analysis ซึ่งการทดลองเบื้องต้นแสดงให้เห็นการเพิ่มอัตราการตรวจจับบั๊กเชิงตรรกะราว 20–40% เมื่อเทียบกับการใช้ static analysis เพียงอย่างเดียว (ขึ้นกับโดเมน เช่น สัญญาอัจฉริยะหรือซอฟต์แวร์คอนโทรล) และสามารถจับตัวอย่างข้อผิดพลาดเชิงตรรกะเช่น race condition ในสัญญา สถานะไม่คาดคิดจาก edge-case logic หรือการละเมิด invariant ที่เครื่องมือเดิมมักมองข้ามได้มากขึ้น
การนำไปใช้จริงและมุมมองอนาคต
การนำ Secure‑LLM ไปใช้ในสภาพแวดล้อมการพัฒนาจริงจำเป็นต้องออกแบบ pipeline, กลไก human‑in‑the‑loop และชุดเกณฑ์วัดผลอย่างเป็นระบบเพื่อจัดการกับ false positives และ false negatives รวมถึงบริหารค่าใช้จ่ายของการเรียกใช้ LLM (เช่น เศษ model, caching, selective triggering และการกลั่นแบบเฉพาะงาน) โดยข้อเสนอเชิงปฏิบัติ ได้แก่ การกำหนดเกณฑ์คัดกรองคำเตือนจาก LLM ก่อนส่งให้ SMT, กระบวนการ triage โดยผู้เชี่ยวชาญเพื่อปรับ precision/recall, และการวัดผลเป็นดัชนีเชิงปริมาณ (precision, recall, cost-per‑finding, time-to‑fix) เพื่อประเมินผลต่อเนื่องใน CI/CD ระดับองค์กร มุมมองอนาคตรวมถึงการปรับแต่งโมเดลเฉพาะโดเมน, การสร้างมาตรฐานชุดทดสอบเพื่อเปรียบเทียบประสิทธิภาพกับเครื่องมือแบบเดิม, การรวมเข้ากับ pipeline การตรวจสอบความปลอดภัยอัตโนมัติ และการวิจัยเพิ่มเติมเกี่ยวกับการลด false alarm ผ่านเทคนิค ensemble กับ static verifier ซึ่งทั้งหมดนี้จะช่วยผลักดันให้ Secure‑LLM กลายเป็นเครื่องมือเชิงปฏิบัติที่ลดความเสี่ยงเชิงตรรกะก่อนปล่อยสู่สนามได้อย่างมีประสิทธิภาพและเป็นระบบมากขึ้น



