
การเคลื่อนไหวล่าสุดจากหน่วยงานกำกับดูแลในภูมิภาคเอเชียที่กำลังผลักดันให้มีการบังคับใช้มาตรฐาน "AI Content Provenance" เพื่อให้สื่อสังเคราะห์ทุกชิ้นติดตราแหล่งที่มา กำลังเปลี่ยนขอบเขตของการสื่อสารดิจิทัลอย่างรวดเร็ว ไม่ว่าจะเป็นวิดีโอรีมิกซ์ที่สร้างด้วยโมเดลสร้างภาพ เสียงสังเคราะห์ในโฆษณา หรือบทความข่าวที่มีการเติมเนื้อหาด้วย AI การติดป้าย provenance จะไม่ใช่เพียงมาตรการด้านความโปร่งใส แต่เป็นการวางกติกาใหม่ที่ส่งผลโดยตรงต่อวิธีการลงโฆษณา การยืนยันความน่าเชื่อถือของข่าวสาร และการบริหารจัดการเนื้อหาบนแพลตฟอร์มแชร์วิดีโอในวงกว้าง

บทความนี้จะอธิบายเทคโนโลยีเบื้องหลังการติดตราแหล่งที่มา—ตั้งแต่ metadata และ watermark เชิงดิจิทัลไปจนถึงการใช้ลายเซ็นเชิงคริปโต รวมถึงกรอบกฎหมายและแนวปฏิบัติที่หน่วยงานกำกับกำลังพิจารณา การวิเคราะห์จะเจาะลึกผลกระทบต่อภาคโฆษณา (เช่น การวัดประสิทธิภาพและความรับผิดชอบของผู้ลงโฆษณา) ภาคสื่อข่าว (การตรวจสอบแหล่งที่มาของข้อมูลและความน่าเชื่อถือทางจริยธรรม) และแพลตฟอร์มวิดีโอ (การจัดการคอนเทนต์สังเคราะห์และโมเดลรายได้) พร้อมทั้งเสนอแนวทางปฏิบัติสำหรับองค์กรทั้งในระดับบรรณาธิการ ฝ่ายการตลาด และฝ่ายเทคนิค เพื่อเตรียมความพร้อมก่อนมาตรฐานจะถูกบังคับใช้จริง
บทนำ: ทำไม 'AI Content Provenance' ถึงกลายเป็นประเด็นเร่งด่วน
บทนำ: ทำไม 'AI Content Provenance' ถึงกลายเป็นประเด็นเร่งด่วน
ท่ามกลางการเติบโตอย่างรวดเร็วของเทคโนโลยี generative AI — ตั้งแต่การสร้างภาพนิ่งและวิดีโอ (deepfakes) ไปจนถึงเสียงสังเคราะห์และข้อความที่ผลิตโดยโมเดล — ผู้กำกับดูแลในภูมิภาคเอเชียกำลังกดดันให้มีการติดตราแหล่งที่มาของคอนเทนต์ (AI Content Provenance) เป็นมาตรฐานบังคับใช้อย่างเร่งรีบ สถิติเพิ่มขึ้นอย่างมีนัยสำคัญ: ตลาด Generative AI ในภูมิภาคเอเชียแปซิฟิกมีการเติบโตแบบ CAGR ประมาณ 35–45% ระหว่างปี 2021–2024 และองค์กรหลายแห่งรายงานว่าในบางแพลตฟอร์มวิดีโอ คอนเทนต์ที่มีองค์ประกอบสังเคราะห์คิดเป็นสัดส่วนประมาณ 15–30% ของเนื้อหาใหม่ที่อัปโหลด ซึ่งสะท้อนถึงความแพร่หลายและการเข้าถึงเทคโนโลยีที่เพิ่มขึ้นอย่างรวดเร็ว
เหตุผลที่เรื่องการระบุแหล่งที่มาของสื่อสังเคราะห์กลายเป็นเรื่องเร่งด่วนมีหลายด้าน ทั้งด้านความปลอดภัยของข้อมูล สถานการณ์ด้านความมั่นคง (เช่น การบิดเบือนข้อมูลทางการเมือง) และการคุ้มครองผู้บริโภค ตัวอย่างเช่น deepfakes ของบุคคลสาธารณะหรือโฆษณาที่ใช้เสียงสังเคราะห์อาจทำให้เกิดความเสียหายต่อชื่อเสียง กระทบความน่าเชื่อถือของสื่อ และเพิ่มความเสี่ยงต่อการฉ้อโกงโฆษณา (ad fraud) นอกจากนี้ แพลตฟอร์มที่ไม่สามารถแยกแยะหรือแสดงแหล่งที่มาของคอนเทนต์ได้จะเผชิญกับปัญหาด้านความโปร่งใสและความรับผิดชอบ ซึ่งส่งผลโดยตรงต่อความเชื่อมั่นของผู้ใช้และมูลค่าทางธุรกิจ
สำหรับผู้อ่านที่เป็นกลุ่มเป้าหมาย — นักการตลาด, บรรณาธิการข่าว, และ ผู้บริหารแพลตฟอร์ม — ข้อกำหนดด้าน AI Content Provenance จะส่งผลทั้งเชิงปฏิบัติการและเชิงกลยุทธ์ นักการตลาดต้องพิจารณาการเปิดเผยแหล่งที่มาของครีเอทีฟเพื่อปกป้องแบรนด์ บรรณาธิการจำเป็นต้องปรับเวิร์กโฟลว์เพื่อตรวจสอบแหล่งที่มาของเนื้อหา ขณะที่ผู้บริหารแพลตฟอร์มต้องประเมินการลงทุนด้านเทคโนโลยีการติดตาม (metadata tagging, watermarking, cryptographic signatures) และการปฏิบัติตามกฎระเบียบที่จะตามมา
บทความนี้จะให้ภาพรวมเชิงลึกเกี่ยวกับการเคลื่อนไหวของหน่วยงานกำกับดูแลในเอเชีย และอธิบายผลกระทบต่อสามภาคส่วนหลัก: โฆษณา, คอนเทนต์ข่าว, และแพลตฟอร์มแชร์วิดีโอ โดยผู้อ่านสามารถคาดหวังว่าจะได้รับ:
- ภาพรวมกฎระเบียบ: แนวทางและกรอบเวลาที่หน่วยงานในประเทศต่าง ๆ กำลังพัฒนา
- มาตรฐานทางเทคนิค: วิธีการที่ใช้กัน เช่น metadata, invisible watermark, และเทคนิคการเซ็นต์ข้อมูลทางคริปโต
- ผลกระทบเชิงปฏิบัติ: การเปลี่ยนแปลงในเวิร์กโฟลว์โฆษณา การตรวจสอบข่าว และนโยบายแพลตฟอร์ม
- แนวทางปฏิบัติและข้อเสนอแนะ: เช็คลิสต์สำหรับการเตรียมความพร้อมเชิงธุรกิจและเทคนิค
สรุปคือ การบังคับใช้ AI Content Provenance ไม่ใช่เพียงประเด็นด้านปกครองเท่านั้น แต่เป็นการเปลี่ยนแปลงเชิงโครงสร้างที่จะกำหนดความน่าเชื่อถือของสื่อ ดุลยภาพระหว่างนวัตกรรมและความรับผิดชอบของสังคม ผู้ที่อ่านบทความนี้จะได้รับเครื่องมือและความเข้าใจเชิงกลยุทธ์เพื่อประเมินความเสี่ยง ปรับกระบวนการ และวางแผนการลงทุนที่จำเป็นต่อการปฏิบัติตามกฎเกณฑ์ใหม่ในภูมิภาค
อะไรคือ 'AI Content Provenance' — คำจำกัดความและองค์ประกอบสำคัญ
อะไรคือ "AI Content Provenance" — คำจำกัดความและองค์ประกอบสำคัญ
AI Content Provenance หมายถึงชุดข้อมูลและกลไกที่ใช้เพื่อบันทึก ระบุ และยืนยันแหล่งที่มา กระบวนการสร้าง และการเปลี่ยนแปลงของสื่อที่สร้างหรือปรับแต่งด้วยเทคโนโลยีปัญญาประดิษฐ์ (เช่น ข้อความ รูปภาพ เสียง หรือวิดีโอ) โดยมีวัตถุประสงค์ทั้งเพื่อความโปร่งใส การตรวจสอบความถูกต้อง และการตอบสนองต่อข้อกังวลด้านจริยธรรม กฎหมาย และความปลอดภัย ในทางปฏิบัติ provenance ต้องประกอบด้วยทั้งข้อมูลเชิงพรรณนา (human-readable) และข้อมูลเชิงเทคนิคที่เครื่องสามารถตรวจสอบได้ (machine-readable) ซึ่งร่วมกันทำให้การอ้างสิทธิ์เกี่ยวกับการเป็นต้นฉบับและประวัติการดำเนินการมีความน่าเชื่อถือ
องค์ประกอบทางเทคนิคของ AI Content Provenance ประกอบด้วยหลายชั้นที่ทำงานร่วมกันเพื่อให้เกิดความสมบูรณ์และความทนต่อการปลอมแปลง โดยองค์ประกอบสำคัญได้แก่:
- Embedded metadata — ข้อมูลเมตาที่เก็บไว้ภายในไฟล์หรือในไฟล์คู่ขนาน (เช่น XMP, EXIF, JSON-LD หรือไฟล์ manifest ตามมาตรฐาน C2PA) บันทึกฟิลด์พื้นฐานเช่น ผู้สร้าง (creator/issuer), เครื่องมือหรือซอฟต์แวร์ที่ใช้, รุ่นโมเดล (model version), ลิงก์ไปยังแหล่งข้อมูลฝึกสอน, ลิขสิทธิ์/อนุญาต และแฮชของข้อมูลต้นฉบับ
- Visible watermarks — ตราหรือตัวบ่งชี้ที่มองเห็นได้บนสื่อ เพื่อให้ผู้ชมทั่วไปรับรู้ทันทีว่าสื่อเป็นสังเคราะห์หรือมีการปรับแต่ง เหมาะสำหรับการป้องกันการเข้าใจผิดในระดับสาธารณะ
- Hidden / imperceptible watermarks — เทคนิคการฝังสัญลักษณ์ที่มองไม่เห็นโดยสายตามนุษย์ แต่สามารถตรวจสอบได้ด้วยเครื่องมือเฉพาะ เพื่อยืนยันแหล่งที่มาโดยไม่รบกวนประสบการณ์ของผู้ใช้ (เช่น การเข้ารหัสข้อมูลลงในสเปกตรัมของสัญญาณภาพหรือเสียง)
- Cryptographic signatures — ลายเซ็นดิจิทัลและแฮชรหัสที่เชื่อมโยงกับคีย์สาธารณะ/คีย์ส่วนตัว เพื่อให้การยืนยันความถูกต้องแบบไม่สามารถปฏิเสธได้และตรวจจับการดัดแปลง เช่น การเซ็น manifest ด้วยระบบ Public Key Infrastructure (PKI) หรือการใช้ Merkle tree สำหรับรายการของการเปลี่ยนแปลง
- Chain-of-custody logs — บันทึกลำดับเหตุการณ์ที่แสดงว่าใครทำอะไรเมื่อใดกับสื่อนั้น ๆ รวมถึงการแปลงข้อมูล การแก้ไข การเผยแพร่ และการถ่ายโอนความรับผิดชอบ บันทึกเหล่านี้อาจเก็บในรูปแบบที่กระจายตัว (distributed ledger) หรือระบบบันทึกที่มีการตรวจสอบได้
มาตรฐานและกรอบแนวปฏิบัติสากลมีบทบาทสำคัญในการทำให้ข้อมูล provenance เป็นไปได้จริงและใช้งานร่วมกันได้ ตัวอย่างองค์กรและมาตรฐานที่เกี่ยวข้องได้แก่ C2PA (Coalition for Content Provenance and Authenticity) ซึ่งพัฒนาชุดมาตรฐานสำหรับการสร้าง manifest ที่บรรจุ assertions เกี่ยวกับต้นกำเนิดและการแปลงสื่อ, W3C ที่ทำงานด้านการนิยามข้อมูลเชิงเว็บ เช่น JSON-LD และ vocabularies ที่ช่วยให้ metadata สามารถอ่านและใช้งานร่วมกันได้ นอกจากนี้ยังมีการอ้างอิงแนวทางจากกลุ่มวิจัยและองค์กรมาตรฐานอื่น ๆ ในการกำหนดรูปแบบการบันทึก การตรวจสอบลายเซ็น และการรักษาความเป็นส่วนตัว
ตัวอย่างข้อมูล provenance ที่ควรถูกบันทึกเพื่อรองรับการตรวจสอบแบบครบวงจร ได้แก่รายการฟิลด์ที่ครอบคลุมคำถามพื้นฐาน who/what/when/how ดังนี้:
- Who — ผู้สร้างหรือผู้ออกประกาศ (creator/issuer), ตัวตนของผู้ใช้งานที่สั่งสร้าง, องค์กรที่เป็นเจ้าของสิทธิ
- What — ประเภทสื่อ, คำอธิบายเนื้อหา, แฮชของไฟล์ต้นทางและไฟล์ผลลัพธ์, รหัสหรือ ID ของเนื้อหาแม่ (ancestry / parent content IDs)
- When — เวลาและโซนเวลาที่สร้างหรือแก้ไขแต่ละครั้ง (timestamp แบบเชื่อมโยงกับลายเซ็นดิจิทัล)
- How — เครื่องมือหรือโมเดลที่ใช้ในการสร้าง (ชื่อโมเดล, รุ่น, พารามิเตอร์สำคัญ), แหล่งข้อมูลฝึกสอน (datasets) หรือพยัญชนะที่ใช้, ขั้นตอนการประมวลผลและการแก้ไขหลังการสร้าง (post-processing), นโยบายการอนุญาตและลิขสิทธิ์
ปฏิบัติการที่ดีสำหรับการใช้งาน provenance ได้แก่การบันทึกทั้งข้อมูลที่อ่านเข้าใจได้โดยมนุษย์และข้อมูลที่ตรวจสอบได้โดยเครื่อง, การฝังหรือผนวกรูปแบบ metadata ที่สอดคล้องกับมาตรฐานสากล (เช่น manifest ของ C2PA หรือ JSON-LD ตาม W3C), การใช้งานลายเซ็นเชิงสาธารณะที่ตรวจสอบได้ และการคำนึงถึงความเป็นส่วนตัวโดยการแยกหรือมาสก์ข้อมูลที่เป็นข้อมูลระบุตัวบุคคลเมื่อจำเป็น ทั้งนี้การออกแบบระบบ provenance ควรยึดหลักความโปร่งใส ความสามารถในการตรวจสอบ และความคงทนต่อการปลอมแปลง เพื่อสนับสนุนการบังคับใช้และสร้างความเชื่อมั่นในระบบนิเวศสื่อดิจิทัลยุค AI
ภูมิทัศน์การกำกับดูแลในเอเชีย: ประเทศตัวอย่างและแนวทางที่แตกต่างกัน
ภูมิทัศน์การกำกับดูแลในเอเชีย: ประเทศตัวอย่างและแนวทางที่แตกต่างกัน
ภูมิภาคเอเชียกำลังพัฒนากรอบการกำกับดูแลสำหรับ AI Content Provenance ด้วยความหลากหลายของแนวทางตั้งแต่การบังคับใช้เชิงกฎหมายอย่างเข้มงวด ไปจนถึงแนวปฏิบัติเชิงแนะนำและการส่งเสริมมาตรฐานอุตสาหกรรมร่วมกัน ความแตกต่างนี้มีนัยสำคัญต่อโฆษณา คอนเทนต์ข่าว และแพลตฟอร์มแชร์วิดีโอ เนื่องจากเอเชียเป็นที่ตั้งของผู้ใช้อินเทอร์เน็ตกว่า 2.5 พันล้านคน และตลาดข้ามพรมแดนที่มีปริมาณการรับส่งข้อมูลสื่อสังเคราะห์สูง การเลือกใช้มาตรการกำกับดูแลจึงส่งผลโดยตรงต่อต้นทุนการปฏิบัติตามข้อกำหนด ระบบตรวจจับการปลอมแปลง (watermarking/metadata) และกระบวนการตรวจสอบเนื้อหา (content takedown/notice-and-action)
อินเดีย — ในอินเดีย มีการหารือเชิงนโยบายอย่างต่อเนื่องเกี่ยวกับการติดฉลากเนื้อหาเทียมและความรับผิดชอบของแพลตฟอร์ม รัฐบาลและหน่วยงานที่เกี่ยวข้องได้เสนอแนวทางเชิงนโยบายเพื่อเพิ่มความโปร่งใสแก่ผู้บริโภค ตัวอย่างข้อเสนอที่ถูกหยิบยกคือการกำหนดให้คอนเทนต์ที่สร้างด้วย AI หรือดัดแปลงด้วยเทคนิค deepfake ต้องติดฉลากชัดเจนสำหรับผู้ชม แม้ยังไม่มีกรอบกฎหมายกลางที่บังคับใช้แบบเป็นรูปธรรมในระดับประเทศทั้งหมด แต่แนวโน้มชัดเจนว่าผู้กำกับดูแลจะเชื่อมโยงมาตรฐานการติดฉลากกับกฎควบคุมสื่อสารออนไลน์ (เช่น IT Rules) ในทางปฏิบัติ ผู้ประกอบการโฆษณาและสื่อข่าวควรเตรียมมาตรการบันทึกแหล่งที่มาและกระบวนการตรวจสอบเพื่อรองรับข้อกำหนดที่อาจประกาศใช้
สาธารณรัฐเกาหลี (เกาหลีใต้) — เกาหลีใต้ดำเนินนโยบายที่ค่อนข้างเข้มงวดต่อเนื้อหา deepfake โดยเฉพาะอย่างยิ่งในกรณีที่กระทบต่อความเป็นส่วนตัวหรือเป็นอันตรายทางเพศ รัฐบาลได้ปรับปรุงบทบัญญัติทางอาญาและหน่วยงานบังคับใช้กฎหมายเคยดำเนินคดีจับกุมผู้เผยแพร่ deepfake ทางเพศหลายกรณี นโยบายมุ่งเน้นทั้งการลงโทษผู้กระทำผิดและการบังคับให้แพลตฟอร์มต้องมีมาตรการตรวจค้น-ลบอย่างรวดเร็ว ผู้ให้บริการวิดีโอสตรีมมิ่งและตลาดโฆษณาจำเป็นต้องมีระบบระบุแหล่งที่มาของสื่อและเครื่องมือแจ้งเตือนผู้ใช้ทันที
ญี่ปุ่น — ญี่ปุ่นเน้นกรอบการจัดการข้อมูลและการกำกับดูแลเทคโนโลยีโดยใช้แนวทางที่ผสมผสานระหว่างกฎข้อบังคับและแนวปฏิบัติภาคธุรกิจ กระทรวงเศรษฐกิจ การค้า และอุตสาหกรรม (METI) รวมถึงหน่วยงานอื่น ๆ ได้ออกแนวทางการใช้ AI ที่เน้นความรับผิดชอบ (human-centric AI) และการคุ้มครองข้อมูลส่วนบุคคล ซึ่งส่งผลให้การติดตามแหล่งที่มาของสื่อเป็นส่วนหนึ่งของการปฏิบัติตามข้อกำหนดด้านข้อมูลและความโปร่งใสสำหรับสื่อสังเคราะห์ ผู้ประกอบการสื่อและผู้พัฒนาโซลูชัน AI มักถูกชักจูงให้ใช้มาตรฐานการติดฉลากเชิงเทคนิคและการจัดเก็บเมตาดาต้าเป็นหลักฐาน
สิงคโปร์ — สิงคโปร์เลือกใช้โมเดลที่เน้นการนำร่อง (sandbox) และแนวปฏิบัติที่เป็นแบบอย่าง เช่น Model AI Governance Framework โดยมีการส่งเสริมการยอมรับมาตรฐานการติดฉลากเชิงอาสาสมัครควบคู่กับการกำกับดูแลด้านความปลอดภัยออนไลน์และกฎหมายคุ้มครองข้อมูลส่วนบุคคล (PDPA) แนวทางนี้เหมาะสำหรับการทดลองเชิงนวัตกรรมและลดภาระด้านการปฏิบัติตามข้อกำหนดสำหรับสตาร์ทอัพ แต่ผู้เล่นระดับใหญ่ในวงการโฆษณาและแพลตฟอร์มต้องเตรียมรับความคาดหวังสูงจากหน่วยงานกำกับดูแลเมื่อเทคโนโลยีมีผลกระทบทางสังคมอย่างชัดเจน
จีน — จีนมีกรอบการควบคุมที่เข้มงวดที่สุดในภูมิภาค โดยหน่วยงานกำกับเช่น CAC (Cyberspace Administration of China) ได้ออกมาตรการควบคุมการสังเคราะห์สื่อ (deep synthesis) ที่ระบุให้ผู้ให้บริการต้องติดเครื่องหมายหรือเปิดเผยข้อมูลที่ใช้สร้างเนื้อหา รวมถึงการเรียกร้องให้ผู้ให้บริการเทคโนโลยีจัดเก็บข้อมูลการสร้างสรรค์และเผยแพร่เพื่อการตรวจสอบ นโยบายจีนเน้นทั้งการป้องกันผลกระทบทางสังคมและการรักษาความมั่นคงของข้อมูล โดยบทลงโทษอาจรวมถึงการปรับเงิน การระงับบริการ และการดำเนินคดีทางอาญา ตัวอย่างเช่น การสั่งปิดแอปหรือบริการที่ไม่ปฏิบัติตามมาตรการหรือเผยแพร่ข้อมูลเทียมที่มีผลกระทบต่อความสงบเรียบร้อย
ตารางสรุป (แบบคำอธิบาย) ของสถานะกฎและบทลงโทษ
- อินเดีย
- สถานะกฎระเบียบ: มีการเสนอและหารือแนวทางการติดฉลากสำหรับเนื้อหา AI; ยังไม่มีกรอบบังคับใช้กลางระดับชาติที่ชัดเจนทั้งหมด
- ข้อกำหนดที่สำคัญ: การเปิดเผยแหล่งที่มาและการติดฉลากที่ชัดเจน (ข้อเสนอในระดับกระทรวงและแนวปฏิบัติของแพลตฟอร์ม)
- ระยะเวลาบังคับใช้: ขึ้นกับการอนุมัติข้อเสนอและการเชื่อมโยงกับ IT Rules; คาดว่าจะขยายเป็นคำสั่งบังคับใน 1–2 ปีถัดไป
- บทลงโทษที่เป็นไปได้: ปรับ, การลงโทษตามกฎระเบียบแพลตฟอร์ม และการจำกัดการให้บริการ
- ตัวอย่างเหตุการณ์: การเผยแพร่คลิปสังเคราะห์ช่วงเหตุการณ์ทางการเมืองที่นำไปสู่การเรียกร้องมาตรการควบคุม
- เกาหลีใต้
- สถานะกฎระเบียบ: มีกฎหมายและนโยบายเข้มงวดต่อ deepfakes โดยเน้นการคุ้มครองความเป็นส่วนตัวและความปลอดภัยของประชาชน
- ข้อกำหนดที่สำคัญ: ควบคุมการสร้าง-เผยแพร่สื่อสังเคราะห์ที่ละเมิดสิทธิผู้อื่น; แพลตฟอร์มต้องมีมาตรการลบ
- ระยะเวลาบังคับใช้: กฎหมายบางหมวดบังคับใช้แล้ว; การบังคับใช้ขึ้นอยู่กับการสืบสวนและคดี
- บทลงโทษที่เป็นไปได้: ค่าปรับ, โทษทางอาญาในกรณีร้ายแรง, การดำเนินคดีและการเรียกคืนบริการ
- ตัวอย่างเหตุการณ์: คดีการเผยแพร่ deepfake ทางเพศที่มีการจับกุมและลงโทษ
- ญี่ปุ่น
- สถานะกฎระเบียบ: ใช้แนวทางผสมผสานระหว่างข้อบังคับด้านข้อมูลและแนวปฏิบัติของภาคเอกชน
- ข้อกำหนดที่สำคัญ: การจัดการข้อมูลอย่างรับผิดชอบ, การเก็บเมตาดาต้า และการโปร่งใสเชิงเทคนิค
- ระยะเวลาบังคับใช้: หลายแนวทางเป็นคำแนะนำที่มีผลบังคับใช้อย่างไม่เป็นทางการ ขณะเดียวกันมีการปรับปรุงกฎหมายความคุ้มครองข้อมูล
- บทลงโทษที่เป็นไปได้: คำสั่งปฏิบัติตาม, ปรับเชิงบริหาร และการฟ้องร้องทางแพ่ง
- ตัวอย่างเหตุการณ์: ภาคธุรกิจต้องมีมาตรการพิสูจน์แหล่งที่มาเมื่อการใช้ AI มีความเสี่ยงต่อความเป็นส่วนตัว
- สิงคโปร์
- สถานะกฎระเบียบ: แนวปฏิบัติเชิงมาตรฐานและ sandbox สำหรับการนำร่อง มุ่งส่งเสริมความรับผิดชอบของอุตสาหกรรม
- ข้อกำหนดที่สำคัญ: แนะนำการติดฉลากและการจัดการเมตาดาต้าเป็นแนวทางปฏิบัติที่ดี
- ระยะเวลาบังคับใช้: ส่วนใหญ่เป็นแนวปฏิบัติในระยะสั้น-กลาง แต่มีผลภายใต้กฎหมายคุ้มครองข้อมูลหากเกี่ยวข้อง
- บทลงโทษที่เป็นไปได้: การปรับและการดำเนินการตาม PDPA หากละเมิดข้อมูลส่วนบุคคล
- ตัวอย่างเหตุการณ์: โครงการนำร่องร่วมกับภาคเอกชนเพื่อทดสอบเทคโนโลยีการติดฉลากและการพิสูจน์แหล่งที่มา
- จีน
- สถานะกฎระเบียบ: บังคับใช้อย่างเข้มงวด มาตรการควบคุมการสังเคราะห์สื่อมีผลบังคับใช้แล้วในหลายมิติ
- ข้อกำหนดที่สำคัญ: ต้องติดเครื่องหมาย/เปิดเผยว่าเป็นสื่อสังเคราะห์, เก็บบันทึกการสร้างและเผยแพร่, ปฏิบัติตามมาตรการด้านความมั่นคงของข้อมูล
- ระยะเวลาบังคับใช้: หลายมาตรการประกาศและบังคับใช้แล้วในช่วงไม่กี่ปีที่ผ่านมา
- บทลงโทษที่เป็นไปได้: ปรับสูง, ระงับหรือสั่งถอดบริการ, การดำเนินคดีทางปกครองหรืออาญา
- ตัวอย่างเหตุการณ์: การสั่งบล็อกหรือปิดแอปที่เผยแพร่ข้อมูลสังเคราะห์โดยฝ่าฝืนข้อกำหนดการกำกับดูแล
ผลต่างเชิงนโยบายและผลกระทบต่อภาคธุรกิจ
ความแตกต่างระหว่างประเทศที่มีกฎเข้มงวด (เช่น จีนและเกาหลีใต้) กับประเทศที่ยังใช้แนวทาง (เช่น สิงคโปร์หรือญี่ปุ่นในหลายมิติ) สร้างผลกระทบเชิงปฏิบัติหลายด้าน: ต้นทุนการปฏิบัติตามข้อกำหนด (การพัฒนา watermarking, การเก็บเมตาดาต้าเชิงพิสูจน์), เวลาสู่ตลาด สำหรับฟีเจอร์ใหม่, และ ความเสี่ยงด้านกฎหมาย เมื่อให้บริการข้ามพรมแดน แพลตฟอร์มโฆษณาต้องออกแบบระบบที่รองรับหลายแอปโซน (region-specific compliance), สำนักข่าวต้องมีกระบวนการยืนยันแหล่งที่มาและสื่อสารเชิงโปร่งใสกับผู้อ่าน ส่วนแพลตฟอร์มแชร์วิดีโอจะถูกกดดันให้ผสานเทคโนโลยีการติดฉลากอัตโนมัติ (automated provenance stamping) และระบบรายงาน-ลบที่รวดเร็ว
สำหรับผู้ประกอบการในภูมิภาค คำแนะนำเชิงปฏิบัติรวมถึง: เริ่มนำระบบติดฉลากและเก็บเมตาดาต้าจากวันนี้, สร้างนโยบายการตรวจสอบคอนเทนต์ที่สอดคล้องกับมาตรฐานระดับสากล, และเตรียมแผนรับมือสำหรับความแตกต่างของข้อกำหนดในแต่ละประเทศ โดยสรุปแล้ว ภูมิทัศน์การกำกับดูแลในเอเชียมีความหลากหลายอย่างมาก และการปฏิบัติตามมาตรฐาน AI Content Provenance จะกลายเป็นตัวแยกสำคัญระหว่างผู้เล่นที่สามารถรักษาความน่าเชื่อถือและการเติบโตในระดับภูมิภาค กับผู้ที่เผชิญความเสี่ยงจากการบังคับใช้กฎระเบียบ
มาตรฐานทางเทคนิคที่ใช้บังคับ: วิธีการทำงานของ metadata, watermark และ signatures
มาตรฐานทางเทคนิคที่ใช้บังคับ: วิธีการทำงานของ metadata, watermark และ signatures
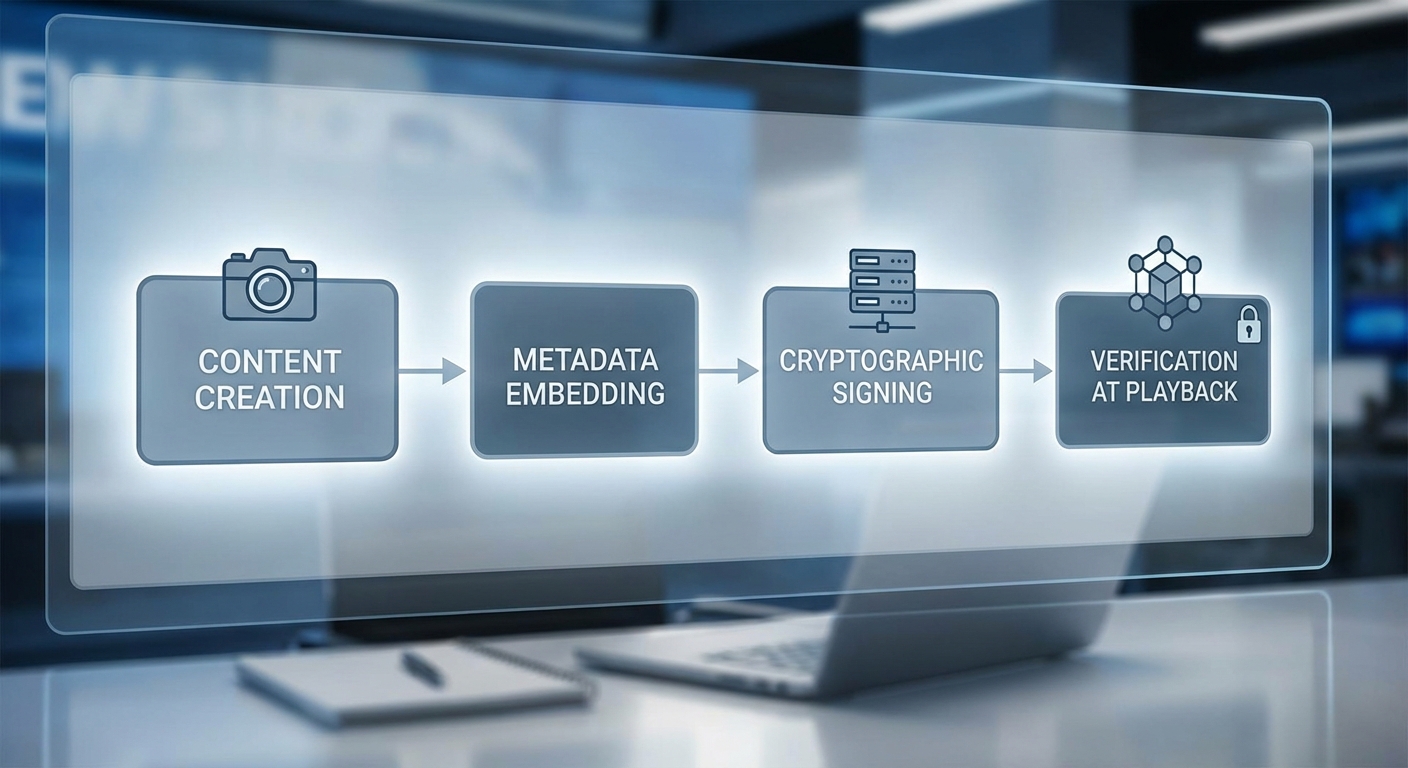
การบังคับใช้มาตรฐาน AI Content Provenance จะอาศัยชุดเทคนิคเชิงวิศวกรรมหลายรูปแบบร่วมกัน เพื่อยืนยันแหล่งที่มา (provenance) และความสมบูรณ์ของสื่อสังเคราะห์ โดยทั่วไปมีสามแกนหลักคือ embedded metadata (ทั้งแบบมองเห็น/ไม่มองเห็นในไฟล์), watermarking (visible/ invisible) และ cryptographic signatures / distributed ledger สำหรับยืนยันทางสากล เทคนิคแต่ละตัวมีบทบาทและข้อจำกัดที่ต่างกัน และระบบมาตรฐานมักผสานหลายวิธีเพื่อให้เกิดความทนทานต่อการบีบอัด การแก้ไข และการลบข้อมูล
ในเชิงปฏิบัติ การฝัง metadata ในไฟล์ (เช่น EXIF, XMP ในภาพ/วิดีโอ, ID3 ในเสียง หรือ container-level atoms เช่น MP4 'udta') จะเก็บข้อมูลเช่น: ผู้สร้าง, รุ่นโมเดล AI, prompt, timestamps, และ hash ของเนื้อหา (content hash) ข้อมูลเหล่านี้สามารถอ่านได้โดยโปรแกรมและ API แต่มีความเสี่ยงถูกรบกวนได้ง่ายจากการแก้ไฟล์หรือการรีแพ็กเกจ การออกแบบมาตรฐานจึงแนะนำให้ จับคู่ metadata ที่ฝังในไฟล์ กับ signature เชิงคริปโตกราฟฟี ที่บันทึกไว้ภายนอก (on-chain หรือในระบบบันทึกแบบกระจาย) เพื่อให้สามารถตรวจสอบความสมบูรณ์ได้แม้ metadata ถูกลบหรือดัดแปลง

เปรียบเทียบ: visible watermark vs invisible metadata vs blockchain signatures
- Visible watermark — ตราน้ำที่มองเห็นได้ (เช่น โลโก้หรือแถบข้อความ):
- ข้อดี: แจ้งผู้ชมทันทีว่าสื่อเป็นสังเคราะห์หรือมีแหล่งที่มาชัดเจน ลดการละเมิดข้อมูลโดยผู้ใช้ทั่วไป
- ข้อจำกัด: ลดประสบการณ์ผู้ใช้ (UX), ถูกตัด/ครอปออกได้โดยง่ายด้วยการตัดต่อหรือครอป และอาจถูกทำให้พร่าโดยการเปลี่ยน contrast หรือ overlay
- Invisible metadata / invisible watermark — ข้อมูลที่ฝังในไบต์ของไฟล์หรือฝังเชิงสัญญาณ (signal-domain watermark เช่น DCT/DWT ใน JPEG/MP4):
- ข้อดี: ไม่รบกวนการรับชม สามารถทำให้ทนต่อการบีบอัดและการเปลี่ยนแปลงในระดับเล็กน้อยหากออกแบบเป็น robust watermark
- ข้อจำกัด: มีทั้งประเภท robust (ทนต่อการบีบอัด/แปลงฟอร์แมต) และ fragile (ตรวจจับการแก้ไข) — แต่ไม่มีกลไกคริปโตกราฟฟีในตัว หากไฟล์ถูกรีคอมเพรสหรือแปลงฟอร์แมตอย่างหนัก watermark อาจถูกทำลายได้ งานวิจัยและการทดสอบในอุตสาหกรรมพบว่าอัตราการสูญเสียข้อมูล watermark หลังการบีบอัดหนักขึ้นกับอัลกอริทึม: อาจอยู่ในช่วง ประมาณ 10–90% ขึ้นอยู่กับพารามิเตอร์
- Cryptographic signatures / Distributed ledger — เซ็นชื่อด้วยกุญแจสาธารณะ/ส่วนตัวและบันทึก hash/metadata บน ledger (หรือเก็บ pointer เช่น CID บน IPFS แล้วบันทึก hash บน chain):
- ข้อดี: ให้การยืนยันความสมบูรณ์และแหล่งที่มาเชิงสากล (non-repudiation) หากสาธารณกุญแจถูกเชื่อถือได้
- ข้อจำกัด: เซ็นบนไบต์ดั้งเดิมเท่านั้น — หากไฟล์ถูกแก้แปลงแม้เล็กน้อย signature จะล้มเหลว จึงมักต้องใช้ควบคู่กับ perceptual hashing หรือการจัดเก็บ fingerprint หลายระดับ นอกจากนี้การบันทึกข้อมูลบน blockchain โดยตรงมีค่าใช้จ่ายและปัญหาด้านสเกล จึงนิยมบันทึกเฉพาะ hash/pointer เท่านั้น
workflow การติดแท็ก provenance: from ingestion → provenance tagging → verification at playback
ระบบมาตรฐานมักออกแบบเป็น pipeline สองชั้น: ชั้นที่จัดการ ingestion และการสร้าง/ฝังข้อมูลของผู้ผลิต และชั้นที่รองรับการตรวจสอบ (verification) เมื่อเผยแพร่หรือเล่นสื่อ กระบวนการหลักมีดังนี้
- Ingestion / Creation:
- จับข้อมูลเมต้า: ผู้สร้างบันทึก metadata (creator id, model id/version, prompt/seed, timestamp)
- คำนวณ content hash: เช่น SHA-256 ของ bytes หรือ fingerprint แบบ perceptual (pHash) เพื่อรองรับการเปลี่ยนแปลงเล็กน้อย
- สร้าง signature: Sign(private_key_creator, hash || metadata_json)
- ฝัง metadata ลงในไฟล์ (XMP/EXIF/ID3) และ/หรือฝัง invisible watermark ในโดเมนสัญญาณ
- บันทึก signature/hash/metadata summary บนระบบบันทึกภายนอก เช่น ledger หรือ database ที่เชื่อถือได้ (อาจบันทึกเฉพาะ hash บน blockchain และเก็บ metadata เต็มบนระบบ off-chain เช่น IPFS หรือ centralized registry)
- Distribution / Storage:
- ส่งมอบไฟล์ไปยัง CDN/แพลตฟอร์ม พร้อม pointer ไปยังการบันทึก provenance (เช่น txID, CID)
- เก็บตัวเลือกสำรอง: thumbnail/preview ที่มี watermark แบบเห็นได้ (visible) เพื่อให้ผู้ใช้รับรู้ทันที
- Verification at Playback:
- อ่าน metadata ฝังในไฟล์และ/หรือสกัด invisible watermark
- เรียกดู ledger/database ด้วย pointer เพื่อรับ public_key และ metadata ต้นฉบับ
- คำนวณ hash หรือ perceptual fingerprint ของไฟล์ปัจจุบันแล้วตรวจสอบ signature หรือเปรียบเทียบ fingerprint กับค่าใน registry
- แสดงผลการตรวจสอบต่อผู้ใช้/ระบบ (เช่น trusted, altered, unverifiable)
ตัวอย่าง pseudo-workflow (ย่อ)
- On creation:
- metadata = {creator, model, prompt, timestamp}
- content_bytes = read(file)
- crypt_hash = SHA256(content_bytes)
- signature = Sign(priv_key_creator, crypt_hash || Serialize(metadata))
- embed XMP(metadata + signature) into file; optionally embed robust invisible watermark(signal_domain)
- onchain_tx = SubmitToLedger(crypt_hash, metadata_summary) → returns tx_id
- return asset_id = {file, tx_id}
- On playback/verification:
- extracted_meta = ReadXMP(file) or ExtractWatermark(file)
- fetched_record = QueryLedger(extracted_meta.tx_id)
- current_hash = SHA256(read(file))
- if VerifySignature(fetched_record.pub_key, current_hash || fetched_record.metadata, extracted_meta.signature) → mark 'verifiable'
- else compute pHash(current_file) and compare to stored perceptual_fingerprint → if match within threshold → mark 'likely altered but same origin'
- else → mark 'unverifiable/altered'
ข้อจำกัดทางเทคนิคและแนวทางบรรเทาความเสี่ยง
แม้ระบบผสมจะเพิ่มความน่าเชื่อถือ แต่มีข้อจำกัดสำคัญที่ต้องพิจารณา:
- การบีบอัดและการแปลงฟอร์แมต: การบีบอัดภาพ/วิดีโอ (เช่น JPEG/AVC/HEVC) สามารถทำลาย watermark แบบอ่อนและลบ metadata ที่ไม่ถูกปกป้องได้ คำแนะนำคือใช้ robust watermarking ที่ฝังในโดเมนความถี่ และเก็บ hash/summary บน ledger เพื่อใช้ตรวจย้อน
- การแก้ไขที่ตั้งใจ: หากผู้ร้ายแก้ไขเนื้อหา (เช่นตัดต่อหรือแทรกเฟรม) cryptographic signature บนไบต์ดั้งเดิมจะล้มเหลว ต้องผสาน perceptual hashing และระบบ fingerprinting ที่ยอมรับการเปลี่ยนแปลงบางชนิด (และต้องออกแบบ threshold อย่างรัดกุม)
- การลบ/แก้ไข metadata: ฝัง metadata ในหลายชั้น (container-level + signal-level watermark + external ledger) ช่วยเพิ่มความทนทาน — การลบทั้งหมดพร้อมกันจะยากขึ้น แต่ไม่เป็นไปไม่ได้ โดยเฉพาะเมื่อไฟล์ถูก re-encode ใหม่
- ความเป็นส่วนตัวและขนาดข้อมูลบน chain: การบันทึก metadata บน blockchain โดยตรงอาจขัดต่อกฎคุ้มครองข้อมูลส่วนบุคคลและมีค่าใช้จ่ายสูง จึงนิยมบันทึกเฉพาะ hash หรือ pointer เท่านั้น และเก็บ metadata เชิงรายละเอียดบนระบบ off-chain ที่มีการคุมสิทธิ์
- สเกลและ latency: แพลตฟอร์มแชร์วิดีโอขนาดใหญ่ต้องรองรับการตรวจสอบแบบเรียลไทม์ — จึงมักใช้การตรวจสอบแบบไฮบริด: ตรวจเบื้องต้น (quick fingerprint/watermark extract) ที่ edge CDN แล้วทำการยืนยันเชิงลึกแบบ asynchronous กับ ledger
สรุปคือ มาตรฐาน AI Content Provenance ที่มีประสิทธิภาพต้องอาศัยการผสมผสานระหว่าง metadata ฝังในไฟล์, invisible/visible watermarking และ cryptographic signatures ที่เชื่อมโยงกับระบบบันทึกเชื่อถือได้ (เช่น distributed ledger) โดยออกแบบ pipeline ให้ยืดหยุ่นต่อการบีบอัด แปลงฟอร์แมต และการแก้ไขระดับเล็ก — พร้อมการบริหารความเสี่ยงด้านความเป็นส่วนตัวและค่าใช้จ่ายการเก็บข้อมูลบน chain
ผลกระทบต่อโฆษณาและการตลาดดิจิทัล
ผลกระทบต่อโฆษณาและการตลาดดิจิทัล
การบังคับใช้มาตรฐาน AI Content Provenance จะส่งผลโดยตรงต่อกระบวนการผลิตและการนำส่งโฆษณาดิจิทัล ตั้งแต่ต้นน้ำของครีเอทีฟจนถึงการรายงานผล ปฏิบัติการที่เคยเป็นแบบยืดหยุ่นจะต้องถูกเติมด้วยขั้นตอนการติดแท็ก แสดงแหล่งที่มา และการรับรองความถูกต้องของสื่อสังเคราะห์ ทำให้ทีมครีเอทีฟ เอเจนซี และฝ่ายกฎหมายต้องปรับ workflow โดยทั่วไปจะเห็นการเพิ่มขึ้นของจุดอนุมัติ (approval gates) เพื่อยืนยันการเปิดเผยการใช้ AI, การฝังเมทาดาต้า (metadata) ที่สอดคล้องกับมาตรฐาน และการผสานข้อมูล provenance เข้ากับระบบ Ad Ops และแพลตฟอร์มการซื้อสื่อ (DSP/SSP)
จากมุมมองเชิงธุรกิจ ผลกระทบทางการเงินและการปฏิบัติตามกฎมีทั้งต้นทุนเพิ่มขึ้นและผลประโยชน์เชิงระยะยาว ต้นทุนที่ต้องคำนึงรวมถึงค่าใช้จ่ายทางเทคนิคสำหรับการติดแท็กและเก็บ log, ค่าปรับปรุงสัญญากับผู้ให้บริการภายนอก, ค่าใช้จ่ายด้านการตรวจสอบภายนอก (audit) และเวลาแรงงานที่เพิ่มขึ้นสำหรับการอนุมัติครีเอทีฟ อย่างไรก็ดี ประโยชน์ที่อาจเกิดขึ้นรวมถึง ความเชื่อมั่นของแบรนด์ที่สูงขึ้น ซึ่งงานสำรวจช่วงปี 2022–2024 ชี้ให้เห็นแนวโน้มว่าโดยรวมผู้บริโภคประมาณ 60–80% ต้องการการเปิดเผยเมื่อเนื้อหาเกี่ยวข้องกับ AI และกลุ่มผู้บริโภคประมาณ 25–40% แสดงความเต็มใจที่จะจ่ายเพิ่มหรือให้ความสำคัญกับเนื้อหาที่มีการรับรองแหล่งที่มา ซึ่งบ่งชี้ว่าแบรนด์ที่โปร่งใสอาจได้รับผลตอบแทนเป็นอัตราการมีส่วนร่วม (engagement) และอัตราการรักษาลูกค้าที่ดีขึ้น
ในด้านการวัดผล (measurement) มาตรฐานการติดตราแหล่งที่มาจะเปลี่ยนวิธีการจัด Attribution และการประเมิน Viewability โดยเฉพาะเมื่อแพลตฟอร์มโฆษณาและเครื่องมือ third‑party verification (เช่น ผู้ให้บริการวัดผลและตรวจสอบความปลอดภัยของโฆษณา) เริ่มนำ provenance metadata ไปใช้ร่วมในกระบวนการตรวจสอบ การเปลี่ยนแปลงนี้อาจทำให้ต้องปรับโมเดล Attribution เพื่อแยกแยะระหว่างการมีส่วนร่วมจากครีเอทีฟที่มนุษย์สร้างและครีเอทีฟที่สังเคราะห์ด้วย AI อีกทั้งยังอาจส่งผลต่อการกำหนดราคาโฆษณา (CPM/CPA) หากตลาดให้มูลค่าสูงกับคอนเทนต์ที่ผ่านการรับรอง
เพื่อให้การเปลี่ยนผ่านเป็นไปอย่างราบรื่น นักการตลาดและเอเจนซีควรนำแนวทางปฏิบัติต่อไปนี้ไปใช้เป็นมาตรฐานภายในองค์กร:
- Labeling ที่ชัดเจนและสอดคล้อง: กำหนดรูปแบบการติดป้ายที่เห็นได้ชัดทั้งในระดับ metadata และการแสดงผลต่อผู้ใช้ (visible disclosure) ตามแนวทางของหน่วยงานกำกับ เพื่อหลีกเลี่ยงความสับสนและความเสี่ยงทางกฎหมาย
- ผนวกข้อกำหนดในสัญญากับผู้ให้บริการ: ระบุให้ผู้ขายครีเอทีฟและผู้ให้บริการเทคโนโลยีต้องส่งมอบ metadata provenance, การยืนยันแหล่งที่มา (attestation), สิทธิการตรวจสอบ (audit rights) และ SLA เกี่ยวกับการเก็บรักษา logs
- ผนวกระบบตรวจสอบภายในและภายนอก: ตั้งกระบวนการ audit รอบด้าน ทั้งการตรวจสอบแบบอัตโนมัติ (hashing, checksum, cryptographic signatures) และการตรวจสอบโดยบุคคลที่สาม เพื่อให้มั่นใจในความครบถ้วนของ chain‑of‑custody
- ปรับ workflow การอนุมัติ: เพิ่มขั้นตอนบังคับสำหรับการยืนยันแหล่งที่มาใน pipeline ของครีเอทีฟและแคมเปญ รวมถึงการฝึกอบรมทีมครีเอทีฟ ฝ่ายกฎหมาย และผู้ซื้อสื่อเกี่ยวกับมาตรฐานใหม่
- บูรณาการกับระบบการวัดและเทคโนโลยีโฆษณา: ทำงานร่วมกับ DSP, SSP, และผู้ให้บริการ verification เพื่อให้ provenance metadata ถูกส่งต่อและอ่านได้ตลอด supply‑chain ของการซื้อสื่อ
สรุปคือ การบังคับใช้มาตรฐาน AI Content Provenance จะนำมาซึ่งต้นทุนการปฏิบัติตามที่จับต้องได้ แต่ในทางเดียวกันก็เปิดโอกาสให้แบรนด์ที่ปรับตัวเร็วได้รับประโยชน์จากความเชื่อมั่นของผู้บริโภคและมูลค่าการตลาดที่เพิ่มขึ้น การวางนโยบายภายในที่ชัดเจน การปรับสัญญากับซัพพลายเออร์ และการลงทุนในระบบตรวจสอบที่เชื่อถือได้ จะเป็นปัจจัยสำคัญที่ทำให้นักการตลาดและเอเจนซีสามารถลดความเสี่ยงด้านกฎระเบียบ และเปลี่ยนความท้าทายนี้ให้เป็นข้อได้เปรียบเชิงแข่งขันได้อย่างยั่งยืน
ผลกระทบต่อสื่อข่าว ห้องข่าว และแพลตฟอร์มแชร์วิดีโอ — แนวทางการปฏิบัติสำหรับครีเอเตอร์
ผลกระทบต่อสื่อข่าว ห้องข่าว และแพลตฟอร์มแชร์วิดีโอ — แนวทางการปฏิบัติสำหรับครีเอเตอร์
การบังคับใช้มาตรฐาน AI Content Provenance จะเปลี่ยนรูปแบบการทำงานของห้องข่าวและแพลตฟอร์มแชร์วิดีโอทั้งในระดับเชิงปฏิบัติและเชิงธุรกิจ โดยเฉพาะในด้านการยืนยันข้อมูล (verification), แหล่งที่มาของคอนเทนต์, และกระบวนการแก้ไขข้อมูล (correction workflows) สำหรับห้องข่าว การมีตรา provenance บนสื่อสังเคราะห์หมายถึงทีมตรวจสอบข่าวต้องปรับกระบวนการเพื่อตรวจสอบเมตาดาต้าใหม่ เพิ่มขั้นตอนการ cross-check กับระบบ C2PA/Adobe Content Credentials หรือโซลูชันภายในองค์กร และติดตามการแก้ไขข้อมูลเมื่อมีการอัปเดต provenance ที่ถูกต้องหรือแก้ไขย้อนหลัง
ตัวอย่างเชิงปฏิบัติ: การประเมินในอุตสาหกรรมพบว่าเวลาเฉลี่ยในการยืนยันแหล่งที่มาของวิดีโอหรือภาพที่มีสัญญาณสังเคราะห์อาจเพิ่มขึ้น 40–70% หากต้องตรวจสอบทั้งไฟล์ต้นฉบับ เมตาดาต้า provenance และแหล่งที่มาทางเทคนิคอื่น ๆ โดยเฉพาะเมื่อไฟล์ถูกส่งผ่านหลายแพลตฟอร์ม นอกจากนี้ หัวหน้าห้องข่าวต้องออกแบบ workflow สำหรับการ versioning ของบทความ—รวมไปถึงการบันทึกเหตุผลและเวลาที่มีการอัปเดต provenance เพื่อให้กระบวนการแก้ไขโปร่งใสและสอดคล้องกับข้อบังคับใหม่
สำหรับแพลตฟอร์มแชร์วิดีโอ ผลที่เห็นได้ชัดคือความจำเป็นในการยกระดับระบบบังคับใช้ (policy enforcement) และระบบตอบสนองการละเมิด (takedown). ความท้าทายสำคัญประกอบด้วยการจัดการกับปริมาณคอนเทนต์ขนาดใหญ่ (scale), การลดอัตรา false positives ที่อาจนำไปสู่การลบคอนเทนต์ถูกต้อง และการออกแบบประสบการณ์ผู้ใช้ (UX) ที่สื่อสาร provenance อย่างชัดเจนแต่ไม่ทำให้ผู้ใช้งง เมื่อระบบอัตโนมัติระบุคอนเทนต์ว่าเป็น “มีที่มาจาก AI” แต่ผู้สร้างอ้างอิงแหล่งที่มาชัดเจน แพลตฟอร์มจำเป็นต้องมีช่องทางอุทธรณ์ที่รวดเร็วและตรวจสอบได้
ความท้าทายเชิงเทคนิคและเชิงปฏิบัติ
- Scale: แพลตฟอร์มที่มีผู้ใช้นับล้านวิดีโอต้องประมวลผลทั้งการเขียนและอ่าน metadata provenance แบบเรียลไทม์ — ระบบต้องสามารถจัดการ throughput ที่สูงโดยไม่ชะลอการอัปโหลดหรือการสตรีม
- False positives / false negatives: โมเดลตรวจจับที่ไม่แม่นยำอาจทำให้ครีเอเตอร์ถูกตีความผิดหรือคอนเทนต์อันตรายรอดพ้นการตรวจจับได้ แพลตฟอร์มต้องปลูกฝังกระบวนการ human-in-the-loop เพื่อลดผลลบเหล่านี้
- UX ในการแสดง provenance: ป้าย (badge) หรือแผงข้อมูลต้องออกแบบให้ชัดเจน เข้าใจง่าย และไม่รบกวนประสบการณ์การรับชม เช่น แสดงไอคอนขนาดเล็กที่เปิด panel รายละเอียด provenance เมื่อคลิก พร้อมลิงก์ไปยัง snapshot ของ metadata
แนวทางปฏิบัติสำหรับครีเอเตอร์
ครีเอเตอร์ต้องปรับมาตรฐานการทำงานเพื่อให้สอดคล้องกับข้อกำกับใหม่ โดยแนวทางสำคัญได้แก่:
- Tagging และ Disclosure: ฝัง metadata provenance ในไฟล์ (C2PA/Content Credentials) และใส่คำชี้แจงเปิดเผย (disclosure) บนหน้าโพสต์/คำบรรยายวิดีโอ เช่น “สร้างด้วยโมเดลภาพ AI รุ่น XYZ — มี content credential แนบ”
- การปรับสัญญาและสิทธิ์: ปรับสัญญากับลูกค้าที่ใช้บริการผลิตคอนเทนต์สังเคราะห์ให้ระบุความรับผิดชอบในการพูดถึง provenance, การเก็บรักษาแหล่งที่มา, และการอนุญาตใช้ metadata เพื่อการตรวจสอบ
- การจัดการลิขสิทธิ์และ monetization: ระบุให้ชัดเจนว่า content ที่เป็นสังเคราะห์มีสิทธิ์นำไป monetize ได้หรือไม่ และหากมีการปิดกั้น/จำกัดการค้นหาเพราะ tagged เป็น AI สปอนเซอร์/โฆษณาควรได้รับการแจ้งล่วงหน้า
เมตริกที่ต้องปรับและตัวอย่าง UI/UX ของป้าย provenance
แพลตฟอร์มและทีมคอนเทนต์จำเป็นต้องเพิ่ม/ปรับเมตริกเพื่อสะท้อนความเป็นจริงของคอนเทนต์สังเคราะห์ เช่น:
- อัตราการยืนยัน (verification rate): เปอร์เซ็นต์ของคอนเทนต์ที่มี metadata provenance และผ่านการตรวจสอบ
- เวลาเฉลี่ยในการยืนยัน (time-to-verify): จากการรับคอนเทนต์ถึงเสร็จสิ้นการตรวจสอบ
- อัตราการแก้ไข/retention หลังการติดป้าย: ผลต่อ CTR, view-through rate, และ CPM ของคอนเทนต์ที่ติดป้าย AI
- อัตรา false positive / appeal success rate: เพื่อติดตามความแม่นยำของระบบบังคับใช้
ตัวอย่าง UI/UX ของป้าย provenance (แนะนำ):
- ไอคอนมุมวิดีโอ (small badge) พร้อม tooltip: “ดูแหล่งที่มาของสื่อ”
- เมื่อคลิกเปิด panel ด้านข้าง แสดง: แหล่งที่มาของไฟล์ (origin), เครื่องมือ/โมเดลที่ใช้, timestamp ของการสร้าง, และ content credential snapshot พร้อมลิงก์ดาวน์โหลด metadata
- แสดงสถานะความน่าเชื่อถือเป็นระดับ เช่น Verified / Unverified พร้อมปุ่มอุทธรณ์หรือส่งข้อมูลเพิ่มเติมสำหรับครีเอเตอร์
Checklist และ Action Plan (3–6 ขั้นตอน)
Checklist สำหรับแพลตฟอร์ม (สรุปเป็น 4 ขั้นตอน):
- 1) ปรับระบบ ingestion ให้รับ/อ่าน C2PA/Content Credentials และเก็บเป็น immutable log
- 2) ติดตั้ง human-in-the-loop moderation สำหรับกรณีที่โมเดลอัตโนมัติระบุคอนเทนต์เสี่ยง
- 3) ออกแบบ UI/UX ป้าย provenance และช่องทางอุทธรณ์ที่ชัดเจน
- 4) ปรับ dashboard เมตริก (time-to-verify, false positive rate, revenue impact) และรายงานต่อผู้เกี่ยวข้อง
Action Plan สำหรับครีเอเตอร์ (3–5 ขั้นตอน):
- 1) ฝัง metadata provenance ในขั้นตอนการผลิต — ตั้งเป็น standard template ใน CMS/DAI ของทีม
- 2) ปรับคำสัญญา/ข้อตกลงกับลูกค้าให้ครอบคลุมการเปิดเผย provenance และการจัดสรรรายได้ (monetization rules)
- 3) เทรนนักสร้างคอนเทนต์และทีมเผยแพร่เกี่ยวกับการอ่าน/เขียน content credentials และขั้นตอนอุทธรณ์
- 4) ตรวจสอบผลกระทบต่อรายได้และ engagement ทุก 30–90 วัน ปรับกลยุทธ์เนื้อหาและการตั้งราคาโฆษณาตามข้อมูล
ตัวอย่างแพลตฟอร์มและฟีเจอร์นำร่อง
หลายองค์กรและโครงการนำร่องที่เกี่ยวข้อง อาทิ C2PA และ Adobe Content Credentials ที่เริ่มให้ความสามารถในการฝัง metadata ในงานสร้างสรรค์ ด้านแพลตฟอร์มมีการทดลองของหลายรายในการแสดงป้ายข้อมูลความน่าเชื่อถือ เช่น panels ข้อเท็จจริงของ BBC/Reuters (ในรูปแบบ information panels) และงานวิจัยจากผู้ประกอบการรายใหญ่ที่ทดสอบการผสาน provenance กับระบบ moderation เพื่อหาจุดสมดุลระหว่างความแม่นยำและประสบการณ์ผู้ใช้
สรุป: การบังคับใช้มาตรฐาน provenance เป็นทั้งความเสี่ยงและโอกาส — ห้องข่าวจะได้รับเครื่องมือเพิ่มความโปร่งใสและความไว้วางใจ แต่ต้องลงทุนในกระบวนการตรวจสอบและ versioning ส่วนแพลตฟอร์มต้องออกแบบระบบอัตโนมัติที่มีการตรวจสอบจากมนุษย์และ UX ที่ชัดเจน ครีเอเตอร์ที่ปรับตัวเร็วด้วยการฝัง metadata, ปรับสัญญา และเปิดเผยที่มาจะได้เปรียบทั้งด้านความน่าเชื่อถือและโอกาสด้านรายได้
ความท้าทายทางปฏิบัติและแนวทางการปฏิบัติตาม (Implementation & Compliance Roadmap)
ความท้าทายเชิงปฏิบัติ (Implementation Challenges)
การบังคับใช้มาตรฐาน AI Content Provenance ในบริบทของหน่วยงานโฆษณา สื่อข่าว และแพลตฟอร์มแชร์วิดีโอ เผชิญกับอุปสรรคเชิงปฏิบัติหลายประการที่ต้องวางแผนล่วงหน้า ได้แก่ ต้นทุนเชิงเทคนิค ความเข้ากันได้ระหว่างระบบ (interoperability) และความตึงเครียดระหว่างความเป็นส่วนตัวกับความโปร่งใสของข้อมูลกลาง
ในด้านต้นทุน องค์กรขนาดกลาง-ใหญ่ควรเผื่อค่าใช้จ่ายเริ่มต้นตั้งแต่ ประมาณ 50,000–500,000 USD ขึ้นอยู่กับระดับอัตโนมัติที่ต้องการ (เช่น การลงชื่อทางดิจิทัล การเก็บ metadata แบบ immutable และการพัฒนา API) และค่าใช้จ่ายประจำเช่น โฮสติ้ง ค่าบำรุงรักษา และค่าบริการ vendor ที่อาจคิดเป็น 5–15% ของงบเทคโนโลยีประจำปี ตัวอย่างเช่น แพลตฟอร์มขนาดใหญ่อาจต้องลงทุนสูงกว่าระบบข่าวท้องถิ่นที่มีปริมาณคอนเทนต์ต่ำ
ความเข้ากันได้ระหว่างแพลตฟอร์มและ vendor ถือเป็นความท้าทายหลัก เนื่องจากขณะนี้ยังมีมาตรฐานและ schema หลายแบบ (เช่น รูปแบบ metadata ต่าง ๆ การใช้ W3C Provenance แบบทั่วไป หรือโซลูชันเช่น cryptographic signatures) องค์กรจะต้องออกแบบสถาปัตยกรรมที่รองรับการ mapping ระหว่าง schema และมีกลไก fallback เพื่อรับมือกับเนื้อหาจากผู้ผลิตภายนอก
ในมุมมองความเป็นส่วนตัว การเปิดเผยแหล่งที่มาของสื่อสังเคราะห์อาจต้องมีการชั่งน้ำหนักระหว่าง transparency กับการปกป้องข้อมูลส่วนบุคคล (เช่น ผู้สร้างคอนเทนต์ บุคคลที่อยู่ในวิดีโอ หรือข้อมูลผู้ใช้งาน) การแก้ปัญหาที่เป็นไปได้รวมถึงการใช้ hashing, pseudonymization, selective disclosure และการออกแบบ consent flows เพื่อให้เป็นไปตามข้อกำหนดด้านข้อมูลส่วนบุคคล เช่น GDPR หรือ PDPA
Roadmap การนำไปปฏิบัติ (Assessment → Pilot → Integration → Full Rollout)
-
1) Assessment (0–3 เดือน)
กิจกรรมหลัก: สำรวจฉากทัศน์คอนเทนต์ (ads, editorial, user-generated video), ทำ inventory ระบบปัจจุบัน, ประเมิน vendor และเทคโนโลยีที่รองรับ provenance, วิเคราะห์ความเสี่ยงด้านความเป็นส่วนตัว และคำนวณต้นทุนเบื้องต้น
Deliverables: รายงาน GAP analysis, ข้อกำหนดเชิงเทคนิค (technical requirements), นโยบายความเป็นส่วนตัวเบื้องต้น
-
2) Pilot (3–6 เดือน)
กิจกรรมหลัก: เลือก use case จำกัด (เช่น โฆษณาบนหน้าแรก หรือวิดีโอที่มียอดวิวสูงสุด 5%), พัฒนา PoC ที่รวมการติด metadata, การลงลายมือชื่อดิจิทัล และ UI สำหรับแสดง provenance, ทดสอบการทำงานข้าม vendor และเก็บ feedback จากผู้ใช้
Deliverables: PoC พร้อมรายงานผลทดสอบความเข้ากันได้ latency ผลกระทบ UX และรายงาน Privacy Impact Assessment (DPIA)
-
3) Integration (6–9 เดือน)
กิจกรรมหลัก: ขยายขอบเขตการติดตั้งให้ครอบคลุมระบบสำคัญ (CMS, Ad servers, Ingest pipelines), สร้าง API/adapter สำหรับ vendor หลัก, วางมาตรการรักษาความปลอดภัย metadata (encryption, key management), และฝึกอบรมทีมปฏิบัติการ
Deliverables: เอกสารสถาปัตยกรรมการผสานระบบ, Service Level Agreements (SLAs) กับ vendor, แผนการสื่อสารแก่ผู้ใช้
-
4) Full Rollout (9–12 เดือน)
กิจกรรมหลัก: เปิดใช้ระบบเต็มรูปแบบ รวมทั้งการติดตามแบบเรียลไทม์ การตรวจสอบความครบถ้วนของ metadata, กระบวนการตอบสนองเหตุฉุกเฉินและการรายงานต่อหน่วยงานกำกับ, และการทดสอบ audit แบบสม่ำเสมอ
Deliverables: ระบบ production พร้อม monitoring dashboard, SOP การปฏิบัติตามกฎระเบียบ, บันทึกการ audit ที่เก็บรักษาเพื่อการตรวจสอบย้อนหลัง
ตัวชี้วัดความสำเร็จ (KPIs)
- Coverage Rate: เปอร์เซ็นต์คอนเทนต์ที่มี provenance metadata ถูกต้อง — เป้าหมายเริ่มต้น ≥ 70% ในช่วง rollout และ ≥ 95% ภายใน 12 เดือน
- Metadata Integrity: อัตราการตรวจสอบความสมบูรณ์ของ metadata ผ่านการยืนยันลายเซ็นหรือ checksum — เป้าหมาย ≥ 99%
- Interoperability Success Rate: สัดส่วนการแลกเปลี่ยน metadata กับ vendor/แพลตฟอร์มภายนอกที่สำเร็จโดยไม่ต้องแก้ไขด้วยมือ — เป้าหมาย ≥ 90%
- Latency Impact: เวลาหน่วงที่เพิ่มขึ้นต่อกระบวนการเผยแพร่เนื้อหา (end-to-end) — เป้าหมายเพิ่มไม่เกิน 100–200 มิลลิวินาทีสำหรับ UX-critical paths
- Privacy Incidents: จำนวนเหตุการณ์ละเมิดข้อมูลส่วนบุคคลที่เกี่ยวข้องกับ provenance — เป้าหมาย = 0 (และการแจ้งเหตุภายใน SLA)
- User Trust / Satisfaction: คะแนนเชิงสำรวจจากผู้ใช้หรือผู้ชมเกี่ยวกับความเชื่อมั่นในคอนเทนต์ — เป้าหมายเพิ่มขึ้น 10–20% หลัง rollout
- Compliance Audit Pass Rate: ผลการตรวจสอบภายใน/ภายนอกเกี่ยวกับการปฏิบัติตามมาตรฐาน — เป้าหมาย ≥ 95%
- Time-to-Flag: เวลาที่ใช้ในการตรวจจับและแยกแยะสื่อสังเคราะห์ที่ไม่มี provenance หรือสงสัยว่าเป็นของปลอม — เป้าหมายน้อยกว่า 24 ชั่วโมงในช่วงแรก และ < 4 ชั่วโมง ในสภาพแวดล้อมที่ต้องการความเร็วสูง
รายการตรวจสอบเพื่อการปฏิบัติตาม (Compliance Checklist)
- นโยบายและกรอบการกำกับ: อัปเดตนโยบายคอนเทนต์และนโยบายความเป็นส่วนตัวให้รวมข้อกำหนด provenance
- Metadata Schema: กำหนด schema ที่ชัดเจน (fields จำเป็น เช่น source_id, model_id/version, creation_timestamp, signing_key_id)
- Cryptographic Assurance: ใช้การลงชื่อดิจิทัลหรือ hash chain เพื่อให้ metadata ตรวจสอบไม่ถูกแก้ไข
- Access Control & Key Management: มาตรการจัดการคีย์ที่ปลอดภัย (HSM/Key Vault) และนโยบายการเข้าถึงแบบ Role-based
- Privacy-by-Design: ทำ DPIA, ใช้การลดข้อมูล (minimization), pseudonymization สำหรับข้อมูลผู้สร้างและผู้ที่อยู่ในคอนเทนต์
- Interoperability Tests: ทดสอบการแลกเปลี่ยน metadata กับ vendor/partner อย่างน้อย 3 ราย และบันทึกผลการทดสอบ
- Monitoring & Logging: ตั้งค่า logging สำหรับการเปลี่ยนแปลง metadata, การยืนยันลายเซ็น และเหตุการณ์ที่เกี่ยวข้อง พร้อม retention policy
- Incident Response Plan: แผนรับมือสำหรับการค้นพบคอนเทนต์ปลอมหรือการละเมิด metadata รวมทั้งช่องทางการรายงานต่อผู้ใช้และหน่วยงานกำกับ
- Contractual Clauses: รวมข้อกำหนด provenance ในสัญญากับผู้ผลิตคอนเทนต์และ vendor (SLA, audit rights, liability)
- UX/Disclosure: กำหนดรูปแบบการแสดงข้อมูล provenance ต่อผู้ชมอย่างชัดเจนและเข้าใจง่าย (e.g., badge, tooltip, link to audit)
- Training & Governance: ฝึกอบรมทีมบรรณาธิการ โฆษณา และทีมปฏิบัติการด้านเทคนิค พร้อมตั้งคณะกรรมการกำกับดูแลภายใน
- Audit Trail & Reporting: เก็บหลักฐานการตรวจสอบเพื่อการตรวจสอบย้อนกลับและรายงานต่อหน่วยงานกำกับอย่างสม่ำเสมอ
การนำมาตรฐาน provenance มาใช้ไม่เพียงเป็นเรื่องเทคนิค แต่ต้องผสานนโยบาย กฎหมาย และการออกแบบ UX เข้าด้วยกัน โดยการปฏิบัติตาม roadmap และใช้ KPIs กับ checklist ข้างต้น องค์กรจะสามารถลดความเสี่ยง เพิ่มความเชื่อมั่นของผู้ใช้ และเตรียมพร้อมตอบสนองต่อข้อกำกับในภูมิภาคเอเชียได้อย่างเป็นระบบ
บทสรุปและคำแนะนำเชิงปฏิบัติ
บทสรุปและคำแนะนำเชิงปฏิบัติ
การติดตามและระบุแหล่งที่มาของสื่อสังเคราะห์ (AI Content Provenance) กำลังกลายเป็นแนวปฏิบัติที่หน่วยงานกำกับดูแลในหลายประเทศเอเชียมีแนวโน้มจะบังคับใช้ในระดับกว้าง ภายในบริบทนี้ องค์กรด้านโฆษณา ห้องข่าว และแพลตฟอร์มแชร์วิดีโอต้องมองเรื่อง provenance เป็นสิ่งเร่งด่วนทั้งด้านความเสี่ยงและโอกาสทางธุรกิจ ไม่เพียงแต่เพื่อลดความเสี่ยงทางกฎหมายและชื่อเสียง แต่ยังสามารถใช้เป็นจุดขายเชิงความน่าเชื่อถือแก่ผู้ใช้และลูกค้าโฆษณาได้
เริ่มจากการประเมิน (assessment) และการทดลองนำร่อง (pilot) ก่อนการลงทุนเชิงโครงสร้างเต็มรูปแบบ ผู้บริหารควรกำหนดแผนการดำเนินงานสามขั้นตอนหลัก: สำรวจสินทรัพย์ดิจิทัลและกระบวนการสร้างคอนเทนต์ (content inventory) ระบุช่องทางที่ใช้โมเดล/เครื่องมือ AI ตรวจสอบซัพพลายเชนของคอนเทนต์ และประเมินความเสี่ยงเชิงกฎหมายและเชิงปฏิบัติการ จากนั้นให้ดำเนินการทดลองร่วมกับพันธมิตรทางเทคนิค (เช่น ผู้พัฒนาระบบ provenance, ผู้ให้บริการคลาวด์, และแพลตฟอร์มตรวจสอบ) เพื่อทดสอบการฝังเมตาดาต้า การตรวจสอบย้อนกลับ และผลกระทบต่อประสบการณ์ผู้ใช้ โดยตั้งเกณฑ์วัดผลที่ชัดเจน เช่น ความถูกต้องของการระบุแหล่งที่มา เวลาแฝง (latency) ในเวิร์กโฟลว์ และการยอมรับจากผู้ใช้
แนวทางปฏิบัติที่ควรเร่งดำเนินการรวมถึง:
- เริ่มการประเมินความเสี่ยงทันที: จัดทำแผน mapping ของคอนเทนต์และจุดที่มีการใช้ AI พร้อมจัดลำดับความเสี่ยงตามผลกระทบต่อผู้ใช้และข้อบังคับ
- ดำเนินการทดลองร่วมกับพันธมิตรทางเทคนิค: ทดสอบมาตรฐาน metadata, วิธีการฝังลายน้ำเชิงดิจิทัล และกระบวนการตรวจสอบย้อนกลับในสภาพแวดล้อมจริง
- ปรับสัญญากับซัพพลายเออร์และพันธมิตร: ระบุข้อกำหนดด้าน provenance ในสัญญา เช่น สิทธิการตรวจสอบ การส่งมอบ metadata และการรับประกันความสมบูรณ์ของข้อมูล
- เตรียมสื่อสารต่อผู้ใช้และลูกค้า: ออกแบบรูปแบบการแสดงป้าย/คำอธิบาย provenance และนโยบายความโปร่งใสที่เข้าใจง่าย เพื่อรักษาความเชื่อมั่น
- ตั้งกลไกกำกับดูแลภายใน: สร้างคณะทำงานข้ามสายงาน (กฎหมาย, เทค, การตลาด, ข่าวสาร) พร้อมกระบวนการตรวจสอบและบันทึก audit logs
นอกจากการลดความเสี่ยงแล้ว การให้ความสำคัญกับ provenance ยังเป็นโอกาสเชิงกลยุทธ์ องค์กรสามารถใช้การระบุแหล่งที่มาเป็นองค์ประกอบของแบรนด์ความน่าเชื่อถือ เช่น การมอบ "ตรายืนยันแหล่งที่มา" สำหรับคอนเทนต์ที่ผ่านการตรวจสอบ การนำเสนอรูปแบบโฆษณาที่เน้นความโปร่งใสสำหรับผู้ลงโฆษณา และการพัฒนาบริการพรีเมียมที่ยืนยันความถูกต้องของเนื้อหา สำหรับห้องข่าว การติดป้าย provenance ช่วยเพิ่มความไว้วางใจของผู้อ่าน ส่วนแพลตฟอร์มวิดีโอสามารถใช้ฟังก์ชันกรองหรือการค้นหาตามระดับการตรวจสอบต้นทางเป็นผลิตภัณฑ์เสริม
สรุป: ให้ดำเนินการแบบเป็นขั้นเป็นตอน เริ่มจากการประเมินและ pilot ภายใน 3–6 เดือนแรกเพื่อเรียนรู้ปัญหาเชิงปฏิบัติการ ก่อนจะขยายการลงทุนและอัปเดตนโยบายระดับองค์การ พร้อมติดตามข้อกำหนดของหน่วยงานกำกับดูแลอย่างใกล้ชิดและเข้าร่วมมาตรฐานอุตสาหกรรมเมื่อต้องการ ความพร้อมเชิงเทคนิคและการสื่อสารที่ชัดเจนจะเปลี่ยนการบังคับใช้ provenance จากภาระเป็นข้อได้เปรียบด้านความน่าเชื่อถือขององค์กร
บทสรุป
หน่วยงานกำกับดูแลในภูมิภาคเอเชียกำลังผลักดันให้การติดตราแหล่งที่มาของสื่อสังเคราะห์ (AI Content Provenance) กลายเป็นมาตรฐานบังคับใช้ ซึ่งจะส่งผลโดยตรงต่อ workflow ของโฆษณา สื่อข่าว และแพลตฟอร์มแชร์วิดีโอ ทั้งในแง่กระบวนการผลิต การจัดการเมตาดาต้า การตรวจสอบความถูกต้อง และนโยบายการเผยแพร่ ตัวอย่างผลกระทบได้แก่ การเพิ่มขั้นตอนในการติดแท็กครีเอทีฟโฆษณาที่สร้างด้วยโมเดลภาษา/ภาพ การผนวกข้อมูล provenance เข้าในระบบ CMS ของสำนักข่าวเพื่อตรวจสอบแหล่งที่มา และการปรับ API/UX ของแพลตฟอร์มวิดีโอเพื่อแสดงข้อมูลแหล่งที่มาและสถานะการตรวจสอบ งานสำรวจและรายงานระดับสากลชี้ว่า 60–75% ของผู้บริโภคต้องการให้มีการเปิดเผยเมื่อคอนเทนต์ถูกสร้างหรือปรับด้วย AI ซึ่งสะท้อนถึงแรงกดดันด้านจริยธรรมและความไว้วางใจที่กำลังเพิ่มขึ้น อีกทั้งมาตรฐานเช่น C2PA ถูกหยิบยกเป็นกรอบอ้างอิงที่องค์กรและผู้ควบคุมอาจใช้เป็นฐานในการออกกฎ
ผลลัพธ์เชิงอนาคตชัดเจน: การเตรียมความพร้อมเชิงเทคนิค (ระบบบันทึกเมตาดาต้า ความสามารถในการฝัง/อ่าน provenance, อินทิเกรชันกับ pipeline โฆษณา/CMS/แพลตฟอร์ม) และเชิงนโยบาย (แนวทางการติดป้าย การเปิดเผยต่อผู้ใช้ นโยบายความเป็นส่วนตัว) เป็นสิ่งจำเป็น และองค์กรที่เริ่มประเมิน ทดลองเชิงปฏิบัติการ และออกแบบกระบวนการตั้งแต่วันนี้จะได้เปรียบทั้งด้านการปฏิบัติตามกฎ (ลดความเสี่ยงทางกฎหมายและค่าปรับ) และภาพลักษณ์ต่อผู้บริโภค (เพิ่มความน่าเชื่อถือและความโปร่งใส) การเตรียมพร้อมควรเป็นแบบเป็นขั้นเป็นตอน — วิเคราะห์ความเสี่ยงภายใน ทดลอง Proof-of-Concept กับมาตรฐานสากล สร้างแผนการ migrate คอนเทนต์เก่า และสื่อสารกับผู้ใช้ชัดเจน — เพื่อให้สามารถปรับตัวได้รวดเร็วเมื่อมาตรฐานถูกบังคับใช้อย่างเต็มรูปแบบในช่วง 1–3 ปีข้างหน้า



