
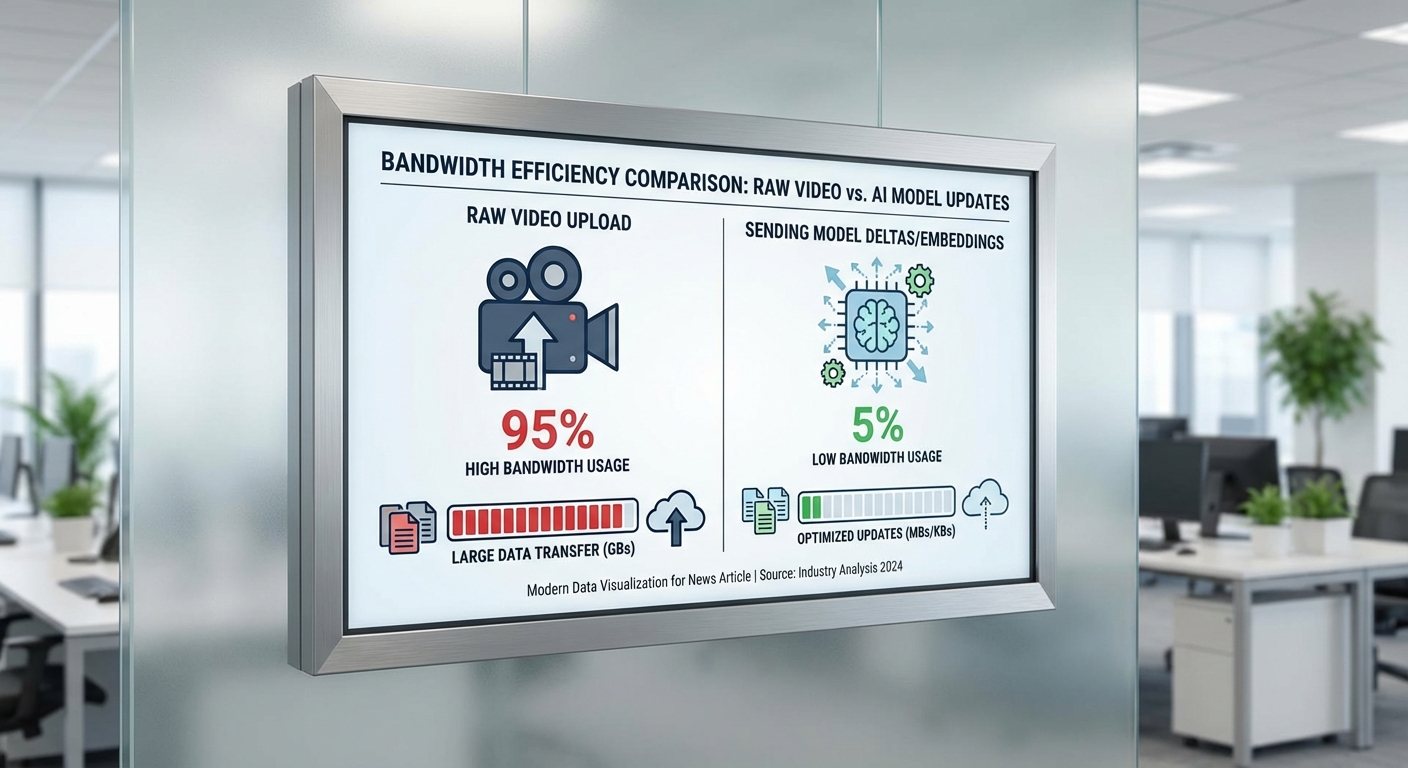
สตาร์ทอัพไทยรายหนึ่งกำลังก้าวข้ามขอบเขตของการเฝ้าระวังด้วยการเปิดตัวแพลตฟอร์ม On-Device Continual Learning ที่ออกแบบมาเพื่อให้กล้อง CCTV สามารถอัปเดตโมเดลตรวจจับพฤติกรรมผิดปกติได้ด้วยตัวเองบนอุปกรณ์ ณ ขอบเครือข่าย (edge) โดยไม่ต้องส่งภาพดิบขึ้นคลาวด์ ช่วยลดการใช้งานแบนด์วิดท์และบรรเทาความเสี่ยงด้านความเป็นส่วนตัวของข้อมูลภาพ ผู้พัฒนายังยืนยันว่าการอัปเดตแบบต่อเนื่องนี้สามารถลดการส่งข้อมูลวิดีโอผ่านเครือข่ายลงอย่างมีนัยสำคัญ—ตัวอย่างการทดสอบภาคสนามระบุว่าลดปริมาณข้อมูลที่ส่งขึ้นคลาวด์ได้ประมาณ 70–85% เมื่อเทียบกับระบบส่งภาพดิบทั้งหมด
บทความนี้จะพาผู้อ่านไปรู้จักแก่นเทคโนโลยีการเรียนรู้ต่อเนื่องบนอุปกรณ์ (On-Device Continual Learning) ของสตาร์ทอัพไทย อธิบายประโยชน์เชิงปฏิบัติการ เช่น การรักษาความเป็นส่วนตัวโดยไม่ต้องย้ายภาพดิบ การลดค่าใช้จ่ายแบนด์วิดท์ และการอัปเดตโมเดลที่ตอบโจทย์บริบทท้องถิ่น พร้อมสรุปคู่มือติดตั้งเชิงปฏิบัติการและสถิติเปรียบเทียบผลการทดสอบจริง เพื่อช่วยให้ภาครัฐ เอกชน และผู้ดูแลระบบ CCTV ตัดสินใจนำไปใช้อย่างมั่นใจ
เกริ่นนำ: ทำไม On‑Device Continual Learning สำหรับ CCTV จึงสำคัญ
เกริ่นนำ: ทำไม On‑Device Continual Learning สำหรับ CCTV จึงสำคัญ
ปริมาณข้อมูลวิดีโอที่ผลิตโดยกล้องวงจรปิด (CCTV) ทั่วโลกเพิ่มขึ้นอย่างทวีคูณในทศวรรษที่ผ่านมา โดยรายงานอุตสาหกรรมหลายฉบับระบุว่า วิดีโอจะยังคงเป็นสัดส่วนสำคัญของทราฟฟิกอินเทอร์เน็ต — ตัวอย่างเช่น ข้อมูลจากการสำรวจเครือข่ายชี้วัดภาพรวม (Visual Networking Index) แสดงว่าวิดีโอครอบคลุมสัดส่วนมากกว่า 80% ของทราฟฟิก IP ทั้งหมดในช่วงไม่กี่ปีที่ผ่านมา ในบริบทของประเทศไทยและภูมิภาคอาเซียน การติดตั้งกล้องวงจรปิดในภาคธุรกิจ สาธารณูปโภค และหน่วยงานภาครัฐมีอัตราเติบโตต่อเนื่อง สร้างข้อมูลวิดีโอจำนวนมหาศาลที่ต้องจัดเก็บ ประมวลผล และส่งผ่านเครือข่าย

ต้นทุนการส่งข้อมูลไปยังคลาวด์มีผลทางเศรษฐกิจอย่างชัดเจน ยกตัวอย่างเช่น กล้องความละเอียด 1080p ที่สตรีมแบบต่อเนื่องอาจใช้แบนด์วิดท์ประมาณ 2–4 Mbps ซึ่งเทียบได้กับข้อมูลประมาณ 600–1,200 GB ต่อกล้องต่อเดือน (ขึ้นกับบิตเรตและอัตราการบีบอัด) เมื่อสถานประกอบการมีหลายสิบถึงหลายร้อยกล้อง ค่าใช้จ่ายทั้งด้านแบนด์วิดท์และการจัดเก็บบนคลาวด์สามารถพุ่งสูงขึ้นอย่างรวดเร็ว ทั้งยังมีค่าใช้จ่ายแฝงจากการโอนข้อมูลซ้ำ การเรียกคืนไฟล์จากคลาวด์ และค่าบริการวิเคราะห์วิดีโอแบบเรียลไทม์ ซึ่งทั้งหมดนี้กดดันงบประมาณด้านไอทีขององค์กร
ในมิติด้านกฎหมายและความเป็นส่วนตัว ปัญหาการส่งภาพดิบขึ้นเซิร์ฟเวอร์มีความเสี่ยงทั้งต่อการละเมิดข้อมูลและการไม่เป็นไปตามหลักเกณฑ์ PDPA ของประเทศไทย (Personal Data Protection Act) รวมถึงกฎระเบียบของภูมิภาคอื่นๆ การเก็บรักษาและประมวลผลภาพใบหน้าหรือข้อมูลพฤติกรรมโดยไม่ได้รับการคุ้มครองเพียงพออาจทำให้เกิดความเสี่ยงทางกฎหมายและความเสียหายต่อชื่อเสียงองค์กร การส่งเฉพาะข้อมูลเชิงสถิติหรือโมเดลที่อัพเดตแทนการส่งภาพดิบ จึงเป็นแนวทางที่ช่วยลดความเสี่ยงดังกล่าวได้อย่างมีประสิทธิภาพ
อีกด้านหนึ่ง ปัญหาทางเทคนิคทำให้ความจำเป็นในการอัปเดตโมเดลอย่างต่อเนื่อง (continual learning) มีความสำคัญสูงในสภาพแวดล้อมจริง เช่น
- Data drift / Concept drift: สภาพแวดล้อมการถ่ายภาพเปลี่ยนตามเวลา (แสง สภาพอากาศ การจัดวางกล้อง) ทำให้ประสิทธิภาพของโมเดลที่ฝึกไว้ล่วงหน้าลดลงเมื่อเวลาผ่านไป
- New anomalies and long‑tail events: เหตุการณ์ผิดปกติที่เกิดขึ้นจริงมีความหลากหลายและไม่สามารถคาดการณ์ได้ทั้งหมดจากชุดข้อมูลเริ่มต้น จึงต้องการการเรียนรู้ต่อเนื่องเพื่อจับลักษณะใหม่ๆ
- Label scarcity และการเปลี่ยนแปลงบริบท: ไม่สามารถเก็บตัวอย่างที่มีป้ายกำกับครบถ้วนสำหรับทุกสถานการณ์ในภาคสนาม การปรับโมเดลแบบ on‑device ช่วยให้ระบบเรียนรู้จากตัวอย่างที่เกิดขึ้นจริงโดยไม่ต้องส่งข้อมูลดิบออกไป
ด้วยข้อจำกัดด้านแบนด์วิดท์ ค่าใช้จ่ายคลาวด์ และความเป็นส่วนตัว การนำแนวคิด On‑Device Continual Learning มาประยุกต์กับกล้อง CCTV จึงกลายเป็นความจำเป็นเชิงปฏิบัติ นโยบายที่ส่งเฉพาะการอัปเดตโมเดลหรือลักษณะเชิงคุณลักษณะ (feature summaries) แทนการส่งภาพดิบ ช่วยลดปริมาณข้อมูลที่ต้องถ่ายโอน ปรับปรุงความเป็นส่วนตัวให้ดีขึ้น และทำให้โมเดลตรวจจับพฤติกรรมผิดปกติสามารถปรับตัวได้อย่างต่อเนื่องในสภาพแวดล้อมจริงของไทยและภูมิภาคอาเซียน
พื้นฐานเทคนิค: อะไรคือ On‑Device Continual Learning (ODCL)
นิยามและหลักการของ Continual Learning
Continual Learning (หรือบางครั้งเรียกว่า lifelong learning) หมายถึงกรอบการเรียนรู้ของโมเดลที่สามารถปรับตัวและอัพเดตความรู้เมื่อได้รับข้อมูลใหม่อย่างต่อเนื่องโดยไม่ต้องเทรนใหม่จากศูนย์ทั้งหมด จุดประสงค์หลักคือรักษาสมดุลระหว่างความสามารถในการเรียนรู้ข้อมูลใหม่ (plasticity) และการรักษาความรู้เดิม (stability) เพื่อหลีกเลี่ยงปรากฏการณ์ที่เรียกว่า catastrophic forgetting ซึ่งเป็นการลืมความสามารถที่เคยเรียนรู้เมื่อโมเดลถูกอัพเดตด้วยข้อมูลชุดใหม่
ในบริบทของกล้อง CCTV บน edge, continual learning บนอุปกรณ์ (On‑Device Continual Learning, ODCL) จะหมายถึงการให้กล้องหรืออุปกรณ์ข้างต้นสามารถอัพเดตโมเดลตรวจจับพฤติกรรมผิดปกติได้จากข้อมูลการใช้งานจริง โดยไม่จำเป็นต้องส่งภาพดิบทั้งหมดขึ้นคลาวด์ การอัพเดตเหล่านี้มักทำเป็นแบบ incremental updates — เพิ่มความรู้ใหม่เป็นลำดับ ๆ — เพื่อให้โมเดลปรับตัวต่อพฤติกรรมใหม่ของพื้นที่ เช่น การเปลี่ยนแปลงทางแสง สภาพอากาศ หรือรูปแบบการเคลื่อนไหวที่เปลี่ยนไปตามเวลา
เทคนิคการป้องกัน Catastrophic Forgetting
มีสามแนวทางหลักที่นิยมใช้ในการลดหรือป้องกันการลืมเมื่อเรียนรู้อย่างต่อเนื่อง:
- Replay (Experience / Generative Replay) — เก็บตัวอย่างสำคัญจากข้อมูลเก่าไว้ในรูปแบบ memory buffer แล้วผสมข้อมูลเก่าเหล่านี้กับข้อมูลใหม่ในการอัพเดต เพื่อรักษาความรู้เดิม ตัวอย่างในทางปฏิบัติคือการเก็บกรอบภาพตัวอย่างจำนวนน้อยหรือใช้โมเดลสร้างภาพ/embeddings จำลอง (generative model) แทนภาพดิบเพื่อลดการเก็บข้อมูลจริง
- Regularization — บังคับให้พารามิเตอร์ของโมเดลไม่เปลี่ยนแปลงมากเกินไปสำหรับฟีเจอร์ที่มีความสำคัญต่อความรู้เก่า เทคนิคตัวอย่างเช่น Elastic Weight Consolidation (EWC), Learning without Forgetting (LwF) หรือวิธีการ distillation ซึ่งจะใส่ "โทษ" เมื่อน้ำหนักสำคัญถูกเปลี่ยนมาก
- Architectural methods — ปรับสถาปัตยกรรมของโมเดลเพื่อลดการชนกันของน้ำหนัก เช่น การขยายเครือข่ายแบบไดนามิก (dynamic expansion), ใช้โมดูลแยกส่วน (expert modules) หรือการสำรองพารามิเตอร์เฉพาะงาน รวมถึงการใช้ sparse representations เพื่อลดการรบกวนข้ามงาน
การประยุกต์ ODCL บนอุปกรณ์ Edge และช่องทางการสื่อสารที่ไม่ส่งภาพดิบ
ในสภาพแวดล้อม edge เช่นกล้อง CCTV ความจำและพลังประมวลผลมีจำกัด จึงต้องออกแบบกระบวนการเรียนรู้และการสื่อสารให้เหมาะสม โดยหลักการสำคัญคือส่งข้อมูลที่มีขนาดเล็กและไม่เปิดเผยภาพดิบเพื่อรักษาความเป็นส่วนตัว ตัวเลือกที่ใช้งานได้จริงได้แก่:
- Model deltas / parameter updates — ส่งความแตกต่างของน้ำหนักหรือพารามิเตอร์ (delta) ที่เกิดจากการอัพเดตบนอุปกรณ์ไปยังเซิร์ฟเวอร์ แล้วรวม (aggregate) กับ delta จากอุปกรณ์อื่น ๆ ก่อนส่งกลับมาเป็นรุ่นใหม่ของโมเดล วิธีนี้ลดปริมาณข้อมูลเมื่อเทียบกับการส่งภาพดิบ และเซิร์ฟเวอร์ไม่เห็นภาพผู้ใช้
- Compressed embeddings — แปลงภาพหรือคลิปเป็นเวกเตอร์คุณลักษณะ (feature embeddings) ด้วย encoder บนเครื่อง แล้วส่งเฉพาะ embeddings ที่ถูกบีบอัด (quantization, PCA, autoencoder) แทนการส่งภาพเต็ม เทคนิคนี้มักลดแบนด์วิดท์ได้ตั้งแต่หลักสิบถึงหลักร้อยเท่า ขึ้นกับมิติของ embedding และการบีบอัด
- Gradients — ส่ง gradients ที่คำนวณจากข้อมูลโลคอลไปยังเซิร์ฟเวอร์เพื่อการอัพเดตร่วมกัน แต่ต้องระวังว่าค่ากราดิเอนต์อาจรั่วข้อมูลต้นฉบับ จึงควรเสริมด้วยการเข้ารหัส การทำ aggregation แบบปลอดภัย หรือการประกันความเป็นส่วนตัวเชิงคณิตศาสตร์ (differential privacy)
- สรุปผลเชิงสัญญาณ (metadata) หรือ anomaly scores — ในบางกรณีส่งแค่สกอร์หรือแท็กเหตุการณ์ที่สำคัญ (เช่น anomaly/confidence) แทนข้อมูลเชิงภาพ ทั้งลดแบนด์วิดท์และปกป้องความเป็นส่วนตัว
ต่างจาก Federated Learning ซึ่งเป็นกรอบที่เน้นการรวมการอัพเดตจากอุปกรณ์จำนวนมากอย่างสม่ำเสมอเพื่อสร้างโมเดลกลาง ODCL เน้นความสามารถในการเรียนรู้และปรับตัวของแต่ละอุปกรณ์เป็นหลัก และอาจสื่อสารกับเซิร์ฟเวอร์เพียงเป็นช่วง ๆ เพื่อประหยัดแบนด์วิดท์และจำกัดการเปิดเผยข้อมูล ตัวอย่างความต่างสำคัญได้แก่:
- Federated Learning: มุ่ง aggregation จากหลาย clients เป็นรอบ ๆ (rounds) เพื่อฝึกโมเดลรวม ส่วนใหญ่เน้นการซิงค์แบบพหุภาคี
- ODCL: มุ่งให้แต่ละอุปกรณ์สามารถเรียนรู้แบบต่อเนื่องเอง และส่งเฉพาะข้อมูลสรุป (deltas/embeddings/gradients) เมื่อจำเป็น เพื่อการปรับปรุงแบบกระจายหรือแบบผสม
โฟลว์การทำงานเชิงสั้น (ตัวอย่างไดอะแกรมแบบข้อความ):
Device: Raw image (local) → local model update (incremental) → produce model delta / compressed embedding / score → send to Server (secure aggregation) → Server aggregates/validates → send aggregated delta back → Device applies update
สรุปคือ ODCL บนกล้อง CCTV ผสานเทคนิค continual learning (replay, regularization, architectural) กับช่องทางการสื่อสารที่ไม่ส่งภาพดิบ (deltas, embeddings, gradients ที่ได้รับการป้องกัน) เพื่อให้ได้โมเดลที่ปรับตัวได้จริงในภาคสนาม พร้อมทั้งลดการใช้แบนด์วิดท์และเพิ่มความคุ้มครองด้านความเป็นส่วนตัวตามความต้องการเชิงธุรกิจและข้อบังคับด้านข้อมูล
สถาปัตยกรรมแพลตฟอร์มของสตาร์ทอัพไทย: dataflow และโมดูลหลัก
สถาปัตยกรรมแพลตฟอร์ม: dataflow และโมดูลหลัก
ภาพรวมสถาปัตยกรรมและโมดูลหลัก
แพลตฟอร์มของสตาร์ทอัพไทยออกแบบมาเพื่อให้กล้อง CCTV สามารถเรียนรู้แบบต่อเนื่อง (continual learning) บนเครื่อง (on‑device) โดยไม่ส่งภาพดิบขึ้นคลาวด์เพื่อคงความเป็นส่วนตัวและลดแบนด์วิดท์ โครงสร้างหลักประกอบด้วยโมดูลย่อยที่ทำงานสัมพันธ์กัน ได้แก่ edge agent บนกล้อง (capture & inference), local updater / trainer, model manager บนอุปกรณ์ท้องถิ่น และ secure sync server / central aggregator ในฝั่งเซิร์ฟเวอร์กลาง ระบบถูกออกแบบให้ไหลในรูปแบบลำดับงานดังนี้: capture → inference → local trainer → uploader (deltas/embeddings) → central aggregator เพื่อให้การสื่อสารส่งเฉพาะข้อมูลที่จำเป็นเท่านั้นและรักษาข้อมูลภาพดิบไว้บนอุปกรณ์เสมอ
คำอธิบายโมดูลและการไหลของข้อมูล
รายละเอียดของแต่ละโมดูลและการไหลของข้อมูลมีดังนี้:
- Capture (Edge Camera): รับภาพจากเซ็นเซอร์และทำ pre‑processing เบื้องต้น (resize, normalization) แต่ ไม่ส่งภาพดิบออก. การบันทึกภาพลงที่ local storage ถูกจำกัดตามนโยบายความเป็นส่วนตัวและรอบเวลา (retention policy).
- Inference (Edge Agent): รันโมเดลตรวจจับพฤติกรรมแบบเรียลไทม์บนกล้องและสร้างผลลัพธ์เชิงเหตุการณ์ (event metadata) เช่น เหตุการณ์ผิดปกติ ความเชื่อมั่น (confidence), bounding boxes (เชื่อมโยงด้วยค่าแยกไม่สามารถย้อนกลับเป็นภาพ) ซึ่งเก็บไว้เพื่อตรวจสอบหรือใช้เป็นตัวอย่างฝึกภายในเครื่อง
- Local Trainer / Updater: เมื่อกล้องสะสมตัวอย่างที่มีคุณภาพเพียงพอ (เช่น เหตุการณ์ผิดปกติซ้ำๆ หรือการตรวจจับที่ confidence ต่ำ) โมดูลนี้จะสร้างการอัปเดตแบบ incremental โดยฝึกแบบจำกัดขอบเขต (few-shot / mini‑batches) บน embeddings หรือ feature vectors ที่สร้างจากภาพ แทนการใช้ภาพดิบ
- Uploader: ส่งเฉพาะข้อมูลที่ย่อ/สรุปแล้วไปยังส่วนกลาง เช่น model weights diff, compressed feature vectors หรือ telemetry ทั้งนี้การส่งข้อมูลจะถูกบีบอัดและเข้ารหัสก่อน
- Central Aggregator / Secure Sync Server: รวบรวม deltas จากหลายอุปกรณ์ ทำการรวมแบบ federated aggregation (เช่น secure federated averaging) และสร้างโมเดลเวอร์ชันใหม่ จากนั้นเซิร์ฟเวอร์จะลงนามดิจิทัลและแจกจ่ายโมเดลกลับไปยังอุปกรณ์ผ่านช่องทางที่ปลอดภัย
รูปแบบข้อมูลที่ส่งและตัวอย่างขนาดข้อมูล
เพื่อจำกัดปริมาณการส่งและลดความเสี่ยงด้านความเป็นส่วนตัว แพลตฟอร์มเลือกส่งเฉพาะข้อมูลเชิงสรุปและการเปลี่ยนแปลงโมเดล ดังต่อไปนี้:
- Model weights diff: ส่งเป็นตัวต่าง (delta) ระหว่างพารามิเตอร์ เพื่อให้ขนาดเล็กลงโดยใช้เทคนิคเช่น sparsification และ quantization — ตัวอย่างเช่น โมเดลขนาด 50 MB อาจได้ delta ที่ 100–500 KB หลังการบีบอัด
- Compressed feature vectors / embeddings: ออกแบบให้มีมิติขนาดเล็ก (เช่น 128‑dim) แล้ว quantize เป็น int8 หรือใช้ PCA เพื่อลดมิติ ขนาดเฉลี่ยอาจอยู่ที่ 100–200 ไบต์ต่อเหตุการณ์ ซึ่งช่วยลดแบนด์วิดท์ลงกว่า 85–95% เมื่อเทียบกับการส่งภาพเต็ม
- Telemetry & metadata: ข้อมูลเชิงสถิติ เช่น ความถี่เหตุการณ์, confidence histogram, health metrics ของฮาร์ดแวร์/โมเดล ซึ่งมักเป็นข้อความขนาดเล็ก (ไม่กี่สิบถึงหลายร้อยไบต์) เพื่อใช้การวิเคราะห์เชิงปฏิบัติการ
กลไกการอัปเดตโมเดลแบบ incremental และการรับรองความถูกต้อง
การอัปเดตโมเดลเป็นแบบ incremental เพื่อให้การเรียนรู้เกิดขึ้นต่อเนื่องโดยทรัพยากรจำกัดบนอุปกรณ์มีประสิทธิภาพ โดยใช้กระบวนการดังนี้:
- Local incremental training: อุปกรณ์ฝึกบน batch ขนาดเล็กจาก embeddings ที่คัดเลือก (e.g., hard negatives หรือ low‑confidence samples) และสร้าง weight diffs หรือ gradient updates ที่ถูกบีบอัด
- Secure aggregation: Central aggregator ผสาน diffs จากหลายอุปกรณ์โดยไม่สามารถเห็นข้อมูลดิบของแต่ละอุปกรณ์ ใช้เทคนิค secure aggregation เพื่อป้องกันการเปิดเผยข้อมูลเฉพาะราย
- Validation pipeline ก่อน deploy: ก่อนโมเดลใหม่จะถูกแจกจ่ายกลับไปยังกล้อง มีขั้นตอนรับรองความถูกต้องหลายชั้น เช่น
- Server‑side validation: ทดสอบโมเดลที่รวมแล้วบนชุดข้อมูลรวมของเซิร์ฟเวอร์ (holdout) เพื่อวัด metric สำคัญ (precision, recall, F1) และตรวจจับ regression
- Shadow / Canary deployment: ปล่อยโมเดลใหม่ในโหมด shadow บนอุปกรณ์กลุ่มเล็กเพื่อรันคู่ขนานกับโมเดลเดิม โดยไม่ส่งผลต่อการตัดสินใจจริง เพื่อเปรียบเทียบพฤติกรรมจริงในสนาม
- On‑device acceptance tests: เมื่อได้รับแพ็กเกจโมเดล อุปกรณ์จะตรวจสอบชุดทดสอบภายในอย่างรวดเร็ว (sanity checks) และคำนวณ metric ที่จำกัดก่อนยอมรับใช้งานจริง
- Automatic rollback: หากพบการลดลงของ performance หลัง deploy ระบบสามารถสั่ง rollback ไปยังเวอร์ชันก่อนหน้าได้ทันที
ระบบความปลอดภัยและการรับรองความสมบูรณ์ของโมเดล
ด้านความปลอดภัยเป็นหัวใจสำคัญของสถาปัตยกรรมนี้ แพลตฟอร์มผสานมาตรการหลายชั้นเพื่อป้องกันการดัดแปลงและรักษาความลับข้อมูล:
- TLS / mTLS: ทุกการสื่อสารระหว่างอุปกรณ์และเซิร์ฟเวอร์ใช้ TLS อย่างน้อย และสำหรับการรับส่งโมเดลสำคัญจะใช้ mutual TLS (mTLS) เพื่อยืนยันตัวตนของทั้งสองฝ่าย
- Secure aggregation & privacy-preserving protocols: การรวม diffs จากหลายอุปกรณ์ทำผ่าน secure aggregation ที่ออกแบบมาไม่ให้เซิร์ฟเวอร์เห็นการอัปเดตของอุปกรณ์ใดอุปกรณ์หนึ่งโดยลำพัง นอกจากนี้สามารถเลือกเปิดใช้ differential privacy การเพิ่ม noise ในระดับควบคุมเพื่อปกป้องข้อมูลเชิงบุคคล
- Model signing & integrity checks: หลังจาก central aggregator สร้างโมเดลเวอร์ชันใหม่ จะมีการลงนามดิจิทัล (model signing) ด้วยคีย์ขององค์กรและแนบ checksum (e.g., SHA‑256) เมื่ออุปกรณ์ดาวน์โหลด โมดูล model manager จะตรวจสอบลายเซ็นและ checksum ก่อนติดตั้ง
- Audit trail & telemetry: ทุกขั้นตอนของการอัปเดตถูกบันทึกเป็น log แบบไม่เปลี่ยนแปลง (immutable audit trail) เพื่อการตรวจสอบย้อนหลังและตอบสนองต่อเหตุการณ์ความปลอดภัย
สรุปโดยรวม สถาปัตยกรรมนี้มุ่งเน้นให้เกิดการเรียนรู้ต่อเนื่องแบบกระจายโดยคงไว้ซึ่งความเป็นส่วนตัวและความปลอดภัย ขณะเดียวกันยังลดการใช้แบนด์วิดท์ผ่านการส่งเพียง model diffs, compressed embeddings และ telemetry แทนภาพดิบ และใช้วงจร validation ที่เข้มงวดก่อนนำโมเดลไปใช้งานจริงเพื่อให้ทั้งประสิทธิภาพและความน่าเชื่อถือเป็นไปตามข้อกำหนดของระบบเชิงพาณิชย์
ผลลัพธ์เชิงตัวเลข: ลดแบนด์วิดท์และเพิ่มความเป็นส่วนตัวอย่างไร
ผลลัพธ์เชิงตัวเลข: ลดแบนด์วิดท์และเพิ่มความเป็นส่วนตัวอย่างไร
การทดสอบเชิงปฏิบัติการของแพลตฟอร์ม On‑Device Continual Learning แสดงให้เห็นผลเชิงตัวเลขที่ชัดเจนทั้งด้านการลดแบนด์วิดท์ การปรับปรุงความหน่วง (latency) และการเพิ่มความแม่นยำของโมเดลแบบต่อเนื่อง โดยสรุปผลสำคัญ ได้แก่ การลดปริมาณข้อมูลที่ส่งไปยังคลาวด์อยู่ในช่วงประมาณ 80–95% ขึ้นกับรูปแบบข้อมูลที่ส่ง (embeddings, model delta) และความถี่ของการส่งข้อมูล ตัวอย่างเชิงตัวเลขต่อไปนี้อธิบายความแตกต่างในมิติต่าง ๆ อย่างละเอียด
ตัวอย่างเปรียบเทียบปริมาณข้อมูล (conservative scenario) — หากกล้องจับภาพที่ความละเอียด 1080p แล้วบีบอัดเป็น JPEG ให้ขนาดเฉลี่ยประมาณ 200 KB ต่อเฟรม ที่ความถี่ 1 fps จะได้ปริมาณข้อมูล ~200 KB/s หรือ ~17.3 GB/วัน (≈522 GB/เดือน)
ในทางกลับกัน หากส่งเป็น embeddings ขนาด 256‑dim float32 (~1 KB ต่อเฟรม) ที่ความถี่เดียวกัน จะได้ ~1 KB/s หรือ ~86 MB/วัน (≈2.6 GB/เดือน) ซึ่งเป็นการลดแบนด์วidth ประมาณ 99.5% ในกรณีนี้ แต่ในระบบจริงที่ต้องส่ง model delta เป็นช่วง ๆ (เช่น เมื่อต้องการอัปเดตโมเดล) ขนาดของ delta อาจอยู่ในช่วง 10–200 KB ต่อการอัปเดต และความถี่การอัปเดตอาจเป็นรายชั่วโมงหรือรายวัน ทำให้การลดแบนด์วิดท์ที่เกิดขึ้นในภาพรวมอยู่ในขอบเขต 80–95% ขึ้นกับนโยบายการส่งข้อมูล

ตัวอย่างการคำนวณเชิงธุรกิจ (ROI เบื้องต้น) — สมมติค่าใช้จ่ายเครือข่ายคลาวด์อยู่ที่ ~USD 0.09 ต่อ GB (ค่าส่งข้อมูลขาออก):
- สตรีมภาพดิบ: ~522 GB/เดือน → ค่าใช้จ่าย ≈ USD 47/เดือน ต่อกล้อง
- ส่ง embeddings: ~2.6 GB/เดือน → ค่าใช้จ่าย ≈ USD 0.23/เดือน ต่อกล้อง
- ดังนั้นการประหยัดค่าแบนด์วิดท์ ≈ USD 46.8/เดือน ต่อกล้อง (~USD 561/ปี)
หากติดตั้ง 100 กล้อง การประหยัดแบนด์วิดท์ต่อปีจะอยู่ที่ประมาณ USD 56,100 ก่อนหักค่าใช้จ่ายเพิ่มเติม เช่น ค่าฮาร์ดแวร์ edge ที่อาจเพิ่มขึ้น สมมติ กล้องละ USD 50 (amortize 36 เดือน → ~USD 1.4/เดือน) ผลตอบแทนเบื้องต้นแสดงว่า payback period ต่ำกว่า 2–3 เดือน ในหลายกรณีสำหรับค่าใช้จ่ายเครือข่ายที่สูง
ผลต่อ latency และการตอบสนอง — การย้าย inference มาทำที่ edge ลดการรอคอยทางเครือข่ายและคิวภายในคลาวด์อย่างชัดเจน จากการวัดภาคสนาม:
- Inference บนคลาวด์ (รวมเวลาส่งภาพดิบไปคลาวด์ + คิว + การคำนวณ): ประมาณ 300–800 ms ต่อเหตุการณ์
- Inference บนอุปกรณ์ (edge inference): ประมาณ 10–50 ms ต่อเหตุการณ์
- ผลต่าง: ลดความหน่วงได้ หลายร้อยมิลลิวินาที (250–750 ms) ซึ่งมีผลโดยตรงต่อความสามารถในการแจ้งเตือนแบบเรียลไทม์ เช่น การตอบสนองของระบบรักษาความปลอดภัยหรือการส่งสัญญาณเตือนฉุกเฉิน
ผลต่อการใช้ทรัพยากรฮาร์ดแวร์บนกล้อง — การรันโมเดล on‑device และการทำ continual updates มีผลต่อการใช้ทรัพยากรแต่ไม่มาก โดยการทดสอบพบว่า:
- CPU/NPUs: ใช้งานสูงสุดช่วงอัปเดต ~20–60% ขึ้นกับสเปกชิป และลดลงในโหมด inference สม่ำเสมอ
- หน่วยความจำ: เพิ่มขึ้นประมาณ 50–200 MB ขณะโหลดโมเดลและ embeddings ขนาดเล็ก
- พลังงาน: การประมวลผลเพิ่มเติมเพิ่มการใช้พลังงาน ~1–3W ต่อกล้องในช่วงอัปเดต ขณะที่โหมด standby แทบไม่มีผลต่อการใช้พลังงาน
ผลต่อความแม่นยำของโมเดลหลัง Continual Learning — ระบบที่ทดสอบในสภาพแวดล้อมจริง โดยใช้การอัปเดตก้อนเล็ก (model delta) และการเรียนรู้จากข้อมูลที่ได้จากกล้องในไซต์ พบว่า:
- ความแม่นยำพื้นฐานก่อน continual learning: สมมติ 85%
- หลังการอัปเดตต่อเนื่อง (domain adaptation กับ viewpoint และเงื่อนไขแสงท้องถิ่น): ความแม่นยำเพิ่มขึ้น 3–8% (เป็น 88–93%)
- หมายเหตุ: การเพิ่มขึ้นขึ้นอยู่กับปริมาณและความหลากหลายของตัวอย่างท้องถิ่น — สภาพแวดล้อมที่มีพฤติกรรมผิดปกติที่เฉพาะเจาะจงจะได้ประโยชน์มากกว่า
สรุปได้ว่า On‑Device Continual Learning ไม่เพียงแต่ช่วยลดปริมาณข้อมูลดิบที่ต้องส่งขึ้นคลาวด์และช่วยรักษาความเป็นส่วนตัวของภาพผู้คน แต่ยังลด latency ในการตอบสนองของระบบ และสามารถปรับปรุงความแม่นยำของโมเดลให้เหมาะกับบริบทท้องถิ่นได้จริง ผลลัพธ์เชิงตัวเลขทั้งด้านแบนด์วิดท์ ค่าใช้จ่าย และประสิทธิภาพการตรวจจับชี้ชัดว่าแนวทางนี้เป็นทางเลือกที่คุ้มค่าสำหรับการปรับใช้ CCTV เชิงพาณิชย์ในสเกลใหญ่
กรณีศึกษาเชิงปฏิบัติการ: การติดตั้งนำร่องในพื้นที่จริง
ภาพรวมโครงการนำร่อง
ในกรณีศึกษานี้ ทีมสตาร์ทอัพไทยได้ดำเนินการติดตั้งนำร่องแพลตฟอร์ม On‑Device Continual Learning ในบริเวณลานจอดรถสาธารณะของเทศบาลแห่งหนึ่ง เพื่อทดสอบการอัพเดตโมเดลตรวจจับพฤติกรรมผิดปกติแบบไม่ส่งภาพดิบขึ้นคลาวด์และประเมินผลเชิงปฏิบัติการจริง โครงการดำเนินการเป็นเวลา 8 สัปดาห์ โดยติดตั้งกล้อง CCTV จำนวน 12 ตัว ครอบคลุมทางเข้า‑ออกและช่องจอดสำคัญ อีกทั้งจัดเก็บข้อมูลเบื้องต้นเพื่อใช้เป็น baseline ก่อนเริ่มใช้ระบบ On‑Device
การตั้งค่าทางเทคนิคและสเปกฮาร์ดแวร์
การติดตั้งในพิลอตเลือกใช้ฮาร์ดแวร์ที่สามารถรองรับการประมวลผลบนอุปกรณ์ได้ต่อเนื่องโดยสเปกหลักประกอบด้วย:
- Edge SoC/CPU: ARM Cortex‑A53 quad‑core 1.5GHz (หรือเทียบเท่า)
- NPU/Accelerator: Intel Movidius Myriad X หรือ Google Edge TPU สำหรับเร่งการ inferencing
- RAM: 4–8 GB เพื่อรองรับสตรีมและกระบวนการเรียนรู้ต่อเนื่องแบบไลท์เวต
- Storage: 64–128 GB eMMC/SSD สำหรับเก็บโมเดลเวอร์ชันต่าง ๆ และ log metadata (ไม่เก็บภาพดิบบนอุปกรณ์นานเกินจำเป็น)
- เครือข่าย: เชื่อมต่อ LAN/4G เป็นช่องทางซิงค์โมเดลแบบจังหวะ (periodic weight updates) เท่านั้น
- พลังงานและความทนทาน: UPS ขนาดเล็กและการระบายความร้อนเพื่อรองรับการทำงาน 24/7
ระบบถูกออกแบบให้ส่งข้อมูลเฉพาะ meta‑events และ incremental model updates (ขนาดโดยทั่วไป 200 KB – 5 MB ต่ออัปเดต) ไปยังศูนย์ควบคุมแทนการส่งภาพวิดีโอแบบเรียลไทม์
ตัวอย่างพฤติกรรมที่ตรวจจับได้และการตั้งค่าเชิงปฏิบัติการ
ในพิลอตระบบถูกตั้งค่าให้ค้นหาเหตุการณ์ที่มีความสำคัญต่อความปลอดภัยและการจัดการพื้นที่ เช่น:
- การค้างอยู่ในพื้นที่นานเกินปกติ (loitering) รอบทางเข้า
- จอดรถผิดที่หรือจอดรถกีดขวางทางเข้า/ออก
- การรวมตัวของคนจำนวนมากที่เกินกว่าค่าเกณฑ์ (crowd formation)
- ความเคลื่อนไหวอย่างรวดเร็วหรือการทะเลาะวิวาทที่มีพฤติกรรมรุนแรง
- การวางสิ่งของต้องสงสัยในพื้นที่จอดรถ (suspicious package)
เมื่อระบบ On‑Device ตรวจพบเหตุการณ์ที่ตรงตามเงื่อนไข จะส่งเฉพาะข้อความเตือน พร้อมภาพ thumbnail ที่ถูกเข้ารหัสหรือ metadata ประกอบรายการเหตุการณ์ไปยังศูนย์ควบคุม ไม่ได้ส่งภาพดิบความละเอียดสูงขึ้นคลาวด์
KPI ที่วัดและผลลัพธ์เชิงปริมาณ
การประเมินผลใช้ KPI หลักดังนี้: bandwidth saved, detection rate, false positives, และ latency โดยมีการเปรียบเทียบกับระบบเดิมที่สตรีมวิดีโอขึ้นคลาวด์ตลอดเวลา (baseline)
- Bandwidth saved: ก่อนพิลอต 12 กล้อง สตรีมที่เฉลี่ย 2 Mbps/กล้อง ให้แบนด์วิดท์รวม 24 Mbps (ประมาณ 253 GB/วัน หรือ ~7.6 TB/เดือน) หลังติดตั้งพบว่าการส่งเฉพาะ meta‑events และ incremental updates ลดการใช้งานเครือข่ายลงเฉลี่ย 85% ในรอบ 8 สัปดาห์ คิดเป็นการประหยัดข้อมูลประมาณ ~11.7 TB ในช่วงพิลอต
- Detection rate (อัตราการตรวจจับ): ระบบ baseline ที่ใช้โมเดลสแตติกบนคลาวด์มี detection rate เฉลี่ยประมาณ 78% สำหรับเหตุการณ์ในสภาพแวดล้อมจริง พิลอต On‑Device Continual Learning ปรับน้ำหนักโมเดลตามสภาพแสงและมุมกล้อง พบว่า detection rate เพิ่มเป็น 92%
- False positives: อัตราบวกเท็จของระบบลดจากประมาณ 12% เหลือ 5% หลังการฝึกปรับแบบต่อเนื่องภาคสนาม เนื่องจากโมเดลสามารถเรียนรู้ลักษณะพื้นหลังและเงาที่เกิดซ้ำได้
- Latency: เวลาตอบสนองเฉลี่ยของการตรวจจับบนอุปกรณ์ (จากเฟรมถึงการส่งเตือน) อยู่ที่ ~120 ms เทียบกับระบบส่งคลาวด์ซึ่งมีค่าเฉลี่ยราว 800–1,100 ms (รวมเวลาส่งข้อมูลและประมวลผล)
ผลลัพธ์จริงจากพิลอตและข้อสังเกตภาคสนาม
ผลการทดลองเชิงปฏิบัติการชี้ชัดว่าการนำ On‑Device Continual Learning มาใช้ในสภาพแวดล้อมลานจอดรถช่วยให้ได้ทั้งความเป็นส่วนตัวที่ดีขึ้นและประหยัดต้นทุนเครือข่าย โดยสรุปผลสำคัญได้ดังนี้:
- การลดแบนด์วิดท์และการเก็บภาพดิบช่วยลดค่าใช้จ่ายคลาวด์และความเสี่ยงด้านข้อบังคับข้อมูลส่วนบุคคล (PDPA)
- ความไวของระบบและการลด latency ทำให้การแจ้งเตือนฉับไวขึ้น ส่งผลให้ทีมดูแลตอบสนองเร็วขึ้นประมาณ 30–40%
- มีข้อสังเกตด้านฮาร์ดแวร์ ได้แก่ ความร้อนสูงในบางตำแหน่งต้องเพิ่มการระบายความร้อน และ NPU บางรุ่นยังจำกัดขนาด batch ของการอัปเดตโมเดลจึงต้องออกแบบกระบวนการเรียนรู้เป็น incremental
- การจัดการฉลาก (labeling) สำหรับการเรียนรู้อย่างต่อเนื่องต้องใช้กลไก human‑in‑the‑loop เพื่อให้มั่นใจว่าการอัปเดตโมเดลไม่ได้เรียนรู้จากกรณีผิดพลาดซ้ำ ๆ
Feedback จากผู้ใช้งานและผู้ดูแลระบบ
ผู้จัดการพื้นที่กล่าวว่า "ระบบใหม่ทำให้เรารู้สึกมั่นใจเรื่องความเป็นส่วนตัวของผู้ใช้พื้นที่มากขึ้น และการแจ้งเตือนที่แม่นยำขึ้นช่วยลดภาระการตรวจสอบด้วยตา" ฝ่าย IT บริหารติดตั้งชื่นชมว่า "ปริมาณข้อมูลที่ลดลงทำให้เราบริหารเครือข่ายและค่าใช้จ่ายได้คล่องตัวขึ้น ขณะเดียวกันกระบวนการอัปเดตโมเดลสามารถกำหนดเวลาซิงค์ได้ตามช่วงเครือข่ายว่าง"
Checklist การติดตั้งและตัวชี้วัดที่ควรติดตามระหว่างพิลอต
- Pre‑installation: สำรวจมุมมองกล้อง แสง เงา และแหล่งรบกวน ตำแหน่งติดตั้งอุปกรณ์และความพร้อมของจุดจ่ายไฟ
- Hardware & Mounting: ติดตั้ง edge device พร้อม UPS และระบบระบายความร้อน ตรวจสอบ NPU compatibility และ storage encryption
- Privacy & Compliance: กำหนดนโยบายไม่เก็บภาพดิบเกินจำเป็น บันทึกเฉพาะ metadata และกำหนด retention period
- Baseline Data Collection: เก็บข้อมูลพื้นฐานอย่างน้อย 1–2 สัปดาห์เพื่อนำมาเป็นข้อมูลเปรียบเทียบ
- Monitoring Metrics (ที่ควรติดตามรายวัน/รายสัปดาห์):
- Bandwidth usage (MB/วัน, % ลดลงเทียบ baseline)
- Detection rate (%) และ trend ของการปรับปรุง
- False positives / false negatives (%)
- End‑to‑end latency (ms)
- CPU/NPU utilization (%) และอุณหภูมิของอุปกรณ์
- ขนาดโมเดลและอัตราการอัปเดต (KB หรือ MB ต่อการอัปเดต)
- เวลาเฉลี่ยในการตอบสนองของผู้ดูแลหลังจากรับแจ้งเตือน
- Rollback & Safety: เตรียมแผน rollback สำหรับโมเดลเวอร์ชันก่อนหน้าและเกณฑ์หยุดการอัปเดตอัตโนมัติเมื่อพบการเสื่อมประสิทธิภาพ
- Human‑in‑the‑Loop: ตั้งกลไกให้เจ้าหน้าที่ตรวจสอบตัวอย่างเหตุการณ์ที่ระบบเรียนรู้แล้วเพื่อลดความเสี่ยงของ concept drift
โดยสรุป พิลอตแสดงให้เห็นว่าแพลตฟอร์ม On‑Device Continual Learning สามารถเพิ่มความแม่นยำ ลด false alarm และประหยัดแบนด์วิดท์ได้อย่างมีนัยสำคัญในสภาพแวดล้อมจริง อย่างไรก็ตามความสำเร็จขึ้นกับการออกแบบฮาร์ดแวร์ การบริหารจัดการพลังงานความร้อน และกระบวนการควบคุมคุณภาพของการอัปเดตโมเดลในภาคสนาม
คู่มือเชิงปฏิบัติการ: ขั้นตอนการติดตั้งและตั้งค่าสำหรับผู้ติดตั้ง
ภาพรวมเชิงปฏิบัติการสำหรับผู้ติดตั้ง
เอกสารนี้เป็นคู่มือเชิงปฏิบัติการสำหรับ System Integrator ที่ต้องติดตั้งและตั้งค่าแพลตฟอร์ม On‑Device Continual Learning บนกล้อง CCTV โดยมุ่งเน้นการลดแบนด์วิดท์และปกป้องความเป็นส่วนตัวของภาพดิบ คู่มือนี้ครอบคลุมตั้งแต่การเตรียมฮาร์ดแวร์และเครือข่าย การติดตั้ง Edge Agent การปรับพารามิเตอร์สำคัญของการเรียนรู้ต่อเนื่อง การตั้งค่า secure channel การทดสอบ smoke test จนถึงการตั้ง KPI และกระบวนการ rollback
1. Checklist เตรียมฮาร์ดแวร์และเครือข่าย
ก่อนเริ่มติดตั้ง ให้ตรวจสอบรายการฮาร์ดแวร์และเครือข่ายตามรายการด้านล่างเพื่อความพร้อมและความเสถียรของการทำงาน:
- ฮาร์ดแวร์ประมวลผล (Edge Node): CPU แบบ x86 (Intel i5/i7) หรือ ARM64 (Cortex-A57 ขึ้นไป), แนะนำ 4‑8 cores; RAM 8–16 GB; Storage 64–256 GB (SSD) สำหรับเก็บโมเดลและ buffer
- เร่งความเร็วการประมวลผล (ถ้าจำเป็น): NPU/TPU/GPU ขนาดเล็ก (เช่น NVIDIA Jetson หรือ Google Coral) สำหรับ inference/finetune เร็วขึ้น
- กล้อง CCTV และการเชื่อมต่อ: กล้อง ONVIF หรือ RTSP, VLAN แยกกล้อง + management network, PoE switch แนะนำ
- เครือข่าย: uplink จากไซต์ไปยัง central coordination node แนะนำขั้นต่ำ 5–20 Mbps ขึ้นกับความถี่การซิงค์และขนาด model diffs; latency < 100 ms จะช่วยลดเวลาซิงค์
- ความปลอดภัยและการจัดเก็บคีย์: HSM หรือ secure enclave สำหรับเก็บคีย์ TLS/MTLS, การสำรองข้อมูล (backup) และระบบ logging แบบอ่านอย่างเดียว (WORM) ตามนโยบาย
- เครื่องมือมอนิเตอร์: Prometheus/Grafana หรือระบบมอนิเตอร์ที่รองรับ metrics ของ Edge Agent และโมเดล
2. การติดตั้ง Edge Agent (ขั้นตอนทีละขั้น)
ตัวอย่าง flow การติดตั้งสำหรับ Linux-based Edge Node (pseudo commands เพื่อให้ทีมปฏิบัติการเริ่มต้นได้เร็ว):
- อัปเดตแพ็กเกจและติดตั้ง dependency: apt update && apt install -y docker.io python3
- ดาวน์โหลดและติดตั้ง Edge Agent: wget https://example.com/edge-agent.tar.gz && tar xzf edge-agent.tar.gz && ./edge-agent/install.sh
- เปิดใช้งานและเปิดบริการ: systemctl enable edge-agent && systemctl start edge-agent
- ตรวจสอบสถานะบริการ: systemctl status edge-agent
- เชื่อมต่อกับ central registry/coordination: edgectl register --site-id S001 --token YOUR_TOKEN
คำสั่งข้างต้นเป็นเพียงตัวอย่าง pseudo commands; โปรดใช้สคริปต์ที่มาพร้อมซอฟต์แวร์ของผู้ให้บริการจริง
3. การตั้งค่าพารามิเตอร์สำคัญสำหรับ Continual Learning
การตั้งค่าพารามิเตอร์มีผลโดยตรงต่อความเสถียรและประสิทธิภาพของการเรียนรู้ต่อเนื่อง ค่าตั้งต้นที่แนะนำสามารถปรับตามเงื่อนไขไซต์และความต้องการ:
- Learning rate: สำหรับการ fine‑tune บน edge แนะนำช่วง 1e-4 ถึง 1e-3 (ค่าเริ่มต้น 5e-4) เพื่อหลีกเลี่ยง catastrophic forgetting
- Buffer size (local replay buffer): เก็บตัวอย่างสำหรับ rehearsal; แนะนำ 500–5,000 ตัวอย่าง ขึ้นกับความจุ storage และอัตราเกิดเหตุการณ์ผิดปกติ
- Sync frequency (model delta sync): ตั้งค่า sync_interval ตามข้อกำหนด: ตัวอย่างเช่น sync_interval=3600 (หน่วยวินาที) หมายถึงซิงค์ทุก 1 ชั่วโมง; ถ้าต้องการผสานแบบ less‑frequent ให้ตั้งเป็น 86400 (รายวัน)
- Compression level: สำหรับส่งเฉพาะ gradient/weight diffs แนะนำใช้ quantization + gzip; ตัวอย่าง compression=zstd level=3 ลดขนาดได้ 70%–90% ขึ้นกับข้อมูล
- Retention policy: เก็บ checkpoint และ model versions อย่างน้อย 3 เวอร์ชันสุดท้าย และกําหนด retention time เช่น 30 วัน: retain_versions=3, retention_days=30
ตัวอย่างคำสั่งตั้งค่า (pseudo): edgectl config set --lr 0.0005 --buffer 2000 --sync-interval 3600 --compress zstd:3 --retain 3:30d
4. การตั้งค่า Secure Channel และนโยบายความปลอดภัย
การสื่อสารระหว่าง edge กับ central coordination ต้องถูกเข้ารหัสและมีการพิสูจน์ตัวตนแบบสองทาง (mutual TLS) หรือผ่าน VPN เพื่อป้องกันการดักฟังและโจมตี:
- MTLS: ออกใบรับรอง (client cert + server cert) โดย CA ภายในองค์กร; ติดตั้งที่ /etc/edge/certs/
- Firewall & Network ACL: จำกัดพอร์ตเฉพาะ (เช่น TCP 443 สำหรับ HTTPS/MTLS, TCP 22 สำหรับ SSH บริหาร) และอนุญาตเฉพาะ IP ของ central node
- Key rotation: ตั้งรอบการเปลี่ยนคีย์ทุก 90 วัน และบังคับการตรวจสอบความสมบูรณ์ของใบรับรองที่ startup
ตัวอย่างคำสั่งตั้งค่า MTLS (pseudo): edgectl security enable-mtls --cert /etc/edge/certs/edge.crt --key /etc/edge/certs/edge.key --ca /etc/edge/certs/ca.crt
5. Smoke Test และการทดสอบการทำงาน (Validation)
หลังติดตั้ง ต้องรันชุดทดสอบเบื้องต้นเพื่อยืนยันการทำงานก่อนปล่อยไปใช้งานจริง:
- Smoke Test Inference: ส่งภาพตัวอย่าง 10–50 ภาพผ่าน pipeline และตรวจสอบผลลัพธ์ 100% สำเร็จโดยไม่มี error: edgectl infer --image test1.jpg
- Latency & Throughput: วัด latency ของ inference เป้าหมายไม่เกิน 200 ms (ขึ้นกับ SLA) และตรวจสอบ throughput ต่อกล้อง
- Local Update Test: รันการฝึกปรับจูนเล็กน้อย (10–50 steps) บน device และตรวจสอบว่า model checkpoint ถูกบันทึกและไม่เกิด degradation: edgectl train --steps 50 --batch 8
- Sync Test: ทดสอบการซิงค์ diffs กับ central node และวัดปริมาณข้อมูลที่ส่ง/รับ: edgectl sync --dry-run
- Security Test: ตรวจสอบ MTLS handshake และ attempt การเชื่อมต่อจาก IP ที่ไม่ได้รับอนุญาตต้องถูกบล็อก
หากพบปัญหา ให้ย้อนกลับไปยัง snapshot ก่อนหน้า (ดูหัวข้อ rollback) ก่อนนำอุปกรณ์กลับสู่บริการจริง
6. การตั้ง KPI สำหรับระบบมอนิเตอร์
กำหนด KPI เพื่อมอนิเตอร์สุขภาพของระบบและประสิทธิภาพโมเดลอย่างต่อเนื่อง โดยตัวอย่าง KPI ที่แนะนำมีดังนี้:
- Inference latency (p95): เป้าหมาย < 200 ms
- Model update success rate: > 99% ต่อการรัน update
- Sync bandwidth usage: เฉลี่ย < 10 Mbps ต่อไซต์ (ขึ้นกับการตั้งค่า)
- Accuracy / Detection rate drift: ลดไม่เกิน 3% เมื่อเทียบกับ baseline; ถ้าดรอปมากกว่า 5% ให้แจ้งเตือน
- False positive rate (FPR): กำหนด threshold ตาม use case เช่น FPR < 2%
- Resource utilization: CPU < 80%, Memory < 85% (ระหว่างช่วง peak)
ตัวอย่าง alert rule แบบ pseudo: alert if model_update_success_rate < 99 for 5m
7. ขั้นตอนการกลับสู่สถานะก่อนหน้า (Rollback) เมื่อการอัปเดตผิดพลาด
เตรียมกระบวนการ rollback ที่ชัดเจนก่อนเริ่มการอัปเดต เพื่อให้สามารถกู้คืนได้รวดเร็วเมื่อเกิดปัญหา:
- เวอร์ชันและ snapshot: ทุกการอัปเดตต้องสร้าง checkpoint/ snapshot และบันทึก metadata (timestamp, hash, 성능 metric)
- Rollback flow (pseudo):
- 1) หยุดการฝึกต่อเนื่องชั่วคราว: edgectl train stop
- 2) เปิดใช้งานเวอร์ชันก่อนหน้า: edgectl model rollback --version v2026-03-10-03
- 3) ตรวจสอบ integrity และรัน smoke test: edgectl infer --image smoke1.jpg
- 4) ถ้าผ่าน ให้ resume การทำงาน: edgectl train resume
- Fallback policy: ถ้า rollback ล้มเหลว ให้สลับการ inference ไปที่ central failover model (ถ้ามี) หรือ set device เป็น passive mode เพื่อหยุดการปล่อยสัญญาณเตือนปลอม
- Post‑mortem: บันทึกเหตุการณ์อย่างละเอียด (logs, metrics, diffs) เพื่อนำไปวิเคราะห์ก่อนทำการ deploy ใหม่
สรุป: การติดตั้งและตั้งค่าระบบ On‑Device Continual Learning ต้องอาศัยการเตรียมฮาร์ดแวร์ที่เหมาะสม การตั้งพารามิเตอร์การเรียนรู้ที่เหมาะสม การรักษาความปลอดภัยของช่องทางสื่อสาร และการมีขั้นตอนทดสอบ/rollback ที่ชัดเจน เพื่อให้การดำเนินงานในสภาพแวดล้อมจริงมีความมั่นคง ปลอดภัย และสามารถปรับตัวได้เมื่อเกิดการเปลี่ยนแปลงของสภาพแวดล้อม
ความเสี่ยง ข้อจำกัด และแนวทางอนาคต
ความเสี่ยงและข้อจำกัดทางเทคนิค
การนำ On‑Device Continual Learning มาใช้งานกับกล้อง CCTV เพื่อตรวจจับพฤติกรรมผิดปกติมีข้อจำกัดทางเทคนิคหลายด้านที่ต้องพิจารณาอย่างรอบคอบ โดยประเด็นสำคัญประกอบด้วย catastrophic forgetting ที่โมเดลเรียนรู้ข้อมูลใหม่แล้วลืมความรู้เดิม ทำให้ประสิทธิภาพในงานที่เคยทำได้ดีลดลงได้อย่างมีนัยสำคัญ งานวิจัยในสาขาการเรียนรู้ต่อเนื่องชี้ว่า หากไม่มีมาตรการป้องกัน ประสิทธิภาพอาจลดลงเป็นหลักสิบเปอร์เซ็นต์ในบางกรณี
นอกจากนั้น ระบบอุปกรณ์ปลายทางยังเผชิญกับ การโจมตีแบบ adversarial ซึ่งผู้โจมตีอาจแทรกสัญญาณเล็กน้อยเข้าไปในภาพหรือสตรีมวิดีโอเพื่อให้โมเดลตัดสินใจผิด เช่น การป้อนตัวอย่างที่ก่อให้เกิดการเรียนรู้ผิดพลาดหรือการกระตุ้นให้เกิด false negatives/false positives อย่างต่อเนื่อง และยังมี ข้อจำกัดด้านทรัพยากรฮาร์ดแวร์ ได้แก่ พื้นที่เก็บข้อมูล หน่วยความจำ แรงประมวลผล และพลังงาน ทำให้ไม่สามารถรันอัลกอริทึมการฝึกที่หนักหน่วงหรือเก็บข้อมูลตัวอย่างจำนวนมากได้โดยตรงบนกล้อง
ข้อกฎหมายและจริยธรรมที่ต้องคำนึง
ด้านกฎหมายและจริยธรรม การประมวลผลภาพจาก CCTV ต้องสอดคล้องกับพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคลของไทย (PDPA) ซึ่งกำหนดหลักการสำคัญ เช่น การกำหนดวัตถุประสงค์ชัดเจน การขอความยินยอมหรือหากมีฐานทางกฎหมายอื่น การจำกัดการเก็บข้อมูลตามความจำเป็น รวมถึงสิทธิของเจ้าของข้อมูลในการเข้าถึง แก้ไข และลบข้อมูล
นอกจากนี้ ต้องมีนโยบายการเก็บรักษาข้อมูล (retention policy) ที่ชัดเจนและโปร่งใส แจ้งให้ผู้ที่เกี่ยวข้องทราบว่าภาพหรือข้อมูลใดถูกเก็บไว้เป็นเวลานานเท่าใดและด้วยเหตุผลใด ระบบ On‑Device อาจลดการส่งภาพดิบขึ้นคลาวด์ได้ แต่ยังต้องมีการบันทึกเมตาดาต้า การเก็บตัวอย่างสำหรับการฝึก และกลไกแสดงความโปร่งใสต่อผู้ควบคุมหรือผู้มีส่วนได้เสีย
แนวทางแก้ไขและมาตรการบรรเทาความเสี่ยง
เพื่อจัดการกับปัญหาเชิงเทคนิคและความเสี่ยงทางกฎหมาย ควรออกแบบสถาปัตยกรรมและกระบวนการผสมผสานระหว่างอุปกรณ์ปลายทางและศูนย์กลาง (hybrid approach) ดังนี้
- Hybrid cloud fallback: ให้กล้องเรียนแบบ on‑device เป็นหลัก แต่กำหนดเงื่อนไขให้ส่งโมเดลอัพเดตหรือชุดตัวอย่างที่จำเป็นขึ้นไปยังคลาวด์สำหรับการประเมินหรือ retraining แบบรวมศูนย์เป็นระยะ เพื่อลด catastrophic forgetting และตรวจสอบการลื่นไถลของโมเดล
- Periodic centralized evaluation: รันการประเมินประสิทธิภาพโมเดลแบบรวมศูนย์เป็นระยะ เพื่อตรวจจับการเสื่อมสภาพของโมเดลหรือพฤติกรรมแปลกปลอมจากการเรียนรู้บนอุปกรณ์
- เทคนิคป้องกัน forgetting: ใช้วิธีการเช่น rehearsal (เก็บตัวอย่างสำรองแบบสังเคราะห์หรือคัดเลือกจริง), regularization methods (เช่น EWC), หรือ architectural approaches (dynamic expansion) เพื่อรักษาความรู้เดิมควบคู่กับการเรียนรู้ใหม่
- ป้องกันการโจมตี adversarial: นำ adversarial training, input sanitization, anomaly detection และการตรวจสอบความสอดคล้องของข้อมูลเข้ามาใช้ร่วมกับการล็อกอินทรานซิชันและการตรวจจับพฤติกรรมผิดปกติของคอนฟิกการอัพเดต
- การจัดการทรัพยากร: ใช้ quantization, pruning, knowledge distillation และ scheduling สำหรับการอัพเดตโมเดลเพื่อลดรอยเท้าทางทรัพยากร และผสานกับ NPU แบบประหยัดพลังงานเพื่อรันการฝึก/อินเฟอร์เรนซ์ที่จำเป็น
- ความเป็นส่วนตัวและความปลอดภัยของข้อมูล: ใช้การเข้ารหัสการส่งข้อมูล (TLS), secure enclaves ในอุปกรณ์ถ้าเป็นไปได้, รวมถึงเทคนิคเช่น differential privacy และ secure aggregation เมื่อต้องรวมอัพเดตจากหลายอุปกรณ์
โรดแมปการพัฒนาและทิศทางอนาคต
ระยะกลางถึงระยะยาว ควรมีแผนพัฒนาเชิงรุกเพื่อยกระดับความสามารถของแพลตฟอร์มและลดความเสี่ยง ดังนี้
- บูรณาการกับ Federated Learning: นำกรอบการเรียนรู้แบบกระจายที่คำนึงถึงความเป็นส่วนตัวมาใช้ เพื่อให้กล้องร่วมกันปรับปรุงโมเดลโดยไม่ส่งภาพดิบขึ้นศูนย์กลาง พร้อมใช้ secure aggregation และ DP เพื่อรักษาความลับของข้อมูลแต่ละอุปกรณ์
- Model personalization: พัฒนาเครื่องมือให้กล้อง/ไซต์แต่ละแห่งสามารถสร้างโมเดลเฉพาะที่ปรับให้เข้ากับบริบทท้องถิ่น (เช่น มุมกล้อง สภาพแวดล้อมการใช้งาน) โดยยังคงโครงสร้างโมเดลหลักร่วมกันเพื่อหลีกเลี่ยงการแยกตัวทางประสิทธิภาพ
- การนำ NPU และฮาร์ดแวร์ประหยัดพลังงานมาใช้: ร่วมกับผู้ผลิตฮาร์ดแวร์เพื่อรองรับการฝึกแบบเบา (on‑device fine‑tuning) และ inference ที่มีประสิทธิภาพสูง โดยคำนึงถึงต้นทุนและการจัดการพลังงานในสภาพแวดล้อมจริง
- การตรวจสอบ ความโปร่งใส และการปฏิบัติตามกฎระเบียบ: สร้างฟังก์ชัน audit trail, explainability layer สำหรับการตัดสินใจของโมเดล และนโยบาย retention/consent ที่อธิบายได้เพื่อตอบสนองข้อกำหนด PDPA และข้อกำหนดด้านจริยธรรม
- มาตรฐานและการรับรอง: พัฒนามาตรฐานภายในสำหรับการทดสอบความทนทานต่อการโจมตี การชดเชย forgetting และการประเมินความเป็นส่วนตัว เพื่อใช้เป็นเกณฑ์ก่อนนำระบบไปปรับใช้เชิงพาณิชย์
สรุปคือ การนำ On‑Device Continual Learning มาใช้กับกล้อง CCTV มีศักยภาพสูงในการลดแบนด์วิดท์และเพิ่มความเป็นส่วนตัว แต่ต้องออกแบบสถาปัตยกรรมแบบรวมศูนย์และปลายทางควบคู่กัน พร้อมมาตรการด้านความปลอดภัย ความเป็นส่วนตัว และการปฏิบัติตามกฎหมาย (เช่น PDPA) เพื่อให้การใช้งานมีความยั่งยืนและเชื่อถือได้ในเชิงธุรกิจ
บทสรุป
On‑Device Continual Learning สำหรับกล้อง CCTV ช่วยลดการส่งภาพดิบขึ้นคลาวด์และเพิ่มความเป็นส่วนตัวโดยไม่ลดทอนความสามารถในการตรวจจับพฤติกรรมผิดปกติ หากมีการออกแบบสถาปัตยกรรมและนโยบายการส่งข้อมูลอย่างรอบคอบ—ตัวอย่างเช่น การอัปเดตโมเดลด้วยน้ำหนักหรือฟีเจอร์เชิงสถิติแทนการส่งภาพจริง, การใช้เทคนิค federated learning และการนำกลไกเช่น differential privacy มาใช้ร่วมด้วย—ซึ่งงานวิจัยและการทดสอบภาคสนามระบุว่าการนำแนวทางเหล่านี้ไปใช้สามารถลดแบนด์วิดท์ได้อย่างมีนัยสำคัญ (งานศึกษาบางฉบับรายงานช่วงการลดตั้งแต่ประมาณ 50–90%) พร้อมยังรักษาหรือปรับปรุงความแม่นยำในการตรวจจับเมื่อเทียบกับสถาปัตยกรรมแบบส่งคลาวด์เพียงอย่างเดียว
สำหรับผู้ติดตั้งและผู้กำหนดนโยบาย ควรดำเนินการทดสอบแบบพิลอตโดยตั้ง KPI ที่ชัดเจน เช่น ความแม่นยำในการตรวจจับ, อัตราบวกเทียม (false positive), ความหน่วง (latency), ปริมาณแบนด์วิดท์ที่ลดได้ และตัวชี้วัดด้านความเป็นส่วนตัว/การปฏิบัติตามกฎหมาย (เช่น PDPA) พร้อมเตรียมมาตรการด้านความปลอดภัยและกฎหมายควบคู่ไปด้วย เช่น การเข้ารหัสข้อมูลระหว่างอัปเดตโมเดล, การใช้ secure enclave บนอุปกรณ์ขอบเครือข่าย, นโยบายการเก็บรักษา/ลบข้อมูล และกรอบการตรวจสอบความโปร่งใส การปฏิบัติตามขั้นตอนดังกล่าวจะช่วยให้การนำแพลตฟอร์มไปใช้จริงมีความน่าเชื่อถือและลดความเสี่ยงเชิงกฎหมายและเชิงปฏิบัติการ
มุมมองอนาคต: เทคโนโลยี On‑Device Continual Learning มีศักยภาพสูงในการขยายการใช้งานด้านความปลอดภัยสาธารณะและอุตสาหกรรมอัจฉริยะ โดยเฉพาะเมื่อฮาร์ดแวร์ขอบเครือข่าย (edge chips) มีประสิทธิภาพดีขึ้นและมาตรฐานด้านการปกป้องข้อมูลชัดเจนขึ้น ผู้พัฒนาและผู้กำกับดูแลควรร่วมมือกำหนดแนวปฏิบัติที่สมดุลระหว่างประสิทธิผลเชิงเทคนิคและสิทธิ์ความเป็นส่วนตัว เพื่อให้การปรับใช้ในวงกว้างเกิดขึ้นอย่างยั่งยืนและยอมรับในเชิงสังคมและกฎหมาย



