
การวินิจฉัยโรคหายากเป็นความท้าทายเชิงคลินิกและข้อมูล: ผู้ป่วยแต่ละรายมีสัดส่วนน้อยในประชากร ข้อมูลเวชระเบียนกระจัดกระจาย และการแชร์ข้อมูลดิบข้ามสถาบันยังกระทบความเป็นส่วนตัวและข้อกฎหมาย ด้วยเหตุนี้ เครือข่ายโรงพยาบาลไทยได้เปิดโครงการทดลองที่น่าสนใจ — การเทรนโมเดลภาษาขนาดใหญ่เชิงการแพทย์แบบกระจาย (Federated‑LLM) เพื่อพัฒนาระบบคัดกรองโรคหายากร่วมกัน โดยยืนยันหลักการสำคัญคือ ไม่แลกเปลี่ยนเวชระเบียนดิบ แต่ยังคงสามารถรวมความรู้จากหลายหน่วยงานได้อย่างปลอดภัย
บทความนี้จะพาอ่านทั้งมุมมองเชิงเทคนิคและเชิงนโยบายของโครงการทดลอง ตั้งแต่ขั้นตอนปฏิบัติ เช่น การเตรียมข้อมูลภายในโรงพยาบาล การตั้งค่าเฟดเดอเรตเทรนนิ่ง การใช้เทคนิคเสริมความเป็นส่วนตัว (เช่น differential privacy และ secure aggregation) ไปจนถึงการตรวจประเมินคุณภาพโมเดลและการนำผลไปใช้ทางคลินิก พร้อมตัวอย่างผลลัพธ์เบื้องต้นที่สะท้อนประสิทธิภาพการคัดกรอง ความแม่นยำในการแยกสัญญาณโรคหายาก และผลต่อกระบวนการส่งต่อผู้ป่วย ทั้งนี้บทความยังนำเสนอกรอบนโยบายด้านจริยธรรม การคุ้มครองข้อมูล และแนวทางการกำกับดูแลที่จำเป็นสำหรับการขยายผลในระดับชาติ
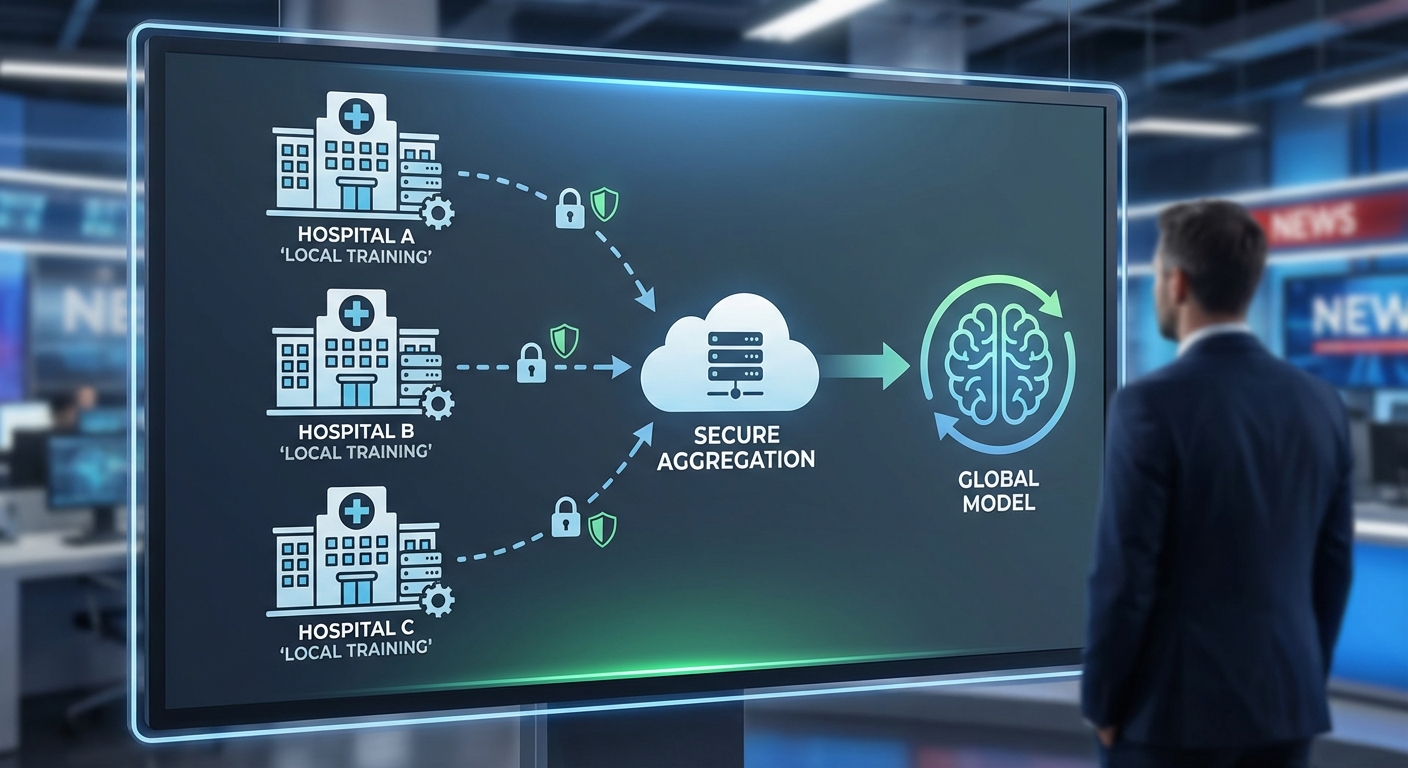
บทนำ: ทำไมต้องใช้ Federated‑LLM กับโรคหายาก
บทนำ: ทำไมต้องใช้ Federated‑LLM กับโรคหายาก
โรคหายาก (rare diseases) เป็นความท้าทายระดับโลกทั้งด้านการแพทย์และระบบสาธารณสุข โดยมีการประมาณการว่ามีโรคหายากมากกว่า 7,000 ชนิด และส่งผลต่อผู้คนรวมกันประมาณ 300 ล้านคนทั่วโลก การกระจายตัวของผู้ป่วยที่เบาบางแต่หลากหลายส่งผลให้การวินิจฉัยมักล่าช้า: งานวิจัยและรายงานหลายฉบับระบุว่าเวลาตั้งแต่เกิดอาการจนถึงการวินิจฉัยอาจใช้เฉลี่ยหลายปี (บางแหล่งรายงานเฉลี่ยประมาณ 4–6 ปี) พร้อมมีอัตราการวินิจฉัยผิดพลาดและการส่งตัวผู้ป่วยหลายครั้งก่อนจะถึงการวินิจฉัยที่ถูกต้อง
ในบริบทของประเทศไทย แม้ขนาดประชากรจะเล็กกว่าแต่ปัญหาพื้นฐานไม่ต่างกัน: ด้วยความถี่ของแต่ละโรคที่ต่ำ ทำให้ฐานข้อมูลผู้ป่วยเปราะบางและกระจัดกระจายอยู่ตามโรงพยาบาลและคลินิกต่าง ๆ จึงคาดว่ามีผู้ป่วยโรคหายากจำนวน หลายแสนถึงล้านคนในประเทศที่ยังไม่ได้รับการวินิจฉัยหรือได้รับการวินิจฉัยล่าช้า ซึ่งสร้างภาระทั้งต่อผู้ป่วย ครอบครัว และระบบสุขภาพ (ด้านค่าใช้จ่าย การทดสอบซ้ำ และการรักษาที่ไม่ตรงจุด)
โมเดลภาษาขนาดใหญ่ (Large Language Models, LLMs) มีศักยภาพสำคัญในการช่วยคัดกรองโรคหายาก เพราะสามารถจับสัญญาณเชิงบริบทจากบันทึกเวชระเบียน เช่น หมายเหตุแพทย์ สรุปการรักษา ผลแลป และประวัติผู้ป่วยแบบอิสระ การประมวลผลภาษาธรรมชาติของ LLMs สามารถสกัดลักษณะอาการ (phenotypic features) คำสำคัญทางการแพทย์ หรือแพทเทิร์นการรักษาที่บ่งชี้โรคหายาก และช่วยสร้างรายการวินิจฉัยแยกโรค (differential diagnosis) หรือแนะนำการตรวจเพิ่มเติม ตัวอย่างการใช้งานที่เป็นไปได้ได้แก่การทำ screening case‑flagging เพื่อส่งต่อผู้ป่วยไปยังศูนย์เฉพาะทาง การจับคู่อาการกับฐานข้อมูล HPO (Human Phenotype Ontology) และการช่วยลดระยะเวลาการค้นหาสิ่งที่เป็นไปได้
อย่างไรก็ตาม การนำข้อมูลเวชระเบียนดิบจากหลายโรงพยาบาลมารวมกันเพื่อเทรนโมเดลกลางเผชิญข้อจำกัดด้านความเป็นส่วนตัวและกฎระเบียบอย่างชัดเจน ในประเทศไทยมีพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ที่กำหนดข้อบังคับการเก็บ รวบรวม และโอนย้ายข้อมูลส่วนบุคคล ขณะเดียวกันกฎหมายและข้อกำหนดระหว่างประเทศ เช่น HIPAA (สหรัฐ) และ GDPR (สหภาพยุโรป) ก็เข้มงวดในแง่ของการปกป้องข้อมูลสุขภาพ การระบุตัวบุคคลจากข้อมูลที่ถูกนิรนามแล้ว (re‑identification) เป็นความเสี่ยงจริงจัง ซึ่งทำให้การส่งต่อเวชระเบียนดิบข้ามสถาบันเป็นเรื่องยุ่งยากและมีอุปสรรคด้านจริยธรรม
Federated‑LLM จึงเป็นแนวทางที่ตอบโจทย์เชิงปฏิบัติ: แทนที่จะส่งข้อมูลดิบจากโรงพยาบาลทั้งหมดไปยังศูนย์กลาง ระบบจะให้โมเดลเริ่มต้นหรือโมเดลกลางถูกกระจายไปยังแต่ละสถานพยาบาลเพื่อทำการเทรนหรือปรับจูนบนข้อมูลท้องถิ่น แล้วส่งเฉพาะพารามิเตอร์ที่ถูกเข้ารหัสกลับมารวมกัน (aggregation) เทคนิคเสริมเช่น secure aggregation, differential privacy และการเข้ารหัสระหว่างการส่งข้อมูล ช่วยลดความเสี่ยงการเปิดเผยข้อมูลส่วนบุคคลและเอื้อให้การร่วมมือระหว่างสถาบันเป็นไปได้ภายใต้กรอบการปฏิบัติตามกฎหมาย
- เหตุผลเชิงปริมาณ: ศูนย์ข้อมูลรวมจะเพิ่มขนาดตัวอย่างให้เพียงพอในการเรียนรู้โรคที่พบยาก
- เหตุผลเชิงคุณภาพ: การรวมความหลากหลายของประชากรช่วยให้โมเดลมีความทนทานต่อความแปรปรวนของข้อมูลและลดอคติ
- เหตุผลเชิงกฎหมายและจริยธรรม: การหลีกเลี่ยงการแลกเปลี่ยนเวชระเบียนดิบช่วยรักษาความลับผู้ป่วย สอดคล้อง PDPA และมาตรฐานสากล
ด้วยบริบทดังกล่าว การประยุกต์ใช้ Federated‑LLM ระหว่างเครือข่ายโรงพยาบาลไทยจึงเป็นแนวทางที่มีเหตุผลทั้งเชิงวิทยาศาสตร์และเชิงนโยบาย: ช่วยเพิ่มโอกาสในการตรวจจับและคัดกรองโรคหายากได้รวดเร็วขึ้น พร้อมกันนั้นยังคงเคารพสิทธิความเป็นส่วนตัวของผู้ป่วยและทำให้การร่วมมือข้ามสถาบันเป็นไปได้ภายใต้กรอบกฎหมายและความรับผิดชอบต่อสังคม
ข้อมูลโครงการทดลอง: เครือข่ายโรงพยาบาลและข้อมูลที่ใช้
ข้อมูลโครงการทดลอง: เครือข่ายโรงพยาบาลและข้อมูลที่ใช้
โครงการทดลองนี้ดำเนินการในรูปแบบเครือข่ายโรงพยาบาลที่มีขนาดกลางถึงใหญ่ โดยมีตัวอย่างเครือข่ายระหว่าง 10–30 แห่ง ครอบคลุมทั้งโรงพยาบาลชุมชน (community hospitals) และโรงพยาบาลวิชาการ/ศูนย์ความเชี่ยวชาญ (academic medical centers) เพื่อให้ได้ความหลากหลายของประชากรผู้ป่วยและรูปแบบเวชระเบียนเชิงปฏิบัติการ ตัวอย่างเช่น เครือข่ายขนาด 20 แห่งอาจให้ข้อมูลรวมประมาณ 0.5–2 ล้านครั้งการพบผู้ป่วย (encounters) ภายในช่วงเวลาศึกษา 3–5 ปีแรก ขนาดของข้อมูลที่แต่ละหน่วยงานส่งเข้าร่วมจะแตกต่างกัน โดยทั่วไปแต่ละแห่งอาจมีข้อมูลตั้งแต่ 10,000 ถึง 200,000 encounter ขึ้นกับขนาดและภาระงานของโรงพยาบาลนั้น ๆ
ชนิดของข้อมูลที่ใช้ในโครงการถูกกำหนดเพื่อสนับสนุนการเทรน LLM สำหรับการคัดกรองโรคหายาก โดยประกอบด้วยชุดข้อมูลหลักดังนี้
- บันทึกทางคลินิกเชิงข้อความ (clinical notes) — ได้แก่ progress notes, discharge summaries, referral letters โดยความยาวเฉลี่ยของบันทึกประมาณ 200–1,500 คำต่อเอกสาร ข้อความเหล่านี้เป็นแหล่งสัญญะสำคัญสำหรับอาการ/การดำเนินโรคที่ไม่อยู่ในรหัสมาตรฐาน
- รหัสวินิจฉัย (ICD-10/ICD-11) — ข้อมูลรหัสช่วยให้มีป้ายบ่งชี้ทางการแพทย์และใช้สำหรับการกรองตัวอย่างเชิงชั้น (labeling) ในการฝึกสอนโมเดล
- ผลตรวจทางห้องปฏิบัติการ (laboratory results) — ค่าเชิงตัวเลขและผลการทดสอบซ้ำ เช่น CBC, CMP, เกณฑ์ชีวเคมี โดยเฉลี่ย 5–20 ผลตรวจต่อ encounter
- รายงานการถ่ายภาพ/ผลชันสูตร (imaging reports / pathology reports) — ใช้เฉพาะข้อความสรุปและ metadata ที่เกี่ยวข้อง ไม่รวมไฟล์รูปภาพดิบ (นอกเหนือกรณีที่มีการจัดการพิเศษตามมาตรฐาน DICOM)
- ข้อมูลเสริม (metadata) — อายุ เพศ พื้นที่ภูมิศาสตร์ระดับจังหวัด สถานะการรับเข้า-ออก (admission/discharge) โดยข้อมูลเชิง demographic ถูกจำกัดระดับความละเอียดเพื่อความเป็นส่วนตัว
มาตรการเตรียมข้อมูลเบื้องต้นถูกออกแบบให้สอดคล้องกับหลักความปลอดภัยและข้อกำหนดด้านความเป็นส่วนตัว หลักปฏิบัติสำคัญได้แก่การลบหรือแปลงข้อมูลระบุตัวบุคคล (PHI) ก่อนการนำไปใช้ในระบบกลาง ได้แก่
- การลบ/ปกปิด PHI (de‑identification / pseudonymization) — ใช้วิธีการตามแนวทาง Safe Harbor หรือการประเมินความเสี่ยงตามมาตรฐานสากล โดยการแทนที่ชื่อ หมายเลขบัตร ประวัติผู้ติดต่อด้วยรหัสเทียม (hashed/pseudonymized IDs) และการเลื่อนวันเวลา (date shifting) เพื่อป้องกันการระบุบุคคล
- การแยก/ลบหน่วยข้อมูลสำคัญในข้อความ (NLP‑based entity redaction) — ประยุกต์ใช้โมดูล Named Entity Recognition (NER) เพื่อค้นหาและแทนที่ชื่อสถานที่ ชื่อบุคคล หมายเลขติดต่อ และข้อมูลระบุอื่น ๆ ใน free text ก่อนการนำไป tokenize
- มาตรฐานการจัดรูปแบบและรหัส — การแมปข้อมูลให้เป็นมาตรฐานเช่น HL7 FHIR สำหรับโครงสร้าง EHR, ICD‑10/ICD‑11 สำหรับรหัสวินิจฉัย, LOINC สำหรับผลตรวจทางห้องปฏิบัติการ และ DICOM metadata สำหรับงานภาพถ่าย แพ็กเกจข้อมูลถูกจัดให้อยู่ในรูปแบบ JSON/HL7 FHIR profiles เพื่อความเข้ากันได้ระหว่างหน่วยงาน
- การ tokenize และการบีบอัดข้อมูลก่อนส่ง — ข้อความถูก tokenize ในลักษณะที่รักษาความหมายเชิงคลินิก แต่ตัดคำที่อาจเปิดเผยตัวตนออกไป และบีบอัด/เข้ารหัสผลลัพธ์ด้วยมาตรฐานการเข้ารหัสการสื่อสาร (TLS/HTTPS, VPN)
นโยบายการเข้าถึงและการแลกเปลี่ยนข้อมูลระหว่างหน่วยงานถูกออกแบบตามหลัก federated learning: ไม่มีเวชระเบียนดิบ (raw EHR) ถูกส่งออกจากโรงพยาบาล ทุกไซต์เก็บข้อมูลภายในสภาพแวดล้อมที่ควบคุม และส่งเพียงการอัปเดตโมเดล (model gradients/weights) ที่ผ่านกระบวนการเข้ารหัสและรวมแบบปลอดภัย (secure aggregation) เท่านั้น นโยบายเพิ่มเติมรวมถึงการกำหนดบทบาทและสิทธิ์การเข้าถึง (role‑based access control), คณะกรรมการกำกับดูแลข้อมูล (data governance board) ระดับเครือข่าย, บันทึกการใช้งานสำหรับการตรวจสอบย้อนหลัง (audit logs), และข้อตกลงทางกฎหมาย (data use agreements) ที่ชัดเจนเกี่ยวกับการนำผลการวิจัยไปใช้ การเก็บรักษาและการลบข้อมูลที่เป็นการสืบค้นได้จะถูกกำหนดตามรอบเวลาที่ตกลงกัน และกรอบปฏิบัติตามกฎหมายคุ้มครองข้อมูลส่วนบุคคล (เช่น PDPA) ตลอดจนการใช้เทคนิคเสริมความเป็นส่วนตัว เช่น differential privacy (การตั้งค่า epsilon ที่เหมาะสม) และการทดสอบบนข้อมูลสังเคราะห์ (synthetic data) เพื่อประเมินประสิทธิภาพก่อนใช้งานจริง
สถาปัตยกรรมระบบ: Federated‑LLM เวิร์กโฟลว์แบบรวม
สถาปัตยกรรมระบบ: Federated‑LLM เวิร์กโฟลว์แบบรวม
สถาปัตยกรรมของ Federated‑LLM ในโครงการเครือข่ายโรงพยาบาลนี้ออกแบบมาเพื่อให้สามารถเทรนโมเดลภาษาขนาดใหญ่สำหรับการคัดกรองโรคหายากโดย ไม่ต้องย้ายเวชระเบียนดิบ ข้ามไซต์ โดยหลักการทำงานคือมีตัวประสานกลาง (orchestrator/aggregator) ที่แจกจ่าย base model เริ่มต้นไปยังแต่ละโรงพยาบาลเป็นชุดน้ำหนักเริ่มต้น โรงพยาบาลแต่ละแห่งจะทำการปรับเทรนภายในไซต์ (on‑site fine‑tuning) บนข้อมูลผู้ป่วยของตนเอง แล้วส่งกลับเฉพาะการอัปเดตพารามิเตอร์หรือกราดิเอนต์ที่ถูกเข้ารหัส ไม่ใช่ข้อมูลดิบ การวนรอบแจก-เทรน-รวมเช่นนี้เกิดขึ้นเป็นรอบ (rounds) จนกว่าโมเดลรวม (global model) จะบรรลุเกณฑ์ประสิทธิภาพที่กำหนด
เวิร์กโฟลว์สามารถสรุปเป็นขั้นตอนหลักได้ดังนี้:
- แจกโมเดลเริ่มต้น: ตัวประสานกลางเผยแพร่เวอร์ชันของ base LLM ไปยังทุกไซต์ พร้อมมาตรฐานไฮเปอร์พารามิเตอร์และนโยบายความเป็นส่วนตัว
- เทรนภายในไซต์: โรงพยาบาลทำการ fine‑tune โมเดลบนเวชระเบียนที่เก็บอยู่ภายในเครือข่ายภายใน (on‑premises) โดยไม่มีการส่งข้อมูลดิบออก
- การป้องกันและแปลงผลลัพธ์: ก่อนส่งกลับจะมีการเข้ารหัส/แปลงพารามิเตอร์ เช่น การใช้ homomorphic encryption หรือการทำ masking ตามโปรโตคอล secure aggregation
- รวมพารามิเตอร์อย่างปลอดภัย: ตัวประสานกลางรวมอัปเดตจากไซต์ต่าง ๆ โดยใช้ secure aggregation เพื่อให้ไม่สามารถย้อนกลับไปหาอัปเดตของไซต์ใดไซต์หนึ่งได้
- อัปเดต global model: โมเดลรวมถูกอัปเดตและทดสอบทางสถิติก่อนเผยแพร่เป็นรอบต่อไป
เพื่อความปลอดภัยและความเป็นส่วนตัว สถาปัตยกรรมนี้บรรจุเทคนิคหลายชั้นประกอบกัน ได้แก่ encryption ระหว่างการส่ง (TLS และการเข้ารหัสแบบขั้นสูงเช่น HE), secure enclave สำหรับการประมวลผลที่ไว้วางใจได้ (เช่น Intel SGX หรือ AMD SEV) เมื่อจำเป็นต้องประมวลผลหรือรวมผลในพื้นที่ที่เชื่อถือได้ และ differential privacy สำหรับการเพิ่ม noise ให้กับกราดิเอนต์หรือพารามิเตอร์ก่อนรวม เพื่อลดความเสี่ยงการเปิดเผยข้อมูลเฉพาะบุคคล
ตัวอย่างเทคนิคการรวมพารามิเตอร์อย่างปลอดภัยที่ใช้ในระบบ:
- Secure Aggregation (Secure Multi‑Party Computation): แต่ละไซต์เข้ารหัสค่าพารามิเตอร์ด้วยคีย์ชั่วคราวและส่งเป็นชิ้นส่วนที่ผสมกัน ตัวประสานกลางสามารถคำนวณผลรวมได้โดยไม่เห็นค่าจริงของแต่ละไซต์
- Homomorphic Encryption (HE): อัปเดตถูกเข้ารหัสในรูปแบบที่ยังสามารถดำเนินการทางคณิตศาสตร์ได้ ซึ่งช่วยให้ตัวประสานกลางรวมค่าโดยไม่ถอดรหัส
- Trusted Execution Environment / Secure Enclave: หากต้องการการประมวลผลแบบรวมที่ไว้วางใจได้ สามารถรันการรวมภายใน enclave ที่มีการตรวจสอบความถูกต้อง (attestation) เพื่อยืนยันสภาพแวดล้อม
- Differential Privacy (DP): การเพิ่ม noise ระดับที่ปรับได้ลงบนกราดิเอนต์หรือพารามิเตอร์ เพื่อรับประกัน bound ด้านการรั่วไหลของข้อมูลบุคคล
นอกจากการรักษาความลับของพารามิเตอร์แล้ว ระบบยังต้องจัดการปัญหาเช่นการตรวจสอบความซ้ำซ้อนของข้อมูล (duplicate records) และการป้องกันการเรียนรู้จากตัวอย่างซ้ำข้ามไซต์ โดยใช้ privacy‑preserving record linkage (PPRL) เช่น bloom‑filter hashing, cryptographic fingerprints หรือเทคนิค secure set intersection เพื่อตรวจจับและจัดการเคสผู้ป่วยที่มาโผล่ในหลายฐานข้อมูลโดยไม่เปิดเผยข้อมูลประจำตัว เช่น ในโครงการนำร่องบางแห่ง การใช้ PPRL ทำให้ลดผลบวกลวงจากข้อมูลซ้ำได้ประมาณ 10–20% ในการประเมินความแม่นยำเบื้องต้น (ตัวเลขขึ้นกับชุดข้อมูลจริงและพารามิเตอร์การจับคู่)
การออกแบบนี้ยังต้องคำนึงถึงนโยบายการกำกับดูแลและการตรวจสอบ (governance & audit) โดยเก็บบันทึก (audit logs) ของการแจกและการรวมโมเดล พร้อมการลงนามดิจิทัลของแต่ละรอบ เพื่อให้สามารถตรวจสอบการเปลี่ยนแปลงของโมเดลได้ในภายหลัง ระบบควรสนับสนุนการทำงานแบบไฮบริด เช่น การรัน aggregation ภายใน secure enclave ของผู้ให้บริการกลางหรือผ่าน consortium blockchain สำหรับการยืนยันความสมบูรณ์ของรอบการเทรน
สรุปคือ Federated‑LLM เวิร์กโฟลว์แบบรวม สำหรับเครือข่ายโรงพยาบาลประกอบด้วยการแจกโมเดลเริ่มต้น การเทรนภายในไซต์ การส่งอัปเดตที่ถูกปกป้องด้วยเทคนิคการเข้ารหัสและ secure aggregation และการอัปเดต global model ภายใต้ชั้นป้องกันด้วย secure enclave และ differential privacy ซึ่งร่วมกันสร้างสมดุลระหว่างประสิทธิภาพของโมเดลและการคุ้มครองข้อมูลผู้ป่วยตามมาตรฐานความเป็นส่วนตัวและข้อกำหนดทางกฎหมาย
การจัดการข้อมูลและการปกป้องความเป็นส่วนตัว (PDPA และมาตรการเทคนิค)
การปฏิบัติตาม PDPA ต่อเวชระเบียนและการยินยอมของผู้ป่วย
ภายใต้พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA, พ.ศ. 2562) ข้อมูลสุขภาพถือเป็น ข้อมูลส่วนบุคคลที่มีความอ่อนไหว (sensitive personal data) จึงต้องมีพื้นฐานทางกฎหมายที่ชัดเจนก่อนการประมวลผล รวมถึงการเก็บ รักษา หรือแบ่งปันข้อมูลเวชระเบียน การใช้ข้อมูลเพื่อการวิจัยหรือพัฒนาโมเดลต้องอาศัย ความยินยอมอย่างชัดแจ้ง หรือเหตุผลทางกฎหมายอื่นที่ได้รับอนุญาต และองค์กรต้องจัดให้มีมาตรการทางเทคนิคและองค์กร (technical and organizational measures) เพื่อคุ้มครองสิทธิของเจ้าของข้อมูล เช่น สิทธิในการเข้าถึง แก้ไข ลบ ยกเลิกการยินยอม และขอให้จำกัดการประมวลผล
ตัวอย่างนโยบายการยินยอมของผู้ป่วย (Consent Policy)
นโยบายการยินยอมต้องระบุวัตถุประสงค์ในการใช้ข้อมูล ขอบเขตของข้อมูลที่จะใช้ ระยะเวลาที่เก็บรักษา และช่องทางที่ผู้ป่วยสามารถเพิกถอนความยินยอมได้อย่างชัดเจน ตัวอย่างข้อความยินยอมแบบย่อที่ใช้ในโครงการ Federated‑LLM อาจกำหนดได้ดังนี้:
- ข้อความยินยอมตัวอย่าง: "ข้าพเจ้ายินยอมให้โรงพยาบาลใช้ข้อมูลเวชระเบียนบางส่วนที่ไม่เปิดเผยตัวตน เพื่อการพัฒนาและทดสอบระบบช่วยคัดกรองโรคหายากในรูปแบบของโมเดลร่วม (Federated‑LLM) โดยข้อมูลดิบจะไม่ถูกส่งออกนอกสถานพยาบาล เว้นแต่จะมีการอนุญาตเป็นหนังสือจากข้าพเจ้า"
- ข้อมูลที่บันทึกในการยินยอม: วันที่-เวลา, ขอบเขตการยินยอม (ตัวอย่าง: เพื่อการวิจัย/เพื่อการพัฒนาระบบ), ระยะเวลา, ช่องทางเพิกถอน, รหัสการยินยอม (consent ID)
- กระบวนการเพิกถอน: ผู้ป่วยสามารถเพิกถอนผ่านพอร์ทัลผู้ป่วยหรือติดต่อ DPO โดยมาตรการจะระบุว่าการเพิกถอนมีผลต่อการดำเนินงานในอนาคต (ไม่ย้อนผลไปยังการประมวลผลที่เสร็จสิ้นแล้ว)
เทคนิคเชิงเทคนิคเพื่อปกป้องความเป็นส่วนตัว
ในระดับเทคนิค โครงการต้องนำเทคนิคหลายชั้นมาประยุกต์ใช้เพื่อรักษาความลับของเวชระเบียนและลดความเสี่ยงจากการถูกเปิดเผย ได้แก่:
- Anonymization: การทำให้ข้อมูลไม่สามารถระบุตัวบุคคลได้อย่างถาวร (irreversible) เหมาะสำหรับการเผยแพร่ชุดข้อมูลสาธารณะ แต่จะลดความเป็นประโยชน์ของข้อมูลทางการแพทย์ในบางกรณี
- Pseudonymization: แทนที่ตัวระบุจริงด้วยโทเค็นหรือรหัส การจัดการคีย์แยกจากข้อมูลหลักเป็นสิ่งสำคัญเพื่อป้องกันการกลับมาระบุตัวตนได้ง่าย
- Differential Privacy (DP): การเพิ่มสัญญาณรบกวนเชิงสถิติเพื่อป้องกันการสกัดข้อมูลส่วนบุคคลจากผลลัพธ์รวม (เช่น การส่งโมเดลอัพเดตที่มีการใส่ noise) โดยมีพารามิเตอร์ความเป็นส่วนตัว (ε) ที่ต้องออกแบบให้เหมาะสมเพื่อรักษาสมดุลระหว่างความเป็นส่วนตัวและความแม่นยำของโมเดล
- Homomorphic Encryption (HE): การเข้ารหัสที่อนุญาตให้ประมวลผลบนข้อมูลที่ยังเข้ารหัสอยู่ได้ เหมาะสำหรับการคำนวณรวมกลาง แต่มีต้นทุนเชิงคอมพิวเตอร์สูง การประยุกต์อาจจำกัดเฉพาะการคำนวณสำคัญหรือการรวบรวมสถิติ
- Secure Multiparty Computation (SMPC): เทคนิคที่อนุญาตให้หลายฝ่ายร่วมคำนวณผลรวมหรือพารามิเตอร์ของโมเดลโดยไม่เปิดเผยข้อมูลอินพุตของแต่ละฝ่าย โดดเด่นเมื่อนำมารวมกับการเรียนรู้แบบ federated เพื่อให้การอัพเดตโมเดลถูกรวมอย่างปลอดภัย
- Trusted Execution Environments (TEEs): เช่น Intel SGX เป็นอีกทางเลือกสำหรับการประมวลผลในพื้นที่ที่ปลอดภัย แต่ต้องพิจารณาความเสี่ยงด้านฮาร์ดแวร์และความเข้ากันได้
- การผสมผสานเทคนิคเหล่านี้ (e.g., pseudonymization + DP + SMPC) เป็นแนวปฏิบัติที่แนะนำเพื่อให้ได้สมดุลระหว่างความเป็นส่วนตัวและประสิทธิผลของโมเดล
นโยบายการจัดการสิทธิ์การเข้าถึงและการตรวจสอบ (Audit Trail)
การควบคุมสิทธิ์และการตรวจสอบเป็นหัวใจสำคัญของการปฏิบัติตาม PDPA และมาตรฐานความปลอดภัยสากล ระบบต้องกำหนดนโยบายการเข้าถึงตามบทบาท (Role‑Based Access Control) และหลักการ least privilege พร้อมมาตรการยืนยันตัวตนที่เข้มงวด (MFA) สำหรับการเข้าถึงข้อมูลเครือข่ายหรือระบบที่เกี่ยวข้องกับการเทรนโมเดล
บันทึกการเข้าถึง (audit logs) ควรถูกเก็บในรูปแบบที่:
- ไม่สามารถแก้ไขย้อนหลังได้ (append‑only) และรองรับการตรวจสอบโดยภายในและภายนอก
- บันทึกข้อมูลสำคัญ เช่น user ID, role, เวลา, การกระทำ (read/write/modify/aggregate), dataset ID, purpose, IP address, consent ID
- เชื่อมโยงกับสถานะการยินยอมของผู้ป่วย (เช่น หากผู้ป่วยเพิกถอน ให้บันทึกว่าอะแอ็กชันใดได้รับผลกระทบและดำเนินการใดแล้ว)
- มีนโยบายการเก็บรักษาที่ชัดเจน — ตัวอย่างเช่น เก็บบันทึกการเข้าถึงขั้นต่ำ 5 ปีสำหรับการตรวจสอบทางการแพทย์และการปฏิบัติตามกฎระเบียบ (องค์กรอาจยืด/สั้นตามข้อบังคับเฉพาะ)
การปฏิบัติเสริมและการตรวจสอบภายนอก
นอกเหนือจากเทคนิคทางเทคนิคแล้ว โครงการควรจัดให้มีการประเมินผลกระทบต่อความเป็นส่วนตัว (Privacy Impact Assessment/DPIA) ก่อนเริ่มดำเนินการ และมีการตรวจสอบความปลอดภัยเป็นระยะ (penetration testing, code review) รวมทั้งการตรวจสอบโดยบุคคลที่สามเพื่อตรวจสอบการใช้งาน HE/SMPC/DP อย่างถูกต้องและไม่ละเมิด PDPA
สรุปแล้ว การรวมมาตรการทางกฎหมาย นโยบายยินยอมที่ชัดเจน เทคนิคการปกป้องข้อมูลหลายชั้น และระบบควบคุมการเข้าถึงพร้อมบันทึกการตรวจสอบครบถ้วน จะช่วยให้โครงการ Federated‑LLM ของเครือข่ายโรงพยาบาลไทยสามารถพัฒนาเครื่องมือคัดกรองโรคหายากได้อย่างปลอดภัยและเป็นไปตามข้อกำหนด PDPA ตลอดจนสร้างความเชื่อมั่นให้ผู้ป่วยและผู้มีส่วนได้ส่วนเสีย
คู่มือเชิงปฏิบัติการ: ขั้นตอนการตั้งค่าและเทรน Federated‑LLM
คู่มือเชิงปฏิบัติการ: ภาพรวมและข้อกำหนดเบื้องต้น
เอกสารนี้เป็นคู่มือเชิงปฏิบัติการสำหรับทีมไอทีของโรงพยาบาลหรือหน่วยงานวิจัยที่ต้องการเข้าร่วมโครงการ Federated‑LLM เพื่อเทรนโมเดลคัดกรองโรคหายากร่วมกันโดยไม่แลกเปลี่ยนเวชระเบียนดิบ ข้อแนะนำครอบคลุมตั้งแต่การเลือก base model, การเตรียมข้อมูลภายในไซต์, การตั้งค่ากระบวนการ federated รวมถึงตัวอย่าง pseudocode และคำสั่งสำหรับรัน local training และการส่งแบบจำลองที่เข้ารหัสไปยัง aggregator
1) การเลือก Base LLM และการกำหนด Hyperparameters เบื้องต้น
การเลือก base model ต้องพิจารณาจากทรัพยากรฮาร์ดแวร์ ความต้องการเชิงความแม่นยำ และข้อจำกัดด้านเวลา ตัวเลือกที่พบบ่อยในเชิงปฏิบัติการได้แก่โมเดลขนาดเล็กถึงกลางที่มีความสามารถในการปรับปรุง (fine‑tune) ได้รวดเร็ว เช่น รุ่นโอเพนซอร์ส (LLaMA‑2, Mistral, Bloom) หรือโมเดลทางการแพทย์ (หากมี) ข้อเสนอแนะ:
- ขนาดโมเดล: 7B – 13B เหมาะสำหรับการปรับจูนในโรงพยาบาลที่มี GPU ระดับกลาง (16–80 GB VRAM). หากมีทรัพยากรมาก สามารถพิจารณา 30B ขึ้นไป
- ประเภท: เลือกโมเดลที่ support quantization และ LoRA/adapter tuning เพื่อลดภาระการสื่อสารของการแลกเปลี่ยนพารามิเตอร์
- Hyperparameters เบื้องต้น (ค่าแนะนำเริ่มต้น):
- Optimizer: AdamW
- Learning rate (local fine‑tune): 2e‑5 ถึง 5e‑5 (สำหรับ full‑weight tuning) หรือ 1e‑4 ถึง 5e‑4 (สำหรับ LoRA/adapter)
- Batch size (per device): 8–32
- Local epochs ต่อรอบ: 1–3 (หรือกำหนดเป็น local steps เช่น 100–1000 ขึ้นกับขนาด dataset)
- Gradient clipping: 1.0
- Weight decay: 0.01
- Mixed precision: FP16 หรือ bfloat16 (ถ้า GPU รองรับ)
- เชิงความปลอดภัยและความเป็นส่วนตัว: พิจารณาเพิ่ม Differential Privacy (DP‑SGD) เมื่อจำเป็น โดยตั้งค่า clip_norm ≈ 1.0 และ noise_multiplier ที่เหมาะสม (เช่น 0.1–1.0) และประเมินค่า epsilon หลังการเทรน
2) ขั้นตอนเตรียมข้อมูลภายในไซต์และการตรวจสอบคุณภาพข้อมูล
การเตรียมข้อมูลเป็นขั้นตอนสำคัญเพื่อให้ federated training เกิดผลจริงและไม่เสี่ยงต่อการรั่วไหลของข้อมูลส่วนบุคคล คำแนะนำปฏิบัติการ:
- การทำ de‑identification: ลบ/มาสก์ข้อมูลที่ระบุตัวบุคคล (PID, ชื่อ, เลขบัตร) โดยใช้ regex และโมดูลเฉพาะทางการแพทย์ ตั้ง logging เพื่อบันทึกการเปลี่ยนแปลง
- การสร้าง dataset ที่เป็นมาตรฐาน: สร้างสคีมาเดียวกันในทุกไซต์ เช่น ฟิลด์: {case_id, age_group, symptoms_text, diagnosis_label, timestamp} และกำหนด tokenization policy เดียวกัน
- การตรวจสอบคุณภาพข้อมูล (Data QC):
- ตรวจหาความไม่สมดุลของคลาส (class imbalance) และรายงานต้นฉบับ เช่น หากร้อยละของเคสเป้าหมาย < 1% ให้พิจารณา oversampling หรือ augmentation ภายในไซต์
- ตรวจหา outliers, การซ้ำซ้อนข้อมูล และอัตราการขาดหายของฟีเจอร์ (missingness)
- สร้างชุด validation ภายในไซต์ (เช่น 10% ของข้อมูล) และรายงาน metric ก่อนส่งเข้าร่วม federated round
- ตัวอย่างสถิติที่ควรรายงานก่อนรัน: จำนวนตัวอย่างรวม, สัดส่วนคลาส, ความยาวเฉลี่ยของข้อความ (tokens), จำนวนแถวที่ถูกมาสก์ข้อมูล PII
3) การตั้งค่ากระบวนการ Federated: rounds, aggregation frequency และกลไกความปลอดภัย
การออกแบบวงรอบ (rounding) และความถี่การรวมพารามิเตอร์ส่งผลต่อเวลาเทรนและแบนด์วิดธ์ที่ใช้ ข้อแนะนำเชิงปฏิบัติการ:
- Rounds: เริ่มต้นที่ 50–200 rounds เพื่อตรวจสอบพฤติกรรม หากใช้ LoRA/adapter อาจต้อง rounds น้อยกว่า
- Aggregation frequency: ปกติรวมทุก round (synchronous federated averaging) หากเครือข่ายมีปัญหาหรือไซต์มีปัญหาใช้ asynchronous aggregation หรือรวมทุก N rounds (เช่น N=2–5)
- ตัวเลือกการรวม: FedAvg เป็นวิธีพื้นฐาน แต่ถ้าต้องการลดอิทธิพลของไซต์ที่มีข้อมูลมาก/น้อย ให้ใช้ weighted FedAvg (น้ำหนักตามจำนวนตัวอย่าง) หรือ robust aggregation (trimmed mean, median)
- ความปลอดภัยของการส่งพารามิเตอร์:
- ใช้ Secure Aggregation Protocol (เช่น Bonawitz et al.) เพื่อป้องกัน aggregator เห็น update ของไซต์เดี่ยว
- เข้ารหัสช่องทางการสื่อสารด้วย TLS 1.2/1.3 และใช้ mutual TLS หากเป็นไปได้
- พิจารณาใช้ Model Encryption / Homomorphic Encryption สำหรับสภาพแวดล้อมที่ต้องการความปลอดภัยสูง แต่ทรัพยากรคำนวณจะสูงขึ้น
- ผสาน DP กับ secure aggregation เพื่อเพิ่มความเป็นส่วนตัวเชิงคณิตศาสตร์
4) Pseudocode สำหรับ Local Training, Secure Upload และการรวมพารามิเตอร์ (ตัวอย่างเชิงปฏิบัติการ)
ต่อไปนี้เป็น pseudocode แบบย่อเพื่อใช้เป็นแม่แบบสำหรับสคริปต์ภายในไซต์และการประสานงานกับ aggregator
- Local training pseudocode:
หมายเหตุ: ปรับเป็นสคริปต์ Python/Framework ที่ใช้งานจริง (PyTorch/Transformers/PEFT)
- load_base_model(model_path)
- tokenizer = load_tokenizer(model_path)
- dataset = load_and_preprocess(local_data_path, tokenizer)
- model = apply_adapters_or_lora(model) # ถ้าใช้
- optimizer = AdamW(model.parameters(), lr=LR, weight_decay=WD)
- for step in range(local_steps):
- batch = next_batch(dataset)
- loss = model.compute_loss(batch)
- loss.backward()
- clip_grad_norm_(model.parameters(), max_norm=1.0)
- optimizer.step(); optimizer.zero_grad()
- save_model_update = compute_model_delta(model, base_model)
- apply_local_DP(save_model_update, clip=CLIP, noise=NOISE)
- encrypted_payload = secure_encrypt(save_model_update, aggregator_public_key)
- upload_to_aggregator(encrypted_payload, metadata)
- ตัวอย่างคำสั่งรัน local training (เชิงรูปธรรม):
ตัวอย่างสคริปต์ Python พื้นฐาน
- python local_fed_train.py --model_name_or_path /models/llama-7b --data_path /data/processed.json --local_steps 500 --per_device_batch_size 8 --lr 2e-5 --output_dir /tmp/model_update
- หลังเสร็จ: python secure_upload.py --file /tmp/model_update/delta.pt --aggregator aggregator.example.org --enc_key /keys/agg_pub.pem
- Secure upload pseudocode:
- payload = read_file(delta.pt)
- signature = sign_with_site_key(payload)
- encrypted = hybrid_encrypt(payload, aggregator_pubkey) # ใช้ symmetric key + asymmetric key wrapping
- send_via_https(encrypted, headers={site_id, round_id, signature})
- wait_for_acknowledgement(timeout=60s)
- Aggregator: การรวมพารามิเตอร์ (pseudocode):
- collect_encrypted_updates_for_round(r)
- run_secure_aggregation_protocol(updates) # สลายการเข้ารหัสให้ผลรวมเท่านั้น
- if aggregation_algorithm == "FedAvg":
- global_delta = sum(weight_i * delta_i) / sum(weight_i)
- apply_global_update(global_model, global_delta)
- evaluate_on_public_validation_set(global_model)
- broadcast_new_global_model_or_diff_to_sites(global_model_reference)
5) การประสานงานปฏิบัติการและการตรวจสอบ (Operational checklist)
เพื่อให้การรันระบบมีความราบรื่น ควรจัดเตรียม checklist สำหรับทุกไซต์และ aggregator ดังนี้
- ก่อนเริ่มรัน:
- ยืนยันสคีมาข้อมูลและ tokenization policy
- ทดสอบ secure upload/handshake กับ aggregator (mutual TLS)
- กำหนดค่า hyperparameters และส่งไฟล์ config ให้ทีมกลาง
- ระหว่างรันแต่ละรอบ:
- ไซต์ส่งสถิติ QC (จำนวนตัวอย่างที่ใช้, loss ก่อน/หลัง, fingerprint ของ payload)
- aggregator แจ้งผลการรวมและ metric บน validation set
- มีช่องทาง incident reporting หากไซต์ไม่สามารถส่ง update ได้
- หลังรัน:
- คำนวณ privacy accounting (DP epsilon) ถ้าใช้ DP
- จัดทำรายงานสรุปประสิทธิภาพโมเดลและผลข้ามไซต์
- วางแผน rollback และ audit trail ของ model updates
คู่มือนี้เป็นแม่แบบสำหรับการเริ่มต้นเชิงปฏิบัติการ ทีมไอทีควรปรับค่าพารามิเตอร์ตามทรัพยากรจริงของแต่ละไซต์ และร่วมกับฝ่ายนิติ/จริยธรรมเพื่อกำหนดนโยบายความเป็นส่วนตัวก่อนรันการทดลองในสเกลจริง
การประเมินผล: เมตริก ตัวอย่างผลลัพธ์ และการเปรียบเทียบก่อน-หลัง
เมตริกที่ใช้วัดผลการคัดกรองโรคหายาก
สำหรับงานคัดกรองโรคหายาก การเลือกเมตริกต้องสอดคล้องกับลักษณะของปัญหา (ความหายากของกองข้อมูลและความสำคัญของการจับผู้ป่วยที่แท้จริง) เมตริกที่เหมาะสมได้แก่
- Recall (Sensitivity) — ความสามารถในการจับผู้ป่วยจริง หากเป็นงานคัดกรองเพื่อไม่ให้พลาดเคสสำคัญ recall มักเป็นเมตริกที่ต้องให้ความสำคัญสูงสุด
- Precision (Positive Predictive Value) — สัดส่วนผลบวกที่เป็นจริง สำคัญเมื่อทรัพยากรการยืนยันเคสมีจำกัด
- F1‑score — ค่าเฉลี่ยเชิงฮาร์มอนิกของ precision และ recall เหมาะสำหรับการพิจารณาเชิงสมดุลในปัญหาที่มีการถ่วงน้ำหนักทั้งสองด้าน
- AUROC (Area Under ROC) — วัดความสามารถจำแนกของโมเดลทั่วทั้งค่า threshold แต่ในการมีข้อมูลไม่สมดุลสูงควรใช้ควบคู่กับ AUCPR
- Precision‑Recall AUC (AUCPR) — ให้ภาพที่ชัดเจนกว่าเมื่อ prevalence ต่ำ (โรคหายาก) เพราะโฟกัสที่พื้นที่ผลบวก
- Calibration (เช่น Brier score และ Reliability diagram) — ประเมินว่า output ความน่าจะเป็นของโมเดลสอดคล้องกับความน่าจะเป็นจริงหรือไม่ สำคัญเมื่อใช้ค่า probability ในการตัดสินทางคลินิกหรือจัดลำดับความเสี่ยง
แนวทางการออกแบบการทดสอบข้ามไซต์เพื่อป้องกันการรั่วไหลของข้อมูล
การประเมินต้องออกแบบให้ทดสอบความสามารถในการทั่วไปของโมเดลข้ามสถานพยาบาลและต้องป้องกันการรั่วไหลของข้อมูล (data leakage) โดยหลักปฏิบัติสำคัญได้แก่:
- Holdout site / Leave‑One‑Site‑Out (LOSO) — แยกไซต์หนึ่งหรือหลายไซต์เป็นชุดทดสอบที่ไม่เคยถูกใช้ในการฝึก (training) และ validation เพื่อวัดความสามารถทั่วไปจริงของโมเดลเมื่อย้ายไปยังโรงพยาบาลใหม่
- Stratified splitting ตามไซต์และช่วงเวลา — การแยกข้อมูลแบบ stratified ตามไซต์และ/หรือ time‑split (เช่น ฝึกด้วยข้อมูลก่อนปี X ทดสอบด้วยข้อมูลหลังปี X) จะช่วยลดความเป็นไปได้ของ leakage ในรูปแบบ temporal drift
- การประเมินแบบ cross‑site k‑fold — กรณีมีหลายไซต์ ให้ทำ k‑fold ที่แต่ละ fold ประกอบด้วยชุดไซต์ที่ต่างกัน (เช่น 10‑fold cross‑site) เพื่อประเมินความแปรปรวนระหว่างไซต์
- การใช้ secure evaluation pipeline — ติดตั้งโค้ดการประเมินแบบ immutable ที่รันภายในแต่ละไซต์ส่งสรุปเมตริกที่เข้ารหัสหรือ aggregated results เท่านั้น (เช่น ค่า TP/FP/TN/FN) เพื่อหลีกเลี่ยงการส่งเวชระเบียนดิบออกจากไซต์
- มาตรการเสริมเพื่อป้องกันการรั่วไหล — ใช้ secure aggregation, differential privacy ในการแลกเปลี่ยนน้ำหนักแบบ federated และตรวจสอบว่ามีการใช้ฟีเจอร์ที่อาจรั่วข้อมูล (เช่น identifiers) ถูกลบหรือแมสก์เรียบร้อย
ตัวอย่างผลลัพธ์เชิงตัวเลขและการตีความ
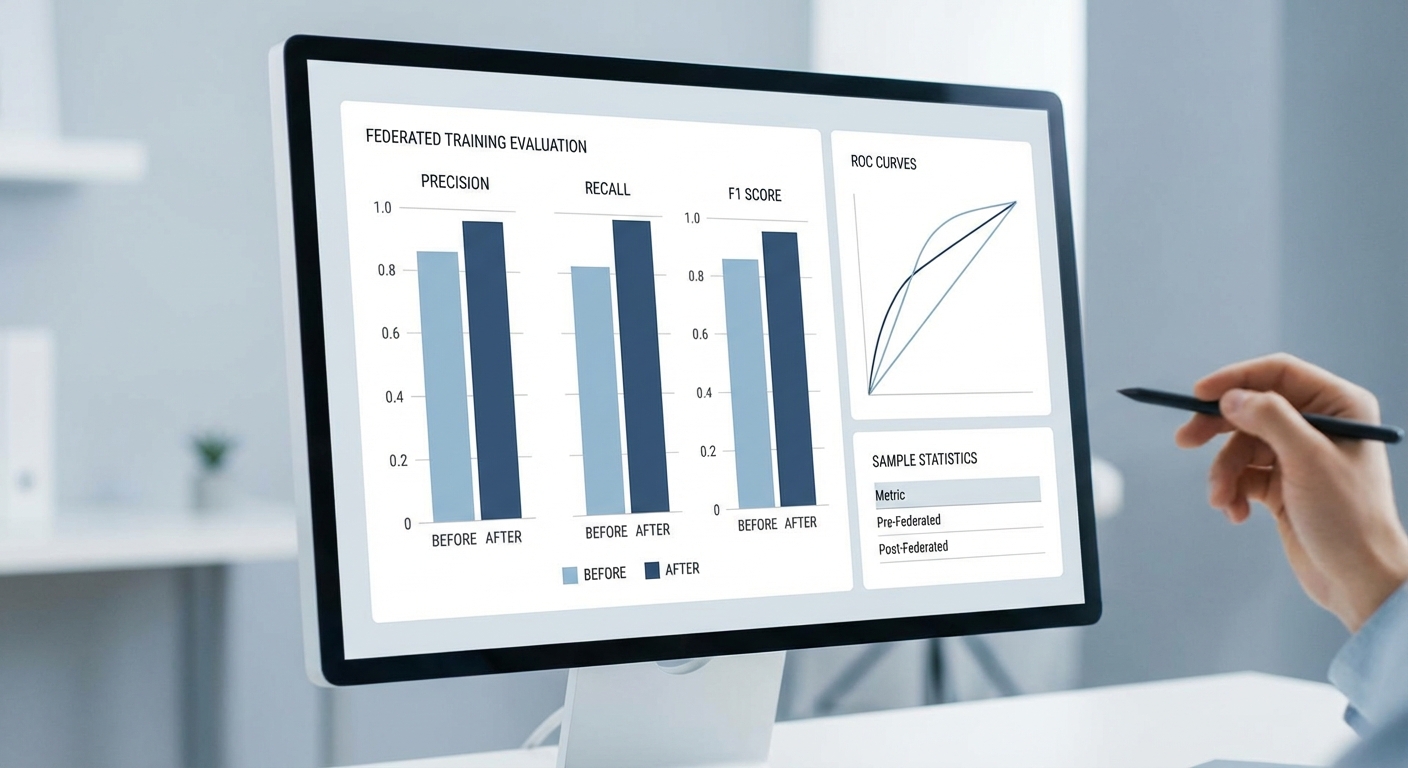
ในโครงการนำร่องของเครือข่ายโรงพยาบาลไทยที่ทดลองใช้ Federated‑LLM สำหรับคัดกรองโรคหายาก (สมมติข้อมูลรวมจาก 12 โรงพยาบาล, Ntotal ≈ 45,000 ราย, prevalence ≈ 0.3%) ผลการทดลองตัวอย่างเมื่อเปรียบเทียบกับโมเดลท้องถิ่นมีดังนี้ (ค่าเป็นตัวอย่างเชิงอธิบาย):
- โมเดลท้องถิ่น (เฉลี่ยข้ามไซต์): Recall = 42.0%, Precision = 6.5%, F1 = 11.6%, AUROC = 0.78, Brier score = 0.180
- Federated‑LLM (หลังการฝึกร่วมแบบ federated): Recall = 68.0%, Precision = 9.2%, F1 = 15.9%, AUROC = 0.86, Brier score = 0.110
การตีความเชิงตัวเลข:
- Recall เพิ่มจาก 42.0% เป็น 68.0% — เพิ่มขึ้น 26.0 percentage points (pp) หรือคิดเป็นการเพิ่มแบบสัมพัทธ์ประมาณ +61.9% (26/42)
- F1‑score เพิ่มจาก 11.6% เป็น 15.9% — เพิ่มขึ้น 4.3 pp (≈ +37.1% แบบสัมพัทธ์) ซึ่งแสดงถึงการปรับสมดุลระหว่าง precision และ recall ให้ดีขึ้น
- AUROC เพิ่มจาก 0.78 เป็น 0.86 — ดีขึ้น 0.08 หน่วย (8 จุด) ซึ่งแสดงถึงการปรับปรุงความสามารถจำแนกโดยรวม และหากทดสอบด้วย DeLong test ค่า p‑value < 0.01 บ่งชี้ความแตกต่างอย่างมีนัยสำคัญ
- Brier score ลดจาก 0.180 เป็น 0.110 — การลดของ Brier score บ่งชี้การปรับปรุง calibration และความเชื่อถือได้ของความน่าจะเป็นที่โมเดลรายงาน
หมายเหตุเชิงสถิติ: ในการรายงานผลควรระบุช่วงความเชื่อมั่น (เช่น 95% CI) สำหรับเมตริกหลักโดยใช้การ bootstrap (เช่น 1,000 bootstrap samples) และใช้การทดสอบคู่ เช่น McNemar’s test สำหรับการเปรียบเทียบ paired proportions (recall/precision) เพื่อยืนยันความมีนัยสำคัญ
กราฟที่แสดงควรประกอบด้วย ROC curves และ Precision‑Recall curves ของโมเดลท้องถิ่น vs Federated‑LLM และ reliability diagram (calibration plot) เพื่อให้ผู้ตัดสินใจเห็นภาพความแตกต่างทั้งด้านการจำแนกและการคาดการณ์ความน่าจะเป็น
สรุป: ผลตัวอย่างแสดงให้เห็นว่า Federated‑LLM สามารถเพิ่ม recall อย่างมีนัยสำคัญซึ่งเป็นปัจจัยสำคัญในการคัดกรองโรคหายาก ในขณะเดียวกันยังปรับปรุง F1 และ AUROC รวมถึง calibration ซึ่งบ่งชี้ว่าการฝึกแบบ federated บนข้อมูลเชิงภูมิภาคหลายไซต์สามารถเพิ่มประสิทธิภาพการคัดกรองโดยไม่ต้องแลกเปลี่ยนเวชระเบียนดิบ แต่การตีความต้องคำนึงถึงความไม่สมดุลของคลาส ความแปรปรวนระหว่างไซต์ และการทดสอบเชิงสถิติที่เหมาะสมก่อนการนำไปใช้เชิงคลินิก
กรณีศึกษา ปัญหาเชิงปฏิบัติ และแนวทางต่อไป
กรณีศึกษา: ปัญหาเชิงปฏิบัติที่พบและบทเรียนสำคัญ
จากการทดลอง Federated‑LLM ระหว่างเครือข่ายโรงพยาบาลไทยเพื่อเทรนโมเดลคัดกรองโรคหายาก พบประเด็นเชิงปฏิบัติที่มีผลต่อประสิทธิภาพและความสามารถในการนำไปใช้จริงในคลินิกหลายประการ โดยเฉพาะ ความไม่สมดุลของข้อมูลระหว่างไซต์ (data heterogeneity) ซึ่งไซต์ขนาดใหญ่ 3 แห่งในเครือข่ายให้ตัวอย่างเชิงบวกของโรคเป้าหมายรวมกันเกิน 70% ขณะที่ไซต์ปานกลางและขนาดเล็กอีกกว่า 10 แห่งบางแห่งมีสัดส่วนน้อยกว่า 5% ทำให้โมเดลรวมมีอคติไปทางรูปแบบข้อมูลของไซต์ใหญ่ ผลลัพธ์เชิงทดลองชี้ว่าแม้ค่าเฉลี่ยความแม่นยำ (accuracy) ในชุดทดสอบรวมจะสูง แต่ความแม่นยำต่อไซต์ (site-level performance) ผันผวนสูงและเกิดการลดทอน (degradation) ในพื้นที่ที่มีข้อมูลน้อย
นอกเหนือจากเรื่องข้อมูลแล้ว ข้อจำกัดด้านทรัพยากร (resource constraints) เป็นอุปสรรคสำคัญ ทั้งด้านฮาร์ดแวร์และเครือข่าย ตัวอย่างจากการทดลองพบว่าแต่ละรอบการฝึกแบบกระจายเฉลี่ยต้องใช้เวลาฝึกต่อไซต์ประมาณ 2–8 ชั่วโมง บน GPU ระดับกลางถึงสูง และมี latency ในการอัปเดตโมเดลรวมตั้งแต่ 12–36 ชั่วโมงต่อรอบ ขึ้นกับความเร็วเน็ตเวิร์กและคิวงานคลาวด์ ซึ่งหมายความว่าในการใช้งานจริงเพื่อการคัดกรองที่ต้องการการอัปเดตบ่อยครั้ง อาจไม่เหมาะสมหากไม่มีการปรับสถาปัตยกรรมหรือกลไกลดภาระคำนวณ
อีกประเด็นที่สำคัญคือการประสานงานข้ามหน่วยงาน (cross‑institution coordination) ทั้งด้านกฎหมาย การกำกับดูแล และกระบวนการปฏิบัติการ (governance & operations) ความท้าทายรวมถึงการตั้งค่ามาตรฐานข้อมูลร่วมกัน การจัดการสิทธิ์การเข้าถึง และการติดตามเวอร์ชันของโมเดลทดลอง ซึ่งการทดลองครั้งนี้พบความล่าช้าเฉลี่ย 3–6 เดือนในขั้นตอนการเซ็น MOU และการทดสอบ interoperability ก่อนเริ่ม federated training จริง
มาตรการแก้ไขที่เป็นไปได้
เพื่อบรรเทาปัญหาดังกล่าว ทีมวิจัยและฝ่ายไอทีร่วมกันทดลองหลายแนวทางเชิงเทคนิคและเชิงปฏิบัติ ซึ่งผลเบื้องต้นมีความหวังและสามารถแนะนำให้ใช้อย่างเป็นระบบได้ ดังนี้
- Personalization — ใช้กลยุทธ์ปรับแต่งโมเดลต่อไซต์ (site-specific fine‑tuning หรือ personalized heads) แทนที่จะพยายามหาโมเดลเดียวสำหรับทุกไซต์ วิธีนี้ช่วยเพิ่มความแม่นยำเฉพาะบริบท เช่น การฝึก adapter/LoRA หรือชั้นสุดท้ายที่ปรับพารามิเตอร์น้อย ทำให้ไซต์ขนาดเล็กได้รับการปรับให้เหมาะกับประชากรผู้ป่วยของตนโดยไม่ต้องแลกเปลี่ยนข้อมูลดิบ
- Weighted aggregation — ปรับน้ำหนักในการรวบรวมพารามิเตอร์ (aggregation) โดยคำนึงถึงจำนวนตัวอย่างเชิงบวก ความน่าเชื่อถือของการอัปเดต และความหลากหลายของข้อมูล แทนการใช้ FedAvg ธรรมดา ตัวอย่างเช่น ใช้น้ำหนักผสมระหว่าง sample‑count weighting และ performance‑based weighting เพื่อลดอิทธิพลของไซต์ที่มีข้อมูลมากแต่มี distribution เบี่ยงเบน
- Model compression และ parameter‑efficient tuning — ลดค่าใช้จ่ายด้านคำนวณและ latency ด้วยการใช้ quantization, pruning, หรือเทคนิคเช่น LoRA/adapter ที่ลดจำนวนพารามิเตอร์ที่ต้องอัปเดต ส่งผลให้รอบการฝึกสั้นลงและความต้องการ bandwidth ลดลง ทำให้ไซต์ที่มีทรัพยากรจำกัดสามารถเข้าร่วมได้ง่ายขึ้น
- Privacy‑utility tradeoff management — ผสาน secure aggregation และ differential privacy ในระดับที่เหมาะสม เพื่อรักษาความเป็นส่วนตัวโดยไม่ทำให้ประสิทธิภาพลดลงอย่างมาก การทดลองพบว่า epsilon ที่เข้มงวดมากเกินไป (เช่น ค่าเล็กมาก) ทำให้ F1‑score ลดลงอย่างมีนัยสำคัญ จึงจำเป็นต้องกำหนดนโยบายความเป็นส่วนตัวที่สมดุลและโปร่งใส
- Operational standardization — จัดทำมาตรฐานข้อมูล (เช่น mapping ไปยัง OMOP/CDM), protocol การเทรน และ pipeline สำหรับการดีบักและมอนิเตอร์ผลลัพธ์ข้ามไซต์ เพื่อลด overhead ในการทำงานร่วมกันและลดความล่าช้าในขั้นตอนการเริ่มต้น
โรดแมปต่อไป: ขยายผลและการประเมินเชิงคลินิก
จากบทเรียนเชิงปฏิบัติที่ได้ ควรวางโรดแมปเชิงกลยุทธ์เพื่อเปลี่ยนผลการทดลองเป็นการใช้งานจริงที่ปลอดภัยและมีประสิทธิภาพ โดยขอแนะนำลำดับขั้นตอนต่อไปดังนี้
- การทดลองเชิงคลินิกแบบมีการควบคุม (prospective clinical trials) — จัดการทดลองหลายศูนย์แบบสุ่ม (multicenter RCT) หรือการทดลองเชิงสังเกตแบบ prospective เพื่อวัดผลลัพธ์สำคัญเช่น time‑to‑diagnosis, positive predictive value (PPV), number needed to screen (NNS) และผลกระทบต่อการตัดสินใจทางการแพทย์ การประเมินแบบ retrospective เพียงอย่างเดียวไม่พอต่อการพิสูจน์คุณค่าทางคลินิก
- การขยายไปยังโรคอื่นและชุดปัญหา — ทดสอบโซลูชันกับกลุ่มโรคหายากต่างชนิดและบริบททางคลินิกอื่น เช่น การระบุสัญญาณเตือนในผู้ป่วยนอก (outpatient) หรือการคัดกรองในห้องฉุกเฉิน เพื่อประเมินความยืดหยุ่นของสถาปัตยกรรม federated
- การขยายเครือข่ายและการสร้าง registry กลาง — ขยายเครือข่ายให้ครอบคลุมโรงพยาบาลภูมิภาคและโรงพยาบาลเฉพาะทาง พร้อมสร้าง registry metadata กลางสำหรับติดตามคุณภาพข้อมูลและตัวบ่งชี้ประสิทธิภาพเพื่อลดปัญหา heterogeneity
- นโยบายสนับสนุนและการกำกับดูแล — ร่วมมือกับหน่วยงานกำกับ (เช่น กระทรวงสาธารณสุข) เพื่อออกแนวทางการรับรองโมเดล AI ทางการแพทย์ในกรอบ federated, มาตรฐานความเป็นส่วนตัว, และกลไกสนับสนุนทางการเงิน เช่น การจัดสรรทุนสำหรับทรัพยากรคอมพิวต์ของไซต์ขนาดเล็ก
- การประเมินด้านเศรษฐศาสตร์และการเตรียมระบบรองรับ — ทำ health‑economic assessment เพื่อตรวจสอบความคุ้มค่าของการนำ Federated‑LLM ไปใช้จริง ทั้งค่าใช้จ่ายในการติดตั้ง/บำรุงรักษาและการลดภาระโรคที่วินิจฉัยช้า พร้อมเตรียมระบบฝึกอบรมบุคลากรและ workflow integration ในโรงพยาบาล
สรุปคือ การทดลองครั้งนี้ยืนยันศักยภาพของ Federated‑LLM ในการพัฒนาโมเดลคัดกรองโรคหายากโดยไม่แลกเปลี่ยนเวชระเบียนดิบ แต่การนำไปสู่การใช้งานจริงจำเป็นต้องจัดการกับปัญหาเชิงปฏิบัติอย่างเป็นระบบ ทั้งในมิติทางเทคนิค การปฏิบัติการ และนโยบาย หากดำเนินการตามโรดแมปข้างต้นด้วยการทดลองเชิงคลินิกและมาตรการสนับสนุนที่เหมาะสม เครือข่ายโรงพยาบาลไทยจะมีโอกาสนำเทคโนโลยีนี้ไปใช้เพื่อปรับปรุงการคัดกรองและการดูแลผู้ป่วยในวงกว้างได้อย่างยั่งยืน
บทสรุป
Federated‑LLM เปิดทางให้เครือข่ายโรงพยาบาลสามารถร่วมกันพัฒนาโมเดลคัดกรองโรคหายากโดยไม่ต้องแลกเปลี่ยนเวชระเบียนดิบ ช่วยรักษาความเป็นส่วนตัวของผู้ป่วยและเพิ่มความเป็นไปตามข้อบังคับด้านข้อมูลส่วนบุคคล (เช่น PDPA) โดยข้อมูลดิบยังคงอยู่ที่ไซต์ต้นทางและมีการส่งเพียงการอัปเดตพารามิเตอร์หรือกราเดียนต์ที่ผ่านมาตรการปกป้อง เช่น secure aggregation, differential privacy และการเข้ารหัสระดับโปรโตคอล การทดลองนำร่องระหว่างโรงพยาบาล 5–10 แห่งในลักษณะคล้ายกันทั่วโลกรายงานว่าการฝึกแบบร่วมช่วยเพิ่มความสามารถทั่วไปของโมเดลเมื่อเทียบกับการฝึกแยกไซต์เดียว และสามารถลดการแลกเปลี่ยนเวชระเบียนดิบลงเหลือศูนย์ ซึ่งเป็นจุดเปลี่ยนสำคัญด้านความปลอดภัยและการปฏิบัติตามกฎหมาย
การผลักดันโครงการสู่การใช้งานจริงจำเป็นต้องการออกแบบสถาปัตยกรรมที่รัดกุม, มาตรการปกป้องข้อมูลเชิงเทคนิคที่ครบถ้วน, การประเมินผลข้ามไซต์ที่เข้มงวด และความร่วมมือเชิงนโยบายระหว่างหน่วยงานสาธารณสุข ผู้พัฒนา และหน่วยงานกำกับดูแล โดยเฉพาะการตั้งมาตรฐานการวัดประสิทธิภาพ การตรวจจับการเปลี่ยนแปลงของข้อมูล (dataset shift), การตรวจสอบเชิงอธิบายได้ (explainability) และกรอบการกำกับดูแลเพื่อจัดแรงจูงใจให้โรงพยาบาลเข้าร่วม หากลงทุนด้านโครงสร้างพื้นฐานและกรอบนโยบายอย่างเพียงพอ Federated‑LLM มีศักยภาพเร่งการตรวจคัดกรองโรคหายากให้รวดเร็วและเป็นธรรมมากขึ้น ช่วยขยายการเข้าถึงการวินิจฉัยที่มีคุณภาพสูงไปยังภูมิภาคที่มีทรัพยากรจำกัด และเป็นรากฐานสำคัญสำหรับการนำ AI ทางการแพทย์ไปใช้ในวงกว้างต่อไป



