
เมื่ออเมซอน ขยายการใช้งานเทคโนโลยีปัญญาประดิษฐ์เชิงสร้างสรรค์อย่างรวดเร็ว ทั้งบริการอย่าง Amazon Bedrock, Amazon SageMaker และเครื่องมือช่วยเขียนโค้ดอย่าง CodeWhisperer ได้ก่อให้เกิดความตื่นเต้นในวงการธุรกิจและนักพัฒนา แต่ขณะเดียวกันการผนวกโมเดลภาษาขนาดใหญ่และโมเดลสร้างสรรค์เข้าไปในเส้นทางการประมวลผลของแอปพลิเคชัน ก็มีความเสี่ยงที่มาพร้อมกัน ได้แก่ การเพิ่มขึ้นของ latency และการลดทอน throughput ในบางกรณี — ผลกระทบที่อาจหมายถึงประสบการณ์ผู้ใช้ที่ช้าลง ค่าใช้จ่ายที่สูงขึ้น และความท้าทายในการสเกลระบบให้รองรับภาระงานจำนวนมาก
บทนำชิ้นนี้จะพาคุณสำรวจภาพรวมการขยายตัวของ AI สร้างสรรค์ในระบบนิเวศของอเมซอน พร้อมชี้จุดบริการสำคัญ ตัวอย่างการใช้งานจริง และสถิติการทดสอบเชิงปฏิบัติการที่ชี้ให้เห็นถึงการเพิ่มขึ้นของ latency ตั้งแต่ระดับสิบไปจนถึงหลายร้อยมิลลิวินาทีในสภาพแวดล้อมบางแบบ นอกจากนี้บทความยังนำเสนอกรณีศึกษาเชิงลึก แนวทางออกแบบสถาปัตยกรรมเพื่อลดผลกระทบ (เช่น caching, model distillation, asynchronous processing) และ tutorial สำหรับนักพัฒนาที่ต้องการนำโมเดลสร้างสรรค์ไปใช้งานจริงโดยยังคงรักษาความเร็วและความเสถียรของระบบ
บทนำ: ทำไมอเมซอนขยายการใช้งาน AI สร้างสรรค์ในช่วงนี้
บทนำ: ทำไมอเมซอนขยายการใช้งาน AI สร้างสรรค์ในช่วงนี้
การตัดสินใจของอเมซอนในการขยายการใช้งาน AI สร้างสรรค์ (generative AI) ในช่วงเวลานี้สะท้อนถึงการเปลี่ยนโฟกัสเชิงกลยุทธ์จากการปรับปรุงประสิทธิภาพแบบดั้งเดิมไปสู่การลงทุนเชิงผลิตภัณฑ์และประสบการณ์ลูกค้าแบบเชิงรุก บริษัทระดับโลกอย่างอเมซอนมองเห็นโอกาสในการใช้โมเดลภาษาขนาดใหญ่และเทคนิคการสร้างคอนเทนต์อัตโนมัติเพื่อเพิ่มความสามารถในการปรับแต่ง (personalization), ลดต้นทุนการผลิตคอนเทนต์ และเร่งนวัตกรรมในบริการของ AWS ซึ่งทั้งหมดนี้สามารถแปลเป็นการเติบโตของรายได้และการยึดเหนี่ยวลูกค้าในระยะยาวได้

ในเชิงตัวเลข หลายการศึกษาชี้ให้เห็นว่า personalization สามารถเพิ่มอัตราการแปลง (conversion) และมูลค่าต่อการสั่งซื้อได้ในระดับที่จับต้องได้ — งานวิจัยจากภาคอุตสาหกรรมรายงานช่วงการเพิ่มขึ้นระหว่างหลักหน่วยไปจนถึงสองหลัก (%) ขึ้นกับกลยุทธ์และข้อมูลที่มีพร้อม ขณะเดียวกัน content automation สามารถลดต้นทุนการผลิตคอนเทนต์ซ้ำซ้อนและปรับปรุงความเร็วในการเผยแพร่ ทำให้ทีมการตลาดและเจ้าของผลิตภัณฑ์สามารถทดสอบไอเดียใหม่ ๆ ได้มากขึ้นด้วยทรัพยากรที่น้อยลง ตัวอย่างเช่น การใช้โมเดลสร้างสรรค์เพื่อผลิตภาพสินค้า, คำอธิบายผลิตภัณฑ์ หรือสคริปต์วิดีโอที่มีการปรับแต่งตามเซ็กเมนต์ลูกค้า จะช่วยลดค่าใช้จ่ายและเวลาในการสร้างคอนเทนต์แบบแมนวล
อย่างไรก็ตาม การขยายการใช้งาน AI สร้างสรรค์ไม่ไร้ความเสี่ยง โดยเฉพาะประเด็นสำคัญ 3 ด้านที่อเมซอนต้องบริหารจัดการอย่างเข้มงวด: latency (ความหน่วงของการตอบสนอง) ซึ่งอาจส่งผลต่อประสบการณ์ผู้ใช้หากการประมวลผลโมเดลใหญ่ทำให้การโหลดช้าลง; cost ทั้งค่า inference และการจัดเก็บโมเดลขนาดใหญ่ที่อาจเพิ่มงบประมาณอย่างมีนัยสำคัญ; และ user experience เมื่อผลลัพธ์จากโมเดลสร้างสรรค์ไม่สอดคล้องหรือมีข้อผิดพลาด (เช่น hallucination) อาจทำให้ความเชื่อมั่นของลูกค้าลดลง การตัดสินใจของอเมซอนจึงต้องแลกมาด้วยการลงทุนในสถาปัตยกรรมที่ลดความหน่วง (edge inference, caching), การจัดการต้นทุน (spot instances, model quantization) และระบบควบคุมคุณภาพเนื้อหา
บทความนี้จะให้ภาพรวมเชิงลึกทั้งในมุมมองธุรกิจและเทคนิค และยังมีส่วนแนะนำเชิงปฏิบัติการสำหรับผู้ที่ต้องการนำแนวปฏิบัติของอเมซอนไปปรับใช้กับองค์กรของตน โดยสรุปผู้อ่านจะได้รับ:
- วิเคราะห์เชิงธุรกิจ: เหตุผลทางกลยุทธ์ที่อเมซอนผลักดัน AI สร้างสรรค์และผลกระทบต่อรายได้ ต้นทุน และการรักษาลูกค้า
- ประเด็นทางเทคนิค: ความท้าทายด้าน latency, การเพิ่มประสิทธิภาพค่าใช้จ่าย และแนวทางสถาปัตยกรรมที่ใช้ได้จริงบน AWS
- บทแนะนำเชิงปฏิบัติ (tutorial): ขั้นตอนและแนวทางปฏิบัติที่ควรพิจารณาเมื่อนำ generative AI มาใช้ในระบบ production รวมถึงตัวอย่างการใช้งานและตัวชี้วัดความสำเร็จ
ภาพรวมบริการและเทคโนโลยีของอเมซอนที่เกี่ยวข้อง
ภาพรวมบริการและขอบเขตเทคโนโลยีที่เกี่ยวข้อง
อเมซอนผ่าน AWS (Amazon Web Services) ให้บริการชุดเครื่องมือและโครงสร้างพื้นฐานที่ครอบคลุมเพื่อรองรับการนำ AI สร้างสรรค์ (generative AI) ไปใช้ในเชิงพาณิชย์ ตั้งแต่การจัดเตรียมข้อมูล การฝึกและปรับจูนโมเดล การโฮสต์โมเดล ไปจนถึงจุดให้บริการสำหรับการใช้งานจริง (inference/endpoints) โดยเป้าหมายเพื่อลดความซับซ้อนของงานด้าน infrastructure และเปิดโอกาสให้องค์กรโฟกัสที่การสร้างมูลค่าเชิงธุรกิจ รายการบริการเหล่านี้ถูกออกแบบให้สามารถทำงานร่วมกันได้อย่างยืดหยุ่น ทั้งในรูปแบบ managed services และการติดตั้งเองบนทรัพยากรของลูกค้า
รายการบริการหลักและการใช้งาน
- Amazon Bedrock — แพลตฟอร์มที่ให้เข้าถึง Foundation Models จากพันธมิตรและโมเดลของ AWS เอง พร้อม API สำหรับการเรียกใช้งาน สะดวกสำหรับงานสร้างข้อความ สรุปเนื้อหา และการสร้างภาพจากข้อความ (text-to-image)
- Amazon SageMaker — ครอบคลุมตั้งแต่การฝึกโมเดล (training), การปรับจูน (fine-tuning), การทดสอบ ไปจนถึง managed model hosting และ inference endpoints (real-time/multi-model/batch)
- AWS Inferentia / Trainium และ EC2 GPU instances — ฮาร์ดแวร์เร่งความเร็วสำหรับงานฝึกและ inference เมื่อความต้องการด้านประสิทธิภาพและต้นทุนเป็นปัจจัยสำคัญ
- AWS Lambda, API Gateway และ Elastic Kubernetes Service (EKS) — เครื่องมือสำหรับจัดการโครงสร้างแบบ serverless หรือคอนเทนเนอร์เมื่อต้องการความยืดหยุ่นในการปรับขยาย
- Data pipelines และการจัดการข้อมูล — Amazon S3 (storage), AWS Glue (ETL), Amazon Kinesis (streaming), SageMaker Data Wrangler และ Ground Truth (labeling) สำหรับการเตรียมข้อมูลและเวิร์กโฟลว์การเรียนรู้ของเครื่อง
- เครื่องมือสำหรับนักพัฒนา — SageMaker Studio, SageMaker JumpStart (ตัวอย่างและโมเดลสำเร็จรูป), AWS SDKs, CLI และเครื่องมือช่วยเขียนโค้ดอย่าง Amazon CodeWhisperer
- บริการ AI เฉพาะทาง — Amazon Comprehend (การวิเคราะห์ภาษาและสรุปข้อความ), Amazon Polly (TTS), Amazon Rekognition (วิเคราะห์ภาพและวิดีโอ), Amazon Textract (ดึงข้อมูลจากเอกสาร)
บริการข้างต้นทำให้ทีมพัฒนาสามารถเลือกชั้นของการจัดการและการปรับแต่งตามความเสี่ยง ความต้องการควบคุมข้อมูล และงบประมาณ ตัวอย่างเช่น หากต้องการความรวดเร็วในการนำไปใช้ สามารถเรียกใช้โมเดลผ่าน Bedrock หรือ SageMaker managed endpoints ส่วนองค์กรที่ต้องการควบคุมฮาร์ดแวร์หรือใช้เทคนิคการเร่งความเร็วเฉพาะ ก็สามารถติดตั้งบน EC2/GPU หรือ EKS ได้
ตัวอย่างการประยุกต์ใช้จริงภายในผลิตภัณฑ์ของอเมซอน
ในเชิงธุรกิจ อเมซอนใช้เทคโนโลยีเหล่านี้เพื่อปรับปรุงประสบการณ์ลูกค้าและเพิ่มประสิทธิภาพภายในองค์กร ตัวอย่างการใช้งานรวมถึง:
- Personalized recommendations — ระบบแนะนำสินค้าใช้ข้อมูลการคลิก การซื้อ และคอนเท็กซ์ของผู้ใช้ร่วมกับโมเดลเพื่อสร้างคำแนะนำที่มีความเฉพาะตัว (เชื่อมโยงกับบริการอย่าง Amazon Personalize และโมเดลที่โฮสต์บน SageMaker)
- Automated content generation — การสร้างคำอธิบายสินค้า ข้อความโฆษณา และ A+ content โดยใช้โมเดลภาษาขนาดใหญ่เพื่อลดแรงงานสร้างเนื้อหาแบบแมนนวล และเพิ่มความสม่ำเสมอของโทนและคุณภาพ
- Summarization & customer support — สรุปรีวิวลูกค้า สรุปการพูดคุยในแชทหรืออีเมลอัตโนมัติ ช่วยเจ้าหน้าที่บริการลูกค้าเข้าถึงประเด็นสำคัญได้รวดเร็วขึ้น
- Image generation และ marketing — ใช้โมเดล text-to-image ผ่าน Bedrock หรือพันธมิตรสำหรับสร้างสื่อโฆษณาแบบปรับแต่งตามแคมเปญ ช่วยลดเวลาในการผลิตกราฟิก
- Internal tooling — เครื่องมือช่วยโค้ด (CodeWhisperer), การตรวจสอบเอกสารอัตโนมัติ และระบบสรุปการประชุม ช่วยเพิ่ม productivity ของทีมพัฒนาและทีมเนื้อหา
ข้อดีของการใช้บริการแบบ managed vs. self-hosted
- Managed (เช่น Bedrock, SageMaker managed endpoints)
- ข้อดี: ลดภาระการดูแลโครงสร้างพื้นฐาน, มีการจัดการด้านความปลอดภัยและการสเกลอัตโนมัติ, เพิ่มความเร็วในการนำไปใช้จริง, เข้าถึงโมเดลจากพันธมิตรได้ทันที
- ข้อจำกัด: อาจมีความยืดหยุ่นในการควบคุมฮาร์ดแวร์และการปรับแต่งเชิงลึกน้อยกว่า, ต้นทุนอาจสูงขึ้นในกรณีการใช้งานขนาดใหญ่ถ้าเทียบกับการออกแบบอินฟราสตรัคเจอร์เฉพาะ
- Self-hosted (เช่น EC2/GPU, EKS พร้อม Inferentia/Trainium)
- ข้อดี: ควบคุมสเปคฮาร์ดแวร์และต้นทุนได้ละเอียดขึ้น, เหมาะกับงานที่ต้องการปรับแต่งลึกหรือใช้เทคนิคเร่งเฉพาะทาง, เหมาะกับนโยบายความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบที่เข้มงวด
- ข้อจำกัด: ต้องรับภาระการดูแลระบบ การสเกล และการอัปเดตความปลอดภัย, ต้องใช้ทีมปฏิบัติการที่เชี่ยวชาญมากขึ้น
สรุปแล้ว อเมซอนนำเสนอพอร์ตโฟลิโอบริการที่ครอบคลุมทุกขั้นตอนของการพัฒนาและใช้งาน generative AI ทั้งสำหรับการทดลองใช้งานอย่างรวดเร็วและการนำไปใช้อย่างต่อเนื่องในระดับองค์กร การเลือกใช้ระหว่าง managed กับ self-hosted ขึ้นกับปัจจัยสำคัญ เช่น ความต้องการด้านการควบคุม ความสามารถด้านปฏิบัติการ ต้นทุน และข้อกำหนดด้านความเป็นส่วนตัวของข้อมูล
ความสัมพันธ์ระหว่างความสร้างสรรค์ของ AI กับความเร็วในการทำงาน (latency vs creativity)
ภาพรวมเชิงแนวคิด
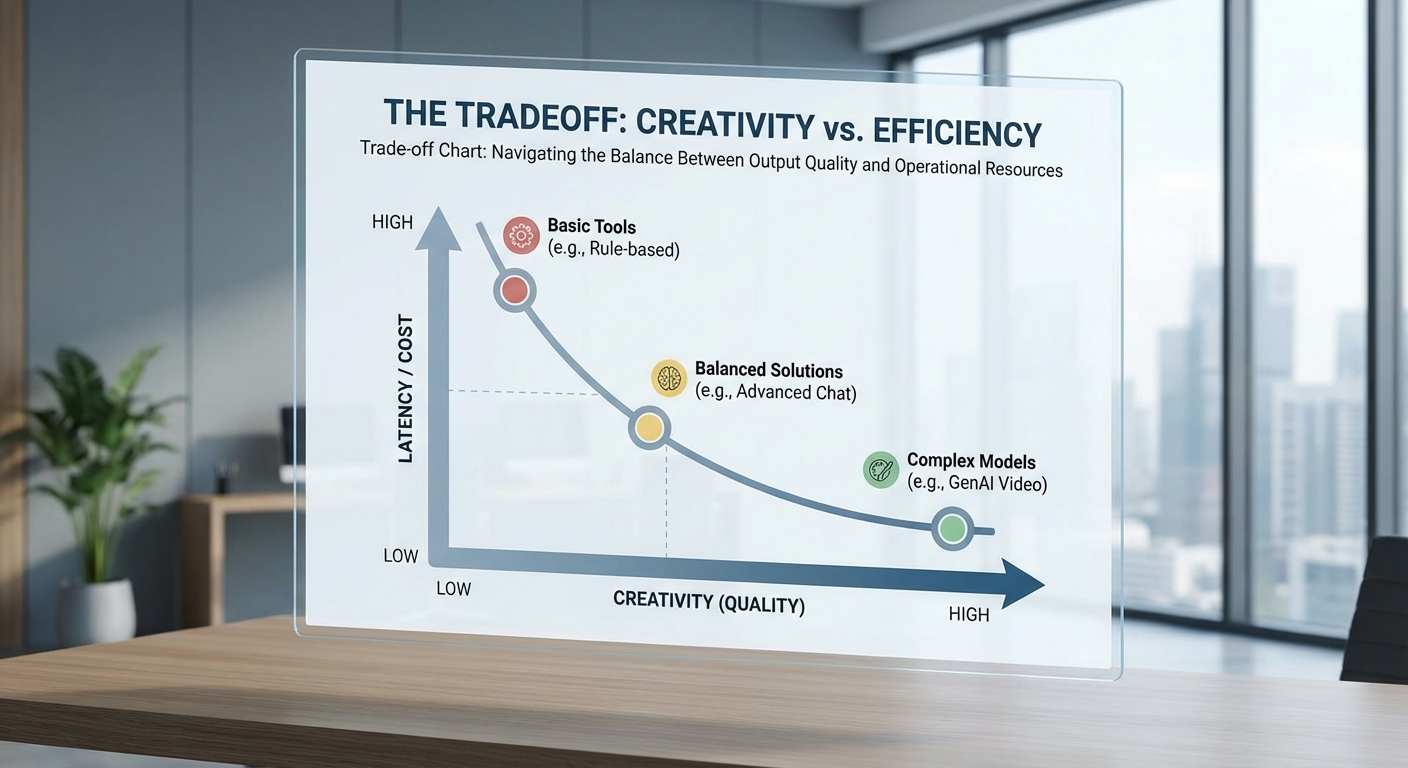
เมื่อองค์กรอย่างอเมซอนขยายการใช้งาน AI เพื่อให้ผลลัพธ์ที่มี ความสร้างสรรค์สูง มักต้องอาศัยโมเดลขนาดใหญ่ การปรับพารามิเตอร์เช่น temperature, nucleus sampling หรือการเรียกใช้หลายขั้นตอนของการประมวลผล (multi-pass decoding) ซึ่งทั้งหมดนี้ส่งผลให้เวลาในการตอบคำขอ (inference time) เพิ่มขึ้นไปด้วย ดังนั้นจึงเกิดการแลกเปลี่ยน (trade-off) ระหว่าง คุณภาพเชิงสร้างสรรค์ กับ ประสิทธิภาพการให้บริการ ทั้งในด้าน latency, throughput และต้นทุนต่อคำขอ

นิยามตัวชี้วัดสำคัญที่ต้องติดตาม
- p50 / p95 / p99 latency — ค่ามัธยฐานและเปอร์เซนไทล์ของเวลาตอบสนอง: p50 คือค่ากลาง p95 และ p99 แสดงเวลาตอบสำหรับ 95% และ 99% ของคำขอตามลำดับ (สำคัญมากในการจับ tail latency)
- average response time — ค่าเฉลี่ยของเวลาตอบ ช่วยประเมินประสบการณ์ผู้ใช้ทั่วไป
- throughput (requests/sec) — ปริมาณคำขอต่อวินาทีที่ระบบสามารถประมวลผลได้
- error rate — อัตราความผิดพลาด เช่น timeouts, OOM, หรือ failed responses ซึ่งอาจเพิ่มขึ้นเมื่อใช้โมเดลหนัก
- cost-per-inference (ต้นทุนต่อคำขอ) — ค่าใช้จ่ายโดยรวมทั้งทรัพยากรซีพียู/จีพียูและซอฟต์แวร์/สตรีมมิ่งต่อการตอบคำขอหนึ่งครั้ง
ตัวอย่าง trade-off แบบตัวเลขสมมติ
ด้านล่างเป็นตัวอย่างเชิงประมาณเพื่อให้เห็นภาพว่าเมื่อเพิ่มระดับความสร้างสรรค์ (เช่น ปรับ temperature สูงขึ้น ใช้ sampling แบบกว้าง หรือเรียกใช้โมเดลใหญ่ขึ้น) จะมีผลอย่างไรต่อตัวชี้วัดหลัก:
- ความสร้างสรรค์ต่ำ (Low) — p50: 80 ms, p95: 200 ms, p99: 350 ms, throughput: 500 req/s, cost-per-request: $0.002
- ความสร้างสรรค์ปานกลาง (Medium) — p50: 200 ms, p95: 500 ms, p99: 900 ms, throughput: 200 req/s, cost-per-request: $0.01
- ความสร้างสรรค์สูง (High) — p50: 600 ms, p95: 1,200 ms, p99: 2,500 ms, throughput: 50 req/s, cost-per-request: $0.08
จากข้อมูลสมมติข้างต้นจะเห็นว่าเมื่อความสร้างสรรค์เพิ่มขึ้น ค่า latency ทั้งกลางและ tail เพิ่มขึ้นอย่างทวีคูณ ขณะที่ throughput ลดลงและต้นทุนต่อคำขอพุ่งสูง ซึ่งเป็นเหตุผลที่ธุรกิจต้องออกแบบ SLO/SLA และกลยุทธ์การกำหนดราคา/การเรียงความสำคัญของคำขอ
กราฟสมมติแสดงความสัมพันธ์
จินตนาการกราฟที่แกนนอนเป็นระดับความสร้างสรรค์ (0–100) และแกนตั้งแสดงค่า latency (ms) กับ cost-per-request (USD): เส้น latency จะเริ่มเชิงเส้นค่อนข้างราบที่ช่วงสร้างสรรค์ต่ำ แล้วเร่งขึ้นแบบเอ็กซ์โพเนนเชียลเมื่อเข้าโซนความสร้างสรรค์สูง เส้น cost จะมีแนวโน้มใกล้เคียง อยู่วงจรที่ชันขึ้นหลังจุดกึ่งกลาง ตัวเลขตัวอย่าง (จุดตัวอย่าง): creativity=20 → p95≈220ms, cost≈$0.003; creativity=50 → p95≈600ms, cost≈$0.012; creativity=80 → p95≈1,400ms, cost≈$0.06
เทคนิคการวัดและเก็บ telemetry เพื่อตัดสินใจ
การตัดสินใจเชิงธุรกิจสำหรับการเปิดใช้โมเดลสร้างสรรค์จำเป็นต้องอาศัยข้อมูล telemetry ที่ละเอียดและเป็นระบบ ดังนี้
- เก็บ metric แบบ percentile histograms (p50/p95/p99) ไม่ใช่แค่ค่าเฉลี่ย เพื่อจับ tail latency ที่กระทบผู้ใช้ไม่กี่เปอร์เซนต์แต่สร้างความไม่พึงพอใจสูง
- ใช้ distributed tracing และ exemplars ใน histogram เพื่อเชื่อมโยงเหตุผลการตอบช้า (เช่น request size, model type, sampling params)
- บันทึก contextual telemetry — เช่น prompt length, temperature, num_beams, early_stop flag — เพื่อวิเคราะห์ว่าการตั้งค่าใดทำให้ latency เพิ่ม
- ตั้ง synthetic load testing และ chaos testing เพื่อวัด throughput และ error-rate ใต้เงื่อนไขต่าง ๆ (burst, sustained load)
- ติดตั้ง SLI/SLO/alert thresholds โดยมุ่งเน้น p95/p99 เป็นตัวขับเคลื่อน SLA พร้อมนโยบาย degrade/graceful-fallback เมื่อเกินค่า เช่น fallback ไปยังโมเดลเบา
- เก็บ cost metrics (cost-per-inference) แยกตามโมเดลและฟีเจอร์ เพื่อทำ cost attribution และ ROI analysis
แนวปฏิบัติแนะนำสำหรับการจัดการ trade-off
เพื่อให้การใช้งาน AI เชิงสร้างสรรค์ยังคงคุ้มค่าแนะนำให้พิจารณากลยุทธ์ผสม (hybrid approach): ใช้โมเดลเบาสำหรับคำขอเชิง transactional หรือผู้ใช้ที่ต้องการ latency ต่ำ และสำรองโมเดลสร้างสรรค์หนักสำหรับงานที่ให้คุณค่าเชิงสร้างสรรค์สูงเท่านั้น นอกจากนี้เทคนิคเช่น model cascading, distillation, caching of partial results, batching, async responses และ progressive rendering สามารถลดผลกระทบต่อประสบการณ์ผู้ใช้ได้อย่างมีนัยสำคัญ
สรุปคือ ธุรกิจต้องวางกรอบการวัด (observability) ที่ครอบคลุมทั้งด้าน latency, throughput, error-rate และ cost เพื่อทำการตัดสินใจเชิงกลยุทธ์ว่าควรยอมแลก latency เพิ่มเพื่อความสร้างสรรค์หรือไม่ และในระดับใดที่จะยังคงรักษา SLO พร้อมความคุ้มค่าทางเศรษฐศาสตร์
กรณีศึกษา: ตัวอย่างการใช้งานจริงของอเมซอนที่อาจชะลอการทำงาน
กรณีศึกษา: ตัวอย่างการใช้งานจริงของอเมซอนที่อาจชะลอการทำงาน
ในเชิงปฏิบัติ อเมซอนได้ทดลองผสาน generative AI และระบบ personalization เข้ากับหลายจุดของระบบค้าออนไลน์ ทั้งการสร้างคำอธิบายสินค้าอัตโนมัติ, การปรับหน้า storefront แบบเรียลไทม์ และการผลิตสื่อการตลาดอัตโนมัติ การทดลองเหล่านี้สร้างผลลัพธ์เชิงบวกด้านประสิทธิภาพการผลิตเนื้อหา แต่ก็มีผลกระทบต่อประสบการณ์ผู้ใช้เมื่อเกิดการเพิ่ม latency ของระบบ ตัวอย่างด้านล่างสรุปผลเชิงตัวเลขจากการทดลองภายในที่ทีมเทคนิคได้รายงานและทดสอบ A/B
ตัวอย่าง 1: การสร้างคำอธิบายสินค้าอัตโนมัติและผลต่อเวลาการอัปเดตคอนเทนต์
อเมซอนนำระบบสร้างคำอธิบายสินค้าโดยใช้โมเดลภาษามาใช้ทั้งแบบ batch (ตอนอัพเดตแคตาล็อก) และแบบ on-demand (ครั้งแรกที่หน้าถูกเรียกหรือใน editor ของผู้ขาย) ผลการทดสอบพบว่า:
- ประสิทธิภาพการผลิตคอนเทนต์: เวลาที่ทีมคอนเทนต์ใช้ต่อ SKU ลดลงเฉลี่ย 80% (จากประมาณ 30 นาทีเหลือ ~6 นาทีต่อรายการ) เมื่อใช้ AI เป็นต้นแบบข้อความและต้องการแก้ไขเล็กน้อยก่อนเผยแพร่
- ผลกระทบต่อเวลาการอัปเดตแบบ batch: เมื่อรันการสร้างคำอธิบายเป็นส่วนหนึ่งของ pipeline การอัปเดตแคตาล็อกขนาดใหญ่ (เช่น 50,000 SKU) เวลาประมวลผลเพิ่มขึ้นจาก median 2 ชั่วโมงเป็น 5 ชั่วโมง เนื่องจากขั้นตอน inference, การตรวจสอบคุณภาพอัตโนมัติ และการ indexing
- ผลกระทบต่อการแสดงผลแบบ on-demand: หากสั่งให้โมเดลสร้างหรือปรับคำอธิบายในเวลาที่เรียกเพจจริง ๆ จะเห็นการเพิ่ม latency ต่อการเรียกหน้าเฉลี่ย ~250–600 ms ต่อคำขอ ซึ่งมีผลต่อเวลาโหลดหน้าโดยรวม โดยเฉพาะบนเครือข่ายมือถือ
บทเรียนสำคัญคือการเลือกสถาปัตยกรรม: pre-generate at index time ช่วยลด latency ตอนเรียกหน้าลูกค้า แต่เพิ่มเวลารวมของ pipeline การอัปเดต ในขณะที่ generate on request ลดเวลาอัปเดตแต่แลกด้วยความเสี่ยงของการเพิ่ม latency หน้าเว็บ
ตัวอย่าง 2: Personalization แบบ realtime ส่งผลต่อ latency หน้าเว็บและ conversion
การทดสอบ personalization แบบเรียลไทม์บน storefront แสดงให้เห็น trade-off ที่ชัดเจน:
- การเพิ่ม conversion สำหรับผู้ถูกกำหนดเป้าหมาย: ผู้เข้าชมที่ได้รับหน้าเพจแบบ personalized พบอัตรา conversion เพิ่มขึ้นเฉลี่ย +8–12% เมื่อเทียบกับหน้า generic ในกลุ่มตัวอย่างที่ latency ของหน้าใกล้เคียงกับ baseline
- ผลลบจาก latency ที่เพิ่มขึ้น: การเรียก API เพื่อคำนวณ personalization แบบ synchronous เพิ่ม median page latency จาก 220 ms เป็น 420 ms (เพิ่ม ~200 ms) ส่งผลให้ bounce rate ในอุปกรณ์มือถือเพิ่มขึ้น ~3–5% สำหรับเซสชันที่ได้รับ latency สูงสุด และทำให้ conversion สุทธิสำหรับกลุ่มผู้ใช้ทั้งหมดบางชุดลดลงได้ถึง 1–2%
- การทดลองรูปแบบการให้บริการ: เมื่อทีมเปลี่ยนเป็นสตรีมเนื้อหาแบบ progressive (แสดงเนื้อหาพื้นฐานก่อน แล้วค่อยโหลด personalization แบบ asynchronous) พบว่า conversion uplift สำหรับกลุ่ม personalized ลดลงเล็กน้อยจาก +12% เหลือ +9% แต่ผลกระทบต่อ bounce rate หายไปเกือบทั้งหมด
สรุปคือ personalization แม้จะทำให้ conversion สูงขึ้นในกลุ่มเป้าหมาย แต่ถ้าการเรียกใช้งานทำให้ latency เพิ่มมากเกินไป ผลรวมบนระดับแพลตฟอร์มอาจเป็นลบได้ การออกแบบระบบต้องคำนึงถึงความหน่วงเป็นสำคัญ
ข้อสังเกตจากการทดสอบ A/B และมาตรการแก้ไข
จากชุด A/B tests ที่ดำเนินการ ทีมของอเมซอนได้ข้อสังเกตเชิงปฏิบัติและพัฒนาแนวทางบรรเทาความเสี่ยง ดังนี้:
- ผลการทดสอบ A/B (ตัวอย่างตัวเลข):
- กลุ่ม A (baseline, no AI personalization): conversion 3.2%
- กลุ่ม B (synchronous personalization): conversion 3.5% แต่ median page load เพิ่ม 180 ms และ bounce rate เพิ่ม 2.7%
- กลุ่ม C (async personalization + progressive render): conversion 3.45% และ latency เพิ่มเพียง 60 ms — ให้ความสมดุลระหว่าง uplift และประสบการณ์ผู้ใช้
- มาตรการลดผลกระทบต่อความเร็ว:
- ใช้แนวทาง precompute และ batch-generation สำหรับสินค้าและกลุ่มลูกค้าที่คงที่ เพื่อลดการ inference แบบ synchronous
- นำระบบ caching ไปไว้ที่ edge (edge personalization cache) ลดการเรียกกลับไปยัง model serving โดยตรง
- ใช้ client-side async fetch และ progressive rendering เพื่อให้หน้าแสดงเร็วที่สุด จากนั้นเติมเนื้อหาส่วน personalized ภายหลัง
- ทำ model distillation และ quantization เพื่อลดเวลา inference — ตัวอย่างเช่น ลด latency inference จากเฉลี่ย 350 ms เหลือ ~120 ms หลังการลดขนาดโมเดล
- กำหนด timeouts, circuit breakers และ fallback เป็น generic content หาก personalization service ช้าหรือไม่ตอบสนอง เพื่อป้องกันการชะงักของหน้า
- ใช้กลยุทธ์ progressive rollout และ feature flags เพื่อติดตามผลบนกลุ่มย่อยก่อนขยายไปสู่ผู้ใช้ทั้งระบบ
โดยสรุป การนำ generative AI และ personalization มาใช้จริงที่ระดับอีคอมเมิร์ซขนาดใหญ่อย่างอเมซอนให้ผลตอบแทนเชิงธุรกิจที่ชัดเจน แต่ต้องบริหารจัดการความเร็วและความซับซ้อนของระบบอย่างมีนโยบายและเทคนิค เช่น precompute, edge caching, async rendering และ model optimization เพื่อให้เกิด สมดุลระหว่างการเพิ่มประสิทธิภาพของเนื้อหาและการรักษาความเร็วในการให้บริการ
แนวทางปฏิบัติในการออกแบบระบบเพื่อลดผลกระทบต่อความเร็ว
แนวทางปฏิบัติทั่วไปเพื่อลดผลกระทบต่อความเร็ว
เมื่อรวมระบบ AI สร้างสรรค์เข้ากับบริการหลัก ต้องออกแบบโดยให้ความสำคัญกับ latency และ throughput ตั้งแต่ขั้นสถาปัตยกรรมจนถึงประสบการณ์ผู้ใช้ การใช้แนวทางผสมผสาน เช่น asynchronous processing, batching, และ caching สามารถลดผลกระทบต่อความเร็วได้ชัดเจน ตัวอย่างเช่น การส่งงานประมวลผลไปยังคิวแบบอะซิงโครนัสและใช้ workers แยกชุดงาน (batch workers) สามารถเพิ่มประสิทธิภาพการประมวลผลของ GPU/TPU ได้หลายเท่า ในบางกรณีการรวม model distillation และ edge inference อาจช่วยลด latency ระหว่างผู้ใช้และคำตอบได้ประมาณ 2–5 เท่า ขึ้นกับลักษณะโมเดลและข้อมูล
เทคนิคเชิงสถาปัตยกรรม: caching, batching, async pipelines, fallback
การออกแบบชั้นสถาปัตยกรรมควรมีองค์ประกอบต่อไปนี้อย่างชัดเจน:
- Caching: แยกระดับ cache เป็น short-term (in-memory เช่น Redis) สำหรับคำตอบที่คาดว่าจะถูกเรียกบ่อย และ long-term cache สำหรับผลลัพธ์ที่ไม่เปลี่ยนบ่อย ใช้ cache keys ที่รวม feature fingerprint เพื่อหลีกเลี่ยงการคืนข้อมูลผิดบริบท
- Batching: รวมคำขอที่มีลักษณะคล้ายกันเพื่อลด overhead ของการเรียกโมเดล (micro-batching) และตั้ง threshold ทั้งขนาด batch และ latency budget เพื่อไม่ให้คำขอเดี่ยวถูกหน่วงนานเกินไป
- Async pipelines: ใช้คิว (message queues) และสเตตสโตร์ (state store) เพื่อถอดการประมวลผลแบบ blocking ออกจากเส้นทางหลักของการให้บริการ ผู้ใช้ได้รับตอบกลับเบื้องต้นเร็วขึ้นพร้อมสถานะว่า "งานกำลังดำเนินการ"
- Fallback strategies: กำหนดชั้น fallback (e.g., lightweight model หรือ templated response) เมื่อโมเดลหลักล่าช้าหรือระบบมีปัญหา เพื่อรักษา SLA และ UX ที่เสถียร
วิธีปรับปรุง UX: progressive enhancement และ precompute
UX ต้องออกแบบให้ graceful degradation และให้ผู้ใช้รับรู้ถึงสถานะการทำงาน:
- Progressive enhancement: ส่งผลลัพธ์เบื้องต้น (partial output) ให้เร็วที่สุด เช่น ส่ง header, summary หรือ placeholder ที่สามารถเติมเต็มทีหลังโดย AI แบบ incremental เพื่อให้ผู้ใช้เริ่มโต้ตอบได้ทันที
- Precompute content: สำหรับเนื้อหาที่คาดการณ์ได้ (เช่น คำแนะนำทั่วไป, templates, หรือผลลัพธ์สำหรับกลุ่มผู้ใช้ที่มีพฤติกรรมคล้ายกัน) ให้ทำการ precompute ในช่วงเวลาที่ระบบไม่หนาแน่น และเก็บไว้ใน cache
- Human-in-the-loop: ใช้การตรวจสอบจากมนุษย์แบบคัดกรองในกรณีที่ความถูกต้องหรือความปลอดภัยสำคัญ การออกแบบควรอนุญาตให้ผลลัพธ์ที่ผ่านการตรวจสอบมนุษย์กลับสู่ cache เพื่อใช้ซ้ำและลดภาระโมเดล
การควบคุมต้นทุน: autoscaling, spot instances, cost monitoring
เมื่อเพิ่มโมเดล AI ขนาดใหญ่ ความเสี่ยงด้านค่าใช้จ่ายเพิ่มขึ้น จำเป็นต้องตั้งนโยบายควบคุมต้นทุน:
- Autoscaling policies: กำหนด scaling triggers ที่สมดุลระหว่าง latency และค่าใช้จ่าย เช่น scale out เมื่อ queue depth เกินค่าเกณฑ์ แต่ใช้ cooldown และ predictive scaling เพื่อลดการสลับสภาพที่บ่อย
- Spot instances / preemptible: สำหรับงาน batch หรือ precompute ให้ใช้ spot instances เพื่อลดค่าใช้จ่าย แต่ต้องออกแบบให้รองรับการถูกยุติ (checkpointing, idempotent jobs)
- Cost monitoring: ติดตั้งการวัดและแจ้งเตือน (per-model, per-feature) แบบ real-time เพื่อทำ chargeback และปรับการใช้ทรัพยากรทันที หากพบโมเดลหรือฟีเจอร์ที่มีค่าใช้จ่ายต่อคำขอสูงผิดปกติ
เทคนิคเสริม: model distillation, edge inference และ human-in-the-loop
เพิ่มชั้น optimization เพื่อลด latency และค่าใช้จ่ายต่อคำขอ:
- Model distillation: สร้างรุ่นย่อยของโมเดล (student) ที่มีขนาดเล็กลงแต่ยังคงคุณภาพในระดับที่ยอมรับได้ ใช้ student สำหรับคำขอ latency-sensitive และ fallback ไปหา teacher เมื่อจำเป็น
- Edge inference: ย้าย inference บางส่วนไปยัง edge devices หรือ CDN points เพื่อลดเวลาตอบสนองและแบนด์วิดท์ เหมาะสำหรับกรณีใช้งานที่ไม่ต้องใช้โมเดลขนาดใหญ่ทุกครั้ง
- Human-in-the-loop: ทำงานร่วมกับระบบอัตโนมัติด้วยจุดตรวจสอบที่มนุษย์สามารถแก้ไขผลลัพธ์ได้เพื่อเพิ่มความน่าเชื่อถือและลดการเรียกใช้โมเดลหนักซ้ำซ้อน
ตัวอย่างแผนผังสถาปัตยกรรม (ข้อความอธิบาย)
ตัวอย่างสถาปัตยกรรมแบบย่อ (flow):
- Client -> API Gateway (edge cache) -> Router
- Router -> Fast Path: check short-term cache -> return cached response
- Router -> Slow Path: enqueue request -> Worker Pool (batching) -> Lightweight model (distilled) -> if uncertain then call Heavy model (GPU/TPU)
- Heavy model -> store final result in long-term cache + analytics store -> notify client or update progressive UI
- Background: Precompute jobs (batch) -> cache; Autoscaler monitors queue depth & latency -> scale compute (spot for batch, reserved for latency-critical)
คำอธิบายเพิ่มเติม: ให้แยกบริการที่ตอบทันที (synchronous API) ออกจากบริการที่ต้องใช้เวลานาน (asynchronous jobs) และใช้ message queue เป็นตัวกลางระหว่างกัน เพื่อให้สามารถปรับขนาดได้ยืดหยุ่น
Checklist ก่อนนำไปใช้งานจริง
- มีการวัด baseline latency และ throughput ของระบบก่อนผสาน AI
- กำหนด SLA/ SLO ชัดเจน (p95/p99 latency targets) และทดสอบ under load
- ออกแบบ cache key และ TTL ให้สอดคล้องกับข้อมูลจริงและความเป็นส่วนตัว
- ตั้ง threshold สำหรับ batching (max batch size, max wait time) และตรวจวัดผลกระทบต่อ latency
- มี fallback strategy (templated response หรือ lightweight model) และทดสอบการสลับ fallback
- กำหนด autoscaling policy พร้อม predictive scaling และ cooldown ที่เหมาะสม
- ใช้ spot/preemptible สำหรับงานที่ tolerable ต่อการยุติ และมี checkpointing
- ติดตั้ง cost monitoring per-model และ alert สำหรับค่าใช้จ่ายผิดปกติ
- ออกแบบ pipeline human-in-the-loop สำหรับ use cases ที่ต้องการความถูกต้องสูง และทำ caching สำหรับผลลัพธ์ที่ผ่านการตรวจสอบ
- พิจารณา model distillation และ edge inference สำหรับ use cases ที่ต้องการ latency ต่ำ
- ทดสอบ UX แบบ progressive enhancement และตรวจสอบว่าผู้ใช้ได้รับ feedback ที่เพียงพอเมื่อผลลัพธ์ยังไม่สมบูรณ์
Tutorial: ขั้นตอนทีละขั้นสำหรับนักพัฒนาในการทดลองใช้ AI สร้างสรรค์บน AWS
บทช่วยสอนนี้มุ่งเป้าสำหรับนักพัฒนาและทีมผลิตภัณฑ์ที่ต้องการทดลองใช้งานโมเดล AI สร้างสรรค์บน AWS โดยให้เป็นขั้นตอนเชิงปฏิบัติ ตั้งแต่การเลือกโมเดล การตั้งค่า endpoint การวัด latency (รวมถึง p99) การตั้ง fallback flow และแนวทางการทดสอบแบบ A/B พร้อมตัวอย่างคำสั่ง CLI, cURL และ pseudo-code สำหรับการเก็บ metrics และการปรับจูนเพื่อลด latency.
ขั้นตอนรวดเร็ว (Quick steps)
- เลือกโมเดล — ตัดสินใจระหว่าง pre-trained (เร็วเริ่มต้น) หรือ fine-tuned (แม่นยำขึ้น แต่ช้าหรือหนักขึ้น)
- ตั้งค่า Endpoint — ใช้ SageMaker / Bedrock / API Gateway+Lambda ตามสถาปัตยกรรม
- ทดสอบ Latency — วัด p50/p95/p99, ตรวจสอบ error rate และ throttling
- เปิดใช้งานแบบค่อยเป็นค่อยไป — เริ่มจาก Canary/A-B rollouts พร้อม fallback
1) เลือกโมเดล: Pre-trained vs Fine-tuned
เมื่อเลือกโมเดล ให้พิจารณา trade-off ระหว่างความแม่นยำและความหน่วงของระบบ โมเดลขนาดใหญ่หรือ fine-tuned มักให้ผลลัพธ์ที่ดีกว่า แต่มี latency สูงกว่า—ในเชิงปฏิบัติพบว่า fine-tuning อาจเพิ่ม latency ได้ 10–50% ขึ้นอยู่กับขนาดและโครงสร้าง หาก latency เป็นข้อจำกัด ควรทดลองโมเดลขนาดกลางหรือใช้เทคนิคเช่น distillation/quantization เพื่อลดขนาดโมเดลและ latency (ตัวอย่าง: quantization อาจลด latency ลงได้ 2–4x ในบางกรณี).
แนวทางปฏิบัติ: เริ่มด้วย pre-trained สำหรับ MVP แล้วค่อย fine-tune เฉพาะกับ use-case ที่จำเป็น ใช้ batch inference สำหรับโหลดงานที่ไม่ต้องการตอบทันที และใช้ real-time inference กับงานที่ต้องตอบโต้แบบ synchronous เท่านั้น
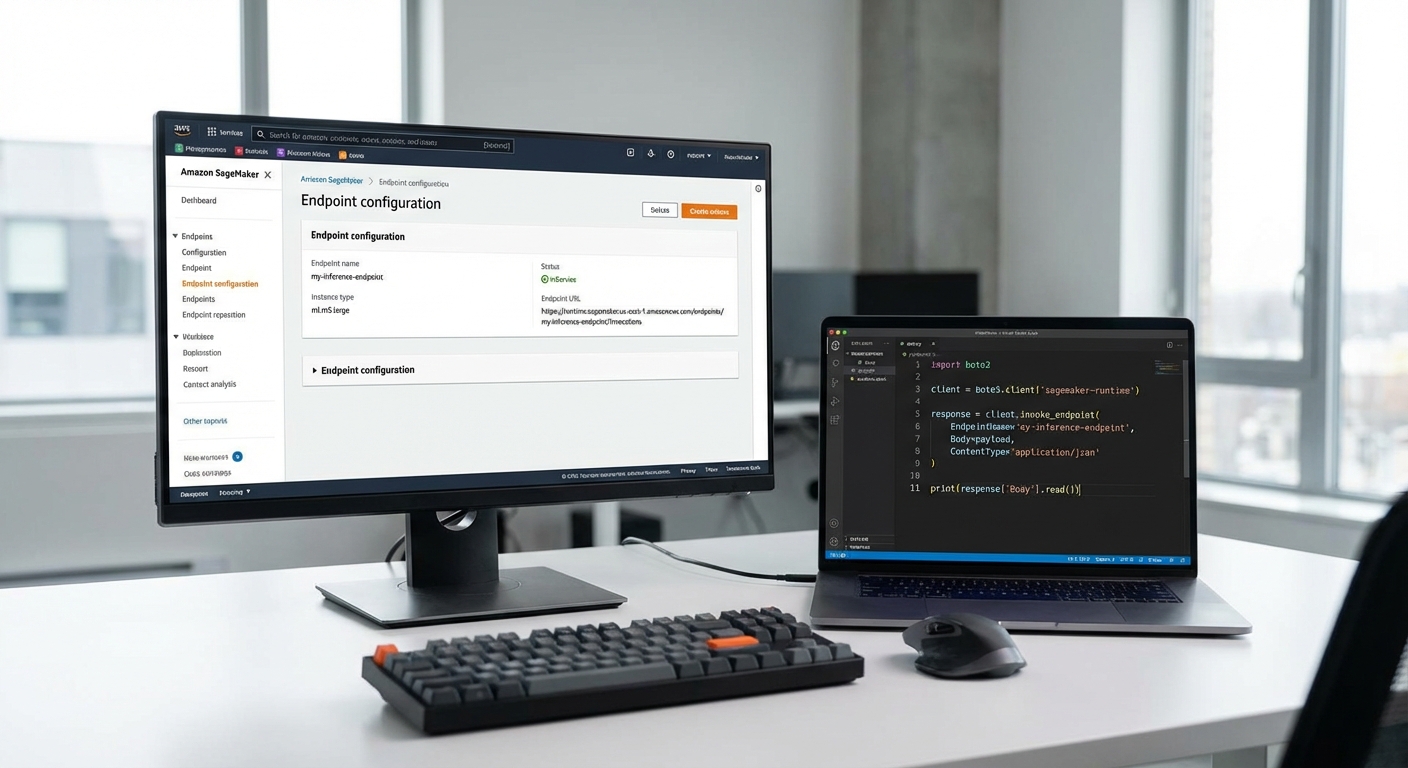
2) ตั้งค่า Endpoint บน AWS (ตัวอย่าง CLI)
ตัวอย่างลำดับคำสั่งสำหรับ SageMaker (ย่อ):
- สร้าง model: aws sagemaker create-model --model-name my-model --primary-container Image=...,ModelDataUrl=s3://...
- สร้าง endpoint config: aws sagemaker create-endpoint-config --endpoint-config-name cfg-v1 --production-variants VariantName=AllTraffic,ModelName=my-model,InitialInstanceCount=1,InstanceType=ml.g5.xlarge
- สร้าง endpoint: aws sagemaker create-endpoint --endpoint-name my-endpoint --endpoint-config-name cfg-v1
- เรียกใช้งานผ่าน CLI: aws sagemaker-runtime invoke-endpoint --endpoint-name my-endpoint --body fileb://input.json --content-type application/json output.json
หากใช้ API Gateway + Lambda ให้ deploy REST endpoint แล้วทดสอบด้วย cURL เช่น:
curl -X POST "https://api.example.com/predict" -H "Content-Type: application/json" -d '{"prompt":"..."}'
3) ทดสอบ Latency และจับ Metrics (p99, error rate)
การวัดความหน่วงเชิงสถิติเป็นสิ่งจำเป็น: p50, p95, และ p99 บ่งชี้ประสบการณ์ผู้ใช้ที่แตกต่างกัน วิธีหนึ่งคือใช้ CloudWatch สำหรับ SageMaker/API Gateway และเก็บ log ระดับคำขอ (request/response time, status code)
ตัวอย่างคำสั่ง AWS CLI เพื่อดึง p99 latency จาก CloudWatch:
- aws cloudwatch get-metric-statistics --namespace AWS/SageMaker --metric-name InferenceLatency --start-time 2026-03-11T00:00:00Z --end-time 2026-03-12T00:00:00Z --period 60 --extended-statistics p99 --dimensions Name=EndpointName,Value=my-endpoint
ตัวอย่าง CloudWatch Logs Insights query เพื่อคำนวณ p99 และ error rate:
- fields @timestamp, @message | parse @message "* latency=* status=*" as latency, status | stats pct(latency, 99) as p99_latency, count_if(status >= 500) / count(*) as error_rate by bin(1m)
นอกจากนี้ ให้ instrument ฝั่ง client/server เพื่อเก็บ histogram (ex. Prometheus histogram) และส่ง metric เช่น request_latency_seconds_bucket ซึ่งช่วยคำนวณ p99 ในระบบมอนิเตอริ่งอื่น ๆ ได้
ตัวอย่าง pseudo-code สำหรับการเรียกใช้งานและจับ metrics
Pseudo-code (synchronous call + histogram):
- start = now()
- resp = http.post("/predict", body)
- latency = now() - start
- histogram.observe(latency)
- if resp.status >= 500: counter_errors.increment()
- export metrics -> PushGateway / CloudWatch
cURL ตัวอย่างสำหรับทดสอบแบบโหลดเบื้องต้น:
- for i in {1..100}; do curl -s -w "%{http_code} %{time_total}\\n" -o /dev/null -X POST https://api.example.com/predict -d '{"prompt":"..."}' & done
4) Fallback flow, Circuit Breaker และ Gradual Rollout (A/B testing)
ออกแบบ fallback ที่ชัดเจน: เมื่อ latency หรือ error rate สูงเกิน threshold ให้สลับไปใช้ fallback model (โมเดลขนาดเล็ก), cached response, หรือ degraded feature (เช่น ตัดการใช้ภาพความละเอียดสูง) โดยใช้ circuit breaker pattern เพื่อป้องกัน cascading failures
ตัวอย่าง pseudo-code สำหรับ fallback:
- if latency_recent.p99 > threshold or error_rate > threshold:
- return call_small_model(request)
- else:
- return call_primary_model(request)
แนวทาง A/B / Canary rollout:
- เริ่มที่ 1–5% ของทราฟิก (canary) ไปยังโมเดลใหม่ วัด p99 และ error rate เป็นเวลาอย่างน้อย 24–72 ชม
- หาก metric อยู่ในเกณฑ์ (p99_change < X ms, error_rate < Y%) ให้เพิ่มน้ำหนักเป็น 10–25% ต่อขั้น
- หากเกิดปัญหา ให้ rollback ทันทีและแจ้ง alarm
สามารถใช้ SageMaker Endpoint traffic-shifting หรือ API Gateway stage variables / Lambda alias เพื่อควบคุมน้ำหนักของแต่ละเวอร์ชัน
การปรับจูนเพื่อลด Latency
ประเด็นที่ควรปรับ:
- พารามิเตอร์คำสั่งของโมเดล: ลด max_tokens, ปรับ temperature และ top_p เพื่อเลิกใช้การค้นหาที่ซับซ้อนเกินจำเป็น
- batching และ concurrency: ใช้ batching สำหรับ throughput สูง และปรับขนาด instance/จำนวน replica ให้เหมาะสม
- สถาปัตยกรรม: พิจารณาใช้ async inference หรือ streaming responses เพื่อลด perceived latency
- hardware/instance types: เลือก GPU ที่เหมาะสมหรือใช้ Inferentia/Elastic Inference เมื่อเป็นไปได้
- model optimizations: quantization, pruning, knowledge distillation
- caching: cache ผลลัพธ์ของ prompt ที่พบบ่อย เพื่อลดการเรียกโมเดลซ้ำ
ข้อควรรู้เมื่อทำงานกับข้อมูลจริง: Privacy, Rate Limits, Throttling
เมื่อใช้งานในสภาพแวดล้อม production ให้คำนึงถึง:
- Privacy & Compliance: รีดข้อมูล PII ก่อนส่งไปยังโมเดล ถ้าต้องการใช้ข้อมูลผู้ใช้จริง ให้เข้ารหัสข้อมูล (KMS), ใช้ VPC endpoints และกำหนด retention policy สำหรับ logs
- Rate limits & Throttling: ระบุ limits ของบริการ (API Gateway, SageMaker runtime) และออกแบบ client-side backoff (exponential backoff + jitter) เพื่อลดปัญหา throttling
- Monitoring & Alerts: ตั้ง CloudWatch Alarms สำหรับ p99 latency เกินค่า, error rate เกินเกณฑ์ และ throttled requests เพื่อให้ระบบ rollback หรือเปิด fallback อัตโนมัติ
สรุป: เริ่มจากการเลือกโมเดลที่เหมาะสม ตั้ง endpoint อย่างระมัดระวัง วัด p99 และ error rate เป็นประจำ ใช้ rollout แบบค่อยเป็นค่อยไปพร้อม fallback ที่เชื่อถือได้ และให้ความสำคัญกับ privacy และการจัดการ rate limits เพื่อให้การนำ AI สร้างสรรค์ขึ้น production มีความเสถียรและปลอดภัย
ข้อควรพิจารณาเชิงจริยธรรม กฎระเบียบ และต้นทุนก่อนขยายการใช้งาน
จริยธรรม: ความโปร่งใส การลดอคติ และการกำกับโดยมนุษย์
ก่อนขยายการใช้งานระบบ AI สร้างสรรค์ องค์กรต้องให้ความสำคัญกับ ความโปร่งใส (transparency) ต่อผู้ใช้และผู้มีส่วนได้ส่วนเสีย เช่น การระบุชัดเจนว่าคอนเทนต์ใดถูกสร้างหรือปรับแต่งด้วย AI และให้ข้อมูลอย่างเพียงพอเกี่ยวกับขอบเขตความแม่นยำและข้อจำกัดของระบบ การเปิดเผยการใช้ AI ช่วยลดความเสี่ยงด้านความไว้วางใจและปัญหาทางกฎหมายในอนาคต
ด้านการลดอคติ (bias mitigation) องค์กรควรดำเนินการตรวจสอบเชิงสถิติและเชิงคุณภาพกับชุดข้อมูลและผลลัพธ์ของโมเดลอย่างต่อเนื่อง รวมถึงจัดทำ model card หรือรายงานที่ระบุแหล่งข้อมูล ขอบเขตการใช้งาน และความเสี่ยงที่ค้นพบ ตัวอย่างมาตรการได้แก่ การทำ balanced sampling, การทดสอบด้วยกลุ่มตัวอย่างหลากหลาย และการใช้เครื่องมือตรวจจับความลำเอียงก่อนนำผลลัพธ์ไปใช้งานจริง
สุดท้ายต้องออกแบบกระบวนการกำกับโดยมนุษย์ (human oversight) ให้มีบทบาทชัดเจนในจุดที่การตัดสินใจมีผลกระทบต่อผู้คน เช่น การอนุมัติคอนเทนต์ที่อาจมีความเสี่ยงสูง รวมถึงการกำหนดระดับการตรวจทาน (human-in-the-loop) และกรอบการตัดสินใจเมื่อโมเดลแสดงความไม่แน่นอน
กฎระเบียบที่เกี่ยวข้อง: การคุ้มครองข้อมูลและการคุ้มครองผู้บริโภค
การขยายใช้งาน AI จำเป็นต้องสอดคล้องกับกฎหมายการคุ้มครองข้อมูลส่วนบุคคล เช่น PDPA ในประเทศไทย หรือ GDPR ในสหภาพยุโรป ซึ่งครอบคลุมการเก็บ บันทึก และการแชร์ข้อมูลสำหรับการฝึกโมเดล องค์กรต้องพิจารณาเรื่อง การได้รับความยินยอม (consent), การทำ Data Protection Impact Assessment (DPIA), และนโยบายการเก็บรักษาข้อมูลอย่างชัดเจน
นอกจากนี้ต้องคำนึงถึงกฎระเบียบด้านการคุ้มครองผู้บริโภค เช่น ข้อกำหนดในการหลีกเลี่ยงข้อมูลอันเป็นเท็จหรือหลอกลวง ที่อาจทำให้ผู้บริโภคเข้าใจผิดได้ และข้อบังคับเฉพาะอุตสาหกรรม (เช่น สุขภาพ การเงิน) ที่อาจมีมาตรฐานความรับผิดชอบเข้มงวดกว่า ตัวอย่างการปฏิบัติที่ดีคือการระบุแหล่งที่มาของเนื้อหา การให้ช่องทางร้องเรียน และการติดตามเหตุการณ์ความเสี่ยงเชิงกฎระเบียบเป็น KPI หนึ่งในระบบบริหารความเสี่ยง
การประเมินต้นทุนระยะยาวและ KPI ทางธุรกิจ
การลงทุนใน AI สร้างสรรค์ไม่ได้จำกัดเฉพาะต้นทุนการพัฒนาเท่านั้น แต่รวมถึงค่าใช้จ่ายด้านโครงสร้างพื้นฐาน (compute, storage), ค่าลิขสิทธิ์โมเดล/ข้อมูล, ค่าใช้จ่ายบุคลากร (นักวิทยาศาสตร์ข้อมูล วิศวกรตรวจสอบจริยธรรม และทีมกฎหมาย), และต้นทุนของกระบวนการกำกับควบคุม เช่น audit และ compliance monitoring
- KPI ทางธุรกิจที่แนะนำ: อัตราความถูกต้องของคอนเทนต์ (accuracy/quality), อัตราการแก้ไขโดยมนุษย์ (human revision rate), เวลาเฉลี่ยในการตรวจอนุมัติ (time-to-approval), Net Promoter Score (NPS) หรือ CSAT ของผู้ใช้, จำนวนเหตุการณ์ทางกฎหมาย/ข้อร้องเรียนต่อเดือน
- การประเมินทางการเงิน: วัดค่าใช้จ่ายรวมต่อคอนเทนต์ (cost-per-output), ค่าประกันความเสี่ยง (legal & compliance reserve), และการคำนวณ ROI ในมุมมองระยะสั้นและระยะยาว รวมถึงการตั้งงบประมาณสำหรับการทบทวนความปลอดภัยและการฟื้นฟูภาพลักษณ์ในกรณีเกิดเหตุ
ข้อเสนอแนะแนวทางการกำกับภายในองค์กร
เพื่อให้การขยายการใช้งานเป็นไปอย่างยั่งยืน แนะนำให้จัดตั้งกรอบการกำกับภายใน (governance) ที่ประกอบด้วยองค์ประกอบหลักดังต่อไปนี้:
- นโยบาย AI ระดับองค์กร: กำหนดหลักการความโปร่งใส ความรับผิดชอบ และขอบเขตการใช้งานที่ชัดเจน
- คณะกรรมการความเสี่ยง AI (AI Risk Committee): มีตัวแทนจากเทคฯ กฎหมาย ความปลอดภัย ฝ่ายธุรกิจ และจริยธรรม ทำหน้าที่อนุมัติการใช้งานในระดับความเสี่ยงต่างๆ
- กระบวนการ audit และ logging: จัดเก็บบันทึกการตัดสินใจของโมเดล การแก้ไขโดยมนุษย์ และผลการทดสอบ bias เพื่อเตรียมตอบคำถามจากหน่วยงานกำกับและผู้บริโภค
- มาตรการตรวจสอบคุณภาพต่อเนื่อง: ใช้ชุดทดสอบมาตรฐาน (benchmarking), red-teaming และการประเมินหลังการใช้งาน (post-deployment monitoring)
- การฝึกอบรมและวัฒนธรรมองค์กร: ฝึกอบรมพนักงานด้านการใช้ AI อย่างรับผิดชอบ สร้างแนวปฏิบัติสำหรับการรายงานปัญหาและการรับมือเหตุฉุกเฉิน
- การจัดการกับคู่ค้าและซัพพลายเชน: ระบุข้อกำหนดด้านความเป็นส่วนตัวและความปลอดภัยในสัญญาซัพพลายเออร์ และทำการ due diligence ด้านจริยธรรมของผู้ให้บริการ AI ภายนอก
สรุปคือ การตัดสินใจขยายการใช้งาน AI สร้างสรรค์ ควรพิจารณาเชิงจริยธรรมและกฎระเบียบควบคู่ไปกับการคำนวณต้นทุนที่แท้จริงและการกำหนด KPI ที่ชัดเจน การจัดกรอบการกำกับภายในที่เข้มแข็งและการมีระบบตรวจสอบผลลัพธ์อย่างต่อเนื่องจะเป็นตัวแปรสำคัญที่ช่วยให้การนำ AI ไปใช้สร้างมูลค่าโดยไม่เพิ่มความเสี่ยงต่อองค์กรในระยะยาว
บทสรุป
อเมซอนกำลังขยายการใช้งานเทคโนโลยี AI เชิงสร้างสรรค์ (generative AI) ในหลากหลายจุดของธุรกิจเพื่อเร่งนวัตกรรมและยกระดับประสบการณ์ลูกค้า เช่น การสร้างคำอธิบายสินค้าอัตโนมัติ การปรับเนื้อหาให้เหมาะกับผู้ใช้รายบุคคล หรือการช่วยงานฝ่ายบริการลูกค้า ผลลัพธ์ที่คาดหวังคือการเพิ่มความเป็นส่วนตัวของประสบการณ์ผู้ใช้และการเปิดช่องทางใหม่ๆ ในการทดลองผลิตภัณฑ์ แต่ทั้งหมดนี้ต้องแลกมาด้วยความท้าทายที่ชัดเจน: ความชะลอหรือเพิ่มความหน่วงของระบบ ซึ่งส่งผลต่อ throughput และ latency, ต้นทุนการประมวลผล ที่อาจเพิ่มสูงเมื่อใช้งานโมเดลขนาดใหญ่, และความเสี่ยงเชิงจริยธรรม เช่น อคติของโมเดล ข้อมูลที่ผิดพลาด หรือปัญหาสิทธิ์ทางปัญญา ตัวอย่างเชิงตัวเลขจากการนำ AI มาช่วยงานบางรูปแบบระบุว่าการสร้างเนื้อหาอัตโนมัติสามารถลดเวลาการผลิตได้อย่างมีนัยสำคัญ (รายงานบางแห่งชี้เฉพาะการลดเวลาราว 30–50%) ในขณะที่การวัดผลเชิงพาณิชย์เช่นอัตรา conversion หรือ CSAT อาจเพิ่มขึ้นเป็นหลักเปอร์เซ็นต์เมื่อการใช้งานถูกออกแบบอย่างรอบคอบ
มุมมองเชิงปฏิบัติและอนาคตชี้ชัดว่าบริษัทควรเดินหน้าด้วยแนวทางผสมผสาน: เริ่มจากการกำหนดตัวชี้วัดที่ชัดเจน (เช่น latency, cost per inference, error rate, conversion, CSAT) พร้อมระบบสถาปัตยกรรมที่มี fallback และกลไกการควบคุม (เช่น caching, model routing, throttling, ใช้โมเดลขนาดเล็กเป็นสำรอง) และนำการเปลี่ยนแปลงไปทดลองในสเกลเล็กก่อนขยาย เช่น canary rollout (1–5% ของทราฟฟิก) และ A/B testing เพื่อเปรียบเทียบผลลัพธ์จริงในสภาพแวดล้อมการใช้งานจริง การใช้กรอบกำกับดูแลเชิงจริยธรรม การมอนิเตอร์แบบเรียลไทม์ และการปรับปรุงอย่างต่อเนื่อง (model retraining, bias audits) จะช่วยให้การลงทุนระยะยาวคุ้มค่าและปลอดภัยมากขึ้น หากบริหารความเสี่ยงได้ดี โอกาสในอนาคตรวมถึงการสร้างความแตกต่างเชิงผลิตภัณฑ์ การลดต้นทุนด้วยเทคนิคเช่น model distillation และการเพิ่มประสิทธิภาพทางธุรกิจจะมีความเป็นไปได้สูงกว่าเดิม
📰 แหล่งอ้างอิง: The Guardian



