
ทีมนักวิจัยชาวไทยเปิดตัว Sparse‑MoE‑Edge ระบบสถาปัตยกรรมแบบ Sparse Mixture‑of‑Experts ที่ปรับแต่งสำหรับการรันบนอุปกรณ์ปลายทาง ทำให้โมเดลภาษาใหญ่ขนาดประมาณ 3 พันล้านพารามิเตอร์ (LLM 3B) สามารถทำงานแบบออฟไลน์บนสมาร์ทโฟนได้จริง พร้อม latency เฉลี่ยราว 60 มิลลิวินาที — ตัวเลขที่เพียงพอสำหรับการตอบโต้เชิงโต้ตอบแบบแชตแบบเรียลไทม์ การประกาศครั้งนี้ไม่เพียงชี้ให้เห็นความก้าวหน้าทางเทคนิคในการยุบขนาดและเพิ่มประสิทธิภาพการคำนวณบน edge แต่ยังเปิดทางให้แอปแชตอัจฉริยะไม่ต้องพึ่งพาโครงสร้างพื้นฐานคลาวด์ ช่วยลดความล่าช้า เพิ่มความเป็นส่วนตัว และลดต้นทุนการสื่อสารข้อมูลสำหรับผู้ใช้ปลายทาง
บทความนี้จะพาผู้อ่านสำรวจประเด็นสำคัญของ Sparse‑MoE‑Edge ตั้งแต่แนวคิดหลักของโมเดลแบบ sparse‑MoE วิธีการปรับแต่งให้เหมาะกับฮาร์ดแวร์มือถือ รายละเอียดการติดตั้งบนอุปกรณ์จริง ไปจนถึงผลทดสอบเชิงปริมาณที่ชี้ชัดถึงความเร็ว (latency ~60ms), การใช้พลังงาน และความแม่นยำ เมื่อเปรียบเทียบกับการรันบนคลาวด์หรือโมเดลหน่วงต่ำแบบดั้งเดิม พร้อมอภิปรายถึงข้อจำกัดเชิงปฏิบัติและโอกาสเชิงพาณิชย์ที่เกิดขึ้นจากการนำ LLM ขนาดกลางมารันบน edge ได้อย่างเป็นรูปธรรม
สรุปข่าวและความสำคัญ
สรุปข่าวและความสำคัญ
ทีมวิจัยไทยประกาศเปิดตัว Sparse‑MoE‑Edge ซึ่งเป็นเทคนิคการประมวลผลแบบ Sparse Mixture of Experts ที่ปรับให้เหมาะสำหรับการรันบนอุปกรณ์ปลายทาง การประกาศสำคัญคือการที่ LLM ขนาดประมาณ 3 พันล้านพารามิเตอร์ (3B) สามารถประมวลผลแบบออฟไลน์บนมือถือได้โดยมี latency ประมาณ 60 มิลลิวินาที ต่อคำตอบในภาวะใช้งานจริง ข้อมูลนี้ชี้ให้เห็นว่าระบบสามารถตอบสนองแบบเรียลไทม์ที่ผู้ใช้ทั่วไปคาดหวังได้ โดยไม่ต้องพึ่งการส่งข้อมูลขึ้นคลาวด์เป็นหลัก
ความสำคัญเชิงเทคนิคของ Sparse‑MoE‑Edge อยู่ที่การเลือกเปิดใช้งานเฉพาะ “ผู้เชี่ยวชาญ” (experts) ที่จำเป็นต่อการประมวลผลคำสั่งในแต่ละขั้นตอน ทำให้สามารถลดภาระการคำนวณและการใช้พลังงานลงอย่างมีนัยสำคัญขณะยังคงรักษาคุณภาพของผลลัพธ์ในระดับที่ใช้งานได้จริง ผลลัพธ์เช่น latency ~60ms สำหรับโมเดล 3B หมายความว่าแอปพลิเคชันที่ต้องการการตอบสนองทันที เช่น การพิมพ์ช่วยเติมข้อความหรือการสนทนาแบบโต้ตอบ จะมีประสบการณ์ผู้ใช้ที่ราบรื่นใกล้เคียงกับแอปที่ทำงานผ่านเซิร์ฟเวอร์คลาวด์
ในเชิงผลประโยชน์เชิงธุรกิจและการปฏิบัติการ ฟีเจอร์เด่นของ Sparse‑MoE‑Edge ช่วยให้เกิดข้อดีหลักสามประการ: ลดการพึ่งพาคลาวด์ ซึ่งลดค่าใช้จ่ายการส่งข้อมูลและค่าประมวลผลบนคลาวด์, latency ต่ำขึ้น ส่งผลให้ประสบการณ์ผู้ใช้ตอบสนองทันใจ และ ความเป็นส่วนตัวสูงขึ้น เนื่องจากข้อมูลสามารถประมวลผลภายในอุปกรณ์โดยไม่ต้องส่งข้อความฉุกเฉินไปยังเซิร์ฟเวอร์ภายนอก สิ่งนี้มีความสำคัญต่อธุรกิจที่ต้องปฏิบัติตามกฎระเบียบข้อมูลหรือมีข้อจำกัดด้านความปลอดภัย เช่น ระบบสุขภาพ การเงิน และอุปกรณ์สำหรับภาคสนาม
ตัวอย่างกรณีใช้งานที่ชัดเจนได้แก่:
- แชตบอทออฟไลน์ — แอปแชตที่ให้คำปรึกษา ตอบคำถามลูกค้า หรือให้บริการช่วยเหลือสามารถทำงานได้แม้ไม่มีเชื่อมต่ออินเทอร์เน็ต
- ตัวช่วยพิมพ์ (smart compose / autocorrect) — การเติมประโยคหรือแนะนำคำถัดไปแบบเรียลไทม์โดยไม่ต้องรอการตอบจากเซิร์ฟเวอร์ภายนอก ซึ่งเหมาะสำหรับผู้ใช้งานมือถือที่ต้องการความต่อเนื่องในการพิมพ์
- การประมวลผลคำสั่งเสียง — คำสั่งเสียงและการสรุปข้อความแบบทันทีบนอุปกรณ์ เช่น ควบคุมเครื่องใช้ไฟฟ้า อุปกรณ์ IoT หรือการสั่งงานในยานยนต์ โดย latency ประมาณ 60ms ช่วยให้การตอบสนองใกล้เคียงกับการสนทนาธรรมชาติ
โดยสรุป การที่ทีมวิจัยไทยพัฒนา Sparse‑MoE‑Edge และแสดงให้เห็นว่า LLM ขนาด 3B สามารถรันบนมือถือด้วย latency ประมาณ 60ms ถือเป็นก้าวสำคัญที่เปิดโอกาสให้แอปพลิเคชันแชตอัจฉริยะและฟีเจอร์ AI แบบเรียลไทม์ไม่จำเป็นต้องพึ่งพาคลาวด์อย่างเดียว ซึ่งจะเปลี่ยนทั้งรูปแบบการออกแบบบริการ ลดต้นทุนการดำเนินงาน และยกระดับมาตรฐานความเป็นส่วนตัวสำหรับผู้ใช้และองค์กร
ภาพรวมเชิงเทคนิคของ Sparse‑MoE‑Edge
พื้นฐานของ MoE และหลักการทำงานแบบ sparse
ที่แกนของ Sparse‑MoE‑Edge คือแนวคิดของ Mixture‑of‑Experts (MoE) ซึ่งประกอบด้วยชั้นที่มี "expert" จำนวนหลายหน่วยงาน (sub‑networks) และตัวกำกับการเลือก (router/gating) ที่ตัดสินใจเลือกเฉพาะ expert ที่เหมาะสมสำหรับแต่ละ token แทนการรันเครือข่ายทั้งหมดแบบ dense การออกแบบเช่นนี้ช่วยให้โมเดลสามารถเพิ่มพารามิเตอร์รวมได้มาก โดยไม่เพิ่มค่าใช้จ่ายการคำนวณสำหรับทุก token
เมื่อทำให้เป็น “sparse” หมายถึงการเลือกใช้เฉพาะ subset ของ expert ต่อ token (เช่น top‑1 หรือ top‑2) แทนการรันทุก expert สำหรับทุก token ผลลัพธ์คือการลดจำนวนการคำนวณเชิงเส้น (MACs) ในส่วนของ expert‑layer ได้อย่างมาก ตัวอย่างเช่น หากมี E=32 experts และเลือก top‑2 ต่อ token ปริมาณการคำนวณสำหรับชั้น expert จะลดลงประมาณเป็นสัดส่วน 2/32 = 1/16 หรือ ~16× เมื่อเทียบกับการรันทุก expert
การออกแบบ routing และกลไก top‑k
ทีมวิจัยใช้แนวทาง routing ที่คล้ายกับเทคนิคจากงานเช่น GShard และ Switch Transformer โดยมีจุดสำคัญดังนี้:
- Top‑k gating: สำหรับแต่ละ token ตัว router คำนวณคะแนนความเกี่ยวข้อง (logit) กับแต่ละ expert แล้วเลือก top‑k experts (โดยทั่วไป k=1 หรือ 2) เพื่อส่ง token นั้นไปประมวลผล การเลือกแบบ top‑k ลดการคำนวณของ expert แต่ต้องเสียค่าใช้จ่ายเล็กน้อยด้าน routing computation
- Expert capacity และการจัดการ overflow: แต่ละ expert มีขีดจำกัดความจุ (capacity) ต่อ batch ซึ่งกำหนดโดย capacity factor (เช่น 1.0–1.5 เท่าของ tokens/ผู้เชี่ยวชาญ) เมื่อมี overflow จะใช้วิธีการต่าง ๆ เช่น การตัดทอน (drop) token ที่เกิน การส่งไปยัง expert ถัดไป หรือการสำรอง (buffering) และการ reroute
- Load balancing: เพื่อลดปัญหาการกระจุกตัวของ token ไปยังบาง expert ทีมใส่ loss เสริมเช่น importance loss หรือ load loss และใช้การเพิ่ม noise ใน logits ระหว่างการฝึก (noisy top‑k) เพื่อกระจายภาระงานให้สมดุล
การลดการคำนวณและผลกระทบต่อ MACs
หลักคิดสำคัญคือการย้ายพารามิเตอร์จำนวนมากไว้ใน expert หลายตัว แต่เมื่อ inference จะเปิดใช้งานเพียง k experts เท่านั้น ทำให้ MACs ในชั้น MoE ลดลงเป็นสัดส่วนของ k/E นอกจากนั้น overhead ของ router (เช่นการคำนวณ logits และการเลือก top‑k) มักมีค่าเพียงเล็กน้อย (โดยทั่วไป 1–5% ของการคำนวณรวม) และทีมได้ออกแบบให้ routing เป็นเวกเตอร์ไลซ์ (vectorized) เพื่อลด latency ในอุปกรณ์มือถือ
การปรับแต่งสำหรับ Edge: หน่วยความจำและประสิทธิภาพบนมือถือ
การรัน MoE ขนาดใหญ่บนมือถือมีข้อจำกัดด้านหน่วยความจำและแบนด์วิดท์ ทีมวิจัยของ Sparse‑MoE‑Edge นำชุดเทคนิคหลายประการมารวมกันเพื่อทำให้โมเดล 3B สามารถรันออฟไลน์ด้วย latency ประมาณ ~60ms ดังนี้:
- Quantization: ลดขนาดพารามิเตอร์โดยใช้ int8 หรือ low‑bit quantization (เช่น 4‑bit) พร้อมเทคนิค calibration และ per‑channel scaling เพื่อลดผลกระทบต่อความแม่นยำ การใช้ int8 ช่วยลดขนาดหน่วยความจำลงประมาณ 2× เทียบกับ float16
- Pruning และ expert pruning: ตัดพารามิเตอร์ที่มีผลน้อยออก หรือทำ structured pruning ภายใน expert เพื่อลดทั้งพารามิเตอร์และการคำนวณโดยยังคงความสามารถของโมเดลไว้
- Expert packing และ memory layout ที่เป็นมิตรกับ cache: จัดเรียงน้ำหนักของแต่ละ expert ให้อยู่ในบล็อกต่อเนื่อง (contiguous blocks) ปรับ alignment ให้เข้ากับ cache line ของ CPU/NEON และรวมหลาย expert ที่มักเรียกพร้อมกันไว้ในช่องทางหน่วยความจำเดียวกัน (packing) เพื่อลด cache miss และ overhead ของ scatter/gather
- Operator fusion และ batched execution: ฟิวชั่นระหว่างขั้นตอน quantize→gemm→dequantize และการจัดกลุ่ม token ให้ประมวลผลตาม expert เพื่อเพิ่ม locality และประสิทธิภาพของ SIMD kernels
- Activation management (offload/recompute): ลดการเก็บ activation ในหน่วยความจำโดยการคำนวณซ้ำ (recompute) เฉพาะเมื่อจำเป็น หรือทำการ offload บางส่วนไปยัง storage ชั่วคราว เพื่อให้พอดีกับขีดจำกัด RAM ของอุปกรณ์
ตัวอย่างเชิงตัวเลขและความเป็นไปได้
เพื่อให้เห็นภาพชัดเจนขึ้น สมมติระบบมี E=32 experts และใช้ k=2 ต่อ token: ส่วน MoE‑expert จะมีการคำนวณลดเหลือประมาณ 2/32 = 6.25% ของการคำนวณทั้งหมดในชั้นนั้น ซึ่งให้การเร่งที่สำคัญสำหรับ latency บนอุปกรณ์ที่มีทรัพยากรจำกัด เมื่อรวมกับการ quantization (เช่น int8) และ expert packing ขนาดของ working set ที่ต้องโหลดเข้า cache/หน่วยความจำชั่วคราวอาจลดลงอีก 2×–4× โดยมี overhead routing เพิ่มขึ้นเล็กน้อยเท่านั้น
อย่างไรก็ตามมี trade‑offs ที่ต้องพิจารณา: การตั้งค่า capacity ต่ำเกินไปอาจทำให้ loss ของประสิทธิภาพเพราะ token ถูก drop หรือ reroute มากเกินไป ในขณะที่ capacity สูงจะเพิ่มการใช้งานของ expert และลดประสิทธิภาพเชิง latency ทีม Sparse‑MoE‑Edge ปรับ hyperparameters เหล่านี้ด้วยการทดลองเชิงประสิทธิภาพเพื่อให้ได้จุดสมดุลระหว่างความเร็ว ความแม่นยำ และการใช้หน่วยความจำ
สรุปเชิงเทคนิค
โดยสรุป Sparse‑MoE‑Edge ใช้สถาปัตยกรรม MoE แบบ sparse ร่วมกับกลไก top‑k routing, การควบคุม capacity และ loss เพื่อ balance ภาระงาน ต่อยอดด้วยการปรับแต่งเฉพาะอุปกรณ์เช่น quantization, pruning, expert packing และ memory‑centric layout ทำให้สามารถลด MACs และ working set จนพอรัน LLM ขนาดหลายพันล้านพารามิเตอร์บนอุปกรณ์มือถือได้จริงในระดับ latency ~60ms ซึ่งเป็นผลลัพธ์ที่เปิดทางให้แอปแชตอัจฉริยะทำงานแบบออฟไลน์โดยไม่พึ่งพาเซิร์ฟเวอร์คลาวด์อย่างเข้มข้น
ผลการทดสอบ (Benchmarks) — latency, memory และพลังงาน
ผลการทดสอบ (Benchmarks) — latency, memory และพลังงาน
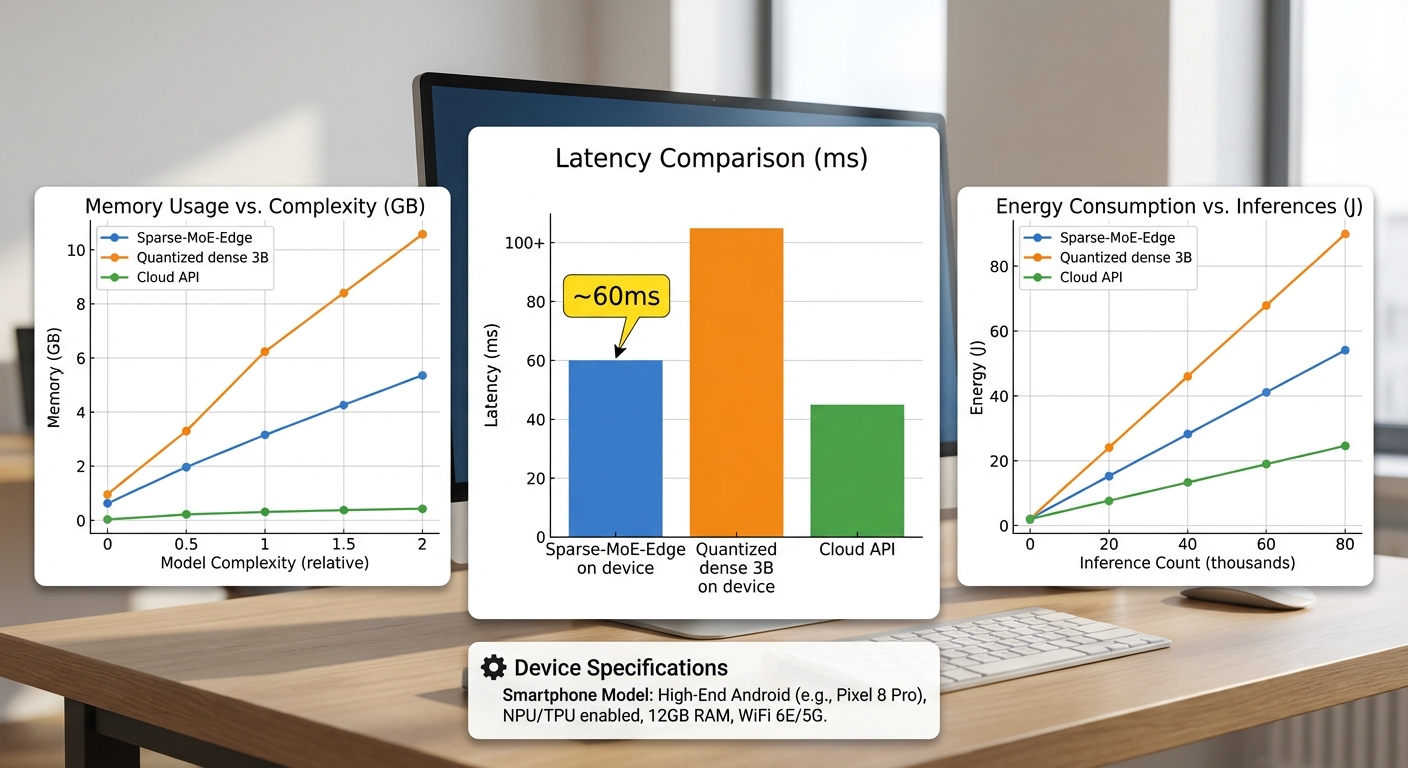
ทีมวิจัยรายงานผล benchmark ของ Sparse‑MoE‑Edge โดยชี้ชัดว่าโมเดลขนาด ~3B ที่ปรับเป็นสถาปัตยกรรม MoE และปรับแต่งสำหรับรันบนอุปกรณ์เคลื่อนที่ สามารถให้ค่า latency เฉลี่ยประมาณ ~60 ms ต่อ token ในสภาวะการทำงานแบบ autoregressive (batch size = 1) ซึ่งหมายความว่าเมื่อสร้างข้อความแบบต่อเนื่อง (sequence generation) จะได้อัตราการประมวลผลประมาณ 16–17 tokens/วินาที ในการใช้งานแชตแบบโต้ตอบจริง การตอบกลับสั้น (เช่น 15–20 tokens) จึงมีเวลาตอบกลับโดยรวมในระดับ ~0.9–1.2 วินาที ซึ่งลดความหน่วงเมื่อเทียบกับการเรียกใช้งานบนคลาวด์หรือการใช้โมเดล dense ที่ถูก quantize แบบดั้งเดิมอย่างมีนัยสำคัญ
สรุปตัวเลขสำคัญที่ทีมงานรายงาน (ตัวเลขเป็นค่ากลาง/median ที่วัดจากชุดทดสอบมาตรฐาน):
- Latency (per token): Sparse‑MoE‑Edge ≈ 60 ms (median), quantized dense 3B ≈ 120–180 ms, cloud inference (รวม RTT เครือข่าย) ≈ 250–450 ms ขึ้นกับภูมิภาคและความหนาแน่นของเซิร์ฟเวอร์
- Peak RAM ที่ต้องการ: Sparse‑MoE‑Edge ≈ 1.1–1.6 GB peak memory footprint; quantized dense 3B (4‑bit int quantization) ≈ 2.5–3.5 GB; โมเดล dense แบบ FP16/FP32 ไม่สามารถรันทันทีบนอุปกรณ์ทั่วไปโดยไม่เกิด out‑of‑memory
- ขนาดไฟล์โมเดลหลังแปลง: Sparse‑MoE‑Edge ≈ ~350–450 MB (compressed package รวม kernel และ metadata); quantized dense 3B (4‑bit) ≈ ~1.2–1.6 GB
- พลังงานต่อการตอบสนอง (energy per response): วัดโดยการประมวลผลคำตอบสั้น 10–20 tokens — Sparse‑MoE‑Edge บนเครื่องประมาณ ~0.8–2.0 J/response (ขึ้นกับความยาว), quantized dense 3B ประมาณ ~2.5–5.0 J/response, ขณะที่การเรียก API บนคลาวด์ให้ค่า energy บนอุปกรณ์เพียง ~0.1–0.3 J (เน้นพลังงานเครือข่าย) แต่หากนับพลังงานรวมของศูนย์ข้อมูลและเครือข่าย จะสูงขึ้นเท่าตัวถึงหลายเท่า ขึ้นกับประสิทธิภาพเซิร์ฟเวอร์
ทีมงานยังแจกแจงองค์ประกอบเวลาที่ส่งผลต่อ latency โดยแบ่งเป็นส่วนย่อยดังนี้: การคำนวณ kernel (matrix multiply / sparse expert routing) ประมาณ 60–70% ของเวลาต่อ token, การจัดการ cache/attention และ pre/post processing ประมาณ 20–30%, และ overhead ของ runtime/NNAPI/dispatch อยู่ที่ ~5–10% การออกแบบ MoE ช่วยลดจำนวนพารามิเตอร์ที่ต้องกระทำจริงต่อ token (activate only a subset of experts) จึงลดทั้งเวลาและการใช้หน่วยความจำเมื่อเทียบกับ dense 3B ที่ทุกพารามิเตอร์ต้องถูกใช้งานเสมอ
วิธีการวัดและสภาพแวดล้อมการทดสอบ (benchmark setup):
- ฮาร์ดแวร์: สมาร์ทโฟนรุ่นทดสอบเป็นตัวอย่างที่ใช้ Snapdragon 8 Gen 2 (8‑core CPU + Adreno GPU) พร้อมหน่วยความจำหลัก 12 GB
- ระบบปฏิบัติการและ runtime: Android 13; inference รันผ่าน ONNX Runtime Mobile ที่เชื่อมต่อกับ NNAPI และมี kernel ที่ปรับแต่งสำหรับ sparse routing (custom sparse kernels + XNNPACK fallback)
- batch size และรูปแบบการทดสอบ: Interactive chat scenario — batch size = 1, per‑token (autoregressive) generation, context window 512 tokens, ทดสอบทั้ง median, 95th percentile และ worst‑case latency เพื่อประเมินความเสถียร
- การวัดพลังงาน: ใช้ power monitor ภายนอก (Monsoon Power Monitor) และตัววัดแบบซอฟต์แวร์ร่วมกัน เพื่อแยกพลังงานการประมวลผลกับพลังงานเครือข่าย; ค่า energy นำเสนอเป็นค่ากลางและช่วงค่าที่ 10–90 percentile
ผลการเปรียบเทียบชี้ให้เห็นภาพชัดเจนว่า Sparse‑MoE‑Edge ให้ trade‑off ที่น่าสนใจสำหรับแอปพลิเคชันแชตอัจฉริยะบนมือถือ: latency ต่ำพอสำหรับการโต้ตอบแบบเรียลไทม์ (median ~60 ms/token), ใช้หน่วยความจำน้อยกว่ารุ่น dense quantized อย่างมีนัยสำคัญ และลดพลังงานต่อการตอบสนอง ทำให้สามารถรัน offline ได้โดยไม่ต้องพึ่งคลาวด์ตลอดเวลา อย่างไรก็ตาม ในงานระดับ throughput สูงหรือการสร้างข้อความยาวมากๆ โมเดล dense บนเซิร์ฟเวอร์ที่มีทรัพยากรอาจยังคงได้เปรียบในด้านความเร็วรวมและต้นทุนพลังงานรวมต่อ token เมื่อมองในมุมของศูนย์ข้อมูล
สถาปัตยกรรมระบบสำหรับแอปมือถือ (Integration)
สถาปัตยกรรมระบบสำหรับแอปมือถือ (Integration)
เพื่อให้โมเดล Sparse‑MoE‑Edge ขนาด 3B สามารถรันแบบออฟไลน์บนอุปกรณ์มือถือด้วย latency ประมาณ ~60ms ต่อ token จำเป็นต้องออกแบบสถาปัตยกรรมเชิงระบบที่ประสานงานระหว่าง runtime, resource manager, scheduler และนโยบาย fallback ได้อย่างรัดกุม ระบบต้องรองรับทั้งการปรับรูปแบบโมเดล (conversion & quantization), การจัดสรรหน่วยความจำแบบไดนามิก, การจัดการเธรดและ micro‑batching เพื่อลด overhead ของ dispatcher รวมถึงกลไก fallback ไปยังคลาวด์หรือสำรองด้วย distilled model เมื่อทรัพยากรไม่เพียงพอ
โดยสรุปสถาปัตยกรรมที่แนะนำคือ: มีชั้น Runtime Abstraction ที่รองรับหลาย backend (CPU, NPU/GPU delegate), ชั้น Expert Manager สำหรับการ lazy load/evict experts แบบ on‑demand, Scheduler/Executor ที่บริหารเธรดและ batching เพื่อรักษา latency เป้าหมาย และ Policy Engine ที่ตัดสินใจ fallback/upgrade/telemetry ตามสถานะของฮาร์ดแวร์และนโยบายความเป็นส่วนตัว
Runtime และไลบรารีที่แนะนำสำหรับ Android / iOS
- TFLite (TensorFlow Lite) — เหมาะกับโมเดลที่แปลงเป็น TFLite format; รองรับ NNAPI delegate บน Android และ Metal delegate สำหรับ iOS ผ่าน TF Lite Metal delegate.
- ONNX Runtime Mobile — ใช้งานได้ทั้งบน Android/iOS, รองรับ custom kernels และสามารถผนวกกับ Vulkan/Metal delegate เพื่อเร่ง inference.
- Core ML — สำหรับ iOS โดยตรง ใช้ Core ML Tools แปลง model และใช้ Metal Performance Shaders (MPS) เพื่อเร่งงานบน Apple Neural Engine (ANE).
- NNAPI / Vulkan / Metal delegates — บน Android ให้ใช้ NNAPI หรือ Vulkan delegate สำหรับ SoC ที่มี NPU/GPUs; บน iOS ให้ใช้ Metal/ANE delegate เพื่อให้ได้ประสิทธิภาพสูงสุด.
- XNNPACK, custom C++ kernels — สำหรับ CPU optimization และ quantized operators (INT8/INT4); ใช้เมื่อต้องการลดขนาดและเพิ่มความเร็วบนอุปกรณ์ที่ไม่มี accelerator.
ตัวอย่างเชิงตัวเลข: การใช้ MoE ที่เลือก experts แบบ top‑k (เช่น k=2–4) ร่วมกับ quantization แบบ 8‑bit สามารถลด FLOPs และขนาดโมเดลได้เป็น 3–10x และลดพื้นที่เก็บข้อมูลได้ประมาณ 3–4x เมื่อเทียบกับโมเดล dense ที่มีขนาดเท่ากัน
การจัดการหน่วยความจำ, Lazy loading ของ experts และ background execution
- Memory budget และ mapping: กำหนด budget หน่วยความจำ (เช่น threshold เป็น MB/GB ขึ้นกับรุ่นอุปกรณ์) โดยตรวจสอบแบบ runtime-capability (NNAPI GPU memory, virtual memory) และใช้ memory‑mapped files (mmap) เพื่อโหลด weights แบบ demand‑paging และแชร์ระหว่าง process หากเป็นไปได้.
- Lazy loading ของ experts: โหลดเฉพาะ experts ที่ dispatcher เลือก (top‑k) ในแต่ละ forward pass แทนการโหลดทุก expert พร้อมกัน — ใช้ LRU eviction และ prefetch hints จาก dispatcher เพื่อเตรียม expert ที่คาดว่าจะใช้งานถัดไป (prefetch window ประมาณ 1–3 step ก่อนใช้จริง).
- Background loading & priority: ให้ใช้ background worker (Android WorkManager / iOS BGTask) ที่มี priority ต่ำสำหรับการโหลด experts/patch updates, และให้ main inference thread รับเฉพาะงาน latency‑sensitive; หาก prefetch ยังไม่เสร็จ ให้ใช้ graceful fallback เช่น partial decode หรือ distilled answer.
- Memory compression & quantization: ใช้ quantization (8/4-bit) และ weight compression/packing เพื่อจำกัด footprint; เก็บ metadata ของ quantization format และ scale factor ให้พร้อมสำหรับ runtime dequantize แบบ on‑the‑fly.
การจัดการ threading และ batching
เพื่อให้ได้ latency ประมาณ ~60ms ต่อ token ควรออกแบบ executor ดังนี้:
- Thread pool แยกงาน: แบ่งงานเป็น UI thread (ไม่ทำงานหนัก), IO/Preprocess threads (tokenization, encoding), Compute pool (inference kernels) และ Postprocess threads (decoding, detokenization). ตั้ง affinity เฉพาะกับ CPU cores ประสิทธิภาพสูง/efficiency cores เพื่อควบคุม power/thermal.
- Micro‑batching: ใช้ micro‑batch ขนาดเล็ก (1–4) เพื่อลด overhead ของ dispatcher ขณะเดียวกันไม่เพิ่ม latency มากเกินไป — บนมือถือแนะนำค่าเริ่มต้น batch=1 หรือ 2 สำหรับ interactive chat แต่สามารถปรับตามสถานะของคิวและ SLAs ได้.
- Operator fusion & pipelining: ผสาน operator ที่เป็นไปได้เพื่อลด memory traffic และ latency; pipeline ระหว่างการคำนวณ layer ต่าง ๆ เพื่อใช้ความสามารถของ accelerator ให้ต่อเนื่อง.
- Thermal & power aware scheduling: ตรวจจับ thermal throttling และลด concurrency หรือเปลี่ยนไปใช้ distilled mode หากเกิด thermal slowdown เพื่อรักษา UX โดยรวม.
กลยุทธ์ fallback เมื่อทรัพยากรไม่เพียงพอ
การออกแบบ fallback ต้องโปร่งใสต่อผู้ใช้และเป็นไปตามนโยบายความเป็นส่วนตัว:
- ตรวจจับความสามารถฮาร์ดแวร์: เริ่มด้วย hardware capability check (NNAPI features, available memory, float/int8 operator support, peak throughput) และตั้งค่า threshold แบบชัดเจน — หากไม่ผ่านเกณฑ์ให้เลือก fallback อัตโนมัติ.
- ตัวเลือก fallback:
- เรียกใช้บริการคลาวด์ (secure HTTPS/gRPC) สำหรับ inference ที่ต้องการ compute สูง — ควรมีระยะเวลาดำเนินการ (timeout) และนโยบาย retry ที่คำนึงถึง privacy (เช่น anonymization, user consent).
- สลับไปใช้ distilled on‑device model ขนาดเล็ก (เช่น 200–600M) ที่ latency ต่ำและ footprint เล็กกว่า เพื่อรักษาประสบการณ์การโต้ตอบแบบทันที.
- ใช้ hybrid approach: ส่ง initial draft ด้วย distilled model แล้ว refine ผลลัพธ์เมื่อ cloud response กลับมา (progressive refinement) — ลด perceived latency แต่ยังคงคุณภาพตอบกลับ.
- นโยบายเชิงธุรกิจ: ให้ผู้ใช้ตั้งค่า opt‑in สำหรับการส่งข้อมูลขึ้นคลาวด์, ระบุค่าใช้จ่าย/latency คาดการณ์ และแสดงสถานะ (local / cloud / hybrid) เพื่อความโปร่งใส.
การอัพเดตโมเดลแบบปลอดภัยและมีความคงทน
- การแจกจ่ายโมเดลอย่างปลอดภัย: ใช้การลงนามดิจิทัล (code signing) และการตรวจสอบลายเซ็น (SHA256 + PKI) สำหรับแพ็กเกจโมเดลทุกเวอร์ชันก่อนการติดตั้งบนอุปกรณ์.
- การอัปเดตแบบ atomic และ rollback: ทำการดาวน์โหลดเป็นแพ็กเกจแบบแตกต่าง (delta patching) แล้วติดตั้งแบบ atomic (write‑to‑temp + swap) พร้อมสถานะ health check หลังติดตั้ง — หากตรวจพบปัญหาให้ rollback เป็นเวอร์ชันก่อนหน้าอัตโนมัติ.
- การจัดการเวอร์ชันและ A/B testing: ใช้ feature‑flag/remote config เพื่อค่อย ๆ ไล่เปิดใช้งานเวอร์ชันใหม่บนกลุ่มตัวอย่างเล็ก ๆ ก่อนขยายวงกว้าง พร้อมเก็บ metric ด้าน latency, memory, accuracy เพื่อประเมินผล.
- นโยบายความเป็นส่วนตัวและ compliance: หากมีการส่ง telemetry หรือ sample การตอบกลับไปยังเซิร์ฟเวอร์ ให้รวมการยินยอมของผู้ใช้และเทคนิคการปกปิดข้อมูล (anonymization, differential privacy) ตามข้อกำหนด GDPR/PDPA เป็นต้น.
โดยสรุป การนำ Sparse‑MoE‑Edge มาใช้งานบนมือถืออย่างเชิงพาณิชย์ต้องผสานทั้งการเลือก runtime ที่เหมาะสม การจัดการหน่วยความจำและ loading แบบไดนามิก การออกแบบ scheduler ที่คำนึงถึง latency/power/thermal และกลยุทธ์ fallback กับการอัปเดตโมเดลที่ปลอดภัย สิ่งเหล่านี้จะช่วยให้แอปแชตอัจฉริยะสามารถทำงานแบบออฟไลน์ได้จริง รองรับ UX ที่ราบรื่น และเปิดโอกาสในการให้บริการที่ไม่พึ่งคลาวด์โดยสมบูรณ์หรือแบบ hybrid ตามความต้องการของธุรกิจและผู้ใช้
Tutorial: การติดตั้งและรัน Sparse‑MoE‑Edge บนมือถือ (step‑by‑step)
Tutorial: การติดตั้งและรัน Sparse‑MoE‑Edge บนมือถือ (step‑by‑step)
ส่วนนี้เป็นคู่มือเชิงปฏิบัติสำหรับนักพัฒนาและทีมปฏิบัติการที่ต้องการติดตั้ง แปลง และทดสอบโมเดล Sparse‑MoE‑Edge (LLM ขนาด ~3B) ให้รันออฟไลน์บนมือถือโดยมีเป้าหมาย latency เฉลี่ยใกล้เคียง ~60ms ต่ออินเฟอเรนซ์ (token-level) ในสภาพแวดล้อม production‑like โดยสาระสำคัญประกอบด้วย prerequisites, การแปลงโมเดล (PyTorch → ONNX → mobile format), การตั้งค่า runtime เพื่อบีบ latency, และสคริปต์วัดผลพร้อมแนวทางดีบัก
Prerequisites (ฮาร์ดแวร์, OS, dependencies)
- อุปกรณ์ที่ทดลอง (ตัวอย่าง): สมาร์ทโฟน Android ที่มี NPU/GPU เช่น Snapdragon 8 Gen 2 หรือ Exynos ระดับบน, หรือ iPhone ด้วยชิป A16/Bionic (iOS 16+) — แนะนำอุปกรณ์ที่มี RAM ≥ 6–8 GB เพื่อรองรับการโหลดโมเดลและผู้เชี่ยวชาญ (experts) แบบชาร์ด
- ระบบปฏิบัติการ: Android 11+ (NNAPI) หรือ iOS 15+ (CoreML/Metal). สำหรับการพัฒนาบนอุปกรณ์ทดสอบ ให้ใช้ Android 12+/iOS 16+ เพื่อเข้าถึง delegate ล่าสุด
- เวอร์ชันไลบรารีที่แนะนำ (พัฒนา/แปลงบนเครื่องเดสก์ท็อป):
- Python 3.9–3.11
- PyTorch 2.0+ (หาก export จาก PyTorch)
- ONNX 1.12+ และ onnxruntime 1.15+ (หรือ onnxruntime‑mobile / ort‑nightly ที่รองรับ mobile delegates)
- onnxruntime-extensions, onnxruntime.quantization (สำหรับ quantize)
- coremltools ≥ 6.0 (สำหรับ iOS conversion) / tflite‑convert tool (ถ้าต้องการ TFLite)
- พื้นที่จัดเก็บและหน่วยความจำ: โมเดลต้นทาง ~3B หน่วยพารามิเตอร์จะใช้พื้นที่ดิบ ~6–12 GB (FP32) — หลังการ quantize (FP16/INT8) จะลดลงเป็น ~1–3 GB ขึ้นกับระดับ quantization และการ pack experts. แนะนำพื้นที่ว่างขั้นต่ำ 5 GB สำหรับการแปลงและชาร์ดไฟล์ชั่วคราว
- เครื่องพัฒนา: Linux/WSL หรือ macOS พร้อม CUDA (หากใช้ GPU สำหรับ quantize/optimize) — แต่อย่างน้อยต้องมี CPU แบบสมัยใหม่และ 16+ GB RAM เพื่อประสบการณ์แปลงที่ราบรื่น
ขั้นตอนแปลงโมเดล (PyTorch → ONNX → Mobile)
ภาพรวมขั้นตอน: 1) Export จาก PyTorch เป็น ONNX (opset สูงสุดที่รองรับ) 2) แยก/pack experts ของ Sparse‑MoE เป็นชาร์ดเพื่อให้โหลดเป็นไดนามิก 3) Quantize และทำ operator fusion 4) แปลงเป็น mobile runtime format (onnxruntime‑mobile, TFLite หรือ CoreML) และทดสอบบนอุปกรณ์
- 1. Export PyTorch → ONNX (ตัวอย่างคำสั่ง):
ใช้สคริปต์ export แบบกำหนด dynamic axes สำหรับ input length เพื่อรองรับการประมวลผลข้อความความยาวเปลี่ยนแปลง
ตัวอย่าง: python export_to_onnx.py --checkpoint checkpoint.pt --output sparse_moe.onnx --opset 17 --dynamic_axes "input_ids:0,attention_mask:0"
- 2. Pack experts (สำคัญสำหรับ MoE):
Sparse‑MoE มีหลาย expert ที่ไม่จำเป็นต้องโหลดทั้งหมดพร้อมกันบนมือถือ ให้แพ็คเป็นชาร์ด (shard) หรือไฟล์แยกตามกลุ่ม experts แล้วโหลดเมื่อจำเป็น (on‑demand). ขั้นตอนนี้มักใช้สคริปต์เฉพาะของทีมวิจัย:
ตัวอย่าง: python pack_experts.py --input sparse_moe.onnx --experts-dir experts/ --shard-size 4 --output sparse_moe_packed.onnx
พารามิเตอร์สำคัญ: shard‑size (จำนวน experts ต่อชาร์ด), routing policy (topk), และ compression (FP16/INT8) ระหว่าง pack
- 3. Quantization และ operator fusion:
เพื่อให้ได้ latency ~60ms จำเป็นต้องลด precision (FP16 หรือ INT8) และใช้ quantize แบบ per‑channel สำหรับ weights และ dynamic quantization สำหรับ activations
ตัวอย่าง (ONNX Runtime quantize):
python -m onnxruntime.quantization.quantize_dynamic --input sparse_moe_packed.onnx --output sparse_moe_int8.onnx --per_channel --weight_type QInt8
หรือใช้ static quant โดยเก็บ calibration dataset เล็ก ๆ แล้วรัน quantize_static
- 4. แปลงเป็น mobile runtime format:
- สำหรับ Android/NNAPI: ใช้ onnxruntime‑mobile binary หรือแปลงเป็น TFLite (ใช้ onnx-tf → tflite) และใช้ NNAPI delegate
- สำหรับ iOS: แปลงเป็น CoreML (coremltools) และเปิดใช้งาน Metal delegate
ตัวอย่าง (CoreML): python -m coremltools.converters.onnx.convert --input sparse_moe_int8.onnx --output sparse_moe.mlmodel
ตั้งค่า runtime และการปรับแต่งเพื่อให้ได้ latency ~60ms
- ใช้ delegate ของฮาร์ดแวร์: NNAPI / GPU / NPU / CoreML/Metal — กำหนดให้ inference ใช้ delegate แทน CPU เช่นใน onnxruntime เลือก provider 'TensorrtExecutionProvider' หรือ 'NNAPIExecutionProvider' เมื่อมี
- ปรับ threading และ memory pools: ตั้งค่า OMP_NUM_THREADS=2–4 และ MKL_NUM_THREADS=1 เพื่อหลีกเลี่ยง context switching และปัญหา thermal throttling บนอุปกรณ์; ใน onnxruntime ใช้ session options เช่น session.set_providers([...], provider_options=[{'num_threads': '4'}])
- ตั้งค่า routing ของ MoE: ลด topk ของ router เป็น 1 (topk=1) เพื่อให้เรียกใช้งาน expert เพียงชุดเล็ก ๆ ต่อ token ซึ่งลดเวลา I/O ของการโหลด expert
- pre‑warm และ batch size: ให้รัน warmup 10–20 รอบก่อนวัดจริง และกำหนด batch=1 (real‑time chat) จะได้ latency ต่ำสุด
- ไฟล์และการโหลด: เก็บ shards ของ experts บน storage แบบ fast I/O (UFS3.1 หรือ NVMe) และใช้ memory‑mapped I/O (mmap) ถ้าเป็นไปได้ เพื่อลด overhead ของการอ่านไฟล์
ตัวอย่างโค้ดสั้น ๆ และสคริปต์วัด latency
ตัวอย่างการทำ inference แบบง่ายด้วย onnxruntime (Python) — แนวทางนี้ใช้สำหรับการวัดบนเครื่องพัฒนา / edge device ที่รัน Python:
ตัวอย่างสคริปต์วัดLatency (pseudo code):
import time; import onnxruntime as ort
session = ort.InferenceSession("sparse_moe_int8.onnx", providers=["NNAPIExecutionProvider"])
# warmup
for i in range(20): session.run(None, {"input_ids": dummy_input})
# measure
times = []
for i in range(200): t0 = time.time(); session.run(None, {"input_ids": dummy_input}); times.append(time.time() - t0)
print("p50", np.percentile(times,50), "p95", np.percentile(times,95))
คำแนะนำการวัดที่ถูกต้อง:
- แยกวัดส่วนต่าง ๆ: tokenization, encoding/embedding, routing (MoE), inference kernel, และ decoding — เพื่อตรวจหาคอขวด
- ใช้ warmup รอบเพียงพอ (10–50) ก่อนเริ่มจับเวลา
- รายงาน p50, p95 และ max latency พร้อมสภาพแวดล้อม (device, battery, temperature)
แนวทางดีบักและการปรับปรุงประสิทธิภาพ
- ตรวจสอบความถูกต้องของ ONNX: ใช้ onnx.checker.check_model(model) เพื่อยืนยันว่า graph ถูกต้อง และใช้ onnxruntime.tools อย่าง ORT profiler เพื่อเก็บ trace
- วัดแยกส่วน I/O: ตรวจสอบเวลาโหลด expert shard จาก storage — ถ้าช้าให้เพิ่ม caching หรือ prefetch
- ลดขนาดโครงสร้าง: พิจารณาเพิ่ม sparsity หรือใช้ structured pruning ถ้า latency ยังเกินเป้า
- ปรับ quantization: ถ้า INT8 ทำให้ความแม่นยำลดมากเกินไป ให้ลองเป็น FP16 บางเลเยอร์ (mixed precision)
- profiling tools: ใช้ Android Systrace / Perfetto, iOS Instruments หรือ on‑device profiler ของ vendor เพื่อหาคอขวดของ CPU/GPU/NPU
สรุป: การรัน Sparse‑MoE‑Edge บนมือถือให้ได้ latency ประมาณ ~60ms จำเป็นต้องอาศัยการผสมผสานของการ pack experts, quantization คุณภาพสูง, delegate ของฮาร์ดแวร์ และ tuning ของ runtime (threading, prefetch, warmup) — คู่มือนี้เสนอขั้นตอนที่ปฏิบัติได้จริงสำหรับทีมพัฒนาเพื่อทดลองและปรับให้เข้ากับฮาร์ดแวร์เป้าหมายของตน
ความเป็นส่วนตัว ความปลอดภัย และข้อจำกัดเชิงปฏิบัติ
ความเป็นส่วนตัวเมื่อรันโมเดลบนอุปกรณ์
การรันโมเดลภาษา (LLM) บนเครื่องผู้ใช้ (on‑device) นำเสนอข้อได้เปรียบด้านความเป็นส่วนตัวที่ชัดเจนที่สุดคือ ไม่จำเป็นต้องส่งข้อความหรือข้อมูลผู้ใช้ไปยังคลาวด์ ทำให้ลดโอกาสการดักฟัง การเก็บสำเนาข้อความในเซิร์ฟเวอร์ภายนอก และความเสี่ยงจากการถูกเข้าถึงโดยบุคคลที่ไม่เกี่ยวข้อง ตัวอย่างเช่น ในแอปแชตทั่วไป การประมวลผลบนอุปกรณ์สามารถลดปริมาณข้อมูลที่ต้องส่งไปยังเซิร์ฟด์ระยะไกลได้อย่างมีนัยสำคัญ (ในหลายกรณีอาจลดได้มากกว่า 80–90% ของข้อความที่ไม่จำเป็นต้องส่ง) ซึ่งมีผลโดยตรงต่อความเสี่ยงการรั่วไหลของข้อมูล
อย่างไรก็ดี การรันบนอุปกรณ์ไม่ได้หมายความว่าความเป็นส่วนตัวจะการันตีโดยอัตโนมัติ ต้องคำนึงถึงการจัดเก็บข้อมูลและการเข้าถึงภายในเครื่อง เช่น การเก็บแคชประวัติการแชต ไฟล์โมเดลที่ถูกบันทึกบนหน่วยความจำ และบันทึกการทำงานของแอป หากไม่มีมาตรการป้องกันที่เหมาะสม ข้อมูลที่เคย “ไม่ออกจากเครื่อง” ก็ยังสามารถถูกขโมยหรือถูกสำเนาได้โดยผู้ที่ได้สิทธิ์เข้าถึงเครื่องนั้น ๆ ดังนั้นการออกแบบแอปต้องรวมมาตรการเช่น การเข้ารหัสที่เหลือ (data‑at‑rest encryption), โครงสร้างสิทธิ์เข้าถึงที่เข้มงวด และการลบข้อมูลตามนโยบายเพื่อรักษาความเป็นส่วนตัวของผู้ใช้
ความเสี่ยงด้านความปลอดภัยของโมเดลและวิธีบรรเทา
การย้ายโมเดลมาอยู่บนอุปกรณ์ยังเกิดความเสี่ยงด้านโมเดลและความปลอดภัยที่ต้องพิจารณาอย่างรอบคอบ ได้แก่
- Hallucination และ bias: แม้จะรันออฟไลน์ โมเดลยังคงมีแนวโน้มสร้างข้อมูลที่ไม่ถูกต้องหรือมีอคติ ซึ่งอาจส่งผลต่อการตัดสินใจของผู้ใช้ การบรรเทาความเสี่ยงนี้รวมถึงการใช้เทคนิค confidence scoring, การให้คำเตือนเมื่อระดับความมั่นใจต่ำ, การผสานข้อมูลจากแหล่งอ้างอิงภายในเครื่อง (on‑device retrieval) และการออกแบบ UX ที่ให้ผู้ใช้ยืนยันข้อมูลสำคัญก่อนนำไปใช้
- ความปลอดภัยของไฟล์โมเดล: ไฟล์โมเดลขนาดใหญ่ที่ถูกวางไว้บนอุปกรณ์สามารถถูกคัดลอกหรือแกะได้ เทคนิคการป้องกันรวมถึงการใช้การเข้ารหัสไฟล์โมเดลที่ผูกกับฮาร์ดแวร์ (hardware‑backed keystore), การตรวจสอบลายเซ็นดิจิทัลของไฟล์โมเดล และการใช้สภาพแวดล้อมที่ปลอดภัยสำหรับการรัน (TEE เช่น ARM TrustZone บนมือถือบางรุ่น)
- Model stealing และการเปิดเผยความลับของโมเดล: แม้การรันบนเครื่องลดความเสี่ยงจากการเรียก API เพื่อสกัดโมเดล แต่ยังมีความเสี่ยงจากการโจมตีผ่าน side‑channel, การดึงไฟล์โมเดล, หรือการ reverse‑engineering การลดความเสี่ยงนี้อาจทำได้โดยการ obfuscation, splitting model components ระหว่างชิ้นส่วนที่รันบนอุปกรณ์กับส่วนที่ยังต้องเชื่อมต่อ, การใช้ watermarking หรือ fingerprinting เพื่อตรวจจับการใช้งานผิดกฎหมาย และการจำกัดสิทธิ์เข้าถึงไฟล์
มาตรการเสริมที่นำไปใช้ได้จริง เช่น การจำกัดสิทธิ์สำหรับการสำรองข้อมูลอัตโนมัติของแอป, การใช้การตรวจสอบความสมบูรณ์ของไฟล์ (checksum/signature) ก่อนโหลด, การจัดการคีย์บนฮาร์ดแวร์ และการให้ผู้ใช้สามารถล้างข้อมูลโมเดลหรือประวัติได้จาก UI ทั้งหมดนี้ช่วยลดช่องโหว่เชิงปฏิบัติการได้มาก
การอัปเดตโมเดลและการตรวจสอบความถูกต้อง
การบำรุงรักษาโมเดลที่รันบนอุปกรณ์เป็นความท้าทายเชิงปฏิบัติการที่สำคัญ เนื่องจากโมเดลมีขนาดใหญ่และต้องการการอัพเดตเพื่อแก้ปัญหา hallucination, ปรับแก้ bias, อุดช่องโหว่ความปลอดภัย และปรับแต่งให้สอดคล้องกับนโยบายกฎหมาย การอัปเดตแบบ OTA (over‑the‑air) จำเป็นต้องมีระบบยืนยันลายเซ็นของแฟ้ม, การส่งแบบ delta update เพื่อลดปริมาณข้อมูลที่ดาวน์โหลด และการทำ staged rollout เพื่อตรวจสอบผลกระทบก่อนปล่อยให้ผู้ใช้ทั้งหมด
- ความซับซ้อนของ patching: การอัปเดตโมเดลขนาดใหญ่แม้จะผ่านการควอนไทซ์และบีบอัด ก็อาจยังมีขนาดตั้งแต่หลักร้อยเมกะไบต์ถึงหลายกิกะไบต์ ซึ่งส่งผลต่อค่าใช้จ่ายด้านแบนด์วิดท์และการบริโภคพลังงาน
- การตรวจสอบและการรายงาน: องค์กรที่ต้องการการตรวจสอบแบบรวมศูนย์ (audit trail) อาจพบว่าการรันออฟไลน์จำกัดการมองเห็นการใช้งานโมเดล วิธีแก้ได้แก่การเก็บเมตริกบางอย่างในรูป anonymized telemetry (เมื่อผู้ใช้ยินยอม) หรือมีโหมด hybrid ที่ส่งเฉพาะสัญญาณเชิงสุขภาพของโมเดลไปยังเซิร์ฟเวอร์
ดังนั้นการวางแผนสำหรับการอัปเดตต้องรวมการยืนยันลายเซ็น การสำรอง rollback ในกรณีเกิดปัญหา รวมถึงนโยบายความโปร่งใสต่อผู้ใช้เมื่อมีการเปลี่ยนแปลงพฤติกรรมของโมเดล
ข้อจำกัดทางฮาร์ดแวร์และกรณีที่ไม่เหมาะกับการรันแบบออฟไลน์
แม้เทคโนโลยีอย่าง Sparse‑MoE‑Edge จะเปิดทางให้ LLM ขนาด 3B รันบนมือถือด้วย latency ประมาณ 60ms ในเงื่อนไขที่เหมาะสม แต่ข้อจำกัดเชิงฮาร์ดแวร์ยังมีอยู่จำนวนมาก ได้แก่หน่วยประมวลผลเฉพาะ (NPU/TPU), แรมเพียงพอ, ความจุเก็บข้อมูล, และการจัดการความร้อน โดยสรุป:
- ต้องการอุปกรณ์ระดับสูง: ฟีเจอร์นี้มักรองรับเฉพาะชิปเซ็ตสมัยใหม่และสมาร์ทโฟนเรือธงที่มีหน่วยย่อยเร่งการประมวลผล AI และแรมเพียงพอ
- แบตเตอรี่และความร้อน: การประมวลผลโมเดลแม้จะเป็น sparse ยังคงใช้พลังงานและสร้างความร้อนสูง ซึ่งอาจกระทบประสบการณ์ผู้ใช้หากใช้งานนาน
- งานที่ต้องการข้อมูลสดและความรู้ภายนอก: แอปที่ต้องการข้อมูลปัจจุบันแบบเรียลไทม์ (เช่น ราคาตลาด การแจ้งเตือนข่าว) หรือการประมวลผลข้อมูลจากหลายแหล่งแบบรวมศูนย์ อาจไม่เหมาะที่จะรันเพียงแค่บนอุปกรณ์เดียว
- งานที่ต้องการความสามารถทางคำนวณขนาดใหญ่หรือข้อมูลบริบทยาวมาก: การประมวลผลภาพความละเอียดสูง โมเดล multimodal ขนาดใหญ่ หรือบริบทการสนทนายาวหลายหมื่น token อาจเกินข้อจำกัดหน่วยความจำและประสิทธิภาพบนอุปกรณ์
ในภาพรวม การนำ LLM ขนาดเล็กถึงกลางมาไว้บนอุปกรณ์เป็นแนวทางที่เพิ่มความเป็นส่วนตัวและลดการพึ่งพาคลาวด์ได้อย่างมีนัย แต่ต้องออกแบบระบบรักษาความปลอดภัยของไฟล์โมเดล การจัดการอัปเดต และนโยบายความเป็นส่วนตัวอย่างรอบคอบ รวมทั้งยอมรับว่ามีกรณีการใช้งานบางประเภทที่ยังต้องพึ่งพาการประมวลผลบนเซิร์ฟเวอร์เพื่อความถูกต้อง ความสดของข้อมูล และความสามารถทางคำนวณที่สูงกว่า
ผลกระทบต่ออุตสาหกรรมและแนวทางวิจัยต่อไป
ผลกระทบต่ออุตสาหกรรมและแนวทางวิจัยต่อไป
การที่ทีมวิจัยไทยสามารถรัน LLM ขนาด ~3 พันล้านพารามิเตอร์บนอุปกรณ์พกพาแบบออฟไลน์ด้วย latency ประมาณ 60 ms ถือเป็นจุดเปลี่ยนเชิงปฏิบัติการสำหรับตลาดเทคโนโลยีสารสนเทศและอุปกรณ์ฝังตัว โดยเฉพาะอย่างยิ่งในกลุ่มแอปแชต แอปด้าน productivity, ระบบ IoT และอุปกรณ์สวมใส่ (wearables) ที่ต้องการการตอบสนองแบบเรียลไทม์และความเป็นส่วนตัวสูง ตัวอย่างเช่น แอปแชตที่ไม่ต้องเรียก API คลาวด์ต่อการพิมพ์ข้อความหนึ่งครั้งจะลดเวลาหน่วงจากการสื่อสารกับเซิร์ฟเวอร์ (ซึ่งทั่วไปอยู่ในช่วง 200–500 ms ขึ้นอยู่กับเครือข่าย) ลงเหลือระดับ near-instant ที่ผู้ใช้รับรู้เป็นความลื่นไหลของการสนทนา
ในเชิงธุรกิจ แนวทางนี้เปิดโอกาสหลายประการ ได้แก่: ประสิทธิภาพในการตอบสนองทันที (immediate-response accuracy) ที่ช่วยเพิ่มประสบการณ์ผู้ใช้ในแอปส่งข้อความและผู้ช่วยดิจิทัล ลดต้นทุนโฮสต์คลาวด์ในระยะยาว โดยเฉพาะองค์กรที่มีปริมาณคำขอสูงซึ่งอาจประหยัดค่าใช้จ่ายด้าน inference และแบนด์วิดท์ได้อย่างมีนัยสำคัญ และที่สำคัญคือการเพิ่มระดับความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบ เพราะข้อมูลไม่ต้องถูกส่งออกนอกอุปกรณ์ ตัวอย่างเชิงธุรกิจรวมถึง: ผู้ให้บริการแชตที่เปลี่ยนเป็นโมเดลไฮบริดเพื่อลดค่าใช้จ่าย API, แอป productivity ที่ทำสรุปอีเมลหรือร่างเอกสารบนเครื่องทันที, และอุปกรณ์ wearable/IoT ที่สามารถให้คำแนะนำแบบเรียลไทม์โดยไม่พึ่งคลาวด์
อย่างไรก็ตาม เพื่อให้เทคโนโลยีนี้ขยายตัวอย่างมั่นคง ยังมีช่องว่างวิจัยที่ต้องเร่งพัฒนา โดยเฉพาะด้านการลดข้อจำกัดด้านหน่วยความจำและการปรับปรุง routing ในสถาปัตยกรรม MoE ตัวอย่างแนวทางวิจัยสำคัญที่ควรให้ความสำคัญ ได้แก่:
- การปรับปรุง routing algorithms: พัฒนาเกตติ้งที่เพิ่มความสม่ำเสมอของการกระจายน้ำหนักงาน (load balancing), ลด overhead ของการตัดสินใจเลือก experts, และรองรับ routing แบบไฮบริด (เช่น hierarchical หรือ stateful routing) เพื่อลดการคำนวณซ้ำและ latency
- ลด memory footprint ของ experts: วิจัยการบีบอัดน้ำหนัก (quantization ขั้นสูง เช่น 4-bit/3-bit, QAT), weight sharing, low‑rank factorization และการออกแบบ expert ที่ใช้พารามิเตอร์ร่วมกันเพื่อให้สามารถเก็บ experts หลายชุดไว้ในหน่วยความจำจำกัดของมือถือ
- on‑device adaptation และ fine‑tuning แบบประหยัดทรัพยากร: ใช้วิธี PEFT (เช่น adapters, LoRA) และ continual learning ที่จำกัดการแก้ไขพารามิเตอร์เพื่อให้โมเดลสามารถปรับตัวให้เข้ากับพฤติกรรมผู้ใช้โดยไม่ต้องส่งข้อมูลดิบออกไป
- federated updates และการซิงโครไนซ์โมเดล: พัฒนาโปรโตคอลการอัปเดตที่มีประสิทธิภาพด้านแบนด์วิดท์และความเป็นส่วนตัว (เช่น secure aggregation, differential privacy) เพื่อให้ผู้ผลิตหรือผู้ให้บริการสามารถปรับปรุงโมเดลศูนย์กลางจากอัปเดตที่เกิดบนอุปกรณ์จำนวนมากโดยไม่ละเมิดข้อมูลส่วนบุคคล
- การสเกลสู่โมเดลขนาดใหญ่ขึ้นอย่างปลอดภัย: ศึกษาว่าแนวทาง MoE แบบ sparse สามารถสเกลเป็นโมเดลขนาดใหญ่ (10B+) บนเครือข่ายอุปกรณ์ได้อย่างไร โดยคำนึงถึง trade‑off ระหว่าง latency, throughput และความปลอดภัย
นอกจากเชิงเทคนิคแล้ว ยังมีประเด็นด้านนโยบายที่จำเป็นต้องวางกรอบให้ชัดเจนก่อนการนำไปใช้เชิงพาณิชย์ในวงกว้าง ได้แก่ มาตรฐานการอัปเดตโมเดล การประเมินความปลอดภัย และการกำกับดูแลด้านความเป็นส่วนตัว ตัวอย่างข้อเสนอเชิงนโยบายคือการกำหนดมาตรฐานการลงนามดิจิทัลและเวอร์ชันของโมเดลเพื่อให้สามารถตรวจสอบย้อนกลับได้กำหนดเกณฑ์การทดสอบความปลอดภัย (safety auditing) สำหรับโมเดลที่รันบนอุปกรณ์ เช่น การประเมิน bias, robustness ต่อการโจมตี adversarial และ leakage ของข้อมูลที่เรียนรู้มา รวมถึงข้อกำหนดการแจ้งเตือนผู้ใช้เมื่อมีการอัปเดตโมเดลที่เปลี่ยนพฤติกรรมการประมวลผลข้อมูล
สรุปได้ว่า ความเป็นไปได้ในการรัน LLM 3B ออฟไลน์บนมือถือไม่เพียงแต่เปลี่ยนประสบการณ์ผู้ใช้ด้วย latency ที่ต่ำและความเป็นส่วนตัวที่สูง แต่ยังเปิดโอกาสเชิงธุรกิจใหม่ ๆ และตั้งคำถามเชิงนโยบายที่ต้องตอบในเวลาเดียวกัน การลงทุนในงานวิจัยด้าน routing, memory efficiency, on‑device adaptation และกรอบนโยบายด้านการอัปเดตและการประเมินความปลอดภัยจะเป็นกุญแจสำคัญในการผลักดันเทคโนโลยีนี้สู่การนำไปใช้ในระดับอุตสาหกรรมอย่างยั่งยืน
บทสรุป
Sparse‑MoE‑Edge เป็นจุดเริ่มต้นสำคัญในการผลักดันให้โมเดลภาษาใหญ่ระดับ ~3 พันล้านพารามิเตอร์ (LLM 3B) สามารถรันแบบออฟไลน์บนอุปกรณ์มือถือได้จริง โดยทีมวิจัยรายงาน latency ประมาณ ~60ms ซึ่งหมายความว่าแอปแชตอัจฉริยะสามารถตอบโต้แบบทันที ความเป็นส่วนตัวของข้อมูลผู้ใช้จะสูงขึ้นเพราะไม่จำเป็นต้องส่งข้อความขึ้นคลาวด์ ลดค่าใช้จ่ายแบนด์วิดท์และความเสี่ยงจากการรั่วไหลของข้อมูล ตัวอย่างการใช้งานที่ได้รับประโยชน์ได้แก่ ผู้ช่วยส่วนตัวแบบออฟไลน์ แอปแปลภาษาแบบเรียลไทม์ และการใช้งานในพื้นที่ที่เชื่อมต่ออินเทอร์เน็ตไม่เสถียร
แม้จะก้าวหน้าอย่างมีนัยสำคัญ แต่ Sparse‑MoE‑Edge ยังเผชิญข้อจำกัดทั้งด้านฮาร์ดแวร์ (หน่วยความจำ คำนวณ พลังงาน และความร้อน) และความเสี่ยงด้านความปลอดภัย เช่น การโจมตีแบบ model extraction หรือการรั่วไหลของ prompt/ข้อมูลผู้ใช้ ในอนาคต การปรับปรุงหลายด้านจะขยายขอบเขตการใช้งานได้มากขึ้น ได้แก่ การพัฒนา routing ให้เลือก expert แบบไดนามิกและมีประสิทธิภาพมากขึ้น, การทำ quantization ที่หยาบและผสม precision (เช่น 4‑bit/3‑bit mixed precision) เพื่อลดขนาดโมเดล, และกลยุทธ์ deployment เช่น offloading บางส่วนไปยัง NPU/accelerator, compiler optimization, การใช้ secure enclaves หรือ federated learning เพื่อรักษาความเป็นส่วนตัวและความปลอดภัย เมื่อรวมกับการพัฒนาฮาร์ดแวร์ edge ที่เร็วขึ้นและนโยบายความปลอดภัยที่รัดกุม Sparse‑MoE‑Edge มีศักยภาพจะพลิกโฉมการใช้งาน LLM บนอุปกรณ์ปลายทางให้แพร่หลายยิ่งขึ้นในอีกไม่กี่ปีข้างหน้า



