
โลกกำลังเผชิญกับการเปลี่ยนแปลงเชิงเทคโนโลยีที่รวดเร็วเมื่อปัญญาประดิษฐ์ (AI) ถูกนำไปใช้ในระบบสำคัญทั้งภาครัฐ ภาคธุรกิจ และชีวิตประจำวัน ตั้งแต่การประมวลผลภาษาเชิงสร้างสรรค์ไปจนถึงระบบอัตโนมัติระดับองค์กร แต่พร้อมกันนั้น ความเสี่ยงด้านความปลอดภัยก็เพิ่มขึ้นอย่างมีนัยสำคัญ — ทั้งการโจมตีที่ใช้โมเดลสร้างเนื้อหาปลอม (deepfake), การโจมตีเพื่อขโมยข้อมูลจากโมเดล (model extraction/inversion), การปนเปื้อนข้อมูลฝึกสอน (data poisoning) และการใช้ AI เป็นเครื่องมือเร่งการโจมตีไซเบอร์ ภาพรวมจากหลายหน่วยงานชี้ว่ากิจกรรมที่เกี่ยวข้องกับภัยคุกคาม AI ขยายตัวในช่วงไม่กี่ปีที่ผ่านมา ทำให้ความจำเป็นในการเร่งพัฒนามาตรการความปลอดภัยและกรอบนโยบายกลายเป็นเรื่องเร่งด่วนระดับชาติและระดับสากล
บทความนี้มุ่งนำเสนอภาพรวมเชิงลึกเกี่ยวกับความปลอดภัยใน AI โดยวิเคราะห์ประเภทความเสี่ยงที่สำคัญ ระบุเทคโนโลยีและสถาปัตยกรรมที่เป็นจุดอ่อน อธิบายนโยบายและมาตรการกำกับดูแลที่กำลังพัฒนา รวมทั้งแนวปฏิบัติของวิศวกรและทีมความปลอดภัยที่ควรยึดเป็นหลักปฏิบัติ นอกจากนี้เรายังนำเสนอแผนปฏิบัติการเชิงปฏิบัติสำหรับองค์กรทั้งในด้านการประเมินความเสี่ยง การเสริมความแข็งแกร่งของโมเดล การตรวจจับพฤติกรรมผิดปกติ และการเตรียมพร้อมรับมือเหตุฉุกเฉิน เพื่อให้ผู้อ่านได้รับทั้งบริบทเชิงนโยบายและเครื่องมือเชิงเทคนิคที่สามารถนำไปใช้ได้จริง
บทนำ: ทำไมความปลอดภัยใน AI ถึงเป็นเรื่องเร่งด่วน
บทนำ: ทำไมความปลอดภัยใน AI ถึงเป็นเรื่องเร่งด่วน

ปัจจุบันปัญญาประดิษฐ์ (AI) ถูกนำไปใช้ในระดับองค์กรและสาธารณูปโภคอย่างรวดเร็ว โดยเฉพาะในภาคการเงิน การแพทย์ และโครงสร้างพื้นฐานที่มีผลต่อความมั่นคงของสังคม แม้แต่ฟังก์ชันที่เคยเป็นงานสนับสนุนก็เริ่มพึ่งพาโมเดล AI เพื่อวิเคราะห์ความเสี่ยง อำนวยความสะดวกในการให้บริการ และตัดสินใจเชิงปฏิบัติการ รายงานจาก McKinsey (2022) ระบุว่ามากกว่า 50% ขององค์กรได้เริ่มใช้งาน AI อย่างน้อยในหนึ่งหน่วยงาน และการประเมินเชิงเศรษฐกิจจาก PwC คาดว่า AI จะเพิ่มผลผลิตและคุณค่าทางเศรษฐกิจหลายล้านล้านดอลลาร์ภายในปี 2030 ซึ่งสะท้อนให้เห็นถึงการฝังรากของ AI เข้ากับระบบธุรกิจและสังคมอย่างจริงจัง
ในขณะที่การนำ AI มาใช้ขยายตัว ผลกระทบจากความไม่ปลอดภัยของโมเดลก็ทวีความรุนแรงขึ้นอย่างเป็นระบบ เหตุการณ์ที่เกี่ยวข้องกับการละเมิดโมเดล (model abuse) การรั่วไหลของข้อมูลฝึกสอน (training data leakage) และการโจมตีแบบปรับแต่งโมเดล (model poisoning) ถูกบันทึกและทดสอบโดยหน่วยงานด้านความปลอดภัยหลายแห่ง ตัวอย่างเช่น ข้อกังวลเกี่ยวกับการเผยแพร่โค้ดและข้อมูลจากระบบช่วยเขียนโค้ด (เช่นกรณีที่สังคมตั้งคำถามต่อ GitHub Copilot ในช่วงก่อนหน้านี้) รวมถึงการโจมตีด้วย prompt injection ที่สามารถหลอกให้โมเดลเปิดเผยข้อมูลที่ควรเก็บเป็นความลับ นอกจากนี้ยังมีกรณีการใช้สื่อสังเคราะห์ (deepfake) เพื่อหลอกลวงทางการเงิน เช่น เหตุการณ์ที่มีรายงานการใช้เสียงปลอมหลอกสั่งโอนเงินจนเกิดความเสียหายทางการเงินแก่บริษัทในต่างประเทศ
ผลกระทบเชิงธุรกิจและสังคม ของช่องโหว่ด้านความปลอดภัยใน AI ไม่ได้จำกัดอยู่แค่การสูญเสียเงินตรงๆ เท่านั้น แต่ยังกระทบต่อความเชื่อมั่นของลูกค้า การปฏิบัติตามกฎระเบียบ และโอกาสทางธุรกิจในระยะยาว ตัวอย่างของผลกระทบ ได้แก่
- ความเสียหายทางการเงิน — ค่าใช้จ่ายจากการตอบสนองต่อเหตุการณ์ การเยียวยาลูกค้า และค่าปรับด้านกฎระเบียบสามารถพุ่งสูงได้
- ความเสื่อมเสียทางชื่อเสียง — การรั่วไหลของข้อมูลหรือการตัดสินใจที่ผิดพลาดของโมเดลอาจทำลายความไว้วางใจของผู้มีส่วนได้ส่วนเสีย
- ความเสี่ยงเชิงระบบ — เมื่อนำ AI ไปใช้ในโครงสร้างพื้นฐาน เช่น ระบบสาธารณสุข เครือข่ายพลังงาน หรือการเงิน ความผิดพลาดหรือการโจมตีอาจลุกลามเป็นผลกระทบต่อสังคมวงกว้าง
- การแพร่กระจายข้อมูลเท็จ — โมเดลที่ถูกใช้สร้างข่าวปลอมหรือสื่อสังเคราะห์สามารถบ่อนทำลายสถาบันสาธารณะและกระบวนการทางประชาธิปไตย
ด้วยเหตุนี้ ความปลอดภัยของ AI จึงต้องถูกมองว่าเป็นความเสี่ยงเชิงระบบ (systemic risk) ไม่ใช่แค่ปัญหาทางเทคนิคระดับจุดเดียว การจัดการความเสี่ยงนี้จำเป็นต้องอาศัยมาตรการทั้งทางเทคนิค นโยบายการกำกับดูแล และการกำหนดกรอบธรรมาภิบาลขององค์กร เพื่อป้องกัน ไม่ให้ความล้มเหลวของโมเดลเดียวกลายเป็นจุดชนวนของความเสียหายระดับวงกว้างสำหรับธุรกิจและสังคม
ภูมิทัศน์ภัยคุกคาม: ประเภทความเสี่ยงในระบบ AI
ภูมิทัศน์ภัยคุกคาม: ประเภทความเสี่ยงในระบบ AI
เมื่อองค์กรนำ AI เข้ามาใช้ในระบบธุรกิจและการให้บริการ ความเสี่ยงที่เกิดขึ้นไม่ได้จำกัดอยู่แค่ข้อผิดพลาดของอัลกอริทึม แต่ขยายไปถึงรูปแบบการโจมตีเชิงเทคนิคและการใช้งานในทางที่ผิดที่หลากหลาย ทั้งนี้ภาษีภัยคุกคามในระบบ AI มีความเฉพาะตัว เพราะผลกระทบสามารถลุกลามได้รวดเร็วและกระทบต่อความน่าเชื่อถือของข้อมูล ผลิตภัณฑ์ และความเป็นส่วนตัวของผู้ใช้ งานวิจัยล่าสุดและรายงานจากหน่วยงานความปลอดภัยจำนวนมากชี้ให้เห็นว่าองค์กรกว่า 40–60% เผชิญกับความพยายามโจมตีหรือการละเมิดความเป็นส่วนตัวที่เกี่ยวข้องกับโมเดล ML/AI ในช่วง 2–3 ปีที่ผ่านมา
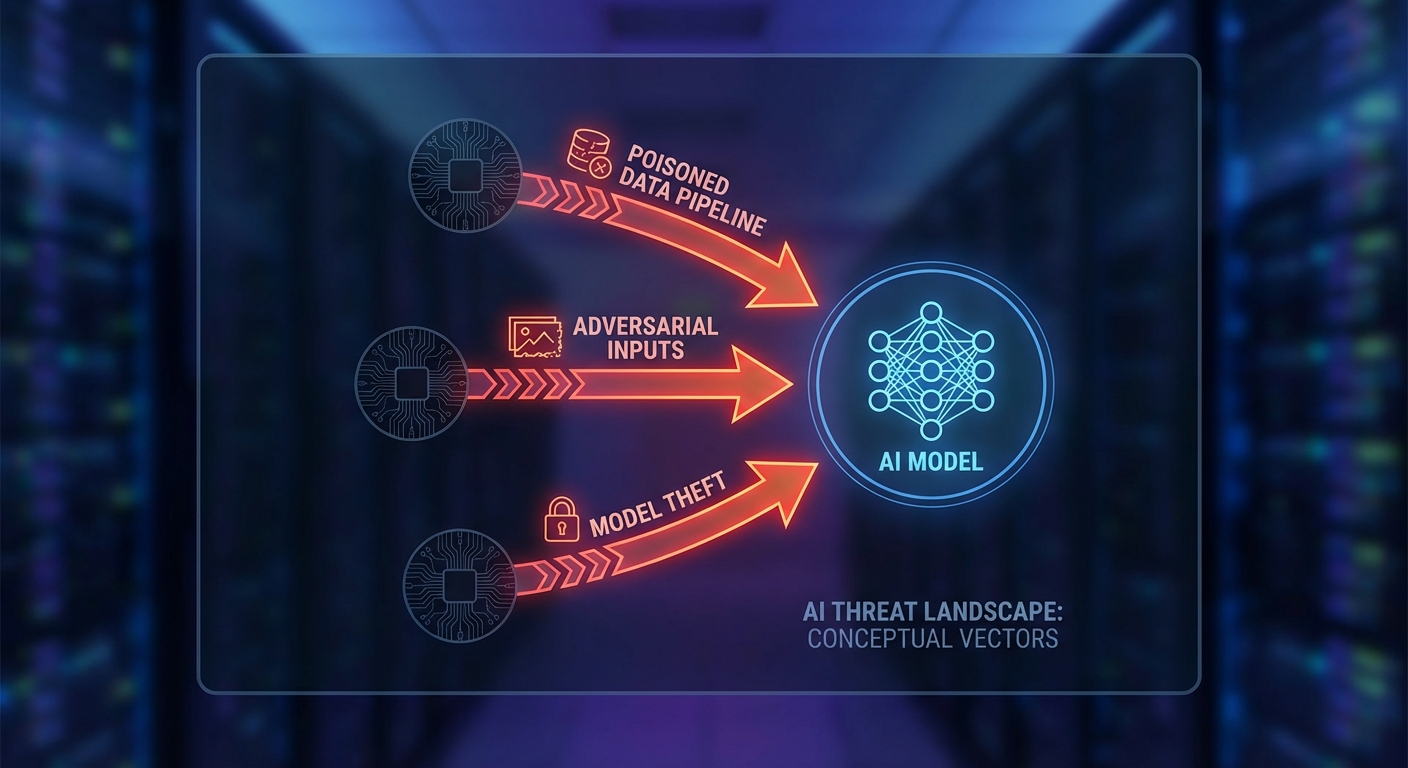
ด้านล่างนี้เป็นการแยกประเภทภัยคุกคามที่สำคัญ พร้อมคำอธิบายสั้น ๆ ตัวอย่างเหตุการณ์จริง และการประเมินระดับความรุนแรงเพื่อช่วยให้ผู้อ่านเห็นภาพเชิงระบบและจัดลำดับความสำคัญของมาตรการป้องกันได้อย่างเป็นระบบ
-
Adversarial attacks
คำอธิบาย: การสร้างอินพุตที่ถูกปรับเปลี่ยนอย่างเจาะจง (เช่น ปรับพิกเซลในภาพหรือเพิ่มสัญญาณรบกวนเล็กน้อย) เพื่อทำให้โมเดลตัดสินใจผิดโดยที่มนุษย์ไม่สังเกตเห็นความแตกต่างได้ง่าย
ตัวอย่างเหตุการณ์จริง: งานวิจัยเช่น Eykholt et al. แสดงให้เห็นว่าการติดสติกเกอร์บนป้ายหยุดรถยนต์สามารถทำให้ระบบจดจำผิดพลาด ส่งผลต่อการขับขี่อัตโนมัติได้จริง
ระดับความรุนแรง: สูง — โดยเฉพาะในระบบที่เกี่ยวข้องกับความปลอดภัย เช่น ยานยนต์อัตโนมัติ การแพทย์ และการยืนยันตัวตน
-
Data poisoning
คำอธิบาย: การแทรกหรือฉีดข้อมูลเป็นพิษลงในชุดฝึกสอน (training data) เพื่อทำให้โมเดลเรียนรู้ค่าที่เบี่ยงเบนหรือถูกฝัง "backdoor" ที่สามารถเปิดใช้งานโดยอินพุตเฉพาะ
ตัวอย่างเหตุการณ์จริง: ในระบบที่อนุญาตให้ข้อมูลจากผู้ใช้หลายแหล่ง (เช่น ระบบเรียนรู้แบบ federated หรือแพลตฟอร์มที่พึ่งพาข้อมูลจากคอมมูนิตี้) พบเหตุการณ์ที่โมเดลถูกทำให้ผิดพลาดหลังจากมีการแทรกข้อมูลที่มีเจตนา เช่น การกระตุ้นให้บอทตอบข้อความแปลกหรือสร้างผลลัพธ์ผิดเพี้ยน
ระดับความรุนแรง: สูง — โดยเฉพาะในองค์กรที่รับข้อมูลจากหลายแหล่งหรือใช้ข้อมูลสาธารณะ ซึ่งการตรวจจับทำได้ยากและแก้ไขมีค่าใช้จ่ายสูง
-
Model inversion
คำอธิบาย: เทคนิคที่ใช้โมเดลเป็น "กำลังย้อนกลับ" เพื่อนำข้อมูลที่เป็นความลับของชุดฝึก (เช่น รูปภาพหรือข้อมูลส่วนบุคคล) กลับคืนมาหรืออนุมานคุณสมบัติที่ละเอียดอ่อน
ตัวอย่างเหตุการณ์จริง: งานวิจัยของ Fredrikson et al. แสดงให้เห็นว่าข้อมูลส่วนบุคคลบางประเภทสามารถถูกฟื้นคืนหรืออนุมานได้จากโมเดลที่เผยให้ใช้งานผ่าน API
ระดับความรุนแรง: สูงถึงวิกฤต — หากโมเดลถูกใช้กับข้อมูลที่มีความเป็นส่วนตัวสูง (เช่น สุขภาพ การเงิน) การฟื้นคืนข้อมูลอาจก่อให้เกิดผลกระทบรุนแรงต่อผู้ใช้
-
Model extraction
คำอธิบาย: การโจมตีเพื่อขโมยโมเดลหรือฟังก์ชันการทำงานของโมเดลผ่านการส่งคำร้องขอและสังเกตผลลัพธ์ จนสามารถสร้างแบบจำลองที่ใกล้เคียงกับต้นฉบับได้
ตัวอย่างเหตุการณ์จริง: งานวิจัยของ Tramer et al. แสดงให้เห็นว่าสามารถทำการ "ขโมย" โมเดลที่ให้บริการผ่าน API โดยการส่งคำถามหลายพันคำถามและเรียนรู้พฤติกรรมการตอบ
ระดับความรุนแรง: กลางถึงสูง — กระทบต่อความลับทางการค้า โมเดลที่เป็นสินทรัพย์ และอาจเปิดทางไปสู่การโจมตีอื่น ๆ เช่น model inversion หรือการใช้งานผิดวัตถุประสงค์
-
Privacy leakage / Membership inference
คำอธิบาย: การสืบหาว่าข้อมูลเฉพาะ (เช่น บุคคลหนึ่งเป็นสมาชิกของชุดฝึกหรือมีข้อมูลเฉพาะอยู่ในฐานข้อมูล) ถูกใช้เป็นส่วนหนึ่งของการโจมตีเพื่อเปิดเผยความสัมพันธ์ส่วนตัว
ตัวอย่างเหตุการณ์จริง: งานทดลองหลายชิ้นแสดงว่าโมเดลที่ถูกฝึกด้วยข้อมูลเฉพาะสามารถถูกตรวจสอบได้ว่ามีตัวอย่างเฉพาะบางอย่างอยู่ในชุดฝึกหรือไม่ ซึ่งก่อให้เกิดปัญหาด้านความเป็นส่วนตัว
ระดับความรุนแรง: กลางถึงสูง — ขึ้นกับประเภทของข้อมูลที่รั่วไหลและบริบททางกฎหมาย/จริยธรรม
-
Supply-chain attacks
คำอธิบาย: การโจมตีที่มุ่งเป้าไปยังห่วงโซ่อุปทานของระบบ AI เช่น การฝังโค้ดอันตรายในไลบรารีที่ใช้บ่อย การแจกจ่ายโมเดล pretrained ที่ถูกฝัง backdoor หรือการแทรกการอัปเดตที่เป็นอันตรายในส่วนประกอบของระบบ
ตัวอย่างเหตุการณ์จริง: เช่น กรณีซอฟต์แวร์หรือแพ็กเกจโอเพนซอร์สถูกปรับแต่งเพื่อแทรกซอฟต์แวร์ที่เป็นอันตราย หรือการเผยแพร่โมเดลที่ถูกฝังซึ่งนำไปสู่การโจมตีในระบบที่นำโมเดลนั้นไปใช้
ระดับความรุนแรง: สูง — เพราะส่งผลกระทบต่อองค์กรจำนวนมากพร้อมกัน และยากต่อการตรวจจับเมื่อติดตั้งผ่านช่องทางที่เชื่อถือได้
-
Misuse / Abuse
คำอธิบาย: การใช้ระบบ AI ในทางที่ผิดโดยเจตนา เช่น สร้าง deepfake เพื่อปลอมแปลงข้อมูล สร้างสแปมหรือฟิชชิ่งอัตโนมัติ ใช้โมเดลเพื่อออกแบบสารที่เป็นอันตราย หรือใช้ข้อมูลเชิงวิเคราะห์เพื่อเลือกเป้าหมายการโจมตีทางไซเบอร์
ตัวอย่างเหตุการณ์จริง: การใช้เทคโนโลยีสังเคราะห์เสียงและภาพเพื่อหลอกลวงองค์กรหรือบุคคล ส่งผลให้เกิดความเสียหายด้านการเงินและชื่อเสียงหลายกรณีในช่วงไม่กี่ปีที่ผ่านมา
ระดับความรุนแรง: สูง — โดยเฉพาะเมื่อผสมกับข้อมูลส่วนบุคคลหรือระบบอัตโนมัติที่สามารถกระจายผลกระทบได้ในวงกว้าง
สรุปแล้ว ภูมิทัศน์ภัยคุกคามของ AI มีความหลากหลายและเชื่อมโยงกัน หากผู้บริหารและผู้รับผิดชอบด้านเทคโนโลยีไม่เข้าใจรูปแบบการโจมตีเหล่านี้ ก็ยากที่จะออกแบบการป้องกันที่ครอบคลุม การประเมินความเสี่ยงเชิงบริบท การตรวจสอบความถูกต้องของข้อมูลและโมเดล การควบคุมการเข้าถึง API และการใช้เครื่องมือตรวจจับพฤติกรรมผิดปกติ เป็นส่วนหนึ่งของแนวทางป้องกันเชิงรุกที่องค์กรควรให้ความสำคัญ
ความท้าทายทางเทคนิคที่ยังแก้ไม่ตก
ความท้าทายทางเทคนิคที่ยังแก้ไม่ตก
ความไม่แน่นอนในการประเมินความทนทานต่อการโจมตี (adversarial robustness) เป็นข้อจำกัดเชิงเทคนิคหลักที่ยังไม่มีคำตอบชัดเจนในเชิงปฏิบัติ งานวิจัยจำนวนมากชี้ให้เห็นว่าโมเดลที่ดูมีความแม่นยำสูงภายใต้ชุดข้อมูลทดสอบแบบดั้งเดิม อาจถูกทำให้ล้มเหลวโดยการโจมตีแบบ adversarial เพียงเล็กน้อย — ในบางกรณีประสิทธิภาพอาจลดลงอย่างมีนัยสำคัญ (งานศึกษาเชิงทดลองรายงานการลดลงเป็นเปอร์เซ็นต์สองหลักในบางสถานการณ์) แต่การออกแบบการทดสอบที่สะท้อนสภาพแวดล้อมจริงยังทำได้ยาก เนื่องจากการโจมตีในโลกจริงมักไม่เป็นไปตามสมมติฐานทางคณิตศาสตร์แบบ Lp-norm ซึ่งเป็นกรอบที่การวิจัยจำนวนมากใช้เป็นมาตรฐานในการประเมิน ดังนั้นผลการทดสอบเชิงห้องปฏิบัติการจึงไม่สามารถแปลเป็นการันตีความปลอดภัยในสนามจริงได้โดยตรง
การทดสอบในสภาพแวดล้อมจริง (real-world validation) ถูกจำกัดด้วยปัจจัยหลายด้าน ได้แก่ ความแปรผันของข้อมูล (distribution shift, concept drift), ข้อมูลมุมอับ (long-tail / rare events) และต้นทุนของการทดลองในระบบที่มีความเสี่ยงสูง เช่น ยานยนต์ขับเคลื่อนอัตโนมัติหรือระบบดูแลผู้ป่วย ตัวอย่างเช่น สถานการณ์ขับขี่ที่เกิดขึ้นเพียงครั้งเดียวหรือเงื่อนไขอากาศพิเศษอาจไม่รวมอยู่ในชุดฝึกฝนหรือชุดทดสอบ แต่กลับมีผลกระทบทางความปลอดภัยสูง นอกจากนี้ วิธีการยืนยันความทนทานแบบเชิงรับรอง (certified defenses) เช่น randomized smoothing ให้ข้อรับรองภายใต้สมมติฐานจำกัด (เช่น ภายใต้การรบกวนในรูปแบบ L2) และมักต้องการทรัพยากรการคำนวณมหาศาล ส่งผลให้การนำไปใช้กับโมเดลขนาดใหญ่หรือการใช้งานข้ามโดเมนทำได้ยาก
ปัญหามาตรฐานการประเมินความปลอดภัยข้ามโดเมนยังขาดความเป็นเอกภาพ — ขณะนี้ยังไม่มีชุดมาตรฐานสากลที่ครอบคลุมทุกโดเมน (ภาพ เสียง ข้อความ ข้อมูลเชิงเวลา) และทุกบริบทการใช้งาน (เช่น สาธารณสุข การเงิน ยานยนต์) ตัวชี้วัดที่ใช้กันในชุมชนวิจัย เช่น accuracy, robustness under Lp attacks, หรือ benchmark เฉพาะทาง (ImageNet-C, GLUE, ADV-C) ให้ความหมายเชิงเทคนิคที่ต่างกันและไม่สอดคล้องกันเมื่อเทียบข้ามอุตสาหกรรม ทำให้หน่วยงานผู้กำกับ ดูแล และผู้ประกอบการยากจะเปรียบเทียบความเสี่ยงและกำหนดข้อกำหนดด้านความปลอดภัยร่วมกันได้อย่างชัดเจน
ความยากในการทำ Explainability / Interpretability เป็นอีกปัญหาที่มีหลายมิติ: วิธีการอธิบายเช่น saliency maps, feature attributions หรือ surrogate models มักเป็นแบบ post-hoc และมีความเปราะบางต่อการบิดเบือน (manipulation) ซึ่งบางครั้งสามารถหลอกให้คำอธิบายดูน่าเชื่อถือแม้โมเดลจะทำงานผิดพลาด นอกจากนี้ การเพิ่มความสามารถในการอธิบายมักนำมาซึ่ง trade-off ด้านประสิทธิภาพหรือความเป็นส่วนตัว — ตัวอย่างเช่น การฝึกด้วยข้อจำกัดความเป็นระเบียน (interpretable architecture) อาจลดความแม่นยำในงานที่ต้องการความซับซ้อนสูง ขณะเดียวกันการเปิดเผยคำอธิบายโดยละเอียดสามารถเป็นช่องทางรั่วไหลของข้อมูลเชิงฝึก (training data leakage) หรือเพิ่มความเสี่ยงต่อการโจมตีแบบสมาชิกภาพ (membership inference)
โดยสรุป รายการความท้าทายเชิงเทคนิคหลักที่ต้องจัดการอย่างเร่งด่วน ได้แก่:
- ช่องว่างระหว่างการทดสอบเชิงห้องทดลองกับการใช้งานจริง: การออกแบบการทดลองที่ครอบคลุมเหตุการณ์หายากและเงื่อนไขจริงยังไม่เพียงพอ
- ข้อจำกัดของวิธีการรับรองความทนทาน: เทคนิคที่ให้การรับรองมักไม่ครอบคลุม threat models ที่หลากหลายและมีต้นทุนด้านคอมพิวเตอร์สูง
- การขาดมาตรฐานข้ามโดเมน: ไม่มีเมตริกหรือโปรโตคอลการประเมินกลางที่ยอมรับในวงกว้างสำหรับความปลอดภัยของโมเดลในทุกอุตสาหกรรม
- ความขัดแย้งระหว่าง explainability, performance และ privacy: การเพิ่มความโปร่งใสอาจทำลายความแม่นยำหรือเปิดเผยข้อมูลส่วนบุคคล
- การสเกลของโมเดลขนาดใหญ่: เทคนิคความปลอดภัยหลายอย่างยังไม่สามารถนำไปใช้ได้อย่างมีประสิทธิภาพกับโมเดลที่มีพารามิเตอร์จำนวนมาก
ผลกระทบทางธุรกิจและสังคมของช่องว่างทางเทคนิคเหล่านี้มีความร้ายแรง — การออกแบบนโยบายและมาตรฐานที่ดีต้องอาศัยงานวิจัยร่วมกันระหว่างนักวิทยาศาสตร์ข้อมูล วิศวกร นักกฎหมาย และผู้กำกับดูแล เพื่อพัฒนาแนวทางการทดสอบที่เป็นมาตรฐาน ครอบคลุม และสามารถใช้งานได้จริง พร้อมทั้งยอมรับการแลกเปลี่ยนเป้าหมายที่หลีกเลี่ยงไม่ได้ระหว่างความปลอดภัย ประสิทธิภาพ และความเป็นส่วนตัว.
นโยบายและการกำกับดูแล: ช่องโหว่ระหว่างกฎหมายกับเทคโนโลยี
นโยบายและการกำกับดูแล: ช่องโหว่ระหว่างกฎหมายกับเทคโนโลยี
การกำกับดูแลปัญญาประดิษฐ์ในระดับสากลกำลังก้าวไปในทิศทางของกรอบความเสี่ยง (risk-based approach) ที่มุ่งจัดระดับการใช้งานและผลกระทบ เช่น แนวทางของ EU AI Act ที่แบ่งระบบออกเป็นระดับความเสี่ยงตั้งแต่ "ห้ามใช้" ถึง "ความเสี่ยงสูง" พร้อมข้อกำหนดด้านความโปร่งใส การทดสอบ และการตรวจสอบก่อนนำสู่ตลาด ขณะเดียวกันสหรัฐอเมริกามุ่งพัฒนาแนวทางผ่านเอกสารนโยบายและมาตรฐานจากหน่วยงานต่าง ๆ เช่น NIST AI Risk Management Framework และคำแนะนำจากรัฐบาลกลางที่เน้นการประสานงานด้านนวัตกรรมและความปลอดภัยของระบบ AI องค์กรมาตรฐานสากลและอุตสาหกรรม (เช่น ISO/IEC, IEEE, Partnership on AI) ก็มีบทบาทในการกำหนดแนวปฏิบัติที่เป็นเทคนิคเพื่อเสริมกรอบกฎหมาย

แม้จะมีกรอบแนวคิดที่ชัดเจน แต่ช่องว่างระหว่างกฎหมายกับการปฏิบัติจริงยังมีอยู่หลายมิติ: โมเดลสมัยใหม่มีความซับซ้อนและมีการเรียนรู้ต่อเนื่อง (continuous learning) ทำให้การประเมินและพิสูจน์ความเป็นไปตามข้อกำหนดทำได้ยาก การใช้โมเดลจากผู้ให้บริการภายนอกหรือโมเดลเปิด (third‑party models) เพิ่มปัญหาด้านความรับผิดชอบและการเข้าถึงข้อมูลเชิงเทคนิค นอกจากนี้การปฏิบัติตามข้อกฎหมายข้ามพรมแดนยังซับซ้อน—ประเด็นเกี่ยวกับถิ่นที่เก็บข้อมูล (data residency), กฎหมายคุ้มครองข้อมูลส่วนบุคคลที่ไม่สอดคล้องกัน และอำนาจในการบังคับใช้เมื่อผู้ให้บริการอยู่ในเขตอำนาจศาลต่างกัน ทำให้หน่วยกำกับดูแลประสบความยากลำบากในการบังคับใช้บทลงโทษหรือการเรียกคืนระบบที่ไม่ปลอดภัย
ในบริบทนี้ บทบาทของผู้มีส่วนได้ส่วนเสียแต่ละฝ่ายจึงมีความสำคัญและต้องชัดเจน โดยสามารถสรุปได้ดังนี้
- ผู้กำกับดูแล (Regulators): พัฒนากรอบที่ยืดหยุ่น เช่น การใช้แนวทางความเสี่ยง, sandbox สำหรับการทดสอบเชิงนโยบาย, กำหนดข้อบังคับสำหรับระบบความเสี่ยงสูง และสร้างกระบวนการบังคับใช้ที่สามารถทำงานร่วมกับหน่วยงานระหว่างประเทศ
- ผู้ให้บริการคลาวด์และแพลตฟอร์ม (Cloud Providers): รับผิดชอบด้าน shared responsibility โดยจัดเตรียมเครื่องมือสำหรับการตรวจสอบ การจัดการสิทธิ์ การบันทึกเหตุการณ์ (logging) และบริการจัดทำเอกสารโพรเวแนนซ์ของโมเดล เพื่ออำนวยความสะดวกต่อการปฏิบัติตามกฎและการตรวจสอบจากภายนอก
- องค์กรผู้ใช้ (Enterprises): ต้องรวมมาตรการกำกับภายใน เช่น การประเมินความเสี่ยงก่อนใช้งาน (pre-deployment risk assessment), การจัดเก็บข้อมูลการตัดสินใจของโมเดล, และการฝึกอบรมบุคลากรด้านจริยธรรมและการปฏิบัติตามกฎระเบียบ
เพื่อปิดช่องว่างระหว่างกฎหมายกับเทคโนโลยีอย่างมีประสิทธิภาพ จำเป็นต้องมีมาตรฐานทางเทคนิคร่วมที่ยอมรับได้ในวงกว้าง เช่น รูปแบบการรายงานความเสี่ยง (risk reporting schema), ข้อกำหนดสำหรับ model cards และ datasheets, เกณฑ์การทดสอบความปลอดภัย (red teaming, adversarial testing) และมาตรฐานการบันทึกเชิงเหตุการณ์ (provenance & audit logs) นอกจากนี้ การตรวจสอบอิสระ (independent audits and third‑party conformity assessments) จะเป็นหัวใจของความน่าเชื่อถือ โดยเฉพาะกับระบบที่จัดว่าเป็น high‑risk ซึ่งการรับรองจากหน่วยงานอิสระช่วยให้ผู้กำกับดูแลสามารถอ้างอิงผลการประเมินเพื่อบังคับใช้แนวทางและตัดสินโทษได้ชัดเจนยิ่งขึ้น
ข้อเสนอเชิงนโยบายที่ควรพิจารณาในระยะสั้นถึงกลาง ได้แก่ การประสานมาตรฐานระหว่างภูมิภาคเพื่อลดความขัดแย้งของกฎระเบียบ, การส่งเสริมห้องทดสอบนวัตกรรมภายใต้การกำกับ (regulatory sandboxes), การตั้งกรอบสำหรับการตรวจสอบอิสระพร้อมเกณฑ์รับรอง และการส่งเสริมความโปร่งใสในโซ่อุปทาน AI ที่ช่วยให้ผู้บังคับใช้และผู้บริโภคสามารถตรวจสอบที่มาของเทคโนโลยีได้ เมื่อหน่วยงานกำกับ ผู้ให้บริการคลาวด์ และองค์กรประกอบกันทำงานตามบทบาทเหล่านี้ จะสามารถลดช่องว่างระหว่างกฎหมายกับเทคโนโลยี และสร้างระบบนิเวศ AI ที่ปลอดภัย เชื่อถือได้ และพร้อมสำหรับการขยายตัวในระดับสากลได้มากขึ้น
แนวทางปฏิบัติของวิศวกร: เครื่องมือและกระบวนการที่ควรนำมาใช้
แนวทางปฏิบัติของวิศวกร: เครื่องมือและกระบวนการที่ควรนำมาใช้
การสร้างระบบ AI ที่ปลอดภัยต้องเริ่มจากการออกแบบและกระบวนการปฏิบัติการที่ชัดเจนและวัดผลได้ ทีมวิศวกรควรยึดหลัก secure-by-design โดยบังคับให้มีกิจกรรมด้านความปลอดภัยเป็นส่วนหนึ่งของวงจรพัฒนาตั้งแต่ระยะออกแบบ (design-time) จนถึงการปฏิบัติการเชิงพาณิชย์ ตัวอย่างแนวปฏิบัติสำคัญรวมถึงการทำ Threat Modeling ตั้งแต่ขั้นสเปคสถาปัตยกรรม การกำหนดขอบเขตการป้องกันข้อมูล (data protection boundary) และการระบุข้อเสี่ยงเชิงตรรกะที่อาจถูกใช้โจมตีระบบหรือข้อมูลฝึกสอน
ในเชิงปฏิบัติ ควรบูรณาการการทดสอบทางศัตรู (adversarial testing) และ fuzzing เข้าไปใน CI/CD pipeline โดยกำหนดให้มีสเตจทดสอบเฉพาะสำหรับ robustness ซึ่งรวมถึงการรันชุดโจมตีเชิงก้ำกึ่ง (FGSM, PGD), การทดสอบเชิงเชิงสอบ (targeted/untargeted attacks) และการนำ fuzzing มาทดสอบส่วนที่รับอินพุต เช่น API และ pre-processing (เครื่องมือที่นิยมนำมาใช้ได้แก่ IBM Adversarial Robustness Toolbox, Foolbox, CleverHans สำหรับ adversarial และ AFL, libFuzzer, DeepHunter สำหรับ fuzzing โมดูล ML หรือ data parsers) ขั้นตอนเหล่านี้ควรถูกตั้งค่าให้รันอัตโนมัติในสเตจ test ของ pipeline และทำเป็นเกณฑ์ผ่าน/ไม่ผ่านก่อนอนุญาตให้ deploy
การบริหารจัดการ Metadata และ Data Lineage เป็นหัวใจของการตรวจสอบย้อนกลับและการรับผิดชอบ (accountability) ทีมต้องจัดเก็บ metadata/lineage ของชุดข้อมูลและการเปลี่ยนแปลงโมเดลอย่างเข้มงวด โดยใช้ระบบจัดการเวอร์ชันของข้อมูลและโมเดล (เช่น DVC, MLflow, Weights & Biases, Pachyderm) ร่วมกับโซลูชันสำหรับ lineage และ governance (เช่น OpenLineage, Apache Atlas, DataHub) เพื่อให้สามารถสืบย้อนที่มาของตัวอย่างข้อมูล, สคริปต์ preprocessing, พารามิเตอร์การฝึกและสภาพแวดล้อมการรัน (container image, dependency manifest) ได้อย่างครบถ้วน ระบบนี้ต้องรองรับการล็อก metadata แบบ immutable และมี logging ที่เป็น audit trail สำหรับการตรวจสอบภายหลัง
ต่อไปนี้เป็น checklist ปฏิบัติการเชิงวิศวกรรม ที่ควรนำไปใช้งานจริงในทีมพัฒนา AI:
- Design-time Threat Modeling: ทำ workshop threat modeling ตั้งแต่ออกแบบสถาปัตยกรรม ใช้เครื่องมือช่วยเช่น Microsoft Threat Modeling Tool หรือ OWASP Threat Dragon เพื่อระบุช่องโหว่และปรับออกแบบก่อนโค้ดถูกเขียน
- Secure-by-Design Requirements: กำหนด security requirements ที่ชัดเจน (authentication, authorization, encryption, input validation, rate limiting, privacy constraints) และบังคับเป็น acceptance criteria ใน user stories
- Adversarial Testing & Fuzzing ใน CI/CD: เพิ่มสเตจทดสอบ robustness ใน pipeline (pre-merge และ pre-deploy) รันชุดโจมตี (ART, Foolbox) และ fuzzing บน parsers/API (AFL, libFuzzer) โดยตั้ง thresholds สำหรับ performance degradation หรือ attack success rate
- Model & Data Versioning: ใช้เครื่องมือ version control สำหรับโมเดลและข้อมูล (MLflow, DVC, W&B) พร้อมบันทึก metadata เช่น dataset hash, training-code commit ID, hyperparameters, environment snapshot
- Lineage & Metadata Governance: ใช้ OpenLineage/Apache Atlas/DataHub เพื่อสร้าง lineage graph และติดป้าย (tag) ข้อมูลสำคัญ เช่น sensitive PII, data contracts, retention policy
- Automated Security Scanning: สแกนโค้ด (SAST: SonarQube, Checkmarx), สแกน dependencies (Snyk, Dependabot), สแกน container images (Trivy, Clair) และสแกน IaC (Checkov, TFsec) ใน pipeline
- Secrets & Configuration Management: แยก secrets ออกจาก repo ใช้ Vault/KMS และตรวจสอบการเข้าถึงด้วย RBAC
- Canary & Shadow Deployments: ใช้กลยุทธ์ deploy แบบ canary และ shadowing เพื่อตรวจจับปัญหาจริงก่อนเปิดให้ผู้ใช้ทั้งหมดใช้งาน
- Monitoring & Model Observability: ตั้งค่า metrics สำหรับ performance, drift (data/feature/label), input distribution, latency และ error rates ใช้ Prometheus/Grafana รวมถึงโซลูชันเฉพาะด้าน ML เช่น Evidently, WhyLabs, Fiddler
- Incident Response Playbooks: จัดทำ playbooks สำหรับกรณีโมเดลถูกโจมตีหรือเกิด data breach ระบุขั้นตอน detection, containment, eradication, recovery, root cause analysis และการสื่อสารทั้งภายในและต่อหน่วยงานกำกับดูแล
- Regular Red Teaming & Penetration Testing: จัดตารางทดสอบเชิงรุก (red team) และ penetration tests ที่มุ่งเป้าไปที่โมเดลและช่องทางอินพุต/เอาต์พุต
- Compliance & Audit Readiness: เก็บหลักฐานการทำงาน (evidence) ของการทดสอบและการตัดสินใจ เพื่อรองรับการตรวจสอบภายในและภายนอก
สุดท้าย ทีมวิศวกรต้องมี incident response playbook ที่เป็นรูปธรรมสำหรับเหตุการณ์ AI-specific เช่น model poisoning, data exfiltration, adversarial attacks และ model misuse ตัวอย่างโครงสร้าง playbook ได้แก่:
- การตรวจจับเบื้องต้น: คัดเลือกสัญญาณเตือน (anomalous input rates, sudden performance drop, spike in rejection rates)
- การกักกัน: ดึง traffic ไปที่ canary/shadow, ปิด endpoint ที่ได้รับผลกระทบ, กู้เวอร์ชันก่อนหน้า (rollback)
- การบูรณะและทดสอบ: รีเทรนจาก dataset ที่ผ่านการตรวจสอบ, รัน full adversarial regression tests ก่อน deploy ใหม่
- การสื่อสาร: แจ้งทีมภายใน, ฝ่ายกฎหมาย, ลูกค้าที่ได้รับผลกระทบ และ regulator ตามข้อบังคับที่เกี่ยวข้อง
- หลังเหตุการณ์: ทำ RCA, อัปเดต threat model, ปรับ pipeline และบันทึกบทเรียนเป็น runbook
การนำแนวทางเหล่านี้มารวมกับเครื่องมือที่เหมาะสมและกระบวนการที่ชัดเจนจะช่วยให้ทีมสามารถลดความเสี่ยงเชิงปฏิบัติการและเพิ่มความยืดหยุ่นต่อการโจมตีในโลกจริงได้อย่างเป็นรูปธรรม
กรณีศึกษาและตัวอย่างจริง: บทเรียนจากเหตุการณ์ที่ผ่านมา
กรณีศึกษาและตัวอย่างจริง: บทเรียนจากเหตุการณ์ที่ผ่านมา
การวิเคราะห์เหตุการณ์ความล้มเหลวด้านความปลอดภัยของระบบ AI ในอดีตให้บทเรียนเชิงปฏิบัติที่ชัดเจนต่อองค์กรทั้งด้านธุรกิจและสาธารณะ ข้อผิดพลาดเหล่านี้มักส่งผลทั้งในแง่ความเชื่อมั่นของผู้ใช้ ต้นทุนทางการเงิน และความเสี่ยงทางกฎหมาย การเรียนรู้จากกรณีจริงช่วยให้สามารถจัดลำดับความสำคัญของการแก้ไขและออกแบบมาตรการป้องกันที่ทนทานต่อภัยคุกคามในอนาคตได้ดียิ่งขึ้น
กรณีที่ 1 — อคติในโมเดลสิทธิ์อาชญากรรม (เช่น COMPAS / ProPublica)
เหตุการณ์: งานสืบสวนของสำนักข่าว ProPublica (2016) พบว่าโมเดลประเมินความเสี่ยงการกระทำซ้ำ (recidivism) ถูกระบุว่า มีอคติทางเชื้อชาติ โดยโมเดลมีแนวโน้มให้คะแนนความเสี่ยงสูงกับผู้ต้องหาผิวดำมากกว่าผู้ต้องหาผิวขาว ส่งผลให้เกิดข้อโต้แย้งด้านความยุติธรรมและการใช้เทคโนโลยีในการตัดสินคดีทางอาญา ผลกระทบเชิงธุรกิจ/สาธารณะรวมถึงการสูญเสียความเชื่อมั่นจากสาธารณะ การดำเนินคดี/กฎหมาย และการทบทวนนโยบายการใช้โมเดลในการตัดสินใจของหน่วยงานรัฐ
วิเคราะห์จุดอ่อน: สาเหตุหลักมาจากข้อมูลฝึก (training data) ที่สะท้อนอคติประวัติศาสตร์ การขาดความโปร่งใสในกระบวนการตัดสินใจของโมเดล และไม่มีการวัดผลความเป็นธรรมในเชิงปริมาณก่อนนำไปใช้งานจริง
ข้อเสนอเชิงปฏิบัติหลังเหตุการณ์: องค์กรควรดำเนิน algorithmic impact assessment ก่อนเผยแพร่ ใช้มาตรการตรวจจับอคติ (fairness metrics) ดำเนินการทดสอบข้ามกลุ่มประชากร จัดทำโมเดลการอธิบาย (explainability) และกำหนดกระบวนการรีวิวโดยมนุษย์สำหรับการตัดสินใจสำคัญ
กรณีที่ 2 — การเก็บรวบรวมข้อมูลภาพและความเป็นส่วนตัว (เช่น Clearview AI)
เหตุการณ์: ผู้ให้บริการรวบรวมภาพใบหน้าจากอินเทอร์เน็ตจำนวนมากเพื่อนำไปฝึกโมเดลจดจำใบหน้า ก่อให้เกิดการประณามทางสังคมและการดำเนินการทางกฎหมายจากหน่วยงานคุ้มครองข้อมูลส่วนบุคคลหลายประเทศ ผลกระทบเชิงธุรกิจรวมถึงการสั่งห้ามการใช้งาน การเรียกเก็บปรับ และการสูญเสียลูกค้ารายใหญ่
วิเคราะห์จุดอ่อน: ขาดการปฏิบัติตามหลักความเป็นส่วนตัว (consent) การขาดนโยบายการจัดการข้อมูลที่ชัดเจนและการประเมินความเสี่ยง (Data Protection Impact Assessment) รวมทั้งการควบคุมการเข้าถึงข้อมูลที่ไม่เพียงพอ
ข้อเสนอเชิงปฏิบัติหลังเหตุการณ์: ต้องดำเนินการล้างข้อมูล (data minimization/retention policies) เพิ่มการเข้ารหัสและการควบคุมการเข้าถึง ปรับนโยบายการเก็บข้อมูลให้สอดคล้องกับกฎหมาย (เช่น GDPR) และนำวิธีการปกป้องความเป็นส่วนตัวเช่น differential privacy หรือ federated learning มาใช้เมื่อต้องการฝึกโมเดลจากข้อมูลเชิงบุคคล
กรณีที่ 3 — การโจมตีแบบ adversarial และข้อผิดพลาดเชิงปฏิบัติการ (เช่น การโจมตีป้ายจราจรในระบบรถขับเคลื่อนอัตโนมัติ / บอทสนทนา)
เหตุการณ์: งานวิจัยและการสาธิตทางวิทยาศาสตร์แสดงให้เห็นว่าแพตช์หรือสติกเกอร์ที่ออกแบบมาโดยเฉพาะสามารถเปลี่ยนการจำแนกภาพได้ เช่น การทำให้ป้ายหยุดถูกจำแนกว่าเป็นป้ายจำกัดความเร็ว ซึ่งนำไปสู่ข้อกังวลด้านความปลอดภัยของยานยนต์อัตโนมัติ อีกกรณีคือบอทสนทนา (เช่น Microsoft Tay ในปี 2016) ถูกผู้ใช้ชี้นำจนตอบข้อความไม่เหมาะสมอย่างรวดเร็ว ผลกระทบได้แก่ความเสี่ยงต่อความปลอดภัย (safety risk), ภาระค่าชดเชยและความรับผิดชอบทางกฎหมาย, รวมทั้งความเสียหายต่อชื่อเสียงบริษัท
วิเคราะห์จุดอ่อน: โมเดลที่ฝึกด้วยข้อมูลที่ไม่ครอบคลุมการโจมตีทางกายภาพหรือสภาพแวดล้อมจริง ขาดการทดสอบเชิงรุก (red-team) และการมอนิเตอร์แบบเรียลไทม์ ระดับการพึ่งพาผลลัพธ์ของโมเดลโดยไม่มีการตรวจสอบจากมนุษย์เพิ่มความเสี่ยง
ข้อเสนอเชิงปฏิบัติหลังเหตุการณ์: นำกระบวนการทดสอบความทนทาน (robustness testing) และการโจมตีจำลอง (adversarial testing) เข้ามาในวงจรพัฒนาผลิตภัณฑ์ ใช้กลยุทธ์ sensor fusion ในระบบยานยนต์ รวมทั้งติดตั้งระบบมอนิเตอร์และการตอบสนองอัตโนมัติเมื่อตรวจพบพฤติกรรมผิดปกติ
สรุปเป็นข้อควรปฏิบัติหลังเหตุการณ์ (post-incident remediation) ที่องค์กรควรนำไปใช้ทันที:
- การกักกันและวิเคราะห์: แยกระบบที่ได้รับผลกระทบ สืบสวนรากเหง้าด้วยหลักฐานที่บันทึกไว้ และประเมินขอบเขตผลกระทบต่อข้อมูลและผู้ใช้
- การสื่อสารเชิงรุก: แจ้งผู้มีส่วนได้ส่วนเสียและหน่วยงานกำกับดูแลตามกฎหมายอย่างโปร่งใส พร้อมแผนการเยียวยา
- การแก้ไขทางเทคนิค: ปรับปรุงข้อมูลฝึก ลบ/แก้ไขข้อมูลที่มีปัญหา เพิ่มเทคนิคการปกป้องความเป็นส่วนตัวและการเข้ารหัส และปรับปรุงการควบคุมการเข้าใช้งาน
- การเสริมความมั่นคงของโมเดล: ดำเนินการทดสอบอคติ ความทนทาน และ adversarial red-team อย่างสม่ำเสมอ
- การกำกับดูแล: อัปเดตนโยบายการใช้ AI จัดตั้งคณะกรรมการกำกับดูแล AI และจัดทำเอกสารโมเดล (model cards) เพื่อความโปร่งใส
- การเรียนรู้และกำหนด KPI: ตั้งตัวชี้วัดความปลอดภัยและความยุติธรรมของโมเดล ติดตามเป็นรอบและนำบทเรียนไปปรับปรุงวงจรพัฒนา
บทเรียนสำคัญคือความปลอดภัยของ AI ต้องถูกปลูกฝังเป็นส่วนหนึ่งของวงจรชีวิตของระบบ (lifecycle) ไม่ใช่แค่การแก้ปัญหาหลังเกิดเหตุ ความร่วมมือระหว่างทีมเทคนิค กฎหมาย และผู้บริหาร การลงทุนในกระบวนการตรวจสอบอิสระ และการวางแผนรับมือเหตุฉุกเฉินเชิงรุกจะช่วยลดความเสี่ยงเชิงธุรกิจและปกป้องชื่อเสียงองค์กรได้อย่างมีประสิทธิภาพ
แผนการและ Roadmap สำหรับองค์กร: ขั้นตอน 12-24 เดือน
แผนการและ Roadmap สำหรับองค์กร: ขั้นตอน 12-24 เดือน
การยกระดับความปลอดภัยสำหรับระบบปัญญาประดิษฐ์ (AI) ในองค์กรต้องอาศัยแผนเชิงปฏิบัติการที่ชัดเจน ครอบคลุมทั้งการประเมินความเสี่ยง การจัดลำดับความสำคัญของทรัพย์สิน การปรับกระบวนการพัฒนา การลงทุนในเครื่องมือที่จำเป็น และการสร้างวัฒนธรรมความปลอดภัยตั้งแต่ระดับผู้บริหารจนถึงผู้พัฒนา แผนต่อไปนี้เสนอแนวทางปฏิบัติสำหรับระยะ 0–24 เดือน พร้อมมาตรวัด (KPI) ที่ควรติดตามเพื่อวัดความก้าวหน้าและความเสี่ยงอย่างเป็นระบบ
การประเมินความเสี่ยงเบื้องต้นและการจัดลำดับความสำคัญของทรัพย์สิน AI
เริ่มจากการจัดทำรายการทรัพย์สิน AI (AI asset inventory) และทำการประเมินความเสี่ยงเบื้องต้นด้วยกรอบที่วัดได้ เช่น การประเมินด้านผลกระทบทางธุรกิจ (Business Impact), ความเป็นไปได้ของการถูกโจมตี (Likelihood), ระดับการเปิดเผยข้อมูล (Exposure) และความสามารถในการตรวจจับ (Detectability) การให้คะแนน (scoring) บนเกณฑ์เดียวกันจะช่วยจัดลำดับความสำคัญของโมเดล ข้อมูล และระบบที่ต้องได้รับการป้องกันก่อน
- ขั้นตอนสำคัญ: รวบรวมรายการโมเดล ข้อมูลเทรน ข้อมูลทดสอบ ระบบ API และเอกสารสัญญา/ผู้ให้บริการภายนอก
- องค์ประกอบการให้คะแนน: Impact × Likelihood × Detectability (ให้ค่าน้ำหนักตามความสำคัญของธุรกิจ)
- ตัวอย่างการจัดลำดับ: ระบบที่เกี่ยวข้องกับการตัดสินใจทางการเงิน การแพทย์ หรือความปลอดภัยของมนุษย์ต้องมีลำดับสูงสุด
- ปรับให้เหมาะกับขนาดองค์กร: องค์กรเล็กอาจใช้แบบฟอร์มประเมินง่าย ๆ ในขณะที่องค์กรขนาดใหญ่ควรใช้เครื่องมือ CMDB/Asset Management เชื่อมโยงกับระบบ MLOps
Roadmap 0–6 เดือน: สร้างพื้นฐานและการกำกับดูแล
ในช่วง 0–6 เดือน โฟกัสไปที่การสร้าง governance และการควบคุมเบื้องต้นเพื่อจำกัดความเสี่ยงโดยเร็วที่สุด เป้าหมายคือให้มีนโยบายที่ชัดเจน การมองเห็น (visibility) ของทรัพย์สิน และมาตรการตอบสนองเบื้องต้น
- ตั้งคณะกรรมการความปลอดภัย AI (AI Security Steering Committee) และแต่งตั้งผู้รับผิดชอบด้านความเสี่ยง AI
- สร้างและบังคับใช้นโยบายพื้นฐาน: การจัดการข้อมูล (data handling), การควบคุมการเข้าถึง (access control), การตรวจสอบไลฟ์ไซเคิลของโมเดล (model lifecycle policy)
- ทำ asset inventory และจัดลำดับความสำคัญโดยใช้แบบสำรวจความเสี่ยงอย่างน้อย 80% ของโมเดลสำคัญ
- ติดตั้งการมอนิเตอร์พื้นฐาน (basic model and data monitoring) สำหรับ drift และ anomalous behavior
- จัดอบรมเบื้องต้นให้ทีมพัฒนา/DevOps เรื่อง secure ML practices และ incident response เบื้องต้น
- Milestones: นโยบาย AI เสร็จสิ้น, inventory ครอบคลุมโมเดลหลัก, monitoring baseline ทำงาน
Roadmap 6–12 เดือน: ขยายมาตรการเชิงเทคนิคและกระบวนการ
ในช่วง 6–12 เดือน ให้ขยายการควบคุมเชิงเทคนิคและผนวกรวมกระบวนการความปลอดภัยเข้าในวงจรการพัฒนา AI (Secure MLOps) เป้าหมายคือการลดความเสี่ยงเชิงปฏิบัติการและเพิ่มความทนทานของโมเดล
- ผนวก Security in CI/CD: automated tests สำหรับ data validation, model validation, adversarial tests และ privacy tests (เช่น differential privacy checks)
- ลงทุนในเครื่องมือ: model versioning, data lineage, feature stores, runtime monitoring, SIEM/Alerting integration และ secrets management
- เริ่มทำการทดสอบเชิงรุก (red team / adversarial testing) กับโมเดลสำคัญ และบันทึกผลเป็น vulnerability backlog
- กำหนด SLA สำหรับการตรวจจับและแก้ไข (MTTD, MTTM) และฝึกซ้อมกลุ่มตอบสนองเหตุการณ์ (incident response tabletop exercises)
- Milestones: automated security tests ใน pipeline, red-team ครั้งแรกเสร็จ, KPI เบื้องต้นกำหนดและเริ่มติดตาม
Roadmap 12–24 เดือน: เพิ่มความทนทาน เชื่อมต่อกับความเสี่ยงธุรกิจ และสเกล
ระยะ 12–24 เดือน คือช่วงที่องค์กรควรจะผลักดันการปฏิบัติการให้เกิดความต่อเนื่องและสอดคล้องกับความเสี่ยงของธุรกิจในระยะยาว มุ่งเน้นการสเกลเครื่องมือ ความร่วมมือกับฝ่ายกฎหมายและความเป็นไปตามข้อกำหนด และการวัดผลเชิงลึก
- ทำ continuous adversarial training และ robustness validation เป็นส่วนหนึ่งของ pipeline
- ขยายการมอนิเตอร์เพื่อตรวจจับการโจมตีเชิงซับซ้อน (model extraction, membership inference, backdoor) และเชื่อมโยงกับระบบจัดการเหตุการณ์ (ticketing/SOC)
- รวม third-party risk management: ตรวจสอบซัพพลายเออร์โมเดลและข้อมูล เปิดเผย SLA ด้านความปลอดภัยในสัญญา
- สร้างวัฒนธรรม: โปรแกรมอบรมต่อเนื่อง, gamified learning, KPIs สำหรับทีม/บุคคล (เช่น % ของ deploys ที่ผ่าน security gate)
- ประเมินผลสัมฤทธิ์เชิงธุรกิจ: ลดผลกระทบจากเหตุการณ์ ความน่าเชื่อถือของระบบ และการยอมรับจากลูกค้า
- Milestones: adversarial CI/CD เป็นมาตรฐาน, third-party risk framework ใช้จริง, KPI ถูกปรับให้เป็นส่วนหนึ่งของการประเมินผลการทำงาน
การลงทุนในเครื่องมือและทรัพยากรที่แนะนำ
การเลือกเครื่องมือควรสอดคล้องกับขนาดองค์กรและระดับความเสี่ยง แนะนำประเภทการลงทุนหลักได้แก่:
- ระบบจัดการทรัพย์สิน/Model Registry + Data Lineage
- เครื่องมือการมอนิเตอร์แบบเรียลไทม์ (performance, data drift, explainability logs)
- แพลตฟอร์ม MLOps ที่รองรับ security scans และ automated testing
- เครื่องมือทดสอบความทนทาน (adversarial toolkits, fuzzing for inputs)
- SOC/ SIEM integration สำหรับ alert และการตอบสนอง
KPI และ Metrics ที่ควรติดตาม
การกำหนด KPI ชัดเจนช่วยให้องค์กรวัดผลและปรับกลยุทธ์ได้อย่างเป็นรูปธรรม โดยตัวชี้วัดสำคัญได้แก่:
- Incident Frequency: จำนวนเหตุการณ์ความปลอดภัยที่เกี่ยวข้องกับ AI ต่อปี (เป้าหมายที่น่าใช้: องค์กรเล็ก <2/ปี, กลาง <5/ปี, ใหญ่ <10/ปี)
- Mean Time to Detect (MTTD): เวลาที่ใช้เฉลี่ยในการตรวจจับเหตุการณ์ (เป้าหมาย: เล็ก <72 ชั่วโมง, กลาง <48 ชั่วโมง, ใหญ่ <24 ชั่วโมง)
- Mean Time to Mitigate/Resolve (MTTM): เวลาที่ใช้เฉลี่ยในการบรรเทาหรือแก้ไข (เป้าหมาย: เล็ก <7 วัน, กลาง <72 ชั่วโมง, ใหญ่ <48 ชั่วโมง)
- Robustness Score: ผลต่างของประสิทธิภาพโมเดลภายใต้การโจมตีหรือ perturbation (เช่น % ลดลงของ accuracy ภายใต้ adversarial perturbation) — ตั้งเป้าลดความเสี่ยงให้อยู่ในระดับที่ยอมรับได้ตามบริบทธุรกิจ
- % Models with Documented Risk Assessment: เปอร์เซ็นต์ของโมเดลสำคัญที่มีการประเมินความเสี่ยงและแผนบรรเทา
- Drift Rate / Data Quality Metrics: จำนวนเหตุการณ์ drift ต่อโมเดลต่อไตรมาส และผลต่อ KPI ทางธุรกิจ
- Coverage of Security Tests: % ของ pipeline ที่มี automated security/adversarial tests ก่อน deployment
- % Engineers Trained: เปอร์เซ็นต์ของทีมพัฒนา/ML ที่ผ่านการอบรมความปลอดภัยประจำปี
การกำหนดเป้าหมายเชิงตัวเลขควรทำโดยอาศัย baseline ในช่วง 0–6 เดือน จากนั้นปรับ target ให้ท้าทายและเป็นไปได้จริงในช่วง 6–24 เดือน ควรมีรายงานรายไตรมาสต่อคณะกรรมการความปลอดภัยและผู้บริหารเพื่อให้การตัดสินใจเชิงทรัพยากรเป็นไปอย่างมีข้อมูลรองรับ
สรุปแล้ว Roadmap 12–24 เดือนที่ประสบความสำเร็จต้องเริ่มจากการเห็นภาพรวมความเสี่ยง จัดลำดับทรัพย์สินที่มีความสำคัญสูง สร้าง governance และ integrate ความปลอดภัยเข้าในวงจรพัฒนาอย่างต่อเนื่อง พร้อมใช้ KPI ที่ชัดเจนในการวัดผลและปรับปรุง—เป็นการลงทุนเพื่อป้องกันความเสียหายในระยะยาวและสร้างความเชื่อมั่นให้กับผู้ใช้และผู้มีส่วนได้เสีย
บทสรุป
ความปลอดภัยใน AI เป็นประเด็นเชิงระบบที่ไม่สามารถแก้ได้ด้วยมาตรการทางเทคนิคเพียงอย่างเดียว แต่ต้องการความร่วมมือระหว่างวิศวกร นักกำหนดนโยบาย และผู้บริหารในการกำหนดแนวทางปฏิบัติที่เป็นรูปธรรมและมาตรฐานร่วมกัน องค์กรควรเริ่มจากการประเมินความเสี่ยงเชิงระบบและเชิงปฏิบัติการ บูรณาการมาตรการด้านความปลอดภัยเข้าไปในวงจรชีวิตของโมเดลตั้งแต่การเก็บข้อมูล การออกแบบ การฝึก การทดสอบ จนถึงการนำสู่การใช้งาน และลงทุนในการตรวจสอบภายใน/ภายนอก การเพิ่มความโปร่งใสในกระบวนการ และระบบตอบสนองต่อเหตุการณ์ เพื่อสร้างความเชื่อถือจากผู้ใช้งานและผู้มีส่วนได้ส่วนเสีย
ในมุมมองอนาคต ความท้าทายด้านความปลอดภัยของ AI จะทวีความรุนแรงหากไม่มีการวางกรอบกฎระเบียบและมาตรฐานร่วมที่ชัดเจน ทั้งภาครัฐและเอกชนต้องเร่งสร้างกลไกการกำกับดูแล การทดสอบอิสระ และการแบ่งปันบทเรียนเชิงปฏิบัติ ตัวอย่างแนวปฏิบัติที่ควรได้รับการผลักดันคือการทำ risk assessment เป็นประจำ การฝัง security-by-design ในทุกเฟสของโมเดล การจัดตั้งทีมตอบสนองเหตุการณ์ที่พร้อมปฏิบัติจริง และการเปิดเผยข้อมูลเชิงโปร่งใสในระดับที่เหมาะสม องค์กรที่ลงมืออย่างรวดเร็วและต่อเนื่องจะไม่เพียงลดความเสี่ยง แต่ยังสร้างความยั่งยืนและความได้เปรียบทางการแข่งขันในยุคที่ AI กลายเป็นปัจจัยขับเคลื่อนหลักของธุรกิจและสังคม
📰 แหล่งอ้างอิง: New Lines Institute



