
กระทรวงดิจิทัลเพื่อเศรษฐกิจและสังคมประกาศแนวปฏิบัติด้าน "AI อธิบายได้" ฉบับใหม่ที่มุ่งกำกับการนำระบบปัญญาประดิษฐ์ไปใช้ในภาคบริการสำคัญ โดยเฉพาะการแพทย์และการเงิน แนวปฏิบัตินี้กำหนดให้ผู้ให้บริการต้องสามารถแสดงเหตุผลและคำอธิบายของการตัดสินใจที่เกิดจากโมเดลก่อนนำไปใช้งานจริง เพื่อเพิ่มความโปร่งใส ลดความเสี่ยงจากอคติและความผิดพลาด และสร้างความเชื่อมั่นแก่ผู้ใช้งานและผู้กำกับดูแล
บทความนี้จะสรุปสาระสำคัญของข้อกำหนดใหม่ วิเคราะห์ผลกระทบทางเทคนิคที่ผู้พัฒนาและผู้ให้บริการต้องเผชิญ และนำเสนอตัวอย่างเช็คลิสต์การปฏิบัติตามแบบเป็นขั้นตอน (step-by-step) เพื่อให้หน่วยงานทางการแพทย์และการเงินสามารถเตรียมความพร้อม ปรับกระบวนการพัฒนา และประเมินความเสี่ยงได้อย่างเป็นรูปธรรมก่อนนำ AI ออกให้บริการจริง
บริบทและความจำเป็นของแนวปฏิบัติ 'AI อธิบายได้'
บริบทและความจำเป็นของแนวปฏิบัติ "AI อธิบายได้"
การนำระบบปัญญาประดิษฐ์ (AI) เข้ามาใช้ในภาคการแพทย์และการเงินสร้างผลประโยชน์เชิงประสิทธิภาพและการประหยัดต้นทุน แต่ในขณะเดียวกันก็เปิดช่องให้เกิดความเสี่ยงเชิงจริยธรรมและความเสี่ยงต่อชีวิตหรือทรัพย์สินของประชาชนได้ง่ายขึ้น เหตุผลสำคัญที่ทำให้หน่วยงานกำกับดูแลและภาครัฐต้องออกแนวปฏิบัติเรื่อง AI อธิบายได้ (explainable AI) มาจากข้อจำกัดด้านความโปร่งใสของโมเดลที่เรียกว่า "black box" ซึ่งไม่สามารถอธิบายได้ชัดเจนว่าโมเดลตัดสินใจอย่างไรเมื่อเผชิญกับข้อมูลใหม่หรือสถานการณ์ที่อยู่นอกขอบเขตการฝึก

ปัญหาความไม่โปร่งใสในโมเดล AI แปลเป็นผลกระทบที่จับต้องได้ในภาคการแพทย์และการเงิน ตัวอย่างเช่น ในงานวิจัยเชิงทบทวนหลายฉบับพบว่าโมเดลทางการแพทย์ที่ผ่านการประเมินภายในชุดข้อมูลฝึก มักมีประสิทธิภาพลดลงเมื่อทดสอบกับข้อมูลภายนอก (out‑of‑distribution) โดยมีการรายงานการเพิ่มขึ้นของอัตราความผิดพลาดในช่วงประมาณ 5–30% ขึ้นอยู่กับโรคและชนิดข้อมูล นอกจากนี้ในภาคการเงิน รายงานจากหน่วยงานกำกับดูแลและการสำรวจเชิงนโยบายชี้ให้เห็นว่า การตัดสินใจสินเชื่อโดยระบบอัตโนมัติเป็นปัจจัยของข้อร้องเรียนผู้บริโภคที่เพิ่มขึ้น โดยมีการประเมินว่าข้อร้องเรียนที่เกี่ยวข้องกับการตัดสินใจโดยอัลกอริธึมอยู่ในช่วงประมาณ 10–25% ของข้อร้องเรียนด้านสินเชื่อในปีล่าสุดของบางเขตอำนาจ
แรงกดดันจากแนวปฏิบัติสากลเป็นอีกปัจจัยสำคัญที่ผลักดันการออกแนวปฏิบัติภายในประเทศ ระเบียบอย่าง EU AI Act ได้จัดประเภทระบบ AI ในภาคการแพทย์และการเงินว่าเป็น "high‑risk" ส่งผลให้ต้องปฏิบัติตามมาตรการด้านความโปร่งใส การประเมินความเสี่ยง และการจัดทำเอกสารประกอบการพัฒนา (technical documentation) เช่นเดียวกับหลักการของ OECD และคำแนะนำจากองค์การระหว่างประเทศอื่น ๆ ที่เน้นความรับผิดชอบ ความโปร่งใส และการตรวจสอบได้ (auditability) หน่วยงานกำกับดูแลในหลายประเทศจึงถูกกระตุ้นให้กำหนดข้อกำหนดที่ชัดเจนเกี่ยวกับการอธิบายการตัดสินใจของโมเดลก่อนนำไปใช้จริง
ตัวอย่างเหตุการณ์จริงที่กระตุ้นความตระหนัก ได้แก่ กรณีโมเดลช่วยวินิจฉัยที่ได้รับคำวิจารณ์เมื่อผลการแนะนำการรักษาไม่สอดคล้องกับฐานข้อมูลทางคลินิกที่หลากหลาย และกรณีการประท้วงต่อการให้สินเชื่อผ่านอัลกอริธึมที่สร้างความไม่เป็นธรรมซ้ำกับกลุ่มประชากรบางกลุ่ม เหตุการณ์เหล่านี้สะท้อนว่าการทดสอบเพียงบนชุดข้อมูลภายในอาจไม่เพียงพอ และทำให้เกิดความจำเป็นในการกำหนดแนวทางที่บังคับให้ผู้ให้บริการต้องแสดงเหตุผลหรือหลักฐานการตัดสินใจของโมเดลก่อนนำไปใช้งานจริง
สรุปแล้ว แนวปฏิบัติเรื่อง AI อธิบายได้ เป็นเครื่องมือเชิงนโยบายที่ตอบโจทย์ทั้งด้านจริยธรรม ความปลอดภัย และการคุ้มครองผู้บริโภค โดยช่วยให้ผู้กำกับดูแล ผู้ประกอบการ และผู้ใช้งานสามารถตรวจสอบ ปรับแก้ และชดเชยความเสี่ยงได้ทันท่วงที ทั้งยังเป็นการสอดรับกับมาตรฐานสากลที่เน้นการโปร่งใส ความรับผิดชอบ และการปกป้องสิทธิมนุษยชนในยุคของระบบอัตโนมัติที่แพร่หลาย
- ปัญหาหลัก: ความไม่โปร่งใสของโมเดล (black box) และการลดทอนประสิทธิภาพในบริบทนอกการฝึก
- แรงกดดันสากล: EU AI Act, OECD Principles, แนวทาง NIST/UNESCO ที่เรียกร้องความโปร่งใสและความรับผิดชอบ
- สถิติชี้ให้เห็น: การเพิ่มขึ้นของอัตราความผิดพลาดในบริบทไม่เคยเห็นมาก่อน (ประมาณ 5–30%) และสัดส่วนข้อร้องเรียนเกี่ยวกับการตัดสินใจอัลกอริทึมในภาคการเงิน (ประมาณ 10–25%)
- เหตุผลเชิงนโยบาย: ป้องกันความเสี่ยงต่อชีวิต/ทรัพย์สิน สร้างความเชื่อมั่น และอำนวยความสะดวกต่อการตรวจสอบและชดเชยความเสียหาย
สรุปข้อกำหนดหลักของแนวปฏิบัติ
สรุปข้อกำหนดหลักของแนวปฏิบัติ
แนวปฏิบัติฉบับล่าสุดจากกระทรวงดิจิทัลกำหนดกรอบข้อบังคับเชิงปฏิบัติสำหรับระบบปัญญาประดิษฐ์ที่จัดเป็นความเสี่ยงสูง โดยเฉพาะในภาคการแพทย์และการเงิน ทั้งนี้เน้นให้ผู้ให้บริการต้องจัดทำเอกสารอธิบายการตัดสินใจ (Decision Explanation) ก่อนนำระบบขึ้นใช้งานจริง และต้องดำเนินการติดตาม ตรวจสอบ และรายงานผลอย่างเป็นระบบตลอดอายุการใช้งานของโมเดล เพื่อความโปร่งใส ความรับผิดชอบ และการปกป้องผู้ใช้ ซึ่งข้อกำหนดหลักสามารถสรุปเป็นประเด็นสำคัญดังต่อไปนี้
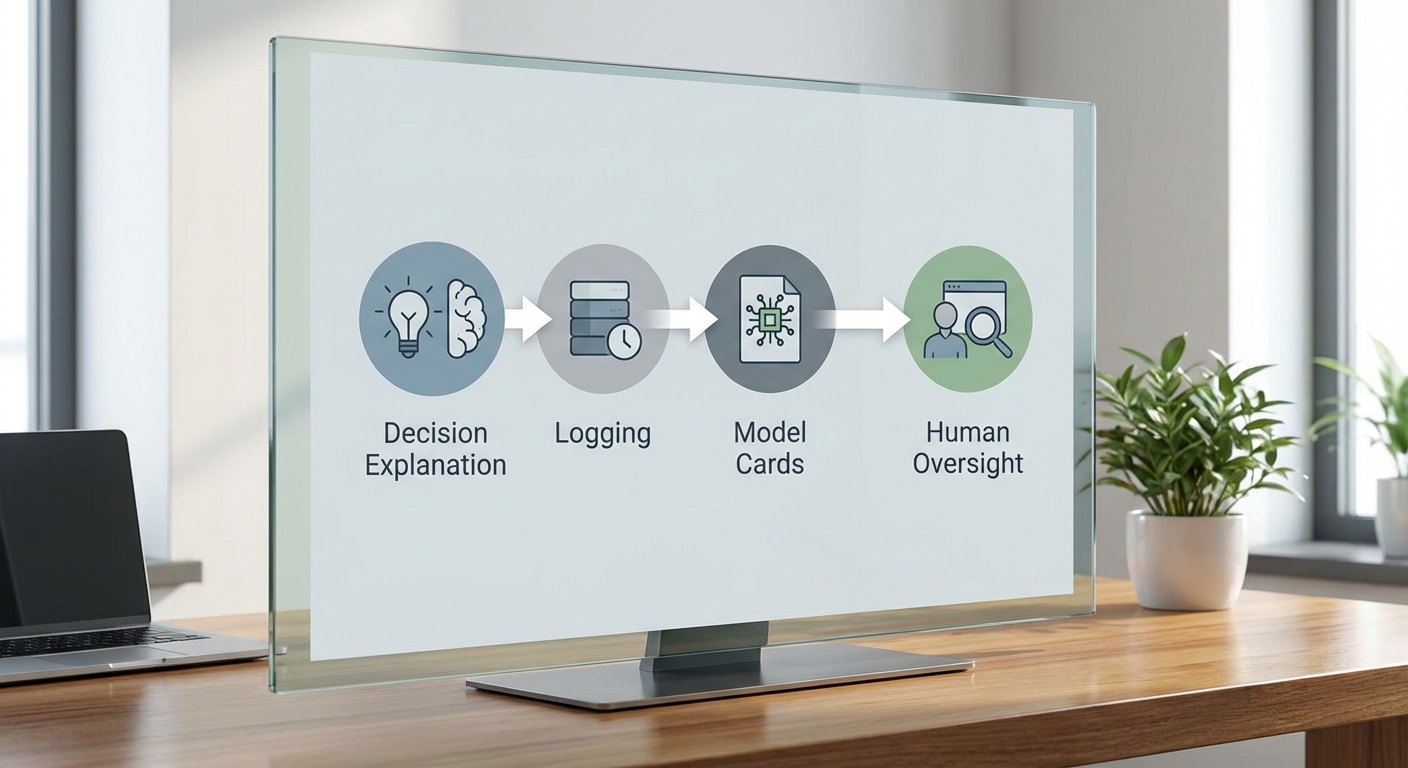
1) การจัดทำรายงานอธิบายการตัดสินใจ (Decision Explanation) ก่อนนำระบบขึ้นใช้งาน
- ผู้ให้บริการต้องจัดส่งรายงาน Decision Explanation ฉบับสมบูรณ์ก่อน deployment ซึ่งต้องระบุวัตถุประสงค์การใช้งาน ขอบเขตการตัดสินใจ (scope) และกลุ่มผู้ได้รับผลกระทบ
- เนื้อหาเชิงเทคนิคต้องรวมถึง: คำอธิบายเชิงกลไกของการตัดสินใจ (feature importance, attribution เช่น SHAP/LIME), ตัวอย่าง local explanations (กรณีตัวอย่างเฉพาะ), counterfactuals ที่อธิบายว่าเหตุใดผลจึงเปลี่ยนแปลง, ค่า confidence/uncertainty พร้อมช่วงความเชื่อมั่น และการวัดประสิทธิภาพหลัก (accuracy, precision/recall, AUC, calibration)
- รูปแบบที่ยอมรับได้: 1) เอกสารอ่านเข้าใจได้สำหรับผู้ไม่เชิงเทคนิค (non-technical summary) 2) รายงานเชิงโครงสร้างสำหรับผู้ตรวจสอบ (machine-readable JSON/XML ที่มีฟิลด์มาตรฐาน) และ 3) ชุดภาพประกอบ/ตารางสรุปเพื่ออธิบายพฤติกรรมโมเดลในระดับประชากรและระดับรายบุคคล
- ต้องแนบการประเมินความเสี่ยง (risk assessment) ก่อนใช้งาน และแผนการลดความเสี่ยง (mitigation plan) กรณีพบความไม่เป็นธรรม (bias), ความไม่เสถียร หรือความเสี่ยงต่อความเป็นส่วนตัว
2) ข้อกำหนดด้าน logging, versioning และ model cards
- Logging: บันทึกข้อมูลการทำงานของระบบอย่างละเอียด ได้แก่ อินพุต-เอาต์พุตของโมเดล, คำอธิบายการตัดสินใจ (explanation artifacts), timestamp, model version, identifier ของ request/transaction (สามารถ pseudonymize ได้เพื่อคุ้มครองข้อมูลส่วนบุคคล) และเหตุการณ์ผิดปกติ (exceptions/anomalies)
- ต้องกำหนดระยะเวลาเก็บบันทึกขั้นต่ำที่สามารถตรวจสอบย้อนหลังได้ สำหรับระบบความเสี่ยงสูง แนวปฏิบัติกำหนดให้เก็บอย่างน้อย 2 ปี พร้อมความสามารถในการดึงข้อมูลเพื่อการสอบสวนหรือการตรวจสอบภายนอก
- Versioning: บังคับใช้การติดหมายเลขเวอร์ชันของโมเดลและ pipeline (ควรใช้ semantic versioning) พร้อม changelog ที่อธิบายความแตกต่างของแต่ละเวอร์ชันและการทดสอบก่อนปล่อย
- Model Cards: ต้องเผยแพร่ model card ที่สรุปข้อมูลสำคัญ เช่น ชื่อโมเดล, เวอร์ชัน, ชุดข้อมูลฝึก/ทดสอบ, เมตริกการประเมินตามกลุ่มตัวอย่าง, ข้อจำกัดการใช้งาน, ข้อมูลเกี่ยวกับความลำเอียงที่รู้จัก และมาตรการลดผลกระทบ ซึ่ง model card ต้องปรับปรุงทุกครั้งเมื่อมีการเปลี่ยนแปลงสำคัญ
- การทดสอบก่อนใช้งาน: ต้องมีการทดสอบเชิงสถิติ (cross-validation, holdout, bootstrap), การทดสอบความเป็นธรรม (fairness metrics ตามกลุ่มประชากร), การทดสอบความทนทานต่อการโจมตี (adversarial robustness) และการทดสอบการพลัดหลง (drift detection)
3) การกำหนด human oversight และกระบวนการอุทธรณ์/ทบทวน
- แนวปฏิบัติกำหนดระดับของการควบคุมโดยมนุษย์ (human oversight) ตามความเสี่ยงของการใช้งาน ได้แก่ human-in-the-loop (ผู้ใช้ต้องอนุมัติก่อนการตัดสินใจสำคัญ), human-on-the-loop (ผู้ควบคุมสามารถตรวจสอบและยกเลิกการตัดสินใจได้) และ human-in-command (มนุษย์มีอำนาจสุดท้ายเหนือระบบ)
- สำหรับกรณีการตัดสินใจที่มีผลกระทบสูง เช่น การวินิจฉัยทางการแพทย์หรือคำแนะนำทางการเงินที่มีผลต่อทรัพย์สิน/สุขภาพ แนวปฏิบัติระบุให้ต้องมีช่องทางให้ผู้ได้รับผลกระทบยื่นคำร้องขอทบทวน (appeal) โดยระบบต้อง: ยอมรับคำร้อง, ตอบรับภายใน 7 วันทำการ และให้ผลการทบทวนภายใน 30 วัน (หรือกำหนดเวลาที่ชัดเจนขึ้นตามความร้ายแรงของกรณี)
- ต้องจัดทำกระบวนการตรวจสอบภายในและการตรวจสอบโดยอิสระ (independent audit) เป็นระยะ เช่น รายงานการตรวจสอบความปลอดภัย/ความเป็นธรรมเป็นครั้งครึ่งปีสำหรับระบบความเสี่ยงสูง และการแจ้งเหตุการณ์ไม่พึงประสงค์ (serious incidents) ให้หน่วยงานกำกับภายใน 72 ชั่วโมง หลังทราบเหตุ
- ผู้ควบคุมมนุษย์ต้องได้รับการฝึกอบรมและมีแนวปฏิบัติการตัดสินใจที่ชัดเจน รวมทั้งช่องทางยกเลิกหรือชะลอการใช้ผลคำแนะนำจากโมเดลเมื่อพบข้อบ่งชี้ว่าข้อมูลหรือบริบทเปลี่ยนแปลง
สรุปโดยรวม แนวปฏิบัติเฉพาะนี้เน้นให้เกิดความสมดุลระหว่างนวัตกรรมและความปลอดภัย: ต้องเปิดเผยเหตุผลการตัดสินใจทั้งในระดับองค์รวมและรายกรณี จัดเก็บบันทึกและเวอร์ชันอย่างเป็นระบบ มี model card เพื่อความโปร่งใส และวางโครงสร้างการควบคุมโดยมนุษย์พร้อมกระบวนการอุทธรณ์ที่ชัดเจน โดยมีกรอบเวลารายงานและการเก็บบันทึกที่กำหนดเพื่อรองรับการตรวจสอบย้อนหลังและการจัดการเหตุฉุกเฉิน
ขอบเขตการบังคับใช้และตัวอย่างกรณีศึกษา
ขอบเขตการบังคับใช้
แนวปฏิบัติด้าน AI อธิบายได้ ที่กระทรวงดิจิทัลออกมามีขอบเขตการบังคับใช้ชัดเจน โดยให้ความสำคัญกับภาคส่วนที่มีผลกระทบเชิงชีวิต สุขภาพ และสถานะทางการเงินเป็นลำดับแรก ได้แก่ ผู้ประกอบการด้านการแพทย์ (เช่น คลินิก โรงพยาบาล หน่วยงานรังสี ห้องปฏิบัติการ และแพลตฟอร์มเทเลเมดิซีน) และผู้ให้บริการด้านการเงิน (เช่น ธนาคาร บริษัทสินเชื่อ ฟินเทค ผู้ให้บริการให้คะแนนเครดิต และผู้ประกันภัยที่ใช้ระบบอัตโนมัติในการตัดสินใจประกันภัย) ทั้งนี้แนวปฏิบัติจะบังคับกับโมเดลที่ถูกนำไปใช้เชิงปฏิบัติการเพื่อช่วยวินิจฉัย การตัดสินใจรักษา การอนุมัติสินเชื่อ หรือการตัดสินใจที่อาจส่งผลกระทบทางเศรษฐกิจต่อบุคคลและครัวเรือนโดยตรง
ขอบเขตการบังคับใช้ยังครอบคลุมถึงผู้พัฒนาโมเดล (developers), ผู้ให้บริการระบบ (service providers), และหน่วยงานที่บูรณาการโมเดลเข้ากับการให้บริการ (integrators) เพื่อให้แน่ใจว่ามีความรับผิดชอบตลอดวงจรชีวิตของระบบ ตั้งแต่การออกแบบ การทดสอบก่อนใช้งานจริง การเปิดเผยข้อมูลไปจนถึงการติดตามผลหลังเปิดใช้งาน
เกณฑ์การพิจารณาว่าเป็น High-risk
- ผลกระทบต่อชีวิตและสุขภาพ: หากการตัดสินใจของโมเดลอาจนำไปสู่การรักษาที่เปลี่ยนแปลงขั้นตอนการรักษา หรือล่าช้าซึ่งมีความเสี่ยงต่ออาการรุนแรงหรือการเสียชีวิต ระบบจะถูกจัดเป็นกลุ่มความเสี่ยงสูง (high-risk)
- ผลกระทบต่อสถานะทางการเงินและเครดิต: ระบบที่ใช้เพื่ออนุมัติหรือปฏิเสธสินเชื่อ การประเมินความสามารถชำระหนี้ หรือการกำหนดเงื่อนไขสินเชื่อซึ่งมีผลต่อเครดิตและการเข้าถึงบริการทางการเงินของผู้บริโภค จะถือเป็น high-risk
- ระดับความเป็นอัตโนมัติ (autonomy): โมเดลที่ทำการตัดสินใจโดยอัตโนมัติแบบไม่ต้องมีการตรวจสอบจากมนุษย์หรือมีบทบาทมนุษย์เพียงเล็กน้อย จะได้รับการควบคุมเข้มงวดกว่าระบบที่ให้คำแนะนำแก่ผู้เชี่ยวชาญเท่านั้น
- ความอ่อนไหวของข้อมูล: การใช้ข้อมูลทางการแพทย์ สถานะสุขภาพระบุได้ หรือข้อมูลเครดิตที่มีความอ่อนไหว จะเพิ่มความเข้มงวดของข้อกำหนดความโปร่งใสและการคุ้มครองข้อมูล
- ขนาดและการแพร่กระจายผลกระทบ: ระบบที่ส่งผลต่อตัวบุคคลจำนวนน้อยอาจได้รับการบังคับใช้ในระดับหนึ่ง ขณะที่ระบบที่นำไปใช้ในระดับชาติหรือมีผู้ได้รับผลกระทบเป็นจำนวนมากจะถูกกำกับเข้มข้นขึ้น
การยกเว้นและเกณฑ์ขั้นต่ำ
แนวปฏิบัตินี้มีการกำหนดเกณฑ์ขั้นต่ำและการยกเว้นบางกรณี เช่น ระบบภายในที่ใช้เพื่อปรับปรุงประสิทธิภาพการทำงาน (workflow optimization) ซึ่งไม่เกี่ยวข้องกับการตัดสินใจเชิงคลินิกหรือการอนุมัติสินเชื่อโดยตรง อาจได้รับการผ่อนปรนในข้อกำหนดด้านการเปิดเผยข้อมูลในบางส่วน แต่ยังต้องปฏิบัติตามหลักการพื้นฐานด้านความปลอดภัยของข้อมูลและการบันทึก (logging) นอกจากนี้ งานวิจัยหรือการทดสอบภายในที่ยังไม่ถูกนำไปใช้ในสถานการณ์จริง (non-production) จะได้รับการยกเว้นจากข้อกำหนดบางประการ ตราบใดที่มีการควบคุมการเข้าถึงและไม่มีการส่งผลกระทบต่อผู้ใช้จริง
ตัวอย่างกรณีศึกษาเชิงประยุกต์
-
กรณีศึกษา 1 — โมเดลช่วยวิเคราะห์ภาพรังสีเพื่อวินิจฉัย
ในโรงพยาบาลแห่งหนึ่ง นำโมเดลปัญญาประดิษฐ์มาช่วยระบุจุดผิดปกติในภาพเอกซ์เรย์และซีทีสแกนเพื่อชี้นำการวินิจฉัย โดยระบบจะต้องปฏิบัติตามแนวปฏิบัติในหลายข้อ เช่น การระบุสาเหตุหรือคุณลักษณะที่ระบบใช้ (เช่น พื้นที่มีคอนโซลิเดชันในปอดขวา), การแสดงค่าความมั่นใจ (confidence score), การให้คำอธิบายเชิงภาพ (heatmap) และการเปิดเผยชุดข้อมูลฝึกสอนและการประเมินความแม่นยำบนประชากรท้องถิ่นก่อนนำไปใช้งานจริง หากระบบแนะนำการรักษาที่สำคัญ (เช่น การผ่าตัด หรือการให้ยาฉุกเฉิน) ต้องมี human-in-the-loop เพื่อให้แพทย์เป็นผู้ตัดสินใจขั้นสุดท้าย พร้อมกับการเก็บบันทึกการตัดสินใจและการติดตามผลลัพธ์ทางคลินิกเพื่อตรวจสอบความปลอดภัยอย่างต่อเนื่อง
-
กรณีศึกษา 2 — ระบบให้คะแนนเครดิตและอนุมัติสินเชื่ออัตโนมัติ
ธนาคารแห่งหนึ่งนำระบบโมเดลคัดกรองผู้กู้มาใช้เพื่อลดเวลาการอนุมัติสินเชื่อ ระบบดังกล่าวจะต้องเปิดเผยตัวแปรสำคัญที่ใช้ในการตัดสินใจ (เช่น รายได้ รายการหนี้คงค้าง ประวัติการชำระ) และสามารถให้คำอธิบายเชิงสาเหตุหรือ counterfactual เช่น “การอนุมัติจะเปลี่ยนหากรายได้เพิ่มขึ้น 15% หรือหากจำนวนสินเชื่อคงค้างลดลง X” เมื่อลูกค้าถูกปฏิเสธ องค์กรต้องจัดให้มี adverse action notice พร้อมช่องทางอุทธรณ์และการทบทวนจากมนุษย์ นอกจากนี้ ต้องรายงานการประเมินความเป็นธรรม (fairness metrics) เช่น การวิเคราะห์ความไม่เป็นธรรมข้ามกลุ่มประชากร และติดตามอัตราการปฏิเสธผิดพลาด (false negative/false positive) เพื่อป้องกันผลกระทบเชิงระบบต่อชุมชนที่เปราะบาง
โดยสรุป แนวปฏิบัติของกระทรวงมุ่งเน้นให้ภาคการแพทย์และการเงินเป็นกลุ่มเป้าหมายหลักที่ต้องปฏิบัติตามกฎเกณฑ์อย่างเคร่งครัด โดยเฉพาะโมเดลที่เข้าข่าย high-risk ซึ่งจะต้องมีการอธิบายเหตุผลการตัดสินใจ ลำดับขั้นการควบคุมมนุษย์ การตรวจสอบก่อนและหลังการใช้งาน รวมถึงมาตรการปกป้องข้อมูลและการติดตามผลกระทบเพื่อคุ้มครองผู้รับบริการและสร้างความเชื่อมั่นในการนำ AI มาใช้เชิงพาณิชย์
ผลกระทบเชิงเทคนิคต่อการพัฒนาและการเลือกโมเดล
ผลกระทบเชิงเทคนิคต่อการพัฒนาและการเลือกโมเดล
แนวปฏิบัติด้าน AI อธิบายได้ ที่กระทรวงดิจิทัลประกาศมีผลโดยตรงต่อสถาปัตยกรรมการพัฒนาโมเดลในระบบที่มีความเสี่ยงสูง เช่น การแพทย์และการเงิน ผู้พัฒนาต้องพิจารณาระหว่างการใช้ interpretable models ที่สามารถอธิบายการตัดสินใจได้โดยตรง (เช่น logistic regression, single decision tree, generalized additive models) กับการเลือกใช้ black-box models (เช่น deep neural networks, gradient-boosted trees) ที่ต้องอาศัยเทคนิคอธิบายผลภายหลัง (post-hoc explainers) ส่งผลให้ pipeline การพัฒนาต้องขยายขอบเขตทั้งในส่วนของ data provenance, feature engineering, การเก็บ log เพื่อสนับสนุนการอธิบาย, และระบบการตรวจสอบ (monitoring & auditing) แบบเรียลไทม์
จากมุมมองเชิงปฏิบัติ การเลือกโมเดลที่อธิบายได้โดยตรงมักง่ายต่อการตรวจสอบ จัดทำเอกสาร และผ่านการตรวจสอบเชิงกฎระเบียบ แต่จะมีข้อจำกัดด้านประสิทธิภาพในบางปัญหา ตัวอย่างเช่น งานจัดหมวดโรคจากภาพทางการแพทย์หรือการคาดการณ์ความเสี่ยงทางการเงินที่มีความสัมพันธ์เชิงซับซ้อนงานวิจัยภาคสนามมักพบว่า black-box อาจเพิ่มค่า AUC หรือ accuracy ประมาณ 3–10% เมื่อเทียบกับโมเดลเชิงเส้นที่ง่ายต่อการอธิบาย ในทางตรงข้าม หากการสูญเสียประสิทธิภาพไม่เกินประมาณ 1–3% หลายองค์กรขนาดใหญ่จะเลือกโมเดลที่อธิบายได้เพื่อลดภาระการควบคุมและเพิ่มความโปร่งใส
เมื่อใช้ post-hoc explainers สถาปัตยกรรมจะต้องรองรับการคำนวณอธิบายผลเป็นขั้นตอนเพิ่มเติม ซึ่งมีผลต่อเวลาแฝง (latency), ค่าคำนวณ (compute cost) และการจัดเก็บผลอธิบาย ตัวอย่างเช่น TreeSHAP ที่ออกแบบมาสำหรับต้นไม้ตัดสินใจให้ผลเร็วกว่าวิธีแบบทั่วไป แต่การคำนวณ SHAP สำหรับโมเดลที่ซับซ้อนหรือชุดคุณลักษณะขนาดใหญ่สามารถเพิ่มเวลาในการตอบคำถามต่อ instance ได้ตั้งแต่หลักสิบมิลลิวินาทีไปจนถึงหลายวินาที ส่วน LIME ซึ่งทำการ perturbation หลักพันตัวอย่างต่อการอธิบายหนึ่งค่า อาจมีค่าใช้จ่ายคำนวณสูงและไม่เหมาะกับงานแบบเรียลไทม์ จึงเป็นเหตุให้ระบบต้องแยกเส้นทาง (asynchronous explanation) หรือทำการ cache คำอธิบายไว้ล่วงหน้า
เทคนิคอธิบายผลที่ควรรู้จักและบทบาททางสถาปัตยกรรม ได้แก่
- SHAP (SHapley Additive exPlanations) – ให้การแจกแจงผลกระทบของแต่ละฟีเจอร์ต่อผลลัพธ์โดยมีหลักการเชิงทฤษฎีของค่า Shapley; เหมาะสำหรับการอธิบายเชิงปริมาณและการเปรียบเทียบข้ามตัวอย่าง แต่มีต้นทุนคำนวณสูง ยกเว้นกรณีที่ใช้ TreeSHAP กับโมเดลต้นไม้
- LIME (Local Interpretable Model-agnostic Explanations) – สร้าง surrogate model แบบง่ายในบริเวณรอบตัว instance เพื่อให้เข้าใจเหตุผลท้องถิ่น; ยืดหยุ่นแต่มีปัญหาเรื่องความเสถียร (stability) เนื่องจากขึ้นกับ sampling
- Counterfactual Explanations – ระบุการเปลี่ยนแปลงน้อยที่สุดของฟีเจอร์ที่จะเปลี่ยนผลลัพธ์ ช่วยให้เกิด actionability (เช่น ลูกค้าต้องเพิ่มเครดิตเท่าไรจึงจะอนุมัติสินเชื่อ) แต่ต้องใช้อัลกอริทึม optimization หรือ generative model เพื่อค้นหา counterfactuals ที่เป็นไปได้
- Feature importance / permutation importance – ให้ค่ารวมของความสำคัญฟีเจอร์ต่อโมเดล เหมาะสำหรับการวิเคราะห์ระดับระบบ แต่ไม่บอกเหตุผลสำหรับแต่ละตัวอย่าง
- Model cards และ datasheets – เอกสารเชิงประกาศข้อมูล (metadata) สำหรับโมเดล เช่น ขอบเขตการใช้งาน ข้อมูลการเทรน ค่า metric, bias/limitations เป็นส่วนหนึ่งของสถาปัตยกรรมเอกสารและกระบวนการ review
- Uncertainty quantification – วิธีเช่น Bayesian approaches, ensembles หรือ MC Dropout ให้ค่าความไม่แน่นอน (confidence intervals, predictive distributions) ซึ่งมีความสำคัญต่อการตัดสินใจในโดเมนที่เสี่ยงสูง
การวัดผลความเข้าใจของคำอธิบายต้องอาศัยทั้งตัวชี้วัดเชิงคณิตศาสตร์และการประเมินโดยมนุษย์ โดยสามมิติหลักที่ต้องติดตามคือ fidelity, stability และ human evaluation:
- Fidelity – วัดว่า explanation สะท้อนการทำงานจริงของโมเดลได้ดีเพียงไร เช่น ในกรณี surrogate model อาจวัด R² หรือ accuracy ของ surrogate เมื่อประมาณพฤติกรรมโมเดล ค่า fidelity ที่ดีมักตั้งเป้าไว้ >0.9 สำหรับการใช้งานเชิงตรวจสอบ ในงานจริงมักพบว่า LIME/locally-linear surrogates ให้ fidelity ระหว่าง 0.7–0.95 ขึ้นกับความซับซ้อนของโมเดล
- Stability – ความคงที่ของคำอธิบายเมื่อมีการเปลี่ยนแปลงเล็กน้อยในข้อมูลหรือพารามิเตอร์ หากคำอธิบายเปลี่ยนแปลงมากจะลดความน่าเชื่อถือ ตัวชี้วัดมักใช้ค่า rank correlation (เช่น Spearman) หรือ Jaccard overlap ของฟีเจอร์ที่สำคัญ; ค่า Spearman >0.8 ถือว่าค่อนข้างเสถียร
- Human evaluation – ทดสอบกับผู้เชี่ยวชาญหรือผู้ใช้ปลายทางเพื่อวัดความเข้าใจ ความน่าเชื่อถือ และผลต่อการตัดสินใจ ตัวอย่างผลการศึกษาแสดงว่า explanation ประเภท counterfactual และ rule-based ทำให้ผู้เชี่ยวชาญทางการแพทย์ประเมินความเสี่ยงได้ถูกต้องเพิ่มจาก ~65% เป็น ~80–85% ในการทดลองควบคุม (ตัวเลขเหล่านี้เป็นตัวอย่างเชิงสนามและขึ้นกับการออกแบบการทดลอง)
การประยุกต์ใช้จริงมักเป็นไปในแนวทางผสมผสาน เช่น ระบบแบ่งเป็นสองชั้น (hybrid architecture): ชั้นแรกใช้ black-box เพื่อให้ได้ performance สูงสุดตามที่ธุรกิจต้องการ และชั้นที่สองเป็นระบบอธิบายผลแบบ asynchronous ที่สร้าง SHAP/LIME/counterfactuals และเก็บไว้ใน audit log สำหรับการตรวจสอบภายหลัง ในกรณีที่คำอธิบายจำเป็นต้องให้แบบเรียลไทม์ องค์กรอาจเลือกจำกัดขนาดฟีเจอร์/ความซับซ้อนของโมเดลหรือใช้ approximation techniques เพื่อลด latency
โดยสรุป การบังคับให้โมเดลต้องอธิบายได้เปลี่ยนแปลงทั้งกระบวนการพัฒนา ตั้งแต่การเลือกสถาปัตยกรรม การออกแบบ pipeline คำนวณ explanation การเพิ่มมาตรการตรวจวัด fidelity/stability และการทำ human-in-the-loop evaluation สำหรับโดเมนเสี่ยงสูง คำแนะนำเชิงปฏิบัติคือ: เลือกโมเดลที่อธิบายได้โดยตรงหากประสิทธิภาพไม่ลดลงมาก (เช่น <5% ใน metric ที่สำคัญ) และหากต้องใช้ black-box ให้เสริมด้วย post-hoc explainers ที่ผ่านการวัด fidelity/stability และการทดสอบกับผู้เชี่ยวชาญเพื่อให้เป็นไปตามข้อกำหนดของหน่วยงานกำกับดูแล
แนวทางการใช้งานจริง: Checklist และขั้นตอนการเตรียมก่อนใช้งาน
ภาพรวมเบื้องต้นและหลักการปฏิบัติ
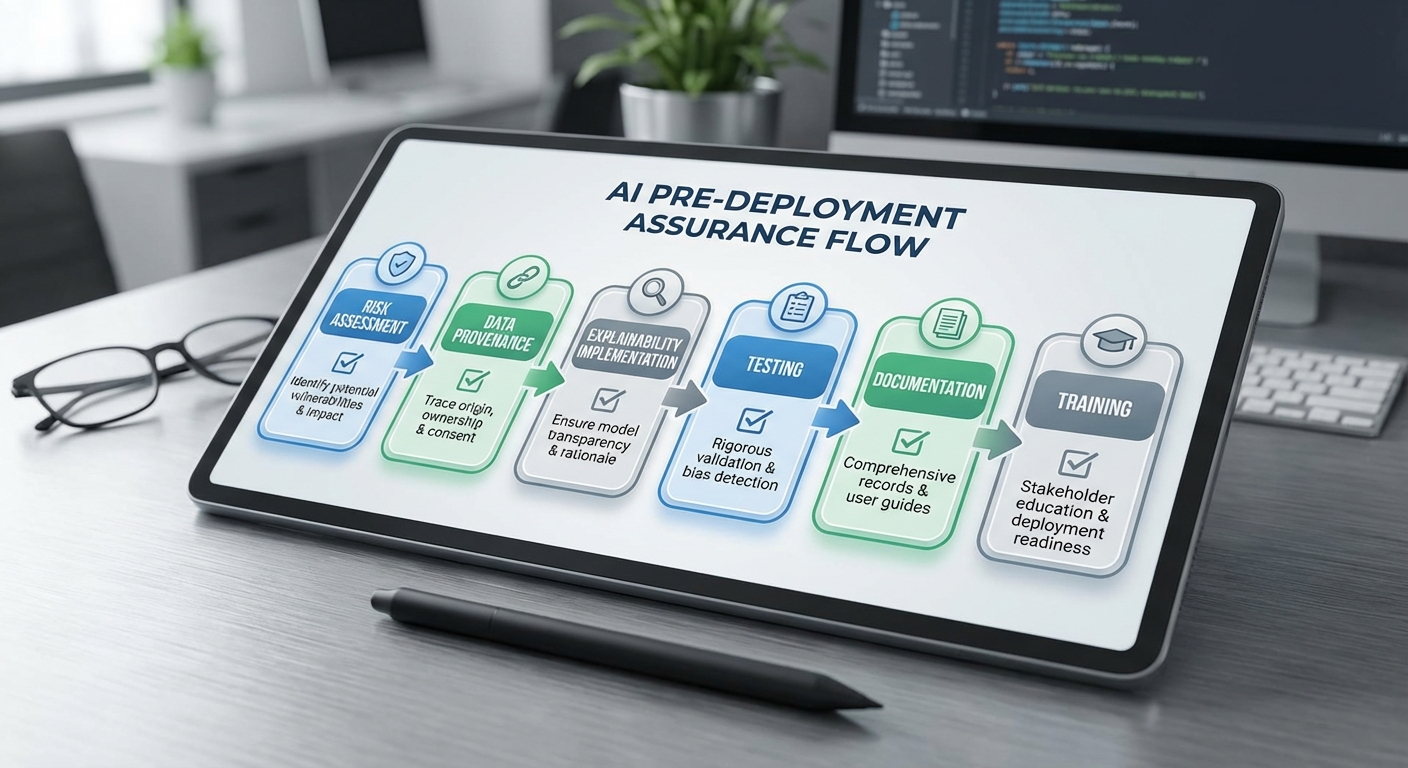
ก่อนนำระบบ AI ที่ต้องอธิบายได้ขึ้นใช้งานจริง โดยเฉพาะในภาคการแพทย์และการเงิน ผู้ให้บริการต้องดำเนินการเตรียมการเชิงระบบ ตั้งแต่การประเมินความเสี่ยง (risk assessment) การตรวจสอบเส้นทางข้อมูล (data lineage/Data Provenance) ไปจนถึงการเลือกและทดสอบเทคนิคที่ใช้ในการอธิบายผล เพื่อให้มั่นใจว่า การตัดสินใจของโมเดลสามารถอธิบายได้ เข้าใจได้โดยผู้ใช้งาน และสอดคล้องกับข้อกำหนดด้านความเป็นธรรมและความปลอดภัย การดำเนินงานตาม checklist เชิงปฏิบัติจะช่วยลดความเสี่ยงของการตัดสินใจผิดพลาดและเพิ่มความโปร่งใสต่อหน่วยกำกับดูแลและผู้ใช้ปลายทาง
เช็คลิสต์ก่อนขึ้นใช้งาน (Pre-deployment checklist)
- การประเมินความเสี่ยง (Risk Assessment)
- ระบุผลกระทบต่อผู้ใช้ (ความเสี่ยงทางสุขภาพ ทางการเงิน หรือสิทธิส่วนบุคคล)
- จัดลำดับความร้ายแรง (severity) และความน่าจะเป็น (likelihood) ของเหตุการณ์ความผิดพลาด
- กำหนดมาตรการบรรเทาความเสี่ยง (mitigation) เช่น การแจ้งเตือนผู้ใช้ การใช้ human-in-the-loop)
- การจัดการ Data Provenance / Data Lineage
- บันทึกแหล่งที่มาของข้อมูล (source), เวอร์ชัน และขั้นตอนการแปลงข้อมูล (ETL)
- ตรวจสอบความสมบูรณ์และความเป็นตัวแทนของข้อมูล รวมถึงการระบุจุดอ่อนที่อาจนำไปสู่ bias
- เตรียม metadata สำหรับแต่ละชุดข้อมูลเพื่อรองรับการตรวจสอบย้อนหลัง (audit trail)
- การทดสอบความเป็นธรรม (Fairness Testing)
- กำหนดกลุ่มเป้าหมายที่มีความเสี่ยงต่อความไม่เป็นธรรม (เช่น ตัวแปรเพศ เชื้อชาติ อายุ ฯลฯ)
- รันชุดทดสอบเชิงสถิติ (เช่น disparate impact, equalized odds) และตั้งเกณฑ์ยอมรับได้
- จัดทำแผนแก้ไข (remediation) หากพบความเอนเอียงเกินกว่าที่ยอมรับได้
- การทดสอบความปลอดภัยและความเป็นส่วนตัว
- การทดสอบการรั่วไหลของข้อมูล (data leakage) และการโจมตีแบบ adversarial
- ตรวจสอบการปฏิบัติตามกฎหมายคุ้มครองข้อมูล เช่น PDPA/ GDPR (ถ้ามีผลบังคับ)
- การวางมาตรการรักษาความต่อเนื่องในการอัปเดต
- กำหนดกระบวนการรีเทรน การตรวจสอบประสิทธิภาพหลังใช้งาน (monitoring) และเกณฑ์ปลดระบบกลับ (rollback)
เอกสารประกอบที่ต้องเตรียม: 'เหตุผลก่อนใช้งานจริง' (What to include)
เอกสารชุดนี้ควรเป็นไฟล์รวมที่อ่านง่ายและนำไปใช้อ้างอิงได้ทันที ประกอบด้วยเอกสารหลักดังต่อไปนี้:
- Model Card / Technical Summary
- วัตถุประสงค์ของโมเดล (Model purpose) และขอบเขตการใช้งานที่ยอมรับได้
- ประเภทโมเดล เวอร์ชัน สถาปัตยกรรม และพารามิเตอร์ที่สำคัญ
- ข้อจำกัด (limitations) และสถานการณ์ที่โมเดลอาจทำงานผิดพลาด
- Datasets และ Data Provenance
- การแปลงข้อมูลที่สำคัญและการจัดการค่าผิดปกติ (outliers) รวมถึงขั้นตอน anonymization ถ้ามี
- Validation Results และ Metrics
- ผลลัพธ์การวัดประสิทธิภาพ (accuracy, AUC, precision/recall) พร้อมค่าแยกตามกลุ่มประชากร
- ผลการทดสอบความเป็นธรรม การทดสอบความทนทานต่อการโจมตี และผลการทดสอบสมมติฐาน (sensitivity analysis)
- Decision Explanation Examples
- ตัวอย่างคำอธิบายการตัดสินใจของโมเดลสำหรับกรณีใช้งานจริง 5–10 เคส ที่ครอบคลุมสถานการณ์ปกติและสถานการณ์ขอบเขต
- รูปแบบคำอธิบายทั้งแบบ technical (feature contributions, SHAP/LIME output) และแบบที่เข้าใจโดยผู้ใช้ทั่วไป (plain-language rationale)
- User-facing Explanation
- เทมเพลตข้อความที่จะแจ้งผู้ใช้ เช่น "เหตุผลที่ระบบให้คำแนะนำ: ..." พร้อมตัวเลือกหากต้องการคำอธิบายเพิ่มเติม
- แนวทางการแสดงผล (UI/UX) เพื่อให้คำอธิบายกระชับ ชัดเจน และไม่ก่อให้เกิดความสับสน
แผนการทดสอบและอบรม: simulation, user testing และ timeline ประมาณการ
การทดสอบและอบรมควรกำหนดเป็นโครงการย่อยที่มีเฟสชัดเจน โดยตัวอย่างกรอบเวลาและกิจกรรมแนะนำสำหรับการยกระดับระบบเริ่มต้น (system uplift) อยู่ที่ 8–12 สัปดาห์ ซึ่งสามารถแบ่งเป็นเฟสดังนี้:
- สัปดาห์ที่ 1–2: เตรียมการและประเมินความเสี่ยง
- จัดตั้งทีมงาน (data owners, model owners, compliance, UX, clinicians/financial experts)
- จัดทำ risk register และกำหนด KPI การทดสอบ
- สัปดาห์ที่ 3–5: Data Provenance และพัฒนา explanation pipeline
- รวบรวมและตรวจสอบ metadata, แยกชุดทดสอบตามกลุ่มความหลากหลาย
- สัปดาห์ที่ 6–8: Simulation และ A/B Testing
- รัน simulation โดยใช้ข้อมูลย้อนหลัง (backtesting) เพื่อประเมินผลการตัดสินใจ
- ทำ A/B testing กับผู้ใช้จริงในสเกลเล็ก (เช่น 5–10% ของทราฟฟิก หรืออย่างน้อย 1,000 เคสในกรณีธุรกรรมสูง)
- วัดผลทั้งเชิงประสิทธิภาพและการเข้าใจของผู้ใช้ (user comprehension)
- สัปดาห์ที่ 9–10: User Testing และการฝึกอบรมภายใน
- จัด session ให้กับเจ้าหน้าที่ที่เกี่ยวข้อง (clinical staff, customer support) เน้นการอ่านคำอธิบายและการตอบคำถามลูกค้า
- ทดสอบความเข้าใจของผู้ใช้ผ่านแบบสอบถามหรือการสัมภาษณ์เชิงคุณภาพ (qualitative feedback)
- สัปดาห์ที่ 11–12: สรุปผลและจัดทำเอกสาร 'เหตุผลก่อนใช้งานจริง'
- รวมผลการวัด ประเด็นการแก้ไข และแผนการ monitor หลังขึ้นใช้งาน
- จัดทำ checklist สุดท้ายสำหรับการอนุมัติขึ้นระบบ (go/no-go criteria)
ตัวอย่างเทมเพลตเร่งด่วน (Quick templates)
ตัวอย่างฟิลด์สำคัญที่ควรมีในเอกสารและเทมเพลตการสื่อสาร:
- Model Card (สรุป 1 หน้า): ชื่อโมเดล | วัตถุประสงค์ | ขอบเขตการใช้งาน | ข้อจำกัด | เวอร์ชัน | ผู้รับผิดชอบ | วันที่
- Decision Explanation Template (user-facing): สถานะการตัดสินใจ | สาเหตุหลัก (3 ประเด็นสำคัญ) | ความเชื่อมั่นของโมเดล (confidence) | คำแนะนำถัดไป | ช่องทางขอคำอธิบายเพิ่มเติม
- Training Plan (สำหรับเจ้าหน้าที่): ระยะเวลาอบรม (2–4 ชั่วโมง/แบบกลุ่ม) | คำสอนหลัก | เคสตัวอย่าง 10 เคส | แบบทดสอบความเข้าใจ
สรุป: การเตรียมความพร้อมก่อนใช้งานจริงต้องเป็นกระบวนการที่มีหลักฐานรองรับ (evidence-based) และมีการมีส่วนร่วมข้ามฝ่าย ตั้งแต่การวิเคราะห์ความเสี่ยง การจัดการข้อมูลอย่างโปร่งใส การเลือกเทคนิคอธิบายผลที่เหมาะสม ไปจนถึงการทดสอบกับผู้ใช้จริงและการอบรมเจ้าหน้าที่ การจัดทำเอกสาร 'เหตุผลก่อนใช้งานจริง' ที่ครบถ้วนจะเป็นหลักฐานสำคัญเมื่อเผชิญการตรวจสอบจากหน่วยงานกำกับดูแลและสร้างความเชื่อมั่นให้ผู้ใช้ปลายทาง
การกำกับดูแล การตรวจสอบ และบทลงโทษ
กรอบการกำกับดูแลเชิงปฏิบัติการ: การรายงานก่อนและหลังการใช้งาน
การกำกับดูแลที่มีประสิทธิผลต้องเริ่มจากการกำหนดให้ผู้ให้บริการรายงานข้อมูลเชิงเทคนิคและเชิงบริบทต่อหน่วยกำกับก่อนการนำโมเดล AI ไปใช้จริง (pre-deployment reporting) และมีการรายงานผลการปฏิบัติงานเป็นระยะหลังการนำใช้งาน (post-deployment reporting) โดยข้อมูลที่ควรรายงานอย่างน้อยประกอบด้วย:
- โมเดลการอธิบายได้: รายงานโครงสร้างโมเดล สถาปัตยกรรม เวอร์ชัน และสาเหตุที่เลือกใช้อัลกอริธึมดังกล่าว
- ชุดข้อมูลและคุณภาพข้อมูล: แหล่งที่มา ขนาด กลยุทธ์การทำความสะอาดข้อมูล และการประเมินความเอนเอียง (bias assessment)
- การประเมินความเสี่ยง: การวิเคราะห์ผลกระทบต่อผู้ใช้ ความเสี่ยงด้านความเป็นธรรม ความเป็นส่วนตัว และความปลอดภัย พร้อมแผนบรรเทาความเสี่ยง
- ผลการทดสอบเชิงปฏิบัติการ: ตัวชี้วัดเช่น ความแม่นยำ (accuracy), false positive/negative, calibration, robustness ต่อ distribution shift และผลการทดสอบการโจมตีเช่น adversarial testing
- แผนการติดตามหลังใช้งาน: KPI สำคัญ, ช่วงเวลาการตรวจสอบ, และเกณฑ์การถอนหรือปรับโมเดล
การตรวจสอบโดยบุคคลที่สามและทะเบียนสาธารณะสำหรับโมเดลความเสี่ยงสูง
สำหรับโมเดลที่จัดเป็น high-risk—เช่น ระบบวินิจฉัยทางการแพทย์หรือระบบให้สินเชื่อ—กระทรวงควรกำหนดให้มีการตรวจสอบโดยภายนอก (third-party audits) จากหน่วยตรวจสอบที่ได้รับการรับรอง โดยมาตรฐานการตรวจสอบควรรวมถึงการทวนสอบโค้ด การตรวจสอบข้อมูล การประเมินผลการทดลองในสภาพแวดล้อมจำลอง และการประเมินผลเชิงจริยธรรมและผลกระทบทางกฎหมาย
นอกจากนี้ ควรจัดตั้ง ทะเบียนสาธารณะ (public registry) สำหรับโมเดลความเสี่ยงสูง ซึ่งเผยแพร่ข้อมูลเมตา (metadata) เช่น เจ้าของโมเดล เวอร์ชัน วันที่ตรวจสอบ ผลการตรวจสอบ สถานะการรับรอง และ KPI หลักที่ใช้ติดตาม การมีทะเบียนสาธารณะช่วยให้หน่วยงานกำกับ ภาคธุรกิจ และประชาชนสามารถตรวจสอบความโปร่งใสและติดตามความเปลี่ยนแปลงของระบบได้อย่างต่อเนื่อง
KPI การติดตาม ผลการประเมิน และกระบวนการร้องเรียน
การกำหนดตัวชี้วัดผลงาน (KPI) ที่เหมาะสมเป็นหัวใจของการตรวจสอบหลังการนำใช้งาน ตัวอย่าง KPI สำคัญได้แก่:
- ประสิทธิภาพเชิงเทคนิค: accuracy, precision, recall, AUC, calibration
- ความยุติธรรมและไม่แบ่งแยก: disparity ในอัตราการปฏิเสธหรือการวินิจฉัยระหว่างกลุ่มประชากร
- ความเสถียรและความทนทาน: อัตราความล้มเหลว การเปลี่ยนแปลง performance เมื่อสภาพแวดล้อมเปลี่ยน
- การควบคุมการดำเนินงาน: อัตราการ override โดยมนุษย์ เวลาในการตอบสนอง และอัตราการร้องเรียน
เมื่อมีข้อร้องเรียนหรือเหตุการณ์ที่บ่งชี้การละเมิด กระทรวงควรกำหนดกระบวนการสอบสวนเชิงรุกที่มีขั้นตอนชัดเจน ได้แก่ การรับเรื่องภายใน 7 วัน การเปิดสอบสวนเชิงเทคนิค การวิเคราะห์สาเหตุรากฐาน (root cause analysis) และการประกาศมาตรการแก้ไขภายในกรอบเวลาที่กำหนด พร้อมกับการแจ้งผู้ได้รับผลกระทบตามกฎหมายคุ้มครองข้อมูลส่วนบุคคล
บทลงโทษและมาตรการแก้ไขเมื่อพบการละเมิด
มาตรการบังคับใช้ควรมีลำดับชั้นตามความรุนแรงของการละเมิดและผลกระทบที่เกิดขึ้น เช่น:
- คำสั่งปรับปรุง: ให้แก้ไขระบบและดำเนินการทดสอบอีกครั้งภายในระยะเวลาที่กำหนด
- บทลงโทษทางปกครอง: ปรับเงินตามขนาดขององค์กรและความรุนแรงของการละเมิด โดยอาจคำนึงถึงรายได้จากการใช้ระบบ AI นั้น
- การระงับการใช้งาน: สั่งระงับการให้บริการหรือถอนทะเบียนโมเดลในกรณีมีความเสี่ยงร้ายแรงต่อสาธารณะ
- ความรับผิดทางแพ่ง: การชดเชยความเสียหายต่อผู้ได้รับผลกระทบ รวมถึงการบังคับชดใช้ค่าเสียหาย
- การเปิดเผยต่อสาธารณะ: ประกาศชื่อผู้ละเมิดและสรุปการกระทำเพื่อสร้างแรงกดดันเชิงนโยบายและป้องปราม
ข้อเสนอแนะแนวทางการประเมินผลและมาตรการป้องกันการละเมิด
เพื่อให้การกำกับดูแลเป็นรูปธรรมและป้องกันการละเมิดอย่างมีประสิทธิภาพ ควรพิจารณามาตรการต่อไปนี้:
- มาตรฐานการตรวจสอบที่เป็นมาตรฐานเดียวกัน: พัฒนามาตรฐานการตรวจสอบเชิงเทคนิคและเชิงจริยธรรมที่อ้างอิงได้ เช่น กรอบการประเมินความเสี่ยงและเมตริกซ์การยอมรับสำหรับแต่ละโดเมน
- การรับรองผู้ตรวจสอบภายนอก: กำหนดข้อกำหนดการรับรองผู้ดำเนินการตรวจสอบเพื่อป้องกันความขัดแย้งทางผลประโยชน์
- ระบบบันทึกที่ไม่สามารถแก้ไขได้: บังคับใช้ audit trails และ immutable logs เพื่อให้สามารถตรวจสอบประวัติการตัดสินใจของโมเดลและการเปลี่ยนแปลงได้
- การทดสอบแบบ Red Team: ให้มีการโจมตีจำลองและทดสอบเชิงรุกเพื่อตรวจจับช่องโหว่ก่อนนำระบบออกสู่การใช้งานจริง
- การกำกับดูแลโดยมนุษย์ (human-in-the-loop): สำหรับการตัดสินใจสำคัญ ให้มีการกำหนดระดับการควบคุมโดยมนุษย์และเงื่อนไขการยกเว้นการตัดสินใจอัตโนมัติ
- การเปิดเผยข้อมูลเชิงโปร่งใส: เผยแพร่รายงานสรุปผลการตรวจสอบและ KPI ที่สำคัญแก่สาธารณะอย่างสม่ำเสมอ
โดยสรุป การกำกับดูแลที่ได้ผลต้องผสมผสานการรายงานก่อน/หลังการใช้งาน การตรวจสอบโดยบุคคลที่สาม การติดตามด้วย KPI ที่เหมาะสม และมาตรการลงโทษที่มีน้ำหนักและสามารถบังคับใช้ได้จริง รวมทั้งการออกแบบแนวทางป้องกันเชิงเทคนิคและการกำกับดูแลเชิงสถาบันเพื่อสร้างความเชื่อมั่นต่อผู้ใช้และความปลอดภัยของระบบ AI ในภาคการแพทย์และการเงิน
คำแนะนำเชิงปฏิบัติสำหรับผู้ให้บริการและสิทธิของผู้ใช้
คำแนะนำเชิงปฏิบัติสำหรับผู้ให้บริการและสิทธิของผู้ใช้
เพื่อให้สอดคล้องกับแนวปฏิบัติเรื่อง AI อธิบายได้ ของกระทรวงดิจิทัล ผู้ให้บริการควรเริ่มจากการวางกรอบการปฏิบัติการที่เป็นระบบและมีลำดับความสำคัญชัดเจน โดยหลักการพื้นฐานคือการจัดลำดับความเสี่ยงของการใช้งาน (risk-based prioritization) และให้ความสำคัญกับกรณีการใช้งานที่มีผลกระทบต่อความปลอดภัยชีวิต สุขภาพ หรือผลทางการเงินของผู้ใช้ก่อนเป็นลำดับแรก เช่น ระบบช่วยตัดสินใจทางการแพทย์ ระบบคัดกรองการรักษา ระบบให้คำแนะนำด้านการลงทุน หรือระบบพิจารณาอนุมัติสินเชื่อที่อาจทำให้ผู้ใช้สูญเสียทรัพย์สิน
ขั้นตอนปฏิบัติแนะนำสำหรับผู้ให้บริการมีดังนี้
- จัดทำแผนที่ระบบและสินทรัพย์ AI (AI inventory) — ระบุทุกโมเดล จุดใช้ข้อมูล และการเชื่อมต่อกับระบบอื่น ๆ เพื่อให้เห็นขอบเขตของความเสี่ยง
- ประเมินความเสี่ยงเชิงเนื้อหาและผลกระทบ (risk assessment) — ประเมินความรุนแรงและความถี่ของผลกระทบที่อาจเกิดกับผู้ใช้ และจัดระดับความเสี่ยงเป็น high/medium/low
- จัดลำดับการดำเนินงานตามความเสี่ยง — เริ่มดำเนินการกับกรณีความเสี่ยงสูงก่อน เช่น การพัฒนาเมคานิซึมอธิบายเหตุผล (explainability modules) และการจัดทำเอกสารประกอบการตัดสินใจ
- ออกแบบการสื่อสารกับผู้ใช้ — สร้างเทมเพลตคำอธิบายเป็นภาษาง่าย (plain-language explanations) สำหรับผู้ใช้ปลายทางและเวอร์ชันเทคนิคสำหรับผู้ตรวจสอบภายใน/ภายนอก
- ติดตั้งกระบวนการอุทธรณ์และช่องทางร้องเรียน — กำหนดขั้นตอน การตอบสนอง และเวลากำหนดชัดเจนสำหรับคำขออธิบายและการอุทธรณ์
- ทดสอบ ตรวจสอบ และบันทึก — ดำเนินการทดสอบความถูกต้อง ความยุติธรรม และความเสถียรของคำอธิบาย พร้อมจัดเก็บบันทึกการตัดสินใจและการสื่อสารกับผู้ใช้เพื่อการตรวจสอบย้อนหลัง
- จัดให้มีการกำกับดูแลจากมนุษย์และการตรวจสอบภายนอก — แต่งตั้งผู้รับผิดชอบระดับองค์กรสำหรับการอนุมัติการปล่อยใช้งาน และเปิดรับการตรวจสอบโดยผู้เชี่ยวชาญหรือผู้ตรวจสอบอิสระ
ตัวอย่างเทมเพลตคำอธิบายแบบอ่านง่ายสำหรับผู้ใช้ปลายทาง (plain-language)
-
เทมเพลตสั้น (สำหรับแจ้งผลทันที)
ผลการตัดสินใจ: {อนุมัติ/ปฏิเสธ/จัดคิว/คำแนะนำ}
ทำไมจึงตัดสินใจเช่นนี้: ระบบพิจารณาจาก {ปัจจัยสำคัญ เช่น ผลตรวจ/รายได้/คะแนนเครดิต} โดยมีความเชื่อมั่นประมาณ {เช่น 82%} หากต้องการข้อมูลเพิ่มเติมหรือขอทบทวน โปรดติดต่อ {ช่องทางติดต่อ} ภายใน {ระยะเวลา เช่น 14 วัน}. -
เทมเพลตฉบับขยาย (สำหรับคำขอต่อเนื่อง)
สรุปการตัดสินใจ: {สรุปผล}
ปัจจัยสำคัญที่มีผลต่อการตัดสินใจ: {รายการปัจจัย 3–5 ข้อ เช่น ผลตรวจล่าสุด, อายุ, ประวัติการชำระเงิน}
วิธีการทำงานโดยสังเขป: {คำอธิบายเชิงตรรกะ เช่น โมเดลได้ถ่วงน้ำหนักปัจจัย A และ B โดยใช้เทคนิค X เพื่อคาดคะเนความเสี่ยง}
ระดับความเชื่อมั่น/ความไม่แน่นอน: {ตัวเลขหรือคำอธิบาย เช่น “ความเชื่อมั่นสูง/ปานกลาง” พร้อมช่วงความไม่แน่นอน}
ทางเลือกและผลกระทบ: {ตัวเลือกที่ผู้ใช้มี เช่น ขอทบทวนโดยมนุษย์, ยื่นข้อมูลเพิ่มเติม, เลือกบริการอื่น}
ช่องทางอุทธรณ์และการร้องเรียน: {อีเมล/โทรศัพท์/แบบฟอร์มออนไลน์} พร้อมคำแนะนำเอกสารที่ควรแนบ เช่น "หลักฐานแพทย์" หรือ "เอกสารแสดงรายได้". -
เทมเพลตฉบับย่อสำหรับผู้ใช้กลุ่มเปราะบาง
ผล: {สรุป}
เพราะอะไร: {เหตุผลสั้น ๆ 1–2 บรรทัด}
ทำอะไรได้บ้าง: {เลือกขอทบทวนหรือขอความช่วยเหลือจากพนักงาน}
ติดต่อ: {ช่องทางและเวลาตอบกลับคาดหวัง}.
สิทธิของผู้ใช้และแนวปฏิบัติด้านการตอบสนอง
- สิทธิขอคำอธิบาย — ผู้ใช้ควรมีสิทธิร้องขอคำอธิบายเกี่ยวกับการตัดสินใจที่มีผลกระทบต่อสิทธิหรือผลประโยชน์ของตน โดยผู้ให้บริการควรกำหนดกรอบเวลาในการให้คำตอบที่ชัดเจน (เช่น คำตอบเบื้องต้นภายใน 7 วันทำการ และคำอธิบายเชิงรายละเอียดภายใน 30 วัน)
- สิทธิขอทบทวนโดยมนุษย์ (human review) — ผู้ใช้ควรมีช่องทางขอให้บุคลากรมนุษย์ทบทวนผลการตัดสินใจ พร้อมคำชี้แจงว่าการทบทวนจะดำเนินการอย่างไรและใช้เวลาเท่าใด
- สิทธิอุทธรณ์และช่องทางร้องเรียน — ระบบต้องมีขั้นตอนการอุทธรณ์ภายในชัดเจน รวมถึงช่องทางร้องเรียนต่อหน่วยงานกำกับดูแลหรือผู้ตรวจสอบอิสระหากผู้ใช้อยู่ในความไม่พอใจต่อคำตอบภายในองค์กร
- การคุ้มครองข้อมูลและความเป็นส่วนตัว — เมื่อผู้ใช้ขอคำอธิบาย ผู้ให้บริการต้องรักษาความลับของข้อมูลและให้ข้อมูลเท่าที่จำเป็นและเหมาะสมตามหลักจริยธรรมและกฎหมายคุ้มครองข้อมูลส่วนบุคคล
- การบันทึกและความรับผิดชอบ — ผู้ให้บริการต้องเก็บบันทึกการตัดสินใจ คำอธิบาย และประวัติการอุทธรณ์เป็นระยะเวลาที่เหมาะสมเพื่อรองรับการตรวจสอบย้อนหลังและลดความเสี่ยงด้านการปฏิบัติผิด
ข้อแนะนำปฏิบัติในการจัดการคำขอและอุทธรณ์: กำหนดผู้ประสานงานแต่ละกรณี มีกระบวนการติดตามสถานะแบบอัตโนมัติ แจ้งผู้ใช้เมื่อมีความคืบหน้า และกำหนด SLA สำหรับแต่ละขั้นตอน (เช่น ตอบรับคำขอภายใน 48 ชั่วโมง ทำการทบทวนภายใน 14 วันทำการ เป็นต้น) รวมทั้งเปิดเผยรายงานสรุปประจำไตรมาสเกี่ยวกับจำนวนคำขอ คำอุทธรณ์ ผลการทบทวน และมาตรการที่นำมาใช้เพื่อเพิ่มความโปร่งใสต่อสาธารณะ
ท้ายที่สุด การนำแนวปฏิบัติเหล่านี้ไปปฏิบัติอย่างมีประสิทธิภาพต้องอาศัยการผสมผสานระหว่างเทคนิคเชิงวิศวกรรม (เช่น โมดูลอธิบายได้, การวัดความไม่แน่นอน) และกระบวนการกำกับดูแลเชิงองค์กร (เช่น นโยบายความรับผิดชอบ, การฝึกอบรมพนักงาน) เพื่อให้การใช้งาน AI เป็นไปอย่างปลอดภัย โปร่งใส และเคารพสิทธิของผู้ใช้
บทสรุป
แนวปฏิบัติ 'AI อธิบายได้' ที่กระทรวงดิจิทัลประกาศเป็นก้าวสำคัญในการยกระดับความโปร่งใสและความรับผิดชอบของระบบอัตโนมัติ โดยเฉพาะในภาคการแพทย์และการเงินที่ความผิดพลาดหรือการตัดสินใจที่ไม่สามารถอธิบายได้อาจส่งผลกระทบรุนแรงต่อชีวิตและทรัพย์สินของประชาชน แนวปฏิบัตินี้กำหนดให้ผู้ให้บริการต้องเตรียมทั้งเชิงนโยบายและเชิงเทคนิค ได้แก่ การประเมินความเสี่ยง (risk assessment) ที่ชัดเจน การคัดเลือกหรือพัฒนาเทคนิคการอธิบายผลที่เหมาะสมกับบริบท (เช่น โมเดลที่สามารถตีความได้โดยตรง, เทคนิคอธิบายผลแบบท้องถิ่นหรือแบบภูมิรวม post‑hoc) และการจัดทำเอกสารเชิงเทคนิคและเชิงนโยบายควบคู่กับกระบวนการตรวจสอบภายในและภายนอกเพื่อยืนยันความสอดคล้องกับแนวปฏิบัติ เช่น รายงานผลการทดสอบความเป็นธรรม ความเสถียร และการทวนสอบย้อนกลับของโมเดล (model cards, audit trails และการรายงานความเสี่ยง).
แนวโน้มในอนาคตคาดว่าแนวปฏิบัตินี้จะเร่งให้ผู้ให้บริการลงทุนในเครื่องมือและกระบวนการที่รองรับการอธิบายได้ของ AI มากขึ้น ทั้งในแง่การพัฒนาบุคลากร การตั้งมาตรฐานเอกสาร และการเปิดเผยข้อมูลเชิงสำคัญต่อหน่วยงานกำกับดูแลและผู้ใช้บริการ การปฏิบัติตามข้อกำหนดอย่างรอบด้านจะช่วยลดความเสี่ยงด้านกฎหมายและชื่อเสียง เพิ่มระดับความเชื่อมั่นของผู้ใช้ และส่งเสริมการใช้งาน AI ที่ปลอดภัยและเป็นธรรม แต่อย่างไรก็ดีองค์กรควรเตรียมรับผลกระทบเชิงปฏิบัติการ เช่น ระยะเวลาในการตรวจสอบยาวขึ้นและต้นทุนการพัฒนาเพิ่มขึ้น ดังนั้นคำแนะนำคือให้วางแผนเชิงกลยุทธ์ทั้งด้านนโยบาย เทคโนโลยี และการตรวจสอบ เพื่อให้การนำ AI เข้าสู่การใช้งานจริงเป็นไปอย่างยั่งยืนและสอดคล้องกับแนวปฏิบัติ.



