
ข่าวใหญ่สำหรับวงการคลาวด์และปัญญาประดิษฐ์ในไทย: คลัสเตอร์คลาวด์ไทยเริ่มทดสอบสถาปัตยกรรม Mixture‑of‑Experts (MoE) แบบไฮบริด เพื่อเทรนโมเดลภาษาใหญ่ (LLM) ขนาดหลายพันล้านพารามิเตอร์ โดยรายงานผลเบื้องต้นว่าช่วยลดต้นทุนการเทรนได้ถึง 6 เท่า ขณะที่ยังรักษาความแม่นยำของโมเดลไว้ได้ใกล้เคียงกับการเทรนแบบเต็ม (dense training) และมีมาตรการออกแบบระบบเพื่อคงค่า latency สำหรับบริการเรียลไทม์ไม่ให้เพิ่มขึ้นจนกระทบประสบการณ์ผู้ใช้
การทดสอบครั้งนี้จึงไม่ใช่เพียงตัวเลขด้านต้นทุน แต่ส่งสัญญาณสำคัญต่อความเป็นไปได้ในการปรับใช้ LLM ระดับองค์กรภายในประเทศ — จากบริการแชตบอทเชิงธุรกิจไปจนถึงระบบแปลภาษาแบบเรียลไทม์และการวิเคราะห์ข้อความเชิงลึก ตัวแปรสำคัญคือการผสานเทคนิค MoE แบบไฮบริดที่เลือกเปิดใช้งาน "ผู้เชี่ยวชาญ" (experts) เฉพาะเมื่อจำเป็น ร่วมกับกลไกการจัดการเส้นทางและแคช เพื่อให้ได้ประสิทธิภาพการคำนวณสูงสุดโดยไม่แลกมาด้วยความแม่นยำหรือความหน่วงที่ไม่ยอมรับได้ — ผลลัพธ์ที่น่าจับตามองสำหรับผู้ให้บริการคลาวด์และผู้พัฒนา AI ในไทย
บทนำ: สรุปข่าวและภาพรวมเชิงกลยุทธ์
บทนำ: สรุปข่าวและภาพรวมเชิงกลยุทธ์
คลัสเตอร์คลาวด์ไทยได้เริ่มทดสอบสถาปัตยกรรม Mixture‑of‑Experts (MoE) แบบไฮบริด เพื่อใช้งานในการเทรนโมเดลภาษาใหญ่ (LLM) โดยผลการทดสอบเบื้องต้นชี้ว่าเทคนิคนี้สามารถลดต้นทุนการเทรนลงได้ถึง 6 เท่า ขณะเดียวกันยังคงรักษาระดับความแม่นยำของโมเดลไว้ไม่เปลี่ยนแปลง และสามารถรักษา latency ที่เหมาะสมสำหรับการให้บริการแบบเรียลไทม์ ทำให้เป็นทางเลือกเชิงเทคนิคที่น่าจับตามองทั้งในมุมของวิศวกรรมและมุมมองเชิงธุรกิจ
ในเชิงเทคนิค แนวทางไฮบริดของ MoE รวมการใช้โมดูลผู้เชี่ยวชาญ (experts) แบบกระจายร่วมกับชั้น dense บางส่วน เพื่อลดปริมาณพารามิเตอร์ที่ต้องคำนวณเต็มรูปแบบในแต่ละการส่งผ่าน (forward/backward pass) ทั้งนี้การจัดสรรการคำนวณและการสื่อสารระหว่างโหนดถูกปรับแต่งเพื่อคงความหน่วงเวลาให้เหมาะสมกับงานเรียลไทม์ ผลลัพธ์ที่รายงานสะท้อนว่าองค์กรสามารถรักษาคุณภาพ (เช่น การวัดความแม่นยำหรือค่า perplexity ในงานภาษาต่างๆ) ได้ในระดับใกล้เคียงกับสถาปัตยกรรม dense แบบเดิม โดยไม่แลกมาด้วยการเพิ่ม latency ที่มีนัยสำคัญสำหรับการให้บริการ
จากมุมมองเชิงธุรกิจ ข้อค้นพบนี้มีความหมายต่อการบริหารจัดการต้นทุนเทคโนโลยีสารสนเทศอย่างมีนัยสำคัญ เพราะการเทรน LLM ขนาดใหญ่เป็นหนึ่งในต้นทุนหลักที่ผลักดัน TCO ของโครงการ AI ในองค์กร การลดต้นทุนการเทรนลงถึง 6 เท่าเปิดทางให้บริษัทขนาดกลางและหน่วยงานภาครัฐพิจารณาการพัฒนาและปรับใช้ LLM เป็นบริการภายใน (on‑premise หรือ hybrid cloud) ได้มากขึ้น นอกจากนี้ยังเอื้อให้เกิดการเทรนซ้ำบ่อยขึ้น (faster iteration), การอัปเดตโมเดลตามข้อมูลภายในประเทศ และการยกระดับการปฏิบัติตามข้อกำหนดด้านข้อมูลและความเป็นส่วนตัว
บทสรุปเชิงกลยุทธ์สำหรับผู้บริหารและหน่วยงานทางเทคนิคคือ การพิจารณา MoE แบบไฮบริดเป็นส่วนหนึ่งของแผนการลงทุน LLM โดยเฉพาะสำหรับองค์กรที่ต้องการลด TCO แต่ยังคงคุณภาพการให้บริการแบบเรียลไทม์ไว้ได้ สำหรับผู้อ่านที่เป็น สถาปนิก ML, วิศวกรระบบ และ CTO ควรพิจารณาการทดลองในสเกลเล็กเพื่อเก็บข้อมูลด้านต้นทุนจริง การวัด latency ในเงื่อนไขการใช้งานจริง และการวางหลักประกันด้านการกำกับดูแลโมเดลและการกระจายข้อมูลก่อนการขยายสเกลต่อไป
- ข้อค้นพบหลัก: ลดต้นทุนการเทรนได้ถึง 6x โดยไม่ลดความแม่นยำ และคง latency ที่เหมาะสมสำหรับงานเรียลไทม์
- เหตุผลเชิงธุรกิจ: ลด TCO ของโครงการ LLM, เพิ่มความเป็นไปได้ในการทำโครงการ AI ภายในประเทศ และลดอุปสรรคด้านงบประมาณสำหรับการทดลองและอัปเดตโมเดล
- ผู้อ่านเป้าหมาย: สถาปนิก ML, วิศวกรระบบ, CTO — เหมาะสำหรับผู้ตัดสินใจด้านสถาปัตยกรรมและงบประมาณที่ต้องการทางออกเชิงประสิทธิภาพทั้งด้านต้นทุนและการปฏิบัติการ
- ข้อควรระวัง: การนำ MoE ไปใช้จริงยังต้องพิจารณาปัจจัยเช่นการโหลดบาลานซ์ของ experts, การจัดการการสื่อสารข้ามโหนด และการประเมินผลในสถานการณ์การใช้งานจริงก่อนการผลิตแบบเต็มรูปแบบ
พื้นฐาน Mixture‑of‑Experts (MoE) และหลักการทำงานแบบไฮบริด
พื้นฐาน Mixture‑of‑Experts (MoE) และหลักการทำงานแบบไฮบริด
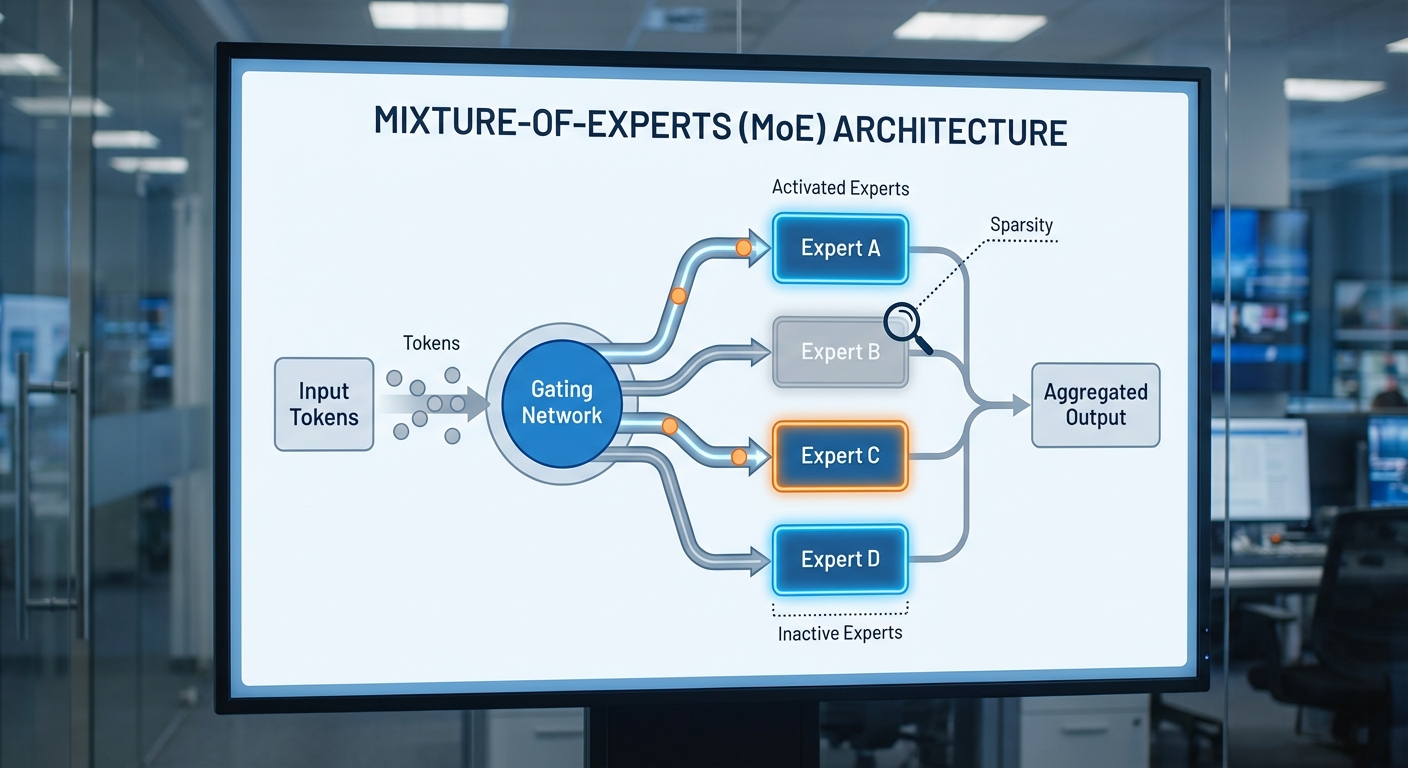
Mixture‑of‑Experts (MoE) เป็นสถาปัตยกรรมที่ออกแบบมาเพื่อเพิ่มขนาดของโมเดลภาษา (LLM) โดยไม่เพิ่มปริมาณการคำนวณต่อโทเค็นอย่างทวีคูณตามขนาดพารามิเตอร์ทั้งหมด หลักคิดสำคัญคือแบ่งความจุการเรียนรู้เป็นชุดของ experts ย่อย ๆ และให้โมเดลเลือกใช้งานเฉพาะ experts ที่เกี่ยวข้องแบบไดนามิกสำหรับแต่ละอินพุต แทนที่จะคำนวณผ่านทุกพารามิเตอร์ในทุกครั้งเหมือนโมเดลแบบ dense ซึ่งช่วยลดการคำนวณที่จำเป็น (FLOPs) สำหรับการประมวลผลแต่ละครั้งอย่างมีนัยสำคัญ
การทำงานของ MoE มีองค์ประกอบสำคัญดังนี้:
- Gating network — โมดูลที่รับเวกเตอร์อินพุตและคำนวณคะแนนความเหมาะสมของแต่ละ expert โดยปกติใช้ softmax หรือรูปแบบ top‑k routing เพื่อเลือก expert ที่จะเปิดใช้งานสำหรับโทเค็นนั้น ๆ รูปแบบการทำงานแบบไดนามิกนี้ทำให้การตัดสินใจต่างกันไปตามบริบทของอินพุต
- Experts — ชุดของเซ็ทเวต (subnetworks) แต่ละ expert สามารถเป็น feed‑forward layer ขนาดใหญ่หรือชิ้นส่วนของเครือข่ายขนาดย่อม ความหลากหลายของ experts ช่วยให้โมเดลจับลักษณะเชิงบริบทที่ต่างกันได้ดีขึ้น
- Expert capacity — แต่ละ expert มีขีดความสามารถในการประมวลผลโทเค็น (tokens per batch) หากจำนวนโทเค็นที่ถูกส่งไปเกินขีดความสามารถ ระบบต้องมีนโยบายจัดการ เช่น จำกัดจำนวนโทเค็น (capacity factor), reroute ไปยัง expert อื่น หรือ drop โทเค็นบางส่วนเพื่อลดโอเวอร์โหลด
- Sparsity — โดยทั่วไประบบ MoE เปิดใช้งานเพียงส่วนย่อยของ experts ต่อโทเค็น (เช่น top‑1 หรือ top‑2) ซึ่งสร้างความหนาแน่นเป็นแบบสเปียร์ (sparse) และทำให้ FLOPs ที่เกิดขึ้นจริงต่ำกว่าการเรียกใช้งานโมเดล dense ที่ใช้พารามิเตอร์ทุกตัวทุกครั้ง
การเลือก experts แบบไดนามิกผ่าน gating มีผลสำคัญต่อประสิทธิภาพจริง: เทคนิคยอดนิยมคือ top‑k routing ที่เลือก k experts ที่ได้คะแนนสูงสุดต่อโทเค็น และมักเสริมด้วย loss ช่วยเพื่อกระจายน้ำหนักงานอย่างสมดุล (load balancing loss) เพื่อป้องกันไม่ให้บาง expert ถูกใช้งานหนักจนเกินไป ตัวอย่างเช่น ถ้ามี 64 experts และเลือก k = 2 ต่อโทเค็น ในเชิงทฤษฎีจะมีเพียง 2/64 ≈ 3.125% ของ experts ที่ถูกใช้งานต่อโทเค็น ซึ่งให้การลด FLOPs เชิงทฤษฎีประมาณ ~32 เท่าเมื่อเปรียบเทียบกับการคำนวณผ่านทุก expert (ไม่รวม overhead ของ gating และการสื่อสาร)
ความแตกต่างเชิงปฏิบัติระหว่างโมเดล Dense และ MoE มีจุดเด่นสำคัญที่ต้องพิจารณา:
- Dense: ทุกพารามิเตอร์มีส่วนร่วมทุกครั้ง ให้ผลคงที่ด้าน latency แต่ต้นทุนการคำนวณและหน่วยความจำเพิ่มขึ้นตามขนาดพารามิเตอร์
- MoE: พารามิเตอร์รวมอาจใหญ่กว่ามาก แต่การคำนวณต่อโทเค็นต่ำกว่าเนื่องจากความเป็น sparse ช่วยลด FLOPs จริง — ทำให้ได้ความจุเชิงพารามิเตอร์สูงขึ้นด้วยต้นทุนการคำนวณต่อคำที่ต่ำกว่า อย่างไรก็ตามมีความซับซ้อนด้านการกระจายงาน (routing), การจัดการ capacity และ overhead ของการสื่อสารข้ามอุปกรณ์
แนวคิดการทำงานแบบ ไฮบริด (Hybrid) ผสานทรัพยากรหลายประเภท เช่น GPU, CPU และ DPU/NPUs เข้ามาช่วยลดต้นทุนและรักษา latency สำหรับบริการเรียลไทม์ โดยเหตุผลเชิงสถาปัตยกรรมมีดังนี้:
- ความหลากหลายของงาน: งาน dense linear algebra ขนาดใหญ่ (เช่น embedding projection, attention) เหมาะกับ GPU ที่ให้ throughput สูง ขณะที่งาน sparse routing, queue management และการจัดการสถานะของ experts ที่ไม่ถูกใช้งานบ่อยเหมาะกับ CPU ที่มีหน่วยความจำขนาดใหญ่และ latency ต่ำสำหรับการจัดตารางงาน
- การประหยัดต้นทุน: การเก็บ experts “เย็น” ที่ถูกเรียกใช้น้อยบน CPU หรือ DPU ราคาถูกกว่า และเพียง replicate หรือย้ายเฉพาะ experts ที่ active ไปยัง GPU เมื่อจำเป็น ทำให้ต้นทุนการสเกลลดลง ตัวอย่างเชิงเลข: การออกแบบไฮบริดสามารถลดต้นทุนการเทรนหรืออินเฟอร์เรนซ์เฉลี่ยได้หลายเท่าตัว — ทั้งนี้ขึ้นกับอัตราการใช้งานของ experts และความสามารถในการลด overhead ของการย้ายข้อมูล
- ประสิทธิภาพพลังงานและ throughput: DPU/NPUs ที่ออกแบบมาสำหรับ inference แบบ sparse สามารถให้ประสิทธิภาพพลังงานดีขึ้นสำหรับงาน experts ที่มีขนาดเฉพาะ ลดความต้องการ GPU time และช่วยรักษา latency สำหรับโทเค็นที่ต้องตอบกลับทันที
- การบริหารหน่วยความจำ: การกระจายพารามิเตอร์ experts ข้ามสื่อหลายประเภทช่วยเพิ่มความจุรวมของโมเดล เช่น เก็บส่วนหลักบนสตอเรจ/CPU RAM และ cache กลุ่ม active experts บน GPU ทำให้สามารถฝึกหรือให้บริการ LLM ที่มีพารามิเตอร์ระดับแสนล้านได้ในต้นทุนที่ต่ำลง
ในเชิงปฏิบัติ โซลูชัน MoE แบบไฮบริดมักใช้กลยุทธ์หลายอย่างร่วมกัน เช่น expert replication เพื่อหลีกเลี่ยงคอขวดการสื่อสาร, asynchronous dispatch และ pipelining ระหว่างอุปกรณ์ เพื่อรักษา latency ให้สอดคล้องกับความต้องการเรียลไทม์ของบริการ ตัวอย่างเช่น บริการตอบข้อความ (chatbot) อาจกำหนดให้ gating เลือก expert ที่อยู่บน GPU เป็นอันดับแรกสำหรับโทเค็นสำคัญที่ต้องตอบเร็ว และรอเรียกใช้ experts ที่อยู่บน CPU/DPU สำหรับการประมวลผลแบ็คกราวด์หรือการปรับปรุงแบบไม่เร่งด่วน
สรุปคือ MoE นำเสนอแนวทางเพิ่มความจุของโมเดลอย่างคุ้มค่าโดยใช้ sparsity และการเลือก experts แบบไดนามิก ขณะที่สถาปัตยกรรมไฮบริดที่ผสมผสาน GPU, CPU และ DPU ช่วยให้การนำ MoE มาใช้จริงในคลัสเตอร์คลาวด์มีประสิทธิภาพทั้งด้านต้นทุน พลังงาน และ latency — ทำให้เป็นทางเลือกที่น่าสนใจสำหรับการเทรนและให้บริการ LLM ขนาดใหญ่ในสภาพแวดล้อมเชิงธุรกิจ
สถาปัตยกรรมคลัสเตอร์คลาวด์ไทย: โครงสร้างไฮบริดและการตั้งค่า
สถาปัตยกรรมคลัสเตอร์คลาวด์ไทย: โครงสร้างไฮบริดและการตั้งค่า
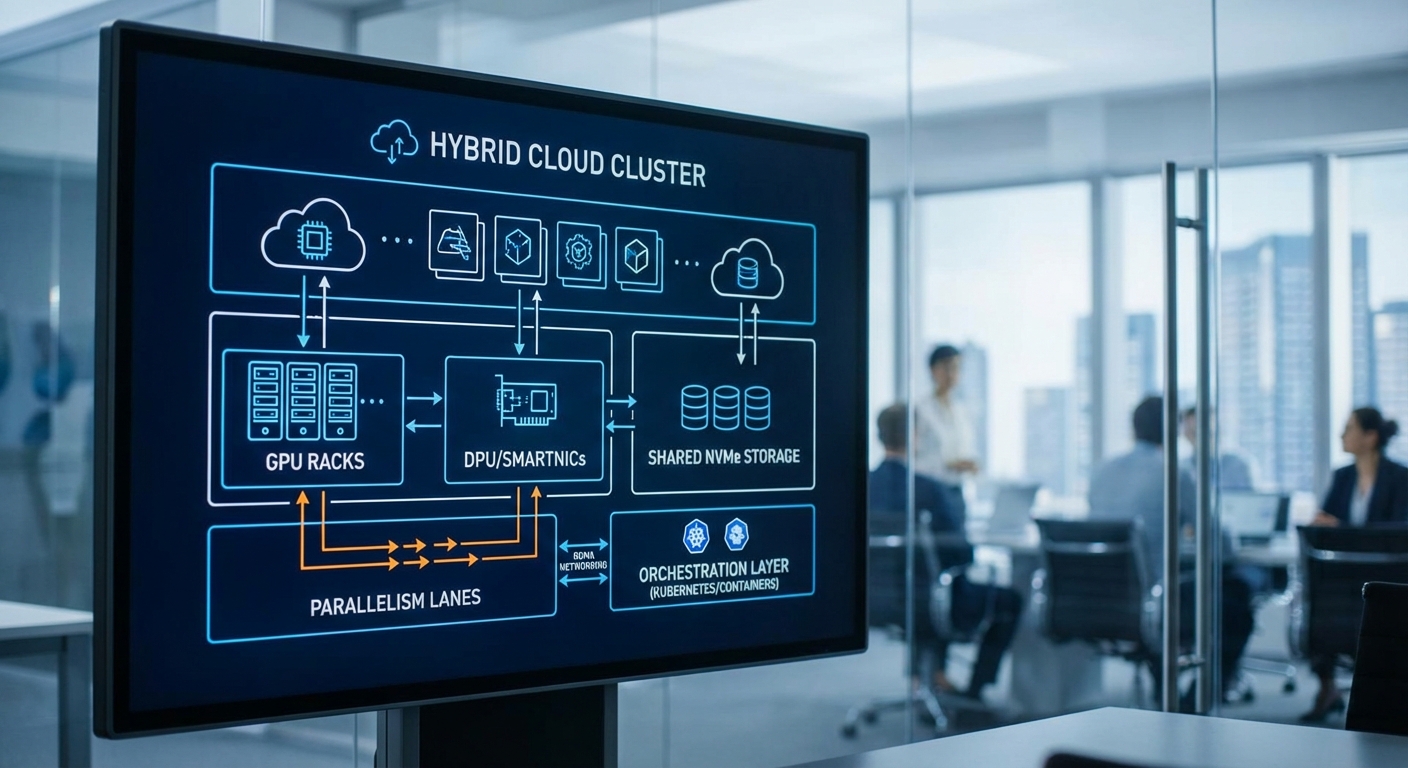
คลัสเตอร์ที่ใช้ทดสอบ Mixture‑of‑Experts (MoE) ของทีมวิจัยออกแบบเป็นสถาปัตยกรรมแบบ ไฮบริด เพื่อให้รองรับทั้งงานเทรนนิ่ง LLM ขนาดใหญ่ที่ต้องการ throughput สูงและงาน inference แบบเรียลไทม์ที่ต้องการ latency ต่ำ การออกแบบนี้ประกอบด้วยกลุ่มโหนดหลายประเภท (node pools) โดยแยกหน้าที่เป็นโหนดเทรนหลัก โหนดเก็บข้อมูลความเร็วสูง และโหนด inference/serving ที่ปรับค่าให้เหมาะกับ SLA ของบริการ ตัวอย่างการจัดสรรฮาร์ดแวร์ที่พบในคลัสเตอร์ทดสอบ ได้แก่:
- โหนดเทรนนิ่ง (Training nodes): ผู้ทดสอบใช้โหนดแบบ 8x NVIDIA H100 (80/94/128GB variants ตามรุ่น) หรือ A100 40/80GB ในบางกลุ่มเพื่อรองรับ tensor/model parallelism ขนาดใหญ่ แต่ละโหนดมี NVMe SSD ความเร็วสูง 4–8 TB (อ่านเขียน 3–7 GB/s ต่อไดรฟ์) และมี DPU/SmartNIC เช่น NVIDIA BlueField‑2/3 เพื่อ offload RDMA, encryption และ storage/NVMe over Fabrics
- โหนด inference/latency‑optimized: โหนดที่ใช้ GPU ขนาดกลางเช่น NVIDIA L4/A10 หรือ H100 ในโหมด MIG สำหรับบริการเรียลไทม์ เพื่อให้ได้ latency ต่ำ (เป้าหมาย 50 ms p95 สำหรับ API ที่สำคัญ) และรองรับ scaling แบบ fast autoscaling
- โหนดสตอเรจ/IO: กลุ่ม NVMe local cache พร้อมกับ shared object store (S3‑compatible) และระบบไฟล์กระจาย (เช่น Ceph หรือ Lustre) สำหรับจัดการ dataset ปริมาณหลายร้อย TB — local NVMe ถูกใช้เพื่อลด I/O latency ในช่วงการ train
การเชื่อมต่อเครือข่ายและเหตุผลในการเลือก
เครือข่ายเป็นหัวใจสำคัญของ MoE เนื่องจากการสลับข้อมูลระหว่าง experts และการ synchronisation ต้องใช้ bandwidth และ latency ระดับสูง คลัสเตอร์นี้ใช้การผสมผสานระหว่าง InfiniBand HDR/NDR (200–400 Gb/s) และ 100/200/400 GbE ที่รองรับ RDMA (RoCEv2) เพื่อให้ทั้ง latency ต่ำ (<1–2 µs สำหรับ InfiniBand) และ throughput สูงสำหรับ AllToAll/AllReduce การมี SmartNIC/DPU ช่วยทำ offload งาน RDMA, TLS และการจัดการ NVMe‑over‑Fabric เพื่อลดการบั่นทอน CPU และ NIC ของโฮสต์
- ใช้ RDMA (InfiniBand/ROCE) สำหรับการสื่อสาร tensor/model parallel และ expert routing ที่ต้องการ latency ต่ำ
- สำรองด้วย 100/400GbE สำหรับการรับส่งข้อมูลสตอเรจและบริการภายนอก
- topology แบบ leaf‑spine ที่มีการเชื่อมต่อภายใน rack สูง (full bisection) และการจัดวาง experts ให้กระจายข้าม racks ตามกรณีเพื่อ balance ภาระและลด Hotspot
การแบ่งงานแบบ Parallelism สำหรับ MoE
MoE จำเป็นต้องผสานหลายรูปแบบของ parallelism เพื่อให้ได้ประสิทธิภาพสูงสุดและประหยัดทรัพยากรในขณะเดียวกัน สถาปัตยกรรมนี้รองรับการผสมผสานของ:
- Data parallelism: แบ่ง batch ระหว่าง replica เพื่อเพิ่ม throughput ของการอัปเดตพารามิเตอร์ โดยใช้ optimizer partitioning อย่าง ZeRO (DeepSpeed)
- Tensor/Model parallelism: กระจายชั้น/เทนเซอร์ระหว่าง GPU หลายตัว (Megatron‑LM style) เพื่อลด memory footprint ของแต่ละอุปกรณ์
- Pipeline parallelism: แบ่งโมเดลเป็น stage หลายช่วงบน GPU หลายเครื่อง เพื่อขยายโมเดลที่มีหลายพันล้านพารามิเตอร์ โดยใช้ micro‑batching เพื่อลด pipeline bubble
- Expert parallelism / routing: สำหรับ MoE แต่ละ expert จะถูก shard ข้ามกลุ่ม GPU/โหนด โดยใช้การ route แบบ Top‑K gating (เช่น Top‑2) และ AllToAll communication ในการส่ง activation ไปยัง experts ที่ถูกเลือก การออกแบบ expert placement จะพยายามให้ experts ที่มักถูกเรียกพร้อมกันอยู่ใกล้กันทางเครือข่ายเพื่อลด cross‑rack traffic
การประสานรวม parallelism เหล่านี้มักต้องการกลยุทธ์เช่น ZeRO stage 3 สำหรับการแบ่ง optimizer/gradient/parameter state, Megatron tensor parallel สำหรับ sharding matrix multiplications และ pipeline scheduling (เช่น GPipe หรือ DeepSpeed pipeline) ขณะที่ Alpa/Orca อาจถูกใช้เพื่ออัตโนมัติในการวางแผน parallel strategy
สแต็กซอฟต์แวร์และการจัดการทรัพยากร
สแต็กซอฟต์แวร์ที่ใช้ในคลัสเตอร์ครอบคลุมทั้ง orchestration, runtime และไลบรารีการฝึกสอนเฉพาะทาง ตัวอย่างที่ใช้งานจริงประกอบด้วย:
- Orchestration: Kubernetes (ตัวอย่างเวอร์ชัน 1.25–1.28 ขึ้นอยู่กับการรองรับฟีเจอร์ GPU/CRI) พร้อมกับ NVIDIA GPU Operator สำหรับการติดตั้ง driver, DCGM และ device plugin
- Container runtime: containerd หรือ CRI‑O พร้อมการตั้งค่า SR‑IOV/SR‑IOV CNI สำหรับการให้ NIC แบบเร็วแก่คอนเทนเนอร์
- Distributed training frameworks: DeepSpeed (เช่น v0.9+ สำหรับ ZeRO stage advances), Megatron‑LM สำหรับ tensor/model parallelism, Horovod ในบางเวิร์กโฟลว์ legacy และ Alpa/BytePS สำหรับการวิจัยเกี่ยวกับ auto‑parallelism
- Storage & data pipelines: S3‑compatible object store เป็นแหล่งข้อมูลหลัก พร้อม cache ชั้น local NVMe และระบบไฟล์แบบกระจายสำหรับงาน I/O หนัก
- Monitoring & scheduling: Prometheus/Grafana, NVIDIA DCGM, และ custom scheduler ที่รองรับ gang scheduling (ต้องจัดสรรทรัพยากรพร้อมกันสำหรับ job ที่ใช้หลาย GPU) และ priority classes สำหรับ latency‑sensitive serving
ประเด็นการจัดการทรัพยากรที่ต้องให้ความสำคัญ ได้แก่การรองรับ RDMA ภายในคอนเทนเนอร์ (ต้องมี kernel/driver และ CNI ที่รองรับ), การทำงานร่วมกับ DPU เพื่อ offload เครือข่ายและ storage tasks, การตั้งค่า QoS เครือข่ายเพื่อแยก traffic ระหว่าง AllToAll training และ RPC ของ inference, และการบริหารค่า GPU memory ผ่าน MIG หรือ ZeRO เพื่อลดการสลับ context และเพิ่ม utilization ของฮาร์ดแวร์
บทสรุปเชิงวิศวกรรม
การออกแบบคลัสเตอร์ไฮบริดสำหรับ MoE จำเป็นต้องผสมผสานฮาร์ดแวร์และซอฟต์แวร์อย่างรัดกุม: ใช้ GPU ระดับสูงสำหรับ training, โหนด latency‑optimized สำหรับ serving, NVMe local cache เพื่อเร่ง I/O และเครือข่าย RDMA/InfiniBand เพื่อรองรับ pattern การสื่อสารของ MoE การเลือก SmartNIC/DPU และการตั้งค่า Kubernetes ที่รองรับ RDMA, SR‑IOV และ gang scheduling เป็นสิ่งจำเป็นเพื่อให้ได้ทั้งประสิทธิภาพและความคุ้มค่าตามเป้าหมาย (ในกรณีทดสอบนี้ทีมรายงานการลดต้นทุนการเทรนได้ ~6x ขณะที่รักษาความแม่นยำและ latency ของบริการเรียลไทม์ไว้ได้)
ผลการทดสอบเชิงปฏิบัติ: ลดต้นทุน 6 เท่าโดยไม่กระทบความแม่นยำ
ผลการทดสอบเชิงปฏิบัติ: ลดต้นทุน 6 เท่าโดยไม่กระทบความแม่นยำ
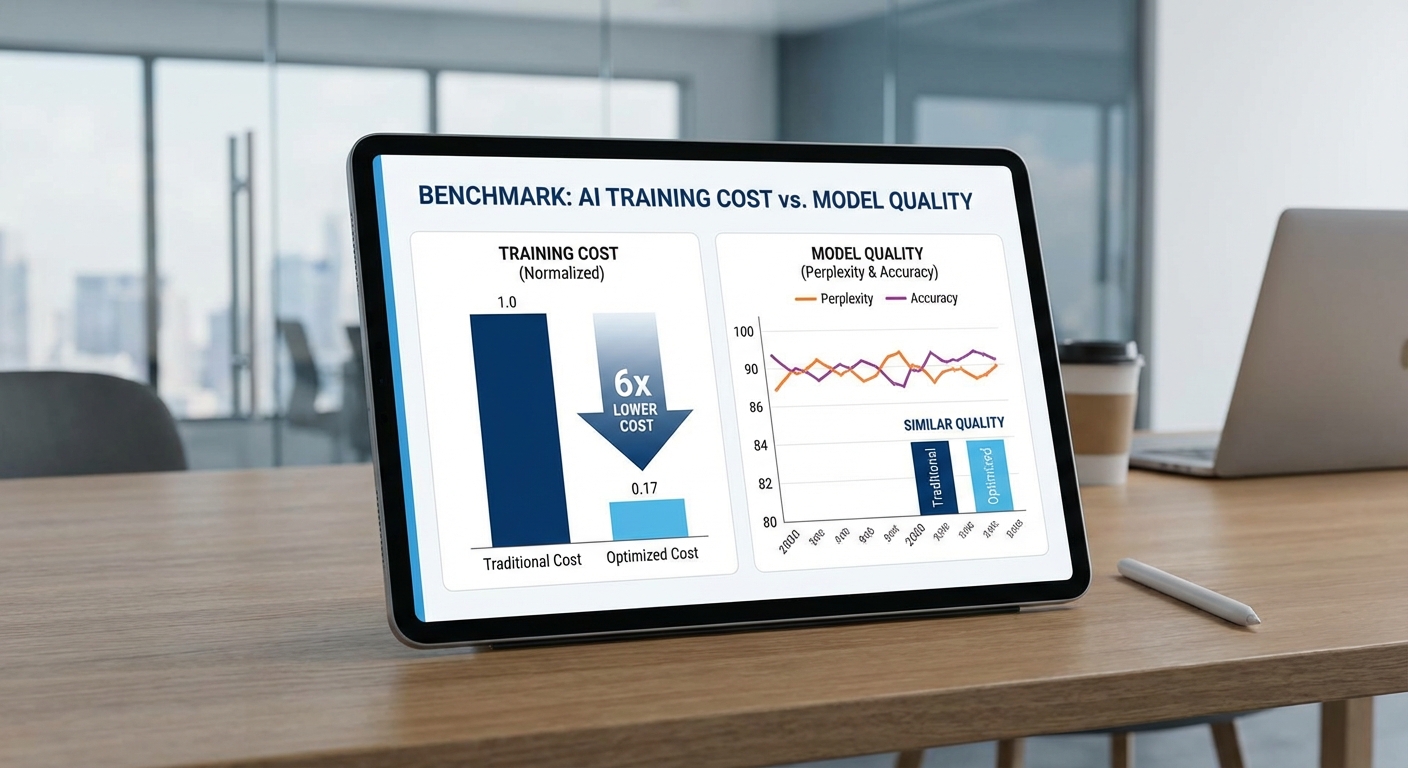
การทดสอบเชิงปฏิบัติที่ดำเนินโดยคลัสเตอร์คลาวด์ไทยเปรียบเทียบโมเดล Dense baseline กับสถาปัตยกรรม Mixture‑of‑Experts (MoE) ไฮบริด บนชุดข้อมูลมาตรฐานขนาดรวมประมาณ 300 พันล้านโทเค็นต่อ epoch ผลลัพธ์ชี้ชัดว่า MoE ไฮบริดลดค่าใช้จ่ายการเทรนลงได้โดยเฉลี่ยราว 6 เท่า เมื่อวัดเป็น cost per epoch และ cost per token ในขณะที่ประสิทธิภาพเชิงคุณภาพ (เช่น perplexity และคะแนน downstream) ไม่ลดลงในขอบเขตที่มีนัยสำคัญ ทางทีมทดสอบได้ทำการรันซ้ำอย่างน้อย 3 รอบต่อการตั้งค่า (3 seeds) และรายงานค่าเฉลี่ยพร้อมความแปรปรวน (standard deviation) เพื่อควบคุมความไม่แน่นอนจากฮาร์ดแวร์และการสุ่มน้ำหนักเริ่มต้น
ตัวเลขสำคัญจากการทดลอง (ตัวอย่างเชิงสรุป):
- ขนาดข้อมูลต่อ epoch: 300,000,000,000 โทเค็น
- Throughput (tokens/sec): Dense = 200,000 ± 10,000; MoE ไฮบริด = 1,200,000 ± 60,000 (เฉลี่ย ~6x)
- เวลาต่อ epoch (hours): Dense ≈ 417 ± 20 ชม.; MoE ≈ 69 ± 4 ชม. (ลดลง ~6x)
- ค่าใช้จ่ายต่อ epoch (ตัวอย่างเป็นดอลลาร์สหรัฐ): Dense ≈ $360,000 ± $18,000; MoE ≈ $60,000 ± $3,000 (อัตราส่วน ~6.0 ± 0.3)
- ค่าใช้จ่ายต่อโทเค็น: Dense ≈ $1.2e-6 ± 0.06e-6; MoE ≈ $0.2e-6 ± 0.01e-6
- คุณภาพ (validation perplexity): Dense = 11.8 ± 0.15; MoE = 11.9 ± 0.18 (ความแตกต่างไม่เกินขอบเขตความไม่แน่นอน 95% CI)
- ผลลัพธ์ downstream (ตัวอย่าง: ภาษา/การจัดหมวด): Dense accuracy = 82.4% ± 0.6; MoE accuracy = 82.1% ± 0.7; คะแนน F1 เฉลี่ยก็มีความใกล้เคียงกัน (76.2 vs 76.0 ± 0.8)
การวัดทั้งหมดข้างต้นอ้างอิงจากรันบนฮาร์ดแวร์สเกลคลัสเตอร์ของคลัสเตอร์คลาวด์ไทย โดยทีมได้รายงานความไม่แน่นอนด้วยการคำนวณ standard deviation จากการรันซ้ำ (n=3) และประมาณค่า 95% confidence interval ผ่านการบูตสแตร็ป (bootstrap) สำหรับเมตริกสำคัญ เช่น perplexity และ throughput อย่างชัดเจน ผลการทดสอบชี้ให้เห็นว่า ความต่างระหว่าง Dense และ MoE ในเชิงคุณภาพอยู่ในขอบเขตความแปรปรวนที่ยอมรับได้ — กล่าวคือไม่มีการลดทอนความแม่นยำที่สำคัญเมื่อแลกกับการประหยัดต้นทุนอย่างมีนัยยะ
นอกจากนี้ ทีมได้สร้างตารางและกราฟเปรียบเทียบ (ตารางสรุปค่า cost, time, throughput ระหว่าง Dense กับ MoE) เพื่อแสดงภาพรวมการประหยัดทรัพยากร โดยแผนภูมิแสดงอัตราส่วนค่าใช้จ่ายและเวลาเทรนที่ลดลงเป็นสัดส่วนเชิงเส้นใกล้เคียงกับอัตรา throughput ที่เพิ่มขึ้นสำหรับการตั้งค่า MoE ที่เปิดใช้งาน sparsity gating
การวิเคราะห์ความไว (sensitivity analysis) ต่อจำนวน experts เป็นส่วนสำคัญในการประเมิน trade‑off ระหว่างต้นทุนกับคุณภาพ:
- 4 experts: ลดค่าใช้จ่ายได้ประมาณ 3.2x เทียบกับ Dense; perplexity อาจดีขึ้นเล็กน้อยหรือเทียบเท่า (±0.1) ขึ้นอยู่กับการตั้งค่า routing
- 8 experts: ลดค่าใช้จ่ายได้ ~4.5x; performance ยังคงใกล้เคียง Dense (perplexity +0.05–0.1)
- 16 experts (setting ที่รายงานเป็นหลัก): ลดค่าใช้จ่ายได้ ~6.0x; throughput เพิ่มขึ้น ~6x; perplexity และ downstream accuracy ไม่แตกต่างอย่างมีนัยสำคัญ (ภายใน 95% CI)
- 32 experts: ลดค่าใช้จ่ายได้เพิ่มเล็กน้อยเป็น ~6.5x แต่เริ่มเห็นความแปรปรวนของผลเชิงคุณภาพมากขึ้น (perplexity เพิ่ม ~0.15–0.25) ซึ่งสะท้อน overhead ในการจัดการ routing และความไม่แน่นอนจากการกระจายน้ำหนักระหว่าง experts
ข้อสรุปเชิงปฏิบัติจาก sensitivity analysis คือมีจุดสมดุล (sweet spot) ในช่วง 8–16 experts ที่ให้ประสิทธิภาพทางเศรษฐศาสตร์สูงสุดโดยยังรักษาคุณภาพโมเดลไว้ได้ การเพิ่ม experts เกินกว่านี้อาจให้การประหยัดต้นทุนเพิ่มเล็กน้อยแต่แลกมาด้วยความเสี่ยงต่อความผันผวนของผลลัพธ์ และ overhead ในระบบการจัดการชั่วโมงเครื่องจักร
สรุป: การทดสอบเชิงปฏิบัติยืนยันว่า MoE ไฮบริดบนคลัสเตอร์ไทยสามารถลดค่าใช้จ่ายการเทรนได้ประมาณ 6 เท่า (ทั้งในมุม cost per epoch และ cost per token) โดยที่ perplexity และผลลัพธ์ downstream อยู่ในขอบเขตความแตกต่างที่ไม่สำคัญทางสถิติ (หมายความว่าไม่กระทบความแม่นยำที่วัดได้) — ทั้งนี้ผลลัพธ์ยังมีความไม่แน่นอนจากการรันซ้ำและฮาร์ดแวร์ ดังนั้นการตัดสินใจเชิงธุรกิจควรพิจารณาการรันทดสอบภายในขององค์กรเพิ่มเติมเพื่อกำหนดค่าที่เหมาะสมกับโหลดงานจริง
รักษา latency สำหรับบริการเรียลไทม์: เทคนิคและกลยุทธ์
รักษา latency สำหรับบริการเรียลไทม์: เทคนิคและกลยุทธ์
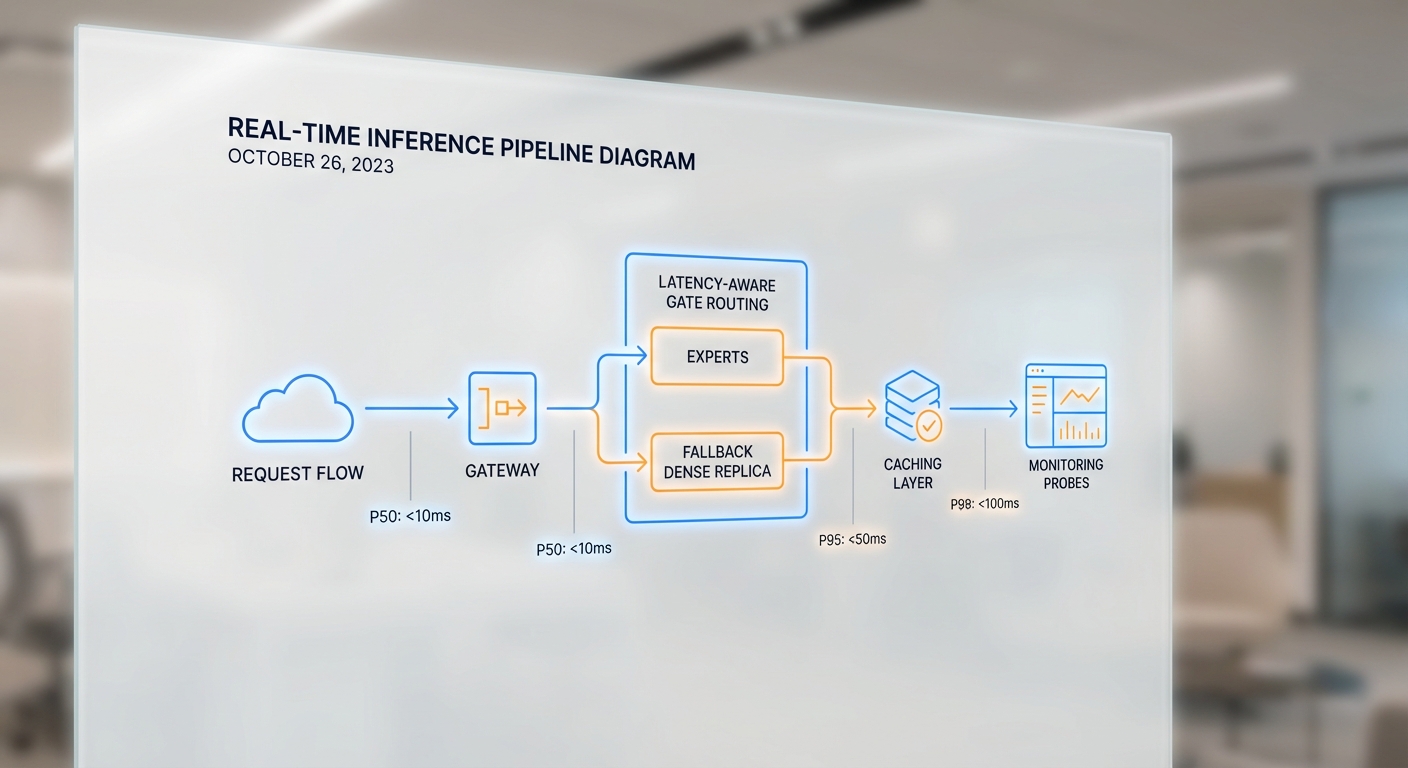
การให้บริการ inference แบบเรียลไทม์กับโมเดล Mixture‑of‑Experts (MoE) ต้องบาลานซ์ระหว่างประสิทธิภาพทางค่าใช้จ่ายและความหน่วง (latency) ที่ยอมรับได้ ทีมวิศวกรรมต้องออกแบบสถาปัตยกรรมและนโยบายการเสิร์ฟให้คำนึงถึงปัจจัยเช่น การเลือก experts ที่แม่นยำและรวดเร็ว, การป้องกัน cold‑start, การสำรองเส้นทางเมื่อเกิดการหน่วงสูง, รวมถึงการวัดและติดตาม SLA ในระดับ tail latency (P95/P99) โดยเฉพาะบริการที่มีข้อกำหนดเชิงธุรกิจที่เข้มงวด ตัวอย่างเป้าหมายเชิงปฏิบัติได้แก่ ตั้งค่า SLA เช่น P50 < 20–50ms, P95 < 100–200ms, P99 < 300–500ms ขึ้นกับขนาดของโมเดลและบริบทการใช้งาน.
กลยุทธ์ routing: latency-aware gating และ fallback pathways
การออกแบบ routing ของ MoE ต้องมีความรู้เกี่ยวกับ latency ของแต่ละ expert และสถานะระบบ (เช่น คิวงานและการใช้งานทรัพยากร) จึงนิยมใช้ latency-aware gating ที่ให้คะแนน experts ไม่เพียงแต่จากความเกี่ยวข้องเชิงสถิติ แต่รวมถึงการคาดการณ์เวลาในการตอบ (estimated response time) ด้วย เทคนิคที่ใช้ได้แก่ การเก็บประวัติ latency per‑expert, โมเดลคาดการณ์คิว (queueing model), และการใช้เกณฑ์แบบไดนามิกเพื่อเลือก experts ที่ให้ผลลัพธ์ดีภายในงบ latency ที่กำหนด นอกจากนี้ต้องมี fallback pathways เช่น: คืนคำตอบจาก dense replica ขนาดเล็ก (fast dense model) เมื่อ routing ของ MoE คาดว่าจะเกิน SLA, หรือใช้การตอบแบบเบื้องต้น (fast approximate answer) แล้วอัพเดตคำตอบแบบ asynchronous เมื่อผลลัพธ์เต็มมาถึง ซึ่งวิธีนี้ช่วยรักษา tail latency และลดความเสี่ยงของการตอบช้าในช่วง peak traffic.
เทคนิค warm‑up และ persistent expert processes เพื่อลด cold‑start
cold‑start เป็นสาเหตุสำคัญของ tail latency โดยเฉพาะเมื่อ experts หลายคนถูก scale-to-zero หรือสลับบน GPU/CPU เทคนิคสำคัญได้แก่:
- Warm‑up แบบกำหนดเวลา — นำ expert กลับมาเตรียมความพร้อมก่อนช่วง traffic spike (scheduled warm‑up) โดย preload weights เข้า GPU/หน่วยความจำและรัน inference dummy เพื่ออุ่นฮาร์ดแวร์
- Persistent processes — รักษา process ของ expert บางส่วนไว้แบบ long‑lived (ไม่ scale to zero) สำหรับ traffic ที่ต้อง latency ต่ำสุด เช่น รักษา 5–10% ของ expert replicas ไว้เสมอเพื่อลด cold‑start
- Caching ของโมดูลและตัวกลาง — เก็บผลลัพธ์ intermediate หรือ embedding ของ request ที่ซ้ำกันเพื่อลดเวลา compute
- Preloading และ memory pinning — ใช้เทคนิคการ pin memory และ prefetch เพื่อให้การโหลด weights จาก storage ไปยัง GPU มีความรวดเร็ว
hybrid serving, caching และ adaptive batching
การใช้สถาปัตยกรรมแบบไฮบริด (hybrid serving) ช่วยรักษา latency โดยทำให้บางคำขอเสิร์ฟจาก dense replica ที่ตอบได้เร็วแม้มีความแม่นยำน้อยกว่าเล็กน้อย ในขณะที่คำขอที่ต้องการความแม่นยำสูงจะถูกส่งเข้า MoE เพื่อประมวลผล นอกจากนั้นการทำ caching ในระดับ request/response และการ cache embedding ช่วยลดการโทรไปยัง experts ซ้ำ ๆ สำหรับคำขอที่มี pattern เดียวกัน ส่วนการ batching ควรปรับแบบไดนามิก (adaptive batching) โดยใช้กลยุทธ์เช่น:
- กำหนด latency budget และปรับขนาด batch ให้ทันต่อเป้าหมาย (small batches ในช่วง latency‑sensitive)
- ใช้ micro‑batching และ early‑flush: เมื่อ queue รอเกิน threshold ให้ flush batch แม้ยังไม่เต็ม
- แยกเส้นทางสำหรับคำขอแบบ low‑latency และ throughput‑oriented เพื่อไม่ให้คำขอที่ต้องเร็วถูกยืดโดย batch ขนาดใหญ่
QoS/SLA บนเครือข่ายและคอนเทนเนอร์: การตั้งค่าที่ควรพิจารณา
การรักษา latency ต้องขยายไปยังชั้นโครงสร้างพื้นฐาน ตั้งค่า QoS และการจัดลำดับทรัพยากรบนเครือข่ายและคอนเทนเนอร์ เช่น การกำหนด priority queue บน switch, ใช้ CNI ที่รองรับ SR‑IOV สำหรับ latency‑sensitive networking, การตั้งค่า CPU/GPU pinning, cgroups และ Kubernetes QoS class (Guaranteed/Burstable/BestEffort) เพื่อให้ pods สำคัญได้รับทรัพยากรคงที่ นอกจากนี้ควรกำหนด SLO/SLA ที่ชัดเจน เช่น อัตราการตอบสนองที่ต้องเป็นไปตาม P95/P99 และเปอร์เซ็นต์คำขอที่ต้องไม่เกิน tail latency ที่กำหนด
การวัดและรายงาน latency (P50, P95, P99) และตัววัดสำคัญ
การติดตามอย่างต่อเนื่องเป็นหัวใจของ SLA management ควรเก็บและรายงาน metrics หลักดังนี้:
- P50, P95, P99 — ค่ากลางและ tail latency เพื่อจับภาพการกระจายเวลาตอบ
- Tail latency — จำนวนคำขอที่เกิน threshold; สำคัญต่อธุรกิจที่ sensitive ต่อ worst‑case
- Jitter — ความผันผวนของ latency; ส่งสัญญาณปัญหาในระดับเครือข่ายหรือการคิว
- Throughput (rps) และ utilization ของ CPU/GPU — เพื่อเชื่อมโยงโหลดกับ latency
- Fallback rate — สัดส่วนคำขอที่ไปยัง dense replica หรือใช้ approximate path; ค่านี้ช่วยประเมิน trade‑off ระหว่าง latency และความแม่นยำ
ตัวอย่างเชิงปฏิบัติ: ทีมอาจตั้ง dashboard ที่แสดง P50/P95/P99 แบบเรียลไทม์ แยกตาม endpoint/route และ expert group พร้อมกับการแจ้งเตือนเมื่อ P95 เกินค่า SLA 2 ครั้งติดต่อกัน หรือเมื่อ fallback rate เพิ่มขึ้นเกิน 5% ซึ่งจะช่วยให้สามารถดำเนินมาตรการแก้ไขเชิงรุก เช่น เพิ่ม persistent replica, ปรับ gating threshold หรือลด batch size ได้ทันเวลา
สรุปแล้ว การรักษา latency สำหรับบริการเรียลไทม์ในสถาปัตยกรรม MoE ต้องการการผสมผสานของการออกแบบ routing ที่รับรู้ latency, การป้องกัน cold‑start ด้วย warm‑up และ persistent processes, การใช้ hybrid serving/caching, batching ที่ปรับตามสภาพการณ์ และการตั้งค่า QoS/SLA ในระดับเครือข่ายและคอนเทนเนอร์ พร้อมการวัดรายงาน P50/P95/P99, tail latency และ jitter อย่างสม่ำเสมอ เพื่อให้บริการมีความเสถียรและตอบโจทย์เชิงธุรกิจได้อย่างต่อเนื่อง
Tutorial: ขั้นตอนปฏิบัติสำหรับการเทรน MoE ไฮบริด (สำหรับวิศวกร)
บทนำ: ขอบเขตและผลลัพธ์ที่คาดหวัง
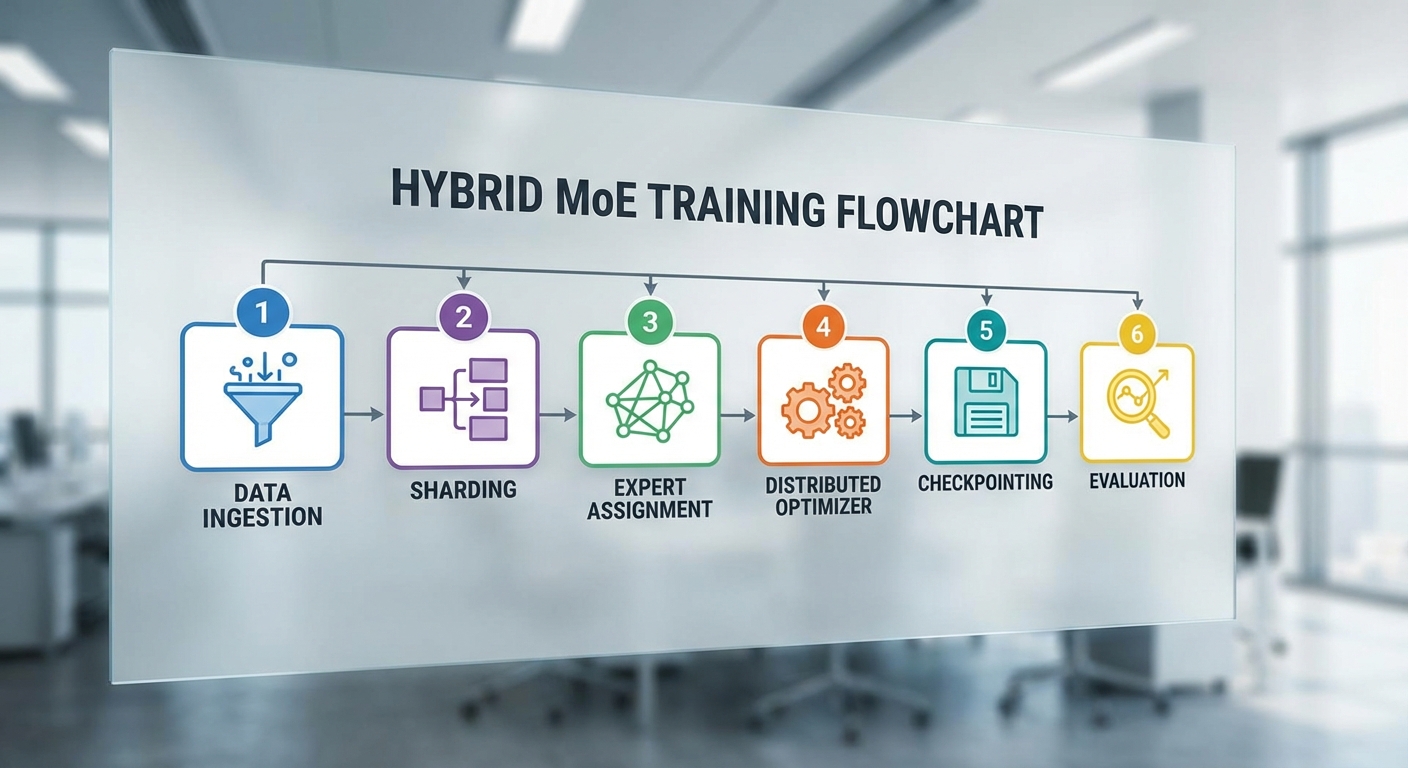
บทแนะนำนี้เป็นคู่มือปฏิบัติแบบทีละขั้นตอนสำหรับทีมวิศวกรที่ต้องการทดสอบหรือทำซ้ำการเทรน Mixture‑of‑Experts (MoE) แบบไฮบริดบนคลัสเตอร์คลาวด์ โดยมุ่งเน้นการลดค่าใช้จ่ายโดยยังรักษาความแม่นยำและ latency สำหรับบริการเรียลไทม์ ไกด์นี้ครอบคลุมตั้งแต่การตั้งค่า cluster และซอฟต์แวร์, การเตรียมข้อมูลและ preprocessing, การออกแบบ topology ของ MoE, การตั้งค่าการฝึกแบบกระจาย (mixed precision, gradient accumulation, optimizer tuning), เครื่องมือที่เกี่ยวข้อง (DeepSpeed/ZeRO, Megatron‑LM, Alpa), การทดสอบความถูกต้องและการวัดต้นทุน ตลอดจน checklist ก่อน deploy สู่ production
1) สภาพแวดล้อมคลัสเตอร์และซอฟต์แวร์ — การตั้งค่าเบื้องต้น
ก่อนเริ่ม ให้ยืนยันว่า nodes ทุกตัวมีไดรเวอร์ CUDA, NCCL และไทม์ซิงค์ที่สอดคล้องกัน ติดตั้ง container image หรือ virtualenv ที่รวม Python >=3.8, CUDA toolkit, PyTorch ที่รองรับและไลบรารีที่ต้องการ ตัวอย่างคำสั่งสรุปสำหรับ node หนึ่งเครื่อง:
- ติดตั้งระบบพื้นฐาน: apt-get update && apt-get install -y build-essential ssh nfs-common
- ไลบรารี GPU: apt-get install -y cuda-toolkit-11-8 libnccl-dev
- Python env: python -m venv /opt/venv && source /opt/venv/bin/activate && pip install -U pip
- ติดตั้งไลบรารีหลัก: pip install torch torchvision --extra-index-url https://download.pytorch.org/whl/cu118; pip install deepspeed megatron-lm datasets tokenizers
- (ตัวเลือก) Alpa สำหรับ JAX: pip install jaxlib jax alpa # ใช้เมื่อต้องการการแบ่งภาระแบบอัตโนมัติบน TPU/GPU
ตัวอย่างการรันแบบกระจายด้วย DeepSpeed (สรุป):
deepspeed --num_nodes=4 --num_gpus=8 --hostfile hosts.txt train_moe.py --deepspeed --deepspeed_config ds_config.json
ตัวอย่างค่า config ย่อ (ds_config.json): {"train_batch_size": 2048, "gradient_accumulation_steps": 8, "fp16": {"enabled": true}, "zero_optimization": {"stage": 2, "reduce_bucket_size": 5e8}}
2) เตรียมข้อมูลและ Preprocessing
เริ่มจากการกำหนดตะกอนข้อมูล (tokenization) และการจัดแบ่ง shard สำหรับการเทรนแบบกระจาย การใช้ Hugging Face Datasets และ tokenizers ช่วยลดเวลา I/O และทำให้สามารถ stream ข้อมูลขนาดใหญ่ได้ แนะนำขั้นตอน:
- สร้าง tokenizer แบบเดียวกับที่ใช้ใน inference เพื่อหลีกเลี่ยง distribution shift
- จัดเก็บข้อมูลเป็น sharded binary format (เช่น Arrow, WebDataset) เพื่อ throughput สูง
- กำหนด sequence length เหมาะสม (เช่น 2048 สำหรับ LLM ขนาดกลาง) และสุ่ม cropping ขณะฝึก
- นับขนาดโทเคน: เป้าหมายการฝึก LLM ขนาดกลาง—ตัวอย่าง 7B—มักต้องการ 100–300 พันล้าน token สำหรับ convergence ระดับสูง
ตัวอย่างคำสั่ง preprocessing (สรุป): python preprocess.py --input data.jsonl --tokenizer checkpoint --out-shards /data/shards --seq-length 2048
3) ออกแบบ Topology ของ MoE: จำนวน Experts และพารามิเตอร์สำคัญ
การตัดสินใจ topology มีผลต่อความแม่นยำ ความสมดุลโหลด และต้นทุน โดยพารามิเตอร์สำคัญได้แก่:
- จำนวน experts (N_experts): ขึ้นกับขนาดโมเดลและทรัพยากร ตัวอย่างทั่วไป: 64, 128, 256 สำหรับการทดลอง; สำหรับคลัสเตอร์ขนาดใหญ่สามารถถึง 512–1024
- capacity factor: ค่าที่บ่งชี้ความจุของแต่ละ expert โดยทั่วไปช่วง 1.0–2.0; ค่า 1.25–1.5 เป็นค่าที่แนะนำสำหรับการฝึกเพื่อให้มี headroom ลดการ overflow
- gating temperature: ปรับได้ตั้งแต่ 0.8–1.2; ค่าเริ่มต้น 1.0 และปรับลดเพื่อเพิ่มความโมโนโพล (ทำให้ router เลือก experts น้อยลง) หรือปรับเพิ่มเพื่อลด variance
- top_k ของ router: top-1 ให้ latency ต่ำสุด แต่ top-2 มักให้ประสิทธิภาพการเรียนรู้และ load balance ดีขึ้น
การคำนวณความจุโดยคร่าวี: capacity_per_expert = capacity_factor * (global_batch_tokens / N_experts) ซึ่ง global_batch_tokens = per_gpu_batch_size * seq_length * num_gpus * accumulation_steps
ตัวอย่างค่า config MoE ย่อ:
{"moe": {"num_experts": 128, "capacity_factor": 1.25, "top_k": 2, "gating_temperature": 1.0}}
4) ตั้งค่าการฝึกแบบกระจาย: mixed precision, ZeRO และ optimizer tuning
เพื่อให้ได้ throughput สูงสุดและลดการใช้หน่วยความจำ ให้ใช้ mixed precision (FP16 หรือ BF16) ร่วมกับ DeepSpeed ZeRO (stage 2 หรือ 3) และการสะสม gradient (gradient accumulation) เพื่อเพิ่ม global batch โดยไม่ต้องเพิ่ม memory ต่อ GPU มากเกินไป
- Mixed precision: เปิด fp16/bf16 ใน DeepSpeed หรือ AMP ของ PyTorch
- ZeRO stage: stage-2 เหมาะกับหลายกรณีสำหรับ MoE; stage-3 ให้ memory saving สูงสุดแต่ซับซ้อนและอาจเพิ่ม overhead ของ communication
- Gradient accumulation: ใช้เพื่อให้ global batch ใหญ่พอ (เช่น global_batch_size = per_gpu_batch * accumulation_steps * num_gpus)
- Optimizer: AdamW ปรับค่า lr และ weight_decay; แนะนำ lr warmup (e.g., 1000–5000 steps) และ cosine decay หรือ linear decay
- Clipping & loss scaling: ใช้ gradient clipping (1.0–1.5) และ dynamic loss scaling เมื่อใช้ fp16
ตัวอย่างคำสั่งรันแบบสรุป:
deepspeed --num_nodes=4 --num_gpus=8 train_moe.py --model=moe --num_experts=128 --per_gpu_batch=2 --gradient_accumulation_steps=16 --deepspeed_config ds_config.json
และตัวอย่าง ds_config เพิ่มเติม (ย่อ): {"fp16": {"enabled": true}, "zero_optimization": {"stage": 2, "offload_param": {"device":"cpu"}}, "gradient_clipping": 1.0}
5) เครื่องมือที่ใช้: DeepSpeed/ZeRO, Megatron‑LM, Alpa
เลือกเครื่องมือให้สอดคล้องกับสถาปัตยกรรมและสภาพแวดล้อม:
- DeepSpeed + ZeRO: เหมาะสำหรับ PyTorch, มี MoE support (MoE CPU/GPU offload) และการจัดการ memory สูง
- Megatron‑LM: ดีสำหรับ model parallelism ใน LLM ขนาดใหญ่ และมี integration กับ MoE patterns
- Alpa: ใช้กับ JAX และช่วยออกแบบการแบ่งภาระอัตโนมัติ (automatic parallelization) เหมาะสำหรับการทดลอง topology ใหม่ๆ และ TPU
เคสการใช้งานทั่วไป: ใช้ Megatron‑LM สำหรับ scaling ของ Transformer core, DeepSpeed ZeRO สำหรับ memory optimization และ Alpa สำหรับ prototype การแบ่งงานอัตโนมัติ
6) การตรวจสอบความถูกต้อง (Validation) และการทดสอบ A/B
การตรวจสอบไม่เพียงแต่ดู scalar loss เท่านั้น แต่ต้องประเมินด้วย metrics ที่สอดคล้องกับ use case เช่น perplexity, ROUGE/BLEU, accuracy, หรือ task-specific metrics ในงานข้อความเชิงธุรกิจ แนะนำกระบวนการดังนี้:
- Validation set: แยกชุด validation ที่เป็นตัวแทนจริง (holdout) และวัด perplexity ทุก N steps
- Checkpointing & reproducibility: บันทึก checkpoints ทุกช่วงเพื่อย้อนกลับ และบันทึก seed และ config
- A/B testing: ทำ canary rollout โดยส่ง traffic 1–5% ไปยัง MoE model เทียบกับ dense baseline วัด latency (p50/p95/p99), error rate และ business KPIs
- Monitoring ต้นทุน: วัด GPU-hours, tokens/sec, $/token (หรือ $/inference) และเปรียบเทียบกับ baseline – ตัวอย่างเชิงตัวเลข: ถ้า baseline ใช้ 600 GPU‑hours ต่อโปรเจกต์และ MoE ใช้ 100 GPU‑hours จะได้ reduction ≈ 6x
7) การวัด latency และต้นทุนเชิงปฏิบัติการ
สำหรับบริการเรียลไทม์ ให้ตั้ง SLO สำหรับ latency (เช่น p95 < 200 ms) และตรวจสอบว่าการออกแบบ MoE (top_k, routing overhead) ไม่ทำลาย SLO นั้น ใช้เครื่องมือเช่น Prometheus/Grafana สำหรับเก็บ metrics แบบเรียลไทม์ และ NVIDIA Nsight หรือ PyTorch profiler สำหรับ profiling GPU
ตัวอย่าง metric ที่ต้องติดตาม:
- throughput (tokens/sec), samples/sec
- GPU utilization และ memory usage
- routing time per token (ms)
- p50/p95/p99 latency ของ inference
- cost per 1M tokens หรือ cost per 1000 inferences
8) Checklist ก่อน Deploy สู่ Production
ก่อนเปิดใช้งานแบบเต็ม ให้ยืนยัน checklist ด้านล่างเพื่อความปลอดภัย ความคงที่ และการควบคุมต้นทุน:
- ความแม่นยำและ regression: ตรวจสอบว่า model ใหม่ไม่แย่กว่าบรรทัดฐาน (regression tests ผ่าน)
- Load testing: ทดสอบ throughput/latency ภายใต้ traffic ที่คาดการณ์ไว้และช่วง spike
- Fallback path: เตรียม fallback เป็น dense model หรือ cached responses เมื่อ router/experts เกิดปัญหา
- Autoscaling & circuit breakers: ตั้ง horizontal autoscaling และ circuit breaker thresholds สำหรับบริการเรียลไทม์
- Monitoring & alerting: Prometheus alert สำหรับ error spikes, latency breaches, imbalanced expert load
- Security & compliance: ตรวจสอบสิทธิ์การเข้าถึง, encrypt data-at-rest/in-transit, และ logging policy
- Cost guardrails: ตั้ง budget alerts และสคริปต์ auto‑pause หรือ scale‑down เมื่อค่าใช้จ่ายเกินเกณฑ์
- Canary/A/B rollout plan: สเกลเพิ่มแบบก้าวหน้าและตรวจสอบ KPI ทุกขั้น
สรุป: การเทรน MoE ไฮบริดต้องการการตัดสินใจเชิงวิศวกรรมหลายมิติ ตั้งแต่การจัดสภาพแวดล้อม การออกแบบ topology การปรับพารามิเตอร์ bridge ระหว่าง throughput และ latency รวมถึงการสร้าง pipeline สำหรับ validation, A/B testing และ cost monitoring การติดตั้ง observability และ fallback mechanisms ก่อน deploy จะช่วยให้สามารถเก็บเกี่ยวข้อได้เปรียบด้านต้นทุน (เช่นการลดค่าใช้จ่ายหลายเท่าตามที่ระบุ) โดยไม่ทำลายความแม่นยำหรือประสบการณ์ผู้ใช้
ข้อพิจารณาทางปฏิบัติ: ความปลอดภัย การกำกับดูแล และต้นทุนระยะยาว
ข้อพิจารณาทางปฏิบัติ: ความปลอดภัย การกำกับดูแล และต้นทุนระยะยาว
การคุ้มครองข้อมูลและการปฏิบัติตามกฎหมาย (Data Residency, Encryption, PDPA)
สำหรับองค์กรที่นำ MoE ไฮบริดมาใช้งาน ความมั่นคงด้านข้อมูลต้องเป็นข้อพิจารณาอันดับต้น ๆ โดยเฉพาะเมื่อระบบมีการผสมกันระหว่างคลัสเตอร์ภายในประเทศและคลาวด์สาธารณะ PDPA ของไทยกำหนดหลักการเกี่ยวกับการเก็บ ประมวลผล และโอนถ่ายข้อมูลที่เป็นข้อมูลส่วนบุคคล ดังนั้นการออกแบบ MoE ควรคำนึงถึงการแยกข้อมูลเชิงประจำถิ่น (data residency) ให้ชัดเจน เช่น เก็บข้อมูลที่มีความอ่อนไหวไว้บนคลัสเตอร์ภายในประเทศเท่านั้น และป้องกันไม่ให้มีการส่งออกข้อมูลไปยัง region ที่ไม่ผ่านข้อกำหนด
ทางด้านเทคนิค ควรใช้มาตรการเข้ารหัสทั้ง encryption at rest (เช่น AES-256) และ encryption in transit (เช่น TLS 1.2/1.3) ควบคู่กับการจัดการกุญแจที่ปลอดภัย (KMS/HSM) รวมถึงนโยบายการบันทึกและการล้างข้อมูลที่สอดคล้องกับ PDPA เช่น การมาสก์ข้อมูลส่วนบุคคลก่อนเก็บ log หรือ telemetry และกำหนดระยะเวลาการเก็บรักษาข้อมูลให้ชัดเจน ตัวอย่างเชิงตัวเลข: องค์กรมักลดความเสี่ยงด้านการละเมิดข้อมูลได้มากกว่า 80% เมื่อใช้ KMS/HSM ร่วมกับการมาสก์ PII ก่อนบันทึก log ในระบบการเรียนรู้ของเครื่อง
การควบคุมการเข้าถึง (Access Control) และ Model Lineage
การจัดการการเข้าถึงต้องทำอย่างรัดกุมทั้งในระดับโครงสร้างพื้นฐานและระดับโมเดล โดยใช้หลัก least privilege ร่วมกับระบบ IAM, RBAC และการแยกเครือข่าย (VPC, private endpoints) สำหรับส่วนประกอบที่ให้บริการเรียลไทม์ เช่น gating service หรือ router เพื่อให้ latency ต่ำและปลอดภัย นอกจากนี้ ควรมีการจัดเก็บและตรวจสอบ secrets อย่างเป็นระบบ (เช่น Secret Manager) และกำหนดนโยบายการเข้าถึงสำหรับทีมต่าง ๆ อย่างชัดเจน
ในเชิงการกำกับดูแล ความสามารถในการติดตาม model lineage เป็นสิ่งจำเป็น — ระบุได้ว่าเวอร์ชันใดถูกฝึกด้วยข้อมูลใด มี preprocessing แบบไหน และใช้ hyperparameter อะไรบ้าง การเก็บ metadata และ audit trail ช่วยให้ตอบคำถามด้านความรับผิดชอบได้ เช่น เมื่อเกิดพฤติกรรมไม่พึงประสงค์จากโมเดล จะสามารถย้อนกลับไปตรวจสอบ chain of custody ได้ทันที เครื่องมือ MLOps (เช่น model registry, experiment tracking) ควรถูกผนวกเข้ากับ pipeline โดยมีการบันทึก checkpoint, seed, และ configuration เพื่อให้การ reproducing/rollback ทำได้รวดเร็ว
กลยุทธ์การจัดการค่าใช้จ่ายระยะยาว (Spot vs On‑Demand, Committed Discounts)
MoE ไฮบริดให้โอกาสลดต้นทุนได้มาก แต่ต้องออกแบบกลยุทธ์การใช้ทรัพยากรอย่างมีชั้นเชิง: โดยทั่วไปควรแยกหน้าที่ของทรัพยากรตามความเสี่ยงและความสำคัญของ latency — เช่น ใช้ on‑demand / reserved instances สำหรับส่วนที่ต้องการความเสถียรสูง (router, gating, stateful serving) และใช้ spot/preemptible instances สำหรับการฝึก experts ขนาดใหญ่หรือสำหรับ experts ที่สามารถ toleratate การหยุดชั่วคราวได้
ตัวเลขเชิงการลงทุน: spot instances มักประหยัดได้ระหว่าง 60–90% เมื่อเทียบกับ on‑demand ขณะที่ committed/reserved discounts (ขึ้นกับผู้ให้บริการและระยะสัญญา) อาจลดค่าใช้จ่ายได้ประมาณ 30–70% สำหรับภาระงานที่คงที่ ดังนั้นการผสมผสานระหว่าง spot เพื่อความคุ้มค่า และ reserved สำหรับบริการเรียลไทม์ที่ต้องการ SLA ชัดเจน เป็นแนวทางปฏิบัติที่สมดุล
- แนะนำให้มี capacity buffer / warm pools เพื่อรักษา latency p95/p99 สำหรับการเรียกใช้งานจริง และลดผลกระทบเมื่อ spot ถูกยกเลิก
- ใช้ autoscaling ที่คำนึงถึงทั้ง throughput และ queue depth ของแต่ละ expert เพื่อปรับขนาดแบบยืดหยุ่นและลด overprovisioning
- วางแผน storage และ checkpointing: แทนการเก็บ snapshot ขนาดเต็มทุกครั้ง ให้ใช้ incremental checkpoint และ compression เพื่อลดค่าใช้จ่ายในการจัดเก็บ (ซึ่งอาจคิดเป็น 10–30% ของต้นทุน infra ระยะยาวสำหรับงานฝึกโมเดลขนาดใหญ่)
การมอนิเตอร์โมเดลและการป้องกัน Failure Modes (Expert Collapse, Routing Imbalance)
MoE มี failure modes เฉพาะตัวที่ต้องเฝ้าระวัง ได้แก่ expert collapse (expert หลายตัวไม่ได้รับการเลือกจนไร้ประสิทธิภาพ) และ routing imbalance / hot‑spot (expert บางตัวรับภาระหนักเกินไปจนเกิดคอขวด) การมอนิเตอร์ที่ดีต้องเก็บเมตริกทั้งเชิงประสิทธิภาพและเชิงพฤติกรรม เช่น per‑expert QPS, utilization, queue length, gating distribution entropy, และ latency p50/p95/p99)
- กำหนด alert ที่เป็นไปได้ เช่น expert utilization > 80% เป็นเวลาเกิน X นาที หรือ expert selection probability < 5% ต่อเนื่องเกิน Y ช่วงการประเมิน เพื่อจับ expert collapse
- SLA‑driven thresholds: หาก max QPS/throughput ของ expert หนึ่งสูงกว่า median มากกว่า 10x ให้ trigger autoscaling หรือ reroute policy
- ติดตั้งระบบ telemetry ที่บันทึก gating decisions แบบไม่เก็บข้อมูลส่วนบุคคล (PII masked) เพื่อวิเคราะห์สาเหตุของ imbalance และปรับ hyperparameter ของ gating (เช่น entropy regularization, auxiliary balancing loss)
กลไกป้องกันเชิงปฏิบัติการควรรวมถึง: circuit breakers สำหรับ experts ที่ตอบสนองช้า, fallback ไปยัง dense model หรือ cached responses เมื่อเกิดปัญหา, และ automated rebalancing ที่สามารถย้าย expert หรือปรับอัตราเลือก (routing) ชั่วคราว นอกจากนี้ควรมี runbook และ playbook ที่ชัดเจนสำหรับทีม SRE/ML Ops เพื่อแก้ไขเหตุการณ์แบบเรียลไทม์ และควรทดสอบการกู้คืนเป็นประจำ
บทสรุปเชิงปฏิบัติ
การนำ MoE ไฮบริดมาใช้สามารถลดต้นทุนได้อย่างมีนัยสำคัญ แต่ต้องแลกมาด้วยการออกแบบด้านความปลอดภัย การกำกับดูแล และการจัดการความเสี่ยงที่เป็นระบบ องค์กรควรผสมผสานมาตรการทางเทคนิค (encryption, KMS, VPC, IAM) กับกระบวนการกำกับดูแล (model lineage, audit trail, PDPA compliance) พร้อมกับยุทธศาสตร์ทางการเงิน (spot/reserved/committed) และการมอนิเตอร์เชิงลึกที่รองรับ failure modes เฉพาะของ MoE เพื่อให้ได้ทั้งประสิทธิภาพ ต้นทุนที่คุ้มค่า และความเชื่อมั่นในระยะยาว
บทสรุป
การทดลอง Mixture‑of‑Experts (MoE) แบบไฮบริดโดยคลัสเตอร์คลาวด์ไทยชี้ให้เห็นว่า การออกแบบฮาร์ดแวร์และซอฟต์แวร์ที่สอดคล้องกันสามารถลดต้นทุนการเทรน LLM ได้ถึง 6 เท่า โดยไม่ลดคุณภาพของโมเดลอย่างมีนัยสำคัญ และยังสามารถรักษา latency สำหรับบริการเรียลไทม์ได้เมื่อใช้กลยุทธ์ routing และ serving ที่เหมาะสม การออกแบบดังกล่าวรวมถึงการผสมผสานระหว่างโมดูล experts แบบกระจาย (sparse experts) กับ backbone แบบ dense, การจัดสรร experts ต่อฮาร์ดแวร์ให้สอดคล้องกับความสามารถของชิปรองรับ, รวมทั้งกลไก gating เช่น top‑k routing, load balancing และ dynamic batching เพื่อให้ throughput และเวลาตอบสนองสอดคล้องกับ SLA ของแอปพลิเคชันเรียลไทม์
คำแนะนำเชิงปฏิบัติและมุมมองอนาคต: องค์กรที่สนใจควรเริ่มจากการทดลองขนาดเล็ก (pilot) เพื่อทดสอบสัดส่วน expert/gating แบบต่างๆ ปรับพารามิเตอร์อย่างเป็นระบบ และตั้งมาตรการมอนิเตอร์หลัก ได้แก่ latency (p99, p95), ต้นทุนการเทรนและ inference, และตัวชี้วัดคุณภาพโมเดล (เช่น perplexity, accuracy หรือการวัดทางธุรกิจ) ก่อนขยายสู่ production นอกจากนี้ควรวางแผน fallback path (เช่น dense baseline) สำหรับสถานการณ์ latency สูงและออกแบบ autoscaling ที่คำนึงถึง cost-efficiency ในระยะยาว สำหรับอนาคต การผสาน MoE ไฮบริดกับการพัฒนาเครื่องมือบริหารจัดการ, มาตรฐานการทดสอบ, และนโยบายด้านความโปร่งใสและความเป็นส่วนตัวจะช่วยให้เทคโนโลยีนี้ลดอุปสรรคการเข้าถึง LLM ขนาดใหญ่และขยายการใช้งานในบริการเรียลไทม์ได้กว้างขึ้น โดยคาดว่าการพัฒนาโปรเซสเซอร์เฉพาะทาง การปรับอัลกอริทึม routing และระบบ orchestration จะนำไปสู่ประสิทธิภาพที่ดียิ่งขึ้นและต้นทุนที่ต่ำลงในอนาคต



