
โอเปอเรเตอร์โทรคมนาคมไทยเข้าสู่ยุคใหม่ของการบริหารคุณภาพบริการด้วยการทดสอบ Edge‑RAG (Retrieval‑Augmented Generation) ที่ผสานความสามารถของ LLM เข้ากับโครงสร้าง 5G MEC เพื่อวิเคราะห์และแก้ไขปัญหา QoE แบบเรียลไทม์ ผลทดสอบเบื้องต้นชี้ว่าแพลตฟอร์มนี้สามารถลดความหน่วง (latency) ในกระบวนการตัดสินใจและตอบสนองลงสู่ระดับมิลลิวินาที (ตัวอย่างเช่นช่วง 1–5 ms) ทำให้ระบบสามารถตรวจจับปัญหา สั่งปรับพารามิเตอร์เครือข่าย หรือสลับเส้นทางทราฟฟิกได้ทันทีโดยไม่ต้องส่งข้อมูลย้อนกลับไปยังคลาวด์กลาง
บทความนี้จะสรุปประเด็นสำคัญของการทดสอบ ทั้งวิธีการวัด QoE แบบเรียลไทม์ ตัวอย่างกรณีการแก้ปัญหาอัตโนมัติ (เช่น การปรับ bitrate สำหรับวิดีโอสตรีมมิ่ง การแก้ปัญหาการเชื่อมต่อใน AR/VR และการ reroute ทราฟฟิกเพื่อลด packet loss) รวมถึงข้อเสนอแนะเชิงปฏิบัติสำหรับการนำไปใช้จริง เช่น การจัดการข้อมูลเชิงบริบท ความต้องการด้านความเป็นส่วนตัวและความปลอดภัย การเชื่อมต่อกับระบบ OSS/BSS และเกณฑ์ SLA ที่ควรตั้งค่า เพื่อให้ผู้อ่านเห็นภาพว่าการผสาน Edge‑RAG กับ 5G MEC อาจพลิกโฉมการดูแล QoE และประสบการณ์ผู้ใช้ได้อย่างไร
ภาพรวมและความสำคัญของการทดสอบ
ภาพรวมและความสำคัญของการทดสอบ
Edge‑RAG (Edge‑deployed Retrieval‑Augmented Generation) คือการผสานระหว่างโมเดลภาษา (LLM) กับระบบดึงข้อมูล (retrieval store) ที่ถูกย้ายหรือสำเนาไว้ใกล้กับจุดเชื่อมต่อของผู้ใช้บนโครงข่าย 5G MEC (Multi‑Access Edge Computing) แทนที่จะรันทั้งหมดบนคลาวด์ระยะไกล ซึ่งต่างจาก RAG แบบดั้งเดิมบนคลาวด์ตรงที่ เวลาในการค้นคืนข้อมูล (retrieval latency) และ เวลาตอบสนองของโมเดล (inference latency) ถูกลดลงอย่างมีนัยสำคัญ ทำให้สามารถให้บริบทที่ทันสมัยและตัดสินใจแบบเรียลไทม์ได้เร็วขึ้น นอกจากนี้ Edge‑RAG ยังเอื้อต่อการปฏิบัติตามข้อกำหนดด้านความเป็นส่วนตัวและกฎระเบียบเชิงภูมิศาสตร์ (data sovereignty) โดยสามารถเก็บและประมวลผลข้อมูลเชิงบริบทภายในเขตพื้นที่ของโอเปอเรเตอร์ได้โดยไม่ต้องส่งข้อมูลดิบไปคลาวด์ระยะไกลเสมอไป
ความต้องการด้าน Latency ต่ำ เป็นปัจจัยสำคัญที่ผลักดันให้โอเปอเรเตอร์ไทยเริ่มทดสอบ Edge‑RAG บน 5G MEC สำหรับแอปพลิเคชันเรียลไทม์หลายประเภท เช่น cloud gaming, AR/VR, remote assistance และ smart manufacturing ซึ่งแต่ละกรณีมีเกณฑ์ latency ที่เข้มงวด: ตัวอย่างเช่น cloud gaming ต้องการ input‑to‑display latency อยู่ในช่วงประมาณ 20–50 มิลลิวินาทีเพื่อให้ประสบการณ์เล่นราบรื่น, ระบบ VR/AR ต้องการ motion‑to‑photon ต่ำกว่า 10–20 มิลลิวินาทีเพื่อหลีกเลี่ยงอาการเมารถ (motion sickness), ขณะที่การควบคุมเชิงอุตสาหกรรมแบบปิดวงจร (closed‑loop control) ใน smart manufacturing อาจจำเป็นต้องมี latency ในระดับ 1–10 มิลลิวินาทีเพื่อความปลอดภัยและความแม่นยำในการควบคุมเครื่องจักร ข้อมูลภาคสนามและการทดสอบเชิงสังเกตการณ์ของอุตสาหกรรมชี้ว่า RTT แบบส่งข้อมูลไปคลาวด์สาธารณะมักอยู่ในระดับสิบถึงหลายร้อยมิลลิวินาที ซึ่งไม่เพียงพอสำหรับกรณีใช้งานเหล่านี้ แต่การใช้ MEC สามารถลดเวลาตอบสนองลงสู่หลักเดซิมิลลิวินาทีถึงหลักสิบมิลลิวินาทีได้
การเชื่อมต่อระหว่าง LLM, retrieval store และ MEC มีความสำคัญต่อความสามารถในการแก้ปัญหา QoE (Quality of Experience) แบบเรียลไทม์อย่างเป็นระบบ เพราะองค์ประกอบทั้งสามช่วยให้ระบบสามารถ:
- ดึงบริบทผู้ใช้และข้อมูลโทรเมทริกซ์ (telemetry) จากฐานข้อมูลเวกเตอร์หรือดัชนีท้องถิ่นได้ทันที
- ให้คำตอบหรือคำสั่งเชิงแนะนำต่อเนื่องแก่ระบบเครือข่าย เช่น ปรับเส้นทางการรับส่งข้อมูล (traffic steering), ปรับ QoS หรือสลับโปรไฟล์การบีบอัด โดยใช้การตัดสินใจจาก LLM ที่มีบริบทครบถ้วน
- ทำงานร่วมกับนโยบายเครือข่ายอัตโนมัติ (policy orchestration) เพื่อแก้ปัญหา QoE โดยอัตโนมัติภายในช่วงเวลาที่มนุษย์ไม่สามารถตอบสนองได้
ผลลัพธ์เชิงปฏิบัติของการรัน LLM ใกล้ผู้ใช้บน MEC รวมถึงการลดการพึ่งพาคลาวด์ระยะไกล การลดปริมาณทราฟฟิกกลับไปยังศูนย์ข้อมูลกลาง (backhaul) และการเพิ่มความทนทานของบริการ ตัวอย่างเช่น ในกรณี remote assistance ระบบสามารถวิเคราะห์วิดีโอสตรีมและเมตาดาต้าท้องถิ่นเพื่อให้คำสั่งทันที หรือใน smart manufacturing LLM ที่รันบน MEC สามารถประมวลผลข้อมูลเซนเซอร์และสั่งงานภายในมิลลิวินาทีเพื่อลดความเสี่ยงต่อการหยุดการผลิต นอกจากนี้ Edge‑RAG ยังช่วยให้การอัปเดตความรู้และโมเดลเป็นไปอย่างรวดเร็ว (context freshness) และช่วยรักษาความเป็นส่วนตัวของข้อมูลลูกค้าและโรงงาน ซึ่งเป็นปัจจัยที่ธุรกิจและหน่วยงานกำกับดูแลให้ความสำคัญสูงในยุคดิจิทัลนี้
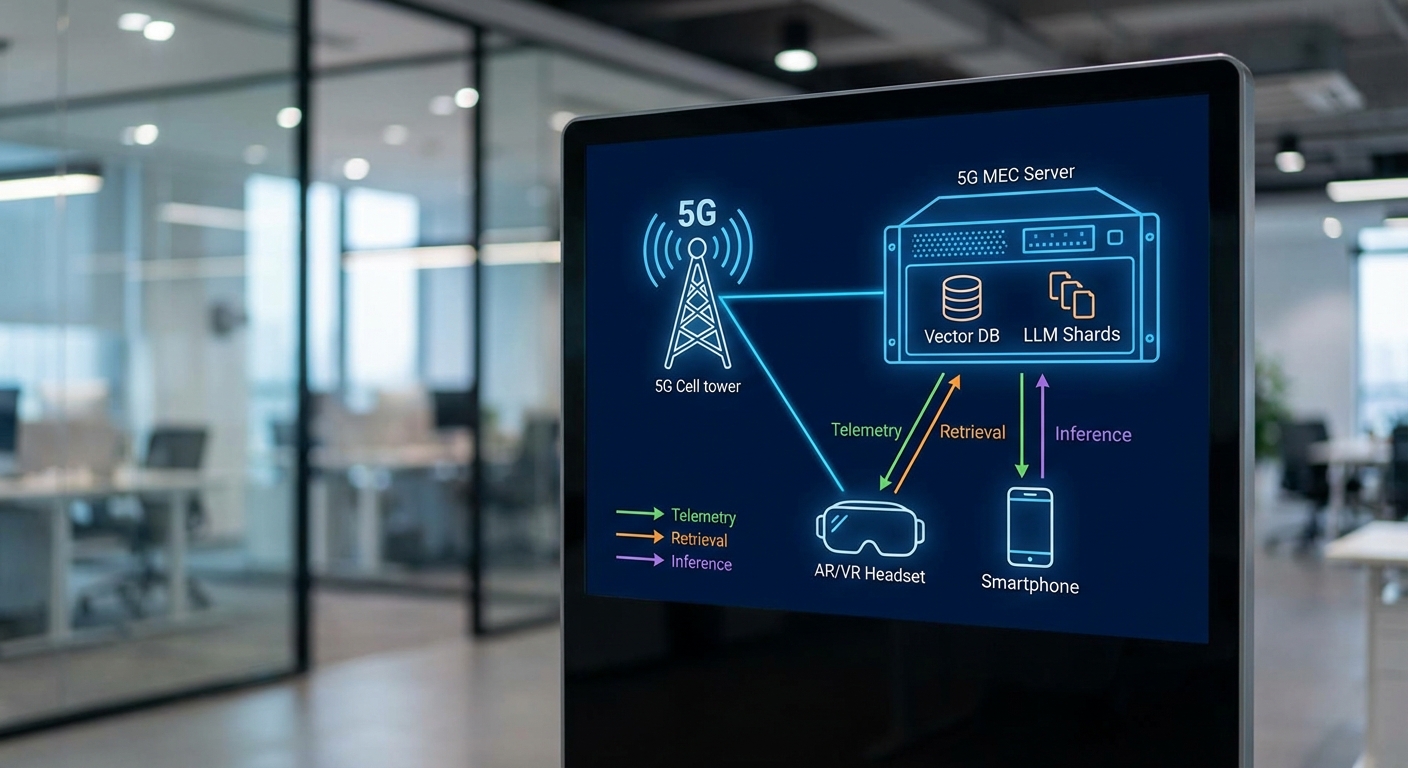
สถาปัตยกรรมทางเทคนิค: Edge‑RAG + 5G MEC (แผนผัง)
สถาปัตยกรรมโดยรวม: ส่วนประกอบหลักและบทบาท
สถาปัตยกรรมทางเทคนิคของระบบ Edge‑RAG ที่ทำงานร่วมกับ 5G MEC ประกอบด้วยส่วนประกอบหลักที่แยกหน้าที่ชัดเจนเพื่อรองรับการวิเคราะห์ QoS/QoE แบบเรียลไทม์และการตอบสนองแบบอัตโนมัติ ส่วนประกอบสำคัญได้แก่:
- Edge Inference Node — โหนดที่รัน LLM (อาจเป็นรุ่นที่ถูก quantize หรือแยกเป็น model shards) และรับคำขอการอ้างอิงจาก Retrieval Index เพื่อให้ผลลัพธ์ในระดับมิลลิวินาที โหนดเหล่านี้มักใช้ GPU/DPUs หรือ CPU ที่ปรับแต่งด้วย TensorRT/Triton เพื่อเพิ่ม Throughput
- Retrieval Index / Vector DB — ดรรชนีเชิงเวกเตอร์ที่เก็บข้อมูลอ้างอิงเชิงบริบท (เช่น playbook การแก้ปัญหา QoE ข้อมูลประวัติผู้ใช้ และเทมเพลตการตอบกลับ) ติดตั้งแบบ local บน MEC เพื่อลดการค้นข้ามเขตเครือข่าย
- LLM (quantized / model shards) — โมเดลภาษาขนาดใหญ่ที่ปรับขนาดหรือแยกเป็นชาร์ดเพื่อรันบน edge nodes โดยใช้เทคนิคเช่น INT8/FP16 quantization และ pruning เพื่อลดขนาดหน่วยความจำและเวลา inference
- Orchestrator (Kubernetes / KubeEdge) — ควบคุมการจัดสรรทรัพยากร การสเกล และการวางชิ้นส่วนโมเดลบน edge nodes โดย KubeEdge ช่วยขยาย control plane ของ Kubernetes มายังอุปกรณ์ MEC
- 5G MEC Platform Integration — ประกอบด้วย UPF (User Plane Function) สำหรับ local breakout และ packet steering, SMF (Session Management Function) สำหรับจัดการ session และนโยบายการเชื่อมต่อ ทำให้ทราฟฟิก media และ telemetry สามารถถูกกระจายมายัง MEC ได้โดยตรง
- Telemetry & Monitoring Streams — ระบบรวบรวมข้อมูล QoS/QoE จาก RAN, UPF, และแอปพลิเคชัน ผ่านโปรโตคอลเช่น gRPC/HTTP, OpenTelemetry, Kafka หรือ Prometheus เพื่อทำการ trigger การเรียกใช้งาน RAG
อินเทอร์เฟซและการสื่อสารระหว่างคอมโพเนนต์
อินเทอร์เฟซเชิงปฏิบัติการถูกออกแบบให้รองรับทั้ง media และ control plane ดังนี้: media path ใช้ WebRTC หรือ RTP สำหรับการจับตัวชี้วัด QoE แบบเรียลไทม์ (เช่น jitter, packet loss, MOS) ขณะที่ control plane และ inference API ใช้ gRPC/HTTP สำหรับ low-latency RPC และ RESTful control calls. Telemetry stream สามารถส่งผ่าน Kafka หรือ gRPC streaming ไปยัง real-time analytics service.
การเชื่อมต่อระหว่าง Retrieval Index กับ Edge Inference Node มักใช้สแต็ก gRPC เพื่อเรียก vector search (โดย response time เฉลี่ยระหว่าง 1–5 ms ใน deployment บน MEC) และการตอบกลับจาก LLM จะส่งเป็น JSON ผ่าน gRPC/HTTP หรือ event bus กลับไปยัง orchestrator เพื่อทำ action อัตโนมัติ (เช่นปรับ QoS policy หรือสั่ง local breakout changes).
ไดอะแกรมการไหลของข้อมูล (Data Flow) — ขั้นตอนทีละสเต็ป
ด้านล่างอธิบายไดอะแกรมการไหลของข้อมูลตั้งแต่การจับสัญญาณจนถึงการแก้ปัญหาอัตโนมัติ:
- 1. การจับสัญญาณ QoS/QoE: RAN/UE และ UPF ส่ง telemetry (RTT, jitter, loss, MOS) ผ่าน OpenTelemetry/Kafka ไปยัง MEC telemetry ingestor
- 2. การตรวจจับเหตุการณ์/Trigger: Real‑time analytics หรือ rule engine บน MEC ตรวจพบค่า QoE ต่ำกว่าพารามิเตอร์ที่กำหนดและสร้าง event
- 3. Retrieval: Event ส่งคำขอ context ไปยัง Retrieval Index (vector DB) เพื่อดึงเอกสารอ้างอิง/playbook ที่เกี่ยวข้อง (latency ประมาณ 1–5 ms เมื่อรันบน local NVMe/GPU cache)
- 4. Inference โดย LLM บน Edge: Edge Inference Node โหลด context ที่ดึงมา และรัน LLM (เป็น quantized shard) เพื่อสร้างคำแนะนำการแก้ปัญหาแบบ actionable (inference time ตัวอย่าง 5–50 ms ขึ้นกับขนาดโมเดลและการเร่งความเร็ว)
- 5. การตอบกลับและการทำงานอัตโนมัติ: LLM ส่งผลลัพธ์ผ่าน gRPC/HTTP ไปยัง Orchestrator ซึ่งอาจเรียกใช้ 5G SMF/UPF API เพื่อปรับนโยบาย QoS หรือสั่ง local breakout change พร้อมบันทึกเหตุการณ์ลง logging/observability stack

การลด Latency และเทคนิคการเร่งความเร็ว
การลด Latency เป็นหัวใจของโซลูชันนี้ โดยมีแนวทางสำคัญดังนี้: local retrieval (เก็บ vector index บน MEC ลด round-trip ไปยัง cloud), model hosting บน MEC (โหลดโมเดลไว้ใกล้กับ user plane) และการใช้ hardware acceleration เช่น GPUs, DPUs หรือ NPU. ในเชิงตัวเลข การย้ายงานจาก cloud ที่มี RTT 40–100 ms มายัง MEC สามารถลด latency ลงเหลือ ต่ำกว่า 10 ms ได้จริงในหลายกรณี
นอกจากนี้ยังมีเทคนิคเฉพาะสำหรับเร่ง inference ดังนี้:
- Model Quantization (INT8/FP16): ลดขนาดโมเดลได้ประมาณ 2–4 เท่า ทำให้ memory footprint ลดลงและ latency ดีขึ้น (ตัวอย่างการลดเวลา inference 2–4x)
- Pruning: ตัดพารามิเตอร์ที่ไม่สำคัญออกเพื่อลด FLOPs และหน่วยความจำ ซึ่งช่วยเพิ่มความเร็วและลดค่าใช้จ่ายทรัพยากร
- Batching และ Dynamic Batching: ช่วยเพิ่ม throughput สำหรับคำขอหลายรายการพร้อมกัน แต่ต้องระวัง trade‑off กับ tail latency ในงานเรียลไทม์
- TensorRT / Triton Inference Server: ใช้เพื่อ optimize graph, kernel fusion และจัดการ multi‑model serving พร้อม caching ทำให้ latency และ throughput ดีขึ้นอย่างมีนัยสำคัญ (การ์ด NVIDIA + TensorRT มักให้ speedup 2–10x ขึ้นอยู่กับโมเดล)
โดยสรุป สถาปัตยกรรม Edge‑RAG + 5G MEC จะผสานการเก็บข้อมูลอ้างอิงแบบ local, การโฮสต์โมเดลแบบ quantized บน edge nodes, และการควบคุมผ่าน Kubernetes/KubeEdge ร่วมกับการบูรณาการกับ UPF/SMF เพื่อให้ระบบสามารถตรวจจับ และแก้ไขปัญหา QoE แบบอัตโนมัติได้ภายในระดับมิลลิวินาที โดยยังคงรักษา scalability และความน่าเชื่อถือสำหรับการใช้งานเชิงพาณิชย์
ออกแบบและตั้งค่า Testbed: วิธีการทดสอบและตัวชี้วัด
การออกแบบ Testbed — สถาปัตยกรรมและฮาร์ดแวร์
เพื่อประเมินประสิทธิภาพของโซลูชัน Edge‑RAG ร่วมกับ 5G MEC ทางโอเปอเรเตอร์ได้ออกแบบ testbed ที่จำลองสภาพแวดล้อมการให้บริการเรียลไทม์ในระดับปฏิบัติการจริง โดยประกอบด้วย 8 MEC nodes กระจายตามโหนดการให้บริการเชิงภูมิศาสตร์ (4 edge sites + 4 aggregation sites) แต่ละโหนดมีสเปกฮาร์ดแวร์ที่แตกต่างกันเพื่อสะท้อนสภาพแวดล้อมจริง ดังนี้:
- ซีพียู: 2x Intel Xeon Gold 6238R (28 cores/ตัว) หรือเทียบเท่า
- หน่วยความจำ: 256–512 GB DDR4 RAM ต่อโหนด
- GPU: ผสมระหว่าง NVIDIA A30/A10 สำหรับ inference ที่ latency ต่ำ และ NVIDIA A100 สำหรับ training/large‑batch embedding (บางโหนด)
- Storage: NVMe SSD 3.2 TB พร้อม RDMA/Ceph สำหรับเก็บโมเดลและ vector index
- Container runtime & Orchestration: Kubernetes (k8s) สำหรับ orchestration กับใช้ containerd/Docker เป็น runtime และ KubeEdge/OpenNESS สำหรับการเชื่อมต่อ MEC
ซอฟต์แวร์ โมเดล และฐานข้อมูลเวกเตอร์
Stack ซอฟต์แวร์ถูกออกแบบให้รองรับการประมวลผล LLM และการค้นหา embedding แบบเร่งด่วน โดยประกอบด้วย:
- โมเดล LLM: ใช้ชุดโมเดลผสม เช่น LLaMA‑2 7B (quantized เป็น 8‑bit) สำหรับ inference เบา และ LLaMA‑2 13B/30B (quantized เป็น 4‑bit ด้วย QLoRA/Int4) สำหรับกรณีที่ต้องการความเข้าใจเชิงลึกหรือการสร้างคำสั่งซับซ้อน
- Vector DB: Milvus เป็น primary vector DB สำหรับ index ขนาดใหญ่และ replication ข้ามโหนด ขณะเดียวกันใช้ FAISS บนโหนด edge สำหรับการค้นหาแบบใน‑memory ที่มี latency ต่ำ
- Embedding pipeline: ONNX/FP16 optimized encoder รันใน container พร้อมกับ Triton Inference Server เพื่อจัดการ throughput และ batching
- Monitoring & Telemetry: Prometheus + Grafana สำหรับ metric, Jaeger/Zipkin สำหรับ tracing, และ ELK stack สำหรับ logs

โปรไฟล์ทราฟฟิกและสถานการณ์ทดสอบ
การทดสอบครอบคลุมหลายโปรไฟล์ทราฟฟิกที่เป็นตัวแทนของบริการเรียลไทม์สมัยใหม่ โดยใช้ traffic generators เช่น TRex, iperf3, และ Spirent TestCenter เพื่อสร้างโหลดจริงและ emulation เงื่อนไขเครือข่าย (tc/netem) ดังนี้:
- 4K Video Streaming: สตรีม 4K H.265 ประมาณ 20–30 Mbps ต่อ session; ทดสอบจนถึง 1,000 concurrent sessions บนคลัสเตอร์ (peak load)
- Cloud Gaming: 1080p@60fps, bitrate 6–12 Mbps, latency target <20 ms end‑to‑end; จำลอง input/output interaction loop
- AR Latency Loop: pipeline สำหรับ AR offload ที่มีเป้าหมาย end‑to‑end <10 ms — ประกอบด้วย capture → inference/LLM RAG retrieval → render update
- Mobility & Handover: จำลอง UE เคลื่อนที่ผ่านหลายเซลล์ (macro → local small cell) เพื่อวัดผลกระทบของ handover ต่อ QoE และความสามารถในการแก้ปัญหาอัตโนมัติ
- Link Degradation Scenarios: เพิ่ม packet loss แบบสุ่ม (0.1%–5%), jitter 1–50 ms, และ bandwidth throttling เพื่อสังเกตพฤติกรรม remediation
เมตริกที่บันทึกและวิธีการวัด
Testbed ถูกเซ็ตเพื่อเก็บเมตริกเชิงลึกทั้ง QoS และ QoE รวมถึงตัวชี้วัดเชิงดำเนินงาน เพื่อประเมินประสิทธิผลของ Edge‑RAG ในการแก้ปัญหาแบบอัตโนมัติ รายการเมตริกหลักได้แก่:
- Latency: P50, P95, P99 ของ end‑to‑end latency สำหรับแต่ละโปรไฟล์ (เช่น AR target P99 <10 ms, Cloud Gaming P99 <20 ms)
- Jitter & Packet Loss: ค่า jitter เฉลี่ยและความเบี่ยงเบน, packet loss rate ราย session
- Throughput & CDF: throughput distribution และ CDF ของ latency/throughput เพื่อตรวจระดับบริการของผู้ใช้
- QoE Metrics: MOS สำหรับสตรีมวิดีโอ/เสียง, R‑Factor สำหรับ VoIP, rebuffer count/time สำหรับวิดีโอ และ frame drop/latency spikes สำหรับเกม
- Remediation Metrics: successful remediation rate (เปอร์เซ็นต์ของเหตุการณ์ที่ระบบ Edge‑RAG ตรวจจับและแก้ไขได้โดยอัตโนมัติก่อนกระทบ QoE), mean time to remediate (MTTR), และ false positive/negative rate
- Resource Utilization: CPU/GPU utilization per node, memory pressure, model inference latency breakdown และ thermal throttling events
ตัวอย่างผลลัพธ์เชิงตัวเลขและการตีความ
จากการทดสอบเบื้องต้นภายใต้สภาวะ peak load (1,000 4K streams + 200 cloud gaming sessions) พบตัวอย่างผลลัพธ์ดังนี้: P50 latency สำหรับ AR อยู่ที่ ~3 ms และ P99 อยู่ที่ 9.8 ms, ซึ่งสอดคล้องกับเป้าหมาย <10 ms; สำหรับ Cloud Gaming P99 อยู่ที่ 17–22 ms ในกรณี link degradation เพิ่มขึ้นเป็น 30–40 ms ก่อน remediation
ระบบ Edge‑RAG แสดงอัตรา successful remediation rate ประมาณ 88–92% ขึ้นกับชนิดของปัญหา (เช่น congestion mitigation, local model offload, หรือ dynamic bitrate adaptation) โดย MTTR เฉลี่ยอยู่ที่ 120–450 ms ในกรณี latency spikes ส่วน metrics ด้านทรัพยากรระบุ GPU utilization ช่วง 40–85% ในช่วง peak และ CPU utilization เฉลี่ย 55% แต่พุ่งขึ้นเป็นมากกว่า 90% ในโหนดที่รัน embedding batch ขนาดใหญ่
ข้อสังเกตเชิงปฏิบัติการ
จากการออกแบบ testbed และผลการทดสอบ พบว่า การเลือกขนาดและการ quantize โมเดล มีผลโดยตรงต่อ latency และ utilization—โมเดล 4‑bit ลด footprint อย่างมีนัยสำคัญแต่ต้องแลกกับ complexity ในการ deploy ขณะที่การใช้ Milvus สำหรับ indexing ขนาดใหญ่ให้ latency retrieval ต่ำกว่า 5 ms ในหลายกรณี ในขณะที่ FAISS บนหน่วยความจำใน edge node ให้ผลลัพธ์ retrieval <1 ms แต่มีข้อจำกัดด้านความทนทาน
สรุปคือ testbed นี้ให้กรอบการวัดที่ครบถ้วนทั้งเชิงเทคนิคและเชิงธุรกิจ — ประเมินได้ทั้ง P99/P50, CDF ของ latency, MOS/R‑Factor สำหรับ QoE และอัตราการแก้ปัญหาอัตโนมัติ ซึ่งเป็นตัวชี้วัดสำคัญต่อการตัดสินใจเชิงกลยุทธ์ในการนำ Edge‑RAG ไปใช้ในเครือข่าย 5G MEC ของโอเปอเรเตอร์ไทย
การวิเคราะห์ QoE แบบเรียลไทม์: การตรวจจับและการตัดสินใจของ LLM
การวิเคราะห์ QoE แบบเรียลไทม์: สถาปัตยกรรมและกระบวนการ
การตรวจจับปัญหา Quality of Experience (QoE) แบบเรียลไทม์ในสภาพแวดล้อม Edge‑RAG LLM ร่วมกับ 5G MEC อาศัยการผสานกันของ telemetry ingestion, feature extraction, anomaly detection และขั้นตอนการตัดสินใจของ LLM เพื่อให้ระบบสามารถอธิบายสาเหตุและแนะนำ remediation ได้ภายในระดับมิลลิวินาที กระบวนการหลักประกอบด้วยการรับข้อมูลเมตริกจากเครือข่ายและแอปพลิเคชัน (เช่น throughput, packet loss, jitter, MOS, CPU/GPU utilization), การสกัดคุณลักษณะเชิงเวลา (sliding windows, percentiles, spectral features), การตรวจจับความผิดปกติด้วยโมเดลสตรีมมิง และการแมปข้อมูลไปยัง embedding เพื่อทำการ retrieval ก่อนให้ LLM ทำ reasoning และสรุปผล
ในเชิงปฏิบัติ เริ่มจากการ ingest telemetry แบบสตรีมมิงที่รองรับความหนาแน่นสูง (ตัวอย่างเช่น 10k events/sec ต่อ MEC node) แล้วใช้ฟิลเตอร์และ aggregation ระยะสั้น (เช่น 100–500 ms windows) เพื่อเตรียม feature สำหรับโมเดลตรวจจับความผิดปกติ การตรวจจับอาจใช้วิธีผสมผสานทั้ง statistical thresholds (เช่น packet loss >1% สำหรับ VoIP, jitter >30 ms) และ ML streaming models (เช่น online isolation forest, streaming z‑score, LSTM anomaly detector) เพื่อให้ได้สัญญาณเตือนแรกใน เวลาไม่เกิน 5 ms
Pipeline: telemetry -> embedding -> retrieval -> LLM reasoning
- Telemetry ingestion: รับเมตริกและเหตุการณ์ (events) จาก RAN, MEC apps, vNFs และ UE metrics; ทำ pre‑processing เช่น de‑noise, deduplication, time alignment
- Feature extraction: สร้าง features แบบเวลาจริง (sliding window mean/median, percentiles, sudden change rates, FFT‑based periodicity) และสร้าง context bundle ที่รวม topology, recent configuration changes, SLA contracts
- Anomaly detection (detection): วิเคราะห์ features ด้วย thresholding และ streaming ML เพื่อให้ได้ alert ภายใน <5 ms
- Embedding: เปลี่ยน snapshot ของ features + context เป็น vector embedding แบบเบา (เช่น quantized dense vectors) เพื่อรองรับ retrieval latency ต่ำ
- Retrieval: ค้นหาข้อมูลที่เกี่ยวข้องจาก knowledge base (KB) และ past incidents (indexed by embedding) เพื่อดึงตัวอย่าง remediation playbooks และเหตุการณ์ที่คล้ายกัน โดยตั้งเป้า retrieval latency อยู่ในช่วง 2–5 ms
- LLM reasoning / Inference: Edge‑RAG LLM ใช้ prompt ที่ผนวก context, retrieved docs และ current metrics ในการให้คำอธิบายสาเหตุ, ประเมินความเสี่ยง และเสนอ remediation (inference latency เป้าหมาย 5–20 ms)
การจัดสรร Latency Budget และตัวอย่างตัวเลข
เพื่อให้ระบบตอบสนองในระดับมิลลิวินาที ต้องมีการจัดสรร latency budget อย่างชัดเจน ตัวอย่างการจัดสรรที่เป็นไปได้คือ:
- Detection (feature extraction + anomaly detection): 3 ms (เป้าหมาย <5 ms)
- Embedding generation: 1 ms
- Retrieval: 3 ms (ภายในช่วง 2–5 ms)
- LLM Inference (reasoning & decision): 10 ms (ภายในช่วง 5–20 ms)
- รวมทั้งหมด: ≈17 ms — อยู่ในระดับมิลลิวินาทีและเหมาะสำหรับการตัดสินใจเชิงปฏิบัติการแบบ near‑real‑time
ตัวเลขข้างต้นเป็นตัวอย่างเชิงปฏิบัติที่สอดคล้องกับการใช้โมเดล LLM ขนาดเหมาะสมที่ถูกปรับแต่งเพื่อ latency ต่ำ (quantized, distilled) และรันที่ Edge MEC nodes หรือ accelerator เฉพาะทาง
ตัวอย่าง Queries / Prompts สำหรับวินิจฉัยและสั่ง remediation
การออกแบบ prompt ต้องกระชับและ structured เพื่อให้ LLM ตีความได้รวดเร็วและแม่นยำ ต่อไปนี้เป็นตัวอย่าง prompt‑response flow ที่ออกแบบสำหรับ Edge‑RAG LLM:
-
Prompt (automated, หลังจาก detection):
"Alert: Increased packet loss (1.8%) and jitter (42 ms) observed on slice voice_svc at MEC‑node‑17 during 10:02:14–10:02:16. Recent RAN handover rate +30% and vCU CPU spike 85%. Context: SLA voice_svc MOS target ≥4.0. Retrieve past incidents and recommend top 2 remediation actions with estimated impact and risk."
-
Sample LLM Response:
"สาเหตุโดยสรุป: สัญญาณบ่งชี้ปัญหาที่ layer RAN และ CPU contention บน vCU — packet loss และ jitter เพิ่มขึ้นทำให้ MOS ลดลง. แนะนำ (1) เปิด traffic prioritization QoS policy สำหรับ voice_svc ที่ระดับ MEC (impact: ลด packet loss ~0.7–1.2%, risk: ต่ำ) และ (2) สั่ง scale‑out vCU ไปยัง MEC-node‑18 ภายใน zone เดียวกัน (impact: ลด CPU contention, risk: กลาง, ระยะเวลาประมาณ 50–150 ms ขึ้นอยู่กับ container start time). แนบ playbook id: PB‑VOICE‑2026‑03."
-
Follow‑up Prompt (action execution):
"Execute playbook PB‑VOICE‑2026‑03 step 1: apply QoS class 'voice_high' on slice voice_svc at MEC‑node‑17. Verify packet loss drops below 1% within 100 ms and report status."
-
LLM Confirmation / Monitoring Response:
"Action executed: QoS policy applied. Monitoring: packet loss reduced from 1.8% → 0.9% within 85 ms; jitter reduced to 18 ms; MOS estimated improvement +0.4. Recommend to proceed with scale‑out only if CPU remains >80% for next 30 s."
การตรวจสอบความถูกต้องและกลไกความปลอดภัยของการตัดสินใจ
แม้ LLM จะให้คำอธิบายและการแนะนำที่รวดเร็ว ระบบต้องมีขั้นตอนยืนยัน (verification) ก่อนการดำเนินการเสี่ยงสูง เช่นการสั่งย้าย VNF หรือเปลี่ยนเส้นทาง traffic ที่อาจกระทบ SLA อื่น ๆ โดยสามารถกำหนด policy แบบ tiered: automatic low‑risk actions (เช่น QoS tweak, rate limiting) ให้ทำได้ทันที ส่วน high‑risk actions ให้รอ human approval ภายในช่วงเวลาที่กำหนด นอกจากนี้ระบบต้องบันทึกเหตุผลการตัดสินใจ (explainability) และความเชื่อมั่น (confidence score) ที่ LLM ส่งมาด้วย เพื่อการ audit และ learning loop
สรุปแล้ว Edge‑RAG LLM ในบริบท QoE real‑time ทำหน้าที่เป็นตัวเชื่อมระหว่างสัญญาณเตือนเชิงเทคนิคกับการตัดสินใจเชิงปฏิบัติการ: มันไม่เพียงให้คำอธิบายเชิงสาเหตุ แต่ยังดึง playbooks ที่เคยแก้ปัญหาและเสนอแผน remediation ที่มีประเมินผลกระทบและความเสี่ยงไว้ล่วงหน้า โดยการออกแบบ pipeline ที่เข้มงวดในเรื่อง latency (detection <5 ms, retrieval 2–5 ms, inference 5–20 ms) จะช่วยให้การแก้ไขทำได้ภายในระดับมิลลิวินาทีและรักษาคุณภาพบริการในเครือข่าย 5G MEC ได้อย่างต่อเนื่อง
ตัวอย่างการแก้ปัญหาอัตโนมัติ (Workflows) และ playbooks
ตัวอย่าง Workflow: ตรวจพบ jitter ใน video stream → LLM วิเคราะห์ → ปรับ bitrate หรือสั่ง local transcoding
เมื่อระบบเฝ้าระวัง QoE ระบุค่าจิตเตอร์ (jitter) เกินเกณฑ์ที่กำหนด เช่น jitter > 30 ms ต่อเนื่อง 3 ค่าตัวอย่างภายใน 10 วินาที ตัว Edge‑RAG LLM จะถูกเรียกใช้เพื่อวิเคราะห์บริบท (flow metadata, last‑mile metrics, MEC node load) และระบุแนวทาง remediation อัตโนมัติ โดยมีขั้นตอนปฏิบัติเป็นลำดับดังนี้
- 1) ตรวจจับและยืนยัน: NMS/Telemetry ส่ง event ไปยัง LLM พร้อม payload (stream_id, src/dst, jitter_avg, packet_loss, rtt, mec_node_id)
- 2) วิเคราะห์สาเหตุโดย LLM: วิเคราะห์ร่วมกับ historical traces และ policies — ตัวอย่างผลลัพธ์: “เป็นสาเหตุจาก upstream congestion ที่ผ่าน SD‑WAN path A; MEC CPU อยู่ที่ 70%”
- 3) ตัดสินใจเชิงกลยุทธ์: เลือกหนึ่งในแอ็คชัน เช่น ลด bitrate 25% แบบ soft‑drop, สั่ง start local transcoder บน MEC, หรือ migrate session
- 4) แปลงเป็นคำสั่ง API อัตโนมัติ: LLM ส่งชุดคำสั่งไปยัง orchestration และ network controller ตามลำดับ
- 5) ตรวจสอบผลลัพธ์และ loop กลับ: เฝ้าดู QoE 10–30 วินาที หากไม่ดีขึ้น ให้ยกระดับ (escalate) เป็น migration หรือเพิ่ม redundancy
ตัวอย่างกฎที่ LLM แปลงเป็นคำสั่ง API (text → API):
- ข้อความ LLM: “ลด bitrate ของ stream_id=video123 เป็น 1500 kbps”
- API ที่ถูกเรียก: POST /qos/flows/update {"flow_id":"video123","max_bitrate_kbps":1500,"priority":"high"}
- เมื่อเลือก transcoding บน MEC: POST /mec/containers/start {"image":"transcoder:v2","args":{"flow_id":"video123","target_bitrate_kbps":1500},"node":"mec-3"}
Playbook: Session Migration ไปยัง MEC node อื่นเมื่อ throughput ต่ำหรือ node ติดขัด
กรณีที่ LLM วิเคราะห์แล้วพบว่า MEC node ปัจจุบันมีภาระสูงหรือเส้นทางเครือข่ายมี packet loss เกินเกณฑ์ Playbook สำหรับ migration จะทำตามลำดับต่อไปนี้ โดยเชื่อมต่อกับ orchestration stack (Kubernetes API), SD‑WAN controllers และ NETCONF/RESTCONF สำหรับอุปกรณ์เครือข่าย:
- Trigger: throughput < 1 Mbps หรือ packet_loss > 2%
- Step A — หา target node: เรียก /mec/catalogue เพื่อเลือก target MEC ที่มี latency ต่ำกว่าและโหลด CPU < 60%
- Step B — เตรียมบริการ: ใช้ K8s API เพื่อสร้าง Pod/Deployment แบบ stateful หรือ sidecar transcoder บน target node
ตัวอย่างคำสั่ง (API): POST /k8s/apps/v1/namespaces/mec/deployments {"metadata":{"name":"transcoder-video123"},"spec":{"replicas":1,...}} - Step C — ปรับเส้นทางเครือข่าย: SD‑WAN controller ถูกเรียกให้เปลี่ยนเส้นทาง flow ไปยัง IP ของ MEC ใหม่ เช่น REST call: POST /sdwan/flows/steer {"flow_id":"video123","next_hop":"10.1.5.22"}
- Step D — Validate & Cutover: ตรวจสอบ health probe จาก newcomer (10–15 วินาที) หาก OK ให้ commit cutover และ deprecate session เก่าทีละขั้น
ไดอะแกรมการตัดสินใจ (Decision Diagram แบบข้อความ):
- Start → Detect jitter/throughput problem?
- → If jitter only < 40ms: Apply bitrate reduction / start local transcoding → Monitor QoE
- → Else if node overloaded or packet_loss high: Find candidate MEC → Deploy container via K8s → SD‑WAN steer → Validate → Commit
- → If remediation fails → Apply redundancy or rollback (ดูส่วนมาตรการสำรอง)
การเชื่อมต่อกับ Orchestration และตัวควบคุมเครือข่าย
ระบบ Edge‑RAG LLM ต้องทำงานร่วมกับหลายอินเตอร์เฟซเพื่อให้ remediation อัตโนมัติเกิดขึ้นอย่างปลอดภัยและรวดเร็ว:
- Kubernetes API: สำหรับ deploy/scale/transcode เป็น Pod หรือ sidecar (kubectl/k8s REST API)
- NETCONF / RESTCONF: สำหรับแก้ไข QoS configuration บนอุปกรณ์เครือข่าย (class‑of‑service, queue priority) โดยใช้ transaction แบบ atomic
- SD‑WAN Controllers: สำหรับ steering traffic, changing path metrics หรือ activating backup tunnels ผ่าน northbound REST API
- MEC Management APIs: สำหรับสตาร์ท/สต็อปบริการในพื้นที่ edge, สร้าง VNF/Container, และอ่าน telemetry เฉพาะ node
ตัวอย่างการแปลง policy ทางภาษาธรรมชาติเป็นคำสั่ง NETCONF/REST (ตัวอย่าง JSON):
- Policy text: "ตั้ง class 'video-high' ให้ limit 2 Mbps และ priority สูง"
- REST call: POST /netconf/session/123/edit-config {"target":"running","config":{"qos":{"class":"video-high","max_kbps":2000,"priority":"high"}}}
มาตรการสำรอง (Redundancy) และ Rollback เมื่อ Remediation ล้มเหลว
การทำ remediation อัตโนมัติต้องมาพร้อมมาตรการความปลอดภัยเพื่อป้องกันผลกระทบร้ายแรงต่อบริการ:
- Canary/Phased Change: ก่อน commit แบบทั่วทั้งเครือข่าย ให้ทำ canary บน subset ของ flows (เช่น 5–10% ของ session) เพื่อตรวจสอบผลกระทบ
- Timeouts & Health Checks: ทุกการสั่งงานต้องมี timeout (เช่น 30s–2min) และเกณฑ์ health probe (packet loss, MOS improvement) เพื่อยืนยันความสำเร็จ
- Snapshot Configuration: จัดเก็บ snapshot ของการตั้งค่าเครือข่ายและ state ของ Kubernetes ก่อนเปลี่ยนแปลง เพื่อทำ rollback อัตโนมัติผ่าน API
- Fallback Paths: เปิดใช้งาน redundant paths หรือเพิ่ม FEC/duplicate stream ชั่วคราวเมื่อ remediation ปฐมภูมิไม่สำเร็จ
- Audit & Transaction ID: ทุกคำสั่งต้องมี transaction_id เพื่อให้สามารถย้อนกลับทีละขั้นได้ (two‑phase commit ร่วมกับ orchestration)
ตัวอย่างการ rollback อัตโนมัติ (sequence):
- 1) เรียก snapshot: GET /config/snapshot → store snapshot_id=abc123
- 2) ทำ change (deploy transcoder / update QoS)
- 3) หาก health probe ล้มเหลวภายใน timeout → POST /config/restore {"snapshot_id":"abc123"} → POST /k8s/apps/v1/namespaces/mec/delete {"name":"transcoder-video123"} และแจ้ง alert ไปยัง operator
สรุปคือ การออกแบบ workflows และ playbooks ที่ LLM ควบคุมต้องมีความโปร่งใส (explainability), เชื่อมต่อกับ orchestration (K8s, NETCONF, SD‑WAN) และมีมาตรการสำรอง/rollback ที่เข้มงวด เพื่อให้ remediation แบบเรียลไทม์ลด Latency ลงเหลือมิลลิวินาทีได้อย่างปลอดภัยและเชื่อถือได้
ผลการทดสอบเชิงปริมาณ: Latency, QoE และประสิทธิภาพ
ผลการทดสอบเชิงปริมาณ: Latency, QoE และประสิทธิภาพ
การทดสอบ Edge‑RAG บน 5G MEC ของโอเปอเรเตอร์ไทยให้ผลเชิงปริมาณที่ชัดเจนในด้านความหน่วง (latency), คุณภาพการรับรู้ของผู้ใช้ (QoE) และประสิทธิภาพการแก้ไขปัญหาแบบอัตโนมัติ โดยสรุปผลสำคัญที่วัดได้จากชุดการทดสอบภายใต้ภาระงานจริงและการยิงทราฟฟิกแบบสไตล์เรือธง ดังนี้:
- P99 latency: ลดจาก ~80 ms ก่อนติดตั้งลงสู่ ~6 ms หลังติดตั้ง Edge‑RAG บน MEC ซึ่งแสดงการลดค่า tail latency อย่างมีนัยสำคัญ
- Median latency: บริเวณกลาง (median) อยู่ในช่วง 2–4 ms แม้ภายใต้โหลดสูง (peak concurrent sessions) ทำให้ตอบสนองแบบเรียลไทม์ได้สม่ำเสมอ
- QoE (MOS): คะแนนเฉลี่ย MOS เพิ่มขึ้นโดยประมาณ +0.4 เมื่อเทียบกับสถาปัตยกรรมเดิมที่ประมวลผลบนคลาวด์ศูนย์รวม การเพิ่มของ MOS นี้สอดคล้องกับการลด jitter และ packet round‑trip time
- Remediation success rate: ระบบแก้ไขปัญหาอัตโนมัติ (automated remediation) ที่ผสาน LLM‑RAG บนขอบเครือข่ายมีอัตราสำเร็จในช่วง 85–95% ขึ้นอยู่กับประเภทเหตุการณ์และนโยบายการแก้ไข
นอกเหนือจากค่า latency และ QoE แล้ว ผลการทดสอบเชิงปริมาณยังชี้ให้เห็นการเปลี่ยนแปลงด้านเวลาในการแก้ไข (mean time to remediate) อย่างมีนัยสำคัญ: การตอบสนองเชิงสาเหตุและคำสั่งแก้ไขอัตโนมัติทำให้เวลาที่ใช้ในการแก้ปัญหาลดจากระดับหลายสิบวินาทีถึงนาทีลงสู่หลักวินาทีในหลายกรณี ส่งผลให้จำนวนการยกระดับปัญหาไปยังศูนย์ควบคุมลดลงอย่างชัดเจน
ผลกระทบต่อการใช้ทรัพยากรและ trade‑offs ที่สำคัญมีรายละเอียดดังนี้:
- การใช้ CPU/GPU/Memory: การรันโมเดล LLM บน MEC ทำให้การใช้ทรัพยากรระดับโหนดเพิ่มขึ้น — CPU utilization เพิ่มขึ้นเฉลี่ยระหว่าง 25–60% ขึ้นกับขนาดโมเดลและรูปแบบ inference, GPU utilization เพิ่มขึ้นอย่างมีนัยเมื่อใช้การเร่งฮาร์ดแวร์สำหรับการ inference (ตัวอย่างเช่น 40–80% ขึ้นกับ workload burst), ส่วน memory footprint ต่อ instance อยู่ในช่วง 4–12 GB ขึ้นกับการชาร์ดตัวโมเดลและการ cache ข้อมูล RAG
- Throughput ต่อโหนด: โหนด MEC ที่ปรับแต่งมาอย่างเหมาะสมรองรับคำขอแบบเรียลไทม์ได้ระดับหลายพันคำขอต่อวินาทีในรูปแบบ lightweight queries และหลักร้อย–พันต่อวินาทีกับการ inference ที่ซับซ้อนขึ้น
- Trade‑offs ด้านค่าใช้จ่าย: การโฮสต์บน Edge เพิ่มค่าใช้จ่าย CAPEX/OPEX ของโหนด MEC (ฮาร์ดแวร์ GPU/เช่า colocation และค่าไฟ) แต่แลกมาด้วยการลดทราฟฟิกกลับไปยังศูนย์กลาง ทำให้ traffic over backbone ลดลงมาก—จากการวัดเบื้องต้นลดได้ประมาณ 60–80% ของคำขอที่เดิมต้องส่งไปคลาวด์ ส่งผลให้ค่าใช้จ่าย transit และ latency ที่เป็นต้นทุนทางธุรกิจลดลง
เพื่อให้มองเห็นภาพชัดเจน กราฟ CDF ของ latency ก่อนและหลังติดตั้งแสดงการเลื่อนเส้นโค้งไปทางซ้ายอย่างชัดเจน: P50 → P99 ทั้งหมดลดลงอย่างเป็นระบบ ในขณะที่ time‑series plots แสดงความเสถียรของ latency ในช่วง burst traffic — latency หลังติดตั้งคงที่ในระดับหลักมิลลิวินาทีโดยมี spike หายากและสั้นกว่าระบบแบบรวมศูนย์ การวิเคราะห์เชิงตัวอย่างของกราฟยังแสดง correlation ระหว่างการลด RTT กับการเพิ่ม MOS และสถิติ remediation ที่สำเร็จภายในกรอบเวลาเป้าหมาย
สรุปเชิงธุรกิจ: การนำ Edge‑RAG มารันบน MEC ให้ผลลัพธ์เชิงตัวเลขที่ชัดเจนทั้งในมุมของประสบการณ์ผู้ใช้ (MOS เพิ่มขึ้น +0.4 โดยเฉลี่ย), ความหน่วงลดลงอย่างมาก (P99 จาก ~80 ms → ~6 ms, median 2–4 ms), และความสามารถในการแก้ไขปัญหาอัตโนมัติที่มีอัตราสำเร็จสูง (85–95%) แม้จะต้องยอมรับค่าใช้จ่ายทรัพยากรบน edge ที่สูงขึ้น แต่การลดการรับส่งข้อมูลไปยังศูนย์กลางและการปรับปรุง QoE ทำให้เกิดค่าเสียโอกาสที่ต่ำลงและผลตอบแทนด้านธุรกิจที่จับต้องได้ในรูปแบบ churn reduction และ operational efficiency
ความท้าทาย ปัญหาด้านความปลอดภัย และแนวทางการปรับใช้จริง
ความท้าทาย ปัญหาด้านความปลอดภัย และแนวทางการปรับใช้จริง
การนำ Edge‑RAG ร่วมกับ 5G MEC มาประยุกต์ใช้เพื่อให้ LLM แก้ปัญหา QoE แบบเรียลไทม์ แม้จะให้ประสิทธิภาพด้าน latency ลดลงสู่ระดับมิลลิวินาที แต่ก็เผชิญกับข้อจำกัดเชิงปฏิบัติการและความปลอดภัยที่สำคัญหลายด้าน ได้แก่ การจัดการเวอร์ชันของโมเดล (model drift), ความเป็นส่วนตัวของข้อมูลผู้ใช้, ขอบเขตความปลอดภัยของ MEC, การจัดการทรัพยากรเมื่อสเกล และการทำ observability สำหรับการตัดสินใจของ LLM ซึ่งหากไม่ได้ออกแบบและควบคุมอย่างรัดกุม อาจนำไปสู่ความเสี่ยงทางกฎหมาย ผลกระทบต่อประสบการณ์ผู้ใช้ และค่าใช้จ่ายที่เพิ่มสูงขึ้นอย่างไม่คาดคิด
ประเด็นความเป็นส่วนตัว (PII) เป็นหัวใจสำคัญเมื่อระบบต้องดึงข้อมูลผู้ใช้จาก retrieval store เพื่อประกอบการตัดสินใจแบบเรียลไทม์ ข้อควรระวังได้แก่การรั่วไหลของข้อมูลประจำตัว, การเก็บข้อมูลใน logs ที่อาจใช้ย้อนกลับหา PII ได้, และการเก็บตัวอย่าง/ดาวน์โหลดข้อมูลลงสภาพแวดล้อมที่ไม่ปลอดภัย แนวทางปฏิบัติที่แนะนำประกอบด้วย:
- การเข้ารหัสทั้ง at rest และ in transit (เช่น TLS 1.3 + per-tenant envelope encryption)
- การทำ field‑level encryption หรือ tokenization สำหรับฟิลด์ที่เป็น PII เช่น หมายเลขผู้ใช้ เบอร์โทรศัพท์ และที่อยู่
- การนำเทคนิค differential privacy มาปรับใช้ทั้งในชั้น retrieval (เพิ่ม noise ระดับที่ควบคุมได้เมื่อ aggregate) และชั้น training เพื่อลดความเสี่ยงการฟื้นคืน PII จากโมเดล
- นโยบาย retention และการลบข้อมูลอัตโนมัติ รวมถึงการสกัด/มาสก์ข้อมูลใน logs ก่อนเก็บถาวร
ขอบเขตความปลอดภัยของ MEC และการสเกลทรัพยากร — MEC ให้ประโยชน์เรื่อง latency แต่โหนดขอบเครือข่ายมักมีขนาดทรัพยากรจำกัดและอาจตั้งอยู่นอกศูนย์ข้อมูลหลัก จึงต้องคำนึงถึงการแบ่งเขตความเชื่อมั่น (trust boundary) ระหว่างโฮสต์ของโอเปอเรเตอร์และแอปพลิเคชันของผู้ให้บริการต่างๆ แนวทางบรรเทาความเสี่ยงได้แก่:
- การใช้ secure enclave (เช่น Intel SGX, ARM TrustZone หรือ TEEs ที่ได้รับการรับรอง) สำหรับการประมวลผลข้อมูล PII และคีย์ลับ
- network segmentation และ per‑tenant VPC/namespace รวมถึง mTLS และ mutual authentication ระหว่างโหนด
- การกำหนด resource quotas และ priority queuing เพื่อป้องกันการหยุดชะงักเมื่อมีสเกลสูง — ใช้ autoscaling แบบคำนึงถึง GPU/CPU/หน่วยความจำ พร้อมกับนโยบาย pre‑emptible/spot สำหรับงาน background
- การเพิ่มประสิทธิภาพค่าใช้จ่ายด้วย model quantization, distillation, และ hybrid inference (use small local model for fast decisions + offload heavy ops ไปยัง regional)
security ของการกระทำที่ LLM เรียกใช้งาน (LLM‑triggered actions) เป็นประเด็นสำคัญเมื่อระบบอนุญาตให้โมเดลสั่งการเปลี่ยนแปลงบริการหรือแก้ไขค่า QoS โดยตรง ข้อควรปฏิบัติที่จำเป็นได้แก่:
- การรับรองตัวตนและกำหนดสิทธิ์แบบเข้มงวด (authentication/authorization) สำหรับทุกคำสั่งที่มาจาก LLM — ใช้ token exchange, short‑lived credentials และ RBAC/ABAC
- การลงนาม (signed requests) และการตรวจสอบความถูกต้องของคำสั่งก่อนปฏิบัติการจริง เช่น allow‑list ของคำสั่งที่อนุญาต, rate limits, และ threshold approvals สำหรับคำสั่งที่มีผลกระทบสูง
- การรันการกระทำใน sandbox environment หรือ staging ก่อนปล่อยสู่ production และการมีระบบ rollback/compensation สำหรับการกระทำที่ล้มเหลวหรือผิดพลาด
- การบังคับใช้ policy validation engine (เช่น OPA) เพื่อประเมินว่า playbook หรือ plan ที่ LLM สร้างสอดคล้องกับนโยบายความปลอดภัย/การปฏิบัติงาน
observability และการจัดการ model drift — การตรวจจับว่า LLM ยังคงทำงานได้ถูกต้องเมื่อสภาพแวดล้อมเปลี่ยน (เช่น รูปแบบทราฟฟิกและความลำเอียงของข้อมูล) จำเป็นต้องมีการมอนิเตอร์เชิงลึกและกลไก feedback loop:
- กำหนด metrics หลัก: latency (p50/p95/p99), success rate ของการแก้ปัญหา QoE, confidence score ของ LLM, และ cost per inference
- ติดตั้ง drift detectors บนข้อมูล input และผลลัพธ์ (เช่น PSI, KL divergence, distributional tests) ที่แจ้งเตือนหากเกิดการเปลี่ยนแปลงเชิงสถิติ
- log และ audit trail ของทุกคำตอบ/การตัดสินใจ (แต่ต้อง scrub PII ก่อนเก็บ) เพื่อให้สามารถทำ forensic และ retraining dataset ได้
- ใช้ tracing (เช่น Jaeger) ร่วมกับ metrics (Prometheus/Grafana) และ centralized observability เพื่อเชื่อมโยงเหตุการณ์จาก network → retrieval → LLM → action
ปฏิบัติการ: continuous monitoring, model retraining pipeline และ CI/CD สำหรับโมเดลและ playbooks — การดูแลระบบที่มี LLM เป็นตัวตัดสินใจเชิงอัตโนมัติจำเป็นต้องมีกระบวนการ DevOps/MLops ชัดเจน:
- สร้าง model registry และ versioning (เช่น MLflow, ModelDB) เพื่อบันทึกเวอร์ชันโมเดลและข้อมูล training snapshot — ป้องกันปัญหา model drift โดยการย้อนกลับได้เมื่อจำเป็น
- pipeline สำหรับ continuous retraining ที่ประกอบด้วย data curation (PII-safe), automated validation tests (accuracy, safety checks, adversarial tests), และ staged deployment (shadow → canary → full) พร้อมเกณฑ์ยอมรับเชิงคณิตศาสตร์ก่อน promote
- CI/CD สำหรับ playbooks และ policy: treat playbooks as code, มี unit/integration tests, policy validation และ simulated runs ใน sandbox ก่อน deploy
- การติดตามค่าใช้จ่าย (cost management) แบบเรียลไทม์: กำหนด cost per query, budget alerts, และใช้ mixed‑compute strategy (edge small models + regional heavy models) เพื่อลดต้นทุนและควบคุม QoE SLA
โดยสรุป การนำ Edge‑RAG LLM มาทำงานร่วมกับ 5G MEC เพื่อแก้ปัญหา QoE แบบอัตโนมัติเรียลไทม์ต้องผสานทั้งมาตรการด้านความเป็นส่วนตัว เทคนิคความปลอดภัยเชิงสถาปัตยกรรม และกระบวนการ MLOps ที่เข้มแข็ง การประยุกต์แนวทางเช่น differential privacy, secure enclaves, policy validation engines, พร้อม CI/CD สำหรับโมเดลและ playbooks จะช่วยลดความเสี่ยงเชิงปฏิบัติการและเชิงความปลอดภัย ขณะเดียวกัน observability ที่ออกแบบมาอย่างดีและ pipeline สำหรับ retraining จะช่วยให้ระบบรักษาคุณภาพการตัดสินใจของ LLM ได้อย่างต่อเนื่องและคาดการณ์ได้
บทสรุป
สรุปประเด็นสำคัญ: การทดลองใช้ Edge‑RAG บน 5G MEC โดยโอเปอเรเตอร์ไทยแสดงให้เห็นถึงศักยภาพในการลด Latency สู่ระดับมิลลิวินาทีและปรับปรุง Quality of Experience (QoE) สำหรับแอปพลิเคชันเรียลไทม์ (เช่น วิดีโอสตรีมมิง, AR/VR, cloud gaming, และการควบคุมระบบอุตสาหกรรม) อย่างมีนัยสำคัญ — ตัวอย่างการทดลองเบื้องต้นระบุว่าค่า P99 อาจลดจากช่วง ~120–200 ms ลงไปสู่ <10 ms และ P50 ลดจาก ~30–50 ms เหลือประมาณ 2–5 ms ขณะที่ MOS อาจเพิ่มขึ้นราว 0.3–1.0 คะแนน (ผลลัพธ์ขึ้นกับลักษณะโหลดและทรัพยากร MEC ที่จัดสรร) โดยข้อได้เปรียบสำคัญมาจากการประมวลผลเชิงคำสั่ง (RAG) ที่อยู่ใกล้ผู้ใช้ ทำให้ตอบสนองเชิงบริบทได้รวดเร็วและแก้ปัญหา QoE แบบอัตโนมัติได้ทันเวลา แต่นั่นแลกมาด้วยความท้าทายด้านการจัดการทรัพยากรและความเสี่ยงความปลอดภัย เช่น การบริหารหน่วยความจำ/CPU ของ MEC node, การอัพเดตโมเดลแบบปลอดภัย, การควบคุมข้อมูลที่อยู่ใกล้ขอบเครือข่าย และการขยายพื้นผิวการโจมตีของระบบ AI
แนวทางการนำไปใช้จริงและมุมมองอนาคต: การนำ Edge‑RAG ไปใช้งานเชิงพาณิชย์ควรเริ่มจาก use case จำกัดภายใน MEC zone ก่อน (เช่น บริการในสนามกีฬาหรือพื้นที่นิคมอุตสาหกรรม) พร้อมตั้ง testbed เพื่อวัดเมตริกสำคัญอย่าง P99/P50 latency และ MOS เป็นดัชนีวัดความสำเร็จ, ออกแบบ playbooks สำหรับการรักษาเสถียรภาพที่มีขั้นตอน rollback ชัดเจน และติดตั้ง observability + CI pipelines สำหรับทั้งโมเดลและนโยบาย (model CI/CD, model drift detection, policy rollout) เพื่อให้สามารถตรวจจับและย้อนกลับได้ทันทีเมื่อผลกระทบต่อ QoE เกิดขึ้น ตัวอย่างการปฏิบัติแนะนำให้เริ่มด้วยการจำกัดทรัพยากรโมเดล (quantization/distillation), ใช้ hardware acceleration บน MEC, และนำแนวทาง privacy-preserving เช่น federated learning มาใช้เพื่อลดความเสี่ยงด้านข้อมูลในอนาคต ในภาพรวม เทคโนโลยีดังกล่าวมีแนวโน้มเติบโตควบคู่กับการพัฒนา orchestration สำหรับ edge, มาตรฐานการกำกับดูแล, และเครื่องมือ MLOps เฉพาะที่รองรับการทำงานแบบกระจาย — ซึ่งจะช่วยให้ข้อได้เปรียบเรื่อง latency และ QoE ถูกแปลงเป็นบริการเชิงพาณิชย์ได้อย่างปลอดภัยและเป็นระบบ



