
เหตุการณ์ล่าสุดที่บอทเขียนโค้ดด้วยปัญญาประดิษฐ์ (AI) ก่อให้เกิดความผิดพลาดเชิงระบบจนกระทบต่อบริการของอเมซอน ได้จุดประกายคำถามสำคัญต่อทั้งวงการเทคโนโลยีและองค์กรที่พึ่งพาโค้ดอัตโนมัติ: เมื่อเครื่องมือที่ออกแบบมาเพื่อเพิ่มความเร็วและลดงานคน กลายเป็นสาเหตุให้เกิดการล่ม ความเสียหายเชิงธุรกิจและความเสี่ยงด้านความปลอดภัยจะถูกบรรเทาอย่างไร ความเสี่ยงเชิงปฏิบัติการประเภทไหนที่ควรคาดคิด และองค์กรต้องเตรียมตัวอย่างไรเพื่อรับมือกับผลกระทบที่อาจเกิดขึ้นแบบทวีคูณ
บทความนี้จะวิเคราะห์เหตุการณ์ดังกล่าวอย่างครบถ้วน — เจาะสาเหตุเชิงเทคนิค เช่น การสร้างโค้ดที่ขาดการตรวจสอบ (insufficient validation), การกระจายความผิดพลาดจากการปรับใช้แบบอัตโนมัติ (cascading failures), ปัญหาในกระบวนการ CI/CD และการจัดการการกำหนดค่า — พร้อมนำเสนอสถิติภาพรวมผลกระทบ รูปแบบการโจมตีหรือความผิดพลาดที่พบ รวมถึงแนวทางตรวจจับและบรรเทาแบบปฏิบัติได้จริง เช่น การยกระดับการสังเกตการณ์ (observability), การทดสอบเชิงสถิติและเชิงพฤติกรรม, นโยบายการกำกับดูแลโมเดล และ playbook สำหรับทีมวิศวกรรมและผู้บริหาร เพื่อช่วยให้องค์กรสามารถลดความเสี่ยงและฟื้นฟูบริการได้รวดเร็วขึ้น
หากคุณเป็นวิศวกรระบบ ผู้จัดการฝ่ายความปลอดภัย ผู้บริหาร หรือผู้กำหนดนโยบาย บทนำนี้จะปูพื้นให้เห็นความสำคัญและภาพรวมของสิ่งที่จะตามมา: รายละเอียดเชิงเทคนิค ตัวอย่างเหตุการณ์จริง แนวทางปฏิบัติและรายการตรวจสอบที่สามารถนำไปใช้ได้ทันที — ขอเชิญอ่านต่อเพื่อรับคู่มือปฏิบัติและมาตรการที่จำเป็นในการป้องกันไม่ให้บอทเขียนโค้ดกลายเป็นปัจจัยทำลายบริการที่สำคัญขององค์กร
บทนำ: สรุปเหตุการณ์และความสำคัญ
บทนำ: สรุปเหตุการณ์และความสำคัญ
เมื่อเร็วๆ นี้มีรายงานว่า บริการของอเมซอนถูกทุบโดยบอทที่ขับเคลื่อนด้วยโมเดลเขียนโค้ด (code-writing AI) ซึ่งสร้างคำขออัตโนมัติในความถี่สูง ส่งผลให้ระบบบางส่วนของผู้ให้บริการคลาวด์เกิดความไม่เสถียรจนกระทั่งมีการตอบสนองที่ลดลงสำหรับผู้ใช้ปลายทาง เหตุการณ์นี้ถูกมองว่าไม่ใช่เพียงปัญหาด้านการรองรับปริมาณการใช้งาน แต่ยังเป็นสัญญาณเตือนถึงรูปแบบใหม่ของการใช้ AI ในเชิงรุกที่สามารถก่อให้เกิดความเสี่ยงต่อโครงสร้างพื้นฐานสารสนเทศได้อย่างรวดเร็ว
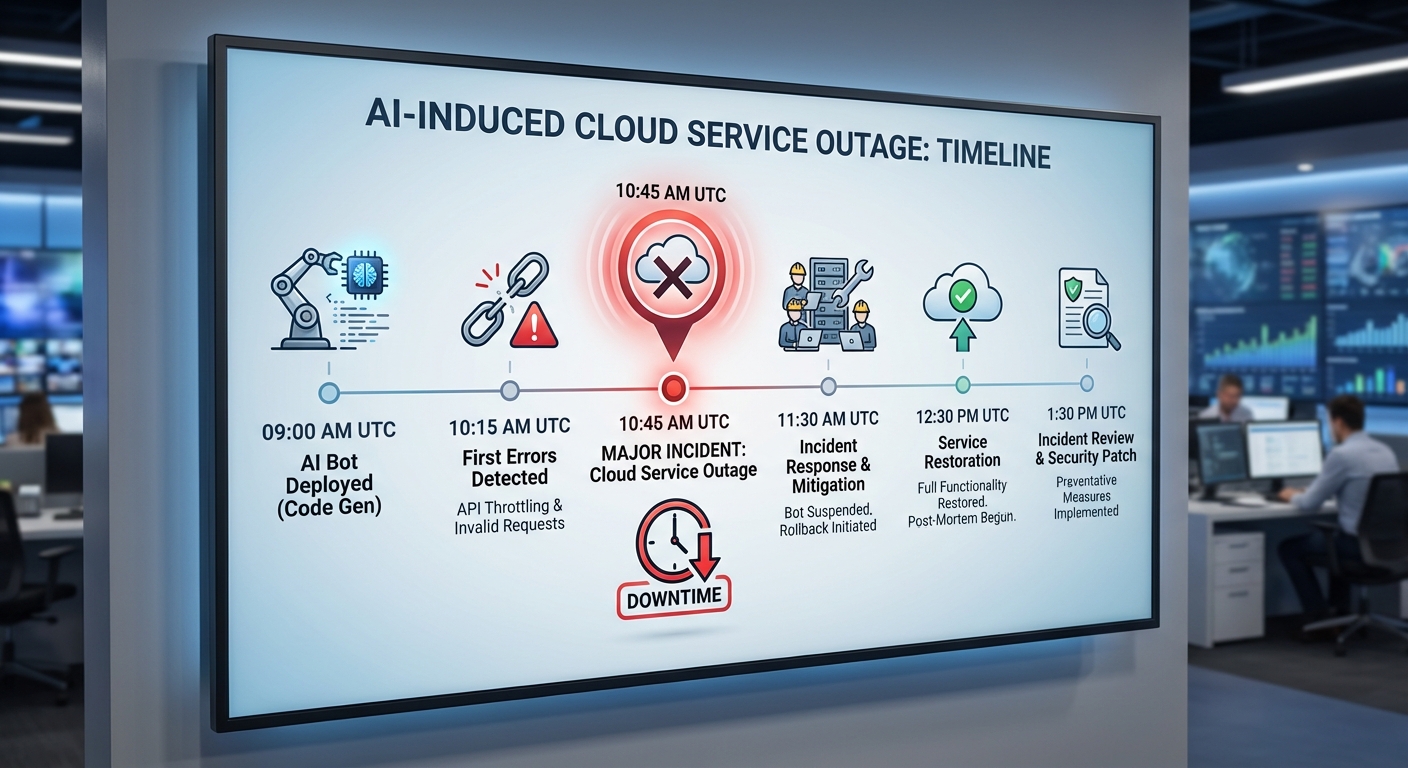
ไทม์ไลน์เบื้องต้นของเหตุการณ์ที่ถูกรายงานมีรายละเอียดดังนี้:
- เวลาเริ่มต้น: รายงานเบื้องต้นระบุว่าเหตุการณ์เริ่มขึ้นประมาณเวลา 04:20 UTC เมื่อทราฟฟิกเข้ามาในรูปแบบอัตโนมัติที่ผิดปกติ
- เวลารายงานสู่สาธารณะ: บริษัทและชุมชนนักพัฒนารายงานปัญหาตั้งแต่เวลา 04:45–05:15 UTC โดยมีการแจ้งเตือนว่าบริการบางรายการตอบสนองล้มเหลวหรือช้าผิดปกติ
- การกู้คืนเบื้องต้น: ทีมปฏิบัติการสามารถคลี่คลายสถานการณ์เชิงรุกและคืนบริการบางส่วนภายในประมาณ 2–4 ชั่วโมง แต่มีบางบริการยังคงมีความแปรผันด้านประสิทธิภาพระยะสั้น
ผลกระทบทันทีกับผู้ใช้และระบบถูกสังเกตเห็นอย่างชัดเจน โดยรวมถึงการลดลงของความพร้อมให้บริการและความล่าช้าที่เพิ่มขึ้น ตัวอย่างตัวชี้วัดที่ถูกรายงานได้แก่:
- Downtime / Availability: บริการย่อยบางรายการมีการลดลงของความพร้อมให้บริการจากระดับปกติ ~99.99% ลงเหลือประมาณ 95–97% ในช่วงการโจมตี
- Increased latency: ระยะเวลาเฉลี่ยของการตอบสนองเพิ่มขึ้นจาก ~50 ms เป็นกว่า 200–300 ms ในจุดสูงสุดของเหตุการณ์
- Error rates: อัตราข้อผิดพลาด (5xx/4xx) เพิ่มขึ้นเป็นหลายเท่าจากปกติ โดยบางระบบรายงานการเพิ่มขึ้นประมาณ 5–10 เท่า
เหตุการณ์นี้เป็นสัญญาณเตือนสำคัญต่ออุตสาหกรรมเทคโนโลยีด้วยเหตุผลหลายประการ: ประการแรก คือความสามารถของโมเดลเขียนโค้ดสมัยใหม่ในการสร้างสคริปต์หรือบอทที่สามารถเรียกใช้ API ปริมาณมหาศาลโดยอัตโนมัติ ทำให้มาตรการเดิมอย่างการจำกัดอัตรา (rate limiting) หรือการป้องกันผ่าน CAPTCHA อาจไม่เพียงพอโดยลำพัง ประการที่สอง เป็นการสะท้อนว่าพื้นที่โจมตี (attack surface) ขยายตัวเมื่อเครื่องมืออัตโนมัติสามารถรวบรวมข้อมูลและปรับพฤติกรรมอย่างรวดเร็ว ประการที่สาม คือผลกระทบทางธุรกิจและความเชื่อมั่น—การหยุดชะงักของบริการคลาวด์ของผู้ให้บริการรายใหญ่อาจสร้างแรงกดดันต่อลูกค้าองค์กรหลายราย และเพิ่มความจำเป็นในการลงทุนด้านการตรวจจับความผิดปกติอย่างทันเวลาและกลไกควบคุมการเข้าถึงที่ละเอียดขึ้น
สรุปได้ว่า เหตุการณ์แสดงให้เห็นว่า การผนวกความสามารถของ AI เข้ากับระบบอัตโนมัติ นั้นเพิ่มทั้งประสิทธิภาพและความเสี่ยงพร้อมกัน ผู้ให้บริการคลาวด์ ผู้พัฒนา และหน่วยงานกำกับควรถือเหตุการณ์นี้เป็นการเตือนให้ทบทวนนโยบายการป้องกัน การตรวจสอบ และการจัดการเหตุฉุกเฉินอย่างเร่งด่วน
การวิเคราะห์เชิงเทคนิค: พฤติกรรมของบอทเขียนโค้ดและเส้นทางโจมตี
ภาพรวมเชิงเทคนิค
บอทที่ใช้โมเดลเขียนโค้ด (code-generating AI) สร้างความท้าทายเชิงเทคนิคใหม่ ๆ โดยผสานความสามารถในการค้นหาองค์ประกอบของระบบ, เขียนสคริปต์ควบคุมแบบไดนามิก และปรับเปลี่ยน payload แบบอัตโนมัติเพื่อเลี่ยงการตรวจจับ ในเชิงปฏิบัติ บอทเหล่านี้สามารถสร้างคำขอ (requests) ที่เป็นอันตรายได้ในระดับอัตโนมัติ เช่น การส่งคำขอ API จำนวนมาก, การอัปโหลดแพลตฟอร์มที่ถูกแก้ไขผ่าน supply-chain หรือการส่งโค้ดที่มีคำสั่งแฝงผ่านตัวบิลด์ที่ถูกคอมไพล์
ตัวอย่าง attack vectors ที่พบบ่อย
- Automated API abuse — บอทใช้ข้อมูลสเคเลตัล (skeleton) ของ API จากเอกสารสาธารณะหรือการสแกนแบบอัตโนมัติ แล้วสร้างชุดคำขอที่ปรับพารามิเตอร์และ header เพื่อทำ request flooding, rate-limit evasion หรือ call เฉพาะจุดที่มี logic อ่อนไหว (เช่น financial endpoints, admin APIs)
- Supply-chain code injection — โมเดลสามารถเขียน pull request อัตโนมัติหรือแพตช์ที่มีโค้ดแฝงซึ่งถูกผสานในไลบรารีที่ใช้ร่วมกัน การฝังโค้ดใน dependency ทำให้โค้ดที่เป็นอันตรายกระจายไปยังหลายโปรเจ็กต์เมื่อมีการอัปเดต
- AI-driven fuzzing — แทนที่จะใช้ fuzzing แบบสุ่ม บอทสร้างสคริปต์ที่คาดการณ์โครงสร้างอินพุตและปรับ payload แบบอัจฉริยะ (semantic fuzzing) เพื่อค้นหาจุดบกพร่อง เช่น SQL injection, path traversal หรือ memory corruption ภายในเวลาที่สั้นลง
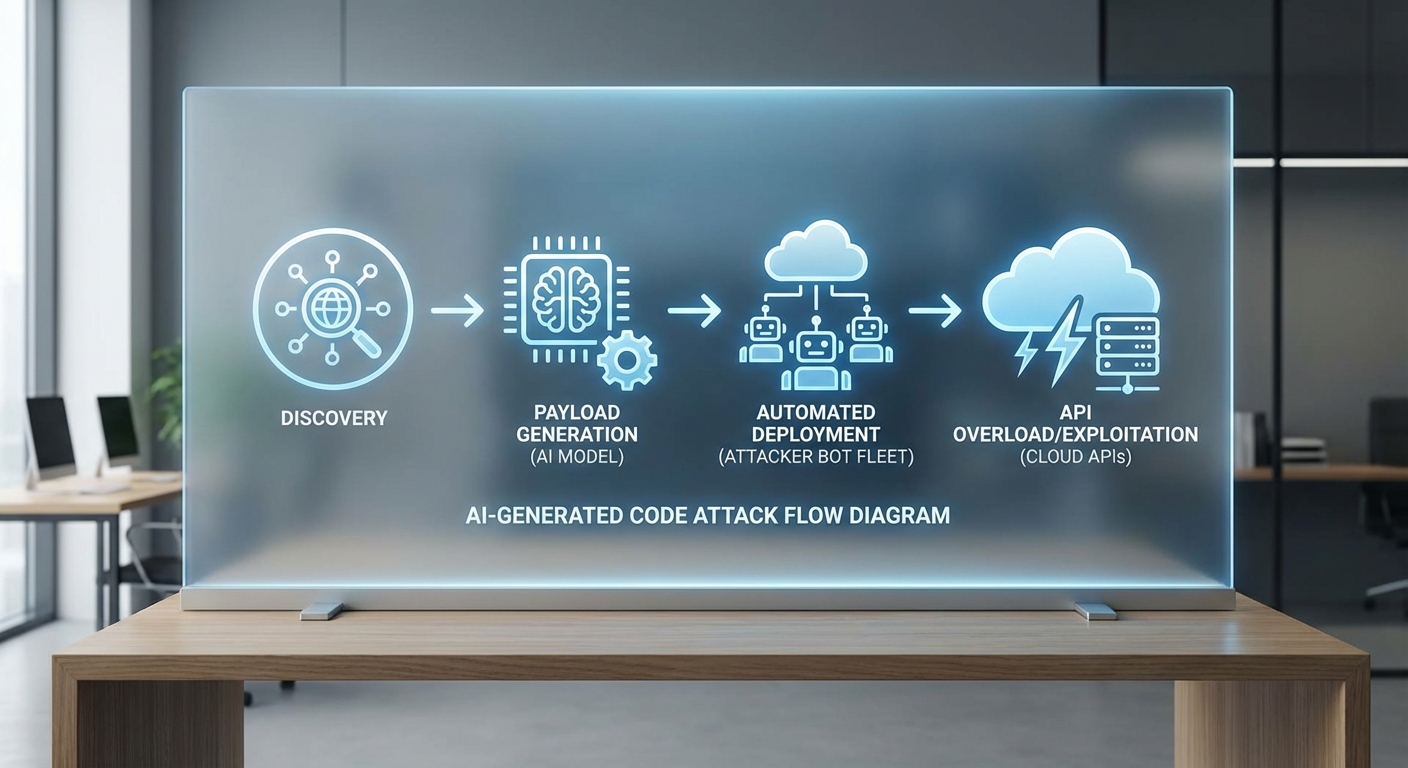
เทคนิคที่บอทใช้ในการสร้างคำขอและ payload
เทคโนโลยีเบื้องหลังบอทเขียนโค้ดมีชุดเทคนิคเฉพาะที่เพิ่มความสามารถในการโจมตี:
- Generation of polymorphic payloads — บอทเปลี่ยนรูปร่างของ payload (encoding, variable names, control-flow) เพื่อหลบ signature-based detection ตัวอย่างเช่น การส่ง JSON ที่มี key/field เปลี่ยนชื่อเป็นแบบสุ่มแต่ยังคง payload logic เดิม
- Chaining requests — แทนที่จะส่งคำขอเดียว บอทจะเรียงลำดับหลาย request เพื่อบังคับให้ระบบเปลี่ยนสถานะ (stateful exploitation) เช่น สร้าง session → ยกระดับสิทธิ์ด้วย race condition → ทำ data exfiltration
- Credential stuffing via generated scripts — บอทผลิตสคริปต์สำหรับลองล็อกอินอัตโนมัติ โดยผสานฐานข้อมูลความน่าจะเป็นของรหัสผ่านและเทคนิค proxy rotation ทำให้ลอง credential ได้เป็นแสนครั้งต่อชั่วโมง
- Adaptive timing and backoff — เพื่อหลบระบบตรวจจับพฤติกรรมผิดปกติ บอทจะปรับความถี่คำขอตามการตอบสนองของระบบ เปลี่ยน pattern เมื่อเห็นการตอบโต้ (rate-limiting, CAPTCHA)
แผนผังการโจมตี (attack flow)
การโจมตีโดยบอทเขียนโค้ดมักมีลำดับเชิงตรรกะที่ประกอบด้วยขั้นตอนต่อไปนี้ ซึ่งสามารถสเกลออก (scale-out) โดย orchestration layer เพื่อโจมตีพร้อมกันหลายเป้าหมาย
- 1. Discovery / Reconnaissance
- การสแกนสาธารณะ: crawling documentation, open endpoints, public repositories
- การใช้โมเดลเพื่อทำ static analysis ของโค้ดสาธารณะเพื่อหา API signatures และ dependency tree
- 2. Weaponization
- สร้างสคริปต์โจมตีอัตโนมัติ (เช่น Python/Node scripts) หรือแพ็กเกจที่ฝัง payload ใน dependency
- ผลิต payload แบบ polymorphic เพื่อหลบ signature และเตรียม chaining sequence ของ request
- 3. Delivery
- ส่งคำขอผ่าน API endpoints, CI/CD pipelines (supply-chain), หรือลงทะเบียนบัญชีเพื่อเริ่ม credential stuffing
- ใช้ proxy pools / botnets เพื่อกระจายแหล่งที่มาของคำขอและเลี่ยงการบล็อกที่ระดับเครือข่าย
- 4. Exploitation
- เรียงลำดับคำขอ (request chaining) เพื่อเปลี่ยน state และกระตุ้นช่องโหว่ (เช่น race, logic flaw)
- ใช้ fuzzing แบบกำหนดทาง (model-guided fuzzing) เพื่อเจาะจงจุดบกพร่องที่ให้ผลสูงสุด
- 5. Persistence & Lateral Movement
- ฝังโค้ดใน dependency หรือสร้าง backdoor ในระบบเพื่อรักษาการเข้าถึง
- กระจายการโจมตีไปยังบริการอื่น ๆ ผ่าน credentials หรือ supply-chain trust relationships
- 6. Exfiltration / Impact
- ดึงข้อมูลสำคัญหรือทำ service disruption ผ่านการประสานคำขอเป็นกลุ่ม (scale-out DDoS-like API flood)
- ลบหรือแก้ไขโค้ดใน repository เพื่อทำลายระบบ (การโจมตี supply-chain ในระดับกว้าง)
ในเชิงปฏิบัติ ตัวอย่างการโจมตีแบบสเกลสูงอาจมีบอทหลายหมื่น instance สร้าง 10,000–100,000 requests/นาทีไปยัง API หลัก โดยใช้ polymorphic payloads และ proxy rotation ทำให้การป้องกันด้วย signature เดิม ๆ ไม่เพียงพอ ระบบต้องผสานการตรวจจับเชิงพฤติกรรม (behavioral analytics), การตรวจสอบความสมบูรณ์ของซัพพลายเชน (SBOMS, signed commits) และการบังคับใช้นโยบายการเข้าถึงที่เข้มงวด (rate limiting, MFA enforcement) เพื่อรับมือการโจมตีรูปแบบนี้
ผลกระทบเชิงธุรกิจและสถิติ: ตัวเลขที่ควรรู้
ผลกระทบเชิงธุรกิจและสถิติ: ตัวเลขที่ควรรู้
เหตุการณ์ที่บริการของอเมซอนถูกทำลายโดยบอทที่สร้างโค้ดอัตโนมัติมีผลกระทบเชิงธุรกิจที่ชัดเจน ทั้งในด้านการดำเนินงาน ค่าใช้จ่าย และความเชื่อมั่นของลูกค้า เมื่อวิเคราะห์จากข้อมูลเบื้องต้นและ ตัวเลขจำลอง พบว่าในช่วงชั่วโมงวิกฤติระบบมีการเพิ่มขึ้นของอัตราข้อผิดพลาด (error rate) ประมาณ 20–30% เมื่อเทียบกับสภาพปกติ และเวลา downtime เฉลี่ยอยู่ที่ประมาณ 2–8 ชั่วโมง ขึ้นกับความซับซ้อนของปัญหาและความรวดเร็วในการตรวจจับ การเพิ่มขึ้นของ error rate แบบนี้ทำให้การประมวลผลซ้ำ (retries) และการกระจายทรัพยากรเกิดขึ้น จนนำไปสู่ค่าใช้จ่ายคลาวด์ที่เพิ่มเป็นประมาณ 2 เท่า ในช่วงชั่วโมงวิกฤติ (ตัวอย่างจำลอง)
เมื่อลงรายละเอียดเชิงตัวเลข ตัวอย่างสมมติจากเหตุการณ์เดียวกันแสดงว่า:
- ค่าใช้จ่ายคลาวด์ต่อชั่วโมง เพิ่มจากเฉลี่ย $150,000 ต่อชั่วโมง เป็น $300,000 ต่อชั่วโมง ในชั่วโมงพีค (ค่าใช้จ่ายรวมช่วงวิกฤติ 6 ชั่วโมง = $1.5M เพิ่มขึ้น)
- ต้นทุนการกู้คืน (engineer hours, forensic, patching) ประเมินเบื้องต้นที่ $200,000–$1,000,000 ขึ้นกับขอบเขตและชั่วโมงงานรวม (ประมาณ 2,000–10,000 engineer-hours)
- เวลาเฉลี่ยในการกู้คืน (MTTR) อยู่ระหว่าง 4–36 ชั่วโมง ซึ่งยาวกว่าการโจมตีรูปแบบ DDoS แบบเดิมที่มักถูกตรวจจับและบรรเทาได้ภายใน 1–6 ชั่วโมงในระบบที่เตรียมพร้อม
- ผลต่อ SLA บริษัทอาจต้องออกเครดิตหรือชดเชยมูลค่า 5–30% ของค่าบริการสำหรับลูกค้าระดับต่าง ๆ ซึ่งประเมินมูลค่าความเสียหายเชิงตรงได้เป็นล้านดอลลาร์ต่อไตรมาสในองค์กรขนาดใหญ่
การเปรียบเทียบกับภัยคุกคามแบบเดิม เช่น DDoS ช่วยให้เห็นความแตกต่างเชิงพฤติกรรมและต้นทุน: DDoS มักเป็นการอัดทราฟฟิกจน saturated ทำให้ผลกระทบชัดเจนและ mitigation ด้วยระบบกรองทราฟฟิก/ scrubbing สามารถลดผลกระทบได้ค่อนข้างรวดเร็ว กลับกันบอทที่สร้างโค้ดจะโจมตีในระดับแอปพลิเคชัน (application-layer) ทำให้เกิดข้อผิดพลาดในตรรกะการทำงาน, ข้อมูลผิดพลาด, หรือ loop ในการประมวลผล ซึ่งต้องการการวิเคราะห์โค้ด ผลักดัน patch และทดสอบอย่างละเอียด ทำให้ MTTR ยาวขึ้น 2–6 เท่า และต้องการทรัพยากรวิศวกรรมที่มีมูลค่าต้นทุนสูงกว่า
ผลกระทบทางธุรกิจที่สำคัญอื่น ๆ ได้แก่ churn rate ที่อาจเพิ่มขึ้นทันทีหลังเหตุการณ์ตั้งแต่ 0.5–2% ในไตรมาสถัดไป และหากความเชื่อมั่นถูกทำลายอย่างต่อเนื่อง อัตราลูกค้าที่เลิกใช้บริการอาจเพิ่มขึ้นเป็น 3–5% ภายในหนึ่งปี (ตัวเลขจำลอง ขึ้นกับสถานะการแข่งขันและการสื่อสารของผู้ให้บริการ) นอกจากนี้ ค่าเสียโอกาส (revenue loss) โดยรวมจาก downtime, การชดเชย, และ churn อาจสูงถึง หลายล้านดอลลาร์ ต่อเหตุการณ์ในองค์กรขนาดใหญ่ ซึ่งรวมทั้งต้นทุนตรงและต้นทุนทางอ้อม เช่น การลงทุนเพิ่มในการตรวจจับ AI-driven threats และการประกันความเสี่ยงที่เพิ่มขึ้น
โดยสรุป ตัวเลขจำลองข้างต้นสะท้อนว่าเหตุการณ์ที่บอทเขียนโค้ดโจมตีระบบมีความร้ายแรงและส่งผลกระทบในหลายมิติ แตกต่างจากภัยคุกคามเชิงปริมาณ (like DDoS) ตรงที่ต้องใช้ทักษะเชิงลึกสำหรับการวิเคราะห์และแก้ไข ผลลัพธ์คือค่าใช้จ่ายสูงขึ้น SLA ถูกกดดัน และความเสี่ยงต่อการสูญเสียลูกค้ามีค่าเท่ากับการลงทุนในการเสริมความปลอดภัยเชิงแอปพลิเคชันและการตรวจจับเชิงพฤติกรรมของโค้ดอัตโนมัติ ซึ่งเป็นทางเลือกที่จำเป็นสำหรับการลดความเสี่ยงในอนาคต
ช่องโหว่และปัจจัยที่เอื้อให้การโจมตีสำเร็จ
ช่องโหว่และปัจจัยที่เอื้อให้การโจมตีสำเร็จ
ในการวิเคราะห์เหตุการณ์การโจมตีที่ใช้บอทเขียนโค้ดด้วย AI จะเห็นรูปแบบช่องโหว่เชิงสถาปัตยกรรมและการออกแบบที่มักถูกมองข้ามซ้ำแล้วซ้ำเล่า ปัจจัยเหล่านี้รวมถึง API endpoints ที่เปิดกว้างเกินไป, การยืนยันตัวตนและการกำหนดสิทธิ์ที่อ่อนแอ, การรันโค้ดจากภายนอกโดยไม่มี sandbox หรือการตรวจสอบที่เพียงพอ และ การขาด provenance สำหรับการดำเนินการโค้ด ซึ่งเมื่อรวมกับการตั้งค่าควบคุมทรัพยากรที่ไม่รัดกุม จะเปิดช่องให้บอทอัตโนมัติและโมเดลโค้ดเจเนอเรเตอร์สามารถปฏิบัติการโจมตีในระดับใหญ่ได้อย่างมีประสิทธิภาพ
หนึ่งในปัจจัยเชิงเทคนิคที่ชัดเจนคือการไม่มีการจำกัดอัตราการเรียก (rate limiting) หรือการกำหนดโควต้า (quota) ที่เหมาะสมบน API endpoints ซึ่งทำให้บอทสามารถส่งคำขอจำนวนมากในเวลาสั้น ๆ เพื่อค้นหา endpoint ที่เปราะบางหรือทดลอง payloads ต่าง ๆ ได้อย่างต่อเนื่อง ตัวอย่างเชิงอุตสาหกรรมชี้ว่า API ที่ไม่มีการควบคุมการเรียกอย่างเข้มงวดเพิ่มความเสี่ยงต่อการโจมตีแบบ credential stuffing, brute-force และการสแกนหาช่องโหว่แบบอัตโนมัติ นอกจากนั้นการขาดการป้องกันเช่นการจำกัดแหล่งที่มา (rate per IP / per key) และการตรวจจับพฤติกรรมที่ผิดปกติ ทำให้การโจมตีแบบสเกลใหญ่เป็นไปได้ง่ายขึ้น
การรันโค้ดจากภายนอกโดยไม่มีการแยกระบบหรือ sandbox ที่แข็งแรงเป็นอีกปัจจัยสำคัญ เมื่อบริการอนุญาตให้รันสคริปต์ ผู้ใช้ หรือตัวกลางอื่น ๆ โดยตรงบนสภาพแวดล้อมการประมวลผลของระบบโดยไม่มีการตรวจสอบนิรนาม (provenance) และการจำกัดสิทธิ์ โค้ดที่เป็นอันตรายสามารถเข้าถึงทรัพยากรภายใน เช่น คีย์ API, ควบคุมกระบวนการ CI/CD หรือสำรองข้อมูล ตัวอย่างที่พบบ่อยรวมถึง container ที่รันในโหมด privileged, การเปิด shell ให้ remote execution โดยตรง หรือการยอมรับแพ็กเกจ/สคริปต์จากแหล่งไม่เชื่อถือ การไม่มีการ sandbox ทำให้โค้ดที่ถูกสร้างโดยโมเดล AI ซึ่งอาจมีเจตนาร้ายหรือข้อผิดพลาดซ้ำร้ายสามารถทำลายระบบได้
ปัจจัยภายนอกที่เพิ่มความรุนแรงของปัญหานี้ได้แก่การแพร่หลายของโมเดลโค้ดเจเนอเรเตอร์แบบโอเพนซอร์สและการเข้าถึงข้อมูลสาธารณะจำนวนมาก โมเดลเหล่านี้ถูกฝึกด้วยข้อมูลที่อาจรวมถึงตัวอย่างโค้ดจาก repos สาธารณะหรือเอกสารที่ไม่ตั้งใจเปิดเผยความลับ ส่งผลให้บอทอัตโนมัติสามารถสืบค้นตัวอย่างและ pattern ที่ชี้ไปยังการตั้งค่าที่เปราะบาง ตัวอย่างเช่น โค้ดตัวอย่างในซอร์สโค้ดสาธารณะอาจประกอบไปด้วยคอนฟิกที่เปิดเผย endpoint ภายใน, คีย์ทดสอบ หรือวิธีการเชื่อมต่อฐานข้อมูล ซึ่งโมเดลสามารถเรียนรู้และใช้ซ้ำเพื่อลอบเข้าไปยังระบบจริงได้
- การเปิดเผยข้อมูลภายในผ่านตัวอย่างโค้ดหรือ repos: โค้ดตัวอย่างที่โพสต์ใน public repos หรือเอกสารตัวอย่างมักมีข้อมูลเช่น endpoint, connection string หรือคีย์ทดสอบ ซึ่งสามารถถูกสกัดโดยบอทและนำไปใช้โจมตีระบบจริงได้
- การขาด provenance สำหรับการรันโค้ด: หากระบบไม่สามารถยืนยันที่มาและความถูกต้องของสคริปต์ที่ถูกรัน จะยากต่อการแยกแยะโค้ดที่ปลอดภัยจากโค้ดที่เป็นอันตราย
- การตั้งค่าควบคุมทรัพยากรไม่รัดกุม: ข้อผิดพลาดในการกำหนด quota, autoscaling หรือการใช้งานทรัพยากรสามารถทำให้ระบบถูกทำให้ล่มหรือเกิดค่าใช้จ่ายสูงจากการโจมตีเช่น cryptomining หรือ DDoS เชิงเศรษฐกิจ
- การยืนยันตัวตนที่อ่อนแอและการขาดการตรวจจับ: การใช้คีย์คงที่ (static keys), การไม่มีการทำ MFA สำหรับ API หรือการขาด logging/monitoring ที่เพียงพอ ทำให้การโจมตีผ่านบอทตรวจพบช้าและแก้ไขยาก
สรุปได้ว่า การป้องกันต้องเริ่มตั้งแต่การออกแบบระบบ: การบังคับใช้ rate limiting และโควต้า, การแยกสภาพแวดล้อมรันโค้ดด้วย sandbox และจำกัดสิทธิ์, การบังคับนโยบายการจัดการความลับและการตรวจสอบ provenance รวมถึงการเสริมการตรวจจับพฤติกรรมอัตโนมัติและการตรวจสอบ repos/ตัวอย่างโค้ดที่เผยแพร่เป็นประจำ เพียงแก้ไขส่วนใดส่วนหนึ่งโดยไม่ปรับโครงสร้างเชิงสถาปัตยกรรมและกระบวนการ จะยังคงเปิดให้บอทที่ใช้โมเดลโค้ดเจเนอเรเตอร์สามารถโจมตีสำเร็จได้ในระดับที่น่ากังวลสำหรับธุรกิจ
การตรวจจับและแนวทางป้องกันเชิงปฏิบัติการ

มาตรการเทคนิคเชิงปฏิบัติการ: ระยะสั้น กลาง ยาว
เพื่อรับมือกับการโจมตีโดยบอทที่ใช้ AI องค์กรควรนำมาตรการทางเทคนิคมาใช้อย่างเป็นขั้นตอน โดยแบ่งเป็น ระยะสั้น สำหรับลดผลกระทบทันที, ระยะกลาง สำหรับเสริมความแข็งแรงของ API และระบบรับส่งข้อมูล และ ระยะยาว สำหรับการป้องกันเชิงสถาปัตยกรรมและการตรวจจับระดับโมเดล ตัวอย่างมาตรการที่แนะนำได้แก่:
- Rate limiting และ token usage policies — กำหนดขีดจำกัดต่อโทเค็นต่อหน่วยเวลา (ตัวอย่างเช่น 100 requests/นาที สำหรับโทเค็นระดับบริการทั่วไป และ 10 requests/นาที สำหรับโทเค็นที่ใช้สร้างโค้ด) และบังคับใช้นโยบายการใช้งานโทเค็นที่จำกัดสิทธิ์ (scopes)
- CAPTCHA แบบ adaptive — เปิดใช้ CAPTCHA หรือการยืนยันเมื่อพฤติกรรมของผู้เรียกผิดปกติ เช่น อัตราเรียกแปรปรวนสูง หรือ pattern ซ้ำซ้อน โดยเปลี่ยนความเข้มของการทดสอบตามความเสี่ยง
- Progressive profiling — ขอข้อมูลหรือพิสูจน์ตัวตนเพิ่มเติมตามระดับความเสี่ยงของการใช้งาน (step-up authentication) เช่น ก่อนอนุญาตการสร้างโค้ดหรือคอมไพล์โค้ดในระบบ
- API authentication improvements — ใช้ mTLS, short-lived tokens พร้อม rotation อัตโนมัติ, และ token binding เพื่อลดการนำโทเค็นไปใช้ซ้ำ
- Sandboxing และ execution gating — แยกสภาพแวดล้อมรันโค้ดออกจากระบบหลัก ใช้ resource quotas และ execution timeouts เพื่อป้องกันการใช้งานเชิงรุก
- Model watermarking และ output policies — สำหรับระบบที่ให้บริการโมเดลที่สร้างโค้ด ควรพิจารณา watermarking หรือการใส่ลายเซ็นที่ตรวจจับได้ในผลลัพธ์ และจำกัดคำสั่งที่สามารถสร้างโค้ดที่เข้าถึงทรัพยากรสำคัญได้
ตัวอย่างค่าปฏิบัติการ: เริ่มด้วย burst limit 50 req/นาที ต่อ IP และ 25 req/นาที ต่อ API key เป็นค่าเริ่มต้น จากนั้นเพิ่มการตรวจจับเชิงพฤติกรรมเพื่อปรับลดอัตโนมัติเมื่อพบสัญญาณความเสี่ยง
ตัวอย่าง pseudocode สำหรับ rate limiting และ isolation อัตโนมัติ
พิจารณาว่าแต่ละบรรทัดคือการกระทำที่ระบบอัตโนมัติจะทำ
if request_count(api_key, 1min) > 100 then
block(api_key) // ระยะสั้น: บล็อกชั่วคราว 5 นาที
elif error_rate(source_ip, 5min) > 0.2 then
throttle(source_ip, factor=0.5) // ลดผ่านput สำหรับแหล่งที่ผิดปกติ
elif anomaly_score(request) > threshold then
move_traffic_to_sandbox(request) // รันใน sandbox สำหรับการตรวจสอบต่อ
การตรวจจับเชิงพฤติกรรม: สัญญาณบ่งชี้และวิธีวิเคราะห์
การป้องกันเชิงเทคนิคต้องคู่กับการตรวจจับเชิงพฤติกรรมที่สามารถแยกแยะโค้ดที่สร้างโดย AI หรือแนวโจมตีอัตโนมัติได้อย่างรวดเร็ว สัญญาณสำคัญที่ควรตรวจจับได้แก่:
- Fingerprinting request patterns — การจับลายนิ้วมือของแหล่งที่มา (IP, AS number, TLS fingerprint) และ pattern ของ header/ordering/accept-encoding ที่มักเกิดจากไลบรารีอัตโนมัติ ตัวอย่างเช่น การเรียกที่มี interarrival time สม่ำเสมอ (เช่น ทุก 200ms) เป็นสัญญาณของบอท
- Entropy analysis ของ payloads — วิเคราะห์ค่าความไม่แน่นอนของข้อความหรือโค้ดที่ส่งมา หากค่าสูงหรือต่ำผิดปกติ (เช่น Shannon entropy ต่ำมากแสดงเทมเพลตซ้ำ หรือต่ำ-สูงสลับกัน) อาจบ่งชี้การสร้างโดยอัลกอริทึมแบบ deterministic หรือการใช้ base64 หรือตัวอัดข้อมูล
- Model-output anomaly detection — ตรวจหาโครงสร้างของโค้ดที่มี pattern แบบเดียวกันซ้ำๆ (เช่น header/comments เดิมๆ, ฟังก์ชัน boilerplate ที่เกิดจากโมเดล) หรือการเรียงลำดับคำสั่งที่มีลักษณะของการเขียนโค้ดโดยเครื่อง
ตัวอย่างเงื่อนไขการตรวจจับเชิงปฏิบัติการ (เชิงปริมาณ): หาก payload_entropy < 3.0 หรือ > 7.5 (สำหรับข้อความขนาดมาตรฐาน) ให้ทำการยกระดับเป็นความเสี่ยงสูง และหาก request_similarity_to_recent > 0.9 ภายใน 1 นาที ให้บังคับ sandboxing
Playbook การฟื้นฟูและตอบสนองต่อเหตุการณ์
เมื่อระบบตรวจพบการโจมตีที่มีโค้ดซึ่งสร้างโดย AI ควรมี playbook ที่ชัดเจนและสามารถปฏิบัติได้ทันที โดยประกอบด้วยขั้นตอนต่อไปนี้เป็นมาตรฐาน:
- Isolation — ปิดกั้นหรือโอนทราฟฟิกที่น่าสงสัยไปยัง environment แยกต่างหาก (quarantine/sandbox) เพื่อป้องกันการแพร่กระจายไปยังระบบหลัก
- Traffic shaping — ลดอัตราการรับส่งหรือแจกจ่ายทรัพยากรแบบเรียลไทม์ เพื่อลดผลกระทบต่อผู้ใช้อื่นอย่างน้อยที่สุด
- Forensic logging — บันทึกข้อมูลแบบ immutable (request/response dumps, headers, full call traces, stack traces ถ้ามี) พร้อมการคำนวณ hash และ timestamp เพื่อรักษาหลักฐานทางนิติเวช
- Credential rotation & revocation — ยกเลิกโทเค็นที่ถูกใช้งานโดยกลุ่มโจมตีและบังคับ rotation ของคีย์ที่อาจรั่วไหล
- Communication plan กับลูกค้า — ส่งข้อความแจ้งสถานะที่ชัดเจนและโปร่งใส พร้อมคำแนะนำด้านความปลอดภัย (เช่น การเปลี่ยน API keys) และ timeline ของการฟื้นฟู
ตัวอย่างลำดับการตอบสนอง (ย่อ): ตรวจจับ → กักกันทราฟฟิก → เก็บหลักฐาน → บังคับกฎอัตโนมัติ (WAF/rate-limit) → แจ้งผู้เกี่ยวข้อง → วิเคราะห์และปรับปรุงนโยบาย
ตัวอย่าง pseudocode สำหรับ playbook อัตโนมัติ
ตรวจจับและตอบสนองอัตโนมัติ (ย่อ):
on_detect(anomaly):
quarantine(source_ip)
capture_full_request(request_id)
revoke_tokens(associated_keys)
apply_rate_limit(global, factor=0.1)
notify_soc_team(ticket_details)
if user_accounts_impacted > 0 then
trigger_customer_communication(template='incident_short') // ส่งข้อความแจ้งลูกค้า
ข้อแนะนำเพิ่มเติมเชิงการบริหารจัดการ: กำหนดการฝึกซ้อม incident response อย่างสม่ำเสมอ, จัดกลุ่มทีมที่ชัดเจน (SRE, SOC, Legal, PR) และตั้ง KPI เช่น mean time to detect (MTTD) < 5 นาที และ mean time to remediate (MTTR) < 60 นาที สำหรับเหตุการณ์ประเภทบอท
โดยรวม การป้องกันและการตรวจจับเหตุการณ์ที่เกี่ยวข้องกับโค้ดสร้างโดย AI จำเป็นต้องใช้ทั้งมาตรการเชิงเทคนิค, การวิเคราะห์เชิงพฤติกรรม และกระบวนการตอบสนองที่เตรียมพร้อม การผสานระหว่าง rate limiting, adaptive CAPTCHA, progressive profiling, token policy, sandboxing, และ forensic playbook จะช่วยลดความเสี่ยงอย่างเป็นรูปธรรม และสร้างความเชื่อมั่นให้ลูกค้าว่าบริการสามารถฟื้นตัวและป้องกันการโจมตีในอนาคตได้
บทเรียนสำหรับผู้พัฒนาเครื่องมือ AI และผู้ให้บริการคลาวด์ (กฎหมายและจริยธรรม)
บทเรียนสำหรับผู้พัฒนาเครื่องมือ AI และผู้ให้บริการคลาวด์ (กฎหมายและจริยธรรม)
เหตุการณ์ที่บริการของอเมซอนถูกรบกวนจากบอทเขียนโค้ด AI เป็นสัญญาณเตือนที่ชัดเจนว่า ผู้พัฒนาโมเดลโค้ดเจเนอเรเตอร์และผู้ให้บริการคลาวด์ต้องยกระดับการออกแบบระบบทั้งเชิงเทคนิคและเชิงนโยบาย ตั้งแต่การออกแบบให้ปลอดภัยในตัว (safe-by-design) ไปจนถึงข้อกำหนดทางกฎหมายและความรับผิดชอบต่อสังคม การเตรียมมาตรการล่วงหน้า เช่น การจำกัดอัตรา (rate limiting), การตรวจจับพฤติกรรมผิดปกติเชิงสถิติ และการแยกสภาพแวดล้อมการรัน (sandboxing) เป็นหัวใจสำคัญในการลดความเสี่ยงที่อาจเกิดขึ้นเมื่อโมเดลสามารถสร้างโค้ดอัตโนมัติขนาดใหญ่ได้
ความรับผิดชอบของผู้พัฒนาโมเดล ควรถูกนิยามด้วยแนวทางเชิงปฏิบัติที่ชัดเจน ได้แก่ การออกแบบแบบ safe-by-design, การกำหนดนโยบายการใช้งาน (usage policies) ที่ครอบคลุม และเงื่อนไขในการให้บริการ (terms of service) ที่ชัดเจนและบังคับใช้ได้จริง ผู้พัฒนาควรผนวกการทดสอบด้านความปลอดภัย (red-teaming) และการประเมินผลด้านจริยธรรมเข้ากับวงจรพัฒนาผลิตภัณฑ์ ตั้งแต่การเก็บและคัดเลือกข้อมูลฝึกสอนไปจนถึงการเปิดใช้งาน API โดยตัวอย่างแนวปฏิบัติได้แก่:
- กำหนดค่าเริ่มต้นที่ปลอดภัย (secure-by-default): เปิดใช้งานการจำกัดอัตราและการยืนยันตัวตนสำหรับการเรียกใช้งานที่เข้มงวด
- นโยบายการใช้งานแบบชัดเจนและบังคับใช้: ระบุกรณีห้ามใช้งาน เช่น การโจมตีระบบอัตโนมัติ การสร้างมัลแวร์ หรือการละเมิดข้อตกลงบุคคลที่สาม
- การตรวจสอบและบันทึก (logging & monitoring): เก็บข้อมูลแบบที่สามารถตรวจสอบย้อนกลับได้เพื่อรองรับการสืบสวนกรณีมีเหตุผิดปกติ
- การทดสอบภายนอก (third‑party audits) และการประเมินความเสี่ยงอย่างต่อเนื่อง
ประเด็นด้านกฎหมาย ที่ต้องพิจารณามีความซับซ้อนและข้ามพรมแดน ผู้ให้บริการต้องเตรียมรับมือทั้งในเชิงสัญญาและกฎหมายสาธารณะ โดยข้อควรพิจารณามีดังนี้:
- Liability (ความรับผิดชอบ): ระบุชัดเจนว่าใครรับผิดชอบเมื่อเกิดความเสียหายจากการใช้โมเดล — ผู้ให้บริการคลาวด์ ผู้พัฒนาโมเดล หรือผู้ใช้ปลายทาง — และควรกำหนดเงื่อนไขการชดเชยทางกฎหมายในสัญญา
- Reporting obligations: หลายเขตอำนาจมีกฎเกณฑ์บังคับให้รายงานการละเมิดหรือเหตุการณ์ด้านไซเบอร์ภายในระยะเวลาที่กำหนด ผู้ให้บริการควรจัดกระบวนการแจ้งเตือนและรายงานที่สอดคล้องกับกฎหมายท้องถิ่นและระหว่างประเทศ
- การสืบสวนอาชญากรรมไซเบอร์: ต้องรักษาหลักฐานดิจิทัลอย่างเป็นระบบ (chain of custody) เพื่อให้หน่วยงานบังคับใช้กฎหมายสามารถดำเนินการสอบสวนได้ และเตรียมช่องทางความร่วมมือกับหน่วยงานภาครัฐเมื่อจำเป็น
- ความท้าทายด้านข้ามพรมแดน: ข้อมูลและการดำเนินการที่เกิดขึ้นในคลาวด์มักเกี่ยวข้องกับหลายเขตอำนาจ ผู้ให้บริการควรวางนโยบายและข้อตกลงที่รองรับความซับซ้อนของกฎหมายระหว่างประเทศ
แนวทางจริยธรรม เป็นเกราะป้องกันเชิงสังคมที่สำคัญนอกเหนือจากมาตรการทางเทคนิคและกฎหมาย ความโปร่งใส (transparency) ในการออกแบบและการใช้งานโมเดล การติดตามแหล่งที่มา (provenance) ของโค้ดที่สร้างขึ้น และการนำเทคนิคการติดเครื่องหมาย (model watermarking) มาใช้อย่างรอบคอบเป็นแนวทางที่ควรพิจารณา ตัวอย่างข้อเสนอปฏิบัติได้แก่:
- เผยแพร่ model cards และเอกสารด้านจริยธรรมที่ระบุขอบเขตการใช้งาน ความสามารถและข้อจำกัดของโมเดลอย่างชัดเจน
- ฝังข้อมูล provenance ในโค้ดที่ถูกสร้าง เช่น เมตาดาต้าเกี่ยวกับต้นกำเนิดของโมเดล เวอร์ชัน และลายเซ็นดิจิทัล เพื่อช่วยการตรวจสอบย้อนหลัง
- พัฒนาเทคนิค watermarking ที่ทนต่อการถูกลบหรือแก้ไขโดยผู้ไม่หวังดี แต่ต้องพิจารณาผลกระทบด้านความเป็นส่วนตัวและการรับรองความถูกต้องของเครื่องหมาย
- ออกแบบมาตรการลดความเสี่ยงจากการใช้งานโดยไม่ตั้งใจ เช่น การเตือนผู้ใช้เมื่อโค้ดที่ได้มีความเสี่ยงสูง การจัดเตรียม sandbox สำหรับการรันโค้ดที่สร้างขึ้น และการให้คำแนะนำเชิงปฏิบัติ
สรุปแล้ว เหตุการณ์ครั้งนี้เน้นย้ำว่าการป้องกันต้องเป็นความร่วมมือระหว่างผู้พัฒนาโมเดล ผู้ให้บริการโครงสร้างพื้นฐานคลาวด์ ผู้กำกับดูแล และชุมชนผู้ใช้ การผสานมาตรฐานด้านความปลอดภัย กรอบกฎหมายที่ชัดเจน และหลักจริยธรรมเชิงปฏิบัติจะช่วยลดความเสี่ยงและสร้างความเชื่อมั่นต่อระบบนิเวศ AI ในระยะยาว อย่างน้อยที่สุด ผู้เล่นในอุตสาหกรรมควรตั้งเป้าสร้างระบบที่ ตรวจจับได้ รวดเร็วในการตอบสนอง และโปร่งใสต่อผู้เกี่ยวข้อง เพื่อป้องกันบทเรียนเดียวกันนี้ไม่ให้เกิดซ้ำในอนาคต
คู่มือสรุปและขั้นตอนปฏิบัติ (Tutorial) สำหรับทีมวิศวกรรม
ส่วนนี้เป็นคู่มือเชิงปฏิบัติสำหรับทีมปฏิบัติการและวิศวกรรมเมื่อเกิดเหตุการณ์บอทเขียนโค้ด AI โจมตีบริการ โดยมุ่งเน้นการตอบสนองฉุกเฉิน การเก็บหลักฐาน การฟื้นฟูระบบ และการป้องกันไม่ให้เกิดซ้ำ ทั้งนี้ให้ถือว่า เวลาเป็นสิ่งสำคัญ — การตัดสินใจภายใน 5–30 นาทีแรกมีผลต่อผลลัพธ์ของเหตุการณ์อย่างมาก
Checklist เร่งด่วน (Immediate actions)
- Isolate: แยกระบบที่ถูกโจมตีออกจากเครือข่ายหลักทันที เช่น เปลี่ยน route, remove from load balancer หรือย้ายไปยัง dedicated quarantine network เพื่อป้องกันการแพร่ขยาย
- Enable strict logging: เปิด logging ระดับละเอียด (debug/trace) กับบริการที่เกี่ยวข้อง, เก็บ logs ไปยังสถานที่ปลอดภัย (immutable storage) และเปิด packet capture หากจำเป็น
- Apply emergency rate-limits: ตั้งอัตราจำกัดฉุกเฉินทั้งบน CDN, WAF, API gateway และระดับบริการภายใน เพื่อหยุดการเรียกอัตโนมัติของบอท
- Notify stakeholders: แจ้งทีมภายใน (incident commander, SRE, security, legal, PR) และผู้มีส่วนได้ส่วนเสียภายนอกตามนโยบาย (ลูกค้า ผู้ให้บริการคลาวด์) พร้อมเปิดช่องทางการสื่อสารฉุกเฉิน
- Preserve forensic evidence: สแนปรูทโวลุ่ม, คัดลอกหน่วยความจำ (memory dump), เก็บ container image และเปิด immutable audit log
- Revoke/rotate credentials: ถอนคีย์หรือโทเค็นที่น่าสงสัย, บังคับรีเซ็ตรหัสผ่านและหมุน keys ในระบบที่อาจรั่วไหล
- Activate mitigation patterns: เปิด maintenance page, redirect non-critical traffic, หรือใช้ blueprint สำรองเพื่อให้บริการหลักทำงานแบบจำกัด
ตัวอย่าง pseudocode — Emergency rate limiter (Token Bucket แบบง่าย)
คำอธิบาย: ใช้เพื่อจำกัดจำนวนคำขอจาก IP หรือ API key ภายในระยะเวลา (window) และสามารถนำไปติดตั้งบน API gateway หรือ edge layer
- function allow_request(key):
- now = current_time()
- bucket = redis.get(key) // เก็บ {tokens, last_time}
- if bucket == null: bucket = {tokens: MAX_TOKENS, last_time: now}
- elapsed = now - bucket.last_time
- bucket.tokens = min(MAX_TOKENS, bucket.tokens + elapsed * REFILL_RATE)
- if bucket.tokens >= 1:
- bucket.tokens -= 1
- bucket.last_time = now
- redis.set(key, bucket, ttl=WINDOW_SECONDS)
- return true
- else:
- return false // ตอบ 429 หรือ block
แนะนำ: ในเวลาฉุกเฉิน ลด MAX_TOKENS และ REFILL_RATE ลงมาก เปิด whitelist สำหรับผู้ใช้สำคัญ และบันทึกเหตุการณ์ทุกครั้งที่ถูกบล็อก
ตัวอย่าง pseudocode — Basic anomaly detection rule
คำอธิบาย: กฎตรวจจับความผิดปกติพื้นฐานที่สามารถรันบนระบบ SIEM หรือ stream processor (เช่น Kafka + Flink)
- stream requests by key (ip/api_key) window = 1 minute
- for each key in window:
- count = count_requests(key)
- if count > THRESHOLD_HIGH and count > baseline(key).mean * MULTIPLIER:
- emit alert(type="rate_spike", key=key, count=count)
- if distinct_endpoints_accessed(key) > ENDPOINT_THRESHOLD:
- emit alert(type="crawler_pattern", key=key)
- if request_pattern_matches_code_gen_signature(key):
- emit alert(type="ai_code_bot_pattern", key=key)
เคล็ดลับ: ใช้ adaptive baselining และประเมิน false positives ด้วย sampling; เชื่อม alert เข้ากับ playbook อัตโนมัติเพื่อบังคับ rate-limit ชั่วคราว
ตัวอย่างการตั้งค่า Sandbox สำหรับการรันโค้ด (ตัวอย่างเชิงนโยบาย)
หลักการ: ทุกระบบที่รับโค้ดจากผู้ใช้หรือรันคำสั่งจากภายนอกต้องถูกจำกัดให้อยู่ใน sandbox ที่แยกเคสอย่างเคร่งครัด ซึ่งรวมถึงการจำกัดเครือข่าย ไฟล์ I/O CPU/RAM และเวลารัน
- ใช้ Kubernetes namespace แยกหรือ dedicated account ในคลาวด์ สำหรับ sandbox workloads
- ตั้ง ResourceQuota และ LimitRange: CPU <= 0.5 vCPU, Memory <= 512Mi, EphemeralStorage จำกัด
- NetworkPolicy: ปิด egress ทั้งหมด ยกเว้น DNS และ internal-logging-endpoint
- Filesystem: mount เป็น read-only และใช้ ephemeral volumes; ห้าม mount hostPath
- Runtime security: ใช้ seccomp, AppArmor/SELinux profile, และรัน container เป็น non-root
- Credential model: issue short-lived ephemeral tokens จาก token broker ที่มี TTL สั้นมาก (เช่น 60–300 วินาที)
- Observability: ส่ง stdout/stderr, resource metrics และ traces ไปยังแหล่งบันทึกแยก และทำ sampling แบบ deterministic
แผนตรวจสอบย้อนหลัง (Post-incident review)
เมื่อสถานการณ์ถูกควบคุม ให้จัด Post-Incident Review (PIR) ตามขั้นตอนต่อไปนี้ภายใน 72 ชั่วโมงและสรุปผลภายใน 7 วัน:
- รวบรวม timeline ของเหตุการณ์ (Timestamps) — detection, mitigation, containment, recovery
- งานวิเคราะห์รากเหง้า (Root Cause Analysis): ใช้วิธี 5 Whys หรือ Fishbone เพื่อระบุช่องโหว่เชิงโครงสร้าง
- รวบรวมเมตริกสำคัญ: request/sec ก่อน/ระหว่าง/หลัง, error rates, latency, จำนวน keys ที่ถูกใช้, ค่าใช้จ่ายที่เกิดขึ้น
- การประเมินผลกระทบต่อธุรกิจ: ผู้ใช้ที่ได้รับผลกระทบ, ข้อมูลที่ถูกเข้าถึง/เปลี่ยนแปลง, ความเสียหายทางการเงินหรือภาพลักษณ์
- ออก Action Items ที่เฉพาะเจาะจง, เจ้าของงาน และกำหนดเวลา (ex: เพิ่ม rate-limits – SRE – 2 สัปดาห์)
- อัปเดต runbooks, playbooks, และสัญญาณเตือน (alerting thresholds) ให้ตรงกับบทเรียนที่ได้
- รายงานแก่ผู้บริหารและกำกับตามข้อกำหนดด้านกฎหมาย/ความเป็นส่วนตัว หากมีข้อมูลส่วนบุคคลรั่วไหล
แผนระยะยาวเพื่อป้องกันการเกิดซ้ำ
นอกเหนือจากการตอบสนองฉุกเฉินแล้ว ให้ลงมือปรับปรุงระบบเชิงสถาปัตยกรรมและกระบวนการเพื่อความทนทานในระยะยาว:
- Review architecture: ตรวจสอบการแยกโดเมนความรับผิดชอบ (segmentation), least privilege สำหรับ service accounts และการแยกบัญชี/namespace สำหรับ workloads ที่เสี่ยง
- Automate Canary tests: สร้าง Canary ที่จำลองการใช้งานจริงและเรียกใช้อัตโนมัติทุกการปรับปรุง (CI/CD) — Canary ควรทดสอบ rate limits, auth flows, และประสิทธิภาพของ WAF
- Continuous chaos & resilience testing: นำ Chaos Engineering มาทดสอบล้มเหลวแบบคาดไม่ถึงอย่างเป็นระบบเพื่อประเมินการตอบสนองอัตโนมัติและ manual playbooks
- Enhance observability: เพิ่ม tracing แบบ distributed, SLO/SLI ที่จับต้องได้ และ dashboards สำหรับ SLA breach detection
- Credential & secret hygiene: บังคับใช้ short-lived credentials, automated secret rotation, และ audit log สำหรับการเข้าถึงความลับ
- Policy as Code: นำการตรวจสอบ policy (e.g., network egress rules, container runtime constraints) เข้าสู่ pipeline โดยอัตโนมัติ
- Tabletop exercises & training: จัดซ้อม scenario-based tabletop exercises อย่างน้อยทุก 6 เดือน เพื่อฝึกการตัดสินใจและการประสานงานข้ามทีม
สุดท้ายนี้ แนะนำให้จัดทำ KPI เพื่อติดตามความคืบหน้าของมาตรการที่ดำเนินการ เช่น เวลาเฉลี่ยในการตรวจจับ (MTTD), เวลาเฉลี่ยในการกู้คืน (MTTR), จำนวน false positives ต่อเดือน และอัตราการปฏิบัติตาม playbook หลังเหตุการณ์ การมีแผนที่ชัดเจนและการซ้อมอย่างสม่ำเสมอจะช่วยลดความเสี่ยงจากบอท AI ที่พุ่งเป้าโจมตีโครงสร้างพื้นฐานของคุณในอนาคต
บทสรุป
เหตุการณ์ที่บริการอเมซอนถูกทุบทำลายโดยบอทที่ขับเคลื่อนด้วยโค้ดเจเนอเรเตอร์ AI เป็นสัญญาณเตือนชัดเจนว่า การมาถึงของเครื่องมือสร้างโค้ดด้วย AI เปลี่ยนรูปแบบของภัยคุกคาม จากการโจมตีแบบแมนนวลสู่การโจมตีอัตโนมัติที่สามารถเขียน รัน และปรับแต่งสคริปต์โจมตีได้แบบเรียลไทม์ ตัวอย่างจากเหตุการณ์แสดงให้เห็นว่าบอทเหล่านี้สามารถสร้างคำขออัตโนมัติเป็นจำนวนมากในเวลาอันสั้น และใช้ช่องโหว่เชิงออกแบบของ API หรือการจัดการสิทธิ์ที่ไม่เข้มงวดเป็นทางเข้า องค์กรจึงต้องเร่งปรับปรุงการออกแบบ API, กลไกการตรวจจับพฤติกรรมที่เน้นลักษณะการเรียกใช้ (behavioral detection), และนโยบายความรับผิดชอบของผู้พัฒนาเพื่อป้องกันไม่ให้โค้ดที่สร้างโดย AI กลายเป็นพาหะของความเสี่ยง
เพื่อรับมือความเสี่ยงใหม่ๆ จำเป็นต้องผสานมาตรการเชิงเทคนิค เช่น rate limiting, sandboxing, และ monitoring กับมาตรการเชิงกฎหมายและการจัดเตรียมความพร้อม (เช่น นโยบายความรับผิดชอบของนักพัฒนา การฝึกซ้อมตอบสนองเหตุการณ์ และการ red‑teaming เป็นประจำ) การบังคับใช้การพิสูจน์ตัวตนแบบเข้มงวด การสร้าง baseline พฤติกรรมผู้ใช้และระบบ รวมถึงการเก็บล็อกเชิงเหตุผลเพื่อการตรวจสอบย้อนหลัง จะช่วยลดความเสี่ยงในระยะยาว ในอนาคต อุตสาหกรรมต้องมุ่งสู่การร่วมมือระดับองค์กรและมาตรฐานกลางเพื่อแลกเปลี่ยนสัญญาณภัยคุกคาม ปรับนโยบายตามวิวัฒนาการของ AI และทำให้การออกแบบความปลอดภัยเป็นส่วนหนึ่งของวงจรการพัฒนาซอฟต์แวร์อย่างต่อเนื่อง หากไม่ดำเนินการเชิงรุก ภัยคุกคามจากโค้ดเจเนอเรเตอร์ AI จะทวีความรุนแรงและซับซ้อนขึ้นเรื่อยๆ
📰 แหล่งอ้างอิง: Financial Times



