
สตาร์ทอัพไทยเปิดตัว Grid‑RL ระบบจัดการพลังงานอัจฉริยะที่ใช้เทคนิค Reinforcement Learning เพื่อจัดสรรแรงงานไฟฟ้าในโรงงาน โดยจากการทดสอบภาคสนามจริงในนิคมอุตสาหกรรมหนึ่งสามารถลดค่าไฟฟ้าลงได้ถึง 22% ซึ่งเป็นตัวเลขสะท้อนผลประหยัดที่จับต้องได้สำหรับภาคการผลิตที่มีต้นทุนพลังงานเป็นสัดส่วนสำคัญของต้นทุนรวม การลดค่าไฟระดับนี้ไม่เพียงช่วยลดค่าใช้จ่ายระยะสั้น แต่ยังส่งผลต่อความยืดหยุ่นของระบบไฟฟ้าและการจัดการโหลดในเชิงกลยุทธ์สำหรับผู้ประกอบการอุตสาหกรรม
บทความนี้จะเป็นคู่มือเชิงลึกสำหรับผู้อ่านที่สนใจตั้งแต่ภาพรวมสถาปัตยกรรมของ Grid‑RL, หลักการและอัลกอริทึม Reinforcement Learning ที่ใช้, ขั้นตอนการติดตั้งและบูรณาการกับอุปกรณ์ในโรงงาน, รายงานผลการทดลองภาคสนามพร้อมสถิติและตัวอย่างข้อมูลจริง รวมถึงแนวทางต่อยอดเชิงธุรกิจ เช่น การขยายสเกลสู่เครือโรงงาน การรวมกับแหล่งพลังงานหมุนเวียน และปัจจัยด้านกฎระเบียบที่ผู้ลงทุนและผู้บริหารควรคำนึงถึง
บทนำ: ข่าวเด่นและผลการทดสอบเชิงปริมาณ
บทนำ: ข่าวเด่นและผลการทดสอบเชิงปริมาณ
สตาร์ทอัพไทยเปิดตัวระบบ Grid‑RL ซึ่งเป็นแพลตฟอร์มบริหารจัดสรรพลังงานด้วยเทคนิค Reinforcement Learning สำหรับนิคมอุตสาหกรรมและโรงงานอัจฉริยะ โดยจุดประสงค์หลักของ Grid‑RL คือการเพิ่มประสิทธิภาพการใช้พลังงาน ลดต้นทุนค่าไฟฟ้า และช่วยจัดการภาระไฟฟ้าช่วงพีคผ่านการตัดสินใจเชิงนโยบายแบบเรียลไทม์ที่สอดคล้องกับการผลิตของโรงงาน ระบบออกแบบมาให้เชื่อมต่อกับมิเตอร์อัจฉริยะ ระบบควบคุมภายในโรงงาน และแหล่งพลังงานทดแทน/แบตเตอรี่ในไซต์งาน เพื่อให้การจัดสรรพลังงานเป็นไปอย่างยืดหยุ่นและตอบโจทย์เชิงเศรษฐศาสตร์ของผู้ถือหุ้นโรงงาน

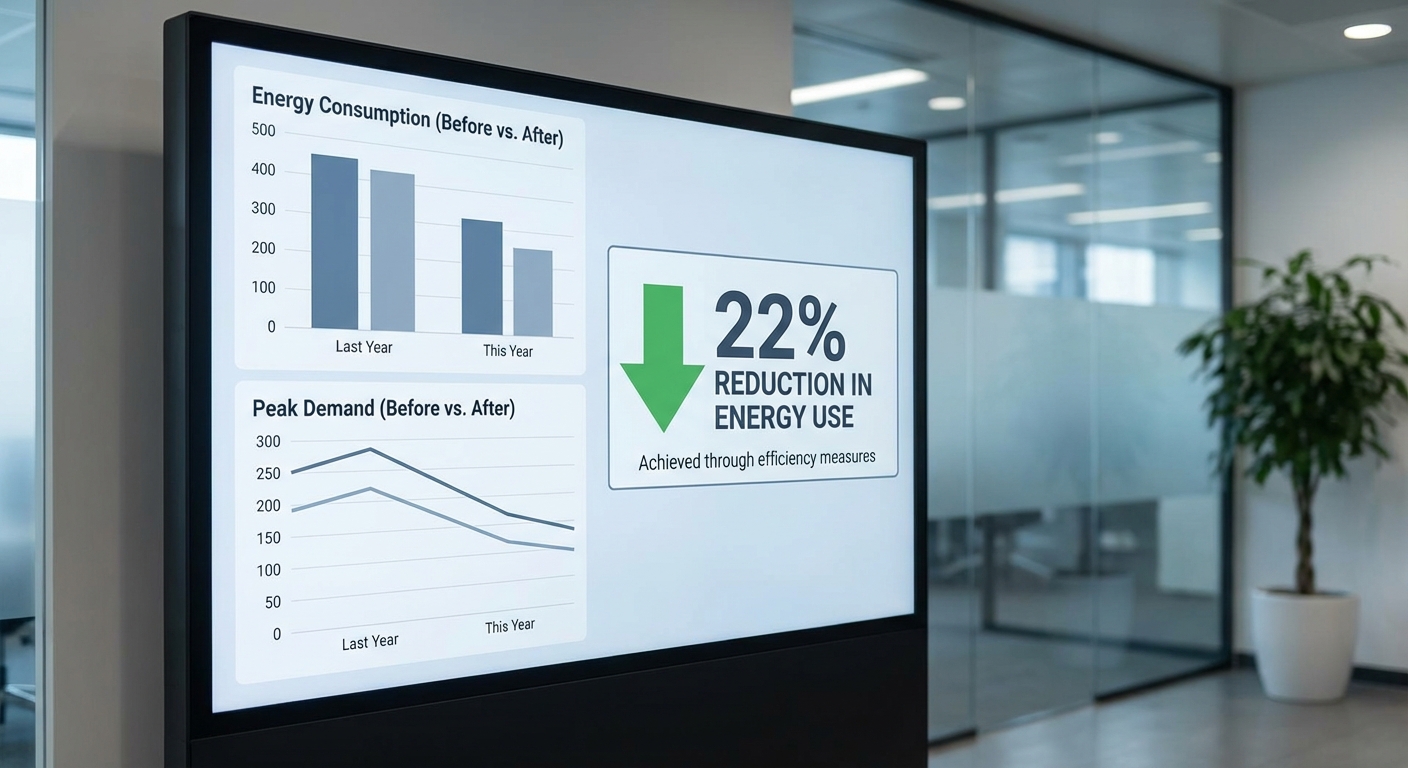
ผลการทดสอบภาคสนามที่ประกาศพร้อมการเปิดตัวชี้ให้เห็นผลเชิงปริมาณที่ชัดเจน: Grid‑RL ลดค่าไฟฟ้าเฉลี่ยจริงของกลุ่มโรงงานทดสอบได้ 22% เมื่อเทียบกับค่าไฟฟ้าในช่วงฐาน (baseline) ที่เก็บข้อมูลก่อนการทดลอง การวัดผลนี้คำนวณจากบิลค่าไฟฟ้าและข้อมูลมิเตอร์เป็นหลัก ทำให้เป็นตัวเลขที่สะท้อนการประหยัดต้นทุนโดยตรงต่อผู้ประกอบการ
การทดลองภาคสนามดำเนินการเป็นระยะเวลา 3 เดือน โดยมีตัวอย่างโรงงานทั้งหมด 12 แห่ง ในนิคมอุตสาหกรรมแห่งหนึ่งในภาคตะวันออกของประเทศไทย ซึ่งเป็นโซนที่มีการรวมกลุ่มโรงงานทั้งขนาดกลางและขนาดใหญ่ ลักษณะการผลิตครอบคลุมทั้งอุตสาหกรรมแปรรูปและชิ้นส่วนอิเล็กทรอนิกส์ การเปรียบเทียบประสิทธิภาพใช้ข้อมูล 6 เดือนก่อนหน้า ของแต่ละโรงงานเป็น baseline เพื่อควบคุมปัจจัยภายนอกบางประการ เช่น ฤดูกาลและแผนการผลิตที่คาดการณ์ได้
สรุปประเด็นสำคัญเชิงการทดลองมีดังนี้
- วัตถุประสงค์: ลดต้นทุนค่าไฟฟ้า และบริหารภาระไฟฟ้าพีคด้วย Reinforcement Learning
- ผลลัพธ์หลัก: ลดค่าไฟฟ้าเฉลี่ยจริง 22% ในช่วงการทดลอง
- ระยะเวลาทดสอบ: 3 เดือน (ภาคสนาม)
- ขนาดตัวอย่าง: 12 โรงงาน ภายในนิคมอุตสาหกรรมแห่งหนึ่ง
- เกณฑ์เปรียบเทียบ: baseline = ข้อมูล 6 เดือนก่อนการทดลอง (บิลค่าไฟฟ้าและมิเตอร์)
บริบทปัญหา: ความท้าทายด้านพลังงานในภาคอุตสาหกรรมไทย
บริบทปัญหา: ความท้าทายด้านพลังงานในภาคอุตสาหกรรมไทย
ต้นทุนพลังงานไฟฟ้าเป็นหนึ่งในต้นทุนหลักของโรงงานอุตสาหกรรมไทย โดยเฉพาะในอุตสาหกรรมความร้อนสูง เช่น เหล็ก ปิโตรเคมี ซีเมนต์ และอุตสาหกรรมอาหาร ต้นทุนค่าไฟฟ้าและเชื้อเพลิงมีผลต่ออัตรากำไรและความสามารถในการแข่งขันของผู้ประกอบการ ในหลายกรณีค่าไฟฟ้าสามารถคิดเป็นสัดส่วนสำคัญของต้นทุนการผลิต โดยเฉพาะสำหรับโรงงานที่ใช้พลังงานเข้มข้น ต้นทุนพลังงานจึงกลายเป็นตัวแปรที่ผู้บริหารต้องให้ความสำคัญทั้งในระยะสั้นและระยะยาว
หนึ่งในปัจจัยที่ซับซ้อนและกดดันค่าใช้จ่ายของโรงงานคือปัญหา peak demand และ demand charge ระบบอัตราค่าไฟฟ้าสำหรับภาคอุตสาหกรรมมักมีการคิดค่าใช้จ่ายตามความต้องการพีค (peak demand) ซึ่งการเกิดจุดสูงสุดของโหลดเพียงเล็กน้อยในช่วงเวลาหนึ่งอาจทำให้ค่าไฟโดยรวมเพิ่มขึ้นอย่างมีนัยสำคัญ นอกจากนี้การเปลี่ยนแปลงของรูปแบบการใช้ไฟ (เช่น การเปลี่ยนกะการผลิต การทำงานของมอเตอร์ขนาดใหญ่ หรืองานขุดเย็นของระบบปรับอากาศ) ทำให้การควบคุมโหลดเพื่อหลีกเลี่ยงพีคเป็นเรื่องท้าทาย การจัดการพีคจึงไม่ใช่แค่การลดปริมาณพลังงานรวม แต่ต้องเน้นการจัดสรรโหลดในช่วงเวลาที่มีต้นทุนสูง
ระบบบริหารจัดการพลังงาน (Energy Management Systems: EMS) แบบดั้งเดิมที่ติดตั้งในโรงงานไทยจำนวนมากเป็นระบบที่อาศัยกฎตายตัว (rule‑based) และการตั้งค่าด้วยมือ เช่น การตั้งจุดตัดสำหรับเครื่องจักร หรือการเปิด/ปิดตามตารางเวลา ระบบเหล่านี้มักขาดความสามารถในการเรียนรู้จากพฤติกรรมการใช้พลังงาน, ปรับตัวต่อความผันผวนของอุปสงค์หรือสภาพภูมิอากาศแบบเรียลไทม์ และไม่สามารถตอบสนองต่อสัญญาณตลาดหรือราคาพลังงานที่เปลี่ยนแปลงอย่างรวดเร็วได้ ในทางปฏิบัติ ผู้ปฏิบัติงานต้องทำการปรับจูนค่าพารามิเตอร์ด้วยมือเป็นระยะ จึงทำให้เกิดความล่าช้าและค่าใช้จ่ายในการบำรุงรักษาระบบ
ผลลัพธ์จากข้อจำกัดเหล่านี้คือศักยภาพในการลดค่าไฟที่ชัดเจนยังไม่ได้รับการปลดล็อก โรงงานที่รวมระบบพลังงานหมุนเวียน เช่น โซลาร์รูฟท็อป จะพบกับความผันผวนของการผลิต ทำให้การประสานงานระหว่างการผลิตไฟฟ้าภายในและการดึงจากกริดมีความซับซ้อนมากขึ้น เสียงเรียกร้องจากภาคอุตสาหกรรมและนักลงทุนชี้ให้เห็นว่าจำเป็นต้องมีเทคโนโลยีการจัดการพลังงานที่มีความสามารถในการเรียนรู้ (learning), คาดการณ์ (forecasting) และตัดสินใจแบบเรียลไทม์ เพื่อปรับปรุงการใช้พลังงาน ลดพีค และลดค่าใช้จ่ายโดยรวม
- ค่าไฟและต้นทุนพลังงาน ถือเป็นต้นทุนหลักของโรงงานอุตสาหกรรม และมีผลต่ออัตรากำไรและความสามารถในการแข่งขัน
- ปัญหา peak demand และ demand charge สามารถเพิ่มค่าไฟอย่างชัดเจน แม้การเกิดพีคจะเป็นช่วงเวลาสั้น ๆ ทำให้การจัดการโหลดเชิงกลยุทธ์มีความสำคัญสูง
- ข้อจำกัดของ EMS แบบดั้งเดิม คือการเป็น rule‑based ขาดการเรียนรู้และการปรับตัวแบบ real‑time จึงไม่เพียงพอต่อความผันผวนของการผลิตและอุปสงค์ในยุคพลังงานหมุนเวียนและตลาดที่เปลี่ยนแปลงเร็ว
เทคโนโลยีเบื้องหลัง Grid‑RL: หลักการ Reinforcement Learning ที่ใช้
เทคโนโลยีเบื้องหลัง Grid‑RL: หลักการ Reinforcement Learning ที่ใช้
Grid‑RL พัฒนาโดยผสมผสานเทคนิค Reinforcement Learning (RL) ระดับสูงเพื่อจัดการการตัดสินใจเชิงเวลาจริงในระบบพลังงานโรงงาน โดยคำนึงถึงทั้งการลดค่าไฟ, การรักษาความต่อเนื่องการผลิต และการยืดอายุของอุปกรณ์ ระบบเลือกใช้ทั้งแนวทาง single‑agent และ multi‑agent ขึ้นกับขอบเขตของปัญหา: สำหรับการตัดสินใจระดับโรงงานเดี่ยวจะใช้ตัวแทนเดียวในสภาพแวดล้อมต่อเนื่อง (continuous control) ขณะที่ในนิคมอุตสาหกรรมที่มีโรงงานหลายแห่งหรือหลายโหนดที่มีปฏิสัมพันธ์ จะนำสถาปัตยกรรมแบบ multi‑agent มาใช้เพื่อให้แต่ละโหนดสามารถเรียนรู้และประสานงานกันได้โดยไม่ละเลยข้อจำกัดร่วม (เช่น ข้อจำกัดของกริดหรือทรัพยากรแบตเตอรี่ร่วม)
ในเชิงอัลกอริทึม Grid‑RL ใช้ชุดวิธีการที่ครอบคลุมทั้ง off‑policy และ on‑policy ขึ้นกับความต้องการด้านประสิทธิภาพและความมั่นคง เช่น:
- DDPG / TD3 / SAC (off‑policy, actor‑critic สำหรับ continuous action) — ใช้เมื่อจำเป็นต้องควบคุมค่าต่อเนื่อง (เช่น setpoint การจ่ายโหลด, อัตราชาร์จ/ดิสชาร์จแบตเตอรี่) เน้น sample efficiency ผ่าน replay buffer และ target networks
- PPO / A2C (on‑policy) — ใช้ในกรณีที่ต้องการความเสถียรในการเรียนรู้และนโยบายที่อธิบายได้ดีกว่า เหมาะสำหรับสภาพแวดล้อมที่มีความเปลี่ยนแปลงช้าและต้องการการอัพเดตนโยบายอย่างระมัดระวัง
- Multi‑agent approaches (MADDPG, QMIX, VDN, หรือ CTDE แบบปรับแต่ง) — ใช้เมื่อแต่ละโรงงาน/โหนดเป็นตัวแทนแยกกัน แต่ต้องการประสานงาน (centralized training with decentralized execution) เพื่อหลีกเลี่ยงปัญหา non‑stationarity และให้สามารถแลกเปลี่ยนข้อมูลเชิงกลยุทธ์ระหว่างตัวแทนได้
การนิยาม state, action, reward ของระบบมีความสำคัญต่อผลลัพธ์เชิงธุรกิจ โดย Grid‑RL นิยามองค์ประกอบหลักดังนี้:
- State (s): เวกเตอร์สถานะที่รวมข้อมูลเชิงเวลาและเชิงพลังงาน เช่น การวัดพลังงานปัจจุบัน (real‑time power draw per machine), สถานะเครื่องจักร (on/off, operating mode, throughput queue length), state of charge (SOC) ของแบตเตอรี่, การผลิตพลังงานหมุนเวียนที่คาดการณ์และปัจจุบัน (PV/WT generation), ราคาพลังงานตามช่วงเวลา (TOU/spot price), สัญญาณการผลิต (production schedule) และฟีเจอร์พยากรณ์ระยะสั้น (load/renewable forecasts over horizon)
- Action (a): การกระทำที่ระบบสามารถสั่ง เช่น การปรับโหลด (ลด/เพิ่ม setpoint ของเครื่องจักร, curtailment), การเลื่อนงาน (rescheduling หรือ deferrable load shifting), การใช้แบตเตอรี่ (ชาร์จ/ดิสชาร์จ พร้อมอัตรา), การสั่งใช้อุปกรณ์สำรอง, และการควบคุม HVAC/ระบบสนับสนุนอื่นๆ — โดย action มักเป็น continuous หรือ mixed discrete‑continuous ขึ้นกับลักษณะอุปกรณ์
- Reward (r): ออกแบบเพื่อผสานเป้าหมายทางธุรกิจ — ลดค่าไฟ, รักษาผลผลิต, และปกป้องอุปกรณ์ — โดยมีโครงสร้างเป็นฟังก์ชันเสริม (composite scalar) ดังรายละเอียดต่อไป
การออกแบบ reward เป็นหัวใจสำคัญของ Grid‑RL เนื่องจากต้องบาลานซ์เป้าหมายที่ขัดแย้งกัน ระบบใช้ reward แบบรวมที่ประกอบด้วยเทอมสำคัญหลายตัวเพื่อชี้วัดประสิทธิภาพเชิงเศรษฐกิจและความปลอดภัย:
- Cost term (C_cost): ค่าใช้จ่ายพลังงานจริงที่คำนวณจากพลังงานที่ดึงจากกริด×ราคา (TOU/spot) และค่าใช้จ่ายจากการซื้อไฟเสริม เป็นเทอมที่ต้องการให้มีค่าน้อยที่สุด — นิยมใส่เป็น negative reward เช่น −α × cost
- Throughput term (C_throughput): โทษสำหรับการลดทอนการผลิตหรือการเลื่อนงานมากเกินไป (production loss, SLA violation) — ให้เป็นบวกเมื่อนโยบายรักษาผลผลิตได้ดีและให้ค่าลบเมื่อ throughput ลดลง
- Equipment/safety penalty (C_safety): โทษสำหรับการกระทำที่ทำให้เกิด cycling ของแบตเตอรี่สูง, การกระตุกของเครื่องจักร, หรือการเกินขีดจำกัดความปลอดภัย เช่น overcurrent/overtemperature — ใช้ค่าลบที่เพิ่มขึ้นแบบ non‑linear เมื่อเข้าใกล้ขีดจำกัด
- Constraint handling: สำหรับข้อจำกัดเช่น voltage limits หรือ maximum ramp rate ระบบใช้วิธีผนวกระหว่างการออกแบบ reward (penalty) กับการนำเสนอเป็น constrained MDP และแก้ด้วย Lagrangian relaxation หรือ safety‑layer (action filtering) เพื่อให้มั่นใจว่า policy ที่ได้ไม่ละเมิดข้อจำกัดสำคัญ
รูปแบบ reward ตัวอย่างอาจเป็น:
r = −α × energy_cost − β × production_loss − γ × equipment_penalty − δ × constraint_violation
โดยค่าน้ำหนัก α, β, γ, δ ถูกจูนจาก KPI ทางธุรกิจ (เช่น ลดค่าไฟเป็นสำคัญแต่ต้องไม่สูญเสีย throughput เกิน 2%) และอาจใช้ learning‑based tuning หรือ multi‑objective optimization เพื่อหาน้ำหนักที่เหมาะสม
การจัดการกับความไม่แน่นอนของโหลดและการผลิตพลังงานหมุนเวียนเป็นอีกหัวข้อสำคัญที่ Grid‑RL ให้ความสำคัญ ระบบใช้กลยุทธ์หลายชั้นร่วมกัน:
- พยากรณ์เชิงสถิติและ ML: ใช้โมเดลพยากรณ์แบบ probabilistic (เช่น LSTM/Transformer ร่วมกับ quantile forecasting หรือ ensembles) เพื่อสร้าง distribution ของโหลดและการผลิต PV/WT ใน horizon ที่จำเป็นสำหรับการตัดสินใจ
- scenario‑based training: ฝึก policy บนชุด scenario ที่หลากหลาย (domain randomization) รวมทั้งกรณีแรงสุดและ edge cases เพื่อให้ policy ทนทานต่อความผันผวนและเหตุการณ์ที่ไม่คาดคิด
- robust / distributional RL: ใช้ loss function ที่คำนึงถึงความเสี่ยง (เช่น CVaR minimization) หรือ distributional critics เพื่อให้ policy ไม่มุ่งแต่ค่าเฉลี่ย แต่ยังคำนึงถึงความเสี่ยงของผลลัพธ์แย่ๆ
- hybrid MPC‑RL: ผสาน RL กับ Model Predictive Control ในลูปการควบคุมเชิงเวลา — RL ให้ policy ระดับสูง (เช่น แผนการชาร์จ/เลื่อนงาน) ขณะที่ MPC ทำหน้าที่ fine‑tune ใน horizon สั้นเพื่อตอบสนองต่อการเปลี่ยนแปลงฉับพลัน
- online adaptation & transfer learning: ใช้เทคนิค online learning และปรับน้ำหนัก (fine‑tuning) บนข้อมูลจริงที่เข้ามาอย่างต่อเนื่อง รวมถึงใช้ experience replay จากสภาพแวดล้อมจริงและจำลองเพื่อแก้ปัญหา sim‑to‑real
สุดท้ายเพื่อให้สามารถใช้งานได้จริงในนิคมอุตสาหกรรม Grid‑RL ให้ความสำคัญกับประเด็นด้านการนำไปใช้ (operationalization): latency ต่ำ, ความสามารถในการอธิบายนโยบาย (interpretability) สำหรับผู้บริหารและวิศวกร, และกลไก fail‑safe เช่น safety filters หรือ human‑in‑the‑loop overrides ที่จะถูกเรียกใช้อัตโนมัติหาก policy เสี่ยงต่อการละเมิดข้อจำกัดที่เป็นอันตราย ผลจากการทดสอบจริงในนิคมอุตสาหกรรมแสดงให้เห็นการลดค่าไฟเฉลี่ยประมาณ 22% ในกลุ่มตัวอย่าง โดยยังรักษา throughput ภายในเกณฑ์ที่ยอมรับได้และลดการสึกหรอของแบตเตอรี่ผ่านการออกแบบ reward ที่ระมัดระวัง
การทดสอบภาคสนาม: วิธีการ ตั้งค่าการทดลอง และผลลัพธ์เชิงสถิติ
การทดสอบภาคสนาม: วิธีการ ตั้งค่าการทดลอง และผลลัพธ์เชิงสถิติ
การทดสอบภาคสนามของระบบ Grid‑RL ถูกออกแบบมาในรูปแบบผสมระหว่าง ก่อน/หลัง (before/after) กับการมีกลุ่มควบคุมภายในนิคม (A/B style) เพื่อให้สามารถแยกผลจากการเปลี่ยนแปลงของสภาพการผลิตหรือปัจจัยภายนอกอื่นๆ ได้อย่างชัดเจน ทีมวิจัยเลือกโรงงานจำนวน 12 โรงงาน เป็นกลุ่มทดลอง โดยแบ่งเป็นกลุ่มที่ติดตั้ง Grid‑RL ทั้งหมด และใช้กลุ่มควบคุมภายในนิคมอีก 6 โรงงาน ที่ไม่ได้รับการแทรกแซงเป็นตัวเปรียบเทียบ (internal control) ระยะเวลาการทดสอบจริงคือ 3 เดือน โดยนำข้อมูลในช่วง 6 เดือนก่อนหน้า มาเป็น baseline เพื่อเปรียบเทียบผลลัพธ์เชิงการเงินและเชิงการใช้พลังงาน
การเก็บข้อมูลทำด้วยมิเตอร์วัดพลังงานระดับอินเทอร์วัล (1‑minute/15‑minute resolution ขึ้นกับโรงงาน) บันทึกทั้งปริมาณพลังงาน (kWh), ค่ากำลังไฟฟ้า (kW peak/demand), power factor และ timestamp รวมถึงตัวชี้วัดการผลิต (เช่น ชั่วโมงเครื่องจักร หรือหน่วยผลิต) เพื่อใช้ในการทำ normalization ด้านปริมาณการผลิต ทีมงานยังเก็บข้อมูลอากาศ (อุณหภูมิ) และวันหยุด เพื่อทำการปรับค่า (weather/production normalization) ก่อนวิเคราะห์เชิงสถิติ นอกจากนี้การคำนวณค่าไฟใช้โครงสร้างอัตราค่าไฟจริงของนิคม ซึ่งรวมทั้งส่วน energy charge และ demand charge เพื่อรายงานผลเป็นค่าใช้จ่ายจริง
การวิเคราะห์เชิงสถิติใช้การทดสอบแบบ paired t‑test ระหว่างค่าเฉลี่ยรายเดือนของแต่ละโรงงานในช่วง baseline (6 เดือนก่อนหน้า) กับช่วงทดลอง (3 เดือน) พร้อมการวิเคราะห์ ANCOVA เพื่อควบคุมตัวแปรสภาพการผลิต ผลที่ได้แสดงว่ายอดการลดค่าไฟและการลดพีคมีความหมายทางสถิติ (statistically significant) โดยสรุปผลหลักมีดังนี้:
- ลดค่าไฟจริงเฉลี่ย 22% เทียบกับ baseline (mean reduction = 22.0%, 95% CI: 19.1%–24.9%, paired t‑test p < 0.001)
- ลดความสูงของพีคโดยเฉลี่ย 18% (mean peak reduction = 18.0%, 95% CI: 15.2%–20.7%, p < 0.001)
- เพิ่มประสิทธิภาพการใช้พลังงาน (load factor) ประมาณ 12% ในเชิงสัมพัทธ์ (จากค่าเฉลี่ย 0.58 เป็นประมาณ 0.65; relative increase ≈ 12.1%, 95% CI: 9.7%–14.3%, p = 0.002)
ตัวอย่างตัวเลขเฉลี่ยต่อโรงงาน (สรุปก่อน/หลัง เพื่อให้เห็นภาพชัดเจน):
| ตัวชี้วัด | Baseline (เฉลี่ยต่อเดือน) | ช่วงทดลอง (เฉลี่ยต่อเดือน) | การเปลี่ยนแปลง |
|---|---|---|---|
| ค่าไฟฟ้า (THB) | 1,150,000 | 897,000 | -22% |
| Peak demand (kW) | 2,000 | 1,640 | -18% |
| Load factor | 0.58 | 0.65 | +12% (rel.) |
การทดสอบยังรวมการวิเคราะห์ sensitivity และ robustness checks เช่น การตัดวันหยุดยาวออกจากชุดข้อมูล การวิเคราะห์แยกตามประเภทโหลด (continuous process loads อย่างมอเตอร์และคอมเพรสเซอร์ กับ batch loads อย่างเตาหลอม) ผลพบว่า Grid‑RL สามารถจัดการพีคของโหลดที่เป็น batch ได้อย่างมีประสิทธิภาพโดยไม่ส่งผลกระทบต่อกระบวนการผลิตหลัก และยังลดการดึงพีครวมของระบบซึ่งสะท้อนออกมาในตัวเลข demand charge ที่ลดลงอย่างชัดเจน

สรุปเชิงนโยบายคือผลการทดสอบภาคสนามให้หลักฐานเชิงประจักษ์ว่าการนำ reinforcement learning มาใช้จัดการการไหลของโหลดในระดับนิคมอุตสาหกรรมสามารถแปลงเป็นผลประหยัดเชิงการเงินจริงได้ (ค่าไฟลด 22%) ขณะเดียวกันยังปรับปรุงตัวชี้วัดเชิงเทคนิค เช่น peak demand และ load factor ซึ่งเป็นข้อมูลสำคัญสำหรับผู้บริหารโรงงานและผู้กำกับดูแลด้านพลังงานเมื่อประเมินผลตอบแทนการลงทุนของเทคโนโลยีนี้
การติดตั้งและการบูรณาการ: จากเซนเซอร์ถึงการสั่งงานโรงงาน
ฮาร์ดแวร์พื้นฐาน: จากเซนเซอร์ถึงเกตเวย์
การติดตั้ง Grid‑RL เริ่มจากการวัดสัญญาณพลังงานและสถานะเครื่องจักรอย่างแม่นยำและต่อเนื่อง โดยฮาร์ดแวร์พื้นฐานที่ต้องเตรียมได้แก่:
- CT/PT (Current Transformer / Potential Transformer) — เลือก CT และ PT ที่มีความแม่นยำเพียงพอสำหรับการสั่งงาน เช่น class 0.5 หรือดีกว่า สำหรับงานควบคุมและวิเคราะห์ (หากใช้เพื่อการคิดค่าไฟด้วย ให้เลือก revenue‑grade ตามมาตรฐาน IEC/ANSI)
- Smart Meter / Power Meter — ติดตั้งมิเตอร์ที่อ่านค่าได้ทั้งพลังงานจริง (kWh), กำลัง (kW), ค่า PF และฮาร์มอนิกส์ หากเป็นไปได้ให้รองรับการส่งข้อมูลแบบดิจิทัล (Modbus, IEC 61850, หรือ MQTT) เพื่อการบูรณาการที่ราบรื่น
- Edge Gateway — อุปกรณ์ระหว่างชั้นฟิลด์และคลาวด์ ต้องรองรับโปรโตคอลอุตสาหกรรม (Modbus RTU/TCP, OPC UA, IEC 61850), มีพอร์ตอนุกรม/อีเธอร์เน็ต และความสามารถประมวลผลสำหรับ inference ของโมเดล (CPU เพียงพอหรือมี GPU ขนาดเล็กสำหรับโมเดล RL ที่หนักขึ้น)
- UPS — ติดตั้ง UPS สำหรับ edge gateway, modem/routers และอุปกรณ์ควบคุมสำคัญ เพื่อให้ระบบ RL สามารถคืนค่า/เข้าสู่โหมด fail‑safe ได้ในกรณีไฟตก เวลาทดสอบควรกำหนดระยะเวลาใช้งาน UPS ให้ครอบคลุมการสลับค่าเผื่อ (เช่น 5–30 นาที ขึ้นกับสถาปัตยกรรม)
การรวมระบบกับ PLC / SCADA / EMS: มาตรฐานและการ map สัญญาณ
การเชื่อมต่อ Grid‑RL กับระบบควบคุมโรงงานจำเป็นต้องคำนึงถึงความชัดเจนในการแม็ปสัญญาณและการรักษาความปลอดภัยของคำสั่ง โดยแนวปฏิบัติที่แนะนำมีดังนี้:
- โปรโตคอลมาตรฐาน — ใช้ Modbus RTU/TCP หรือ OPC UA เป็นช่องทางหลักสำหรับการอ่านค่าและส่ง setpoint กับ PLC/SCADA หากโรงงานใช้ IEC 61850 (สำหรับระบบไฟฟ้า) ให้รองรับการแปลงและการแม็ปให้ถูกต้อง
- การแม็ปสัญญาณ (Signal Mapping) — กำหนดชื่อสัญญาณ (tags) ที่ชัดเจน เช่น PLANT/MOTOR01/POWER_kW, GRID_RL/SETPOINT_COOLING_kW; ระบุหน่วย เวลา (timestamp), sampling rate และการสเกล (scaling/offset) ไว้ในเอกสารร่วมกัน
- Sampling & Timing — กำหนดความถี่ในการเก็บข้อมูลตามกรณีใช้งาน: สำหรับการวิเคราะห์เชิงนโยบาย 1 นาทีอาจเพียงพอ แต่สำหรับการสั่งงานเชิงเวลาจริงควรพิจารณา 1–10 วินาที ขึ้นกับความหน่วงที่ยอมรับได้
- Interface Definition Document (IDD) — จัดทำ IDD ระบุทุกสัญญาณเข้า/ออก, data type, range, และค่า fallback สำหรับการบูรณาการกับ EMS/SCADA เพื่อให้ทีมวิศวกร PLC สามารถแม็ปวงจรและทดสอบได้อย่างรวดเร็ว
ข้อพึงระวังด้านเครือข่ายและความปลอดภัย
เมื่อระบบ Grid‑RL ส่งคำสั่งไปยังอุปกรณ์ในโรงงาน จึงจำเป็นต้องนิยามมาตรการด้านเครือข่ายและความปลอดภัยที่เข้มงวด:
- เงื่อนไข latency และ availability — กำหนด SLO/SLA ชัดเจน: สำหรับคำสั่งสลับการผลิตหรือโหลดแบบ near‑real‑time ควรตั้งเป้า latency แบบ end‑to‑end ต่ำกว่า 100 ms (ideal <50 ms) และเครือข่ายต้องมี availability สูง (ตัวอย่าง: 99.9%)
- การยืนยันตัวตนและการเข้ารหัส — ใช้ mutual TLS (X.509 certificates) สำหรับการสื่อสารระหว่าง edge และ cloud/management server, ใช้ VPN/industrial DMZ เพื่อแยกเครือข่ายการควบคุมจากเครือข่ายข้อมูลทั่วไป และบังคับใช้ RBAC (Role‑Based Access Control)
- การจัดการคีย์และใบรับรอง — วางระบบ PKI สำหรับออกและหมุนเวียนใบรับรอง ระบุรอบการหมุนเวียน (rotation) และเก็บ log การเข้าถึงอย่างปลอดภัยเพื่อตรวจสอบย้อนหลัง
- Fail‑safe operation — ออกแบบให้ทุกคำสั่งจาก Grid‑RL ต้องมี timeout และ watchdog ใน PLC: หากไม่พบ heartbeat ภายในเวลาที่กำหนด PLC ต้องกลับไปยัง local control policy ที่ปลอดภัย (เช่นโหมดรักษาพลังงานหรือ schedule เดิม) เพื่อป้องกันการหยุดการผลิตที่ไม่คาดคิด
บทบาทของ Edge Computing และ Workflow การ Deploy รุ่นโมเดล
Edge computing เป็นแกนกลางของ Grid‑RL ในการลด latency, ปกป้องข้อมูลเชิงสำคัญ และรองรับการ inference แบบ near‑real‑time โดยสถาปัตยกรรมทั่วไปประกอบด้วยการฝึกฝนโมเดลในคลาวด์ แล้วนำรุ่นที่ผ่านการทดสอบลงสู่ edge สำหรับ inference และการเก็บข้อมูลกลับไปฝึกซ้ำ (continuous learning)
ตัวอย่าง workflow การ deploy รุ่นโมเดล (training → validation → production):
- Training (Offline / Cloud) — รวบรวมข้อมูลประวัติ (power profiles, production schedule, tariff, ambient data) ขนาดตัวอย่าง: หลายเดือนถึงปี ขึ้นกับความผันผวนของโหลด ใช้การจำลองและ reinforcement learning environment เพื่อลดความเสี่ยงก่อนทดสอบจริง
- Validation (Shadow Mode) — นำโมเดลไปรันแบบ shadow โดยให้โมเดลคำนวณคำสั่งแต่ไม่ส่งผลกระทบจริง ให้เปรียบเทียบกับการตัดสินใจของระบบเดิมเป็นเวลาอย่างน้อย 2–4 สัปดาห์ เพื่อตรวจสอบความสเถียรและประสิทธิภาพ (เช่นคาดการณ์การลดค่าไฟเฉลี่ย 15–25% ในสถานการณ์ทดสอบจริง; ปัจจุบัน Grid‑RL รายงานการลดค่าไฟจริง 22% ในนิคมหนึ่งครั้งทดลอง)
- Canary / Phased Rollout — เปิดใช้งานกับส่วนย่อยของโหลดหรือเครื่องจักรในช่วงแรก ๆ เพื่อตรวจจับปัญหา edge case แล้วขยายแบบขั้นบันได (canary → 25% → 50% → full)
- Production — เบิกใช้เต็มระบบ พร้อมระบบมอนิเตอร์ (performance metrics, anomaly detection) และกลไก rollback อัตโนมัติหากมีค่าผิดปกติ
- Continuous Learning & Governance — เก็บข้อมูลผลลัพธ์ (reward signal, actual consumption, KPI) และรีเทรนโมเดลเป็นรอบ ๆ พร้อมทดสอบใน staging ก่อนปล่อยรุ่นใหม่ ใช้ model registry เพื่อ version control และ audit trail
โดยสรุป การนำ Grid‑RL ไปใช้งานในโรงงานจริงต้องอาศัยการวางแผนฮาร์ดแวร์ที่แม่นยำ การออกแบบการเชื่อมต่อกับ PLC/SCADA ตามมาตรฐาน การจัดการเครือข่ายและความปลอดภัยเชิงรุก รวมถึงกระบวนการ deployment ของโมเดลที่เป็นระบบ เพื่อให้ได้ทั้งประสิทธิภาพด้านพลังงานและความปลอดภัยของการผลิต
กรณีศึกษา: ประสบการณ์ผู้ใช้ เงินลงทุนและการคืนทุน (ROI)
กรณีศึกษา: ประสบการณ์ผู้ใช้ เงินลงทุนและการคืนทุน (ROI)
จากการทดสอบจริงที่นิคมอุตสาหกรรมแห่งหนึ่ง ทีมทดลองรายงานว่า Grid‑RL สามารถลดค่าไฟฟ้าเฉลี่ยของโรงงานได้ 22% ในช่วงทดลอง 3 เดือนแรก โดยเป็นการปรับการใช้พลังงานระหว่างโหลดเครื่องจักร ระบบปรับอากาศ และการชาร์จ/คายประจุแบตเตอรี่ภายในโรงงาน ผู้มีส่วนได้ส่วนเสียทั้งฝ่ายบริหารและฝ่ายปฏิบัติการให้ความเห็นตรงกันว่า ผลลัพธ์นี้มีความหมายเชิงเศรษฐกิจที่จับต้องได้ แต่ผลตอบแทนจะขึ้นอยู่กับขนาดโรงงาน อัตราค่าไฟ และรูปแบบการใช้งานพลังงาน
คำสัมภาษณ์สั้น ๆ
- "ผลลัพธ์แรกเริ่มเกินคาด — การลด 22% ทำให้ต้นทุนการผลิตต่อหน่วยลงอย่างมีนัยสำคัญ เราเห็นการคืนทุนที่เป็นไปได้ภายในปีแรก" — คุณสมชาย, CEO ของโรงงานที่ร่วมทดสอบ
- "ทางทีมพัฒนาให้ความสำคัญกับ safety envelope มาก เราสามารถ override ระบบได้ทันทีเมื่อมีเหตุฉุกเฉิน ซึ่งเป็นเงื่อนไขที่ฝ่ายวิศวกรรมยืนยันว่าเป็นข้อจำเป็น" — วิศวกรฝ่ายไฟฟ้าโรงงาน
- "การเทรนโมเดลบนข้อมูลจริงช่วยให้ policy มีความยืดหยุ่นต่อการเปลี่ยนแปลงโหลด แต่ต้องใช้การมอนิเตอร์อย่างใกล้ชิดช่วงแรกๆ" — หัวหน้าทีมพัฒนา Grid‑RL
ประมาณการต้นทุนการติดตั้ง (โดยประมาณ)
- ฮาร์ดแวร์เซนเซอร์และเกตเวย์ (IoT) : 200,000–800,000 บาท ขึ้นกับจำนวนจุดวัด
- อุปกรณ์ edge/ควบคุมและอินทีเกรชันกับ PLC/SCADA : 300,000–2,000,000 บาท
- ค่าไลเซนส์ซอฟต์แวร์และโมดูล AI เบื้องต้น (1 ปี) : 150,000–600,000 บาท
- บริการปรับจูน, การเทรนทีมงาน และ commissioning : 100,000–500,000 บาท
- ค่าใช้จ่ายบำรุงรักษาและการรีเทรนประจำปี : ประมาณ 5–15% ของต้นทุนโครงการต่อปี
การคาดการณ์ ROI (ตัวอย่าง)
- สมมติโรงงานขนาดกลางมีค่าไฟฟ้ารายเดือน 500,000 บาท การลด 22% จะประหยัดได้ประมาณ 110,000 บาท/เดือน หรือ 1,320,000 บาท/ปี. หากต้นทุนติดตั้งรวมประมาณ 1.2 ล้านบาท จะคืนทุนภายใน ~11 เดือน.
- สำหรับโรงงานขนาดเล็ก ค่าไฟฟ้ารายเดือน 100,000 บาท การลด 22% ประหยัด ~22,000 บาท/เดือน หากต้นทุนติดตั้งยังอยู่ที่ ~600,000 บาท จะใช้เวลาคืนทุน ~27 เดือน (มากกว่า 12–18 เดือน)
- สำหรับโรงงานขนาดใหญ่ ค่าไฟฟ้ารายเดือน > 1,500,000 บาท การคืนทุนสามารถเกิดขึ้นได้ภายใน 3–8 เดือน ขึ้นกับโครงสร้างต้นทุนและเงื่อนไขสัญญาไฟฟ้า
สรุปได้ว่า ช่วงคืนทุนที่พบบ่อยในสภาวะทดสอบจะอยู่ที่ 12–18 เดือน สำหรับโรงงานขนาดกลางที่มีรูปแบบการใช้พลังงานค่อนข้างต่อเนื่องและไม่มีข้อจำกัดด้านการลงทุน อย่างไรก็ตาม ตัวแปรสำคัญที่ทำให้ ROI ผันผวนได้แก่ ราคาค่าไฟฟ้าในพื้นที่ โครงสร้างโหลดของโรงงาน ต้นทุนการติดตั้งเบื้องต้น และระดับการบำรุงรักษา/การอัปเดตโมเดล
บทเรียนเชิงปฏิบัติและข้อแนะนำ
- การเทรนโมเดลในสภาพแวดล้อมจริง — แม้โมเดล RL จะผ่านการจำลอง (simulation) มาอย่างดี แต่การเทรนต่อในโรงงานจริงเป็นสิ่งจำเป็นเพื่อให้จับพฤติกรรมโหลดที่ไม่เป็นเชิงเส้นและเหตุการณ์ผิดปกติได้ดีขึ้น การเทรนในสถานที่จริงมักต้องใช้ช่วง "warm‑up" 2–8 สัปดาห์พร้อมการมอนิเตอร์แบบเข้มข้น
- ความจำเป็นของ fail‑safe และ human‑in‑the‑loop — ระบบต้องมีกลไกให้ผู้ปฏิบัติการสามารถ override นโยบายอัตโนมัติได้ทันที และต้องมีข้อจำกัดเชิงนโยบาย (safety envelope) ที่บังคับใช้ แม้ RL จะเลือกการกระทำที่ประหยัดพลังงาน ระบบควรห้ามการตัดสินใจที่เสี่ยงต่อความปลอดภัยหรือการผลิต
- คุณภาพข้อมูลและการตรวจจับ anomalous — ข้อมูลที่มี missing, latency หรือ noise สูงจะทำให้โมเดลเรียนรู้ผิดพลาด จึงควรลงทุนใน pipeline การทำความสะอาดข้อมูลและระบบตรวจจับ anomaly ก่อนนำเข้าการเทรน
- การเปลี่ยนแปลงเชิงองค์กร — การยอมรับจากฝ่ายปฏิบัติการและการฝึกอบรมเป็นปัจจัยสำคัญ ควรจัด workshop และการฝึกใช้ระบบอย่างต่อเนื่องเพื่อลดแรงเสียดทานจากการเปลี่ยนแปลง
- การวัดผลแบบต่อเนื่อง — ต้องตั้ง KPI ชัดเจน (เช่น % ลดค่าไฟ, ความต่อเนื่องการผลิต, จำนวน override) และมีรายงานผลแบบรายเดือนเพื่อประเมิน ROI ที่แท้จริง
โดยรวมแล้ว ประสบการณ์จากการทดสอบ Grid‑RL แสดงให้เห็นว่าการนำ RL มาใช้ในการจัดสรรพลังงานเชิงปฏิบัติการสามารถให้ผลตอบแทนทางการเงินที่ชัดเจนได้ภายในกรอบเวลา 12–18 เดือนสำหรับกรณีที่เหมาะสม แต่ความสำเร็จเชิงปฏิบัติจำเป็นต้องมีการวางแผนทางเทคนิคและการจัดการเปลี่ยนแปลงอย่างรัดกุม รวมทั้งระบบเซฟตี้ที่เชื่อถือได้เพื่อรองรับการดำเนินงานในสภาพแวดล้อมอุตสาหกรรมจริง
ข้อจำกัด ความเสี่ยง และแนวทางต่อยอดเชิงธุรกิจและเทคนิค
ข้อจำกัดทางเทคนิคของการใช้ RL ในการจัดสรรพลังงานโรงงาน
แม้ผลการทดสอบของ Grid‑RL ในนิคมอุตสาหกรรมจะแสดงให้เห็นการลดค่าไฟเฉลี่ย 22% แต่การนำโมเดล RL ไปใช้กับโรงงานอื่นมีความท้าทายด้าน generalization สูง โมเดล RL มักจะเรียนรู้พฤติกรรมจากสภาพแวดล้อมที่จำเพาะ (scenario-specific) จึงเสี่ยงต่อการเกิด overfitting กับลักษณะโหลด การจัดการอุปกรณ์ และนโยบายการควบคุมของโรงงานที่ใช้ในการฝึก หากสภาพแวดล้อมจริงแตกต่างจากข้อมูลฝึก ผลการควบคุมอาจด้อยลงจนไม่คุ้มค่าในการนำไปใช้
นอกจากนี้ RL แบบเชิงทดลองยังมีข้อจำกัดด้าน sample efficiency และทรัพยากรคอมพิวเตอร์—การฝึกโมเดลที่เสถียรอาจต้องการข้อมูลการปฏิบัติงานจำนวนมาก (อาจเป็นแสนถึงล้าน timestep) และเวลาฝึกบน GPU/CPU cluster ที่ยาวนาน ซึ่งเป็นปัญหาเมื่อข้อมูลจากโรงงานจริงมีจำกัดหรือไม่สามารถทดลองการกระทำที่เสี่ยงต่อการผลิตได้โดยตรง
ปัญหาอื่นที่ต้องพิจารณาคือความไม่เสถียรของสภาพแวดล้อม (non‑stationarity) เช่น การเปลี่ยนแปลงโหลดตามฤดูกาล การปิดซ่อมเครื่องจักร หรือการปรับปรุงกระบวนการผลิต ซึ่งจะทำให้ประสิทธิภาพของโมเดลลดลงหากไม่มีกลไก adaptation/online learning ที่ปลอดภัยและมีการควบคุม
ความเสี่ยงด้านความปลอดภัยและข้อกำกับดูแล
การนำ RL มาใช้ควบคุมอุปกรณ์โรงงานมีความเสี่ยงด้านความปลอดภัยที่ต้องจัดการอย่างเข้มงวด โดยเฉพาะเมื่อมีข้อกำหนดให้การผลิตไม่สะดุด การตัดสินใจแบบ black‑box ของโมเดลอาจนำไปสู่การกระทำที่ละเมิดข้อจำกัดทางเทคนิค (เช่น กระแสเกิน แรงดันต่ำ) หรือขัดกับมาตรฐานการปฏิบัติการของโรงงาน ซึ่งจะก่อให้เกิดความเสี่ยงต่อความปลอดภัยของอุปกรณ์และบุคลากร
ด้านกฎระเบียบ การเข้าร่วมตลาดไฟฟ้า (เช่น กรณีให้บริการ Demand Response หรือการขายกำลังไฟออก) จำเป็นต้องปฏิบัติตามกฎของผู้ให้บริการระบบส่งกำลัง/จำหน่าย (TSO/DSO) ซึ่งมักกำหนดข้อจำกัดเรื่องความน่าเชื่อถือ การรายงาน และการตรวจสอบย้อนหลัง หากระบบอัตโนมัติไม่สามารถให้การรับประกันตามข้อกำหนดเหล่านี้ ผู้ใช้หรือผู้ให้บริการอาจถูกปรับหรือปฏิเสธไม่ให้เข้าแข่งขันในตลาด
แนวทางลดความเสี่ยงทางเทคนิคและการปฏิบัติตามกฎระเบียบ
- Domain adaptation & transfer learning: ใช้เทคนิคการทำให้โมเดลทนทานต่อการเปลี่ยนแปลง เช่น domain randomization, fine‑tuning บนข้อมูลโรงงานเป้าหมาย หรือ meta‑learning เพื่อลดเวลาและข้อมูลที่ต้องใช้ในการปรับใช้งาน
- Model‑based / hybrid approaches: รวมแบบจำลองเชิงกายภาพ (digital twin) กับ RL เพื่อลดการทดลองที่เป็นความเสี่ยงและเพิ่ม sample efficiency โดยสามารถจำลองสถานการณ์ฉุกเฉินก่อนนำไปใช้งานจริง
- Constraint‑aware & safe RL: ใช้กรอบงานเชิงคณิตศาสตร์ เช่น Constrained MDP, Lyapunov‑based control, หรือการติดตั้ง “safety shield” ที่ตรวจสอบและกรองคำสั่งจาก RL ก่อนส่งให้ PLC/EMS เพื่อรับประกันว่าไม่ละเมิดข้อจำกัดสำคัญ
- Human‑in‑the‑loop และ fallback policies: ตั้งระดับการควบคุมแบบลำดับชั้น—ให้ RL แนะนำการกระทำ แต่ต้องผ่านการยืนยันอัตโนมัติจากกฎเชิงตรรกะหรือผู้ปฏิบัติการในกรณีความไม่แน่นอนสูง พร้อม fallback controllers แบบ deterministic เมื่อสัญญาณผิดปกติ
- Monitoring, audit และ certification: ติดตั้งระบบมอนิเตอร์แบบเรียลไทม์และบันทึกเหตุการณ์สำหรับการตรวจสอบย้อนหลัง เพื่อให้สอดคล้องกับข้อกำกับดูแล และพัฒนา KPI ด้านความพร้อมใช้งาน (availability), เวลาแฝง (latency) และความเชื่อถือได้ (reliability)
โอกาสต่อยอดเชิงธุรกิจและโมเดลเชิงพาณิชย์
โซลูชันอย่าง Grid‑RL มีโอกาสต่อยอดเชิงธุรกิจได้หลายแนวทางที่สอดรับกับแนวโน้มพลังงานดิจิทัล ตัวอย่างสำคัญได้แก่การขยายสู่ Virtual Power Plant (VPP) เพื่อรวมกำลังจากโรงงานหลายแห่งและทรัพยากรพลังงานกระจาย (DERs) เข้าเป็นหน่วยจัดการเดียว ทำให้สามารถเข้าแข่งขันในตลาด Ancillary Services และให้บริการควบคุมความถี่หรือสำรองกำลังไฟ
อีกช่องทางคือการให้บริการ Demand Response (DR) โดยขายความสามารถในการลดโหลดในช่วงพีคแก่ผู้ให้บริการระบบหรือผู้จำหน่ายพลังงาน ซึ่งงานวิจัยเชิงอุตสาหกรรมชี้ว่าโปรแกรม DR สามารถสร้างรายได้ต่อปีให้กับผู้เข้าร่วมได้ในรูปแบบจูงใจทางการเงินตามขนาดการลดโหลดและความพร้อมใช้งาน
ด้านโมเดลธุรกิจ Grid‑RL สามารถนำเสนอเป็น SaaS (Software‑as‑a‑Service) หรือ Managed Service — คิดค่าบริการแบบ subscription สำหรับซอฟต์แวร์วิเคราะห์และการพยากรณ์ หรือแบบ performance‑based fee ที่คิดตามส่วนแบ่งจากการลดค่าไฟจริง/รายได้จากตลาด ซึ่งช่วยลดอุปสรรคการลงทุนเริ่มต้นของผู้ประกอบการโรงงาน
คำแนะนำเชิงกลยุทธ์สำหรับการนำไปใช้และการขยายตลาด
- เริ่มต้นด้วยโครงการนำร่อง (pilot): รันในโรงงานที่มีความเสี่ยงต่ำและมีข้อมูลเพียงพอ กำหนด KPI ชัดเจน (เช่น ลดค่าไฟ %, MTBF, ระดับการละเมิดข้อจำกัด) ก่อนขยายสู่ไซต์อื่น
- สร้าง digital twin และชุดทดสอบมาตรฐาน: ใช้การจำลองเพื่อตรวจสอบพฤติกรรมของ RL ในสถานการณ์หลากหลาย ลดช่องว่างระหว่าง simulation กับ real‑world
- พันธมิตรกับผู้ให้บริการพลังงานและหน่วยงานกำกับ: ทำงานร่วมกับ TSO/DSO และผู้ให้บริการตลาดเพื่อออกแบบอินเตอร์เฟซทางเทคนิคและการรายงานที่สอดคล้องกับกฎระเบียบ
- ขยายแนวบริการ: รวมบริการด้าน Analytics, Predictive Maintenance และ Optimization เป็นแพ็กเกจ เพื่อสร้างคุณค่าเพิ่มและช่องทางรายได้ใหม่
สรุปคือ Grid‑RL มีศักยภาพเชิงพาณิชย์ที่ชัดเจน แต่การขยายผลต้องอาศัยแนวทางเชิงเทคนิคและการปฏิบัติตามกฎระเบียบที่รัดกุม ทั้งการออกแบบสถาปัตยกรรมที่ยืดหยุ่น การผสมผสานโมเดลกับกฎความปลอดภัย และโมเดลธุรกิจที่ออกแบบให้ลดความเสี่ยงของผู้ประกอบการ เพื่อให้สามารถไปสู่การเป็นเครื่องมือสำคัญในระบบพลังงานยุคดิจิทัลได้อย่างยั่งยืน
บทสรุป
Grid‑RL ซึ่งเป็นระบบจัดสรรพลังงานโดยใช้เทคนิค Reinforcement Learning แสดงศักยภาพเชิงปฏิบัติที่ชัดเจนในการลดค่าไฟฟ้าของโรงงาน — ในการทดสอบเชิงภาคสนามที่นิคมอุตสาหกรรมสามารถลดค่าไฟได้จริงถึง 22% — ทำให้เทคโนโลยี RL เป็นทางเลือกที่น่าจับตามองสำหรับโรงงานที่ต้องการลดต้นทุนพลังงานและเพิ่มประสิทธิภาพการใช้พลังงาน ตรงนี้ไม่เพียงชี้ให้เห็นผลลัพธ์เชิงตัวเลข แต่ยังสะท้อนความเป็นไปได้ของการนำ AI มาบริหารจัดการโหลดเชิงปฏิบัติการในสเกลอุตสาหกรรม
อย่างไรก็ตาม การนำ Grid‑RL ไปใช้งานจริงจำเป็นต้องคำนึงหลายด้าน เช่น สถาปัตยกรรมการติดตั้งที่เหมาะสม การผสานกับระบบ SCADA/EMS เดิม การรักษาความปลอดภัยของการควบคุม (cyber‑physical security) และการปรับแต่งโมเดลให้สอดรับกับลักษณะโหลดและกระบวนการของแต่ละโรงงาน การพัฒนาเชิงธุรกิจมีโอกาสสูง — จากการขยายสู่ Virtual Power Plant (VPP) บริการจัดการพลังงานแบบครบวงจร และโมเดลให้บริการแบบ SaaS/Managed Services — โดยการเดินหน้าแนะนำให้เริ่มจากการทดสอบนำร่อง ปรับโมเดลแบบต่อเนื่อง และออกแบบกลไกการติดตามผลเพื่อยืนยัน ROI ก่อนขยายสเกลสู่การใช้งานจริงในวงกว้าง



