
ในยุคที่ปริมาณข้อมูลและความสามารถด้านปัญญาประดิษฐ์กลายเป็นหัวใจในการแข่งขันทางธุรกิจ แต่ข้อจำกัดด้านความเป็นส่วนตัวและการเข้าถึงข้อมูลคุณภาพสูงยังเป็นอุปสรรคสำคัญ SynthExchange ตลาดข้อมูลสังเคราะห์รายแรกในไทยก้าวเข้ามาตอบโจทย์นี้ด้วยการเสนอชุดข้อมูลสังเคราะห์ที่ได้รับการรับรองความเป็นส่วนตัวแบบ Differential Privacy (DP-certified) ทำให้สตาร์ทอัพและนักพัฒนาโมเดลสามารถฝึกและทดสอบโมเดลได้โดยไม่ต้องใช้ข้อมูลส่วนบุคคล (PII) จริง ช่วยลดความเสี่ยงด้านกฎหมายและความเป็นส่วนตัว ตลอดจนเร่งเวลาในการพัฒนาผลิตภัณฑ์ AI
บทความนี้จะพาผู้อ่านสำรวจภาพรวมของ SynthExchange ตั้งแต่เทคโนโลยีเบื้องหลังการสร้างข้อมูลสังเคราะห์และการประยุกต์ใช้ Differential Privacy ไปจนถึงโมเดลธุรกิจของแพลตฟอร์ม—ทั้งรูปแบบการขายชุดข้อมูล การให้สิทธิ์ใช้งาน และบริการตรวจสอบความเป็นส่วนตัว—พร้อมประเมินผลลัพธ์การใช้งานจริงในภาคอุตสาหกรรมตัวอย่าง และวิเคราะห์ความสอดคล้องกับพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ที่ธุรกิจไทยต้องเผชิญ เพื่อให้ผู้อ่านเห็นข้อดี ข้อจำกัด และโอกาสที่เกิดขึ้นจากการเกิดขึ้นของตลาดข้อมูลสังเคราะห์ในประเทศ
บทนำ: ทำไมตลาดข้อมูลสังเคราะห์ถึงเกิดขึ้นในไทยตอนนี้
บทนำ: ทำไมตลาดข้อมูลสังเคราะห์ถึงเกิดขึ้นในไทยตอนนี้
การประกาศเปิดตัว SynthExchange ในประเทศไทยเป็นจังหวะที่สอดคล้องกับความต้องการเชิงธุรกิจและข้อจำกัดด้านกฎหมายของยุคปัญญาประดิษฐ์: SynthExchange เสนอตลาดข้อมูลสังเคราะห์ที่ขายชุดข้อมูลพร้อมการรับรองความเป็นส่วนตัวแบบ Differential Privacy (DP) ซึ่งช่วยให้สตาร์ทอัพและองค์กรสามารถนำข้อมูลไปใช้ฝึกโมเดลได้โดยไม่ต้องประมวลผลข้อมูลระบุตัวบุคคล (PII) ตรงจุดขายที่เด่นชัดคือการให้ "ความสามารถใช้งานจริง" ร่วมกับ "การรับรองความเป็นส่วนตัว" ซึ่งลดภาระด้านกฎหมายและความเสี่ยงจากการรั่วไหลของข้อมูลต้นฉบับ
ความต้องการข้อมูลคุณภาพสูงสำหรับการฝึกโมเดล AI ในไทยและภูมิภาคเอเชียตะวันออกเฉียงใต้เพิ่มขึ้นอย่างมีนัยสำคัญในช่วงไม่กี่ปีที่ผ่านมา ทั้งจากการขยายตัวของผลิตภัณฑ์ด้านการเงินดิจิทัล (FinTech), การค้าอิเล็กทรอนิกส์, สุขภาพดิจิทัล และบริการอัจฉริยะสำหรับภาครัฐและเอกชน รายงานเชิงวิวัฒนาการของเศรษฐกิจดิจิทัลในภูมิภาคชี้ให้เห็นถึงการเติบโตของมูลค่าตลาดดิจิทัลและการลงทุนด้านเทคโนโลยี ซึ่งแปลเป็นความต้องการข้อมูลเพื่อฝึกโมเดลเพิ่มขึ้น ขณะเดียวกันจำนวนสตาร์ทอัพและชุมชนนักพัฒนาที่มุ่งเน้น AI/ML ในไทยมีแนวโน้มเพิ่มขึ้นเป็นทวีคูณ ทำให้ความต้องการชุดข้อมูลที่มีคุณภาพและสอดคล้องมาตรฐานเติบโตตามไปด้วย
ปัจจัยเร่งอีกประการหนึ่งมาจากแรงกดดันด้านกฎระเบียบ โดยเฉพาะพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคลของไทย (PDPA) และแนวปฏิบัติด้านความเป็นส่วนตัวของข้อมูลที่เข้มงวดขึ้นในภูมิภาค ทำให้การใช้ข้อมูล PII เพื่อฝึกโมเดลมีความเสี่ยงทั้งทางกฎหมายและภาพลักษณ์ องค์กรจำนวนมากจึงมองหาแนวทางที่ช่วยลดความเสี่ยง เช่น การใช้ข้อมูลสังเคราะห์หรือการรับรองด้วยมาตรการเช่น DP เพื่อให้มั่นใจได้ว่าการใช้งานข้อมูลไม่สามารถย้อนกลับสู่ข้อมูลจริงของผู้ใช้ได้ง่าย ๆ ซึ่งเพิ่มความน่าสนใจให้กับตลาดข้อมูลสังเคราะห์อย่างชัดเจน
ด้วยบริบทด้านความต้องการเชิงธุรกิจ การลงทุน และข้อจำกัดด้านกฎหมาย SynthExchange จึงตอบโจทย์เชิงปฏิบัติได้ตรงจุด: เป็นแพลตฟอร์มที่เชื่อมโยงผู้ผลิตชุดข้อมูลสังเคราะห์ที่ได้รับการรับรอง DP กับผู้บริโภคข้อมูล—โดยเฉพาะสตาร์ทอัพและทีมพัฒนาที่ต้องการทดลองและปรับใช้โมเดลอย่างรวดเร็วและปลอดภัย ผลลัพธ์ที่คาดหวังคือการลดเวลาในการเข้าถึงข้อมูลที่พร้อมใช้ (time-to-data), ลดต้นทุนด้านการปฏิบัติตามข้อกำหนด, และเร่งการนำ AI สู่การใช้งานเชิงพาณิชย์ในภาคอุตสาหกรรมต่าง ๆ เช่น ฟินเทค สุขภาพ และอีคอมเมิร์ซ
- สรุปปัจจัยสนับสนุนตลาด: การเติบโตของความต้องการข้อมูล AI, การลงทุนด้านเทคโนโลยีในภูมิภาค, แรงกดดันด้าน PDPA และความเสี่ยงจากการใช้ PII
- คุณค่าหลักของ SynthExchange: ชุดข้อมูลพร้อมการรับรอง DP ช่วยให้การทดลอง/พัฒนาโมเดลเป็นไปอย่างปลอดภัยและเป็นไปตามข้อกำหนด
- ประโยชน์ต่อสตาร์ทอัพ: ลดความเสี่ยงด้านกฎหมาย เร่งเวลาในการพัฒนาโมเดล และลดต้นทุนในการจัดการข้อมูลต้นทาง
ผลิตภัณฑ์และบริการของ SynthExchange: ตลาด ขาย และการรับรอง DP
ภาพรวมผลิตภัณฑ์ของ SynthExchange: ตลาดชุดข้อมูลสังเคราะห์สำหรับสตาร์ทอัพและองค์กร
SynthExchange เปิดตัวในรูปแบบ dataset marketplace ที่ออกแบบมาเพื่อให้ผู้พัฒนาโมเดลและสตาร์ทอัพสามารถเข้าถึงชุดข้อมูลสังเคราะห์ที่มีการรับรองความเป็นส่วนตัวโดยไม่ต้องใช้ข้อมูลส่วนบุคคล (PII) จริง ๆ บนแพลตฟอร์ม ผู้ขาย (data providers) และผู้สร้างชุดข้อมูลสังเคราะห์สามารถนำชุดข้อมูลขึ้นขายพร้อมเมตาดาต้าเชิงลึก ขณะที่ผู้ซื้อสามารถค้นหา เปรียบเทียบ และทดลองใช้งานได้ผ่านอินเทอร์เฟซที่รองรับการค้นหาตามโดเมนอุตสาหกรรม ความละเอียดของข้อมูล และระดับความเป็นส่วนตัว
รูปแบบชุดข้อมูลที่จำหน่ายและเมตาดาต้า (schema, provenance, utility metrics)
SynthExchange รองรับชุดข้อมูลสี่ประเภทหลักที่ตอบโจทย์การใช้งานโมเดลสมัยใหม่:
- Tabular datasets — เหมาะกับงานด้านการเงิน การวิเคราะห์ลูกค้า และการทำโมเดลพยากรณ์แบบมีคอลัมน์ เช่น ข้อมูลธุรกรรม, profile attributes
- Time-series datasets — สำหรับ IoT, telemetry, และการพยากรณ์ลำดับเวลา เช่น ข้อมูลเซนเซอร์, ข้อมูลการใช้งานระบบ
- Image datasets — ชุดข้อมูลภาพสำหรับงาน Computer Vision เช่น การตรวจจับความบกพร่อง, การวินิจฉัยทางการแพทย์ที่ผ่านการปกปิดข้อมูลระบุตัวตน
- Textual datasets — ข้อความสนทนา, บันทึกทางการแพทย์ที่ถูกทำให้เป็นสังเคราะห์, หรือเอกสารเพื่อฝึกโมเดล NLP
ทุกรายการบนตลาดมาพร้อมเมตาดาต้าครบถ้วน ได้แก่ schema (รายการฟีลด์, ประเภทข้อมูล), provenance (ที่มาของข้อมูลและเวอร์ชัน), และชุดของ utility metrics เช่นความสอดคล้องของการแจกแจงฟีเจอร์ (feature distribution alignment), coverage ของกรณีใช้งาน, ค่า KL divergence หรือ FID score สำหรับภาพ เพื่อให้ผู้ซื้อประเมินได้ว่าชุดข้อมูลนั้นเหมาะสมกับงานจริงหรือไม่
กระบวนการรับรอง Differential Privacy (DP) และการออกใบรับรองความเป็นส่วนตัว
SynthExchange นำเสนอ DP certification workflow ที่โปร่งใสและตรวจสอบได้ กระบวนการจะเริ่มจากการกำหนดนโยบายความเป็นส่วนตัวและพารามิเตอร์หลัก ได้แก่ค่า epsilon และ privacy budget ต่อชุดข้อมูล:
- การกำหนดค่า epsilon — แพลตฟอร์มอนุญาตให้ระบุช่วงค่า epsilon ที่หลากหลาย (ตัวอย่างเช่น epsilon ระหว่าง 0.1 ถึง 10 ขึ้นอยู่กับความต้องการ trade-off ระหว่าง privacy และ utility)
- การจัดการ privacy budget — ระบบติดตามการใช้ budget ตามหลัก composition theorem เพื่อประเมินผลกระทบเมื่อนำชุดข้อมูลไปใช้หลายครั้งหรือร่วมกับแหล่งข้อมูลอื่น
- การตรวจสอบด้วยกลไก DP — SynthExchange ใช้กลไกมาตรฐานเช่น Laplace และ Gaussian mechanisms รวมทั้งการประเมิน empirical privacy risk ผ่านการโจมตีย้อนกลับ (reconstruction attacks) ในสภาพแวดล้อมทดสอบ
เมื่อชุดข้อมูลผ่านการทดสอบความเป็นส่วนตัวและ utility แล้ว แพลตฟอร์มจะออก ใบรับรองความเป็นส่วนตัว (privacy certificate) ที่มีรายละเอียดสำคัญ เช่นค่า epsilon ที่ใช้, metadata ของกระบวนการสร้างสังเคราะห์, และรหัสตรวจสอบดิจิทัล (cryptographic signature) เพื่อให้ผู้ซื้อสามารถตรวจสอบความน่าเชื่อถือของการรับรองได้แบบ machine-verifiable และใช้เป็นหลักฐานสำหรับการปฏิบัติตามกฎคุ้มครองข้อมูล (เช่น PDPA หรือ GDPR ในการใช้งานข้ามประเทศ)
ฟีเจอร์ทดลองใช้งาน: sandbox, model cards, sample downloads และการประเมิน utility ก่อนการซื้อ
SynthExchange วางระบบทดลองเพื่อให้ผู้ซื้อประเมินคุณภาพก่อนตัดสินใจซื้อจริง โดยมีฟีเจอร์เด่นดังนี้:
- Sandbox environment — พื้นที่คลาวด์แยกส่วนสำหรับรันการทดลองฝึกโมเดลกับชุดข้อมูลสังเคราะห์โดยไม่ต้องดาวน์โหลดข้อมูลเต็มชุด ผู้ใช้สามารถรัน pipeline เบื้องต้น ประเมินการเทรน และดูผลลัพธ์เช่น accuracy, ROC-AUC หรือ MSE
- Model cards — แต่ละชุดข้อมูลมาพร้อม model card ที่สรุปการใช้งานแนะนำ ข้อจำกัด ความเสี่ยงเชิงจริยธรรม และชุดการทดสอบที่แนะนำ เพื่อช่วยในการตัดสินใจ
- Sample downloads — ตัวอย่างข้อมูลขนาดเล็ก (เช่น 0.1%–5% ของชุดข้อมูลเต็ม หรือไฟล์ตัวอย่างที่มี schema เต็มรูปแบบ) ให้ดาวน์โหลดไปทดสอบแบบ offline
- Utility evaluation tools — เครื่องมืออัตโนมัติที่ประเมินความเหมาะสมของชุดข้อมูลกับงานเฉพาะด้าน เช่น scoring ของ feature relevance, data drift metrics, และ benchmark comparison กับชุดข้อมูลจริงหรือชุดข้อมูลสังเคราะห์อื่น ๆ
จากการทดสอบภายในเวอร์ชันเบต้า พบว่าองค์กรที่ทดลองใช้ sandbox สามารถลดเวลาการประเมินชุดข้อมูลลงเฉลี่ยประมาณ 40% และมีการตัดสินใจซื้อเร็วขึ้น ซึ่งช่วยให้สตาร์ทอัพสามารถนำข้อมูลสังเคราะห์ไปฝึกโมเดลได้อย่างมีประสิทธิภาพโดยยังรักษามาตรฐานความเป็นส่วนตัว
การค้นหาและการผสานการใช้งานในงานจริง
ผู้ซื้อสามารถค้นหาชุดข้อมูลโดยใช้ฟิลเตอร์เช่นประเภทข้อมูล (tabular/time-series/image/text), ระดับ epsilon, คะแนน utility, ราคา และอุตสาหกรรมตัวอย่าง ในหน้ารายละเอียดแต่ละชุดข้อมูลจะแสดงตัวอย่างฟิลด์ (schema), lineage ของข้อมูล (provenance), และตัวชี้วัดที่ช่วยให้เปรียบเทียบชุดข้อมูลได้อย่างเป็นระบบ หากต้องการจะทดลองใช้งาน ผู้ใช้สามารถเรียกใช้งานผ่าน sandbox หรือดาวน์โหลด sample เพื่อนำไปทดสอบกับ pipeline ของตนเองก่อนตัดสินใจซื้อจริง
โดยสรุป SynthExchange พยายามผสานความต้องการด้าน privacy และ utility เข้าด้วยกันผ่านตลาดข้อมูลที่โปร่งใส มีการรับรอง DP เชิงเทคนิค และชุดเครื่องมือทดลองที่ช่วยให้ธุรกิจตัดสินใจได้อย่างรวดเร็วและปลอดภัยจากการพึ่งพาข้อมูล PII จริง
เข้าใจ Differential Privacy (DP) สำหรับข้อมูลสังเคราะห์: แนวคิดและการวัดค่า
หลักการพื้นฐานของ Differential Privacy
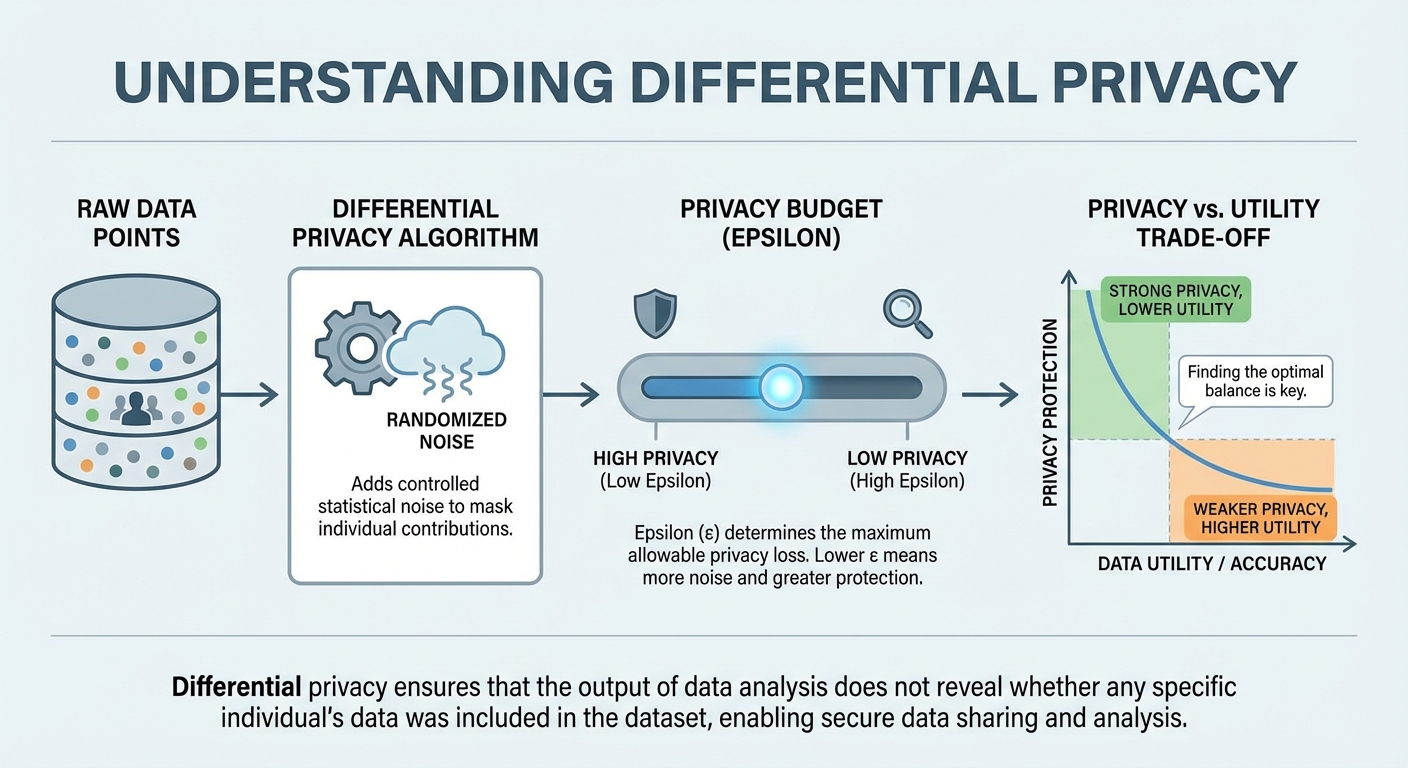
Differential Privacy (DP) เป็นกรอบแนวคิดที่ออกแบบมาเพื่อให้การประมวลผลข้อมูลรวม (เช่น การฝึกโมเดลหรือการตอบแบบสอบถามเชิงสถิติ) ไม่สามารถเปิดเผยข้อมูลเฉพาะตัวของบุคคลใดบุคคลหนึ่งได้อย่างมีนัยสำคัญ แนวคิดสำคัญคือผลลัพธ์จากอัลกอริธึมที่ให้การคุ้มครอง DP ควรมีความน่าจะเป็นใกล้เคียงกันไม่ว่าจะมีหรือไม่มีข้อมูลของบุคคลหนึ่งอยู่ในชุดข้อมูล กล่าวอีกนัยหนึ่ง อัตราส่วนความน่าจะเป็นของผลลัพธ์ระหว่างชุดข้อมูลสองชุดที่ต่างกันเพียงเรคคอร์ดเดียวจะถูกจำกัดด้วยพารามิเตอร์ความเป็นส่วนตัว:
สำหรับอัลกอริธึม A และชุดข้อมูลที่ต่างกันเพียงหนึ่งรายการ D และ D' แล้วสำหรับทุกผลลัพธ์ชุด S: Pr[A(D) ∈ S] ≤ eε · Pr[A(D') ∈ S]
นิยามนี้หมายความว่า การสังเกตผลลัพธ์จากระบบที่เป็น DP จะไม่ให้เบาะแสที่ชัดเจนว่าบุคคลใดบุคคลหนึ่งมีอยู่ในข้อมูลหรือไม่ ซึ่งเป็นหัวใจสำคัญที่ช่วยให้ผู้ให้บริการอย่าง SynthExchange สามารถรับรองความเป็นส่วนตัวของชุดข้อมูลสังเคราะห์โดยไม่ต้องเปิดเผย PII (Personally Identifiable Information)
ค่า epsilon: ตัวชี้วัดความเข้มของการป้องกันและการแลกเปลี่ยนกับ utility
ค่า ε (epsilon) เป็นตัวชี้วัดความเข้มของการป้องกันในกรอบ DP โดยมีความหมายคร่าว ๆ ดังนี้:
- ε เล็ก (เช่น 0.1) — ให้การป้องกันสูง ผลลัพธ์จากการวิเคราะห์มีความแตกต่างกันเพียงเล็กน้อยเมื่อมีหรือไม่มีข้อมูลของบุคคลหนึ่ง ดังนั้นความเสี่ยงการรั่วไหลของข้อมูลเฉพาะตัวจะต่ำมาก
- ε กลาง (เช่น 1) — ให้ความสมดุลระหว่างความเป็นส่วนตัวและประโยชน์ใช้งาน (utility) ของข้อมูล เหมาะกับงานเชิงปฏิบัติที่ต้องการความแม่นยำระดับปานกลาง
- ε ใหญ่ (เช่น 10) — ให้การป้องกันค่อนข้างอ่อน ผลลัพธ์อาจแตกต่างอย่างชัดเจนเมื่อมีหรือไม่มีข้อมูลของบุคคลหนึ่ง แต่ utility โดยรวมจะสูงกว่า
ต้องเข้าใจว่า ε ไม่ได้เป็นหน่วยของความเสี่ยงโดยตรง แต่เป็นพารามิเตอร์ทางคณิตศาสตร์ที่บอกขอบเขตความต่างของการแจกแจงผลลัพธ์ — ค่ายิ่งเล็กหมายถึงการแจกแจงยิ่งใกล้เคียงกันมากขึ้น ซึ่งแปลว่าการเปิดเผยข้อมูลเฉพาะตัวทำได้ยากขึ้น แต่ก็แลกมาด้วยการสูญเสียความแม่นยำของสถิติหรือโมเดล
ตัวอย่างเชิงตัวเลข: ผลกระทบของค่า ε ต่อความแม่นยำของโมเดลจำแนก
ต่อไปนี้เป็นตัวอย่างสมมติที่แสดงภาพรวมของผลกระทบ: สมมติมีชุดข้อมูลสำหรับงานจำแนกประเภทพื้นฐาน (เช่น การจำแนกภาพหรือข้อความ) โดยฐานอ้างอิง (ไม่มีการเพิ่มเสียงหรือทำ DP) ให้ความแม่นยำ (accuracy) ประมาณ 90%. เมื่อนำการป้องกันแบบ DP เข้ามา (เช่น การเพิ่ม Laplace/Gaussian noise หรือการฝึกแบบ DP-SGD) จะมีการลดความแม่นยำตามระดับของ ε ดังนี้ (ตัวเลขเป็นการประมาณเชิงสาธิต):
- ε = 10 (ความเป็นส่วนตัวอ่อน) — ความแม่นยำประมาณ 86–89%. การสูญเสีย utility เล็กน้อย แต่ความเสี่ยงการเปิดเผยข้อมูลเฉพาะตัวยังค่อนข้างสูงเมื่อเทียบกับค่ายต่ำ
- ε = 1 (ความเป็นส่วนตัวระดับกลาง) — ความแม่นยำประมาณ 78–84%. ถือเป็นจุดสมดุลที่ใช้งานได้จริงในหลายกรณีของธุรกิจและการทดลองโมเดล
- ε = 0.1 (ความเป็นส่วนตัวสูง) — ความแม่นยำประมาณ 58–72%. เหมาะสำหรับสถานการณ์ที่ความเป็นส่วนตัวสำคัญมาก แต่ utility ของโมเดลจะถูกจำกัดอย่างมีนัยสำคัญ
ตัวเลขข้างต้นเป็นตัวอย่างเชิงภาพเพื่อสื่อสารแนวโน้ม — ผลลัพธ์จริงขึ้นกับขนาดชุดข้อมูล สถาปัตยกรรมโมเดล เทคนิคการเพิ่ม noise และการตั้งค่าการฝึกซึ่งรวมทั้งการปรับพารามิเตอร์และการใช้กลยุทธ์เสริม (เช่น การเพิ่มข้อมูล หรือการใช้โมเดลขนาดใหญ่ขึ้น)
การประเมินความเสี่ยงและแนวทางใช้งานเชิงธุรกิจ
สำหรับผู้บริหารและทีมผลิตภัณฑ์ การตัดสินใจเลือกระดับ ε ควรพิจารณาร่วมกันทั้งมุมมองความเสี่ยง ความต้องการด้านคุณภาพของโมเดล และผลกระทบทางกฎหมาย/กฎระเบียบ ตัวอย่างแนวทางเชิงปฏิบัติได้แก่:
- กำหนดเกณฑ์ความเสี่ยงภายในองค์กรว่าระดับ ε ไหนยอมรับได้สำหรับกรณีใช้งานต่าง ๆ
- ทดลองเชิงประสิทธิผล (A/B testing) โดยใช้ค่าต่าง ๆ ของ ε เพื่อวัด trade-off ระหว่าง privacy และ utility ในบริบทของงานจริง
- ใช้การรับรอง DP ร่วมกับการประเมินความเสี่ยงแบบอื่น ๆ (เช่น threat modeling, auditing) เพื่อให้การคุ้มครองมีความแข็งแกร่งยิ่งขึ้น โดยไม่ต้องจัดเก็บหรือเผยแพร่ PII
สรุปแล้ว DP ให้กรอบที่ชัดเจนและวัดค่าได้สำหรับการปกป้องความเป็นส่วนตัวของข้อมูลในตลาดข้อมูลสังเคราะห์อย่าง SynthExchange: ผู้ซื้อสามารถรับข้อมูลที่ช่วยให้การฝึกโมเดลมีประสิทธิภาพพอใช้งานได้ ในขณะที่ผู้ขายสามารถให้การรับรองความเป็นส่วนตัวเชิงคณิตศาสตร์โดยไม่ต้องเปิดเผย PII — ทั้งนี้การเลือกค่า ε ที่เหมาะสมเป็นการตัดสินใจเชิงกลยุทธ์ที่ต้องพิจารณาจากเป้าหมายเชิงธุรกิจและข้อจำกัดด้านความปลอดภัย
กรณีศึกษา: สตาร์ทอัพไทยใช้ข้อมูลสังเคราะห์อย่างไร (ตัวอย่างสมมติและผลลัพธ์)
กรณีศึกษาโดยย่อ
ต่อไปนี้เป็นกรณีศึกษาสมมติจากสตาร์ทอัพไทยในกลุ่ม fintech, healthtech และ e-commerce ที่นำชุดข้อมูลสังเคราะห์ซึ่งได้รับการรับรองความเป็นส่วนตัวแบบ Differential Privacy (DP-certified synthetic data) จากแพลตฟอร์มเช่น "SynthExchange" ไปใช้ในการพัฒนาและทดสอบโมเดล ผลลัพธ์ที่นำเสนอเป็นตัวอย่างสมมติเพื่อแสดงแนวโน้มเชิงปริมาณของประสิทธิภาพ เวลาในการพัฒนา ต้นทุน และความเสี่ยงด้านความเป็นส่วนตัวเมื่อเทียบกับการใช้ข้อมูลจริงที่มี PII
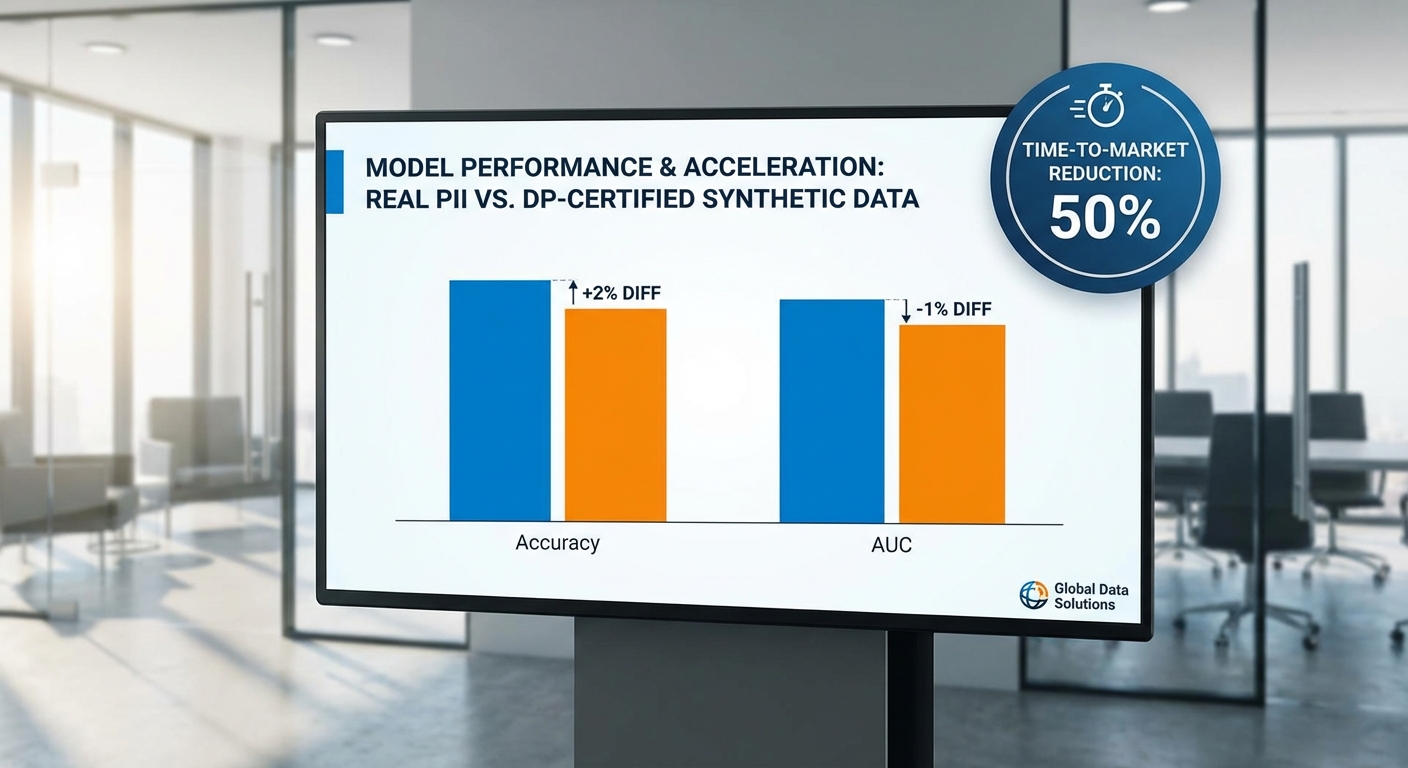
กรณีศึกษา 1 — Fintech: ระบบตรวจจับการฉ้อโกงจากบันทึกธุรกรรม
สตาร์ทอัพ fintech สมมติแห่งหนึ่งต้องการโมเดลตรวจจับการฉ้อโกงจาก transaction logs แต่การขออนุญาตใช้ข้อมูลจริง (ที่มี PII) ใช้เวลานานและมีข้อจำกัดด้าน compliance หลายชั้น ทีมงานจึงทดลองใช้ชุดข้อมูลสังเคราะห์ DP-certified ที่เลียนแบบ distribution ของพฤติกรรมธุรกรรมจริง
- ผลลัพธ์เชิงโมเดล (สมมติ):
- Accuracy (ข้อมูลจริง): 0.87 vs (synthetic DP): 0.84 — ลดลงประมาณ 3.4%
- Recall (การจับพฤติกรรมฉ้อโกง): 0.79 vs 0.76 — ลดลง ~3.8%
- AUC: 0.91 vs 0.89 — ลดลง 2–3%
- ผลต่อเวลาและการปฏิบัติตามกฎระเบียบ:
- Time-to-market (development + compliance): ข้อมูลจริงเฉลี่ย 12 สัปดาห์ vs synthetic 8.4 สัปดาห์ — เร็วขึ้น ~30%
- เวลาในการขออนุญาตข้อมูลและการตรวจสอบภายในลดลงอย่างมีนัยสำคัญ เนื่องจากไม่ต้องไล่ลบ PII และผูกพันตามสัญญา data sharing
- ต้นทุน:
- Cost per sample (รวมค่าเอกสาร/สัญญา/legal): ข้อมูลจริง ~฿15–30/ตัวอย่าง vs synthetic ~฿1–5/ตัวอย่าง — ลดต้นทุนโดยรวมมากกว่า 70%
- สรุป: แม้ประสิทธิภาพจะลดลงเล็กน้อย (2–4%) แต่การใช้ synthetic DP-certified ช่วยเร่งการพัฒนาและลดภาระทางกฎหมาย ทำให้ทีมผลิตซอฟต์แวร์สามารถทดสอบการอัปเดตโมเดลและปล่อยฟีเจอร์ใหม่ได้เร็วขึ้นอย่างมีนัยสำคัญ
กรณีศึกษา 2 — Healthtech: การสร้างต้นแบบโมเดลคัดกรองผู้ป่วยโดยใช้เวชระเบียนสังเคราะห์
สตาร์ทอัพ healthtech สมมติรายหนึ่งต้องการทดลองโมเดลคัดกรองความเสี่ยงโรคเรื้อรังจากเวชระเบียน (electronic health records) แต่การใช้งานข้อมูลจริงมีข้อจำกัดด้านกฎหมายและจริยธรรมอย่างเข้มงวด ทีมงานจึงเลือกใช้ชุดข้อมูลผู้ป่วยสังเคราะห์ที่ได้รับการรับรอง DP เพื่อทำ rapid prototyping และ validation เบื้องต้น
- ผลลัพธ์เชิงโมเดล (สมมติ):
- Accuracy: ข้อมูลจริง 0.92 vs synthetic DP 0.90 — ลดลง ~2.2%
- AUC: 0.94 vs 0.92 — ลดลง ~2.1%
- Bias indicators (เช่น disparate impact ratio): ข้อมูลจริง 0.88 vs synthetic 0.89 — ไม่มีการเพิ่มความลำเอียงที่มีนัยสำคัญ; ในบางกรณี synthetic ช่วยลด bias เล็กน้อย
- ความเสี่ยงและการปฏิบัติตามกฎ:
- ลดความเสี่ยงการละเมิดข้อมูลส่วนบุคคล เนื่องจากไม่มี PII อยู่ในชุดข้อมูลที่ใช้ทดลอง
- ระยะเวลาในการได้รับอนุมัติจากคณะกรรมการจริยธรรม (IRB) ลดลงอย่างมาก — จาก 8–12 สัปดาห์ เหลือ 1–3 สัปดาห์สำหรับงานวิจัยเชิงสำรวจที่ใช้ข้อมูลสังเคราะห์
- ต้นทุนและประสิทธิภาพการพัฒนา:
- ค่าใช้จ่ายในการได้มาซึ่งข้อมูลและเอกสารกำกับลดลง โดยเฉพาะค่าใช้จ่ายด้าน legal และ data governance
- ทีมสามารถทำ iterating ของฟีเจอร์ได้บ่อยขึ้น และเมื่อต้องการยืนยันกับข้อมูลจริงก็ทำเป็นการทดสอบขั้นสุดท้ายก่อนผลิตจริง
- สรุป: การใช้ synthetic DP-certified เหมาะสำหรับการพัฒนาและทดสอบต้นแบบในสภาพแวดล้อมด้านสุขภาพ ช่วยให้ลดความเสี่ยงด้านความเป็นส่วนตัวและเร่งการวิจัยเชิงพัฒนาได้โดยไม่กระทบต่อความน่าเชื่อถือของโมเดลอย่างมีนัยสำคัญ
กรณีศึกษา 3 — E‑commerce: ระบบแนะนำสินค้าและ personalisation
แพลตฟอร์ม e-commerce รายเล็กในไทยต้องการพัฒนาระบบแนะนำสินค้า (recommendation) ที่เรียนรู้จากประวัติการคลิกและสั่งซื้อ แต่การใช้งานข้อมูลลูกค้าที่แท้จริงมีต้นทุนด้านการปกป้องข้อมูลและข้อจำกัดทางการตลาด ทีมงานจึงทดลองใช้ synthetic customer interaction logs เพื่อเทรนโมเดลและทดสอบ A/B ก่อนนำไปใช้งานจริง
- ผลลัพธ์เชิงโมเดล (สมมติ):
- CTR (click-through rate) ในการทดลอง: ข้อมูลจริง 3.8% vs synthetic-trained model 3.6% — ลดลง ~0.2 percentage point
- Precision@10: 0.42 vs 0.40 — ลดลง ~4.8%
- AUC สำหรับการคาดการณ์การซื้อ: 0.78 vs 0.76 — ลดลง ~2.6%
- ต้นทุนการได้มาของข้อมูล:
- Cost per sample: ข้อมูลจริง ~฿8–12/ตัวอย่าง vs synthetic ~฿0.8–2/ตัวอย่าง — ลดลงโดยประมาณ 80–90%
- เวลาในการทดสอบและเปิดตัว:
- ด้วย synthetic data ทีมสามารถรัน A/B test และ iterate ได้รวดเร็วขึ้น ทำให้ time-to-market ของฟีเจอร์ใหม่สั้นลง 20–40%
- สรุป: สำหรับงาน personalization ที่เน้นการทดลองและการปรับแต่งบ่อยครั้ง การใช้ synthetic DP-certified data ช่วยลดต้นทุนและเพิ่มความคล่องตัว แม้จะแลกมาด้วยการสูญเสียประสิทธิภาพเล็กน้อยที่มักอยู่ในช่วงยอมรับได้
การวัดผลและตัวชี้วัดที่ควรติดตาม
เมื่อเปรียบเทียบการใช้ข้อมูลจริงที่มี PII กับ synthetic DP-certified ควรติดตามเมตริกหลักดังนี้:
- Model performance: Accuracy, AUC, Precision/Recall, F1-score
- Business metrics: CTR, conversion rate, false positive/negative cost
- Bias & fairness indicators: disparate impact, equal opportunity difference, demographic parity
- Operational metrics: time-to-market, development cycles per quarter
- Cost metrics: cost per sample (รวมค่า legal/compliance), total cost of data acquisition
- Privacy risk: probability of re-identification (สำหรับชุดข้อมูลจริง) เทียบกับระดับความคุ้มกันที่ DP epsilon ระบุ
ตัวอย่างการเปรียบเทียบสรุป (สมมติ): ประสิทธิภาพลดลงเฉลี่ย 2–4% เมื่อใช้ synthetic DP-certified แต่ได้ประโยชน์เชิงปฏิบัติทั้งด้านเวลา (เร็วขึ้น 20–40%) และต้นทุน (ลดลง 50–90% ขึ้นกับประเภทข้อมูลและค่าใช้จ่ายทางกฎหมาย) ซึ่งเป็นเหตุผลว่าทำไมสตาร์ทอัพจำนวนมากมักเลือกใช้ synthetic data ในช่วง prototyping และการพัฒนาเชิงทดลอง ก่อนจะยืนยันผลสุดท้ายด้วยชุดข้อมูลจริงในสเกลที่จำเป็นเท่านั้น
คุณภาพข้อมูล ข้อจำกัด และวิธีประเมิน (fidelity, utility, bias)
ภาพรวม: ความสำคัญของการประเมินคุณภาพข้อมูลสังเคราะห์
เมื่อสตาร์ทอัพหรือองค์กรใช้งานชุดข้อมูลสังเคราะห์จากตลาดอย่าง SynthExchange สิ่งสำคัญคือต้องวัดและยืนยันว่า ข้อมูลสังเคราะห์มีคุณภาพเพียงพอทางสถิติและใช้งานได้จริง (fidelity & utility) และไม่ขยายหรือสร้างความไม่เป็นธรรม (bias) ให้กับโมเดลหรือการตัดสินใจ ผู้ซื้อควรมีกรอบการประเมินที่ชัดเจน ซึ่งรวมถึงการทดสอบเชิงสถิติ การประเมินประสิทธิภาพของโมเดลจริง และการตรวจสอบความเอนเอียงในกลุ่มย่อยต่าง ๆ เพื่อให้มั่นใจว่าข้อมูลที่ได้รับสามารถใช้แทนข้อมูลจริงได้อย่างปลอดภัยและมีความรับผิดชอบ
การวัด Fidelity (ความคล้ายคลึงทางสถิติ)
Fidelity วัดได้จากการเปรียบเทียบการแจกแจงของตัวแปรและความสัมพันธ์ระหว่างตัวแปรในชุดข้อมูลจริงกับชุดข้อมูลสังเคราะห์ โดยนิยมใช้เมตริกต่อไปนี้:
- KS-test (Kolmogorov–Smirnov) สำหรับตัวแปรเชิงต่อเนื่อง: ใช้เปรียบเทียบ CDF ของตัวแปรเดียวกัน ถ้า p-value สูง (ตัวอย่างเช่น > 0.05) แสดงว่าไม่สามารถปฏิเสธความคล้ายกันทางสถิติได้ แต่ต้องระวังว่า KS-test มีความไวต่อขนาดตัวอย่าง
- Wasserstein distance (Earth Mover's Distance): วัดระยะทางระหว่างการแจกแจงเชิงปริมาณ ค่าที่ใกล้ 0 บ่งชี้ความคล้ายคลึงสูง ค่ามาตรฐานที่รับได้ขึ้นอยู่กับสเกลของข้อมูล แต่การเปรียบเทียบเชิงสัมพัทธ์หรือการ normalized Wasserstein จะช่วยให้ตีความง่ายขึ้น
- Pairwise distribution comparisons: ตรวจสอบการแจกแจงร่วมระหว่างคู่ตัวแปร (joint distributions) โดยใช้ correlation matrix comparisons, mutual information, หรือการเปรียบเทียบ pairwise scatter/contingency tables สำหรับตัวแปรเชิงหมวดหมู่ใช้ Chi-square / Cramér's V
- อื่น ๆ: MMD (maximum mean discrepancy), PCA/latent-space similarity, และการเปรียบเทียบ feature importance ระหว่างโมเดลที่ฝึกจากข้อมูลจริงกับสังเคราะห์
ตัวอย่างเชิงปฏิบัติ: หาก KS-test ให้ p-value = 0.12 และ Wasserstein distance = 0.01 ในตัวแปรสำคัญหลายตัว ถือเป็นสัญญาณบวกว่า fidelity ดี แต่ควรตรวจสอบ joint distributions เพิ่มเติม โดยเฉพาะความสัมพันธ์ที่มีนัยสำคัญต่อ downstream task
การวัด Utility (ประสิทธิภาพของโมเดลในงานจริง)
Utility วัดโดยการนำข้อมูลสังเคราะห์ไปใช้ฝึกโมเดลและประเมินผลบนชุดทดสอบจริง (holdout real test set) เพื่อดูผลกระทบต่อประสิทธิภาพของโมเดล เมตริกและวิธีการที่ควรใช้ ได้แก่:
- Downstream task performance: เปรียบเทียบค่า Accuracy, AUC, F1-score, Precision/Recall, RMSE ฯลฯ ของโมเดลที่ฝึกด้วยข้อมูลสังเคราะห์และข้อมูลจริง พร้อมคำนวณ delta (เช่น drop ของ AUC ไม่ควรเกิน 2–5% สำหรับหลายกรณีการใช้งานเชิงธุรกิจ แต่เกณฑ์นี้ขึ้นกับความเสี่ยงและบริบท)
- Cross-validation: ใช้ cross-validation ทั้งในชุดสังเคราะห์และการทดสอบกับชุดจริงเพื่อประเมินความเสถียรของผลลัพธ์และประเมินความแปรปรวน
- Sensitivity analysis: ทดลองปรับขนาดตัวอย่างสังเคราะห์ (oversampling/undersampling), ระดับการปกป้องความเป็นส่วนตัว (เช่นค่า epsilon ใน Differential Privacy), และ hyperparameters ของตัวสร้างข้อมูลสังเคราะห์ เพื่อตรวจสอบว่าประสิทธิภาพเปลี่ยนแปลงอย่างไร
- การเปรียบเทียบ feature importances: ตรวจสอบว่าอันดับความสำคัญของฟีเจอร์ระหว่างโมเดลที่ฝึกด้วยข้อมูลสังเคราะห์และจริงสอดคล้องกันหรือไม่ (เช่นใช้ SHAP, permutation importance)
ตัวอย่าง: หากโมเดลที่ฝึกด้วยข้อมูลสังเคราะห์มี AUC = 0.86 ขณะที่โมเดลจริงให้ AUC = 0.89 การลดลง 0.03 อาจยอมรับได้ในบริบทบางอย่าง แต่ต้องดูผลกระทบต่อธุรกิจและความเสี่ยง
การตรวจสอบและแก้ไข Bias
การตรวจหา bias สำคัญต่อการรับรองความยุติธรรมของระบบ โดยต้องประเมินทั้ง metric ทั่วไปและทำ stress-test กับกลุ่มย่อย (subgroups) ดังนี้:
- Fairness metrics: ประเมินด้วย Demographic Parity difference/ratio, Equalized Odds (ความแตกต่างของ false positive/false negative rates ระหว่างกลุ่ม), Predictive Parity, Disparate Impact เป็นต้น — นิยมใช้เครื่องมืออย่าง IBM AIF360 และ Microsoft Fairlearn เพื่อคำนวณและรายงาน
- Stress-test กับ subgroup เล็ก ๆ: ทดสอบกลุ่มที่มีสัดส่วนน้อย (เช่นประชากรที่เป็นชนกลุ่มน้อย < 5%) เพื่อดูว่าประสิทธิภาพหรือความลำเอียงเปลี่ยนแปลงอย่างมีนัยสำคัญหรือไม่ การตรวจสอบนี้สำคัญเพราะข้อมูลสังเคราะห์อาจทำให้สัญญาณของกลุ่มเล็กหายไปหรือถูกเบี่ยงเบน
- Diagnostic tools: ใช้ confusion matrix แยกตามกลุ่มย่อย, subgroup AUC/F1, calibration plots per-group และ disparity heatmaps เพื่อมองเห็นรูปแบบความไม่เป็นธรรม
- Remediation: หากพบ bias ให้พิจารณา re-sampling, re-weighting, constraint-based synthesis (เช่น conditional generation เพื่อรักษาสัดส่วนกลุ่ม) หรือนโยบาย post-processing ของโมเดล (threshold adjustments) และประเมินผลซ้ำ
ตัวอย่างเชิงตัวเลข: ถ้าพบว่า Demographic Parity difference ระหว่างกลุ่ม A และ B = 0.18 (ค่าสูง) และ false negative rate ของกลุ่ม B สูงกว่ากลุ่ม A ถึง 12% ควรถือว่าเป็นสัญญาณของ bias ที่ต้องแก้ไขก่อนใช้งานในระบบจริง
กรอบการประเมินปฏิบัติการ (Recommended workflow) และข้อจำกัด
แนะนำ workflow สั้น ๆ ดังนี้: (1) กำหนดชุดตัวแปรสำคัญและกรณีการใช้งาน, (2) รันชุดการทดสอบ fidelity (KS, Wasserstein, MMD, pairwise), (3) ฝึกโมเดลบนข้อมูลสังเคราะห์และประเมิน utility บน real holdout set พร้อม cross-validation, (4) ตรวจสอบ fairness และทำ stress-test กับ subgroups, (5) ทำ sensitivity analysis ต่อระดับ DP (epsilon) และขนาดตัวอย่าง, (6) ตัดสินใจรับ/ปฏิเสธหรือขอปรับปรุงจากผู้ขาย
ข้อจำกัดที่ควรตระหนัก: การทดสอบสถิติเช่น KS-test อาจให้ผลบวมหรือผลลบตามขนาดตัวอย่าง, ค่า epsilon ของ DP จะสร้าง trade-off ระหว่าง privacy และ utility, และเมตริกเชิงโมเดลอาจไม่ครอบคลุมทุกความเสี่ยงด้านธุรกิจ การใช้เครื่องมือหลายชนิด (เช่น SDV/Gretel/ctgan, scipy, scikit-learn, AIF360, Fairlearn, SHAP) ร่วมกับการรายงานแบบ multi-metric จะช่วยลดความเสี่ยงจากการพึ่งพาเมตริกเดียว
สรุป: การประเมิน fidelity, utility และ bias ของข้อมูลสังเคราะห์ต้องใช้ชุดเครื่องมือและเมตริกหลากหลาย ควบคู่กับการทดสอบเชิงปฏิบัติ (ฝึกโมเดลจริงและ stress-test กลุ่มย่อย) เพื่อให้มั่นใจว่าชุดข้อมูลจาก SynthExchange สามารถนำไปใช้ในงานจริงได้อย่างปลอดภัย มีประสิทธิภาพ และเป็นธรรม
โมเดลธุรกิจ ราคา และนิเวศน์ของตลาด (สำหรับผู้ขาย ผู้ซื้อ และผู้ตรวจสอบ)
โมเดลธุรกิจและแผนราคา (Pricing)
SynthExchange จะรวมโมเดลหารายได้หลากหลายเพื่อรองรับความต้องการของผู้ซื้อและผู้ขายข้อมูล โดยหลักประกอบด้วย per-dataset licensing, subscription tiers, pay-per-sample และ enterprise licensing พร้อมการแบ่งรายได้ (revenue share) ให้ผู้ให้ข้อมูลต้นทาง ตัวอย่างโครงสร้างราคาสมมติที่ช่วยให้เข้าใจต้นทุนและความคุ้มค่าได้ง่าย:
- Per-dataset licensing (หนึ่งครั้งหรือรายปี) — ชุดข้อมูลขนาดเล็ก (10k–100k ตัวอย่าง) ฿20,000–฿100,000; ชุดกลาง (100k–1M ตัวอย่าง) ฿150,000–฿500,000; ชุดขนาดใหญ่ (>1M ตัวอย่าง) ฿700,000–฿2,500,000 ขึ้นอยู่กับความละเอียดและ DP-guarantee
- Pay-per-sample — สำหรับการทดลองหรือใช้งานแบบจ่ายตามจริง ราคาตัวอย่างสมมติ ฿0.5–฿5.0/ตัวอย่าง ขึ้นกับชนิดข้อมูล (เช่น ข้อความ รูปภาพ เวชระเบียนเชิงโครงสร้าง)
- Subscription tiers (รายเดือน/รายปี) — เพื่อการเข้าถึงชุดข้อมูลและ API ต่อเนื่อง เช่น
- Basic: ฿5,000/เดือน — จำกัดการดาวน์โหลด 50k ตัวอย่าง และเข้าถึงชุดตัวอย่างตัวอย่าง (sampled previews)
- Pro: ฿25,000/เดือน — ดาวน์โหลด 500k ตัวอย่าง, API calls สูงขึ้น, การสนับสนุนระดับธุรกิจ
- Enterprise: เริ่มที่ ฿200,000/เดือน — SLA, การรับรอง DP แบบกำหนดค่า, การติดตั้ง on-premise/VCN และสัญญาใช้งานเฉพาะ
- Enterprise licensing / Custom contracts — สัญญาแบบกำหนดเองรวมค่าปรับแต่งข้อมูล การให้คำปรึกษา privacy, การผสานเข้าระบบภายใน และการรับประกันทางกฎหมาย ราคามักเป็นแบบเริ่มต้นจากหลายแสนถึงล้านบาทต่อโปรเจกต์
สำหรับการแบ่งรายได้กับผู้ให้ข้อมูล (data providers) SynthExchange สามารถนำโมเดลแบ่งรายได้เป็นสัดส่วน เช่น แพลตฟอร์มเก็บคอมมิชชั่น 20–40% และจ่ายคืนให้ผู้ให้ข้อมูล 60–80% ของรายได้สุทธิ (ขึ้นกับระดับความพิเศษหรือการให้สิทธิพิเศษแบบ exclusive) รวมถึงสัญญาจ่ายล่วงหน้า (advance guarantees) เพื่อจูงใจผู้ขายเข้าสู่ระบบ
นิเวศน์ของตลาด (Marketplace Ecosystem)
นิเวศน์ของ SynthExchange ประกอบด้วยผู้มีบทบาทหลัก 4 กลุ่มที่ทำงานร่วมกันเพื่อให้ตลาดเติบโตอย่างยั่งยืน:
- ผู้ให้ข้อมูล (Data Providers) — องค์กรสาธารณสุข โรงพยาบาล ธนาคาร ผู้ให้บริการโทรคมนาคม ผู้ค้าปลีก และหน่วยงานภาครัฐที่มีข้อมูลเชิงปริมาณ ซึ่งสามารถอนุญาตให้แพลตฟอร์มสร้างข้อมูลสังเคราะห์จากแหล่งข้อมูลจริงได้ โดยแลกกับรายได้และการรักษาความเป็นส่วนตัว
- ผู้สร้างข้อมูลสังเคราะห์ (Synthetic Data Creators) — ทีมภายในของ SynthExchange หรือพาร์ทเนอร์ third-party ที่พัฒนาโมเดลในการสร้างข้อมูลสังเคราะห์ (GANs, Diffusion, DP mechanisms) และปรับแต่ง distribution ให้สอดคล้องกับ use-case
- ผู้ตรวจสอบ/รับรอง (Certifiers & Auditors) — องค์กรภายนอกที่ประเมินกระบวนการ DP (เช่น การระบุค่า epsilon, composition analysis, post-processing checks) และออกใบรับรองความเป็นส่วนตัว เพื่อสร้างความเชื่อมั่นให้ผู้ซื้อ โดยบทบาทนี้สำคัญต่อความน่าเชื่อถือและการยอมรับทางกฎหมาย
- ลูกค้า (Startups, SMEs, Enterprises) — ผู้ซื้อที่ต้องการข้อมูลสำหรับฝึกโมเดล ML/AI, พัฒนาผลิตภัณฑ์ หรือทดลองไอเดีย โดยเฉพาะสตาร์ทอัพที่ต้องการลดความเสี่ยงด้าน PII และองค์กรใหญ่ที่ต้องการปฏิบัติตามกฎระเบียบ
กลยุทธ์การตลาดของ SynthExchange จะมุ่งไปยังสองด้านหลัก: ดึงผู้ขาย ด้วยการเสนอสัญญารายได้ที่เป็นธรรม สิทธิประโยชน์ทางการเงิน (advance payments, higher revenue share สำหรับ exclusive datasets) และบริการลดภาระทางกฎหมาย; และ ดึงผู้ซื้อ ด้วยการให้ทดลองฟรี/credit, benchmark datasets ที่มีผลการทดลองที่ชัดเจน, บริการ integration (SDK/API) และการรับประกัน privacy ผ่านการรับรองจาก third-party
บทบาทของ Third-Party Auditors และ DP Certifiers
การมี third-party auditors/DP certifiers เป็นกุญแจสำคัญของตลาดข้อมูลสังเคราะห์ เนื่องจากใบรับรองจากผู้ตรวจสอบอิสระช่วยลดความเสี่ยงทางกฎหมายและเพิ่มความเชื่อมั่นให้ผู้ซื้อ ตัวบทบาทสำคัญได้แก่:
- ดำเนินการตรวจสอบเทคนิค: ตรวจวัดค่า epsilon, delta, composition analysis และยืนยันว่า algorithm ตรงตามมาตรฐาน DP ที่ระบุ
- ทดสอบการย้อนกลับ (re-identification risk) ด้วยวิธีการโจมตีเชิงสถิติและการทดลองจริง เพื่อประเมินว่าข้อมูลสังเคราะห์สามารถนำไปใช้เชื่อมโยงกลับกับ PII ได้หรือไม่
- ออกใบรับรองและคำชี้แจง (signed DP certificate) ที่มีเมทาดาต้าอธิบายขอบเขตการคุ้มครองและข้อจำกัด (เช่น ระบุค่า epsilon, วันที่ตรวจสอบ และช่วงข้อมูลที่ตรวจสอบ)
- ให้บริการซ้ำ/ต่ออายุการตรวจสอบตามรอบเวลา (เช่น ทุก 6–12 เดือน) และจัดทำ audit trail ที่สามารถนำไปใช้ในกระบวนการตรวจสอบภายในหรือการจัดซื้อขององค์กรใหญ่
ค่าใช้จ่ายการตรวจสอบสามารถเป็นอีกแหล่งรายได้ของระบบได้ เช่น ค่าตรวจสอบเบื้องต้น ฿10,000–฿50,000 และการตรวจสอบเชิงลึก/รับรองเชิงองค์กร ฿100,000–฿500,000 ขึ้นกับความซับซ้อนและจำนวนนายจ้าง ผู้ตรวจสอบอิสระยังสามารถนำเสนอระดับการรับรองหลายระดับ (bronze/silver/gold) เพื่อสะท้อนระดับการรับรอง DP และช่วยผู้ซื้อเลือกชุดข้อมูลที่เหมาะสมกับความเสี่ยงทางกฎหมายและความต้องการด้านความเป็นส่วนตัว
โดยสรุป โมเดลธุรกิจของ SynthExchange ผสมผสานการตั้งราคาเชิงยืดหยุ่น (per-dataset, pay-per-sample, subscription, enterprise) กับโครงสร้างการแบ่งรายได้ที่เป็นธรรมเพื่อจูงใจผู้ให้ข้อมูล พร้อมทั้งสร้างระบบนิเวศที่มี third-party certifiers เป็นกลไกสร้างความน่าเชื่อถือ ซึ่งจะช่วยผลักดันการยอมรับข้อมูลสังเคราะห์ในเชิงพาณิชย์ของสตาร์ทอัพและองค์กรไทยได้อย่างยั่งยืน
กฎหมาย ความเสี่ยง และข้อเสนอแนะเชิงนโยบาย (PDPA และแนวปฏิบัติ)
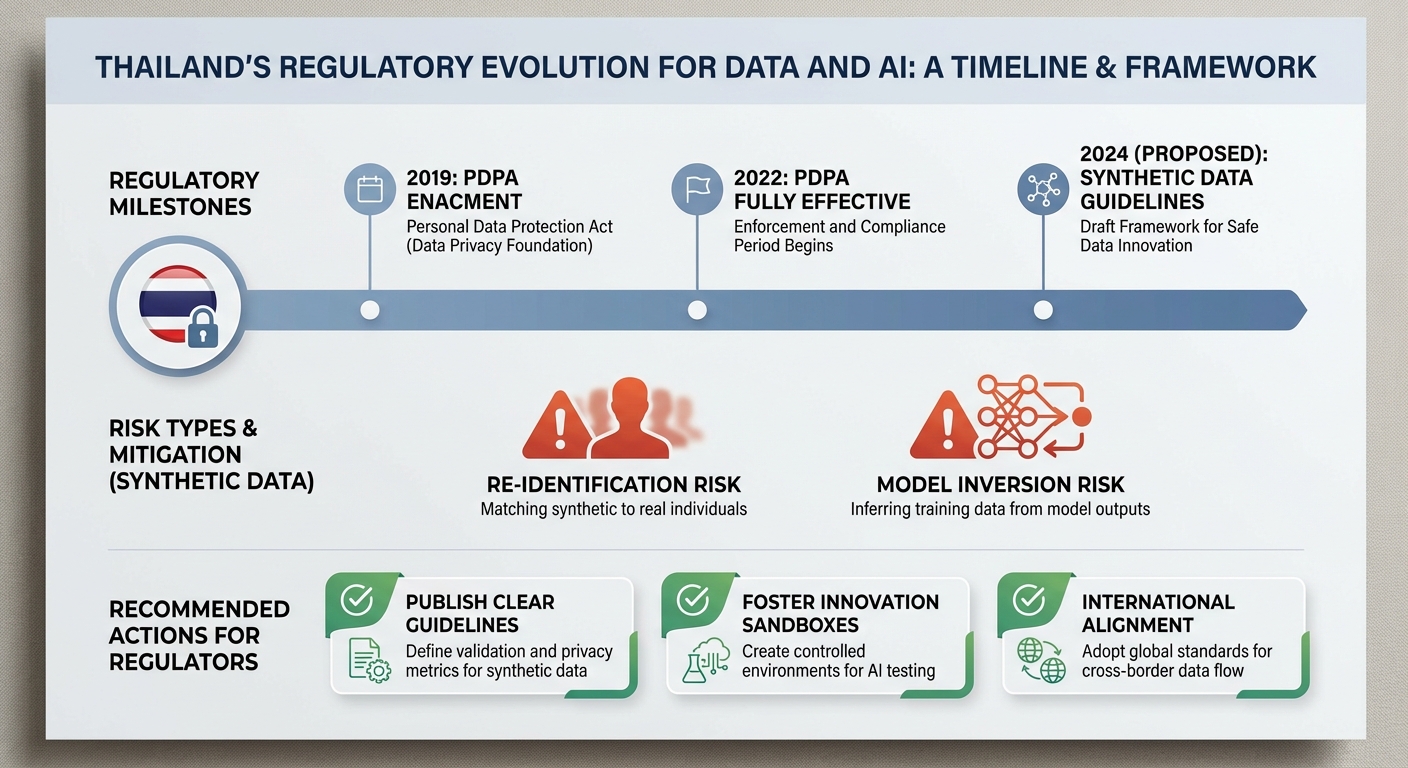
ความสอดคล้องกับ PDPA: ขอบเขต กรณีที่อยู่นอกกฎหมาย และการประเมินความเสี่ยง
ภายใต้พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ของไทย ข้อมูลที่ไม่สามารถระบุตัวบุคคลได้ (non‑personal data) โดยทั่วไปอาจอยู่ภายนอกขอบเขตของกฎหมาย แต่เมื่อข้อมูลถูกสร้างจากชุดข้อมูลจริงหรือมีความสัมพันธ์เชิงสถิติกับข้อมูลบุคคลเดิม ความเสี่ยงของการระบุตัวตน (re‑identification) หรือการสกัดข้อมูลย้อนกลับอาจทำให้ข้อมูลนั้นกลับเข้ามาอยู่ภายใต้ PDPA อีกครั้ง ผู้ให้บริการข้อมูลสังเคราะห์ต้องไม่ถือว่าสถานะ “synthetic” เป็นข้อยกเว้นโดยอัตโนมัติ และต้องมีการประเมินความเสี่ยงอย่างเป็นระบบก่อนการจำหน่ายหรือเผยแพร่
ตัวอย่างเช่น หากชุดข้อมูลสังเคราะห์ถูกสร้างจากข้อมูลสุขภาพหรือข้อมูลการเงินของผู้ใช้จริงและโมเดลสังเคราะห์มีลักษณะจำเพาะสูง (high-fidelity) ตัวแปรบางตัวอาจช่วยให้ตรวจจับบุคคลได้โดยอ้อม ผลักดันให้การใช้ข้อมูลดังกล่าวต้องพิจารณานโยบายการคุ้มครองข้อมูล ลักษณะความรับผิดชอบของผู้ควบคุมข้อมูลและผู้ประมวลผล รวมถึงความจำเป็นในการจัดทำบันทึกการประเมินผลกระทบด้านความเป็นส่วนตัว (Data Protection Impact Assessment - DPIA)
ความเสี่ยงทางเทคนิค: การโจมตีและมาตรการบรรเทา
การใช้ข้อมูลสังเคราะห์ไม่ได้ทำให้ความเสี่ยงด้านความเป็นส่วนตัวหมดไป โดยความเสี่ยงทางเทคนิคที่สำคัญได้แก่
- Model inversion — การใช้ผลลัพธ์หรือพารามิเตอร์ของโมเดลเพื่อสันนิษฐานหรือกู้คืนข้อมูลต้นทาง
- Membership inference — การตรวจสอบว่าเรคอร์ดใดเรคอร์ดหนึ่งเป็นส่วนหนึ่งของข้อมูลฝึกหรือไม่ ซึ่งงานวิจัยหลายชิ้นรายงานอัตราความสำเร็จที่แตกต่างกันตามสถาปัตยกรรมและข้อมูล (ในบางบริบทอาจสูงถึงระดับสองหลักสิบเปอร์เซ็นต์หรือมากกว่า)
- Data leakage จาก pipeline — ข้อมูลตัวอย่างหรือเมตาดาต้าที่เผยแพร่พร้อมชุดสังเคราะห์อาจเปิดช่องให้เกิดการเชื่อมโยงกลับ
มาตรการที่ควรนำมาใช้เพื่อลดความเสี่ยงประกอบด้วย:
- การฝึกด้วย Differential Privacy (DP) — เช่น DP‑SGD พร้อมการตั้งค่า epsilon ที่รัดกุม; แนวปฏิบัติทั่วไปยอมรับว่า epsilon ต่ำกว่า 1 เป็นค่าที่รัดกุมในหลายบริบท ขณะที่ค่าในช่วง 1–10 มักใช้ในงานบางประเภทโดยยอมแลกกับประสิทธิภาพในการเรียนรู้
- การทดสอบเชิงรุก (adversarial testing / red‑team) — จำลองการโจมตีเช่น membership inference และ model inversion โดยทีมภายในหรือบุคคลที่สาม เพื่อประเมินความเสี่ยงจริง
- tight privacy budgets และ accounting — ใช้การจัดการงบประมาณความเป็นส่วนตัวอย่างเคร่งครัด ติดตามการใช้ epsilon ตลอด lifecycle ของโมเดล
- การปิดบังเมตาดาต้าและหลักฐานการเชื่อมโยง — ลดการเปิดเผยรายละเอียดการสร้างสังเคราะห์ เช่น ไม่เผย seed ที่ใช้ หรือพารามิเตอร์ที่อนุมานข้อมูลต้นทางได้
- validation metrics และ privacy risk scoring — พัฒนาชุดดัชนีที่วัดทั้ง utility และ privacy เพื่อใช้เป็นเกณฑ์อนุญาตการปล่อยข้อมูล
ข้อเสนอแนะเชิงนโยบายเพื่อสร้างมาตรฐานและความเชื่อมั่น
เพื่อให้ตลาดข้อมูลสังเคราะห์ในประเทศเติบโตอย่างยั่งยืนโดยไม่ละเมิดสิทธิส่วนบุคคล ข้อเสนอเชิงนโยบายที่ควรพิจารณามีดังนี้
- กำหนดมาตรฐานการรับรอง DP ระดับประเทศ — รัฐควรกำหนดกรอบมาตรฐานทางเทคนิคสำหรับการประกาศว่าชุดข้อมูลเป็น “privacy‑certified” โดยมีการกำหนดเกณฑ์เช่น epsilon thresholds, วิธีการวัดความเสี่ยง และหลักปฏิบัติการตรวจวัดผลกระทบ
- สร้าง sandbox สำหรับการทดลอง — จัดสภาพแวดล้อมควบคุมที่ให้ผู้พัฒนาและผู้ตรวจสอบทดสอบการใช้งานข้อมูลสังเคราะห์ ภายใต้ข้อจำกัดและการดูแลของหน่วยงานกำกับ เพื่อประเมินความเสี่ยงจริงก่อนปล่อยสู่สาธารณะ
- ส่งเสริม third‑party audits และ independent verification — บังคับหรือจูงใจให้มีการตรวจสอบโดยองค์กรอิสระที่สามารถทดสอบการรับรอง DP, การทนทานต่อการโจมตี และการปฏิบัติตาม PDPA
- ข้อกำหนดการเปิดเผยข้อมูลเชิงโปร่งใส — ผู้ให้บริการต้องเผยแพร่ metadata ที่จำเป็น เช่น วิธีการสร้างสังเคราะห์ ระดับ DP ที่ใช้ (epsilon, delta) และผลการทดสอบความเสี่ยง เพื่อให้ผู้ใช้งานสามารถตัดสินใจอย่างมีข้อมูล
- safe harbor และความรับผิดชอบตามเงื่อนไข — พิจารณากรอบที่ให้ความคุ้มครองทางกฎหมายแก่ผู้ให้บริการที่ปฏิบัติตามมาตรฐานรับรอง แต่ต้องไม่เป็นข้ออ้างให้หลีกเลี่ยงความรับผิดชอบหากเกิดการละเมิดจริง
- การสร้างศักยภาพและแนวทางปฏิบัติสำหรับภาคธุรกิจ — ให้ความรู้ ฝึกอบรม และคู่มือปฏิบัติที่ชัดเจนสำหรับสตาร์ทอัพและผู้ซื้อข้อมูล เพื่อยกระดับความเข้าใจเรื่อง DP, risk assessment และการปฏิบัติตาม PDPA
โดยสรุป การพัฒนาตลาดข้อมูลสังเคราะห์เช่น "SynthExchange" จำเป็นต้องมีทั้งมาตรการทางเทคนิคที่เข้มงวดและกรอบนโยบายที่ชัดเจนเพื่อสร้างความเชื่อมั่นต่อผู้ใช้และผู้กำกับดูแล การตั้งมาตรฐานการรับรอง DP ในระดับชาติ การเปิด sandbox สำหรับทดสอบ และการสนับสนุน third‑party audits เป็นหัวใจหลัก ที่จะช่วยให้ประโยชน์จากข้อมูลสังเคราะห์สามารถถูกนำมาใช้จริงโดยไม่บ่อนทำลายสิทธิส่วนบุคคลหรือความน่าเชื่อถือของระบบนิเวศข้อมูลในประเทศ
บทสรุป
SynthExchange เป็นสัญญาณชัดเจนว่าตลาดข้อมูลสังเคราะห์ในไทยกำลังเริ่มเติบโต ซึ่งช่วยให้สตาร์ทอัพทั้งในกลุ่ม FinTech, HealthTech และ Consumer AI เข้าถึงชุดข้อมูลเพื่อฝึกโมเดลได้เร็วขึ้นโดยไม่ต้องใช้ข้อมูลระบุตัวบุคคล (PII) ตรงจุดนี้ช่วยลดความเสี่ยงด้านการละเมิดความเป็นส่วนตัวและภาระการปฏิบัติตามกฎหมาย แต่ไม่อาจละเลยความท้าทายเรื่องสมดุลระหว่าง privacy และ utility — ผู้พัฒนาและผู้ซื้อชุดข้อมูลต้องเห็นการวัดคุณภาพที่ชัดเจน เช่น ค่า epsilon ในการรับรอง Differential Privacy (DP), ตัวชี้วัดความถูกต้องของโมเดล (accuracy, F1) และการประเมินความเที่ยงแท้ของข้อมูลสังเคราะห์เมื่อเทียบกับข้อมูลจริง รายงานอุตสาหกรรมระบุว่าตลาดข้อมูลสังเคราะห์ระดับโลกเติบโตแบบทศนิยมถึงหลักสิบเปอร์เซ็นต์ต่อปี ซึ่งสะท้อนความต้องการที่เพิ่มขึ้นของเครื่องมือฝึก AI ที่ปลอดภัยและรวดเร็ว
เพื่อสร้างความเชื่อมั่นและลดความเสี่ยงจากการละเมิดข้อมูล ผู้เกี่ยวข้องควรยึดกรอบการรับรอง DP ที่ชัดเจน ร่วมกับแนวปฏิบัติ PDPA ของไทย และการตรวจสอบอิสระ (third‑party audits) ที่เปิดเผยผลการทดสอบทั้งด้านความเป็นส่วนตัวและประสิทธิภาพของข้อมูล ตัวอย่างแนวทางปฏิบัติที่แนะนำได้แก่ การกำหนดเกณฑ์การยอมรับของค่า epsilon, การทดสอบโจมตีย้อนกลับ (membership inference) และการออกใบรับรองเชิงมาตรฐานสำหรับชุดข้อมูลสังเคราะห์ในตลาด หากทำได้ ประเทศไทยมีโอกาสพัฒนาเป็นศูนย์กลางข้อมูลสังเคราะห์ในภูมิภาค โดยต้องอาศัยความร่วมมือระหว่างภาครัฐ ผู้ประกอบการ และชุมชนตรวจสอบอิสระเพื่อสร้างมาตรฐานที่สมดุลระหว่างนวัตกรรมและการคุ้มครองสิทธิส่วนบุคคล



