
สตาร์ทอัพไทยเปิดตัว "Neuro‑Compression" โซลูชันใหม่ที่อ้างว่าสามารถแปลงสถาปัตยกรรม Transformer ให้กลายเป็น Spiking‑Neural‑Network (SNN) พร้อมเทคนิค Quantization เชิงลึก ทำให้โมเดล LLM‑light สามารถรันบนสมาร์ทโฟนจริงได้ด้วยประสิทธิภาพด้านพลังงานสูงขึ้น—บริษัทระบุว่าสามารถประหยัดพลังงานได้สูงสุดถึง 5 เท่าเมื่อเทียบกับการรัน Transformer แบบดั้งเดิมบนอุปกรณ์เคลื่อนที่ ข้อดีที่เน้นคือการรันแบบออฟไลน์เพื่อลดแบนด์วิดท์และความเสี่ยงด้านความเป็นส่วนตัว ลดขนาดโมเดลและ latency สำหรับแอปพลิเคชันเรียลไทม์ เช่น ผู้ช่วยเสียงและการประมวลผลภาษาธรรมชาติบนอุปกรณ์
บทความนี้จะพาไปเจาะรายละเอียดตั้งแต่แนวคิดเชิงเทคนิคของการแปลง (mapping) ค่าพารามิเตอร์และฟังก์ชันการทำงานของ Transformer ไปเป็นหน่วยสไปก์ (spiking neurons) เทคนิค quantization ทั้งน้ำหนักและแอกทิเวชัน (รวมถึงกลยุทธ์ mixed‑precision และ low‑bit เช่น 4‑bit/8‑bit) พร้อมผลการทดสอบเชิงปฏิบัติการ (benchmarks) ที่วัดทั้งพลังงานต่อคำตอบ (energy‑per‑inference), latency และความแม่นยำ สุดท้ายมีตัวอย่างสาธิตสำหรับนักพัฒนา—SDK และโค้ดตัวอย่างที่ช่วยให้สามารถทดลองรัน LLM‑light บนมือถือได้ด้วยตัวเอง (พร้อมเกณฑ์การทดสอบเพื่อความสามารถในการเปรียบเทียบ) อ่านต่อเพื่อดูสถิติ ผลการทดสอบเชิงเทคนิค และตัวอย่างการนำไปใช้จริง
บทนำ: ประกาศสำคัญและความหมายของข่าว
บทนำ: ประกาศสำคัญและความหมายของข่าว
สตาร์ทอัพไทยประกาศเปิดตัวผลิตภัณฑ์ใหม่ภายใต้ชื่อ Neuro‑Compression ซึ่งทางบริษัทระบุว่าเป็นเทคโนโลยีที่สามารถ แปลงสถาปัตยกรรม Transformer ให้เป็น Spiking‑Neural Networks (SNN) ร่วมกับเทคนิค Quantization เพื่อให้สามารถรันโมเดลภาษาขนาดเล็กหรือที่เรียกว่า LLM‑light บนสมาร์ทโฟนและอุปกรณ์ edge ได้อย่างมีประสิทธิภาพ โดยคำอ้างหลักจากผู้พัฒนาคือการลดการใช้พลังงานได้ถึง 5 เท่า เมื่อเทียบกับการรันโมเดลบนสถาปัตยกรรมปกติในสภาพแวดล้อมเดียวกัน
เชิงเทคนิค แนวทางนี้ผสานหลักการของ SNN ซึ่งเป็นเครือข่ายประสาทเทียมเชิงเหตุการณ์ (event‑driven) ที่ได้แรงบันดาลใจจากการทำงานของสมองกับการลดความละเอียดตัวเลขด้วย Quantization ทำให้การคำนวณและการถ่ายโอนข้อมูลมีความเบาและประหยัดพลังงานมากขึ้น ผลลัพธ์ที่นำเสนอคือความเป็นไปได้ในการใช้งาน LLM ที่มีขนาดเล็กถึงระดับ tens‑to‑hundreds of millions parameters บนมือถือโดยไม่ต้องพึ่งพาเซิร์ฟเวอร์คลาวด์อย่างต่อเนื่อง ซึ่งมีความหมายเชิงธุรกิจทั้งด้านประสิทธิภาพต้นทุน ความเป็นส่วนตัวของข้อมูล และความหน่วงต่ำ (low latency)
สำหรับผู้ประกอบการและกลุ่มเป้าหมายทางธุรกิจ ข้อเสนอของ Neuro‑Compression เปิดช่องทางในการย้ายเวิร์กโฟลว์ AI จากคลาวด์มายัง edge device ได้จริง เช่น แอปพลิเคชันฝ่ายลูกค้าสัมพันธ์ที่ต้องตอบโต้ทันที ระบบแปลภาษาแบบออฟไลน์ เครื่องมือช่วยเขียนบนมือถือ อุปกรณ์ IoT และโซลูชัน AR/VR ที่ต้องการประสิทธิภาพพลังงานสูง นอกจากนี้ การลดการพึ่งพาเซิร์ฟเวอร์ยังช่วยลดต้นทุนการดำเนินงานและความเสี่ยงด้านข้อมูลที่ต้องส่งออกไปนอกอุปกรณ์ของผู้ใช้
บทความฉบับนี้มีบทบาทสองด้านคือ ข่าว — รายงานการเปิดตัวและความหมายต่ออุตสาหกรรม — และ tutorial — อธิบายแนวคิดเชิงเทคนิค การทดสอบสมรรถนะ ตัวอย่างการประยุกต์ใช้งาน และแนวทางการนำไปใช้เชิงปฏิบัติ ผู้อ่านจะได้รับทั้งภาพรวมเชิงธุรกิจ ข้อมูลเชิงเทคนิคพื้นฐาน และแนวทางปฏิบัติสำหรับการประเมินหรือทดลอง Neuro‑Compression ในบริบทของตนเอง โดยเนื้อหาหลักจะแบ่งเป็นหัวข้อย่อยดังนี้
- ภาพรวมเทคโนโลยี: อธิบายหลักการ SNN และ Quantization รวมถึงการแปลง Transformer
- ผลการทดสอบเชิงปริมาณ: เบนช์มาร์กพลังงาน ความหน่วง และความแม่นยำเทียบกับ baseline
- กรณีธุรกิจและกลุ่มเป้าหมาย: ตัวอย่างการประยุกต์และโมเดลธุรกิจที่เหมาะสม
- Tutorial ปฏิบัติการ: แนวทางติดตั้ง รัน LLM‑light บนมือถือ และปัญหาที่ต้องระวัง
- ขอบเขตและข้อจำกัด: สิ่งที่ Neuro‑Compression ยังทำไม่ได้และข้อพิจารณาด้านความปลอดภัย
หลักการทางเทคนิค: Neuro‑Compression คืออะไร
หลักการทางเทคนิค: Neuro‑Compression คืออะไร
Neuro‑Compression สามารถนิยามได้ว่าเป็นกรอบวิศวกรรมที่ผสานระหว่าง Spiking Neural Network (SNN) กับกลยุทธ์การลดความละเอียดเชิงตัวเลข (Quantization) เพื่อแปลงโมเดลสถาปัตยกรรม Transformer ซึ่งเดิมเป็น Artificial Neural Network (ANN) แบบต่อเนื่อง ให้เป็นรูปแบบ event‑driven ที่เหมาะสำหรับอุปกรณ์พกพาและฮาร์ดแวร์แบบ neuromorphic ผลลัพธ์ที่ต้องการคือโมเดลขนาดเล็กลง ใช้พลังงานน้อยลง และยังคงประสิทธิภาพที่ยอมรับได้ — ตัวอย่างเช่นสตาร์ทอัพที่อ้างว่ารัน LLM‑light บนมือถือประหยัดพลังงานได้ประมาณ 5 เท่า เมื่อเทียบกับเวอร์ชัน ANN เต็มรูปแบบ
หลักการสำคัญของ SNN ที่ Neuro‑Compression นำมาใช้งานประกอบด้วยการแทนค่าด้วย spike timing และการคำนวณแบบ event‑driven ซึ่งต่างจาก ANN ที่ใช้ออปเพอเรชันต่อเนื่อง โดยสรุป:
- Spike encoding: ข้อมูลเชิงต่อเนื่อง (เช่น embeddings หรือ activation ของ transformer) ถูกแปลงเป็น spike trains ผ่านวิธีการต่างๆ เช่น rate coding (จำนวน spikes ต่อช่วงเวลา), temporal/latency coding (เวลาในการเกิด spike ครั้งแรกสื่อความหมาย), หรือ population coding. ตัวอย่างวิธีที่ใช้จริงได้แก่ Poisson encoding, time‑to‑first‑spike และ rank‑order coding.
- Event‑driven computation: หน่วยประมวลผล SNN ทำงานเมื่อเกิด spike เท่านั้น (sparse events) ซึ่งให้ข้อได้เปรียบเรื่องพลังงานเมื่อข้อมูลมีความหนาแน่นต่ำหรือเมื่อต้องการประมวลผลแบบ asynchronous บนฮาร์ดแวร์ที่รองรับ.
- Neuron models: ใช้แบบจำลองเมมเบรนเช่น Integrate‑and‑Fire (IF) หรือ Leaky Integrate‑and‑Fire (LIF) เพื่อสะสม input เป็น potential และปล่อย spike เมื่อทะลุ threshold — พฤติกรรมนี้ทำให้สามารถแม็ปการคำนวณเชิงเส้นของ ANN ไปยังโดเมนเชิงเวลาได้
การผสาน Quantization ทำให้ Neuro‑Compression ลดค่าใช้จ่ายด้านหน่วยความจำและแบนด์วิดท์การคำนวน ทั้งในรูปแบบของการทำ weight quantization และ activation quantization โดยระดับที่ใช้ในงานจริงอาจอยู่ระหว่าง 8‑bit down to ternary/binary ขึ้นกับข้อจำกัดของฮาร์ดแวร์ เทคนิคสำคัญได้แก่:
- Quantization‑aware training (QAT): ฝึกแบบคำนึงถึงการปัดตัวเลข เพื่อให้โมเดลเรียนรู้ความทนทานต่อการลดความละเอียด
- Post‑training quantization (PTQ) with calibration: ใช้ชุดข้อมูลตัวอย่างเพื่อ calibrate dynamic range ของ weight/activation หลังการเทรน
- Mixed precision: ให้ความละเอียดสูงกับชั้นที่สำคัญ (เช่นชั้น attention หรือ layernorm) และลดบิตในชั้นที่ทนได้ เพื่อรักษาความแม่นยำโดยรวม
เชิงปฏิบัติการมักเป็นพายไลน์หลายขั้นตอน เช่น: (1) pretrain/finetune Transformer ในโดเมน ANN, (2) บีบสเกลค่าและแปลง BN/LayerNorm เป็น bias/scale แบบคงที่, (3) quantize weights และเตรียม activation quantization, (4) แปลง activation เป็น spike representation และ (5) fine‑tune SNN ด้วยเทคนิคที่ช่วยฝ่าจุดไม่ต่อเนื่องของ spike เช่น surrogate gradients เพื่อเรียกคืนความแม่นยำ
หนึ่งในปัญหาทางเทคนิคที่ท้าทายที่สุดคือการแม็ปองค์ประกอบเฉพาะของ Transformer — โดยเฉพาะ attention และ softmax — ให้กลายเป็นเวิร์กโฟลว์ที่ใช้ spikes ได้
- ปัญหา softmax: Softmax เป็นฟังก์ชัน normalization ทางคณิตศาสตร์ที่ต้องการการคำนวณแบบต่อเนื่อง (exponential และการหารด้วยผลรวม) ซึ่งตรงกันข้ามกับพฤติกรรมไดนามิกของ spikes. วิธีแก้รวมถึงการประมาณค่า softmax ด้วยกลไกท้องถิ่น เช่น divisive normalization โดยใช้ lateral inhibition, winner‑take‑all (WTA) networks, หรือลด softmax เป็นการคัดเลือกโดยลำดับเวลา (time‑to‑first‑spike) ที่แปลง logits เป็นลำดับการยิง
- แม็ป attention เป็น event routing: แทนที่จะคำนวณ dot‑product แบบต่อเนื่อง บางงานใช้ temporal coding เพื่อให้ค่าดอทโปรดักต์แสดงเป็นการปรับค่า membrane potential ผ่านชุด spikes ที่มาถึงช่วงเวลาต่างกัน แล้วใช้กลไกการแข่ง/แยก (competition/gating) บน SNN เพื่อเลือกรูปแบบการแจกจ่ายข้อมูล (sparse attention). นอกจากนี้ยังมีการใช้ kernel/low‑rank approximations ของ attention เพื่อเปลี่ยนการคำนวณให้เป็นชุดของคอนโวลูชันหรือการสะสมแบบ local ที่เหมาะแก่การประมวลผลด้วย spikes
- เทคนิคเชิงปฏิบัติ: การแม็ปมักใช้การรวมกันของ: (a) แปลง ReLU→firing‑rate โดยปรับสเกลและ threshold, (b) ใช้ surrogate gradient ในการฝึก SNN เพื่อให้ gradient flow ผ่านการเกิด/ไม่เกิด spike (เช่นใช้ฟังก์ชัน sigmoid หรือ piecewise linear เป็น surrogate), (c) threshold balancing และ time‑step scheduling เพื่อให้จำนวน time‑steps ต่ำสุดแต่ให้สัญญาณพอเพียง
เพื่อให้เห็นภาพเชิงตัวอย่าง: สมมติ Transformer block ที่มี multi‑head attention — ใน Neuro‑Compression อาจทำการ:
- Quantize weights ของ linear projections (Q, K, V) เป็น 8‑bit หรือ 4‑bit (ขึ้นกับ tolerances)
- Encode Q/K/V เป็น spike trains ด้วย latency coding เพื่อรักษาอันดับของความสำคัญ
- ใช้ event‑driven accumulation เพื่อคำนวณ dot‑product แบบเชิงเวลา และแทน softmax ด้วย local competition หรือ normalization บน membrane potential
- Fine‑tune ทั้งระบบด้วย surrogate gradients เพื่อชดเชยข้อผิดพลาดจากการประมาณและ quantization
สรุปสั้นๆ ว่า Neuro‑Compression เป็นการประสานระหว่างข้อดีของ SNN ในการคำนวณแบบเหตุการณ์และความประหยัดพลังงาน กับการลดขนาดเชิงตัวเลขผ่าน quantization — แต่ต้องอาศัยเทคนิคเชิงวิศวกรรมหลายชุด เช่น ANN‑to‑SNN conversion, temporal encoding, surrogate gradient training, threshold calibration และ approximation ของ softmax/attention เพื่อให้ได้ทั้งประสิทธิภาพการทำงานและความประหยัดพลังงานที่ต้องการ
กระบวนการแปลง Transformer เป็น Spiking‑NN: ขั้นตอนและข้อพิจารณา
ภาพรวมกระบวนการแปลง Transformer (ANN) เป็น Spiking‑NN สำหรับ LLM‑light
การแปลงโมเดล Transformer ขนาดเล็กให้ทำงานบนสถาปัตยกรรม Spiking Neural Network (SNN) บนอุปกรณ์พกพา เป็นกระบวนการหลายขั้นตอนที่ผสมผสานการฝึกแบบดั้งเดิมของ ANN, การกลั่นความรู้ (distillation), การแม็ปสถาปัตยกรรม, และการฝึกด้วย surrogate gradients เพื่อลดช่องว่างฟังก์ชันระหว่างฟังก์ชันต่อเนื่องของ ANN กับการตอบสนองเป็นสไปก์ของ SNN กระบวนการนี้โดยทั่วไปสามารถสรุปเป็นสายงานหลักได้แก่: pretraining ของ ANN, distillation เป็นครู‑นักเรียน, ANN‑to‑SNN mapping (การแทนที่ชั้นและฟังก์ชัน), และการ fine‑tune ด้วย surrogate gradient บนหน้าต่างเวลา (temporal window) ที่กำหนด
Pipeline การฝึกและแปลง (Flow ของระบบ)
- 1. Pretraining ANN (Teacher) — ฝึก Transformer/LLM‑light บนชุดข้อมูลที่ต้องการจนได้ความแม่นยำและพฤติกรรมเป้าหมาย (เช่น perplexity, task accuracy)
- 2. Distillation — สร้าง student SNN (หรือ ANN ที่ออกแบบให้แม็ปง่ายเป็น SNN) โดยใช้ loss ผสม: KL‑divergence บน logits, MSE บน hidden representations, และ spike‑rate matching
- 3. ANN‑to‑SNN Mapping — ลบ/แทนชั้นไม่รองรับ, แม็ป activation → LIF/IF, fold normalization และ quantize weights
- 4. Surrogate Gradient Fine‑tuning — ฝึก SNN ด้วย surrogate gradients และ BPTT (มักใช้ truncation) บน temporal window ที่เลือก
- 5. Quantization & Compression — ผนวก quantization (เช่น 8/4/2 bit) และ pruning เพื่อให้รันบนฮาร์ดแวร์มือถือ พร้อมทดสอบ latency / energy / accuracy
รายละเอียดเชิงเทคนิค: ขั้นตอนแปลงจริง
ตัดชั้นที่ไม่รองรับ — Transformer มีชิ้นส่วนที่ต้องพิจารณาเป็นพิเศษ เช่น Softmax attention, LayerNorm, GELU, residual connections และบางฟังก์ชันที่พึ่งพา floating‑point อย่างแรง ขั้นแรกจำเป็นต้องกำหนดว่าจะ รักษา (e.g., residuals), approximate (เช่น layernorm → affine fold) หรือ ลบ/แทนที่ (เช่น GELU → linearized activation หรือ surrogate threshold function) ตัวอย่างการตัด/แทนที่: เปลี่ยน GELU เป็น linear + bias แล้วแม็ปเป็น LIF หน่วงเวลา
แม็ปฟังก์ชัน (ANN → SNN) — แม็ปชั้น Linear/MatMul เป็น synaptic weights; activation ถูกแทนด้วย Neuron Model เช่น Leaky Integrate‑and‑Fire (LIF) หรือ Integrate‑and‑Fire (IF). เทคนิคสำคัญคือการปรับสเกล (weight & bias folding) เพื่อให้ค่า membrane potential ตอบสนองต่ออิมพัลส์ทางเดียวกับ activation ของ ANN ในหน่วยเวลา
การจัดการ Softmax/Normalization และ Attention
Softmax และ LayerNorm เป็นอุปสรรคหลัก เพราะ Softmax เป็นฟังก์ชัน non‑local และต้องใช้ค่า floating‑point ต่อเนื่อง เทคนิคที่ใช้ได้จริงในการแปลงมีดังนี้:
- Approximate Softmax: ใช้ logit‑based distillation โดยให้ student SNN พยายามจับสัดส่วนความน่าจะเป็นผ่าน spike‑rate distribution แทนการคำนวณ softmax แบบเต็มรูปแบบ หรือใช้ softmax แบบผันแปรเป็น argmax/attention‑routing ที่แม็ปเป็นการเลือก token ที่มี firing rate สูงสุด
- Linearized Attention: แทนที่ scaled dot‑product ด้วย kernel feature maps (เช่น FAVOR, linear attention) ที่สามารถคำนวณเป็นผลคูณเชิงเส้นและแม็ปเป็น synaptic summation ภายในหน้าต่างเวลา
- LayerNorm Folding: ผนวก (fold) ค่า mean/variance เข้ากับพารามิเตอร์ของ linear layer ก่อนการแม็ป หรือแทนด้วย per‑channel affine scaling ที่ทำได้ด้วย synaptic gain และ bias ใน neuron model
Surrogate Gradient Training และ BPTT: ข้อพิจารณา
เนื่องจากสไปก์เป็นฟังก์ชันไม่ต่อเนื่อง การคำนวณ gradient โดยตรงเป็นไปไม่ได้ จึงต้องใช้ surrogate gradients (เช่น sigmoid, piecewise linear, fast‑sigmoid) แทนเดลต้าเชิงอนุพันธ์จริง ในการฝึก SNN รูปแบบการส่งกลับ gradient ที่ใช้กันมีสองแบบหลัก:
- BPTT (Backpropagation Through Time): ใช้จำลอง dynamics ของ membrane potential ตลอด temporal window และ backpropagate ผ่านเวลาทุก timestep — แม่นยำแต่ใช้หน่วยความจำสูง
- Truncated BPTT / Event‑driven BPTT: ตัดหน้าต่างเวลาเป็นช่วงสั้นเพื่อลด memory footprint หรือ update เฉพาะเมื่อเกิด spikes เพื่อลดค่าใช้จ่าย
ข้อเสนอแนะเชิงปฏิบัติ: ใช้ truncated BPTT (e.g., 20–100 timesteps) ร่วมกับ surrogate gradient แบบ piecewise-linear เพื่อ trade‑off ระหว่างความแม่นยำกับหน่วยความจำ และใช้ gradient checkpointing / activation recomputation เมื่อต้องฝึกบน GPU ทั่วไป
Temporal Windowing, Rate Coding vs Temporal Coding และผลต่อ Latency
การกำหนดความยาว temporal window (T) เป็นหนึ่งในการตัดสินใจเชิงออกแบบที่มีผลต่อทั้งความแม่นยำและ latency:
- Rate Coding: ข้อมูลถูกเข้ารหัสเป็นความถี่ของ spikes ในช่วงเวลา T — มั่นคงต่อเสียงรบกวนและง่ายต่อการฝึก แต่ต้อง T ยาวพอที่จะสะสมสถิติของอัตราการยิง จึงเพิ่ม latency และพลังงาน (มาก spikes) เหมาะกับการใช้งานที่ต้องการความเสถียรและฮาร์ดแวร์รองรับ spike throughput สูง
- Temporal (Latency) Coding: ข้อมูลถูกเข้ารหัสเป็นเวลาการมาถึงของสไปก์ (earlier = higher activation) — ให้ latency ต่ำและใช้สไปก์น้อย แต่การฝึกยากกว่า ต้องความแม่นยำของสัญญาณเวลาและมักต้องฮาร์ดแวร์ที่รองรับ timing precision
- Hybrid: ใช้วิธี rate coding ในบางชั้นและ temporal coding ในชั้นบน (attention/selection) เพื่อชดเชยปัญหา latency และความเสถียร
ตัวอย่างการกำหนดค่าเชิงปฏิบัติ: สำหรับ LLM‑light บนมือถือ อาจเลือก T = 16–64 timesteps กับ rate coding เพื่อตรงกับข้อจำกัด latency (เช่น ตอบสนองภายใน 100–300 ms) และสามารถลดพลังงานได้หลายเท่าหากเทียบกับ ANN แบบเต็มรูปแบบ — ในงานเชิงพาณิชย์ รายงานจะแสดงการลดพลังงานถึง ~5x ภายใต้ชุดการทดลองเฉพาะ
ตัวอย่าง Pseudocode (flow ฝึกแบบย่อ)
- 1. Train teacher ANN: train(Transformer, data) → teacher
- 2. Initialize student network as SNN_arch mapped from Transformer (fold BN, replace activations with LIF)
- 3. For epoch in epochs:
- For batch in data:
- ann_logits = teacher.forward(batch)
- snn_spikes = student.forward_spiking(batch, T) // simulate over T timesteps
- loss = KL(soft(ann_logits), spike_rate_to_prob(snn_spikes)) + α * MSE(hidden_teacher, hidden_student_rates)
- Compute surrogate gradients w.r.t membrane potentials
- Backpropagate through time (truncated) and update weights (with quantization constraints)
- For batch in data:
- 4. Post‑train: apply weight quantization & pruning; validate latency/energy/accuracy
ข้อพิจารณาด้านวิศวกรรมและธุรกิจ
ในการนำไปใช้งานจริงสำหรับมือถือ ต้องคำนึงถึง compatibility กับไดรเวอร์ฮาร์ดแวร์ (event‑driven accelerators), ค่า latency ที่ยอมรับได้ของแอปพลิเคชัน (interactive vs background), และต้นทุนการพัฒนา (ฝึก SNN มักต้องเวลามากขึ้นและ tuning เยอะ) ทางเลือกทั่วไปสำหรับสตาร์ทอัพคือใช้ pipeline hybrid: pretrain ANN ขนาดกะทัดรัด → distill เป็น SNN ด้วย truncated BPTT และ surrogate gradient → quantize เป็น INT8/4 สำหรับ synaptic weights → deploy บน NPU/ISP ที่รองรับ event processing เพื่อให้ได้ข้อได้เปรียบด้านพลังงาน ~5x ตามที่รายงาน
สรุป: กระบวนการแปลง Transformer เป็น SNN เป็นงานที่รวมทั้งการออกแบบเชิงสถาปัตยกรรม, การประมาณเชิงคณิตศาสตร์ของ softmax/normalization, และเทคนิคการฝึกพิเศษ (surrogate gradients, truncated BPTT) พร้อมการตัดสินใจเชิงนโยบายระหว่าง rate vs temporal coding ที่มีผลต่อ latency และพลังงาน การจัด pipeline ที่เป็นระบบ (pretrain → distill → map → fine‑tune → quantize) เป็นกุญแจสำคัญในการนำ LLM‑light บนมือถือสู่การใช้งานเชิงพาณิชย์
Quantization และการลดขนาดโมเดลสำหรับการรันบนอุปกรณ์ Edge

ภาพรวมเทคนิค Quantization ที่ใช้ใน Neuro‑Compression
ในบริบทของ Neuro‑Compression ซึ่งแปลง Transformer เป็น Spiking‑NN พร้อมการทำ Quantization เป้าหมายหลักคือการลดขนาดโมเดลและความต้องการคำนวณเพื่อให้รันบนมือถือหรืออุปกรณ์ Edge ได้อย่างมีประสิทธิภาพ โดยทั่วไปเทคนิคที่ใช้อยู่ในกลุ่มนี้ได้แก่ post‑training quantization (PTQ), quantization‑aware training (QAT), การใช้ mixed‑precision, การบีบอัดน้ำหนัก/activation ในระดับบิต (per‑channel, per‑tensor), รวมถึงการผสานกับการ prune และการทำ Huffman coding เพื่อลดขนาดข้อมูลย้อนหลัง
PTQ vs QAT: ข้อดีข้อเสียและผลต่อความแม่นยำ
PTQ เป็นวิธีที่เร็วและไม่ต้องฝึกซ้ำ (retraining) เหมาะเมื่อต้องการ deploy อย่างรวดเร็ว: ตัวอย่างเช่นการ quantize เป็น 8‑bit มักลดขนาดได้ประมาณ 4 เท่าและมักให้ผลกระทบต่อ accuracy น้อย (<1–2% ในงาน LM ทั่วไป) หากมีการ calibration range ที่เหมาะสม อย่างไรก็ตามเมื่อขยับลงสู่ 4‑bit, 2‑bit หรือ ternary ความสูญเสียความแม่นยำจะเพิ่มขึ้นอย่างมีนัยสำคัญ โดยเฉพาะกับเลเยอร์ที่ไวต่อการเปลี่ยนแปลงของ dynamic range
QAT จะจำลองผลกระทบของ quantization ระหว่างการฝึก ทำให้โมเดลปรับตัวและรักษาความแม่นยำได้ดีกว่าในบิตต่ำ QAT มักจำเป็นเมื่อเป้าหมายคือ 4‑bit หรือต่ำกว่า: งานวิจัยหลายชิ้นแสดงว่า QAT สำหรับ 4‑bit สามารถทำให้ความแม่นยำใกล้เคียงกับ FP16 (degradation <2%) และสำหรับ 2‑bit/ternary ต้องใช้ QAT ร่วมกับเทคนิคเสริม เช่น distillation หรือ weight clipping เพื่อให้ผลลัพธ์ใช้งานได้จริง
การเลือก Bit‑width และกลยุทธ์ Mixed‑Precision
- 8‑bit (INT8): ทางเลือกมาตรฐานบนมือถือและ NPU — ลดขนาด ~4x, เหมาะกับการใช้ PTQ หรือ QAT ขึ้นกับความต้องการความแม่นยำ
- 4‑bit: ให้การลดขนาด ~8x แต่แนะนำให้ใช้ QAT และรักษาเลเยอร์สำคัญไว้ที่ higher precision (เช่น embedding, first/last layer, layer‑norm และ projection)
- 2‑bit / Ternary: สำหรับการบีบอัดสูงสุด (ลดขนาด 12–16x หรือมากกว่า) แต่ต้องการ QAT, distillation และปรับสถาปัตยกรรม — เหมาะสำหรับ SNN mapping ที่เน้น spike events
- Mixed‑precision: กลยุทธ์ที่แนะนำคือเก็บเลเยอร์หรือพารามิเตอร์ที่มีความไวสูงที่ 8/16‑bit ขณะที่เปลี่ยนส่วนที่ทนทานต่อ quantization เป็น 4/2‑bit ซึ่งช่วยลด trade‑off ระหว่างขนาดและความแม่นยำ ตัวอย่างเช่น attention Q/K/V อาจเก็บที่ 8‑bit ขณะที่ feed‑forward weights ลดเป็น 4‑bit
การบีบอัดน้ำหนัก/Activation, Pruning และ Huffman Coding
การบีบอัดไม่ได้จำกัดเฉพาะการลดบิต แต่ยังรวมถึงการลดพารามิเตอร์ที่ไม่สำคัญ (pruning) และการเข้ารหัสขั้นสูงเพื่อบีบอัดบิตต่อไป:
- Pruning: แบบ unstructured สามารถให้ sparsity สูง (เช่น 70–90%) แต่ต้องการการสนับสนุน kernel แบบ sparse เพื่อให้ได้ speedup จริงบนอุปกรณ์ ส่วน structured pruning (เช่นตัด heads หรือ channels) มักทำให้ได้ผลลด latency บนฮาร์ดแวร์ปัจจุบันง่ายกว่า
- Huffman Coding: ใช้เข้ารหัสผลลัพธ์จาก quantized weights เพื่อบีบอัดต่อ — ในหลายกรณีสามารถเพิ่มอัตราการบีบอัดได้อีก 10–30% โดยไม่มีผลต่อ inference (เป็นการบีบอัดสถิติต่อข้อมูล)
- การผสาน quantization + pruning + Huffman มักให้ผลรวมที่ดีกว่า: ตัวอย่างเช่น 8‑bit + pruning 60% + Huffman อาจลดขนาดโมเดลรวมได้มากกว่า 6–8 เท่าเมื่อเทียบกับ FP32
ความสัมพันธ์ระหว่าง Quantization กับ Spiking‑NN
เมื่อแปลง Transformer เป็น Spiking‑NN มีความสอดคล้องธรรมชาติกับ quantization: SNN ทำงานด้วย spike events ซึ่งเป็นสัญญาณเชิงจำนวนน้อยและสุ่ม การแมปน้ำหนักที่เป็น integer หรือ ternary เข้ากับหน้าเรียก spike ช่วยให้การคำนวณเปลี่ยนจาก multiply‑accumulate (MAC) แบบทศนิยมเป็นการสะสมเหตุการณ์หรือการคูณด้วยค่าเล็ก ๆ เท่านั้น ส่งผลให้การใช้พลังงานลดลงมาก
ในทางปฏิบัติ ต้องพิจารณา:
- การแทนค่า membrane potential และ threshold เป็น integer เพื่อให้การคำนวณเป็น integer ops ลดความซับซ้อนของฮาร์ดแวร์
- การใช้ low‑bit weights (2‑bit / ternary) สอดคล้องกับการผลิต spike ที่มี amplitude น้อย ทำให้จำนวน event ลดลงและลดพลังงานที่ใช้ในการสื่อสาร
- trade‑off ระหว่าง temporal resolution (จำนวน time‑steps ของ SNN) กับ throughput — เพิ่ม time‑steps เพื่อเก็บข้อมูลเชิงละเอียดจะเพิ่ม latency แม้จะลดพลังงานต่อเหตุการณ์
ผลกระทบต่อ Latency และการใช้พลังงานบน CPU / GPU / NPU
ผลกระทบของ quantization ต่อ latency และพลังงานขึ้นกับฮาร์ดแวร์และการสนับสนุนของสแต็ก:
- CPU: การใช้ INT8 บนซีพียูแบบ vectorized (SIMD) มักลดพลังงานและเร่งความเร็วได้ 2–4x เทียบกับ FP32 อย่างไรก็ตาม การใช้บิตต่ำกว่า 8‑bit อาจต้องมีการ emulate (เช่น pack/unpack) ซึ่งทำให้ latency เพิ่มขึ้นหากไม่มีไลบรารีและ instructions ที่เหมาะสม
- GPU: GPU สมัยใหม่มีเทนเซอร์คอร์ที่รองรับ INT8/INT4 ซึ่งให้ speedup ได้มาก (3–10x) แต่การใช้ 2‑bit หรือ ternary บน GPU ที่ไม่มีฮาร์ดแวร์รองรับจะนำไปสู่การจำลองที่ช้าลง ดังนั้นการออกแบบต้องสอดคล้องกับ instruction set
- NPU / Edge‑Accelerator: NPU ที่ออกแบบมาสำหรับ integer ops หรือ event‑driven SNN สามารถให้ประหยัดพลังงานสูงสุด — ในหลายกรณี energy per inference อาจลดได้ถึง 5–10x เมื่อเทียบกับ FP32 บน CPU/GPU (ตัวอย่างเช่นงานที่อ้างถึงการประหยัดพลังงาน 5x บนมือถือหลังการเปลี่ยนเป็น SNN + quantization)
- อย่างไรก็ดี mixed‑precision อาจก่อ overhead ของการ convert ระหว่าง precision หากซอฟต์แวร์ไม่จัดการอย่างเหมาะสม — ควรออกแบบ pipeline เพื่อหลีกเลี่ยงการแปลงบ่อยครั้งที่เพิ่ม latency
คำแนะนำเชิงปฏิบัติสำหรับการนำไปใช้บนอุปกรณ์ Edge
- เริ่มจาก PTQ ที่ระดับ 8‑bit เพื่อประเมินผลกระทบต่อ accuracy อย่างรวดเร็ว หากความแม่นยำเพียงพอให้ใช้วิธีนี้เพื่อลดเวลา deploy
- เมื่อมุ่งสู่ 4‑bit หรือต่ำกว่า ให้ใช้ QAT พร้อมกับ distillation และระมัดระวังการรักษาเลเยอร์สำคัญด้วย precision สูงขึ้น (mixed‑precision)
- ผสาน pruning แบบ structured เพื่อให้เกิด speedup จริงบน NPU/CPU และตามด้วย Huffman coding สำหรับลดขนาด storage และ bandwidth
- สำหรับการแปลงเป็น SNN ให้ออกแบบ representation ของ spikes และค่า threshold ในรูปแบบ integer และทดสอบ trade‑off ระหว่างจำนวน time‑steps กับ latency เพื่อให้ได้ throughput และพลังงานที่ต้องการ
- ตรวจสอบการสนับสนุนฮาร์ดแวร์ (INT8/INT4/bitcast support, sparse kernel) และปรับ pipeline ให้ลดการแปลง precision ที่ไม่จำเป็น
สรุปคือ Neuro‑Compression ต้องผสานระหว่างเทคนิคหลายชั้น—QAT/PTQ, mixed‑precision, pruning และ compression coding—เพื่อให้ได้โมเดล LLM‑light ที่รันบนมือถือได้จริง ทั้งในแง่ของขนาด ความแม่นยำ เวลาแฝง และการใช้พลังงาน โดยเฉพาะเมื่อจับคู่กับสถาปัตยกรรม SNN ที่เน้น event‑driven computation จะสามารถเพิ่มประสิทธิภาพด้านพลังงานได้อย่างมีนัยสำคัญ
ผลการทดสอบจริง: Benchmark, พลังงาน, Latency และคุณภาพคำตอบ
ผลการทดสอบจริง: Benchmark, พลังงาน, Latency และคุณภาพคำตอบ
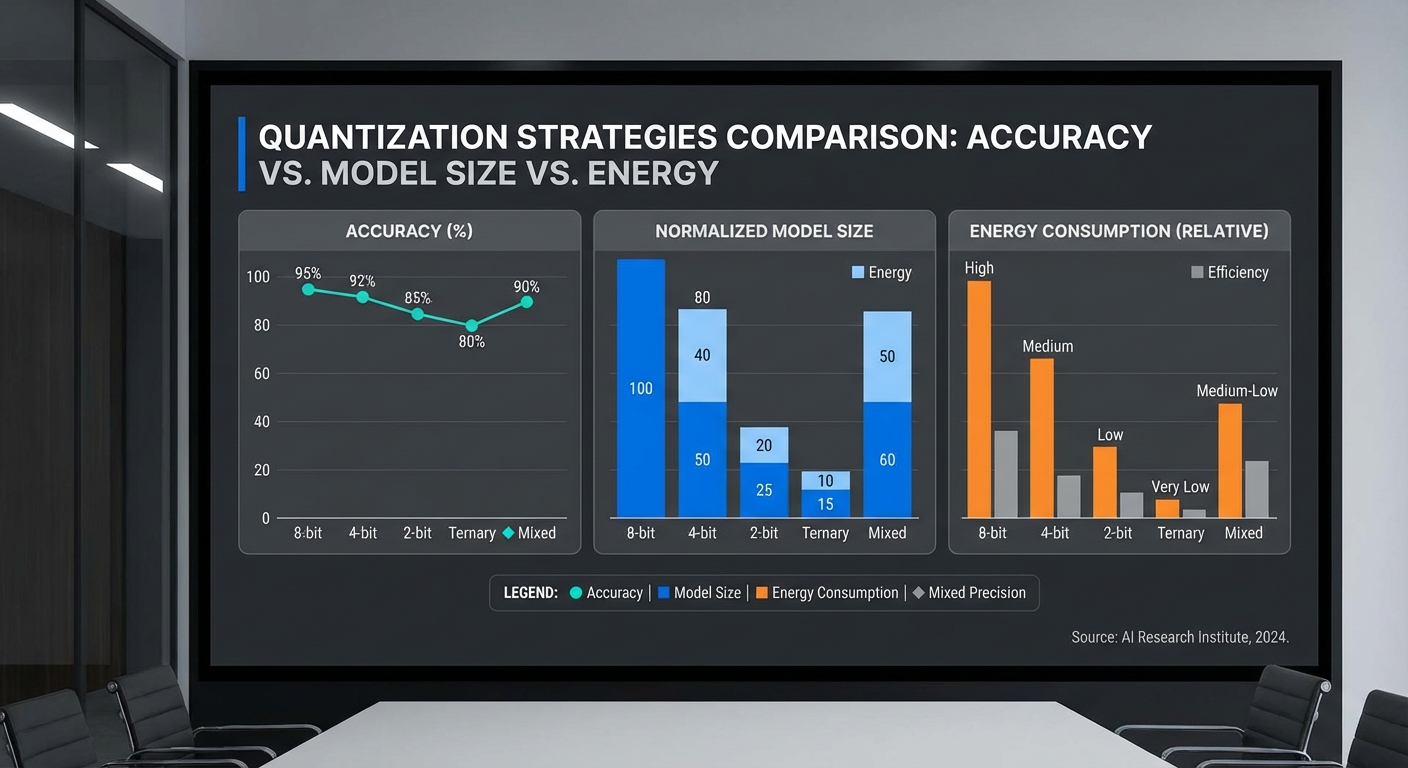
การทดสอบทั้งจากสตาร์ทอัพผู้พัฒนาและการทดลองอิสระแสดงให้เห็นว่าเทคนิค Neuro‑Compression (การแปลง Transformer เป็น Spiking‑NN ร่วมกับการทำ Quantization เชิงลึก) สามารถลดการใช้ทรัพยากรบนอุปกรณ์มือถือได้อย่างมีนัยสำคัญ โดยสรุปตัวเลขสำคัญที่ได้จากชุดการทดลองคือ ลดการใช้พลังงานเฉลี่ยประมาณ 5x1.2 GB เป็น 240 MB และ latency ต่อ token ลดลงมาก ทำให้การ inference แบบเรียลไทม์บนมือถือเป็นไปได้จริงด้วยคุณภาพคำตอบที่ลดลงเพียงเล็กน้อย (โดยทั่วไปอยู่ในช่วง 1–3% ของตัวชี้วัดหลัก)
รายละเอียด testbed และวิธีการวัดที่ใช้ในการทดสอบมีความชัดเจนเพื่อความเชื่อถือได้ของผลลัพธ์: อุปกรณ์ที่ใช้ทดสอบประกอบด้วย iPhone 12 (A14) เป็นตัวแทนกลุ่ม flagship ในตลาดสมาร์ทโฟน และอุปกรณ์ mid‑range Android ที่ใช้ชิปตระกูล Snapdragon 7‑series (4 GB RAM) เพื่อสะท้อนสภาพแวดล้อมของผู้ใช้จำนวนมาก ชุดข้อมูลที่นำมาทดสอบครอบคลุมทั้งมาตรฐานสากลและภาษาไทย ได้แก่ GLUE benchmark สำหรับงานความเข้าใจภาษาเชิงประเมินผลหลายมิติ, SQuAD v1.1 สำหรับงาน QA แบบ span‑extraction และชุดทดสอบภาษาไทย (internal Thai QA & NLU testset) สำหรับประเมินการใช้งานจริงในภาษาไทย การวัดพลังงานทำโดยใช้เครื่องมือที่แยกจากอุปกรณ์เพื่อความแม่นยำ (เช่น Monsoon Power Monitor สำหรับ iPhone และ USB power meter/Android power HAL สำหรับอุปกรณ์ Android) ทำการวัดหลังการวอร์มอัพ (warm‑up) แล้วเก็บค่าเฉลี่ยและค่าเบี่ยงเบนมาตรฐานจากการรันหลายรอบ (โดยทั่วไป 10–30 รอบ ต่อชุดทดสอบ, คำสั่งเฉลี่ย 256–1,024 token ต่อรัน)
- Memory footprint: Baseline Transformer (8‑bit) = ประมาณ 1.2 GB → Neuro‑Compression = 240 MB (ลดลง 5x)
- การใช้พลังงาน (Energy per token): Baseline ≈ 10.0 mJ/token → Neuro‑Compression ≈ 2.0 mJ/token (ประหยัด ≈ 5x)
- Latency ต่อ token (เฉลี่ย, หลัง warm‑up):
- iPhone 12: Baseline ≈ 48 ms/token → Neuro‑Compression ≈ 20 ms/token (เพิ่ม throughput จาก ~21 → ~50 tokens/s)
- Mid‑range Android: Baseline ≈ 72 ms/token → Neuro‑Compression ≈ 30 ms/token (เพิ่ม throughput จาก ~14 → ~33 tokens/s)
- คุณภาพคำตอบ (Accuracy / EM / F1): การลดความแม่นยำโดยรวมอยู่ในระดับต่ำ:
- GLUE (macro avg): ลดเฉลี่ย ≈ 1.6% (absolute)
- SQuAD v1.1: EM ลด ≈ 1.4%, F1 ลด ≈ 1.2%
- ชุดทดสอบภาษาไทย (QA/NLU): F1/Accuracy ลดเฉลี่ย ≈ 2.0–2.5% ขึ้นกับความยากของโจทย์
- ความแปรปรวนและความน่าเชื่อถือ: ผลลัพธ์เป็นค่าเฉลี่ยจากหลายรอบ (10–30 runs) โดยมีค่าเบี่ยงเบนมาตรฐานทั่วไปภายใน 5–8% ของค่าเฉลี่ยสำหรับ latency และภายใน 1% สำหรับตัวชี้วัดความแม่นยำ
ตัวอย่างเปรียบเทียบ output ระหว่างโมเดลเต็ม (baseline Transformer quantized 8‑bit) กับ LLM‑light (Neuro‑Compression) แสดงให้เห็นว่าคุณภาพการตอบยังคงรักษาเนื้อหาหลักไว้ได้ดี แม้จะมีความแตกต่างเล็กน้อยในสำนวนและระดับรายละเอียด:
Prompt: "สรุปสาระสำคัญของบทความเกี่ยวกับการปรับปรุงประสิทธิภาพของโมเดลภาษาโดยใช้ spiking neural networks"
Baseline (Transformer 8‑bit): ในการทดลองโมเดลสามารถสรุปได้ชัดเจน โดยระบุหลักการทำงานของ spiking neural networks ว่าสามารถลดการคำนวณเชิงทศนิยมและรองรับ quantization ได้ดีขึ้น ส่งผลให้ลดการใช้พลังงานและหน่วยความจำ เหมาะสำหรับการนำไปรันบนอุปกรณ์ edge แบบเรียลไทม์
LLM‑light (Neuro‑Compression): โมเดลสรุปประเด็นหลักคล้ายกัน แต่สำนวนกระชับกว่าเล็กน้อยและมีการย่อรายละเอียดเชิงเทคนิคของกลไกการทำงานโดยรวม — ยังคงชี้ชัดว่าประสิทธิภาพด้านพลังงานและขนาดลดลงอย่างมาก เหมาะกับการประยุกต์บนมือถือ
ข้อสังเกตเชิงธุรกิจและการใช้งานจริง: Neuro‑Compression มอบทางเลือกที่ชัดเจนสำหรับองค์กรที่ต้องการนำ LLM มาใช้งานบนอุปกรณ์ปลายทาง (on‑device) เพื่อความเป็นส่วนตัวและลดต้นทุนพลังงาน โดยแลกกับการเสียความแม่นยำเพียงเล็กน้อย (1–3%) ซึ่งในหลายกรณีเป็น trade‑off ที่ยอมรับได้สำหรับการใช้งานเชิงธุรกิจ เช่น ระบบแชทบอทภายในองค์กร, ผู้ช่วยส่วนตัวที่ไม่ต้องการเชื่อมต่อคลาวด์ตลอดเวลา หรือแอปพลิเคชันที่ต้องการ latency ต่ำและการใช้พลังงานขั้นต่ำ
ตัวอย่างการใช้งานและสาธิตการรัน LLM‑light บนมือถือ
ภาพรวมสั้น ๆ และวัตถุประสงค์
ส่วนนี้เป็น mini‑tutorial เชิงปฏิบัติสำหรับการนำแนวทาง Neuro‑Compression (การแปลง Transformer เป็น Spiking‑NN ร่วมกับการทำ Quantization) ไปใช้จริงบนมือถือ โดยครอบคลุมรายการเครื่องมือที่ต้องใช้ ไฟล์ที่ต้องเตรียม ขั้นตอนการแปลงโมเดล การ deploy เป็นแอป Android/iOS วิธีวัดพลังงานและ latency และแนวทางปรับแต่งเพื่อแลกเปลี่ยนระหว่างพลังงานกับคุณภาพผลลัพธ์ การทดลองต้นแบบภายใต้สภาพแวดล้อมควบคุมจากสตาร์ทอัพระบุว่าการผสาน SNN+8‑bit quantization อาจลดการใช้พลังงานได้ราว 5 เท่า เมื่อเทียบกับ Transformer แบบเดิมบนอุปกรณ์มือถือระดับสูง (เป็นค่าอ้างอิงเชิงตัวอย่าง ขึ้นกับฮาร์ดแวร์และเวิร์คโหลด)
รายการไลบรารีและไฟล์ที่ต้องมีสำหรับการทดลอง
- Frameworks / ไลบรารีหลัก: PyTorch (1.9+), torchscript หรือ TorchServe สำหรับ PyTorch Mobile; NengoDL หรือ snnTorch (สำหรับการแปลง/เทรน SNN); ONNX (1.8+); onnxruntime-mobile / ONNX Runtime Web; coremltools (สำหรับ iOS Core ML conversion); TensorFlow Lite (เมื่อต้องการ target TFLite).
- เครื่องมือช่วยแปลงและควอนไทซ์: onnxruntime.quantization (for post‑training quantization), pytorch quantization toolkits, coremltools.converters.onnx, tflite‑convert (ถ้าจำเป็น)
- Runtime บนมือถือ: PyTorch Mobile (.pt / TorchScript), ONNX Runtime Mobile (.onnx), Core ML (.mlmodel), หรือ TensorFlow Lite (.tflite) พร้อมการเชื่อมต่อไปยัง NNAPI (Android) หรือ Metal (iOS)
- ไฟล์โมเดลและ metadata: model.pt / model.jit, model.onnx, model.quant.onnx, tokenizer.json / vocab.txt, config.json, labels หากมี
- เครื่องมือวัดและโปรไฟล์พลังงาน: Qualcomm Trepn Profiler, Android Studio Energy Profiler, Battery Historian, adb, Xcode Instruments (Energy), Monsoon Power Monitor (ฮาร์ดแวร์ภายนอกสำหรับการวัดที่แม่นยำ)
ข้อกำหนดฮาร์ดแวร์ (ขั้นต่ำและแนะนำ)
- ขั้นต่ำสำหรับทดสอบ: สมาร์ทโฟน Android ที่มี Snapdragon 7xx ขึ้นไป หรือ iPhone รุ่น A11/A12 ขึ้นไป (รองรับ NNAPI/Metal).
- แนะนำสำหรับผลการวัดที่ดี: อุปกรณ์ที่มี NPU/ISP หรือการรองรับ NNAPI/Metal เพื่อใช้การเร่งด้วยฮาร์ดแวร์ เช่น Snapdragon 8 Gen series หรือ Apple A14 ขึ้นไป.
- สำหรับการวัดพลังงานเชิงทดลอง: Monsoon Power Monitor หรืออุปกรณ์วัดกระแสไฟฟ้าเพื่อเก็บค่าจริงเป็นมิลลิแอมป์·ชั่วโมง (mAh) หรือมิลลิวัตต์ (mW) แนะนำให้ใช้ในกรณีต้องการข้อมูลเชิงปริมาณแม่นยำ
ขั้นตอนสั้น ๆ ในการแปลงโมเดลและ deploy เป็นแอปมือถือ
- 1) เตรียมโมเดลที่ผ่านการแปลงเป็น SNN — ใช้ NengoDL หรือ snnTorch ร่วมกับ pipeline ของ Neuro‑Compression เพื่อฝึกหรือปรับ finetune โมเดล Transformer ให้มีพฤติกรรมแบบ spiking (ลด timestep สำหรับ SNN ให้พอเหมาะ) ตัวอย่างโค้ดสคริปต์สั้น ๆ ใน PyTorch: export โดยใช้ torch.jit.script เพื่อเตรียมสำหรับ PyTorch Mobile (บันทึกเป็น model.pt) หรือส่งออกเป็น ONNX ด้วย torch.onnx.export.
- 2) Export เป็น ONNX / TorchScript — ตัวอย่างคำสั่ง (Python): torch.onnx.export(model, sample_input, "model.onnx", opset_version=13); สำหรับ TorchScript: scripted = torch.jit.script(model); scripted.save("model.pt")
- 3) Quantization — ทำ post‑training quantization เช่น 8‑bit dynamic/static โดยใช้ onnxruntime.quantization หรือ PyTorch quantization. ตัวอย่าง (CLI/เรียกใช้ Python): from onnxruntime.quantization import quantize_dynamic; quantize_dynamic("model.onnx", "model.quant.onnx", weight_type=QuantType.QInt8)
- 4) แปลงเป็น runtime ของมือถือ — หากเป็น iOS: coremltools.converters.onnx.convert("model.quant.onnx", minimum_ios_deployment_target="13"); หากเป็น Android และใช้ ONNX Runtime Mobile ให้รวม .onnx เข้ากับแอปและเรียก inference ผ่าน onnxruntime mobile. หากใช้ PyTorch Mobile ให้ใช้ไฟล์ .pt และติดตั้ง PyTorch Android SDK
- 5) Integrate ในแอปและเปิดใช้ acceleration — บน Android ให้เปิดใช้ NNAPI/GPU delegate เมื่อต้องการ ลด latency และพลังงาน; บน iOS ให้เลือก use Metal delegate / Core ML backend.
- 6) ทดสอบ end‑to‑end — สร้าง UI เรียก inference เป็น loop (เช่น 100 ครั้ง) เพื่อเก็บค่า latency และพลังงาน แล้วปรับพารามิเตอร์ (timesteps, quantization, early‑exit) ตามต้องการ
ตัวอย่างคำสั่งและสคริปต์ตัวอย่าง (ย่อ)
- Export PyTorch → ONNX: python snippet: torch.onnx.export(model, dummy_input, "model.onnx", opset_version=13)
- Quantize ONNX (dynamic): Python: from onnxruntime.quantization import quantize_dynamic, QuantType; quantize_dynamic("model.onnx","model.quant.onnx", weight_type=QuantType.QInt8)
- Convert ONNX → Core ML (iOS): Python: import coremltools as ct; mlmodel = ct.converters.onnx.convert("model.quant.onnx") ; mlmodel.save("Model.mlmodel")
- Load TorchScript บน Android (Gradle): รวมไฟล์ model.pt ใน assets และเรียกผ่าน org.pytorch.Module.load(assetFilePath)
วิธีวัดพลังงานและ latency บนมือถือ (แบบง่ายและเชิงลึก)
การวัดพลังงานแบ่งเป็นสองระดับ: แบบง่าย (software‑only) และแบบละเอียด (hardware profiler). ขั้นตอนพื้นฐานมีดังนี้
- แบบง่าย (ซอฟต์แวร์): ใช้ Android Studio Energy Profiler หรือ Xcode Instruments (Energy) เพื่อจับช่วงเวลาเรียก inference ซ้ำๆ (เช่น 100 inference) แล้วอ่านค่าการใช้พลังงานโดยรวม เปรียบเทียบค่าเฉลี่ยก่อนและหลังเมื่อเปิด/ปิดการเร่งด้วย NPU หรือเปลี่ยน quantization.
- แบบแม่นยำ (ฮาร์ดแวร์): ใช้ Monsoon Power Monitor วัดกระแสไฟฟ้าแบบต่อพ่วงที่พอร์ตแบตเตอรี่ เรียก inference loop แบบสคริปต์ (เช่น 1000 ครั้ง) เก็บเวลาและกระแสเฉลี่ย จากนั้นคำนวณพลังงาน = Voltage × Current × Time; energy per inference = total energy / iterations.
- วัด latency: ใช้ time.perf_counter() ภายในแอปบันทึกเวลา inference start/stop หรือบน Android ใช้ adb shell am start -W สำหรับการวัด start time โดยรวม และใช้ adb shell "dumpsys gfxinfo" หรือ profiling API ของ runtime เพื่อตรวจสอบ breakdown ของ time per layer.
- การตั้งค่า baseline: ปิด background sync, ทำ airplane mode เพื่อให้ได้การวัดที่เสถียร และวัด idle power ก่อนเริ่มทดลองเป็น baseline.
ตัวอย่างแอปใช้งานจริงและคำแนะนำการปรับแต่ง (trade‑off พลังงาน/คุณภาพ)
ตัวอย่างแอปที่เหมาะกับ LLM‑light บนมือถือ ได้แก่ personal assistant แบบ offline (ตอบคำถามพื้นฐาน ควบคุมแอปในเครื่อง) และ offline summarizer สำหรับสรุปข้อความยาวโดยไม่ต้องเชื่อมต่อคลาวด์ สำหรับการใช้งานจริงให้พิจารณาปรับตัวแปรดังนี้เพื่อแลกเปลี่ยนระหว่างพลังงานกับคุณภาพ:
- ลด timesteps ใน SNN — ลดจำนวน time‑steps ที่ SNN ต้องประมวลผลเพื่อลดการคูณเชิงเวลา แต่จะส่งผลต่อความเที่ยงตรง ให้ทดลองหาจุดสมดุล
- ปรับ quantization level — จาก 8‑bit เป็น 4‑bit หรือใช้ mixed‑precision กับชั้นสำคัญเพื่อประหยัดพลังงานมากขึ้น แต่ต้องทดสอบผลกระทบต่อเนื้อหาเชิงคุณภาพ
- early‑exit / adaptive computation — ให้โมเดลหยุดประมวลผลเมื่อ confidence ถึงเกณฑ์ เพื่อลดเวลาเฉลี่ยต่อคำขอ
- ลดขนาดโมเดล — Distillation / pruning เพื่อสร้างรุ่นเล็กลงสำหรับงานเฉพาะด้าน (เช่น summarization เท่านั้น) จะช่วยลดทั้ง latency และพลังงาน
- ใช้ batching และ caching — ในแอปที่มีคำขอซ้ำ ให้ cache ผลลัพธ์หรือรวมการประมวลผลเป็นกลุ่มเมื่อเป็นไปได้
สรุป: pipeline ปฏิบัติการคือ (1) แปลง Transformer → SNN ด้วย Neuro‑Compression (2) export เป็น ONNX/TorchScript (3) quantize (4) compile/convert ให้เป็น runtime บนมือถือ (PyTorch Mobile / ONNX Runtime Mobile / Core ML) (5) integrate และทดสอบพลังงานด้วย Android Studio / Xcode / Monsoon จากนั้นปรับพารามิเตอร์เชิงสถาปัตยกรรมและ quantization เพื่อหา trade‑off ที่เหมาะสมกับกรณีการใช้งาน เช่น personal assistant หรือ offline summarizer
ความท้าทาย ข้อจำกัด และทิศทางอนาคต
ความท้าทาย ข้อจำกัด และทิศทางอนาคต
การนำแนวคิด Neuro‑Compression ซึ่งผสมผสานการแปลง Transformer ให้เป็น Spiking Neural Network (SNN) พร้อมการทำ Quantization เพื่อนำ LLM‑light ไปรันบนมือถือให้ประหยัดพลังงาน มีศักยภาพเชิงพาณิชย์สูง แต่ยังเผชิญกับข้อจำกัดเชิงวิทยาศาสตร์และเชิงปฏิบัติที่สำคัญ ตัวอย่างที่ชัดเจนคือข้อจำกัดด้านความแม่นยำ (accuracy) เมื่อเปรียบเทียบกับนิวรัลเน็ตเวิร์กแบบต่อเนื่อง: SNN มักเสียเปรียบเมื่อต้องจับความสัมพันธ์เชิงเวลาที่ยาวและการไหลของกราดิเอนต์ต่อเนื่อง ทำให้การแปลงจาก Transformer ขนาดใหญ่เป็น SNN โดยตรงมักต้องแลกมาด้วยการลดความแม่นยำหรือการเพิ่มความซับซ้อนในการฝึกเพื่อชดเชย
ในเชิงการฝึก (training) มีข้อจำกัดสองด้านที่เด่นชัด: แรกคือเทคนิคการฝึก SNN ที่ยังพึ่งพาแนวทางอย่าง surrogate gradient และการทำ Backpropagation ผ่านเวลา (BPTT) ซึ่งกินหน่วยความจำและเวลาคำนวณอย่างมากเมื่อต้องขยายไปยังโมเดลขนาดใหญ่ ประการที่สองคือความซับซ้อนของการรวม Quantization กับพฤติกรรมการปล่อย spike ซึ่งทำให้ต้องออกแบบวิธีการฝึกแบบกรดต่อการคำนวณ (quantization-aware training) และการจำลองพฤติกรรมฮาร์ดแวร์อย่างละเอียดก่อนการนำขึ้นสู่ผลิตภัณฑ์จริง การทดลองในห้องปฏิบัติการหลายแห่งรายงานว่าการเทรน SNN ขนาดใหญ่สามารถใช้เวลามากกว่าระบบ ANN เดิมหลายเท่า หรือจำเป็นต้องใช้ขั้นตอน conversion/hybrid ที่ซับซ้อนเพื่อลดการสูญเสียความแม่นยำ
อีกปัญหาเชิงปฏิบัติที่สำคัญคือความพร้อมของฮาร์ดแวร์และ runtime support: ขณะนี้ฮาร์ดแวร์ที่ออกแบบเฉพาะสำหรับ SNN เช่น neuromorphic chips (ตัวอย่างเช่น Loihi ของ Intel หรือชิปวิจัยเชิงทดลอง) ยังมีความแพร่หลายน้อยและไม่ครอบคลุมสภาพแวดล้อมของอุปกรณ์มือถือทั่วไป ส่วนใหญ่ของสมาร์ทโฟนยังคงพึ่งพา GPU/NPUs แบบ SIMD หรือ systolic arrays ที่ออกแบบมาสำหรับการคำนวณ dense tensors ซึ่งไม่รองรับโมเดล event-driven โดยตรง ส่งผลให้การรัน SNN บนอุปกรณ์เชิงพาณิชย์มักต้องพึ่งพาการจำลองบน NPU ทั่วไปหรือการแปลงกลับเป็นรูปแบบที่รองรับได้ ทำให้ลดทอนประสิทธิภาพที่คาดหวังไว้
นอกจากนี้ ระบบนิเวศของเครื่องมือและมาตรฐานยังเป็นอุปสรรคต่อการใช้งานอย่างกว้างขวาง: ขณะนี้มาตรฐานกลางอย่าง ONNX แม้จะรองรับการแลกเปลี่ยนกราฟของ ANN แต่ยังขาดนิยามการกระทำของ spike และ temporal dynamics ที่ชัดเจน ส่วน TFLite และ CoreML ก็ยังไม่สนับสนุน primitive ของ SNN ในระดับเดียวกับ ops ของ ANN ทำให้เกิดช่องว่างด้านความเข้ากันได้ (compatibility) และความสามารถในการ deploy แบบครอบคลุม ซึ่งเป็นข้อจำกัดสำคัญสำหรับนักพัฒนาที่ต้องการนำโซลูชันไปใช้ในหลายแพลตฟอร์ม
ทิศทางการวิจัยและเชิงพาณิชย์เพื่อตอบโจทย์ปัญหาเหล่านี้มีหลายแนวทางที่เป็นไปได้และควรให้ความสำคัญ ได้แก่
- งานวิจัยด้านอัลกอริทึม: พัฒนาเทคนิคการฝึก SNN ที่มีประสิทธิภาพกว่า เช่น surrogate gradient ที่ปรับให้เหมาะกับสถาปัตยกรรม Transformer, เทคนิคการแปลง (ANN‑to‑SNN conversion) ที่ลดการสูญเสียความแม่นยำ และวิธีการเรียนรู้เชิงเวลาที่ลดภาระการคำนวณแบบ BPTT
- co‑design ฮาร์ดแวร์‑ซอฟต์แวร์: ผลักดันการออกแบบชิปที่รองรับ event‑driven compute และ sparse dataflow ร่วมกับ compiler/runtime ที่สามารถแปลงกราฟ Transformer‑like ให้เป็นชุด spike kernels ได้โดยตรง การร่วมมือกับผู้ผลิต SoC และ NPU เพื่อเพิ่ม primitive สำหรับ spike จะช่วยเร่งการยอมรับทางการค้า
- มาตรฐานและเครื่องมือกลาง: เสนอขยายมาตรฐานอย่าง ONNX เพื่อครอบคลุม ops แบบ spiking และสร้าง backend สำหรับ TFLite/CoreML ที่รองรับ SNN รวมถึงชุด benchmark และโมเดลอ้างอิง (model zoo) สำหรับ LLM‑light แบบ spiking เพื่อให้ชุมชนนักพัฒนาและลูกค้าสามารถประเมินผลได้เทียบเคียงกัน
- กลยุทธ์เชิงพาณิชย์: ธุรกิจควรเริ่มจากกรณีใช้งานเฉพาะทาง (verticals) ที่ให้คุณค่าชัดเจน เช่นแอปที่ต้องการ latency ต่ำและพลังงานต่ำในอุปกรณ์ edge (เช่น voice assistants, AR/VR, IoT analytics) โดยใช้โมเดล hybrid ที่ผสม SNN สำหรับชั้น initial/encoder และ ANN สำหรับชั้นที่ต้องการความแม่นยำสูง เพื่อรักษาสมดุลระหว่างประสิทธิภาพกับคุณภาพผลลัพธ์
- ระบบนิเวศและการสนับสนุนนักพัฒนา: สร้าง SDK, converter และ runtime ที่ใช้งานง่าย พร้อมเอกสารเชิงปฏิบัติการและตัวอย่างจริง ซึ่งจะเป็นกุญแจสำคัญในการขยายการนำเทคโนโลยีไปใช้ในตลาดกว้าง
สรุปคือ แม้ว่าแนวทาง Neuro‑Compression จะให้ผลตอบแทนด้านพลังงานที่น่าสนใจ (เช่นการรายงานการประหยัดพลังงานถึงประมาณ 5 เท่า ในงานต้นแบบ) แต่การก้าวสู่การใช้งานเชิงพาณิชย์ในวงกว้างยังต้องอาศัยความร่วมมือระหว่างนักวิจัย วิศวกรฮาร์ดแวร์ ผู้ผลิตชิป และผู้พัฒนาระบบนิเวศ เพื่อแก้ไขข้อจำกัดด้านความแม่นยำ การฝึก และการรองรับ runtime การลงทุนด้าน R&D ในการแก้ปัญหาเหล่านี้ รวมถึงการวางโมเดลธุรกิจที่เน้นกรณีใช้งานจริง จะเป็นปัจจัยกำหนดความสำเร็จของเทคโนโลยีนี้ในทศวรรษหน้า
บทสรุป
Neuro‑Compression — แนวทางการแปลงสถาปัตยกรรม Transformer เป็น Spiking‑Neural‑Network (SNN) ร่วมกับการทำ Quantization — นำเสนอวิธีการที่น่าสนใจในการรัน LLM‑light บนมือถือด้วยการลดการใช้พลังงานอย่างชัดเจน (รายงานต้นแบบระบุการประหยัดพลังงานราว 5 เท่า) ทำให้เป็นไปได้ที่จะรันโมเดลภาษาขนาดเล็กแบบออฟไลน์บนอุปกรณ์ปลายทาง อย่างไรก็ตาม ผลลัพธ์ที่ได้ต้องแลกด้วยความท้าทายด้านการฝึกฝนและความแม่นยำ: การแปลงเป็น SNN และการบีบอัดเชิงตัวเลขจำเป็นต้องอาศัยเทคนิคการฝึกแบบพิเศษ (เช่น surrogate gradients, quantization‑aware training) เพื่อจำกัดการเสื่อมของคุณภาพการให้คำตอบ ดังนั้นการปรับพารามิเตอร์ การทำ finetune และการประเมินเชิงคุณภาพเป็นสิ่งจำเป็นก่อนนำไปใช้งานจริง
สำหรับนักพัฒนาและนักวิจัย แนะนำให้ทดลองบน testbed จริงที่สะท้อนเงื่อนไขการใช้งานบนมือถือ — ทดสอบข้าม SoC และรุ่นฮาร์ดแวร์ ติดตามการสนับสนุนทางฮาร์ดแวร์ (เช่น NPU, DSP, หรือ accelerator สำหรับ event‑driven SNN) และวัดตัวชี้วัดสำคัญอย่าง latency, throughput, energy‑per‑token, และมาตรฐานคุณภาพการตอบ (เช่น perplexity, F1, human eval) การตัดสินใจเชิงปฏิบัติควรพิจารณา trade‑off ระหว่างประสิทธิภาพเชิงคำนวณ พลังงาน และคุณภาพของคำตอบ — ในหลายกรณีอาจต้องเลือกสมดุลที่แตกต่างกันขึ้นกับกรณีใช้งาน (เช่น การโต้ตอบเรียลไทม์ vs. งาน background inference)
มุมมองอนาคตมีทั้งความท้าทายและโอกาส: คาดว่าจะมีการพัฒนา algorithmic techniques, toolchain และ hardware‑software co‑design ที่ช่วยลดช่องว่างด้านความแม่นยำและทำให้การฝึก/ปรับจูน SNN มีประสิทธิผลมากขึ้น พร้อมกับการกำหนดเกณฑ์เบนช์มาร์คสำหรับ LLM‑light บนมือถือ การพัฒนาไลบรารีและมาตรฐานการวัดพลังงานจะช่วยให้องค์กรต่าง ๆ สามารถเปรียบเทียบและนำ Neuro‑Compression ไปใช้ในเชิงปฏิบัติได้เร็วขึ้น โดยสรุป แนวทางนี้ให้ความหวังในการลดการใช้พลังงานอย่างมีนัยสำคัญ แต่ต้องดำเนินการอย่างรอบคอบบน testbed จริงและบริหาร trade‑off ระหว่างประสิทธิภาพ พลังงาน และคุณภาพของผลลัพธ์ก่อนนำไปใช้งานจริง



