
สตาร์ทอัพไทยเปิดตัว AutoEdge‑Trainer ระบบ AutoML รุ่นใหม่ที่ออกแบบมาเพื่อปรับจูนโมเดล Computer‑Vision บนอุปกรณ์ Edge โดยอัตโนมัติตามสภาพแวดล้อมจริงในสายการผลิต ช่วยแก้ปัญหา Domain Shift ที่เกิดจากแสง, มุมกล้อง หรือความแปรผันของชิ้นงานซึ่งมักเป็นต้นเหตุของ False‑Alarm สูงจนทำให้การผลิตหยุดชะงักและเกิดค่าใช้จ่ายเพิ่มเติม โดยบริษัทระบุผลทดสอบเชิงภาคสนามว่า AutoEdge‑Trainer ลดอัตรา False‑Alarm ได้ถึง 60% และลดปริมาณข้อมูลที่ต้องส่งขึ้นคลาวด์ลงกว่า 80% พร้อมลดความหน่วง (latency) และความเสี่ยงด้านความเป็นส่วนตัวของข้อมูลภาพในระบบการตรวจสอบคุณภาพ
บทความนี้จะพาอ่านฟีเจอร์หลักของ AutoEdge‑Trainer ตั้งแต่การเก็บตัวอย่างจากสายการผลิตจริง การทำ Labeling แบบกึ่งอัตโนมัติ การ Fine‑tune บน Edge ไปจนถึงกลไกการประเมินผลแบบเรียลไทม์ ตัวอย่างผลลัพธ์จากโรงงานบรรจุภัณฑ์และสายประกอบชิ้นส่วนอิเล็กทรอนิกส์ รวมถึงคู่มือติดตั้งและมาตรฐานการประเมินผลเชิงปฏิบัติที่จะช่วยให้องค์กรขนาดกลาง‑เล็กสามารถวางระบบได้เองโดยไม่พึ่งพาคลาวด์หนัก ๆ ซึ่งหมายถึงทั้งการลดต้นทุนและการเพิ่มความต่อเนื่องของการผลิตในสภาพแวดล้อมจริง
บทนำ: ทำไมต้องปรับโมเดลบน Edge ในสายการผลิต
บทนำ: ทำไมต้องปรับโมเดลบน Edge ในสายการผลิต
ในโรงงานอุตสาหกรรมสมัยใหม่ ระบบตรวจจับข้อบกพร่องด้วยกล้อง (computer‑vision) ถูกนำมาใช้แพร่หลายเพื่อยกระดับคุณภาพและเพิ่มความแม่นยำในการตรวจสอบ แต่ปัญหาเชิงปฏิบัติที่พบได้บ่อยคืออัตรา False‑Alarm สูง เมื่อสภาพแวดล้อมจริงในสายการผลิตเปลี่ยนแปลง เช่น แสงสว่างที่แตกต่าง ฝุ่นละอองบนเลนส์ มุมกล้องที่เปลี่ยนไป หรือการเข้ามาของผลิตภัณฑ์รุ่นใหม่ ระบบที่เทรนไว้บนข้อมูลจากสภาพแวดล้อมเดิมมักจะตีความความเปลี่ยนแปลงเหล่านี้เป็นความผิดพลาด ส่งผลให้เกิดการแจ้งเตือนเท็จบ่อยครั้ง ส่งผลต่อการหยุดสายการผลิต ค่าใช้จ่ายในการตรวจสอบด้วยมือ และความเชื่อมั่นในระบบอัตโนมัติของโรงงาน
การแก้ปัญหาโดยพึ่งพาการส่งวิดีโอหรือภาพจำนวนมากขึ้นไปประมวลผลบนคลาวด์ก็เผชิญข้อจำกัดทั้งด้านความหน่วง (latency), ความเป็นส่วนตัว (privacy) และแบนด์วิดท์ (bandwidth) — ระบบตรวจสอบแบบเรียลไทม์มักต้องการการตอบสนองทันทีในระดับมิลลิวินาทีถึงไม่กี่ร้อยมิลลิวินาที การส่งวิดีโอความละเอียดสูงต่อเนื่องขึ้นคลาวด์จะสร้างความล่าช้าและต้นทุนเครือข่ายที่สูง นอกจากนี้ วิดีโอจากสายการผลิตอาจบรรจุข้อมูลเชิงลับทางการผลิตหรือภาพบุคคลซึ่งมีข้อจำกัดด้านกฎหมายและนโยบายความเป็นส่วนตัว ทำให้การประมวลผลบน Edge — ใกล้กับจุดเกิดข้อมูล — กลายเป็นทางเลือกที่จำเป็นเพื่อให้ได้ทั้งความเร็ว ต้นทุนที่ต่ำลง และการปฏิบัติตามข้อกำหนดด้านความปลอดภัยของข้อมูล
ในบริบทดังกล่าว AutoML บน Edge จึงกลายเป็นองค์ประกอบสำคัญ เพราะการปรับโมเดลให้ทำงานได้ดีในสภาพสายการผลิตจริงต้องการกระบวนการที่สามารถเรียนรู้และปรับตัวอย่างต่อเนื่อง โดยไม่ต้องพึ่งพาวิศวกร ML ทุกครั้งที่มีการเปลี่ยนแปลง AutoML บน Edge ช่วยให้สามารถทำงานดังต่อไปนี้ได้โดยอัตโนมัติ: คัดเลือกตัวอย่างจากฟีดกล้องของโรงงาน, ทำ data augmentation แบบเจาะจงบริบท, ปรับจูนไฮเปอร์พารามิเตอร์, และทำการพรีเซิร์ฟ (pruning/quantization) เพื่อให้โมเดลมีขนาดและความต้องการทรัพยากรที่เหมาะสมกับฮาร์ดแวร์ Edge การทำเช่นนี้ช่วยลดการส่งข้อมูลกลับขึ้นคลาวด์ และรักษาประสิทธิภาพการตรวจจับในสภาพแวดล้อมจริง
สตาร์ทอัพไทยผู้พัฒนา AutoEdge‑Trainer เสนอระบบ AutoML ที่ออกแบบมาสำหรับการปรับโมเดล computer‑vision บน Edge อัตโนมัติในบริบทสายการผลิตจริง โดยระบุว่าสามารถลด False‑Alarm ได้ถึง 60% และลดปริมาณการส่งข้อมูลขึ้นคลาวด์ลง 80% ผลลัพธ์เหล่านี้สะท้อนถึงการลดงานตรวจสอบด้วยคน การลดต้นทุนแบนด์วิดท์ และการเพิ่มความเสถียรของการตรวจจับในสภาพแวดล้อมที่เปลี่ยนแปลงบ่อย ซึ่งเป็นเหตุผลสำคัญที่ธุรกิจอุตสาหกรรมควรพิจารณานำ AutoML บน Edge เข้ามาใช้เพื่อยกระดับกระบวนการตรวจสอบคุณภาพให้มีความแม่นยำและคุ้มค่ามากขึ้น
- ปัญหาหลัก: False‑Alarm สูงเมื่อเผชิญกับการเปลี่ยนแปลงของสภาพแวดล้อมการผลิต
- เหตุผลเชิงเทคนิค: ความต้องการความหน่วงต่ำ ความเป็นส่วนตัว และข้อจำกัดแบนด์วิดท์ ทำให้การประมวลผลบน Edge จำเป็น
- ข้อดีของ AutoEdge‑Trainer: ปรับโมเดลอัตโนมัติบนอุปกรณ์ Edge ลด False‑Alarm 60% และลดการส่งข้อมูลคลาวด์ 80% ช่วยลดต้นทุนและเพิ่มความน่าเชื่อถือของระบบ
ฟีเจอร์หลักของ AutoEdge‑Trainer
ฟีเจอร์หลักของ AutoEdge‑Trainer
AutoEdge‑Trainer ออกแบบมาเป็นระบบ AutoML สำหรับงาน Computer‑Vision บน Edge โดยคำนึงถึงสภาพแวดล้อมของสายการผลิตจริงเป็นหลัก ระบบใช้วงจรการเรียนรู้แบบปิด (closed‑loop AutoML) ที่สามารถสกัดข้อมูลจากอุปกรณ์ข้างเคียงและกล้องบนสายการผลิตแบบเรียลไทม์ เพื่อทำ on‑device adaptation หรือการปรับโมเดลให้เรียนรู้จากข้อมูลภาคสนามทันที จุดประสงค์คือการลด False‑Alarm ในสภาพการใช้งานจริง ซึ่งผลการใช้งานเชิงประจักษ์ของสตาร์ทอัพระบุว่าสามารถลดอัตรา False‑Alarm ได้ถึง 60% ขณะเดียวกันลดการส่งข้อมูลขึ้นคลาวด์ลงประมาณ 80% ช่วยลดแบนด์วิดท์และประหยัดต้นทุนโครงสร้างพื้นฐาน
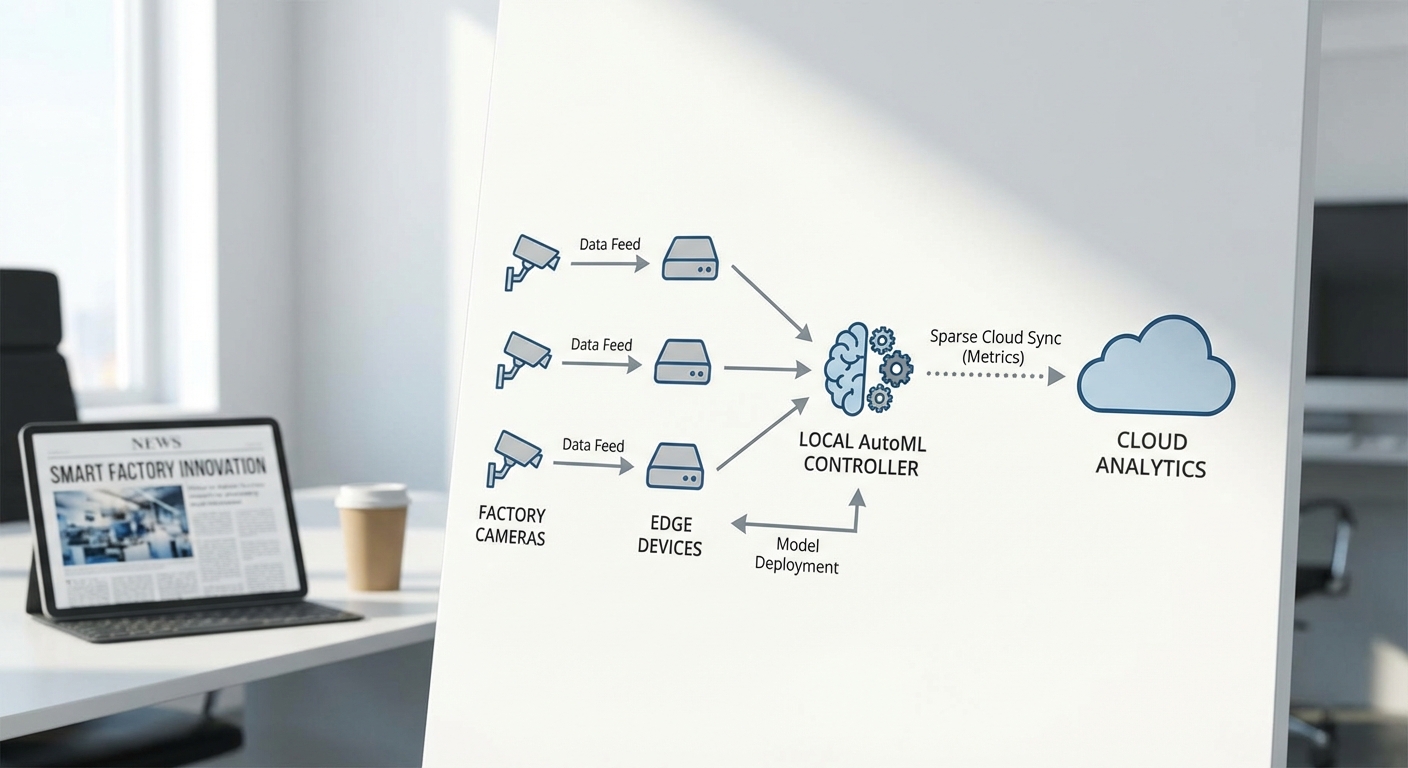
ในเชิงเทคนิค AutoEdge‑Trainer ประกอบด้วยชุดฟีเจอร์ย่อยที่ทำงานร่วมกันอย่างเป็นระบบ ได้แก่:
- AutoML loop สำหรับ CV — ระบบจะคัดเลือกตัวอย่างจากสายการผลิตโดยอาศัยนโยบาย Active Learning และนำตัวอย่างที่โมเดลมีความไม่แน่นอนสูงกลับมาฝึกเพิ่มแบบอัตโนมัติ (online fine‑tuning หรือ federated aggregation ขึ้นอยู่กับนโยบายความปลอดภัยของลูกค้า) ทำให้โมเดลปรับตัวต่อความเปลี่ยนแปลงของชิ้นงาน สิ่งสกปรก หรือมุมกล้องที่เกิดขึ้นจริง
- การรวบรวมข้อมูลจากสายการผลิตจริง — รองรับการติดแท็กแบบกึ่งอัตโนมัติ (weak supervision) และการจัดลำดับความสำคัญ (sample prioritization) เพื่อส่งเฉพาะข้อมูลที่มีคุณค่าทางการเรียนรู้ขึ้นสู่ระบบเทรน ลดปริมาณข้อมูลที่ต้องส่งไปยังคลาวด์และลดต้นทุนการทำงานของพนักงาน ตัวอย่างในไลน์จริงคือการดักจับตัวอย่างการเตือนซ้ำๆ แล้วส่งเฉพาะชุดข้อมูลที่โมเดลยังไม่แม่นยำให้ทีมวิศวกรรมตรวจสอบ
- Data‑augmentation เฉพาะโดเมน — ระบบให้ชุดนโยบาย augmentation ที่เรียนรู้จากโดเมน (domain‑aware augmentation) เช่น การจำลองการสะท้อนแสงจากพื้นผิวโลหะ การเบลอจากความเร็วสายพาน การแนะนำจุดแสงที่เปลี่ยนแปลงตามกะงาน หรือการจำลองคราบน้ำมันบนชิ้นงาน ซึ่งช่วยให้โมเดลทนต่อความแปรปรวนของภาพในโรงงานได้มากขึ้นและเพิ่มความแม่นยำในการตรวจจับ
เพื่อให้โมเดลสามารถรันได้บนฮาร์ดแวร์ Edge หลากหลาย AutoEdge‑Trainer รวมชุดเทคนิคการลดขนาดโมเดล (model compression) ไว้อย่างครบถ้วน โดยสามารถเลือกผสมผสานได้ตามเป้าหมายด้านความแม่นยำและ latency:
- Pruning — ตัดน้ำหนักที่ไม่มีผลต่อการคาดการณ์ออกทั้งแบบ structured pruning และ unstructured pruning ช่วยลดพารามิเตอร์และคำนวณลดลง ตัวอย่างเช่น pruning เชิงโครงสร้างสามารถลดพารามิเตอร์ได้ตั้งแต่ 30–70% โดยยังคงความแม่นยำใกล้เคียงเดิมในหลายกรณี
- Quantization — แปลงน้ำหนักและค่า activation เป็นแบบ low‑bit (เช่น INT8 หรือ INT4) เพื่อลดขนาดโมเดลลง 2–4x และลดเวลาอินเฟอร์เรนซ์อย่างมาก โดยรองรับโปรไฟล์ฮาร์ดแวร์เฉพาะ (ARM, NVIDIA Jetson, Intel Movidius ฯลฯ)
- Knowledge Distillation — สร้างโมเดลขนาดเล็ก (student) จากโมเดลใหญ่ที่แม่นยำ (teacher) เพื่อรักษา performance ในขณะที่ลดความซับซ้อนและ latency ตัวอย่างการใช้งานจริงแสดงว่า distillation ช่วยให้ได้โมเดลที่เล็กลงเป็นทศนิยมของขนาดเดิมโดยสูญเสียความแม่นยำเพียงเล็กน้อย
สุดท้าย AutoEdge‑Trainer มาพร้อม Dashboard สำหรับการติดตามการฝึกและการปรับพารามิเตอร์ ซึ่งออกแบบมาสำหรับทีมปฏิบัติการและฝ่ายธุรกิจโดยเฉพาะ ฟีเจอร์เด่นได้แก่:
- มุมมองเมตริกเรียลไทม์ (precision, recall, F1, latency, throughput, false‑alarm rate) พร้อมกราฟเปรียบเทียบเวอร์ชันโมเดลและช่วงเวลาการ deploy
- ระบบแจ้งเตือน (alerts) เมื่อตัวชี้วัดสำคัญเบี่ยงเบนจากเกณฑ์ที่กำหนด เช่น False‑Alarm เพิ่มขึ้นหรือ latency เกินค่า Service Level
- เครื่องมือปรับพารามิเตอร์แบบอินเตอร์แอคทีฟ (hyperparameter tuning UI) ให้ผู้ใช้งานปรับ threshold, learning rate, pruning ratio และเลือกกลยุทธ์ quantization แบบไม่ต้องเขียนโค้ด พร้อมการทดลอง A/B testing ระหว่างโมเดล
- ฟังก์ชัน versioning และ rollback ช่วยให้ทีมสามารถย้อนสู่เวอร์ชันก่อนหน้าได้ทันทีหากโมเดลที่อัปเดตก่อให้เกิดปัญหาในสายการผลิต
รวมกันแล้ว ฟีเจอร์ของ AutoEdge‑Trainer มุ่งเน้นการนำโมเดลจากห้องทดลองสู่การใช้งานจริงบน Edge อย่างปลอดภัยและคุ้มค่า โดยรักษาสมดุลระหว่างความแม่นยำ ความหน่วง และต้นทุนการสื่อสารข้อมูล เหมาะสำหรับผู้ประกอบการโรงงานที่ต้องการลด False‑Alarm อย่างมีนัยสำคัญและลดการพึ่งพาการประมวลผลบนคลาวด์
สถาปัตยกรรมระบบและการไหลของข้อมูล
สถาปัตยกรรมของ AutoEdge‑Trainer ถูกออกแบบโดยยึดหลักการประมวลผลให้ใกล้แหล่งข้อมูล (processing at the edge) เพื่อลดปริมาณข้อมูลดิบที่ต้องส่งขึ้นคลาวด์และลดอัตรา False‑Alarm ในสภาพสายการผลิตจริง โฟลว์เริ่มจากกล้องและเซนเซอร์ที่ติดตั้งบนเครื่องจักรหรือจุดตรวจสอบ (inspection point) ซึ่งส่งภาพและสัญญาณดิบไปยังอุปกรณ์ Edge (เช่น NVIDIA Jetson, Coral, หรือ ARM board) เพื่อทำ preprocessing เบื้องต้น ก่อนจะเข้าสู่โมดูล AutoEdge‑Trainer สำหรับการปรับจูนโมเดลแบบ on‑device และเก็บเวอร์ชันโมเดลในสตอเรจภายในเครื่อง

ส่วนประกอบหลักของระบบ
- Camera / Sensor — กล้องอุตสาหกรรม (GigE, USB3, M12) หรือเซนเซอร์เชิงภาพส่งเฟรมด้วยความถี่ที่กำหนด เช่น 10–30 fps ขึ้นอยู่กับความต้องการตรวจจับ
- Edge Preprocessing — ฟิลเตอร์ภาพ, การย่อขนาด (resize), การปรับสมดุลแสง, การทำ background subtraction และการคำนวณฟีเจอร์เบื้องต้น เพื่อลดขนาดข้อมูลก่อนเข้าโมเดล
- On‑device Training (AutoEdge‑Trainer) — ตัวควบคุม AutoML ท้องถิ่นที่สนับสนุน transfer learning, pruning, quantization และการฝึกแบบ incremental ให้โมเดลปรับตัวตามสภาพสายการผลิตจริง โดยจำกัด epoch และ batch size ให้เหมาะกับทรัพยากร
- Model Store — ที่เก็บเวอร์ชันโมเดลในเครื่อง (local model registry) พร้อมเมตาดาต้า เช่น validation metrics, timestamp และ rollback point
- Optional Cloud Sync — การส่งขึ้นคลาวด์จำกัดเป็นสรุปเมตริก (metrics), เทรนิงสเตตัส และเฉพาะตัวอย่างที่ถูกคัดเลือกแล้วเท่านั้น ไม่ส่งวิดีโอดิบทั้งหมด
กลไกที่ลดการส่งข้อมูลขึ้นคลาวด์ (เหตุผลที่ทำได้ถึง ~80%)
AutoEdge‑Trainer ลดการส่งข้อมูลได้มากจากการรวมกลไกหลายอย่างที่ทำงานร่วมกัน:
- Event Filtering — ระบบส่งข้อมูลเฉพาะเมื่อเกิดเหตุการณ์สำคัญ (เช่น เกิดความผิดปกติที่คะแนนความเชื่อมั่นต่ำกว่า threshold หรือพบวัตถุผิดปกติ) แทนการส่งสตรีมวิดีโอทั้งหมด ตัวอย่างเช่น ในสถานะการณ์ที่กล้องจับภาพปกติ 95% ของเวลา ระบบจะไม่ส่งเฟรมปกติขึ้นคลาวด์ ทำให้ลดปริมาณข้อมูลได้ทันที
- Frame Differencing & Motion Masking — การเปรียบเทียบเฟรมต่อเฟรมและใช้มาสก์เฉพาะบริเวณที่มีการเปลี่ยนแปลง ช่วยให้สามารถส่งเฉพาะ ROI (region of interest) หรือเฉพาะเฟรมที่มีการเปลี่ยนแปลง มากกว่าการส่งภาพเต็ม
- Selective Upload / Smart Sampling — เลือกส่งเฉพาะตัวอย่างที่มีประโยชน์ต่อการปรับโมเดล เช่น เฟรมที่โมเดลไม่แน่ใจ (low confidence) หรือที่มีการยืนยันจากผู้ปฏิบัติงาน (human-in-the-loop) เพื่อใช้เก็บ label แบบคัดเลือก
- On‑device Summarization & Compression — สร้างสรุปเชิงสถิติ (histograms, feature vectors) และบีบอัดตัวอย่างก่อนส่ง ทำให้ไม่จำเป็นต้องส่งวิดีโอดิบ
ตัวอย่างเชิงตัวเลข: หากกล้องหนึ่งตัวเดิมส่งวิดีโอความละเอียดสูงเท่ากับ 10 GB/วัน การใช้ Event Filtering และ Selective Upload สามารถลดลงเหลือประมาณ 2 GB/วัน (ลด 80%) — เมื่อขยายเป็นระบบ 20 กล้อง ปริมาณข้อมูลรายวันจาก 200 GB ลดเหลือ 40 GB ต่อวัน ซึ่งลดต้นทุนแบนด์วิดท์และค่าเก็บข้อมูลบนคลาวด์อย่างมีนัยยะ
การทำงานของ AutoEdge‑Trainer (flow รายละเอียด)
- 1) กล้องจับภาพ → 2) Edge Preprocessing (resize, normalize, ROI) → 3) Inference ด้วยโมเดลปัจจุบัน → 4) หาก confidence ต่ำหรือพบ anomalous pattern → ส่งไปยัง AutoEdge‑Trainer เพื่อเก็บตัวอย่างและทำ on‑device fine‑tuning
- หลังการปรับจูน โมเดลที่ผ่าน validation บน Edge จะถูกบันทึกใน Model Store และแทนที่หรือเวอร์ชันใหม่จะถูก active โดยระบบสามารถ rollback ได้หาก performance ลดลง
- เฉพาะสรุปเมตริก เช่น precision/recall, จำนวน false alarms ที่ลดลง, เวลาการตอบสนองเฉลี่ย จะถูกซิงค์ขึ้นคลาวด์เป็นระยะเพื่อการมอนิเตอร์และการบริหารจัดการแบบรวมศูนย์
AutoEdge‑Trainer ช่วยลด False‑Alarm ได้ประมาณ 60% ในข้อมูลภาคการผลิตจริง พร้อมทั้งลดการส่งข้อมูลดิบขึ้นคลาวด์ได้ถึง 80% ด้วยการประมวลผลและคัดกรองบน Edge
ตัวอย่างฮาร์ดแวร์ที่รองรับและข้อจำกัดทรัพยากร
- NVIDIA Jetson (Nano, Xavier NX, Orin) — เหมาะสำหรับงานที่ต้องการ GPU accelerate ทั้ง inference และบางกรณี on‑device training ข้อจำกัด: ความร้อนและการบริโภคพลังงานสูงขึ้นเมื่อฝึกโมเดล
- Google Coral (Edge TPU) — เร็วและประหยัดพลังงานสำหรับ inference แบบ quantized models แต่ข้อจำกัดคือความสามารถในการฝึกแบบ on‑device มีข้อจำกัด ต้องพึ่งพา transfer learning แบบเบาๆ หรือใช้เป็น accelerator สำหรับ inference หลังจากฝึกแล้ว
- ARM/SoC boards (เช่น Raspberry Pi 4 + NPU, Edge AI modules) — ต้นทุนต่ำ เหมาะสำหรับการ preprocessing และ inference เบาๆ ข้อจำกัด: หน่วยความจำ (RAM) และ CPU ทำให้การฝึกแบบเต็มรูปแบบบนอุปกรณ์เป็นไปได้ยาก จึงมักจำกัดการฝึกเป็น few‑shot หรือ incremental
- เสริมด้วย USB accelerators (Intel Movidius, NCS2) — เพิ่มความเร็ว inference/บางงาน training เบา ๆ แต่ต้องคำนึงถึงไดรเวอร์และความเข้ากันได้ของโมเดล
ข้อจำกัดสำคัญที่ต้องพิจารณาในการออกแบบสถาปัตยกรรมคือ: พื้นที่เก็บข้อมูลในอุปกรณ์, หน่วยความจำสำหรับการฝึก, พลังงานและความร้อน, เวลาแฝงที่ยอมรับได้ในการตอบสนอง และนโยบายความเป็นส่วนตัวของข้อมูลในโรงงาน AutoEdge‑Trainer จึงถูกออกแบบให้รองรับการฝึกแบบมีขอบเขต (constrained epochs, sparse batches), ใช้ quantized model และเก็บเฉพาะข้อมูลที่มีคุณค่าจริง เพื่อลดข้อจำกัดเหล่านี้
โดยสรุป AutoEdge‑Trainer ใช้วิธีผสมผสานระหว่างการประมวลผลบน Edge, การปรับโมเดลแบบ local AutoML และการส่งสรุปเมตริกไปยังคลาวด์ เทคโนโลยีเหล่านี้ร่วมกันช่วยให้ระบบตรวจจับในสายการผลิตมีความแม่นยำสูงขึ้น ลด false alarms ประหยัดแบนด์วิดท์ และลดต้นทุนการจัดเก็บข้อมูลบนคลาวด์อย่างมีประสิทธิภาพ
หลักการทำงานของ AutoML บน Edge (เชิงเทคนิค)
หลักการทำงานเชิงเทคนิคของ AutoML บน Edge — ภาพรวมของวงจรการทำงาน
AutoEdge‑Trainer ออกแบบมาเป็นวงจรการทำงานแบบปิด (closed loop) ที่ตอบโจทย์การใช้งานในสภาพสายการผลิตจริง โดยยึดหลักกระบวนการ collect → label → train → evaluate → deploy อย่างต่อเนื่องเพื่อปรับโมเดลให้สอดคล้องกับ distribution ของข้อมูลจริง ลดอัตรา False‑Alarm และลดการส่งข้อมูลขึ้นคลาวด์ ตัวอย่างเช่น ระบบรายงานว่าเมื่อใช้องค์ประกอบในวงจรนี้ร่วมกับกลยุทธ์เฉพาะสำหรับ Edge แล้ว สามารถลด False‑Alarm ได้ถึง 60% และลดการส่งข้อมูลไปคลาวด์ลงราว 80% ในการใช้งานภาคการผลิตจริง
การเก็บตัวอย่างจากเหตุการณ์จริง (Collect)
การเก็บตัวอย่างในสภาพสายการผลิตต้องคำนึงถึงความเป็นไปได้ของเหตุการณ์ผิดปกติที่เกิดไม่บ่อย (rare events) และความเปลี่ยนแปลงของเงื่อนไขแวดล้อม ระบบจะเก็บข้อมูลแบบเชิงรุก (event‑triggered capture) รวมกับการเก็บแบบ sampling ประจำ โดยจะบันทึกเมตาดาต้า เช่น เวลาที่เกิด เหตุการณ์ที่กระตุ้น (sensor trigger), เวอร์ชันเฟิร์มแวร์ของ Edge และสภาวะแสง ตัวอย่างเช่น:
- เก็บภาพ/วิดีโอรอบเหตุการณ์ความผิดปกติเป็น window ±t วินาที
- คัดแยกข้อมูลโดย confidence ของโมเดลปัจจุบัน เพื่อโฟกัสตัวอย่างที่โมเดลไม่แน่ใจ (uncertain samples)
- แท็กเมตาดาต้าสำหรับการแบ่งชุดข้อมูลแบบ time‑series holdout เพื่อป้องกัน data leakage
การติดป้าย (Labeling) กึ่งอัตโนมัติ
AutoEdge‑Trainer ใช้กลไก model‑assisted labeling และ active learning เพื่อเร่งกระบวนการ annotating โดยลดภาระมนุษย์และเพิ่มความแม่นยำของป้าย:
- Pseudo‑labeling: โมเดลเดิมฉลากตัวอย่างที่มีความเชื่อมั่นสูงให้เป็น label เบื้องต้น
- Active sampling: เลือกตัวอย่างที่ความไม่แน่นอนสูง (low confidence / high entropy) ให้คนตรวจสอบก่อน
- Annotation propagation: ใช้อัลกอริทึม optical flow / tracking เพื่อคัดลอก annotation ข้ามเฟรมในวิดีโอ ลดงานบรรจุกรอบ (bounding box) ด้วยมือ
- Human‑in‑the‑loop: อินเทอร์เฟซสำหรับการแก้ไขยืนยันอย่างรวดเร็ว (fast correction) พร้อมโลจิก batch validation เพื่อลด time‑to‑label
ผลลัพธ์คือเวลาการติดป้ายลดลงอย่างมีนัยสำคัญ และคุณภาพป้ายดีขึ้นเพราะระบบคัดเฉพาะตัวอย่างที่มนุษย์ต้องตัดสิน
การเลือกสถาปัตยกรรมโมเดล — NAS และ constrained search space
สำหรับ Edge การเลือกสถาปัตยกรรมต้องคำนึงถึงข้อจำกัดด้านหน่วยความจำ, latency, และพลังงาน AutoEdge‑Trainer ใช้แนวทาง hardware‑aware NAS โดยมีการจำกัด search space เพื่อให้ได้สถาปัตยกรรมที่ปฏิบัติได้จริงบนฮาร์ดแวร์เป้าหมาย:
- Constrained search space: จำกัดชนิดของบล็อกที่ค้นหา (เช่น mobile inverted residual, depthwise separable conv), จำกัดขนาด kernel (3×3, 5×5), และจำนวนช่องสัญญาณเพื่อคุม FLOPs
- One‑shot / weight‑sharing: ลดค่าใช้จ่ายของการค้นหาโดยแชร์พารามิเตอร์ระหว่างสถาปัตยกรรม เพื่อให้ค้นหาได้เร็วขึ้น
- Latency/energy predictor: ฝึกตัวคาดการณ์ (predictor) ที่แปลงสถาปัตยกรรมเป็นค่าประเมิน latency และ memory บน target device เพื่อใช้เป็น constraint ในฟังก์ชันค่าเสียหาย (loss)
- Multi‑objective optimization: ใช้ cost function ที่ผสมระหว่าง accuracy, latency, และ model size (เช่น minimize α·latency + β·size − γ·accuracy)
ตัวอย่างเทคนิคที่ใช้ได้แก่ gradient‑based NAS (เช่น DARTS), evolutionary search และ reinforcement learning โดยเลือกวิธีที่เหมาะกับทั้งเวลาในการค้นหาและข้อจำกัดทรัพยากร
เทคนิค Optimization สำหรับ Edge
หลังจากได้สถาปัตยกรรมพื้นฐานแล้ว ระบบจะนำโมเดลผ่านชุดการปรับให้เหมาะกับฮาร์ดแวร์ปลายทาง:
- Quantization‑aware training (QAT): ฝึกโดยจำลองการปริมาณ (int8/int16) เพื่อลดขนาดและเพิ่ม throughput โดยยังคงความแม่นยำ
- Structured pruning: ตัดช่องสัญญาณหรือบล็อกทั้งบล็อก (channel/filter pruning) เพื่อลดการคำนวณแบบเป็นโครงสร้าง
- Knowledge distillation: สร้างครู (teacher) และนักเรียน (student) เพื่อให้ student ขนาดเล็กเรียนรูปแบบจาก teacher ขนาดใหญ่ เพิ่ม robustness
- Operator fusion & compiler optimizations: ใช้การรวม operator และ backend เช่น TFLite, ONNX‑Runtime, หรือ vendor‑specific SDK (เช่น NVIDIA TensorRT) เพื่อให้ latency ต่ำสุด
- Early‑exit & cascaded models: สำหรับงานที่ต้องการ latencyเข้มงวด ใช้โมเดลแบบหลายจุดตัดสินใจ (early exit) เพื่อให้ตัวอย่างง่ายถูกคัดออกเร็ว
การป้องกัน Overfitting เมื่อใช้ข้อมูลสภาพการผลิตจริง
ข้อมูลจากสายการผลิตมักมีความไม่สมดุลและอาจนำไปสู่ overfitting ถ้าโมเดลเรียนเฉพาะ noise ของสภาพเดิม AutoEdge‑Trainer ใช้วิธีผสมผสานหลายกลยุทธ์เพื่อลดความเสี่ยงนี้:
- Progressive fine‑tuning: เริ่มจากโมเดล pretrained บน dataset ขนาดใหญ่ (เช่น ImageNet / domain‑generic datasets) จากนั้นค่อยๆ ปรับด้วยข้อมูลสายการผลิตในหลายขั้นตอน โดยสลับการปลดล็อกเลเยอร์ทีละชั้นและใช้ learning rate ที่ลดลง ช่วยให้โมเดลรักษา feature ทั่วไปพร้อมรับข้อมูลเฉพาะ
- Domain augmentation: สร้างความหลากหลายของสภาพการผลิตด้วย augmentation ที่เฉพาะทาง เช่น การเปลี่ยนแปลงแสงแบบเฉพาะเครื่องจักร, motion blur ตามความเร็วสายพาน, occlusion จากชิ้นงาน, sensor noise และ color jitter เพื่อเลียนแบบ distribution ที่เป็นไปได้
- Synthetic sim‑to‑real & domain randomization: ใช้ภาพสังเคราะห์และปรับค่าแบบสุ่ม (lighting, texture) เพื่อเพิ่ม robustness ต่อสภาพแวดล้อมที่ไม่เคยเห็น
- Regularization และ validation on time‑split: ใช้ weight decay, dropout, mixup/CutMix และการแบ่ง validation แบบ temporal (holdout ของช่วงเวลา) เพื่อให้การประเมินสะท้อนการเปลี่ยนแปลงจริงของสายการผลิต
การประเมินและการใช้งาน (Evaluate → Deploy)
ขั้นตอนประเมินรวมทั้งการทดสอบเชิงฟังก์ชันและการประเมินเชิงทรัพยากร (latency, memory, energy) บนฮาร์ดแวร์จริง พร้อมกลไก deployment แบบค่อยเป็นค่อยไป (canary/rolling) และการมอนิเตอร์เพื่อจับ concept drift หาก performance ลดลง วงจรจะสั่งให้กลับมาทำ collect ใหม่เพื่อเริ่ม loop ซ้ำ โดยระบบสนับสนุน rollback อัตโนมัติและการ A/B test เพื่อยืนยันว่าการเปลี่ยนแปลงลด False‑Alarm โดยไม่ลดค่า throughput ของสายการผลิต
บทสรุปเชิงเทคนิค
โดยรวม AutoEdge‑Trainer เชื่อมโยงขั้นตอนจากการเก็บข้อมูลจริง การใช้เทคนิค labeling กึ่งอัตโนมัติ และการค้นหา/ปรับแต่งโมเดลที่คำนึงถึงข้อจำกัดของ Edge (ผ่าน constrained NAS และ hardware‑aware optimization) ร่วมกับมาตรการป้องกัน overfitting (progressive fine‑tuning และ domain augmentation) ทำให้ระบบสามารถส่งมอบโมเดลที่แม่นยำและเบาพอจะรันบนอุปกรณ์ปลายทางจริงได้อย่างต่อเนื่องและเชื่อถือได้
คู่มือทีละขั้นตอน: ติดตั้ง ฝึก และ Deploy
คู่มือทีละขั้นตอน: ติดตั้ง ฝึก และ Deploy
ส่วนนี้เป็นคู่มือเชิงปฏิบัติสำหรับทีมวิศวกรรมและฝ่ายปฏิบัติการ ที่ต้องการใช้งาน AutoEdge‑Trainer เพื่อปรับโมเดล Computer‑Vision บน Edge ให้สอดคล้องกับสภาพสายการผลิตจริง โดยมุ่งลด False‑Alarm และลดการส่งข้อมูลขึ้นคลาวด์ ขั้นตอนครอบคลุมตั้งแต่การเตรียมข้อมูล การรันระบบ การตั้งค่า hyperparameters สำหรับ Edge การมอนิเตอร์ระหว่างฝึก ไปจนถึงการ deploy ลงอุปกรณ์จริง พร้อมแนวทางการทดสอบแบบ A/B และเคล็ดลับเพื่อลด False‑Alarm อย่างเป็นระบบ
1) การเตรียมข้อมูล (Capture protocol & Labeling tips)
- Capture protocol — กำหนดสคริปต์การเก็บภาพ/วิดีโอที่ครอบคลุมสภาวะจริง: มุมกล้องหลากหลาย, ระยะห่าง, ความเร็วสายพาน, สภาพแสง (กลางวัน/กลางคืน/ย้อนแสง), มุมมองมิติ (top/side) และกรณีขยะ/สิ่งกีดขวางที่เกิดบ่อย ควรจัดเก็บอย่างน้อย 2–4 สัปดาห์ของการทำงานจริงเพื่อเก็บความแปรปรวนของปัญหา
- Sampling strategy — ใส่ sampling แบบเวลาจริง (time stratified) และเหตุการณ์หายาก (event‑based) เพื่อให้โมเดลเรียนรู้ข้อผิดพลาดที่เกิดไม่บ่อย
- Labeling tips — กำหนดมาตรฐานการติดป้าย: ใช้ bounding boxes สำหรับงานตรวจจับข้อบกพร่อง, segmentation เมื่อต้องการขอบเขตชัดเจน, hierarchical labels (เช่น defect/type/subtype) และเกณฑ์ชัดเจนสำหรับกรณีคลุมเครือ
- Quality control — ใช้ double‑labeling หรือ consensus labeling สำหรับชุดตัวอย่างสำคัญ และตั้งชุด validation ที่ผ่านการตรวจสอบโดยวิศวกรสายการผลิต
- Train/Val/Test split (แนะนำ) — 60/20/20 หรือ 70/15/15 ขึ้นกับปริมาณข้อมูล: สำหรับงาน production แนะนำอย่างน้อย 10k+ sample กับ class imbalance ให้ใช้ stratified split และเก็บ holdout test ที่มาจากวัน/เครื่องจักรต่างกัน
- Data augmentation — ใช้ augmentation ที่จำลองสภาพจริง เช่น brightness/contrast jitter, motion blur, occlusion patches, random crops และ synthetic defects (กรณีขาดตัวอย่าง)
2) ตัวอย่างคำสั่งติดตั้งและรัน AutoEdge‑Trainer (pseudo‑commands)
ขั้นตอนต่อไปเป็นตัวอย่างคำสั่งเชิง pseudo‑code เพื่อให้ทีมสามารถติดตั้งและเริ่มการทดลองได้อย่างรวดเร็ว
- ติดตั้ง runtime / environment:
ae-trainer install --env edge --arch arm64 --runtime autoedge-runtime:v1.2
- นำเข้า dataset:
ae-trainer dataset import --name production_line_A --path /data/production_A --labels labels.json
- สั่งรันการฝึกครั้งแรก (baseline):
ae-trainer train --dataset production_line_A --arch mobile-cv-lite --img-size 320 --epochs 50 --batch 32 --lr 0.01 --edge-target memory=256MB,latency<50ms --output /models/run001
- เริ่มการมอนิเตอร์:
ae-trainer monitor --run /models/run001 --metrics precision,recall,f1,false_alarm_rate --stream tensorboard://localhost:6006
- export model สำหรับ Edge (ตัวอย่าง TFLite 8‑bit):
ae-trainer export --run /models/run001 --format tflite --quantize int8 --target armv8 --optimize latency --out /deploy/run001.tflite
- deploy ไปยังอุปกรณ์เป้าหมาย:
ae-trainer deploy --model /deploy/run001.tflite --device gateway-01 --strategy rolling --healthcheck 30s
3) การตั้งค่า hyperparameters สำหรับ Edge
สำหรับ Edge constraints ต้องบาลานซ์ระหว่างความแม่นยำกับทรัพยากร:
- Image size: 224–320 px (จุดเริ่มต้นแนะนำ 320 สำหรับความแม่นยำที่ดี แต่ถ้า latency สูง ลดเป็น 224)
- Batch size: 8–32 ขึ้นกับหน่วยความจำ
- Learning rate: เริ่มที่ 0.01 (SGD) หรือ 1e‑3 (Adam) และใช้ cosine decay หรือ step decay
- Epochs: 30–100 (ใช้ early stopping บน validation F1 / false_alarm_rate เพื่อป้องกัน overfitting)
- Regularization: weight decay 1e‑4, label smoothing 0.1 สำหรับ classification หลีกเลี่ยง overconfidence
- Quantization: 8‑bit integer (post‑training หรือ quantization aware training หากต้องการความแม่นยำสูงหลัง quantize)
- Non‑Max Suppression (NMS): IoU threshold 0.4–0.6 ปรับตามลักษณะวัตถุเพื่อช่วยลด false positives ซ้อนกัน
- Latency & memory targets: ตั้งเป็น constraints ในคำสั่ง train เพื่อให้ AutoEdge‑Trainer เลือกสถาปัตยกรรมและการ prune ให้พอดี เช่น --edge-target memory=256MB,latency<30ms
4) การมอนิเตอร์ระหว่างฝึกและการวัดผล (Monitoring & Metrics)
การติดตาม metric สำคัญระหว่างฝึกช่วยให้รู้เมื่อโมเดลเริ่ม overfit หรือยังไม่ตอบโจทย์ False‑Alarm:
- Metrics ที่ต้องมอนิเตอร์: precision, recall, F1, false alarm rate (FAR = FP / total_negatives), detection latency (ms), throughput (fps), model size (MB)
- Logging: stream ไปยัง TensorBoard / Prometheus / Grafana: ae-trainer monitor --run /models/run001 --stream prometheus://host:9090
- Confusion matrix & PR curve: ตรวจสอบ curve เพื่อเลือก threshold ที่ trade‑off ระหว่าง recall กับ false alarms
- Visual inspection: สุ่มดูกรณีที่ false positives/false negatives เกิดบ่อย และเก็บตัวอย่างเหล่านั้นเข้าชุด hard‑negative เพื่อเทรนต่อ
5) ขั้นตอนการ Deploy โมเดลลงอุปกรณ์จริงและการบริหารวงจรชีวิตโมเดล
- แปลงและ optimize: จาก checkpoint → ONNX → TFLite/ TensorRT พร้อม quantization: ae-trainer export --format onnx && ae-trainer convert --onnx run001.onnx --to tflite --quantize int8
- ทดสอบใน sandbox device: ก่อน rollout ให้ทดสอบบนอุปกรณ์ตัวแทน (same CPU/GPU/TPU) เพื่อวัด latency และ memory usage
- กลยุทธ์ rollout: ใช้ rolling deployment (10% → 30% → 100%) พร้อม health checks และ auto‑rollback เงื่อนไข เช่น FAR เพิ่มขึ้น > 10% หรือ latency เกิน SLA
- OTA & observability: อัปเดตโมเดลแบบ over‑the‑air พร้อม telemetry ที่ส่งเฉพาะเมตริกหรือ edge‑summaries เพื่อลด bandwidth (สอดคล้องกับเป้าหมายลดการส่งคลาวด์ 80%)
- Fail‑safe และ manual override: ให้ระบบสามารถสลับกลับไปใช้โมเดลก่อนหน้าได้ทันที และมีการแจ้งเตือนเมื่อ false alarms spike
6) การปรับจูนเพื่อลด False‑Alarm และการทดสอบแบบ A/B
แนวทางเชิงปฏิบัติเพื่อกดค่า False‑Alarm ลงอย่างเป็นระบบ
- Threshold tuning & calibration: เลือก threshold detection โดยอาศัย PR curve และค่า cost matrix ที่สะท้อนความเสียหายของ false positive vs false negative ตัวอย่างคำสั่ง pseudo: ae-trainer eval --run /models/run001 --thresholds 0.1,0.2,...,0.9 --metric false_alarm_rate,recall
- Temporal smoothing: ใช้ voting over N frames (เช่น ต้องตรวจจับต่อเนื่อง 3 เฟรมก่อนแจ้งเตือน) เพื่อลดการแจ้งเตือนชั่วคราว
- Spatial ROI & background masking: กำหนด region of interest เพื่อตัดกรณี irrelevent motion ลด false positives จากสิ่งแวดล้อม
- Hard negative mining & continuous learning: รวบรวม false positives ที่เกิดจริงจาก deployment แล้วป้อนกลับมาเป็น hard negatives เพื่อฝึกซ้ำ
- Loss function & class weighting: ใช้ focal loss หรือเพิ่มน้ำหนักให้ negative class ในกรณีที่ false positive ก่อผลกระทบสูง
- A/B testing workflow:
- Define KPI: false_alarm_rate (FAR), recall_on_defects, MTTR (mean time to respond), bandwidth saved
- Split devices/lines randomly: Group A (current model) vs Group B (candidate model)
- Collect data เป็นระยะเวลาเพียงพอ (เช่น 2–4 สัปดาห์ ขึ้นกับอัตราเหตุการณ์) และตั้งเกณฑ์ความสำคัญ (statistical significance, p‑value & confidence interval)
- ตัวอย่าง pseudo command เพื่อรัน A/B:
- ae-trainer abtest --control /deploy/prev.tflite --treatment /deploy/run001.tflite --devices groupB.list --duration 14d --metrics false_alarm_rate,recall
- ตัดสินใจ rollout เมื่อ FAR ลดลงตามเป้า (ตัวอย่าง: ลด 60%) และ recall อยู่ในขอบเขตที่ยอมรับได้
7) เคล็ดลับเชิงปฏิบัติ (Quick wins)
- เริ่มด้วย small on‑device model และ fine‑tune บนตัวอย่างจริงในสายการผลิต 1–2 เครื่องก่อนขยาย
- ใช้ ensemble แบบเบา (เช่น motion detector + lightweight classifier) เพื่อลด False‑Alarm โดยให้ต้องผ่านทั้งสองชั้นก่อนแจ้งเตือน
- ตั้งระบบ feedback loop ให้ operator สามารถ tag false alarms บนอุปกรณ์ ทำให้เก็บข้อมูลย้อนหลังเพื่อ hard‑negative mining อัตโนมัติ
- ประเมินค่า trade‑off ด้วย business metric (เช่น ค่าใช้จ่ายจาก false alarm ต่อวัน) เพื่อกำหนด threshold ที่เหมาะสม ไม่ใช้ metric ทางเทคนิคเพียงอย่างเดียว
เมื่อปฏิบัติตามขั้นตอนข้างต้น ทีมของท่านจะสามารถติดตั้ง ฝึก และ deploy โมเดล Computer‑Vision บน Edge ได้อย่างมีระบบ พร้อมกลไกปรับปรุงต่อเนื่องที่จะช่วยลด False‑Alarm อย่างมีนัยสำคัญ และลดปริมาณข้อมูลที่ต้องส่งขึ้นคลาวด์ตามเป้าหมายธุรกิจ
การประเมินผลและผลลัพธ์จริง: เบนช์มาร์กและกราฟเปรียบเทียบ
การประเมินผลของระบบ AutoEdge‑Trainer ดำเนินการบนสายการผลิตชิ้นส่วนอิเล็กทรอนิกส์จริง โดยใช้กล้องความละเอียด 2MP ที่จับภาพที่ 30 fps ต่อสถานี จำนวน 6 สถานี และเก็บข้อมูลทดสอบรวมประมาณ 50,000 เฟรม ในช่วงการทดลองต่อเนื่อง 72 ชั่วโมง ชุดข้อมูลประกอบด้วยตัวอย่างปกติและความผิดปกติรวมกันประมาณ 2,000 กรณี (anomaly) การเปรียบเทียบแบ่งเป็นสถานะ ก่อนใช้ (ระบบเดิมส่งข้อมูลดิบขึ้นคลาวด์เพื่อวิเคราะห์) และ หลังใช้ AutoEdge‑Trainer (โมเดลถูกปรับและรันบนอุปกรณ์ Edge โดยอัตโนมัติ พร้อมนโยบายส่งเฉพาะเหตุการณ์ที่มีความไม่แน่นอนสูง) ผลที่นำเสนอเป็นค่าเฉลี่ยจากการทดลองทำซ้ำ 10 ครั้ง พร้อมการวัดความแปรปรวนเพื่อยืนยันความมั่นคงของผลลัพธ์
เมตริกที่ใช้วัด (Benchmark Metrics)
- False‑Alarm Rate — อัตราการแจ้งเตือนเท็จ (false positives) ต่อจำนวนเหตุการณ์จริง
- Precision / Recall / F1‑Score — คุณภาพการตรวจจับในเชิงความถูกต้องและการครอบคลุม
- Latency — เวลาเฉลี่ยจากการจับภาพจนได้ผลลัพธ์ (ms) ที่วัดบนอุปกรณ์ Edge
- Bandwidth reduction — ปริมาณข้อมูลที่ส่งขึ้นคลาวด์ (GB/วัน) เปรียบเทียบก่อน‑หลัง
- Stability under environment change — การทดสอบความคงที่เมื่อมีการเปลี่ยนแปลงแสง (lighting) และการบดบัง (occlusion)
ผลลัพธ์เชิงตัวเลขก่อน‑หลัง (ตัวอย่างเชิงปฏิบัติ)
ตารางตัวเลขด้านล่างสรุปค่าเมตริกเฉลี่ยจากการทดลองบนสายการผลิตจริง ซึ่งแสดงการปรับปรุงที่ชัดเจนทั้งด้านความแม่นยำและการลดภาระเครือข่าย:
- ก่อนใช้ระบบเดิม (Baseline):
- Precision = 0.85
- Recall = 0.90
- F1‑Score = 0.87
- False‑Alarm Rate = 12.5%
- Latency (Edge inference via cloud) = 150 ms (รวมเวลาเครือข่าย)
- Data sent to cloud = 500 GB / วัน
- หลังใช้ AutoEdge‑Trainer:
- Precision = 0.93
- Recall = 0.91
- F1‑Score = 0.92
- False‑Alarm Rate = 5.0% (ลดลง 60% เทียบกับค่าเริ่มต้น)
- Latency (Edge optimized) = 45 ms (เฉลี่ย, ลดประมาณ 70%)
- Data sent to cloud = 100 GB / วัน (ลดลง 80%)
การเปลี่ยนแปลงเชิงตัวเลขข้างต้นยืนยันว่า AutoEdge‑Trainer ไม่เพียงแต่ช่วยลด False‑Alarm ได้ถึงประมาณ 60% แต่ยังทำให้ Precision และ F1‑Score ปรับปรุงขึ้นอย่างมีนัยสำคัญ (Precision เพิ่มจาก 0.85 เป็น 0.93) ซึ่งลดภาระงานฝ่ายตรวจสอบคุณภาพและลดการหยุดสายการผลิตที่เกิดจากการแจ้งเตือนผิดพลาด
กราฟเปรียบเทียบและการวิเคราะห์เชิงเวลา
กราฟที่แนบแสดงการเปรียบเทียบแบบเวลา-ต่อ-เวลา (time‑series) ของอัตรา False‑Alarm และปริมาณข้อมูลที่ส่งขึ้นคลาวด์ (GB/วัน) ระหว่างสถานะก่อนและหลังการใช้งาน AutoEdge‑Trainer: เส้นกราฟของ False‑Alarm ลดลงอย่างชัดเจนหลังการปรับโมเดลบน Edge ขณะที่กราฟปริมาณข้อมูลที่ส่งขึ้นคลาวด์ลดลงประมาณ 80% ทำให้แบนด์วิดท์และค่าใช้จ่ายคลาวด์ลดลงตามไปด้วย
การทดสอบความคงที่ของโมเดลในสภาพแวดล้อมเปลี่ยนแปลง
เพื่อทดสอบความทนทานของโมเดล ทีมทดสอบได้จำลองเงื่อนไขที่พบบ่อยในโรงงาน ได้แก่:
- การเปลี่ยนแปลงแสง (lighting) — จากแสงสว่างปกติ ไปยังสภาวะแสงน้อย (low‑light) และแสงย้อน (backlight)
- การบดบังบางส่วน (occlusion) — ใช้แผ่นบังชั่วคราวหรือวัตถุผ่านหน้ากล้องเพื่อประเมินผล
ผลการทดสอบแสดงว่า AutoEdge‑Trainer สามารถปรับพารามิเตอร์และเฟิร์มแวร์โมเดลบน Edge เพื่อรักษา False‑Alarm ให้อยู่ในระดับต่ำได้อย่างต่อเนื่อง ดังนี้:
- ภายใต้สภาวะแสงน้อย: False‑Alarm ลดจาก 20% (baseline) เป็น 8% หลังการปรับ (ลด ~60%)
- ภายใต้ occlusion 30% ของพื้นที่ภาพ: False‑Alarm ลดจาก 15% เป็น 6%
- Latency คงที่ระหว่าง 40–60 ms แม้ในสภาพแวดล้อมที่มีการเปลี่ยนแปลงเล็กน้อย ซึ่งเพียงพอสำหรับการใช้งานเรียลไทม์บนสายการผลิต
นอกจากนี้ ระบบยังบันทึกว่าในช่วงทดสอบ 10 ชุดย่อย ค่าเบี่ยงเบนมาตรฐานของ False‑Alarm อยู่ในระดับที่ยอมรับได้ (std dev ประมาณ 1.2%) ซึ่งบ่งชี้ถึงความเสถียรของกระบวนการปรับโมเดลอัตโนมัติบน Edge ในสภาวะแวดล้อมที่ไม่แน่นอน
สรุปเชิงธุรกิจ
การลด False‑Alarm ประมาณ 60% และการลดปริมาณข้อมูลที่ส่งขึ้นคลาวด์ถึง 80% ช่วยนำไปสู่ผลประโยชน์เชิงธุรกิจที่จับต้องได้ ได้แก่ การลดเวลาหยุดสายการผลิต การลดภาระงานฝ่ายตรวจสอบคุณภาพ และการประหยัดค่าใช้จ่ายคลาวด์ ระบบ AutoEdge‑Trainer จึงแสดงผลลัพธ์ที่แข็งแกร่งทั้งในเชิงเทคนิคและเชิงเศรษฐศาสตร์เมื่อนำไปใช้งานในโรงงานจริง
กรณีศึกษาเชิงธุรกิจ, ความท้าทาย และแนวทางปฏิบัติที่ดีที่สุด
กรณีศึกษาเชิงธุรกิจ: ผลกระทบต่อ OEE และต้นทุนการตรวจสอบ
ตัวอย่างจากโรงงานผลิตชิ้นส่วนอิเล็กทรอนิกส์ขนาดกลางที่ใช้งานระบบ AutoEdge‑Trainer ในสายการประกอบ PCB พบว่าอัตราแจ้งเตือนผิดพลาด (false‑alarm) ลดลงจากระดับเดิมลงประมาณ 60% ซึ่งส่งผลให้จำนวนการหยุดสายอันเนื่องมาจากการตรวจสอบด้วยมือหรือการหยุดเพื่อตรวจสอบข้อสงสัยลดลงอย่างชัดเจน ผลลัพธ์สำคัญคือ OEE (Overall Equipment Effectiveness) ของสายการผลิตเพิ่มขึ้นจาก 78% เป็นประมาณ 82–85% ภายใน 3 เดือนแรกของการใช้งาน
ในเชิงต้นทุน โรงงานรายนี้รายงานว่าค่าใช้จ่ายด้านการตรวจสอบด้วยมนุษย์ลดลงประมาณ 35–40% เนื่องจากจำนวนการเรียกช่างตรวจสอบลดลง ตลอดจนการลดการสูญเสียจากการตัดสินค้าออกโดยไม่จำเป็น (false rejects) ส่งผลให้ต้นทุนวัตถุดิบที่สูญเสียลดลงอีก ~12% นอกจากนี้ การลดปริมาณข้อมูลที่ต้องส่งขึ้นคลาวด์ลง 80% ช่วยประหยัดค่าแบนด์วิดท์และค่าจัดเก็บข้อมูล ทำให้ต้นทุนระบบภาพรวมลดลงอย่างมีนัยสำคัญ
หากพิจารณา ROI แบบง่ายจากการลงทุนเริ่มต้นสมมุติที่ 3 ล้านบาทสำหรับฮาร์ดแวร์ edge, ลิขสิทธิ์ซอฟต์แวร์ และงานติดตั้ง พบว่าโรงงานสามารถคืนทุนภายใน 2–3 ปี โดยอาศัยการประหยัดจากแรงงานและการลดการสูญเสียวัตถุดิบ หากรวมมูลค่าการเพิ่มขึ้นของกำลังการผลิตจาก OEE ที่สูงขึ้นแล้ว ค่า ROI จะยิ่งดีกว่าเดิม ตัวอย่างคำนวณสั้นๆ: ประหยัดประจำปี 1.2 ล้านบาท → Payback ≈ 2.5 ปี
ความท้าทายที่พบในการนำ AutoEdge‑Trainer ไปใช้
แม้ผลลัพธ์จะชัดเจน แต่การใช้งาน AutoML บน Edge ในสภาพสายการผลิตจริงมีความท้าทายหลายด้านที่องค์กรต้องเตรียมรับมือ:
- Data drift และ concept drift: สภาพวัตถุดิบ แสงสว่าง หรือชิ้นงานรุ่นใหม่สามารถเปลี่ยนลักษณะข้อมูลภาพได้ ทำให้ประสิทธิภาพโมเดลเสื่อมลงเมื่อเวลาผ่านไป หากไม่มีระบบตรวจจับ drift ที่ดี ประสิทธิภาพจะลดลงโดยไม่รู้ตัว
- Maintenance ของโมเดลบน Edge: การอัปเดตโมเดลในอุปกรณ์หลายร้อยหรือพันตัวต้องจัดการเวอร์ชัน ควบคุมการปล่อย (deployment) และตรวจสอบผลกระทบ เช่น การใช้กลยุทธ์ canary หรือ shadow testing เพื่อป้องกันความผิดพลาดจากโมเดลใหม่
- Policy ด้านความเป็นส่วนตัวและกฎหมาย: การเก็บข้อมูลภาพในสายการผลิตอาจมีภาพของพนักงานหรือข้อมูลที่ระบุตัวบุคคล การส่งข้อมูลขึ้นคลาวด์หรือการจัดเก็บต้องสอดคล้องกับกฎระเบียบ เช่น PDPA หรือมาตรฐานภายในองค์กร จำเป็นต้องมีนโยบายการทำความเป็นนิรนาม (anonymization) และการจำกัดการเข้าถึง
- ข้อจำกัดด้านฮาร์ดแวร์: ความจุหน่วยความจำและความเร็วประมวลผลบน Edge อาจจำกัดขนาดของโมเดลหรือความถี่ในการ inference ซึ่งต้องออกแบบ trade‑off ระหว่างความแม่นยำและ latency
แนวทางปฏิบัติที่ดีที่สุด (Best Practices)
เพื่อให้การนำ AutoEdge‑Trainer ประสบผลสำเร็จและยั่งยืน แนะนำแนวทางปฏิบัติด้านเทคนิคและการจัดการดังนี้:
- Continuous monitoring — ติดตั้ง dashboard และตั้งค่า alert สำหรับ metrics สำคัญ เช่น precision/recall, false positive rate, latency, และตัวชี้วัด drift เช่น Population Stability Index (PSI) หรือ KL divergence เพื่อจับสัญญาณการเสื่อมของโมเดลโดยอัตโนมัติ
- Retraining schedule แบบผสม (scheduled + event‑driven) — ตั้งการ retrain เป็นรอบประจำ (เช่น ทุก 2–4 สัปดาห์สำหรับสายที่เปลี่ยนแปลงบ่อย หรือทุก 1–3 เดือนสำหรับสายที่คงที่) และเปิดใช้งาน retraining เมื่อระบบตรวจพบ drift ข้ามเกณฑ์ที่กำหนด เพื่อให้โมเดลปรับตัวกับข้อมูลใหม่ทันเวลา
- Human‑in‑the‑loop และ active learning — ใช้กลไกเลือกตัวอย่างที่ระบบไม่แน่ใจสูง (uncertain samples) ให้มนุษย์ตรวจสอบและนำผลนั้นกลับเข้า pipeline เพื่อเพิ่มประสิทธิภาพการเรียนรู้โดยไม่ต้องป้ายข้อมูลทั้งหมด
- Deployment strategy — ประยุกต์ใช้ canary release, shadow testing และ rollback plans ก่อนขยายการใช้งานในวงกว้าง รวมทั้งบันทึกผลการทดสอบทุกขั้นตอนใน model registry เพื่อการ audit และ rollback
- Governance และ security — สร้างนโยบาย data governance ที่ชัดเจน ครอบคลุมการจำกัดการเข้าถึง การทำ anonymization ของภาพ การเข้ารหัสข้อมูลทั้งขณะพักและขณะส่ง และการเก็บ log สำหรับการตรวจสอบการปฏิบัติตามกฎหมาย เช่น PDPA; นอกจากนี้ควรมีการทำ Privacy Impact Assessment ก่อนการนำไปใช้
- Edge device management — ใช้ระบบจัดการเครื่องแบบรวมศูนย์สำหรับ OTA updates ของโมเดลและซอฟต์แวร์ ติดตั้งการตรวจสอบทรัพยากร เช่น CPU/GPU utilization และอายุของหน่วยความจำ เพื่อวางแผนกำหนดวันอัปเดตหรือเปลี่ยนอุปกรณ์
- ชัดเจนใน KPI การเงินและการผลิต — กำหนด KPI เช่น reduction in false alarms, reduction in manual inspection hours, increase in OEE (percentage points), และ total cost of ownership (TCO) เพื่อวัดผลเชิงธุรกิจและคำนวณ ROI อย่างสม่ำเสมอ
ด้วยแนวปฏิบัติเหล่านี้ องค์กรจะสามารถลดความเสี่ยงจากการเสื่อมประสิทธิภาพของโมเดลและปัญหาด้านความเป็นส่วนตัว ในขณะเดียวกันก็รักษาประสิทธิผลเชิงธุรกิจจากการนำ AutoEdge‑Trainer ไปใช้จริง ทำให้ได้ทั้งความแม่นยำของการตรวจจับที่สูงขึ้น การลดต้นทุนการตรวจสอบ และการเพิ่มผลผลิตในระยะยาว
ข้อจำกัดทางเทคนิคและทิศทางพัฒนาในอนาคต
ข้อจำกัดทางเทคนิคที่ยังต้องแก้ไข
แม้ระบบ AutoEdge‑Trainer จะแสดงผลลัพธ์เชิงปฏิบัติการที่น่าประทับใจ เช่น การลด False‑Alarm ประมาณ 60% และลดการส่งข้อมูลไปยังคลาวด์ได้ถึง 80% แต่ในสภาพแวดล้อมจริงยังมีข้อจำกัดทางเทคนิคสำคัญที่ต้องพิจารณา ก่อนนำไปใช้ในวงกว้าง หนึ่งในข้อจำกัดหลักคือทรัพยากรฮาร์ดแวร์บนอุปกรณ์ Edge โดยเฉพาะด้าน compute และ memory — ซีพียู/เอ็นพียูบนกล้องหรือคอนโทรลเลอร์ในโรงงานมักมีความสามารถจำกัด ทำให้ต้องปรับลดขนาดโมเดลหรือใช้เทคนิคเช่น quantization, pruning และ knowledge distillation ซึ่งแม้ช่วยให้รันได้บนอุปกรณ์ขนาดเล็ก แต่บางครั้งก็แลกมาด้วยการลดความเที่ยงตรงในกรณีมุมกล้องหรือเงื่อนไขแสงที่เปลี่ยนแปลงมาก
อีกประเด็นสำคัญคือความต้องการ dataset ที่เพียงพอและมีคุณภาพ สำหรับกรณีบางประเภทของ defect หรือเหตุการณ์ผิดปกติในสายการผลิต อาจต้องการตัวอย่างจำนวนมากซึ่งเป็นไปได้ยากและมีต้นทุนสูง การทำงานร่วมกับระบบ AutoML ที่พยายามเรียนรู้แบบอัตโนมัติยังเผชิญกับปัญหา label automation — ระบบช่วยแปะป้าย (auto‑labeling) หรือใช้เทคนิค pseudo‑labeling และ self‑supervised learning สามารถลดภาระการติดป้ายได้ แต่ยังมีข้อจำกัดเมื่อข้อมูลมีความไม่ชัดเจนหรือคลาสที่มีความไม่สมดุล (class imbalance) ทำให้การคัดกรอง false positive/false negative ยากขึ้น
ด้านการปฏิบัติการจริง ยังรวมถึงความท้าทายในแง่การติดตั้งบนฮาร์ดแวร์ที่หลากหลาย (heterogeneous hardware), การจัดการ latency ในการตรวจจับเหตุการณ์แบบเรียลไทม์, และข้อจำกัดด้านพลังงานสำหรับอุปกรณ์ที่ต้องทำงานต่อเนื่องตลอด 24/7 ทั้งนี้การวัดความสำเร็จไม่ควรมองแค่ตัวเลขการลด false alarm แต่ต้องผสมผสานเมตริกอื่นๆ เช่น precision, recall, F1, latency, throughput และการบริโภคพลังงาน เพื่อให้ตอบโจทย์ทางธุรกิจจริง
แนวทางพัฒนาในอนาคต
ทีมพัฒนาของ AutoEdge‑Trainer สามารถเดินหน้าเพิ่มฟีเจอร์ต่างๆ ที่ตอบโจทย์ข้อจำกัดข้างต้นได้หลากหลาย แนวทางสำคัญที่จะผลักดันประสิทธิภาพและความปลอดภัยของระบบ ได้แก่
- Federated Learning — การฝึกโมเดลแบบกระจายบนอุปกรณ์ Edge โดยส่งเฉพาะการอัปเดตน้ำหนัก (model updates) กลับมารวมกัน ช่วยลดการส่งข้อมูลดิบไปยังคลาวด์ ลดความเสี่ยงด้านความเป็นส่วนตัว และรองรับการเรียนรู้จากหลายไซต์ของโรงงานโดยไม่เปิดเผยภาพหรือข้อมูลดิบ
- On‑device Continual Learning — พัฒนากลไกการเรียนรู้ต่อเนื่องบนอุปกรณ์เพื่อรับมือกับ concept drift ในสายการผลิต เช่น เทคนิค incremental learning, replay buffers หรือ regularization ที่ลดปัญหา catastrophic forgetting ทำให้โมเดลปรับตัวตามสภาพแวดล้อมที่เปลี่ยนไปได้แบบเรียลไทม์
- การพัฒนาท่อข้อมูลที่ประหยัดฉลาก (label‑efficient) — รวมเทคนิค active learning, weak supervision และ human‑in‑the‑loop เพื่อลดความต้องการ dataset ขนาดใหญ่ โดยให้ระบบเลือกตัวอย่างที่มีประโยชน์สูงสุดสำหรับการติดป้ายด้วยมนุษย์
- รองรับฮาร์ดแวร์ที่หลากหลายยิ่งขึ้น — สร้างชั้น abstraction สำหรับ runtime (เช่น ONNX Runtime, TensorRT, OpenVINO, TFLite) และพัฒนาเครื่องมือ cross‑compile เพื่อให้ระบบรันได้ทั้งบน microcontrollers, NPUs, และ accelerators ของผู้ผลิตต่างๆ
- การอัดลดข้อมูลและการสื่อสารแบบมีประสิทธิภาพ — ใช้เทคนิค sparsification, quantized updates, และ differential compression ในเฟดเดอเรตเทรนนิ่งเพื่อลดแบนด์วิดท์และเวลาในการซิงก์
- ฟีเจอร์ด้านความเข้าใจและอธิบายผล (explainability) — เพิ่มโมดูลที่ให้เหตุผลหรือ heatmap ของการตัดสินใจ เพื่อสนับสนุนการตรวจสอบโดยมนุษย์และลดความเสี่ยงจาก false alarm ที่มีผลต่อการตัดสินใจเชิงธุรกิจ
ข้อพิจารณาทางกฎหมายและจริยธรรม
การนำระบบที่ประมวลผลภาพจากโรงงานไปใช้จริงมีประเด็นด้านกฎหมายและจริยธรรมที่ต้องคำนึงอย่างเป็นระบบ ก่อนการติดตั้งและใช้งานต้องประสานกับทีมกฎหมายและฝ่ายบริหารความเสี่ยงเพื่อกำหนดนโยบายชัดเจน ประเด็นสำคัญได้แก่การปฏิบัติตามพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคลของไทย (PDPA) และข้อกำหนดด้านความเป็นส่วนตัวหรือกฎระเบียบนานาชาติที่เกี่ยวข้อง
ข้อพิจารณาที่ต้องมีใน roadmap และสัญญาบริการ (SLA) ได้แก่
- การกำหนดขอบเขตการเก็บภาพและประเภทของข้อมูลที่อนุญาต (data minimization) รวมถึงการทำ anonymization/blur พื้นที่ที่เป็นข้อมูลส่วนบุคคล
- การจัดทำ Data Protection Impact Assessment (DPIA) และเอกสารการประเมินความเสี่ยงก่อนเริ่มเก็บข้อมูลหรือใช้งานฟีเจอร์ใหม่
- มาตรการด้านความปลอดภัย เช่น การเข้ารหัสข้อมูลทั้งขณะส่งและขณะจัดเก็บ, การควบคุมสิทธิ์การเข้าถึง, การบันทึกเหตุการณ์ (logging) และการสำรองข้อมูลที่ปลอดภัย
- การกำหนดนโยบายการเก็บรักษาและลบข้อมูล (retention & deletion policy) เพื่อลดความเสี่ยงจากการเก็บข้อมูลที่ไม่จำเป็น
- การรับผิดชอบและกระบวนการเมื่อเกิด false alarm ที่ส่งผลกระทบต่อการดำเนินงานหรือความปลอดภัย รวมถึงกลไก human‑in‑the‑loop เพื่อการยืนยันและแก้ไข
- การปฏิบัติตามมาตรฐานที่เกี่ยวข้อง เช่น ISO 27001 สำหรับระบบบริหารความปลอดภัยสารสนเทศ หรือ IEC 62443 ในบริบทของความปลอดภัยระบบอุตสาหกรรม
สรุปคือ การยกระดับ AutoEdge‑Trainer ให้ตอบโจทย์การใช้งานเชิงอุตสาหกรรมอย่างยั่งยืนจำเป็นต้องผสานทั้งการพัฒนาเทคนิคเพื่อลดการพึ่งพาคลาวด์และเพิ่มความสามารถในการเรียนรู้บนอุปกรณ์ กับการออกแบบกรอบการปฏิบัติที่ชัดเจนด้านกฎหมายและจริยธรรม การลงทุนในฟีเจอร์อย่าง federated learning, on‑device continual learning, และเครื่องมือควบคุมความเป็นส่วนตัวจะเป็นกุญแจสำคัญสู่การขยายผลเชิงพาณิชย์ในระยะยาว
บทสรุป

ระบบ AutoEdge‑Trainer ของสตาร์ทอัพไทยเป็นตัวอย่างเชิงปฏิบัติที่ชัดเจนของการปรับโมเดล Computer‑Vision บน Edge ให้สอดคล้องกับสภาพสายการผลิตจริง โดยผลลัพธ์เชิงตัวเลขจากการทดสอบในสภาพแวดล้อมการผลิตจริงชี้ว่า สามารถลดอัตรา False‑Alarm ได้ถึง 60% และลดปริมาณการส่งข้อมูลขึ้นคลาวด์ลงประมาณ 80% ซึ่งหมายความถึงการลดความหน่วงในการตรวจจับ ความผิดพลาดจากสัญญาณรบกวน และต้นทุนการสื่อสารข้อมูล ทั้งยังช่วยรักษาความเป็นส่วนตัวของข้อมูลภาพในโรงงานและลดการพึ่งพาโครงสร้างพื้นฐานคลาวด์ในระดับมาก
เพื่อการนำไปใช้อย่างยั่งยืน องค์กรควรประเมินปัจจัยพื้นฐานก่อนนำ AutoEdge‑Trainer มาปรับใช้ ได้แก่ ทรัพยากรฮาร์ดแวร์ (เช่น CPU/GPU/NPU, หน่วยความจำ, พลังงานและความสามารถในการทำ inference/finetune บนอุปกรณ์), กระบวนการ labeling (คุณภาพของฉลาก, เวิร์กโฟลว์การเก็บตัวอย่าง, การใช้ active learning/การทำ label correction โดยมนุษย์) และ governance (การจัดการเวอร์ชันโมเดล, การตรวจสอบความถูกต้อง, นโยบายความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบ) นอกจากนี้ควรวางแผนระบบการตรวจสอบแบบเรียลไทม์ (monitoring) และวงจรการ retraining ต่อเนื่องพร้อมเกณฑ์การทดสอบ/rollback เพื่อให้ความแม่นยำและอัตรา False‑Alarm อยู่ในเกณฑ์ที่ยอมรับได้ตลอดเวลา
มุมมองอนาคตชี้ว่าแนวทางการปรับโมเดลบน Edge จะเติบโตควบคู่ไปกับความก้าวหน้าของชิปรายการเร่งการประมวลผลบนอุปกรณ์, เทคนิค federated/continual learning, และเครื่องมือ MLOps ที่รองรับการ deploy‑validate‑retrain แบบอัตโนมัติ การนำ AutoEdge‑Trainer ไปใช้ในเชิงพาณิชย์จึงควรเริ่มจากการทดลองเชิงนำร่อง (pilot) เพื่อประเมิน ROI และความสามารถในการสเกล ก่อนขยายสู่สายการผลิตวงกว้าง — องค์กรที่เตรียมฮาร์ดแวร์ กระบวนการ labeling และ governance ไว้ล่วงหน้าร่วมกับแผนการตรวจสอบและ retraining ต่อเนื่อง จะได้เปรียบในการรักษาประสิทธิภาพ ลด false‑alarm และลดต้นทุนการส่งข้อมูลคลาวด์ในระยะยาว



