
กระทรวงศึกษาธิการ ประกาศเปิดตัวโครงการ 'Tutor‑LLM' ระบบสอนเฉพาะบุคคลด้วยปัญญาประดิษฐ์ที่ผสานแนวทาง Student‑Model, Knowledge‑Tracing และ Spaced‑Repetition เข้าด้วยกัน เพื่อยกระดับทักษะการอ่านและการเขียนของเด็กนักเรียนสังกัดรัฐอย่างเป็นระบบ ในรอบนำร่องที่เพิ่งสรุปผล กระทรวงรายงานว่าโครงการช่วยลดช่องว่างการอ่าน‑เขียนระหว่างนักเรียนกลุ่มเป้าหมายได้ถึง ร้อยละ 30 โดยระบบจะวิเคราะห์แบบเรียลไทม์ระบุช่องว่างความรู้ ปรับแผนการสอนให้เหมาะกับผู้เรียนแต่ละคน และจัดตารางทบทวนแบบเป็นช่วงเวลา (spaced‑repetition) เพื่อเสริมความจำระยะยาว
บทนำของข่าวนี้จะพาไปดูรายละเอียดผลการทดลอง—ทั้งวิธีการวัดผลเชิงปริมาณ ตัวอย่างการปรับบทเรียนสำหรับนักเรียนแต่ละราย ข้อเสนอแผนขยายผลสู่โรงเรียนทั่วประเทศ รวมถึงข้อกังวลด้านการคุ้มครองข้อมูลส่วนบุคคล ความเป็นธรรมของแบบจำลอง และบทบาทของครูในระบบใหม่ ที่กระทรวงวางแผนจะนำไปต่อยอดในปีการศึกษาถัดไป เพื่อหวังลดความเหลื่อมล้ำทางการศึกษาในระดับชาติอย่างยั่งยืน
ภาพรวมโครงการ 'Tutor‑LLM' และเป้าหมายเชิงนโยบาย
ภาพรวมโครงการ 'Tutor‑LLM'
Tutor‑LLM เป็นโครงการนำร่องที่พัฒนาระบบสอนเฉพาะบุคคลบนฐานโมเดลภาษาเชิงปริมาณ (Large Language Model) ซึ่งถูกออกแบบให้ผสานเทคนิคสำคัญ 3 ด้าน ได้แก่ Student‑Model เพื่อสร้างโปรไฟล์การเรียนรู้รายบุคคล, Knowledge‑Tracing เพื่อติดตามและพยากรณ์การได้มาซึ่งความรู้ และ Spaced‑Repetition เพื่อเพิ่มการจดจำระยะยาว โดยระบบจะปรับเนื้อหา คำถาม และกิจกรรมการเรียนให้สอดคล้องกับระดับทักษะและจังหวะการเรียนรู้ของเด็กแต่ละคน จุดประสงค์หลักคือเสริมการอ่าน‑เขียนของนักเรียนในโรงเรียนสังกัดรัฐผ่านการสอนแบบส่วนบุคคลและการใช้ข้อมูลเชิงวิเคราะห์ (learning analytics) เพื่อขับเคลื่อนการตัดสินใจเชิงการสอนของครูและผู้บริหารการศึกษา

ผู้ริเริ่มและเหตุผลในการนำร่อง
โครงการนี้ริเริ่มโดย กระทรวงศึกษาธิการ ภายใต้ความร่วมมือกับหน่วยงานภาครัฐและภาคเอกชน เพื่อแก้ไขปัญหาความเหลื่อมล้ำเชิงทักษะการอ่านและการเขียนของนักเรียนในระบบโรงเรียนสังกัดรัฐที่ยังคงเป็นปัญหาสำคัญระดับชาติ กระทรวงเลือกทดลองใช้เทคโนโลยี Tutor‑LLM เนื่องจากงานวิจัยระบุว่า การเรียนรู้แบบเฉพาะบุคคล (personalized learning) และการทบทวนเชิงมีแบบแผน (spaced‑repetition) สามารถเพิ่มผลสัมฤทธิ์และการจดจำได้อย่างมีนัยสำคัญเมื่อเทียบกับการสอนแบบเดิม นอกจากนี้ ระบบยังให้ข้อมูลเชิงลึกแก่ครูเพื่อปรับกลยุทธ์การสอนในชั้นเรียนจริง ลดภาระงานแอดมิน และเพิ่มประสิทธิผลทรัพยากรการศึกษาที่จำกัด
ขอบเขตรอบนำร่อง
รอบนำร่องถูกออกแบบให้มีขอบเขตเชิงปฏิบัติการเพื่อทดสอบผลลัพธ์ในวงจำกัดก่อนการขยายผล ซึ่งประกอบด้วย:
- จำนวนโรงเรียน: 200 โรงเรียนสังกัดรัฐ
- จำนวนผู้เรียน: ประมาณ 18,000 คน (กลุ่มเป้าหมายหลักเป็นนักเรียนประถมศึกษาปีที่ 1–4)
- จังหวัด: กระจายใน 10 จังหวัดตัวอย่างที่มีระดับความยากจนและดัชนีการอ่าน‑เขียนต่ำกว่าค่าเฉลี่ย (เพื่อทดสอบความสามารถในการลดช่องว่างทางการศึกษา)
- ระยะเวลา: รอบนำร่องระยะเวลา 12 เดือน (รวมการติดตั้งระบบ การฝึกอบรมครู การเก็บข้อมูลเชิงพื้นฐาน และการประเมินผลปลายรอบ)
การคัดเลือกโรงเรียนประเมินจากดัชนีหลายด้าน เช่น ผลการประเมินการอ่าน‑เขียนระดับชาติในช่วง 2–3 ปีก่อนหน้า อัตราการเข้าเรียน และความพร้อมด้านโครงสร้างพื้นฐานเทคโนโลยี (เช่น อินเทอร์เน็ตและอุปกรณ์) เพื่อให้การทดลองสะท้อนบริบทจริงในโรงเรียนรัฐหลากหลายรูปแบบ
เป้าหมายเชิงนโยบายและตัวชี้วัดการวัดผล
เป้าหมายเชิงปริมาณที่ประกาศคือการลด ช่องว่างการอ่าน‑เขียนของเด็กสังกัดรัฐลง 30% ในรอบนำร่อง โดยนิยามช่องว่างเป็นความต่างระหว่างคะแนนเฉลี่ยการอ่าน‑เขียนของนักเรียนในโรงเรียนสังกัดรัฐกับคะแนนเฉลี่ยระดับประเทศก่อนดำเนินโครงการ (baseline) และตั้งเป้าลดความต่างดังกล่าวลง 30% เมื่อสิ้นสุดรอบนำร่อง
ตัวชี้วัดที่จะใช้ในการประเมินผลประกอบด้วย:
- คะแนนการอ่าน (Reading Accuracy): ร้อยละการอ่านออกเสียงถูกต้องต่อคำ/ประโยค จากแบบทดสอบมาตรฐาน
- ความเข้าใจในการอ่าน (Reading Comprehension): คะแนนจากชุดข้อสอบวัดความเข้าใจข้อความในระดับสถิติก่อน‑หลัง (pre/post)
- ความคล่องในการเขียน (Writing Fluency): จำนวนคำที่เขียนได้ต่อหน่วยเวลาและความถูกต้องของไวยากรณ์พื้นฐาน
- Retention Rate (ผ่าน Spaced‑Repetition): อัตราการจำเนื้อหาเมื่อทดสอบซ้ำในช่วง 1, 3 และ 6 เดือน
- Mastery Trajectory (ผ่าน Knowledge‑Tracing): สัดส่วนของหน่วยเนื้อหาที่ระบบคาดการณ์ว่านักเรียนบรรลุความชำนาญ (mastery) ตามโมเดลความก้าวหน้า
- ลดช่องว่างเชิงพื้นที่และเชิงกลุ่ม: การลดความเหลื่อมล้ำระหว่างโรงเรียนในพื้นที่ต่าง ๆ และระหว่างกลุ่มประชากร (เช่น เด็กชนบท/เขตเมือง)
- ดัชนีความมีส่วนร่วมและการยอมรับของครู: อัตราการใช้งานระบบโดยครู ความพึงพอใจจากการประเมินเชิงคุณภาพ และเวลาที่ระบบช่วยลดงานเอกสาร
การประเมินจะใช้การวัดเชิงหาปริมาณควบคู่กับการวิจัยเชิงคุณภาพ (เช่น สัมภาษณ์ครูและผู้ปกครอง การสังเกตชั้นเรียน) เพื่อให้ได้ภาพการเปลี่ยนแปลงที่ครอบคลุมทั้งผลสัมฤทธิ์การเรียนและผลกระทบด้านการปฏิบัติการสอน
พันธมิตรทางเทคโนโลยีและสถาบันการศึกษา
โครงการทำงานร่วมกับพันธมิตรหลากหลายกลุ่มเพื่อผสมผสานองค์ความรู้เชิงเทคนิคและบริบทการศึกษา ได้แก่
- หน่วยงานวิจัยด้าน AI และสถาบันพัฒนานโยบายดิจิทัลของรัฐ
- สถาบันอุดมศึกษาและศูนย์วิจัยการศึกษา (ร่วมออกแบบการประเมินและการวิจัยเชิงปฏิบัติการ)
- บริษัทพัฒนาซอฟต์แวร์และสตาร์ทอัพ EdTech ที่เชี่ยวชาญด้านระบบการเรียนรู้เฉพาะบุคคลและการประมวลผลภาษาธรรมชาติ
- ผู้ให้บริการโครงสร้างพื้นฐานดิจิทัลเพื่อรองรับการใช้งานในโรงเรียน เช่น ผู้ให้บริการเครือข่ายและฮาร์ดแวร์ที่ได้รับการคัดเลือก
พันธมิตรเหล่านี้ถูกคัดเลือกตามเกณฑ์ด้านความเชี่ยวชาญทางเทคนิค ความสามารถในการปรับระบบให้สอดคล้องกับบริบทการเรียนของเด็กไทย และความสามารถในการสนับสนุนการฝึกอบรมครูและการบำรุงรักษาระบบในระยะยาว
ผลการนำร่อง: ตัวเลขและการตีความเชิงสถิติ
ในการประเมินผลรอบนำร่องของโครงการ Tutor‑LLM กระทรวงศึกษาธิการรายงานผลจากการทดสอบก่อนและหลัง (pre‑test/post‑test) ในกลุ่มตัวอย่างรวม 1,200 นักเรียน จาก 50 โรงเรียน ในพื้นที่นำร่อง (เฉลี่ย 24 คนต่อโรงเรียน) โดยการออกแบบการทดลองเป็นรูปแบบ cluster‑randomized trial — โรงเรียนถูกสุ่มแบ่งเป็นกลุ่มนำร่อง (intervention) 25 โรงเรียน และกลุ่มควบคุม (control) 25 โรงเรียน ส่งผลให้มีกลุ่มนักเรียนประมาณ 600 คนต่อแต่ละแขน ของการทดลอง การทดสอบประกอบด้วยการวัดหลายมิติ ได้แก่ คะแนนมาตรฐานการอ่าน‑เขียน (composite literacy score), ความถูกต้องในการอ่าน (% accuracy), ความเร็วการอ่าน (words per minute) และคะแนนความเข้าใจข้อความ (reading comprehension)。การทดสอบทำการวัดก่อนการสอน, ทันทีหลังสิ้นสุดโปรแกรม 12 สัปดาห์ และติดตามผลยืนยันความทรงจำ (delayed post‑test) อีกในช่วง 8 สัปดาห์หลังสิ้นสุด
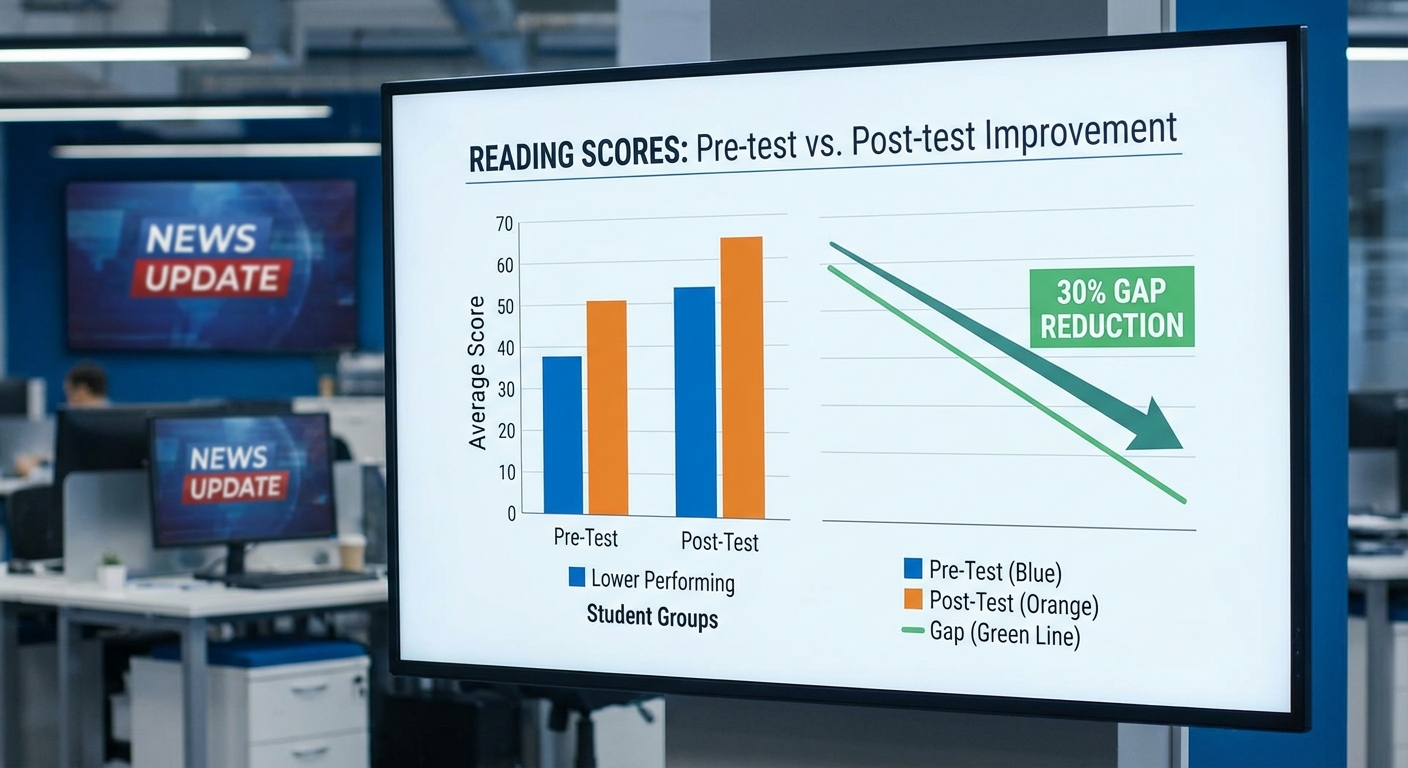
วิธีการวัดและสถิติหลัก
ผลสำคัญที่รายงานคือ "ลดช่องว่างการอ่าน‑เขียน 30%" ซึ่งถูกนิยามเป็นการลดแบบ relative ของสัดส่วนเด็กที่อยู่ต่ำกว่าระดับความชำนาญ (below proficiency threshold) เมื่อเปรียบเทียบระหว่าง pre‑test และ immediate post‑test ตัวอย่างเช่น ในกลุ่มควบคุมสัดส่วนเด็กต่ำกว่าระดับความชำนาญเปลี่ยนจาก 43% (pre) เป็น 41% (post) ขณะที่กลุ่มที่ได้รับ Tutor‑LLM เปลี่ยนจาก 43% เป็น 30% ซึ่งเท่ากับการลดลงราว 13 percentage points หรือคิดเป็นการลดลงเชิงสัมพัทธ์ประมาณ 30% (=13/43)
การวิเคราะห์เชิงสถิติเพิ่มเติมที่รายงานประกอบด้วย:
- การทดสอบความแตกต่างของค่าเฉลี่ย (paired t‑test) ระหว่าง pre‑test และ post‑test พบความแตกต่างเชิงสถิติที่มีนัยสำคัญในกลุ่มนำร่อง (p < 0.001)
- แบบจำลองผสมเชิงเส้น (mixed‑effects linear regression) ที่ควบคุมตัวแปรพื้นฐาน (baseline score, ชั้นปี, ดัชนีเศรษฐกิจสังคม) และปรับการจัดกลุ่มระดับโรงเรียนเป็น random intercept พบว่าโปรแกรมมีผลบวกต่อคะแนนรวมเทียบกับกลุ่มควบคุม: เพิ่มขึ้นเฉลี่ย +7.4 คะแนน (SD 2.1) เทียบกับการเพิ่มในกลุ่มควบคุมที่ +2.1 คะแนน; ขนาดผล (Cohen’s d) อยู่ที่ประมาณ 0.42 ซึ่งถือว่าเป็นผลขนาดปานกลาง; ค่าสำคัญทางสถิติคือ p < 0.001
- อัตราส่วนความน่าจะเป็น (adjusted odds ratio) สำหรับการอยู่ใต้ระดับความชำนาญเมื่อเปรียบเทียบกลุ่มนำร่องกับกลุ่มควบคุม = 0.62 (95% CI: 0.50–0.78), p = 0.0003 — แปลว่าโอกาสที่จะยังคงอยู่ต่ำกว่ามาตรฐานลดลงประมาณ 38%
- การวัดเฉพาะตัวชี้วัดอื่นๆ: ความเร็วการอ่านเพิ่มเฉลี่ย +22 words per minute, ความถูกต้องการอ่านเพิ่มเฉลี่ย +18 percentage points, และความถูกต้องการเขียนเพิ่มเฉลี่ย +20 percentage points (ทั้งหมด p < 0.01 หลังปรับคลัสเตอร์)
การวิเคราะห์เสริมและความยั่งยืนของผล
การวิเคราะห์แบบ intent‑to‑treat และ per‑protocol ให้ผลสอดคล้องกัน โดยผลเชิงบวกยังคงมีนัยสำคัญหลังปรับปัจจัยชี้นำต่างๆ ส่วนการติดตามผลหลัง 8 สัปดาห์พบว่าเด็กยังคงรักษาได้ประมาณ 75% ของการปรับปรุงทันที (즉. ผลลดลงเล็กน้อยแต่ยังคงเหนือกลุ่มควบคุมอย่างมีนัยสำคัญ, p < 0.01) การทดสอบความไวต่อสมมติฐาน (sensitivity analyses) ด้วย robust standard errors และการปรับให้เหมาะสมกับการขาดหายของข้อมูล (multiple imputation) ไม่เปลี่ยนผลสรุปหลัก
กรณีศึกษาเด่น (ตัวอย่างนักเรียน)
เพื่อให้เห็นภาพการเปลี่ยนแปลงในระดับปัจเจก ทีมวิจัยได้นำเสนอกรณีศึกษา 3 รายที่แสดงการเปลี่ยนแปลงชัดเจน:
- นักเรียน A (ป.3): คะแนน composite literacy pre = 58 → post = 86 (+28 points); ความถูกต้องการอ่านจาก 60% → 88%; ความเร็วจาก 45 wpm → 80 wpm. นักเรียน A จากระดับต่ำกว่าเกณฑ์ขยับขึ้นสู่ระดับความชำนาญอย่างชัดเจนภายใน 12 สัปดาห์
- นักเรียน B (ป.2): มีปัญหาการสะกดคำและความเข้าใจเบื้องต้น; pre writing accuracy = 40% → post = 72% (+32 pp); composite score เพิ่ม 25 points; ครูรายงานว่านักเรียนมีความมั่นใจในการอ่านออกเสียงและการเขียนบันทึกสั้นๆ มากขึ้น
- นักเรียน C (ป.4): เริ่มต้นที่ borderline proficiency; pre comprehension = 54% → post = 79% (+25 pp); ผลการติดตาม 8 สัปดาห์ยังคงอยู่ที่ 72% แสดงถึงการรักษาผลได้ส่วนใหญ่
การรายงานผลสำหรับกรณีศึกษาใช้รูปแบบตารางและแผนภูมิ (table of before/after metrics และ line charts ของคะแนนตามเวลา) เพื่อแสดงการเปลี่ยนแปลงทั้งเชิงปริมาณและเชิงคุณภาพ — ตารางตัวอย่างจะประกอบด้วยคอลัมน์สำหรับ pre‑score, post‑score, change (absolute & relative) และคอลัมน์หมายเหตุสำหรับการสังเกตเชิงคุณภาพจากครู
บทสรุปเชิงตัวเลข: ในรอบนำร่อง โครงการ Tutor‑LLM แสดงผลเชิงสถิติที่มีนัยสำคัญต่อการลดสัดส่วนเด็กที่ไม่ผ่านเกณฑ์การอ่าน‑เขียนลงประมาณ 30% (relative reduction), โดยมีค่า p ที่รายงานเทียบได้กับมาตรฐานการวิจัยเชิงทดลอง (p < 0.001) และขนาดผลที่มีความหมายทางการปฏิบัติ (Cohen’s d ≈ 0.4–0.5) ซึ่งส่งสัญญาณว่านวัตกรรมการสอนเชิงปัจเจกที่ผสาน Student‑Model, Knowledge‑Tracing และ Spaced‑Repetition สามารถสร้างผลลัพธ์ที่จับต้องได้ในบริบทโรงเรียนสังกัดรัฐ แต่ยังต้องมีการขยายการทดลองในวงกว้างและติดตามระยะยาวเพื่อยืนยันความคงทนของผลและประเมินผลต่อความเหลื่อมล้ำในบริบทต่างๆ
เทคโนโลยีเบื้องหลัง: Student‑Model, Knowledge‑Tracing และ Spaced‑Repetition
เทคโนโลยีเบื้องหลัง: ภาพรวมและความสัมพันธ์เชิงระบบ
โครงการ Tutor‑LLM ใช้สถาปัตยกรรมที่ผสานกันระหว่าง Student‑Model, Knowledge‑Tracing และ Spaced‑Repetition เพื่อมุ่งลดช่องว่างการอ่าน‑เขียนของนักเรียนภาครัฐ โดยแต่ละองค์ประกอบมีหน้าที่เฉพาะและทำงานร่วมกันในลูปการปรับแต่งการสอนแบบเรียลไทม์ ทั้งนี้การนำข้อมูลผลการทดสอบ, พฤติกรรมการเรียนออนไลน์ และเมตริกเชิงบริบท (เช่น เวลาในการตอบ, จำนวนครั้งที่ผิด) มาประมวลผล ทำให้ระบบสามารถคาดการณ์จุดอ่อนและออกแบบกิจกรรมทบทวนอย่างมีประสิทธิภาพ ซึ่งเป็นหนึ่งในปัจจัยที่ช่วยให้โครงการนำร่องรายงานผลลดช่องว่างได้ประมาณ 30% ในระยะสั้น
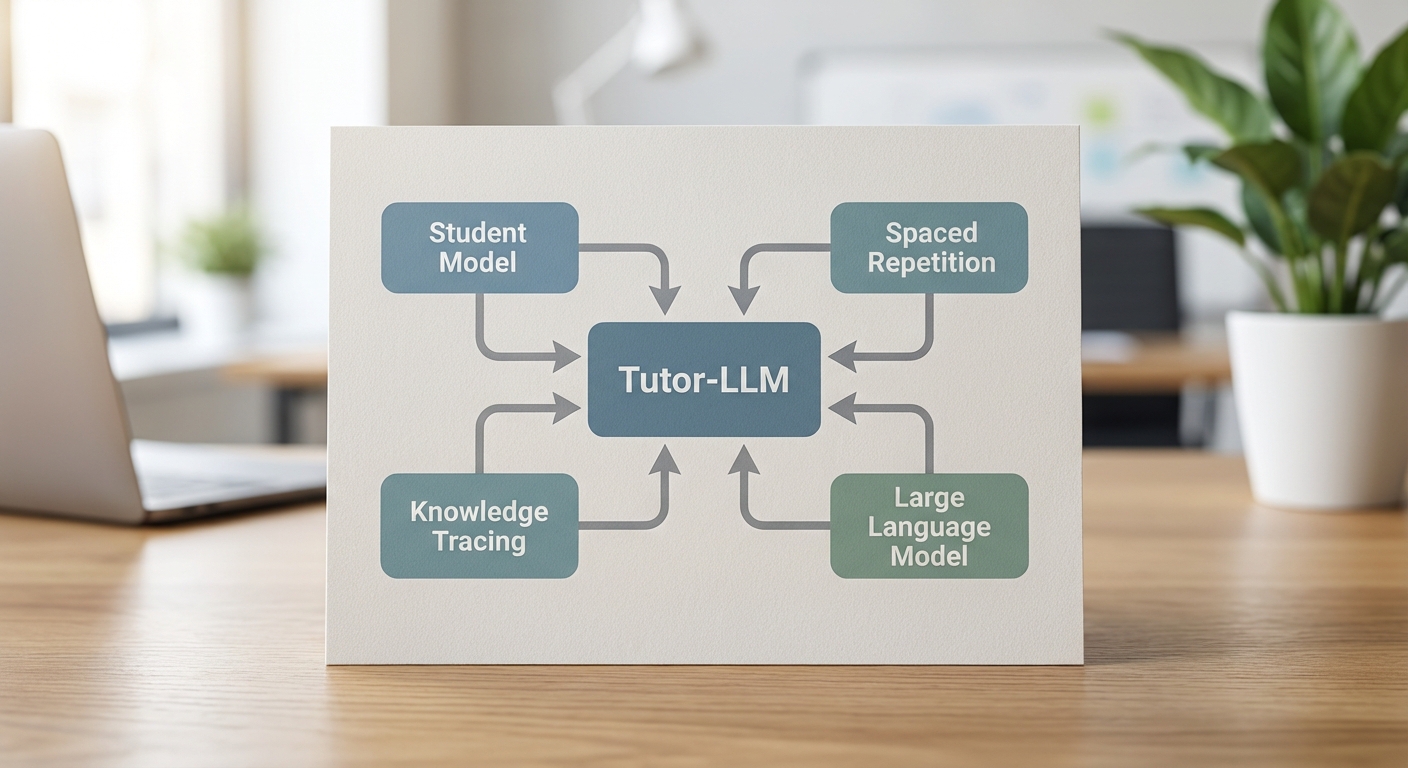
Student‑Model: นิยาม หน้าที่ และข้อมูลที่ใช้
Student‑Model หรือแบบจำลองสภาวะผู้เรียน หมายถึงตัวแทนเชิงคณิตศาสตร์และข้อมูลที่บันทึกสถานะของผู้เรียนในมุมมองต่าง ๆ เช่น ระดับความรู้ต่อหน่วยทักษะ (skill mastery), ความมั่นใจ, รูปแบบข้อผิดพลาด, จังหวะการเรียนรู้ และสถานะด้านอารมณ์/พฤติกรรม ข้อมูลที่ป้อนเข้าระบบอาจรวมถึงผลการตอบคำถาม (ถูก/ผิด), เวลาที่ใช้, ลำดับกิจกรรม, คำตอบแบบเปิด และข้อมูลเมตาเช่นอายุ/ระดับชั้น
หน้าที่หลักของ Student‑Model คือการสร้างโปรไฟล์ที่ใช้ในการตัดสินใจสอนอัตโนมัติ (instructional decision-making) ได้แก่:
- การประเมินระดับความเชี่ยวชาญเฉพาะทักษะ (skill-level mastery)
- การระบุรูปแบบความผิดพลาดซ้ำ (error patterns) และความเข้าใจผิด (misconceptions)
- การคัดกรองกิจกรรมที่เหมาะสมกับจุดพร้อมของผู้เรียน (personalized problem selection)
- การเป็นอินพุตให้กับโมดูล Knowledge‑Tracing และ Spaced‑Repetition เพื่อวางแผนการทบทวน
Knowledge‑Tracing: หลักการและตัวชี้วัดการทำนาย
Knowledge‑Tracing คือเทคนิคในการติดตามการเปลี่ยนแปลงของความรู้หรือความสามารถของผู้เรียนตามเวลา โดยทั่วไปจะคาดการณ์ความน่าจะเป็นที่ผู้เรียนจะตอบคำถามเกี่ยวกับทักษะหนึ่ง ๆ ได้ถูกต้องในอนาคต โมเดลนี้ช่วยให้ระบบรู้ว่าเมื่อไรผู้เรียน "เข้าใจแล้ว" หรือยังต้องการการทบทวน
ตัวอย่างอัลกอริธึมที่นิยมใช้:
- Bayesian Knowledge Tracing (BKT) — ใช้แบบจำลอง Hidden Markov Model ระบุสถานะ (ไม่ชำนาญ/ชำนาญ) และคำนวณพารามิเตอร์เช่น learning rate, guess, slip
- Deep Knowledge Tracing (DKT) — ใช้ RNN/LSTM เพื่อจับลำดับการตอบและบริบทที่ซับซ้อนกว่า ทำให้จับรูปแบบการเรียนรู้ที่ไม่เป็นเชิงเส้นได้ดีขึ้น
- Performance Factors Analysis (PFA) และวิธีผสมอื่น ๆ — ผสมคุณลักษณะหลายมิติ เช่น จำนวนครั้งที่ฝึกและผลลัพธ์ก่อนหน้า
ตัวชี้วัดสำคัญที่ใช้ประเมินประสิทธิภาพของ Knowledge‑Tracing ได้แก่ prediction accuracy (เช่น AUC, RMSE), calibration (ความสอดคล้องระหว่างความน่าจะเป็นที่ทำนายกับผลจริง), และเมตริกเชิงการศึกษา เช่น learning gain และ retention rate โมเดลที่มี calibration ดีจะทำให้การวางแผนทบทวนมีประสิทธิภาพมากขึ้น
Spaced‑Repetition: การจัดตารางทบทวนเพื่อการจำระยะยาว
Spaced‑Repetition เป็นกลยุทธ์จัดการช่วงเวลาทบทวนตามหลักจิตวิทยาการเรียนรู้ เพื่อเพิ่มการคงจำระยะยาว โดยทบทวนเนื้อหาในช่วงเวลาที่เหมาะสมก่อนเกิดการลืม ตัวอย่างอัลกอริธึมที่ใช้งานจริงคือ SM‑2 (จากระบบ SuperMemo) ซึ่งปรับช่วงเวลาตามการประเมินความยากของรายการแต่ละชิ้น
การผสาน Spaced‑Repetition กับ Student‑Model และ Knowledge‑Tracing ทำงานเป็นวงจร: Knowledge‑Tracing คาดการณ์ความน่าจะเป็นของการลืม/การตอบถูก; Student‑Model ให้บริบทเพิ่มเติมเกี่ยวกับความยากของผู้เรียนแต่ละคน; จากนั้น Spaced‑Repetition กำหนดตารางทบทวน (scheduling) ที่ปรับได้แบบไดนามิก ตัวอย่างการใช้งานเชิงประยุกต์ได้แก่:
- กำหนดช่วงเวลาทบทวนที่ยาวขึ้นสำหรับทักษะที่มี mastery สูง และสั้นลงสำหรับทักษะที่มีความเสี่ยงจะลืม
- ปรับช่องว่างแบบส่วนบุคคลโดยใช้ probabilistic decay model ที่คำนึงถึงเวลา‑ตั้งแต่การเห็นล่าสุดและผลการตอบก่อนหน้า
- รวมปัจจัยบริบทเช่น เวลาว่างของนักเรียนและแรงจูงใจ เพื่อเพิ่ม adherence ในโปรแกรมทบทวน
การผสานกับ LLM: สร้างคำอธิบายตามบริบทและการสื่อสารเชิงปรับตัว
- สร้างคำอธิบายเชิงสแควฟโฟลด (scaffolded explanations) ที่ปรับตามระดับความเข้าใจ เช่น ย่อ/ขยายความ อธิบายด้วยตัวอย่างหรือภาพประกอบ
- ออกแบบคำถามแบบไล่ระดับความยาก และสร้าง distractors ที่ช่วยวินิจฉัย misconceptions
- สร้างฟีดแบ็กเชิงสาเหตุ (explanatory feedback) เมื่อผู้เรียนตอบผิด เพื่อลดการเกิด pattern ของความผิดพลาดซ้ำ
- ผลิตข้อความกระตุ้นความมุ่งมั่น (motivational nudges) และแผนการทบทวนที่สอดคล้องกับ Spaced‑Repetition
ตัวอย่างการทำงานร่วมกันเชิงเทคนิค: โมดูล Knowledge‑Tracing ให้ความน่าจะเป็น p(t|skill) ว่าผู้เรียนจะตอบถูกในเวลา t ต่อไป LLM จะใช้ค่า p นี้เพื่อเลือกรูปแบบคำอธิบาย—ถ้า p ต่ำ LLM จะให้อธิบายพื้นฐานเชิงแนะนำและกิจกรรมเสริม ถ้า p สูง LLM อาจเสนอแบบฝึกหัดที่ท้าทายมากขึ้น นอกจากนี้ LLM สามารถช่วยสร้าง prompt templates ที่ประมวลผลคุณลักษณะจาก Student‑Model (เช่น error patterns, preferred examples) เพื่อให้คำอธิบายมีความเฉพาะตัวมากขึ้น
ข้อพิจารณาเชิงปฏิบัติและการประเมิน
ในทางปฏิบัติ การนำระบบมาปฏิบัติการต้องคำนึงถึงความถูกต้องของ Student‑Model, ความเป็นส่วนตัวของข้อมูล และการตรวจสอบ bias ของ LLM วิธีการประเมินเชิงปฏิบัติรวมถึงการวัด retention ระยะกลาง‑ยาว, การเปลี่ยนแปลง mastery per skill, และตัวชี้วัดการมีส่วนร่วมของผู้เรียน (engagement, completion rate) ซึ่งเมตริกเหล่านี้จะเป็นเกณฑ์เปรียบเทียบว่าแนวทางผสานกันของ Tutor‑LLM ส่งผลต่อการลดช่องว่างการอ่าน‑เขียนอย่างเป็นรูปธรรมหรือไม่
การใช้งานในห้องเรียน: ครูเป็นศูนย์กลางหรือ AI ช่วยเสริม?
เมื่อกระทรวงศึกษาธิการนำโครงการ Tutor‑LLM มาทดสอบในโรงเรียนรัฐ ผลการนำร่องชี้ให้เห็นว่าการผสานเทคโนโลยี Student‑Model, Knowledge‑Tracing และ Spaced‑Repetition สามารถลดช่องว่างการอ่าน‑เขียนลงได้ประมาณ 30% ภายในรอบนำร่อง ข้อสำคัญในการใช้งานจริงคือการออกแบบรูปแบบการสอนที่เป็น blended learning โดยครูยังคงเป็นผู้กำกับการเรียนรู้แต่ AI ทำหน้าที่เป็นผู้ช่วยเฉพาะบุคคลที่ปรับระดับเนื้อหาและให้ข้อเสนอแนะแบบเรียลไทม์ ทั้งนี้การปฏิบัติจริงจำเป็นต้องคำนึงถึงโครงสร้างชั้นเรียน ขนาดกลุ่ม และทรัพยากรด้านฮาร์ดแวร์/ซอฟต์แวร์

รูปแบบการสอนที่ใช้ Tutor‑LLM
- 1:1 ผ่านแท็บเล็ตหรือแล็ปท็อป — นักเรียนทำแบบฝึกหัดและบทเรียนที่ปรับตาม Student‑Model แต่ละครั้งระบบจะบันทึกพัฒนาการ (accuracy, response time, hint requests) เพื่อเสนอแผนทบทวนแบบ Spaced‑Repetition ตัวอย่าง: นักเรียน A ที่สะดุดเรื่องการอ่านออกเสียงจะได้รับชุดแบบฝึกหัด 10 นาทีทุก 3 วัน และกิจกรรมเสียงเสริมในเวลาที่เหมาะสม
- กลุ่มย่อย (small groups) — ครูแบ่งห้องเป็นกลุ่มตามความสามารถที่ระบบระบุ ระบบช่วยออกคำถามเชิงกระตุ้น (scaffolded prompts) เพื่อให้ครูเน้นการอภิปรายเชิงลึกและประเมินเชิงคุณภาพ ตัวอย่าง: กลุ่มพื้นฐานทำกิจกรรมอ่านนำ ส่วนกลุ่มก้าวหน้าทำงานโครงงานเขียนเชิงวิเคราะห์
- บทเสริมหลังเลิกเรียน / tutoring session — ศูนย์การเรียนหรือกิจกรรมนอกเวลาใช้ Tutor‑LLM ในการจัดเส้นทางการฟื้นฟู (remediation) โดยเฉพาะเรื่องที่ Knowledge‑Tracing ระบุว่านักเรียนมีแนวโน้มจะลืม
เครื่องมือและแดชบอร์ดสำหรับครูเพื่อสังเกตความก้าวหน้าและปรับบทเรียน
แดชบอร์ดครูของ Tutor‑LLM ถูกออกแบบให้เป็นศูนย์กลางการตัดสินใจ โดยรวมข้อมูลเชิงปริมาณและเชิงคุณภาพไว้ด้วยกัน ฟีเจอร์สำคัญได้แก่:
- ภาพรวมความก้าวหน้า (Progress Overview) — แสดงค่า mastery per skill เป็นกราฟความถี่และแนวโน้ม (e.g., 70% mastery ในการอ่านความเข้าใจ เพิ่มขึ้น 12% จากสัปดาห์ก่อน)
- การแจ้งเตือนการแทรกแซง (Intervention Alerts) — ระบบส่งสัญญาณเมื่อนักเรียนมีแนวโน้มถดถอยหรือไม่ตอบสนองต่อแผนปัจจุบัน พร้อมคำแนะนำการสอนสั้นๆ ที่ครูสามารถนำไปใช้
- คำอธิบายเชิงอธิบาย (Explainability) — ให้เหตุผลที่ระบบเลือกกิจกรรม เช่น “เลือกแบบฝึกหัดนี้เพราะนักเรียนยังผิดพลาดกับเสียง consonant blend 60%” ช่วยให้ครูเข้าใจที่มาของคำแนะนำ
- เครื่องมือปรับแผน (Planner & Template) — ครูสามารถปรับแผนการสอนรายบุคคลหรือสร้าง template สำหรับกลุ่มย่อย แล้วส่งไปยังนักเรียนได้ทันที
- รายงานสำหรับผู้ปกครองและผู้บริหาร — สรุปความคืบหน้ารายเดือนในรูปแบบที่อ่านง่าย (คะแนน, ระดับความเสี่ยง, กิจกรรมแนะนำ)
ตัวอย่างกิจกรรมการสอนเฉพาะบุคคล
- การอ่านเป็นคู่: ระบบจับคู่นักเรียนที่ต้องการฝึกการอ่านออกเสียงกับกิจกรรมเสียงที่ปรับระดับ จากนั้นครูหมุนเวียนสังเกตและให้ฟีดแบ็กเชิงกลยุทธ์
- แบบฝึกหัดเชิงโปรเจกต์: นักเรียนกลุ่มย่อยได้รับโจทย์เดียวกัน แต่ระบบแจกแหล่งข้อมูลและระดับคำถามต่างกันตาม Student‑Model
- เซสชันทบทวนเวลา 10 นาที: ระบบสร้างชุดทบทวนแบบ Spaced‑Repetition ให้ครูเลือกให้เป็นการบ้านหรือกิจกรรมในชั่วโมงเรียน
ประเด็นปฏิบัติการ: การฝึกอบรมครู ความน่าเชื่อถือของคำแนะนำ AI และการยอมรับของนักเรียน
การนำ Tutor‑LLM มาใช้ไม่เพียงแต่ติดตั้งซอฟต์แวร์ แต่ต้องลงทุนในการฝึกอบรมครูใน 3 ระดับหลัก: เทคนิคการใช้งานแดชบอร์ด (ประมาณ 10–20 ชั่วโมงอบรมเชิงปฏิบัติ), การแปลผลข้อมูลเชิงการเรียนรู้และปรับแผนการสอน (coaching แบบประจำเดือน 6 เดือนแรกรายโรงเรียน), และการจัดการชั้นเรียนแบบผสม (pedagogical strategies) เพื่อให้ครูสามารถผสมบทบาทระหว่างผู้สอนและผู้ควบคุมการเรียนรู้ได้อย่างมีประสิทธิภาพ
ประเด็นเรื่องความน่าเชื่อถือของคำแนะนำ AI เป็นอีกด้านที่ต้องให้ความสำคัญ เพราะระบบอาจให้คำแนะนำที่ดูสมเหตุสมผลแต่ไม่สอดคล้องกับบริบทท้องถิ่นหรือหลักสูตร ครูต้องทำหน้าที่เป็น "ผู้ตรวจสอบสุดท้าย" โดยใช้แดชบอร์ดที่มี explainability และบันทึกการตัดสินใจของครูเป็นหลักฐานการปรับแผน นอกจากนี้การยอมรับของนักเรียนขึ้นกับการออกแบบอินเทอร์เฟซ (ใช้งานง่าย สนุก และมีการให้รางวัลเชิงบวก) และต้องคำนึงถึงความไม่เท่าเทียมด้านอุปกรณ์ — โรงเรียนที่มีนักเรียน 30% ไม่มีอุปกรณ์เพียงพอจะต้องมีแผนสำรอง เช่น การสอนเป็นกลุ่มย่อยหรือการให้แล็ปท็อปแบบพกพา
ข้อดีและข้อจำกัดจากมุมมองครู
- ข้อดี
- ช่วยลดภาระงานเชิงซ้ำ (grading, assigning differentiated practice) และให้ข้อมูลเชิงลึกที่ครูอาจมองไม่เห็นในชั้นเรียนขนาดใหญ่
- สนับสนุนการสอนเฉพาะบุคคล ทำให้ครูสามารถโฟกัสการสอนเชิงรูปแบบสูงขึ้น เช่น การสอนคิดวิเคราะห์และการให้ฟีดแบ็กเชิงคุณภาพ
- รายงานอัตโนมัติช่วยสื่อสารกับผู้ปกครองและผู้บริหารได้รวดเร็วขึ้น
- ข้อจำกัด
- ภาระงานเริ่มต้นเพิ่มขึ้นจากการเรียนรู้ระบบและการเตรียมเนื้อหาเฉพาะบุคคล หากไม่มีการฝึกอบรมและการสนับสนุนทางเทคนิคที่เพียงพอ ครูจะรู้สึกล้นมือ
- ความน่าเชื่อถือของ AI ไม่สมบูรณ์ — ต้องระวังผลจากข้อมูลบิดเบือน (bias) และการตอบสนองที่คลุมเครือ (hallucination) ซึ่งต้องมีกระบวนการตรวจสอบ
- ข้อกังวลด้านความเป็นส่วนตัวของข้อมูลนักเรียนและการปฏิบัติตามนโยบายคุ้มครองข้อมูลต้องเป็นไปตามกฎหมายและแนวปฏิบัติที่ชัดเจน
โดยสรุป การนำ Tutor‑LLM มาใช้ในห้องเรียนควรเน้นที่การออกแบบเป็นระบบ — ผสมผสานเทคโนโลยีกับการฝึกอบรมเชิงวิชาชีพของครู เพื่อให้ครูคงบทบาทเป็นผู้กำกับการเรียนรู้และใช้ AI เป็นผู้ช่วยที่มีข้อมูลประกอบการตัดสินใจ การวางมาตรการตรวจสอบความน่าเชื่อถือของคำแนะนำ AI การสนับสนุนทางเทคนิคอย่างต่อเนื่อง และการออกแบบอินเทอร์เฟซที่เอื้อต่อการใช้งานจริง จะเป็นปัจจัยสำคัญที่กำหนดความสำเร็จในระยะยาว
ความเป็นส่วนตัว จริยธรรม และการคุ้มครองข้อมูลนักเรียน
ความเสี่ยงด้านความเป็นส่วนตัวและประเภทของข้อมูลที่เก็บ
โครงการ Tutor‑LLM จะสร้างข้อมูลหลากหลายรูปแบบจากการโต้ตอบของผู้เรียน ซึ่งรวมถึง ข้อมูลประสิทธิภาพการเรียน (เช่น คำตอบ คะแนน ความถี่ในการผิดพลาด), ข้อมูลพฤติกรรมการใช้งาน (เช่น เวลาที่ใช้บนแพลตฟอร์ม เส้นทางการเรียนรู้), ข้อมูลเมตา (เช่น หมายเลขอุปกรณ์ IP, timestamps) และในกรณีที่ระบบผสาน biometric หรือ multimedia อาจมีการเก็บ ข้อมูลชีวมิติ เช่น ภาพใบหน้า เสียง หรือข้อมูลการเคลื่อนไหว การเก็บข้อมูลเหล่านี้สร้างความเสี่ยงหลายประการ ได้แก่ การระบุตัวบุคคลจากข้อมูลผสม (re‑identification), ความเสี่ยงต่อการรั่วไหลของข้อมูลอ่อนไหว, การนำข้อมูลไปใช้ในวัตถุประสงค์ที่นอกเหนือจากการศึกษา และการถูกรวบรวม/วิเคราะห์โดยบุคคลภายนอกที่ไม่ได้รับอนุญาต ซึ่งมีผลโดยตรงต่อความเป็นส่วนตัวของนักเรียนโดยเฉพาะกลุ่มผู้เยาว์
ความเสี่ยงเชิงเทคนิคและเชิงบริบทที่ต้องคำนึงถึง เช่น การเก็บล็อกการโต้ตอบระยะยาวซึ่งสามารถสร้างโปรไฟล์พฤติกรรม, การใช้ biometric ที่เพิ่มความเสี่ยงหากระบบถูกเจาะ, และการถ่ายโอนข้อมูลไปยังผู้ให้บริการคลาวด์หรือซัพพลายเออร์ต่างประเทศซึ่งอาจอยู่ภายใต้กฎหมายที่แตกต่างกัน ทั้งนี้ข้อมูลของนักเรียนนับเป็น ข้อมูลอ่อนไหว ที่ต้องการการคุ้มครองเชิงรุก
มาตรการคุ้มครองข้อมูลที่แนะนำ
เพื่อจำกัดความเสี่ยง จำเป็นต้องออกแบบมาตรการด้านเทคนิคและนโยบายควบคู่กัน โดยหลักสำคัญได้แก่ data minimization, privacy by design และการได้รับ consent จากผู้ปกครองตามกฎหมาย โดยข้อเสนอเชิงปฏิบัติได้แก่
- การลดการเก็บข้อมูล (Data minimization): ระบุเฉพาะข้อมูลที่จำเป็นต่อการให้บริการการสอนแบบเฉพาะบุคคลเท่านั้น เช่น เก็บผลการทดสอบและบันทึกโต้ตอบที่เกี่ยวข้องกับการวิเคราะห์การเรียนรู้ หลีกเลี่ยงการเก็บรูปหรือเสียงเว้นแต่จำเป็นจริง
- การทำให้ไม่ระบุตัวตนหรือทำให้เป็นนามแฝง (Anonymization / Pseudonymization): ก่อนเก็บเพื่อการวิเคราะห์เชิงสถิติให้แยกคีย์ระบุตัวตนออกจากข้อมูลการเรียนรู้ และใช้การทำให้เป็นนามแฝงเมื่อเก็บระยะยาว
- การเข้ารหัส (Encryption): เข้ารหัสข้อมูลทั้งขณะเก็บ (at rest) และขณะส่ง (in transit) ด้วยมาตรฐานที่ทันสมัย เช่น AES‑256/TLS 1.2+ และบริหารคีย์อย่างปลอดภัย
- การควบคุมการเข้าถึง (Access controls): ใช้แนวทาง least privilege, การพิสูจน์ตัวตนแบบหลายปัจจัย (MFA), การแยกสิทธิ์ระหว่างผู้ดำเนินงานและนักพัฒนา, และการบันทึกล็อกการเข้าถึงเพื่อการตรวจสอบ
- นโยบายการเก็บและลบข้อมูล (Data retention): กำหนดระยะเวลาเก็บข้อมูลที่ชัดเจนตามวัตถุประสงค์ เช่น ข้อมูลเชิงปฏิบัติการเก็บไม่เกิน 6–24 เดือน ขณะที่ข้อมูลสรุปเชิงสถิติเชิงการวิจัยควรทำให้ไม่ระบุตัวตนก่อนเก็บระยะยาว และจัดให้มีขั้นตอนการลบ/ทำลายข้อมูลเมื่อตกลงสิ้นสุด
- การจัดการความยินยอมและสิทธิผู้ปกครอง: ได้รับความยินยอมแบบชัดแจ้งจากผู้ปกครองหรือผู้ดูแลตาม PDPA ของไทย ระบุวัตถุประสงค์การใช้ข้อมูล แจ้งสิทธิในการถอนความยินยอม และจัดช่องทางให้เด็ก/ผู้ปกครองสามารถเรียกร้องให้ลบข้อมูลได้
- การประเมินผลกระทบด้านความเป็นส่วนตัว (DPIA): ดำเนิน DPIA ก่อนและระหว่างรันโปรเจกต์ รวมถึงประเมินผลกระทบเชิงความเสี่ยงเมื่อเพิ่มฟีเจอร์ใหม่ เช่น biometric
- มาตรการตอบสนองเมื่อเกิดเหตุ: แผนแจ้งเตือนผู้เกี่ยวข้องและหน่วยงานกำกับดูแลภายในกรอบเวลาที่ชัดเจน พร้อมบันทึกเหตุการณ์และแผนฟื้นฟูข้อมูล
ประเด็นจริยธรรม: ความไม่ลำเอียง การตีความผล และผลต่อโอกาสทางการศึกษา
นอกเหนือจากการคุ้มครองข้อมูลแล้ว ต้องพิจารณาประเด็นจริยธรรมที่ส่งผลต่อความยุติธรรมทางการศึกษา ความลำเอียงของโมเดล (model bias) อาจเกิดจากชุดข้อมูลการฝึกที่ไม่สะท้อนความหลากหลายของนักเรียนในระบบศึกษาภาครัฐ ส่งผลให้คำแนะนำหรือการประเมินมีเอนเอียงต่อกลุ่มใดกลุ่มหนึ่ง ตัวอย่างเช่น โมเดลอาจประเมินพฤติกรรมภาษาเฉพาะถิ่นเป็นข้อผิดพลาดหรือให้คะแนนเชิงลบโดยไม่เหมาะสม
เพื่อจัดการเรื่องนี้ ควรกำหนดมาตรการเชิงจริยธรรม ได้แก่ การทดสอบมาตรฐานความยุติธรรมด้วยตัวชี้วัดหลายมิติ (เช่น equal opportunity, demographic parity), การมี human‑in‑the‑loop ในการตัดสินใจที่มีผลกระทบสูง, การให้คำอธิบายผลการประเมินที่ชัดเจนต่อครูและผู้ปกครอง และช่องทางอุทธรณ์หรือขอทบทวนผลการตัดสินใจอัตโนมัติ นอกจากนี้ต้องระมัดระวังไม่ให้การใช้โมเดลกลายเป็นเครื่องมือคัดเลือกหรือจำกัดโอกาสทางการศึกษาของเด็ก โดยต้องใช้ระบบเพื่อเสริมการเรียนรู้ ไม่ใช่แทนหน้าที่ครูหรือเป็นฐานในการตัดสินชี้ชัดโอกาสการศึกษาระยะยาว
กรอบการกำกับดูแลและการควบคุมเพื่อความยั่งยืน
การปฏิบัติที่ดีควรรวมทั้งกรอบนโยบายภายในและการกำกับดูแลภายนอก เช่น การตั้งคณะกรรมการกำกับดูแลประกอบด้วยผู้แทนกระทรวงศึกษาธิการ ครู ตัวแทนผู้ปกครอง นักกฎหมายความเป็นส่วนตัว และผู้เชี่ยวชาญด้าน AI/จริยธรรม เพื่อทบทวนผลการทดสอบ ความปลอดภัย และความยุติธรรมเป็นระยะ นโยบายสัญญาจัดซื้อจัดจ้างต้องผูกพันผู้ให้บริการเทคโนโลยีให้ปฏิบัติตามมาตรฐานการคุ้มครองข้อมูล เช่น PDPA, ISO/IEC 27001 และต้องมีข้อกำหนดด้านการตรวจสอบอิสระ (independent audit) และการเปิดเผยรายงานความโปร่งใส (transparency report)
สรุปแล้ว การดำเนินโครงการ Tutor‑LLM ให้ประสบผลสำเร็จและยั่งยืนต้องผสานมาตรการทางเทคนิค นโยบายคุ้มครองข้อมูล และกรอบจริยธรรมที่ชัดเจน เพื่อปกป้องสิทธิความเป็นส่วนตัวของนักเรียน ลดความเสี่ยงด้านอคติ และรักษาโอกาสทางการศึกษาที่เท่าเทียม โดยมีการตรวจสอบและปรับปรุงอย่างต่อเนื่องตามผลการประเมินและข้อคิดเห็นจากผู้มีส่วนได้ส่วนเสีย
งบประมาณ การขยายผล และความยั่งยืนของโครงการ
งบประมาณ — โมเดลต้นทุนเบื้องต้นและตัวอย่างการประเมิน
การประเมินต้นทุนของโครงการ Tutor‑LLM จำเป็นต้องแยกองค์ประกอบหลักอย่างชัดเจน เพื่อให้สามารถวางแผนงบประมาณทั้งระยะสั้นและระยะยาวได้อย่างเป็นรูปธรรม องค์ประกอบต้นทุนสำคัญได้แก่: ค่าโครงสร้างพื้นฐานด้านเครือข่ายและฮาร์ดแวร์, ค่าไลเซนส์และบริการ LLM (รวมถึงการเรียกใช้งาน API), ค่าใช้จ่ายกระบวนการฝึกสอนและพัฒนาครู, ต้นทุนการบำรุงรักษาและอัปเดตโมเดล รวมทั้งค่าใช้จ่ายด้านการบริหารจัดการข้อมูลและความปลอดภัย
ตัวอย่างการประเมินราคาเบื้องต้น (ประมาณการเชิงตัวอย่าง ต่อโรงเรียนขนาดกลาง 300–500 นักเรียน):
- ค่าโครงสร้างพื้นฐานเริ่มต้น (one‑time): อุปกรณ์ปลายทาง (แท็บเล็ต/คอมพิวเตอร์เพื่อการเรียน) 30–50 เครื่อง @ 5,000–10,000 บาท = ประมาณ 150,000–500,000 บาท; ติดตั้งเครือข่าย/เราเตอร์/UPS ประมาณ 50,000–150,000 บาท
- ค่าเชื่อมต่ออินเทอร์เน็ต (รายปี): แบนด์วิธเพียงพอสำหรับการเรียกใช้งาน LLM และการซิงก์ข้อมูล 50–200 Mbps ประมาณ 60,000–240,000 บาท/ปี
- ค่าไลเซนส์ LLM และการใช้งาน (รายปี): หากใช้บริการคลาวด์/API ของผู้ให้บริการเชิงพาณิชย์ อาจอยู่ในช่วง 300,000–3,000,000 บาท/ปี ขึ้นกับปริมาณการใช้งานและข้อตกลง (enterprise plan); หากเลือกโฮสต์ภายใน (self‑hosted) จะมีต้นทุน GPU/เซิร์ฟเวอร์สำหรับ fine‑tuning และ inference ประมาณ 500,000–5,000,000 บาท ในรอบปีแรก
- ค่าออกแบบและฝึกอบรมครู (one‑time + ต่อเนื่อง): คอร์สพัฒนาทักษะการใช้ Tutor‑LLM และการวิเคราะห์ Student‑Model ประมาณ 5,000–20,000 บาท/คน; สมมติโรงเรียนมีครู 10 คน จะอยู่ที่ 50,000–200,000 บาท ต่อการฝึกอบรมรอบเริ่มต้น โดยมีค่าโค้ชชิ่งต่อเนื่อง 20–50% ของค่าสอนเริ่มต้น/ปี
- ค่าบำรุงรักษาและการอัปเดต (รายปี): การอัปเดตเนื้อหา การรักษาความปลอดภัย และการซัพพอร์ตทางเทคนิค ประมาณ 10–25% ของ CAPEX รวมต่อปี
- ค่าใช้จ่ายด้านข้อมูล/การติดตามผล (รายปี): ระบบ Knowledge‑Tracing, Spaced‑Repetition และฐานข้อมูล Student‑Model ค่าพัฒนา-บำรุงรักษา 100,000–500,000 บาท/ปี (ขึ้นกับศูนย์ข้อมูลและจำนวนนักเรียน)
แผนการขยายผล (Scale‑up) และเกณฑ์การคัดเลือกโรงเรียนรุ่นต่อไป
การขยายผลควรกำหนดเป็นระยะ (phased rollout) โดยมีด่านประเมินผลชัดเจน เพื่อป้องกันการใช้งบประมาณเกินและลดความเสี่ยงจากปัจจัยภายนอก แผนขยายตัวตัวอย่างแบ่งเป็น 3 เฟส: เฟสพิสูจน์แนวคิด (pilot, เสร็จแล้ว), เฟสขยายภูมิภาค (regional scale‑up), และเฟสขยายระดับชาติ (national roll‑out)
- เงื่อนไขการขยาย: โรงเรียนที่จะเข้าร่วมรุ่นถัดไปต้องมี (1) การเชื่อมต่อพื้นฐานที่สอดคล้องกับข้อกำหนด (latency และ bandwidth ที่รองรับ), (2) จำนวนครูที่ผ่านการฝึกอบรมพื้นฐานอย่างน้อย 60–80%, (3) โครงสร้างพื้นฐานอุปกรณ์เพียงพอหรือได้รับการสนับสนุนจากงบประมาณร่วม, และ (4) ความร่วมมือจากผู้บริหารสถานศึกษาในการติดตามผล
- เกณฑ์ประเมินความสำเร็จก่อนขยาย:
- ผลสัมฤทธิ์ทางการอ่าน‑เขียนเพิ่มขึ้นตามมาตรฐานประเมินของกระทรวงอย่างน้อย 20–30% เมื่อเทียบกับ baseline ในรอบนำร่อง
- อัตราการยึดติด (engagement) ของนักเรียนต่อระบบ Tutor‑LLM ≥ 60% (ใช้งานสม่ำเสมอตามแผนการเรียน)
- อัตราการยอมรับจากครู (การใช้ระบบเป็นส่วนหนึ่งของการสอนประจำวัน) ≥ 70%
- ค่าใช้จ่ายต่อเด็กที่ได้ผลสัมฤทธิ์ (cost per improved student) อยู่ในระดับที่ยอมรับได้ตามเกณฑ์งบประมาณของกระทรวง
- กลไกการขยาย: ใช้โมเดลผสมผสาน Funding‑as‑Service โดยในเฟสแรกให้รัฐจัดสรรงบพื้นฐานร่วมกับโครงการความร่วมมือภาคเอกชนเพื่อชดเชยค่าไลเซนส์ และเปิดกองทุนพัฒนาท้องถิ่นสำหรับการจัดหาอุปกรณ์เพิ่มเติม พร้อมสร้างศูนย์ซัพพอร์ตระดับภูมิภาคสำหรับการบำรุงรักษาและฝึกอบรมต่อเนื่อง
แหล่งเงินทุนและตัวชี้วัดความยั่งยืนเชิงการศึกษา
แหล่งเงินทุนที่เหมาะสมควรผสมผสานระหว่างงบประมาณรัฐ (สำหรับค่าโครงสร้างพื้นฐานและการประกันคุณภาพ), ความร่วมมือภาคเอกชน (สำหรับซอฟต์แวร์/ไลเซนส์หรืออุปกรณ์ในรูปแบบ CSR/Procurement), และเงินทุนพัฒนา/ต่างประเทศ (grants/technical assistance) สำหรับการวิจัยและการประเมินผลเชิงอิสระ
- รูปแบบการเงินที่แนะนำ: งบประมาณหลักจากกระทรวงศึกษาธิการ + ข้อตกลงวงเงินร่วมกับผู้ให้บริการ LLM (ลดราคาหรือการอุดหนุน) + กองทุนการแข่งขัน/ผลลัพธ์ (impact bonds) ที่จ่ายตามผลลัพธ์การเรียนรู้จริง
- ตัวชี้วัดความยั่งยืนเชิงการศึกษา (KPIs):
- เพิ่มขึ้นของสัดส่วนเด็กที่อ่าน‑เขียนได้ตามเกณฑ์ระดับชาติ (%) ต่อปี
- ค่าใช้จ่ายต่อเด็กที่คะแนนเพิ่มขึ้น (cost per learning gain) และการเปรียบเทียบกับโครงการทางเลือก
- อัตราการคงอยู่ของการใช้ระบบโดยครูและนักเรียนหลังสิ้นสุดการสนับสนุนภายนอก (%)
- การบูรณาการเนื้อหา Tutor‑LLM เข้ากับหลักสูตรอย่างเป็นทางการ (นโยบาย/ประกาศ) ภายใน 2–3 ปี
- การขยายความสามารถทางเทคนิคของระบบ (เช่น จำนวน Student‑Model ที่พร้อมให้บริการต่อภูมิภาค)
ความเสี่ยงด้านทรัพยากรและข้อเสนอการสร้างความยั่งยืน
มีความเสี่ยงสำคัญที่ต้องบริหารอย่างเป็นระบบ ได้แก่ ความไม่พร้อมของโครงสร้างพื้นฐาน (อินเทอร์เน็ต/อุปกรณ์), ภาระค่าใช้จ่ายต่อเนื่องจากไลเซนส์ LLM, ความเสี่ยงด้านความเป็นส่วนตัวของข้อมูลนักเรียน และความเสี่ยงจากการพึ่งพาผู้ให้บริการรายเดียว (vendor lock‑in)
- ข้อเสนอการบรรเทาความเสี่ยง:
- ใช้สถาปัตยกรรมแบบผสม (hybrid) โดยให้บางเวิร์กโหลดรันบนเซิร์ฟเวอร์ท้องถิ่น (edge/offline mode) เพื่อลดค่าแบนด์วิธและทำงานต่อเนื่องเมื่ออินเทอร์เน็ตขาดช่วง
- เจรจาสัญญาไลเซนส์ที่ยืดหยุ่น เช่น ราคาตามการใช้งาน (pay‑per‑use) และสิทธิ์ในการโฮสต์โมเดลพื้นฐานบนโครงสร้างของรัฐ (on‑premise) เพื่อป้องกัน vendor lock‑in
- ลงทุนในระบบ Data Governance และการเข้ารหัสข้อมูล เพื่อให้สอดคล้องกฎหมายคุ้มครองข้อมูลส่วนบุคคล และเพิ่มความเชื่อมั่นของผู้ปกครอง
- จัดตั้งโปรแกรมพัฒนากำลังคนระยะยาว (teacher‑training pipeline) รวมถึงระบบโค้ชชิ่งและชุมชนการปฏิบัติ (communities of practice) เพื่อลดความเสี่ยงจากการเปลี่ยนบุคลากร
- ออกแบบโมเดลการเงินที่เน้นการชำระด้วยผลลัพธ์ (outcome‑based financing) และสำรองงบประมาณบำรุงรักษาอย่างน้อย 10–20% ของงบลงทุนในแต่ละปี
- ดัชนีชี้วัดติดตามความเสี่ยง: อัตราการขัดข้องของระบบ, เวลาเฉลี่ยในการแก้ไขปัญหา (MTTR), อัตราการละทิ้งการใช้งานของนักเรียน/ครู, และการปฏิบัติตามมาตรการคุ้มครองข้อมูล (%)
สรุปได้ว่าโครงการ Tutor‑LLM สามารถขยายผลได้อย่างยั่งยืนหากมีการวางแผนงบประมาณที่ชัดเจน ข้อตกลงด้านไลเซนส์ที่ยืดหยุ่น การพัฒนากำลังคนอย่างต่อเนื่อง และกลไกการระดมทุนผสมระหว่างภาครัฐ เอกชน และแหล่งเงินระหว่างประเทศ โดยต้องติดตามตัวชี้วัดผลลัพธ์ทางการศึกษาและต้นทุนอย่างใกล้ชิดเพื่อบริหารความเสี่ยงและปรับโมเดลการขยายผลให้เหมาะสมกับบริบทของโรงเรียนสังกัดรัฐในแต่ละภูมิภาค
เสียงจากผู้มีส่วนได้ส่วนเสียและกรณีศึกษาที่โดดเด่น
มุมมองจากกระทรวงและทีมพัฒนา
นายกรัฐมนตรีช่วยกระทรวงศึกษาธิการ ระบุว่าโครงการ Tutor‑LLM เป็นความพยายามเชิงนโยบายที่ผสมผสานเทคโนโลยีเพื่อแก้ปัญหาความเหลื่อมล้ำทางการศึกษา โดยย้ำว่า "ผลการวัดรอบนำร่องชี้ให้เห็นว่าช่องว่างการอ่าน‑เขียนลดลงประมาณ 30% ซึ่งสะท้อนศักยภาพของการสอนแบบเฉพาะบุคคลที่มีโครงสร้างแบบ Student‑Model, Knowledge‑Tracing และ Spaced‑Repetition" ตัวแทนจากทีมพัฒนายังชี้แจงเพิ่มเติมว่าโครงการนำร่องครอบคลุมโรงเรียนรัฐใน 12 จังหวัด รวมผู้เรียนประมาณ 3,800 คน และมีการปรับแต่งโมเดลตามโปรไฟล์ผู้เรียนรายบุคคลเพื่อให้เกิดผลลัพธ์ที่วัดได้ในช่วง 6 เดือนแรก
หัวหน้าทีมพัฒนาเทคโนโลยีกล่าวถึงการออกแบบระบบว่า "เรานำข้อมูลการประเมินความสามารถเดิมมาสร้าง Student‑Model และเชื่อมต่อกับระบบ Knowledge‑Tracing เพื่อทำนายจุดอ่อน จากนั้นใช้กลยุทธ์ Spaced‑Repetition ในการทบทวนเนื้อหา ผลคือการเพิ่มความถี่การฝึกซ้อมที่มีประสิทธิภาพโดยไม่เพิ่มภาระงานของครูอย่างมีนัยสำคัญ" ทีมยังเน้นการเก็บข้อมูลเชิงพฤติกรรมและการวัดผลเชิงคุณภาพควบคู่กับคะแนนทดสอบเพื่อให้เห็นภาพการพัฒนาแบบองค์รวม
ประสบการณ์ของครูและนักเรียน — กรณีศึกษาเชิงรายบุคคล
ครูประจำชั้นจากโรงเรียนในจังหวัดนครราชสีมา ให้ความเห็นว่าโครงการช่วยให้สามารถระบุเด็กที่เสี่ยงหลุดจากกระบวนการอ่านไวกว่าเดิม "ก่อนหน้านี้ต้องรอผลสัมฤทธิ์ปลายภาค แต่ตอนนี้เรารู้ว่าผู้เรียนคนใดต้องได้รับการสนับสนุนภายใน 2–3 สัปดาห์แรก" เธอรายงานว่าผู้เรียนในชั้นเรียนที่ใช้ Tutor‑LLM มีอัตราการเข้าใจข้อความเพิ่มขึ้นและความมั่นใจในการอ่านดีขึ้น รวมทั้งตัวอย่างกรณีเด็กชั้น ป.3 คนหนึ่งที่คะแนนการอ่านพัฒนาเพิ่มจากระดับที่ต้องการการช่วยเหลือเป็นระดับพื้นฐานภายใน 10 สัปดาห์
ในทางกลับกัน กรณีศึกษาอีกแห่งจากโรงเรียนในพื้นที่ห่างไกลชี้ปัญหาด้านโครงสร้างพื้นฐาน: อินเทอร์เน็ตไม่เสถียรทำให้ระบบไม่สามารถซิงก์โปรไฟล์ผู้เรียนกับเซิร์ฟเวอร์ได้ทันเวลา ส่งผลให้การแนะนำแบบปรับเฉพาะบุคคลหยุดชะงักเป็นช่วงๆ ครูผู้ดูแลจึงต้องจัดกิจกรรมสำรองเพื่อไม่ให้การเรียนรู้สะดุด ปัญหานี้สะท้อนว่าความสำเร็จของโครงการขึ้นกับการลงทุนด้านฮาร์ดแวร์และเครือข่ายควบคู่ไปกับซอฟต์แวร์
นักเรียนที่สัมภาษณ์แสดงความเห็นเป็นกลางถึงบวก ตัวอย่างเช่น เด็กนักเรียน ป.4 กล่าวว่ารู้สึกว่าการฝึกซ้ำที่ระบบจัดให้ "ไม่เบื่อและเข้าใจมากขึ้น" ขณะที่นักเรียนคนอื่นตั้งคำถามเกี่ยวกับความเป็นส่วนตัวของข้อมูลและต้องการให้ครูอธิบายการใช้ข้อมูลของตนอย่างชัดเจน ซึ่งชี้ให้เห็นความจำเป็นของการสื่อสารกับผู้ปกครองและผู้เรียนอย่างโปร่งใส
ความเห็นจากผู้เชี่ยวชาญด้านการศึกษาและ AI และแนวทางปรับปรุง
ผู้เชี่ยวชาญด้านนโยบายการศึกษาชี้ว่า ผลลัพธ์เชิงบวกในรอบนำร่อง ควรถูกตีความอย่างระมัดระวัง โดยเสนอให้มีการประเมินผลระยะยาวและการสุ่มตัวอย่างที่กว้างขึ้นเพื่อยืนยันประสิทธิผลในบริบทที่หลากหลาย ทั้งนี้ควรวัดตัวชี้วัดหลายมิติ เช่น ผลสัมฤทธิ์ ระดับความต่อเนื่องของการเรียนรู้ และผลกระทบต่อความเหลื่อมล้ำในระยะยาว
นักวิชาการด้าน AI และจริยธรรมเทคโนโลยีกล่าวว่า "จำเป็นต้องมีมาตรการคุ้มครองข้อมูลส่วนบุคคล การทดสอบความเป็นธรรม (fairness testing) และการเปิดเผยการทำงานของโมเดลให้ผู้มีส่วนได้ส่วนเสียเข้าใจได้" และเสนอข้อเสนอแนะเชิงปฏิบัติ ได้แก่
- โปร่งใสและยินยอม — แจ้งผู้ปกครองและนักเรียนถึงประเภทข้อมูลที่เก็บ วิธีใช้ และระยะเวลาจัดเก็บ พร้อมช่องทางถอนความยินยอม
- ความเป็นมนุษย์ในห่วงโซ่การตัดสินใจ — ให้ครูยังคงมีสิทธิ์ปรับแผนการสอนและทบทวนคำแนะนำจากระบบก่อนนำไปใช้
- การทดสอบและตรวจสอบ — ดำเนินการทดสอบเชิงสถิติของโมเดลเพื่อค้นหาอคติ และมีการตรวจสอบเป็นระยะโดยทีมอิสระ
- การพัฒนาโครงสร้างพื้นฐาน — ลงทุนในเครือข่ายและอุปกรณ์ให้เพียงพอโดยเฉพาะโรงเรียนในพื้นที่ห่างไกล
- การฝึกอบรมครู — จัดหลักสูตรยกระดับทักษะดิจิทัลและการใช้ผลวิเคราะห์เชิงปฏิบัติ เพื่อประกันว่าครูแปลผลข้อมูลเชิงเทคนิคเป็นการจัดการชั้นเรียนได้
สรุป — เสียงจากผู้มีส่วนได้ส่วนเสียสะท้อนทั้งความหวังและความท้าทาย: ผลการนำร่องแสดงสัญญาณบวกที่ชัดเจน แต่การขยายผลในวงกว้างจำเป็นต้องอาศัยการออกแบบเชิงนโยบายที่รัดกุม มาตรการคุ้มครองข้อมูล และการลงทุนด้านโครงสร้างพื้นฐานควบคู่กัน เพื่อให้ Tutor‑LLM กลายเป็นเครื่องมือที่ยั่งยืนและยกระดับการเรียนรู้ของเด็กไทยได้อย่างแท้จริง
บทสรุป
โครงการ Tutor‑LLM ของกระทรวงศึกษาธิการที่ผสานแนวทาง Student‑Model, Knowledge‑Tracing และ Spaced‑Repetition แสดงศักยภาพเชิงปริมาณในการลดช่องว่างการอ่าน‑เขียนของเด็กนักเรียนในสังกัดรัฐได้ประมาณ 30% ในรอบนำร่อง ผลลัพธ์นี้ชี้ให้เห็นว่าการปรับการสอนเชิงเฉพาะบุคคลด้วยโมเดลภาษาขนาดใหญ่และเทคนิคการติดตามพัฒนาการมีผลลัพธ์ที่เป็นรูปธรรม อย่างไรก็ตาม ก่อนการขยายผลจำเป็นต้องมีการตรวจสอบการออกแบบการทดลองอย่างรอบคอบ (เช่น ขนาดกลุ่มตัวอย่าง การมีกรุ๊ปควบคุม การควบคุมปัจจัยรบกวน และความสม่ำเสมอของการวัดผล) รวมถึงการประเมินความยั่งยืนทางการเงินเพื่อให้แน่ใจว่าการนำไปใช้ในวงกว้างสามารถดำเนินต่อได้โดยไม่สร้างภาระงบประมาณในระยะยาว
ความสำเร็จในระยะยาวของโครงการขึ้นกับการจัดกรอบการคุ้มครองข้อมูลที่ชัดเจน การลงทุนในการฝึกครูและบุคลากรทางการศึกษาที่จะใช้เครื่องมือเหล่านี้ และการจัดระบบประเมินผลที่โปร่งใสเพื่อตรวจจับและแก้ไขอคติของโมเดล รวมถึงการรับรองคุณภาพการสอนผ่านมาตรฐานและตัวชี้วัดที่เปิดเผย แนะนำให้ดำเนินการทดลองเพิ่มเติมในรูปแบบที่เข้มงวดขึ้น เช่น การทดลองแบบสุ่มควบคุม และการวิเคราะห์ต้นทุน‑ผลประโยชน์ ควบคู่ไปกับการนำเทคโนโลยีคุ้มครองความเป็นส่วนตัวมาใช้ เพื่อสร้างความเชื่อมั่นแก่ผู้ปกครอง ครู และภาครัฐก่อนการขยายผลเชิงนโยบาย



