
ตลาดซอฟต์แวร์และบริการทางกฎหมายกำลังเผชิญความเปลี่ยนแปลงอย่างรวดเร็วที่ท้าทายทั้งโมเดลธุรกิจและกรอบกฎระเบียบเดิม เมื่อเทคโนโลยีปัญญาประดิษฐ์ (AI) ถูกนำมาใช้ในงานตรวจสอบสัญญา วิเคราะห์คดี และให้คำปรึกษาทางกฎหมายขั้นต้น ผลการสำรวจและรายงานต่างประเทศชี้ว่าการนำ AI มาใช้สามารถลดเวลาในการทำงานซ้ำซ้อนได้ราว 30–50% และช่วยเพิ่มความแม่นยำในงานเอกสาร ทำให้ผู้ให้บริการทางกฎหมายแบบดั้งเดิมต้องปรับตัวอย่างเร่งด่วนเพื่อรักษาความสามารถในการแข่งขัน
บทความนี้จะพาไปวิเคราะห์ภาพรวมตลาด ตั้งแต่สถิติการเติบโตของซอฟต์แวร์กฎหมาย (LegalTech) และกรณีศึกษาที่เด่นเช่นการนำระบบวิเคราะห์สัญญาไปใช้ในองค์กรขนาดใหญ่ ไปจนถึงปัญหาด้านกฎระเบียบ ความเป็นส่วนตัว ความรับผิดชอบของระบบ AI และผลกระทบต่อแรงงานทางกฎหมาย ทั้งยังสรุปคู่มือปฏิบัติสำหรับผู้บริหารและนักพัฒนา—รวมถึงแนวทางทางเทคนิคและเชิงนโยบาย—เพื่อรับมือกับความตึงเครียดในภาคกฎหมายที่เกิดจากคลื่นลูกใหม่นี้
ภาพรวมตลาดซอฟต์แวร์และบริการทางกฎหมาย
ภาพรวมตลาดซอฟต์แวร์และบริการทางกฎหมาย
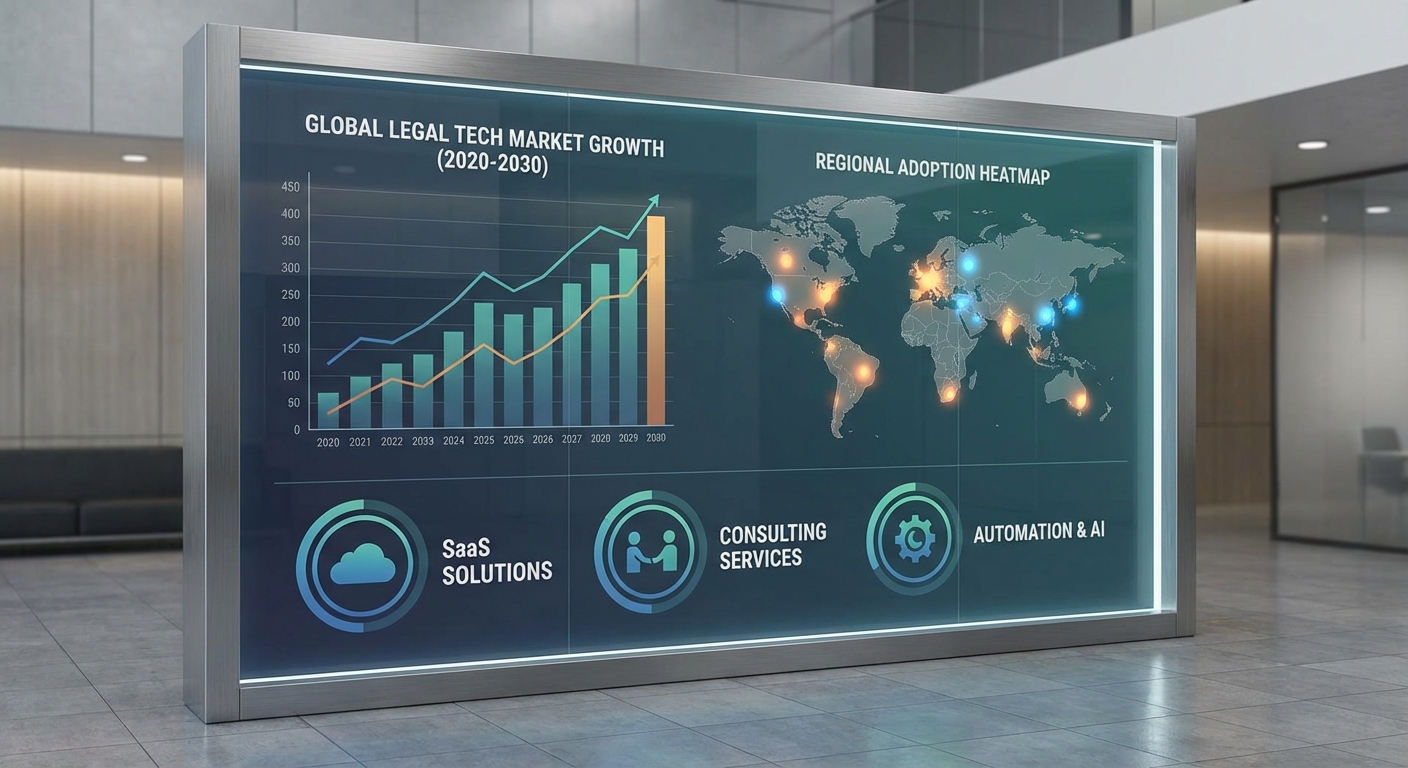
ตลาดซอฟต์แวร์และบริการทางกฎหมาย (LegalTech) กำลังอยู่ในช่วงขยายตัวอย่างชัดเจน โดยภาพรวมระดับโลกถูกประเมินว่ามีมูลค่าหลายพันล้านดอลลาร์ และคาดว่าในอีก 5–7 ปีข้างหน้าจะเติบโตด้วยอัตราเฉลี่ยต่อปี (CAGR) ประมาณ 8–12% จากแรงขับเคลื่อนทั้งการปรับปรุงกระบวนการภายในองค์กร การย้ายสู่โมเดลการคิดค่าบริการแบบ subscription และการลงทุนในระบบอัตโนมัติด้านเอกสารและงานวิจัยกฎหมาย เหตุนี้ทำให้ผู้ให้บริการซอฟต์แวร์และที่ปรึกษาทางกฎหมายทั้งรายใหญ่และสตาร์ทอัพต่างเร่งพัฒนาผลิตภัณฑ์เพื่อรองรับความต้องการดังกล่าว
การกระจายตัวของตลาดมีลักษณะไม่เท่ากันตามภูมิภาค โดย อเมริกาเหนือ ยังเป็นตลาดใหญ่สุด คิดเป็นสัดส่วนประมาณ 40–50% ของมูลค่าตลาดโลก ตามด้วย ยุโรป ที่มีสัดส่วนราว 25–30% และ เอเชีย-แปซิฟิก ที่เติบโตรวดเร็วและมีสัดส่วนเพิ่มขึ้นเป็น 15–25% ส่วนตลาดในลาตินอเมริกาและแอฟริกายังคงมีโอกาสเติบโตสูงแต่เริ่มจากฐานที่เล็กกว่า การกระจายนี้สะท้อนทั้งความหลากหลายของกรอบกฎหมาย การลงทุนด้าน IT และระดับการเปลี่ยนผ่านสู่ดิจิทัลในแต่ละภูมิภาค
แรงขับเคลื่อนหลักของการเติบโตประกอบด้วย: การลดต้นทุน (cost reduction) ผ่านการอัตโนมัติของงานที่ใช้เวลาจำนวนมาก เช่น การตรวจเอกสารและ e-discovery; การเพิ่มประสิทธิภาพ (efficiency) ของทีมกฎหมายทั้งภายในและภายนอก; และความต้องการบริการแบบ subscription ที่ช่วยเปลี่ยนรูปแบบการคิดค่าบริการจากแบบคิดต่อคดี/งาน มาเป็นการชำระเป็นระยะ ทำให้องค์กรสามารถคาดการณ์งบประมาณได้ดีขึ้น นอกจากนี้การเปลี่ยนแปลงวิถีทำงาน (เช่น remote/hybrid work) และแรงกดดันด้านการปฏิบัติตามกฎระเบียบ (compliance) ก็เป็นตัวเร่งสำคัญให้ลูกค้ารายใหญ่ลงทุนในโซลูชัน LegalTech มากขึ้น
ตลาดกำลังเกิดการรวมตัวและการแข่งขันในหลายชั้น ผู้เล่นดั้งเดิมรายใหญ่ (enterprise vendors) เช่น Thomson Reuters, LexisNexis/RELX และ Wolters Kluwer ยังคงครองส่วนแบ่งสำคัญ ขณะเดียวกัน SaaS ผู้เชี่ยวชาญด้านแนวคิดใหม่ ๆ เช่น Clio, iManage, Ironclad และผู้เล่นในกลุ่ม contract lifecycle management, e-discovery และการวิเคราะห์เอกสารเช่น Relativity, ContractPodAI และ Luminance ก็เติบโตรวดเร็ว ทำให้เกิดระบบนิเวศที่ประกอบด้วย vendors ขนาดใหญ่ สตาร์ทอัพที่มุ่งนวัตกรรม และผู้ให้บริการด้านการให้คำปรึกษา/outsourcing
- แนวโน้มการรวมตัวของตลาด: M&A และพันธมิตรเชิงกลยุทธ์เพิ่มขึ้น ผู้เล่นขนาดกลางและเล็กมักถูกซื้อโดยผู้ให้บริการรายใหญ่เพื่อเติมเต็มฟังก์ชัน AI/Automation
- การยอมรับโดย BigLaw และองค์กรขนาดใหญ่: ทีมกฎหมายภายในบริษัทใหญ่ (in-house) และสำนักงานกฎหมายรายใหญ่มักนำโซลูชันแบบ SaaS และเครื่องมือ AI มาใช้ ทั้งในด้านการจัดการสัญญา (CLM), การค้นคว้าวิจัยกฎหมาย, และการทำ e-discovery
- โมเดลธุรกิจ: Subscription และ consumption-based pricing ถูกนำมาใช้มากขึ้น ซึ่งช่วยสร้างรายได้ที่สม่ำเสมอและเพิ่มมูลค่าต่อผู้ให้บริการซอฟต์แวร์
สรุปได้ว่า ภาพรวมตลาดซอฟต์แวร์และบริการทางกฎหมายอยู่ในภาวะเติบโตและเปลี่ยนผ่านอย่างรวดเร็ว โดยมี CAGR ประมาณ 8–12% ในอีก 5–7 ปีข้างหน้า แรงขับเคลื่อนจากการลดต้นทุน การเพิ่มประสิทธิภาพ และความต้องการโซลูชันแบบ subscription รวมทั้งการรวมตัวของผู้เล่นทั้งรายใหญ่และสตาร์ทอัพ ทำให้ตลาดนี้มีทั้งโอกาสและความท้าทายสำหรับผู้ประกอบการและผู้ใช้บริการทางกฎหมายทุกกลุ่ม
เทคโนโลยี AI ที่เขย่าภาคกฎหมาย: จาก LLMs ถึง RPA
ท่ามกลางความเปลี่ยนแปลงในตลาดซอฟต์แวร์และบริการทางกฎหมาย เทคโนโลยีปัญญาประดิษฐ์ (AI) หลายประเภทเข้ามาเปลี่ยนรูปแบบการทำงานของสำนักงานกฎหมาย ฝ่ายกฎหมายภายในองค์กร และผู้ให้บริการด้าน e-discovery อย่างรวดเร็ว ตั้งแต่การประมวลผลภาษาธรรมชาติ (NLP) ที่ใช้สำหรับสรุปเอกสารและค้นหาข้อมูล ไปจนถึงระบบอัตโนมัติแบบโรโบติก (RPA) ที่ลดงานซ้ำซ้อน เทคโนโลยีเหล่านี้ไม่เพียงช่วยเพิ่มความเร็ว แต่ยังช่วยลดต้นทุนและข้อผิดพลาดในกระบวนการทางกฎหมายได้อย่างมีนัยสำคัญ
LLMs และ NLP: สรุปและค้นหาข้อความทางกฎหมาย
Large Language Models (LLMs) เช่น GPT-4 ของ OpenAI, Claude ของ Anthropic และโมเดลเชิงพาณิชย์จากผู้ให้บริการคลาวด์ ถูกนำมาใช้ร่วมกับเทคนิค NLP เพื่อสรุปคดี เอกสารการค้นพบ และถอดความข้อกฎหมายให้สั้น กระชับ และค้นหาได้ง่าย ผู้ให้บริการทางกฎหมายเช่น Casetext (CoCounsel), LexisNexis (Lexis+), และ Thomson Reuters (เช่น Westlaw Edge) ใช้ NLP/LLM ในการช่วยร่างคำให้การ สร้างสรุปคดี และเพิ่มประสิทธิภาพการค้นหาแบบเชิงบริบท
- ผลการใช้งาน: รายงานจากผู้ให้บริการหลายรายระบุว่าสรุปเอกสารและการค้นหาด้วย LLM สามารถลดเวลาที่บุคลากรต้องใช้ในการอ่านและสรุปเอกสารลงได้ประมาณ 60–80% ในกรณีเอกสารยาว เช่น บทคัดย่อคดีหรือรายงานทางเทคนิค
- ตัวอย่างการใช้งานจริง: การใช้ LLM สร้างร่างตอบโต้ข้อกฎหมายหรือสรุปข้อเท็จจริงก่อนการพิจารณา ทำให้ทีมกฎหมายสามารถโฟกัสงานเชิงกลยุทธ์มากขึ้น
Contract analytics และ CLM: ลดเวลาตรวจสัญญาอย่างมีนัยสำคัญ
Contract Analytics และระบบจัดการวงจรสัญญา (Contract Lifecycle Management — CLM) เช่น Kira Systems, Luminance, Evisort, Ironclad, ContractPodAI และ DocuSign CLM นำ Machine Learning และ NLP มาช่วยในการสกัดข้อความสำคัญ (เช่น ข้อผูกพัน เงื่อนไขต่อรอง วันที่สิ้นสุด) การทำคลัสเตอร์ข้อยกเว้น และการให้คะแนนความเสี่ยงแบบอัตโนมัติ
- ผลลัพธ์เชิงประสิทธิภาพ: ผู้ให้บริการและลูกค้ารายงานว่าเทคโนโลยีเหล่านี้สามารถลดเวลาในการตรวจสัญญาขั้นต้นได้ 50–90% ขึ้นอยู่กับระดับความซับซ้อนของเอกสารและการอบรมโมเดล
- ฟีเจอร์สำคัญ: การค้นหาข้ามสัญญา การสกัดข้อผูกพันอัตโนมัติ การเชื่อมต่อกับฐานข้อมูลเงื่อนไขมาตรฐาน และการแจ้งเตือนวงจรสัญญาเพื่อลดความเสี่ยงจากการพลาดวันครบกำหนด
- ผลกระทบเชิงธุรกิจ: ลดรอบเวลาในการปิดดีล (contract cycle time) ลงอย่างมีนัยสำคัญ ช่วยให้ทีมกฎหมายสามารถรองรับปริมาณงานที่เพิ่มขึ้นโดยไม่ต้องขยายทีมมาก
RPA และ Workflow Automation: ลดงานซ้ำซ้อนและต้นทุน
Robotic Process Automation (RPA) โดยผู้เล่นหลักอย่าง UiPath, Automation Anywhere และ Blue Prism ถูกผสานเข้ากับระบบกฎหมายเพื่อออโตเมตงานที่มีลักษณะซ้ำซ้อน เช่น การป้อนข้อมูลเข้าระบบ จัดการการเรียกเก็บเงิน (billing/docketing) การสร้างเอกสารมาตรฐาน และการเชื่อมต่อการอนุมัติภายในระบบ CLM
- ประสิทธิผล: กรณีศึกษาจากองค์กรหลายแห่งแสดงให้เห็นว่า RPA สามารถลดชั่วโมงงานที่ต้องใช้แรงงานมนุษย์ได้ 30–70% และลดต้นทุนการดำเนินงานลงอย่างมีนัยสำคัญ (ตัวเลขความคุ้มค่าต่างกันไปตามกระบวนการ)
- การใช้งานร่วมกับ AI: เมื่อนำ RPA มาใช้ร่วมกับ NLP/LLM และ OCR ระบบสามารถอ่านเอกสาร ดึงข้อมูลสำคัญ อัปเดตฐานข้อมูล และส่งต่อไปยังขั้นตอนต่อไปแบบอัตโนมัติ
- ตัวอย่าง: กระบวนการ intake ลูกค้ารายใหม่ การอัปเดตสถานะคดีสู่ระบบบริหารความสัมพันธ์ลูกค้า (CRM) และการเตรียมรายงานค่าธรรมเนียมอัตโนมัติ
เทคโนโลยีเสริม: OCR, Knowledge Graphs และ e-Discovery ที่ขับเคลื่อนด้วย ML
นอกจากโมเดลภาษาและ RPA แล้ว เทคโนโลยีเสริมอย่าง OCR (เช่น ABBYY, Tesseract) ช่วยให้สามารถดึงข้อความจากภาพสแกนและ PDF เก่าๆ ได้อย่างแม่นยำ และเทคโนโลยี Knowledge Graphs (เช่น Neo4j) ถูกใช้เพื่อเชื่อมโยงหน่วยข้อมูล บุคคล และเหตุการณ์ข้ามเอกสาร ทำให้การวิเคราะห์คดีและการตรวจสอบความสัมพันธ์ระหว่างเอกสารเป็นไปได้อย่างมีประสิทธิภาพ
- e-Discovery: แพลตฟอร์มเช่น Relativity, Logikcull, Everlaw และ Disco ใช้ ML ในการจัดกลุ่ม เรียกคืนเอกสารที่เกี่ยวข้อง และประเมินเนื้อหาเชิงบริบท การประยุกต์ใช้ Predictive Coding และ Near-duplicate detection สามารถลดปริมาณเอกสารที่ต้องรีวิวด้วยคนลงได้มาก — บางกรณีลดลงถึง 60–90%
- ผลประโยชน์รวม: การผนวก OCR, Knowledge Graphs และ ML ช่วยให้ทีมกฎหมายสามารถค้นพบเชิงลึก (insights) เร่งการตอบคำขอข้อมูล และเพิ่มความแม่นยำในการตัดสินใจเชิงความเสี่ยง
โดยสรุป เทคโนโลยี AI ตั้งแต่ LLMs, NLP, Contract Analytics และ RPA ไปจนถึง OCR และ Knowledge Graphs ก่อให้เกิดการเปลี่ยนแปลงทั้งในเชิงปริมาณและคุณภาพของงานกฎหมาย อย่างไรก็ตาม การนำไปใช้ต้องคำนึงถึงการควบคุมความเสี่ยง การตรวจสอบโดยมนุษย์ (human-in-the-loop) และข้อกำหนดด้านความเป็นส่วนตัว/การปฏิบัติตามกฎระเบียบ เพื่อให้การปรับใช้ AI เกิดประโยชน์สูงสุดและยั่งยืนต่อองค์กร
ผลกระทบต่อสำนักงานกฎหมายและบริการลูกค้า
ผลกระทบต่อสำนักงานกฎหมายและบริการลูกค้า
การนำเทคโนโลยีปัญญาประดิษฐ์เข้ามาใช้ในสำนักงานกฎหมายจะเปลี่ยนแปลงบทบาทของทนายความและพาราลีกัลอย่างชัดเจน งานที่มีลักษณะเป็นกระบวนการซ้ำ ๆ เช่น การตรวจร่างสัญญา (contract review), การค้นคว้ากฎหมาย (legal research) และการจัดทำเอกสารมาตรฐาน จะถูกระบบอัตโนมัติช่วยลดเวลาทำงานลงอย่างมีนัยสำคัญ โดยการประเมินเบื้องต้นชี้ว่า เวลางานซ้ำอาจลดลงได้ราว 30–70% ขึ้นกับประเภทงานและระดับการปรับใช้เทคโนโลยี ตัวอย่างเช่น การตรวจสอบเอกสาร due diligence ที่เคยใช้เวลาหลายวัน อาจลดเหลือเพียงชั่วโมงถึงหนึ่งวันเมื่อใช้เครื่องมือ NLP ที่ปรับแต่งมาเฉพาะทาง
ผลกระทบเชิงธุรกิจจะเห็นได้จากการเปลี่ยนแปลงโมเดลราคาบริการ ลูกค้าสำนักงานกฎหมายเริ่มคาดหวังโครงสร้างค่าบริการที่ชัดเจนและคุ้มค่ามากขึ้น เช่น fixed fee สำหรับงานมาตรฐาน, subscription สำหรับบริการให้คำปรึกษาต่อเนื่อง และโมเดลราคาตามผลลัพธ์ (outcome-based pricing) สำหรับงานที่มีความเสี่ยงร่วมกัน สำนักงานกฎหมายที่พัฒนารูปแบบการเสนอขายแบบแพลตฟอร์ม (SaaS) จะสามารถเสนอแพ็กเกจบริการรายเดือน ตั้งแต่การให้สิทธิ์ใช้งานเครื่องมือวิเคราะห์สัญญาจนถึงบริการให้คำปรึกษาเชิงกลยุทธ์แบบผสมผสาน ซึ่งจะสร้างรายรับซ้ำและความผูกพันกับลูกค้ามากขึ้น
ในห่วงโซ่คุณค่า (value chain) ของอุตสาหกรรมจะเกิดการแยกหน้าที่อย่างชัดเจน: งานเชิงปฏิบัติการและการผลิตเอกสารจะถูกย้ายไปยังผู้ให้บริการเทคโนโลยีหรือตัวกลางแพลตฟอร์ม ขณะที่ทนายความที่มีทักษะสูงจะเน้นการให้คำปรึกษาเชิงกลยุทธ์ การเจรจาต่อรองที่ซับซ้อน และการจัดการความเสี่ยงขององค์กร นอกจากนี้ การเชื่อมต่อข้อมูลกับระบบของลูกค้า (API integration) จะทำให้บริการตอบสนองได้เร็วขึ้นและเป็นส่วนตัวมากขึ้น ส่งผลให้โครงสร้างต้นทุนและช่องทางการให้บริการเปลี่ยนจากการขายชั่วโมงเป็นการขายผลลัพธ์และการเข้าถึงข้อมูลแบบ on-demand
ผลต่อการเข้าถึงความยุติธรรม (access to justice) มีทั้งโอกาสและความเสี่ยง ด้านบวกคือการลดค่าใช้จ่ายและเวลาในการเข้าถึงบริการทางกฎหมาย ตัวอย่างเช่น เครื่องมือให้คำปรึกษาเริ่มต้นอัตโนมัติและเทมเพลตสัญญาที่ใช้ได้ทันที สามารถช่วยประชาชนและธุรกิจขนาดเล็กเข้าถึงคำปรึกษาเบื้องต้นได้กว้างขึ้น อย่างไรก็ดี ต้องเฝ้าระวังปัญหาเรื่องความแม่นยำ ความเอนเอียงของอัลกอริทึม และประเด็นความเป็นส่วนตัว ซึ่งต้องการมาตรการกำกับดูแลและการตรวจสอบผลลัพธ์จากมนุษย์ควบคู่ไปด้วย
ด้านบุคลากร สำนักงานกฎหมายต้องลงทุนใน upskilling และปรับโครงสร้างทีมเพื่อรองรับการทำงานแบบใหม่ พาราลีกัลและทีมงานปฏิบัติการจะถูกย้ายบทบาทไปสู่การดูแลเครื่องมือ การตรวจสอบคุณภาพของผลลัพธ์ และการออกแบบกระบวนงานอัตโนมัติ ตำแหน่งงานใหม่ที่คาดว่าจะเกิดขึ้นได้แก่:
- Legal AI Specialist — ผู้ปรับแต่งและทดสอบโมเดล NLP สำหรับงานกฎหมาย
- Legal Data Steward — ผู้ดูแลชุดข้อมูลและการปกป้องข้อมูลเชิงกฎหมาย
- Legal Solutions Architect — ผู้ออกแบบโซลูชันผสมผสานระหว่างกระบวนการทางกฎหมายและเทคโนโลยี
- ML Compliance Officer — ผู้รับผิดชอบเรื่องการปฏิบัติตามกฎระเบียบและการควบคุมความเสี่ยงของ AI
การประมาณการด้านแรงงานชี้ให้เห็นว่าแม้จะมีการลดเวลาทำงานซ้ำมากถึง 30–70% แต่จะตามมาด้วยการสร้างบทบาทเชิงเทคนิคและการจัดการ ซึ่งในสำนักงานที่ลงทุนอย่างจริงจัง อาจเห็นการเปลี่ยนสัดส่วนงานจากการทำงานแบบปฏิบัติการไปสู่การให้คำปรึกษาเชิงกลยุทธ์เพิ่มขึ้น 20–40% ในรอบ 3–5 ปีแรก ดังนั้นการวางแผนด้านกำลังคน การฝึกอบรมภายใน และการว่าจ้างผู้เชี่ยวชาญทางเทคนิคจะเป็นปัจจัยสำคัญที่กำหนดความสำเร็จของสำนักงานกฎหมายในยุค AI
กฎระเบียบ จริยธรรม และความเสี่ยงด้านความปลอดภัย
ความเป็นความลับของลูกค้ากับการใช้ข้อมูลบนคลาวด์
การนำ AI เข้ามาใช้ในงานกฎหมายสร้างความท้าทายสำคัญต่อ ความลับระหว่างทนายความและลูกค้า (attorney-client privilege) โดยเฉพาะเมื่อนำข้อมูลคดี ข้อความสนทนา หรือเอกสารภายในไปประมวลผลบนคลาวด์ ข้อมูลเหล่านี้อาจถูกจัดเก็บหรือถูกประมวลผลโดยผู้ให้บริการภายนอกซึ่งเพิ่มความเสี่ยงทั้งด้านการเข้าถึงโดยไม่ได้รับอนุญาตและการรั่วไหล ข้อพึงระวังสำหรับองค์กรกฎหมาย ได้แก่ การกำหนดนโยบายการส่งข้อมูลไปยังบริการคลาวด์ การใช้การเข้ารหัสทั้ง in transit และ at rest และการกำหนดขอบเขตของข้อมูลที่สามารถนำไปใช้ฝึกโมเดล (data minimization) เพื่อจำกัดปริมาณข้อมูลความลับที่ออกสู่ระบบภายนอก
ตัวอย่างเชิงสถิติจากการสำรวจภายในอุตสาหกรรมชี้ให้เห็นว่าองค์กรกฎหมายส่วนใหญ่ระบุว่า ความเสี่ยงด้านข้อมูลเป็นความกังวลอันดับต้นๆ เมื่อพิจารณาจะเลือกใช้ผู้ให้บริการ AI/คลาวด์ นอกจากนี้ ยังต้องคำนึงถึงข้อกำหนดด้านกฎหมายท้องถิ่น เช่น กฎคุ้มครองข้อมูลส่วนบุคคล การเจรจาสัญญาที่ชัดเจน (DPA) และการตรวจสอบว่าผู้ให้บริการมีมาตรฐานความปลอดภัย เช่น ISO 27001 หรือ SOC 2

ความโปร่งใส ความสามารถในการอธิบาย และความลำเอียงของโมเดล
หนึ่งในปัญหาจริยธรรมที่เด่นชัดคือ ความลำเอียงของโมเดล (bias) และการอธิบายผลลัพธ์ไม่ได้ (explainability) โมเดลภาษาขนาดใหญ่ (LLMs) และระบบตัดสินใจอัตโนมัติอาจให้คำตอบที่มีอคติทางเพศ เชื้อชาติ หรือภูมิศาสตร์ ซึ่งส่งผลต่อความยุติธรรมของการให้คำปรึกษาทางกฎหมายหรือการคัดกรองคดี ตัวอย่างที่เคยเกิดขึ้นในวงกว้าง เช่น ระบบประเมินความเสี่ยงผู้ต้องขังที่ให้คะแนนไม่เป็นกลางต่อกลุ่มประชากรบางกลุ่ม
เพื่อจัดการความเสี่ยงเหล่านี้ องค์กรควรบังคับใช้แนวทางเช่น model cards และ documentation สำหรับแต่ละโมเดล ระบุขอบเขตการใช้งาน ข้อมูลฝึก และข้อจำกัด นอกจากนี้ ควรมีการทำ model audit และการทดสอบความลำเอียงด้วยชุดข้อมูลที่หลากหลาย รวมถึงกระบวนการอธิบายผล (explainability techniques) ที่เพียงพอให้ผู้ใช้งานระดับทนายความเข้าใจว่าโมเดลให้คำตอบมาได้อย่างไร และจะใช้คำตอบนั้นอย่างไรอย่างปลอดภัยในเชิงวิชาชีพ
กฎระเบียบ การกำกับดูแล และความเสี่ยงจากหน่วยงานกำกับ
ระดับการกำกับดูแลต่อ AI กำลังเข้มงวดขึ้นอย่างรวดเร็ว ตัวอย่างเช่น EU AI Act กำหนดการจัดประเภทระบบ AI เป็นระดับความเสี่ยง และบังคับให้ระบบที่จัดว่าเป็น high‑risk ต้องผ่านการประเมินความเสี่ยงและมีเอกสารประกอบ (conformity assessment) ก่อนวางจำหน่าย ขณะเดียวกัน หน่วยงานกำกับดูแลระดับชาติและสมาคมทนายความในหลายประเทศออกคำแนะนำด้านจริยธรรม เช่น ข้อบังคับด้านการปกป้องข้อมูล การเปิดเผยการใช้งาน AI ต่อคู่กรณี และการรับผิดชอบด้านวิชาชีพ
ตัวอย่างข้อกำหนดเชิงนโยบาย: ระบบ AI ที่ส่งผลต่อสิทธิของบุคคลควรได้รับการประเมินความเสี่ยงเชิงระบบและมีการบันทึกการตัดสินใจเพื่อความโปร่งใสและการตรวจสอบย้อนหลัง
แนวปฏิบัติพื้นฐานในการลดความเสี่ยง
- Data minimization: จำกัดการส่งข้อมูลที่สามารถระบุตัวบุคคลหรือข้อมูลคดีที่เป็นความลับไปยังระบบภายนอกเฉพาะที่จำเป็น
- Encryption: ใช้การเข้ารหัสทั้งในระหว่างการส่งข้อมูลและเมื่อจัดเก็บ (TLS, AES-256 เป็นต้น)
- Access controls: บังคับใช้การควบคุมการเข้าถึงแบบบทบาท (RBAC), การยืนยันตัวตนแบบหลายปัจจัย (MFA) และนโยบายสิทธิ์ขั้นต่ำ (least privilege)
- Audit log: จัดเก็บบันทึกกิจกรรมการเข้าถึงและการประมวลผลเพื่อรองรับการตรวจสอบภายในและการแจ้งเหตุเมื่อเกิดเหตุผิดปกติ
- Model audit & red‑teaming: ทดสอบความปลอดภัยและความลำเอียงของโมเดลอย่างสม่ำเสมอ รวมถึงการทดสอบการโจมตีเชิง adversarial
- Vendor due diligence: ทำการตรวจสอบผู้ให้บริการ (security posture, certifications, incident history), ระบุข้อผูกพันในสัญญา (DPA, SLA, breach notification) และกำหนดสิทธิ์ในการตรวจสอบ (right to audit)
- Privacy‑enhancing technologies: พิจารณาการใช้เทคนิคเช่น differential privacy, การทำข้อมูลเทียม (synthetic data) หรือการทำ pseudonymization เพื่อลดความเสี่ยงของข้อมูลต้นทาง
การผสานมาตรการด้านเทคนิค นโยบายภายใน และข้อผูกพันทางสัญญาเป็นสิ่งจำเป็นสำหรับสำนักงานกฎหมายที่ต้องการนำ AI มาใช้โดยไม่ละทิ้งความรับผิดชอบทางจริยธรรมและการกำกับดูแล ในสภาวะที่กฎระเบียบพัฒนาอย่างรวดเร็ว การก่อสร้างกระบวนการตรวจสอบความเสี่ยงเชิงต่อเนื่อง (continuous compliance) จะช่วยให้สามารถตอบสนองต่อข้อซักถามจากลูกค้าและหน่วยงานกำกับได้อย่างรวดเร็วและมีความน่าเชื่อถือ
อุปสรรคในการนำ AI ไปใช้และกลยุทธ์การปรับตัว
การนำเทคโนโลยีปัญญาประดิษฐ์ (AI) เข้ามาใช้ในตลาดซอฟต์แวร์และบริการทางกฎหมายเผชิญทั้งอุปสรรคเชิงเทคนิค เศรษฐกิจ และวัฒนธรรมองค์กร ซึ่งหากไม่จัดการอย่างเป็นระบบจะทำให้โครงการล้มเหลวหรือไม่ได้ผลตามคาด การระบุปัญหาและกำหนดกลยุทธ์ตอบโต้ที่ชัดเจนเป็นสิ่งจำเป็น เพื่อให้การลงทุนเกิดผลตอบแทนที่จับต้องได้และสอดคล้องกับข้อกำหนดทางกฎหมายและมาตรฐานความปลอดภัยข้อมูล
อุปสรรคหลัก
- ระบบเก่า (Legacy systems) — ระบบบริหารจัดการคดีและเอกสารเดิมมักเป็นสถาปัตยกรรมเก่า ใช้ฐานข้อมูลหลายชุดและไม่มี API มาตรฐาน ทำให้การผสานรวมกับโมเดล AI เป็นไปได้ยาก ตัวอย่างเช่น บริษัทกฎหมายขนาดกลางถึงใหญ่หลายแห่งใช้ระบบที่พัฒนามานานกว่า 10 ปี ทำให้ต้องลงทุนทั้งด้านการปรับสถาปัตยกรรมหรือสร้างชั้นเชื่อมต่อ (integration layer) ใหม่
- ค่าใช้จ่ายเริ่มต้น — การลงทุนในซอฟต์แวร์ AI, ฮาร์ดแวร์ และการจัดการข้อมูลมีต้นทุนสูง โดยเฉพาะเมื่อรวมค่าใช้จ่ายในการบริหารการเปลี่ยนแปลง การฝึกอบรมพนักงาน และการตรวจสอบความเป็นไปตามข้อกำหนด ตัวอย่างการประเมิน: โครงการนำร่องขนาดเล็กอาจต้องใช้เงิน 500,000–2,000,000 บาท ขึ้นกับขอบเขตและการปรับแต่ง
- คุณภาพข้อมูลและการจัดการข้อมูล — ข้อมูลทางกฎหมายมักมีรูปแบบหลากหลาย ทั้งเอกสารสแกน ข้อความที่ไม่ได้โครงสร้าง และเมตาดาต้าที่ไม่ครบถ้วน หากข้อมูลไม่สะอาดหรือมีความคลาดเคลื่อน โมเดลจะให้ผลลัพธ์ที่ผิดพลาด การสำรวจพบว่าองค์กรกว่า 60% ระบุว่าข้อมูลที่ไม่พร้อมคืออุปสรรคอันดับต้น ๆ
- ความไม่ไว้วางใจจากผู้ใช้และการต่อต้านเชิงวัฒนธรรม — ทนายความและบุคลากรทางกฎหมายมักกังวลเรื่องความแม่นยำ ความรับผิดชอบ และผลกระทบต่ออาชีพ การไม่สื่อสารถึงขอบเขตการทำงานของ AI และการไม่มีแนวทางกำกับดูแลภายในจะเพิ่มแรงต้านภายในองค์กร
- ข้อกำหนดกฎหมายและความไม่แน่นอนเชิงกฎระเบียบ — กฎระเบียบด้านความเป็นส่วนตัว ข้อกำหนดด้านการเก็บรักษาเอกสาร และข้อจำกัดการใช้โมเดลภายนอกยังมีความไม่ชัดเจนในหลายเขตอำนาจ ทำให้ความเสี่ยงทางกฎหมายเป็นปัจจัยที่ต้องพิจารณาอย่างจริงจัง
กลยุทธ์การปรับตัวเชิงปฏิบัติ
การตอบโจทย์อุปสรรคข้างต้นต้องเป็นไปอย่างเป็นระบบ โดยยึดหลัก เริ่มเล็ก วัดผล แล้วขยาย (pilot → measure → scale) ควบคู่กับการบริหารการเปลี่ยนแปลง (change management) และการพิสูจน์แนวคิดร่วมกับผู้ขาย (vendor proof-of-concept)
- โครงการนำร่องที่มีขอบเขตชัดเจน — เริ่มด้วย use case ที่มีผลกระทบสูงแต่ควบคุมความเสี่ยงได้ เช่น การสรุปข้อเท็จจริงคดี (document summarization) หรือการค้นหาเอกสารที่เกี่ยวข้อง (e-discovery) ระยะเวลา 3–6 เดือน พร้อมเกณฑ์ความสำเร็จที่กำหนดไว้ล่วงหน้า
- วัด KPI อย่างเป็นระบบ — กำหนดตัวชี้วัดหลัก เช่น TAT (turnaround time), cost per matter, accuracy / error rate และอัตราการยอมรับผลลัพธ์จากผู้ใช้ ตัวอย่าง: ตั้งเป้าลด TAT ลง 30% และลดค่าใช้จ่ายต่อคดี 15% ภายใน 6 เดือนของโครงการนำร่อง โดยยอมรับ error rate ไม่เกิน 2–5% ขึ้นกับความร้ายแรงของความผิดพลาด
- จัดสรรงบประมาณเพื่อการฝึกอบรมและการเปลี่ยนแปลง — แบ่งงบประมาณสำหรับการฝึกอบรมบุคลากร 1–3% ของงบไอทีทั้งหมดในปีแรก เพื่อสร้างความเข้าใจในขอบเขตการใช้งาน AI และทักษะการตรวจสอบผลลัพธ์ พร้อมการสร้างแนวทางปฏิบัติ (playbook) ภายใน
- การบริหารการเปลี่ยนแปลง (Change Management) — สร้างทีมผู้นำการเปลี่ยนแปลงที่รวมทั้งฝั่งกฎหมาย ฝั่งไอที และตัวแทนผู้ใช้ จัดเวิร์กช็อปสาธิตการใช้งานจริง เปิดช่องทางรับฟังข้อกังวล และกำหนดนโยบายการใช้งาน (governance) ที่ชัดเจน
- Proof-of-Concept (POC) กับผู้ขาย — เลือกผู้ขายที่ยินดีทำ POC ภายใต้ข้อมูลจริงหรือชุดข้อมูลจำลองที่สะท้อนงานจริง กำหนดเกณฑ์การประเมินเชิงเทคนิคและเชิงธุรกิจ เช่น เวลาในการติดตั้ง ความง่ายในการผสานรวมกับระบบเดิม และประสิทธิภาพตาม KPI ที่ตั้งไว้
- แนวทางการเลือกผู้ขาย — ประเมินความสามารถด้านความปลอดภัยข้อมูล (encryption, access control), ความโปร่งใสของโมเดล (explainability), นโยบายการจัดการข้อมูล (data residency), และการสนับสนุนหลังการขาย รวมถึงฟีเจอร์การผสานรวมกับระบบเดิม
ตัวอย่าง roadmap เชิงปฏิบัติ
- เฟสที่ 1 — วิเคราะห์ความพร้อมข้อมูลและระบบ (1–2 เดือน): กำหนดแหล่งข้อมูล สำรวจคุณภาพข้อมูล และระบุ use case ที่เหมาะสม
- เฟสที่ 2 — โครงการนำร่อง (3–6 เดือน): ทำ POC กับผู้ขาย วัด KPI (TAT, cost per matter, accuracy) และรวบรวม feedback จากผู้ใช้
- เฟสที่ 3 — ปรับปรุงและขยายผล (6–12 เดือน): ขยายขอบเขตงาน ปรับสคริปต์/โมเดล แก้ไขการผสานรวมกับระบบ legacy และเพิ่มการฝึกอบรม
- เฟสที่ 4 — Governance ระยะยาว: ตั้งคณะกรรมการกำกับดูแล AI ภายใน จัดทำ playbook ด้านความเสี่ยงและการตรวจสอบคุณภาพข้อมูลอย่างต่อเนื่อง
หากองค์กรปฏิบัติตามกรอบข้างต้น — เริ่มด้วยโครงการนำร่องที่ชัดเจน วัดผลด้วย KPI ที่เป็นรูปธรรม ลงทุนในฝึกอบรม และเลือกผู้ขายที่ยอมรับการทดสอบจริง — โอกาสที่การนำ AI จะสร้างมูลค่า ลดต้นทุน และยกระดับบริการทางกฎหมายจะเพิ่มขึ้นอย่างมีนัยสำคัญ แม้จะต้องเผชิญกับอุปสรรคจากระบบเก่าและความไม่แน่นอนด้านกฎระเบียบก็ตาม
กรณีศึกษาและตัวอย่างจริงจากตลาด
กรณีศึกษา A — สำนักงานกฎหมายขนาดกลาง: Contract Analytics ลดเวลาในการตรวจสัญญา ~60%
สำนักงานกฎหมายขนาดกลางที่ให้บริการด้าน M&A และธุรกรรมเชิงพาณิชย์เริ่มนำระบบ contract analytics ที่ขับเคลื่อนด้วย AI มาใช้เพื่อช่วยตรวจและจัดหมวดหมู่ข้อสัญญาในพอร์ตสัญญาจำนวนมาก ผลลัพธ์เชิงปริมาณชัดเจน: เวลาที่ใช้สำหรับการตรวจสัญญาเฉลี่ยต่อฉบับลดลงจากประมาณ 5 ชั่วโมงต่อสัญญาเหลือประมาณ 2 ชั่วโมงต่อสัญญา หรือคิดเป็นการลดเวลาโดยเฉลี่ย ~60% และต้นทุนแรงงานต่อสัญญาลดลงอย่างมีนัยสำคัญ (รายงานภายในแสดงการลดค่าใช้จ่ายต่อสัญญาโดยประมาณ 40–65% ขึ้นกับความซับซ้อนของสัญญา)
นอกจากการลดเวลาและค่าใช้จ่าย สำนักงานยังระบุผลพลอยได้อื่นๆ เช่น ความสม่ำเสมอของการตีความข้อกำหนดหลักเพิ่มขึ้น ความสามารถในการให้บริการลูกค้าได้รวดเร็วยิ่งขึ้น และการจัดเก็บข้อสัญญาเพื่อเรียกใช้งานซ้ำที่มีประสิทธิภาพมากขึ้น ตัวอย่างเช่น งาน “due diligence” ในดีลระดับกลางที่เคยใช้เวลาทั้งโครงการ 3–4 สัปดาห์ สามารถย่นเหลือ 1–2 สัปดาห์ได้เมื่อผสานเทคโนโลยีเข้ากับกระบวนการที่ชัดเจน
กรณีศึกษา B — ฝ่ายกฎหมายองค์กร: e-Discovery ลดเวลาในการค้นพยาน 70% ในคดีขนาดใหญ่
ฝ่ายกฎหมายขององค์กรพลังงานรายใหญ่ใช้แพลตฟอร์ม e-discovery ที่รวมความสามารถด้านการจัดทำดัชนี เรียงลำดับความสำคัญเอกสาร และการวิเคราะห์เชิงความหมาย (semantic analysis) ในการเตรียมคดีฟ้องร้องจำนวนหลายล้านเอกสาร ผลลัพธ์จากกรณีตัวอย่างหนึ่งระบุว่าเวลาที่ต้องใช้ในการค้นหาและระบุพยานหลักฐานที่เกี่ยวข้องลดลงจากระยะเวลาที่เคยต้องใช้เป็นเดือนเหลือเพียงสัปดาห์เดียวหรือสั้นกว่า คิดเป็นการลดเวลา ~70%
นอกเหนือจากการย่นเวลาการค้นหา ผลกระทบที่วัดได้รวมถึงการลดค่าใช้จ่ายด้านภายนอกสำหรับการรีวิวเอกสารอย่างมีนัยสำคัญ การลดความเสี่ยงจากการพลาดพยานหลักฐานที่สำคัญ และความสามารถในการจำลองสถานการณ์ (case simulation) ได้เร็วขึ้น ซึ่งส่งผลให้ฝ่ายกฎหมายสามารถวางกลยุทธ์การดำเนินคดีได้แม่นยำขึ้น
กรณีศึกษา C — สตาร์ทอัพ: AI-as-a-Service สำหรับงานสืบค้นกฎหมาย
สตาร์ทอัพด้านเทคโนโลยีการกฎหมาย (LegalTech) ให้บริการแบบ AI-as-a-Service ที่เน้นการค้นและสรุปเนื้อหากฎหมาย (legal research & summarization) ให้กับทนายความอิสระและทีมกฎหมายของ SMEs ผลลัพธ์เชิงธุรกิจจากลูกค้ากลุ่มนำร่องแสดงว่าเวลาในการค้นกรณีตัวอย่างและบทบัญญัติที่เกี่ยวข้องลดลงประมาณ 50–65% และความพึงพอใจของผู้ใช้ในการใช้งานเครื่องมือใหม่อยู่ที่ระดับสูง (NPS ภายในเฟสทดลอง ~+40)
โมเดลธุรกิจของสตาร์ทอัพนี้เน้นการปรับแต่งโมเดลภายในขอบเขตของกฎหมายท้องถิ่น การรวมฐานข้อมูลกฎหมายที่ได้รับอนุญาต และการให้ API สำหรับผสานรวมกับระบบภายในของลูกค้า ทำให้ลูกค้ารายย่อยสามารถเข้าถึงความสามารถเชิง AI ที่ก่อนหน้านี้มีเพียงองค์กรขนาดใหญ่เท่านั้นที่สามารถใช้ได้
บทเรียนสำคัญจากกรณีศึกษา
- การเตรียมข้อมูล (Data preparation) — การทำความสะอาด เรียงลำดับ และจัดป้ายกำกับข้อมูลอย่างเป็นระบบเป็นหัวใจของความสำเร็จ: โมเดล AI จะให้ผลลัพธ์ที่แม่นยำและใช้งานได้จริงก็ต่อเมื่อมีข้อมูลฝึกที่มีคุณภาพและสอดคล้องกัน
- การฝึกอบรมผู้ใช้ (User training) — การลงทุนในฝึกอบรมทั้งทักษะการใช้เครื่องมือและการตีความผลลัพธ์ของ AI เป็นตัวชี้วัดสำคัญของอัตราการยอมรับและ ROI: ยกตัวอย่างสำนักงานกฎหมายที่จัด workshop และ playbook ให้ผู้ตรวจสัญญา พบว่าอัตราการยอมรับระบบเพิ่มขึ้นกว่า 70% ภายใน 3 เดือน
- การวัดผลที่ชัดเจน — ตั้ง KPI ที่จับต้องได้ เช่น เวลาต่อสัญญา, ต้นทุนต่อคดี, อัตราความถูกต้องของการค้นหา (precision/recall) และอัตราการใช้งานจริง เพื่อประเมินประสิทธิผลอย่างเป็นระบบ
- การปรับกระบวนการ (Process integration) — เทคโนโลยีต้องถูกผสานเข้ากับกระบวนการทำงานที่มีอยู่ หากขาดการปรับกระบวนการ ผลประหยัดเวลาและต้นทุนอาจไม่เป็นไปตามที่คาด
- การกำกับดูแลข้อมูลและความเสี่ยง (Governance) — ต้องมีนโยบายการจัดการข้อมูลที่ชัดเจน ทั้งเรื่องความเป็นส่วนตัว ความปลอดภัย และการตรวจสอบผลลัพธ์ของ AI เพื่อป้องกันความเสี่ยงทางกฎหมายและภัยคุกคามด้านข้อมูล
คู่มือปฏิบัติ (Tutorial) สำหรับผู้บริหารและนักพัฒนา
คู่มือปฏิบัติ (Tutorial) สำหรับผู้บริหารและนักพัฒนา
บทนำ: คู่มือนี้ออกแบบมาเพื่อช่วยผู้บริหารและทีมพัฒนาแปลงบทวิเคราะห์จากผลกระทบของ AI ต่อซอฟต์แวร์และบริการทางกฎหมายให้เป็นกระบวนการปฏิบัติที่ชัดเจน ตั้งแต่การประเมินความพร้อมก่อนนำ AI มาใช้ จัดลำดับความสำคัญของ Use Case การประเมินผู้จำหน่าย การตั้ง KPI ไปจนถึงการทดสอบและประเมินผลเมื่อรันพายโลท (pilot) โดยมุ่งเน้นความเสี่ยงด้านกฎหมาย ความปลอดภัยข้อมูล และผลตอบแทนทางธุรกิจ
Checklist ก่อนเริ่ม (Assess & Prepare)
- Business case: ระบุวัตถุประสงค์เชิงธุรกิจให้ชัดเจน เช่น ลดเวลาในการร่างสัญญา 40%, ลดต้นทุนการตรวจสอบภายนอก 30% หรือเพิ่มความเร็วการตอบกลับลูกค้าใน 24 ชั่วโมง ติดตั้งเมตริกที่วัดผลได้และระยะเวลาคืนทุน (payback period)
- Data mapping & readiness: ทำแผนที่ข้อมูล (data inventory) ระบุที่มา (source), ชนิดของข้อมูล (structured/unstructured), ฟอร์แมต (PDF, DOCX, database), คุณภาพ (completeness, consistency) และข้อจำกัด เช่น ข้อมูลส่วนบุคคลหรือข้อมูลลับของลูกค้า
- Legal & compliance review: ตรวจสอบข้อกำหนดทางกฎหมาย (เช่น ข้อบังคับด้านความเป็นส่วนตัว, GDPR/PDPA, กฎระเบียบวิชาชีพทนาย) และเตรียมข้อตกลงการใช้ข้อมูลกับผู้ให้บริการ AI รวมถึงการควบคุมข้อมูล (data residency, retention policies)
- Security & access control: กำหนดมาตรการการเข้ารหัส, การจัดการคีย์, การจัดสิทธิ์เข้าถึง (role-based access) และบันทึกการใช้งาน (audit logs)
- Budget & resourcing: ประมาณค่าใช้จ่ายล่วงหน้า (license, cloud compute, integration, change management, training) และกำหนดทีมรับผิดชอบ (product owner, legal SME, data engineer, devops, change manager)
ขั้นตอนการเลือก Use Case และการจัดลำดับความสำคัญ (Use Case Prioritization)
การเลือก Use Case ควรพิจารณาจากผลกระทบ (impact) และความพร้อม (feasibility) โดยใช้แมทริกซ์ 2 แกน (Impact vs Feasibility):
- ขั้นตอนปฏิบัติ:
- รวบรวมรายการ Use Case ที่เป็นไปได้ (เช่น การร่างสัญญาอัตโนมัติ, การสรุปข้อกำหนด, การค้นหาประวัติ clause)
- ประเมิน Impact (ธุรกิจ) เช่น ประหยัดเวลา, ลดความเสี่ยงทางกฎหมาย, เพิ่มรายได้
- ประเมิน Feasibility ทางเทคนิคและข้อมูล: ความพร้อมของข้อมูล, ความซับซ้อนของการรวมระบบ, ความเสี่ยงด้านกฎหมาย
- จัดลำดับ (Prioritize) โดยให้คะแนนเชิงตัวเลขและเลือก use cases ในกลุ่ม “สูง-สูง” เพื่อเริ่มพายโลท
- ตัวอย่างคะแนน: Impact (1–5), Feasibility (1–5). เลือก Use Case ที่มีผลรวม ≥ 8 เป็นลำดับแรก
เทมเพลตการประเมินผู้จำหน่าย (Vendor Evaluation Template)
- Criteria & Weighting (ตัวอย่าง):
- ความถูกต้องของโมเดล (Accuracy / Legal correctness) — weight 25%
- ความสามารถในการอธิบาย (Explainability / Traceability) — weight 15%
- ความปลอดภัยและการปฏิบัติตามข้อบังคับ — weight 20%
- การรวมเข้ากับระบบเดิม (Integration & APIs) — weight 15%
- Total Cost of Ownership (licenses, infra, support) — weight 15%
- การสนับสนุนและ SLA — weight 10%
- วิธีให้คะแนน: แต่ละหัวข้อให้คะแนน 1–5 แล้วคูณด้วยน้ำหนัก ผลรวมคะแนนสูงสุด 100 ใช้เป็นฐานตัดสินใจเบื้องต้น
- เงื่อนไขสัญญา: ระบุข้อเรียกร้องด้าน Data Usage, IP rights, Liability cap และการประกันความเสียหาย (indemnity)
KPI และเมทริกซ์ที่ควรติดตาม
กำหนด KPI ที่วัดได้ชัดเจน แนะนำกลุ่ม KPI หลักดังนี้:
- TAT (Turn-Around Time): เวลาที่ใช้ตั้งแต่ได้รับงานจนเสร็จสมบูรณ์ เช่น เวลาร่างสัญญาเฉลี่ยลดจาก 48 ชั่วโมงเป็น 12 ชั่วโมง — เป้าหมายระบุเป็น % การปรับปรุง
- Cost Savings: ค่าใช้จ่ายที่ลดได้จากการใช้ AI (เช่น ลดชั่วโมงงานมนุษย์) คำนวณเป็นเงินต่อเดือน/ปี
- User Adoption: อัตราการใช้งานของผู้ใช้ปลายทาง (MAU/DAU หรือ % ของเคสที่ผ่านระบบ AI) — เป้าหมายเริ่มต้น 30–50% ภายใน 6 เดือน
- Error Rate / Compliance Errors: อัตราความผิดพลาดที่ต้องแก้ไขโดยมนุษย์ (เช่น False Positive/Negative ในการค้นหา clause) — ตั้งค่าเกณฑ์ยอมรับได้เช่น < 5% สำหรับ production
- Quality Metrics: F1-score, precision/recall สำหรับงาน NER หรือ classification, ความพึงพอใจผู้ใช้ (CSAT)
ขั้นตอนนำร่อง (Pilot) — POC → Evaluate → Iterate → Scale
- 1) Proof of Concept (POC):
- กำหนดขอบเขตย่อย (scoped use case) เช่น อัตโนมัติการสรุปข้อกำหนดของสัญญา NDA 100 ฉบับ
- เตรียมชุดข้อมูลทดสอบ (golden dataset) อย่างน้อย 200–500 ตัวอย่าง เพื่อวัด baseline และตั้งเกณฑ์ความสำเร็จ
- กำหนดระยะเวลา POC (4–8 สัปดาห์) และงบประมาณชัดเจน
- 2) Evaluate (ตาม KPI):
- รันชุดทดสอบเทียบกับ baseline คนทำงาน พร้อมบันทึก TAT, accuracy, error types
- ทำ user acceptance testing (UAT) กับกลุ่มผู้ใช้จริง และเก็บ feedback เชิงคุณภาพ
- 3) Iterate: แก้ไขโมเดล ปรับ prompt/heuristics ปรับ pipeline ETL และวัดผลซ้ำ จน KPI อยู่ในเกณฑ์ที่ยอมรับได้
- 4) Scale: วางแผน rollout ทีละส่วน (phased rollout) รวม governance, monitoring, rollback plan และ training สำหรับผู้ใช้
การทดสอบและประเมินผลเมื่อรันพายโลท
- Test types: unit tests, integration tests, end-to-end tests, regression tests, performance/load tests
- Evaluation process:
- ใช้ชุด validation แยกจาก training data และวัด metrics (precision/recall/F1, TAT)
- ตั้ง threshold acceptance criteria เช่น F1 ≥ 0.85 และ Error Rate ≤ 5% ก่อนขยาย
- ใช้ A/B testing เมื่อเป็นไปได้ (ระบบเดิม vs ระบบ AI) เพื่อวัดผลเชิงธุรกิจ
- จัดให้มี human-in-the-loop ในขั้นตอนที่มีความเสี่ยงสูง เช่น การแก้ไข clause ที่มีความไม่แน่นอน
- Monitoring & Feedback Loop: ติดตั้ง dashboard แสดง KPI แบบ near real-time, เก็บ log ของคำตอบที่ผิดพลาดเพื่อ feed กลับในการฝึกซ้ำ (retraining)
ตัวอย่างแนวคิดโค้ด (pseudocode/flow) สำหรับนักพัฒนา: เชื่อมต่อ LLM กับระบบจัดการสัญญา
ภาพรวมสถาปัตยกรรม: Contract DB → Preprocessing → Retrieval (RAG) → LLM Prompting → Post-processing → Audit Log → UI/Workflow
Flow (conceptual pseudocode):
- 1. Load contract metadata and text from Contract Management System (CMS)
- 2. Preprocess: clean text, chunk long documents, extract key fields (party, effective_date, clauses)
- 3. Index chunks into semantic store (embeddings)
- 4. On user request: retrieve top-k relevant chunks using embedding similarity
- 5. Construct prompt template (include instruction + retrieved context + question)
- 6. Call LLM API with prompt and safety constraints (max_tokens, temperature)
- 7. Post-process LLM output: validate format, run rule-based checks, map outputs to structured fields
- 8. Save audit log (input prompt, retrieved context ids, LLM output, user edits)
- 9. If confidence < threshold then route to human reviewer
Pseudocode แบบสั้น:
- function handleContractQuery(contract_id, user_query):
- doc = CMS.load(contract_id)
- chunks = preprocess(doc.text)
- indexes = embeddings.index(chunks)
- ctx = retrieval.top_k(indexes, user_query, k=5)
- prompt = buildPrompt(system_instructions, ctx, user_query)
- llm_resp = LLM.call(prompt, params)
- result, confidence = postprocessAndScore(llm_resp)
- if confidence < CONF_THRESHOLD: routeToHumanReview(result)
- audit.log(contract_id, user_query, ctx.ids, llm_resp, result, confidence)
- return result
- end
หมายเหตุสำหรับการพัฒนา: ควรออกแบบ prompt templates ให้สามารถ audit ได้, บันทึก context ids เสมอเพื่อย้อนกลับตรวจสอบแหล่งอ้างอิง, และแยกชั้นของการอนุญาตการเข้าถึงเมื่อแสดงข้อมูลที่มีความลับ
สรุป: การนำ AI เข้าสู่ระบบด้านกฎหมายต้องเริ่มจากการวางกรอบเชิงธุรกิจและความเสี่ยงอย่างเป็นระบบ ใช้ POC เพื่อทดสอบสมมติฐานตาม KPI ที่ชัดเจน และออกแบบ pipeline ที่มีการตรวจสอบและ audit อย่างเข้มงวดก่อนขยายสู่ production
บทสรุป
AI เป็นแรงขับเคลื่อนสำคัญที่กำลังเปลี่ยนรูปแบบตลาดซอฟต์แวร์และบริการทางกฎหมายอย่างรวดเร็ว โดยเปิดโอกาสให้สำนักงานกฎหมายและผู้ให้บริการสามารถลดต้นทุน เพิ่มประสิทธิภาพ และเร่งความเร็วการทำงานในงานที่ทำซ้ำได้ เช่น การร่างสัญญา การค้นคว้ากฎหมาย และการจัดการคดีพร้อมกัน อย่างไรก็ตาม การนำ AI มาใช้ยังมาพร้อมกับความเสี่ยงสำคัญด้านความเป็นความลับของข้อมูล ความปลอดภัย การเกิดข้อผิดพลาดหรือ “hallucination” ของโมเดล และปัญหาจริยธรรมและอคติที่อาจกระทบต่อผลลัพธ์ทางกฎหมายและความเชื่อมั่นของลูกค้า
องค์กรที่เตรียมความพร้อมด้วยกลยุทธ์นำร่อง (pilot), การประเมินความพร้อมด้านข้อมูล, การฝึกอบรมบุคลากร และกรอบการกำกับดูแลภายในที่ชัดเจน จะมีโอกาสสูงกว่าในการใช้ประโยชน์จาก AI อย่างปลอดภัยและยั่งยืน ในอนาคตคาดว่าจะเห็นการบังคับใช้กฎระเบียบมากขึ้น การเกิดระบบงานแบบผสมผสานระหว่างมนุษย์และเครื่องจักร และการแข่งขันที่ขับเคลื่อนด้วยการใช้ข้อมูลอย่างรับผิดชอบ ผู้เล่นที่ลงทุนในโครงสร้างข้อมูล นโยบายความเป็นส่วนตัว และการควบคุมความเสี่ยงตั้งแต่วันนี้จะได้รับข้อได้เปรียบเชิงกลยุทธ์ทั้งในมุมของต้นทุน คุณภาพบริการ และความน่าเชื่อถือในระยะยาว
📰 แหล่งอ้างอิง: Barron's



