
ตลาดข้อมูลสังเคราะห์กำลังก้าวสู่ช่วง “ระเบิดตัว” ด้วยบริการรูปแบบ Marketplace‑as‑a‑Service ที่รวบรวมชุดข้อมูลสังเคราะห์พร้อมการรับรองความเป็นส่วนตัวแบบ Differential Privacy (DP) ทำให้สถาปัตยกรรมข้อมูลสำหรับการพัฒนาโมเดล AI เปลี่ยนจากการพึ่งพาข้อมูลจริงที่มีข้อจำกัดด้านกฎหมายและความเสี่ยง มาเป็นการใช้ข้อมูลสังเคราะห์ที่มีการันตีระดับความเป็นส่วนตัว ธนาคารไทยที่เผชิญกับภารกิจเร่งด่วนทั้งการพัฒนา eKYC ให้เชื่อถือได้และการเสริมระบบตรวจจับการฉ้อโกง (Fraud Detection) จะได้รับประโยชน์จากแนวทางนี้ทั้งในแง่ความเร็วของการทดลอง (time‑to‑market) การขยายชุดข้อมูลให้หลากหลายขึ้น และการลดความเสี่ยงด้านความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบ
บทความนี้จะนำผู้อ่านผ่านภาพรวมเชิงตลาดและแนวทางเชิงปฏิบัติสำหรับธนาคารไทย: ทำไม Marketplace‑as‑a‑Service สำหรับ synthetic data ที่รับรอง Differential Privacy จึงเป็นเกมเชนเจอร์ วิธีการเลือกผู้ให้บริการ การออกแบบชุดข้อมูลสังเคราะห์เพื่อเร่งโมเดล eKYC และระบบตรวจจับการฉ้อโกง ขั้นตอนนำไปใช้งานจริง รวมถึงตัวชี้วัดสำคัญที่ต้องติดตาม เช่น ประสิทธิภาพโมเดล (accuracy, AUC), อัตราการเตือนเท็จ (false positive rate), เวลาในการพัฒนาและปรับใช้ (time‑to‑deploy) และพารามิเตอร์ความเป็นส่วนตัว (privacy budget / ε) — เพื่อให้ผู้บริหารด้านเทคโนโลยีและความเสี่ยงของธนาคารไทยมีแผนปฏิบัติการที่ชัดเจนและสามารถตัดสินใจเชิงกลยุทธ์ได้อย่างมั่นใจ
ภาพรวมตลาด: ทำไม 'ข้อมูลสังเคราะห์' กำลังระเบิดตัว
ภาพรวมตลาด: ทำไม 'ข้อมูลสังเคราะห์' กำลังระเบิดตัว
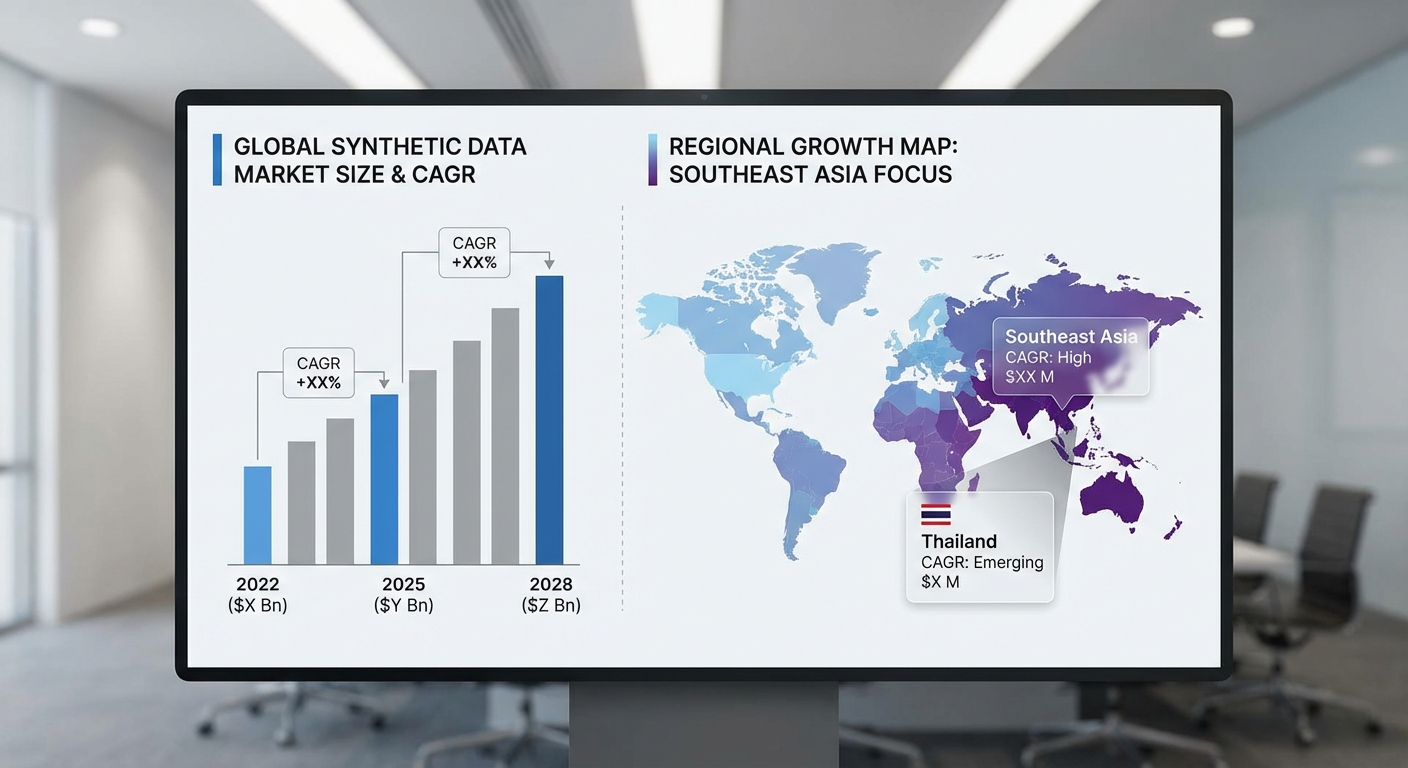
ในช่วงไม่กี่ปีที่ผ่านมา ตลาดข้อมูลสังเคราะห์ (synthetic data) เริ่มปรากฏตัวเป็นหนึ่งในเทคโนโลยีพื้นฐานที่ผู้ประกอบการด้านข้อมูลและสถาบันการเงินให้ความสนใจอย่างมาก โดยแนวโน้มการเติบโตสะท้อนจากการลงทุนและการนำไปใช้จริง ทั้งในระดับโลกและภูมิภาคเอเชีย-แปซิฟิก จากการประเมินเชิงอุตสาหกรรม ตลาดข้อมูลสังเคราะห์ระดับโลกมีการคาดการณ์การเติบโตแบบทวีคูณ โดยคาดว่าจะเติบโตด้วยอัตรา CAGR ราว 30–40% ต่อปี ในช่วง 5–8 ปีข้างหน้า ส่วนภูมิภาคเอเชีย‑แปซิฟิกแสดงอัตราเติบโตที่สูงกว่าเฉลี่ยของโลก โดยคาดการณ์ว่าอาจสูงถึง 35–45% CAGR เนื่องจากการลงทุนด้านดิจิทัลและความต้องการโซลูชันที่สอดคล้องกับกฎคุ้มครองข้อมูลส่วนบุคคลเพิ่มขึ้นอย่างรวดเร็ว
ปัจจัยผลักดันการเติบโตของตลาดสามารถสรุปเป็นข้อหลัก ๆ ได้ดังนี้
- กฎข้อบังคับด้านข้อมูลส่วนบุคคล (PDPA/GDPR) — การบังคับใช้กฎหมายคุ้มครองข้อมูลส่วนบุคคลทั้งในยุโรปและในหลายประเทศเอเชีย ทำให้องค์กรต้องมองหาวิธีการทดลองและพัฒนาระบบโดยไม่ละเมิดสิทธิผู้ใช้ ข้อมูลสังเคราะห์ที่สร้างขึ้นด้วยเทคนิคที่รับรองความเป็นส่วนตัว เช่น Differential Privacy จึงกลายเป็นทางเลือกที่น่าเชื่อถือ
- การขาดแคลนข้อมูลที่มีฉลาก (labeled data) — โมเดล AI โดยเฉพาะงานเช่น eKYC และ Fraud Detection ต้องการข้อมูลตัวอย่างที่หลากหลายและมีฉลากสภาพการณ์ผิดปกติ (edge cases) ซึ่งหายากในข้อมูลจริง ข้อมูลสังเคราะห์ช่วยเติมช่องว่างนี้และเพิ่มตัวอย่างสำหรับการเทรนได้อย่างมีประสิทธิภาพ
- ความเสี่ยงด้านความปลอดภัยและค่าใช้จ่ายในการจัดการข้อมูลจริง — การเก็บ รักษา และแชร์ข้อมูลจริงมีค่าใช้จ่ายสูง ทั้งด้านโครงสร้างพื้นฐานและมาตรการรักษาความปลอดภัย การสร้างข้อมูลสังเคราะห์สามารถลดต้นทุนและความเสี่ยงจากการรั่วไหลของข้อมูล
เชิงปฏิบัติ การนำข้อมูลสังเคราะห์มาใช้ในสถาบันการเงินทำให้เกิดผลลัพธ์ที่วัดได้ เช่น ลดเวลาในการจัดเตรียมข้อมูลสำหรับการเทรนโมเดลได้ถึง 30–50% และ ลดต้นทุนการรวบรวมและทำฉลากข้อมูล ในหลายกรณีสถาบันพบว่าสามารถลดค่าใช้จ่ายในขั้นตอน data acquisition และ data annotation ได้มากเมื่อเทียบกับการพึ่งพาข้อมูลจริงเพียงอย่างเดียว นอกจากนี้ การใช้ข้อมูลสังเคราะห์ที่ผ่านการรับรองความเป็นส่วนตัว (เช่น Differential Privacy certification) ยังช่วยลดความเสี่ยงทางกฎหมายและข้อกำหนดการทำ compliance audit ซึ่งเป็นปัจจัยสำคัญในการตัดสินใจของธนาคาร
สำหรับธนาคารไทย ผลกระทบที่จับต้องได้จากการเปลี่ยนมาใช้ข้อมูลสังเคราะห์คือการเร่งความเร็วในการพัฒนาโซลูชัน eKYC และระบบตรวจจับการฉ้อโกง ตัวอย่างเช่น การจำลองพฤติกรรมการฉ้อโกงที่ไม่บ่อยครั้ง (rare fraud patterns) สามารถเพิ่มอัตราการตรวจจับก่อนเกิดความเสียหายจริง ช่วยให้ทีม Data Science สามารถทดสอบสมมติฐานและปรับโมเดลได้เร็วขึ้น นอกจากนี้ การใช้ข้อมูลสังเคราะห์ยังลดความเสี่ยงด้านการปฏิบัติตาม PDPA เมื่อมีการแชร์ชุดข้อมูลระหว่างหน่วยงานภายในหรือกับพันธมิตรภายนอก ทำให้กระบวนการ PoC (Proof of Concept) และการนำโมเดลเข้าสู่การผลิต (production) สั้นลงและปลอดภัยยิ่งขึ้น
สรุปได้ว่า การเติบโตอย่างรวดเร็วของตลาดข้อมูลสังเคราะห์เป็นผลมาจากการผสานกันของปัจจัยทางกฎระเบียบ ความขาดแคลนข้อมูลที่มีคุณภาพ และแรงกดดันด้านความปลอดภัย ขณะที่ธนาคารไทยกำลังเผชิญกับเรื่องเร่งด่วนทั้งการปรับปรุงประสบการณ์ลูกค้าและการลดความเสี่ยง การนำเสนอ Marketplace‑as‑a‑Service สำหรับ synthetic data พร้อมการรับรองด้านความเป็นส่วนตัวจึงเป็นกลไกสำคัญที่จะเร่งการนำ AI เข้าสู่การใช้งานจริงอย่างปลอดภัยและรวดเร็ว
ข้อมูลสังเคราะห์คืออะไร: วิธีสร้างและระดับความสมจริง
ข้อมูลสังเคราะห์คืออะไร — คอนเซ็ปต์และประโยชน์หลัก
ข้อมูลสังเคราะห์ (synthetic data) หมายถึงชุดข้อมูลที่สร้างขึ้นโดยแบบจำลองคอมพิวเตอร์เพื่อเลียนแบบโครงสร้างและความสัมพันธ์ของข้อมูลจริง โดยไม่ต้องเปิดเผยข้อมูลต้นทางของผู้ใช้ การนำข้อมูลสังเคราะห์มาใช้ช่วยลดความเสี่ยงด้านความเป็นส่วนตัว เพิ่มความคล่องตัวในการแลกเปลี่ยนข้อมูล และช่วยเร่งพัฒนาโมเดลเช่น eKYC และ Fraud Detection ได้รวดเร็วขึ้นในสภาพแวดล้อมที่ต้องการข้อมูลจำนวนมากหรือการทดสอบภายใต้สถานการณ์หายาก เช่น กรณีฉ้อโกง (rare fraud events)

เทคนิคการสร้างข้อมูลสังเคราะห์ที่นิยม
- Statistical sampling & copulas — ใช้สำรวจการแจกแจงเชิงสถิติและจับความสัมพันธ์เชิงมาร์จินัล/ร่วม (marginal/joint distributions) โดย copula เป็นเครื่องมือสำคัญสำหรับการจำลองความสัมพันธ์ระหว่างตัวแปรเชิงต่อเนื่อง เหมาะกับข้อมูล tabular และการคำนวณสถิติสรุป
- Variational Autoencoders (VAEs) — โครงข่ายที่เรียนรู้การแจกแจงเชิงซ้อนผ่าน latent space เหมาะสำหรับการสร้างตัวอย่างต้านทานต่อ noise และการสร้างตัวแปรต่อเนื่องหรือผสม (mixed-type)
- Generative Adversarial Networks (GANs) — ใช้กันอย่างแพร่หลายในการสร้างภาพและข้อมูลที่มีมิติสูง (high-dimensional) เช่น รูปภาพใบหน้า หรือ sequence ของธุรกรรม GANs สามารถให้ความสมจริงสูง แต่เสี่ยงต่อการจำลองตัวอย่างเฉพาะเจาะจง (mode collapse หรือ overfitting)
- Agent‑based simulation & rule‑based simulators — จำลองพฤติกรรมของผู้ใช้งานหรือระบบผ่านกฎและตัวแทน (agents) เหมาะกับการสร้างเหตุการณ์เชิงลำดับเวลา (time‑series) และสถานการณ์สมมติ เช่น สถานการณ์โจมตีทางการเงิน หรือพฤติกรรมการทำธุรกรรมผิดปกติ
- Hybrid approaches — ผสมผสานวิธีข้างต้น เช่น ใช้ copulas กับ GANs เพื่อรักษาสถิติระดับสูง พร้อมให้ความสมจริงในรายละเอียด
ชนิดของข้อมูลที่สามารถสร้างได้ และความท้าทายเฉพาะ
- Tabular / Transactional data — ข้อมูลบัญชีและธุรกรรม: การรักษาสถิติสรุป (mean, variance, quantiles), ความสัมพันธ์ระหว่างฟีเจอร์ และการจำลองค่า missing/rare events เป็นความท้าทายหลัก เทคนิคที่เหมาะสมได้แก่ copulas, VAEs, และ agent‑based simulation สำหรับลำดับธุรกรรม
- Image data — รูปภาพใบหน้า หรือเอกสารบัตรประชาชน: GANs ให้ความสมจริงสูง แต่ต้องระวัง identity leakage (การซ้ำภาพจริง) และ artefact ทางภาพที่บ่งชี้ว่าเป็นสังเคราะห์ การประเมินต้องใช้ metrics ทางภาพ เช่น FID (Fréchet Inception Distance)
- Biometric data — ลายนิ้วมือ เสียง หรือ IRIS: ความอ่อนไหวสูงต่อการระบุตัวบุคคล ขณะเดียวกันความแม่นยำของโมเดลต้องไม่ถูกทำลาย การใช้ differential privacy หรือการสร้างแบบ latent‑mixing ช่วยลดความเสี่ยง
- Sequential / Time‑series data — ธุรกรรมตามเวลา, session logs: ต้องรักษาโครงสร้างเชิงลำดับและความเชื่อมโยงเชิงพฤติกรรม เช่น burstiness และ seasonality; agent‑based simulators หรือ RNN‑based generative models มักถูกใช้งาน
ตัวชี้วัดคุณภาพของข้อมูลสังเคราะห์
- Fidelity — วัดความใกล้เคียงเชิงสถิติระหว่างข้อมูลจริงกับสังเคราะห์ ใช้เครื่องมือเช่น KL divergence, Wasserstein distance, FID (สำหรับภาพ) และการเปรียบเทียบ distribution ของฟีเจอร์เป็นรายตัว ความสมจริงสูงหมายถึงการจับรูปแบบสถิติได้ใกล้เคียง
- Utility — ประสิทธิภาพเชิงปฏิบัติการของข้อมูลสังเคราะห์ในการฝึก/ทดสอบโมเดล เช่น ความแม่นยำ (accuracy), AUC ของโมเดล Fraud Detection หรือ eKYC หากโมเดลที่ฝึกด้วยข้อมูลสังเคราะห์ให้ผลใกล้เคียงกับข้อมูลจริง แสดงว่า utility สูง
- Privacy risk (re‑identification rate) — อัตราความเสี่ยงที่ตัวอย่างสังเคราะห์จะถูกแมตช์กลับไปยังผู้ใช้จริงหรือเปิดเผยว่าบุคคลนั้นอยู่ในชุดข้อมูลต้นฉบับ รวมถึงการประเมิน membership inference attack และ identity leakage โดยมักรายงานเป็น re‑identification rate หรือตัวเลขความเสี่ยงภายใต้การโจมตีที่กำหนด
ข้อจำกัดและช่องว่างทางความสมจริง (fidelity, utility, bias leakage)
แม้ข้อมูลสังเคราะห์จะมีประโยชน์ชัดเจน แต่ต้องทราบข้อจำกัดสำคัญ: ความสมจริง (fidelity) อาจไม่ครอบคลุม edge cases หรือ rare events ที่สำคัญสำหรับการตรวจจับการทุจริตจริง ๆ; utility อาจลดลงหากฟีเจอร์สำคัญสูญเสียความสัมพันธ์เชิงสาเหตุ; และ bias leakage — หากแบบจำลองเรียนรู้อคติในข้อมูลต้นฉบับ ข้อมูลสังเคราะห์อาจสืบทอดหรืาขยายอคตินั้น ๆ ทำให้โมเดลที่ฝึกแล้วยังคงตัดสินใจแบบไม่เป็นธรรม
ตัวอย่างเปรียบเทียบ: ข้อมูลจริง vs ข้อมูลสังเคราะห์
- Transactional (ตารางธุรกรรม)
จริง: แถวแสดงธุรกรรมจริงที่มีค่าอ้างอิง, จำนวนเงิน, เวลา, merchant category ซึ่งมี rare fraud patterns ใน 0.2% ของรายการ
สังเคราะห์: ชุดข้อมูลรักษา distribution ของจำนวนเงินและความถี่ของ merchant category แต่ rare fraud patterns อาจถูกลดทอนหรือแปรผัน ตั้งแต่ detection rate ลดลง 10–30% หากไม่จำลอง rare events ให้ถูกต้อง
- Image / Biometric (รูปภาพบัตรหรือใบหน้า)
จริง: ภาพถ่ายบัตรประชาชนหรือสแกนใบหน้าที่มีแสง การเบลอ และมุมต่าง ๆ
สังเคราะห์: GANs สามารถสร้างภาพที่ดูสมจริงในระดับสายตา แต่สังเกตได้ด้วย metrics ว่าอาจมี artefact เล็กน้อย และความเสี่ยงในการรั่วไหลของ identity หาก generator overfits
สรุปได้ว่า การเลือกเทคนิคสร้างข้อมูลสังเคราะห์ต้องพิจารณา trade‑off ระหว่าง fidelity, utility และ privacy โดยการวัดประเมินควรประกอบด้วยตัวชี้วัดเชิงสถิติ การประเมินประสิทธิภาพโมเดล และการทดสอบความเสี่ยงด้านการระบุตัวตน (re‑identification / membership inference) เพื่อให้ข้อมูลสังเคราะห์นำไปใช้ในบริบทเชิงธุรกิจ เช่น eKYC และ Fraud Detection ได้อย่างมั่นใจและมีความรับผิดชอบ
Marketplace‑as‑a‑Service: โมเดลธุรกิจและสถาปัตยกรรมการให้บริการ
Marketplace‑as‑a‑Service: ภาพรวมและบทบาทของผู้เล่นในระบบนิเวศ
โมเดล Marketplace‑as‑a‑Service (MaaS) สำหรับข้อมูลสังเคราะห์ออกแบบมาเพื่อเชื่อมโยงผู้สร้างข้อมูล (creators/data providers), ผู้ตรวจรับรองความเป็นส่วนตัวและคุณภาพ (verifiers/certifiers) และผู้บริโภคข้อมูล (consumers) ภายในแพลตฟอร์มเดียวอย่างเป็นระบบ โดยผู้เล่นแต่ละฝ่ายมีบทบาทชัดเจน: ผู้สร้างจัดเตรียมชุดข้อมูลสังเคราะห์และโมเดลในการสร้างข้อมูล, ผู้ตรวจรับรองดำเนินการประเมินคุณภาพและการปกป้องความเป็นส่วนตัว (เช่น การรับรอง differential privacy) และผู้ประกอบการตลาด (marketplace operator) ทำหน้าที่เป็นตัวกลางด้านการค้นหา การจัดเก็บสัญญา และระบบการชำระเงิน
ในบริบทของธนาคาร ผู้บริโภคส่วนใหญ่คือทีม Data Science, ML Ops และฝ่ายความเสี่ยงที่ต้องการชุดข้อมูลสำหรับ eKYC, การตรวจจับการฉ้อโกง (Fraud Detection) และการทดสอบระบบ โดย MaaS จะช่วยลดเวลาการเข้าถึงข้อมูลจริงและลดความเสี่ยงจากการเปิดเผยข้อมูลส่วนบุคคล
รูปแบบการเสนอขายและช่องทางการเข้าถึง
Marketplace นำเสนอโมเดลการขายที่ยืดหยุ่นเพื่อตอบโจทย์องค์กรขนาดต่างๆ โดยรูปแบบยอดนิยมได้แก่:
- Subscription: การสมัครสมาชิกระดับต่างๆ เพื่อเข้าถึงคลังข้อมูลและสิทธิ์ใช้งานรายเดือน/รายปี เหมาะสำหรับทีมที่ต้องการชุดข้อมูลจำนวนมากและการอัปเดตบ่อยครั้ง
- Per‑dataset: การซื้อแยกตามชุดข้อมูลหรือกรณีการใช้งาน — เหมาะสำหรับโปรเจ็กต์เฉพาะหรือการทดสอบ Proof‑of‑Concept
- API access: คิดค่าบริการตามการเรียกใช้งาน (pay‑per‑call) สำหรับการสร้างข้อมูล on‑demand ผ่าน API ที่ผสานเข้ากับระบบทดสอบหรือ pipeline ของธนาคาร
ช่องทางการเข้าถึงที่แพลตฟอร์มต้องรองรับ ได้แก่ Web portal สำหรับการค้นหาและจัดการสิทธิ์, REST/GraphQL API สำหรับการดึงข้อมูลเชิงโปรแกรม และ SDK (Python, Java) สำหรับทีม Data Science ที่ต้องการผสานการสร้างข้อมูลเข้ากับ workflow ของโมเดลโดยตรง
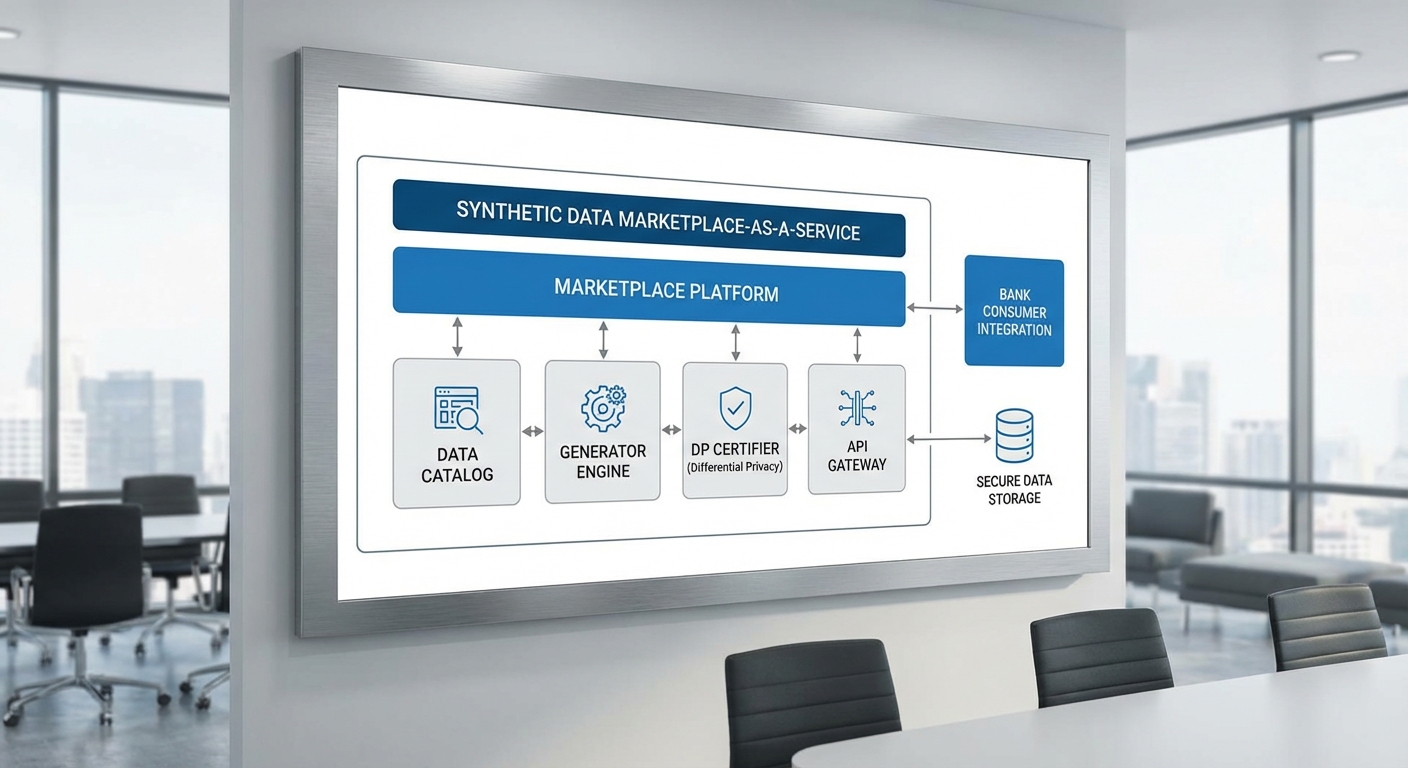
สถาปัตยกรรมเทคนิคที่จำเป็นสำหรับ MaaS ข้อมูลสังเคราะห์
สถาปัตยกรรมของ MaaS ต้องผสานความสามารถด้านการสร้างข้อมูล, การจัดการสิทธิ์, ความมั่นคงปลอดภัย และการตรวจสอบย้อนหลัง โดยองค์ประกอบสำคัญได้แก่:
- Catalog & Marketplace Layer: ดัชนีเมตาดาต้า (schema, provenance, privacy guarantees) และระบบค้นหาที่อนุญาตให้ผู้บริโภคกรองตามการรับรอง differential privacy, ประเภทข้อมูล และการใช้งานที่เหมาะสม
- Data Generator Engine: โมดูลที่เรียกใช้โมเดลสังเคราะห์ (GANs, Diffusion, synthetic tabular generators) พร้อมพารามิเตอร์ควบคุมเชิงคุณภาพ เช่น balance class, scenario stitching (การจำลองพฤติกรรมการทำธุรกรรมที่ผิดปกติ)
- Secure Enclave / Confidential Computing: สภาพแวดล้อมการประมวลผลที่แยกจากระบบหลักเพื่อรันการสร้างข้อมูลและกระบวนการตรวจรับรองโดยไม่เปิดเผยข้อมูลดิบหรือคีย์สำคัญ
- Key Management: ระบบจัดการคีย์แบบ HSM/Cloud KMS ที่ควบคุมการเข้ารหัสข้อมูลทั้งขณะพักและขณะส่ง ตลอดจนการจัดการคีย์สำหรับการเข้ารหัส payload ของ API
- Access Control & Policy Engine: RBAC/ABAC สำหรับควบคุมสิทธิ์การเข้าถึง dataset ตามบทบาท การใช้งาน และข้อตกลงการอนุญาต รวมถึงการบังคับใช้ข้อจำกัดด้านการใช้งาน (usage constraints) และข้อตกลงการซื้อขาย
- Audit Logs & Usage Logging: บันทึกการใช้งานแบบไม่เปลี่ยนแปลง (immutable logs) สำหรับการตรวจสอบย้อนหลังและการปฏิบัติตามกฎระเบียบ—รวมถึง telemetry ของการเรียก API, การสร้างชุดข้อมูล และการดาวน์โหลด
- Verifier / Certification Pipeline: โมดูลอัตโนมัติและมือคนสำหรับประเมิน quality metrics (statistical similarity, utility for downstream tasks) และตรวจสอบความเป็นส่วนตัว (DP epsilon accounting) ก่อนออกตรารับรอง
ข้อได้เปรียบเชิงปฏิบัติสำหรับธนาคาร: eKYC และ Fraud Detection
การนำ MaaS ข้อมูลสังเคราะห์มาใช้กับงาน eKYC และการตรวจจับการฉ้อโกงให้ประโยชน์เชิงปฏิบัติหลายด้าน เช่น:
- เร่งการพัฒนาและทดสอบโมเดล: ทีม ML สามารถเรียกชุดข้อมูลสังเคราะห์เพื่อเทรนและทดสอบโมเดลได้ทันที โดยลดเวลาในการขออนุญาตเข้าถึงข้อมูลจริงซึ่งมักใช้เวลาหลายสัปดาห์
- ทดแทนข้อมูลที่มีความเสี่ยงสูง: ชุดข้อมูลสังเคราะห์ช่วยลดการใช้ PII ในสภาพแวดล้อมการพัฒนาและ staging ทำให้ลดความเสี่ยงด้านการรั่วไหลและภาระการควบคุมข้อมูล
- จำลองกรณีผิดปกติและความหายาก: สามารถสร้างเหตุการณ์การฉ้อโกงที่มีความถี่ต่ำ (rare events) หรือรูปแบบ eKYC edge cases เพื่อปรับปรุงความไวและลด false negative ของโมเดล
- การปฏิบัติตามข้อกำหนดและการตรวจสอบได้: เมื่อข้อมูลสังเคราะห์มาพร้อมการรับรอง differential privacy และ audit trail ธนาคารสามารถอ้างอิงหลักฐานการปกป้องข้อมูลต่อหน่วยงานกำกับดูแลได้ชัดเจน
ตัวอย่างเชิงตัวเลข: รายงานทางอุตสาหกรรมบางฉบับ ระบุว่าการใช้ข้อมูลสังเคราะห์ควบคู่กับข้อมูลจริงอาจลดเวลาการพัฒนาโมเดลได้กว่า 20–40% และช่วยปรับปรุงประสิทธิภาพการตรวจจับกรณีฉ้อโกงในกลุ่มที่หายากได้หลายสิบเปอร์เซ็นต์ในบางสภาพแวดล้อม อย่างไรก็ตาม ตัวเลขที่แท้จริงขึ้นกับคุณภาพของ generator และการออกแบบการรับรองความเป็นส่วนตัว
สรุปแล้ว Marketplace‑as‑a‑Service สำหรับ synthetic data ที่ออกแบบด้วยสถาปัตยกรรมด้านความปลอดภัยครบถ้วน (secure enclave, key management, usage logging, audit) พร้อมระบบ certification จะเป็นเครื่องมือเชิงกลยุทธ์สำหรับธนาคารไทยในการเร่งการพัฒนา eKYC และระบบตรวจจับการฉ้อโกงอย่างปลอดภัยและตรวจสอบได้
Differential Privacy และการรับรอง: ทำไมต้องมี 'ใบอนุญาตความเป็นส่วนตัว'
Differential Privacy เบื้องต้น: แนวคิดและความหมายของ ε (epsilon)
Differential Privacy (DP) คือกรอบทางคณิตศาสตร์ที่ให้ความคุ้มครองความเป็นส่วนตัวแบบมีการวัดผลได้ โดยนิยามว่ากระบวนการหรืออัลกอริทึมหนึ่ง ๆ ให้ผลลัพธ์ที่ไม่แตกต่างกันมากนักเมื่อนำหรือไม่ใส่เร็กคอร์ดของบุคคลใดบุคคลหนึ่งเข้าไปในชุดข้อมูล นั่นหมายความว่า ผู้โจมตีไม่สามารถยืนยันได้อย่างมีนัยสำคัญว่าบุคคลใดคนนั้นอยู่ในชุดข้อมูลหรือไม่
พารามิเตอร์สำคัญคือ ε (epsilon) และ δ (delta) โดย epsilon เป็นตัวชี้วัดระดับความเป็นส่วนตัวที่เป็นเชิงปริมาณ: ค่า ε ยิ่งเล็ก ยิ่งให้ความเป็นส่วนตัวมากขึ้น แต่แลกกับประสิทธิภาพหรือคุณภาพของผลลัพธ์ที่อาจลดลง ในเชิงปฏิบัติ ค่า ε ที่นิยมเลือกใช้ในงานจริงมักอยู่ในช่วงคร่าว ๆ ระหว่าง 0.01 ถึง 10 ขึ้นกับบริบทและความเสี่ยงที่ยอมรับได้ สำหรับ delta มักถูกตั้งให้มีค่าน้อยมาก เช่น ต่ำกว่า 1/N (N = ขนาดข้อมูล) หรือค่าเช่น 1e‑5 ถึง 1e‑9 เพื่อเป็นการจำกัดความเป็นไปได้ของเหตุการณ์ความเป็นส่วนตัวที่ผิดพลาด
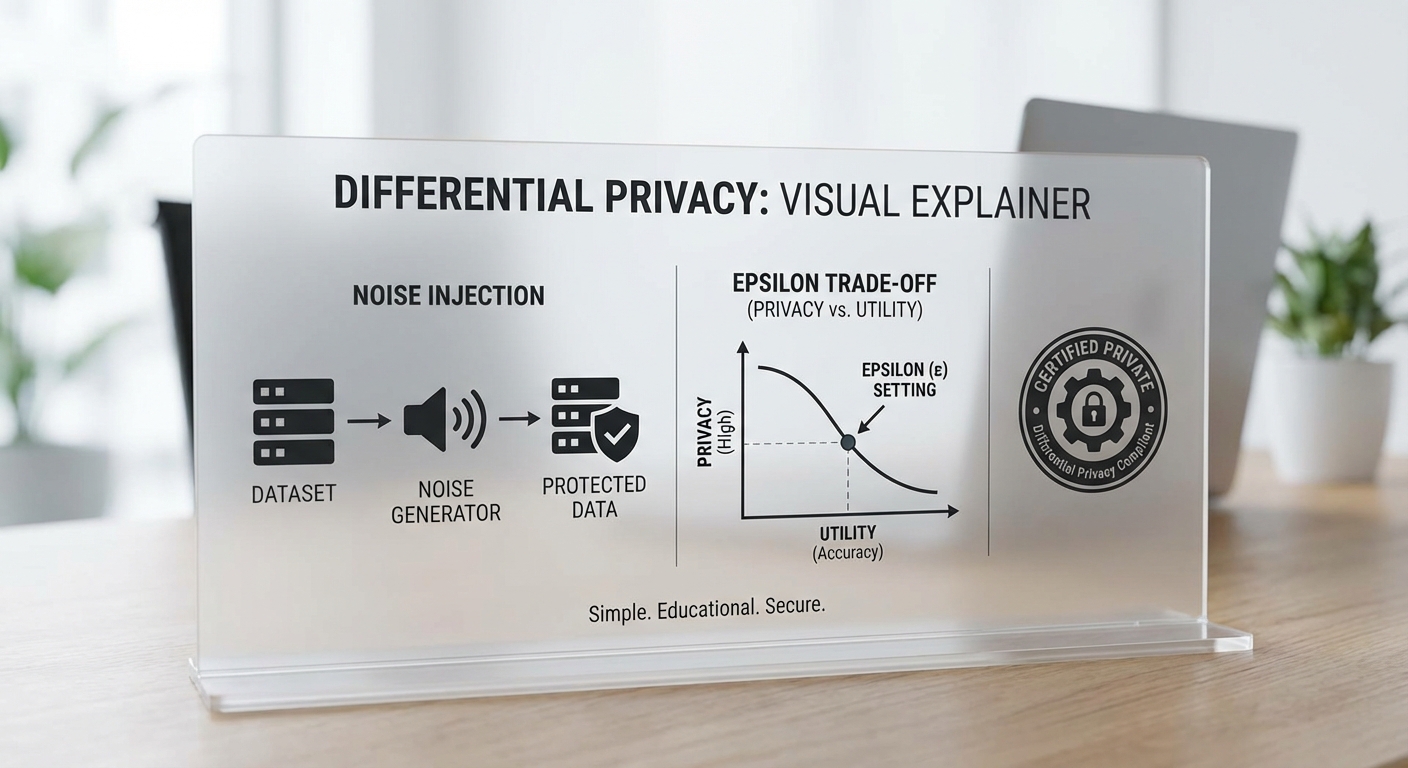
การนำ DP ไปใช้กับการสร้าง Synthetic Data: เทคนิคและตัวอย่างเชิงเทคนิค (เช่น DP‑GAN)
การสร้างข้อมูลสังเคราะห์ที่มาพร้อมการรับประกัน DP นิยมใช้องค์ประกอบทางคณิตศาสตร์สองกลุ่มหลัก: (1) การเพิ่มเสียงสุ่มตามกลไกที่เหมาะสม เช่น Laplace หรือ Gaussian mechanism เพื่อทำให้ผลลัพธ์ไม่สามารถชี้ชัดถึงเร็กคอร์ดใด ๆ ได้ และ (2) การจัดการงบประมาณความเป็นส่วนตัว (privacy budget) รวมถึงการติดตามผลรวมของการรั่วไหลของความเป็นส่วนตัวเมื่อมีการเรียกใช้งานซ้ำ
ตัวอย่างที่พบมากในงานวิจัยและเชิงพาณิชย์คือ DP‑GAN (Differentially Private Generative Adversarial Network) ซึ่งเป็นการรวมแนวคิด GAN กับ DP‑SGD: ในขั้นตอนการอัปเดตพารามิเตอร์ของผู้ฝึก (discriminator/generator) จะมีการ clipping ขนาดของ gradient แต่ละตัวอย่างและเพิ่ม Gaussian noise เข้าไปก่อนนำมาบวกอัปเดตพารามิเตอร์ การทำเช่นนี้ทำให้การเรียนรู้ไม่สามารถรั่วข้อมูลเฉพาะของเร็กคอร์ดได้โดยตรง ในการใช้งานจริงยังมีเทคนิคเสริม เช่น moments accountant หรือ Rényi DP เพื่อคำนวณและติดตามค่า ε รวมเมื่อมีการเทรนเป็นจำนวนรอบหลายครั้ง
ในเชิงปฏิบัติ ตัวอย่างการตั้งค่าที่ธุรกิจมักพิจารณา: หากต้องการ synthetic dataset สำหรับโมเดล eKYC/AML ของธนาคารที่ต้องรักษาความเที่ยงตรงของลักษณะสถิติ (statistical fidelity) อาจเลือกใช้ DP‑GAN ที่กำหนด ε ระหว่าง 0.5–2.0 ขึ้นกับการทดสอบ utility และความเสี่ยง แต่หากงานต้องการความเป็นส่วนตัวที่เข้มงวดสูง เช่นการเผยแพร่ข้อมูลต่อสาธารณะ ค่า ε อาจลดลงต่ำกว่า 0.5 ซึ่งต้องยอมรับการสูญเสียความเที่ยงตรงบางส่วน
กระบวนการรับรอง (Certification) และการออดิท: ขั้นตอนและองค์ประกอบหลัก
การอ้างว่าข้อมูลสังเคราะห์เป็น "DP‑certified" ต้องมีหลักฐานเชิงเทคนิคและกระบวนการตรวจสอบที่โปร่งใส กระบวนการรับรองโดยทั่วไปควรประกอบด้วยองค์ประกอบดังนี้:
- Independent audit: ผู้ตรวจสอบภายนอก (third‑party auditor) ตรวจสอบโค้ด การตั้งค่าการเทรน บัญชีความเป็นส่วนตัว (privacy accountant) และกระบวนการสุ่ม (seeding) เพื่อยืนยันค่าส่งออก ε และ δ ที่รายงาน
- Certification report: รายงานประกอบต้องระบุชัดเจนว่าใช้กลไกใด (เช่น Gaussian mechanism, DP‑SGD), พารามิเตอร์ที่สำคัญ (clipping norm, noise multiplier), ค่า ε/δ ที่ได้รวมทั้งสมมติฐานการประกอบ (composition assumptions) และผลการประเมิน utility เช่นความใกล้เคียงของการแจกแจง (KS test, Wasserstein distance) และประสิทธิภาพโมเดล (AUC, F1) เมื่อเทรนด้วย synthetic data
- Empirical attack testing: การทำ penetration test ทางความเป็นส่วนตัว เช่น membership inference, attribute inference, reconstruction attacks เพื่อตรวจสอบความต้านทานจริงต่อการโจมตีเชิงสถิติ
- Data lineage และ governance: เอกสารแสดงแหล่งที่มาของข้อมูล การตกลงสิทธิ์ (consent) การลบข้อมูลต้นทาง และนโยบายการเก็บรักษา/รีเฟรช synthetic datasets พร้อมวางแผนการรี‑ออดิทเป็นระยะ
- Compliance mapping กับกฎระเบียบ: แผนและเอกสารแสดงการแม็ปความคุ้มครอง DP เข้ากับความต้องการทางกฎหมาย เช่น PDPA ของไทย (ดูรายละเอียดด้านล่าง)
การแม็ปความสอดคล้องกับ PDPA ของไทยและมาตรฐานสากล
ในบริบทของประเทศไทย กฎหมาย PDPA ให้ความสำคัญกับการคุ้มครองข้อมูลส่วนบุคคลผ่านหลักการเช่น consent, purpose limitation, data minimization และ security แม้ synthetic data ที่ผ่านกระบวนการ DP จะช่วยลดความเสี่ยงการระบุตัวบุคคลได้อย่างมีมาตรฐานทางคณิตศาสตร์ แต่การกล่าวอ้างว่าข้อมูลถูก "นิรนาม" หรือไม่อยู่ภายใต้ PDPA จำเป็นต้องมีการประเมินอย่างเป็นระบบและเอกสารรับรองจากผู้เชี่ยวชาญทางกฎหมาย
มาตรฐานสากลที่เกี่ยวข้องและควรอ้างอิงในการรับรอง ได้แก่ ISO/IEC 20889 (Privacy enhancing data de‑identification) และแนวทางรวมถึงงานวิจัยและมาตรฐานที่หน่วยงานอย่าง NIST/สถาบันวิจัยสาธารณะกำลังพัฒนา ซึ่งช่วยกำหนดแนวทางการวัดผลและทดสอบความปลอดภัยของการนิรนามข้อมูล การแม็ปกับ PDPA ควรรวมถึง:
- การระบุฐานทางกฎหมายในการประมวลผลข้อมูลต้นทางและการสร้าง synthetic data
- การจัดทำข้อตกลงและข้อกำหนดกับผู้ให้บริการ Marketplace‑as‑a‑Service ว่าต้องแจ้งค่า ε/δ, กลไกที่ใช้ และข้อจำกัดการใช้งาน
- การคงรักษาเอกสารการออดิทและรายงานการทดสอบไว้เป็นหลักฐานสำหรับการตรวจสอบของหน่วยงานกำกับ
สรุปเชิงธุรกิจ: ทำไมต้องมี "ใบอนุญาตความเป็นส่วนตัว"
ใบอนุญาตความเป็นส่วนตัว (privacy license) ในเชิงปฏิบัติหมายถึงการออกเอกสารรับรองที่รวมทั้งค่าสถิติ DP (ε/δ), รายงานการออดิทอิสระ, ผลการทดสอบการโจมตีเชิงความเป็นส่วนตัว และการแม็ปความสอดคล้องทางกฎหมาย การมีใบอนุญาตดังกล่าวช่วยสร้างความเชื่อมั่นให้กับธนาคารและผู้ซื้อข้อมูลว่าข้อมูลสังเคราะห์ที่ได้มานั้นมีการวัดและควบคุมความเสี่ยงอย่างเป็นระบบ ลดอุปสรรคทางกฎหมายและก่อให้เกิดความโปร่งใสในตลาด synthetic data ซึ่งเป็นปัจจัยสำคัญในการเร่งใช้งานโมเดล eKYC และ Fraud Detection ในระบบธนาคารไทย
โดยสรุป: DP ให้กรอบการรับประกันความเป็นส่วนตัวที่วัดผลได้ แต่การแปลงการรับประกันเชิงคณิตศาสตร์ให้เป็นความเชื่อมั่นเชิงการค้าและกฎหมายจำเป็นต้องอาศัยการออดิทอิสระ รายงานการรับรองที่ชัดเจน และการแม็ปไปยัง PDPA รวมถึงมาตรฐานสากล เพื่อให้ marketplace‑as‑a‑service ของ synthetic data ถูกใช้อย่างปลอดภัยและเป็นไปตามข้อกำหนดของภาคการเงิน
กรณีใช้งานเชิงปฏิบัติ: เร่ง eKYC และระบบตรวจจับ Fraud ด้วย synthetic data
การนำข้อมูลสังเคราะห์ (synthetic data) มาใช้ในกระบวนการพัฒนาโมเดล eKYC และ Fraud Detection ของธนาคาร ช่วยแก้ปัญหาคอขวดด้านความเป็นส่วนตัว การขาดแคลนตัวอย่างเหตุการณ์หายาก และระยะเวลาการเตรียมข้อมูลที่ยาวนานได้อย่างมีประสิทธิผล ในเชิงวิศวกรรม เราสามารถออกแบบ pipeline แบบ pretraining on synthetic → fine‑tuning with anonymized real data เพื่อให้โมเดลเรียนรู้สัญญาณเชิงโครงสร้างจากข้อมูลสังเคราะห์ที่ควบคุมได้ ก่อนนำไปปรับแต่งกับข้อมูลจริงที่ผ่านการทำ anonymization และมาตรการ Differential Privacy ที่รับรองความเสี่ยงด้านความเป็นส่วนตัว
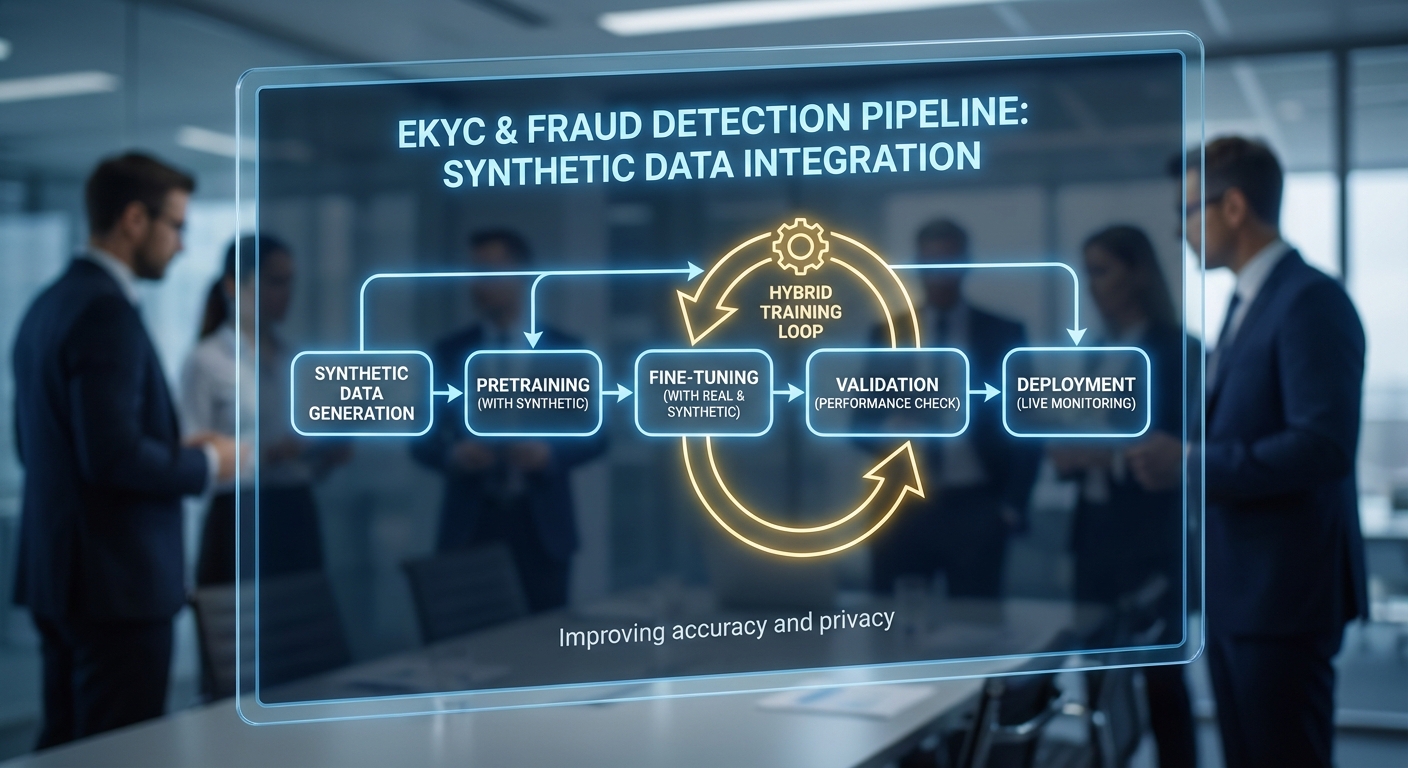
ตัวอย่าง pipeline เชิงวิศวกรรม (eKYC & Fraud)
- Data Generation & Specification: กำหนดสกีมา (schema) ของข้อมูล eKYC (เช่น ฟิลด์ชื่อ, วันเกิด, รูปบัตรประชาชน, รูปเซลฟี่, metadata การล็อกอิน) และ Fraud scenario (เช่น account takeovers, synthetic identity, mule accounts, transaction bursts) แล้วใช้ generator แบบ conditional GAN / VAE หรือ rule‑based synthesizer สร้างชุดข้อมูลจำลองขนาดใหญ่ (ตัวอย่างสมมติ: 2 ล้านเรคคอร์ดสำหรับ pretraining eKYC และ 500k กรณี transactions สำหรับ pretraining fraud model)
- Validation & Privacy Certification: วิเคราะห์สถิติการกระจาย (KS test, MMD) ระหว่าง synthetic กับ real, ตรวจวัดค่า privacy budget (เช่น DP ε) และทำ membership inference test เพื่อลดความเสี่ยงการรั่วไหลของข้อมูลจริง
- Pretraining: ฝึกโมเดลเบื้องต้นบนข้อมูลสังเคราะห์เพื่อเรียนรู้ representation เช่น face embedding, ID text parsing หรือ transaction pattern recognition — ลดความต้องการข้อมูลจริงจำนวนมากสำหรับการเรียนรู้ขั้นต้น
- Hybrid Fine‑tuning: นำโมเดลที่ผ่าน pretraining มาปรับน้ำหนัก (fine‑tune) บนชุดข้อมูลจริงที่ถูก anonymize/hashed และผ่านการคัดกรอง (ตัวอย่างสมมติ: fine‑tune ด้วย 20k–50k เรคคอร์ดจริง) เพื่อปรับ domain shift และ calibrate ความน่าเชื่อถือ
- Evaluation & Monitoring: ทดสอบบน holdout set ของข้อมูลจริง (ไม่ใช้ในการ fine‑tune) ตรวจวัด metric สำคัญ เช่น Recall, Precision, F1 และตั้งระบบตรวจจับ drift หลัง deploy
การจำลองเหตุการณ์ฉ้อโกงหายากและเทคนิค augmentation
เหตุการณ์ฉ้อโกงมักเป็น rare events ทำให้โมเดลที่เรียนจากข้อมูลจริงมี recall ต่ำ การใช้ synthetic data ช่วยสร้างตัวอย่างเชิงสถานการณ์ (scenario-based) และตัวอย่างผสม (mixed‑scenario) เพื่อเพิ่มความหลากหลายของพฤติกรรมโจมตี ตัวอย่างเทคนิคที่ใช้ได้แก่:
- Conditional generation: สร้าง transactions ที่มีลักษณะเฉพาะ (เช่น high‑velocity transfers, round‑trip payments) โดยกำหนดเงื่อนไขเชิงพารามิเตอร์
- Importance sampling & oversampling: ปรับ sampling weight เพื่อผลิตตัวอย่าง rare events ให้มากขึ้นโดยไม่เบี่ยงเบนการกระจายของข้อมูลปกติ
- Adversarial augmentation: ใช้ GAN เพื่อสร้างตัวอย่างโจมตีที่ยากต่อการแยกแยะ เพิ่มความทนทานของโมเดลต่อการโจมตีเชิงกลยุทธ์
- Scenario stitching: ผสม sequence ของกิจกรรมจริงกับเหตุการณ์สังเคราะห์ (เช่น เติม session ต่างประเทศหลัง login ปกติ) เพื่อจำลองพฤติกรรมขั้นสูงของผู้โจมตี
ตัวเลขสมมติผลลัพธ์เชิงปฏิบัติ
จากการทดลองเชิงสมมติของธนาคารที่นำแนวทางข้างต้นไปใช้ จะเห็นประโยชน์ชัดเจนทั้งด้านเวลาพัฒนาและประสิทธิภาพโมเดล ตัวอย่างตัวเลขสมมติ (เพื่อให้เห็นภาพเชิงปริมาณ):
- ลดเวลาในการเตรียมข้อมูล: การใช้ synthetic data สำหรับ pretraining และการสร้างตัวอย่างเหตุการณ์หายาก ช่วยลดเวลาในการเตรียมและคัดกรองข้อมูลจริงลงประมาณ 40–70% (ขึ้นกับขอบเขตของข้อมูลและความซับซ้อนของ scenario)
- ผลต่อ F1‑score ของโมเดล Fraud: โมเดลที่ผ่าน pretraining บน synthetic แล้ว fine‑tune ด้วยข้อมูลจริง มีการเพิ่ม F1‑score ประมาณ 8–12% (ตัวอย่างสมมติ) เมื่อเทียบกับโมเดลที่ฝึกจากข้อมูลจริงล้วน
- เพิ่ม Recall ในการจับ Fraud หายาก: การเติมตัวอย่าง rare events ด้วย synthetic data ทำให้ recall เพิ่มขึ้น 15–30% ในกลุ่มเหตุการณ์ประเภทที่เคยได้ recall ต่ำ
- ขนาดข้อมูลและเวลาฝึก: ตัวอย่าง pipeline: pretrain บน 2M synthetic records (เวลาฝึก 48–72 ชั่วโมงบนคลัสเตอร์ GPU), fine‑tune บน 50k anonymized real records (เวลาฝึก 4–8 ชั่วโมง) — ลดความจำเป็นในการรวบรวมและจัดทำ labeling ของข้อมูลจริงจำนวนมาก
สรุปคือ การผสาน synthetic data ในรูปแบบ pretraining + hybrid fine‑tuning ร่วมกับการตรวจสอบเชิงสถิติและการรับรองความเป็นส่วนตัว ช่วยให้ทีมวิศวกรรมได้นำโมเดล eKYC และ Fraud Detection เข้าสู่การใช้งานจริงได้เร็วขึ้น มีความมั่นคงด้านความเป็นส่วนตัวสูง และเพิ่มอัตราการจับเหตุการณ์ฉ้อโกงที่เคยเป็น rare events ได้อย่างมีนัยสำคัญ
แนวทางนำไปใช้จริงในธนาคารไทย: checklist และขั้นตอนทีละสเต็ป
Checklist ก่อนเริ่มโครงการ
ก่อนเริ่มนำ Synthetic Data และ Marketplace‑as‑a‑Service มาใช้ในธนาคาร ควรเตรียม checklist ตรวจสอบความพร้อมอย่างเป็นระบบเพื่อป้องกันความเสี่ยงและกำหนดขอบเขตงานอย่างชัดเจน:
- Use case และเป้าหมายเชิงธุรกิจ: ระบุชัดเจนว่าใช้ข้อมูลสังเคราะห์เพื่ออะไร (เช่น eKYC, Fraud Detection, Model Fairness, Stress‑testing) พร้อม KPI เช่น ต้องการเพิ่ม ROC‑AUC เท่าไร หรือลด False Positive เปอร์เซ็นต์เท่าไร
- ชนิดของข้อมูล (data types): ระบุประเภทข้อมูลที่ต้องการ (structured transactional data, PII เช่น ชื่อ/เลขบัตร, รูปภาพ, ไทม์ซีรีส์) เพราะแต่ละชนิดมีข้อจำกัดและเทคนิคการสังเคราะห์ต่างกัน
- ขอบเขตการปฏิบัติตามกฎระเบียบ (compliance scope): สอดคล้อง PDPA ของไทย, นโยบายความเป็นส่วนตัวของธนาคาร, และข้อกำหนดของหน่วยงานกำกับ ดูว่าจำเป็นต้องมี Data Protection Impact Assessment (DPIA) หรือไม่
- ผู้มีส่วนได้เสีย (stakeholders): ระบุทีมที่เกี่ยวข้อง: Data/ML, Legal & Compliance, InfoSec, Privacy Officer, Business Owner, Internal Audit และ Vendor Management
- ทรัพยากรและงบประมาณ: ประเมินทรัพยากรที่ต้องใช้ ทั้งคน เวลา โครงสร้างพื้นฐาน และงบสำหรับ SLA, Audit, และการฝึกอบรม
ขั้นตอนปฏิบัติ: POC → Validation → Pilot → Production Roll‑out
กำหนดกระบวนการทำงานเป็นเฟสชัดเจนเพื่อควบคุมความเสี่ยงและวัดผลได้จริง โดยแบ่งเป็นสเต็ปดังนี้
- POC (Proof of Concept):
- เลือก use case ขนาดเล็กที่มี ROI ชัดเจน เช่น เพิ่มประสิทธิภาพโมเดล eKYC บนชุดข้อมูลลูกค้าตัวอย่าง 10k‑50k record
- กำหนด success criteria (เช่น ไม่ลด AUC มากกว่า 1–2% เมื่อเทียบกับใช้ข้อมูลจริง และไม่มีการเพิ่มความเสี่ยงด้านการเปิดเผยข้อมูล)
- ทดสอบการเชื่อมต่อกับ vendor marketplace, การขอ synthetic dataset แบบ on‑demand และวิเคราะห์ latency/throughput
- Validation:
- ทดสอบคุณภาพข้อมูล (utility) ด้วย metric เช่น distributional similarity (KS, Wasserstein), feature importance stability, model performance (AUC, precision@k), และ fairness indicators
- ทดสอบความปลอดภัยของข้อมูล เช่น membership inference attack, attribute inference test และตรวจสอบ privacy budget accounting
- จัดทำรายงานผล validation สำหรับทีม Legal/Compliance และ InfoSec เพื่อรับรองความเหมาะสมก่อนขยาย
- Pilot (ขยายเป็นสเกลกลาง):
- ขยายไปยังชุดข้อมูลหลากหลายมากขึ้น เช่น นำข้อมูลหลายสาขา/ผลิตภัณฑ์เข้ามาทดลอง ใช้ synthetic data ใน workflow บางส่วน (เช่น feature engineering pipeline)
- ตั้ง SLA กับ vendor เรื่องคุณภาพข้อมูล เวลาตอบสนอง การรับประกัน privacy (รวมการแจ้งเตือนเมื่อเกิดเหตุผิดพลาด)
- ทำ A/B testing ระหว่างโมเดลที่ฝึกด้วยข้อมูลจริงและข้อมูลสังเคราะห์เพื่อตรวจสอบผลกระทบเชิงธุรกิจ
- Production Roll‑out:
- นำ synthetic data เข้าสู่ pipeline การพัฒนาโมเดลจริงแบบควบคู่กับข้อมูลจริง โดยมีกลไก fallback และ canary release
- ตั้งกระบวนการตรวจสอบหลัง deploy เช่น data drift detection, model performance monitoring และ privacy budget consumption tracking
- จัดทำ runbook สำหรับเหตุฉุกเฉิน เช่น กรณีพบ leak หรือ vendor ถอนการให้บริการ
การตั้งค่า Privacy Budget และการทดสอบคุณภาพ
การกำหนด privacy budget (ε) ต้องพิจารณาเป็นนโยบายขององค์กรและบริบทการใช้งาน: ยิ่ง ε ต่ำ ยิ่งปกป้องความเป็นส่วนตัวมาก แต่ utility อาจลดลง ดังนั้นควรกำหนดนโยบายแบบชั้นต้น (tiered policy):
- นโยบายตัวอย่าง (ตัวอย่างทางปฎิบัติ): สำหรับกรณีที่ต้องการความเป็นส่วนตัวสูง (PII แบบละเอียด) ตั้ง ε ในช่วง 0.1–1; สำหรับ utility สูงขึ้นอาจเลือก ε ในช่วง 1–8; ควรหลีกเลี่ยง ε สูงมาก (>10) หากต้องการการันตีการปกป้องข้อมูล
- การจัดสรร budget: แบ่ง ε ตามช่องทางการใช้งาน (per query, per dataset release, per model training) และติดตาม cumulative ε เพื่อไม่ให้เกินขีดจำกัดที่องค์กรกำหนด
- การทดสอบคุณภาพ (Quality Testing): สร้างชุดทดสอบมาตรฐาน (benchmarks) สำหรับแต่ละ use case เช่น ชุดทดสอบ eKYC ที่วัด AUC, FPR, calibration และตรวจสอบว่าการฝึกด้วย synthetic data ยังรักษาคุณภาพภายในเกณฑ์ที่ยอมรับได้
- การประเมินความเสี่ยงการเปิดเผย: รัน attack simulation (membership/attribute inference) และตรวจสอบว่าความเสี่ยงอยู่ในระดับที่ยอมรับได้ตาม PDPA และนโยบายภายใน
การรวมเข้ากับ CI/CD ของโมเดล
การนำ synthetic data มาใช้ต้องผสานกับ pipeline การพัฒนาโมเดลอย่างเป็นระบบ เพื่อให้มีการตรวจสอบอัตโนมัติและสามารถย้อนกลับได้เมื่อเกิดปัญหา:
- ขั้นตอนใน CI/CD: (1) Data generation stage — เรียก marketplace API เพื่อดึงชุดข้อมูลสังเคราะห์แบบ versioned; (2) Pre‑validation stage — รัน quick checks (schema, nulls, basic distributions); (3) Training stage — ฝึกโมเดลบนสภาพแวดล้อมแยก; (4) Validation stage — รันทดสอบ performance & privacy gates ก่อน merge/deploy
- Gate/Guardrails: ตั้ง threshold อัตโนมัติ เช่น หาก AUC ลดลงเกิน 2% หรือ privacy budget เกิน ให้ปิดการ deploy อัตโนมัติและแจ้งทีมที่เกี่ยวข้อง
- Versioning & Reproducibility: เก็บเวอร์ชันของ synthetic dataset, seed, generator config และ privacy parameters เพื่อการ audit และการทำซ้ำการฝึกโมเดล
- Monitoring หลัง Deploy: Dashboard สำหรับติดตาม model drift, feature distribution drift และ privacy budget consumption ต่อวัน/ต่อแอพพลิเคชัน
การจัดทำเอกสาร PDPA, Internal Audit และ SLA กับ Vendor
การปฏิบัติตาม PDPA และการตรวจสอบภายในเป็นหัวใจสำคัญของการยอมรับใช้งานในองค์กรการเงิน:
- เอกสาร PDPA ที่ต้องเตรียม: Data Flow Diagram, DPIA (Data Protection Impact Assessment), รายงานการประเมินความเสี่ยง, รายการข้อมูลที่ส่งให้ vendor และหลักฐานการได้รับการันตี privacy (เช่น differential privacy proof, third‑party certification)
- Internal Audit: จัดรอบ audit ตามระดับความเสี่ยง (เช่น รายไตรมาสสำหรับระบบที่ใช้ใน production สูง) ตรวจสอบ trail ของการสร้างข้อมูลสังเคราะห์, การใช้ privacy budget, log ของการเข้าถึง และผลลัพธ์การทดสอบการโจมตีเชิงลบ
- SLA กับ Vendor ควรระบุชัด: uptime ของ API, response time, turnaround time สำหรับการสร้าง dataset ขนาดต่างๆ, ระดับการรับประกัน privacy (ระบุ ε และการรับรอง), การแจ้งเตือนเหตุการณ์ความปลอดภัยภายใน 24–72 ชั่วโมง, การสนับสนุนด้าน legal/forensic เมื่อเกิดเหตุ
- ข้อกำหนดทางสัญญา: ระบุเรื่องความรับผิดชอบทางกฎหมาย (liability), การเก็บรักษา logs, การทำ penetration test / third‑party audit รวมถึงสิทธิในการยุติสัญญาเมื่อมีความเสี่ยงทางข้อมูล
การฝึกอบรมบุคลากรและการเปลี่ยนผ่านภายใน
การใช้เทคโนโลยีใหม่ต้องอาศัยการยอมรับและความเข้าใจจากคนในองค์กร จัดโปรแกรมการฝึกอบรมเชิงปฏิบัติการและการสื่อสารภายในดังนี้:
- คอร์สพื้นฐาน: ความเข้าใจ Differential Privacy เบื้องต้น, หลักการของ Synthetic Data, ข้อจำกัดและความเสี่ยง
- คอร์สเชิงปฏิบัติ: การใช้งาน Marketplace API, การตั้งค่า privacy budget, การประเมินคุณภาพข้อมูล, การรันโจมตีจำลอง (membership/attribute inference) และการอ่านรายงาน validation
- บทบาทเฉพาะ: เตรียม workshop สำหรับ Data Engineers (pipeline & CI/CD), Data Scientists (validation & model training), Compliance/Legal (การตรวจสอบเอกสาร) และ Ops/Runbook training สำหรับ Incident Response
- ความถี่และการวัดผล: จัดอบรมเบื้องต้นเมื่อเริ่มโครงการ และอบรมซ้ำทุก 6–12 เดือน พร้อมวัดผลด้วยการทดสอบความเข้าใจ และการประเมินความสามารถผ่านการทำ POC ขนาดเล็ก
สรุป การนำ synthetic data พร้อม differential privacy มาประยุกต์ในธนาคารไทยต้องเริ่มจากการเตรียม checklist ทางธุรกิจและกฎหมาย ดำเนินการแบบเป็นเฟส (POC → Validation → Pilot → Production) ควบคู่กับการกำหนด privacy budget ที่เหมาะสม การทดสอบคุณภาพและความเสี่ยงอย่างรอบด้าน และการผนวกกระบวนการเข้ากับ CI/CD พร้อมการจัดทำเอกสาร PDPA, SLA ที่ชัดเจน รวมถึงการฝึกอบรมบุคลากรและแผนการตรวจสอบภายในเพื่อให้การใช้งานเกิดประโยชน์สูงสุดโดยไม่ละเลยความปลอดภัยของข้อมูล
การประเมินผล ความเสี่ยงและค่าใช้จ่าย: KPI, ROI และการเลือกผู้ให้บริการ
การประเมินผลและ KPI สำคัญ
เมื่อใช้ synthetic data ในงาน eKYC และระบบตรวจจับการทุจริต (Fraud Detection) ของธนาคาร การประเมินผลต้องเป็นระบบและมีตัวชี้วัดชัดเจนเพื่อวัดทั้งความแม่นยำของโมเดล ประสิทธิภาพการพัฒนา และระดับความเป็นส่วนตัวที่ได้รับการปกป้อง KPI ที่ควรติดตามอย่างน้อยได้แก่:
- การเปลี่ยนแปลงของประสิทธิภาพโมเดล (AUC / F1): วัดเป็น delta ระหว่างโมเดลที่เทรนด้วยข้อมูลจริงเท่านั้น เทียบกับโมเดลที่ผสม synthetic data หรือเทรนด้วย synthetic เป็นหลัก ตัวอย่างเช่น ตั้งเป้า AUC เพิ่มขึ้นหรือไม่ลดลงเกิน 0.5–1.0 จุดเปอร์เซ็นต์ หรือ F1-score ไม่ลดลงเกิน 1–2% จาก baseline
- เวลาในการนำสู่ตลาด (time‑to‑market) / Data prep time reduction: วัดชั่วโมงหรือสัปดาห์ที่ลดลงในขั้นตอนการเตรียมข้อมูล (anonymization, labeling, reconciliation) เช่น เป้าหมายลดเวลาการเตรียมข้อมูล 30–60% เมื่อใช้ synthetic data
- ต้นทุนต่อชุดข้อมูล (cost per dataset): ติดตามค่าใช้จ่ายจริงต่อชุดข้อมูลหรือชุด generation (เช่น บาท/ล้าน records หรือ subscription รายปี) เพื่อคำนวณค่าใช้จ่ายต่อการทดลองและการ deploy
- การใช้ Privacy Budget / ความเสี่ยงด้านความเป็นส่วนตัว: สำหรับผู้ให้บริการที่รับรอง Differential Privacy ให้ติดตามค่า ε (epsilon) ที่ใช้ต่อชุดข้อมูล รวมทั้ง composition ของ epsilon เมื่อมีการใช้งานซ้ำ เพื่อตรวจสอบว่าการคุ้มครองอยู่ในขอบเขตที่ยอมรับได้
- มาตรวัดความเสี่ยงเพิ่มเติม: การทดสอบ membership‑inference, attribute‑inference attack simulation และการวัด statistical distance ระหว่าง distribution จริงกับ synthetic (e.g., KS‑statistic, Wasserstein distance) เพื่อประเมินความเสมือนจริงและความเสี่ยงของการฟื้นข้อมูล
ตัวอย่างการคำนวณ ROI เบื้องต้น
การคำนวณ ROI สำหรับการลงทุนใน synthetic data ควรเป็นแบบง่ายและโปร่งใส เพื่อให้ผู้บริหารสามารถตัดสินใจได้รวดเร็ว สูตรง่ายที่ใช้กันทั่วไปคือ:
ROI (เบื้องต้น) = (Time saved × Developer cost per hour + Reduced compliance fines/avoidance of breach cost + Productivity gains) − Vendor cost
ตัวอย่างเชิงตัวเลข (สมมติ):
- เวลา saved = 200 ชั่วโมง/โครงการ (ระยะการเตรียมข้อมูลที่ลดลง)
- Developer cost = 800 บาท/ชั่วโมง → ประหยัด = 200 × 800 = 160,000 บาท
- ลดความเสี่ยงค่าปรับ/การละเมิดข้อมูล สมมติประหยัดได้ 500,000 บาทต่อปี (การหลีกเลี่ยงงาน audit/ค่าปรับ/ค่าเสียโอกาส)
- Vendor cost = ค่าสมัครรายปี 300,000 บาท + ค่า generation เพิ่ม 50,000 บาท → รวม 350,000 บาท
ดังนั้น ROI แบบง่าย = (160,000 + 500,000) − 350,000 = 310,000 บาท ซึ่งหมายความว่าการลงทุนคุ้มค่าในปีแรก ถ้าคำนวณอัตราผลตอบแทน = 310,000 / 350,000 ≈ 88.6% (หรือ payback < 1 ปี)
คำแนะนำ: ให้ทำ sensitivity analysis โดยปรับค่าตัวแปรหลัก (เช่น ชั่วโมงที่ประหยัดได้, ค่า developer, ค่า fine ที่หลีกเลี่ยงได้) ในรูปแบบ conservative, base และ optimistic เพื่อประเมินความเสี่ยงทางการเงิน
ความเสี่ยงเชิงเทคนิคและธุรกิจที่ต้องระวัง
- Overfitting to synthetic patterns / Bias transfer: โมเดลอาจเรียนรู้รูปแบบเทียมที่ไม่มีอยู่ในข้อมูลจริง ทำให้ performance บนข้อมูลจริงตก วิธีลดคือทดสอบกับ holdout real data, ใช้ mixed training (real+synth) และวิเคราะห์ fairness/bias metrics ก่อน deployment
- Bias transfer: หาก generator มีอคติเดิม อคติจะถูกขยายเข้าสู่ชุด synthetic จึงต้องตรวจสอบ distribution per subgroup, disparity metrics (e.g., equalized odds, demographic parity) และ remediate ก่อนใช้งานใน eKYC
- Privacy leakage / legal exposure: แม้ผู้ขายจะรับรอง Differential Privacy แต่ต้องยืนยันค่า ε ที่ยอมรับได้, การ composition เมื่อใช้ซ้ำ และการปฏิบัติตาม PDPA/กฎระเบียบอื่นๆ การไม่ได้กำหนดขอบเขตชัดเจนอาจนำไปสู่ความรับผิดชอบทางกฎหมาย
- Vendor lock‑in: ข้อจำกัดด้าน portability ของ synthetic datasets หรือโมเดลที่พึ่งพา proprietary formats ทำให้ย้ายผู้ให้บริการได้ยาก ควรเจรจาสิทธิ์ในการดาวน์โหลด metadata, reproducible seeds, และสิทธิ์ในการ export datasets
- Operational risk: SLA ระหว่างการให้บริการ เช่น latency ของ generation, availability ของ API, และความสามารถในการ scale เมื่อมีเหตุการณ์ฉุกเฉิน
หลักเกณฑ์การคัดเลือกผู้ให้บริการ / Marketplace
- การันตีทางเทคนิคและการตรวจสอบอิสระ: เลือกผู้ให้บริการที่มีการตรวจสอบโดย third‑party audit (เช่น DP audits) และมีรายงานการประเมินความเสี่ยงความเป็นส่วนตัว (privacy impact assessment)
- ความโปร่งใสของ Privacy Budget: ผู้ขายต้องระบุค่า ε และนโยบาย composition ชัดเจน พร้อมเอกสารอธิบาย trade‑off ระหว่าง utility กับ privacy
- ความสามารถในการบูรณาการและมาตรฐานข้อมูล: API ที่เป็นมาตรฐาน, metadata เชิงโปรวิเนนซ์ (provenance), schema mapping, และสนับสนุนรูปแบบข้อมูลที่สอดคล้องกับระบบ eKYC/Fraud ของธนาคาร
- ความคล่องตัวด้านราคาและรูปแบบการคิดค่าใช้จ่าย: ตรวจสอบว่ามีตัวเลือกคิดเป็นชุด, เป็นเรคคอร์ด หรือเป็น subscription และมี transparency ในค่าใช้จ่ายเพิ่มเติม (retrain, generation, support)
- ข้อสัญญาและสิทธิ์การใช้งาน: ควรมี clause สำหรับ data portability, exit strategy, audit rights, และ liability cap รวมถึง SLA ทางด้าน uptime และ response time
- รองรับการทดสอบจริง (benchmarking): ขอทดลอง (pilot) และ benchmark บริการโดยใช้ชุดข้อมูลตัวอย่างของธนาคารเพื่อตรวจสอบ AUC/F1, time savings และ privacy metrics ก่อนเซ็นสัญญาระยะยาว
สรุปสั้น ๆ: ธนาคารควรตั้ง KPI เชิงปริมาณ (AUC/F1, เวลาเตรียมข้อมูล, cost per dataset, privacy budget) ทำการคำนวณ ROI แบบ conservative พร้อม sensitivity analysis และระบุความเสี่ยงเชิงเทคนิคและธุรกิจให้ชัดเจน เมื่อคัดเลือก vendor ให้ยึดหลักความโปร่งใสของ privacy guarantees, ความสามารถในการบูรณาการ, pricing transparency, และข้อสัญญาที่ปกป้องสิทธิ์ทางธุรกิจและความเป็นส่วนตัวของลูกค้า
บทสรุป
การจำหน่ายข้อมูลสังเคราะห์ผ่าน Marketplace‑as‑a‑Service ที่มาพร้อมการรับรองด้วย Differential Privacy เปิดทางลัดที่ปลอดภัยและคุ้มค่าในการเร่งพัฒนาโมเดล eKYC และระบบตรวจจับการฉ้อโกงของธนาคารไทย โดยช่วยลดการพึ่งพาข้อมูลจริงที่มีความเสี่ยงด้านความเป็นส่วนตัว ลดต้นทุนและเวลาในการเก็บข้อมูลจริง รวมทั้งทำให้สามารถทดลองและปรับแต่งโมเดลในสเกลใหญ่ได้รวดเร็วขึ้น—หลายองค์กรในอุตสาหกรรมรายงานว่าการใช้ข้อมูลสังเคราะห์สามารถลดเวลาในการพัฒนาและทดสอบโมเดลลงได้ในระดับสิบเปอร์เซ็นต์ถึงหลักสิบเปอร์เซ็นต์ ขณะที่ยังรักษาหรือปรับปรุงประสิทธิภาพของโมเดลในงานเช่นการยืนยันตัวตนผ่านภาพใบหน้า การจำลองรูปแบบการทำธุรกรรมเพื่อฝึกระบบตรวจจับการฉ้อโกง และการสร้างชุดกรณีทดสอบที่หายากหรือความผิดปกติ (edge cases)
อย่างไรก็ดี การนำข้อมูลสังเคราะห์ไปใช้จริงจำเป็นต้องคำนึงถึงหลายประเด็นสำคัญ ได้แก่ การประเมินคุณภาพข้อมูลเชิงปริมาณ (เช่นความคล้ายเชิงสถิติ การสูญเสียข้อมูลเชิงสเปกตรัม และความสามารถในการใช้งานกับโมเดลจริง) การตั้งค่า privacy budget อย่างรอบคอบ (เช่นการเลือกค่า epsilon ใน Differential Privacy เพื่อบริหาร trade‑off ระหว่างความเป็นส่วนตัวและประโยชน์ใช้งาน) และการจัดกระบวนการตรวจสอบ/รับรองที่โปร่งใสเพื่อให้สอดคล้องกับ พ.ร.บ.คุ้มครองข้อมูลส่วนบุคคล (PDPA) และสร้างความเชื่อมั่นให้ผู้ใช้และลูกค้าธนาคาร การออกมาตรฐานการตรวจวัด การบันทึกแหล่งที่มา (provenance) และการตรวจสอบโดยหน่วยงานอิสระจะช่วยลดความเสี่ยงทางกฎหมายและด้านความน่าเชื่อถือ
มองไปข้างหน้า ตลาดข้อมูลสังเคราะห์ที่รับประกันด้วย Differential Privacy มีแนวโน้มเติบโตต่อเนื่องและจะผลักดันให้เกิดมาตรฐานการปฏิบัติที่ชัดเจนสำหรับภาคการเงินไทย รวมถึงการผสานกับเทคนิคอื่นๆ เช่น federated learning และ privacy‑preserving ML เพื่อเพิ่มความเป็นส่วนตัวแบบองค์รวม ธนาคารควรเริ่มจากโครงการนำร่องที่ชัดเจน กำหนดนโยบาย privacy budget และเกณฑ์ประเมินคุณภาพ พร้อมจัดตั้งกลไกการตรวจสอบภายนอกเพื่อสร้างความเชื่อมั่น โดยการดำเนินการเชิงรุกเหล่านี้จะเป็นกุญแจสำคัญในการยกระดับความรวดเร็วและความปลอดภัยของบริการ eKYC และระบบตรวจจับการฉ้อโกงในอนาคต



