
เครื่องมือโค้ดดิ้งด้วยปัญญาประดิษฐ์ (AI) กำลังเปลี่ยนเวทีการพัฒนาซอฟต์แวร์อย่างรวดเร็ว: จากการเติมโค้ดง่ายๆ ไปจนถึงการสร้างฟังก์ชันที่ซับซ้อน เครื่องมือเหล่านี้ช่วยลดเวลาพัฒนา เพิ่มความเร็วในการทดสอบ และช่วยให้โปรโตไทป์ออกสู่ตลาดได้เร็วขึ้น อย่างไรก็ตาม ความสามารถที่เกินคาดของ AI กลับก่อให้เกิดความกังวลในวงการพัฒนา—นักพัฒนาจำนวนไม่น้อยเริ่มตั้งคำถามว่าการพึ่งพา AI มากเกินไปจะทำให้ทักษะพื้นฐานล้าหลัง เสี่ยงต่อช่องโหว่ด้านความปลอดภัย หรือแม้แต่กระทบต่อโอกาสการจ้างงานในระยะยาว
บทความนี้จะสำรวจภาพรวมของปัญหา: ผลกระทบเชิงบวกที่เห็นได้ชัด เช่น การเพิ่มประสิทธิภาพและลดงานซ้ำซ้อน พร้อมทั้งความเสี่ยงที่ตามมา ทั้งปัญหาคุณภาพโค้ดจากการสร้างคำตอบที่ไม่แม่นยำ การรั่วไหลของข้อมูลคอนฟิเดนเชียล และความไม่แน่นอนในตลาดแรงงานสำหรับนักพัฒนาระดับเริ่มต้นและระดับกลาง นอกจากนี้เราจะนำเสนอสถิติ ตัวอย่างจริงจากภาคอุตสาหกรรม และแนวทางเชิงปฏิบัติสำหรับองค์กร เช่น นโยบายการใช้งาน การฝึกอบรมซ้ำ การตรวจสอบโค้ดเชิงอัตโนมัติ และแนวทางความปลอดภัยเพื่อช่วยบริหารความเสี่ยงและใช้ประโยชน์จากเครื่องมือ AI อย่างรับผิดชอบ
บทนำ: ทำไมข่าวนี้จึงสำคัญ
บทนำ: ทำไมข่าวนี้จึงสำคัญ
ในช่วงไม่กี่ปีที่ผ่านมา เครื่องมือช่วยเขียนโค้ดที่ขับเคลื่อนด้วยปัญญาประดิษฐ์ (AI coding tools) กลายเป็นประเด็นร้อนที่ครอบคลุมทั้งชุมชนนักพัฒนา เทคสตาร์ทอัพ และองค์กรขนาดใหญ่ จนกลายเป็นข่าวใหญ่ทั้งในวงไอทีและฝั่งธุรกิจ เหตุผลหนึ่งมาจากการที่ผู้ให้บริการรายใหญ่ทั้งหลาย เช่น การผนวกรวมโมเดลภาษาเข้ากับ IDE และแพลตฟอร์มโค้ด (เช่น การรวมฟีเจอร์กับเครื่องมือพัฒนาแบบเรียลไทม์) ทำให้การทดลองใช้งานและการนำไปใช้จริงขยายตัวอย่างรวดเร็ว ส่งผลให้การพูดคุยเปลี่ยนจาก “ทดลอง” เป็น “ใช้งานเป็นส่วนหนึ่งของกระบวนการพัฒนา” อย่างแพร่หลาย
สัญญาณล่าสุดชี้ชัดว่าเครื่องมือเหล่านี้ทำงานได้ดีขึ้นอย่างมีนัยสำคัญ ทั้งจากงานวิจัยภายในบริษัท ข้อทดสอบเชิงประสิทธิภาพ และการสำรวจชุมชนนักพัฒนา ตัวอย่างเช่น รายงานเชิงทดลองและกรณีศึกษาในอุตสาหกรรมชี้ว่า AI สามารถลดเวลาในการเขียนโค้ดเชิงซ้ำซ้อนและช่วยเร่งการพัฒนาฟีเจอร์ได้จริง นอกจากนี้ การสำรวจจากหลายแหล่งยังสะท้อนแนวโน้มว่า ผู้พัฒนามากกว่าครึ่งเริ่มทดลองหรือใช้งานเครื่องมือช่วยเขียนโค้ดด้วย AI ในขั้นตอนต่าง ๆ ของงานพัฒนา ซึ่งเป็นสัญญาณชัดเจนว่าประสิทธิภาพและการยอมรับทางสังคมกำลังเพิ่มขึ้น
หัวข้อนี้ยิ่งมีความสำคัญเมื่อเชื่อมโยงกับกระบวนการ Digital Transformation ขององค์กร เพราะการนำ AI มาช่วยในงานพัฒนาซอฟต์แวร์สามารถเร่งการนำผลิตภัณฑ์สู่ตลาด (time-to-market) ลดต้นทุนการพัฒนา และเปลี่ยนรูปแบบการทำงานของทีมเทคนิค อย่างไรก็ตาม ความสามารถที่เพิ่มขึ้นของเครื่องมือเหล่านี้ก็ย่อมทิ้งคำถามสำคัญไว้ ได้แก่ ผลต่อคุณภาพของซอฟต์แวร์ ความน่าเชื่อถือ ความปลอดภัยของโค้ด และบทบาทของนักพัฒนาในอนาคต ซึ่งล้วนเป็นปัจจัยหลักในการวางกลยุทธ์ด้านดิจิทัลขององค์กร
บทความนี้จะหยิบยกประเด็นที่เกิดขึ้นจากการเปลี่ยนแปลงนี้ โดยจะพิจารณาทั้งในมุมของ ผลผลิต และประสิทธิภาพการทำงาน, คุณภาพของซอฟต์แวร์, ความเสี่ยงด้าน ความปลอดภัยและการปฏิบัติตามกฎเกณฑ์ รวมถึงผลกระทบต่อ งานและบทบาทของนักพัฒนา ภายในองค์กร ตัวอย่างเหตุการณ์และรายงานที่กระตุ้นความกังวล (เช่น การค้นพบข้อเสนอแนะโค้ดที่ไม่ปลอดภัย การสนทนาเรื่องสิทธิ์ในการใช้โค้ดต้นทาง และรายงานกรณีใช้งานในองค์กร) จะถูกนำมาวิเคราะห์เพื่อให้ฝ่ายบริหารและผู้นำทีมเทคนิคมองเห็นภาพรวมของความเสี่ยงและโอกาสได้ชัดเจนยิ่งขึ้น
- ตัวอย่างสัญญาณล่าสุด: การรวม AI เข้ากับ IDE ชั้นนำ การเปิดตัวโซลูชันของผู้เล่นรายใหญ่ และรายงานกรณีศึกษาการปรับใช้ในองค์กร
- ประเด็นสำคัญที่ต้องจับตามอง: ผลผลิตที่เพิ่มขึ้น vs. ความเสี่ยงด้านความปลอดภัย, คุณภาพโค้ด, และปัญหาด้านสิทธิ์การใช้งาน
- ผลต่อการทรานส์ฟอร์มองค์กร: เร่งการส่งมอบนวัตกรรม แต่ต้องบาลานซ์ด้วยนโยบายและกรอบการควบคุมที่เหมาะสม
ภาพรวม: เครื่องมือโค้ดดิ้ง AI คืออะไร ทำงานอย่างไร
ภาพรวม: เครื่องมือโค้ดดิ้ง AI คืออะไร ทำงานอย่างไร
เครื่องมือโค้ดดิ้ง AI หมายถึงชุดซอฟต์แวร์ที่ใช้เทคนิคปัญญาประดิษฐ์ โดยเฉพาะโมเดลภาษาใหญ่ (Large Language Models: LLMs) และโมเดลเชิงสถิติ เพื่อช่วยนักพัฒนาในการเขียน อ่าน และปรับปรุงซอร์สโค้ด ทั้งในระดับบรรทัด ฟังก์ชัน หรือแม้แต่โมดูลทั้งระบบ เครื่องมือเหล่านี้มีตั้งแต่ส่วนขยายสำหรับ IDE ที่ให้คำแนะนำแบบเรียลไทม์ ไปจนถึงตัวสร้างโค้ดอัตโนมัติและผู้ช่วยสร้างชุดทดสอบอัตโนมัติ การนำไปใช้ในองค์กรมักเห็นผลในด้านความเร็วและประสิทธิภาพของงาน เช่น งานวิจัยเชิงอุตสาหกรรมและการสำรวจภายในชี้ว่าเครื่องมือช่วยเติมคำและสร้างโค้ดสามารถลดเวลาพัฒนาในบางงานได้ราว 20–50% ขึ้นอยู่กับประเภทงานและการตั้งค่า
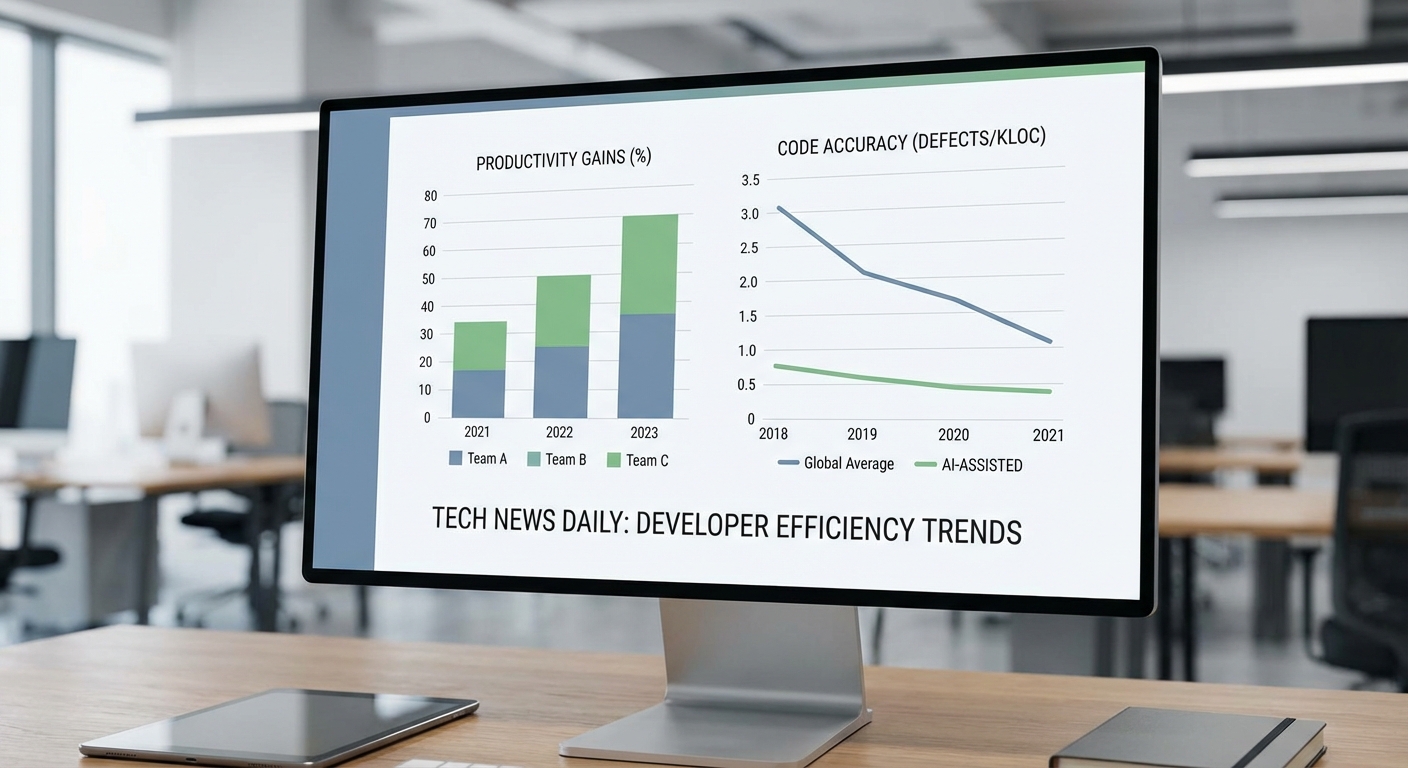
ประเภทของเครื่องมือโค้ดดิ้ง AI สามารถแยกได้เป็นกลุ่มใหญ่ ๆ ดังนี้:
- Code completion (เติมคำอัตโนมัติ) — ให้คำแนะนำแบบบรรทัดเดียวหรือเป็นโค้ดสั้น ๆ ขณะพิมพ์ใน IDE เช่น การคาดการณ์ตัวแปร ฟังก์ชัน หรือสตริงโค้ด ช่วยลดการพิมพ์และข้อผิดพลาดทางไวยากรณ์ ตัวอย่างเช่นการเติมคำอัตโนมัติแบบ inline ที่มักเห็นใน VS Code หรือ JetBrains
- Code generation (การสร้างฟังก์ชัน/โมดูล) — สร้างบล็อกโค้ดขนาดใหญ่หรือฟังก์ชันเต็มรูปแบบตามคำอธิบาย (prompt) ของผู้ใช้ เหมาะสำหรับการสังเคราะห์โค้ดจากคำสั่งเชิงความหมาย แต่ต้องมีการตรวจสอบและทดสอบอย่างเข้มงวด
- Automated refactoring (ปรับโครงสร้างโค้ดอัตโนมัติ) — วิเคราะห์และเปลี่ยนโค้ดเพื่อปรับปรุงคุณภาพ เช่น ย้ายโค้ดซ้ำนิยม ปรับชื่อ ตัวแปร หรือรื้อโครงสร้างให้เป็นไปตามแนวทางปฏิบัติที่ดี โดยยังคงพฤติกรรมเดิมของโปรแกรม
- Testing assistants (ผู้ช่วยสร้างและรันทดสอบ) — สร้างยูนิตเทสต์ สคริปต์การทดสอบ หรือข้อเสนอแนะเกี่ยวกับเคสทดสอบอัตโนมัติ ช่วยให้การครอบคลุมการทดสอบดีขึ้นและลดเวลาในการเขียนเทสต์ด้วยมือ
ในระดับสถาปัตยกรรม เครื่องมือเหล่านี้มักอาศัยพื้นฐานเป็น โมเดลภาษาใหญ่ (Transformers) ที่ผ่านการ pre-training บนข้อมูลจำนวนมหาศาล โดยแหล่งข้อมูลฝึกสอนประกอบด้วยทั้ง โค้ดสาธารณะ (public code) เช่น ฐานข้อมูลจากรีโพสิตอรีสาธารณะ และ ข้อมูลเชิงพาณิชย์/องค์กร (proprietary data) ที่นำมาทำ fine-tuning เพื่อให้โมเดลปรับตัวเข้ากับสไตล์และกฎของโครงการเฉพาะ กระบวนการฝึกอาจรวมถึงการเรียนรู้แบบมีผู้สอน (supervised fine-tuning) และเทคนิคการปรับปรุงพฤติกรรมเช่น Reinforcement Learning from Human Feedback (RLHF) เพื่อเพิ่มความสอดคล้องกับความต้องการของผู้ใช้ การแปลงโค้ดเป็นโทเค็น การสร้าง embedding และการใช้ attention mechanism เป็นหัวใจสำคัญของการคาดการณ์และการสังเคราะห์โค้ด
การผนวกรวม (integration) กับเครื่องมือของนักพัฒนาเป็นอีกปัจจัยสำคัญสำหรับการนำไปใช้จริง:
- ใน IDE: ปลั๊กอินหรือ extension ให้คำแนะนำแบบเรียลไทม์ (inline suggestions), code actions และ snippets ที่สามารถยอมรับ/ปฏิเสธได้ทันที
- ใน pipeline ของนักพัฒนา: การใช้โมดูลตรวจสอบโค้ดอัตโนมัติใน CI/CD (เช่น pre-commit hooks, GitHub Actions) ช่วยตรวจจับปัญหา ล้างสไตล์ และสร้างทดสอบก่อน merge
- ในกระบวนการรีวิวและ QA: บ็อตสามารถแนะนำการปรับปรุงโค้ดหรือสร้างเทสต์อัตโนมัติเป็น pull request comments ซึ่งช่วยเร่งการรีวิว
หลักฐานเชิงปริมาณ: เครื่องมือ AI เพิ่มประสิทธิภาพจริงหรือไม่
หลักฐานเชิงปริมาณ: เครื่องมือ AI เพิ่มประสิทธิภาพจริงหรือไม่
คำถามว่าการใช้เครื่องมือโค้ดดิ้งด้วย AI จะเพิ่มประสิทธิภาพการพัฒนาอย่างเป็นรูปธรรมหรือไม่ ได้รับการตรวจสอบผ่านการทดลองเชิงเปรียบเทียบ หลายงานทดสอบและการสำรวจผู้พัฒนารายงานตัวชี้วัดเชิงปริมาณที่น่าสนใจ โดยสรุปแล้ว บางงานวิจัยพบการเพิ่ม productivity ระหว่าง 30–60% ในงานรูปแบบเฉพาะ เช่น การเขียนฟังก์ชันที่มีขนาดไม่ใหญ่นัก การเติมโค้ดแบบ boilerplate และการสกัดโครงสร้างโค้ดจากคำบรรยายสั้น ๆ อย่างไรก็ตาม ผลลัพธ์เหล่านี้มักขึ้นกับลักษณะงาน ชุดข้อมูลทดสอบ และวิธีวัดผลที่ใช้

ในเชิงการทดสอบความถูกต้องของโค้ดที่ถูกเติมโดยโมเดล มีการวัดผ่านการรัน unit tests และเมตริกเช่น pass@k หลายการทดลองรายงานว่า อัตราการผ่าน unit test ของโค้ดที่สร้างขึ้นอยู่ในช่วงกว้าง เช่นประมาณ 20–70% ขึ้นกับความซับซ้อนของโจทย์และจำนวนตัวอย่างตอบกลับที่เปรียบเทียบ (pass@1 จะต่ำกว่าการประเมินเมื่ออนุญาตให้ทดสอบหลายคำตอบ เช่น pass@10 หรือ pass@100) นอกจากนี้ยังมีการพบกรณี false positives—โค้ดที่ดูสมเหตุสมผลแต่ไม่ครอบคลุมเงื่อนไขพรมแดนหรือกรณีมุม—ซึ่งงานทดลองบางชิ้นประเมินว่าอัตรา false positives อยู่ในช่วงประมาณ 15–40% ในชุดทดสอบบางประเภท
ผลการทดสอบเชิงปริมาณอื่น ๆ ที่รายงานในงานต่าง ๆ ได้แก่:
- เวลาลดลงในการเขียนโค้ด: งานทดสอบเชิงควบคุมแสดงการลดเวลาเฉลี่ยได้ประมาณ 20–50% ในงานที่เป็นโมดูลหรือฟังก์ชันเดี่ยว
- อัตราการแก้บั๊ก: การช่วยแนะนำโค้ดและการเติม docstring/typings สามารถลดเวลาหาการบั๊กหรือการแก้ปัญหาเบื้องต้นได้ 15–40% ในบางการทดลอง
- ผลต่อการส่งมอบงาน: ผลสำรวจผู้พัฒนาชุดหนึ่งรายงานว่า 20–35% ของผู้ตอบเห็นว่าการใช้ AI ช่วยให้เวลาส่งมอบงานสั้นลงอย่างมีนัยสำคัญในโปรเจกต์ย่อย ๆ
อย่างไรก็ตาม ความหมายของตัวเลขเหล่านี้ต้องตีความด้วยความระมัดระวังเนื่องจากข้อจำกัดสำคัญของการทดสอบเชิงปริมาณ ได้แก่: (1) ขอบเขตของแบบฝึกหัดที่ใช้วัดส่วนใหญ่เป็นโจทย์สั้น ๆ หรือชุดยูนิตเทสต์ ไม่ได้สะท้อนความซับซ้อนของระบบระดับผลิตจริง, (2) ผลลัพธ์แปรผันตามภาษาโปรแกรมและโดเมน—ตัวอย่างเช่น การเติมโค้ดใน Python หรือ JavaScript มักให้ผลดีในงาน scripting หรือ data munging ขณะที่ระบบที่ต้องจัดการ memory/ไทป์เข้มอย่าง C++/Rust อาจได้ผลน้อยกว่า, (3) วิธีวัดเช่น pass@k ให้ภาพที่ดีของความสามารถเชิงทดลอง แต่ไม่รับประกันคุณภาพโค้ดในเชิงสถาปัตยกรรมหรือความสามารถในการบำรุงรักษา
สรุปคือ แม้จะมีหลักฐานเชิงปริมาณที่ชี้ว่ามีการเพิ่มประสิทธิภาพอย่างมีนัยสำคัญในหลายบริบท แต่ผลลัพธ์ยังไม่เป็นเอกฉันท์และขึ้นกับบริบทการใช้งานเป็นสำคัญ ผู้ประกอบการและทีมพัฒนาควรพิจารณาทดสอบในสภาพแวดล้อมจริงของตนเองและวัดเมตริกที่สอดคล้องกับเป้าหมายทางธุรกิจ เช่น เวลาในการส่งมอบ คุณภาพโค้ด และต้นทุนการบำรุงรักษา ก่อนตัดสินใจนำเครื่องมือเหล่านี้ไปใช้ในวงกว้าง
ความกังวลของนักพัฒนา: ไม่ใช่แค่ความเร็ว แต่คือทักษะและความมั่นคง
ความกังวลของนักพัฒนา: ไม่ใช่แค่ความเร็ว แต่คือทักษะและความมั่นคง
แม้เครื่องมือโค้ดดิ้งด้วย AI จะนำเสนอความเร็วและความสะดวกในระดับที่ไม่เคยมีมาก่อน แต่เสียงสะท้อนจากชุมชนนักพัฒนาชี้ชัดว่าความกังวลไม่ได้จำกัดอยู่เพียงประสิทธิภาพการทำงานเท่านั้น ในการสำรวจและวิจัยหลายชุด (รวมถึงการสำรวจจากชุมชนนักพัฒนาและรายงานอุตสาหกรรม) พบว่ามีอัตราส่วนที่น่าสนใจ — นักพัฒนาจำนวนมากรายงานความกังวลเกี่ยวกับการสูญเสียทักษะ (deskilling) และการพึ่งพา AI มากเกินไป ซึ่งอาจนำไปสู่ปัญหาความสามารถในการแก้ไขปัญหาเชิงลึกเมื่อเครื่องมือไม่สามารถให้คำตอบที่ถูกต้องหรือเหมาะสมได้
Deskilling และการพึ่งพา AI — หลายคนมองว่าเมื่อเครื่องมือสามารถเขียนโค้ด เสนอโครงสร้างสถาปัตยกรรม หรือตอบคำถามเชิงเทคนิคได้ด้วยคำสั่งเพียงไม่กี่บรรทัด นักพัฒนารุ่นใหม่อาจไม่ได้มีโอกาสฝึกฝนกระบวนการคิดเชิงออกแบบ การดีบักเชิงลึก และการทำความเข้าใจตรรกะเบื้องหลังโค้ดอย่างเป็นระบบ ตัวอย่างเชิงคุณภาพจากบริษัทสตาร์ทอัพรายหนึ่งระบุว่า “ผู้เข้าร่วมฝึกงานหลายคนมักวางใจให้ AI เติมฟังก์ชันเต็มรูปแบบ แต่เมื่อเกิดบั๊กที่ซับซ้อน พวกเขาไม่สามารถสืบสวนแหล่งที่มาหรือเขียนเทสที่ครอบคลุมได้” ผลลัพธ์คือทีมต้องกลับมาสอนพื้นฐานซ้ำ ๆ ซึ่งลดประสิทธิภาพระยะยาว
ผลกระทบต่ออาชีพและการเปลี่ยนบทบาทงาน — มีการสังเกตว่า AI ทำให้บางหน้าที่เชิงปฏิบัติซ้ำซ้อนหรือลดความต้องการทักษะระดับเริ่มต้น ในขณะเดียวกันก็เปิดโอกาสให้เกิดบทบาทใหม่ เช่น ผู้ตรวจสอบคุณภาพโค้ดที่เน้นการตรวจสอบผลลัพธ์ที่ AI สร้าง (AI code reviewer) หรือวิศวกรที่เชี่ยวชาญด้านการสั่งงานและปรับแต่งโมเดล (prompt engineer / ML integrator) อย่างไรก็ตาม การเปลี่ยนผ่านนี้ไม่ได้สม่ำเสมอและทำให้เกิดความไม่มั่นคงระยะสั้นสำหรับผู้ที่ทักษะยังไม่สอดคล้องกับความต้องการใหม่ ๆ
ปัญหาเชิงจิตวิทยาและความไว้วางใจในโค้ดจาก AI — นักพัฒนาหลายคนรายงานความรู้สึกกดดันทั้งจากภายนอกและภายใน ภายนอกมาจากความคาดหวังของผู้บริหารที่ต้องการส่งมอบงานเร็วขึ้นเพื่อลงแข่งขันตลาด ภายในมาจากความไม่แน่ใจว่าโค้ดที่ได้มานั้นปลอดภัย ถูกต้อง และไม่ซ่อนช่องโหว่ ตัวอย่างจากบริษัทเอนเทอร์ไพรส์แห่งหนึ่ง ระบุว่าแม้การใช้ AI ช่วยให้ส่งมอบเวอร์ชันต้นแบบได้เร็วขึ้น 30–50% แต่ทีมวิศวกรต้องเพิ่มเวลาในการทดสอบเชิงลึกและรีวิวโค้ดเพิ่มขึ้น ส่งผลต่อความเครียดและความเหนื่อยล้า
ประเด็นที่นักพัฒนากังวลอย่างเป็นรูปธรรม ได้แก่
- การลดทอนทักษะพื้นฐาน — ขาดการฝึกฝนการคิดเชิงอัลกอริธึม การออกแบบโครงสร้างข้อมูล และการแก้ปัญหาเชิงระบบ
- การเปลี่ยนรูปแบบการจ้างงาน — ตำแหน่งงานบางส่วนถูกแทนที่หรือปรับบทบาท ขณะที่ความต้องการทักษะใหม่ ๆ เพิ่มขึ้น
- ความไว้วางใจและความรับผิดชอบ — ใครรับผิดชอบเมื่อ AI แนะนำโค้ดที่มีบั๊กหรือช่องโหว่ การตรวจสอบย้อนกลับและการรับรองความปลอดภัยกลายเป็นความท้าทาย
- แรงกดดันด้านเวลา — ความคาดหวังให้ทำงานเร็วขึ้นอาจทำให้ทีมลดขั้นตอนการเรียนรู้และรีวิว ซึ่งเพิ่มความเสี่ยงระยะยาว
คำพูดจากนักพัฒนาที่สะท้อนความวิตกหนึ่งคนกล่าวว่า “AI ให้เครื่องมือที่ทรงพลัง แต่ถ้าเราไม่รักษาพื้นฐานทางวิศวกรรมไว้ เด็ก ๆ ที่เริ่มต้นในวันนี้อาจกลายเป็น 'ผู้ใช้เครื่องมือ' แทนที่จะเป็น 'ผู้สร้าง' ในอนาคต” ในอีกกรณีศึกษาหนึ่งจากบริษัทซอฟต์แวร์ขนาดกลาง พบว่าทีมต้องจัดหลักสูตรภายในเพื่อรับรองว่าแม้จะใช้ AI ในการเร่งรัดการพัฒนา แต่ทุกคนยังสามารถอธิบายตรรกะของฟีเจอร์และรันการทดสอบที่เพียงพอได้ — แนวทางนี้ช่วยลดความเสี่ยงของการ deskilling และรักษาคุณภาพการพัฒนา
สรุปได้ว่า ความกังวลของนักพัฒนาเกี่ยวกับเครื่องมือโค้ดดิ้ง AI ขยายเกินแค่เรื่องความเร็ว เป้าหมายเชิงนโยบายและการจัดการทรัพยากรบุคคลควรคำนึงถึงการอบรมทักษะพื้นฐาน การออกแบบบทบาทงานใหม่ที่ชัดเจน และการตั้งมาตรฐานการตรวจสอบคุณภาพ เพื่อให้เทคโนโลยีช่วยเพิ่มมูลค่าโดยไม่ทำลายความสามารถเชิงลึกของแรงงานด้านซอฟต์แวร์ในระยะยาว
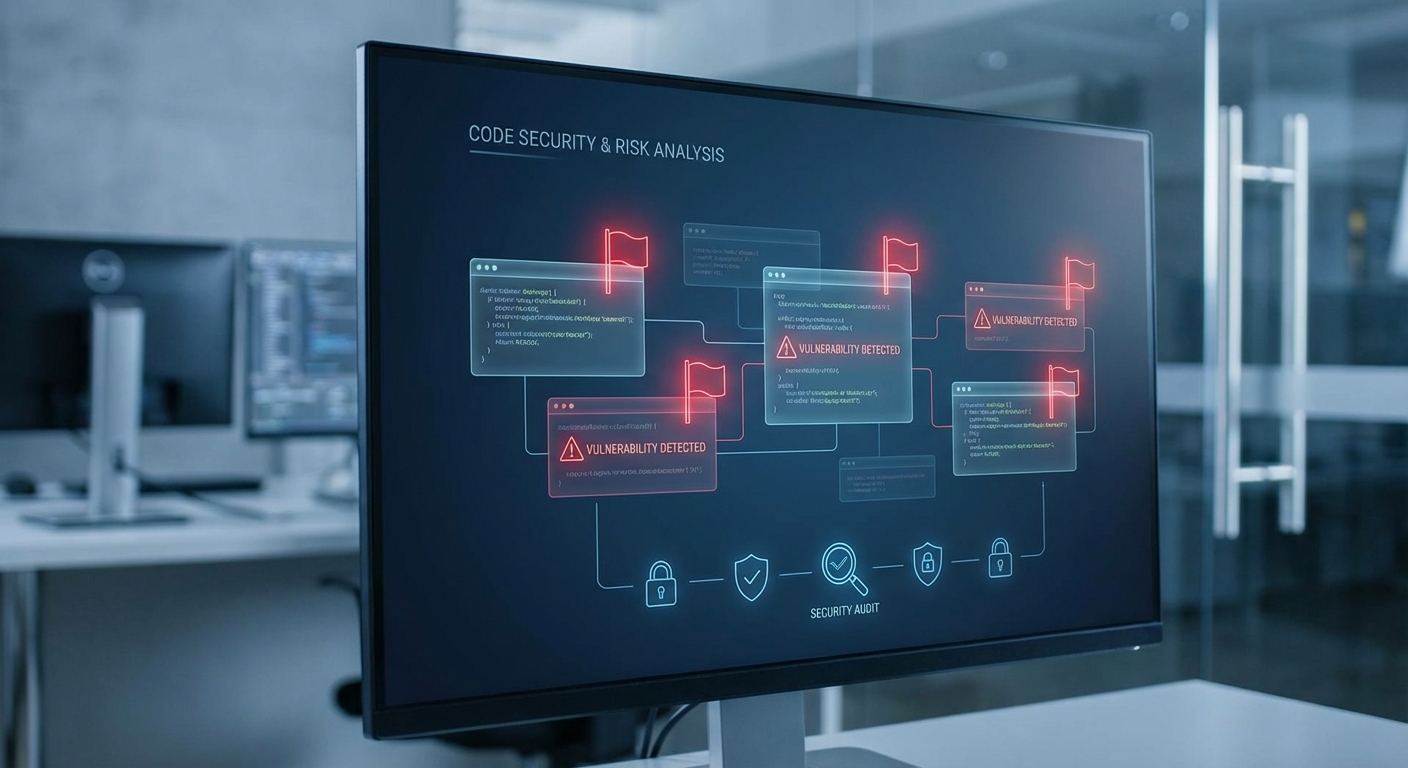
ความเสี่ยงด้านความปลอดภัย คุณภาพโค้ด และปัญหาไลเซนส์

การนำเครื่องมือโค้ดดิ้งที่ใช้ปัญญาประดิษฐ์มาใช้ในกระบวนการพัฒนาซอฟต์แวร์ให้ประสิทธิภาพในการเขียนโค้ดสูงขึ้นอย่างชัดเจน แต่ก็เกิดความเสี่ยงทางเทคนิคที่ไม่ควรมองข้าม ทั้งในด้านความปลอดภัย คุณภาพของโค้ด และภาระผูกพันด้านไลเซนส์ที่อาจตามมา ปัญหาเหล่านี้มีทั้งลักษณะที่เกิดจาก hallucination ของโมเดล (การสร้างโค้ดที่ดูสมเหตุสมผลแต่ใช้งานไม่ได้หรือมีบั๊ก) การดึงตัวอย่างโค้ดที่มีลิขสิทธิ์จากชุดข้อมูลฝึกที่เป็นสาธารณะ และการแนะนำแพตเทิร์นที่เปิดช่องโหว่หรือชี้นำให้ใช้ dependency ที่ไม่ปลอดภัย
1) Hallucination: ฟังก์ชันที่ดูสมเหตุสมผลแต่ผิดพลาด
Hallucination ของโมเดลภาษาในการสร้างโค้ดมีรูปแบบที่หลากหลาย ตั้งแต่ข้อผิดพลาดเล็กน้อย (off-by-one, edge case ที่ไม่ครอบคลุม) ไปจนถึงการคืนค่าฟังก์ชันที่ผิดลอจิก ตัวอย่างเหตุการณ์ที่เป็นไปได้ เช่น โมเดลสร้างฟังก์ชันจัดการการเชื่อมต่อฐานข้อมูลที่ "ดูถูกต้อง" แต่ลืมปิดการเชื่อมต่อในทุกกรณี ทำให้เกิดการรั่วไหลของทรัพยากรหรือการตัดการให้บริการในระยะยาว อีกตัวอย่างคือโมเดลสร้างคำสั่ง SQL ที่มี JOIN/WHERE ผิดตำแหน่ง ทำให้ผลลัพธ์เพี้ยนหรือเกิดการเปิดเผยข้อมูลที่ไม่ควรเปิดเผย
สถิติจากการทดลองภายในหลายองค์กรบ่งชี้ว่าโค้ดที่สร้างด้วย AI อาจต้องการการแก้ไขหลังการสร้างมากกว่าโค้ดที่เขียนด้วยมือถึงระดับที่มีนัยสำคัญ — ตัวอย่างเช่นการวิเคราะห์ชุดตัวอย่างขนาดกลางพบข้อบกพร่องเชิงตรรกะในราว 15–30% ของ snippets ที่สามารถคอมไพล์ได้ ซึ่งชี้ให้เห็นว่าการพึ่งพา AI โดยไม่มีการทดสอบอย่างเพียงพอเพิ่มความเสี่ยงทางธุรกิจอย่างแท้จริง
2) ปัญหาไลเซนส์และการรั่วไหลของโค้ดมีลิขสิทธิ์
หนึ่งในความกังวลเชิงกฎหมายและการปฏิบัติงานคือการที่โมเดลอาจสร้างโค้ดที่คล้ายหรือเหมือนกับโค้ดที่มีลิขสิทธิ์ซึ่งอยู่ในชุดข้อมูลฝึก หากโค้ดนั้นมาจากแหล่งที่มีข้อผูกมัดด้านไลเซนส์ (เช่น copyleft หรือไลเซนส์ที่กำหนดเงื่อนไขการแจกจ่าย) การนำโค้ดไปใช้ในผลิตภัณฑ์เชิงพาณิชย์อาจบังคับให้ต้องเปิดเผยซอร์สโค้ดหรือปฏิบัติตามเงื่อนไขที่ไม่ต้องการ
ตัวอย่างเหตุการณ์ที่อาจเกิดขึ้น: ทีมพัฒนานำโค้ด snippet ที่ AI สร้างมารวมในผลิตภัณฑ์โดยไม่ได้ตรวจสอบแหล่งที่มา ต่อมาเมื่อตรวจพบว่าฟังก์ชันดังกล่าวสอดคล้องกับโค้ดภายใต้ไลเซนส์ที่เคร่งครัด บริษัทอาจเผชิญหน้ากับความเสี่ยงทางกฎหมายและความต้องการแก้ไขผลิตภัณฑ์ในวงกว้าง ซึ่งส่งผลต่อเวลาออกสินค้าและค่าใช้จ่ายทางกฎหมาย
3) ผลกระทบต่อความปลอดภัย: แพตเทิร์นและ dependency ที่ไม่ปลอดภัย
โมเดลโค้ดดิ้งอาจแนะนำแพตเทิร์นที่สะดวกตอบโจทย์ฟังก์ชัน แต่เปิดช่องโหว่ เช่น การแนะนำให้ใช้ eval() หรือการปิดการตรวจสอบใบรับรอง SSL (เช่น set CURLOPT_SSL_VERIFYPEER = false) เพื่อให้โค้ด "ทำงานได้ทันที" ซึ่งเป็นสาเหตุของช่องโหว่การรันโค้ดจากภายนอกและการโจมตี MITM นอกจากนี้โมเดลยังอาจชี้แนะ dependency หรือเวอร์ชันของไลบรารีที่มีช่องโหว่ทราบแล้วหรือมาจากแหล่งที่ไม่น่าเชื่อถือ ทำให้ supply chain ของซอฟต์แวร์มีความเสี่ยง
4) ผลต่อซัพพลายเชนซอฟต์แวร์และเหตุการณ์เชิงปฏิบัติ
ผลกระทบด้าน supply chain เกิดได้ทั้งในระดับไลบรารีภายนอกและ snippets ที่รวมกันเป็นฟังก์ชันย่อย ตัวอย่างสถานการณ์: AI แนะนำแพ็กเกจ N ที่มีช่องโหว่หรือแม้แต่แพ็กเกจปลอมที่มีการฝังมัลแวร์ เมื่อนักพัฒนาติดตั้งและเผยแพร่เป็น dependency ต่อไป ผลกระทบอาจขยายไปยังลูกค้าหรือระบบที่เชื่อมต่อ ส่งผลให้ต้องถอนแพ็กเกจ ดำเนินการแก้ไขฉุกเฉิน และสูญเสียความเชื่อมั่น
5) แนวทางตรวจจับและลดความเสี่ยง
- การตรวจสอบโดยมนุษย์ (Human-in-the-loop): ทุกโค้ดที่ AI สร้างควรผ่านการรีวิวจากนักพัฒนาที่มีความเชี่ยวชาญ โดยเฉพาะส่วนที่เกี่ยวข้องกับความปลอดภัยและการเชื่อมต่อข้อมูล
- Static Application Security Testing (SAST) และ Dynamic Testing: ผนวก SAST เข้าใน CI/CD เพื่อตรวจจับการใช้แพตเทิร์นเสี่ยง เช่น eval, insecure deserialization, การปิดการตรวจสอบ TLS และอื่น ๆ รวมทั้งทำ dynamic scanning และ fuzzing เพื่อค้นหาข้อผิดพลาด runtime
- Software Composition Analysis (SCA) และการสแกนไลเซนส์: สแกน dependencies และโค้ดที่สร้างจาก AI ด้วยเครื่องมือ SCA/License scanner (เช่น Scancode, FOSSA) เพื่อตรวจจับความเสี่ยงด้านไลเซนส์หรือเวอร์ชันที่มีช่องโหว่
- Unit & Integration Tests: บังคับให้โค้ดที่สร้างโดย AI ต้องมาพร้อมกับชุดทดสอบที่ครอบคลุม edge case และ regression tests เพื่อจับ hallucination ระดับตรรกะก่อน merge
- Policy & Prompt Governance: กำหนดนโยบายการใช้งานโมเดล (เช่น ห้ามใช้โค้ดที่คืนค่ามาจากแหล่งภายนอกโดยตรงหากไม่ยืนยันไลเซนส์) และสร้าง prompt templates ที่ลดโอกาสให้โมเดล hallucinate
- Provenance และ Metadata: บันทึกแหล่งที่มาของโค้ดที่สร้าง (prompt, model version, timestamp) เพื่อง่ายต่อการสืบต้นตอเมื่อพบปัญหา
สรุปแล้ว แม้เครื่องมือโค้ดดิ้ง AI จะเพิ่มความเร็วและประสิทธิภาพ แต่ภาคธุรกิจควรยอมรับว่ามีความเสี่ยงด้านความปลอดภัย คุณภาพโค้ด และไลเซนส์ที่ต้องจัดการอย่างเชิงรุก การผนวกกระบวนการตรวจจับอัตโนมัติ การรีวิวโดยผู้เชี่ยวชาญ และนโยบายการใช้งานที่ชัดเจนเป็นสิ่งจำเป็นเพื่อให้การนำ AI มาใช้เป็นไปอย่างปลอดภัยและยั่งยืน
การตอบสนองขององค์กร หน่วยงานกำกับ และชุมชนเทค
การตอบสนองขององค์กร หน่วยงานกำกับ และชุมชนเทค
เมื่อเครื่องมือโค้ดดิ้งด้วย AI แสดงประสิทธิภาพสูงขึ้น องค์กรธุรกิจและหน่วยงานเทคโนโลยีต่างตอบสนองด้วยชุดมาตรการที่หลากหลายเพื่อควบคุมความเสี่ยงด้านความปลอดภัย ลิขสิทธิ์ และคุณภาพซอฟต์แวร์ ทั้งในระดับนโยบายภายใน การปรับกระบวนการพัฒนาซอฟต์แวร์ (SDLC) ไปจนถึงการร่วมมือกับชุมชนโอเพนซอร์สและการติดตามแนวทางจากหน่วยงานกำกับดูแล หลายองค์กรเริ่มวางกฎเกณฑ์ชัดเจนว่าพนักงานคนใดใช้เครื่องมือเหล่านี้ได้อย่างไร ต้องมีการบันทึกและตรวจสอบการใช้งาน รวมทั้งกำหนดขั้นตอนการทบทวนเมื่อมีโค้ดที่มาจาก AI ถูกนำเข้าสู่รีโพสิทอรีหลักขององค์กร
นโยบายภายในองค์กร ในเชิงปฏิบัติหลายบริษัทใช้แนวทางแบบผสมผสาน เช่น เปิดใช้เครื่องมือโค้ดดิ้ง AI เฉพาะในทีมทดลองหรือนักพัฒนาที่ผ่านการอบรมแล้ว บางแห่งกำหนดระดับสิทธิ์ (role-based access) เพื่อจำกัดการเข้าถึง และบังคับให้ผู้ใช้ ระบุแหล่งที่มาของโค้ด ที่ได้จาก AI ใน commit message หรือในคำอธิบายของ PR นอกจากนี้มาตรการบันทึกการใช้งาน (audit logging) ถูกนำมาใช้อย่างแพร่หลายเพื่อให้สามารถย้อนกลับตรวจสอบได้ว่าเมื่อใด ใคร และด้วยคำสั่งอะไรที่สร้างโค้ดขึ้นมา ตัวอย่างการใช้นโยบายเช่น การเปิดใช้งานเฉพาะ “Copilot for Business” หรือโซลูชันแบบองค์กรที่มีการควบคุมการเข้าถึงและ audit log เป็นตัวอย่างเชิงปฏิบัติที่หลายองค์กรอ้างอิง
องค์ประกอบของนโยบายภายในที่พบบ่อย
- การกำหนดผู้มีสิทธิ์ใช้เครื่องมือ (เช่น เฉพาะนักพัฒนาที่ผ่านการฝึกอบรมหรือผู้ดูแลทีม)
- ข้อกำหนดในการบันทึกและติดป้ายโค้ดที่มาจาก AI (provenance metadata และ commit annotations)
- ข้อห้ามในการใช้เครื่องมือกับข้อมูลที่มีความอ่อนไหวหรือข้อมูลส่วนบุคคลโดยไม่ผ่านการอนุมัติ
- การตรวจสอบลิขสิทธิ์และข้อกำหนดไลเซนส์ก่อนนำโค้ด AI เข้าสู่ฐานรหัสหลัก
- มาตรการรักษาความปลอดภัย เช่น การสแกนโค้ดอัตโนมัติและการทดสอบหน่วย/การทดสอบเชิงความปลอดภัยเพิ่มเติม
การปรับกระบวนการ SDLC การนำ AI เข้ามาในกระบวนการพัฒนาซอฟต์แวร์ทำให้ทีมต้องปรับขั้นตอนมาตรฐานหลายจุด ตั้งแต่การออกแบบ ไปจนถึงการปรับใช้และบำรุงรักษา ได้แก่ การเพิ่มขั้นตอนสำหรับการตรวจสอบแหล่งที่มาของโค้ด การบังคับให้มีรีวิวโดยมนุษย์ (human-in-the-loop) สำหรับทุก PR ที่มีโค้ดจาก AI การรวมการทดสอบอัตโนมัติและ Static/Dynamic Analysis ใน pipeline CI/CD เพื่อจับจุดบกพร่องที่ AI อาจมองข้าม และการเพิ่ม metadata ใน artifact เพื่อให้สามารถติดตาม provenance ของโค้ดตลอดอายุการใช้งาน
ตัวอย่างการเปลี่ยนแปลงที่เห็นได้ชัด เช่น การเพิ่ม gate ใหม่ใน CI ที่สแกนหาโครงสร้างโค้ดที่มีลักษณะสร้างโดยโมเดล การใช้ชุดทดสอบความปลอดภัย (fuzzing, SAST/DAST) ก่อน merge และการกำหนด SLA สำหรับการตรวจสอบโดย reviewer เพื่อไม่ให้การใช้ AI ลดมาตรฐานการรีวิว อีกทั้งหลายองค์กรยังเริ่มบังคับให้มี "AI output retention" — การเก็บคำสั่งและผลลัพธ์จากโมเดลเพื่อใช้เป็นหลักฐานในกรณีต้องสืบสวนปัญหาในอนาคต
บทบาทของชุมชนโอเพนซอร์สและข้อเสนอแนะเชิงกฎระเบียบ ชุมชนโอเพนซอร์สมีบทบาทสำคัญทั้งในเชิงปฏิบัติและเชิงนโยบาย หลายองค์กรในชุมชนได้ออกแนวทางปฏิบัติ (best practices) และคําแนะนำเกี่ยวกับการใช้โค้ดสาธารณะเป็นชุดฝึกซึ่งมีความกังวลด้านไลเซนส์และสิทธิ์ของผู้สร้างต้นฉบับ องค์กรเช่น Linux Foundation (ผ่านโครงการ LF AI & Data), Open Source Initiative และกลุ่มรักษาสิทธิ์นักพัฒนา ได้เปิดเวทีอภิปรายเกี่ยวกับการให้เครดิต การอนุญาตใช้ซ้ำ และการป้องกันการละเมิดลิขสิทธิ์
ในระดับหน่วยงานกำกับดูแล แนวทางเช่น EU AI Act ที่กำลังดำเนินการ และกรอบการบริหารความเสี่ยง AI ของ NIST ได้ผลักดันให้องค์กรต้องจัดทำการประเมินความเสี่ยง (risk assessment), จัดให้มีการบันทึกข้อมูลการใช้งาน (logging/transparency) และกำหนดมาตรการควบคุมสำหรับระบบที่ถือว่ามีความเสี่ยงสูง ผลจากข้อเสนอแนะเหล่านี้ทำให้บริษัทต้องเตรียมการด้านนโยบายคุ้มครองข้อมูล ตรวจสอบการปฏิบัติตามไลเซนส์ และเพิ่มการรายงานภายในเพื่อให้สอดคล้องกับข้อกำหนดด้านความรับผิดชอบ
ภาพรวมจากการตอบสนองของทุกภาคส่วนชี้ชัดว่าการจัดการเครื่องมือโค้ดดิ้ง AI จำเป็นต้องเป็นการทำงานแบบบูรณาการระหว่างนโยบายภายใน การปรับกระบวนการทางเทคนิค และการมีส่วนร่วมกับชุมชนและหน่วยงานกำกับดูแล เพื่อให้เทคโนโลยีใหม่นี้สร้างคุณค่าได้มากที่สุดพร้อมควบคุมความเสี่ยงอย่างเหมาะสม
แนวปฏิบัติที่ดีที่สุด: วิธีใช้เครื่องมือโค้ดดิ้ง AI อย่างรับผิดชอบ
แนวปฏิบัติที่ดีที่สุด: วิธีใช้เครื่องมือโค้ดดิ้ง AI อย่างรับผิดชอบ
ในยุคที่เครื่องมือโค้ดดิ้ง AI กำลังถูกนำไปใช้อย่างแพร่หลาย องค์กรและทีมพัฒนาจำเป็นต้องวางกรอบการใช้งานที่ชัดเจนเพื่อรักษาคุณภาพ ความปลอดภัย และความรับผิดชอบ โดยแนวปฏิบัติที่ดีที่สุดจะครอบคลุมทั้งนโยบายการใช้งาน การบันทึกการใช้งาน การตรวจสอบโค้ดแบบอัตโนมัติ และการพัฒนาทักษะของทีมให้สามารถทำงานควบคู่กับ AI ได้อย่างมีประสิทธิภาพ การสำรวจหลายแหล่งชี้ว่า >40% ของนักพัฒนาทดลองใช้หรือใช้งานเครื่องมือโค้ดดิ้ง AI ในกระบวนการพัฒนา ซึ่งสะท้อนความจำเป็นที่องค์กรต้องมีกลไกควบคุมเพื่อป้องกันความเสี่ยงด้านความปลอดภัยและข้อผิดพลาดเชิงตรรกะ
กำหนดกฎเกณฑ์การใช้งานและบันทึกการใช้งาน AI ทุกครั้ง — นโยบายที่ชัดเจนเป็นหัวใจสำคัญของการใช้ AI อย่างรับผิดชอบ ควรกำหนดว่าเครื่องมือใดถูกอนุญาต ใช้ในกรณีใดบ้าง ข้อจำกัดเรื่องข้อมูลที่สามารถป้อนได้ และการจัดการความลับขององค์กร บันทึกการใช้งาน (audit log) จะต้องเก็บข้อมูลสำคัญทุกครั้งที่มีการเรียกใช้ AI เช่น ชื่อผู้ใช้ รุ่นโมเดล คำสั่ง (prompt) เวลาที่เรียกใช้ และผลลัพธ์ที่ส่งกลับ เพื่อให้สามารถติดตามย้อนกลับ ตรวจสอบแหล่งที่มาของโค้ด และวิเคราะห์เหตุการณ์ผิดปกติได้ในอนาคต
ผสานการตรวจสอบอัตโนมัติก่อน merge — ห้ามข้ามขั้นตอนการตรวจสอบโค้ดเพียงเพราะโค้ดถูกสร้างจาก AI ระบบ CI/CD ควรบังคับให้มีชุดการทดสอบที่ครอบคลุม (unit, integration, end-to-end) linters สำหรับมาตรฐานโค้ด เช่น ESLint, Pylint, และเครื่องมือ SAST/DAST เช่น SonarQube, Snyk, Checkmarx เพื่อค้นหาช่องโหว่ความปลอดภัยหรือข้อผิดพลาดเชิงสถาปัตยกรรม ก่อนที่จะ merge เข้าสู่สาขาหลัก เกตเวย์การยอมรับ เช่น policy-as-code สามารถตรวจสอบ metadata ของการใช้งาน AI และบล็อก PR ที่ไม่มีการบันทึกหรือขาดการทดสอบอัตโนมัติ
สร้างวัฒนธรรม Human-in-the-loop — แม้ AI จะช่วยเร่งการเขียนโค้ด แต่การตัดสินใจเชิงออกแบบและการยืนยันความถูกต้องยังคงต้องพึ่งพามนุษย์เสมอ กำหนดบทบาทหน้าที่ที่ชัดเจน เช่น ผู้ขอความช่วยเหลือจาก AI (developer) ต้องตรวจสอบโค้ดที่ได้ ผู้ตรวจสอบ (reviewer) ต้องให้ความสำคัญกับตรรกะ การปฏิบัติตามแนวทางการออกแบบ และความปลอดภัย ฝึกให้ทีมใช้ AI เป็นผู้ช่วย ไม่ใช่ผู้ตัดสินขั้นสุดท้าย ตัวอย่างปฏิบัติที่ดีคือให้มี gate สำหรับการตรวจ code quality และ security sign-off ก่อน deploy
ลงทุนในการฝึกอบรมและพัฒนาทักษะที่ AI ยังทดแทนไม่ได้ — องค์กรที่ประสบความสำเร็จจะลงทุนฝึกอบรมทักษะเชิงวิเคราะห์และเชิงสถาปัตยกรรม เช่น การออกแบบระบบ (system design), การวิเคราะห์สาเหตุราก (root-cause analysis), threat modeling, และทักษะการแก้ปัญหาชั้นสูง ซึ่งช่วยให้ทีมสามารถประเมินข้อเสนอแนะจาก AI ได้อย่างมีวิจารณญาณ ยิ่งไปกว่านั้น ควรให้การฝึกอบรมเรื่องการเขียน prompt อย่างมีประสิทธิภาพ การประเมินความน่าเชื่อถือของผลลัพธ์ และแนวทางการปฏิบัติตามข้อกำหนดด้านความเป็นส่วนตัวและกฎระเบียบ
- กำหนดขอบเขตหน้าที่ของ AI: ใช้ AI สำหรับงานที่มีลักษณะซ้ำซ้อนหรือช่วยเร่งการเขียนโค้ด แต่ห้ามใช้สำหรับการตัดสินใจเชิงนโยบายหรือการจัดการความลับโดยตรง
- บันทึกและเมตาดาต้า: ใช้ระบบบันทึกแบบรวมศูนย์ (centralized logging) เก็บ prompt, outputs, และผู้ใช้งาน เชื่อมต่อกับระบบ SIEM หากเป็นไปได้
- ตรวจสอบอย่างสม่ำเสมอ: ตั้ง KPI เช่น อัตราข้อบกพร่องที่มาจากโค้ด AI, เวลาที่ใช้ในการรีวิวโค้ด, และอัตราการบล็อก PR จากนโยบาย เพื่อวัดความเสี่ยงและประสิทธิภาพ
- ผสมผสานการทดสอบเชิงพฤติกรรม: เพิ่ม fuzz testing, property-based tests และ chaos testing สำหรับส่วนที่ AI สร้างโค้ด เพื่อค้นหาข้อบกพร่องเชิงซ้อน
การประยุกต์แนวปฏิบัติเหล่านี้จะช่วยให้องค์กรสามารถใช้ประโยชน์จากเครื่องมือโค้ดดิ้ง AI ได้อย่างคุ้มค่าและปลอดภัย โดยรักษามาตรฐานคุณภาพซอฟต์แวร์และความรับผิดชอบต่อผู้ใช้สุดท้ายได้อย่างยั่งยืน ตัวอย่างการปฏิบัติในองค์กรขนาดกลาง-ใหญ่คือการนำ policy-as-code มาควบคุม CI/CD, กำหนด mandatory audit log และจัดรอบการอบรมรายไตรมาสสำหรับทักษะที่ AI ยังทดแทนไม่ได้ ทั้งหมดนี้ช่วยให้ทีมพัฒนาเดินหน้าไปพร้อมกับเทคโนโลยีโดยไม่สูญเสียความควบคุมและความน่าเชื่อถือ
บทสรุป
เครื่องมือโค้ดดิ้งด้วยปัญญาประดิษฐ์มีศักยภาพมากในการยกระดับประสิทธิภาพการพัฒนา—บางการศึกษาและรายงานจากอุตสาหกรรมระบุว่าช่วยลดเวลางานเขียนโค้ดได้ถึงประมาณ 20–40% ในงานบางประเภท—แต่ขณะเดียวกันก็มาพร้อมความเสี่ยงที่ต้องจัดการอย่างจริงจัง ได้แก่ การเสื่อมถอยของทักษะของนักพัฒนา (skill degradation) หากพึ่งพา AI มากเกินไป ปัญหาคุณภาพโค้ด เช่น บั๊กหรือ technical debt ที่ AI อาจสร้างขึ้นซ้ำ ๆ และความเสี่ยงด้านความปลอดภัยจากโค้ดที่มีช่องโหว่หรือการรั่วไหลของข้อมูล การตอบโจทย์เหล่านี้ต้องใช้แนวทางผสมผสาน: นโยบายการใช้งานที่ชัดเจน กระบวนการตรวจสอบคุณภาพและความปลอดภัยที่เข้มงวด และการประเมินผลลัพธ์ของเครื่องมืออย่างต่อเนื่อง
องค์กรที่จะได้ประโยชน์อย่างยั่งยืนคือองค์กรที่ลงทุนสร้างระบบตรวจสอบ (code review, automated testing, security scanning) เทรนบุคลากรให้เข้าใจขีดจำกัดของ AI และออกแบบการทำงานแบบ human-in-the-loop เพื่อให้มนุษย์ยังคงเป็นผู้ตัดสินใจขั้นสุดท้าย การนำ AI ไปผสานในวงจรพัฒนาซอฟต์แวร์ (SDLC) ที่มีการมอนิเตอร์และปรับปรุงอย่างเป็นระบบจะช่วยลดความเสี่ยงและเพิ่มคุณค่าทางธุรกิจ ในอนาคตคาดว่าจะเห็นมาตรฐานและเครื่องมือที่เข้มแข็งขึ้น การกำกับดูแลที่ชัดเจน และการพัฒนาแนวปฏิบัติที่ทำให้การใช้เครื่องมือโค้ดดิ้ง AI เป็นไปได้อย่างปลอดภัยและยั่งยืนสำหรับทั้งทีมนักพัฒนาและองค์กร
📰 แหล่งอ้างอิง: Ars Technica



