
หน่วยงานกำกับได้ออกคำสั่งใหม่ที่อาจเปลี่ยนโครงสร้างการสื่อสารดิจิทัลอย่างมีนัยสำคัญ: แพลตฟอร์มข่าวและโฆษณาออนไลน์ต้องติดป้าย "AI‑Generated Watermark" บนเนื้อหาที่สร้างหรือปรับแต่งด้วยปัญญาประดิษฐ์ พร้อมทั้งเปิดเผยที่มาโมเดล (model provenance) และเก็บบันทึกเมทาดาต้าอย่างเป็นระบบ คำสั่งนี้ตอบรับความกังวลของสาธารณะเกี่ยวกับความโปร่งใสของเนื้อหา AI — งานสำรวจหลายแห่งชี้ว่าผู้บริโภคมากกว่า 50% ต้องการการเปิดเผยที่ชัดเจนเมื่อพบเนื้อหาที่เกี่ยวข้องกับ AI — และยังสอดคล้องกับมาตรฐานความรับผิดชอบดิจิทัลที่กำลังได้รับความสนใจ เช่น C2PA (Content Credentials) เพื่อยืนยันแหล่งที่มาและเส้นทางการสร้างเนื้อหา
บทความนี้เป็นคู่มือปฏิบัติสำหรับแพลตฟอร์มที่ต้องการปฏิบัติตามคำสั่งดังกล่าว: เราจะสรุปข้อกำหนดทางกฎหมายและระยะเวลาในการบังคับใช้ อธิบายแนวทางเทคนิคตั้งแต่การฝังวอเตอร์มาร์กแบบมองเห็นได้จนถึงการจัดเก็บเมทาดาต้าเชิงโครงสร้าง พร้อมตัวอย่างการตั้งนโยบายภายในและเช็คลิสต์ปฏิบัติสำหรับทีมวิศวกรรมและฝ่ายปฏิบัติการด้านเนื้อหา นอกจากนี้ยังมีข้อพิจารณาด้านความเป็นส่วนตัว การรักษาความมั่นคงของข้อมูล และความเสี่ยงด้านการบังคับใช้ที่แพลตฟอร์มต้องเตรียมรับมือ เพื่อให้การเปลี่ยนผ่านสู่การเปิดเผยเนื้อหา AI เป็นไปอย่างราบรื่นและยั่งยืน
บทนำ: ทำไมหน่วยงานกำกับต้องออกคำสั่งนี้
บทนำ: ทำไมหน่วยงานกำกับต้องออกคำสั่งนี้
การแพร่หลายของเทคโนโลยีสร้างสรรค์ด้วยปัญญาประดิษฐ์ (Generative AI) ทำให้การผลิตเนื้อหาเชิงข้อมูล ภาพ วิดีโอ และเสียงที่มีลักษณะเหมือนงานมนุษย์เป็นไปได้ในวงกว้างและรวดเร็ว สิ่งนี้ส่งผลให้เกิดความเสี่ยงด้านสังคมและเศรษฐกิจ เช่น การเผยแพร่ข่าวเท็จ (misinformation) การใช้เนื้อหา AI ในการโฆษณาเชิงหลอกลวง และการเบียดบังแนวทางปฏิบัติด้านจริยธรรมของสื่อมวลชน หน่วยงานกำกับจึงถือว่าจำเป็นต้องออกคำสั่งเพื่อสร้างกรอบบังคับที่ชัดเจนในการระบุแหล่งที่มาของเนื้อหา รวมทั้งเพื่อปกป้องผู้บริโภคและรักษาความน่าเชื่อถือของระบบข้อมูลสาธารณะ

หลักการสำคัญเบื้องหลังคำสั่งนี้คือ การป้องกันการหลอกลวง และ การเพิ่มความโปร่งใส โดยกำหนดให้แพลตฟอร์มและผู้เผยแพร่ต้องติดเครื่องหมายแสดงว่าเนื้อหาถูกสร้างหรือปรับแต่งด้วย AI (AI‑Generated Watermark) และเปิดเผยข้อมูลเกี่ยวกับที่มาของโมเดล รวมทั้งเก็บบันทึกเมทาดาต้าสำหรับการตรวจสอบย้อนหลัง การดำเนินการดังกล่าวช่วยให้ผู้ใช้ ผู้สื่อข่าว และหน่วยงานตรวจสอบสามารถแยกแยะเนื้อหามนุษย์กับเนื้อหา AI ได้ง่ายขึ้น ลดโอกาสการใช้เนื้อหาเพื่อชักจูงหรือบิดเบือนข้อมูล และเพิ่มความรับผิดชอบของผู้เผยแพร่และผู้ให้บริการแพลตฟอร์ม
คำสั่งครอบคลุมพื้นที่ที่ส่งผลกระทบสูงต่อสาธารณะ ได้แก่ ข่าวออนไลน์ โพสต์สปอนเซอร์ และ โฆษณาออนไลน์ ที่ถูกสร้างหรือปรับแต่งโดยเทคโนโลยี AI ทั้งหมด โดยระบุกรอบข้อกำหนดตัวอย่างเช่น:
- การติดป้ายแจ้งชัดเจน (visible watermark หรือข้อความประกาศ) เมื่อนำเสนอเนื้อหาที่สร้างด้วย AI
- การเปิดเผยแหล่งที่มาของโมเดล เช่น ชื่อผู้พัฒนา โมเดลเวอร์ชัน และเงื่อนไขการใช้งาน
- การเก็บรักษาเมทาดาต้า ที่ระบุการประมวลผล สต็อกร่องรอย (logs) และหลักฐานการสร้าง เพื่อการตรวจสอบโดยหน่วยงานกำกับหรือผู้ตรวจสอบอิสระ
ตัวอย่างสถิติและแหล่งข้อมูลที่เหมาะจะอ้างอิงประกอบบทนำ (โปรดตรวจสอบแหล่งจริงก่อนเผยแพร่):
- รายงานการสำรวจทัศนคติของประชาชนต่อข่าวปลอมจากสถาบันเช่น Reuters Institute และ Pew Research Center ที่ชี้ให้เห็นระดับความกังวลเกี่ยวกับข้อมูลที่ไม่เชื่อถือได้
- งานวิจัยและเอกสารของสถาบันด้าน AI เช่น Stanford HAI หรือ OECD เกี่ยวกับการเติบโตของเนื้อหา Generative AI และความเสี่ยงเชิงสังคม
- รายงานอุตสาหกรรมจาก IAB หรือหน่วยงานกำกับสื่อของประเทศต่าง ๆ (เช่น Ofcom ในสหราชอาณาจักร หรือรายงานของคณะกรรมาธิการยุโรป) ที่วิเคราะห์ผลกระทบต่อตลาดโฆษณาออนไลน์
โดยสรุป คำสั่งนี้มุ่งหมายให้เกิดสมดุลระหว่างการส่งเสริมนวัตกรรมกับการคุ้มครองสาธารณะ ผ่านการบังคับให้มีสัญลักษณ์บ่งชี้เนื้อหา AI การเปิดเผยที่มาของโมเดล และการเก็บเมทาดาต้าเพื่อการตรวจสอบ ซึ่งคาดว่าจะช่วยลดการบิดเบือน เพิ่มความรับผิดชอบของแพลตฟอร์ม และช่วยฟื้นฟูความไว้วางใจของผู้บริโภคต่อข้อมูลข่าวสารและโฆษณาออนไลน์
สาระสำคัญของคำสั่ง: อะไรบ้างที่แพลตฟอร์มต้องทำ
สาระสำคัญของคำสั่ง: อะไรบ้างที่แพลตฟอร์มต้องทำ
คำสั่งบังคับเกี่ยวกับการติดป้ายและการเปิดเผยแหล่งกำเนิดของเนื้อหา AI กำหนดภาระหน้าที่เชิงปฏิบัติให้กับแพลตฟอร์มสื่อออนไลน์หลายประการ โดยสรุปแล้ว แพลตฟอร์มต้องดำเนินการในสามแนวทางหลักคือ: (1) ติดป้ายที่ชัดเจนแยกความต่างของเนื้อหา AI จากมนุษย์, (2) เปิดเผยข้อมูลเกี่ยวกับโมเดลและแหล่งที่มาอย่างโปร่งใส, และ (3) เก็บบันทึกเมทาดาต้าที่จำเป็นเพียงพอสำหรับการตรวจสอบและการบังคับใช้ กรอบรายละเอียดด้านล่างอธิบายรูปแบบป้าย ข้อมูลที่ต้องเปิดเผย และข้อกำหนดด้านการเก็บบันทึกอย่างครบถ้วน
รูปแบบป้ายกำกับที่ยอมรับได้ — คำสั่งมักเน้นทั้งการแสดงป้ายแบบมองเห็นได้แก่ผู้ใช้และการฝังแท็กที่เครื่องอ่านได้ (machine‑readable). รูปแบบที่เป็นไปได้รวมถึง:
- ป้ายมองเห็น (visible/explicit label): คำระบุบนตัวเนื้อหาเช่น "สร้างด้วย AI" หรือ "AI‑Generated" ที่ปรากฏอย่างชัดเจนบริเวณต้นหรือท้ายของบทความ/โฆษณา เพื่อให้ผู้ใช้ทั่วไปรับทราบทันที
- แท็กที่เครื่องอ่านได้ (machine‑readable tag): เมทาดาต้าเชิงมาตรฐานที่ฝังในไฟล์ (เช่น HTTP header, EXIF, sidecar file) หรือในรูปแบบ JSON‑LD/Schema.org สำหรับเนื้อหาเว็บ เพื่อรองรับการตรวจสอบโดยอัตโนมัติและการค้นคืนข้อมูล
- มาตรฐานการแสดงผล: คำสั่งอาจกำหนดขนาด ฟอนต์ สี ความเด่นชัด หรือตำแหน่ง เพื่อให้ป้ายไม่ถูกมองข้าม และกำหนดวิธีการ fallback เมื่อรูปแบบป้ายมองเห็นไม่ได้ (เช่น บริการสตรีมมิ่งหรือข้อความสั้น)
ข้อมูลที่ต้องเปิดเผยเกี่ยวกับโมเดลและแหล่งที่มา — แพลตฟอร์มต้องระบุข้อมูลขั้นต่ำที่ชัดเจนและตรวจสอบได้เกี่ยวกับโมเดลที่ใช้ในการสร้างเนื้อหา รายการข้อมูลทั่วไปประกอบด้วย:
- ชื่อโมเดล (model name) — ระบุชื่อทางการของโมเดลที่ใช้ เช่น "ModelX" หรือชื่อผู้ให้บริการและแบรนด์โมเดล
- เวอร์ชัน (model version) — ระบุหมายเลขหรือรหัสเวอร์ชันเพื่อให้สามารถย้อนกลับไปยังพารามิเตอร์และการอัปเดตของโมเดลได้
- ผู้ให้บริการ/แหล่งที่มา (provider/source) — ระบุว่ามาจากผู้ให้บริการรายใด (เช่น ผู้ให้บริการคลาวด์หรือโมเดลโอเพนซอร์ส) และถ้ามี ให้ระบุเงื่อนไขการใช้งาน (license) หรือข้อมูลเกี่ยวกับชุดข้อมูลฝึก (เมื่อกฎหมายกำหนด)
- ข้อมูลเสริมที่อาจร้องขอ — เช่น ระบุว่าเนื้อหาได้รับการปรับแต่ง (fine‑tuned) หรือรวมความสามารถจากโมเดลหลายตัว รวมถึงหมายเลขการเรียก API หรือรหัสระบุตัวตนของการเรียกเพื่อการตรวจสอบ
ข้อกำหนดด้านการเก็บบันทึกเมทาดาต้า — การเก็บรักษาเมทาดาต้าเป็นหัวใจสำคัญของการบังคับใช้ คำสั่งมักกำหนดรายการข้อมูลขั้นต่ำและกรอบเวลาเก็บรักษาเพื่อให้หน่วยงานกำกับสามารถตรวจสอบย้อนหลังได้ ข้อมูลที่มักถูกบันทึกได้แก่:
- prompt hash / prompt fingerprint — ค่าแฮชของคำสั่งหรือ prompt ที่ใช้ (ไม่จำเป็นต้องเก็บข้อความดิบเพื่อคงความเป็นส่วนตัว แต่ต้องสามารถพิสูจน์การเรียกใช้งานได้)
- timestamp — เวลาที่สร้างหรือเผยแพร่เนื้อหา
- content hash — แฮชของไฟล์เนื้อหาที่ผลิต (เพื่อตรวจสอบความสมบูรณ์และการเปลี่ยนแปลง)
- ข้อมูลเกี่ยวกับผู้ร้องขอการสร้าง — เช่น รหัสผู้ใช้หรือการระบุตัวตนแบบ pseudonymized ตามข้อกำหนดความเป็นส่วนตัว
- chain‑of‑custody / audit log — ประวัติการแก้ไข การเผยแพร่ และการเข้าถึงเมทาดาต้า
กรอบการเก็บรักษาและการเข้าถึงโดยหน่วยงานกำกับ — คำสั่งมักกำหนดระยะเวลาและเงื่อนไขการอนุญาตให้หน่วยงานกำกับเข้าถึงข้อมูล ตัวอย่างโครงกรอบที่พบบ่อย:
- ระยะเวลาเก็บรักษา: ขั้นต่ำ มักอยู่ในช่วง 12–24 เดือนสำหรับเมทาดาต้าพื้นฐาน และอาจขยายเป็น 3–5 ปีสำหรับกรณีที่เกี่ยวกับข้อพิพาทหรือการสอบสวนที่ซับซ้อน กรอบเวลาที่แน่นอนขึ้นอยู่กับข้อกำหนดของหน่วยงานกำกับในแต่ละเขตอำนาจ
- การเข้าถึงโดยหน่วยงานกำกับ: ข้อมูลต้องสามารถมอบให้ได้เมื่อมีคำขอทางกฎหมาย โดยมีมาตรการคุ้มครองข้อมูลส่วนบุคคล เช่น การให้เข้าถึงผ่านช่องทางปลอดภัย และการ redaction ข้อมูลที่เป็นความลับทางการค้า
- ความมั่นคงและความสมบูรณ์: ข้อมูลต้องถูกเก็บรักษาอย่างปลอดภัย (การเข้ารหัสเมื่อพัก/ส่งต่อ) และมีลายเซ็นดิจิทัลหรือเครื่องมือยืนยันความไม่เปลี่ยนแปลงของบันทึก
ข้อยกเว้นและเงื่อนไขพิเศษ — คำสั่งมักอนุญาตข้อยกเว้นในบริบทจำกัด แต่มีเงื่อนไขเคร่งครัด เช่น:
- งานข่าวด่วนหรือสื่อมวลชนที่มีความสำคัญต่อสาธารณประโยชน์ อาจได้รับการยกเว้นบางประการ แต่ต้องมีการแจ้งเหตุผลและบันทึกประกอบ
- เนื้อหาที่เป็นการแสดงความคิดสร้างสรรค์เช่น บทความล้อเลียน/สตันท์ (satire/parody) อาจผ่อนปรนการตีความป้าย แต่ยังคงต้องยอมรับหลักการโปร่งใสอย่างน้อยในระดับเมทาดาต้า
- กรณีที่มีข้อจำกัดทางเทคนิค (technical infeasibility) แพลตฟอร์มต้องสามารถแสดงหลักฐานว่าการปฏิบัติตามเป็นไปไม่ได้และจัดมาตรการทดแทน เช่น การปรากฏป้ายในหน้ารายละเอียดของเนื้อหา
- ข้อยกเว้นต้องมีการบันทึกและตรวจสอบได้ และไม่ควรถูกนำมาใช้เป็นช่องทางหลบเลี่ยงภาระหน้าที่ของการเปิดเผย
โดยสรุป แพลตฟอร์มต้องผสานการแสดงป้ายที่มองเห็นได้กับการเก็บเมทาดาต้าในรูปแบบที่เครื่องอ่านได้และปลอดภัย พร้อมทั้งเปิดเผยชื่อและเวอร์ชันของโมเดลที่ใช้ ภายใต้กรอบการเก็บรักษาและการอนุญาตเข้าถึงสำหรับหน่วยงานกำกับที่ชัดเจน ข้อยกเว้นมีได้แต่ต้องจำกัดและตรวจสอบได้ การปฏิบัติตามคำสั่งเชิงปฏิบัติการเหล่านี้จะมีผลต่อกระบวนการออกแบบผลิตภัณฑ์ ระบบบันทึกข้อมูล และนโยบายคุ้มครองข้อมูลของแพลตฟอร์มอย่างมีนัยสำคัญ
ผลกระทบต่อแพลตฟอร์ม ผู้เผยแพร่ และผู้โฆษณา
ผลกระทบต่อแพลตฟอร์ม ผู้เผยแพร่ และผู้โฆษณา
คำสั่งบังคับให้ติด AI‑Generated Watermark และบันทึกเมทาดาต้าของโมเดลจะส่งผลกระทบเชิงธุรกิจและประสบการณ์ผู้ใช้ในหลายมิติ ทั้งด้านประโยชน์เชิงความเชื่อมั่นและความเสี่ยงเชิงต้นทุนและความเป็นส่วนตัว สำหรับแพลตฟอร์มและผู้เผยแพร่ ประเด็นสำคัญได้แก่ต้นทุนในการปรับระบบ การจัดเก็บและการตรวจสอบย้อนกลับ (provenance), การเปลี่ยนแปลงด้านสัญญาและกระบวนการผลิตคอนเทนต์ ตลอดจนผลกระทบต่อรายได้จากโฆษณา
ต้นทุนการเปลี่ยนแปลงระบบและการตรวจสอบย้อนกลับ: การนำมาตรการที่ต้องติดป้ายและเก็บเมทาดาต้าจะสร้างต้นทุนตรงและต้นทุนแฝงสำหรับทุกฝ่าย ต้นทุนตรงที่สำคัญได้แก่
- พัฒนาระบบและการบูรณาการ — วิศวกรต้องออกแบบ API และ pipeline เพื่อฝัง watermark, เซ็นข้อมูลเชิงดิจิทัล และเชื่อมโยงเมทาดาต้ากับไฟล์สื่อ การเปลี่ยนแปลงนี้อาจต้องใช้เวลาหลายสัปดาห์ถึงหลายเดือนและงบประมาณที่สำคัญ โดยเฉพาะกับแพลตฟอร์มขนาดใหญ่ที่มีคอนเทนต์จำนวนมาก
- พื้นที่เก็บข้อมูลและการประมวลผล — เมทาดาต้าระดับรายการจะเพิ่มความต้องการสตอเรจและระบบค้นหา (indexing) เพื่อรองรับการตรวจสอบย้อนหลังและคำร้องขอข้อมูลจากหน่วยงานกฎระเบียบ
- การตรวจสอบและการตรวจสอบย้อนกลับ (audit) — ต้องจัดตั้งกระบวนการ audit, logging และเครื่องมือวิเคราะห์เพื่อตรวจสอบความถูกต้องของ watermark และความสมบูรณ์ของเมทาดาต้า ซึ่งเป็นต้นทุนประจำที่เพิ่มขึ้นทั้งด้านบุคลากรและเครื่องมือ
- ภาระทางกฎหมายและการปฏิบัติตามกฎระเบียบ — ทีมกฎหมายต้องร่างสัญญาใหม่กับผู้ผลิตคอนเทนต์ กำหนดนโยบายการเก็บข้อมูล (retention policy) และประเมินความสอดคล้องกับกฎหมายคุ้มครองข้อมูลส่วนบุคคล เช่น PDPA/GDPR
ผลต่อประสบการณ์ผู้ใช้: ความชัดเจน versus ความรำคาญของป้าย
- ในด้านบวก การติดป้ายแสดงแหล่งที่มาของโมเดลและการมีเมทาดาต้าชัดเจนสามารถเพิ่มความเชื่อถือของผู้ใช้ ลดการแพร่กระจายของข้อมูลเท็จ และช่วยให้ผู้อ่านประเมินความน่าเชื่อถือของคอนเทนต์ได้ดียิ่งขึ้น ซึ่งสำหรับผู้ใช้ที่ให้ความสำคัญกับแหล่งที่มาและความโปร่งใส นโยบายนี้อาจเป็นปัจจัยสร้างความจงรักภักดีต่อแพลตฟอร์ม
- ในทางกลับกัน การแสดงป้ายที่เด่นชัดหรือซ้ำซ้อนอาจกลายเป็นสิ่งรบกวน (friction) โดยเฉพาะในสื่อเชิงบันเทิงหรือโฆษณาที่ต้องเน้นประสบการณ์ไร้รอยต่อ ผู้ประกอบการต้องตัดสินใจเชิงออกแบบว่าจะวางป้ายอย่างไรให้ยังคงความโปร่งใสโดยไม่ลดอัตราการมีส่วนร่วม (engagement)
- ผลการทดสอบภายในอุตสาหกรรมบางกรณีชี้ว่า ป้ายและคำเตือนที่ชัดเจนอาจลด CTR หรือเวลาเข้าชมในบางบริบท แต่สามารถเพิ่มความไว้วางใจในระยะยาว โดยเฉพาะเมื่อผู้ใช้สามารถเข้าถึงข้อมูลแหล่งที่มาได้อย่างง่ายดาย
ผลต่อธุรกิจโฆษณา: การกำหนดราคาและการกำกับการแสดงโฆษณา
- การเปิดเผยที่มาของคอนเทนต์และการระบุว่าเป็นงานที่สร้างโดย AI จะเปลี่ยนโครงสร้างมูลค่าของ Inventory โฆษณา: แบรนด์บางรายอาจยินดีจ่ายพรีเมียมสำหรับคอนเทนต์ที่ยืนยันว่าเป็นงานมนุษย์สร้าง ในขณะที่คอนเทนต์ที่ติดป้ายว่าเป็น AI‑generated อาจถูกตั้งราคาต่ำลงหรือต้องมีการกำกับพิเศษ
- แพลตฟอร์มอาจต้องปรับกลไกการประมูลโฆษณา (auction logic) และตัวชี้วัดคุณภาพ เช่น เพิ่มตัวกรองสำหรับโฆษณาที่ต้องการไม่ให้แสดงคู่กับคอนเทนต์ AI หรือกำหนดราคาแบบแยกชั้นตามโพรเวนแนนซ์ ซึ่งนำไปสู่ความซับซ้อนของระบบรายได้และการรายงานแก่ผู้โฆษณา
- นอกจากนั้น ความเสี่ยงจากการตรวจสอบย้อนหลัง (retroactive accountability) ทำให้ผู้โฆษณาต้องการหลักประกันเพิ่มเติม เช่น cryptographic signatures หรือใบรับรองการตรวจสอบเพื่อหลีกเลี่ยงปัญหาทางกฎหมายหรือภาพลักษณ์ ซึ่งเป็นต้นทุนเพิ่มทั้งฝั่งผู้โฆษณาและแพลตฟอร์ม
สรุปได้ว่า คำสั่งบังคับเรื่อง watermark และเมทาดาต้าจะเพิ่มความโปร่งใสและอาจเสริมความเชื่อถือของระบบนิเวศดิจิทัล แต่ก็สร้างภาระด้านต้นทุน การออกแบบ UX ที่ละเอียดอ่อน และแรงกดดันต่อโมเดลธุรกิจโฆษณา แพลตฟอร์มขนาดใหญ่มีความสามารถในการกระจายต้นทุนเหล่านี้ได้ดีกว่า ผู้เผยแพร่ขนาดเล็กอาจได้รับผลกระทบรุนแรงกว่า จึงจำเป็นต้องมีการวางแผนเชิงกลยุทธ์ ทั้งในด้านเทคนิค นโยบายสัญญา และการสื่อสารกับผู้ใช้และผู้โฆษณา เพื่อรักษาสมดุลระหว่างความโปร่งใสและศักยภาพในการสร้างรายได้
แนวทางเทคนิค: วิธีการติด 'AI‑Generated Watermark' ทุกระดับ
การบังคับติดเครื่องหมายบ่งชี้เนื้อหา AI (AI‑Generated Watermark) จำเป็นต้องอาศัยแนวทางเชิงเทคนิคหลายชั้น เพื่อให้ครอบคลุมทั้งความโปร่งใสต่อผู้ใช้ การพิสูจน์แหล่งที่มา และความทนทานต่อการดัดแปลง ในส่วนนี้เราจะอธิบายเทคนิคหลักสามประเภท — visible overlay, invisible robust watermark / fingerprinting และ embedded metadata tags — พร้อมข้อดีข้อเสีย ตัวอย่างการใช้งาน และแนวทางการผสมผสานให้เหมาะสมกับบริบทต่าง ๆ (ข่าว, รูปภาพ, วิดีโอ, โฆษณา)
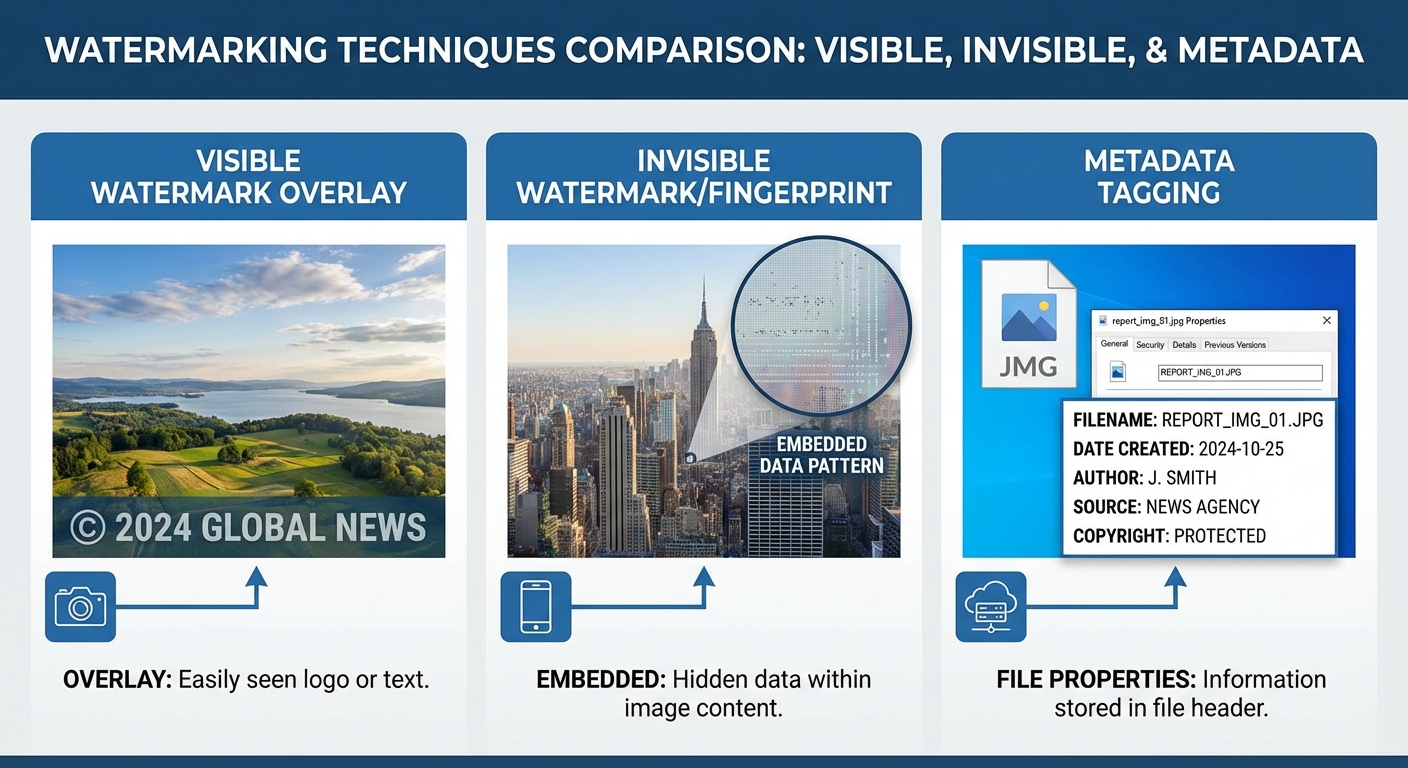
1) Visible watermark (สัญลักษณ์เปิดเผยต่อผู้ใช้)
ลักษณะ: เป็นสัญลักษณ์หรือข้อความที่ปรากฏชัดเจนบนหน้าจอ เช่น คำว่า “AI‑Generated” หรือโลโก้ ข้อมูลนี้มักวางในตำแหน่งมุมภาพหรือเป็นแถบด้านล่าง
- ข้อดี: ชัดเจนต่อผู้ใช้ ปฏิบัติตามกฎระเบียบได้รวดเร็ว สื่อสารความโปร่งใสโดยตรง
- ข้อเสีย: รบกวนประสบการณ์ผู้ใช้ (UX) โดยเฉพาะในเนื้อหาที่ต้องการความสุนทรีย์หรือมีพื้นที่ภาพจำกัด และอาจถูกตัด/เบลอโดยผู้ไม่ประสงค์ดี
- ตัวอย่างเชิงปฏิบัติ: ในข่าวออนไลน์ ควรวาง visible tag บนหัวข้อหรือรูปประกอบบทความ ขนาดและความโปร่งใสต้องมีมาตรฐาน เช่น ความทึบไม่เกิน 30% เพื่อไม่บดบังเนื้อหา
- สถิติเชิงตัวอย่าง: ในการทดลองภายในบางองค์กร พบว่าการติด visible watermark ลดการใช้ภาพโดยไม่ได้รับอนุญาตลงประมาณ 20–40% ในระดับโซเชียลมีเดีย (ผลลัพธ์อาจแตกต่างตามบริบท)
2) Invisible robust watermark / fingerprinting (สัญลักษณ์ซ่อนที่ทนทาน)
ลักษณะ: สัญลักษณ์ที่ฝังลงในเนื้อหาเชิงสัญญาณ ไม่แสดงผลต่อผู้ใช้ทั่วไป แต่สามารถตรวจจับได้ด้วยเครื่องมือเฉพาะ เช่น เทคนิคในโดเมนความถี่ (DCT/DWT), spread‑spectrum, หรือ deep‑learning based watermarking
- ข้อดี: ไม่รบกวน UX ทนทานต่อการเปลี่ยนรูป เช่น คอมเพรสชั่น สเกล ครอป และการแปลงรูปแบบ เป็นเครื่องมือหลักสำหรับการพิสูจน์แหล่งที่มาเมื่อถูกรายงาน
- ข้อเสีย: ตรวจจับและถอดรหัสได้ยาก ต้องมีโครงสร้างพื้นฐานสำหรับการตรวจสอบ (APIs/clients/key) บางเทคนิคอาจถูกทำลายด้วยการโจมตีเชิงประดิษฐ์ (adversarial attacks)
- เทคนิคที่ใช้งานจริง: ฝังข้อมูลแบบ error‑correcting codes เพื่อให้สามารถกู้คืนข้อมูลได้แม้เนื้อหาถูกบีบอัด ใช้ hashing ร่วมกับ spread‑spectrum เพื่อเพิ่มความทนทาน
- ตัวอย่างการใช้งาน: สำหรับวิดีโอ ควรฝัง watermark ทั้งในช่องภาพ (luminance) และช่องเสียง (audio watermark) เพื่อเพิ่มความแน่นอนในการตรวจจับ
3) Embedded metadata tags (แท็กเมทาดาต้าแบบฝัง)
ลักษณะ: บันทึกข้อมูลเกี่ยวกับที่มาของโมเดล การตั้งค่า (prompt/seed/temperature) และลายนิ้วมือดิจิทัลภายในเมทาดาต้า เช่น EXIF/XMP สำหรับรูปภาพ, sidecar JSON‑LD สำหรับเว็บ, หรือ manifest ตามมาตรฐาน C2PA
- ข้อดี: ให้รายละเอียดเชิงบริบทและปริมาณสารสนเทศสูง สามารถทำเป็น machine‑readable และ signed cryptographically เพื่อยืนยันความถูกต้อง
- ข้อเสีย: เมทาดาต้าสามารถถูกลบหรือแก้ไขได้เมื่อมีการแปลงไฟล์หรือผ่าน pipeline ที่ไม่รักษา metadata ต้องมีการเซ็นลายมือดิจิทัล (digital signature) และการเก็บ hash บนระบบภายนอกเพื่อเพิ่มความน่าเชื่อถือ
- มาตรฐานที่เกี่ยวข้อง: C2PA (Coalition for Content Provenance and Authenticity), XMP/EXIF, JSON‑LD สำหรับเว็บ และการใช้ cryptographic signatures/hashes (SHA‑256) ที่เชื่อมกับ manifest
4) แนวทางการผสมผสานและการเลือกใช้ตามบริบท
การปฏิบัติตามข้อกำหนดด้านการเปิดเผยควรใช้วิธีการหลายชั้น (defense‑in‑depth) โดยผสม visible watermark กับ invisible watermark และ metadata tags เพื่อให้ได้ทั้งความโปร่งใสต่อผู้ใช้และความสามารถในการพิสูจน์ย้อนกลับ
- ข่าวออนไลน์: แนะนำให้มี visible label ที่ชัดเจนบน article header ร่วมกับ embedded metadata (signed) เพื่อให้ระบบตรวจสอบอัตโนมัติและผู้ตรวจสอบภายนอกสามารถยืนยันที่มาได้
- รูปภาพ: ใช้ visible watermark ใน thumbnail หรือภาพที่แชร์สาธารณะ พร้อมฝัง invisible watermark และ XMP metadata ที่เซ็นแล้วเพื่อเป็นหลักฐานเชิงเทคนิค
- วิดีโอ: ควรใช้ visible overlay ในช่วงเริ่มต้น/สิ้นสุดวิดีโอ (เพื่อไม่รบกวนเนื้อหาตลอดเวลา) พร้อมฝัง invisible watermark ในทั้งภาพและเสียง และมี manifest ที่เชื่อมโยงกับ hash ของไฟล์
- โฆษณา (ads): ความละเอียดต้องบาลานซ์กับ UX — แนะนำ visible cue แบบ subtle (ไอคอนหรือคำสั้น) พร้อม metadata ที่เครื่องอ่านได้โดยแพลตฟอร์มโฆษณาและหน่วยงานกำกับ
5) องค์ประกอบเชิงปฏิบัติการ: การคำนวณ hash, เซ็นชื่อ และระบบตรวจสอบ
ระบบที่ครบถ้วนควรมีขั้นตอนหลักดังนี้
- คำนวณ cryptographic hash (เช่น SHA‑256) ของไฟล์ต้นฉบับและเวอร์ชันที่เผยแพร่
- ฝังหรือเชื่อมโยง hash กับ signed manifest ที่เก็บข้อมูล provenance (ผู้สร้างโมเดล, เวอร์ชันโมเดล, prompt metadata, เวลา และลำดับการประมวลผล)
- ใส่ visible watermark ในจุดที่เป็นมาตรฐานของแพลตฟอร์ม และฝัง invisible watermark เพื่อรองรับการตรวจสอบหลังเกิดการดัดแปลง
- จัดเก็บและทำดัชนีข้อมูลการพิสูจน์ (audit logs) โดยอาจใช้ระบบ ledger แบบกระจายหรือฐานข้อมูลที่สามารถตรวจสอบย้อนหลังได้
6) ข้อควรระวังและคำแนะนำสรุป
แม้วิธีการทั้งหมดจะช่วยเพิ่มความโปร่งใสและความน่าเชื่อถือ แต่ต้องระวังด้านปฏิบัติการและกฎหมาย เช่น การคำนึงถึงสิทธิส่วนบุคคลในเมทาดาต้า การรักษาประสิทธิภาพของระบบเมื่อมีการเข้ารหัส/เซ็นชื่อ และความสามารถในการอัปเดตสัญลักษณ์เมื่อมาตรฐานเปลี่ยน
ข้อเสนอแนะเชิงปฏิบัติ:
- ออกแบบมาตรฐาน visible watermark ของแพลตฟอร์มให้เป็นกลางและทดสอบกับกลุ่มผู้ใช้เพื่อลดผลกระทบต่อ UX
- เลือกเทคนิค invisible watermark ที่ผ่านการทดสอบต่อการบีบอัดและการดัดแปลงแบบทั่วไป พร้อมมาตรการสำรองข้อมูล (redundancy & error correction)
- ใช้เมทาดาต้าแบบ signed และผสานกับมาตรฐานเปิด (เช่น C2PA) เพื่อให้การตรวจสอบเป็นไปได้ระหว่างแพลตฟอร์มและหน่วยงานกำกับ
- พัฒนา API/เครื่องมือสาธารณะสำหรับการตรวจสอบ (verification) เพื่อให้หน่วยงานกำกับและผู้ใช้สามารถตรวจสอบความถูกต้องได้ง่าย
สรุป: การติด AI‑Generated Watermark ที่มีประสิทธิผลต้องอาศัยการผสมผสานระหว่าง visibility เพื่อการสื่อสารต่อผู้ใช้, robust invisible techniques เพื่อการพิสูจน์ย้อนกลับ และ signed metadata เพื่อความสมบูรณ์ของข้อมูล provenance — โดยการเลือกโซลูชันต้องสอดคล้องกับลักษณะเนื้อหาและข้อจำกัดด้าน UX ของแต่ละบริบท
การออกแบบเมทาดาต้าและการจัดเก็บบันทึก (Provenance Metadata)
ภาพรวมและหลักการออกแบบเมทาดาต้า
การบันทึกเมทาดาต้าเชิงต้นกำเนิด (provenance metadata) สำหรับเนื้อหา AI‑generated มีความสำคัญต่อความโปร่งใส การตรวจสอบย้อนกลับ และการปฏิบัติตามกฎระเบียบที่กำหนดให้ติด AI‑Generated Watermark เมทาดาต้าควรถูกออกแบบให้เป็นทั้งเครื่องมือสำหรับการตรวจสอบทางเทคนิคและหลักฐานเชิงบริหาร โดยต้องรองรับการระบุโมเดล ผู้ให้บริการ เวลาในการสร้าง กระบวนการแปลง/แก้ไข (transformation history) และค่าความเชื่อมั่น (confidence score) อย่างเป็นระบบ

ฟิลด์สำคัญที่ควรบันทึก
อย่างน้อยระบบควรเก็บฟิลด์ต่อไปนี้เพื่อให้การตรวจสอบมีประสิทธิภาพและครบถ้วน:
- model_name — ชื่อโมเดลที่ใช้ (เช่น "gpt‑vision‑x")
- model_version — เวอร์ชันของโมเดล (เช่น "2025.11.2")
- provider — ผู้ให้บริการหรือองค์กรที่จัดหาโมเดล
- prompt_hash — แฮชของ prompt/คอนเท็กซ์ที่ใช้ในการสร้าง (ไม่เก็บข้อความดิบเพื่อปกป้องความเป็นส่วนตัว)
- generation_timestamp (หรือ timestamp) — เวลาที่เนื้อหาเกิดขึ้นในรูปแบบ ISO‑8601 (UTC)
- transformation_history — รายการของขั้นตอนหลังการสร้าง (post‑processing) เช่น การปรับแต่งภาพ การย่อ/ขยาย หรือการเรนเดอร์ใหม่ พร้อมแฮชและเวลาของแต่ละขั้นตอน
- confidence_score — คะแนนเชื่อมั่นหรือเมตริกความแน่นอนที่โมเดลรายงาน (ถ้ามี)
- artifact_id — ตัวระบุเอกสาร/ไฟล์ที่เชื่อมโยงกับเมทาดาต้านี้ (เช่น UUID หรือ path ใน object storage)
- signature — ลายเซ็นดิจิทัลหรือ HMAC ของเมทาดาต้าเพื่อยืนยันความสมบูรณ์
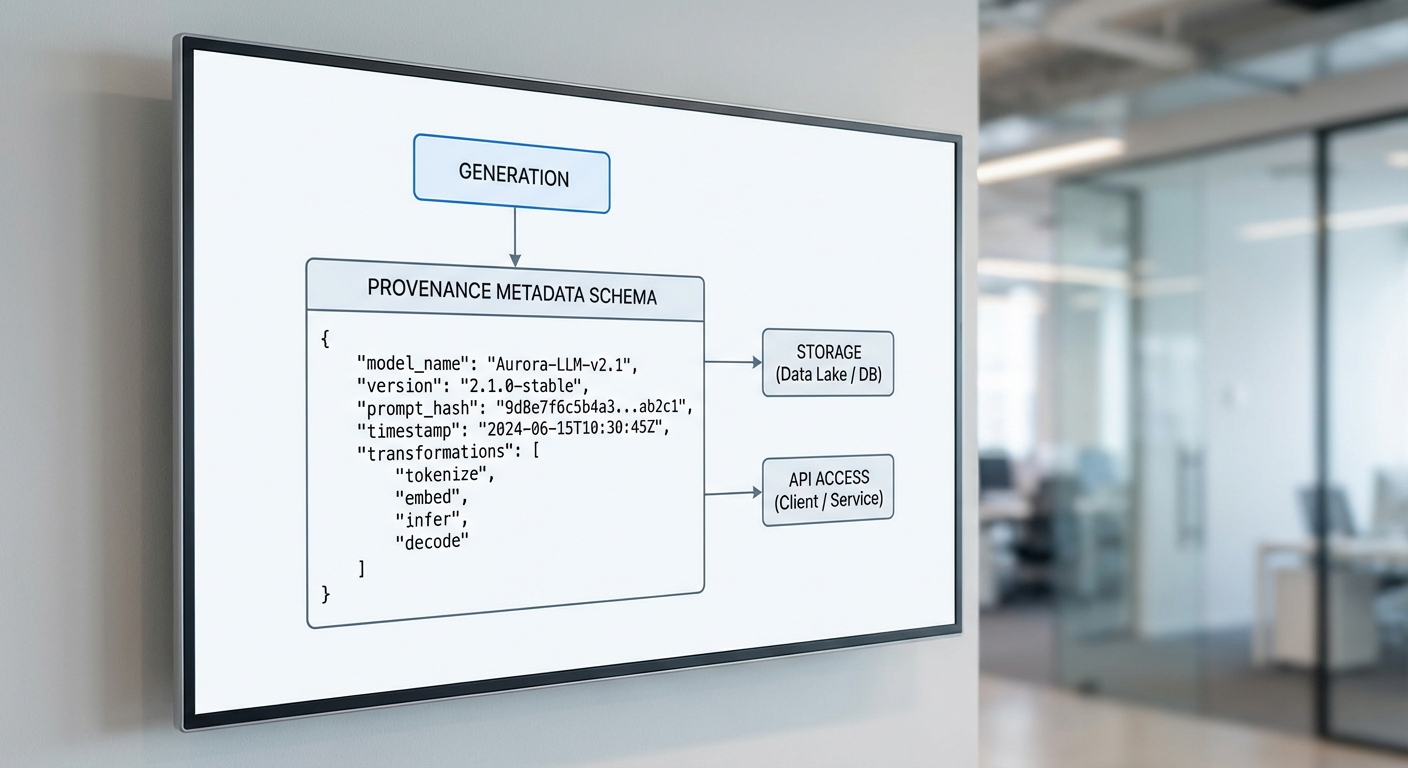
ตัวอย่าง JSON Schema ของเมทาดาต้า
ตัวอย่าง JSON ที่เป็นตัวอย่างการออกแบบเมทาดาต้า (เพื่อให้ระบบสามารถนำไปใช้จริง) — หมายเหตุ: ค่า prompt ถูกแทนที่ด้วยแฮชเพื่อคุมความเป็นส่วนตัว
{ "artifact_id": "f47ac10b-58cc-4372-a567-0e02b2c3d479", "model_name": "gpt-vision-x", "model_version": "2025.11.2", "provider": "ExampleAI Inc.", "prompt_hash": "sha256:3f786850e387550fdab836ed7e6dc881de23001b", "generation_timestamp": "2026-01-15T09:23:45Z", "transformation_history": [ { "step": "image_enhancement", "timestamp": "2026-01-15T09:24:02Z", "actor": "platform-service-1", "details": "contrast_adjustment=+10", "hash": "sha256:a1b2c3..." }, { "step": "watermark_embedding", "timestamp": "2026-01-15T09:24:10Z", "actor": "watermark-service", "details": "algorithm=v1,opacity=0.15", "hash": "sha256:d4e5f6..." } ], "confidence_score": 0.87, "signature": "edsig:Zk9s... (base64)", "metadata_version": "1.0" }
แนวทางการจัดเก็บและสถาปัตยกรรมข้อมูล
ระบบจัดเก็บเมทาดาต้าควรออกแบบให้สอดคล้องกับข้อกำหนดด้านความปลอดภัยและการตรวจสอบย้อนหลัง โดยแนวทางเชิงปฏิบัติที่แนะนำได้แก่:
- Index ในฐานข้อมูลเชิงสัมพันธ์ (RDBMS) — เก็บฟิลด์ดัชนี (artifact_id, model_name, provider, timestamp) เพื่อการค้นหาและรายงานที่รวดเร็ว
- Object storage สำหรับ JSON metadata และไฟล์ขนาดใหญ่ — เก็บ JSON เมทาดาต้าเต็มรูปแบบหรือบันทึกขั้นตอน (transformation artifacts) ใน S3‑like storage พร้อมเวอร์ชันและ ACL
- WORM / Append‑only ledger — เก็บบันทึกการเปลี่ยนแปลงเชิงล็อกในรูปแบบที่ไม่สามารถแก้ไขย้อนหลังได้ (Write Once Read Many) เพื่อการตรวจสอบทางกฎหมาย เช่นใช้ object lock ของ S3 หรือ distributed ledger สำหรับรายการสำคัญ
- Integrity checks & cryptographic signing — สร้างแฮชของเมทาดาต้าและลายเซ็นดิจิทัลเพื่อยืนยันว่าไม่ได้ถูกดัดแปลง
- สำรองข้อมูลและ retention policy — กำหนดนโยบายเก็บรักษาและลบข้อมูลที่ชัดเจนสำหรับการปฏิบัติตามข้อบังคับและคุ้มครองความเป็นส่วนตัว
มาตรการปกป้องข้อมูลส่วนบุคคลเมื่อเมทาดาต้าระบุตัวบุคคลได้
เมทาดาต้าบางรายการ เช่น prompt หรือบริบทอาจมีความเสี่ยงที่จะระบุตัวบุคคล (PII) จึงต้องนำมาตรการปกป้องมาใช้ดังนี้:
- หลักการย่อม/จำกัดข้อมูล (Data minimization) — เก็บเฉพาะฟิลด์ที่จำเป็นเท่านั้น หลีกเลี่ยงการเก็บ prompt ดิบ หากจำเป็นให้บันทึกเป็น prompt_hash พร้อม salt
- แฮชและการสุ่มเกลือ (Hash + Salt) — ใช้ SHA‑256 หรือฟังก์ชันแฮชที่มั่นคง พร้อม salt และการจัดการคีย์อย่างรัดกุม เพื่อให้ไม่สามารถย้อนกลับเป็นข้อความดิบได้
- การทำให้เป็นนามแฝง (Pseudonymization) และการทำให้ไม่ระบุตัวตน (Anonymization) — แทนข้อมูลระบุตัวบุคคลด้วยรหัสภายใน และเมื่อไม่จำเป็นให้ใช้เทคนิคการทำให้ไม่สามารถระบุตัวตนกลับได้
- การเข้ารหัสทั้งที่พักและที่ส่ง (Encryption at rest & in transit) — ใช้ TLS สำหรับการขนส่ง และ AES‑256 สำหรับข้อมูลที่เก็บ พร้อมการจัดการกุญแจที่เหมาะสม
- ควบคุมการเข้าถึง (Access control & auditing) — บังคับสิทธิ์แบบ least privilege, บันทึกการเข้าถึง และทำการตรวจสอบเป็นระยะ
- นโยบายการเก็บรักษาและการลบ — กำหนดระยะเวลาการเก็บรักษาตามข้อกฎหมาย และมีขั้นตอนการลบ/ทำลายข้อมูลเมื่อถึงเวลา
- การปฏิบัติตามกฎหมายและขอความยินยอม — ระบุฐานทางกฎหมายสำหรับการประมวลผลข้อมูลและรับความยินยอมเมื่อจำเป็น (เช่น GDPR)
ข้อแนะนำเพิ่มเติมสำหรับการนำไปปฏิบัติ
เมื่อตั้งค่าเมทาดาต้าและระบบจัดเก็บ ควรดำเนินการทดสอบความสมบูรณ์ของกระบวนการ (end‑to‑end provenance testing), การประเมินผลกระทบด้านข้อมูลส่วนบุคคล (DPIA) และเตรียมแบบแสดงเมทาดาต้าให้ผู้ใช้งานหรือหน่วยงานกำกับตรวจสอบได้เข้าถึงตามข้อกำหนด นอกจากนี้การกำหนดรูปแบบเวอร์ชันของเมทาดาต้า (metadata_version) จะช่วยให้สามารถขยายฟิลด์ในอนาคตได้โดยไม่ทำลายความเข้ากันได้ย้อนหลัง
การตรวจสอบและการรายงาน: APIs, Audit Trails และการปฏิบัติตามกฎ
การออกแบบ API สำหรับการเปิดเผยเมทาดาต้า: การค้นหาโดย ID/URL และการเข้าถึงแบบมีสิทธิ
เพื่อให้การเปิดเผยข้อมูลต่อหน่วยงานกำกับและสาธารณะมีความชัดเจนและใช้งานได้จริง แพลตฟอร์มควรจัดทำ API สาธารณะและภายใน ที่รองรับการค้นหาและดึงเมทาดาต้าตามตัวระบุหลัก เช่น content_id, source_url, footprint_hash หรือ watermark_signature โดย API ควรออกแบบให้รองรับพารามิเตอร์การค้นหาเช่น date_range, publisher_id, model_id และ confidence_score เพื่อความยืดหยุ่นในการตรวจสอบ
ข้อเสนอเชิงปฏิบัติในการออกแบบ API ได้แก่:
- รูปแบบการยืนยันตัวตนและสิทธิ (Authentication & Authorization): ใช้ OAuth2.0 / JWT พร้อม scopes เฉพาะ (เช่น metadata:read, audit:read) เพื่อจำกัดการเข้าถึงเมทาดาต้าแบบละเอียด
- รูปแบบการตอบกลับที่มาตรฐาน: JSON Schema ที่ประกอบด้วยฟิลด์สำคัญ เช่น model_name, model_version, prompt_hash/summary, generation_timestamp, publisher_id, watermark_signature, provenance_chain และ content_hash
- การค้นหาโดย URL/ID: endpoints เช่น /api/v1/metadata?content_id={id} และ /api/v1/metadata?source_url={url} พร้อมการรองรับการค้นหาแบบ partial match และ pagination
- การบันทึกการเข้าถึง: ทุกคำขอควรถูกบันทึกใน audit log (รวมถึงผู้ขอ, scope, timestamp, IP) เพื่อให้สามารถตรวจสอบการเข้าถึงเมทาดาต้าได้
- มาตรการป้องกันข้อมูลสำคัญ: ฟิลด์ที่อาจมีข้อมูลส่วนบุคคลหรือความลับทางการค้าควรถูก redacted หรือส่งในรูปแบบเข้ารหัสเมื่อผู้ขอไม่มีสิทธิเต็ม
Audit Trails ที่ไม่สามารถแก้ไขได้ (Immutable Logs) เพื่อรองรับการตรวจสอบ
เพื่อให้การตรวจสอบมีความน่าเชื่อถือ แพลตฟอร์มจำเป็นต้องจัดเก็บ audit trail ที่ ไม่สามารถแก้ไขย้อนหลังได้ โดยใช้เทคนิคเช่น write-once media (WORM), hash chaining หรือ Merkle tree และการลงลายมือชื่อดิจิทัลบนแต่ละบันทึก การผนวกการลงทะเบียนเวลา (timestamping) กับผู้ให้บริการเวลาที่เชื่อถือได้ (trusted timestamp authority) จะช่วยยืนยันความสมบูรณ์ของบันทึก
องค์ประกอบสำคัญของระบบ audit trail ได้แก่:
- บันทึกแบบ append-only: ไม่อนุญาตให้แก้ไขหรือลบรายการ บันทึกการเปลี่ยนแปลงสถานะของเนื้อหา (เช่น สร้าง แก้ไข ตรึง/ยกเลิกการเผยแพร่ ตัดสินใจตรวจสอบ)
- เชื่อมโยงกับ metadata และไฟล์เนื้อหา: แต่ละรายการควรมี content_hash และ pointer ไปยัง metadata เพื่อให้สามารถยืนยันความสอดคล้องระหว่างข้อมูล
- การตรวจสอบโดยบุคคลที่สาม: ควรเปิดให้มีการตรวจสอบแบบ third‑party attestation หรือการ audit โดยหน่วยงานอิสระเพื่อลดความขัดแย้งทางผลประโยชน์
- ความสามารถในการสืบย้อน (forensic traceability): ระบบต้องรองรับการสืบย้อนตั้งแต่การเรียกใช้งานโมเดล, เวอร์ชันของโมเดล, input prompts, ระยะเวลาที่สร้าง ไปจนถึงการเผยแพร่และการทำ watermark
Retention Policy, การปฏิบัติตามกฎ และแนวทางรายงาน
การกำหนดนโยบายเก็บรักษาข้อมูล (retention policy) ต้องสอดคล้องกับกฎหมายคุ้มครองข้อมูลและความต้องการด้านการตรวจสอบ แนะนำแนวปฏิบัติดังนี้: เก็บเมทาดาต้าเชิงเทคนิคและ audit logs อย่างน้อย 3–7 ปี ขึ้นกับข้อกำหนดของหน่วยงานกำกับและความเสี่ยงของเนื้อหา โดยแยก retention สำหรับประเภทข้อมูล เช่น metadata (longer retention), raw prompts/inputs (ขอแนะนำเก็บในช่วงสั้นกว่าและเข้ารหัส) และเนื้อหาที่มี PII (ตามกฎหมายความเป็นส่วนตัว)
หลักการดำเนินการจัดการ retention ควรรวมถึง:
- นโยบายขั้นต่ำและการขยาย: ระบุ retention minimum, default, และขั้นตอนขอขยายระยะเวลาสำหรับคดีที่เกี่ยวข้องกับการสอบสวน
- กระบวนการลบ/ทำลายที่ตรวจสอบได้: เมื่อครบกำหนดต้องมีการดำเนินการลบที่สามารถยืนยันได้ (secure deletion) และบันทึกพยานหลักฐานการลบ
- การควบคุมการเข้าถึงเชิงบทบาท: จำกัดการเข้าถึงข้อมูลที่เก็บไว้ให้ผู้มีสิทธิเท่านั้น และบันทึกการเข้าถึงทั้งหมด
กรอบการบังคับใช้ การรายงานตามรอบเวลา และการตอบสนองต่อการร้องเรียน
เพื่อให้แนวทางกำกับดูแลมีผลบังคับจริง ควรกำหนดกรอบการรายงานและการตอบสนองที่ชัดเจน เช่น:
- Reporting cadence: รายงานสรุปรายงานความโปร่งใส (transparency report) แบบรายไตรมาสที่รวมสถิติการใช้โมเดล, จำนวนเนื้อหาที่ติด watermark, จำนวนคำขอข้อมูลจากหน่วยงานกำกับ และตัวชี้วัดการปฏิบัติตาม (compliance KPIs). รายงานประจำปีควรรวมการรับรองการตรวจสอบจากบุคคลที่สาม
- Service level for complaints: กำหนด SLA ในการตอบรับเรื่องร้องเรียน — ยืนยันการรับเรื่องภายใน 48 ชั่วโมง, การตรวจสอบเบื้องต้นภายใน 7 วัน, และรายงานผลการสอบสวนภายใน 30 วัน (สามารถขยายได้ตามเหตุผล) พร้อมช่องทางอุทธรณ์
- Workflow การจัดการข้อร้องเรียน: ขั้นตอนชัดเจนคือ Intake → Triage (ความร้ายแรงและลักษณะการละเมิด) → Investigation (ดึง metadata & audit trail แบบ immutable) → Remediation (เช่น แก้ไข watermark, ถอดเนื้อหา, คำชี้แจง) → Notification (แจ้งผู้ร้องและหน่วยงาน) → Post‑incident review
มาตรการบังคับใช้และบทลงโทษควรมีลำดับความรุนแรงและความโปร่งใส เช่น การเตือนเป็นลายลักษณ์อักษร, คำสั่งแก้ไขภายในระยะเวลาที่กำหนด, ค่าปรับตามความรุนแรงและความถี่ของการละเมิด, การสั่งพักการให้บริการบางรายการ หรือการเปิดเผยสาธารณะถึงการละเมิดในกรณีร้ายแรง โดยควรกำหนดเกณฑ์ที่ชัดเจน เช่น การไม่เปิดเผยโมเดลที่ใช้หรือการปลอมแปลงเมทาดาต้าเป็นการกระทำที่มีความร้ายแรงสูงและจะถูกลงโทษอย่างเข้มงวด
สรุป: การตรวจสอบและการรายงานที่มีประสิทธิภาพต้องอาศัยการออกแบบ API ที่ปลอดภัยและยืดหยุ่น, ระบบ audit trail ที่ immutable, นโยบาย retention ที่ชัดเจน และกรอบการบังคับใช้ที่โปร่งใสและเป็นสัดเป็นส่วน ซึ่งจะช่วยให้หน่วยงานกำกับสามารถตรวจสอบการปฏิบัติตามข้อกำหนดได้อย่างเชื่อถือและประชาชนได้รับความเชื่อมั่นว่าข่าวและโฆษณาที่ระบุว่าเป็น AI‑generated มีแหล่งที่มาที่ชัดเจนและตรวจสอบได้
เช็คลิสต์ปฏิบัติการสำหรับแพลตฟอร์มและตัวอย่างนโยบายที่ใช้ได้จริง
เช็คลิสต์ปฏิบัติการสำหรับแพลตฟอร์มและตัวอย่างนโยบายที่ใช้ได้จริง
เอกสารนี้นำเสนอเช็คลิสต์เชิงปฏิบัติการสำหรับการปฏิบัติตามคำสั่งบังคับติด AI‑Generated Watermark ในข่าวและโฆษณาออนไลน์ โดยแบ่งเป็นขั้นตอนสำหรับ ทีมเทคนิค, ทีมกฎหมาย และ ทีมคอนเทนต์ รวมทั้งตัวอย่างข้อความประกาศแก่ผู้ใช้, ข้อความชี้แจงในหน้าโฆษณา, แม่แบบนโยบายภายใน และแผนทดสอบพร้อมเกณฑ์การยอมรับ (acceptance criteria) เพื่อให้สามารถนำไปปรับใช้ได้ทันที
1. เช็คลิสต์ขั้นตอนสำหรับทีมเทคนิค
- ตรวจจับคอนเทนต์ที่สร้างด้วย AI:
- กำหนดจุดตัดสินใจ (trigger points) — เช่น การอัปโหลดไฟล์ สตรีมโฆษณา หรือการเผยแพร่บทความ
- ติดตั้งระบบตรวจจับเบื้องต้น (heuristic markers) และ/หรือใช้โมเดลตรวจจับการสร้างคอนเทนต์ด้วย AI
- ระบุความเชื่อมั่น (confidence score) และเกณฑ์ความแน่นอน เช่น threshold ≥ 0.75 เพื่อพิจารณาว่าเป็น AI‑generated
- ติดป้าย (watermark) อัตโนมัติ:
ออกแบบ watermark แบบมองเห็นได้และ/หรือไม่มองเห็น (visible/invisible) ตามประเภทสื่อ — รูปภาพ, วิดีโอ, ข้อความ - กำหนดตำแหน่ง ขนาด และความโปร่งใสของ watermark ให้ไม่บดบังเนื้อหาแต่ชัดเจนเพียงพอ
- ผสานการติดป้ายกับ pipeline การเรนเดอร์ (rendering pipeline) เพื่อให้ทำงานแบบ synchronous/async ตามสเปค
- กำหนดชุดเมทาดาต้าขั้นต่ำ: model_name, model_version, prompt_snippet (ถ้าอนุญาต), generation_time, confidence_score, watermark_type, detected_by (auto/manual)
- บันทึกลงฐานข้อมูลที่เชื่อถือได้และ immutable logs (เช่น append-only store หรือ WORM storage)
- จัดเก็บ metadata ทั้งในไฟล์สื่อ (เมื่อเป็นไปได้ เช่น EXIF/XMP) และในฐานข้อมูลศูนย์กลาง
- ออกแบบ API สาธารณะ/สำหรับพาร์ตเนอร์: GET /content/{id}/ai-origin ให้คืนค่า metadata ที่เกี่ยวข้อง
- กำหนดนโยบายการเข้าถึง (RBAC) — ข้อมูลบางชนิดอาจถูกจำกัด (prompt_full) เพื่อคุ้มครองความเป็นส่วนตัวและทรัพย์สินทางปัญญา
- ให้ log audit เมื่อมีการเรียก API เพื่อวัตถุประสงค์ด้านตรวจสอบ
- เก็บ logs การตรวจจับ การติดป้าย และการเปลี่ยนแปลง metadata อย่างน้อย 2 ปี (หรือเป็นไปตามข้อกำหนดทางกฎหมายในเขตอำนาจ)
- สำรองข้อมูล (backup) และเข้ารหัส log ขณะพักและขณะส่ง
- ติดตั้งระบบแจ้งเตือนเมื่อมีการลบ/แก้ไข metadata ที่ผิดปกติ
2. เช็คลิสต์สำหรับทีมกฎหมาย
- ประเมินข้อกำหนดทางกฎหมายและการกำกับดูแล:
- อัปเดตนโยบายความเป็นส่วนตัวและข้อกำหนดการให้บริการให้สอดคล้องกับคำสั่งบังคับ
- ระบุข้อจำกัดในการเปิดเผยข้อมูล (เช่น ข้อมูลเชิงพาณิชย์หรือ prompt ที่เป็นความลับ)
- ร่างข้อความแจ้งสิทธิของผู้ใช้และการยินยอม:
- จัดทำแบบฟอร์มยินยอมเฉพาะเมื่อจำเป็น (consent) สำหรับการใช้ข้อมูลผู้ใช้ในการฝึกโมเดลหรือเผยแพร่เมทาดาต้า
- เตรียมแม่แบบนโยบายภายในและการฝึกอบรม:
- สร้างนโยบายการจัดการ AI‑generated content, การเก็บ logs, และแนวทางการเปิดเผยข้อมูล
- จัดการฝึกอบรมด้านความเสี่ยงและการปฏิบัติตามกฎระเบียบให้ทีมคอนเทนต์และทีมสนับสนุน
3. เช็คลิสต์สำหรับทีมคอนเทนต์
- ขั้นตอนสร้าง/ตรวจสอบคอนเทนต์:
- กำหนดกระบวนการให้ชัดเจนเมื่อใช้เครื่องมือ AI — ผู้สร้างต้องระบุแหล่งที่มาและรันการตรวจจับก่อนเผยแพร่
- ใช้แท็ก/metadata ภายในระบบ CMS เพื่อระบุสถานะ (AI‑generated / AI‑assisted / Human‑created)
- ข้อความประกาศต่อผู้อ่านและผู้โฆษณา:
- แสดงข้อความชี้แจงชัดเจนบนหน้าเนื้อหาและหน้าการตั้งค่าโฆษณา (ตัวอย่างข้อความด้านล่าง)
- การจัดการข้อร้องเรียนและการตรวจสอบ:
- กำหนดช่องทางสำหรับผู้ใช้แจ้งข้อสงสัยเกี่ยวกับการติดป้ายหรือความถูกต้องของการเปิดเผย
- มีกระบวนการตรวจสอบภายในกรณีข้อพิพาท พร้อมบันทึกการตัดสินใจ
4. ตัวอย่างข้อความประกาศแก่ผู้ใช้และคำชี้แจงในหน้าโฆษณา
ตัวอย่างข้อความประกาศแก่ผู้ใช้ (เว็บไซต์ / แอป):
ประกาศ: "เนื้อหาบางส่วนบนแพลตฟอร์มนี้ถูกสร้างหรือปรับปรุงด้วยเทคโนโลยีปัญญาประดิษฐ์ (AI). เพื่อความโปร่งใส เราได้ติดป้ายและบันทึกข้อมูลแหล่งที่มาของโมเดล รวมถึงเวอร์ชันและวันเวลา หากต้องการข้อมูลเพิ่มเติมเกี่ยวกับแหล่งที่มาของคอนเทนต์ กรุณาตรวจที่ลิงก์ 'ข้อมูล AI‑Origin' ในแต่ละบทความหรือโฆษณา."
ตัวอย่างข้อความชี้แจงบนหน้าโฆษณา:
คำชี้แจงโฆษณา: "โฆษณานี้มีคอนเทนต์ที่สร้างด้วย AI และติดป้ายตามข้อกำกับดูแล: Model: {model_name} v{model_version}; Generated: {generation_time}; สำหรับรายละเอียดเพิ่มเติม คลิก 'ข้อมูลที่มา'."
5. แม่แบบนโยบายภายใน (Policy Templates)
นโยบายการติดป้ายและบันทึกเมทาดาต้า — Template (ฉบับย่อ)
- วัตถุประสงค์: เพื่อกำหนดแนวปฏิบัติในการตรวจจับ ติดป้าย และบันทึกเมทาดาต้าของคอนเทนต์ที่สร้างด้วย AI
- ขอบเขต: ครอบคลุมคอนเทนต์บนเว็บไซต์ แอป และโฆษณาที่จัดการโดยบริษัท
- ข้อกำหนดปฏิบัติตาม:
- ทุกคอนเทนต์ที่ผ่านการตรวจสอบแล้วว่ามีความเป็นไปได้สูงที่จะเป็น AI‑generated ต้องติด Watermark และมี metadata อย่างน้อย: model_name, model_version, generation_time, watermark_type
- เก็บ logs การตรวจจับและการติดป้ายอย่างน้อย 24 เดือน
- เปิด API สำหรับการเรียกดู metadata ที่อนุญาต โดยมีการควบคุมการเข้าถึง
- บทลงโทษและการรายงาน: กำหนดโทษและขั้นตอนการรายงานเมื่อไม่ปฏิบัติตามนโยบาย
นโยบายการเปิดเผยข้อมูลต่อสาธารณะ — Template (ฉบับย่อ)
- แพลตฟอร์มจะแจ้งให้ผู้ใช้ทราบเมื่อคอนเทนต์ถูกสร้างหรือปรับปรุงด้วย AI และจัดให้มีลิงก์ไปยัง metadata ที่เกี่ยวข้อง
- ข้อมูลที่เปิดเผยต้องไม่ล่วงละเมิดความลับการค้า หรือข้อมูลส่วนบุคคลที่ไม่ได้รับอนุญาต
- กำหนดรูปแบบการแสดงผล (banner, tooltip, metadata panel) และข้อความมาตรฐานที่ใช้ในทุกหน้าที่เกี่ยวข้อง
6. แผนทดสอบ (Test Plan), ตัวอย่าง Test Cases และเกณฑ์การยอมรับ
แผนทดสอบ (สรุป): ทดสอบระบบตรวจจับ, การติดป้าย, การเก็บ metadata, การเปิดเผยผ่าน UI และ API, รวมถึงการเก็บรักษา logs และการกู้คืนจาก backup
- Test Case 1 — การตรวจจับคอนเทนต์ AI:
- ขั้นตอน: อัปโหลดรูปภาพ/บทความที่สร้างจากโมเดล X
- คาดหวัง: ระบบต้องระบุเป็น AI‑generated พร้อม confidence ≥ threshold
- Acceptance Criteria: Detection accuracy ≥ 95% บนชุดทดสอบภายใน (precision ≥ 0.95 และ recall ≥ 0.90)
- Test Case 2 — การติด watermark:
- ขั้นตอน: เผยแพร่คอนเทนต์ที่ตรวจพบเป็น AI‑generated
- คาดหวัง: Watermark ปรากฏในตำแหน่งและรูปแบบที่กำหนด ทั้งในหน้าเว็บและไฟล์ดาวน์โหลด
- Acceptance Criteria: Watermark ตรวจพบได้ใน 100% ของตัวอย่างที่เกี่ยวข้อง และไม่ทำให้เนื้อหาเสียรูปแบบการแสดงผล
- Test Case 3 — การบันทึก metadata และ API:
- ขั้นตอน: ตรวจสอบฐานข้อมูลและเรียก API GET /content/{id}/ai-origin
- คาดหวัง: Metadata ถูกบันทึกครบถ้วนและ API ส่งคืนข้อมูลตามสิทธิ์
- Acceptance Criteria: Metadata field ครบตามสเปคใน 100% ของเคส และเวลาตอบ API ≤ 300 ms ภายใต้โหลดมาตรฐาน
- Test Case 4 — Logging & Retention:
- ขั้นตอน: ดูประวัติการตรวจจับ/แก้ไขคอนเทนต์ใน logs
- คาดหวัง: แนวทางการเก็บรักษาตามนโยบายและสามารถกู้คืน log ได้
- Acceptance Criteria: Logs เก็บครบ 24 เดือน, สำรองข้อมูลและทดสอบการกู้คืนสำเร็จ ≥ 99% ของข้อมูลตัวอย่าง
- Test Case 5 — UX Messaging:
- ขั้นตอน: ผู้ใช้เข้าดูบทความ/โฆษณาที่ติดป้าย
- คาดหวัง: ข้อความประกาศและลิงก์ข้อมูลที่มาแสดงอย่างชัดเจน
- Acceptance Criteria: ผู้ทดสอบ 20 ราย สามารถระบุได้ว่าเนื้อหาเป็น AI‑generated โดยอ่านข้อความประกาศ ≥ 90%
7. ข้อแนะนำเชิงปฏิบัติและการเตรียมการเพิ่มเติม
แนะนำให้จัดทำเอกสาร SOP รายละเอียดของแต่ละขั้นตอน (playbook) และไฟล์ตัวอย่าง metadata สำหรับทีมพัฒนา รวมถึงระบบมอนิเตอร์ที่ติดตามอัตราการตรวจจับ false positive/false negative และ dashboard รายงานสำหรับทีมกฎหมายและผู้บริหาร
นอกจากนี้ ควรมีการทบทวนกระบวนการอย่างน้อยทุก 6 เดือนเพื่อตรวจสอบความสอดคล้องกับกฎหมายใหม่และการอัปเดตโมเดล AI ที่ใช้บนแพลตฟอร์ม
บทสรุป
หน่วยงานกำกับได้สั่งบังคับให้ติด AI‑Generated Watermark และเก็บเมทาดาต้าในข่าวและโฆษณาออนไลน์เป็นมาตรการเชิงบังคับเพื่อเพิ่มความโปร่งใสและป้องกันการหลอกลวง (เช่น deepfakes หรือการอ้างผลงานเท็จ) โดยข้อกำหนดดังกล่าวรวมถึงการเปิดเผยที่มาโมเดล การบันทึกพารามิเตอร์สำคัญ และการเก็บ audit logs ที่สามารถตรวจสอบย้อนหลังได้ ข้อมูลเชิงสำรวจในช่วงปี 2023–2024 ชี้ให้เห็นว่าผู้ใช้มากกว่าร้อยละ 60 ต้องการการเปิดเผยว่าเนื้อหาใดถูกสร้างหรือปรับปรุงด้วย AI ซึ่งสะท้อนความจำเป็นของมาตรการเหล่านี้ แต่การนำมาบังคับใช้ต้องสมดุลกับข้อกังวลเรื่องความเป็นส่วนตัว กฎระเบียบในการคุ้มครองข้อมูล และประสบการณ์ผู้ใช้ (เช่น ความหน่วงโหลด ความสอดคล้องของการแสดงผล และปัญหา false positives/negatives)
แพลตฟอร์มที่ต้องปฏิบัติตามคำสั่งควรเตรียมทั้งมาตรการเชิงเทคนิคและเชิงบูรณาการอย่างครบถ้วนในเชิงปฏิบัติ: ทางเทคนิคต้องรวมถึงการฝัง watermark ที่ทนทานต่อการแปลงไฟล์ การออกแบบ metadata schema มาตรฐาน (เช่น ฟิลด์สำหรับชื่อโมเดล เวอร์ชัน ค่า confidence และแหล่งที่มา) และระบบ audit logs พร้อมนโยบายการเก็บรักษา (ตัวอย่าง: ระยะเวลาบันทึกที่สมเหตุสมผล เช่น 90–180 วัน ขึ้นกับข้อกำหนดทางกฎหมาย) ฝั่งบูรณาการควรรวมการปรับนโยบายภายใน การเปิด API สำหรับรายงานและการตรวจสอบ การฝึกอบรมทีมบรรณาธิการและฝ่ายเทคนิค รวมถึงการจัดกระบวนการตอบคำถามทางกฎหมายและการร้องเรียนของผู้ใช้เพื่อให้การปฏิบัติตามมีประสิทธิผลและยั่งยืน
มุมมองอนาคตชี้ให้เห็นว่าการบังคับนี้จะเร่งการพัฒนามาตรฐานเมทาดาต้าระดับสากล เครื่องมือตรวจสอบแบบอัตโนมัติ และทางเลือกที่คำนึงถึงความเป็นส่วนตัว เช่น การใช้ลายเซ็นเชิงคริปโตเพื่อตรวจสอบความถูกต้องโดยไม่เปิดเผยข้อมูลส่วนบุคคลมากเกินไป แพลตฟอร์มที่ลงทุนในโครงสร้างพื้นฐานที่ยืดหยุ่น ร่วมมือกับอุตสาหกรรมและหน่วยงานกำกับ และทดสอบผลกระทบต่อ UX อย่างต่อเนื่องผ่าน A/B testing จะสามารถรักษาความน่าเชื่อถือ ลดความเสี่ยงทางกฎหมาย และยังคงมอบประสบการณ์ผู้ใช้ที่ราบรื่นได้ในระยะยาว



