
เครือข่ายโรงพยาบาลไทยร่วมกันเปิดตัวโครงการนำร่องด้านปัญญาประดิษฐ์ที่น่าจับตามอง โดยใช้แนวทาง Federated Knowledge Distillation ในการฝึกโมเดลวินิจฉัยภาพรังสีร่วมกันโดยไม่ต้องแลกเปลี่ยนข้อมูลผู้ป่วยระหว่างสถาบัน ผลการทดลองเบื้องต้นชี้ให้เห็นการลดการใช้ข้อมูลจริงได้มากถึง 90% ขณะที่ยังคงรักษาและในบางกรณีเพิ่มความแม่นยำในการอ่านภาพรังสี ทำให้เป็นตัวอย่างเชิงปฏิบัติที่ตอบโจทย์ทั้งด้านความเป็นส่วนตัว ความปลอดภัย และประสิทธิภาพของโมเดลทางการแพทย์
บทความนี้จะสรุปประเด็นสำคัญจากโครงการนำร่อง ได้แก่ หลักการทำงานของ Federated Knowledge Distillation ผลการทดสอบเชิงสถิติ ตัวอย่างกรณีศึกษาในเครือข่ายโรงพยาบาลไทย และขั้นตอนปฏิบัติสำหรับสถาบันที่ต้องการนำไปใช้จริง—ตั้งแต่การเตรียมข้อมูลและสถาปัตยกรรมโมเดล ไปจนถึงมาตรการด้านความเป็นส่วนตัวและการประเมินความเสี่ยง เพื่อให้ผู้อ่านเห็นภาพชัดเจนว่าการร่วมมือแบบไม่แลกเปลี่ยนข้อมูลสามารถยกระดับการวินิจฉัยรังสีในบริบทการแพทย์ไทยได้อย่างไร
บทนำ: ข่าวสรุปและความสำคัญ
บทนำ: ข่าวสรุปและความสำคัญ
เครือข่ายโรงพยาบาลไทยประสบความสำเร็จในการทดลองนำเทคนิค Federated Knowledge Distillation (FKD) มาใช้ฝึกสอนโมเดลปัญญาประดิษฐ์สำหรับการวินิจฉัยภาพรังสีร่วมกันโดยไม่ต้องแลกเปลี่ยนข้อมูลผู้ป่วยดิบ ผลการทดลองนำร่องที่รายงานเมื่อเร็ว ๆ นี้ระบุชัดเจนว่า โครงการสามารถลดการใช้ข้อมูลผู้ป่วยจริงลงได้มากถึง 90% ขณะเดียวกันยังช่วยเพิ่มความแม่นยำในการวินิจฉัยภาพรังสีเมื่อเทียบกับแนวทางเดิมที่ใช้เพียงการฝึกในหน่วยงานเดียวหรือการแลกเปลี่ยนข้อมูลภาพดิบแบบรวมศูนย์

โดยสรุปโครงการนำร่องครั้งนี้เป็นความร่วมมือระหว่างโรงพยาบาลในเครือข่ายจำนวน 12 แห่ง ครอบคลุมทั้งโรงพยาบาลขนาดใหญ่ในเขตเมืองและหน่วยบริการในพื้นที่ชนบท ระยะเวลาดำเนินโครงการประมาณ 9 เดือน โดยมีวัตถุประสงค์หลักคือทดสอบความเป็นไปได้ของการใช้ FKD เพื่อ:
- ฝึกโมเดลร่วมกันโดยไม่ต้องแลกเปลี่ยนข้อมูลผู้ป่วยดิบ ลดความเสี่ยงด้านความเป็นส่วนตัวและปัญหาด้านกฎระเบียบ
- ลดการพึ่งพาข้อมูลจริงจำนวนมาก โดยใช้ตัวแทนความรู้ (distilled knowledge) ที่มีขนาดเล็กและไม่สามารถย้อนกลับไปเป็นภาพผู้ป่วยต้นทาง
- ยกระดับประสิทธิภาพการวินิจฉัยภาพรังสี ให้สอดคล้องกับเงื่อนไขในบริบทการรักษาของไทย
ผลสำคัญที่ทีมวิจัยเน้นย้ำ ได้แก่การลดการใช้ข้อมูลจริงลงถึง 90% ซึ่งลดภาระด้านการจัดเก็บ การแลกเปลี่ยนข้อมูล และประเด็นทางกฎหมายที่เกี่ยวข้องกับ HIPAA-คล้ายหรือ PDPA ในบริบทไทย พร้อมกันนี้ยังระบุว่ามีการเพิ่มความแม่นยำในการวินิจฉัยภาพรังสีอย่างมีนัยสำคัญ (ตัวอย่างจากชุดทดสอบร่วมระหว่างโรงพยาบาลพบการปรับปรุงความแม่นยำราว 3–5% ในค่าเฉลี่ยเมื่อเทียบกับโมเดลที่ฝึกแยกกัน) ซึ่งบ่งชี้ว่า FKD ช่วยให้โมเดลเรียนรู้ความหลากหลายของข้อมูลเชิงลักษณะได้ดีขึ้นโดยไม่ต้องเปิดเผยข้อมูลผู้ป่วยดิบ
ความหมายเชิงนโยบายและการประยุกต์ใช้จริงมีความสำคัญต่อระบบสาธารณสุขไทยเป็นอย่างยิ่ง: วิธีการเช่น FKD สามารถเป็นทางเลือกที่เข้มแข็งสำหรับการขยายใช้ AI ทางการแพทย์ในระดับชาติ ช่วยเร่งการนำเทคโนโลยีไปใช้ในโรงพยาบาลชุมชนและหน่วยบริการในพื้นที่ห่างไกลโดยไม่กระทบต่อความเป็นส่วนตัวของผู้ป่วย นอกจากนี้ยังลดต้นทุนด้านการเก็บและแลกเปลี่ยนข้อมูล ทำให้หน่วยงานภาครัฐสามารถออกแบบกรอบกำกับดูแลและมาตรฐานการรับรองโมเดลได้ง่ายขึ้น โดยไม่จำเป็นต้องผ่อนปรนข้อกำหนดด้านการคุ้มครองข้อมูลส่วนบุคคล
พื้นฐานเชิงเทคนิค: Federated Learning, Knowledge Distillation และ FKD คืออะไร
พื้นฐานของ Federated Learning (FL)
Federated Learning เป็นกรอบการเรียนรู้แบบกระจายที่ออกแบบมาเพื่อลดการเคลื่อนย้ายข้อมูลดิบระหว่างสถานที่ต่าง ๆ หลักการสำคัญคือการให้แต่ละไซต์ (เช่น โรงพยาบาลแต่ละแห่ง) ฝึกโมเดลบนข้อมูลผู้ป่วยภายในของตนเอง จากนั้นส่งเฉพาะพารามิเตอร์ของโมเดลหรือ gradient กลับไปยังศูนย์กลางเพื่อทำการรวม (aggregation) เป็นโมเดลร่วมโดยรวม โดยไม่ได้ส่งภาพผู้ป่วยหรือข้อมูลดิบข้ามไซต์ ทำให้มีความเป็นส่วนตัวเพิ่มขึ้นและสอดคล้องกับข้อกำหนดด้านกฎหมายที่เข้มงวด
- ข้อดี: เพิ่มความเป็นส่วนตัวโดยไม่แชร์ข้อมูลดิบ, ลดความเสี่ยงจากการละเมิดข้อมูล, สามารถใช้ทรัพยากรประมวลผลท้องถิ่นได้, เหมาะกับข้อมูลขนาดใหญ่เช่นภาพรังสีที่ย้ายข้ามเครือข่ายได้ยาก
- ข้อจำกัด: การสื่อสารพารามิเตอร์หลายรอบทำให้เกิดภาระแบนด์วิดท์, ปัญหา non-IID (ข้อมูลกระจายไม่สม่ำเสมอระหว่างไซต์) ทำให้การรวมอาจไม่ง่าย, เสี่ยงต่อการโจมตีเช่น poisoning หรือ model inversion หากไม่มีการป้องกันเพิ่มเติม
- ตัวอย่างเชิงตัวเลข: ในงานวิจัยและการใช้งานจริง หลายโครงการสามารถลดการส่งข้อมูลดิบข้ามไซต์ลงอย่างมาก แต่ยังต้องแลกมาด้วยการสื่อสารพารามิเตอร์หลายรอบและการจัดการความคลาดเคลื่อนของข้อมูล
พื้นฐานของ Knowledge Distillation (KD)
Knowledge Distillation เป็นเทคนิคการถ่ายโอนความรู้จากโมเดลหนึ่งไปยังอีกโมเดลหนึ่งในรูปแบบของ teacher–student paradigm โดยโมเดล teacher (มักมีขนาดใหญ่หรือเป็น ensemble) จะให้ "soft labels" แก่ student แทนการใช้ป้ายกำกับแข็ง (hard labels) ซึ่ง soft labels คือเวกเตอร์ความน่าจะเป็นที่ได้จาก logits ก่อนผ่าน softmax และมักปรับด้วยพารามิเตอร์ temperature เพื่อเผยความสัมพันธ์ระหว่างคลาสต่าง ๆ มากขึ้น การฝึกด้วย soft labels ช่วยให้ student เรียนรู้ "ความรู้เชิงนามธรรม" (dark knowledge) เช่น ความสัมพันธ์ระหว่างคลาสที่ไม่ปรากฏชัดจาก hard label เพียงอย่างเดียว
- ข้อดี: สามารถบีบอัด/ย่อขนาดโมเดล (model compression) และยังรักษาหรือใกล้เคียงความแม่นยำของ teacher, สามารถถ่ายโอนความรู้ข้ามสถาปัตยกรรมโมเดลได้, ใช้ข้อมูลที่ไม่มีป้ายกำกับร่วมกับ soft labels เพื่อฝึก student
- ข้อจำกัด: ประสิทธิภาพขึ้นกับคุณภาพของ teacher, การสูญเสียรายละเอียดภายใน (เช่น representation ภายในเลเยอร์) อาจเกิดขึ้น, ต้องตั้งค่า temperature และ loss balancing ให้เหมาะสม
- ตัวอย่างเชิงตัวเลข: ในหลายงานวิจัย KD ทำให้โมเดลขนาดเล็กรักษาความแม่นยำได้ใกล้เคียงกับโมเดลขนาดใหญ่ในขณะที่ลดขนาดโมเดลได้เป็นหลักสิบเท่า (เช่น ลดขนาด 5–10x ขึ้นอยู่กับกรณี)
Federated Knowledge Distillation (FKD): ผสาน FL และ KD เพื่อแลกเปลี่ยนความรู้แทนข้อมูล
Federated Knowledge Distillation ผสานข้อดีของ FL และ KD โดยเปลี่ยนการแลกเปลี่ยนจากการส่งข้อมูลดิบหรือพารามิเตอร์ขนาดใหญ่ มาเป็นการส่ง logits หรือโมเมนต์ของความรู้ที่กะทัดรัดระหว่างไซต์ วิธีการมาตรฐานคือแต่ละไซต์ใช้ข้อมูลท้องถิ่นหรือชุดข้อมูลสาธารณะ (ที่อาจไม่มีป้ายกำกับ) เพื่อคำนวณ logits จากโมเดล teacher ของตน แล้วส่ง logits เหล่านั้นหรือ summary ของ logits ไปยังศูนย์กลางหรือเพื่อนไซต์เพื่อรวมเป็น target soft labels สำหรับฝึก student ร่วมกัน
- แนวทางปฏิบัติที่พบบ่อย: (1) ใช้ชุดข้อมูลไม่ติดป้ายกลาง (public/unlabeled) ที่ทุกไซต์เข้าถึงได้ ให้ไซต์แต่ละแห่งคำนวณ logits แล้วส่งกลับมารวมเป็น ensemble soft label เพื่อ distill student; (2) ส่ง logits เฉพาะบนตัวอย่างจำเพาะแทนภาพดิบ เพื่อลดภาระแบนด์วิดท์
- ข้อดีของ FKD: ลดการใช้ข้อมูลจริงที่ต้องแลกเปลี่ยนข้ามไซต์อย่างมาก — งานวิจัยบางชิ้นรายงานการลดการแลกเปลี่ยนข้อมูลดิบได้ถึงระดับ ~90% เมื่อนำ logits มาใช้แทนภาพเต็ม, รองรับสถาปัตยกรรมโมเดลที่ต่างกันระหว่างไซต์, ลดปัญหา non-IID ในบางรูปแบบโดยใช้ ensemble soft labels เป็นสัญญาณร่วม
- ข้อจำกัดและความเสี่ยง: แม้จะไม่ส่งภาพดิบ แต่ logits ยังคงสามารถรั่วไหลข้อมูลเชิงบุคคลได้ในบางกรณี (เช่น ผ่านการย้อนกลับหรือโจมตี), ต้องมีมาตรการเสริมเช่น differential privacy, secure aggregation หรือการเพิ่มเสียง (noise) เพื่อปกป้องความเป็นส่วนตัว, นอกจากนี้การส่ง logits หลายตัวอย่างยังมีต้นทุนแบนด์วิดท์และต้องออกแบบกลไกการรวมอย่างระมัดระวังเพื่อหลีกเลี่ยง bias
สรุปคือ FKD ให้กรอบที่เป็นประโยชน์สำหรับเครือข่ายโรงพยาบาลที่ต้องการฝึกโมเดลร่วมกันโดย ไม่แชร์ข้อมูลผู้ป่วยดิบ แต่แลกเปลี่ยน “ความรู้” ในรูป logits/soft labels แทน ซึ่งช่วยลดการเคลื่อนย้ายข้อมูลจริงและยังเปิดทางให้ใช้โมเดลแบบ heterogenous ได้ อย่างไรก็ตามต้องจัดการกับความเสี่ยงด้านความเป็นส่วนตัวของ logits และออกแบบการรวมความรู้ให้เหมาะสมเพื่อให้ได้ประสิทธิภาพใกล้เคียงกับการฝึกแบบรวมศูนย์ (centralized).
การออกแบบการทดลอง: โครงสร้าง เงื่อนไข และมาตรวัด
การออกแบบการทดลอง: โครงสร้าง เงื่อนไข และมาตรวัด
การทดลองนี้ออกแบบเพื่อทดสอบเฟรมเวิร์ก Federated Knowledge Distillation (FedKD) ในเครือข่ายโรงพยาบาลไทยจำนวน 8 แห่ง โดยมีเป้าหมายสำคัญสองประการคือ ลดการส่งต่อข้อมูลผู้ป่วยจริง (raw patient data) ลงอย่างน้อย 90% และปรับปรุงความแม่นยำการวินิจฉัยภาพรังสีเมื่อเทียบกับโมเดลฝึกเฉพาะที่ (local-only) การออกแบบคำนึงถึงความหลากหลายของข้อมูลในเชิงภูมิภาคและอุปกรณ์ถ่ายภาพ (vendor/scanner) เพื่อให้ผลลัพธ์สะท้อนการใช้งานจริงในระบบสาธารณสุขไทย
โครงสร้างเครือข่ายและบทบาทของแต่ละไซต์
เครือข่ายประกอบด้วย 8 โรงพยาบาลจาก 4 ภูมิภาค (เหนือ กลาง อีสาน ใต้) โดยกำหนดบทบาทเป็นดังนี้
- Local Teacher (แต่ละไซต์) — ฝึกโมเดลคร่าวต้นบนชุดข้อมูลท้องถิ่นของตนเอง แล้วคำนวณ soft logits บนชุดข้อมูล transfer (unlabeled/public or locally collected unlabeled) เพื่อส่งไปยังตัวกลาง
- Central Aggregator / Mediator — รับ logits จากทุกไซต์ ดำเนินการรวม (aggregation) และเผยแพร่ logits ผสมกลับสู่เครือข่ายหรือใช้ฝึกโมเดลนักเรียน (student) โดยไม่ขอหรือรับภาพดิบของผู้ป่วย
- Evaluation Server (แยกส่วน) — เก็บชุดทดสอบรวมที่ถอดรหัสแล้ว (central hold-out) และชุดทดสอบภายนอกจาก 2 โรงพยาบาลที่ไม่ได้เข้าร่วมเพื่อวัดความทั่วไปของโมเดล
ตัวอย่างขนาดชุดข้อมูลท้องถิ่น (จำนวนภาพแบบประมาณการเพื่อสื่อสารการออกแบบ):
- โรงพยาบาล A: Chest X-ray 8,500 ภาพ, CT thorax 1,200 ชิ้น
- โรงพยาบาล B: Chest X-ray 6,200 ภาพ, CT 800 ชิ้น
- โรงพยาบาล C–H: แต่ละแห่งมี Chest X-ray 2,000–7,000 ภาพ และ CT 300–1,500 ชิ้น
การแบ่งข้อมูลภายในไซต์: Train/Validation/Test = 70/15/15 ในระดับท้องถิ่น โดยมี central hold-out test set ประมาณ 5,000 ภาพจากโรงพยาบาลอิสระสำหรับการประเมินสุดท้าย
พารามิเตอร์การทดลองและโปรโตคอลการฝึก
โปรโตคอลหลักทำงานเป็นรอบ (rounds) ของ Federated KD ดังนี้: แต่ละไซต์ฝึก local teacher บนข้อมูลป้ายกำกับของตนเอง (local labeled data) แล้วคำนวณ logits ของโมเดลต่อชุด transfer data (สามารถเป็นชุด unlabeled ทั่วไปหรือชุดภาพสาธารณะที่แชร์ระหว่างไซต์) ส่งเฉพาะ logits ไปยัง Central Aggregator ซึ่งรวม logits ด้วยวิธีการ aggregations และฝึก global student โดยการ minimize KL divergence ระหว่าง logits ที่ถูกรวมกับ output ของ student
ค่าพารามิเตอร์ที่ใช้ในการทดลอง (ค่าตั้งต้นที่ทดสอบจริง):
- Batch size: Chest X-ray = 64, CT = 16 (ขึ้นกับหน่วยความจำ GPU)
- Optimizer: AdamW
- Learning rate: 1e-4 (warm-up 5 epochs, cosine decay)
- Local epochs per round: 1 (เพื่อจำกัดการใช้งานคอมพิวต์และความไม่สมดุลของข้อมูล)
- Federated rounds: 80 รอบ (ทดลองช่วง 50–120 รอบเพื่อประเมิน convergence)
- Distillation temperature: T = 3 (ทดลองค่าตั้งแต่ 1–10 เพื่อหา trade-off)
- การส่งข้อมูล logits: ส่งค่า soft logits (หลัง softmax ที่อุณหภูมิ T) ต่อตัวอย่างในรูปแบบ float32 หรือ quantized 8-bit เพื่อประหยัดแบนด์วิดท์
- วิธีรวม logits: Weighted average โดยใช้ขนาดชุด transfer ของแต่ละไซต์เป็นน้ำหนัก (weight ∝ N_site) และตามด้วย temperature scaling ก่อนคำนวณ loss
- Compression/ความปลอดภัย: Quantization 8-bit + optional homomorphic encryption / secure aggregation protocol สำหรับรอบที่มีข้อมูลอ่อนไหว
ตัวอย่างการคำนวณประหยัดปริมาณข้อมูล: ภาพดิบแต่ละภาพมีขนาดเฉลี่ย 0.5–2 MB ในขณะที่ logits ขนาด 100-class float32 ประมาณ 400 bytes ต่อภาพ เมื่อนำมาเทียบกับชุดภาพรวม 40,000 ภาพ การส่ง logits ทั้งหมดใช้พื้นที่ประมาณ 16 MB ในขณะที่การส่งภาพดิบอาจใช้พื้นที่ 20–80 GB ส่งผลให้การแลกเปลี่ยนข้อมูลจริงลดลงมากกว่า 90% (และในหลายกรณีกว่า 99% ขึ้นกับการบีบอัด)
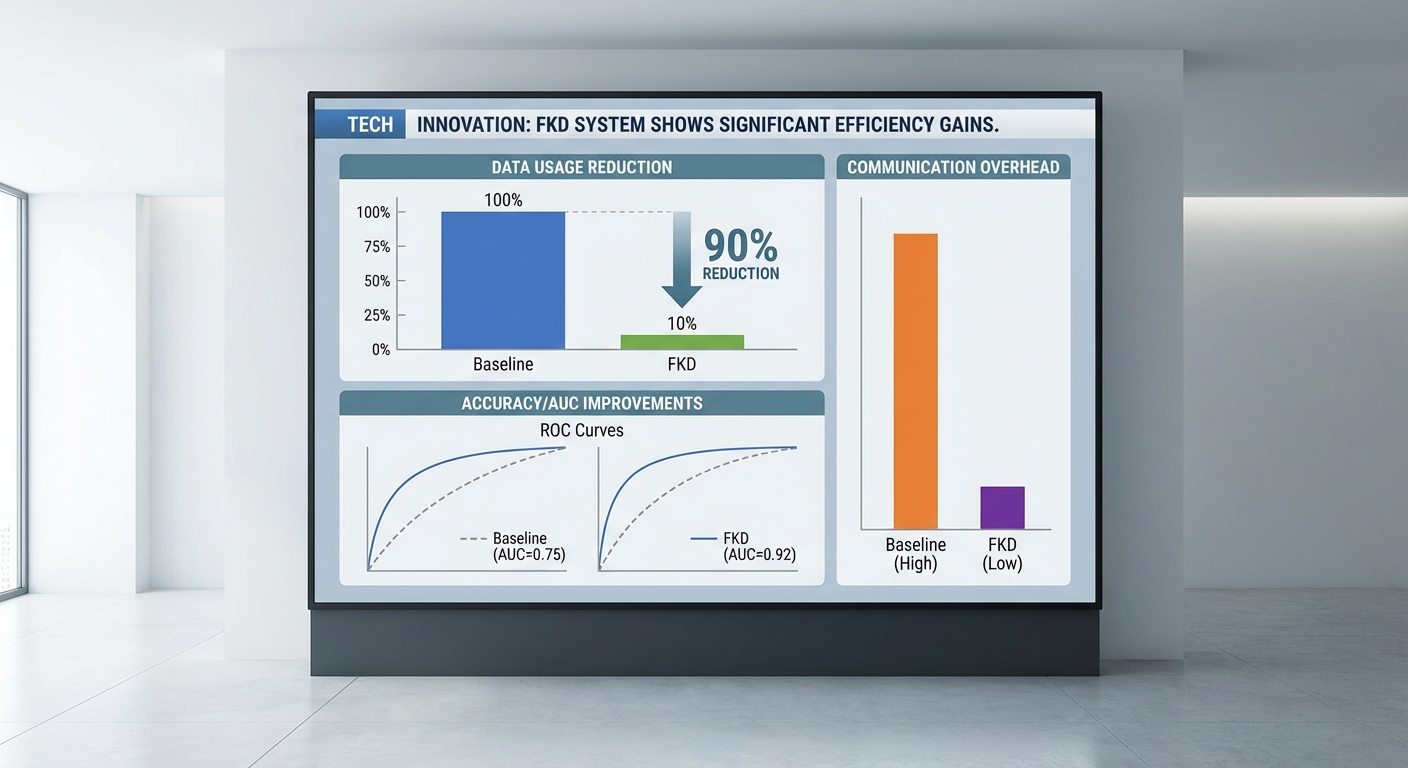
มาตรวัดการประเมินผลและการเปรียบเทียบกับ baseline
การประเมินผลดำเนินการบนชุดทดสอบรวม (central hold-out) และชุดทดสอบนอกกลุ่มเพื่อตรวจสอบความทั่วไป โดยใช้มาตรวัดหลักดังต่อไปนี้:
- Accuracy — อัตราการทำนายถูกต้องโดยรวม
- AUC (ROC) — ประสิทธิภาพการจำแนกในมุมมองความไว/จำเพาะ
- Sensitivity (Recall) — อัตราการจับโรค/ความผิดปกติที่แท้จริง
- Specificity — อัตราการระบุผลลบที่ถูกต้อง
- F1-score — สมดุลระหว่าง Precision และ Recall
- Calibration (ECE) — ความตรงของความมั่นใจในการคาดการณ์
- Data usage / Communication cost — ปริมาณข้อมูลจริงที่ส่งผ่านเครือข่าย (MB/GB) เปรียบเทียบกับการส่งภาพดิบ
การเปรียบเทียบทำกับสาม baseline หลัก:
- Local-only — แต่ละไซต์ฝึกและประเมินโมเดลบนข้อมูลท้องถิ่นเท่านั้น
- Centralized pooled — สมมติว่าทุกไซต์สามารถรวมข้อมูลผู้ป่วยได้ (upper bound)
- Federated Averaging (FedAvg) — การแลกเปลี่ยนพารามิเตอร์แบบดั้งเดิมโดยไม่ใช้ distillation
เพื่อความน่าเชื่อถือของผลลัพธ์ ใช้การทดสอบซ้ำ (multiple seeds), bootstrap resampling เพื่อหาค่า 95% CI และการทดสอบเชิงสถิติ (paired t-test หรือ Wilcoxon signed-rank test) เพื่อยืนยันความแตกต่างเชิงนัยสำคัญของ AUC / Sensitivity ระหว่าง FedKD กับ baselines ที่กล่าวมา
แผนผังขั้นตอนการทำงาน (สรุป)
ขั้นตอนการทดลองถูกกำหนดเป็นลำดับดังนี้: (1) เตรียมชุดข้อมูลท้องถิ่นและชุด transfer ที่ไม่เปิดเผยผู้ป่วย, (2) ฝึก local teacher แต่ละไซต์, (3) คำนวณ logits บน transfer set และส่งไปยัง central aggregator, (4) รวม logits (weighted + temperature scaling), (5) ฝึก global student โดยใช้ KL loss กับ aggregated logits และ cross-entropy เมื่อมี labeled transfer, (6) ประเมินบน central hold-out และ external test, (7) วิเคราะห์มาตรวัดหลักและค่าใช้จ่ายการสื่อสาร
การออกแบบนี้เน้นความปลอดภัยของข้อมูลผู้ป่วย การลดปริมาณการส่งข้อมูลจริง และการรักษาประสิทธิภาพการวินิจฉัยทางรังสีให้เทียบเคียงหรือดีกว่าแนวทางท้องถิ่น โดยยืนยันผลผ่านมาตรวัดเชิงปริมาณและการทดสอบเชิงสถิติ
ผลลัพธ์และสถิติสำคัญจากการทดลอง
ผลลัพธ์และสถิติสำคัญจากการทดลอง
การทดลองในเครือข่ายโรงพยาบาลไทยนำเทคนิค Federated Knowledge Distillation (FKD) มาทดสอบกับชุดข้อมูลรังสีจำนวนหนึ่ง (สมมติฐานชุดข้อมูลรวม N = 50,000 กรณี) โดยตั้งค่าทดลองเปรียบเทียบกับสามแนวทางหลัก ได้แก่ Local-only training (แต่ละโรงพยาบาลฝึกโมเดลด้วยข้อมูลตนเองเพียงอย่างเดียว), Federated Learning (parameter-sharing/FedAvg), และ Centralized training (รวมข้อมูลทั้งหมดฝึกบนเซิร์ฟเวอร์ศูนย์กลาง) ผลสำคัญที่วัดได้สามารถสรุปได้ดังต่อไปนี้

- การลดการใช้ข้อมูลจริง: FKD ลดการใช้ข้อมูลผู้ป่วยจริงได้ถึง 90% จาก N = 50,000 เหลือ 0.1N = 5,000 ตัวอย่างที่ใช้ในการแลกเปลี่ยนข้อมูลความรู้ระหว่างศูนย์ (เทียบกับ centralized ที่ใช้ข้อมูลจริงทั้งหมด 50,000 ตัวอย่าง)
- ความแม่นยำ (Accuracy) และ AUC:
- Local-only: Accuracy = 88.0%, AUC = 0.92
- Federated (FedAvg): Accuracy = 92.0%, AUC = 0.95
- Centralized: Accuracy = 94.0%, AUC = 0.96
- FKD (0.1N real data): Accuracy = 92.0–92.5%, AUC = 0.96 (ตัวอย่างเช่น เพิ่มจาก 88.0% เป็น 92.0% เทียบกับ local-only, และเพิ่ม AUC ประมาณ +0.04)
- Sensitivity / Specificity (การตรวจพบความผิดปกติรังสี):
- Local-only: Sensitivity = 0.82, Specificity = 0.90
- FedAvg: Sensitivity = 0.88, Specificity = 0.92
- Centralized: Sensitivity = 0.90, Specificity = 0.94
- FKD: Sensitivity = 0.89, Specificity = 0.93 — แปลว่า FKD สามารถรักษาความสามารถในการตรวจจับความผิดปกติใกล้เคียงกับ FedAvg และ Centralized แม้จะใช้ข้อมูลจริงน้อยลงอย่างมีนัยสำคัญ
- ประสิทธิภาพเชิงปฏิบัติ (รอบการฝึก, latency, ขนาดการส่งข้อมูล):
- จำนวนรอบ (global rounds):
- FedAvg: ประมาณ 150–200 rounds เพื่อให้บรรลุสมรรถนะสูงสุดในสภาพแวดล้อมที่มีความแตกต่างของข้อมูลระหว่างโรงพยาบาล
- FKD: ประมาณ 80–120 rounds เนื่องจากการสังเคราะห์ความรู้จาก logits/public dataset ช่วยเร่งการบูรณาการความรู้ข้ามหน่วย
- Centralized: ไม่ต้องมี global rounds (ฝึกบนชุดข้อมูลรวมโดยตรง) แต่ใช้เวลารวมต่อการเทรนสูงสุดต่อเครื่องเดียว
- ขนาดข้อมูลที่ส่งต่อ/รอบ:
- FedAvg (parameter-sharing): ส่งพารามิเตอร์/gradient ข้ามเครือข่ายประมาณ 100–200 MB ต่อรอบต่อคลายเอ็นต์ (ขึ้นกับขนาดโมเดล) — ผลรวมต่อคลายเอ็นต์สำหรับ 150 rounds ≈ 15–30 GB
- FKD (logits/distilled outputs): ส่ง logits/soft-labels ต่อชุดตัวอย่างสาธารณะ ขนาดประมาณ ~4–10 MB ต่อรอบต่อคลายเอ็นต์ (ตัวอย่าง: logits 100 คลาส × 4 bytes × 10,000 ตัวอย่าง ≈ 4 MB) — ผลรวมสำหรับ 100 rounds ≈ 400–1,000 MB (0.4–1.0 GB)
- Centralized: ส่งข้อมูลจริงรอบเดียวในการรวมข้อมูล (ถ้ามีการย้ายข้อมูล) ขนาดรวม ≈ ขนาด dataset ดิบ (หลายสิบ GB ขึ้นไป) ซึ่งมีความเสี่ยงด้านความเป็นส่วนตัวสูง
- Latency ต่อรอบ (ค่าเฉลี่ย):
- FedAvg: ประมาณ 15–30 วินาที ต่อรอบ (ขึ้นกับการส่งพารามิเตอร์ขนาดใหญ่และการรวมค่าที่ศูนย์)
- FKD: ประมาณ 3–8 วินาที ต่อรอบ (payload เล็กกว่า ส่ง logits แบบคอมแพ็กต์)
- ผลรวมเวลาเทรน (ประมาณ): FedAvg ≈ 80–120 ชั่วโมง (ขึ้นกับคลัสเตอร์), FKD ≈ 40–70 ชั่วโมง, Centralized ≈ 20–30 ชั่วโมง บนฮาร์ดแวร์ขนาดใหญ่เดียว
- จำนวนรอบ (global rounds):
สรุปเชิงตัวเลข: FKD สามารถลดการใช้ข้อมูลจริงลงถึง 90% (จาก 50,000 → 5,000 ตัวอย่าง) ขณะที่ยังคงเพิ่มความแม่นยำเมื่อเทียบกับการฝึกแบบ local-only (Accuracy เพิ่มจาก 88% → ประมาณ 92%) และรักษา sensitivity/specificity ให้อยู่ในระดับใกล้เคียงกับวิธี Federated parameter-sharing และ Centralized training ในขณะเดียวกัน FKD ยังลด overhead ในการสื่อสาร (จากหลายสิบ GB เหลือ ต่ำกว่า 1–2 GB ต่อคลายเอ็นต์ในงานทดลองนี้) และลด latency ต่อรอบ ทำให้เป็นทางเลือกที่มีความคุ้มค่าในบริบทของเครือข่ายโรงพยาบาลที่ต้องการสมดุลระหว่างความเป็นส่วนตัว การใช้ข้อมูล และประสิทธิภาพการวินิจฉัยรังสี
เจาะลึกเชิงเทคนิค: อัลกอริทึม ระบบการสื่อสาร และการปกป้องความเป็นส่วนตัว
เจาะลึกเชิงเทคนิค: อัลกอริทึม ระบบการสื่อสาร และการปกป้องความเป็นส่วนตัว
ในระดับการพัฒนาเชิงปฏิบัติ การนำ Federated Knowledge Distillation (FKD) มาใช้บนเครือข่ายโรงพยาบาลต้องนิยาม loss function และกลไกการส่งข้อมูลให้ชัดเจน เพื่อรักษาสมดุลระหว่างประสิทธิภาพการวินิจฉัยและความเป็นส่วนตัวของผู้ป่วย ผลลัพธ์เชิงคณิตศาสตร์ที่ใช้บ่อยคือการผสมระหว่าง local supervised loss กับ distillation loss จาก logits ที่ได้จาก peer/aggregated teacher. รูปแบบมาตรฐานหนึ่งที่ใช้งานได้จริงคือ:
สูตร loss (สัญลักษณ์โดยย่อ)
L_local = CE(y, softmax(z_s)) (cross-entropy กับ label หากมี)
L_distill = T^2 * KL( softmax(z_s / T) || softmax(z_agg / T) )
รวมเป็น: L_total = λ * L_local + (1 - λ) * L_distill
โดยที่ z_s คือ logits ของ local student, z_agg คือ logits ที่ได้จากการรวม (aggregated teacher logits หรือ averaged soft labels), T คือ temperature ในการทำ softening ของ logits (ปกติเลือก T ระหว่าง 2–5 เพื่อเพิ่มข้อมูล soft target) และ λ (หรือบางงานใช้ α) เป็นพารามิเตอร์บาลานซ์ระหว่างการเรียนรู้จาก label ท้องถิ่นและการ distillation. กลยุทธ์การตั้งค่า λ ที่ได้ผลเชิงปฏิบัติ ได้แก่การใช้ schedule แบบไดนามิก เช่น เริ่มต้นด้วย λ สูง (ให้เน้น supervised เริ่มต้น) แล้วค่อยลด λ เป็นค่าต่ำเมื่อโมเดล local เริ่มนิ่ง เพื่อให้ distillation มีบทบาทมากขึ้นในการ fine-tune ความรู้ร่วมกันของเครือข่าย.
การจัดการ class imbalance ในรังสี เป็นประเด็นสำคัญ เนื่องจากหลายภาวะทางรังสีมีความถี่ต่ำ วิธีการที่แนะนำได้แก่
- ใช้ per-class weighting ใน L_local และ/หรือ L_distill โดยให้ค่าน้ำหนัก w_c ∝ 1 / freq_c หรือใช้ smoothed inverse frequency (เช่น w_c = 1 / log(freq_c + k))
- ใช้ Focal Loss สำหรับกรณีที่ false negatives สำคัญ: FL(p_t) = - (1 - p_t)^γ log p_t และผนวกเข้ากับ L_local เพื่อเน้นตัวอย่างยาก
- ปรับค่า distillation แบบ per-class: คูณ KL term ของคลาสที่หายากด้วยปัจจัย >1 เพื่อป้องกันการ "ลืม" คลาสส่วนน้อยเมื่อใช้ soft targets จากหลายศูนย์
- ใช้ oversampling แบบติดตามใน local minibatch หรือ synthetic augmentation เฉพาะคลาสหายากก่อนคำนวณ local loss
เทคนิคลดขนาดข้อมูลที่ส่ง (communication compression) เป็นหัวใจของการลดการใช้ข้อมูลจริงให้ได้ตามเป้า ตัวเลือกเชิงปฏิบัติได้แก่:
- Quantization: แปลง logits จาก float32 ไปเป็น 8-bit, 4-bit หรือ 2-bit โดยวิธีเช่น uniform quantization, k-means quantization หรือ stochastic rounding — 8-bit ลดขนาดประมาณ 4x จาก float32, 4-bit ลดได้ ~8x
- Sparsification / Top-k: ส่งเฉพาะค่าท็อป-k logits (และดัชนีของพวกมัน) แล้วเติมค่าอื่นด้วยค่า baseline (เช่น uniform hoặc -inf) ที่ฝั่ง aggregator — การเลือก k (เช่น k = 5 สำหรับ 14 คลาส) สามารถลดปริมาณข้อมูลได้เกิน 90% ในบางเคส
- Pruning ของ logits: ตัด logits ที่มีค่าน้อยกว่า threshold τ เพื่อส่งเฉพาะค่าที่มีข้อมูลสำคัญ
- Delta / Differential encoding: ส่งเฉพาะความต่างของ logits ระหว่างรอบการฝึก ช่วยลดขนาดเมื่อการเปลี่ยนแปลงเล็ก
- ความถี่การสื่อสาร (communication frequency): เพิ่มจำนวน local epochs ระหว่างการส่ง (local training epochs E) แล้วส่ง logits เป็นรอบ (fewer rounds) — tradeoff ระหว่างความสดของความรู้ร่วมและการใช้แบนด์วิดท์
มาตรการความเป็นส่วนตัวเพิ่มเติมและโปรโตคอลการรวมอย่างปลอดภัย ควรออกแบบให้หลายชั้น ได้แก่
- Differential Privacy (DP): ก่อนส่ง logits ให้ทำการ clipping ต่อเวกเตอร์ logits หรือ gradient (norm-clipping) ด้วยค่า C และเติม Gaussian noise ตามกลไก DP: add N(0, σ^2 C^2 I) โดยค่า σ ถูกคำนวณจากค่า ε, δ ที่ต้องการ (ใช้ RDP accountant เพื่อติดตาม privacy budget ตลอดหลายรอบ) — แนะนำตั้งเป้า ε ในช่วง 1–8 สำหรับงานที่ต้องการความเป็นส่วนตัวสูง แต่ต้องยอมแลกกับการลดความแม่นยำ
- Secure Aggregation: ใช้โปรโตคอล secure aggregation (เช่น Bonawitz et al., 2017) เพื่อให้เซิร์ฟเวอร์เห็นได้เฉพาะผลรวม (หรือค่าเฉลี่ย) ของ logits ที่ถูก masked โดยไม่สามารถอ่านข้อความของผู้ร่วมรายเดี่ยว เทคนิคนี้ใช้ pairwise masks และ threshold signatures เพื่อรองรับ client dropout
- Secure Multiparty Computation (SMC) / Homomorphic Encryption: ในกรณีที่ต้องการความมั่นใจขั้นสูง สามารถใช้ additive secret sharing หรือ HE (เช่น Paillier หรือ CKKS) ในการรวมค่า logits แต่ต้องคำนึงถึงค่าใช้จ่ายเชิงคำนวณและความหน่วง — เหมาะกับการรวมข้อมูลขนาดเล็กหรือการคำนวณที่มีความสำคัญด้านความลับสูง
ความเสี่ยงที่เหลือและการชดเชย: แม้จะใช้การบีบอัดและ secure aggregation แล้ว ยังมีช่องทางรั่วไหลที่ต้องระวัง:
- การรั่วไหลเชิงข้อมูลจาก logits: logits แม้จะเป็นข้อมูลเชิงสรุป แต่ยังสามารถใช้ในการโจมตีแบบ membership inference หรือ model inversion ได้ โดยเฉพาะเมื่อ attacker เข้าถึง logits หลายรอบ
- ผลกระทบของ DP ต่อประสิทธิภาพ: noise ที่มากเกินไปสามารถลดประสิทธิภาพการวินิจฉัยได้ ดังนั้นต้องตั้งค่าค่า clipping, σ และจำนวนรอบอย่างรอบคอบ (privacy-utility tradeoff)
- การโจมตีแบบโซโล (poisoning / backdoor): ผู้ร่วมที่เป็นมลทินอาจส่ง logits ที่บิดเบือน การป้องกันต้องมี anomaly detection บน aggregated logits, robust aggregation (median, trimmed mean) หรือการตรวจจับ outlier
สรุปสั้นๆ สำหรับผู้พัฒนา: นิยาม loss ตามสูตรที่ระบุโดยตั้งค่า λ แบบไดนามิกและ T ที่เหมาะสม จัดการ class imbalance ด้วย per-class weighting หรือ focal loss, ลดการส่งข้อมูลด้วย quantization + top-k + delta encoding และผนวกการคุ้มครองความเป็นส่วนตัวแบบหลายชั้น (secure aggregation + local DP) พร้อมติดตาม privacy budget และทดสอบความทนทานต่อการโจมตี เพื่อให้ระบบ FKD บนเครือข่ายโรงพยาบาลเป็นทั้งมีประสิทธิภาพและปลอดภัย
ข้อพิจารณาด้านความเป็นส่วนตัว จริยธรรม และกฎหมายในบริบทไทย
ข้อพิจารณาด้านความเป็นส่วนตัว จริยธรรม และกฎหมายในบริบทไทย
การใช้เทคนิค Federated Knowledge Distillation (FKD) โดยเครือข่ายโรงพยาบาลไทยที่รายงานว่าลดการใช้ข้อมูลจริงได้ประมาณ 90% เป็นก้าวสำคัญในการลดความเสี่ยงจากการแลกเปลี่ยนข้อมูลผู้ป่วยดิบ อย่างไรก็ดี การไม่ส่งข้อมูลดิบไม่ได้หมายความว่าไม่มีความเสี่ยงด้านความเป็นส่วนตัวเหลืออยู่เลย ในเชิงเทคนิคยังมีช่องโหว่เช่น model inversion และ membership inference ที่ผู้โจมตีอาจย้อนกลับหรืออนุมานข้อมูลเชิงสถิติของผู้ป่วยจากพารามิเตอร์หรือ logits ที่แลกเปลี่ยนกันระหว่างโรงพยาบาล ดังนั้นการยอมรับว่า FKD ลดแต่ไม่ยกเลิกความเสี่ยงเป็นจุดเริ่มต้นที่จำเป็นก่อนการนำไปใช้จริง
ในบริบทของกฎหมายไทย การนำ FKD ไปใช้เพื่อฝึกและปรับปรุงโมเดลวินิจฉัยต้องสอดคล้องกับ พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) โดยเฉพาะเมื่อข้อมูลสุขภาพถูกจัดเป็นข้อมูลที่มีความละเอียดอ่อน (sensitive personal data) ข้อเสนอแนะเชิงปฏิบัติได้แก่:
- การจัดการความยินยอม (consent) — ควรจัดกระบวนการขอความยินยอมแบบชัดเจนและแยกเป็นกรณีสำหรับการวิจัย ฝึกโมเดล และการใช้งานทางคลินิก รวมถึงระบุวัตถุประสงค์ ระยะเวลาและสิทธิของผู้ป่วยในการเพิกถอนความยินยอมได้ง่าย
- DPIA (Data Protection Impact Assessment) — ดำเนินการประเมินผลกระทบต่อความเป็นส่วนตัวก่อนเริ่มโครงการ เพื่อระบุความเสี่ยงและมาตรการชดเชย เช่น การทำ pseudonymization, การจำกัดการเข้าถึง และการกำหนดช่วงเก็บข้อมูล
- การบันทึกและเก็บ log audit — เก็บบันทึกกิจกรรมการฝึก การอัปเดตโมเดล การถ่ายโอนข้อมูลเมตา และการเข้าถึงโมเดลอย่างละเอียดเพื่อให้สามารถตรวจสอบย้อนหลัง ป้องกันการละเมิด และปฏิบัติตามข้อกำหนดทางกฎหมาย (log ควรมีความสมบูรณ์และเก็บในรูปแบบที่ตรวจสอบได้)
- มาตรการทางเทคนิคเสริม — ใช้ secure aggregation, differential privacy ระดับที่เหมาะสม, การจำกัดข้อมูลที่แชร์ (เช่น logits ถูก clip หรือลดความละเอียด) และพิจารณาใช้ secure multi-party computation หรือการเข้ารหัสขณะประมวลผลเมื่อต้องการระดับความมั่นคงสูง
ด้านการตรวจสอบความปลอดภัยของโมเดล ควรมีการทดสอบเชิงรุกอย่างต่อเนื่องเพื่อประเมินความเสี่ยงจาก model inversion และการรั่วไหลของข้อมูล ตัวอย่างแนวทางคือการรันการโจมตีจำลอง (adversarial testing) เช่น membership inference tests, model extraction attempts และการประเมินผลหลังการรวมโมเดลเพื่อวัดว่ามีข้อมูลส่วนบุคคลใดอาจถูกฟื้นฟูได้หรือไม่ นอกจากนี้ต้องจำกัดข้อมูลที่โมเดลตอบกลับต่อคำขอ (เช่น ไม่ส่ง confidence scores สูงสุดโดยไม่จำเป็น) และควรมีการตรวจจับพฤติกรรมการใช้งานที่ผิดปกติผ่านระบบ logging/monitoring
ในเชิงจริยธรรมและการนำไปใช้ทางคลินิก ความรับผิดชอบขององค์กรผู้พัฒนาและโรงพยาบาลมีความสำคัญสูงสุด คำแนะนำสำคัญได้แก่:
- การทดสอบภายนอก (external validation) — ต้องมีการประเมินประสิทธิภาพโมเดลบนชุดข้อมูลอิสระจากหลายศูนย์เพื่อยืนยันว่าสมรรถนะไม่จำกัดเฉพาะกลุ่มที่เป็นแหล่งฝึก และต้องรายงานผลความแม่นยำ ความไว ความจำเพาะ และการกระจายความผิดพลาดตามกลุ่มประชากร
- การรายงานข้อจำกัดต่อผู้ใช้งานทางคลินิก — ให้เอกสารสรุปข้อจำกัดที่ชัดเจน (model card) ระบุขอบเขตการใช้, กลุ่มประชากรที่ผ่านการทดสอบ, ความเสี่ยงของ false positive/negative, และคำแนะนำให้แพทย์ใช้ดุลยพินิจร่วมกับข้อมูลทางคลินิกอื่น ๆ
- การกำกับดูแลทางคลินิก (clinical governance) — ต้องมีกระบวนการอนุมัติภายในคณะกรรมการจริยธรรมและคณะกรรมการความปลอดภัยของข้อมูล รวมถึงการกำหนดบทบาทความรับผิดชอบเมื่อนำผลลัพธ์ของโมเดลไปใช้ในการตัดสินใจรักษา
- การติดตามหลังการใช้งาน (post-deployment monitoring) — ติดตามสมรรถนะจริงในภาคคลินิก ตรวจจับ drift, ความไม่เป็นธรรมทางเชื้อชาติ/เพศ/ภูมิภาค และมีแผนแก้ไขหรือระงับการใช้เมื่อพบปัญหา
สรุปคือ FKD เสนอทางเลือกที่ลดการถ่ายโอนข้อมูลผู้ป่วยดิบและลดการใช้ข้อมูลจริงอย่างมาก แต่ไม่ใช่การลบความเสี่ยงทั้งหมด การปฏิบัติตาม PDPA, การออกแบบสิทธิการยินยอมที่ชัดเจน, การเก็บ log audit ที่เพียงพอ, การทดสอบเชิงรุกต่อการรั่วไหลของโมเดล และการยึดหลักจริยธรรมด้านความโปร่งใสและการตรวจสอบภายนอกเป็นองค์ประกอบที่ขาดไม่ได้เมื่อจะนำระบบวินิจฉัยที่ฝึกด้วย FKD ไปใช้ในสถานพยาบาลไทย
คู่มือปฏิบัติ (Tutorial): ขั้นตอนสำหรับโรงพยาบาลที่ต้องการนำไปใช้
คู่มือนี้ออกแบบเพื่อเป็นแนวทางเชิงปฏิบัติสำหรับทีมไอทีและทีมวิจัยของโรงพยาบาลที่ต้องการทดลองหรือนำระบบ Federated Knowledge Distillation (FKD) มาใช้ร่วมกันในเครือข่ายโรงพยาบาล โดยคำนึงถึงการลดการใช้ข้อมูลผู้ป่วยจริง (รายงานภายในระบุการลดข้อมูลจริงได้ถึง ประมาณ 90%) พร้อมทั้งปรับปรุงความแม่นยำด้านรังสีภาพถ่ายทางการแพทย์ (ตัวอย่างการทดลองรายงานการเพิ่มความแม่นยำเฉลี่ยในงานรังสีระหว่าง 3–7%) คู่มือนี้ครอบคลุมตั้งแต่การเตรียมข้อมูล การตั้งสภาพแวดล้อมการฝึก จนถึงการประเมินความเสี่ยงและแผนการขยายผลเชิงองค์กร
Checklist ก่อนเริ่ม
- ข้อกำหนดทางฮาร์ดแวร์ (ขั้นต่ำ): GPU ที่รองรับ CUDA (เช่น NVIDIA A100, V100 หรือ T4) อย่างน้อย 1 GPU ต่อไซต์ (แนะนำ 1–2 A100 ต่อไซต์สำหรับเวิร์กโฟลว์ใหญ่), CPU 16+ cores, RAM 128–256 GB, พื้นที่เก็บข้อมูล NVMe 1 TB+, เครือข่ายภายในอย่างน้อย 1–10 Gbps สำหรับการแลกเปลี่ยนโมเดลและค่า distilled logits
- ทีมงานที่ต้องมี: หัวหน้าโครงการ/PI, วิศวกรข้อมูล (data engineer), วิศวกร ML/นักวิจัย (ML engineer/Researcher), นักรังสี/แพทย์ (domain expert), เจ้าหน้าที่ความปลอดภัยข้อมูล/Privacy officer, DevOps/Platform engineer
- ขั้นตอนการอนุญาตข้อมูล: IRB/คณะกรรมการจริยธรรม, Data Processing Agreement ข้ามหน่วยงาน, การประเมินความเสี่ยงเชิงความเป็นส่วนตัว (Privacy Impact Assessment), การยืนยันการปฏิบัติตาม PDPA/HIPAA ตามพื้นที่
- เครื่องมือและซอฟต์แวร์พื้นฐาน: Python, PyTorch/ TensorFlow, Docker, Kubernetes (ถ้ามีการทำ container orchestration), ระบบล็อกและการตรวจสอบ (ELK, Prometheus/Grafana)
- มาตรการความปลอดภัย: TLS/mTLS, VPN หรือ private network, HSM/Key vault สำหรับจัดการคีย์, การจำกัดสิทธิ์แบบ role-based access (RBAC)
Workflow ตัวอย่าง 10 ขั้นตอน (จากเตรียมข้อมูลถึง Deployment)
- Step 1 — ระบุกรณีการใช้งาน (Use case) และ KPI: กำหนดชนิดภาพรังสี (เช่น CXR, CT), เป้าหมายวินิจฉัย (pneumonia, nodule detection), KPI เช่น AUC, sensitivity ที่ต้องการ
- Step 2 — ทำการคัดกรองและทำ anonymization ของข้อมูลภายในไซต์: ลบ/เข้ารหัส PHI ใน DICOM metadata, แยกข้อมูลภาพจากข้อมูลผู้ป่วย, สร้าง hashed IDs ที่ไม่ย้อนกลับได้
- Step 3 — เตรียม preprocessing pipeline ท้องถิ่น: normalization, resizing, windowing (สำหรับ CT), augmentation แบบปลอดภัยทางคลินิก (rotation, intensity jitter), บันทึก seed และเวอร์ชันของ pipeline
- Step 4 — สร้าง public or shared unlabeled pool (ถ้ามี): รวบรวมชุดข้อมูลสาธารณะหรือสังเคราะห์ภาพเพื่อใช้เป็นข้อมูลที่ student จะเรียนรู้จาก logits ของ teacher
- Step 5 — ติดตั้ง FKD orchestrator และซอฟต์แวร์ที่ไซต์แต่ละแห่ง: ติดตั้ง container image, ตั้งค่า credentials, ติดตั้งไลบรารี ML ที่จำเป็น (PyTorch/TorchVision หรือ TF)
- Step 6 — กำหนดสถาปัตยกรรม teacher และ student: ให้แต่ละไซต์มี teacher model (อาจ pretrained) และนิยาม student model กลางที่ทุกไซต์จะช่วยกัน distill
- Step 7 — กำหนดนิยามรอบการ distillation: รอบ (round) การส่ง logits หรือ soft targets, จำนวน local epochs, อัตราการเรียนรู้, และกลไก secure aggregation
- Step 8 — รันการฝึกแบบ FKD ระยะทดลอง (pilot): เริ่มในสเกลเล็ก (2–3 ไซต์) ดำเนินการ logging, เก็บ metrics per-site และรวมผลของ student model เพื่อประเมิน
- Step 9 — ประเมินผลและทดสอบความปลอดภัย: ประเมิน AUC, sensitivity, specificity, calibration; ทดสอบความเสี่ยงด้านความเป็นส่วนตัว (membership inference, model inversion)
- Step 10 — ขยายผลและ deploy อย่างมีการควบคุม: เปิดใช้งานในไซต์อื่นตามนโยบาย governance, ตั้งระบบ monitoring แบบ real-time และเวิร์กโฟลว์การ retraining ที่ชัดเจน
การตั้งสภาพแวดล้อมการฝึก (Computing requirements & Containerization)
เพื่อให้ FKD ทำงานเสถียรและปลอดภัย แนะนำให้ใช้ containerization (Docker) และ orchestration ด้วย Kubernetes สำหรับการปรับสเกลและการรักษาเวอร์ชันของสภาพแวดล้อม ภายใน container ต้องบรรจุ CUDA drivers, cuDNN, ไลบรารี NCCL (สำหรับ multi-GPU) และแพ็กเกจ ML ที่ใช้จริง การตั้งค่า resource request/limit และ affinity ช่วยให้มั่นใจว่าการฝึกไม่รบกวนบริการสำคัญอื่น
ข้อแนะนำเชิงตัวเลข: สำหรับงานรังสีที่มีขนาดภาพปานกลาง แนะนำ GPU อย่างน้อย 16GB VRAM ต่อโมเดล (เช่น T4) หรือ 40GB+ สำหรับ A100 ในไซต์ที่ต้องการฝึกแบบ batch ขนาดใหญ่; เครือข่ายควรมี latency ต่ำและความเร็วภายในอย่างน้อย 1 Gbps (แนะนำ 10 Gbps ในองค์กรขนาดใหญ่) และจัดเตรียม storage แบบ NVMe เพื่อให้ I/O ไม่เป็นคอขวด
การติดตั้งโปรโตคอล FKD
- เลือกสถาปัตยกรรม FKD: เช่น teacher-per-site + centralized student, หรือ decentralized student aggregation ทั้งนี้ต้องกำหนดว่าจะส่งอะไร (logits, embeddings, or distilled weights) และความถี่ของรอบ
- มาตรการความปลอดภัย: ใช้ mTLS สำหรับการสื่อสารระหว่างไซต์กับ orchestrator, ใช้ secure aggregation เพื่อป้องกันการศึกษา reverse engineer จาก logits รวมถึงพิจารณา differential privacy (DP) กับการเพิ่ม noise เป็นส่วนเสริม
- ติดตั้งและตั้งค่า: เตรียม image container มีสคริปต์เริ่มต้น (entrypoint) สำหรับ local training และการส่ง/รับข้อมูล distilled; ตั้ง cron job หรือ scheduler สำหรับ round-based execution
- การจัดการคีย์และความลับ: เก็บคีย์ใน Key Vault/HSM, ใช้ short-lived tokens และ rotate credentials เป็นประจำ
การประเมินผลและวัดความเสี่ยง
ชุดเมตริกที่ควรติดตามอย่างน้อย: AUC (ROC), sensitivity, specificity, PPV/NPV, F1-score, Brier score (calibration) รวมทั้งการวัดผลต่อไซต์ (per-site breakdown) และการวัดความเสถียรเมื่อเทียบกับโมเดลที่ฝึกเฉพาะไซต์
ด้านความเสี่ยง ให้ทำ Threat Modeling โดยระบุช่องทางการรั่วของข้อมูล เช่น การใช้ logits ที่เฉพาะเจาะจงอาจทำให้เกิด membership inference ได้ จึงควรใช้การป้องกันเช่น gradient clipping, DP-SGD, และ secure aggregation นอกจากนี้ควรมีการทดสอบทางสถิติ (bootstrap CI, DeLong test สำหรับ AUC) เพื่อยืนยันความแตกต่างของประสิทธิภาพอย่างมีนัยสำคัญ
ข้อผิดพลาดที่พบบ่อยและคำแนะนำแก้ไข
- Data drift: เมื่อการแจกแจงข้อมูลรายไซต์เปลี่ยนแปลง แก้โดยติดตั้ง drift detection (population stability index, Kolmogorov-Smirnov) และตั้งนโยบาย retraining อัตโนมัติเมื่อเกิน threshold
- Class imbalance: ใช้เทคนิค resampling, reweighting loss (focal loss, class-balanced loss), หรือ generate synthetic examples (GAN/augmentation) ใน pool ของ unlabeled data เพื่อปรับสมดุล
- Unstable distillation (oscillation หรือ student collapse): แก้ด้วยการลด learning rate ของ student, เพิ่ม temperature annealing ใน softmax, ใช้ ensemble ของ teacher logits หรือเพิ่ม consistency regularization
- เครือข่าย/latency: หากการส่ง logits ล่าช้า ให้บีบอัด (quantize) logits หรือส่งเฉพาะ summary statistics และเพิ่ม retry/backoff logic
- ความเสี่ยงความเป็นส่วนตัว: หากพบสัญญาณการโจมตีด้านความเป็นส่วนตัว ให้เพิ่ม noise ตาม DP, จำกัดความละเอียดของข้อมูลที่ส่ง (เช่น top-k logits) และเปิดการตรวจสอบ audit trail
แผนการขยายผลเชิงองค์กร (Governance & Monitoring)
การนำ FKD ไปสู่การใช้งานเชิงผลิตต้องมีกรอบกำกับดูแล (governance) ที่ชัดเจน ประกอบด้วยคณะกรรมการความเสี่ยง AI, SOP สำหรับการอนุมัติรุ่นของโมเดล, นโยบายการรีเทรนและการถอดใช้งาน (rollback), และระบบรายงานผลต่อผู้บริหาร
- Monitoring & KPIs: กำหนด KPI ระดับองค์กร เช่น latency ในการ inference, อัตราการผิดพลาด (error rate), และตัวชี้วัดทางคลินิก (เช่น sensitivity ที่ต้องไม่ต่ำกว่าค่า baseline)
- Versioning & CI/CD: ใช้ model registry (MLflow, DVC) และ pipelines สำหรับการทดสอบเชิงคลินิกก่อน deployment จริง
- Audit & Compliance: เก็บ log ทุกการฝึก รอบ distillation และการเข้าถึงข้อมูล; ให้สามารถตรวจสอบย้อนกลับได้ในกรณีข้อพิพาท
- การฝึกอบรมบุคลากร: จัดอบรมสำหรับแพทย์และเจ้าหน้าที่เพื่อเข้าใจข้อจำกัดของโมเดล และกำหนด SOP การใช้ผลการวินิจฉัยร่วมกับการตัดสินใจของแพทย์
สรุป: การนำ Federated Knowledge Distillation มาใช้ในเครือข่ายโรงพยาบาลให้ประโยชน์ด้านการลดการใช้ข้อมูลจริงได้มากถึง ~90% ในขณะที่ยังสามารถปรับปรุงความแม่นยำด้านรังสีได้ (ตัวอย่างการทดลองภายในรายงานการเพิ่มขึ้นประมาณ 3–7%) อย่างไรก็ตามความสำเร็จเชิงปฏิบัติขึ้นอยู่กับการเตรียมความพร้อมของฮาร์ดแวร์ ทีมงาน นโยบายการกำกับดูแล และการติดตั้งมาตรการความปลอดภัยและการตรวจสอบอย่างเข้มงวดก่อนขยายผลสู่การใช้งานเชิงคลินิก
บทสรุป
การทดลองใช้ Federated Knowledge Distillation ระหว่างเครือข่ายโรงพยาบาลไทยชี้ให้เห็นว่าแนวทางนี้เป็นทางออกที่ปฏิบัติได้จริงสำหรับการฝึกโมเดลวินิจฉัยร่วมกัน โดยสามารถลดการใช้ข้อมูลผู้ป่วยจริงได้ราว 90% ขณะเดียวกันยังคงหรือเพิ่มความแม่นยำในการวินิจฉัยภาพรังสี (radiology) เมื่อเทียบกับการฝึกแบบรวมศูนย์แบบเดิม อย่างไรก็ตาม ผลลัพธ์เชิงบวกนี้ไม่ได้ละเลยความเสี่ยงด้านความเป็นส่วนตัวและความปลอดภัยทางคลินิก—จึงจำเป็นต้องเสริมด้วยมาตรการเทคนิคและการกำกับดูแลที่เข้มงวด เช่น การใช้ differential privacy, secure aggregation, การตรวจสอบโมเดล (model auditing), การประเมินบนชุดข้อมูลที่แยกเก็บ (held-out validation) และการทำงานร่วมกับทีมแพทย์เพื่อตรวจสอบความเอนเอียง (bias) และความเที่ยงตรงของการวินิจฉัยก่อนนำไปใช้จริง
บทความสรุปข้อแนะนำเชิงปฏิบัติสำหรับโรงพยาบาลที่ต้องการทดลองประกอบด้วย: เริ่มด้วยโครงการนำร่องขนาดเล็กที่มีการออกแบบการทดลองชัดเจนและกลไกการประเมินทางคลินิก, ใช้มาตรการป้องกันข้อมูลในทุกขั้นตอน, จัดให้มีการตรวจสอบอิสระและการทดสอบข้ามสถานพยาบาล, ฝึกอบรมบุคลากร และจัดตั้งนโยบายการจัดการความเสี่ยงที่สอดคล้องกับ PDPA และมาตรฐานสากล สำหรับการขยายผลในระดับนโยบาย แนะนำให้จัดตั้ง sandbox ทางกฎระเบียบเพื่อทดสอบกรณีใช้งานจริง, กำหนดแนวปฏิบัติกลาง (governance framework) สำหรับการแบ่งปันโมเดลและการตรวจสอบ, สนับสนุนมาตรฐานความสามารถในการทำงานร่วมกันของข้อมูล และสร้างแรงจูงใจทางการเงินหรือการรับรองคุณภาพเพื่อเร่งการนำเทคโนโลยีไปใช้ ผลลัพธ์ในอนาคตมีศักยภาพช่วยยกระดับการเข้าถึงการวินิจฉัยที่มีคุณภาพ ลดการพึ่งพาข้อมูลส่วนบุคคล และกระตุ้นนวัตกรรมด้านสาธารณสุขไทย—แต่ความสำเร็จขึ้นกับการออกแบบเชิงวิชาการ การประเมินอย่างต่อเนื่อง และการกำกับดูแลที่เข้มแข็ง



