
สตาร์ทอัพไทยเปิดตัวโซลูชันใหม่ที่ผสานพลังของ TinyML กับความสามารถด้านภาษาของ LLM เพื่อรันการวิเคราะห์ภาพจากกล้อง CCTV บนอุปกรณ์ edge แบบออฟไลน์ — ไม่ต้องส่งวิดีโอหรือภาพดิบขึ้นคลาวด์ ช่วยลดการใช้แบนด์วิธได้ถึง 10× และยกระดับการปกป้องความเป็นส่วนตัวของบุคคล ข้อได้เปรียบชัดเจนคือการสกัดข้อมูลเชิงเหตุการณ์ (metadata) และผลวิเคราะห์ที่มีความหมาย เช่น การตรวจจับพฤติกรรมผิดปกติ การนับผู้เข้าเยี่ยมชม หรือการแจ้งเตือนเรียลไทม์ โดยข้อมูลที่ส่งออกจากอุปกรณ์เป็นข้อความสรุปหรือเหตุการณ์สำคัญแทนการส่งภาพเต็มรูปแบบ ทำให้องค์กรลดค่าใช้จ่ายคลาวด์และความเสี่ยงด้านกฎหมาย เช่น การปฏิบัติตาม พ.ร.บ.คุ้มครองข้อมูลส่วนบุคคล (PDPA)
เทคโนโลยีดังกล่าวนำโมเดลคอมพิวเตอร์วิชันที่ปรับแต่งให้เบา (TinyML) มาทำการสกัดฟีเจอร์จากภาพ พร้อมกับ LLM ที่รันท้องถิ่นเพื่อแปลงผลให้เป็นภาษาธรรมชาติหรือคำสั่งที่เข้าใจง่ายสำหรับระบบผู้ใช้งาน ผลลัพธ์คือการตอบสนองแบบเรียลไทม์ ลดความหน่วง และสามารถทำงานได้แม้เชื่อมต่อเครือข่ายไม่เสถียร ตัวอย่างเช่น กล้อง 1080p ที่ปกติจะสร้างข้อมูลหลายเมกะบิตต่อวินาที สามารถถูกแทนที่ด้วยการส่งข้อมูลสรุปเพียงหลักกิโลบิตต่อวินาทีเท่านั้น การปรับใช้ในเชิงพาณิชย์ครอบคลุมสาขา เช่น ห้างสรรพสินค้า โรงงาน และเมืองอัจฉริยะ ซึ่งต้องการสมดุลระหว่างความแม่นยำ การคุ้มครองข้อมูล และต้นทุนการดำเนินงาน
บทนำ: ทำไมต้อง TinyML‑LLM สำหรับกล้องวงจรปิด
สตาร์ทอัพไทยเพิ่งเปิดตัวโซลูชัน TinyML‑LLM ที่รันการวิเคราะห์ภาพจากกล้องวงจรปิดแบบออฟไลน์ ซึ่งชูจุดเด่นด้านการปกป้องความเป็นส่วนตัวและการประหยัดแบนด์วิธ บริษัทอ้างว่าสามารถลดปริมาณข้อมูลที่ต้องส่งขึ้นคลาวด์ได้ถึง 10× พร้อมทั้งลดค่าใช้จ่ายและปรับปรุงความหน่วง (latency) ในการแจ้งเตือนเหตุการณ์ที่สำคัญ เหตุการณ์นี้สะท้อนการเปลี่ยนผ่านเชิงเทคโนโลยีจากการส่งวิดีโอดิบขึ้นศูนย์กลาง ไปสู่การประมวลผลที่ขอบเครือข่าย (edge) ด้วยโมเดลขนาดเล็กและเทคนิคการบีบอัดความรู้ของ LLM เพื่อให้สามารถทำงานได้บนฮาร์ดแวร์กล้องหรือกล่องประมวลผลท้องถิ่น

ปัญหาของระบบ CCTV แบบเดิม
ระบบกล้องวงจรปิดแบบดั้งเดิมมักจะส่งวิดีโอดิบขึ้นไปยังคลาวด์เพื่อทำการวิเคราะห์หรือเก็บสำรอง ซึ่งก่อให้เกิดปัญหาหลักหลายด้าน ได้แก่:
- แบนด์วิธและค่าใช้จ่ายสูง: กล้อง 1080p@30fps ให้ข้อมูลประมาณ 3–6 Mbps ต่อกล้อง ขณะที่กล้อง 4K อาจให้ข้อมูล 15–25 Mbps ในระบบที่มีหลายสิบถึงหลายร้อยกล้อง ปริมาณข้อมูลนี้แปลงเป็นค่าใช้จ่ายด้านเครือข่ายและคลาวด์อย่างมีนัยสำคัญ
- ความหน่วง (Latency): การส่งข้อมูลขึ้นไปประมวลผลบนคลาวด์และรอผลวิเคราะห์อาจเพิ่มเวลาเป็นหลายร้อยมิลลิวินาทีถึงหลายวินาที ส่งผลให้การตอบสนองต่อเหตุฉุกเฉินหรือการตรวจจับแบบเรียลไทม์ล่าช้า
- ความเป็นส่วนตัวและความเสี่ยงการรั่วไหล: การเก็บรักษาวิดีโอดิบบนคลาวด์เพิ่มโอกาสการละเมิดข้อมูลส่วนบุคคลและความเสี่ยงด้านกฎระเบียบ (เช่น PDPA / GDPR) หากเกิดการรั่วไหลจึงมีผลกระทบทางกฎหมายและชื่อเสียง
แนวทางใหม่: ประมวลผลที่ขอบเครือข่ายด้วย TinyML และ LLM ท้องถิ่น
แนวคิดของ TinyML‑LLM คือการรันโมเดลวิเคราะห์ภาพขนาดเล็ก (TinyML) ร่วมกับโมดูล LLM ที่ถูกย่อขนาดหรือ distilled เพื่อทำหน้าที่ตีความและสรุปเหตุการณ์แบบภาษาธรรมชาติทั้งหมดบนอุปกรณ์ท้องถิ่น โดยส่งเฉพาะ เมตาดาต้า เช่น bounding boxes, event labels, timestamps หรือข้อความสรุปแทนการส่งวิดีโอดิบ ซึ่งช่วยลดปริมาณข้อมูลที่ต้องถ่ายโอนอย่างมาก ตัวอย่างเช่น หากกล้องส่งข้อมูลดิบ 5 Mbps ต่อกล้อง การลดแบนด์วิธ 10× ตามที่สตาร์ทอัพอ้าง จะทำให้เหลือประมาณ 0.5 Mbps ต่อกล้อง — ลดต้นทุนเครือข่ายและค่าเก็บข้อมูลในคลาวด์อย่างมีนัยสำคัญ
เทคโนโลยีที่ใช้รวมถึงการบีบอัดโมเดล (quantization, pruning), knowledge distillation เพื่อสร้าง Tiny LLM, โครงข่ายประมวลผลแบบเร่งความเร็วบนฮาร์ดแวร์ (ARM Cortex‑M/A, NPUs, DSPs), และซอฟต์แวร์รันไทม์เช่น TensorFlow Lite Micro หรือ ONNX Runtime ที่ปรับแต่งเพื่อการ inferencing บน edge การออกแบบนี้ยังสนับสนุนกลไกความปลอดภัยเพิ่มเติม เช่น การเข้ารหัสข้อมูลแบบขณะพักและในระหว่างส่ง, secure enclave และการอัปเดตโมเดลแบบ federated learning เพื่อลดการแลกเปลี่ยนวิดีโอดิบระหว่างอุปกรณ์กับเซิร์ฟเวอร์
สรุปแล้ว แนวทาง TinyML‑LLM สำหรับกล้องวงจรปิดมอบข้อได้เปรียบเชิงปฏิบัติทั้งในแง่การลดแบนด์วิธ (บริษัทอ้างว่า ลดได้ถึง 10×), การปรับปรุงความหน่วงที่ส่งผลให้การตอบสนองใกล้เคียงแบบเรียลไทม์ และการลดความเสี่ยงการรั่วไหลของข้อมูลผ่านการจำกัดการส่งวิดีโอดิบไปยังคลาวด์ ทำให้เป็นทางเลือกที่น่าสนใจสำหรับองค์กรที่ต้องการสมดุลระหว่างประสิทธิภาพ ต้นทุน และการปกป้องข้อมูลส่วนบุคคล
เทคโนโลยีเบื้องหลัง: TinyML และ LLM บน Edge
เทคโนโลยีเบื้องหลัง: TinyML และ LLM บน Edge
ระบบวิเคราะห์ภาพจากกล้อง CCTV แบบออฟไลน์ที่รันบนอุปกรณ์ขอบเครือข่าย (edge) อาศัยหลักการของ TinyML เพื่อย่อขนาดโมเดลการมองเห็นและลดการคำนวณลงอย่างมาก รวมทั้งผสานกับ LLM ขนาดเล็กบนเครื่อง เพื่อให้สามารถเข้าใจบริบทและสร้างคำอธิบายเหตุการณ์เชิงภาษาธรรมชาติได้โดยไม่ต้องพึ่งพาคลาวด์ ข้อได้เปรียบสำคัญได้แก่การปกป้องความเป็นส่วนตัวของผู้ใช้งาน ลดแบนด์วิธออกไปได้มาก (ตัวอย่างเช่นงานหนึ่งที่ระบุการส่งข้อมูลขึ้นคลาวด์ลดลงประมาณ 10×) และลดความหน่วงในการแจ้งเตือนแบบเรียลไทม์
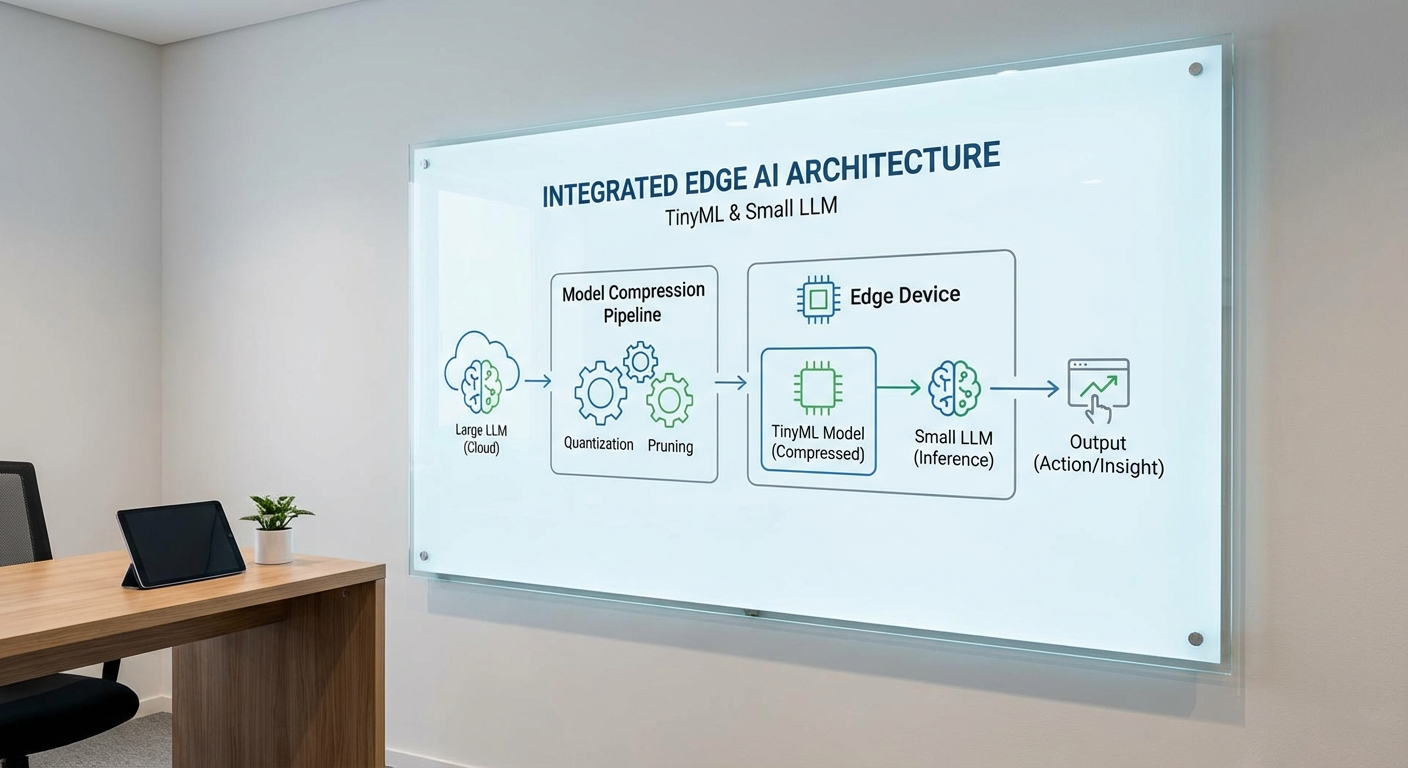
กระบวนการทำให้โมเดลเล็กลงประกอบด้วยเทคนิคหลัก 3 กลยุทธ์ที่ใช้ร่วมกันได้เพื่อรักษาความแม่นยำขณะลดขนาดและการคำนวณ:
- Quantization — แปลงค่าพารามิเตอร์จาก FP32 ไปเป็นตัวแทนที่ต้องการหน่วยความจำน้อยกว่า เช่น int8 (8‑bit) ซึ่งลดขนาดโมเดลประมาณ 4× และบางกรณีใช้ 4‑bit ลดขนาดได้ถึง 8× ขณะเดียวกันมีเทคนิคการปรับแต่งแบบ post‑training หรือ quantization-aware training เพื่อลดการสูญเสียความแม่นยำ
- Pruning — ตัดน้ำหนักหรือโครงสร้างที่ไม่สำคัญออก เช่น structured pruning สำหรับการตัดนิวรอนหรือคอนโวลูชันทั้งฟิลเตอร์ ซึ่งช่วยลดค่า FLOPs และหน่วยความจำได้ (ตัวอย่าง: pruning ระดับ 50–90% ขึ้นอยู่กับงานและการปรับแต่ง)
- Knowledge distillation — นำโมเดลขนาดใหญ่ (teacher) มาสอนโมเดลขนาดเล็ก (student) ให้เรียนรู้พฤติกรรมเชิงสถิติของ teacher ทำให้ student มีประสิทธิภาพใกล้เคียงในขณะที่พารามิเตอร์น้อยลงอย่างชัดเจน (ตัวอย่างการลดขนาด 5–10× โดยยังคงความแม่นยำ ~90–98% ของโมเดลต้นแบบ)
สำหรับงานวิเคราะห์ภาพ CCTV บน edge มักออกแบบเป็นพายพ์ไลน์แบบชั้นชั้น (cascade): ชั้นแรกเป็นโมดูล TinyCV (เช่นเบสไลน์ MobileNetV2/EdgeTPU‑optimized backbone หรือโมเดล object detection ขนาดเล็ก) ที่รันอย่างเบาและต่อเนื่องเพื่อตรวจจับเหตุการณ์พื้นฐาน จากนั้นเมื่อเกิดเหตุที่น่าสนใจ ระบบจะเรียกใช้ LLM ขนาดเล็กบนเครื่องเพื่อวิเคราะห์บริบท สร้างคำอธิบายเหตุการณ์ คัดกรอง false positives และจัดเตรียมข้อความสรุปสำหรับการแจ้งเตือนหรือเก็บบันทึก ตัวอย่างเช่น โมเดลตรวจจับคนขนาดเล็กจะส่งเฉพาะเมตาดาต้า (ตำแหน่งเวลา เหตุการณ์ประเภท และภาพย่อ) ไปยัง LLM บนเครื่องเพื่อสรุปว่าเป็น "คนเดินผ่านประตูหลักเวลา 08:12 น." แทนการส่งวิดีโอเต็มความยาวขึ้นคลาวด์
การเลือกสถาปัตยกรรมฮาร์ดแวร์เป็นปัจจัยสำคัญที่กำหนดความเป็นไปได้ของการรัน TinyML + LLM บน edge:
- Edge CPU / ARM Cortex‑A (เช่น Cortex‑A53, A72): เหมาะกับอุปกรณ์ edge ที่มีหน่วยความจำมากพอ สามารถรันโมเดล quantized int8 และ LLM ขนาดเล็ก (หลายร้อย MB) พร้อม latency ในระดับสิบถึงร้อยมิลลิวินาที ขึ้นอยู่กับโมเดล
- Microcontroller / ARM Cortex‑M (เช่น Cortex‑M4/M7, M33): เหมาะกับการรัน TinyML ขนาดจิ๋ว (โมเดลขนาดไม่กี่สิบ KB ถึงไม่กี่ MB) ด้วยเฟรมเวิร์กเช่น TensorFlow Lite Micro หรือ CMSIS‑NN สำหรับการตรวจจับเบื้องต้นบนอุปกรณ์ที่ใช้พลังงานต่ำ
- NPU / Accelerator (เช่น Arm Ethos‑U, Google Edge TPU, Intel Movidius Myriad, Qualcomm Hexagon, NVIDIA Jetson): ช่วยเร่ง inference ของทั้งโมเดลวิชั่นและ LLM ที่ถูก quantize ทำให้สามารถรัน inference แบบเรียลไทม์หรือใกล้เรียลไทม์โดยใช้พลังงานต่ออินเฟอเรนซ์ต่ำกว่า CPU เพียงอย่างเดียว
สแต็กซอฟต์แวร์ที่ใช้งานจริงมักประกอบด้วยเครื่องมือแปลงและรันไทม์ที่รองรับการปรับแต่งเชิงประสิทธิภาพดังนี้:
- TensorFlow Lite (TFLite) & TFLite Micro — สนับสนุน post‑training quantization, edge deployment และมี runtime ที่เบาสำหรับ microcontroller
- ONNX Runtime & PyTorch Mobile / TorchScript — ใช้ในกรณี workflow พัฒนา PyTorch และต้องการแปลงโมเดลไปยังรูปแบบที่รองรับหลายแพลตฟอร์ม
- Apache TVM / XLA / OpenVINO — คอมไพล์และทำ optimization แบบ low‑level เพื่อสร้าง binary ที่เร็วขึ้นสำหรับ CPU/accelerator เฉพาะ
- Vendor SDKs & Runtimes — เช่น NNAPI (Android), Arm Compute Library / Ethos SDK, Edge TPU runtime, Qualcomm Hexagon SDK สำหรับการเรียกใช้งาน NPU/DSP
- Toolkits สำหรับ quantization & pruning — TensorFlow Model Optimization Toolkit, ONNX quantization tools และไลบรารีในการทำ quantization‑aware training หรือ fine‑tuning หลัง pruning
การผสาน TinyML กับ LLM บน edge มีรูปแบบการออกแบบที่สำคัญในเชิงธุรกิจ: ใช้โมเดลวิชั่นขนาดเล็กสำหรับการตรวจจับต่อเนื่องและเรียกใช้งาน LLM เฉพาะเมื่อจำเป็น (event‑triggered), ใช้ quantization/pruning/distillation ลดขนาดโมเดลและค่าใช้จ่ายด้านพลังงาน, และเลือกฮาร์ดแวร์ที่มี NPU เพื่อให้ได้ latency และ throughput ที่เหมาะสม ผลลัพธ์คือระบบที่สามารถให้คำอธิบายเหตุการณ์เชิงบริบทได้แบบ on‑device ปกป้องความเป็นส่วนตัว ลดการส่งข้อมูลคลาวด์ >10× และตอบสนองต่อเหตุการณ์ในเวลาจริง ซึ่งตรงกับความต้องการขององค์กรและลูกค้าทางธุรกิจในภาคภาพและความปลอดภัย
สถาปัตยกรรมการทำงานของระบบ
สถาปัตยกรรมการทำงานของระบบ
สถาปัตยกรรมที่สตาร์ทอัพไทยใช้ผสานเทคโนโลยี TinyML สำหรับการตรวจจับและจำแนกวัตถุบนอุปกรณ์ขอบเครือข่าย (edge) กับ LLM ขนาดเล็กสำหรับการให้บริบทเชิงความหมาย โดยมีเป้าหมายสำคัญคือการปกป้องความเป็นส่วนตัวของผู้ใช้งานและลดการใช้งานแบนด์วิธของคลาวด์อย่างมีนัยสำคัญ (ประมาณลดแบนด์วิธได้มากกว่า 10× เมื่อเทียบกับการส่งวิดีโอทั้งหมดขึ้นคลาวด์แบบเรียลไทม์) สถาปัตยกรรมครอบคลุมตั้งแต่การจับภาพ ไล่ตั้งแต่การ preprocess, การรัน inference บนอุปกรณ์, การทำ contextualization ด้วย LLM แบบท้องถิ่น/บนเกตเวย์ ไปจนถึงการส่งเฉพาะเมตาดาต้า/เหตุการณ์ไปยังคลาวด์เมื่อจำเป็น
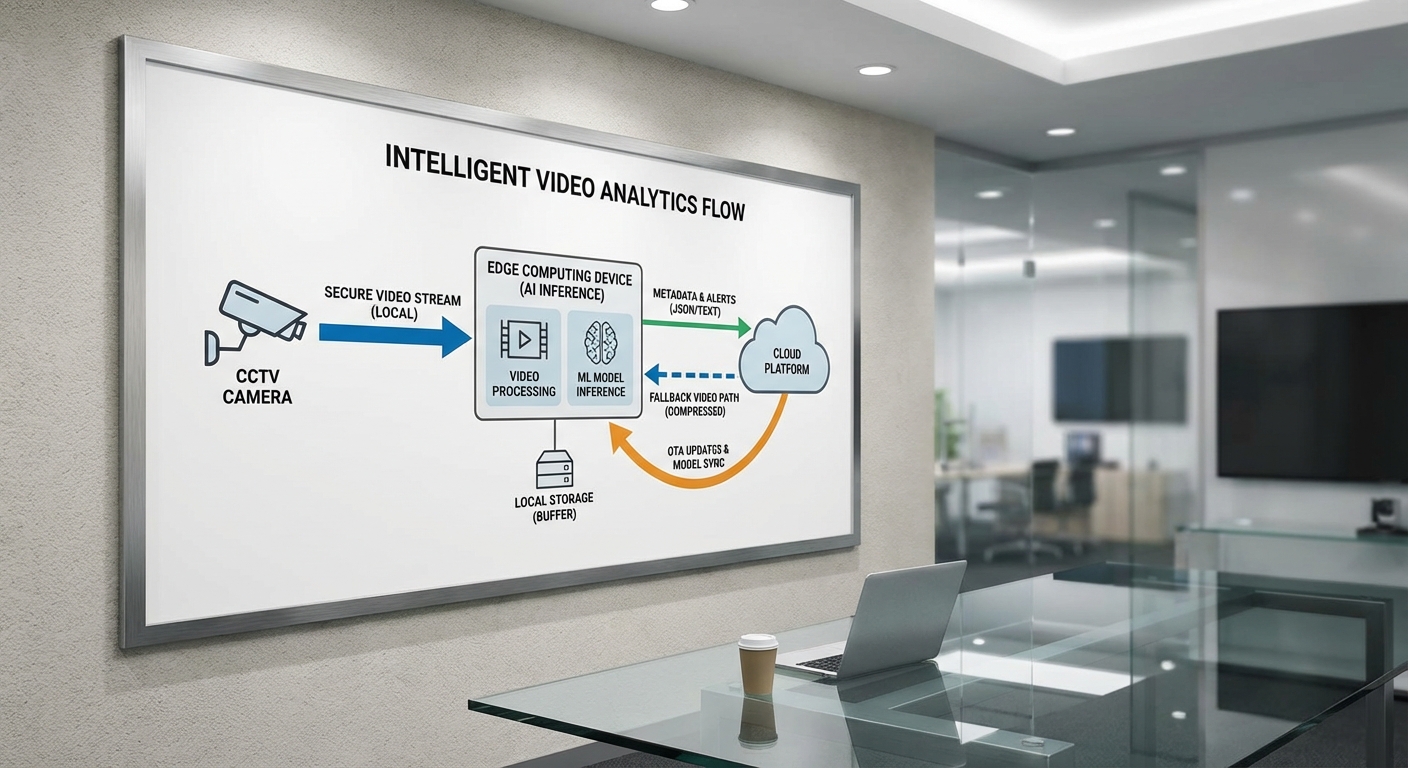
ไหลของข้อมูลถูกออกแบบให้ชัดเจนและมีจุดตัดสินใจ (decision points) หลักเพื่อจำกัดปริมาณข้อมูลที่ส่งขึ้นไปยังศูนย์กลาง ดังนี้
- Video capture: กล้องจับภาพแบบต่อเนื่อง โดยอุปกรณ์จะเก็บบัฟเฟอร์แบบวงกลม (circular buffer) ขนาดสั้นเพื่อรองรับการย้อนกลับในกรณีที่ต้องส่งคลิปสั้น ๆ สำหรับการตรวจสอบ
- Preprocessing: กระบวนการเช่น resize, color normalization, background subtraction และ frame-sampling ที่ลดภาระข้อมูลและช่วยให้โมเดล TinyML ทำงานได้มีประสิทธิภาพบนฮาร์ดแวร์จำกัด (ตัวอย่าง: ลดเฟรมเรตลงเหลือ 5–10 fps สำหรับการตรวจจับทั่วไป)
- TinyML inference (object detection/classification): โมเดลขนาดเล็กที่ผ่านการ quantize และ pruning (เช่น โมเดลขนาด 200–800 KB แบบ int8) รันบน MCU, NPU ขนาดเล็ก หรือ DSP เพื่อระบุเหตุการณ์หรือวัตถุที่สนใจ เช่น บุคคล ยานพาหนะ การกระทำที่ผิดปกติ โดยคืนค่าคะแนนความเชื่อมั่น (confidence score) และพิกัดหยาบ
- LLM for contextualization: LLM ขนาดเล็ก (หรือโมดูลภาษาบนเกตเวย์ที่ใช้ quantized transformer ขนาดเล็ก) รับเมตาดาต้าจาก TinyML เพื่อจัดทำคำบรรยายเชิงบริบท, สรุปเหตุการณ์, หรือประเมินความรุนแรง (เช่น “บุคคลวิ่งข้ามรั้วในพื้นที่ฉุกเฉิน”) ก่อนส่งผลลัพธ์สุดท้ายเป็นเหตุการณ์หรือเมตาดาต้า
- ส่งเฉพาะเมตาดาต้า/เหตุการณ์ไปคลาวด์: เฉพาะข้อมูลเช่น ประเภทเหตุการณ์, เวลา, พิกัด, confidence, และ hash ของคลิปเท่านั้นที่ถูกส่งขึ้นคลาวด์เพื่อลดปริมาณข้อมูลและปกป้องความเป็นส่วนตัว
ระบบออกแบบให้รองรับการทำงานแบบออฟไลน์อย่างเต็มรูปแบบ: เมื่อเครือข่ายขาดหาย อุปกรณ์ยังสามารถทำ TinyML inference และเก็บเหตุการณ์เชิงเมตาดาต้าในพื้นที่ได้ และเมื่อเครือข่ายกลับมาพร้อมจะซิงก์เมตาดาต้าที่จำเป็นไปยังคลาวด์ตามนโยบายการส่งข้อมูล
การจัดการโมเดลและวงจรชีวิตของโมเดล (MLOps สำหรับ edge) ถูกวางโครงสร้างเพื่อความปลอดภัยและความต่อเนื่องของบริการ โดยมีองค์ประกอบสำคัญดังนี้
- Deployment แบบ OTA (Over‑The‑Air): โมเดลและคอนฟิกมีการเซ็นชื่อด้วยคีย์ของบริษัทและส่งเป็นแพ็กเกจมาตรฐาน ระบบอุปกรณ์จะดาวน์โหลดแพ็กเกจแบบ delta update เพื่อลดข้อมูลที่ต้องรับส่ง และติดตั้งในโหมดทดสอบก่อนสลับใช้งานจริง
- Canary/Phased rollout และ safety rollback: การปล่อยโมเดลทำเป็นขั้นตอน (canary) เริ่มจากกลุ่มอุปกรณ์เล็ก ๆ เฝ้าติดตามเมตริกด้านประสิทธิภาพและความเสถียร หากพบความผิดปกติ (เช่น อัตราการผิดพลาดเพิ่มขึ้น latency สูงขึ้น หรือ resource spike) ระบบจะสั่งให้ rollback ไปยังเวอร์ชันก่อนหน้าโดยอัตโนมัติ
- MLOps สำหรับ edge: มี pipeline สำหรับการเก็บ telemetry (เช่น สถิติ inference, confidence distribution, อัตราการ fallback) พร้อมกระบวนการรีเทรนและตรวจสอบโมเดลบนเซิร์ฟเวอร์กลาง โดยข้อมูลฝึกสอนจะมาจากการเลือกตัวอย่างแบบเป็นมาตรการความเป็นส่วนตัว (anonymized / blurred frames หรือ metadata-only uploads) เพื่อให้วงจรพัฒนาโมเดลสามารถปรับได้โดยไม่ละเมิดกฎคุ้มครองข้อมูล
- ความปลอดภัยและการควบคุมเวอร์ชัน: ทุกโมเดลมีการเก็บ hash และ metadata ของเวอร์ชัน การอนุญาตการ deploy ถูกควบคุมโดยระบบ IAM และมี audit trail สำหรับการตรวจสอบย้อนหลัง
นโยบาย fallback (fallback to cloud) ถูกกำหนดอย่างรัดกุมเพื่อสมดุลระหว่างความถูกต้องและความเป็นส่วนตัว โดยมีแนวทางปฏิบัติหลักดังนี้
- ส่งเฉพาะวิดีโอหรือคลิปเต็มไปยังคลาวด์เฉพาะเมื่อ: เหตุการณ์ถูกจัดว่าเป็น high‑priority/critical (เช่น ความปลอดภัยต่อชีวิตหรือทรัพย์สิน), หรือต้องการการตรวจสอบจากมนุษย์ (human verification) เพื่อการตัดสินใจขั้นสุดท้าย
- ใช้ threshold confidence และกฎการตัดสินใจ: หากคะแนน confidence จาก TinyML ต่ำกว่าเกณฑ์ที่กำหนด (ตัวอย่างเช่น < 0.6) หรือลักษณะเหตุการณ์ไม่เคยปรากฏในฐานข้อมูล โมดูลจะส่งการร้องขอ contextualization/วิดีโอไปยังคลาวด์หรือศูนย์ตอบสนอง
- ส่งแบบ selective clip upload: แทนการส่งวิดีโอแบบไหลเต็มเวลา ระบบจะส่งคลิปสั้น ๆ เท่านั้น (เช่น 5–15 วินาที รอบเหตุการณ์) พร้อมการเข้ารหัส TLS และการเก็บรักษาตามนโยบาย retention/erase เพื่อลดความเสี่ยงทางความเป็นส่วนตัว
- mechanism for human‑in‑the‑loop: เมื่อคลาวด์ได้รับคลิปเพื่อการตรวจสอบ ทีมโอเปอเรชันสามารถให้ feedback กลับไปยัง MLOps pipeline เพื่อใช้เป็นข้อมูลฝึกสอนสำหรับเวอร์ชันถัดไป
สถาปัตยกรรมนี้ออกแบบให้สามารถปรับขนาดทางธุรกิจได้ (scalable) โดยการย้ายภาระการประมวลผลเชิงหนักขึ้นไปยังคลาวด์เมื่อต้องการการวิเคราะห์เชิงลึก แต่ยังคงรักษากลไกการทำงานอัตโนมัติบน edge เพื่อให้บริการทำงานได้อย่างรวดเร็ว ปลอดภัย และเป็นไปตามข้อกำหนดด้านความเป็นส่วนตัวของลูกค้าและกฎระเบียบที่เกี่ยวข้อง
กรณีศึกษาและตัวเลขเชิงปฏิบัติ: จากห้างถึงโรงงาน
กรณีศึกษาและตัวเลขเชิงปฏิบัติ: จากห้างถึงโรงงาน
สตาร์ทอัพที่นำ TinyML‑LLM มาประยุกต์ใช้งานกับระบบวิเคราะห์ภาพ CCTV รายงานผลเชิงปฏิบัติจากโครงการนำร่องหลายแห่ง พบว่าการประมวลผลบนอุปกรณ์ขอบเครือข่าย (edge) ร่วมกับ LLM ในการกรองเหตุการณ์สำคัญ สามารถลดปริมาณข้อมูลที่ส่งขึ้นคลาวด์, ย่นระยะเวลาการแจ้งเตือน และยังช่วยคงความเป็นส่วนตัวของผู้ใช้งาน ข้อมูลต่อไปนี้สรุปจากการทดลองภาคสนามใน 3 บริบท ได้แก่ ห้างสรรพสินค้า, โรงงาน และเมืองอัจฉริยะ
กรณีห้างสรรพสินค้า — ในโครงการหนึ่งที่ติดตั้งกล้องจำนวนมากเพื่อเฝ้าระวังพื้นที่ขาย ความต้องการเดิมคือการส่งวิดีโอแบบต่อเนื่องขึ้นคลาวด์ประมาณ 500 GB/วัน เพื่อวิเคราะห์และเก็บเหตุการณ์ หลังนำ TinyML มาทำการตรวจจับเบื้องต้นบนกล้อง และส่งเฉพาะคลิปที่มีเหตุการณ์สำคัญไปให้ LLM บน edge หรือคลาวด์เล็กๆ ตรวจสอบเพิ่มเติม ปรากฏว่า ปริมาณข้อมูลที่ส่งลดลงเหลือประมาณ 50 GB/วัน หรือมีการลดลง ≈10× ผลกระทบเชิงเศรษฐกิจรวมถึง ค่าใช้จ่ายแบนด์วิธและค่าใช้บริการคลาวด์ลดลงประมาณ 70–90% ขณะเดียวกัน throughput ต่ออุปกรณ์ในงานนี้อยู่ที่ประมาณ 10–20 เฟรมต่อวินาที สำหรับการตรวจจับเบื้องต้น โดยมีอัตราการส่งคลิปขึ้นคลาวด์เพียงราว 0.5–2% ของเฟรมทั้งหมด ทำให้ค่าใช้จ่ายเก็บบันทึกและการวิเคราะห์ย้อนหลังลดลงอย่างมีนัยสำคัญ
กรณีโรงงาน (พื้นที่อันตราย) — โครงการในสายการผลิตที่ต้องตรวจจับการบุกรุกพื้นที่อันตรายรายงานว่า การแจ้งเตือนฉุกเฉินแบบเดิมมีค่าเฉลี่ยเวลาตอบสนองประมาณ 6 วินาที จากการใช้ระบบ TinyML ที่ประมวลผลภาพบนอุปกรณ์และเรียก LLM สำหรับกรองเหตุการณ์สำคัญแบบบนอุปกรณ์ (on-device rescoring) เวลาตอบสนองเฉลี่ยลดลงเหลือเพียง 1.5 วินาที ซึ่งช่วยให้การตัดสินใจปิดสายการผลิตหรือสั่งหยุดอุปกรณ์ฉุกเฉินทำได้เร็วขึ้น ผลลัพธ์เชิงปฏิบัติรวมถึงการลดความรุนแรงของเหตุการณ์และเวลาหยุดการผลิต โดยประมาณการลดความสูญเสียจากอุบัติการณ์ได้ราว 30–50% การวัดผลทางเทคนิคชี้ว่า TinyML model ที่ปรับแต่งแล้วให้ความแม่นยำในการตรวจจับบุคคลในพื้นที่อันตรายอยู่ในช่วง 90–94% เมื่อเทียบกับ model ขนาดใหญ่บนคลาวด์ที่อาจให้ค่า 94–97% แต่เมื่อใช้ LLM เป็นตัวกรองหลัง (LLM rescoring) อัตรา false positive ของระบบลดจากราว 8–12% ลงเหลือประมาณ 1–2% ทำให้จำนวนการแจ้งเตือนเท็จ (nuisance alarms) ลดลงอย่างชัดเจน
กรณีเมืองอัจฉริยะ (นับยานพาหนะ/คน) — เมืองที่ทดลองใช้งานรายงานว่าการนับยานพาหนะและคนสำหรับการจัดการจราจรและนโยบายสาธารณูปโภค สามารถดำเนินการบนกล้อง edge ด้วย TinyML และส่งเฉพาะข้อมูลเชิงสรุปหรือเหตุการณ์ผิดปกติขึ้นไปยังศูนย์กลาง ทำให้ปริมาณข้อมูลส่งออกและค่าใช้จ่ายการจัดเก็บลดลงประมาณ 60–85% ความแม่นยำในการนับและแยกประเภทอยู่ที่ประมาณ 88–95% ขึ้นกับสภาพแสงและมุมกล้อง โดย throughput ต่ออุปกรณ์ที่ใช้งานจริงอยู่ที่ประมาณ 8–15 inferences ต่อวินาที สำหรับการนับแบบเรียลไทม์ และระบบที่ใช้ LLM กรองคำอธิบายเหตุการณ์สามารถลด false positive ลงเหลือ 1–3% ทั้งนี้การเลือกเฟรมที่จะส่งและการทำ anonymization ก่อนส่งข้อมูลช่วยเสริมความเป็นส่วนตัวของประชาชน
- การลดแบนด์วิธ (ตัวอย่างห้าง): จาก 500 GB/วัน → 50 GB/วัน (≈10× ลดลง)
- การลดเวลาแจ้งเตือนฉุกเฉิน (ตัวอย่างโรงงาน): จากเฉลี่ย 6 s → 1.5 s
- ความแม่นยำ (TinyML vs model ขนาดใหญ่): TinyML ≈ 88–94% vs ขนาดใหญ่ ≈ 92–97% (ความต่างมักอยู่ในระดับ 2–6%)
- อัตรา false positive หลังใช้ LLM กรอง: ก่อน ≈ 8–12% → หลัง ≈ 1–3%
- throughput ต่ออุปกรณ์: โดยทั่วไป 8–20 inferences/วินาที หรือ 8–20 FPS ขึ้นกับขีดจำกัดฮาร์ดแวร์และการปริมิติภาพ
- ประหยัดค่าใช้จ่ายโดยรวม: ขึ้นกับสเกลและสถาปัตยกรรม แต่โครงการนำร่องหลายแห่งรายงานการลด OPEX ประมาณ 60–80% ในส่วนของการส่งข้อมูลและค่าใช้จ่ายประมวลผลบนคลาวด์
สรุปได้ว่า TinyML‑LLM ให้ผลเชิงปฏิบัติที่เด่นชัดในแง่ของการลดปริมาณข้อมูลที่ส่งขึ้นคลาวด์และเวลาตอบสนองสำหรับเหตุการณ์ฉุกเฉิน โดยมี trade‑off ด้านความแม่นยำเล็กน้อยเมื่อเทียบกับโมเดลขนาดใหญ่ แต่การนำ LLM มากรองขั้นสุดท้ายสามารถชดเชยจุดอ่อนในเรื่อง false positive ได้อย่างมีประสิทธิภาพ สำหรับองค์กรที่ต้องการความเป็นส่วนตัวและลดค่าใช้จ่ายระยะยาว แนวทาง hybrid edge‑LLM นี้เป็นทางเลือกที่คุ้มค่าและพร้อมใช้งานเชิงพาณิชย์ได้จริง
ความเป็นส่วนตัวและการปฏิบัติตามกฎ (Privacy & Compliance)
ความเป็นส่วนตัวและการปฏิบัติตามกฎ (Privacy & Compliance)
การประมวลผลภาพ CCTV แบบออฟไลน์ด้วย TinyML‑LLM ช่วยลดความเสี่ยงเชิงข้อมูลส่วนบุคคลโดยหลักการว่า ข้อมูลภาพต้นฉบับไม่ถูกส่งไปยังคลาวด์ จึงลดโอกาสการรั่วไหลของข้อมูลสำคัญและการถูกเข้าถึงโดยบุคคลที่ไม่ได้รับอนุญาต ตัวอย่างเช่น แทนที่จะสตรีมวิดีโอความละเอียดสูงตลอดเวลา (ซึ่งสร้างภาระแบนด์วิธและพื้นที่เก็บข้อมูลขนาดใหญ่) ระบบจะประมวลผลบนอุปกรณ์ ทริกเกอร์เฉพาะเหตุการณ์ที่เกี่ยวข้อง และส่งเพียง metadata หรือ descriptor ที่ผ่านการสังเคราะห์แล้วเท่านั้น การออกแบบเช่นนี้สามารถลดการใช้แบนด์วิธคลาวด์ได้มากกว่า 10× ตามที่ระบบ TinyML‑LLM ระบุ ซึ่งเป็นการลดพื้นผิวการโจมตีด้านความเป็นส่วนตัวอย่างมีนัยสำคัญ
เพื่อคงความมั่นคงของข้อมูลที่ยังคงต้องเก็บไว้ ระบบควรนำแนวปฏิบัติดังต่อไปนี้มาใช้: การเข้ารหัสข้อมูลบนอุปกรณ์ (on-device encryption) ทั้ง metadata และ feature vectors ก่อนจัดเก็บหรือส่งออก โดยใช้มาตรฐานการเข้ารหัสที่ยอมรับในระดับสากล (เช่น AES‑256 สำหรับการเก็บข้อมูล และ TLS 1.2/1.3 สำหรับการสื่อสาร) พร้อมกับการบริหารจัดการกุญแจอย่างเข้มงวด (KMS) นอกจากนี้ การควบคุมการเข้าถึงแบบบทบาท (role‑based access control, RBAC) ควบคู่กับการพิสูจน์ตัวตนหลายชั้น (MFA) และการบันทึกเหตุการณ์การเข้าถึง (audit logs) จะช่วยให้สามารถติดตาม ตรวจสอบ และจำกัดการเข้าถึงข้อมูลได้ตามหลัก least‑privilege
นโยบายการเก็บรักษาข้อมูล (minimum retention) เป็นหัวใจของการลดความเสี่ยงทางกฎหมายและเชิงเทคนิค โดยควรกำหนดเกณฑ์ชัดเจนว่าเก็บอะไรนานเท่าใด เช่น เก็บเฉพาะ metadata ที่ไม่สามารถย้อนกลับไปสร้างภาพใบหน้าผู้คนได้เป็นค่าเริ่มต้น และลบข้อมูลอัตโนมัติเมื่อพ้นระยะเวลาที่จำเป็น ตัวอย่างนโยบายปฏิบัติจริงอาจกำหนดให้: metadata ทั่วไปเก็บไว้ไม่เกิน 7–14 วัน, เหตุการณ์ที่มีความเสี่ยงหรือคดีเก็บไว้ไม่เกิน 30–90 วันตามความจำเป็นเชิงนิติบัญญัติ หรือเก็บต่อเมื่อมีคำร้องตามกฎหมายเท่านั้น ระบบควรสนับสนุนการลบอย่างปลอดภัย (secure deletion) และการทำ pseudonymization/anonymization เพื่อลดความสามารถในการย้อนกลับ
ด้านกฎหมาย การปฏิบัติตาม PDPA ของไทยและมาตรฐานสากลเช่น GDPR จำเป็นต้องอาศัยกรอบการจัดการข้อมูลที่ครบถ้วน: เริ่มจากการประเมินผลกระทบด้านการคุ้มครองข้อมูล (Data Protection Impact Assessment, DPIA) เพื่อชี้แจงความเสี่ยงและมาตรการบรรเทา, การจัดทำบันทึกการประมวลผล (Record of Processing Activities, RoPA), และการกำหนดฐานทางกฎหมายในการประมวลผลข้อมูล (เช่น ข้อตกลงสัญญา หรือความยินยอมที่ชัดแจ้งในกรณีที่จำเป็น) สำหรับการขอความยินยอม (consent) ระบบต้องมีวิธีสื่อสารที่โปร่งใส เช่น ป้ายแจ้งการติดตั้งกล้อง การให้ข้อมูลเกี่ยวกับวัตถุประสงค์ ระยะเวลาการเก็บ และช่องทางการติดต่อเพื่อขอสิทธิของเจ้าของข้อมูล (เช่น การเข้าถึง แก้ไข หรือลบข้อมูล) โดยต้องมีวิธีบันทึกและจัดเก็บหลักฐานการยินยอมอย่างปลอดภัย
- แนวทางการรายงานความเสี่ยงและเหตุการณ์ด้านความเป็นส่วนตัว: กำหนดขั้นตอนแจ้งภายใน (incident response) ที่รวมการประเมินผลกระทบ การแจ้งผู้ควบคุมข้อมูลภายในองค์กร และเมื่อต้องตามกฎหมาย ให้แจ้งผู้กำกับดูแลและผู้มีส่วนได้เสียภายนอกภายในกรอบเวลาที่กฎหมายกำหนด (เช่น GDPR กำหนดการแจ้งเหตุละเมิดภายใน 72 ชั่วโมงเมื่อมีความเสี่ยงสูง)
- การจัดการข้ามพรมแดน: หากข้อมูลจำเป็นต้องส่งออก ให้ปฏิบัติตามข้อกำหนดการถ่ายโอนข้อมูลระหว่างประเทศ เช่น การใช้มาตรการคุ้มครองที่เหมาะสม (adequacy, Standard Contractual Clauses) และการตรวจสอบผู้รับข้อมูล
- การตรวจสอบและรับรอง: ควรมีการตรวจสอบภายใน/ภายนอกเป็นระยะ (security/privacy audits, penetration testing) และพิจารณาการรับรองมาตรฐาน เช่น ISO 27001 หรือการปฏิบัติตามแนวทาง Privacy by Design เพื่อลดความเสี่ยงเชิงระบบ
สรุปได้ว่า การออกแบบ TinyML‑LLM สำหรับวิเคราะห์ภาพ CCTV อย่างรับผิดชอบต้องรวมการประมวลผลแบบออฟไลน์เพื่อลดการเปิดเผยข้อมูล, การเข้ารหัส metadata และการใช้นโยบายเก็บรักษาแบบ minimum retention ร่วมกับการควบคุมการเข้าถึงเชิงบทบาทและกระบวนการด้านกฎหมายที่สอดคล้องกับ PDPA/GDPR การดำเนินการเชิงรุกเหล่านี้ไม่เพียงแต่ช่วยปกป้องสิทธิส่วนบุคคล แต่ยังเพิ่มความเชื่อมั่นให้กับลูกค้าและผู้มีส่วนได้เสียทางธุรกิจด้วย
ผลกระทบทางธุรกิจและโมเดลค่าใช้จ่าย (TCO)
ผลกระทบทางธุรกิจและโมเดลค่าใช้จ่าย (TCO)
การย้ายการวิเคราะห์ภาพ CCTV จากการส่งไฟล์วิดีโอขึ้นคลาวด์แบบต่อเนื่องไปเป็น TinyML‑LLM รันบนอุปกรณ์แบบออฟไลน์ จะส่งผลโดยตรงต่อค่าใช้จ่ายด้านแบนด์วิธและการประมวลผลบนคลาวด์ โดยเฉพาะในงานที่มีกล้องจำนวนมากและสตรีมวิดีโอต่อเนื่อง ตัวอย่างเช่น หากแต่ละกล้องสตรีมอย่างต่อเนื่องที่ความเร็วเฉลี่ย 2 Mbps จะสร้างข้อมูลประมาณ 0.65 TB/เดือนต่อกล้อง (ประมาณ 650 GB) สำหรับระบบ 100 กล้อง จะเป็น ~65 TB/เดือน หากระบบ TinyML ลดปริมาณข้อมูลที่ต้องส่งขึ้นคลาวด์ได้ 10× (ตามกรณีศึกษาของสตาร์ทอัพ) ค่าใช้จ่ายแบนด์วิธและการเก็บข้อมูลบนคลาวด์สามารถลดลงได้มากถึง ~90% ซึ่งในเชิงตัวเงินอาจเท่ากับการประหยัดหลายพันดอลลาร์ต่อเดือนและหลายหมื่นดอลลาร์ต่อปี ขึ้นกับราคาผู้ให้บริการคลาวด์ที่ต่างกัน
การประเมิน TCO เบื้องต้น (ตัวอย่างเชิงตัวเลขสมมติ): สมมติค่าใช้จ่ายแบนด์วิธ/การเก็บข้อมูลบนคลาวด์สำหรับ 100 กล้องอยู่ที่ประมาณ 5,000–6,000 USD/เดือน หากลดปริมาณข้อมูลลง 10× จะเหลือประมาณ 500–600 USD/เดือน การประหยัดราว 4,500–5,400 USD/เดือน หรือ ~54,000–65,000 USD/ปี นอกจากนี้การย้ายงาน inference ออกจากคลาวด์ยังช่วยลดค่าใช้จ่ายด้าน instance/GPU สำหรับการประมวลผลภาพแบบเรียลไทม์ ซึ่งอาจลดค่าใช้จ่ายส่วนนี้ได้เพิ่มอีก 30–70% ขึ้นกับการออกแบบสถาปัตยกรรมเดิมขององค์กร เมื่อรวบรวมปัจจัยทั้งหมด การลด TCO รวมอาจอยู่ในช่วง 30–60% ภายในปีแรกของการใช้งาน ขึ้นกับขนาด สนามใช้งาน และรูปแบบราคาปัจจุบันขององค์กร
โมเดลธุรกิจและโครงสร้างราคา: สตาร์ทอัพมักเสนอโมเดลแบบผสมระหว่างฮาร์ดแวร์และ SaaS เพื่อรองรับการติดตั้งแบบเอนด์ทูเอนด์ ซึ่งโมเดลทั่วไปได้แก่
- ขายอุปกรณ์ (one‑time hardware): ราคาหน่วยสำหรับอุปกรณ์ TinyML เช่นโมดูลหรือกล่องอินไคน์อาจอยู่ในช่วง 100–500 USD ขึ้นกับฟีเจอร์และปริมาณการสั่งซื้อ
- license per device: ค่าลิขสิทธิ์/การสนับสนุนแบบต่อกล้องหรืออุปกรณ์ เช่น 5–30 USD/เดือน/อุปกรณ์ สำหรับโมเดล inference, การตั้งค่าเริ่มต้น และรายงานพื้นฐาน
- subscription สำหรับ OTA updates และ analytics: ค่าสมัครสมาชิกสำหรับการอัปเดตโมเดลแบบ over‑the‑air, dashboard วิเคราะห์ภาพรวม, API และ SLA — สามารถตั้งเป็น per‑device หรือ per‑site โดยมีระดับราคาเช่น Basic/Pro/Enterprise (ตัวอย่าง: 1–10 USD/เดือน/อุปกรณ์ สำหรับ Basic และสัญญา per‑site แบบ flat 500–5,000 USD/เดือน สำหรับองค์กรขนาดใหญ่)
- pricing per camera vs per site: สำหรับลูกค้าที่มีกล้องจำนวนมาก โมเดลราคา per‑site แบบ flat หรือ volume discount จะเหมาะกว่าในแง่การเจรจา ROI ยกตัวอย่าง ลูกค้าขนาดกลาง/ใหญ่อาจเลือกจ่ายเป็นรายไซต์ (เช่น 1,500 USD/เดือน) แทนการจ่ายต่อกล้อง หากต้องการการบริหารจัดการแบบรวมศูนย์และ SLA ระดับสูง
คำแนะนำสำหรับ CIO/CTO ที่พิจารณานำไปใช้:
- เริ่มด้วย Proof‑of‑Concept ขนาดเล็ก (10–25 กล้อง) ระยะเวลา 2–3 เดือน เพื่อวัดผลด้านประสิทธิภาพจริง เช่น อัตราการลดแบนด์วิธ ความแม่นยำของการตรวจจับ และความเสถียรของ OTA
- กำหนด KPI ชัดเจนและวัดได้ เช่น
- ปริมาณแบนด์วิธ (GB/เดือน) ก่อนและหลังใช้งาน
- ค่าใช้จ่ายคลาวด์ที่เกี่ยวข้อง (USD/เดือน)
- latency ในการตรวจจับเหตุการณ์ (ms–s)
- precision/recall และอัตรา false positive/false negative
- MTTR (Mean Time To Respond) และจำนวนเหตุการณ์ที่ตอบสนองได้ภายใน SLA
- จำนวนเหตุการณ์ที่ลดการสูญเสีย/ค่าเสียหาย (เพื่อประเมินมูลค่า ROI)
- คำนวณ ROI แบบรวมค่าใช้จ่ายทั้งหมด (TCO) — รวมค่าอุปกรณ์ ต้นทุนการติดตั้ง ค่าลิขสิทธิ์/สมัครสมาชิก ค่าใช้จ่ายในการบำรุงรักษา และการประหยัดจากแบนด์วิธและการประมวลผลบนคลาวด์ ตัวอย่าง: หากการลงทุนเริ่มต้น (ฮาร์ดแวร์+ติดตั้ง) สำหรับ 100 กล้องเท่ากับ 30,000 USD และลดค่าใช้จ่ายปฏิบัติการรายปีได้ 80,000 USD จะเห็น payback ภายใน 6–12 เดือน ขึ้นกับโมเดลราคา
- พิจารณาข้อกำหนดด้านความปลอดภัยและความเป็นส่วนตัว — การประมวลผลบนอุปกรณ์ลดความเสี่ยงจากการรั่วไหลของข้อมูลส่วนบุคคลและช่วยให้เป็นไปตามกฎหมายคุ้มครองข้อมูล (เช่น PDPA) ซึ่งลดความเสี่ยงค่าปรับและค่าเสียหายเชิงกฎหมาย
- จัดทำสัญญา SLA และแผนการอัปเดต (OTA) — ระบุการบริการอัปเดตความปลอดภัยและโมเดล การตอบสนองต่อความเสี่ยง และกลไก fallback หากอุปกรณ์เกิดปัญหา
สรุปคือ TinyML‑LLM สำหรับการวิเคราะห์ภาพแบบออฟไลน์สามารถลดต้นทุนด้านแบนด์วิธและคลาวด์อย่างมีนัยสำคัญ เพิ่มความเร็วในการตรวจจับเหตุการณ์และเพิ่มประสิทธิภาพในการตอบสนอง ส่งผลให้ ROI ดีขึ้นเมื่อเทียบกับสถาปัตยกรรมที่พึ่งพาคลาวด์เต็มตัว อย่างไรก็ตาม การประเมินเชิงลึกผ่าน PoC และการติดตาม KPI ที่ชัดเจนเป็นสิ่งจำเป็นก่อนการขยายผลในระดับองค์กรเพื่อให้ได้ผลลัพธ์ทางการเงินและการปฏิบัติการตามที่คาดหวัง
ความท้าทาย ข้อจำกัด และแนวทางอนาคต
ความท้าทาย ข้อจำกัด และแนวทางอนาคต
การนำ TinyML‑LLM มารันวิเคราะห์ภาพจากกล้อง CCTV แบบออฟไลน์ให้ผลสำเร็จเชิงพาณิชย์มีข้อจำกัดทางเทคนิคและเชิงนโยบายที่ต้องพิจารณาอย่างรอบด้าน ในเชิงเทคนิคหนึ่งในข้อจำกัดชัดเจนคือ trade-off ระหว่างขนาดโมเดลกับความแม่นยำ — โมเดลขนาดเล็กที่ได้รับการคอมเพรสหรือควอนไทซ์เพื่อรันบนฮาร์ดแวร์ edge จะมีข้อจำกัดด้านความสามารถในการจับบริบทเชิงลึก ทำให้มีโอกาสเกิดความผิดพลาดสูงขึ้นเมื่อเทียบกับโมเดลขนาดใหญ่บนคลาวด์ (จากการทดลองภาคสนามและการศึกษาเบื้องต้น พบว่าความแม่นยำอาจลดลงในช่วง ประมาณ 5–15% ขึ้นกับภารกิจและสภาพแวดล้อม) นอกจากนี้ยังมีปัญหาเรื่อง ความหลากหลายของฮาร์ดแวร์ (CPU, NPU, DSP ที่ต่างกัน), การจัดการหน่วยความจำ, และการบริโภคพลังงาน ซึ่งเพิ่มความซับซ้อนในการบำรุงรักษาและการปรับแต่งโมเดลบนอุปกรณ์หลายรุ่นในสนามจริง
ประเด็นการบำรุงรักษา (maintenance) ของโมเดลบนอุปกรณ์จำนวนมากเป็นอีกความท้าทายสำคัญ — ต้องมีระบบอัปเดตโมเดลที่ปลอดภัย (secure OTA), สามารถตรวจสอบสถานะได้, และรองรับ rollback เมื่อเกิดปัญหา การอัปเดตที่ไม่มีการป้องกันอาจเปิดช่องให้เกิดการโจมตีหรือการเปลี่ยนแปลงพฤติกรรมของโมเดลได้ ในขณะเดียวกันการอัปเดตบ่อยครั้งอาจทำให้เกิด model drift (โมเดลไม่สอดคล้องกับข้อมูลจริงที่เปลี่ยนแปลง) จึงจำเป็นต้องมีระบบ validation pipelines ที่เข้มงวดก่อนนำโมเดลขึ้นสู่ production เช่น การทดสอบแบบ shadow mode, A/B testing, และการตั้งค่าธรณี (threshold) สำหรับเมตริกเช่น precision/recall, false positive rate เป็นต้น
ด้านความเป็นส่วนตัว, จริยธรรม และกฎระเบียบ การรันวิเคราะห์ภาพบนอุปกรณ์ในพื้นที่ช่วยลดการส่งข้อมูลภาพดิบไปยังคลาวด์ (รายงานเบื้องต้นระบุการลดแบนด์วิธได้สูงสุด 10×) แต่ยังต้องคำนึงถึง การปกป้องข้อมูลส่วนบุคคล เช่น การทำให้ไม่สามารถระบุตัวบุคคลได้ (anonymization), นโยบายการเก็บรักษาข้อมูล (data retention), และการได้มาซึ่งความยินยอม (consent) ตาม PDPA และมาตรฐานสากลอื่นๆ การออกแบบต้องคำนึงถึงความโปร่งใสและการตรวจสอบย้อนกลับ (audit trail) เพื่อให้สามารถตอบคำถามเชิงจริยธรรม เช่น การใช้งานในพื้นที่สาธารณะ การตรวจจับพฤติกรรมที่เสี่ยงต่อการเลือกปฏิบัติ (bias) และการรายงานข้อผิดพลาดต่อผู้มีส่วนได้ส่วนเสียได้อย่างเหมาะสม
แนวทางแก้ไขเชิงเทคนิคที่เป็นไปได้ประกอบด้วย:
- Federated Learning — อนุญาตให้อุปกรณ์ฝึกโมเดลจากข้อมูลภายในโดยไม่ส่งข้อมูลดิบขึ้นเซิร์ฟเวอร์ รวมกับเทคนิค secure aggregation และ differential privacy เพื่อลดความเสี่ยงด้านความเป็นส่วนตัวและช่วยให้โมเดลปรับตัวต่อสภาพแวดล้อมท้องถิ่น
- Continual Learning และการลดผลกระทบจาก catastrophic forgetting — ใช้กลยุทธ์ replay, regularization หรือ parameter-efficient tuning เพื่อให้โมเดลบนอุปกรณ์เรียนรู้จากข้อมูลใหม่โดยไม่ลืมความสามารถเดิม
- Secure OTA และ Validation Pipelines — ออกแบบการอัปเดตที่มีการลงนามดิจิทัล (code signing), canary deployment, automated validation (shadow testing, synthetic and real-world benchmarks) และการมอนิเตอร์หลังการปล่อย (post-deployment monitoring) เพื่อความมั่นคงและความน่าเชื่อถือ
- Model Compression + Hardware-aware Optimization — เทคนิคเช่น quantization-aware training, pruning, knowledge distillation และการปรับแต่งให้สอดคล้องกับ NPU/accelerator แต่ละรุ่น เพื่อรักษาความแม่นยำให้สูงสุดในงบประมาณทรัพยากรที่จำกัด
สำหรับแนวทางอนาคต (roadmap) ที่สามารถผลักดันการพัฒนาและการขยายเชิงพาณิชย์ได้ มีแผนเชิงลำดับดังนี้:
- ระยะสั้น (6–12 เดือน): เพิ่ม robustness ของ TinyML‑LLM ผ่าน quantization-aware training และการขยายชุดทดสอบ (edge benchmarks), ติดตั้ง secure OTA และ validation pipelines ในพilot sites
- ระยะกลาง (12–24 เดือน): เปิดตัว federated learning framework เชื่อมต่อกับ edge fleet, เริ่มผสานฟังก์ชัน continual learning และมาตรฐาน audit trail, เริ่มรับรองตามเกณฑ์ความปลอดภัยเบื้องต้น (เช่น ISO 27001 alignment)
- ระยะยาว (2–5 ปี): พัฒนาไปสู่ multimodal LLM ที่รวมการประมวลผลภาพ เสียง และข้อความบน edge/edge-cloud hybrid, ได้รับการรับรองตามมาตรฐานสากล (เช่น ISO/IEC, NIST) และขยายเชิงพาณิชย์ไปยังภาคสาธารณสุข (เช่น การตรวจจับภาวะฉุกเฉินในโรงพยาบาลโดยไม่ละเมิด HIPAA/PDPA) และภาคคมนาคม (เช่น การตรวจจับอุบัติเหตุแบบเรียลไทม์เพื่อลดเวลาแทรกแซง)
การนำเสนอนวัตกรรมเหล่านี้ต้องมาพร้อมกับความร่วมมือข้ามภาคส่วน — บริษัทเทคโนโลยี ผู้ควบคุมกฎระเบียบ โรงพยาบาล และองค์การขนส่ง — เพื่อให้เกิดความสมดุลระหว่างประสิทธิภาพทางเทคนิคและความรับผิดชอบเชิงจริยธรรม การยอมรับเชิงพาณิชย์จะขึ้นกับความสามารถในการพิสูจน์ผลลัพธ์เชิงประสิทธิภาพ (เช่นการลดแบนด์วิธจริง, การลดค่าใช้จ่ายคลาวด์, การลด latency) ควบคู่กับการรับรองด้านความปลอดภัยและความเป็นส่วนตัวที่ชัดเจน
บทสรุป
TinyML‑LLM บน edge เป็นแนวทางที่ช่วยให้การวิเคราะห์ภาพจากกล้อง CCTV เกิดขึ้นแบบออฟไลน์ ลดปริมาณข้อมูลที่ต้องส่งขึ้นคลาวด์ได้มาก (ตัวอย่างเช่นการลดแบนด์วิธได้ประมาณ 10× — กรณีสมมติ กล้อง 100 ตัว ที่ส่งวิดีโอ 2 Mbps/ตัว รวมเป็น 200 Mbps หากประมวลผลบน edge และส่งเฉพาะเมตาดาต้าหรือเหตุการณ์ที่สำคัญไปยังคลาวด์ ปริมาณข้อมูลที่ส่งอาจลดเหลือ ~20 Mbps) ภายใต้เงื่อนไขที่ยังคงรักษาประสิทธิภาพการตรวจจับเหตุการณ์ (accuracy) และความหน่วงเวลา (latency) ให้อยู่ในระดับที่ยอมรับได้ การประมวลผลบนอุปกรณ์ช่วยปกป้องข้อมูลส่วนบุคคลเพราะภาพดิบไม่จำเป็นต้องออกจากไซต์ ช่วยลดความเสี่ยงด้านความเป็นส่วนตัวและค่าใช้จ่ายแบนด์วิธคลาวด์
องค์กรควรเริ่มด้วยโครงการนำร่อง (PoC) ขนาดเล็กเพื่อทดสอบและวัด KPI สำคัญ ได้แก่ bandwidth, latency, และ accuracy พร้อมกำหนดนโยบายความเป็นส่วนตัวควบคู่ เช่น การทำ data minimization, การทำไม่ระบุตัวตน (anonymization), ระยะเวลาการเก็บข้อมูล และกระบวนการอัปเดตโมเดล (secure OTA updates, เวิร์กโฟลว์การรีเทรนและการตรวจสอบผล) PoC ควรกำหนดเกณฑ์รับได้ชัดเจนและมีแผนสเกลอัพเมื่อผ่านเกณฑ์ ในมุมมองอนาคต เทคโนโลยี TinyML‑LLM จะพัฒนาให้มีประสิทธิภาพมากขึ้น ร่วมกับ federated learning และฮาร์ดแวร์เร่งความเร็ว ทำให้องค์กรสามารถขยายการใช้งานอย่างปลอดภัย คุ้มค่า และสอดคล้องกับข้อกฎหมายด้านความเป็นส่วนตัวได้มากขึ้น ดังนั้นการทดลองนำร่องตอนนี้จะช่วยให้องค์กรได้เปรียบเชิงยุทธศาสตร์ทั้งด้านต้นทุน ความปลอดภัย และการปฏิบัติตามกฎระเบียบ



