
โรงงานไทยกำลังก้าวสู่ยุคการผลิตอัจฉริยะด้วยการทดสอบใช้งาน Digital‑Twin Agent ที่ผสานความสามารถของ Large Language Models (LLMs) เข้ากับ Reinforcement Learning เพื่อควบคุมสายการผลิตแบบเรียลไทม์ — ผลลัพธ์จากโปรเจกต์นำร่องแจ้งว่าสามารถลดเวลาหยุดเครื่อง (downtime) ลงถึง 40% ในช่วงที่ทดลองใช้งานจริง ทำให้ผู้ประกอบการมองเห็นโอกาสในการเพิ่มความต่อเนื่องของการผลิตและลดต้นทุนจากการหยุดชะงักของเครื่องจักร
ในบทนำนี้เราจะสรุปประเด็นสำคัญของโปรเจกต์: หลักการทำงานของ Digital‑Twin Agent ที่จำลองสภาพการผลิตแบบเรียลไทม์และใช้ LLM ช่วยวิเคราะห์ภาษาธรรมชาติร่วมกับนโยบายการตัดสินใจที่เรียนรู้ด้วย Reinforcement Learning เพื่อสั่งการปรับพารามิเตอร์การผลิตแบบอัตโนมัติ ผลเบื้องต้นแสดงการปรับปรุงประสิทธิภาพและการตอบสนองต่อเหตุขัดข้องได้รวดเร็วขึ้น พร้อมทั้งแผนขยายผลเชิงธุรกิจ เช่น การติดตั้งในสายการผลิตเพิ่มเติมและการเชื่อมโยงกับระบบ ERP — แต่ในขณะเดียวกันมีข้อพึงระวังด้านความปลอดภัยข้อมูล ความเป็นส่วนตัว และการกำกับดูแลโมเดลที่ต้องจัดการอย่างเข้มงวดก่อนขยายสเกล
ภาพรวมโครงการ: ทำไมโรงงานต้อง Digital‑Twin Agent
ภายใต้บริบทของอุตสาหกรรมการผลิตในไทย โรงงานหลายแห่งกำลังเผชิญแรงกดดันด้านต้นทุน การแข่งขันจากตลาดโลก และความคาดหวังสูงขึ้นของลูกค้าในด้านคุณภาพและความเร็วในการส่งมอบ การหยุดเครื่องจักรแบบไม่คาดคิด (downtime) ยังคงเป็นปัญหาหลักที่ส่งผลโดยตรงต่อผลผลิตและต้นทุนการผลิต โครงการนำร่องที่ใช้ Digital‑Twin Agent ซึ่งผสานความสามารถของ Large Language Models (LLM) กับ Reinforcement Learning (RL) ถูกออกแบบมาเพื่อลดปัญหาเหล่านี้ โดยผลลัพธ์เบื้องต้นจากโปรเจกต์นำร่องแสดงให้เห็นการลดเวลาหยุดเครื่องลงถึง 40% ซึ่งสะท้อนถึงศักยภาพในการเปลี่ยนแปลงกระบวนการผลิตเชิงปฏิบัติการได้อย่างสำคัญ

ความท้าทายหลักของโรงงาน: Downtime, MTTR, และ OEE
ปัญหาที่มักพบในโรงงานไทยรวมถึง:
- Downtime — เวลาที่สายการผลิตหยุดทำงาน จากสาเหตุเครื่องจักรเสีย การรออะไหล่ หรือการตั้งค่าที่ไม่ถูกต้อง ส่งผลให้สูญเสียโอกาสการผลิตและรายได้
- MTTR (Mean Time To Repair) — เวลาเฉลี่ยในการซ่อมแซม เมื่อเกิดความผิดปกติ MTTR ที่สูงบ่งชี้ถึงกระบวนการวินิจฉัยที่ช้า การขาดคู่มือเชิงปฏิบัติการ หรือหาชิ้นส่วนไม่ทัน
- OEE (Overall Equipment Effectiveness) — ประสิทธิภาพรวมของอุปกรณ์ซึ่งสะท้อนถึงการใช้ทรัพยากรอย่างมีประสิทธิผล โรงงานที่ยังมี OEE ต่ำกว่า 60% มักมีช่องว่างทั้งด้านความพร้อมใช้งาน คุณภาพ และประสิทธิภาพความเร็ว
ปัญหาเหล่านี้ผสมผสานกันเป็นวงจรที่ยากจะแก้ไขด้วยวิธีการแบบเดิมๆ เช่น การซ่อมตามกำหนด (time‑based maintenance) หรือการพึ่งพาประสบการณ์บุคลากรเพียงอย่างเดียว ทำให้การลงทุนในระบบที่สามารถ คาดการณ์ ปัญหา และ ตัดสินใจเชิงนโยบาย แบบอัตโนมัติเป็นสิ่งจำเป็น
Digital Twin: จำลองสถานะจริงของเครื่องจักรแบบเรียลไทม์
Digital Twin คือการสร้างแบบจำลองดิจิทัลของอุปกรณ์หรือกระบวนการผลิตที่อัปเดตด้วยข้อมูลเรียลไทม์จากเซนเซอร์และระบบควบคุมภาคสนาม (PLC/SCADA) ทำให้ผู้ปฏิบัติงานและผู้บริหารมองเห็นสถานะของเครื่องจักรอย่างต่อเนื่องและสามารถจำลองสถานการณ์ต่างๆ ได้ เช่น การทดสอบค่าพารามิเตอร์ การคำนวณผลกระทบของการหยุดเครื่อง หรือการประเมินความเสี่ยงก่อนการปรับเปลี่ยนการตั้งค่า
ฟีเจอร์สำคัญที่ Digital Twin มอบให้ได้แก่:
- การมอนิเตอร์สภาวะแบบเรียลไทม์ (temperature, vibration, throughput)
- การคาดการณ์ความเสียหายและการสึกหรอผ่านโมเดลเชิงสถิติและ ML
- การจำลองผลลัพธ์จากนโยบายการดำเนินการต่างๆ ก่อนนำไปใช้จริง
Agent ที่ผสาน LLM กับ Reinforcement Learning: ตัดสินใจและเรียนรู้จากการปฏิบัติจริง
การรวม LLM และ RL ในรูปแบบของ Digital‑Twin Agent ให้ความสามารถเชิงปฏิบัติการที่เกินกว่าการวิเคราะห์ข้อมูลแบบดั้งเดิม โดยบทบาทของแต่ละเทคโนโลยีมีความชัดเจนดังนี้:
- LLM — ทำหน้าที่ในการตีความข้อมูลทางเทคนิค เอกสารงาน ซ่อมบำรุง (SOPs) และการสื่อสารกับผู้ปฏิบัติงานแบบภาษาธรรมชาติ ช่วยให้การแปลผลการวิเคราะห์เป็นข้อเสนอแนะเชิงปฏิบัติการที่เข้าใจง่ายและสามารถอธิบายเหตุผลเชิงบริบทได้
- Reinforcement Learning — ทำหน้าที่เรียนรู้และปรับนโยบายการควบคุมจากการทดลองใน Digital Twin และผลตอบรับจากระบบจริง โดยอาศัยฟังก์ชันรางวัล (reward) ที่สะท้อนเป้าหมายเช่นการลด downtime, ลด MTTR หรือเพิ่ม OEE
เมื่อนำสององค์ประกอบนี้มาทำงานร่วมกัน ผลที่ได้คือ เอเจนต์เชิงนโยบาย ที่สามารถเสนอการตัดสินใจเชิงปฏิบัติการ (เช่น ปรับเลื่อนการบำรุงรักษา ปรับค่าการควบคุมหรือจัดลำดับความสำคัญของงานซ่อม) พร้อมทั้งเรียนรู้จากผลลัพธ์จริงเพื่อลดความเสี่ยงและเพิ่มประสิทธิภาพอย่างต่อเนื่อง ตัวอย่างการใช้งานในงานจริงได้แก่การแนะนำชุดคำสั่งการซ่อมที่ลดเวลา MTTR, การปรับพารามิเตอร์เครื่องจักรเพื่อลดการสั่นสะเทือนที่นำไปสู่การหยุดเครื่องน้อยลง หรือการจัดการสต็อกอะไหล่แบบคาดการณ์ล่วงหน้า
โดยสรุป จุดมุ่งหมายของโปรเจกต์นำร่องคือการผนวกรากฐานของ Digital Twin เข้ากับเอเจนต์ที่ขับเคลื่อนด้วย LLM+RL เพื่อให้โรงงานมีความสามารถในการตัดสินใจเชิงนโยบายแบบเรียลไทม์ ลด downtime และ MTTR ในขณะที่ยกระดับ OEE และลดต้นทุนการบำรุงรักษาอย่างยั่งยืน ก่อนขยายผลสู่สายการผลิตขนาดใหญ่ในระยะถัดไป
เทคโนโลยีเบื้องหลัง: LLM ผสาน Reinforcement Learning ทำงานร่วมกันอย่างไร
เทคโนโลยีเบื้องหลัง: LLM ผสาน Reinforcement Learning ทำงานร่วมกันอย่างไร
การรวม Large Language Models (LLM) กับ Reinforcement Learning (RL) ในรูปแบบ Digital‑Twin Agent บนสายการผลิตเป็นการเชื่อมต่อความสามารถสองฝั่งเข้าด้วยกัน โดยแต่ละเทคโนโลยีมีบทบาทเฉพาะและเสริมซ้อนกันเพื่อให้ระบบสามารถตัดสินใจแบบเรียลไทม์และสื่อสารกับผู้ปฏิบัติงานได้อย่างมีความหมาย ในระดับสูง LLM ทำหน้าที่ตีความบริบทจากข้อมูลหลายมิติ ไม่ว่าจะเป็นข้อความแจ้งเตือนจากเซนเซอร์ รายงานเชิงเหตุการณ์จากผู้ปฏิบัติงาน หรือบันทึกประวัติการหยุดเครื่อง แล้วแปลงข้อมูลเหล่านั้นเป็นนโยบายเชิงคำสั่ง (policy prompt) หรือข้อเสนอแนะที่มนุษย์สามารถเข้าใจได้ ในขณะเดียวกัน RL จะนำข้อเสนอแนะเหล่านี้ไปเป็นจุดเริ่มต้นในการเรียนรู้เชิงนโยบายการควบคุมแบบปฏิบัติการ และปรับปรุงนโยบายโดยอาศัยผลลัพธ์จริงที่ได้จากการทดลองหรือการจำลอง
บทบาทของ LLM: LLM ทำหน้าที่เป็นตัวกลางเชิงบริบทและการสื่อสาร—เมื่อเกิดเหตุการณ์ผิดปกติ LLM จะวิเคราะห์เหตุการณ์ในมุมมองเชิงสาเหตุ (root cause) รวมถึงประวัติการเกิดซ้ำ จากนั้นจะแปลงคำอธิบายเชิงภาษาธรรมชาติให้เป็นชุดคำสั่งหรือนโยบายระดับสูง เช่น “ลดความเร็วสายการผลิต 10% จนกว่าจะปรับพารามิเตอร์อุณหภูมิได้ภายใน 5 นาที” หรือ “แนะนำลำดับการเปลี่ยนแม่พิมพ์เพื่อลดเวลาหยุดเครื่อง” นอกจากนี้ LLM ยังทำหน้าที่สร้างคำอธิบายที่มนุษย์เข้าใจได้เพื่อสนับสนุนการตัดสินใจของผู้บริหารและช่างเทคนิค ช่วยเพิ่มความโปร่งใสและความเชื่อมั่นในการนำเสนอการกระทำอัตโนมัติ
บทบาทของ RL: RL มีหน้าที่ปรับแต่งนโยบายเชิงปฏิบัติการโดยตรงผ่านการทดลองและรางวัล (reward) ที่นิยามตาม KPI ของโรงงาน เช่น เวลาหยุดเครื่อง (downtime), ผลผลิตต่อชั่วโมง (throughput), อัตราผลิตภัณฑ์ผ่านคุณภาพ (yield) และการใช้พลังงาน (energy). ระบบ RL จะลองนโยบายต่าง ๆ บนตัวแทนดิจิทัลหรือในสภาพแวดล้อมจริงแบบจำกัด (safe trials) และเรียนรู้จากผลลัพธ์เพื่อเพิ่มค่าสะสมรางวัล ตัวอย่างการนิยามรางวัลเชิงปฏิบัติการคือฟังก์ชันเชิงน้ำหนัก: reward = −α·downtime + β·throughput − γ·energy + δ·quality_bonus ซึ่งช่วยให้การฝึกมุ่งตรงไปยังเป้าหมายเชิงธุรกิจได้ชัดเจน
สถาปัตยกรรมการฝึกและการย้ายจากจำลองสู่จริง (sim‑to‑real): เพื่อความปลอดภัยและลดความเสี่ยงก่อนการนำไปใช้จริง โครงสร้างการฝึกมักเริ่มจากการฝึกในซิมูเลเตอร์ความละเอียดสูง (high‑fidelity simulator) ที่สร้าง Digital Twin ของเครื่องจักรและกระบวนการผลิต แล้วใช้เทคนิคต่าง ๆ เพื่อเพิ่มความทนทานต่อช่องว่างระหว่างจำลองและโลกจริง ตัวอย่างเทคนิคสำคัญได้แก่
- Domain randomization: เปลี่ยนพารามิเตอร์จำลอง (เช่น ค่าสัมประสิทธิ์การเสียดสี, แรงรบกวนเซนเซอร์, ความล่าช้าในสัญญาณ) ในช่วงกว้างเพื่อให้นโยบายเรียนรู้ได้ทั่วไปและทนต่อความแปรผันในสภาพแวดล้อมจริง
- System identification & hardware‑in‑the‑loop (HIL): ปรับพารามิเตอร์จำลองจากการวัดจริง และทดสอบนโยบายบางส่วนบนฮาร์ดแวร์จริงในสภาพแวดล้อมที่ควบคุมได้ก่อนขยายการใช้งาน
- Progressive deployment / curriculum learning: เริ่มจากงานที่เสี่ยงต่ำและค่อยเพิ่มความยาก เช่น ทดสอบนโยบายเฉพาะช่วงเวลาที่การผลิตไม่สำคัญ จากนั้นขยายช่วงเวลาจนระบบสามารถทำงานในกะปกติ
ตัวอย่างสถาปัตยกรรมการฝึก (ตัวอย่างเชิงปฏิบัติ): ในโปรเจกต์นำร่องอาจใช้สแต็กผสมที่ประกอบด้วย LLM ชั้นบนที่สร้างนโยบายระดับภารกิจ (task‑level policy) และ RL ชั้นล่างที่ควบคุมพารามิเตอร์ระดับอุปกรณ์ (actuator‑level). กระบวนการฝึกอาจมีลำดับดังนี้: (1) สร้างเหตุการณ์และสถานการณ์การผลิตในซิมูเลเตอร์ แล้วให้ LLM สังเคราะห์นโยบายเบื้องต้นเป็น prompt; (2) ใช้ RL (เช่น PPO, SAC หรือ DDPG ขึ้นกับลักษณะปัญหา) เพื่อฝึกนโยบายการควบคุมในซิมจนกว่าจะได้ผลลัพธ์ตาม KPI; (3) นำแบบจำลองเข้าสู่ HIL เพื่อทดสอบบนอุปกรณ์จริงภายใต้สภาวะควบคุม; (4) เปิดใช้งานในสภาพแวดล้อมจริงแบบจำกัดและใช้ online fine‑tuning พร้อม human‑in‑the‑loop oversight
การออกแบบรางวัลและการป้องกันพฤติกรรมผิดรูป (reward shaping & safety): การออกแบบรางวัลที่สอดคล้องกับ KPI ของธุรกิจเป็นหัวใจหลัก เพราะรางวัลที่นิยามไม่ดีอาจนำไปสู่ “reward hacking” หรือพฤติกรรมที่ได้รางวัลแต่ไม่สอดคล้องกับเป้าหมายธุรกิจ เทคนิคที่ใช้ได้แก่การใช้รางวัลแบบมีความหนาแน่น (dense reward) ร่วมกับรางวัลเสริม (auxiliary rewards) เพื่อกระตุ้นพฤติกรรมระยะสั้นและระยะยาว การใช้ constrained RL เพื่อบังคับเงื่อนไขความปลอดภัย และการนำมนุษย์เข้าตรวจสอบผลลัพธ์เป็นขั้นตอนบังคับก่อนอนุมัติการเปลี่ยนแปลงสำคัญในไลน์การผลิต
สรุปคือ เมื่อ LLM ทำหน้าที่ตีความบริบทและแปลงความรู้เชิงภาษาธรรมชาติเป็นนโยบายเชิงคำสั่ง และ RL ปรับปรุงนโยบายเหล่านั้นโดยอาศัยการทดลองและรางวัลที่เชื่อมโยงกับ KPI การผสานทั้งสองจึงสร้าง Digital‑Twin Agent ที่ไม่เพียงทำงานเชิงปฏิบัติการได้มีประสิทธิภาพ แต่ยังสามารถอธิบายการตัดสินใจและทำงานร่วมกับมนุษย์ได้อย่างโปร่งใส กระบวนการฝึกแบบ sim‑to‑real และแนวทางควบคุมความเสี่ยงช่วยให้การนำไปใช้งานจริงเป็นไปอย่างปลอดภัยและมีประสิทธิผล — ซึ่งเป็นปัจจัยสำคัญที่ช่วยให้โปรเจกต์นำร่องสามารถลดเวลาหยุดเครื่องลงได้ถึง 40% ในกรณีศึกษาที่ผ่านมา
รายละเอียดโปรเจกต์นำร่องที่โรงงานไทย
รายละเอียดโปรเจกต์นำร่องที่โรงงานไทย
โปรเจกต์นำร่องถูกติดตั้งในโรงงานผลิตชิ้นส่วนอิเล็กทรอนิกส์และอุปกรณ์ไฟฟ้าขนาดกลาง-ใหญ่ของไทย โดยครอบคลุมทั้งสายการผลิตตัวอย่างเช่น สายประกอบอุปกรณ์ไฟฟ้า, สายผลิตชิ้นส่วนยานยนต์ และ สาย SMT/PCB สำหรับอุปกรณ์อิเล็กทรอนิกส์ จุดเริ่มต้นเป็นการนำร่อง 3 สายการผลิต (2 สายประกอบ ขนาดสายละประมาณ 20–30 เครื่องจักร และ 1 สาย SMT ขนาด ~40 สถานี) เพื่อจำลองภาระการผลิตที่แตกต่างกันตั้งแต่งานชิ้นเล็กไปจนถึงการผลิตเป็นชุดใหญ่ ระยะเวลาโปรเจกต์รวมระหว่างการเก็บข้อมูล, การพัฒนาโมเดล และการปรับใช้แบบควบคุมอยู่ที่ประมาณ 6 เดือน (เดือนที่ 1–2 เก็บข้อมูลและจำลอง, เดือนที่ 3–4 ฝึก LLM + RL ในสภาพแวดล้อมจำลอง, เดือนที่ 5–6 ทดสอบและปรับใช้เชิงปฏิบัติการ)
สภาพแวดล้อมข้อมูลประกอบด้วยสัญญาณจาก PLC/SCADA, MES, เซนเซอร์สภาพเครื่องจักร (vibration, temperature, current), และบันทึกการซ่อมจากระบบ CMMS ทีมงานได้ออกแบบวงจรการทดลองโดยมีการตั้งค่าพื้นฐาน (baseline) จากข้อมูลย้อนหลัง 3 เดือน เพื่อเปรียบเทียบผลลัพธ์หลังการใช้ Digital‑Twin Agent ที่ผสาน LLM สำหรับการวิเคราะห์เชิงภาษาธรรมชาติและการสื่อสารกับช่าง กับโมดูล Reinforcement Learning สำหรับการตัดสินใจเชิงนโยบายการควบคุมแบบเรียลไทม์ (เช่น การปรับพารามิเตอร์การขับเคลื่อน, การจัดคิวงาน, และการสั่งหยุด/สำรองแบบปลอดภัย)
ทีมที่เกี่ยวข้องถูกจัดเป็นกลุ่มสหสาขาวิชาชีพเพื่อรับประกันการบูรณาการระหว่างระบบไอทีและการผลิต ประกอบด้วย:
- วิศวกรกระบวนการ (4 คน): ออกแบบการทดสอบ, กำหนดข้อจำกัดเชิงเทคนิค และตรวจสอบความปลอดภัยของนโยบายที่ RL แนะนำ
- Data Scientists (5 คน): สร้างฟีเจอร์จากสัญญาณเครื่องจักร, ฝึก LLM สำหรับการวิเคราะห์เหตุการณ์และสร้างคำสั่งสนับสนุนการตัดสินใจ
- DevOps / OT Integration (3 คน): ทำงานกับระบบ PLC/SCADA/MES เพื่อเชื่อมต่อข้อมูลแบบเรียลไทม์ และจัดการ CI/CD สำหรับโมเดล
- บุคลากรฝ่ายบำรุงรักษาและผู้ปฏิบัติงาน (รวมเป็นเครือข่ายการปฏิบัติการในไซต์): ได้รับการฝึกสอนให้ใช้คำแนะนำจาก LLM และเปิดช่องทางย้อนกลับเพื่อนำข้อมูลการซ่อมเพิ่มคุณภาพให้กับโมเดล
ผลลัพธ์เชิงตัวเลขที่วัดได้จากการนำร่องมีความเด่นชัดเมื่อเปรียบเทียบกับ baseline:
- Downtime ลดลง 40% — วัดจากชั่วโมงการหยุดสายผลิตต่อเดือน (จากเหตุการณ์หยุดโดยไม่คาดคิดและการหยุดเพื่อช่างบำรุงรักษา)
- MTTR (Mean Time To Repair) ลดลง 30% — เนื่องจาก LLM ให้คำแนะนำการวินิจฉัยและขั้นตอนการซ่อมแบบทีละขั้น ทำให้ช่างสามารถแก้ไขได้รวดเร็วขึ้น
- Throughput เพิ่มขึ้น 12% — การใช้ RL ในการจัดคิวงานและปรับพารามิเตอร์การทำงานช่วยลดคอขวดและเพิ่มอัตราผลิตจริงต่อชั่วโมง
ตัวอย่างเหตุการณ์จริงที่เกิดขึ้นระหว่างการนำร่อง:
- กรณีที่ 1 — เซนเซอร์ตรวจพบการสั่นสะเทือนของมอเตอร์เพิ่มขึ้นในสายประกอบชิ้นส่วนยานยนต์: ระบบ RL แนะนำให้ลดความเร็วการป้อนชิ้นงานลง 15% ชั่วคราวและย้ายงานไปยังสายสำรอง ผลลัพธ์คือหลีกเลี่ยงการหยุดฉุกเฉิน ซึ่งลด downtime ได้โดยตรง
- กรณีที่ 2 — เกิดปัญหาความร้อนผิดปกติในโมดูล SMT: LLM วิเคราะห์ล็อกเหตุการณ์และให้คำแนะนำเชิงปฏิบัติการแก่ช่าง (ขั้นตอนตรวจเช็กฟิลเตอร์อากาศและการปรับค่าแรงลม) ทำให้การแก้ไขสำเร็จภายในครึ่งหนึ่งของเวลาที่เคยใช้ (ลด MTTR ~50% ในเหตุการณ์นั้นเฉพาะ)
- กรณีที่ 3 — การรี‑จัดคิวงานโดย RL ในช่วงชั่วโมงเร่งด่วนช่วยลดเวลารอวัสดุและการสลับเครื่องมือ ทำให้ throughput ของสาย SMT เพิ่มขึ้นประมาณ 12% ในสัปดาห์ทดสอบ
จากผลการนำร่อง โรงงานได้ยืนยันแนวทางการต่อยอดสู่การขยายใช้ในระดับโรงงานทั้งโรง โดยมีแผนงานสำหรับการปรับปรุงมาตรฐานการเชื่อมต่อ OT, การเพิ่มชุดข้อมูลประสิทธิภาพ และการออกแบบกรอบกำกับความปลอดภัย (safety guardrails) เพื่อให้การตัดสินใจของ Digital‑Twin Agent สามารถปฏิบัติได้จริงและสอดคล้องกับนโยบายการผลิตขององค์กร
สถาปัตยกรรมระบบและการบูรณาการกับ OT/IT
สถาปัตยกรรมระบบและการบูรณาการกับ OT/IT
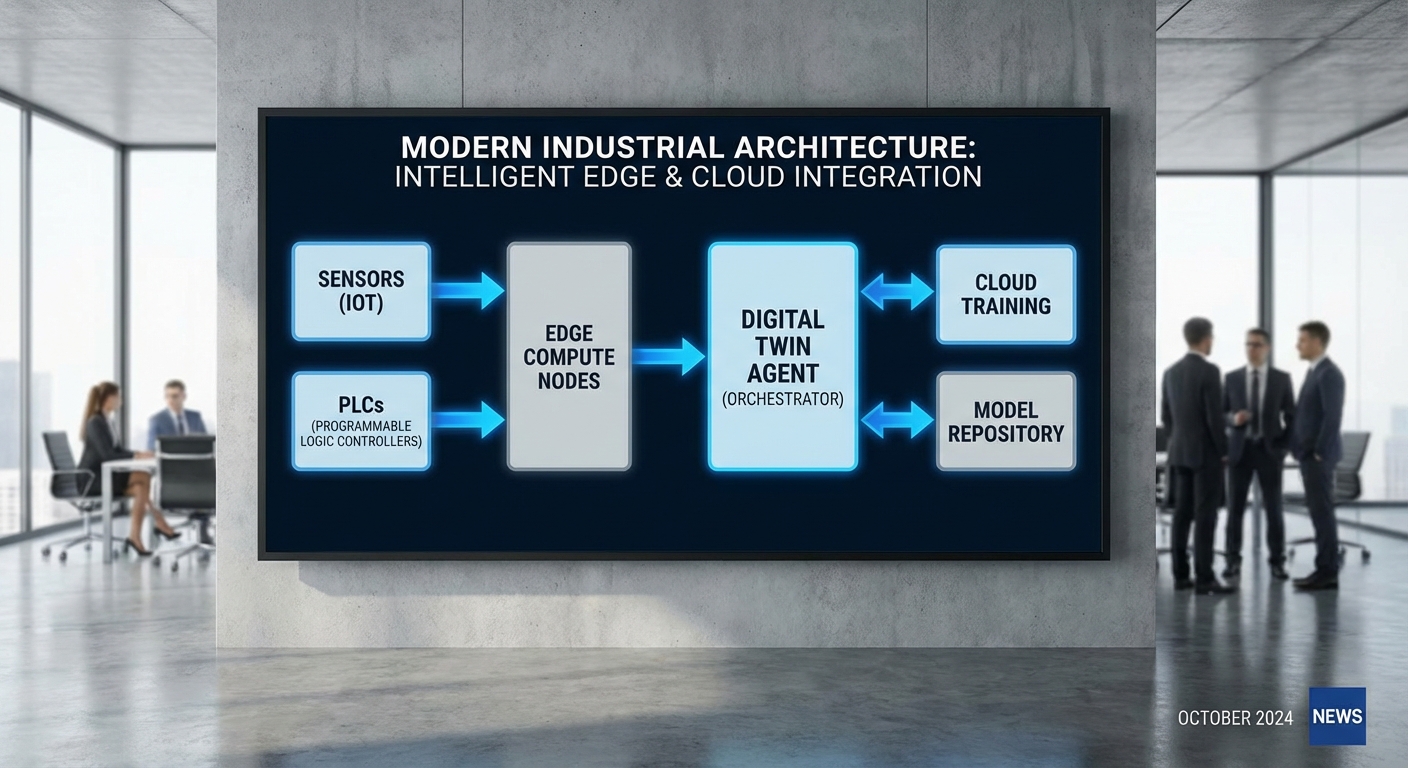
สถาปัตยกรรมของโปรเจกต์นำร่องนี้ออกแบบมาเพื่อรองรับการทำงานแบบเรียลไทม์และรักษาความมั่นคงของเครือข่าย OT/IT โดยมีหลักการชัดเจนคือการแยกชั้นการทำงาน (separation of concerns) ระหว่าง sensor/PLC, edge nodes, digital twin และ cloud สำหรับการฝึกและจัดเก็บโมเดล ตัวอย่างการไหลของข้อมูลเชิงเทคนิคคือ: เซนเซอร์ส่งสัญญาณไปยัง PLC/RTU ผ่าน fieldbus/industrial Ethernet (เช่น Profinet, EtherNet/IP) → PLC ส่งข้อมูลเชิงกระบวนการไปยัง edge gateway โดยใช้โปรโตคอลมาตรฐานอุตสาหกรรมเช่น OPC UA หรือ MQTT → edge nodes ทำการ pre-processing, time-series buffering และ inference แบบ low‑latency → digital twin ที่รันบน edge/edge‑cloud ผนวกข้อมูลสถานะจริงและโมเดลเชิงฟิสิกส์/ML เพื่อคำนวณนโยบาย → LLM+RL agent ตัดสินใจในรูปแบบ action proposals → คำสั่ง actuation ถูกส่งกลับไปยัง PLC/SCADA เพื่อขยับอุปกรณ์หรือปรับพารามิเตอร์การผลิต
ในทางปฏิบัติ โฟลว์ข้อมูลที่ควรระบุไว้ในสถาปัตยกรรมมีดังนี้:
- Sensor → PLC → Edge Gateway: เซนเซอร์ (sampling rate 10–1,000 Hz ขึ้นกับชนิด) ส่งสัญญาณไปยัง PLC/RTU แล้ว PLC ทำการ logical aggregation ก่อนส่งออกผ่าน OPC UA/MQTT ไปยัง edge gateway ซึ่งทำหน้าที่เป็น protocol broker และ buffer (เช่น time-series DB: InfluxDB หรือ kdb+) เพื่อรองรับการสูญหายของเครือข่ายและลดภาระบน PLC
- Edge Processing → Digital Twin: Edge nodes (เช่น server แบบ rugged หรือ edge GPU เช่น NVIDIA Jetson/Intel NUC) ทำ inference ของ LLM/RL ที่ถูก optimized สำหรับ latency ต่ำ (quantization, TensorRT) และรัน digital twin model เพื่อจำลองสถานะเครื่องจักรแบบ near‑real‑time (sync interval ระหว่าง 50–500 ms ขึ้นกับ use case)
- Digital Twin → Agent → Actuation: Agent ประมวลผลโดยใช้ข้อมูลจาก twin (state, prediction, reward signals) และให้คำสั่งในรูปแบบที่ PLC/SCADA ยอมรับได้ เช่น OPC UA method calls หรือ MQTT commands ผ่าน secure gateway
- Cloud (Training & Model Store): ข้อมูลประวัติและ telemetry ถูกส่งเป็น batch ไปยัง cloud สำหรับการฝึก RL/LLM แบบ distributed (เช่น RLlib, Ray) และจัดเก็บเวอร์ชันของโมเดลใน model registry/feature store (เช่น MLflow, Kubeflow, S3) เพื่อสนับสนุน lifecycle ของโมเดล
ด้านการแยกเครือข่ายและความมั่นคงปลอดภัย ระบบออกแบบให้มีการแบ่งแยกชัดเจนระหว่าง OT และ IT โดยใช้ VLAN และ policy‑based firewalls พร้อม DMZ/Gateway เป็นชั้นกลางสำหรับการแลกเปลี่ยนข้อมูลระหว่างสองโดเมนนี้ Gateway ทำหน้าที่เป็น protocol translator, data diodes (หากต้องการทิศทางเดียว) และ enforce access control ก่อนส่งข้อมูลขึ้นไปยัง IT/Cloud เพื่อป้องกัน lateral movement ภายในเครือข่าย OT ตามแนวปฏิบัติมาตรฐานอุตสาหกรรม (เช่น IEC 62443, NIST)
มาตรการความปลอดภัยเชิงเทคนิคที่ใช้รวมถึง:
- Network segmentation & VLAN: แยก traffic ของ PLC/SCADA, edge management และ IT services พร้อม firewall rules เฉพาะ
- Gateway/DMZ: ข้อมูลจาก OT ถูกผ่าน gateway DMZ ที่ทำ deep packet inspection, protocol normalization และ security logging
- Encryption: การเชื่อมต่อทุกส่วนใช้ TLS 1.2/1.3 หรือ OPC UA secure channels สำหรับการสื่อสาร และข้อมูลที่เก็บจะเข้ารหัสที่เหลือ (AES‑256) ทั้งที่ edge และ cloud
- IAM & RBAC: การควบคุมสิทธิ์แบบรัดกุม (Role‑Based Access Control) ผสาน MFA สำหรับผู้ดูแล ระบบใช้ identity provider (เช่น Active Directory/LDAP หรือ IAM cloud) และมีการกำหนด least privilege
- Key management & HSM: การจัดการคีย์ด้วย HSM/Key Vault สำหรับ signing และการจัดเก็บ credential ของโมเดล/agent
- Audit & Logging: เก็บ audit trail ของคำสั่ง actuation, model decisions และการเข้าถึงระบบ เพื่อการตรวจสอบย้อนหลังและ forensic
การรวม LLM และ RL agent เข้ากับระบบ SCADA/ERP เกิดขึ้นผ่านชุด API ที่ได้มาตรฐานและมี middleware คั่นกลาง: Agent ให้ผลลัพธ์เป็น action proposals ผ่าน REST/gRPC หรือ OPC UA interfaces ส่วน SCADA จะรับคำสั่ง actuation และส่ง telemetry กลับ โดย ERP/ MES จะได้รับ event level updates (เช่น OEE, downtime event) ผ่าน event broker (Kafka) หรือ REST API เพื่อให้มีการวางแผนเชิงธุรกิจและการบำรุงรักษาแบบอัตโนมัติ
สุดท้าย การบริหารจัดการวงจรชีวิตของโมเดล (ML CI/CD) และการมอนิเตอร์เป็นหัวใจสำคัญสำหรับความต่อเนื่องของระบบ:
- CI/CD สำหรับโมเดล: โค้ดและโมเดลถูกจัดการด้วย GitOps pipelines (เช่น GitLab CI, Jenkins) โดย pipeline จะประกอบด้วย unit test, integration test กับ simulator/digital twin, static analysis, container build (Docker) และ deployment แบบ canary/rolling ผ่าน Kubernetes/Edge orchestration
- Model Registry & Versioning: ใช้ model store (MLflow/ModelDB) สำหรับเก็บ metadata, hyperparameters, performance metrics และการรับรองเวอร์ชันก่อน promote ไปยัง production edge
- Model Monitoring: มอนิเตอร์ทั้ง performance metrics (reward trends, latency, inference error), data drift / concept drift (statistical tests, PSI/KS), และ safety constraints (invariant checks) ด้วยระบบ alerting (Prometheus + Grafana, ELK) และ automated rollback เมื่อพบ degradation
- Shadow/Canary Testing & A/B: ทดสอบโมเดลใหม่แบบ shadow หรือ canary บน subset ของเครื่องจักรก่อนสลับจริง เพื่อลดความเสี่ยงในการทำงานจริง
โดยภาพรวม สถาปัตยกรรมนี้ผสานความสามารถของ edge latency‑sensitive processing กับความยืดหยุ่นของ cloud training and governance และรักษามาตรฐานความปลอดภัยในระดับอุตสาหกรรม ทำให้ LLM+RL Agents สามารถตัดสินใจแบบเรียลไทม์ ลดเวลาหยุดเครื่องและสนับสนุนการขยายผลสู่องค์กรได้อย่างมั่นคงและตรวจสอบได้
การควบคุมแบบเรียลไทม์: การตัดสินใจ ระดับนโยบายและการปฏิบัติ
การควบคุมแบบเรียลไทม์: การตัดสินใจ ระดับนโยบายและการปฏิบัติ
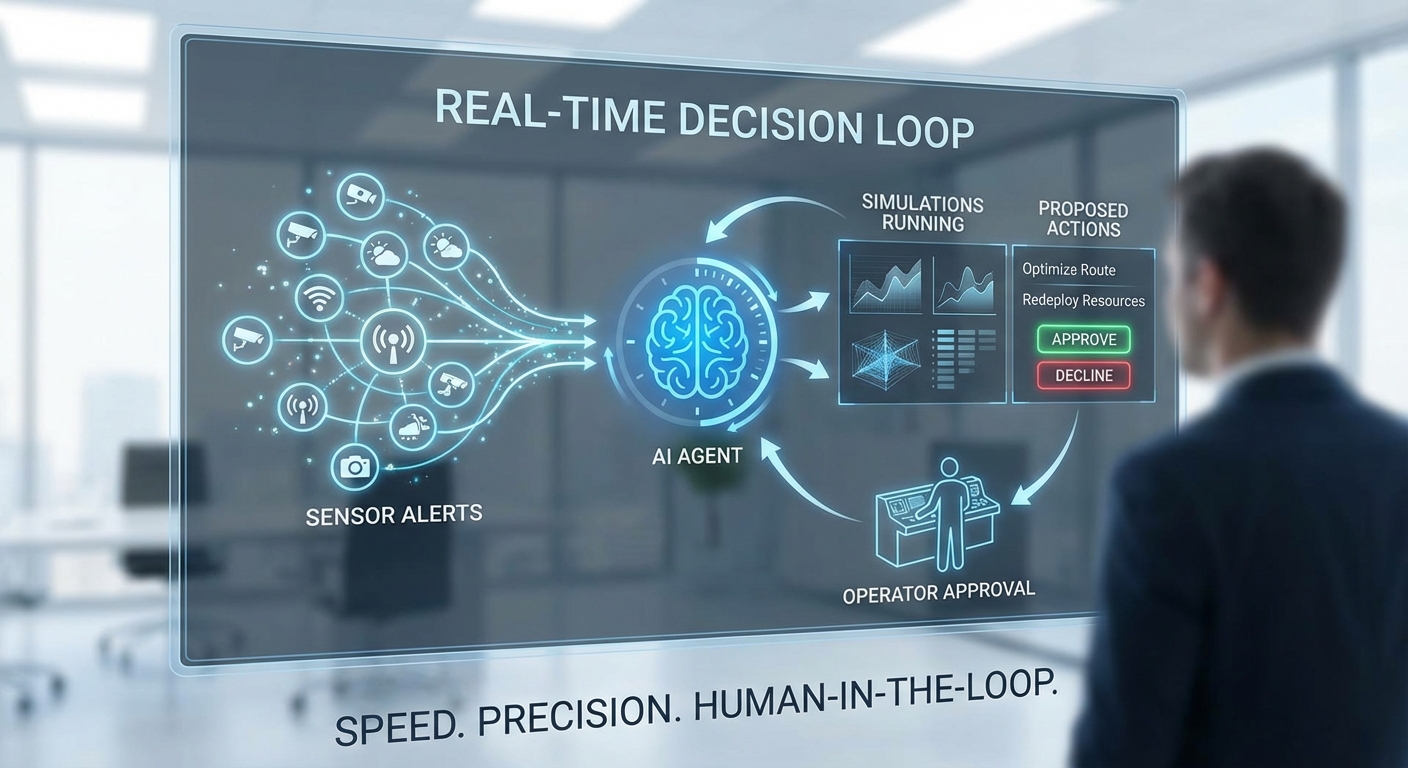
ในโปรเจกต์นำร่องที่โรงงานไทยนำ Digital‑Twin Agent ซึ่งผสานความสามารถของ Large Language Models (LLMs) กับ Reinforcement Learning (RL) มาควบคุมสายการผลิตแบบเรียลไทม์ การตัดสินใจถูกออกแบบเป็นชั้นชัดเจนตั้งแต่การตรวจจับเหตุการณ์ไปจนถึงการปฏิบัติจริงโดยคำนึงถึงความปลอดภัยและความสามารถในการตรวจสอบย้อนหลัง (auditability) ทำให้สามารถลดเวลาหยุดเครื่องลงได้ถึง 40% ในรอบการทดสอบ ทั้งนี้ระบบต้องตอบสนองภายในหน้าต่างการตัดสินใจที่สั้น—โดยทั่วไปภายในไม่กี่วินาทีสำหรับเหตุการณ์ความเสี่ยงต่ำ และมีช่วงเวลาอนุมัติของมนุษย์สำหรับเหตุการณ์ความเสี่ยงสูง
Pipeline การตัดสินใจ (detect → diagnose → propose → act) ถูกออกแบบเป็นลำดับงานอัตโนมัติที่มีการประเมินความเสี่ยงในทุกขั้นตอน:
- Detect — เซ็นเซอร์และโมดูลวิเคราะห์สัญญาณ (เช่น vibration, temperature, I/O alarms) ตรวจพบความผิดปกติและส่งเหตุการณ์ไปยัง Digital Twin ในรูปแบบสตรีมเหตุการณ์แบบ low‑latency
- Diagnose — โมดูลวินิจฉัยใช้ข้อมูลประวัติ ระบบกายภาพจำลอง และนโยบายที่เรียนรู้จาก RL ในการจัดลำดับความเป็นไปได้ของสาเหตุ (root‑cause probabilities) พร้อมค่าสถานะความเชื่อมั่น
- Propose — ตัวแทนเลือกนโยบายปฏิบัติการที่เหมาะสมตามบทลงโทษ (reward/penalty) ที่เรียนรู้มา แล้วใช้ LLM แปลงนโยบายเชิงเทคนิคเป็นคำแนะนำเชิงบริบทที่ชัดเจนสำหรับช่างและผู้จัดการ
- Act — การสั่งงานจะถูกดำเนินการโดยระบบอัตโนมัติทันทีหรือรอการยืนยันจากมนุษย์ ขึ้นกับระดับความเสี่ยงและข้อกำหนดความปลอดภัย
ในเชิงเทคนิค RL จะรับบทในการเลือกนโยบายเชิงนโยบาย (policy selection) โดยคำนวณค่า Q‑value หรือ expected return ของชุดการกระทำภายใต้สภาวะที่ตรวจพบ ระบบมีการกำหนดเกณฑ์ความเสี่ยง (risk thresholds) เช่น หากความเสี่ยงต่ำกว่า 0.2 (20%) ระบบอาจอนุญาตให้ดำเนินการอัตโนมัติทันที แต่หากสูงกว่า 0.2 จะเข้าสู่โหมด human‑in‑the‑loop เพื่อรอการอนุมัติจากผู้ควบคุม การตั้งค่าเกณฑ์นี้สามารถปรับได้ตามนโยบายองค์กรและประเภทของอุปกรณ์
LLM ทำหน้าที่เป็นสะพานเชิงสื่อสารสำคัญระหว่างระบบเชิงเทคนิคกับผู้ใช้งานมนุษย์ — ไม่ใช่เพียงแค่สร้างข้อความเท่านั้น แต่ยังจัดบริบทให้เหมาะสมกับบทบาท: สำหรับช่างอาจให้ขั้นตอนปฏิบัติการโดยละเอียด เช่น "หยุดมอเตอร์ A, ปล่อยแรงดันระบบ, ตรวจสอบเซ็นเซอร์ X ภายใน 3 นาที" ส่วนสำหรับผู้จัดการจะสรุปความเสี่ยง ผลกระทบต่อการผลิต และคำแนะนำเชิงนโยบาย เช่น "แนะนำให้ยุติการผลิตช่วง B เพื่อป้องกันความเสียหายต่อเครื่องจักร และจัดทีมซ่อมภายใน 2 ชั่วโมง" ข้อความที่สร้างโดย LLM ยังแนบเหตุผลเชิงสาเหตุและตัวชี้วัดที่ใช้ในการตัดสินใจ เพิ่มความโปร่งใสแก่ผู้รับผิดชอบ
กลไกการยั้ง/อนุมัติของมนุษย์ (human‑in‑the‑loop) ออกแบบมาเพื่อความปลอดภัยและการปฏิบัติตามกฎระเบียบ: ระบบจะส่งชุดข้อมูลสรุปความเสี่ยง ตัวเลือกการปฏิบัติและผลลัพธ์ที่คาดไว้ พร้อมตัวเลือก อนุมัติ หรือ ปฏิเสธ โดยมีตัวบันทึกการตัดสินใจ (decision log) สำหรับการตรวจสอบย้อนหลัง ในโปรเซสนี้ยังมีเกณฑ์อัตโนมัติ เช่นการกำหนดสิทธิ์อนุมัติแตกต่างกันตามตำแหน่งงาน—ช่างอาวุโสอนุมัติการซ่อมระดับปานกลาง ส่วนการตัดสินใจที่มีผลกระทบต่อความปลอดภัยหรือสิ่งแวดล้อมจะต้องได้รับการอนุมัติจากผู้จัดการระดับสูง
ตัวอย่างสเต็ปการตัดสินใจเมื่อเกิดเหตุขัดข้อง (fault example: สายพานลำเลียงสะดุด):
- Detect: เซ็นเซอร์ความสั่นสะเทือนและกล้องแสดงการชะงักของสายพาน — Event ถูกส่งไปยัง Digital Twin ภายใน 0.5 วินาที
- Diagnose: โมเดลวิเคราะห์เชิงสาเหตุชี้ว่าเป็นไปได้ 70% มาจากมอเตอร์โอเวอร์โหลด, 20% มาจากวัตถุติดขัด และ 10% เป็น false alarm พร้อมให้ค่าความเชื่อมั่น
- Propose: RL เลือกนโยบายที่ลดความเสี่ยงสูงสุด (เช่น ลดความเร็วชั่วคราวและสั่งหยุดมอเตอร์หากค่าโหลดเกินค่าเกณฑ์) และ LLM สร้างคำสั่งสำหรับช่าง: "ลดความเร็วสายพานเหลือ 30% และตรวจสอบมอเตอร์ A หากอุณหภูมิยังสูงให้สลับการทำงานและเรียกช่างซ่อมภายใน 15 นาที"
- Act (approve & execute): ถ้าความเสี่ยงประเมินต่ำ ระบบจะสั่งการอัตโนมัติทันที หากความเสี่ยงสูง ผู้ควบคุมได้รับแจ้งและมีเวลา 2 นาทีในการอนุมัติ เมื่อได้รับอนุมัติ ระบบจะดำเนินการตามแผน และบันทึกผลลัพธ์เพื่อนำไปใช้ฝึกโมเดล RL ต่อไป
สรุปได้ว่า การควบคุมแบบเรียลไทม์ของ Digital‑Twin Agent ประกอบด้วยการเชื่อมต่อระหว่างการตรวจจับความผิดปกติ การประเมินความเสี่ยงเชิงปริมาณ การเลือกนโยบายที่เรียนรู้จาก RL และการสื่อสารเชิงบริบทโดย LLM พร้อมกลไก human‑in‑the‑loop เพื่อรับประกันความปลอดภัยและความรับผิดชอบ การออกแบบนี้ช่วยให้โรงงานสามารถลด downtime ได้อย่างมีนัยสำคัญ ขณะเดียวกันยังรักษามาตรฐานความปลอดภัยและความโปร่งใสในการตัดสินใจระดับนโยบายและการปฏิบัติ
ความท้าทาย ข้อจำกัด และแนวทางบริหารความเสี่ยง
ความท้าทาย ข้อจำกัด และแนวทางบริหารความเสี่ยง
การนำ Digital‑Twin Agent ที่ผสาน Large Language Models (LLM) กับ Reinforcement Learning (RL) มาใช้ควบคุมสายการผลิตแบบเรียลไทม์ เปิดโอกาสด้านประสิทธิภาพ — ตัวอย่างโปรเจกต์นำร่องที่ลดเวลาหยุดเครื่องลง 40% เป็นหลักฐานหนึ่ง — แต่ก็มาพร้อมความเสี่ยงและข้อจำกัดที่ต้องบริหารอย่างเป็นระบบ ทั้งด้าน latency, ความน่าเชื่อถือของโมเดล, data drift, ความมั่นคงปลอดภัยของข้อมูล และการสอดคล้องตามกฎหมายข้อมูลส่วนบุคคล (เช่น PDPA และกรณีข้ามประเทศอาจสัมพันธ์กับ GDPR)
Latency และความน่าเชื่อถือของระบบ — ระบบควบคุมแบบเรียลไทม์มีข้อกำหนดด้านเวลา (timing) ที่เข้มงวด: ในลูปการตัดสินใจบางประเภท ต้องการ end-to-end latency ระดับไม่กี่สิบมิลลิวินาที ขณะที่ลูปเชิงวางแผนอาจยอมรับได้มากกว่า (เช่น 100–500 ms) จึงควรวางสถาปัตยกรรมแบบ edge-first เพื่อลดความหน่วง, ใช้ quantization/optimizations ของโมเดล, และจัดวาง SLA (เช่น availability > 99.9%) เพื่อป้องกันการขัดข้องที่กระทบการผลิต นอกจากนี้ควรมีการทดสอบภาระงานและการทดสอบเชิงสตรูกรัม (structured stress/soak testing) อย่างสม่ำเสมอเพื่อจำลองสภาพการณ์สูงสุดและเสริมความทนทาน
Model drift, overspecialization และการดูแลโมเดลอย่างต่อเนื่อง — โมเดลทั้ง LLM และ RL มีแนวโน้มเกิด data drift และ overspecialization เมื่อสภาพแวดล้อมการผลิตเปลี่ยนแปลง (เช่น วัตถุดิบใหม่ หรือการบำรุงรักษาเครื่องจักร) จึงต้องมีระบบมอนิเตอร์ที่วัดเมตริกเชิงพฤติกรรม เช่น reward distribution, action distribution, inference confidence, latency และอัตราความผิดพลาดของคำสั่ง เมื่อตรวจพบสัญญาณ drift ควรกำหนดนโยบายการ retrain ทั้งแบบตามกำหนดเวลาและแบบ trigger-based (เช่น retrain เมื่อ performance ลดลงกว่าเกณฑ์ 5–10%) พร้อมกระบวนการจัดเก็บข้อมูลที่มีคุณภาพสำหรับการ label และ validation โดยควรใช้ digital twin และ sandbox environment ในการทดสอบการ retrain ก่อนนำขึ้นระบบจริง
ความมั่นคงปลอดภัยและความเป็นส่วนตัวของข้อมูลเซนเซอร์ — เซนเซอร์และข้อมูลไทม์ซีรีส์ของเครื่องจักรถือเป็นข้อมูลเชิงปฏิบัติการที่มีความสำคัญ การบริหารความเสี่ยงต้องรวมการเข้ารหัสทั้ง at-rest และ in-transit, การควบคุมสิทธิ์แบบ Role-Based Access Control (RBAC) และแนวทาง Zero Trust เพื่อลดความเสี่ยงจากการเข้าถึงโดยไม่ได้รับอนุญาต ควรพิจารณาออกแบบให้ข้อมูลที่มีความละเอียดสูงหรือข้อมูลที่อาจมีข้อมูลส่วนบุคคล (เช่น metadata ของผู้ปฏิบัติงาน) ถูกประมวลผลเฉพาะที่ edge และทำการอุดรูรั่วด้วยการ anonymization/aggregation ก่อนส่งไปยัง cloud เพื่อให้สอดคล้องกับ PDPA/GDPR รวมถึงกำหนดระยะเวลาการเก็บข้อมูลและนโยบายการลบอย่างชัดเจน
แผนสำรองและการจัดการความผิดพลาด (Safe fallback plans) — เมื่อ Agent ทำงานผิดพลาด ต้องมีระดับ fallback หลายชั้น เช่น
- Fail-safe physical states: การออกแบบเครื่องจักรให้เข้าสู่สถานะปลอดภัยอัตโนมัติเมื่อไม่มีคำสั่งเชื่อถือได้
- Degraded/autonomous mode: เปลี่ยนกลับไปใช้การควบคุมแบบ deterministic หรือ rule‑based ที่ทดสอบแล้ว
- Human-in-the-loop: สลับการตัดสินใจไปยังผู้ควบคุมมนุษย์พร้อมแสดงเหตุผลและข้อมูลบริบทอย่างชัดเจน
- Circuit breakers และ rate limits: ป้องกันการวนคำสั่งผิดพลาดซ้ำ ๆ ด้วยการหยุดชั่วคราวหรือจำกัดคำสั่งต่อวินาที
การบันทึก ติดตาม และ audit trail เพื่อความโปร่งใสและการตรวจสอบ — ควรบันทึกข้อมูลเชิงเหตุผล (provenance) อย่างครบถ้วน ได้แก่ input sensor snapshot, prompt/observation ที่ส่งให้ LLM, action ที่ออกโดย Agent, reward/feedback, และ timestamp โดยเก็บในระบบที่ไม่สามารถแก้ไขได้ (WORM) และเชื่อมต่อกับ SIEM/ระบบตรวจจับเหตุการณ์ การบันทึกเหล่านี้สำคัญสำหรับการสอบสวนเหตุขัดข้อง, การพิสูจน์ความสอดคล้องตามกฎระเบียบ และการปรับปรุงโมเดล นอกจากนี้ควรกำหนดนโยบาย retention, encryption keys rotation และการเข้าถึงเชิง audit เพื่อให้สอดคล้องกับข้อกำหนดทางกฎหมาย
แนวทางปฏิบัติที่แนะนำโดยสรุป — ระบบต้องออกแบบด้วยแนวคิด Defense‑in‑Depth และ Observability ตั้งแต่การทดสอบเชิงสตรูกรัม, shadow/canary deployment ก่อน rollout เต็มรูปแบบ, continuous monitoring ของ performance และ drift, กลไก retrain ที่มี governance, การเข้ารหัสและนโยบาย privacy-by-design, รวมถึง safe fallback plans และ immutable audit trail การลงทุนในมาตรการเหล่านี้จะช่วยลดความเสี่ยงเชิงปฏิบัติการและกฎหมาย ทำให้โครงการ Digital‑Twin Agent สามารถยกระดับผลผลิตอย่างปลอดภัยและยั่งยืน
ผลกระทบทางธุรกิจ การขยายผล และข้อเสนอเชิงนโยบาย
ผลกระทบทางธุรกิจและการคำนวณเบื้องต้น (ROI)
การนำ Digital‑Twin Agent ที่ผสาน Large Language Models (LLM) และ Reinforcement Learning มาคุมสายการผลิตแบบเรียลไทม์ส่งผลโดยตรงต่อการลด downtime และเพิ่ม throughput ซึ่งสามารถแปลงเป็นมูลค่าทางการเงินได้ชัดเจน ตัวอย่างการคำนวณเชิงอนุรักษ์โดยสมมติค่าพื้นฐานเพื่อเป็นแนวทางประเมิน:
- สมมติฐานพื้นฐาน: ดั้งเดิม downtime = 1,200 ชั่วโมง/ปี, ต้นทุนการหยุดเครื่องเฉลี่ย = 40,000 บาท/ชั่วโมง → ต้นทุน downtime ต่อปี = 48,000,000 บาท
- ผลลัพธ์จากโครงการนำร่อง: ลด downtime ได้ 40% → ประหยัดค่าเสียโอกาส = 19,200,000 บาท/ปี
- ผลต่อ throughput: สมมติรายได้จากการผลิตปกติ = 300,000,000 บาท/ปี และเพิ่ม throughput ได้ 5% → รายได้เพิ่ม = 15,000,000 บาท/ปี
- ผลประโยชน์รวมต่อปี (เบื้องต้น): 34,200,000 บาท/ปี (19.2M + 15M)
- ต้นทุนการลงทุนและค่าใช้จ่าย: CapEx พัฒนา/ติดตั้งระบบ = 18,000,000 บาท, OpEx ประจำปี (ไลเซนส์, คลาวด์, บำรุงรักษา) = 4,000,000 บาท, ค่าอบรมและ reskilling ปีแรก = 1,200,000 บาท
- การคำนวณ ROI แบบง่าย: ปีแรกสุทธิ = 34.2M - (18M + 4M + 1.2M) ≈ 11M บาท → ระยะคืนทุน (Payback) ≈ 1.6 ปี
ข้อสังเกต: ตัวเลขข้างต้นเป็นแบบจำลองตัวอย่าง การประเมินจริงควรปรับให้สอดคล้องกับขนาดโรงงาน ค่าเสียหายต่อชั่วโมงที่แท้จริง การเปลี่ยนแปลงราคา และข้อจำกัดทางปฏิบัติ เช่น ความสามารถในการใช้กำลังการผลิตเพิ่ม และต้นทุนทางกฎหมายหรือประกันภัยที่เกี่ยวข้อง สำหรับการตัดสินใจเชิงกลยุทธ์ ควรคำนวณ Net Present Value (NPV) และ Internal Rate of Return (IRR) บนสมมติฐานกระแสเงินสดหลายปี รวมทั้งวิเคราะห์ความเสี่ยง (sensitivity analysis) ต่อการลด downtime และอัตราเพิ่ม throughput
ผลกระทบต่อแรงงานและโครงการ Reskilling
การนำระบบอัตโนมัติระดับสูงมาใช้จะเปลี่ยนบทบาทงานของช่างและทีมปฏิบัติการจากงานเชิงปฏิบัติการสู่การควบคุมดูแลระบบ (supervision) และการวิเคราะห์ข้อมูลอย่างเข้มข้น ดังนั้นการออกแบบโครงการ reskilling เป็นสิ่งจำเป็นเพื่อรักษาความสามารถของแรงงานและลดผลกระทบทางสังคม
- โครงสร้างโปรแกรม: หลักสูตรแบบโมดูล ประกอบด้วย (1) ความรู้เบื้องต้นเกี่ยวกับ AI/ML และ Digital Twin, (2) การใช้งานและปรับแต่ง LLM สำหรับการสื่อสารภายในระบบ, (3) พื้นฐาน Reinforcement Learning สำหรับการปรับกลยุทธ์การควบคุม, (4) การแก้ไขปัญหาเชิงปฏิบัติการและการดีบัก, (5) มาตรการความปลอดภัยและการจัดการข้อมูล
- วิธีการฝึกสอน: Blended learning (e‑learning + เวิร์กช็อปภาคสนาม), sandbox ฝึกปฏิบัติบน digital twin ของสายผลิตจริง, mentorship ร่วมกับผู้จำหน่ายระบบ และการประเมินผ่านการทดสอบเชิงปฏิบัติ
- ระยะเวลาและค่าใช้จ่ายตัวอย่าง: โปรแกรมตั้งแต่ 3–6 เดือนต่อบุคคล ค่าใช้จ่ายเฉลี่ยประมาณ 30,000–50,000 บาท/คน ขึ้นกับความเข้มข้นและการใช้เครื่องมือจำลอง
- การบริหารทรัพยากรบุคคล: ควรมีแผนการโยกย้ายตำแหน่ง (redeployment), สิทธิประโยชน์เพื่อรักษาพนักงาน (retention incentives) และเส้นทางเติบโตที่ชัดเจน เช่น การรับรองระดับภายในองค์กร
การลงทุนใน reskilling ไม่เพียงเพิ่มความสามารถในการปฏิบัติงานกับระบบใหม่ แต่ยังช่วยลดความเสี่ยงด้านความปลอดภัยในการใช้งานระบบอัตโนมัติ และเพิ่มความยืดหยุ่นในการบริหารกำลังคนเมื่อเกิดการเปลี่ยนแปลงเทคโนโลยีในอนาคต
กลยุทธ์การขยายสู่โรงงานอื่น (Scaling & Rollout)
การขยายผลจากโปรเจกต์นำร่องสู่โรงงานอื่นควรดำเนินการแบบเป็นเฟส มีมาตรฐานและแม่แบบ (templates) ที่สามารถทำซ้ำได้เพื่อลดความเสี่ยงและต้นทุนการติดตั้งใหม่ในแต่ละไซต์
- เฟสการขยาย: (1) แปลงบทเรียนจากพilot เป็น playbook ด้านเทคนิคและธุรกิจ, (2) พัฒนาชุด integration template สำหรับ PLC/SCADA และ ERP, (3) ตั้งศูนย์ความเป็นเลิศ (Center of Excellence) เพื่อให้การสนับสนุนและฝึกอบรม, (4) ขยายแบบลำดับชั้นโดยเริ่มจากสายที่มีความเสี่ยงต่ำไปสูง
- การจัดการทางเทคนิค: ออกแบบให้รองรับทั้ง on‑premise และ hybrid/cloud, มาตรฐาน API และ data schema ที่ชัดเจน, พร้อมตัวชี้วัด (KPIs) เช่น MTTR, OEE, และ % downtime reduction เพื่อวัดผลเทียบข้ามไซต์
การขยายที่ประสบความสำเร็จขึ้นอยู่กับการมีข้อมูลการดำเนินงานที่เป็นมาตรฐาน แผนบริหารการเปลี่ยนแปลงของบุคลากร และโมเดลค่าธรรมเนียมที่สอดคล้อง (เช่น การเป็นบริการแบบ subscription หรือ success‑based pricing เพื่อแบ่งความเสี่ยงกับลูกค้า)
ข้อเสนอเชิงนโยบายสำหรับผู้กำกับดูแลและภาครัฐ
เพื่อสนับสนุนการประยุกต์ใช้ Digital‑Twin Agent อย่างปลอดภัยและยั่งยืน รัฐและหน่วยกำกับควรออกมาตรการเชิงนโยบายที่ครอบคลุมทั้งมาตรฐานความปลอดภัย การกำกับดูแลข้อมูล และการสนับสนุนทางการเงินและแรงงานดังนี้
- มาตรฐานความปลอดภัยและการรับรอง: กำหนดแนวทางด้าน safety requirements สำหรับระบบอัตโนมัติที่มี AI เช่น การมี human‑in‑the‑loop การทดสอบความทนทาน (robustness testing) ก่อนใช้งานจริง และการรับรองความปลอดภัยจากหน่วยงานกลาง
- การปกครองข้อมูล (Data Governance): กำหนดหลักการจัดเก็บ การควบคุมการเข้าถึง และการแบ่งปันข้อมูลระหว่างผู้ผลิตและผู้ให้บริการ โดยเน้นการอนามัยข้อมูล (anonymization), การติดตาม provenance, และข้อกำหนดเรื่อง audit trail เพื่อให้สามารถตรวจสอบเหตุการณ์ย้อนหลังได้
- กรอบความรับผิดชอบและกฎหมาย: ชี้ชัดความรับผิดชอบกรณีเกิดความเสียหายจากการตัดสินใจของ AI (liability framework) รวมถึงมาตรการการรายงานเหตุการณ์ความปลอดภัยและการบังคับใช้มาตรฐาน
- สนับสนุนทางการเงินและภาษี: ประยุกต์มาตรการจูงใจ เช่น เครดิตภาษีสำหรับการลงทุนในระบบอุตสาหกรรม 4.0, กองทุนสนับสนุนการ reskilling ของแรงงานที่ได้รับผลกระทบ และเงินอุดหนุนสำหรับ SMEs ในการเข้าถึงโซลูชัน
- โครงการนำร่องและ regulatory sandbox: จัดตั้ง sandbox ทางกฎระเบียบเพื่อให้ผู้ประกอบการทดสอบเทคโนโลยีภายใต้การกำกับดูแลที่จำกัด และใช้ผลลัพธ์เพื่อปรับปรุงมาตรฐานและแนวทางปฏิบัติ
- การส่งเสริมมาตรฐานเปิดและความสามารถในการทำงานร่วมกัน: สนับสนุนการพัฒนามาตรฐานข้อมูลและ API ระดับชาติ เพื่อให้ระบบจากผู้จำหน่ายต่างรายสามารถทำงานร่วมกันได้ ลดต้นทุนการผนวกรวม และกระตุ้นตลาดผู้ให้บริการท้องถิ่น
สรุป: การประยุกต์ Digital‑Twin Agent ให้ผลทางธุรกิจที่ชัดเจนเมื่อมีการวัดผลอย่างเป็นระบบและการลงทุนเชิงกลยุทธ์ในการฝึกอบรมบุคลากร ควบคู่ไปกับกรอบนโยบายที่เข้มแข็งด้านความปลอดภัยและการปกครองข้อมูล จะช่วยให้การขยายผลเป็นไปอย่างรวดเร็ว ปลอดภัย และยั่งยืน ทั้งสำหรับผู้ประกอบการและสังคมโดยรวม
บทสรุป
โซลูชัน Digital‑Twin Agent ที่ผสมผสานความสามารถของ Large Language Models (LLM) กับเทคนิค Reinforcement Learning ในการควบคุมสายการผลิตแบบเรียลไทม์ แสดงผลลัพธ์เชิงปฏิบัติได้ชัดเจน—โปรเจกต์นำร่องรายงานการลดเวลาหยุดเครื่อง (downtime) ลงประมาณ 40% ซึ่งชี้ให้เห็นถึงศักยภาพในการปรับปรุงความต่อเนื่องการผลิตและประสิทธิภาพ (OEE) อย่างมีนัยสำคัญ อย่างไรก็ดี การนำระบบดังกล่าวสู่การใช้งานจริงจำเป็นต้องออกแบบสถาปัตยกรรมที่รัดกุมและการบริหารความเสี่ยงอย่างครบวงจร ทั้งด้านการสำรองระบบ ความแม่นยำของแบบจำลอง (model fidelity), การป้องกันการสำรวจที่ไม่ปลอดภัย (safe exploration), การป้องกันการลักลอบทางไซเบอร์ และกลไก human‑in‑the‑loop เพื่อป้องกันความล้มเหลวเชิงระบบหรือผลกระทบต่อความปลอดภัยของการผลิต
การขยายผลในวงกว้างต้องอาศัยการลงทุนเชิงโครงสร้างพื้นฐาน (เช่น เซ็นเซอร์คุณภาพสูง edge computing และเครือข่ายความหน่วงต่ำ), โปรแกรมฝึกอบรมและพัฒนาทักษะบุคลากร เพื่อให้ช่างเทคนิคและวิศวกรสามารถใช้งาน รักษา และตรวจสอบตัวแทนอัจฉริยะได้อย่างมีประสิทธิภาพ รวมทั้งต้องมีกรอบกำกับดูแลที่ชัดเจน (governance, compliance, KPI และการตรวจสอบความถูกต้องของแบบจำลอง) เพื่อให้การเปลี่ยนผ่านสู่การผลิตอัตโนมัติเป็นไปอย่างปลอดภัยและยั่งยืน หากออกแบบการขยายผลเป็นขั้นบันได มีการทดสอบในสภาพแวดล้อมจำลองและ sandbox พร้อมมาตรการวัดผลที่ชัดเจน ระบบเหล่านี้สามารถยกระดับการบำรุงรักษาเชิงคาดการณ์ ปรับสายการผลิตได้อย่างยืดหยุ่น และขับเคลื่อนการปรับปรุงต่อเนื่องในการผลิตอุตสาหกรรมไทยในระยะยาว



