
ในยุคทองของปัญญาประดิษฐ์ที่ขับเคลื่อนด้วยเงินลงทุนและคาดหวังสูง เส้นทางสู่ความสำเร็จของบริษัท AI กลับไม่เคยเรียบง่าย: การล้มเหลวกลายเป็นปรากฏการณ์ที่เกิดซ้ำ ทั้งจากความคาดหวังที่เกินจริง ต้นทุนด้านข้อมูลและบุคลากรที่สูง ความเสี่ยงด้านกฎระเบียบ และปัญหาการปรับใช้เทคโนโลยีจริงในเชิงพาณิชย์ สถิติทั่วไปชี้ให้เห็นว่าแม้สตาร์ทอัพเทคโนโลยีจะได้รับทุนมหาศาล แต่อัตราการล้มเหลวยังคงสูง การยอมรับว่าการล้มเหลวแบบนี้ “หลีกเลี่ยงไม่ได้” ในบางบริบทจะช่วยให้เรามองเห็นบทเรียนเชิงกลยุทธ์และโอกาสในการเริ่มต้นใหม่อย่างมีสติและมีประสิทธิภาพมากขึ้น
บทความนี้จะพาผู้อ่านสำรวจสาเหตุที่ทำให้บริษัท AI พังทลาย ตีความผลกระทบต่อผู้ก่อตั้ง นักลงทุน ลูกค้า และตลาดแรงงาน และเสนอกรอบปฏิบัติการเชิงปฏิบัติที่เน้นการฟื้นตัวอย่างยั่งยืน ตั้งแต่การกลับมาทบทวน product–market fit การออกแบบสถาปัตยกรรมที่ยืดหยุ่น ยุทธศาสตร์ข้อมูลและการบริหารความเสี่ยง ไปจนถึงการจัดการเงินทุน ทีมงาน และการสร้างวัฒนธรรมที่รองรับการทดลองซ้ำๆ ผู้ที่อ่านต่อจะได้รับทั้งตัวอย่างเชิงปฏิบัติ ข้อสรุปจากกรณีศึกษาจริง และขั้นตอนที่สามารถนำไปปฏิบัติได้เพื่อเปลี่ยนความพังทลายให้เป็นจุดเริ่มต้นของการเติบโตใหม่
บทนำ: การยอมรับว่า "การล้มเหลว" เป็นส่วนหนึ่งของนวัตกรรม AI
บทนำ: การยอมรับว่า "การล้มเหลว" เป็นส่วนหนึ่งของนวัตกรรม AI
ในโลกของเทคโนโลยีปัญญาประดิษฐ์ (AI) การล้มเหลวไม่ใช่เพียงความเป็นไปได้แต่เป็นส่วนหนึ่งของกระบวนการนวัตกรรมที่หลีกเลี่ยงไม่ได้ เมื่อพูดถึงบริษัทที่พัฒนาโมเดลหรือบริการ AI เราควรยอมรับว่าเส้นทางสู่ความสำเร็จมักประกอบด้วยการทดลองซ้ำ การปรับทิศทาง และความล้มเหลวบางครั้งที่เปิดโอกาสให้เกิดการเรียนรู้เชิงลึก จากสถิติทั่วไปพบว่า ≈90% ของสตาร์ทอัพไม่ประสบความสำเร็จ และงานวิจัยหลายฉบับระบุว่า 50–70% ของโครงการ AI ในองค์กรไม่สามารถขยายผล (scale) หรือสร้างคุณค่าเชิงพาณิชย์ตามที่คาดหวังได้ ซึ่งสะท้อนว่าแม้มีทรัพยากรหรือเทคโนโลยีขั้นสูง ความเสี่ยงยังคงสูง
ในบริบทของบริษัท AI เราจำเป็นต้องนิยามคำว่า การล้มเหลว ให้ชัดเจน เพราะความหมายจะแตกต่างตามมิติการวัดผลหลัก ๆ ได้แก่:
- Product–market fit: ผลิตภัณฑ์หรือโมเดลไม่ตอบโจทย์ความต้องการของตลาดในเชิงการใช้งานหรือมูลค่าทางธุรกิจ
- Scalability: ระบบไม่สามารถขยายขนาดทั้งด้านเทคนิค (เช่น latency, throughput, ค่าใช้จ่ายในการรันโมเดล) หรือธุรกิจ (เช่นช่องทางการขาย) เมื่อปริมาณการใช้งานเพิ่มขึ้น
- Governance: ปัญหาด้านข้อมูล จริยธรรม ความเป็นส่วนตัว หรือการปฏิบัติตามกฎระเบียบที่ทำให้ผลิตภัณฑ์ต้องถูกชะลอ ปรับเปลี่ยน หรือยุติ
เหตุผลที่ทำให้ความเสี่ยงในวงการ AI สูงเป็นเรื่องเชิงระบบ ไม่ใช่ปัจจัยเดียว แต่เป็นการรวมกันของหลายปัจจัย ได้แก่
- เทคโนโลยีใหม่และไม่แน่นอน: โมเดลและสถาปัตยกรรมเปลี่ยนเร็ว ทำให้การลงทุนในเทคโนโลยีหนึ่งอาจล้าสมัยในเวลาอันสั้น
- ตลาดที่ยังพัฒนาไม่เต็มที่: ความต้องการของลูกค้ายังไม่ชัดเจนหรือแตกต่างกันมากในแต่ละอุตสาหกรรม จึงยากต่อการหาจุดสมดุลของคุณค่า
- ต้นทุนทรัพยากร: ความต้องการด้านคอมพิวต์และข้อมูลสูง ส่งผลให้ต้นทุนการทดลองและการขยายผลเพิ่มขึ้นอย่างรวดเร็ว
- ความเสี่ยงด้านการปกครองข้อมูลและกฎระเบียบ: กฎคุ้มครองข้อมูลที่เข้มงวดและความเสี่ยงด้านจริยธรรมอาจทำให้ผลิตภัณฑ์ถูกจำกัดหรือปรับใช้ได้ช้า
- การแข่งขันและเอฟเฟกต์เครือข่าย: ผู้เล่นรายใหญ่มีทรัพยากรเหนือกว่าในด้านข้อมูลและโครงสร้างพื้นฐาน ทำให้สตาร์ทอัพต้องเผชิญกับแรงกดดันสูง
วัตถุประสงค์ของบทความชิ้นนี้คือการให้ทั้งมุมมองเชิงวิเคราะห์และแนวทางเชิงปฏิบัติแก่ผู้อ่าน: เราจะวิเคราะห์รูปแบบการล้มเหลวที่พบบ่อยในบริษัท AI อธิบายสาเหตุเชิงระบบ พร้อมยกตัวอย่างกรณีศึกษา และเสนอชุดเครื่องมือที่ใช้วินิจฉัย ปรับแก้ และวางแผน การเริ่มต้นใหม่ (restart) อย่างมีประสิทธิภาพ โดยผู้อ่านจะได้เรียนรู้หลักการสำคัญ เช่น ตัวชี้วัดการล้มเหลวที่ต้องติดตาม (เช่น time-to-PM fit, unit economics ของโมเดล, ค่าใช้จ่ายในการ inference), กรอบการตัดสินใจเมื่อต้อง pivot หรือ wind down, และแนวปฏิบัติด้าน governance ที่ช่วยลดความเสี่ยงเชิงระบบ
โครงสร้างบทความจะถูกจัดเป็นส่วน ๆ ที่ชัดเจน ได้แก่ การจำแนกโหมดของการล้มเหลว, การตรวจสอบเหตุเชิงระบบ, บทเรียนจากกรณีศึกษา, แผนปฏิบัติการสำหรับการเริ่มต้นใหม่ และแนวทางเชิงนโยบายสำหรับผู้บริหารและนักลงทุน เพื่อให้ผู้อ่าน—ไม่ว่าจะเป็นซีอีโอ นักลงทุน หรือนักพัฒนาผลิตภัณฑ์—มีกรอบคิดและเครื่องมือที่สามารถนำไปใช้ได้จริงในการจัดการความล้มเหลวและเปลี่ยนความเสี่ยงเป็นโอกาสอีกครั้ง
สาเหตุหลักที่ทำให้บริษัท AI ล้มเหลว
สาเหตุหลักที่ทำให้บริษัท AI ล้มเหลว
การพัฒนาและนำระบบปัญญาประดิษฐ์ไปใช้เชิงพาณิชย์เป็นงานที่มีความซับซ้อนทั้งด้านเทคนิคและธุรกิจ สาเหตุที่ทำให้บริษัท AI ล้มเหลวจึงมักเป็นผลจากปัจจัยหลายด้านที่ซ้อนทับกัน ตั้งแต่คุณภาพข้อมูล โมเดลที่ออกแบบไม่สอดคล้องกับปัญหาจริง ต้นทุนคอมพิวต์สูง ไปจนถึงช่องว่างในการสร้างมูลค่าให้ลูกค้าและปัญหาการกำกับดูแล เมื่อองค์ประกอบใดองค์ประกอบหนึ่งล้มเหลว ผลกระทบสามารถขยายตัวจนกระทบต่อการเงิน ชื่อเสียง และการปฏิบัติตามกฎระเบียบขององค์กร

ปัญหาด้านข้อมูล เป็นสาเหตุที่พบบ่อยที่สุด หน่วยงานวิจัยและผู้ปฏิบัติงานหลายรายรายงานว่าเวลาส่วนใหญ่ของทีม ML ถูกใช้ไปกับการรวบรวม ทำความสะอาด และป้ายกำกับข้อมูล (data wrangling) มากกว่าการพัฒนาโมเดล ตัวอย่างปัญหาได้แก่ ข้อมูลไม่เพียงพอ ข้อมูลมีคุณภาพต่ำ หรือมีอคติ (bias) ที่ฝังตัวอยู่ในชุดข้อมูล เมื่อโมเดลถูกฝึกด้วยข้อมูลที่มีอคติ ผลลัพธ์จะสะท้อนอคตินั้นและสร้างความเสียหายต่อความน่าเชื่อถือและการยอมรับของผลิตภัณฑ์
- ขาดข้อมูลคุณภาพสูง: ข้อมูลที่ไม่ครบถ้วนหรือมีสัญญาณรบกวนทำให้โมเดลเรียนรู้ผิดพลาดและไม่สามารถใช้งานในสถานการณ์จริง
- ข้อมูลมีอคติ: อคติทางเพศ เชื้อชาติ หรือภูมิศาสตร์ในข้อมูลนำไปสู่ผลลัพธ์ที่ไม่เป็นธรรมและความเสี่ยงด้านกฎหมาย
- ค่าใช้จ่ายในการจัดเตรียมข้อมูล: การเก็บและป้ายกำกับข้อมูลระดับคุณภาพอาจมีต้นทุนและเวลา สูง ซึ่งหลายสตาร์ทอัพประเมินต่ำไป
ข้อจำกัดด้านเทคโนโลยี ทำให้บริษัท AI หลายแห่งไม่สามารถสเกลโมเดลหรือรักษาประสิทธิภาพเมื่อใช้งานจริงได้ ปัญหาเหล่านี้รวมถึงความซับซ้อนในการบริหารโครงสร้างพื้นฐาน ML (MLOps), โมเดลโอเวอร์ฟิตกับชุดข้อมูลเทรน และต้นทุนการฝึกโมเดลที่สูงมาก โมเดลขนาดใหญ่ (large models) อาจต้องใช้ทรัพยากรคอมพิวต์และพลังงานที่ส่งผลให้ต้นทุนต่อการพัฒนาและต่อการปรับใช้สูงขึ้นอย่างรวดเร็ว
- ความยากในการสเกล: โมเดลที่ทำงานดีในสเกลทดลองอาจไม่สามารถตอบโจทย์ในสเกลผู้ใช้จริงได้ ทั้งเรื่อง latency, throughput และความทนทาน
- ต้นทุนคอมพิวต์สูง: การฝึกโมเดลขั้นสูงอาจมีต้นทุนอยู่ในระดับหมื่นถึงหลายล้านดอลลาร์ ขึ้นกับขนาดและความถี่การฝึกซ้ำ ซึ่งสร้างแรงกดดันต่อเงินทุนของบริษัท
- โอเวอร์ฟิตและความไม่สามารถทั่วไป: โมเดลที่โอเวอร์ฟิตจะทำงานไม่ดีเมื่อต้องรับมือข้อมูลจริงที่มีความหลากหลายและเบี่ยงเบนจากข้อมูลเทรน
- ช่องว่างด้าน MLOps และการบูรณาการ: ขาดระบบอัตโนมัติสำหรับการตรวจสอบการทำงาน (monitoring), การจัดการเวอร์ชันโมเดล และการปรับใช้อย่างต่อเนื่อง ทำให้การนำไปใช้จริงสะดุด
ปัญหาทางธุรกิจ มักเป็นสาเหตุเชิงผลลัพธ์ที่ชัดเจนที่สุด: ถ้าผลิตภัณฑ์ AI ไม่สามารถสร้างมูลค่า (value) ให้ลูกค้าได้จริง หรือสร้างมูลค่าได้แต่ไม่มีโมเดลธุรกิจรองรับ บริษัทจะประสบปัญหาการเติบโต ตัวอย่างสาเหตุได้แก่ ขาด product-market fit, การตั้งราคาที่ไม่เหมาะสม และขาดกลยุทธ์การขายหรือการเติบโต (go-to-market)
- ขาด Product–Market Fit: เทคโนโลยีที่มีความซับซ้อนสูงแต่ไม่ตอบโจทย์ความต้องการเชิงธุรกิจจะถูกมองว่าเป็นของเล่น (nice-to-have) แทนที่จะเป็นเครื่องมือที่ลูกค้า "ต้องมี"
- การตั้งราคาไม่เหมาะสม: ตั้งราคาแพงเกินไปโดยไม่สามารถพิสูจน์ ROI หรือตั้งราคาต่ำเกินไปจนไม่ครอบคลุมต้นทุนการดำเนินงาน ทั้งสองกรณีทำให้โมเดลธุรกิจไม่ยั่งยืน
- ขาดกลยุทธ์การขายและการนำไปใช้: ทีมขายที่ไม่เข้าใจเทคโนโลยีหรือไม่สามารถสื่อสารคุณค่าทางธุรกิจ ทำให้การสรรหาลูกค้าและการรักษาลูกค้าทำได้ยาก
- ระยะเวลาที่ใช้ในการเห็นผลลัพธ์: หากผลประโยชน์จาก AI ต้องรอนานและไม่ชัดเจน ลูกค้าจะเลิกลงทุนหรือเปลี่ยนไปใช้ทางเลือกอื่น
ปัจจัยเสริม — การกำกับดูแลและจริยธรรม ไม่อาจมองข้าม บริษัท AI ที่ละเลยประเด็นความเป็นส่วนตัว ความโปร่งใส หรือมาตรฐานทางจริยธรรมมักเผชิญกับความเสี่ยงทางกฎหมายและการถูกปฏิเสธจากตลาด ตัวอย่างเช่น การรั่วไหลของข้อมูลหรือการตัดสินใจที่ไม่เป็นธรรมสามารถนำไปสู่บทลงโทษและความเสียหายต่อชื่อเสียงอย่างร้ายแรง
โดยสรุป ความล้มเหลวของบริษัท AI มักเกิดจากการผสมผสานของปัญหาด้านข้อมูล ข้อจำกัดด้านเทคโนโลยี และช่องว่างทางธุรกิจ รวมทั้งความไม่พร้อมด้านการกำกับดูแลและจริยธรรม องค์กรที่ประสบความสำเร็จมักลงทุนในการสร้างข้อมูลที่มีคุณภาพ ปรับสถาปัตยกรรมทางเทคนิคให้ยืดหยุ่น วางกลยุทธ์ทางธุรกิจที่ชัดเจน และออกแบบกระบวนการกำกับดูแลที่โปร่งใสตั้งแต่ระยะแรก
กรณีศึกษา: บทเรียนจากความล้มเหลวจริง
กรณีศึกษาเชิงสังเกต: บทเรียนจากความล้มเหลวของสตาร์ทอัพ AI แบบสมมติ
ตัวอย่างต่อไปนี้เป็นกรณีศึกษาเชิงสังเกตของบริษัทสตาร์ทอัพ AI สมมติชื่อว่า “AIsurge” ซึ่งสะท้อนรูปแบบปัญหาที่เกิดขึ้นบ่อยในวงการ การวิเคราะห์นี้รวมไทม์ไลน์เหตุการณ์สำคัญ สถิติที่ชี้วัด และบทเรียนเชิงปฏิบัติที่สามารถนำไปใช้ได้จริงสำหรับผู้บริหารและนักลงทุนในภาค AI โดยมิได้อ้างอิงถึงบริษัทใดบริษัทหนึ่งโดยตรง
ไทม์ไลน์เหตุการณ์สำคัญ (สรุป)
- ปีที่ 0 – ก่อตั้งและระดมทุนเริ่มต้น: AIsurge ก่อตั้งและได้รับ Seed funding จำนวน 5 ล้านดอลลาร์ เพื่อพัฒนาระบบวิเคราะห์ภาพทางการแพทย์ด้วยโมเดล deep learning
- ปีที่ 1 – Series A และการเร่งสเกล: ปิด Series A ที่ 40 ล้านดอลลาร์ หลังจากผลทดสอบในห้องทดลองมีความแม่นยำ 94% นักลงทุนเร่งให้ขยายทีมขายและนำผลิตภัณฑ์เข้าสู่ตลาดเชิงพาณิชย์ภายใน 9 เดือน
- ปีที่ 2 – เปิดตัวผลิตภัณฑ์เชิงพาณิชย์: มีลูกค้าองค์กร 120 รายในไตรมาสแรก แต่พบอัตราการแก้ไข false positive/negative เพิ่มขึ้นเมื่อนำไปใช้ในระบบจริง (accuracy ลดจาก 94% ในชุดทดสอบเป็น 68% ใน production)
- ปีที่ 2.5 – ปัญหาปฏิบัติการและความน่าเชื่อถือ: เกิด model drift, ข้อมูลที่รับจากลูกค้ามี distribution ต่างจากข้อมูลเทรน มีเคสผลวินิจฉัยผิดพลาดและคำร้องเรียนต่อ regulator ส่งผลให้ churn เพิ่มจาก 5% เป็น 25% ต่อเดือน
- ปีที่ 3 – ปัญหาการเงินและความปลอดภัย: ค่าใช้จ่ายคลาวด์สูงขึ้นเนื่องจากการสเกลโมเดลอินเฟราสตรัคเจอร์ Burn rate เพิ่มจน runway เหลือ 6 เดือน เกิดเหตุละเมิดข้อมูลเล็กน้อยที่กระทบความเชื่อมั่น
- ปีที่ 3.5 – พยายาม pivot และการลดขนาด: บริษัทพยายาม pivot เป็นระบบให้คำปรึกษาแบบ human-in-the-loop แต่ผลจากการลงทุนเพิ่มไม่เพียงพอ จบลงด้วยการปลดพนักงานครั้งใหญ่และขายสินทรัพย์บางส่วน
การวิเคราะห์สาเหตุของความล้มเหลว
จากไทม์ไลน์ข้างต้น สาเหตุของความล้มเหลวสามารถสรุปได้เป็นประเด็นหลักดังนี้: 1) Product-market mismatch — ผลิตภัณฑ์ถูกออกแบบบนชุดข้อมูลที่ไม่เป็นตัวแทนของสภาพจริง ทำให้ประสิทธิภาพด้อยลงเมื่อนำไปใช้งานจริง (สถิติการลดลงของความแม่นยำจาก 94% เป็น 68% ชี้ว่ามีการ overfit ต่อข้อมูลทดสอบ) 2) ขาดระบบปฏิบัติการสำหรับ AI ที่แข็งแรง (MLOps & Data Governance) — ไม่ได้ลงทุนใน monitoring, versioning และ pipeline สำหรับจัดการ model drift จึงตอบสนองต่อปัญหาได้ช้าและมีผลกระทบต่อผู้ใช้จำนวนมาก 3) การบริหารการเงินและการสเกลที่ผิดจังหวะ — การเร่งขยายทีมขายและอินเฟราสตรัคเจอร์ก่อน validate โมเดลในหลายกรณีจริง ทำให้ค่าใช้จ่ายพุ่งและ runway สั้นลง 4) การละเลยด้านความปลอดภัยและการปฏิบัติตามกฎระเบียบ — ความผิดพลาดด้าน data privacy และ compliance ทำลายความเชื่อมั่นของลูกค้าและสร้างความเสี่ยงทางกฎหมาย
บทเรียนเชิงปฏิบัติ: Do's and Don'ts
- Do: ลงทุนในงาน MLOps และ Data Ops ตั้งแต่ระยะต้น — ติดตั้งระบบ monitoring, alerting, model explainability และ data lineage เพื่อจับการเปลี่ยนแปลงของข้อมูลและประเมิน performance แบบเรียลไทม์
- Do: ทดสอบในหลายบริบทจริง (field pilots) ก่อนสเกล — ทำ pilot กับลูกค้าจำนวนจำกัดในบริบทที่หลากหลาย เพื่อเก็บ feedback และปรับโมเดล ลดความเสี่ยงของ product-market mismatch
- Do: วางแผนการเงินอย่างระมัดระวังและออกแบบ runway ที่ยืดหยุ่น — อย่าสเกลค่าใช้จ่ายคงที่ตามคาดการณ์เชิงบวกเพียงอย่างเดียว ให้มี contingency plan และ KPI ที่ชัดเจนก่อนขยายทีม
- Do: ให้ความสำคัญกับความปลอดภัยและความเป็นส่วนตัวตั้งแต่ต้น — ทำ security audits, data minimization และ compliance checks เป็นมาตรฐานในกระบวนการพัฒนา
- Don't: เร่งเปิดตัวเชิงพาณิชย์โดยละเลยการตรวจสอบความเชื่อมั่นของโมเดล — การประกาศตัวเลขความแม่นยำจากชุดทดสอบเพียงอย่างเดียวอาจทำให้เกิดความคาดหวังที่ไม่เป็นจริง
- Don't: มองข้ามเสียงลูกค้าและทีมปฏิบัติการ — ฝ่าย R&D ต้องร่วมงานอย่างใกล้ชิดกับทีมลูกค้าสัมพันธ์และการสนับสนุนเพื่อนำ feedback มาปรับปรุงอย่างต่อเนื่อง
- Don't: พึ่งพาโมเดลเดียวเป็นทางออกเดียว — ควรออกแบบสถาปัตยกรรมให้รองรับ hybrid approach เช่น human-in-the-loop, ensemble models หรือ fallback rules เพื่อลดความเสี่ยงในกรณีโมเดลล้มเหลว
สรุปคือ ความล้มเหลวในเส้นทาง AI มักเกิดจากการผสมผสานของปัจจัยทางเทคนิค ธุรกิจ และการปฏิบัติตามข้อกำหนด การเรียนรู้จากกรณีศึกษาอย่างเป็นระบบและนำบทเรียนนั้นไปปฏิบัติจริง—โดยเฉพาะการเสริมความแข็งแกร่งให้กับ MLOps, governance และการวางแผนทางการเงิน—จะช่วยเพิ่มโอกาสในการเริ่มต้นใหม่และลดความเสี่ยงในการล้มเหลวซ้ำ
ผลกระทบต่ออุตสาหกรรม นักลงทุน และแรงงาน
ผลกระทบต่ออุตสาหกรรม นักลงทุน และแรงงาน
การล้มเหลวของบริษัท AI ในวงกว้างมีผลกระทบที่หลากหลายทั้งในมิติการเงิน ตลาดแรงงาน และทิศทางการจัดสรรทรัพยากร โดยในเชิงสถิติ การศึกษาจากหลายแหล่งชี้ให้เห็นว่า อัตราการล้มเหลวของสตาร์ทอัพอยู่ในช่วงสูง—การประมาณทั่วไปมักระบุไว้ระหว่าง 70–90% สำหรับสตาร์ทอัพโดยรวม ขณะที่การศึกษาของ Harvard Business School (Shikhar Ghosh) ระบุว่าโดยประมาณ 75% ของสตาร์ทอัพที่ได้รับการสนับสนุนจากเงินทุนเสี่ยง (venture-backed) ไม่สามารถคืนทุนให้กับนักลงทุนได้ นอกจากนี้การวิเคราะห์ของ CB Insights ยังคงยืนยันว่าเหตุผลหลักของความล้มเหลวคือ ไม่มีความต้องการของตลาด (ประมาณ 42%) รองลงมาเป็นการขาดสภาพคล่อง/เงินทุน (ประมาณ 29%) และทีมที่ไม่เหมาะสม (ประมาณ 23%) ซึ่งข้อมูลเหล่านี้สะท้อนว่าความเสี่ยงด้านตลาดและการบริหารเงินทุนยังคงเป็นปัจจัยสำคัญ
ในมิติของนักลงทุน ผลกระทบมักเริ่มจากความระมัดระวังที่เพิ่มขึ้นต่อการลงทุนในภาค AI โดยเฉพาะในสตาร์ทอัพที่ยังไม่มีการพิสูจน์รูปแบบธุรกิจอย่างชัดเจน นักลงทุนสถาบันและกองทุน VC จะให้ความสำคัญกับ การแสดงผลลัพธ์เชิงธุรกิจ (traction), อัตราการเติบโตของรายได้, ข้อสัญญากับลูกค้าองค์กร และความชัดเจนด้านการปฏิบัติตามกฎระเบียบ การตอบสนองนี้มักนำไปสู่รูปแบบการระดมทุนที่ระมัดระวังมากขึ้น เช่น การให้ทุนแบบเป็นรอบ (staged financing), การกำหนดมาตรวัด KPI เชิงทวนสอบได้ และการเพิ่มกระบวนการตรวจสอบสถานะ (due diligence) อย่างเข้มงวด อย่างไรก็ตาม แหล่งเงินทุนระดับโลกยังคงมีสภาพคล่องสะสม (so-called “dry powder”) ในระดับสูง ซึ่งหมายความว่า ทุนยังคงมีอยู่ แต่จะถูกจัดสรรไปยังโครงการที่มีความเสี่ยงคุ้มค่าและสามารถแสดงผลลัพธ์เชิงธุรกิจหรือข้อได้เปรียบเชิงเทคโนโลยีที่ชัดเจน
- นักลงทุนรายย่อยและแองเจิล อาจหดหู่ออกจากการลงทุนในไอเดียต้นกำเนิด แต่ยังคงสนับสนุนทีมที่มีผลงานพิสูจน์ได้
- กองทุนขนาดใหญ่และสถาบัน จะเน้นดีลที่มีความปลอดภัยของรายได้ เช่น การเป็นหุ้นส่วนกับองค์กรขนาดใหญ่หรือสัญญาระยะยาว
- ผลต่อมูลค่าตลาด การล้มเหลวที่เป็นข่าวอาจลดความเชื่อมั่นในภาคและทำให้รอบการประเมินมูลค่าลดลง โดยเฉพาะกับโครงการที่เน้นการเติบโตแบบคาดการณ์
ฝั่งแรงงานโดยเฉพาะบุคลากรเชิงเทคนิค ผลกระทบอาจปรากฏทั้งในรูปแบบเชิงลบและเชิงบวก ในระยะสั้นการปิดบริษัทหรือการปรับลดพนักงานจะสร้างการว่างงานด้านเทคนิคในกลุ่มที่มีทักษะเฉพาะด้าน เช่น นักวิจัย NLP, วิศวกร ML, นักวิทยาศาสตร์ข้อมูลที่มีประสบการณ์กับโมเดลขนาดใหญ่ อย่างไรก็ตาม ทักษะเหล่านี้มีความสามารถในการย้ายที่สูงและมีความต้องการในสาขาใกล้เคียง เช่น cloud engineering, data engineering, cybersecurity, fintech และ healthtech ทำให้แรงงานสามารถย้ายไปยังภาคที่มีความต้องการทักษะคล้ายกันได้ค่อนข้างเร็ว
นอกจากนี้ การล้มเหลวสามารถเร่งให้เกิดการเคลื่อนย้ายทรัพยากรมนุษย์และความรู้ (talent redistribution) ซึ่งมีผลสองด้าน: ฝ่ายบวกคือความรู้และประสบการณ์ที่ถูกปล่อยออกมาสู่ตลาดสามารถสร้างสตาร์ทอัพใหม่หรือต่อยอดนวัตกรรมในภาคอื่นได้ ฝ่ายลบคืออาจเกิดแรงกดดันด้านค่าจ้างในช่วงสั้น และความไม่แน่นอนในการประกอบอาชีพสำหรับพนักงานสัญญาระยะสั้น นักธุรกิจและนโยบายสาธารณะจึงควรเตรียมกลไกสนับสนุน เช่น โครงการ reskilling/upskilling, การเชื่อมโยงกับเครือข่ายการจ้างงาน และการสนับสนุนการเปลี่ยนผ่านไปสู่ภาคที่ต้องการทักษะดังกล่าว
สรุปคือ การล้มเหลวของบริษัท AI แม้จะทำให้เกิดความเสี่ยงและความกังวลทั้งต่อนักลงทุนและแรงงาน แต่ก็เป็นกระบวนการคัดกรองที่ช่วยเคลียร์การจัดสรรทุนและบุคลากรที่ไม่สอดคล้องกับตลาดออกไป หากการตอบสนองประกอบด้วยนโยบายการสนับสนุนแรงงาน การทำ due diligence ที่เข้มแข็ง และการลงทุนในโครงการที่มีหลักฐานเชิงธุรกิจชัดเจน ภาค AI ที่แข็งแรงและยั่งยืนย่อมมีโอกาสเกิดขึ้นจากสภาพแวดล้อมใหม่นี้
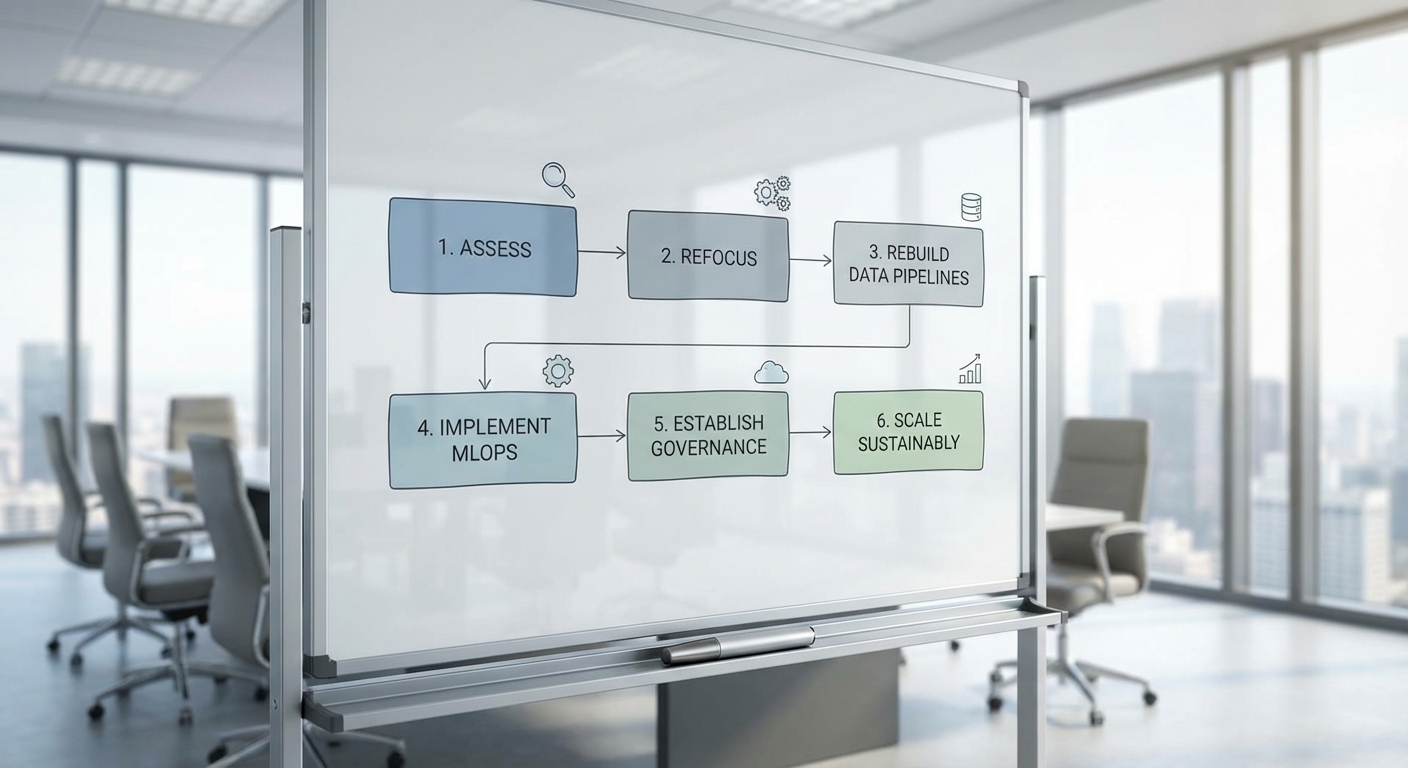
กลยุทธ์การเริ่มต้นใหม่สำหรับบริษัท AI (Playbook ฟื้นตัว)
กลยุทธ์การเริ่มต้นใหม่สำหรับบริษัท AI (Playbook ฟื้นตัว)
การฟื้นตัวของบริษัท AI ต้องเริ่มจากการประเมินแบบรอบด้านและดำเนินการเชิงปฏิบัติที่ชัดเจน: รีเซ็ต product-market fit, ลดขนาดและโฟกัสที่ตลาดย่อย (niche), ลงทุนในโครงสร้างข้อมูลและระบบ MLOps, และสร้างกรอบการกำกับดูแล (governance) พร้อมระบบทดสอบและมอนิเตอร์เพื่อความน่าเชื่อถือของโมเดล แนวทางนี้ไม่ใช่แค่นโยบายเชิงทฤษฎี แต่เป็นแผนปฏิบัติการที่ออกแบบมาเพื่อลดความเสี่ยงซ้ำและคืนความเชื่อมั่นในผลิตภัณฑ์ต่อผู้ใช้งานและผู้ลงทุน
1) ประเมินใหม่: Product-market fit แบบเชิงคุณภาพและเชิงปริมาณ
เริ่มด้วยการวิเคราะห์เหตุผลที่ทำให้การเติบโตชะงัก—การวิจัยหลายชิ้นรวมถึงรายงานจาก CB Insights ระบุว่าร้อยละของสตาร์ทอัพที่ล้มเหลวมีสาเหตุหลักจาก ไม่มีความต้องการของตลาด (no market need) ประเมินด้วยทั้งข้อมูลเชิงปริมาณ (usage metrics, conversion rates, churn, LTV/CAC) และเชิงคุณภาพ (สัมภาษณ์ลูกค้า, usability testing) เพื่อระบุว่าโมดูลส่วนใดของผลิตภัณฑ์แก้ปัญหาได้จริงและส่วนใดเป็นฟีเจอร์ฟุ่มเฟือย
- ทำ mapping ของลูกค้าปัจจุบันและผู้มีแนวโน้มเป็นลูกค้า (segment-by-pain)
- ใช้การทดลองขนาดเล็ก (pilot) กับกลุ่ม niche เพื่อวัด willingness-to-pay และ retention
- ตัดสินใจอย่างรวดเร็ว: เก็บสิ่งที่สร้างมูลค่าและบันทึกสิ่งที่ต้องยกเลิก
2) รีสเกล (Downsize) และโฟกัสในตลาดที่มี Pain Point ชัดเจน
เมื่อระบุ niche ที่มี pain point ชัดเจน ให้ ลดขอบเขตผลิตภัณฑ์และทรัพยากร เพื่อรักษา runway ทางการเงินและเพิ่มโอกาสสำเร็จเชิงพาณิชย์ ตัวอย่างแนวปฏิบัติที่ได้ผลคือการลดฟีเจอร์ที่ไม่จำเป็น, ปิดโครงการที่ไม่มี traction และย้ายทีมไปยังโมดูลหลักที่สร้างรายได้เร็วขึ้น
- ตั้ง KPI ระยะสั้น 30–90 วัน เพื่อวัด traction ใน niche
- จัดสรรทรัพยากรคนให้เป็นทีมเล็กแบบ cross-functional (product, ML, infra, sales) เพื่อความเร็วในการตัดสินใจ
- พิจารณาการปลดพนักงานแบบมีมนุษยธรรม (severance, outplacement) พร้อมเก็บทักษะสำคัญไว้ให้เพียงพอสำหรับการฟื้นตัว
3) ลงทุนในโครงสร้างข้อมูลและ MLOps เพื่อลดความเสี่ยงซ้ำ
การพึ่งพาโมเดลที่ไม่มีระบบ data lineage, reproducibility หรือ CI/CD จะเสี่ยงต่อความผิดพลาดและค่าใช้จ่ายที่สูง ให้จัดลำดับการลงทุนในโครงสร้างข้อมูลและ MLOps ดังนี้:
- สร้าง data contract และ data catalog เพื่อความชัดเจนของแหล่งข้อมูล
- ออกแบบ retraining schedule และ automations สำหรับ feature engineering เพื่อรักษาความสอดคล้องของข้อมูล
- วัดผลด้วยมาตรวัดสำคัญ เช่น accuracy, AUC, latency, inference cost และ business KPIs (เช่น revenue per query)
องค์กรที่นำ MLOps มาใช้อย่างเป็นระบบมักจะลดเวลาในการ deploy และความผิดพลาดที่เกิดจากสภาพแวดล้อมที่ไม่ซ้ำกัน ซึ่งช่วยลดความเสี่ยงในการล้มเหลวซ้ำเมื่อขยายการใช้งาน
4) สร้าง Governance, Testing และ Monitoring เพื่อความน่าเชื่อถือของโมเดล
เพื่อคืนความเชื่อมั่น ต้องมีกระบวนการกำกับดูแลและทดสอบที่ชัดเจน: ตั้ง model governance (policy, roles, approval flows), testing suites (unit tests for preprocessing, integration tests, adversarial tests) และระบบ monitoring แบบเรียลไทม์ที่จับการเกิด data drift และ concept drift
- จัดทำ Model Card และ Datasheet for Datasets เพื่อความโปร่งใสต่อผู้ใช้และผู้กำกับ
- กำหนด SLAs ของโมเดลและตั้ง alert thresholds สำหรับ performance degradation
- นำการทดสอบแบบเชิงบวกและเชิงลบ (bias tests, fairness audits, security fuzzing) เข้าเป็นส่วนหนึ่งของ release pipeline
5) Partnership และการใช้ทรัพยากรคลาวด์อย่างมีประสิทธิภาพ
การร่วมมือกับพันธมิตรเชิงยุทธศาสตร์สามารถเติมเต็มข้อจำกัดด้านข้อมูล domain expertise หรือกำลังคน ขณะเดียวกันการปรับใช้คลาวด์อย่างมีประสิทธิภาพช่วยลดต้นทุนและเพิ่มความคล่องตัว
- มองหา partnerships กับผู้ให้บริการข้อมูลเชิงลึก, ผู้เชี่ยวชาญด้านอุตสาหกรรม, หรือบริษัทที่ให้บริการ MLOps แบบ managed
- ใช้แนวปฏิบัติด้านคลาวด์ที่ช่วยประหยัดค่าใช้จ่าย เช่น right-sizing, reserved/committed discounts, spot instances และ serverless สำหรับงานบางประเภท — องค์กรบางแห่งรายงานการลดค่าใช้จ่ายคลาวด์ได้หลักหลายสิบเปอร์เซ็นต์เมื่อใช้นโยบายเหล่านี้อย่างจริงจัง
- พิจารณา hybrid approach: เก็บข้อมูลสำคัญภายในองค์กรและใช้คลาวด์สำหรับการสเกลเฉพาะเวลาที่จำเป็น
6) แผนปฏิบัติการระยะ 90 วัน (ตัวอย่าง)
เพื่อให้การเริ่มต้นใหม่มีความเป็นรูปธรรม แนะนำ roadmap ระยะสั้นที่เน้นผลลัพธ์:
- วัน 0–30: Audit สินค้าและข้อมูล — ปิดฟีเจอร์ที่ไร้ traction, ระบุ niche เพื่อทดสอบ
- วัน 30–60: ตั้งทีมเล็กข้ามฟังก์ชัน, เปิด pilot ใน niche, เริ่มตั้งค่า MLOps เบื้องต้น (CI, versioning, monitoring)
- วัน 60–90: ขยาย pilot ที่มีผลตอบรับดี, สร้าง governance framework, ทำ cost optimization บนคลาวด์ และเตรียมรายงานผลให้ผู้ลงทุน
สรุปแล้ว การเริ่มต้นใหม่สำหรับบริษัท AI ต้องสมดุลระหว่างการตัดสินใจเชิงกลยุทธ์และการลงมือเชิงปฏิบัติ: รีสเกลอย่างมีเป้าหมาย, ลงทุนในโครงสร้างข้อมูลและ MLOps, และ สร้างระบบกำกับดูแลพร้อมการทดสอบและมอนิเตอร์ ทั้งหมดนี้ควรสนับสนุนด้วยพันธมิตรเชิงยุทธศาสตร์และการใช้คลาวด์อย่างมีประสิทธิภาพ เพื่อเปลี่ยนความล้มเหลวที่หลีกเลี่ยงไม่ได้ให้เป็นโอกาสในการฟื้นตัวและเติบโตอย่างยั่งยืน
โอกาสที่เกิดขึ้นจากความล้มเหลว: M&A, specialization และ vertical AI
ในบริบทของอุตสาหกรรม AI ที่เติบโตอย่างรวดเร็ว ความล้มเหลวของสตาร์ทอัพหรือโครงการวิจัยไม่ใช่เพียงความเสียหายเท่านั้น แต่ยังเป็นแหล่งทรัพยากรที่มีค่า — ทั้งในรูปแบบของทีมงานที่มีทักษะ ข้อมูลเชิงโดเมน เทคโนโลยีที่พัฒนามาบางส่วน และการเรียนรู้จากความผิดพลาด การศึกษาและภาพรวมตลาดชี้ให้เห็นว่าสตาร์ทอัพโดยรวมมีอัตราล้มเหลวค่อนข้างสูง (งานวิเคราะห์หลายฉบับระบุช่วงประมาณ 80–90%) ซึ่งหมายความว่ามีทรัพยากรจำนวนมากถูกปล่อยสู่ตลาดให้สามารถนำกลับมาใช้ใหม่ได้อย่างมีประสิทธิภาพผ่านกลไกต่างๆ
M&A และ acqui-hire: วิธีการลดความสูญเสียและรักษาทรัพยากร
M&A และการซื้อเพื่อได้ทีม (acqui-hire) เป็นกลไกสำคัญที่ช่วยเปลี่ยนความล้มเหลวให้เป็นมูลค่าเชิงกลยุทธ์ สำหรับผู้ซื้อ (ส่วนใหญ่เป็นบริษัทเทคโนโลยีขนาดใหญ่หรือผู้เล่นที่ต้องการเสริมความสามารถ) การเข้าซื้อเหล่านี้ช่วยลดเวลาในการสรรหาและฝึกอบรม สร้างศักยภาพในการบูรณาการเทคโนโลยีที่มีอยู่ และปกป้องทรัพย์สินทางปัญญาที่อาจสูญหายจากการปิดกิจการ
- ลดการสูญเสียค่าใช้จ่าย: การซื้อกิจการบางส่วนหรือการเข้าซื้อทีมช่วยรักษามูลค่าที่ลงทุนไปแล้ว ทั้งซอร์สโค้ด โมเดลเบื้องต้น และชุดข้อมูลที่จัดเก็บไว้
- รักษาคนและทักษะ: Acqui-hire เก็บคนที่มีความเชี่ยวชาญเชิงเทคนิคและเชิงธุรกิจไว้กับองค์กรอื่น ซึ่งเป็นการป้องกันการสูญเสียสมอง (brain drain)
- เร่งเวลาสู่ผลิตภัณฑ์ที่ใช้งานได้จริง: การบูรณาการทีมและเทคโนโลยีจากกิจการที่ล้มเหลวช่วยให้บริษัทใหญ่สามารถนำฟีเจอร์หรือผลิตภัณฑ์ไปสู่ตลาดได้เร็วขึ้น
ตัวอย่างเช่น ภายในช่วงไม่กี่ปีที่ผ่านมา บริษัทเทคโนโลยีขนาดใหญ่หลายรายใช้กลยุทธ์เข้าซื้อทีมจากสตาร์ทอัพ AI เพื่อเสริมทัพด้านโมเดลภาษา การประมวลผลภาพ และวิศวกรรมข้อมูล ข้อมูลเชิงตลาดชี้ว่าการทำดีลในแนวนี้มีแนวโน้มเพิ่มขึ้นเมื่อการแข่งขันด้านทาเลนต์และโมเดลเฉพาะทางเข้มข้นขึ้น
การมุ่งสู่ verticalization เพื่อเพิ่มคุณค่าและความต่าง
Vertical AI หมายถึงการพัฒนา AI ที่เจาะจงไปยังอุตสาหกรรมหรือโดเมนเฉพาะ เช่น การแพทย์ การเงิน การเกษตร ภาคอุตสาหกรรม และโลจิสติกส์ การเปลี่ยนจากแนวทางทั่วไป (horizontal) ไปสู่ verticalization ช่วยให้สตาร์ทอัพสร้างความแตกต่างเชิงคุณค่าได้ชัดเจนขึ้น เนื่องจาก:
- ข้อมูลเชิงโดเมนมีมูลค่าสูง: ข้อมูลทางการแพทย์หรือข้อมูลทางการเงินที่ถูกต้องและได้รับการอนุญาตมีความยากในการหา ทำให้สร้างกำแพงทางการแข่งขันได้
- ความต้องการเชิงธุรกิจชัดเจน: ลูกค้าในโดเมนมักมีปัญหาเฉพาะที่ยินดีจ่ายสำหรับโซลูชันที่ตรงจุด ซึ่งเพิ่ม ARPU และลดความกดดันด้านการเติบโตจากตลาดกว้าง
- การปฏิบัติตามกฎระเบียบและการปรับแต่ง: การเข้าใจข้อกำหนดทางกฎหมายในโดเมนช่วยให้ผลิตภัณฑ์มีความน่าเชื่อถือและเป็นที่ยอมรับได้เร็วยิ่งขึ้น
การมุ่งสู่ vertical AI ยังเป็นทางเลือกที่ดีสำหรับทรัพยากรที่ปล่อยออกมาจากความล้มเหลว เพราะองค์ความรู้และโมเดลบางส่วนสามารถปรับใช้กับปัญหาเชิงโดเมนได้ ตัวอย่างเช่น โมเดลตรวจจับภาพที่เคยพัฒนาสำหรับแอปเชิงค้าปลีกอาจปรับไปใช้ตรวจสภาพพืชในภาคเกษตรได้โดยการนำข้อมูลเฉพาะโดเมนมาเสริม
โอกาสสำหรับสตาร์ทอัพใหม่ที่เรียนรู้จากข้อผิดพลาดของรุ่นก่อน
ความล้มเหลวของรุ่นก่อน ให้บทเรียนเชิงปฏิบัติที่มีค่าแก่ผู้ก่อตั้งรุ่นใหม่ — ทั้งในด้านการบริหารจัดการผลิตภัณฑ์ กลยุทธ์การหาลูกค้า การจัดการต้นทุนของคอมพิวติ้ง และการวางแผนการเงิน ผู้ที่ศึกษาเหตุผลแห่งความล้มเหลวสามารถนำองค์ความรู้เหล่านี้มาออกแบบธุรกิจที่ยั่งยืนกว่าได้
- การนำทรัพยากรกลับมาใช้: ทีมที่แยกตัวออกมาจากสตาร์ทอัพที่ล้มเหลวมักตั้งสตาร์ทอัพใหม่ (spin-out) โดยใช้เทคโนโลยีเดิม แต่ปรับโมเดลธุรกิจให้เหมาะสมกับตลาดจริง
- เปิดช่องสำหรับนวัตกรรมเฉพาะทาง: เมื่อเทคโนโลยีพื้นฐานแพร่หลาย ตลาดจะให้ความสำคัญกับการแก้ปัญหาเชิงโดเมน ซึ่งเป็นโอกาสสำหรับผู้เริ่มต้นที่มีความเข้าใจลึก
- การร่วมมือกับองค์กรใหญ่และ VC: นักลงทุนมักมองหาทีมที่มีประสบการณ์ผ่านความล้มเหลว เพราะถือว่ามีความสามารถในการเรียนรู้และปรับตัวได้ดี
ท้ายที่สุดแล้ว ความล้มเหลวในวงการ AI ไม่ควรมองเป็นจุดสิ้นสุด แต่เป็นขั้นตอนในระบบนิเวศนวัตกรรม — แหล่งทรัพยากรที่สามารถจัดสรรต่อผ่าน M&A, acqui-hire, การสร้าง vertical AI และการก่อรูปสตาร์ทอัพรุ่นใหม่ที่เติบโตบนบทเรียนของอดีต การจัดการทรัพยากรเหล่านี้อย่างชาญฉลาดคือกุญแจสู่การเริ่มต้นใหม่ที่มีประสิทธิภาพและยั่งยืน
บทบาทของนโยบายและมาตรฐานในการลดความเสี่ยง
บทบาทของนโยบายและมาตรฐานในการลดความเสี่ยง
การพัฒนาและปรับใช้เทคโนโลยีปัญญาประดิษฐ์ในระดับอุตสาหกรรมต้องอาศัยกรอบนโยบายและมาตรฐานที่ชัดเจนเพื่อสร้างความมั่นใจทั้งแก่ผู้พัฒนา ผู้ลงทุน และผู้ใช้บริการ ภาครัฐและองค์กรมาตรฐานสามารถลดความเสี่ยงเชิงระบบได้โดยการจัดสรรทรัพยากร สนับสนุนการทดสอบในสภาพแวดล้อมควบคุม และกำหนดหลักการความรับผิดชอบที่ชัดเจน ซึ่งจะช่วยให้การทดลองเชิงนวัตกรรมเกิดขึ้นได้โดยไม่เสี่ยงต่อสาธารณะมากเกินไป
นโยบายที่สนับสนุนการทดสอบและการปรับขนาดในสภาพแวดล้อมควบคุม (regulatory sandboxes และ testbeds) มีบทบาทสำคัญในการลดความเสี่ยงเชิงปฏิบัติ ตัวอย่างที่เห็นผลได้แก่ sandbox ด้านการเงินที่ช่วยลดอุปสรรคต่อสตาร์ทอัพ fintech และกรอบการทดลองด้าน AI ที่ให้ผู้ประกอบการทดสอบระบบกับข้อมูลจริงภายใต้ข้อกำหนดด้านความปลอดภัยและการรายงาน การจัดตั้งโครงการร่วมระหว่างภาครัฐ-เอกชน เช่น ศูนย์ทดสอบเชิงปฏิบัติการ (living labs) หรือโครงการสนับสนุน R&D ด้วยเงินอุดหนุนและการจัดซื้อภาครัฐ (public procurement) ช่วยให้บริษัท AI สามารถขยายผลการทดลองสู่การใช้งานจริงได้เร็วขึ้นพร้อมกับการตรวจวัดผลกระทบและปรับปรุงระบบอย่างเป็นระบบ
กรอบกฎหมายเรื่องความรับผิดชอบและความเป็นส่วนตัวเป็นอีกปัจจัยสำคัญที่ลดความไม่แน่นอนเชิงธุรกิจ หากมีข้อกำหนดที่ชัดเจนเกี่ยวกับความรับผิดชอบของผู้พัฒนา ผู้ปรับใช้ และผู้ให้บริการ (เช่น กรอบความรับผิดชอบแบบแยกบทบาทหรือการกำหนดมาตรฐานความระมัดระวังในแต่ละระดับความเสี่ยง) บริษัทสามารถประเมินต้นทุนด้านความเสี่ยงและจัดกลยุทธ์การรับประกัน (insurance, indemnity) ได้ดีขึ้น นอกจากนี้ กฎหมายคุ้มครองข้อมูลส่วนบุคคลที่ชัดเจน เช่น แนวทางการรักษาความเป็นส่วนตัว ข้อจำกัดการให้บริการข้ามพรมแดน และหลักเกณฑ์ในการใช้ข้อมูลเทรนนิ่ง จะช่วยลดความเสี่ยงด้านการฟ้องร้องและความเสียหายต่อชื่อเสียง ซึ่งเป็นสาเหตุหลักของการล้มเหลวของสตาร์ทอัพด้านเทคโนโลยีในหลายกรณี
มาตรฐานอุตสาหกรรมสำหรับการประเมินความเสี่ยงและการตรวจสอบโมเดลเป็นเครื่องมือที่ช่วยให้การตรวจประเมินมีความสอดคล้องและสามารถเปรียบเทียบได้ เช่น แนวทางการประเมินความเสี่ยง (risk assessment frameworks), การจัดทำเอกสารประกอบโมเดล (model cards, datasheets for datasets), และการตรวจสอบโดยภายนอก (third-party audits, red-teaming) องค์กรมาตรฐานระดับสากลและเครือข่ายวิชาชีพ—รวมถึงคอมมิตตี้มาตรฐานด้าน AI, มาตรฐาน ISO ที่เกี่ยวข้อง และแนวปฏิบัติจากหน่วยงานอย่าง NIST—ได้จัดทำแนวทางเพื่อให้ผู้ประกอบการมีหลักปฏิบัติที่เป็นระบบ ตัวอย่างมาตรการปฏิบัติได้แก่:
- การประเมินความเสี่ยงตามวงจรชีวิตของโมเดล (from data collection → model design → deployment → monitoring) เพื่อชี้จุดเสี่ยงและมาตรการบรรเทา
- การตรวจสอบอิสระและการรับรอง โดยหน่วยงานภายนอกที่มีความเชี่ยวชาญเพื่อยืนยันความปลอดภัยและความเป็นธรรมของระบบ
- มาตรฐานการรายงานและความโปร่งใส เช่น การเผยแพร่ข้อมูลเกี่ยวกับชุดข้อมูล การประเมินความเอนเอียง และผลการทดสอบเชิงสภาพแวดล้อม
- การทดสอบแบบต่อเนื่องและการติดตามผลหลังการใช้งาน (continuous monitoring & post-deployment audits) เพื่อลดความเสี่ยงจาก drift หรือปัจจัยสภาพแวดล้อมที่เปลี่ยนแปลง
เมื่อภาครัฐและภาคอุตสาหกรรมร่วมมือกันสร้างกรอบนโยบายและมาตรฐานที่ชัดเจน จะเกิดสภาพแวดล้อมที่เอื้อต่อการทดลองที่ปลอดภัยและการปรับขนาดเชิงพาณิชย์ไปพร้อมกัน ทั้งยังช่วยลดความเสี่ยงเชิงระบบและเพิ่มความน่าเชื่อถือให้แก่บริษัท AI ซึ่งท้ายที่สุดจะสนับสนุนการเรียนรู้จากความล้มเหลวและการเริ่มต้นใหม่ที่มีประสิทธิภาพมากขึ้น
บทสรุป
การล้มเหลวของบริษัท AI เป็นเรื่องที่เกิดขึ้นได้จริงในวงการที่มีการเปลี่ยนแปลงอย่างรวดเร็ว: โครงการจำนวนมากเผชิญกับปัญหาด้านข้อมูล คุณภาพโมเดล การนำสู่การใช้งานจริง และการกำกับดูแล ทำให้ผลลัพธ์ไม่เป็นไปตามเป้า อย่างไรก็ตาม เหตุล้มเหลวเหล่านี้สามารถเปลี่ยนเป็นบทเรียนได้ผ่านการวิเคราะห์สาเหตุเชิงลึก (root-cause analysis) การทำ post‑mortem เพื่อดึงบทเรียน การปรับกลยุทธ์เชิงผลิตภัณฑ์และธุรกิจ และการเสริมระบบกำกับดูแล (governance) ที่ชัดเจน ตัวเลขจากรายงานอุตสาหกรรมชี้ว่าโครงการ AI หลายโครงการไม่ได้ขึ้นสู่ production ในช่วงแรก แต่การเรียนรู้จากความล้มเหลวกับการปรับกระบวนการสามารถลดความเสี่ยงในรอบถัดไปได้
มุมมองอนาคตชี้ให้เห็นว่าบริษัทที่มีความยืดหยุ่นสามารถรีสเกล (rescale) โฟกัสเข้าสู่ตลาดที่ชัดเจน และลงทุนอย่างจริงจังในคุณภาพข้อมูล ระบบ MLOps และการสังเกตการณ์ (observability) จะมีโอกาสฟื้นตัวและเติบโตท่ามกลางการเปลี่ยนแปลงทางดิจิทัล การเน้นการสร้างข้อได้เปรียบจากข้อมูลที่เหนือกว่า การตั้งค่า pipeline ที่ทนทาน และการกำกับดูแลที่โปร่งใส จะช่วยให้ผลิตภัณฑ์ AI ข้ามจากการทดลองสู่การใช้งานเชิงพาณิชย์ได้จริง — นั่นหมายความว่าแม้ความล้มเหลวจะเป็นไปได้ แต่ด้วยการวางแผนที่ถูกต้องและการลงทุนเชิงโครงสร้าง บริษัท AI สามารถเริ่มต้นใหม่และเติบโตได้ในระยะยาว
📰 แหล่งอ้างอิง: The Guardian



