เมื่อโลกอุตสาหกรรมก้าวสู่ยุคดิจิทัลอย่างเต็มตัว เครือข่ายภายในโรงงานต้องตอบโจทย์ความต้องการที่เข้มงวดทั้งด้านความหน่วงต่ำ ความน่าเชื่อถือ และการรับประกันระดับบริการ (SLA) สำหรับอุปกรณ์ IIoT ตั้งแต่หุ่นยนต์อุตสาหกรรมจนถึงเซ็นเซอร์ตรวจสอบสภาพการทำงาน 5G กับฟีเจอร์อย่าง Network‑Slicing จึงถูกมองเป็นกุญแจสำคัญในการแยกทราฟฟิกและจัดสรรทรัพยากรให้ตรงตามความต้องการของแอปพลิเคชันแต่ละประเภท โดยมีเป้าหมายเช่น latency ใกล้เคียง 1 ms และความพร้อมใช้งานในระดับสูง (เช่น ≥99.99%) เพื่อรองรับงานที่ต้องการความแม่นยำและความต่อเนื่องของการผลิต
บทความนี้จะพาผู้อ่านไล่ตั้งแต่แนวคิดสถาปัตยกรรมของการผสาน 5G กับเทคนิค Reinforcement Learning สำหรับการจัดสรร Network‑Slicing แบบเรียลไทม์ ไปจนถึงรายละเอียดอัลกอริทึม (เช่น นโยบายเชิงลึกและการเรียนรู้เชิงเสริมแบบหลายตัวแทน) ผลการทดลองเชิงตัวเลขที่สะท้อนการลด latency และการปฏิบัติตาม SLA รวมถึงแนวปฏิบัติที่ดีที่สุดสำหรับการทดสอบใช้งานจริงในโรงงาน ตัวอย่างผลการศึกษาเบื้องต้นชี้ให้เห็นว่าการใช้ RL ในการจัดสรรสไลซ์แบบไดนามิกอาจช่วยลด latency ในช่วงการใช้งานพีคลงอย่างมีนัยสำคัญ พร้อมเพิ่มความทนทานของระบบ IIoT เมื่อเทียบกับวิธีการคงที่ทั่วไป — และบทนำนี้คือหน้าต่างให้ผู้อ่านเตรียมเข้าไปสำรวจรายละเอียดเชิงเทคนิคและเชิงปฏิบัติการที่เหลือในบทความต่อไป
บทนำ: ทำไม 5G + RL จึงสำคัญต่อโรงงานยุคใหม่
อุตสาหกรรมสมัยใหม่กำลังก้าวสู่การผลิตที่เชื่อมต่อสูง (Connected Factories) โดยใช้อุปกรณ์ IIoT, หุ่นยนต์อัตโนมัติ (AGV/AMR), ระบบวิชันสำหรับตรวจสอบคุณภาพ และระบบความปลอดภัยแบบเรียลไทม์ สิ่งเหล่านี้ต้องการเครือข่ายที่มี latency ต่ำ และ ความพร้อมใช้งานสูง เพื่อให้การควบคุมแบบปิดวง (closed-loop control) และการสื่อสารเหตุฉุกเฉินทำงานได้อย่างต่อเนื่อง ตัวอย่างเช่น การควบคุมหุ่นยนต์อุตสาหกรรมและระบบสั่งหยุดฉุกเฉินอาจต้องการความหน่วงระดับ 1–10 มิลลิวินาที และความน่าเชื่อถือสูงกว่า 99.999% ในขณะที่ระบบวิชันสำหรับตรวจจับข้อบกพร่องต้องได้แบนด์วิดท์และความเสถียรสูงเพื่อหลีกเลี่ยงการผิดพลาดที่ทำให้เกิดชิ้นงานเสีย
ความต้องการของ IIoT: latency ต่ำ ความพร้อมใช้งานสูง และการแยกทราฟฟิก
ความหลากหลายของแอปพลิเคชันในโรงงานสร้างความต้องการเครือข่ายที่แตกต่างกันอย่างชัดเจน — จากความต้องการ latency ต่ำสุดสำหรับการควบคุมเชิงเวลา ไปจนถึงการรองรับอุปกรณ์จำนวนมาก (massive connections) สำหรับเซ็นเซอร์ ประเด็นสำคัญได้แก่:
- Latency และ jitter ต้องถูกจำกัดเพื่อรักษาเสถียรภาพของการควบคุมแบบเรียลไทม์
- ความพร้อมใช้งาน (availability) และการรับประกัน SLA เพื่อหลีกเลี่ยงการหยุดสายการผลิตที่มีต้นทุนสูง
- การแยกทราฟฟิก (isolation) เพื่อให้แอปพลิเคชันวิกฤตไม่ถูกรบกวนจากทราฟฟิกที่ไม่สำคัญ
Network‑Slicing บน 5G: ทางออกแต่ยังมีข้อจำกัด
เครือข่าย 5G มาพร้อมกับความสามารถด้าน Network‑Slicing ซึ่งอนุญาตให้ผู้ให้บริการสร้างเครือข่ายเสมือนหลายรูปแบบบนโครงสร้างพื้นฐานเดียว เช่น สไลซ์สำหรับ URLLC (ultra‑reliable low‑latency communications) สำหรับการควบคุม หรืิอสไลซ์สำหรับ eMBB (enhanced mobile broadband) สำหรับแอปพลิเคชันวิชัน การแบ่งสไลซ์ช่วยให้สามารถกำหนดนโยบาย QoS, แบนด์วิดท์ และทรัพยากรเครือข่ายแยกกันได้อย่างชัดเจน แต่การจัดสรรแบบคงที่หรือตามกฎที่กำหนดล่วงหน้าไม่เพียงพอในสภาพแวดล้อมโรงงานที่เปลี่ยนแปลงเร็ว:
- ทราฟฟิกอาจพุ่งกระฉูดชั่วขณะเมื่อมีการสแกนงานหรือมีกระบวนการซ่อมบำรุง
- AGV/หุ่นยนต์เคลื่อนที่ทำให้ความต้องการเครือข่ายเปลี่ยนตำแหน่งและเวลา
- เหตุการณ์ฉุกเฉินหรือความผิดปกติของเครื่องจักรต้องการการตอบสนองแบบไดนามิกเพื่อรับประกัน SLA
ทำไมต้องใช้ Reinforcement Learning ในการ Orchestration แบบเรียลไทม์
Reinforcement Learning (RL) เสนอโซลูชันที่เหมาะกับปัญหาการจัดสรรทรัพยากรแบบไดนามิกในเครือข่าย 5G โดยมีข้อได้เปรียบหลักดังนี้: RL เรียนรู้ นโยบาย (policy) ที่ปรับตามสภาพแวดล้อมจริงโดยไม่ต้องพึ่งพาแบบจำลองเครือข่ายที่สมบูรณ์ (model‑free) ทำให้สามารถตอบสนองต่อการเปลี่ยนแปลงของทราฟฟิก ความล่าช้า และความผิดปกติได้แบบเรียลไทม์ นอกจากนี้ RL สามารถเพิ่มประสิทธิภาพแบบหลายวัตถุประสงค์ — ลด latency, ลด packet loss, และรักษา SLA พร้อมกัน — ซึ่งเป็นสิ่งที่การตั้งค่าคงที่ไม่สามารถทำได้อย่างมีประสิทธิภาพ
ในทางปฏิบัติ การใช้ RL ร่วมกับ 5G Network‑Slicing หมายถึงการให้ตัวแทน (agent) เรียนรู้การจัดสรรทรัพยากรระหว่างสไลซ์ เช่น ปรับแบนด์วิดท์ จัดลำดับความสำคัญของคิวใน MEC node หรือตั้งพารามิเตอร์ QoS แบบเรียลไทม์ เพื่อให้บริการสำคัญของโรงงานได้รับการรับประกัน SLA เมื่อเทียบกับระบบที่กำหนดนโยบายล่วงหน้า งานวิจัยและการทดลองภาคสนามแสดงให้เห็นว่าแนวทาง RL สามารถลด latency เฉลี่ยและอัตราการสูญเสียแพ็กเก็ตได้อย่างมีนัยสำคัญในสภาพแวดล้อมที่ไม่แน่นอน — ทำให้เป็นกุญแจสำคัญในการยกระดับความทนทานและความน่าเชื่อถือของ IIoT บนเครือข่าย 5G
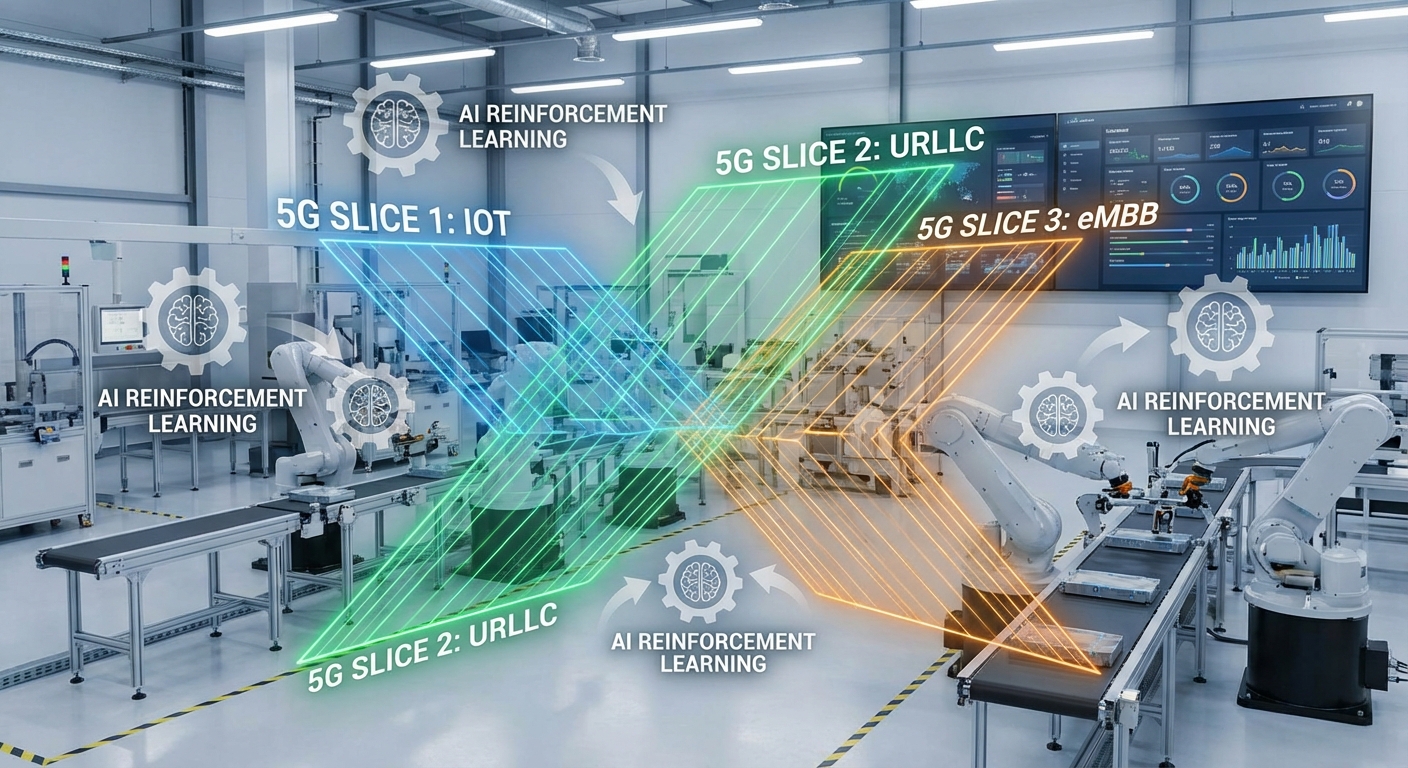
ภาพรวมเทคโนโลยี: 5G, Network Slicing และความต้องการของ IIoT
ภาพรวมเทคโนโลยี: 5G, Network Slicing และความต้องการของ IIoT
เทคโนโลยีเครือข่ายรุ่นที่ห้า (5G) ถูกออกแบบมาเพื่อตอบโจทย์การสื่อสารที่หลากหลายผ่านสามแกนหลัก ได้แก่ eMBB (enhanced Mobile Broadband) เพื่อความเร็วและแบนด์วิดท์สูง, mMTC (massive Machine Type Communications) เพื่อรองรับการเชื่อมต่ออุปกรณ์จำนวนมาก และ URLLC (Ultra-Reliable Low-Latency Communications) สำหรับงานที่ต้องการความหน่วงต่ำและความเชื่อถือได้สูง เช่น การควบคุมแบบเรียลไทม์ในโรงงานหรือยานยนต์ไร้คนขับ ซึ่ง 3GPP ระบุว่า URLLC รองรับ latency ในระดับมิลลิวินาที; ในทางปฏิบัติ deployment สาธารณะมักอยู่ที่ 10–50 ms ขึ้นกับสภาพแวดล้อมและการออกแบบเครือข่าย
สำหรับภาคอุตสาหกรรม บริบทของ 5G ไม่ได้หมายถึงเพียงความเร็ว แต่หมายถึงความสามารถในการแยกและจัดการทราฟฟิคให้กับบริการที่แตกต่างกันอย่างเป็นระบบ ซึ่งนำไปสู่บทบาทสำคัญของ Network‑Slicing—แนวคิดการสร้างเครือข่ายตรรกะ (logical networks) หลายชั้นบนโครงสร้างพื้นฐานเดียวกัน โดยแต่ละ slice สามารถกำหนดนโยบาย QoS, แบนด์วิดท์, ความสำคัญ (priority) และการแยกทรัพยากรเพื่อให้สอดคล้องกับข้อกำหนดของแอปพลิเคชันเฉพาะทาง เช่น slice สำหรับการควบคุมเครื่องจักรต้องการ latency ต่ำและ availability สูง ขณะที่ slice สำหรับการวิเคราะห์วิดีโออาจเน้น throughput
โรงงานอุตสาหกรรมสมัยใหม่มีข้อกำหนดด้านเครือข่ายที่ชัดเจนและเข้มงวดเพื่อรับประกันการทำงานของระบบอัตโนมัติและ IIoT (Industrial IoT) ตัวอย่างของเป้าหมายเชิงตัวเลขได้แก่:
- Latency – การควบคุมแบบ closed‑loop และหุ่นยนต์อุตสาหกรรมมักต้องการ latency ต่ำกว่า 10 ms ในการปฏิบัติงานเชิงปฏิบัติ การออกแบบที่อุดมคติสำหรับ URLLC อยู่ที่ระดับ ~1 ms ทางทฤษฎี แต่ deployment จริงในสาธารณะมักเห็นค่าอยู่ระหว่าง 10–50 ms
- Jitter – ต้องต่ำมาก (เช่น <1 ms ถึงไม่กี่มิลลิวินาที) เพื่อหลีกเลี่ยงการสั่นไหวของการควบคุมแบบเรียลไทม์
- Packet loss – ควรต่ำสุดเท่าที่เป็นไปได้สำหรับคำสั่งควบคุม (ตัวอย่างเช่น <0.1% หรือต่ำกว่า ขึ้นกับความสำคัญของแอปพลิเคชัน)
- Availability – สำหรับงาน mission‑critical บางระบบต้องการ SLA ระดับสูง เช่น 99.999% (“five nines”) เพื่อให้มั่นใจว่าการผลิตไม่ถูกขัดจังหวะ
ในเชิงตลาดและการใช้งานจริง อุปกรณ์ IIoT และการลงทุนในเครือข่ายสำหรับภาคอุตสาหกรรมกำลังเติบโตอย่างรวดเร็ว: รายงานและการคาดการณ์หลายฉบับระบุว่าอุปกรณ์ IIoT ทั่วโลกมีแนวโน้มเพิ่มขึ้นอย่างต่อเนื่อง — ประมาณการโดยรวมชี้ว่าอุปกรณ์ IIoT อาจเพิ่มจากระดับปัจจุบันไปสู่ระดับหลายสิบพันล้านหน่วยภายในทศวรรษถัดไป โดยอัตราการเติบโตเฉลี่ยต่อปี (CAGR) อยู่ในช่วงตัวเลขหลักหนึ่งถึงสองหลัก ขึ้นกับนิยามของ IIoT และภาคอุตสาหกรรมที่พิจารณา
นอกจากนี้ การนำ 5G เข้าสู่โรงงาน (โดยเฉพาะในรูปแบบ private 5G) ถูกคาดการณ์ว่าจะเพิ่มขึ้นอย่างมีนัยสำคัญในระยะใกล้ถึงกลาง เนื่องจาก 5G ช่วยให้สามารถจัดสรรสไลซ์ที่แยกกันตาม SLA, ลดผลกระทบจากสัญญาณรบกวนภายนอก และเพิ่มความทนทานของโครงสร้างการสื่อสาร การนำ Network‑Slicing มาใช้ร่วมกับนโยบาย SLA ที่ชัดเจนจึงกลายเป็นหัวใจสำคัญของการเปลี่ยนผ่านสู่โรงงานอัจฉริยะ (Smart Factory)
สรุปคือ 5G และ Network‑Slicing ให้กรอบการทำงานที่จำเป็นต่อการตอบโจทย์ IIoT ระดับอุตสาหกรรม ทั้งในแง่การรับประกันค่า latency, jitter, packet loss และ availability ที่เข้มงวด ขณะที่ความต้องการอุปกรณ์และการลงทุนในเครือข่ายสำหรับโรงงานยังคงมีแนวโน้มเติบโตอย่างต่อเนื่อง ซึ่งเปิดโอกาสให้เทคนิคการจัดสรรทรัพยากรแบบเรียลไทม์ (รวมถึงการเรียนรู้เชิงเสริมแรงในกรณีต่อไป) เข้ามาช่วยยกระดับการปฏิบัติการและการรับประกัน SLA ได้ดียิ่งขึ้น
Reinforcement Learning (RL): ทำไมเหมาะกับการจัดสรร Slice แบบเรียลไทม์
Reinforcement Learning (RL): ทำไมเหมาะกับการจัดสรร Slice แบบเรียลไทม์
หลักการพื้นฐานของ Reinforcement Learning (RL) — RL ประกอบด้วยองค์ประกอบสำคัญคือ agent (ตัวตัดสินใจ), environment (สภาพแวดล้อมที่ agent ปฏิสัมพันธ์ด้วย), state (สถานะปัจจุบันของสิ่งแวดล้อมหรือเครือข่าย), action (การกระทำที่ agent เลือก เช่น การจัดสรรทรัพยากรให้ slice ใด) และ reward (ผลตอบแทนหรือค่าตอบแทนที่สะท้อนความสำเร็จของการกระทำนั้น) ทั้งนี้เป้าหมายของ agent คือการเรียนรู้นโยบาย (policy) ที่ทำให้ผลรวมของ reward ในระยะยาวสูงสุด ตัวอย่างเช่น ในงานจัดสรร network‑slicing agent อาจได้รับ reward บวกเมื่อ latency ต่ำกว่า SLA และมี throughput เพียงพอ แต่ได้รับ penalty เมื่อเกิด packet loss หรือใช้งบประมาณทรัพยากรมากเกินไป
ความสามารถในการเรียนรู้จาก telemetry จริงแบบต่อเนื่อง — เครือข่าย 5G และระบบ IIoT ผลิตข้อมูล telemetry ระดับแพ็กเก็ตและเซสชันอย่างต่อเนื่อง เช่น latency, jitter, throughput, packet loss, สถานะช่องสัญญาณ และการใช้งาน CPU/RAM ของ MEC การออกแบบ RL ให้รับข้อมูลเหล่านี้เป็น state ทำให้ agent สามารถปรับนโยบายการจัดสรรแบบ online ได้ทันทีตามพฤติกรรมการใช้งานจริง ตัวอย่างเช่น หากเกิดงานล็อตการผลิตที่เพิ่มจำนวนอุปกรณ์พร้อมกัน RL สามารถเรียนรู้จากการเปลี่ยนแปลงของ telemetry และปรับ slice quota เพื่อรักษา latency ให้สอดคล้องกับ SLA ทั้งนี้การอัพเดตนโยบายสามารถทำเป็นแบบต่อเนื่อง (online learning) หรือเป็นช่วง ๆ ขึ้นกับความเสี่ยงต่อบริการ
รองรับ objective หลายมิติและการออกแบบ reward ที่สะท้อน SLA/นโยบายธุรกิจ — ปัญหาการจัดสรรทรัพยากรในโรงงานเป็นปัญหาเชิงหลายวัตถุประสงค์ (latency vs throughput vs reliability vs cost) ซึ่ง RL มีความยืดหยุ่นสูงในการนิยามฟังก์ชัน reward เพื่อสะท้อนเป้าหมายเชิงธุรกิจ ตัวอย่างรูปแบบ reward ที่ใช้ได้แก่:
- ค่าบวกเมื่อ latency ต่ำกว่าเกณฑ์ SLA (เช่น <1 ms สำหรับ URLLC ในกรณีเฉพาะ) และค่าลบเมื่อเกิน
- รางวัลสัดส่วนกับ throughput ที่ส่งมอบให้แอปพลิเคชันสำคัญ
- บทลงโทษสำหรับ packet loss, retransmission หรือการใช้ทรัพยากรเกินงบประมาณ
- การนำเงื่อนไขเชิงนโยบายธุรกิจ เช่น ค่าความสำคัญของงานผลิต (priority weighting) มารวมใน reward เพื่อจัดลำดับความสำคัญของ slice
นอกจากนี้ยังสามารถใช้กรอบงานเช่น constrained reinforcement learning (เช่น CMDP หรือวิธี Lagrangian) เพื่อรับประกันข้อจำกัด SLA แบบ hard constraint ขณะเดียวกันยังเพิ่ม objective เสริมเช่นลดต้นทุนการดำเนินงาน
การปรับตัวต่อสภาวะเปลี่ยนแปลงและเทคนิคลดเวลาฝึกสอนในสภาพแวดลจริง — หนึ่งในเหตุผลสำคัญที่ทำให้ RL เหมาะกับการจัดสรร slice คือความสามารถในการปรับตัวเมื่อสภาวะเครือข่ายเปลี่ยน เช่น ความแปรปรวนของการรบกวนสัญญาณ ความหนาแน่นของอุปกรณ์ หรือการเปลี่ยนแปลงของงานผลิต เทคนิคเช่น transfer learning (ย้ายความรู้จากสถานการณ์จำลองหรือไซต์อื่นมาช่วยเริ่มต้น) และ offline RL (เรียนรู้จากข้อมูลล็อก telemetry ที่เก็บไว้โดยไม่ต้องลงมือทดลองในระบบจริง) ช่วยลดความเสี่ยงและเวลาที่ต้องใช้ฝึกสอนในสภาพแวดลจริง ตัวอย่างกระบวนการปฏิบัติได้แก่ การฝึกในซิมูเลเตอร์ที่จำลองการจราจร IIoT และสถานการณ์การณ์ผิดปกติ แล้วนำมา fine‑tune บนข้อมูลจริงด้วย offline RL หรือการฝึกแบบ centralized แล้ว deploy เป็นโมเดลที่ปรับได้แบบ decentralized
Multi‑agent RL สำหรับการตัดสินใจแบบกระจาย — ในสถาปัตยกรรมเครือข่ายเช่น RAN, MEC และ Core อาจเหมาะที่จะมีตัวแทนหลายตัว (เช่น agent ระดับ gNodeB, MEC node, หรือ slice controller เฉพาะงาน) ทำให้เกิดข้อได้เปรียบด้านสเกล ความหน่วง และความทนทาน Multi‑agent RL (MARL) ช่วยให้การตัดสินใจเป็นแบบกระจาย โดยใช้กลยุทธ์เช่น centralized training with decentralized execution (CTDE), การแชร์พารามิเตอร์, หรือการแลกเปลี่ยนสัญญาณสถานะระหว่าง agent เพื่อประสานงาน ตัวอย่างเช่น agent ของแต่ละไซต์สามารถปรับ bandwidth สำหรับ slice ท้องถิ่น ในขณะที่ agent ส่วนกลางประสานการจัดลำดับความสำคัญข้ามไซต์เพื่อให้ SLA ของโรงงานทั้งหมดเป็นไปตามเป้า
โดยสรุปแล้ว RL นำเสนอกรอบการทำงานที่ยืดหยุ่นและเหมาะสมต่อการบริหารจัดการ network‑slicing แบบเรียลไทม์ในสภาพแวดล้อม IIoT: เรียนรู้จาก telemetry จริง ปรับตัวต่อความเปลี่ยนแปลง รองรับเป้าหมายหลายมิติ และสามารถออกแบบให้ทำงานแบบกระจายด้วยเทคนิคสมัยใหม่เพื่อลดเวลาฝึกสอนและความเสี่ยงเมื่อนำไปใช้ในโรงงานอุตสาหกรรมจริง
สถาปัตยกรรมการผสาน: RAN/CORE, RIC, Orchestrator, MEC และ RL‑Agent
สรุปสถาปัตยกรรมการผสาน (RAN/CORE, RIC, Orchestrator, MEC และ RL‑Agent)
สถาปัตยกรรมเชิงวิศวกรรมสำหรับการผสาน 5G กับ Reinforcement Learning (RL) เพื่อจัดการ Network‑Slicing แบบเรียลไทม์ประกอบด้วยองค์ประกอบหลักหลายชั้นที่ทำงานร่วมกันอย่างใกล้ชิด ได้แก่ gNodeB/RAN (Radio Access Network), 5G Core พร้อมฟังก์ชันสำคัญอย่าง SMF/AMF/UPF, near‑RT RIC และ Non‑RT RIC/SMO (Service Management and Orchestration) รวมทั้ง MEC (Multi‑access Edge Computing) และ SDN controller สำหรับการควบคุมเส้นทางทราฟฟิกและทรัพยากรเครือข่ายขนส่ง การผสานนี้ถูกออกแบบให้ RL‑agent ทำหน้าที่ตัดสินใจเชิงการควบคุมแบบ near‑real‑time โดยมี Non‑RT RIC/SMO ทำหน้าที่เป็นชั้นบริหารเชิงยุทธศาสตร์และจัดการวงชีวิตของ slice (lifecycle) และ model orchestration

การทำงานร่วมกันเชิงสัญญาณและการควบคุมถูกจัดวางตามบทบาท: gNodeB/RAN เป็นจุดรวบรวม telemetry ระดับวิทยุและสถานะ queue/scheduling; 5G Core (AMF/SMF/UPF) จัดการ session, PDU session routing และ QoS parameters (5QI, ARP); near‑RT RIC รับผิดชอบนโยบายการจัดสรรทรัพยากรที่ต้องการความหน่วงตอบสนองต่ำ (เวลาในการตัดสินใจในช่วงประมาณ 10ms–1s) โดยเชื่อมต่อกับ gNodeB ผ่าน E2 interface ตามมาตรฐาน O‑RAN; Non‑RT RIC/SMO (หรือ ONAP ในโซลูชันบางราย) ทำหน้าที่วางนโยบายเชิงกลยุทธ์, ฝึกโมเดลแบบไม่เรียลไทม์ และสั่ง deploy model ใหม่ไปที่ near‑RT RIC
ในมุมมองของการใช้งานอุตสาหกรรม (IIoT) MEC ถูกจัดวางเป็นจุดประมวลผลสำหรับ workload ที่ต้องการ latency ต่ำ เช่นการควบคุมหุ่นยนต์แบบ closed‑loop หรือการประมวลผลวิดีโอตรวจสอบคุณภาพ ซึ่งจะผูกกับ slice เฉพาะ (dedicated slice) เพื่อรับประกัน SLA และลดเส้นทางไปยัง cloud ส่วน SDN controller ทำงานร่วมกับ SMF/UPF เพื่อปรับเส้นทางทราฟฟิกแบบไดนามิก (path steering) และบังคับใช้การแบ่งทรัพยากรในระดับ transport เช่นการใช้ Segment Routing หรือ SRv6 เพื่อให้เส้นทางตรงไปยัง MEC หรือทรัพยากรสำรอง
ตำแหน่งและบทบาทของ RL‑Agent
การวาง RL‑agent ไว้ที่ near‑RT RIC ให้ความสมดุลระหว่างมุมมองเชิงยุทธศาสตร์และความต้องการ latency ของการตัดสินใจ near‑real‑time: agent สามารถรับ telemetry ความถี่สูงจาก gNodeB/UPF/MEC และส่งคำสั่งไปยัง MAC scheduler, SMF, SDN controller หรือ MEC orchestrator ภายในช่วงเวลาที่เหมาะสม (10ms–1s) ในขณะที่ Non‑RT RIC/SMO ทำหน้าที่ฝึกโมเดลแบบ non‑real‑time, ตีความนโยบายเชิงธุรกิจ และอัปเดตนโยบาย/โมเดลให้กับ near‑RT RIC เพื่อให้การตัดสินใจสอดคล้องกับ SLA ระยะยาว
ข้อมูล Telemetry ที่ต้องเก็บสำหรับ RL
- Latency per slice: เวลา end‑to‑end และ per‑hop (RAN → UPF → MEC)
- Queue length / buffer occupancy ที่ gNodeB, UPF และ switch เพื่อจับสัญญาณความแออัด
- Link quality: CQI, RSRP/RSRQ, packet loss rate สำหรับการตัดสินใจเกี่ยวกับ radio scheduling และ handover
- CPU / memory usage ของ MEC instances และ VNFs เพื่อการ scale‑out/scale‑in ของบริการ edge
- Throughput per slice และ per UE เพื่อประเมิน QoE และ adherence ต่อ SLA
- Transport network metrics: latency, jitter และ utilization ของเส้นทางที่ SDN controller รายงาน
- Event logs และ alarm เช่น handover failures, congestion events เพื่อเป็น input ใน reward shaping และ fault‑aware policies
Action Space ที่ RL‑Agent สามารถสั่งได้
- ปรับ bandwidth allocation ระหว่าง slices (slice bandwidth cap หรือ priority queues)
- ปรับค่า scheduling weights และ priority ใน MAC scheduler ของ gNodeB (เช่นเปลี่ยน proportion ของ RBs ให้ slice ที่ต้องการ latency ต่ำ)
- เปลี่ยนการ routing หรือ path‑steering ผ่าน SDN controller/SMF/UPF (เช่นสลับเส้นทางทราฟฟิกไปยัง MEC ใกล้เคียงเพื่อลด RTT)
- ปรับ priority markings (DSCP/QoS flow identifiers) เพื่อให้ UPF/transport network ใช้นโยบาย QoS ที่ต่างกัน
- สั่ง scale ของ MEC/VNF (เพิ่ม/ลด CPU, spin up VNFs หรือ container) ผ่าน MEC orchestrator หรือ SMO
- ปรับค่า PDU session หรือ QoS profile ผ่าน SMF (เช่นเปลี่ยน 5QI, ARP หรือสร้าง new PDU session ไปยัง UPF เฉพาะ)
การผสานเชิงปฏิบัติการและการรับประกัน SLA
การทำงานแบบองค์รวมจำเป็นต้องใช้ Open APIs และฟังก์ชัน orchestration อัตโนมัติ: near‑RT RIC สื่อสารกับ gNodeB ผ่าน E2 interface, ส่วน Non‑RT RIC/SMO ใช้ A1 ทั้งในการส่ง policy และรับ feedback เพื่อการปรับโมเดล Non‑RT นอกจากนี้การเชื่อมต่อกับแพลตฟอร์ม orchestration เช่น ONAP หรือ SMO ผ่าน O‑RAN APIs/REST จะเป็นหัวใจสำคัญในการสั่งปรับ slice lifecycle (instantiate, scale, reconfigure) อัตโนมัติ เมื่อ RL‑agent ตัดสินใจเปลี่ยน topology หรือ resource allocation การสั่งงานจะไหลจาก near‑RT RIC → SMF/SDN controller/MEC orchestrator → gNodeB/UPF/MEC
เพื่อรับประกันความทนทานของ IIoT และ SLA เชิงธุรกิจ ต้องมี layer ของนโยบายป้องกัน (safety constraints) ที่ถูกบังคับใช้โดย SMO/Non‑RT RIC ซึ่งจำกัด action space ของ RL‑agent ในระดับที่ปลอดภัย เช่น จำกัดการลด bandwidth ต่ำกว่าค่า SLA หรือต้องตรวจสอบก่อนทำ failover ข้ามไซต์ การออกแบบ reward function ควรรวมทั้งการปฏิบัติตาม SLA, ลด latency, ลด packet loss และเพิ่มความทนทาน (redundancy) เพื่อให้ตัวแทนเรียนรู้พฤติกรรมที่สอดคล้องกับเป้าหมายเชิงธุรกิจ
สรุปคือ การวาง RL‑agent ที่ near‑RT RIC ร่วมกับ MEC สำหรับงาน latency‑sensitive และการเชื่อมต่อกับ SMO/ONAP/O‑RAN APIs จะทำให้การจัดสรร Network‑Slicing แบบเรียลไทม์เป็นไปได้จริง ทั้งในแง่ประสิทธิภาพ ความทนทาน และการรับประกัน SLA สำหรับโรงงานอุตสาหกรรมที่ต้องการบริการ IIoT ที่เชื่อถือได้
อัลกอริทึมและกลยุทธ์ RL ที่เหมาะสมกับการตัดสินใจแบบเรียลไทม์
อัลกอริทึมและกลยุทธ์ RL ที่เหมาะสมกับการตัดสินใจแบบเรียลไทม์
ในการนำ Reinforcement Learning มาใช้กับการจัดสรร Network‑Slicing แบบเรียลไทม์ในโรงงานอุตสาหกรรม ต้องเลือกอัลกอริทึมให้สอดคล้องกับข้อจำกัดด้านเวลา ตำแหน่งการตัดสินใจ และความเสี่ยงต่อการละเมิด SLA สำหรับกรณีที่ต้องตอบสนองทันทีและมีบริบทจำกัด contextual bandits และ multi‑armed bandits (MAB) เป็นตัวเลือกที่เหมาะสม เนื่องจากมีความเรียบง่ายและความต้องการตัวอย่าง (sample) ต่ำกว่าระบบ DRL เต็มรูปแบบ ตัวอย่างการใช้งานคือการเลือก template ของ slice หรือระดับ QoS สำหรับ flow ใหม่ในช่วงเวลาสั้น ๆ — นโยบายที่ได้สามารถคำนวณได้ใน O(1) ต่อการตัดสินใจ ทำให้ latency เวลาตัดสินใจต่ำเพียงไม่กี่มิลลิวินาที ซึ่งเหมาะกับการตัดสินใจที่ต้องทำซ้ำและเร็วในเครือข่ายสภาพแวดล้อม IIoT
เมื่อปัญหามีมิติของ action สูงหรือเป็นค่าต่อเนื่อง เช่น การแจกจ่ายแบนด์วิดท์เป็นสัดส่วนต่อแต่ละ slice หรือการปรับอัตราการส่งข้อมูลแบบต่อเนื่อง จะต้องพิจารณาใช้ Deep Reinforcement Learning (DRL) รุ่นสมัยใหม่ เช่น PPO (Proximal Policy Optimization), SAC (Soft Actor‑Critic) และ DDPG (Deep Deterministic Policy Gradient). โดยทั่วไป PPO ให้ความเสถียรและง่ายต่อการฝึกในกรอบที่เป็น on‑policy; SAC เหมาะสำหรับนโยบายต่อเนื่องที่ต้องการความสมดุลระหว่าง exploration กับ exploitation และมักมีความทนทานต่อความผันผวนของสัญญาณ reward; ขณะที่ DDPG เหมาะกับ action space ต่อเนื่องแต่ต้องระวังด้านความไม่เสถียรของการเรียนรู้เนื่องจากเป็น off‑policy deterministic method. ในการประยุกต์จริง มักต้องคำนึงถึงความสามารถในการปฏิบัติการแบบเรียลไทม์ (inference latency) — นโยบายที่ใช้ neural network ขนาดเล็กหรือ quantized model สามารถลดเวลา inference ให้เหมาะสมกับการใช้งานเชิงอุตสาหกรรมได้
ในระบบที่มีจุดตัดสินใจหลายตำแหน่ง เช่น หลาย gNodeB หรือหลายตัวควบคุมภายในบริเวณโรงงาน Multi‑Agent RL (MARL) จะช่วยให้แต่ละตัวแทน (agent) ประสานงานกันเพื่อจัดสรร slice อย่างมีประสิทธิผล แต่ต้องจัดการปัญหา non‑stationarity และการสื่อสารระหว่าง agent การออกแบบสถาปัตยกรรมอาจเลือกใช้แบบ centralized training with decentralized execution เพื่อลด overhead ขณะรันจริง และใช้แนวทางเช่น parameter sharing หรือ value decomposition เพื่อเพิ่มเสถียรภาพ นอกจากนี้ การแบ่งปันข้อมูลบริบทที่สำคัญ (เช่น latency metric และ queue length) ระหว่าง agent ช่วยลดความไม่แน่นอนและปรับปรุงการปฏิบัติการแบบเรียลไทม์
เพื่อรับประกัน SLA และความปลอดภัยของการดำเนินงานต้องใช้กลยุทธ์ safe / constrained RL เช่นการฟอร์มูเลตปัญหาเป็น Constrained Markov Decision Process (CMDP) และใช้ Lagrangian relaxation หรือ safe policy improvement techniques ที่ลดความเสี่ยงในการทดลองในระบบจริง เทคนิคอื่น ๆ ที่มักนำมาใช้ร่วมกันเพื่อเพิ่มประสิทธิภาพและความปลอดภัย ได้แก่:
- Reward shaping — ออกแบบฟังก์ชันรางวัลให้สะท้อนค่าเสียโอกาสจากการละเมิด SLA เช่นให้โทษหนักเมื่อ latency หรือ packet loss เกินเกณฑ์ เพื่อเร่งการเรียนรู้ทิศทางที่ปลอดภัย
- Reward clipping — ป้องกันค่า reward ผันผวนอย่างรุนแรงที่อาจทำให้การฝึกไม่เสถียร
- Prioritized Experience Replay — เลือกตัวอย่างสำคัญจาก buffer เพื่อเร่งการเรียนรู้จากเหตุการณ์ที่สำคัญต่อ SLA (เช่นช่วงที่เกิด congestion)
- Shielding / runtime safety checks — ใช้กฎตรวจสอบก่อนปฏิบัติการจริงเพื่อบล็อก action ที่อาจละเมิด SLA
- Simulation / Digital Twin — ฝึกและทดสอบนโยบายในสภาพแวดล้อมจำลองที่สะท้อนพฤติกรรมของเครือข่ายและ IIoT device ก่อนนำขึ้นสู่ระบบจริง เพื่อลดความเสี่ยงและเพิ่ม sample efficiency
ในทางปฏิบัติ การรวมกันของวิธีการข้างต้นมักให้ผลดีที่สุด: ใช้ contextual bandits หรือ MAB เป็น first‑line decision engine สำหรับการตัดสินใจ latency‑sensitive ที่มีบริบทจำกัด; ใช้ DRL (PPO/SAC/DDPG) สำหรับงาน allocation ที่ต้องการนโยบายต่อเนื่องและความสามารถในการปรับตัวระยะยาว; และผสาน safe RL กับ digital twin เพื่อให้การเปลี่ยนผ่านจากการทดลองสู่การใช้งานจริงสามารถรักษา SLA ได้ตลอดเวลา ทั้งนี้ ควาวัดผลเชิงปริมาณ เช่น latency target ของโรงงาน (ตัวอย่าง: เป้าหมาย end‑to‑end latency ≤ 10–50 ms) และอัตราการยึด SLA (SLA compliance > 99%) เพื่อนำมาเป็นเกณฑ์การออกแบบและประเมินนโยบายก่อนนำไปใช้จริง
ผลลัพธ์เชิงประสิทธิภาพ: ลด Latency รับประกัน SLA และเพิ่มความทนทาน — ตัวอย่างเชิงตัวเลข
ผลลัพธ์เชิงประสิทธิภาพ: ลด Latency รับประกัน SLA และเพิ่มความทนทาน — ตัวอย่างเชิงตัวเลข
จากชุดการทดลองในแล็บและโครงการนำร่อง (PoC) ของโรงงานอุตสาหกรรมที่ผสาน 5G กับอัลกอริทึม Reinforcement Learning (RL) เพื่อจัดสรร Network‑Slicing แบบเรียลไทม์ พบผลลัพธ์เชิงตัวเลขที่ชัดเจนทั้งในมิติของ latency, การปฏิบัติตาม SLA, packet loss และ availability ของระบบเครือข่าย โดยผลลัพธ์ส่วนใหญ่เป็นผลจากการทดลองจริงหรือการจำลองเชิงอุตสาหกรรมที่ปรับพารามิเตอร์ให้ใกล้เคียงสภาพแวดล้อมการผลิตจริง (industrial emulation).
ตัวอย่างเชิงตัวเลขจาก PoC และการจำลอง (ค่าสรุปจากหลายงานวิจัยและ PoC):
- Latency เฉลี่ยลดลง 20–60% ใน use‑case ประเภทการควบคุมแบบ closed‑loop และ real‑time monitoring (เช่น motion control, robotic coordination) — ในหลายกรณีที่มีการผันผวนทราฟฟิกปานกลางถึงสูง RL สามารถปรับ slice bandwidth และ prioritization ได้ทันเวลาจนลด latency tail (p95–p99) ลงอย่างมีนัยสำคัญ
- SLA compliance เพิ่มจากระดับฐานตัวอย่างเช่น 85% → >95% เมื่อใช้กลยุทธ์ RL ที่มีนโยบายความปลอดภัยเชิงนโยบาย (safe RL) และมีการมอนิเตอร์ต่อเนื่องแบบออนไลน์ (online monitoring + corrective actions)
- Packet loss ลดลงในช่วง 30–80% ในการทดลองที่มีการจัดการ congestion แบบ slice‑aware และการทำ selective retransmission/edge caching ที่ควบคุมโดย RL
- Availability ของบริการเพิ่มขึ้นจากตัวอย่างเช่น 99.0% → 99.6–99.99% ขึ้นอยู่กับระดับ redundancy ของ RAN/edge และนโยบาย failover ที่ถูกเรียนรู้และปรับโดย RL
นอกจากค่าสถิติเฉลี่ยแล้ว PoC หลายโครงการรายงานการปรับปรุงในมิติ tail latency และความสม่ำเสมอของการให้บริการ ตัวอย่างเช่น:
- p95 latency ดีขึ้นประมาณ 30–70% และ p99 latency ดีขึ้น 40–80% เมื่อเทียบกับนโยบาย static slicing
- อัตราการผิดพลาดเชิงเวลาหรือ violation ของ SLA (SLA breaches) ลดลงมากกว่า 50–90% ใน use‑case ที่มีการผันผวนทราฟฟิกชัดเจน เช่น การสลับโหมดการผลิต
ข้อสังเกตสำคัญ: ผลลัพธ์ข้างต้นมีความผันแปรขึ้นกับสเกลของเครือข่าย ระดับของความผันผวนของทราฟฟิก และคุณภาพของ telemetry/measurement ที่ส่งมายังตัวควบคุม RL ในกรณีศึกษาเช่น
- ในเครือข่ายขนาดเล็ก (ตัวอย่าง: โรงงานขนาดเล็กที่มี 5–10 gNodeB/edge nodes) พบว่า RL เรียนรู้นโยบายได้เร็วและปรับปรุง latency ได้ชัดเจน (ด้านล่างของช่วงตัวเลขข้างต้น)
- ในเครือข่ายสเกลใหญ่ (ตัวอย่าง: คอมเพล็กซ์โรงงานหรือ campus ที่มี >50 gNodeB/หลายคลัสเตอร์) ผลลัพธ์ขึ้นกับการออกแบบ state representation, การแบ่งงานระหว่าง centralized และ distributed agents และปริมาณ telemetry — ถ้า telemetry ไม่เพียงพอหรือมี latency ในการสื่อสาร ผลตอบแทนอาจลดลง
- ความผันผวนของทราฟฟิกสูง (burst traffic) ทำให้ต้องมีนโยบาย RL ที่เน้นความทนทาน (robust RL และ conservative exploration) เพื่อหลีกเลี่ยงการ overshoot ที่อาจกระทบ SLA
สรุปเชิงปฏิบัติการ: การผสาน RL กับ 5G network‑slicing ในสภาพแวดล้อม IIoT สามารถให้ผลเชิงปริมาณที่โดดเด่น เช่นการลด latency ค่าเฉลี่ย 20–60%, การเพิ่ม SLA compliance เป็น >95%, การลด packet loss อย่างมีนัยสำคัญ และการยกระดับ availability ให้ใกล้เคียงระดับ carrier‑grade ในหลาย PoC อย่างไรก็ตาม การจะทำซ้ำผลลัพธ์เหล่านี้ในสเกลการผลิตจริงจำเป็นต้องมีการออกแบบ telemetry, นโยบายความปลอดภัยของ RL, และการทดสอบการปรับตัวต่อความผันผวนก่อนนำไปใช้งานจริง
การนำไปใช้จริง: ขั้นตอน เครื่องมือ ความท้าทาย และแนวปฏิบัติที่ดีที่สุด
แนวทางการเริ่มต้น: PoC → Pilot → Production
การนำระบบ 5G ผสาน Reinforcement Learning (RL) เพื่อจัดสรร Network‑Slicing แบบเรียลไทม์ ควรเดินหน้าเป็นขั้นตอนชัดเจนโดยเริ่มจาก Proof‑of‑Concept (PoC) แล้วขยายสู่ Pilot ก่อนขึ้น Production ทั้งนี้แนะนำกระบวนการดังนี้:
- กำหนดขอบเขต Use‑case ที่ชัดเจน — เริ่มจาก use‑case จำกัด เช่น remote control path ของหุ่นยนต์ในไลน์การผลิต หรือ critical monitoring slice สำหรับการตรวจจับเหตุฉุกเฉิน โดยกำหนด KPI ที่จับต้องได้ เช่น latency ≤ 5 ms สำหรับ remote control, jitter ≤ 1 ms, packet loss ≤ 10⁻⁵, และ SLA compliance ≥ 99.99% ในช่วงการทดลอง
- PoC (Lab/Emulation) — ใช้ testbed หรือ digital twin เพื่อสร้างสถานการณ์จำลอง traffic และเหตุการณ์ผิดปกติ ฝึก RL agent ด้วยข้อมูลสังเคราะห์และ trace จริง ตรวจสอบพฤติกรรม policy ภายใต้เงื่อนไขแตกต่างกันจนผ่านเกณฑ์ยอมรับ (acceptance criteria) ที่กำหนด
- Pilot (Controlled Field Trial) — ขยายไปยังเซลล์การผลิตจริงแบบจำกัด (เช่น บริเวณหนึ่งของโรงงานหรืออุปกรณ์ชนิดเดียว) ใช้ canary deployment, เก็บ metric ทุกชั้น (radio, transport, core, application) และเปรียบเทียบกับ baseline แบบ non‑RL
- Production (Phased Rollout) — ขยายแบบค่อยเป็นค่อยไปโดยมี rollback plan ที่ชัดเจน, human‑in‑the‑loop และระบบ monitoring ที่เตรียมไว้สำหรับสั่งยกเลิกหรือย้อนกลับอัตโนมัติหากพบการเบี่ยงเบนจาก SLA
การใช้ Simulation และ Digital Twin เพื่อฝึกและทดสอบ RL
การใช้ simulation และ digital twin เป็นหัวใจสำคัญเพื่อลดความเสี่ยงก่อน deploy จริง โดยแนะนำแนวปฏิบัติดังนี้:
- สร้าง digital twin ของเครือข่ายและโรงงานที่ผสานทั้งชั้นฟิสิกส์ (radio channel, propagation) และชั้นแอปพลิเคชัน IIoT — ตัวอย่างเครื่องมือ: NS‑3, OMNeT++, OpenAirInterface, 5G‑LENA, MATLAB/Simulink
- ฝึก RL agent ในสภาพแวดล้อมจำลองที่ครอบคลุมเหตุการณ์ edge case (เช่น congestion, link failure, handover) และทำ hardware‑in‑the‑loop (HIL) เพื่อทดสอบกับอุปกรณ์จริงบางส่วน
- ใช้ frameworks สำหรับ RL ที่รองรับ distributed training และ reproducibility เช่น Ray RLlib, Stable Baselines3, TensorFlow, PyTorch รวมทั้งเก็บ experiment metadata และ model checkpoints สำหรับการ audit และ rollback
- วัดผลเชิงสถิติก่อนย้ายสู่ภาคสนาม เช่น ประสิทธิภาพเฉลี่ย, ความแปรปรวน (variance), และ worst‑case latency percentiles (p99, p999)
การตั้ง KPI, SLA และการตรวจวัด (Monitoring)
การกำหนดตัวชี้วัดอย่างเป็นรูปธรรมเป็นสิ่งจำเป็นต่อการยอมรับทางธุรกิจและการควบคุมความเสี่ยง:
- KPI ตัวอย่าง — Latency (ms; avg/p95/p99), Jitter (ms), Throughput (Mbps), Packet loss (%), Slice isolation (cross‑slice interference incidents), SLA compliance rate (%)
- SLA และ SLO — กำหนด Service Level Objectives (SLO) และเป้าการปฏิบัติตาม SLA ที่ชัดเจน เช่น p99 latency ≤ 10 ms สำหรับ critical slice และ penalty/mitigation plan หากไม่เป็นไปตาม SLA
- Monitoring Stack — ใช้เครื่องมือมาตรฐานเช่น Prometheus/Grafana สำหรับ metric, ELK/EFK สำหรับ logs, และ tracing tools สำหรับติดตาม flows ระหว่าง slice และแอปพลิเคชัน
- Alerting & Fallback — กำหนด threshold และ automated alerts พร้อม fallback policy เช่นการลดความเป็น dynamic ของ RL ให้กลับไปใช้ static allocation หรือส่ง traffic ไปยัง redundant slice เมื่อเกิด anomaly
เครื่องมือ มาตรฐาน และสถาปัตยกรรมที่เกี่ยวข้อง
การผสาน RL กับสถาปัตยกรรมเครือข่ายต้องอิงมาตรฐานและแพลตฟอร์มที่เป็นที่ยอมรับ:
- O‑RAN RIC — Near‑RT RIC สำหรับการตัดสินใจเรียลไทม์และ Non‑RT RIC สำหรับ learning/optimization และ policy management
- ETSI NFV/SMO และ ONAP — สำหรับจัดการ lifecycle ของ network functions และ orchestration ของ network‑slice
- MEC (Multi‑access Edge Computing) — เพื่อรัน inference หรือส่วนจัดการ slice ใกล้ edge ลด latency และสนับสนุน decision loop ที่เร็ว
- Integration Tools — APIs สำหรับ telemetry (gNB/CU‑DU counters), message bus (Kafka), model serving (KFServing/Seldon) และ MLOps toolchain สำหรับ CI/CD ของโมเดล
ความท้าทายด้านความปลอดภัย ความโปร่งใส และ Governance
การนำ RL มาใช้ในเครือข่ายอุตสาหกรรมมีความเสี่ยงเฉพาะด้านที่ต้องออกแบบมาตรการป้องกันอย่างเป็นระบบ:
- ความปลอดภัย — ป้องกันการโจมตีต่อ model (poisoning, evasion), secure model update (signed artifacts), และการสื่อสารที่เข้ารหัสระหว่าง RIC, orchestrator และ edge
- ความโปร่งใส (Explainable AI) — ใช้เทคนิค XAI เพื่อให้ operator เข้าใจเหตุผลของการตัดสินใจ เช่น feature attribution, decision‑tree surrogate models หรือ policy visualizations เพื่อการตรวจสอบและ debugging
- Governance และ Compliance — กำหนด policy สำหรับ model validation, audit logs, version control, และ periodic model retraining/validation รวมถึงการปฏิบัติตามข้อกำกับภายในและข้อบังคับภายนอก
- Ethics & Safety — ใช้แนวทาง safe‑RL (constrained RL, shielded RL, conservative policy updates) และทดสอบ worst‑case scenarios เพื่อหลีกเลี่ยงพฤติกรรมอันตรายในสภาพแวดล้อมการผลิต
แนวปฏิบัติที่ดีที่สุด: safe‑RL, Rollback และ Human‑in‑the‑loop
เพื่อให้การใช้งานเป็นไปอย่างมั่นคงและยืดหยุ่น ควรปฏิบัติตามแนวทางดังนี้:
- ใช้ safe‑RL และ constraints — บังคับข้อจำกัดทางเทคนิค (เช่น bound on resource reallocation per time window) และใช้ reward shaping เพื่อลด incentive ของ policy ที่ไม่ปลอดภัย
- Canary & Gradual Rollout — เปิดใช้เฉพาะบางส่วนก่อน (canary), วัดผลแบบเรียลไทม์ และขยายการใช้งานทีละน้อยเมื่อมั่นใจ
- Rollback Plans — เตรียมกลไกสำหรับ rollback อัตโนมัติเมื่อพบ SLA degradation เช่น feature flags, versioned models, และ cold‑start policies ที่ปลอดภัย
- Human‑in‑the‑Loop — ตั้งระดับการควบคุมที่ให้ operator สามารถ intervence ได้เมื่อระบบพบเหตุการณ์ผิดปกติ รวมถึง dashboards ที่แสดงเหตุผลของการตัดสินใจและ suggested actions
- Continuous Monitoring & Auditing — ตรวจสอบทั้ง performance และ safety metrics แบบเรียลไทม์ พร้อมบันทึก audit trail ของการตัดสินใจ การเปลี่ยนแปลงนโยบาย และ model updates
สรุปเชิงปฏิบัติการสำหรับองค์กร
องค์กรที่ต้องการทดลองหรือนำไปใช้จริงควรเริ่มจาก use‑case ที่มีขอบเขตและ KPI ชัดเจน ฝึกและทดสอบ RL ใน environment จำลองหรือ digital twin ก่อนขึ้นสู่ pilot ในสภาพแวดล้อมจริง โดยยึดหลักการใช้มาตรฐาน (O‑RAN RIC, ETSI NFV/SMO, ONAP, MEC) ตั้งระบบ monitoring และ fallback ที่แข็งแรง รวมทั้งกำหนด governance และ safety‑controls เช่น safe‑RL, explainability, และ rollback plan การปฏิบัติตามแนวทางเหล่านี้จะช่วยให้การนำ 5G + RL มาจัดการ network‑slicing สำหรับ IIoT เป็นไปอย่างมั่นคง ปลอดภัย และสามารถรับประกัน SLA ได้จริงในสเกลการผลิต
บทสรุป
การผสานเครือข่าย 5G กับ Reinforcement Learning (RL) สำหรับการจัดสรร Network‑Slicing แบบเรียลไทม์ช่วยมอบศักยภาพสำคัญในการลดความหน่วง (latency), รับประกัน SLA และเพิ่มความทนทานให้ระบบ IIoT ของโรงงานอุตสาหกรรม โดยการใช้ความสามารถของ 5G เช่น URLLC และ edge computing ร่วมกับนโยบายการเรียนรู้เชิงเสริม ทำให้สามารถปรับ slice แบบไดนามิกเพื่อตอบสนองความต้องการแอปพลิเคชันที่ต่างกันได้ทันที ตัวอย่างเช่น การจัดลำดับความสำคัญทราฟฟิกควบคุมการผลิตแบบเรียลไทม์ให้มี latency ต่ำและ jitter คงที่ ขณะที่ข้อมูลการวิเคราะห์หรือภาพถ่ายความละเอียดสูงอาจถูกย้ายไปยัง slice ที่เน้น throughput สูง ผลลัพธ์จากการทดลองและ PoC หลายแห่งบ่งชี้ว่าการจัดสรรแบบอัตโนมัติสามารถลด latency ได้อย่างมีนัยสำคัญ (ตั้งแต่ระดับสิบมิลลิวินาทีลงไปจนใกล้ระดับ sub‑ms ภายใต้เงื่อนไข URLLC และ edge offloading) และช่วยรักษา SLA เช่น availability ที่ระดับสูง (ตัวอย่าง SLA เช่น latency <10 ms สำหรับการควบคุมไทม์คริติคัล หรือ availability ≥99.999% สำหรับกลุ่มงานสำคัญ)
แต่ความสำเร็จขึ้นกับการออกแบบสถาปัตยกรรมและอัลกอริทึมอย่างรอบคอบ: ต้องเลือกตัวแทน RL, ฟังก์ชันรางวัล, ขอบเขตของ action/state และกลไกการสำรอง/rollback ที่เหมาะสม รวมถึงการวางตำแหน่งฟังก์ชันการตัดสินใจที่ edge vs. cloud เพื่อไม่ให้เกิด single point of failure ด้านปฏิบัติ การนำไปใช้จริงควรเริ่มจากการทำ Proof of Concept (PoC) ที่มุ่งเป้าไปยัง use‑case สำคัญ (เช่น การควบคุมหุ่นยนต์, การตรวจจับข้อผิดพลาดแบบเรียลไทม์) ใช้ simulation หรือ digital twin ในการฝึก RL ก่อนนำสู่สนามจริง กำหนด KPI ชัดเจน (latency, jitter, packet loss, slice isolation, handover success rate, SLA breach rate) และนำแนวปฏิบัติด้านความปลอดภัย การกำกับดูแล (governance) และระบบ monitoring/observability มาประยุกต์ใช้อย่างเข้มงวด เช่น การเข้ารหัสช่องสื่อสาร การยืนยันตัวตนของฟังก์ชัน orchestration การบันทึกเหตุการณ์เชิงนโยบาย และการตั้งระบบ alarm/rollback อัตโนมัติเพื่อรับประกันการใช้งานในภาคอุตสาหกรรมมีผลจริงและต่อเนื่อง
แนวโน้มในอนาคตคาดว่าเทคโนโลยีจะพัฒนาไปสู่สถาปัตยกรรมที่ผสาน multi‑agent RL, federated learning สำหรับการฝึกที่เป็นส่วนตัวและกระจาย, และมาตรฐานการจัดการ slice ที่สอดคล้องกันระหว่างผู้ให้บริการและโรงงาน ซึ่งจะเอื้อต่อการขยายตัวจาก PoC สู่โครงสร้างเชิงพาณิชย์อย่างปลอดภัยและคุ้มค่า ในระยะยาวองค์กรที่วางรากฐานด้าน simulation, KPI, security และ governance ได้ดีจะสามารถเก็บเกี่ยวประโยชน์จากความยืดหยุ่นของเครือข่าย 5G แบบไดนามิก เพิ่มความทนทานของระบบ IIoT ลดความเสี่ยงด้านการหยุดชะงัก และสร้างความได้เปรียบทางการแข่งขันในอุตสาหกรรมดิจิทัลได้อย่างยั่งยืน